INTELIGENCIA EN REDES DE COMUNICACIONESjvillena/irc/practicas/12-13/libro1213.pdf · construir...
108
INTELIGENCIA EN REDES DE COMUNICACIONES Trabajos de la asignatura Curso 12-13 Departamento de Ingeniería Telemática Universidad Carlos III de Madrid
Transcript of INTELIGENCIA EN REDES DE COMUNICACIONESjvillena/irc/practicas/12-13/libro1213.pdf · construir...

INTELIGENCIA EN REDES DE COMUNICACIONES
Trabajos de la asignatura
Curso 12-13
Departamento de Ingeniería Telemática
Universidad Carlos III de Madrid


INTELIGENCIA EN REDES DE COMUNICACIONES
Trabajos de la asignatura
Curso 12-13
Julio Villena Román Departamento de Ingeniería Telemática
Universidad Carlos III de Madrid [email protected]
ÍNDICE
1. Sudoku ...................................................................................... 1Daniel de la Casa Riballo, M .ª del Rocío Casco Muga
El juego del Sudoku se presenta como un problema de optimización que tiene una única solución. Se estudiarán sus orígenes y sus características, además de la aplicación de diversas técnicas de resolución de problemas y optimización.
Palabras clave: Sudoku, Optimización, Resolución de Problemas, Java.
2. Sistema Experto en Actividades de Ocio .................................. 10Sherezade Fraile Paniagua
Se ha diseñado un sistema basado en el conocimiento (SBC) en lenguaje CLIPS, que sugiera posibles planes de ocio según gustos. Básicamente se trata de un programa, que previo almacenamiento de un conjunto de actividades (en el programa como tal puede ya estar cargado), interactúa con el usuario para adquirir las características básicas de las actividades que le gustan. Tras ello, el programa realizará una búsqueda dentro del conjunto de actividades, para seleccionar aquellas que se ajustan a la información obtenida del usuario y mostrarla por pantalla..
Palabras clave: Sistemas expertos (SE), reglas, actividades de ocio, búsqueda.
- i -

3. Project Glass: Realidad aumentada, reconocimiento deimágenes y reconocimiento de voz. .......................................... 18 Lucas García, Paloma Jimeno, Leticia Manso
Después de la presentación del Project Glass de Google sobre sus gafas derealidad aumentada nos planteamos las tecnologías necesarias para eldesarrollo de este dispositivo. Este es el objetivo del siguiente escrito,profundizar en las tecnologías de reconocimiento de voz y de imágenes yde su integración y utilización para un dispositivo de RealidadAumentada. Tras una breve introducción a cerca de las gafas de Google,se explicarán conceptos sobre realidad aumentada relacionándolas con elproyecto, sobre reconocimiento de imágenes y voz. Por último se haráuna mención sobre redes neuronales, base de las dos tecnologías dereconocimiento explicadas..
Palabras clave: Realidad aumentada, imagen virtual, GPS,marcadores, pantalla transparente, HDM, patrón, sensor, clasificador,OSR, biometría, RGB, entrenamiento, modelo oculto de Markov,aprendizaje inductivo, Redes Neuronales, Perceptrón Multicapa (MLP),Backpropagation.
4. Diseño e implementación de jugador virtual de Mentiroso ...... 33David Sandoval, Juan Antonio Fernández de Alba
En este documento se detalla el diseño y la implementación de un jugador virtual del conocido juego de cartas “Mentiroso”. Se analizará en detalle las técnicas y algoritmos utilizados en dicho diseño para dotar de capacidad de aprendizaje y decisión al jugador virtual.
Palabras clave: Partida, ronda, jugador virtual, jugador humano, levantar cartas, echar cartas, credibilidad, mentir, cartas verdaderas y cartas falsas.
5. Juego Mancala con algoritmo Minimax realizado con interfazgráfica en java .........................................................................42 Lucia Ruiz Ruiz, Artem Motsarenko, José Ángel León Calvo
En este documento vamos a realizar un juego basado en Mancala usandocomo algoritmo Minimax con poda alfa-beta y dos niveles de búsqueda.Estará realizado con lenguaje de programación Java y una interfazgráfica para que el usuario pueda jugar contra un usuario programado.
Palabras clave: Mancala, Minimax, Java, GUI, poda alfa-beta, Juegosde mesa.
6. Domótica ................................................................................ 50Javier García Martín, Eva Mansilla López
La Inteligencia artificial también comprende lo que se conoce como la Domótica la cual estudia la inteligencia de las casas. Sistemas que
- ii -

realicen que las luces del pasillo se activen al pasar sin pulsar ningún interruptor, encender la calefacción mediante una simple llamada de teléfono, generar alarmas por la entrada de intrusos cuando no estamos en casa, persianas a través de la televisión con un mando a distancia, desde cualquier teléfono y esto sin requerir mayor esfuerzo sino simplemente por una maquina quien es capaz de recibir órdenes y actuar sin protestar, ni quejas.
Palabras clave: Domótica, sostenibilidad, vivienda inteligente, energética, confort, seguridad, ahorro, aprendizaje.
7. Técnicas para exploración de bases de datos ........................... 59Daniel Aceituno Gómez, Miguel Alcolea Sánchez
El objetivo del trabajo es conseguir las imágenes más parecidas a una dada dentro de una base de datos de 6600. Para ello se utilizarán dos técnicas de búsqueda, una de ellas basada en agrupamiento (k-medias) y otra según el criterio de mínima distancia (distancia Euclídea). La base de datos proporcionada está formada por siluetas de animales marinos. El código Matlab desarrollado debe ser capaz de encontrar los contornos más parecidos al de muestra, independientemente de la rotación, posicionamiento y escalado de éste.
Palabras clave: Clustering, Matlab, algoritmos de búsqueda, exploración de bases de datos.
8. Sistemas expertos: MAGERIT .................................................. 67Adrián García Diéguez, Jesús García Jiménez
En este documento vamos a explicar el significado de lo que es un Sistema Experto mediante el análisis de sus principales componentes y características. En concreto analizaremos el sistema experto MAGERIT basado en el análisis y gestión de riesgos de los sistemas de información de las administraciones públicas.
Palabras clave: Sistemas expertos (SE), gestión del riesgo, seguridad, activos, dominio.
9. Aplicaciones de la Minería de datos en las empresas ............... 77Silvia Briones Herranz
En este trabajo veremos la importancia de apoyarse en la minería de datos a la hora de la toma de decisiones en una empresa, basándose en el descubrimiento de información útil en las bases de datos para fundamentar mejor sus decisiones. Además analizaremos mediante dicha técnica un ejemplo ficticio de las ventas de consolas con el fin de encontrar las preferencias de los clientes y así conseguir hacer a las empresas más competitivas.
- iii -

Palabras clave: Minería de datos, base de datos, algoritmia, datos extraños.
10. Implementación de un agente autónomo en Super Mario ........85Pablo González Fernández, Alberto Chicharro Sobrino
En este documento se explica cómo se podría utilizar la teoría de resolución de problemas en un entorno controlado como es el mundo de Super Mario. La solución propuesta consta de un árbol de decisión, que en función de las variables de entrada que se le pasen por parámetro decidirá cuál es la mejor acción a llevar a cabo. Para la implementación de este agente inteligente se utilizan las librerías proporcionadas en [1].
Palabras clave: Mario Bros, agente inteligente, enemigos, escenario, algoritmo.
11. Inteligencia artificial aplicada a personas con discapacidad ... 94Alejandro E. Reyes Bascuñana, Javier Santofimia Ruiz
En este documento se intentara dar un vistazo general a las distintasformas en las que la Inteligencia Artificial puede ayudar a la integración,facilidad de acceso a la información y en general a la mejora de lacalidad de vida de personas que sufren una discapacidad física opsíquica..
Palabras clave: Deficiencia, discapacidad, minusvalía, ASIBOT, RAH,OCR, acceso, alternativo, aumentativo, movilidad, ambiental, virtual,BCI, P300.
- iv -

SUDOKU
Daniel de la Casa Riballo Estudiante Ing. Telecomunicación Universidad Carlos III de Madrid
Avda. De la Universidad, 30 28911, Leganés (Madrid-España)
M .ª del Rocío Casco Muga Estudiante Ing. Telecomunicación Universidad Carlos III de Madrid
Avda. De la Universidad, 30 28911, Leganés (Madrid-España)
RESUMEN
El juego del Sudoku se presenta como un problema de optimización que tiene una única solución. Se estudiarán sus orígenes y sus características, además de la aplicación de diversas técnicas de resolución de problemas y optimización.
Categorías y Descriptores de Temas
[Java] Lenguaje de programación.
Términos Generales
Backtracking, Método Humano, Búsqueda Aleatoria, Exact Cover, Búsqueda Tabú, Algoritmos Genéticos.
Palabras Clave
Sudoku, Optimización, Resolución de Problemas, Java.
1. INTRODUCCIÓN
El Sudoku es un juego que consiste en un tablero de R x C casillas, donde R nota el número de filas y C el número de columnas. El tablero está dividido en un número k de bloques de tamaño r x c (con r = √𝑅 y c = √C ) en los que colocaremos r x c elementos diferentes.
Figura 1 : Sudoku 9x9 en blanco, remarcando las 9 casillas que forman un bloque.
El objetivo del Sudoku en su versión clásica, y más popular, es rellenar una cuadrícula de 81 casillas, en 9 filas y 9 columnas, divididas en cajas de 3x3, con los números del 1 al 9. Al rellenar el Sudoku debemos conseguir que no se repita ningún número en las filas, columnas y tampoco en las cajas de 3x3. Un Sudoku estará bien planteado si su solución es única.
Sin embargo, también podemos encontrar otras versiones de Sudokus con diferentes restricciones, variantes respecto a la colocación de los bloques, e incluso utilizando conjuntos de elementos que no sean exclusivamente numéricos.
Figura 2 : Sudoku 9x9 en blanco, con bloques de 9 casillas asimétricos.
Hay que tener en cuenta que los Sudokus vienen con un conjunto de valores numéricos ya incluidos, denominados pistas. Las pistas no son colocadas en orden aleatorio. El número de pistas incluidas inicialmente en el Sudoku nos determinará su nivel de dificultad. Aunque la dificultad también está relacionada con el tiempo que toma encontrar la solución.
-1-

1.1 Historia El juego del Sudoku tiene sus orígenes en civilizaciones antiguas como la china o la árabe. En estas civilizaciones existían unos juegos denominados “cuadrados mágicos” a los que se les atribuía propiedades especiales, siendo utilizados en los campos de la Astrología y el Esoterismo.
El origen más antiguo de los cuadrados mágicos se encuentra en una leyenda china, datada del año 2200 a.C., la cual se denominaba “Lo Shu”. Dicho nombre significa “hoja de río”, y la leyenda cuenta que el emperador chino vio salir una gran tortuga del río Amarillo. La historia tenía que ver con un sacrificio al dios del río, ya que el rio se desbordaba e inundaba los campos sembrados, perjudicando la economía del país.
Figura 3: Representación del caparazón de la tortuga y la equivalencia de cada uno de los números que forman el cuadrado mágico.
La tortuga en su caparazón tenía pintados en forma de cuadrado los números del 1 al 9. Lo sorprendente era que el resultado de la suma tanto en horizontal como en vertical era siempre el mismo. En ese momento el emperador le dio una interpretación mística y sagrada a la tortuga, la consideraba como un presagio para su país, ya que simbolizaba la longevidad y la protección.
Debido a este presagio el emperador empezó a levantar palacios con una distribución en cuadrícula semejante a la encontrada en el caparazón de la tortuga sagrada. La suma de los números coincidía con el número de días que tiene cada uno de los 24 ciclos lunares del año chino.
La idea del cuadrado mágico fue transmitida a los árabes por los chinos. En la Enciclopedia del año 990 realizada por un grupo de eruditos árabes muestra una lista de cuadrados de todos los órdenes desde 3 a 9. En 1225 Ahmed al-Buni mostró como construir cuadrados mágicos mediante una técnica de bordeado.
La primera aparición del cuadrado mágico en la literatura islámica se da en el Jabirean Corpus. Este libro recomendaba los cuadrados mágicos como hechizos para facilitar el nacimiento de los niños. Dichos cuadrados consistían en 9 celdas con los números del 1 al 9 ordenados con 5 en el centro de forma que el contenido de cada fila, columna y las dos diagonales sumaran 15. Los cuadrados mágicos pudieron ser introducidos en Europa a través de España durante el siglo XII.
El concepto de cuadrados latinos se conoce desde los tiempos medievales, aparecieron con manuscritos árabes del siglo XIII. Dicho cuadrado contiene celdas en el cual cada fila y cada columna tiene el mismo conjunto de símbolos, a diferencia del cuadrado mágico, en el cual no hay repetición.
En 1776 Euler mostraba como construir cuadrados mágicos con un cierto número de celdas, en particular 9, 16, 25 y 36. Euler puso en una rejilla letras en latín y lo llamó cuadrado latino. Más tarde añadió letras griegas y de ahí que surgiera el cuadrado greco-latino.
En sus últimos años Euler encontró el problema de combinar dos conjuntos de n símbolos de manera que en ninguna fila o columna se repitieran una pareja de símbolos.
Otro ejemplo en el cual se muestra un cuadrado mágico de orden 4 es en la fachada de la Pasión del Templo Expiatorio de la Sagrada Familia en Barcelona, diseñada por el escultor Josep María Subirachs.
La constante mágica del cuadrado es 33, la edad de Jesucristo en la Pasión. Estructuralmente dos de los números del cuadrado (el 12 y el 16) están disminuidos en dos unidades (10 y 14) con lo que aparecen repeticiones. Esto permite rebajar la constante mágica en 1.
Figura 4: Cuadrado mágico en la fachada de la Sagrada Familia en Barcelona.
El Sudoku es en realidad un caso especial de los cuadrados latinos. El Sudoku impone la restricción adicional de que los subgrupos de 3*3 deben contener también los dígitos del 1 al 9. Este tipo de rompecabezas se publicó por primera vez a finales de las décadas de los 70 en la revista “Math Puzzles and Logic Problems” de Dell Magazines. El nombre que dio Dell a este rompecabezas fue “Number Place”. Dell tomó el concepto de Euler de cuadrado latino y lo aplicó a una rejilla de 9*9 con la adición de 9 cajas, cada una de ellas contiene los números del 1 al 9.
-2-

En 1984, Nikoli, la compañía líder en creación de puzles de Japón descubrió el “Number place” y decidió mostrarlo a los fans japoneses de los rompecabezas. En 1986, después de añadir varias mejoras, sobretodo creando patrones simétricos y reduciendo el número de pistas dadas, el Sudoku se convirtió en uno de los rompecabezas más vendidos en Japón.
Cuando se dieron cuenta de que uno de los principales problemas era el nombre tan largo que tenía inicialmente Suuji Wa Dokushin Ni Kagiru (los números deben existir sólo una vez), el presidente de Nikoli, lo abrevió a Sudoku (Su = número; Doku = único, soltero).
Dos años después, los japoneses introducen dos innovaciones que lleva el juego a una mayor popularidad en el país del Sol Naciente, el número de las cifras no puede pasar de 30 y las cuadrículas se hacen simétricas, es decir, que las cifras están distribuidas de forma rotatoria y simétrica en las casillas, lo que concede al conjunto un aspecto más estético.
En 1997 Wayne Gould, juez neozelandés, durante una visita a Hong Kong lo descubrió y preparó algunos Sudokus para el diario británico “The Times”.
Figura 5: Muestra de la fiebre del Sudoku que se vivió a partir del año 2005.
Gould que creó un programa de ordenador que generaba Sudokus de diferentes niveles de dificultad, no pedía dinero por los rompecabezas. El Times decidió darle una oportunidad y publicó en 2004 su primer Sudoku. La publicación de un Sudoku en el “London Times” fue solo el principio de un enorme fenómeno que rápidamente se extendió por toda Gran Bretaña y países como Australia y Nueva Zelanda. Tres días después, el “Daily Mail” empezó a publicar Sudokus. El Daily Telegraph de Sydney los siguió en 2005.
A finales de 2005 el rompecabezas se publicaba de forma regular en varios periódicos. Además el Sudoku fue incluido diariamente
en el teletexto del Canal 4. La BBC Radio comenzó a leer los números en voz alta en la primera versión radiofónica del Sudoku.
La revista “Teachers”, financiada por el gobierno, recomienda el Sudoku como un ejercicio mental en las clases y se ha insinuado que la resolución de Sudokus puede ayudar a frenar la progresión de enfermedades como el Alzheimer.
El sudoku completó el círculo volviendo a Manhattan como un elemento habitual del New York Post. La moda del Sudoku a otras partes de EEUU cuando tanto el “The Daily News” como el “USA today” lanzaron Sudokus el mismo día.
Hoy en día hay clubes de Sudoku, chats, libros de estrategia, vídeos, juegos para móviles, juegos de cartas, competiciones e incluso un programa de televisión. El Sudoku ha aparecido en los periódicos de todo el mundo y se le describe en los medios de todo el mundo como “el cubo Rubik” del siglo XXI y como el “rompecabezas” que más rápido ha crecido del mundo.
2. RESOLUCIÓN DEL SUDOKU MEDIANTE ALGORITMOS
El Sudoku tiene asociado dos problemas básicos: la generación de tableros válidos y la búsqueda de una solución que lo solucione. Respecto a la generación de un tablero válido, se dice que existen dos alternativas, una de las cuales es mantener almacenados en una base de datos un conjunto de tableros que se conocen de antemano como válidos y realizar una carga aleatoria de los mismos. La segunda forma es desarrollar un algoritmo capaz de generar los tableros por sí mismos.
Pero en esta sección nos vamos a centrar a la búsqueda de una solución, dicha solución está demostrado que se trata de un problema NP-completo, con lo cual no se ha descubierto hasta hoy un algoritmo que le de solución en un tiempo polinomial. Sin embargo, el Sudoku se ha convertido en uno de los problemas principales de estudio de los programadores, los cuales siguen desarrollando formas de resolución cada vez más eficientes. A continuación explicaremos los más conocidos.
2.1 Técnica Backtracking El algoritmo implementado con esta técnica se denomina en realidad “Branch -&- Bound” o ramificación y poda, es uno de los más elogiados por los programadores debido a la velocidad con la que encuentra la respuesta. Sin embargo, para los investigadores se trata del menos útil a causa de su ineficiencia.
Dicha técnica se basa en un algoritmo de búsqueda en el cual se explora un árbol de soluciones en anchura o profundidad. Una de las alternativas de esta técnica es la de emplearlo en su forma más primitiva, que es la de un algoritmo de fuerza bruta.
En este caso el algoritmo se encargará de probar en cada casilla, y a partir de una casilla inicial, cada uno de los valores disponibles, analizando inmediatamente la validez de la decisión tomada. Si la
-3-

solución parcial no satisface las condiciones de la Regla Única, el algoritmo retrocederá (backtrack) al nivel de búsqueda anterior y generará otro tablero, con el siguiente valor disponible ubicado en la posición última de análisis. Este proceso se repetirá hasta concretar el análisis de la última casilla, con lo cual el costo computacional será de 𝑛(𝑅×𝐶)−𝑝, con “n” igual al número de valores posibles, “R” el número de filas, “C” el número de columnas y “p” el número de casillas con pista. A este costo se debe agregar, también, el de cada consulta de validez con lo cual el número es extremamente grande.
Para determinados tableros, entonces, el algoritmo tardará mucho tiempo, aún con el hardware actual. La ventaja, sin embargo, radica en que el algoritmo devolverá, tarde o temprano, la solución esperada. En la siguiente figura mostramos el espacio de soluciones para un pequeño Sudoku de ejemplo de 22 × 22 casillas, con 𝑁 = {1,2,3,4} .
Figura 6: Espacio de soluciones (acotado) para un tablero sudoku de 4 x 4 de ejemplo. Obsérvese que el algoritmo de backtracking no expande los nodos que no son válidos, y corta la búsqueda al encontrar la solución.
Otro de los algoritmos basados en backtracking consiste en relacionar la búsqueda de una solución a un tablero Sudoku con el cásico problema de coloreo de grafos. Un grafo G = ⟨V, E⟩ es una estructura formada por un conjunto de vértices “V” y un conjunto de aristas o arcos “E” que los unen. El problema de coloreo de grafos es un problema NP, y consiste en hallar la cantidad mínima de colores necesarios para colorear cada vértice del grafo, teniendo en cuenta que dos vértices adyacentes (unidos entre sí por un arco) no pueden ser coloreados de la misma forma.
Si tenemos en cuenta que el conjunto de colores será el de los valores que se utilizan para completar el Sudoku, el quid de esta relación radica en hallar una forma para representar el tablero Sudoku con un grafo tal que cumpla las condiciones del problema de coloreo. Sea “V” el conjunto de vértices de nuestro grafo. Si consideramos 𝑉 = {(𝑖, 𝑗), 0 ≤ 𝑗, 𝑖 ≤ 9} (es decir, tomamos cada casilla del tablero como un vértice del grafo), podemos construir “E” (el conjunto de aristas o arcos) de acuerdo al siguiente criterio: “dos vértices u y v están unidos por un arco no dirigido (u,v) sí y solo sí u y v comparten la misma fila, columna o bloque”. En la siguiente figura se observa, para el Sudoku del ejemplo anterior, cómo queda conformado el subgrafo de vértices adyacentes para la casilla siguiendo el criterio enunciado.
Figura 7: Subgrafo creado a partir de las casillas relacionadas con la (1,1). Se omitieron los vínculos entre todos los demás vértices por cuestiones de prolijidad.
Luego, dicho algoritmo debe solo recorrer el grafo obtenido coloreando de forma válida cada uno de los vértices, a partir del conjunto “N” de colores o de cifras del sudoku. En nuestro caso no tendremos que encontrar el conjunto mínimo de colores, sino buscar un coloreo válido para el grafo. Como todo tablero Sudoku debe admitir una y sólo una posible solución, queda asegurado que si el tablero es válido, el algoritmo devolverá un resultado satisfactorio en un tiempo exponencial, cuya expresión es una función de la cantidad de vértices que restan por colorear (cantidad de casillas vacías) y de la cantidad de colores disponibles (cantidad de valores con los que puede completarse una casilla).
2.2 Método Humano Este método de resolución es muy interesante para utilizarse algorítmicamente, ya que permite deducir cómo el usuario podría resolver un Sudoku por su cuenta.
En la revista “NAW” se publicaron siete reglas básicas para el desarrollo del análisis humano. Entre ellas, una de las más simples y utilizadas “baby steps” que dice que cuando se conocen ocho cifras de una misma fila, columna o bloque, el dígito restante es el que ocupa la última casilla libre. Otra de las reglas es “singles” la
-4-

cual expresa que cuando hay un solo lugar por elementos dado en una columna, fila o bloque, o cuando hay solo un dígito que puede ir en un bloque dado, escribirlo allí. Por último otra de las reglas es “pair markup” que dice que si en una casilla pueden ir dos o más valores posibles, escribirlos como subíndices de tal forma que puedan realizarse los análisis correspondientes en el resto del Sudoku, si se produce una contradicción al considerar uno de los dígitos, entonces se detendrá el análisis de ese y probar con alguno de los restantes.
Esta demostrado que siguiendo estos tres pasos más los otros cuatro de una complejidad mayor puede encontrarse la solución a cualquier Sudoku. La dificultad que presenta este algoritmo es que su complejidad temporal es muy difícil de calcular con exactitud, puesto que los pasos deben ejecutarse en un orden lineal y, cuando se utiliza el método de nivel inferior, deben repetirse todos los anteriores.
Por este motivo la solución de algunos tableros se alcanza en tiempos mínimos, mientras que para otros el análisis puede ser mucho más largo. Por último podemos afirmar que la eficiencia del algoritmo dependerá de la estrategia utilizada para la codificación de los pasos. Este método se utiliza para calcular la dificultad de los Sudokus que se publican en libros y revistas para su resolución a mano.
2.3 Búsqueda Aleatoria La búsqueda aleatoria es otro de los métodos que pueden seguirse para encontrar el resultado de un Sudoku. La estrategia consiste en primero, comenzar aleatoriamente colocando números en las casillas vacías del tablero, y calcular luego el número de errores cometidos. Después de esto se intercambian los números insertados a lo largo del tablero hasta que la cantidad de errores se reduzca a cero. Cuando se llegue a esto, se habrá llegado a la solución.
La ventaja de este método, es que el tablero no tiene que ser “soluble lógicamente” para que el algoritmo pueda resolverse. Es decir, que los tableros con los que se prueba el algoritmo no deben ser especialmente construidos de tal forma que se provean suficientes pistas al usuario como para completarlo usando lógica encadenada solamente. Dicho método es el menos usado, debido a que trata de una búsqueda nada sistemática y con bastante azar.
2.4 Exact Cover El Sudoku puede describirse en términos de un caso particular del problema de “Exact Cover”, o recubrimiento exacto. Este método es un problema NP completo que consiste en, dado un universo de elementos y una colección de subconjunto, hallar una subcolección tal que cada elemento esté exactamente en un conjunto.
Por tratarse de un problema que no se resuelve en un tiempo polinomial, pueden plantearse soluciones por aproximación o definirse un algoritmo de backtracking que le de respuesta. Como alternativa a estas dos opciones el Dr. Donald Knuth publicó un algoritmo que recibe el nombre de “Dancing Links” que resuelve el problema de “Exact Cover”, obviamente en un tiempo exponencial.
La relación entre la resolución de Sudokus y el problema de “Exact Cover” se basa en definiciones de conjuntos y en términos matemáticos.
2.5 Búsqueda Tabú La Búsqueda Tabú es una técnica de optimización combinatoria que utiliza conceptos de memoria adaptativa y exploración sensible. La exploración sensible de Búsqueda Tabú se basa en la idea de que una mala decisión tomada por una estrategia produce más información que una buena selección realizada de forma aleatoria. Implementa una estrategia de búsqueda local para explorar de forma eficiente el espacio entorno una configuración. Cada solución tiene asociado un conjunto de vecinos. Con esta estructura se permite pasar a la mejor opción vecina, o si ya estamos en la mejor vamos a la menos peor, donde se aplica de nuevo búsqueda local sobre la nueva vecindad en busca del óptimo. En cada paso deben analizarse todos los vecinos (al menos un conjunto grande de ellos), por lo que es un método de alto coste computacional.
La configuración inicial se genera rellenando cada columna con los números faltantes, de forma que no se repitan los números en ninguna columna. Esta configuración inicial no cumplirá normalmente con la condición de las filas y de los subcuadros.
El vecindario para una configuración se define según las siguientes estrategias:
1) Cambiar un número repetido en una columna por un número que no esté en esa columna.
2) Cambiar un número repetido en una fila por un número que no se encuentre en esa fila.
3) Cambiar un número repetido en un subcuadrado por otro que no aparezca en ese subcuadro.
4) Intercambiar en una misma columna los números de dos celdas.
5) Intercambiar en una misma fila los números de dos celdas.
En lugar de evaluar la función objetivo recorriendo el cuadro completamente para analizar el número de repeticiones por filas, columnas o subcuadros, se realiza una estimación de la variación de la función objetivo para un vecino partiendo de la función objetivo de la configuración actual, ahorrando en tiempo computacional. La estimación de la función objetivo se realiza de acuerdo al tipo de variación hecha para llegar a la configuración vecina.
2.6 Algoritmos Genéticos Los algoritmos genéticos son una técnica de búsqueda a través del espacio de soluciones del problema (configuraciones). Inicialmente fue idealizado usando los mecanismos de la evolución de la genética natural. Este algoritmo inicia con la selección de una población inicial. Después, realiza un proceso de selección entre las configuraciones para permitirles participar en la generación de nuevos
-5-

descendientes, para después formar parejas para ser sometidas a un proceso de recombinación. Finalmente se realiza un proceso de mutación que altera los elementos de algunas configuraciones. Este proceso tiene como finalidad generar diversidad en la población y está controlado por un parámetro llamado tasa de mutación que determina cuantos cambios se realizarán sobre la población. Tras finalizar este proceso obtenemos los elementos de la nueva generación.
El buen desempeño del algoritmo depende de la selección adecuada de los parámetros de control (tamaño de la población inicial, tasa de recombinación y de mutación) y la forma en la que se realiza la selección, recombinación y mutación. El algoritmo aplicado a l Sudoku consta de las siguientes etapas:
1) Codificación del problema: Cada configuración del problema es una matriz con números entre el 1 y 9. En nuestra representación, cada individuo o cromosoma se representa con un array de 9 genes de 9 elementos cada uno. Cada gen es una fila del tablero.
Figura 8: Codificación del problema
2) Población inicial: Las posiciones fijas del tablero se
mantienen como están, pero las posiciones vacías se representan como 0. Se genera de forma aleatoria para cada celda en blanco del problema un número entre 1 y 9 sin generar elementos repetidos dentro de una fila (gen). El proceso se repetirá para cada configuración de la población.
3) Cálculo de la función objetivo: Debe reflejar la cantidad de
números que se repiten por fila, columna y subcuadro. Esto se realiza de forma más eficiente determinando qué números faltan en cada fila columna o subcuadro.
Figura 9: Números que faltan en cada fila, cada columna y cada subcuadro.
4) Proceso de selección: Es proporcional y realizado mediante el
método de la ruleta. Para ello se utiliza una función de adaptación que garantiza selectividad y transforma el valor de función objetivo original de minimización a maximización.
𝐹𝑎𝑖 = max(𝐹0���) ∙ 𝑘 − 𝐹0𝑖 Donde: 𝐹𝑎𝑖: Función de adaptación del individuo i-ésimo. 𝐹0���: Vector función objetivo de los individuos. 𝑘: Tasa de adaptación (k>1).
5) Proceso de recombinación: Se realiza de tal manera que se conservan las mejores características de las soluciones anteriores. Como el proceso de la población se mantiene constante, cada pareja de padres tendrá dos hijos: el primero tendrá los mejores subcuadros de los dos progenitores (aquellos que tienen menos repeticiones) y el segundo tendrá las mejores filas o columnas de los dos, seleccionando aleatoriamente con la misma probabilidad de ocurrencia.
6) Proceso de mutación: Se realiza para generar diversidad. La solución es única y debe explorarse adecuadamente el espacio de soluciones. Se pueden realizar cuatro tipos de mutaciones: intercambio de dos elementos en una fila, intercambio de dos elementos en una columna, intercambio de dos elementos en un subcuadro y reemplazo de un número de individuo por otro número generado de forma aleatoria entre 1 y 9.
Figura 10: Ejemplo de mutaciones
Además, para no perder el rastro de búsqueda, si en la población nueva no hay un individuo mejor o igual a la incumbente, se reemplaza el peor individuo de la población por la mejor solución encontrada. En caso de no encontrar solución, el proceso para cuando un número predefinido de iteraciones se alcanza.
3. ALGORITMO DE BACKTRACKING PARA EL SUDOKU EN JAVA
Con el algoritmo backtracking implementamos una técnica de resolución de problemas mediante una búsqueda sistemática de soluciones.
-6-

Para optimizar el backtracking se descompone cada tarea en tareas parciales y se prueba de manera sistemática cada una de estas subtareas.
Cuando al elegir una tarea comprobamos que no lleva a una solución, volvemos hacia atrás y probamos con una nueva.
El siguiente fragmento de código Java comprueba utilizando backtracking si a través de una serie de pistas podemos obtener una solución de un Sudoku, o si no existe solución para esas pistas.
public class Sudoku { public static final int DIMENSION =9; public static void main(String[] args){ int[][] tablero= new int[][] { {0,7,0, 0,0,0, 0,8,0}, {0,5,0, 6,0,0, 0,0,1}, {0,0,3, 1,4,0, 0,0,0}, {9,0,6, 0,5,0, 3,0,0}, {0,0,0, 0,0,0, 0,0,0}, {0,0,5, 0,2,0, 1,0,7}, {0,0,0, 0,6,5, 7,0,0}, {3,0,0, 0,0,1, 9,2,0}, {0,4,0, 0,0,0, 0,1,0}, }; imprimir(tablero); if(!resolver(tablero)){ System.out.println("El Sudoku no tiene solución"); } } public static void imprimir(int[][] tablero){ for(int i=0;i<DIMENSION;i++){ if(i%3==0){ System.out.println(); } for(int j=0; j<DIMENSION;j++){ if(j%3==0){ System.out.print(" "); } System.out.print(tablero[i][j]); } System.out.println(); } } public static boolean resolver(int[][] tablero){ for(int i=0; i<DIMENSION; i++){ for(int j=0; j<DIMENSION; j++){ if(tablero[i][j]!=0){ continue; } for(int k=1;k<=9;k++){
if(esPosibleInsertar(tablero,i,j,k)){ tablero[i][j]=k; boolean b=resolver(tablero); if(b){ return true; } tablero[i][j]=0; } } return false; } } System.out.println("Encontrada solución:"); imprimir(tablero); return true; } public static boolean esPosibleInsertar(int [][] tablero, int i, int j, int valor){ //Comprueba columna for(int a=0; a<DIMENSION; a++){ if(a!=i &&tablero[a][j]==valor){ return false; } } //Comprueba fila for(int a=0; a<DIMENSION; a++){ if(a!=j &&tablero[i][a]==valor){ return false; } } //Comprueba cuadardo int y= (i/3)*3; int x= (j/3)*3; for(int a=0; a<DIMENSION/3;a++){ for(int b=0;b<DIMENSION/3;b++){ if(a!=i &&b!=j&&tablero[y+a][x+b]==valor){ return false; } } } return true; } }
-7-

Utilizando este ejemplo, obtenemos como resultado la solución del Sudoku:
Figura 10: Solución del Sudoku en Java mediante backtracking.
Podemos comprobar un ejemplo en el cual no obtengamos solución para el Sudoku. Para ello, modificamos en el código el tablero, obteniendo la siguiente solución:
Figura 11: Sudoku sin solución implementado en Java mediante backtracking.
4. CONCLUSIONES
Se planteo el Sudoku, como un problema de optimización que presenta características de alta complejidad matemática, como la presencia de una solución única y se propone un modelo matemático.
La estrategia de búsqueda local que implementa “Búsqueda Tabú” permite salir de configuraciones que tienen pocas repeticiones pero en las que pequeños cambios muestran un empeoramiento en la solución (óptimo locales). Al prohibir movimientos en celdas modificadas recientemente se consigue escapar de esos óptimos locales.
El proceso de cruzamiento empleado por el algoritmo genético, da prioridad a las mejores configuraciones y extrae sus mejores atributos para generar la nueva población. Este comportamiento hace que el método no se desvíe y siempre trate de mejorar la solución durante el proceso de búsqueda.
El sudoku tiene solución única, lo que significa que no se consideran soluciones válidas los tableros con situaciones cercanas a la solución. En este sentido, el Sudoku no parece un problema adecuado para resolver utilizando un algoritmo genético; pero si es un problema muy útil para experimentar con diferentes operadores genéticos sobre permutaciones, dado su alto grado de dificultad.
Los algoritmos de backtracking se caracterizan por permitirnos obtener la solución a todo problema de satisfacción de restricciones o de optimización. El costo computacional, sin embargo, está acotado en O (𝑛𝑘), con n representando la cantidad de hijos de cada nodo y k la cantidad de niveles del espacio de soluciones.
Como se ha dicho antes, nuestros tableros sudokus están formados por 81 casillas, y hasta hoy se han descubierto sudokus que pueden ser resueltos por el ser humano si tienen un mínimo de 17 pistas. Si consideramos que n es la cantidad de casillas modificables de un tablero y que k representa la cantidad de valores posibles que pueden ocupar una celda, el costo final de un algoritmo de backtracking sin poda es O (981−17) = O (964).
Ahora bien, las podas implementadas en nuestro algoritmo de backtracking nos permiten reducir la complejidad temporal significativamente, de acuerdo a un criterio que depende de forma exclusiva de las características de los tableros. Esto es, cuanto mayor sea la densidad de pistas en las primeras celdas del sudoku, el número de iteraciones se disminuirá. De la misma forma, si los primeros valores de la solución son altos y no están dados como pistas, el número de iteraciones necesarias se incrementará.
-8-

5. REFERENCIAS
[1] Historia de los Cuadrados Mágicos http://www.portalplanetasedna.com.ar/cuadrados_magicos3.htm
[2] Los Cuadrados Mágicos http://eloviparo.wordpress.com/2010/04/19/los-cuadrados-magicos/
[3] Historia del Sudoku http://www.playsudoku.biz/historia-sudoku.aspx
[4] Historia del Sudoku http://www.articles3k.com/es/405/28951/La-historia-de-Sudoku/
[5] Historia del Cuadrado Mágico de la Sagrada Familia http://es.wikipedia.org/wiki/Cuadrado_m%C3%A1gico#El_cuadrado_m.C3.A1gico_de_la_Sagrada_Familia
[6] Hal 9000 contra los Sudokus Mutantes http://www.linux-magazine.es/issue/13/Sudokus.pdf
[7] Algoritmos de Backtracking http://ocw.uc3m.es/ingenieria-informatica/programacion/transparencias/tema7.pdf
[8] Algoritmo Genético http://www.cesfelipesegundo.com/revista/articulos2007b/Articulosudoku.pdf
[9] Wikipedia. Sudoku. http://en.wikipedia.org/wiki/Sudoku. [10] Enumerating possible Sudoku grids www.afjarvis.staff.shef.ac.uk/sudoku/sudoku.pdf
[11] Conceptos matemáticos del Sudoku http://en.wikipedia.org/wiki/Mathematics_of_Sudoku [12] Algoritmos para resolver Sudokus http://en.wikipedia.org/wiki/Algorithmics_of_Sudoku
-9-

Sistema Experto en Actividades de Ocio
Sherezade Fraile PaniaguaIngenierıade Telecomunicacion
Universidad Carlos III
Avda. de la Universidad, 30
28911, Leganes
7 de diciembre de 2012
Resumen
Se ha disenado un sistema basado en el conocimiento(SBC) en lenguaje CLIPS, que sugiera posibles planes deocio segun gustos.
Basicamente se trata de un programa, que previo alma-cenamiento de un conjunto de actividades (en el programacomo tal puede ya estar cargado), interactua con el usua-rio para adquirir las caracterısticas basicas de las activi-dades que le gustan. Tras ello, el programa realizara unabusqueda dentro del conjunto de actividades, para selec-cionar aquellas que se ajustan a la informacion obtenidadel usuario y mostrarla por pantalla.
Categorıa
Sistema Experto y Aplicaciones
Palabras clave
Sistema Experto, CLIPS, reglas, actividades de ocio,busqueda.
1. Introduccion
Creado en 1985, CLIPS (C Language Integrated Sys-tem) provee una herramienta para manejar una amplia va-
riedad de conocimientos. Esta basado en las reglas, y esde tipo procesal.
La programacion basada en reglas, permite que el cono-cimiento sea representado como heurıstica, es decir, espe-cifican un sistema de acciones que se realizaran para unasituacion dada.
Se trata de un lenguaje caracterizado por:
Portabilidad: Capaz de ser instalado en muchos ydiversos sistemasoperativos sin cambios en el codi-go.
Integracion/extensibilidad: Se puede integrar conlenguajes tales como C,Java, FORTRAN y ADA.Ademas se puede ampliar facilmente por un usuariocon el uso de varios protocolos bien definidos.
Bajo costo:Se trata de un software de dominio pu-blico
Probablemente CLIPS se tratedel sistema experto masampliamente usado sobre todo debido a que es rapido,eficiente y gratuito. Aunque ahora es de dominio publi-co, aun es actualizado y mantenido por su autor original,Gary Riley.
-10-

2. Descripcion del proyecto
2.1. Identificacion
El primer paso es saber en que consiste el problema,pensar en si es apropiado para resolverlo con un SBC, yencontrar fuentes de conocimiento que ayuden a solucio-narlo.
Cuando como en este caso, no existe una solucion al-gorıtmica adecuada facil, es necesario usar un sistema ex-perto. Por tanto, el problema es apropiado para ser resuel-to por un SBC.
2.2. Fuentes de informacion
Como el tema es bastante sencillo para casi cualquierpersona, los ”expertos” hemos sido nosotros mismos, yaque conocemos bastantes actividades de ocio.
Para la parte tecnica, hemos consultado programas pa-recidos, como el sistema experto de ”reparacion de averıasde coche”
2.3. Descripcion del problema
Al final, nuestro problema queda en:
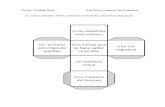
1. Preguntar datos sobre el usuario.Estos incluyen, co-mo mınimo:
si quiere gastar mucho o poco
si va o no en grupo
que actividades le gustan y cuales no le gustan
2. Buscar entre las actividades existentes, aquellas quese ajustan.
3. Escribir en pantalla el resultado.
2.4. Conceptualizacion
Es importante describir que elementos tiene el proble-ma, y que relacion hay entre ellos.
2.5. Conceptos
Una actividad necesita tener:
Nombre:Dato mostrado en la pantalla final.
Tipo: Se indica en que categorıa de las quese pre-gunta se encuentra: cultural, entretenimiento, gas-tronomica, aventura, deportiva o parque tematica.
Costo: Se indica si la actividad requiere un precioalto o no.
Grupal: Si es apropiada para ir en grupo o no.
Recomendada:Nos indicara si laactividad se ajustaa los gustos, y que esta actividad ya ha sido recomen-dad una vez, por lo que no la volvera a recomendarotra vez durante la ejecucion.
Una persona tiene:
Presupuesto
Si va en grupo o no
Gustos sobre actividades
2.6. Preguntas
Tras pensar en diversas soluciones, la mejor opcionconsiste en agrupar mucha informacion bajo una sola pre-gunta, de ahı que se trabaje con preguntas genericas.
Ademas, se hacen preguntas fijas: si va en grupo, si leimporta el precio, . . .
2.6.1. Cantidad de informacion
En algunas preguntas, la respuesta nos sirve para orien-tar las proximas preguntas: la pregunta ”¿Prefieres un ac-tividad tranquila?” nos indica si tenemos que consultarlesobre actividades de caracter sosegado o vivaz. Esta re-lacion de hechos esta basada en el conocimiento que seposee, y naturalmente no cumple los gustos de todos losusuarios, pero sı de la mayorıa. En esta parte es cuandoel conocimiento del problema nos ayuda a simplificar lainformacion.
-11-

