
Solución de ecuaciones no lineales y aplicaciones a la cuadratura ...
64
Solución de ecuaciones no lineales y aplicaciones a la cuadratura numérica Javier Segura Departamento de Matemáticas, Estadística y Computación Universidad de Cantabria, Spain Fundamentos de Matemática Aplicada (INVESMAT) J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 1 / 45
Transcript of Solución de ecuaciones no lineales y aplicaciones a la cuadratura ...

Solución de ecuaciones no lineales yaplicaciones a la cuadratura numérica
Javier Segura
Departamento de Matemáticas, Estadística y ComputaciónUniversidad de Cantabria, Spain
Fundamentos de Matemática Aplicada (INVESMAT)
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 1 / 45

Contenidos:
1 Repaso de métodos básicosBisecciónMétodo de la secanteEl método de Newton
2 Métodos de punto fijoSoluciones numéricas de punto fijoPunto fijo y aproximaciones analíticas: dos ejemplos
3 Cuadraturas gaussianas y ceros de polinomios ortogonales
4 Método de autovalores para relaciones de recurrenciaCeros de polinomios ortogonalesCeros de soluciones mínimas de relaciones de recurrenciaPros y contras de los métodos de recurrencias
5 El método de Golub-Welsch
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 2 / 45

Repaso de métodos básicos Bisección
Bisección
Teorema (Bolzano).Si f (x) es continua en el intervalo [a,b] con f (a)f (b) ≤ 0, entoncesexiste al menos un α ∈ [a,b] tal que f (α) = 0.
Algoritmo (Bisección)
Algoritmo: Bisección en un intervalo [a,b], tal que f (a)f (b) < 0
(1) Sea c = (b + a)/2(2) Si b − c ≤ ε, aceptar c; parar(3) Si f (b)f (c) ≤ 0, tomar a = c; y si no: b = c.(4) Volver a (1)
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 3 / 45

Repaso de métodos básicos Bisección
Bisección
Teorema (Bolzano).Si f (x) es continua en el intervalo [a,b] con f (a)f (b) ≤ 0, entoncesexiste al menos un α ∈ [a,b] tal que f (α) = 0.
Algoritmo (Bisección)
Algoritmo: Bisección en un intervalo [a,b], tal que f (a)f (b) < 0
(1) Sea c = (b + a)/2(2) Si b − c ≤ ε, aceptar c; parar(3) Si f (b)f (c) ≤ 0, tomar a = c; y si no: b = c.(4) Volver a (1)
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 3 / 45

Repaso de métodos básicos Bisección
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 4 / 45
Repaso de métodos básicos Bisección
1 Bisección es lo óptimo para resolver una ecuación f (x) = 0cuando no sabemos nada de f salvo calcular su signo.
2 El cero está siempre dentro de un intervalo de acotación yconverge siempre que f cambie de signo, aunque también puedeconverger a una discontinuidad.
3 Lento aunque seguro: a lo sumo, el orden de convergencia es 1.4 Inespecífico: el número de iteraciones sólo depende del intervalo
[a,b] y del cero α ∈ [a,b].
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 5 / 45

Repaso de métodos básicos Bisección
1 Bisección es lo óptimo para resolver una ecuación f (x) = 0cuando no sabemos nada de f salvo calcular su signo.
2 El cero está siempre dentro de un intervalo de acotación yconverge siempre que f cambie de signo, aunque también puedeconverger a una discontinuidad.
3 Lento aunque seguro: a lo sumo, el orden de convergencia es 1.4 Inespecífico: el número de iteraciones sólo depende del intervalo
[a,b] y del cero α ∈ [a,b].
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 5 / 45

Repaso de métodos básicos Bisección
1 Bisección es lo óptimo para resolver una ecuación f (x) = 0cuando no sabemos nada de f salvo calcular su signo.
2 El cero está siempre dentro de un intervalo de acotación yconverge siempre que f cambie de signo, aunque también puedeconverger a una discontinuidad.
3 Lento aunque seguro: a lo sumo, el orden de convergencia es 1.
4 Inespecífico: el número de iteraciones sólo depende del intervalo[a,b] y del cero α ∈ [a,b].
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 5 / 45

Repaso de métodos básicos Bisección
1 Bisección es lo óptimo para resolver una ecuación f (x) = 0cuando no sabemos nada de f salvo calcular su signo.
2 El cero está siempre dentro de un intervalo de acotación yconverge siempre que f cambie de signo, aunque también puedeconverger a una discontinuidad.
3 Lento aunque seguro: a lo sumo, el orden de convergencia es 1.4 Inespecífico: el número de iteraciones sólo depende del intervalo
[a,b] y del cero α ∈ [a,b].
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 5 / 45

