
Análisis de supervivencia y análisis multivariado - unav.edu · Editorial El m anual m oderno...
21
© Editorial El manual moderno Fotocopiar sin autorización es un delito. 1 Análisis de supervivencia y análisis multivariado Miguel Ángel Martínez González, Jokin de Irala–Estévez NOCIONES DE ANÁLISIS DE SUPERVIVENCIA En este apartado se exponen los principios del estudio formal de factores pronósticos que condicionan la supervivencia de un paciente 1-4 . También se puede considerar como resulta- do la aparición de complicaciones o la curación en vez de la muerte. En este segundo caso lo que se suele estudiar es la “supervivencia libre de complicaciones”. Por tanto, aunque se le siga denominando análisis de supervivencia, no siempre tiene que ser la muerte el acon- tecimiento de desenlace. Pero en principio debe tratarse de acontecimientos que, como la muerte, marcan un punto de no retorno. Los procedimientos más habituales requieren además que el desenlace sólo pueda ocurrir una vez como la muerte. Para valorar el pronóstico, en ambas situaciones, suelen aplicarse técnicas estadísticas de análisis de supervivencia 3 . La supervivencia incorpora el concepto dinámico del tiempo y es por tanto una variable compuesta de dos elementos: respuesta y tiempo. La respuesta o desenlace de interés no es una cantidad numérica 1 , como la presión arterial, ni una cua- lidad dicotómica como enfermar o no, sino que toma la forma de “tiempo transcurrido hasta un suceso” (time-to-event), lo que supone utilizar como desenlace o respuesta (“variable
Transcript of Análisis de supervivencia y análisis multivariado - unav.edu · Editorial El m anual m oderno...

© E
dit
ori
al E
l man
ual m
od
ern
o
Fot
ocop
iar
sin
auto
rizac
ión
es u
n de
lito.
1
Análisis de supervivenciay análisis multivariado
Miguel Ángel Martínez González, Jokin de Irala–Estévez
NOCIONES DE ANÁLISIS DE SUPERVIVENCIA
En este apartado se exponen los principios del estudio formal de factores pronósticos quecondicionan la supervivencia de un paciente1-4. También se puede considerar como resulta-do la aparición de complicaciones o la curación en vez de la muerte. En este segundo casolo que se suele estudiar es la “supervivencia libre de complicaciones”. Por tanto, aunque sele siga denominando análisis de supervivencia, no siempre tiene que ser la muerte el acon-tecimiento de desenlace. Pero en principio debe tratarse de acontecimientos que, como lamuerte, marcan un punto de no retorno. Los procedimientos más habituales requierenademás que el desenlace sólo pueda ocurrir una vez como la muerte.
Para valorar el pronóstico, en ambas situaciones, suelen aplicarse técnicas estadísticasde análisis de supervivencia3. La supervivencia incorpora el concepto dinámico del tiempoy es por tanto una variable compuesta de dos elementos: respuesta y tiempo. La respuestao desenlace de interés no es una cantidad numérica1, como la presión arterial, ni una cua-lidad dicotómica como enfermar o no, sino que toma la forma de “tiempo transcurrido hastaun suceso” (time-to-event), lo que supone utilizar como desenlace o respuesta (“variable
2 Manual de medicina basada en la evidencia (Capítulo 17)
dependiente” en la jerga matemática) la combinación de ambas cosas (cualidad + variablenumérica).
– La cualidad corresponde a si se ha producido o no el suceso y es una variable dicotómica(muerte, recidiva, aparición de una complicación o un nuevo síntoma, etc.).
– La variable numérica indica cuánto tiempo ha tardado en llegarse a ese desenlace.
En estas situaciones se deben emplear los llamados métodos de análisis de supervivencia. Eltiempo de supervivencia tiene una característica que lo hace inadecuado para otro tipo deanálisis estadísticos: la existencia de información truncada o individuos censurados (censored).Se dice que un paciente ofrece una información truncada o es un individuo censuradocuando se acaba el periodo de seguimiento para él, por un motivo distinto del desenlace oresultado que se está estudiando. Por ejemplo, los pacientes que no mueren durante eltiempo de seguimiento que dura el estudio no presentarán el resultado que se está obser-vando, y por tanto se desconocerá cuál es para ellos su tiempo de supervivencia. Seríantruncados o censurados tanto los que llegan al final del estudio sin sufrir el desenlace(supervivientes), como los que lo abandonan por su voluntad (abandonos, o pérdidas, lostto follow–up) o los retirados por los investigadores (retiradas, withdrawals).
Los métodos más habituales (Kaplan–Meier, Log–Rank, Cox, ver más adelante) asumenque los sujetos que se van del estudio antes de su finalización (censurados) se habrían com-portado del mismo modo que los que han sido seguidos hasta el final. A este supuesto básicose le llama censura no informativa5. Con ello se quiere expresar que saber que han sidocensurados no informa adicionalmente respecto a su pronóstico. Desde el punto de vistapráctico se requiere asumir que quienes se censuraron precozmente no sean sujetos peculiares.
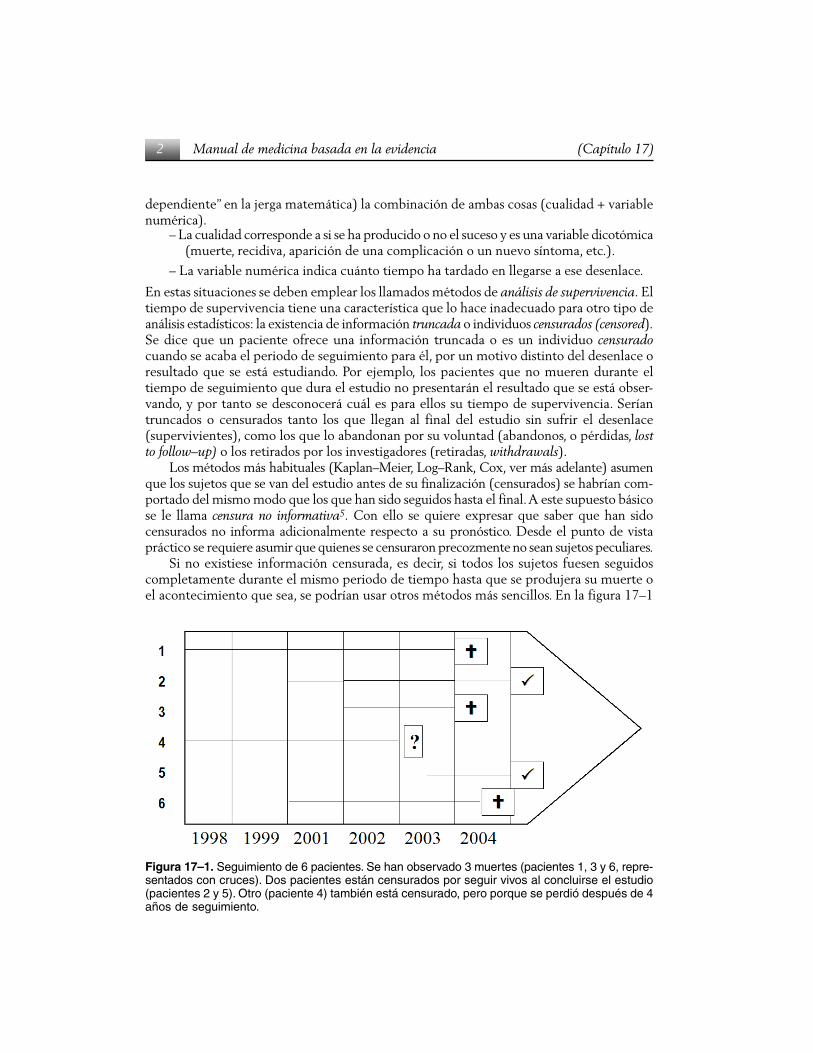
Si no existiese información censurada, es decir, si todos los sujetos fuesen seguidoscompletamente durante el mismo periodo de tiempo hasta que se produjera su muerte oel acontecimiento que sea, se podrían usar otros métodos más sencillos. En la figura 17–1
Figura 17–1. Seguimiento de 6 pacientes. Se han observado 3 muertes (pacientes 1, 3 y 6, repre-sentados con cruces). Dos pacientes están censurados por seguir vivos al concluirse el estudio(pacientes 2 y 5). Otro (paciente 4) también está censurado, pero porque se perdió después de 4años de seguimiento.
Análisis de supervivencia y análisis multivariado 3©
Ed
ito
rial
El m
anua
l mo
der
no
F
otoc
opia
r si
n au
toriz
ació
n es
un
delit
o.
se representa el tiempo de seguimiento de cada paciente por una línea. Hay dos situacionesposibles: aquéllos cuyo periodo de seguimiento acaba porque fallecen (representados poruna cruz) o aquellos que están vivos cuando dejan de ser observados (se van del estudio, setrasladan de ciudad, acaban el estudio estando vivos), en estos se representa su final poruna señal de visto bueno.
