
cálculo numerico_Lima
70
Notas de Aula Cálculo Numérico Percy Antonio Ticona Centeno Universidad Nacional de San Agustín Departamento Académico de Matemáticas y Estadística Junio de 2009 Arequipa - Perú
-
Upload
fernandodiaz -
Category
Documents
-
view
12 -
download
0
description
mathemathics
Transcript of cálculo numerico_Lima

Notas de Aula
Cálculo Numérico
Percy Antonio Ticona Centeno
Universidad Nacional de San AgustínDepartamento Académico de Matemáticas y Estadística
Junio de 2009Arequipa - Perú

Introducción
La matemática está comprendida de varias partes, cada una de ellas tieneimportancia propia, pero algunas también son fundamentales en diferentesdisciplinas.
Muchos problemas de la vida real pueden ser representados por for-mulaciones matemáticas, las cuales son denominadas modelos matemáticos.Usando argumentos matemáticos teóricos, algunas veces es posible garanti-zar la existencia de soluciones para esos modelos matemáticos, pero encontrarmanualmente esas soluciones puede resultar extremadamente difícil y a vecesimposible.
Estudiar métodos numéricos desde un punto de vista general nos permi-tirá analizar mecanismos de cálculo capaces de otorgar soluciones, o aproxi-maciones a las soluciones, allí donde las herramientas teóricas fracasaban.Estos mecanismos numéricos de cálculo deben caminar de la mano con elcomputador, pues en su mayoría requieren de muchos pasos y frecuentementeestán orientados a la resolución de problemas de grandes dimensiones.
La importancia del estudio de métodos numéricos es indiscutible, puesgran parte de las investigaciones en ciencias, ingenierías, economía, etc., re-curren a técnicas numéricas para la obtención de resultados.
iii

Capítulo 1
Nociones Básicas Sobre Errores
En este primer capítulo aún no estudiaremos los métodos numéricos, sinoque veremos algunos conceptos básicos y señalaremos algunos factores queintervendrán en la resolución de problemas mediante el computador.
Existen diversas fases cuando intentamos resolver un problema mediantemétodos numéricos, la siguiente figura esquematiza ese procedimiento.
Puede suceder que los resultados finales obtenidos no sean justamente losesperados, aunque todas las fases hayan sido ejecutadas correctamente, losmotivos pueden ser varios y los estudiaremos a continuación.
1.1. Factores que intervienen en la resoluciónnumérica de problemas
La mayoría de los métodos numéricos que veremos aquí tienen un carácteriterativo, esto significa que iniciarán con una estimativa inicial de la solución,digamos x(0), para luego contruir una sucesión de valores
©x(0), x(1), x(2), ...
ª1

CAPÍTULO 1. NOCIONES BÁSICAS SOBRE ERRORES 2
de modo que lımk→∞ x(k) = x∗, donde x∗ es la solución. Por lo general,x(k+1) será calculado a partir de x(k) mediante un procedimiento debida-mente fundamentado. Frecuentemente, este procedimiento requerirá un grannúmero de cálculos, por lo que será necesario el auxilio de un computador.Lamentablemente, los computadores presentan algunos inconvenientes que,si no se controlan, pueden ocasionar respuestas catastróficas.
Ejemplo 1.1 Considere el trecho de un programa en MatLab, tal como semuestra en la figura 1.1. Observe que en teoría, debería cobrarse $1000000.
Figura 1.1: Un error numérico grave cometido por el computador.
Sin embargo, debido al error cometido por el computador, se terminaría pa-gando $2000000. (Vea también el ejemplo 1.3)
Laboratorio 1.1 Haga un programa en algún lenguaje de programación queusted conozca, de modo que en la práctica corrobore el Ejemplo 1.1.
Al resolver un problema por métodos numéricos, los resultados obtenidospueden depender de:
1. La precisión de los datos de entrada
2. La forma cómo éstos son representados en el computador
3. Las operaciones numéricas efectuadas
Cada uno de estos temas serán explicados a continuación.

CAPÍTULO 1. NOCIONES BÁSICAS SOBRE ERRORES 3
1.1.1. Precisión de los datos de entrada
Cuando ingresamos los datos de un problema, ya sea para calcular en un papelo trabajar en el computador, ellos contienen una imprecisión inherente, quieredecir que no hay cómo evitarlos. El siguiente ejemplo aclara esta afirmación.
Ejemplo 1.2 Sabemos que para calcular el área de un círculo, tenemos queingresar numéricamente el radio r y el valor de π. El valor de r quizá puedaser conocido exactamente (r = 2), pero apenas podemos conocer una aproxi-mación de π con un número finito de dígitos. Así, aproximando el valor deπ por 3,14, el área del círculo será:
3,14× (2)2 = 12,56m2Si consideramos 3,1416, entonces el área del círculo estará dada por:
3,1416× (2)2 = 12,5664m2Pero si consideramos 3,141592654, entonces el área será
3,141592654× (2)2 = 12,566370616m2Claramente, las imprecisiones de los datos de entrada ocasionan impreci-siones en los resultados.
En el ejemplo anterior vimos que el mejor resultado se obtuvo en el úl-timo caso. Pero, cuando usamos un computador, ¿cuántos dígitos decimalesreconoce éste? El siguiente ejemplo intentará aclarar esta situación.
Ejemplo 1.3 Usando MatLab 6.0 en una PC de 32-bit con sistema operativoWindows XP, hicimos la siguiente operación:
0,00000000000001 + 1
y el resultado obtenido fue 1,0000000000001, lo cual es satisfactorio. Luego,hicimos:
0,000000000000001 + 1
y obtuvimos como respuesta 1. ¿Qué sucedió?
El ejemplo anterior nos hace ver que en el primer caso, cuando se usanlos 14 dígitos decimales a la derecha del punto, el sistema de cómputo nocomete error. Mientras que, si se usan 15 dígitos, el sistema nos otorga unarespuesta errada.
La razón se debe a que todo computador trabaja con un número finitoy bien reducido de dígitos, en nuestro caso 14 a la derecha del punto, si elnúmero de dígitos sobrepasa lo esperado, el sistema lo trunca o redondea,dependiendo del sistema utilizado.

CAPÍTULO 1. NOCIONES BÁSICAS SOBRE ERRORES 4
Laboratorio 1.2 Utilice un paquete o lenguaje de programación en un com-putador, para corroborar los resultados obtenidos en el Ejemplo 1.3.
1.1.2. Representación de los datos en el computador
Un número con representación decimal finita puede tener una representacióninfinita en el sistema binario. Como un computador trabaja con el sistemabinario y con una cantidad fija de dígitos, necesariamente trabajará con unaaproximación, por lo tanto no se obtendrán resultados finales exactos.
El sistema con el que trabajamos comunmente es el decimal, un númerox en este sistema lo representaremos algunas veces, cuando se preste a con-fusión, por (x)10. Por otro lado, el sistema con el que trabaja un computadorhoy en día es el binario, un número y en este sistema será representado por(y)2. Así por ejemplo,
(5)10 y (101)2
representan el número 5 en el sistema decimal y binario, respectivamente. Elsiguiente ejemplo muestra cómo esta representación aparentemente inofensi-va, puede generar terribles errores cuando se trabaja en un computador.
Ejemplo 1.4 Considere la siguiente sumatoria:
S =30000Xi=1
ai
Para ai = 0,5, el resultado exacto debería ser
S = 0,530000Xi=1
1 = 0,5× 30000 = 15000
Después de implementar un pequeño programa en computador, el resultadofue también 15000. Claramente, no hay por qué preocuparse en este caso,los resultados son los mismos. Pero, para ai = (0,11)10, el resultado exactodebería ser
S = (0,11)10 × 30000 = 3300Sin embargo, el resultado obtenido por el computador fue
S = 3300,00000000063
¿Cómo explicar la diferencia de resultados en este caso?

CAPÍTULO 1. NOCIONES BÁSICAS SOBRE ERRORES 5
Esto se debe a que el número (0,11)10, cuya representación en el sistemadecimal es finita, tiene una representación binaria infinita:¡
0,000111000010100011110101110000101000111101¢2
Si el computador trabajara con 14 dígitos después del punto, el número deberíaser cortado o redondeado, lo cual representa ya un error. Todos los cálculossubsiguientes serán afectados por este hecho.
Laboratorio 1.3 Utilizando algún lenguaje de programación, haga un pro-grama para ejecutar lo tratado en el ejemplo 1.4.
Por lo general, el error ocurrido depende de la representación de losnúmeros en la máquina utilizada. La representación de un número dependede la base elegida o disponible en la máquina en uso, y, del número máxi-mo de dígitos usados en su representación. Cualquier cálculo que envuelvanúmeros que no pueden ser representados a través de un número finito dedígitos, no otorgará como resultado un valor exacto. Cuanto mayor sea elnúmero de dígitos utilizados, mayor será la precisión obtenida.
Como vimos en el ejemplo 1.4, un número puede tener representaciónfinita con respecto a una base, pero una representación infinita en otra base.La base decimal es la que empleamos generalmente, pero antiguamente fueronempleadas otras bases, como la base 12 y la base 60. Un computador operanormalmente en el sistema binario.
Observe lo que pasa cuando un usuario interactúa con el computador: Losdatos de entrada son enviados al computador por el usuario en el sistemadecimal, esa información es convertida al sistema binario por el computador,y, todas las operaciones son realizadas en ese sistema. Los resultados finalesserán convertidos para el sistema decimal y, finalmente, serán transmitidoshacia el usuario. Todo este proceso es una fuente de errores que afecta elresultado final de los cálculos.
1.1.3. Las operaciones numéricas efectuadas
Pero errores no sólo ocurren el la imprecisión de los datos de entrada y surepresentación binaria. Errores ocurren también en las operaciones numéricasefectuadas por un sistema de cómputo (binario).

CAPÍTULO 1. NOCIONES BÁSICAS SOBRE ERRORES 6
Conversión de Números en los Sistemas Decimal y Binario
Cualquier número entero en la base β, de la forma (ajaj−1, ...a2a1a0)β, donde0 ≤ ak ≤ β − 1 y k = 0, ..., j, puede ser escrito en la forma polinomial
ajβj + aj−1βj−1 + ...+ a2β
2 + a1β1 + a0β
0
Mediante esa representación, podemos convertir fácilmente un número enterorepresentado en el sistema binario para el sistema decimal, e inversamente.Por ejemplo: (10111)2 puede ser representado por
1× 24 + 0× 23 + 1× 22 + 1× 21 + 1× 20
Reordenando y resaltando la base 10
(10111)2 = 1× 24 + 0× 23 + 1× 22 + 1× 21 + 1× 20= 2
¡23 + 2
¢+ 3 = 2× 101 + 3× 100
= (23)10
Laboratorio 1.4 En algún lenguaje de programación, haga un programa talque, dado un número entero binario, retorne su equivalente decimal. E in-versamente, dado un entero decimal, otorgue su equivalente binario.
¿Cómo Convertir un Número Fraccionario de Representación Deci-mal a Binario?
Consideremos ahora la conversión de un número fraccionario de base 10 parala base 2. Por ejemplo, r = 1,25, s = 0,666..., t = 0,414213562..., etc.
Notemos que r tiene una representación finita, pero s y t tienen repre-sentaciones infinitas. En términos generales, dado un número entre 0 y 1 enel sistema decimal, ¿cómo obtener su representación binaria?
Considerando el número decimal fraccionario r = 0,125, existen dígitosbinarios
d1, d2, ..., dj, ...
tal que (0.d1d2...dj...)2 será su representación binaria en la base 2. Así,
(0,125)10 = d1 × 2−1 + d2 × 2−2 + ...+ dj × 2−j + ... (1.1)
Multiplicando cada término de la expresión (1.1) por 2, tendremos
2× 0,125 = d1 + d2 × 2−1 + d3 × 2−2 + ...+ dj × 2−j+1 + ...

CAPÍTULO 1. NOCIONES BÁSICAS SOBRE ERRORES 7
Por tanto, d1 representa la parte entera de 2×0,125, que es igual a 0, mientrasque
d2 × 2−1 + d3 × 2−2 + ...+ dj × 2−j+1 + ...
representa la parte fraccionaria de 2× 0,125, que es 0,250.
Aplicando ahora el mismo procedimiento para 0,250, tendremos
0,250 = d2 × 2−1 + d3 × 2−2 + ...+ dj × 2−j+1 + ...
2× 0,250 = 0,5 = d2 + d3 × 2−1 + d4 × 2−2 + ...+ dj × 2−j+2 + ...
de donde d2 = 0. Repitiendo el procedimiento para 0,5 tenemos
0,5 = d3 × 2−1 + d4 × 2−2 + ...+ dj × 2−j+2 + ...
2× 0,5 = 1 = d3 + d4 × 2−1 + ...+ dj × 2−j+3 + ...
de donde d3 = 1. Como la parte fraccionaria de 2 × 0,5 es cero, el procesode conversión termina. En resumen tenemos: d1 = 0, d2 = 0 y d3 = 1. Por lotanto, el número (0,125)10 tiene representación finita en la base 2:
(0,125)10 = (0,001)2
Laboratorio 1.5 Usando los procedimientos anteriores para convertir núme-ros fraccionarios decimales, a binarios, haga un programa usando algún lengua-je de programación y verifique que:
1. El número (0,5)10 tiene una representación binaria finita (0,1)2
2. El número (0,11)10 tiene una representación binaria infinita¡0,000111000010100011110101110000101000111101
¢2
3. Verifique cuántos dígitos el computador está considerando.
El hecho de que un número no tenga representación finita en el sistemabinario, puede ocasionar la ocurrencia de errores aparentemente inexplicablesen los cálculos efectuados en sistemas computacionales binarios. Un computa-dor que opera en el sistema binario, necesariamente tendrá que almacenaruna aproximación para (0,11)10, debido a que sólo posee una cantidad fijade posiciones para guardar los dígitos de la mantisa de un número. Al seresta aproximación usada para realizar los cálculos, no puede esperarse unresultado exacto.

CAPÍTULO 1. NOCIONES BÁSICAS SOBRE ERRORES 8
Laboratorio 1.6 (Precisión de una máquina) La precisión de la máqui-na se define como el menor número ε > 0 en aritmética de punto flotante,tal que (1 + ε) > 1. Este número depende totalmente del sistema de rep-resentación de la máquina: base numérica, total de dígitos en la mantisa,de la forma cómo son realizadas las operaciones y del compilador utilizado.Es importante conocer la precisión de la máquina porque en varios algorit-mos se requiere ingresar como dato de entrada un valor positivo, próximo decero, para que sea usado como criterio de comparación para la detención delalgoritmo. El siguiente algoritmo determina dicha precisión:
Paso 1: A← 1, S ← 2
Paso 2: Mientras S > 1, hacer
A ← A
2
S ← 1 +A
Paso 3: Hacer prec = 2A e imprimir prec.
1. Haga un programa en algún lenguaje de programación que ejecute elalgoritmo anterior.
2. Discuta su significado práctico.
Aritmética de Punto Flotante
Cualquier computador o calculadora representa un número en un sistemadenominado aritmética de punto flotante. En este sistema, el número r serárepresentado en la forma:
± (.d1d2...dt)× βe
donde
β : La base en que la máquina operat : El número de dígitos en la mantisa, 0 ≤ dj ≤ β − 1, j = 1, ..., t, d1 6= 0e : El exponente en el intervalo [−u;u],
el valor de u depende de la máquina con que se esté trabajando
En una computadora, sólo una pequeña cantidad de números son repre-sentados exactamente, por lo general, la representación será realizada pormedio de truncamiento o redondeo.

