
Tema 5: Sistemas de Almacenamiento DistribuidoSSDD... · Operaciones: crear, abrir, cerrar, leer,...
116
Tema 5: Sistemas de Almacenamiento Distribuido Sistemas Distribuidos Marcos López Sanz [Curso 2012-2013]
Transcript of Tema 5: Sistemas de Almacenamiento DistribuidoSSDD... · Operaciones: crear, abrir, cerrar, leer,...

Tema 5: Sistemas de Almacenamiento Distribuido
Sistemas Distribuidos Marcos López Sanz [Curso 2012-2013]

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Índice
Introducción
Distribución de ficheros Arquitectura de servicios de ficheros
NFS
Distribución de datos Principios de BBDD distribuidas
Arquitectura de BBDD Distribuidas
Diseño de BBDD Distribuidas
Consultas distribuidas: descomposición y localización
Otros sistemas de almacenamiento de datos Data Warehouse

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Introducción
Objetivo Compartir información almacenada en localizaciones
distribuidas
Enfoques de almacenamiento: No persistente:
Almacenamiento en memoria compartida
Almacenamiento de objetos: CORBA, EJB, etc.
Persistente: Datos no estructurados (ficheros):
NFS, xFS…gNutella, Peer-to-Peer
Datos estructurados: BBDD distribuidas/federadas/paralelas, Datawarehousing

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de ficheros
Caracterización Sistema o servicio de ficheros: software cuyo propósito es emular
la funcionalidad de un sistema de ficheros no distribuido Objetivo: permitir a programas clientes acceder a los ficheros
como si estuvieran en su nodo local
Conceptos implicados Ficheros: elementos almacenados formados por “datos”
(secuencias de bits) y “atributos” (longitud, tipo, timestamp, propietario, ACL, etc.)
Directorios: ficheros especiales que contienen nombres (id) de ficheros dependientes de él
Metadatos: información usada para la gestión del sistema de ficheros
Operaciones: crear, abrir, cerrar, leer, escribir, posicionar, eliminar, renombrar, asignar atributos

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de ficheros
Requisitos de los sistemas de ficheros distribuidos Transparencia: equilibrio entre flexibilidad y
escalabilidad de la transparencia frente a complejidad y rendimiento del SW De acceso: los clientes no deben ser conscientes de la
distribución de los ficheros conjunto único de operaciones De localización: los clientes deben ver un único espacio de
nombres de ficheros uniforme transferencia de ficheros sin que cambie el ‘pathname’
De movilidad: información en los clientes acerca de los ficheros no debe variar cuando se migra un fichero
De rendimiento: los clientes deben seguir con su rendimiento aun cuando la carga del servicio de ficheros distribuidos aumenta
De escalabilidad: el sistema de ficheros debe ser capaz de escalar sin que mermen sus capacidades

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de ficheros
Requisitos de los sistemas de ficheros distribuidos
Actualizaciones concurrentes de ficheros: los cambios hechos a un fichero por parte de un cliente no deben afectar al acceso a ese fichero por parte de otros clientes
Replicación de ficheros: un mismo nombre de fichero puede referirse a varios ficheros replicados Ventaja: reparto de carga y tolerancia a fallos
Desventaja: actualizaciones y mantenimiento de copias

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de ficheros
Requisitos de los sistemas de ficheros distribuidos Tolerancia a fallos: recuperación ante fallos del cliente
o del servidor
Consistencia: debido a la existencia de replicación, todas las copias de un fichero deben ser iguales propagación de cambios
Seguridad: mecanismos de control de acceso a los ficheros
Eficiencia: un sistema de ficheros distribuidos debe ofrecer, al menos, la misma eficiencia que uno local
Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de ficheros
Ejemplos de sistemas de ficheros distribuidos Arquitectura de servicio de ficheros:
Modelo arquitectónico genérico sobre el que se asientan NFS o AFS Basado en la división de responsabilidades entre el cliente y el
servidor
NFS: Network File System Idea de Sun Microsystems (1985) Protocolo NFS: RFC 1813 (1995) Relación simétrica entre clientes y servidores (multiplataforma)
AFS: Andrew File System Entorno de computación distribuido de la CMU (1986) Basado en la transferencia de grandes bloques de ficheros y el uso
de cachés
Sistemas distribuidos – Curso 2011-2012 www.kybele.es
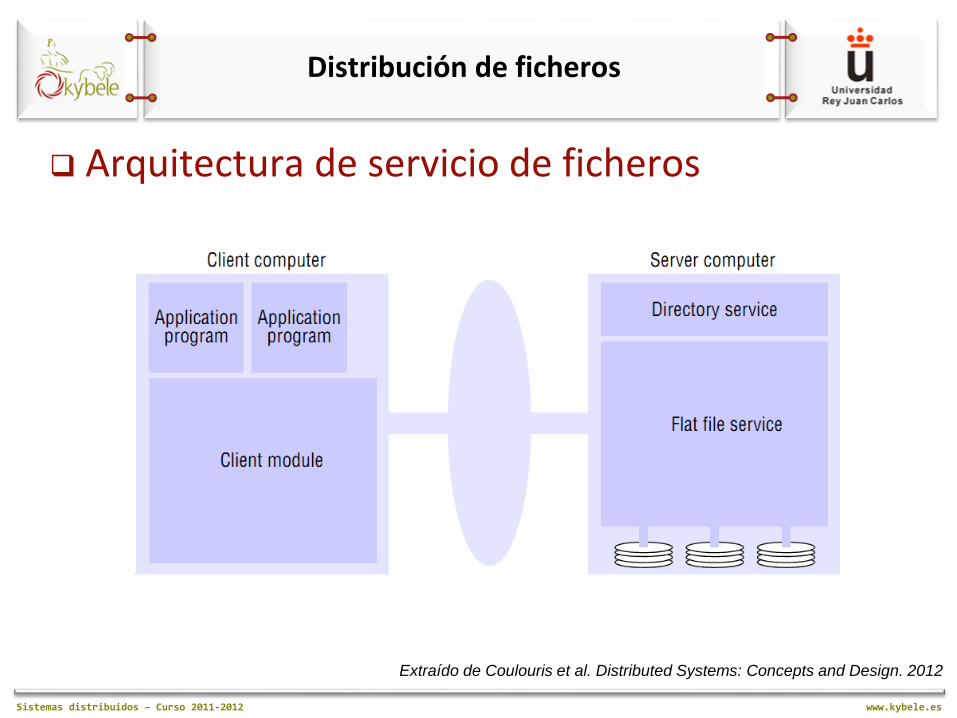
Distribución de ficheros
Arquitectura de servicio de ficheros
Extraído de Coulouris et al. Distributed Systems: Concepts and Design. 2012

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de ficheros
Arquitectura de servicio de ficheros. Componentes Servicio de ficheros planos:
Implementa las operaciones en los contenidos de los ficheros para su acceso
Crea UFIDs (Unique File Identifiers) para representar cada fichero físico
Servicio de directorio: Mapea nombres (texto) a UFIDs
Gestiona ficheros y directorios
Módulo cliente: Integra y extiende las operaciones del servicio de ficheros
planos y del servicio de directorio
Crea una interfaz común de acceso para aplicaciones cliente

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de ficheros
Arquitectura de servicio de ficheros. Interfaces
Interfaz del servicio de ficheros planos
Conjunto de operaciones usadas por un cliente
Basado en RPC (usado por el cliente) en las que se indica un UFID (global al sistema de ficheros distribuido pero resuelto por un servidor concreto)
Interfaz del servicio de directorio
Propósito: ofrecer una forma de trasladar nombres de ficheros planos a UFIDs.
Ofrece también operaciones sobre directorios

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de ficheros
Arquitectura de servicio de ficheros
Control de acceso
Se realiza cada vez que se resuelve (en el cliente) un nombre de fichero (texto plano) a UFID, o bien,
Se envía la identidad del usuario al servidor para su comprobación antes de cada operación de fichero
Otras características
Sistema jerárquico de ficheros: pathnames
Grupos de ficheros: conjunto de ficheros almacenados en un servidor (independientemente de los directorios)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de ficheros
NFS (Network File System)
Extraído de Coulouris et al. Distributed Systems: Concepts and Design. 2012

