





Muestreo probabilístico para la recuperación de los ... · [email protected] ¿Quiénes somos? ......
61
Muestreo probabilístico para la recuperación de los microdatos del censo general de 1930 Universidad Autónoma Chapingo
-
Upload
hoangxuyen -
Category
Documents
-
view
231 -
download
0
Transcript of Muestreo probabilístico para la recuperación de los ... · [email protected] ¿Quiénes somos? ......

Muestreo probabilístico para la recuperación de los microdatos del censo general de 1930
Universidad Autónoma Chapingo

Presentación
Dr. Francisco José Zamudio Sá[email protected]
¿Quiénes somos?
• Universidad Autónoma Chapingo
• Licenciatura en estadística
• Grupo de Estadísticas Sociales
http://www.chapingo.mx/dicifo/demyc/idh/new/

Metas y compromisos
• Realizar un diseño de muestreo probabilístico sobre las boletas del Censo de 1930 que existieran físicamente, el cual permitierá recabar el 10% de la información a nivel individual
• Digitalizar las boletas censales originales de la muestra para su posterior manejo y con ello asegurar la preservación de los documentos originales
• Capturar todos los microdatos de las boletas seleccionadas en la muestra, por ambos lados
• Construir una base de datos en SAS codificada y validada, compatible con otros manejadores de bases de datos
• Generar una propuesta de inclusión de los datos faltantes, que se ajustara a los totales estatales y el total nacional existentes en la información nacional

• Realizar la programación de un código en SAS que permita el manejo de la Base de Datos
• Realizar estimaciones e inferencias de la población
• Escribir un artículo científico sobre los principales hallazgos demográficos y socioeconómicos de la población de 1930
• BD lista para su publicación en línea por INEGI
• Nota: Tenemos todo instrumentado para la captura total del censo de 1930.
Metas y compromisos

L. E. Javier Jiménez [email protected]
Diseño de la muestra y digitalización de las boletas
• Objetivo
• Diseño de muestreo
• Selección y obtención de la muestra
• Captura de información (aprendizaje)

Utilizar un diseño de muestreo probabilístico para:
• Seleccionar una muestra del 10% de los registros, con niveles de precisióny confianza medibles
• Capturar los microdatos de la muestra seleccionada
Objetivo

Supuesto:
• Las boletas del censo de 1930 están organizadas en cajas, separadas porentidad y dentro de las cajas existe una clasificación municipal
Propuesto:
• Muestreo Estratificado por Conglomerados
• Los estratos -> las entidades federativas
• Los conglomerados -> las boletas
• Selección de los conglomerados o boletas dentro de los estratos: se elige unesquema de muestreo sistemático con inicio aleatorio
Diseño de muestreo

Fortalecimiento:
• Muestra Piloto 1% por el Minnesota Population Center
• Profesor Robert McCaa
• Más de 20 años de experiencia en capturar padrones censales de losEstados Unidos (1850 a 1940)
• Puesto en marcha proyectos similares en varios países europeos
Diseño de muestreo

Organización física de las boletas:• Aguascalientes -> Aguascalientes: 1, 2, 3, 4, 5,6, 7, …
-> Asientos : 1, 2, 3, 4, 5, …
Prueba Piloto 1%:
• Muestra 44, todos los folios 44, 144, 244, …
Instrumentado:• Muestreo Estratificado por Conglomerados con selección sistemática
• Los estratos -> Municipios
• Los conglomerados -> Boletas (Haz y envés)
• Folios: 04, 14, 24, 34, 44, 54,… (muestra 4)
02, 102, 202, 302, 402 … («No respuesta» y «familias completas »)
Diseño de muestreo
Muestreo Estratificado por Conglomerados con selección sistemática

• El AGN tiene el resguardo de aproximadamente el 76% de las boletascensales, (posee información de 12’555,147 personas)
• La información está contenida en 3,723 libros y 179,012 boletas
• Los microdatos referentes a 3’997,575 de personas están extraviados, entreellos todos los registros del DF (1’229,576)
• Se fotografiaron un total de 21,359 folios (11.9%)
• Se cuenta con 36,126 fotografías
Digitalización de la muestra seleccionada


Recomendaciones
Regla de oro:
• Capturar copia fiel de la información del documento original
• Base de datos original
• Base de datos «editada»
Segunda regla:
• La unidad de muestreo es el folio (foja) para aprovechar la estructura de los hogares (familias completas)
Entre otras recomendaciones

• Plantilla de captura en Excel:• Uso de etiquetas para diferenciar los tipos de información:
• Del empadronador• De supervisores del levantamiento
• Alrededor de 150 capturistas activos (estudiantes, trabajadores de laUniversidad, amas de casa, etcétera)
• 15 validadores de captura• 5 supervisores de validadores• 3 jefes de procesos
• Proceso de selección• Capacitación constante• Manual de captura
• Consolidación de BD’s
Captura de Información