Por ejemplo, el primer paciente murió tras haber estado 5 años en el estudio y elúltimo paciente entró tarde y murió a los 3,5 años de entrar en el estudio. A pesar de queel seguimiento de cada paciente suele haberse empezado en fechas de calendario diferen-tes, debe imaginarse que todos han empezado el estudio en la misma fecha. Esto suponeasumir que se trata de pacientes “homogéneos” en el sentido de que los distintos tiemposde entrada en el estudio no están relacionados con el efecto de interés.
aicnevivrepusedsisilánanurecaharapsotadsolednóicaraperP.1–71ordauC
ETNEICAP OPMEIT ODATSE
5 5,1 0
3 2 1
6 5,3 1
2 4 0
4 4 0
1 5 1
-resboaheleslaucleetnarudopmeitle,adnugesaL.etneicapadacednóicacifitnediedoremúnleacidnianmulocaremirpaLodicellafnaheuqsola1nuodangisaaheS.otneimiugesledlaniflaetneicapledodatseleacidnianmulocarecretaL.odav
-iugesledlaniflasovivnaíugeseuqsola0nuy)aicnevivrepususednóicarudal,otnatrop,seotneimiugesedopmeitus(etnednecsanedronenóicavresboedopmeitlenúgesodanedronayahessotadsoleuqetnatropmiyumsE.otneim
Un supuesto importante en el diseño de estudios de factores pronósticos es que setrate de una cohorte de incepción. Esto supone que todos entrarán en el estudio en el mismomomento de la historia natural de su enfermedad. Si los momentos de entrada en el estu-dio corresponden a distintas fases de la evolución de la enfermedad se producirá un sesgoen los resultados.
Con los pacientes de la figura 17–1, los datos para hacer un análisis de supervivenciaserán los que muestra la cuadro 17–1. La variable estado se ha codificado así: fallecido=1;vivo=0. Es posible así estimar la probabilidad de la supervivencia para un periodo dado. Siexisten dos o más grupos también se pueden comparar sus probabilidades de superviven-cia. El método más usado es el de Kaplan–Meier que no asume que los datos tengan unadistribución particular, ni se basa en utilizar parámetros de resumen (media, desviaciónestándar, etc.). El único supuesto importante que se exige para aplicarlo es que la censurano sea informativa. Aunque ya lo hemos comentado, vale la pena insistir en que este su-puesto significa que la probabilidad de ser censurado no sea distinta, según los pacientespresenten un peor o mejor pronóstico. La probabilidad de ser censurado debe ser indepen-diente del efecto de interés. Es decir, no puede aplicarse el método de Kaplan–Meier congarantías si se sabe que los que se retiran del estudio antes de que acabe son pacientes

4 Manual de medicina basada en la evidencia (Capítulo 17)
peculiares, que probablemente tendrán una supervivencia distinta (mejor o peor) de losque son seguidos hasta el final.
En el ejemplo de los 6 pacientes antes comentado, si se excluyen los casos de los cualesno se sabe cuánto han tardado en morir, ya que la última información sobre ellos es queseguían vivos Pacientes censurados (pacientes 5, 2 y 4 que se han sombreado); y se conside-ran sólo aquellos que se sabe cuanto han tardado en morir (pacientes 3, 6 y 1), se podríacalcular fácilmente la supervivencia.
Si nos olvidásemos de los censurados, podría pensarse que la supervivencia (S) en cadatiempo valdría:
• A los dos años: ha muerto 1 y sobreviven 2........................ S2 = 2/3 = 0,67 (67%)
• A los 3,5 años: han muerto 2 y sobrevive 1 ........................ S3,5 = 1/3 = 0,33 (33%)
• A los 5 años: han muerto los 3 ............................................ S5 = 0/3 = 0 (0%)
Pero hacer esto no es correcto, pues supone, por un lado desaprovechar la información queproporcionan los sujetos 5, 2 y 4 y, por otro lado, algo más importante: no es verdad, porejemplo que a los 3,5 años la supervivencia sea del 33%, ya que los pacientes número 2 y 4han sobrevivido al menos 4 años. Por tanto, hay que usar un método que incluya en loscálculos a estos pacientes, como el 5, 2 y 4, de los que tenemos una información “truncada”o “censurada”. En el método de Kaplan–Meier para aprovechar esta información la super-vivencia a tiempo t (St) se define como:
Donde la letra pi mayúscula (P) es un símbolo análogo al sumatorio (S), pero que significa“productorio” o “multiplicatorio”, es decir, en vez de expresar “sumar todo” quiere decir“multiplicar todo”; si son los supervivientes en el tiempo ti, y ni son los que están a riesgo defallecer al inicio del tiempo ti. Es el producto de una serie de probabilidades condicionales,y se calcula por multiplicación. La condición es haber llegado vivo hasta el instante inme-diatamente anterior a ese tiempo ti. Lo que expresa este estimador de Kaplan–Meier no esuna única cantidad, sino una función que variará a lo largo del tiempo, por eso se indicacomo St, donde el subíndice t indica que la supervivencia será distinta de un tiempo a otro.En la cuadro 17–2 se representa, paso a paso cómo se calcula el estimador de Kaplan–Meier para los datos del ejemplo.
Cualquier análisis de supervivencia se suele acompañar de la respectiva representacióngráfica para expresar visualmente cómo va disminuyendo la probabilidad de sobrevivir amedida que pasa el tiempo. Siempre se sitúa el tiempo en el eje de abscisas (“x”) y laestimación del el porcentaje de los que sobreviven en el eje de ordenadas (“y”). Las curvasde supervivencia calculadas con el método de Kaplan–Meier son un procedimiento des-criptivo: sirven para resumir la historia de una serie de pacientes en cuanto a su riesgo defallecimiento, o visto en términos positivos, en cuanto a su probabilidad de supervivencia.
St = ΠΠΠΠΠSi
ni

Análisis de supervivencia y análisis multivariado 5©
Ed
ito
rial
El m
anua
l mo
der
no
F
otoc
opia
r si
n au
toriz
ació
n es
un
delit
o.
Como muestra la figura 17–2, para construir una curva de supervivencia se deben darlos siguientes pasos:
a. Ordenar ascendentemente los tiempos de supervivencia (o tiempos de observación).
b. Hacer una cuadro donde una columna (ti) corresponda a los tiempos de observaciónpara cada participante y otra al estado de los individuos al finalizar su periodo deseguimiento.
c. Calcular para cada periodo de tiempo el cociente entre los que sobreviven y los queestán a riesgo de fallecer (si/ni). Se crea otra columna para estos cocientes entrequienes sobreviven (si) y los que están a riesgo (ni) de fallecer (son los que entranvivos en ese tiempo). En esta columna sólo hay datos para cuando alguien fallece. Esimportante hacer notar que entre los que entran a riesgo de morir (ni) se incluyentambién el individuo o individuos que van a morir en ese periodo, aunque mueranjustamente en el inicio del periodo.
d. Multiplicar en cada periodo de tiempo los cocientes (si/ni) por los de los tiemposanteriores. La supervivencia en ese momento será precisamente este producto.
e. Finalmente, siempre es recomendable representarlo gráficamente. Se debe empezar conuna supervivencia de 1, que se mantiene hasta que se produce el primer falleci-miento. En ese momento la gráfica da un salto correspondiente al descenso de la super-vivencia a partir de ese momento (en el ejemplo pasa a 0,80). Y así sucesivamente.