Repaso de métodos básicos Bisección
Orden de convergenciaSea {xn} una sucesión que converge a α y definamos εn = xn − α. Siexite un número p y una constante C 6= 0 tales que
limn→∞
|εn+1||εn|p
= C
se dice que el orden de convergencia es p siendo C la constante deerror asintótica.
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 6 / 45
Repaso de métodos básicos Bisección
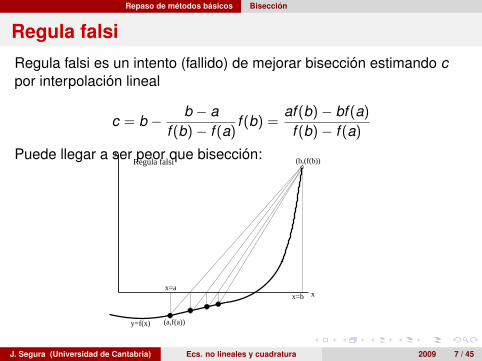
Regula falsi
Regula falsi es un intento (fallido) de mejorar bisección estimando cpor interpolación lineal
c = b − b − af (b)− f (a)
f (b) =af (b)− bf (a)
f (b)− f (a)
Puede llegar a ser peor que bisección:
y=f(x)
y
xx=a
x=b
(a,f(a))
(b,(f(b))Regula falsi
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 7 / 45

Repaso de métodos básicos Método de la secante
Método de la secante
Igual que regula falsi, pero sin tener en cuenta los signos
xn+1 = xn −xn − xn−1
f (xn)− f (xn−1)f (xn) (1)
x
y
x0
α
y=f(x)
´Metodo de la secante
x1x2x3
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 8 / 45

Repaso de métodos básicos Método de la secante
Orden de convergencia:Con εk = xk − α, desarrollando f (xk ) = f (α + εk ) y llevándolo a (1),tenemos que
εn+1 =f ′′(α)
2f ′(α)εnεn−1
Con esto, se puede comprobar que el orden es p = (1 +√
5)/2(Vamos mejorando, ¡si es que converge!)
Criterio de parada: como el orden es p > 1:
|xn+1 − xn||xn − α|
≤ 1 +|xn+1 − α||xn − α|
→ 1
cuando n→ +∞. Se puede entonces utilizar |xn+1 − xn| para estimarel error.
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 9 / 45

Repaso de métodos básicos Método de la secante
Otra forma de interpretar el método de la secante
Teorema (Teorema del resto)
Sea f (x) una función continua en [a,b] y derivable n + 1 veces en (a,b). SiPn(x) es el polinomio de grado menor o igual que n que interpola f (x) entrelos n + 1 nodos distintos x0...xn ∈ [a,b] (es decir, tal que Pn(xk ) = f (xk ))entonces ∀x ∈ [a,b] ∃ζx ∈ (a,b), dependiente de x, tal que
f (x) = Pn(x) +f (n+1)(ζx )
(n + 1)!
n∏j=0
(x − xj ) ≡ Pn(x) + Rn(x)
donde se dice que Rn(x) es el resto.
Utilizando diferencias divididas de Newton:
f (x) = f [x0] + f [x0, x1](x − x0) + ...+ f [x0, x1, ..., xn](x − x0)...(x − xn−1)
+f [x0, ..., xn, x ]n∏
j=0
(x − xj )
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 10 / 45

Repaso de métodos básicos Método de la secante
Resolver la ecuación f (x) = 0, con solución x = α es equivalente a evaluarα = g(0) donde g = f (−1).Aproximando g(y) por interpolación lineal para los puntos (yn, xn),(yn−1, xn−1) (yk = f (xk )), tenemos:
g(y) =y − yn−1yn − yn−1
g(yn) +yn − y
yn − yn−1g(yn−1) + E
=y − fn−1
fn − f n − 1xn +fn − y
fn − fn−1xn−1 + E
E =g(ζ)
2 (y − yn)(y − yn−1) =g′(ζ)
2 (y − fn)(y − fn−1), para cierto ζ.
Haciendo y = 0:
α =fnxn−1 − fn−1xn
fn − fn−1+
g(ζ)
2fnfn−1
De donde εn+1 ≈g(0)
2 f ′(α)2εnεn−1
Esta idea se puede generalizar para más puntos de interpolación, de maneraque se pueden obtener métodos de order arbitrariamente alto, pero...
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 11 / 45

Repaso de métodos básicos Método de la secante
Recordemos que con el método de la secante no tenemos intervalosde acotación de la raíz.¿ Cómo garantizar que el método converge?
¿ Cómo escoger los valores iniciales?Existen algoritmos que combinan bisección y secante que:
1 Garantizan la convergencia y dan un intervalo de acotación2 Convergen más rápidamente que bisección
Los métodos de Dekker (bisección + secante) y Brent (bisección +interpolación cuadrática inversa) son dos ejemplos populares.
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 12 / 45

Repaso de métodos básicos Método de la secante
Recordemos que con el método de la secante no tenemos intervalosde acotación de la raíz.¿ Cómo garantizar que el método converge?¿ Cómo escoger los valores iniciales?Existen algoritmos que combinan bisección y secante que:
1 Garantizan la convergencia y dan un intervalo de acotación
2 Convergen más rápidamente que bisección
Los métodos de Dekker (bisección + secante) y Brent (bisección +interpolación cuadrática inversa) son dos ejemplos populares.
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 12 / 45