Esquema de las preguntas:
¿Contamos con un presupuesto alto (si/no)?
¿Se trata de una actividad individual (si/no)?
¿Quieres una actividad tranquila (si/no)?
• Sı
◦ ¿Te gustan lasactividades culturales(si/no)?
◦ ¿Te gustan las actividades de entreteni-miento (si/no)?
◦ ¿Te gustan las actividades gastronomicas(si/no)?
• No
◦ ¿Te gustan las actividades de aventura(si/no)?
◦ ¿Te gustan las actividades deportivas(si/no)?
◦ ¿Te gustan los parques tematicos (si/no)?
Todas las preguntas nos aportan informacion concretapara la funcionalidad de nuestro programa, ya sea para eldescarte o la seleccion de actividades.
2.7. Condiciones que se comprueban
Para decir si una actividad es buena, se comprueban enese orden, las distintas condiciones:
1. La actividad es apta para tu bolsillo.
2. La actividad es apropiada para tu tamano de grupo.
3. La actividad es del tipo que le gusta.
Si finalmente no se ha encontrado ninguna actividadque se ajuste, se mostrara un mensaje en pantalla para in-dicarlo.
2.8. Incertidumbre
Toda la informacion que se obtiene es fiable, consisten-te, fija (excepto un atributo que indica si una actividad esapta o no, el resto no cambia con el tiempo), y precisa.
En ningun momento tenemos que corregir las decisio-nes tomadas, porque se trabaja siempre con hechos segu-ros.
Sin embargo, hay que tener en cuentra que a la horade introducir una actividad en el sistema, las premisas pa-ra senalar si una actividad es grupal o individual, cara obarata,. . . son una abstraccion de un criterio personal.
3. Implementacion
Como se indico anteriormente, se ha creado un progra-ma en lenguaje CLIPS, caracterizado por estar basado enreglas para la representacion del conocimiento, ademas depor su portabilidad e integridad.
En el programa encontramos distintas partes, para unamejor comprension:
En la partedeffunction, se han definido las funcio-nes correspondientes a la impresion de las preguntas y suanalisis (sera admisible solo un ”s” como respuesta afir-mativa o una ”n” como respuesta negativa).
En defftemplates, se definen 3 ”clases”.
Actividad: En un objeto inicialmente vacio de estaclase sera donde seintroducira la informacion obte-nida mediante las diferentes preguntas (cada pregun-ta modificara el valor por defecto de cada uno de losslots).
(deftemplate actividad(slot presupuesto (type SYMBOL)
(allowed-values si no nose)(default nose))
(slot individual (type SYMBOL)(allowed-values si no nose)(default nose))
(slot tranquila (type SYMBOL)(allowed-values si no nose)(default nose))
(slot cultural (type SYMBOL)
-12-

(allowed-values si no nose)(default nose))
(slot entrenamiento (type SYMBOL)(allowed-values si no nose)(default nose))
(slot gastronomica (type SYMBOL)(allowed-values si no nose)(default nose))
(slot aventura (type SYMBOL)(allowed-values si no nose)(default nose))
(slot deporte (type SYMBOL)(allowed-values si no nose)(default nose))
(slot tematica (type SYMBOL)(allowed-values si no nose)(default nose))
)
Actividades-programadas:Encontraremos distintosobjetos de estas clase,que corresponderan a lasactividades almacenas, que una vez seleccionada,sera mostrada por pantalla.
(deftemplate actividades-programadas(slot nombre (type SYMBOL))(slot tipo (type SYMBOL)
(allowed-values culturalentrenamiento gastronomicaaventura deporte tematica) )
(slot costo (type SYMBOL)(allowed-values si no nose)(default nose))
(slot grupal (type SYMBOL)(allowed-values si no nose)(default nose))
(slot recomendada (type SYMBOL)(allowed-values si no nose)(default nose))
)
Actividad-no-encontrada:Encontraremos ununicoobjeto de esta clase,que sera empleada para deter-minar si no existe ninguna actividad a recomendar,ya que solo cuando se encuentre una actividad quese ajusta a las necesidades, su valor sera modificado.
(deftemplate actividad-no-encontrada(slot encontrada (type SYMBOL)
(allowed-values si no)(default no))
)
A continuacion se encuentradeffacts. En esta partesera donde se crearan los distintos objetos, anteriormentemencionados. Un ejemplo de cada tipo serıa:
(deffacts actividad-no-encontrada(actividad-no-encontrada (encontrada no))
)
(deffacts actividades-programadas(actividades-programadas (nombre Exposiciones
)(tipo cultural)(costo no)(grupal no)(recomendada nose)
)
(deffacts inicia(actividad))
Realmente de launica clase que habra mas de un obje-to, sera de actividades-programadas.
Seguidamente encontraremosreglas. En ella se definenlas reglas fundamentales del programa. Basicamente en-contraremos un conjunto de reglas parecidas, para la in-troduccion de los datos enActividad dependiendo de lapregunta realizada; y dos reglas finales, una para la selec-cion e impresion de las Actividades-programadas elegidasfinalmente (segun expusimos en la descripcion del pro-yecto), y otra para el caso en el que no se haya encontradoninguna actividad recomendada.
A continuacion se muestra un ejemplo de regla para laintroduccion de datos enActividad.
(defrule determina-presupuesto ""?A <- (actividad (presupuesto nose))=>(if (si-o-no-p "Contamos con un presupuesto
alto (si/no)? ")then (modify ?A (presupuesto si))else (modify ?A (presupuesto no))))
-13-

Se trata de una regla en la que se realizara una pregun-ta porpantalla y a partir de su respuesta, se introducira elvalor correspondiente a lo deseado por el usuario. Concre-tamente se determinara con que presupuesto contamos.
Tambien se puede ver el codigo de la regla fundamentaldel programa:
(defrule actividades ""?p <- (actividades-programadas (nombre ?x)(tipo ?t)(costo ?c)(grupal ?g)(recomendada ?r))?A <- (actividad (presupuesto ?pre) (
individual ?ind) (cultural ?cul) (entrenamiento ?en) (gastronomica ?gas) (aventura ?av) (deporte ?de) (tematica ?tem))
?e <- (actividad-no-encontrada (encontrada ?find))
(test (eq ?c ?pre))(test (neq ?g ?ind))(or(test (and (eq ?cul si) (eq ?t cultural)))(test (and (eq ?en si) (eq ?t entrenamiento)))(test (and (eq ?gas si) (eq ?t gastronomica)))(test (and (eq ?av si) (eq ?t aventura)))(test (and (eq ?de si) (eq ?t deporte)))(test (and (eq ?tem si) (eq ?t tematica))))(test (eq ?r nose))=>
(modify ?e (encontrada si))(modify ?p (recomendada si))(printout t "Se recomienda la actividad:" ?x "
." crlf)
)
Regla encargada de una vez adquiridos todos los datoscomprobar de una enuna las distintas actividades y ver sise ajustan a lo deseado, en cuyo caso la mostraremos porpantalla.
Aunque ya se menciono anteriormente, remarcaremosla importancia de la modificacion de los valores, encon-trada y recomendada. Al cambiar el valor de encontradoa si, laultima regla no se activara, puesto que hemos en-contrado una actividad que se ajusta como mınimo. Y al
cambiar el valor de recomendada, no aseguramos que laactividad, no entrara en un bucle y sera recomendada in-finitamente.
Finalmente encontramosInicia, que incluye la reglaque inicia el programa, donde se mostrara como mensajede bienvenida: Sistema Experto de Actividades de Ocio.
(defrule inicia(declare (salience 1))=>(printout t crlf crlf)(printout t "Sistema Experto de Actividades
de Ocio")(printout t crlf crlf))
El archivo concluye con las acciones de carga y ejecu-cion del programa.
El sistemaha sido implementado de modo que pode-mos anadir una nueva actividad-programada en cualquiermomento, y el sistema seguira funcionando correctamen-te, teniendo en cuenta esta nueva posibilidad introducida.
4. Ejemplos
En esta parte, mostraremos distintos comportamientosdel programa.
Para ello, se muestran distintas tablas, correspondientesa las actividades programadas introducidas en el sistemapara las diferentes pruebas.
Figura 1: Actividades Gastronomicas
-14-

Figura 2: Actividades Culturales
Figura 3: Actividades Entrenamiento
Figura 4: Actividades Deportivas
Cada tabla correspondera aun tipo diferente de activi-dad.
Estas se encuentra dividida en dos: en parte superior,las actividades de bajo coste y en la parte inferior, las ac-tividades de coste elevado (Excepto actividades Gastro-nomicas que solo contendra parte inferior). Ademas, seha anadido un codigo de colores para diferenciar a sim-ple vista, las actividades de caracter individual, frente alas de caracter colectivo, mas concretamente, empleare-mos naranjas para actividades individuales y verde paralas actividades grupales.
Aunque existe mas actividades introducidas por defec-to, solo expondremos aquellas que seran empleadas paralas pruebas.
NOTA: Para realizar las distintas tenemos que tener en cuenta comofunciona el programa.
Para cargar el programa emplearemos:
$ CLIPS> (batch actividades.clp)
El programa quedara, como se muestra a continuacion.
$ CLIPS> (run)
Pulsaremos un intro el programa arrancara.
Una vez laejecucion termine, si queremos volver a ejecutarlo, prime-ro deberemos dar unreset, para limpiar los hechos introducidos dentrode los objetos, seguido de unrun para que se ejecute.
Si queremos introducir nuevas actividades en mitad de la ejecucion,primero deberemos hacer elreset, luego introducir la informacion me-dianteassert, y por ultimorun.
4.1. Ejemplos1
En este primer ejemplo (ver figura 5), realizaremos unaejecucion en la que la persona consta de un alto presu-puesto, y desea una actividad individual y tranquila (entranquila no se va a descartar ninguna de las subclases).
Por tanto, la recomendacion que esperamos de nuestrosistema, siguiendo las tablas anteriormente comentadas,es la compuesta por todas las actividades individuales ycaras, dentro del tipo cultural, gastronomico y de entrete-nimiento:
Culturales:Teatro y Concierto deMusica Clasica
Entretenimiento:Spa y Curso
Gastronomica:Cata y Degustacion.
Como se ve en la realizacion, el programa funciona co-rrectamente ya que obtenemos la salida esperada.
4.2. Ejemplos2
En este segundo ejemplo (ver figura 6), realizaremosuna ejecucion en la que la persona dispone tambien de unalto presupuesto, y desea una actividad individual y tran-quila, pero dentro de estas, solo les gustan las actividadesgastronomicas.
-15-

Figura 5: Ejemplo1
Figura 6: Ejemplo2
Podemos observar quelas actividades recomendadas,son una pequena parte de la anterior (las correspondien-tes a las actividades gastronomicas), cumpliendose asi, elcomportamiento deseado.
4.3. Ejemplos3
En este ejemplo, mostraremos dos ejecuciones, en lascuales el comportamiento es el mismo. En la primera eje-cucion se mostrara una persona en la que tras elegir unaactividad tranquila, no le gusta ninguna de las subcate-gorıas (ver figura 7) y por lo tanto, no se le puede reco-mendar ninguna actividad. Y una segunda, en la que aun-que se selecciona un tipo de estas, en el momento de laejecucion, no existe actividad que satisfaga los requisitos
de costo y numero de componentes a realizarla (ver figura8), por lo que del mismo modo, no se le puede recomendarninguna actividad.
Figura 7: Ejemplo3a
Figura 8: Ejemplo3b
En ambos casos podemoscomprobar que el resultadoes el mismo. En ambos casos no existen actividades a re-comendar.
4.4. Ejemplos4
En esteultimo ejemplo, mostraremos tambien dos eje-cuciones. En ambas se hara la misma busqueda, pero trasla primera, introduciremos una nueva actividad (ver figu-ra 9 y 10 respectivamente).Esta se ajustara a la busqueda
-16-

y que por tanto, debera ser mostrada en lasegunda ejecu-cion.
Figura 9: Ejemplo4a
Figura 10: Ejemplo4b
Como era de esperar, mientras en la primera ejecucionno aparece, ya que aun no existe. En la segunda tras inser-tarla, la acepta y pasa a ser procesada, recomendandola.
5. Mejoras
Quizas una mejora serıa la inclusion de nuevos criteriosque aportaran mas informacion acerca de la actividad parauna mejor seleccion de esta, tales como edad, duracion, yhorario.
Otra buena opcion puede ser, incluir preguntar para elanalisis de las subcategorias. Por ejemplo, una vez quesabemos que a un cierto usuario le gustan las actividadesculturales, podriamos preguntar¿Quiere opinar sobre ac-tividades culturales (si/no)?, ya que dentro de esta, podrıahaber actividades que no son de su interes.
Referencias
[1] http://ccc.inaoep.mx/ emorales/Cursos/Representa/-node65.html
[2] http://ocw.uc3m.es/ingenieria-telematica/inteligencia-en-redes-de-comunicaciones/material-de-clase-1/04b-clips/view
[3] es.wikipedia.org/wiki/CLIPS
-17-

Project Glass: Realidad aumentada, reconocimiento de imágenes y reconocimiento de voz.
Lucas García Ing. Superior De Telecomunicación
Universidad Carlos III de Madrid [email protected]
Paloma Jimeno Ing. Superior De Telecomunicación
Universidad Carlos III de Madrid [email protected]
Leticia C. Manso Ing. Superior De Telecomunicación
Universidad Carlos III de Madrid [email protected]
Abstract
Después de la presentación del Project Glass de Google sobre sus
gafas de realidad aumentada nos planteamos las tecnologías
necesarias para el desarrollo de este dispositivo. Este es el
objetivo del siguiente escrito, profundizar en las tecnologías de
reconocimiento de voz y de imágenes y de su integración y
utilización para un dispositivo de Realidad Aumentada.
Tras una breve introducción a cerca de las gafas de Google, se
explicarán conceptos sobre realidad aumentada relacionándolas
con el proyecto, sobre reconocimiento de imágenes y voz. Por
último se hará una mención sobre redes neuronales, base de las
dos tecnologías de reconocimiento explicadas.
PALABRAS CLAVE
Realidad aumentada, imagen virtual, GPS,marcadores, pantalla
transparente, HDM, patrón, sensor, clasificador, OSR, biometría,
RGB, entrenamiento, modelo oculto de Markov, aprendizaje
inductivo, Redes Neuronales, Perceptrón Multicapa (MLP),
Backpropagation.
1. INTRODUCTIÓN
El 27 de Junio de 2012 Sergey Brin, cofundador de Google junto
con otros integrantes corporativos del proyecto Project Glass,
presentaron sus gafas de realidad aumentad.
Este proyecto entra dentro de Google X Lab, departamento cuya
función es desarrollar tecnologías avanzadas e innovadoras.
El propósito principal de este dispositivo se identifica con la de un
Smartphone pero evitando el uso de las manos para las acciones
interactivas. ¿Cómo? Haciéndolas innecesarias y sustituyéndolas
mediante comandos de voz (parecido a Siri de Mac), lectura de
imágenes o incluso parpadeos. Es necesario decir que aun así, se
sigue disponiendo de un controlador táctil integrado en una de las
patas de las gafas.
Una de las aplicaciones integradas más destacadas tanto en el
vídeo promocional como en la presentación es la de poder realizar
una navegación interactiva incluyendo elementos virtuales en el
campo visual del usuario para ayudarle y marcarle el camino. Con
este ejemplo, queda clara los puntos clave del aparato: la
integración de una pantalla de mezcla de imágenes que no llegue a
molestar al cliente y la necesidad de precisión para un correcto
posicionamiento.
Figura 1
Para la primera parte, fue BabakParviz, ingeniero eléctrico. Para
la segunda, Google contó con Steve Lee, especialista en
geolocalización y jefe del proyecto.
Aparte de una pantalla sobre el ojo que se encargará de
sobreponer las figuras virtuales, las gafas integran una cámara de
fotos y de vídeo, micrófonos para capturar voz y una superficie
táctil en uno de los laterales para los controles.
En su comercialización se deberá estudiar las prioridades en
cuanto a que las gafas realizan notificaciones que dependiendo de
la situación pueden ser innecesarias, molestas o incluso
peligrosas.
En la presentación, se usaron vídeos promocionales que
potenciaban el hecho de disponer de una cámara integrada en
situaciones tales como salto en paracaídas. Aunque algo
sensacionalista, se entiende que no se publicita el hecho de tener
un dispositivo de captura de imágenes adaptado a la situación
(problema que ya ha sido solucionado con cámaras integradas en
-18-

diademas), sino de disponer de una cámara en todo momento en
un formato ligero sin necesidad de un aparato específico.
Al estar desarrolladas en Android y dado a que se plantea como
un sustituto de los Smartphone basados en dicho software, las
gafas se podrán manipular a través de los móviles. En nuestra
opinión, esta posibilidad se podría haber añadido como puente
para los clientes menos atrevidos y más asentados en la actual
modalidad de dispositivos celulares.
Para poder desarrollar la tecnología de Realidad aumentada, y
aunque no se especificó en la presentación, se supone que también
tendrá sensores como giroscopios, GPS, Etc...para saber la
posición y su movimiento.
Figura 2
En resumen, en cuánto a tecnología, las gafas dispondrán de:
Control táctil
Reconocimiento de voz (micrófono)
Controlador a través de Smartphone Android
Acelerómetros y giroscopios
GPS
Batería integrada en la patilla
Almacenamiento interno
Aunque en el 2013 las gafas estarán disponibles por 1500 $ para
los desarrolladores, su comercialización no se prevé hasta el 2014.
La patente de estas gafas ya fue fijada para Google.
2. REALIDAD AUMENTADA
La realidad aumentada puede definirse de varias formas. En este
trabajo asumiremos que es un sistema capaz de aumentar la
percepción de la realidad a través de la implementación de
elementos virtuales en la misma. Estos elementos virtuales pueden
ser nuevas imágenes, sonidos o vídeos que se colocan junto a la
imagen tomada de la realidad o en sustitución de ella.
Se podría clasificar una tecnología de realidad aumentada aquella
que:
− Combina mundo real y mundo virtual.
− Es interactivo en tiempo real.
− Se registra en 3 dimensiones.
Figura 3
Con la figura 1 ejemplificamos las tres características relacionadas
con la tecnología de realidad aumentada: se diferencian los
elementos virtuales añadidos a la imagen real de la carretera, se
intuye que la imagen se modificará con el movimiento del
usuario, y tiene carácter tridimensional por la naturaleza de su
funcionamiento.
Para poder desarrollarla deberemos recoger información sobre el
mundo real (una imagen, posicionamiento, fotografía o vídeo ),
conseguir procesarla a través de software (reconocimiento de
patrones o de imágenes en el caso de que la información sea una
imagen), mezclar de forma sintética la información que tenemos
con la imagen real y proyectar la síntesis de ambas. La imagen
que se toma no tiene por qué tener una relación coherente con la
información que vayamos a mezclar con ella. Podremos utilizar
marcadores (hojas de papel con símbolos, ejemplificado en la
figura 2) y relacionarlos con información determinada sobre algo
que aparentemente no tiene conexión. El uso de marcadores o no
marcará una clasificación de la tecnología RA y se detallará más
adelante (2.5).
Figura 4
2.1 Realidad aumentada VS realidad virtual
Aunque parezca que este apartado pierda relación con el hilo del
trabajo, responde a una necesidad, ya que es muy común que se
confundan estas dos tecnologías. Para entender la diferencia entre
ambas, vamos a proceder a definir el término de realidad virtual
(RV). “Realidad virtual” es definido como el campo interactivo
generado por un computador en dónde un elemento real, por lo
general el usuario, es introducido, participando en él en tiempo
real.
La clave es la participación que tiene lo real dentro del producto
final de la tecnología de la que hablemos. En la realidad
aumentada (RA) se mantiene en el sistema la presencia de la
imagen real siendo la información virtual añadida y combinada la
que amplia el valor de la misma. Por el contrario, en la realidad
-19-

virtual, el usuario es el que se encuentra en un mundo totalmente
no real controlado por el ordenador.
Del mismo modo, en RA se nos permitirá interactuar con
elementos reales, mientras que en un sistema RV toda
modificación que hagamos del entorno no afectará a ningún
elemento real sino imaginario.
Otra forma de explicarlo es que la RV remplaza la realidad con
ficción, mientras que la RA le añade elementos virtuales
aumentando la visión que el usuario tiene de ella.
Con la siguiente figura 3, nos haremos una idea de hasta qué
punto se parecen y a la vez se diferencian la tecnología RA y RV.
Figura 5
2.2 Historia
Para contar los principios de la realidad aumentada, deberemos
contar con la fuerte relación que tiene con la realidad virtual.
Explicaremos desde los hitos más importantes de su desarrollo:
50´s-60´s nace la idea de crear un mundo diferente al
real, una realidad virtual.
1962, Morton Heilig, director de fotografía, tras escribir
sobre ‘Cine de experiencia’, crea ‘Sensorama’ con cinco
filmes a las que se le añade efectos de vibración, olfato
y sonidos. La figura 4 nos da una idea de cómo era el
dispositivo.
Figura 6
1966 Ivan Sutherland con su ayudante Bob Sproul
construyeron lo que será el primer visor virtual montado
en la cabeza (Head Mounted Display, HMD, modelo
estudiado en el apartado 2.6). El interfaz era pésimo y
los gráficos eran modelos de alambre. Además el
instrumento era pesado y debía de colgarse del techo
como en la siguiente figura 5:
Figura 7
En 1975, Myron Krueger, un laboratorio de VR
llamado ‘Videoplace’, donde se crea un sistema en el
cual los usuarios permiten interactuar con objetos
virtuales.
A finales de los 80 se popularizo el término Realidad
Virtual por Jaron Lanier, cuya compañía fundada por él
(VPL Research) creo los primeros guantes y anteojos de
Realidad Virtual (figura 6).
Figura 8
El termino Realidad Aumentada fue introducido por el
investigador Tom Caudell en Boeing, en 1992. Caudell
tuvo que configurar los tableros de los trabajadores, y
encontró como solución crear unos tableros virtuales
sobre los reales genéricos. El término Realidad
Aumentada fue dado al público en un paper en 1992.
En 1992 Steven Feiner, Blair MacIntyre y Doree
Seligmann crean un prototipo de sistema realidad
aumentada llamada KARMA.
En 1999 Hirokazu Kato desarrolla ARToolKit en
HitLab.también realidad aumentada.
En los años 2000’s los avances en los sistemas
informáticos hacen que se desarrolle al máximo la
realidad aumentada.
En el año 2000, Bruce H. Thomas da a conocer el
primer juego al aire libre con dispositivos móviles de
realidad aumentada ARQuake.
A finales del 2008 Android saca a la ventaWIkitude
Guía (figura 7), una aplicación para viajes y turismo
basada en sistemas deGPS, brújula digital, sensores de
-20-

orientación y acelerómetro, mapas,video y contenidos
informativos de la Wikipedia, desarrollada para la
plataformaAndroid.
Figura 9
Finalmente, en el año 2009 se estandariza la
tecnología RA y se identifica con el siguiente
logo:
Figura 10
En el 2012 Google diseñan las google glasses
bautizando su proyecto como Project Glass. 2014 será el
año de su comercialización.
2.3 Funcionamiento
El siguiente esquema explica a través de un tipo de aplicación de
RA (figura 9, toma y salida de vídeo, no de imagen) las partes que
componen el proceso general.
Figura 11
1. Se toma a través de un dispositivo una imagen fija o un
vídeo del mundo real. Dependiendo de la aplicación de
la que estemos hablando podríamos necesitar
información sobre posición (GPS) sumada a la imagen,
o en exclusividad. Se explicará en el apartado de
aplicaciones de RA.
2. A través de la toma del apartado uno se produce un
reconocimiento de imagen (Graphics System) que da
lugar a un objeto virtual.
3. Se combina o se modifica, según la aplicación
desarrollada lo virtual como lo real creando un objeto
aumentado.
4. Se muestra a través de un dispositivo monitor el vídeo o
la imagen de realidad aumentada. El modo en la que se
muestre dará lugar a las tres arquitecturas de
dispositivos RA que se comentarán más adelante, tanto
en el apartado de arquitecturas (2.6) como en el de
pantallas transparentes (2.4).
Tal y como se ha hecho mención al comienzo de esta parte del
escrito, el uso de marcadores en esta tecnología es lo más común,
aunque como se explicará en el apartado de aplicaciones (2.7)
existen desarrolladas muchas de ellas como las de
posicionamiento que basan su funcionamiento más en la
información de GPS que en la imagen propia de la realidad que
pueda obtener el dispositivo de entrada.
Otro tipo de tecnología que no necesita de toma de imagen es la
HOE (Holographic optical element), que explicaremos en el
siguiente apartado dentro de pantallas transparentes, cuyas
aplicaciones se conocen como SAR.
2.4 Pantallas transparentes en AR
Las pantallas transparentes son una de las formas de presentar la
imagen aumentada combinación del mundo real con objetos
visuales al usuario.
Existen dos tipos: pantalla de mezcla de imágenes y pantalla
óptica transparente.
El primer tipo de pantalla es la que típicamente se utiliza en los
dispositivos HMD o los dispositivos de mano (Smartphone, iPod,
cascos monitores (2.6)). Con ella los gráficos virtuales se integran
con las muestras visuales reales obtenidas por la
-21-

cámaraactualizando las imágenes finales a través de un sistema de
rastreo continuo.
El segundo tipo de display se basa en la tecnología HOE
(holographic optical element) basado en los hologramas. En este
sistema no existe rastreo ni grabación, sino que el usuario verá
diferentes imágenes dependiendo de la posición que tenga con
respecto la pantalla.
Este sistema se basa en la muestra simultánea de imágenes desde
diferentes ángulos sobre la pantalla HOE. Así son visibles solo
dentro de pequeños ángulos de visión y así el usuario puede ver
mirando hacia el mismo punto diferentes imágenes según la
posición relativa con respecto a él. Si las imágenes seleccionadas
pertenecen a la misma imagen y siguen un orden coherente, se
conseguirá un holograma, tal y como indica la tecnología HOE
holographic optical element. Estas aplicaciones se denominan
también SAR (space augmented reality).
2.5 Tipos de aplicaciones RA
De forma general podríamos dividir las aplicaciones que usan RA
en dos: las que usan marcadores y las que no. Las tecnologías que
no usan marcadores o trackers se valen de GPS o acelerómetros,
brújulas y se denominan track-less.
En la siguiente imagen se podrá ver un ejemplo de un marcador:
Figura 12
Las aplicaciones con marcadores basan su funcionamiento en el
reconocimiento de patrones buscándolos en los distintos
fotogramas que toman de la realidad. Cuando reconoce uno de los
patrones toma su objeto virtual relacionado y hace que se muestre
sobre el marcador.
La aplicación que se desarrolla en Project Glasses de Google es
trackless. Aunque la información que se encuentra de su
desarrollo es limitada, intuimos y asumimos en este trabajo que
hace uso de la información obtenida por el GPS integrado en ella
y de un sistema de reconocimiento de caracteres y de imágenes.
Con esta última se interpretará escritos u objetos que se muestren
a la aplicación y a partir de su interpretación se nos ofrecerá
posibilidades relacionadas.
Del mismo modo que las aplicaciones que hacen uso de
marcadores, a partir de la información obtenida por los periféricos
asociados (lectura de caracteres o GPS por ejemplo) el sistema
mezcla virtual con real. Es de apreciar que al no tener que
procesar imágenes se gasta menos esfuerzo en el microprocesador
pero se antoja más compleja la unión de los elementos añadidos.
Podemos asociar de forma genérica que las aplicaciones trackless
están desarrolladas en dispositivos móviles, mientras que los que
usan marcadores están relacionados aelementos tales como PC´s o
más fijos como lectura delibros (figura 11).
Figura 13
2.6 Arquitecturas RA
La parte que hará diferenciar las tres arquitecturas que puede tener
un dispositivo AR será la forma de mostrar al usuario la imagen
final:
Lentes reflectantes (sistema óptico)
Cascos con monitores (sistema de vídeo)
Monitores (sistema de vídeo)
2.6.1 Lentes reflectantes
En esta arquitectura, los objetos virtuales se sobreponen en la
visión real del mundo a través de una lente. Esta lente transparente
deja pasar del 50% al 30% de la luz real (dependiendo de la
longitud de onda con que la luz incida en ella) y refleja la imagen
del monitor.
Como se puede observar en la imagen, la información añadida a la
imagen real aumentada no se toma de una visualización del
mundo, sino del Head Tracker (rastreador), que aporta
información sobre la posición del usuario. Este rastreador es
importante para generar la imagen 3D y que esta se mueva dando
la sensación de ser fija para el observador.
Figura 14
-22-

2.6.2 Cascos con monitores
A diferencia del anterior la imagen se compone antes de mostrarse
al usuario a través de un monitor.
Figura 15
Aunque en la imagen las flechas hacen pensar que el generador de
objetos añadidos no necesita de imágenes del exterior, se da el
caso en el que a parte del rastreador en el HMD o un sistema GPS,
el generador de imagen necesite de una toma de la realidad, por
ejemplo, para interpretarla y traducirla (marcadores, por ejemplo).
Aunque el uso más común de esta arquitectura usa el
posicionamiento del usuario en el mundo real.
Esta arquitectura es la que se desarrolla en las Google Glasses.
2.6.3 Monitores externos
Figura 16
La última arquitectura de RA que presentamos en este trabajo es
parecida a la anterior, pero sin tener integrado el monitor ni la
cámara de toma de realidad en un casco.
La posición de estos elementos en esta arquitectura es remota.
Su funcionamiento es igual que la anterior: a través de una cámara
se toman imágenes reales que se interpretarán y combinaran para
generar una visión aumentada. Podrá usar o no un elemento de
posicionamiento, tal y como se ha dicho anteriormente, pero en
esta arquitectura es más común que no la necesite. La tecnología
de los marcadores es más típica en esta arquitectura.
2.7 Aplicaciones RA
2.7.1 Sistemas de navegación:
Los famosos sistemas de navegación por GPS han dejado el uso
de los mapas atrás. Estos sistemas han sufrido un gran avance en
los últimos y hoy en día se consideran casi necesarios.
En este campo, la RA podría ser un paso más pudiendo proyectar
directamente los gráficos en nuestro parabrisas añadiendo
información relevante a la misma sobre sitios de interés cercanos
a nuestro camino. La empresa General Motors ya está trabajando
en una aplicación así.
Si pasamos esta idea a un dispositivo móvil y autónomo como un
Smartphone o las gafas Google, podremos ver que el uso en
ambientes no automovilísticos se encuentra más desarrolladas este
tipo de aplicaciones, haciendo de un paseo un posible camino
turístico o un callejero virtual. .
2.7.2 Televisión
Las grandes y costosas escenografías y utilerías podrían ser
remplazadas algún día por esta tecnología de vanguardia,
sustituyendo costosos atrezos en fondos “macros” en los que se
podrá proyectar imágenes 3D con las distintas escenas que se
necesiten.
Obviamente cualquier uso de RA como entretenimiento o valor
añadido de todo tipo, también estará incluido en este ámbito.
2.7.3 Medicina
Figura 17
En este ámbito por ejemplo sería de utilidad que durante una
operación, el doctor pudiera disponer de información útil sobre
anteriores pruebas médicas tales como resonancias, pudiendo
-23-

sobreponerla en el paciente teniendo una mejor idea del problema
médicoque va a tratar. O saber las constantes vitales o parámetros
vitales de los órganos de los pacientes durante la operación sin
tener que apartar su mirada del paciente y sin ayudantes médicos.
2.7.4 Educación
Para explicar la utilidad que la RA puede ofrecer a la educación
usaremos el famoso dicho: una imagen vale más que mil palabras.
Y si es en 3D, mejor.
Tanto en museos como en aulas y libros imágenes aumentadas
en 3d pueden ayudar sobremanera al aprendizaje de los niños.
Figura 18
Además, existen libros llamados “IMagic Books” con marcas de
RA que permiten visualizar una escena completa virtual como si
fuera una obra de teatro en miniatura.
2.7.5 Entretenimiento
En este campo el uso de la realidad aumentada ya esta
ampliamente desarrollada. Empresas como Sony con Eyetoy para
la PS2 a través de una cámara permiten interactuar con el juego.
Nintendo con su 3DS también ha desarrollado juegos en los que a
través de marcadores que el usuario disponía se le añadía un extra
a la realización de misiones que protagonista debía de superar.
Figura 19
Los dispositivos móviles tales como PDAs o Smartphone
también poseen aplicaciones de entretenimiento desarrolladas en
parte por la tecnología RA.
Figura 20
2.7.6 Otras aplicaciones
Entre otras aplicaciones actuales podemos citar:
• Servicios militares y de emergencia (instrucciones, mapas,
localización de enemigos, células de fuego, etc.).
· Publicidad en 3D.
• Visualización de arquitectura (visión virtual de edificios
destruidos o simulación de planes de proyectos de construcción).
-24-

Figura 21
• Visión aumentada: etiquetas o cualquier texto relacionado a
objetos o lugares, reconstruir ruinas, edificios o inclusive paisajes
como eran en el pasado.
• Simulación: simuladores de vuelo y de automóviles (coches,
autobuses, camiones).
• Conferencias con participantes reales y virtuales, trabajo en
conjunto con modelos simulados 3D.
2.7.7 Aplicaciones en dispositivos móviles
Hoy en día las aplicaciones más populares y utilizadas son las que
se ven integradas mediante software como los de google
(Android) o los de Apple.
Se tratará de aplicaciones sin marcadores, con pantalla
transparente de mezcla de imágenes y según su arquitectura, con
monitor externo, el propio dispositivo móvil.
En este apartado elegiremos las cinco mejores según
(REFERENCIA):
Layar: Se creo como navegador especial para RA. La
aplicación permite ir añadiendo capas con información
de la imagen tomada. Existen 312 capas diferentes,
desde una que te permite ver los Tweets más cercanos,
hasta consultas a Wikipedia, o restaurantes cercanos.
Está disponible en Android y es gratuita.
TwittARound: Al igual que una de las capas de Layar,
puedes observar los tweets publicados cerca de tu
posición. Fue desarrollada por Michael Zoellner,alemán.
Está para iPhone y no es gratuita pero tampoco cara,
0.99 $.
Wikitude World Brownser : Aplicación preferida por
Augmented planet para móviles. Persigue al igual que
Wikipedia, llegar a ser la enciclopedia del nuevo siglo.
TAT augmented ID : Ya no es la posición quien es
estudiada, sino la persona a la que haces una fotografía.
A través de ella, la aplicación es capaz de dar datos de
la persona. Criticada porque limita con la privacidad del
individuo.
Yelp Monocle: Sirve para buscar información sobre
locales, comercios restaurantes,…Tiene rasgos de red
social , donde los usuarios puntúan y opinan acerca de
los lugares cercanos a tu posición.
3. RECONOCIMIENTO DE IMÁGENES
3.1 Historia
En la década de los 60, en el MIT se comienza a estudiar la visión
artificial, lo que implicaba no solo captar imágenes a través de una
cámara, sino también la comprensión de lo que estas imágenes
representa.
Desde ese momento se ha ido desarrollando la tecnología, y en los
últimos años este ámbito ha evolucionado mucho, surgiendo
multitud de aplicaciones que utilizan software de reconocimiento
de imágenes.
3.2 Reconocimiento de patrones
Para explicar el reconocimiento de imágenes primeramente se
hace imprescindible a nuestro entender realizar una breve
descripción del reconocimiento de patrones, que es la base en la
que se sustenta el reconocimiento de imágenes.
El objetivo del procesamiento e interpretación de datos sensoriales
es lograr una descripción concisa y representativa del universo
observado. La información de interés incluye nombres,
características detalladas, relacionamientos, modos de
comportamiento, etc. que involucran a los elementos del universo
(objetos, fenómenos, conceptos).
Estos elementos se perciben como patrones y los procesos que
llevan a su comprensión son llamados procesos perceptuales. El
etiquetado (clasificación, asignación de nombres) de esos
elementos es lo que se conoce como reconocimiento de patrones.
Por lo tanto, el reconocimiento de patrones es una herramienta
esencial para la interpretación automática de datos sensoriales.
El sistema nervioso humano recibe aproximadamente 109 bits de
datos sensoriales por segundo y la mayoría de esta información es
adquirida y procesada por el sistema visual. Análogamente, la
mayoría de los datos a ser procesados automáticamente aparecen
en forma de imágenes.
El procesamiento de imágenes de escenas complejas es un
proceso en múltiples niveles, en el que hay dos tipos de
metodologías necesarias:
Reconocimiento de patrones basado en atributos
Reconocimiento de patrones basado en la estructura
3.2.1 Modelo de reconocimiento de patrones
Los procesos perceptuales del ser humano pueden ser modelados
como un sistema de tres estados:
-25-

Adquisición de datos sensoriales
Extracción de características
Toma de decisiones
Por lo tanto es conveniente dividir el problema del
reconocimiento automático de una manera similar:
La figura 22 anterior presenta el esquema básico de un
reconocimiento de patrones
Sensor Su propósito es proporcionar una representación factible
de los elementos del universo a ser clasificados. Es un sub-sistema
crucial ya que determina los límites en el rendimiento de todo el
sistema.
Idealmente uno debería entender completamente las propiedades
físicas que distinguen a los elementos en las diferentes clases y
usar ese conocimiento para diseñar el sensor, de manera que esas
propiedades pudieran ser medidas directamente. En la práctica
frecuentemente esto es imposible porque:
no se dispone de ese conocimiento
muchas propiedades útiles no se pueden medir
directamente (medición no intrusiva)
no es económicamente viable
Extracción de Características Esta etapa se encarga, a partir del
patrón de representación, de extraer la información
discriminatoria eliminando la información redundante e
irrelevante. Su principal propósito es reducir la dimensió del
problema de reconocimiento de patrones.
Clasificador La clasificación trata de asignar las diferentes partes
del vector de características a grupos o clases, basándose en las
características extraídas. En esta etapa se usa lo que se conoce
como aprendizaje automático, cuyo objetivo es desarrollar
técnicas que permitan a las computadoras aprender.Utiliza
habitualmente uno de los siguientes procedimientos:
▪ Geométrico (clustering): Los patrones deben ser
mostradas en gráficas. En éste enfoque se emplea el
cálculo de distancias, geometría de formas, vectores
numéricos, puntos de atracción, etc.
▪ Estadístico: Se basa en la teoría de la probabilidad y la
estadística, utiliza análisis de varianzas, covarianzas,
dispersión, distribución, etc.
Supone que se tiene un conjunto de medidas numéricas con
distribuciones de probabilidad conocidas y a partir de ellas se hace
el reconocimiento.
▪ Sintáctico estructural: se basa en encontrar las
relaciones estructurales que guardan los objetos de
estudio, utilizando la teoría de lenguajes formales, teoría
de autómatas, etc. El objetivo es construir una gramática
que describa la estructura del universo de objetos.
▪ Neuro reticular: se utilizan redes neuronales que se
‘entrenan’ para dar una cierta respuesta ante
determinados valores.
▪ Lógico combinatorio: se basa en la idea de que el
modelado del problema debe ser lo más cercano posible
a la realidad del mismo, sin hacer suposiciones que no
estén fundamentadas. Se utiliza para conjuntos difusos y
utiliza lógica simbólica, circuitos combinacionales y
secuenciales, etc.
Según tengamos constancia o no de un conjunto previo que
permita al sistema aprender, la clasificación puede ser
supervisada, parcialmente supervisada o no supervisada.
a) Clasificación supervisada: muy conocida también como
clasificación con aprendizaje. Está basada en la capacidad de las
áreas de entrenamiento. Éstas son áreas de las que se conoce a
priori la clase a la que pertenecen, y que se utilizarán para generar
una signatura espectral para cada una de las clases. Se denominan
clases informacionales, en contraposición a las clases espectrales
que genera la clasificación no supervisada.
La figura 23 presenta un esquema de esta clasificación:
Algunos métodos de la clasificación supervisada:
Funciones discriminantes: si son dos clases, se busca obtener
una función g tal que para un nuevo objeto O, si g(O) ≥ 0 se
asigna a la clase 1 y en otro caso a la 2. Si son múltiples
clases se busca un conjunto de funciones gi y el nuevo objeto
se ubica en la clase donde la función tome el mayor valor.
Vecino más cercano: un nuevo objeto se ubica en la clase
donde esté el objeto de la muestra original que más se le
parece.
Redes neuronales artificiales: denominadas habitualmente
RNA o en sus siglas en inglés ANN. Se supone que imitan a
las redes neuronales reales en el desarrollo de tareas de
aprendizaje.
b) Clasificación no supervisada: este tipo de clasificación no
utiliza información externa, y realiza un ajuste automático de los
parámetros. Además, se produce una autoorganización de la
información.
La figura 24 presenta un esquema de esta clasificación:
Figura 23
Figura 22
Figura 23
-26-