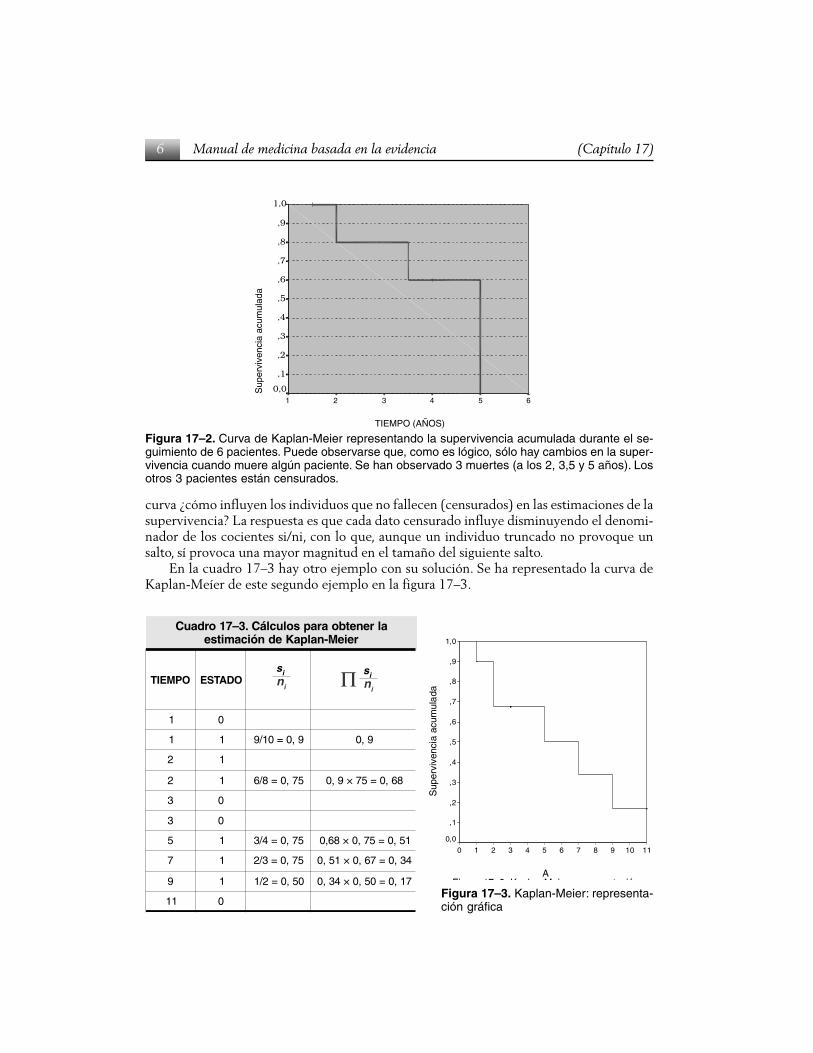
Cuando el más largo de los tiempos corresponde a alguien que seguía vivo al final delperiodo de observación, se deja una línea horizontal al final. Si todos hubieran fallecido(como sucede en el ejemplo) se traza una vertical hasta el punto 0 de supervivencia. En lafigura 17–2 se ha presentado la curva que de Kaplan–Meier correspondiente a los datos delejemplo. Se observa en la figura 17–3 que los saltos se dan sólo cuando ocurre algunamuerte, cabría preguntarse entonces: si sólo los pacientes fallecidos provocan un salto en la
reieM-nalpaKedodotémleropaicnevivrepusalednóicamitsE.2–71ordauC
ETNEICAP OPMEIT ODATSE
5 5,1 0
3 2 1 8,0=5/4 8,0
6 5,3 1 57,0=4/3 6,0=57,0×8,0
2 4 0
4 4 0
1 5 1 0=1/0 0=0×6,0
-oseuqsetneicapednóicroporpalamitseanmulocamitlúnepaL.1–71ordaucledsalnocnedicniocsanmulocsaremirp3saLroP.otneimicellafnúglaavresboeseuqsolnesopmeitsolleuqaarapaluclácesolósorep,opmeitadacedállasámneviverb
n(soña2solarecellafedogseirasetneicap5yah,olpmeje i -iverbossolleed;1y4,2,6,3setneicapsolnossotsé,)4=s(4nev i setneicoclE.)4= i n/ i -selaednopserrocanmulocamitlúaL.soñasámo2riviverboseddadilibaborpalamitse8,0=
ssetneicocsolodnacilpmitlumavyreieM-nalpaKedrodamit i n/ i ricedsomerdop,ísA.oiverpotcudorpleropopmeitadaced%0ledsoña5solay%06ledsoña5,3sola,%08ledaresoña2solaadalumucaaicnevivrepusaleuq
6 Manual de medicina basada en la evidencia (Capítulo 17)
A
11109876543210
Sup
ervi
venc
ia a
cum
ula
da
1,0
,9
,8
,7
,6
,5
,4
,3
,2
,1
0,0
Fi 17 3 K l M i t ió
TIEMPO (AÑOS)
654321
Sup
ervi
venc
ia a
cum
ulad
a
1,0
,9
,8
,7
,6
,5
,4
,3
,2
,1
0,0
curva ¿cómo influyen los individuos que no fallecen (censurados) en las estimaciones de lasupervivencia? La respuesta es que cada dato censurado influye disminuyendo el denomi-nador de los cocientes si/ni, con lo que, aunque un individuo truncado no provoque unsalto, sí provoca una mayor magnitud en el tamaño del siguiente salto.
En la cuadro 17–3 hay otro ejemplo con su solución. Se ha representado la curva deKaplan-Meíer de este segundo ejemplo en la figura 17–3.
alrenetboarapsolucláC.3–71ordauCreieM-nalpaKednóicamitse
OPMEIT ODATSE
1 0
1 1 9,0=01/9 9,0
2 1
2 1 57,0=8/6 86,0=57×9,0
3 0
3 0
5 1 57,0=4/3 15,0=57,0×86,0
7 1 57,0=3/2 43,0=76,0×15,0
9 1 05,0=2/1 71,0=05,0×43,0
11 0Figura 17–3. Kaplan-Meier: representa-ción gráfica
Figura 17–2. Curva de Kaplan-Meier representando la supervivencia acumulada durante el se-guimiento de 6 pacientes. Puede observarse que, como es lógico, sólo hay cambios en la super-vivencia cuando muere algún paciente. Se han observado 3 muertes (a los 2, 3,5 y 5 años). Losotros 3 pacientes están censurados.
sini
sini
Π
Análisis de supervivencia y análisis multivariado 7©
Ed
ito
rial
El m
anua
l mo
der
no
F
otoc
opia
r si
n au
toriz
ació
n es
un
delit
o.
Para comparar dos o más curvas de supervivencia se usan diversas pruebas estadísticasde contraste de hipótesis. La más empleada es el test del Log–Rank. Su hipótesis nula es quelas supervivencias de los grupos que se comparan (2 o más) son las mismas.
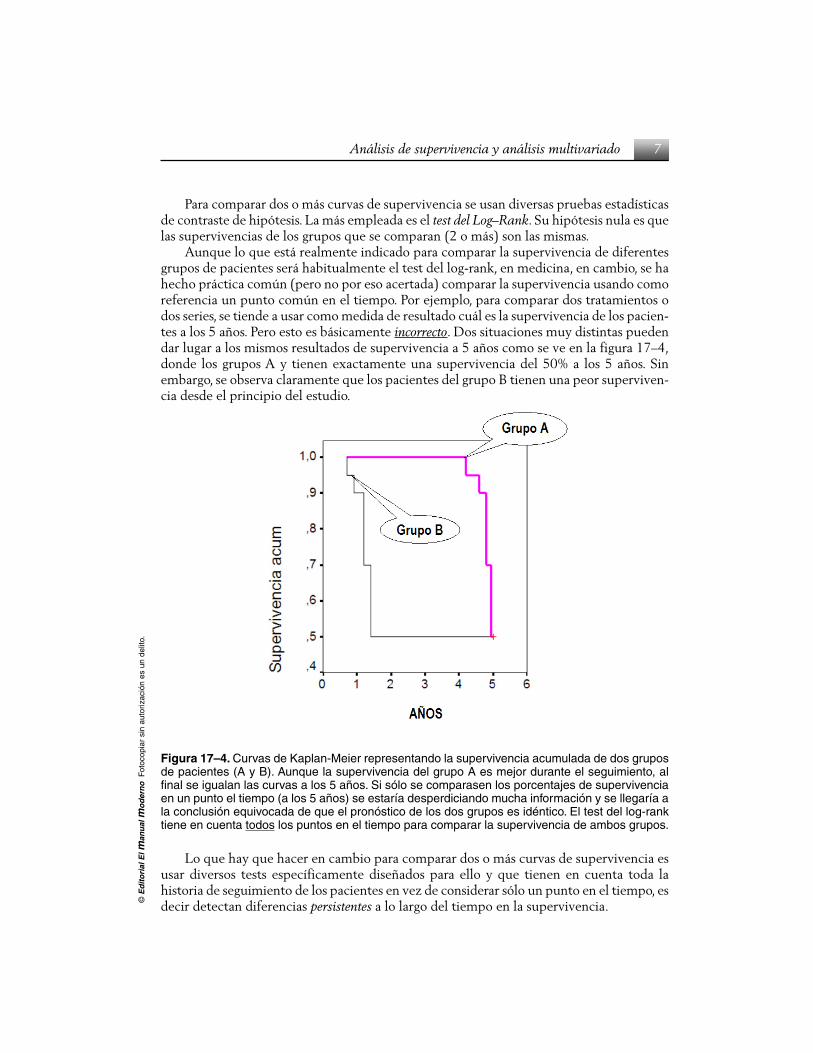
Aunque lo que está realmente indicado para comparar la supervivencia de diferentesgrupos de pacientes será habitualmente el test del log-rank, en medicina, en cambio, se hahecho práctica común (pero no por eso acertada) comparar la supervivencia usando comoreferencia un punto común en el tiempo. Por ejemplo, para comparar dos tratamientos odos series, se tiende a usar como medida de resultado cuál es la supervivencia de los pacien-tes a los 5 años. Pero esto es básicamente incorrecto. Dos situaciones muy distintas puedendar lugar a los mismos resultados de supervivencia a 5 años como se ve en la figura 17–4,donde los grupos A y tienen exactamente una supervivencia del 50% a los 5 años. Sinembargo, se observa claramente que los pacientes del grupo B tienen una peor superviven-cia desde el principio del estudio.
