
PRESENTACIONES ESTADISTICAS - Instituto Universitario de ... · hay relativamente pocas...
36
Universidad de Mendoza Ing. Jesús Rubén Azor Montoya ______________________________________________________________________ Cátedra Estadística Aplicada II 1 PRESENTACIONES ESTADISTICAS Distribuciones de frecuencia : Son tablas en las que se agrupan lo valores posibles de una variable y se registra el número de valores observados que corresponden a cada clase. Como ejemplo se verá la distribución de frecuencias de los salarios semanales para 100 trabajadores: Salario semanal (en pesos) Número de Trabajadores (frecuencia) 140 – 159 07 160 – 179 20 180 – 199 33 200 – 219 25 220 – 239 11 240 – 259 04 Total=100 (tamaño de la muestra) Intervalos de Clase : Un ejemplo de ellos lo constituye 140 - 159, los límites de clase superior e inferior son: 159 y 140 respectivamente. Estos indican los valores incluidos dentro de la clase. Las fronteras de clase o límites exactos son puntos específicos de la escala que sirven para "separar clases adyacentes". Se pueden determinar identificando los puntos que están en la mitad entre los límites superior e inferior de las clases adyacentes. Por ejemplo, para 140 - 159 y 160 - 179 la frontera de clase está en 159.50. El intervalo de clase indica el rango de valores incluídos dentro de una clase y se puede determinar restando la frontera de clase inferior de la frontera de clase superior. Puede ser útil el punto medio de clase , que se determina sumando la mitad del intervalo de clase a la frontera inferior de clase.
Transcript of PRESENTACIONES ESTADISTICAS - Instituto Universitario de ... · hay relativamente pocas...

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
1
PRESENTACIONES ESTADISTICAS
Distribuciones de frecuencia:
Son tablas en las que se agrupan lo valores posibles de una variable y se registra el
número de valores observados que corresponden a cada clase.
Como ejemplo se verá la distribución de frecuencias de los salarios semanales para
100 trabajadores:
Salario semanal
(en pesos)
Número de Trabajadores
(frecuencia)
140 – 159 07
160 – 179 20
180 – 199 33
200 – 219 25
220 – 239 11
240 – 259 04
Total=100 (tamaño de la
muestra)
Intervalos de Clase:
Un ejemplo de ellos lo constituye 140 - 159, los límites de clase superior e inferior
son: 159 y 140 respectivamente. Estos indican los valores incluidos dentro de la clase. Las
fronteras de clase o límites exactos son puntos específicos de la escala que sirven para
"separar clases adyacentes". Se pueden determinar identificando los puntos que están en la
mitad entre los límites superior e inferior de las clases adyacentes.
Por ejemplo, para 140 - 159 y 160 - 179 la frontera de clase está en 159.50.
El intervalo de clase indica el rango de valores incluídos dentro de una clase y se
puede determinar restando la frontera de clase inferior de la frontera de clase superior.
Puede ser útil el punto medio de clase, que se determina sumando la mitad del intervalo de
clase a la frontera inferior de clase.

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
2
Resumiendo:
Salario semanal
(límite de clases)
Fronteras de
clase
Punto medio
de clase
Nro. de
Trabajadores
140 - 159 139.5 - 159.5 149.5 7
160 - 179 159.5 - 179.5 169.5 20
180 - 199 179.5 - 199.5 189.5 33
200 - 219 199.5 - 219.5 209.5 25
220 - 239 219.5 - 239.5 229.5 11
240 - 259 239.5 - 259.5 249.5 4
Total: 100
Conviene que los intervalos de clase sean iguales. Se puede determinar el intervalo
de clase en forma aproximada del siguiente modo:
Para el caso anterior, supuesto que los valores menores y mayores de los datos no
agrupados fueran 142 y 258 respectivamente, y se desean 6 clases:
Int_aprox258 142
6
Int_aprox 19.333
El más próximo será 20.
Para datos distribuido "irregularmente" pueden ser convenientes intervalos
irregulares de clase. Se utilizan intervalos mayores para los rangos de valores en los que
hay relativamente pocas observaciones.
HISTOGRAMAS Y POLIGONOS DE FRECUENCIA
Un histograma es un diagrama de barras de una distribución de frecuencias, donde
en ordenadas se representan las observaciones y en abscisas las fronteras de clase. En
general es conveniente que el número de observaciones sea superior a las 30.
Para el caso del ejemplo considerado:

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
3
Un polígono de frecuencias es un gráfico de distribución de frecuencias de tipo
lineal.
Es posible trabajar con estas figuras de resumen en forma más dinámica a través de
la utilización de Matlab.
Para la realización del histograma, se deben definir el vector que comprenda a los
datos no agrupados y el vector de los intervalos. Luego, mediante una operación que se
verá más adelante, se podrá observar cómo se calcula un tercer vector correspondiente a la
distribución de frecuencia en cada intervalo.
La forma más sencilla de representar el histograma es cuando se tienen los datos
agrupados como en el ejemplo. Para esto basta representar "la función" en diagrama de
barras", mediante el siguiente segmento de programa que utiliza la función bar:
function barras
% Permite representar graficamente en un diagrama de barras elvector
% de puntos medios de clase y el de frecuencias
% Entradas: puntos: vector de puntos medios de clase

