TALLER CONOCIMIENTOS PREVIOS APLICACIONES … · taller conocimientos previos aplicaciones web...
44
TALLER CONOCIMIENTOS PREVIOS APLICACIONES WEB ACTIVIDAD DE PROYECTO – CONFIGURACION DE SERVICIOS DE RED TECNOLOGIA EN GESTIÓN DE REDES DE DATOS CENTRO DE SERVICIOS Y GESTIÓN EMPRESARIAL SENA, MEDELLÍN LUIS FERNANDO MONTENEGRO OVIEDO TECNOLOGÍA EN GESTIÓN DE REDES DE DATOS 259747 INSTRUCTOR MAURICIO ORTIZ SERVICIO NACIONAL DE APRENDIZAJE SENA CENTRO DE SERVICIOS Y GESTION EMPRESARIAL MEDELLIN 2012
Transcript of TALLER CONOCIMIENTOS PREVIOS APLICACIONES … · taller conocimientos previos aplicaciones web...

TALLER CONOCIMIENTOS PREVIOS APLICACIONES WEB ACTIVIDAD DE PROYECTO – CONFIGURACION DE SERVICIOS DE RED
TECNOLOGIA EN GESTIÓN DE REDES DE DATOS CENTRO DE SERVICIOS Y GESTIÓN EMPRESARIAL
SENA, MEDELLÍN
LUIS FERNANDO MONTENEGRO OVIEDO
TECNOLOGÍA EN GESTIÓN DE REDES DE DATOS
259747
INSTRUCTOR MAURICIO ORTIZ
SERVICIO NACIONAL DE APRENDIZAJE
SENA
CENTRO DE SERVICIOS Y GESTION EMPRESARIAL
MEDELLIN
2012

1. Definición de RAID. Es un conjunto redundante de discos independientes, hace referencia a un sistema de almacenamiento que usa múltiples discos duros entre los que distribuye o replica los datos Dependiendo de su configuración. RAID utiliza múltiples discos como si se tratara de una unidad lógica sola. El sistema operativo y el usuario ven un solo disco, pero en realidad la información es almacenada en todos los discos. En términos generales, crear un espejo de la información en dos o más discos duros produce un gran aumento en la velocidad de lectura, pues permite leer múltiples sectores de datos de cada disco duro al mismo tiempo utilizando canales de transferencia de datos distintos. También es una gran ventaja en la seguridad de la información. 2. Por qué es útil RAID en servidores? · Al romperse un disco duro la información sigue estando duplicada en otro disco duro de forma correcta. · Mayor integridad. · Mayor tolerancia a fallos. · Mayor capacidad. · Mayor rendimiento . Mayor velocidad de lectura-escritura 3. ¿Cuál es la diferencia de implementar RAID por hardware o por software? El RAID por software permite incrementar increíblemente el rendimiento y la fiabilidad del disco sin necesidad de comprar controladoras o sistemas RAID, se pueden combinar estas particiones y redireccionarlas como un único dispositivo RAID. Un sistema RAID por software es mucho más económico que por Hardware, pero obtendremos un rendimiento menor y un alto consumo de CPU tan sólo para su gestión. En cuanto a RAID por hardware, evidentemente es mucho más costoso, pero obtendremos una mejora en el rendimiento, al descargar al sistema de buena parte de la gestión de los datos en los discos. Los RAID por hardware se suelen montar con discos SCSI y, sobre todo, con discos SATA. Sólo en controladoras económicas o de bajo rendimiento encontramos RAID sobre discos IDE. Con esto, además de ganar en seguridad, también lo hacemos en rendimiento.

4. ¿Cuál es la función de una controladora RAID? Puedes hacer funcionar varios discos rígidos como si fueran uno (una matriz de discos), además puedes tener toda la información duplicada por seguridad (una matriz de 100 Gb la veras como un disco de 50 Gb,) 5. Explique los principales niveles de RAID. Utilice imágenes. RAID 0. Este sistema multiplica la capacidad del menor de los discos por el número de discos instalados, creando una capacidad de almacenamiento equivalente al resultado de esta operación, utilizable como una sola unidad. A la hora de usar estos discos, divide los datos en bloques y escribe un bloque en cada disco, lo que agiliza bastante el trabajo de escritura/lectura de los discos, dándose el mayor incremento de ganancia en velocidad cuando esta instalado con varias controladoras RAID y un solo disco por controladora.

RAID 1. Un RAID 1 crea una copia exacta (o espejo) de un conjunto de datos en dos o más discos. Esto resulta útil cuando el rendimiento en lectura es más importante que la capacidad. Un conjunto RAID 1 sólo puede ser tan grande como el más pequeño de sus discos. Un RAID 1 clásico consiste en dos discos en espejo, lo que incrementa exponencialmente la fiabilidad respecto a un solo disco; es decir, la probabilidad de fallo del conjunto es igual al producto de las probabilidades de fallo de cada uno de los discos (pues para que el conjunto falle es necesario que lo hagan todos sus discos).
RAID 2. Divide los datos a nivel de bits en lugar de a nivel de bloques, usando el código de Hamming (que permite detectar errores en uno o dos bits y corregirlos) en lugar de la paridad (que permite detectar errores en un bit, sin corregirlo) para la corrección de errores. Permite unas tasas de transferencia altísimas, pero, en teoría, en un sistema moderno necesitaría 39 discos para funcionar. 32 para almacenar los datos (código de 32 bits, 1 bit en cada disco) más 7 para la corrección de errores.

RAID 3. Un RAID 3 usa división a nivel de bytes con un disco de paridad dedicado. El RAID 3 se usa rara vez en la práctica. Uno de sus efectos secundarios es que normalmente no puede atender varias peticiones simultáneas, debido a que por definición cualquier simple bloque de datos se dividirá por todos los miembros del conjunto, residiendo la misma dirección dentro de cada uno de ellos. Así, cualquier operación de lectura o escritura exige activar todos los discos del conjunto.

RAID 4. Pero con los datos divididos a nivel de bloque, más un disco de paridad. Esto supone que se active un solo disco si pedimos una información que ocupe un solo bloque con controladoras que lo permitan, puede atender varias operaciones de lectura simultáneamente. También podría hacer varias operaciones de escritura a la vez, pero al existir un solo disco de paridad, esto supondría un cuello de botella. Son necesarios, al igual que en RAID 3, al menos 3 discos duros
. RAID 5. Graba la información en bloques de forma alternativa, distribuida entre todos los discos. A diferencia de RAID 4, no asigna un disco para la paridad, sino que distribuye ésta en bloques entre los discos, eliminando el cuello de botella que el tener un disco para la paridad supone. Si tenemos el número suficiente de discos, el rendimiento se aproxima al de RAID 0. Son necesarios un mínimo de 3 discos para implementar RAID 5, si bien el Rendimiento óptimo se alcanza con 7 discos.

RAID 6. Pero con un segundo esquema de paridad distribuido entre los discos. Ofrece una Tolerancia extremadamente alta tanto a fallos como a caídas de disco, reemplazando los datos prácticamente en tiempo real, pero tiene el inconveniente de que necesita unas controladoras RAID que soporten esta doble paridad, bastante complejas y muy caras, por lo que no se suele usar comercialmente. Es el mejor tipo de RAID para grandes sistemas, en los que tanto la rapidez como la seguridad e integridad de los datos están por encima del costo del sistema, que es altísimo.
6. Describa cómo se realiza una implementación de RAID por software en los sistemas operativos Windows y Linux. WINDOWS. Ejecutar el comando "compmgmt.msc" desde Inicio-Ejecutar. Después aparecerá el administrador de equipos. Antes de nada tenemos que pasar los discos duros como Discos Dinámicos, sino no podremos crear el conjunto de espejos. La siguiente ilustración muestra como hacerlo. Hay que pulsar con el botón derecho del ratón donde pone Disco 0 y Disco 1 y en el menú que aparece hay que pulsar sobre Actualizar a disco dinámico. Como vemos hay que seleccionar el disco que queremos Actualizar a Dinámico. Y todo debe quedar como la siguiente imagen. Ahora pasaremos a crear el espejo, primero seleccionaremos con el boton derecho del ratón la unidad C: y aparecerá un menú en el cual debemos seleccionar Agregar espejo. En la siguiente ventana que aparece hay que seleccionar el disco donde se creará el espejo de C: en este caso será el Disco 1.

Pulsaremos sobre el botón agregar espejo y aparecerá una ventana advirtiéndonos que para poder arrancar con el disco espejo tenemos que modificar el fichero boot.ini, en nuestro caso no tenemos que modificar nada. Simplemente pulsamos aceptar. Seguidamente se pondrá a formatear el Disco 1 y a crear una "Regeneración" del Disco 0 partición C. Este proceso puede llevar bastante tiempo, depende del tamaño del disco, en el caso de C es aproximadamente entre 20 y 30 minutos. Cuando termina el proceso el estado de los discos debe quedar como la siguiente imagen. Después este proceso se debe de hacer de forma idéntica para la otra partición, por supuesto no es necesario convertir los discos otra vez a dinámico, pues ya lo están. LINUX. Manual que nos va a permitir crear RAID por software. Este manual esta hecho para hacer un RAID 5, pero los pasos serías similares para hacer cualquier otro RAID. Es una matriz o volumen que se hace para aumentar la seguridad de los datos mediante redundancia. Lo primero que tenemos que hacer es montar los discos duros Instalamos el administrador de RAID con apt-get install mdadm En /dev están los dispositivos físicos del sistema Lo que tenemos que hacer es activar el modo RAID 5 con el comando modprobe raid5 El siguiente paso es inicializar los discos con el gparted (Hay un pequeño manual en el articulo de copias de segurad). - Creamos particiones sin formato en los discos aplicamos. - Botón derecho encima de la partición Seguimos este paso para los tres discos duros. Ahora tenemos que comprobar que están preparados para un RAID con el comando fdisk Si nos sale en la última columna Linux raid autodetect está correcto. Para comprobar si hay matrices creadas tenemos que ejecutar cat /proc/mdstat Nos dice que no hay ninguna matriz creada Para decir donde va a estar la matriz mknod /dev/md0 b 9 0 Para crear la matriz en si hacemos lo siguiente.

