
Tercera Parte Prob y Estad Plan Especial 2012.pdf
48
150 VIII.- INFERENCIA ESTADÍSTICA PARAMETRICA 8.1.- Definiciones Preliminares El campo de la inferencia estadística está formado por los métodos utilizados para tomar decisiones o para obtener conclusiones sobre una Población, Lote, Proceso. Estos métodos utilizan la información contenida en una muestra de la Población, Lote, Proceso para obtener conclusiones. La inferencia estadística la podemos dividir en tres grandes áreas: 1).- Estimación de parámetros 2).- Prueba de hipótesis e intervalos de confianza para parámetros poblacionales. 3).- Ajuste de modelos teóricos a un conjunto de datos empíricos y medir la bondad de dicho ajuste. De lo anterior, podemos desprender de que la calidad de la información obtenida, como también la acertividad de la decisión tomada, dependen esencialmente de la muestra. (Que es de donde obtenemos los datos). Población, Lote, Proceso. En muchos problemas estadísticos, es necesario utilizar una muestra de observaciones tomadas de la población de interés con objeto de obtener conclusiones acerca de ella. Muestra Para que las inferencias sean válidas, la muestra debe ser representativa de la población. Un mecanismo de selección que asegura la representatividad es la aleatorización. En consecuencia la selección de una muestra es un experimento aleatorio, y cada observación de la muestra es el valor observado de una variable aleatoria. Las observaciones en la población determinan la distribución de probabilidad de la variable aleatoria. La calidad de las medida(s) o valor(es) obtenidos de las muestras dependen, entre otros factores, de los equipos de medición (exactitud, precisión, capacidad, etc.). Una muestra representativa, evita que se produzca una información sesgada.
-
Upload
pablo-andres -
Category
Documents
-
view
58 -
download
2
Transcript of Tercera Parte Prob y Estad Plan Especial 2012.pdf

150
VIII.- INFERENCIA ESTADÍSTICA PARAMETRICA 8.1.- Definiciones Preliminares El campo de la inferencia estadística está formado por los métodos utilizados para tomar decisiones o para obtener conclusiones sobre una Población, Lote, Proceso. Estos métodos utilizan la información contenida en una muestra de la Población, Lote, Proceso para obtener conclusiones.
La inferencia estadística la podemos dividir en tres grandes áreas:
1).- Estimación de parámetros 2).- Prueba de hipótesis e intervalos de confianza para parámetros poblacionales. 3).- Ajuste de modelos teóricos a un conjunto de datos empíricos y medir la bondad de dicho
ajuste. De lo anterior, podemos desprender de que la calidad de la información obtenida, como también la acertividad de la decisión tomada, dependen esencialmente de la muestra. (Que es de donde obtenemos los datos). Población, Lote, Proceso.
En muchos problemas estadísticos, es necesario utilizar una muestra de observaciones tomadas de la población de interés con objeto de obtener conclusiones acerca de ella. Muestra
Para que las inferencias sean válidas, la muestra debe ser representativa de la población. Un mecanismo de selección que asegura la representatividad es la aleatorización. En consecuencia la selección de una muestra es un experimento aleatorio, y cada observación de la muestra es el valor observado de una variable aleatoria. Las observaciones en la población determinan la distribución de probabilidad de la variable aleatoria. La calidad de las medida(s) o valor(es) obtenidos de las muestras dependen, entre otros factores, de los equipos de medición (exactitud, precisión, capacidad, etc.). Una muestra representativa, evita que se produzca una información sesgada.

151
8.2.- Estimación Estimador, Estadística.
Estimación Puntual
Propiedades de los estimadores: 1.- Insesgado: Un estimador debe arrojar, en promedio, valores muy próximo al verdadero valor del parámetro. 2.- Mínima Varianza: Si se consideran todos los estimadores insesgados de del parámetro θ,el que tiene la menor varianza recibe el nombre de estimador insesgado de varianza mínima. 3.- Consistentes: A medida de que el tamaño de la muestra aumenta, (n N), el estimador
tiende a coincidir con el parámetro. 4.- Eficientes: Si se utilizan dos estadígrafos o estimadores del mismo parámetro , aquel cuya
distribución muestral tenga menor error estándar , es un estimador más eficaz que otro . 5.- Suficiente: Un estimador suficiente del parámetro θ , es aquel que agota toda la
información pertinente sobre θ de que se pueda disponer en la muestra.
Por ejemplo, el promedio μ (desconocido) de la Población, puede ser estimado a través del promedio aritmético de la muestra, X ; también puede ser estimado por la Mediana de la muestra, X~ . Pero X tiene menor varianza que X~ . (Es decir X , es más eficiente que X~ ) Uno de los mejores métodos para obtener un estimador puntual de un parámetro es el método de Máxima Verosimilitud. Tal como su nombre lo señala, el estimador será el valor del parámetro que maximiza la función de verosimilitud. (No será expuesto en el presente desarrollo , pero puede ser revisado en Textos de Estadística Matemática o de Probabilidades y Estadística)

152
8.3.- Distribuciones de muestreo
Por ejemplo, la distribución de probabilidad del promedio aritmético X , se conoce como distribución de muestreo (muestral) de la media. La distribución de muestreo de una estadística o estimador depende de la distribución de la población, del tamaño de muestra y del método utilizado para seleccionar la muestra. Teorema del Límite Central
Error Estándar
Por ejemplo el promedio aritmético X , tiene un error estándar de n
2σ . Pero en muchas
oportunidades el parámetro debe ser estimado por la varianza muestral , obteniéndose entonces
un error estándar estimado igual an
S 2
.
El error estándar da alguna idea sobre la precisión de la estimación

153
8.4.- Prueba de Hipótesis e intervalo de confianza. En muchos problemas de Ingeniería, Ciencias Naturales, Ciencias Sociales, Administración y Negocios , etc ., requieren que se tome una decisión entre aceptar o rechazar una proposición sobre algún parámetro. Esta proposición recibe el nombre de Hipótesis, y el procedimiento de toma de decisión sobre la hipótesis se conoce como Prueba de Hipótesis. Este es uno de los aspectos más útiles de la inferencia estadística, puesto que muchos tipos de problemas de toma de decisiones, pruebas o experimentos en el mundo de la Ingeniería, pueden formularse como problemas de prueba de hipótesis. Es conveniente considerar la prueba de hipótesis estadísticas como la etapa de análisis de datos de un experimento comparativo, en el que el ingeniero está interesado, por ejemplo, en mejorar un rendimiento promedio en un proceso, después de haber hecho una innovación en el mismo. La finalidad es probar hipótesis con respecto a los parámetros de las dos situaciones.
En la prueba de hipótesis intervienen siempre dos hipótesis denominadas como:
H0: conocida como hipótesis nula o hipótesis de prueba.
H1 : denominada hipótesis alternativa
La estructura general de una Prueba de Hipótesis, la podemos resumir en el siguiente cuadro
Los procedimientos de pruebas de hipótesis dependen del empleo de la información que obtiene al procesar los datos contenidos en una muestra aleatoria de la población de interés. Es por esto que la verdad o falsedad de una hipótesis en particular nunca puede conocerse con certidumbre, a menos que pueda examinarse a toda la población. Usualmente esto es imposible en muchas situaciones prácticas. Dado que estamos trabajando con información muestral para aceptar o rechazar la hipótesis de prueba, es que debemos asumir que podemos cometer alguno de estos dos tipos de errores denominados: Error Tipo I , Error Tipo II.

154
Este es el tipo de Error con el que usualmente se realiza la prueba de Hipótesis
Al utilizar una muestra para obtener conclusiones sobre una población existe el riesgo de llegar a una conclusión incorrecta. Cuando se toma una decisión referente a una hipótesis basada en la teoría de la probabilidad, ésta puede ser: Decisión Correcta: • Se acepta una hipótesis cuando es verdadera. • Se rechaza una hipótesis cuando no es verdadera. Decisión Incorrecta • Error Tipo I (α).- Se rechaza un hipótesis que es verdadera, es decir, se rechaza la Hipótesis
Nula (H0) cuando en realidad es cierta.
• Error Tipo II (β).- Se acepta una hipótesis que no es verdadera, es decir, no se rechaza la Hipótesis Nula (H
0) cuando es falsa y se debiera rechazar.
Para mayor claridad observamos el siguiente cuadro:

155
De estos dos errores el más frecuente es β, pero es el más difícil de controlar. De ahí que el más usado en la práctica es α.
El nivel de significación debe ser especificado antes de que una prueba sea hecha, de otra manera, el resultado obtenido en la prueba puede influir en la decisión. Los niveles de significación más utilizados son: α = 0,05 y α = 0,01 Al emplear un nivel de significación del 5% tenemos la confianza del 95% de que hemos tomado una decisión correcta, aunque pudimos estar equivocados en un 5%.
La región crítica o de rechazo es la medida del resultado del proceso de una muestra (Estadístico de Prueba) cuando es mayor o igual que un valor fijado (Valor Crítico), entonces se rechaza la hipótesis nula (H0); como también se rechaza la hipótesis nula en el caso de que la medida sea menor que un valor fijado (Valor Crítico).

156
El error de Tipo II (β) se puede determinar solamente respecto a un valor específico incluido en el rango de la Hipótesis Alternativa (H
1).
8.4.1.- Etapas básicas a considerar en la prueba de hipótesis: A continuación se enunciarán un conjunto secuenciados de procedimientos a tener en consideración, para prueba de hipótesis en el caso de muchos problemas prácticos.
1.- Del contexto del problema, identificar el parámetro de interés. 2.- Establecer la hipótesis nula, H
0.
3.- Establecer una apropiada hipótesis alternativa, H1.
4.- Seleccionar un nivel de significancia α, para probar la hipótesis H
0.
5.- Establecer una estadístico de prueba apropiado. 6.- Establecer la Región de Rechazo para el estadístico de prueba, que está señalada por la
hipótesis alternativa ( < , > , ≠ ).
7.- Calcular todas las cantidades o estimadores a partir de los datos muestrales, para sustituirlas en la expresión del estadístico de prueba, obtener el valor correspondiente.
8.- Decidir si debe o no rechazarse H
0 y expresar o redactar esto, en el contexto del problema.
8.4.2.- Aplicaciones de la Distribución Normal en la Prueba de Hipótesis y la construcción de intervalos de confianza.
En forma muy general, podemos decir que la distribución normal se aplica en temas relacionados con la inferencia estadística cuando la Variable en estudio tiene un comportamiento que es modelizado por esta distribución, se conoce el valor del parámetro denominado varianza, o el tamaño de la muestra es suficientemente grande, como para invocar que el estadígrafo muestral tiene un comportamiento normal. 8.4.2.1.- Prueba de hipótesis e intervalo de confianza acerca una proporción "p". En muchos problemas de ingeniería, se tiene interés en una variable aleatoria que sigue o se comporta como una distribución Bernoulli. Por ejemplo, considérese un proceso productivo que fabrica artículos que son clasificados como aceptables o defectuosos; o bien un proceso de monitoreo que controla una variable específica mediante una lectura muestral, y la muestra se clasifica como contaminada ( + ) o no contaminada ( - ). El parámetro binomial " p " representa la proporción de artículos (o muestras) defectuosos (contaminados) producidos.

157
El valor de p es la proporción de unidades con la característica buscada. Entonces X = pn ˆ⋅ es la
cantidad de unidades muestrales con la característica buscada. El valor p0
es la proporción que hipotéticamente existe en la población. El valor " n p
0 " representa entonces el valor esperado de
unidades con la característica buscada, en la muestra de tamaño "n". Intervalo de Confianza para p de nivel (1 - α)
Tamaño de la muestra
nppZp )ˆ1(ˆˆ 2/1
−± −α
2
0
00 )1()1(⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
−
−+−=
ppppZppZ
n βα prueba bilateral
2
0
002/ )1()1(⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
−
−+−=
ppppZppZ
n βα prueba unilateral
8.4.2.2.- Prueba de hipótesis acerca de la diferencia entre dos proporciones " p1 y p2”. Las pruebas de hipótesis del punto 6.4.2.2 pueden extenderse al caso donde existen dos parámetros binomiales de interés (por ejemplo p1 y p2 ) y se desea probar que son iguales o que difieren en una cantidad δ .
Esta prueba de hipótesis, para asegurar la convergencia a la distribución normal de los parámetros muestrales, necesita que los tamaños de las respectivas muestras tomadas independientemente en cada una de las poblaciones sean de tamaño grande (preferentemente superior o igual a 100).
Los estimadores de las proporciones poblacionales son 1p = 1
1
nX
, 2
22ˆ
nXp = y que tienen
distribuciones aproximadamente normales.
Para probar la hipótesis H0, se debe calcular π = 21
21
nnXX
++
, donde X1 y X2 representan las
cantidades de unidades, en cada una de las muestras, que poseen la característica en estudio.

