
ANTOLOGIA ESTADISTICA 2
114
Unidad Académica del Norte Estadística MUESTREO Y DISTRIBUCIONES MUESTRALES El objetivo de la inferencia estadística es obtener información acerca de una población, partiendo de la información que contiene una muestra. Comenzaremos con la descripción de dos casos en los que se lleva acabo un muestreo para proporcionar información, sobre una población, a un gerente o a quien tome decisiones. 1. Un fabricante de neumáticos ha desarrollado un nuevo producto que, según cree, tendrá una mayor duración en relación con las millas recorridas comparada con la línea actual de neumáticos. Para evaluar el nuevo neumático, los gerentes necesitan un estimado (o una estimación de la medida de las millas que dura el nuevo producto. Selecciona una muestra de 120 neumáticos nuevos para probarlos. El resultado de la prueba es una medida de la muestra de 36,500 millas. En consecuencia, se usan 36,500 millas como estimado de la medida para la población de neumáticos nuevos. 2. Los miembros de un partido político desean respaldar a determinado candidato en la elección sanatorial. Para decidir si el candidato participará en la elección primaria, los dirigentes necesitan un estimado de la proporción de votantes empadronados que respaldan al candidato. Por el tiempo y el costo necesarios para recabar los datos de cada individuo de la población de votantes registrados resultan prohibitivos. En consecuencia, se selecciona una muestra de 400 votantes registrados. Si 160 de ellos indican preferencia hacia el candidato, un estimado de la proporción de la población de votantes registrados que favorece al candidato, un estimado de la proporción de la población de votantes registrados que favorece al candidato es 160/400= .40. Los ejemplos anteriores muestran cómo se pueden emplear el muestro y los resultados de una muestra para obtener estimados de las características de una población. Observe que en el ejemplo de la duración de millas, el M.A.C. Ing. Josué Salvador Sánchez Rodríguez 1 Una medida de muestra suministra un estimado de una medida poblacional, y una proporción de muestra suministra un estimado de una proporción poblacional. Con estimados como los anteriores cabe esperar cierto error de muestreo, o valor + . En este capítulo, un argumento clave es que pueden aplicar métodos
description
Antologia de estadistica
Transcript of ANTOLOGIA ESTADISTICA 2

Unidad Académica del Norte Estadística
MUESTREO Y DISTRIBUCIONES MUESTRALES
El objetivo de la inferencia estadística es obtener información acerca de una población, partiendo de la información que contiene una muestra. Comenzaremos con la descripción de dos casos en los que se lleva acabo un muestreo para proporcionar información, sobre una población, a un gerente o a quien tome decisiones.
1. Un fabricante de neumáticos ha desarrollado un nuevo producto que, según cree, tendrá una mayor duración en relación con las millas recorridas comparada con la línea actual de neumáticos. Para evaluar el nuevo neumático, los gerentes necesitan un estimado (o una estimación de la medida de las millas que dura el nuevo producto. Selecciona una muestra de 120 neumáticos nuevos para probarlos. El resultado de la prueba es una medida de la muestra de 36,500 millas. En consecuencia, se usan 36,500 millas como estimado de la medida para la población de neumáticos nuevos.
2. Los miembros de un partido político desean respaldar a determinado candidato en la elección sanatorial. Para decidir si el candidato participará en la elección primaria, los dirigentes necesitan un estimado de la proporción de votantes empadronados que respaldan al candidato. Por el tiempo y el costo necesarios para recabar los datos de cada individuo de la población de votantes registrados resultan prohibitivos. En consecuencia, se selecciona una muestra de 400 votantes registrados. Si 160 de ellos indican preferencia hacia el candidato, un estimado de la proporción de la población de votantes registrados que favorece al candidato, un estimado de la proporción de la población de votantes registrados que favorece al candidato es 160/400= .40.
Los ejemplos anteriores muestran cómo se pueden emplear el muestro y los resultados de una muestra para obtener estimados de las características de una población. Observe que en el ejemplo de la duración de millas, el reunir datos sobre la vida implica gastar cada neumático probado. Claramente no es posible probar todos los neumáticos de la población, una muestra es el único método realista para obtener los datos buscados de duración. En el ejemplo de la elección primaria, teóricamente es posible entrevistar a cada votante registrado en la población, pero el tiempo y costo de hacerlos son prohibitivos, así que se prefiere una muestra de los votantes registrados.
Los ejemplos ilustran algunas de las razones por las que se recurre a las muestras. Sin embargo, es importante darse cuenta de que los resultados de la muestra sólo dan estimados (o estimaciones) de los valores de las características de la población. Esto es, no esperamos que la media de la muestra 36,500 millas sea exactamente igual que la media, en millas, de todos los neumáticos de la población; tampoco esperamos que sea exactamente el 40% de la población registrada de votantes el que favorezca al candidato. La razón simplemente es que la muestra contiene sólo una parte de la población. Con los métodos adecuados de muestreo, los resultados muestrales darán “buenos” estimados de las características de la población. Pero ¿qué tan buenos esperamos que sean estos resultados? Por fortuna, disponemos de procedimientos estadísticos para contestar esta pregunta.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 1
Una medida de muestra suministra un estimado de una medida poblacional, y una proporción de muestra suministra un estimado de una proporción poblacional. Con estimados como los anteriores cabe esperar cierto error de muestreo, o valor +. En este capítulo, un argumento clave es que pueden aplicar métodos estadísticos para hacer afirmaciones probabilísticas acerca del tamaño del error de muestreo.

Unidad Académica del Norte Estadística
MUESTREO ALEATORIO SIMPLE
Se pueden seleccionar varios métodos para seleccionar una muestra a partir de una población; uno de los más comunes es el muestreo aleatorio simple. La definición de este método y el proceso de seleccionar una muestra aleatoria siempre dependen de si la población es finita o infinita. Como en el problema de muestreo de EAI interviene, una población finita de 2500 gerentes, primero describiremos el muestreo para poblaciones finitas.
MUESTREO PARA POBLACIONES FINITAS
Una muestra aleatoria simple de tamaño n, de una población finita de tamaño N, se define como sigue.
Muestra aleatoria simple (población finita)Una muestra aleatoria simple de tamaño n, de una población N, es una muestra seleccionada de tal manera
que cada muestra posible de tamaño n tenga la misma posibilidad de ser seleccionada.
Un procedimiento para identificar una muestra aleatoria simple a partir de una población finita es seleccionar uno por uno los elementos que constituyen a la muestra, de tal modo que cada uno de los elementos que aún queden en la población tenga la misma posibilidad de ser seleccionados. Al muestrear n elementos de esa forma, se satisfará la definición de una muestra aleatoria simple de una población finita.
Para seleccionar una muestra aleatoria simple de la población finita en el problema de EAI, supondremos primero que se han numerado los 2500 gerentes, asignándoles un número progresivo, es decir, 1, 2, 3,….., 2499 y 2500, en el orden en que aparecen en el archivo del personal de la empresa. A continuación, consultaremos la tabla 7.1 de números aleatorios. En el primer renglón de la tabla cada dígito: 6, 3, 2,….., es aleatorio, porque tiene igual probabilidad de presentarse. Como el número en la lista de la población de gerentes EAI es 2500 y tiene 4 dígitos, seleccionaremos números aleatorios de la tabla en grupos o conjuntos de cuatro dígitos. Al usar el primer renglón de la tabla7.1, los números aleatorios de 4 dígitos son:
6327 1599 8671 7445 1102 1514 1807
En vista de que los números de la tabla son aleatorios, esos grupos de cuatro dígitos son igualmente probables. Ahora podemos usar los números de la tabla que son aleatorios, esos grupos de cuatro dígitos son igualmente probables.
Ahora podemos usar los números de cuatro dígitos para dar, a cada elemento de la población, la misma oportunidad de ser seleccionado para la muestra. El primer número, 6327, es mayor que 2500, no corresponde a un elemento de la población y, en consecuencia, lo descartamos. El segundo número, 1599, está entre 1 y 2500. Así, el primer individuo seleccionado para la muestra es el gerente número 1599 en la lista de los gerentes de EAI. Al continuar el proceso pasamos por alto 8671 y 7445 e identificamos a los individuos 1102, 1514 y 1807 como los siguientes de la muestra. Este proceso de selección de gerentes continúa hasta haber obtenido la muestra aleatoria simple de tamaño 30.
Al llevar a acabo el proceso de selección de la muestra aleatoria simple, es posible que aparezca de nuevo, en la tabla, un número aleatorio que antes ya se ha usado antes de completar la selección de la muestra de 30 gerentes de EAI. Como se trata de seleccionar tan sólo una vez a los gerentes, todos los números aleatorios que ya se han empleado no se vuelven a tomar en cuanta, porque los gerentes correspondientes ya son parte de la muestra. La selección de una muestra en esta forma se llama muestrear sin remplazo. Si hubiéramos seleccionado la muestra en tal forma que los números aleatorios usados antes se aceptaran, y algunos gerentes se pudieran incluir dos o más veces en la muestra, hubiéramos muestreado con remplazo. El muestro con remplazo es una forma válida de identificar una muestra aleatorio. Sin embargo, lo que se usa con más frecuencia es el muestreo con remplazo. Cuando digamos muestreo aleatorio simple supondremos que ese muestreo es sin remplazo.
Tabla 7.1 Números aleatorios
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 2

Unidad Académica del Norte Estadística
Se pueden seleccionar aleatorios en cualquier lugar de la tabla. Aunque comenzamos por el primer renglón como ejemplo, podríamos haber comenzado en cualquier otro punto de la tabla continuado en cualquier dirección. Una vez elegido el punto de partida, se recomienda usar un procedimiento sistemático predeterminado, por ejemplo avanzar por columnas o por reglones, para seleccionar los números siguientes.
MUESTREO PARA POBLACIONES INFINITAS
La mayoría de los casos de muestreo en los negocios y la economía son de poblaciones finitas, pero en algunas situaciones, la población es infinita o (si es infinita) es tan grande que, para fines prácticos, se puede considerar como infinita. Al muestrear una población infinita debemos usar una nueva definición de muestra aleatoria simple. Además, como no se pueden enumerar los elementos de una población infinita, debemos emplear un proceso distinto para seleccionar los elementos de la muestra.
Supongamos que se desea estimar el tiempo promedio que transcurre entre colocar un pedido y recibirlo, para los clientes de un restaurante de comida rápida, entre las 11:30 a.m. y la 1:30 p.m. que es el horario del almuerzo. Si consideramos la población de todos los posibles clientes, vemos que no sería factible especificar un límite finito de la cantidad de posibles visitas. De hecho, si definimos que la población es todas las visitas de clientes que se pudieran recibir concebiblemente durante la hora del almuerzo, podemos considerar que la población es infinita. Nuestra tarea consiste en seleccionar una muestra aleatoria simple de n clientes de esa población. A continuación vemos la definición de muestra aleatoria simple de una población finita.
Muestra aleatoria simple (población infinita)
Una muestra aleatoria simple de una población es aquella que se selecciona en tal forma que se satisfacen las siguientes condiciones.
1. Cada elemento seleccionado proviene de la misma población.2. Cada elemento se selecciona en forma independiente.
En el caso del problema de seleccionar una variable aleatoria simple de asistencias de clientes a un restaurante de comida rápida, vemos que se satisface la primera condición antes mencionada, para cualquier asistencia de cliente durante el horario del almuerzo, estando trabajando el restaurante con su personal regular y bajo condiciones “normales” de funcionamiento. La segunda condición se satisface asegurando que la selección de determinado cliente no influye sobre la selección de cualquier otro. Esto es, los clientes son seleccionados en forma independiente.
Un restaurante muy conocido de comita rápida implemento un procedimiento de muestreo aleatorio simple para este caso. El procedimiento de muestreo se basa en el hecho de que algunos clientes presentan cupones de descuento en precios de emparedados, bebidas, papas fritas, etc. Siempre que un cliente presenta un cupón de descuento, se selecciona para la muestra al siguiente cliente que llega. Como los clientes que presentan cupones de descuento lo hacen al azar e independientemente, la empresa considera que el plan de muestro satisface las dos condiciones del muestro aleatorio simple de poblaciones infinitas.
OTROS MÉTODOS DE MUESTREO
El muestreo aleatorio simple no es el único método de muestreo con el que se cuenta. Existen otros, como el muestreo aleatorio estratificado, el de conglomerados y el sistemático, que son alternativas del muestreo aleatorio simple.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 3

Unidad Académica del Norte Estadística
MUESTREO ALEATORIO ESTRATIFICADO
En este tipo de muestreo, primero se divide a la población en grupos de elementos llamados estratos, de tal manera que cada elemento en la población pertenece a uno y sólo a un estrato. La base de formación de los estratos, por ejemplo, por departamento, ubicación, edad, giro industrial, etc. queda a discreción de quien señala la muestra. Si embargo, los mejores resultados se obtienen cuando los elementos dentro de cada estrato son tan semejantes como sea posible. La figura 7.15 es un diagrama de una población divida en H estratos.
Después de formar los estratos se toma una muestra aleatoria simple de cada uno. Se dispone de fórmulas para combinar los resultados para las muestras de estrato individual en un estimado del parámetro poblacional de interés. El valor del muestreo estratificado depende de cuan homogéneos sean los elementos dentro de los estratos. Si son similares (homogeneidad), los estratos tendrán bajas varianzas. En este caso se pueden usar varios tamaños de muestras relativamente pequeños para obtener buenos estimado de las características de los estratos. Si los estratos son homogéneos, el procedimiento de muestreo aleatorio estratificado producirá resultados tan precisos como el muestreo aleatorio simple, pero con menor tamaño total de la muestra.
MUESTREO POR CONGLOMERADOS
En el muestreo por conglomerados, se divide primero a la población en conjuntos separados de elementos, llamados conglomerados. Cada elemento de la población pertenece a uno y sólo a un grupo (veáse la figura 7.16). A continuación se toma una muestra aleatoria simple de los conglomerados. Todos los elementos dentro de cada conglomerado muestreado forman la muestra. El muestreo de conglomerados tiende a proporcionar los mejores resultados cuando los elementos de los conglomerados son heterogéneos (desiguales). En el caso ideal, cada conglomerado es una versión representativa, en pequeña escala, de toda la población. El valor el muestreo por conglomerados depende de cuán representativo sea cada conglomerado de la población total.
Si al respecto todos los conglomerados se asemejan entre sí, al muestrear una pequeña cantidad de conglomerados se obtendrán buenos estimados de los parámetros de población.
Una de las principales aplicaciones del muestro por conglomerados es el muestreo de áreas, en los que los conglomeraos son manzanas urbanas, u otras áreas bien definidas. Por lo general, el muestreo de conglomerados requiere un tamaño de muestra total mayor que el muestreo aleatorio simple o el muestreo aleatorio estatificado. Sin embargo puede originar ahorros porque cuando se manda a un entrevistador a aplicar un cuestionario a un conglomerado muestreado (por ejemplo, una manzana urbana), se pueden obtener muchas observaciones muestrales en un tiempo relativamente corto. En consecuencia, se puede obtener un mayor tamaño de muestra con un costo bastante menor por elemento, y por ende, probablemente un costo total menor.
MUESTRO SISTEMÁTICO
En algunos casos, en especial cuando hay grandes poblaciones, es tardada la elección de una muestra aleatoria simple cuando se determina primero un número aleatorio y después se cuenta o se busca en la lista de elementos de la población hasta encontrar el elemento correspondiente. Una alternativa al muestreo aleatorio simple es el muestreo sistemático. Por ejemplo, si se desea una muestra de tamaño 50 de una población con 5000 elementos, podríamos muestrear un elemento de cada 5000/50 = 100 en la población. Una muestra sistemática en este caso implica seleccionar al azar uno de los primeros 100 elementos de la lista de la población. Se identifican los demás elementos de la muestra comenzando por el primero obtenido al azar y a continuación seleccionando cada 100o. elemento. En efecto, se identifica la muestra de 50 recorriendo la población en forma sistemática, e identificado cado 100o. elemento después del primero que se seleccionó al azar. Por lo general será más fácil identificar la muestra de 50 de este modo que si se usara el muestreo aleatorio simple. Está hipótesis de aplica en especial cuando la lista de los elementos de la población es una ordenación aleatoria de ellos.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 4

Unidad Académica del Norte Estadística
MUESTREO POR CONVENIENCIA
Los métodos de muestro que se han descrito se llaman técnicas de muestreo probabilístico. Los elementos seleccionados de la población tiene una probabilidad conocida de ser incluidos en la muestra. La ventaja del muestreo probabilístico es que la distribución del estadístico demuestra que se trate, por lo general, se puede identificar. Se pueden usar formulas como las del muestreo aleatorio simple, que se presentaron en este capítulo, para determinar las propiedades de la distribución muestral. Ésta se puede usar a continuación para establecer afirmaciones probabilísticas acerca de posibles errores de muestreo asociados con los resultados de la muestra
El muestreo por conveniencia es una técnica de muestreo no probabilístico como su nombre lo indica, la muestra se identifica, principalmente, por conveniencia. Se incorporan elementos en la muestra sin probabilidades preespecificadas o conocidas de selección. Por ejemplo, un profesor que lleva a cabo una investigación universitaria puede usar alumnos voluntarios para formar una muestra, tan solo porque dispone fácilmente de ellos participan como elementos a un costo pequeño o nulo. Igualmente, un inspector puede muestrear un embarque de naranjas seleccionándolas, con mucho tedio y dificultad, entre varias cajas. Sería poco práctico marcar cada naranja y usar un método de probabilidad para el muestreo. Muestras como animales salvajes o plantes silvestres, o equipos de voluntarios para investigación de mercados, también son muestras por conveniencia.
Las muestras por conveniencia tiene la ventaja de fácil selección y recolección de sus datos. Sin embargo, es imposible evaluar la “bondad” de la muestra en función de su representatividad de la población. Una muestra por conveniencia puede dar buenos resultados o no. No hay un procedimiento estadísticamente justificado que permita un análisis de probabilidades o inferencias acerca de la calidad de los resultados de esa muestra. A veces los investigadores aplican métodos estadísticos diseñados para muestras de probabilidad a una muestra por conveniencia, y dicen que ésta se puede manejar como si fuera una muestra aleatoria. Sin embargo, no se puede sostener este argumento, y debemos tener mucho cuidado al interpretar los resultados de muestras por convenienia, cuando se usan para hacer inferencias acerca de poblaciones.
MUESTREO POR JUICIO
Otra técnica más de muestreo n probabilístico es el muestreo por juicio. En este método, la persona más capaz en el tema de estudio selecciona a los individuos u otros elementos de la población que siente son los más representativos de esa población. Con frecuencia es una manera relativamente fácil de seleccionar una muestra. Por ejemplo, un reportero puede muestrear a dos o tres senadores, considerando que ellos reflejan la opinión general de todos lo senadores. Sin embargo, la calidad de los resultados muestrales dependen del juicio de la persona que selecciona la muestra. De nuevo, se necesita tener gran cuidado al llegar a conclusiones basadas en muestra por juicio, para después hacer inferencias acerca de poblaciones.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 5

Unidad Académica del Norte Estadística
PROBABILIDADEn nuestra vida nos enfrentamos a situaciones de toma de decisiones cuando interviene la incertidumbre.
Quizá alguna vez hemos analizado algunas de las siguientes situaciones:
1.- ¿Cuál es la posibilidad de que las ventas disminuyan si aumenta el precio del producto?
2.- ¿Cuál es la probabilidad de que el nuevo método de ensamble aumente la productividad?
3.- ¿Qué tan probable es que el proyecto termine a tiempo?
4.- ¿Cuáles son las probabilidades de que la nueva inversión sea rentable?
Los métodos de mayor eficacia para manejar tales incertidumbres se basan en el concepto de la probabilidad. En lenguaje cotidiano la probabilidad indica una medida numérica de la certidumbre de que sucederá determinado evento. Por ejemplo, si consideramos el evento “lloverá mañana” entendemos que, cuando el pronóstico climático en la TV indica una “probabilidad de lluvia cercana a cero” casi no hay posibilidad de lluvia. Sin embargo, si el pronóstico es 90% de probabilidad, sabemos que hay una gran posibilidad, cercana a la certeza, de que llueva. Una probabilidad del 50% indica que es tan probable que llueva como que no llueva.
Los valores de probabilidad siempre se asignan en una escala de 0 a 1. Una probabilidad cercana a 0 indica que es difícil que el evento ocurra; una cercana a 1 indica que es casi seguro que sucederá. Otras probabilidades entre 0 y 1 representan grados de certeza de que el evento ocurra.
LA PROBABILIDAD COMO MEDIDA NUMÉRICA DE LA POSIBILIDAD DE OCURRENCIA
Mayor posibilidad de ocurrencia
0 .5 1.0 Probabilidad:
La ocurrencia del evento es tan probable como improbable
La probabilidad es importante en la toma de decisiones, porque suministra un mecanismo para medir, expresar y analizar la incertidumbre asociada con eventos futuros.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 6
Una parte de los primeros trabajos sobre probabilidades se originó en una serie de cartas entre Pierre de Fermat y Blaise Pascal, en la década de 1650.

Unidad Académica del Norte Estadística
EXPERIMENTOS, ESPACIO DE UNA MUESTRA Y REGLAS DE CONTEO
Aplicando la terminología de la probabilidad, el término experimento se define como cualquier proceso que genera resultados bien definidos. Con lo anterior queremos decir que, en toda repetición única del experimento, solo ocurrirá uno y sólo uno de los resultados experimentales posibles. A continuación vemos algunos ejemplos de experimentos y sus resultados asociados.
Experimento Resultados del ExperimentoLanzar una MonedaSeleccionar una parte para inspeccionarlaTelefonema de ventasTirar un dadoJugar un partido de fútbol
Sol, águilaDefectuosa, no defectuosaCompra, no compra1, 2, 3, 4, 5, 6.Ganar, perder, empatar.
El primer paso para analizar un determinado experimento consiste en definir con cuidado los resultados experimentales. Cuando hayamos definido todos los resultados posibles, habremos identificado el espacio muestral, o espacio de una muestra del experimento. Esto es, se define al espacio muestral como el conjunto de todos los resultados experimentales posible. Cualquier resultado experimental particular se llama punto muestral, y es un elemento del espacio muestral.
Veamos el experimento de lanzar una moneda. El resultado experimental se define por la cara superior de la moneda -un sol o una cruz-. Si S representa al espacio muestral podremos usar la siguiente notación para describirlo a él y a sus puntos muestrales para el experimento.
S = {sol, águila}
Con esta notación, el experimento de seleccionar una parte e inspeccionarla tendría el siguiente espacio muestral y los siguientes puntos maestrales:
S={defectuosa, no defectuosa }
REGLAS DE CONTEO
La capacidad de identificar y contar los puntos muestrales de un experimento es un paso importante para comprender lo que puede suceder en él. Veamos un experimento que consiste en lanzar dos monedas, donde los resultados experimentales se definen en función del comportamiento de soles o águilas que dan hacia arriba en las dos monedas. ¿Cuántos resultados experimentales (o puntos muestrales) son posibles en este experimento?
Podemos considerar que el experimento de lanzar dos monedas se lleva a cabo en dos etapas: la etapa 1 corresponde a lanzar la primera moneda, y la etapa 2 a lanzar la segunda. El diagrama de árbol es un dispositivo gráfico útil para visualizar un experimento de varias etapas y enumerar los resultados experimentales.
Etapa 1 Etapa 2 Punto muestra
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 7
Los elementos del espacio muestral se llaman puntos muestrales, o puntos de muestra. Ya que los resultados experimentales son puntos muestrales, el conjunto de todos los resultados experimentales (puntos muestrales) es el espacio muestral, o espacio de la muestra.

