
Classificador de Bayes - vision.ime.usp.brnina/cursos/ibi5031-2007/pr.pdf · Teorema de Bayes...
25
Cap´ ıtulo 1 Classificador de Bayes Vers˜ ao de 18 de setembro de 2007 1.1 Revis˜ ao de Probabilidade e Estat´ ıstica Experimento Espa¸ co amostral Evento Probabilidade Distribui¸ c˜ ao de probabilidade Distribui¸ c˜ oes conjuntas, distribui¸ c˜ oes condicionais, distribui¸ c˜ oes marginais Independˆ encia estat´ ıstica Teorema de Bayes Esperan¸ ca, variˆ ancia, covariˆ ancia, correla¸ c˜ ao Amostras, amostras i.i.d. Estat´ ıstica amostral Referˆ encia indicada: qualquer bom livro de introdu¸ c˜ ao ` a probabilidade e estat´ ıstica. Por exem- plo, [DeGroot, 1989, Meyer, 1969]. 1.2 Classifica¸ c˜ ao Bayesiana Sejam padr˜ oes x =(x 1 ,x 2 ,...,x d ) ∈ R d e classes {ω 1 ,ω 2 ,...,ω c }. Em reconhecimento de padr˜ oes ou classifica¸ c˜ ao, estamos interessados em associar a um padr˜ ao uma classe. A abordagem Bayesiana sup˜ oe que as probabilidades de cada classe P (ω i ) e as densidades de pro- babilidade condicionais p(x|ω i ) de x com respeito a cada uma das classes ω i , i =1, 2,...,c, s˜ ao conhecidas. Na ausˆ encia de qualquer outra informa¸ c˜ ao, poder´ ıamos classificar um padr˜ ao x como sendo da classe ω i 1
Transcript of Classificador de Bayes - vision.ime.usp.brnina/cursos/ibi5031-2007/pr.pdf · Teorema de Bayes...

Capıtulo 1
Classificador de Bayes
Versao de 18 de setembro de 2007
1.1 Revisao de Probabilidade e Estatıstica
Experimento
Espaco amostral
Evento
Probabilidade
Distribuicao de probabilidade
Distribuicoes conjuntas, distribuicoes condicionais, distribuicoes marginais
Independencia estatıstica
Teorema de Bayes
Esperanca, variancia, covariancia, correlacao
Amostras, amostras i.i.d.
Estatıstica amostral
Referencia indicada: qualquer bom livro de introducao a probabilidade e estatıstica. Por exem-plo, [DeGroot, 1989, Meyer, 1969].
1.2 Classificacao Bayesiana
Sejam padroes x = (x1, x2, . . . , xd) ∈ Rd e classes {ω1, ω2, . . . , ωc}. Em reconhecimento de padroes ouclassificacao, estamos interessados em associar a um padrao uma classe.
A abordagem Bayesiana supoe que as probabilidades de cada classe P (ωi) e as densidades de pro-babilidade condicionais p(x|ωi) de x com respeito a cada uma das classes ωi, i = 1, 2, . . . , c, saoconhecidas.
Na ausencia de qualquer outra informacao, poderıamos classificar um padrao x como sendo da classe ωi
1

de maior probabilidade. Porem, dado que x foi observado, isto parece uma decisao muito ingenua (acer-tarıamos a classificacao com probabilidade P (ωi), porem errarıamos com probabilidade
∑j 6=i P (ωj)).
Como temos as condicionais, podemos utilizar o teorema de Bayes e calcular a probabilidade P (ωi|x),ou seja,
P (ωi|x) =P (ωi)p(x|ωi)
p(x)
na qual P (ωi) e a priori, p(x|ωi) e a densidade condicional ou verossimilhanca, p(x) =∑c
j=1 P (ωj)p(x|ωj)e a evidencia e P (ωi|x) e a posteriori, e tomar a decisao baseada nesses a posterioris.
1.2.1 Regra de decisao de Bayes para mınima taxa de erro
A regra de decisao de Bayes que resulta em mınima taxa de erro e dada por
Decidir ωi se P (ωi|x) ≥ P (ωj |x) para todo j 6= i
[Definir taxa de erro e incluir a demonstracao de que essa decisao realmente minimiza a taxa de erro!]
1.2.2 Regra de decisao de Bayes para risco mınimo
Enquanto a taxa de erro leva em conta apenas se a clasificacao esta correta ou nao, ha situacoesem que diferentes tipos de erro (por exemplo, falso positivo e falso negativo em caso de diagnosticomedico) nao sao necessariamente igualmente graves. Nessas situacoes, podemos ter preferencia porerros menos graves.
Para acomodar casos como esses, podemos considerar a regra de decisao de Bayes que envolve oconceito de perda. Considera-se um conjunto de acoes {α1, α2, . . . , αa} e funcoes de perda dadospor
λ(αi|ωj),
ou seja, funcoes que definem a perda associada a acao αi quando a classe verdadeira da observacao eωj .
A perda media ou risco condicional de uma acao αi com respeito a um dado padrao x e dada por
R(αi|x) =c∑
j=1
λ(αi|ωj)P (ωj |x)
e o risco total e dado por
R =∫
R(α(x)|x)p(x)dx
na qual α(x) e uma funcao que associa uma acao ao padrao x.
Desta forma, a regra de decisao de Bayes para o caso geral consiste na minimizacao do risco total,que pode ser obtido minimizando-se os riscos condicionais. Ou seja, deve-se calcular R(αi|x) parai = 1, 2, . . . , a, e escolher a acao αi para a qual o risco condicional R(αi|x) e mınimo.
A regra de decisao de Bayes para mınima taxa de erro e apenas um caso particular dessa formulacaogeral. Basta considerarmos αi como sendo a acao correspondente a escolher a classe ωi e a funcao deperda
λ(αi|ωj) ={
1, se i 6= j,0, se i = j.
2

1.3 Funcoes discriminantes
Uma forma para se representar classificadores e atraves de funcoes discriminantes. Se temos c classes,entao podemos considerar funcoes gi(x), i = 1, 2, . . . , c, e classificar um padrao x como sendo da classeωi se gi(x) > gj(x) para todo j 6= i.
O classificador de Bayes pode ser representado pelas funcoes discriminantes
gi(x) = P (ωi|x), i = 1, 2, . . . , c
para o caso da mınima taxa de erro e pelas funcoes
gi(x) = −R(αi|x), i = 1, 2, . . . , c
para o caso geral (risco mınimo).
Observe ainda que, dado um conjunto de funcoes discriminantes, se essas forem transformadas poruma mesma funcao monotonicamente crescente a relacao de ordem entre elas se mantem. Dessa forma,pode-se simplificar as funcoes discriminantes. Por exemplo, no caso do classificador de Bayes paramınima taxa de erro, as funcoes discriminantes
gi(x) = P (ωi|x) =P (ωi)p(x|ωi)
p(x)
gi(x) = P (ωi)p(x|ωi)
gi(x) = lnP (ωi) + ln p(x|ωi)
sao equivalentes em termos de discriminacao.
Note tambem que se c = 2 (caso de suas classes), entao em vez de considerarmos duas funcoesdiscriminantes g1(x) e g2(x), podemos considerar apenas uma funcao discriminante g(x) = g1(x) −g2(x) e classificar um padrao x como sendo da classe ω1 se g1(x) > 0 e como sendo da classe ω2 emcaso contrario.
Os classificadores geram o que chamamos de regiao de decisao Ri. Em termos das funcoes discri-minantes, a regiao Ri, i = 1, 2, . . . , c, e definida por
Ri = {x ∈ Rd : gi(x) > gj(x) para todo j 6= i}
Essas regioes nao sao necessariamente conexas e formam uma particao do espaco Rd (ou seja, Ri∩Rj =∅ se i 6= j, ∪c
i=1Ri = Rd).
Os pontos nos quais gi(x) = gj(x) sao denominados de fronteiras de decisao (ou superfıcies dedecisao).
1.4 Distribuicoes condicionais gaussianas
A seguir consideramos o caso em que a condicional p(x|ωi) e uma densidade normal (gaussiana).O estudo dessa classe de densidades em reconhecimento de padroes recebe muita atencao pelo fatodessa dsitribuicao poder ser tratada analiticamente, pelo fato de muitas vezes os dados observadospoderem ser considerados perturbacoes aleatorias de um prototipo µ e tambem pelo fato de estatısticasamostrais (como a media amostral) possuırem uma distribuicao aproximadamente normal (devido aoTeorema do limite central).
3