3.3 Campos de reconocimiento
El reconocimiento de imágenes ha evolucionado a medida que
mejora la tecnología. Puede encontrarse en numerosos campos.
3.3.1 Reconocimiento de caracteres
En los últimos años la digitalización de la información (textos,
imágenes, sonido, etc.) ha devenido un punto de interés para la
sociedad. En el caso concreto de los textos, existen y se generan
continuamente grandes cantidades de información escrita,
tipográfica o manuscrita en todo tipo de soportes. En este
contexto, poder automatizar la introducción de caracteres evitando
la entrada por teclado, implica un importante ahorro de recursos
humanos y un aumento de la productividad, al mismo tiempo que
se mantiene, o hasta se mejora, la calidad de muchos servicios.
El reconocimiento de caracteres engloba un conjunto de métodos
y algoritmos que permiten realizar una fase de entrenamiento que
al final permitirá reconocer de forma automática caracteres. Cabe
recalcar que el reconocimiento de caracteres no solo se utiliza
para reconocimiento de textos escritos, sino que además tiene
muchas otras aplicaciones:
Reconocimiento de texto manuscrito
Reconocimiento de matrículas
Indexación en bases de datos
Reconocimiento de datos estructurados con ROC Zonal
3.3.2 Identificación de personas para investigaciones
policiacas
Aunque las técnicas aun están en desarrollo en este campo, y aun
no existe una aplicación totalmente confiable, es evidente la
importancia del reconocimiento de imágenes para la identificación
de personas en investigaciones policíacas. Muchas veces en
investigaciones de crímenes un testigo puede describir con mucho
detalle el rostro de un criminal. Un dibujante profesional convierte
la descripción verbal del testigo en un dibujo sobre papel. El
trabajo de la computadora consiste en buscar el rostro del criminal
en una base de datos de imágenes. En las investigaciones
policíacas también se utiliza la búsqueda de huellas dactilares en
una base de datos.
3.3.3 Biometría
La biometría es el reconocimiento del cuerpo humano a través de
ciertas características físicas, como el tamaño de los dedos de la
mano, las huellas dactilares o los patrones en las retinas de los
ojos.
Los sistemas de computadoras actuales permiten tener mejores
niveles de seguridad utilizando la biometría. Por ejemplo, una
persona puede tener acceso a un área restringida, por medio del
reconocimiento de las características físicas de su mano en un
dispositivo especial. Si en el proceso de validación se verifica que
la persona tiene permiso para entrar al área, entonces le permitirá
el acceso. Este tipo de sistemas se está volviendo cada vez más
utilizado, desplazando los sistemas antiguos de identificación.
3.4 Reconocimiento de imágenes
3.4.1 Representación de colores en imágenes
digitales
Normalmente, los colores primarios son el rojo, el amarillo y el
azul, y a partir de la mezcla de estos se crean los otros colores. Sin
embargo, en las imágenes digitales los colores primarios son el
rojo (Red), el verde (Green) y el azul (Blue) y se utilizan las
intensidades de luz para obtener nuevos colores. Esto dio lugar al
sistema RGB.
Una imagen digital está compuesta por una matriz bidimensional
de elementos RGB. En imágenes digitales de color verdadero, se
utilizan 8 bits (1 byte) para representar la intensidad de cada
componente o canal de color, y por ser 3 componentes por color,
se necesitan 24 bits (3 bytes) para formar un solo color, lo que es
equivalente a un píxel. Entonces, una imagen de 10 x 10 píxeles
utiliza 2400 bits, o sea, 300 bytes.
Siguiendo el esquema de 1 byte por cada componente o canal, y
sabiendo que el valor máximo que puede ser representado por 1
byte es 255, la intensidad de una canal está en un rango de 0 a
255, por lo que un píxel estará compuesto por tres diferentes
intensidades de R, G y B en un rango de 0 a 255.
En el sistema RGB el blanco es RGB (255, 255, 255) y el negro es
RGB (0, 0, 0), donde cada dato entre paréntesis representa las
intensidades de cada uno de los canales RGB. RGB(255,0,0),
RGB(0,255,0) y RGB(0,0,255) representan el rojo, el verde y el
azul respectivamente. Al mezclar el color rojo con el azul se
obtiene el obtiene el color morado, RGB(255, 0, 255). Se pueden
crear todos los colores disponibles variando las intensidades de las
componentes RGB.
3.4.2 Funcionamiento
La función diferenciaes la base del reconocimiento de imágenes;
indica la distancia entre dos imágenes.
Esta función indica que tan diferentes son dos imágenes. Si el
valor de la función diferencia es cero significa que las imágenes
son idénticas. Entre más grande es el valor de la función,
lasimágenes son más distintas entre si. La mejor imagen será
aquella que dé el menor valor al ser comparada con el cuadro de
la imagen original utilizando la función diferencia. Esta es la parte
más importante del proceso, por lo que en la implementación esta
función debe ser especialmente eficiente.
Existen diversas estrategias para reconocimiento de imágenes
digitales de acuerdo al tipo de aplicación y de los recursos del
sistema.
La manera más directa de comparar la imagen original con una
colección de imágenes, es comparar cada píxel del cuadro de la
imagen original con su correspondiente píxel en la imagen de la
colección imágenes, y acumularlas distancias entre cada pareja de
-27-

píxeles para determinar la distancia general entre las dos
imágenes. Aunque esta es una estrategia relativamente buena para
comparar imágenes, la cantidad de comparaciones necesarias es
muy grande. Por cada comparación debe calcularse la distancia
entre los píxeles de las dos imágenes y por cada pareja de píxeles
debe compararse cada uno de los tres canales RGB.
3.4.2.1 Método lineal
La distancia D entre dos píxeles está dada por:
( ) ( ) ( ) Esta distancia es calculada por cada píxel y por cada canal de
color en lasimágenes comparadas. En la figura 25 se presenta un
pequeño algoritmo de este método:
3.4.2.2 Método cuadrático
Se puede acentuar el efecto de la diferencia de cada píxel
utilizando una diferencia cuadrática o distancia euclidiana.
√( ) ( ) ( )
Este requiere más procesamiento que el método lineal pero es el
más utilizado por la calidad de sus resultados. Puede acentuarse
aun mas la diferencia utilizando diferentes potencias en la
fórmula, pero usualmente no es necesario. En la figura 26 se
presenta un pequeño algoritmo de este método:
Como aclaración, en estos dos métodos presentados asumimos
que las dos imágenes tienen las mismas dimensiones y que cada
píxel esta compuesto por tres canales de color RGB.
3.4.3 Programas
3.4.3.1 Google goggles
Google Goggles es un servicio de Google disponible para Android
e iPhone que permite reconocer cualquier objeto mediante fotos
realizadas con un móvil y devolver resultados de búsqueda e
información relacionada.
Actualmente este sistema reconoce:
Lugares
Obras de arte
Logotipos
Monumentos
Texto
Vinos
Revistas
Libros
Funcionamiento
Busca haciendo una foto: apunta con la cámara de tu móvil a un
cuadro, un lugar famoso, un código de barras o QR, un producto,
un logotipo o una imagen popular. Si Google lo encuentra en su
base de datos, te ofrecerá información útil. Goggles puede
reconocer texto en francés, inglés, italiano, español, portugués,
turco y ruso, y puede traducirlo a otros idiomas. Goggles también
sirve como escáner de códigos de barras y QR.
Incluso, si localiza en un lugar destacado mediante el GPS puede
devolver información sobre el lugar. También dispone de
traducción automática de texto en diversos idiomas a partir de una
foto tomada en tiempo real, reconoce textos en inglés, francés,
italiano, alemán y español, aunque la traducción está habilitada
para todos los idiomas que soporta Google Translate.
Al igual que la tecnología de reconocimiento de voz y la
traducción automática, el reconocimiento de imágenes funciona
mediante el aprendizaje automatizado basado en ejemplos. La
web tiene una infinidad de imágenes de distintas cosas, y la
mayoría cuenta con información acerca de lo que se puede ver en
la imagen. Por otro lado, mientras más popular sea algo, más
imágenes habrá en la web y existirá una mayor probabilidad de
que el algoritmo las reconozca.
Debido a la privacidad tan extrema del funcionamiento de esta
aplicación por parte de Google, para explicarla remitimos
Figura 24
Figura 25
Figura 27
-28-

directamente a una conferencia realizada por su director de
investigación:
Les explicaré brevemente cómo funciona el reconocimiento de
imágenes: todo comienza identificando puntos de interés en una
imagen – los puntos, líneas y patrones que contrastan o hacen
sobresalir a algo del fondo de la imagen. Funciona de forma
similar al modo en que el ojo humano identifica los contornos
mediante el contraste que generan con el fondo.
Lo siguiente es identificar cómo estos puntos se relacionan entre
sí – la geometría de los puntos en conjunto. Lo podemos imaginar
como una constelación de estrellas, solo que en este caso el
modelo matemático que analiza estos puntos y su relación es
mucho más compleja.
Por último, el sistema compara ese modelo con otros modelos
dentro de una enorme base de datos. Esos otros modelos
provienen de imágenes en la web que ya fueron analizadas.
Entonces, busca y coteja la base de datos en busca de un modelo
con el que corresponda, sin que sea necesario que
empalmeperfectamente. De hecho, es importante que el sistema
sea flexible, para que no importe tanto si la imagen está volteada,
reducida o ligeramente torcida – tomando en cuenta que
diferentes fotos de un mismo objeto serán distintas. Por ejemplo,
el Taj Mahal seguirá teniendo la misma geometría básica, sin
importar que lo hayan fotografiado desde ángulos ligeramente
distintos. Cuando Google detecta al modelo que mejor
corresponde con la imagen, puede adivinar que probablemente se
trate del Taj Mahal.
El asunto de hacer “una pregunta” que en realidad es solo una
imagen resulta algo profundo. Hemos ido más allá de las
búsquedas basadas en sólo una cadena de texto. Ahora, pueden
presentarle una imagen a Google y esperar obtener información
relevante al respecto, pero, ¿cuál es la mejor respuesta a una
pregunta que es solo una imagen? Por ahora, podemos relacionar
imágenes con texto, sin embargo existe mucho que hacer para
entender el verdadero significado que una imagen puede tener. Es
ahí donde nuestra investigación en temas de inteligencia artificial
pudiera ayudarnos.
(Peter Norvig, Director de Investigación en Google)
3.4.3.2 Blinkster
Blinkster es una aplicación móvil gratuita y fácil de usar para
explorar y descubrir contenido cultural. Blinkster utiliza imágenes
tomadas desde un dispositivo móvil para buscar en bases de datos
con información de instituciones, aficionados y expertos sobre la
obras de arte.
Blinkster utiliza una pequeña aplicación en el teléfono para llamar
a sus servidores y mostrar el contenido en formatos de fácil
navegar por las listas.Los resultados muestran información sobre
pinturas, esculturas, monumentos y proponen nuevos lugares para
ir a ver, obras de arte e itinerarios por descubrir.
4. RECONOCIMIENTO DE VOZ
4.1 Introducción
Dentro de los procesos tecnológicos que se buscan para el
mejoramiento de las rutinas y tareas del hombre se encuentra el
reconocimiento de la voz, una de las principales herramientas para
la comunicación con la civilización, que comprende nuestro
lenguaje y lo procesa para así determinar el mensaje. En los
avances científicos está el hecho de que los sistemas actuales
puedan, por medio de métodos matemáticos, identificar ese
mensaje para desarrollar sus tareas programadas. Es el caso del
proceso de reconocimiento de la voz por patrones utilizando una
RED NEURONAL ARTIFICIAL que nos permita identificar el
lenguaje. Una vez identificado el lenguaje, extraeremos
información de dicho conjunto de datos y lo transformaremos en
una estructura comprensible, para su uso posterior.
Dado que como hemos mencionado en el párrafo anterior, nuestro
objetivo no es sólo el reconocimiento de la voz, sino que una vez
descifrado el lenguaje querremos utilizar esos datos de entrada
para su posterior uso, haremos acopio de dos herramientas de la
Inteligencia Artificial:
- Aprendizaje inductivo supervisado mediante Redes
Neuronales.
- Minería de datos (para el caso de detección de
canciones).
4.2 ¿Qué es un sistema de reconocimiento de
voz?
El reconocimiento de voz generalmente es utilizado como una
interfaz entre humano y computadora para algún software.
Debe cumplir tres tareas:
Pre-procesamiento: convierte la entrada de voz a una forma
que el reconocedor pueda procesar.
Reconocimiento: identifica lo que se dijo (traducción de
señal a texto).
Comunicación: envía lo reconocido al sistema que lo
requiere.
La aplicación de reconocimiento de voz consta con los
siguientes componentes:
Existe una comunicación bilateral en aplicaciones, en las que la
interfaz de voz está íntimamente relacionada al resto de la
aplicación. Éstas pueden guiar al reconocedor especificando las
palabras o estructuras que el sistema puede utilizar.
Figura 28
-29-

4.3 Funcionamiento Sistema de
Reconocimiento de Voz
El reconocimiento automático del habla es una tarea muy
compleja, sobre la que influyen varios factores:
- Dependencia/independencia del locutor
- Palabras aisladas/conectadas/habla continua
- Tamaño del vocabulario
- Grado de confusión del vocabulario
- Gramática
Además, deben hacer frente a los siguientes problemas:
- Variabilidad lingüística: fonética, sintaxis,
semántica…
- Variabilidad del usuario: ritmo, pronunciación,
inflexión, fatiga…
- Variabilidad del canal: ruido, cambios en el medio
de transmisión…
- Co-articulación: contexto de los fonemas
Para superar estos problemas, los sistemas de reconocimiento de
voz incluyen tres procesos:
1. Extracción de índices acústicos de la señal hablada.
2. Estimación de la probabilidad de que la cadena
índice fuese originada por un hipotético segmento
de pronunciación.
3. Determinación de la pronunciación reconocida a
través de una búsqueda entre hipotéticas
alternativas.
La estimación de la probabilidad de una cadena índice incluye un
modelo de producción de índices por cada determinado segmento
de pronunciación, por ejemplo una palabra. Los modelos ocultos
de Markov se utilizan para este propósito (figura 29). El sistema
de reconocimiento desea encontrar la pronunciación más probable
que podría originar el índice acústico observado. Esa probabilidad
es el producto de dos factores: la probabilidad de que la
pronunciación producirá la cadena y la probabilidad de que el
hablante querrá producir la pronunciación (la probabilidad del
modelo de lenguaje).
El entrenamiento de un sistema de reconocimiento de voz consiste
en la lectura de un texto que proporciona al sistema no sólo un
vocabulario más o menos extenso, sino un modelo de
pronunciación. Terminada esta primera fase de lectura, entra en
funcionamiento el entrenamiento de la red neuronal y la
construcción del mencionado modelo oculto de Markov. Por
último, el programa desarrollará un modelo gramatical para las
secuencias de fonemas registradas.
Es cierto que a mayor entrenamiento del sistema (tanto en la
opción inicial como durante el posterior uso del programa) se
comprueba una disminución clara en el índice de errores.
4.4 Funcionamiento para reconocimiento de
canciones
Nuestra aplicación, deberá detectar e identificar patrones en
sonidos basándonos en métodos de IA y algoritmos que ya se
utilizan pero modificados para adaptarlos a nuestras necesidades,
en nuestro caso, identificar un sonido concreto para actuar en
consecuencia.
Para poder realizar este tipo de aplicaciones llevaremos a cabo
una serie de técnicas y métodos sobre una representación del
sonido a procesar, el espectrograma:
En la figura 30 se puede observar el espectrograma generado por
la señal que aparece en la imagen de abajo. El espectrograma se
representa mediante la frecuencia (eje y), el tiempo (eje x) y la
intensidad de la señal (representado por el color, más claro más
intensidad).
Las técnicas de análisis mediante algoritmos habituales de IA son
la combinación de diferentes resultados de procesar el
espectrograma mediante Redes neuronales (percepción multicapa
entrenado con backpropagation).
Para la clasificación mediante redes neuronales hemos decidido
utilizar un MLP (perceptrón multicapa) el cual se entrena
mediante la regla Backpropagation. Los datos utilizados para el
entrenamiento son la representación vectorizada del
espectrograma centrado en la zona más relevante. La principal
ventaja de utilizar una red neuronal para nuestro clasificador
consiste en la rapidez de respuesta.
Por último, en el caso de utilizar el reconocimiento de voz para
buscar, por ejemplo, una canción, utilizaremos el siguiente
algoritmo. Obtendremos una tabla “hash” en la cual se relacionan
los picos de frecuencia con los intervalos de tiempo en los que se
producen, datos sacados del espectrograma. Con esta información
correlacionaremos una nueva entrada con una serie de plantillas
de otros espectros, obteniendo así un resultado.
Figura 29
Figura 30
-30-

Un problema podría ser que si se recibe un intervalo de la canción
que no coincide con el hash que tenemos en nuestras bases de
datos la canción no es detectada. Sin embargo nuestro sistema, al
utilizar técnicas predictivas, puede generalizar el patrón recibido
para así correlacionarlo con alguna de nuestras entradas de la base
de datos, es decir, nos devolverá el sonido “que más se parezca”.
5. Redes Neuronales: Perceptrón Multicapa
con entrenamiento en backpropagation.
Una red neuronal es un procesador que recibe una serie de
entradas con pesos diferentes, las procesa y proporciona una
salida única. Se trata de una forma de conocimiento inductivo, en
la que se busca que el sistema pueda, automáticamente, conseguir
los conocimientos necesarios a partir de ejemplos reales sobre la
tarea que se desea modelar.
La red neuronal más simple consta de una única capa o nivel,
pudiendo estar formada por tantas como se desee y en donde las
salidas de una capa están conectadas a las entradas de la siguiente.
Los pesos son propios de cada neurona, y no se está obligado a
tener todas las conexiones.
En un sentido amplio, una red neuronal, como la que observamos
en la figura 31, consta de tres elementos principales:
1. Topología: cómo está una red neuronal organizada en
capas y cómo se conectan estas capas.
2. Aprendizaje: cómo se almacena la información en la
red.
3. Recuperación: cómo esta información almacenada en la
red puede recuperarse.
El objeto de este trabajo es el proceso de aprendizaje, por lo que
nos centraremos en él.
En una red neuronal el proceso de aprendizaje es supervisado. Es
un caso de entrenamiento. Se presentan dos vectores (entrada y
salida deseada). La salida computada por la red se compara con la
salida deseada, y los pesos de la red se modifican en el sentido de
reducir el error cometido. Se repite iterativamente, hasta que la
diferencia entre salida computada y deseada se hace
aceptablemente pequeña.
Utilizaremos un aprendizaje basado en Corrección de Error.
Este tipo de aprendizaje ajusta los pesos de conexión entre
neuronas en proporción a la diferencia entre los valores deseados
y computados para cada neurona de la capa de salida.
Dependiendo del número de capas de la red podemos distinguir
dos casos:
a) Red de dos capas: puede capturar mapeos lineales entre
las entradas y las salidas.
b) Red multicapa: puede capturar mapeos no lineales
entre las entradas y las salidas. Este modelo se compone
de:
- Capa de entrada: sólo se encarga de recibir las
señales de entrada y propagarlas a la siguiente
capa.
- Capa de salida: proporciona al exterior la
respuesta de la red para cada patrón de entrada.
- Capas ocultas: realizan un procesamiento no lineal
de los datos de entrada.
La propagación de los patrones de entrada en el
perceptrón multicapa define una relación entre las
variables de entrada y variables de salida de la red. Esta
relación se obtiene propagando hacia delante los valores
de entrada. Cada neurona de la red procesa la
información recibida por sus entradas y produce una
respuesta o activación que se propaga, a través de las
conexiones correspondientes, a las neuronas de la
siguiente capa.
El entrenamiento en redes con capas ocultas se realiza a
través del método de “backpropagation”. Éste consiste
en:
- Empezar con unos pesos sinápticos cualquiera
(generalmente elegidos al azar).
- Introducir unos datos de entrada (en la capa de
entradas) elegidos al azar entre los datos de entrada
que se van a usar para el entrenamiento.
- Dejar que la red genere un vector de datos de salida
(propagación hacia delante).
- Comparar la salida generada por la red con la salida
deseada.
- La diferencia obtenida entre la salida generada y la
deseada (denominada error) se usa para ajustar los
pesos sinápticos de las neuronas de la capa de
salidas.
- El error se propaga hacia atrás (back-propagation),
hacia la capa de neuronas anterior, y se usa para
ajustar los pesos sinápticos en esta capa.
- Se continúa propagando el error hacia atrás y
ajustando los pesos hasta que se alcance la capa de
entradas.
Figura 31
Figura 32
-31-

Este proceso se repetirá con los diferentes datos de
entrenamiento.
6. REFERENCES
[1] http://www.fayerwayer.com/2012/06/google-entrega-mas-
detalles-sobre-google-glass-y-anuncia-su-salida-para-2013/
[2] http://156.35.151.9/~smi/5tm/10trabajos-
teoricos/5/RealidadAumentada_archivos/frame.html
[3] http://www.extremetech.com/extreme/131877-ive-seen-the-
future-hands-on-with-google-glass
[4] http://blogdigitalsignage.com/2012/07/27/realidad-
aumentada-con-pantallas-transparentes-kinect/
[5] http://www.xataka.com/otros/google-glass-explorer-edition
[6] Daniel Abril Redondo, Realidad Aumentada.Universidad
Carlos III de Madrid, Leganésm
[7] Rubén Fernández Santiago, David González, Gutiérrez, Saúl
Remis García, Realidad Aumentada. Escuela Politécnica de
Ingeniería de Gijón, Universidad de Oviedo,
[email protected]; [email protected];
[8] http://tecnologiayproductosgoogle.blogspot.com.es/2011/11/l
a-tecnologia-de-reconocimiento-de.html
[9] http://psicologiapercepcion.blogspot.com.es/p/percepcion-
facial.html
[10] Luis Feijoo, Aplicaciónparareconocimiento de caracteres a
través de redesneuronales. Loja –Av.Paltas y EstadosUnidos
[11] Cristina Díaz Moreno. Clasificación no supervisada:
clustering y mapas autoorganizativos. 50webs.com
[12] José Luis Alba, Jesús Cid. Reconocimiento de patrones.
Universidad de Vigo y Universidad Carlos III de Madrid
[13] Gustavo A. Lara Rodríguez. Técnicas de reconocimiento de
imágenes para la creación de fotomosaicos. Universidad de
Guatemala, 2003
[14] J. Kittler. Reconocimiento de patrones. Universidad de
Sirrey, 2002
[15] http://ict.udlap.mx/people/ingrid/Clases/IS412/index.html
[16] http://www.buenastareas.com/ensayos/Reconocimiento-De-
Voz/3973305.html
[17] http://www.conganat.org/3congreso/cvhap/conferencias/006/
texto.htm#funcionam
[18] http://perso.wanadoo.es/alimanya/backprop.htm
[19] Jesu Bernal Bermúdez, Jesús Bobadilla Sancho, Pedro
Gómez Vilda, Reconocimiento de voz y fonética acústica.
[20] Deller, Proakis y Hansen: Discrete Time Processing of
Speech Signals.
[21] J. C. Junqua: Robust Speech Recognition in Embedded
Systems and PC Applications.
-32-

Diseño e implementación de jugador virtual de Mentiroso
David Sandoval Ingeniería de Telecomunicación Universidad Calos III de Madrid [email protected]
Juan Antonio Fernández de Alba Ingeniería de Telecomunicación Universidad Carlos III de Madrid [email protected]
RESUMENEn este documento se detalla el diseño y la implementación de
un jugador virtual del conocido juego de cartas “Mentiroso”. Se
analizará en detalle las técnicas y algoritmos utilizados en dicho
diseño para dotar de capacidad de aprendizaje y decisión al
jugador virtual.
Categorías y descripcionesJava [Lenguaje de programación].
Términos generalesÁrboles de decisión, algoritmo de decisión, capacidad de
aprendizaje de la experiencia.
Palabras clavePartida, ronda, jugador virtual, jugador humano, levantar cartas,
echar cartas, credibilidad, mentir, cartas verdaderas y cartas
falsas.
1. INTRODUCCIÓNEl juego del “Mentiroso” se suele jugar con la baraja española y
nuestra implementación está basada en ese tipo de baraja.
Aunque también se podría jugar con la baraja francesa, en cuyo
caso el diseño sería muy parecido, sólo habría pequeñas
diferencias en la implementación.
El número de jugadores preferiblemente suele ser mayor de tres,
ya que con sólo dos jugadores conoces las cartas de tu
adversario. Se reparten todas las cartas de la baraja y el objetivo
del juego consiste en deshacerte de todas las cartas lo antes
posible. El jugador que lo consigue primero gana la partida.
El jugador que inicia la partida echa las cartas que quiere boca
abajo, diciendo el número de cartas que echa y del tipo que son.
Los diferentes tipos son: ases, doses, treses, cuatros, cincos,
seises, sietes, sotas, caballos y reyes. Por ejemplo: echo dos
caballos. El siguiente jugador debe decidir entre levantar las
cartas o echar más cartas del tipo al que se está jugando. El
turno va pasando de un jugador a otro cíclicamente hasta que
uno de ellos decide levantar las cartas.
En el momento que se levantan las cartas, se levantan
únicamente las del último jugador y se realiza la comprobación.
Si las cartas son las que dice haber echado, el jugador que ha
levantado se lleva todas las cartas del montón y comienza una
nueva ronda. En caso contrario, las cartas no son las que dice
haber echado, el jugador anterior se lleva las cartas del montón y
empieza la siguiente ronda. El jugador que empieza la ronda,
igual que al principio de la partida, es el que decide el tipo de
carta el que se va a jugar.
Como bien indica su nombre, el juego consiste en no decir
siempre la verdad. Es decir, decir que echas dos caballos
cuando en realidad estás echando un dos y una sota.
La dificultad del jugador virtual de “Mentiroso” radica en
atribuir a una máquina o computadora una característica propia
de los seres humanos como es mentir. Por ello podemos
definirlo como un problema de Inteligencia Artificial.
Otra capacidad que se le pide a nuestro jugador virtual o
inteligente es que sea capaz de aprender de la experiencia
pasada. Esto es, tratar de predecir el comportamiento del jugador
que está antes de él en base a los resultados de jugadas pasadas.
De este modo, levantará las cartas cuando piense que miente y
no lo hará cuando piense que dice la verdad.
Si un jugador tiene las cuatro cartas de un mismo tipo, por ej:
los cuatro reyes, se puede descartas de ellas. El descarte consiste
en desprenderte de las cartas. Éstas pasan a un montón a parte y
ya no forman parte del juego en lo que resta de partida.
2. ÁRBOLES DE DECISIÓNComo en la mayoría de los juegos, en el caso del Mentiroso los
movimientos o acciones del jugador virtual no aseguran por si
solos la victoria, hay que tener en cuenta los movimientos de los
rivales. Esto es, debemos ejecutar acciones que maximicen
nuestro beneficio (ganar) pero a la vez minimizando el del
contrario (que el contrario no gane).
Los árboles de decisión ayudan al jugador virtual a elegir las
acciones a ejecutar dentro de un conjunto predefinido. Estas
acciones son:
Elegir el tipo de carta a la que se juega cuando es él el
que comienza la ronda.
Decidir entre levantar las cartas o echar más cartas.
Si decide echar carta decidir si miente o no y cuántas
cartas echa.
En el caso de elegir entre levantar las cartas o echar más cartas y
en el de si mentir o no y cuántas cartas echar, las decisiones son
aleatorias. Basándonos en nuestra propia experiencia, hemos
diseñado estas decisiones para que unas sean más probables que
otras. Más adelante analizaremos en detalle cada uno de
algoritmos. Por el contrario, la decisión de qué tipo de carta
escoger al principio de la ronda es una decisión determinista.
-33-

2.1 Árbol de decisión de jugador virtual El jugador virtual toma distintas decisiones dependiendo de si es
él quien comienza la ronda o si ya está empezada.
Algoritmo de selección de carta cuando
empiezas ronda Cuando el jugador virtual comienza la ronda y después de haber
elegido a qué se juega, decide si en su primer turno miente o no.
Algoritmo para echar carta falsa Una vez que el jugador virtual he decidido que va a mentir, ya
sea cuando comienza la ronda o cuando está empezada, debe
decidir si echa una o dos cartas.
Inicio
Clasifica
cartas
Descarte
Empieza
ronda?
Elige a qué
se juega
Algoritmo
selección
jugada
Algoritmo
selección carta
cuando empiezas
Si No
Echar 1 carta
verdad min=nº cartas
del tipo que
menos tengo
Mentimos?
Inicio
Si No
Algoritmo echar
carta falsa
Echa esa
carta
Suma
minimos=1
?
Credibili
dad?
min=1? Min=1?
Echa 1
carta suelta
Echa carta
(rompo
pareja) Echa 2
sueltas
distintas
Echa 2
cartas
iguales
Si No
Si, echa
2 cartas No, echa
1 carta
Inicio
-34-

Algoritmo selección de jugada cuando no
empiezas ronda En el caso de que el jugador virtual no empiece la ronda, debe
decidir si levanta las cartas del jugador anterior o echa más
cartas. Si opta por echar cartas, debe decidir si miente o no.
Además en ambos casos debe decidir cuántas echa.
2.2 Árbol de decisión de jugador humano A pesar de que no es el objetivo del presente documento, el
siguiente árbol de decisión muestra las acciones que realiza un
jugador humano. Éstas son: elegir a qué se juega si comienza la
ronda, elegir si levanta las cartas o echa más y decidir que cartas
echa (este caso no se diferencia entre si miente o no, es su
propia elección).
3. CAPACIDAD DE APRENDIZAJEComo mencionamos en la introducción, el jugador virtual debe
ser capaz de aprender de la experiencia. Para implementar esta
característica, debemos almacenar datos sobre la credibilidad de
los jugadores. Esta credibilidad estará inicializada a un valor por
defecto. Cuando se levantan las cartas y se ha mentido, la
credibilidad de ese jugador disminuye y si no ha mentido
aumenta. Además para tener información de cuándo cada
jugador suele mentir, guardamos un valor de credibilidad por
cada turno.
4. DISEÑO DEL JUGADOR VIRTUALPara decidir qué acción ejecutar en cada momento de la partida
debemos recorrer el árbol de decisión. Dentro del árbol hay
decisiones deterministas (por ej: ¿empiezas la ronda?) y otras
aleatorias (por ej: ¿levantas las cartas del jugador anterior?).
Algoritmo de selección mentir o no cuando
empiezas ronda Cuando un jugador empieza la ronda, debe elegir el tipo de carta
a la que se va a jugar en esa ronda. Para maximizar su beneficio
el jugador escogerá el tipo de carta del que tenga mayor número.
En caso de que tenga varios tipos con un número máximo de
Inicio
Hay cartas a
qué se juega?
Miento?
Levantas?
Verdad?
1 o varias
cartas
verdaderas?
Hay cartas a
qué se juega?
Contrario
lleva cartas
Algoritmo
echar carta
falsa
Echa resto
cartas verdad
Echa 1 carta
verdad
Te llevas
cartas
Si
Si No
No
No Si
Si
No
No Si
Inicio
Empieza
ronda?
Levantas? Elige a qué
se juega
Echa cartas
Echa cartas
Si
Si
Verdad?
Te llevas
cartas
Contrario
lleva
cartas
No
No
No
Si
-35-

cartas, la elección de uno u otro es irrelevante. Esta es una
decisión determinista.
Una vez que ha elegido el tipo tiene que echar cartas y debe
decidir entre mentir en el primer turno o echar cartas verdaderas
del tipo. Esta decisión será aleatoria.
Si mentimos (echamos cartas que no son del tipo) y el siguiente
jugador levanta las cartas, nos las llevaremos y volveremos a
tener el turno. Por tanto, la lógica indica que es rentable mentir
en el primer turno porque el riesgo que corremos es nulo y
podemos desprendernos de cartas sueltas que no nos hacen
mucho juego.
Como el número de cartas que hay en juego es cero, el único
factor que influirá en la decisión será la credibilidad que
tengamos en la primera ronda. El siguiente método ilustra la
decisión. Podemos ver que ésta es aleatoria por que utilizamos
un número aleatorio.
public boolean miente_no_riesgo(int numero_jugada,double
random){
return random>1-credibilidad[numero_jugada];
}
Algoritmo de selección mentir o no cuando no
empiezas ronda Ahora nos encontramos en una situación distinta al caso anterior
porque no es el primer turno de la ronda. Hay cartas en juego,
por tanto si mentimos y nos levantan las cartas nos las vamos a
llevar. Por tanto, el número de cartas en juego va a condicionar
nuestra decisión de mentir. La lógica nos recomienda que si hay
muchas cartas, riesgo alto, no deberíamos mentir.
Para modelar la decisión de no mentir utilizamos la siguiente
función de probabilidad en función del número de cartas en
juego y de nuestra credibilidad. La gráfica muestra la función de
probabilidad sin tener en cuenta la credibilidad.
De esta manera, cuando hay pocas cartas siempre decidimos
mentir, cuando hay muchas nunca mentimos y en un punto
intermedio tomamos una decisión en función del número de
cartas en juego y de nuestra credibilidad. En este último caso la
decisión que tomamos es aleatoria, mientras que en los otros es
determinista.
Algoritmo para echar carta falsa Una vez que el jugador virtual toma la decisión de mentir debe
decidir las cartas que va a echar. La lógica nos dice que a la hora
de mentir tenemos que echar las cartas que tenemos sueltas, las
del tipo que sólo tenemos una. Entonces lo primero que vemos
es cuántos tipos de cartas tenemos con una sola carta. Si sólo
tenemos un tipo echamos esa carta.
Si éste no es el caso, comprobamos la credibilidad que tenemos
con el algoritmo de selección de mentir o no cuando empiezas
ronda. Si tenemos poca credibilidad es más lógico echar una
sola carta falsa para no levantar sospechas en el rival y si nuestra
credibilidad es alta echar dos cartas falsas. Descartamos echar
más de dos cartas falsas cuando mentimos porque esto sería muy
sospechoso.
Algoritmo de selección de levantar o no las
cartas. En cada turno distinto del primer turno de la ronda el jugador
debe decidir entre levantar las cartas del rival anterior o no. En
caso de que no levantemos las cartas del rival anterior estamos
obligados a echar cartas. La estrategia que hemos elegido es
comprobar si tenemos cartas del tipo al que se juega, y en
función de si las tenemos o no, tomar una decisión.
Si tenemos cartas del tipo al que se juega la decisión más lógica
que tomaría un jugador humano sería no levantar las cartas del
rival porque él tiene cartas del tipo que quiere quitarse sin
necesidad de mentir. Por el contrario, si no tenemos cartas del
tipo al que se juega sabemos que en todos los turnos de la ronda
estaremos obligados a mentir. De modo que la tendencia será
levantar las cartas lo antes posible para evitar que el riesgo
crezca y nos descubran la mentira cuando hay muchas cartas en
juego.
Para modelar la decisión de levantar o no las cartas del rival
tendremos en cuenta el número de cartas en juego y la
credibilidad del rival anterior. La siguiente gráfica nuestra la
probabilidad de levantar las cartas en función únicamente del
número de cartas en juego. La idea es que cuando hay pocas
cartas en juego aunque no tengamos cartas del tipo al que se
juega decidamos no levantar y mentir. Si hay muchas cartas
querremos destapar pero deberíamos tener en cuenta datos sobre
la credibilidad del rival en esa ronda. Para el caso intermedio, la
decisión está condicionada por el número de cartas en juego y
deberíamos introducir información sobre la credibilidad del
rival.
-36-

Los condicionantes que hemos mencionado antes, la
credibilidad del rival, están incluidos en la siguiente función de
probabilidad. Vemos que cuando hay pocas cartas la decisión es
determinista, mientras que cuando hay más de 3 es aleatoria.
Algoritmo de tirar cartas verdaderas En el caso de que tengamos cartas del tipo al que se está
jugando, bien porque nosotros hayamos elegido a qué se juega o
lo haya elegido otro jugador, y decidimos no mentir y echar
cartas verdaderas, la pregunta es ¿cuántas cartas echo?
Si tengo varias cartas del tipo al que se juega y las echo todas en
el primer turno, no me quedarán más cartas para los siguientes
turnos y estaré obligado a mentir. Tampoco es una buena
estrategia mentir o echar pocas cartas del tipo durante varios
turnos porque otro jugador puede levantar las cartas y cambiar el
tipo, quedándonos con las cartas sin habernos desprendido de
ellas.
La estrategia óptima y que normalmente adoptamos los humanos
a la hora de jugar es: en el primer turno echamos una carta y en
el siguiente turno echaremos el resto de cartas verdaderas.
También podría ser válido que tengamos cartas del tipo pero que
en el primer turno decidamos mentir.
La siguiente función de probabilidad modela la decisión de
cuántas cartas verdaderas echar. Si hay pocas cartas en juego
echamos sólo una carta verdadera. Si hay muchas echamos el
resto de cartas verdaderas y en una situación intermedia
tomamos una decisión aleatoria en función del número de cartas.
La gráfica muestra la probabilidad de echar una o todas las
cartas cuando hay más de 5 cartas y menos 15 cartas en juego.
Probabilidad igual a 1 significa que echamos todas las cartas
verdaderas y probabilidad igual a 0 que sólo echamos una.
5. IMPLEMENTACIÓN DEL JUGADOR
VIRTUAL La implementación del jugador virtual de “Mentiroso” ha sido
realizada en el lenguaje de programación Java utilizando tres
clases:
Clase Jugador: que principalmente implementa la
funcionalidad del jugador virtual, aunque también la
del jugador humano.
Clase Partida: que implementa el método principal
llamado Juego().
Clase Mentiroso: en esta clase está incluido el método
main().
5.1 Clase Jugador La clase Jugador implementa la funcionalidad tanto del jugador
virtual como de los jugadores humanos proveyendo distintos
métodos dependiendo del tipo de jugador.
5.1.1 Atributos Los atributos almacenan información relevante de cada jugador.
Las decisiones tomadas por nuestro jugador máquina se basará
en ellos.
5.1.1.1 identi El atributo identi es un entero que representa unívocamente el
número de jugador que tiene asignado cada jugador dentro de la
partida. Es imprescindible para saber en cada momento a quien
le corresponde el turno dentro de la partida.
5.1.1.2 cartas El atributo cartas es un vector o array de enteros con 10
posiciones. Representa las cartas que tiene cada jugador en cada
momento. La forma de representar las cartas es almacenando el
número de cartas de cada tipo en la posición que representa
dicho tipo. Por ej: si tenemos dos reyes, almacenamos un 2 en la
posición 10 del vector.
Cartas debe ser un reflejo fiel de la situación del jugador en todo
momento. Por tanto, debemos modificarle cuando el jugador
echa cartas, se lleva las cartas después de que el siguiente rival
las haya levantado o cuando se descarta de algún tipo.
5.1.1.3 cartas_en_mano cartas_en_mano es un entero que representa el número de cartas
de que cada jugador tiene. Gracias a él cada jugador sabe de
manera rápida y fácil cuántas cartas tiene sin necesidad de tener
que recorrer el vector de cartas. La principal aplicación es avisar
a un jugador, cuando su valor es 0, de que el rival anterior se ha
quedado sin cartas y debe levantarlas para evitar que gane.
5.1.1.4 credibilidad credibilidad es un vector de números reales con 10 posiciones
donde almacenamos la credibilidad o factor de confianza de
cada jugador en cada una de los turnos. Por defecto, estará
inicializado a 0.7 para todos los turnos. Su valor aumentará o
disminuirá en función de si nos descubren diciendo la verdad o
mintiendo respectivamente.
Este atributo es muy importante porque va a influir en muchas
de las decisiones que el jugador virtual debe tomar. Además es
la forma que éste tiene de adquirir conocimientos (aprendizaje).
-37-

5.1.2 Métodos Los métodos de la clase Jugador implementan las principales
acciones y decisiones, aunque algunos de ellos sirven de soporte
a otros.
5.1.2.1 descarte descarte es el método que realiza los descartes, valga la
redundancia. Comprueba si en el vector cartas existe algún tipo
con 4 cartas. Si se da el caso, elimina todas las cartas del tipo y
actualiza el atributo cartas_en_mano.
5.1.2.2 cartaMax El método cartaMax sirve de soporte para métodos como el de
elegir el tipo de carta a la que se va a jugar. Devuelve el número
correspondiente al tipo de carta del que tenemos un mayor
número. Si tenemos varios tipos con un número máximo de
cartas escoge el primero que se encuentra porque es irrelevante
cual de ellos elegir.
5.1.2.3 miente_no_riesgo Implementa el algoritmo de selección de mentir o no cuando se
empieza la ronda. En el primer turno de la ronda no hay cartas
en juego, por tanto, el riesgo que corremos si mentimos y nos
levantan las cartas es nulo. De ahí que para tomar esta decisión
sólo se tenga en cuenta nuestra credibilidad para el primer turno.
Devuelve un boolean: true mentir, false no mentir.
5.1.2.4 miente_riesgo Implementa el algoritmo de selección de mentir o no cuando no
se empieza ronda. En este caso hay cartas en juego por lo que
para tomar la decisión debemos tener en cuenta tanto
credibilidad como el número de cartas en juego.
5.1.2.5 cartasMin cartasMin es un método que ofrece soporte al método
tirarCartaFalsa. Comprueba en el vector cartas qué tipos tienen
un valor mínimo de cartas (distinto de 0 claro está) y devuelve
un vector de 10 posiciones en el que pone el dicho número
mínimo en la posición correspondiente a los tipos que lo tienen.
Explicado de otra manera, nos dice cuales son los tipos que
tienen menor número de cartas.
5.1.2.6 tirarCartaFalsa Este método implementa el algoritmo para echar carta falsa. El
objetivo es que cuando eche cartas falsas, éstas sean las que peor
juego me hacen. Todo jugador quiere tener todas sus cartas
emparejadas, esto es, no quiere tener tipos con una sola carta.
De modo que si el jugador ha decidido mentir y tiene una única
carta sin emparejar, la va a echar. En cualquier otro caso,
decidirá si echar 1 o 2 cartas falsas en función de su
credibilidad. Como hemos dicho antes, el jugador tratará de
evitar en la medida de lo posible tener que desemparejar las
cartas a la hora de mentir.
Después de haber tomado la decisión de cuantas cartas va a
echar, este método devuelve un vector de 10 posiciones con las
cartas que echa.
5.1.2.7 numeroTipos numeroTipos es un método que nos proporciona información
sobre el número de tipos distintos con cartas que un jugador
tiene. Es muy útil en el caso de que el jugador virtual empiece la
ronda y sólo tenga cartas de un tipo. Cualquier jugador sabe que
si él empieza la ronda y sólo le quedan cartas de un tipo, ha
ganado la partida. Para evitar que el jugador virtual cometa el
error de no echar todas las cartas a la vez, con una llamada a este
método garantizamos que las echará todas a la vez y ganará la
partida.
5.1.2.8 tirarCarta El método tirarCartas realiza la acción de tirar una única carta
del tipo que le especificamos, devolviendo un vector de 10
posiciones con dicha carta. No toma ningún tipo de decisión,
únicamente ejecuta una acción predeterminada.
5.1.2.9 tirarCartasVerdaderas Una vez que hemos decidido no mentir, tirarCartasVerdaderas
se encarga de implementar el algoritmo de tirar cartas
verdaderas. Ejecuta la acción de echar cartas del tipo al que se
juega en esa ronda después de decidir cuántas echa. Esta
decisión estará condicionada por el número de cartas que hay en
juego.
Este método ayuda a tomar una decisión correcta para evitar dos
cosas: por un lado que aun teniendo cartas del tipo las echemos
todas en el primer turno y estemos obligados a mentir en el resto
y por otro lado, que seamos demasiado conservadores,
guardemos las cartas del tipo para el final y se acabe la ronda sin
habernos desprendido de ellas.
5.1.2.10 destapar destapar devuelve un boolean: true levantar, false no levantar.
Implementa el algoritmo de levantar o no las cartas. Toma la
decisión en función de las cartas en juego y de la credibilidad.
El jugador virtual se plantea levantar las cartas sólo en el caso
de que no tenga cartas del tipo al que se está jugando, decisión
bastante lógica. El método está implementado de forma que el
jugador virtual sea bastante conservador e intente evitar el
riesgo. Esto es, si no tiene cartas del tipo va a intentar levantar
las cartas de su rival lo antes posible para evitar que le pillen
mintiendo y se lleve un buen montón de cartas.
5.1.2.11 tirarCartaHumano Este método únicamente es invocado por los jugares reales o
humanos, no por el jugador virtual. En este caso es propio
jugador el que toma la decisión de mentir o no y de cuántas
cartas echar. Recibe un vector de 10 posiciones con las cartas
que el jugador quiere echar y actualiza el vector cartas después
de ejecutar la acción. Devuelve un vector con las cartas echadas.
5.1.2.12 Otros métodos auxiliares A parte de los métodos ya citados, existen otros que les sirven
de apoyo pero que no realizan acciones o toman decisiones
propias del juego. Éstos son:
getCartas
numeroCartas
getCredibilidad
setCredibilidad
printCartas
addCartas
-38-