Si volvemos a mostrar las matrices creadas, deberá mostrar el md que acabamos de Crear con esto lo único que hemos hecho es crear el RAID. Ahora hay que formatear El siguiente paso es montar. 1. Crear una carpeta en media llamada raid_5. 2. /mount –t ext3 /dev/md0 /media/raid5 Lo añadimos al fstab para que cada vez que lo inicie monte el volumen con nano /etc/fstab 7. Diseñe uno o varios gráficos en los que se muestre todo el proceso de comunicación usando el modelo OSI, de la interacción cliente servidor de una petición Web. Comience desde que el usuario ingresa la URL en el navegador Web y tenga en cuenta las consultas a los servidores DNS. Suponga dirección IP privada para el cliente (Dentro de una LAN) y dirección IP pública para el servidor Web. Puede usar Packet Tracer como ayuda y analizar la PDU de cada capa del modelo OSI.
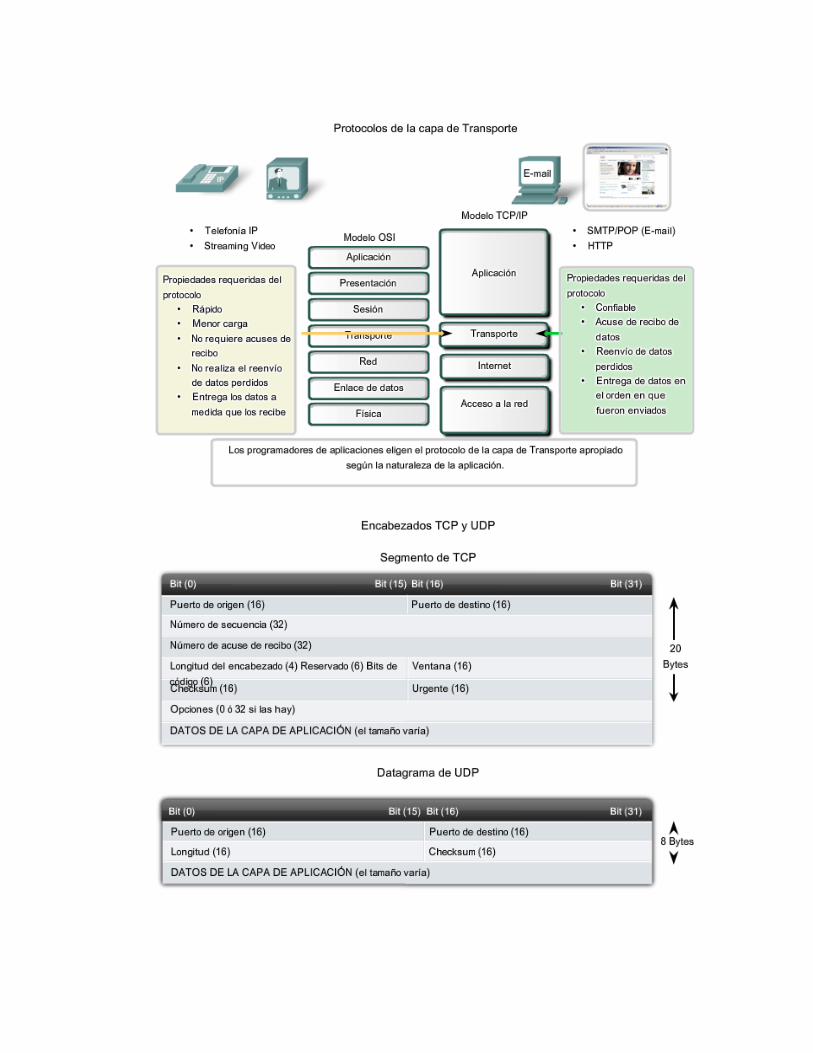


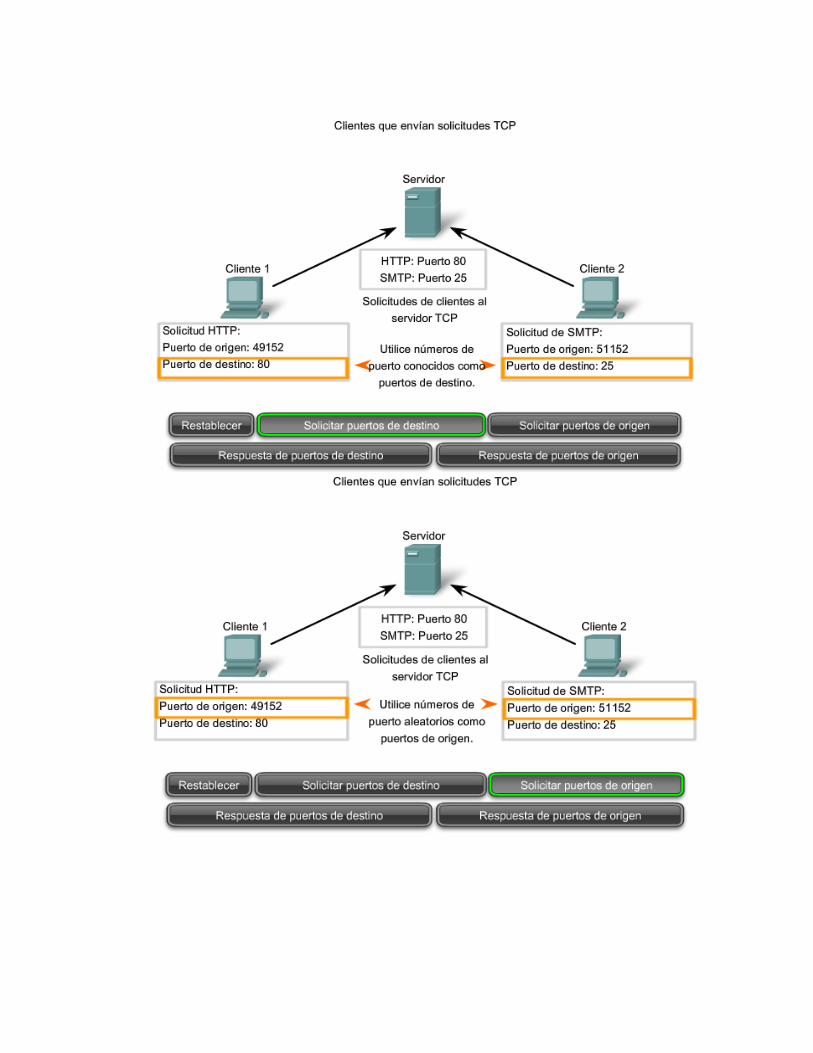
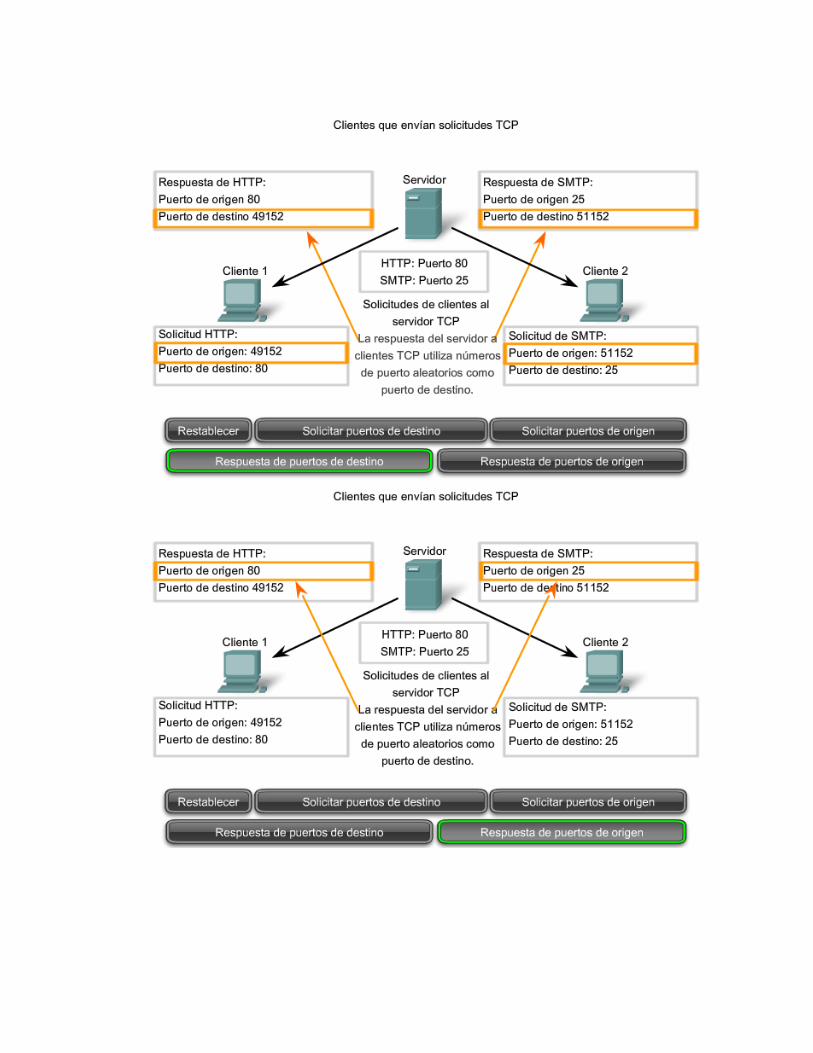