CAPÍTULO 1. NOCIONES BÁSICAS SOBRE ERRORES 9
Ejemplo 1.5 Considere una máquina que opera en el sistema β = 10, t =3, e ∈ [−5;+5]. Los números no nulos representados en este sistema seránde la forma
± (.d1d2d3)× 10e, 0 ≤ dj ≤ 9, d1 6= 0, e ∈ [−5;+5]El menor número, no nulo y en valor absoluto, expresado en esta máquinaserá:
m = 0,100× 10−5Mientras que el mayor número es:
M = 0,999× 10+5
Ahora, en esta misma máquina. consideremos el subconjunto de númerosreales caracterizados por:
G = {x ∈ R : m ≤ |x| ≤M}Pueden ocurrir varias cosas:
x ∈ G Por ejemplo, si x = 235,89 = 0,23589 × 10+3. Este número posee 5dígitos en la mantisa. Debido a que t = 3, este número no será conside-rado de forma exacta en esta máquina. Si la máquina usa truncamien-to, entonces el número será representado como 0,235 × 10+3. Pero sila máquina usa redondeo, entonces el número será representado por0,236× 10+3.
|x| < m Por ejemplo, si x = ±0,345×10−7. Este número no puede ser repre-sentado en esta máquina porque el exponente e es menor que −5. Lamáquina en estas condiciones retorna una advertencia de underflow.
|x| > M Por ejemplo, x = ±0,875×109. En este caso, el exponente es mayorque 5 y la máquina no lo puede representar, advierte la ocurrencia deoverflow.
Algunos lenguajes de computador permiten que las variables sean decla-radas en doble precisión. En este caso, tal variable será representada en elsistema de aritmética de punto flotante de la máquina, pero con aproximada-mente el doble de dígitos disponibles en la mantisa. Debemos resaltar queen estas condiciones, el tiempo de ejecución y requerimientos de memoriaaumentan considerablemente.
La adición en aritmética de punto flotante requiere el alineamiento delos puntos decimales de los dos números. Para eso, la mantisa de menorexponente debe ser desplazada para la derecha.

CAPÍTULO 1. NOCIONES BÁSICAS SOBRE ERRORES 10
Ejemplo 1.6 Sumar
x = 0,937× 104 y y = 0,1272× 102
Alineando los puntos decimales, tenemos
x = 0,937× 104 y y = 0,001272× 104
Entonces,
x+ y = (0,937 + 0,001272)× 104 = 0,938272× 104
El resultado almacenado después del truncamiento será 0,9382×104. Mientrasque después del redondeo será 0,9383× 104.El cero puede representarse con una mantisa nula y cualquier exponente.
Por lo general, se utiliza el menor exponente posible de la máquina. Casocontrario, si se usa cualquier exponente para denotar el cero, se pueden perderdígitos significativos, tal como muestra el siguiente ejemplo.
Ejemplo 1.7 Supongamos que tenemos una máquina que opera con base 10y 4 dígitos en la mantisa. Si denotáramos al cero por 0,0000×104, al sumarloal número y = 0,3134× 102:
0,0000× 104 + 0,3134× 102 = 0,0000× 104 + 0,003134× 104= (0,0000 + 0,003134)× 104= 0,003134× 104
El resultado después del truncamiento sería 0,0031×104 = 0,3100×102. Estosignifica que fueron perdidos 2 dígitos del valor exacto.
Ejemplo 1.8 Represente los siguientes números en un sistema de aritméticade punto flotante (con redondeo y con truncamiento) de 3 dígitos, cuandoβ = 10, m = 10−4 y M = 10+4:
3,14 10,053 − 238,15 2,71828 0,000007 718235,82
Para el primer caso, con truncamiento nos resulta 0,314× 10, mientras quecon redondeo 0,314 × 10. Para el segundo caso, con trucamiento obtenemos0,100× 102 y con redondeo 0,100× 102. Y así sucesivamente:
−0,238× 103 −0,238× 1030,271× 10 0,272× 10underflow underflowoverflow overflow

CAPÍTULO 1. NOCIONES BÁSICAS SOBRE ERRORES 11
Todo esto nos da una idea de los posibles errores que pueden suceder, yasea por desconocimiento nuestro o por la limitación del computador, en elproceso de la resolución numérica de problemas. Debemos advertir que aúnes posible realizar un análisis más completo del manejo de errores, pero esolo veremos en otra ocasión.
1.2. Errores Absolutos y Errores Relativos
Definimos el error absoluto como la diferencia entre el valor exacto de unnúmero x y su valor aproximado x:
EAx = x− x (1.2)
Frecuentemente, sólo nos interesa la magnitud de este error. Así por ejemplo,si x = 12,60 y x = 12,81, el error absoluto es EAx = 12,60− 12,81 = −0,21.Mientras que la magnitud de este error es |−0,21| = 0,21.Esta idea puede ser extendida para comparar la proximidad de vectores.
Por ejemplo, consideremos los vectores en R3 dados por
x =
6,15,8−11,3
y x =
6,25,9−10,9
Entonces, usando la norma euclídea, la magnitud del error estaría dada ahorapor
kx− xk =q(6,1− 6,2)2 + (5,8− 5,9)2 + (−11,3− (−10,9))2 = 0,4243
No obstante, el error absoluto definido en (1.2) quizá no tenga interés prácticoen este caso.
En general, apenas el valor de x es conocido, lo que hace imposible obtenerel error absoluto exacto. Lo que se puede hacer en ese caso es obtener unacota superior o una estimativa para el módulo del error absoluto, tal comomuestra el siguiente ejemplo.
Ejemplo 1.9 Conociéndose que π ∈ h3,14; 3,15i, podemos tomar para x unvalor dentro de este intervalo y tendremos que:
|EAπ| = |π − x| < 0,01En este caso diremos que el error absoluto de x con respecto a π, en módulo,es menor que 0,01. Más aún, diremos que el número x está representado conpresición menor que 0,01.

CAPÍTULO 1. NOCIONES BÁSICAS SOBRE ERRORES 12
Ejemplo 1.10 En la práctica, a veces no es recomendable controlar algunosprocesos basados en el error absoluto. Por ejemplo, si usted gana un premiode S/. 10000000, y cuando va a recogerlo le dicen que sólo tienen S/. 9999990,entonces a usted puede que no le importe la diferencia, pues apenas hay unerror absoluto de S/. 10. Pero qué pasa si usted ganó S/. 20 de premio, ycuando usted va a recogerlo le dicen que apenas tienen S/. 10, observe queel error absoluto sigue siendo S/. 10, probablemente no le agrade nada estaúltima situación, pues se trata de la mitad del premio.
Para evitar situaciones como la anterior, en la práctica es mejor utilizarotro criterio para medir el error, éste es conocido como error relativo.
El error relativo es definido como el valor absoluto dividido por el valoraproximado, es decir:
ERx =EAx
x=
x− x
xFrecuentemente, también se suele trabajar con el módulo de este valor. Ob-serve que el error relativo respecto al primer premio de S/.10000000 es
ER10000000 =10
9999990≈ 0,000001
Mientras que el error relativo respecto al segundo premio es
ER20 =10
10= 1
Con esto, digamos que en este caso se midió el error con más justicia.
Ejercicio 1.1 Convierta los siguientes números decimales para su forma bi-naria: 26, 1278 y 0,1217.
Ejercicio 1.2 Convierta los siguientes números binarios para su forma deci-mal: (101101)2, (0,111111101)2 y (0,1101)2.
Laboratorio 1.7 El siguiente algoritmo calcula de una forma aproximadala raíz n-ésima de un número no negativo a.
Ingresan: a, n y ε > 0, donde ε es la precisión deseada (ε = 10−9)x = aMientras |xn − a| > ε (controlando la magnitud del error absoluto)
x = x− (xn − a) / (nxn−1) , x 6= 0Retorna x (una aproximación para n
√a)
En algún lenguaje de programación, haga un programa para ejecutar este al-goritmo. Modifique el programa para que retorne también el número de pasos(iteraciones). ¿Cómo utilizaría el error relativo para controlar el algoritmo?

CAPÍTULO 1. NOCIONES BÁSICAS SOBRE ERRORES 13
Laboratorio 1.8 (Cálculo de ex) En algún lenguaje de programación, ha-ga un programa para calcular ex mediante la serie de Taylor con n términos.El valor de x y el número de términos de la serie, n, deben ser dados en laentrada de su programa. Para valores negativos de x, el programa debe calcu-lar ex de dos formas: En una de ellas el valor de x es usado directamente enla serie de Taylor y, en la otra forma, el valor usado en la serie será y = −x,y en seguida, se calcula el valor de ex por medio de 1
ex.
1. Experimente su programa con varios valores de x (x próximo de cero ydistante de cero) y, para cada valor de x, experimente el cálculo de laserie con varios valores de n. Analice los resultados obtenidos.
2. (Dificultades con el cálculo del factorial) El cálculo de k! necesario enla serie de Taylor puede ser hecho de modo a evitar la ocurrencia deoverflow. Para esto es necesario analizar cuidadosamente el k-ésimotérmino, xk
k!. Intente combinar el cálculo del numerador con el del de-
nominador y realizar divisiones intermedias. Estudie una manera derealizar esta operación de modo que k! no se sobrecargue.
3. Con la modificación del segundo ítem, la serie de Taylor puede sercalculada con los términos que se desee. ¿Cuál sería el criterio paradetener su programa e interrumpir el cálculo de la serie?

Capítulo 2
Ceros reales de funciones reales
En esta sección vamos a resolver la ecuación representada por
f (x) = 0 (2.1)
donde f : [a; b] ⊂ R 7→ R. Resolver tal ecuación significa encontrar ξ ∈ [a; b]de modo que f (ξ) = 0.
Algunas de las técnicas para resolver esta ecuación, es decir, encontraruna raíz de la ecuación (2.1) o simplemente un cero de f , requieren de unprocedimiento que comprende esencialmente dos fases. En la primera fase unintervalo conteniendo la raíz es obtenido (aislamiento de las raíces). En lasegunda fase, se obtiene una aproximación de la raíz deseada (refinamiento).
2.1. Aislamiento de las Raíces
Si ξ es una raíz de f , el procedimiento de aislamiento de una raíz consisteen obtener un intervalo [a; b] que contenga ξ.
Una primera alternativa sería mediante una observación gráfica, proba-blemente con ayuda de un computador o una calculadora.
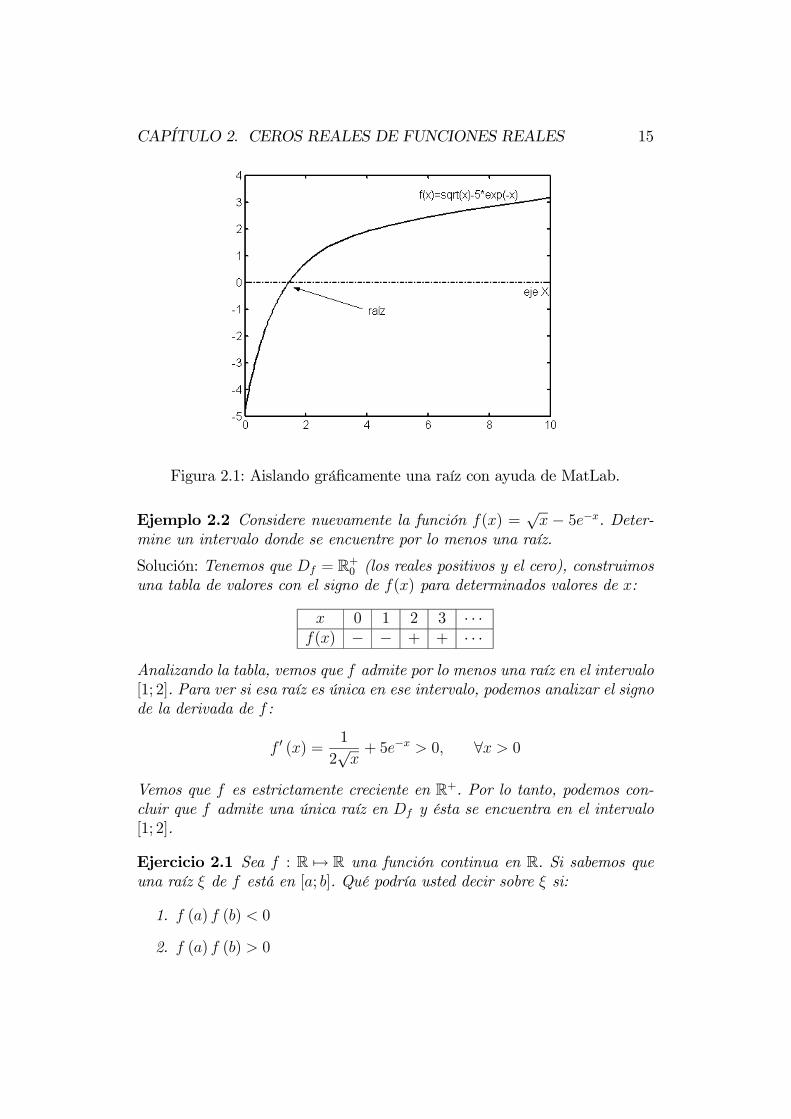
Ejemplo 2.1 Para el aislamiento de una raíz de f(x) =√x − 5e−x, pro-
cedemos a graficar utilizando MatLab. Observamos que en el intervalo [0; 4]se encuentra una raíz. La figura 2.1 muestra esta situación.
Otra alternativa para el aislamiento de una raíz consiste en analizar elcambio de signo de los valores de la función, tal como explica el siguienteejemplo.
14
CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 15
Figura 2.1: Aislando gráficamente una raíz con ayuda de MatLab.
Ejemplo 2.2 Considere nuevamente la función f(x) =√x − 5e−x. Deter-
mine un intervalo donde se encuentre por lo menos una raíz.
Solución: Tenemos que Df = R+0 (los reales positivos y el cero), construimosuna tabla de valores con el signo de f(x) para determinados valores de x:
x 0 1 2 3 · · ·f(x) − − + + · · ·
Analizando la tabla, vemos que f admite por lo menos una raíz en el intervalo[1; 2]. Para ver si esa raíz es única en ese intervalo, podemos analizar el signode la derivada de f :
f 0 (x) =1
2√x+ 5e−x > 0, ∀x > 0
Vemos que f es estrictamente creciente en R+. Por lo tanto, podemos con-cluir que f admite una única raíz en Df y ésta se encuentra en el intervalo[1; 2].
Ejercicio 2.1 Sea f : R 7→ R una función continua en R. Si sabemos queuna raíz ξ de f está en [a; b]. Qué podría usted decir sobre ξ si:
1. f (a) f (b) < 0
2. f (a) f (b) > 0

