
UNIVERSIDAD DE EXTREMADURA - umbc.edu · Diagramas de flujo de datos ... en base a unos valores de...
134
UNIVERSIDAD DE EXTREMADURA Escuela Politécnica Ingeniería Informática Proyecto Fin de Carrera Desarrollo de nuevos algoritmos para procesamiento de imágenes hiperespectrales en ORFEO Toolbox Luis Ignacio Jiménez Gil Junio, 2011
Transcript of UNIVERSIDAD DE EXTREMADURA - umbc.edu · Diagramas de flujo de datos ... en base a unos valores de...

UNIVERSIDAD DE EXTREMADURA
Escuela Politécnica
Ingeniería Informática
Proyecto Fin de Carrera
Desarrollo de nuevos algoritmos para procesamiento de imágenes
hiperespectrales en ORFEO Toolbox
Luis Ignacio Jiménez Gil
Junio, 2011

UNIVERSIDAD DE EXTREMADURA
Escuela Politécnica
Proyecto Fin de Carrera
Desarrollo de nuevos algoritmos para procesamiento de imágenes
hiperespectrales en ORFEO Toolbox
Autor: Luis Ignacio Jiménez Gil
Director: Antonio J. Plaza Miguel
Tribunal Calificador
Presidente:
Fdo:
Secretario:
Fdo
Vocal:
Fdo:

1
Tabla de contenido
ÍNDICE DE IMÁGENES ................................................................................. 4
RESUMEN ..................................................................................................... 7
CAPÍTULO 1. Motivaciones y objetivos ......................................................... 9
1.1. Motivaciones ..................................................................................... 9
1.2. Objetivos ......................................................................................... 11
CAPÍTULO 2. Antecedentes ........................................................................ 13
2.1. Análisis hiperespectral ....................................................................... 13
2.2 El problema de la mezcla ................................................................... 17
2.3. Firmas espectrales puras. ................................................................. 19
2.4. Análisis del software disponible para el tratamiento de imágenes
hiperespectrales ....................................................................................... 23
2.4.1. Software comercial existente para el análisis hiperespectral ...... 23
2.4.2. Software libre existente para el análisis hiperespectral ............... 26
2.4.3. ORFEO Toolbox .......................................................................... 26
2.4.4. Ventajas del software libre para el tratamiento de imágenes
hiperespectrales. ................................................................................... 29
CAPÍTULO 3. Algoritmos implementados ................................................... 31
3.1. Algoritmos previamente disponibles .................................................. 33
3.1.1. PCA ............................................................................................. 33
3.1.2. SPP (Spatial Preprocessing) ....................................................... 36
3.1.3. OSP ............................................................................................. 40
3.1.4. N-FINDR ...................................................................................... 42
3.1.5. SSEE ........................................................................................... 45
3.1.6. AMEE .......................................................................................... 48

2
3.2. Nuevos algoritmos implementados .................................................... 53
3.2.1. VCA ............................................................................................. 53
3.2.2. IEA ............................................................................................... 56
3.2.3. Unmixing ..................................................................................... 61
CAPÍTULO 4. Resultados experimentales ................................................... 63
4.1. Descripción de imágenes hiperespectrales ....................................... 63
4.1.1. Sintética (Fractal) ........................................................................ 63
4.1.2. Real (Cuprite) .............................................................................. 68
4.2. Comparativa de algoritmos ................................................................ 72
4.2.1. Optimización de los parámetros del algoritmo SSEE .................. 73
4.2.2. Optimización de los parámetros del algoritmo AMEE.................. 78
4.2.3. Comparativa de los resultados entre los algoritmos. ................... 79
4.2.4. Análisis de la influencia de la señal de ruido aditivo en los
resultados. ............................................................................................. 81
4.2.5. Análisis de tiempo computacional de los algoritmos ................... 85
CAPÍTULO 5. Conclusiones y líneas futuras ............................................... 89
5.1. Conclusiones ..................................................................................... 89
5.2. Líneas futuras .................................................................................... 91
REFERENCIAS BIBLIOGRÁFICAS ............................................................. 93
APÉNDICE 1. Descripción de la herramienta .............................................. 98
Análisis de la herramienta ........................................................................ 98
Objetivos y funcionalidades deseadas .................................................. 98
Diagramas de flujo de datos ................................................................ 101
Diagrama de clases ............................................................................. 109
Manual del usuario ................................................................................. 111
1. GUÍA RÁPIDA ............................................................................... 111

3
2. ALGORITMOS DE PREPROCESADO ......................................... 114
3. ALGORITMOS DE EXTRACCIÓN DE ENDMEMBERS .................. 117
4. OPCIONES ..................................................................................... 123
5. RESOLUCIÓN DE PROBLEMAS ................................................... 127
6. ¿CÓMO INSTALAR LA HERRAMIENTA HYPERMIX?................... 128

4
ÍNDICE DE IMÁGENES
Figura 2.1: Ejemplo de imagen multi-espectral de cuatro bandas.
Figura 2.2: Procedimiento de análisis hiperespectral.
Figura 2.3: Firmas espectrales de vegetación obtenidas por el sensor multiespectral Landsat TM (7 bandas) y el sensor hiperespectral AVIRIS (224 bandas).
Figura 1.4: Tipos de píxels en las imágenes hiperespectrales.
Figura 2.5: Mezcla macroscópica
Figura 2.6: Mezcla íntima.
Figura 2.7: modelo lineal de mezcla.
Figura 2.8: Interpretación gráfica del modelo lineal de mezcla.
Figura 2.9: Interfaz proporcionada por el sofware ENVI ITT.
Figura 2.10: Captura de pantalla de la herramienta PCI Geomatica.
Figura 2.11: Captura de una aplicación basada en ORFEO Toolbox para el tratamiento de imágenes.
Figura 3.1: Cadena completa de desmezclado o unmixing de imágenes hiperespectrales.
Figura 3.2: Ilustración gráfica de la transformación PCA.
Figura 3.3: Metodología de preprocesado espacial de imágenes hiperespectrales.
Figura 3.4: Interpretación geométrica del método del preprocesado.
Figura 3.5: Funcionamiento del algoritmo N-FINDR.
Figura 3.6: descomposición de la imagen en subconjuntos y obtención de autovectores.
Figura 3.7 Proyección de los píxels sobre los autovectores y obtención de los píxels candidatos.
Figura 3.8: Proceso llevado a cabo en el tercer paso.
Figura 3.9: Operaciones morfológicas extendidas de erosión y dilatación.

5
Figura 3.10: Cálculo del índice MEI mediante la combinación de operaciones morfológicas de erosión y dilatación.
Figura 3.11: Diagrama de bloques del funcionamiento del algoritmo AMEE.
Figura 3.12: Diagrama de dispersión de dos dimensiones de las mezclas de los tres endmembers.
Figura 3.13: Distribución espectral irregular de endmembers en el método IEA.
Figura 3.14: Representación de la mezcla de tres endmembers.
Figura 4.1: Imagen Fractal 1 usada para crear la imagen sintética (izquierda). Fractal 1 dividida en clusters (derecha).
Figura 4.2: Firmas insertadas en la imagen Fractal 1.
Figura 4.3: Verdad terreno del Fractal 1 en escala de grises.
Figura 4.4: Imagen hiperespectral AVIRIS sobre la región Cuprite en Nevada, Estados Unidos.
Figura 4.5: Mapa de minerales obtenidos por el U.S. Geological Survey a través del algoritmo Tetracorder en la región Cuprite en Nevada, Estados Unidos.
Figura 4.6: Firmas espectrales puras correspondientes a los minerales más representativos en la región Cuprite en Nevada, Estados Unidos.
Figura A.1: Distribución de la interfaz seguida en el desarrollo de la
herramienta.
Figura A.2: DFD del proceso de leer imágenes hiperespectrales.
Figura A.3: DFD's de los algoritmos de preprocesado espacial SPP y PCA.
Figura A.4: DFD's de los procesos que realizan los algoritmos de extracción de endmembers AMEE y OSP.
Figura A.5: DFD's de los procesos que realizan los algoritmos de extracción de endmembers N-FINDR y VCA.
Figura A.6: DFD's de los procesos que realizan los algoritmos de extracción de endmembers IEA y SSEE.
Figura A.7: DFD del algoritmo de demezclado.
Figura A.8: DFD del proceso de composición de bandas.
Figura A.9 DFD sobre el proceso de presentación de los resultados.

6
Figura A.10: DFD sobre el proceso de presentación de imágenes de las bandas de una imagen hiperespectral.
Figura A.11: DFD sobre el proceso de guardado de resultados.
Figura A.12: Diagrama de clase de la herramienta HyperMix.
Figura A.13. Aspecto general herramienta HyperMix.
Figura A.14: Ventana de selección de fichero.
Figura A.15: Ventana de opciones del algoritmo de preprocesado (SSP).
Figura A.16: Ventana de opciones del algoritmo PCA.
Figura A.17: Imagen de la ventana de selección de parámetros para el algoritmo AMEE.
Figura A.18: Ventana de selección de parámetros para el algoritmo OSP.
Figura A.19: Ventana de selección de parámetros para el algoritmo N-FINDR.
Figura A.20: Ventana de selección de parámetros para el algoritmo VCA.
Figura A.21: Ventana de selección de parámetros para el algoritmo IEA.
Figura A.22: Ventana de selección de parámetros para el algoritmo SSEE.
Figura A.23: Ventana de selección de parámetros para el algoritmo de Unmixing.
Figura A.24: Ventana de selección de bandas de la imagen hiperespectral para componer una imagen RGB.
Figura A.25: Ventana de selección de parámetros para la comparación de los resultados obtenidos por los algoritmos con los datos de referencia de las imágenes hiperespectrales.
Figura A.26: Contenido de la carpeta Hyper/bin.
Figura A.27: Consola de comandos con el código a ejecutar para la instalación de ORFEO ToolBox.
Figura A.28: Imagen del aspecto inicial de la configuración de Cmake.
Figura A.29: Error previsto en la configuración de OTB.
Figura A.30: Imagen de consola con el comando que debemos ejecutar y el contenido del directorio.
Figura A.31: Contenido final del directorio de instalación.

7
RESUMEN
El análisis hiperespectral constituye una nueva técnica en observación
remota de la Tierra que permite obtener imágenes con gran resolución
espectral (cientos de bandas) para una misma zona de la superficie
terrestre. El modelo lineal de mezcla constituye una aproximación clásica al
análisis de datos hiperespectrales. Esta técnica generalmente consta de dos
partes: 1) la extracción de firmas espectrales puras de materiales presentes
en una escena hiperespectral (denominados endmembers en la literatura), y
2) la descomposición de las escenas en fracciones de abundancia relativas a
dichos endmembers.
En el presente trabajo se ha desarrollado una nueva herramienta que
integra diferentes técnicas de extracción de endmembers y demezclado de
imágenes hiperespectrales. Para ello se ha utilizado ORFEO ToolBox (OTB)
que es una librería software libre desarrollada por el CNES (Centre National
d’Etudes Spatiales de Francia) en el marco del “ORFEO Accompaniment
Program”. OTB se basa en la librería de procesamiento de imágenes
médicas ITK, y ofrece funcionalidades especiales para el procesado de
imágenes de teledetección en general, y para imágenes de alta resolución
espacial y espectral en particular. En particular, los nuevos algoritmos
implementados en el presente trabajo son
1. IEA (Iterative Error Analysis).
2. VCA (Vertex Component Analysis).
3. LSU (Linear Spectral Unmixing).
Además de ha desarrollado una herramienta comparativa que permite
ejecutar sobre imágenes hiperespectrales tanto los algoritmos citados
anteriormente como otros algoritmos clásicos de extracción de endmembers
(OSP, N-FINDR…) y algoritmos de preprocesado espacial (PCA y SPP).
Esta herramienta ha sido desarrollada usando la FLTK (Fast Ligth Tool Kit)
que es una librería multiplataforma (UNIX®/Linux® (X11), Microsoft®

8
Windows®, and MacOS® X) de herramientas GUI para C++. Proporciona
una moderna funcionalidad sin los excesos y apoyos gráficos 3D mediante
OpenGL®.
En este proyecto también se incluye una comparativa analítica de
todos los métodos usados para la extracción de endmembers y demezclado
en base a unos valores de referencia previamente calculados.
La memoria del proyecto se encuentra organizada de la siguiente
forma. En el primer capítulo se describen las motivaciones y objetivos del
proyecto. A continuación, se presentan los antecedentes y trabajos previos
sobre análisis hiperespectral, así como una breve descripción la librería
ORFEO ToolBox y sus funcionalidades. En el siguiente capítulo se describen
los algoritmos implementados, tanto los previamente disponibles como las
nuevas contribuciones propuestas en este proyecto. El siguiente capítulo
expone los resultados experimentales obtenidos sobre dos supuestos (uno
sintético y otro real), utilizando imágenes hiperespectrales de referencia y
analizando los parámetros óptimos para cada algoritmo. En el último capítulo
se exponen las conclusiones obtenidas del trabajo y se proponen las líneas
futuras de trabajo sobre este campo.
Esta memoria contiene un documento anexo que describe la
herramienta desarrollada desde un punto de vista técnico, así como un
manual de usuario para su correcto uso.

9
CAPÍTULO 1. Motivaciones y objetivos
1.1. Motivaciones
El trabajo desarrollado en este Proyecto Fin de carrera (PFC) se
enmarca dentro de las líneas de trabajo del grupo de investigación de
“Computación Hiperespectral” (HyperComp) de la Universidad de
Extremadura, entre las cuales se encuentra el desarrollo de nuevas técnicas
para demezclado de imágenes hiperespectrales de la superficie terrestre
basadas en la extracción de referencias espectrales puras o endmembers
[1]. En el presente trabajo, algunas de dichas técnicas (tanto ya disponibles
en el grupo como otras nuevas) han sido adaptadas a la librería ORFEO
ToolBox (OTB) con vistas a desarrollar una herramienta basada en software
libre que permita a cualquier investigador aplicar dichas técnicas de forma
eficiente. Conviene destacar que esta contribución supone una importante
novedad en el campo del análisis hiperespectral, ya que hasta la fecha
dichos algoritmos se encontraban disponibles de forma pública únicamente
en forma de software propietario, por ejemplo en paquetes como el conocido
Research Systems ENVI de ITTVisual Solutions1.
Así el presente Proyecto Fin de Carrera pretende el desarrollo de
nuevos algoritmos usando la librería ORFEO ToolBox, especializada en el
tratamiento de imágenes terrestres obtenidas de forma remota, en lenguaje
C++ así como realizar una comparativa de los resultados obtenidos por los
diferentes algoritmos. Como ya se ha comentado, la gran ventaja de esta
librería es que es software libre, permitiendo su libertad de uso, así como de
redistribución. Por otro lado, esta característica de la librería nos permite
pensar en el desarrollo y mantenimiento a largo plazo de aplicaciones y
algoritmos pudiendo compartirse con otros centros dedicados al mismo tipo
1 http://www.ittvis.com/language/en-us/productsservices/envi.aspx

10
de investigación. Con todo se eliminan las restricciones de uso que imponen
las licencias de software propietario y los problemas que pueden surgir con
actualizaciones no controladas.
Es pretensión también del presente trabajo el desarrollo de una
aplicación para el manejo sencillo y útil de dichos algoritmos así como de
otras funcionalidades que se crea pertinente incluir en dicha aplicación
utilizando la librería Fast Ligth Tool Kit y el entorno de desarrollo, integrado
en dicha librería, FLUID. En concreto, los algoritmos incluidos en la
comparativa que abarca la presente memoria son: OSP (Orthogonal
Subspace Proyections) [5], N-FINDR, AMEE (Automatic Morfological
endmember Extraction) [6], SSEE (Spatial Spectral Endmember Extraction)
[7], SPP (Spatial Pre-Processing) [8], IEA (Iterative Error Analysis) [4] , VCA
(Vertex Component Analysis) [3] y LSU (Linear Spectral Unmixing) [1]. Los
tres últimos algoritmos han sido implementados específicamente con motivo
del presente trabajo, mientras que los anteriores se encontraban disponibles
y han sido integrados en la herramienta y comparados con los nuevos
desarrollos, dando lugar a un exhaustivo estudio cuantitativo y comparativo
que supone una gran novedad en la literatura relacionada con análisis de
imágenes hiperespectrales mediante técnicas de desmezclado espectral ó
unmixing.

11
1.2. Objetivos
Como se ha comentado en el anterior apartado el principal objetivo de
este proyecto es el desarrollo de nuevos algoritmos de procesamiento de
imágenes hiperespectrales usando la librería ORFEO ToolBox. El desarrollo
de una aplicación para el manejo de dichos algoritmos de forma gráfica y
amigable completa los objetivos generales de este Proyecto Fin de Carrera.
De forma más específica los objetivos que se han ido planteando son
los siguientes:
Adquirir los conocimientos necesarios sobre los algoritmos
implementados así como sobre el tratamiento de imágenes
hiperespectrales en general.
Aprender a utilizar la librería Orfeo ToolBox, en particular las
funciones más importantes para el tratamiento de imágenes
hiperespectrales.
Conocer y aprender a usar la librería Fast Ligth Tool Kit así
como el entorno de desarrollo FLUID para el desarrollo en C++
de aplicaciones gráficas.
Implementar en el lenguaje de programación C++ utilizando la
librería Orfeo Toolbox los algoritmos utilizados en la presente
memoria: OSP, NFINDR, AMEE, SSEE, SPP, IEA, VCA y LSU
así como otros algoritmos de soporte para reducir la
dimensionalidad de las imágenes hiperespectrales (por ejemplo
PCA).
Ajustar los parámetros de entrada de los diferentes algoritmos
para optimizar sus resultados en base a las imágenes
sintéticas y reales utilizadas, permitiendo así una comparativa
justa de los diferentes algoritmos empleados en el estudio. En
este sentido, conviene destacar que el estudio experimental
utiliza las mejores versiones posibles de los algoritmos

12
comparados en cada caso de estudio, lo cual permite
extrapolar las conclusiones obtenidas en el presente estudio a
diferentes situaciones, en virtud de la variedad de experimentos
realizados utilizando tanto imágenes sintéticas como imágenes
reales.

