
Open Office Calc para uso estadístico Guía breve...
18
Open Office Calc para uso estadístico Guía breve ejemplificada Vicente Manzano Arrondo, 2012 Índice Tres consejos sobre la hoja de cálculo (2) Estudio univariable (3) Crear la tabla de frecuencias (3) Valores, frecuencias, porcentajes, acumulados y totales. Estadísticos o índices de descripción univariable (4) Media, mediana, moda, desviación tipo, MAD, % de la moda. Medidas de posición (5) Percentiles, distancias estandarizadas. Estimación por intervalo (6) De una media y de una proporción. Prueba de significación de la hipótesis nula (7) Caso de comparación de una distribución de frecuencias observadas y una teórica. Chi cuadrado de Pearson. Para el resto univariable: intervalos de confianza. Estudio bivariable (9) Chi cuadrado de Pearson para una tabla de contingencia (9) Coeficiente de correlación lineal simple de Pearson (11) t de Student longitudinal (datos apareados) (13) t de Student transversal (muestras independientes) (14) Selección de funciones estadísticas en Open Office Calc (18) 1
Transcript of Open Office Calc para uso estadístico Guía breve...

Open Office Calc para uso estadísticoGuía breve ejemplificadaVicente Manzano Arrondo, 2012
ÍndiceTres consejos sobre la hoja de cálculo (2)Estudio univariable (3)
Crear la tabla de frecuencias (3)Valores, frecuencias, porcentajes, acumulados y totales.
Estadísticos o índices de descripción univariable (4)Media, mediana, moda, desviación tipo, MAD, % de la moda.
Medidas de posición (5)Percentiles, distancias estandarizadas.
Estimación por intervalo (6)De una media y de una proporción.
Prueba de significación de la hipótesis nula (7)Caso de comparación de una distribución de frecuencias observadas y una teórica. Chi cuadrado de Pearson. Para el resto univariable: intervalos de confianza.
Estudio bivariable (9)Chi cuadrado de Pearson para una tabla de contingencia (9)Coeficiente de correlación lineal simple de Pearson (11)t de Student longitudinal (datos apareados) (13)t de Student transversal (muestras independientes) (14)
Selección de funciones estadísticas en Open Office Calc (18)
1

Tres consejos sobre la hoja de cálculo
Hay tres aspectos que no se refieren directamente al análisis de los datos, sino al manejo de la hoja de cálculo, que ayudan mucho a mejorar el trabajo y los resultados: especificar celdas o áreas, nombrar áreas de datos, controlar la precisión o número de decimales que se muestran.
Especificar celdas o áreasEn las funciones y cálculos es normal acudir a celdas individuales o a áreas. No es necesario escribir
literalmente las coordenadas. Es posible utilizar el ratón para ahorrar trabajo. Un ejemplo: para escribir la expresión “=promedio(A3:A39)-D21*D22” no es necesario escribirla entera. No solo es un ahorro de pulsaciones sino que en ocasiones es difícil buscar con la vista las coordenadas (qué fila y qué columna) y evitar equivocarse. Un modo alternativo es (en el caso de este ejemplo):
– escribe =promedio( [no aceptes tras escribirlo, pues debes seguir en la misma celda donde estás introduciendo esto]
– con el ratón pulsa sobre en la celda A3 y, sin levantar la pulsación, arrastra hasta A39– escribe )-– pulsa sobre la casilla D21– escribe *– pulsa sobre la casilla D22– acepta, es decir, pulsa la tecla Enter, Retorno o Intro
Nombrar un áreaLa primera acción recomendable es capturar los datos de la variable y definir ese área con un
nombre, para evitar introducir las coordenadas del área cada vez que necesitamos esos datos.– Selecciona A3:A27– Pulsa Datos/Definir área– Escribe el nombre “datos”– Pulsa Aceptar
En este ejemplo también utilizo un área de una sola casilla, cuando pienso que voy a acudir a esa información con frecuencia. Ocurre en el caso del tamaño de la muestra, n.
Definir una precisiónEl número de decimales que se muestran en una celda se controla mediante Formato/Celdas... En
este ejemplo, las celdas, mayoritariamente, muestran una precisión de dos decimales. No es necesario definirla celda a celda. Hazlo en una, copiala [por ejemplo, con Ctrl+C] y después pégala en las celdas donde desees aplicar el mismo formato. Pero no puedes hacer un copiado directo [como el que se haría mediante Ctrl+V], sino mediante un pegado especial. Para ello, selecciona el área de celdas donde vas a aplicar el formato copiado, pulsa con el botón derecho del ratón, escoge la opción Pegado especial y selecciona únicamente la casilla de verificacion Formato. La hoja de cálculo recuerda esta configuración, por lo que a partir de este momento, cada vez que acudas a esta opción de Pegado especial, verás que la selección que hiciste (sólo Formato) permanecerá activa mientras no la modifiques, por lo que esta tarea se hace muy rápido.
2