Repaso de métodos básicos Método de la secante
Recordemos que con el método de la secante no tenemos intervalosde acotación de la raíz.¿ Cómo garantizar que el método converge?¿ Cómo escoger los valores iniciales?Existen algoritmos que combinan bisección y secante que:
1 Garantizan la convergencia y dan un intervalo de acotación2 Convergen más rápidamente que bisección
Los métodos de Dekker (bisección + secante) y Brent (bisección +interpolación cuadrática inversa) son dos ejemplos populares.
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 12 / 45

Repaso de métodos básicos El método de Newton
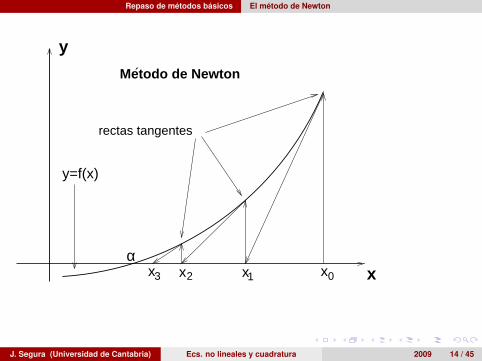
El método de Newton
El método de Newton consiste en resolver la ecuación f (x) = 0invirtiendo la aproximación lineal de Taylor alrededor de x = α(f (α) = 0)
0 = f (xn − εn) = f (xn)− f ′(xn)εn +f ′′(ζn)
2ε2n
donde εn = xn − αDespreciando el error
α ' xn+1 = xn −f (xn)
f ′(xn)
Orden de convergencia = 2Parece buena idea caso de que se disponga de la derivada f ′(x)
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 13 / 45
Repaso de métodos básicos El método de Newton
x
y
xxxx 0123
α
y=f(x)
Metodo de Newton´
rectas tangentes
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 14 / 45

Repaso de métodos básicos El método de Newton
Posibles problemas del método de Newton
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 15 / 45

Repaso de métodos básicos El método de Newton
En el plano complejo los problemas aumentan
El método de Newton también se puede utilizar para calcular ceros enel plano complejo.Supongamos que queremos resolver f (z) = 0 donde f (z) = z3 − 1.
Tenemos zn+1 = zn −z3
n − 13z2
n. El conjunto de los valores iniciales que
dan convergencia a z0 = 1 es...
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 16 / 45

Repaso de métodos básicos El método de Newton
En el plano complejo los problemas aumentan
El método de Newton también se puede utilizar para calcular ceros enel plano complejo.Supongamos que queremos resolver f (z) = 0 donde f (z) = z3 − 1.
Tenemos zn+1 = zn −z3
n − 13z2
n. El conjunto de los valores iniciales que
dan convergencia a z0 = 1 es...
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 16 / 45

Métodos de punto fijo
Métodos de punto fijo
Los métodos de punto fijo responden a esquemas
xn+1 = T (xn)
Ejemplo: el método de Newton, T(x)=x-f(x)/f’(x)Si T is contínua y, dado cierto x0, existe limn→∞ xn = α entoncesα = T (α) (α punto fijo de T ).
TeoremaSi T (x) es continua en I = [a,b] y T (I) ⊂ I entonces existe al menosun punto fijo de T (x), α ∈ [a,b].
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 17 / 45

Métodos de punto fijo
x
y
y=x
y=g(x)AB
a b
a
bpuntos fijos
´
la linea y=x para alcanzarLa curva debe cruzar
B desde A puesto quela curva esta confinadaen la caja
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 18 / 45

Métodos de punto fijo
Teorema (Continuación)Si, además T (x) es continuamente diferenciable en (a, b) y
|T ′(x)| ≤ M < 1 , ∀x ∈ (a, b) ,
entonces
1 T (x) tiene un único punto fijo α en [a, b]
2 Para cada x0 ∈ [a, b], la sucesión definida como
xn+1 = T (xn)
converge al único punto fijo α.
3 La estimación del error de la enésima iteración está dada por
|xn − α| ≤Mn
1− M|x1 − x0|
4 Si T ′(α) 6= 0, y ∃N > 0 : an 6= α ∀n > N entonces
limn→∞
α− xn+1
α− xn= T ′(α).
Es decir, que si T ′(α) 6= 0 el orden de convergencia es 1.
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 19 / 45

Métodos de punto fijo
Teorema (Continuación)Si, además T (x) es continuamente diferenciable en (a, b) y
|T ′(x)| ≤ M < 1 , ∀x ∈ (a, b) ,
entonces
1 T (x) tiene un único punto fijo α en [a, b]
2 Para cada x0 ∈ [a, b], la sucesión definida como
xn+1 = T (xn)
converge al único punto fijo α.
3 La estimación del error de la enésima iteración está dada por
|xn − α| ≤Mn
1− M|x1 − x0|
4 Si T ′(α) 6= 0, y ∃N > 0 : an 6= α ∀n > N entonces
limn→∞
α− xn+1
α− xn= T ′(α).
Es decir, que si T ′(α) 6= 0 el orden de convergencia es 1.
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 19 / 45