13
CAPÍTULO 2. Antecedentes
El este capítulo se presentan los principales conceptos básicos que se
van a utilizar a lo largo del documento. En primer lugar se describe el
concepto de imagen hiperespectral, detallando las particularidades y
características propias de este tipo de imágenes de alta dimensionalidad. A
continuación se explica el problema de la mezcla que se presenta en este
tipo de imágenes así como los diferentes modelos de mezcla que se pueden
utilizar, con particular énfasis en la extracción de firmas espectrales puras o
endmembers. Por último, procederemos a describir la librería ORFEO
ToolBox en general así como las principales funcionalidades que ofrece para
el tratamiento de imágenes hiperespectrales.
2.1. Análisis hiperespectral
En la actualidad, existe un amplio conjunto de instrumentos o
sensores capaces de medir singularidades espectrales en diferentes
longitudes de onda a lo largo de áreas espaciales extensas [10]. La
disponibilidad de estos instrumentos ha motivado una redefinición del
concepto de imagen digital a través de la extensión de la idea de píxel. Así
en una imagen en escala de grises podemos decir que un píxel está
constituido por un único valor discreto, mientras que, en una imagen
hiperespectral, un píxel consta de un conjunto amplio de valores. Estos
valores pueden ser entendidos como vectores N-dimensionales [11], siendo
N el número de bandas espectrales en las que el sensor mide información.
La ampliación del concepto de píxel da lugar a una representación en
forma de cubo de datos, tal y como aparece en la Figura 2.1. En este caso el
orden de magnitud de N permite realizar una distinción a la hora de hablar
de imágenes multidimensionales. Así, cuando el valor de N es reducido,

14
típicamente unas cuantas bandas espectrales [12] se habla de imágenes
multi-espectrales, mientras que, cuando el orden de magnitud de N es de
cientos de bandas [13] se hablad de imágenes hiperespectrales.
Figura 2.1: Ejemplo de imagen multi-espectral de cuatro bandas
En este sentido, el análisis hiperespectral se basa en la capacidad de
los sensores hiperespectrales para adquirir imágenes digitales en una gran
cantidad de canales espectrales muy cercanos entre sí, obteniendo, para
cada píxel, una firma espectral característica de cada material [10]. Este
proceso facilita la identificación y cuantificación de los materiales en la
escena [14,15].

15
Figura 2.2: Procedimiento de análisis hiperespectral.
Tal y como hemos comentado anteriormente, el resultado de la toma
de datos por parte de un sensor hiperespectral sobre una determinada
escena puede ser representado en forma de cubo de datos, con dos
dimensiones para representar la ubicación espacial de un píxel, y una
tercera dimensión para representar la singularidad espectral de cada píxel
en diferentes longitudes de onda. La Figura 2.2 ilustra el procedimiento de
análisis hiperespectral mediante un sencillo diagrama, en el que se ha
considerado como ejemplo descriptivo el sensor Airbone Visible Infrared
Imaging Spectometer (AVIRIS) de NASA Jet Propulsion Laboratory. La
capacidad de observación de este sensor es mucho más avanzada que la de
otros dispositivos similares, en particular en términos de relación señal-ruido
(SNR) del sensor [13], y permite la obtención de píxels formados por
doscientos veinticuatro valores espectrales, a partir de los cuales puede

16
obtenerse una firma espectral característica que será utilizada en el proceso
de análisis.
Para concluir este subapartado, la Figura 2.3 muestra un ejemplo de
dos firmas espectrales asociadas a una cubierta vegetal, utilizada en este
caso como un sencillo ejemplo ilustrativo. La primera de ellas (izquierda) fue
adquirida por un sensor multiespectral, en concreto, Landsat Thematic
Mapper[36], que dispone de un total de siete bandas en el rango 0.48 –
2.21 . La segunda (derecha) fue obtenida por el sensor hiperespectral
AVIRIS, anteriormente comentado. Como puede apreciarse en la Figura 2.3,
la firma espectral obtenida mediante un sensor hiperespectral se asemeja a
un espectro continuo de valores, mientras que la firma proporcionada por un
sensor multiespectral es mucho menos detallada.
Figura 2.3: Firmas espectrales de vegetación obtenidas por el sensor multiespectral Landsat TM (7 bandas) y el sensor hiperespectral AVIRIS (224 bandas).

17
2.2 El problema de la mezcla
Como se ha mencionado en el apartado anterior, la capacidad de
observación de sensores hiperespectrales como AVIRIS permite la
obtención de una firma espectral detallada para cada píxel de la imagen,
dada por los valores de reflectancia adquiridos por el sensor en diferentes
longitudes de onda, lo cual permite una caracterización muy precisa de la
superficie de nuestro planeta. Conviene destacar que, en este tipo de
imágenes, es habitual la existencia de mezclas a nivel de subpíxel, por lo
que a grandes rasgos podemos encontrar dos tipos de píxels en estas
imágenes: píxels puros y píxel mezcla. Se puede definir un píxel mezcla
como aquel en el que cohabitan diferentes materiales [5, 21-23].
Este tipo de píxels son los que constituyen la mayor parte de la
imagen hiperespectral, en parte, debido a que este fenómeno es
independiente de la escala considerada ya que tiene lugar incluso a niveles
microscópicos [2]. La Figura 2.4 muestra un ejemplo del proceso de
adquisición de píxels puros (a nivel macroscópico) y mezcla en imágenes
hiperespectrales.
Figura 2.4: Tipos de píxels en las imágenes hiperespectrales.

18
Los píxels mezcla constituyen la mayor parte de los píxels de una imagen
hiperespectral, y su existencia se debe a una de las dos razones que
mencionamos a continuación:
Mezcla macroscópica. Si el tamaño de píxel no es lo suficientemente
grande para separar diferentes materiales, dichos elementos
ocuparan el espacio asignado al píxel, con lo que el espectro
resultante obtenido por el sensor será en realidad un espectro
correspondiente a una mezcla de componentes [24]. Esta situación
aparece ilustrada mediante un ejemplo en la Figura 2.5.
Figura 2.5: Mezcla macroscópica
Mezcla íntima. Pueden obtenerse píxels mezcla cuando diferentes
materiales se combinan, dando lugar a lo que se conoce como mezcla
intima entre materiales [25,26]. Podemos observar esta situación en la
Figura 2.6.

19
Figura 2.6: Mezcla íntima.
2.3. Firmas espectrales puras.
Un píxel mezcla puede ser descompuesto en una colección de
espectros "puros" o "característicos" (denominados endmembers en la
terminología) y en un conjunto de valores denominados abundancias que
indican la proporción o contribución individual de cada uno de los espectros
puros en el píxel mezcla [11]. El modelo utilizado para describir la situación
anteriormente comentada es el denominado “modelo de mezcla”, el cual
considera que cualquier escena está constituida por un conjunto de
endmembers con propiedades espectrales características y diferentes entre
sí, y que aparecen mezclados en distintas proporciones [27,28]. Dentro del
modelo de mezcla, se consideran dos posibilidades diferentes: lineal y no
lineal.
El modelo lineal de mezcla supone que cada haz de radiación solar
incidente solamente interactúa con un único componente o endmember, de
forma que la radiación total reflejada por un píxel mezcla se puede

20
descomponer de forma proporcional a la abundancia de cada uno de los
endmembers en el píxel [29,30]. El modelo lineal proporciona resultados
adecuados en gran cantidad de aplicaciones [37], y se caracteriza por su
simplicidad [38]. Por su parte, el modelo no lineal ha sido utilizado con gran
éxito en determinadas aplicaciones de carácter específico, especialmente en
aplicaciones orientadas a estudiar las propiedades de cubiertas vegetales
(Zarco-Tejada y col., 2001).
Este modelo aparece ilustrado gráficamente en la Figura 2.7.
Figura 2.7: modelo lineal de mezcla.
Como aparece reflejado en la Figura 2.7 el modelo lineal de mezcla
presupone que la proporción de componentes o endmembers que se
mezclan en un determinado píxel de la imagen sigue un proceso lineal. Sea
s la firma espectral obtenida por un sensor hiperespectral en un determinado
píxel. Este espectro puede ser considerado como un vector N-dimensional,
donde N es el número de bandas espectrales del sensor. El vector s puede

21
modelarse en términos de una combinación lineal de vectores endmembers,
, i=1. Y, de acuerdo con la expresión 2.1 que se muestra a continuación.
∑ (2.1)
Donde E es el número total de endmembers, es un valor escalar
que representa la abundancia del endmember en el píxel , y es un
vector de error que debe ser lo más reducido posible. El modelo lineal de
mezcla puede interpretarse de forma gráfica utilizando un diagrama de
dispersión entre dos bandas poco correlacionadas de la imagen, tal y como
se muestra en la Figura 2.8. En la misma, puede apreciarse que todos los
puntos de la imagen quedan englobados dentro del triángulo formado por los
tres puntos más extremos (elementos espectralmente más puros). Los
vectores asociados a dichos puntos constituyen un nuevo sistema de
coordenadas con origen en el centroide de la nube de puntos, de forma que
cualquier punto de la imagen puede expresarse como combinación lineal de
los puntos más extremos, siendo estos puntos son los mejores candidatos
para ser seleccionados como endmembers. El paso clave a la hora de
aplicar el modelo lineal de mezcla consiste en identificar de forma correcta
los elementos extremos de la nube de puntos N-dimensional.

22
Figura 2.8: Interpretación gráfica del modelo lineal de mezcla.

23
2.4. Análisis del software disponible para el tratamiento de
imágenes hiperespectrales
2.4.1. Software comercial existente para el análisis hiperespectral
En la actualidad existen varios softwares comerciales dedicados al
tratamiento de imágenes hiperespectrales. En este apartado del proyecto
vamos a analizar dos de ellos: ENVI y PCI Geomatics.
ENVI es un software para el procesamiento y análisis de imágenes
geoespaciales utilizado por profesionales GIS, científicos,
investigadores y analistas de imágenes propuesto por ITT Visual
Information Solutions. ENVI combina procesamientos de las imágenes
espectrales más recientes con tecnología de análisis de imagen
mediante una interfaz intuitiva y fácil de usar que ayuda a obtener
información significativa de las imágenes tratadas.
Como programa está constituido sobre lenguaje (IDL)
especializado en el manejo de datos multidimensionales y su
visualización. Se diferencia de otros programas similares en que
contiene funciones especialmente adaptadas al trabajo con
información territorial o geográfica. ENVI se caracteriza por ser
multiplataforma, existiendo versiones para Windows, Linux y varias
versiones de UNIX, lo que lo hace muy versátil, además es el primer
software totalmente compatible con ArcGIS [42]. A continuación
podemos ver una imagen de ENVI (Figura 2.9).

24
Figura 2.9: Interfaz proporcionada por el sofware ENVI ITT.
El software PCI Geomatica para Procesamiento Digital de Imágenes
Satelitales de todo tipo de sensor aeroespacial se ofrece con dos
niveles de funciones:
o Geomatica Core con todo lo necesario para clasificar imágenes
multiespectrales (paquete básico).
o Geomatica Prime que ofrece muchas funciones analíticas de
geoprocesamiento Raster (paquete ampliado).
PCI Geomatica integra en un solo entorno, las herramientas
comúnmente utilizadas en la teledetección y análisis espacial [43]. En
la Figura 2.10 vemos un ejemplo de esta herramienta.

25
Figura 2.10: Captura de pantalla de la herramienta PCI Geomatica.
Ambas herramientas proporcionan un amplio número de
funcionalidades de forma sencilla y amigable. Por supuesto, el hecho de que
sean software propietario provoca que su uso y las funcionalidades
aportadas dependan del soporte dado por las respectivas compañías que los
desarrollan.

26
2.4.2. Software libre existente para el análisis hiperespectral
En este apartado hablaremos de las herramientas para imágenes
hiperespectrales en MATLAB (Hyperspectral Image Analysis Toolbox, HIAT).
Este conjunto de herramientas están previstas para el análisis de datos
hiperespectrales y multiespectrales. HIAT es una colección de funciones que
amplían las capacidades del entorno informático numérico MATLAB. Se ha
implementado para los sistemas Macintosh y PC con Windows
utilizando MATLAB. El propósito de esta caja de herramientas es
proporcionar al usuario un entorno en el que pueden
utilizar diferentes métodos de procesamiento de imágenes de datos
hiperespectrales y multiespectrales.
HIAT proporciona los métodos estándar de procesamiento de
imágenes tales como el análisis discriminante, componentes principales, la
distancia euclídea, y de máxima verosimilitud.
En comparación con las aplicaciones del apartado anterior ofrecen
algunas de las mismas funcionalidades particularmente útiles para el
tratamiento de imágenes hiperespectrales en código libre. Por el contrario,
este mismo hecho, al ser código MATLAB, hace que su eficiencia sea, en
comparación, bastante reducida.
2.4.3. ORFEO Toolbox
CNES decide desarrollar ORFEO ToolBox (OTB) como un conjunto
encapsulado de algoritmos en una librería de software [16]. El objetivo que
se plantean para OTB es establecer una metodología savoir faire (“don de
gentes”) para adoptar un enfoque de desarrollo incremental con el objetivo

27
de explotar, de manera eficiente, los resultados obtenidos en el marco de los
estudios I + D.
Todos los avances desarrollados están basados en FLOSS (Free
Open Source Software) o en desarrollos previos por parte del CNES. OTB es
distribuido bajo licencia CéCILL (http://www.cecill.info/licences/Licence_CeCILL_V2-
en.html). En la figura 2.11 podemos ver un ejemplo de aplicación usando la
librería ORFEO.
Figura 2.11: Captura de una aplicación basada en ORFEO Toolbox para el tratamiento de imágenes.
OTB está implementado en C++ y se basa principalmente en ITK
(Insight Toolkit). ITK es una librería desarrollada por US National Library of
Medicine of the National Institutes of Health. Es usada como elemento
principal de OTB, por esa razón, muchas las clases de OTB heredan sus
funcionalidades de algunas de las clases de ITK. Para establecer una
continuidad en el aprendizaje, la documentación de OTB, sigue las mismas

28
líneas de organización y diseño que la documentación de ITK, de tal manera
que, para el usuario, la navegación por los distintos métodos y clases de las
dos librerías se hace mucho más sencilla.
OTB fue creado desde su inicio de forma colaborativa. La enseñanza,
la investigación y los usos comerciales, de este conjunto de herramientas
son algunos de los objetivos previstos que se tenían para esta librería. Los
desarrolladores proponen, que de usarse, se colabore en su mejora
mediante el reporte de errores, la contribución con nuevas clases y su
difusión mediante cursos para llegar al mayor número posible de
colaboradores. De estas sugerencias se observa una clara disposición al
mantenimiento a largo plazo de la librería, el cual, puede ser un punto a
tener en cuenta en futuros proyectos.
Como conclusión podemos decir que la librería ORFEO ToolBox
provee de un conjunto de recursos (como los ofrecidos por software
comerciales) para el tratamiento de imágenes hiperespectrales bastante
útiles, además de las ventajas que supone ser software libre en la
investigación y el estudio, así como, en el desarrollo de nuevas
funcionalidades. Además provee de estas funcionalidades en código C por lo
que su eficiencia, en comparación a otros toolboxes, es mucho mayor.

29
2.4.4. Ventajas del software libre para el tratamiento de imágenes
hiperespectrales.
En este apartado se comentarán las ventajas del desarrollo mediante
software libre de una aplicación en general, y para el tratamiento de
imágenes hiperespectrales en particular, frente a herramientas de código
propietario como puede ser ENVI. Entre ellas destacaremos las siguientes:
Libertad para el usuario para que pueda utilizar el software como más
le convenga en cuestiones de modificación y difusión. Estas dos
cuestiones son muy importantes para aplicaciones de investigación ya
que las aplicaciones se mantienen más actualizadas en el ámbito de
nuevos avances en la materia que se trate. La apuesta por el bien
común hace que se pueda mejorar aplicaciones o algoritmos de otros
desarrolladores teniendo en el mismo tiempo más y mejores
aplicaciones ya que no se tiene que partir de cero.
En la cuestión económica simplemente hacer hincapié en el bajo o
nulo coste de los productos libres con la consiguiente rebaja en los
gastos en licencias de uso de software propietario. Esto permite y
motiva a tener un mayor número de desarrolladores e investigadores
ya que la limitación de puestos de trabajo es menor.
El soporte y compatibilidad a largo plazo, más que una ventaja del
software libre es una desventaja del software propietario. A un
vendedor, una vez alcanzado el número máximo de ventas, le
interesa sacar un nuevo producto más que mejorar el presente para
que los usuarios sigan trabajando con él. Esto obliga al vendedor a
intentar en la medida de lo posible hacer obsoleto el producto anterior.
Con el uso de software libre se pretende centrar la atención el uso de
la aplicación en sí, teniendo estas vidas más largas ya que se van
solucionando los fallos a medida que se descubre y aportando nuevas
funcionalidades sin necesidad de aprender un nuevo entorno de
trabajo.