Unidad Académica del Norte Estadística
Primera moneda Segunda moneda
Sol (S, S)
Sol (S, A)
Águila
Sol (A, S)
Águila (A, A)
Águila
La figura anterior, es un diagrama de árbol para el experimento de lanzar las monedas, con ramas de sol o águila para la primera moneda (etapa 1) seguidas de ramas que corresponden a sol o águila en la segunda moneda (etapa 2). Se usa la notación (S,S) para representar el resultado que corresponde a un sol en la primera moneda y un sol en la segunda. Igualmente, (S,A) indica el resultado de un sol en la primera moneda y un águila en la segunda. Así, cada uno de los puntos del lado derecho del árbol corresponde a un punto muestral –un resultado experimental-.
Vemos que hay cuatro resultados experimentales del hecho de lanzar dos monedas, y el espacio muestral del mismo se puede representar mediante:
S= {(S,S), (S,A), (A,S), (A,A)}
Una regla útil para determinar la cantidad de puntos muestrales para un experimento de varias etapas es la siguiente.
Reglas de conteo para experimentos de etapas múltiples
Si un experimento se puede escribir como una sucesión de k etapas, en las que hay n1 resultados posibles en la primera etapa, n2 en la segunda, etc., la cantidad total de resultados experimentales es igual a (n1)(n2)...(nK). Esto es, la cantidad de resultados del experimento total es el producto de las cantidades en cada etapa.
Veamos ahora como se puede aplicar la regla de experimentos de etapas múltiples en el análisis de un proyecto de expansión de capacidad que encara Kentucky Power and Light Company (KP&L). El proyecto se divide en dos etapas sucesivas: la etapa 1 (diseño) y la etapa 2 (construcción). Si bien cada etapa se programará y controlará tan cuidadosamente como sea posible, la dirección no puede predecir el tiempo exacto para terminarla. Un análisis de proyectos similares de construcción ha demostrado que los tiempos de terminación de la etapa de diseño son 2, 3 o 4 meses, y los de terminación para la etapa de construcción son 6, 7 u 8 meses. Como la necesidad de energía eléctrica adicional es crítica, la dirección ha establecido una meta de 10 meses para terminar todo el proyecto.
Como hay tres tiempos posibles de terminación para la etapa de diseño (primera etapa) y tres tiempo de terminación posibles para la etapa de construcción (etapa 2), se puede aplicar en este caso la regla de conteo para experimentos con múltiples etapas, y así se determina que hay un total de (3)(3) = 9 resultados experimentales.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 8
Sin el diagrama de árbol se podría creer fácilmente que solo hay tres resultados experimentales de dos lanzamientos de moneda: 0 soles, 1 sol y 2 soles-

Unidad Académica del Norte Estadística
Para describirlos usaremos una notación de dos números; por ejemplo (2, 6) indicará que la etapa de diseño se termina en 2 meses y la de la construcción en 6 meses. Este resultado experimental da un total de 2+6=8 meses para terminar todo el proyecto. La siguiente tabla resume los nueve resultados experimentales del proyecto:
LISTA DE RESULTADOS EXPERIMENTALES (PUNTOS MUESTRALES)
Tiempo de terminación (meses) Notación del resultado
experimental(punto muestral)
Tiempo total de terminación del proyecto (meses)Etapa 1
(diseño)Etapa 2
(construcción)222333444
678678678
(2, 6)(2, 7)(2, 8)(3, 6)(3, 7)(3, 8)(4, 6)(4, 7)(4, 8)
891091011101112
El diagrama de árbol siguiente muestra como se generan los nueve resultados (puntos muestrales):
DIAGRAMA DE ÁRBOL PARA EL PROYECTO
Tiempo total de Etapa 1 Etapa 2 Resultados terminación
(Diseño) (Construcción) Experimentales del proyecto
6 meses (2, 6) 8 meses
7 meses (2, 7) 9 meses
8 meses (2, 8) 10 meses 2 meses
6 meses (3, 6) 9 meses
3 meses 7 meses (3, 7) 10 meses
8 meses (3, 8) 11 meses
4 meses
6 meses (4, 6) 10 meses
7 meses (4, 7) 11 meses
8 meses (4, 8) 12 meses
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 9

Al muestrar una población finita de tamaño N, se usa la regla de conteos para combinaciones con el fin de determinar la cantidad de diferentes muestras de tamaño n que se pueden seleccionar.
Unidad Académica del Norte Estadística
Hemos aplicado la regla de conteo y el diagrama de árbol para ayudar al gerente del proyecto a identificar los resultados experimentales y determinar los tiempos de terminación posibles del proyecto. Vemos que el tiempo para terminarlo será de 8 a 12 meses, y que seis de los resultados cumplen con el tiempo deseado, que es de 10 meses o menos. Si bien fue útil haber identificado los resultados experimentales, necesitaremos considerar como se le pueden asignar valores de probabilidad para poder hacer una evaluación final de la probabilidad de terminar el proyecto dentro de los 10 meses deseados. Las asignaciones de probabilidades a los resultados experimentales se analizaran más delante....
Otra regla de conteo que con frecuencia es de utilidad nos permite contar la cantidad de resultados experimentales cuando se han de seleccionar n objetos entre un conjunto de N objetos. Se llama regla de conteo para combinaciones.
Reglas de Conteo para Combinaciones.
N N! (1) =
n n! (N – n )!
En donde:N!= N(N – 1)(N – 2) ... (2)(1)
n! = n(n – 1)(n – 2) ... (2)(1)y
0! = 1
La notación ! significa factorial; por ejemplo, 5 factorial es 5!=(5)(4)(3)(2)(1) = 120.Por definición, 0! es igual a 1.
Un ejemplo de la regla de conteo para combinaciones es un procedimiento de control de calidad en el que el inspector selecciona al azar dos de cinco partes, para examinarlas y ver si tiene defectos. En un grupo de cinco partes, ¿cuántas combinaciones de dos partes se pueden seleccionar? La regla de conteo de la ecuación 1 indica que para N=5 y n=2 el resultado es:
5 = 5! = (5)(4)(3)(2)(1) = 120 = 102 2! (5 – 2)! (2)(1)(3)(2)(1) 12
Así hay 10 resultados en el experimento de seleccionar al azar dos partes de un grupo de cinco. Si identificamos las cinco partes como A, B, C, D y E, las 10 combinaciones o resultados experimentales se pueden identificar como AB, AC, AD, AE, BC, BD, BE, CD, CE y DE.
Otro ejemplo es el siguiente: La Lotería de Ohio emplea selección aleatoria de seis números de un grupo de 47 para determinar al ganador semanal. Se puede aplicar la regla de conteo (1) para combinaciones, para calcular la cantidad de maneras en que se pueden seleccionar seis números distintos de entre un grupo de 47 números.
47 = 47! = 47! = (47)(46)(45)(44)(43)(42) = 10,737,573 6 6! (47– 6)! 6! 41! (6)(5)(4)(3)(2)(1)
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 10

Unidad Académica del Norte Estadística
La regla de conteo para combinaciones nos dice que hay más de 10 millones de resultados experimentales para determinar al ganador de la lotería. Si una persona compra un boleto de lotería y elige seis de los 47 números, tiene una posibilidades de ganar entre 10,737,573.
Las reglas de conteo como la de experimentos de etapas múltiples y la de las combinaciones ayudan a determinar la cantidad de resultados en un experimento estadístico.
NOTA.- En estadística, la noción de experimento es algo distinta de la noción en ciencias físicas. En las ciencias físicas, por lo general, un experimento se lleva a cabo en un laboratorio o en un ambiente controlado, para aprender acerca de un hecho científico. Cuando se repiten los experimentos en física bajo condiciones idénticas, se espera obtener el mismo resultado. En los experimentos estadísticos, los resultados están determinados por el azar. Aun cuando el experimento se repita exactamente en la misma forma, puede obtenerse un resultado completamente distinto. Debido a esta diferencia de resultados, se dice que los experimentos en estadísticas son experimentos aleatorios.
EJERCICIOS
1) ¿De cuántas maneras se pueden seleccionar tres artículos de un grupo de seis? Use las letras A, B, C, D, E y F para identificar los artículos, y haga una lista de cada una de las distintas combinaciones de tres artículos.
2) Un experimento consiste en hacer tres llamadas de venta. En cada una habrá compra o no compra.a) Trace un diagrama de árbol de este experimento en tres etapas.b) Identifique cada punto muestral y el espacio muestral. ¿Cuántos puntos muestrales hay?c) ¿Cuántos puntos muestrales habría si el experimento consistiera en cuatro llamadas de venta?
3) A un gran hotel en Florida le interesan las condiciones climáticas en el noroeste y en el propio estado de Florida. Al caracterizar la temperatura en ambas zonas se usaron las tres categorías siguientes: debajo del promedio, en el promedio o sobre el promedio. Una combinación de temperaturas debajo del promedio en el noroeste con temperaturas sobre el promedio en Florida indica un mayor volumen de negocios en el hotel. El experimento consiste en observar las condiciones climáticas en determinado día.
a) ¿Cuántos resultados experimentales son posibles?b) Trace un diagrama de árbol para el experimento.
4) Un inversionista tiene dos acciones: de A y de B. Cada una puede aumentar o disminuir de valor, o permanecer inalterada. El experimento consiste en invertir en las dos acciones y observar el cambio (si es que lo hay) en su valor.
a) ¿Cuántos resultados experimentales son posibles?b) Trace un diagrama de árbol para el experimento.c) ¿Cuántos de los resultados experimentales originan un aumento en el valor de al menos una de las
acciones?d) ¿Cuántos de los resultados experimentales originan un aumento en el valor de las dos acciones?
5) ¿Cuántas manos de cinco cartas de póquer son posibles con una baraja de 52 cartas?
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 11

Unidad Académica del Norte Estadística
ASIGNACIÓN DE PROBABILIDADES A LOS RESULTADOS EXPERIMENTALES
Veamos ahora cómo se pueden determinar las probabilidades de los resultados experimentales (puntos muestrales). Recordemos la descripción donde afirmamos que la probabilidad de un resultado experimental es una medida numérica de la posibilidad de que ocurra ese resultado. Se pueden usar varios métodos para asignar las probabilidades a los resultados experimentales; sin embargo, independientemente de la forma, se deben satisfacer dos requisitos básicos.1. Los valores de probabilidad que se asignen a cada resultado experimental (punto muestral) deben ser entre 0 y
1. Esto es, si Ei representa el resultado experimental i y P(E i) representa la probabilidad de este resultado experimental, se debe cumplir.
0 < P(Ei ) < 1 para toda i (A.1)2. La suma de todas las probabilidades de resultados experimentales debe ser 1. Si un espacio muestral tiene k
resultados experimentales, se debe cumplir.
P(E1) + P(E2) +... + P(Ek) = ∑ P(Ei) = 1 (A.2)
Se puede aceptar cualquier método de asignar valores de probabilidad a los resultados experimentales, siempre que cumpla con estos dos requisitos y produzca medidas numéricas razonables de la posibilidad de los resultados. En la práctica se usa uno de los tres métodos siguientes.
1. Método clásico2. Método de frecuencia relativa3. Método subjetivo
MÉTODO CLÁSICO
Para ilustrar el método clásico de asignación de probabilidades veamos nuevamente el experimento de lanzar una moneda. En cualquier lanzamiento observaremos uno de dos resultados experimentales: sol o águila. Parecería razonable suponer que los dos resultados son igualmente probables. En consecuencia, como uno de los resultados igualmente probables es sol, lógicamente debemos llegar a la conclusión de que la probabilidad de observar un sol es ½ o 0.50. De igual manera, la probabilidad de observar un águila es 0.50. Cuando se usa la hipótesis de resultados igualmente probables como base para asignar probabilidades, al método se le llama método clásico. Si un experimento tiene n resultados posibles, con el método clásico se asignaría una probabilidad de 1/n a cada resultado experimental.
Otro ejemplo del método clásico es el experimento de tirar un dado, el espacio muestral y los puntos muestrales para este experimento son:
S = { 1, 2, 3, 4, 5, 6}
Parece razonable llegar a la conclusión de que los seis resultados experimentales son igualmente posibles, y en consecuencia a cada uno de ellos se le asigna la probabilidad 1/6. Así, si P(1) representa la probabilidad de que aparezca un punto en la cara superior del dado, entonces P(1) =1/6. En igual forma P(2) = 1/6, P(3) = 1/6, P(4) = 1/6, P(5) = 1/6 y P(6) = 1/6. Observe que esta asignación de probabilidades cumple con los dos requisitos básicos que mencionamos. De hecho, cuando se usa el método clásico siempre se satisfacen los requisitos de las ecuaciones (A.1) y (A.2) porque a cada uno de los n puntos muestrales se le asigna una probabilidad de 1/n.
El método clásico fue desarrollado en un principio para analizar problemas de juego, donde con frecuencia parece razonable la hipótesis de resultados igualmente posibles. Sin embargo, en muchos problemas comerciales esta hipótesis no es valida. Por consiguiente se requieren métodos alternativos para asignar probabilidades.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 12

Unidad Académica del Norte Estadística
MÉTODO DE LA FRECUENCIA RELATIVA
Para ilustrar el método de la frecuencia relativa supongamos que una empresa se prepara para vender un nuevo producto. Para estimar la probabilidad de que un cliente lo compre, se ha organizado una evaluación de mercado en la que los vendedores telefonean a los posibles clientes.
Por cada telefonema hay dos resultados posibles: el cliente compra el producto o el cliente no compra el producto. Como no hay razón para superar que los dos resultados experimentales son igualmente posibles, no es adecuado el método clásico de asignar probabilidades.
Supongamos que en la evaluación del mercado del producto se llamó a 400 clientes potenciales; que 100 compraron realmente el producto, pero que 300 no lo compraron. De hecho, entonces, repetimos el experimento de telefonear 400 veces a un cliente y encontramos que el producto fue comprado 100 veces. En consecuencia, podemos optar por usar la frecuencia relativa como un estimado de la probabilidad de que un cliente haga una compra. Podríamos asignar una probabilidad de 100/400 = 0.25 el resultado experimental de comprar el producto. En forma parecida, se podría asignar 300/400 = 0.75 al resultado experimental de no comprar el producto. A este método de asignar probabilidades se le llama método de la frecuencia relativa.
MÉTODO SUBJETIVO
Los métodos clásico y de frecuencia relativa no se pueden aplicar a todos los casos en donde se desean evaluar probabilidades. Por ejemplo, hay casos en que los resultados experimentales no son igualmente posibles, y en los que no se cuenta con datos de frecuencia relativa. Por ejemplo, considérese un juego de fútbol en el que participan los Acereros de Pittsburgh. ¿Qué probabilidad tienen de ganar? Los resultados experimentales de ganar, perder o empatar no necesariamente tienen la misma posibilidad. También, como los equipos que participan no han jugado varias veces antes en este año, no hay datos de frecuencia relativa de los cuales se pueda hechar mano para el juego venidero. Así si deseamos un estimado de la probabilidad que tiene de ganar los Acereros, debemos recurrir a una opinión subjetiva sobre su valor (el de la probabilidad).
Con el método subjetivo de asignar probabilidades a los resultados experimentales podemos usar cualquier dato disponible, y también nuestra experiencia e intuición. Sin embargo, después de considerar toda la información disponible, se debe especificar un valor de probabilidad que exprese el grado de creencia de que se presente el resultado experimental. A este método de asignar probabilidades de le llama método subjetivo. Como la probabilidad subjetiva expresa el grado de creencia de una persona, entonces tiene un carácter personal. Cabe entonces esperar que dos personas distintas asignen diferentes probabilidades al mismo evento. No obstante, se debe tener cuidado al aplicar el método subjetivo, para asegurar que se cumpla con los requisitos (A.1) y (A.2). Esto es, independientemente del grado de creencia de una persona, el valor de probabilidad, asignado a cada resultado experimental, debe estar entre 0 y 1, y la suma de todas las probabilidades de esos resultados debe ser igual a 1.
Aun en casos en que se pueda aplicar el método clásico o el de frecuencia relativa, la administración puede desear conocer estimados de probabilidades subjetivas. En tales casos, los mejores estimados se consiguen, con frecuencia, combinando los del método clásico o de la frecuencia relativa, con estimados subjetivos de probabilidad.
PROBABILIDADES PARA EL PROBLEMA DE LA COMPAÑÍA KP&L
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 13

Unidad Académica del Norte Estadística
Para ahondar en el análisis del problema de KP&L (Kentucky Power and Light Company) debemos evaluar las probabilidades de cada uno de los nueve resultados experimentales. Con base en la experiencia y en el buen juicio, la administración llegó a la conclusión de que los resultados experimentales no eran igualmente posibles. En consecuencia, no se pudo usar el método clásico de asignar probabilidades. Se decidió entonces llevar a cabo un estudio de los tiempos de terminación de proyectos similares realizados por la empresa durante los últimos tres años. En la siguiente tabla se resumen los resultados de estudios de 40 proyectos similares.
RESULTADOS DE LA TERMINACIÓN DE 40 PROYECTOS DE KP&L
Tiempo de terminación (meses)Punto Muestral
Cantidad de proyectos anteriores con los siguientes tiempos de
terminación.Etapa 1 Etapa 2
222333444
678678678
(2, 6)(2, 7)(2, 8)(3, 6)(3, 7)(3, 8)(4, 6)(4, 7)(4, 8)
662482246
Total 40
Después de revisar los resultados del estudio, la gerencia decidió emplear el método de la frecuencia relativa para asignar las probabilidades. Podrían haber optado por estimados subjetivos de probabilidades, pero les pareció que el proyecto actual era muy similar a los 40 anteriores. Por ello fue que se juzgo que el mejor método era el de la frecuencia relativa.
Al emplear los datos de la tabla anterior para calcular probabilidades, observemos que el resultado (2,6) -etapa 1 terminada en 2 meses y etapa 2 en 6-, se presentaba seis veces en los 40 proyectos. Con el método de la frecuencia relativa se puede asignar una probabilidad de 6/40= 0.15 a este resultado. Similarmente, el resultado (2,7) también se presentó en 6 de los 40 proyectos, dando como resultado una probabilidad de 6/40= 0.15. Continuando de esta forma obtenemos las asignaciones de probabilidad para los puntos muestrales del proyecto KPyL que vemos en la siguiente tabla:
ASIGNACIONES DE PROBABILIDADES EN EL PROBLEMA KP&L BASADA EN EL METODO DE FRECUENCIA RELATIVA. Tabla 1
Punto muestralTiempo de terminación del
proyectoProbabilidad del punto muestral
(2, 6)(2, 7)(2, 8)(3, 6)(3, 7)(3, 8)(4, 6)(4, 7)(4, 8)
8 meses 9 meses10 meses 9 meses10 meses11 meses10 meses11 meses12 meses
P (2, 6) = 6/40 = 0.15P (2, 7) = 6/40 = 0.15P (2, 8) = 2/40 = 0.05P (3, 6) = 4/40 = 0.10P (3, 7) = 8/40 = 0.20P (3, 8) = 2/40 = 0.05P (4, 6) = 2/40 = 0.05P (4, 7) = 4/40 = 0.10P (4, 8) = 6/40 = 0.15
Total 1.00
Observe que P (2,6) representa la probabilidad del punto muestral (2,6), P (2,7) la del punto muestral (2,7) y así sucesivamente.EJERCICIOS
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 14

Unidad Académica del Norte Estadística
1) Un experimento con tres resultados se ha repetido 50 veces, y se vio que E1 sucedió 20 veces, E2 13 y E3 17. Asigne las probabilidades a los resultados. ¿Qué método usó?
2) Un experimento consiste en seleccionar una carta de un mazo de 52.a) ¿Cuántos puntos muestrales son posibles?b) ¿Qué método (clásico, de frecuencia relativa o subjetivo) recomendaría usted para asignar probabilidades
a los puntos muestrales?c) ¿Cuál es la asignación de probabilidad para cada carta?d) Demuestre que sus asignaciones de probabilidad satisfacen los dos requisitos básicos.
3) Un pequeño almacén de electrodomésticos ha reunido datos sobre las ventas de refrigeradores en las últimas 50 semanas. Los datos aparecen en la tabla siguiente. Suponga que nos interesa el experimento de observar la cantidad de refrigeradores vendidos en una semana de actividades del almacén.
Número de refrigeradores vendidos
Cantidad de semanas
012345
6121510 5 2
Total 50a) ¿Cuántos resultados experimentales hay?b) ¿Qué método recomendaría usted para asignar probabilidades a los resultados experimentales?c) Asigne las probabilidades y asegúrese de que su asignación satisfaga los dos requisitos básicos.
4) Hay muchas escuelas en la actualidad que permiten a sus alumnos el acceso a Internet. En 1996 se inscribieron 21,733 escuelas elementales, 7286 secundarias y 10,682 preparatorias en Internet (Statistical Abstract of The United States, 1997). Hay un total de 51,745 escuelas elementales, 14,012 secundarias y 17,229 preparatorias.a) Si el lector visitara una escuela elemental al azar, ¿qué probabilidad tiene de encontrar acceso a Internet?b) Si usted escoge al azar visitar una escuela elemental, ¿cuál es la probabilidad de que ésta tenga acceso a
Internet?c) ¿Cuál sería la probabilidad si visitara una escuela secundaria al azar?d) ¿Y si visitara una preparatoria al azar?
EVENTOS Y SUS PROBABILIDADES
Hasta ahora hemos empleado el término evento como lo manejamos en el lenguaje cotidiano. Ahora presentaremos la definición formal relacionada con probabilidad de un evento.
EventoUn evento es un conjunto de puntos muestrales.
Para entenderlo mejor, volvamos al problema de KP&L (Kentucky Power and Light Company) y
supongamos que al gerente de proyecto le interesa el evento en el que todo el proyecto se puede terminar en 10 meses o menos. Al consultar la tabla 1 vemos que hay seis puntos muestrales -(2,6), (2,7), (2,8), (3,6), (3,7) y (4,6)- que dan un tiempo de terminación de 10 meses o menos. Sea C el evento que el proyecto termina en 10 meses o menos; escribimos:
C = {(2,6), (2,7), (2,8), (3,6), (3,7), (4,6)}Se dice que el evento C ocurre si cualquiera de los seis puntos muestrales de arriba llega a ser el resultado experimental.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 15

Unidad Académica del Norte Estadística
Otros eventos que podrían interesar a la gerencia de KP&L son los siguientes: L = el evento que el proyecto se termina en menos de 10 meses. M= el evento que el proyecto se termina en más de 10 meses.Con la información de la tabla 1, vemos que esos eventos consisten en los siguientes puntos muestrales.
L = {(2,6), (2,7), (3,6)}M = {(3,8), (4,7), (4,8)}
Se puede definir una amplia variedad de eventos adicionales para el problema de esta compañía, pero en cada caso el evento debe identificarse como un conjunto de puntos muestrales del experimento.
Dadas las probabilidades de los puntos muestrales en la tabla 1 podemos usar la siguiente definición para calcular la probabilidad de cualquier evento que pudiera interesar a la gerencia de KP&L.
PROBABILIDAD DE UN EVENTO
La probabilidad de un evento es igual a la suma de las probabilidades de los puntos muestrales en el evento.
Con esta definición calcularemos la probabilidad de determinado evento, sumando las probabilidades de los resultados experimentales que lo forman. Ya podemos calcular la probabilidad de que el proyecto dure 10 meses o menos en terminarse. Como este evento está definido por C = {(2,6), (2,7), (2,8), (3,6), (3,7), (4,6)}, la probabilidad P del evento C es:
P(C) = P(2,6) + P(2,7) + P(2,8) + P(3.6) + P(3,7) + P(4,6)
Al consultar en la tabla 1 las probabilidades de los puntos muestrales, llegamos a
P(C) = 0.15+0.15+0.05+0.10+0.20+0.05 =0.70
Igualmente, como el evento de que el proyecto se termine en menos de 10 meses se expresa como L = {(2,6), (2,7), (3,6)}, la probabilidad de este evento es:
P(L) = P(2,6) + P(2,7) + P(3,6) P(L) = 0.15+0.15+0.10 = 0.40
Por último, para el evento de que el proyecto se termine en más de 10 meses tenemos M = {(3,8), (4,7), (4,8)}, y en consecuencia
P(M) = P(3,8) + P(4,7) +P(4,8) P(M) = 0.05+0.10+0.15 = 0.30
Con los anteriores resultados probabilísticos, ya podemos informar a la gerencia de KP&L que hay una probabilidad de 0.70 de que el proyecto se termine en 10 meses o menos, una de 0.40 de que se termine en menos de 10 meses, y una de 0.30 de que se termine en más de 10 meses. Este procedimiento para calcular probabilidades de eventos se puede repetir para cualquier evento que interese a la dirección de KP&L.
Siempre que podamos identificar a todos los puntos muestrales de un experimento y asignar las probabilidades correspondientes a los puntos muestrales, podemos aplicar la definición para calcular la probabilidad de un evento. Sin embargo, en muchos experimentos la cantidad de puntos muestrales es grande, y la identificación de ellos, así como la determinación de sus probabilidades asociadas, es demasiado tediosa, si no es que imposible.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 16
1. El espacio muestral, S, es un evento. Como contiene todos los resultados experimentales, tiene una probabilidad de 1, esto es P (S)=1.
2. Cuando se usa el método clásico para asignar probabilidades, se supone que todos los resultados experimentales son igualmente posibles. En esos casos, la probabilidad de que un evento se puede calcular contando la cantidad de resultados experimentales en el evento, y dividiendo el resultado ente la cantidad total, de resultados experimentales.