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de ficheros
NFS. Conceptos básicos Protocolo NFS: conjunto de llamadas a procedimiento remoto que
ofrecen las capacidades necesarias para que los clientes puedan realizar operaciones sobre un almacenamiento de ficheros remoto
Protocolo de nivel de aplicación en la pila OSI
Clientes y servidores NFS: Un servidor y varios clientes Se comunican por RPCs siguiendo el protocolo NFS Comunicación con operaciones síncronas Con TCP o UDP por debajo
Únicas restricciones de uso: que la petición esté bien formulada y
que el usuario tenga las credenciales adecuadas

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de ficheros
NFS. Componentes Sistema de ficheros virtuales
Módulo que implementa la transparencia de acceso Conoce si debe transmitir una petición de acceso a fichero al
sistema local de ficheros o al cliente NFS para acceso remoto (remote filesystem)
Módulo cliente NFS: Integración con el cliente Ofrece una interfaz adecuada para ser utilizada por
aplicaciones cliente En UNIX suele estar integrado en el kernel
• Acceso a ficheros con llamadas al sistema (sin recompilar) no como librería
• Un único módulo atiende a varias aplicaciones cliente
Se comunica y coordina con el sistema de ficheros virtuales

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de ficheros
NFS. Componentes Control de acceso y autenticación
El servidor NFS no guarda el estado de apertura de un fichero (stateless) chequeo de permisos ante cada petición cliente
Problema: cualquiera podría enviar una petición RPC con la ID de otro usuario encapsulada en la petición
Solución parcial: Kerberos + Sun NFS
Interfaz del servidor NFS Read, Write, getattr, setattr, lookup, create, mkdir, etc.
‘Mount service’ Permite agregar enlaces simbólicos a árboles de directorios/ficheros
en local haciendo referencia a subárboles remotos UNIX: /etc/exports nombres de los filesystems locales que pueden
ser montados en clientes NFS
Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de ficheros
NFS. Optimizaciones Automounter: mantiene una tabla de puntos de montado
(pathnames). Cuando un cliente hace un lookup(), el automounter pregunta a todos los servidores NFS por el fichero solicitado y monta el filesystem localmente (enlace simbólico) para acceder a ese fichero
Server caching y client caching: demonios que permiten hacer ‘read-ahead’ y ‘write-delay’ para mejorar el rendimiento en la gestión de ficheros accedidos por un cliente
Securización con Kerberos: uso de un protocolo de autenticación en redes inseguras (criptografía de clave segura y existencia de un servidor de confianza)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Principios de Bases de Datos Distribuidas Objetivos de las BD: integración frente a centralización Base de Datos Distribuida (DDBS):
“a collection of multiple, logically interrelated databases distributed over a computer network”
Sistema gestor de BBDD distribuidas (Distributed DBMS): “the software system that permits the management of the distributed database
and makes the distribution transparent to the users”
Discretización: es DDBS si…
Los datos están lógicamente relacionados Existe una estructura lógica que los relaciona
(más allá de una jerarquía de organización) Los datos están físicamente distribuidos
(no residen sólo en un nodo) Se utiliza una red de comunicaciones para su acceso
(no sobre una estrategia de memoria o disco compartido) El acceso debe hacerse a través de una interfaz común

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Alternativas de distribución de datos Criterios
Modos de entrega de datos • Pull-only. Iniciado por una petición del cliente (tradicional) • Push-only. Iniciado por los servidores • Hybrid. Query continua: primero pull x1 y después push xN
Frecuencia
• Periodic. Peticiones acordadas (acciones bancarias diarias) • Conditional. Envío en función de condición (aviso por umbral) • Ad-hoc o irregular. Entornos híbridos o pull-only (tradicional)
Métodos de comunicación
• Unicast. Comunicación uno-a-uno cliente-servidor • One-to-many. Envío de un servidor a varios clientes (multicast o
broadcast)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Ventajas de los DDBS:
Gestión transparente de datos distribuidos y replicados
Acceso fiable a datos a través de transacciones distribuidas
Mejora del rendimiento
Expansión sencilla del sistema (escalabilidad)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Gestión transparente de datos distribuidos y replicados Objetivo: que el usuario cree consultas que no tengan en cuenta la
fragmentación, localización o replicación de los datos
Formas de abordar la transparencia en DDBS Independencia de datos. Inmunidad de los usuarios frente a la organización de
datos o en la definición de los mismos: Definición a nivel lógico: Definición del esquema de la BD inmunidad frente a cambios en
la estructura lógica de la BD (esquema) Definición a nivel físico: Definición de los datos físicos ocultación de las estrategias de
almacenamiento físico de los datos
Transparencia de red. No debe haber diferencia entre el acceso a almacenamiento local o distribuido Forma uniforme de acceder a los datos Evitar que el usuario especifique la localización de los datos
Transparencia de replicación. Gestión de la existencia de réplicas (no su localización) por parte del sistema
Transparencia de fragmentación. Tratamiento de un conjunto de fragmentos (para mejora de rendimiento, fiabilidad y disponibilidad) como si no existieran Fragmentación vertical: una relación se divide en varias de acuerdo a las tuplas (filas ) Fragmentación horizontal: una relación se divide en varias de acuerdo a los atributos
(columnas)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Fiabilidad mediante transacciones distribuidas Transacción: unidad básica y coherente de computación que
consta de una serie de sentencias para la BD que se ejecutan como si fuera una sola
Objetivo: hacer que la BD se mantenga en un estado coherente antes y después de la ejecución de la transacción
Consecuencia: mantiene la integridad de la BD en ejecuciones concurrentes de transacciones
Requisitos: implementar control de concurrencia y fiabilidad distribuida (2PC y protocolos de recuperación distribuida)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Mejora del rendimiento
Basado en la existencia de fragmentos
Almacenamiento cercano al lugar donde se van a utilizar los datos
Contención del uso de CPU y E/S en el acceso a los datos
La localización (cercana) reduce el tiempo y latencia de red
La distribución, a pesar de las mejoras HW, sigue existiendo (comunicaciones con satélite o entre organizaciones)
Basado en la paralelización de las consultas
Intra-query: división de una consulta en varias
Inter-query: ejecución de múltiples consultas a la vez

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Expansión sencilla del sistema (escalabilidad)
Expansión basada en añadir componentes de computación y almacenamiento
Aumento de las prestaciones en entornos distribuidos más sencillo que incremento de potencia en monopuestos (mainframes)
Las estrategias de gestión distribuida son aplicables a un número variable de recursos

