
Bioestadística
33
1 UD 3: Temas del 13 al 16: Introducción a los diseños de UD 3: Temas del 13 al 16: Introducción a los diseños de investigación y a la Estadística Inferencial: estimación investigación y a la Estadística Inferencial: estimación Diplomatura de Enfermería. Curso 1º. Diplomatura de Enfermería. Curso 1º. Catedrático: José Almenara Barrios Catedrático: José Almenara Barrios Profesor Asociado (Algeciras): Pascasio Peña González Profesor Asociado (Algeciras): Pascasio Peña González DISEÑOS BÁSICOS EN INVESTIGACIÓN 1.-Descriptivos 2.-Analíticos 3.-Experimentales Tema 13
-
Upload
juan-a-cordon -
Category
Education
-
view
715 -
download
0
Transcript of Bioestadística

1
UD 3: Temas del 13 al 16: Introducción a los diseños de UD 3: Temas del 13 al 16: Introducción a los diseños de investigación y a la Estadística Inferencial: estimacióninvestigación y a la Estadística Inferencial: estimación
Diplomatura de Enfermería. Curso 1º.Diplomatura de Enfermería. Curso 1º.Catedrático: José Almenara BarriosCatedrático: José Almenara BarriosProfesor Asociado (Algeciras): Pascasio Peña GonzálezProfesor Asociado (Algeciras): Pascasio Peña González
DISEÑOS BÁSICOS EN INVESTIGACIÓN
1.-Descriptivos
2.-Analíticos
3.-Experimentales
Tema 13

2
DISEÑOS DESCRIPTIVOS
Estudios Descriptivos
1.-Transversales o estudios de prevalencia
2.-Estudios de tamizado3.-Series de Casos clínicos
4.-Estudios ecológicos
ESTUDIOS TRANSVERSALES
En los estudios transversales o de prevalencia estudiamos habitualmente la relación entre una enfermedad y un conjunto de variables en una
población dada. Una de las características fundamentales de este diseño, es que la exposición y la enfermedad se observan
simultáneamente, lo que dificulta la posibilidad de establecer relaciones causales. No existe
período de seguimiento en un estudio transversal, por lo tanto falta la secuencia
temporal.

3
--PREVALENCIA PUNTUALPREVALENCIA PUNTUAL• Es la proporción de casos existentes (anteriores y
nuevos) en una población en un único punto en el tiempo.
ESTUDIOS TRANSVERSALES
Nº de casos existentes en una población
definida en un momento o punto de tiempo (t)
P = = = = Nº total de personas en la población definida en
el momento (t) ( o población a riesgo)
ESTUDIOS TRANSVERSALES
Ventajas1.-Se pueden llevar a cabo en muestras representativas de la
población, lo que permite generalizaciones con mayor validez.
2.-Se realizan en períodos de tiempo cortos.
3.-Suelen tener un coste bajo.
4.-Puede poner en evidencia relaciones transversales de interés, que se configuran como hipótesis para otro tipo de diseños.

4
ESTUDIOS TRANSVERSALES
Desventajas
1.-Presentan dificultad para establecer relaciones causales.
2.-No son útiles para estudiar enfermedades de baja incidencia.
3.-Estudian solo los casos existentes en ese momento (casos prevalentes).
4.-La posibilidad de desviarse de la realidad (incurrir en sesgos) es mayor que en otros diseños.
ESTUDIOS DE TAMIZADO
Entendemos aquí como estudios de tamizado la realización de un cribado a poblaciones de individuos aparentemente sanos con objeto de identificar personas con alto riesgo de padecer una enfermedad en sus fases iniciales

5
SERIE DE CASOS CLÍNICOS
1. Es un tipo especial de estudio descriptivo donde la muestra se obtiene de una población de enfermos en lugar de una población general.
2. Suelen ser estudios longitudinales y no transversales, que presentan información recopilada a lo largo del tiempo en un servicio u hospital.
3. La gran desventaja de este tipo de estudio es la carencia de grupo control, por lo que pueden generar hipótesis pero tienen dificultades para verificarlas.
ESTUDIOS ECOLÓGICOS
La característica fundamental de los estudios ecológicos es que la unidad de análisis no viene representada por un individuo sino por conjunto de sujetos, siendo estas agrupaciones generalmente de naturaleza geográfica (pueblos, Comunidades, ciudades, Zonas Básicas de Salud, etc..). A veces la información que se requiere se encuentra disponible en anuarios estadísticos o en otro tipo de soportes, por lo que su análisis es relativamente fácil.