1.4.1 Normal univariada
Denotada usualmente por N(µ, σ2), a funcao densidade de probabilidade normal com media µ evariancia σ2 e dada por
p(x) =1√2πσ
exp{− 1
2(x− µ
σ)2
}, x ∈ R
1.4.2 Normal multivariada
Denotada usualmente por N(µ,Σ), a funcao densidade de probabilidade normal com media µ e matrizde covariancia Σ e dada por
p(x) =1
(2π)d/2|Σ|1/2exp
{− 1
2(x− µ)tΣ−1(x− µ)
}, x ∈ Rd
na qual x = (x1, x2, . . . , xd) ∈ Rd, µ ∈ Rd e o vetor de medias, Σ e uma matriz d× d, Σ−1 e a inversade Σ, |Σ| e o determinante de Σ, e (x− µ)t e o vetor transposto de x− µ.
A matriz de covariancia e dada por Σ = (σij)di,j=1 com σii = E[(xi − µi)2] (variancia da componente
xi) e σij = E[(xi − µi)(xj − µj)], i 6= j, a covariancia entre as componentes xi e xj .
Como σij = σji, a matriz de covariancia e simetrica. Mais ainda, ela e tambem positiva semi-definida.
Lembrete: Uma matriz A e positiva definida se xtAx > 0 para todo x 6= 0. E positiva semi-definida se xtAx ≥ 0 para todo x 6= 0.
Os auto-valores de matrizes positivas definidas sao positivas.
Toda matriz positiva definida e inversıvel e sua inversa e tambem positiva definida.
Lembrete: Uma matriz A e simetrica se At = A.
Os autovetores de auto-valores distintos de uma matriz simetrica sao ortogonais.
Se (λi, ei) sao os pares de auto-valores e respectivos auto-vetores da matriz de covariancia Σ de umanormal mutivariada, pode-se mostrar que (1/λi, ei) sao os pares de auto-valores e respectivos auto-vetores da matriz Σ−1.
No caso bivariado, a figura 1.1 mostra as elipses para as seguintes matrizes de covariancia:
a) Σ =[
2 00 2
]b) Σ =
[4 00 2
]c) Σ =
[2 00 4
]d) Σ =
[2 .75
.75 2
]e) Σ =
[2 .75
.75 4
]f) Σ =
[2 −2−2 4
]As elipses correspondem aos contornos com uma densidade constante, ou seja, sao os pontos x nosquais (x− µ)tΣ−1(x− µ) = c2.
No caso multivariado, pode-se mostrar que essas elipsoides tem centro em µ e eixos ±c√
λiei (na qualλi e um auto-valor de Σ e ei e o correspondente auto-vetor).
4

(a) (b) (c)
(d) (e) (f)
Figura 1.1: Exemplos.
1.4.3 Funcoes discriminantes
Usando funcoes discriminantes, vimos que o classificador de Bayes com mınima taxa de erro pode serrepresentado pelas funcoes
gi(x) = ln p(x|ωi) + lnP (ωi), i = 1, 2, . . . , c
Quando a condicional e gaussiana, ou seja, p(x|ωi) ∼ N(µi,Σi), temos
gi(x) = −12(x− µi)tΣ−1
i (x− µi)−d
2ln 2π − 1
2ln |Σi|+ lnP (ωi)
Vejamos como sao as superfıcies de decisao para tres possıveis casos.
Caso 1: Σi = σ2I
No caso em que as c classes sao independentes (covariancia nula) e possuem a mesma variancia σ2,temos |Σi| = σ2d e Σ−1
i = (1/σ2)I. Alem disso, tanto d2 ln 2π quanto |Σi| nao dependem de i (sao
apenas constantes) e para efeitos comparativos podem ser ignorados.
Assim, podemos considerar uma outra funcao discriminante equivalente:
gi(x) = −||x− µi||2σ2
+ lnP (ωi)
5