30
Por contra un software como ENVI ofrece una garantía de calidad que
el software libre no puede asegurar.

31
CAPÍTULO 3. Algoritmos implementados
En esta sección describimos los algoritmos de extracción de
endmembers y desmezclado espectral que se han incluido en la herramienta
desarrollada, distinguiendo entre los algoritmos que ya se encontraban
disponibles al comienzo del presente trabajo y los nuevos algoritmos
desarrollados. Antes de describir las soluciones disponibles Como puede
apreciarse en la figura 3.1, la metodología parte de una imagen pre-
procesada, es decir, corregida geométricamente [39] y atmosféricamente
[40]. A continuación, se efectúan los siguientes pasos:
1. Reducción dimensional. Este paso es opcionalmente utilizado por
ciertos algoritmos con objeto de reducir la carga computacional de
pasos sucesivos mediante la eliminación de ruido e información
redundante en la imagen.
2. Identificación de endmembers. En este paso se identifican las firmas
espectrales puras que se combinan para dar lugar a pixels mezcla en
la imagen.
3. Estimación de abundancias. La abundancia de las firmas espectrales
puras o endmembers es estimada en cada pixel de la imagen.

32
Figura 3.1: Cadena completa de desmezclado o unmixing de imágenes hiperespectrales.
A partir del conjunto de pasos anteriormente descrito, el paso de
identificación de endmembers y el paso de estimación de abundancias
pueden ser considerados problemas separados.
Extracción de
endmembers
0
1000
2000
3000
4000
5000
300 600 900 1200 1500 1800 2100 2400
Longitud de onda (nm)
Refl
ecta
ncia
(%
*10
0)
endmembers
Extracción de
endmembers
0
1000
2000
3000
4000
5000
300 600 900 1200 1500 1800 2100 2400
Longitud de onda (nm)
Refl
ecta
ncia
(%
*10
0)
endmembers
Extracción de
endmembers
0
1000
2000
3000
4000
5000
300 600 900 1200 1500 1800 2100 2400
Longitud de onda (nm)
Refl
ecta
ncia
(%
*10
0)
endmembers
LSU,
FCLSU
PCA, MNF, ICA
Imagen pre-procesada
Reducción
dimensional
Imagen reducida
dimensionalmente
Reducción
dimensional
Imagen reducida
dimensionalmente
Mapas de abundancia
Estimación de
abundancias
Mapas de abundancia
Estimación de
abundancias

33
3.1. Algoritmos previamente disponibles
En primer lugar mencionamos los algoritmos de los cuales estaban
disponibles al comienzo del presente proyecto.
3.1.1. PCA
El método de análisis de componentes principales o Principal
Component Analysis (PCA) aprovecha la elevada correlación existente entre
bandas consecutivas de una imagen hiperespectral para reducir su
dimensionalidad [34]. La transformación PCA permite obtener un conjunto
reducido de bandas (denominadas autovectores) poco correlacionadas entre
sí, (ortogonales, en el caso ideal) que contienen la mayor parte de la
información presente en la imagen original. Así, el primer autovector
contiene el mayor porcentaje de la varianza de la imagen original; el
segundo contiene mayor porcentaje de varianza que el tercero, y así
sucesivamente. Las últimas bandas de la descomposición suelen venir
caracterizadas por un escaso contenido en cuanto a información relevante,
estando en su mayor parte compuestas por el ruido presente en la imagen
original). De esta forma, la transformación PCA permite separar ruido de
información útil [35]. Es importante destacar que el conjunto de bandas
resultante de la transformación PCA es obtenido a partir de combinaciones
lineales de las bandas originales de la imagen [41].
Esta transformación sirve para reducir la dimensionalidad del conjunto
de datos, en el caso de las imágenes hiperespectrales, el número de
componentes por píxel. Por ejemplo el algoritmo de extracción de
endmembers N-FINDR utiliza los resultados de este algoritmo para extraer
dichos endmembers a partir una imagen dimensionalmente “reducida”. La
etapa de reducción dimensional no es, en sí misma, necesaria para el

34
análisis de imágenes hiperespectrales [33]. Sin embargo, se trata de un paso
que muchos algoritmos incorporan, debido a la alta dimensionalidad de los
datos analizados.
La transformación PCA aparece ilustrada de forma gráfica en la
Figura 3.1. Como puede apreciarse en la figura, esta transformación permite
obtener un nuevo sistema de coordenadas sobre el que se proyectan los
datos.
Figura 3.1: Ilustración gráfica de la transformación PCA.
El algoritmo comienza creando una matriz a partir de los píxels de la
imagen hiperespectral. De esta matriz se extraen los autovectores mediante
una descomposición SVD o Singular Value Descomposition, que es una
factorización de una matriz real o compleja de la siguiente forma:
(3.1)
donde es una matriz unitaria de , es una matriz diagonal con
números reales no negativos en la diagonal, y es la conjugada
transpuesta de que es una matriz unitaria de .
Estos autovectores se multiplican por la matriz para obtener la matriz
PCA que será base para la imagen de salida. Esta imagen de salida tendrá
Banda X
Ban
da
Y
Componente 1
Componente 2

35
el mismo número de píxels que la original pero con el número de
componentes deseadas.

36
3.1.2. SPP (Spatial Preprocessing)
El preprocesado espacial es un método por el cual se introduce
información espacial en el proceso de búsqueda de endmembers, de tal
manera que posteriormente al preprocesado se puedan aplicar métodos
clásicos de extracción de endmembers a la imagen preprocesada para así
obtener las firmas puras en base a criterios espaciales y espectrales. La
Figura 3.10 muestra el funcionamiento del método.
Figura 3.2: Metodología de preprocesado espacial de imágenes hiperespectrales.
En el método de preprocesado se calcula un factor escalar para cada
píxel relacionado con la similitud del píxel con sus vecinos. A continuación se
usa ese factor escalar para dar un peso a la información espectral de dicho
píxel. El factor se calcula como:
( ) ∑ ∑ ( ) ( )
, (3.2)

37
donde (i,j) denota las coordenadas espaciales de un píxel de la imagen
hiperespectral. Si suponemos que dicho píxel (vector) se denota como X(i,j),
tenemos:
( ) ( ( ) ( )), (3.3)
siendo SAD el ángulo espectral o spectral angle distance que determina la
similaridad espectral entre dos firmas espectrales [1].
Como se observa en la expresión (3.2) el valor de γ es ponderado por
β. Esto permite al método aplicar mayor peso a los píxels más cercanos que
a los más alejados. Más concretamente, tenemos:
( ) (3.4)
( )
(3.5)
donde:
∑ ∑ ( ) ( )
(3.6)
Una vez obtenido el factor escalar anterior se pondera cada uno de
los píxels en función de este factor de la siguiente manera:
( ) ( √ ( )) (3.7)

38
( )
( )( ( ) ) (3.8)
Donde es el centroide de la imagen, es decir, la media de todos los
píxels de la imagen, ( ) es el nuevo píxel y ( ) es el píxel original. Con
este se pretende desplazar hacia el centroide aquellos píxels que se
encuentren rodeados de vecinos espectralmente diferentes a él mismo y un
desplazamiento menor cuanto más parecidos sean. Esta situación la
podemos observar de forma gráfica en la Figura 3.3.
Figura 3.3: Interpretación geométrica del método del preprocesado.

39
Para concluir este apartado, es importante recalcar que el método de
preprocesado espacial anteriormente descrito se aplica en combinación con
un método de extracción de endmembers puramente espectral. En el
presente trabajo, utilizamos el método de preprocesado con dos algoritmos
clásicos en la literatura para extraer endmembers utilizado información
espectral: OSP y NFINDR, así como los nuevos algoritmos desarrollados:
VCA e IEA. A continuación describimos dichos algoritmos.

40
3.1.3. OSP
El algoritmo OSP fue inicialmente desarrollado para encontrar firmas
espectrales utilizando el concepto de proyecciones ortogonales. El algoritmo
hace uso de un operador de proyección ortogonal que viene dado por la
expresión:
𝑃┴
( 𝑇 ) 𝑇 (3.9)
donde es una matriz de firmas espectrales, 𝑇es la traspuesta de dicha
matriz, e es la matriz identidad. El algoritmo utiliza el operador mostrado
anteriormente de forma repetitiva hasta encontrar un conjunto de p píxels
ortogonales a partir de un píxel inicial. El proceso iterativo efectuado por este
algoritmo puede resumirse en los siguientes pasos:
1. Calcular , el píxel más brillante de la imagen hiperespectral,
utilizando la siguiente expresión: 𝑔, ( ) ( )𝑇 ( )- ,
donde ( )es el píxel en las coordenadas ( ) de la imagen. Como
puede comprobarse, el píxel más brillante es aquel que resulta en
mayor valor al realizarse el producto vectorial entre el vector asociado
a dicho píxel y su transpuesto ( )𝑇o lo que es lo mismo, la norma
primera del píxel.
2. Aplicar un operador de proyección ortogonal que denotamos como
𝑃┴
, basado en la expresión anterior, con . Este operador se
aplica a todos los píxels de la imagen hiperespectral.
3. A continuación, el algoritmo encuentra un nuevo endmember con el
mayor valor en el espacio complementario < .>┴, ortogonal a , de

41
la siguiente forma: 𝑔, ( ),𝑃𝑈┴ ( )-𝑇 ,𝑃𝑈
┴ ( )-- . En
otras palabras, el algoritmo busca el píxel con mayor ortogonalidad
con respecto a .
4. El siguiente paso es modificar la matriz añadiendo el nuevo
endmember encontrado, es decir , -.
5. Seguidamente el algoritmo encuentra un nuevo endmember con el
mayor valor en el espacio complememtario < >┴, ortogonal a y ,
de la siguiente forma: 𝛶 𝑔, (𝑥 𝑦),𝑃𝑈┴ 𝐹( )-𝑇 ,𝑃𝑈
┴ 𝐹( )--.
Es preciso tener en cuenta que, a diferencia del paso 3) en el que
en este puto el proyector ortogonal se basa en la matriz
, -.
6. El proceso se repite, de forma iterativa hasta encontrar el número de
endmembers que deseemos.
Como puede comprobarse en los experimentos realizados, este
algoritmo es efectivo a la hora de identificar un conjunto de endmembers
espectralmente diferenciados gracias a la condición de ortogonalidad
impuesta en el proceso de búsqueda. Como característica negativa, tal y
como se muestra en los resultados experimentales el algoritmo puede ser
sensible a outliers y píxels anómalos, los cuales podrían ser descartados
mediante un proceso capaz de incorporar información espacial de forma
previa. También conviene destacar que este algoritmo se ha utilizado en este
trabajo en todos los casos en los que resultaba necesario extraer un
conjunto de firmas espectrales diferenciadas a partir de un proceso previo
basado en la información espacial. En este sentido, el algoritmo OSP
descrito en este subapartado se ha empleado en combinación con los
algoritmos basados en información espacial AMEE, SSEE y SPP (descritos
en detalle en apartados posteriores) para seleccionar un conjunto final de

42
firmas espectrales como paso final de dichos algoritmos.
3.1.4. N-FINDR
El algoritmo N-FINDR utiliza una técnica basada en identificar los
endmembers como los vértices del simplex de mayor volumen que puede
formarse en el conjunto de puntos. N-FINDR no trabaja con todo el cubo de
datos sino con una simplificación del mismo a tantas bandas como
endmembers se deseen encontrar.
Para este tipo de reducciones se suele utilizar la técnica PCA
(Principal Component Analysis) o MNF (Minimum Noise Fraction). El único
parámetro que tiene este algoritmo es el número de endmembers a
identificar. El funcionamiento del algoritmo se describe en los siguientes
pasos:
1. Realizar una reducción de la imagen a un número de bandas igual al
número de endmembers que se desean extraer mediante PCA o MNF
(en nuestro caso PCA). Seleccionar un número aleatorio de píxels
que se etiquetan como endmembers. Ésta selección inicial será
refinada de forma iterativa.
2. El segundo paso consiste en seleccionar un píxel de la imagen
original. Este píxel se va intercambiando de forma sucesiva a cada
uno de los endmembers inicialmente seleccionados.
3. A medida que el píxel se va intercambiando con los endmembers
iniciales se calcula el volumen del hiperpolígono formado con el nuevo
punto considerado.
4. Si el volumen obtenido tras el intercambio es mayor que el que había
antes del intercambio, el nuevo punto trae como consecuencia un
reemplazamiento en el conjunto de endmembers y el nuevo píxel

43
pasa a formar parte del conjunto de endmembers. En caso contrario,
se deshace el intercambio.
5. Los pasos 3-5 se repiten de forma iterativa hasta comprobar todos los
píxels de la imagen. De tal forma que al final del proceso tendremos
un conjunto de endmembers tal que su volumen es el mayor posible.
Conviene destacar que, en el primer paso del algoritmo, se establece
de forma aleatoria un conjunto inicial de endmembers. Si la estimación inicial
es adecuada, el algoritmo llegará a la solución óptima. Por el contrario, una
estimación inicial errónea puede dar como resultado que no se llegue a la
solución óptima sino que nos quedemos en un máximo local de la función de
crecimiento del hiperpolígono.
El algoritmo presupone que un aumento en el volumen del
hiperpolígono definido al incorporar un nuevo píxel en el conjunto de
endmembers conlleva una mayor calidad de los mismos. Sin embargo, la
Figura 3.4 muestra que el hecho de utilizar un polígono de mayor volumen
no asegura una mejor descripción del conjunto de puntos. Un parámetro más
fiable es el aumento en el número de píxels que pueden describirse
utilizando el nuevo conjunto de endmembers.

44
Figura 3.4: Funcionamiento del algoritmo N-FINDR.
Para concluir la descripción de este método, es importante destacar
que los endmembers identificados por el algoritmo N-FINDR corresponden a
píxels pertenecientes al conjunto de datos original. Utilizando este algoritmo,
no es posible generar endmembers artificiales, pues los reemplazamientos
se realizan siempre utilizando puntos existentes en el conjunto de muestras
disponibles. De este modo, puede ocurrir que los endmembers
seleccionados no sean los más puros. Además, el método es sensible a
outliers (entendidos como píxels con ruido), situación que puede remediarse
en parte al incorporar la información espacial en el proceso de búsqueda.
Una vez descritas dos aproximaciones clásicas al problema de extracción de
endmembers basadas en información espectral, procedemos a describir
métodos que también incorporan información espacial en el proceso.

45
3.1.5. SSEE
El algoritmo SSEE es un método representativo de las
aproximaciones que consideran la información espacial y espectral de forma
separada, no simultánea.
El algoritmo puede desglosarse en una secuencia de cuatro pasos:
1. En el paso uno se utiliza la descomposición SVD para obtener una
serie de autovectores que nos den una muestra de la varianza
espectral de subconjuntos o subregiones de una imagen [31,32]. En el
primer paso se divide la imagen en subconjuntos cuadrados, estos
subconjuntos son de igual tamaño, deben ocupar toda la imagen y no
pueden solaparse. Es por esto que el tamaño del subconjunto (lado
del cuadrado que forma el subconjunto) debe ser como máximo la
imagen entera (si la imagen es cuadrada), como mínimo la raíz
cuadrada del número de bandas de la imagen (para poder aplicar la
descomposición SVD al subconjunto) y además debe ser divisor de
las dimensiones de la imagen (para que ocupen toda la imagen y no
se solapen). A cada subconjunto de píxels se realizará una
descomposición SVD para obtener los autovectores (ver Figura 3.5 )
Figura 3.5: descomposición de la imagen en subconjuntos y obtención de autovectores.

46
2. En el segundo paso se proyectan todos los vectores de cada píxel
sobre cada uno de los autovectores obtenidos en el paso anterior,
seleccionando como píxels candidatos aquellos píxels cuya
proyección sea máxima o mínima (ver Figura 3.6).
Figura 3.6: Proyección de los píxels sobre los autovectores y obtención de los píxels candidatos.
3. El tercer paso comienza con una ampliación del conjunto de píxels
candidatos. Para realizar esta ampliación se van cogiendo cada uno
de los píxels candidatos y de una vecindad dada por una ventana
cuadrada de lado igual al tamaño del subconjunto del paso 1 y
centrada en el píxel candidato en cuestión, se añaden aquellos
vecinos que tengan una distancia de ángulo espectral SAD menor a
un valor de umbral. Una vez expandido el conjunto de píxels
candidatos se realiza una media entre aquellos píxels que sean
espectralmente similares y estén relacionados espacialmente. Más
concretamente se va cogiendo cada píxel candidato, a continuación
se examinan aquellos píxels candidatos vecinos que tengan un SAD
menor a un valor de umbral y se realiza una media entre todos ellos
para asignársela al píxel en cuestión. Este proceso se repite una serie
de veces, de tal manera que los píxels espacial y espectralmente
similares irán convergiendo hacia la media de todos ellos (ver Figura
3.7).

47
Figura 3.7: Proceso llevado a cabo en el tercer paso.
4. El último paso se trata de extraer los endmembers. Este proceso se
puede hacer automáticamente aplicando un algoritmo de extracción
de endmembers que tome en cuenta simplemente las características
espectrales a los píxels resultantes del paso anterior o
semiautomáticamente mediante la ordenación de los píxels
candidatos resultantes del paso anterior con respecto a una medida
de distancia entre ellos, para a continuación agruparlos en clases y
obtener los endmembers. En el presente trabajo, hemos optado por
emplear el algoritmo OSP para realizar esta función, debido
principalmente al carácter automático de dicho algoritmo y a su
efectividad a la hora de proporcionar un conjunto de firmas
espectrales ortogonales y espectralmente diferenciadas.