6
ESTUDIOS ECOLÓGICOS
1.-Diseños ecológicos de grupos múltiples:1.1.-Exploratorios Tasas de mortalidad o enfermedad entre diferentes
regiones durante el mismo periodo de tiempo, con el fin último de buscar patrones diferentes que puedan sugerir hipótesis etiológicas
1.2.-AnalíticosAsociación llamada ecológica entre el nivel promedio
de exposición o prevalencia a un factor y las tasas de enfermedad o mortalidad en los grupos, habitualmente en una región geográfica.
ESTUDIOS ECOLÓGICOS
Skrabanek, McCormick, 1992

7
ESTUDIOS ECOLÓGICOS
2.-De tendencia temporal o series temporales2.1.-ExploratoriosSe compara las tasas de enfermedad o mortalidad a lo
largo del tiempo en una población definida, construyendo posteriormente gráficas de series temporales.
2.2.-AnalíticosLa asociación ecológica entre la prevalencia de una
exposición a lo largo del periodo de estudio y el cambio en la tasa de enfermedad o mortalidad.
Evolución de la mortalidad en España. (1900-1920)
0
5
10
15
20
25
30
35
1900 1901 1902 1903 1904 1905 1906 1907 1908 1909 1910 1911 1912 1913 1914 1915 1916 1917 1918 1919 1920
Años
TM
G p
or m
il.
32,091919
32,321918
26,211917
T.M.G.Años• Mortalidad en San Fernando
(1917,1918,1919)• Fuentes: I.N.E. y Registro Civil.

8
Estudios de casos y controles.Estudios de casos y controles.
Denominados también estudios de caso control, de caso compañero, caso referencia o estudio retrospectivo..
DISEÑOS ANALÍTICOS
Perea-Milla, 1998
Estudios de casos y controles. Ventajas.Estudios de casos y controles. Ventajas.
1.1.--Es una forma barata y sencilla de estudiar Es una forma barata y sencilla de estudiar fenfenóómenos raros, es decir enfermedades de muy baja menos raros, es decir enfermedades de muy baja prevalencia y/o un periodo de latencia muy largo prevalencia y/o un periodo de latencia muy largo entre la exposicientre la exposicióón y la aparicin y la aparicióón de la enfermedad. n de la enfermedad.
2.2.--Es de gran utilidad para generar hipEs de gran utilidad para generar hipóótesis que tesis que puedan verificarse con posterioridad, dada la gran puedan verificarse con posterioridad, dada la gran cantidad de mediciones que podemos hacer en ambos cantidad de mediciones que podemos hacer en ambos grupos y por lo tanto evaluar mgrupos y por lo tanto evaluar múúltiples factores que ltiples factores que pueden desencadenar una sola enfermedad. pueden desencadenar una sola enfermedad.
DISEÑOS ANALÍTICOS

9
Estudios de casos y controles. Debilidades.Estudios de casos y controles. Debilidades.
1.-No permite calcular ni la incidencia, ni la prevalencia ni el riesgo relativode una enfermedad, dada las características de selección de los individuos.
2.-No permiten evaluar factores asociados a más de una enfermedad, ya que sólo intervienen sujetos enfermos de una sola patología.
3.-Existe una posibilidad importante de introducir sesgos, que ha de estar presente para intentar controlarlos en las fases de diseño y de análisis.
DISEÑOS ANALÍTICOS
Estudios de cohortes.Estudios de cohortes.Llamados también estudios prospectivos, se caracterizan
en contraste con los estudios de casos y controles porque miran hacia adelante en el tiempo
DISEÑOS ANALÍTICOS
Perea-Milla, 1998

10
Estudios de cohortes. Ventajas.Estudios de cohortes. Ventajas.
1.-Admiten el verdadero calculo de la incidencia tanto en el grupo de los expuestos como en el de los no expuestos, lo que permite el calculo del riesgo relativo.
2.-Nos permite establecer una correcta secuencia temporal entre el factor ( que actúa como causa) y el efecto o enfermedad final.
3.-Conlleva el poder evaluar la posible relación entre una causa con varias enfermedades.
4.-Y podemos evaluar la existencia de una relación dosis-respuesta, es decir sujetos con un mayor tiempo de exposición o una exposición más elevada sufren la enfermedad estudiada con mayor frecuencia.
DISEÑOS ANALÍTICOS
Estudios de cohortes. Debilidades.Estudios de cohortes. Debilidades.1.-No se muestran útiles para el estudio de enfermedades
raras, ya que se podría dar el caso de largos periodos de espera para obtener sólo un caso de la enfermedad.
2.-Son estudios largos en el tiempo.3.-Requieren un número elevado de participantes, ya que
al tener que dejar correr el tiempo se obtienen perdidas a lo largo de estudio: fallecimientos, cambios de domicilio, incumplimiento de controles, etc.
4.-Por las propias características del tipo de diseño suelen tener un coste elevado.
DISEÑOS ANALÍTICOS