Figura 17–4. Curvas de Kaplan-Meier representando la supervivencia acumulada de dos gruposde pacientes (A y B). Aunque la supervivencia del grupo A es mejor durante el seguimiento, alfinal se igualan las curvas a los 5 años. Si sólo se comparasen los porcentajes de supervivenciaen un punto el tiempo (a los 5 años) se estaría desperdiciando mucha información y se llegaría ala conclusión equivocada de que el pronóstico de los dos grupos es idéntico. El test del log-ranktiene en cuenta todos los puntos en el tiempo para comparar la supervivencia de ambos grupos.
Lo que hay que hacer en cambio para comparar dos o más curvas de supervivencia esusar diversos tests específicamente diseñados para ello y que tienen en cuenta toda lahistoria de seguimiento de los pacientes en vez de considerar sólo un punto en el tiempo, esdecir detectan diferencias persistentes a lo largo del tiempo en la supervivencia.

8 Manual de medicina basada en la evidencia (Capítulo 17)
Cuando el evento de resultado es poco frecuente o si las curvas son aproximadamenteparalelas (no se cruzan) el log-rank es el método más indicado. También se le conoce comotest de Mantel y Haenszel. Cuando las curvas se cruzan (al principio hay mejor supervi-vencia en un grupo y luego en el otro), entonces puede estar indicado el uso de otro test decomparación de curvas de supervivencia que se llama de Wilcoxon (o también de Breslow).Un tercer test que se emplea con menos frecuencia es el de Tarone–Ware. En estos tests sehace una ponderación y se le da distinto peso a las diferencias según ocurran más precoz omás tardíamente a lo largo del seguimiento. En resumen, puede decirse que estos teststienen las siguientes características comunes:
• Hipótesis nula (H0): las supervivencias de los grupos que se comparan (2 ó más) es lamisma.
• Hipótesis alternativa (H1): al menos uno de los grupos tiene una supervivencia diferente.• Estadístico utilizado: jicuadrado con k-1 grados de libertad, siendo k el número de
grupos (nº de curvas que se comparan).
ERROR ESTÁNDAR E INTERVALOS DE CONFIANZAPARA LA SUPERVIVENCIA
Si se desea calcular un intervalo de confianza para la estimación de la supervivencia a undeterminado tiempo se puede realizar a partir del error estándar de cada estimación de lasupervivencia acumulada. Este error estándar para cada tiempo (EESt) es el producto de lasupervivencia estimada para ese tiempo por la raíz de la suma de los cocientes entre elnúmero de fallecidos en cada momento y el producto de supervivientes y pacientes ariesgo en ese tiempo3. Es decir,
Así, para la supervivencia acumulada a 2 años que aparece en la cuadro 17–3, su errorestándar se calcularía multiplicando la supervivencia estimada (0,68) por la suma de loscocientes entre fallecidos y el producto de totales por supervivientes sumando los deltiempo previo (1/(10 × 9)) y los de ese tiempo (2/(8x6)). Es decir, el error estándar valdríaEES2=0,68 × [(1/90)+(2/48)]0,5 = 0,16. En cambio, para la supervivencia al año, EES1=0,9 ×(1/90)0,5= 0,095. Para los 5 años, EES1= 0,19.Una aproximación poco fina pero conservadora para estimar los intervalos de confianza al95% será aplicar la siguiente expresión:
IC 95% St = Superv t ± 1,96 EE
(1,96 es el valor z de la normal para un error alfa bilateral del 5%)

Análisis de supervivencia y análisis multivariado 9©
Ed
ito
rial
El m
anua
l mo
der
no
F
otoc
opia
r si
n au
toriz
ació
n es
un
delit
o.
Por ejemplo, si en el listado de SPSS vemos la salida que aparece en las tres primerascolumnas de la cuadro 17–4 (corresponden a los datos del ejemplo de la cuadro 17–3), lasestimaciones de supervivencia con sus límites de confianza serían las presentadas en las dosúltimas columnas de la tabla.
odotéM.4–71ordauC elbajesnocased aznaifnocedsolavretnisolramitsearapraicnevivrepusaled
OPMEIT AICNEVIVREPUS %59CI
1 9,0 9490,0 17,0 90,1
2 576,0 1551,0 73,0 99,0
5 3605,0 8681,0 41,0 88,0
7 5733,0 7581,0 30,0- 17,0
9 8861,0 2151,0 31,0- 74,0
arap%59laaznaifnocedsolavretnisolednóicamitsealyradnátseserorresolodaluclacnahes3–71ordaucledsotadsolnoCsolegoceranmulocarecretal,3–71ordaucledamitlúalyaremirpalnocnedicniocsanmulocsaremirp2saL.aicnevivrepusal
-nilesamitlúsodsaly)SSPSomoc,selanoicnevnocerawtfosedsamargorpsolratneserpneleuseuqsolnos(radnátseserorre-nevivrepusalednóicamitseadacaradnátserorrelesecev69,1ramusyratserlaetnemelpmisodaluclacaznaifnocedolavret
revedeupomoc.aic .odrusbaselaucol,sovitagennoseuqsortoy1ednedecxeeuqaznaifnocedsetimílyah,es ordauclenE.amelborpetseedserbil,sadaucedasámsenoicamitsesalnatneserpes5–71
Pero, el método simplista de sumar y restar 1,96 veces el error estándar a la supervi-vencia estimada es desaconsejable porque proporciona intervalos de confianza que son ne-gativos y otros que exceden de 1,0, lo cual es absurdo. Se puede usar otra expresión másadecuada3, calculando un error estándar transformado (EEt).
Método recomendable para estimar los intervalos de confianza de la Supervivencia
[ ] ∑ −×=ii
iit sn
sn
SEE
2)(ln
1
[ ] 54,034
1
68
2
910
1
)5063,0(ln
12
=
×+
×+
××=tEE
79,014,05063,0%95 )54,096,1( −== ×±EXPIC
IC 95% St = StEXP (± 1, 96EEt)
Donde ln significa logaritmo natural (neperiano) y EXP supone elevar a la cantidad corres-pondiente el número e, base de los logaritmos naturales. Así, para la supervivencia a 5 añosdel ejemplo anterior (S5 = 0,5063), el intervalo de confianza al 95% sería:

10 Manual de medicina basada en la evidencia (Capítulo 17)
En la cuadro 17–5 se recogen los intervalos de confianza para cada tiempo, así calculados.Puede apreciarse que los intervalos de confianza son más estrechos y además nunca soninferiores a 0 ni superiores a 1.
solodaluclacnahesseroiretnasordaucsodsoledsotadsomsimsolnoC.5–71ordauClaaznaifnocedsolavretnisolednóicamitsealy)tEE(sodamrofsnartradnátseserorre
euqarapadaucedanóiserpxealnocnaluclacesayednodaicnevivrepusalarap%59elbajesnocasámleseodotémetsE.0leodadinualacnunnesaperboson
aicnevivrepusaledaznaifnocedsolavretnisolramitsearapelbadnemocerodotéM
OPMEIT AICNEVIVREPUS %59CI
1 9,0 1 74,0 99,0
2 576,0 85,0 92,0 88,0
5 3605,0 45,0 41,0 97,0
7 5733,0 15,0 50,0 76,0
9 8861,0 38,0 00,0 07,0
Puede programarse una hoja de cálculo (p. ej., en Microsoft Excel) para obtener intervalosde confianza al 95% de la supervivencia a partir del output convencional que proporcionaun paquete estadístico de análisis de supervivencia. Se indican a continuación las órdenesque deben dársele a la hoja de cálculo5. Si se ha introducido el valor de la supervivencia enla casilla A2 y su error estándar convencional (el que aparece por ejemplo en SPSS en lacasilla B2), deberá indicarse
C2 = (((B2/A2)^2) * (1/(LN(A2))^2))^0,5 Devolverá el error estándar transformado
D2 = (A2)^EXP(1,96*C2) Devolverá el límite inferior de confian-
za al 95%
E2 = A2^EXP(-1,96*C2) Devolverá el límite superior de confian-
za al 95%
Puede encontrarse un programa en Excel ya preparado en la siguiente dirección de internetwww.unav.es/preventiva —> docencia —> bioestadística
ANÁLISIS MULTIVARIADO
En la medicina basada en la evidencia resulta útil aplicar modelos multivariantes paraintentar explicar un fenómeno, teniendo en consideración varias variables simultáneamen-
[ ] ∑ −×=ii
iit sn
sn
SEE
2)(ln
1

Análisis de supervivencia y análisis multivariado 11©
Ed
ito
rial
El m
anua
l mo
der
no
F
otoc
opia
r si
n au
toriz
ació
n es
un
delit
o.
te o para realizar predicciones. Por ejemplo, puede resultar de interés conocer qué factorespronósticos influyen en la supervivencia de los pacientes con infarto de miocardio, o si lasupervivencia de los pacientes con un determinado tumor se ve afectada por diversostratamientos (quimioterapia, radioterapia) u otros factores, como por ejemplo, el estadopsicológico del paciente. En general, la aplicación de una técnica de análisis multivariantesignifica que se tienen en cuenta simultáneamente muchas variables en el análisis de losdatos. La principal ventaja que ofrecen estas técnicas, es que permiten controlar de modoeficiente muchos factores de confusión al mismo tiempo cuando se trata de estudiar aso-ciaciones potencialmente causales entre una determinada exposición y un efecto o desen-lace. Ésta ha sido y sigue siendo su principal aplicación en la investigación médica en lasúltimas 3 décadas. El ajuste multivariante supone la aplicación de un modelo matemáticoque hace más comparables a los grupos de individuos expuestos y no expuestos, evitandola distorsión que supondría que, por ejemplo, los expuestos fuesen de mayor edad o seencontrasen con mayor frecuencia sometidos a otros factores pronósticos distintos del quese está estudiando. Así se consigue que la comparación de interés quede depurada de otrosfactores y se pueda apreciar mejor cuál es su efecto verdaderamente independiente. Haymuchos procedimientos y técnicas de ajuste multivariante. Los más utilizados se suelenbasar en un modelo de regresión. El más simple es la regresión lineal.