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Factores de complejidad de las BBDD distribuidas Replicación de los datos: el DDBMS es responsable de…
Encontrar y seleccionar las copias almacenadas de los datos replicados a la hora de recuperar la información
Asegurarse de la propagación de los cambios a todas las instancias de los datos modificados
Fallo de los nodos: el DDBMS es responsable de… Si una sentencia se está ejecutando, debe asegurarse de que los cambios se
realizan sobre el nodo caído (o no accesible) cuando se produce la recuperación
Sincronización de transacciones: Es compleja debido a la imposibilidad de conocer al momento inmediato qué
ocurre en el resto de nodos
Otros: Coste de replicar recursos, gestión de la distribución, gestión de acuerdos entre
nodos, etc.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
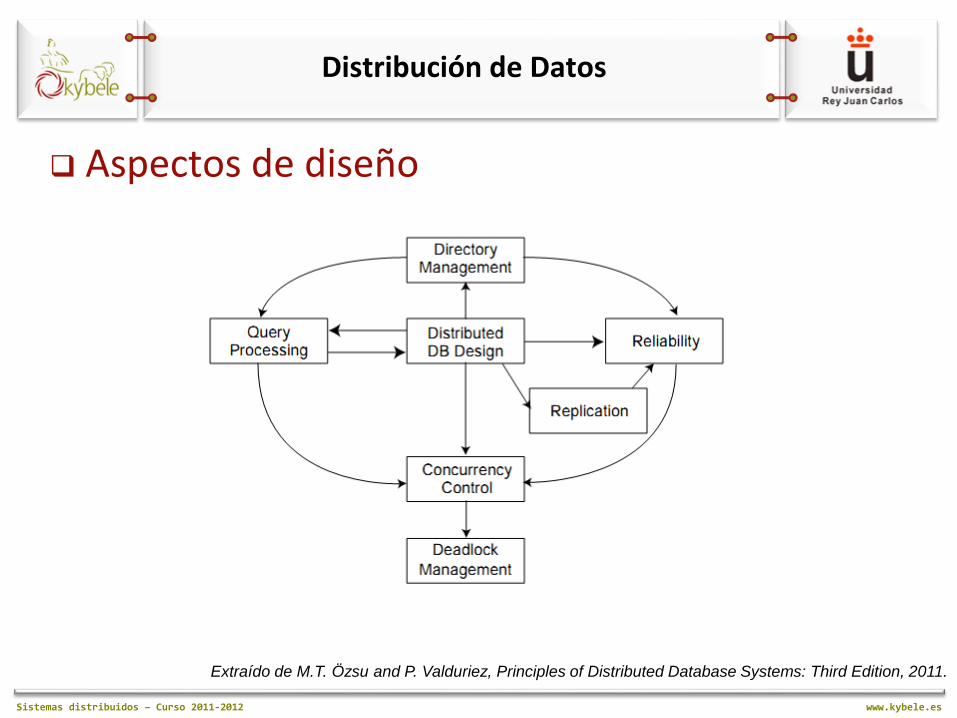
Distribución de Datos
Aspectos de diseño Diseño de la BD distribuida:
¿Datos particionados (no replicados)?
¿Datos replicados? • ¿Totalmente replicados?
• ¿Parcialmente replicados?
Aspectos involucrados: • Fragmentación. Separación de la BD en particiones (fragmentos)
• Distribución. Asignación óptima de fragmentos a nodos
Gestión del directorio distribuido ¿Directorio global o local a cada nodo?
¿Directorio centralizado o distribuido?
¿Copia única o replicada?

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Aspectos de diseño Procesamiento distribuido de consultas
Se centra en diseñar algoritmos que analizan consultas y las convierten en operaciones de manipulación de datos
Factores a considerar: • Distribución de los datos • Coste de la comunicación • Limitaciones de la información local disponible
Control de concurrencia distribuido Sincronización de accesos al DDBS Integridad de una BD local + consistencia de múltiples copias Soluciones:
• Pesimistas. Sincronización de la ejecución de las peticiones del cliente antes de que ocurran
• Optimistas. Ejecución y posterior comprobación de la consistencia de la BD tras la ejecución
Primitivas utilizadas: • Bloqueos (locks) • Timestamps

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Aspectos de diseño Gestión de los interbloqueos distribuidos
Competición entre usuarios por el acceso a un recurso Alternativas: prevención, ‘avoidance’, detección/recuperación
Fiabilidad de los DDBS
Caída de nodos el DDBS tiene que ser consistente aun con nodos caídos o inaccesibles
Recuperación de nodos el DDBS debe actualizar los nodos al estado actual
Replicación Ante réplicas se debe establecer una política de actualización
• Proactiva (eager). Forzar que las actualizaciones se produzcan en todos los nodos antes de terminar la transacción
• Pasiva (lazy). Esperar a que termine la transacción para actualizar el resto de nodos
Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Aspectos de diseño
Extraído de M.T. Özsu and P. Valduriez, Principles of Distributed Database Systems: Third Edition, 2011.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Arquitecturas de DDBS
Arquitectura ANSI/SPARC
Arquitectura centralizada
Arquitecturas distribuidas
DDBS en entornos cliente-servidor
DDBS puros (Peer-to-Peer)
Sistemas de multibases de datos

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Arquitectura ANSI/SPARC
Extraído de M.T. Özsu and P. Valduriez, Principles of Distributed Database Systems: Third Edition, 2011.
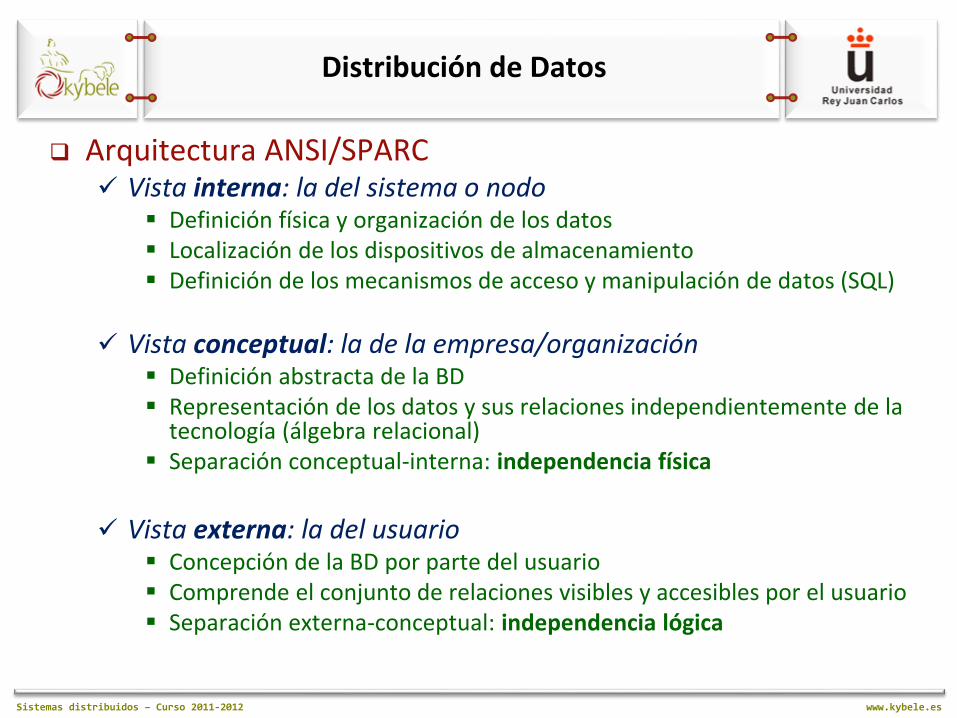
Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Arquitectura ANSI/SPARC Vista interna: la del sistema o nodo
Definición física y organización de los datos Localización de los dispositivos de almacenamiento Definición de los mecanismos de acceso y manipulación de datos (SQL)
Vista conceptual: la de la empresa/organización Definición abstracta de la BD Representación de los datos y sus relaciones independientemente de la
tecnología (álgebra relacional) Separación conceptual-interna: independencia física
Vista externa: la del usuario
Concepción de la BD por parte del usuario Comprende el conjunto de relaciones visibles y accesibles por el usuario Separación externa-conceptual: independencia lógica

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Arquitectura de una BD centralizada
Extraído de M.T. Özsu and P. Valduriez, Principles of
Distributed Database Systems: Third Edition, 2011.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Arquitecturas de BBDD distribuidas
Criterios
Autonomía
Distribución
Heterogeneidad

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Criterios de clasificación de DDBS. Autonomía Grado en que los componentes de un DDBS pueden operar
independientemente. Afecta al control de cada nodo de BD. Requisitos:
Las operaciones ejecutadas localmente no dependen de su participación en el DDBS
La optimización de operaciones tampoco La consistencia de la BD local no se ve afectada cuando deja de pertenecer al
DDBS
Valores: Autonomía de diseño. Independencia en técnicas de gestión de transacciones y
modelos de datos Autonomía de comunicación. Independencia a la hora de ofrecer la información
a otros nodos o al SW que controla la ejecución global Autonomía de ejecución. Independencia para ejecutar una transacción de la
manera que se quiera.
Tipos de DDBS según su autonomía: Fuertemente integrados. Misma imagen en cada nodo. Control centralizado. Semiautónomos. Parte de la BD local se dedica a ser compartida. BD federadas. Aislamiento total. BBDD totalmente independientes (no distribuidas).