na qual ||x− µi|| corresponde a norma euclideana. Expandindo a expressao anterior, temos
gi(x) = − 12σ2
[xtx− 2µtix + µt
iµi] + lnP (ωi) .
O termo xtx, que e quadratico, nao depende de i. Logo podemos tambem ignora-lo e considerar outrafuncao discriminante
gi(x) = wtix + ωi0
na qual
wi =1
2σ2µi
eωi0 = −1
2µt
iµi + lnP (ωi)
Ou seja, as funcoes discriminantes sao lineares. Consequentemente, as superfıcies de decisao entreduas classes (ou seja, os pontos nos quais gi(x) = gj(x)) sao tambem lineares (pois gi(x)− gj(x) = 0e uma funcao linear) ou seja, hiperplanos. Alem disso, as superfıcies de decisao entre as classes ωi eωj sao hiperplanos ortogonais ao vetor µi − µj .
Um exemplo para d = 2 e c = 2 e mostrado na figura 1.2.
Figura 1.2: Superfıcie de decisao para o caso em que Σi = σ2I.
Caso 2: Σi = Σ
No caso em que todas as c classes possuem uma mesma matriz de covariancia Σ, seguindo um raciocıniosimilar ao caso 1, temos novamente uma superfıcie de decisao que e um hiperplano. Porem, agora elesnao sao ortogonais ao vetor µi − µj .
Um exemplo para d = 2 e c = 2 e mostrado na figura 1.3.
Caso 3: Σi sao arbitrarias
No caso em que as matrizes de covariancia sao arbitrarias, as funcoes discriminantes resultantes contemtermos quadraticos. Como consequencia, as superfıcies de decisao podem ser hiperquadricas e a regiaode decisao correspondente a uma classe ωi nao necessariamente e conexa.
Dois exemplos para d = 2 e c = 2 sao mostrados na figura 1.4.
6
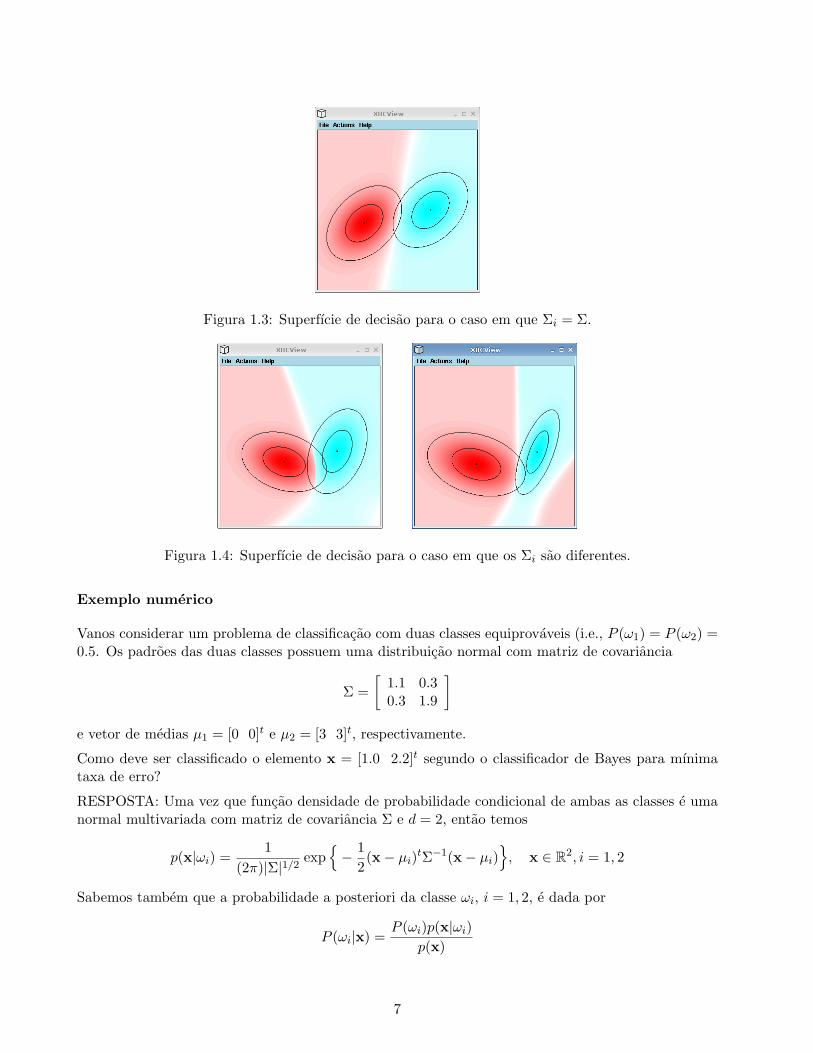
Figura 1.3: Superfıcie de decisao para o caso em que Σi = Σ.
Figura 1.4: Superfıcie de decisao para o caso em que os Σi sao diferentes.
Exemplo numerico
Vanos considerar um problema de classificacao com duas classes equiprovaveis (i.e., P (ω1) = P (ω2) =0.5. Os padroes das duas classes possuem uma distribuicao normal com matriz de covariancia
Σ =[
1.1 0.30.3 1.9
]e vetor de medias µ1 = [0 0]t e µ2 = [3 3]t, respectivamente.
Como deve ser classificado o elemento x = [1.0 2.2]t segundo o classificador de Bayes para mınimataxa de erro?
RESPOSTA: Uma vez que funcao densidade de probabilidade condicional de ambas as classes e umanormal multivariada com matriz de covariancia Σ e d = 2, entao temos
p(x|ωi) =1
(2π)|Σ|1/2exp
{− 1
2(x− µi)tΣ−1(x− µi)
}, x ∈ R2, i = 1, 2
Sabemos tambem que a probabilidade a posteriori da classe ωi, i = 1, 2, e dada por
P (ωi|x) =P (ωi)p(x|ωi)
p(x)
7

Como o denominador p(x) nao depende de i, entao importa-nos apenas o numerador. Expressando omesmo como uma funcao discriminante podemos (uma vez que a funcao ln e monotonica) escrever
gi(x) = lnP (ωi)p(x|ωi) = lnP (ωi) + ln p(x|ωi), i = 1, 2
Em particular, para a densidade condicional normal multivariada temos
gi(x) = −12(x− µi)tΣ−1(x− µi)−
d
2ln 2π − 1
2ln |Σ|+ lnP (ωi)
Mas, como P (ω1) = P (ω2) a ambas as densidades condicionais possuem a mesma matriz de covariancia,entao podemos eliminar alguns termos assim com constantes da expressao acima, e obtemos
gi(x) = −(x− µi)tΣ−1(x− µi)
Segundo o classificador de Bayes, devemos “Decidir ω1 se g1(x) > g2(x); decidir ω2 se g2(x) > g1(x),e ω1 ou ω2 caso g2(x) = g1(x)”. Portanto, vamos calcular g1(x) e g2(x) para x = [1.0 2.2]t.
Para tanto, precisamos calcular Σ−1. Sabemos que ΣΣ−1 = I. Logo, precisamos resolver[0.1 0.30.3 1.9
] [a bc d
]=
[1 00 1
]que resulta no sistema de equacoes lineares
0.1a + 0.3c = 10.1b + 0.3d = 00.3a + 1.9c = 00.3b + 1.9d = 1
Segue entao que a = −1.9c0.3 e portanto 1.1(−1.9c
0.3 )+0.3c = 1, ou seja, −2.09c+0.09c = 0.3 =⇒ c = −0.15e a = 0.95. De forma similar, temos b = −0.15 e c = 0.55. Logo,
Σ−1 =[
0.95 −0.15−0.15 0.55
]Entao, para x = [1.0 2.2]t temos
g1(x) = −[1.0 2.2][
0.95 −0.15−0.15 0.55
] [1.02.2
]= −[0.62 1.06]
[1.02.2
]= −2.952
De forma similar, temosg2(x) = −3.672
Como g1(x) > g2(x) x devera ser classificado como da classe ω1.
Quais sao os eixos principais da elipse centrada em µ1 = [0 0]t e como desenhar a elipse que correspondea uma distancia de Mahalanobis constante dm =
√2.952 do centro?
Lembre-se que a distancia de Mahalanobis e dada por : dm = ((x− µ)tΣ−1(x− µ))1/2.
As regioes de decisao de ambas as classes bem como o ponto x podem ser plotados usando o bcviewcom o o aqruivo de dados (carregado via opcao File -> Load Data...)
8

X Y C1.0 2.2 X
e o arquivo com o classificador de bayes (carregado via opcao File -> Load Classifier ...)
/*----------------------------------------------------------------------
----------------------------------------------------------------------*/dom(X) = IR;dom(Y) = IR;dom(C) = { a, b };
/*----------------------------------------------------------------------full Bayes classifier
----------------------------------------------------------------------*/fbc(C) = {prob(C) = {a: 0.5,b: 0.5 };
prob(X,Y|C) = {a: N([0, 0],
[1.1],[0.3, 1.9]),
b: N([3, 3],[1.1],[0.3, 1.9])
};};
A figura 1.5 mostra o plot do bcview.
Figura 1.5: As distribuicoes de ω1 (rosa) e de ω2 (azul). Observe que a superfıcie de decisao e umhiperplano e que o ponto x esta na regiao R1 (rosa).
9

