
Espacios muestrales-2
33
-
Upload
idalialucerorosas -
Category
Documents
-
view
1.306 -
download
3
Transcript of Espacios muestrales-2


1. Un experimento aleatorio es aquel queproporciona diferentes resultados aun cuando serepita siempre de la misma manera.
2. El conjunto de los posibles resultados de unexperimento aleatorio recibe el nombre deespacio muestral del experimento. Denotaremosel espacio muestral con la letra S.
3. Un evento es un subconjunto del espaciomuestral de un experimento aleatorio.

1. Espacio muestral es el conjunto formado portodos los resultados posibles de un experimentoo fenómeno aleatorio. Lo denotamos con laletra E
E = {2, 3, 4, 5, 6, 7,8,9,10,11,12}

1. Suceso de un fenómeno aleatorio es cada unode los subconjuntos del espacio muestral E. Paradesignar cualquier suceso, también llamadosuceso aleatorio, de un experimento aleatorioutilizaremos letras mayúsculas.
2. Al conjunto de todos los sucesos que ocurren enun experimento aleatorio se le llama espaciomuestral y se designa por S.

• Salir múltiplo de 5:
A={5, 10}
• Salir número primo:
B= {2, 3, 5, 7, 11}
• Salir mayor o igual que 10:
C= {10, 11, 12}

• Sucesos compuestos son los que están formados por dos o más resultados del experimento; es decir, por dos o más sucesos elementales.
• Suceso seguro es el que se verifica al realizar el experimento aleatorio. Está formado por todos los resultados posibles del experimento y, por tanto, coincide con el espacio muestral.
• Suceso imposible es el que nunca se verifica. Se representa por

S
A = Alta resistencia a los golpes
B
B = Altas resistencias en las ralladuras
A
S = Espacio muestral

SIntersección de dos eventos
B
A∩B = resistencia a las ralladuras y los golpes son altas
A
A B
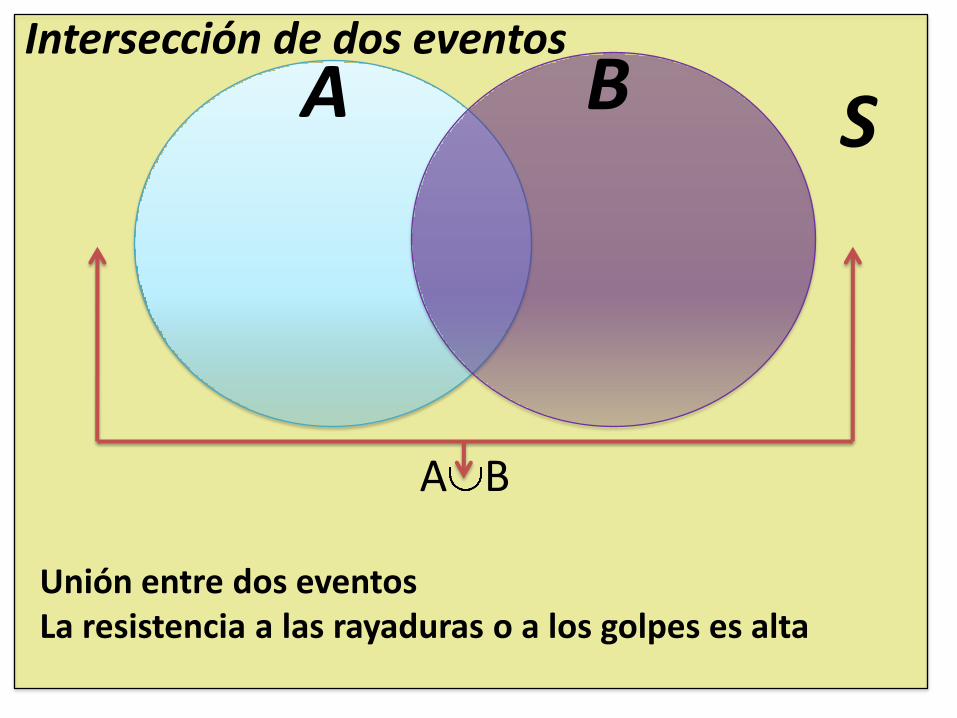
SIntersección de dos eventos
BA
A B
Unión entre dos eventos La resistencia a las rayaduras o a los golpes es alta

S
Operaciones con eventos
AA
c
S = Humano
A = Masculino A = Femeninoc



Probabilidad condicional

Eventos independientes


TIPOS DE FRECUENCIA
La distribución de frecuencia es unadisposición tabular de datos estadísticos,ordenados ascendente o descendentemente,de acuerdo a la frecuencia de cada dato. Lasfrecuencias pueden ser:
FRECUENCIA ABSOLUTA (fi)
FRECUENCIA ACUMULADA (Fi)

FRECUENCIA ABSOLUTA (fi)
• Es el número de veces que se repite undeterminado valor de la variable (xi). Sedesigna por fi
• PROPIEDAD: la suma de todas las frecuenciasabsolutas es igual al total de observaciones(n).

FRECUENCIA ACUMULADA (Fi) • Las frecuencias acumuladas de una distribución
de frecuencias son aquellas que se obtienen delas sumas sucesivas de las fi que integran cadauna de las filas de una distribución de frecuencia,esto se logra cuando la acumulación de lasfrecuencias se realiza tomando en cuenta laprimera fila hasta alcanzar la ultima. Lasfrecuencias acumuladas se designan con las letrasFi. Se calcula:
• PROPIEDAD: La última frecuencia acumuladaabsoluta es igual al total de observaciones.