5.2 Clase Partida
5.2.1 Atributos Los atributos de la clase Partida almacenan información
necesaria relativa al desarrollo y evolución de la misma.
5.2.1.1 jugadores El atributo jugadores es un vector de objetos de la clase
Jugador. Se utiliza para almacenar información acerca de los
jugadores de la partida y a la que va a acceder nuestro jugador
virtual para consultar la credibilidad del jugador anterior a él.
También tendría acceso para ver las cartas que tienen el resto de
jugadores. Evidentemente esta acción no está implementada
porque sería el equivalente a mirar las cartas de los rivales en la
realidad, hacer trampas.
5.2.1.2 jugador_actual Es un índice que indica a qué jugador le toca jugar en cada
turno. El índice se incrementa cíclicamente para que después del
último jugador continúe al primero.
5.2.1.3 cartas_mesa Este atributo indica las cartas que hay en juego, es decir, en el
montón. Cada vez que los jugadores echan cartas se actualiza su
valor, lo mismo ocurre cuando se levantan las cartas y se
inicializa a 0 para empezar una nueva ronda.
Muchos métodos lo reciben como parámetro porque sus
decisiones dependen del número de cartas en el montón, de ahí
su importancia.
5.2.1.4 randomGenerator El atributo randomGenerator es un objeto da la clase Random y
genera números aleatorios. Como se dijo en la parte de diseño,
algunas de las decisiones tomadas son aleatorias. Pues bien, este
carácter aleatorio se debe a la generación de randomGenerator.
5.2.1.5 a_que_se_juega Es un entero que puede tomar valores entre 0 y 9. Almacena el
tipo de cartas a la que se juega en una ronda, por lo que su valor
no cambia dentro de ella. Su valor lo decide al jugador que
comienza cada ronda.
5.2.1.6 descartados Es un vector de enteros de 10 posiciones y se utiliza para
almacenar los tipos de cartas de los cuales los jugadores se han
descartado.
5.2.1.7 todas_cartas_mesa El atributo todas_cartas_mesa es un vector de enteros de 10
posiciones en el que se almacenan todas las cartas que se han
echado en la presente ronda. En la posición de cada tipo se
almacena el número de cartas de dicho tipo.
Este vector es actualizado cada vez que se echan cartas y se
inicializa cuando algún jugador se lleva las cartas del montón.
Su función básica es que cuando se levantan las cartas y un
jugador se las lleva debemos tener información de cuales son las
cartas que hay en el montón.
5.2.1.8 ultima_jugada Es un vector de enteros de 10 posiciones que se utiliza para
almacenar las cartas que se han echado en el turno anterior. Es
necesario almacenar información del último turno porque si el
jugador levanta las cartas del jugador anterior hay que
comprobar si las cartas que ha echado realmente son las mismas
que dice haber echado.
5.2.1.9 numero_jugadas Es un índice que indica el número de turnos que se han jugado
en la presente ronda. Nos da información a cerca del número de
vueltas que ha dado la ronda. Este atributo es necesario para
acceder a la posición correcta en credibilidad.
5.2.2 Métodos La clase Partida cuenta con un único método llamado Juego()
que es el que implementa toda la funcionalidad tanto del jugador
virtual como de los jugadores humanos.
5.2.2.1 Juego() Primeramente se crea un vector con la 40 cartas de la baraja
española, se barajean y se reparten, en este caso en concreto
como el número de jugadores es 4 todos reciben el mismo
número de cartas.
Una vez que todos los jugadores tienen sus cartas, comienza el
juego en sí. La funcionalidad de la partida está implementada
por dos bucles while. El primero de ellos representa la partida
misma y se sale de él cuando hay jugador ganador (el que logra
deshacerse el primero de todas sus cartas). El segundo
representa cada una de las rondas y se sale de él cada vez que un
jugador levanta las cartas. Dentro de una ronda se avanza
cíclicamente de un jugador a otro. Cuando se comienza una
nueva ronda, el jugador que comienza depende del resultado del
levantamiento de cartas previo: si era mentira continúa el
jugador que mintió y si era cierto continúa el jugador que
levantó las cartas.
Dentro de cada ronda dependiendo del jugador ejecuta una
funcionalidad distinta. En el caso del jugador virtual se ejecutan
las acciones descritas en el árbol de decisión del jugador virtual.
Por el contrario, en el caso de los jugadores humanos se ejecutan
las acciones descritas en el árbol de decisión de jugadores
humanos. En este último caso las acciones y decisiones de echar
cartas, elegir el tipo de carta al que se va a jugar y de elegir si
levantar o no las cartas las realiza el propio jugador humano a
través de la consola, es decir, interacciona con el programa.
6. POSIBLES MEJORASDentro de las posibles mejoras del jugador virtual podemos citar
varias. La primera de ellas es modelar los ases como comodines.
En el juego real los ases funcionan como comodines. Esto es
que los comodines pueden tomar el valor que más convenga al
jugador en cada situación, es decir, los comodines se consideran
como una carta más del tipo al que se juega. Además los
jugadores están obligados a descartarse cuando tienen las cuatro
cartas del mismo tipo, a excepción de los ases. De modo que hay
8 cartas de cada tipo en juego, los 4 comodines y las 4 cartas del
tipo.
Otra mejora que podríamos introducir es almacenar información
de las cartas de cada jugador. Cada jugador tiene sus cartas
ocultas y no podemos verlas excepto en el caso de que se
levanten las cartas. Cuando se levantan las cartas no vemos
todas las que había en el montón pero sí las de la última jugada
o turno, que serían las que almacenaríamos. Con la información
de las cartas de otros jugadores y considerando las del jugador
-39-

virtual, éste podría tomar decisiones más precisas porque cuenta
con mayor información.
Nuestra implementación está pensada para jugar con cuatro
jugadores, uno virtual y tres humanos. Sería conveniente que se
pudiese seleccionar el número de jugadores, siempre que fuese
mayor de dos. Esta mejora no conlleva cambios en el diseño,
únicamente ligeras modificaciones en la implementación.
Para finalizar, en el juego real aunque un jugador se deshaga de
todas las cartas y gane, el juego continúa hasta que sólo queda
un jugador que sería el “absoluto perdedor”. Pues bien, nuestra
implementación para cuando el primer jugador se deshace de
todas las cartas, gana. Una posible mejorar sería cambiar para
que el juego continuase hasta que sólo quedara un único
jugador. Esta mejora no supondría cambios en el diseño, sino
ligeras modificaciones en la implementación.
7. CÓDIGO FUENTEEn esta sección se incluye parte del código generado en la
implementación no su totalidad. Únicamente se muestran los
métodos más importantes y representativos.
7.1 Clase jugador public class Jugador{
/*Atributos*/
private int identi;
private int[] cartas;
private double[] credibilidad;
private int cartas_en_mano;
public Jugador(int[] cartas_input,int id){
cartas = new int[10];
for(int i=0;i<cartas.length;i++){
cartas[cartas_input[i]]++;
}
this.credibilidad = new double[10]; //10 jugadas como
máximo
for(int j =0;j<credibilidad.length;j++){
credibilidad[j] =0.6; //En principio la credibilidad en todos
los turnos es alta
}
identi = id;
cartas_en_mano = 10; //empiezas con 10 cartas
}
public boolean miente_no_riesgo(int numero_jugada,double
random){
return random>1-credibilidad[numero_jugada];
}
public boolean miente_riesgo(int jugada, double random,int
cartas_mesa){
double threshold;
if(cartas_mesa <= 5)return true;
if(cartas_mesa >= 20)return false;
threshold = (1+(double)(cartas_mesa-20)/15)
*credibilidad[jugada];
return random>threshold;
}
public int[] tirarCartaFalsa(int numero_jugada,double
random,int a_que_se_juega){
//Necesitamos saber a qué se juega para no tirar una carta de
ese tipo.
int[] cartas_min;
int suma=0;
int index=0;
int min_value = 0;
int primer_index=0;
int[] result = new int[10];
boolean tiras_varias =false;
numero_jugada = (int)numero_jugada/4; //para saber 'la
ronda'
cartas_min = cartasMin();
cartas_min[a_que_se_juega] = 0; //ignoramos a lo que se
juega, porque eso no lo vamos a tirar.
//tienes que mirar si tienes más de una carta de valor min
for(int i=0;i<10;i++){
if(cartas_min[i] != 0){
min_value = cartas_min[i];
primer_index=i; //no es el primer_index en principio
}
suma = suma+cartas_min[i];
}
if(suma ==1){ //sólo tenemos una carta de valor min=1
cartas_en_mano--;
return cartas_min;
}
else{ //tienes varias cartas de valor min
//mirar credibilidad
tiras_varias = miente_no_riesgo(numero_jugada,random);
//no es mentir, es ver si tiras 1 o varias, pero es equivalente
if(!tiras_varias){//solo tiras una
//tiras la primera que te encuentras
cartas[primer_index]--;
result[primer_index] = 1;
cartas_en_mano--;
return result;
}
else{ //tiramos varias
int j=0;
int veces =0;
if(min_value == 1){ //tiramos 2 cartas cualesquiera
while(j<10 && veces < 2){
if(cartas_min[j] != 0){
cartas[j]--;
result[j] = 1;
veces++;
}
j++;
}
}
else{ //min_value != 1
while(j<10 && veces == 0){
if(cartas_min[j] != 0){
cartas[j] = cartas[j] -2;
result[j] = 2;
veces = 1;
-40-

}
j++;
}
}
cartas_en_mano -= 2;
}
return result;
}
}
public int[] tirarCartasVerdaderas(int cartas_mesa, int
a_que_se_juega, double random){
int[] result = new int[10];
double threshold;
if(cartas_mesa <= 5){//tiramos 1
cartas[a_que_se_juega]--;
result[a_que_se_juega] = 1;
cartas_en_mano--;
return result;
}
if(cartas_mesa >= 15){//tiramos todas
result[a_que_se_juega] = cartas[a_que_se_juega];
cartas_en_mano -= cartas[a_que_se_juega];
cartas[a_que_se_juega] = 0;
return result;
}
threshold = (1-(double)(cartas_mesa-5)/10);
if (random>threshold){ //tiramos 1
cartas[a_que_se_juega]--;
cartas_en_mano--;
result[a_que_se_juega] = 1;
return result;
}
else{ //tiramos todas
cartas_en_mano -= cartas[a_que_se_juega];
result[a_que_se_juega] = cartas[a_que_se_juega];
cartas[a_que_se_juega] = 0;
return result;
}
}
public boolean destapar(double[] credibilidad, int
numero_jugada, int cartas_mesa, double random){
double threshold;
if(cartas_mesa <= 3){
return false;
}
if(cartas_mesa >= 6){
threshold = (1-credibilidad[(int)numero_jugada/4]);
return random<threshold;
}
threshold = (1-(double)(cartas_mesa-3)/3)*(1-
credibilidad[(int)numero_jugada/4]);
return random<threshold;
}
}
7.2 Clase Partida No se ha incluido la funcionalidad del método Juego() porque es
muy extensa. En ella se sigue el mismo flujo que en los árboles y
se llaman a métodos definidos en la clase Jugador.
public class Partida{
/*Atributos*/
Jugador[] jugadores;
int jugador_actual;
int cartas_mesa;
Random randomGenerator;
int a_que_se_juega; //esto es un índice en el vector de 10
posibles cartas
int[] descartados; //array de los números descartados
int[] todas_cartas_mesa;
int[] ultima_jugada;
int jugador_ganador=-1;
int numero_jugadas=0; //dentro de una ronda, cuantas vueltas
se han dado.
/*Constructor*/
public Partida(){
randomGenerator = new Random();
jugadores = new Jugador[4];
jugador_actual = randomGenerator.nextInt(4);//elijo el
jugador que comienza aleatoriamente
a_que_se_juega = -1;
cartas_mesa = 0;
descartados = new int[10];
todas_cartas_mesa = new int[10];
ultima_jugada = new int[10];
numero_jugadas = 0;
}
7.3 Clase Mentiroso public class Mentiroso{
public static void main(String args[]){
Partida p = new Partida();
p.Juego();
}
}
8. REFERENCIAS[1] Manual sobre reglas del Mentiroso
http://portaljuegos.wdfiles.com/local--
files/mentiroso/ManualMentiroso.pdf
[2] Apuntes de la asignatura Inteligencia en Redes de
Comunicaciones
[3] API de java
http://docs.oracle.com/javase/6/docs/api/
-41-

JUEGO MANCALA CON ALGORITMO MINIMAX REALIZADO
CON INTERFAZ GRÁFICA EN JAVA
Lucia Ruiz Ruiz Universidad Carlos III de Madrid [email protected]
Inteligencia en Redes de Comunicaciones
Artem Motsarenko Universidad Carlos III de Madrid [email protected]
Ingeniería Sup. en Telecomunicación
Jose Angel Leon Calvo Universidad Carlos III de Madrid [email protected]
Quinto curso, 1º cuatrimestre
ABSTRACT
En este documento vamos a realizar un juego basado en Mancala
usando como algoritmo Minimax con poda alfa-beta y dos niveles
de búsqueda. Estará realizado con lenguaje de programación Java
y una interfaz gráfica para que el usuario pueda jugar contra un
usuario programado.
Descriptores de los métodos
[Java]: public Movimiento MiniMaxAB(int [][] tableroActual,int
turno, int prof)
Este es el método fundamental del algoritmo Minimax que
detallaremos más adelante.
[Java]: public class JugadorTotal{public static void main(String[]
args) {
Esta es la clase que tiene el metodo main, esto es la que usaremos
para ejecutar el Mancala.
Términos GeneralesAlgorithms, Design, Reliability, Human Factors, Languages,
Theory.
KeywordsMancala, Minimax, Java, GUI, poda alfa-beta, Juegos de mesa,
1. INTRODUCCIÓN
Se desea implementar un jugador para una variante de la familia
de juegos Mancala. En nuestro caso, tendremos dos jugadores que
realizarán movimientos en turnos alternados. En cada uno de ellos
el jugador redistribuye (siembra) las piezas (semillas) de un hoyo
con el objetivo de capturar las piezas de su oponente.
El tablero del juego está formado por 2 filas de 6 hoyos cada una
y un contenedor. Una fila pertenece a un jugador y la otra a su
oponente. Una característica de este juego es que el número total
de semillas en el tablero permanece constante, y que cada jugador
sólo siembra en su fila. Por tanto, si un jugador captura semillas
del otro jugador está obligado a sembrar de nuevo estas semillas
en sus hoyos.
Para el desarrollo del algoritmo, se utilizará el procedimiento
minimax y una mejora de éste conocida como poda alfa-beta, el
cual permite generar un árbol de búsqueda para representar el
juego y elegir la mejor jugada en un momento determinado, sin
tener que examinar todas las posibles jugadas.
La motivación para el estudio de este tipo de juegos viene de lo
explicado en clase de Inteligencia en redes de comunicación y
especialmente de la parte de juegos con algoritmo Minimax [1].
En nuestra implementación no hemos llevado a cabo todas las
reglas que existen para Mancala, sino que hemos hecho una
implementación con las reglas básicas.
2. HISTORIA DE MANCALA [2]
Mancala es el nombre de una familia de juegos de tablero muy
extendidos por toda África. Este juego se practicaba ya en el
antiguo Egipto, pues se han encontrado tableros en la pirámide de
Keops, y de allí debió extenderse a otros países de África y Asia.
Forma parte desde tiempos muy remotos de la tradición cultural
de muchos pueblos y tribus, principalmente de África, y su
práctica ha estado ligada a diferentes hechos, como a ritos
funerarios, con motivo de mantener entretenido al espíritu del
difunto; a ceremonias nupciales, para asegurar la fertilidad de la
unión; y además, en casi todos los pueblos ha sido objeto de
adivinación. Hoy, sin embargo, se juega sobre todo por placer y se
ha convertido en el juego nacional de muchos países africanos,
donde es conocido bajo diversas denominaciones, conociéndose
casi doscientas variantes del juego, aunque todas ellas poseen
características comunes.
Los tableros varían ligeramente en cuanto material de
construcción en función de la zona a la que pertenecen, pero todos
cuentan con las dos filas de seis huecos, llamados pits de juego,
cada una, y las dos cavidades mayores, que se denominan Kalahs,
que sirven de depósito de las fichas capturadas por los jugadores.
El número de fichas con los que se comienza a jugar varía mucho
en función de la variante jugada, aunque lo más normal es
comenzar con 3 ó 4 fichas por hoyo de juego. Las reglas del juego
también varían en función de la variante jugada, aunque todas
ellas tienen una base común [3].
Las versiones de Mancala más corrientes en Europa, son el Awale
(también llamado Wari), el Kakua, el Mweso o Hus (que se juega
con 64 fichas en un tablero de 32 huecos), el Oware, que es una de
las variantes más sencilla, y el Kalah, Kalaha o conocido
simplemente como Mancala, que es la variante egipcia, la más
extendida y conocida en Occidente, y es la implementada en este
proyecto.
La filosofía en que se basa el Mancala es la siguiente: [4]
-42-

Las tiradas se desarrollan en 2 fases: sembrar y cosechar.
Se juega sobre un tablero con doce de agujeros, 6 por cada
jugador. Los agujeros es donde se siembra y donde se cosecha.
Las fichas del Mancala (normalmente semillas) son
indiferenciadas, todas iguales. Y no pertenecen a ningún jugador.
Se aplica el dicho “Las semillas son de quien las necesita. Quién
mejor siembra, mejor cosechará”.
En el Mancala hay 2 normas sagradas:
“No se puede eliminar al adversario”. Se entiende que cuando se
destruye al adversario, también se destruye la tierra que él cultiva.
Quien lo hiciera por error, perdería la partida. Se aplica el dicho
“Quien destruye la tierra donde cosecha, no podrá cosechar nunca
más”.
“No se puede dejar pasar hambre al adversario”. Esto significa
que si nuestro rival se queda sin semillas, debemos ceder de las
nuestras para que pueda seguir jugando.
3. ASPECTOS MATEMÁTICOS EN
MANCALA [5]
Los juegos de la familia Mancala son visto como algo simple ya
que son del tipo determinista (no influye el azar en forma de dado
u otro elemento aleatorio), tenemos información perfecta (excepto
por la dificultad de recordar todos los elementos del juegos) y no
hay demasiadas elecciones en cada movimiento, normalmente no
tenemos más posibilidades que el número de hoyos en una fila.
Sin embargo, el hecho que un solo movimiento tiene efecto en el
contenido de todos los hoyos del tablero, hace complicado ver las
consecuencias a largo a plazo o simplemente unos cuantos
movimientos hacia adelante.
Una propiedad matemática que nos permite ver la complejidad de
juegos como el Mancala es el número de posibles posiciones. Una
posición en Mancala consiste en un cierta distribución de las
semillas en los hoyos del tablero, pero también incluimos un
contador para las semillas que se pueden capturar o las que
mantenemos en nuestro poder sino tenemos nada que capturar. El
número de posibles posiciones depende del número de hoyos en
nuestro tablero y del número de semillas que tengamos en cada
uno. Este número, p, puede ser obtenido usando la siguiente
fórmula de combinatoria:
p = k * ( )
En este formula k, es el número de jugadores, m es el número
total de semillas y n es tanto el número total de hoyos y semillas
juntas o el número total de hoyos incrementado con el número
total de jugadores, sino almacenamos nada. El número p se
incrementa muy rápido con el incremento de hoyos y semillas. En
la tabla siguiente podemos ver el número de posibles posiciones
en un tablero de Mancala con dos filas de seis hoyos y dos
semillas para dos jugadores:
Tabla 1: Número de posibles movimientos en Mancala
Podemos ver como el número de posibles posiciones decrece,
cuando solo nos fijamos en las semillas que hay en el tablero.
Como podemos intuir solo un cierto número de estas posibles
posiciones aparecen durante el juego, ya que, esto depende de la
posición inicial del juego y de las normas que estemos usando. En
una variación del Mancala, el Kalah, solo un 5% de estas posibles
posiciones aparecen en un juego real [6].
4. INTELIGENCIA ARTIFICIAL EN
MANCALA
Inteligencia Artificial (IA) es una rama de la informática que
pretende que un ordenador pueda realizar lo que normalmente se
considera como inteligente o simular el comportamiento humano.
Hay dos motivos principales por las que se realiza esta
investigación: el primero es evitar esfuerzos a humanos con la
ayuda del ordenador. La segunda motivación es tratar de entender
cómo la inteligencia humana u operaciones mentales trabajan a
través de la simulación por ordenador. Los juegos han jugado un
papel importante en la inteligencia artificial, porque para jugar a
estos se considera como una tarea típicamente inteligente, pero
también porque los juegos casi siempre forman un ambiente
cerrado con posibilidades limitadas y reglas claramente definidas.
Esto último hace que para los investigadores en IA sea mucho
más fácil tratar con juegos que tratar, por ejemplo, con el mercado
de valores, pues este último está sometido a múltiples variables y
no se comporta según un conjunto de reglas cerradas. El resultado
más famoso de la IA en los juegos es, por supuesto, el hecho de
que en los ordenadores hoy en día se puede jugar al ajedrez a
nivel de gran maestro e incluso derrotando el ex campeón del
mundo. En la carrera competitiva entre ordenadores capaces de
jugar al ajedrez mediante programas, las técnicas se han
desarrollado mucho y se están aplicando actualmente estas
técnicas otras áreas de la IA y la informática. Se podría decir que
los juegos (y en especial el ajedrez) son la Fórmula 1 de la
informática.
La familia de juegos Mancala se ha introducido en Inteligencia
Artificial relativamente pronto, aunque la mayor parte de
investigación se limita a sólo dos juegos: Kalah y Awari.
Las instancias más pequeñas de Kalah fueron resueltos al
considerar todas las posiciones que en realidad pueden surgir
durante una partida de Kalah. Las bases de datos se han creado en
que cada posición y su valor de teoría de juegos se almacenan.
Los casos más grandes de Kalah se resolvieron mediante la
búsqueda de juegos de árbol (mismo mecanismo que usaremos
-43-

nosotros en nuestra implementación). Para estos casos, sólo se
conoces una estrategia ganadora partiendo de una posición inicial
en concreto. El programa es, sin embargo, capaz de encontrar una
estrategia óptima para cada posición que pueda ocurrir durante un
juego de Kalah.
Esto significa que Kalah no es de interés para los investigadores
ya que la IA desea que el equipo para jugar el juego de Kalah
como sustitutos o de forma superior a los humanos. Sin embargo,
para los investigadores de la IA del juego y psicólogos que estén
interesados en el aspecto humano del juego de los resultados que
se obtuvieron siguen haciendo de Kalah algo muy útil.
5. APLICACIONES EDUCATIVAS DE
MANCALA [7]
Los juegos basados en Mancala ofrecen la oportunidad de ver
fácilmente cómo se puede mejorar con la práctica, y por lo tanto
ayudan a aprender a trabajar en algo para obtener una meta. Estos
juegos de mesa también enseñan a los niños a seguir
instrucciones, a acatar las reglas, jugar limpio y hacer frente a las
derrotas. Ayudan con la interacción cara a cara, la cooperación y
la competencia, y a mejorar las habilidades sociales. Su herencia
multicultural va en contra de las actitudes racistas y enseña la
cooperación. También aumentan la conciencia y el respeto hacia
su propio patrimonio cultural, en particular entre los jugadores de
África y Asia.
El Mancala se ha considerado una herramienta pedagógica muy
útil en la educación de niños y adultos durante siglos.
El juego Mancala mejora la capacidad de observación, los
jugadores tienen que desarrollar habilidades cognitivas para
distinguir buenos movimientos de los malos y posiciones
favorables del tablero frente a las desfavorables. Son ejercicios
que fortalecen la memoria y la concentración.
Mancala enseña el pensamiento analítico, ya que los jugadores
deben aprender a planificar y desarrollar estrategias, para ser un
jugador ganador tienen que prever lo que va a pasar varios
movimientos por adelantado. El juego obliga a los jugadores a
anticipar los próximos movimientos de su oponente. Tienen que
ponerse en la posición de otra persona, ya que de lo contrario
pueden ser derrotados fácilmente.
También ayuda con el pensamiento matemático, ya que para
empezar, uno tiene que mantener un registro del número de
piedras en cada agujero. Ellos ayudan con las habilidades básicas
de cálculo, pero también ofrecen grandes retos para los
matemáticos y científicos informáticos. Una variación moderna
llamada Aritmética fue diseñada específicamente para enseñar
aritmética en las escuelas primarias. Mancala también han sido
utilizados por las escuelas en los EE.UU. para ayudar a los niños
con discalculia (dificultad en el aprendizaje de las matemáticas).
Los juegos de Mancala desarrollan la motricidad fina., estas
incluyen el seguimiento visual, la coordinación mano-ojo, y la
capacidad de manipular objetos pequeños mediante la
transferencia en un proceso conocido como "siembra" (poner las
semillas en el tablero).
6. INTRODUCCIÓN ALGORITMO
MINIMAX CON PODA ALFA-BETA
La idea principal del algoritmo es tomar como punto de partida
una posición y utilizar un generador de movimientos para generar
un conjunto de posiciones de posibles sucesores, por lo que se
aplica una función de evaluación estática y se selecciona el mejor
movimiento obteniendo el valor. Los pasos que usaremos son los
siguientes [1]:
Generar el árbol de juego, alternando movimientos de
MAX y MIN y asignándoles los valores apropiados
(MAX>0, MIN<0).
Calcular la función de utilidad de cada nodo final,
recorriendo recursivamente los nodos hasta el estado
inicial.
Elegir como jugada a realizar aquel primer movimiento
que conduce al nodo final con mayor función de
utilidad.
En el desarrollo de los juegos de dos jugadores, a uno se le
denominará MAX y al otro MIN, cada uno con su turno
correspondiente
Esta búsqueda realizada se puede definir en base a: un Estado
Inicial, Movimientos Posibles (Sucesores, luego de aplicar la
Función de evaluación), un Estado Final, Valor o Función de
Utilidad; los mismos que a su vez vienen a definir un árbol de
juego y donde se desarrollará primero una búsqueda en
profundidad, para nuestro caso profundidad limitada.
Usualmente se puede decir en una búsqueda cualquiera, que la
estrategia óptima se logra alcanzar cuando tras un conjunto de
movimientos posibles se llega a la meta u objetivo que viene a ser
el estado ganador; sin embargo, la estrategia óptima que aquí
vamos a implementar no va por ese camino, sino más bien
consideramos que tras la realización de una jugada MAX, viene
una jugada MIN y tras la misma viene otra MAX y puede ser vista
en el árbol de juego (generado dado una cierta profundidad),
evaluando la función de valor Mínimax en cada nodo.
Debido a que uno de los problemas que tiene implícito el
algoritmo es el gran uso que hace de la memoria, realizaremos una
poda alfa-beta que nos permitirá no expandir todo los caminos
posibles, sino solo aquellos que mejoran el camino por el que
vamos, donde alfa y beta representan, respectivamente, las cotas
inferior y superior de los valores que se van a ir buscando en la
parte del subárbol que queda por explorar. Si alfa llega a superar o
igualar a beta, entonces no será necesario seguir analizando las
ramas del subárbol.
En pseudocódigo el algoritmo Minimax para el juego de Mancala
sería [8]:
Entrada: nodoJuego (Mancala), Profundidad, turnoPC, Alfa
(inicialmente -inf), Beta (inicialmente +inf)
Salida: el nodo (Mancala) a Jugar
1. Si el estado del nodoJuego es un final (Juego Terminado) o la
profundidad de análisis restante es cero,
1.1. Devolver nodoJuego cuyo valor sea el valor calculado
mediante la función de Evaluación respectiva.
1.2. En caso contrario, hacer
-44-

1.2.1 Calcular los SUCESORES del nodoJuego
1.2.2 Si la lista de SUCESORES es vacía
1.2.2.1 Devolver nodoJuego cuyo valor sea el valor
calculado mediante la función de Evaluación respectiva.
1.2.2.2 En caso contrario, si el jugador del
nodoJuego es MAX
1.2.2.2.1 Devolver el nodo de la lista de
SUCESORES obtenido con la función MAXIMIZADOR-A-B
1.2.2.2.2 Sino Devolver el nodo de la lista de
SUCESORES obtenido con la función MINIMIZADOR-A-B
7. REGLAS DEL JUEGO [9]
El juego consiste en recolocar o redistribuir las semillas de un
hoyo en otros hoyos de la misma fila con el objetivo de capturar el
mayor número posible de semillas al oponente. El juego termina
cuando uno de los dos jugadores consiga que su oponente posea
una o ninguna semilla en su fila, en tal caso es el ganador de la
partida.
7.1 Estado inicial Se selecciona un hoyo que contenga semillas, y que
preferiblemente permita hacer una captura. Se siembran las
semillas del hoyo seleccionado en los sucesivos hoyos, yendo de
izquierda a derecha (relativas al jugador situado frente a su fila), y
depositando una semilla en cada hoyo. En el caso de que se
llegara sembrando al final de la fila (hoyo 5) se continúa
sembrando desde el principio (hoyo 1) y en la misma fila del
jugador.
Figura 1. Estado inicial del tablero Mancala
7.2 Captura/cesión Se da sólo cuando tras la siembra, la última semilla se deposita en
un hoyo que ya tenía semillas (hoyo de última siembra) y en el
hoyo opuesto del otro jugador también tiene semillas. En este
caso, se pueden dar las siguientes alternativas:
Captura semillas: Si cae en un hoyo con un número
impar de semillas (antes de depositar la nueva) y el
contrario en el hoyo opuesto también tiene un número
impar de semillas, se capturan las semillas del hoyo
opuesto y se siembran en la fila del jugador,
comenzando a sembrar a partir del siguiente hoyo a la
derecha del de última siembra. Tras la nueva siembra,
volverá a analizarse el nuevo hoyo de última siembra
para comprobar si de nuevo hay captura (en cuyo caso
se repetiría todo el proceso hasta que finalicen las
capturas) o cesión.
Figura 2: Estado de captura por jugador humano (parte inferior)
Como vemos en la figura 2, el jugador 2 tiene la posibilidad de
realizar una captura de las 2 semillas que tiene el oponente en el
cubilete 2 de su lado del tablero, por lo que realizando este
conseguirá 3 semillas más para su marcador (1 bola suya + las 2
que captura)
Cede semillas y cambio de turno: Si cae en un hoyo con
3 o más semillas que no cualifica para captura, y si el
contario tiene una o dos pero menos de 3 semillas en su
hoyo opuesto (en ambos casos, antes de depositar la
nueva), se ceden al hoyo contrario todas las semillas del
hoyo de última semilla y se pasa el turno al oponente.
Cambio de turno: En cualquier otro caso, se termina la
jugada y se pasa el turno al oponente.
7.3 Fin de turno
Un jugador finaliza su turno cuando se da alguno de los siguientes
casos:
después de la siembra inicial o captura, la última semilla
cae en un hoyo de su fila sin semillas.
cuando después de una captura no se puede realizar otra
captura.
cuando tiene que ceder semillas al contrario.
Figura 4. Estado del tablero Mancala cuando ha terminado el
turno del jugador 2
-45-

Si un usuario mete su última semilla en su recogedor puede repetir
turno como en el caso siguiente:
Figura 5. Estado del tablero Mancala antes de jugar el Jugador 2
El jugador 2 pulsará en el cubilete con 4 semillas por lo que podrá
volver a pulsar en otro sin tener que ceder el turno al contrincante
Figura 6. Estado del tablero Mancala cuando ha terminado el
turno del jugador 2 y sigue en su turno
7.4 Fin del juego
Existen dos posibilidades de fin de juego: por victoria de uno de
los jugadores o por tablas. Un jugador gana la partida cuando
consigue que su oponente tenga en su fila una o ninguna semilla o
cuando el oponente abandona o si su función de evaluación
comete algún error, por ejemplo abortando.
Otro factor que hace que un jugador gane es que tenga mayor
número de semillas que el contrario, en nuestro caso si tiene más
de 24 semillas en su contenedor, el jugador ganará la partida.
Figura 7: Estado final del tablero de Mancala
8. ALGORITMO MINIMAX PARA
MANCALA
Para la representación del algoritmo de Mancala usaremos una
representación en forma de árbol, que es la más usada para este
tipo de algoritmos, ya que nos permite clasificar el algoritmo
según el número de niveles que tenemos que recorrer y dar un
valor a cada una de las ramas de un nodo:
8.1 Estado inicial
Figura 8: Representación estado inicial del tablero de Mancala
Representaremos como uno de los posibles estados del tablero de
juegos con un nodo del árbol y por medio de flechas evaluaremos
con la función de evaluación los distintos escenarios posibles.
El árbol estará formado por nodos ordenados en niveles de
profundidad en los cuales cada uno pertenecerá respectivamente a
nuestro turno y el siguiente al jugador adversario.
8.2 Representación de los dos niveles de
búsqueda
Figura 9: Representación árbol con profundidad 2
La figura que hemos dibujado representa la búsqueda en dos
niveles (aunque para simplificar el dibujo simplemente hemos
expandido el árbol en un nodo). Esta búsqueda como vemos tiene
el problema de ser muy costosa en términos de memoria, ya que la
búsqueda en términos computacionales sería del orden de:
Complejidad = 6!*6! = 518400 posibilidades lo que resulta ser un
número bastante elevado y simplemente estamos expandiendo en
dos niveles.
Si realizamos una búsqueda en más niveles obtenemos los
siguientes datos:
3 niveles 3733248000
4 niveles 268738560000
5 niveles 193491763200000
Tabla 2: Número de movimientos en el árbol Minimax
Estado
Inicial
-46-

Como podemos observar si aumentamos el número de niveles, los
valores se vuelven en términos computacionales y de memoria
imposibles de manejar, por lo que además de reducir el número de
niveles que vamos a manejar, también aplicaremos la poda alfa-
beta que nos ayudará a no tener que manejar todas las
posibilidades del árbol, sino quedarnos con únicamente las que
mejoran el camino.
Estamos realizando una búsqueda en profundidad (DFS) que
puede mejorar su eficiencia usando una técnica de ramificación y
acotación, con la cual una solución parcial se abandona cuando se
comprueba que es peor que otra solución conocida o umbral.
Por lo tanto, la estrategia de poda del algoritmo Minimax que
usaremos es la llamada poda alfa-beta, puesto que dado que
existen dos jugadores maximizador y minimizador, existen dos
valores umbral alfa y beta para acotar la búsqueda de cada uno
respectivamente.
El valor alfa representa la cota inferior del valor que
puede asignarse en último término a un nodo
maximizante.
El valor beta representa la cota superior del valor que
puede asignarse en último término a un nodo
minimizante.
En un nivel dado, el valor de umbral alfa o beta según
corresponda, debe actualizarse cuando se encuentra un umbral
mejor.
Aparte de este algoritmo que sería una implementación básica,
existe otros métodos para refinar el algoritmo y conseguir mejores
resultados La efectividad del procedimiento alfa-beta depende en
gran medida del orden en que se examinen los caminos. Si se
examinan primero los peores caminos no se realizará ningún
corte. Pero, naturalmente, si de antemano se conociera el mejor
camino no necesitaríamos buscarlo.
La efectividad de la técnica de poda en el caso perfecto ofrece una
cota superior del rendimiento en otras situaciones. Según Knuth y
Moore (1975), si los nodos están perfectamente ordenados, el
número de nodos terminales considerados en una búsqueda de
profundidad d con alfa-beta es el doble de los nodos terminales
considerados en una búsqueda de profundidad d/2 sin alfa-beta.
Esto significa que en el caso perfecto, una búsqueda alfa-beta nos
da una ganancia sustancial pudiendo explorar con igual costo la
mitad de los nodos finales de un árbol de juego del doble de
profundidad.
Describimos ahora otras modificaciones del procedimiento
MINIMAX que también mejoran su rendimiento.
La poda de inutilidades es la finalización de la
exploración de un subárbol que ofrece pocas
posibilidades de mejora sobre otros caminos que ya han
sido explorado
Espera del reposo: Cuando la condición de corte de la
recursión del algoritmo MINIMAX está basada sólo en
la profundidad fija del árbol explorado, puede darse el
llamado efecto horizonte. Esto ocurre cuando se evalúa
como buena o mala una posición, sin saber que en la
siguiente jugada la situación se revierte. La espera del
reposo ayuda a evitar el efecto horizonte. Una de las
condiciones de corte de recursión en el algoritmo
MINIMAX debería ser el alcanzar una situación estable.
Si se evalúa un nodo de un árbol de juego y este valor
cambia drásticamente al evaluar el nodo después de
realizar la exploración de un nivel más del árbol, la
búsqueda debería continuar hasta que esto dejara de
ocurrir. Esto se denomina esperar el reposo y nos
asegura que las medidas a corto plazo, por ejemplo un
intercambio de piezas, no influyen indebidamente en la
elección.
Búsqueda secundaria: Otra manera de mejorar el
procedimiento MINIMAX es realizar una doble
comprobación del movimiento elegido, para
asegurarnos que no hay una trampa algunos
movimientos más allá de los que exploró la búsqueda
inicial. Luego de haber elegido un movimiento en
concreto con un procedimiento MINIMAX que explora
n niveles, la técnica de búsqueda secundaria realiza una
búsqueda adicional de d niveles en la única rama
escogida para asegurar que la elección sea buena.
Uso de movimientos de libro: La solución ideal de un
juego sería seleccionar un movimiento consultando la
configuración actual en catálogo y extrayendo el
movimiento correcto. Naturalmente en juegos
complicados esto es imposible de realizar, pues la tabla
sería muy grande y además nadie sabría construirla. Sin
embargo, este enfoque resulta razonable para algunas
partes de ciertos juegos. Se puede usar movimientos de
libro en aperturas y finales, combinando con el uso de
búsqueda MINIMAX para la parte central de la partida,
mejorando el rendimiento del programa. Por ejemplo,
las secuencias de apertura y los finales del ajedrez están
altamente estudiados y pueden ser catalogados.
Búsqueda sesgada: Una forma de podar un árbol de
juegos es hacer que el factor de ramificación varíe a fin
de dirigir más esfuerzo hacia las jugadas más
prometedoras. Se puede realizar una búsqueda sesgada
clasificando cada nodo hijo, quizás mediante un
evaluador estático rápido y luego utilizando la siguiente
fórmula:
R(hijo) = R(padre) - r(hijo)
donde R es el número de ramas de un nodo y r es el
lugar que ocupa un nodo entre sus hermanos ordenados
según la evaluación estática rápida.
Una variante respecto a la que hemos estudiado es tener en cuenta
la inteligencia del adversario, esto es, que pueda obtener algún
movimiento que este en alguna capa más profunda que la que
estudia nuestro algoritmo. Aun suponiendo que el algoritmo
siempre explora a una mayor profundidad que el adversario, éste
último puede equivocarse y no elegir el camino óptimo. La
consecuencia es que el algoritmo elige el movimiento basándose
en una suposición errada.
Ante una situación de derrota, según sugiere Berliner (1977),
podría ser mejor asumir el riesgo de que el oponente puede
cometer un error.
Análogamente, cuando se debe elegir entre dos movimientos
buenos, uno ligeramente mejor que el otro, podría resultar mejor
elegir el menos mejor si al asumir el riesgo de que el oponente se
equivoque nos conduce a una situación muchos más ventajosa.
Para tomar esta clase de decisiones correctamente, el algoritmo
debería modelar el estilo de juego de cada oponente en particular.
Esto permitiría estimar la probabilidad de que cometa distintos
errores. Sin lugar a dudas, esto es muy difícil de lograr y se
-47-

necesita contar con técnicas de aprendizaje para que el algoritmo
obtenga conocimiento sobre su oponente a lo largo del juego.
9. ALGORITMO MINIMAX
IMPLEMENTADO
Vamos a describir la implementación que hemos realizado para
nuestro juego de Mancala empezando por la función de
evaluación:
La función de evaluación que se ha implementado es muy
sencilla, el jugador automático elegirá como movimiento optimo
el que le permite depositar más semillas en su contenedor, sin
verificar ningún otro parámetro. Hemos elegido esta estrategia por
simplicidad en la ejecución y porque es la que más se parece a un
jugador novato o con poca experiencia en este tipo de juegos.
Una forma de mejorar esta función de evaluación sería que el
jugador también tuviese en cuenta el número de semillas que
puede capturar con su movimiento o que jugase de una forma
defensiva, esto es, en vez de intentar llenar su contenedor mover
de tal forma que el oponente estuviera bloqueado y no pudiese
rellenar su contenedor.
Una vez comentada la función de evaluación vamos a comentar
como hemos realizado en Java el Mancala.
Las dos filas de hoyos las hemos realizado como un array de siete
columnas y dos filas (en las que incluimos también los
recogedores de cada jugador) y en nuestro juego, hemos colocado
como estado inicial que cada hoyo tenga 4 semillas:
iniciales = 4;
bolas = new int[7][2];
bolas[6][0]= 0;
bolas[6][1]= 0;
for(int j =0;j<2;j++){
for (int i = 0;i<6;i++){
bolas[i][j]=iniciales;
}
}
El juego termina cuando un jugador obtiene más de la mitad de las
semillas que hay en el sistema completo, esto es, cuando obtiene
más de 24 semillas en su contenedor:
Dentro del método haGanado():
if( bolas[6][0]<24 ){
System.out.println("Ha ganado el jugador 2");
return 1;
}else if(bolas[6][0]>24){
System.out.println("Ha ganado el jugador 1");
return 0;
}
if(bolas[6][0]==24){
System.out.println("Empate");
return 3;
}
Vamos a explicar el algoritmo Minimax que hemos usado cuyo
código es el siguiente:
public Movimiento MiniMaxAB(int [][] tableroActual,int turno,
int prof){
cuantasVeces++;
System.out.println("MINIMAX:"+cuantasVeces);
int valores[][]= tableroActual;
imprimeTablero(valores);
List <Movimiento> lista= PosiblesMovimientos(valores, turno);
Movimiento mov= new Movimiento();
Movimiento movAux= new Movimiento();
Movimiento pulsar = new Movimiento();
System.out.println("PROFUNDIDAD = "+prof);
if(prof<=0 || lista == null || lista.isEmpty()){
System.out.println("Ultimo nivel : PROFUNDIDAD = "+prof);
if(lista == null || lista.isEmpty()){
System.out.println("No hay movimientos posibles");}
for(int i = 0 ;i<lista.size();i++){
if(i==0)movAux= lista.get(i);
mov = lista.get(i);
imprimeTablero(mov.getTablero());
if(mov.getPuntos()> movAux.getPuntos())
movAux= mov;
}
return movAux;
}
for(int i = 0 ;i<lista.size();i++){ //recorremos lista
if(turno==0)turno=1;else turno=0
Movimiento m=
MiniMaxAB((lista.get(i)).getTablero(),turno,prof-1);
if(i==0)pulsar=m;
(lista.get(i)).setPuntos(m.getPuntos());
if(lista.get(i).getY()==0){
if(lista.get(i).getPuntos()>pulsar.getPuntos())
pulsar= lista.get(i);
}
else{
if(lista.get(i).getPuntos()<pulsar.getPuntos())
pulsar= lista.get(i);
}}
return pulsar;
Esta función va hasta el nivel más profundidad dado por el valor
de la profundidad (a más profundidad mayor gasto en memoria) y
-48-

una vez estemas en lo más profundo del árbol, evaluamos cada
una de las ramas de ese nodo. Una vez tengamos todos los nodos
almacenados en una lista de posibles movimientos elegimos aquel
que tenga un mayor valor (en nuestro caso aquel que permita
meter un mayor número de semillas en el recogedor en el
siguiente movimiento) y hacemos lo mismo con todos los nodos
de este último nivel.
Una vez se haya obtenido el mayor valor para este nivel,
recorremos de forma inversa el árbol, realizando la misma
operación con los nodos superiores, hasta llegar a la raíz de la
cima con todos los nodos, hasta el nivel de profundidad
correspondiente, evaluados. Nos quedamos con aquel que nos da
un mayor valor neto, este es el que nos permite meter mayor
número de semillas en nuestro recogedor en el siguiente
movimiento y posteriores.
10. REFERENCIAS
[1] Villena, Julio. Apuntes de la asignatura Inteligencia en redes
de comunicación. Universidad Carlos III de Madrid
[2] Recurso web:
http://www.dma.fi.upm.es/docencia/primerciclo/matrecreativ
a/juegos/mancala/historia.htm.
[3] Recurso web: http://brainking.com/es/GameRules?tp=103
[4] Recurso web:
http://aprendiendomatematicas.com/tag/mancala/
[5] Jeroen Donkers, Jos Uiterwijk and Alex de Voogt, Mancala
games - Topics in Mathemathics and Artificial Intelligence
[6] Irving, G., Donkers, H. H. L. M., & Uiterwijk, J. W. H. M.
(2000). Solving Kalah. ICGA Journal, 23(3), 139-146.
[7] Retschitzki, J. (1990). Stratégies des joueurs d’awélé. Paris:
L’Harmattan
[8] Recurso web: http://nineil-leissi-
cs.blogspot.com.es/2008/06/proyecto-1-unidad-juego-
mancala.html
[9] Recurso web: http://www.bgamers.com/mancrul.htm
-49-