48
3.1.6. AMEE
El algoritmo AMEE es un método representativo de las
aproximaciones que consideran la información espacial y espectral de forma
simultánea. Este método de operaciones utiliza operaciones morfológicas
extendidas de erosión y dilatación. (Las cuales aparecen ilustradas en la
Figura 3.8).
Figura 3.8: Operaciones morfológicas extendidas de erosión y dilatación.
Como puede apreciarse en la figura, la operación de dilatación
expande las zonas espectralmente puras de la imagen; dicha expansión se
realiza de una forma que depende de las características especiales del

49
elemento estructural utilizado. Por el contrario, la operación de erosión da
como resultado una reducción de las zonas espectralmente puras según el
tamaño y forma del elemento estructural utilizado. En ambos casos, los
operadores consideran de forma simultánea la información espacial y
espectral a la hora de producir su resultado. Una vez introducidas las
características básicas de las operaciones morfológicas en las que se basa
el método AMEE, procederemos a describir el algoritmo en sí, el cual puede
desglosarse en una operación de cuatro pasos:
1. Consiste en la aplicación de los operadores morfológicos extendidos
sobre la imagen hiperespectral original. Cada píxel es evaluado en
términos de su pureza espectral en el dominio espacial definido por el
elemento estructural de la operación morfológica. En este paso, se
consideran elementos estructurales progresivamente crecientes, lo
cual permite interpretar la pureza espectral del píxel en diferentes
escalas espaciales. Este proceso se basa en el cálculo de una
medida de distancia entre el píxel máximo y el mínimo. Para ello,
introducimos una medida de calidad denominada índice de
excentricidad morfológico o Morphological Eccentricity Index (MEI),
cuya interpretación gráfica aparece descrita en la Figura 3.8.
Siguiendo la notación utilizada en dicha figura, sean ( ) las
coordenadas espaciales del píxel ( )( ), seleccionando como
máximo en la vecindad que rodea a ( ), y sea ( )( ) el píxel
mínimo de dicha vencindad. El índice de excentricidad asociado al
píxel ( ) se calcula utilizando la siguiente expresión, donde
es una medidad de distancia punto a punto entre vectores:
( ) *( )( ) ( )( ) + (3.10)

50
2. Tiene como objetivo la identificación automatizada de un conjunto de
píxels puros a partir de la información obtenida en la etapa anterior. El
proceso de selección de píxels puros a partir de dicha imagen se
realiza utilizando el método de umbralizado automático de Otsu.
3. Consiste en aplicar un proceso opcional de crecimiento de regiones,
que permite obtener un conjunto de regiones coherentes desde un
punto de vista espacial y espectral, a partir de las cuales se obtienen
una lista de endmembers.
4. El último paso del algoritmo tiene como objetivo la eliminación de
posibles instancias redundantes en la lista final de endmembers
obtenida como resultado de la etapa de crecimiento.

51
Figura 3.9: Cálculo del índice MEI mediante la combinación de operaciones morfológicas de erosión y dilatación.
Para concluir este apartado la Figura 3.9 muestra un diagrama
ilustrativo del método AMEE. Es importante destacar que la implementación
del método considerada en el presente trabajo corresponde a una variación
de la versión publicada del algoritmo, la cual corresponde a una nueva
versión del algoritmo en la que se omite el paso 3 (crecimiento de regiones)
y se sustituye por el algoritmo OSP descrito en anteriores apartados de esta
memoria. El principal motiva por el que se utiliza OSP para seleccionar el
conjunto final de endmembers es que es el método que selecciona las firmas

52
espectrales más ortogonales entre sí, dando lugar a un conjunto de
endmembers espectralmente diferenciados y no redundantes.
Figura 3.10: Diagrama de bloques del funcionamiento del algortimo AMEE.

53
3.2. Nuevos algoritmos implementados
3.2.1. VCA
El algoritmo, Vertex Component Analysis, sirve, al igual que los
anteriores, para la separación en mezclas espectrales de endmembers. Este
algoritmo se basa en dos ideas principales:
1. Los endmembers son los vértices de la envoltura convexa de un
conjunto de ( ) puntos independientes afines a un espacio
euclídeo de dimensión o mayor, o simplex.
2. La transformación afín de un simplex es también un simplex.
VCA, al igual que el algoritmo N-FINDR, asume que existe píxels
puros en la imagen. El algoritmo iterativamente proyecta la información en
una dirección ortogonal al subespacio abarcado por los endmembers
calculados hasta ese momento, siendo el nuevo endmember el extremo de
esa proyección [3]. El algoritmo itera hasta que todos los endmembers han
sido extraídos.
A continuación veremos los fundamentos geométricos de este
algoritmo. En un escenario de mezcla lineal cada vector espectral tiene la
siguiente forma:
(3.11)
donde es un vector L-dimensional (siendo L el número de bandas de la
imagen hiperespectral), , - es la matriz de las mezclas
espectrales siendo las firmas espectrales de los endmembers y el
número de endmembers presentes en la imagen; donde es un
modelo a escala de un factor de variabilidad de la iluminación debido a la

54
topografía del terreno [3]. , -𝑇 es el vector de abundancias de
los endmembers y es el ruido aditivo asociado a la imagen.
Debido a las limitaciones físicas las abundancias son positivas
( ) . Cada píxel puede ser visto como un vector L-dimensional del
espacio euclídeo, donde cada canal es asignado a un eje del espacio. Ya
que el conjunto * 𝑇 + es un simplex, por tanto el
conjunto 𝑥 * 𝑇 + es también un simplex.
Aunque fijemos , el conjunto de vectores pertenecen a *
𝑇 + que es un cono convexo, debido al factor
escalar .
Figura 3.11: Diagrama de dispersión de dos dimensiones de las mezclas de los tres endmembers.
La Figura 3.11 muestra tanto un simplex como un cono, proyectados
en un espacio bidimensional para la mezcla de tres endmembers. Los
colores azul y amarillo (con valores discretos dentro de la superficie de los

55
polígonos) simulan la mezcla espectral perteneciente al simplex 𝑥( ) y
del cono ( ) respectivamente.
El simplex * ( 𝑇 )⁄ + es la proyección
proyectiva del cono convexo sobre el plano 𝑇 , donde la elección
de asegura que no haya vectores ortogonales.
Después de hallar , VCA iterativamente proyecta información sobre
una dirección ortogonal al subespacio abarcado por los endmembers. El
nuevo endmember corresponde al extremo de esa proyección. En la
siguiente iteración, el endmember , se halla proyectando sobre la
dirección que es ortogonal a . El algoritmo termina cuando se halla el
número de endmembers deseados.

56
3.2.2. IEA
Iterative Error Analysis. Una de las técnicas para el procesamiento de
imágenes hipersespectrales es el demezclado espectral, el cual sirve en las
situaciones en las que los distintos componentes de las firmas espectrales
ocupan, de forma conjunta, un solo píxel debido a insuficiente precisión de
los sensores que captan las imágenes.
Matemáticamente definimos la imagen hiperespectral captada por el
sensor como:
( ) ∑ ( ) (3.12)
donde es el número de bandas de la imagen, ( ) son las coordenadas
espaciales de un píxel, es la respuesta espectral del endmember , es
el número total de endmembers, es la abundancia del endmember en el
píxel ( ) y ( ) es el vector de ruido aplicado en dicho píxel.
La solución a esta ecuación es el conjunto de endmembers (* +
)
que se ajusta a los valores del píxel. Este conjunto es el que obtenemos con
cada algoritmo de extracción de endmembers.
El algoritmo IEA pretende resolver este problema siguiendo los
siguientes pasos:
1. Inicialización. El algoritmo calcula una muestra inicial n-dimensional,
llamada , que funciona como endmember inicial y resulta de hacer la
media de todos los píxeles de la imagen donde es el número de filas
y el número de columnas de la imagen.

57
𝑥 ∑ ∑ ( )
(3.13)
Comienzo del cálculo de endmembers. Se establece el conjunto de
endmembers inicialmente vacio ( ). El primer endmember
se calcula de la siguiente manera:
Primero se genera una versión reconstruida de la imagen
original obteniéndose a partir de la realización de un demezclado
espectral de usando como único endmember del conjunto. En
este trabajo se aplica un demezclado espectral simple sin
restricciones a cada píxel de de la siguiente manera:
( 𝑇 ) 𝑇 ( ) (3.14)
Como resultado de esta operación obtenemos el valor de
abundancia del endmember ( ), para cada píxel de la imagen
( ( )). Ahora la imagen reconstruida se obtiene aplicando:
( ) (3.15)
El siguiente paso debe ser calcular la raíz del error cuadrático
medio (root mean square error, RMSE), o lo que es lo mismo, la
diferencia componente a componente, entre las imágenes original y
la reconstruida .

58
( ) (
𝑥 )∑ ∑ (
∑ , ( ) ( )-
)
(3.16)
Por último seleccionamos como el primer endmember el
píxel con el mayor error asociado ( 𝑔 ( ) ( ) ( ))
y lo guardamos en el conjunto de endmembers * +.
2. Proceso iterativo. En este paso se calculan los endmembers
pertenecientes al intervalo realizando un demezclado
espectral a cada píxel ( ) usando el conjunto actual de
endmembers como se muestra a continuación:
( 𝑇 ) 𝑇 ( ) (3.17)
El resultado de esta operación es el conjunto de valores de
abundancia * ( )+
por cada píxel siendo el número de
endmembers calculados hasta el momento. La imagen se reconstruye
ahora de la siguiente manera:
( ) ∑ ( ) (3.18)
Para obtener un nuevo endmember que añadir al conjunto
volvemos a calcular 𝑔 ( ) ( ) ( ). De esta forma
iterativamente acabaremos teniendo en el conjunto de endmembers
* +.

59
3. Condición de terminación. El cálculo de nuevos endmembers termina
cuando . Obtenemos como resultado final el conjunto de
endmembers * + y la correspondencia de su abundancia
en cada píxel * ( )+
para el conjunto de píxels de la imagen
( ).
A partir de los pasos anteriores, podemos intuir que el método IEA es
sensible a la selección del vector inicial a partir del que se realiza todo el
proceso. En este caso, la elección del centroide (vector promedio de todos
los datos de la imagen) de la nube de puntos puede considerarse, en
términos generales, una decisión acertada, aunque otra alternativa, no
considerada por los autores del método, podría ser el elemento más alejado
del centroide, la cual, ahorraría una iteración.
Una particularidad del método es que no tiene en cuenta la distribución
espectral de los endmembers seleccionados, con lo que pueden tenerse
muchos endmembers en una determinada zona y muy pocos en otra, tal y
como se muestra en la figura 3.12.
Figura 3.12: Distribución espectral irregular de endmembers en el método IEA.
x y
z Endmember 1
Endmember 2
Endmember 3
Endmember 4

60
Finalmente, destacamos que IEA selecciona endmembers que se
corresponden en todo momento a píxels pertenecientes al conjunto de datos
original, no siendo posible generar endmembers artificiales.

61
3.2.3. Unmixing
Los píxeles de una imagen, representan áreas de uno a varios metros
cuadrados. Estos píxeles, generalmente están compuestos por mezclas de
materiales, lo cual nos lleva a la conclusión de que los píxeles puros no son
muy frecuentes. Así la firma espectral medida por la mayoría de los sensores
en un determinado punto es una mezcla de materiales que puede
expresarse como una combinación lineal de los espectros "puros" o
endmembers y sus pesos en la combinación lineal dependen de la fracción
de área que ocupan.
Los píxeles mezcla, pueden analizarse usando un modelo matemático
donde el espectro observado es el resultado de la suma de los productos
entre el espectro puro del material “extremo” por el porcentaje de
abundancia correspondiente. La Figura 3.12 ilustra lo descrito anteriormente.
Figura 3.13: Representación de la mezcla de tres endmembers.

62
Este proceso forma parte de varios de los algoritmos comentados
anteriormente. Consiste en, a partir de los datos de la imagen hiperespectral,
obtener un conjunto de datos según la siguiente expresión:
( 𝑇 ) ( ) (3.19)
donde la abundancia de ese conjunto de endmembers en ese píxel, es
la matriz con los valores de los endmembers y ( ) es un vector con los
valores para un píxel determinado de la imagen. Aplicando esta operación a
cada píxel de la imagen podemos obtener imágenes que representan la
concentración de un endmember en la imagen (mapas de abundancia).

63
CAPÍTULO 4. Resultados experimentales
4.1. Descripción de imágenes hiperespectrales
En el presente trabajo se contemplan tanto imágenes sintéticas como
imágenes reales. Las imágenes sintéticas nos proporcionan un conocimiento
verdadero del terreno y por tanto se puede evaluar cuantitativamente la
capacidad de los algoritmos empleados para extraer correctamente los
endmembers. Por el contrario, estas imágenes no corresponden a ninguna
situación real y por lo tanto en ellas no influyen factores que sí están
presentes en las imágenes reales, como pueden ser, los efectos de la
atmósfera o las características del propio sensor. Por otro lado tenemos las
imágenes reales en las cuales resulta más difícil determinar con exactitud la
verdad terreno, con lo que los resultados obtenidos son menos precisos.
4.1.1. Sintética (Fractal)
La imagen que vamos a considerar en este estudio como imagen
sintética esta generada a partir de un patrón similar a los hallados en la
naturaleza. Al generar esta imagen (Fractal) se consideró un patrón fractal,
ya que son patrones geométricos recursivamente, lo que nos permite
obtener esa similitud que buscábamos.

64
Figura 4.1: Imagen Fractal usada para crear la imagen sintética (izquierda). Fractal dividida en clusters (derecha).
Las imágenes fractales se han generado con una gran variedad de
colores, es decir, se ha intentado que el ancho de banda de la imagen sea lo
más amplio posible para poder extraer el máximo número de clusters. Las
imágenes se dividen en clusters o clases para a continuación insertar una
firma espectral en cada cluster, es por ello que el número de clusters debe
ser mayor que el número de firmas puras que queramos insertar. Para dividir
en clusters las imágenes fractales se ha utilizado un algoritmo de
clasificación de píxels no supervisado: “k-means” [17]. Al generar la imagen
fue necesario decidir qué firma se iba a introducir en cada cluster Las firmas
que fueron insertadas fueron obtenidas aleatoriamente de una librería
espectral de minerales proporcionada por el Instituto Geológico de Estados
Unidos (USGS), cuya versión completa dispone de un total de 420 firmas
espectrales correspondientes a diferentes minerales. La librería espectral se
encuentra disponible en la siguiente dirección web:
http://speclab.cr.usgs.gov. En la Figura 4.2 se muestran las firmas
espectrales de minerales consideradas en las simulaciones.

65
Figura 4.2: Firmas insertadas en la imagen Fractal 1.
Es importante destacar que en la imagen fractal se han insertado
nueve firmas puras. En la Figura 4.3 se puede observar las fracciones de
abundancia en escala de grises de la verdad terreno del Fractal 1, lo cual
ofrece una idea acerca del aspecto de la imagen hiperespectral simulada.

66
Figura 4.3: Verdad terreno del Fractal 1 en escala de grises.

67
La imagen sintética responde a la siguiente ecuación:
( ) ∑ ( ) ( ) (4.1)
Donde ( ) representa el píxel en la posición ( ) de la imagen,
( ) es la fracción de abundancia de la firma para el píxel de
la posición ( ) , ( ) denota las firmas espectrales utilizadas para
simular la imagen y que es la relación señal-ruido introducida en la
imagen que puede entenderse, en términos globales, como la relación entre
la amplitud de la señal obtenida y la amplitud del ruido o, lo que es lo mismo,
la cantidad de señal adquirida por unidad de ruido. La aproximación utilizada
en el presente trabajo para añadir ruido a las imágenes simuladas se basa
en la definición de Harsanyi y Chang [6], la cual ha sido utilizada
ampliamente en la literatura para imponer una relación señal-ruido
predeterminada en cada una de las bandas de una imagen simulada. De
este modo, se puede generar una relación SNR de r1 en las diferentes
bandas del sensor utilizando la siguiente expresión:
( ) .
( )/ ( ) (4.2)
donde ( ) es la firma espectral original, ( ) es un vector que se
multiplica a la firma antes mencionada para simular el efecto introducido por
el ruido, y ( ) es el espectro ruidoso resultante.
En el presente trabajo para la imagen Fractal existen varias imágenes,
cada una de ellas con una relación SNR diferente. Las SNR empleadas se
han basado en valores de r de 30, 70 y sin ruido, con lo que al final se han
generado un total de tres imágenes sintéticas. Para denotar dichas
imágenes, utilizamos la convención “Fractalk_noise_r”, donde k hace
referencia al número de fractal utilizado y r hace referencia al valor de SNR
utilizado. Así, la imagen “Fractal1_noise_30” corresponde a la imagen

68
sintética simulada a partir del Fractal, con relación SNR de 30, y así
sucesivamente.
4.1.2. Real (Cuprite)
La imagen real utilizada en el presente estudio fue obtenida por el
sensor AVIRIS sobre el distrito minero de Cuprite, Nevada, el cual ha sido
utilizado a lo largo de los años como una zona de estudio para la validación
de algoritmos de tratamiento de imágenes hiperespectrales, sobre todo, para
evaluar la precisión de algoritmos de extracción de endmembers [18,19].
Esto ha sido posible gracias a la obtención repetitiva de datos en sucesivas
campañas utilizando diferentes sensores hiperespectrales (en concreto, el
sensor AVIRIS de NASA lleva obteniendo datos en Cuprite año tras año
desde 1990). Además, el Instituto Geológico de Estados Unidos (USGS) ha
realizado, de forma paralela a las campanas de adquisición de imágenes,
estudios sobre el terreno que han permitido la obtención de información de
verdad terreno muy extensa, favoreciendo la utilización de esta imagen
como un estándar a la hora de validar algoritmos de tratamiento de
imágenes hiperespectrales.
La imagen que hemos utilizado en el estudio (denominada AVCUP95)
fue adquirida por el sensor AVIRIS en 1995 y se encuentra disponible online
(http://aviris.jpl.nasa.gov). La Figura 4.4 muestra la ubicación de la imagen
sobre una fotografia aérea de la zona. Visualmente, puede apreciarse la
existencia de zonas compuestas por minerales, así como abundantes suelos
desnudos y una carretera interestatal que cruza la zona en dirección norte-
sur. La imagen utilizada en el estudio consta de 350x350 píxels, cada uno de
los cuales contiene 224 valores de reflectancia en el rango espectral 0.4 a
2.5 . La información de las firmas presentes en esta imagen se ha
obtenido a partir de los datos obtenidos por el USGS en esta región

69
(disponibles online en la dirección http://speclab.cr.usgs.gov). En la Figura
4.5 se puede observar un mapa de minerales generado mediante la
herramienta Tetracorder de USGS [20] (disponible online en la dirección
(http://speclab.cr.usgs.gov/PAPERS/tetracorder/), y que describe la
localización de diferentes minerales y alteraciones de dichos minerales en la
región Cuprite. Por otra parte, la Figura 4.6 muestra las firmas espectrales
USGS de los minerales con mayor presencia en la zona de estudio, las
cuales incluyen las firmas de los minerales alunite, buddingtonite, calcite,
kaolinite y muscovite. Dichos minerales serán utilizados como referencia en
el presente estudio, de modo que sus firmas espectrales asociadas se
utilizaran como verdad-terreno a la hora de evaluar la bondad de los
algoritmos de extracción de endmembers considerados en la selección de
firmas espectrales puras en dicha zona.
Figura 4.4: Imagen hiperespectral AVIRIS sobre la región Cuprite en Nevada, Estados Unidos.