Unidad Académica del Norte Estadística
EJERCICIOS 1) Un experimento tiene tres resultados, con P(E1) = 0.35, P(E2) = 0.40, P(E3) = 0.25.
a) ¿Cuál es la probabilidad de que ocurra E1 o E2?b) ¿Cuál es la probabilidad de que ocurra E1 o E3?c) ¿Cuál es la probabilidad de que ocurra E1, E2 o E3?
2) Suponga que un gerente de un gran complejo de apartamentos elabora los estimados subjetivos de probabilidad que vemos en la tabla de abajo, sobre la cantidad de apartamentos que estarán vacíos el próximo mes.
Haga una lista de los puntos muestrales que forman cada uno de los siguientes eventos y determine su probabilidad.a) No hay apartamentos vacíosb) Cuando menos hay cuatro apartamentos vacíosc) Hay dos o menos apartamentos vacíos
3) El gerente de una mueblería vende de 0 a 4 cofres de porcelana cada semana. Con base en la experiencia, se asignan las siguientes probabilidades de vender 0, 1, 2, 3 o 4 cofres: P(0) = 0.08; P(1) = 0.18; P(2) = 0.32; P(3) = 0.30; y P(4) = 0.12.a) ¿Son válidas estas asignaciones de probabilidad? ¿Por qué sí o por qué no?b) Sea A el evento en el cual se venden 2 o menos en una semana. Determine P(A).c) Sea B el evento en el cual se venden 4 o más en una semana. Determine P(B).
4) El estudio de suscriptores de Wall Street Journal de 1995 reveló características como responsabilidades en los negocios, actividades de inversión, características del estilo de vida e ingresos personales. Los datos siguientes muestran el valor total de las acciones poseídas por las 2,536 personas que respondieron.
Cantidad (dólares) SuscriptoresMenor que $15,000$ 15,000 – 49,999$ 50,000 – 99,999$100,000 – 299,999$300,000 o más
347411335619824
Suponga que se selecciona un suscriptor al azar. ¿Cuáles son las probabilidades de los siguientes eventos?a) Sea A el evento en que el valor total de las acciones poseídas es al menos de $50,000 dólares, pero
menor de $100,000 dólares. Determine P(A).b) Sea B el evento en que el valor total de las acciones poseídas es menor de $50,000 dólares. Determine
P(B).c) Sea C el evento en que el valor total de las acciones poseídas es $100,000 dólares o más. Determine
P(C).
ALGUNAS RELACIONES BÁSICAS DE PROBABILIDAD
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 17
Vacantes Probabilidad Vacantes Probabilidad012
0.050.150.35
345
0.250.100.10

Unidad Académica del Norte Estadística
Complemento de un evento
Dado un evento A, el complemento de A se define como el evento formado por todos los puntos muestrales que no están en A. El complemento de A se representa con Ac. La figura 1 es un diagrama, conocido como diagrama de Venn, que ilustra el concepto de un complemento. El área rectangular representa el espacio muestral del experimento, y como tal contiene todos los puntos muestrales posibles. El círculo representa el evento A y sólo contiene los puntos muestrales que pertenecen a A. La región sombreada del rectángulo contiene todos los puntos muestrales que no están en el evento A y, por definición, es el complemento de A.
En cualquier aplicación de probabilidades, debe suceder, ya sea el evento A o su complemento Ac. En consecuencia,
P(A) + P(Ac) = 1
Al despejar P(A) obtenemos el siguiente resultado:
Cálculo de probabilidad mediante el complemento
P(A) = 1 – P(Ac) (3)
Espacio muestral
S
Evento A
La ecuación (3) indica que la probabilidad de un evento A se puede calcular con facilidad si se conoce la probabilidad de su complemento, P(Ac).
Por ejemplo, veamos el caso de un gerente de ventas que, después de revisar los informes de ventas, dice que el 80% de los contactos con nuevos clientes no resultan en venta alguna. Si se define a A como el evento de una venta y Ac el de no venta, lo que el gerente dice es que P(Ac) = 0.80. Al aplicar (3) tenemos:
P(A) = 1 – P(Ac) = 1 - 0.80 = 0.20
Podemos concluir que la probabilidad de que se haga una venta al entrar en contacto con un nuevo cliente es 0.20.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 18
Ac
Figura 1 COMPLEMENTO DEL EVENTO A
La unión de un evento y de su complemento es el espacio muestral total.

Unidad Académica del Norte Estadística
En otro ejemplo, un agente de compras dice que hay una probabilidad de 0.90 de que un proveedor mande un embarque sin partes defectuosas. Recurriendo al complemento, podemos decir que hay una probabilidad de 1 - 0.90 = 0.10 de que el embarque contenga partes defectuosas.
Ley aditiva
La ley aditiva es útil cuando se tienen dos eventos, y se desea conocer la probabilidad de que ocurra al menos uno de ellos. Esto es, con los eventos A y B nos interesa conocer la probabilidad de que suceda el evento A, o el evento B, o ambos.
Antes de presentar la ley aditiva, necesitamos analizar dos conceptos relacionados con la combinación de eventos: la unión de eventos y la intersección de éstos. Dados dos eventos, A y B, la unión de A y B se define como sigue.
Unión de dos eventos
La unión de A y B es el evento que contiene todos los puntos muestrales que pertenecen a A o a B, o a ambos. La unión de A y B se representa con A U B.
El diagrama de Venn de la figura 2 muestra la unión de los eventos A y B. Observe que los dos círculos contienen todos los puntos muestrales del evento A y los puntos muestrales del evento B. El hecho de que círculos se traslapen indica que algunos puntos muestrales están contenidos tanto en A como en B al mismo tiempo.
Espacio Muestral
S
Evento A Evento B
La definición de la intersección de dos eventos A y B es la siguiente.
Intersección de dos eventos
Dados dos eventos, A y B, la intersección de A y B es el evento que contiene los puntos muestrales que pertenecen simultáneamente a A y a B, ésta se representa como A ∩ B.
El diagrama de Venn que muestra la intersección de los dos eventos es el de la figura 3. El área donde se traslapan los dos círculos es la intersección; contiene los puntos muestrales que están en A y también en B.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 19
Figura 2 UNIÓN DE LOS EVENTOS A Y B

Unidad Académica del Norte Estadística
Espacio Muestral
S
Evento A Evento B
Nota: El área de traslape representa
a A ∩ B.
Continuemos ahora con la descripción de la ley aditiva. Esta ley proporciona una forma de calcular la probabilidad de que ocurra el evento A o el B, o de ambos. En otras palabras, la ley se enuncia como sigue.
Ley aditiva P(A U B) = P(A) + P(B) – P(A∩B) (4)
Para captar intuitivamente la ley aditiva observe que los primeros términos en ella, P(A) + P(B), se asocian con todos los puntos muestrales en A U B. Sin embargo, como los puntos muestrales en la intersección A∩B están en A y en B al mismo tiempo, al calcular P(A) + P(B) de hecho contamos dos veces a cada uno de los puntos en A∩B. Al restar P(A∩B) corregimos el doble conteo.
Como ejemplo de aplicación de la ley aditiva, consideremos el caso de una pequeña ensambladora con 50 empleados. Se espera que cada trabajador termine a tiempo sus labores de trabajo además de que el producto armado pase una inspección final. A veces, algunos de los trabajadores no pueden cumplir con los estándares de desempeño porque terminan su trabajo tarde y/o arman productos defectuosos. Al terminar un periodo de evaluación de desempeño, el gerente de producción vio que 5 de los 50 trabajadores habían terminado tarde su trabajo, que 6 de los 50 trabajadores habían armado productos defectuosos, y que 2 habían terminado el trabajo tarde y también habían armado productos defectuosos.
Sean L = el evento de que el trabajo se termina tarde. D = el evento de que el producto armado es defectuoso.
La información anterior sobre frecuencias relativas conduce a las siguientes probabilidades:
P(L) = _5_ = 0.10 50
P(D) = _6_ = 0.1250
P(L∩D) = _2_= 0.04 50
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 20
Figura 3 INTERSECCIÓN DE LOS EVENTOS A Y B

Unidad Académica del Norte Estadística
Después de revisar los datos, el gerente de producción optó por asignar una mala calificación de desempeño al empleado cuyo trabajo se presentara tarde o fuera defectuoso; en consecuencia, el evento de interés es L U D. ¿Qué probabilidad hay de que asigne una mala calificación a un empleado?
Observe que desde el punto de vista probabilístico, la cuestión se relaciona con la unión de dos eventos. En forma específica, queremos conocer P(L U D). Aplicamos (4) y obtenemos
P(L U D) = P(L) + P(D) – P(L∩D)
Conocemos los valores de las tres probabilidades del lado derecho de esta ecuación, y podemos escribir
P(L U D) = 0.10 + 0.12 - 0.04 = 0.18
Esto nos dice que hay probabilidad de 0.18 de que un empleado reciba una mala calificación de desempeño.
En otro ejemplo de la ley aditiva veamos un estudio reciente que llevó a cabo el gerente de personal de una gran empresa de programas de cómputo. Encontró que el 30% de los empleados que salieron de la compañía de los dos últimos años lo hicieron principalmente por no estar satisfechos con su salario; el 20% salió por no estar satisfechos con las actividades en su trabajo y el 12% de todos los anteriores manifestaron no estar satisfechos ni con su salario ni con sus trabajos. ¿Cuál es la probabilidad de que un empleado que haya salido en los dos últimos años lo haya hecho por no estar satisfecho con su sueldo, su trabajo o con ambas cosas?
Sean S = el evento de que el empleado sale debido al salario.
W = el evento de que el empleado sale por sus actividades en el trabajo.
Entonces P(S) = 0.30, P(W) = 0.20, y P(S∩W) = 0.12. Aplicando (4), la ley aditiva, vemos que P(S U W) = P(S) + P(W) – P(S∩W) = 0.30 + 0.20 - 0.12 = 0.38
Resulta que hay 0.38 de probabilidad de que un empleado salga por motivos de sueldo o de actividades en el trabajo.
Antes de terminar nuestra descripción de la ley aditiva veamos un caso especial que surge con los eventos mutuamente excluyentes.
Eventos mutuamente excluyentes
Se dice que dos eventos son mutuamente excluyentes si no tienen puntos muestrales en común.
Espacio muestral S
Evento A Evento B
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 21
Un evento y su complemento son eventos mutuamente excluyentes
Figura 4 EVENTOS MUTUAMENTE EXCLUYENTES

Unidad Académica del Norte Estadística
Esto es, los eventos A y B son mutuamente excluyentes si, cuando ocurre uno, el otro no puede ocurrir. Así, un requisito para que A y B sean mutuamente excluyentes, es que su intersección no debe contener puntos muestrales. El diagrama de Venn donde se muestran dos elementos, A y B, mutuamente excluyentes, se presenta en la figura 4. En este caso, P(A∩B)=0 y la ley aditiva se puede expresar como sigue.
Ley aditiva para eventos mutuamente excluyentes
P(A U B ) = P(A) + P(B)
EJERCICIOS 1) Suponga que un espacio muestral tiene cinco resultados experimentales igualmente posibles: E1, E2, E3, E4, E5.
Sean A = { E1, E2} B = { E3, E4} C = { E2, E3, E5}a) Determine P(A), P(B) y P(C).b) Determine P(A U B). ¿Son A y B mutuamente excluyentes?c) Determine Ac, Cc, P(Ac), y P(Cc).d) Determine A U Bc, y P(A U Bc).e) Determine P(B U C).
2) Según una encuesta de Business Week/Harris, el 14% de los adultos creía muy posible un colapso bursátil durante 1988, y el 43% lo creía poco probable (Business Week, 29 de diciembre de 1997). Si se preguntara a un adulto al azar, ¿cuál es la probabilidad de que responda que no es probable un colapso bursátil durante 1988?
3) Una encuesta de la publicación News/UCLA realizada con 867 directivos de empresas de entretenimiento en Hollywood estudió cómo se considera a sí misma la industria de entretenimiento en términos de la cantidad de violencia en la televisión y de la calidad en general de la programación de TV (U. S. News & World Report, 9 de mayo de 1994). Los resultados indicaron que 624 directivos pensaron que había aumentado la cantidad de programas violentos en los últimos 10 años, 390 opinaron que la calidad de la programación había disminuido durante los mismos 10 años, y 234 ejecutivos respondieron que había aumentado la cantidad de programas violentos y también que la calidad de la programación había disminuido.
a) Si V es el evento en que la cantidad de programas violentos ha aumentado y Q el evento en que la calidad de la programación ha disminuido, calcule las siguientes probabilidades: P(V), P(Q), y P(V∩Q).
b) Use las probabilidades del inciso a para determinar la probabilidad que un ejecutivo haya hecho al menos uno de los dos comentarios siguientes: La cantidad de programas violentos ha aumentado, o la calidad de la programación ha disminuido.
c) ¿Cuál es la probabilidad de que un ejecutivo no esté de acuerdo con cualquiera de los dos comentarios?
4) La encuesta entre suscritores de Forbes indicó que el 45.8% habían rentado un automóvil durante los últimos 12 meses por motivos de negocios, 54% por motivos personales y 30% por motivos de negocios y personales a la vez (Forbes, Estudio de suscriptores 1993).
a) ¿Cuál es la probabilidad de que un suscriptor rente un automóvil durante los últimos 12 meses por motivos de negocios o personales?
b) ¿Cuál es la probabilidad de que un suscriptor no rente un automóvil durante los últimos 12 meses por motivos de negocios o personales?
5) Durante el invierno en Cincinnati, el Sr. Krebs tiene dificultades para arrancar sus dos automóviles. La probabilidad de que el primero arranque es de 0.80 y la del segundo es 0.40. Hay una probabilidad de 0.30 de que arranquen.
a) Defina los eventos que intervienen y emplee notación de probabilidades para mostrar la información anterior.
b) ¿Cuál es la probabilidad de que al menos un automóvil arranque?c) ¿Cuál es la probabilidad de que el Sr. Krebs no pueda arrancar uno de los dos automóviles?
PROBABILIDAD CONDICIONAL
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 22

Unidad Académica del Norte Estadística
Con frecuencia, la probabilidad de un evento se ve influida por la ocurrencia (o no presentación) de otro evento relacionado. Supongamos que tenemos un evento A con probabilidad P(A). Si obtenemos nueva información y vemos que ha ocurrido un evento relacionado, representado por B, quisiéramos aprovechar esta información para calcular una nueva probabilidad del evento A. Esa nueva probabilidad se representa como P(A B). La notación indica el hecho de que se considera la probabilidad del evento A dada la condición de que ha ocurrido el evento B. En consecuencia, la notación P(A B) se lee “la probabilidad de A dado B”.
Como ejemplo de la aplicación de la probabilidad condicional, veamos el caso de la promoción de oficiales, hombres y mujeres, de una gran policía metropolitana. La fuerza policial esta formada de 1,200 oficiales, 960 hombres y 240 mujeres. En los últimos dos años fueron ascendidos 324 oficiales. En la tabla 2 se muestra el detalle específico de las promociones de oficiales hombres y mujeres.
Después de revisar el registro de promociones, un comité de oficiales mujeres interpuso una demanda por discriminación, con base en que 288 oficiales hombres habían recibido el ascenso, mientras que solo 36 oficiales mujeres habían sido promovidas. La administración dijo que la cantidad relativamente baja de ascensos de oficiales mujeres no se debía a la discriminación, sino a la cantidad relativamente reducida de oficiales mujeres en la fuerza policial. Veamos como se puede usar la probabilidad condicional para analizar la demanda por discriminación.
Sean M = evento de que un oficial es hombre W = evento de que un oficial es mujer A = evento de que un oficial es ascendido Ac = evento de que un oficial no es ascendido
Dividiendo los valores de los datos de la tabla 2 entre el total de 1200 oficiales podemos resumir la información disponible en los siguientes valores de probabilidad.
P(M∩A) = 288/1200= 0.24 = probabilidad de que un oficial seleccionado al azar sea hombre y también que sea ascendido.
P(M∩Ac) = 672/1200= 0.56 = probabilidad de que un oficial seleccionado al azar sea hombre y también que no sea ascendido.
P(W∩A) = 36/1200= 0.03 = probabilidad de que un oficial seleccionado al azar sea mujer y también que sea ascendido.
P(W∩Ac) = 204/1200= 0.17 = probabilidad de que un oficial seleccionado al azar sea mujer y también que no sea ascendido.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 23
Hombres Mujeres Totales
Ascendidos 288 36 324No ascendidos 672 204 876 Totales 960 240 1200
Tabla 2 ASCENSOS DE OFICIALES DE POLICÍA DURANTE LOS ÚLTIMOS DOS AÑOS

Unidad Académica del Norte Estadística
Como cada uno de esos valores expresa la probabilidad de la intersección de dos eventos, las probabilidades se llaman probabilidades conjuntas. La tabla 3, que muestra un resumen de la información sobre los ascensos en la policía, se llama tabla de probabilidad conjunta, o de probabilidades conjuntas.
Los valores en los márgenes de la tabla de probabilidad conjunta muestran por separado las probabilidades de cada evento. Esto es, P(M) =0.80, P(W) =0.20, P(A) =0.27 y P(Ac) =0.73. Esas probabilidades se llaman probabilidades marginales, por su ubicación en los márgenes de la tabla de probabilidad conjunta. Observamos que las probabilidades marginales se determinan sumando las probabilidades conjuntas de un mismo renglón o columna de esta tabla. Por ejemplo, la probabilidad marginal de ser ascendido es P(A) = P(M∩A) + P(W∩A) =0.24 + 0.03 = 0.27. Vemos, en las probabilidades marginales, que el 80% de la policía son hombres, que el 20% son mujeres, que el 27% de todos los oficiales recibieron ascenso y que el 73% no lo recibieron.
Comenzaremos el análisis de las probabilidades condicionales calculando la probabilidad de que un oficial sea ascendido dado que es hombre. En notación de probabilidad condicional, lo que tratamos de calcular es P(A M). Para hacerlo, primero vemos que esta notación indica simplemente que estamos considerando la probabilidad del evento A (promoción) dado que se sabe que existe la condición llamada evento M (el oficial es hombre). Así, P(A M) nos indica que ahora sólo nos ocupamos sobre la promoción de los 960 oficiales hombres. Como 288 de los 960 oficiales hombres fueron ascendidos, la probabilidad de ser promovido, cuando el oficial es hombre, es 288/960 = 0.30. En otras palabras, dado que el oficial es hombre, hubo un 30% de probabilidades de recibir un ascenso en los dos últimos años.
El procedimiento anterior fue fácil de aplicar en nuestro ejemplo, porque los valores de los datos en la tabla 2 indican la cantidad de oficiales en cada categoría. Ahora demostraremos como se pueden calcular las probabilidades condicionales, como P(A M) directamente a partir de probabilidades de evento y no de datos de frecuencia como los de la tabla 2.
Hemos demostrado que P(A M) = 288/960 = 0.30. Dividamos ahora el numerador y el denominador de esta fracción entre 1,200, la cantidad total de oficiales en el estudio.
P(A M)= 288 = 288/1200 = 0.24 = 0.30 960 960/1200 0.80
Vemos ahora que la probabilidad condicional P(A M) se puede calcular como 0.24/0.80. En la tabla 3 de
probabilidad conjunta, observamos en particular que 0.24 es la probabilidad conjunta de A y M; esto es, P(A∩M) = 0.24. También observamos que 0.80 es la probabilidad marginal de que un oficial seleccionado al azar sea hombre; esto es P(M) = 0.80. Así, la probabilidad condicional P(A M) se puede calcular como la relación de la probabilidad conjunta, P(A∩M) entre la probabilidad marginal P(M).
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 24
Tabla 3 TABLA DE PROBABILIDADES CONJUNTAS DE ASCENSOS
Hombres (M) Mujeres (W) Totales
Ascendidos 0.24 0.03 0.27No ascendidos 0.56 0.17 0.73
Totales 0.80 0.20 1.00
Las probabilidades conjuntas aparecen en el interior de la tabla
Las probabilidades marginales aparecen en los márgenes de la tabla

Unidad Académica del Norte Estadística
P(A M) = P(A∩M) = 0.24 = 0.30 P(M) 0.80
El hecho de que se puedan calcular las probabilidades condicionales como la relación de una probabilidad conjunta entre una probabilidad marginal justifica la siguiente ecuación general de los cálculos de probabilidad condicional para dos eventos, A y B.
Probabilidad condicional P(A B) = P(A∩B) (5) P(B)
o sea P(B A) = P(A∩B) (6)
P(A)
El diagrama de Venn de la figura 5 ayuda a obtener una idea intuitiva de la probabilidad condicional. El círculo de la derecha muestra que ha ocurrido el evento B; la parte del círculo que se traslapa con el evento A representa al evento (A∩B). Sabemos que una vez que ha sucedido el evento B, la única forma en que podamos observar también al evento A es que suceda el evento (A∩B). Así, la relación P(A∩B)/P(B) da como resultado la probabilidad condicional de que observemos al evento A, dado que ya ocurrió el evento B.
Regresemos ahora a la cuestión de la discriminación de oficiales mujeres. La probabilidad marginal en el renglón 1 de la tabla 3 muestra que la probabilidad de ascenso de un oficial es P(A) = 0.27, independientemente de si es hombre o mujer. Sin embargo, el asunto crítico en esta demanda implica las dos probabilidades condicionales, P(A M) y P(A W). Esto es, ¿cuál es la probabilidad de ascenso dado que el oficial es hombre, y cuál es la probabilidad de ascenso dado que el oficial es mujer? Si esas dos probabilidades son iguales, no tiene fundamento
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 25
Figura 5 PROBABILIDAD CONDICIONAL
Evento A ∩ B
Evento A Evento B
Una vez transcurrido el evento B:
Evento B con probabilidad P(B) Evento A ∩ B con probabilidad P(A ∩ B)
Entonces, P(A B) = P(A ∩ B) P(B)

Unidad Académica del Norte Estadística
la demanda por discriminación, porque son iguales las posibilidades de promoción para oficiales hombres y mujeres. Sin embargo, sí las dos probabilidades condicionales son distintas, sí tendrá fundamento la afirmación de que los oficiales hombres y mujeres reciben trato diferente en las decisiones de ascenso.
Ya determinamos que P(A M) = 0.30. Ahora usaremos los valores de probabilidad de la tabla 3, y la ecuación básica (5) de la probabilidad condicional, para calcular la probabilidad de que un oficial seleccionado al azar reciba ascenso, dado que el oficial es mujer; esto es, P(A W). Aplicando la ecuación (5) obtenemos:
P(A W) = P(A∩W) = 0.03 = 0.15 P(W) 0.20
¿A qué conclusiones llega usted? La probabilidad de una promoción, dado que el oficial es hombre es de 0.30, el doble de la probabilidad 0.15 de una promoción, dado que el oficial es mujer. Si bien el empleo de la probabilidad condicional no demuestra por sí mismo que exista discriminación en este caso, los valores de la probabilidad sí respaldan la demanda presentada por las oficiales mujeres.
Eventos independientes
En el ejemplo anterior, P(A) = 0.27, P(A M) = 0.30 y P(A W) = 0.15. Vemos que la probabilidad de un ascenso (evento A) se ve afectada o influida por el hecho de que el oficial sea hombre o mujer. En especial, como P(A M) P(A), diríamos que los eventos A y M son dependientes. Esto es, la probabilidad del evento A (ascenso) se altera o cambia con la ocurrencia (o no ocurrencia) de M (el oficial es hombre). Igualmente, con P(A W) P(A), diríamos que los eventos A y W son dependientes. Si no cambia la probabilidad del evento A por la ocurrencia del evento M, esto es, P(A M) = P(A), diríamos que los eventos A y M son independientes. Esto nos conduce a la siguiente definición de la independencia entre dos eventos.
Eventos independientesDos eventos, A y B, son independiente si
P(A B) = P(A) (7)
o si
P(B A) = P(B) (8)
De lo contrario, los eventos son dependientes.
Ley multiplicativa
Mientras que la ley aditiva de la probabilidad se usa para determinar la probabilidad de una unión entre dos eventos, la ley multiplicativa se usa para determinar la probabilidad de una intersección de dos eventos. La ley multiplicativa se basa en la definición de la probabilidad condicional. Al Aplicar las ecuaciones (5) y (6) y despejar P(A∩B) obtenemos la ley multiplicativa.
Ley multiplicativa P(A∩B) = P(B) P(A B) (9)
o también
P(A∩B) = P(A) P(B A) (10)Para ilustrar la aplicación de la ley multiplicativa, supongamos que en el departamento de circulación de
un diario se sabe que el 84% de las familias de una determinada colonia tiene una suscripción para recibir el periódico de lunes a sábado. Si hacemos que D represente el evento de que una familia tiene tal tipo de suscripción, P(D) = 0.84. Se sabe que la probabilidad de que una familia, cuya suscripción, además de ser de lunes a sábado, también se suscriba a la edición dominical (evento S), es de 0.75; esto es, P(S D) = 0.75. ¿Cuál es la probabilidad de que la suscripción de una familia incluya tanto a la edición dominical como a la de lunes a sábado? Con la ley multiplicativa calculamos la P(S∩D) necesaria como sigue:
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 26
Los eventos mutuamente excluyentes con probabilidades distintas de cero no pueden ser independientes.