Domótica
Javier García Martín 100071014
Eva Mansilla López 100066852
ABSTRACT La Inteligencia artificial también comprende lo que se conoce como la Domótica la cual estudia la inteligencia de las casas.
Sistemas que realicen que las luces del pasillo se activen al pasar sin pulsar ningún interruptor, encender la calefacción mediante una simple llamada de teléfono, generar alarmas por la entrada de intrusos cuando no estamos en casa, persianas a través de la televisión con un mando a distancia, desde cualquier teléfono y esto sin requerir mayor esfuerzo sino simplemente por una maquina quien es capaz de recibir órdenes y actuar sin protestar, ni quejas.
KeywordsDomótica, sostenibilidad, vivienda inteligente, energética, confort, seguridad, ahorro, aprendizaje
1. INTRODUCCIÓNEl Hogar Digital o la Vivienda Inteligente es una casa donde las necesidades de los habitantes referentes a la seguridad, confort, gestión y control, ocio y entretenimiento, telecomunicaciones, ahorro de energía, tiempo y recursos son atendidas mediante la integración de sistemas, productos, nuevas tecnologías y servicio.
Por ello la Domótica cobra un importante papel para la creación de dichos hogares ya que, su definición es la automatización y control de aparatos y sistemas electrotécnicos en la vivienda. Los objetivos principales de la domótica es aumentar el confort, ahorrar energía y mejorar la seguridad.
El hogar hoy en día dispone de un gran número de equipos y sistemas autónomos y redes digitales no conectados entre ellos como la telefonía, los sistemas de acceso, la televisión, etc.
El hogar digital o la vivienda inteligente es el resultado del proceso de integración de estos equipos y sistemas autónomos. La integración de sistemas de en una Viviendas Inteligentes en combinación con el servicio de Banda Ancha nos lleva al concepto. Además de los sectores de la domótica, electrodomésticos y seguridad, un gran número de fabricantes también ha llegado a utilizar el concepto Hogar Digital o Vivienda Inteligente para sus productos y sistemas. Esto nos lleva a la siguiente definición del concepto del Hogar Digital:
“El Hogar Digital es una vivienda que a través de equipos y
sistemas, y la integración tecnológica entre ellos, ofrece a sus
habitantes funciones y servicios que facilitan la gestión y el
mantenimiento del hogar, aumentan la seguridad; incrementan el
confort; mejoran las telecomunicaciones; ahorran energía, costes
y tiempo, y ofrecen nuevas formas de entretenimiento, ocio y
otros servicios dentro de la misma y su entorno.”
Centrándonos en el concepto de domótica tiene muchos años de existencia como tal, desde que a un universitario se le ocurrió
conectar dos cables eléctricos a las manecillas de un reloj despertador, para que poco tiempo después, y movidos por dichas manecillas, los cables cerraran un circuito formado por una pila y una lámpara. Ese pudo ser el momento en que nació la idea de temporizar una función eléctrica. La idea de la moderna automatización de hogares, lugares de trabajo, etc. Se dio para proporcionar a los usuarios mayor comodidad, ahorro de energía y por supuesto, dinero, tiene pocos años, y fue desarrollada y patentada por una empresa escocesa utilizando un novedoso sistema de transmisión de señales a través de la red eléctrica. Más tarde se fue perfeccionando dicha idea y se utilizaron una serie de emisores que se enchufaban en una parte de la red eléctrica y que eran capaces de emitir una señal que circulaba a través de ella.
El objetivo del uso de la domótica es el aumento del el confort, el ahorro energético y la mejora de la seguridad personal y patrimonial en la vivienda.
La configuración de un sistema domótico está íntimamente ligada a los procedimientos de transmisión de información que posibilitan el diálogo entre dichos periféricos y la unidad central. Los terminales (radiadores de calefacción, electrodomésticos, puntos de luz, etc.). Suelen ser equipos convencionales a los que se aporta una inteligencia o capacidad de comunicación a través de una interfaz. Los elementos de campo comprenden todo el conjunto de sensores que permiten convertir una magnitud física en señal eléctrica, y los actuadores u órganos de mando, capaces de transformar una señal eléctrica en una acción sobre el entorno físico. Todos los elementos de campo envían y reciben señales a través de una red de comunicaciones (bus domótico), para comunicarse entre ellos y con la unidad central encargada de gestionar los intercambios de información. Estas señales de control están codificadas de una determinada forma (protocolos de comunicación), por lo que se necesitan unos elementos que pasen las señales bus y, a su vez, de señales bus a señales de salida a los actuadores (relés, interruptores, etc.). Estos elementos se suelen denominar de diferentes formas: módulos de entrada/salida, acopladores, interfaces, etc.
Un sistema domótico puede trabajar de forma centralizada o descentralizada. El funcionamiento global del sistema depende de la programación introducida en la central domótica. En cambio, en los sistemas descentralizados cada elemento es inteligente y se programa de forma individual. Las posibilidades de aplicación de la domótica en el espacio domestico son muy amplias. No obstante, las áreas en las que se han dedicado mayores esfuerzos son las relativas a la seguridad, la automatización de tareas domésticas o el confort, la gestión de la energía y las comunicaciones. De hecho para calificar de domótica una vivienda debe contemplar estas cuatro familias de servicios.
-50-

2. HISTORIAEn el año 1984, la empresa American Association of House Builders aculó el término de domótica, al iniciar el desarrollo del concepto, implementando componentes electrónicas en las casas. Éstas, que ya disponían de paneles solares, basaban su inteligencia en una interacción de la tecnología en su interior. Aunque en 1967 ya se empezó a implementar este sistema, su éxito no tuvo mucha acogida, ya que su coste era muy elevado, las condiciones de las viviendas no eran las adecuadas y el desarrollo tecnológico no era suficiente para encontrar recursos que verdaderamente fueran útiles para el usuario.
Figura 1
La base de esos sistemas es el llamado Protocolo X-10, base de las comunicaciones entre dispositivos, y que actualmente sigue utilizándose. A diferencia de otros éste hace uso de la red eléctrica (Power Line Communication) para la intercomunicación de los distintos equipos al módulo central, el cual está encargado de controlar los dispositivos de forma remota, y así no necesita cableado adicional. Este sistema fue desarrollado por ingenieros de PicoElectronics implementado en un microchip que pudiera ser acoplado a cualquier conjunto y así controlarlo de forma remota.
A lo largo del tiempo se han diferenciado dos tipos de sistemas domóticos.
El primero de ellos es el centralizado, el cual concentra la inteligencia en un módulo central que se encarga de obtener información del resto de equipos y en base a ello ejecuta las órdenes pertinentes.
El segundo se trata del sistema modular o distribuido en el que los equipos tienen la autonomía suficiente para procesar la información y en base a ella actuar de forma independiente. Este sistema obliga a la instalación de un cableado complementario que haga de bus para los dispositivos implicados.
La principal ventaja de éste último es la existencia de un único controlador y receptor que aseguran el control total sobre la casa, mientras que el caso centralizado no puede acceder a algunos dispositivos, por lo que el estándar X10 se vuelve indispensable en el sistema modular.
El término de Edificio Inteligente surgió en EE.UU. cuando se incrementó la construcción de edificios en los que la monitorización de calefacción, aire y ventilación era algo indispensable, debido en parte a la concienciación sobre el ahorro energético que comenzaba a estar presente en la sociedad. Esto
conllevó la integración de una red de datos que simplificara los largos cableados a desplegar.
El término domótica en sí empezó a usarse en la década de los 2000, cuando ya estos dispositivos estaban presentes de una forma u otra en los nuevos edificios, que con su simple presencia de una forma u otra automatiza el hogar.
Actualmente, se dan a conocer los beneficios de una casa automatizada y conjuntamente se han desarrollado regulaciones del mercado. Además, las modificaciones en las viviendas han ido acompañadas de las necesidades de las personas.
Los inconvenientes iniciales de las comunicaciones entre dispositivos por cable, se han atenuado con la utilización de redes de naturaleza inalámbrica, junto con la reducción de su precio. Sin embargo, tienen el inconveniente de ser más vulnerables, al mismo tiempo que aparecen limitaciones en cuanto a distancia y ancho de banda. Por ello es necesario buscar un compromiso entre ambas haciendo uso de cada en función de las condiciones de la instalación.
El sistema central del sistema domotizado es la llamada Pasarela Residencial, la cual contiene la conexión de redes, el control centralizado y las aplicaciones. Se pueden diferenciar las de banda ancha (routers, módems,…) que hacen de puente entre la red interna e Internet; y por otro lado está la pasarela multiservicios, encargadas de aplicaciones en tiempo real, y nexo entre las redes de control y datos.
En el futuro la domótica hará gran uso de la tecnología LED, donde el ahorro se convertirá en un elemento crucial. Además los proveedores podrán controlar la energía de forma remota (incluso la que produzca el propio hogar) y tendrán el control de la demanda. Aquí entrarán a jugar un papel importante los científicos sociales, cuyo papel será desarrollar el mercado al mismo tiempo que formar a los usuarios tanto en tecnología como en sostenibilidad.
Los empresarios por su parte, ven en este mercado una posibilidad de inversión por etapas. Esto quiere decir que el servicio va creciendo uniformemente implantándose de poco en poco en diferentes facetas, como por ejemplo la ayuda a ancianos y discapacitados, obligando a la continua innovación y desarrollo. En el caso de las personas discapacitadas se barajan opciones como el uso de iris como medio de comunicación. Como este hay multitud de mejoras que estarán acompañadas de economías de escala, con lo que su uso será inherente como puede ser la telefonía móvil o internet.
3. DOMÓTICA
3.1 Áreas
3.1.1 Energética El aspecto más valorado en el sector domótico es su uso para la eficiencia energética, ya que disminuye el consumo energético y reduce el impacto medioambiental.
Domótica y eficiencia energética en la actualidad van de la mano. Si hace treinta años la principal funcionalidad del hogar inteligente era la seguridad, hoy en día la mayor parte se profundiza sobre este sector, en gran medida por el importante ahorro económico que tiene el consumidor así como con la
-51-

reducción del impacto medioambiental, que tan de moda está en nuestros días.
Un sistema domótico se puede instalar prácticamente en cualquier hogar. Su complejidad depederá en buena parte de las necesidades del usuario y las características del proyecto. En España existe la asociación CEDOM, que integra a todos los organismos domóticos a nivel nacional.
Domótica y eficiencia energética son conjuntamente en las siguientes partes de la casa: control de iluminación, gestión de climatización, puesta en marcha de electrodomésticos y monotorización de consumo eléctrico.
Figura 2. Electrodomésticos domóticos
En cuanto al control de iluminación, se implantan dispositivos de adaptación del nivel de la iluminación a determinadas situaciones, como puede ser un área de la casa específica, la iluminación natural o no de ésta, o la presencia de personas en ella. Estos se activan de forma automática de manera que se regulan toldos y persianas, así como dispositivos lumínicos artificiales.
En la parte de climatización, el hogar digital busca el máximo ahorro del consumo energético y la reducción, también máxima del impacto medioambiental. Se consigue mediante el control de la calefacción y el aire acondicionado, manejando variables entre las que se encuentran temperatura exterior e interior, presencia de personas, apertura de personas o aprovechamiento de la luz solar con toldos, persianas y cortinas. Por poner un ejemplo, una diferencia de 1ºC de temperatura, supone un incremento de un 10% del consumo.
Para el tema de los electrodomésticos, la aplicación domótica no es tanto en el ahorro energético (ya que éstos se diseñan cada vez más con un compromiso con el medio ambiente) sino más en los horarios de funcionamiento. Se buscan aquellos en los que el precio de la electricidad es menor así como los que mejor se amolden a las necesidades del usuario. Por ejemplo, una persona que no se encuentra todo el día en casa, puede dejar tranquilamente su ropa en la lavadora y ésta se encargará de programar su lavado y secado para que esté disponible para el día siguiente.
La función de la monitorización del consumo, consiste en la generación de una serie de informes y estadísticas de consumo de la vivienda, con los que se pueden analizar los fallos como exceso de consumo, y sus respectivas causas. Las conclusiones nos ayudarán a corregir algoritmos y reglas y poder aconsejar al
usuario incluso, mejorando así la sostenibilidad y el medio ambiente.
3.1.2 Confort El confort conlleva todas las actuaciones que se puedan llevar a cabo que mejoren el confort en una vivienda. Dichas actuaciones pueden ser de carácter tanto pasivo, como activo o mixtas. iluminación (apagado general de todas las luces de la vivienda, automatización del apagado/ encendido en cada punto de luz, regulación de la iluminación según el nivel de luminosidad ambiente), automatización de todos los distintos sistemas/ instalaciones / equipos dotándolos de control eficiente y de fácil manejo, integración del portero al teléfono, o del videoportero al televisor, control vía Internet, gestión Multimedia y del ocio electrónicos, generación de macros y programas de forma sencilla para el usuario.
Para el control de riego a través de un sensor de humedad o de lluvia, detecta la humedad del suelo y de forma automática riega sólo cuando es necesario.
Los sistemas de regulación de la calefacción, adaptan la temperatura de la vivienda en función de la variación de la temperatura exterior, lo hora de día o la presencia de personas de la casa.
El control automático inteligente de toldos, persianas y cortinas de la vivienda, gestiona la captación de energía solar, permitiendo aprovecharla al máximo en invierno, y evitándola en la medida de lo posible en verano.
Figura 3. Salón domótico
La detección de apertura y cierre de ventanas y puertas, avisan al usuario de si están abiertas cuando está activada la climatización, y si procede, reduce el consumo o incluso apaga los sistemas de climatización
3.1.3 Seguridad El área de seguridad se encarga del control de los riesgos de accidentes, inundaciones, incendios, escapes de gas, robos, etc. Lo más importante actualmente se centra en las alarmas y en la protección de estas casa delos robos y de la intrusión.
Los sistemas de seguridad y alarmas en el contexto del edificio y hogar se pueden clasificar en cuatro áreas:
Alarmas de Intrusión (movimiento, presencia, presión, etc.)
-52-

Alarmas Técnicas (incendio, humo, inundación/agua, gas, fallo de suministro eléctrico, fallo de línea telefónica, etc.)
Alarmas Personales (SOS y asistencia)
Video Vigilancia (IP y CCTV)
Los sistemas de Seguridad actúan según la programación horaria, la información recogida por los detectores del sistema, la información proporcionada por otros sistemas interconectados y la interacción directa por parte de los distintos usuarios (usuario final, gestor de sistema, CRA, etc.).
Muchos sistemas de seguridad permiten la conexión y comunicación con otros sistemas dentro del edificio y/o hogar. El sistema de seguridad puede por ejemplo emitir una señal si detecta movimiento en el exterior para que el sistema de domótica recoja esa señal y encienda la luz exterior y baje las persianas. Pero también puede integrar las funcionalidades de domótica, inmótica y telecomunicaciones directamente en el mismo sistema de seguridad, que pueden variar desde funcionalidades muy sencillas, como encender una luz, hasta la gestión total de la instalación domótica o inmótica del edificio y/o hogar. Cada vez es también más común, que los sistemas de domótica e inmótica permitan funcionalidades de seguridad, incluso implementando los protocolos de seguridad para su conexión a una CRA.
Generalmente los sistemas de seguridad pueden ser instalados, mantenidos y gestionados o bien por el propietario directamente, o bien por empresas profesionales y homologadas de seguridad.
También entra en el término de la seguridad la prevención de fuga de gases para lo que se implantan sistemas suya función es detectar y avisar en caso de fuga de gas, provocando un corte en el suministro que evite los peligros que pudieran ocasionarse y el consecuente gasto inútil de gas consumido
Los sistemas de fugas de agua detectan si se produce una inundación, dan señal de aviso, y provocan un corte de suministro, evitando los problemas que genera la acumulación de agua, así como el daño en suelos y muebles y el gasto producido por un grifo de agua abierto.
Estos sistemas están cada día avanzando más y teniendo mayor importancia.
3.1.4 Comunicaciones Las aplicaciones de telecomunicaciones contemplan el intercambio de información, tanto entre personas, entre éstas y equipos domésticos y entre equipos y equipos, ya sea dentro de la propia vivienda como desde ésta con el exterior. En este grupo se incluyen todas las infraestructuras necesarias para la comunicación de voz y de datos que nos permiten disfrutar de los servicios de telefonía o de las funciones de distribución de ficheros de texto o multimedia, compartir recursos entre dispositivos, acceder a Internet varios usuarios simultáneamente, etc.
Estas aplicaciones gestionan la información de las demás áreas domóticas ayudando al propietario a controlar si hogar sin necesidad de estar en casa, mediante su teléfono móvil por medio de correos electrónicos, llamadas o telecontrol.
3.2 Domótica con el medio ambiente Actualmente, la construcción de la vivienda, se implica en una minimización del impacto sobre el medio ambiente, de forma que contribuya al ahorro sostenible que mejore las condiciones del planeta. Esto se consigue con una contribución a la generación de recursos que pueden surtir a la vivienda y a la red, eliminando el uso de energías no renovables. Además las condiciones climáticas donde se construyan y las necesidades de los habitantes dan lugar a multitud de posibilidades en cuanto a su implementación y diseño.
Las casas ecológicas, deben de ayudarse en lo posible de los factores circundantes que contribuyan a facilitar su construcción o uso. Algunas estrategias a seguir en base a esto pueden ser la orientación, el control del sol/viento y la potenciación de las vistas, pero bien es cierto que existirá un predominio de unos sobre otros en función de cada situación.
Figura 4. Casa abovedada
Por ejemplo, en el caso de una región con gran predominio de viento en una dirección, sería conveniente diseñar la estructura abovedada del techo de forma que facilite su paso y no actúe de obstáculo, creando un flujo laminar como en la conformación del ala de un avión. Además se pueden orientar molinos eólicos para el suministro eléctrico y entradas de ventilación y refrigeración. Al mismo tiempo se puede aprovechar para construir patios interiores con al fin de regular la temperatura y complementariamente, un sistema de regulación de la humedad en base a esto.
En el caso de situación en zona volcánica, si el edificio hace uso de las piedras del propio volcán y de las cenizas, puede servir de aislamiento térmico. Así mismo la captación de energía fotovoltaica a través de placas solares convenientemente adaptadas, puede dotar a la vivienda de abastecimiento. La captación térmica simple puede funcionar como sistema de calentamiento del agua.
Si la casa se sitúa en una región con alta concentración de sol (área desértica/árida), debe situarse orientada hacia el levante y protegida del poniente. Los paneles fotovoltaicos gozarán de gran protagonismo en este caso, dotando de energía y agua caliente al hogar. Si es posible, es conveniente la construcción de los muros con la utilización de rocas basálticas (volcánicas), que creen un aislamiento del interior para los cambios de temperaturas externos al edificio.
-53-

Si la zona es subdesarrollada, una vivienda de bajo coste con materiales reciclados es la mejor elección. Se debe minimizar el impacto medioambiental, y las técnicas de construcción serán dinámicas y ligeras.
En cuanto al emplazamiento de la vivienda también es recomendable seguir unos principios básicos, en el que el más importante es que la vivienda esté alejada de zonas industriales con elevada contaminación atmosférica o que tenga gran novel de ruido como pueden ser aeropuertos y que no se sitúe en las proximidades de líneas de alta tensión o de transformadores sectoriales.
La abundancia de vegetación es un factor de relevancia (también en el interior de la vivienda) ya que contribuye a crear un equilibrio térmico y un grado de humedad correcto, además de reducir la contaminación atmosférica. A eso se le suma la importancia de poder disfrutar de vistas y paisajes relajantes, con grandes beneficios para la salud.
La orientación solar, como se ha comentado anteriormente, es un factor de relevancia, ya que ayuda a regular temperatura, presión y aire, mejorando así la eficiencia energética. Las barreras topográficas son también importantes en este aspecto.
En cuanto a la utilización de materiales, lo más recomendable es la tendencia al uso de componentes lo más naturales posible: Ejemplos de ello pueden ser los ladrillos, cerámicos, piedra, madera, fibras vegetales, adobe y el uso de morteros con cal. Es conveniente evitar aquellos que contengan radioactividad, gases o electricidad estática, véase plásticos, superficies lacadas y fibras sintéticas.
En cuanto a pinturas, las de silicato son las más sanas, ya que son totalmente minerales, resisten al fuego y a la contaminación, son lavables, no tóxicas y permiten la respiración de las paredes.
Las maderas interiores, tanto de mobiliario como de decoración, deben de estar compuestas por barnices y aceites ecológicos, evitando aglomerados y formaldehido.
Una ventilación correcta es esencial para evitar acumular tóxicos en la vivienda.
Es recomendable no disponer de una ubicación próxima a líneas eléctricas ni transformadores, así como evitar aparatos eléctricos en lugares de reposo.
En cuanto a las orientaciones de la cama, lo mejor es colocarla hacia el Norte Magnético para un descanso relajado, y hacia el este para recuperar fuerzas.
En resumen, el ahorro energético es necesario para la construcción de una casa en la que tanto moradores como entorno tengan una máxima satisfacción. Ahorrar no significa pasar necesidad, sino más bien hacer un uso racional de los recursos.
Sin duda la mayor provisión de la casa domótica ecológica es la energía solar. Ésta es una energía de gran calidad desde el punto de vista energético, cuyo impacto ecológico es minúsculo y demás tiene la ventaja de que se trata de una energía renovable inagotable. A pesar de esto tiene algún inconveniente como por ejemplo su aprovechamiento, debido a que llega a la Tierra dispersa, o la existencia de noche y día o de las estaciones del año. La energía solar se puede captar por dos vías diferentes: térmica y fotónica.
Figura 5. Hogar con células fotovoltaicas
La primera de ellas funciona interceptándola por una superficie absorbente produciéndose un efecto térmico. Esto se puede producir de forma pasiva o activa (ayudado por elementos mecánicos).
En cuanto a la captación fotónica, la radiación solar se recoge directamente convirtiendo la energía de los fotones de la luz en electrones. En resumen, convierte la luz en electricidad.
El estudio de la energía solar pasiva (también conocida como bioclimática) resulta muy interesante, ya que se basa en las características de los materiales de la construcción y en el aprovechamiento de la circulación del aire, como bien se ha mencionado anteriormente. Los sistemas pasivos se construyen sobre la estructura del edificio y por tanto, tienen igual tiempo de vida que la propia estructura del edificio. Aún así esta arquitectura está condicionada por los siguientes factores: ganancia solar, almacenamiento de energía, distribución de calor e iluminación natural. Para ello elementos como elementos como acristalamientos toman una gran importancia, ya que funcionan como elementos concentradores de calor por efecto invernadero al hacer uso conjunto de ventanas y muros colectores y así captar mejor la energía. Todos estos elementos deben tener una orientación sur (en una ubicación del hemisferio norte) y orientación de una pared de aislamiento dirección norte para evitar la orientación fría.
Muros y techos constituyen lo que se llama “masa térmica”, que es aquella parte de la casa, cuya finalidad es almacenar la energía solar captada, transfiriéndola al interior de la casa.
En cuanto a la refrigeración, la utilización de toldos y persianas es fundamental. La ventilación inducida y el enfriamiento por evaporación hacen un papel importante en cuanto a la extracción nocturna del calor.
La iluminación se consigue a base de reflejar luz indirecta con paneles reflectantes y con la correcta utilización de pinturas que reflejen más o menos los rayos. Esta manipulación de la luz no produce ningún impacto sobre el medio ambiente. No actúa obre atmósfera, suelo o ecosistemas, debido a que aprovecha los recursos del entorno.
Existe otro elemento estructural de gran importancia, que es el llamado muro Trombe, el cual actúa como acumulador de energía de la misma forma que el efecto invernadero. Junto a él el colector
-54-

pasivo hace un máximo aprovechamiento de la radiación térmica. También cabe mencionar los acumuladores que se encargan de almacenar tanto agua como electricidad, luz, etc.
En el caso de España, como en casi todo el mundo, las construcciones ecológicas se encuentran bastante dispersas. La mayor parte de ellas sirven para la experimentación y el estudio. Aunque también hay que afirmar que no son raros los casos de viviendas tanto adosadas como aisladas que emplean energía solar pasiva.
Para la próxima década se calcula que se podrá duplicar el aprovechamiento de la energía solar pasiva y en consecuencia se podrá lograr por fin una reducción del 50% de las emisiones de CO2 y así se podrá llevar a cabo un importante ahorro económico.
Aunque todavía queda mucho por investigar, están en estudio nuevos materiales, características ópticas de las superficies, ventanas, tipologías constructivas, modelos de simulación, manuales de cálculo para constructores, etc.
3.3 Arquitectura La Arquitectura de los sistemas de domótica hace referencia a la estructura de su red. La clasificación se realiza en base de donde reside la “inteligencia” del sistema domótico. Las principales arquitecturas son:
3.3.1 Tipos de arquitectura
3.3.1.1 Arquitectura Centralizada En un sistema de domótica de arquitectura centralizada, un controlador centralizado, envía la información a los actuadores e interfaces según el programa, la configuración y la información que recibe de los sensores, sistemas interconectados y usuarios.
Figura 6. Esquema de Arquitectura de Sistema Domótica Centralizada
3.3.1.2 Arquitectura Descentralizada En un sistema de domótica de Arquitectura Descentralizada, hay varios controladores, interconectados por un bus, que envía información entre ellos y a los actuadores e interfaces conectados a los controladores, según el programa, la configuración y la información que recibe de los sensores, sistemas interconectados y usuarios.
Figura 7. Esquema de Arquitectura de Sistema Domótica Descentralizada
3.3.1.3 Arquitectura Distribuida En un sistema de domótica de arquitectura distribuida, cada sensor y actuador es también un controlador capaz de actuar y enviar información al sistema según el programa, la configuración, la información que capta por si mismo y la que recibe de los otros dispositivos del sistema.
Figura 8. Esquema de Arquitectura de Sistema Domótica Distribuida
3.3.1.4 Arquitectura Híbrida / Mixta En un sistema de domótica de arquitectura híbrida (también denominado arquitectura mixta) se combinan las arquitecturas de los sistemas centralizadas, descentralizadas y distribuidas. A la vez que puede disponer de un controlador central o varios controladores descentralizados, los dispositivos de interfaces, sensores y actuadores pueden también ser controladores (como en un sistema “distribuido”) y procesar la información según el programa, la configuración, la información que capta por si mismo, y tanto actuar como enviarla a otros dispositivos de la red, sin que necesariamente pasa por otro controlador.
-55-

Figura 9. Esquema de Arquitectura de Sistema Domótica Híbrida/Mixta
3.3.2 Medios de transmisión El medio de transmisión de la información, interconexión y control, entre los distintos dispositivos de los sistemas de domótica puede ser de distintos tipos, que se resumen básicamente en transmisión por cable (propio o compartido) y transmisión inalámbrica.
3.3.2.1 Cableado propio Es el medio más común de transmisión para los sistemas de domótica, principalmente son del tipo: par apantallado, par trenzado, coaxial o fibra óptica.
3.3.2.2 Cableado compartido Varios soluciones utilizan cables compartidos y/o redes existentes para la transmisión de su información, como por ejemplo la red eléctrica, la red telefónica o la red de datos.
3.3.2.3 Inalámbrico Muchos sistemas de domótica utilizan soluciones de transmisión inalámbrica entre los distintos dispositivos, principalmente tecnologías de radiofrecuencia o infrarrojo.
3.3.3 Protocolos Los protocolos de comunicación son los procedimientos utilizados por los sistemas de domótica para la comunicación entre todos los dispositivos con la capacidad de “controlador”.
Existen una gran variedad de protocolos, algunos específicamente desarrollados para la domótica y otros protocolos con su origen en otros sectores, pero adaptados para los sistemas de domótica. Los protocolos pueden ser del tipo estándar abierto (uso libre para todos), estándar bajo licencia (abierto para todos bajo licencia) o propietario (uso exclusivo del fabricante o los fabricantes propietarios).
Los dispositivos electrónicos de la casa deben comunicarse entre sí y generalmente lo hacen usando el protocolo X-10. Su desarrollo empezó en los años 70 y ha sido tal su éxito que durante los últimos 15 años se han vendido más de 150 millones de equipos X-10. Es la principal tecnología usada en la casa domótica para la red de control.
X-10 es un "lenguaje" de comunicación que aprovecha la instalación eléctrica existente de 220V de la vivienda
4. APRENDIZAJE DE LA CASAPara que se produzca una correcta interacción del sistema domótico con las necesidades del usuario, es necesario crear unos diálogos entre la casa y el medio u otros agentes. El sistema dispone de unos sensores mediante los cuales va acumulando información y va construyendo un aprendizaje a través de esta experiencia. Para que todo esto funcione correctamente deben de configurarse unos modelos de planificación y comportamiento. Estos funcionan de manera que, una vez recogida la información a través de los sensores, el sistema tendrá que tener una cierta capacidad de predecir los movimientos del usuario en función de sus hábitos o gustos. Este proceso tiene su base en la utilización de algoritmos de búsqueda que irán ramificando las acciones con cierta probabilidad en un árbol según las acciones del usuario (interacción pasiva) o por configuración directa según las preferencias (interacción activa). Al final, se consigue un modelo que representa los hábitos y preferencias del usuario, adaptado prácticamente en la totalidad a él.
Hay que tener en cuenta que todo esto está controlado por un sistema central, el cual irá configurando las características del sistema mediante la recogida de datos así como con la interacción con los elementos del sistema. Así el sistema puede predecir el estado de ánimo del inquilino y actuar en consecuencia, por ejemplo configurando una temperatura adecuada, sintonizando su música favorita o regulando la luz de la casa.
Aquí entra en escena el elemento planificador, el cual se encarga de juntar algoritmos y patrones de comportamiento del usuario para conseguir la configuración domótica óptima. Su funcionamiento consiste en la consecución de unas metas, pasando por distintos estados. El salto de un estado a otro es lo que llamamos acción y para conseguir llegar a la meta es necesaria la configuración de un plan. Para explicar esto, un buen ejemplo puede ser el momento en el que el sistema detecte, a través de reconocimiento facial por ejemplo, que el usuario sufre de dolor de cabeza en un determinado momento. El sistema se encuentra en un estado acorde con las características habituales y tiene que llegar a la meta de estado tranquilo y relajante. Para ello tiene que llevar a cabo un plan a través de unas acciones como regular la luz, poner música relajante, regular la temperatura, etc.
El sistema en sí también tiene que ser capaz de ser predictivo. Por ejemplo si, uno de los habitantes suele ir a trabajar en coche por un determinado trayecto y ese mismo día se ha producido un accidente, el sistema podría actuar de manera que le avisara despertándole un poco antes u ofreciéndole una ruta alternativa.
Dentro del sistema domótico también es imposible la implementación de macros. Una macro es la ejecución de una serie de acciones a partir de una ordeno o comando. Un ejemplo sería que al decir “home cinema” se configurara la habitación para la visualización de una película (regulando la luz con persianas y luces interiores, desplegando el proyector, reclinando los sofás, etc.) y dando lugar a otra macro como puede ser “Gladiator en versión original” y configura la película elegida.
Estas macros pueden estar programadas de serie, con un simple reconocimiento de voz, o el aprendizaje de la casa puede ir añadiéndolas en función de los gustos del usuario.
-56-

5. PROYECTOS DE FUTURO Como hemos observado a lo largo de este trabajo la domótica está a la orden del día y va a seguir creciendo y evolucionando hasta estar completamente adaptada a nuestro modo de vida. El crecimiento de la domótica sigue distintas vías que vamos a desarrollar brevemente.
En primer lugar el ahora energético proporcionado por la domótica va a evolucionar creando casas, edificios y posteriormente ciudades más ecológicas y verdes, para volver a adaptarnos a vivir en consonancia con la naturaleza y beneficiarnos de sus recursos de forma más eficiente, en este rango la domótica se está estudiando para poder reciclar nuestros desechos y convertirlos en energía, ahorrando así provocar mayor gasto y evitar la contaminación.
Figura 10. Prototipo de papelera ecológica de marca Braun.
Por otro lado también se están estudiando el obtener energía a partir de otros medios de energía renovable que podemos tener en nuestros hogares como puede ser la energía de biomasa producida por los espacios verdes y mejorar las actuales obtenciones de energía solar.
Figura 11. Edificio bioclimático en la escuela de arte de Singapur
Otros de los avances más significativos de este sector, es el de hacernos la vida cada vez más cómoda, algunos ejemplos de este avance son por ejemplo los sistemas de detección biométricos estos sistemas de detección pueden ser usados para por ejemplo entrar en la casa sin necesidad de usar las llaves o por ejemplo dar órdenes a distintos sistemas a través del reconocimiento de voz.
Está tecnología nos llevará a estar en un futuro que muchas personas imaginaban, en el que las casas dejan pasar a sus dueños
sin necesidad de llaves, o que hacen la compra a medida de las necesidades de sus dueños, mejorando así su confort y dándoles la posibilidad utilizar mejor su tiempo en cosas más provechosas.
6. CONCLUSIONES El uso de la domótica ha ido tomando mayor relevancia a lo largo de la historia reciente. Los grandes avances que se han ido produciendo, han llevado a crear sistemas inteligentes capaces de crear un ambiente de confort regulado a las condiciones y preferencias de los habitantes de la casa.
Las distintas áreas en las que se ha ido implantando han dado ventajas sustanciales a los usuarios de estos sistemas así como ha manejado un compromiso con el medio ambiente que mejora su sostenibilidad. El hecho de que sea posible entrar en aspectos como la reducción del consumo, simplificación de tareas (confort), mejora de los sistemas de seguridad o la intercomunicación entre distintos apartados crea un nivel superior sobre el que construir la vivienda del futuro, haciendo la vida mucho más fácil.
Aún así la conjunción vivienda nueva y domótica es un hecho todavía sin una implantación clara, ya que los precios de los dispositivos utilizados tienen un precio alto. Por ello la relación calidad de vida-inversión no es buena.
Poco a poco las economías de escala y la difusión de la domótica harán que su penetración en el mercado vaya aumentando, hasta conseguir su asentamiento total.
La casa inteligente cada día está más cerca. Es cuestión de tiempo.
Figura 12. Casa domótica
7. REFERENCIAS [1] Mayo Bayón, Ricardo. 2005.Aplicación al diseño y
desarrollo de sistemas domóticos/inmóticos. Curso de
doctorado Universidad de Oviedo.
[2] García Plaza, David. 2010. Sistema de gestión domótica de una vivienda. Proyecto Final de Carrera Universidad
Politécnica de Cataluña.
[3] Morales Pallarés, Marcos. 2007. Estudios de los sitemas domóticos y diseño de una aplicación. Proyecto Final de
Carrera Universidad Politécnica de Cataluña.
-57-

[4] Artículo sobre Inteligencia Artificial en Monografías.com. DOI= http://www.monografias.com/trabajos87/inteligencia-artificial-domotica/inteligencia-artificial-domotica.shtml
[5] Web de domótica domoticaviva. DOI= http://www.domoticaviva.com
[6] Web de domótica indomo. DOI= http://www.indomo.es/
[7] Web de competición de casas inteligentes. DOI= http://www.sdeurope.org/
[8] Dossier Inove sobre ahorro energético. DOI= www.inovedomotica.com
[9] Herrera, Rosa María. Artículo: Casas Inteligentes vs. Casas Ecológicas.
[10] CEDOM. Artículo: Como ahorrar energía instalando domótica en su vivienda. DOI= www.idae.es
-58-