REGRESIÓN MÚLTIPLE
Se emplea cuando se desea estudiar como influyen varios factores (o variables indepen-dientes) en una sola variable de respuesta (la variable dependiente o desenlace), que ha deser en este caso una variable cuantitativa numérica, como por ejemplo la talla o el peso. Laecuación de la regresión lineal simple es la ecuación de una recta; éste es el modelo mate-mático más sencillo:
y = a + bx
Donde “y” es la variable dependiente o desenlace, mientras que “x” es la variable indepen-diente o factor predictor. A la constante “a” se le llama ordenada en el origen y al coeficiente“b”, se le llama pendiente de la recta. Pero esta ecuación se puede generalizar para el caso enque haya más de una variable independiente. Supongamos que haya 3 variables indepen-dientes o factores predictores: x1, x2, x3. Podría construirse la ecuación:
y = a + b1x1 + b2x2 + b3x3
Cada variable independiente xi tiene un coeficiente de regresión propio bi (análogo a la“pendiente”). Así como la ecuación simple de una recta se puede concebir imaginariamenteen un plano de dos dimensiones, la ecuación multivariante con 3 predictores independien-tes no es imaginable, ya que se necesitaría un espacio de 4 dimensiones. Aunque no seaimaginable, sí resulta comprensible e interpretable. El coeficiente bi de cada variable inde-pendiente xi se interpretará como el cambio en la variable dependiente (“y”), por unidadde cambio en cada variable independiente (x1, x2 o x3) a igualdad de nivel de las otrasvariables independientes. Por ejemplo, supongamos que la talla (cm) de una muestra deniños se utiliza como variable dependiente (y), intentando predecirla a partir de tres facto-

12 Manual de medicina basada en la evidencia (Capítulo 17)
res o variables independientes, x1, x2 y x3 que corresponden respectivamente a la edad enaños del niño (edad: x1), la talla del padre en cm (TPADRE: x2) y la talla de la madretambién en cm (TMADRE: x3) y resulta la siguiente ecuación:
y = 30 + 8 x1 + 0,06x2 + 0,07x3
Talla = 30 + 8(Edad) + 0,06(Tallapadre) + 0,07(Tallamadre)
La interpretación será que por cada año más de edad que cumple el niño su talla aumentaen 8 cm, independientemente de cuál sea la talla del padre o de la madre. Por cada cm másde altura del padre, el niño tendrá, (sea cual sea su edad y sea cual sea la talla de su madre)0,06 cm más de altura. Y por cada cm más de altura de la madre, el niño será 0,07 cm másalto, independientemente de cuál sea la altura de su padre y cuál sea su edad.
Es posible también introducir variables categóricas en el modelo tales como el sexo delniño. Para ello introduciríamos en el modelo otra nueva variable (sexo= x4), con dos códi-gos: varón = 1 y mujer = 0. Generalmente se le da el valor 0 a aquella categoría en la que seespera un nivel menor o basal. Cómo las niñas suelen tener una menor talla que los niñosse les da en este ejemplo el valor 0. Un ejemplo del modelo que se obtendría al ajustar asíuna regresión múltiple sería el siguiente:
y = 30 + 4x1 +8x2
Talla = 30 + 30 +4(Sexo) +8(Edad)
En realidad tenemos 2 ecuaciones de regresión, una para los niños:
talla = 30 + 4(Sexo) + 8(Edad) = 30 + 4 + 8(Edad) = 34 + 8(Edad)
y otra para las niñas:
talla = 30 + 4(Sexo) + 8(Edad) = 30 + 0 + 8(Edad) = 30 + 8(Edad)
En resumen, la regresión múltiple se usa cuando se valoran diversos predictores de unresultado o desenlace que tiene carácter cuantitativo. Es decir, se usa cuando la variabledependiente es cuantitativa (tensión arterial, índice de masa corporal, glucemia, etc.). Esdeseable que la variable cuantitativa que se usa como resultado siga una distribución aproxi-madamente normal (gaussiana).
REGRESIÓN LOGÍSTICA
Los modelos matemáticos derivados de la regresión múltiple son muy útiles enepidemiología, pues desempeñan un papel importante en el control de los sesgos de confu-sión, pero se basan en una serie de supuestos cuyo cumplimiento no siempre es fácil com-probar. Por ejemplo, no siempre existe una relación lineal entre la variable de exposición(variable independiente, “x”) y la variable de respuesta (variable dependiente, “y”). Cuandolo que se desea conocer es cómo una serie de factores influyen en una variable binaria o

Análisis de supervivencia y análisis multivariado 13©
Ed
ito
rial
El m
anua
l mo
der
no
F
otoc
opia
r si
n au
toriz
ació
n es
un
delit
o.
dicotómica, es decir con dos posibilidades, como por ejemplo estar sano o enfermo, res-ponder a un tratamiento o no responder, etc. en vez de utilizar la regresión lineal, se va autilizar la regresión logística. En este caso, al ser dicotómica la respuesta o resultado, sehablaría de regresión logística binaria.
La regresión logística se usará, por tanto, cuando se valoran diversos predictores de unresultado o desenlace que tiene carácter dicotómico. Por ejemplo cuando se intentan valorarlas variables que pueden predecir la aparición de diabetes. El coeficiente bi de cada uno delos predictores utilizado como exponente del número e, base de los logaritmos naturales,equivale a la odds ratio (OR), como se explica a continuación.
La función logística es aquélla que halla, para cada individuo, según los valores de unfactor predictor (x), la probabilidad (p) de que presente el efecto o desenlace estudiado. Laexpresión de la función logística es:
Con una manipulación algebraica de esta ecuación, tomando logaritmos neperianos (ln), seobtiene una función llamada logit y hace que se parezca a la regresión lineal:
ln (p/1-p) = a + bx
Esta expresión, en efecto, es muy similar a la sencilla ecuación de la recta. El único cambio esque se ha sustituido la variable dependiente (“y”) por otra expresión. Ahora la variable de-pendiente es el logaritmo neperiano (ln) de la probabilidad (p) de que ocurra un suceso,dividido por la probabilidad de que no ocurra (1–p). A ln (p/1-p) se le llama el logit. Es decir:
logit = ln (p/1-p)
Debemos decir que lo que hay dentro del paréntesis (p/1-p) corresponde al concepto de odds.A este cociente se le llama en inglés “odds” y en español se ha querido traducir por “ventaja”.Una odds es la probabilidad (p) dividida por el complementario de la probabilidad (1-p).
p1
p
−=odds
Podremos afirmar por tanto que
logit = ln (p/1-p) = ln (odds) = a + bx
Es más fácil calcular una odds que definirla. Si en un estudio que incluye a 250 pacientesobesos, 50 de ellos han desarrollado después diabetes, la odds de desarrollar diabetes secalcularía dividiendo 50 entre 200 (odds =1/4). También puede expresarse como una odds= 1:4 y se interpreta como que apareció un diabético por cada 4 no-diabéticos.