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 16
3. f (a) f (b) ≤ 04. f (a) f (b) ≥ 0
Laboratorio 2.1 Usando un computador y un programa adecuado, grafiquelas siguientes funciones y determine aquellos intervalos que incluyan algunaraíz:
1. f(x) = 1000 sin(x3 + 1)/ log(5 + x2), x ∈ [−2; 1]2. g(x) = ln (x2 + 1)− 200 (x+ 10)3 + 9x2 + 5, x ∈ R3. h(x) = 0,00037x11 − (x− π)2 + x2 + 5x− 100, x ∈ R
2.2. Refinamiento: Métodos Iterativos
Una vez que tenemos un intervalo que contenga la raíz, el siguiente pasoes construir un mecanismo que nos otorgue aproximaciones razonables a lasolución exacta. En esta sección veremos algunos métodos numéricos clásicoslos cuales nos otorgarán aproximaciones a una raíz de f . En su mayoría,estos métodos son iterativos, es decir, que inician con una estimativa de lasolución inicial y utilizan ésta para encontrar la siguiente, y así por delante,hasta obtener una aproximación a la solución.
Cuando se use un método iterativo, debemos considerar un criterio paradetener el algoritmo respectivo. En los métodos que buscan una raíz, éstosse repetirán hasta que xk sea próxima a la raíz exacta ξ con precisión ε > 0,esto ocurrirá si:
1. |xk − ξ| < ε, o
2. |f ¡xk¢ | < ε
Pero, ¿cómo efectuar el primer ítem si no se conoce ξ? Una forma esreducir el intervalo que contiene a la raíz en cada iteración. Al conseguirseun intervalo [a; b] tal que
ξ ∈ [a; b] y b− a < ε
entonces ∀x ∈ [a; b], |x − ξ| < ε. En estas condiciones, cualquier x ∈ [a; b]podría ser la aproximación requerida.
CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 17
Figura 2.2: f(ξ) = 0
El orden de grandeza de los números con que trabajamos puede darnospoca información, tal como mostraba el ejemplo 1.10, es aconsejable en estoscasos utilizar el error relativo. Por ejemplo, podemos considerar xk próximode una raíz, si
|f(xk)|L
< ε
donde L = |f (x) |, para algún x escogido en una vecindad de la raíz ξ.
Otro aspecto que debemos tener en cuenta es el máximo número de ite-raciones permitidas por el algoritmo. Esto ayuda a evitar que el programaen computador trabaje indefinidamente, sobre todo en el caso cuando elalgoritmo no converge.
Antes de todo, debemos hacer una aclaración con respecto a método yalgoritmo. Entendemos por método a un procedimiento con las justificacionesmatemáticas necesarias para resolver un determinado problema. Mientrasque por algoritmo, entendemos como el resumen del método, una especie dereceta.
Existen varios métodos numéricos para obtener un cero real de una fun-ción real, algunos simplemente requieren que la función sea continua, mien-tras que otros requieren que la función sea diferenciable. En lo que resta deeste capítulo analizaremos cada uno de los métodos más populares que exis-ten hoy en día. En nuestro caso, analizar comprenderá la construcción delmétodo, estudiar las propiedades de convergencia y la rapidez del mismo.
CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 18
Para estudiar la convergencia debemos dar las hipótesis para que el méto-do garantice una solución. Por otro lado, para analizar la rapidez del método,es necesario tener en consideración dos criterios:
El número de iteraciones: Dada la precisión deseada ε, determinar el nú-mero de iteraciones, k, para que el algoritmo respectivo se detenga.
La rapidez: Una vez garantizada la convergencia. Determinar cuál es la tasao rapidez (velocidad) de convergencia con que trabaja el algoritmo
Lo más deseable es obtener el número de iteraciones que un algoritmorequiere para resolver el problema, al menos una cantidad aproximada deéste, pero no siempre es posible tal hazaña. A veces es posible obtener sólo latasa de convergencia del algoritmo, esto también dará información sobre eldesempeño del mismo, lo cual permitirá realizar comparaciones para decidirpor el algoritmo más eficiente para un determinado problema. Los detallesrelacionados a estos conceptos serán explicados a medida que vayamos avan-zando.
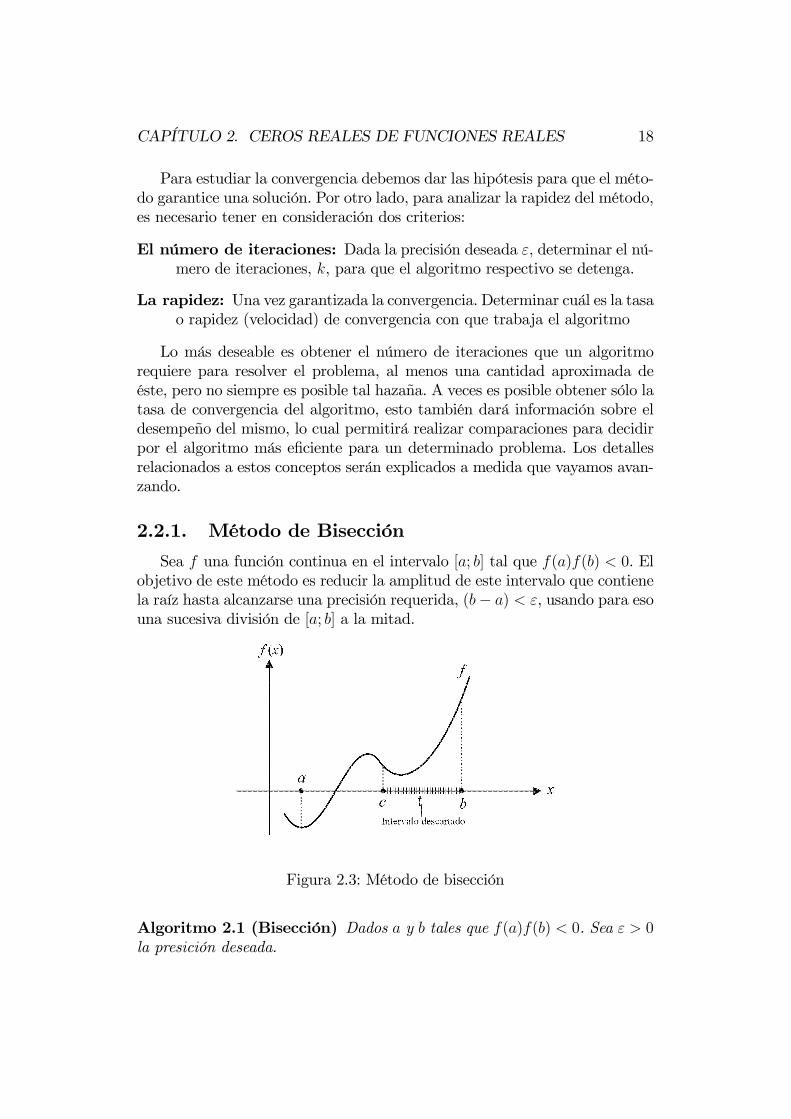
2.2.1. Método de Bisección
Sea f una función continua en el intervalo [a; b] tal que f(a)f(b) < 0. Elobjetivo de este método es reducir la amplitud de este intervalo que contienela raíz hasta alcanzarse una precisión requerida, (b− a) < ε, usando para esouna sucesiva división de [a; b] a la mitad.
Figura 2.3: Método de bisección
Algoritmo 2.1 (Bisección) Dados a y b tales que f(a)f(b) < 0. Sea ε > 0la presición deseada.

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 19
1. Si (b− a) < ε. Elegir x ∈ [a; b] y terminar el algoritmo. Caso contrario,ir al paso 2.
2. Hacer k = 1 e ir al paso 3.
3. Hacer c = a+b2e ir al paso 4.
4. Si f (a) f (c) > 0, hacer a = c e ir al paso 5. Caso contrario, hacerb = c e ir al paso 5.
5. Si b − a < ε, elegir x ∈ [a; b] y finalizar el algoritmo. Caso contrario,hacer k = k + 1 y volver al paso 3.
Estudio de la Convergencia del Método de Bisección Bajo las hipóte-sis establecidas, es claro que el método de la bisección construirá una sucesión{xk} que converge a una raíz. Para probar esto analíticamente procedemosdel siguiente modo.
Supongamos que [a0; b0] sea el intervalo inicial y ξ la única raíz de f enel interior de ese intervalo. El método de la bisección genera tres sucesiones:
La sucesión {ak}k∈N: No decreciente y acotada superiormente por b0. Luego,existe r ∈ R tal que lımk→∞ ak = r.
La sucesión {bk}k∈N: No creciente y limitada inferiormente por a0. Luego,existe s ∈ R tal que lımk→∞ bk = s.
La sucesión {ck}k∈N: Generada por ck = ak+bk2, donde ak < ck < bk, para
todo k = 1, 2, ....
Observe que el tamaño de cada intervalo es la mitad del intervalo anterior.Así, para k = 1, 2, ...
b1 − a1 =b0 − a02
b2 − a2 =b1 − a12
=b0 − a022
b3 − a3 =b2 − a22
=b0 − a023
...
bk − ak =b0 − a02k
(2.2)

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 20
Entonces,
lımk→∞
(bk − ak) = lımk→∞
(b0 − a0)
2k= 0
Como {ak}k∈N y {bk}k∈N son convergentes:
lımk→∞
bk − lımk→∞
ak = 0 =⇒ s− r = 0
Por lo tanto, s = r. Sea λ = s = r el límite de las dos sucesiones. Dado quepara todo k = 1, 2, ... el punto ck ∈ hak; bki, entonces
lımk→∞
ck = λ
Resta probar apenas que λ es un cero de la función f , o sea, f (λ) = 0.Observe que en cada iteración k = 1, 2, ... tenemos que f (ak) f (bk) < 0.Entonces, dado que hemos asumido f continua en [a; b]:
0 ≥ lımk→∞
f (ak) f (bk) = lımk→∞
f (ak) lımk→∞
f (bk)
= f( lımk→∞
ak)f( lımk→∞
bk) = f (r) f (s) = f (λ) f (λ)
= (f (λ))2
de donde concluimos que f (λ) = 0. Por tanto, lımk→∞ ck = λ es un cero def , como habíamos asumido que en el intervalo había una única raíz, tenemosque λ = ξ.
Estimación del Número de Iteraciones
Dada una precisión ε > 0 y un intervalo inicial [a; b], es posible saber,a priori, cuántas iteraciones serán efectuadas por el método de la bisección(algoritmo 2.1) hasta que se cumpla b− a < ε.
Vimos en (2.2) que para k = 1, 2, ...
bk − ak =bk−1 − ak−1
2=
b0 − a02k
(2.3)
Observe que el algoritmo 2.1 se detendrá cuando bk−ak < ε, según la ecuación(2.3) esto equivale a encontrar un valor de k de modo que
b0 − a02k
< ε

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 21
Esto a su vez equivale a decir que
2k >b0 − a0
ε
Lo cual implica quek > log2 (b0 − a0)− log2 (ε) (2.4)
Por lo tanto, en el algoritmo 2.1, si el número de iteraciones k es por lo menos
blog2 (b0 − a0)− log2 (ε)c+ 1
el intervalo [ak; bk] conteniendo a la raíz ξ verifica bk−ak < ε, en estas condi-ciones cualquier x ∈ [ak; bk] debería ser la aproximación a la raíz buscada ξ,pues |x− ξ| ≤ bk − ak < ε.
Podemos concluir sobre este algoritmo que el número de iteraciones de-penderá de la longitud del intervalo [a; b] y de la precisión deseada ε. Comomuestra la ecuación (2.4), ese número de iteraciones no debería ser grande,debido a la presencia del logaritmo.
Ejemplo 2.3 Usando el algoritmo 2.1, se desea encontrar una aproximacióna un cero de la función definida por
f (x) = x log10 x− 1
la cual está en el intervalo [2; 3] y con precisión ε = 10−2. ¿Cuántas itera-ciones debería efectuar el algoritmo?
Solución: Según (2.4) vemos que
k ≥ ¥log2 (3− 2)− log2
¡10−2
¢¦+ 1 =
¥log2 1− log2
¡10−2
¢¦+ 1
=¥− log2 ¡10−2¢¦+ 1 = 7
Luego, el algoritmo debería detenerse con k = 7 iteraciones.
Conclusión 2.1 (sobre el método de bisección) Si f : R 7→ R es con-tinua en el intervalo [a; b] y f (a) f (b) < 0:
El método de bisección genera una sucesión que converge a la raíz def (x) = 0, esto se consigue mediante las reducciones sucesivas del in-tervalo de búsqueda hasta una precisión deseada.
Cada iteración no requiere cálculos complicados.

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 22
No se requieren derivadas.
Las hipótesis no son rigurosas.
Converge razonablemente rápido (comparado a otros métodos se le con-sidera lento).
Laboratorio 2.2 En algún lenguaje de programación de su preferencia, im-plemente el algoritmo de la bisección, resuelva las siguientes ecuaciones:
1. ln (x2 + 1) = 200 (x+ 10)3 − 9x2 − 5, en R2. 1000 sin(x3 + 1)/ log(5 + x2) = 0, en [−2; 1]3. 0,00037x11 − (x− π)2 + x2 = −5x+ 100, en R
2.2.2. Método de la Posición Falsa
Sea f : R 7→ R continua en [a; b] tal que f (a) f (b) < 0. Suponga que elintervalo [a; b] contiene una única raíz de la ecuación f (x) = 0. Podemosesperar conseguir una raíz aproximada usando las informaciones sobre losvalores de f disponibles a cada iteración.
Por ejemplo, en la figura 2.4 se aprecia que al ser |f (a)| pequeño en com-paración a |f (b)|, podemos sospechar que la raíz se encuentra más cercanaal punto a que al punto b. Luego, en cada iteración, en vez de tomar ck comoel punto medio, como lo hacía el método de bisección, podemos tomarlo dela siguiente manera:
ck =a |f (b)|+ b |f (a)||f (b)|+ |f (a)|
que en realidad es una media aritmética ponderada entre a y b, con pesos|f (b)| y |f (a)|. Después de unos cálculos, tenemos:
ck =af (b)− bf (a)
f (b)− f (a)
Lo que resta del método de la posición falsa es análogo al método de bisección,la parte donde no se encuentra la raíz debería ser desechada y el intervalodebería ser reducido hasta una presición deseada.
Lamentablemente, las cosas no son como parecen, pues el valor de |f (a)|puede ser pequeño y sin embargo, la raíz puede estar muy lejos de a, talcomo se aprecia en la figura 2.5. Esto muestra que la sospecha puede estartotalmente errada, lo que retrasaría la convergencia del método, de ahí elnombre.
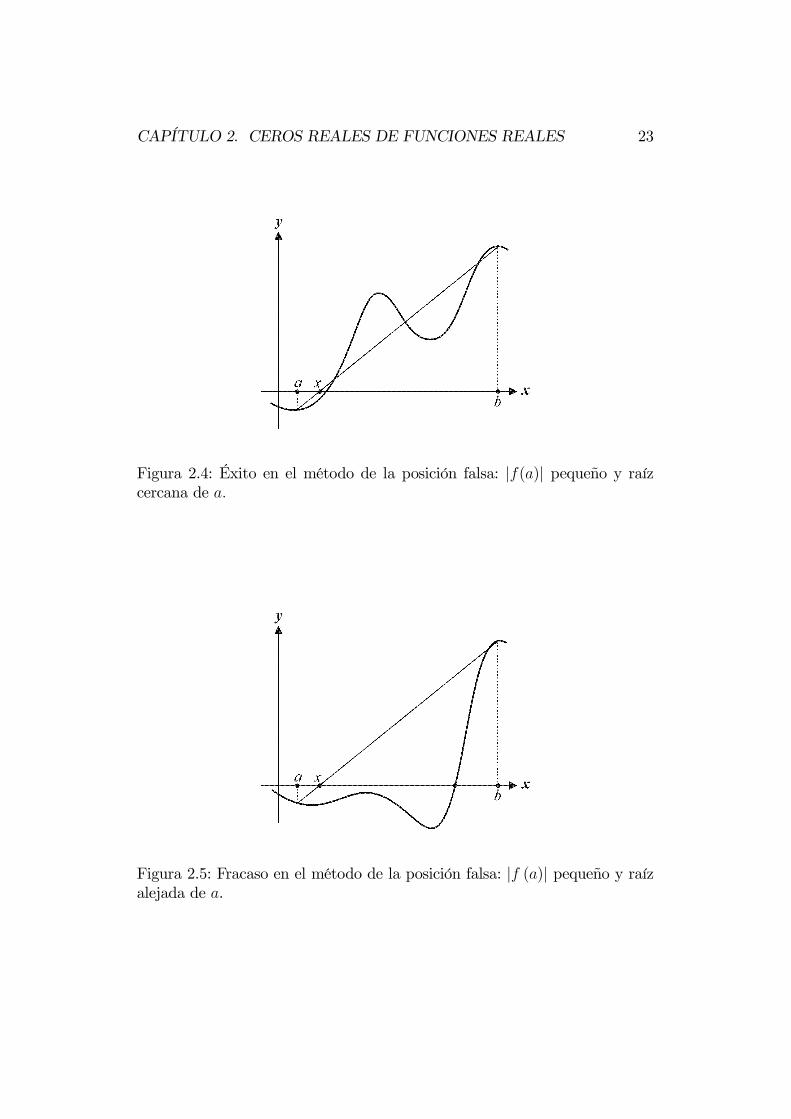
CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 23
Figura 2.4: Éxito en el método de la posición falsa: |f(a)| pequeño y raízcercana de a.
Figura 2.5: Fracaso en el método de la posición falsa: |f (a)| pequeño y raízalejada de a.