Imagen de plantilla de captura: amigable

¿Por qué se desarrolló esta plataforma?
● Se requería una herramienta multi-usuario: facilidad para que losestudiantes colaboraran a distancia
● Integración simultánea: no tener archivos por cada usuario
● Para ser usada a distancia: en diferentes lugares dentro y fuera de laUniversidad
● La necesidad de un instrumento que acotara automáticamente variascaracterísticas para la calidad requerida en la BD
● La facilidad de la validación de la captura
● Reducción de costos e incremento de la productividad del equipo
● La posibilidad de capturar todo el censo

● Control de los usuarios (capacitados) por un administrador
● Formato similar a la boleta del Censo
● Repetición automática de valores y control de errores
● Tipos de variables (numérica, texto, categórica, binaria)
● Guardado parcial y final de captura
● Asignación automática de una nueva boleta
● Reportar boletas ilegibles
● Validación de la captura en línea
Características de la plataforma

● Estadísticas de usuario
● Comunicación en línea con capturistas para la corrección de errores
● Descarga de la base de datos directamente de la plataforma
● Uso de imágenes para otros procesos
● Consulta y presentación de información
Video
Características de la plataforma

● La calidad de la captura mejoró 30%
● Se redujo el tiempo de captura en 20%
● Se eliminó el proceso de integración de las bases de datos individuales
● Se tuvo mayor control sobre todos los actores del proceso
Resultados de la plataforma

1.0001.000
0.9910.957
0.888
0.787
0.666
0.541
0.423
0.319
0.234
0.1670.116
0.0790.053 0.034 0.022 0.014 0.009 0.005
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
0.0% 1.0% 2.0% 3.0% 4.0% 5.0% 6.0% 7.0% 8.0% 9.0% 10.0%
Prob
abili
dad
de a
cept
ació
n
Porcentaje de defectos en un conglomerado
Curva característica de operación Muestreo de aceptación simple
Plan(n=127, c=4)
• 5 000 registros• Nomograma (Montgomery 2009)• Se rechazaba con más de 4 errores• 127 celdas a revisar de las 3,000 posibles entradas
Muestreo de aceptación para validación de captura

Plantilla de validación

Diagrama de validación de captura

Procesos para hacer
consistente la información de
la BDCreación de variables de edición para condensación de la información
Asignación de códigos generales para la revisión de datos vacíos,
ilegibles y sin especificar
SEXO
Hombre Mujer Sexo_E
XN M
XN XN 333
XN M
777
XR XNA H
Edición de la base de datos

Contraste de variables para revisar incongruencias
Habla castellano (español)
Habla castellano (español) Editado
Otro idioma o dialecto
Otro idioma o dialecto
(editado)
XN 777 Chontal 777
XN 1 777
XN 1 Chontal Chontal
XN 1 777
XN 1 777
XNA 777 777
XN 1 Chontal Chontal
Obtención de tablas de frecuencia para análisis y revisión bibliográfica
Captura RevisiónChinalteco ChinantecoChocho ChocholtecoChontal ChontalCuitleco CuitlecoMayaquiché Mam quichéMayo MayoSental TzeltalSoque ZoqueTojolabal TojolabalTriqui Triqui
Información agregada por los editores de la base
Más de un registro por línea Código 888, información no disponible
Casos especiales

Obtención de tablas de frecuencias para cada variable
Religión FrecuenciaCatólica 1312413Ninguna 13454
Protestante 7519Evangélica 1819
777 1477333 820
Menonita 542Otra 450
Israelita 372Masónica 358Budista 265
Cristiana 260… …
Bautista 77Espirita 76Deísta 65
888 59Sabática 39
Presbiteriana 24Pentecostal 21Ortodoxa 19Metodista 17Teosófica 17
Musulmana 16Total 1470604
Creación de catálogos
Variable Etiqueta Código Etiqueta_códigoX40E_2 E-Religión 1 AdventistaX40E_2 E-Religión 2 AnglicanaX40E_2 E-Religión 3 BautistaX40E_2 E-Religión 4 BrahamistaX40E_2 E-Religión 5 BudistaX40E_2 E-Religión 6 CatólicoX40E_2 E-Religión 7 CismáticaX40E_2 E-Religión 8 ComunistaX40E_2 E-Religión 9 ConfucionistaX40E_2 E-Religión 10 CristianoX40E_2 E-Religión 11 DeístaX40E_2 E-Religión 12 HebreoX40E_2 E-Religión 13 EspiritaX40E_2 E-Religión 14 EspiritistaX40E_2 E-Religión 15 EvangélicoX40E_2 E-Religión 16 GentilX40E_2 E-Religión 17 IsraelitaX40E_2 E-Religión 18 JudaístaX40E_2 E-Religión 19 LuteranoX40E_2 E-Religión 20 MasónX40E_2 E-Religión 21 MenonitaX40E_2 E-Religión 22 MetodistaX40E_2 E-Religión 23 MormónX40E_2 E-Religión 24 MusulmánX40E_2 E-Religión 25 NingunaX40E_2 E-Religión 26 OrtodoxoX40E_2 E-Religión 27 OtraX40E_2 E-Religión 28 PentecostalX40E_2 E-Religión 29 ProtestanteX40E_2 E-Religión 30 SabáticoX40E_2 E-Religión 31 TeosóficaX40E_2 E-Religión 32 UnitaristaX40E_2 E-Religión 33 PresbiterianoX40E_2 E-Religión 333 No especifica religiónX40E_2 E-Religión 777 VacíoX40E_2 E-Religión 888 Ilegible
CÓDIGO
Codificación de la base de datos