70
Figura 4.5: Mapa de minerales obtenidos por el U.S. Geological Survey a través del algoritmo Tetracorder en la región Cuprite en Nevada, Estados Unidos.

71
Figura 4.6: Firmas espectrales puras correspondientes a los minerales más representativos en la región Cuprite en Nevada, Estados Unidos.

72
4.2. Comparativa de algoritmos
En este apartado analizaremos los resultados obtenidos por cada uno
de los algoritmos para los dos tipos de imágenes, evaluando la precisión
dada por cada uno en el proceso de extracción de endmembers, para la cual
se utilizan las firmas espectrales vistas anteriormente como referencia.
La medida utilizada para medir la precisión será el ángulo espectral o
spectral angle distance (SAD) que calcula el ángulo formado por dos firmas
espectrales sin tener en cuenta su magnitud, lo cual hace que esta medida
sea robusta en presencia de condiciones de iluminación variable en la
escena.
El método de comparación entre las firmas espectrales de referencia y
los endmembers extraídos por los algoritmos será el emparejamiento
óptimo-global. Este método consiste en realizar los emparejamientos de tal
forma que la solución global sea óptima, es decir, la suma de los SAD de
todos los emparejamientos sea mínima. Este algoritmo se implementa
siguiendo una estructura de vuelta a atrás (Backtracking) que irá probando
todas las posibles formas de realizar los emparejamientos y se quedara con
la mejor. Cabe destacar que la complejidad computacional de este método
de emparejamiento es mucho mayor que la de los anteriores, puesto que
hay que calcular todas las posibles formas de emparejar los endmembers,
es decir, complejidad exponencial O nm .
El proceso de análisis consistirá en varios pasos:
1. Optimización de los parámetros del algoritmo SSEE.
2. Optimización de los parámetros del algoritmo AMEE.
3. Comparativa de los diferentes algoritmos entre sí.
Llegados a este punto, es muy importante destacar que en el resto de
algoritmos considerados (aparte de SSEE y AMEE) el único parámetro

73
de entrada es el número de endmembers a detectar, por eso no es
necesario optimizar los parámetros de entrada ya que dicho parámetro
se fijará a un mismo valor para todos los algoritmos considerados en
cada prueba.
En cada uno de los apartados sucesivos se estudiarán primero los
resultados obtenidos para la imagen sintética y posteriormente los de la
imagen real.
En el caso de la imagen sintética haremos también un estudio de la
influencia en los resultados que ejerce la relación señal-ruido (signal-
noise, SNR) en los distintos algoritmos, ya que el proceso de
construcción de la imagen sintética nos permite definir este parámetro a
priori.
4.2.1. Optimización de los parámetros del algoritmo SSEE
Los parámetros que se contemplan para este algoritmo es el tamaño
del subconjunto, SAD de similaridad y número de iteraciones del algoritmo.
El tamaño del subconjunto debe cumplir los siguientes requisitos:
1. Debe ser mayor que la raíz cuadrada del número de bandas de la
imagen, en este caso el mínimo debe ser 15 (√ ).
2. Debe ser como máximo el tamaño máximo de la imagen en el caso de
que esta sea cuadrada, en nuestro caso 100x100 píxels.
3. Debe ser divisor de las dimensiones de la imagen, es nuestro caso
debe ser divisor de 100.
Basándonos en esta información los valores posibles que tenemos son
20, 25, 50 y 100 eliminando del valor 20 ya que la diferencia con 25 es
mínima. Para el resto de parámetros se usarán los valores de 0,01 para el
SAD de similaridad y 5 iteraciones.

74
En la tabla 4.1 podemos observar que el mejor de los resultados,
basándonos en el SAD de similaridad promedio de los endmembers, es el
del tamaño de subconjunto 25x25.
1 2 3 4 5 6 7 8 9 SAD
25x25 0,002 0,002 0,011 0,000 0,010 0,001 0,002 0,009 0,000 0,004
50x50 0,002 0,002 0,399 0,000 0,011 0,206 0,002 0,224 0,000 0,094
100x100 0,012 0,122 0,315 0,107 0,007 0,001 0,018 0,009 0,000 0,066
Tabla 4.1: Firmas Fractal 1: 1-Kaolinite KGa-1 (wxyl), 2-Dumortierite HS190.3B, 3-Nontronite GDS41, 4-Alunite GDS83 Na63, 5-Sphene HS189.3B, 6-Pyrophyllite PYS1A fine g, 7-Halloysite NMNH106236, 8-Muscovite GDS108 9-Kaolinite CM9. Resultados obtenidos por el algoritmo SSEE con SAD 0,01 y 5 iteraciones, por el método de emparejamiento del óptimo global y SAD promedio del conjunto de firmas.
En la tabla 4.2 se comparan los resultados obtenidos para los
diferentes valores de SAD de similaridad de 0.01, 0.02 y 0.03 manteniendo
el resultado óptimo de tamaño de subconjunto y 5 iteraciones.
1 2 3 4 5 6 7 8 9 SAD
SAD 0,01 0,002 0,002 0,011 0,000 0,010 0,001 0,002 0,009 0,000 0,004
SAD 0,02 0,002 0,002 0,011 0,000 0,010 0,001 0,002 0,176 0,000 0,023
SAD 0,03 0,002 0,002 0,011 0,000 0,010 0,001 0,002 0,007 0,000 0,004
Tabla 4.2: Firmas Fractal 1: 1-Kaolinite KGa-1 (wxyl), 2-Dumortierite HS190.3B, 3-Nontronite GDS41, 4-Alunite GDS83 Na63, 5-Sphene HS189.3B, 6-Pyrophyllite PYS1A fine g, 7-Halloysite NMNH106236, 8-Muscovite GDS108 9-Kaolinite CM9. Resultados obtenidos por el algoritmo SSEE con tamaño de subconjunto 25x25 y 5 iteraciones, por el método del emparejamiento del óptimo-global y SAD promedio del conjunto de firmas.

75
Como vemos el SAD de similaridad más alto es el que mejores
resultados obtiene, aunque el SAD promedio sea igual que para 0.01. Por
tanto el valor óptimo de SAD de similaridad es 0.03.
Por último, en la tabla 4.3, vemos el comportamiento de los resultados
en función del número de iteraciones del algoritmo SSEE.
1 2 3 4 5 6 7 8 9 SAD
5 Iter. 0,002 0,002 0,011 0,000 0,010 0,001 0,002 0,009 0,000 0,004
7 Iter. 0,002 0,002 0,011 0,000 0,010 0,003 0,002 0,009 0,000 0,004
11 Iter. 0,002 0,002 0,005 0,000 0,010 0,003 0,002 0,009 0,000 0,004
Tabla 4.3: Firmas Fractal 1: 1-Kaolinite KGa-1 (wxyl), 2-Dumortierite HS190.3B, 3-Nontronite GDS41, 4-Alunite GDS83 Na63, 5-Sphene HS189.3B, 6-Pyrophyllite PYS1A fine g, 7-Halloysite NMNH106236, 8-Muscovite GDS108 9-Kaolinite CM9. Resultados obtenidos por el algoritmo SSEE con tamaño de subconjunto 25x25 y SAD de similaridad 0.01, por el método del emparejamiento del óptimo-global y SAD promedio del conjunto de firmas.
Los resultados nos muestran como a mayor número de iteraciones el
algoritmo resulta más preciso particularmente en la firma asociada al mineral
Nontrite GDS41.
Por tanto obtenemos que los valores óptimos para el algoritmo SSEE
en la imagen sintética Fractal son 25x25 de tamaño de subconjunto, 0.03 de
SAD de similaridad y 11 iteraciones. Más adelante se usarán estos valores
para comparar los resultados de todos los algoritmos.
Para la imagen real los posibles subconjuntos considerados son 50,
70, 175 y 350. Como se puede ver los resultados para la imagen real, en la
tabla 4.4, van mejorando a medida que se amplía el subconjunto siendo 175
la medida óptima.

76
1 2 3 4 SAD
50x50 0,084 0,102 0,170 0,095 0,11
70x70 0,084 0,102 0,164 0,095 0,11
175x175 0,084 0,073 0,148 0,081 0,1
350x350 0,084 0,073 0,208 0,081 0,11
Tabla 4.4: Firmas imagen Cuprite 1-Alunite, 2-Budinggtonite, 3-Kaolinite y 4-Muscovite. Resultados del emparejamiento obtenidos por el método óptimo global con los parámetros fijos de SAD de similaridad de 0,01 y 5 iteraciones y SAD promedio del conjunto de firmas.
En la tabla 4.5 vemos los resultados obtenidos para los distintos
valores de SAD de similaridad de 0.01, 0.02 y 0.03. En este caso los
resultados son más precisos a con un SAD de similaridad menor. Por tanto
el valor óptimo de los probados es 0.01.
1 2 3 4 SAD
SAD-0,01 0,084 0,073 0,148 0,081 0,096
SAD-0,02 0,086 0,071 0,168 0,081 0,101
SAD-0,03 0,954 0,071 0,168 0,081 0,318
Tabla 4.5: Firmas imagen Cuprite 1-Alunite, 2-Budinggtonite, 3-Kaolinite y 4-Muscovite. Resultados del emparejamiento obtenidos por el método óptimo global con los parámetros fijos de tamaño de subconjunto 175 y 5 iteraciones y SAD promedio del conjunto de firmas.
Por último vemos los resultados obtenidos para los diferentes valores
de iteración del algoritmo. En la tabla 4.6 vemos como el algoritmo SSEE no
ofrece variación alguna más allá de las 5 iteraciones, por lo que este será
nuestro valor óptimo.

77
1 2 3 4 SAD
5-Iter 0,084 0,073 0,148 0,081 0,096
7-Iter 0,084 0,073 0,148 0,081 0,096
11-Iter 0,084 0,073 0,148 0,081 0,096
Tabla 4.6: Firmas imagen Cuprite 1-Alunite, 2-Budinggtonite, 3-Kaolinite y 4-Muscovite. Resultados del emparejamiento obtenidos por el método óptimo-global con los parámetros fijos de tamaño del subconjunto 175 y SAD de similaridad 0,01 y SAD promedio del conjunto de firmas.
Los resultados ofrecen como parámetros óptimos para el algoritmo
SSEE en la imagen real Cuprite: tamaño del subconjuto 175, SAD de
similaridad 0.01 y 5 iteraciones. Al igual que para la imagen sintética
usaremos estos valores más adelante.

78
4.2.2. Optimización de los parámetros del algoritmo AMEE
El único parámetro que se debe optimizar en el algoritmo AMEE es el
tamaño de la ventana (píxels x píxels) a los que se debe aplicar las
operaciones morfológicas extendidas de erosión y dilatación. Para realizar el
ajuste del parámetro tamaño de ventana los valores tomados son: 3, 5, 7, 9 y
11.
1 2 3 4 5 6 7 8 9 SAD
3x3 0,104 0,184 0,010 0,001 0,005 0,354 0,002 0,223 0,090 0,108
5x5 0,341 0,275 0,010 0,422 0,008 0,371 0,002 0,280 0,453 0,240
7x7 0,333 0,275 0,005 0,422 0,005 0,407 0,597 0,303 0,453 0,311
9x9 0,419 0,359 0,005 0,499 0,080 0,407 0,623 0,339 0,453 0,354
11x11 0,402 0,359 0,005 0,512 0,134 0,396 0,597 0,347 0,453 0,356
Tabla 4.7: Firmas Fractal 1: 1-Kaolinite KGa-1 (wxyl), 2-Dumortierite HS190.3B, 3-Nontronite GDS41, 4-Alunite GDS83 Na63, 5-Sphene HS189.3B, 6-Pyrophyllite PYS1A fine g, 7-Halloysite NMNH106236, 8-Muscovite GDS108 9-Kaolinite CM9. Resultados obtenidos por el algoritmo AMEE con los diferentes tamaños de ventana para la realización de operaciones morfológicas extendidas y SAD promedio del conjunto de firmas.
En la tabla 4.7 podemos apreciar que la precisión de los endmembers
extraídos se reduce a medida que aumenta el tamaño de la ventana. Este
fenómeno es producido por la pérdida de información al realizar las
operaciones de erosión y dilatación. Por lo tanto cogemos como valor óptimo
para las posteriores comparaciones el tamaño de ventana más pequeño:
3x3.

79
1 2 3 4 SAD
3x3 0,084 0,073 0,266 0,180 0,151
5x5 0,138 0,214 0,145 0,193 0,172
7x7 0,138 0,214 0,145 0,193 0,172
9x9 0,138 0,214 0,145 0,193 0,172
11x11 0,138 0,214 0,145 0,193 0,172
Tabla 4.8: Firmas imagen Cuprite 1-Alunite, 2-Budinggtonite, 3-Kaolinite y 4-Muscovite. Resultados obtenidos por el método de emparejamiento óptimo-global para distintos tamños de ventana en el algoritmo AMEE para la imagen Cuprite y SAD promedio del conjunto de firmas.
En la tabla 4.8 como para los valores superiores a 5x5 de tamaño de
ventana no se obtiene resultados más precisos. Al igual que en la imagen
sintética el valor óptimo que cogeremos para posteriores comparaciones
para el tamaño de ventana del algoritmo AMEE será 3x3.
4.2.3. Comparativa de los resultados entre los algoritmos.
En este apartado haremos una comparación de los resultados
obtenidos con todos los algoritmos de extracción de endmembers sobre las
imágenes sintética y real. Los parámetros obtenidos anteriormente como
óptimos para los algoritmos SSEE y AMEE son los que se han utilizado para
la obtención de estos resultados, y en todas las pruebas se fija el número de
endmembers a extraer por parte de cada algoritmo. En el caso de la imagen
sintética fijamos el valor a 9 endmembers ya que este número constituye el
número real de endmembers utilizados en el proceso de generación de las
imágenes. En el caso de la imagen real fijamos el valor a 19 endmembers
tras estimar el número de endmembers de dicha imagen utilizando el
concepto de dimensionalidad virtual [1].
En la tabla 4.9 podemos observar que el algoritmo OSP es el más
preciso de todos seguido de VCA. Los algoritmos IEA, OSP, VCA y SSEE

80
obtienen resultados muy parecidos pero tanto IEA como SSEE difieren
sustancialmente en el endmember 5 (Sphene HS189.3B).
1 2 3 4 5 6 7 8 9 SAD
IEA 0,002 0,002 0,007 0,000 0,288 0,001 0,002 0,009 0,000 0,034
NFINDR 0,083 0,013 0,151 0,082 0,160 0,004 0,002 0,093 0,028 0,068
OSP 0,002 0,002 0,005 0,000 0,007 0,001 0,002 0,009 0,000 0,003
VCA 0,002 0,002 0,010 0,000 0,007 0,001 0,002 0,007 0,000 0,003
AMEE 0,104 0,184 0,010 0,001 0,005 0,354 0,002 0,223 0,090 0,108
SSEE 0,002 0,002 0,005 0,000 0,010 0,003 0,002 0,009 0,000 0,004
Tabla 4.9: Firmas Fractal 1: 1-Kaolinite KGa-1 (wxyl), 2-Dumortierite HS190.3B, 3-Nontronite GDS41, 4-Alunite GDS83 Na63, 5-Sphene HS189.3B, 6-Pyrophyllite PYS1A fine g, 7-Halloysite NMNH106236, 8-Muscovite GDS108 9-Kaolinite CM9. Resultados obtenidos mediante el método de emparejamiento por óptimo-global para la imagen Fractal con los distintos algoritmos de extracción de endmembers y SAD promedio del conjunto de firmas y SAD promedio del conjunto de firmas.
En la tabla 4.10 se nos muestra que por el contrario a la imagen
sintética, la imagen real obtiene resultados más precisos con el algoritmo
SSEE, seguido de IEA. En esta imagen los que se encuentran más alejados
de los valores de referencia son los algoritmos N-FINDR y VCA.