158
H0 : p1 - p2 = δ Estadístico de prueba H1: p1 - p2 < δ
H1 : p1 - p2 > δ
H1 : p1 - p2 ≠δ
ZObs =
)11)(1(
)ˆˆ(
21
21
nn
pp
+−
−−
ππ
δ
Intervalo de confianza de nivel (1 - α ) Tamaño de la muestra
21 ˆˆ( pp − ) ± Z1 – α/2 )11)(1(21 nn
+−ππ
( )
221
2
22112121
)(2/))((pp
qpqpZqqppZn
−
++++= βα
La fórmula que permite calcular el tamaño muestral está dada en el caso de realizar una prueba de hipótesis con alternativa unilateral. En el caso de que se desee realizar una prueba bilateral ( ≠ ), entonces es necesario remplazar Zα por Zα/2
Si el interés del investigador estuviese en probar si la cantidad esperada de unidades, X, que tienen una cierta característica cuando se extrae de esa población, lote, o proceso una muestra de tamaño "n”, entonces la estructura de la prueba de hipótesis sería:
H0 : np =n p0 = X0
Estadístico de prueba
H1 : n p < X0
H1 : n p > X0
H1: np ≠ X0
Z0bs = )1(
)(
00
0
pnpnpX−
−
Ejercicio 1.- En una ciudad, que se dividió en dos sectores, A y B, se colectaron muestras de 160 y 200 hogares respectivamente, para tomar información acerca del consumo de un cierto producto para el lavado de ropa (ACE). Contestaron favorablemente 80 hogares en "A" 115 hogares en "B". a).- Redacte las hipótesis para probar de que existe una diferencia estadísticamente significativa en la preferencia por el producto, entre ambas ciudades. b).- Determine un intervalo de confianza del 90 % para la verdadera diferencia entre la preferencia por el producto entre ambas ciudades. c).- ¿Cuál es el tamaño muestral adecuado en la ciudad A, para estimar la proporción de personas que prefieren el producto con un 90 % de confianza y un error de muestreo del 4 %?

159
2.- Los administradores (no médicos) de los hospitales en muchos casos se encargan de obtener y calcular algunas estadísticas que son de suma importancia para los médicos y para los encargados de decidir en el hospital. En los registros de un hospital se tiene que 52 hombres (mayores de 50 años) en una muestra de 500; y que 25 mujeres (mayores de 50 años) de una muestra de 550, ingresaron al hospital y necesitan intervención quirúrgica cardiovascular. a).- Con estos datos, ¿ existe evidencia suficiente como para pensar de que existe una mayor tasa de
afecciones cardíacas en los hombres que en las mujeres?. Plantee y prueba esta hipótesis.- b).- Determine un intervalo de confianza del 90 % para la diferencia en la proporción de hombres y
mujeres que necesitan intervención quirúrgica cardiovascular. c) Con un intervalo de confianza del 95 %, estime la proporción de hombres mayores de 50 años que
necesitan intervención quirúrgica cardiovascular.- 2.- En una muestra aleatoria de 450 teléfonos residenciales tomada en cierta ciudad A en el año 1990, se encontró que 130 no aparecen en el directorio. En el mismo año, en otra muestra aleatoria de 600 teléfonos para una ciudad B, se encontró que 120 no aparecen en el directorio (Teléfono privado). a) Redacte y Realice todos los pasos de la prueba de hipótesis y use α = 0,05 para probar si existe una tendencia mayoritaria en la ciudad A, respecto de B, a la existencia de una mayor proporción de teléfonos privados. b) Determine un intervalo de confiabilidad del 95%, para la proporción de teléfonos privados en la ciudad B c) Si se desea estimar la proporción de teléfonos privados en la ciudad B con una confiabilidad del 95 % y un error de muestreo no mayor a 0.06 ¿Cuántas hogares seleccionados debe tener la muestra?

160
8.4.3.- Aplicaciones de la Distribución t - Student en la Prueba de Hipótesis y la construcción de intervalos de confianza. Cuando se prueban hipótesis a cerca del promedio μ de una población o la diferencia entre promedios de dos poblaciones diferentes y cuando 2σ es desconocida, es posible utilizar los procedimientos antes descritos (remplazando p por μ) siempre y cuando el tamaño de la muestra sea grande. Sin embargo, cuando la muestra es pequeña y 2σ es desconocida, debe plantearse una hipótesis sobre la forma de la distribución subyacente con la finalidad de obtener un procedimiento de prueba. En muchos casos, una hipótesis razonable es que la distribución que modeliza el comportamiento de los datos, es normal. Pero en el caso de muestras pequeñas y varianza desconocida, se ha desarrollado una distribución denominada “t – de Student”. Esta distribución se origina como el cuociente de dos distribuciones, donde una de ellas es la distribución normal. De hecho, la distribución “t – de Student” tiene una forma muy parecida a la Normal. (Tabla al final del texto) Muchas de las poblaciones que se encuentran en la práctica, quedan bien aproximadas por la distribución normal, razón por la cual esta hipótesis conduce a un procedimiento de prueba de gran aplicabilidad. De hecho, un alejamiento moderado de la normalidad estadística tiene poco efecto sobre la validez de la prueba. Cuando la hipótesis no es razonable, entonces puede especificarse otra distribución (Exponencial, Weibull, lognormal, etc.) y usar algún método general para la construcción de pruebas de hipótesis con la finalidad de obtener un procedimiento válido, o también pueden utilizarse pruebas no- paramétricas que son válidas para cualquier distribución estadística. 8.4.3.1.- Prueba de hipótesis e intervalo de confianza para el promedio “μ “ Supóngase que la población tiene una distribución normal con media “μ” y varianza 2σ , con ambos parámetros desconocidos. Se desea probar la hipótesis de que μ es igual a una constante μ0. Necesitamos la información muestral del promedio aritmético X y la varianza muestral S2 .
H0 : μ = μ0 Estadístico de prueba Intervalo de confianza
H1 : μ < μ0
H0 : μ > μ0
H0 : μ ≠ μ0 TObs =
nS
uX2
0
ˆ( −
υα ,2/1−±TX n
S 2ˆ
T1 - α/2 ,ν , es un valor obtenido de una tabla que contiene la distribución t - student y el valor ν = n - 1. Este símbolo nos indica los grados de libertad de la distribución, los cuales están indicados en la fila de la tabla. Es igual al número de datos muestrales menos 1. Para rechazar la hipótesis H0 , a favor de H1 , se debe cumplir que el valor del estadístico de prueba caiga en la región de rechazo indicada por la hipótesis alternativa H1
Además, recordemos que 1
)(ˆ
2
11
2
−
−=∑=
=
n
XXS
ni
i ; n
XXS
ni
ii∑
=
=
−= 1
2
2)(
maudiaz
Nota adhesiva
Es H1 en vez de H0
maudiaz
Nota adhesiva
Es H1 en vez de H0
maudiaz
Nota adhesiva
Es H1 en vez de H0
maudiaz
Nota adhesiva
Se cierra con un parentesis.

161
8.4.3.2.- Prueba de hipótesis e intervalo de confianza para los promedio de dos distribuciones muestras independientes Ahora se considerará una prueba de hipótesis sobre la diferencia de los promedio µ1 - µ2 = δ, de dos distribuciones normales donde las varianza 2
1σ y 22σ son desconocidas pero iguales, estimadas a
través de sus respectivas varianzas muestrales 21S y 2
2S . Las muestras obtenidas de cada población son independientes entre si. Tal como se indicó en la prueba homónima en puntos anteriores, se requiere la hipótesis de normalidad para desarrollar el procedimiento de prueba, pero los alejamientos o distanciamientos moderados de la normalidad estadística no tendrán efectos adversos sobre el procedimiento (Concepto de prueba robusta). H0 : µ1 - µ2 = δ
Estadístico de Prueba
H1 : µ1 - µ2 < δ
H1: µ1 - µ2 > δ
H1: µ1 - µ2 ≠ δ
Tobs =
⎟⎟⎠
⎞⎜⎜⎝
⎛+
−+−+−
−−
2121
222
211
21
112
ˆ)1(ˆ)1(
)(
nnnnSnSn
XX δ
El valor del Estadístico de prueba se compara con valores obtenidos de una Tabla Estadística de la distribución t-Student , adjunta al final del texto, según se la hipótesis alternativa H1 que se esté utilizando. Los grados de libertad, son iguales al tamaño de la muestra menos 1. El intervalo de confianza de nivel (1-α ), para la diferencia entre los promedios poblacionales µ1 - µ2, está dado por
⎟⎟⎠
⎞⎜⎜⎝
⎛+
−+−+−
±− −2121
222
211
);2/1(2111
2
ˆ)1(ˆ)1()(
nnnnSnSn
TXX υα
Los grados de libertad ν para la distribución son ν = 221 −+ nn
Ejercicios: 1.- Dos proveedores fabrican un engranaje plástico utilizado en una impresora láser. Una característica importante de estos engranajes es la resistencia al impacto, la cual se mide en pies-libras. Una muestra aleatoria de 10 engranajes suministrados por el proveedor "A" y de 15 engranajes suministrados por el proveedor "B", entregan los siguientes resultados:
Proveedor Tamaño Muestra Promedio Desv. Estándar A 10 290 12 B 15 321 15

162
a).- ¿Existe evidencia que apoye la afirmación de que los engranajes del proveedor "B" tienen una mayor resistencia promedio al impacto ?. Utilice α = 0,05. b).- Los datos apoyan la afirmación de que la resistencia promedio al impacto de los engranajes del proveedor "B" es al menos 20 pies-libra mayor que la del proveedor "A" c).- Construya un intervalo de confiabilidad del 95 %, para la diferencia promedio entre las resistencias de los engranajes suministrados por ambos proveedores.
2.- Las organizaciones de empresas de manufactura incurren en costos considerables para la capacitación de nuevos empleados. Estas empresas buscan programas de capacitación que puedan llevar a los empleados a un grado máximo de eficiencia en el menor tiempo posible. Los datos siguientes presentan el tiempo, en minutos, que demoran los empleados para ensamblar la misma componente bajo dos métodos: uno estándar y uno nuevo Procedimiento Estándar Procedimiento Nuevo 32 37 35 28 41 40 35 31 34 36 35 31 29 25 34 31 38 27 32 29 26 28 26 30 33 34 35 24 31 29 28 33 30 a).- ¿Existe alguna diferencia estadísticamente significativa en la disminución entre los tiempos promedios de ensamblaje ?. Realice todos los pasos de la prueba de hipótesis y use α = 0,05. b).- Determine un intervalo de confianza del 95% para la diferencia entre los tiempos promedio de ensamblaje. c).- Determine un intervalo de confianza del 95 % para la desviación estándar del tiempo de ensamblaje del nuevo procedimiento. 3.- Se realizan pruebas de dureza en dos tipos de bolas, X e Y, que se utilizan en molinos de la gran minería. Se desea estudiar el desempeño de estas bolas en el proceso de molienda. Se toman muestras independientes de cada uno de los tipos y se encuentran los siguientes resultados. Bola X 75 46 57 43 58 39 61 56 44 65 60 50 Bola Y 52 41 43 47 32 49 52 44 57 60 45 50 55 a).- Redacte y pruebe la hipótesis de que ambos tipos de bolas no presentan diferencias estadísticamente significativas en su resistencia promedio. Use alfa = 0,05. ¿Que recomendación daría usted, respecto de cual tipo de bola usar? Justifique su respuesta. b).- Determine con 95% de confianza entre que valores se encuentra la resistencia promedio de cada uno de los tipos de bolas. c).- Determine un intervalo de confianza del 90% para la desviación estándar de la dureza del tipo de bola Y. d).- Se desea estimar la dureza promedio de la bola tipo X con una confiabilidad del 95 % y un error de estimación no mayor a 1,5 unidades, ¿Cuántas muestras sería necesario seleccionar para cumplir estas exigencias? 3 Pts