● La proporción media de jefes de familia por foja es de 0.2187, por lo que una familia en promedio se integra por 4.57 personas (1/0.2187)
Distribución de jefes de familia por foja y de miembros por familia:
Validación automática

● Utilizando esta distribución, si usamos el criterio 2 sigma es necesariorevisar los folios cuya proporción está fuera del rango [0.085 0.352], estoes 589 folios
● Utilizando el criterio 3 sigma, el rango aceptable es [0.019 0.419], quecorresponde a 335 folios a revisar, de un total de 19,274 folios
Validación automática
corresponde a 335 folios a revisar, de un total de 19,274 folios

Unidades Primarias de Muestreo (UPM)
El diseño de muestreo es representativo para todos los dominios
Estimaciones: Dominios de estudio

Unidades Primarias de Muestreo (UPM)
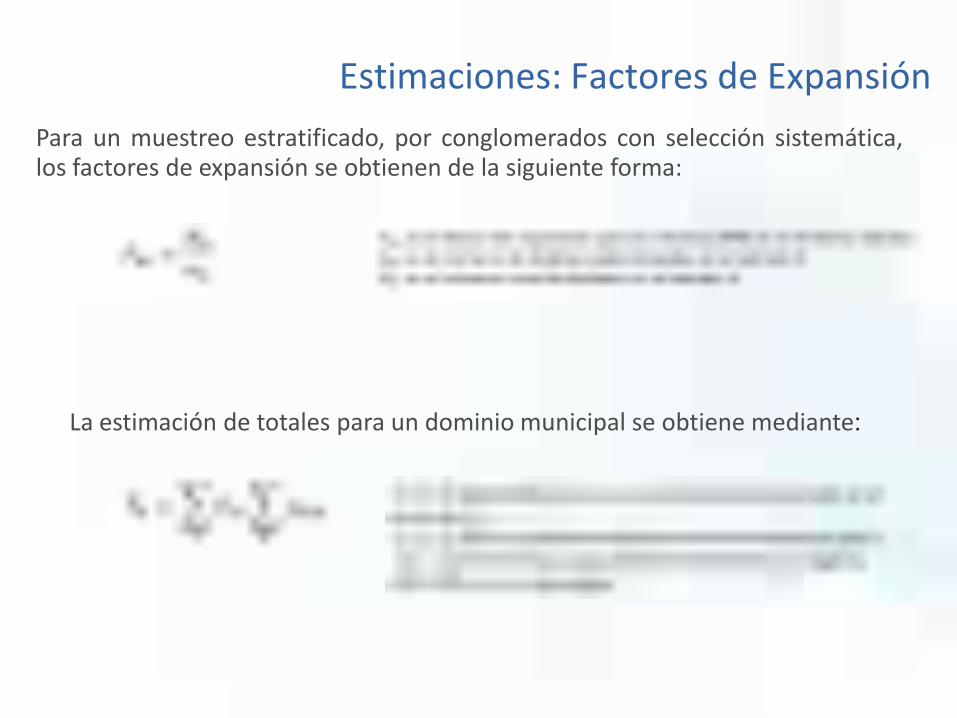
Para un muestreo estratificado, por conglomerados con selección sistemática,los factores de expansión se obtienen de la siguiente forma:
La estimación de totales para un dominio municipal se obtiene mediante:
Estimaciones: Factores de Expansión

Sin embargo, al aplicar los factores de expansión para estimar la población totalde cada municipio se obtiene lo siguiente:
En el eje “x” aparece el error relativo de la estimación. En el eje “y” aparece elporcentaje de municipios. El error absoluto se calculó en base la poblacióntotal por municipio que aparece en las publicaciones de INEGI para el censo de1930
Estimaciones: Factores de Expansión

