
Oseda, D. - 2010 - Estadística Descriptiva e Inferencial.pdf
Upload
tibhy4323643Category
view
17download
0
Una introducción a la ESTADÍSTICA INFERENCIAL
José Chacón
Esta obra está bajo una licencia Reconocimiento‐No comercial‐Compartir bajo la misma licencia 2.5 de Creative Commons. Para ver una copia de esta licencia, visite
http://creativecommons.org/licenses/by‐nc‐sa/2.5/ o envie una carta a Creative Commons, 559 Nathan Abbott Way, Stanford, California 94305, USA.


Tema 1. Introducción
Esta asignatura ha sido orientada a entender los principios en los que se basa la estadística inferencial. Entender significa que es posible saber, en primer lugar, qué razones han llevado a elegir un determinado cálculo y, no menos importante, la rele‐vancia real de los resultados de ese cálculo.
La estadística inferencial no es más que un argumento. Un buen argumento hace creíble una afirmación. En nuestro caso, cualquier estudio necesitará, al menos dos argumentos sólidos: el estadístico y el relativo al diseño de investigación (lo que se puede aprender en Métodos I y II). Desde este punto de vista, nuestra tarea es po‐der entender (y calibrar) los argumentos estadísticos y también poder construirlos nosotros mismos.
La estadística inferencial es necesaria cuando queremos hacer alguna afirmación sobre más elementos de los que vamos a medir. La estadística inferencial hace que ese sal‐to de la parte al todo se haga de una manera “controlada”. Aunque nunca nos ofrecerá seguridad absoluta, sí nos ofrecerá una respuesta probabilística. Esto es importante: la estadística no decide; sólo ofrece elementos para que el investigador o el lector deci‐dan. En muchos casos, distintas personas perciben diferentes conclusiones de los mismos datos.
El proceso será siempre similar. La estadística dispone de multitud de modelos que están a nuestra disposición. Para poder usarlos hemos de formular, en primer lugar, una pregunta en términos estadísticos. Luego hemos de comprobar que nues‐tra situación se ajusta a algún modelo (si no se ajusta no tendría sentido usarlo). Pero si se ajusta, el modelo nos ofrecerá una respuesta estadística a nuestra pregunta esta‐dística. Es tarea nuestra devolver a la psicología esa respuesta, llenándola de conte‐nido psicológico.
1. Definiciones e ideas previas
En el ámbito científico, la estadística, en general, y la estadística inferencial, en particular, es el camino que hay que recorrer para llegar de una pregunta a la res‐puesta adecuada. Así, la estadística no es más que un argumento para defender nuestras ideas.
¿Cuándo es necesaria la estadística inferencial? Cuando queremos hacer alguna afirmación sobre más elementos de los que vamos a medir.
La estadística descriptiva, como indica su nombre, tiene por finalidad descri‐bir. Así, si queremos estudiar diferentes aspectos de, por ejemplo, un grupo de per‐sonas, la estadística descriptiva nos puede ayudar. Lo primero será tomar medidas, en todos los miembros del grupo, de esos aspectos o variables para, posteriormente, indagar en lo que nos interese. Por ejemplo, para saber cuál es la “edad del grupo”, podemos resumir el conjunto de todas las edades mediante la media. Eso nos dice, aproximadamente, alrededor de qué edad se sitúan todos. Ya sabemos, pongamos, que la edad media es 40 años. Pero además podemos utilizar la desviación típica, si

1. Introducción, 2
queremos saber si el grupo tiene edades muy dispares (por ejemplo, una desviación típica de 12 años) o si, por el contrario, tienen edades parecidas (una desviación típi‐ca de 2 años). Sólo con esos indicadores ya podemos hacernos una idea, podemos describir a ese conjunto de personas, al menos en referencia a su edad.
Pero el tamaño de los grupos que suelen interesar es demasiado grande, a ve‐ces tan grande como “todo el mundo”. Y esto, más que ser una rareza, es en muchos campos la norma. Por ejemplo, cuando se afirma que las personas tenemos una agu‐deza visual menor que la de los halcones, podemos estar seguros de que no hemos medido la agudeza visual de todos los humanos ni la de todos los halcones.
Pues bien, la estadística inferencial es la que va a permitir dar ese salto de los resultados obtenidos para un grupo a la totalidad.
Planteemos una cuestión concreta: Un profesor de estadística afirma que se aprende mejor estadística inferencial utilizando los ordenadores para mostrar lo que se estudia. ¿Cómo podemos decidir si esta afirmación es cierta? Una posible forma sería seleccionando dos grupos de alumnos (equivalentes) que estudien estadística inferencial, y dar las mismas clases a ambos, incluido el mismo profesor, idénticos ejercicios, etc., excepto que uno de ellos utilizan los ordenadores en su aprendizaje y otro no.
Veamos las definiciones en relación a este ejemplo, suponiendo que realiza‐mos el estudio con los alumnos de los grupos F (con ordenador) y G (sin ordenador):
Grupo F (con ordenador) Grupo G (sin ordenador)
Población: un conjunto de elementos (generalmente personas, en psicología) que comparten al menos una característica bien definida. Estudiantes de primero de psicología que cursan estadística inferencial con ordenador
Estudiantes de primero de psicología que cur‐san estadística inferencial sin ordenador
Muestra: es un subconjunto de elementos extraídos de una población. Los estudiantes de primero de psicología de la
UCM, grupo F Los estudiantes de primero de psicología de la
UCM, grupo G Variable: Característica de los elementos de una población que puede tomar diversos valores (al menos, dos). Nivel de conocimientos en estadística II, me‐
didos a través de un examen. Nivel de conocimientos en estadística II, me‐
didos a través de un examen. Datos: Valores obtenidos al medir una variable en una muestra. Conjunto de notas obtenidas en el examen de estadística para los alumnos del grupo F
Conjunto de notas obtenidas en el examen de estadística para los alumnos del grupo G
Estadístico: Es un valor numérico que expresa una característica de una muestra. Formalmente, un estadístico es una función definida sobre una variable. Media ( X ) de las notas obtenidas en el exa‐men de estadística para alumnos del grupo F
Media ( X ) de las notas obtenidas en el exa‐men de estadística para alumnos del grupo G