81
1 2 3 4 SAD
OSP 0,084 0,072 0,192 0,163 0,128
IEA 0,084 0,075 0,192 0,108 0,115
NFINDR 0,228 0,150 0,279 0,113 0,192
VCA 0,204 0,160 0,160 0,181 0,176
SSEE 0,084 0,073 0,148 0,081 0,096
AMEE 0,084 0,073 0,266 0,180 0,151
Tabla 4.10: Firmas Fractal 1: 1-Kaolinite KGa-1 (wxyl), 2-Dumortierite HS190.3B, 3-Nontronite GDS41, 4-Alunite GDS83 Na63, 5-Sphene HS189.3B, 6-Pyrophyllite PYS1A fine g, 7-Halloysite NMNH106236, 8-Muscovite GDS108 9-Kaolinite CM9. Resultados obtenidos por el método de emparejamiento óptimo-global en la imagen real Cuprite con los distintos algoritmos de extracción de endmembers propuestos y SAD promedio del conjunto de firmas.
4.2.4. Análisis de la influencia de la señal de ruido aditivo en los
resultados.
A continuación expondremos los resultados obtenidos por los
diferentes algoritmos para la imagen Fractal variando la cantidad de ruido
aditivo presente en la imagen. Los valores de SNR utilizados son: 0:0, 30:1 y
70:1. Con este estudio se pretende discernir cuales de los distintos
algoritmos afronta mejor y cuales afrontan peor la presencia de ruido en a
imagen. Los parámetros utilizados para los algoritmos son los óptimos en
cada caso.
En la tabla 4.11 vemos la disposición de los resultados por algoritmos
de tal manera que observamos el comportamiento de cada uno de ellos
según los valores de SNR. Todos los algoritmos parecen perder precisión a
medida que aumenta SNR a excepción del algoritmo AMEE que aumenta la
precisión en alguno de los endmembers. También podemos ver como el
algoritmo VCA parece resultar ser el más estable. Para comprobar estas

82
suposiciones veremos en la tabla 4.12 el SAD promedio por imagen de cada
algoritmo.
1 2 3 4 5 6 7 8 9
nonoise 0,002 0,002 0,011 0,000 0,010 0,001 0,002 0,007 0,000
noise-30 0,002 0,003 0,011 0,000 0,010 0,002 0,002 0,022 0,000
noise-70 0,438 0,029 0,049 0,025 0,066 0,027 0,028 0,035 0,084
nonoise 0,104 0,184 0,010 0,001 0,005 0,354 0,002 0,223 0,090
noise-30 0,092 0,229 0,010 0,001 0,006 0,148 0,002 0,164 0,034
noise-70 0,087 0,029 0,049 0,027 0,066 0,027 0,029 0,043 0,027
nonoise 0,002 0,002 0,005 0,000 0,007 0,001 0,002 0,009 0,000
noise-30 0,002 0,002 0,005 0,000 0,005 0,001 0,002 0,009 0,000
noise-70 0,022 0,029 0,049 0,025 0,066 0,028 0,029 0,035 0,030
nonoise 0,002 0,002 0,007 0,000 0,288 0,001 0,002 0,009 0,000
noise-30 0,002 0,002 0,005 0,000 0,040 0,001 0,002 0,009 0,000
noise-70 0,110 0,029 0,048 0,025 0,077 0,027 0,026 0,035 0,032
nonoise 0,002 0,002 0,005 0,352 0,017 0,001 0,002 0,009 0,735
noise-30 0,002 0,002 0,005 0,000 0,017 0,001 0,002 0,007 0,000
noise-70 0,004 0,009 0,030 0,009 0,020 0,008 0,010 0,013 0,010
nonoise 0,083 0,013 0,151 0,082 0,160 0,004 0,002 0,093 0,028
noise-30 0,044 0,013 0,280 0,021 0,178 0,004 0,002 0,093 0,074
noise-70 0,059 0,028 0,159 0,042 0,069 0,025 0,037 0,165 0,079
Tabla 4.11: Firmas Fractal 1: 1-Kaolinite KGa-1 (wxyl), 2-Dumortierite HS190.3B, 3-Nontronite GDS41, 4-Alunite GDS83 Na63, 5-Sphene HS189.3B, 6-Pyrophyllite PYS1A fine g, 7-Halloysite NMNH106236, 8-Muscovite GDS108 9-Kaolinite CM9. Resultados obtenidos por el método de emparejamiento óptimo-global para los distintos algoritmos de extracción de endmembers en las imágenes sintéticas Fractal1_nonoise, Fractal1_noise_30 y Fractal1_noise_70. SSEE (amarillo), AMEE (verde), OSP (rojo), IEA (azul), VCA (rosa) y N-FINDR (morado).

83
Algoritmo SAD promedio
SSEE-nonoise 0,0039
SSEE-noise-30 0,0058
SSEE-noise-70 0,0868
AMEE-nonoise 0,1081
AMEE-noise-30 0,0760
AMEE-noise-70 0,0426
OSP-nonoise 0,0031
OSP-noise-30 0,0030
OSP-noise-70 0,0349
IEA-nonoise 0,0344
IEA-noise-30 0,0068
IEA-noise-70 0,0453
VCA-nonoise 0,1248
VCA-noise-30 0,0039
VCA-noise-70 0,0124
NFIDR-nonoise 0,0683
NFIDR-noise-30 0,0786
NFIDR-noise-70 0,0737
Tabla 4.12: SAD promedio de cada imagen Fractal sin ruido, con SNR 30 y con SNR 70 para los distintos algoritmos de extracción de endmembers.
En la tabla 4.12 comprobamos que la primera suposición de que todos
los algoritmos, a excepción del algoritmo AMEE, pierden precisión a medida
que aumenta SNR no es el todo correcta. El algoritmo AMEE si es el único
que mejora la precesión, pero los algoritmos IEA y VCA obtienen los mejores
resultados para la imagen Fractal1_noise_30. Además la suposición de que
el algoritmo VCA es el más estable también es errónea, ya que como se ve,
el SAD promedio de similaridad de la imagen sin ruido es del rango de diez
veces el de las otras dos imágenes. En este punto podemos afirmar que el
algoritmo más estable respecto al SNR de las imágenes es N-FINDR,

84
aunque los resultados que ofrezca no sean los más precisos entre todos los
algoritmos.
Por último en la tabla 4.13 comprobamos la precisión general de los
algoritmos a instancias de la señal de ruido presente en las distintas
imágenes. Como se puede observar el algoritmo OSP es el que ofrece un
SAD de similaridad promedio más bajo seguido del algoritmo IEA. Por contra
los algoritmos que menor precisión ofrecen son AMEE y N-FINDR, en ese
orden.
Algoritmo SAD promedio entre imágenes
SSEE 0,03219
AMEE 0,07557
OSP 0,01364
IEA 0,02885
VCA 0,04707
N-FINDR 0,07351
Tabla 4.13: SAD promedio entre las imágenes Fractal1_nonoise, Fractal1_noise_30 y Fractal1_noise70 para los distintos algoritmos de extracción de endmembers.
Resumiendo los datos obtenidos por el estudio podemos decir que:
En función de la precisión de los datos obtenidos para la imagen
sintética podemos clasificar los algoritmos de la siguiente manera:
OSP, IEA, SSEE, VCA, N-FINDR y AMEE. Mientras que para la
imagen real la clasificación sería: SSEE, IEA, OSP, AMEE, VCA y N-
FINDR. Claramente se pueden considerar a los tres primeros
algoritmos los más precisos según el presente estudio.
En función de su resistencia al impacto del ruido aditivo a la imagen
podemos concluir que el más resistente es el algoritmo N-FINDR.
Los tamaños de ventana más apropiados para el algoritmo AMEE son
los tamaños de ventana pequeños, siendo en general el tamaño de
ventana 3x3. El ruido afecta por igual a todos los tamaños de ventana,

85
no existiendo ningún tamaño de ventana que minimice el impacto de
la señal de ruido.
Respecto al algoritmo SSEE podemos concluir que el tamaño del
subconjunto depende de la imagen, pero por lo general, suelen ser los
más pequeños los que mejores resultados ofrecen. Los parámetros
de SAD y número de iteraciones en el algoritmo SSEE son los menos
críticos, ya que no varían demasiado la solución del algoritmo. El valor
optimo del parámetro SAD al igual que el tamaño de subconjunto
varia de unas imágenes a otras, aunque por lo general el que mejor
se comporta es el 0.01 radianes. Por su parte el número de
iteraciones que mejor se comporta en la mayoría de los casos es 11
4.2.5. Análisis de tiempo computacional de los algoritmos
En este apartado comentaremos, basados en la experiencia de su
uso, las variaciones de tiempo que se dan entre los algoritmos y las razones
que influyen en ello. Las medidas de tiempo tomadas son aproximadas y
siempre basadas en las ejecuciones realizadas con la herramienta
desarrollada en este proyecto, la cual añade complejidad computacional a
los resultados ya que realiza otras funcionalidades antes de presentar los
resultados. A pesar de esto, ya que esas funcionalidades se realizan
exactamente igual para todos los algoritmos el error cometido al valorarlos
es mínimo.

86
Tiempo de ejecución
OSP < 10 segundos
IEA < 10 segundos
VCA < 10 segundos
AMEE Aprox. 1 minutos
PCA + N-FINDR Aprox. 2 minutos
SSEE > 10 minutos
Tabla 4.14: Comparativa aproximada de tiempos de ejecución de los distintos algoritmos con los parámetros considerados ideales en los apartados anteriores usando la imagen Fractal en el cálculo de 9 endmembers.
En la tabla 4.14 los algoritmos están ordenados en función del tiempo
requerido. Los tres primeros son aquellos que no consideran información
espacial para el cálculo de los endmembers por lo que los resultados
obtenidos en comparación a AMEE, N-FINDR y SSEE, que consideran dicha
información, son claramente entendibles.
A partir de la gráfica 4.15, que representa la tendencia de tiempos de
computación en función del número de endmembers, podemos decir que
IEA es el más rápido en base a un número de endmembers bajo, ya que a
medida que aumenta el número de endmembers lo hace también el tiempo
de ejecución de manera significativa. VCA al contrario parece estabilizar la
duración de la computación a con un número de endmembers alto. Por
último OSP es el algoritmo que se muestra menos influido por el número de
endmembers, por lo que concluimos que es el que mejores resultados da (en
función del tiempo de ejecución) entre los algoritmos analizados en este
punto.

87
Gráfica 3.15: Tendencia en la variación del tiempo de ejecucución en función del número de endmembers calculados para los algoritmos OSP, IEA y VCA.
En cuanto a los algoritmos que manejan información espacial la
diferencia de tiempos entre ellos se explica de la siguiente manera:
Aunque el algoritmo de extracción de endmembers N-FINDR no
maneja información espacial, en la herramienta desarrollada su
ejecución se basa en un preprocesado PCA. Por separado podemos
decir que N-FINDR es casi inmediato en su ejecución por lo que el
resultado mostrado en la tabla 4.14 es en su mayor parte culpa del
algoritmo PCA.
AMEE da el resultado más rápidamente que SSEE fundamentalmente
por la razón de la subdivisión que hace SSEE de la información de la
imagen. Además a medida que aumenta el tamaño de ventana de
operaciones morfológicas del algoritmo AMEE los resultados se
hacen más discretos por lo que su complejidad se reduce.
Por último destacar que la razón de que SSEE tenga unos tiempos de
ejecución tan altos en relación a los demás algoritmos se basa en la

88
reiteración que aplica el algoritmo al calcular los endmembers,
primero al dividir la imagen en subconjuntos de información y segundo
por el número de iteraciones que procesa en cada subconjunto.

89
CAPÍTULO 5. Conclusiones y líneas futuras
5.1. Conclusiones
En el presente trabajo se han implementado en forma de software
libre en el entorno Orfeo Toolbox diferentes algoritmos de extracción de
endmembers, así como, algoritmos de preprocesado espacial con el objetivo
de realizar una comparativa equitativa de dichos algoritmos y en qué
condiciones su uso resulta más apropiado en aplicaciones de desmezclado
de imágenes hiperespectrales. Dicha comparativa ha estado centrada en la
precisión de dichos algoritmos en la tarea de extracción de endmembers, así
como en otros factores tales como su sensibilidad a ruido, ajuste de
parámetros, tiempo computacional, etc.
Para abordar la comparativa desde distintos puntos de vista se han
utilizado imágenes sintéticas e imágenes reales. Las imágenes sintéticas
elaboradas en anteriores trabajos siguen patrones espaciales similares a los
que produce la naturaleza mediante la utilización de fractales y comprenden
una detallada simulación mediante el uso de firmas espectrales reales y
ruido en diferentes proporciones. Por su parte, la imagen real empleada en
la comparativa fue proporcionada por el sensor AVIRIS sobre el distrito
minero de Cuprite, en Nevada, Estados Unidos, y para dicha imagen se
dispones de información de referencia muy detallada a través del Instituto
Geológico de los Estados Unidos (USGS), la cual se ha empleado para
analizar la precisión de los diferentes algoritmos comparados en la tarea de
extraer endmembers a partir de dicha imagen.
Una de los aspectos principales del estudio ha sido la optimización de
los algoritmos considerados para cada una de las imágenes utilizadas,
siendo consecuencia de esto, que los resultados obtenidos en la
comparativa son provenientes de las mejores versiones de los algoritmos en

90
cada caso. Además se han estudiado los efectos del ruido aditivo sobre los
resultados proporcionados por los algoritmos.
Respecto a la implementación de los algoritmos desarrollados en la
librería ORFEO ToolBox concluimos que su utilidad está más que justificada
dad la sencillez que ofrece para la resolución de algunos problemas en la
implementación de los algoritmos para el tratamiento de imágenes
hiperespectrales, así como a las posibilidades de distribución en forma de
código abierto de dichos algoritmos por primera vez en la comunidad
científica dedicada a análisis de imágenes hiperespectrales, lo cual
constituye una contribución altamente novedosa del presente proyecto. En
este sentido, tanto la librería ORFEO ToolBox como algunas en las que se
apoya su funcionamiento (FLTK, VNL, ITK...) reducen la complejidad y carga
de trabajo para código implementado, y además, proveen de funcionalidades
adicionales relacionadas con la utilización de los algoritmos en forma de
componentes, con funciones de entrada y salida perfectamente estudiadas,
lo que permite entre otras cosas, la adecuada compartición del código de
forma totalmente libre y abierta.

91
5.2. Líneas futuras
En las líneas de trabajo que han quedado abiertas en el presente
trabajo podemos mencionar las siguientes. En el apartado de las
comparativas, la posibilidad de incluir nuevos algoritmos para la extracción
de endmembers, existiendo muchos más de los planteados. Por otra parte,
solo se ha utilizado una imagen real (AVIRIS Cuprite), si bien es cierto que
se trata de la escena estándar más estudiada en aplicaciones relacionadas
con extracción de endmembers (debido a la disponibilidad de firmas
espectrales USGS de referencia para la misma), sería interesante comparar
los algoritmos en otras escenas hiperespectrales reales para extrapolar las
conclusiones obtenidas en el presente trabajo a otros contextos. Finalmente,
se considera como línea futura de trabajo la implementación eficiente de
algoritmos como SSEE en arquitecturas paralelas que permitan mejorar el
rendimiento computacional de dicho algoritmo ya que emplea tiempos muy
elevados en completar sus cálculos y puede optimizarse mediante la
incorporación de técnicas de procesamiento paralelo en su diseño e
implementación.
Desde el punto de vista de la herramienta implementada las líneas
futuras de trabajo se deberían centrar en la inclusión de nuevos algoritmos,
así como, extender sus funcionalidades para posibilitar su uso a un mayor
nivel académico. La continua actualización de las librerías utilizadas
posibilita nuevas opciones de implementación como puede ser la extracción
de imágenes en formatos estándar (jpeg, png, étc) para almacenar los
resultados obtenidos en las gráficas, mapas de abundancia y bandas de la
imagen hiperespectral. Otra posibilidad bastante interesante sería la
migración de la herramienta a otras plataformas, ya que las librerías que se
han utilizado para el presente trabajo están disponibles para sistemas
operativos Windows.

92
Debido a que existen aplicaciones propietarias mucho más complejas,
una ventaja que podría explotar una herramienta más ligera como esta sería
la de su implementación como servicio Web.

93
REFERENCIAS BIBLIOGRÁFICAS
[1]. A. Plaza, P. Martinez, R. Perez, and J. Plaza, “A quantitative and
comparative analysis of endmember extraction algorithms from hyperspectral
data”, IEEE Transactions on Geoscience and Remote Sensing, vol. 42, no. 3,
pp. 650–663, 2004.
[2]. R. A. Neville, K. Staenz, T. Szeredi, J. Lefebvre, and P. Hauff,
“Automatic endmember extraction from hyperspectral data for mineral
exploration”, Proc. 21st Canadian Symp. Remote Sensing., pp. 21–24, 1999.
[3]. J. M. P.Nascimento, J. M.Bioucas Dias, “Vertex Component Analysis: A
fast algorithm to umnix hyperspectral data”, IEEE Transactions on
Geoscience and Remote Sensing, vol 43, no. 4 pp. 899, 2005.
[4]. S. Sánchez, A. Paz, A. Plaza, “Real-time spectral umixing using Iterative
Error Analysis on commodity graphics processing units”.
[5] J.C. Harsanyi and C.-I. Chang, “Hyperspectral image classification and
dimensionality reduction: An orthogonal subspace projection”, IEEE
transactions on Geoscience and Remote Sensing, vol. 32, no. 4, pp. 779–
785.
[6] A. Plaza, P. Martinez, R. Perez, and J. Plaza, “Spatial/spectral
endmember extraction by multidimensional morphological operations”, IEEE
Transactions on Geoscience and Remote Sensing, vol. 40, no. 9, pp. 2025–
2041, 2002.
[7] J. H. Bowles, P. J. Palmadesso, J. A. Antoniades, M. M. Baumback, and
L. J. Rickard, “Use of filter vectors in hyperspectral data analysis”, Proc.
SPIE Infrared Spaceborne Remote Sensing III, vol. 2553, pp. 148–157, 1995.