Técnicas para exploración de bases de datos
Daniel Aceituno Gómez Estudiante Ing. Telecomunicación Universidad Carlos III de Madrid Avenida de la Universidad, 30
28911, Leganés (Madrid-España) [email protected]
Miguel Alcolea Sánchez Estudiante Ing. Telecomunicación Universidad Carlos III de Madrid Avenida de la Universidad, 30
28911, Leganés (Madrid-España) [email protected]
RESUMEN
El objetivo del trabajo es conseguir las imágenes más parecidas a una dada dentro de una base de datos de 6600. Para ello se utilizarán dos técnicas de búsqueda, una de ellas basada en agrupamiento (k-medias) y otra según el criterio de mínima distancia (distancia Euclídea). La base de datos proporcionada está formada por siluetas de animales marinos. El código Matlab desarrollado debe ser capaz de encontrar los contornos más parecidos al de muestra, independientemente de la rotación, posicionamiento y escalado de éste.
Categorías y Descriptores de Temas
[Exploración de bases de datos]: agrupamiento, técnicas y aplicaciones de búsqueda de imágenes, visión artificial.
Términos Generales
Clustering, Matlab, algoritmos de búsqueda, exploración de bases de datos.
Palabras clave K-medias, Euclídea, bases de datos.
1. INTRODUCCIÓN
Uno de los principales objetivos de la visión artificial [1] es poder diferenciar los objetos presentes en una imagen (en este caso, en una imagen digital), de tal manera, que esto logre que la identificación de los mismos sea una tarea más fácil de realizar.
En el problema de diferenciar los objetos en cualquier imagen, como es hecho por los seres humanos, una importante pregunta abierta aparece: ¿Qué información es, tanto suficiente como necesaria, para poder llevar a cabo esta tarea? Es muy difícil poder expresar este conocimiento o información de una manera algorítmica.
Dentro de la visión artificial se encuentra el procesamiento de imágenes, y dentro de éste, una parte muy importante se encarga del análisis de las mismas. Esto es, dada una imagen, lo que se desea obtener es una descripción de dicha imagen. Por otra parte, la segmentación se encarga de simplificar y/o cambiar la representación de una imagen en otra más significativa y más fácil de analizar. Se usa tanto para localizar objetos como para encontrar los límites de estos dentro de una imagen. Más
precisamente, la segmentación [2] de la imagen es el proceso de asignación de una etiqueta a cada píxel de la imagen de forma que los píxeles que compartan la misma etiqueta también tendrán ciertas características visuales similares.
El resultado de la segmentación de una imagen es un conjunto de segmentos que cubren en conjunto a toda la imagen, o un conjunto de las curvas de nivel extraídas de la imagen (detección de bordes). Cada uno de los píxeles de una región son similares en alguna característica, como el color, la intensidad o la textura. Regiones adyacentes son significativamente diferentes con respecto a la(s) misma(s) característica(s).
En la sección 2 del presente trabajo se analizarán las técnicas y métodos necesarios para llevar a cabo el desarrollo del algoritmo de exploración y clasificación. En la sección 3 se describirá detalladamente el funcionamiento del código Matlab realizado y en la sección 4 se presentarán los resultados de las pruebas. Por último, en la sección 5 se detallarán las conclusiones.
2. DESARROLLO TEÓRICO
A continuación, se describirán las técnicas usadas para el desarrollo del algoritmo de exploración.
2.1 Descriptores de imágenes
Un descriptor de una imagen es una forma de representar a una imagen por sus características, con fines de almacenamiento y recuperación, en donde el descriptor es una formulación matemática. La formulación del descriptor se realiza tanto para características locales como globales. Existen tres grandes grupos de descriptores: de frontera, de región y relacionales.
1) Descriptores de frontera: extraen información de laforma del contorno de los objetos.
2) Descriptores de región: caracterizan no al contorno de laforma, sino al interior de la misma.
3) Descriptores relacionales: describen la estructura de losobjetos y las relaciones (cercanía, inclusión…) entre suscomponentes.
Debida a la naturaleza de las imágenes de la base de datos proporcionada y para cumplir los requisitos de independencia de rotación, posición y escalado, se va a trabajar con los de frontera y en concreto con los descriptores de Fourier [3].
-59-

2.1.1 Descriptores de Fourier
Representan la forma del objeto destacando que, los primeros descriptores indican la forma general del objeto y los últimos los más pequeños detalles. Para una clasificación correcta, un pequeño conjunto de descriptores puede ser suficiente. La gran ventaja de los descriptores de Fourier es que son invariantes frente a la traslación, la rotación, la escalabilidad y son tolerantes al ruido. Un requisito indispensable para aplicar estos descriptores es que los objetos o contornos deben ser cerrados.
Una curva cerrada puede ser representada mediante series de Fourier con una parametrización adecuada. Si se considera un contorno x(n) constituido por N puntos en el plano XY [4]:
€
x n( ) = xn,yn[ ],n =1...N (1)
donde cada punto se puede considerar como un número complejo:
€
x n( ) = xn + jyn (2)
Empezando en un punto arbitrario del contorno y siguiendo alguna dirección de avance (por ejemplo, a favor de las agujas del reloj), se tiene una secuencia de números complejos. La transformada discreta de Fourier X = F(x) de la secuencia se obtiene mediante la siguiente ecuación:
€
X k( ) = x n( )exp − j2πkn /N( ) 0 ≤ k ≤ N −1n= 0
N−1
∑ (3)
De esta forma, los descriptores de Fourier pueden representar un contorno cerrado arbitrario. Esta representación tiene la ventaja de que, generalmente, se logra una buena descripción en base a pocos términos.
Sea la base de datos de nbase siluetas:
€
SR i( ),1≤ i ≤ nr con 1≤ R ≤ nbaseCada silueta se regulariza a N puntos (N es potencia de 2):
€
SR i( )→ ZR n( ) 1≤ n ≤ N
Supóngase que se tiene una silueta escena
€
S__
obtenida de una imagen y regularizada a N puntos:
€
S__→ Z
__n( ) 1≤ n ≤ N
El problema consiste en identificar
€
Z__
con alguna silueta
€
Z__
Rbajo la hipótesis de que puede haber sufrido:
1) Desplazamiento en el origen de referencia del vector dela silueta: δ
2) Rotación respecto al centro de masas del objeto: θ
3) Escalado de la imagen: λ
4) Desplazamiento del centro de masas del objeto Cx , Cyen la coordenada x-y respectivamente.
A continuación, se analiza cuál es la transformación en la transformada de Fourier de una silueta bajo cada una de estas operaciones:
1) Desplazamiento δ
Sea la secuencia:
€
x n( )→ X k( ) = x n( )exp − j2πkn /N( ) 0 ≤ k ≤ N −1 (4)n= 0
N−1
∑Se define la nueva secuencia:
€
x__n( ) =
x__n( ) = x n + δ( ) , 0 ≤ n ≤ N −1−δ
x__n( ) = x n − N + δ( ) , N -δ ≤ n ≤ N −1
(5)
Sustituyendo en (4) se tiene:
€
X__k( ) = x
__n( )exp − j2πkn /N( ) =
n= 0
N−1
∑
= x n + δ( )exp − j2πkn /N( ) + x n − N + δ( )exp − j2πkn /N( )n=N−δ
N−1
∑n= 0
N−1−δ
∑ (6)
Intercambiando coeficientes y reagrupando se obtiene que:
€
X__k( ) = X k( )exp j2πkn /N( ) (7)
2) Rotación θ
Sea la secuencia x(n), la nueva secuencia es:
€
x__n( ) = exp jθ( )x n( ) (8)
La relación entre transformadas de Fourier es:
€
X__k( ) = exp jθ( )X k( ) (9)
3) Escalado λ
Sea la secuencia x(n), la nueva secuencia es:
€
x__n( ) = λx n( ) (10)
La relación entre transformadas es:
€
X__k( ) = λX k( ) (11)
4) Desplazamiento c=cx+jcySea la secuencia x(n), la nueva secuencia es:
€
x__n( ) = x n( ) + c (12)
La relación entre transformadas es:
€
X__k( ) = X k( ) + cN (13)
-60-

2.2 Método de agrupamiento
El objetivo del análisis de agrupamiento [5], visto como procedimiento de clasificación, es determinar grupos dentro de una muestra multivariada que tengan algún grado de asociación o similitud entre los miembros de cada grupo y, simultáneamente, los miembros de distintos grupos presenten bajo grado de asociatividad o similaridad. El resultado del análisis de agrupamiento es poner de relieve las similitudes entre los datos.
El problema del Agrupamiento: Dado un conjunto S de n puntos en un espacio Euclídeo de dimensión Rm, el problema es como particionar S en k grupos, clases o nidos. Si llamamos Pk a todas las particiones de S en k nidos, y definimos un criterio de agrupamiento W(Pk) donde cada P es una medida de la confiabilidad de la partición en k nidos. El problema es, entonces, encontrar la partición P' que maximiza (o minimiza) el criterio sobre todas las particiones en k nidos.
Existen muchos algoritmos para resolver este problema. Se puede hacer una clasificación primaria en: métodos jerárquicos y no jerárquicos.
1) Métodos jerárquicos:En estos métodos, los individuos no se particionan en clusters de una sola vez, sino que se van haciendo particiones sucesivas a distintos niveles de agregación o agrupamiento.
Fundamentalmente, los métodos jerárquicos suelen subdividirse en métodos aglomerativos (ascendentes), que van sucesivamente fusionando grupos en cada paso; y métodos divisivos (descendentes), que van desglosando en grupos cada vez más pequeños el conjunto total de datos.
Dentro de este grupo se encuentran los algoritmos de los “vecinos más cercanos” y “vecinos lejanos”. 1.1) Vecinos más cercanos:
El criterio de agrupamiento que se utiliza es:
€
dmin Di,Dj( ) =min x −x ′
donde x pertenece a Di y x´ a Dj. Cuando el algoritmo se termina con la verificación de un umbral sobre la función de criterio de agrupamiento, se conoce como “algoritmo de encadenamiento simple”. Este algoritmo siempre genera un árbol (los bordes entre clases siempre evolucionan a distintas clases) es decir que no se generan ciclos.
1.2) Vecinos lejanos:
El algoritmo es igual al anterior pero la función de criterio de agrupamiento es:
€
dmax Di,Dj( ) =max x −x ′
Además si se agrega un criterio de terminación sobre esta función, se conoce como “algoritmo de encadenamiento completo”.
Con el algoritmo de vecinos cercanos la distancia entre clases es la distancia entre las muestras más cercanas. En el de vecinos lejanos la distancia entre clases es la de muestras más lejanas.
2) Métodos no jerárquicos:Estos métodos generan grupos disjuntos, es decir, que la intersección de a pares es vacío. Son muy útiles cuando el conjunto de datos es plano. Hay tres ejemplos claros de este tipo de método: algoritmo k-medias, k-medias secuencial y Fuzzy k-medias. Éste último se basa en el concepto de lógica difusa que toma lo relativo de lo observado como posición diferencial. Las fronteras entre los conjuntos son difusas, es decir, los elementos presentan un “grado de pertenencia” a un conjunto en vez de formar parte de uno exclusivamente.
El candidato elegido para el trabajo ha sido el k-medias.
2.2.1 El algoritmo k-medias
El algoritmo K-medias [6] es una técnica iterativa que se utiliza para dividir una imagen en K clusters. Una primera aproximación a su funcionamiento es la siguiente:
1) Se escogen K centros de clusters, ya sea de formaaleatoria o basándose en alguno método heurístico.
2) Se asigna a cada píxel de la imagen el clúster queminimiza la varianza entre el píxel y el centro delclúster.
3) Se recalculan los centros de los clusters haciendo lamedia de todos los píxeles del clúster.
4) Se repiten los pasos 2 y 3 hasta que se consigue laconvergencia (por ejemplo, los píxeles no cambian declusters).
En este caso, la varianza es la diferencia absoluta entre un píxel y el centro del clúster. En general, la diferencia se basa típicamente en el color, la intensidad, la textura, y la localización del píxel, o una combinación ponderada de estos factores. El número K se puede seleccionar manualmente, aleatoriamente, o por una heurística. Este algoritmo garantiza la convergencia, pero puede devolver una solución que no sea óptima. La calidad de la solución depende de la serie inicial de clusters y del valor de K. En estadística y aprendizaje automático, el algoritmo de las k-medias es un algoritmo de agrupamiento para dividir objetos (N) en K grupos, donde K < N. Es similar al algoritmo de maximización de expectativas para las mezclas de gaussianas ya que ambos pretenden encontrar los centros de agrupaciones naturales de los datos. El modelo requiere que los atributos del objeto correspondan a los elementos de un espacio vectorial. El objetivo es intentar alcanzar al mínima varianza total entre clusters, o, la función de error al cuadrado.
El algoritmo de las k-medias usa una heurística de refinamiento conocida como el algoritmo de Lloyd [7]. Funciona de la siguiente manera:
1) Comienza dividiendo los puntos de entrada en Kconjuntos iniciales, ya sea al azar o usando algunosdatos heurísticos y a continuación, calcula el puntomedio o centro de gravedad de cada conjunto.
2) Se construye una nueva partición, asociando cada puntocon el centro de gravedad más cercano.
3) Se recalculan los baricentros para los nuevos clusters,
4) El algoritmo se repite alternando la aplicación de estosdos pasos (2 y 3) hasta que converja. Dichaconvergencia se obtiene cuando los puntos ya no
-61-

cambian de clúster (o los centros de gravedad ya no se modifican).
Los algoritmos de Lloyd y de las K-medias a menudo se utilizan como sinónimos, pero en realidad el algoritmo de Lloyd es una heurística para resolver el problema de las K-medias, como ocurre con ciertas combinaciones de puntos de partida y baricentros. El algoritmo de Lloyd puede converger a una solución incorrecta. Existen otras variantes, pero el algoritmo de Lloyd es el más popular, porque converge muy rápidamente. En cuanto al rendimiento, el algoritmo no garantiza que se devuelva un óptimo global.
La calidad de la solución final depende en gran medida del conjunto inicial de clusters, y puede, en la práctica, ser mucho más pobre que el óptimo global. Dado que el algoritmo es extremadamente rápido, es un método común ejecutar el algoritmo varias veces y devolver las mejores agrupaciones obtenidas. Un inconveniente del algoritmo de las k-medias es que el número de clusters K es un parámetro de entrada. Una elección inadecuada de K puede dar malos resultados. El algoritmo también asume que la varianza es una medida adecuada de la dispersión del cluster.
A continuación, se presenta una explicación matemática del algoritmo: Suponga que se tienen n características en vectores x1, x2, ..., xn, donde cada x, está representado en un espacio m dimensional y se sabe que están agrupados en k cúmulos (k < n).
Se define mj como la media del j-ésimo cúmulo. Si los cúmulos están bien separados, se puede usar una mínima distancia de clasificación para separarlos. Se puede decir que xi está en el j-ésimo cúmulo si || xi – mj || es el mínimo con respecto a los k cúmulos.
Ésto sugiere el siguiente algoritmo para encontrar la k medias:
1) Se hace una estimación inicial para la k medias m1, m2, ..., mk. Mientras no cambie alguna media:
Se usa la media estimada para clasificar los datos en cúmulos. b(i,j) = 1 si el i-ésimo dato, es el más cercano a la j-ésima media.
2) Para cada uno de los cúmulos, se calcula la nueva media mj, utilizando la nueva clasificación.
En la siguiente imagen hay un ejemplo que muestra la ejecución del algoritmo k-medias.
Éste puede ser visto como un algoritmo voraz para particionar en k cúmulos. Pero este algoritmo tiene algunas debilidades:
1) La manera de inicializar no se especifica.
2) Los resultados dependerán del valor inicial de las medias y frecuentemente ocurre que particiones subóptimas son encontradas. La solución estándar es calculada utilizando diferentes puntos de arranque.
3) Puede pasar que un conjunto de ejemplos cercano a una media esté vacío, por lo que no puede ser modificada. Esto es un inconveniente del método y debe ser manejado en la implementación, pero puede ser ignorado.
4) Los resultados dependen de la métrica utilizada para medir || x - mj ||. Una solución popular es normalizar cada variable por la desviación estándar, aunque no siempre es deseable.
5) La solución depende del número de cúmulos seleccionado.
2.3 Distancia Euclídea La distancia Euclídea [8] es la disimilaridad más conocida y más sencilla de comprender, pues su definición coincide con el concepto más común de distancia. En un espacio bidimensional, la distancia euclidiana entre dos puntos P1 y P2 de coordenadas (x1, y1) y (x2, y2) respectivamente, es:
€
dE P1,P2( ) = x2 − x1( )2 + y2 − y1( )2
A continuación, se ilustra la formulación matemática:
-62-

La distancia Euclídea, a pesar de su sencillez de cálculo y de que verifica algunas propiedades interesantes tiene dos graves inconvenientes:
1) El primero de ellos es que es una distancia sensible a las unidades de medida de las variables. Las diferencias entre los valores de variables medidas con valores altos contribuirán en mucha mayor medida que las diferencias entre los valores de las variables con valores bajos. Como consecuencia de ello, los cambios de escala determinarán, también, cambios en la distancia entre los individuos.
Una posible vía de solución de este problema es la tipificación previa de las variables, o la utilización de la distancia Euclídea normalizada.
2) El segundo inconveniente no se deriva directamente de la utilización de este tipo de distancia, sino de la naturaleza de las variables. Si las variables utilizadas están correlacionadas, estas variables darán una información, en gran medida redundante. Parte de las diferencias entre los valores individuales de algunas variables podrían explicarse por las diferencias en otras variables. Como consecuencia de ello la distancia euclídea inflará la disimilaridad o divergencia entre los individuos.
La solución a este problema pasa por analizar las componentes principales (que están incorrelacionadas) en vez de las variables originales. Otra posible solución es ponderar la contribución de cada par de variables con pesos inversamente proporcionales a las correlaciones, lo que conduce a la utilización de la distancia de Mahalanobis.
La distancia Euclídea será, en consecuencia, recomendable cuando las variables sean homogéneas y estén medidas en unidades similares y/o cuando se desconozca la matriz de varianzas.
3. FUNCIONAMIENTO DEL ALGORITMO
En esta sección se detallará minuciosamente el proceso que se sigue en el procesado de las imágenes, el cálculo de los descriptores, las dos técnicas empleadas para la exploración de la base de datos y la obtención de los resultados. El esquema básico es el siguiente:
Este esquema se ha plasmado en un programa creado en Matlab que se llama agrupamiento.
function []=agrupamiento(numeroImagen,tipoClasificador)
Dicha función recibe como parámetros de entrada el índice de la imagen de muestra de la que se quieren obtener imágenes similares de la base de datos y el tipo de clasificador a utilizar (k-medias o distancia mínima). El resultado de la ejecución es un conjunto de imágenes similares a la de entrada. El tamaño de dicho conjunto es de 20 imágenes como máximo. Es el criterio de parada que se ha utlizado para la subdivision en el algoritmo de k-medias.
3.1 Carga de imágenes
En primer lugar, hay que cargar en Matlab las imágenes contenidas en la base de datos. Éstas están almacenadas en archivos con extensión .con y suman un total de 6600. Tras leer y almacenar dichos ficheros, se obtienen los pares de puntos correspondientes a cada silueta o contorno. Posteriormente se realiza una conversion de las coordenadas al dominio complejo para calcular los descriptores de Fourier. Debido a que las imágenes son muy diversas, hay que encontrar una manera de normalizar los contornos. De esta manera, todos tendrán el mismo número de coeficientes. Se ha fijado este valor en 700 ya que es, aproximadamente, el valor medio del número de puntos que hay en cada imagen.
Carga de imágenes y conversión a complejo
Cálculo de los descriptores de Fourier
Procesado invarianza de escalado y rotación
K-medias Distancia Euclídea
BBDD: siluetas animales marinoos
Nº Imagen
1 2
Imágenes similares Imágenes similares
Algoritmo?
-63-

Imagen 1 Imagen 2 Imagen 3 - Imagen
6600
Coef 1
Coef 2
Coef 3
-
Coef 700
Esta tarea es muy costosa computacionalmente. Por lo tanto, solo se realizará una vez y el resultado se almacena en el archivo basededatos.mat que contiene las imágenes perfectamente normalizadas y listas para su uso en la aplicación.
3.2 Cálculo y procesado de los descriptores de Fourier
Para obtener los descriptores, se calcula la transformada de Fourier para cada imagen. En Matlab se utiliza la función fft que proporciona los coeficientes ak.
A partir de ellos se obtienen los descriptores. Para que sean invariantes frente a rotación, hay que eliminar la información de fase. Por ello se obtiene el módulo de cada coeficiente complejo.
Respecto al posicionamiento, no es necesario realizar ninguna operación ya que se ha de tener en cuenta que la transformada de Fourier para imagen tiene la propiedad de “desplazamiento circular”. Esto es, el módulo (que es lo que usa) para cada una de las siguientes imágenes es igual:
En cuanto al escalado, cada imagen se normaliza respecto al valor máximo de módulo. Para ello se divide cada coeficiente entre el máximo. De esta forma se asegura que el valor de los coeficientes de las imágenes son comparables entre sí independientemente del tamaño del contorno de cada una de ellas.
3.3 Agrupamiento por K-medias
Una vez que la base de datos está normalizada, se procede a seleccionar aquellas imágenes más parecidas a la de muestra. En caso de que el tipo de clasificador seleccionado sea el número 1, se ejecutará el algoritmo de k-medias.
El algoritmo se ejecuta como sigue:
1) Se ha diseñado el algoritmo para generar dos centroides.Se calcula la distancia de cada imagen a ellos. Cada unoestará asociado a las imágenes más cercanas, de estaforma se obtienen dos grupos. De esos dos grupos, seselecciona aquel en el que se encuentre la imagen demuestra para continuar con la búsqueda de las imágenesmás parecidas a la elegida.
2) En el nuevo grupo formado, se vuelven a calcular doscentroides y las distancias de las imágenes a ellos por loque se crean dos nuevos grupos. De nuevo, el grupoelegido para hacer otra subdivisión es aquel donde seencuentra la imagen de muestra.
3) Se repite el proceso hasta que quede un grupo formadopor la muestra y un máximo de diecinueve imágenes.
Hay que tener en cuenta que este algoritmo se inicializa de forma aleatoria y posteriormente ajusta los centroides en función de las muestras. Debido a esa inicialización aleatoria, el resultado puede variar de una a otra ejecución.
Durante el proceso de subdivisión en dos grupos, se muestra por pantalla el número de imágenes que contiene el grupo seleccionado. De esta forma se puede ver el progreso del algoritmo.
Por último, se representa la imagen de muestra así como una figura con los mejores resultados encontrados.
3.4 Mínima distancia
Es una técnica simple que tiene bajo coste computacional y por tanto se ejecuta de una manera muy rápida. Como se comprobará en la posterior evaluación, de una forma más simple, se consiguen unos resultados muy buenos.
El funcionamiento es el siguiente:
1) Se calcula la distancia Euclídea entre el vector dedescriptores de la imagen de referencia y el resto deimágenes. Cada uno de estos vectores tendrá dimensión700.
2) Tras el cálculo, se eligen los veinte contornos queproporcionen menor distancia Euclídea. Hay que teneren cuenta que como primer resultado, el sistemaobtendrá la imagen original que es la que tiene distanciacero.
La formulación matemática es la que sigue:
Cij: coeficiente i de la imagen j
Cir: coeficiente i de la imagen de referencia
Del vector distEucl_imgn_j, se obtienen las distancias mínimas y se mapea la distancia minima con la imagen de la base de datos que la produce.
-64-

4. EVALUACIÓN
En esta sección se va a evaluar el programa desarrollado utilizando tres imágenes muy distintas.
El primer contorno (imagen de la izquierda) se puede corresponder con un tiburón, el segundo (centro) con una raya y el tercero con un animal marino prehistórico (derecha).
4.1 Imagen 739 4.1.1 Resultados por k-medias
Tras la ejecución, se han obtenido 17 contornos muy similares al de muestra. Además, se puede comprobar que la invarianza a rotación y escalado funciona perfectamente.
4.1.2 Resultados por distancia Euclídea
En este caso, mediante la distancia Euclídea se ha obtenido dos contornos más (19) que con el algoritmo k-medias.
4.2 Imagen 4482 4.2.1 Resultados por k-medias
De nuevo, para la raya se han conseguido devolver 17 contornos muy parecidos a ésta. Se observa que hay animales con la cabeza más redonda, otros la tienen más triangular, pero en general todos son similares.
4.2.2 Resultados por distancia Euclídea
Por el criterio de mínima distancia se devuelven 19 contornos pero se detectan errores. Ha clasificado 6 siluetas como rayas cuando realmente no lo son. Por lo tanto, en este caso los resultados por este segundo método, menos costoso computacionalmente, no son tan buenos como los que arroja el algoritmo k-medias.
-65-

4.3 Imagen 4405 4.3.1 Resultados por k-medias
La clasificación para este tipo de animal es algo más difusa que en los casos anteriores. Se devuelven 17 contornos y todos ellos tienen relación con la imagen de muestra aunque hay algunos con menos similitud que otros.
4.3.2 Resultados por distancia Euclídea
En este ejemplo, se observa que la recuperación de imágenes es ligeramente mejor que con k-medias. La mayoría de contornos guardan una estrecha relación con la imagen de muestra. El criterio de mínima distancia es capaz de detectar los bordes puntiagudos del animal. Para este tipo de contorno, el k-medias recupera resultados con los bordes redondeados y suavizados alejándose un poco de la figura original. Da la sensación de que la mínima distancia tiene mayor poder expresivo.
5. CONCLUSIONES
Para determinar que técnica ofrece mejores resultados y cuál de ellas sería la óptima para ser incorporada en un sistema real, hay que tener en cuenta varios factores.
En primer lugar, es muy importante prestar atención a la naturaleza de las imágenes con las que se va a trabajar. El algoritmo de k-medias funciona bastante bien si los contornos o siluetas tienen bordes suavizados y redondeados. Por el contrario, si éstos tienen aristas más pronunciadas, hay que recurrir al poder expresivo de la mínima distancia. También hay que tener en cuenta el tiempo de ejecución de cada método. Se ha comprobado que el k-medias es mucho más pesado y más lento que la mínima distancia. Por otra parte, la formulación de ambos algoritmos dista mucho entre sí. El método que utiliza el k-medias es muy complejo comparado con la simple diferencia de descriptores que utiliza el método de mínima distancia.
Finalmente, en base a los distintos factores discutidos, no se puede concluir que uno de los métodos es bueno o malo. Se puede decir que ambos funcionan bien y hay que buscar un compromiso entre la fiabilidad de los resultados, el coste computacional y la naturaleza de las imágenes a recuperar.
6. AGRADECIMIENTOS
Queremos dar las gracias al profesor de la asignatura por darnos la oportunidad de investigar y trabajar en esta parte de la visión artificial.
7. REFERENCIAS
[1] Richard Szeliski. Computer Vision: Algorithm & Applications. 30 de Marzo 2008
[2] Segmentación http://dsp1.materia.unsl.edu.ar/Segmentacion.pdf
[3] Dengsheng Zhang and Guojun Lu. Gippsland School of Computing and Info Tech Monash University Churchill, Victoria 3842. Generic Fourier Descriptor for Shape-based Image Retrieval
[4] Elizabeth González García. Universidad de Matanzas, Cuba. Descriptores de Fourier para identificación y posicionamiento de objetos en entornor 2D. Septiembre 2004.
[5] Métodos de agrupamiento
http://davidcuria.blogspot.com.es/2009/07/analisis-de-atributos-metodos-de.html
[6] Wikipedia – K-means clustering http://en.wikipedia.org/wiki/K-means_clustering
[7] Prof. Leonard Schulman, Department of Computer Science, California Institute of Technology. A theoretical analysis of Lloyd’s algorithm for k-means clustering. 13 Noviembre 2009.
[8] Wikipedia – Distancia Euclídea http://en.wikipedia.org/wiki/Euclidean_distance
-66-

SISTEMAS EXPERTOS. MAGERIT
Adrián García Diéguez Estudiante Ing. Telecomunicación Universidad Carlos III de Madrid Avda. De la Universidad, 30 28911, Leganés (Madrid - España) [email protected]
RESUMEN
En este documento vamos a explicar el significado de lo que es un Sistema Experto mediante el análisis de sus principales componentes y características.
En concreto analizaremos el sistema experto MAGERIT basado en el análisis y gestión de riesgos de los sistemas de información de las administraciones públicas.
Palabras clave
Sistemas expertos (SE), gestión del riesgo, seguridad, activos, dominio
1. INTRODUCCIÓN
Un sistema experto o un sistema basado en el conocimiento es un sistema informático capaz de emular las prestaciones de un experto humano en un área de conocimiento especializado.
Debido a la dependencia creciente de las administraciones públicas y de toda la sociedad de las tecnologías de la Información y las Comunicaciones, surgió el sistema experto MAGERIT.
MAGERIT es un método formal para investigar los riesgos que soportan los Sistemas de Información y para recomendar las medidas apropiadas que deberían adoptarse para
Jesús García Jiménez Estudiante Ing. Telecomunicación Universidad Carlos III de Madrid Avda. De la Universidad, 30 28911, Leganés (Madrid - España) [email protected]
controlar esos riesgos. Por ello, permite aportar racionalidad en el conocimiento del estado de seguridad de los Sistemas de Información y en la introducción de medidas de seguridad
2. LOS SISTEMAS EXPERTOS
Un sistema experto puede definirse como un sistema basado en los conocimientos que imita el pensamiento de un experto, para resolver problemas de un terreno particular de aplicación.
Una de las características principales de los sistemas expertos es que están basados en reglas, es decir, contienen unos conocimientos predefinidos que se utilizan para tomar todas las decisiones.
Por ello, el creador de un sistema experto tiene que comenzar por identificar y recoger del experto humano los conocimientos que este utiliza, pero sobre todo los conocimientos empíricos que se adquieren con la
práctica. Dado que los programas están basados en el conocimiento, un aspecto fundamental es la
-67-

programación del conocimiento. En ella se hace uso de la representación explícita del conocimiento a usar por el sistema y de su interpretación y manipulación lógica por medio de métodos de inferencia que permiten deducir nuevo conocimiento a partir del que ya se dispone.
De este modo, un sistema experto no pretende reproducir el pensamiento humano, sino simplemente la pericia de un profesional competente. Por ello para que un sistema actúe como un verdadero experto, debe reunir una serie de características del experto humano:
- Habilidad para adquirir conocimiento
- Fiabilidad, para poder confiar en sus resultados o apreciaciones
- Solidez en el dominio de su conocimiento
- Capacidad para resolver problemas
Podemos dividir un sistema experto en 3 componentes principales:
- Base de conocimiento - Motor de inferencia - Base de hechos - Interfaz de usuario
Figura 1. Componentes de un SE
También destacan otros módulos que forman parte de un sistema experto:
- Módulo de comunicaciones - Módulo de explicaciones - Módulo de adquisición de
conocimiento
A continuación se analizan cada una de estas partes.
2.1 Base del conocimiento
La base del conocimiento es una estructura de datos que contiene una gran cantidad de información sobre un tema específico, generalmente introducida por un experto en dicho tema, sobre el cual se desarrolla la aplicación. Es decir se trata del conocimiento convenientemente formalizado y estructurado que posee un sistema experto, sobre un tema específico.
Este conocimiento los constituye la descripción de:
- Descripción de los objetos - Relación entre ellos - Casos particulares y excepciones - Diferentes estrategias de
resolución con sus condiciones de aplicación
2.1.1 Tipos de conocimiento
Los conocimientos que se suelen almacenar son de cuatro tipos:
Objetivo, describe la situaciónreal del sistema
De sucesos, relacionado con lossucesos que ocurren en eltiempo de ejecución
Del funcionamiento delsistema, cómo se hacen lascosas
Metaconocimiento, capacidadpara buscar en la base deconocimiento y abordar laresolución del problema de unamanera inteligente
-68-

2.1.2 Representación del conocimiento La representación del conocimiento por lo general es sencilla y mediante reglas, aunque existen varias formas de representarlo.
Marcos. Estructuras de datos representados por una serie de campos y los valores asociados a los mismos.
Redes semánticas Representaciones gráficas del conocimiento
Reglas Declaraciones estructuradas en forma de oraciones condicionales
2.2 Motor de inferencia También llamado intérprete de reglas, es el corazón de todo sistema experto. El cometido principal de esta componente es el de sacar conclusiones aplicando el conocimiento a los datos, es decir, se encarga de las operaciones de búsqueda y selección de reglas a utilizar en el proceso de razonamiento. Las conclusiones obtenidas por el motor de inferencia pueden estar basadas en el conocimiento determinista o probabilístico. 2.3 Base de hechos
Se trata de una memoria auxiliar que almacena los datos del usuario, datos iniciales del problema y los resultados intermedios a lo largo del proceso de resolución, además de permitir saber el estado actual del sistema y como se ha llegado a él. 2.4 Interfaz de usuario Se trata del enlace entre el sistema experto y el usuario, que gobierna el diálogo entre ambos. Su objetivo es el de permitir un diálogo en un lenguaje cuasi-natural con la máquina. Para ello “traduce” el lenguaje español (o cualquier otra lengua) al lenguaje interno y viceversa. 2.5 Otros módulos Otros módulos que forman parte de este tipo de herramientas, son los siguientes:
Módulo de comunicaciones, permite la interactuación entre sistemas, además de con el experto, para recoger información o consultar la base de datos
Módulo de explicaciones, permite explicar al usuario tanto las reglas usadas como el conocimiento aplicado en la resolución de un problema
Módulo de adquisición de conocimiento, permite al experto la construcción de la base de conocimiento de una forma sencilla
Figura2. Estructura de un sistema
expero -69-

2.6 Aplicaciones de los SE
De acuerdo con la función que ejercen los SE, se pueden clasificar en distintas categorías como muestra la tabla a continuación.
2.7 Ventajas y desventajas de los SE
2.7.1 Ventajas
Un sistema experto tiene numerosas ventajas, entre las que podemos destacar:
Total disponibilidad con máximodesempeño en entornos hostiles ypeligrosos
Se puede duplicar ilimitadamente Siempre se ajustan a las normas
establecidas y son consistentes en sudesempeño. No desarrollanapreciaciones subjetivas,tendenciosas, irracionales oemocionales
Siempre están dispuestos a darexplicaciones, asistir o enseñar a lagente y no padecen de olvido, fatiga oerrores de cálculo
Pueden tener una vida de servicioilimitada
2.7.2 Desventajas
Por otro lado se pueden destacar algunos inconvenientes:
Muy costosos de desarrollar ymantener
La aproximación de cada experto a lasituación evaluada puede ser diferente
La extracción del conocimiento a losexpertos humanos es difícil
Noción limitada acerca del contextodel problema. No puede percibir todaslas cosas que un experto humanopuede aprecias de una situación
No saben subsanar sus limitaciones.No son capaces de trabajar en equipoo investigar algo nuevo.
-70-

3. MAGERIT La gestión global de seguridad de los sistemas de información es una acción recurrente (se ha de reemplazar periódicamente) que comprende dos grandes bloques. Uno bloque está compuesto por varias fases que se apoyan en técnicas generales adaptadas al campo de la seguridad. El otro bloque está constituido por la fase de Análisis y Gestión de Riesgos, núcleo de la medición y el cálculo de la seguridad. Para realizar esto, el Consejo Superior de Informática ha elaborado MAGERIT, una metodología de Análisis y Gestión de Riesgos de los sistemas de información de las Administraciones Públicas, como respuesta a la dependencia creciente de éstas (y de toda la sociedad) de las tecnologías de la información y Comunicaciones. El objetivo es investigar la seguridad de los sistemas de información en un dominio. Para ello MAGERIT recomienda las salvaguardas o las medidas apropiadas que deben adoptarse para promover y asegurar dicha seguridad 3.1 Análisis En la realización de un análisis y gestión de riesgos según MAGERIT, el analista de riesgos es el profesional especialista que maneja una serie de elementos básicos: . Activos . Amenazas . Vulnerabilidades . Impactos . Riesgos
Estos elementos guardan una relación según la figura 3.
Figura3. Análisis y gestión del riesgo
Para poder identificar estos elementos en
cada dominio, es importante que el
responsable del dominio protegible cumpla
una serie de características:
- Conozca, transmita y valore los
aspectos de la seguridad de los
Activos de su Dominio
- Comprenda su Vulnerabilidad, es
decir, la posibilidad de ataque de
cada amenaza
- Valore el Impacto consecuente al posible ataque
3.1.1 Activos
Los activos son los recursos del
sistema de información o relacionados con
éste, necesarios para que la organización
funcione correctamente y alcance los
objetivos propuestos.
Como no tiene sentido hablar del sistema de
información aislado desde el punto de vista
del riesgo, MAGERIT tiene en cuenta 5
grandes categorías de Activos:
El entorno o soporte del sistema de
información (personal, equipamiento
-71-

de suministros auxiliar, activos
tangibles)
El sistema de información
propiamente dicho del dominio
(hardware, software básico,
aplicaciones etc.)
La propia información requerida,
soportada o producida por el sistema
de información que incluye los datos
informatizados, entrantes y
resultantes, así como su
estructuración (formatos, códigos,
claves de cifrado) y sus soportes.
Las funcionalidades del dominio que
justifican al sistema de información
Otros activos de naturaleza variada
(imagen de la organización, la
confianza que inspire, etc.)
Estas 5 categorías de Activos se conocen
como las 5 capas principales en el diseño de la
seguridad, activos relacionados entre sí.
El Activo puede tener dos formas clásicas de
valoración:
- Cualitativa, su valor de uso
- Cuantitativa, su valor de cambio
3.1.2 Amenazas
Las amenazas se definen como los eventos que pueden desencadenar un incidente en la organización, produciendo
daños materiales o pérdidas inmateriales en sus activos. MAGERIT considera distintos ‘productores’ de las amenazas para así tener en cuenta la diversidad de sus causas. Cada tipo de productores genera un tipo de causas de los cambios del estado de seguridad en los Activos. Las amenazas se clasifican así en:
Grupo A de Accidente
A1. Accidente físico de origen industrial A2. Avería A3. Accidente físico de origen natural A4. Interrupción de servicios o de suministros esenciales A5. Accidentes mecánicos o electromagnéticos
Grupo E de Errores
E1. Errores de utilización E2. Errores de diseño E3. Errores de ruta, secuencia o entrega E4. Inadecuación de monitorización, trazabilidad, registro del tráfico de información
Grupo P de Amenazas IntencionalesPresenciales
P1. Acceso físico no autorizado con inutilización por destrucción o sustracción P2. Acceso lógico no autorizado con intercepción pasiva simple de la información P3. Acceso lógico no autorizado con alteración o sustracción de la información en tránsito o de configuración P4. Acceso lógico con corrupción o destrucción de información en tránsito o de configuración
-72-

P5. Indisponibilidad de recursos
Grupo T de Amenazas Intencionales Teleactuadas T1. Acceso lógico no autorizado con intercepción pasiva T2. Acceso lógico no autorizado con corrupción o destrucción de información en tránsito o de configuración T3. Acceso lógico no autorizado con modificación de información en tránsito T4. Suplantación de Origen o de Identidad T5. Repudio del Origen o de la Recepción de información en tránsito
3.1.3 Vulnerabilidades Se define como la potencialidad o posibilidad de ocurrencia de la materialización de una amenaza sobre un activo. Es una propiedad entre un activo y una amenaza.
MAGERIT evita los términos probable y probabilidad y emplea los conceptos potencial y potencialidad (frecuencia o posibilidad) para medir la Vulnerabilidad.
3.1.4 Impactos
El impacto en un activo es la consecuencia sobre éste de la materialización
de una amenaza. Véase en la Figura4.
Figura 4. Impacto MAGERIT considera tres grandes grupos de impactos:
- Cualitativos con pérdidas funcionales del Activo
- Cualitativos con pérdidas orgánicas - Cuantitativos
El impacto puede ser acumulado o repercutido.
Figura5. Impactos 3.1.5 Riesgo Es la posibilidad de que se produzca un impacto en un activo o en el dominio. Para MAGERIT el cálculo del riesgo ofrece un indicador que permite tomar decisiones por comparación con un umbral de riesgo. Se pueden clasificar en:
1. Crítico. Requiere atención urgente 2. Grave. Requiere atención 3. Apreciable. Puede ser objeto de
estudio
-73-

4. Asumible. No se toman acciones paraatajarlo
3.2 Tratamiento
Para tratar la gestión del riesgo MAGERIT ofrece unas salvaguardas o unas medidas que deben adoptarse para promover y asegurar dicha seguridad.
En la figura 6 se muestra cómo se incorpora al análisis este nuevo tratamiento.
Figura 6. Tratamiento
Un mecanismo de salvaguarda es el procedimiento o dispositivo, físico o lógico, capaz de reducir el riesgo. Actúa de dos formas posibles:
Neutralizando o bloqueando lamaterialización de la amenaza antes deser agresión
Mejorando el estado de seguridad deactivo ya agredido, por reducción delimpacto
3.2.1 Características
Las salvaguardas deben ser efectivas. Para ello han de cumplir una serie de características:
- Tienen que ser adecuadas al peligro que conjura
- Deben estar instaladas, mantenidas, monitorizadas y actualizadas
- El personal debe estar instruido: usuarios, operadores y administradores
3.2.2 Tratamiento del riesgo
La forma de tratar el riesgo se basa en dos premisas muy claras:
- Si se puede, el riesgo se evita - En caso contrario, se deben de
plantear una estrategia
. Medidas preventivas . Plan de emergencia . Plan de recuperación
3.3 Resumen
Recopilando lo anteriormente descrito podemos describir el proceso de MAGERIT en cuatro etapas:
Figura 7. Proceso MAGERIT
Planificación del Análisis y Gestión deRiesgos, donde se establecen lasconsideraciones necesarias paraarrancar el proyecto, definiendo losobjetivos que ha de cumplir y el
-74-

dominio que abarcará.
Análisis de riesgos, donde se identifican y valoran los diversos elementos componentes del riesgo, obteniendo una estimación de los umbrales del riesgo deseable
Gestión de riesgos, donde se identifican las posibles funciones y servicios de salvaguarda reductores del riesgo calculado, se seleccionan los aceptables en función de las existentes y otras restricciones y se especifican los elegidos finalmente
Selección de salvaguardas, donde se escogen los mecanismos de salvaguarda a implantar, se elabora una orientación de ese plan de implantación, se establecen los procedimientos de seguimiento para la implantación y se recopila la información necesaria para obtener los producto finales del proyecto y realizar las presentaciones de resultados
4. CONCLUSIONES
Como hemos podido observar la implantación de sistemas expertos en distintos ámbitos de la vida, es una realidad. Desde la predicción y diagnóstico de enfermedades hasta la gestión de la seguridad de los sistemas de información, los sistemas expertos están presentes y ayudan en distintas tareas de cualquier profesional experto en un ámbito concreto. Es cierto que el desarrollo o la adquisición de un sistema experto en general es caro, pero el mantenimiento y el coste marginal de su uso repetido es relativamente bajo. Además la ganancia en términos monetarios, tiempo y precisión son muy altas.
Por ello, hay numerosos motivos para la utilización de los sistemas expertos:
- Con los SE, personal con poca experiencia puede resolver problemas que requieren un conocimiento de experto
- El conocimiento de varios expertos puede combinarse, dando lugar a SE más fiables
- Pueden responder a preguntar y resolver problemas mucho más rápidamente que un experto humano
- Suministran respuestas rápidas y fiables en situaciones en las que los expertos humanos no pueden
- Pueden ser utilizados para realizar operaciones monótonas, aburridas e inconfortables para un humano
Esto no quiere decir que un experto humano deje de ser necesario, al contrario, debe existir una armonía y cooperación entre el experto humano que proporciona el conocimiento y la herramienta del sistema experto que lo gestiona. En nuestro caso MAGERIT intenta proporcionar una mayor seguridad en los sistemas de información. Frente al actual auge de las nuevas tecnologías hay que destacar la mayor vulnerabilidad que sufren todas ellas frente a cualquier tipo de amenaza. Sistemas expertos como MAGERIT facilitan y proporcionan medidas para aumentar la seguridad de cualquier sistema, ya que cualquier posible pérdida de información supone un gran peligro. No cabe duda que a lo largo de los años se irán perfeccionando estos sistemas expertos y que seguirán ayudando al experto humano a desarrollar de una manera más optima su labor.
-75-