1. Introducción, 3
Parámetro: Es un valor numérico que expresa una característica de una población. Media (µ) de las notas obtenidas en el exa‐men de estadística para todos los estudiantes de primero de psicología que cursan estadís‐
tica inferencial con ordenador.
Media (µ) de las notas obtenidas en el examen de estadística para todos los estudiantes de primero de psicología que cursan estadística
inferencial sin ordenador.
2. El azar y la probabilidad
La estadística inferencial resulta de aplicar la probabilidad a los estadísticos que ya conocemos por la estadística descriptiva. Los resultados de esa aplicación vendrán expresados, pues, en lenguaje probabilístico.
Y esto no ayuda precisamente a sentirse cómodo con la estadística inferencial. Además de ser matemática, tiene la fea costumbre de no decir sí o no. En lugar de ello, sus respuestas suenan a veces a excusas, eso sí, muy diplomáticas, como “no hay suficiente evidencia” o “esa afirmación es altamente improbable”. Pero en lenguaje matemático. El resultado es quizás extraño, difuso pero preciso; no se decanta pero nos da cuatro decimales: “a partir de los datos que me ofrece, la probabilidad de que ocurra eso que usted afirma es 0.2381”1.
Pero aun así nos permite incrementar nuestro conocimiento. Las afirmaciones anteriores pretenden ilustrar algo fundamental: las afirmaciones que nos permite hacer la estadística inferencial tienen un riesgo, y quien la usa debe saberlo. No es difícil, de todas maneras, porque todas estas afirmaciones están formuladas en tér‐minos de riesgo, de seguridad e inseguridad: de probabilidad.
El azar es, por definición, lo impredecible. ¿Cómo es posible entonces utilizar lo impredecible para obtener información? La clave está en que incluso lo impredeci‐ble, para poder serlo, ha de cumplir algunas normas. El conjunto de esas normas, y las técnicas para extraer información del azar, es lo que llamamos probabilidad.
No hay nada mágico en el azar; resulta de una sucesión de circunstancias no controlables que lleva a no poder predecir el resultado. Fijémonos en la moneda de toda la vida. Lo que hace que lanzarla sea un experimento aleatorio es que es imposible controlar la fuerza con la que se lanza, los giros que da y los ángulos con que golpea el suelo una y otra vez hasta detenerse2. Basta situar la moneda de canto en una mesa y empujarla deliberadamente en una dirección para que desaparezca el azar. Pero si estando de canto la hacemos girar rápidamente volvemos a disponer de un experi‐mento aleatorio.
Pero, ¿podemos realmente utilizar esta información para decidir sobre algo re‐al? Supongamos que lanzamos la moneda al aire. ¿Cuáles son esas normas que po‐
1 Las respuestas que obtendremos serán ligeramente diferentes, pero esa frase sirve para ilustrar el estilo. 2 Esto no es completamente cierto: hay prestidigitadores que se entrenan hasta controlar el lanzamien‐to de las monedas. Controlan la fuerza, los giros y el momento justo de detener el movimiento para conseguir cierto resultado. El truco consiste, por tanto, en que no hay azar.

1. Introducción, 4
demos utilizar? En este caso, que la moneda tiene dos caras, y que no hay preferencia por una u otra a la hora de posarse. Es decir: las dos únicas posibilidades se reparten por igual el “derecho” a ser el resultado final. Si aplicamos los conceptos básicos de la probabilidad, y recordando que la probabilidad total es 1, tenemos que las proba‐bilidades de que salga cara o cruz son:
( ) 0.5( ) 0.5
P caraP cruz
=⎧⎨ =⎩
Lo que suele ser difícil de digerir para nuestro entendimiento son cuestiones como, por ejemplo, que aunque un determinado suceso tenga una probabilidad ínfi‐ma, como 0.01 (un 1 por ciento), también puede ocurrir.
Aunque todo el que lea esto esté realmente convencido de que es verdad, la experiencia demuestra que no aplicamos este conocimiento.
3. El muestreo
Para extraer conclusiones de una población a partir de una muestra, es vital que la muestra sea representativa.
Hay dos tipos de muestreo: probabilístico (se conoce, o puede calcularse, la probabilidad de cada elemento, por tanto, de cada muestra posible) y no probabilísti‐co (se desconoce o no interesa la probabilidad de cada elemento; el investigador se‐lecciona aquella muestra que considera más representativa o que le resulta más fácil).
Cuidado: no es que el muestreo no probabilístico no permita generar muestras representativas; lo que ocurre es que no tenemos ninguna información sobre el grado de representatividad de la muestra elegida.
El muestreo probabilístico puede darse de diferentes formas, según estemos considerando poblaciones finitas (los votantes de la Comunidad de Madrid, los pa‐cientes con insomnio) o infinitas (los posibles tiempos de reacción ante una tarea de búsqueda visual), y según consideremos (en las finitas) un muestreo con o sin reposi‐ción.
El muestreo aleatorio simple se da cuando se cumple la igualdad de distribuciones (cualquier valor tiene la misma probabilidad de salir en cada extracción) e indepen‐dencia (la probabilidad de obtener un determinado valor no se modifica por los valo‐res ya obtenidos).
Otros tipos de muestreo probabilístico son el m. a. sistemático, el m. a. estrati‐ficado y el m. a. por conglomerados.