163
8.4.3.3.- Prueba de hipótesis e intervalo de confianza para los promedio de dos distribuciones, muestras dependientes. En el caso las muestras obtenidas de cada población son dependientes entre si , como ejemplo , cuando la misma muestra es sometida a análisis por laboratorios diferentes que utilizan la misma metodología ; la misma unidad muestreada es sometida a una medición pre y post ; puede ser también cuando las observaciones sobre las dos poblaciones de interés se recopilan por pares , tomadas bajo condiciones homogéneas , pero estás pueden cambiar de un par a otro . Esta prueba recibe el nombre de prueba " t pareada”. Se calcula la diferencia entre cada par de observaciones di = X i - Yi desde i = 1 , 2.........n
Con los valores de di, se obtiene su promedio aritmético n
dd
ni
ii∑
=
== 1 , 1
)(ˆ 1
2
2
−
−=∑=
=
n
ddS
ni
ii
d
Para remplazarlos en el estadístico de prueba H0 : µ1 - µ2 = δ
Estadístico de Prueba
H1 : µ1 - µ2 < δ
H1: µ1 - µ2 > δ
H1: µ1 - µ2 ≠ δ
TObs =
nS
d
d2ˆ
)( δ−
El valor del Estadístico de prueba se compara con valores obtenidos de una Tabla Estadística de la distribución t-Student , adjunta al final del texto, según se la hipótesis alternativa H1 que se esté utilizando. Los grados de libertad, son iguales al tamaño de la muestra menos 1. El intervalo de confianza de nivel (1-α ), para la diferencia entre los promedios poblacionales µ1 - µ2, está dado por
2/1 α−−Td n
Sd2ˆ≤ µ1 - µ2 ≤ 2/1 α−+Td
nSd
2ˆ
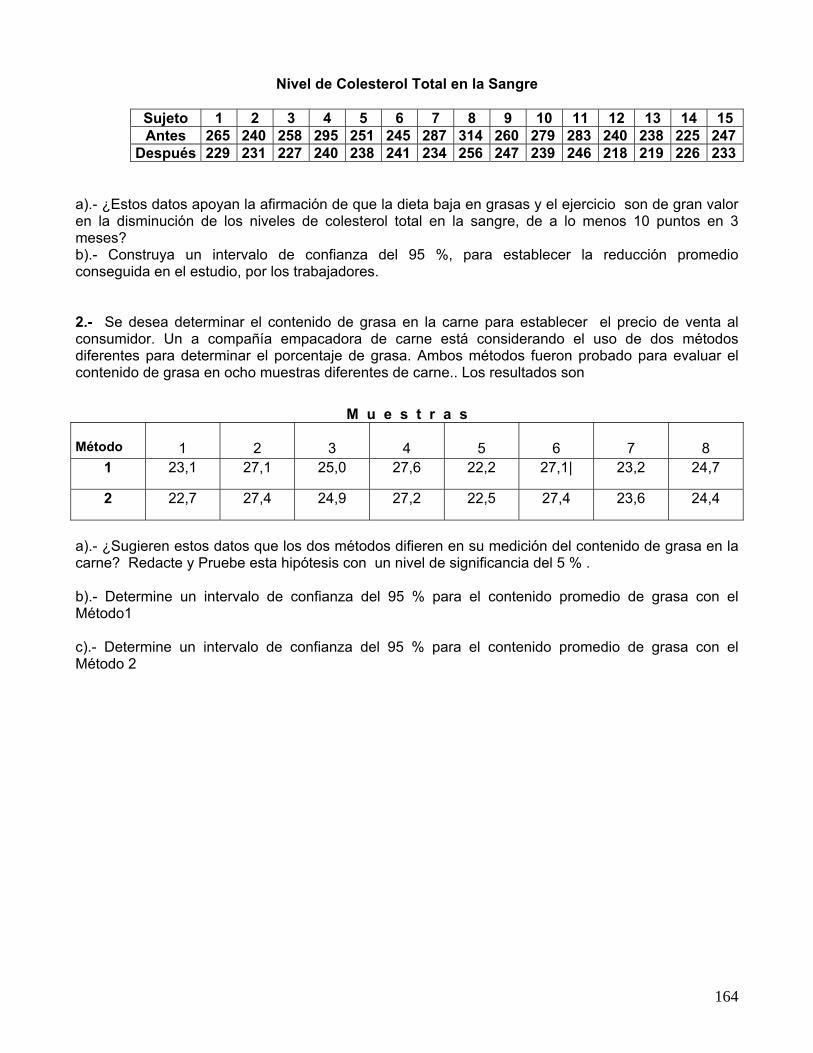
Ejercicios : Quince hombres adultos trabajadores de una Empresa Minera de la II Región, cuyas edades fluctúan entre los 35 y 50 años , participaron en un estudio aeróbico para evaluar el efecto de la dieta y el ejercicio sobre los niveles de colesterol en la sangre . El colesterol total fue medido al inicio del estudio en cada trabajador, y tres meses después de participar en el estudio y de haber cambiado la alimentación a una dieta baja en grasas y un programa de acondicionamiento físico, se obtuvieron los siguientes resultados:
164
Nivel de Colesterol Total en la Sangre
Sujeto 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Antes 265 240 258 295 251 245 287 314 260 279 283 240 238 225 247
Después 229 231 227 240 238 241 234 256 247 239 246 218 219 226 233 a).- ¿Estos datos apoyan la afirmación de que la dieta baja en grasas y el ejercicio son de gran valor en la disminución de los niveles de colesterol total en la sangre, de a lo menos 10 puntos en 3 meses? b).- Construya un intervalo de confianza del 95 %, para establecer la reducción promedio conseguida en el estudio, por los trabajadores.
2.- Se desea determinar el contenido de grasa en la carne para establecer el precio de venta al consumidor. Un a compañía empacadora de carne está considerando el uso de dos métodos diferentes para determinar el porcentaje de grasa. Ambos métodos fueron probado para evaluar el contenido de grasa en ocho muestras diferentes de carne.. Los resultados son
M u e s t r a s
Método
1
2
3
4
5
6
7
8 1 23,1 27,1 25,0 27,6 22,2 27,1| 23,2 24,7
2 22,7 27,4 24,9 27,2 22,5 27,4 23,6 24,4
a).- ¿Sugieren estos datos que los dos métodos difieren en su medición del contenido de grasa en la carne? Redacte y Pruebe esta hipótesis con un nivel de significancia del 5 % . b).- Determine un intervalo de confianza del 95 % para el contenido promedio de grasa con el Método1 c).- Determine un intervalo de confianza del 95 % para el contenido promedio de grasa con el Método 2

165
8.4.4.- Aplicaciones de la Distribución Chi-Cuadrado. La distribución de probabilidad Chi-cuadrado, o distribución 2χ , fue descrita por primera vez por Karl Pearson alrededor del año 1900. Es una variable aleatoria y que a la vez se utiliza como estadígrafo de contraste o de prueba, al igual que las distribuciones Normal, t de Stdudent. Tiene amplias aplicaciones y variadas utilizaciones, las que entre las más frecuentes se cuentan:
o Prueba de hipótesis e intervalos de confianza para la varianza de la población o Prueba de Independencia en tablas de contingencia o de asociación o Prueba de la Bondad de Ajuste
8.4.4.1.- Prueba de hipótesis e intervalos de confianza para la varianza de una sola población. En algunas oportunidades se necesitan pruebas sobre la varianza o la desviación estándar de una población (dispersión) o distribución.
Supóngase que se desea probar la hipótesis de la varianza de una población normal 2σ es igual a un valor específico, por ejemplo, 2
0σ . De una muestra aleatoria de tamaño "n" extraída de la
población, se calcula el valor 2S
H0 : 2σ = 20σ Estadístico de prueba
H1 : 2σ < 20σ H1 : 2σ > 2
0σ H1 : 2σ ≠ 20σ 2
0
22
ˆ)1(σ
χ SnObs
−=
El valor del Estadístico de prueba se compara con valores obtenidos de una Tabla Estadística de la distribución Chi-cuadrado , adjunta al final del texto, según se la hipótesis alternativa H1 que se esté utilizando. Los grados de libertad, al igual que en la distribución t –Student, son iguales al tamaño de la muestra menos 1. Un intervalo de confianza de nivel (1 - α ) para la varianza de la población está dado por la expresión
22/
22
22/1
2 ˆ)1(ˆ)1(
αα χσ
χSnSn −
≤≤−
−
Ejemplo: La desviación estándar de cierto proceso de producción es de 2 pulgadas. Se sospecha que la varianza se ha hecho demasiado grande (ha aumentado). Se toma una muestra de 9 partes producidas en dicho proceso y sus medidas son:
50 , 57 , 52 , 54 , 58 , 59 , 58 , 56 , 55

166
La prueba de hipótesis, de forma simbólica, tiene la siguiente estructura:
H0: 2σ = 4 v / s H1: 2σ > 4 a un nivel de significancia α = 0,05
8.4.4.2.- Prueba de Independencia en tablas de contingencia o de asociación En muchas ocasiones, los "n" elementos de una muestra tomada de una población pueden clasificarse de forma conjunta de acuerdo con dos criterios o variables diferentes. Sea estas variables " R " y " C". Es decir, podemos observar en cada elemento dos variables, que generalmente tiene como respuesta una característica cualitativa o atributo.
La tabla estadística que se genera se denomina tabla de contingencia o de asociación, que tiene " i " filas y " j " columnas Resulta de interés saber si existe algún grado de dependencia o de asociación entre los niveles de clasificación de las variables. Por ejemplo, se desea averiguar si hay alguna asociación estadísticamente significativa entre "Nivel de Formación Académica "y el "Rendimiento Laboral". Si existe alguna asociación estadísticamente significativa entre el " Ausentismo Laboral " y la " Edad “, etc. “ La hipótesis nula a probar es la de que las Variables " R " y " C " son independientes. Esto es de que no hay asociación o relación entre las dos variables. La hipótesis alternativa es la negación de la hipótesis nula. Bajo el contexto de la hipótesis H 0 , es decir de independencia entre las variables , es de esperar que la Probabilidad Conjunta entre las variables se igual al producto de las probabilidades Marginales de cada una de ellas, es decir
P (Ri , Cj ) = P ( Ri ) x P ( Cj) Los valores de las frecuencias conjuntas en cada una de las casillas, se comparan con los valores esperados para cada casilla. Los valores esperados para cada casilla se calculan multiplicando los totales en cada fila por los totales en cada columna y luego este producto se divide por el total " n " de la tabla Por ejemplo el valor esperado conjunto en la columna 2, fila 3 ( 23f ) se obtiene multiplicando el total de fila 2 por el total en la columna 3 . Luego dividir por el total de datos
Es decir, nfff 32
23ˆ •• ×=
Se probará la hipótesis H 0 comparando cada frecuencia conjunta observada con su respectiva frecuencia esperada.