11
1.-En este tipo de diseño el investigador manipula la variable independiente o variable predictora (la intervención que llevamos a cabo) y observa el efecto de dicha manipulación.
2.-En general el objetivo de este tipo de estudios es evaluar la eficacia de un tratamiento, de una intervención rehabilitadora o preventiva.
3.-Son por su estructura los que mejor permiten establecer relaciones de naturaleza causal siendo los más óptimos para controlar la influencia de variables de confusión.
ESTUDIOS EXPERIMENTALES
ENSAYO CLÍNICO ALEATORIO (ECA)
Argimon, Jiménez, 2000
Enmascaramientoo ciego

12
MUESTREO EN BIOESTADÍSTICA
POBLACIÓNµ, σ2,π
MUESTRAx , s2, p
AZAR INFERENCIAESTADÍSTICA
PROBABILIDADPredicción
Tema 14
Universo: Conjunto de individuos(personas, células, historias clínicas, etc.) de los cuales queremos conocer cierta información y generalmente inaccesible en su totalidad para el investigador. También recibe el nombre de población objetivo o poblaciónsimplemente.
Muestra: Subconjunto representativode la población, formado por individuos elegidos mediante alguna de las técnicas de muestreo. El objetivo último de seleccionar una muestra es permitir al investigador conocer determinadas características del universo. El poder trabajar con una muestra conlleva una serie de ventajas como, reducir costes en la investigación, agilizar el trabajo y ahorrar tiempo. A la muestra también se le llama población muestral.

13
unidad de análisisa todo sujeto que forma parte de la población, que a su vez forman parte de una y sola unidad de muestreoo divisiones en las que partimos a la población original, de forma que el conjunto completo de unidades de muestreo constituyen el marco muestral.
marco muestral
unidad de análisis
unidad de muestreo
TIPOS DE MUESTREO
1.-Muestreos probabilísticos, donde las muestras son seleccionadas mediante técnicas aleatorias, es decir, interviene el azar a la hora de seleccionar a los sujetos que formarán parte de la muestra.
2.-Muestreos no probabilísticos, la selección de las muestras no se realiza mediante técnicas aleatorias, o estas intervienen solo en parte del proceso de selección (semiprobabilístico).

14
MUESTREOS PROBABILÍSTICOS
1.-Muestreo aleatorio simple.
2.-Muestreo aleatorio sistemático.
3.-Muestreo aleatorio estratificado.
4.-Muestreo aleatorio por conglomerados.
MUESTREOS PROBABILÍSTICOS
Muestreo aleatorio simple.
1.-Equiprobabilístico
2.-Sin o con reemplazamiento
3.-Tener un censo de la población
4.-Tabla de dígitos aleatorios
En definitiva pretendemos obtener una muestra de tamaño n, procedente de una población de N sujetos, de forma que n≤ N .

15
MUESTREOS PROBABILÍSTICOS
Muestreo aleatorio sistemático. 1.-Variante del anterior. Sistematización sencilla.2.-Enumerar los elementos poblacionales de 1 a N .3.-Constante de muestreo o coeficiente de elevación,
dada por el cociente N/n4.-Un número aleatorio z no superior a la constante de
muestreo (arranque aleatorio)5.-Sumar a z la constante de muestreo, y así
sucesivamente hasta obtener la sucesión de tamaño n pretendida.
MUESTREOS PROBABILÍSTICOS
Muestreo aleatorio sistemático.
N =10.000 enfermeros/as
n = 1.000
Cte = 10
z=7, 7+ 10 = 17 , 17 + 10 = 27

16
MUESTREOS PROBABILÍSTICOS
Muestreo aleatorio sistemático.
Sánchez (1973): “La selección sistemática tiene las ventajas de extender la muestra sobre toda la población, ser de fácil aplicación, y conseguir un efecto similar a la estratificación si las unidades se han ordenado previamente siguiendo un cierto criterio”.
MUESTREOS PROBABILÍSTICOS
Muestreo aleatorio estratificado.
1.-Dividimos la población en subgrupos o estratos.
2.-Dentro de cada uno de ellos seleccionamos una muestra de manera aleatoria.
3.-Variabilidad entre los estratos debe ser lo más alta posible, es decir la variabilidad intraestrato debe ser lo más baja posible.

