Tema 8: Introducci n al aprendizaje autom tico · Capaz de representar cualquier subconjunto de...
78
Tema 8: Introducci´ on al aprendizaje autom´ atico M. A. Guti´ errez Naranjo F. J. Mart´ ın Mateos J. L. Ruiz Reina Dpto. Ciencias de la Computaci´on e Inteligencia Artificial Universidad de Sevilla Inteligencia Artificial 2013–2014 Tema 8: Introducci´on al aprendizaje autom´ atico
Transcript of Tema 8: Introducci n al aprendizaje autom tico · Capaz de representar cualquier subconjunto de...

Tema 8: Introduccion al aprendizaje automatico
M. A. Gutierrez NaranjoF. J. Martın MateosJ. L. Ruiz Reina
Dpto. Ciencias de la Computacion e Inteligencia ArtificialUniversidad de Sevilla
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Contenido
Introduccion
Aprendizaje de arboles de decision
Aprendizaje de reglas
El teorema de Bayes
Clasificacion mediante modelos probabilısticos: naive Bayes
Aprendizaje basado en instancias: kNN
Clustering: k-medias
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
Seccion 1
Seccion 1
Introduccion
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Aprendizaje
Definiciones de aprendizaje:
Cualquier cambio en un sistema que le permita realizar lamisma tarea de manera mas eficiente la proxima vez (H.Simon)Modificar la representacion del mundo que se esta percibiendo(R. Michalski)Realizar cambios utiles en nuestras mentes (M. Minsky)
Aprendizaje automatico: construir programas que mejoranautomaticamente con la experiencia
Ejemplos de tareas:
Construccion de bases de conocimiento a partir de laexperienciaClasificacion y diagnosticoMinerıa de datos, descubrir estructuras desconocidas engrandes grupos de datosResolucion de problemas, planificacion y accion
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Tipos de aprendizaje y paradigmas
Tipos de aprendizaje
SupervisadoNo supervisadoCon refuerzo
Paradigmas
Aprendizaje por memorizacionClasificacion (Clustering)Aprendizaje inductivoAprendizaje por analogıaDescubrimientoAlgoritmos geneticos, redes neuronales
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Ejemplo de aprendizaje
Conjunto de entrenamiento
Ejemplos: dıas en los que es recomendable (o no) jugar al tenisRepresentacion como una lista de pares atributo–valor
Ej. Cielo Temperatura Humedad Viento JugarTenisD1 Soleado Alta Alta Debil -D2 Soleado Alta Alta Fuerte -D3 Nublado Alta Alta Debil +D4 Lluvia Suave Alta Debil +. . .
Objetivo: Dado el conjunto de entrenamiento, aprender elconcepto “Dıas en los que se juega al tenis”
Se trata de aprendizaje supervisado
Problema: ¿Como expresar lo aprendido?
En este tema, veremos algoritmos para aprender arboles dedecision, reglas, modelos probabilısticos,...
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Seccion 2
Seccion 2
Aprendizaje de arboles de decision
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
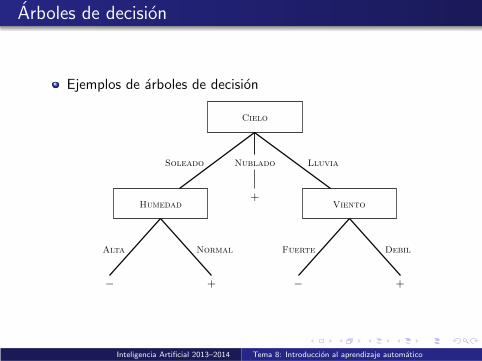
Arboles de decision
Ejemplos de arboles de decision
Cielo
LluviaSoleado Nublado
+Viento
Debil
+
Humedad
Alta
+− −
Normal Fuerte
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
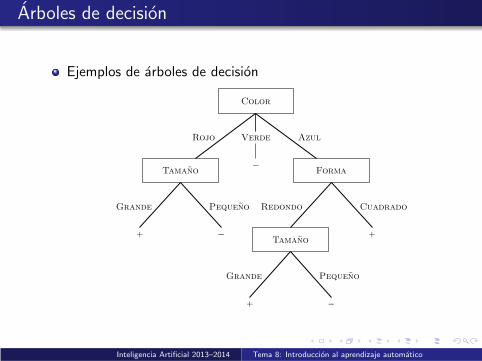
Arboles de decision
Ejemplos de arboles de decision
Color
Rojo Verde Azul
Forma
Redondo Cuadrado
Grande
Tamano
Pequeno
Grande
−
Tamano
Pequeno
+ −
+ −
+
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Arboles de decision
Arboles de decision
Nodos interiores: atributosArcos: posibles valores del nodo origenHojas: valor de clasificacion (usualmente + o −, aunque podrıaser cualquier conjunto de valores, no necesariamente binario)Representacion de una funcion objetivo
Disyuncion de reglas proposicionales:
(Cielo=Soleado ∧ Humedad=Alta → JugarTenis= −)∨ (Cielo=Soleado ∧ Humedad=Normal → JugarTenis= +)∨ (Cielo=Nublado → JugarTenis= +)∨ (Cielo=Lluvioso ∧ Viento=Fuerte → JugarTenis= −)∨ (Cielo=Lluvioso ∧ Viento=Debil → JugarTenis= +)
Capaz de representar cualquier subconjunto de instancias
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Aprendizaje de arboles de decision
Objetivo: aprender un arbol de decision consistente con losejemplos, para posteriormente clasificar ejemplos nuevos
Ejemplo de conjunto de entrenamiento:
Ej. Cielo Temperatura Humedad Viento JugarTenisD1 Soleado Alta Alta Debil -D2 Soleado Alta Alta Fuerte -D3 Nublado Alta Alta Debil +D4 Lluvia Suave Alta Debil +. . .
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
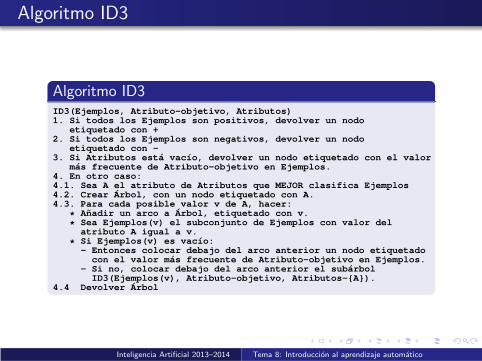
Algoritmo ID3
Algoritmo ID3ID3(Ejemplos, Atributo-objetivo, Atributos)1. Si todos los Ejemplos son positivos, devolver un nodo
etiquetado con +2. Si todos los Ejemplos son negativos, devolver un nodo
etiquetado con -3. Si Atributos esta vacıo, devolver un nodo etiquetado con el valor
mas frecuente de Atributo-objetivo en Ejemplos.4. En otro caso:4.1. Sea A el atributo de Atributos que MEJOR clasifica Ejemplos4.2. Crear Arbol, con un nodo etiquetado con A.4.3. Para cada posible valor v de A, hacer:
* Anadir un arco a Arbol, etiquetado con v.