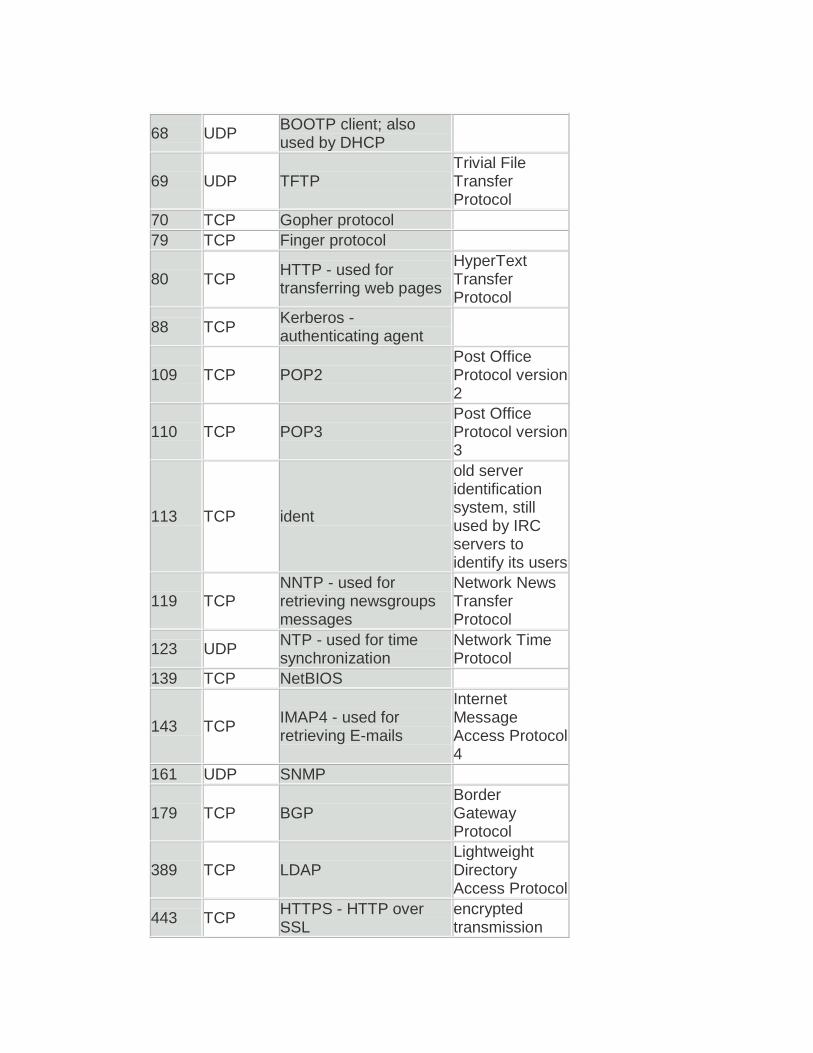
8. ¿Cuáles son los puertos bien conocidos del modelo TCP/IP? Puertos Conocidos
Puerto Protocolo Servicio Observaciones
1 TCP TCPMUX TCP port service multiplexer
7 TCP - UDP
ECHO protocol
9 TCP - UDP
DISCARD Protocol
13 TCP - UDP
DAYTIME protocol
17 TCP QOTD protocol Quote of the Day
19 TCP CHARGEN protocol Character Generator
19 UDP CHARGEN protocol
20 TCP FTP - data port File Transfer Protocol
21 TCP FTP - control port command
22 TCP SSH - used for secure logins, file transfers and port forwarding
Secure Shell (scp, sftp)
23 TCP Telnet protocol - unencrypted text communications
25 TCP SMTP - used for sending E-mails
Simple Mail Transfer Protocol
37 TCP - UDP
TIME protocol
53 TCP DNS Domain Name Server
53 UDP DNS
67 UDP BOOTP server; also used by DHCP
BootStrap Protocol - Dynamic Host Configuration Protocol
68 UDP BOOTP client; also used by DHCP
69 UDP TFTP Trivial File Transfer Protocol
70 TCP Gopher protocol
79 TCP Finger protocol
80 TCP HTTP - used for transferring web pages
HyperText Transfer Protocol
88 TCP Kerberos - authenticating agent
109 TCP POP2 Post Office Protocol version 2
110 TCP POP3 Post Office Protocol version 3
113 TCP ident
old server identification system, still used by IRC servers to identify its users
119 TCP NNTP - used for retrieving newsgroups messages
Network News Transfer Protocol
123 UDP NTP - used for time synchronization
Network Time Protocol
139 TCP NetBIOS
143 TCP IMAP4 - used for retrieving E-mails
Internet Message Access Protocol 4
161 UDP SNMP
179 TCP BGP Border Gateway Protocol
389 TCP LDAP Lightweight Directory Access Protocol
443 TCP HTTPS - HTTP over SSL
encrypted transmission
445 TCP Microsoft-DS
Active Directory, Windows shares, Sasser-worm, Agobot
445 UDP Microsoft-DS SMB file sharing
465 TCP SMTP over SSL
514 UDP syslog protocol used for system logging
540 TCP UUCP Unix-to-Unix Copy Protocol
591 TCP FileMaker 6.0 Web Sharing
HTTP Alternate, see port 80
636 TCP LDAP over SSL encrypted transmission
666 TCP id Software's DOOM multiplayer game played over TCP
993 TCP IMAP4 over SSL encrypted transmission
995 TCP POP3 over SSL encrypted transmission
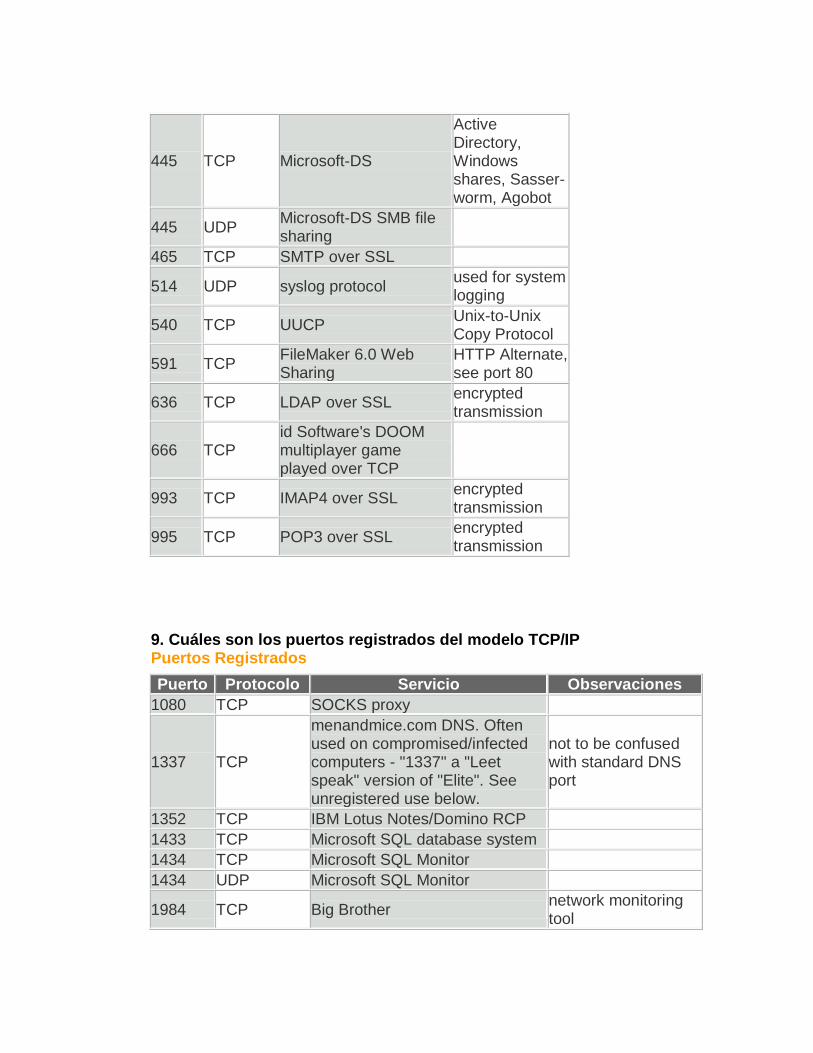
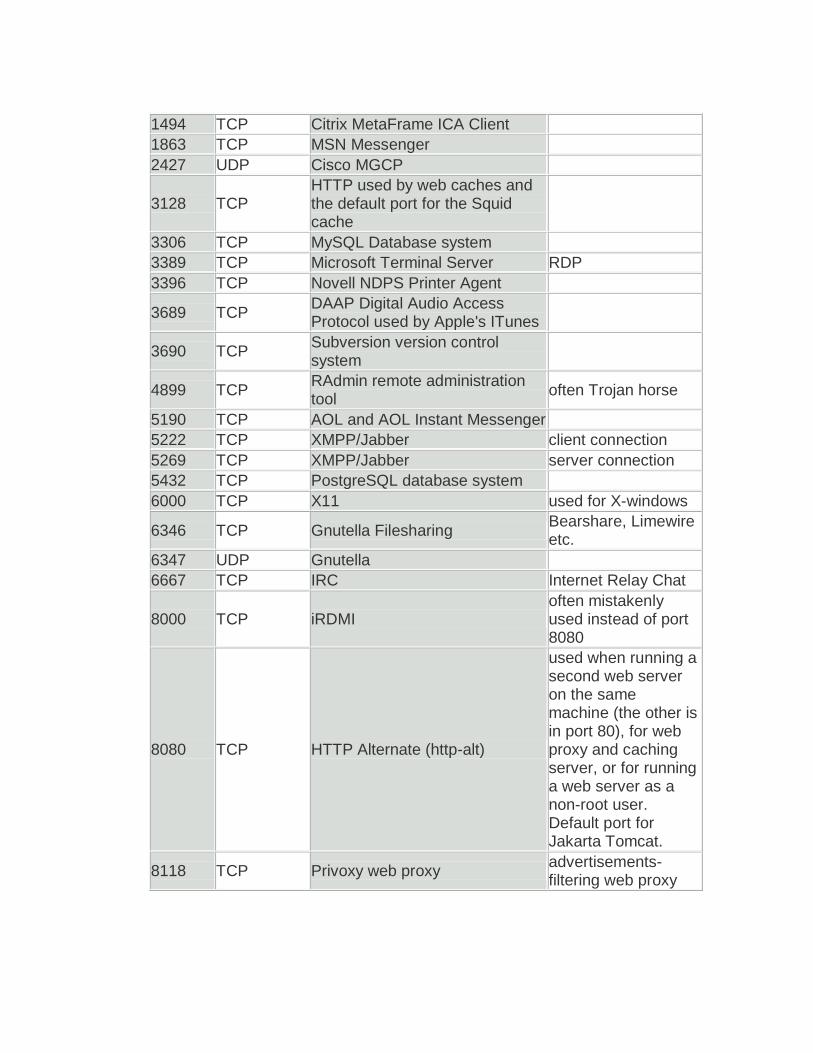
9. Cuáles son los puertos registrados del modelo TCP/IP Puertos Registrados
Puerto Protocolo Servicio Observaciones
1080 TCP SOCKS proxy
1337 TCP
menandmice.com DNS. Often used on compromised/infected computers - "1337" a "Leet speak" version of "Elite". See unregistered use below.
not to be confused with standard DNS port
1352 TCP IBM Lotus Notes/Domino RCP
1433 TCP Microsoft SQL database system
1434 TCP Microsoft SQL Monitor
1434 UDP Microsoft SQL Monitor
1984 TCP Big Brother network monitoring tool
1494 TCP Citrix MetaFrame ICA Client
1863 TCP MSN Messenger
2427 UDP Cisco MGCP
3128 TCP HTTP used by web caches and the default port for the Squid cache
3306 TCP MySQL Database system
3389 TCP Microsoft Terminal Server RDP
3396 TCP Novell NDPS Printer Agent
3689 TCP DAAP Digital Audio Access Protocol used by Apple's ITunes
3690 TCP Subversion version control system
4899 TCP RAdmin remote administration tool
often Trojan horse
5190 TCP AOL and AOL Instant Messenger
5222 TCP XMPP/Jabber client connection
5269 TCP XMPP/Jabber server connection
5432 TCP PostgreSQL database system
6000 TCP X11 used for X-windows
6346 TCP Gnutella Filesharing Bearshare, Limewire etc.
6347 UDP Gnutella
6667 TCP IRC Internet Relay Chat
8000 TCP iRDMI often mistakenly used instead of port 8080
8080 TCP HTTP Alternate (http-alt)
used when running a second web server on the same machine (the other is in port 80), for web proxy and caching server, or for running a web server as a non-root user. Default port for Jakarta Tomcat.
8118 TCP Privoxy web proxy advertisements- filtering web proxy