Factor de expansión inicial:
En este caso las UPM dentro de un estrato tuvieron la misma probabilidad deser seleccionas, y por tanto su factor de expansión también es igual para todas
Factor de expansión corregido:
Con este nuevo cálculo, las UMP dentro de estrato tienen asociado diferentes factores de expansión
Estimaciones: Corrección a los Factores de Expansión

Número equivalente de boletas muestreadas:
Estimaciones: Corrección al Factor de Expansión

Al aplicar el factor de expansión modificado, para estimar una nueva variable,población total de mujeres de cada municipio, se obtiene lo siguiente:
En el eje “x” aparece el error relativo de la estimación. En el eje “y” apareceel porcentaje de municipios. El error absoluto se calculó en base la poblacióntotal de mujeres por municipio que aparece en las publicaciones de INEGIpara el censo de 1930
En el eje “x” aparece el error relativo de la estimación. En el eje “y” aparece
Estimaciones: Factor de expansión modificado

• Como primera aproximación las estimaciones, utilizando el factor deexpansión modificado, mejoran sustancialmente
• No obstante, se pretende someter a más pruebas esta modificación delfactor de expansión, haciendo comparaciones con los totales de otrasvariables publicadas por INEGI para el censo de 1930 a escala estatal
• Finalmente, se obtendrán las expresiones que permitan calcular el errorestándar para cada tipo de estimador que se utilice (total, media yproporción)
Estimaciones: Factor de expansión modificado

Incorporación de la información faltante

• Descripción del problema
• Método propuesto
• Comentarios sobre la propuesta
• Ejemplo
Outline

• Proponer un método para recuperar la información faltante
• Pérdida parcial vs. Pérdida total
• 276 municipios
• 4 MM de habitantes
Descripción del problema
24%
12%

Información faltante:
• Las 12 delegaciones del Distrito Federal
• Las capitales de 13 entidades federativas y del país
• Sólo en Tabasco no hay información perdida
Descripción del problema

-
5
10
15
20
25
30
35
40
45
0%
20%
40%
60%
80%
100%
Mu
nic
ipio
s
Po
bla
ció
n
Población
Municipios
Descripción del problema

• Se emplearán similitudes con otros municipios, o bien relacionesentre variables
• Condiciones de similitud: tamaño demográfico, densidad depoblación, y otras variables ya estimadas
Método propuesto

Aguascalientes:
• Población: 102,126 (77%)
• Municipios: 3 (de 7)
Municipio PoblaciónAguascalientes 82,184 Asientos 11,266 Calvillo 12,179 Cosío 2,404 Jesús María 7,763 Rincón de los Romo 12,354 Tepezalá 4,750
Ejemplo

• En caso de no haber similitudes, se recurrirá al uso de covariables
• Para el caso de las capitales, se tomarán las diferencias con losvalores publicados oficiales de 1930
Método de recuperación
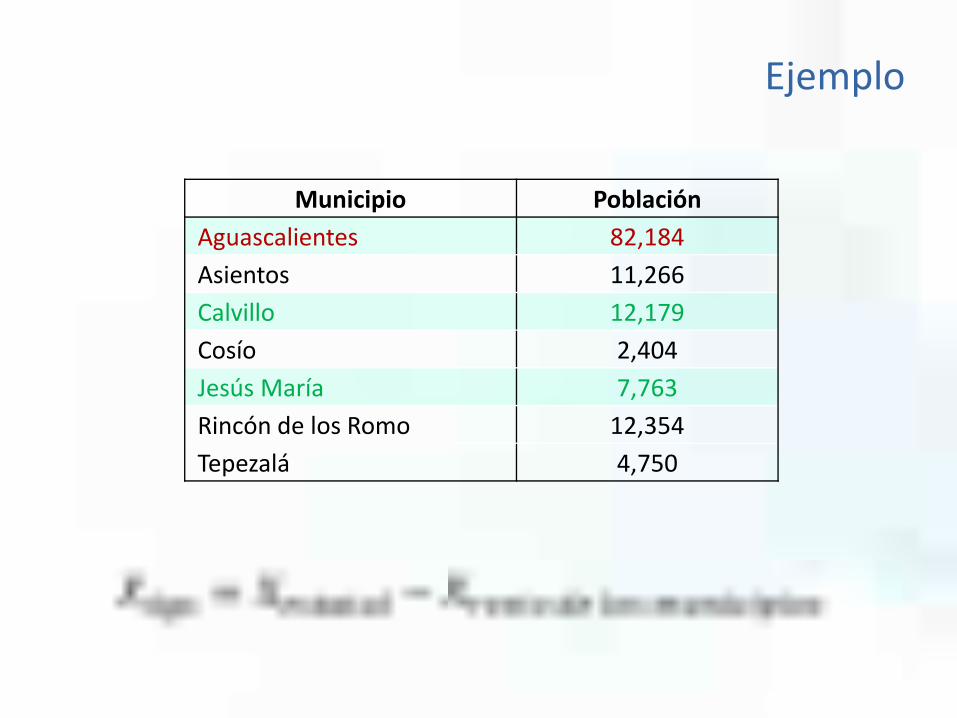
Municipio PoblaciónAguascalientes 82,184 Asientos 11,266 Calvillo 12,179 Cosío 2,404 Jesús María 7,763 Rincón de los Romo 12,354 Tepezalá 4,750
Ejemplo