* Sea Ejemplos(v) el subconjunto de Ejemplos con valor delatributo A igual a v.
* Si Ejemplos(v) es vacıo:- Entonces colocar debajo del arco anterior un nodo etiquetado
con el valor mas frecuente de Atributo-objetivo en Ejemplos.- Si no, colocar debajo del arco anterior el subarbol
ID3(Ejemplos(v), Atributo-objetivo, Atributos-{A}).4.4 Devolver Arbol
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

¿Como saber que atributo clasifica mejor?
Entropıa de un conjunto de ejemplos D (resp. de unaclasificacion):
Ent(D) = − |P||D| · log2
|P||D| −
|N||D| · log2
|N||D|
donde P y N son, respectivamente, los subconjuntos deejemplos positivos y negativos de D
Notacion: Ent([p+, n−]), donde p = |P | y n = |N|
Intuicion:
Mide la ausencia de “homegeneidad” de la clasificacionTeorıa de la Informacion: cantidad media de informacion (enbits) necesaria para codificar la clasificacion de un ejemplo
Ejemplos:
Ent([9+, 5−]) = − 914 · log2
914 − 5
14 · log2514 = 0,94
Ent([k+, k−]) = 1 (ausencia total de homogeneidad)Ent([p+, 0−]) = Ent([0+, n−]) = 0 (homogeneidad total)
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Ganancia de informacion
Preferimos nodos con menos entropıa (arboles pequenos)
Entropıa esperada despues de usar un atributo A en el arbol:∑
v∈Valores(A)|Dv ||D| · Ent(Dv )
donde Dv es el subconjunto de ejemplos de D con valor delatributo A igual a v
Ganancia de informacion esperada despues de usar unatributo A:Ganancia(D,A) = Ent(D)−
∑
v∈Valores(A)|Dv ||D| · Ent(Dv )
En el algoritmo ID3, en cada nodo usamos el atributo conmayor ganancia de informacion (considerando los ejemploscorrespondientes al nodo)
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
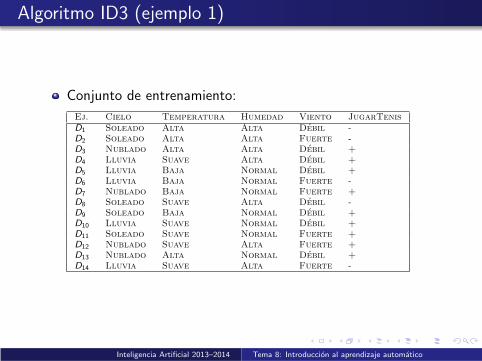
Algoritmo ID3 (ejemplo 1)
Conjunto de entrenamiento:
Ej. Cielo Temperatura Humedad Viento JugarTenisD1 Soleado Alta Alta Debil -D2 Soleado Alta Alta Fuerte -D3 Nublado Alta Alta Debil +D4 Lluvia Suave Alta Debil +D5 Lluvia Baja Normal Debil +D6 Lluvia Baja Normal Fuerte -D7 Nublado Baja Normal Fuerte +D8 Soleado Suave Alta Debil -D9 Soleado Baja Normal Debil +D10 Lluvia Suave Normal Debil +D11 Soleado Suave Normal Fuerte +D12 Nublado Suave Alta Fuerte +D13 Nublado Alta Normal Debil +D14 Lluvia Suave Alta Fuerte -
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
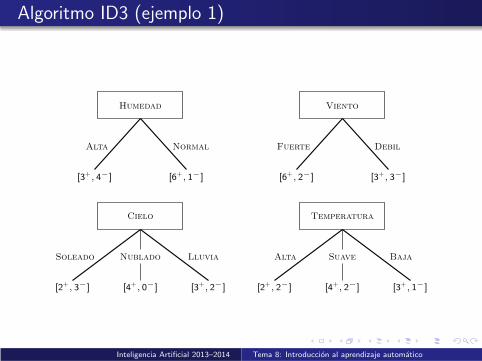
Algoritmo ID3 (ejemplo 1)
Normal
Humedad
Alta
[3+, 4−] [6+, 1−]
Viento
Fuerte Debil
[6+, 2−] [3+, 3−]
TemperaturaCielo
[2+, 2−] [4+, 2−] [3+, 1−]
BajaSuaveAltaLluvia
[2+, 3−] [3+, 2−][4+, 0−]
Soleado Nublado
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Algoritmo ID3 (ejemplo 1)
Entropıa inicial: Ent([9+, 5−]) = 0,94
Seleccion del atributo para el nodo raız:
Ganancia(D,Humedad) =0,94− 7
14 · Ent([3+, 4−])− 714 · Ent([6+, 1−]) = 0,151
Ganancia(D,Viento) =0,94− 8
14 · Ent([6+, 2−])− 614 · Ent([3+, 3−]) = 0,048
Ganancia(D,Cielo) =0,94− 5
14 · Ent([2+, 3−])− 414 · Ent([4+, 0−])
− 514 · Ent([3+, 2−]) = 0,246 (mejor atributo)
Ganancia(D,Temperatura) =0,94− 4
14 · Ent([2+, 2−])− 614 · Ent([4+, 2−])
− 414 · Ent([3+, 1−]) = 0,02
El atributo seleccionado es Cielo
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Algoritmo ID3 (ejemplo 1)
Arbol parcialmente construido:
?
Cielo
Soleado Nublado Lluvia
+ ?