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 24
Ejercicio 2.2 Haga un algoritmo que resuma el método de la posición falsa.
Laboratorio 2.3 En algún lenguaje de programación de su preferencia, im-plemente el algoritmo de la posición falsa, pruebe con varios ejemplares ycompare el número de iteraciones con el método de bisección.
Ejercicio 2.3 Investigue sobre la convergencia y el número de iteracionesrequeridas por el método de la posición falsa.
2.2.3. Método del Punto Fijo (MPF)
Sea f : R 7→ R una función. Se dice que λ es un punto fijo de f , sif (λ) = λ. Este concepto es el mismo para una función vectorial de variablevectorial.
El Método del Punto Fijo consiste en lo siguiente:
1. Transformar la ecuación f (x) = 0 en una ecuación equivalente:
x = θ (x)
2. Dado un punto inicial x0 ∈ R, generar una sucesión {xk} de aproxima-ciones hacia ξ, la raíz buscada, mediante la relación
xk+1 = θ (xk)
Observe que la función θ debe ser una función que cumpla: f (ξ) = 0 si,y sólo si, θ (ξ) = ξ. De este modo, resolver el problema de encontrar una raízde una ecuación se convierte en un otro problema de hallar un punto fijo deuna función. Aunque a simple vista no parezca, más adelante veremos queesta idea trae ciertas ventajas.
La función θ con esa característica se denomina función iteración asociadaa la ecuación f (x) = 0. Naturalmente, pueden existir muchas funcionesiteración asociadas a una sola ecuación.
Ejemplo 2.4 Dada la ecuación x2 + 2x − 10 = 0. Algunas candidatas afunción iteración son las siguientes:
1. θ (x) = 5− x2
2
2. θ (x) = 10x+2
, x 6= −2

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 25
3. θ (x) = 10x− 2, x 6= 0
Definición 2.1 (Forma general de una función iteración) Una funcióniteración asociada a la ecuación f(x) = 0, está dada de una forma generalpor:
θ (x) = x+A (x) f (x)
con la condición que en ξ, punto fijo de θ, se tenga A (ξ) 6= 0.
Teorema 2.1 Si θ es una función iteración de la ecuación f (x) = 0, en-tonces f (ξ) = 0 si, y sólo si, θ (ξ) = ξ.
Prueba. ( =⇒ ) Sea ξ tal que f (ξ) = 0. Como θ (ξ) = ξ + A (ξ) f (ξ),claramente tenemos θ (ξ) = ξ.
(⇐= ) Si θ (ξ) = ξ, entonces ξ+A (ξ) f (ξ) = ξ implica que A (ξ) f (ξ) =0, esto a su vez implica que f (ξ) = 0, pues A (ξ) 6= 0 por definición.
Estudio de la Convergencia del Método del Punto Fijo
Dependiendo de la elección de la función iteración θ, el método del puntofijo puede o no convergir a la solución de la ecuación f (x) = 0. El siguienteteorema establece las condiciones suficientes para que esta convergencia suce-da.
Teorema 2.2 Sea ξ una raíz de la ecuación f (x) = 0, aislada en un in-tervalo abierto I centrado en ξ. Sea θ una función iteración asociada a estaecuación. Si
1. θ y θ0 son funciones continuas en I.
2. |θ0 (x) | ≤M < 1, para todo x ∈ I.
3. x0 ∈ I
Entonces, la sucesión {xk} generada por la regla xk+1 = θ (xk), k = 0, 1, 2, ...converge hacia ξ.
Prueba. La prueba consta de dos partes:
1. Si x0 ∈ I, entonces xk ∈ I, para todo k = 0, 1, 2, ...
2. lımk→∞ xk = ξ

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 26
Primero, como ξ es una raíz exacta de la ecuación f (x) = 0, se tiene quef (ξ) = 0 ⇐⇒ ξ = θ (ξ). Además, para cualquier k = 0, 1, 2, ... se tienexk+1 = θ (xk), desde aquí
xk+1 − ξ = θ (xk)− θ (ξ)
Como θ es continua y diferenciable en I, por el teorema del valor medio,existe ck entre xk y ξ, tal que
xk+1 − ξ = θ (xk)− θ (ξ) = θ0 (ck) (xk − ξ) k = 0, 1, 2, ...
Luego,
|xk+1 − ξ| = |θ0 (ck) ||xk − ξ| ≤M |xk − ξ| < |xk − ξ| k = 0, 1, 2, ... (2.5)
Es decir, la distancia entre xk+1 y ξ es menor que la distancia entre xk y ξ,como I está centrado en ξ, vemos que si xk ∈ I entonces xk+1 ∈ I. Luego, six0 ∈ I, claramente xk ∈ I para todo k = 1, 2, ....
Para probar la segunda parte, lımk→∞ xk = ξ, desde (2.5) vemos que:
|x1 − ξ| ≤ M |x0 − ξ||x2 − ξ| ≤ M |x1 − ξ| ≤M2|x0 − ξ|
...
|xk − ξ| ≤ Mk|x0 − ξ|de donde lımk→∞ |xk− ξ| = 0, pues 0 ≤M < 1. Por lo tanto, lımk→∞ xk = ξ.
Ejemplo 2.5 Sea la función f (x) = x2 + 2x− 10 cuya raíz es ξ ≈ 2,3166.Dadas las funciones iteración
θ1 (x) = 5− x2
2
y
θ2 (x) =10
x+ 2, x 6= −2
Observe que
|θ01 (x) | = |− x| = |x| < 1 ⇐⇒ x ∈ h−1, 1iLuego, no existe un intervalo I centrado en ξ tal que |θ01 (x) | < 1 para todox ∈ I. El teorema 2.2 no afirma nada con respecto de la convergencia de la

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 27
sucesión {xk} generada por xk+1 = θ1 (xk), pues θ1 no cumple la hipótesis, elmétodo del punto fijo puede convergir o no cuando se utilice θ1 como funcióniteración.
Por otro lado, si usamos la función iteración θ2, la situación es diferente.Observe que
|θ02 (x)| =¯
10
(x+ 2)2
¯< 1 ⇐⇒ x ∈
D−∞;−√10− 2
E∪D√10− 2;+∞
E≈
h−∞;−5,1622i ∪ h1,1622;+∞iLuego, existe un intervalo I centrado en ξ, tal que |θ02 (x)| < 1 para todox ∈ I. En este caso, el teorema asegura la convergencia del MPF tomandox0 ∈ I.
Ejercicio 2.4 Analice el caso para la función f (x) = x2+2x−10, cuya raízes ξ ≈ 2,3166, cuando se usa como función iteración:
θ3 (x) =10
x− 2, x 6= 0
Además, analice el otro caso, cuando consideramos como raíz a ξ ≈ −5,1622.
Algoritmo 2.2 (Punto Fijo) Considere la ecuación f (x) = 0 y la ecuaciónequivalente x = θ (x). Supongamos que θ ya es conocida explícitamente y lashipótesis suficientes del teorema 2.2 son satisfechas. Dada una precisión de-seada ε > 0, el algoritmo se detendrá cuando |f (xk)| < ε. La aproximaciónal punto fijo ξ (la raíz buscada) será x.
1. Datos iniciales:
a) x0, la aproximación inicial
b) ε1 y ε2 las precisiones deseadas
2. Si |f (x0)| < ε1, hacer x = x0, finalizar el algoritmo
3. k = 1
4. x1 = θ (x0)
5. Si |f (x1)| < ε1 o si |x1 − x0| < ε2, hacer x = x1, finalizar el algoritmo
6. x0 = x1
7. k = k + 1. Volver al paso 4.

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 28
Laboratorio 2.4 En algún lenguaje de programación de su preferencia, im-plemente el MPF y ejecute el programa sobre el problema del ejemplo 2.5.Observe que el método diverge cuando usamos θ1, pruebe con varios puntosiniciales e interprete los resultados.
Tasa de Convergencia del Método de Punto Fijo
Cuando vimos el método de la bisección, notamos que era posible obteneruna cota inferior para el número de iteraciones a ser realizadas por el algorit-mo. Pero eso no siempre es posible, así, necesitamos de algunos parámetrosque nos indiquen con qué rapidez la sucesión generada por un algoritmo con-verge a la solución deseada. Eso nos permitirá calificar a un algoritmo comolento o rápido.
Definición 2.2 (Tasa o rapidez de convergencia) Sea la sucesión©r(k)ª
generada por algún algoritmo, de modo que lımk→∞ r(k) → r. Asumamos quer(k) 6= r para todo k = 0, 1, 2, ..., la tasa de convergencia del algoritmo es elsupremo P de los números no negativos p satisfaciendo:
lımk→∞
°°r(k+1) − r°°
kr(k) − rkp = β <∞
Si P = 1 y el radio de convergencia β < 1, la sucesión se dice que tieneuna tasa de convergencia lineal (por lo menos lineal). Si P ≥ 1 y β = 0, lasucesión tiene tasa de convergencia súper lineal. Si P = 2 y β <∞, entoncesdiremos que la sucesión tiene una tasa de convergencia cuadrática.
Una manera natural de ver esta situación es la siguiente: supongamosque
©r(k)ªes una sucesión generada por un algoritmo la cual converge a
la solución r, donde el algoritmo presenta una tasa de convergencia lineal,entonces: °°r(k+1) − r
°°| {z } ≈ β
ek+1
°°r(k) − r°°| {z }
ek
, ∀k ≥ k0
nos dice que el error ek+1 cometido en la iteración k+1 es menor (linealmente)que el error ek en la iteración k, cuando k0 es grande.
En el caso de una tasa de convergencia cuadrática, es claro que el errorcometido en la iteración k + 1 es aproximadamente el cuadrado del errorcometido en la iteración anterior. Esto indica que para valores grandes de k0y en las proximidades de r, el error ek+1 disminuye considerablemente conrespecto a ek: °°r(k+1) − r
°°| {z }ek+1
≈ β°°r(k) − r
°°2| {z }e2k
, ∀k ≥ k0

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 29
Así, un algoritmo con tasa de convergencia cuadrática convergirá conmayor rapidez hacia un punto de acumulación, que uno que posee tasa deconvergencia súper lineal. Por otro lado, un algoritmo con tasa de conver-gencia súper lineal será más rápido que uno con tasa de convergencia lineal.Más adelante veremos que el Método Secante tiene una tasa de convergenciaP = 1,618...
Proposición 2.1 (Tasa de convergencia de MPF) Asumamos que la su-cesión generada por el Método del Punto Fijo converge a ξ, la raíz de f ,entonces la tasa de convergencia es por lo menos lineal.
Prueba. Desde (2.5), tenemos
|xk+1 − ξ| = |θ0 (ck) ||xk − ξ|, ck entre xk y ξ, k = 0, 1, 2, ...
Luego,
|xk+1 − ξ||xk − ξ| = |θ
0 (ck) |, ck entre xk y ξ, k = 0, 1, 2, ...
Tomando límites, por la continuidad de θ y θ0, tenemos
lımk→∞
|xk+1 − ξ||xk − ξ| = lım
k→∞|θ0 (ck) | =
¯θ0³lımk→∞
ck´¯= |θ0 (ξ)| = β ≤M < 1
Así, vemos que el método del punto fijo posee una tasa de convergencialineal, por este motivo muchas veces se le considera lento. Sin embargo, elmétodo de bisección también posee esa misma velocidad, tal como lo afirmael siguiente ejercicio.
Ejercicio 2.5 Muestre que la tasa de convergencia del método de la bisecciónes lineal.
2.2.4. El Método de Newton-Raphson
Cuando estudiamos el método del punto fijo, notamos que:
1. Una de las condiciones para la convergencia es que |θ0 (x) | ≤ M < 1,para todo x ∈ I, donde I es un intervalo centrado en la raíz.
2. La convergencia del método será más rápida cuanto menor sea |θ0 (ξ) |.

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 30
La segunda afirmación se debe al siguiente hecho: cuando analizamos latasa de convergencia del MPF, vimos que
lım|xk+1 − ξ||xk − ξ| = |θ
0 (ξ) | < 1
Entonces, acelerar la convergencia del MPF se conseguiría escogiendo unafunción iteración de modo que θ0 (ξ) = 0, pues en este caso la tasa de con-vergencia sería por lo menos súper-lineal.
Hacia este objetivo, dada la ecuación f (x) = 0 cuya raíz es ξ. Consider-amos la forma general de la función iteración θ (x) = x +A (x) f (x), dondeA (ξ) 6= 0, con la nueva condición θ0 (ξ) = 0. Así,
θ (x) = x+A (x) f (x) =⇒ θ0 (x) = 1 +A0 (x) f (x) +A (x) f 0 (x)
Luego,
θ0 (ξ) = 1 +A0 (ξ) f (ξ) +A (ξ) f 0 (ξ) =⇒ θ0 (ξ) = 1 +A (ξ) f 0 (ξ)
de donde
θ0 (ξ) = 0 ⇐⇒ 1 +A (ξ) f 0 (ξ) = 0 ⇐⇒ A (ξ) = − 1
f 0 (ξ), f 0 (ξ) 6= 0
Esto nos motiva a definirA (ξ) = − 1
f 0 (ξ)Entonces, dada la ecuación f (x) = 0, la función iteración deseada será de laforma:
θ (x) = x− f (x)
f 0 (x), f 0(x) 6= 0 (2.6)
Observe que
θ0 (x) = 1− (f0 (x))2 − f (x) f 00 (x)
(f 0 (x))2=
f (x) f 00 (x)
(f 0 (x))2, f 0 (x) 6= 0
y como f (ξ) = 0, se tiene que θ0 (ξ) = 0.
Por lo tanto, usando la función iteración definida en (2.6) obtenemos uncaso particular del método del punto fijo, a éste se le denomina método deNewton.
En resumen, dado x0 ∈ R, el Método de Newton consiste en construiruna sucesión definida por la regla
xk+1 = xk − f (xk)
f 0 (xk), f 0 (xk) 6= 0, k = 0, 1, 2, ... (2.7)

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 31
Otro Enfoque del Método de Newton-Raphson
Desde el punto de vista geométrico, el método de Newton puede ser vistocomo la solución de un problema difícil, mediante la sucesiva resolución deproblemas fáciles. Es decir, dada una aproximación inicial xk ∈ R a la raízbuscada, el problema difícil será hallar una raíz de la ecuación no linealf (x) = 0, mientras que el problema fácil asociado será resolver la ecuaciónLk (x) = 0, donde L es una función lineal afín que es parecida, al menoslocalmente, a la función no lineal f en torno al punto xk.
Así, sea el problema (difícil) que consiste en hallar una raíz de f (x) = 0y x0 ∈ R una aproximación inicial. Por el teorema de Taylor, existe δ > 0 talque
f (x) ≈ L0 (x) = f (x0) + f 0 (x0) (x− x0)
para todo x ∈ hx0 − δ, x0 + δi. Luego, denotando por x1 la solución de laecuación lineal
L0 (x) = 0 (2.8)
y asumiendo que f 0(x0) 6= 0, entonces L0 (x) = 0 si, y sólo si,
f (x0) + f 0 (x0) (x− x0) = 0
de donde
x1 = x0 − f (x0)
f 0 (x0)
Esperamos que x1 sea una mejor aproximación que x0 a la solución def(x) = 0. Este procedimiento puede ser repetido iterativamente, creándoseuna sucesión {xk}∞k=0, donde
xk+1 = xk − f (xk)
f 0 (xk), f 0 (xk) 6= 0, k = 0, 1, 2, ...
Bajo algunas hipótesis se consigue que lımk→∞ xk = ξ.
Convergencia del Método de Newton-Raphson
A continuación damos las condiciones bajo las cuales se asegura la con-vergencia del método de Newton.
Teorema 2.3 Sean f , f 0 y f 00 continuas en un intervalo abierto I que con-tiene en su interior la raíz ξ de f (x) = 0, donde f 0 (ξ) 6= 0, entonces existe

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 32
Figura 2.6: Iteraciones Newton
un intervalo abierto I ⊂ I conteniendo la raíz ξ, tal que si x0 ∈ I, la sucesión{xk} generada por
xk+1 = xk − f (xk)
f 0 (xk), f 0 (xk) 6= 0, k = 0, 1, 2, ...
convergirá para ξ.
Prueba. Observe que el método de newton es en realidad un MPF confunción iteración θ (x) = x− f(x)
f 0(x) . Así, para probar la convergencia debemosprobar que existe un I ⊂ I, centrado en ξ, tal que:
1. θ y θ0 son continuas en I
2. |θ0 (x) | ≤M < 1, para todo x ∈ I
Vemos que θ (x) = x− f(x)f 0(x) , θ
0 (x) = f(x)f 00(x)(f 0(x))2 y por hipótesis f
0 (ξ) 6= 0. Comof 0 es continua en I, es posible obtener un intervalo abierto I1 ⊂ I, ξ ∈ I1, talque f 0 (x) 6= 0 para todo x ∈ I1.
Así, en el intervalo I1 se tiene que f, f 0 y f 00 son continuas y f 0 (x) 6= 0,∀x ∈ I1. Por lo tanto, θ y θ
0 son continuas en I1.
Como θ0 (x) = f(x)f 00(x)(f 0(x))2 , θ
0 es continua en I1 y θ0 (ξ) = 0, entonces es
posible obtener otro intervalo abierto I2 ⊂ I1, centrado en ξ, tal que |θ0 (x) | <1 para todo x ∈ I2.