17
MUESTREOS PROBABILÍSTICOS
K = 3
N
n1 n2 n3
MUESTREOS PROBABILÍSTICOS
Muestreo aleatorio estratificado.
Tres ventajas fundamentales, (Münch, 1988):
1.-Facilitamos la recolección y análisis de los datos.
2.-Obtenemos estimaciones más precisas de los parámetros poblacionales, ya que la variabilidad dentro de cada estrato es menor que la poblacional.
3.-Obtenemos estimadores separados para los parámetros de cada estrato sin seleccionar otra muestra.

18
MUESTREOS PROBABILÍSTICOS
Muestreo aleatorio por conglomerados.
1.-La unidad de muestreo no son individuos, sino un conjunto de individuos.
2.-En esencia este tipo de muestreo consiste en elegir al azar un conjunto de conglomerados.
3.-Para mantener la precisión es necesario que el conglomerado sea lo más heterogéneo posible.
MUESTREOS PROBABILÍSTICOS
BAJAALTA
CONGLOMERADOS
ALTABAJA
ESTRATOS
Variabilidad
INTER
Variabilidad
INTRA
Tipo de Variabilidad
Según diseño.

19
MUESTREOS NO PROBABILÍSTICOS
1.-En este tipo de muestreo se selecciona a las unidades que forman parte de la muestra de manera no aleatoria.
2.-Las muestra son seleccionadas basándonos en criterios de comparabilidad y no de aleatoriedad.
TIPOS
1.-Muestreo consecutivo
2.- Muestreo por cuotas
3.-Voluntarios
ESTIMACIÓN DE PARÁMETROS. CONCEPTO DE ESTIMADOR
POBLACIÓNµ, σ2,π
MUESTRAx , s2, p
AZAR INFERENCIAESTADÍSTICA
PROBABILIDADPredicción
Tema 15
20
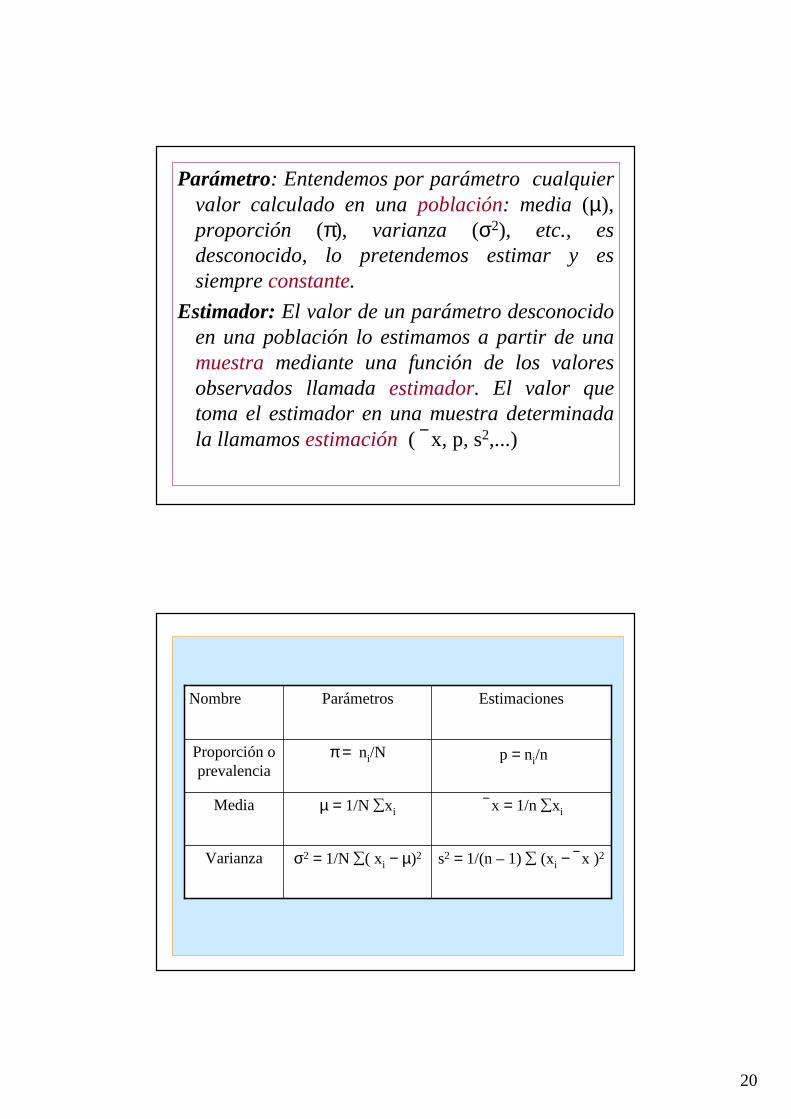
Parámetro: Entendemos por parámetro cualquier valor calculado en una población: media (µ),proporción (π), varianza (σ2), etc., es desconocido, lo pretendemos estimar y es siempre constante.
Estimador:El valor de un parámetro desconocido en una población lo estimamos a partir de una muestra mediante una función de los valores observados llamada estimador. El valor que toma el estimador en una muestra determinada la llamamos estimación( x, p, s2,...)
s2 = 1/(n – 1) ∑ (xi − x )2σ2 = 1/N ∑( xi − µ)2Varianza
x = 1/n ∑xiµ = 1/N ∑xiMedia
p = ni/nπ = ni/NProporción o prevalencia
EstimacionesParámetrosNombre