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Algoritmo ID3 (ejemplo 1)
Seleccion del atributo para el nodo Cielo=Soleado
DSoleado = {D1,D2,D8,D9,D11} con entropıaEnt([2+, 3−]) = 0,971
Ganancia(DSoleado,Humedad) =0,971− 3
5 · 0− 25 · 0 = 0,971 (mejor atributo)
Ganancia(DSoleado,Temperatura) =0,971− 2
5 · 0− 25 · 1− 1
5 · 0 = 0,570Ganancia(DSoleado,Viento) =0,971− 2
5 · 1− 35 · 0,918 = 0,019
El atributo seleccionado es Humedad
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Algoritmo ID3 (ejemplo 1)
Seleccion del atributo para el nodo Cielo=Lluvia:
DLluvia = {D4,D5,D6,D10,D14} con entropıaEnt([3+, 2−]) = 0,971
Ganancia(DLluvia,Humedad) =0,971− 2
5 · 1− 35 · 0,918 = 0,820
Ganancia(DLluvia,Temperatura) =0,971− 3
5 · 0,918− 25 · 1 = 0,820
Ganancia(DLluvia,Viento) =0,971− 3
5 · 0− 25 · 0 = 0,971 (mejor atributo)
El atributo seleccionado es Viento
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
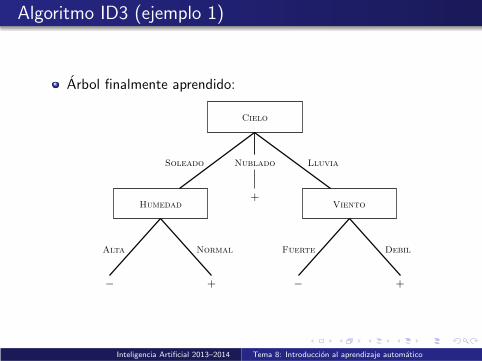
Algoritmo ID3 (ejemplo 1)
Arbol finalmente aprendido:
Cielo
LluviaSoleado Nublado
+Viento
Debil
+
Humedad
Alta
+− −
Normal Fuerte
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Algoritmo ID3 (ejemplo 2)
Conjunto de entrenamiento:
Ej. Color Forma Tamano ClaseO1 Rojo Cuadrado Grande +O2 Azul Cuadrado Grande +O3 Rojo Redondo Pequeno -O4 Verde Cuadrado Pequeno -O5 Rojo Redondo Grande +O6 Verde Cuadrado Grande -
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Algoritmo ID3 (ejemplo 2)
Entropıa inicial en el ejemplo de los objetos, Ent([3+, 3−]) = 1
Seleccion del atributo para el nodo raız:
Ganancia(D,Color) =1− 3
6 ·Ent([2+, 1−])− 1
6 ·Ent([1+, 0−])− 2
6 ·Ent([0+, 2−]) = 0,543
Ganancia(D,Forma) =1− 4
6 · Ent([2+, 2−])− 26 · Ent([1+, 1−]) = 0
Ganancia(D,Tamano) =1− 4
6 · Ent([3+, 1−])− 26 · Ent([0+, 2−]) = 0,459
El atributo seleccionado es Color
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Algoritmo ID3 (ejemplo 2)
Arbol parcialmente construido:
?
Color
Rojo Verde Azul
− +
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Algoritmo ID3 (ejemplo 2)
Seleccion del atributo para el nodo Color=Rojo:
DRojo = {O1,O3,O5} con entropıa Ent([2+, 1−]) = 0,914
Ganancia(DRojo,Forma) =0,914− 1
3 · Ent([1+, 0−])− 23 · Ent([1+, 1−]) = 0,247
Ganancia(DRojo,Tamano) =0,914− 2
3 · Ent([2+, 0−])− 13 · Ent([0+, 1−]) = 0,914
El atributo seleccionado es Tamano
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
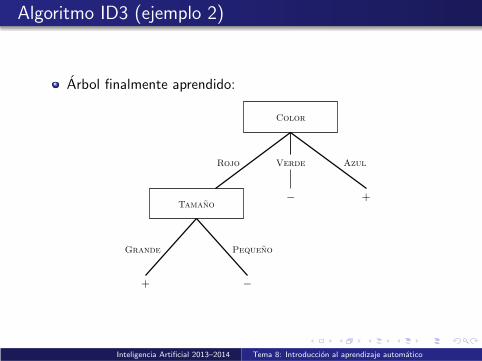
Algoritmo ID3 (ejemplo 2)
Arbol finalmente aprendido:
Grande
Color
Rojo Verde Azul
−Tamano
Pequeno
+
+ −
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Busqueda y sesgo inductivo
Busqueda local en un espacio de hipotesis
Espacio de todos los arboles de decisionUn unico arbol candidato en cada pasoSin retroceso (peligro de optimos locales), busqueda enescaladaDecisiones tomadas a partir de conjuntos de ejemplos
Sesgo inductivo
Se prefieren arboles mas cortos sobre los mas largosSesgo preferencial, implıcito en la busquedaPrincipio de la navaja de Occam
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Algunos cuestiones practicas a resolver en aprendizajeautomatico
Validar la hipotesis aprendida
¿Podemos cuantificar la bondad de lo aprendido respecto de laexplicacion real?
Sobreajuste
¿Se ajusta demasiado lo aprendido al conjunto deentrenamiento?
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Medida del rendimiento del aprendizaje
Conjuntos de entrenamiento y prueba (test)
Aprender con el conjunto de entrenamientoMedir el rendimiento en el conjunto de prueba:
proporcion de ejemplos bien clasificados en el conjunto deprueba
Repeticion de este proceso
Curva de aprendizajeEstratificacion: cada clase correctamente representada en elentrenamiento y en la prueba
Si no tenemos suficientes ejemplos como para apartar unconjunto de prueba: validacion cruzada
Dividir en k partes, y hace k aprendizajes, cada uno de ellostomando como prueba una de las partes y entrenamiento elresto. Finalmente hacer la media de los rendimientos.En la practica: validacion cruzada, con k = 10 y estratificacion
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Sobreajuste y ruido
Una hipotesis h ∈ H sobreajusta los ejemplos deentrenamiento si existe h′ ∈ H que se ajusta peor que h a losejemplos pero actua mejor sobre la distribucion completa deinstancias.