• Poblaciones atípicas
• Totales municipales
• Errores de estimación
Comentarios sobre la propuesta

Población Microdatos %
Población 16,552,722 1,483,717 9.0%
Población en
AGN12,555,147 1,483,717 11.8%
Boletas 179,012 21,359 11.9%
Entidades 32 31 96.9%
Municipios 2,293 2,019 88.1%
4 GeográficasEntidad FederativaMunicipioPobladoCategoría
4 DemográficasEdadSexoLugar de nacimientoNacionalidad
2 CulturalesReligiónIdioma
3 EconómicasProfesiónBienes raícesSin trabajo
3 SocialesEstado civilAlfabetismoDefectos físicos y mentales
Microdatos recuperados

*Datos preliminares. Microdatos 1930 sin expandir
Los microdatos indicaron que en 1930 había 96.6 hombres por cada 100mujeres, en 2010 hay 95.4
*
mujeres, hay
Grupos de edad
102.4106.9
90.3 90.192.7 93.3
98.3 96.4102.2
106.3
88.8 90.5 92.7 92.5 96.694.2
103.2 102.9 100.392.3
91.3 91.1 89.983.8
0-4 5-14 15-19 20-39 40-49 50-59 60-69 70 Y MÁS
1930 1930 2010
Población por sexo y relación hombres/mujeres por grupos de edad
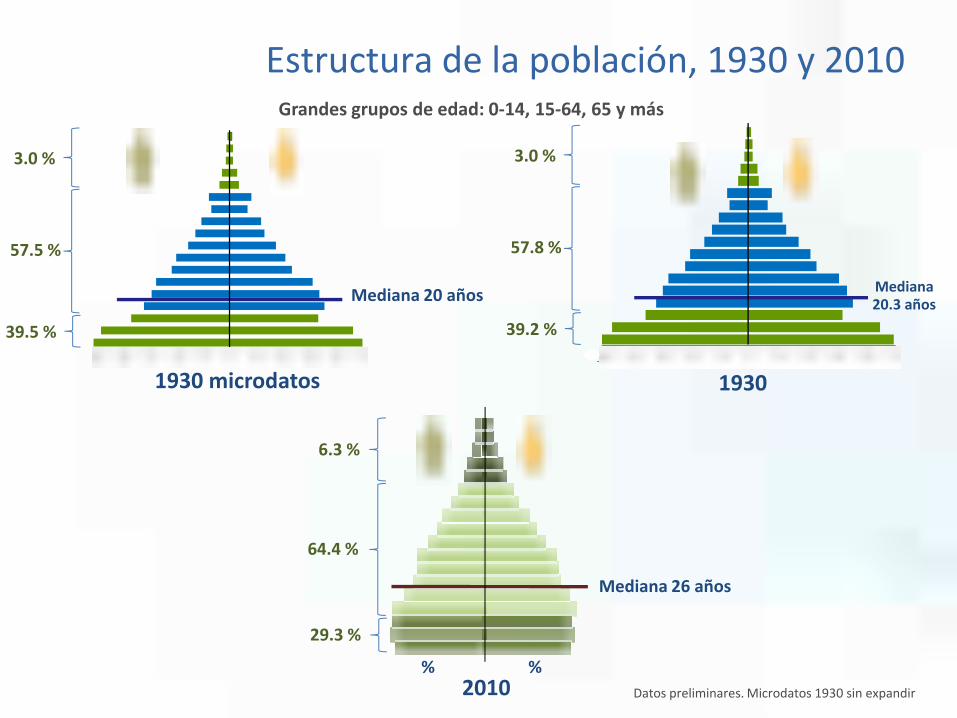
2010
6.3 %
64.4 %
29.3 %
Mediana 26 años
% %
Mediana 20.3 años
Datos preliminares. Microdatos 1930 sin expandir
1930 microdatos-50 -40 -30 -20 -10 0 10 20 30 40 50
3.0 %
57.5 %
39.5 %
Mediana 20 años
Grandes grupos de edad: 0-14, 15-64, 65 y más
3.0 %
57.8 %
39.2 %
1930
Estructura de la población, 1930 y 2010