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
4
% frecuencias: vector con las correspondientes frecuencias
% Salida: Histograma
% Vectores de entrada
puntos =[149.5000 169.5000 189.5000 209.5000 229.5000 249.5000];
frecuencias =[7 20 33 25 11 4];
% Grafico de barras
bar(puntos,frecuencias)
que da el siguiente resultado:
Si se poseen los datos no agrupados, como podrían ser 1000 números aleatorios
comprendidos entre 0 y 10, se procede del siguiente modo utilizando la función hist:
function aleatorio
% Permite ver el histograma de un conjunto de datos no agrupados, como podrían
% ser 1000 números aleatorios comprendidos entre 0 y 10
% Entrada: datos, vector de datos
%
% Salida: Histograma
% Vector de datos
for i=1:1000, datos(i)=rand*10;end
% Vector con los centros de intervalos
x=0.5:1:9.5;
% Histograma
m=hist(datos,x);
hist(datos,x)
m %vector de frecuencias en cada intervalo
Para esta corrida, el vector de frecuencias resultante es:

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
5
[103 91 91 99 96 106 112 101 100 101]
y el histograma correspondiente:
Si se quisiera obtener el "polígono de frecuencia" basta con cambiar las
características de la presentación gráfica, pasando a representar en el formato "línea". Para
ello se recurre a:
function poligono
% Permite representar graficamente el poligono de frecuencias
% Entradas: puntos: vector de puntos medios de clase
% frecuencias: vector con las correspondientes frecuencias
% Salida: Poligono de frecuencias
% Vectores de entrada
puntos =[149.5000 169.5000 189.5000 209.5000 229.5000 249.5000];
frecuencias =[7 20 33 25 11 4];
% Grafico
plot(puntos,frecuencias)
que entrega por resultado:

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
6
Es posible hallar la "Curva de Frecuencia" haciendo un polígono suavizado. Para
ello se puede utilizar la función "spline cúbica" incorporada en Matlab.
SPLINE Interpolación de datos con spline Cúbico
YY = SPLINE(X,Y,XX) usa la interpolación spline cúbica para encontrar YY, los
valores de la función subyacente Y en los puntos en los cuales están dados los datos Y.
Esto se puede observar corriendo el siguiente segmento de programa:
function suave
% Permite representar graficamente el poligono de frecuencias en forma suavizada
% Entradas: puntos: vector de puntos medios de clase
% frecuencias: vector con las correspondientes frecuencias
% Salida: Poligono de frecuencias suavizado
% Vectores de entrada
puntos =[149.5000 169.5000 189.5000 209.5000 229.5000 249.5000];
frecuencias =[7 20 33 25 11 4];
% Calculo del spline
x=puntos(1):puntos(length(puntos)); % malla para representar el suavizado
PP = spline(puntos,frecuencias,x); % vector resultante de la interpolacion
% Grafico
plot(x,PP)
que da como salida:

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
7
En términos de disimetría se las puede clasificar en:
En términos de curtosis se las puede clasificar en:
DISTRIBUCION DE FRECUENCIA ACUMULADA
Salario semanal
(límite de clases)
Fronteras Superior
de clase
Nro. de
Trabajadores
Frecuencia
Acumulada
140 - 159 159.5 7 7
160 - 179 179.5 20 20+7=27
180 - 199 199.5 33 27+33=60
200 - 219 219.5 25 60+25=85
220 - 239 239.5 11 85+11=96
240 - 259 259.5 4 96+4=100
Total: 100

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
8
La tabla de arriba explicita este concepto:
El gráfico de una distribución de frecuencia acumulada se llama "Ojiva". Para el
tipo "menor que", el gráfico indica la frecuencia acumulada debajo de cada frontera de
clase, obtenido mediante el siguiente segmento de programa:
function ojiva
% Permite representar graficamente la distribucion de frecuencia acumulada
% Entradas: puntos: vector de puntos medios de clase
% frecuencias: vector con las correspondientes frecuencias
% Salida: distribucion de frecuencia acumulada (ojiva)
% Vectores de entrada
puntos =[149.5000 169.5000 189.5000 209.5000 229.5000 249.5000];
frecuencias =[7 20 33 25 11 4];
% Vector de frecuencias acumuladas
f_acumulada(1)=frecuencias(1);
for i=2:length(puntos), f_acumulada(i)=f_acumulada(i-1)+frecuencias(i);
end
% Grafico
plot(puntos,f_acumulada)
que gráficamente entrega el siguiente resultado:
Si se suaviza se obtiene la "curva ojiva suavizada".

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
9
DISTRIBUCION DE FRECUENCIA RELATIVA
Es aquella en que el número de observaciones de cada clase se convierte en una
frecuencia relativa dividiéndola por el número total de observaciones en la distribución.
POBLACIONES Y MUESTRAS
Un conjunto de observaciones x1, x2,…,xn constituye una muestra aleatoria de una
población finita de tamaño n de una población finita de medida N, si es elegida en forma tal
que cada subconjunto de tamaño n de los N elementos de la población tenga la misma
probabilidad de ser elegida.
Un conjunto de observaciones x1, x2,…,xn constituye una muestra aleatoria de una
población infinita con densidad de probabilidad f(x) si:
Cada xi es un valor de una variable aleatoria cuya distribución tiene los valores
conforme a f(x)
Estas n variables aleatorias son independientes
En general, se pretende hacer inferencias sobre los parámetros de la población ( o ).
Para efectuar las inferencias se utilizan estadísticos (como o s) que son cantidades
calculadas a partir de observaciones de muestras.
DISTRIBUCIÓN MUESTRAL DE LA MEDIA ( conocida)
Si de alguna población de parámetros conocidos se extraen n muestras es difícil que
la medias de tales muestras coincidan.
Ejemplo I: Dada la población infinita cuya distribución está dada por:

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
10
x f(x)
1 0.25
2 0.25
3 0.25
4 0.25
listar las 16 muestras posibles de tamaño 2 (24
= 16) y construir la distribución de para
muestras aleatorias de tamaño 2 de la población.
1,1 1,2 1,3 1,4
2,1 2,2 2,3 2,4
3,1 3,2 3,3 3,4
4,1 4,2 4,3 4,4
las medias correspondientes a cada muestra son;
1 1.5 2 2.5
1.5 2 2.5 3
2 2.5 3 3.5
2.5 3 3.5 4
con lo que se puede hacer el siguiente agrupamiento de la distribución de medias:
frecuencia
1.0-1.49 1
1.5-1.99 2
2.0-2.49 3
2.5-2.99 4
3.0-3.49 3
3.5-3.99 2
4.0-4.49 1
Gráficamente, se puede observar el histograma ejecutando las siguientes sentencias
en Matlab:
>> x=1.25:0.5:4.25; f=[1 2 3 4 3 2 1];bar(x,f)

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
11
Ejemplo II: Hallar 500 muestras aleatorias de tamaño n=10 extraída de una población que
tiene distribución uniforme discreta que responde a la siguiente función densidad:
1/10 para x=0,1,…,9
f(x) =
0 en los demás casos
si el muestreo es con reemplazo se puede considerar a la población como infinita. Es
posible hallar la media de cada muestra y formar el arreglo correspondiente, mediante la
corrida del siguiente segmento de programa:
function muestras
% Permite obtener un vector de n medias de muestras de tamaño 10 de
% una poblacion uniformemente distribuida
%
% Salida: vector de medias
n=500;
for i=1:n,a=0;
for j=1:10, a=a+floor(rand*10); end
m(i)=a/10;
end
m
% guarda el resultado en el archivo ascii m.prn
save m.prn -ascii m
A partir de aquí se puede organizar la distribución de frecuencias y el histograma
correspondiente:
function hist_muestras
% Permite obtener el histograma del conjunto de valores que conforman
% el archivo "m.prn"

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
12
% Entrada: m, Vector obtenido desde el archivo "m.dbf"
%
% Salida: f, vector de frecuenncias
% Histograma
load m.prn
% generacion del vector de puntos medios de n intervalos
n=10 % numero de intervalos
delta=(max(m)-min(m))/n % ancho de cada intervalo
I(1)=min(m)+delta/2
for i=2:n, I(i)=I(i-1)+delta; end
% Grafico de barras (histograma)
bar(H)
De la corrida del programa se obtiene como vectores de puntos medios de intervalo
y de frecuencia en cada intervalo:
2.455 2.965 3.475 3.985 4.495 5.005 5.515 6.025 6.535 7.045
17 27 46 84 101 105 64 42 11 3
y el siguiente histograma:
A modo de verificación, si se quiere averiguar la media y la varianza de la simulación,
se procede a ejecutar las siguientes sentencias de Matlab:
>> load m.prn
>> mean(m)
ans =
4.5874

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
13
>> var(m)
ans =
0.8715
La teoría dice que la media de la distribución dada por f(x) está dada por:
1
9
i
xi pi
0 1 2 3 4 5 6 7 8 9( )1
10 4.5
y la varianza por:
con lo que resulta:
Con lo que se puede apreciar la proximidad entre los valores reales (4.5874, 0.8715) y
teóricos de media y varianza (4.5, 0.825).
FÓRMULAS PARA y
Si una muestra aleatoria de tamaño n se elige de una población que tiene la media
y varianza 2, entonces es un valor de una variable aleatoria cuya distribución tiene la
media .
Prueba: sea una muestra de tamaño n de una población con media y varianza 2 con
notación (x1, x2, … , xn). La misma se puede individualizar como n valores observados de
una variable aleatoria X. También se pueden considerar a estos n valores como
observaciones simples de n variables aleatorias X1, X2, … , Xn que tienen la distribución
de X (media y varianza 2) y que son independientes (ya que los valores de la muestra
independientes). Luego la media muestral vale:
X X1 X2 .. Xn
n
X1
n
X2
n ....
Xn
n
X X1 X2 .. Xn
n
X1
n
X2
n ....
Xn
n
X E X
EX1
n
EX2
n
.... EXn
n
n....
n
Para muestras tomadas de poblaciones infinitas, la varianza de esta distribución es:
Prueba: bajo las condiciones de la prueba anterior, la varianza de la suma de variables
aleatorias independientes es la suma de las varianzas de cada una de las variables:

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
14
X X1
n
X2
n ....
Xn
n
var X
varX1
n
varX2
n
.... varXn
n
La varianza de una constante por una variable aleatoria es:
var c X( ) c2
var X( )
luego, la expresión anterior queda:
X
2 2
n
2
n ....
2
n n
2
n2
2
n
Para muestras tomadas de poblaciones finitas de tamaño N, la varianza de esta
distribución es:
La corrección no tiene entidad cuando la muestra es menor que el 5% de la
población.
TEOREMA DE CHEBYSHEV
Cuando la muestra es pequeña (n<30) y se supone que la población no está
normalmente distribuida, no es posible utilizar la distribución de probabilidad normal ni la
t-Student para construir un intervalo de confianza.
El Teorema de Chebyshev establece: La proporción de las medias en un
conjunto de datos que se sitúa dentro de las k desviaciones estándar de la media no es
menor de 1-1/k2, siendo k > 1.
Demostración: Considérese una distribución cualquiera de función densidad f(x), mostrada
en la figura.
A partir de aquí se puede verificar que:
2
k
xf x( ) x 2
d
k
k
xf x( ) x 2
d
k
xf x( ) x 2
d