Tema 2. Estimación de parámetros
Cuando queremos estimar el valor de un parámetro, disponemos de dos aproximaciones: La estimación puntual y la estimación por intervalos.
1. Estimación puntual
La estimación puntual asigna directamente al parámetro el valor obtenido pa‐ra el estadístico.
[La estimación por intervalos, en cambio, proporciona un intervalo, un rango de valores entre los que estará situado el parámetro con una cierta probabilidad. Para poder co‐nocer esa probabilidad debemos conocer previamente la distribución de probabilidad del esta‐dístico que estemos usando como estimador: la distribución muestral del estadístico. En los puntos 2 y 3 veremos estas dos cuestiones con más detalle.]
La estimación puntual constituye la inferencia más simple que podemos reali‐zar: asignar al parámetro el valor del estadístico que mejor sirva para estimarlo. Pero para que un estadístico sea considerado un buen estimador ha de cumplir ciertas condiciones. Si usamos los símbolosθ para un parámetro cualquiera, y θ̂ , para un posible estimador de θ , podemos enunciar las propiedades de la siguiente forma:
• Carencia de sesgo: Un estimador,θ̂ , será insesgado si su valor esperado coinci‐de con el del parámetro a estimar, θ .
ˆ( )E θ θ=
• Consistencia: Un estimador,θ̂ , será consistente si, conforme aumenta el tamaño muestral, n, su valor se va aproximando a θ . Expresado más formalmente, in‐dica que dada una cantidad arbitrariamente pequeña, δ , cuando n tiende a in‐finito,
ˆ(| | ) 1P θ θ δ− < →
• Eficiencia: Dados dos posibles estimadores 1̂θ y 2̂θ , diremos que 1̂θ es un esti‐mador más eficiente que 2̂θ si se cumple que
1 2
2 2ˆ ˆθ θ
σ σ<
• Suficiencia: Un estimador,θ̂ , será suficiente si utiliza toda la información mues‐tral disponible. La tabla a continuación muestra los estimadores de algunos parámetros:
Estimadores Insesgados Consistentes Eficientes
Parámetros
X X X µ 21nS −
2nS
21nS − , 2
nS 2σ
P P P π

2. Estimación de parámetros, 6
Y el siguiente gráfico puede ilustrar el significado de esas propiedades:
2. Distribución muestral de la media
La distribución muestral (de la media o de cualquier otro estadístico) es fun‐damental: si la conocemos podemos saber con qué probabilidad puede adoptar de‐terminados valores. Eso nos permitirá responder a ciertas cuestiones, por ejemplo, obtener el intervalo de confianza para la media, hacer un contraste de hipótesis o cal‐cular la potencia de un contraste de hipótesis.
Conocer la distribución muestral de un estadístico (de aquí en adelante, la media) implica conocer su forma y sus parámetros. Por ejemplo, saber si su forma es la de la distribución normal, y saber que los parámetros son: media, 30 y desviación típica, 6.5. A fin de cuentas, lo que nos interesa es que la distribución muestral coin‐cida con alguna conocida, de la que dispongamos de tablas.
La forma en que la estadística nos permitirá conocer la DMM es a través de condiciones o supuestos: Si nuestros datos cumplen lo que pide un procedimiento estadístico, entonces ese procedimiento estadístico nos da alguna información útil. Por ejemplo,
Si… entonces…
1
… tenemos un muestreo aleatorio,…… y las observaciones son indepen‐dientes,… … y el tamaño de la muestra es n,
… los parámetros de la DMM son
XX
XX n
µ µ
σ σ
=
=
2
… tenemos un muestreo aleatorio,…… y las observaciones son indepen‐dientes,… … y la distribución de la variable X es normal,
… la DMM es normal, con indepen‐dencia del tamaño de la muestra, n… … y con parámetros
XX
XX n
µ µ
σ σ
=
=