Puertos no Registrados
Puerto Protocolo Servicio Observaciones
981 TCP
Sofaware Remote HTTPS management for firewall devices running embedded Checkpoint Firewall-1 software
1337 TCP WASTE Encrypted File Sharing Program
CONFLICT with registered use: menandmics DNS
1521 TCP Oracle database default listener
CONFLICT with registered use: nCube License Manager
1761 TCP Novell Zenworks Remote Control utility
CONFLICT with registered use: cft-0
2082 TCP CPanel's default port
CONFLICT with registered use: Infowave Mobility Server
2086 TCP Web Host Manager's default port CONFLICT with registered use: GNUnet
5000 TCP Universal plug-and-play (UPnP)
Windows network device interoperability; Sybase ASE database on Windows platforms; CONFLICT with registered use: commplex-main
5223 TCP XMPP/Jabber default port for SSL Client Connection
5517 TCP Setiqueue Proxy server client for SETI@Home project
5800 TCP VNC remote desktop protocol for use over HTTP
6112 UDP Blizzard's Battle.net gaming service
CONFLICT with registered use: dtspcd
5900 TCP VNC remote desktop protocol regular port
6600 TCP mpd default port that mpd listens for client connects on

6881 TCP BitTorrent port often used
6969 TCP BitTorrent tracker port CONFLICT with registered use: acmsoda
8000 TCP Common port used for internet radio streams such as those using SHOUTcast
27010 UDP Half-Life and its mods, such as Counter-Strike
27015 UDP Half-Life and its mods, such as Counter-Strike
27960 UDP id Software's Quake 3 and Quake 3 derived games
through 27969
31337 TCP Back Orifice - remote administration tool
(often Trojan horse) ("31337" is the "Leet speak" version of "Elite")
50000 TCP DB2 database
10. Defina HTTP. Protocolo de transferencia de hipertexto usado en cada transacción de la Web. HTTP es un protocolo sin estado, es decir, que no guarda ninguna información sobre conexiones anteriores. El desarrollo de aplicaciones web necesita frecuentemente mantener estado. Para esto se usan las cookies, que es información que un servidor puede almacenar en el sistema cliente. Esto le permite a las aplicaciones web instituir la noción de "sesión", y también permite rastrear usuarios ya que las cookies pueden guardarse en el cliente por tiempo indeterminado.
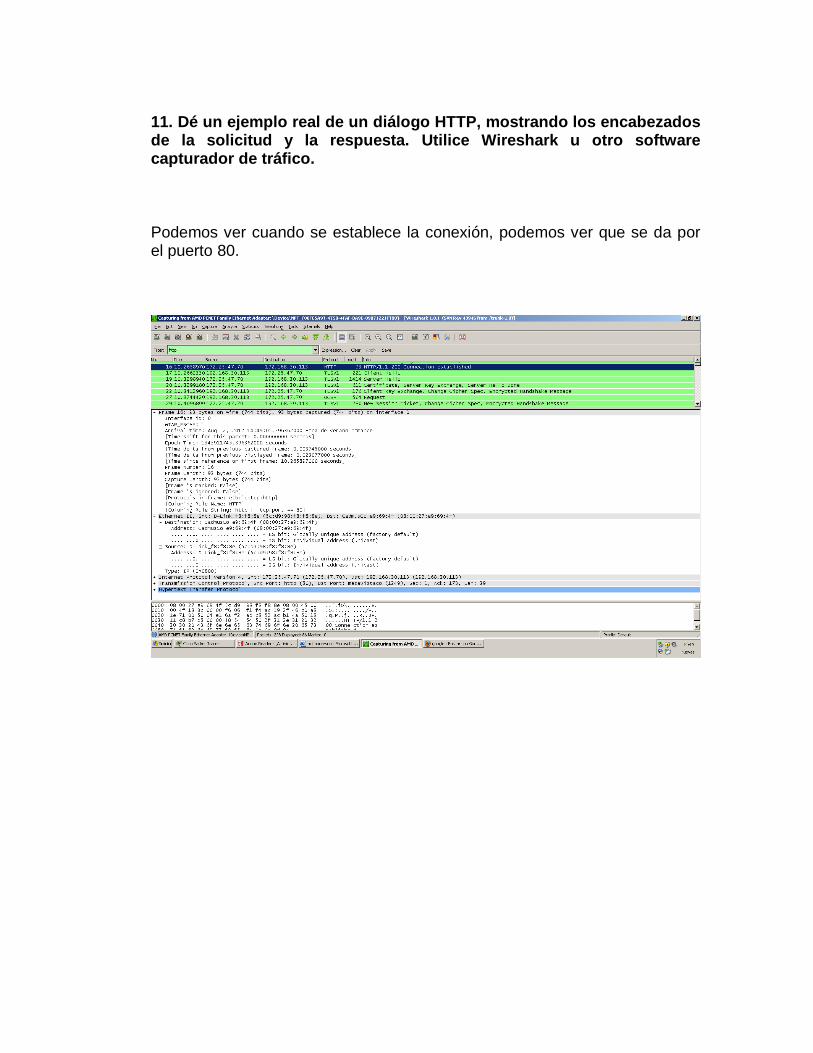
11. Dé un ejemplo real de un diálogo HTTP, mostrando los encabezados de la solicitud y la respuesta. Utilice Wireshark u otro software capturador de tráfico. Podemos ver cuando se establece la conexión, podemos ver que se da por el puerto 80.