167
El estadístico de prueba es:
∑∑= =
−−
−=
J
j
K
k ij
ijkj f
ffij
1 1
22
)1)(1( ˆ)ˆ(
(χ (Estadístico de Prueba)
Aquí el contraste es unilateral y el valor del estadístico de prueba se compara con el valor obtenido de una tabla de Distribución Chi-cuadrado con grados de libertad igual al producto (número de filas - 1)x( número de columnas - 1 ) , para un nivel de confianza específico 8.4.4.3.- Prueba de la Bondad de Ajuste El procedimiento de prueba requiere de una muestra aleatoria de tamaño " n " proveniente de la población la cual tiene una distribución de probabilidad desconocida. Estas "n" observaciones se ubican en los " k " intervalos reales, cada uno de ellos conteniendo una cantidad "f i ". Seguidamente se representan gráficamente en un histograma de frecuencia. Se supone o propone una distribución de probabilidad, bajo la cual se calculan las frecuencias esperadas para cada uno de los intervalos, las que se denotan por " if ". Hipótesis nula Ho es: " Los datos muestrales se distribuyen según la distribución propuesta" Hipótesis Alternativa H 1 es " Los datos muestrales no se ajustan o no provienen de la
distribución propuesta”.
El estadístico de prueba es ∑=
=
−=
ki
i i
iiObservado f
ff1
22
ˆ)ˆ(
χ
La prueba de Bondad del Ajuste 2χ es sólo una de varios procedimientos utilizados para tal efecto.
Cuando se trabaja con variables aleatorias continuas, la prueba chi-cuadrada (2χ ) tal vez no sea el
mejor procedimiento, pero está ampliamente difundida su utilización.
Desde el desarrollo de aspecto teóricos de la estadística matemática, se demuestra que si la población sigue o se distribuye según el modelo de probabilidad propuesto, el valor de 2
Observadoχ tiene de manera aproximada una distribución Chi-cuadrada con " 1−− pk " grados de libertad, donde k representa la cantidad de intervalos utilizados; p es el número de parámetros estimados a partir de los datos muestrales. La aproximación a la distribución puede mejorar si el tamaño de la muestra aumenta.
La hipótesis nula Ho es rechazada cuando el valor de 2
Observadoχ > que el valor entregado por la tabla 2χ con un nivel de confianza " α−1 y 1−− pk " grados de libertad.
Existe una técnica gráfica para probar si Ho se cumple . Esto se realiza por medio de la "grafica de probabilidad”. Si el modelo de probabilidad propuesto ajusta a los datos, entonces el gráfico de probabilidad mostrará que los datos tenderán a alinearse en torno a una línea recta.
168
Observaciones:
Este procedimiento de prueba está muy relacionado con la "magnitud o cantidad" de las frecuencias esperadas. Si estas frecuencias son muy pequeñas, entonces el estadístico de prueba
2Observadoχ no reflejará cabalmente el alejamiento entre lo observado y lo esperado, sino sólo la
pequeña magnitud de las frecuencias esperadas.
No existe un acuerdo respecto de cual sería la cantidad mínima a aceptar como frecuencia esperada, pero en general los valores 3, 4 y 5 son los que más se utilizan como mínimos. Algunos autores sugieren que la frecuencia esperada puede se tan pequeña como 1 o 2, siempre y cuando que muchas de ellas en la tabla de distribución de los datos resulten ser mayores que 5.
Si una frecuencia esperada en un intervalo es pequeña, entonces pueden juntarse con la frecuencia esperada del intervalo adyacente. Las frecuencias observadas correspondientes también se combinan, por lo que entonces el N° "k " de intervalos también disminuye.
También se debe destacar entonces de que no es necesario de que los intervalos tengan la misma longitud o ancho. 8.4.4.4.- Desarrollo de Ejercicios de Aplicación. 1.- Supóngase, que se desea averiguar si hay alguna asociación significativa entre el nivel de formación académica y el rendimiento laboral
Rendimiento Enseñanza Humanista- Científica
Enseñanza Técnica Profesional
Técnica Universitaria
Excelente 10 40 10 Bueno 30 30 20
Regular 10 30 20 En primer lugar se debe construir la tabla con las frecuencias esperadas
Rendimiento Enseñanza Humanista-Científica
Enseñanza Técnica Profesional
Técnica Universitaria TOTAL
Excelente 15 =(50 X60)/200 30=(100 X60)/200 15=(50 X60)/200 60 Bueno 20=(50 X80)/200 40=(100 X80)/200 20=(50 X80)/200 80
Regular 15=(50 X60)/200 30=(100 X60)/200 15=(50 X60)/200 60 TOTAL 50 100 50 200
El Estadístico de Prueba es
+−
+−
+−
=15
)1510(30
)3040(15
)1510( 2222Obsχ ..........+
15)1520( 2− = 17,5

169
En la tabla de distribución 2χ al final del texto, encontramos que para un nivel de confianza del 95
% y con grados de libertad υ υ = (número de filas - 1) x( número de columnas - 1) = υ 2 x 2 = 4 el valor es de 9,48773.
Por lo tanto se debe rechazar la hipótesis nula de que no existe relación significativa entre la formación académica de los empleados y su rendimiento laboral El Coeficiente de Contingencia es una medida del grado de interrelación, asociación o dependencia de las clasificaciones en una tabla de contingencia que se calcula de la siguiente forma
NCC
Obs
Obs
+= 2
2
.χχ
Donde N es el Total de datos
Cuanto mayor es el valor del C.C , mayor es el grado de asociación entre las variables
En este caso el C.C = 2005.175.17
+ = 0,0897
Este coeficiente varía entre cero y uno.
Para tablas de contingencia con "i" filas y "j" columnas, el mayor valor que puede tomar dicho
coeficiente es k
k )1( − donde k = mínimo{ i, j}.
La Correlación de Atributos es una medida del grado de dependencia, asociación o interrelación entre los niveles de medición (atributos o clasificaciones) de las variables que definen la tabla. Un coeficiente de esta naturaleza es el Coeficiente V de Cramer`s
V = )1(
2
−× kNObsχ
donde k = mínimo { i , j}.
En este ejemplo el V = )13(200
5.17−×
= 0,2092

170
2.- En un proceso de embalaje de manzanas de calidad 1 , que se exportan a la Comunidad Económica Europea , se realiza un muestre en 60 cajas . Se observan la totalidad de manzanas envasadas y se cuentan cuantas de ellas resultan "disconformes " con la definición de calidad 1 y por lo tanto se les considera defectuosa.
Número de Defectos 0 1 2 3
Frecuencia Observada 32 15 9 4
¿La cantidad de manzanas defectuosas por cajas se distribuye o proviene de una distribución de Poisson?
Ho: La cantidad de manzanas defectuosas por cajas se distribuye o proviene de una distribución de Poisson H 1: La cantidad de manzanas defectuosas por cajas NO se distribuye o NO proviene de una distribución de Poisson
Dado que el parámetro λ de la distribución de Poisson se estima a través del promedio de los datos muestrales entonces λ = 0.75 Manzanas defectuosas por caja. Con este valor se determinan las probabilidades esperadas en cada intervalo y que multiplicado por el total de cajas n = 60, se obtiene la respectiva frecuencia esperada en el intervalo. a continuación se detalla el procedimiento a seguir.
P ( X = 0 ) = !0
75,0 75,00 −× e = 0.472 32,2860472,01 =×=f
P ( X = 1 ) = 354,0!1
75,0 75,01
=× −e
24,2160354,0ˆ2 =×=f
P ( X = 2 ) = 133,0!2
75,0 75,02
=× −e
98,760133,03 =×=f
P ( X ≥ 3 ) = 1 - P (X=0) - P(X=1) - P(X=2) = 0,041 46,260041,0ˆ
4 =×=f
Tenemos entonces que
Número de Defectos 0 1 2 3 o más Frecuencia Observada if 32 15 9 4
Frecuencia Esperada if 28,32 21,24 7,98 2,46
Y por lo tanto ∑=
=
−=
ki
i i
iiObservado f
ff1
22
ˆ)ˆ(
χ = 2,94
171
El valor de tabla Chi-cuadrado, con nivel de confianza del 95 % y grados de libertad igual a 3-1- 1 = 1 es de 3,84. Como el valor de Chi-cuadrado observado es menor que el valor de tabla ,entonces concluimos de que no es posible rechazar la hipótesis nula Ho, con cual podemos afirmar con 95 % de confianza que la cantidad de manzanas defectuosas por cajas se comporta según el modelo de probabilidad Poisson. 8.4.4.5.- Ejercicios de Aplicación Propuestos 1.- Se realizó una encuesta para evaluar la eficacia de una nueva vacuna contra la gripe y el resfrío, que fue aplicada en una ciudad, en el período de otoño La vacuna se proporcionó de forma gratuita en una secuencia de dos inyecciones en un período de dos semanas a quienes desearan aprovecharla. Algunas personas recibieron las dos inyecciones, otras se presentaron solamente a la primera inyección y otras no recibieron ninguna inyección.
Una encuesta aplicada a 1000 personas de la ciudad al inicio del período de verano, proporcionó la siguiente información.
Ninguna inyección Una inyección Dos inyecciones Total
Gripe 24 9 13 46
No gripe 289 100 565 954
Total 313 109 578 1000
¿Presentan los datos suficiente evidencia para indicar una dependencia entre la clasificación según la vacunación y la ocurrencia o no de la gripe?
2.- Una compañía opera cuatro máquinas en tres turnos al día. De los registros de producción , se obtienen los datos siguientes sobre el número de fallas.
M á q u i n a s
TURNO A B C D 1 41 20 12 16
2 31 11 9 14
3 15 17 16 10
Pruebe la hipótesis (con α= 0,05) de que el número de fallas es independiente de l turno.

172
3.- Un estudio que se realizó con una muestra de 81 personas referente a la relación entre la cantidad de violencia vista en la televisión y la edad del televidente entregó los siguientes resultados.
E D A D
Grado de violencia vista en televisión
16 - 34 35 - 54 55 o más
Poca violencia 8 12 21
Mucha violencia 18 15 7
¿Indican los datos que ver violencia en la televisión depende de la edad del televidente?
Use α=0,05
4.- El número de llamadas que se reciben en un tablero de central telefónica desde la 8:01 a las 8:01 de la mañana durante un período de 100 días es el siguiente
Número de llamadas 0 1 2 3 4 5 6 7 Total
Frecuencia 3 10 25 30 15 12 5 0 100
A un nivel de significancia α=0,05 pruebe la hipótesis de la frecuencia observada proviene de :
a).- Una distribución de Poisson
b).- Una distribución Binomial
5.- La estatura de 205 empleados en una industria presenta la siguiente distribución de frecuencia
Estatura ( cm ) Frecuencia Observada 150 - 155 9
155 - 160 20
160 - 165 45
165 - 170 55
170 - 175 43
175 - 180 17
180 - 185 11
185 - 190 5
A un nivel de significancia α=0,05 pruebe la hipótesis de la frecuencia observada proviene de una distribución Normal:

173
VIII.- ANÁLISIS DE VARIANZA Las técnicas de Diseño Experimental basadas en la estadística son particularmente útiles en el mundo de la Ingeniería en lo que corresponde a la mejora del rendimiento de los procesos de manufactura. Estas técnicas también tienen una extensa aplicación en el desarrollo de nuevos procesos. Muchos procesos pueden describirse en términos de varias variables controladas o controlables, tales como temperatura, presión, Ph, concentración, etc. Mediante el empleo de experimentos diseñados , los ingenieros pueden determinar el subconjunto de variables del proceso que tienen mayor influencia sobre el rendimiento de éste.. Los resultados de estos experimentos pueden conducir a:
1.- Mejorar el rendimiento del proceso 2.- Reducir la variabilidad del proceso y acercarlo a los requerimientos nominales 3.- Disminución de los tiempos de diseño y desarrollo 4.- Disminución de los costos de operación
Los métodos de diseño experimental también son útiles en las actividades de ingeniería de diseño, donde se desarrollan nuevos productos y se mejoran los existentes. Algunas aplicaciones representativas de los experimentos diseñados de manera estadística en la ingeniería de diseño incluyen: 1.- Evaluación y comparación de configuración de diseños básicos 2.- Evaluación de materiales diferentes ocupados con un mismo fin 3.- Selección de parámetros de diseño de modo que el producto funcione bien bajo una amplia gama de condiciones de campo o de operación ( diseño robusto ).
4.- Determinación de los parámetros de diseño importantes del producto que tienen impacto sobre el funcionamiento de éste.
El empleo del diseño experimental en el proceso de diseño puede dar como resultado productos que son más fáciles de fabricar, productos que tienen un desempeño y una confiabilidad mejores que los de la competencia, y productos que pueden diseñarse, desarrollarse y producirse en menor tiempo.
Los experimentos diseñados se utilizan, de manera usual, secuencialmente. Esto es, el primer experimento con un sistema complejo (quizás un proceso de fabricación) que tiene muchas variables controladas es, a menudo, un experimento de diagnóstico diseñado para determinar qué variables son las más importantes. Los experimentos que siguen a éste se utilizan para refinar la información y determinar los ajustes que deben hacerse a las variables críticas para mejorar el proceso. Finalmente el objetivo del experimentador es la optimización, es decir, la determinación de los niveles que deben tener las variables críticas para obtener el mejor desempeño del proceso. Todo experimento implica una secuencia de actividades: 1.- Conjetura : La hipótesis original que motiva el experimento 2.- Experimento : Prueba efectuada para investigar la conjetura. 3.- Análisis : Análisis estadístico de los datos obtenidos del experimento. 4.- Conclusión : Lo que se ha aprendido de la conjetura original con la realización del experimento. A menudo , éste conduce a una nueva conjetura y a un nuevo experimento , y así sucesivamente.