Ruido: ejemplos incorrectamente clasificados. Causasobreajuste
Ejemplo: supongamos que por error, se incluye el ejemplo<Azul,Redondo,Pequeno> como ejemplo negativo
El arbol aprendido en este caso serıa (sobrejustado a losdatos):
Color
Rojo Verde Azul
Grande
−Tamano
+ −
Pequeno
+
Color
Rojo Verde Azul
Forma
CuadradoGrande
−Tamano
+ − − +
RedondoPequeno
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Sobreajuste y ruido
Otras causas de sobreajuste:
Atributos que en los ejemplos presentan una aparenteregularidad pero que no son relevantes en realidadConjuntos de entrenamiento pequenos
Maneras de evitar el sobreajuste en arboles de decision:
Parar el desarrollo del arbol antes de que se ajusteperfectamente a todos los datosPodar el arbol a posteriori
Poda a posteriori, dos aproximaciones:
Transformacion a reglas, podado de las condiciones de lasreglasRealizar podas directamente en el arbolLas podas se producen siempre que reduzcan el error sobre unconjunto de prueba
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
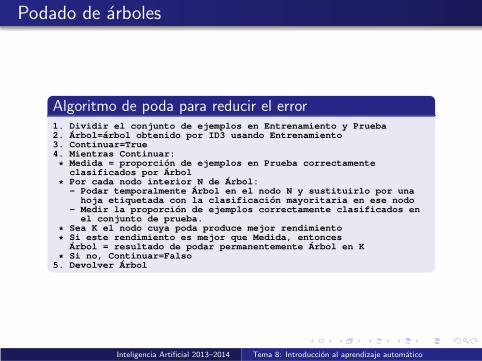
Podado de arboles
Algoritmo de poda para reducir el error1. Dividir el conjunto de ejemplos en Entrenamiento y Prueba2. Arbol=arbol obtenido por ID3 usando Entrenamiento3. Continuar=True4. Mientras Continuar:
* Medida = proporcion de ejemplos en Prueba correctamenteclasificados por Arbol
* Por cada nodo interior N de Arbol:- Podar temporalmente Arbol en el nodo N y sustituirlo por una
hoja etiquetada con la clasificacion mayoritaria en ese nodo- Medir la proporcion de ejemplos correctamente clasificados en
el conjunto de prueba.
* Sea K el nodo cuya poda produce mejor rendimiento
* Si este rendimiento es mejor que Medida, entoncesArbol = resultado de podar permanentemente Arbol en K
* Si no, Continuar=Falso5. Devolver Arbol
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Otras cuestiones practicas del algoritmo ID3
Extensiones del algoritmo:
Atributos con valores contınuosOtras medidas para seleccionar atributosOtras estimaciones de errorAtributos sin valoresAtributos con coste
Algoritmos C4.5 y C5.0 (Quinlan)
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
Seccion 3
Seccion 3
Aprendizaje de reglas
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Cambiando la salida: reglas proposicionales
Reglas de clasificacion:
R1: Si Cielo=Soleado ∧ Humedad=Alta
Entonces JugarTenis= −R2: Si Astigmatismo=+ ∧ Lagrima=Normal
Entonces Lente=Rigida
Ventaja de usar el formalismo de reglas
ClaridadModularidadExpresividad: pueden representar cualquier conjunto deinstanciasMetodos generalizables a primer orden de manera naturalFormalismo usado en sistemas basados en el conocimiento
Reglas y arboles de decision
Facil traduccion de arbol a reglas, pero no a la inversa
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Aprendizaje de reglas
Objetivo: aprender un conjunto de reglas consistente con losejemplos
Una regla cubre un ejemplo si el ejemplo satisface lascondicionesLo cubre correctamente si ademas el valor del atributo en laconclusion de la regla coincide con el valor que el ejemplotoma en ese atributo
Una medida del ajuste de una regla R a un conjunto deejemplos D:
Frecuencia relativa: p/t (donde t = ejemplos cubiertos por Ren D, p = ejemplos correctamente cubiertos). Notacion:FR(R ,D)
Algoritmos de aprendizaje de reglas:
ID3 + traduccion a reglasCoberturaAlgoritmos geneticos
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
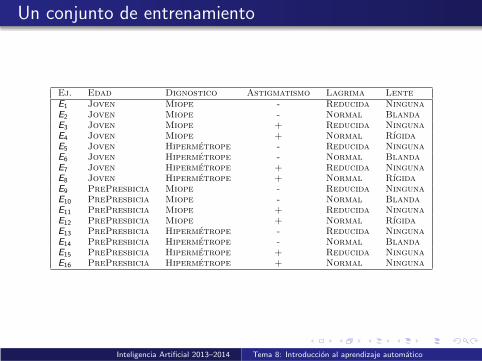
Un conjunto de entrenamiento
Ej. Edad Dignostico Astigmatismo Lagrima LenteE1 Joven Miope - Reducida NingunaE2 Joven Miope - Normal BlandaE3 Joven Miope + Reducida NingunaE4 Joven Miope + Normal RıgidaE5 Joven Hipermetrope - Reducida NingunaE6 Joven Hipermetrope - Normal BlandaE7 Joven Hipermetrope + Reducida NingunaE8 Joven Hipermetrope + Normal RıgidaE9 PrePresbicia Miope - Reducida NingunaE10 PrePresbicia Miope - Normal BlandaE11 PrePresbicia Miope + Reducida NingunaE12 PrePresbicia Miope + Normal RıgidaE13 PrePresbicia Hipermetrope - Reducida NingunaE14 PrePresbicia Hipermetrope - Normal BlandaE15 PrePresbicia Hipermetrope + Reducida NingunaE16 PrePresbicia Hipermetrope + Normal Ninguna
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
Un conjunto de entrenamiento
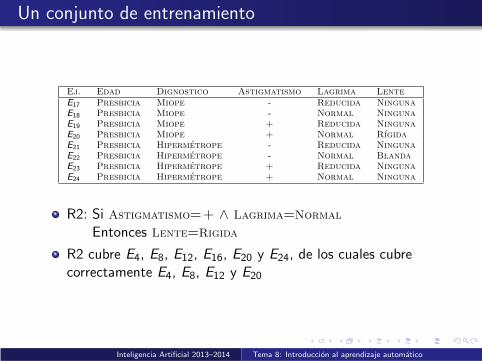
Ej. Edad Dignostico Astigmatismo Lagrima LenteE17 Presbicia Miope - Reducida NingunaE18 Presbicia Miope - Normal NingunaE19 Presbicia Miope + Reducida NingunaE20 Presbicia Miope + Normal RıgidaE21 Presbicia Hipermetrope - Reducida NingunaE22 Presbicia Hipermetrope - Normal BlandaE23 Presbicia Hipermetrope + Reducida NingunaE24 Presbicia Hipermetrope + Normal Ninguna
R2: Si Astigmatismo=+ ∧ Lagrima=Normal
Entonces Lente=Rigida
R2 cubre E4, E8, E12, E16, E20 y E24, de los cuales cubrecorrectamente E4, E8, E12 y E20
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Aprendiendo reglas que cubren ejemplos
Aprender una regla para clasificar Lente=Rigida
Si ?Entonces Lente=Rigida
Alternativas para ?, y frecuencia relativa de la regla resultante
Edad=Joven 2/8Edad=PrePresbicia 1/8Edad=Presbicia 1/8Diagnostico=Miopıa 3/12Diagnostico=Hipermetropıa 1/12Astigmatismo=− 0/12Astigmatismo=+ 4/12 *Lagrima=Reducida 0/12Lagrima=Normal 4/12 *
Regla parcialmente aprendida
Si Astigmatismo=+Entonces Lente=Rigida
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Aprendiendo reglas que cubren ejemplos
Continuamos para excluir ejemplos cubiertos incorrectamente
Si Astigmatismo=+ ∧ ?Entonces Lente=Rigida
Alternativas para ?, y frecuencia relativa de la regla resultante