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 33
Por lo tanto, hemos encontrado un intervalo abierto I = I2 centrado en ξdonde θ y θ0 son continuas y |θ0 (x) | < 1, ∀x ∈ I. Así, si x0 ∈ I, la sucesión{xk} generada por la regla de correspondencia xk+1 = xk − f (xk) /f
0 (xk)converge hacia la raíz ξ de f (x) = 0.
En pocas palabras, lo que dice el teorema anterior es que el método deNewton converge sólo si el punto inicial es tomado lo suficientemente próximode la solución ξ, esta propiedad se conoce como convergencia local, la cuales una desventaja. Más adelante veremos que, en cierta forma, ese defecto secompensa con la rapidez con que converge el método.
Algoritmo 2.3 (Newton-Raphson) Dada la ecuación f (x) = 0. Supongaque las hipótesis de suficiencia dadas en el teorema 2.3 son satisfechas. Elalgoritmo otorgará una aproximación x a las raíz ξ.
Paso inicial: Sea x0 una aproximaxión inicial de ξ y ε1, ε2 > 0 las preci-siones deseadas.
Paso principal: Si |f (x0) | < ε1, hacer x = x0 y finalizar. Caso contrario,hacer:
1. k = 1
2. x1 = x0 − f (x0) /f0 (x0)
3. Si |f (x1) | < ε1 o si |x1− x0| < ε2, hacer x = x1 y finalizar. Casocontrario, hacer
a) x0 = x1
b) k = k + 1. Volver al paso 2.
Laboratorio 2.5 En algún lenguaje de programación de su preferencia, im-plemente el algoritmo de Newton y experiméntelo con diversos ejemplares.Compare sus resultados con los métodos anteriormente estudiados.
Tasa de Convergencia del Método de Newton-Raphson
Dada ξ una raíz exacta de la ecuación f (x) = 0. Sea {xk} la sucesióngenerada por el método de newton, tal que lımk→∞ xk = ξ.
Debido a que el método de Newton es un caso particular de MPF, en-tonces debe tener por lo menos una tasa de convergencia lineal. Nosotrosmostraremos que es mucho más que eso, debido a la condición θ0 (ξ) = 0, elmétodo alcanzará una tasa cuadrática, es decir, en la definición 2.2, P = 2.

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 34
Supongamos además que se satisfacen todas las hipótesis del teorema 2.3.Observe que
xk+1 = xk− f (xk)
f 0 (xk)=⇒ xk+1−ξ = xk−ξ− f (xk)
f 0 (xk)=⇒ ek+1 = ek− f (xk)
f 0 (xk)
donde ek = xk − ξ. Usando la serie de Taylor para f en torno al punto xk:
f (x) = f (xk) + f 0 (xk) (x− xk) +1
2f 00 (ck) (x− xk)
2 , ck está entre x y ck
Para x = ξ, tenemos
0 = f (xk) + f 0 (xk) (ξ − xk) +1
2f 00 (ck) (ξ − xk)
2
de dondef (xk) = f 0 (xk) (xk − ξ)− 1
2f 00 (ck) (xk − ξ)2
Dividiendo entre f 0 (xk), obtenemos
f (xk)
f 0 (xk)= (xk − ξ)− f 00 (ck) (xk − ξ)2
2f 0 (xk)
= ek − f 00 (ck) e2k2f 0 (xk)
Luego,f 00 (ck) e2k2f 0 (xk)
= ek − f (xk)
f 0 (xk)= ek+1
de dondeek+1e2k
=f 00 (ck)2f 0 (xk)
(2.9)
Después de unos cálculos, vemos que
θ00 (x) =(f 0 (x))2 (f 0 (x) f 00 (x) + f (x) f 000 (x))− (f (x) f 00 (x)) ¡(f 0 (x))2¢0
(f 0 (x))4
de donde θ00 es continua en ξ y
θ00 (ξ) =f 00 (ξ)f 0 (ξ)
Llevando (2.9) al límite, tenemos
lımk→∞
|ek+1||ek|2 = lım
k→∞|f 00 (ck) ||2f 0 (xk) |
=1
2
|f 00 (lımk→∞ ck) ||f 0 (lımk→∞ xk) | =
1
2
|f 00 (ξ) ||f 0 (ξ) | =
1
2|θ00 (ξ) | = β
Por lo tanto, el método de Newton tiene una tasa de convergencia cuadrática.
CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 35
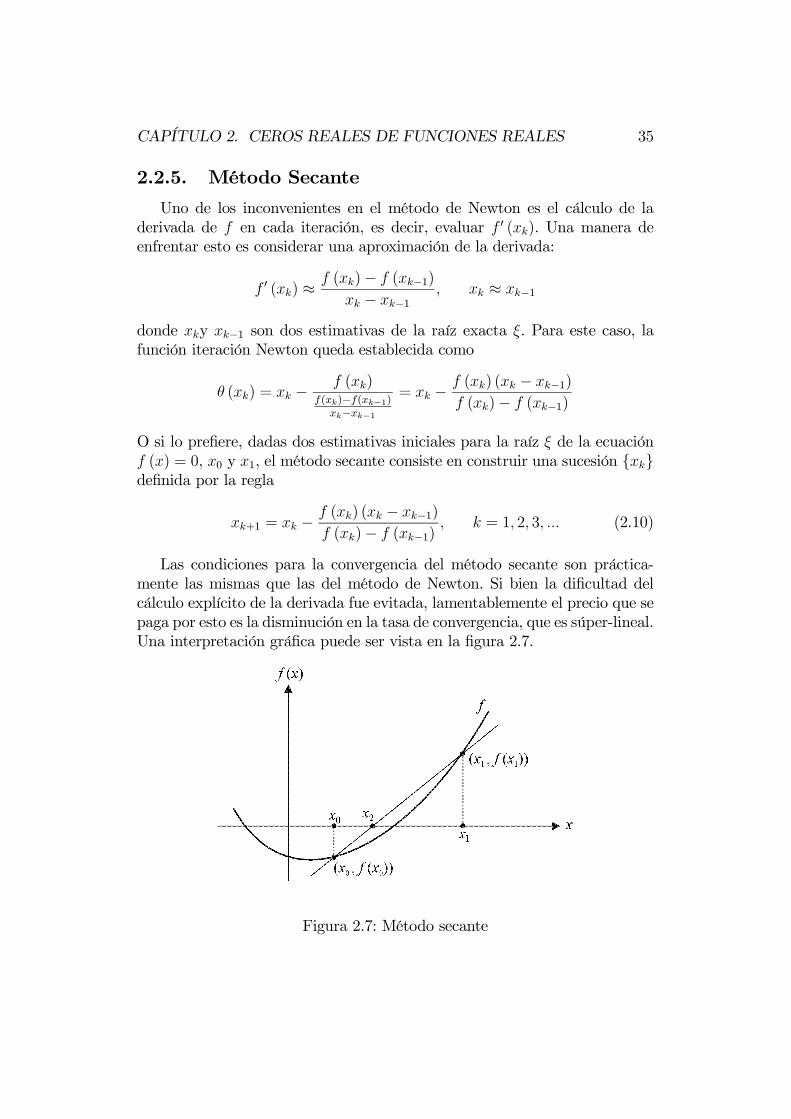
2.2.5. Método Secante
Uno de los inconvenientes en el método de Newton es el cálculo de laderivada de f en cada iteración, es decir, evaluar f 0 (xk). Una manera deenfrentar esto es considerar una aproximación de la derivada:
f 0 (xk) ≈ f (xk)− f (xk−1)xk − xk−1
, xk ≈ xk−1
donde xky xk−1 son dos estimativas de la raíz exacta ξ. Para este caso, lafunción iteración Newton queda establecida como
θ (xk) = xk − f (xk)f(xk)−f(xk−1)
xk−xk−1= xk − f (xk) (xk − xk−1)
f (xk)− f (xk−1)
O si lo prefiere, dadas dos estimativas iniciales para la raíz ξ de la ecuaciónf (x) = 0, x0 y x1, el método secante consiste en construir una sucesión {xk}definida por la regla
xk+1 = xk − f (xk) (xk − xk−1)f (xk)− f (xk−1)
, k = 1, 2, 3, ... (2.10)
Las condiciones para la convergencia del método secante son práctica-mente las mismas que las del método de Newton. Si bien la dificultad delcálculo explícito de la derivada fue evitada, lamentablemente el precio que sepaga por esto es la disminución en la tasa de convergencia, que es súper-lineal.Una interpretación gráfica puede ser vista en la figura 2.7.
Figura 2.7: Método secante

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 36
Convergencia del Método Secante
Al igual que el Método de Newton, la convergencia del Método Secanteestá asegurada cuando los puntos iniciales x0 y x1 fueron tomados lo suficien-temente próximos de la raíz buscada ξ. El teorema a seguir formaliza estaafirmación.
Teorema 2.4 Sea ξ una raíz de f (x) = 0 y suponga que f ∈ C2 en unavecindad en torno de ξ donde f 0 (ξ) 6= 0. Si los puntos iniciales x0 y x1 estánsuficientemente próximos de ξ, entonces lımk→∞ xk = ξ.
Prueba. Desde la ecuación (2.10), tenemos
ξ − xk+1 = ξ − xk +f (xk) (xk − xk−1)f (xk)− f (xk−1)
= − (ξ − xk−1) (ξ − xk)
f(ξ)−f(xk)
ξ−xk− f(xk)−f(xk−1)
xk−xk−1ξ−xk−1
f(xk)−f(xk−1)xk−xk−1
= − (ξ − xk−1) (ξ − xk)
µf 00(γk)2f 0(ηk)
¶(2.11)
donde γk está entre ξ,xk y xk−1, mientras que ηk está entre xk y xk−1. Comof ∈ C2, existe una vecindad I = [ξ − δ, ξ + δ], con δ > 0, tal que f 0 y f 00 soncontinuas y f 0(x) 6= 0 para todo x ∈ I. Por tanto, existe M > 0 tal que
M = maxx∈I
¯f 00(γk)2f 0(ηk)
¯Elijamos los puntos iniciales x0, x1 ∈ I, de modo que
M |ξ − x0| < 1 y M |ξ − x1| < 1
Definamos ahora t = max {M |ξ − x0| ,M |ξ − x1|}, claramente t < 1. Así,por (2.11) tenemos
M |ξ − x2| = M
¯(ξ − x1) (ξ − x0)
µf 00(γk)2f 0(ηk)
¶¯= M2 |ξ − x1| |ξ − x0| ≤ t2 ≤ t < 1
de donde|ξ − x2| < t
M= max {|ξ − x0| , |ξ − x1|} < δ

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 37
Así, x2 ∈ I. Usando este argumento, tenemos por inducción que xk ∈ I, parak ≥ 2. En general se tiene
M |ξ − x2| = M2 |ξ − x1| |ξ − x0| ≤ t2
M |ξ − x3| = M2 |ξ − x2| |ξ − x1| ≤ t3
M |ξ − x4| = M2 |ξ − x3| |ξ − x2| ≤ t5
...
M |ξ − xk+1| = M2 |ξ − xk| |ξ − xk−1| ≤ tFk
de donde Fk es el k-ésimo término de la sucesión de Fibonacci. Por lo tanto,lımk→∞M |ξ − xk| = 0.
Tasa de Convergencia del Método Secante
A continuación analizaremos la tasa o rapidez de convergencia que elMétodo Secante posee. Debemos recalcar que algunos autores denominan aesta propiedad como el orden de convergencia.
Teorema 2.5 Sea ξ una raíz de f(x) = 0. Asumamos que la sucesión gene-rada por el Método Secante converge hacia ξ. Si f ∈ C2 y f 0(ξ) 6= 0, entoncesel Método secante tiene una tasa de convergencia p = 1+
√5
2= 0,618... y
lımk→∞
ξ − xk+1(ξ − xk)
p = −µf 00(γk)f 0(ηk)
¶p−1
Prueba. Desde (2.11) tenemos
ξ − xk+1 = − (ξ − xk−1) (ξ − xk)
µf 00(γk)2f 0(ηk)
¶(2.12)
donde γk está entre ξ,xk y xk−1, mientras que ηk está entre xk y xk−1. Re-solviendo (2.12) obtenemos
(ξ − xk) =1
KApnBrn (2.13)
donde K = − f 00(γk)2f 0(ηk)
, p = 1+√5
2, r = 1−√5
2, A =
³((ξ−x0)K)r(ξ−x1)K
´ 1r−p
y B =³(ξ−x1)K((ξ−x0)K)p
´ 1r−p, la solución de (2.12) dada por (2.13) se puede comprobar
por sustitución directa. Por lo tanto,
ξ − xk+1(ξ − xk)
p = Kp−1Brn (r − p)

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 38
y
lımk→∞
ξ − xk+1(ξ − xk)
p = lımk→∞
Kp−1 lımk→∞
Brn (r − p) = −µf 00(γk)2f 0(ηk)
¶p−1
Como se puede observar, lımk→∞ξ−xk+1(ξ−xk)p existe para p =
1+√5
2≈ 1,61803398,
el cual en cierta forma nos recuerda al número áureo, 0,61803398..., con-cluimos entonces que la tasa o rapidez (orden) de convergencia del MétodoSecante es aproximadamente 1,618.
Como se puede observar, el Método Secante posee una tasa de convergen-cia un tanto inferior al Método de Newton, que tiene una tasa cuadrática.No obstante, la tasa de convergencia de 1,618 es superior a una lineal, y enla práctica esa disminución en la velocidad de convergencia se compensa conel hecho de no requerir el cálculo explícito de la derivada y su evaluación encada iteración..
Laboratorio 2.6 En algún lenguaje de programación de su preferencia, im-plemente el método secante y experiméntelo con diversos ejemplares. Compareen la práctica sus resultados con los métodos anteriormente estudiados.
Ejercicio 2.6 Experimente y compare los métodos estudiados en este capí-tulo, hallando una raíz de la ecuación f (x) = 0, donde
f (x) = x− x ln (x)
Ejercicio 2.7 Experimente y compare los métodos estudiados en este capí-tulo, hallando una raíz de la ecuación f (x) = 0, donde
f (x) = ex − 4x2
Ejercicio 2.8 Sea
f (x) =x2
2+ x (ln (x)− 1)
Halle sus puntos críticos (puntos donde f 0 (x) = 0) usando un método itera-tivo estudiado en este capítulo.
Ejercicio 2.9 Halle un punto donde la función
f (x) = x2 + x3 ∗ (log(x)− 3) + 850
alcanza un mínimo sobre el intervalo [10, 20].