21
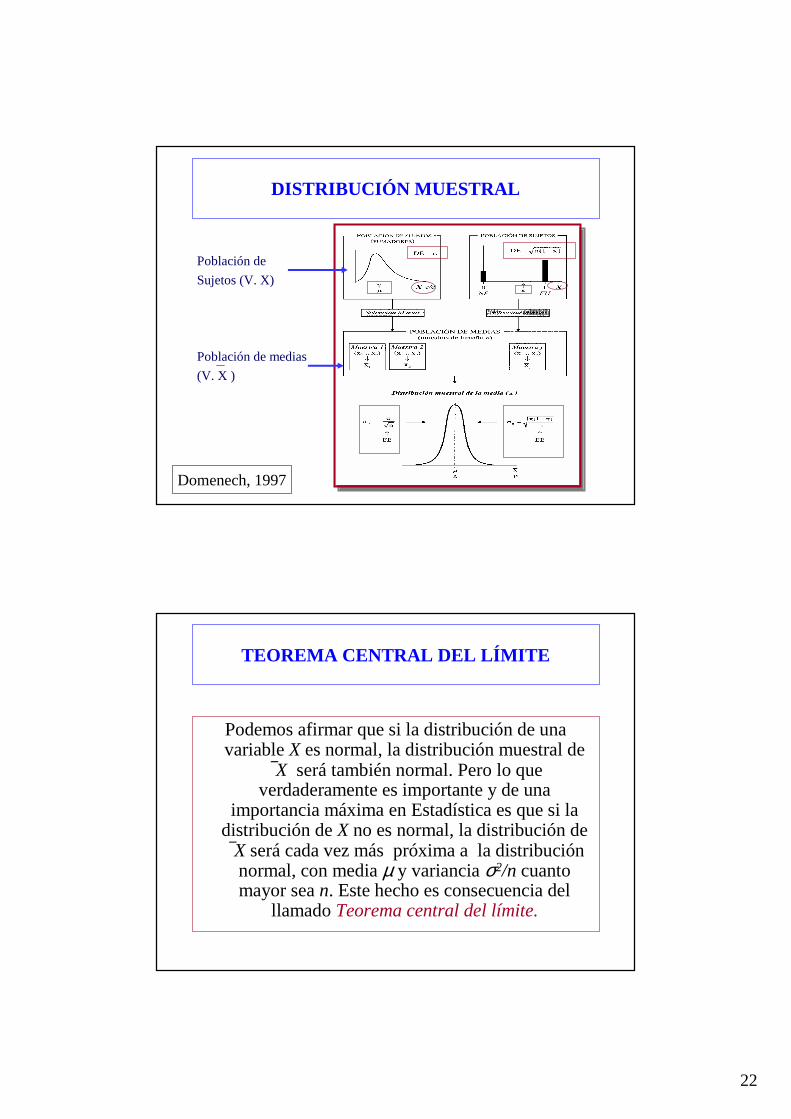
DISTRIBUCIÓN MUESTRAL
De una manera general llamamos distribución muestralde un estadístico, que puede ser la media, la proporción, etc., a la distribución de los valores obtenidos al calcular el estadístico en todas las posibles muestras, de un mismo tamaño, extraídas aleatoriamente de la población.
DISTRIBUCIÓN MUESTRAL
V.a. X
E(X) = µ
σ2
V(X) = .n
22
DISTRIBUCIÓN MUESTRAL
Población de
Sujetos (V. X)
Población de medias
(V. X )
Domenech, 1997
TEOREMA CENTRAL DEL LÍMITE
Podemos afirmar que si la distribución de una variable X es normal, la distribución muestral de
X será también normal. Pero lo que verdaderamente es importante y de una
importancia máxima en Estadística es que si la distribución de X no es normal, la distribución de X será cada vez más próxima a la distribución
normal, con media µ y variancia σ2/n cuanto mayor sea n. Este hecho es consecuencia del
llamado Teorema central del límite.