Edad=Joven 2/4Edad=PrePresbicia 1/4Edad=Presbicia 1/4Diagnostico=Miopıa 3/6Diagnostico=Hipermetropıa 1/6Lagrima=Reducida 0/6Lagrima=Normal 4/6 *
Regla parcialmente aprendida
Si Astigmatismo=+ ∧ Lagrima=Normal
Entonces Lente=Rigida
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Aprendiendo reglas que cubren ejemplos
Continuamos para excluir ejemplos cubiertos incorrectamente
Si Astigmatismo=+ ∧ Lagrima=Normal ∧ ?Entonces Lente=Rigida
Alternativas para ?, y frecuencia relativa de la regla resultante
Edad=Joven 2/2 *Edad=PrePresbicia 1/2Edad=Presbicia 1/2Diagnostico=Miopıa 3/3 *Diagnostico=Hipermetropıa 1/3
Regla finalmente aprendida (no cubre incorrectamente ningunejemplo)
Si Astigmatismo=+ ∧ Lagrima=Normal ∧Diagnostico=Miopia
Entonces Lente=Rigida
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Aprendiendo reglas que cubren ejemplos
Queda un ejemplo con Lente=Rigida no cubierto por R2
Comenzamos otra vez con “Si ? Entonces Lente=Rigida”,pero ahora con D ′ = D \ {E4,E12,E20}
Reglas finalmente aprendidas para Lente=Rigida:
R1: Si Astigmatismo= + ∧ Lagrima=Normal ∧Diagnostico=Miopia
Entonces Lente=Rigida
R2: Si Edad=Joven ∧ Astigmatismo= + ∧Lagrima=Normal
Entonces Lente=Rigida
Cubren correctamente los 4 ejemplos de Lente=Rigida (y sesolapan)
Ahora se podrıa continuar para aprender reglas queclasifiquen:
Lente=Blanda
Lente=Ninguna
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Algoritmo de aprendizaje de reglas por cobertura
Algoritmo de aprendizaje por coberturaAprendizaje-por-Cobertura(D,Atributo,v)1. Hacer Reglas-aprendidas igual a vacıo2. Hacer E igual a D3. Mientras E contenga ejemplos cuyo valor de Atributo es v, hacer:3.1 Crear una regla R sin condiciones y conclusion Atributo=v3.2 Mientras que haya en E ejemplos cubiertos por R incorrectamente
o no queden atributos que usar, hacer:3.2.1 Elegir la MEJOR condicion A=w para anadir a R, donde A es
un atributo que no aparece en R y w es un valor de losposibles que puede tomar A
3.2.2 Actualizar R anadiendo la condicion A=w a R3.3 Incluir R en Reglas-aprendidas3.4 Actualizar E quitando los ejemplos cubiertos por R4. Devolver Reglas-Aprendidas
Algoritmo para aprender un conjunto de reglas (a partir de D)
Reglas para predecir situaciones en las que un Atributo dadotoma un valor v
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Control en el algoritmo de cobertura
Bucle externo:
Anade reglas (la hipotesis se generaliza)Cada regla anadida cubre algunos ejemplos correctamenteElimina en cada vuelta los ejemplos cubiertos por la reglaanadidaY se anaden reglas mientras queden ejemplos sin cubrir
Bucle interno:
Anade condiciones a la regla (la regla se especializa)Cada nueva condicion excluye ejemplos cubiertosincorrectamenteY esto se hace mientras haya ejemplos incorrectamentecubiertos
Cobertura frente a ID3
Aprende una regla cada vez, ID3 lo hace simultaneamenteID3: elecciones de atributosCobertura: elcciones de parejas atributo-valor
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Algoritmo de cobertura (propiedades)
Diferentes criterios para elegir la mejor condicion en cadavuelta del bucle interno:
Se anade la condicion que produzca la regla con mayorfrecuencia relativa (como en el ejemplo)Se anade la que produzca mayor ganancia de informacion:
p · (log2p′
t′− log2
pt)
donde p′/t ′ es la frecuencia relativa despues de anadir lacondicion y p/t es la frecuencia relativa antes de anadir lacondicion
Las reglas aprendidas por el algoritmo de cobertura se ajustanperfectamente al conjunto de entrenamiento (peligro desobreajuste)
Podado de las reglas a posterioriEliminar progresivamente condiciones hasta que no seproduzca mejoraCriterio probabilıstico para decidir la mejora
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
Seccion 3
Seccion 3
El teorema de Bayes
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Formulacion de la regla de Bayes
De P(a ∧ b) = P(a|b)P(b) = P(b|a)P(a) podemos deducir lasiguiente formula, conocida como regla de Bayes
P(b|a) =P(a|b)P(b)
P(a)
Regla de Bayes para variables aleatorias:
P(Y |X ) =P(X |Y )P(Y )
P(X )
recuerdese que esta notacion representa un conjunto deecuaciones, una para cada valor especıfico de las variables
Version con normalizacion:
P(Y |X ) = α · P(X |Y )P(Y )
Generalizacion, en presencia de un conjunto e deobservaciones:
P(Y |X , e) = α · P(X |Y , e)P(Y |e)
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Ejemplo de uso de la regla de Bayes
Sabemos que la probabilidad de que un paciente de meningitistenga el cuello hinchado es 0.5 (relacion causal)
Tambien sabemos la probabilidad (incondicional) de tenermeningitis ( 1
50000) y de tener el cuello hinchado (0.05)
Estas probabilidades provienen del conocimiento y laexperiencia
La regla de Bayes nos permite diagnosticar la probabilidad detener meningitis una vez que se ha observado que el pacientetiene el cuello hinchado
P(m|h) =P(h|m)P(m)
P(h)=
0,5× 150000
0,05= 0,0002
Alternativamente, podrıamos haberlo hecho normalizandoP(M|h) = α〈P(h|m)P(m);P(h|¬m)P(¬m)〉Respecto de lo anterior, esto evita P(h) pero obliga a saberP(h|¬m)
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Relaciones causa-efecto y la regla de Bayes
Modelando probabilısticamente una relacion entre una Causay un Efecto:
La regla de Bayes nos da una manera de obtener laprobabilidad de Causa, dado que se ha observado Efecto:
P(Causa|Efecto) = α · P(Efecto|Causa)P(Efecto)
Nos permite diagnosticar en funcion de nuestro conocimientode relaciones causales y de probabilidades a priori
¿Por que calcular el diagnostico en funcion del conocimientocausal y no al reves?