Métodos de punto fijo
Teorema (Continuación)Si, además T (x) es continuamente diferenciable en (a, b) y
|T ′(x)| ≤ M < 1 , ∀x ∈ (a, b) ,
entonces
1 T (x) tiene un único punto fijo α en [a, b]
2 Para cada x0 ∈ [a, b], la sucesión definida como
xn+1 = T (xn)
converge al único punto fijo α.
3 La estimación del error de la enésima iteración está dada por
|xn − α| ≤Mn
1− M|x1 − x0|
4 Si T ′(α) 6= 0, y ∃N > 0 : an 6= α ∀n > N entonces
limn→∞
α− xn+1
α− xn= T ′(α).
Es decir, que si T ′(α) 6= 0 el orden de convergencia es 1.
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 19 / 45

Métodos de punto fijo
Teorema (Continuación)Si, además T (x) es continuamente diferenciable en (a, b) y
|T ′(x)| ≤ M < 1 , ∀x ∈ (a, b) ,
entonces
1 T (x) tiene un único punto fijo α en [a, b]
2 Para cada x0 ∈ [a, b], la sucesión definida como
xn+1 = T (xn)
converge al único punto fijo α.
3 La estimación del error de la enésima iteración está dada por
|xn − α| ≤Mn
1− M|x1 − x0|
4 Si T ′(α) 6= 0, y ∃N > 0 : an 6= α ∀n > N entonces
limn→∞
α− xn+1
α− xn= T ′(α).
Es decir, que si T ′(α) 6= 0 el orden de convergencia es 1.
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 19 / 45

Métodos de punto fijo
x3 x2 x1 x0 x
y
α
y=xy=g(x)
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 20 / 45

Métodos de punto fijo
x2x0x1 x
y y=x
α
y=g(x)
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 21 / 45

Métodos de punto fijo
x0 x1x2 x3
y y=x
y=g(x)
x
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 22 / 45

Métodos de punto fijo
x0 x1
y=x
x
y=g(x)y
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 23 / 45

Métodos de punto fijo
Teorema (Otra versión)Sea T (x) continua en I ≡ [a,b] y continuamente diferenciable en(a,b). Si ∃α ∈ I : T (α) = α y se verifica que |g′(x)| ≤ M < 1 en (a,b),entonces se cumplen los resultados enunciados en el anterior.
Consecuencia de esto es que si T es continuamente diferenciable enun entorno de α y |T ′(α)| < 1, entonces existe un entorno de α tal quexn+1 = T (xn) converge a α para cualquier x0 en ese entorno(convergencia local).
Teorema (Convergencia monótona)Si T (x) tiene derivada primera continua en un intervalo I que contieneun punto fijo de T (x) y 0 ≤ T ′(x) < 1 en I, entonces hay sólo un puntofijo de T (x) en I, la iteración de punto fijo xn+1 = T (xn) es convergente∀x0 ∈ I y la convergencia es de tipo monótono, es decir:Si x0 > α, entonces x0 > x1 > ... > xn > ... > αSi x0 < α, entonces x0 < x1 < ... < xn < ... < α
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 24 / 45

Métodos de punto fijo
Dado un método de punto fijo xn+1 = T (xn) y T (α) = α, si la primeraderivada no nula en α de T (x) es la m − sima (y es continua),entonces el método tiene orden de convergencia m con constante deerror asintótica C = T (m)(α)/m!.En efecto:
xn+1 = T (α + εn) = T (α) +T (m)(ζn)
m!εmn
Luego
εn =T (m)(ζn)
m!εmn
con ζn entre α y xn, luego
limn→∞
εn+1
εmn= T (m)(α)/m!
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 25 / 45

Métodos de punto fijo
Dos ejemplos de métodos de punto fijo con ordenm ≥ 2
1 El método de Newton cuando f ′(α) 6= 0:
T (x) = x − f (x)/f ′(x)→ T ′(x) = f (x)f ′′(x)/f ‘(x)2
→ T ′(α) = 0, T ′′(α) = f ′′(α)/f ′(α)
Orden 2
2 Método de arctan(Newton)
T (x) = x − 1w(x)
arctan(w(x)y(x)/y ′(x))
para cierto w(x).¿Cuál es el orden si y(x) es solución dey ′′(x) + w(x)2y(x) = 0 ?
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 26 / 45

Métodos de punto fijo
Dos ejemplos de métodos de punto fijo con ordenm ≥ 2
1 El método de Newton cuando f ′(α) 6= 0:
T (x) = x − f (x)/f ′(x)→ T ′(x) = f (x)f ′′(x)/f ‘(x)2
→ T ′(α) = 0, T ′′(α) = f ′′(α)/f ′(α)
Orden 22 Método de arctan(Newton)
T (x) = x − 1w(x)
arctan(w(x)y(x)/y ′(x))
para cierto w(x).¿Cuál es el orden si y(x) es solución dey ′′(x) + w(x)2y(x) = 0 ?
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 26 / 45