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 39
Ejercicio 2.10 (ciclaje en el método de newton) Las iteraciones del Méto-do de Newton entrarán en un ciclo ilimitado si
xn+1 − a = − (xn − a)
Esto a su vez sucede si f satisface
x− a− f(x)
f 0(x)= − (x− a)
La anterior expresión es una ecuación diferencial ordinaria separable de laforma
f 0(x)f(x)
= − 1
2(x− a)
cuya solución esf(x) = sign(x− a)
p|x− a|
donde la función sign es la función signo, el cero de f es claramento x = a.Grafique f para el caso a = 2. Seguidamente, use un punto inicial x0, dondex0 6= a, y ejecute el algoritmo de Newton.
Ejercicio 2.11 Se considera la función F (x) = x5+2x. Mediante el Métodode Newton, hallar el menor núumero positivo x (con tres decimales) para elcual F (x) = 4.
Ejercicio 2.12 Probar, mediante el método de Newton, que la ecuación
xn+1 = xn(2− axn)
se puede utilizar para aproximar 1/a si x0 es una estimación inicial delrecíproco de a. Nótese que este método de aproximar recíprocos utiliza só-lo operaciones de suma y multiplicación. (Considerar f(x) = 1
x− a). Pruebe
para los casos:
1. 13
2. 111
Ejercicio 2.13 Pruebe que, al ser aplicado el método de Newton en la reso-lución de la ecuación ax+b = 0, donde a 6= 0, éste requiere sólo una iteración,sin importar qué punto inicial fue tomado.
Ejercicio 2.14 En los casos siguientes, aplicar el método de Newton con laestimación inicial propuesta, explicar por qué falla el método.

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 40
1. y = 2x3 − 6x2 + 6x− 1, donde x0 = 12. y = 4x3 − 12x2 + 12x− 3, donde x0 = 3
2
3. y = −x3 + 3x2 − x+ 1, donde x0 = 1
4. y = 3√x− 1, donde x0 = 2
2.3. Comparación de los Métodos Iterativos
El esfuerzo computacional para la ejecución de cada uno de los métodosdepende de varios factores, los más importantes son:
1. La complejidad de los cálculos, sobre todo para la derivada.
2. El número total de iteraciones
3. Condiciones para la convergencia
El método de la bisección y el método de la posición falsa exigen pocascondiciones para garantizar la convergencia, el inconveniente está en que elnúmero de iteraciones puede ser grande. Observe que su tasa de convergenciaes lineal.
Los métodos de punto fijo frecuentemente son más rápidos, pero a cambioexigen muchas hipótesis para la convergencia.
El más rápido es el método de newton, pero requiere el cálculo de laderivada y demanda, al igual que los métodos de punto fijo, hipótesis rigu-rosas para su convergencia.
El método secante puede ser práctico cuando el cálculo de la derivada escomplicado, pero no es tan rápido como el método de Newton.
Se puede concluir que la elección del método más eficiente depende de laecuación que se intenta resolver. Cada método tiene sus ventajas y desven-tajas.
Como un comentario adicional, después de llevar al computador cada unode estos métodos y experimentarlos con diversos ejemplares, probablemente elestudiante halle que las diferencias de tiempo de ejecución, entre un programay otro, sea insignificante cuando se aplica a la resolución de una ecuación,y ese afán por buscar el método más rápido parecería no tener sentido. Esa

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 41
percepción es equivocada, pues estos métodos deben verse como subrutinasde otros métodos iterativos más sofisticados, para otro tipo de problemas,donde la pérdida de una fracción de segundo retrasaría el desempeño delmétodo en su conjunto.
2.4. Problemas
Problema 2.1 Considere las dos vigas de 30m y 20m cruzándose a unaaltura de 8m del suelo, tal como se muestra en la figura 2.8. Determine elancho del pasadizo, H.
Figura 2.8: Problema de las vigas
Problema 2.2 La concentración c de una bacteria contaminante en un lagodecrece según la expresión c(t) = 80e−2t + 20e−0,5t, siendo t el tiempo enhoras. Determinar el tiempo que se necesita para que el número de bacteriasse reduzca a 7.
Problema 2.3 Una determinada sustancia se desintegra según la ecuaciónA(t) = Pe−0,0248t, donde P es la cantidad inicial en el tiempo t = 0 y Ala cantidad resultante después de t años. Si inicialmente se depositan 500miligramos de dicha sustancia, ¿cuánto tiempo debe transcurrir para quequede el 1 por ciento de ésta? Utilizar el Método de Newton.
Problema 2.4 Una medicina administrada a un paciente produce una con-centración en la sangre dada por c(t) = Ate−t/3mg /ml, t horas después deque se hayan administrado A unidades. La máxima concentración sin peligroes de 1mg /ml, y a esta cantidad se le denomina concentración de seguridad.

CAPÍTULO 2. CEROS REALES DE FUNCIONES REALES 42
1. ¿Qué cantidad debe ser inyectada para alcanzar como máximo esta con-centración de seguridad? ¿Cuándo se alcanza este máximo?
2. Una cantidad adicional se debe administrar al paciente cuando la con-centración baja a 0,25mg /ml. Determínese con un error menor de 1minuto cuándo debe ponerse esta segunda inyección.
Problema 2.5 El crecimiento de poblaciones grandes puede modelarse enperíodos cortos suponiendo que el crecimiento de la población es una funcióncontinua en t mediante una ecuación diferencial cuya solución es:
N(t) = N0eλt +
v
λ
¡eλt − 1¢
donde N(t) es el número de individuos en el tiempo t (medido en años), λes la razón de natalidad, N0 es la población inicial y v es un razón constantede inmigración, que se mide en número de inmigrantes al año. Supóngaseque una población dada tiene un millón de individuos inicialmente y unainmigración de 400, 000 individuos al año. Se observa que al final del primeraño la población es de 1506000 individuos. Se pide:
1. Determinar la tasa de natalidad.
2. Hacer una previsión de la población al cabo de tres años.

Capítulo 3
Resolución de Sistemas Lineales
Sistemas de ecuaciones lineales aparecen en la resolución de diversosproblemas de la vida real, frecuentemente, algunos de esos problemas in-volucran un gran número de variables y ecuaciones. Claramente, el métodobasado en la sustitución de variables, empleado para resolver pequeños sis-temas de dos o tres variables, resulta obsoleto en estos casos, por lo quees necesario conocer métodos numéricos especializados para hacer frente aestas situaciones. Estos métodos numéricos no podrían trabajar sin la inter-vención de un computador, debido a la cantidad de cálculo envuelto en eseprocedimiento. Todo esto sin lugar a dudas torna importante el estudio desistemas de ecuaciones lineales desde el punto de vista numérico. Pero la res-olución de sistemas de ecuaciones lineales no sólo tiene importancia propia,sino que constituye también una herramienta indispensable en la resoluciónde sistemas de ecuaciones no lineales. Más aún, es la base para la resoluciónde muchos otros problemas que surgen en diferentes áreas.
Considere el siguiente sistema de ecuaciones lineales compuesto de dosecuaciones y dos variables:½
a1,1x1 + a1,2x2 = b1a2,1x1 + a2,2x2 = b2
En sistemas simples como éste, podemos notar lo siguiente:
1. Solución única½3x1 + 2x2 = 10x1 − x2 = 5
=⇒·x1x2
¸=
·4−1¸
2. Soluciones infinitas½3x1 − 3x2 = 15x1 − x2 = 5
=⇒·x1x2
¸=
·5 + tt
¸, t ∈ R
43

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 44
3. Ninguna solución ½2x1 − 2x2 = 8x1 − x2 = 5
Gráficamente, cada ecuación representa a una recta, un punto que satis-face ambas ecuaciones al mismo tiempo deberá estar en la intersección deambas rectas (figura 3.1).
Figura 3.1: Representación gráfica de sistemas de ecuaciones lineales
Por otro lado, cuando tenemos 3 variables, cada ecuación representaríaun plano, un punto que satisface tres ecuaciones de un sistema simultánea-mente estará en la intersección de tres planos. Para el caso n-dimensional, lasituación es análoga, pero el conjunto definido por cada ecuación se denominan-hiperplano.
3.1. Aspectos Teóricos
Para un caso general, un sistema de m ecuaciones lineales y n variableses la formulación matemática siguiente:
a1,1x1 + a1,2x2 + · · · + a1,nxn = b1a2,1x1 + a2,2x2 + · · · + a2,nxn = b2...
......
.... . .
......
......
am,1x1 + am,2x2 + · · · + am,nxn = bm
(3.1)
Usando la notación matricial, el mismo sistema puede ser visto por
Ax = b (3.2)

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 45
donde A ∈ Rm×n, b ∈ Rm y x ∈ Rn es el vector de las variables o incógnitas,definidas por:
A =
a1,1 a1,2 · · · a1,na2,1 a2,2 · · · a2,n...
.... . .
...am,1 am,2 · · · am,n
, b =
b1b2...bm
y x =
x1x2...xn
Una solución para el sistema (3.1) es un vector x =
£x1 · · · xn
¤t ∈ Rn elcual satisface simultáneamente cada una de las m ecuaciones que conformanel sistema. En un sistema lineal puede suceder lo siguiente:
1. El sistema lineal tiene única solución
2. El sistema lineal posee infinitas soluciones
3. El sistema lineal no posee soluciones
Cuando n = m y A es inversible en (3.2), entonces la solución es única,en consecuencia, dicha solución puede ser obtenida haciendo x = A−1b. Noobstante, se debe advertir que este procedimiento tiene sólo un valor teórico,pues desde el punto de vista computacional es considerado costoso por elexcesivo número de operaciones involucradas para calcular la inversa de A.En contraste, existen métodos más apropiados que no requieren el cálculoexplícito de A−1, como los que veremos más adelante.
3.1.1. Conjunto Imagen de una Matriz A
Dada una matriz A ∈ Rm×n, definimos la imagen de A, denotado porIm (A), como el conjunto:
Im (A) = {y ∈ Rm : ∃x ∈ Rn, y = Ax}
Algunas veces a este conjunto se le donomina espacio imagen de A, debido alo siguiente:
Ejercicio 3.1 Muestre que Im (A) es un subespacio vectorial de Rm.
Desde el punto de vista de las columnas de A ∈ Rm×n, note que
Ax =nX
j=1
ajxj

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 46
donde aj representa la j-columna de A y xj es la j-componente del vectorx ∈ Rn. Luego, resolver el sistema Ax = b significa obtener escalares x1, ..., xnque permitan escribir b ∈ Rm como una combinación lineal de las columnasde A, es decir:
b = a1x1 + ...+ anxn
Por esta razón, al conjunto Im (A) también se le conoce como espacio colum-na de A. En consecuencia, la dimensión de la imagen de A, denotada pordim (Im (A)), está determinada por el máximo número de columnas lineal-mente independientes de A.
3.1.2. Rango de una Matriz A
El rango de la matriz A ∈ Rm×n, denotado por rango (A), es definido por
rango (A) = dim (Im (A))
Una manera práctica de encontrar el rango (A) consiste en determinar elmayor número de columnas linealmente independientes de A. En ÁlgebraLineal se conoce que rango (A) = rango (At), por consiguiente, para encontrarel rango (A) basta determinar también el mayor número de filas linealmenteindependientes de A, esto último suele ser de gran ayuda en muchos casos.
Con respecto a la resolución del sistema de ecuaciones lineales Ax = b,podemos destacar lo siguiente:
1. Si m = n, puede pasar lo siguiente:
a) Si rango (A) = n, el sistema Ax = b tiene solución única, puesA es inversible. En estas condiciones, se dice que el sistema escompatible y determinado.
b) Si rango (A) < n, puede pasar lo siguiente
1) Si b ∈ Im (A), el sistema Ax = b admitirá infinitas soluciones.En estas condiciones, se dice que el sistema es compatible eindeterminado.
2) Si b 6∈ Im (A), el sistema no admite solución. En estas condi-ciones, se dice que el sistema es incompatible.
2. Si m > n, aunque rango (A) = n, el sistema puede no tener solución,debido a que es muy frecuente que b 6∈ Im (A).

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 47
Matriz A ∈ Rm×n m < n m = n m > n
Rango completorango (A) = minfinitas soluc.
rango (A) = nsolución única
rango (A) = nb ∈ Im (A) so lución única
b 6∈ Im (A) incompatib le
Rango b ∈ Im (A) infinitas soluc. infinitas soluc. infinitas soluc.deficiente b 6∈ Im (A) incompatible incompatible incompatible
Cuadro 3.1: Soluciones de un sistema de ecuaciones lineales
3. Si m < n, es muy probable que el sistema sea compatible e indeter-minado si b ∈ Im (A). En el caso que b 6∈ Im (A), el sistema seráincompatible.
El cuadro 3.1 esquematiza las soluciones de un sistema de ecuaciones lineales.
3.2. Métodos Numéricos para Resolver Sis-temas de Ecuaciones Lineales
Los métodos numéricos que estudiaremos en este capítulo requieren queel sistema (3.1) esté constituido de n filas y n columnas, es decir, n = m.Al final de este capítulo, en el problema 3.4, será discutida una estrategiapara enfrentar sistemas lineales donde m < n. Por otro lado, sistemas dondem > n se denominan sobredeterminados, ellos serán discutidos en el siguientecapítulo.
Los métodos para resolver sistemas de ecuaciones lineales de n×n puedenser de dos tipos, directos e iterativos.
Directos: Si la solución existe, otorgan la solución exacta del sistema li-neal después de un número finito de operaciones, excepto errores deredondeo.
Iterativos: Dada una aproximación inicial x0, generan una sucesión de vec-tores {xk}∞k=0. Si la solución existe, bajo ciertas condiciones, esta suce-sión converge a la solución.
A simple vista, parece ser que la elección de un método directo es la másadecuada. No obstante, como veremos más adelante, los métodos directostienen un alto costo computacional, requiriendo alrededor de n3 operacioneselementales para resolver un sistema lineal de n×n. En contraste, los métodositerativos parecen menos atractivos, sin embargo, sólo requieren alrededor de

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 48
n2 operaciones elementales por cada iteración1, eso los torna más viables enla resolución de sistemas de ecuaciones lineales de grandes dimensiones2.
En las siguientes secciones analizaremos algunos de los métodos más im-portantes para la resolución numérica de sistemas de ecuaciones lineales.
3.3. Método de Cramer
La “Regla de Cramer” puede ser enfocada como un método directo.Proviene de un teorema en álgebra lineal, mediante el cual se puede obtenerla solución de un sistema lineal de ecuaciones en términos de determinantes.Recibe este nombre en honor a Gabriel Cramer (1704 - 1752).
Si Ax = b es un sistema de ecuaciones lineales, donde A ∈ Rn×n esinversible y b ∈ Rn es un vector columna, entonces la solución del sistema secalcula así:
xj =det (Aj)
det (A)j = 1, ..., n (3.3)
donde Aj es la matriz que resulta de reemplazar la j-columna de A por b.
Ejercicio 3.2 El determinante de una matriz real cuadrada de orden n estádefinido por
det (A) =nX
j=1
(−1)j+1 a1,j det (A [1, j]) (3.4)
donde a1,j es el elemento en la 1-fila y j-columna de la matriz A, mientrasque A [i, j] es la submatriz obtenida al eliminar la 1-fila y la j-columna de A.Muestre que el número de multiplicaciones necesarias para hallar det (A) esaproximadamente n!
Es posible calcular el determinante de una matriz sin utilizar directamentela definición dada en (3.4), pero eso tomará por lo menos alrededor de n3
operaciones elementales. Por lo tanto, para fines prácticos, métodos como elde Cramer deben estar fuera de nuestro interés, debido a que resulta muycostoso en la resolución numérica de sistemas de ecuaciones lineales3.
1Pero pueden requerir muchas iteraciones.2Frecuentemente, cuando n > 1000.3La regla de Cramer tiene un valor teórico, pues se utiliza en la demostración de muchas
propiedades.