5. REFERENCIAS
[1] Sistemas Expertos, por Alberto Martín de Santos
[2] Sistemas Expertos, por Césari Matilde
[3] Sistemas Expertos, por Jorge Pineda
[3] Gestión de Riesgos y Análisis y Tratamiento MAGERIT, por José A.Mañas
[4] Metodología de Análisis y Gestión de Riesgos de los Sistemas de Información
-76-

Aplicaciones de la Minería de datos en las empresas
Silvia Briones Herranz Universidad Carlos III
NIA: 100079044
RESUMEN
En este trabajo veremos la importancia de apoyarse
en la minería de datos a la hora de la toma de
decisiones en una empresa, basándose en el
descubrimiento de información útil en las bases de
datos para fundamentar mejor sus decisiones. Además
analizaremos mediante dicha técnica un ejemplo
ficticio de las ventas de consolas con el fin de
encontrar las preferencias de los clientes y así
conseguir hacer a las empresas más competitivas.
Términos generales
Teoría, hardware, data warehouse
Palabras clave
Minería de datos, base de datos, algoritmia, datos
extraños
1. INTRODUCCIÓN
A lo largo de existencia de una empresa se acumulan
grandes cantidades de datos que son almacenados,
algunos de ellos se usarán y otros incluso se perderán
por falta de actualidad o por cambios en las políticas
de manejo de datos. Todos estos datos serían de
utilidad si fuera posible aprovecharlos mediante
procesos que nos otorgaran información útil.
La mayoría de las organizaciones no sufren por falta
de datos, sino más bien por exceso, por lo que cada
vez es más complicado buscar datos específicos y
significativos que permitan tener una visión más
completa y clara de la situación estratégica de la
empresa para mejorar la manera en que se toman las
decisiones.
La minería de datos es una herramienta que sirve para
la extracción de datos y su análisis mediante técnicas
estadísticas de grandes bases de datos. Sirve para
examinar a los clientes y a la competencia, para saber
quiénes son los mejores candidatos para un programa
o un producto en especial, es mejor lanzar un
producto haciendo una estrategia de mercado con una
base de datos explorada. Por ello la empresa debe
trabajar en la construcción de bases de datos,
mantenerlas enriquecidas, actualizadas.
2. CONCEPTO
La minería de datos tiene como fin descubrir, extraer
y almacenar información relevante de amplias bases
de datos, a través de programas de búsqueda e
identificación de patrones y relaciones globales,
tendencias, desviaciones y otros indicadores que en
un principio pueden parecer caóticos pero que tienen
una explicación que se puede descubrir mediante
distintas técnicas de esta herramienta.
Esta técnica es ampliamente usada en el entorno
empresarial para determinar el comportamiento de los
consumidores, el análisis de productos, ofertas,
demandas, volumen y valor de las exportaciones e
importaciones, además del análisis de la competencia,
análisis de las telecomunicaciones y de los medios de
comunicación, detección de fraude, mejora en la
gestión de riesgo, etc.
-77-

El objetivo fundamental es aprovechar el valor de la
información localizada y usar los patrones
preestablecidos para que los directivos tengan un
mejor conocimiento de su negocio y puedan tomar
decisiones más fiables.
3. VENTAJAS DE ESTA TÉCNICA
Las características a destacar son las siguientes:
La minería de datos ayuda a los empresarios
en el procesamiento de reservas de datos para
descubrir relaciones de las que, en algunos
casos, anteriormente ni siquiera se daba
cuenta.
La información conseguida a través de la
minería de datos ayuda a los directivos a
elegir cursos de acción y a desarrollar nuevas
estrategias competitivas, porque conocen
información que solo ellos pueden emplear.
Puede trabajar siguiendo los mismos criterios
con grandes cantidades de información
histórica.
Las personas tenemos la capacidad de
percibir anomalías y excepciones
rápidamente pero, sin embargo, no somos
capaces de deducir relaciones entre grandes
volúmenes de datos, por lo que la minería de
datos, mediante modelos avanzados y reglas
de inducción, pueden examinar gran cantidad
de datos y encontrar patrones difíciles de
identificar a simple vista.
El curso de la búsqueda puede ser realizado
por herramientas que automáticamente
buscan ciertos patrones ya que así están
programadas y despliegan las trivialidades
más importantes.
4. ESTRUCTURA
4.1 Algoritmos o programas de búsqueda
mineros
La minería de datos hace uso de programas de
búsqueda para detectar desviaciones, tendencias y
patrones ocultos en los datos históricos.
Los mineros son programas pensados y diseñados por
el usuario, en los que se utilizan diversas técnicas
para la explotación de datos, tales como redes
neuronales,clustering,asociaciones,clasificación,visua
lizacion,detección de desviaciones, algoritmos
genéticos entre otros. Todos ellos necesitan bases de
datos de un tamaño considerable para ser eficientes.
La función de los programas mineros es relacionar los
criterios de selección y búsqueda con los datos
históricos, si descubren algo interesante lo presentan
al usuario como un logro.
Los programas mineros trabajan con procesos
automáticos principalmente sobre bases de datos
relacionales para buscar datos extraños, patrones,
tendencias o desviaciones; pueden ser ejecutados
fuera de las horas pico, usando tiempos de máquina
excedentes de noche o en horas de poco proceso, lo
que los convierte en ayudantes importantes.
Una ventaja de los mineros es que no requieren
hardware especial o dedicado. Trabajan en las redes
de oficinas nacionales o regionales, utilizando por las
noches el servidor de la base de datos relacional, y
las PC’s o estaciones de trabajo ya existentes. Es
decir, trabajan sobre datos ya recogidos, en máquinas
ya existentes, realizando labores útiles mientras los
usuarios no se encuentren trabajando.
4.2 Datos históricos
Son datos estables y coherentes que se van
acumulando a lo largo de la vida operativa de una
empresa.
4.3 Criterios de búsqueda
Son las normas, tendencias y patrones desde los
cuales los programas mineros realizarán el proceso de
selección y búsqueda en los datos históricos. La
prioridad de la búsqueda, los criterios de interés y las
explicaciones de situaciones extrañas son definidas
por el usuario. Una vez establecidos los criterios de
selección y búsqueda se analizarán los datos
históricos guardando los hallazgos encontrados
inmediatamente en un archivo para su posterior
revisión y decisión final.
4.4 Almacenamiento de hallazgos
Los hallazgos son los datos resultantes de relacionar
los criterios de selección y búsqueda con los datos
históricos. El ser humano desempeña un papel
-78-

fundamental, ya que sólo él puede decidir si este
patrón, tendencia o criterio, tiene importancia,
coherencia y utilidad para la empresa.
5. CICLO DE LA MINERÍA DE DATOS
El proceso de la minería de datos es un ciclo, debido
a que los resultados obtenidos pueden ser usados de
nuevo en dicho proceso, principalmente son cuatro
pasos:
1. Los usuarios que controlan la información
deberán identificar los problemas que tiene el
negocio y las áreas en donde los datos pueden
dar valor añadido a la empresa, es decir, a
raíz de un problema surge la necesidad de
analizar al detalle los datos de la empresa
para poder encontrar posibles soluciones al
mismo, o bien, información que haga que las
decisiones tomadas sean las mas correctas
posibles. De la misma manera, es importante
identificar las áreas en donde la información
es muy cambiante, pero imprescindible para
la competitividad de la empresa. Para ello
pueden manejarse diferentes criterios, que
dependerán de las características de la
empresa, con el fin de determinar las ideas,
criterios, normas y preguntas que funcionaran
como entrada para el proceso de la minería de
datos.
2. El usuario mediante la selección del
algoritmo o algoritmos adecuados de minería
analizará la información histórica.
Posteriormente, estos algoritmos son
traducidos a programas mineros que
realizarán la búsqueda con los criterios
previamente definidos.
Existen varias dificultades que pueden entorpecer
el resultado que se obtenga del análisis, y esto es
debido a que los datos se pueden encontrar en
diversas formas, formatos y en múltiples
sistemas, unido a que pueden provenir de fuentes
internas o externas; para resolver dicho problema
actualmente se ha hecho uso del data warehouse,
que pretende reunir los datos más importantes de
la empresa en una especie de base de datos
corporativa, sin embargo, es posible hacer
minería de datos sin necesidad de tener el data
warehouse, pero es muy importante tener claro
que la información deberá estar lo más uniforme
y acorde posible, ya que depende de esto la
certeza de los resultados que obtengamos.
3. Incorporar la información obtenida a través
del proceso de minería de datos al proceso de
tomas de decisiones; así como mostrar los
descubrimientos encontrados a los
responsables de las operaciones de manera
que la información obtenida pueda formar
parte de los procesos de la empresa y pueda
aplicarse en la solución de los problemas.
4. Medir los resultados; Medir el valor de los
hallazgos encontrados, que se otorgan a la
persona que toma las decisiones con relación
a la solución de los problemas identificados y
a los criterios definidos anteriormente.
-79-

6. APLICACIONES DE MINERÍA DE
DATOS EN DIVERSAS EMPRESAS
Las operaciones comerciales, de algunas de las
grandes empresas, se basan hoy en día en informes
periódicos producidos por consultas en base de datos
pregrabadas; ¿cuál es la cifra de ventas de una
tienda?, ¿qué tendencias se derivan de esas cifras de
ventas? Los informes con referencias cruzadas
forman la base de la mayoría de las decisiones de los
ejecutivos. Las consultas se elaboran de forma
interactiva con el usuario para garantizar que la
información presente una estructura eficiente. Estos
informes se han elaborado para responder a preguntas
recurrentes.
Los hallazgos encontrados por los programas mineros
ayudan a los directivos a analizar los hábitos de los
clientes a fin de satisfacer mejor su demanda, mejorar
la administración de inventarios y, en general,
aumentar sus márgenes de utilidad.
Hay empresas que utilizan soluciones de información
estratégica para maximizar sus beneficios y mantener
un alto nivel de satisfacción entre sus clientes. Para
ello administran los movimientos a través de la red de
distribución de acuerdo con la información acerca de
lo que se vende en las tiendas; estos datos permiten
conocer las variaciones de cada temporada. No
obstante, para mantenerse en el negocio no solo hay
que tener en cuenta estas soluciones. Para competir es
necesario información en tiempo real sobre lo que
sucede, como ejemplo tomaremos a los conductores
de camiones que llevan ordenadores conectados por
radio para informar cada vez que visitan a un
minorista. Con esta información inmediata, las
principales empresas pueden hacer ajustes sin tardar
demasiado y sacar el mejor provecho posible.
Además, la información procedente de las
aplicaciones de información estratégica sobre lo que
se vende y lo que no, permite a las empresas cambiar
su producción en la fábrica para adaptarse a la
demanda.
Otro caso es el de la moda, esta es estacional, por lo
tanto tiene un periodo de uso aproximado de tres
meses, es decir, está un periodo relativamente corto
de tiempo en el almacén, un alto índice de cambio de
existencias y otorga grandes beneficios.
Además es de vital importancia detectar rápidamente
las nuevas tendencias ya que así se podrá predecir
exactamente cuáles serán las prendas que se
compraran durante un periodo determinado en una
tienda, consiguiendo consigo reducir el inventario de
la tienda, el desembolso del capital y aumentando los
beneficios.
La minería de datos, que permite la gestión en tiempo
real de manera eficaz, es una herramienta aplicable a
cualquier tipo de empresa. Un amplio número de
compañías pueden tener aplicaciones exitosas con
ella.
Conocer al cliente es el primer paso para satisfacer
sus necesidades. Para ello, las empresas pueden hacer
un seguimiento de las compras de un cliente. La
comprensión de tales hábitos de compra permite
desarrollar promociones destinadas a un tipo concreto
de clientes pudiendo llegar a aumentar su fidelidad y
frecuencia de compra.
En general, estos ejemplos muestran las ventajas que
tiene el uso en minería de datos para comprender
mejor al cliente y que las empresas puedan desarrollar
campañas de ventas más eficaces, así como una
técnica de mercado mejor dirigida y estrategias
innovadoras de desarrollo de productos que den como
resultado mayores ingresos y rentabilidad.
-80-

A continuación analizaremos mediante minería de
datos las ventas de consolas en distintos días y
supermercados con el fin de poder predecir las
preferencias de los clientes y así poder hacer a la
empresa más competitiva.
7. ANÁLISIS VENTAS DE CONSOLAS
Para dicho análisis nos valdremos de una herramienta
de software desarrollada en Java de dominio público
orientado a la extracción de conocimientos desde
bases de datos con grandes cantidades de
información, dicha herramienta recibe el nombre de
WEKA. Para ello únicamente se requiere que los
datos a analizar se almacenen con un cierto formato,
conocido como .arff (Attribute-Relation File Format).
Objetivo del análisis
Antes de utilizar dicha herramienta debemos hacer
una comprensión del dominio de aplicación y
establecer una idea clara acerca de los objetivos del
usuario final, cuando lo hagamos hecho nos
dedicaremos a la búsqueda de relaciones y modelos
subyacentes en los datos. Así, el proceso de análisis
de datos, permitirá dirigir la búsqueda y hacer
distinciones, con una interpretación adecuada de los
resultados generados. Los objetivos, aplicaciones,
etc., del análisis realizado deben ser considerados con
detenimiento como primer paso del estudio.
En nuestro caso hemos elegido las ventas de consolas
para analizar ya que está dedicado a un tipo concreto
de clientes. Podremos ver como varían las ventas en
función de las preferencias de los clientes y así
desarrollar, mediante los resultados obtenidos a través
de minería de datos, ajustes dedicados a conseguir
aumentar la fidelidad y frecuencia de compra.
Este análisis tiene un enfoque introductorio e
ilustrativo para acercarse a las técnicas disponibles y
su manipulación desde la herramienta.
Pre procesamiento de datos
Esta etapa es siempre la más costosa y por lo tanto la
que consume el mayor tiempo en el desarrollo de un
proyecto de minería de datos.
En nuestro ejemplo dispondremos de los siguientes
datos:
@attribute 'edad comprador' NUMERIC
@attribute consola {'Play Station 3', 'XBOX
360','Nintendo Wii'}
@attribute color {'negro mate', 'negro brillante',
blanco, negro}
@attribute 'capacidad almacenamiento' {512MB,
4GB, 160GB, 250GB}
@attribute 'lugar compra' {'MediaMarkt', 'Game',
'Worten', Carrefour,'PC city'}
@attribute 'dia semana compra' {lunes, martes,
miercoles, jueves, viernes, sabado, domingo}
@attribute oferta? {SI, NO}
@attribute 'medio pago' {'tarjeta debito','tarjeta
credito', efectivo}
El campo ¿oferta? es binario (sólo puede tomar como
valores sí o no). Además el último atributo medio de
pago, es la etiqueta de clase que se desea predecir. A
partir de los datos, las técnicas de minería de datos
podrían generar un modelo de los datos, consistente
en un conjunto de reglas, que permitiesen predecir en
el futuro, el posible comportamiento de un cliente que
quisiera comprar una consola.
En WEKA se generan los gráficos con los datos que
hemos puesto de ejemplo, seleccionando la pestaña
Visualize. Se muestran, por defecto, gráficos para
todas las combinaciones de atributos tomados dos a
dos, así, se puede estudiar la relación entre dos
atributos cualesquiera.
-81-

Figura4: Relación entre datos dos a dos
Ahora seleccionamos uno de los cuadros para mostrar
la relación existente. Por ejemplo entre la edad de los
clientes y los colores elegidos:
Figura5: Relación entre edades y colores consola
En esta última gráfica podemos ver como la mayoría
de los clientes con edades comprendidas entre los 13
y 30 años prefieren que el color de la consola sea
negro brillante seguido del color negro mate y de una
pequeña minoría que la quiere negra y blanca
respectivamente. Hay en otros casos como el de la
relación entre modo de pago y día de la semana que
dependen de otros factores como es el caso de la edad
del comprador.
Figura6: Relación entre modo de pago y día de la
semana
Por lo tanto, podemos deducir que el modo visual nos
ayuda a tener una idea de los datos pero no a
conocerlos en su totalidad.
Árboles de decisión
Los árboles son una manera práctica para visualizar la
clasificación de un conjunto de datos. El algoritmo
J48 (árbol de decisión C4.5) siempre destaca por su
precisión, con prácticamente cualquier tipo de datos.
Por ello, lo aplicamos a los datos de
ventaConsolas.arff usando un cross-validation con 10
folds.
-82-

Figura6: Ejecución del algoritmo de clasificación
J48
Como podemos observar en los resultados obtenidos
de la ejecución del algoritmo J48, el 70% de las
instancias fueron clasificadas correctamente y el 30
% incorrectamente. Al final de los resultados aparece
la matriz de confusión que muestra como s
clasificaron las instancias. Si la diagonal toma valores
y el resto son ceros en esa matiz, indicaría que todas
las instancias fueron clasificadas correctamente.
El gráfico del árbol generado es el siguiente:
Figura7: Árbol de decisión generado con el
algoritmo J48
A partir de la figura anterior, se puede observar una
fuerte relación entre los atributos medio de pago y
edad del comprador. Conociendo la edad de quien
compra una consola es posible deducir su medio de
pago con una exactitud del 70%. Si el individuo es
menor de 24 años con seguridad pagará en efectivo,
pero si tiene 25 años utilizará tarjeta de débito y si es
mayor de 25 años usará tarjeta de crédito.
Si ahora cambiamos la etiqueta de clase a los colores
preferentes de los clientes obtenemos el siguiente
árbol de decisión:
Figura7: Árbol de decisión generado con el
algoritmo J48
De la figura podemos decir que conociendo el tipo de
consola es posible deducir el color con una exactitud
del 85%. Si el cliente elige la Play Station 3 con
seguridad elegirá el color negro mate para la misma,
si en cambio, elige la consola XBOX 360 el color
será negro brillante y si por último elige la Nintendo
Wii el color seleccionado será en negro.
-83-

8. CONCLUSIÓN
Hoy en día el valor de la información ha crecido
hasta el límite de convertirse en un activo estratégico
indispensable para la competitividad de una empresa.
De esta selección de información depende una buena
parte para que la toma de decisiones sea la mejor para
la empresa.
La minería de datos ayuda a los directivos a conseguir
una visión más completa y detallada de su negocio ya
que les permite buscar datos extraños, es decir
aquellos que se salen de los rangos que están
considerados como normales de lo que, en parte,
depende que podamos confiar en la información
obtenida para la toma de decisiones.
En la medida en la que una empresa recoja datos de
sus actividades diarias tendrá la oportunidad de
relacionarlos entre ellos y hacer descubrimientos que
les ayuden a identificar posibles clientes, lugares
estratégicos de venta, entre otros.
La minería de datos tiene futuro dentro de las
empresas, debido a que existen grandes bases de
datos que contienen valores desaprovechados; los
mercados están más saturados de empresas y se
requiere análisis intensos para captar la atención de
los clientes.
En todo el proceso de la minería de datos, el ser
humano es el factor más importante, ya que solamente
es él el que tiene la capacidad de analizar y decidir si
los patrones, normas o funciones encontradas tienen
importancia, lógica y utilidad para su empresa.
9. REFERENCIA
[1] Artículo: “Data mining: torturando a los datos
hasta que confiesen”.
Luis Carlos Molina Felix
Univertitat Politécnica de Catalunya
[2] Villena, J. Apuntes de la asignatura Inteligencia
en redes de Comunicaciones. 5º Ingeniería de
Telecomunicaciones
Universidad Carlos III de Madrid
[3] “INTRODUCCION A LA MINERIA DE
DATOS”
José Hernández Orallo, M.José Ramírez
Quintana, Cèsar Ferri Ramírez
Editorial Pearson, 2004. ISBN: 84 205 4091 9
[4] Mineria de datos para empresas
http://www.gerencie.com/mineria-de-datos-para-
empresas.html
[5] Trabajo de Adscripción Minería de Datos
Universidad Nacional del Nordeste
Adscripta: Sofia J. Vallejos - L.U.: 37.032
Materia: Diseño y Administración de Datos
-84-

Implementación de un agente autónomo en Super Mario Pablo González Fernández
Estudiante Ing. Telecomunicación Universidad Carlos III de Madrid
Avda. De la Universidad, 30 28911, Leganés (Madrid-España)
Alberto Chicharro Sobrino
Estudiante Ing. Telecomunicación Universidad Carlos III de Madrid
Avda. De la Universidad, 30 28911, Leganés (Madrid-España)
ABSTRACT
En este documento se explica cómo se podría utilizar la
teoría de resolución de problemas en un entorno controlado
como es el mundo de Super Mario. La solución propuesta
consta de un árbol de decisión, que en función de las
variables de entrada que se le pasen por parámetro decidirá
cuál es la mejor acción a llevar a cabo. Para la
implementación de este agente inteligente se utilizan las
librerías proporcionadas en [1].
Descripción de categorías y temas
[Agente]: Un Agente es un sistema autónomo capaz de
tomar decisiones en tiempo real. Estos agentes se apoyan en
la toma de datos del entorno para su toma de decisiones.
[Mario Bros]: Videojuego de plataformas que fue lanzado
para la videoconsola NES en 1985.
Terminos generales. Árbol de decisiones, agente autónomo, búsqueda heurística.
Palabras clave. Mario Bros, agente inteligente, enemigos, escenario,
algoritmo.
1. INTRODUCCION
En este documento se explicarán los pasos que se han
tomado a la hora de realizar un agente autónomo en el
videojuego de Mario Bross. Para la implementación de
éste, veremos las posibles alternativas dentro de los
algoritmos de búsqueda, donde en este caso la búsqueda
sería llegar al final del escenario, sin recibir golpes. Dentro
de estos algoritmos hay dos grandes tipos: los de búsqueda
a ciegas y los heurísticos. Dado nuestro problema, los que
encajaban mejor eran los algoritmos de búsqueda
heurística, ya que nuestro soporte de librerías nos ofrecía
información sobre el mapa en todo momento.
En primer lugar, se explicará el funcionamiento de la
plataforma utilizada para desarrollar el agente autónomo,
explicando las distintas soluciones clásicas que se han
empleado en él con relativo éxito. Finalmente,
presentaremos en detalle un agente desarrollado por
nosotros, que, por simplicidad, utiliza una decisión reactiva
codificada mediante un árbol de decisión en función de
distintos parámetros del entorno, en lugar de recurrir a
técnicas más complejas y efectivas como búsquedas sobre
los posibles nodos a los que desplazarse o aprendizaje
máquina.
2. INTELIGENCIA ARTIFICIAL EN
JUEGOS
Los juegos son una importante herramienta en el ámbito del
desarrollo y experimentación en inteligencia artificial (AI).
Esto es debido a que los juegos proporcionan entornos
desafiantes y sencillos de escalar en dificultad, sobre los
que es posible aplicar conceptos de procesado de
información y comportamiento inteligente. Además de estas
aplicaciones relacionadas con la investigación en
inteligencia artificial, los juegos en sí pueden beneficiarse
de la aplicación de algoritmos y desarrollos de AI con el
objetivo de crear oponentes autónomos interesantes y
creíbles o crear mundos más complejos y desafiantes para
los jugadores humanos.
Entre las características principales que convierten un juego
en útil para el entorno de la inteligencia artificial se incluye
la capacidad para tener en cuenta habilidades cognitivas
humanas interesantes, su vistosidad, cómo de entretenido
sea, para fomentar la motivación en el desarrollo y como de
general sea en su representación del entorno y de los
elementos de entrada y salida, de modo que un número
amplio de algoritmos distintos de AI puedan aplicarse sobre
él de forma sencilla y natural; además, debe ser sencillo de
aprender; es decir, tener un conjunto de reglas intuitivas y
simples que sean comprensibles de forma rápida por un
conjunto amplio de jugadores, pero al mismo tiempo debe
ser complicado de jugar de una forma experta; es decir, que
ese conjunto de reglas simples deben ser suficientes como
para dar lugar a oponentes y/o entornos complejos y a un
crecimiento en dificultad suave, que permita la generación
de niveles de dificultad adaptables, que varíen de una forma
lenta desde los más sencillos a aquellos que solo un número
muy reducido de jugadores sean capaces de completar.
-85-

De esta forma, será posible diferenciar entre jugadores (o
algoritmos) con más o menos habilidad en función del
número de niveles que sean capaces de completar, y
también de obtener información rápida sobre si nuestro
sistema evoluciona favorablemente o se comporta peor a
medida que modificamos su comportamiento.[1]
Los juegos de plataforma son un tipo concreto de
videojuegos que se caracterizan porque el juego transcurre
sobre un entorno en el que hay que atravesar un mundo,
sobreponiéndose a un conjunto variado de enemigos,
mediante un conjunto de acciones (generalmente caminar,
saltar, correr, escalar, disparar) y se recogen una serie de
objetos a lo largo del recorrido.[2]
Se cree que los juegos de
plataforma tienen interés con respecto al aprendizaje
computacional y la inteligencia artificial en general debido
a que tienen espacios de entrada y salida de dimensión
elevada, un conjunto de estados amplio y requieren poner
en práctica distintas habilidades en secuencia para atravesar
las pantallas.
En nuestro caso hemos optado por desarrollar un agente
para el entorno de desarrollo “Infinite Mario Bros”, un clon
del clásico juego de plataforma “Super Mario Bros”
desarrollado por Sergey Karakovskiy y Julian Togelius.
Según los autores, se trata del primer sistema para
implementación de algoritmos de inteligencia artificial
llevado a cabo sobre un juego de plataforma en el que se
lleva a cabo una competición. Los autores presentan el
código desarrollado para la implementación de la
plataforma (como software libre), que además del propio
entorno incluye un conjunto de librerías destinadas a
facilitar la creación de todo tipo de agentes autónomos. De
este modo, se incluye un conjunto de métodos y variables
destinados a recabar información del entorno. Respetando
el carácter clásico del juego de Super Mario, solo es posible
obtener información de un pequeño entorno de Mario, que
siempre se sitúa en el centro de la pantalla (una matriz de
19x19 casillas, aunque es posible acceder a la información
a resolución de pixel en lugar de a resolución de casilla si el
agente desarrollado requiere de esta precisión para
funcionar correctamente).
3. PERSPECTIVA SOBRE TIPOS DE
AGENTES PROPUESTOS
Dadas las características del juego de Super Mario, si
consideramos como objetivo el de atravesar el nivel en el
menor tiempo posible y sin perder vidas (sin preocuparnos
ni de matar a todos los enemigos ni de recuperar todas las
monedas), categoría en la que funciona principalmente el
campeonato y para la que hemos desarrollado nosotros
también nuestro código, teniendo en cuenta que los
adversarios de Mario son completamente deterministas, el
problema de AI resultante puede ser considerado como uno
de resolución de problemas sobre el que podrían por tanto
emplearse cualquier tipo de algoritmo de búsqueda sobre el
espacio de movimientos de Mario, eligiendo como estado
de partida la situación actual de Mario y como conjunto de
estados de llegada los puntos de la parte derecha de la
pantalla. Sin embargo, dada la necesidad de que el
algoritmo funcione en tiempo real (en particular, debe dar
un resultado de ejecución cada 40ms, para que el juego
pueda ejecutarse a 25 frames por segundo), se impone un
fuerte requisito de tiempo de ejecución que excluye los
algoritmos de búsqueda completa, por lo que es mejor
utilizar algún tipo de búsqueda heurística.
Desde la creación de la plataforma, ha habido
competiciones anuales en las que se han propuesto distintos
tipos de agentes autónomos que han obtenido resultados
bastante importantes dentro de “Infinite Mario Bros”; a
continuación se presenta un recorrido sobre los tipos
principales de algoritmos empleados y los resultados
obtenidos por cada uno de ellos.
En primer lugar, los algoritmos más frecuentes fueron los
creados directamente codificando a mano agentes reactivos;
es decir, sistemas de búsqueda para los que el propio
programador definió un conjunto de situaciones posibles y
las reacciones de Mario frente a ellas, sin utilizar ningún
tipo de aprendizaje adaptativo, ni búsqueda.
Un segundo tipo fueron los basados en aprendizaje
máquina; sistemas que utilizaban algoritmos de aprendizaje
(principalmente redes neuronales) empleando sistemas de
entrenamiento tanto supervisados como no supervisados.
Sin embargo, el tipo de agente más exitoso de entre los
propuestos para las competiciones ha sido el compuesto por
agentes de búsqueda A*. Ya se ha explicado que las
características del juego de plataforma Super Mario Bros se
ajustan de una forma muy buena a cualquier tipo de
algoritmo de búsqueda, y en particular a los que sacrifican
optimización ahorrando tiempo. De hecho, aun utilizando
este tipo de búsqueda heurística, algunos de los agentes
propuestos optaron por “cortar” la búsqueda a los 40ms, en
caso de que el algoritmo estuviese tardando demasiado, y
devolver el mejor nodo explorado hasta el momento. Para
emplear este tipo de algoritmo, es necesario familiarizarse
con la física de Mario: el movimiento de éste depende de
formas relativamente complejas de la velocidad de
movimiento actual, su posición en salto o en tierra y otra
serie de variables. A continuación se presentan dos
ejemplos de situaciones posibles de Mario, así como los
puntos a los que sería posible que Mario se moviese desde
dichas posiciones. [3]
-86-

4. ALGORITMO DE BUSQUEDA: ÁRBOL
DE DECISIÓN
De entre los tipos considerados anteriormente, el algoritmo
empleado por nosotros entraría en la categoría de agentes
reactivos. Sin preocuparse de realizar una exploración
sobre el espacio de nodos a los que puede desplazarse,
nuestro agente simplemente determina una respuesta
concreta en base a las observaciones que recibe del espacio.
Se trata de un mecanismo simple y poco efectivo, a pesar de
lo que hemos conseguido superar con relativo éxito el nivel
cero de dificultad de la plataforma.
Para el desarrollo de éste hemos realizado un árbol de
decisiones, donde el agente comprobará una a una las
condiciones del árbol para saber en cada momento cual es
la mejor acción posible a tomar.
Este tipo de algoritmos se basan en el análisis secuencial de
los datos que ofrece la interfaz, para posteriormente decidir
cuál es la mejor solución posible en el entorno en el que se
encuentra el agente. Estas comprobaciones deben ser
tomadas por los programadores de dicho agente, pudiendo
ser erróneas si los programadores no identifican bien los
problemas que puede tener el agente. Además, esta misma
característica, hace que el agente sea muy dependiente del
ambiente que los programadores han empleado como
referencia. En concreto, en este caso, con el nivel de
dificultad: dado que entre niveles de dificultad se modifica
el tipo de enemigos que aparecen en el mapa y ciertas
características del mismo (presencia o ausencia de
precipicios, zonas “sin salida” en las que hay que
retroceder), nuestro agente –que fue codificado para
funcionar en el nivel 0- será incapaz de actuar
correctamente en ninguno de los niveles superiores, como
se verá en el apartado de estadísticas.
En el árbol de decisiones se tienen unas variables de salida
y otras de entrada. Las de entrada son las que ofrece en el
entorno para poder tomar las decisiones correctas en cada
momento y, las de salida son aquellas variables sobre las
que el agente puede tomar decisiones. Las decisiones que
tome el agente dependen de las comprobaciones que se
realicen dentro del árbol y de las variables de entrada que
se obtengan. En nuestro caso, las variables de entrada de
nuestro sistema son la posición de los enemigos cercanos a
Mario Bros y el escenario. Las variables de salida son:
saltar, ir hacia un lado u otro, correr y disparar para poder
matar enemigos.
Un ejemplo de árbol de decisiones es el siguiente [4]
:
5. DISEÑO DEL ALGORITMO
Una vez se han explicado los conceptos básicos sobre el
funcionamiento de un agente autónomo y concretamente las
diferencias entre agentes basados en búsqueda y agentes
reactivos, explicaremos el diseño de nuestro algoritmo.
Para ello hemos utilizado un árbol de decisiones binario
con cada una de las variables de salida en las que podíamos
actuar.
A continuación mostraremos los árboles de decisión de
cada una de las variables de salida que tenemos.
En primer lugar mostramos la toma de decisiones para
saltar o no saltar. La salida depende en este caso de
numerosos factores:
En primer lugar se comprueba si estamos en el
suelo, en caso de estar en el aire hemos optado por
mantener presionada siempre la tecla de saltar,
Figura 1: Ejemplos de nodos a explorar por
A* en función de la situación de Mario
Figura 2: Ejemplo de árbol de decisión
-87-

obteniendo así potencia máxima en todos los
saltos.
A continuación, se examina la posible existencia
de un enemigo cercano que pueda causarnos un
daño.
Seguimos revisando si cerca de la posición actual
de nuestro agente hay una pared que bloquee el
camino de Mario Bross. En caso de que la haya se
procederá a saltar.
La última verificación consiste en ver si cerca de
Mario hay un precipicio. En caso de que lo haya se
saltará y en caso contrario no.
El siguiente árbol que definiremos será el de la decisión de
si debemos o no ir hacia la derecha del escenario. Al igual
que en el caso anterior se realizarán varias comprobaciones.
Este caso es bastante similar al caso de saltar o no saltar.
Con la salvedad del caso “habitual”, en el que no hay ni
enemigos ni hueco ni pared próximos, en el que se deberá
avanzar hacia la derecha pero no saltar, en el resto de casos
el salto va siempre acompañado de movimiento hacia la
derecha.
En primer lugar examinaremos la posible
existencia de un enemigo cercano.
En caso de que hubiera un monstruo cerca de
nuestro agente se comprobaría si puede saltar. En
caso de que pudiera hacerlo se activará esta acción
y no lo hará en el contrario.
En caso de que no hubiera ningún enemigo cerca
se procedería a revisar la posible existencia de un
hueco.
En caso de que hubiera un hueco cercano a Mario
se verificará si el agente esta en el suelo y es capaz
de saltar, en caso afirmativo se irá hacia la derecha
y no en el caso contrario.
El tercer árbol muestra la toma de decisiones sobre si ir o
no hacia la izquierda. El orden en el que se revisará las
condiciones es:
En primer lugar se comprobará si Mario Bross es
capaz de saltar. En caso afirmativo no será
necesario retroceder.
En el caso afirmativo anterior se comprobará la
existencia de un Hueco, o de un enemigo cercano.
En caso de que alguna de las dos preguntas sea
afirmativa el agente retrocederá para no sufrir
daño alguno.
El razonamiento detrás de esta forma de actuación es que
sólo utilizaremos el movimiento hacia la izquierda como
medida de precaución en los casos en los que no sea posible
saltar (porque justo acabemos de pisar el suelo) y exista un
peligro delante de nosotros. En caso de poder saltar o de no
existir ningún peligro, Mario no deberá retroceder ya que el
objetivo del algoritmo es llegar al final del nivel en el
menor tiempo posible. Existe otro caso en el que se utiliza
el movimiento hacia la izquierda que se expone en el
apartado 7.4.
Figura 3: Árbol de decisión para “saltar”
Figura 4: Árbol de decisión para “derecha”
Figura 5: Árbol de decisión para “izquierda”
-88-

Por último se muestra el árbol de decisiones sobre correr.
Este caso es muy sencillo, ya que solo correremos cuando
no haya enemigos cerca de la posición de Mario. Además
de evitar tener que considerar la excesiva velocidad de
Mario en los momentos en los que haya algún peligro
cercano, con esto también conseguimos que Mario dispare
continuamente cuando no se encuentra en peligro, con lo
que existe la posibilidad de que alguna de las bolas que
lanza impacte contra algún potencial futuro enemigo.
Como podemos ver en los grafos, la toma de decisiones
para cada una de las acciones en las que nuestro agente
puede actuar es totalmente independiente una de otra, lo
que permite a Mario ser mas versátil y adaptarse mejor a las
distintas situaciones que se pueda encontrar a lo largo de
los escenarios.
5.1 Mario en el suelo
Esta comprobación nos permite saber si Mario puede saltar
en este momento. Es muy importante ya que en función de
que pueda o no, el evitar enemigos es mas difícil si uno está
en el aire.
5.2 Enemigo cercano
Con el conocimiento de la posición de los enemigos
cercanos podemos determinar las acciones de nuestro
agente, en función de la distancia a la que se encuentren las
posibles amenazas en el mapa.
5.3 Pared cercana
Siendo una de las variables de entrada de nuestro agente el
escenario generado podemos hacer que nuestro agente
decida saltar cuando se encuentre una pared vertical,
infranqueable para Mario a no ser que este salte.
5.4 Hueco
Con esta ultima comprobación, nuestro agente es capaz de
predecir cuándo hay un hueco cerca de él y poder decidir
cuándo es mejor saltar.
6. ESTUDIO DE LAS VARIABLES
PROPORCIONADAS POR LA LIBRERÍA
Para la implementación del agente autónomo, previamente
expuesto, utilizaremos el código proporcionado por 2012
Mario AI Championship cuyas librerías nos servirán de
apoyo para realizar las comprobaciones necesarias.
6.1 Variables de entrada: El escenario.
Lo más importante de las librerías ofrecidas es el estudio
del escenario. Según las librerías ofrecidas por la web, la
clase Environment ofrece información sobre el escenario
actual. En concreto es la función
getLevelSceneObservationZ la que nos permite ver el
entorno cercano de nuestro agente, ofreciendo información
sobre las 9 casillas entorno a las que se encuentra,
generando esta función un array de 19x19. En este array de
bytes se guarda la información sobre todos los tipos de
superficies existentes en el escenario, desde los posibles
obstáculos en el escenario, pasando por las monedas e,
incluso, los bloques que se pueden destruir. Con esta
función únicamente nos ofrece la información sobre el
terreno, en caso de querer obtener la información sobre los
enemigos deberemos obtenerla a partir
getEnemiesObservationZ que devuelve lo mismo que la
función anterior, pero esta vez con los monstruos en vez de
con los obstáculos. Existe una tercera función que une
ambas informaciones que es getMergedObservationZZ.
Toda esta funcionalidad viene implementada por un agente
inteligente básico, por lo que, extendiendo de esta clase
tendremos toda esta información en unas variables, lo que
facilita la obtención de las variables de entrada,
permitiendo una más sencilla comprobación de estas a la
hora de tomar decisiones en nuestro árbol.
6.2 Variables de salida: Las acciones posibles.
Las variables de salida son: correr, ir hacia derecha o
izquierda, disparar y saltar. En las librerías proporcionadas
nos permiten realizar todas estas acciones, pero en el caso
de correr y disparar, esta acción es la misma, por lo que
será un poco más complicado decidir cuándo se debe de
correr y cuando disparar.
Las acciones que deseemos realizar vienen todas definidas
en un array de boolean, donde cada acción ocupa una
posición dentro de éste.
Además, para facilitar la depuración del código, cada una
de las posiciones del array tiene una macro asociada. Estas
macros son:
action[Environment.Mario.Key_RIGHT]
action[Environment.Mario.Key_LEFT]
Figura 6: Árbol de decisión para “correr”
-89-

action[Environment.Mario.Key_JUMP]
action[Environment.Mario.Key_SPEED]
Existe una quinta variable de salida: agacharse, que solo es
útil cuando Mario no está en el estado “Small”. Sin
embargo, no la hemos considerado dentro del algoritmo
dado que la utilidad que proporciona es importante
únicamente cuando existen cañones u otro tipo de
adversarios que pueden ser esquivados de forma sencilla
mediante esta acción, y ese no era el caso en el nivel
considerado para el desarrollo del agente.
6.3 Variables de ayuda.
Además de las variables de entrada y de salida, previamente
comentadas, las librerías nos ofrecen otras variables que
nos permiten conocer el estado actual de Mario y su
entorno.
6.3.1 isMarioOnGround
Esta variable nos permite saber si Mario esta en el suelo. En
caso de que esto sea cierto, podremos saltar si lo deseamos.
6.3.2 marioEgoCol y marioEgoRow
Estas dos variables nos permiten saber cuál es la posición,
dentro de array de tanto en el de escenario, como en el de
enemigos. Estas variables no servirán para comprobar como
de lejos estamos de los enemigos y de los obstáculos que
nos impidan el paso.
6.3.3 marioFloatPos
Esta último variable nos permite saber en que posición total
del mapa estamos. Esto es útil para retroceder de un lugar
en el que consideramos que hay peligro, como cuando un
enemigo cae sobre ti tras un precipicio.
7. IMPLEMENTACION DEL ÁRBOL DE
DECISIONES.
Una vez ya sabemos cuáles son las variables de entrada,
salida y las que tenemos de ayuda, tenemos que decidir
cuáles son los umbrales a partir de los cuales nuestro agente
debe realizar según la situación actual del escenario.
7.1 Enemigos cercanos.
Para saber si tenemos un enemigo cerca de nuestro agente
tenemos que comprobar la variable enemies, que nos
proporciona la clase BasicMarioAIAgent. Para facilitar las
comprobaciones, cada vez que se llama al proceso
recorremos el array de enemies en busca de alguna posición
en la que el byte sea distinto de 0. En caso de que sea
distinto de 0, indica que en esa posición hay un enemigo y
procedemos a guardarlo en un vector. Realizamos esta
operación para que la comprobación de de posibles
monstruos en el escenario sea más simple de comprobar.
Un agente más complicado podría tomar en consideración
el tipo de enemigo, leyendo el valor concreto de enemies en
ese punto del array en lugar de comprobando si es o no
cero.
Una vez tenemos todos los enemigos en un vector,
procedemos a comprobar que en las proximidades de Mario
no hay ningún enemigo cerca. Las posiciones que se
comprueban son las que aparecen marcadas en el siguiente
dibujo de Mario. En este caso Mario empieza a saltar justo
en la siguiente comprobación de la acción que debe tomar.
Figura 7: Cuadrícula de Mario
Figura 8: Reacción de Mario ante un enemigo
próximo
-90-