174
Los experimentos diseñados estadísticamente permiten eficiencia y economía en el proceso experimental, y el empleo de los métodos estadísticos para el análisis de los datos brinda objetividad científica al obtener conclusiones
Uno de los métodos estadísticos para analizar los experimentos diseñados estadísticamente es el Análisis de Varianza . 9.1.- Experimento completamente aleatorizado , de un solo factor. Es evidente que en una investigación determinada podemos estudiar el efecto o la respuesta que se produce en la unidad de experimentación por el hecho de haberles aplicado alguna variable independiente controlable. En diseño , particularmente estas variables reciben el nombre genérico de tratamientos ( o combinación de tratamientos ) , que implica el conjunto particular de condiciones experimentales que deben imponerse a una unidad experimental dentro de los marcos en que se efectúa el diseño. La combinación de tratamientos y su acción combinada recibe el nombre de interacción. En muchas oportunidades el término tratamiento se indica o denomina como Factor , el cual puede ser: 1.- Cualitativos: Como máquinas diferentes, operarios, ubicación geográfica, tipo de material utilizado, etc. 2.- Cuantitativos: Como temperatura, presión, dosificación de reactivos , concentración, tiempo de residencia , etc. Debido a su simplicidad, este diseño es ampliamente utilizado. Sin embargo, el ingeniero o investigador debe ser cauteloso de que su uso debe limitarse a aquellos casos en que se dispone de material o unidades experimentales lo más homogéneas posibles, y el número de tratamientos es pequeño (menor o igual que 5 ).
La matriz de datos obtenidos de un diseño experimental a un factor, el que tiene k niveles o tratamientos, generalmente presenta la siguiente estructura.
Tratamientos 1
2 3 4 k
Y11 Y12 Y13 Y14 Y15 . . . 11nY
Y21 Y22 Y23 Y24 Y25 . . . 22nY
Y31 Y32 Y33 Y34 Y35 . . . 33nY
Y41 Y42 Y43 Y44 Y45 . . . 44nY
Yk1 Yk2 Yk3 Yk4 Yk5 . . . kk nY
Totales por tratamientos
Promedios por tratamientos

175
En el Análisis de Varianza a un Factor en interés está centrado en probar la igualdad de los promedios μ1, μ2 , μ3 ,............, μk. Las observaciones de la tabla anterior pueden describirse con el Modelo estadístico Lineal
Yij = μ + τi + εij i = 1 , 2 , 3,............k ; j = 1 ,2, 3, ………ni
Donde Yij = Es una variable aleatoria que denota la (ij)-ésima observación. μ es una parámetro común a todos los tratamientos denominado Media Global τ i es un parámetro asociado con el i-ésimo tratamiento denominado efecto del i-ésimo tratamiento ε ij es un componente de error aleatorio que se comporta según el modelo normal de probabilidades , con promedio igual a cero y varianza σ2 constante , y no correlacionados entre sí La prueba de hipótesis consiste en probar H0 de que no existen diferencias estadísticamente significativas, en los efectos promedios de los distintos niveles del factor contra la hipótesis alternativa H1 de que existe algún efecto promedio que difiere significativamente de los demás. Es decir :
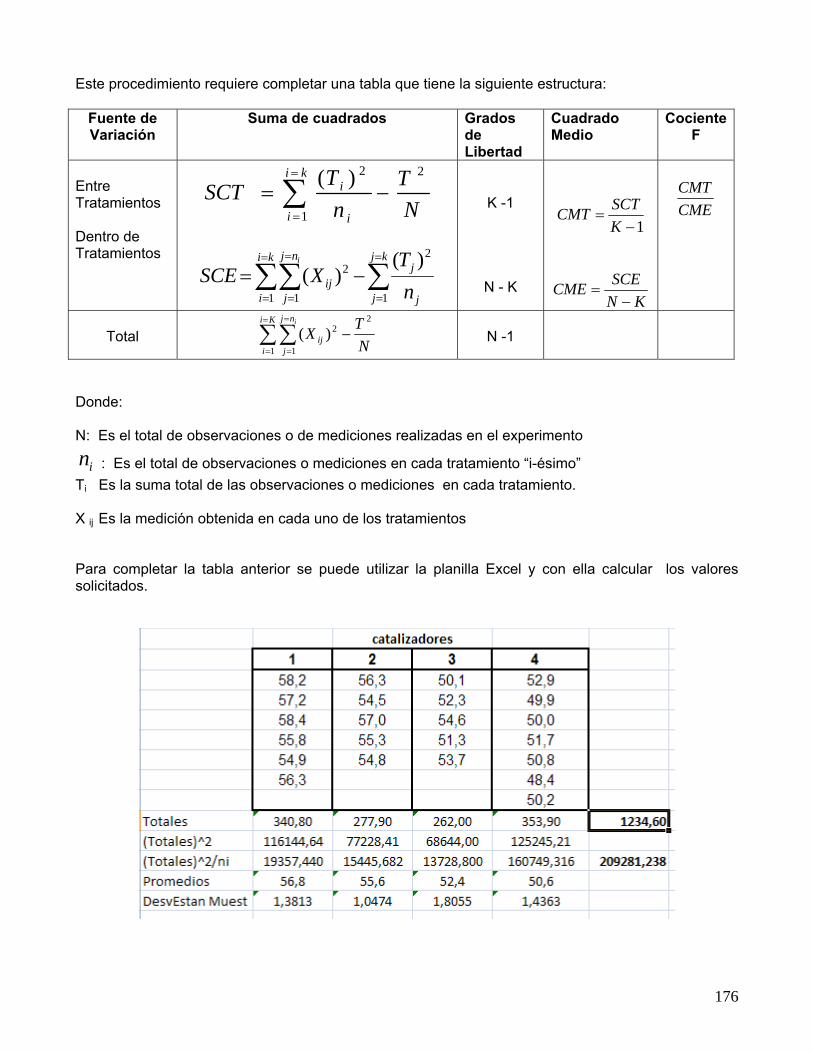
H0 : τ1 = τ2 = .............= τk v/s H1 : τi ≠ τj para algún i ≠ j Ejemplo: Se están investigando cuatro catalizadores que pueden afectar la concentración de un
componente en una mezcla líquida. Se obtuvieron las siguientes concentraciones
Catalizador
1
2
3
4
58,2 57,2 58,4 55,8 54,9 56,3
56,3 54,5 57,0 55,3 54,8
50,1 52,3 54,6 51,3 53,7
52,9 49,9 50,0 51,7 50,8 48,4 50,2
Desarrollo: a) Las hipótesis a probar son:
H0 : No existen diferencias estadísticamente significativas en las concentraciones promedios de los catalizadores utilizados. H1 : Existe algún catalizador que produce un efecto promedio en la concentración, que difiriere significativamente de los demás.
176
Este procedimiento requiere completar una tabla que tiene la siguiente estructura:
Fuente de Variación
Suma de cuadrados Grados de Libertad
Cuadrado Medio
CocienteF
Entre Tratamientos
Dentro de Tratamientos
NT
nTSCT
ki
i i
i2
1
2)(−= ∑
=
=
∑∑∑=
=
=
=
=
=
−=kj
j j
jki
i
nj
jij n
TXSCE
i
1
22
1 1
)()(
K -1
N - K
1−=
KSCTCMT
KNSCECME−
=
CMECMT
Total N
TXKi
i
nj
jij
i 2
1 1
2)( −∑∑=
=
=
=
N -1
Donde: N: Es el total de observaciones o de mediciones realizadas en el experimento
in : Es el total de observaciones o mediciones en cada tratamiento “i-ésimo” Ti Es la suma total de las observaciones o mediciones en cada tratamiento. X ij Es la medición obtenida en cada uno de los tratamientos Para completar la tabla anterior se puede utilizar la planilla Excel y con ella calcular los valores solicitados.
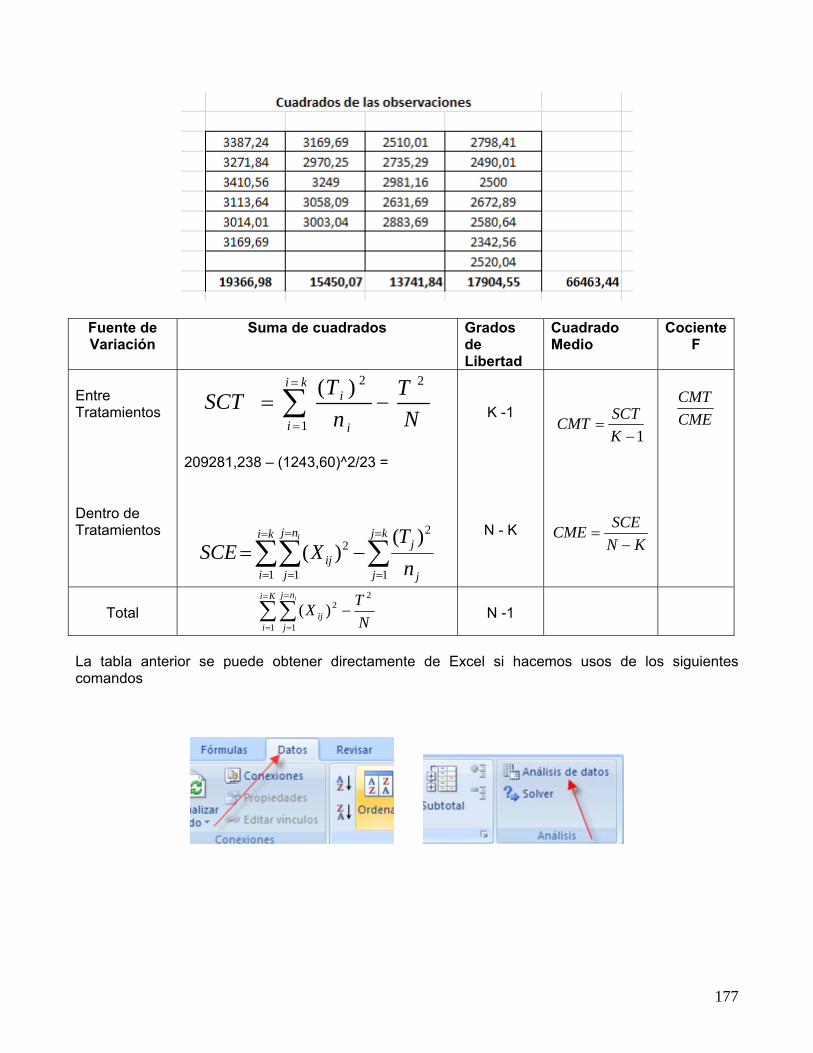
177
Fuente de Variación
Suma de cuadrados Grados de Libertad
Cuadrado Medio
CocienteF
Entre Tratamientos
Dentro de Tratamientos
NT
nTSCT
ki
i i
i2
1
2)(−= ∑
=
=
209281,238 – (1243,60)^2/23 =
∑∑∑=
=
=
=
=
=
−=kj
j j
jki
i
nj
jij n
TXSCE
i
1
22
1 1
)()(
K -1
N - K
1−=
KSCTCMT
KNSCECME−
=
CMECMT
Total N
TXKi
i
nj
jij
i 2
1 1
2)( −∑∑=
=
=
=
N -1
La tabla anterior se puede obtener directamente de Excel si hacemos usos de los siguientes comandos
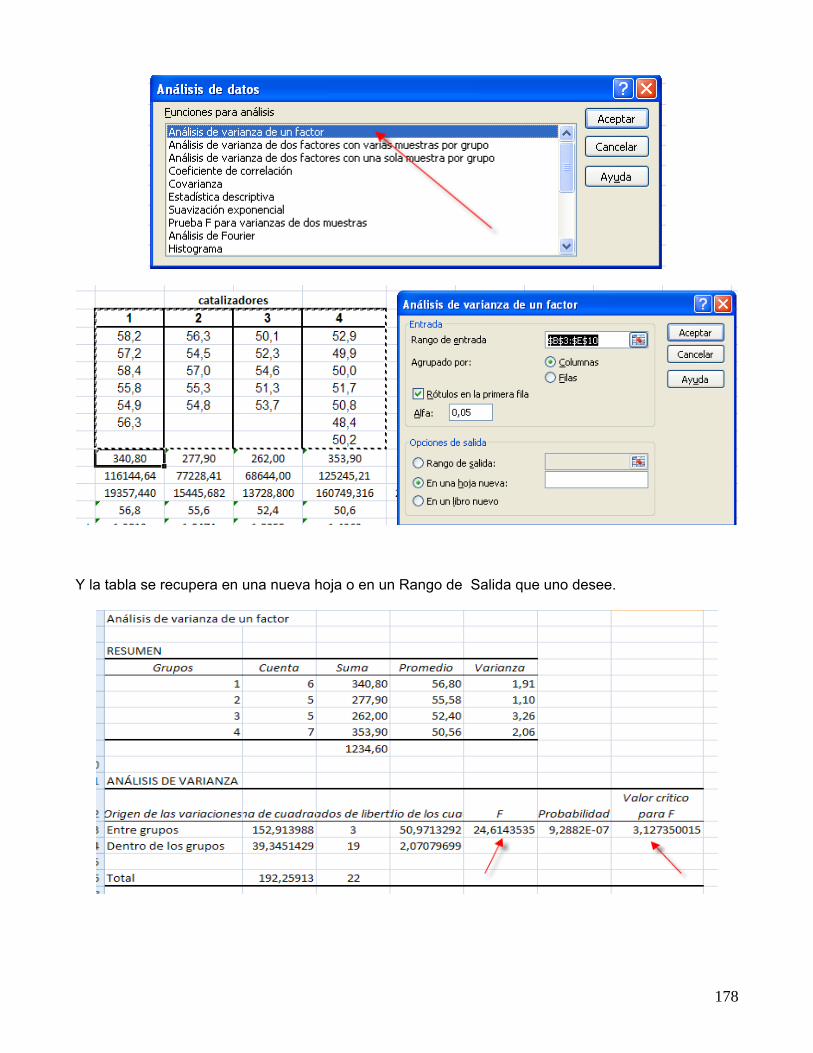
178
Y la tabla se recupera en una nueva hoja o en un Rango de Salida que uno desee.
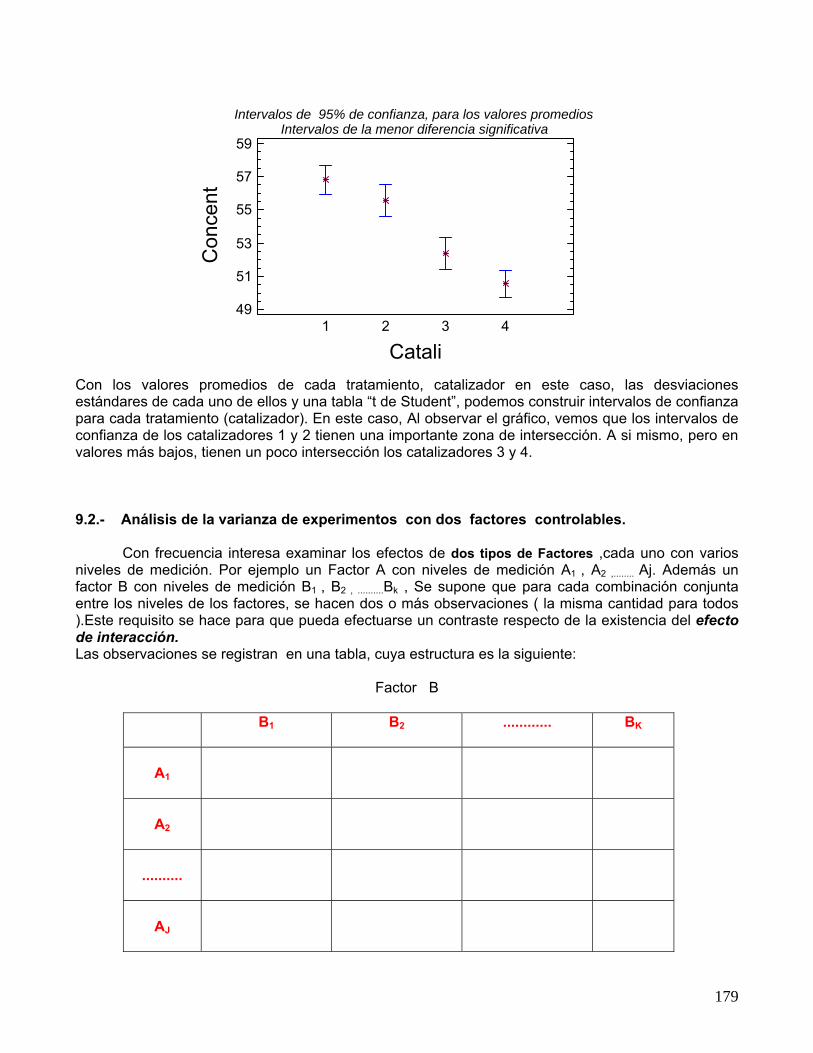
179
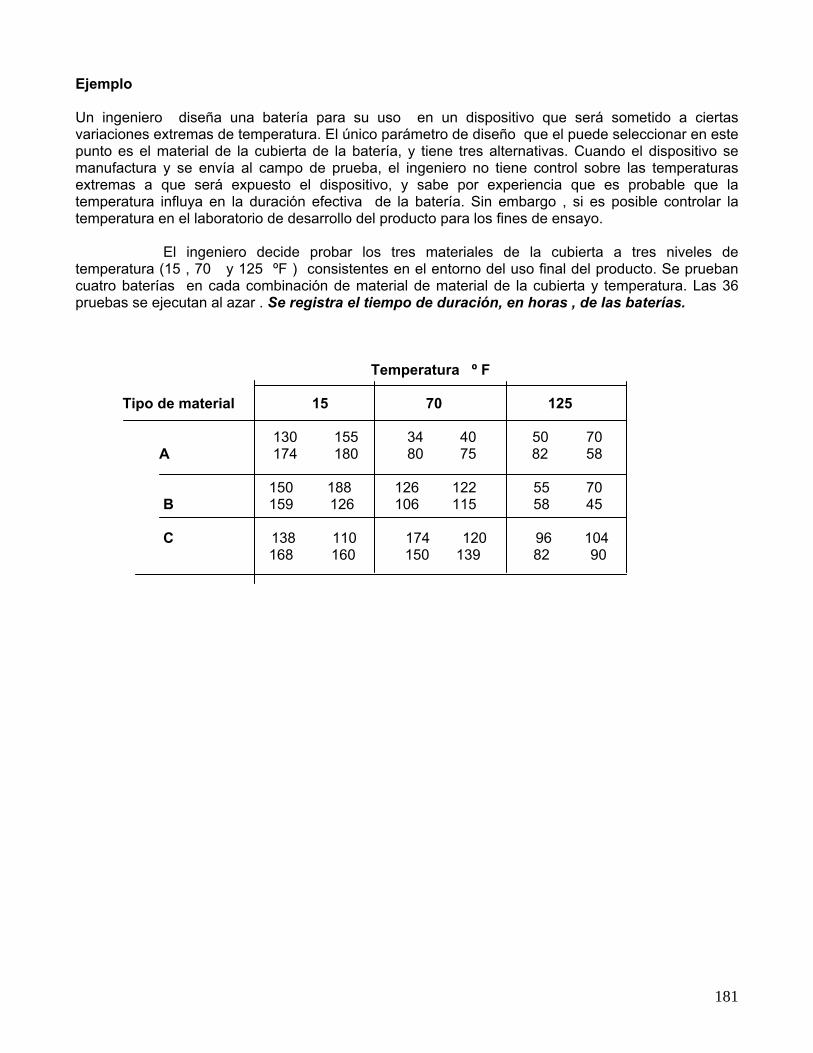
Con los valores promedios de cada tratamiento, catalizador en este caso, las desviaciones estándares de cada uno de ellos y una tabla “t de Student”, podemos construir intervalos de confianza para cada tratamiento (catalizador). En este caso, Al observar el gráfico, vemos que los intervalos de confianza de los catalizadores 1 y 2 tienen una importante zona de intersección. A si mismo, pero en valores más bajos, tienen un poco intersección los catalizadores 3 y 4.
9.2.- Análisis de la varianza de experimentos con dos factores controlables. Con frecuencia interesa examinar los efectos de dos tipos de Factores ,cada uno con varios niveles de medición. Por ejemplo un Factor A con niveles de medición A1 , A2 ,........ Aj. Además un factor B con niveles de medición B1 , B2 , ..........Bk , Se supone que para cada combinación conjunta entre los niveles de los factores, se hacen dos o más observaciones ( la misma cantidad para todos ).Este requisito se hace para que pueda efectuarse un contraste respecto de la existencia del efecto de interacción. Las observaciones se registran en una tabla, cuya estructura es la siguiente:
Factor B
B1
B2 ............ BK
A1
A2
..........
AJ
Intervalos de 95% de confianza, para los valores promedios
Catali
Con
cent
Intervalos de la menor diferencia significativa
1 2 3 449
51
53
55
57
59