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Criterios de clasificación de DDBS. Distribución
Grado en que los datos se distribuyen físicamente en diferentes localizaciones
Tipos de DDBS según su distribución:
Cliente/servidor. Reparto de funcionalidades sobre los datos
• Los servidores se encargan de las tareas de gestión de datos
• Los clientes ofrecen el entorno de aplicación incluyendo la interfaz de usuario
Peer-to-Peer (‘puras’). Distribución total de funcionalidades de gestión de datos
• Cada nodo tiene todas las funcionalidades propias de un SGBD

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Criterios de clasificación de DDBS. Heterogeneidad
Grado en que el DDBS se construye utilizando modelos de datos, lenguajes de consulta o protocolos de gestión de transacciones diferentes
Heterogeneidad en DDBS: De modelos de datos.
• En función de la expresividad de cada modelo de datos, las capacidades de representar los datos varían
De lenguaje de consultas
• A pesar de que SQL es el lenguaje estándar de acceso a BD, cada vendedor tiene sus particularidades de implementación

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Arquitecturas de BBDD distribuidas
Extraído de M.T. Özsu and P. Valduriez, Principles of Distributed Database Systems: Third Edition, 2011.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Arquitectura de DDBS cliente/servidor
Extraído de M.T. Özsu and P. Valduriez,
Principles of Distributed Database Systems:
Third Edition, 2011.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Arquitectura de DDBS cliente/servidor
Extraído de M.T. Özsu and P. Valduriez, Principles of Distributed Database Systems: Third Edition, 2011.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Arquitectura de DDBS Peer-to-Peer (DDBS ‘puro’) Peer-to-Peer: hace referencia a que no hay diferencia en las
funcionalidades implementadas por los nodos del sistema Diferencia con sistemas P2P actuales:
Envergadura: actualmente P2P se refiere a miles de nodos interconectados
Objetivo de los P2P: compartir ficheros
Esquemas en DDBS Local Internal Schema (LIS): organización física de los datos en cada
nodo Global Conceptual Schema (GCS): describe la estructura lógica de todos
los nodos como un todo (vista externa y “empresarial”) Local Conceptual Schema (LCS): descripción conceptual de cada LIS en
cada nodo. Sirve para gestionar la replicación y la fragmentación de los datos
External Schemas (ES): vista del DDBS que percibe el usuario final (por encima del GCS)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Arquitectura de DDBS Peer-to-Peer (DDBS ‘puro’)
Extraído de M.T. Özsu and P. Valduriez, Principles of Distributed Database Systems: Third Edition, 2011.
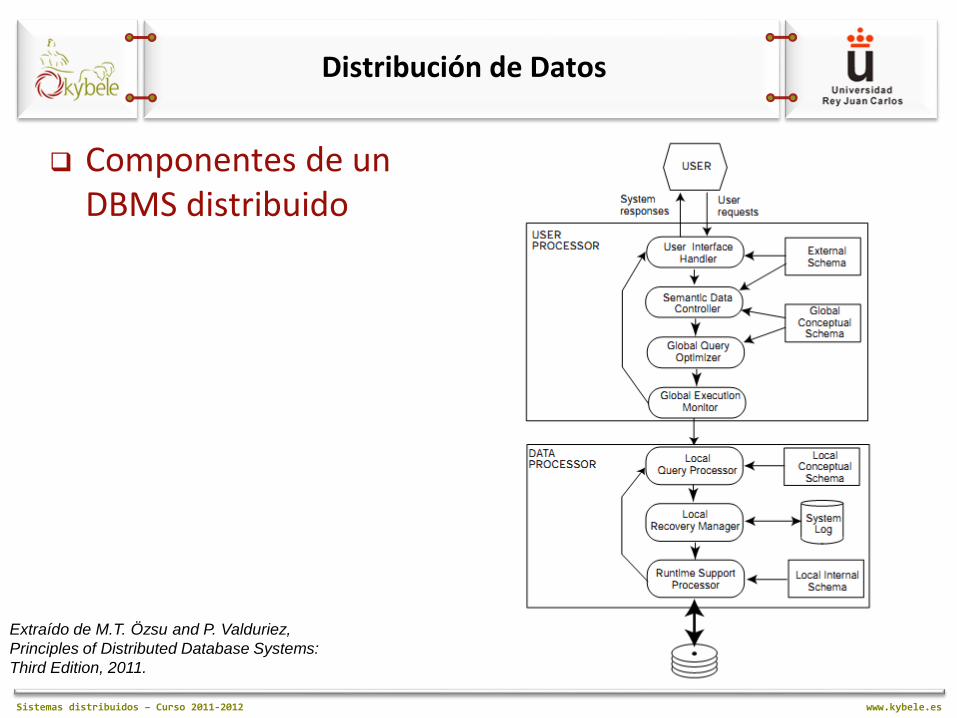
Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Componentes de un DBMS distribuido
Extraído de M.T. Özsu and P. Valduriez,
Principles of Distributed Database Systems:
Third Edition, 2011.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Componentes de un DBMS distribuido Procesador de usuario. Gestiona la interacción con el
usuario final Manejador del interfaz de usuario
• Interpreta los comandos de usuario
Controlador de datos semánticos • Gestiona las autorizaciones y la restricciones de integridad de
acuerdo al GCS para saber si se puede ejecutar la petición del usuario.
Optimizador de consultas globales y ‘descomponedor’ • Determina la estrategia de ejecución minimizando los costes. • Transforma las consultas globales a consultas locales utilizando el
GCS y el LCS (así como el directorio global donde está la dirección de cada nodo)
Monitor/Gestor de ejecución distribuida • Coordina la ejecución distribuida de la petición de usuario • Diferentes nodos se comunican entre sí a través de este módulo

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Componentes de un DBMS distribuido Procesador de datos. Gestiona el acceso a los datos
locales Optimizador de consultas locales
• Selecciona la mejor ruta de acceso a los datos locales
Gestor de recuperación local • Encargado de mantener la consistencia local aun en presencia
de fallos
Procesador de soporte en tiempo real • Accede físicamente a los datos locales de acuerdo a los
comandos físicos enviados por el optimizador de consultas locales
• Actúa de interfaz con el sistema operativo

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Distribución de Datos
Arquitectura de una multibase de datos
Extraído de M.T. Özsu and P. Valduriez, Principles of Distributed Database Systems: Third Edition, 2011.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Datos de ejemplo

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Premisas Una copia del DDBMS existe en cada nodo La distribución de los programas se hará dependiendo de
cómo se diseñe el DDBS
Estrategias de diseño Top-Down
Desde el análisis de los requisitos hasta el diseño físico de la BD (LIS), pasando por los GCS y ES
Objetivo: a partir del GCS diseñar los LCS Pasos: fragmentación y localización
Bottom-Up Parte de BD locales existentes (LCS) para llegar a ES Objetivo: derivar un GCS mediante integración Pasos: traducción de esquemas e integración de esquemas

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Diseño Top-Down:
Extraído de M.T. Özsu and P. Valduriez,
Principles of Distributed Database Systems:
Third Edition, 2011.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Diseño Bottom-Up:
Extraído de M.T. Özsu and P. Valduriez,
Principles of Distributed Database Systems:
Third Edition, 2011.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Aspectos de diseño de distribución de datos Razones de fragmentación (granularidad)
Subconjuntos de relaciones como unidad porque así es como acceden las aplicaciones
¿Relación como unidad? • Problemas de transferencia de información (completa) • Problemas de replicación y propagación de actualizaciones
Fragmentos • Permiten ejecutar consultas concurrentemente
Desventajas de fragmentación Degradación de rendimiento en aplicaciones que trabajan con
fragmentos Control de integridad requiere accesos a datos de múltiples
fragmentos