2. Estimación de parámetros, 7
3
… tenemos un muestreo aleatorio,…… y las observaciones son indepen‐dientes, … y no conocemos la distribución de la variable X,
… la DMM se aproximará a la normal, conforme aumenta el tamaño de la muestra, n… … y con parámetros
XX
XX n
µ µ
σ σ
=
=
4
… estamos en cualquiera de los ca‐sos anteriores,… … y desconocemos σ,
… la DMM se aproximará a la distri‐bución t con n – 1 grados de libertad, … … y con parámetros
XX
nX S n1
µ µ
σ −
=
≈
De (1) obtenemos los parámetros de la DMM: la media y la desviación típica,
que suele denominarse error típico de la media. De (2) podemos deducir que, si nuestra variable de interés es normal en la po‐
blación, también lo será nuestra DMM. De (3) extraemos que, aunque la distribución de la variable X en la población
no sea normal o, lo más frecuente, si no sabemos si es o no normal, la DMM sí será normal si el tamaño de la muestra, n, es lo suficientemente grande (aproximadamen‐te mayor que 30).
Gracias a (4) solucionamos un problema bastante común: el no conocer la des‐
viación típica poblacional de la variable X. En este caso usamos como estimador Sn‐1, pero entonces la DMM sigue la forma de la distribución t. Las distribuciones normal y t se diferencian visiblemente sólo cuando los grados de libertad son pequeños, co‐mo se observa en las gráficas siguientes. Cuando aumenta n, σ y Sn‐1 se van pare‐ciendo más y más, y las distribuciones normal y t también. Es por esto que, a un nivel práctico, a partir de un n mayor que 30 suelen usarse indistintamente. En las dos grá‐ficas que siguen se pueden ver las distribuciones normal (azul) y t (rojo) para dos tamaños de muestra distinto: n igual a 5 (arriba) y n igual a 30 (debajo). Para ambas se calcula los límites que abarcan un 95% del área total de cada curva. Las discrepan‐cias son evidentes con n igual a 5, pero inapreciables para n = 30.

2. Estimación de parámetros, 8
con n = 5.
con n = 30. A efectos prácticos, todo lo visto supone lo que detallamos a continuación.
Considérese siempre que el muestreo es aleatorio (los datos proceden de elementos representativos) e independiente (es decir, que el haber elegido un elemento no afec‐ta a la probabilidad de elegir otros). En estas condiciones, puede ocurrir lo siguiente:
• Como es difícil conocer σ, consideraremos siempre de partida que la DMM se distribuirá segùn tn‐1, ya sea cuando sepamos que la variable X se distribuye normalmente o cuando n sea igual o mayor que 30 o ambas cosas. Como las ta‐blas de la distribución t aparecen tipificadas (con media = 0 y desviación típica = 1), para hacer cualquier uso de ella deberemos tipificar el valor de interés, X:
11
emp nn
Xt tS n
µ−
−
−= →
• Si, en el caso anterior, conocemos además la desviación típica poblacional, en‐tonces la DMM se distribuirá según la distribución normal: Por la misma razón de antes, para usar las tablas previamente debemos tipificar:
(0,1)empXz N
nµ
σ−
= →
• Pero si no conocemos la forma de la distribución de la variable X, ni el n es lo suficientemente grande como para hacer uso del punto (3), entonces no pode‐

2. Estimación de parámetros, 9
mos utilizar esta información. [Pero no todo está perdido: En ese caso habría que estudiar la forma de la distribución de la variable X, transformar las pun‐tuaciones hasta que adopten una forma normal o, en última instancia, usar pruebas no paramétricas, que no imponen supuestos sobre la forma de la dis‐tribución. Todo esto son conceptos que se verán más adelante.] Como regla general utilizaremos siempre la distribución t (rara vez conocere‐
mos σ), aunque podremos usar la tabla de la distribución normal (siempre que n sea suficientemente grande) para localizar valores que no aparezcan en la tabla de la dis‐tribución t.
¿Qué obtenemos de todo esto? Lo que afirmábamos anteriormente: que conociendo cómo se comportan las
medias (su distribución muestral o distribución de probabilidad), podemos usar estas probabilidades siempre que sea necesario. Una de ellas, que veremos ahora, es la ob‐tención de intervalos de confianza. Otra aplicación, más adelante, será utilizada en el contraste de hipótesis.
3. Estimación por intervalos
Supongamos que conociésemos la población. Podríamos obtener la DMM para un determinado tamaño de la muestra, n. Una vez caracterizada la DMM, seríamos capaces de decir, con una determinada seguridad, dónde estarán las medias que po‐dremos obtener si muestreamos.
Invirtiendo el razonamiento (y yendo a la realidad), dada una muestra, pode‐mos calcular la DMM donde, con una cierta seguridad, estará la media poblacional que buscamos. Este razonamiento se muestra en la figura siguiente.

2. Estimación de parámetros, 10
Observando vemos que a partir de la muestra (recuérdese que la población y sus parámetros son desconocidos) el IC, al 95%, para la media poblacional es [54.03, 65.90]. Eso quiere decir que la probabilidad de haber “atrapado” la media poblacio‐nal es 0.95, la probabilidad de haber acertado. O dicho de otro modo: la probabilidad de habernos equivocado, de no haber “atrapado” la media poblacional es 0.05, el 5%.
En el caso de la figura anterior, la media poblacional (64.31) cae dentro del in‐tervalo, pero esto no siempre es así: si repetimos el proceso, un 5% de las veces la media poblacional quedará fuera del intervalo propuesto, como se observa en la fi‐gura siguiente:
La obtención de un determinado intervalo es fácil, dado que conocemos la DMM. Basta con:
1. Localizar en la distribución de probabilidad (normal o t) los valores que contie‐nen el nivel de confianza.
2. Traducir esos dos valores a la escala de nuestra variable, X. En la práctica, deberemos definir un nivel de confianza (NC), que determinará
un nivel de riesgo, α = 1‐NC. A partir de ahí, y asumiendo que se sigue la distribu‐ción t:
1. Obtener los límites inferior y superior, es decir, los valores para tn‐1 que dejan a la izquierda y a la derecha α/2 (la mitad del nivel de riesgo). Estos valores serán
1, 2nt α− y 1,1 2nt α− − .
2. Traducir esos dos valores a la escala de nuestra variable, X. Así, y teniendo en cuenta que 1,1 2 1, 2n nt tα α− − −= los límites serían:

2. Estimación de parámetros, 11
11, 2
11, 2
ni n
ns n
Sl X tnSl X tn
α
α
−−
−−
⎧ = −⎪⎪⎨⎪ = +⎪⎩
Al término que es sumado y restado de la media suele denominársele error máximo, y se denota por Emax. En estos términos, los límites de un intervalo de con‐fianza suelen expresarse genéricamente como
max
max
i
s
l X El X E
⎧ = −⎪⎨
= +⎪⎩
En resumen, una vez obtenido el intervalo de confianza se puede afirmar lo siguiente:
( ) 1i sP l lµ α< < = −
Que significa que la probabilidad de que la media poblacional esté situada de‐
ntro del intervalo obtenido es igual al nivel de confianza especificado (1 – α).

Tema 3. Contraste de hipótesis
1. Contraste de hipótesis
Un contraste de hipótesis es un proceso de decisión en el que una hipótesis formulada en términos estadísticos es puesta en relación con los datos empíricos para determinar si es o no compatible con ellos.
Los datos empíricos siempre provendrán de un muestra, un subconjunto limi‐tado de la población de referencia. Las hipótesis, por el contrario, siempre pregunta‐rán acerca de la población. Piénsese que es absurdo preguntar si una media obtenida en una muestra, por ejemplo, 5’8, es mayor que 5. Por supuesto que lo es, y nadie (exceptuando los que estudian estadística) puede hacerse semejante pregunta seria‐mente.
Lo que sí es relevante preguntar es si la media poblacional, que no conocemos, es mayor que 5. En tanto no la conocemos, usaremos la media muestral como un es‐timador (una aproximación) de esa media poblacional.
1.1 Las hipótesis estadísticas (la pregunta, formalizada) Una hipótesis estadística es una afirmación sobre una o más distribuciones de
probabilidad; más concretamente, sobre la forma de una distribución de probabilidad o sobre el valor de un parámetro de esa distribución de probabilidad. En cuanto a nuestro ejemplo, nos centraremos en una distribución de probabilidad con el paráme‐tro media poblacional igual a 5. El contraste de hipótesis nos dirá si es más o menos probable, bajo esa distribución de probabilidad, obtener en una muestra aleatoria una media igual a 5’8.
Todo contraste necesita dos hipótesis: H0 y H1, que serán exhaustivas y mu‐tuamente exclusivas.
H0 es la hipótesis nula, y es la que se somete a contraste. H1 es la hipótesis alternativa a H0, y es la negación de H0. Mientras que H0 es
exacta, H1 suele ser inexacta. Un detalle importante: el signo “=” siempre va en la H0, sea exacta o inexacta.
Es sobre este signo “=” sobre el que se construirá el modelo probabilístico, como ya hemos visto.
1.2 Los supuestos (¿nuestra situación se parece a la del modelo?) Son un conjunto de afirmaciones que necesitamos establecer (sobre la pobla‐
ción de partida y la muestra utilizada) para conseguir determinar la distribución de probabilidad en la que se basará nuestra decisión sobre H0. Si nuestra situación no se ajusta a estas condiciones, necesarias, entonces no debemos usar el modelo. La razón es obvia: el modelo no nos sirve, luego cualquier cosa que deduzcamos de él será inexacta y/o errónea.