180
El modelo estadístico lineal que lo describe es: Yij = μ + τi + βj + (τβ)ij εijk i = 1 , 2 , 3,.......a ; j = 1 ,2, 3, .. …b ; k = 1,2,…….n
Donde Yij = Es una variable aleatoria que denota la ij-ésima observación.
μ es una parámetro común a todos los tratamientos denominado Media Global
τ i es el efecto del i -ésimo nivel factor τ
β j es el efecto del j-ésimo nivel del factor β
(τβ )ij es el efecto de interacción de los factores τ y β
ε ij k es un componente de error aleatorio que se comporta según el modelo normal de probabilidades , con promedio igual a cero y varianza σ2 constante , y no correlacionados entre sí.
En este modelo se deben probar tres hipótesis a saber:
1.- En primer lugar debe establecerse si es significativo es el efecto de interacción entre los factores principales. 2.- Si existen diferencias significativas en los efectos promedio del factor A .
3.- Si existen diferencias significativas en los efectos promedio del factor B Para discutir o analizar las hipótesis planteadas se necesita una base de datos empírica que contenga los datos maestrales que represente a los efectos planteados en las hipótesis. Para ello, se descompone la medida de la variabilidad total, en términos que recojan la variabilidad debido a los tratamientos o niveles del Factor A . La variabilidad debida debido a los tratamientos o niveles de medición del factor B , la variabilidad debida a la interacción entre los factores , y por último , la ocasionada por el error aleatorio muestral ε ij k.
Por ejemplo, en la investigación de mercados , se pueden clasificar los vendedores por dos factores, tales como el segmento o intervalo de edad (A) y su nivel de escolaridad (B). El objetivo podría ser determinar si la edad y el nivel de escolaridad o formación alcanzada tiene algún efecto significativo sobre el volumen de ventas. Tal vez interese no solo el efecto individual de cada uno de estos dos factores sino también el efecto conjunto o interacción.
Los cálculos fundamentales del análisis de varianza se realizarán utilizando un software
estadístico. En todo caso a continuación se plantea un problema para visualizar mejor los aspectos enunciados.
181
Ejemplo Un ingeniero diseña una batería para su uso en un dispositivo que será sometido a ciertas variaciones extremas de temperatura. El único parámetro de diseño que el puede seleccionar en este punto es el material de la cubierta de la batería, y tiene tres alternativas. Cuando el dispositivo se manufactura y se envía al campo de prueba, el ingeniero no tiene control sobre las temperaturas extremas a que será expuesto el dispositivo, y sabe por experiencia que es probable que la temperatura influya en la duración efectiva de la batería. Sin embargo , si es posible controlar la temperatura en el laboratorio de desarrollo del producto para los fines de ensayo.
El ingeniero decide probar los tres materiales de la cubierta a tres niveles de
temperatura (15 , 70 y 125 ºF ) consistentes en el entorno del uso final del producto. Se prueban cuatro baterías en cada combinación de material de material de la cubierta y temperatura. Las 36 pruebas se ejecutan al azar . Se registra el tiempo de duración, en horas , de las baterías.
Temperatura º F
Tipo de material 15 70 125 130 155 34 40 50 70 A 174 180 80 75 82 58 150 188 126 122 55 70 B 159 126 106 115 58 45 C 138 110 174 120 96 104 168 160 150 139 82 90

182
Metodología de solución y análisis del problema 1º Paso: Para resolver este tipo de problemas o ejemplos ,debe crear un archivo en Statgraphics que contenga tres columnas o variables . Es decir, construir la Base de Datos. Una de ellas deben contener el tipo de material ( Factor ). Otra columna de contener los niveles de temperatura (Factor B ) . Una tercera columna debe contener el valor de la medición (respuesta cuantitativa) .Por ejemplo:
Tip_ Mat Temp Duración A 15 130 A 15 155 A 15 174 A 15 180 A 70 34 A 70 40 A 70 80 A 70 75 A 125 50 A 125 70 A 125 82 A 125 58 B 15 150 B 15 188B 15 159 B 15 126
……. …….. ……..
C 125 96 C 125 104 C 125 82 C 125 90
2º Paso: Redactar las hipótesis a probar , en el contexto del enunciado del problema
• H0 : No existen diferencias estadísticamente significativas en la duración de las baterías , según el tipo de material utilizado. H1 : Existe algún tipo de material utilizado en la fabricación de las baterías que produce una duración promedio significativamente diferente a los demás.
• H0 : No existen diferencias estadísticamente significativas en la duración de las baterías , según la temperatura de trabajo a la que sean sometidas.
H1 : Existe alguna temperatura de trabajo a la que se someten las baterías de las baterías que produce una duración promedio significativamente diferente a las demás.