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Aspectos de diseño de distribución de datos
Alternativas de fragmentación
Partición horizontal • Se realiza repartiendo las tuplas de una relación de acuerdo al
valor que toma uno de los atributos (columnas) de la relación
Partición vertical • Se realiza separando los atributos (columnas) en diferentes
fragmentos
• La clave primaria se incluye en todos los fragmentos (causa: 1FN)
Partición híbrida • Anidamiento de las particiones horizontales y verticales

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Aspectos de diseño de distribución de datos Grado de fragmentación
Extremos: no fragmentar nada vs. fragmentar a nivel de tupla o de atributos individuales
Solución: compromiso dependiente de las aplicaciones que usan el DDBS
Reglas de corrección de la fragmentación Objetivo: que la BD no sufra cambios semánticos durante la
fragmentación
Regla 1: Completitud Si una relación R se divide en fragmentos R1, R2,…,Rn, cada dato de R se puede encontrar en uno o más Ri
Regla 2: Reconstrucción Si una relación R se divide en fragmentos R1, R2,…,Rn, existe un operador aplicable a Ri que da como resultado R.
Regla 3: Desunión (‘disjointness’) • F. Vertical: Salvo la clave primaria, un atributo únicamente se encuentra en un
fragmento • F. Horizontal: Los datos (tuplas) únicamente se encuentran en un fragmento

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Aspectos de diseño de distribución de datos Alternativas de localización
Premisa: la BD está fragmentada correctamente
Opciones: datos replicados o únicos
Razones: fiabilidad y eficiencia
Aspecto clave: ratio consultas de lectura vs. actualización
Tipos de DDBS según localización • Particionada: fragmentos localizados en varios nodos pero sin
replicación
• Totalmente replicada: toda la BD existe en cualquiera de los nodos
• Parcialmente replicada: existen fragmentos replicados en varios nodos

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Aspectos de diseño de distribución de datos
Totalmente replicada
Parcialmente replicada
Particionada
Procesamiento de consultas Fácil Dificultad similar
Gestión del directorio Fácil o inexistente Dificultad similar
Control de concurrencia Moderado Difícil Fácil
Fiabilidad Muy alto Alto Bajo
Realismo Posible aplicación Realista Posible aplicación

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Fragmentación. Horizontal Tipos de partición horizontal
Primaria: la fragmentación se realiza únicamente con la información de una relación (selección en la propia tabla)
Derivada: la fragmentación se realiza usando información procedente de una consulta de selección previa sobre otra tabla relacionada
Requisitos de información para fragmentación horizontal Información de la BD:
• Relaciones entre tablas del GCS (joins)
Información de la aplicación: • Detectar cuáles son los criterios de filtrado más habituales
• Regla 80/20 entre datos recuperados/consultas más utilizadas
• Establecer sus complementarios para cumplir con el criterio de completitud

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Fragmentación. Horizontal Primaria Se define con una operación de selección sobre una de
las relaciones existentes (w) en un esquema de la BD
Dada una relación R, sus fragmentos se definen como: Ri = σFi (R), 1 ≤ i ≤ w
Resultado: Cada fragmento contendrá el conjunto de tuplas que cumplen
el criterio de selección Habrá tantos fragmentos como predicados de selección sean
diseñados Existen algoritmos para comprobar que los predicados de
selección cumplen con las propiedades de completitud y mínima cardinalidad

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Fragmentación. Horizontal Primaria
Ejemplo
Dos nodos
Objetivo: almacenar aquellos empleados con un salario superior a 30.000€ y en otro lugar los que cobren menos
Predicados iniciales (simples): Pr = { P1, P2 } • P1: SAL ≥ 30000
• P2: SAL < 30000
Comprobación de que los predicados son mínimos y completos algoritmo COM_MIN: Pr es mínimo y completo
Obtención de fragmentos algoritmo PHORIZONTAL
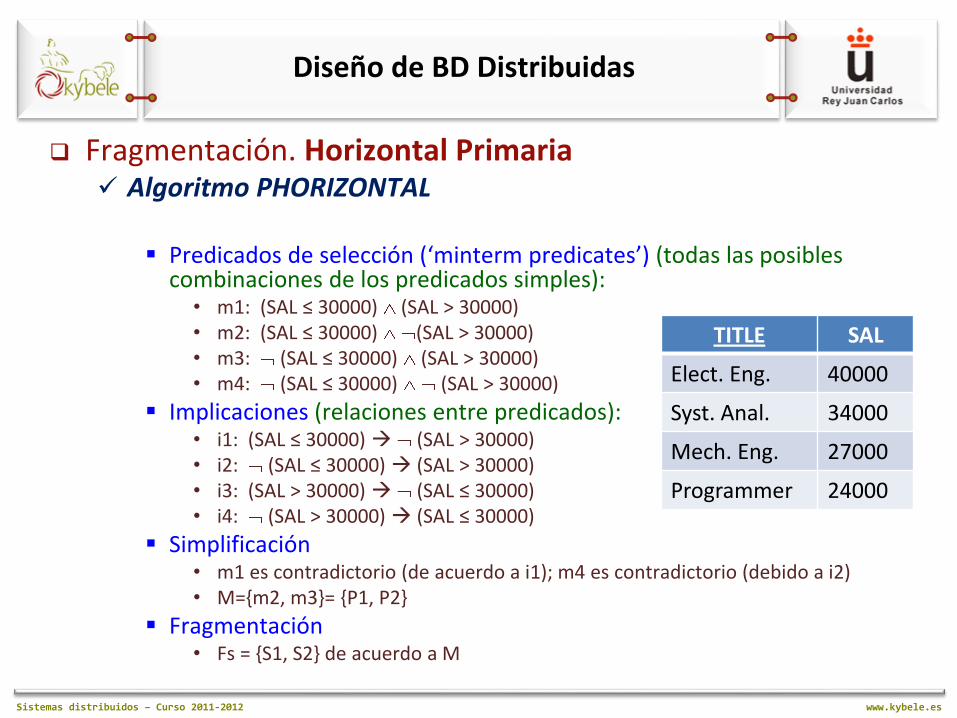
Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Fragmentación. Horizontal Primaria Algoritmo PHORIZONTAL
Predicados de selección (‘minterm predicates’) (todas las posibles
combinaciones de los predicados simples): • m1: (SAL ≤ 30000) (SAL > 30000) • m2: (SAL ≤ 30000) (SAL > 30000) • m3: (SAL ≤ 30000) (SAL > 30000) • m4: (SAL ≤ 30000) (SAL > 30000)
Implicaciones (relaciones entre predicados): • i1: (SAL ≤ 30000) (SAL > 30000) • i2: (SAL ≤ 30000) (SAL > 30000) • i3: (SAL > 30000) (SAL ≤ 30000) • i4: (SAL > 30000) (SAL ≤ 30000)
Simplificación • m1 es contradictorio (de acuerdo a i1); m4 es contradictorio (debido a i2) • M={m2, m3}= {P1, P2}
Fragmentación • Fs = {S1, S2} de acuerdo a M
TITLE SAL
Elect. Eng. 40000
Syst. Anal. 34000
Mech. Eng. 27000
Programmer 24000

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Fragmentación. Horizontal Derivada Se define con una operación de selección sobre una relación
que está relacionada con alguna de las relaciones existentes (w) en un esquema de la BD sobre la que se hará la fragmentación
Dada una relación R, sus fragmentos se definen como: Ri = R < Si, 1 ≤ i ≤ w partición derivada de R en semijoin con S Si = σFi (S) partición primaria de S
Elementos necesarios: Conjunto de fragmentos de la relación con partición primaria Relación que se desea fragmentar Atributo de unión entre las relaciones
Problemas Encontrar cuál es el atributo por el que hacer el (semi-)join
• Aquél que tiene mejores características de unión (menor nº de fragmentos) • Aquél que deriva en fragmentos más utilizados por aplicaciones