23
TEOREMA CENTRAL DEL LÍMITE
ContinuasVariables no normales
n ≥ 30
Cualitativasnπ ≥ 5 y n( 1-π) ≥ 5.
Domenech, 1997
Dado que conocemos que la distribución muestral sigue en líneas generales una distribución normal, podemos preguntarnos cuál es el intervalo que contiene el 95% de todas las medias observablesen infinitas muestras.
Sabemos que en la distribución normal tipificada nosotros podemos buscar un intervalo simétrico, que si queremos que cumpla la condición impuesta en el párrafo anterior (contener el 95% de todas las medias posibles), tiene un valor de probabilidad 1−α .
INTERVALO DE PROBABILIDAD
P( − zα/2 ≤ z ≤ zα/2) =1−α

24
INTERVALO DE PROBABILIDAD
x − µz = .
σ / √ n
x − µP( − zα/2 ≤ ≤ zα/2) =1−α.
σ/√ n
P(µ−zα/2 σ/√ n ≤ x ≤ µ +zα/2 σ/√ n) = 1 −α.
INTERVALO DE PROBABILIDAD
IP1-α de x : µ ± zα/2 σ/ √ n
Por lo tanto este único intervalo contiene a la mayor parte de las posibles medias muestrales (95%), procedentes de muestras del mismo tamaño n y para un nivel α fijado (0,05 en nuestro caso) que representa la probabilidad de que las observaciones caigan fuera del intervalo construido.
De manera análoga
IP1-α de p : π±zα/2 √ π(1-π)/ n

25
• Nos resuelve el problema de la predicción.
• Parte del parámetro conocido de la población.
• Contiene la mayor parte de las medias, proporciones,...en muestras de tamaño n.
• Para cada valor n y α fijados, existe un único intervalo de probabilidad.
• Siendo α la probabilidad de que las observaciones caigan fuera del intervalo construido.
INTERVALO DE PROBABILIDAD
n = 100 , µ = 70 Kg., σ = 9Kg.
Para un α = 0,05, sabemos que z = 1,96, luego:
IP1 −α de x : 70 ± 1,96 × 9/√100 = 68,23 : 71,76.
Es decir los extremos del intervalo de probabilidad calculado son 71,76 Kg. y 68,32 Kg., por lo que podemos afirmar que el 95% de las posibles medias muestrales estarían comprendidas entre
esos dos valores.
Sabemos que en la población andaluza, el peso de las mujeres sanas, sigue una distribución normal de media 70Kg y desviación típica 9Kg. Se quiere determinar entre qué valores se encuentra el 95% central de todas las medias que podemos obtener con muestras aleatorias de tamaño 100.

26
Lo que asumimos al calcular un intervalo de confianza es que si obtuviéramos un número de muestras extraídas al azar de una misma población con un valor constante en un parámetro, el 95% ( ó 99%) de los intervalos de confianza construidos contienen el valor del parámetro que buscamos y sólo en un 5% ( ó 1%) de los casos el intervalo no contendría el verdadero valor del parámetro.
INTERVALO DE CONFIANZA
P( − zα/2 ≤ z ≤ zα/2) =1−α
Tema 16
INTERVALO DE CONFIANZA
x − µz = .
σ / √ n
x − µP( − zα/2 ≤ ≤ zα/2) =1−α.
σ/√ n
P(−zα/2 σ/√ n ≤ x − µ ≤ zα/2 σ/√n ) = 1 −α.