Métodos de punto fijo Soluciones numéricas de punto fijo
Como ejemplo consideremos el cálculo de los ceros de
κx sin(x)− cos(x) = 0→ tan x =1κx
Invirtiendo
x = arctan(
1κx)
+ mπ ≡ Tm(x), m = 1,2, ...;T0(x) = π/2− arctan(κx)
Tenemos un cero en cada intervaloIm = ((m − 1/2)π/2, (m + 1/2)π/2), m ∈ N y otro en I0 = (0, π/2) siκ > 0.
T (Im) ⊂ Im ,T ′(x) = − κ
1 + κ2x2
Converge al cero en Im dando x0 ∈ Im, con la duda de κ > 1 en I0.
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 27 / 45

Métodos de punto fijo Punto fijo y aproximaciones analíticas: dos ejemplos
Aproximaciones analíticas: un ejemplo simple
Consideremos de nuevo el ejemplo κx sin(x)− cos(x) = 0.Vamos a construir una aproximación para ceros grandes (o no tanto).Partimos de x0 = mπ e iteramos con Tm para aproximar el cero αm enIm.Como |T ′m(x)| = O(m−2), tenemos, iterando una vez:
α(m) = arctan(
1κmπ
)+ mπ +O(m−2) = mπ +
1πκm
+O(m−2)
E iterando dos veces
α(m) = Tm(Tm(xm))+O(m−4) = mπ+µ−1−(κ+
13
)µ−3+O(µ−5) (2)
donde µ = πκm
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 28 / 45

Métodos de punto fijo Punto fijo y aproximaciones analíticas: dos ejemplos
Otra forma de hacer lo mismo es por resustitución:Empezamos con α(m) ∼ mπ. Teníamos Tm(x) = arctan(1/(κx)) + mπ.Como
arctan(
1z
)=
1z− 1
3z3 +1
5z5 − . . . , (3)
quedándonos sólo con el primer término y sustituyendo con la primeraaproximación mπ. Tenemos:
α(m)1 = mπ +
1κmπ
.
Resustituyendo de nuevo:
α(m)2 = mπ +
1κα1− 1
3(κα1)3
y expandiendo tenemos (2).
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 29 / 45

Métodos de punto fijo Punto fijo y aproximaciones analíticas: dos ejemplos
Un caso más general
El anterior ejemplox − arctan(1/κx) = mπ
para m grande es un ejemplo particular de un caso más general:
f (x) = w
donde
f (x) = x +n∑
i=0
fix i +O(x−n−1), x →∞
En el que se puede comprobar la validez del esquema anteriorconsiderando
T (x) = w − g(x), g(x) = f (x)− x =n∑
i=0
fix i +O(x−n−1)
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 30 / 45

Métodos de punto fijo Punto fijo y aproximaciones analíticas: dos ejemplos
Un ejemplo no trivial
Expansion de McMahon para ceros grandes de las funciones deBesselLa función de Bessel function Jν(z), solución regular en el origen de
z2y ′′ + zy ′ + (z2 − ν2)y = 0
se puede escribir
Jν(z) =
√2πz{P(ν, z) cos ξ −Q(v , z) sin ξ} , |arg z| < π, (4)
donde ξ = z − νπ/2− π/4 y P y Q tienen conocidas expansiones cuando
z →∞, con Q/P ∼ µ− 18z (1 +O(z−1)), µ = 4ν2.
Para aproximar los ceros, tomamos tan(ξ) = P/Q e invertimos:
z = β − arctan(Q/P), β = (s + ν/2− 1/4)π, s = 1,2, . . . . (5)
Una primera aproximación para los ceros de Jν(x) es jν,s ∼ β and the second
jν,s ∼ β −µ− 1
8β, (6)
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 31 / 45

Métodos de punto fijo Punto fijo y aproximaciones analíticas: dos ejemplos
Expansion de McMahon (continuación)
Repitiendo el proceso, se puede escribir
jν,s ∼ β −µ− 1
2
∞∑i=0
Pi (µ)
(4β)2i+1 , (7)
con Pi (µ) polinomios en µ de grado i , que se pueden escribir
Pi (µ) = ci
i∑k=0
(−1)i−k a(k)i µk , ci ∈ Q+, a(k)
i ∈ N. (8)
Algunos de los coeficientes (usando Maple) soni ci a(0)
i a(1)i a(2)
i a(3)i a(4)
i a(5)i
0 1 1 — — — — —1 1/3 31 7 — — — —2 2/15 3779 982 83 — — —3 1/105 6277237 1585743 153855 6949 — —4 2/305 2092163573 512062548 48010494 2479316 70197 —5 2/3465 8249725736393 1982611456181 179289628602 8903961290 287149133 5592657
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 32 / 45

Métodos de punto fijo Punto fijo y aproximaciones analíticas: dos ejemplos
McMahon no basta
Para valores de ν moderados, McMahon funciona hastapara los primeros ceros.
Para ν grande McMahon falla y se necesitanaproximaciones uniformes (mucho más complicadas)Es habitual que haya que combinar métodos (como pasacon el ejemplo más sencillo)Aunque hay otras estrategias para ciertas funciones,incluida la función de Bessel
Volveremos al asunto, de alguna forma...
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 33 / 45