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
15
y también que:
2
k
xf x( ) x 2
d
k
xf x( ) x 2
d
Las regiones R1 U R3 (R1 “unión” R3) verifican:
x k y x 2 k2
2
Luego:
2
k
xf x( ) k2
2
d
k
xf x( ) k2
2
d
2
k2
2
k
xf x( )
d
k
xf x( )
d
1
k2
P x k o bien P x k 1
k2
También:
P x k 11
k2
Al aplicarlo a la distribución de muestreo de una media, la probabilidad de que una
media muestral se sitúe dentro de k unidades de error estándar ( ) a partir de la
media de la población es:

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
16
P x
k x
11
k2
haciendo , queda:
Para que | – | sea pequeño (menor o igual que ) basta con hacer n grande.
Ejemplo I: Para una muestra de tamaño n=15 tubos de TV, la vida útil media de operación
es = 8900 con una desviación estándar de s = 500. Construir un intervalo de confianza
90% para la media de la población si en este caso la vida útil media de operación de todos
los tubos no puede suponerse normalmente distribuida.
Ya que se pide un intervalo de confianza 90%:
11
k2
0.90 k 3.16
La confiabilidad de la media como una estimación de es medida a menudo por el
llamado error estándar de la media:
Si la media proviene de una población grande (n > 30, aún suponiendo que no se
conozca la varianza de la misma) es posible definir una variable aleatoria llamada media
estandarizada cuyos valores están dados por:
y que tiene una distribución normal estándar.
Ejemplo II: Supóngase los datos del problema anterior, pero con la misma media extraída
de una muestra de tamaño n=40.
Como la confianza debe ser del 90%, a ambos lados de la “campana” deben quedar
colas con áreas de 5%. Esto implica la siguiente desigualdad que define el intervalo de
confianza:

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
17
Gráficamente:
Luego en base a los datos, despejando :
lo que lleva a:
8900 1.645500
40 8900 1.645
500
40
8770 9030 Intervalo de confianza
desde ya que se aprecia un acotamiento del mismo debido a dos hechos:
La aplicación del estadístico z, en vez de usar el Teorema de Chebishev
El incremento del tamaño de la muestra.
TOREMA CENTRAL DEL LÍMITE
Sea la variable aleatoria Y = X1 + X2 + … + Xn , donde X1, X2, … , Xn son variables
aleatorias distribuidas idénticamente, cada una con media y varianza finita Luego la
distribución de:

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
18
zn
Y n
n
se aproxima a una distribución normal estándar cuando n tiende a infinito.
Este teorema establece que la suma de un número grande de variables aleatorias
tendrá una distribución normal, independientemente de la distribución individual de la
variables sumandos.
Además:
Y n
n
Y
nn
n
n
n
X
n o sea:
La media de n variables aleatorias independientes, idénticamente distribuidas, es decir
la media de una muestra aleatoria, tendrá aproximadamente una distribución normal.
Más generalmente, cuando las variables aleatorias individuales sólo hacen una
contribución “relativamente pequeña” respecto a la suma total, este teorema se cumple aún
cuando las variables sumandos no tengan idéntica distribución. Esta es una propiedad que
se utiliza en Teoría de Errores en el campo de las medidas con instrumentos, ya que
usualmente los errores consisten de la suma de muchos componentes independientes y
pequeños.
Si las variables aleatorias individuales que conforman la muestra tienen una
distribución desconocida y su número no es suficientemente grande, no puede suponerse
que la distribución de la media muestral es normal.
Ejemplo I: Se considerará una muestra extraída de una población con distribución
triangular:
f x( ) 2 x 2 función densidad (válida para 0 < x < 1)
la función acumulada es, por simple integración:
Gráficamente, las funciones densidad y distribución se ven a continuación:

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
19
Si se despeja x de esta expresión y se hace tomar a F(x) valores uniformemente
distribuidos entre 0 y 1, se obtiene una muestra con distribución de triangular. Esto se logra
resolviendo en x la siguiente ecuación cuadrática:
x2
2 x F x( ) 0
que implica dos soluciones:
de las que sólo tiene sentido la de signo menos.
La simulación de una muestra de este tipo, se puede ver en el siguiente segmento de
programa Matlab:
function trian(n)
% Obtencion de una muestra de n elementos con distribucion triangular
% Entrada: n, entero, numero de elementos de la muestra
% Salida: T, vector, con elementos distribuidos triangularmente
% Generacion de la muestra
for i=1:n, T(i)=1-sqrt(1-rand);end
% Grafico para verificacion
hist(T)
Ejecutando la sentencia:
>> trian(1000)
se obtiene:

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
20
Una población triangular tiene una media y una varianza que se calculan del
siguiente modo:
Para verificar el Teorema Central del Límite, se habrán de tomar 1000 muestras de
tamaño 5 y a cada una de ellas se les extraerá la media para posteriormente estudiar la
distribución de estas. Para ello se plantea:
function central(n,m)
% Verificacion del Teorema Central del Limite para una distribucion triangular
% Entrada: n, entero, numero de elementos cada muestra
% m, entero, numero de medias para la prueba
% Salida: M, vector, con elementos distribuidos normalmente
% Generacion de la muestra de medias
for j=1:m,
s=0;
for i=1:n, T(i)=1-sqrt(1-rand); s=s+T(i);end
M(j)=s/n;
end

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
21
% Grafico para verificacion
hist(M)
mean(M)
var(M)
Ejecutando:
>> central(5,1000)
se obtiene:
ans =
0.3354 media
ans =
0.0115 varianza
que significa una gran concordancia con los resultados teóricos. Recuérdese que la media
de la distribución de medias coincide con la de la población, pero la varianza es la
correspondiente a la misma pero dividida por el tamaño de la muestra sobre la que se
obtiene la media.
El resultado gráfico muestra cómo la distribución de las medias conforma una
normal.
k1 0 n1 1 índice auxiliar
Para verificar que el conjunto de valores determinados por el vector z tiene
distribución normal standard, se elabora con él el histograma correspondiente y superpuesto
a este último se dibuja la distribución normal standard correspondiente a los mismos