27
INTERVALO DE CONFIANZA
Como buscamos entre que valores se encuentra µ restamos de todos los miembros x y obtenemos,
P( −x −zα/2 σ/√ n ≤ −µ ≤ −x + zα/2 σ/√ n ) = 1 −α.
Si multiplicamos por − 1 y ordenamos, obtenemos:
P( x − zα/2 σ/√ n ≤ µ ≤ x + zα/2 σ/√ n ) = 1 −α.
IC1 − α de µ : x ± zα/2 σ/√ n
INTERVALO DE CONFIANZA
Armitage, 1997
28
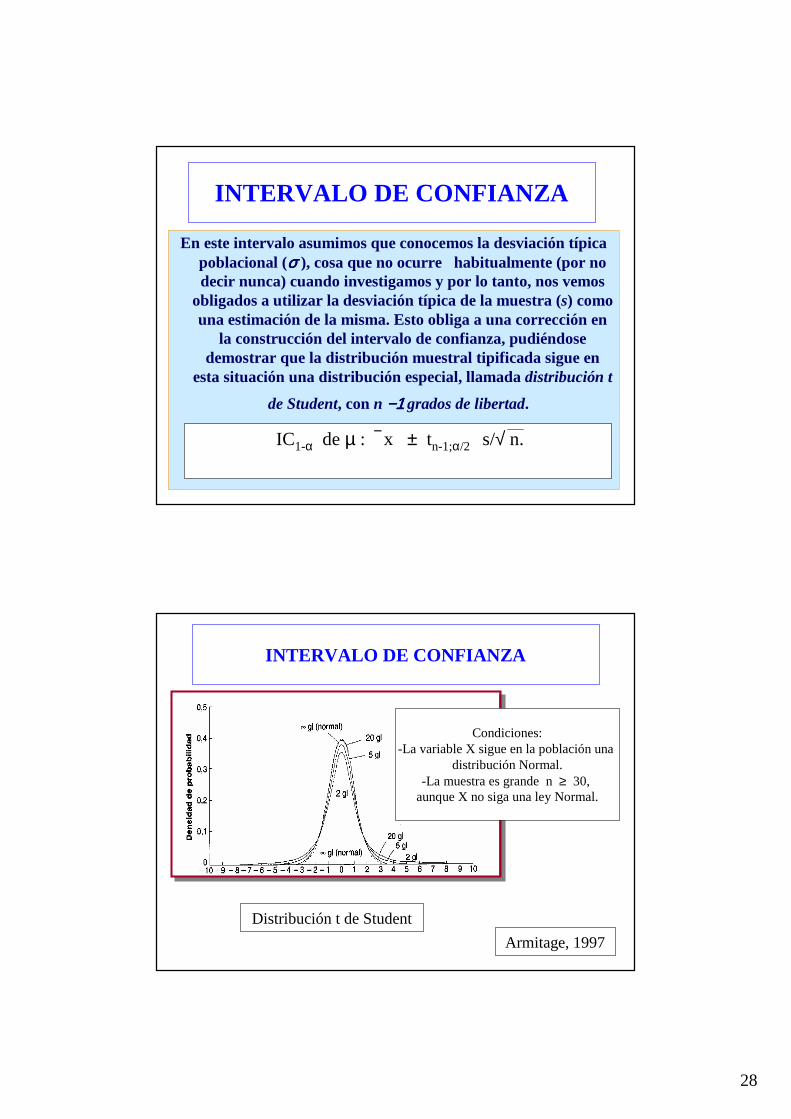
En este intervalo asumimos que conocemos la desviación típica poblacional (σσσσ ), cosa que no ocurre habitualmente (por no decir nunca) cuando investigamos y por lo tanto, nos vemos
obligados a utilizar la desviación típica de la muestra (s) como una estimación de la misma. Esto obliga a una corrección en
la construcción del intervalo de confianza, pudiéndose demostrar que la distribución muestral tipificada sigue en
esta situación una distribución especial, llamada distribución t
de Student, con n −1−1−1−1 grados de libertad.
INTERVALO DE CONFIANZA
IC1-α de µ : x ± tn-1;α/2 s/√ n.
INTERVALO DE CONFIANZA
Armitage, 1997
Distribución t de Student
Condiciones:-La variable X sigue en la población una
distribución Normal.-La muestra es grande n ≥ 30,
aunque X no siga una ley Normal.