Unidad Académica del Norte Estadística
P(S∩D) = P(D) P(S D) = 0.84(0.75) = 0.63
Sabemos ahora que el 63% de las familias tiene suscripción de las ediciones dominicales y entre semana.
Antes de terminar esta temática estudiaremos el caso especial de la ley multiplicativa cuando los eventos implicados en ella son independientes. Recordemos que dos eventos son independientes entre sí siempre y cuando P(A B) = P(A) o P(B A) = P(B). Por consiguiente, aplicando las ecuaciones (9) y (10) para el caso especial de dos eventos independientes obtenemos la siguiente ley multiplicativa.
Ley multiplicativa para eventos independientes
P(A∩B) = P(A)P(B) (11)
Para calcular la probabilidad de la intersección de dos eventos independientes, tan sólo se multiplican las probabilidades correspondientes. Observe que la ley multiplicativa para eventos independientes representa otro método para determinar si A y B son independientes. Esto es, si P(A∩B) = P(A)P(B), entonces A y B son independientes; si P(A∩B) P(A)P(B), entonces A y B son dependientes.
Como una aplicación de la ley multiplicativa para eventos independientes, veamos el caso de un gerente de una gasolinera que sabe, por su experiencia, que el 80% de los clientes usan tarjeta de crédito al comprar gasolina. ¿Cuál es la probabilidad de que los dos clientes siguientes que compren gasolina usen tarjeta de crédito? Si hacemos que:
A = el evento en que el primer cliente usa tarjeta de créditoB = el evento en que el segundo cliente usa tarjeta de crédito
Entonces el evento de interés es A∩B. Como no contamos con más información, podemos suponer razonablemente que A y B son eventos independientes. Entonces,
P(A∩B) = P(A)P(B) = (0.80)(0.80) = 0.64
EJERCICIOS 1) Suponga que hay dos eventos, A y B, con P(A) = 0.50, P(B) = 0.60, y P(A ∩ B) = 0.40.
a) Calcule P(A | B).b) Calcule P(B | A).c) ¿Son independientes A y B? ¿Por qué sí o por qué no?
2) Suponga que hay dos eventos, A y B, mutuamente excluyentes. Suponga además que se sabe que P(A) = 0.30 y P(B) = 0.40.
a) ¿Cuál es (cuánto vale) P(A U B)?b) ¿Cuál es P(A | B)?c) Un estudiante de estadística dice que en realidad los conceptos de eventos mutuamente excluyentes y
eventos independientes son iguales, y que si los eventos son mutuamente excluyentes, entonces deben ser independientes. ¿Está usted de acuerdo con esta afirmación?. Aplique la información de las probabilidades en este problema para justificar su respuesta.
d) ¿A qué conclusión general llegaría usted acerca de los eventos mutuamente excluyentes y los eventos independientes, en vista de los resultados de este problema?
3) Un club nocturno tiene los siguientes datos sobre la edad y el estado civil de 140 clientes.Estado civil
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 27
NOTA: No se debe confundir entre sí el concepto de eventos mutuamente excluyentes con el de eventos independientes. Dos eventos cuyas probabilidades son distintas de cero no pueden ser de manera simultánea mutuamente excluyentes e independientes entre sí. Si ocurre uno de los eventos mutuamente excluyentes, la probabilidad de que suceda el otro se reduce a cero. En consecuencia, son dependientes.

Unidad Académica del Norte Estadística
Soltero Casado
EdadMenor de 30 77 1430 o mayor 28 21
a) Forme una tabla de probabilidad conjunta para estos datos.b) Aplique las probabilidades marginales para comentar sobre la edad de los clientes del club.c) Emplee las probabilidades marginales para comentar sobre el estado marital de los clientes.d) ¿Cuál es la probabilidad de encontrar un cliente que sea soltero y menor que 30 años?e) Si un(a) cliente tiene menos de 30 años ¿cuál es la probabilidad de que sea soltero(a)?f) El estado civil de los clientes, ¿es independiente de su edad?. Explique por qué, empleando
probabilidades.
4) Los siguientes datos pertenecen a una muestra de 80 familias de cierta población, éstos muestran la escolaridad de los padres y la de sus hijos.
HijoFue a la
universidadNo fue a la universidad
PadreFue a la universidad 18 7
No fue a la universidad 22 33
a) Elabore la tabla de probabilidad conjunta.b) Use las probabilidades marginales para hacer comparaciones de la escolaridad entre padres e hijos.c) ¿Cuál es la probabilidad de que el hijo vaya a la universidad, si su padre asistió?d) ¿Cuál es la probabilidad de que el hijo vaya a la universidad, si su padre no lo hizo?e) Es independiente la asistencia del hijo a la universidad del hecho de que el padre fuera o no a la
universidad? Explique la respuesta empleando argumentos probabilísticos.
5) En el estudio de Suscriptores 1995 de The Wall Street Journal se obtuvo la siguiente tabla acerca de TV vía satélite. Los datos se separan para las cuatro partes del país en las que se publica una edición diferente de ese diario.
Región geográficaEste Medioeste Suroeste Oeste
Televisión por satélite
La tiene 17 8 7 13Probablemente la compre 107 95 30 93
Ninguna 488 403 98 275a) Forme una tabla de probabilidades conjuntas.b) ¿Cuál es la probabilidad de que un suscriptor posea TV vía satélite?c) ¿Cuál es la probabilidad de que uno de los suscriptores encuestados sea del suroeste?d) ¿Cuál es la probabilidad de que un suscriptor del suroeste posea TV vía satélite? e) ¿En qué región del país es mayor la probabilidad de poseer TV vía satélite?f) ¿En qué región del país es mayor la probabilidad de poseer TV vía satélite dentro de un año?
6) Un agente de compras colocó pedidos urgentes de determinada materia prima con dos proveedores distintos, A y B. Si ningún pedido llega en cuatro días, debe parar su proceso de producción hasta que llegue, al menos uno de ellos. La oportunidad de que el proveedor A pueda entregar el material en cuatro días es de 0.55, y de que el proveedor B pueda entregar en cuatro días es de 0.35.
a) ¿Cuál es la probabilidad de que ambos proveedores surtan su material en cuatro días? Como se trata de dos proveedores diferentes, se puede suponer que son independientes entre si.
b) ¿Cuál es la probabilidad de que al menos un proveedor entregue el material en cuatro días?c) ¿Cuál es la probabilidad de que se detengad) 0 el proceso de producción dentro de cuatro días por falta de materia prima (esto es, de que ambos
pedidos se entreguen tarde)?
GLOSARIO
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 28

Unidad Académica del Norte Estadística
Probabilidad. Experimento. Espacio muestral. Punto muestral. Diagrama de árbol. Requisitos básicos de probabilidad. Método clásico Método de la frecuencia relativa. Método subjetivo. Evento. Complemento del evento A. Diagrama de Venn. Unión de eventos A y B. Intersección de A y B. Ley aditiva. Eventos mutuamente excluyentes. Probabilidad condicional. Eventos independientes. Ley multiplicativa.
FORMULAS CLAVE
Regla de conteo para combinaciones N = N!_____ n n!(N – n)!
Cálculo de una probabilidad mediante el complemento P(A) = 1 – P(Ac)
Ley aditiva P(A U B) =P(A) + P(B) – P(A∩B)
Probabilidad condicional P(A B) = P(A∩B) P(B)
Ley multiplicativa P(A∩B) = P(B) P(A B)
Ley multiplicativa para eventos independientes P(A∩B) = P(A)P(B)
VARIABLES ALEATORIASAnteriormente definimos el concepto de un experimento y sus resultados asociados. Una variable aleatoria
es un medio de describir los resultados experimentales con valores numéricos. Veamos la definición de variable aleatoria.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 29

Unidad Académica del Norte Estadística
Variable aleatoriaUna variable aleatoria es una descripción numérica del resultado de un experimento.
En efecto, una variable aleatoria asocia un valor numérico con cada resultado posible. El valor numérico de la variable aleatoria depende del resultado del experimento. Se puede clasificar una variable como discreta o continua, dependiendo de los valores numéricos que asume.
VARIABLES ALEATORIAS DISCRETAS
Una variable aleatoria que puede asumir una cantidad finita de valores, o una sucesión infinita de valores como 0, 1, 2, ..., se llama variable aleatoria discreta. Por ejemplo, imaginemos el experimento en que un contador presenta un examen de certificación de contaduría pública. El examen consta de cuatro partes. Podemos definir la variable aleatoria discreta como x = la cantidad de partes del examen aprobadas. Esa variable discreta puede asumir la cantidad finita de valores 0, 1, 2, 3 o 4.
Otro ejemplo de variable aleatoria discreta: un experimento de los vehículos que llegan a una caseta de cobro. La variable aleatoria de interés es x = cantidad de vehículos que llegan en un día. Los valores posibles de x provienen de la sucesión de enteros 0, 1, 2, etc. Por consiguiente, x es una variable aleatoria discreta que toma uno de los valores de esta sucesión infinita.
Aunque muchos experimentos tienen resultados que se pueden describir naturalmente con valores numéricos, hay otros que no. Por ejemplo, una pregunta de una encuesta puede pedir a la persona que recuerde el mensaje de un comercial televisivo reciente. Habrían dos resultados experimentales: el individuo no puede recordar el mensaje y el individuo sí puede recordarlo. Podemos seguir describiendo esos resultados experimentales en forma numérica, si definimos la variable aleatoria discreta x como sigue: sea x = 0 sí el individuo no puede recordar el mensaje, y x = 1 si sí lo puede recordar. Los valores numéricos para esta variable aleatoria son arbitrarios (podríamos haber usado 5 y 10), pero se pueden aceptar en términos de la definición de variable aleatoria: x es una variable aleatoria porque asigna una descripción numérica al resultado del experimento.
La tabla A muestra algunos ejemplos adicionales de variables aleatorias discretas. Observe que en cada ejemplo, la variable aleatoria discreta asume, o toma, una cantidad finita de valores o una sucesión infinita de valores como 0, 1, 2, ...Variables aleatorias discretas como ésas son las que se describen detalladamente en esta temática.
VARIABLES ALEATORIAS CONTINUAS
Si una variable aleatoria puede tomar cualquier valor numérico en un intervalo o conjunto de intervalos se llama variable aleatoria continua. Los resultados experimentales que se basan en escalas de medición como el tiempo, el peso, la distancia y la temperatura se pueden describir mediante variables aleatorias continuas. Por ejemplo, imaginemos un experimento que consiste en monitorear las llamadas telefónicas que entran a la oficina
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 30
Tabla A EJEMPLOS DE VARIABLES ALEATORIAS DISCRETAS
Experimento
Llamar a cinco clientes
Inspeccionar un embarque de 50 radiosFuncionamiento de un restaurante durante un díaVender un automóvil
Variable aleatoria (x)
Cantidad de clientes que hacen pedido
Cantidad de radios defectuosos
Cantidad de clientes Sexo del cliente
Valores posibles dela variable aleatoria
0, 1, 2, 3, 4, 5
0, 1, 2, ... 49, 50
0, 1, 2, 3, ...
0 si es hombre; 1 si es mujer

Unidad Académica del Norte Estadística
de ajustes de una gran aseguradora. Supongamos que la variable aleatoria de interés es x = el tiempo entre llamadas consecutivas, en minutos. Esta variable aleatoria puede asumir cualquier valor en el intervalo x > 0. En realidad, hay una cantidad infinita de valores posibles para x, como 1.26 minutos, 2.757 minutos, 4.3333 minutos, etc. Otro ejemplo: un tramo de 90 kilómetros de la carretera Internacional México-Nogales, en el norte de Nayarit. Podríamos definir, para un servicio de ambulancia de emergencia en Nayarit, la variable aleatoria x = la ubicación del siguiente accidente de tránsito en este tramo carretero. En este caso, x sería una variable aleatoria continua, que asume cualquier valor en el intervalo 0 < x < 90. En la tabla B vemos otros ejemplos de variables aleatorias continuas. Observe que cada uno describe una variable aleatoria que puede asumir cualquier valor en un intervalo de valores. Las variables aleatorias continuas, y sus distribuciones de probabilidad, serán el tema de estudio en la siguiente temática.
EJEMPLOS
1. El experimento consiste en lanzar una moneda dos veces.a. Haga una lista de los resultados experimentales.b. Defina una variable aleatoria que represente la cantidad de soles que pueden presentarse en los dos
lanzamientos.c. Indique qué valor tomaría la variable en cada uno de los resultados experimentales.d. Esta variable aleatoria ¿es discreta, o continua?
2. Un experimento consiste en un trabajador que ensambla un producto, y se registra el tiempo que tarda en hacer esto.
a. Defina una variable aleatoria que represente el tiempo, en minutos, requerido para ensamblar el producto.
b. ¿Qué valores puede asumir la variable aleatoria?c. Esa variable aleatoria ¿es discreta o continua?
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 31
NOTA: Una forma de determinar si una variable aleatoria es discreta o continúa es imaginarse que los valores de esa variable son puntos en una recta numérica. Se eligen dos puntos que representan valores de la variable aleatoria. Si todo el segmento de la recta entre los dos puntos también representa valores posibles de la variable, esa variable aleatoria es continua.
Tabla B EJEMPLOS DE VARIABLES ALEATORIAS CONTINUAS
Experimento
Funcionamiento de un banco
Llenar una lata de bebida(máx = 12.2 onzas)
Proyecto para construir una nueva bibliotecaEnsayar un nuevo proceso químico
Variable aleatoria (x)
Tiempo en minutos, entre llegadas de clientesCantidad de onzas
Porcentaje terminado del proyecto en seis mesesTemperatura cuando se lleva a cabo la reacción deseada (mín 150o F; máx 212 o F)
Valores posibles deLa variable aleatoria
x > 0
0 < x < 12.2
0 < x < 100
150 < x < 212

Unidad Académica del Norte Estadística
3. Las tasas de interés de préstamos hipotecarios fueron publicadas por 12 instituciones crediticias de Florida (The Tampa Tribune, 25 de febrero de 1995). Suponga que la variable aleatoria de interés es la cantidad de instituciones crediticias de este grupo que ofrecen una tasa fija a 30 años, de 8.5% o menos. ¿Qué valores puede asumir esta variable aleatoria?
4. La tabla adjunta es una lista de experimentos y variable aleatoria asociada. En cada caso, identifique los valores que puede asumir la variable aleatoria y diga si esa variable es discreta o continua.
DISTRIBUCIONES DISCRETAS DE PROBABILIDAD
La distribución de probabilidad de una variable aleatoria describe cómo se distribuyen las probabilidades de los diferentes valores de la variable aleatoria. Para una variable aleatoria discreta x, la distribución se describe mediante una función de probabilidad, representada por f(x). La función de probabilidad define la probabilidad de cada valor de la variable aleatoria.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 32
ExperimentoHacer un examen con 20 preguntas.Observar los automóviles que llegan a una caseta durante una hora.Auditar 50 devoluciones de impuestos.Observar el trabajo de un empleado.
Pesar un embarque de productos.
Variable aleatoria (x)Cantidad de preguntas bien contestadasCantidad de automóviles que llegan a la caseta.Cantidad de devoluciones con errores.Cantidad de horas no productivas en una jornada de ocho horas.Cantidad de libras

Unidad Académica del Norte Estadística
Como ejemplo de una variable aleatoria discreta y su distribución de probabilidad, veamos el caso de las ventas de automóviles por parte de DiCarlo Motors en Saratoga, Nueva York. Durante los últimos 300 días de operación, los datos de ventas muestren que en 54 días no se vendieron automóviles, en 117 se vendió 1 automóvil, en 72 se vendieron 2; en 42,3 en 12,4 y en 3 días se vendieron 5 automóviles. Supongamos que un experimento consiste en seleccionar un día hábil de DiCarlo Motors. Definiremos la variable aleatoria de interés como x = la cantidad de automóviles vendidos durante un día. De acuerdo con los datos históricos, sabemos que x es una variable aleatoria discreta que puede asumir valores 0, 1, 2, 3, 4 o 5. En notación de la función de probabilidad, f(0) define la probabilidad de 0 automóviles vendidos, f(1) la de 1 automóvil vendido, y así sucesivamente. Como los datos históricos muestran que en 54 de 300 días no se vendieron automóviles, asignaremos el valor 54/300 = 0.18 a f(0), para indicar que la probabilidad de vender 0 automóviles en un día es de 0.18. Igualmente, como se vendió un automóvil en 117 de los 300 días, asignaremos a f(1) el valor 117/300 = 0.39. Continuando en esta forma para los demás valores de la variable aleatoria, calculamos los valores de f(2), f(3), f(4) y f(5) que aparecen en la tabla C, la distribución de probabilidad de la cantidad de automóviles vendidos en un día por DiCarlo Motors.
Una ventaja importante de definir una variable aleatoria y su distribución de probabilidad es que, una vez conocida esa distribución, es relativamente fácil determinar la probabilidad de varios eventos que puedan interesar a quien toma decisiones. Por ejemplo, si consultamos la distribución de probabilidad para DiCarlo Motors en la tabla C, veremos que la cantidad más probable de vehículos que se venden en un día es de 1 con una probabilidad de f(1) = 0.39. Además, hay una probabilidad f(3) + f(4) + f(5) = 0.14 + 0.04 + 0.01 = 0.19 de vender 3 o más automóviles en un día. Esas probabilidades y otras más que pueda solicitar quien toma las decisiones, dan información que pueden ayudar a comprender el proceso de venta de automóviles en DiCarlo Motors.
Al asignar una función de probabilidad para cualquier variable discreta, se deben satisfacer las dos condiciones siguientes.
Condiciones requeridas para una función de probabilidad discreta
f(x) > 0 (1) Σ f(x) = 1 (2)
La tabla C muestra que las probabilidades de la variable aleatoria x satisfacen la condición (1), ya que f(x) es mayor o igual a 0, para todos los valores de x. Además, las probabilidades suman 1, de modo que también se satisface la ecuación (2). Por consiguiente, en el caso de DiCarlo Motors, la función de probabilidad indicada es una función de probabilidad discreta válida.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 33
Tabla C DISTRIBUCIÓN DE PROBABILIDAD DE LA CANTIDAD DE AUTOMÓVILES VENDIDOS EN DICARLO MOTORS DURANTE UN DÍA
x f(x)0.180.390.240.140.040.01
Total 1.00

Pro
babi
lida
d
Unidad Académica del Norte Estadística
También podemos presentar gráficamente las distribuciones de probabilidad. En la figura 1 se muestran los valores de la variable aleatoria x en el eje horizontal, y la probabilidad asociada con ellos en el eje vertical.
Además de las tablas y las gráficas, una fórmula que expresa f(x) para todo valor de x puede definir la distribución de probabilidad para algunas variables aleatorias discretas. El ejemplo más sencillo de distribución de probabilidad discreta expresada con una fórmula es la distribución uniforme de probabilidad discreta, cuya función de probabilidad es la siguiente:
Función uniforme de probabilidad discreta
f(x) = 1/n (3)
en donde n = cantidad de valores que puede asumir la variable aleatoria.
Por ejemplo, imaginemos el experimento de tirar un dado y definamos a x, la variable aleatoria, como el número en la cara superior. Hay n = 6 valores posibles de la variable aleatoria, que son x = 1, 2, 3, 4, 5 y 6. Por consiguiente, la función de probabilidad para esta variable aleatoria es:
f(x) = 1/6 x = 1, 2, 3, 4, 5 y 6
Los valores posibles de la variable aleatoria, y de sus probabilidades asociadas, Son los siguientes:
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 34
Figura 1
REPRESENTACIÓN GRÁFICA DE LA DISTRIBUCIÓN DE PROBABILIDAD DE VENTAS DE AUTOMÓVILES EN DICARLO MOTORS
x f(x)1/61/61/61/61/61/6
f(x) 0.40 0.30 0.20 0.10 0.00 x 0 1 2 3 4 5 Cantidad de automóviles vendidos en un día
Pro
babi
lida
d

Unidad Académica del Norte Estadística
Observe que los valores de la variable aleatoria son los igualmente probables.
Otro ejemplo: se tiene la variable aleatoria x con la siguiente distribución de probabilidad.
Esta distribución de probabilidades también se puede definir con la fórmula
f(x) = x para x = 1, 2, 3 o 4 10
Al evaluar f(x) para determinado valor de la variable aleatoria se conocerá la probabilidad asociada. Por ejemplo, aplicando la función anterior de probabilidad, vemos que f(2) = 2/10 da la probabilidad de que la variable aleatoria asuma el valor de 2.
Las distribuciones discretas de probabilidad que más se usan se especifican, por lo general mediante formulas. Hay tres casos importantes, que son los de las distribuciones binomial, de Poisson e hipergeométrica, y se describirán más adelante.
EJERCICIOS
1. La distribución de probabilidades de la variable x aparece en la tabla siguiente.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 35
x f(x)1/102/103/104/10
x f(x) 20 0.20
25 0.1530 0.2535 0.40
Total 1.00

Unidad Académica del Norte Estadística
a. ¿Es correcta esta distribución de probabilidad? Compruebe que se cumplan las ecuaciones (1) y (2).b. ¿Cuál es la probabilidad de que x = 30?c. ¿Cuál es la probabilidad de que x sea menor que o igual a 25?d. ¿Cuál es la probabilidad de que x sea mayor que 30?
2. Se recabaron los siguientes datos a partir del conteo de la cantidad de salas de operación en uso en el Hospital General de Tampa durante 20 días: en 3 días sólo se usó 1 sala de operaciones, en 5 se usaron 2, en 8 se usaron 3 y en 4 días se usaron las cuatro salas de operaciones del hospital.
a. Emplee el método de la frecuencia relativa para formar una distribución de probabilidad para la cantidad de salas de operación que se usan en un día determinado.
b. Trace una gráfica de la distribución de probabilidad.c. Demuestra que su distribución de probabilidad satisface las condiciones requeridas.
3. El director de admisiones de una escuela evaluó subjetivamente una distribución de probabilidades de x, la cantidad de alumnos de nuevo ingreso, que se muestra en la tabla siguiente.
a. ¿Es válida esta distribución de probabilidad?b. ¿Cuál es la probabilidad de que haya 1200 alumnos de nuevo ingreso o menos?
VALOR ESPERADO Y VARIANZA
Valor esperado
El valor esperado, o media, de una variable aleatoria es una medida de la localización central (o tendencia central) de esa variable. La ecuación matemática del valor esperado de una variable aleatoria discreta x es la siguiente.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 36
x f(x) 1000 0.15
1100 0.201200 0.301300 0.25
1400 0.10