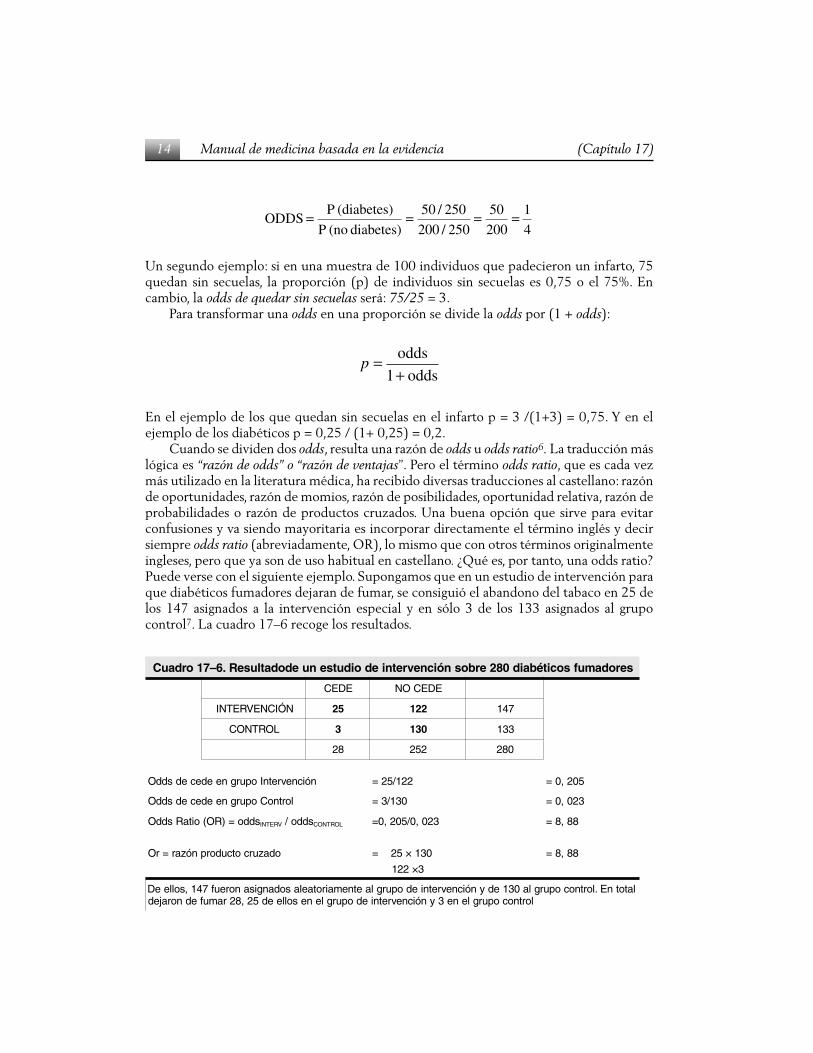
14 Manual de medicina basada en la evidencia (Capítulo 17)
4
1
200
50
250/200
250/50
diabetes) (no P
(diabetes) PODDS ====
Un segundo ejemplo: si en una muestra de 100 individuos que padecieron un infarto, 75quedan sin secuelas, la proporción (p) de individuos sin secuelas es 0,75 o el 75%. Encambio, la odds de quedar sin secuelas será: 75/25 = 3.
Para transformar una odds en una proporción se divide la odds por (1 + odds):
odds1
odds
+=p
En el ejemplo de los que quedan sin secuelas en el infarto p = 3 /(1+3) = 0,75. Y en elejemplo de los diabéticos p = 0,25 / (1+ 0,25) = 0,2.
Cuando se dividen dos odds, resulta una razón de odds u odds ratio6. La traducción máslógica es “razón de odds” o “razón de ventajas”. Pero el término odds ratio, que es cada vezmás utilizado en la literatura médica, ha recibido diversas traducciones al castellano: razónde oportunidades, razón de momios, razón de posibilidades, oportunidad relativa, razón deprobabilidades o razón de productos cruzados. Una buena opción que sirve para evitarconfusiones y va siendo mayoritaria es incorporar directamente el término inglés y decirsiempre odds ratio (abreviadamente, OR), lo mismo que con otros términos originalmenteingleses, pero que ya son de uso habitual en castellano. ¿Qué es, por tanto, una odds ratio?Puede verse con el siguiente ejemplo. Supongamos que en un estudio de intervención paraque diabéticos fumadores dejaran de fumar, se consiguió el abandono del tabaco en 25 delos 147 asignados a la intervención especial y en sólo 3 de los 133 asignados al grupocontrol7. La cuadro 17–6 recoge los resultados.
serodamufsocitébaid082erbosnóicnevretniedoidutsenuedodatluseR.6–71ordauC
EDEC EDECON
NÓICNEVRETNI 52 221 741
LORTNOC 3 031 331
82 252 082
nóicnevretnIopurgneedecedsddO 221/52= 502,0=
lortnoCopurgneedecedsddO 031/3= 320,0=
sddo=)RO(oitaRsddO VRETNI sddo/ LORTNOC 320,0/502,0= 88,8=
odazurcotcudorpnózar=rO 031×52=
3×221
88,8=
latotnE.lortnocopurgla031edynóicnevretniedopurglaetnemairotaelasodangisanoreuf741,solleeDlortnocopurglene3ynóicnevretniedopurglenesolleed52,82ramufednorajed

Análisis de supervivencia y análisis multivariado 15©
Ed
ito
rial
El m
anua
l mo
der
no
F
otoc
opia
r si
n au
toriz
ació
n es
un
delit
o.
Como puede apreciarse en la cuadro 17–6, la odds ratio (OR) es simplemente el co-ciente entre las odds del resultado, en este caso, el resultado es dejar de fumar. Tambiénpuede calcularse la odds ratio mediante el cociente de los productos cruzados de la tabla2x2 (figura 17–5). El resultado (OR = 8,88) significa que para la intervención se ha obser-vado una efectividad que casi 9 veces mayor que para el grupo control.
Nos hemos detenido en explicar el concepto de odds ratio (OR) porque esta medidade asociación es el fruto más interesante que se suele obtener habitualmente al hacer unaregresión logística. Calcular la OR mediante regresión logística aporta la ventaja de que sepuede ajustar esta medida por otras variables que también pudiesen influir en el resultado(p. ej., en el caso anterior podría pensarse que es más fácil que respondan bien a unaintervención los diabéticos con mayor nivel educativo y debería plantearse la cuestión de siel nivel educativo medio del grupo de intervención y del grupo control eran similares). Aesas otras variables se les llama «factores de confusión» y se pueden controlar o «ajustar porellos» mediante un modelo de regresión logística8-9. En efecto, volviendo a la regresiónlogística, la ecuación antes vista
ln (p/1-p) = a + bx
se puede extender a situaciones multivariables, donde en vez de un solo factor predictor(x), <NI>haya una serie de predictores (x1, x2,...xp):
ln (p/1-p) = a + b1x1 + b2x2 +... + bpxp
que podría escribirse también así:
ln (p/1-p) = a + b1x1 + b2x2 +... + bpxp
Figura 17–5. La odds ratio (OR) se calcula en un tabla 2 × 2 mediante la rzón de los productoscruzados.
16 Manual de medicina basada en la evidencia (Capítulo 17)
La transformación logarítmica es necesaria para adaptarse a un fenómeno como la probabi-lidad, cuyos límites teóricos son tan estrechos como 0 y 1. En cambio, los límites teóricosde ln (odds) son desde –infinito hasta +infinito. La interpretación de la regresión logísticaes bastante directa, ya que cada coeficiente de regresión bi expresa el logaritmo neperianode la odds ratio (OR) de que ocurra un fenómeno por unidad de cambio del factor predictor(variable independiente, xi).
bi = ln (OR)
Tomando antilogaritmos, tendríamos:
OR = antilog(bi)
Esto hace a la regresión logística un procedimiento muy útil para construir modelos mate-máticos que ajusten por factores de confusión, ya que sus resultados son interpretablescomo odds ratios estimadas en el supuesto de que los demás factores incluidos en el mode-lo (los otros predictores: x2, x3,...xp) fuesen exactamente iguales para los individuos de losgrupos que se comparan. Por este motivo, la regresión logística es muy utilizada, cada vezmás, tanto en epidemiología de factores de riesgo como en epidemiología clínica, ya quelibera a las estimaciones de la presencia de confusores indeseados8.
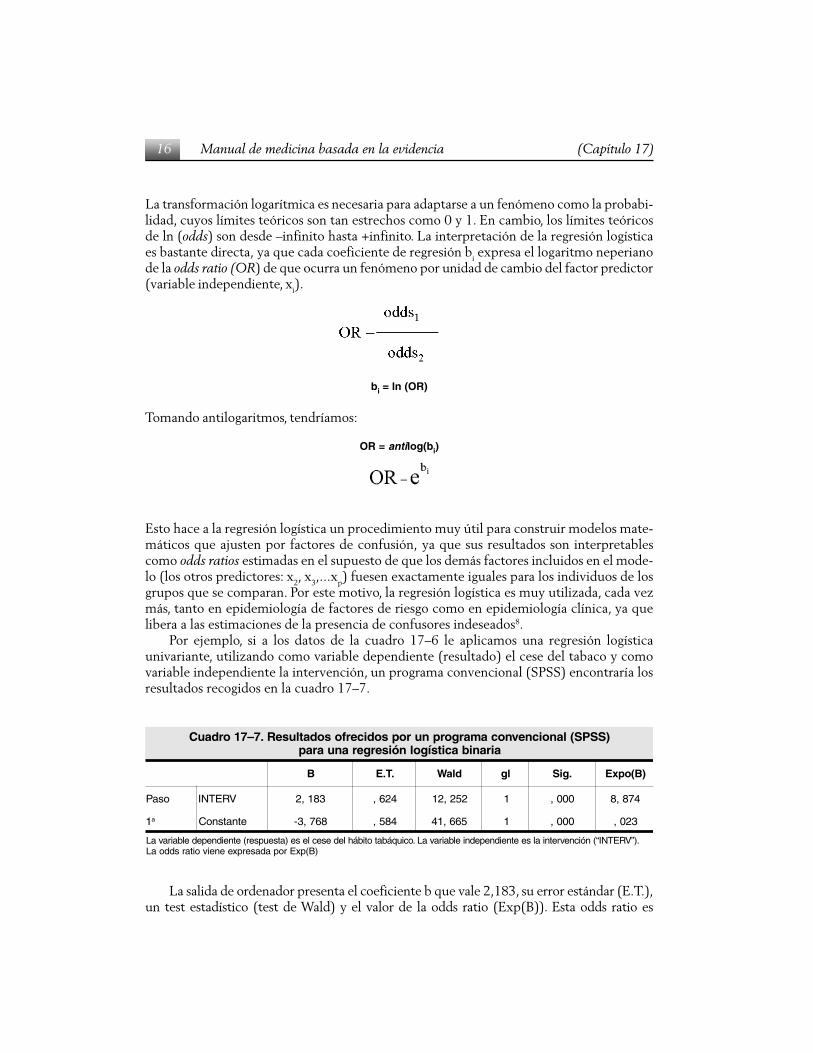
Por ejemplo, si a los datos de la cuadro 17–6 le aplicamos una regresión logísticaunivariante, utilizando como variable dependiente (resultado) el cese del tabaco y comovariable independiente la intervención, un programa convencional (SPSS) encontraría losresultados recogidos en la cuadro 17–7.