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 49
3.4. Método de Gauss
Este método numérico es el más conocido y encuadra dentro de los méto-dos directos.
Dado el sistema lineal de n× na1,1x1 + a1,2x2 + · · · + a1,nxn = b1a2,1x1 + a2,2x2 + · · · + a2,nxn = b2...
......
.... . .
......
......
an,1x1 + an,2x2 + · · · + an,nxn = bn
(3.5)
El método de eliminación de Gauss consiste en transformar el sistema (3.5),de un modo equivalente, a un sistema triangular superior:
a01,1x1 + a01,2x2 + · · · + a01,nxn = b01a02,2x2 + · · · + a02,nxn = b02
. . ....
......
...a0n,nxn = b0n
(3.6)
El beneficio de esto es que se puede resolver el sistema triangular (3.6) demodo eficiente, es así que de la última ecuación de (3.6) tenemos
xn =b0na0n,n
Luego, xn−1 puede ser obtenido mediante
xn−1 =b0n−1 − a0n−1,nxn
a0n−1,n−1
Y así sucesivamente, obtenemos xn−2, xn−3, ..., x2, finalmente
x1 =b01 − a01,2x2 − a01,3x3 − · · ·− a01,nxn
a01,1
3.4.1. Resolviendo un Sistema Triangular
El siguiente algoritmo resuelve un sistema de ecuaciones lineales de ordenn, el cual ya está en la forma triangular superior.

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 50
Algoritmo 3.1 (Resolución de un sistema triangular superior) Dadoun sistema triangular superior Ax = b de orden n, con elementos de A so-bre la diagonal no nulos. Los valores de las variables xn, xn−1, ..., x2, x1 sonobtenidos mediante:
xn = bn/an,nPara k = (n− 1) , ..., 1
s = 0Para j = (k + 1) , ..., n
s = s+ ak,jxjxk = (bk − s) /ak,k
Ejercicio 3.3 Análogamente al algoritmo 3.1, diseñar un algoritmo que re-suelva un sistema triangular inferior de orden n.
Ejercicio 3.4 ¿Cuántas operaciones elementales (sumas, restas, multiplica-ciones, divisiones y comparaciones) son necesarias para la ejecución del al-goritmo 3.1 y el algoritmo planteado en el ejercicio 3.3?
Laboratorio 3.1 En algún lenguaje de programación, implementar el algo-ritmo 3.1 y el algoritmo planteado en el ejercicio 3.3.
La conversión de un sistema de orden n a un sistema equivalente, y trian-gular superior, es posible en virtud al siguiente teorema del álgebra lineal:
Teorema 3.1 Sea Ax = b un sistema de ecuaciones lineales. Aplicando so-bre las ecuaciones de este sistema una sucesión de operaciones elementales:
1. Cambiar dos ecuaciones
2. Multiplicar una ecuación por una constante no nula
3. Adicionar un múltiplo de una ecuación a otra ecuación
obtenemos un nuevo sistema Ax = b, el cual es equivalente4 al sistema ori-ginal Ax = b.
4Equivalente, en el sentido que tienen las mismas soluciones

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 51
3.4.2. Conversión de un Sistema de Ecuaciones Linea-les a uno Triangular Superior
El siguiente algoritmo usa el Teorema 3.1 y convierte un sistema de ecua-ciones lineales Ax = b en un sistema triangular superior equivalente.
Algoritmo 3.2 Dado el sistema lineal Ax = b de n × n. Suponga que elelemento ak,k 6= 0 al inicio de la etapa k:
Para k = 1, ..., n− 1Para i = k + 1, ..., n
mi,k = ai,k/ak,kai,k = 0Para j = k + 1, ..., n
ai,j = ai,j −mi,kak,jbi = bi −mi,kbk
Definición 3.1 El número
mi,k =ai,kak,k
, i = 2, ..., n, k = 1, ..., n− 1
introducido en el algoritmo 3.2, lo denominaremos (i, k)-multiplicador de lamatriz A. Además, ak,k se denomina el k-ésimo pivote.
Ejemplo 3.1 Considere el siguiente sistema de ecuaciones lineales Ax = b,donde
A = A(0) =
1 2 3 02 2 4 101 1 −2 11 0 0 2
y b = b(0) =
2460
Aplicando el Algoritmo 3.2, para k = 1, los multiplicadores respectivos sonm2,1 = 2, m3,1 = 1 y m4,1 = 1, de donde:
A(1) =
1 2 3 00 −2 −2 100 −1 −5 10 −2 −3 2
y b(1) =
204−2
Para k = 2, m3,2 = 0,5, m4,2 = 1 y
A(2) =
1 2 3 00 −2 −2 100 0 −4 −40 0 −1 −8
y b(2) =
204−2

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 52
Finalmente, para k = 3 tenemos m4,3 = 0,25 y
A(3) =
1 2 3 00 −2 −2 100 0 −4 −40 0 0 −7
y b(3) =
204−3
Resta sólo aplicar el Algoritmo 3.1 para resolver el sistema triangular superiorA(3)x = b(3), de donde obtuvimos
x =
−6/725/7−10/73/7
Un inconveniente que puede suceder en la aplicación de los algoritmos 3.2
y 3.1, es el cálculo del multiplicador mi,k, pues se necesita que ak,k 6= 0 encada iteración. Pero el simple hecho que ak,k sea pequeño puede ocasionarque el multiplicador mi,k tome valores inmensamente grandes, lo que puedeocasionar a su vez el mal condicionamiento5 del sistema.
Ejemplo 3.2 (Sistema mal condicionado) Utilice algún lenguaje de pro-gramación para resolver, usando los algoritmos 3.2 y 3.1, el siguiente sistemade ecuaciones: ½
11x1 + 2x2 = 51016x1 + 0,5x2 = 9
Después de aplicar consecutivamente los algoritmos, obtuvimos como solu-ción:
x =
·7,26691434300103× 10−16
2,5
¸Al verificar si realmente es solución, vemos que
Ax =
·5
8,51691434300102
¸6= b =
·59
¸Este fenómeno se debe a que el pivote A1,1 = 11, cuando comparado conA2,1 = 10
16, es muy pequeño. Observe que en estas condiciones, el multipli-cador
m2,1 =a2,1a1,1
=1016
11
es muy grande, lo que ocasionará impresiciones en los cálculos siguientes,pues el computador trabaja con precisión finita.
5La matriz A tiende a ser no inversible en la práctica, aunque en teoría lo sea. Estopuede producir imprecisiones en los cálculos realizados por el computador.

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 53
¿Pero qué significa mal condicionamiento? Ese concepto es de gran ayu-da en la resolución de sistemas lineales. A continuación formalizaremos esetérmino.
3.5. Sensibilidad en Sistemas Lineales: Númerode Condición
Considere el sistema Ax = b, donde A es inversible y b es un vector nonulo. Digamos que x sea la única solución. Consideremos ahora una pertur-bación ∆b de b, el sistema lineal perturbado será
Ay = b+∆b (3.7)
Observe que el sistema (3.7) también tiene única solución, digamos que éstasea y. Denotemos ∆x = y − x, en consecuencia, y = x + ∆x. Es naturalesperar que cuando ∆b sea pequeño, entonces ∆x también lo sea.
Para cuantificar el tamaño de vectores, usaremos la norma vectorial eu-clídea6 k·k. Así, la medida de ∆b relativa a b es k∆bk / kbk, mientras que lamedida de ∆x relativa a x es dada por k∆xk / kxk. Por lo tanto, en térmi-nos más precisos, esperamos que cuando k∆bk / kbk sea pequeño, entoncesk∆xk / kxk también lo sea.Así, como y es solución del sistema (3.7), entonces
Ay = b+∆b =⇒ A (x+∆x) = b+∆b =⇒ A (∆x) = ∆b =⇒ ∆x = A−1 (∆b)
Considerando la normamatricial inducida por la vectorial, kAk = maxx6=0 kAxkkxk ,tenemos
∆x = A−1 (∆b) =⇒ k∆xk = °°A−1 (∆b)°° ≤ °°A−1°° k∆bk (3.8)
Por otro lado,
b = Ax =⇒ kbk = kAxk ≤ kAk kxk =⇒ 1
kxk ≤kAkkbk (3.9)
Por (3.8) y (3.9) tenemos
k∆xkkxk ≤
°°A−1°° kAk k∆bkkbk
6Si x ∈ Rn, kxk =px21 + ...+ x2n.

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 54
Observe que, si k∆bk / kbk es pequeño y kA−1k kAk es un número razona-blemente pequeño, entonces k∆xk / kxk debería ser también pequeño. Sinembargo, si kA−1k kAk es extremadamente grande, a pesar que k∆bk / kbksea pequeño, no hay garantía que k∆xk / kxk también lo sea. En otras pa-labras, si kA−1k kAk es grande, podemos advertir que el sistema Ax = bpuede ser susceptible a grandes alteraciones en la solución si b es ligeramenteperturbado. Esto es crucial, pues el método de Gauss altera el vector b encada iteración.
Como se puede apreciar, el papel del número kA−1k kAk juega un rolimportante en la determinación de la estabilidad del sistema de ecuacioneslineales. A continuación lo formalizamos.
Definición 3.2 (Número de condición) Dada la matriz A ∈ Rn×n in-versible. El número de condición de A, denotado por cond (A), es
cond (A) =°°A−1°° kAk
Si cond (A) es grande, diremos que la matriz es mal condicionada, caso con-trario, ella será bien condicionada.
Ejercicio 3.5 Mostrar que, si k·k es una norma matricial inducida por lanorma vectorial euclídea en Rn, cond (A) ≥ 1.Solución. Observe que la norma matricial usada es consistente, así:
I = A−1A =⇒ 1 = kIk = °°A−1A°° ≤ °°A−1°° kAk = cond (A)Observación 3.1 Algunas veces se utiliza también la siguiente expresión,rcond (A), la cual está definida por
rcond (A) = 1/ cond (A)
Claramente, si recond (A) es próximo a cero, la matriz A será mal condi-cionada.
3.6. Estrategia con Pivotamiento Parcial
Como habíamos comentado anteriormente, uno de los inconvenientes en laaplicación del método de Gauss consistía en el cálculo de los multiplicadores,si el multiplicadormi,k = ai,k/ak,k es demasiado grande, éste podría ocasionarcálculos imprecisos en el sistema de cómputo. Algunas de las estrategias paraevitar tal inconveniente son:

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 55
1. Estrategia con pivotamiento parcial
2. Estrategia con pivotamiento total
Aquí veremos en qué consiste la estrategia de pivoteamiento parcial:
En el inicio de la etapa k de la eliminación gaussiana, escoger comopivote el elemento de mayor módulo entre los coeficientes: ak−1i,k , parai = k, k + 1, ..., n, donde ak−1i,k representa la (i, k)-componente en laiteración k − 1.Permutar la fila k e i, si fuera necesario.
Ejemplo 3.3 Considere un sistema de orden n, donde n = 4 y la iteraciónk = 2. Observe que
£A(1) b(1)
¤=
3 2 1 −1 50 1 0 3 60 −3 −5 7 70 2 4 0 15
Note que
£A(1) b(1)
¤representa la situación del sistema en la primera ite-
ración. Ahora, para el inicio de la segunda iteración
1. Escoger el pivote: maxj=2,3,4 |a1j,2| = |a13,2| = 3, entonces el pivote es −32. Cambiamos las líneas 2 y 3, de donde obtenemos
£A(1) b(1)
¤=
3 2 1 −1 50 −3 −5 7 70 1 0 3 60 2 4 0 15
Observe que en este caso los multiplicadores respectivos serán:
m3,2 =1
−3 = −1
3
m4,2 =2
−3 = −2
3
Así, al escoger el mayor elemento en módulo entre los candidatos apivote, se consigue que los multiplicadores m, en módulo, estén entrecero y uno, lo que evita la propagación de errores de redondeo.

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 56
La estrategia con pivoteamiento parcial no elimina del todo la acumu-lación de errores de redondeo, existe otra estrategia denominada estrategiacon pivoteamiento completo. En contraste al pivoteamiento parcial, que buscael mejor pivote en una porción de cada columna en cada iteración, la estrate-gia de pivoteamiento completo analiza toda matriz. A pesar que en teoría estoelimina definitivamente las imprecisiones numéricas que puedan ocurrir, suuso no es cómun en la práctica pues requiere mucho esfuerzo computacional,es decir, requiere muchas operaciones elementales (comparaciones) para suejecución.
Problema 3.1 Investigue la estrategia de pivoteamiento completo.
3.7. Descomposición LU
Esta estrategia consiste en descomponer la matriz A como el productode dos matrices factores: A = LU , donde L es una matriz triangular inferiorcon unos sobre su diagonal, es decir
L =
1 0 · · · 0
2,1 1 · · · 0...
.... . .
...n,1 n,2 · · · 1
y U es una matriz triangular superior
U =
u1,1 u1,2 · · · u1,n0 u2,2 · · · u2,n...
.... . .
...0 0 · · · un,n
De ese modo, resolver el sistema Ax = b, o sino LUx = b, es equivalente aresolver consecutivamente:
1. Ly = b
2. Ux = y
Una de las principales ventajas que tiene resolver sistemas mediante estemétodo, en contraste con el método de Gauss, es la siguiente: supongamosque se quiere resolver los sistemas Ax = b y Ax = b0, una vez obtenidos talesfactores L y U , bastaría resolver consecutivamente los sistemas triangulares:
Ly = b Ux = y (3.10)

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 57
yLy = b0 Ux = y (3.11)
Observe que los mismos factores L y U fueron usandos para resolver lossistemas (3.10) y (3.11), los cuales son fáciles de resolver usando el algoritmo3.1 para sistemas triangulares superiores.
3.7.1. Cálculo de los Factores L y U
El cálculo de las matrices L y U de modo que A = LU , está basado en losmultiplicadores mi,j introducidos en la eliminación gaussiana (definión 3.1).Supongamos que tenemos la matriz
A0 =
a01,1 a01,2 a01,3
a02,1 a02,2 a02,3
a03,1 a03,2 a03,3
= A
Primera iteración: Los respectivos multiplicadores están dados por
m2,1 = a02,1/a01,1
m3,1 = a03,1/a01,1
para deshacernos de la variable x1 en las i-filas, para i = 2, 3, hacemos
a11,j = a01,j j = 1, 2, 3
a1i,j = a0i,j −mi,1a01,j i = 2, 3, j = 1, 2, 3
y obtenemos
A1 =
a11,1 a11,2 a11,3
0 a12,2 a12,3
0 a13,2 a13,3
Observe que A1 =M0A0, donde
M0 =
1 0 0−m2,1 1 0−m3,1 0 1

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 58
Segunda iteración: Para eliminar x2 de las restantes líneas, calculamos elmultiplicador m3,2 = a13,2/a
12,2 y hacemos
a21,j = a11,j j = 1, 2, 3
a22,j = a12,j j = 2, 3
a23,j = = a13,j −m3,2a12,j j = 1, 2, 3
y obtenemos
A2 =
a21,1 a21,2 a21,3
0 a22,2 a22,3
0 0 a23,3
Observe que
A2 =M1A1
donde
M1 =
1 0 00 1 00 −m3,2 1
Además, A2 es triangular superior y podemos definir U = A2. Luego:
U =M1A1 =M1¡M0A0
¢=¡M1M0
¢A0 =
¡M1M0
¢A
Es decir,A =
¡M1M0
¢−1U =
¡M0¢−1 ¡
M1¢−1
U
y como
¡M0¢−1 ¡
M1¢−1
=
1 0 0−m2,1 1 0−m3,1 0 1
−1 1 0 00 1 00 −m3,2 1
−1
=
1 0 0m2,1 1 0m3,1 0 1
1 0 00 1 00 m3,2 1
= 1 0 0
m2,1 1 0m3,1 m3,2 1
concluimos que la matriz triangular inferior debería ser
L =
1 0 0m2,1 1 0m3,1 m3,2 1
de modo que A = LU .