El cliente envía un mensaje de saludo
El servidor responde con otro mensaje de saludo

Luego el servidor empieza a responder las solicitudes del cliente.
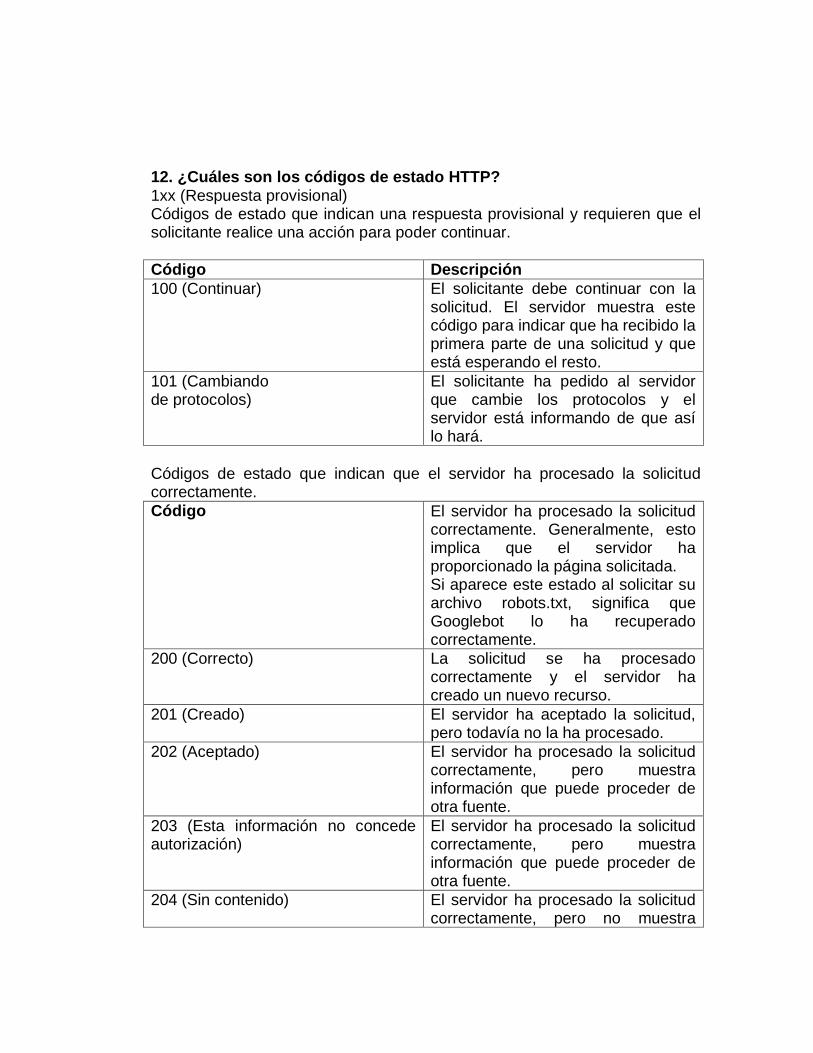
12. ¿Cuáles son los códigos de estado HTTP? 1xx (Respuesta provisional) Códigos de estado que indican una respuesta provisional y requieren que el solicitante realice una acción para poder continuar.
Código Descripción
100 (Continuar) El solicitante debe continuar con la solicitud. El servidor muestra este código para indicar que ha recibido la primera parte de una solicitud y que está esperando el resto.
101 (Cambiando de protocolos)
El solicitante ha pedido al servidor que cambie los protocolos y el servidor está informando de que así lo hará.
Códigos de estado que indican que el servidor ha procesado la solicitud correctamente.
Código El servidor ha procesado la solicitud correctamente. Generalmente, esto implica que el servidor ha proporcionado la página solicitada. Si aparece este estado al solicitar su archivo robots.txt, significa que Googlebot lo ha recuperado correctamente.
200 (Correcto) La solicitud se ha procesado correctamente y el servidor ha creado un nuevo recurso.
201 (Creado) El servidor ha aceptado la solicitud, pero todavía no la ha procesado.
202 (Aceptado) El servidor ha procesado la solicitud correctamente, pero muestra información que puede proceder de otra fuente.
203 (Esta información no concede autorización)
El servidor ha procesado la solicitud correctamente, pero muestra información que puede proceder de otra fuente.
204 (Sin contenido) El servidor ha procesado la solicitud correctamente, pero no muestra
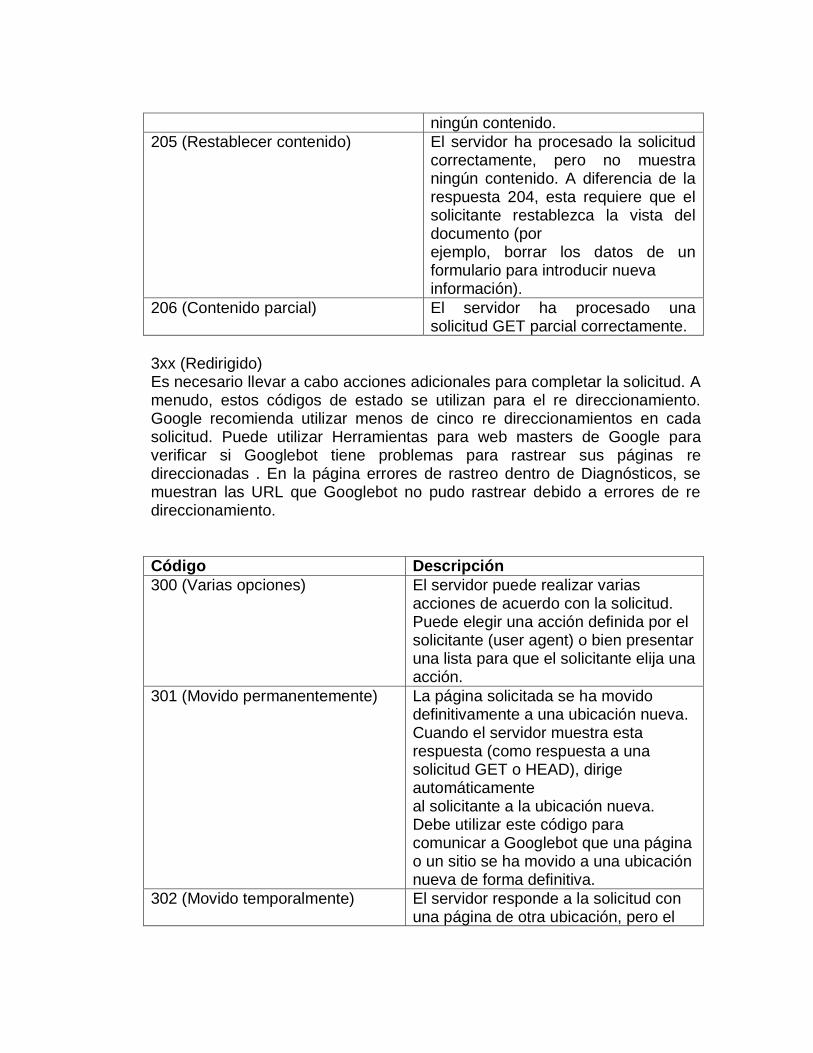
ningún contenido.
205 (Restablecer contenido) El servidor ha procesado la solicitud correctamente, pero no muestra ningún contenido. A diferencia de la respuesta 204, esta requiere que el solicitante restablezca la vista del documento (por ejemplo, borrar los datos de un formulario para introducir nueva información).
206 (Contenido parcial) El servidor ha procesado una solicitud GET parcial correctamente.
3xx (Redirigido) Es necesario llevar a cabo acciones adicionales para completar la solicitud. A menudo, estos códigos de estado se utilizan para el re direccionamiento. Google recomienda utilizar menos de cinco re direccionamientos en cada solicitud. Puede utilizar Herramientas para web masters de Google para verificar si Googlebot tiene problemas para rastrear sus páginas re direccionadas . En la página errores de rastreo dentro de Diagnósticos, se muestran las URL que Googlebot no pudo rastrear debido a errores de re direccionamiento.
Código Descripción
300 (Varias opciones) El servidor puede realizar varias acciones de acuerdo con la solicitud. Puede elegir una acción definida por el solicitante (user agent) o bien presentar una lista para que el solicitante elija una acción.
301 (Movido permanentemente) La página solicitada se ha movido definitivamente a una ubicación nueva. Cuando el servidor muestra esta respuesta (como respuesta a una solicitud GET o HEAD), dirige automáticamente al solicitante a la ubicación nueva. Debe utilizar este código para comunicar a Googlebot que una página o un sitio se ha movido a una ubicación nueva de forma definitiva.
302 (Movido temporalmente) El servidor responde a la solicitud con una página de otra ubicación, pero el
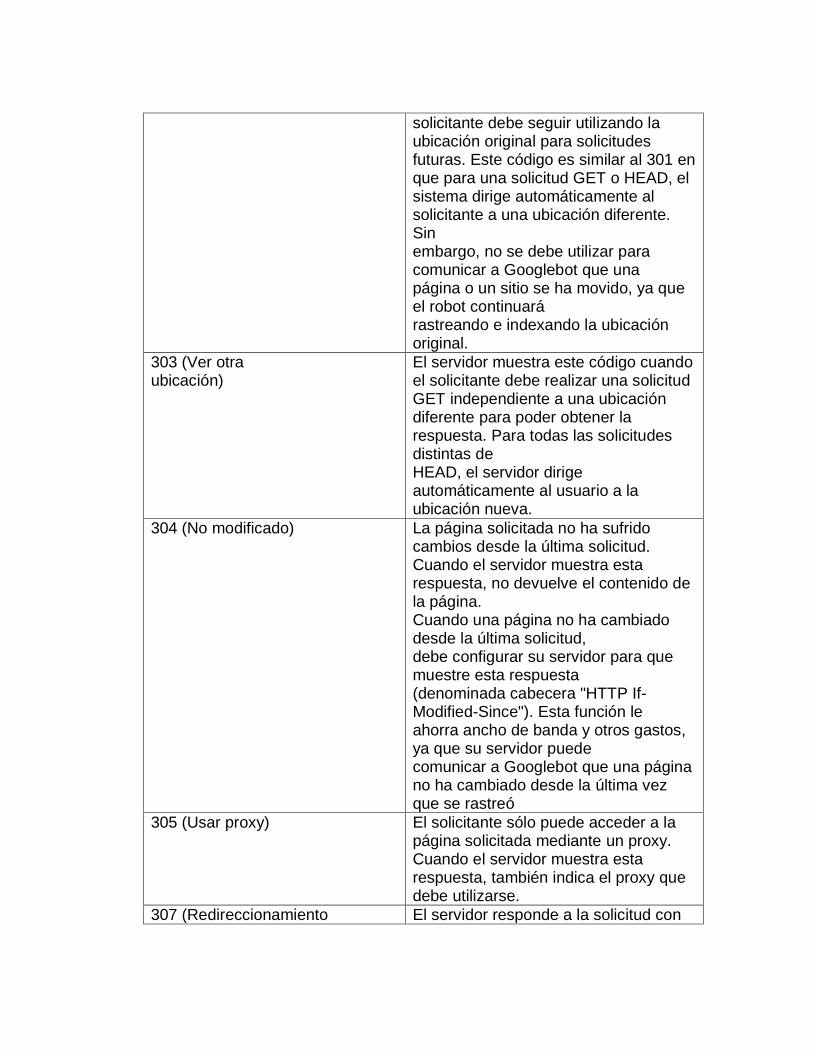
solicitante debe seguir utilizando la ubicación original para solicitudes futuras. Este código es similar al 301 en que para una solicitud GET o HEAD, el sistema dirige automáticamente al solicitante a una ubicación diferente. Sin embargo, no se debe utilizar para comunicar a Googlebot que una página o un sitio se ha movido, ya que el robot continuará rastreando e indexando la ubicación original.
303 (Ver otra ubicación)
El servidor muestra este código cuando el solicitante debe realizar una solicitud GET independiente a una ubicación diferente para poder obtener la respuesta. Para todas las solicitudes distintas de HEAD, el servidor dirige automáticamente al usuario a la ubicación nueva.
304 (No modificado) La página solicitada no ha sufrido cambios desde la última solicitud. Cuando el servidor muestra esta respuesta, no devuelve el contenido de la página. Cuando una página no ha cambiado desde la última solicitud, debe configurar su servidor para que muestre esta respuesta (denominada cabecera "HTTP If-Modified-Since"). Esta función le ahorra ancho de banda y otros gastos, ya que su servidor puede comunicar a Googlebot que una página no ha cambiado desde la última vez que se rastreó
305 (Usar proxy) El solicitante sólo puede acceder a la página solicitada mediante un proxy. Cuando el servidor muestra esta respuesta, también indica el proxy que debe utilizarse.
307 (Redireccionamiento El servidor responde a la solicitud con