Unidad Académica del Norte Estadística
El valor esperado de una variable aleatoria discreta
E(x) = µ = Σ x f(x) (4)
Se pueden usar las notaciones E(x) y µ para representar el valor esperado de una variable aleatoria.Vemos, en la ecuación (4), que para calcular el valor esperado de una variable aleatoria discreta debemos multiplicar x, cada valor de ella, por f(x), su probabilidad correspondiente, y después sumar todos los productos obtenidos. Volviendo al ejemplo de las ventas de automóviles en DiCarlo Motors que se vio anteriormente, en la tabla D describimos el cálculo del valor esperado de la cantidad de automóviles que se venden en un día. La suma de los elementos de la columna x f(x) muestra que el valor esperado es de 1.50 automóviles por día. En consecuencia, sabemos que, aunque es posible vender 1, 2, 3, 4 o 5 automóviles en cualquier día, DiCarlo puede esperar, a la larga, la venta de un promedio de 1.50 automóviles por día. Si suponemos que la operación durante un mes, equivale a 30 días podemos usar el valor esperado de 1.50 para anticipar que las ventas mensuales promedio son 30(1.50) = 45 automóviles.
Varianza
Si bien el valor esperado representa el valor promedio de la variable aleatoria, con frecuencia se necesita conocer una medida de dispersión o variabilidad. Así como usamos la varianza en el capítulo 3 para resumir la dispersión en un conjunto de datos, ahora la usaremos para resumir la variabilidad en los valores de una variable aleatoria. La ecuación matemática de la varianza de una variable aleatoria es la siguiente.
Varianza de una variable aleatoria discreta
Var(x) = ơ2 = ∑(x - µ)2 f(x) (5)
Como indica esta ecuación, una parte esencial de la fórmula de la varianza es la desviación, x - µ, que mide lo alejado que se encuentra un valor determinado del valor esperado o media, µ, de la variable aleatoria. Para calcular la varianza de una variable aleatoria se elevan al cuadrado las desviaciones y se ponderan con el valor correspondiente de la función de probabilidad. La suma de esas desviaciones elevadas al cuadrado y ponderadas, para todos los valores de la variable aleatoria, se llama varianza. Se usan las notaciones Var(x) y ơ2 para representar la varianza de una variable aleatoria.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 37
Tabla D CÁLCULO DEL VALOR ESPERADO DE LA CANTIDAD DE AUTOMÓVILES VENDIDOS EN DICARLO MOTORS DURANTE UN DÍA
E(x) = µ = Σxf(x)
x f(x)0 0.181 0.392 0.243 0.144 0.045 0.01
x f(x)0(.18) = 0.001(.39) = 0.392(.24) = 0.483(.14) = 0.424(.04) = 0.165(.01) = 0.05
1.50

Unidad Académica del Norte Estadística
El cálculo de la varianza para la distribución de probabilidad de la cantidad de automóviles vendidos en DiCarlo Motors durante un día se resume en la tabla E. Vemos que la varianza es de 1.25. La desviación estándar, ơ, se define como la raíz cuadrada positiva de la varianza. Así, la desviación estándar de la cantidad de autos vendidos en un día es
ơ = 1.25 = 1.118
La desviación estándar se mide con las mismas unidades que la variable aleatoria (ơ = 1.118 automóviles) y en consecuencia se prefiere en muchas ocasiones para describir la variabilidad de una variable aleatoria. La varianza ơ2 se mide con las unidades elevadas al cuadrado, y por ello es más difícil de interpretar.
EJERCICIOS
1. La tabla siguiente es una distribución de probabilidad para la variable aleatoria x.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 38
NOTA: La varianza es un promedio ponderado de las desviaciones de una variable aleatoria respecto a su promedio, elevadas al cuadrado. Los factores de ponderación son las probabilidades.
Tabla E CÁLCULO DE LA VARIANZA DE LA CANTIDAD DE AUTOMOVILES VENDIDOS EN DICARLO MOTORS DURANTE UN DÍA
ơ = Σ(x – µ)2 f(x)
(x – µ)2 f(x) 2.25 (.18) = 0.4050 0.25 (.39) = 0.0975 0.25 (.24) = 0.0600 2.25 (.14) = 0.3150 6.25 (.04) = 0.250012.25 (.01) = 0.1225 1.2500
x012345
x – µ0 – 1.50 = – 1.50 1 – 1.50 = –0.50 2 – 1.50 = 0.503 – 1.50 = 1.50 4 – 1.50 = 2.50 5 – 1.50 = 3.50
(x – µ)2
2.25 0.25 0.252.25 6.25
12.25
f (x)0.180.390.240.140.040.01
x f(x) 3 0.25
6 0.50 9 0.25
Total 1.00

Unidad Académica del Norte Estadística
a. Calcule E(x), el valor esperado de x.b. Calcule ơ 2, la varianza de x.c. Calcule ơ, la desviación estándar de x.
2. La tabla siguiente es una distribución de probabilidad de la variable aleatoria y.
a. Calcule E(y)b. Calcule Var (y) y ơ.
3. El Statistical Abstract of the United States de 1997 muestra que la cantidad promedio de televisores por familia es de 2.3. Suponga que la distribución de probabilidad de la cantidad de televisores por familia es la que se muestra en la tabla siguiente.
a. Calcule el valor esperado de la cantidad de televisores por familia, y compárelo con el promedio que menciona el Statistical Abstract.
b. ¿Cuáles son la varianza y la desviación estándar de la cantidad de televisores por familia?
DISTRIBUCIÓN BINOMIAL DE PROBABILIDAD
La distribución binomial de probabilidades es una distribución discreta de probabilidad que tiene muchas aplicaciones. Se relaciona con un experimento de etapas múltiples que llamamos binomial.
UN EXPERIMENTO BINOMIAL Un experimento binomial tiene cuatro propiedades:
Propiedades de un experimento binomial
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 39
y f(y) 2 0.20
4 0.30 7 0.40
8 0.10 Total 1.00
x f(x) 0 0.01
1 0.23 2 0.41
3 0.20 4 0.10 5 0.05

Unidad Académica del Norte Estadística
1. El experimento consiste en una sucesión de n intentos o ensayos idénticos.2. En cada intento o ensayo son posibles dos resultados. A uno lo llamaremos éxito y al otro fracaso.3. La probabilidad de un éxito, representada por p, no cambia de un intento o ensayo a otro. En
consecuencia, la probabilidad de un fracaso, representada por 1 - p, no cambia de un intento a otro.4. Los intentos o ensayos son independientes.
Si existen las propiedades 2, 3 y 4, se dice que los intentos se generan mediante un proceso de Bernoulli. Si, además existe la propiedad 1, se dice que se tiene un experimento binomial. La figura 1 muestra una sucesión posible de resultados de un experimento binomial en el que intervienen ocho intentos. En este caso, hay 5 éxitos y 3 fracasos.
En un experimento binomial nos interesa la cantidad de éxitos que suceden en los n intentos. Si hacemos que x represente la cantidad de éxitos en los n intentos, vemos que x puede asumir los valores 0, 1, 2, 3,..., n. Como la cantidad de valores es finita, x es una variable aleatoria discreta. La distribución de probabilidad asociada con esa variable aleatoria se llama distribución binomial de probabilidad. Por ejemplo, veamos el experimento de lanzar una moneda cinco veces y, en cada tirada, observar si la moneda cae con el sol o el águila hacia arriba. Suponga que nos interese contar la cantidad de soles que aparece en las cinco tiradas. ¿Tiene este experimento las propiedades de un experimento binomial? ¿Cuál es la variable aleatoria de interés? Observe que:
1. El experimento consiste en cinco intentos idénticos, y cada intento implica lanzar una moneda.2. Son posibles dos resultados para cada intento: un solo sol o un águila. Podemos convenir en que sol es un
éxito y águila un fracaso.3. La probabilidad de un sol y la probabilidad de un águila son iguales para cada intento, siendo p = 0.5 y
1- p = 0.5.4. Los intentos, o lanzamientos, son independientes, porque el resultado de cualquier intento no se afecta por
lo que suceda en los demás intentos o lanzamientos.
Entonces, vemos que satisfacen las propiedades de un experimento binomial. La variable aleatoria de interés es x = la cantidad de soles en los cinco intentos. En este caso, x puede asumir los valores de 0, 1, 2, 3, 4 o 5.
Como otro ejemplo, supongamos que un vendedor de seguros visita a 10 familias seleccionadas al azar. El resultado asociado con cada visita se clasifica como un éxito si la familia compra una póliza de seguro, y como un fracaso si no lo hace. De acuerdo con la experiencia, el vendedor sabe que la probabilidad de que una familia seleccionada al azar compre una póliza de seguro es de 0.10. Al comprobar si se satisfacen las propiedades de un experimento binomial vemos que:
1. El experimento consiste en 10 intentos idénticos, y cada experimento implica llegar a una familia.2. En cada intento son posibles dos resultados: la familia compra una póliza (éxito) o la familia no la compra
(fracaso).
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 40
DIAGRAMA DE UN EXPERIMENTO BINOMIAL CON OCHO INTENTOSFigura 1
Propiedad 1: El experimento consiste en n = 8 intentos idénticosPropiedad 2: Cada intento da como resultado un éxito (s) o un fracaso (f).
Intentos 1 2 3 4 5 6 7 8
Resultados S F F S S F S S

Unidad Académica del Norte Estadística
3. Se supone que las probabilidades de una compra y de una no compra son iguales para cada llamada de ventas, siendo p = 0.10 y 1 - p = 0.90.
4. Los intentos son independientes, porque las familias se seleccionan aleatoriamente.
En vista de que se cumplieron las cuatro hipótesis, el experimento es binomial. La variable aleatoria de interés es la cantidad de ventas obtenidas al interactuar con 10 familias. En este caso, x puede asumir los valores 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 y 10.
La propiedad 3 del experimento binomial se llama supuesto de estacionariedad, y a veces se confunde con la propiedad 4, de independencia de los intentos. Para visualizar esa diferencia, pensemos de nuevo en el caso del vendedor que llama a las familias para venderles pólizas de seguro. Si al avanzar el día, el vendedor se cansó y perdió su entusiasmo, la probabilidad de éxito (vender una póliza) podría bajar a 0.05, por ejemplo, a la décima llamada. En este caso no se cumpliría la propiedad 3 (hay constancia), y no tendríamos un experimento binomial. Esto sería valido aun si se conservara la propiedad 4, esto es, las decisiones de cada familia fueron hechas independientemente.
En aplicaciones donde intervienen los experimentos binomiales se puede aplicar una fórmula matemática especial, llamada función de probabilidad binomial, para calcular la probabilidad de x éxitos en los n intentos. Con los conceptos de probabilidad que presentamos en los temas anteriores, mostraremos cómo se puede deducir la fórmula en el contexto de un problema ilustrativo.
El problema de Martín Clothing Store
Fijémonos en las decisiones de compra de los siguientes tres clientes que entran a Martín Clothing Store. Con base en su experiencia, el gerente de la tienda estima que la probabilidad de que cualquier cliente compre es de 0.30. ¿Cuál es la probabilidad de que dos de los siguientes tres clientes hagan una compra?
Recurrimos a un diagrama de árbol (figura 2) y podemos ver que el experimento de observar a los tres clientes al tomar su decisión de compra tiene ocho resultados distintos posibles. Si S representa el éxito (una compra) y F el fracaso (no compra), nos interesan los resultados experimentales donde intervienen dos éxitos en los tres intentos (decisiones de compra). A continuación comprobaremos que el experimento que implica la sucesión de tres decisiones de compra se puede considerar un experimento binomial.Al comprobar los cuatro requisitos de un experimento binomial, vemos que:
1. El experimento se puede describir como una sucesión de tres intentos idénticos, uno para cada uno de los tres clientes que entran a la tienda.
2. En cada experimento son posibles dos resultados; el cliente hace una compra (éxito) o el cliente no lo hace (fracaso).
3. La probabilidad de que el cliente haga una compra (0.30) o que no lo haga (0.70) se supone igual para todos los clientes.
4. La decisión de compra de cada cliente haga es independiente de las decisiones de los demás clientes.En consecuencia, están presentes las propiedades de un experimento binomial.
Primer Segundo Tercer Resultados Valor de x cliente cliente cliente
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 41
DIAGRAMA DE ÁRBOL PARA EL PROBLEMA DE MARTÍN CLOTHING STOREFigura 2

Unidad Académica del Norte Estadística
S (S,S,S) 3 S F (S,S,F) 2
S F S (S,F,S) 2
F (S,F,F) 1
S (F,S,S) 2
S F F (F,S,F) 1
S (F,F,S) 1
F F (F,F,F) 0
S = CompraF = No comprax = Cantidad de clientes que compran
La cantidad de resultados experimentales que dan exactamente x éxitos en n intentos se puede calcular con la siguiente fórmula.
Cantidad de resultados experimentales que dan exactamente x éxitos en n intentos
n = n ____ x x(n – x)
en donde n = n(n – 1)(n – 2)...(2)(1)
y 0 = 1
Regresaremos ahora al experimento de Martín Clothing Store donde intervienen las decisiones de compra de tres clientes. Se puede aplicar la ecuación (3) para determinar la cantidad de resultados experimentales que implican dos compras; esto es, la cantidad de maneras de obtener x = 2 éxitos en los n = 3 intentos. De acuerdo con esta misma ecuación,
n = 3 = 3 ____ = (3)(2)(1) = 6 = 3 x 2 2(3 – 2) (2)(1)(1) 2
La ecuación (3) indica que tres de los resultados producen dos éxitos. En la figura 2 vemos que esos tres éxitos se representan por SSF, SFS y FSS.
Al aplicar la ecuación (3) para determinar cuántos resultados experimentales tienen tres éxitos (compras) en los tres intentos, obtenemos:
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 42
(3)

Unidad Académica del Norte Estadística
n = 3 = 3 ____ = 3 _ = (3)(2)(1)_ = 6 = 1 x 3 3(3 – 3) 30 (3)(2)(1)(1) 6
Vemos en la figura 2 que el único resultado experimental con tres éxitos se representa con SSS.
Sabemos que la ecuación (3) se puede usar para determinar la cantidad de resultados experimentales que conducen a x éxitos. Pero si hay que determinar la probabilidad de x éxitos en n intentos, también debemos conocer la probabilidad asociada con cada uno de los resultados experimentales. Como los intentos de un experimento binomial son independientes, tan sólo con multiplicar las probabilidades asociadas con cada resultado de la prueba podemos determinar la probabilidad de una determinada serie de resultados.
La probabilidad de compras por parte de los dos primeros clientes, y de no compras por el tercer cliente es
p p (1 – p)
Con una probabilidad de 0.30 de compra en cualquier intento, la probabilidad de una compra en cada uno de los dos primeros y de no compra en el tercero es
(0.30)(0.30)(0.70) = (0.30)2(0.70) = 0.063
Las otras dos series de resultados producen dos éxitos y un fracaso. Las probabilidades de que las tres series tengan dos éxitos se muestran a continuación.
Resultados de la prueba Notación éxito-
fracaso
Probabilidad del resultado
experimentalPrimer cliente
Segundo cliente
Tercer cliente
Compra Compra No compra SSFpp(1 - p) = p2(1 - p) = (.30)2(.70) = .063
Compra No compra Compra SFSp(1 - p)p = p2(1 -p) = (.30)2(.70) = .063
No compra Compra Compra FSS(1 - p)pp= p2(1 - p) = (.30)2(.70) = .063
Observe que los tres resultados con dos éxitos tienen exactamente la misma probabilidad. Esta observación tiene validez general. En cualquier experimento binomial, todas las series de resultado que producen x éxitos en n intentos tienen la misma probabilidad de ocurrir. La probabilidad de que cada serie de intentos produzca x éxitos en n intentos es:
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 43
Probabilidad de determinadaserie de resultados con x éxitos = px (1 – p)(n – x) (4)en n intentos

Unidad Académica del Norte Estadística
Para el almacén Martín Clothing Store, esta ecuación indica que cualquiera de los resultados con dos éxitos tiene la probabilidad p2(1 – p)(3 – 2) = p2(1 – p)1 = (0.30)2(0.70)1 = 0.063, como ya se había demostrado.
Como la ecuación (3) indica la cantidad de resultados en un experimento binomial que alcanzan x éxitos, y la ecuación (4) expresa la probabilidad de cada sucesión que tiene x éxitos, combinamos las dos ecuaciones para obtener la siguiente función de probabilidad binomial.
Función de probabilidad binomial
n f(x) = x px (1 –p) (n - x) (5)
en donde
f(x) = la probabilidad de x éxitos en n intentos n = la cantidad de intentos
n n!____ x = x! (n – x)!
p = la probabilidad de un éxito en cualquier intento (1 – p) = la probabilidad de un fracaso en cualquier intento
En el ejemplo de Martín Clothing Store calcularemos la probabilidad de que ningún cliente haga una compra, la de que exactamente un cliente la haga, la de que exactamente dos clientes la hagan, y de que los tres clientes hagan una compra. Estos cálculos se resumen en la tabla 1, que da la distribución de probabilidad de la cantidad de clientes que compran. La figura 3 es una gráfica de esta distribución de probabilidad.
La función de probabilidad binomial se puede aplicar a cualquier experimento binomial. Si en un caso se satisfacen las propiedades de un experimento binomial, y si conocemos los valores de n, p y (1 – p), podemos aplicar la ecuación (5) para calcular la probabilidad de x éxitos en n intentos.
Si consideramos variantes del experimento de Martín, como 10 clientes en lugar de 3 que entran al almacén, la función de probabilidad binomial se sigue aplicando de acuerdo con la ecuación (5). Por ejemplo, la probabilidad de efectuar exactamente cuatro ventas a 10 clientes potenciales que entran a la tienda es:
10! f(4) = 4!6! (0.30)4(0.70)6 = 0.2001
Es un experimento binomial con n = 10, x = 4, y p = 0.30.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 44
Tabla 1 DISTRIBUCIÓN DE PROBABILIDAD DE LA CANTIDAD DE CLIENTES QUE COMPRAN
x
0
1
2
3
f(x)
3! (.30)0(.70)3 = .3430!3! 3! (.30)1(.70)2 = .4411!2! 3! (.30)2(.70)1 = .1892!1! 3! (.30)3(.70)0 = .0273!0! 1.000

Unidad Académica del Norte Estadística
Uso de tablas de probabilidades binomiales
Hay tablas que muestran la probabilidad de x éxitos en n intentos en un experimento binomial. Por lo general, esas tablas son más fáciles de utilizar y su aplicación es más rápida que la ecuación (5). En la tabla 2 aparece una parte de las tablas existentes. Para usar esa tabla debemos especificar los valores de n, p y x para el experimento binomial de interés. En el ejemplo de la parte superior de la tabla 2 vemos que la probabilidad de x = 3 éxitos en un experimento binomial con n = 10 y p = 0.40 es de 0.2150. Puede usted emplear la ecuación (5) para comprobar que se obtiene la misma respuesta cuando se usa directamente la función de probabilidad binomial.
VER ANEXO A: VALORES DE LA TABLA DE DISTRIBUCIÓN BINOMIAL PAG 194
A continuación emplearemos esta tabla para comprobar la probabilidad de cuatro éxitos en 10 intentos, en el problema de Martín Clothing Store. Observe que el valor de f(4) = 0.2001 se puede leer directamente de la tabla de probabilidades binomiales, con n = 10, x = 4, y p = 0.30.
Si bien las tablas de probabilidades binomiales son relativamente fáciles de usar, es imposible contar con tablas que muestren todos los valores posibles de n y p que pudieran encontrarse en une experimento binomial. Sin embargo, contando con las calculadoras actuales y aplicando la ecuación (5), no es difícil calcular la probabilidad
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 45
Con las calculadoras modernas esas tablas son casi innecesarias. Es fácil evaluar directamente la ecuación (5)
Figura 3 REPRESENTACIÓN GRÁFICA DE LA DISTRIBUCIÓN DE PROBABILIDAD EN EL PROBLEMA DE MARTÍN CLOTHING STORE
f(x)
x

Unidad Académica del Norte Estadística
que se desea, en especial si la cantidad si la cantidad de intentos no es grande. En los ejercicios el estudiante debe practicar, con la ecuación (5), el cálculo de las probabilidades binomiales, a menos que en el problema se le pida específicamente usar la tabla de probabilidad binomial. Los paquetes de programas estadísticos, como Minitab y algunas hojas de cálculo, como Excel, tiene la capacidad de calcular propiedades binomiales.
Valor esperado y varianza para la distribución binomial de probabilidad
En temas anteriores presentamos ecuaciones para calcular el valor esperado y la varianza de una variable aleatoria discreta. En el caso especial en que la variable aleatoria tiene una distribución binomial de probabilidad, con una cantidad conocida n de intentos y una probabilidad conocida p de éxito, se pueden simplificar las ecuaciones generales del valor esperado y la varianza. Los resultados son los siguientes:
Valor esperado y varianza para la distribución binomial de probabilidad
E(x) = µ = np Var(x) = σ2 = np(1 – p)
Para el problema de Martín Clothing Store con tres clientes, podemos aplicar la ecuación (6) para calcular la cantidad esperada de clientes que hacen una compra.
E(x) = np = 3(0.30) = 0.9
Supongamos que para el mes próximo, Martín Clothing Store pronostica que 1000 clientes entrarán a su tienda. ¿Cuál es la cantidad esperada de clientes que harán una compra? La respuesta es µ = np = (1000)(.3) = 300. Así, para aumentar la cantidad esperada de ventas, Martín debe inducir a más clientes a entrar a su tienda y/o aumentar la probabilidad, de alguna manera, de que cualquier cliente individual haga una compra después de entrar.
Para el problema de Martín Clothing Store con tres clientes, vemos que la varianza y la desviación estándar de la cantidad de clientes que hacen una compra son
σ2 = np(1 – p) = 3(0.30)(0.70) = 0.63 σ = 0.63 = 0.79
Para los siguientes 1000 clientes que entren a la tienda, la varianza y la desviación estándar de la cantidad de clientes que hacen una compra son:
σ2 = np(1 – p) = 1000(0.30)(0.70) = 210
σ = 210 = 14.49
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 46
(6)(7)
NOTAS: Algunas tablas binomiales muestran valores de p sólo hasta p = 0.50. Sin embargo, sí se pueden usar, si se observa que la probabilidad de n – x fracasos es también la probabilidad de x éxitos. Cuando la probabilidad de éxito es mayor que p = 0.50, se puede calcular, en su lugar, la probabilidad de n – x fracasos. La probabilidad de un fracaso, 1 – p, será menor que 0.50 cuando p > 0.50.Algunas fuentes presentan las tablas binomiales en forma acumulada. Al usar esas tablas se debe hacer una resta para determinar la probabilidad de x éxitos en n intentos. Por ejemplo, f(2) = P(x < 2) – P(x < 1). Las tablas en algunos libros se muestran directamente estas probabilidades. Para calcular las probabilidades acumuladas con este tipo de tablas, tan sólo se suman las probabilidades individuales. Por ejemplo, para calcular P(x < 2) con las tablas, se suman f(0) + f(1) + f(2).