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
22
intervalos.
DISTRIBUCION MUESTRAL DE LA MEDIA ( desconocida)
Como se ha dicho más arriba, cuando n es grande (mayor de 30) no hay problema
en reemplazar a por s (desviación estándar de la muestra).
Si se supone que la muestra no es grande (n menor que 30) pero que proviene de
una población normal, se puede probar el siguiente teorema:
Si es la media de una muestra aleatoria de tamaño n tomada de una población normal
que tiene media y varianza 2 , entonces:
tx
s
n es el valor de una variable aleatoria con distribución t-Student y parámetro =n-1
(grados de libertad).
La varianza depende de los grados de libertad . Cuando este valor tiende a
infinito(n grande) la varianza de la distribución tiende a 1 y la t_Student se convierte en
normal estándar.
Hay tablas de valores de para t (valor de t para el cual el área bajo la distribución a
la derecha de él es igual a . Por ejemplo t0.75 para =3, vale 0.765. Gráficamente:
Ejemplo: Un fabricante de fusibles asegura que, con una sobrecarga del 20%, sus fusibles
fundirán al cabo de 12.40 minutos () en promedio. Para probar esta afirmación, una

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
23
muestra de n=20 de los fusibles fue sometida a una sobrecarga del 20% y los tiempos que
tardaron en fundirse tuvieron una media de 10.63 minutos ( ), y la desviación estándar de
2.48 minutos (s). Si se supone que los datos constituyen una muestra aleatoria de una
población normal ¿tienden a apoyar o a refutar la afirmación del fabricante?.
Se procede a calcular el estadístico t, mediante la siguiente expresión:
tx
s
n
10.63 12.4
2.48
20
3.192 n 1 19
Como t < t0.005 (un valor razonable el de 0.005 para el nivel de significación), los
datos tienden a refutar la afirmación.
Los fusibles con sobrecarga del 20% fundirán en menos de 12.40 minutos
En la práctica, se necesita que la población que se está muestreando tenga forma
acampanada y no sea demasiado asimétrica.
TABLA DE RESUMEN PARA ESTIMACION DE INTERVALOS DE CONFIANZA
PARA LA MEDIA DE UNA POBLACI ÓN.

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
24
DISTRIBUCIÓN MUESTRAL DE LA VARIANZA
Al estudiar la distribución muestral de la varianza, una de las primeras
apreciaciones es que no puede ser negativa, luego es evidente que no puede responder a una
distribución normal.
Ejemplo I: Se produce una simulación tal como la de extraer muestras de tamaño n=5 de
una población normal estándar (=0, =1), se calcula la varianza de cada una de estas
muestras y finalmente se presenta el histograma para apreciar la forma de la distribución.
Esto se puede realizar con el siguiente programa:
function dis_var(n,m)
% Verificacion de la dsitribucion muestral de varianzas desde una
% poblacion con distribucion normal estandar
% Entrada: n, entero, numero de elementos de cada muestra
% m, entero, numero de muestras para la prueba
% Salida: M, vector, con elementos distribuidos en forma de chi-cuadrado
% Generacion de la muestra de varianzas
for j=1:m,
for k=1:n,
% Generacion de la muestra normal estandar
s=0;
for i=1:12, s=s+rand;end
T(k)=s-6;
end
M(j)=var(T);
end
% Grafico para verificacion
hist(M/m)
Ejecutando la instrucción:
>> dis_var(5,1000)
se obtiene el siguiente gráfico:

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
25
La distribución correspondiente es la llamada Chi-cuadrado (2) la cual está
tabulada para valores 2 (con parámetro que son los llamados grados de libertad).
2 es
tal que el área bajo la distribución a su derecha es .
La función densidad correspondiente a esta distribución esta dada por:
F x e
x
2
2
2
x
2
21
En el gráfico se observa el resultado que se obtendría de una tabla entrando con un
valor de 2 = 8 y con = 5 grados de libertad. Sin embargo, las tablas trabajan con algunos
valores de típicos, como por ejemplo 0.05. En ese caso, lo que se obtiene como respuesta
es la abscisa 2 =11:

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
26
Si s2 es la varianza de una muestra aleatoria de tamaño n tomada de una
población normal cuya varianza es 2 , entonces:
2
n 1( )s2
2
es un valor de una variable aleatoria que tiene la distribución chi-cuadrado con
parámetro =n-1.
Ejemplo II: Una población normal tiene una varianza de 15. Si se extraen muestras de
tamaño 5 de esta población ¿Qué porcentaje puede tener varianzas a) menores que 10, (b)
mayores que 20, (c) entre 5 y 10.
a) se calcula el estadístico
y con él se calcula el área bajo la curva, a la izquierda, con esa abscisa.
Un programa en Matlab que puede calcular esta área es:
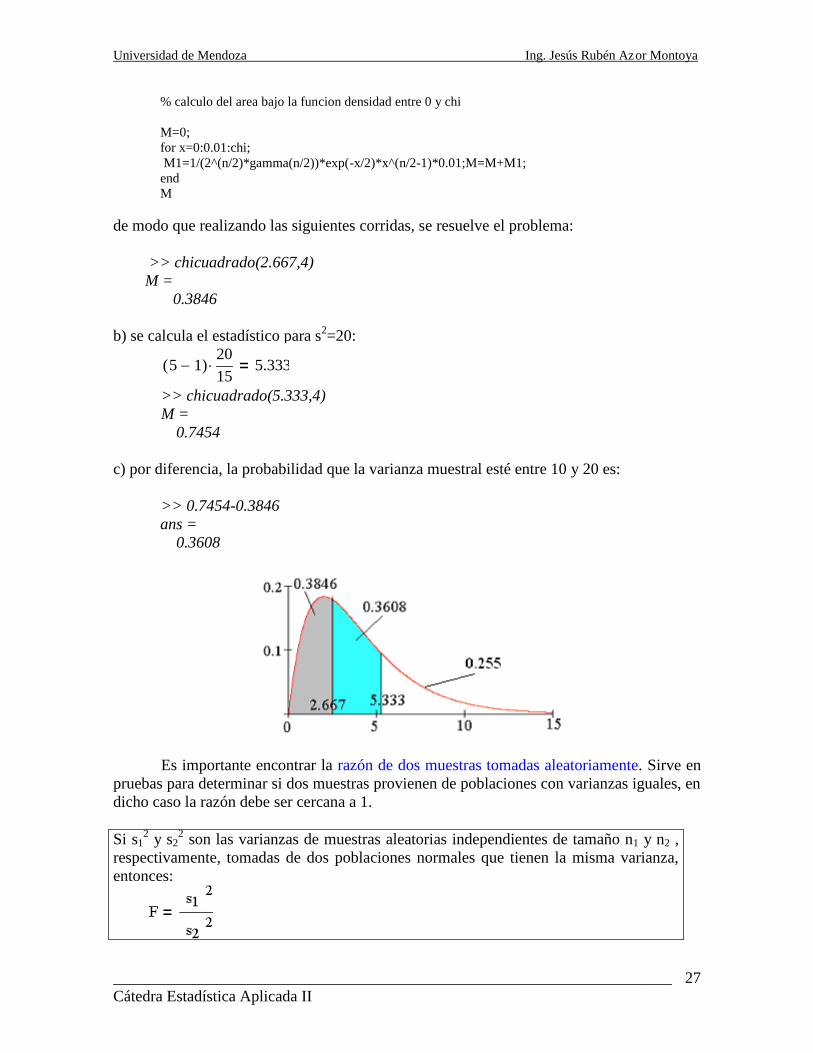
function chicuadrado(chi,n)
% Calcula el area a la izquierda del valor chi en una distribucion chi-cuadrado
% con n grados de libertad, mediante integraci´on por el metodo rectangular
% Entradas: chi, real, valor del estad´istico chi-cuadrado
% n, entero, grados de libertad
% Salida: M, real, Area a la izquierda de chi, bajo la curva
Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
27
% calculo del area bajo la funcion densidad entre 0 y chi
M=0;
for x=0:0.01:chi;
M1=1/(2^(n/2)*gamma(n/2))*exp(-x/2)*x^(n/2-1)*0.01;M=M+M1;
end
M
de modo que realizando las siguientes corridas, se resuelve el problema:
>> chicuadrado(2.667,4)
M =
0.3846
b) se calcula el estadístico para s2=20:
5 1( )
20
15 5.333
>> chicuadrado(5.333,4)
M =
0.7454
c) por diferencia, la probabilidad que la varianza muestral esté entre 10 y 20 es:
>> 0.7454-0.3846
ans =
0.3608
Es importante encontrar la razón de dos muestras tomadas aleatoriamente. Sirve en
pruebas para determinar si dos muestras provienen de poblaciones con varianzas iguales, en
dicho caso la razón debe ser cercana a 1.
Si s12 y s2
2 son las varianzas de muestras aleatorias independientes de tamaño n1 y n2 ,
respectivamente, tomadas de dos poblaciones normales que tienen la misma varianza,
entonces:

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
28
es una variable aleatoria que tiene la distribución F con parámetros 1 = n1 – 1 (grados
de libertad del numerador) y 2 = n2 – 1 (grados de libertad del denominador)
La distribución correspondiente es la llamada F, la cual está tabulada para valores
F (con parámetros y . F es tal que el área bajo la distribución a su derecha es .
En el gráfico se observa el resultado que se obtendría de una tabla entrando con un
valor de F = 3.181 y con = 4 grados de libertad del numerador y = 6 grados de libertad
del denominador.
La función densidad de esta distribución está dada por:
f x 1 2 1
0.5 12
0.5 2
1 2
2
0.5 1 0.5 2
x0.5 1 2
2 1 x 0.5 1 2
Ejemplo III: Si dos muestras aleatorias independientes de tamaños n1=7 y n2= 13 se toman
de una población normal ¿Cuál es la probabilidad de que la primera sea al menos 3 veces
más grande que la de la segunda?.
function F(f,nu1,nu2)
% Calcula el area a la derecha del valor f en una distribucion F
% con nu1 y nu2 grados de libertad, mediante integracion por el metodo rectangular
% Entradas: f, real, valor del estadistico F
% nu1 y nu2, enteros, grados de libertad
% Salida: M, real, Area a la izquierda de f, bajo la curva
% calculo del area bajo la funcion densidad entre 0 y f
M=0;K=gamma((nu1+nu2)/2)/gamma(nu1/2)/gamma(nu2/2)*nu1^(nu1/2)*nu2^(nu2/2);
for x=0:0.01:f;
M1=K*x^((nu1-2)/2)/(nu1*x+nu2)^((nu1+nu2)/2)*0.01;M=M+M1;
end
1-M
de modo que realizando la siguiente corrida, se resuelve el problema:
>> F(3,6,12)