Métodos de punto fijo Punto fijo y aproximaciones analíticas: dos ejemplos
McMahon no basta
Para valores de ν moderados, McMahon funciona hastapara los primeros ceros.Para ν grande McMahon falla y se necesitanaproximaciones uniformes (mucho más complicadas)
Es habitual que haya que combinar métodos (como pasacon el ejemplo más sencillo)Aunque hay otras estrategias para ciertas funciones,incluida la función de Bessel
Volveremos al asunto, de alguna forma...
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 33 / 45

Métodos de punto fijo Punto fijo y aproximaciones analíticas: dos ejemplos
McMahon no basta
Para valores de ν moderados, McMahon funciona hastapara los primeros ceros.Para ν grande McMahon falla y se necesitanaproximaciones uniformes (mucho más complicadas)Es habitual que haya que combinar métodos (como pasacon el ejemplo más sencillo)
Aunque hay otras estrategias para ciertas funciones,incluida la función de Bessel
Volveremos al asunto, de alguna forma...
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 33 / 45

Métodos de punto fijo Punto fijo y aproximaciones analíticas: dos ejemplos
McMahon no basta
Para valores de ν moderados, McMahon funciona hastapara los primeros ceros.Para ν grande McMahon falla y se necesitanaproximaciones uniformes (mucho más complicadas)Es habitual que haya que combinar métodos (como pasacon el ejemplo más sencillo)Aunque hay otras estrategias para ciertas funciones,incluida la función de Bessel
Volveremos al asunto, de alguna forma...
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 33 / 45

Métodos de punto fijo Punto fijo y aproximaciones analíticas: dos ejemplos
McMahon no basta
Para valores de ν moderados, McMahon funciona hastapara los primeros ceros.Para ν grande McMahon falla y se necesitanaproximaciones uniformes (mucho más complicadas)Es habitual que haya que combinar métodos (como pasacon el ejemplo más sencillo)Aunque hay otras estrategias para ciertas funciones,incluida la función de Bessel
Volveremos al asunto, de alguna forma...
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 33 / 45

Métodos de punto fijo Punto fijo y aproximaciones analíticas: dos ejemplos
Otras dos aproximaciones para el mismoproblema (el sencillo, claro)
◦ Para κ pequeño y ceros no muy grandes:
x = arctan(
1κx
)+mπ = (m+ 1
2)π−arctan(κx), m = 0,1,2, . . . , (9)
Consideramos xn+1 = T (xn) con
T (x) = Λπ − arctan(κx), Λ = (m + 12). (10)
Para κ pequeño y moderado x , |T ′(x)| ∼ κ y, empezando con x0 = Λπtenemos un O(κ) en cada iteración. Iterando tres veces:
α(m)(κ) ∼ Λπ
[1− κ+ κ2 +
(−1 +
Λ2π2
3
)κ3 +O(κ4)
], κ→ 0.
(11)Esta expansión es útil para κ pequeño y ceros no muy grandes (casopara el que la anterior expansion no funciona).
α(m)(κ) ∼ Λπ
[1− κ+ κ2 +
(−1 +
Λ2π2
3
)κ3 +O(κ4)
], κ→ 0.
(12)
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 34 / 45

Métodos de punto fijo Punto fijo y aproximaciones analíticas: dos ejemplos
Para κ grande, el primer cero de κx sin x − cos x = 0 tiende a hacersepequeño. Una primera aproximación viene de resolver
κx sin x − cos x ' −1 + (κ+ 1/2)x2 − (κ/6 + 1/24)x4 = 0
Expandiendo el menor cero en potencias de κ−1:
α(0) ∼ 1√κ
(1− 1
6κ
)El método de punto fijo para T0(x) = π
2 − arctan(κx) no es tan fácil deaplicar ahora porque T ′(α(0)) = κ/(1 + κ2α(0)) ∼ 1, pero se puede...Resultado:
α(0) = 1√κ
(1− 1
6κ−1 + 11
360κ−2 − 17
5040κ−3
− 281604800κ
−4 + 44029119750400κ
−5 + . . .).
(13)
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 35 / 45

Métodos de punto fijo Punto fijo y aproximaciones analíticas: dos ejemplos
Combinando los tres:
κ 1 2 3 4 5 60.01 2 10−7 (2) 6 10−6 (2) 2 10−6 (2) 4 10−5 (2) 6 10−5 (2) 1 10−4 (2)0.1 4 10−4 (2) 4 10−3 (2) 1 10−2 (2) 5 10−3 (1) 2 10−3 (1) 6 10−4 (1)1 1 10−4 (3) 2 10−5 (1) 5 10−5 (1) 5 10−6 (1) 9 10−7 (1) 2 10−7 (1)10 1 10−10 (3) 2 10−6 (1) 3 10−8 (1) 3 10−9 (1) 5 10−10 (1) 1 10−10 (1)
Y aprovechando la convergencia local del método de Newton tenemosun método eficiente y seguro para todo κ.
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 36 / 45