Datos preliminares. Microdatos 1930 sin expandir
Quintana RooBaja California
Baja California SurMéxicoColima
MorelosTamaulipasQuerétaroCampeche
Nuevo LeónNayarit
AguascalientesDistrito Federal
Estados Unidos MexicanosChihuahua
SonoraTlaxcalaHidalgo
JaliscoCoahuila de Zaragoza
DurangoZacatecas
San Luis PotosíSinaloa
Michoacán de OcampoVeracruz de Ignacio de la Llave
GuanajuatoPuebla
TabascoYucatánOaxaca
GuerreroChiapas
54.045.1
39.737.0
29.627.9
25.323.8
22.721.3
20.720.5
19.818.4
17.617.3
16.416.3
14.214.0
12.512.0
10.710.310.19.99.79.69.0
8.37.0
6.03.6
20101930 microdatos
Estados Unidos Mexicanos
Veracruz de Ignacio de la Llave
54.5853.10
29.7226.40
21.1220.43
16.3015.9015.68
14.5713.6313.60
12.5511.52
8.958.04
6.756.67
6.046.03
4.734.504.104.003.803.573.523.483.39
2.752.16
1.18
QUINTANA ROOBAJA CALIFORNIA NORTE
BAJA CALIFORNIA SURTAMAULIPAS
COAHUILACOLIMA
CHIHUAHUAAGUASCALIENTES
SONORANUEVO LEON
DURANGOMORELOS
ESTADOS UNIDOS MEXICANOSNAYARIT
VERACRUZSAN LUIS POTOSI
TLAXCALASINALOA
CAMPECHEZACATECAS
HIDALGOCHIAPASJALISCO
GUANAJUATOPUEBLA
QUERETAROESTADO DE MEXICO
YUCATANMICHOACAN
TABASCOGUERRERO
OAXACA
Estados con mayor incremento de
migrantes:- Edo. México- Querétaro- Campeche
Estados con mayor decremento de
migrantes:- Baja Carlifornia- Coahuila - Durango
Porcentaje de población nacida en otra entidad o paíspor entidad federativa
%%
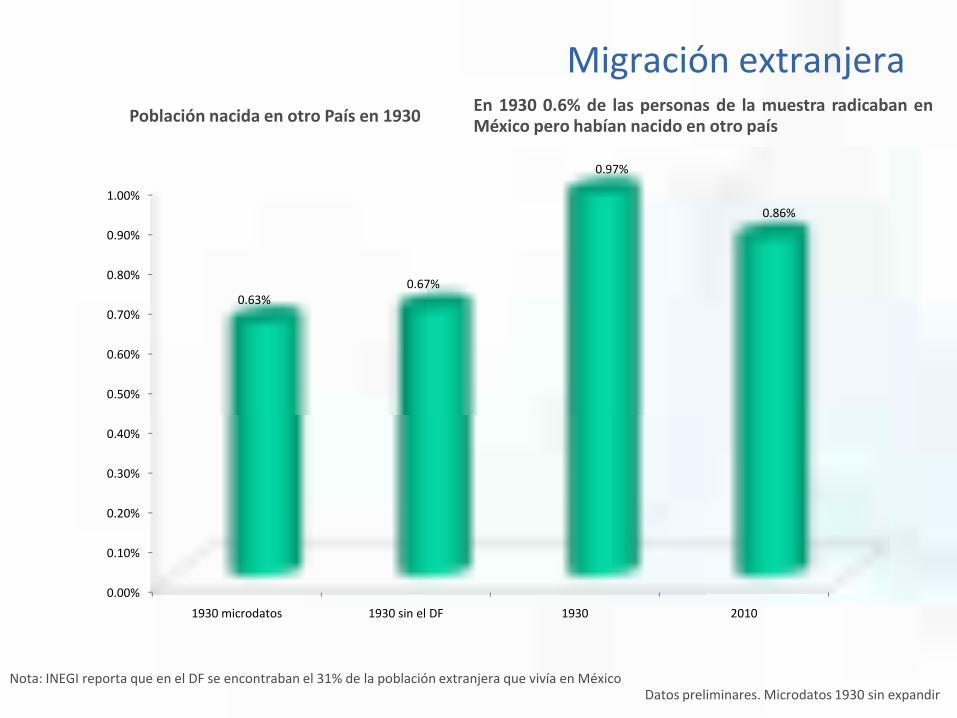
Población nacida en otro País en 1930
Nota: INEGI reporta que en el DF se encontraban el 31% de la población extranjera que vivía en MéxicoDatos preliminares. Microdatos 1930 sin expandir
En 1930 0.6% de las personas de la muestra radicaban enMéxico pero habían nacido en otro país
0.00%
0.10%
0.20%
0.30%
0.40%
0.50%
0.60%
0.70%
0.80%
0.90%
1.00%
1930 microdatos 1930 sin el DF 1930 2010
0.63%0.67%
0.97%
0.86%
Migración extranjera