Estudio univariable
Partimos del ejemplo siguiente, incluido en el archivo EstudioUnivariableTabla.ods.
Crear la tabla de frecuencias
Primero definimos los nombres de las columnas de la tabla:– C2: X– D2: f– E2: F– F2: %– G2: %a
ValoresPara la columna de valores, podemos introducirlos a mano o bien utilizar el recurso de capturar el
número de la fila. Para este segundo caso:– C3: =fila()-2– Copia el contenido de C3 en C4:C9. [Recuerda: para copiar en un área no hace falta que copies
celda a celda, sino que selecciones todo el área y pulsa Ctrl-V o botón-derecho/pegar]
Frecuencias– D3: =contar.si(datos;C3)– Copia D3 en D4:D9– D10: =suma(D3:D9) [también valdría =contar(datos)]
3

Frecuencias acumuladasPara el primer valor:
– E3: =D3 [pues la primera F coincide con f]Para el resto de los valores:
– E4: =D4+E3– Copia E4 en E5:E9
Porcentajes– F3: =D3/n*100 [he definido el área D10 con el nombre “n”]– Copia F3 en F4:F9.– F10: =suma(F3:F9)
Porcentajes acumulados– Copia E3:E9 en G3:G9
El resultado que debes observar es:
Estadísticos o índices de descripción univariable
Aunque podemos calcular cada uno de ellos gracias a que contamos tanto con los datos originales como con la tabla de frecuencias, en su mayoría no es necesario, pues ya hay definidas funciones específicas para estos índices. Como sabemos, cada índice de representación numérica o tendencia central debe ir acompañado de su correspondiente índice de bondad de representación o dispersión.
Media aritmética y desviación tipo– C14: Media– D14: =promedio(datos)– C15: Desv. tipo– D15: =desvestp(datos) [cuidado: desvest(datos) pondría la cuasidesviación tipo]
Mediana y MAD– C16: Mediana– D16: =mediana(datos)– C17: MAD– Para calcular MAD:
4

– Genera una columna con las diferencias de los datos originales a la mediana, teniendo en cuenta que el primer valor está en A3 y lo que nos interesa es la distancia en términos absolutos, por lo que aplicamos abs(). 1) J5: abs(A3-mediana(datos)) 2) copia J5 en J6:J29
– Calcula la mediana de esa columna. D17: =mediana(J5:J29)
Moda y porcentaje de la moda– C18: Moda– D18: =modo(datos)– C19: % Moda– D19: 28 [directamente] o bien F7 [lugar donde se encuentra % de la moda]
Medidas de posición
PercentilesComo sabemos, a partir de ellos podemos obtener otras medidas habituales como los deciles o los
cuartiles. Para probar el procedimiento, acudimos a los percentiles P20, P45, P55 y P80.– E15: Percentiles– E16: P20– E17: P45– E18: P55– E19: P80– F16: =percentil(datos;0,2)– F17: =percentil(datos;0,45)– F18: =percentil(datos;0,55)– F19: =percentil(datos;0,8)
Distancias estandarizadasSe podría añadir una columna más a la tabla de frecuencias, para obtener las distancias
estandarizadas, pero vamos a generar un área específica junto al resto de los índices descriptivos. Por otro lado, aunque existe la función normalización() que se encarga de estandarizar, no ayuda mucho, puesto que la fórmula de estandarización es muy sencilla, así que la calcularemos directamente.
– G12: X– De G13 a G19: completa la columna de valores (o utiliza la función fila())– H12: Z– H13: =(G13-promedio(datos))/desvestp(datos) [recuerda utilizar desvestp() y no desvest()]– Copia H13 en H14:H19
El resultado que debes observar es el que sigue.
5