1.5 Estimacao de funcao densidade de probabilidade
O classificador de Bayes considera que as probabilidades P (ωi) das classes e as densidades condicionaisp(x|ωi) sao conhecidas. No entanto, na pratica isto dificilmente acontece.
Em situacoes praticas dispomos apenas de um conjunto de amostras D = {x1,x2, . . . ,xn}. Vamossupor que os padroes deste conjunto tem classificacao conhecida. As probabilidades a priori das classespodem ser estimadas de forma relativamente simples: basta considerarmos a frequencia relativa deobservacoes de cada classe. Podemos tambem estimar a funcao densidade de probabilidade que deuorigem a esta amostra, embora neste caso a estimacao nao seja tao simples e possamos sofrer coma insuficiencia de dados. Existem duas abordagens para fazer essa estimacao: a parametrica e anao-parametrica. A seguir descrevemos brevemente essas duas abordagens e as principais tecnicasutilizadas em cada uma delas. Maiores detalhes podem ser obtidos em boas referencis sobre estatıstica,principalmente sobre a estimacao parametrica pois esta trata-se de um problema classico em estatıstica.
1.5.1 Estimacao parametrica
Nesta abordagem, supoe-se que o tipo de distribuicao e conhecido. Por exemplo, e possıvel quesaibamos que as observacoes em D provem de densidades normais, ou seja, que p(x|ωi) ∼ N(µi,Σi),mas nao saibamos quais sao os valores dos parametros que caracterizam essa densidade, ou seja, osvalores da media µi e da matriz de covariancia Σi.
A estimacao parametrica trata de casos deste tipo. Os parametros da distribuicao sao estimados apartir da amostra disponıvel.
A seguir apresentamos tres tecnicas de estimacao parametrica, usadas na area de reconhecimento depadroes. Para tal, iremos fazer algumas consideracoes. Consideramos que as observacoes da classe ωi,denotados por Di, formam uma amostra i.i.d (independentes identicamente distribuıdas), obtidas deuma funcao densidade condicional p(x|ωi). Essa densidade depende de um conjunto de parametrosθi e para explicitar essa dependencia, denotamos a funcao densidade condicional por p(x|ωi, θi). Porexemplo, no caso em que essas densidades condicionais sao normais com media e matriz de covarianciadesconhecidas, o vetor de parametros pode ser dado por θi = (µi,Σi).
Iremos supor tambem que os parametros θi relativos a uma classe ωi nao tem relacao com as amostrasde outra classe ωj e vice-versa. Portanto, no caso de c classes, podemos tratar a estimacao dasc densidades condicionais como problemas similares, independentes um do outro. Na pratica, asamostras disponıveis D devem ser separados em c subconjuntos Di, i = 1, 2, . . . , c, cada um contendoas amostras das respectivas classes. Nas descricoes das tecnicas a seguir, iremos simplificar a notacaoe utilizar D para indicar amostras provenientes de uma certa funcao densidade p(x|θ) que caracterizaa distribuicao dos padroes de uma das classes.
Estimacao por maxima verossimilhanca
Seja D = {x1,x2, . . . ,xn} uma amostra i.i.d.∼ p(x|θ). A funcao de verossimilhanca e definida por
p(D|θ) = p(x1,x2, . . . ,xn|θ) = p(x1|θ) . . . p(xn|θ) =n∏
i=1
p(xi|θ)
A penultima igualdade na equacao acima e devida ao fato das amostras serem independentes.
10

O metodo da maxima verossimilhanca consiste em calcular o valor de θ que maximiza a funcao deverossimilhanca acima. Isto equivale a calcular, dentre todos os valores possıveis para θ, aquele quecaracteriza a funcao densidade que muito possivelmente deu origem a amostra D. Ou seja, a estimativade maxima verossimilhanca e dada por
θMV = arg maxθ
n∏i=1
p(xi|θ)
A funcao de verossimilhanca dada acima e uma funcao em θ, que e uma variavel multidimensional.Para calcular o ponto de maximo dessa funcao devemos calcular o seu gradiente e encontrar os zeros domesmo. Uma vez que o logaritmo e uma funcao monotona, ao aplicarmos na funcao de verossimilhancaobtemos a funcao de verossimilhanca logaritmica que possui o mesmo ponto de maximo, poreme mais tratavel:
L(θ) = lnn∏
i=1
p(xi|θ) =n∑
i=1
ln p(xi|θ) .
Entao, calculamos os zeros de seu gradiente, dado por
∇θL =n∑
i=1
∇θ ln p(xi|θ)
na qual ∇θ e o operador gradiente vetorial (derivadas parciais com respeito a cada um dos componen-tes).
Apresentamos a seguir um exemplo para ilustrar o uso dessa tecnica. Considere D = {x1,x2, . . . ,xn}uma amostra i.i.d.∼ N(µ,Σ) e suponha que apenas µ e desconhecida. Relembramos que a densidadenormal multivariada e dada pela equacao
p(x|µ) =1
(2π)d/2|Σ|1/2exp
{− 1
2(x− µ)tΣ−1(x− µ)
}, x ∈ Rd .
Observe que o µ em p(x|µ) indica que se µ for dado, entao a densidade e completamente conhecida.
Aplicando o logaritmo natural, temos
L(µ) = −n
2ln((2π)d|Σ|)− 1
2
n∑i=1
(xi − µ)tΣ−1(xi − µ)
e, portanto,
∇µL =n∑
i=1
Σ−1(xi − µ)
A funcao ∇µL tem valor zero no ponto
µMV =1n
n∑i=1
xi
que e a media amostral.
11