3. Contraste de hipótesis, 13
1.3 El estadístico de contraste y su distribución de probabilidad Un estadístico de contraste no es más que un cálculo o función que cumple lo
siguiente: (1) expresa de forma adecuada nuestra pregunta psicológica, (2) tiene una distribución muestral (de probabilidad) conocida, y (3) viene traducido (o expresado) en la escala de esa distribución de probabilidad.
1.4 La decisión (¿H0 sí o H0 no?) La decisión requiere, en primer lugar, trazar un punto de corte (o dos, en el
contraste bilateral), que definirá dos zonas, una de rechazo (o crítica) y otra de acepta‐ción. Ese punto de corte vendrá dada por el nivel de confianza y el nivel de riesgo, α.
La decisión consiste en rechazar la H0 si el estadístico de contraste cae en la re‐gión de rechazo, y mantenerla si cae en la región de aceptación.
Mantener la H0 significa que la hipótesis es compatible con los datos. Rechazarla implica que ambos son incompatibles, luego consideramos la H0
falsa.
Caso general Ejemplo específico 1. Hipótesis
• Contr. Bilateral: 0 0
1 0
::
HH
µ µµ µ
=⎧⎨ ≠⎩
• Contr. Unil. Der.: 0 0
1 0
::
HH
µ µµ µ
≤⎧⎨ >⎩
• Contr. Unil. Izq.: 0 0
1 0
::
HH
µ µµ µ
≥⎧⎨ <⎩
¿Hay un nivel de aciertos mayor que el esperado por azar, en 20 ensayos? NC = 0.95; n = 48.
0
1
: 10: 10
HH
µµ
≤⎧⎨ >⎩
2. Supuestos • Población de partida normal • Muestra aleatoria de tamaño n.
Tenemos un n suficientemente grande pa‐ra garantizar una DMM normal.
3. Estadístico de contraste
• emp nn
Xt tS n 1
1
µ−
−
−= →
10.44 10 0.44 1.25580.34842.41 48empt
−= = =
4. La decisión Primero, la zona de rechazo según α
• Contr. Bilateral: 1, 2
1,1 2
teor_inf n
teor_sup n
t tt t
α
α
−
− −
=⎧⎨ =⎩
• Contr. Unil. Der.: 1,1teor nt t α− −=
• α = 1 – NC = 1 – 0.95 = 0.05; • Contraste unilateral derecho, luego
1,1 47 ,0.95 1.676teor nt t tα− −= = = • El estadístico de contraste cae en la re‐
gión de aceptación:
emp teort t<
3. Contraste de hipótesis, 14
• Contr. Unil. Izq.: 1,teor nt t α−=
La regla de decisión • Se rechaza H0 si temp cae en la zona
de rechazo determinada por tteor.
• Luego mantenemos la H0: los resulta‐
dos son compatibles con una media igual a 10, es decir, son compatibles con los aciertos esperados por azar.
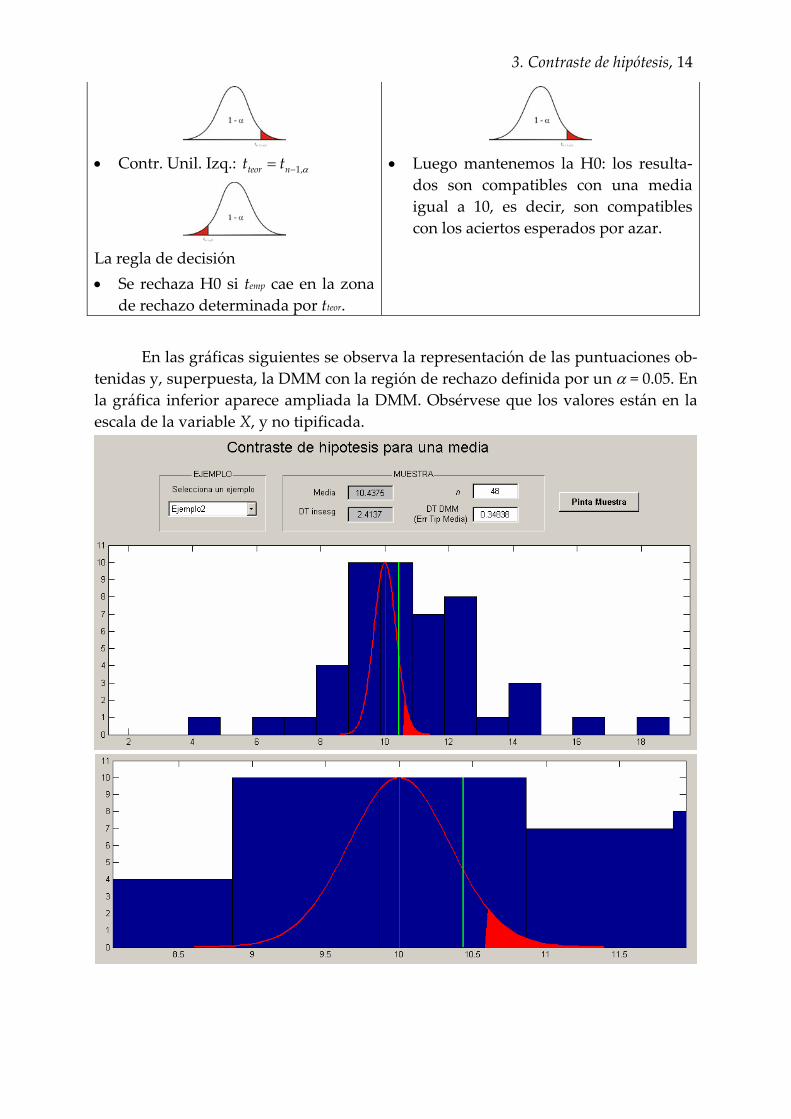
En las gráficas siguientes se observa la representación de las puntuaciones ob‐
tenidas y, superpuesta, la DMM con la región de rechazo definida por un α = 0.05. En la gráfica inferior aparece ampliada la DMM. Obsérvese que los valores están en la escala de la variable X, y no tipificada.