Estimación por intervalo
Aunque podríamos hacerlo de muchos modos, vamos a suponer la seguridad habitual del 95% y a exponer el valor del error de precisión y los límites inferior y superior del intervalo de estimación.
– C22: Estimaciones por intervalo con seguridad del 95%
Estimación de una media aritmética– C23: Media– D23: ep– D24: Lim. inferior– D25: Lim. superior– E23: =confianza(0,05;desvest(datos);n) [he utilizado desvest() y no desvestp() porque la primera es la
función específica de la cuasidesviación tipo, que es lo que tenemos que utilizar como estimación puntual de la desviación tipo poblacional, que es lo que requiere la función confianza(). Por otro lado, la fórmula contiene la expresión “n”, que es el nombre del área definida por una sola celda, la D10, que contiene el tamaño de la muestra]
– E24: =promedio(datos)-E23– E25: =promedio(datos)+E23– D26: Luego, media poblacional entre 4 y 5,28
Estimación de una proporciónEscojo, para mostrar el procedimiento, la estimación de la proporción de datos en la población que
tiene el valor X=5. Vamos a realizar este cometido pensando directamente en porcentajes. Como la hoja de cálculo no realiza estimación de proporciones directamente, vamos a generar una columna de cálculo intermedio donde figuren ceros y unos. El 0 representa a un dato de la columna original cuyo valor es distinto de 5. El 1 representa a un dato de la columna original que cumple con la condición X=5.
– K5: =si(A3=5;1;0)– Copia K5 en K6:K29– C27: % de X=5– D27: ep– D28: Lim. inferior– D29: Lim. superior– E27: =confianza(0,05;desvest(K5:K29);n)*100– E28: =promedio(K5:K29)*100-E27– E29: =promedio(K5:K29)*100+E27
6
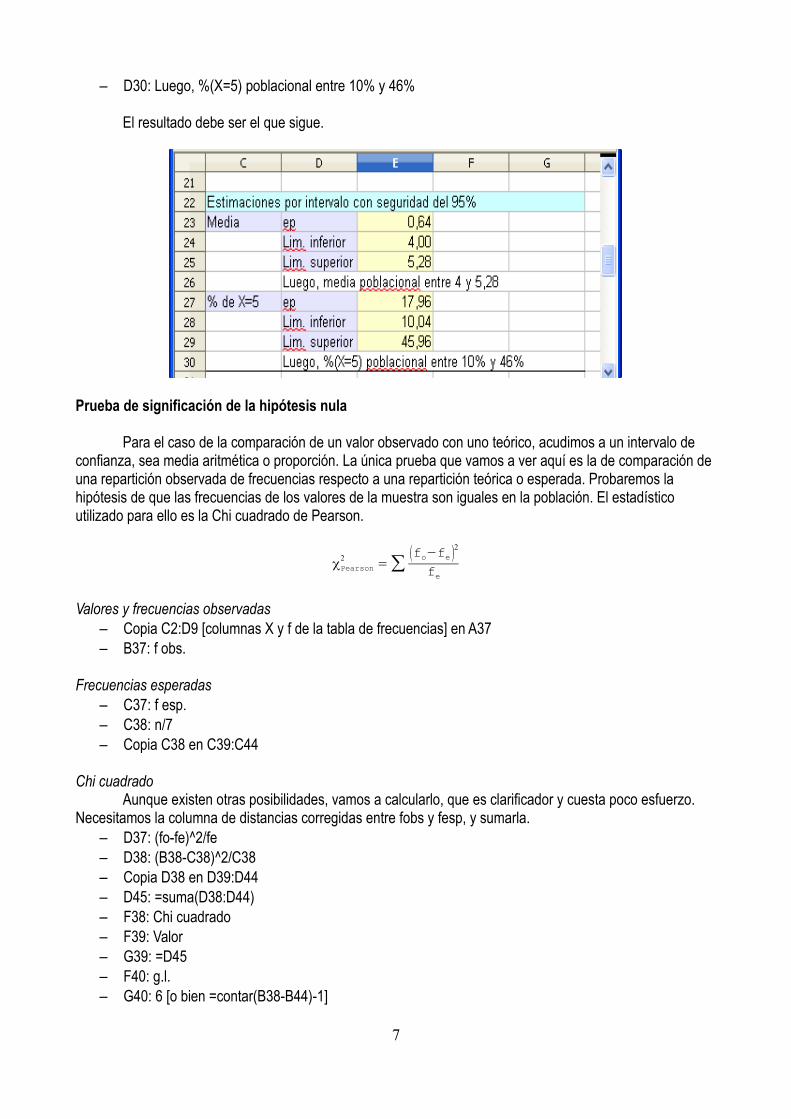
– D30: Luego, %(X=5) poblacional entre 10% y 46%
El resultado debe ser el que sigue.
Prueba de significación de la hipótesis nula
Para el caso de la comparación de un valor observado con uno teórico, acudimos a un intervalo de confianza, sea media aritmética o proporción. La única prueba que vamos a ver aquí es la de comparación de una repartición observada de frecuencias respecto a una repartición teórica o esperada. Probaremos la hipótesis de que las frecuencias de los valores de la muestra son iguales en la población. El estadístico utilizado para ello es la Chi cuadrado de Pearson.
χPearson2 =∑ (fo−fe )2
fe
Valores y frecuencias observadas– Copia C2:D9 [columnas X y f de la tabla de frecuencias] en A37– B37: f obs.
Frecuencias esperadas– C37: f esp.– C38: n/7– Copia C38 en C39:C44
Chi cuadradoAunque existen otras posibilidades, vamos a calcularlo, que es clarificador y cuesta poco esfuerzo.
Necesitamos la columna de distancias corregidas entre fobs y fesp, y sumarla.– D37: (fo-fe)^2/fe– D38: (B38-C38)^2/C38– Copia D38 en D39:D44– D45: =suma(D38:D44)– F38: Chi cuadrado– F39: Valor– G39: =D45– F40: g.l.– G40: 6 [o bien =contar(B38-B44)-1]
7