29
INTERVALO DE CONFIANZA
La construcción del intervalo de confianza para estimar πse basa en criterios similares al estudiado para construir el intervalo de confianza para una media. Sabemos que la distribución muestral de las estimaciones puntuales p de muestras de tamaño n sigue una distribución normal
N (π, √ π(1−π)/n). Por lo que, podemos construir un intervalo tal que;
INTERVALO DE CONFIANZA
IC1 − α de π : p± zα/2 √ p q/n.
Siendo q igual a 1 − p.

30
• Nos resuelve el problema de la estimación.
• Partimos de la media, proporción, etc., obtenida de una muestra de tamaño n.
• Para cada valor n y α fijados, existen infinitos intervalos de confianza.
• Tiene gran probabilidad de contener el parámetro desconocido de la población origen de la muestra.
• Siendo α la probabilidad de que el intervalo no contenga al parámetro desconocido.
INTERVALO DE CONFIANZA
En una investigación se procedió a determinar diferentes medidas antropométricas en una muestra de 124 sujetos hipertensos. De ellas, el perímetro del abdomen presentaba una media de 108 cm con una D.E. de 11 cm. ¿Cuál será el intervalo de confianza que contiene el valor de la media poblacional?. Nivel de confianza del 95%.
n = 124, x = 108 cm., s = 11cm.Para α = 0,05 , y 123 grados de libertad t = 1,98
IC1 −α de µ : 108 ± 1,98 × 11/√ 124 = 106 – 110 cm.
Que se interpreta, como que la media poblacional del perímetro del abdomen de los sujetos hipertensos, se sitúa con una confianza del 95% entre los valores: 106 y 110 cm.

31
Se ha determinado en una muestra de 129 casos diagnosticados de esquizofrenia paranoide dados de alta en un hospital básico, que en 22 ocasiones precisan un reingreso. ¿Cuál será el intervalo de confianza de la prevalencia de los reingresos en la entidad clínica esquizofrenia paranoide?. Nivel de confianza del 95%.
n = 129, p = 22/129 = 0,171.Para α = 0,05, z = 1,96, luego:
IC1 −α de π: 0,171 ± 1,96 √0,171 × 0,829/129 = = 0,106 - 0,235
Que se interpreta, como que la prevalencia de reingresos en los pacientes dados de alta por esquizofrenia
paranoide se sitúa entre un 10,6% y un 23,5%, con una confianza del 95%.
e = 4,6%35,7 ± 4,6 = 31,1- 40,3%
Luego puede ser inclusoINFERIOR AL 31,4%• Supongamos que 31,4 se obtuvo con una muestra
que produjo tal estimación con un error de un 6,0%
e = 6 %31,4 ± 6 = 25,4 – 37,4 %
LUEGO DETRAS DE LA AFIRMACIÓN DE ARRIBA PODRÍA ESTAR “BAJÓ DEL 36 AL
31,2%”.
A partir de una rigurosa muestra aleatoria de 100.000 personas, los expertos han estimado que el porcentaje de votos para el partido X subió de 31,4 a 35,7 %

32
Cálculo del tamaño de una muestra
Sabemos que IC1 − α ( µ) = (x ± zα/2 σ/√ n ),
luego:
e ≤ zα/2 σ/√ n
n ≥ (zα/2 σ)2/e2
Cálculo del tamaño de una muestra
Como generalmente no se conoce el valor de la varianza poblacional:
n ≥ (zα/2 s)2/e2
Análogamente para calcular el tamaño de muestra en la estimación de una proporción:
n ≥ (zα/2)2pq/e2

33
n ≥ (zα/2 σ)2/e2
n ≥ (1.96 x 14)2/22=188,24
Luego se necesitan del orden de 189 sujetos para poder estimar la media con las condiciones establecidas.
Calcular el tamaño de muestra necesario para poder estimar con una precisión de 2Kg el peso medio de individuos de una determinada población. En un estudio piloto previo se determina que la desviación típica era de 14kg. El nivel de confianza se establece en un 95%.
n ≥ (zα/2)2pq/e2
n ≥ (1.96)2 x 0.2 x 0.8 /0.032 = 683
Luego se necesitan del orden de 683 sujetos para poder estimar la proporción con las condiciones establecidas.
Se desea estimar el tamaño de muestra necesario para conocer la prevalencia de sujetos con hipertensión que desconocen tener dicha enfermedad. Sabemos que en la población general los sujetos no diagnosticados se acercan al 20%. Queremos tener una precisión del 3% y un nivel de confianza del 95%.


