)SSPS(lanoicnevnocamargorpnuropsodicerfosodatluseR.7–71ordauCairanibacitsígolnóisergeranuarap
B .T.E dlaW lg .giS )B(opxE
osaP VRETNI 381,2 426, 252,21 1 000, 478,8
1a etnatsnoC 867,3- 485, 566,14 1 000, 320,
.)”VRETNI“(nóicnevretnialseetneidnepednielbairavaL.ociuqábatotibáhledeseclese)atseupser(etneidnepedelbairavaL)B(pxEropadaserpxeeneivoitarsddoaL
La salida de ordenador presenta el coeficiente b que vale 2,183, su error estándar (E.T.),un test estadístico (test de Wald) y el valor de la odds ratio (Exp(B)). Esta odds ratio es
Análisis de supervivencia y análisis multivariado 17©
Ed
ito
rial
El m
anua
l mo
der
no
F
otoc
opia
r si
n au
toriz
ació
n es
un
delit
o.
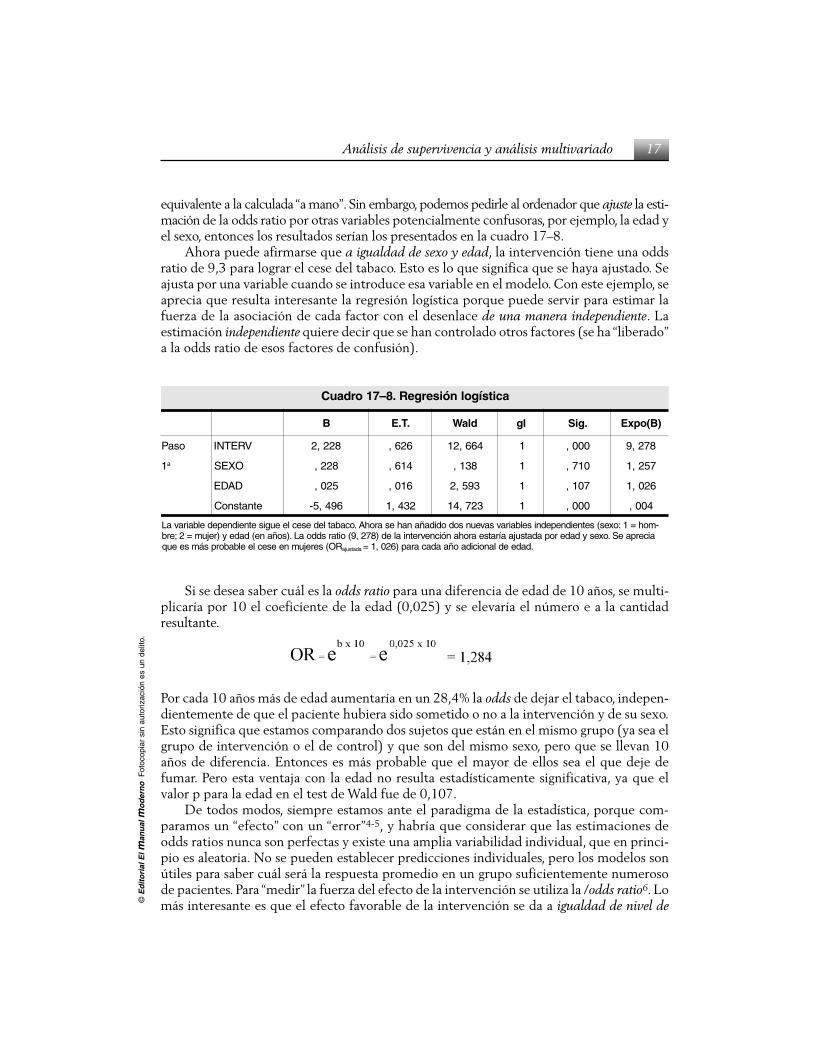
equivalente a la calculada “a mano”. Sin embargo, podemos pedirle al ordenador que ajuste la esti-mación de la odds ratio por otras variables potencialmente confusoras, por ejemplo, la edad yel sexo, entonces los resultados serían los presentados en la cuadro 17–8.
Ahora puede afirmarse que a igualdad de sexo y edad, la intervención tiene una oddsratio de 9,3 para lograr el cese del tabaco. Esto es lo que significa que se haya ajustado. Seajusta por una variable cuando se introduce esa variable en el modelo. Con este ejemplo, seaprecia que resulta interesante la regresión logística porque puede servir para estimar lafuerza de la asociación de cada factor con el desenlace de una manera independiente. Laestimación independiente quiere decir que se han controlado otros factores (se ha “liberado”a la odds ratio de esos factores de confusión).
acitsígolnóisergeR.8–71ordauC
B .T.E dlaW lg .giS )B(opxE
osaP VRETNI 822,2 626, 466,21 1 000, 872,9
1a OXES 822, 416, 831, 1 017, 752,1
DADE 520, 610, 395,2 1 701, 620,1
etnatsnoC 694,5- 234,1 327,41 1 000, 400,
-moh=1:oxes(setneidnepedniselbairavsaveunsododidañanahesarohA.ocabatledesecleeugisetneidnepedelbairavaLaicerpaeS.oxesydaderopadatsujaaíratsearohanóicnevretnialed)872,9(oitarsddoaL.)soñane(dadey)rejum=2;erb
RO(serejumneesecleelbaborpsámseeuq adatsuja .dadeedlanoicidaoñaadacarap)620,1=
Si se desea saber cuál es la odds ratio para una diferencia de edad de 10 años, se multi-plicaría por 10 el coeficiente de la edad (0,025) y se elevaría el número e a la cantidadresultante.
Por cada 10 años más de edad aumentaría en un 28,4% la odds de dejar el tabaco, indepen-dientemente de que el paciente hubiera sido sometido o no a la intervención y de su sexo.Esto significa que estamos comparando dos sujetos que están en el mismo grupo (ya sea elgrupo de intervención o el de control) y que son del mismo sexo, pero que se llevan 10años de diferencia. Entonces es más probable que el mayor de ellos sea el que deje defumar. Pero esta ventaja con la edad no resulta estadísticamente significativa, ya que elvalor p para la edad en el test de Wald fue de 0,107.
De todos modos, siempre estamos ante el paradigma de la estadística, porque com-paramos un “efecto” con un “error”4-5, y habría que considerar que las estimaciones deodds ratios nunca son perfectas y existe una amplia variabilidad individual, que en princi-pio es aleatoria. No se pueden establecer predicciones individuales, pero los modelos sonútiles para saber cuál será la respuesta promedio en un grupo suficientemente numerosode pacientes. Para “medir” la fuerza del efecto de la intervención se utiliza la /odds ratio6. Lomás interesante es que el efecto favorable de la intervención se da a igualdad de nivel de

18 Manual de medicina basada en la evidencia (Capítulo 17)
edad y sexo. Es decir, de modo independiente de la edad y sexo. El modelo está “ajustado”por edad y sexo9. Cada predictor independiente (xi) que se introduzca en el modelo supo-ne un ajuste y un control del sesgo de confusión que ese predictor podría provocar. Al igualque en la regresión lineal múltiple, es posible introducir variables independientes (xi) cate-góricas o dicotómicas en los modelos (el sexo en nuestro caso). También es posible incluircomo variables independientes, variables cualitativas con varias categorías, como estadocivil (soltero, casado, viudo, etc.). Pero ello requeriría la creación de una serie de variablesartificiales también conocidas como variables indicadoras o variables dummy.