– F41: Sign.– G41: =distr.chi(D45;G40)
V de CramerPara calcular el tamaño de efecto asociado, utilizamos la fórmula que ya conocemos:
V=√ χ2
n(k−1)donde n=25 y k es el número de valores (7).
– F42: V de Cramer– G42: =raiz(G39/(B45*6))
El resultado que debes observar es el siguiente.
Todos los resultados del estudio univariable se encuentran en el archivo EstudioUnivariableResultados.ods
8

Estudio bivariable
Partimos del ejemplo siguiente, incluido en el archivo EstudioBivariableTabla.ods.
El significado de cada variable es:
Chi cuadrado de Pearson para una tabla de contingencia
En este caso primero construimos la tabla, conteniendo las frecuencias observadas y esperadas para, acto seguido, elaborar una tabla específica de diferencias con el cálculo del estadístico. Por último, con la función distr.chi(), calculamos la significación estadística.
– F8: Chi cuadrado Exper-Sexo.
Tabla de contingencia– Formato de la tabla
– F9: Tabla de contingencia– H11: Sexo– H13: Mujer– H15: Hombre
9

– H16: Total– G10: Exper– G11: No (0)– H11: Sí (1)– I11: Total– J12: f obs.– J13: f esp.– J14: f obs.– J15: f esp.
– Frecuencias observadas– G12: =contar.si(C3:C12;0)– H12: =contar.si(C3:C12;1)– G14: =contar.si(C13:C22;0)– H14: =contar.si(C13:C22;1)– I13: =G12+H12– I15: =G14+H14– G16: =G12+G14– H16: =H12+H14– I16: =G16+H16
– Frecuencias esperadas– G13: =I13*G16/I16– H13: =I13*H16/I16– G15: =I15*G16/I16– H15: =I15*H16/I16
Prueba de significaciónAunque no es estrictamente necesario crear una tabla específica para exponer el proceso, sin
embargo resulta muy ilustrativo, así que vamos a llevarlo a cabo.– F18: Prueba de significación Chi cuadrado– Tabla específica
– Combinaciones– F20: mujer-no– F21: mujer-sí– F22: hombre-no– F23: hombre-sí
– Columna de frecuencias observadas– G19: f obs.– G20: =G12– G21: =H12– G22: =G14– G23: =H14– G24: =suma(G20:G23)
– Columna de frecuencias esperadas– H19: f esp.– H20: =G13– H21: =H13– H22: =G15
10

– H23: =H15– H24: =suma(H20-H23)
– Columna de cálculos– I19: (fo-fe)^2/fe– I20: =(G20-H20)^2/H20– Copia I20 en I21:I23– I24: =suma(I20:I23)
– Significación– J20: Chi cuadrado– J21: Valor– K21: =I24– J22: g.l.– K22: 1 [pues se trata de una tabla de 2 filas por 2 columnas, es decir, g.l.=(2-1)(2-1)]– J23: Sign.– K23: =distr.chi(K21;K22)
– V de Cramer (tamaño de efecto)– J24: V de Cramer– K24: =raiz(K21/G24) [pues k=2 y n se encuentra, por ejemplo, en G24]
El resultado que debes observar es el que sigue.
Coeficiente de correlación lineal simple de Pearson
El cálculo es muy sencillo, pues viene facilitado por una función específica, pearson(). La única complicación es que el valor de correlación debe ser transformado en una t de Student con n-2 grados de libertad para obtener finalmente la significación estadística. La transformación es la siguiente, a la que añado cómo indicarlo a la hoja de cálculo suponiendo que r está en la celda H10 y n en la B23:
11