Estimacao maximo a posteriori
No caso da estimacao maximo a posteriori, supoe-se que o parametro θ e uma v.a. com densidade apriori p(θ) conhecida. De forma similar ao caso da maxima verossimilhanca, a estimativa maximo aposteriori (MAP) e o valor de θ que maximiza a posteriori p(θ|D). Pelo teorema de Bayes, sabemosque
p(θ|D) =p(θ)p(D|θ)
p(D)
Observe que se considerarmos uma a priori uniforme, entao encontrar θ que maximiza p(θ|D) corres-ponde a encontrar θ que maximiza p(D|θ), ou seja, a funcao de verossimilhanca. Portanto, no caso deuma a priori uniforme, as estimativas MV e MAP coincidem.
A priori permite ao usuario embutir algum conhecimento previo sobre θ na estimacao. A estimativa eportanto baseada nesse conhecimento a priori e nos dados observados (no caso da estimativa MV, elae baseada apenas nos dados observados).
Estimacao Bayesiana
Tanto a estimacao MV como MAP determinam um valor para o parametro θ. Para entendermos aestimacao Bayesiana, recordemos que no contexto de classificacao o objetivo e classificarmos um padraoobservado x. Se as probabilidades a priori e as densidades condicionais a cada classe forem conhecidas,basta escolhermos a classe com probabilidade a posteriori maxima. No entanto, estamos lidando agoracom uma situacao na qual os valores dos parametros das densidades condicionais nao sao conhecidos.A ideia e que esses serao, de alguma forma, estimados a partir da amostra D = {x1,x2, . . . ,xn}disponıvel.
Vamos entao escrever a probabilidade a posteriori p(ωi|x) da seguinte forma, para mostrar que estedepende de D:
p(ωi|x,D) =p(x|ωi,D)P (ωi|D)∑c
j=1p(x|ωj ,D)P (ωj |D)
E razoavel supormos que P (ωi|D) = P (ωi) (ou seja, que a priori e conhecida). Conforme ja foicomentado anteriormente, vamos supor tambem que as amostras de uma classe ωi nao afetam aestimacao os parametros de outra classe e vice-versa. Assim, podemos reescrever a expressao anteriorcomo
p(ωi|x,D) =p(x|ωi,Di)P (ωi)∑c
j=1p(x|ωj ,Dj)P (ωj)
Precisarıamos entao calcular p(x|ωi,Di) para cada uma das classes ωi. Porem, justamente por causa daindependencia entre as classes, temos c problemas independentes, e portanto o ındice i nao e relevante.Assim, deixando o ındice i de lado, temos uma situacao na qual nao conhecemos p(x) e desejamoscalcular p(x|D).
A densidade p(x) e desconhecida, mas estamos supondo que possui uma forma parametrica conhecidacom parametros θ. Logo, para explicitar essa dependencia, escrevemos p(x|θ). Supomos tambem queo parametro θ e uma v.a. com a priori p(θ) conhecida. A respectiva a posteriori p(θ|D) pode sercalculada usando o teorema de Bayes.
Agora relacionamos θ e p(x|D), da seguinte forma:
p(x|D) =∫
p(x, θ|D)dθ =∫
p(x|θ)p(θ|D)dθ
12

Uma vez calculado esse valor para um determinado x (para cada uma das c classes), e possıvel entaocalcularmos as respectivas a posterioris p(ωi|x,D).
Note que se p(θ|D) tem pico em algum θ, entao p(x|D) ≈ p(x|θ).Uma das desvantagens desta abordagem e a complexidade computacional, uma vez que o calculo dep(x|D) envolve integrais multiplas. Portanto, na pratica, a abordagem MV e bastante utilizada.
1.5.2 Estimacao nao-parametrica
Na estimacao nao-parametrica, a unica informacao disponıvel sao as amostras D = {x1,x2, . . . ,xn}.Nao se tem nenhuma informacao adicional sobre as distribuicoes que originaram essas amostras. Oproblema que estamos tentando resolver e o de estimar p(x).
Descrevemos a seguir uma tecnica para estimar densidades baseada em histogramas e uma evolucaoda mesma, conhecida por metodo de janelas de Parzen.
Estimacao via histogramas
Para entender o metodo de histogramas, vamos considerar inicialmente o caso unidimensional (i.e.,D = {x1, x2, . . . , xn}, xi ∈ R). Podemos dividir o eixo x em segmentos igualmente espacados, detamanho h. Em seguida, para cada segmento, contamos o numero de amostras que estao no intervalocorrespondente ao segmento e associamos a cada segmento a frequencia relativa. Ou seja, se k e onumero de amostras num determinado segmento, a esse segmento associamos P = k/n.
Supondo que a pdf p(x) varia pouco e de forma suave em cada segmento e denotando o ponto mediodo segmento por x podemos definir
p(x) = p(x) =1h
k
n
para todo x tal que |x − x| ≤ h/2. Isto e, a todos os pontos do segmento associa-se uma mesmadensidade p(x) e desta forma definimos densidades para os pontos que nao aparecem entre as amostras.O coeficiente 1/h garante que a area totaliza 1 (para que se possa caracterizar uma funcao densidadede probabilidade).
A ideia acima pode ser facilmente generalizada para padroes multidimensionais, considerando-se, emvez dos segmentos, hipercubos de tamanho e volume constantes.
Duas das vantagens desta abordagem sao a facilidade de implementacao e a nao necessidade de armaze-namento das amostras. No entanto, ha tambem desvantagens. No caso de espacos multidimensionais,o numero de hipercubos para cobrir o domınio das amostras e exponencial com respeito a dimensaodo espaco. Isto implica tambem na necessidade de uma grande quantidade de dados para se estimaras densidades em cada hipercubo. Como geralmente a quantidade de dados disponıveis nao e grande,as caudas das distribuicoes estimadas tendem a ficar com densidade nula. Alem disso, a funcao es-timada apresenta pontos de descontinuidade, o que pode ser indesejavel em certas situacoes. Outradesvantagem e que dependendo do volume do hipercubo, bem como o posicionamento dos mesmos noespaco, diferentes funcoes densidades sao obtidas.
Janelas de Parzen
Seja H um hipercubo em Rd de lados com tamanho h. O volume de H e dado por V = hd. Porexemplo, para d = 2 temos que H e um quadrado e sua area e h2.
13

Considere a funcao definida por, para todo u = (u1, u2, . . . , un) ∈ Rd,
φ(u) ={
1, se |uj | ≤ 1/2, j = 1, 2, . . . , d0, caso contrario.
Exemplo:
[ESPACO para inserir uma figura]
Em palavras, φ define um hipercubo unitario (lados de tamanho 1), centrado na origem.
Seja x um ponto fixo em Rd, y qualquer e h uma constante. Qual o significado de
φ(x− y
h)
Podemos ver que φ((x− y)/h) = 1 se e somente se |(xj − yj)/h| ≤ 1/2, para j = 1, 2, . . . , d, ou seja,quando y esta localizado no hipercubo de lados com tamanho h, com centro em x.
Dado um conjunto D = {x1,x2, . . . ,xn} de amostras, o numero de amostras dentro de um hipercubode lados com tamanho h, com centro em x, pode ser portanto expresso por
k =n∑
i=1
φ(x− xi
h)
Juntando essa expressao com o valor estimado de p(x) via metodo de histogramas, temos entao
p(x) =1V
k
n=
1V
( 1n
n∑i=1
φ(x− xi
h))
Em relacao ao metodo de historamas, a diferenca esta no fato de que o posicionamento do hipercubonao e fixo. Neste caso, os hipercubos sao posicionados sobre o ponto x para o qual desejamos estimara densidade de probabilidade.
A funcao φ definida acima ilustra a ideia por tras da tecnica de janelas de Parzen. A questao queainda nao sabemos e se as estimativas assim obtidas definem de fato uma fdp. Parzen mostrou quepara garantir que a funcao estimada p(x) seja uma fdp basta escolhermos funcoes φ que satisfazem
φ(x) ≥ 0
e ∫φ(u)du = 1
considerando-se V = hd.
Alguns exemplos de kernels unidimensionais utilizados estao listados a seguir:
14