183
H0: No existe una interacción significativa entre tipo de material utilizado y la temperatura de trabajo, que produzca duraciones promedios significativamente diferentes en la duración de las baterías. H1: Existe una interacción significativa entre algún tipo de material utilizado y alguna temperatura de trabajo, que producen duraciones promedios significativamente diferentes en la duración de las baterías. ANOVA Factorial - Duración -------------------------------------------------------------------------------- Fuente Suma de cuadrados GL Cuadrado Medio Cociente-F P-Valor --------------------------------------------------------------------------------
EFECTOS PRINCIPALES A:Temp 40110,4 2 20055,2 53,58 0,0000 B:Tip_ Mat 6772,06 2 3386,03 9,05 0,0010 INTERACCIONES AB 12948,8 4 3237,19 8,65 0,0001 RESIDUOS 10105,7 27 374,287 -------------------------------------------------------------------------------- TOTAL (CORREGIDO) 69937,0 35 -------------------------------------------------------------------------------- Los cocientes F están basados en el error cuadrático medio residual.
Gráficos para los valores promedios, en cada uno de los niveles del factor
Gráficos para los valores promedio de las interacciones o combinaciones de niveles de los factores involucrados.

184

185
Taller de Análisis de la Varianza
A.- Análisis de la Varianza a un Factor 1.- Se están investigando cuatro catalizadores que pueden afectar la concentración de un componente en una mezcla líquida formada por tres componentes. Se obtuvieron las siguientes concentraciones: a).- ¿Producen los catalizadores el mismo efecto promedio en la concentración del componente en la mezcla líquida?. Redacte y pruebe las hipótesis planteadas. b).- Determine los intervalos de confianza del 95 % para el efecto promedio producido por cada catalizador. Muestre la situación anterior, de forma gráfica.
c).- En caso de ser rechazada la hipótesis H0, aplique pruebas de comparaciones múltiples para identificar los que tienen efectos promedios similares y los que son diferentes. 2.- Se están estudiando tres marcas de baterías. Se sospecha que la duración (en semanas) de las tres marcas es diferente. Se prueban cinco baterías de cada marca y los resultados que se obtienen son los siguientes.
Semanas de duración
Marca 1 Marca 2 Marca 3 100
96
92
96
92
76
80
75
84
82
108
100
96
98
100
Aplique la metodología de trabajo indicada al inicio del taller, para verificar si los datos proporcionan evidencia suficiente que indiquen una diferencia significativa en la duración promedio de las baterías.
a).- ¿Tienen las baterías el mismo tiempo promedio de duración?. Redacte y pruebe las hipótesis planteadas. b).- Determine los intervalos de confianza del 95 % para el tiempo promedio por cada batería. Muestre la situación anterior, de forma gráfica. ¿Cuál batería usaría usted y por qué?
c).- En caso de ser rechazada la hipótesis H0 , aplique pruebas de comparaciones múltiples para identificar las baterías que tienen duración promedios similares y las que son diferentes.
d).- Determine un intervalo de confianza del 95 % para la diferencia entre los tiempo promedios de duración entre las baterías 2 y 3.
Catalizador 1 58,2 57,2 58,4 55,8 54,9 Catalizador 2 56,3 54,5 57,0 55,3 Catalizador 3 50,1 54,2 55,4 Catalizador 4 52,9 49,9 50,0 51,7
186
3.- Se está estudiando la resistencia a la tensión de Cemento Pórtland. Cuatro técnicas de mezclado pueden ser usadas económicamente. Se han recolectado los siguientes datos. Técnica de mezclado Resistencia a la tensión (lb / plg 2 )
1 3129 3000 2865 2890 2 3200 3300 2975 3150 3 2800 2900 2985 3050 4 2600 2700 2600 2765
Aplique la metodología de trabajo indicada al inicio del taller, para verificar si los datos proporcionan evidencia suficiente que indiquen si la resistencia a la tensión del cemento, varía según la técnica de mezclado.
a).- Redacte y pruebe las hipótesis para probar si existen diferencias estadísticamente significativas en la resistencia promedio a la tensión, según la técnica de mezclado. b).- Determine intervalos de confianza para la resistencia media de cada una de la técnicas de mezclado. Construya la gráfica para cada caso. 4.- Una pequeña fábrica de textiles cuenta con cinco telares. Se supone que tienen la misma producción de tela por minuto. Para investigar esta suposición, se mide la cantidad de tela producida en cinco tiempos diferentes. Se obtienen los datos siguientes.
Telar Producción (lb / min) 1 14,0 14,1 14,2 14,0 14,1 2 13,9 13,8 13,9 14,0 14,0 3 14,1 14,2 14,1 14,0 13,9 4 13,6 13,8 14,0 13,9 13,7 5 13,8 13,6 13,9 13,8 14,0
Aplique la metodología de trabajo indicada al inicio del taller, para verificar si los datos proporcionan evidencia suficiente que indiquen una diferencia significativa en la producción media de los Telares.
a).- Redacte y pruebe las hipótesis para probar si existen diferencias estadísticamente significativas en la producción promedio de los telares. b).- Determine intervalos de confianza para la producción media para cada uno de los telares. Construya la gráfica para cada caso. 5.- Se desea comprobar si ciertos cambios en el proceso de fabricación del cemento aumentan su resistencia a la compresión. Para ello, se compara la resistencia de probetas construidas con el método tradicional, (método A), con aquellas fabricadas mediante los procedimientos que se desean probar (métodos B y C). Los datos originales se han expresado en unidades convenientes para facilitar los cálculos.
Método A Método B Método C 16 14 42 38 23
27 30 26 20 76
61 33 37 63 65

187
Aplique la metodología de trabajo indicada al inicio del taller, para verificar si los datos proporcionan evidencia suficiente que indiquen una diferencia significativa en la resistencia promedio a la compresión, según el método utilizado.
¿Qué resultados podemos concluir de los datos anteriores, aplicando los conceptos vistos para el análisis de la varianza a un factor?.
6.- Cuatro grupos de vendedores de una agencia de ventas de revistas fueron sometidos a diferentes programas de entrenamiento en ventas. Debido a que hubo varias deserciones durante el entrenamiento, el número de personas fue diferente para cada grupo. Al final del programa de entrenamiento, a cada vendedor le fue asignada aleatoriamente una zona de ventas de entre un grupo de zonas que tienen aproximadamente el mismo potencial de ventas. En la tabla siguiente aparece el número de ventas efectuadas por cada uno de los vendedores de cada grupo durante la primera semana posterior al entrenamiento.
Grupo de entrenamiento 1 2 3 4 65 87 73 79 81 69
75 69 83 81 72 79 90
59 78 67 62 83 76
94 89 80 88
Aplique la metodología de trabajo indicada al inicio del taller, para verificar si los datos proporcionan evidencia suficiente que indiquen una diferencia significativa en las ventas promedio, según el programa de entrenamiento.
¿Hay suficiente evidencia que indique una diferencia estadísticamente significativa en los resultados promedio de los cuatro programas de entrenamiento?. Redacte un informe completo de la situación analizada.
188
7.- Con el propósito de compara los precios del pan ( de un tipo específico) , se llevó a cabo un experimento en cuatro zonas de una ciudad. En cada una de las zonas , 1, 2, 3 y 4 , se tomaron muestras en los lugares donde se expende el producto. Se consulto por el precio del kilo de pan. El precio está dado en pesos ($ )
Zona
1 2 3 4
590
630
650
610
640
580
600
610
580
610
640
630
570
600
630
600
550
590
550
580
590
560
600
550
690
700
680
700
660
710
690
Aplique la metodología de trabajo indicada al inicio del taller, para verificar si los datos proporcionan evidencia suficiente que indiquen una diferencia significativa en el precio promedio del pan , según la zona de la ciudad.
Usando un intervalo de confianza del 95 % , estime la diferencia de precio promedio entre las zonas 1 y 4.
8.- Una agencia gubernamental para la protección del medio ambiente ha establecido reglamentos muy estrictos para el control de los desechos de las fábricas. Una empresa tiene cuatro plantas y sabe que la planta “A” satisface los requisitos impuestos por el gobierno, pero quisiera determinar cuál es la situación de las otras tres. Para tal efecto se toman cinco muestras de los líquidos residuales de cada una de las plantas y se determina la cantidad de contaminantes. Los resultados del experimento aparecen en la tabla siguiente:
Planta Cantidad de Contaminantes
A 1,65 1,72 1,50 1,37 1,60
B 1,70 1,85 1,46 2,05 1,80
C 1,40 1,75 1,38 1,65 1,55
D 2,10 1,95 1,65 1,88 2,00
Aplique la metodología de trabajo indicada al inicio del taller, para verificar si los datos proporcionan evidencia suficiente que indiquen una diferencia significativa en la cantidad media de contaminantes para las cuatros plantas. Además use intervalos de confianza del 90% para estimar la diferencia de la cantidad promedio de desechos contaminantes en las plantas A y B : Entre las plantas A y C . Entre las plantas A y D

189
9.- Se ha realizado un experimento para determinar si cuatro temperaturas específicas de horneado afectan la densidad de un cierto tipo de ladrillo. El experimento proporciona los siguientes datos:
Temperatura
100 125 150 175
21,8
21,9
21,7
21,6
21,7
21,7
21,4
21,5
21,4
21,9
21,8
21,8
21,6
21,5
21,9
21,7
21,8
21,4
Aplique la metodología de trabajo indicada al inicio del taller, para verificar si los datos proporcionan evidencia suficiente que indiquen una diferencia en la densidad del ladrillo, según la temperatura de horneado. ¿Qué densidades medias, según la temperatura de horneado difieren significativamente?
10.- Un fabricante de equipos de televisión está interesado en el efecto que tienen sobre la conductividad de los cinescopios de televisión a color, cuatro diferentes tipos de recubrimiento. Se obtuvieron los siguientes datos de conductividad:
Tipo de Recubrimiento
1 2 3 4
143
141
150
146
152
149
137
143
134
136
132
127
129
127
132
129
Aplique la metodología de trabajo indicada al inicio del taller, para verificar si los datos proporcionan evidencia suficiente que indiquen una diferencia significativa en la conductividad promedio, según el tipo de recubrimiento. ¿Cuál es el tipo de recubrimiento que produce la máxima conductividad, y entre que valores se comporta el 95% de la veces?
11.- Se estudia la duración efectiva de líquidos aislantes a una carga acelerada de 35 Kw. Se han obtenido datos de prueba para cuatro tipos de líquidos. Se obtienen los siguientes resultados.
Tipo de Líquido
1 2 3 4
17,6 16,9 21,4 19,3

190
18,9
16,3
17,4
20,1
21,6
15,3
18,6
17,1
19,5
20,3
23,6
19,4
18,5
20,5
22,3
21,1
16,9
17,5
18,3
19,8
Aplique la metodología de trabajo indicada al inicio del taller, para verificar si los datos proporcionan evidencia suficiente que indiquen una diferencia significativa en la duración promedio entre los tipos de líquidos aislantes?.
12.- Un fabricante supone de que existen diferencias en el contenido de calcio en lotes de materia que le son suministrados por su proveedor. Actualmente hay cinco lotes en la bodega. Un analista químico realiza cinco pruebas sobre cada lote y obtiene los siguientes resultados:
Lote 1 Lote 2 Lote 3 Lote 4 Lote 5
23,46
23,48
23,56
23,39
23,40
23,59
23,46
23,42
23,49
23,50
23,51
23,64
23,46
23,52
23,49
23,39
23,49
23,52
23,46
23,32
23,40
23,50
23,49
23,39
23,38
Aplique la metodología de trabajo indicada al inicio del taller, para verificar si los datos proporcionan evidencia suficiente que indiquen una diferencia significativa en el contenido de calcio de un lote a otro.
13.- En una forja se utilizan tres hornos para calentar muestras de metal. Se supone que todos los hornos operan a la misma temperatura, aunque se sospecha que quizás esto probablemente no es cierto. Se calientan los hornos y se registran sus temperaturas. Los resultados son:
Horno