t = r √ n − 21 − r 2
→ =abs(H10*raiz((B23-2)/(1-H10^2)))
La traducción a hoja de cálculo contiene una modificación: forzar el valor de t en valores absolutos, para que el cálculo de la significación no dé problemas. Ese cálculo se realiza mediante la expresión distr.t(t;n-2;2), suponiendo el valor t, n-2 grados de libertad y que la prueba es de dos colas.
Vamos a realizar el cálculo de la r mediante una tabla completa y, también, directamente con la función específica pearson(). Para facilitar el proceso es bueno que las variables Antes y Después tengan definida su área (ver el apartado específico para definir áreas de datos). Para ello, recordemos que el cálculo de r a partir de distancias estandarizadas es:
r xy =∑ Z x Z y
n
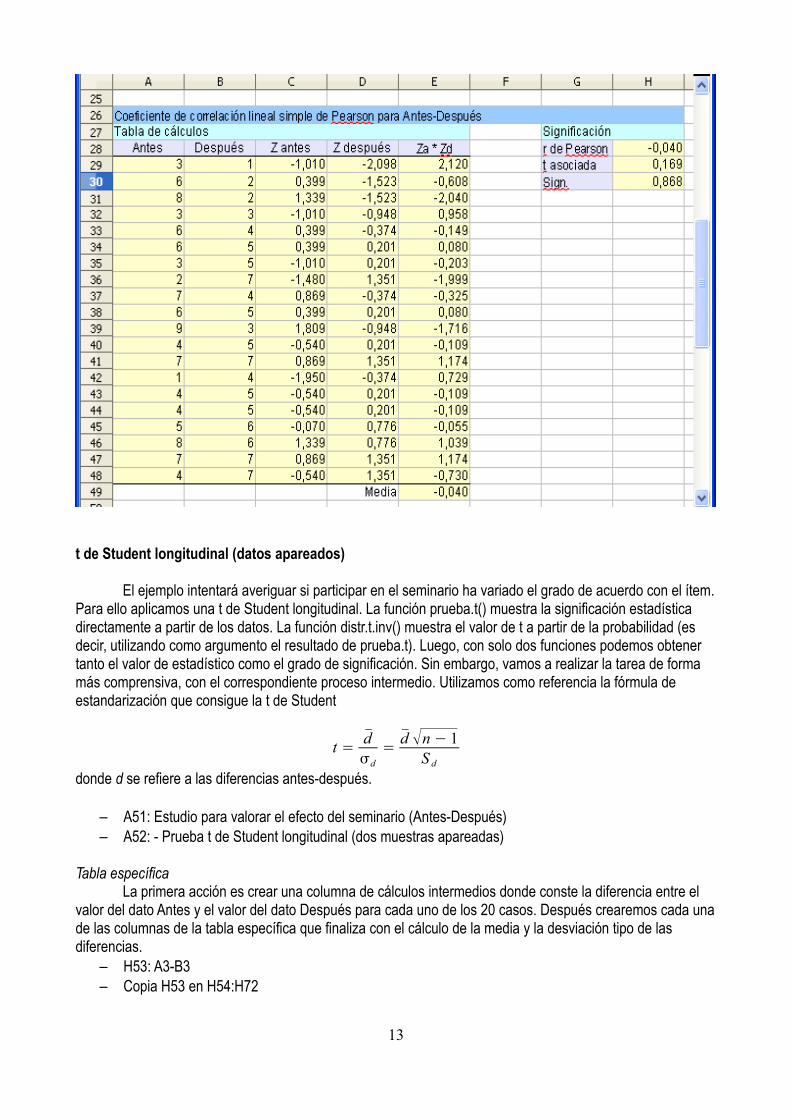
– A26: Coeficiente de correlación lineal simple de Pearson para Antes-Después
Cálculo de la r. Versión corta– G27: Significación– G28: r de Pearson– H28: =pearson(antes;después)
Cálculo de la r. Versión de proceso– A27: Tabla de cálculos– Copiar la tabla del área A2:B22 a A26– C28: Z antes– C29: =(A29-promedio(antes))/desvestp(antes)– Copia C29 en C30:C48– D28: Z después– D29: =(B29-promedio(después))/desvestp(después)– Copia D29 en D30:D48– E28: Za * Zb– E29: =C29*D29– Copia E29 en E30:E48– E49: =suma(E29:E48)/n– D49: Media
SignificaciónEl valor de la versión corta o procesual es el mismo (-0,040), como no podía ser de otro modo. Ahora
queda traducir este valor a una t y calcular la significación estadística asociada a ese valor t con n-2 grados de libertad y dos colas.
– G29: t asociada– H29: =abs(H28*raiz((n-2)/(1-h28^2)))– G30: Sign.– H30: =distr.t(H29;n-2;2)
El resultado debería ser el que figura a continuación.
12
t de Student longitudinal (datos apareados)
El ejemplo intentará averiguar si participar en el seminario ha variado el grado de acuerdo con el ítem. Para ello aplicamos una t de Student longitudinal. La función prueba.t() muestra la significación estadística directamente a partir de los datos. La función distr.t.inv() muestra el valor de t a partir de la probabilidad (es decir, utilizando como argumento el resultado de prueba.t). Luego, con solo dos funciones podemos obtener tanto el valor de estadístico como el grado de significación. Sin embargo, vamos a realizar la tarea de forma más comprensiva, con el correspondiente proceso intermedio. Utilizamos como referencia la fórmula de estandarización que consigue la t de Student
t =dd
=d n − 1S d
donde d se refiere a las diferencias antes-después.
– A51: Estudio para valorar el efecto del seminario (Antes-Después)– A52: - Prueba t de Student longitudinal (dos muestras apareadas)
Tabla específicaLa primera acción es crear una columna de cálculos intermedios donde conste la diferencia entre el
valor del dato Antes y el valor del dato Después para cada uno de los 20 casos. Después crearemos cada una de las columnas de la tabla específica que finaliza con el cálculo de la media y la desviación tipo de las diferencias.
– H53: A3-B3– Copia H53 en H54:H72
13