Porque es mas facil y robusto disponer de probabilidadescausales que de probabilidades de diagnostico (lo que se sueleconocer es P(Efecto|Causa) y el valor que ha tomado Efecto).
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Regla de Bayes: ejemplo
Consideremos la siguiente informacion sobre el cancer demama
Un 1% de las mujeres de mas de 40 anos que se hacen unchequeo tienen cancer de mamaUn 80% de las que tienen cancer de mama se detectan conuna mamografıaEl 9.6% de las que no tienen cancer de mama, al realizarseuna mamografıa se le diagnostica cancer erroneamente
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Regla de Bayes: ejemplo
Pregunta 1: ¿cual es la probabilidad de tener cancer si lamamografıa ası lo diagnostica?
Variables aleatorias: C (tener cancer de mama) y M(mamografıa positiva)P(C |m) = αP(C ,m) = αP(m|C )P(C ) =α〈P(m|c)P(c);P(m|¬c)P(¬c)〉 = α〈0,8 · 0,01; 0,096 · 0,99〉 =α〈0,008; 0,09504〉 = 〈0,0776; 0,9223〉Luego el 7.8% de las mujeres diagnosticadas positivamentecon mamografıa tendran realmente cancer de mama
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Reglas de Bayes: ejemplo
Pregunta 2: ¿cual es la probabilidad de tener cancer si tras dosmamografıas consecutivas en ambas se diagnostica cancer?
Variables aleatorias: M1 (primera mamografıa positiva) y M2
(segunda mamografıa positiva)Obviamente, no podemos asumir independencia incondicionalentre M1 y M2
Pero es plausible asumir independencia condicional de M1 yM2 dada CPor tanto, P(C |m1,m2) = αP(C ,m1,m2) =αP(m1,m2|C )P(C ) = αP(m1|C )P(m2|C )P(C ) =α〈P(m1|c)P(m2|c)P(c);P(m2|¬c)P(m2|¬c)P(¬c)〉 =α〈0,8 · 0,8 · 0,01; 0,096 · 0,096 · 0,99〉 = 〈0,412; 0,588〉Luego aproximadamente el 41% de las mujeres doblementediagnosticadas positivamente con mamografıa tendranrealmente cancer de mama
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Seccion 6
Seccion 6
Clasificacion mediante modelos probabilısticos: naive Bayes
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Clasificadores Naive Bayes
Supongamos un conjunto de atributos A1, . . . ,An cuyosvalores determinan un valor en un conjunto finito V deposibles “clases” o “categorıas”
Tenemos un conjunto de entrenamiento D con una serie detuplas de valores concretos para los atributos, junto con suclasificacion
Queremos aprender un clasificador tal que clasifique nuevasinstancias 〈a1, . . . , an〉
Es decir, el mismo problema en el tema de aprendizaje dearboles de decision y de reglas (pero ahora lo abordaremosdesde una perspectiva probabilıstica).
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Clasificadores Naive Bayes
Podemos disenar un modelo probabilıstico para un problemade clasificacion de este tipo, tomando los atributos y laclasificacion como variables aleatorias
El valor de clasificacion asignado a una nueva instancia〈a1, . . . , an〉, notado vMAP vendra dado por
argmaxvj∈V
P(vj |a1, . . . , an)
Aplicando el teorema de Bayes podemos escribir
vMAP = argmaxvj∈V
P(a1, . . . , an|vj)P(vj)
Y ahora, simplemente estimar las probabilidades de la formulaanterior a partir del conjunto de entrenamiento
Problema: necesitarıamos una gran cantidad de datos paraestimar adecuadamente las probabilidades P(a1, . . . , an|vj)
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
Clasificadores Naive Bayes
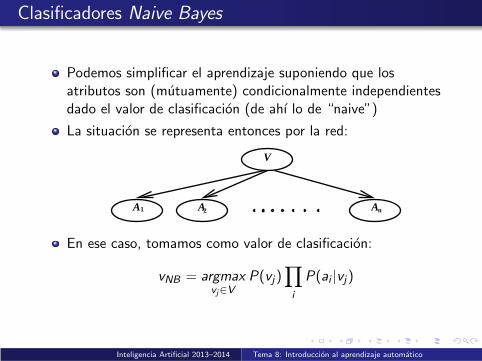
Podemos simplificar el aprendizaje suponiendo que losatributos son (mutuamente) condicionalmente independientesdado el valor de clasificacion (de ahı lo de “naive”)
La situacion se representa entonces por la red:
V
A A A1 n2
En ese caso, tomamos como valor de clasificacion:
vNB = argmaxvj∈V
P(vj)∏
i
P(ai |vj)
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Estimacion de probabilidades Naive Bayes
Para el proceso de aprendizaje, solo tenemos que estimar lasprobabilidades P(vj) (probabilidades a priori) y P(ai |vj)(probabilidades condicionadas). Son muchas menos que en elcaso general.Mediante calculo de sus frecuencias en el conjunto deentrenamiento, obtenemos estimaciones de maximaverosimilitud de esas probabilidades:
P(vj) =n(V = vj)
NP(ai |vj) =
n(Ai = ai ,V = vj)
n(V = vj)
donde N es el numero total de ejemplos, n(V = vj) es elnumero de ejemplos clasificados como vj y n(Ai = ai ,V = vj)es el numero de ejemplos clasificados como vj cuyo valor en elatributo Ai es ai .A pesar de su aparente sencillez, los clasificadores Naive Bayestienen un rendimiento comparable al de los arboles dedecision, las reglas o las redes neuronales
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
Clasificador Naive Bayes: un ejemplo
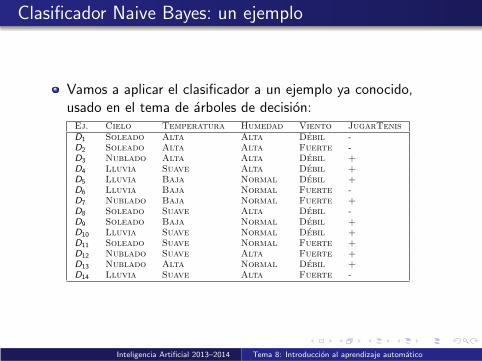
Vamos a aplicar el clasificador a un ejemplo ya conocido,usado en el tema de arboles de decision:Ej. Cielo Temperatura Humedad Viento JugarTenisD1 Soleado Alta Alta Debil -D2 Soleado Alta Alta Fuerte -D3 Nublado Alta Alta Debil +D4 Lluvia Suave Alta Debil +D5 Lluvia Baja Normal Debil +D6 Lluvia Baja Normal Fuerte -D7 Nublado Baja Normal Fuerte +D8 Soleado Suave Alta Debil -D9 Soleado Baja Normal Debil +D10 Lluvia Suave Normal Debil +D11 Soleado Suave Normal Fuerte +D12 Nublado Suave Alta Fuerte +D13 Nublado Alta Normal Debil +D14 Lluvia Suave Alta Fuerte -
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Clasificador Naive Bayes: un ejemplo