Cuadraturas gaussianas y ceros de polinomios ortogonales
Cuadratura gaussiana
A continuación trataremos de obtener los nodos y los pesos paracuadraturas de integrales tales que∫ b
af (x)w(x)dx =
n∑i=1
wi f (xi) + γnf (2n)(λ)
(2n)!, λ ∈ (a,b)
siendo w(x) una función peso.Estas son cuadraturas gaussianas (con el mayor grado de exactitudposible para n nodos)Ejemplos clásicos:
1 Gauss-Hermite:∫ +∞−∞ f (x)e−x2
dx
2 Gauss-Laguerre:∫ +∞
0 f (x)xαe−xdx , α > −1
3 Gauss-Jacobi:∫ +1−1 f (x)(1− x)α(1 + x)βdx , α, β > −1
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 37 / 45

Cuadraturas gaussianas y ceros de polinomios ortogonales
Cuadratura gaussiana
A continuación trataremos de obtener los nodos y los pesos paracuadraturas de integrales tales que∫ b
af (x)w(x)dx =
n∑i=1
wi f (xi) + γnf (2n)(λ)
(2n)!, λ ∈ (a,b)
siendo w(x) una función peso.Estas son cuadraturas gaussianas (con el mayor grado de exactitudposible para n nodos)Ejemplos clásicos:
1 Gauss-Hermite:∫ +∞−∞ f (x)e−x2
dx
2 Gauss-Laguerre:∫ +∞
0 f (x)xαe−xdx , α > −1
3 Gauss-Jacobi:∫ +1−1 f (x)(1− x)α(1 + x)βdx , α, β > −1
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 37 / 45

Cuadraturas gaussianas y ceros de polinomios ortogonales
Cuadratura gaussiana
A continuación trataremos de obtener los nodos y los pesos paracuadraturas de integrales tales que∫ b
af (x)w(x)dx =
n∑i=1
wi f (xi) + γnf (2n)(λ)
(2n)!, λ ∈ (a,b)
siendo w(x) una función peso.Estas son cuadraturas gaussianas (con el mayor grado de exactitudposible para n nodos)Ejemplos clásicos:
1 Gauss-Hermite:∫ +∞−∞ f (x)e−x2
dx
2 Gauss-Laguerre:∫ +∞
0 f (x)xαe−xdx , α > −1
3 Gauss-Jacobi:∫ +1−1 f (x)(1− x)α(1 + x)βdx , α, β > −1
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 37 / 45

Cuadraturas gaussianas y ceros de polinomios ortogonales
Teorema
Sea w(x) una función peso en [a, b] y pn el polinomio mónico de grado n tal que∫ b
axk pn(x)w(x) dx = 0, k = 0, . . . , n − 1. (14)
Sean x1, . . . , xn los ceros of pn y wi definido por
wi =
∫ b
aLi(x)w(x) dx , Li(x) =
n∏k=1,k 6=i
x − xk
xi − xk, (15)
donde i = 1, 2, . . . , n. Entonces, la regla de cuadratura∫ b
af (x)w(x) dx ≈ QG
n (f ) =n∑
i=1
wi f (xi) (16)
es exacta para polinomios de grado menor o igual que 2n − 1.Si f tiene derivada continua f (2n) en [a, b], entonces
∃λ ∈ (a, b) :
∫ b
af (x)w(x) dx = QG
n (f ) + γnf (2n)(λ)
(2n)!, (17)
donde γn =∫ b
a pn(x)2w(x) dx.J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 38 / 45

Cuadraturas gaussianas y ceros de polinomios ortogonales
Teorema
Los polinomios ortogonales mónicos {pk} asociados al peso w(x) en el intervalo [a, b] satisfacen la relación de recurrence
p1(x) = (x − B0)p0(x),
pk+1(x) = (x − Bk )pk (x)− Ak pk−1(x), k = 1, 2, . . . ,(18)
donde
Ak =||pk ||
2
||pk−1||2 , k ≥ 1, Bk =
< xpk , pk >
||pk ||2 , k ≥ 0. (19)
Algoritmo (Stieltjes)
Input: a, b, w(x).
Output: B0, Ai , Bi , pi (x), i = 1, 2, . . . , n
• p−1(x) = 0; A0 = 0;
• p0(x) = 1, B0 =< x, 1 > / < 1, 1 >;
• DO i = 1, . . . , n − 1:pi+1(x) = (x − Bi )pi (x)− Ai pi−1(x).
Ai+1 = ||pi+1||2/||pi ||2; Bi+1 =< x, pi+1 > /||pi+1||2.
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 39 / 45

Método de autovalores para relaciones de recurrencia
Método de recurrencias, construcción “general”
Consideremos relaciones de recurrencia
anyn+1(x) + bnyn(x) + cnyn−1(x) = g(x)yn(x), n = 0,1, . . . ,
Las primeras N relaciones se pueden escribir
JNYN(x) + aN−1yN(x)eN + c0y−1(x)e1 = g(x)YN(x),
e1 = (1,0, . . . ,0)T , eN = (0, . . . ,0,1)T , YN(x) = (y0(x), . . . , yN−1(x))T
JN =
b0 a0 0 . . 0c1 b1 a1 0 . 00 c2 b2 a2 . 0. . . . . 0. . . . . aN−20 0 0 . cN−1 bN−1
. (20)
Si para cierto x = x0 aN−1yN(x0) = c0y−1(x0) = 0 tenemos un problema deautovalores con autovalor g(x0)
Esto es así cuando x0 es un zcero of yN(x) (o de y−1(x)) y, por algúnmotivo, c0y−1(x) = 0 (o aN−1yN(x) = 0).
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 40 / 45