94
[8] M. Zortea and A. Plaza, “Spatial preprocessing for endmember
extraction”, IEEE Transactions on Geoscience and Remote Sensing,
aceptado para publicacion, en prensa, 2009.
[9] OTB Development Team, “The ORFEO Tool Box Software Guide”, Sixth
Edition Updated for OTB-2.2, CNES, 2008.
[10] D. Landgrebe, “Hyperspectral Image Data Analysis”, IEEE Signal
Processing Magazine, vol. 19, no. 1, pp. 17-28, 2002.
[11] J.W. Boardman, F.A. Kruse, and R. O. Green, “Mapping Target
Signatures Via Partial Unmixing of Aviris Data”, Proc. VII NASA/JPL Airborne
Earth Science Workshop, pp. 23–26, 1995.
[12] P.-F. Hsieh, D. Landgrebe, Classification of High Dimensional Data.
Tesis Doctoral, School of Electrical and Computer Engineering, Purdue
University, 1998.
[13] R.O. Green, y col., “Imaging Spectroscopy and the Airborne
Visible/Infrared Imaging Spectrometer (AVIRIS)”, Remote Sensing of
Environment, vol. 65, pp. 227-248, 1998.
[14] G. Shaw, D. Manolakis, “Signal processing for hyperspectral image
exploitation”, IEEE Signal Processing Magazine, vol. 19, pp. 12-16, 2002.
[15] D.W. Stein, S.G. Beaven, L.E. Hoff, E.M. Winter, A.P. Schaum, A.D.
Stocker, “Anomaly Detection from Hyperspectral Imagery”, IEEE Signal
Processing Magazine, vol. 19, pp. 58-69, 2002.
[16] OTB Development Team, “The ORFEO ToolBox software guide.
Updated for OTB 3.8”, 2010.
[17] J. A. Richards y X. Jia. “Remote Sensing Digital Image Analysis”.
Springer-Verlag, 1999.

95
[18] G. Swayze, “The hydrothermal and structural history of the cuprite
miningdistrict, Southwestern Nevada: An integrated geological and
geophysical approach,” Ph.D. dissertation, Univ. Colorado, Boulder, CO,
1997.
[19] R. Clark, et al. “The U.S. Geological Survey Digital Spectral Library:
Version1: 0.2 to 3.0 m”, U.S. Geological Survey Open File Rep. 93–592,
1993.
[20] R. Clark y col. “Imaging Spectroscopy: Earth and Planetary Remote
Sensing with the USGS Tetracorder and Expert Systems”, Journal of
Geophysical Research, 2003.
[21] W.P. Kustas, J.M. Norman, “Evaluating the Effects of Subpíxel
Heterogeneity on Píxel Average Fluxes”, Remote Sensing of Environment,
vol. 74, pp. 327-342, 2002.
[22] M. Faraklioti, M. Petrou, “Illumination invariant unmixing of sets of mixed
píxels”. IEEE Transactions on Geoscience and Remote Sensing, vol. 39, pp.
2227-2234, 2001.
[23] T.M. Tu, H.C. Shyu, C.H.Lee,C.-I Chang, “An oblique subspace
projection approach for mixed píxel classification in hyperspectral images”,
Pattern Recognition, vol. 32, pp. 1399-1408, 1999.
[24] J.M. Chen, “Spatial Scaling of a Remotely Sensed Surface Parameter
byContexture”, Remote Sensing of Environment, vol. 69, pp. 30-42, 1999.
[25] N. Keshava, J.F. Mustard, “Spectral unmixing”, IEEE Signal Processing
Magazine, vol. 19, pp. 44-57, 2002.
[26] P.E. Johnson, M.O. Smith, S. Taylor-George, J.B. Adams, “A Semi-
Empirical Method for Analysis of the Reflectance Spectra of Binary Mineral
Mixtures”. Journal of Geophysical Research, vol. 99, pp. 3557-3561, 1983.

96
[27] F.A. Kruse, “Spectral Identification of Image Endmembers Determined
fromAVIRIS Data”, Proc. VII NASA/JPL Airborne Earth Science Workshop,
1998.
[28] J.J. Settle, “On the Relationship between Spectral Unmixing and
SubspaceProjection”, IEEE Transactions on Geoscience and Remote
Sensing, vol. 34, pp. 1045–1046, 1996.
[29] M. Petrou, P.G. Foschi, “Confidence in linear spectral unmixing of single
píxels”, IEEE Transactions on Geoscience and Remote Sensing, vol. 37, pp.
624 – 626, Jan. 1999.
[30] Y. H. Hu, H. B. Lee, F. L. Scarpace, “Optimal Linear Spectral Unmixing”,
IEEE Transactions on Geoscience and Remote Sensing, vol. 37, pp. 639–
644, 1999.
[31] G. Healey, & D. Slater, “Models and methods for automated
materialidentification in hyperspectral imagery acquired under unknown
illumination andatmospheric conditions”, IEEE Transactions on Geosciencce
and Remote Sensing, 37, 2706−2717, 1999.
[32] B. Thai, G. Healey, D. Slater, “Invariant subpíxel material identification in
AVIRIS imagery”. Proc. JPL AVIRIS workshop, JPL Publication 99-17, 1999.
[33] L.O. Jiménez, D. Landgrebe, Tesis de Jiménez., 1996.
[34] A. Ifarraguerri, C.-I Chang, "Multispectral and hyperspectral image
analysis with projection pursuit," IEEE Transactions on Geoscience and
Remote Sensing, vol. 38, pp. 2529-2538, 2000.
[35] S. Subramanian, N. Gat, A. Ratcliff, M. Eismann, “Hyperspectral Data
Reduction Using Principal Components Transformation”, en Proc. X
NASA/JPL Airborne Earth Science Workshop, 2000.
[36] C.-I Chang, C.M. Brumley, “A Kalman Filtering Approach to Multispectral
Image Classification and Detection of Changes in Signature Abundance”.

97
IEEE Transactions on Geoscience and Remote Sensing, vol. 37, pp. 257 –
268, 1999.
[37] E.F. Collins, D.A. Roberts, C.C. Borel, “Spectral Mixture Analysis of
Simulated Thermal Infrared Spectrometry Data: An Initial Temperature
Estimate Bounded TESSMA Search Approach” . IEEE Transactions on
Geoscience and Remote Sensing, vol. 39, no. 7, pp. 1435- 1446, 2001.
[38] C.A. Bateson, G.P. Asner, C.A. Wessman, “Endmember Bundles: A New
Approach to Incorporating Endmember Variability into Spectral Mixture
Analysis”, IEEE Transactions on Geoscience and Remote Sensing, vol. 38,
pp. 1083–1094, 2000.
[39] P. Strobl, A. Müller, D. Schläpfer, M. Schaepman, "Laboratory
Calibration and Inflight Validation of the Digital Airborne Imaging
Spectrometer DAIS 7915 for the 1996 Flight Season", en: Proc. SPIE
Algorithms for Multispectral and Hyperspectral Imagery III, vol. 3071, pp.
225-235, 1997.
[40] R. Richter, "Bandpass resampling effects on the retrieval of radiance and
surface reflectance". Applied Optics, vol. 39, pp. 5001-5005, 2000.
[41] J.R. Eastman, and M. Fulk, (1993) "Long Sequence Time Series
Evaluation using Standardized Principal Components", Photogrammetric
Engineering and Remote Sensing, 59, 8, 1307-1312.
[42] “ENVI Software Image Processing & Analysis Solutions from ITT” main
page of ITT.
[43] Geosoluciones, “Manual de PCI Geomatica 10”, 1-5.

98
APÉNDICE 1. Descripción de la herramienta
Análisis de la herramienta
Objetivos y funcionalidades deseadas
Uno de los objetivos principales de este Proyecto Fin de Carrera es
desarrollar una aplicación que facilite el manejo y la visualización de los
algoritmos implementados para el tratamiento de imágenes hiperespectrales.
A continuación se van a detallar el proceso llevado a cabo para
establecer el diseño final de la herramienta, partiendo de unos objetivos
básicos planteados, pasando por el diseño de las funcionalidades
propuestas, para llegar a un esquema de implementación final.
Inicialmente esta aplicación debe satisfacer una serie de objetivos
específicos, los cuales son:
Manejo de los diferentes algoritmos de preprocesado espacial.
Manejo de los diferentes algoritmos de extracción de endmembers.
Satisfacer el uso de funcionalidades básicas de una aplicación, tales
como: abrir y leer archivos o salvar los resultados.
Presentación de los resultados obtenidos de forma adecuada.
Presentación de la información asociada a la imagen hiperespectral.
Para satisfacer cada uno de estos objetivos de forma más concreta
comentaremos cuales deben ser las funcionalidades específicas de la
aplicación asociadas a cada uno de ellos:
Ejecución con los parámetros adecuados de los algoritmos de
preprocesado espacial SPP y PCA.

99
Ejecución con los parámetros adecuados de los algoritmos de
extracción de endmembers AMEE, OSP, N-FINDR, VCA, IEA y
SSEE.
Ejecución con los parámetros adecuados del algoritmo de
demezclado, posibilitando la extracción de endmembers en el mismo
proceso si lo desea el usuario.
Abrir imágenes hiperespectrales y leer su contenido adecuadamente.
Incluyendo en este proceso la posibilidad de visualizar las distintas
bandas de la imagen hiperespectral por separado.
Almacenar los resultados obtenidos por los distintos algoritmos, datos
de las firmas espectrales y abundancias de estas en la imagen
hiperespectral, además de presentarlos al usuario de forma adecuada
para su comprensión.
Prsentación de la información contenida en la imagen hiperespectral,
tanto datos como metadatos, y del algoritmo utilizado (nombre, rutas
de los fichero, etc).
Complementariamente a estas funcionalidades concretadas se ha
añadido la posibilidad de componer una imagen RGB a partir de las
bandas, seleccionadas por el usuario, de la imagen hiperespectral.
Otro requerimiento especificado es la distribución que debe seguir la
aplicación de cara al usuario para hacer más fácil y amigable el uso de la
herramienta. El esquema seguido al implementar la herramienta se
puede ver en la Figura A.1.

100
Figura A.1: Distribución de la interfaz seguida en el desarrollo de la herramienta.

101
Diagramas de flujo de datos
En este apartado mostraremos los diagramas de flujo de datos
generados con la idea de representar, de la forma más simple posible, el
funcionamiento de las distintas opciones que da la herramienta.
Abrir y leer imagen hiperespectral
Figura A.2: DFD del proceso de leer imágenes hiperespectrales.
En la Figura A.2 se observa como el usuario de la aplicación
establece el nombre de la imagen que se desea leer y el proceso carga la
metainformación de la imagen la cual permite leer apropiadamente el
contenido de la imagen hiperespectral.

102
Algoritmos de preprocesado espacial
Figura A.3: DFD's de los algoritmos de preprocesado espacial SPP y PCA.
En los algoritmos de preprocesado espacial el usuario debe introducir
los parámetros apropiados para cada algoritmo (ver Figura A.3). En el caso
de SPP es el tamaño de las ventanas en las cuales se dividirá la imagen
para el preprocesado, mientras que en el caso de PCA será el número de
componentes dimensionales a los que queremos reducir la imagen original.
Una vez introducidos, junto con el nombre de la imagen los procesos
obtienen los metadatos y almacenan los resultados apropiados.

103
Algoritmos de extracción de endmembers
Figura A.4: DFD's de los procesos que realizan los algoritmos de extracción de endmembers AMEE y OSP.
Figura A.5: DFD's de los procesos que realizan los algoritmos de extracción de endmembers N-FINDR y VCA.

104
Figura A.6: DFD's de los procesos que realizan los algoritmos de extracción de endmembers IEA y SSEE.
Al igual que en los algoritmos de preprocesado espacial el usuario
debe introducir los parámetros adecuados en cada algoritmo (estos
parámetros se detallan en el manual de usuario) haciendo que estos
procesos adquieran, a partir del nombre de la imagen hiperespectral, los
metadatos necesarios para ejecutar los algoritmos y obtener a partir de ellos
los valores de los endmembers (ver Figuras A.4, A.5 y A.6).

105
Figura A.7: DFD del algoritmo de demezclado.
Por otro lado, en la Figura A.6 vemos como el algoritmo de
demezclado se inicia igual que los algoritmos anteriores pero al dar la
posibilidad de extraer los endmembers o no hacerlo, los resultados a obtener
por el proceso global (la imagen demezclada, y los endmembers extraídos)
deben hallarse mediante dos procesos específicos diferenciados. En esta
herramienta el proceso de extracción de endmembers a través de la opción
de demezclado se realiza siempre con el algoritmo de extracción de
endmembers OSP.
Composición de una imagen a partir de bandas de la imagen hiperespectral
Figura A.8: DFD del proceso de composición de bandas.
Este proceso (ver Figura A.8) representa la acción, por parte del
usuario, de la composición de una imagen RGB a partir de tres bandas

106
(distintas o no) pertenecientes a la imagen hiperespectral abierta. El
resultado obtenido por el proceso se presenta al usuario mediante una
ventana con la imagen generada.
Presentación de los resultados
Figura A.9: DFD sobre el proceso de presentación de los resultados.
En la Figura A.9 se representa el proceso por el cual la aplicación
muestra los resultados obtenidos al usuario. En primer lugar el proceso
recopila la información necesaria de los resultados de los procesos
anteriormente vistos y el número de endmember que se desea visualizar. A
partir de aquí se generan de forma independiente los datos sobre los
endmembers (un documento con los valores de cada uno de los
endmembers calculados) y los datos sobre los mapas de abundancia (una
imagen RGB en escala de grises).

107
Presentación de la información sobre las bandas
Figura A.10: DFD sobre el proceso de presentación de imágenes de las bandas de una imagen hiperespectral.
En la Figura A.10, una vez leída la imagen hiperespectral, con los
datos obtenidos de ella, más el número de banda deseado por el usuario, se
genera una imagen RGB en escala de grises que representa la información
contenida en dicha banda.

108
Salvar los resultados
Figura A.11: DFD sobre el proceso de guardado de resultados.
En el proceso representado en la Figura A.11 se generan los archivos
que guardan la información de los resultados obtenidos por un algoritmo en
formato .hdr/.bsq. Para ello recopila tanto datos proporcionados por la
imagen como los datos almacenados en memoria sobre los resultados de los
algoritmos utilizados. En la generación de los archivos se utiliza como
nombre del fichero el proporcionado por el usuario (opcional según el
salvado sea automático o no) o el generado por la aplicación por defecto.

109
Diagrama de clases
Basándonos en los diagramas de flujo de datos anteriores y tras
seguir los procesos pertinentes de implementación se muestra en la Figura
A.12 la representación reducida del diagrama de clases generado
.
Figura A.12: Diagrama de clase de la herramienta HyperMix.
La clase principal HYPER representa el conjunto de relacionadas con
la interfaz gráfica y los eventos, así como las clases específicas encargadas
de lanzar los métodos de los algoritmos implementados mediante ORFEO
Toolbox. Este conjunto de clases ha sido codificado de forma automática (en
su mayor parte) mediante la herramienta de diseño de interfaces gráficas
FLUID contenida en el paquete de la librería FLTK.
Las clases OSP, IEA, NFINDR, UNMIX, PREPROCESSING, PCA y
VCA implementan los algoritmos de mismo nombre. Por otra parte la clase
AMEE implementa también el algoritmo de mismo nombre pero se apoya

110
sobre la clase OMORFOLOGICAS que implementa las operaciones
morfológicas extendidas de erosión y dilatación. Por último, las clases
RESULTSSSEE, AVERAGEPÍXELS, SSEESTEP2 y SVD implementan las
distintas etapas del algoritmo SSEE.
Por otro lado la clase COLORS implementa los métodos necesarios
para la elección de colores en las gráficas de los endmembers calculados.