31.0%
7.4%
17.8%
19.9%
13.6%
9.8% 0.5% SOLTERO
CASADO POR LO CIVIL
CASADO POR LA IGLESIA
CASADO POR LO CIVIL Y CASADO POR LA IGLESIA
UNIÓN LIBRE
VIUDO
DIVORCIADO
31.5%
7.1%
16.5%
21.0%
13.5%
9.9% 0.5%
Microdatos 1930
Población 1930
Datos preliminares. Microdatos 1930 sin expandir
35.2 %
40.5 %
14.4 %5.2%
SOLTEROS
CASADOS
UNIÓN LIBRE
DIVORCIADOS
Población 2010
Distribución porcentual de la población de 14 años y más por situación conyugal 1930

0.00%
5.00%
10.00%
15.00%
20.00%
25.00%
1930 microdatos 1930 2010
11.76%
8.45%
0.87%
8.92%
7.60%
5.09%
20.68%
16.05%
5.96%
Solo habla lengua indígena Hablan español y alguna lengua indígena Habla lengua indígena
Población de 5 años y más hablante de lengua indígenaque no habla español
Datos preliminares. Microdatos 1930 sin expandir
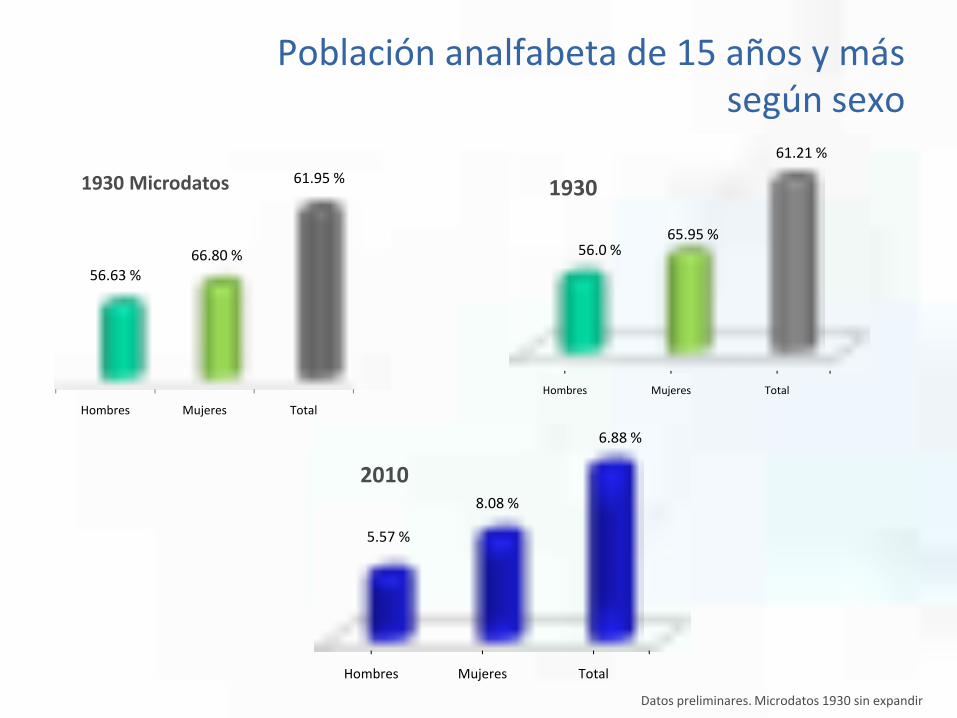