FRECUENCIA RELATIVA (hi)
Es aquella que resulta de dividir cada una delas frecuencias absolutas entre el númerototal de datos. Las frecuencias relativas sedesignan con las letras hi. Se calcula,
PROPIEDAD: la suma de todas las frecuencias relativas es igual a la unidad.

FRECUENCIA RELATIVA ACUMULADA (Hi)
• Es aquella que resulta de dividir cada una delas frecuencias acumuladas entre númerototal de datos. Se designa con las letras Hi . Secalcula;
• PROPIEDAD: La última frecuencia relativaacumulada es la unidad.

Una tabla que presenta de manera ordenadalos distintos valores de una variable y suscorrespondientes frecuencias.
Su forma mas común es la siguiente:

Tabla de frecuencias, número de hijos, que tomalos valores existentes entre 0 y 6 hijos y lasfrecuencias son el conjunto de familias



Distribución Binomial (n,p)
La distribución binomial es una distribucióndiscreta muy importante que surge en muchasaplicaciones bioestadísticas. Esta distribuciónaparece de forma natural al realizarrepeticiones independientes de unexperimento que tenga respuesta binaria,generalmente clasificada como “éxito” o“fracaso”.

Distribución Binomial (n,p)
Por ejemplo, esa respuesta puede ser el hábito de fumar(sí/no), si un paciente hospitalizado desarrolla o no unainfección, o si un artículo de un lote es o no defectuoso.La variable discreta que cuenta el número de éxitos en npruebas independientes de ese experimento, cada una deellas con la misma probabilidad de “éxito” igual a p, sigue unadistribución binomial de parámetros n y p. Este modelo seaplica a poblaciones finitas de las que se toma elementos alazar con reemplazo, y también a poblacionesconceptualmente infinitas, como por ejemplo las piezas queproduce una máquina, siempre que el proceso de producciónsea estable (la proporción de piezas defectuosas se mantieneconstante a largo plazo) y sin memoria (el resultado de cadapieza no depende de las anteriores).

Distribución Hipergeométrica (N,R,n)Suele aparecer en procesos muestrales sin reemplazo, en los que seinvestiga la presencia o ausencia de cierta característica. Piénsese, porejemplo, en un procedimiento de control de calidad en una empresafarmacéutica, durante el cual se extraen muestras de las cápsulasfabricadas y se someten a análisis para determinar su composición.
Durante las pruebas, las cápsulas son destruidas y no pueden serdevueltas al lote del que provienen. En esta situación, la variable quecuenta el número de cápsulas que no cumplen los criterios de calidadestablecidos sigue una distribución hipergeométrica. Por tanto, estadistribución es la equivalente a la binomial, pero cuando el muestreose hace sin reemplazo.
Esta distribución se puede ilustrar del modo siguiente: se tiene unapoblación finita con N elementos, de los cuales R tienen unadeterminada característica que se llama “éxito”


Distribución Geométrica (p)
Supóngase, que se efectúa repetidamente unexperimento o prueba, que las repeticiones sonindependientes y que se está interesado en la ocurrenciao no de un suceso al que se refiere como “éxito”, siendola probabilidad de este suceso p.La distribución geométrica permite calcular laprobabilidad de que tenga que realizarse un número k derepeticiones hasta obtener un éxito por primera vez. Asípues, se diferencia de la distribución binomial en que elnúmero de repeticiones no está predeterminado, sinoque es la variable aleatoria que se mide y, por otra parte,el conjunto de valores posibles de la variable es ilimitado.

Ejemplo
• Cierto medicamento opera exitosamente ante laenfermedad para la cual fue concebido en el 80% delos casos a los que se aplica; la variable aleatoria“intentos fallidos en la aplicación del medicamentoantes del primer éxito” sigue una distribucióngeométrica de parámetro p=0,8.
• Otro ejemplo de variable geométrica es el número dehijos hasta el nacimiento de la primera niña. Ladistribución geométrica se utiliza en la distribución detiempos de espera, de manera que si los ensayos serealizan a intervalos regulares de tiempo, esta variablealeatoria proporciona el tiempo transcurrido hasta elprimer éxito.

Distribución Poisson (lambda)
• La distribución de Poisson, que debe su nombre almatemático francés Simeón Denis Poisson
• (1781-1840), ya había sido introducida en 1718 porAbraham De Moivre como una forma límite de ladistribución binomial que surge cuando se observa unevento raro después de un número grande derepeticiones10. En general, la distribución de Poissonse puede utilizar como una aproximación de labinomial, Bin(n, p), si el número de pruebas n esgrande, pero la probabilidad de éxito p es pequeña;una regla es que la aproximación Poisson-binomial es“buena” si n³20 y p£0,05 y “muy buena” si n³100 yp£0,01.

Distribución Normal (Mu, Sigma)La distribución normal es la más importante del Cálculo deprobabilidades y de la Estadística, la importancia de ladistribución normal queda totalmente consolidada por ser ladistribución límite de numerosas variables aleatorias, discretas ycontinuas, como se demuestra a través de los teoremas centralesdel límite. Las consecuencias de estos teoremas implican la casiuniversal presencia de la distribución normal en todos los camposde las ciencias empíricas: biología, medicina, psicología, física,economía, etc. En particular, muchas medidas de datos continuosen medicina y en biología (talla, presión arterial, etc.) seaproximan a la distribución normal.
Parámetros:
Mu: media de la distribución,
Sigma: desviación estándar de la distribución, Sigma > 0



