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
29
ans =
0.0496
luego la probabilidad buscada es cercana al 5%.
Una propiedad de esta distribución es que:
esto se puede apreciar, a partir del trabajo con tablas, para =0.95, 1=7 y 2= 13, resulta:
F0.95 7 13( ) 2.832 F0.05 13 7( ) 0.353
dichos números son evidentemente uno el recíproco del otro.
INFERENCIAS RELATIVAS A MEDIAS
Estimación Puntual: La estimación puntual se refiere a la elección de un estadístico, es
decir un número calculado a partir de los datos muestrales (y quizás de más información)
respecto al cual tenemos alguna esperanza o seguridad de que esté “razonablemente cerca”
del parámetro que se ha de estimar.
Estimador Insesgado: Un estadístico es un estimador insesgado, si y sólo si la media de la
distribución de estimados es igual a .
Si se comparan las distribuciones muestrales de la media y la mediana de muestras
aleatorias de tamaño n de la misma población normal. Las dos distribuciones tienen la
misma media , ambas son simétricas y con forma acampanada , pero sus varianzas
difieren. Para la primera es /n y para la segunda es 1.5708*
/n (para poblaciones
infinitas).
Esto se puede apreciar mediante el siguiente programa:
function eficiente(m,n)
% Distribucion de m medias y medianas de muestras de tamaño n
% de una poblacion normal
% Entradas: m, entero, numero de muestras
% n, entero, tamaño de las muestras
% Salida: M, real, relacion de varianzas de la distribucion de
% medianas a la de medias
% Generacion de la muestra de varianzas
for j=1:m,
for k=1:n,
% Generacion de muestras con distribucion normal
s=0;
for i=1:12, s=s+rand;end
T(k)=s-6;
end
media(j)=mean(T);
mediana(j)=median(T);

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
30
end
M=var(mediana)/var(media)
en el que se generan m muestras de tamaño n con distribución normal, extrayéndosele a
cada una la media y la mediana, realizándose a posteriori el cociente de las varianzas de
ambas. La corrida correspondiente es:
>> eficiente(1000,20)
ans =
M =
1.5771
cuyo resultado concuerda con el enunciado teórico.
Luego, es más probable que la media esté más cerca de que la mediana.
Un estadístico es un estimador insesgado más eficiente del parámetro que el
estadístico si:
1) y son ambos estimadores insesgados de
2) La varianza de la distribución muestral del primer estimador es menor que la del
segundo.
En la práctica, la media muestral es un estadístico aceptable para estimar la media
de la población .
La posibilidad de acertar exactamente a es escasa, por ello es conveniente
acompañar la estimación puntual de con una afirmación de cuán cercana podemos
razonablemente esperar que se encuentre la estimación.
El error x
es la diferencia entre la estimación y la cantidad que se supone
estima. Para n grande, se puede asegurar con una probabilidad 1- que la desigualdad:
z
2
x
n
z
2
o bienx
n
z
2
será satisfecha.
Donde es una abscisa tal que el área bajo la curva normal estándar a su derecha
es de /2.

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
31
E es el valor máximo de x
o sea, el Error Máximo de Estimación:
a los valores y se los denomina Límites de Confianza.
Los valores de mayor uso para 1- son 0.95 y 0.99 y los valores correspondientes
serán:
z0.01 2.326 z0.05 1.645 z0.005 2.576 z0.025 1.96
Ejemplo I: Un supervisor intenta utilizar la media de una muestra aleatoria de tamaño
n=150 para estimar la aptitud mecánica promedio (la cual se mide con una cierta prueba) de
los obreros de una línea de ensamblado. Si por su experiencia puede suponer que =6.2
para tales datos. ¿Qué podemos asegurar con una probabilidad de 0.99 sobre la media
máxima de este error?.
1 0.99 0.01
20.005
E z0.056.2
150 2.575
6.2
150 1.304
se puede asegurar con una probabilidad del 99% que el error será a lo sumo 1.304.
Si al recoger los datos se obtiene x
69.5 ¿Se puede asegurar aún con probabilidad
99% que el error es a lo sumo 1.304?
Se hacen afirmaciones de probabilidad acerca de valores futuros de variables
aleatorias (digamos error potencial de una estimación) y afirmaciones de confianza una vez
que los datos han sido obtenidos.
Luego, se diría que el supervisor puede tener una confianza del 99% de que el error
de estimación para x
69.5 sea a lo sumo 1.304.
Un Intervalo de Confianza para la media es un intervalo estimado construido con
respecto a la media de la muestra, por el cual puede especificarse la probabilidad que el
intervalo incluya el valor de la media poblacional.
El Grado de Confianza, asociado con un intervalo de confianza, indica el porcentaje
de los intervalos que incluirán el parámetro que se está estimando.
Si se desea usar la media de una muestra grande aleatoria para estimar la media de
una población y que se quiere asegurar con probabilidad 1- que el error será a lo sumo una
cantidad predeterminada E, el número de elementos de la muestra debe ser:
E z
2
n n z
2
E
2
Ejemplo II: Una investigación quiere determinar el tiempo promedio que un mecánico tarda
en intercambiar los neumáticos de un auto, y además desea poder asegurar con una