191
1 2 3
491,50
498,30
498,10
493,50
493,60
488,50
484,65
479,90
477,35
490,10
484,80
488,25
473,00
471,85
478,65
Aplique la metodología de trabajo indicada al inicio del taller, para verificar si los datos proporcionan evidencia suficiente que indiquen una diferencia significativa en las temperatura promedio alcanzada por cada horno.
B- Análisis de la Varianza a dos Factores B.1.- En un artículo publicado en Industrial Quality Control , se describe un experimento para investigar el efecto del tipo de vidrio y el tipo de fósforo sobre la brillantez de un cinescopio de televisor. La variable de respuesta es la corriente necesaria ( en micro amperes) para obtener un nivel de brillantez especificado. Los datos son:
Tipo de fósforo Tipo de
vidrio 1 2 3
1
280
290
285
300
310
295
290
285
290
2
230
235
240
260
240
235
220
225
230
a).- Existe evidencia de que alguno de los factores influya en la brillantez
b).- Interactúan entre si ambos factores
B.2.- Se encuentra en estudio el rendimiento de un proceso químico. Se cree que las dos variables más relevantes son la presión y la temperatura. Se seleccionan tres niveles de cada factor y se realiza un experimento factorial con dos réplicas. Se recopilan los siguientes datos:
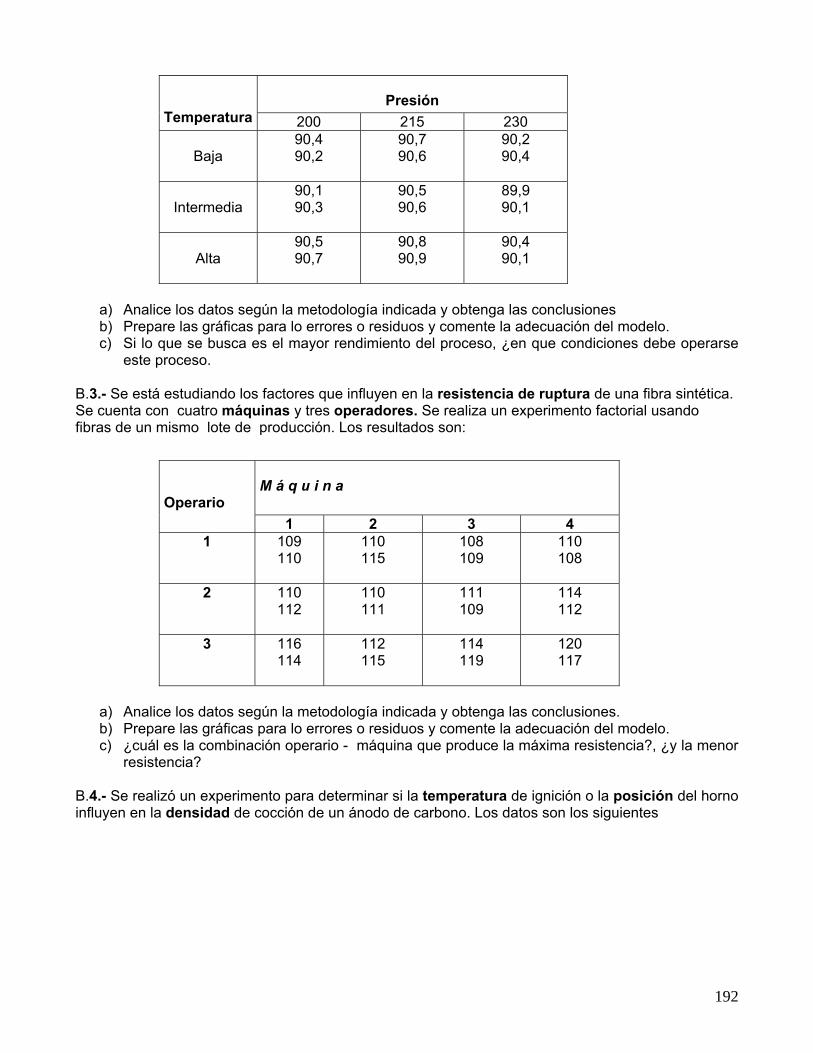
192
Presión
Temperatura 200 215 230
Baja
90,4 90,2
90,7 90,6
90,2 90,4
Intermedia
90,1 90,3
90,5 90,6
89,9 90,1
Alta
90,5 90,7
90,8 90,9
90,4 90,1
a) Analice los datos según la metodología indicada y obtenga las conclusiones b) Prepare las gráficas para lo errores o residuos y comente la adecuación del modelo. c) Si lo que se busca es el mayor rendimiento del proceso, ¿en que condiciones debe operarse
este proceso.
B.3.- Se está estudiando los factores que influyen en la resistencia de ruptura de una fibra sintética. Se cuenta con cuatro máquinas y tres operadores. Se realiza un experimento factorial usando fibras de un mismo lote de producción. Los resultados son:
a) Analice los datos según la metodología indicada y obtenga las conclusiones. b) Prepare las gráficas para lo errores o residuos y comente la adecuación del modelo. c) ¿cuál es la combinación operario - máquina que produce la máxima resistencia?, ¿y la menor
resistencia? B.4.- Se realizó un experimento para determinar si la temperatura de ignición o la posición del horno influyen en la densidad de cocción de un ánodo de carbono. Los datos son los siguientes
M á q u i n a
Operario 1 2 3 4
1
109 110
110 115
108 109
110 108
2
110 112
110 111
111 109
114 112
3
116 114
112 115
114 119
120 117

193
T e m p e r a t u r a Posición 800 825 850
1
570 565 583
1063 1080 1043
565 510 590
2
528 547 521
988 1026 1004
526 538 532
a) Analice los datos según la metodología indicada y obtenga las conclusiones. b) Prepare las gráficas para lo errores o residuos y comente la adecuación del modelo. c) ¿Qué combinación Temperatura – Posición recomendaría usted si se desea una mayor
densidad a un menor costo? (observación: se supone que una mayor temperatura eleva los costos)
B.5.- Un ingeniero mecánico estudia la fuerza de empuje producida por un taladro. Sospecha que los factores más importantes son las revoluciones de la broca y la alimentación. Ser realiza un experimento con cuatro niveles de alimentación, y se usan los niveles de rotación baja y alta para representar las condiciones de operación de la máquina. Se obtienen los siguientes datos.
Rapidez de alimentación
Velocidad de la broca
0,015
0,030
0,045
0,060
125
2,70 2,78
2,45 2,49
2,60 2,72
2,75 2,86
200
2,83 2,86
2,85 2,80
2,86 2,87
2,94 2,88
a) Analice los datos según la metodología indicada y obtenga las conclusiones. b) Prepare las gráficas para lo errores o residuos y comente la adecuación del modelo.

194
B.6.- Una ingeniera de manufactura sospecha que la terminación de la superficie de una pieza metálica depende de la alimentación y de la profundidad de corte. Se prueban tres niveles de alimentación con cuatro niveles de profundidad de corte. Se colectan los siguientes datos:
Profundidad de corte (plg) Rapidez de Alimentación (plg/min)
0,15 0,18 0,20 0,25
0,20
74 64 60
79 68 73
82 88 92
99 104 96
0,25
92 86 88
98 104 88
99 108 95
104 110 99
0,30
99 98
102
104 99 95
108 110 99
114 111 107
a) Analice los datos según la metodología indicada y obtenga las conclusiones. b) Prepare las gráficas para lo errores o residuos y comente la adecuación del modelo. c) ¿Qué combinación de los niveles de los factores hace que se obtenga la mejor calidad de
terminación en la superficie?, ¿Cuál combinación hace que se obtenga la peor calidad? Los datos de los siguientes problemas, son el resultado de experimentos con dos factores controlados u observados. Un aspecto a considerar es que solo tienen una observación o dato en cada combinación de niveles de los factores. Esto implica un ligera variación en el análisis de los datos, en el sentido de que no se puede plantear hipótesis de interacción entre los factores. B.7.- Jonson y Leone describen un experimento para investigar el alabeo de placas de cobre. Los dos factores estudiados fueron temperatura y contenido de cobre de las placas. La variable de respuesta fue una medida de la cantidad de alabeo. Los datos son:
C o n t e n i d o d e c o b r e ( % )
Temperatura (º C )
40 60 80 90 50
75
100
125
17,20
12,90
16,12
21,17
16,21
18,13
18,21
23,21
24,22
17,12
25,23
23,22
28,27
27,31
30,23
29,31

195
a) Analice los datos según la metodología indicada y obtenga las conclusiones. b) Analice los residuos del experimento. c) Si lo que se desea es un mínimo de alabeo en la placa, ¿Qué nivel de contenido de cobre
especificaría usted como investigador? B.8.- Se cree que la adhesividad de un pegamento depende de la presión y de la temperatura al ser aplicado. Se realiza un experimento con estos dos factores y se obtienen los siguientes resultados:
T e m p e r a t u r a º F
Presión (lb / plg2 )
250 260 270
120 130 140 150
9,60 9,69 8,43 9,98
11,28 10,10 11,01 10,44
9,00 9,57 9,03 9,80
a) Analice los datos según la metodología indicada y obtenga las conclusiones. b) Analice los residuos del experimento. c) Si lo que se desea es aumentar la adhesividad , ¿Cuál es la mejor combinación?.
Los datos de los siguientes problemas, son el resultado de experimentos con tres factores controlados u observados. Tienen más de una observación o dato en cada combinación de niveles de los factores. Esto implica un ligera variación en el análisis de los datos, en el sentido de que se puede plantear hipótesis de hasta tres interacción entre los factores. B.9.- Se están investigando los efectos sobre la resistencia que producen el porcentaje de la concentración de fibra de madera (harwood) en la pulpa , presión del tanque y el tiempo de cocción de la pulpa. Se seleccionan tres niveles de la concentración de ,madera y de la presión, y dos niveles de tiempo de cocción. El experimento se realiza con dos replicas y reobtienen los siguientes datos: T i e m p o d e c o c c i ó n 3,0 horas 4,0 horas
Presión durante tiempo de Cocción de 3,0 hrs
Presión durante tiempo de Cocción de 4,0 hrs
Concentración Porcentual De Fibra
400 500 650 400 500 650
2
196,6 196,0
197,7 196,0
199,8 199,4
198,4 198,6
199,6 200,4
200,6 200,9
4
198,5 197,2
196,0 196,9
198,4 197,6
197,5 198,1
198,7 198,0
199,6 199,0
8
197,5 196,6
195,6 196,2
197,4 198,1
197,6 198,4
197,0 197,8
198,5 199,8

196
a) Analice los datos del experimento según la metodología indicada y obtenga las respectivas conclusiones. b) Analice los residuos del experimento. c) ¿Bajo qué conjunto de condiciones debe operarse este proceso? , ¿por qué?

197
B.10.- En el Departamento de Control de Calidad de una planta de acabado de telas se está estudiando el efecto de diversos factores que influyen sobre el teñido de tela de algodón y fibra sintética, la cual se utiliza en la confección de camisas para hombre. Se realizó una experimento donde participaron tres operadores, con tres niveles de tiempo y dos niveles de temperatura y se tiñeron tres muestras de tela dentro de cada conjunto de condiciones. La tela teñida fue comparada con un estándar y se le asignó una calificación numérica. Los datos resultantes fueron:
Temperatura a 300 º
Temperatura a 400 º
Operario
Operario
Tiempo de
Ciclo
1 2 3 1 2 3
40
23 24 25
27 28 26
31 32 29
24 23 28
38 36 35
34 36 39
50
36 35 36
34 38 39
33 34 35
37 39 35
34 38 36
34 36 31
60
28 24 27
35 35 34
26 27 25
26 29 25
36 37 34
28 26 24
a) Analice los datos del experimento según la metodología indicada y obtenga las
respectivas conclusiones. b) Analice los residuos del experimento, es decir , la idoneidad del modelo. c) ¿Bajo qué conjunto de condiciones debe operarse este proceso? , ¿por qué?


