temporal) una página de otra ubicación, pero el solicitante debe seguir utilizando la ubicación original para solicitudes futuras. Este código es similar al 301 en
13. ¿Qué son las cookies? Es un fragmento de información que se almacena en el disco duro del visitante de una página web a través de su navegador, a petición del servidor de la página. Esta información puede ser luego recuperada por el servidor en posteriores visitas. En ocasiones también se le llama "huella". Las cookies son utilizadas habitualmente por los servidores web para diferenciar usuarios y para actuar de diferente forma dependiendo del usuario. Las cookies se inventaron para ser utilizadas en una cesta de la compra virtual, que actúa como dispositivo virtual en el que el usuario va "colocando" los elementos que desea adquirir, de forma que los usuarios pueden navegar por el sitio donde se muestran los objetos a la venta y añadirlos y eliminarlos de la cesta de la compra en cualquier momento. Las cookies permiten que el contenido de la cesta de la compra dependa de las acciones del usuario 14. ¿Cuál es la diferencia entre una aplicación en el lado del cliente una aplicación en el lado del servidor? Dé ejemplos.
Los servidores abren los puertos bien conocidos del modelo TCP/IP, de acuerdo a la aplicación y los clientes abren los puertos registrados del modelo TCP/IP. Ejem: el servidor web abre el puerto 80 cuando recibe una petición; mientras que el cliente puede abrir el puerto 1800 cuando hace la petición.
Los servidores necesitan instalar software que permitan administrar un servicio en la red, mientras que el cliente solo necesita una aplicación que permita utilizar ese servicio. Ejem: el servidor FTP necesita una el VSFTPD (Linux) para poder administrar el servicio, mientras que el cliente solo necesita un explorador para poder tener acceso a los archivos del FTP.
15. Explique la diferencia entre una página Web dinámica y una página estática. PAGINA WEB ESTATICA Una página Web estática es aquella que es básicamente informativa, el visitante y administrador Web no pueden interactuar con la página para modificar su contenido NO se utilizan bases de datos ni se requiere programación. Para desarrollar una página web estática es suficiente utilizar código HTML.

PAGINA WEB DINAMICA Una página Web dinámica es aquella que puede interactuar con el visitante y/o administrador Web, pudiéndose modificar el contenido de la página. Ejemplos de esto son: cuando el usuario puede escribir un comentario, escoger los productos y ponerlos en un carrito de compras, subir archivos o fotografías, etc. En este caso si se utilizan bases de datos y se requiere programación Web. El lenguaje utilizado puede ser alguno de los siguientes: PHP, ASP, ASP.NET o Java. 16. ¿Cuáles son los elementos y atributos de una estructura HTML? En esta sección conoceremos los cuatro elementos básicos que "marcan" la estructura de un documento HTML. Pero antes de nada veamos el esqueleto de un documento HTML vacío: <!DOCTYPE> <html> Delimita el documento HTML, indicando al navegador el comienzo y fin de la página html. <head> viene del ingles cabeza y su funcion es delimitar cabecera del documento. </head> <body> Delimita el cuerpo del documento. Aquí van todos los contenidos de la página </body> </html> Elemento title Indica el título del documento. <title> y </title> ATRIBUROS title = texto Este atributo ofrece información consultiva sobre el elemento para el cual se establece. Para los siguientes atributos, los valores permitidos y su interpretación depende del perfil: name = name [CS] Este atributo identifica un nombre de propiedad. Esta especificación no enumera los valores legales para este atributo. content = cdata [CS] Este atributo especifica el valor de una propiedad. Esta especificación no enumera los valores legales para este atributo. scheme = cdata [CS] Este atributo especifica un esquema que se usará para interpretar el valor de la propiedad (véase la sección sobre perfiles para más detalles). http-equiv = name [CI] Este atributo puede utilizarse en lugar del atributo name. Los servidores HTTP utilizan este atributo para obtener información sobre los encabezados del mensaje de respuesta HTTP.