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
32
confianza del 95% que el error de su muestra sea a lo sumo de E=0.50 minutos. Si puede
presumir, por experiencia que =1.6 minutos. ¿Qué tamaño deberá tener la muestra?.
1 0.95 0.05
20.025
n z0.025
E
2
1.961.6
0.5
2
39.338
vale decir la muestra debe tener un tamaño de 40.
E es el factor de error “más o menos” permitido en el intervalo (siempre es la mitad
del Intervalo de Confianza).
Hasta aquí era necesario conocer o su valor aproximado por s (desviación
estándar muestral) requiriendo n grande. Para n chico, si se está muestreando en una
población normal:
tx
s
n t es una variable aleatoria con distribución t-Student con =n-1 grados de libertad.
Luego, el error máximo de estimación será:
E t
2
s
n
o con una confianza del (1-)100% de que el error sea menor que esa cantidad.
Ejemplo III: Una muestra de 10 medidas de diámetro de una esfera dio una media de
=10.95 cm y una desviación típica de s=0.15 cm. Hallar los límites de confianza para el
diámetro verdadero del a) 95% y b) 99%.
Los valores de E para 95% (=0.05) y para 99% (=0.01) con =n-1=9
E95 t 0.025
0.15
10 2.262
0.15
10 0.107
E99 t 0.0050.15
10 3.25
0.15
10 0.154
lo que lleva al intervalo para =0.05:
10.95 0.107 x
10.95 0.107 10.843 x
11.057
y para =0.01
10.95 0.154 x
10.95 0.154 10.796 x
11.104
con lo que se puede decir en la confianza del 95% que el valor verdadero de la media se
encuentra entre 10.843 y 11.057, o en la confianza del 995 que se encuentra entre 10.796 y

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
33
11.104.
ESTIMACIÓN POR INTERVALOS
Dado que la probabilidad de estimar puntualmente es cero, es preferible reemplazar
a esta con estimaciones por intervalos.
Para ilustrar esto, supongamos una muestra grande (n > 30)con y 2 conocidos.
z
2
x
n
z
2
z
2
n x
z
2
n
x
z
2
n x
z
2
n
se puede asegurar con una confianza del (1-)100% que el intervalo
x
z
2
n x
z
2
n
contiene .
Este es un Intervalo de Confianza para , con un Nivel de Confianza 1-
Cuando se desconoce (y n > 30) se la sustituye por la desviación estándar
muestral.
Ejemplo I: Las medidas de los diámetros de una muestra de 200 cojinetes de bolas hechos
por una determinada máquina durante una semana dieron una media de 2.06 cm y una
desviación típica de 0.105 cm. Hallar los límites de confianza del a) 95% y b) 99% para el
diámetro de todos los cojinetes.
a) para =0.05
E z
2
n 1.96
0.105
200 0.015
luego, el intervalo de confianza es:
2.06 0.015 2.06 0.015 2.045 2.075
b) para =0.01
E z
2
n 2.576
0.105
200 0.019
luego, el intervalo de confianza es:
2.06 0.019 2.06 0.019 2.041 2.079
ESTIMACIÓN BAYESIANA

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
34
REGLA DE BAYES
Si a los eventos Aj se los llama “causas”, la fórmula puede considerarse como la
probabilidad de que el evento B, que ha ocurrido, sea el resultado de la causa Ak , esto es,
para la probabilidad de que la causa Ak esté actuando, calculada bajo la hipótesis de que
hemos observado B. Por lo tanto, este es un método para calcular la probabilidad de una
causa dado el efecto.
Ejemplo I: Una urna contiene 3 monedas C1 C2 y C3 con probabilidad de caer cara iguales a
0.4, 0.5 y 0.6 respectivamente. Una moneda se extrae aleatoriamente y se arroja 20 veces.
Aparece cara hacia arriba 11 veces. Encontrar la probabilidad de que la moneda elegida sea
la legal (p=0.5).
Sin ninguna información, la probabilidad de extraer la moneda legal es 1/3. Esta se
denomina “a priori”.
Con la información dada, podemos proceder como sigue: sea Aj el evento tal que la
moneda Cj se extrae, y sea B el evento tal que se obtuvieron 11 caras en 20 pruebas.
Entonces, en la fórmula de Bayes:
P(Aj) =1/3 (j=1, 2, 3)
y la respuesta es:
que es mayor que la previa. Esta es la llamada probabilidad “a posteriori”.
Hay métodos de inferencia que consideran a los parámetros como variables
aleatorias. Aquí se valoran conceptos de probabilidad subjetiva.
Se presentará un método bayesiano para estimar la media de una población
considerando a como una variable aleatoria, cuya distribución es subjetiva.
Para el analista, esta clase de Distribución A Priori, obtenida de manera subjetiva,
tiene una media 0 y una desviación standard 0.

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
35
Como problema concreto, supóngase un problema de emisión de óxido de azufre de
una planta industrial, donde el ingeniero jefe supone, por experiencia, que la emisión tiene
las siguientes características (Distribución A Priori):
17.5 2.5 media y desviación standard
x 12 12.1 24 rango de variación de x (para graficar la distribución)
f x( )1
2 exp
x ( )2
2 2
función densidad de la distribución 'a priori'
18
19
xf x( )
d 0.146487
Probabilidad que la emisión esté entre 18 y 19
gráficamente:
Si posteriormente se realiza la toma de 80 muestras y los resultados dan:
x' 18.85 5.55 media y desviación standard de las 80 muestras
n 80 número de muestras
Los parámetros de la distribución "a posteriori" serán (aquí se combinan creencias
previas con evidencias muestrales directas):
n x'
2 2
n 2
2
18.771659
2
2
n 2
2
0.602236
f1 x( )1
2 exp
x ( )2
2 2
función densidad de la distribución 'a
posteriori'

Universidad de Mendoza Ing. Jesús Rubén Azor Montoya
______________________________________________________________________
Cátedra Estadística Aplicada II
36
18
19
xf1 x( )
d 0.547674
Probabilidad que la emisión esté entre 18 y 19
gráficamente:
Si no se hubiese hecho el análisis bayesiano y se hubiera considerado la muestra
"cruda", la probabilidad de emisión entre 18 y 19 sería:
x' 18.85 5.55
80
f2 x( )1
2 exp
x x'( )2
2 2
18
19
xf2 x( )
d 0.51014
evidentemente menor que aplicando Bayes (0.55).


