– A54: Estadístico– A55: Media– A56:. Des. tipo– B54: Antes– B55: =promedio(Antes)– B56: =desvestp(Antes)
Prueba t– A58: Prueba de significación– B59: t– C59: =D55/D56*raiz(n-1)– B60: Sign.– C60: distr.t(D59;n-1;2) [es decir, valor de t contenido en D59, n-1 grados de libertad y 2 colas]– B61: r (t.e.) [ponemos (t.e.) para recordar que se trata de una medida del tamaño del efecto y no de
un interés directo en conocer el valor de la correlación]– C61: =C59/raiz(C59^2+n-2)
El resultado lo tienes en:
t de Student transversal (muestras independientes)
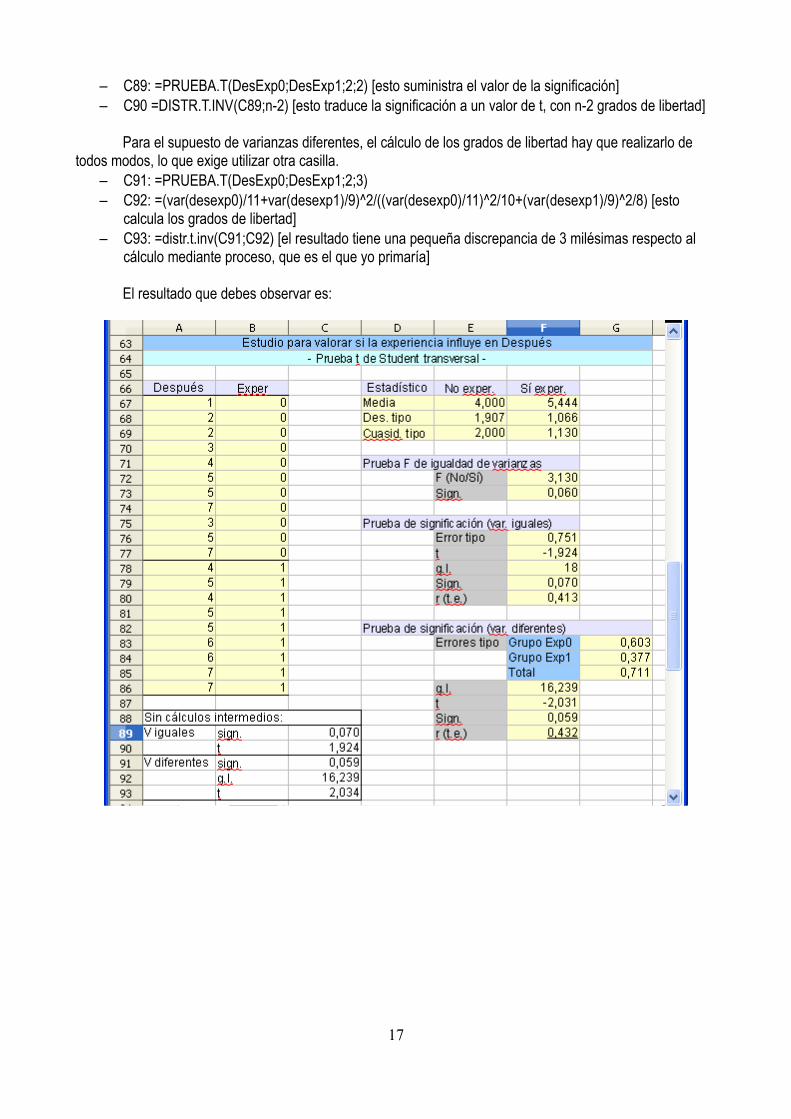
Para mostrar el proceso vamos a tomar un objetivo concreto: comprobar si el grado de acuerdo Después varía según que las personas hayan contando o no con experiencia previa en seminarios, es decir, abordar la relación entre Después y Exper.
La t de Student transversal requiere conocer previamente si se puede mantener el supuesto de igualdad de varianzas, es decir, si se puede o no mantener la hipótesis de que las varianzas de los dos grupos son iguales en la población. Por ese motivo, antes de aplicar t, hemos de llevar a cabo una prueba de hipótesis de igualdad de varianzas con cualquiera de los recursos disponibles que, en nuestro caso, va a ser una prueba F calculada mediante la razón entre la cuasidesviación tipo mayor de entre ambos grupos de datos, respecto a la menor:
F =SM2
Sm2
No obstante, sea cual sea el resultado, aquí vamos a mostrar los dos procesos t: para varianzas iguales y para varianzas diferentes.
14