SCHEME El atributo scheme permite a los autores proporcionar a los agentes de usuario más contexto para la interpretación correcta de los metadatos. Definiciones de atributos en BODY background = uri [CT] El valor de este atributo es un URI que designa un recurso de imagen. En general la imagen se repite para rellenar el fondo (en navegadores visuales). text = color [CI] Este atributo establece el color de primer plano para el texto (en navegadores visuales). link = color [CI] Este atributo establece el color del texto que marca los vínculos de hipertexto no visitados (en navegadores visuales) vlink = color [CI] Este atributo especifica el color del texto que marca los vínculos de hipertexto visitados (en navegadores visuales). alink = color [CI] Este atributo especifica el color del texto que marca los vínculos de hipertexto cuando son seleccionados por el usuario (en navegadores visuales). id = name [CS] Este atributo asigna un nombre a un elemento. Este nombre debe ser único en un documento. class = lista de cdata [CS] Este atributo asigna un nombre de clase o un conjunto de nombres de clase a un elemento. 17. Cree una tabla en la que muestre las etiquetas y atributos correspondientes a los siguientes elementos de un documento HTML (Dé ejemplos):
ELEMENTOS APERTURA ATRIBUTOS CIERRE
Inicio y final de un documento HTML
<html> HEAD y BODY </html>
Cabecera de un documento HTML
<head> BASE, TITLE, ISINDEX, NEXTID, META
</head>
Título de la <title> ninguno </title>
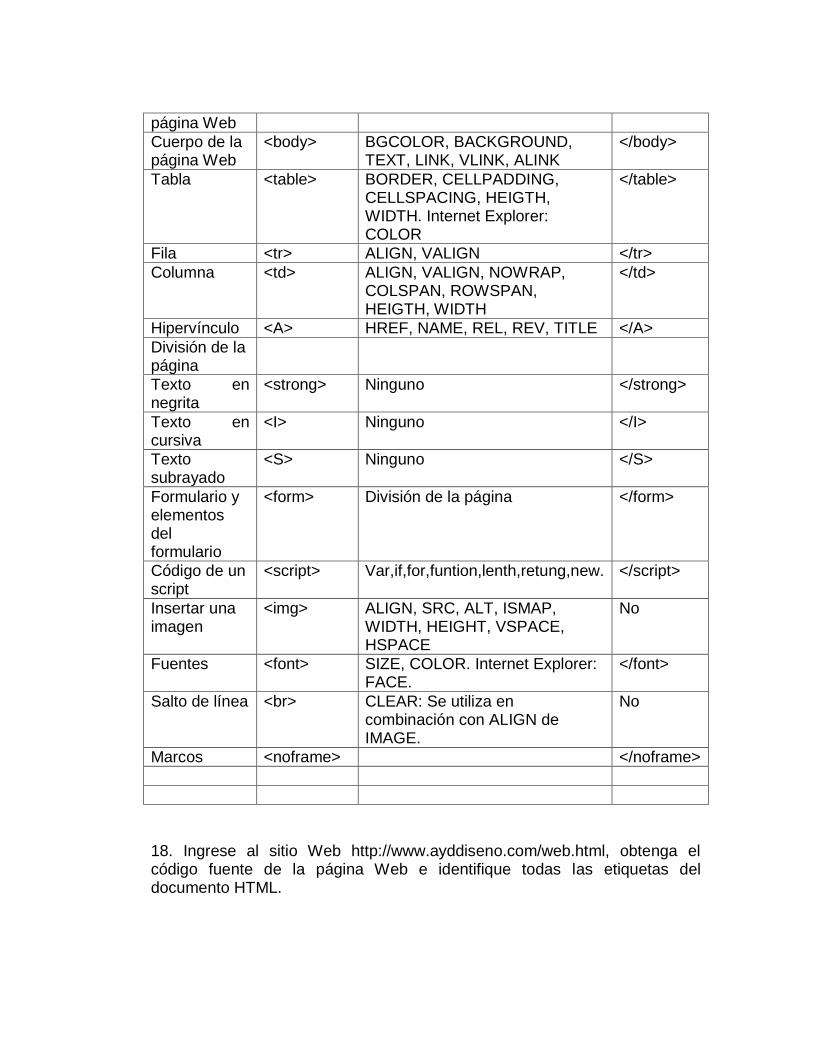
página Web
Cuerpo de la página Web
<body> BGCOLOR, BACKGROUND, TEXT, LINK, VLINK, ALINK
</body>
Tabla <table> BORDER, CELLPADDING, CELLSPACING, HEIGTH, WIDTH. Internet Explorer: COLOR
</table>
Fila <tr> ALIGN, VALIGN </tr>
Columna <td> ALIGN, VALIGN, NOWRAP, COLSPAN, ROWSPAN, HEIGTH, WIDTH
</td>
Hipervínculo <A> HREF, NAME, REL, REV, TITLE </A>
División de la página
Texto en negrita
<strong> Ninguno </strong>
Texto en cursiva
<I> Ninguno </I>
Texto subrayado
<S> Ninguno </S>
Formulario y elementos del formulario
<form> División de la página </form>
Código de un script
<script> Var,if,for,funtion,lenth,retung,new. </script>
Insertar una imagen
<img> ALIGN, SRC, ALT, ISMAP, WIDTH, HEIGHT, VSPACE, HSPACE
No
Fuentes <font> SIZE, COLOR. Internet Explorer: FACE.
</font>
Salto de línea <br> CLEAR: Se utiliza en combinación con ALIGN de IMAGE.
No
Marcos <noframe> </noframe>
18. Ingrese al sitio Web http://www.ayddiseno.com/web.html, obtenga el código fuente de la página Web e identifique todas las etiquetas del documento HTML.

19. Consulte la tabla de colores RGB con su correspondiente código hexadecimal Esta es una tabla con una variedad de posibles colores asociados a su valor hexadecimal #rrggbb. Estos valores pueden ser utilizados, tanto para obtener colores de fondo como colores de texto, en la creación de páginas web. Obviamente aquí no están todos los colores, pero os podréis hacer una idea de como combinar los valores hexadecimales para conseguir el color que queráis Estos valores van del 1 al 9 y de la A a la F

20. ¿Qué son las hojas de estilo (CSS)? Modo de funcionamiento de las CSS consiste en definir, mediante una sintaxis especial, la forma de presentación que le aplicaremos a:
Un web entero, de modo que se puede definir la forma de todo el web de una sola vez.
Un documento HTML o página, se puede definir la forma, en un pequeño trozo de código en la cabecera, a toda la página.
Una porción del documento, aplicando estilos visibles en un trozo de la página.
Una etiqueta en concreto, llegando incluso a poder definir varios estilos diferentes para una sola etiqueta. Esto es muy importante ya que ofrece potencia en nuestra programación. Podemos definir, por ejemplo, varios tipos de párrafos: en rojo, en azul, con márgenes, sin ellos.
La potencia de la tecnología salta a la vista. Pero no solo se queda aquí, ya que además esta sintaxis CSS permite aplicar al documento formato de modo mucho más exacto. Si antes el HTML se nos quedaba corto para maquetar las páginas y teníamos que utilizar trucos para conseguir nuestros

efectos, ahora tenemos muchas más herramientas que nos permiten definir esta forma:
Podemos definir la distancia entre líneas del documento.
Se puede aplicar editando las primeras líneas del párrafo.
Podemos colocar elementos en la página con mayor precisión, y sin lugares errores.
Y mucho más, como definir la visibilidad de los elementos, margenes, subrayados, tachados.
Y seguimos mostrándolos ventajas, ya que si con el HTML tan sólo podíamos definir atributos en las páginas con pixeles y porcentajes, ahora podemos definir utilizando muchas más unidades como:
Pixeles (px) y porcentaje (%), como antes
Pulgadas (in)
Puntos (pt)
Centímetros (cm)
21. ¿Qué es una aplicación Web? Realice una lista de 20 aplicaciones Web. En la ingeniería de software se denomina aplicación web a aquellas herramientas que los usuarios pueden utilizar accediendo a un servidor web a través de Internet o de una intranet mediante un navegador. En otras palabras, es una aplicación software que se codifica en un lenguaje soportado por los navegadores web en la que se confía la ejecución al navegador. Las aplicaciones web son populares debido a lo práctico del navegador web como cliente ligero, a la independencia del sistema operativo, así como a la facilidad para actualizar y mantener aplicaciones web sin distribuir e instalar software a miles de usuarios potenciales. 22. Explique los siguientes lenguajes de programación y conceptos relacionados con las aplicaciones Web: - PHP - ASP - Perl - Python - CGI - .NET - JSP

PHP: es un lenguaje de programación interpretado, diseñado originalmente para la creación de páginas web dinámicas. PHP nos permite embeber sus pequeños fragmentos de código dentro de la página HTML y realizar determinadas acciones de una forma fácil y eficaz, combinando lo que ya sabemos del desarrollo HTML. ASP: (Active Server Pages), es un lenguaje de programación de servidores para generar páginas Web dinámicamente. Se conocen cuatro versiones de este lenguaje las 1.0, 2.0, 3.0 y la ASP.NET que se la conoce como la ASP Clásica. El ASP es un lenguaje de programación para servidores es adecuado para acceso a bases de datos, lectura de ficheros, etc. Se vale de dos lenguajes de Script, como son el VBScript y el JavaScript para que lo que programemos con el ASP sea visible. PERL: Practical Extraction and Report Language es un sofisticado lenguaje de programación diseñado a finales de los años 80 por el lingüista norteamericano Larry Wall. PERL combina en forma concisa las mejores características de lenguajes como C, sed, awk y sh. En general, es posible reducir extensos programas escritos en C a pocas líneas de código de un programa PERL, con la ventaja adicional de que corren sin cambio sobre casi cualquier plataforma existente, lo que convierte a PERL en el lenguaje ideal para desarrollo de prototipos y aplicaciones robustas 100% portables. PYTHON: es un lenguaje de scripting independiente de plataforma y orientado a objetos, preparado para realizar cualquier tipo de programa, desde aplicaciones Windows a servidores de red o incluso, páginas web. Es un lenguaje interpretado, lo que significa que no se necesita compilar el código fuente para poder ejecutarlo, lo que ofrece ventajas como la rapidez de desarrollo e inconvenientes como una menor velocidad. CGI: CGI no es un lenguaje. Es simplemente un protocolo que puede ser usado para comunicarse entre formas Web y tu programa Un script CGI puede ser escrito en cualquier lenguaje que pueda leer de STDIN, escribir en STDOUT, y leer variables de entorno como virtualmente cualquier lenguaje de programación, incluyendo C, Perl, o incluso scripts de Shell.