Método de autovalores para relaciones de recurrencia
Método de recurrencias, construcción “general”
Consideremos relaciones de recurrencia
anyn+1(x) + bnyn(x) + cnyn−1(x) = g(x)yn(x), n = 0,1, . . . ,
Las primeras N relaciones se pueden escribir
JNYN(x) + aN−1yN(x)eN + c0y−1(x)e1 = g(x)YN(x),
e1 = (1,0, . . . ,0)T , eN = (0, . . . ,0,1)T , YN(x) = (y0(x), . . . , yN−1(x))T
JN =
b0 a0 0 . . 0c1 b1 a1 0 . 00 c2 b2 a2 . 0. . . . . 0. . . . . aN−20 0 0 . cN−1 bN−1
. (20)
Si para cierto x = x0 aN−1yN(x0) = c0y−1(x0) = 0 tenemos un problema deautovalores con autovalor g(x0)
Esto es así cuando x0 es un zcero of yN(x) (o de y−1(x)) y, por algúnmotivo, c0y−1(x) = 0 (o aN−1yN(x) = 0).
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 40 / 45

Método de autovalores para relaciones de recurrencia Ceros de polinomios ortogonales
Para polinomios ortogonales mónicos, yn = Pn(x), g(x) = x y an andcn tienen el mismo signo.Además c0P−1 = 0, de modo que cuando yn(x0) = PN(x0) = 0:
JNYN(x0) = x0YN(x0),
Luegos los ceros de los polinomios ortogonales (nodos of cuadraturasgaussianas) son exactamente los autovalores de la matriz de Jacobimatrix JN .Wilf (1967), Golub-Welsch (1969)
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 41 / 45

Método de autovalores para relaciones de recurrencia Ceros de soluciones mínimas de relaciones de recurrencia
Consideremos otra vez
JNYN(x) + aN−1yN(x)eN + c0y−1(x)e1 = g(x)YN(x),
y ahora consideremos que son los ceros de y−1(x) los que se buscan.Si yN(x) es suficientemente pequeño para N grande y y−1(x0) = 0
JNYN(x0) ≈ g(x0)YN(x)
Esta aproximación funciona aproximadamente para soluciones mínimas derecurrencias lineales y homogéneas con tres términos, y particularly para lasfunciones de Bessel Jν(x) (Grad y Zakrajšek (1973), Ikebe (1975),..., Ball(2000)).Unas solución {fn} de una recurrencia a tres términos
yn+1 + βnyn + αnyn−1 = 0
es mínima (o recesiva) cuando
limn→+∞
fngn
= 0
para cualquier otra solución {gn} any other solution de la recurrenciaindependiente de fn.
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 42 / 45

Método de autovalores para relaciones de recurrencia Pros y contras de los métodos de recurrencias
Pros1 Todos los ceros de los P.O. se pueden calcular simultáneamente.2 Los ceros complejos también se pueden evaluar cuando existen.3 El método sólo requiere de los coeficientes de la recurrencia, y no
es necesario evaluar la función.
Cons1 Todos los ceros se calculan2 El condicionamiento no siempre es bueno.3 El tipo de recurrencias es restrictivo4 Para soluciones mínimas: ¿dónde truncar la matriz?5 Eficiencia?
Otros métodos más flexibles, menos específicos y globalmenteconvergentes existen.
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 43 / 45

El método de Golub-Welsch
Volviendo al cálculo de cuadraturas gaussianas, consideremos elproblema de calcular los nodos y pesos de una cuadratura gaussiana.Los nodos, como ya dijimos, se pueden obtener como autovalores dela matriz de Jacobi.Para los polinomios ortogonales mónicos teníamos:
p1(x) = (x − B0)p0(x),pk+1(x) = (x − Bk )pk (x)− Akpk−1(x), k = 1,2, . . . ,
(21)
donde
Ak =||pk ||2
||pk−1||2, k ≥ 1, Bk =
< xpk ,pk >
||pk ||2, k ≥ 0. (22)
Recurrencia para polinomios ortonormalesNormalizando los polinomios, pk = ||pk ||pk , tenemos
αk+1pk (x) + βk pk (x) + αk pk−1(x) = xpk (x),αm = ||pm||/||pm−1||, βk = Bk
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 44 / 45

El método de Golub-Welsch
Partiendo de las recurrencias para polinomios ortonormales, essencillo obtener también los pesos, a partir de los autovectores.
Ver:A. Gil, J. Segura, N.M. TemmeNumerical Methods for Special Functions, pp. 141-147
Pues veamos:
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 45 / 45

El método de Golub-Welsch
Partiendo de las recurrencias para polinomios ortonormales, essencillo obtener también los pesos, a partir de los autovectores.
Ver:A. Gil, J. Segura, N.M. TemmeNumerical Methods for Special Functions, pp. 141-147
Pues veamos:
J. Segura (Universidad de Cantabria) Ecs. no lineales y cuadratura 2009 45 / 45


