111
Manual del usuario
Este manual de usuario tiene como objetivo la resolución de dudas
con respecto al manejo de la aplicación HyperMix y con el significado de
alguno de los términos utilizados en ella. No pretende explicar el
funcionamiento interno de los distintos algoritmos ni el significado útil de los
datos obtenidos.
1. GUÍA RÁPIDA
Figura A.13: Aspecto general de la herramienta HyperMix.
Según se puede observar en la Figura A.13 el aspecto final de la
herramienta en funcionamiento se distribuye en varias zonas. En la parte

112
superior están los menús desplegables que contienen las distintas
posibilidades que ofrece la aplicación.
Justo por debajo se encuentran dos marcos con la información que se
está manejando. El de la izquierda indica el algoritmo último que se ha
usado y la información sobre la imagen cargada.
El panel de la derecha informa sobre la ruta de la imagen cargada, la
ruta del fichero de salida con la información de los endmembers y la ruta de
la imagen de salida resultado de algunos algoritmos.
Por debajo de estos paneles se encuentran tres ventanas:
La primera de ellas (izquierda) muestra la imagen concerniente a una
sola banda de la imagen hiperespectral, seleccionable mediante el menú
desplegable situado por debajo.
La segunda (centro) muestra el mapa de abundancia de un
endmember seleccionado. Cada mapa de abundancia muestra la
concentración de cada endmember en la imagen siendo mayor cuanto más
oscuro es el píxel.
La tercera (derecha) muestra una gráfica con los valores de
reflectancia de los endmembers, siendo posible seleccionar cada uno por
separado o todos a la vez mediante el menú desplegable situado por debajo
(automáticamente se despliega el mapa de abundancia correspondiente al
endmember elegido).
Por último, una barra indicadora de la acción que se está realizando
en el momento.
Ahora explicaremos como se pueden ejecutar y en que parámetros
los distintos algoritmos.
Preprocesado espacial
o SSP

113
o PCA
Extracción de endmembers
o AMEE
o OSP
o NFINDR
o VCA
o EAI
o SEE

114
2. ALGORITMOS DE PREPROCESADO
Lo primero que debemos hacer para usar nuestra aplicación es cargar
una imagen hiperespectral válida. Para ello desplegaremos el menú File →
Open Image (o presionar Ctrl + O). Como resultado se abrirá un selector de
archivos (ver Figura A.14) donde deberemos seleccionar el archivo cabecera
(.hdr) de la imagen que queremos.
Figura A.14: Ventana de selección de fichero
Al seleccionar un archivo se nos abrirán las distintas posibilidades que
ofrece la aplicación para tratar con dicha imagen. Las tres últimas imágenes
válidas abiertas correctamente podrán ser referenciadas directamente desde
la pestaña File → Recent Files.

115
Los distintos algoritmos de preprocesado espacial que podemos
ejecutar son los siguientes.
2.1. Preprocesado (SSP)
Se ejecuta seleccionando en el menú Spatial Preprocessing →
Preprocessing (o F2), debiendo emerger la ventana mostrada en la Figura
A.15.
En esta ventana necesitamos seleccionar el valor del tamaño de la
ventana a partir del cual se calculará el preprocesado de la imagen (por
defecto 1) siendo este valor correspondiente a una ventana de dimensiones
nxn (ej. 1x1 píxels). También deberemos seleccionar la ruta de un archivo
.hdr donde vayamos a almacenar el resultado (de aquí en adelante se
obviará el hecho de tener que escribir la extensiones de los ficheros
indicadas en los recuadros de entrada de datos, siendo obligatorio para el
usuario en todos los casos excepto que se diga lo contrario).
Figura A.15: Ventana de opciones del algoritmo de preprocesado (SSP)

116
2.2. PCA
Se ejecuta seleccionando en el menú Spatial Preprocessing → PCA (o F3),
debiendo emerger la ventana mostrada en la Figura A.16.
En esta ventana será necesario elegir, al igual que en el algoritmo de
Preprocesado, la ruta donde queremos que se guarde la imagen resultado
del algoritmo. Además debemos seleccionar el número de componentes o
bandas, igual al número de endmembers a extraer con NFINDR (explicación
más adelante), al cual se quiere reducir el problema.
Figura A.16: Ventana de opciones del algoritmo PCA

117
3. ALGORITMOS DE EXTRACCIÓN DE ENDMEMBERS
3.1. AMEE
Se ejecuta seleccionando en el menú Endmembers Extraction →
AMEE (o F4), debiendo emerger la ventana mostrada en la Figura A.17.
Los parámetros que deben introducirse en este algoritmo son el
tamaño de la ventana (nxn) al cual se aplicarán los procesos de erosión y
dilatación (operaciones morfológicas extendidas) de píxels. El número de
endmembers que se obtendrán como resultado y la ruta del fichero donde se
almacenarán los valores de dichos endmembers.
Figura A.17: Imagen de la ventana de selección de parámetros para el algoritmo AMEE.

118
3.2. OSP
Se ejecuta seleccionando en el menú Endmembers Extraction → OSP
(o F5), debiendo emerger la ventana mostrada en la Figura A.18.
Los parámetros requeridos en este algoritmo son únicamente el
número de endmembers que queremos extraer y la ruta del archivo donde
queremos guardar el resultado.
Figura A.18: Ventana de selección de parámetros para el algoritmo OSP.

119
3.3. NFINDR
Se ejecuta seleccionando en el menú Endmembers Extraction →
NFINDR (o F6), debiendo emerger la ventana mostrada en la Figura A.19.
Este algoritmo requiere como parámetros seleccionar la ruta original
de la imagen seleccionada. Como este algoritmo se basa en PCA,
necesitamos introducir también la ruta de un archivo imagen resultado del
algoritmo PCA para la imagen original seleccionada. Por último como en los
demás algoritmos deberemos introducir el número de endmembers a extraer
y la ruta donde queremos el fichero resultado.
Figura A.19: Ventana de selección de parámetros para el algoritmo N-FINDR.

120
3.4. VCA
Se ejecuta seleccionando en el menú Endmembers Extraction → VCA
(o F7), debiendo emerger la ventana mostrada en la Figura A.20.
Este algoritmo define dos posibilidades:
Introducir manualmente un valor para la relación S/N. Si nos
decantamos por esta opción el algoritmo variará su ejecución en función de
si este valor introducido es mayor o menor que el teórico calculado.
Marcar la casilla “Select SNR ratio” para usar un valor teórico
calculado por el algoritmo.
Los demás parámetros son el número de endmembers a extraer y la
ruta del fichero donde almacenaremos los resultados.
Figura A.20: Ventana de selección de parámetros para el algoritmo VCA.

121
3.5. IEA
Se ejecuta seleccionando en el menú Endmembers Extraction → IEA
(o F10), debiendo emerger la ventana mostrada en la Figura A.21.
Los parámetros requeridos en este algoritmo, al igual que en OSP,
son únicamente el número de endmembers que queremos extraer y la ruta
del archivo donde queremos guardar el resultado.
Figura A.21: Ventana de selección de parámetros para el algoritmo IEA.

122
3.6. SSEE
Se ejecuta seleccionando en el menú Endmembers Extraction → IEA
(o F11), debiendo emerger la ventana mostrada en la Figura A.22.
Este algoritmo como se puede apreciar requiere mayor cantidad de
parámetros. Por supuesto necesitaremos conocer el número de
endmembers que se desean extraer y la ruta donde almacenaremos dichos
endmembers, pero además debemos conocer el “Subset size” que es el
valor, en número de píxels, en el que vamos a subdividir la imagen para la
ejecución del algoritmo. “Iterations” es el número de iteraciones que va a
realizar el algoritmo en su ejecución. “Load image” indica si en el mismo
directorio donde se encuentra la imagen original existe una imagen común
(.png) la cual se debe usar durante la ejecución, por defecto este parámetro
indica que no existe lo cual hará que el algoritmo genere dicha imagen en el
directorio indicado para los endmembers. Y “RMS” que es el valor umbral
usado en relación al ángulo espectral de los píxeles candidatos.
Figura A.22: Ventana de selección de parámetros para el algoritmo SSEE.

123
4. OPCIONES
4.1. Demezclado
Se ejecuta seleccionando en el menú Unmixixng → Unconstrained (o
F8), debiendo emerger la ventana mostrada en la Figura A.23.
En relación a los algoritmos de extracción de endmembers no varía
mucho su utilización. Para su ejecución debe introducirse la ruta de la
imagen que se va a procesar. Es necesario además los valores de los
endmembers extraídos de dicha imagen por lo que se pide también la ruta
de un fichero de salida de alguno de los algoritmos de extracción de
endmembers, siendo calcular un número de endmembers de la imagen
dentro del algoritmo usando dicha ruta como lugar donde almacenar los
Figura A.23: Ventana de selección de parámetros para el algoritmo de Unmixing.

124
resultados. De ser este el caso se necesitará el número de endmembers a
extraer. Por último debemos especificar la ruta donde guardaremos el
archivo que contendrá los resultados (la abundancia de los endmembers en
la imagen).
4.2. Composición de Bandas
Se ejecuta seleccionando en el menú Options → Composing band (o
F9), debiendo emerger la ventana mostrada en la Figura A.24.
En esta opción queremos generar una imagen RGB a partir de tres
bandas, iguales o distintas, de las pertenecientes a la imagen abierta
originalmente. Para ello en cada una de las tres andas se desplegaran las
distintas opciones a elegir. La imagen resultante se mostrara en una ventana
independiente.
Figura A.24: Ventana de selección de bandas de la imagen hiperespectral para componer una imagen RGB.

125
4.3. Salvar Resultados
La aplicación permite salvar los resultados obtenidos, aclarando que
estos resultados que se guardan son:
o Un fichero .bsq con los valores de los últimos endmembers calculados
(matriz de endmembers).
o Un fichero .bsq con los valores del mapa de abundancia que
actualmente este pintado en la aplicación.
Asociados a estos ficheros habrá dos ficheros cabeceras .hdr con la
metainformación de cada uno de ellos.
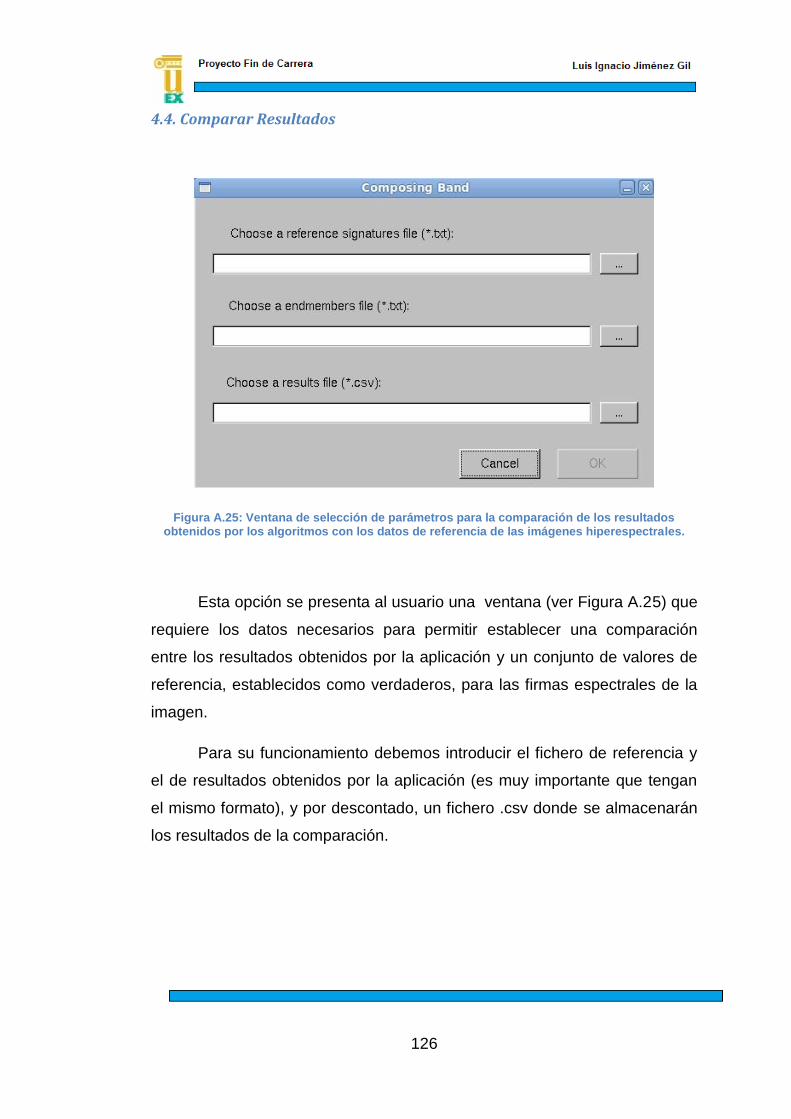
126
4.4. Comparar Resultados
Figura A.25: Ventana de selección de parámetros para la comparación de los resultados obtenidos por los algoritmos con los datos de referencia de las imágenes hiperespectrales.
Esta opción se presenta al usuario una ventana (ver Figura A.25) que
requiere los datos necesarios para permitir establecer una comparación
entre los resultados obtenidos por la aplicación y un conjunto de valores de
referencia, establecidos como verdaderos, para las firmas espectrales de la
imagen.
Para su funcionamiento debemos introducir el fichero de referencia y
el de resultados obtenidos por la aplicación (es muy importante que tengan
el mismo formato), y por descontado, un fichero .csv donde se almacenarán
los resultados de la comparación.

127
5. RESOLUCIÓN DE PROBLEMAS
5.1. La aplicación Hyper no responde.
Cuando la aplicación no reconoce los eventos del ratón significa que
el proceso ha quedado inactivo y no responde. La única solución es reiniciar
la aplicación. Para ello en:
Sistema → Administración → Monitor del Sistema
Seleccionamos el proceso “HYPER” y hacemos click en “Finalizar
Tarea”.
En el caso de no hacerlo de esta manera corremos el riesgo de tener
varios procesos abiertos e inactivos que ralentizarían la ejecución de la
aplicación que si esté activa.
5.2 .La aplicación no reconoce la imagen HDR.
En la mayoría de los casos suele ser por la extensión de los archivos.
La aplicación está diseñada para abrir los archivos con extensión .hdr y a su
vez el fichero asociado SIN EXTENSIÓN.
Muchas veces el fichero asociado viene con la extensión .bsq. De ser
este el caso habrá que quitarle la extensión a este fichero para que la
aplicación lo abra correctamente.

128
6. ¿CÓMO INSTALAR LA HERRAMIENTA HYPERMIX?
El ejemplo de instalación que veremos a continuación está descrito
para un sistema operativo Ubuntu 10.04 recién instalado, por lo que puede
ocurrir que, en su instalación, alguno de los paquetes necesarios durante la
instalación ya pertenezca al equipo. En ese caso simplemente la instalación
obviará dicho paso.
Obtenemos el archivo Hyper-1.2.tar donde tendremos todo lo
necesario para ejecutar la aplicación.
Extraeremos el contenido de este archivo. El resultado es una carpeta
con el nombre “Hyper” que contiene otra carpeta “bin” (ver Figura A.26).
Accedemos a esta última desde consola de comandos y veremos que debe
contenerlos siguientes archivos:
o Hyper-1.2.tar
o install_otb.sh
o OrfeoToolBox-3.6.0.tar
o Leeme.txt
Figura A.26: Contenido de la carpeta Hyper/bin.

129
6.1. Instalando ORFEO ToolBox
El primer paso para que funcione nuestra aplicación es instalar la
librería Orfeo ToolBox en nuestro equipo. Para ello ejecutamos en modo
superusuario:
#sh install_otb.sh
A lo largo de la instalación se nos requerirá aceptar varias veces si
queremos instalar los paquetes, como se ve en la Figura A.27. Para aceptar
introduciremos “s” y pulsamos ENTER.
Los paquetes que se van a instalar son los siguientes:
o libpng12-0 , libpng12-dev
o libtiff4 , libtiff4-dev , libtiffxx0c2 , libtiff-tools
o geotiff-bin , libgeotiff-dev , libgeotiff-epsg , libgeotiff1.2
o libgdal1-1.6.0 , libgdal1-dev
o g++
o cmake-curses-gui
o libfltk1.1 , libfltk1.1-dev , libfltk1.1-dbg
Una vez instalados se aparecerá la pantalla mostrada en la Figura
A.28, resultado de ejecutar cmake (automáticamente):
Figura A.267: Consola de comandos con el desarrollo de la instalación de ORFEO ToolBox.

130
Los pasos a seguir son:
Presionamos “c” para configurar cmake. Mientras configura cmake
nos avisará de que no encuentra GDAL en nuestro equipo. Para
continuar presionamos “e”.
En este momento tendremos una lista de opciones donde indicar
los directorios donde se encuentran en nuestro equipo las librerías
necesarias. Al volver a presionar “c” nos debe aparecer lo
mostrado en la Figura A.29.
Figura A.28: Imagen del aspecto inicial de la configuración de CMake.

131
Para resolver esto presionamos “e” para salir de este mensaje
y después presionamos “t” para desplegar las opciones
avanzadas. Una de estas opciones es OTB_USE_VISU_GUI
por defecto con valor ON. Debemos ponerla con valor OFF.
Una vez hecho esto, volvemos a presionar “c” para configurar
cmake.
Una vez configurado deberá salir la opción “[g] to generate and
exit”. De no salir por la ocurrencia de algún error, presionar “c”
hasta que aparezca ya que cmake añadirá la configuración por
defecto en estos errores en cada ejecución de la configuración.
Presionamos “g” para generar el Makefile. Una vez fuera de
Cmake comenzará automáticamente la ejecución del comando
“make”.
Cuando termine debe salir en consola el mensaje “ORFEO TOOLBOX
HAS BEEN INSTALLED SUCCESFULLY”.
6.2. Instalando Hyper
Una vez instalado Orfeo vamos a la carpeta ./Hyper/bin y
descomprimimos Hyper-1.2. Ya en esa carpeta ejecutamos tal y como
aparece en la Figura A.30 el siguiente comando:
~$ cmake .
Figura A.29 Error previsto en la configuración de OTB.

132
Volveremos a tener delante la pantalla de cmake. Presionamos “c”
hasta que salga la opción de generar (no tiene que dar ningún tipo de error si
se configuró correctamente antes). Una vez salga presionamos “g”.
En consola tecleamos:
~$ make
Una vez finalizado deberemos tener en la carpeta los ficheros que
aparecen en la Figura A.31.
Ahora ejecutamos HYPER para usar la aplicación:
~$ ./HYPER
Figura A.31: Contenido final del directorio de instalación.
Figura A.30: Imagen de consola con el comando que debemos ejecutar y el contenido del directorio.


