• Retangular
φ(u) ={
12 se |u| < 1,0 c.c.
• Triangular
φ(u) ={
1− |u| se |u| < 1,0 c.c.
• Biweight
φ(u) ={
1516(1− u2)2 se |u| < 1,0 c.c.
• Normal (um dos mais usados)
φ(u) =1√2π
e−u2
2 ,∀u ∈ R
• Bartlett-Epanechnenko {34(1− u2
√5) se |u| <
√5,
0 c.c.
A escolha de h e importante. Dependendo do seu valor, a fdp pode variar bastante. A seguir fazemosuma analise breve sobre escolhas extremas. Lembre-que a estimativa por densidade e dada por
p(x) =1V
k
n=
1V
( 1n
n∑i=1
φ(x− xi
h))
• h pequeno
Se o valor de h for pequeno, entao |x−xih | e grande (ou seja, esta longe da origem. Uma vez que
os kernels tem pico na origem e descrescem ou ficam nulos a medida que se afasta da origem,temos que φ(x−xi
h ) e um valor pequeno ou nulo.
Isto implica que o kernel φ tende a ter picos proximos as amostras xi apenas e valores muitomenores ou nulos nas demais regioes. Como consequencia, a fdp tende a ser uma superfıcie comoscilacoes (picos) bruscos em torno das amostras.
• h grande
Se o valor de h for grande, entao |x−xih | e pequeno (um valor proximo de 0). Logo, φ(x−xi
h ) tendea ser um valor proximo de φ(0), sendo significativamente diferente de φ(0) (ou seja, um numeroproximo de zero) apenas quando |x− xi| e bastante grande.
Isto implica que o kernel tende a ter uma superfıcie mais suave e espalhada em torno do pontocentral. Como consequencia, a fdp tende a ser uma superfıcie mais suave, sem picos abruptos.Em outras palavras, amostras distantes tambem contribuem para a estimacao de densidade deum certo local.
Pode-se mostrar propriedades de convergencia para as fdps estimadas pelo metodo dos kernels. Maisprecisamente, pode-se mostrar que quando n tende a infinito e V para zero, E[p(x)] = p(x) eV ar[p(x)] = 0. Veja demonstracao em [Duda et al., 2001].
Exemplo: A seguir mostramos alguns exemplos de estimacao da funcao densidade de probabilidadepor kernels, usando diferentes kernels e diferentes valores para h. Os graficos foram gerados usando o
15

software R. Na funcao density usada no R, uma forma de variar o valor de h e variando o parametroadjust. Os graficos abaixo mostram diferentes valores de adjust, identificados nas legendas na formade adjust*bw (bw e o bandwidth default usado pelo R).
[Espaco para inserir graficos]
1.6 Classificador de Bayes Naive
A utilizacao do classificador de Bayes para a classificacao de um padrao x requer o calculo do valorde c funcoes discriminantes gi(x), i = 1, 2, . . . , c. Essas funcoes discriminantes dependem das pro-babilidades P (ωi) a priori das classes bem como das densidades condicionais p(x|ωi). Apenas pararelembrar, um possıvel conjunto de funcoes discriminamtes e dado por
gi(x) = P (ωi)p(x|ωi), x = (x1, x2, . . . , xd) ∈ Rd, i = 1, 2, . . . , c .
Conforme vimos, em geral essas probabilidades e densidades nao sao conhecidas. Elas podem serestimadas a partir de amostras de treinamento. No caso das probabilidades, a estimacao e simples(pois trata-se apenas da frequencia relativa de padroes de cada classe na amostra). No caso dasdensidades, podemos utilizar tanto a estimacao parametrica (quando o tipo da funcao densidade econhecida) ou entao a estimacao nao-parametrica pelo metodo dos kernels (ou janelas de Parzen).
No entanto, nos casos em que d e grande, e necessario uma grande quantidade de amostras para seobter uma estimacao precisa. Na pratica, a quantidade de amostras disponıveis em geral nao e muitogrande e acaba inviabilizando a estimacao das fdps.
Uma alternativa bastante utilizada para contornar esta dificuldade e a abordagem conhecida porclassificador naive de Bayes. Neste caso, supoe-se que as caracterısticas (variaveis) do padrao saoestatisticamente independentes. Desta forma, usando a propriedade de independencia, podemos es-crever p(x|ωi) = p(x1, x2, . . . , xd|ωi) = p(x1|ωi)p(x2|ωi) . . . p(xd|ωi) =
∏dj=1 p(xj |ωi). Desta forma, o
problema de estimar uma fdp d-dimensional reduz-se ao problema de estimar d fdps unidimensionais.
O classificador naive de Bayes e bastante utilizado, por exemplo, em filtros de spam em sistemasde e-mails. As caracterısticas que compoem o padrao (um e-mail) sao palavras-chaves comumenteencontradas nas mensagens.
16

1.7 Classificador baseado nos vizinhos mais proximos
1.7.1 Estimacao da posteriori
O classificador de Bayes e definido em funcao das probabilidades a posteriori
P (ωi|x) =P (ωi)p(x|ωi)
p(x).
Em vez de estimarmos a probabilidade a priori e a densidade condicional (verossimilhanca) no classi-ficador de Bayes, poderıamos pensar em estimar a posteriori a partir da amostra. Para isso, convemlembrarmos que a estimativa de p(x) baseada em densidade (no caso da tecnica de histogramas oupor kernels) e dada por
p(x) =k
nV
na qual k e o numero de amostras dentro da celula (hipercubo) que contem x, n e o total de amostrase V e o volume da celula.
Se supormos um problema com c classes e uma amostra total de n elementos dessas c classes, umapossıvel estimativa da densidade de x conjunta com a classe ωi seria
p(x, ωi) =ki
nV
na qual ki e o numero de amostras da classe ωi na celula que contem x.
Observe que
p(x) =c∑
i=1
p(x, ωi) =k
nV.
Logo, lembrando que P (A,B) = P (A)P (B|A), temos que
p(ωi|x) =p(x, ωi)p(x, ωi)
=ki
k.
Ou seja, uma estimativa para a posteriori de ωi seria a frequencia relativa de amostras dessa classe nacelula.
Para efeitos de computacao, de forma similar a estimacao nao-parametrica das fdps, podemos consi-derar um celula de volume V fixo centrada em x, ou entao, a menor celula centrada em x que contemum numero fixo k de amostras.
A segunda opcao corresponde a uma popular tecnica de classificacao conhecida por classificacao pelosvizinhos mais proximos (ou NN, do ingles nearest neighbors).
1.7.2 Classificacao pelos vizinhos mais proximos
Seja D = {x1,x2, . . . ,xn} um conjunto de amsotras com classificacao conhecida. Dado um padrao xqualquer, queremos classifica-lo.
Na secao anterior, vimos que uma possıvel forma para se fazer isso e considerar um hipercubo centradoem x, que englobe exatamente k amostras, e decidir associar a x a classe que ocorre com maiorfrequencia dentre as amostras cobertas pelo hipercubo.
17

As k amostras no hipercubo podem ser vistos como as k amostras mais “proximas” de x segundoa distancia de norma infinita (mais detalhes adiante). Esta ideia de considerar as amostras maisproximas pode ser generalizada para diferentes nocoes de distancia. Uma vez fixada a nocao dedistancia entre padroes, podemos entao elaborar as seguintes regras de decisao (para classificacao).
Regra de decisao pelo vizinho mais proximo (1-NN)
Esta regra consiste em associar ao padrao a ser classificado a mesma classe da amostra mais proximaa ele segundo a distancia adotada.
No caso de padroes no espaco 2D, esta regra particiona o espaco em regioes que correspondem aodiagrama de Voronoi.
Esta regra e conhecida por 1-NN (nearest-neighbor rule) e e um caso particular da regra apresentadaa seguir.
Regra de decisao pelos k vizinhos mais proximos (k-NN)
Esta regra consiste em associar ao padrao x a ser classificado a classe que ocorre com maior frequenciadentre as k amostras mais proximas a ele segundo a distancia adotada.
Em caso de empate, pode-se escolher uma das classes.
A sigla k-NN vem de k nearest-neighbors.
1.7.3 Analise de erro do classificador 1-NN
Pode-se mostrar que quando o tamanho da amostra tende a infinito, a taxa de erro do classificador1-NN nao e superior a duas vezes a taxa de erro do classificador de Bayes.
[Falta colocar a demonstracao. Ver [Duda et al., 2001, Kohn, 1999]]
18