El proceso va a ser: 1) reproducir las columnas Después y Exper, ordenando los valores según esta segunda columna, para observar con claridad los dos grupos en la variable Después, 2) calcular la media, la desviación tipo y la cuasidesviación tipo de ambos grupos (tabla descriptiva), 3) Prueba F, 4) t suponiendo varianzas iguales, 5) t suponiendo varianzas diferentes, lo que lleva a calcular también 6) los grados de libertad para la situación de varianzas diferentes.
– A63: Estudio para valorar si la experiencia influye en Después– A64: - Prueba t de Student transversal -
Tabla de datos y áreas– Copia B3:C22 en A66:B86– Ordena los datos según Exper:
– Selecciona A67:B86– Pulsa Datos/Ordenar– Escoge Ordenar según columna B
– Nombra el área A67:A77 con DesExp0– Nombra el área A78:A86 con DesExp1
Tabla descriptiva– D66: Estadístico– D67: Media– D68: Des. tipo– D69: Cuasid. tipo– E66: No exper.– E67: =promedio(desexp0)– E68: =desvestp(desexp0)– E69: =desvest(desexp0)– F66: Sí exper.– F67: =promedio(desexp1)– F68: =desvestp(desexp1)– F69: =desvest(desexp1)
Prueba F– D71: Prueba F de igualdad de varianzas– E72: F (No/Sí)– F72: E69^2/F69^2– E73: Sign.– F73: distr.F(F72;10;8) [valor F contenido en E72, grados de libertad del numerador y grados de
libertad del denominador]
Prueba t para varianzas iguales
t =X 1 − X 2
X 1 − X 2
, con X 1 − X 2 = 1n1 1n2 n1S 12 n2 S2
2
n− 2y g.l.= n-2
– D75: Prueba de significación (var. iguales)– E76: Error tipo
15

– F76: =raiz((1/11+1/9)*((11*E68^2+9*F68^2)/(n-2)))– E77: t– F77: =(E67-F67)/F76– E78: g.l.– F78: =n-2– E79: Sign.– F79: =distr.t(abs(F77);F78;2) [los valores t negativos dan problemas en esta función, por lo que
utilizamos el valor absoluto de con la función abs()]– E80: r (t.e.)– F80: abs(F77)/raiz(F77^2+n-2)
Prueba t para varianzas diferentesDado que el valor de significación estadística de F es mayor que 0,05 (como no hemos dicho otra
cosa, partiremos del valor habitual), se mantiene la hipótesis de igualdad de varianzas y, por tanto, hay que uilizar la t anterior. Aún así, abordamos también la t para el supuesto de varianzas poblacionales diferentes. El cálculo de t sigue siendo la estandarización de la diferencia entre medias, aunque el valor del error tipo y el valor de los grados de libertad, son diferentes.
X 1− X 2 = X 12 X 2
2 = S12
n1
S 22
n2 y
g.l.= X 1−X 24
X 14
n1− 1
X 24
n2− 1
= S1
2
n1
S22
n2 2
S 12
n1 2
n1− 1 S1
2
n2 2
n2− 1
– D82: Prueba de significación (var. diferentes)– E83: Errores tipo– F83: Grupo Exp0– G83: =raiz(E69^2/11)– F84: Grupo Exp1– G84: =raiz(F69^2/9)– F85: Total– G85: =raiz(G82^2+G83^2)– E86: g.l.– F86: =G84^4/(G82^4/10+G83^4/8)– E87: t– F87: =(E67-F67)/G84– E88: Sign.– F88: =distr.t(abs(F86);F85;2)– E89: r (t.e.)– F89: =abs(F87)/raiz(F87^2+n-2)
Cálculos directosPara obtener los valores de t, gl y sign. sin realizar cálculos intermedios, podemos acudir a las
funciones prueba.t() y distr.t.inv(). La primera calcula el valor de sign., mientras que la segunda obtiene el valor de t que ha generado esa signficación, siempre y cuando se le pase también el valor de los grados de libertad. En el caso de supuesto de varianzas iguales, el proceso es sencillo. Para exponerlo escojo una localización arbitraria:
16
– C89: =PRUEBA.T(DesExp0;DesExp1;2;2) [esto suministra el valor de la significación]– C90 =DISTR.T.INV(C89;n-2) [esto traduce la significación a un valor de t, con n-2 grados de libertad]
Para el supuesto de varianzas diferentes, el cálculo de los grados de libertad hay que realizarlo de todos modos, lo que exige utilizar otra casilla.
– C91: =PRUEBA.T(DesExp0;DesExp1;2;3)– C92: =(var(desexp0)/11+var(desexp1)/9)^2/((var(desexp0)/11)^2/10+(var(desexp1)/9)^2/8) [esto
calcula los grados de libertad]– C93: =distr.t.inv(C91;C92) [el resultado tiene una pequeña discrepancia de 3 milésimas respecto al
cálculo mediante proceso, que es el que yo primaría]
El resultado que debes observar es:
17