Unidad Académica del Norte Estadística
EJERCICIOS
1. Se tiene un experimento binomial con n = 10 y p = 0.10. Emplee las tablas binomiales para responder del inciso a al d.
a. Determine f(0).b. Determine f(2).c. Determine P(x < 2).d. Determine P(x > 1).e. Determine E(x).f. Var (x) y ơ
2. La mayor cantidad de quejas de propietarios de automóviles con dos años de uso se debe al funcionamiento del sistema eléctrico (Consumer Reports 1995 Buyer’s Guide). Suponga que un cuestionario anual se manda a propietarios de más de 300 modelos y marcas de automóvil, y resulta que el 10% de los propietarios de automóviles de dos años de antigüedad han tenido problemas con los componentes del sistema eléctrico, incluyendo el motor de arranque, al alternador, la batería, los interruptores, los instrumentos, el cableado, las luces y el radio.
a. ¿Cuál es la probabilidad de que en una muestra de 12 propietarios de automóviles con dos años de uso haya exactamente dos con problemas en el sistema eléctrico?
b. ¿Cuál es la probabilidad de que en una muestra de 12 propietarios haya cuando menos dos con problemas en el sistema eléctrico?
c. ¿Cuál es la probabilidad de que en una muestra de 20 propietarios haya cuando menos uno con problemas en el sistema eléctrico?
3. Cuando una máquina nueva funciona bien, sólo el 3% de los artículos que produce tienen defectos. Suponga que se seleccionan al azar dos partes producidas en las máquinas, y que interesa la cantidad de partes defectuosa encontradas.
a. Describa las condiciones bajo las cuales este caso sería un experimento binomial.b. Trace un diagrama de árbol como el de la figura 2, que muestre un experimento binomial.c. ¿Cuántos de los resultados experimentales consisten en encontrar exactamente un defecto?d. Calcule las probabilidades asociadas con no encontrar defectos, encontrar exactamente un defecto, y dos
defectos.
4. El 5% de los camioneros en Estados Unidos son mujeres. Suponga que se seleccionan al azar 10 camioneros para una encuesta acerca de las condiciones de trabajo.
a. ¿Cuál es la probabilidad de que dos de los camioneros sean mujeres?b. ¿Cuál es la probabilidad de que al menos uno sea mujer?
5. En el libro 100% American, de Daniel Evan Weiss se informan más de 1000 resultados estadísticos acerca de Estados Unidos y su gente. Uno de los resultados dice que el 64% de las personas viven en el estado en que nacieron.
a. ¿Cuál es la probabilidad de que en una muestra aleatoria de 10 personas haya al menos ocho que vivan en el estado donde nacieron?
b. ¿Cuál es la probabilidad de que en una muestra aleatoria de tres personas haya exactamente una persona en el estado donde nació?
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 47

Unidad Académica del Norte Estadística
6. Los sistemas militares de radar y de detección de misiles deben advertir a un país de los ataques del enemigo. Una interrogante sobre su confiabilidad consiste en determinar si un sistema de detección podrá identificar un ataque y emitir una alarma. Suponga que determinado sistema de detección tiene un .90 de probabilidad de detectar un ataque con misiles. Aplique la distribución binomial de probabilidad para contestar las siguientes preguntas.
a. ¿Cuál es la probabilidad de que un solo sistema de detección descubra un ataque?b. Si se instalan dos sistemas de detección en la misma zona y funcionan independientemente, ¿cuál es la
probabilidad de que al menos uno de los sistemas advierta sobre un ataque?c. Si se instalan tres sistemas, ¿cuál es la probabilidad de que al menos uno de ellos descubra el ataque?d. ¿Recomendaría usted usar sistemas múltiples de detección? Explique su respuesta.
7. Una encuesta de la American Association of Individual Investors encontró que el 23% de sus miembros había comprado acciones directamente a través de una oferta pública inicial (OPI) (AAII Journal, julio de 1994). En una muestra de 12 miembros de la AAII.
a. ¿Cuál es la probabilidad de que exactamente tres miembros hayan comprado OPI?b. ¿Cuál es la probabilidad de que al menos un miembro haya compra OPI?c. ¿Cuál es la probabilidad de que dos o más miembros hayan comprado OPI?
8. Una universidad se enteró de que el 20% de sus alumnos se dan de baja del curso de introducción a la estadística. Suponga que en este trimestre se inscribieron 20 alumnos a ese curso.
a. ¿Cuál es la probabilidad de que dos o menos se den de baja?b. ¿Cuál es la probabilidad de que se den de baja exactamente cuatro?c. ¿Cuál es la probabilidad de que se den de baja más de tres?d. ¿Cuál es la cantidad esperada de deserciones?
DISTRIBUCIÓN DE PROBABILIDAD DE POISSON
En esta temática describiremos una variable aleatoria discreta que se usa con frecuencia para estimar la cantidad de sucesos u ocurrencias en determinado intervalo de tiempo o espacio. Por ejemplo, la variable aleatoria de interés podría ser la cantidad de llegadas a un autobaño en una hora, la cantidad de reparaciones que necesitan 10 kilómetros de carretera, o la cantidad de fugas en 100 kilómetros de oleoducto. Si se satisfacen las dos propiedades siguientes, la cantidad de ocurrencias es una variable aleatoria que se describe con la función de probabilidad de Poisson.
Propiedades de un experimento de Poisson
1. La probabilidad de una ocurrencia es igual en dos intervalos cualesquiera de igual longitud.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 48
La distribución de Poisson se utiliza frecuentemente para el modelado de tasas de llegadas en situaciones de espera en fila.

Unidad Académica del Norte Estadística
2. La ocurrencia o no ocurrencia en cualquier intervalo es independiente de la ocurrencia o no ocurrencia en cualquier otro intervalo.
La función de probabilidad de Poisson está definida por la ecuación (8).
Función de Probabilidad de Poisson
f(x) = µ x e -µ x!en donde
f(x) = probabilidad de x ocurrencias en un intervalo µ = valor esperado o cantidad promedio de ocurrencias en un intervalo e = 2.71828
Antes de pasar a un ejemplo específico para ver cómo se aplica la distribución de Poisson, observemos que no hay límite superior para x, la cantidad de ocurrencias. Es una variable aleatoria discreta que puede asumir una secuencia infinita de valores (x = 0, 1, 2, ...). La variable aleatoria de Poisson no tiene límite superior.
Ejemplo donde intervienen intervalos de tiempo
Supongamos que nos interesa la cantidad de llegadas a la ventanilla de servicio de automóvil de un banco, durante un periodo de 15 minutos en las mañanas, de los días hábiles. Si podemos suponer la probabilidad de que llegue un automóvil durante dos intervalos cualesquiera de igual longitud de tiempo, y que la llegada o no llegada en cualquier intervalo de tiempo no depende de la llegada o no llegada en cualquier otro periodo, se puede aplicar la función de probabilidad de Poisson. Suponga que se satisfacen esas hipótesis y que un análisis de datos históricos muestra que la cantidad promedio de automóviles que llega en un periodo de 15 minutos es 10; en ese caso, se aplica la siguiente función de probabilidad:
f(x) = 10 x e -10 x!
La variable aleatoria en este caso es x = la cantidad de automóviles que llegan en cualquier periodo de 15 minutos.
Si la gerencia deseara conocer la probabilidad de que hayan exactamente cinco llegadas en 15 minutos, igualaríamos x = 5 para obtener así:
Probabilidad exacta = f(5) = 10 5 e -10 = 0.03785 llegadas en 15 minutos 5!
Aunque esta probabilidad se determinó evaluando la función de probabilidad con µ = 10 y x = 5, muchas veces es más fácil consultar tablas de la distribución de probabilidades de Poisson. En esas tablas aparecen las probabilidades por valores específicos de x y µ. Por lo que una recomendación es que deberás buscar dichas tablas para consultarlas. Por comodidad, en la tabla 5.9 vemos reproducida una parte de dicha tabla. Observe que para usarla, sólo necesitamos conocer los valores de x y µ. Vemos en la tabla 5.9 que la probabilidad de 5 llegadas en un periodo de 15 minutos se determina ubicando el valor en el renglón que corresponde a x = 5 y en la columna que corresponde a µ = 10. En consecuencia, obtenemos el valor f(5) = 0.0378.
En nuestro ejemplo se calcula la probabilidad de cinco llegadas en un periodo de 15 minutos, pero se pueden usar otros intervalos de tiempo. Supongamos que deseamos calcular la probabilidad de una llegada en un
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 49
(8)

Unidad Académica del Norte Estadística
periodo de tres minutos. Como 10 es la cantidad esperada de llegadas en un intervalo de 15 minutos, vemos que 10/15 = 2/3 es la cantidad esperada de llegadas en un periodo de un minuto, y que (2/3)(3 minutos) = 2 es la cantidad esperada de llegadas en un periodo de tres minutos. Entonces, la probabilidad de x llegadas en un periodo de tres minutos con µ = 2 se expresa con la siguiente función de probabilidad de Poisson.
f(x) = 2 x e -2 x!
Para determinar la probabilidad de que haya una llegada en un periodo de tres minutos, podemos usar la tabla de la distribución de probabilidades de Poisson, o bien calcularla directamente.
Probabilidad de exactamente = f(1) = 2 1 e -2 = 0.27071 llegada en 3 minutos 1!
Ejemplo donde intervienen intervalos de longitud o distancia
Presentaremos una aplicación donde no intervienen intervalos de tiempo, pero sin embargo, la distribución de probabilidades de Poisson es útil. Supongamos que nos interesa la ocurrencia de defectos grandes en un tramo de carretera, un mes después de recubrirla. Supondremos que la probabilidad de un defecto en este tramo de carretera es igual para dos intervalos cualesquiera, de igual longitud, y que la ocurrencia o no ocurrencia de un defecto en cualquier intervalo no depende de la ocurrencia o no ocurrencia de uno en cualquier otro intervalo. En consecuencia, se puede aplicar la distribución de probabilidades de Poisson.
Supongamos que se ve que los defectos grandes, un mes después de recubrir la carretera, se presentan con una frecuencia promedio de dos por milla. Vamos a determinar la probabilidad de que no haya defectos grandes en determinado tramo de tres millas de la carretera. Como nos interesa un intervalo de tres millas de longitud, µ = (2 defectos / milla)(3 millas) = 6 representa la cantidad esperada de defectos grandes en el tramo de tres millas de carretera. Mediante la ecuación (8) o la tabla de la distribución de probabilidades de Poisson, determinamos que la probabilidad de ningún defecto grande es de 0.0025. Es decir, es muy improbable que no haya defectos grandes en el tramo de tres millas. De hecho, hay una probabilidad de 1 - 0.0025 = 0.9975 de que al menos haya un defecto grande en ese tramo.
Aproximación de Poisson a la distribución binomial de probabilidad
Se puede usar la distribución de probabilidad de Poisson como aproximación a la distribución binomial cuando p, la probabilidad de éxito, es pequeña y n, la cantidad de intentos, es grande. Tan sólo se iguala µ = np y se usan las tablas de Poisson. Como regla general, la aproximación será buena siempre y cuando p < 0.05 y n > 20.
Por ejemplo, se desea calcular la probabilidad binomial de x = 3 éxitos en n = 250 intentos, cuando p = 0.01. Para usar la aproximación de Poisson, igualamos µ = np = 250(0.01) = 2.5. Al ver las tablas de distribución de Poisson vemos que f(3) = 0.2138. Por consiguiente, diríamos que aproximadamente, la probabilidad binomial de tres éxitos es f(3) = 0.2138.
EJERCICIOS
1. Se tiene una distribución de probabilidad de Poisson con μ = 3a. Escriba la función correcta de probabilidad de Poisson.b. Calcule f(2)c. Calcule f(1)d. Calcule P (x > 2)
2. Al Departamento de Reservaciones de Aerolíneas Regionales llegan en promedio 48 llamadas por hora.M.A.C. Ing. Josué Salvador Sánchez Rodríguez 50
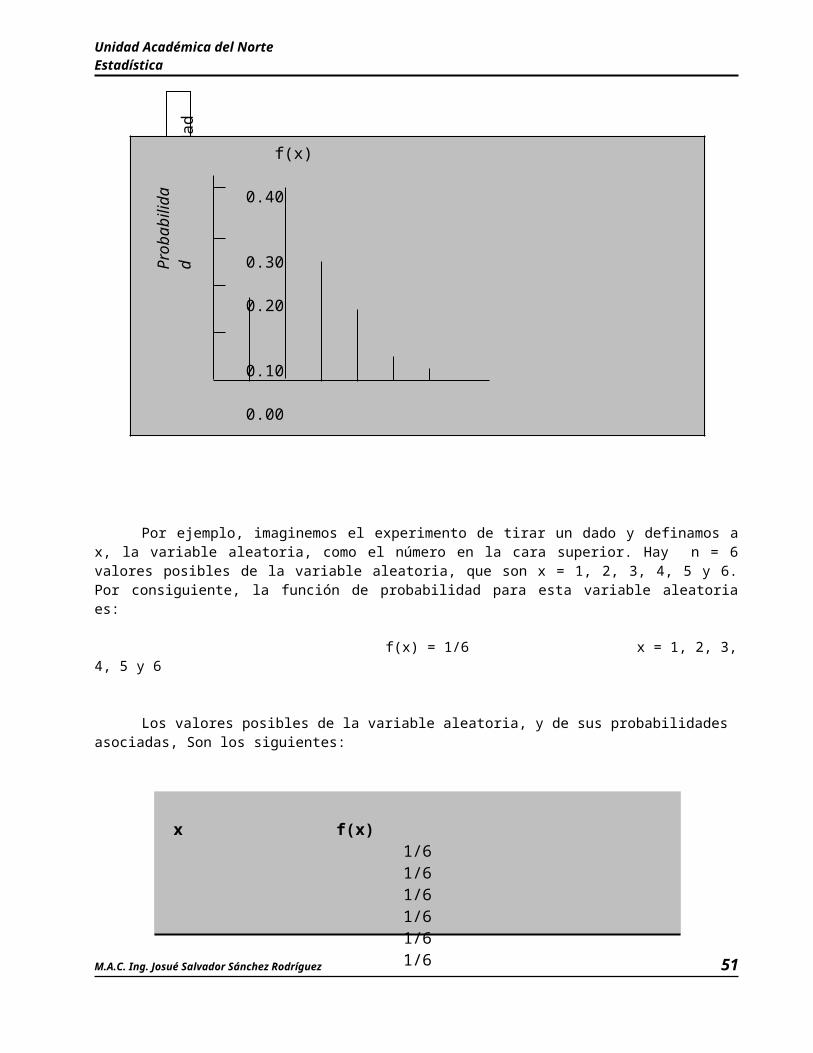
Unidad Académica del Norte Estadística
a. Calcule la probabilidad de recibir tres llamadas en un intervalo de cinco minutos.b. Calcule la probabilidad de recibir exactamente 10 llamadas en 15 minutos.c. Suponga que actualmente no hay llamadas esperando si el agente tarda cinco minutos en atender una
llamada. ¿Cuántas llamadas cree que estarán esperando cuando cuelgue la bocina? ¿Cuál es la probabilidad de que ninguna este esperando?
d. Si actualmente no hay llamadas pendientes. ¿Cuál es la probabilidad de que el agente pueda ausentarse tres minutos sin interferir con la atención a las llamadas?
3. El promedio anual de las veces de los suscriptores de Barron´s toman vuelos locales por motivos personales es 4 (Barron´s 1995 Primary Reader Survey)
a. ¿Cuál es la probabilidad de que un suscriptor tome dos vuelos locales en un año, por motivos personales?
b. ¿Cuál es la cantidad promedio de vuelos locales por motivos personales en un trimestre?c. ¿Cuál es la probabilidad de que un suscriptor tome uno o más vuelos locales, por motivos personales,
durante un semestre?
4. Durante las horas de tráfico intenso los accidentes se presentan en una zona urbana con una frecuencia de dos por hora. El periodo matutino de tráfico intenso dura una hora y 30 minutos, y el vespertino dos horas.
a. En determinado día, ¿cuál es la probabilidad de que no haya accidentes durante el periodo matutino de tráfico intenso?
b. ¿Cuál es la probabilidad de dos accidentes durante el periodo vespertino de tráfico intenso?c. ¿Cuál es la probabilidad de cuatro o más accidentes durante el periodo matutino de tráfico intenso?
5. Los pasajeros de las aerolíneas llegan al azar e independientemente a la sección de documentación en un gran aeropuerto internacional. La frecuencia promedio de llegadas es de 10 pasajeros por minuto.
a. ¿Cuál es la probabilidad de no llegadas en un intervalo de un minuto?b. ¿Cuál es la probabilidad de que lleguen tres pasajeros o menos en un intervalo de un minuto?c. ¿Cuál es la probabilidad de no llegadas en un periodo de 15 segundos?d. ¿Cuál es la probabilidad de al menos una llegada en un periodo de 15 segundos?
DISTRIBUCIÓN HIPERGEOMÉTRICA DE PROBABILIDAD
La distribución hipergeométrica de probabilidad se relaciona estrechamente con la distribución binomial. La diferencia principal entre las dos estriba en que, con la distribución hipergeométrica, los intentos no son independientes, y en que la probabilidad de éxito cambia de un intento a otro.
La notación que se acostumbra al aplicar la distribución hipergeométrica de probabilidad es que r represente la cantidad de elementos en la población de tamaño N, que se identifican como éxitos, y que N – r represente la cantidad de elementos en la población que se identifican como fracasos. La distribución hipergeométrica de probabilidad se usa para calcular la probabilidad de que, en una muestra aleatoria de n artículos, seleccionados sin reemplazo, obtengamos x elementos identificados como éxitos y n – x identificados como fracasos. Para que suceda esto debemos obtener x éxitos de los r en la población, y n – x fracasos de los N – r de la población. La siguiente función hipergeométrica de probabilidad determina f(x), la probabilidad de obtener x éxitos en una muestra de tamaño n.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 51

Unidad Académica del Norte Estadística
Función de probabilidad hipergeométrica
r N- r f(x) = x n- x para 0 < x < r
N n
en donde f(x) = probabilidad de x éxitos en n intentos
n = la cantidad de intentos N = la cantidad de elementos en la población r = cantidad de elementos identificados como éxito en la población.
NObserve que n representa la cantidad de formas en las que se puede seleccionar una muestra de tamaño n de una población de tamaño N; que r representa la cantidad de maneras en las que se pueden seleccionar x x
éxitos de un total de r éxitos de la población, y que N - r representa la cantidad de maneras en que se pueden n - xseleccionar n - x fracasos de un total de N – r fracasos en la población.
Para demostrar los cálculos implicados al usar la ecuación (9), veamos el problema de seleccionar dos miembros de comité, entre cinco, que asistan a una convención en Las Vegas. Suponga que el comité de cinco miembros está formado por tres mujeres y dos hombres. Para determinar la probabilidad de seleccionar dos mujeres al azar, podemos aplicar la ecuación (9) con n = 2, N = 5, r = 3, y x = 2.
3 2 3! 2! f(2) = 2 0 = 2!1! 2!0! = 3 = 0.30
5 5! 10 2 2!3!
Supongamos que después nos enteramos de que los que harán el viaje serán tres personas del comité. Si usamos n = 3, N = 5, r = 3, y x = 2, la probabilidad de que exactamente dos de los tres miembros sean mujeres es
3 2 3! 2! f(2) = 2 1 = 2!1! 1!1! = 6 = 0.60
5 5! 10 2 2!3!
Como otro ejemplo, supongamos que una población consiste en 10 artículos, cuatro de los cuales son defectuosos y los seis restantes son no defectuosos. ¿Cuál es la probabilidad de que una muestra aleatoria de tamaño tres contenga dos artículos defectuosos? En este caso podemos imaginar que un “éxito” consiste en obtener un artículo defectuoso. Aplicando la ecuación (9) con n = 3, N = 10, r = 4, y x = 2, podemos calcular f(2) como sigue:
4 6 4! 6! f(2) = 2 1 = 2!2! 1!5! = 36 = 0.30
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 52
(9)

Unidad Académica del Norte Estadística
10 10! 120 3 3!7!
EJERCICIOS
1. Suponga que N = 10 y r = 3. Calcule las probabilidades hipergeométricas para los siguientes valores de n y x:a. n = 4, x = 1.b. n = 2, x = 2.c. n = 2, x = 0.d. n = 4, x = 2.
2. Según la revista Beverage Digest, La Coca clásica y la Pepsi ocuparon el primero y segundo lugares en la preferencia de las personas (The Wall Street Journal Almanac, 1988). Suponga que en un grupo de 10 personas, seis prefieren Coca clásica y cuatro prefieren Pepsi. Se selecciona una muestra aleatoria de tres miembros de ese grupo.
a. ¿Cuál es la probabilidad de que exactamente dos prefieran Coca clásica?b. ¿Cuál es la probabilidad de que la mayoría (dos o tres) prefieran Pepsi?
3. Epsilon fabrica computadoras personales en dos plantas, una en el Oriente y la otra en el Sur de Estados Unidos. Hay 40 empleados en la planta del Oriente y 20 en la del Sur. A una muestra aleatoria de 10 empleados se le pedirá que llene un cuestionario sobre ventajas laborales.
a. ¿Cuál es la probabilidad de que ninguno sea de la planta del Sur?b. ¿Cuál es la probabilidad de que nueve sean de la planta del Oriente?
4. Un embarque de 10 artículos contiene dos unidades defectuosas y ocho no defectuosas. Al revisarlo, se tomará una muestra y las unidades se inspeccionarán. Si se encuentra una unidad defectuosa, se rechazará todo el embarque.
a. Si se selecciona una muestra de tres artículos, ¿cuál es la probabilidad de rechazar el embarque?b. Si se selecciona una muestra de cuatro artículos, ¿cuál es la probabilidad de rechazar el embarque?c. Si se selecciona una muestra de cinco artículos, ¿cuál es la probabilidad de rechazar el embarque?d. Si la gerencia estuviera de acuerdo en que hubiera una probabilidad de 0.90 de rechazar un embarque
con dos unidades defectuosas y ocho no defectuosas, ¿de qué tamaño se debe seleccionar la muestra?
GLOSARIO Variable aleatoria Variable aleatoria discreta Variable aleatoria continua Distribución de probabilidad Función de probabilidad Función de distribución uniforme de probabilidad discreta Valor esperado Varianza Desviación estándar Experimento binomial Distribución binomial de probabilidad Distribución de probabilidad de Poisson Distribución hipergeométrica de probabilidad Función de probabilidad binomial Función de probabilidad de Poisson
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 53

Unidad Académica del Norte Estadística
Función hipergeométrica de probabilidad
FORMULAS CLAVEFunción de probabilidad uniforme discreta
f (x) = 1/ndonde n = cantidad de valores que puede asumir la variable aleatoria
Valor esperado de una variable aleatoria discretaE(x) = µ = Σ xf(x)
Varianza de una variable aleatoria discretaVar(x) = ơ2 = ∑(x - µ)2 f(x)
Cantidad de resultados experimentales con exactamente x éxitos en n intentos n = n ____
x x(n – x)
Función de probabilidad binomial n f(x) = x px (1 –p) (n - x) Valor esperado de la distribución binomial de probabilidad
E(x) = µ = np Varianza de la distribución binomial de probabilidad
Var(x) = σ2 = np(1 – p)Función de probabilidad de Poisson
f(x) = µ x e -µ x!
Función hipergeométrica de probabilidad r N- r f(x) = x n- x para 0 < x < r N
n
DISTRIBUCIONES CONTINUAS DE PROBABILIDAD
LA DISTRIBUCIÓN UNIFORME DE PROBABILIDAD
Veamos la variable aleatoria x que representa el tiempo de vuelo de un avión que va de Chicago a Nueva York. Supongamos que el tiempo de vuelo puede ser cualquier valor en el intervalo de 120 a 140 minutos. Como la variable aleatoria x puede tomar cualquier valor en ese intervalo, x es una variable aleatoria continua y no discreta. Supongamos que hay suficientes datos reales de tiempo de vuelo para llegar a la conclusión de que la probabilidad de un tiempo de vuelo dentro de cualquier intervalo de un minuto es igual a la correspondiente dentro a otro intervalo similar dentro del rango de 120 y 140 minutos. Si cualquier intervalo de un minuto es igualmente probable, se dice que la variable aleatoria x tiene una distribución uniforme de probabilidad. La función de densidad de probabilidad, que define a la distribución uniforme de probabilidad de la variable aleatoria tiempo de vuelo es:
1/20 cuando 120 < x < 140
f(x) =
0 en cualquier otro lugar
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 54
Siempre que la probabilidad sea proporcional a la longitud del intervalo, la variable tiene distribución uniforme.
Figura 1 FUNCIÓN DE DENSIDAD DE PROBABILIDAD UNIFORME PARA EL TIEMPO DE VUELO