.NET: .Net es la nueva plataforma de desarrollo que ha lanzado al mercado Microsoft, y en la que ha estado trabajado durante los últimos años. Sin duda alguna va a ser uno de los entornos de desarrollo que reinen durante los próximos años. .NET es un conjunto de tecnologías de software, compuesto de varios lenguajes de programación que se ejecutan bajo el .NET Framework. Es además un entorno completamente orientado a objetos y que es capaz de ejecutarse bajo cualquier plataforma. . La plataforma .NET no es más que un conjunto de tecnologías para desarrollar y utilizar componentes que nos permitan crear formularios web, servicios web y aplicaciones Windows. JSP: JSP es un acrónimo de Java Server Pages, que en castellano vendría a decir algo como Páginas de Servidor Java. Es, pues, una tecnología orientada a crear páginas web con programación en Java. Con JSP podemos crear aplicaciones web que se ejecuten en variados servidores web, de múltiples plataformas, ya que Java es en esencia un lenguaje multiplataforma. Las páginas JSP están compuestas de código HTML/XML mezclado con etiquetas especiales para programar scripts de servidor en sintaxis Java. Por tanto, las JSP podremos escribirlas con nuestro editor HTML/XML habitual. 23- Defina WAMP, LAMP y XAMPP XAMPP es un servidor independiente de plataforma, software libre, que consiste principalmente en la base de datos MySQL, el servidor Web Apache y los intérpretes para lenguajes de script: PHP y Perl. El nombre proviene del acrónimo de X (para cualquiera de los diferentes sistemas operativos), Apache, MySQL, PHP, Perl. El programa está liberado bajo la licencia GNU y actúa como un servidor Web libre, fácil de usar y capaz de interpretar páginas dinámicas. Actualmente XAMPP está disponible para Microsoft Windows, GNU/Linux, Solaris, y MacOS X. LAMP presenta una funcionalidad parecida a XAMP, pero enfocada en Linux, y WAMP lo hace enfocado en Windows. 24- ¿Qué es una base de datos? Una base de datos o banco de datos (en ocasiones abreviada con la sigla BD o con la abreviatura b. d.) es un conjunto de datos pertenecientes a un mismo contexto y almacenados sistemáticamente, y de forma ordenada para su posterior uso. Existen programas denominados sistemas gestores de bases de datos, abreviados SGBD, que permiten almacenar y posteriormente acceder a los datos de forma rápida y estructurada.

25- ¿Cuáles son las principales características de SQL? El lenguaje de consulta estructurado o SQL (por sus siglas en inglés structured query language) es un lenguaje declarativo de acceso a bases de datos relacionales que permite especificar diversos tipos de operaciones en estas. Una de sus características es el manejo del álgebra y el cálculo relacional permitiendo efectuar consultas con el fin de recuperar -de una forma sencilla- información. 26- Cuáles son los principales sistemas de gestión de bases de datos (Explique brevemente cada uno de ellos) Filemaker: sistema de bases de más fácil de usar. Es compatible con Mac y Windows tanto para servidores equipos de escritorio y aplicaciones Web. Oracle: sistema de gestión de bases de datos desarrollado por Oracle Corporation. Fue punto de crítica de expertos en cuanto a su seguridad, ya que se detectaron 22 fallas que fueron corregidas con parches mejorando así el sistema MySQL: sistema de gestión de base de datos desarrollada por Sun Microsystem y más usada en el mundo fuera de ser software libre con un Licenciamiento de GNU GPL. Utilizado en plataformas Linux, Windows. Microsoft Access: sistema de gestión de base de datos creado por Microsoft para pequeñas empresas; pertenece a la categoría de Gestión y no de la ofimática. Sybase ASE: es un sistema de gestión de base de datos de la compañía Sybase. Es un motor de bases de datos de alto rendimiento, y puede manejar grandes volúmenes de información Borland Paradox: sistema de base de datos para entornos Windows, anteriormente estaba disponible para DOS y Linux. Fue desarrollada por Corel e incluida a WordPerfect (suite ofimática) Microsoft SQL server: sistema de gestión de bases de datos y su propietario es Microsoft. Se basa en un lenguaje transact-SQL. 27- Instale un gestor de base de datos MYSQL en Windows y un gestor de base de datos MYSQL en Linux. Cree una base de datos y diferentes tablas y campos, mediante un software de administración gráfica y mediante línea de comandos. Use máquinas virtuales y evidencie el proceso.

MYSQL en Windows XP Primero descargamos el software que nos permitirá crear y administrar bases de datos MYSQL
Para crear y administrar las bases de datos, nos dirigimos a phpMyadmin.
Desde la interfaz grafica de este software podemos crear nuestras bases de datos, añadirle tablas, columnas, filas, etc. (es muy fácil, puesto que es interfaz grafica).
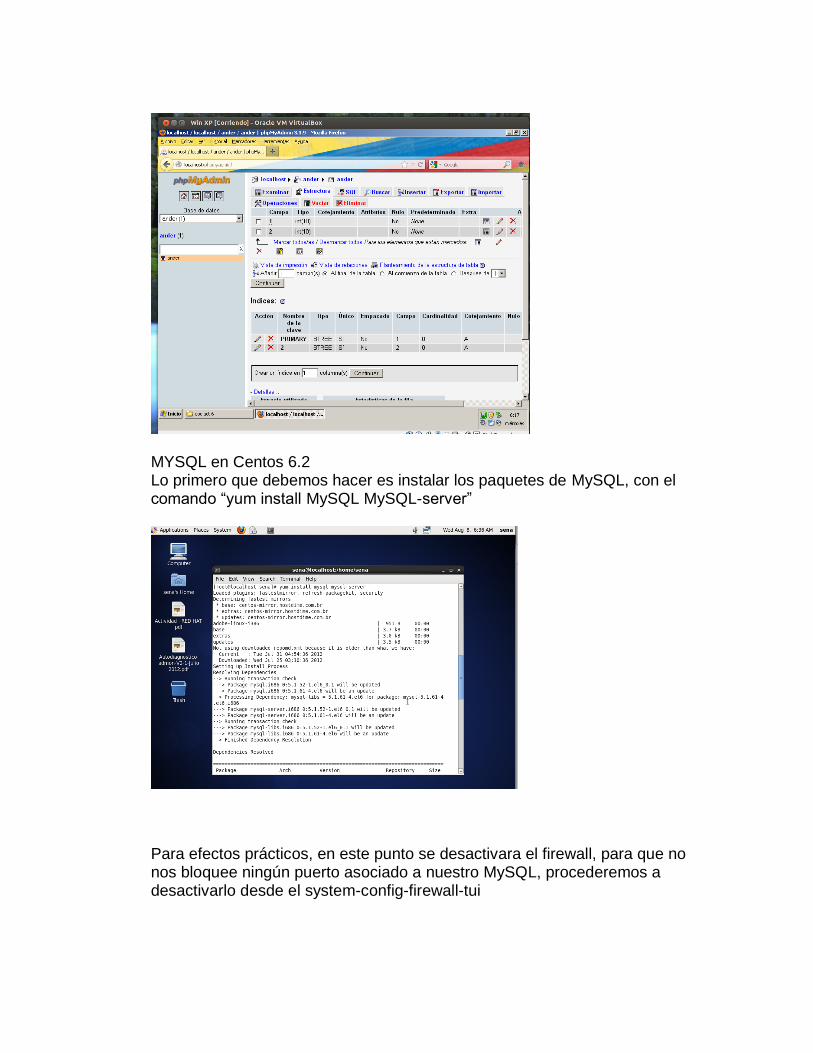
MYSQL en Centos 6.2 Lo primero que debemos hacer es instalar los paquetes de MySQL, con el comando “yum install MySQL MySQL-server”
Para efectos prácticos, en este punto se desactivara el firewall, para que no nos bloquee ningún puerto asociado a nuestro MySQL, procederemos a desactivarlo desde el system-config-firewall-tui
Ahora procederemos a configurar las iptables, para añadir permisos al puerto asociado con MySQL (3306). Luego guardamos la configuración de iptables.
Reiniciamos el servicio iptables, para que coja la configuración dada. Ejecutamos
Ejecutamos los siguientes comandos para que SELinux permita al usuario regular establecer conexiones hacia el zócalo de MySQL, y para que SELinux permita al MySQL conectarse a cualquier puerto distinto al 3306.

Para que MySQL permanezca activo lo configuramos con chkconfig, y luego procedemos a iniciar el servicio MySQL con el comando service MySQL Start.
Agregamos la contraseña al root del MySQL.
Para crear bases de datos lo hacemos con create, y para eliminar bases de datos le damos la opción drop.

Para entrar y utilizar MySQL, basta con poner MySQL en la terminal, pero si ya hemos creado una contraseña y un usuario debemos darle el comando MySQL –u root –p
Para listar las bases de datos existentes, damos “show databases;” Para usar la base de datos que queramos, damos USE ”base_de_datos;” Podemos ver que la base de datos “basededatos” esta listada.

Luego nos dirigimos a la base de datos que queramos, y estando ahí ya podemos crear, o modificar la base de datos. Para crear tablas lo hacemos con “create table “nombre” (especificaciones);” y podemos especificar los campos que va a tener (char). Es importante poner el punto y coma (;) luego de cualquier directriz para que se pueda ejecutar eficientemente.
Nos dirigimos a la base de datos deseada, y listamos las tablas que contiene con el comando “show tables;”

Para introducir datos en los campos, lo hacemos con “INSERT INTO nombre_tabla VALUES ('dato', 'dato');” Luego miramos que si quedaron dichos campos en la tabla, lo hacemos con “SELECT * from nombre_tabla;”
Para el entorno grafico de MySQL en Centos, podemos instalar phpmyadmin, el cual nos sirve para la administración por entorno grafico de MySQL.

28. Realice una lista de comandos para administrar una base de datos MYSQL SHOW databases; => para listar las bases de datos que hay. USE nombre_base_datos; => la utilizamos para usar una base de datos especifica. INSERT INTO nombre_tabla VALUES ('dato', 'dato'); => Para insertar datos en la tabla. Desc nombre_tabla; => Ver especificación de una tabla. Show index from nombre_tabla; => Ver índices de una tabla. ALTER TABLE nombre_tabla ADD COLUMN nombre_columna CHAR(11) NOY NULL; => Crear columna. ALTER table nombre_tabla RENAME TO nuevo_nombre; => Renombrar tabla. DROP table tabla1[, tabla2,…]; => Eliminar tabla ALTER TABLE nombre_tabla DROP COLUMN nombre_columna; => Eliminar columna