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Fragmentación. Horizontal. Análisis de criterios de corrección
Completitud: depende de los predicados de selección • En una fragmentación primaria se cumplirá si el predicado se
ejecuta correctamente
• En una fragmentación derivada se cumplirá si se cumple la integridad referencial (las tuplas de un fragmento están también en la relación con la que se hace el join)
Reconstrucción: la relación original se forma mediante la unión de los fragmentos
Disjointness: • En una fragmentación primaria se cumplirá si el predicado definido
conlleva la creación de fragmentos mutuamente excluyentes
• En una fragmentación derivada depende de los datos (se debe estudiar en detalle)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Fragmentación. Vertical. Produce fragmentos R1, R2,…,Rn cada uno de los cuales contiene un
subconjunto de los atributos (columnas) de R así como la clave primaria de R
Fragmentación óptima: aquella que produce un esquema de fragmentación tal que reduce el tiempo de ejecución de las aplicaciones sobre estos fragmentos
Complejidad: Dados m atributos candidatos a clave primaria Nº de posibles fragmentos ≈ mm
Aproximaciones heurísticas Agrupamiento: dividir completamente los atributos e ir uniendo hasta
satisfacer un criterio (1985) Desdoblamiento: ir dividiendo quitando atributos hasta que se deja de
cumplir el criterio (1984)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Fragmentación. Vertical. Requisitos de información para fragmentación vertical
Depende del uso que las aplicaciones hagan de los atributos frecuencia de acceso a los atributos
Pretende encontrar los atributos que más veces se acceden juntos “afinidad” de atributos
Algoritmo de fragmentación A partir de un conjunto de consultas se crea una “matriz de uso de
atributos” A partir de esa matriz y de la frecuencia de usos de cada consulta se
crea una “matriz de afinidad” Se utiliza un algoritmo para ordenar los atributos de la matriz y
“juntar” los que más afinidad tienen entre sí (más peso) Finalmente se “divide” la matriz entre los atributos más utilizados y
los menos

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Fragmentación. Vertical.
Comprobación de la corrección de la fragmentación
Completitud • Se garantiza porque cada atributo al menos está en una
partición
Reconstrucción • Se consigue mediante el join de todos los fragmentos
Disjointness • La clave primaria se repite en cada fragmento lo que permite
saber que las tuplas no se repiten

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Fragmentación. Híbrida. Se basa en la utilización de fragmentaciones
verticales y horizontales independientemente del orden en que se ejecuten
Se produce un árbol estructurado de fragmentos
Comprobación de la corrección Completitud: se cumple si se cumple en las
fragmentaciones individuales
Reconstrucción: se empieza por las hojas y se va subiendo en el árbol
Disjointness: se cumple si se cumple en las fragmentaciones individuales

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Localización
Foco del problema: posicionar los datos en una red de computadores más que en el diseño en sí de la BD
Aspectos:
Definición del problema de localización
Requisitos de información asociados a la localización
Modelo de localización
Métodos de solución a la localización

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Localización.Problema de localización Premisa: existen una serie de fragmentos (Fi) distribuibles en
una serie de nodos (Si) y que son accedidos por una serie de aplicaciones (Qi)
Objetivo: distribución óptima de F en S
Medidas de optimalidad: Coste mínimo: función compuesta que indica el coste de…
• Almacenar cada Fi en cada Sj • Consultar cada Fi en cada Sj • Actualizar cada Fi en los nodos en los que esté almacenado
Rendimiento: • Minimizar el tiempo de respuesta • Maximizar la tasa de transferencia en cada sitio
Problema: complejidad de los algoritmos de distribución de fragmentos en nodos (NP-completo)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Localización. Requisitos de información Información de la BD
Número de tuplas de un fragmento Fj que son accedidas por una aplicación Qi
Tamaño de las tuplas de un fragmento Fj
Información de la aplicación Número de accesos de lectura y de actualización que un programa Qi
hace a un fragmento Fj Nodo que origina la consulta y su localización Máximo tiempo de respuesta admisible por una aplicación
Información de los nodos Capacidad/Coste de almacenamiento y de procesamiento
Información de la red Coste de comunicación entre dos nodos Si y Sj

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de BD Distribuidas
Localización. Modelo de localización Modelo matemático que intenta minimizar el coste total de
procesamiento y almacenamiento de datos cumpliendo ciertas restricciones de tiempo
NP-Completo Define funciones para cálculo de costes de procesamiento y
almacenamiento y de la influencia de las restricciones
Localización. Métodos de solución Heurísticos
Problema de la mochila Técnicas ‘branch-and-bound’ Algoritmos de flujo de red
Centrados en reducir la complejidad ‘Query processing optimization’ Ignorar la replicación

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Álgebra relacional (recordatorio) Operadores primitivos
Proyección ( )
Selección ( )
Unión ( )
Diferencia(-)
Producto Cartesiano (x)
Operadores derivados: Combinación o Join ( )
Intersección ( )
División (:)
O. Unarios
O. Binarios

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Proyección ( ): La proyección de una relación sobre un conjunto de sus atributos es otra relación definida sobre ellos, eliminando las tuplas duplicadas que hubieran podido resultar al seleccionar los atributos indicados nacionalidad (Autor)
Selección ( ): La selección de una relación mediante una expresión lógica (predicado de selección) da
como resultado una relación formada por el conjunto de tuplas que satisfacen dicha expresión nacionalidad=”Española” (Autor)
Unión ( ): La unión de dos relaciones R1 y R2, compatibles en su esquema, es otra relación definida
sobre el mismo esquema de relación, cuya extensión estará constituida por el conjunto de tuplas que pertenezcan a R1, a R2 o a ambas (sin duplicar) Autor Editor
Diferencia(-): La diferencia de dos relaciones R1 y R2, compatibles en su esquema, es otra relación
definida sobre el mismo esquema de relación, cuya extensión estará constituida por el conjunto de tuplas que pertenecen a R1 y no pertenecen a R2 Autor – Editor
Producto Cartesiano (x): El producto cartesiano de dos relaciones R1 y R2 de cardinalidades m1 y m2
respectivamente, es una relación definida sobre la unión de los atributos de ambas relaciones y cuya extensión estará constituida por las m1 x m2 tuplas formadas concatenando cada tupla de la primera relación con cada una de las tuplas de la segunda relación LIBRO x EDITORIAL

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Selección ( ) Proyección ( ) Producto (x)
Unión ( ) Diferencia ( - )
a b c
x y
a a b b c c
x y x y x y

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Combinación o Join ( , ). La combinación de dos relaciones, R1 y R2, respecto a una cierta condición de combinación, es otra relación constituida por todos los pares de tuplas ti y tj concatenadas, tales que, en cada par, las correspondientes tuplas satisfacen la condición especificada. Cuando el operador es la igualdad, se denomina combinación natural LIBRO LIBRO.nombre-e = EDITORIAL.nombre EDITORIAL
Intersección ( ): La intersección de dos relaciones R1 y R2 compatibles en su esquema es otra relación definida sobre el mismo esquema de relación y cuya extensión estará constituida por las tuplas que pertenecen a ambas relaciones AUTOR EDITOR
División (:) : La división de una relación R1(dividendo) por otra relación R2 (divisor) es una relación R (cociente) tal que, al realizarse su combinación con el divisor, todas las tuplas resultantes se encuentran en el dividendo. R1 : R2 = C(R1) - C(R2 x C(R1)-R1) AUTOR_EDITORIAL : EDITORIAL

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Procesador de consultas
Transforma una consulta de alto nivel (en cálculo relacional, SQL-like) en un equivalente de bajo nivel (álgebra relacional)
En DDBS no es suficiente con el álgebra relacional necesita seleccionar dónde es mejor realizar la consulta