Unidad Académica del Norte Estadística
f(x)
1
20
x
120 125 130 135 140
Tiempo de vuelo en minutos
La figura 1 es una gráfica de esta función de densidad de probabilidad. En general, la función de densidad uniforme de probabilidad de una variable aleatoria x define la siguiente ecuación.
Función de densidad de probabilidad
1__ cuando a < x < b
f(x) = b – a
0 en cualquier otro lugar
En el ejemplo del tiempo de vuelo, a = 120 y b = 140.
La gráfica de la función f(x) de densidad de probabilidad proporciona la altura o el valor de la función en cualquier valor determinado de x. Observe que para una función de densidad de probabilidad uniforme, la altura de la función es igual para todos los valores de x. Por ejemplo, en el caso del tiempo de vuelo, f(x) = 1/20 para todos los valores de x entre 120 y 140. En general, la función f(x), de densidad de probabilidad, a diferencia de la de una variable aleatoria discreta, no representa la probabilidad. Más bien proporciona tan sólo la altura de la función en determinado valor de x.
Para una variable aleatoria continua sólo se maneja la probabilidad en términos de la posibilidad de que una variable aleatoria tenga un valor dentro de un intervalo especificado. En el ejemplo del tiempo de vuelo, una pregunta válida, desde el punto de vista de probabilidades, es:¿cuál es la probabilidad de que el tiempo de vuelo sea entre 120 y 130 minutos? Esto es, ¿cuál es P(120< x < 130)? Como el tiempo de vuelo debe estar entre 120 y 140 minutos, y como la probabilidad se describe como uniforme en este intervalo, decimos que P(120< x <130) = 0.50. En la siguiente subsección demostraremos que esta probabilidad se puede calcular como el área de la gráfica de f(x) de 120 a 130.
El área como medida de probabilidad
Hagamos una observación acerca de la gráfica en la figura 2. Veamos el área bajo la gráfica de f(x) en el intervalo de 120 a 130. La región es rectangular, y el área de un rectángulo tan sólo es igual al ancho multiplicado por la altura. Si el ancho del intervalo es igual a 130 – 120 = 10 y la altura es igual al valor de la función de densidad de probabilidad f(x) = 1/20, entonces área = ancho x alto = 10(1/20) = 10/20 = 0.50.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 55
(10)

Unidad Académica del Norte Estadística
f(x) P(120 < x < 130) = Área = 1/20(10) = 10/20 = 0.50
1
20
120 125 130 135 140 x
Tiempo de vuelo en minutos
¿Qué observación puede hacer el lector acerca del área bajo la gráfica de f(x) y la probabilidad? ¡Son idénticas! En realidad esto es válido para todas las variables aleatorias continuas. Una vez identificada una función f(x) de densidad de probabilidad, la probabilidad de que x tome un valor intermedio entre algún valor inferior x 1 y otro superior x2 se puede determinar calculando el área bajo la gráfica de f(x) en el intervalo de x1 a x2.
Una vez que sabemos cuál es la distribución adecuada de probabilidad, y que es aceptada la interpretación del área como probabilidad, podemos contestar cualquier interrogante acerca de probabilidades. Por ejemplo, ¿cuál es la probabilidad de que el tiempo de vuelo esté entre 128 y 136 minutos? El ancho del intervalo es de 136 – 128 = 8. Con la altura uniforme de 1/20, vemos que P(128< x <136) = 8(1/20) = 0.40.
Observe que P(120< x <140) = 20(1/20) = 1. Esto es, el área total bajo la gráfica de f(x) es igual a 1. Esta propiedad es válida para todas las distribuciones continuas de probabilidad, y es el análogo de la condición que la suma de las probabilidades debe ser igual a 1 para una función de probabilidad discreta. Para una función continua de densidad de probabilidad también se requiere que f(x)>0 para las funciones discretas de probabilidad.
Hay dos diferencias principales entre el manejo de las variables aleatorias continuas y el de sus contrapartes las variables discretas.
1. Ya no se habla de la probabilidad de que la variable aleatoria tome determinado valor. En su lugar se habla de la probabilidad de que la variable aleatoria asuma un valor dentro de cierto intervalo dado.
2. La probabilidad de que la variable aleatoria tome un valor dentro de determinado intervalo dado de x1 a x2 se define como el área bajo la gráfica de la función de densidad de probabilidad entre x1 y x2. Esto implica que la probabilidad de que la variable aleatoria continua asuma exactamente determinado valor es cero, porque el área bajo la gráfica de f(x) en un solo punto es cero.
El cálculo del valor esperado y la varianza para una variable aleatoria continua es análogo al de una variable aleatoria discreta. Sin embargo, como el procedimiento de determinación interviene el cálculo integral, dejaremos la deducción de las ecuaciones para textos más avanzados.
Para la distribución continua uniforme de probabilidades que presentamos en esta temática, las ecuaciones para el valor esperado y la varianza son:
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 56
Figura 2 EL ÁREA ES LA PROBABILIDAD DE QUE EL TIEMPO DE VUELO ESTÉ ENTRE 120 Y 130 MINUTOS
10

Unidad Académica del Norte Estadística
E(x) = a + b 2
Var(x) = (b – a) 2 12
Aquí a es el valor mínimo y b el máximo que puede tomar la variable aleatoria.
Al aplicar esas ecuaciones a la distribución uniforme de probabilidades de los tiempos de vuelo entre Chicago y Nueva York obtenemos:
E(x) = (120 + 140) = 130 2
Var(x) = (140 – 120) 2 = 33.33 12
La desviación estándar de los tiempos de vuelo se calcula sacando la raíz cuadrada de la varianza. Por consiguiente, σ = 5.77 minutos.
EJERCICIOS
1. Se sabe que la variable aleatoria x está uniformemente distribuida entre 10 y 20.a) Trace la gráfica de la función de densidad de probabilidad.b) Determine P(x < 15).c) Determine P(12 < x < 18).d) Determine E(x).e) Determine Var(x).
2. Delta Airlines cita un tiempo de vuelo de 2 horas 5 minutos de Cincinnati a Tampa. Suponiendo que los tiempos reales de vuelo se distribuyen uniformemente entre 2 horas y 2 horas 20 minutos.
a) Trace la gráfica de la función de densidad de probabilidad de los tiempos de vuelo.b) ¿Cuál es la probabilidad de que el vuelo no llegue más de cinco minutos tarde?c) ¿Cuál es la probabilidad de que el vuelo llegue más de 10 minutos tarde?d) ¿Cuál es el tiempo esperado de vuelo?
3. La mayoría de los lenguajes de cómputo tienen una función para generar números aleatorios. En Excel, de Microsoft, se usa la función ALEATORIO para generar números aleatorios entre 0 y 1. Si x representa el número aleatorio generado, debe ser una variable continua con la siguiente función de densidad de probabilidad: 1 cuando 0 < x < 1 f(x) =
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 57
Para visualizar que la probabilidad de cualquier punto único es 0, véase la figura 2 y calcule la probabilidad en determinado punto, por ejemplo, x = 125.P(x = 125) = P(125< x <125) = 0(1/20) = 0.
NOTAS: 1. Ya que para una variable continua la probabilidad de determinado valor es cero, P(a< x <b) = P(a< x <b). Esta ecuación indica que la probabilidad de que una variable aleatoria asuma un valor en cualquier intervalo es igual, estén incluidos o no los extremos del intervalo.2. Para ver con más claridad por qué la altura de una función de densidad de probabilidad no es una probabilidad, imaginemos una variable aleatoria con la siguiente distribución uniforme de probabilidad.
2 cuando 0< x < 0.5 f(x) =
0 en cualquier otro lugar
La altura de la función de densidad de probabilidad es 2 para valores de x entre 0 y 0.5. Sin embargo, sabemos que las probabilidades nunca pueden ser mayores que uno.

Unidad Académica del Norte Estadística
0 en cualquier otro lugar
a) Grafique la función de densidad de probabilidad.b) ¿Cuál es la probabilidad de generar un número aleatorio entre 0.25 y 0.75?c) ¿Cuál es la probabilidad de generar un número aleatorio con valor menor o igual a 0.30?d) ¿Cuál es la probabilidad de generar un número aleatorio con valor mayor que 0.60?
4. La etiqueta de una botella de detergente líquido indica que el contenido es de 12 onzas. En las operaciones de producción se llenan las botellas uniformemente, de acuerdo con la siguiente función de densidad de probabilidad. 8 cuando 11.975 < x < 12.10 f(x) =
0 en cualquier otro lugar
a) ¿Cuál es la probabilidad de que una botella sea llenada con un peso entre 12 y 12.05 onzas?b) ¿Cuál es la probabilidad de que la una botella sea llenada con un peso de 12.02 onzas o más?c) El departamento de control de calidad acepta botellas con un peso de llenado con una desviación hasta
de 0.02 onzas respecto al contenido mencionado en la etiqueta. ¿Cuál es la probabilidad de que una botella de este detergente líquido no pueda cumplir con la norma de control de calidad?
CUESTIONARIO
1. ¿Cuáles son las características de una distribución normal?2. ¿Cómo se comporta la distribución normal al variar la desviación estándar?3. ¿Cómo determinamos la probabilidad de la variable aleatoria normal?4. ¿Cuáles son las diferencias de las distribuciones uniforme y normal para efectos de calcular probabilidades?5. ¿Cómo se considera los valores de µ y σ para que una variable aleatoria tenga distribución normal estándar de
probabilidad?6. ¿Qué letra representa la variable aleatoria normal especial o estándar?
LA DISTRIBUCIÓN NORMAL DE PROBABILIDAD
Quizá la distribución más importante de probabilidad para describir una variable aleatoria continua sea la distribución normal de probabilidad. Se ha usado en una gran variedad de aplicaciones prácticas en las que las variables aleatorias son altura y peso de personas, coeficientes de inteligencia, mediciones científicas, precipitaciones, etc. Para usar esta distribución de probabilidad se requiere que la variable aleatoria sea continua. Sin embargo, como veremos más delante, una variable aleatoria continua y normal se puede usar como aproximación en casos en los que intervienen variables aleatorias discretas.
La curva normal
La forma de la distribución normal de probabilidad es la curva acampanada de la figura 1. La función de densidad de probabilidad que la define es la siguiente.
Función de densidad normal de probabilidad
f(x) = 1 e -(x - µ)² / 2ơ ²
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 58
Abraham de Moivre matemático francés, publicó la doctrina de las probabilidades en 1733. Dedujo la distribución normal de probabilidad

Unidad Académica del Norte Estadística
2π ơ (11)
en donde µ = promedio ơ = desviación estándar π = 3.14159 e = 2.71828
Hay ciertas observaciones por hacer acerca de las características de la distribución normal de probabilidad.
1. Hay toda una familia de distribuciones normales de probabilidad. Cada distribución normal específica se distingue por su media µ y su desviación estándar ơ.
2. El punto más alto de la curva normal es la media, que también es la mediana y la moda de la distribución.
3. La media de la distribución puede ser cualquier valor numérico: negativo, cero o positivo. A continuación vemos tres curvas normales con la misma desviación estándar, pero con tres medias distintas (-10, 0, y 20).
x
-10 0 20
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 59
Figura 1 CURVA ACAMPANADA DE LA DISTRIBUCIÓN DE PROBABILIDAD NORMAL
Desviación estándar ơ
xµ
Promedio
La curva normal tiene dos parámetros: µ y ơDeterminan el lugar y la forma de la distribución.

Unidad Académica del Norte Estadística
4. La distribución normal de probabilidad es simétrica, y su forma a la izquierda de la media es una imagen especular de la forma a la derecha de la media. Las colas, es decir, los extremos o los lados de la curva se prolongan al infinito en ambas direcciones y, teóricamente, nunca tocan al eje horizontal.
5. La desviación estándar determina el ancho de la curva. A valores mayores de la desviación estándar se tienen curvas más anchas y bajas, que muestran una mayor dispersión en los datos. A continuación vemos dos distribuciones normales con el mismo promedio, pero con distintas desviaciones estándar.
ơ = 5
ơ = 10
x µ
6. El área total bajo la curva de la distribución normal de probabilidad es 1. Esto es válido para todas las distribuciones continúas de probabilidad.
99.72%
95.44%
68.26%
x
µ - 3ơ µ - 1ơ µ µ + 1ơ µ + 3ơ
µ - 2ơ µ + 2ơ
7. La probabilidad de la variable aleatoria normal se determinan con las áreas bajo la curva. Las probabilidades de ciertos intervalos que más se usan son:
a. El 68.26% de las veces, una variable aleatoria normal asume una valor entre más o menos una desviación estándar respecto a su media.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 60
Figura 2 ÁREAS BAJO LA CURVA DE CUALQUIER DISTRIBUCIÓN DE PROBABILIDAD NORMAL

Unidad Académica del Norte Estadística
b. El 95.44% de las veces, una variable aleatoria normal toma un valor entre más o menos dos desviaciones estándar respecto a su media.
c. El 99.72% de las veces, una variable aleatoria normal asume un valor entre más o menos tres desviaciones estándar respecto a su media. En la figura 2 se representan gráficamente las propiedades de los incisos a, b y c.
La distribución estándar de probabilidad
Se dice que una variable aleatoria que tiene una distribución normal con media cero y desviación estándar uno tiene distribución normal estándar de probabilidad. Casi siempre se usa la letra z para indicar esta variable aleatoria normal especial. La figura 3 representa la gráfica de este tipo de distribución. Tiene el mismo aspecto general que otras distribuciones normales, pero con las propiedades especiales de µ = 0 y ơ = 1.
ơ = 1
0 z
Como con otras variables aleatorias continuas, los cálculos de probabilidad con cualquier distribución normal se lleva a cabo determinando las áreas bajo la gráfica de la función de densidad de probabilidad. Así, para determinar la probabilidad de que una variable aleatoria normal esté dentro de un intervalo específico, debemos calcular el área bajo la curva normal en ese intervalo. Para la distribución normal estándar de probabilidad se han determinado las áreas bajo la curva normal, y se muestran en tablas que se pueden usar par calcular probabilidades.
Para conocer el empleo de la tabla de áreas bajo la curva de la distribución normal estándar (véase la tabla 6.1) en la determinación de probabilidades, analicemos algunos ejemplos. Después veremos cómo se puede usar esa misma tabla para calcular las probabilidades de cualquier distribución normal. Empezaremos demostrando cómo se puede calcular la probabilidad de que el valor z, para la variable aleatoria normal estándar, quede entre 0.00 y 1.00, esto es, P(0.00< z <1.00). La parte sombreada de la siguiente gráfica muestra esa área, o probabilidad.
P(0.00 < z < 1.00)
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 61
Estos porcentajes son la base de la regla empírica.
Para la distribución uniforme, la altura de la función de densidad de probabilidad es constante, y por eso es fácil calcular el área bajo la curva. En el caso de la función de densidad de probabilidad normal, la altura varía y se requiere de cálculo infinitesimal para calcular las áreas que representan la probabilidad. La tabla 6.1 se elaboró recurriendo al cálculo integral.
Figura 3 6.5
LA DISTRIBUCIÓN DE PROBABILIDAD NORMAL ESTÁNDAR

Unidad Académica del Norte Estadística
z
0 1
Los elementos de la tabla 6.1 proporcionan el área bajo la curva normal estándar entre la media, z = 0, y el valor positivo correspondiente de z (véase la gráfica en la parte superior de la tabla). En este caso nos interesa el área entre z = 0 y z = 1.00. Por lo tanto, debemos encontrar el elemento de la tabla que corresponde a z = 1.00. Para hacerlo, primero localizamos 1.0 en la columna izquierda de la tabla, y después localizamos a .00 en el renglón superior. Buscando en el interior de la tabla, vemos que el renglón de 1.0 y la columna de .00 se intersecan en el valor 0.3413. Hemos determinado la probabilidad que buscábamos: P(.00< z <1.00 ) = 0.3413. A continuación vemos una parte de esa tabla, donde se indica el procedimiento.
Z .00 .01 .02... .9 .3159 .3186 .32121.0 .3413 .3438 .34611.1 .3643 .3665 .36861.2 .3849 .3869 .3888...
P (.00 < z < 1.00)
Siguiendo el mismo método podemos determinar P(.00< z <1.25). Primero encontramos el renglón de 1.2, y después avanzamos por él hasta la columna de .05, y encontramos que P(.00< z <1.25) = .3944.
Como otro ejemplo del empleo de la tabla de áreas para la distribución normal estándar, calcularemos la probabilidad de obtener un valor z entre z = -1.00 y z = 1.00; esto es, P(-1.00< z <1.00).
Recuerde que ya hemos usado la tabla para demostrar que la probabilidad de un valor de z entre z = .00 y z = 1.00 es .3413, y también que la distribución normal de probabilidades es simétrica. Así, la probabilidad de un valor de z entre z =.00 y z = -1.00 es la misma probabilidad de un valor de z entre z = -1.00 y z = +1.00 es:
P(-1.00< z <.00) + P(.00< z <1.00) = .3413 + .3413 = .6826
En la siguiente figura vemos gráficamente esta área.
P(-1.00 < z < .00) = .3413 P(.00 < z < 1.00) = .3413
P(-1.00 < z < 1.00) = .6826
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 62

Unidad Académica del Norte Estadística
z
-3 -2 -1 0 +1 +2 +3
Del mismo modo podemos usar los valores de la tabla 6.1 para demostrar que la probabilidad de un valor z entre –2.00 y +2.00 es .4772 +.4772 = .9544 y que la de un valor de z entre –3.00 y +3.00 es .4986 + .4986 = .9972. Como sabemos que la probabilidad total, o área total bajo la curva, de cualquier variable aleatoria continua debe ser 1.0000, la probabilidad .9972 nos dice que el valor de z estará casi siempre entre –3.00 y +3.00.
A continuación calcularemos la probabilidad de obtener un valor mínimo de z de 1.58; esto es, P(z>1.58). Comenzamos en el renglón z = 1.5 y la columna .08 de la tabla 6.1, para encontrar que P(.00< z <1.58) = .4429. A continuación, como la distribución normal de probabilidades es simétrica, y el área total es igual a 1, sabemos que el 50% del área debe estar arriba del promedio (es decir, de z = 0) y el 50% abajo del promedio. Como .4429 es el área entre el promedio y z = 1.58, el área de probabilidad corresponde a z > 1.58 debe ser .5000 - .4429 = .0571. La siguiente figura muestra esta probabilidad.
.5000 del área total
.5000 del área total es mayor que z = .00
está debajo de z = .00
.4429 es el área entre
z = .00 y z = 1.58 P(z > 1.58)
= .5000 - .4429 = .0571
-3 -2 -1 0 +1 +2 +3
Otro ejemplo: determinemos la probabilidad de que la variable aleatoria z asuma un valor de -.50 o mayor, esto es, P(z > -.50). Para este cálculo observamos que la probabilidad que buscamos se puede escribir en forma de la suma de dos probabilidades: P(z > - .50) = P(-.50 < z < .00) + P(z > 0.00). Ya vimos antes que P(z > .00) = .50. También sabemos que, como la distribución normal es simétrica, P(-.50 < z < .00) = P(.00 < z <.50). Al consultar la tabla 6.1 vemos que P(.00<z<.50) = .1915. Por consiguiente, P(z>-.50) = .1915 + .5000 = .6915. La siguiente gráfica muestra esta área.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 63

Unidad Académica del Norte Estadística
P(-.50 < z < .00) = .1915
P(z > .00) = .50
El área total sombreada es P(z > .50) = .6915
z
-3 -2 -1 0 +1 +2 +3
Ahora calcularemos la probabilidad de obtener un valor de z entre 1.00 y 1.58; esto es, P(1.00< z <1.58). De acuerdo con los ejemplos anteriores, sabemos que hay una probabilidad de .3413 de un valor entre z = 0.00 y z = 1.00 y que hay una probabilidad de .4429 de un valor entre z = 0.00 y z = 1.58. Por consiguiente, debe haber una probabilidad de .4429 - .3413 = .1016 de un valor entre z = 1.00 y z = 1.58. Es decir, P(1.00 < z < 1.58) = .1016. La presentación gráfica aparece en la siguiente figura.
El área entre la media
y z = 1.58 es .4429
El área entre la media
y z = 1.00 es .3413
El área entre z = 1.00 y z = 1.58 es
.4429 - .3413 = .1016
-3 -2 -1 0 +1 +2 +3 z
VER ANEXO B: ÁREAS O PROBABILIDADES, PARA LA DISTRIBUCIÓN ESTÁNDAR NORMAL PAG 226
Como ejemplo final determinaremos un valor de z tal que la probabilidad de obtener uno mayor sólo sea .10. En la siguiente figura vemos representado este caso.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 64

Unidad Académica del Norte Estadística
Probabilidad o área .10
-3 -2 -1 0 +1 +2 +3 z
¿Cuál es el valor de z?
Este problema es el inverso de los ejemplos anteriores. Antes especificábamos el valor de z que nos interesaba, para después determinar la probabilidad o área correspondiente. En este ejemplo el dato es la probabilidad o área, y se nos pide determinar el valor correspondiente de z. Para hacerlo usamos la tabla de áreas para la distribución normal estándar de probabilidad (tabla 6.1), en forma algo distinta.
Recordamos que en el cuerpo de la tabla 6.1 aparece el área bajo la curva, entre la media y determinado valor de z. Contamos con la información que el área en la cola derecha (o superior) de la curva es .10. En consecuencia, debemos determinar cuánto del área está entre la media y el valor de z que nos interesa. Como sabemos que .5000 del área está arriba de la media, .5000 - .1000 = .4000 debe ser el área bajo la curva entre la media y el valor deseado de z. Al buscar en el cuerpo de la tabla encontramos que .3997 es el valor de probabilidad que más se acerca a .4000. A continuación vemos la sección de la tabla donde aparece este resultado.
Z .06 .07 .08 .09...1.0 .3554 .3577 .3599 .36211.1 .3770 .3790 .3810 .38301.2 .3962 .3980 .3997 .40151.3 .4131 .4147 .4162 .41771.4 .4279 .4292 .4306 .4319.. Valor del área en la
tabla. más cercano a .4000
Al leer el valor de z desde la columna de la izquierda y el renglón superior de la tabla, vemos que ese valor es 1.28. Así, habrá un área aproximada de .4000 (en realidad, .3997) entre el promedio y z = 1.28. En términos de lo que originalmente se preguntó, hay una probabilidad aproximada de .10 de que el valor de z sea mayor que 1.28.
Los ejemplos demuestran que se puede usar la tabla de áreas de la distribución normal estándar de probabilidad, para determinar las probabilidades asociadas con los valores de la variable aleatoria normal estándar z. Pueden surgir dos tipos de preguntas. El primero especifica uno o más valores de z y pide determinar las áreas o probabilidades correspondientes por medio de la tabla. El segundo cita un área o probabilidad y pide determinar el valor correspondiente de z, mediante la tabla. Así, necesitamos ser flexibles al usar la tabla de distribución normal estándar de probabilidad para contestar la duda específica. En la mayoría de los casos es útil trazar una gráfica de
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 65

Unidad Académica del Norte Estadística
esta distribución, sombreando el área o la probabilidad que se trate, para visualizar el caso correspondiente y así obtener la respuesta correcta.
Determinación de probabilidades para cualquier distribución normal
La razón de haber descrito con tanto detalle la distribución normal estándar es que todas las probabilidades de todas las distribuciones normales se determinan con la distribución normal estándar. Esto es, cuando nos encontramos con una distribución normal con media µ y desviación estándar ơ, resolvemos las siguientes interrogantes acerca de su distribución convirtiéndola primero a una distribución normal estándar. A continuación podemos usar la tabla 6.1 y los valores adecuados de z para determinar las probabilidades deseadas. La fórmula que se usa para pasar de cualquier variable aleatoria normal x, con media µ y desviación estándar ơ, a la distribución normal estándar es la siguiente.
Conversión a la distribución normal estándar z = x - µ ơ
Un valor de x igual a su media µ da como resultado z = (µ -µ)/ơ = 0. Vemos entonces que un valor de x igual a su media µ corresponde a un valor de z en su media 0. Supongamos ahora que x está a una desviación estándar arriba de su media; esto es, que, x = µ + ơ. Al aplicar la ecuación (12), vemos que el valor correspondiente de z es z = [( µ + ơ) - µ]/ơ = ơ/ơ = 1. Por consiguiente, un valor que está a una desviación estándar arriba de su media da como resultado z = 1.En otras palabras, podemos interpretar a z como la cantidad de desviaciones estándar que la variable aleatoria x se aleja de su promedio µ.
Para ver cómo esta conversión nos permite calcular las probabilidades de cualquier distribución normal, supongamos que cierta distribución tiene µ = 10 y ơ = 2. ¿Cuál es la probabilidad de que la variable aleatoria x esté entre 10 y 14? Aplicando la ecuación (12), tenemos que cuando x = 10, z = (x - µ)/ơ = (10 – 10)/2 = 0 y que cuando x = 14, z = (14 – 10)/2 = 4/2 = 2. Así, la respuesta a nuestra pregunta sobre que la probabilidad de que x esté entre 10 y 14 queda determinada por la probabilidad equivalente de que z esté entre 0 y 2 en la distribución normal estándar. En otras palabras, la probabilidad que buscamos es la de que la variable aleatoria x esté entre su media y dos desviaciones estándar arriba de la media. Si usamos z = 2.00 en la tabla 6.1, vemos que esa probabilidad es .4772. En consecuencia, la probabilidad de que x esté entre 10 y 14 es .4772.
El problema de Grear Tire Company
El siguiente caso es un ejemplo de aplicación de la distribución normal de probabilidad. La empresa Grear Tire Company acaba de desarrollar un neumático radial con banda de acero que venderá a través de una cadena nacional de tiendas de descuento. Como ese neumático es producto nuevo, la dirección de Grear cree que la garantía de millas recorridas que se ofrece con el neumático será un factor importante en la aceptación. Antes de formalizar esa política, la dirección desea contar con información acerca de las millas que duran los neumáticos.
En pruebas reales en carretera, el grupo de ingeniería de Grear ha estimado que el promedio de distancia recorrida es µ = 36,500 millas, y que la desviación estándar es ơ = 5000. Además, los datos reunidos indican que la adopción de la distribución normal es una hipótesis razonable. ¿Qué porcentaje de neumáticos se puede esperar que duren más de 40,000 millas? En otras palabras, ¿cuál es la probabilidad de que las millas recorridas rebasen las 40,000? Esta duda se puede resolver determinando el área de la región sombreada en la figura 4.
Cuando x = 40,000, tenemos que z = x - µ = 40,000 – 36,500 = 3500 = .70
ơ 5000 5000
Veamos la parte inferior de la figura 4. Un valor de x = 40,000 en la distribución normal de Grear Tire corresponde a un valor de z = .70 en la distribución normal estándar. Al emplear la tabla 6.1 vemos que el área entre el promedio y z = .70 es .2580. En la figura 4, además, vemos que el área entre x = 36,500 y x = 40,000 en la M.A.C. Ing. Josué Salvador Sánchez Rodríguez 66
(12)