Hombres Mujeres Total
56.63 %66.80 %
61.95 %
Hombres Mujeres Total
5.57 %
8.08 %
6.88 %
Hombres Mujeres Total
56.0 %65.95 %
61.21 %
19301930 Microdatos
2010
Población analfabeta de 15 años y más según sexo
Datos preliminares. Microdatos 1930 sin expandir
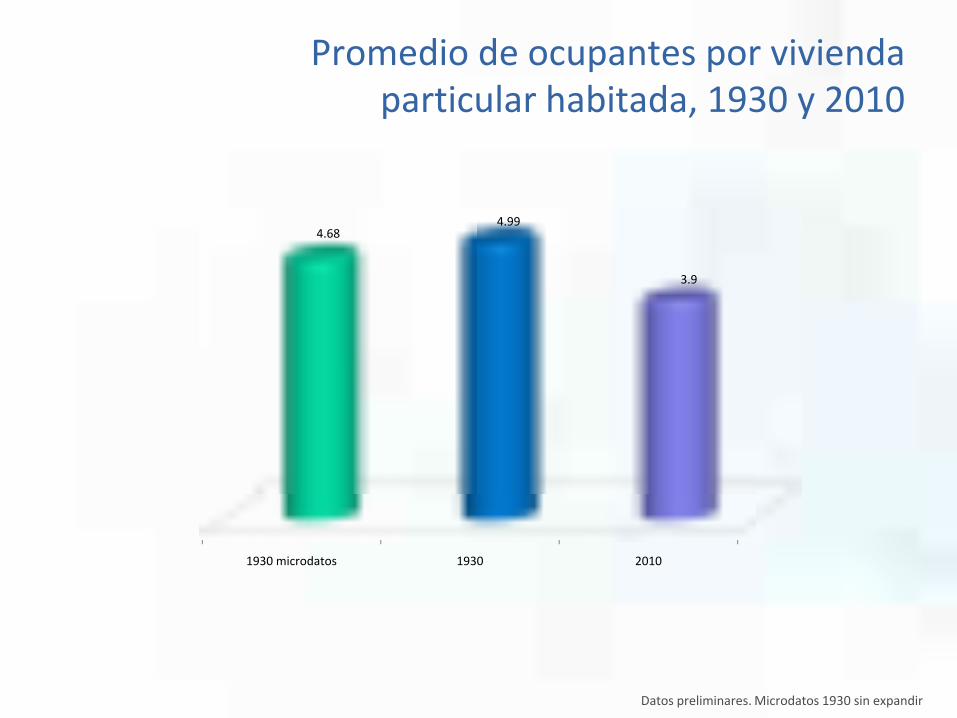
1930 microdatos 1930 2010
4.684.99
3.9
Promedio de ocupantes por vivienda particular habitada, 1930 y 2010
Datos preliminares. Microdatos 1930 sin expandir
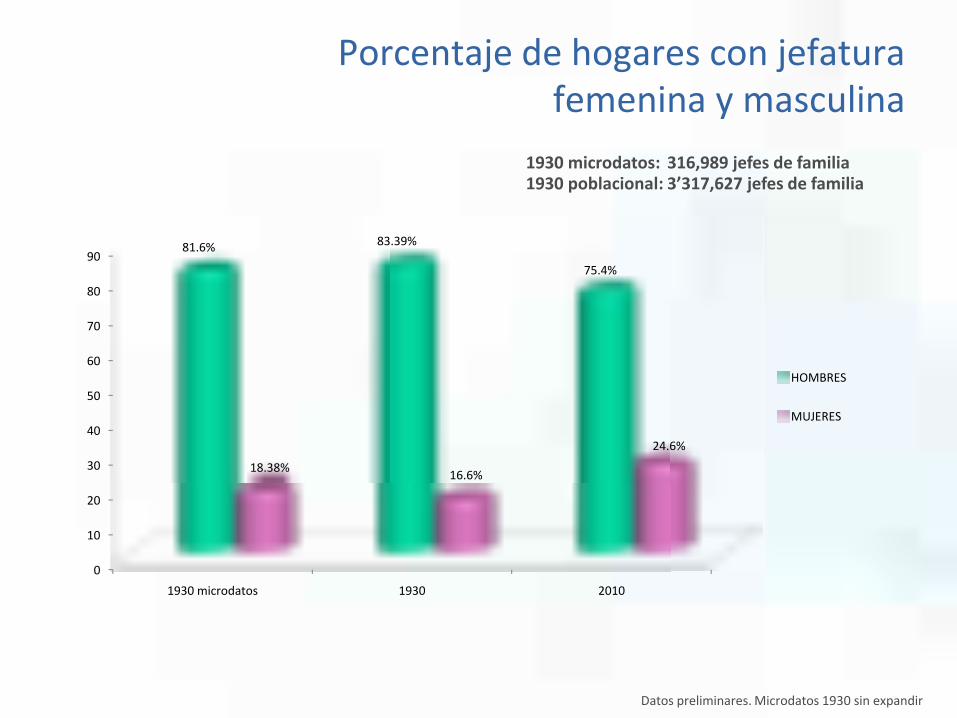
0
10
20
30
40
50
60
70
80
90
1930 microdatos 1930 2010
81.6% 83.39%
75.4%
18.38% 16.6%
24.6%
HOMBRES
MUJERES
1930 microdatos: 316,989 jefes de familia1930 poblacional: 3’317,627 jefes de familia
Porcentaje de hogares con jefatura femenina y masculina
Datos preliminares. Microdatos 1930 sin expandir

G r a c i a s


