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Ejemplo
Nodo 5
Nodo 1
Nodo 2 Nodo 3
Nodo 4
Adaptado de M.T. Özsu and P. Valduriez, Principles of Distributed Database Systems: Third Edition, 2011 y
EMP1
EMP2
ASG1
ASG2
Query
EMP (ENO, ENAME, TITLE) ASG (ENO, PNO, RESP, DUR)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Ejemplo
Consulta (cálculo relacional): SELECT ENAME
FROM EMP, ASG
WHERE EMP.ENO = ASG.ENO
AND RESP = “Manager”
Consulta (álgebra relacional):
Opción 1:
• ENAME ( RESP=‘Manager’ EMP.ENO = ASG.ENO (EMP x ASG))
Opción 2: (intuitivamente consume menos recursos, evita el producto cartesiano)
• ENAME (EMP ENO ( RESP=‘Manager’ (ASG))

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Ejemplo
Fragmentación y distribución en nodos:
Nodo 1: ASG1 = ENO ≥ ‘E3’ (ASG)
Nodo 2: ASG2 = ENO < ‘E3’ (ASG)
Nodo 3: EMP1 = ENO ≥ ‘E3’ (EMP)
Nodo 4: EMP2 = ENO < ‘E3’ (EMP)
Lanzamiento de la consulta:
Nodo 5
ENAME (EMP ENO ( RESP=‘Manager’ (ASG))

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
ENAME (EMP ENO ( RESP=‘Manager’ (ASG))
Diseño de Consultas Distribuidas
Ejemplo
Estrategia A: transferir todos los fragmentos al nodo 5
Enviar EMP1 Enviar EMP2 Enviar ASG1 Enviar ASG2
Nodo 3 Nodo 4 Nodo 1 Nodo 2
Nodo 5 ENAME (
( ENO, ENAME (EMP1 EMP2)) EMP.ENO= ASG.ENO
( ENO ( RESP=‘Manager’ (ASG1 ASG2)) )
Recibir EMP1 Recibir EMP2 Recibir ASG1 Recibir ASG2

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
ENAME (EMP ENO ( RESP=‘Manager’ (ASG))
Diseño de Consultas Distribuidas
Ejemplo
Estrategia B: enviar resultados intermedios
Enviar EMP1’
Enviar ASG1’
Nodo 3
Nodo 1 Nodo 5
ASG1’ = RESP=‘Manager’ (ASG1)
Enviar ASG2’
Nodo 1
ASG2’ = RESP=‘Manager’ (ASG2)
EMP1’ =EMP1 ASG1’
Recibir ASG1’
Enviar EMP2’
Nodo 4
EMP2’ =EMP2 ASG2’
Recibir ASG2’
Recibir EMP1’ Recibir EMP2’
ENAME (EMP1 EMP2)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Ejemplo
Costes:
Acceder a una tupla: 1 unidad
Transferir una tupla: 10 unidades
Cardinalidad de EMP: 400
Cardinalidad de ASG: 1000
20 asignaciones para “Manager” en ASG
Tuplas uniformemente distribuidas: nodos 1 y 2 devuelven 10 tuplas por filtro “manager” en cada ASGi
Todos los nodos se pueden comunicar con todos
ENAME (EMP ENO ( RESP=‘Manager’ (ASG))

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Ejemplo Costes de las estrategias:
Estrategia 1: • Transferir EMP1 al nodo 5: 200 * 10 = 2000 • Transferir EMP2 al nodo 5: 200 * 10 = 2000 • Transferir ASG1 al nodo 5: 500 * 10 = 5000
• Transferir ASG2 al nodo 5: 500 * 10 = 5000
• Filtrado por “Manager”: 1000 accesos (sin índices) = ASG’ • Join entre la unión de EMP (400 tuplas) y ASG’ (20 tuplas) = 400 * 20 = 8000 • Total = 2000 + 2000 + 5000 + 5000 + 1000 + 8000 = 23.000
Estrategia 2: • Producir ASG1’ en nodo 1: 10 (indizado)
• Producir ASG2’ en nodo 1: 10 (indizado)
• Trasferir ASG1’ a nodo 3: 10*10 = 100
• Trasferir ASG2’ a nodo 4: 10*10 = 100
• Producir EMP1’ en nodo 3 (join indizado por EMP): 1 * 10 = 10 • Producir EMP2’ en nodo 4 (join indizado por EMP): 1 * 10 = 10 • Transferir EMP1’ al nodo 5: 10 * 10 = 100 • Transferir EMP2’ al nodo 5: 10 * 10 = 100 • Lecturas para unión de EMP1’ y EMP2’ en nodo 5: 20 • Total = 10*2 + 100*2 + 10*2 + 100*2 + 20 = 460
ENAME (EMP ENO ( RESP=‘Manager’ (ASG))

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Procesamiento de consultas distribuidas Objetivo: transformar una consulta de alto nivel,
ejecutada por un usuario que percibe el DDBS como único, en una estrategia de ejecución eficiente expresado en un lenguaje de bajo nivel para cada BD local
Medidas utilizadas:
Coste total (de la ejecución de la consulta) • BD centralizadas: reducir coste de E/S (lecturas a disco) y CPU
(acceso a memoria) • BD distribuidas: reducir coste de comunicaciones (datos
transferidos)
Tiempo de respuesta (entre que se ejecuta la consulta y se obtienen los resultados)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Procesamiento de consultas distribuidas Caracterización de consultas distribuidas
Lenguajes: cálculo relacional (~SQL) y álgebra relacional Tipos de optimización: exhaustivo vs. heurístico Temporización de la optimización:
• Estáticamente: antes de ejecutar la consulta • Dinámicamente: durante la ejecución
Uso de estadísticas para selección del orden de ejecución de pasos en una consulta
Toma de decisiones acerca de la estrategia de optimización: centralizada vs. distribuida
Análisis de la topología de red (cercanía) Análisis de los fragmentos Uso de la operación de semijoin como primitiva para reducir la
cantidad de datos enviada (selección de las columnas que se utilizarán en pasos posteriores)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Etapas del procesamiento de consultas distribuidas
Diseño de Consultas Distribuidas
Extraído de Connolly & Begg,
Database Systems. Fourth Edition, 2005.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Etapas del procesamiento de consultas distribuidas (I)
Descomposición de consultas Transformación de la consulta desde una notación de cálculo
relacional a una de tipo algebraico sobre el GCS
Pasos:
1. Reescritura de la consulta en forma normalizada (prioridad de operadores)
2. Análisis de la consulta normalizada: detección y eliminación de consultas con errores (uso de grafos semánticos)
3. Simplificación de la consulta: eliminación de predicados redundantes
4. Reestructuración de la consulta: de cálculo relacional a álgebra. Transformación para conseguir una versión “mejorada” (desde el punto de vista del rendimiento). Se usan reglas simples de transformación

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Etapas del procesamiento de consultas distribuidas (I)
Descomposición de consultas. Paso 1. Normalización:
• Reglas de equivalencia usadas para obtener una “forma canónica” de la consulta (basada en AND o en OR)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Etapas del procesamiento de consultas distribuidas (I)
Descomposición de consultas. Paso 2. Análisis: comprobación de la semántica de la consulta
grafos
Paso 3. Eliminación de la redundancia • Reglas de eliminación

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Etapas del procesamiento de consultas distribuidas (I)
Descomposición de consultas. Paso 4. Reescritura: transformación a álgebra relacional
• Paso 4.1. Traducción directa
• Paso 4.2. Simplificación del árbol de operadores para mejora de rendimiento
» Reglas de transformación
1. Conmutatividad de los operadores binarios:
2. Asociatividad de los operadores binarios
3. Idempotencia de los operadores unarios
4. Conmutatividad de selección con proyección
5. Conmutatividad de selección con operadores binarios
6. Conmutatividad de projección con operadores binarios
» Consejo para optimización:
» Que los operadores unarios se ejecuten lo más cerca posible de las hojas (relaciones o fragmentos)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Reglas de transformación
1. Conmutatividad de los operadores binarios (sólo prod. cartesiano, join y unión)
2. Asociatividad de los operadores binarios
3. Idempotencia de los operadores unarios
4. Conmutatividad de selección con proyección
5. Conmutatividad de selección con operadores binarios Si R y T son “unión compatible”:
6. Conmutatividad de proyección con operadores binarios