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 59
Teorema 3.2 Dada una matriz cuadrada A de orden n, sea la matriz Ak
constituida de las primeras k líneas y k columnas de A. Suponga que det (Ak) 6=0 para k = 1, ..., n− 1. Entonces, existe una única matriz triangular inferiorL = [mi,j], con mi,i = 1, para i = 1, ..., n, y una única matriz triangularsuperior U = [ui,j] tales que A = LU . Además, det (A) = u1,1u2,2...un,n.
Ejercicio 3.6 Investigue la demostración del teorema 3.2.
Ejemplo 3.4 Resolver el siguiente sistema de ecuaciones lineales utilizandola descomposición LU.
x1 + 2x2 + 3x3 = 102x1 + 5x2 − x3 = 20−x1 + 2x2 + x3 = 6
Observe que
A =
1 2 32 5 −1−1 2 1
y b =
10206
Luego,
m2,1 = 2, m3,1 = −1, A1 =
1 2 30 1 −70 4 4
y
m3,2 = 4, A2 =
1 2 30 1 −70 0 32
Por lo tanto,
A =
1 2 32 5 −1−1 2 1
= 1 0 0
m2,1 1 0m3,1 m3,2 1
A2 = 1 0 02 1 0−1 4 1
1 2 30 1 −70 0 32
= LU
Puesto que Ax = b lo podemos expresar como (LU)x = b, usando el algo-ritmo 3.1 y el ejercicio 3.3 para resolver sistemas triangulares, calculamosconsecutivamente:
Ly = b =⇒ y =
10016
y
Ux = y =⇒ x =
3/27/21/2

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 60
3.8. Descomposición de Cholesky
Una estrategia que tiene suma importancia, sobre todo en optimización,es la descomposición de Cholesky.
Definición 3.3 (Matriz definida positiva) Se dice que una matriz A ∈Rn×n simétrica y de orden n es definida positiva, si xtAx > 0, para todox ∈ Rn y x 6= 0.
Teorema 3.3 (Descomposición de Cholesky) Si A es una matriz de or-den n, simétrica y definida positiva, entonces existe una única matriz trian-gular inferior de orden n y con diagonal positiva, tal que
A = GGt
Ejercicio 3.7 Investigue la demostración del teorema 3.3.
3.8.1. Cálculo del factor de Cholesky
Dada una matriz simétrica y definida positiva:
A =
a1,1 a1,2 · · · a1,na2,1 a2,2 · · · a2,n...
.... . .
...an,1 an,2 · · · an,n
El factor G será obtenido de la ecuación matricial:
a1,1 a1,2 · · · a1,na2,1 a2,2 · · · a2,n...
.... . .
...an,1 an,2 · · · an,n
=
g1,1 0 · · · 0g2,1 g2,2 · · · 0...
.... . .
...gn,1 gn,2 · · · gn,n
g1,1 g2,1 · · · gn,10 g2,2 · · · gn,2...
.... . .
...0 0 · · · gn,n
La columna 1:
a1,1a2,1...
an,1
=
g1,1 0 · · · 0g2,1 g2,2 · · · 0...
.... . .
...gn,1 gn,2 · · · gn,n
g1,10...0
=
g1,1g1,1g2,1g1,1...
gn,1g1,1
luego
g1,1 =√a1,1 y gj,1 =
aj,1g1,1
para j = 2, ..., n

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 61
La columna 2:a1,2a2,2a3,2...
an,2
=
g1,1 0 · · · 0g2,1 g2,2 · · · 0...
.... . .
...gn,1 gn,2 · · · gn,n
g1,2g2,20...0
=
g1,1g1,2g22,1 + g22,2
g3,1g2,1 + g3,2g2,2...
gn,1g2,1 + gn,2g2,2
de donde
g1,2g1,1 = a1,2 =⇒ g1,2 = g2,1 =a1,2g1,1
g22,1 + g22,2 = a2,2 =⇒ g2,2 =qa2,2 − g22,1
Comogj,1g2,1 + gj,2g2,2 = aj,2 j = 3, ..., n
y los gj,1, j = 1, ..., n, ya fueron calculados, entonces
gj,2 =(aj,2 − gj,1g2,1)
g2,2j = 3, ..., n
Columna k: Los elementos de la columna k de G son:£0 · · · 0 gk,kgk+1,k · · · gn,k
¤tk = 2, ..., n
haciendo
ak,1ak,2...
ak,kak+1,k...
an,k
=
g1,1 0 · · · 0g2,1 g2,2 · · · 0...
.... . .
...gn,1 gn,2 · · · gn,n
gk,1gk,2...
gk,k0...0
tenemos
ak,k = g2k,1 + g2k,2 + · · ·+ g2k,k
de donde
gk,k =
Ãak,k −
k−1Xi=1
g2k,j
!1/2Y como
aj,k = gj,1gk,1 + gj,2gk,2 + · · ·+ gj,kgk,k j = k + 1, ..., n

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 62
y como los elementos gi,k, i = 1, ..., k − 1, ya fueron calculados, tenemos
gj,k =
³aj,k −
Pk−1i=1 gj,igk,i
´gk,k
j = k + 1, ..., n
Algoritmo 3.3 Sea A una matriz simétrica y definida positiva.
Para k = 1, ..., nsuma = 0;Para j = 1, ... (k − 1)
suma = suma+ g2k,jr = ak,k − suma ..............(*)gk,k =
√r
Para i = k + 1, ..., nsuma = 0Para j = 1, ..., k − 1
suma = suma+ gi,jgk,jgi,k = (ai,k − suma) /gk,k
Por lo general, ver si una matriz simétrica es definida positiva usando ladefinición es una tarea prácticamente imposible. Sin embargo, podemos usarel algoritmo de Cholesky para verificar si A es definida positiva. Si en (*) setiene que r ≤ 0, entonces la descomposición no es posible y A no es definidapositiva. Caso contrario, el algoritmo otorga la matriz triangular inferior Gtal que A = GGt.
La descomposición de Cholesky requiere alrededor de n3/6 operacionesde multiplicación para la descomposición. Este número es aproximadamentela mitad del número de operaciones necesarias para la realización de la elim-inación en la descomposición LU, pues requería n3/3.
Al igual que la descomposición LU, una vez conocido A = GGt, es posibleresolver el sistema lineal asociado: Ax = b, del siguiente modo: como
Ax = b ⇐⇒ ¡GGt
¢x = 0
entonces
1. Resolver Gy = b
2. Resolver Gtx = y

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 63
Laboratorio 3.2 En algún lenguaje de programación de su preferencia, im-plemente el algoritmo de Cholesky, de modo que: cuando la matriz A seadefinida positiva, devuelva la matriz triangular inferior G. Caso contrario,debería emitir un mensaje anunciando que A no es definida positiva.
Ejercicio 3.8 Usando el algoritmo de Cholesky, verifique que la matriz27 12 10 2412 9 16 2910 16 42 7024 29 70 137
es realmente definida positiva.
Ejercicio 3.9 Una duda común es, ¿podría ser definida positiva una matrizla cual tiene algunas componentes negativas? Verifique si la matriz
27 12 10 2412 9 16 1110 16 42 −224 11 −2 137
es o no definida positiva (use el algoritmo).
Ejercicio 3.10 Una matriz simétrica A ∈ Rn×n se llama semidefinida pos-itiva, si xtAx ≥ 0, para todo x ∈ Rn. Probar que, para cualquier matrizB ∈ Rm×n, la matriz C = BtB es semidefinida positiva.
Solución: Observe que C ∈ Rm×m es simétrica, pues
Ct =¡BtB
¢t= Bt
¡Bt¢t= BtB = C
yxtCx = xt
¡BtB
¢x = (Bx)t (Bx) = kBxk2 ≥ 0
donde k·k es la norma euclídea.Ejercicio 3.11 Probar que, si A ∈ Rn×n es definida positiva, entonces A esinversible. Lo recíproco no siempre es válido, de un contraejemplo.
Solución: Recordemos el teorema de álgebra lineal que nos decía: “Una matrizA ∈ Rn×n es inversible si, y sólo si, el sistema Ax = 0 tiene como únicasolución la trivial”.
Ahora, con respecto al ejercicio, realizaremos una prueba por contradic-ción. Asumamos que A es definida positiva y no inversible. Entonces, el

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 64
sistema Ax = 0 tiene una solución no trivial, digamos que existe x 6= 0 talque Ax = 0. Luego,
0 < xtAx = xt0 = 0
Lo cual es una contradiccion. Esto completa la prueba.
Para verificar la segunda parte del ejercicio, basta hacer notar que lamatriz · −1 0
0 −1¸
es inversible pero no es definida positiva (en realidad es definida negativa).
3.9. Métodos Iterativos
La idea de los métodos iterativos para resolver sistemas de ecuacionesestá inspirada en el método de punto fijo.
Dado el sistema lineal de ecuaciones
Ax = b (3.12)
donde A ∈ Rn×n y b ∈ Rn. Los métodos iterativos consisten en expresar elsistema (3.12) en una ecuación matricial equivalente:
x = Dx+ d (3.13)
donde D ∈ Rn×n y d ∈ Rn. Note que en este caso θ (x) = Dx + d es unafunción iteración n-dimensional.
Así, los métodos de este tipo construyen una sucesión {xk ∈ Rn}∞k=0 defini-da por la regla
xk+1 = θ (xk) = Dxk + d
Observe que, si lımk→∞ xk = x∗, entonces x∗ es un punto fijo de θ. Bajociertas condiciones, x∗ debería ser también la solución del sistema originalAx = b.
Método de Gauss-Jacobi
Este método se caracteriza por transformar el sistema Ax = b a la formax = Dx+ d, del siguiente modo:

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 65
Sea el sistema original
a1,1x1 + a1,2x2 + · · · + a1,nxn = b1a2,1x1 + a2,2x2 + · · · + a2,nxn = b2...
......
.... . .
......
......
an,1x1 + an,2x2 + · · · + an,nxn = bn
Suponiendo que ai,i 6= 0 para i = 1, ..., n, despejamos las variables x1, ..., xnde las n ecuaciones, respectivamente:
x1 =1
a1,1(b1 − a1,2x2 − a1,3x3 − ...− a1,nxn)
x2 =1
a2,2(b2 − a2,1x2 − a2,3x3 − ...− a2,nxn)
...
xn =1
an,n(bn − an,1x1 − an,2x2 − ...− an,n−1xn−1)
De esta forma tenemos
x1x2...xn
=
b1a1,1
b2a2,2
...bnan,n
+
0 −a1,2
a1,1−a1,3
a1,1· · · −a1,n
a1,1
−a2,1a2,2
0 −a2,3a2,2
· · · −a2,na2,2
......
.... . .
...
− an,1an,n
− an,2an,n
− an,3an,n
· · · 0
x1x2...xn
Es decir, la función iteración quedaría establecido por
x = θ (x) = Dx+ d
donde
D =
0 −a1,2
a1,1−a1,3
a1,1· · · −a1,n
a1,1
−a2,1a2,2
0 −a2,3a2,2
· · · −a2,na2,2
......
.... . .
...
− an,1an,n
− an,2an,n
− an,3an,n
· · · 0
y d =
b1a1,1
b2a2,2
...bnan,n
(3.14)
El método de Gauss-Jacobi consiste en lo siguiente: dado x0, una aproxi-mación inicial a la solución del sistema linealAx = b, obtener x1, x2, ..., xk, ...pormedio de la relación recursiva
xk+1 = Dxk + d

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 66
donde D y d están definidos en este caso por (3.14). O sino:
xk+11 =1
a1,1
¡b1 − a1,2x
k2 − a1,3x
k3 − ...− a1,nx
kn
¢xk+12 =
1
a2,2
¡b2 − a2,1x
k2 − a2,3x
k3 − ...− a2,nx
kn
¢(3.15)
...
xk+1n =1
an,n
¡bn − an,1x
k1 − an,2x
k2 − ...− an,n−1xkn−1
¢Una característica de los métodos iterativos, a diferencia de los métodosdirectos, es que sólo convergen si algunas hipótesis son satisfechas.
Criterio de convergencia para el método de Gauss-Jacobi Dado elsistema lineal Ax = b, sea
αi =
Pnj=1j 6=i |ai,j||ai,i| y α = max
1≤i≤n{αi}
Si α < 1, entonces el método de Gauss-Jacobi genera una sucesión de vec-tores
©xkª∞k=0, la cual converge a la solución del sistema lineal Ax = b,
independientemente de la elección del vector inicial x0.
3.10. Comparación entre Métodos Directos eIterativos
Convergencia: Los métodos directos son procesos finitos y, teóricamente,encuentran la solución exacta de cualquier sistema de ecuaciones, des-de que ésta exista. En la práctica no es bien cierto esta última afir-mación, pues debemos tener en cuenta los errores de cálculo del sis-tema de cómputo y el mal condicionamiento del sistema. Por otrolado, los métodos iterativos apenas convergen cuando son satisfechosalgunos requerimientos. Esto último parece tornarlos poco atractivosen la práctica, pero debemos tener en cuenta el espacio requerido enmemoria-computador, observe por ejemplo la ecuación (3.15), notaráque para operar el método de Gauss-Jacobi, sólo necesitamos almacenaren memoria la matriz A y el vector b, el resto de cálculos no requieren laconstrucción de matrices auxiliares como en el método directo basadoen la descomposición LU.

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 67
Errores de redondeo: Métodos directos modifican el sistema original, porejemplo, en la triangularización hecha por el método de Gauss, adi-cionalmante a los errores cometidos por un sistema de cómputo, losdatos del problema original son alterados y la solución no es precisadesde un punto de vista computacional. Por otro lado, los métodositerativos no modifican el sistema original y, una vez asegurada la con-vergencia, los errores numéricos son menores a los cometidos por losmétodos directos.
Problema 3.2 Investigue la prueba del criterio de convergencia del métodode Gauss-Jacobi.
Problema 3.3 Investigue sobre el método iterativo de Gauss-Seidel.
Problema 3.4 Elaborar una estrategia para resolver un sistema de ecua-ciones lineales indeterminado, es decir, donde el número de ecuaciones esmenor que el número de variables (m < n).
Una de las opciones sería la siguiente: Asumamos que el sistema está definidopor Ax = b, donde A ∈ Rm×n, b ∈ Rm y m < n. Inicialmente, asumamos queel rango de A es completo, es decir, m. Por este motivo, existe una submatrizcuadrada e inversible B, tal que, posiblemente después de un intercambiocompatible de posiciones de columnas de A y de variables de x, tenemos:
A =£B N
¤x =
·xBxN
¸Así, Ax = b es equivalente a
£B N
¤ · xBxN
¸= b ⇐⇒ BxB +NxN = b ⇐⇒ xB = B−1b−B−1NxN
Luego, las soluciones x ∈ Rn serían generadas dando valores arbitrarios axN ∈ Rn−m, mediante:
x =
·xBxN
¸=
·B−1b−B−1NxN
xN
¸Así por ejemplo, haciendo xN = 0 ∈ Rn−m, tendríamos:
x =
·B−1b0
¸

CAPÍTULO 3. RESOLUCIÓN DE SISTEMAS LINEALES 68
el cual, claramente, es una solución para el sistema Ax = b. Se debe advertirque, a diferencia de la resolución de sistemas cuadrados, la estrategia ex-puesta no es eficiente, pues encontrar las columnas de A que conformarán Bpuede ser extremadamente costoso. Esto se debe a que resolver sistemas inde-terminados, y también sobredeterminados, es realmente difícil. El estudiantedebería investigar otras opciones además de la expuesta aquí.


