Unidad Académica del Norte Estadística
distribución normal de Grear Tire también es de .2580. Así, .5000 - .2580 = .2420 es la probabilidad de que x sea mayor que 40,000. Podemos concluir que un 24.2% de los neumáticos durarán más de 40,000 millas.
ơ = 5000
P(x > 40,000) = ?
x
40,000 µ = 36,500
z 0 .70
Nota: z = 0 corresponde Nota: z = .70 corresponde a x = µ = 36,500 a x = 40,000
Ahora supongamos que Grear planea una garantía según la cual el usuario recibirá un descuento en sus neumáticos de repuesto si los neumáticos originales no rebasan la distancia en millas especificada en la garantía.
¿Cuáles deben ser las millas recorridas para que no haya más de 10% de los neumáticos que aprovechen el descuento de la garantía? Esta pregunta se interpreta gráficamente en la figura 5.
Según esa misma figura, el 40% del área debe estar entre la media y las millas recorridas, según la garantía, que por el momento se desconocen. Buscamos .4000 en el cuerpo de la tabla 6.1 y vemos que esa área está aproximadamente a 1.28 desviaciones estándar abajo de la media. Esto es, z = - 1.28 es el valor de la variable aleatoria normal que corresponde a la garantía deseada de millas recorridas en la distribución normal para Grear Tire. Para calcular x, la distancia recorrida que corresponde a z = -1.28, hacemos lo siguiente:
z = x - µ = -1.28 ơ
x - µ = -1.28ơ
x = µ - 1.28ơ
o sea que µ = 36,500 y ơ = 5000, x = 36,500 – 1.28(5000) = 30,100
En consecuencia, una garantía de 30,100 millas cumplirá con el requisito de que aproximadamente el 10% de los neumáticos sean elegibles para aprovechar la garantía. Quizá con esta información la empresa establezca en 30,000 su garantía de millas recorridas.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 67
Figura 4 DISTRIBUCIÓN DELA DURACIÓN, EN MILLAS, DE LOS NEUMÁTICOS DE GREAR TIRE COMPANY

Unidad Académica del Norte Estadística
Vemos nuevamente el papel importante que desempeñan las distribuciones de probabilidad para obtener información en la toma de decisiones. Una vez establecida una distribución de probabilidad para determinada aplicación, se puede emplear con rapidez y facilidad para obtener información acerca del problema. Las probabilidades no establecen directamente una recomendación para la decisión, sino que producen información que ayuda, a quien toma las decisiones, a comprender mejor los riesgos e incertidumbre relacionados con el problema. En último término, esta información puede ayudar a que quien toma decisiones se decida por una buena opción.
ơ = 5000
El 10% de los neumáticos califican
para la garantía del descuento
x
Duración bajo la garantía en millas = ? µ = 36,500
EJERCICIOS
1. Con la figura 2 como guía, trace una curva normal para una variable aleatoria x que tiene media µ = 100 y desviación estándar σ = 10. Indique los valores 70, 80, 90, 100, 110, 120 y 130 en el eje horizontal.
2. Si z es una variable aleatoria normal estándar, trace su curva normal. Indique los valores -3, -2, -1, 0, 1, 2, y 3 en el eje horizontal. A continuación use la tabla de probabilidades de la distribución normal estándar para determinar las probabilidades siguientes:
a) P(0 < z < 1)b) P(0 < z < 1.5)c) P(0 < z < 2)d) P(0 < z < 2.5)
3. Si z es una variable aleatoria normal estándar, determine las probabilidades siguientes:a) P(0 < z < .83)b) P(-1.57 < z < 0)c) P(z > .44)d) P(z > -.23)e) P(z < 1.20)f) P(z < -.71)
4. Si z es una variable aleatoria normal estándar, determine z en cada caso.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 68
Figura 5 LA GARANTÍA DE DESCUENTO DE GREAR

Unidad Académica del Norte Estadística
a) El área entre 0 y z es .4750.b) El área entre 0 y z es .2291.c) El área a la derecha de z es .1314.d) El área a la izquierda de z es .6700.
5. El tiempo promedio que emplea un suscriptor de The Wall Street Journal en leer esa publicación es de 49 minutos (The Wall Street Journal Estudio de Suscriptores, 1996). Suponga que la desviación estándar es de 16 minutos, y que los tiempos de lectura tienen distribución normal.
a) ¿Cuál es la probabilidad de que un suscriptor tarde cuando menos 1 hora en leer la publicación?b) ¿Cuál es la probabilidad de que un suscriptor no tarde más de 30 minutos en leerla?c) ¿Cuál es el intervalo de tiempo de lectura en el que el 10% de los lectores tardan más leyéndola?
6. Durante los últimos años ha crecido el volumen de acciones negociadas en la Bolsa de Nueva York. Durante las dos primeras semanas de enero de 1998, el volumen diario promedio fue de 646 millones de acciones (Barron’s enero de 1998). La distribución de probabilidad del volumen diario es aproximadamente normal, con desviación estándar de unos 100 millones de acciones.
a) ¿Cuál es la probabilidad de que el volumen negociado sea menor de 400 millones de acciones?b) ¿Qué porcentaje de las veces el volumen negociado es mayor de 800 millones de acciones?c) Si la Bolsa quiere emitir un boletín de prensa sobre el 5% de los días más activos, ¿qué volumen activará
la publicación?
7. Los chóferes miembros del Sindicato de Traileros ganan un salario promedio de $17.15 dólares por hora (U.S. News World Report, 11 de abril de 1994). Suponga que los datos disponibles indican que los sueldos se distribuyen normalmente con desviación estándar de $2.25 dólares.
a) ¿Cuál es la probabilidad de que los salarios estén entre $15.00 y $20.00 dólares por hora?b) ¿Cuál es el salario por hora correspondiente al 15% mejor pagado de los chóferes del Sindicato?c) ¿Cuál es la probabilidad de que los sueldos sean menores de $12.00 dólares por hora?
8. La edad promedio que tiene una persona al casarse por primera vez es de 26 años (U.S. News World Report, 6 de junio de 1994). Suponga que las edades en el primer casamiento tienen una distribución normal, con desviación estándar de 4 años.
a) ¿Cuál es la probabilidad de que una persona que se casa por primera vez tenga menos de 23 años de edad?
b) ¿Cuál es la probabilidad de que una persona que se casa por primera vez tenga entre 20 y 30 años de edad?
c) El 90% de las personas que se casan por primera vez, ¿a que edad lo hacen?
9 Mensa es una asociación internacional de personas con alto coeficiente intelectual. Para pertenecer a ella, una persona debe tener un coeficiente de 132 o más alto (USA Today, 13 de febrero de 1992). Si las calificaciones del coeficiente de inteligencia se distribuyen normalmente con promedio 100 y desviación estándar 15, ¿qué porcentaje de las personas califica para ser miembro de Mensa?
10 El tiempo necesario para terminar un examen final en determinado curso se distribuye normalmente con 80 minutos de media y 10 minutos de desviación estándar. Con estos datos conteste lo siguiente:
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 69

Unidad Académica del Norte Estadística
a. ¿Cuál es la probabilidad de terminar el examen en una hora o menos?b. ¿Cuál es la probabilidad de que un alumno termine el examen en más de 60 minutos, pero en
menos de 75 minutos?c. Suponga que en el grupo hay 60 alumnos, y que el tiempo del examen es de 90 minutos. ¿Cuántos
alumnos espera que no puedan terminar el examen en el tiempo indicado?
APROXIMACIÓN NORMAL A LA DISTRIBUCIÓN BINOMIAL
Anteriormente presentamos la distribución binomial de probabilidad. Recordamos que un experimento binomial consiste en una sucesión de n intentos independientes idénticos, y que cada intento tiene dos resultados posibles: un éxito o un fracaso. La probabilidad de un éxito en un intento es igual para todos los intentos, y se representa por p. La variable aleatoria binomial es la cantidad de éxitos en los n intento, y las cuestiones de probabilidad se relacionan con la probabilidad de x éxitos en los n intentos.
Cuando la cantidad de intentos es grande, es difícil calcular la probabilidad binomial a mano o con una calculadora. Además, las tablas binomiales no muestran valores de n mayores de 20. En consecuencia, cuando nos encontramos con que un problema de la distribución binomial de probabilidad tiene una gran cantidad de intentos, podemos hacer uso de una aproximación a la distribución binomial. En los casos en los que la cantidad de intentos es mayor de 20, np > 5, y n (1 – p) > 5 la distribución normal de probabilidad da como resultado una aproximación a las probabilidades binomiales, y es fácil de aplicar.
Al usar la aproximación normal a la binomial, se igualan µ = np y ơ = np(1 - p) en la definición de la curva normal. Veamos un ejemplo de esta aproximación, suponiendo que una empresa se ha visto que en el 10% de sus facturas se cometen errores. Se ha tomado una muestra de 100 facturas y se desea calcular la probabilidad de que 12 de ellas contengan errores. Esto es, determinaremos la probabilidad binomial de 12 éxitos en 100 intentos.
Para aplicar la aproximación normal a la binomial, igualamos µ = np = (100)(.1) = 10 y ơ = np (1 – p) = (100)(.1)(.9) = 3. Una distribución normal con µ = 10 y ơ = 3 aparece en la figura 6.
No olvidemos que, con una distribución continua de probabilidades, éstas se calculan como áreas bajo la función de densidad de probabilidad. Como resultado de lo anterior, la probabilidad de cualquier valor único de la variable aleatoria es cero. Para aproximar la probabilidad binomial de 12 éxitos debemos calcular el área bajo la curva normal correspondiente entre 11.5 y 12.5. El .5 que sumamos y restamos de 12 se llama factor de corrección
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 70
Para una n dada, la aproximación normal será óptima cuando p = .50.

Unidad Académica del Norte Estadística
por continuidad. Se introduce porque se usa una distribución continua de probabilidad para aproximar una distribución discreta. Así, P(x = 12) para la distribución binomial discreta se aproxima mediante P(11.5 < x < 12.5) en la distribución normal continua.
ơ = 3
Área = .1052
x
11.5
µ = 10 12.5
Al pasar a la distribución normal estándar, para calcular P(11.5 < x < 12.5), tenemos que
z = x - µ = 12.5 – 10.0 = .83 en x = 12.5 ơ 3y
z = x - µ = 11.5 – 10.0 = .50 en x = 11.5 ơ 3
En la tabla 6.1 encontramos qué el área bajo la curva (véase la figura 6) entre 10 y 12.5 es de .2967. Igualmente, el área bajo la curva entre 10 y 11.5 es de .1915. En consecuencia, el área bajo la curva entre 11.5 y 12.5 es de .2967 - .1915 = .1052. La aproximación normal a la probabilidad de 12 éxitos en 100 intentos es de .1052.
En otro caso, supongamos que se desea calcular la probabilidad de 13 errores o menos en la muestra de 100 facturas. En la figura 7 vemos que el área bajo la curva normal se aproxima a ese valor. Observe que el empleo del factor de corrección por continuidad produce el valor 13.5, que se usa para calcular la probabilidad deseada. El valor de z que corresponde a x = 13.5 es
z = 13.5 – 10.0 = 1.17 3.0
La tabla 6.1 indica que el área bajo la curva normal estándar, entre 0 y 1.17, es de .3790. El área bajo la curva normal que aproxima la probabilidad de 13 errores o menos es la parte no sombreada de la figura 7. La probabilidad es de .3790 + .5000 = .8790.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 71
Figura 6APROXIMACIÓN NORMAL A UNA DISTRIBUCIÓN BINOMIAL DE PROBABILIDAD CON n = 100 Y p = .10 SE MUESTRA LA PROBABILIDAD DE 12 ERRORES
Figura 7APROXIMACIÓN NORMAL A UNA DISTRIBUCIÓN BINOMIAL DE PROBABILIDAD, CON n = 100 Y p = .10 SE MUESTRA LA PROBABILIDAD DE 13 ERRORES O MENOS

Unidad Académica del Norte Estadística
La probabilidad
de 13 errores o menos
es .8790
x
10 13.5
EJERCICIOS
1. Una distribución binomial de probabilidad p = .20 y n = 100.a. ¿Cuál es la media y la desviación estándar?b. ¿Es un caso en el que las probabilidades binomiales se pueden aproximar con la distribución normal de
probabilidad? Explique por qué.c. ¿Cuál es la probabilidad de tener exactamente 24 éxitos?d. ¿Cuál es la probabilidad de tener entre 18 y 22 éxitos?e. ¿Cuál es la probabilidad de tener 15 éxitos o menos?
2. Una encuesta de Customer Reports citó a los distribuidores de los automóviles Saturn. Infiniti y Lexus como los tres mejores en lo que respecta a servicio al cliente (Consumer Reports, abril de 1994). Saturn quedó en primer lugar, y sólo el 4% de sus clientes mencionó alguna inconformidad con la agencia. Conteste las siguientes preguntas acerca de un grupo de 250 clientes de Saturn.
a. ¿Cuál es la probabilidad de que 12 clientes o menos tengan cierta inconformidad con la agencia?b. ¿Cuál es la probabilidad de que 5 o más clientes estén descontentos con la agencia?c. ¿Cuál es la probabilidad de que 8 clientes estén descontentos con la agencia?
3. El departamento de Justicia de Estados Unidos presentó una demanda contra Microsoft Corporación, en diciembre de 1997, por ligar su navegador de red Internet Explorer®, con su sistema operativo Windows 95®, (Fortune, 2 de febrero de 1998). La opinión pública se dividió acerca de si Microsoft es un monopolio. En una encuesta de Fortune, el 41% de quienes contestaron concordaron con la afirmación “Microsoft es un monopolio”
a. En una muestra de 800 personas, ¿cuántas espera el lector que coincidan en que Microsoft es un monopolio?
b. En esa muestra, ¿cuál es la probabilidad de que 300 personas o menos coincidan en que Microsoft es un monopolio?
c. Nuevamente en una muestra de 800 personas, ¿cuál es la probabilidad de que más de 450 personas no concuerden en que Microsoft es un monopolio?
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 72

Unidad Académica del Norte Estadística
4. Un hotel de Bahía Tranquila tiene 120 cuartos. En los meses de primavera, la ocupación aproximada en ese hotel es de 75%.Aplique la aproximación normal a la distribución binomial para contestar lo siguiente.
a. ¿Cuál es la probabilidad de que al menos se ocupe la mitad de los cuartos en cierto día?b. ¿Cuál es la probabilidad de que se ocupen 100 o más cuartos en cierto día?c. ¿Cuál es la probabilidad de que se ocupen 80 cuartos o menos en cierto día?
DISTRIBUCIÓN EXPONENCIAL DE PROBABILIDAD
Una distribución continua de probabilidad que es útil para describir el tiempo que se tarda en realizar una actividad es la distribución exponencial de probabilidad. Se puede usar la variable aleatoria exponencial para describir cosas tales como el tiempo entre llegadas a un autobaño, el tiempo necesario para cargar un camión, la distancia entre los principales defectos en una carretera, etc. A continuación presentamos la función de densidad de probabilidad exponencial.
Función de densidad de probabilidad exponencial
f(x) = 1 e-x/µ para x > 0, µ > 0 (13)
µ
Como ejemplo de una distribución exponencial de probabilidad, supongamos que el tiempo que se tarda en cargar un camión en el muelle de Mercurio sigue esa distribución. Si la media del tiempo, o tiempo promedio para cargarlo es de 15 minutos (µ = 15), su función de densidad de probabilidad es
f(x) = 1 e-x/15
15
La figura 8 es la gráfica de esta función de densidad.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 73
Si las llegadas se apegan a una distribución de Poisson, el tiempo entre llegadas debe apegarse a una distribución exponencial.
Figura 8 DISTRIBUCIÓN EXPONENCIAL DE PROBABILIDAD PARA EL EJEMPLO DEL MUELLE DE CARGA MERCURIO

-x0/15
Unidad Académica del Norte Estadística
f(x)
.07
.05
.03
.01
x
0 5 15 25 35 45
Tiempo de carga
Determinación de las probabilidades en la distribución exponencial
Como en cualquier distribución continua de probabilidad, el área bajo la curva que corresponde a cierto intervalo equivale a la probabilidad de que la variable aleatoria asuma un valor en ese intervalo. En el ejemplo del muelle de Mercurio, la probabilidad de que la carga de un camión dure 6 minutos o menos (x < 6) se define como el área bajo la curva de x = 0 a x = 6 en la figura 8. Igualmente, la probabilidad de que la carga de un camión dure 18 minutos o menos (x < 18) es el área bajo la curva, de x = 0 a x = 18. También observamos que la probabilidad de que la carga de un camión dure de 6 a 18 minutos (6 < x < 18) se expresa por el área bajo la curva de x = 6 a x = 18.
Para calcular probabilidades exponenciales como las que acabamos de describir empleamos la siguiente ecuación, que cada como resultado la probabilidad de obtener un valor de la variable aleatoria exponencial igual o menor que determinado valor específico de x, representado por x0.
Distribución exponencial de probabilidad
P(x < x0) = 1 – e –x° /µ
Para el ejemplo del muelle de carga de Mercurio, esta ecuación se puede escribir como sigue: P(tiempo de carga < x0) = 1 - e
En consecuencia, la probabilidad de que la carga de un camión dure seis minutos o menos (x < 6) es P(tiempo de carga < 6) = 1 – e-6/15 = .3297
La figura 9 muestra el área o la probabilidad de un tiempo de carga de seis minutos o menos. También observe que la probabilidad de cargar un camión en 18 minutos o menos (x < 18) es P(tiempo de carga < 18) = 1 – e-18/15 = .6988
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 74
(14)
Figura 9 PROBABILIDAD DE UN TIEMPO DE CARGA DE 6 MINUTOS O MENOS

Unidad Académica del Norte Estadística
.07 f(x)
.06
.05 P(x < 6) = .3297
.04
.03
.02
.01
x
0 5 10 15 20 25 30 35 40 45
Tiempo de carga
Así, la probabilidad de que la carga de un camión tarde de seis a 18 minutos es igual a .6988 - .3297 = .3691. De este modo se pueden calcular las probabilidades para cualquier otro intervalo.
Relación entre las distribuciones de Poisson y exponencial
Anteriormente analizamos la distribución de Poisson como distribución discreta de probabilidad, que se usa con frecuencia para examinar la cantidad de ocurrencias de un evento en un intervalo específico de tiempo o de espacio. Recordamos que la función de probabilidad de Poisson es
f(x) = µ x e -µ x!
en donde µ = valor esperado o cantidad promedio de ocurrencias en un intervalo.
La distribución exponencial continua de probabilidad se relaciona con la distribución discreta de Poisson, porque si ésta da una descripción adecuada de la cantidad de ocurrencias por intervalo, la distribución exponencial suministra una descripción de la longitud del intervalo entre ocurrencias.
Un ejemplo de esta relación es el siguiente, suponga que la cantidad de automóviles que llegan a un autobaño durante una hora se describe con una distribución de probabilidad de Poisson con una media de 10 vehículos por hora. La función de probabilidad de Poisson que expresa la probabilidad de x llegadas por hora es
f(x) = 10 x e -10 x!
Como la cantidad promedio de llegadas es de 10 por hora, el tiempo promedio entre los automóviles que llegan es
1 hora = 0.1 hora/ carro 10 carros
Así, la distribución exponencial correspondiente que describe el tiempo entre llegadas tiene promedio µ = 0.1 hora por automóvil; la función de densidad de probabilidad exponencial adecuada es
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 75

Unidad Académica del Norte Estadística
f(x) = 1 e-x/0.1 = 10e-10x
0.1
EJERCICIOS1. Se tiene la siguiente función de densidad de probabilidad exponencial.
f(x) = 1 e - x/8 para x > 0 8
a. Determine P (x < 6). b. Determine P(x < 4).c. Determine P (x > 6). d. Determine P(4 < x < 6).
2. Se tiene la siguiente función de densidad de probabilidad exponencial.f(x) = 1 e - x/3 para x > 0
3a. Deduzca la fórmula de P (x < x0). b. Determine P(x < 2).c. Determine P (x > 3). d. Determine P(x < 5).e. Determine P (2 < x < 5).
3. El tiempo entre llegadas de vehículos a determinado crucero sigue una distribución exponencial de probabilidad, con una media de 12 segundos.
a. Grafique esta distribución exponencial de probabilidadb. ¿Cuál es la probabilidad de que el tiempo entre las llegadas de dos vehículos sea de 12 segundos o
menos?c. ¿Cuál es la probabilidad de que ese tiempo sea de seis segundos o menos?d. ¿Cuál es la probabilidad de que haya 30 segundos o más entre las llegadas de vehículos?
4. Con frecuencia se supone que los tiempos de espera siguen una distribución exponencial de probabilidad. Un estudio de tiempos de espera en restaurantes de comida rápida, efectuado por The Orlando Sentinel en octubre de 1993 demostró que el tiempo promedio de espera para recibir la comida, después de hacer el pedido en Burguer King, McDonal´s y Wendy´s era de 60 segundos. Suponga que se aplica a los tiempos de espera una distribución exponencial de probabilidad.
a. ¿Cuál es la probabilidad de que un cliente espere 30 segundos o menos?b. ¿Cuál es la probabilidad de que un cliente espere 45 segundos o menos?c. ¿Cuál es la probabilidad de que un cliente esperé más de dos minutos?
GLOSARIO
Distribución uniforme de probabilidad Función de densidad de probabilidad Distribución normal de probabilidad Distribución normal estándar de probabilidad Factor de corrección por continuidad Distribución exponencial de probabilidad
FORMULAS CLAVE
Función de densidad uniforme de probabilidad
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 76

Unidad Académica del Norte Estadística
1__ cuando a < x < b f(x) = b – a 0 en cualquier otro lugar
Función de densidad normal de probabilidad f(x) = 1 e -(x - µ)² / 2ơ ²
2π ơ
Conversión a la distribución normal estándar z = x - µ ơ
Función de densidad exponencial de probabilidad
f(x) = 1 e -x/µ para x > 0, µ > 0 µ
Distribución exponencial de probabilidades
P(x < x0) = 1 – e –x° /µ
BIBLIOGRAFÍA RECOMENDADA
Estadística para Administradores. Richard I. Levin, David S. Rubin. 1996.Prentice Hall.
Elementos de Estadística en la Economía y los Negocios. Mc Allister. 1987.ECASA.
Estadística. Murria R. Spiegel. 1990. Mc Graw Hill.
Estadística para Administración y Economía. William J. Stevenson. 1981. Harla.
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 77

Unidad Académica del Norte Estadística
Probabilidad y Estadística para Ingeniería y Administración. William W. Hines, Douglas C. Montgomery. 1997. CECSA
M.A.C. Ing. Josué Salvador Sánchez Rodríguez 78


