Capıtulo 2
Analise de aglomerados (Clustering)
Dado um conjunto de objetos em Rd, desejamos encontrar uma particao do conjunto, de forma que aspartes representem agrupamentos “naturais” dos dados. A analise de agrupamentos (ou clustering)refere-se a esse processo de particionamento do conjunto de dados.
O particionamento ideal e aquele no qual os objetos em uma mesma parte sejam similares entre si,enquanto objetos em duas partes distintas sejam dissimilares. Note que existem tecnicas denominadasde fuzzy clustering , que permitem que um objeto faca parte de mais de uma parte; neste caso associa-se a cada objeto um grau de pertinencia para cada um dos agrupamentos. Neste texto consideraremosapenas hard clustering , ou seja, tecnicas de clustering que geram agrupamentos que formam umaparticao do domınio dos objetos.
Seja X = {x1,x2, . . . ,xm} um conjunto com m objetos em Rd. Uma particao de X e uma colecao desubconjuntos nao vazios X1,X2, . . . ,Xk, k > 0, tal que
• ∪ki=1Xi = X
• Xi ∩Xj = ∅, i, j = 1, 2, . . . , k e i 6= j.
Para agrupar os objetos, e preciso antes de mais nada definir uma medida de similaridade. Tal medidade similaridade e altamente dependente de contexto. Veremos mais adiante algumas medidas desimilaridade bastante utilizadas.
Uma vez definida a medida de similaridade, objetos similares segundo essa medida podem ser agrupa-dos em um mesmo agrupamento, de forma que dentro de um agrupamento os objetos sejam similarese entre agrupamentos sejam dissimilares. Existem basicamente duas abordagens classicas para o par-ticionamento: o hierarquico (que pode ser aglomerativo ou divisivo) e o particional que encontra umaparticao do conjunto (usualmente, ajusta uma particao inicial de forma a minimizar algum criterio decusto).
Clustering e uma das tecnicas bastante utilizadas em analise exploratoria de dados, na qual um analistatenta familiarizar-se com os dados e descobrir estruturas de padroes intrınsecos aos dados. Pelo fatode nao se ter classificacao previa dos dados, e tambem conhecida por classificacao nao-supervisionada.
19

2.1 Medidas de (dis)similaridade
2.1.1 Medidas entre padroes
A definicao de medidas de similaridade entre padroes deve levar em consideracao a natureza de suascomponentes (variaveis/caracterısticas). A natureza das variaveis podem ser: discreta, contınua oubinaria. Ja os valores dessas variaveis podem ser nominais, ordinais, intervalos ou uma razao.
Para variaveis contınuas, as nocoes de distancia usuais sao muitas vezes adequadas. Uma funcaoD : Rd × Rd → R e uma distancia se
• e simetrica, ou seja, D(xi,xj) = D(xj ,xi) para todo xi e xj ,
• e positiva, ou seja, D(xi,xj) ≥ 0 para todo xi e xj .
Alem disso, se ela satisfaz
• a desigualdade triangular, ou seja, se D(xi,xj) ≤ D(xi,xk) + D(xk,xj) para todo xi,xj e xk,
• reflexifidade, ou seja se D(xi,xj) = 0 se e somente se xi = xj ,
entao ela e denominada uma metrica.
De forma parecida, podemos definir uma funcao de similaridade. Uma funcao de similaridade euma funcao S que satisfaz:
• a simetria, ou seja, S(xi,xj) = S(xj ,xi) para todo xi e xj ,
• a positividade, ou seja, 0 ≤ S(xi,xj) ≤ 1 para todo xi e xj ,
Alem disso, se satisfizer
• S(xi,xj)S(xj ,xk) ≤[S(xi,xj) + S(xj ,xk)
]S(xi,xk) e
• S(xi,xj) = 1 se e somente se xi = xj ,
entao ela e denominada metrica de similaridade.
A seguir listamos algumas metricas bastante conhecidas: a metrica de Minkowski e definida por
D(xi,xj) =[ d∑
i=k
(xik − xjk)n]1/n
Se n = 1 temos a distancia city-block, se n = 2 temos a distancia euclideana e se n → ∞ temos asup-distance (oudistancia de Chebychev). Em geral, ao se variar o valor de n muda-se o peso dadoa pequenas e grandes diferencas.
A distancia de Mahalanobis e definida por
D(xi,xj) = (xi − xj)t Σ−1 (xi − xj)
na qual Σ e a matriz de covarianca amostral. E invariante a todas as transformacoes lineares naosingulares.
20

Similaridade Coseno: e invariante ao comprimento do vetor e a rotacao, mas nao a transformacoeslineares. Muito usado em processamento de documentos.
S(xi,xj) = cosα =xi xj
||xi|| ||xj ||
Para caracterısticas binarias, distancias euclideanas nao sao uteis em geral. Vamos supor que se umacaracterıstica xi toma o valor 1 em um exemplo, entao isto significa que a caracterıstica i esta presentenesse objeto. Similarmente, o valor 0 indica a ausencia da caracterıstica no objeto.
Sejam xi e xj dois objetos. Definimos n11 como sendo o numero de caracterısticas que tem valor 1 emambos os objetos. Similarmente, n00 denota o numero de caracterısticas que tem valor 0 em ambose n10 e n01 denota o numero de caracterısticas com valores distintos entre os dois objetos. Note qued = n11 + n00 + n10 + n01.
Medidas que consideram alguma razao que envolve os casamentos:n11 + n00
n11 + n00 + ω(n10 + n01)
ω = 1 casamento simplesω = 2 medida de Roger & Tanimotoω = 1/2 medida de Gower e Legendre
Medidas que consideram alguma razao que envolve apenas os casamentos do tipo 1−1 (os casamentosdo tipo 0− 0 sao desconsiderados, tratados como irrelevantes):
n11
n11 + ω(n10 + n01)
ω = 1 coeficente de Jaccardω = 2 medida de Sokal e Sneathω = 1/2 medida de Gower e Legendre
Pode-se construir similaridades a partir de distancias. Por exemplo, podemos fazer
S(xi,xj) =1
1 + D(xi,xj)
Se a distancia for mınima, ou seja, se D(xi,xj) = 0, entao a similaridade e maxima, ou seja, S(xi,xj) =1. Quanto maior a distancia, mais proximo de 0 torna-se a similaridade. Note, porem, que distanciasque sao metricas nem sempre podem ser construıdas a partir de uma similaridade.
Da mesma forma, medidas de dissimilaridade podem ser obtidas a partir de similaridades da seguinteforma:
D(xi,xj) = 1− S(xi,xj)
Para caracterısticas nominais, nao binarias, uma possıvel medida de similaridade e dada por:
S(xi,xj) =1
d∑d
i=1 Sijl
na qual
Sijl ={
0 se xi e xj nao coincidem em l,1 se xi e xj coincidem em l.
Se as caracterısticas nominais podem ser ordenadas, entao pode-se utilizar uma medida de distancia.No caso de mistura de tipos de variaveis, o que pode ser feito???
21