3. Contraste de hipótesis, 15
2. Estimación por intervalos y contraste de hipótesis
Es fácil darse cuenta de la relación que existe entre un contraste de hipótesis y el intervalo de confianza.
Por ejemplo, calculamos un intervalo de confianza, al 95%, para la media espe‐rada. Como resultado, si la media obtenida está dentro de ese intervalo, considera‐remos que no se aleja lo suficiente como para considerarla distinta.
Eso es justamente lo que hacemos en un contraste de hipótesis bilateral: esta‐blecemos dos puntos de corte y comprobamos si la media obtenida está dentro del intervalo definido o no. Sobre este hecho realizamos la decisión.
Es diferente si consideramos un contraste unilateral. En ese caso, todo el nivel de riesgo se sitúa en un lado. En tanto todos los intervalos están construidos “de forma bilateral”, la equivalencia no es perfecta. Habría que multiplicar el alfa por dos para que fuera equivalente.
3. Errores tipo I y II. Potencia de un contraste.
Hemos aprendido a realizar un contrate de hipótesis, y ahora sabemos tomar una decisión acerca de si rechazamos o no la H0. Además, conocemos las probabili‐dades asociadas a cualquiera de las decisiones tomadas. Podemos representar gráfi‐camente esta situación (ver figura anterior). Pero todas estas decisiones se basan en que H0 sea cierta. ¿Qué ocurre, entonces, si H0 es falsa? Esto puede resumirse en la siguiente tabla:
Situación de H0 H0 Verdadera H0 Falsa
Mantener H0 Decisión correcta
P = 1 – α Nivel de confianza
Error tipo II P = β
Decisión
Rechazar H0 Error tipo I
P = α
Decisión correcta P = 1 ‐ β
Potencia ¿Cómo podemos representar gráficamente esta nueva perspectiva? Lo primero
será considerar que, si H0 se considera falsa, adoptaremos como valor de H1 el obte‐nido en nuestra muestra. A partir de ahí, podemos plantear una nueva DMM, cen‐trada precisamente en H1 (donde µ = 10.44):

3. Contraste de hipótesis, 16
Ahora podemos ver que ese punto de corte determina otras dos áreas en la
DMM para H1. Si analizamos la DMM para H1 es fácil saber lo que indican esas dos áreas: la de la izquierda (en verde), la probabilidad de que, siendo H0 falsa (es decir, adoptando H1 como verdadera), consideremos que H0 es cierta (o H1 es falsa), es de‐cir, el error tipo II.
El área de la derecha (sin relleno), por el contrario, nos indica la probabilidad de rechazar H0 (y, por tanto, considerar cierta H1), 1‐ β.
Tenemos, por tanto, dos áreas (probabilidades) de error: α y β, y dos áreas de “acierto”, 1‐α y 1‐β. Pues bien, si α y β son los errores tipo I y tipo II, respectivamen‐te, sus complementarios son el nivel de confianza (1‐ α) y la potencia (1‐ β).
Hasta hace poco, sólo se prestaba atención al nivel de riesgo o error tipo I, α. Pero ahora es cada vez más habitual (y siempre recomendable) ver incluida la poten‐cia en los estudios publicados.
¿Para qué sirve, después de todo? Pues para varias cosas: 1. Primero, su valor siempre es informativo. Démonos cuenta de que también es
importante que, si H1 es cierta, la probabilidad de elegirla (la potencia) sea alta. 2. Permite, dado un alfa, aumentar la potencia a través de un “truco”. ¿Cuál? Au‐
mentando el n. Es habitual obtener la potencia a partir del tamaño del efecto (ver punto siguien‐
te) utilizando las tablas apropiadas.
4. Nivel crítico y tamaño del efecto
Hay dos informaciones más que podemos extraer y que pueden ser extrema‐damente útiles.
Por un lado, el nivel crítico, p: es la probabilidad asociada al estadístico de contraste o, dicho de otro modo, el nivel de significación más pequeño al que una H0 puede ser rechazada con nuestro estadístico de contraste, temp. Así, y en el caso de un contraste unilateral derecho, p puede definirse como la probabilidad de encontrar valores mayores que nuestro estadístico de contraste:
( )empp P t t= >

3. Contraste de hipótesis, 17
Con el nivel crítico se pretende salir de la decisión binaria (sí/no) y proporcio‐nar al lector la probabilidad asociada al estadístico de contraste obtenido. Así, puede observarse la compatibilidad o discrepancia entre la H0 y la evidencia obtenida de la muestra (a través del estadístico de contraste).
El siguiente cuadro muestra cuatro resultados y las diferentes decisiones se‐gún se use (de forma mecánica) un criterio basado en un α tomado a priori o aten‐diendo al estadístico de contraste y su nivel crítico o p asociada:
¿Se rechaza la H0? (α = 0.05) t p Contr. Hipótesis Decisión en función de p
0.1517 0.560 No No 1.6658 0.051 No Repetir el contraste con otra muestra 1.6861 0.049 Sí Repetir el contraste con otra muestra 3.0177 0.002 Sí Sí
El tamaño del efecto es otra información interesante. Su utilidad se aprecia an‐te la siguiente pregunta: ¿Una diferencia significativa implica una diferencia grande?
La respuesta es no. Supongamos el siguiente ejemplo: se pone a prueba si un nuevo método de
enseñanza del inglés es mejor que el anterior. Tras medir a 500 alumnos a los que se les ha aplicado el nuevo método y comparar la media obtenida con la anterior, vemos que existen diferencias significativas (t500 = 2.02; p < 0.022). Efectivamente, la media anterior se situaba en 6.35 puntos y, con el método actual se ha alcanzado una media de 6.42. La diferencia es significativa pero, ¿es grande? O lo que es más importante, ¿es relevante? ¿Cómo para cambiar todo un sistema educativo? Parece que no.
En estos casos, el tamaño del efecto nos informa de la diferencia entre el valor propuesto (en la H0) y el valor obtenido. Y para evitar diferencias aparentes en fun‐ción de la escala de la variable medida, esa diferencia se divide por la desviación típi‐ca de los datos obtenidos:
0
1n
Xd
Sµ
−
−=
De esta forma, el tamaño del efecto viene expresado en unidades de desvia‐ción típica: un valor de 0.5 significa que la diferencia entre la media obtenida y la propuesta en la H0 representa 0.5 veces el tamaño de la desviación típica.
¿Cómo interpretar el tamaño del efecto? Cohen (1977) propone unos valores orientativos:
Pequeño: d = 0.2; Moderado: d = 0.5; Grande: d = 0.8.