SELECCIÓN DE FUNCIONES ESTADÍSTICAS EN OPEN OFFICE CALCRelación alfabética y descripción breve de las funciones utilizadas en este documento.
aleatorio() Número aleatorio entre 0 y 1.confianza(alfa;s;n) Error de precisión para la estimación de una media aritmética con un alfa de valor alfa, una
desviación tipo poblacional de valor s y un tamaño de muestra de valor n.contar(datos) n de datos.contar.si(datos;k) Número de veces que el valor k se encuentra en el área datos.cuartil(datos;tipo) A partir de un vector o matriz indicado por datos, calcula uno de cinco valores posibles según
el tipo: mínimo (1), máximo (5), y los cuartiles 1, 2 ó 3 (respectivamente, tipo=2,3,4).desvestp(datos) Desviación tipo.desvest(datos) Cuasidesviación tipo.desvprom(datos) Desviación media.distr.chi(chi;gl) Grado de significación asociado a la ji cuadrado de valor chi y con gl grados de libertad.distr.f(f;gl1;gl2) Grado de significación de una prueba de análisis de la varianza con un valor f para la razón
entre varianzas y grados de libertad gl1 y gl2. En una prueba transversal, gl1 es grados de libertad inter o entre (número de grupos -1) y gl2 son los grados de libertad dentro o intra (número de datos menos el número de grupos).
distr.normal(x;m;s;1) Probabilidad acumulada de la distribución normal de media m, desviación tipo s, asociado a un valor x. Si en lugar de 1 se expresa 0 como cuarto valor, lo que se calcula es la función de densidad normal. Si m=0 y s=1, es la distribución estandarizada. Para garantizar una cola: distr.normal(2m-x;m;s;1). Para dos colas: 2*distr.normal(2m-x;m;s;1).
distr.t(x;gl;c) Grado de significación de la distribución t, asociada al valor x, con gl grados de libertad y c colas.
fila() Número de la fila actual.media.acotada(datos;p) Media aritmética excluyendo los extremos del conjunto ordenado. La proporción de cada
extremo que se excluye es p/2.mediana(datos) Mediana. No hay función expresa para MAD. Para calcular MAD será necesario calcular una
columna con las distancias absolutas a la mediana -abs()- y pedir la mediana de esa columna.modo(datos) Moda.normalizacion(x;m;s) Distancia estandarizada del valor x en una distribución de media m y desviación tipo s.pearson(datos1;datos2) Coeficiente de correlación lineal simple de Pearson.percentil(datos;p) Percentil p (en proporción).promedio(datos) Media aritmética.prueba.chi(datos1;datos2) Ji cuadrado de una distribución observada (datos1) y otra teórica (datos2).prueba.f(datos1;datos2) F de Snedecor.prueba.t(datos1;datos2;c;k) Significación estadística en una prueba T de Student, donde c es el número de colas y k es el
código de tipo de prueba: longitudinal (1), transversal con varianzas iguales (2) o con varianzas diferentes (3).
var(datos) Cuasivarianza.varp(datos) Varianza.
18


