Supongamos que queremos predecir si un dıa soleado, detemperatura suave, humedad alta y viento fuerte es buenopara jugar al tenisSegun el clasificador Naive Bayes:
vNB = argmaxvj∈{+,−}
P(vj)P(soleado|vj )P(suave|vj )P(alta|vj )P(fuerte|vj )
Ası que necesitamos estimar todas estas probabilidades, lo quehacemos simplemente calculando frecuencias en la tablaanterior:
p(+) = 9/14, p(−) = 5/14, p(soleado|+) = 2/9,p(soleado|−) = 3/5, p(suave|+) = 4/9, p(suave|−) = 2/5,p(alta|+) = 2/9, p(alta|−) = 4/5, p(fuerte|+) = 3/9 yp(fuerte|−) = 3/5
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Clasificador Naive Bayes: un ejemplo
Por tanto, las dos probabilidades a posteriori son:
P(+)P(soleado|+)P(suave|+)P(alta|+)P(fuerte|+) = 0,0053P(−)P(soleado|−)P(suave|−)P(alta|−)P(fuerte|−) = 0,0206
Ası que el clasificador devuelve la clasificacion con mayorprobabilidad a posteriori, en este caso la respuesta es − (no esun dıa bueno para jugar al tenis)
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Detalles tecnicos sobre las estimaciones: log-probabilidades
Tal y como estamos calculando las estimaciones, existe elriesgo de que algunas de ellas sean excesivamente bajas
Si realmente alguna de las probabilidades es baja y tenemospocos ejemplos en el conjunto de entrenamiento, lo masseguro es que la estimacion de esa probabilidad sea 0
Esto plantea dos problemas:
La inexactitud de la propia estimacionAfecta enormemente a la clasificacion que se calcule, ya que semultiplican las probabilidades estimadas y por tanto si una deellas es 0, anula a las demas
Una primera mejora tecnica, intentado evitar productos muybajos: usar logaritmos de las probabilidades.
Los productos se transforman en sumas
vNB = argmaxvj∈V
[log(P(vj )) +∑
i
log(P(ai |vj))]
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Detalles tecnicos sobre las estimaciones: suavizado
Problema en la estimaciones:Probabilidades nulas o muy bajas, por ausencia en el conjuntode entrenamiento de algunos valores de atributos en algunascategorıasSobreajuste
Idea: suponer que tenemos m ejemplos adicionales, cuyosvalores se distribuyen teoricamente a priori de alguna manera.
Estimacion suavizada de una probabilidad, a partir deobservaciones:
n′ +m · p
n +mn′ y n son, respectivamente, el numero de ejemplos favorablesy totales observadosp es una estimacion a priori de la probabilidad que se quiereestimar.m es una constante (llamada tamano de muestreo equivalente)que indica el numero de ejemplos adicionales (ficticios)
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Suavizado aditivo (o de Laplace)
Un caso particular de lo anterior se suele usar para laestimacion de las probabilidades condicionales en Naive Bayes:
P(ai |vj) =n(Ai = ai ,V = vj) + k
n(V = vj) + k |Ai |
donde k es un numero fijado y |Ai | es el numero de posiblesvalores del atributo |Ai |.
Intuitivamente: se supone que ademas de los del conjunto deentrenamiento, hay k ejemplos en la clase vj por cada posiblevalor del atributo Ai
Usualmente k = 1, pero podrıan tomarse otros valores
Eleccion de k : experimentando con los dstintos rendimientossobre un conjunto de validacion
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
Seccion 7
Seccion 7
Aprendizaje basado en instancias: kNN
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Clasificacion mediante vecino mas cercano
Una tecnica alternativa a construir el modelo probabilıstico escalcular la clasificacion directamente a partir de los ejemplos(aprendizaje basado en instancias)
Idea: obtener la clasificacion de un nuevo ejemplo a apartir delas categorıas de los ejemplos mas “cercanos”.
Debemos manejar, por tanto, una nocion de “distancia” entreejemplos.En la mayorıa de los casos, los ejemplos seran elementos de Rn
y la distancia, la euclıdea.Pero se podrıa usar otra nocion de distancia
Ejemplo de aplicacion: clasificacion de documentos
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

El algoritmo k-NN
El algoritmo k-NN (de “k nearest neighbors”):
Dado un conjunto de entrenamiento (vectores numericos conuna categorıa asignada) y un ejemplo nuevoDevolver la categorıa mayoritaria en los k ejemplos delconjunto de entrenamiento mas cercanos al ejemplo que sequiere clasificar
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Distancias para k-NN
Posibles distancias usadas para definir la “cercanıa”:
Euclıdea: de(x, y) =√
∑ni=1(xi − yi )2
Manhattan: dm(x, y) =∑n
i=1 |xi − yi |Hamming: numero de componentes en las que se difiere.
La euclıdea se usa cuando cada dimension mide propiedadessimilares y la Mahattan en caso contrario; la distanciaHamming se puede usar aun cuando los vectores no seannumericos.
Normalizacion: cuando no todas las dimensiones son delmismo orden de magnitud, se normalizan las componentes(restando la media y dividiendo por la desviacion tıpica)
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Algunas observaciones sobre k-NN
Eleccion de k :
Usualmente, basandonos en algun conocimiento especıficosobre el problema de clasificacionTambien como resultado de pruebas en conjuntos maspequenos (conjuntos de validacion)Si la clasificacion es binaria, preferiblemente impar, paraintentar evitar empates (k=5, por ejemplo)
Variante en kNN: para cada clase c , sumar la similitud (con elque se quiere clasificar) de cada ejemplo de esa clase queeste entre los k mas cercanos. Devolver la clase que obtengamayor puntuacion.