3. Contraste de hipótesis, 18
Para obtener la potencia a partir del tamaño del efecto debemos calcular pri‐mero ∆:
d n∆ = Y luego utilizamos la tabla de potencias, donde a partir de α y ∆ podemos ob‐
tener la potencia del contraste. Y de igual forma podríamos calcular el n necesario para alcanzar una determinada potencia:
2
2nd∆
=
Así, dado d y el α del contraste, podemos buscar en la tabla de potencias cuál es la que desearíamos alcanzar y localizar el valor D correspondiente. Sustituyendo en la fórmula anterior obtendríamos el tamaño de la muestra necesario para conse‐guirlo.
Resumiendo todo esto en una tabla como la anterior: 5. Nivel crítico p asociada al temp = 1.2558 • Contr. Bilateral: empp P t t2 ( )= >
• Contr. Unil. Der.: empp P t t( )= >
• Contr. Unil. Izq.: empp P t t( )= <
p P t( 1.2558) 1 0.8944 0.1056= > = − =
Lo que indica que hay un 10.56% de prob. de obtener resultados iguales o mayores que los nuestros. Muy superior al 5 % establecido como para rechazar H0.
6. Intervalo de confianza IC al nivel de confianza de 0.95
• IC = i n n
s n n
l X t S n
l X t S n1, / 2 1
1, / 2 1
/
/α
α
− −
− −
⎧ = −⎪⎨
= +⎪⎩
( )( )( )( )
i
s
l
l
10.44 1.96 2.41/ 48 9.76
10.44 1.96 2.41/ 48 11.12
⎧ = − − ⋅ =⎪⎨
= + − ⋅ =⎪⎩
P(9.76 11.12) 0.95µ< < =
7. Tamaño del efecto
• 0
1n
Xd
Sµ
−
−= d 10.44 10 0.18
2.41−
= =
(valor pequeño, según Cohen, 1977) 8. Potencia
• d n∆ = • Mirar en tabla L, para α y ∆ Cálculo de n para una potencia dada
•
2
2nd∆
=
0.18 48 1.25∆ = = 1 0.35β− =
Para una potencia de 0.75, ∆ = 2.35
n2
22.35 5.52 170.45 1710.18 0.032
= = = ≈
Apéndice: Solución mediante el SPSS
Si utilizáramos el SPSS, lo primero sería introducir los datos (o si ya están in‐troducidos, cargarlos abriendo el fichero correspondiente). El aspecto sería el si‐guiente:

3. Contraste de hipótesis, 19
Realizamos el contraste el contraste mediante el menú Analizar:
Especificamos la variable a analizar (la única presente) y el valor de compara‐ción (el definido en la H0) para realizar el contraste. Obsérvese que en ningún mo‐mento se indica el nivel de confianza o α, el nivel de riesgo o también llamado nivel de significación del contraste.

3. Contraste de hipótesis, 20
Damos a aceptar y obtenemos los siguientes resultados:
Prueba T Estadísticos para una muestra
48 10.44 2.414 .348AciertosN Media
Desviacióntíp.
Error típ. dela media
Prueba para una muestra
1.256 47 .215 .438 -.26 1.14Aciertost gl Sig. (bilateral)
Diferenciade medias Inferior Superior
95% Intervalo deconfianza para la
diferencia
Valor de prueba = 10
Inicialmente, el procedimiento ofrece unos descriptivos básicos en el primer recuadro, y los resultados del contraste en el segundo. En este último, si atendemos al recuadro “Sig. (bilateral)” vemos cómo SPSS nos ofrece el nivel crítico, p, de forma bilateral por defecto. Como nuestro contraste es unilateral, deberemos dividirlo por dos (p = 0.1075) para conocer nuestro verdadero nivel crítico (también llamado proba‐bilidad asociada al estadístico de contraste, o significación del estadístico de contraste).
Como se observa, la salida del SPSS no proporciona información sobre el ta‐maño del efecto ni la potencia, pero podemos calcularlo tal como hemos visto.
En cuanto a la interpretación de estos resultados, es idéntica a la que hicimos: Este resultado nos llevaría a mantener la H0 a un nivel α (también llamado nivel de riesgo o nivel de significación) de 0.05, ya que p es superior (0.1075; la significación bilateral, 0.215, dividida por 2).
En términos estadísticos, el nivel crítico, p, obtenido nos indica que la probabi‐lidad de obtener unos resultados como los nuestros, supuesta cierta la H0, es de 0.1075, es decir, algo más de un 10% de las veces (si repitiéramos indefinidamente este experimento sobre una H0 cierta). Por tanto, es razonable considerar este resul‐tado demasiado probable como para llevarnos a pensar que la H0 es falsa.


