La regresión logística se emplea habitualmente en uno de los diseños epidemiológicosmas utilizados: los estudios de casos y controles8. Sin embargo en los de estudios de casosy controles emparejados no se debe aplicar la regresión logística convencional, sino que seha de utilizar un tipo especial de regresión logística: la regresión logística condicional
Los resultados obtenidos en la cuadro 17–7 deberían presentarse en un trabajo de investi-gación de manera resumida, indicando simplemente cuál es la estimación de la odds ratioajustada (y quizá también sin ajustar o «cruda) para cada variable y cuál es su intervalo deconfianza, habitualmente calculado al 95%. Los paquetes estadísticos suelen tener opcio-nes para pedir los intervalos de confianza. Se calculan así:
LA REGRESIÓN DE COX (PROPORTIONAL HAZARDS MODEL)
En 1972 Cox publicó un articulo, Regression models and life tables (Modelos de regresión ytablas de vida) que se ha convertido en un auténtico bestseller, ya que es uno de los artículosmás citados en la bibliografía científica10-11. Se utiliza la regresión de Cox (proportionalhazards model), cuando la variable dependiente esté relacionada con la supervivencia de losindividuos y se desee averiguar simultáneamente el efecto independiente una serie de fac-tores sobre esta supervivencia.
Por ejemplo, si se deseara saber en qué medida el trasplante de hígado mejora la super-vivencia de los pacientes con hepatocarcinoma y simultáneamente se desea valorar el efec-to del estadio tumoral y de otros factores (sexo, edad, etc.) sobre la supervivencia de lospacientes, se empleará la regresión de Coxe:12. Téngase en cuenta que no se trata sólo desaber el efecto sobre la supervivencia después de un tiempo determinado de seguimiento(p. ej., la supervivencia a los 5 años), sino de valorar cuál es el efecto sobre la función desupervivencia a lo largo de todo el periodo de observación de los pacientes, sea cual sea elpunto temporal que se elija para la comparación. Si sólo interesase estudiar el efecto sobrela supervivencia en un punto del tiempo (p. ej., a los 5 años), entonces bastaría con unanálisis de regresión logística, porque la variable de respuesta sería dicotómica (sí sobrevi-ven o no sobreviven). Sólo la regresión de Cox permite afirmar que una supervivencia másventajosa puede ser atribuida a un determinado tratamiento, porque, por ejemplo, com-prueba que a igualdad de edad, sexo, estadio tumoral, etc., los pacientes que fueron trata-dos con transplante hepático sobrevivieron más en cualquier punto posible dentro delseguimiento que ha existido en el estudio. A este procedimiento multivariable de tener en

Análisis de supervivencia y análisis multivariado 19©
Ed
ito
rial
El m
anua
l mo
der
no
F
otoc
opia
r si
n au
toriz
ació
n es
un
delit
o.
cuenta los niveles de todos los demás factores y poder asegurar que un efecto pertenecerealmente a una determinada variable y no a los otros factores, se le denomina “ajustar” poresos otros factores como hemos visto en la regresión logística.
La ecuación de la regresión de Cox es:
Donde lambda dependiente del tiempo, lt como se recoge en la figura 17–7, es la tasa (eninglés hazard) de fallecer más allá del instante “t” (es decir, la tasa instantánea de fallecer).En lo demás, todo es bastante parecido al análisis de regresión logística. La tasa se diferen-cia del riesgo en que la tasa expresa la rapidez con la cual se enferma (fallecimientos porunidad de tiempo), mientras que el riesgo sólo es una proporción y no tiene en cuenta másque el número de sujetos inicialmente a riesgo de fallecer. El hazard es una tasa instantá-nea, que conceptualmente corresponde a una duración de tiempo infinitesimal.
Se demuestra que para un factor pronóstico dicotómico xi cuyo valor sea 1 para losexpuestos a ese factor y 0 para los no expuestos, la razón de hazards (hazard ratio, HR) será:
Esta medida de asociación aunque se expresa por algunos como un riesgo relativo y seinterpreta como tal (razón de proporciones) es en realidad una hazard ratio, y se asemejamás a la razón de densidades de incidencia (RDI, razón de tasas) que a la razón de inciden-cias acumuladas (razón de proporciones o riesgo relativo). Una hazard ratio de 2 significa,en realidad, que se multiplica por 2 la rapidez con la cual fallecen los sujetos que estánexpuestos al factor pronóstico que se estudia. Un hazard ratio de 1, significa que el efectodel factor es nulo: no es un factor que afecte al pronóstico. Un hazard ratio de 0,5 significaque esa exposición en vez de asociarse a un mal pronóstico, lo mejora, ya que reduce lavelocidad de ocurrencia de fallecimientos a la mitad. Si la exposición fuese cuantitativahabría que elevar el número e al coeficiente correspondiente (bi), pero multiplicando antesel coeficiente por el incremento en unidades de la variable independiente cuyo hazardratio queramos estimar, tal como se podía hacer en el ejemplo de regresión logística con laedad para calcular una odds ratio. Cuando se emplea el modelo de regresión de Cox, seasume que la razón de tasas (hazard ratio) es constante a lo largo del tiempo. Hay métodospara verificar si es cierta esta suposición y también hay técnicas que permiten trabajar conmodelos de riesgo no proporcionales cuya descripción y análisis superan los objetivos deeste texto.
POTENCIA ESTADÍSTICA Y TAMAÑO MUESTRAL
La expresión para calcular aproximadamente el número necesario de eventos3 que debenobservarse en un análisis de supervivencia es

20 Manual de medicina basada en la evidencia (Capítulo 17)
Donde:n: número de eventos que deben observarse
z±/2 = valor de la distribución normal para el error alfa deseado (a 2 colas)
z² = valor de la distribución normal para el error beta deseado (a 1 cola)
HR = hazard ratio (equivalente al riesgo relativo, responde a la pregunta ¿cuántas
veces esperamos que sea superior el evento en un grupo que en otro?)
Así, para un riesgo relativo de 1,5, con un error alfa de 0,05 (z=1,96) y un error beta de 0,2(potencia del 80%, z=0,84), necesitaríamos observar 256 eventos.
[ ]22
)5,1ln()28,196,1(4
256+=
En la siguiente cuadro y figura se representan diversos supuestos, con el número necesariode eventos que se deben observar.
[ ]22
2/
)HRln(
)zz(4n βα +
=
=aicnetoP %09 %08 %06
RH ↓ ↓ ↓
2,1 5621 549 095
3,1 116 754 582
4,1 273 872 471
5,1 652 191 021
6,1 191 341 98
7,1 051 211 07
8,1 221 19 75
9,1 301 77 84
2 88 66 14
1,2 77 85 63
2,2 86 15 23
3,2 16 64 92
4,2 55 14 62
5,2 15 83 42
6,2 74 53 22
7,2 34 23 02
8,2 04 03 91
9,2 83 82 81
3 53 72 71

Análisis de supervivencia y análisis multivariado 21©
Ed
ito
rial
El m
anua
l mo
der
no
F
otoc
opia
r si
n au
toriz
ació
n es
un
delit
o.
REFERENCIAS
1. Greenhalgh T. Statistics for the non–statistician. I: Different types of data need different statisticaltests. BMJ 1997: 364–6. 4.
2. Altman DG. Practical statistics for medical research. Londres, Chapman and Hall, 1991. 3.3. Collet D. Modelling survival data in medical research. Londres, Chapman and Hall, 1994.4. Martínez-González MA, de Irala J, Seguí-Gómez M (eds.). Métodos en Salud Pública (4ª ed.).
Pamplona: Ulzama Digital, 2003.5. Martínez González MA, De Irala Estévez J, Faulín Fajardo FJ (eds.). Bioestadística amigable.
Madrid: Díaz de Santos, 2001.6. Martínez–González MA, de Irala J, Guillen F. ¿Qué es una odds ratio? Med Clin 1999; 112: 416–422.7. Canga N, de Irala J, Vara E, Duaso MJ, Ferrer A, Martínez-González MA. Intervention study for
smoking cessation in diabetic patients, a randomized controlled trial in both clinical and primary caresettings. Diabetes Care 2000;23:1455-60.
8. De Irala J, Martínez-González MA, Seguí-Gómez M (eds.). Epidemiología aplicada Barcelona:Ariel. 2004.
9. De Irala J, Martínez-González MA, Guillén-Grima F. ¿Qué es un factor de confusión? Med Clin(Barc.) 2001;117:377-385. (fe errores: Med Clin (Barc.) 2001;117: 775).
10. Cox DR. Regression model and life tables. J Roy Statist Soc B 1972; 34: 187–220.11. Cox DR, Oakes D. The analysis of survival data. Londres, Chapman and Hall, 1984.12. Sangro B, Herraiz M, Martínez-González MA, Bilbao I, Herrero I, Beloqui O, Betés M, de la
Peña A, Cienfuegos JA, Quiroga J, Prieto J. Prognosis of hepatocellular carcinoma in relation totreatment: a multivariate analysis of 178 patients from a single European institution. Surgery1998;124:575-83.


