La función que nos permite conocer si hay algún enemigo
cerca de nuestro agente es la siguiente:
private boolean enemigoEn(int Row, int
Col,boolean abajo) {
int variabledefinida = 0;
//Comprobamos para todos los enemigos que hay
guardados //en el vector previamente comentado
while
(variabledefinida<enemigos1.size()){
//Comprobamos que no esté en la misma casilla
que mario
if
(enemigos1.elementAt(variabledefinida)==Row
&&
enemigos2.elementAt(variabledefinida)==Col) {
return true;
}
//Comprobamos que no esté en la casilla inferior a
mario
if
(enemigos1.elementAt(variabledefinida)==Row+1
&&
enemigos2.elementAt(variabledefinida)==Col) {
return true;
}
//Comprobamos que no esté dos casillas por
debajo de mario
if
(enemigos1.elementAt(variabledefinida) ==
Row+2 &&
enemigos2.elementAt(variabledefinida)==Col) {
return true;
}
//Comprobamos que no esté una casilla por encima
de mario
if
(enemigos1.elementAt(variabledefinida)==Row-1
&&
enemigos2.elementAt(variabledefinida)==Col) {
return true;
}
variabledefinida++;
}
return false;
}
Para comprobar cada columna lo que hacemos es invocar
este método dentro de un bucle for, lo que nos permite ver
si en alguna de las posiciones, que en la imagen anterior
están tachadas hay algún enemigo.
7.2 Pared cercana
Para verificar esta condición se comprobará que la siguiente
casilla a la que ocupa Mario. También hay que tener
cuidado ya que en algunos casos al ser Mario grande no
puede pasar al ser mas grande, es por ello que hay que
comprobar esa situación, evitando que Mario se quede
atascado en esta posición.
En este caso vemos como Mario se encuentra un bloque
enfrente de él y, tras comprobar la situación de los
elementos del escenario decide saltar. En la primera imagen
Figura 9: Mario detecta pared
Figura 10: Reacción de Mario ante una pared
-91-

se incluyen las posiciones que se comprueban para que
nuestro agente no se quede estancado en ese bloque.
El código para comprobar este obstáculo es el siguiente:
if ((levelScene[marioEgoRow][i]!=0) || (marioMode>0 &&
levelScene[marioEgoRow-1][i]!=0))
action[Environment.MARIO_KEY_JUMP] = true;
Esta comprobación se realiza dentro del árbol de decisión
de si se salta o no. Como podemos ver se compraba la
posición siguiente y, en caso de que Mario sea más grande,
se comprueba la casilla superior también.
7.3 Comprobar Hueco
Por último, se comprueba que en las posiciones siguientes a
Mario no haya un desfiladero. Para ello comprobamos la
ultima fila a la que tenemos acceso comprobando que esta
sea distinta de 0. En caso de que esta fuera igual a 0.
Como podemos ver en estas dos imágenes, nuestro agente
salta cuando ve que se acerca a un precipicio.
Esta comprobación se realiza dentro del árbol de decisión
que decide si debe saltar o no.
7.4 Consideraciones menores
Además de todas las consideraciones anteriores, que
constituyen los principales elementos del árbol de decisión,
se han incluido dentro del código una serie de cuestiones
menores, destinadas a evitar ciertos casos particulares que
se daban con cierta frecuencia para el agente desarrollado.
Entre estos elementos destinados a evitar fallos menores
destacan el hecho de que Mario deje de moverse a la
derecha y se mueva en su lugar a la izquierda cuando
detecta un objetivo justo delante suyo en medio de un salto,
con el objetivo de evitar que Mario cayese tan a menudo
justo delante de un enemigo, punto en el que le era
imposible saltar por acabar de tocar el suelo y quedaba
inevitablemente a merced de su adversario. Esta sección de
código demostró experimentalmente ser eficaz en evitar el
problema anterior, aunque no en el 100% de los casos. Al
incluir esta condición, se daba el hecho de que Mario
quedaba bloqueado cuando ante él se encontraba un
enemigo atrapado entre dos bloques justo antes y justo
después suyo, con lo que saltaba hacia la derecha y nada
más saltar volvía a la izquierda. Se decidió solucionar este
otro problema de la misma manera, incluyendo el caso
particular de que cuando Mario detecta un adversario entre
dos bloques consecutivos anula el efecto anterior de
movimiento hacia la izquierda.
8. ESTADÍSTICAS OBTENIDAS
Con el fin de estudiar la adecuación de nuestro agente al
problema desarrollado, se ha modificado el método main de
la plataforma para recoger las estadísticas de número de
pantallas superadas para cada nivel, de entre las que el
sistema proporciona generadas de forma aleatoria a partir
de una semilla definida por el usuario. Los resultados se
incluyen en la tabla a continuación.
Nivel Ganados Tiempo medio en ganados (de 200 s)
0 67.4% 46s
1 0% -
Figura 11: Mario detecta un hueco
Figura 12: Reacción de Mario ante un hueco
Figura 13: Estadísticas
-92-

9. REFERENCIAS[1] Sergey Karakovskiy and Julian TogeliusDing 2012.
The Mario AI Benchmark and Competitions
[2] http://es.wikipedia.org/wiki/Juego_de_plataforma
[3] Julian Togelius, Sergey Karakovskiy and Robin
Baumgarten 2009. The 2009 Mario AI Competition
[4] https://www.edx.org/static/content-berkeley-
cs188x~2012_Fall/handouts/global/slides/FA12%20cs
188%20lecture%202%20and%203%20--
%20search%20(2PP).a7a79f0c498b.pdf
-93-

Inteligencia artificial aplicada a personas con
discapacidad
Alejandro E. Reyes Bascuñana Universidad Carlos III de Madrid
Leganés, Madrid, España
Javier Santofimia Ruiz Universidad Carlos III de Madrid
Leganés, Madrid, España
RESUMEN
En este documento se intentara dar un vistazo general a las
distintas formas en las que la Inteligencia Artificial puede ayudar a
la integración, facilidad de acceso a la información y en general a la
mejora de la calidad de vida de personas que sufren una
discapacidad física o psíquica.
Palabras Clave
Deficiencia, discapacidad, minusvalía, ASIBOT, RAH, OCR,
acceso, alternativo, aumentativo, movilidad, ambiental, virtual,
BCI, P300.
1. INTRODUCCIÓN
Estudios recientes de la OMS (Organización Mundial de la Salud)
relatan que en la actualidad un 15% de la población mundial tiene
alguna discapacidad física, psíquica o sensorial que dificulta de una
manera u otra su integración en el mundo actual.
La inteligencia artificial, y en general las nuevas tecnologías, cada
vez avanzan más y proponen nuevas soluciones para realizar más
fácil la integración de estas personas.
Se pueden clasificar en cinco grupos las distintas tecnologías
empleadas como ayuda a personas discapacitadas:
1. Sistemas Alternativos y Aumentativos de Acceso a la
Información:
Se trata de sistemas de ayuda para personas con
problemas de visibilidad y/o auditiva, que proporcionan
otra vía para hacer llegar información a una persona
discapacitada. Cabe destacar los siguientes sistemas
actuales:
Tecnologías del habla.
Sistemas multimedia interactivos.
Comunicaciones Avanzadas.
Rehabilitación cognitiva.
2. Sistemas de acceso:
Interfaces adaptativos que ayudan a las personas con
discapacidad física o sensorial a poder usar un
ordenador. Podemos mencionar los siguientes sistemas:
Telelupas: sistemas de magnificación de imágenes
basados en circuitos cerrados de TV que posibilitan
la lectura a personas con disminución visual.
Sintetizador Braille: ordenador personal para
invidentes con sintetizador de voz ó voz digitalizada
que permite invidente escribir información
simulando a una máquina Perkins y verificar luego
la misma.
Reconocimiento óptico de caracteres (OCR):
permite al usuario reproducir información desde un
ordenador con la ayuda de un scanner que lee y
reconoce texto, para después sintetizarlo en voz o
braille.
Teclado de conceptos: Ideado para personas con
discapacidad motriz. Consiste en una cuadrícula en
blanco que se puede agrupar de acuerdo a varios
conceptos temáticos asignados por los terapeutas.
Sobreteclados: de muchos tipos, adaptados a la
necesidad del usuario.
Ratones: tipo palancas, pedal, esférico, touch, etc...
Pizarras Electrónicas Copiadoras: facilitan que
personas sordas e hipoacúsicas, o aquellas con
dificultades motrices puedan obtener copias de
clases presenciales sin perder la observación y
atención de las mismas.
Pantallas táctiles: para personas con dificultades
motrices puedan mover cursores con el tacto.
Interruptores: según la necesidad de cada usuario:
Los hay bucales, infrarrojos, fotoeléctricos, etc…
Navegadores: para facilitar la navegación por la red.
3. Sistemas Alternativos y Aumentativos de Comunicación:
Tienen por objeto sustituir o aumentar el habla de
personas con dificultades de comunicación verbal y/o
auditiva. Se clasifican en 2 tipos de sistemas:
Sistemas con ayuda: requieren del empleo de algún
instrumento para comunicarse, aparte del propio
cuerpo del usuario. Ejemplos: escritura,
pictogramas, tableros de comunicación,
ordenadores, etc.
-94-

Sistemas sin ayuda: comprenden formas de
comunicación producidas por la persona que se
tiene que comunicar. Ejemplos: lengua de señas,
palabra complementada, otros gestos como la
indicación, etc.
4. Sistemas de Movilidad:
Relacionados a la movilidad personal y a las barreras
arquitectónicas. Ejemplos: brazos o soportes articulados,
emuladores de mouse, varillas, micro-robots, etc. que se
combinan con sistemas alternativos y aumentativos de
comunicación.
5. Sistemas de control de entornos:
Permiten la manipulación de dispositivos que ayudan a
controlar un entorno. Hay 2 tipos de sistemas:
Inteligencia Ambiental: Permiten a personas con
discapacidad motora poder controlar dispositivos de
uso doméstico. Ejemplo: domótica en casas
inteligentes.
Sistemas de Realidad Virtual: Desarrollo de una
Tecnología Adaptativa mediante nuevos
dispositivos de entrada y salida avanzados.
Ejemplos: guantes sensitivos, dispositivos de
seguimiento de movimientos oculares,
posicionadores 3D, etc. Estos sistemas traen
muchas posibilidades futuras en el diseño de
sistemas de asistencia a personas con discapacidad.
En las páginas siguientes intentaremos ahondar en un sistema de
inteligencia artificial de cada uno de los 5 grupos presentados.
2. SISTEMAS ALTERNATIVOS Y
AUMENTATIVOS DE ACCESO A LA
INFORMACIÓN: Reconocimiento Automático
del Habla
2.1 Introducción
El Reconocimiento Automático del Habla (RAH) o
Reconocimiento Automático de Voz es una parte de la Inteligencia
Artificial que tiene como objetivo permitir la comunicación hablada
entre seres humanos y computadoras electrónicas.
Un sistema de reconocimiento de voz es una herramienta
computacional capaz de procesar la señal de voz emitida por el ser
humano y reconocer la información contenida en ésta,
convirtiéndola en texto o emitiendo órdenes que actúan sobre un
proceso. En su desarrollo intervienen diversas disciplinas, tales
como: la fisiología, la acústica, el procesamiento de señales, la
inteligencia artificial y la ciencia de la computación.
Estos sistemas pueden ser útiles para personas con discapacidades
que les impidan teclear con fluidez, así como para personas con
problemas auditivos, que pueden usarlos para obtener texto escrito
a partir de habla. Esto permitiría, por ejemplo, que los aquejados
de sordera pudieran recibir llamadas telefónicas.
2.2 Historia de los sistemas RAH
Los primeros intentos por construir máquinas que realizaran tareas
de reconocimiento del habla se remontan a la década de los 50,
cuando diversos investigadores trataban de explotar los principios
fundamentales de la fonética acústica. En 1952, los laboratorios
Bell, crearon un sistema electrónico que permitía identificar para
un solo hablante, pronunciaciones de los 10 dígitos realizadas de
forma aislada. El fundamento de esta máquina se basaba en
medidas de las resonancias espectrales del tracto vocal para cada
dígito.
En los años 60 se comenzó a experimentar con normalización
temporal según la detección de los puntos de comienzo y fin de las
palabras.
Los años 70 representan un periodo muy activo para esta
disciplina, avanzando de forma significativa las investigaciones en
el reconocimiento de palabras aisladas. También comienzan los
primeros intentos de reconocimiento de habla continua y la
experimentación en reconocimiento independiente del locutor.
En los años 80 se produce un giro metodológico como
consecuencia de pasar de métodos basados en comparación de
plantillas a los métodos basados en modelado estadístico. Se
empezaron a emplear los modelos ocultos de Markov (HMM),
obteniendo excelentes resultados en el modelado de voz. A partir
de entonces se han desarrollado numerosas mejoras y actualmente
constituyen los mejores modelos disponibles para capturar y
modelar la variabilidad presente en el habla.
La década de los 90 supone en cierta manera la continuidad en los
objetivos ya propuestos, ampliando eso sí, el tamaño de los
vocabularios a la vez que se diversifican los campos de aplicación.
2.3 Clasificación y características de los
sistemas RAH
Podemos clasificar los sistemas RAH según el tipo de aprendizaje
que usen:
Aprendizaje deductivo: se basa en la transferencia de
conocimientos que un experto humano posee, a un
sistema informático. Un ejemplo lo constituyen los
Sistemas Basados en el Conocimiento, en particular, los
Sistemas Expertos.
Aprendizaje inductivo: se basa en que el sistema pueda,
automáticamente, conseguir los conocimientos necesarios
a partir de ejemplos reales sobre la tarea que se desea
modelizar. Un ejemplo lo constituyen aquellas partes de
los sistemas basados en los modelos ocultos de Markov o
en las redes neuronales artificiales que son configuradas
automáticamente a partir de muestras de aprendizaje.
Aparte de esta clasificación inicial, los sistemas de reconocimiento
de voz tienen distintas características, dependiendo de la aplicación
para la que se vayan a emplear:
Entrenabilidad: determina si el sistema necesita un
entrenamiento previo antes de empezar a usarse.
-95-

Dependencia del hablante: determina si el sistema debe
entrenarse para cada usuario o es independiente del
hablante.
Continuidad: determina si el sistema es capaz de
reconocer habla continua o si el usuario debe hacer
pausas entre palabra y palabra.
Robustez: determina si el sistema está diseñado para
usarse con señales poco ruidosas, ya sea ruido de fondo,
ruido procedente del canal o la presencia de voces de
otras personas.
Tamaño del dominio: determina la cantidad de palabras
que el sistema es capaz de reconocer.
3. SISTEMAS DE ACCESO. Reconocimiento
óptico de caracteres.
3.1 Introducción.
El reconocimiento óptico de caracteres (OCR) es un proceso que
permite digitalizar texto a partir de imágenes, reconociendo los
símbolos del alfabeto correspondiente para poder tratar los datos
digitalizados de la manera que se precise.
Este sistema ha sido un gran avance para aquellas personas
invidentes, o concierto grado de discapacidad visual, puesto que les
ha facilitado su integración en la sociedad actual, consiguiendo
acceder a la palabra escrita por medio de este tipo de sistemas,
integrados en conjunto con sintetizadores Braille ó sintetizadores
de voz, por ejemplo, que permitan la reproducción del texto
reconocido.
Para llevar a cabo este sistema, han de usarse un conjunto de
técnicas basadas en estadística, en las formas de caracteres,
transformadas y en comparaciones, que complementándose entre
sí, se emplean para distinguir de manera automática los distintos
caracteres. Lo que se consigue no es reconocer un carácter, sino
distinguir entre patrones que se asemejen lo máximo posible a
ellos, por lo que no se puede asegurar que no se puedan cometer
errores en el proceso.
Los sistemas OCR se caracterizan por tener cuatro etapas
significativas:
Adecuación de imagen ó etapa de pre-procesamiento.
Selección de la zona de interés ó etapa de segmentación.
Representación digital de la imagen ó etapa de extracción
de características.
Difusión del carácter contenido en la imagen ó etapa de
reconocimiento.
El paso más difícil es el de la etapa de extracción de características,
por lo que elegir unas características idóneas puede ser
determinante. Además hay que tener en cuenta el gasto
computacional que acarren dichas características.
Los sistemas de reconocimiento de caracteres se pueden basar en
tres técnicas:
3.2 Etapas de sistemas OCR.
Como ya explicamos antes, los sistemas OCR se basan en cuatro
etapas:
Etapa de preprocesamiento: En esta etapa se pretende
eliminar cualquier tipo de ruido o imperfección que pueda
haber en la imagen, que no pertenezca al carácter analizado,
además de normalizar el tamaño de carácter.
Para eliminar el ruido se pueden usar distintos algoritmos:
o Etiquetado.
o Erosión.
o Fijar umbral del histograma.
Etapa de segmentación: Tras el preproceso, es necesario
fragmentar la imagen para reconocer los caracteres. Es el
proceso más costoso de todos. Implica la detección mediante
procedimientos de etiquetado determinista o estocástico de los
contornos o regiones de la imagen, basándose en la intensidad
o información espacial.
La fragmentación permite la descomposición de un texto en
distintas entidades lógicas para su reconocimiento. Han de ser
suficientemente invariables para poder identificarse.
Etapa de extracción de características: Acabada la anterior
etapa, ahora tenemos información tratada susceptible de ser
clasificada.
La extracción de características es una de las etapas más
difíciles de los sistemas de reconocimientos de caracteres.
Para considerar una característica como buena, debe ser:
o Diferente de otra característica.
o Igual valor para mismas clases
o Características incorreladas entre ellas.
o Pequeño espacio para características.
Algunos de los métodos empleados para extracción de
características basados en transformaciones del espacio de
representación de muestras son:
o Principal Component Analysis (PCA).
o Linear Discrimination Analysis (LDA).
o Independent Component Analysis (ICA).
o Non-linear Discriminant Analysis (NDA).
Etapa de reconocimiento: Tras haber obtenido las
características importantes de la imagen a analizar, debemos
determinar el carácter correspondiente por medio de técnicas
de minería de datos:
o OCR basado en el algoritmo KNN: (K vecinos más
próximos) método muy popular por su sencillez y
sus propiedad estadísticas que proporcionan buen
comportamiento para afrontar problemas de
clasificación.
-96-

Dado un conjunto de objetos prototipo de los que ya
se conoce su clase, y dado un nuevo objeto cuya
clase no conocemos, buscamos entre el conjunto de
prototipos los “k” más parecidos al nuevo objeto. A
este se le asigna la clase más numerosa entre los “k”
objetos prototipo seleccionados.
Para poder trabajar con KNN, necesitamos una
base de datos de imágenes de los tipos de caracteres
(procesados y sin ningún tipo de ruido) que
posteriormente se desean reconocer. Esta es la
llamada fase de entrenamiento. Tras ello, ya
podemos usar el algoritmo para reconocer
caracteres. Es la fase de test.
o OCR basado en árboles binarios: En esta técnica
el aprendizaje es inductivo. Los patrones a evaluar
de un carácter constituyen los nodos del árbol. Los
resultados finales se almacenan en las hojas del
mismo. Este tipo de estructura favorece la velocidad
del cálculo.
El orden de evaluación de los parámetros es muy
importante para realizar el ajuste óptimo del árbol.
La forma de recorrerlo consiste en que si se llega a
una hoja, esa serie de patrones recorridos
corresponden a cierto carácter conocido. De no
llegar a ninguna hoja, se crea una nueva hoja en el
árbol para guardar el nuevo resultado final.
o OCR basado en redes neuronales: Minerías de
datos que emulan la arquitectura del cerebro.
Formadas por neuronas (unidad básica), que reciben
una entrada, la multiplican por unos pesos y
presentan una salida con una función de ajuste,
dependiente de la salida de la etapa anterior.
Son muy útiles para representar y ajustar de forma
óptima difíciles funciones algebraicas, con lo que
usarlo para el reconocimiento de caracteres es una
buena alternativa.
Se pueden utilizar diferentes topologías:
Feed Forward: Sin bucles. Entradas
conectadas con salida de etapa anterior.
Feed Back: Con bucles.
Lateral: Adicionalmente, se permite
comunicación vertical entre neuronas de
la misma etapa.
También podemos clasificar una red neuronal según origen de
datos y el aprendizaje que realizan. OCR es un lenguaje
supervisado. Puede tratarse de datos continuos, normalmente
basados en el perceptron o binarios normalmente basados en redes
de Hamming.
4. SISTEMAS ALTERNATIVOS Y
AUMENTATIVOS DE COMUNICACIÓN:
Interfaces Ordenador Cerebro (BCI)
4.1 Introducción
Las BCIs (Brain Computer Interfaces) están dirigidas a crear una
comunicación directa entre el cerebro y un dispositivo externo. En
los últimos años, las investigaciones en este campo han crecido de
una manera espectacular, y hoy en día se considera una de las
aplicaciones con más éxito de las neurociencias.
Estos sistemas pueden proporcionar un aumento de la calidad de
vida de pacientes que sufran patologías que les impidan
comunicarse tanto de forma verbal como escrita, por ejemplo
pacientes que sufran esclerosis lateral, infarto cerebral, etc…
Podemos clasificar estos sistemas en dos tipos, según como
acceden a las respuestas cerebrales:
BCIs invasivos: Un array de micro-electrodos se
implanta en el cerebro del paciente (principalmente en la
zona motora o premotora o en la corteza parietal).
BCIs no invasivos: Principalmente
electroencefalogramas (EEGs) tomados en el cuero
cabelludo. Hay tres tipos principales de BCIs basados en
electroencefalogramas:
o SSVEP (State Visually Evoked Potential):
Cuando un sujeto se centra en un estimulo
visual que parpadee a una cierta frecuencia f,
esta frecuencia y sus armónicos aparecen en la
transformada de Fourier del EEG.
Mostrándole al usuario varios estímulos con
distintas frecuencias de parpadeo, y asociando
cada una a una acción predefinida, los
usuarios son capaces de conducir un coche en
la pantalla del ordenador o marcar un número
de teléfono.
o El segundo tipo de BCIs basados en
electroencefalogramas se basan en detectar
tareas mentales (imaginar movimientos de
manos a izquierda/derecha, asociaciones de
palabras, etc) que se detectan mediante SCP
(Slow Cortical Potentials), RP (Readiness
Potential) o ERD (Event-Related
Desynchronization).
o ERP (Event Related Potential): es una
respuesta electro-fisiológica estereotipada a
un estimulo interno o externo. Una de los
ERPs más conocidos y estudiados es el ERP
P300. Este aparece cuando un sujeto intenta
clasificar dos tipos de eventos, presentándose
uno de ellos de manera infrecuente. El evento
infrecuente provocara en el EGG del sujeto un
ERP con una componente positiva de duración
aproximada de 300ms.
-97-

Figura 1. Respuesta en EGG del ERP P300
4.2 P300 Mind-Speller de IMEC
Mind Speller es un dispositivo basado en EEG que interpreta las
ondas cerebrales para deletrear palabras y frases en fase de
desarrollo por investigadores de IMEC (Interuniversity
Microelectronics Centre). Se basa en detectar e interpretar ERP
P300 en el electroencefalograma de una persona que está
seleccionando caracteres de una pantalla en la que se presentan
columnas y filas de caracteres alternando. Cuando se ilumina una
columna o una fila en la que se encuentra el carácter que se quiere
seleccionar, se provocara un ERP P300, detectando este ERP el
BCI es capaz de indicar cuál es el carácter que el usuario tiene en
mente.
Figura 2. Interfaz de usuario para el Mind-Speller P300
Para detectar el ERP en el electroencefalograma, normalmente no
es suficiente con un solo intento y es necesario realizar una media
de varios intentos. Esto es debido a que la señal obtenida con el
EEG es la superposición de todas las actividades cerebrales que se
están llevando a cabo. Se añadirán a la media los eventos que se
detecten en momentos de tiempo en los que haya pasado cierto
evento y se sacarán de ella los que ocurran fuera de tiempo ya que
serán debidos a otro estimulo que no nos interesa. Es decir, cuanto
más fuerte sean las señales ERP, menos intentos se necesitarán
para detectar el carácter, y viceversa.
Figura 3. Media de acierto de clasificación en function del
numero de intensificaciones para todos los clasificadores
considerados.
En uno de los últimos estudios realizados por el grupo de trabajo
del Mind Speller P300 de IMEC [13], se compara el rendimiento
de 7 clasificadores distintos:
LDA (Fisher’s Linear Discriminant Analysis)
SWLDA(Stepwise Linear Discriminant Analysis)
BLDA (Bayesian Linear Discriminant Analysis)
SVM (Linear Support Vector Machine)
nSVM (Nonlinear Support Vector Machine)
FE (Method Based on Feature Extraction)
NN (Artificial Neural Network)
Las conclusiones del estudio, probado en pacientes de ELA
(Esclerosis Lateral Amiotrófica), indican que, en general, los
clasificadores no lineales se comportan igual o peor que los
lineales. Esto puede ser debido a la tendencia de los clasificadores
no lineales de sobreajustar los datos de entrenamiento, guiando a
una menor generalización. Por tanto se recomienda emplear
clasificadores lineales, ya que resultando en mejores o iguales
resultados, minimizan el tiempo de entrenamiento.
5. SISTEMAS DE MOVILIDAD:
5.1 Introducción
Uno de los problemas más graves a los que se enfrentan las
personas con lesiones en la medula, enfermedades degenerativas,
etc, es el de poder moverse de forma autónoma.
Para solventar este problema, o al menos, suavizarlo, el elemento
más empleado en la actualidad es la silla de ruedas. Pero hoy en
-98-

día, el concepto de silla de ruedas es muy amplio, desde la clásica
silla de ruedas mecánica, la cual carece totalmente de ningún tipo
de alta tecnología, pasando por la silla eléctrica y llegando a sillas
más complejas, que hacen uso de varias formas de inteligencia.
A continuación analizaremos un proyecto llevados a cabo por
investigadores de Massachusetts Institute of Technology (MIT), en
el cual están desarrollando una silla de ruedas inteligente.
Figura 4. Silla de ruedas inteligente desarrollada por
investigadores del MIT
Esta silla, además de funcionar a través de comandos de voz, es
capaz de aprender la estructura de cualquier edificio, mobiliario
incluido, y llevar a su ocupante a través de él siguiendo comandos
de voz, trazando su propio camino. A diferencia de otros robots
similares, que basaban su funcionamiento en la memorización
visual de un plano o mapa, el sistema desarrollado por el MIT
aprende, según sus creadores, de una forma similar a como lo haría
un ser humano. Basta con realizar una visita guiada por el espacio
por el que se quiere que la silla se mueva y ella memorizará los
caminos a seguir.
5.2 Funcionamiento general
Dado que este robot es un sistema muy complejo, nos centraremos
en la parte de su inteligencia que se encarga de aprender,
memorizar e interpretar las rutas y localizaciones de los elementos
que se le quieran enseñar.
El robot aprenderá del entorno empleando supervisión humana. El
humano dirigirá un camino guiado, describiendo sitios destacados y
objetos verbalmente, mientras el robot le seguirá. El robot irá
adquiriendo representaciones del entorno tanto métricas como
topológicas, y lo relacionará todo con etiquetas semánticas.
La estructura del robot es la siguiente:
Base del robot: Esta compuesta por un sensor láser y
odometría (estimación de la posición de vehículos con
ruedas). Este bloque conduce al robot a una cierta
velocidad rotacional y traslacional.
Seguimiento de ruta:
o Rastreo de personas: Localiza al guía usando
un sensor láser.
o Seguimiento de personas: Controla al robot
para que se mueva siguiendo un guía.
Interpretación de ruta:
o SLAM (Simultaneous Localization And
Mapping): Construye mapas en tiempo real
durante el tour guiado.
o Gestor de conversaciones: Reconoce
expresiones del usuario y extrae etiquetas
semánticas.
o División del mapa: Particiona el mapa
obtenido, incorporando etiquetas semánticas a
cada parte.
5.3 Seguimiento de personas
Para comenzar el tour, el guía indicara verbalmente al robot que
están enfrente de él, el robot seleccionara a esa persona como guía
e indicara que está en modo seguimiento. El guía podrá iniciar y
pausar el tour indicándolo verbalmente.
Una vez iniciado el tour, el robot se moverá de forma que no invada
las zonas espaciales del guía o de los elementos del entorno,
diferenciando 3 zonas según la distancia a la que se encuentre del
guía:
Zona íntima (<0.45m del guía): El robot no realizará
ningún movimiento.
Zona personal (entre 0.45m y 1.2m del guía): El robot
rotará en el lugar o se moverá, dependiendo del contexto.
Zona de seguimiento (>1.2m del guía): El robot seguirá a
la persona.
Para poder calcular la velocidad de rotación y traslación, el
algoritmo primero obtendrá los obstáculos del entorno empleando
los LIDAR (Light Detection and Ranging). Después seleccionara el
camino objetivo en la que avanzar basándose en el espacio libre
entre cada una de los caminos posibles y la meta. Por último
calculará la velocidad necesaria para moverse por el camino
elegido. El proceso a seguir es el siguiente:
-99-

1) Obtención de obstáculos: El algoritmo extraerá la
localización de los obstáculos, registrando y
discretizando el campo de vista del láser.
2) Selección de camino: El sistema elegirá un camino
basándose en el entorno y la localización del guía.
3) Velocidad rotacional: Se calcula mediante la diferencia
entre la dirección del robot y la dirección del camino.
Esta velocidad se calcula de forma que se eviten
rotaciones excesivamente rápidas, o para evitar que el
robot realice grandes arcos, por ejemplo cuando el guía
cruce una esquina.
4) Velocidad traslacional: La velocidad de translación se
calculará teniendo en cuenta la distancia al guía y la
distancia con los obstáculos, reduciéndose esta cuando
haya obstáculos cerca, y aumentando cuando el guía se
aleje.
5.4 Interpretación de ruta
El objetivo del subsistema de interpretación de ruta es adquirir
representación métrica, topológica y semántica del entorno
atravesado durante el tour. El algoritmo utilizado para realizar el
mapa en tiempo real (SLAM) será iSAM[1].
El resultado es un conjunto de mapas métricos, uno por cada planta
visitada. La representación topológica es un conjunto de nodos,
cada uno correspondiente a cada región espacial con espacio libre.
La información semántica, tales como nombres de las zonas o
salas, esta adjunta a cada uno de los nodos de la representación
topológica del mapa.
El mecanismo de gestión de diálogos extrae etiquetas semánticas
de las declaraciones del guía. Usa el reconocedor de habla
SUMMIT[2]. Cada declaración es analizada para determinar su
información útil de la siguiente forma:
<loc tagging> = <perspective> <prop> <place>
Perspectiva de la declaración (perspective): Una
localización puede ser etiquetada desde la perspectiva del
guía (“I am now in the loungue”) o desde la perspectiva
del robot (“You are now near the restroom”). La
localización métrica se obtendrá desde la posición del
guía o el robot dependiendo de la perspectiva.
Posición relativa del evento de etiquetado (prop): Una
localización puede ser etiquetada dentro del propio
espacio o cerca de él. Los espacios que se etiquetan
empleando “in” o “at” se consideran que están dentro del
espacio, y son incorporados en el proceso de
segmentación. Los espacios etiquetados usando “near”
no afectan a la segmentación.
Lugar/nombre del objeto (place): La etiqueta semántica
adquirida del evento de etiquetado.
6. SISTEMAS DE CONTROL DE
ENTORNOS. Inteligencia Ambiental.
6.1 Introducción.
Actualmente, la inteligencia ambiental es un área en fase
inicial y son pocas las aplicaciones reales implantadas las que
podemos encontrar.
La inteligencia ambiental implica diseñar tecnología de tal forma
que éstas tengan en cuenta la presencia de la persona y la situación
en la que se encuentra, adaptándose y respondiendo a sus
necesidades, costumbres y emociones. Cada vez trabajan más
empresas y universidades en este tipo de sistemas.
De estos sistemas podemos destacar tres características:
Ubicuidad: permite acompañar al usuario donde vaya.
Invisibilidad: pasar desapercibido en la vida diaria.
Inteligencia: capacidad de adaptación a las personas.
Estas investigaciones involucran a expertos de diversas áreas de
conocimiento como psicología cognitiva, ergonomía, ingeniería de
software, filología, inteligencia artificial y otras.
En resumen, la inteligencia ambiental es una tecnología de
tecnologías al servicio de la sociedad para hacernos la vida más
sencilla.
6.2 Historia de la Inteligencia Ambiental.
A principios de los 80 del pasado siglo, Mark Weiser,
investigador en el Xerox Parc Lab de California, elaboró el primer
escenario de cientos de pequeños ordenadores interconectado que
pasaban inadvertidos, como insignias, tarjetas y pizarras
electrónicas. Weiser decía “estos ordenadores ubicuos deberán
saber en qué habitación se encontraban para adaptarse al entorno e
identificarán a su usuario por medio de un sistema de
radiobúsqueda internacional”.
En 1998 Simon Birrell (director de Silicon Artists), Eli
Zelkha (vicepresidente de Compaq), y Stefano Marzano (CEO de
Philips Design tiempo después), junto a otros expertos, definieron
la visión en que estos ordenadores ubicuos interconectados
aprenderían de sus usuarios y de verdad mejorarían la vida de la
gente. El ser humano no tendría que adaptarse a las máquinas, sino
que la tecnología se adaptaría a él. “La inteligencia penetrará en el
entorno como una presencia ambiental, en el que nuestras
necesidades se verán satisfechas del mismo modo en que la sangre
circula en nuestro cuerpo: sin mediar una orden consciente”, decían
estos pioneros.
La inteligencia Ambiental ha sido denominada por la Comisión
Europea como el principal escenario de futuro para el siglo XXI.
6.3 Actividades de la Inteligencia Ambiental.
Las principales actividades a llevar a cabo son las del hogar,
educación, trabajo ó salud. Estos sistemas se pueden crear bajo
entornos inteligentes, en los que se puede:
Capturar experiencias diarias.
-100-

Acceder a la información.
Soportar comunicación y colaboración.
Desarrollar entornos sensibles al contexto.
Proporcionar nuevas formas de interacción hombre-
máquina.
Ejercer de guía automática.
Facilitar el aprendizaje y entrenamiento.
Las personas con discapacidad y la población de la tercera edad
son los núcleos de la sociedad que más verán mejorar su calidad de
vida con estos sistemas. Nos acercamos cada vez más a la sociedad
del bienestar.
El objetivo final de la inteligencia ambiental es facilitar y mejorar
la vida de las personas recogiendo ingentes cantidades de
información, analizándolas y proveyendo un entorno exclusivo
personalizado mejor adecuado a sus ocupantes.
6.4 Ejemplo: ASIBOT.
ASIBOT (“Desarrollo y experimentación de un robot personal
portátil de ayuda a personas discapacitadas y mayores en
actividades en la vida diaria”) ha sido desarrollado por la entidad
coordinadora RoboticsLab, del Departamento de Ingeniería de
Sistemas y Automática de la Universidad Carlos III de Madrid
junto con la Fundación Hospital nacional de Parapléjicos de Toledo
para la Investigación y la Integración (FUHNPAIN).
Se trata de un robot portátil, que proporciona al usuario
“capacidades aumentadas” gracias a uso del sistema sensorial
(cubre deficiencias perceptivas), y al sistema locomotor (cubre
deficiencia motoras), y que se desplaza donde el usuario vaya. Se
trata del primer robot de asistencia portátil.
Figura 5. ASIBOT integrado en una silla de ruedas.
El conjunto de robot y dispositivo móvil (denominados “núcleo
asistencial portátil”) se encuentran en la silla de ruedas. Cualquier
dispositivo móvil sirve para la ejecución de distintas tareas
secuenciales. Las tareas a realizar son transparentes a cada usuario,
según como se programe.
Los puntos desarrollados en ASIBOT para considerarlo como
portátil y un robot de movilidad extendida son:
Sistema locomotor-manipulador: robot escalador
manipulador, manejable por una persona.
Interfase con el usuario: Dispositivo móvil.
Procesamiento distribuido: entre CPU + Móvil + robot.
Sistema de comunicaciones: WIFI, Bluetooth, etc.
Sistema sensorial: mínima sensorización a bordo.
La planificación de tareas de alto nivel son las que decide dar el
usuario al robot según sus necesidades. Este tipo de
funcionamiento satisface la “domótica proactiva”, que quiere decir
que el robot tiene la capacidad de integrarse al entorno que
proporciona la Inteligencia Ambiental.
ASIBOT consta de cinco grados de libertad, que traduce en cinco
motores para su funcionamiento. Puede de anclarse por cada uno de
sus extremos, a la pared o a la silla de ruedas. Es autónomo, salvo
por su conexión para alimentación.
El extremo que queda libre se usa para dos cosas:
Anclar portaherramientas, para realizar diferentes tareas:
una taza, conector para cubiertos, cepillo de dientes, etc.
Usar una “garra” de tres dedos retráctiles, que sirve para
manipular objetos, que se esconde cuando es necesario.
Figura 6. Distintos portaherramientas de ASIBOT.
ASIBOT posee tres modos de operación:
Modo autónomo: el robot se mueve por sí mismo.
Control directo: Mediante voz, móvil, joystick para
realizar algo puntual que desee el usuario.
Tareas de alto nivel: tareas que el usuario repite con
frecuencia. Son un conjunto de actividades
semiautónomas del robot, cuyos pasos quedan
registrados mediante una red de Petri.
Las principales tareas relacionadas con ASIBOT son las de ámbito
doméstico. En el diseño se decidió que para tareas como dar de
comer, cepillar dientes, o afeitarse, sería el usuario el que realizaría
un pequeño movimiento para llevarlo a cabo cuando se le presente
el utensilio. Es muy importante el control de la trayectoria del
control, aceleración, velocidad en cada movimiento, puesto que se
mueve muy cerca del usuario.
En resumen, podemos decir que se ha logrado integrar en un diseño
innovador y portátil las funcionalidades de robots escaladores y
brazos manipuladores con un propósito asistencial para personas
discapacitadas, y anclando el robot a una silla de ruedas del
usuario, el ámbito de operación no se limita al entorno doméstico.
-101-

REFERENCIAS
[1] M. Kaess, A. Ranganathan, and F. Dellaert, “iSAM:
Incremental Smoothing and Mapping,” Robotics, IEEE
Transactions on, vol. 24, no. 6, pp. 1365–1378, 2008.
[2] J. Glass, “A Probabilistic Framework for Segment-Based
Speech Recognition,” in Computer Speech and Language 17,
pp. 137–152, 2003.
[3] Sachithra Hemachandra, Thomas Kollar, Nicholas Roy and
Seth Teller, “Following and Interpreting Narrated Guided
Tours” http://groups.csail.mit.edu/rrg/papers/sachi_icra11.pdf
[4] David Chandler, MIT News Office, “Robot wheelchair finds
its own way” http://web.mit.edu/newsoffice/2008/wheelchair-
0919.html
[5] A. Jardón, R. correal, S. Martinez, A. Giménez, C.Balaguer,”
“ASIBOT: robot portátil de asistencia a discapacitados.
concepto, arquitectura de control y evaluación clínica”.
RoboticsLab, Universidad Carlos III de Madrid.
http://roboticslab.uc3m.es/publications/Cap.%208.pdf
[6] J. Rivera Altimir. “Inteligencia ambiental” Universitat
Politènica de Catalunya, Barcelona.
http://www.lsi.upc.edu/~bejar/ia/material/trabajos/Inteligencia
%20Ambiental.pdf
[7] Wikipedia. “Reconocimiento óptico de caracteres”
http://es.wikipedia.org/wiki/Reconocimiento_%C3%B3ptico_
de_caracteres
[8] J. Arlandis Navarro. ”OCR, Sistema de reconocimiento de
caracteres”. ITI-Instituto tecnológico de Informática.
http://www.iti.es/media/about/docs/tic/13/articulo2.pdf
[9] Carlos Javier Sánchez Fernández, Victor Sandonís Consuegra,
“Reconocimiento Óptico de Caracteres (OCR)”. Universidad
Carlos III de Madrid.
http://www.it.uc3m.es/jvillena/irc/descarga.htm?url=practicas
/08-09/09.pdf
[10] Carlos de Castro Lozano, Cristóbal Romero Morales,
“Tecnología para el apoyo a personas con discapacidades”,
Universidad de Córdoba.
http://www.uco.es/investiga/grupos/eatco/automatica/ihm/des
cargar/discapacitados.pdf
[11] Lic. Ricardo A. Koon,” El impacto tecnológico en las
personas con discapacidad”.
http://diversidad.murciaeduca.es/tecnoneet/docs/2000/14-
2000.pdf
[12] N. Chumerin, N. V. Manyakov, A. Combaz, and M. M. Van
Hulle, “An Application of Feature Selection to On-Line P300
Detection in Brain-Computer Interface,” in IEEE
International Workshop on Machine Learning for Signal
Processing, Grenoble, 2009, p. a16.
[13] Nikolay V. Manyakov, Nikolay Chumerin, Adrien Combaz,
and Marc M. Van Hulle, “Comparison of Classification
Methods for P300 Brain-Computer Interface on Disabled
Subjects,” Computational Intelligence and Neuroscience, vol.
2011, Article ID 519868, 12 pages, 2011.
doi:10.1155/2011/519868
-102-