Ası un ejemplo cuenta mas cuanto mas cercano este
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
Seccion 8
Seccion 8
Clustering
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Clustering
Como ultima aplicacion del aprendizaje estadıstico, trataremostecnicas de agrupamiento o clustering
Se trata de dividir un conjunto de datos de entrada ensubconjuntos (clusters), de tal manera que los elementos decada subconjunto compartan cierto patron o caracterısticas apriori desconocidas
En nuestro caso, los datos seran numeros o vectores denumeros y el numero de clusters nos vendra dado
Aprendizaje no supervisado: no tenemos informacion sobreque cluster corresponde a cada dato.
Aplicaciones de clustering:
Minerıa de datosProcesamiento de imagenes digitalesBioinformatica
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Dos ejemplos
Color quantization:
Una imagen digital almacenada con 24 bits/pixel (aprox. 16millones de colores) se tiene que mostrar sobre una pantallaque solo tiene 8 bits/pixel (256 colores)¿Cual es la mejor correspondencia entre los colores de laimagen original y los colores que pueden ser mostrados en lapantalla?
Mezcla de distribuciones:
Tenemos una serie de datos con el peso de personas de unpais; no tenemos informacion sobre si el peso viene de unvaron o de una mujer, pero sabemos que la distribucion depesos es de tipo normal, y que en los hombres es distinta queen las mujeresAtendiendo a los datos, ¿podemos aprender de que dosdistribuciones de probabilidad vienen?
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Clustering basado en distancia
Idea: dado el numero k de grupos o clusters, buscar k puntoso centros representantes de cada cluster, de manera que cadadato se considera en el cluster correspondiente al centro quetiene a menor “distancia”
Como antes, la distancia serıa especıfica de cada problema:
Expresara la medida de similitudLa distancia mas usada es la euclıdea
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Un algoritmo clasico: k-medias
Entrada: un numero k de clusters, un conjunto de datos{xi}
Ni=1 y una funcion de distancia
Salida: un conjunto de k centros m1, . . . ,mk
k-medias(k,datos,distancia)1. Inicializar m i (i=1,...,k) (aleatoriamente o con algun
criterio heurıstico)2. REPETIR (hasta que los m i no cambien):
2.1 PARA j=1,...,N, HACER:Calcular el cluster correspondiente a x j, escogiendo,de entre todos los m i, el m h tal quedistancia(x j,m h) sea mınima
2.2 PARA i=1,...,k HACER:Asignar a m i la media aritmetica de los datosasignados al cluster i-esimo
3. Devolver m 1,...,m n
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico
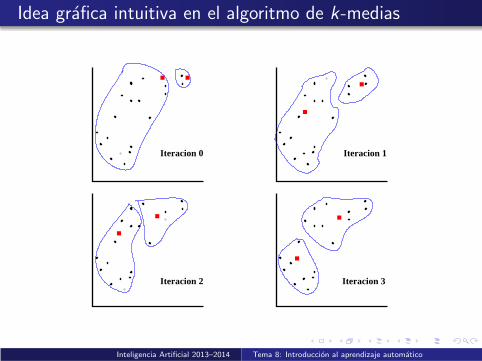
Idea grafica intuitiva en el algoritmo de k-medias
■■■
■
■ ■
Iteracion 1
Iteracion 3
Iteracion 0
Iteracion 2
■
■
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Ejemplo en el algoritmo k-medias
Datos sobre pesos de la poblacion: 51, 43, 62, 64, 45, 42, 46,45, 45, 62, 47, 52, 64, 51, 65, 48, 49, 46, 64, 51, 52, 62, 49,48, 62, 43, 40, 48, 64, 51, 63, 43, 65, 66, 65, 46, 39, 62, 64,52, 63, 64, 48, 64, 48, 51, 48, 64, 42, 48, 41
El algoritmo, aplicado con k = 2 y distancia euclıdea,encuentra dos centros m1 = 63,63 y m2 = 46,81 en tresiteraciones
19 datos pertenecen al primer cluster y 32 al segundo cluster
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Diversas cuestiones sobre el algoritmo k-medias
Busqueda local:
Puede verse como un algoritmo de busqueda local, en el que setrata de encontrar los centros mi que optimizanΣjΣibijd(xj ,mi )
2, donde bij vale 1 si xj tiene a mi como elcentro mas cercano, 0 en otro casoComo todo algoritmo de busqueda local, no tiene garantizadoencontrar el optimo global
Inicializacion: aleatoria o con alguna tecnica heurıstica (porejemplo, partir los datos aleatoriamente en k clusters yempezar con los centros de esos clusters)
En la practica, los centros con los que se inicie el algoritmotienen un gran impacto en la calidad de los resultados que seobtengan
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Otro ejemplo en el algoritmo k-medias
El archivo iris.arff del sistema WEKA contiene 150 datossobre longitudes y anchura de sepalo y petalo de plantas delgenero iris, clasificadas en tres tipos (setosa, versicolor yvirgınica)
Ejemplo de instancia de iris.arff:5.1,3.5,1.4,0.2,Iris-setosa
Podemos aplicar k-medias, con k = 3 y distancia euclıdea,ignorando el ultimo atributo (como si no se conociera):
En 6 iteraciones se estabilizaDe los tres clusters obtenidos, el primero incluye justamente alas 50 instancias que originalmente estaban clasificadas comoiris setosaEl segundo cluster incluye a 47 versicolor y a 3 virgınicasEl tercero incluye 14 versicolor y 36 virgınicasNo ha sido capaz de discriminar correctamente entre versicolory virgınica
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico

Bibliografıa
Mitchell, T.M. Machine Learning (McGraw-Hill, 1997)
Caps. 3,6,8 y 10
Russell, S. y Norvig, P. Artificial Intelligence (A ModernApproach) (3rd edition) (Prentice Hall, 2010)
Seccs. 18.1, 18.2, 18.3, 20.1 y 20.2
Russell, S. y Norvig, P. Inteligencia Artificial (Un enfoquemoderno) (segunda edicion en espanol) (Pearson Education,2004)
Seccs. 18.1, 18.2, 18.3, 18.8, 20.1, 20.2 y 20.4
Witten, I.H. y Frank, E. Data mining (Second edition)(Morgan Kaufmann Publishers, 2005)
Cap. 3, 4, 5 y 6.
Inteligencia Artificial 2013–2014 Tema 8: Introduccion al aprendizaje automatico