2.1.2 Medidas entre padroes e clusters
2.1.3 Medidas entre clusters
2.2 Abordagens para o calculo de clusters
2.2.1 Clustering hierarquico
Aglomerativo
Nos processos de clustering hierarquico aglomerativo, inicia-se o processo com os objetos individuais.Ou seja, inicialmente ha tantas partes quanto ha de objetos. Duas partes que sao os mais similaressao agrupados, culminando na fusao dessas duas partes em uma nova parte que e a uniao delas. Esteprocesso e repetido sequencialmente ate que reste apenas uma unica parte.
Dentre os metodos hierarquicos, os mais comuns sao os linkage methods. Ha tres criterios de linkagepara a fusao de parte que sao bastante utilizados
• Single linkage: a distancia entre duas partes e considerada como sendo a menor distancia dentretodas as distancias entre objetos dois a dois, um de cada parte.
Nao e capaz de separar clusters que estao muitos, pois o link e baseado na distancia mınima.Por outro lado, e capaz de gerar clusters que possuem formas alongadas, enquanto muitos outrosmetodos tendem a gerar clusters ovalados. Tende a gerar clusters que possuem aparencia de umacorrente; isto pode ser ruim quando extremos opostos dessa corrente sao bem dissimilares.
• Complete linkage: a distancia entre duas partes e considerada como sendo a maior distanciadentre todas as distancias entre objetos dois a dois, um de cada parte.
Tende a gerar partes compactas.
• Average linkage: a distancia entre duas partes e considerada como sendo a distancia media detodas as distancias entre objetos dois a dois, um de cada parte.
Os algoritmos dessa classe seguem basicamente os seguintes passos:
• comecar com m partes, cada um com um dos objetos, e com uma matriz m×m com as distancias(ou similaridades) D = {dij}.
• Procure na matriz o par de clusters (partes) que possuem a menor distancia (sao mais similares).Denote esses clusters por U e V
• Unir os clusters U e V , criando-se o cluster UV . Atualizar a matriz de distancias eliminando-seas linhas e colunas correspondentes a U e V , adicionando-se uma linha e coluna correspondenteao cluster UV com a distancia deste cluster para os demais clusters remanescentes.
• Repetir os passos 2 e 3 um total de m − 1 vezes (todos os objetos farao parte de um unicocluster). Armazene a identidade dos clusters que sao unidos e a distancia (similaridade) entreeles.
Os metodos aglomerativos sao sensıveis a ruıdos e outliers. Uma vez agrupados, nao ha forma doagrupamento ser desfeito posteriormente.
22

Divisivo
Nos processos de clustering hierarquico divisivo, inicia-se o processo a partir de uma unica parte (oconjunto todo) e divide-se cada uma das partes sequencialmente em subpartes, ate que cada partecontenha um simples elemento.
Enquanto no caso aglomerativo temos uma construcao de botttom-up, neste caso temos uma cons-trucao top-down. Aparentemente processos divisivos nao sao muito populares. Um possıvel algoritmoseria algo similar a arvores de decisao.
Uma vez dividida uma parte, as duas partes geradas nao poderao mais ser unidas novamente, nementre si, nem com outras partes.
Comentarios
A particao gerada por metodos hierarquicos pode ser representado por um diagrama bidimensionaldenominado dendograma. Dendogramas sao estruturas parecidas com arvores. No nıvel mais baixoencontram-se os objetos, organizados num eixo horizontal. No eixo vertical encontra-se a medida desimilaridade. Quando duas partes sao unidas, traca-se segmentos verticais sobre as partes ate a alturacorrespondente a similaridade entre elas e une-se esses segmentos por um segmento horizontal. Osobjetos sao dispostos no eixo horizontal de forma que partes agrupadas fiquem adjacentes.
Por armazenar essa sequencia de fusao de partes, a quantidade de memoria utilizada por esses algo-ritmos e grande.
2.2.2 Clustering particional
Nos processos de clustering particional, comeca-se o processo com uma particao inicial qualquer ouentao com um conjunto de objetos que correspondem as “sementes” de cada parte.
Um dos algoritmos mais populares e o k-means, que em sua versao mais simples e composta dasseguintes tres etapas:
• Particionar o conjunto em k partes iniciais (ou entao comecar com k objetos que funcionamcomo os k centroides iniciais)
• Percorrer a lista de objetos e associar o objeto a parte cujo centoide e mais proximo. Recalculeo centroide da parte que recebeu e de que perdeu o objeto.
• Repetir o segundo passo ate que nenhuma realocacao seja possıvel.
O resultado final de um processo de clustering particional depende da particao (ou sementes) inicialescolhida. Para testar a estabilidade da particao, convem reexecutar o algoritmo com diferentesparticoes iniciais.
Algumas variacoes comuns do algoritmo k-means sao: (1) unir duas partes cuja distancia entre seuscentroides e menor que um dado limiar, (2) dividir uma parte se a sua variancia e maior que um dadolimiar.
Abordagens particionais sao particularmente recomendados quando a quantidade de dados e muitogrande. Uma vez que essa abordagem gera apenas uma particao final (a partir de modificacoes deuma particao inicial), a quantidade de memoria requerida e da ordem do numero de objetos. Ja a
23

abordagem hierarquica, por manter o historico das fusoes efetuadas, necessita de maior espaco dememoria.
O k-means e um algoritmo que faz parte de uma abordagem baseada em erro quadratico. Maisprecisamente, os metodos particionais podem ser encarados como aqueles que devolvem uma particaootima, segundo algum criterio. Um desses criterios e a soma de erro quadratico, que e dado por
J(Γ,M) =c∑
i=1
m∑j=1
γij ||xj −mi||2
na qual Γ e uma matriz de particao dada por
γij ={
1, se xj pertence a classe ωi
0, caso contrario
com, para todo j,k∑
i=1
γij = 1
M e a matriz de centroides das partes (clouna i e o centroide da parte i), ou seja, mi = (1/m)∑m
j=1 γijxj.
2.2.3 Outras abordagens
2.3 Exemplos
24

Referencias Bibliograficas
[DeGroot, 1989] DeGroot, M. H. (1989). Probability and Statistics. Addison-Wesley, 2nd edition.
[Duda et al., 2001] Duda, R. O., Hart, P. E., and Stork, D. G. (2001). Pattern Classification. JohnWiley and Sons.
[Kohn, 1999] Kohn, A. F. (1999). Reconhecimento de Padroes - Uma Abordagem Estatıstica. EPUSP.
[Meyer, 1969] Meyer, P. L. (1969). Probabilidade - Aplicacoes a Estatıstica. Ao Livro Tecnico S.A.Versao traduzida do original em ingles.
25


