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Ejemplo:
Extraído de M.T. Özsu and P. Valduriez,
Principles of Distributed Database Systems: Third Edition, 2011.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Etapas del procesamiento de consultas distribuidas (y II)
Localización de datos Entrada: consulta en forma algebraica
Objetivo: localizar los datos referenciados en la consulta teniendo en cuenta fragmentos y réplicas
Transforma la consulta en una consulta fragmentada (distribuida) reducida (eliminación de consultas sobre fragmentos que producen resultados vacíos)
Reducción para fragmentación horizontal primaria
• Regla 1. Con selección:
• Regla 2. Con join:
Reducción para fragmentación vertical
• Regla 3. no tiene sentido si Ri no contiene atributos de D

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Etapas del procesamiento de consultas distribuidas (y II) Optimización global de la consulta
Entrada: consulta fragmentada en forma algebraica Objetivo: encontrar una estrategia de ejecución óptima (heurística) Notación: álgebra relacional + primitivas de envío/recepción Algoritmos.
• Centrados en optimizar la ordenación de joins/semijoins • Aplicación de algoritmos centralizados a datos distribuidos
» Dynamic*-QOA » Static*-QOA » Basados en semijoin » SQAllocation
Optimización local: optimización usando el LCS Algoritmos centralizados
• Algoritmos dinámicos: INGRES. Descomposición en mini-consultas y optimización individual
• Algoritmos estáticos: System R. Búsqueda exhaustiva del árbol de soluciones de consultas posibles. Optimalidad.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Diseño de Consultas Distribuidas
Algoritmos de optimización (centralizados):
Extraído de M.T. Özsu and P. Valduriez,
Principles of Distributed Database Systems: Third Edition, 2011.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Contexto Business Intelligence:
Capacidad para tomar decisiones de negocio rápidas y precisas Relación con los sistemas distribuidos: SSDD como fuente de la que extraer
información de negocio y generar conocimiento (BI)
Sistemas de soporte a la decisión (DSS): Conjunto de herramientas utilizadas para ayudar en la toma de decisiones ¿Cómo?Combinación de datos históricos de operación con modelos de
negocio que representan las actividades de negocio Componentes (Coronel et al.):
• Sistema de almacenamiento » Datos de negocio. Resumen y reorganización de los datos operativos optimizados
para conseguir rapidez de consultas y análisis de datos (externos y operativos). » Datos de modelos de negocio. Modelan el negocio para identificar y mejorar el
conocimiento que se tiene de las situaciones de negocio (análisis y previsiones). • Componente de filtrado/extracción de datos. Obtiene los datos de fuentes externas para su
almacenamiento • Herramienta de consulta de usuario. Permite a un usuario definir las consultas sobre el
sistema de almacenamiento. • Herramienta de presentación de datos. Permite seleccionar la forma en que se mostrará la
información extraída.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Arquitectura genérica de una solución de BI: dato + contexto
= información
información + acervo científico = conocimiento
Obtenido de:
http://www.sinnexus.com/business_intelligence/arquitectura.aspx

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Data Warehouse Definición: “El Data Warehouse es una colección de datos
integrados, orientados a un tema/propósito, no volátiles e historiados, organizados para el apoyo de un proceso de ayuda a la decisión” Integrados. BD que consolida e integra datos de una organización y de
múltiples fuentes con diversos formatos. Un DW debe tener una representación unificada de los datos.
Orientados a un tema. Los datos se organizan y optimizan para responder a preguntas de diferentes partes de una empresa. La organización de los datos debe estar supeditada a las necesidades de estos departamentos (consulta frente a actualización). OLAP vs. OLTP
No volátiles. “Una vez los datos entran en el DW, nunca salen”. Los datos crecen, pero no se borran
Historiados. Un DW debería representar una vista (snapshot) de los datos de una compañía en un momento determinado.
Objetivo: ayuda a la toma de decisiones
Inmon. Bill & Chuck Kelley."The 12 Rules of Data Warehouse for a Client/Server World". Data Management Rev. 4(5). May, 1994

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Data Warehouse. 12 reglas: 1. El DW y los datos operativos están separados 2. Los datos del DW están integrados 3. El DW contiene datos históricos de largo recorrido 4. Los datos del DW se refieren a momentos concretos de los datos de una
empresa 5. Los datos del DW están orientados a un tema 6. Los datos del DW son, básicamente, datos de sólo lectura con actualizaciones
periódicas en segundo plano. No se permiten las actualizaciones manuales (on-line)
7. El proceso de desarrollo de un DW está dirigido por los datos, no por los procesos que acceden a él
8. Existen diferentes niveles de detalle de los datos almacenados por un DW: actuales, viejos, resúmenes breves y resúmenes extendidos
9. El entorno de un DW se caracteriza por transacciones de solo lectura sobre grandes conjuntos de datos
10. El entorno de un DW contiene un sistema que permite hacer trazas de orígenes de datos, transacciones y almacenamiento
11. Los metadatos del DW son un aspecto crítico 12. El DW cuenta con un mecanismo de optimización enfocado a priorizar las
consultas realizadas por usuarios finales
Inmon. Bill & Chuck Kelley."The 12 Rules
of Data Warehouse for a Client/Server
World". Data Management Rev. 4(5).
May, 1994

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
OLAP vs. OLTP OLTP (On-line Transaction Processing)
Caracterizados por un número significativo de operaciones transaccionales (INSERT, UPDATE, DELETE)
Énfasis: procesamiento rápido de consultas, mantenimiento de la integridad de los datos en entornos de accesos múltiples.
Eficiencia medida en transacciones por segundo Datos y esquemas definidos según un modelo relacional y normalizado
OLAP (On-line Analytical Processing) Caracterizados por un volumen relativamente bajo de transacciones Las consultas son complejas y suelen involucrar agregaciones de datos Eficiencia medida en tiempo de respuesta Técnicas utilizadas: data mining, data analysis, decision making… Estrategias de almacenamiento basados en datos multidimensionales y
esquemas en estrella

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
OLTP (Sistema operacional)
OLAP (Data Warehouse)
Orígenes de los datos Datos operacionales. OLTPs son la fuente
original de los datos Datos consolidados. Diferentes fuentes OLTP
Propósito de los datos Controlar y ejecutar tareas fundamentales del
negocio Ayuda a la toma de decisiones, planificación y
resolución de problemas
Qué representan los datos
El estado actual de la ejecución de los procesos de negocio
Vistas multidimensionales de varias actividades de negocio
Inserts y Updates Pequeños y rápidos a petición de los usuarios Trabajos en segundo plano periódicos
Consultas Consultas simples devolviendo pocos datos Consultas complejas
Velocidad de procesamiento
Normalmente muy rápida Depende de la cantidad de datos involucrados
(hasta horas y días)
Requisitos de espacio Relativamente pequeños Muy altos (agregación de datos)
Diseño de la BD Altamente normalizados Normalmente desnormalizados con pocas
tablas (esquemas en estrella o copo de nieve)
Backup y recuperación Backup necesario (los datos operacionales son
críticos para el negocio) Backup por recarga de los orígenes OLTP

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Tipos de DW (según tamaño) (Elmasri et al., 2003) DW de nivel empresarial (constelaciones de DW) DW virtuales. Ofrecen vistas de BD operacionales materializadas para
acceso eficiente Data-marts. Subconjuntos de DW enfocados a un departamento o
fracción de la empresa Poco volumen de datos Mayor rapidez de consulta Validación directa de la información Facilidad para el almacenamiento histórico de los datos
Ejemplos de soluciones comerciales para DW IBM DB2 Warehouse 9.5 Microsoft SQL Server 2008 Oracle Database 11g Teradata Enterprise Data Warehouse 12.0 Sybase IQ Netezza Performance Server
Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
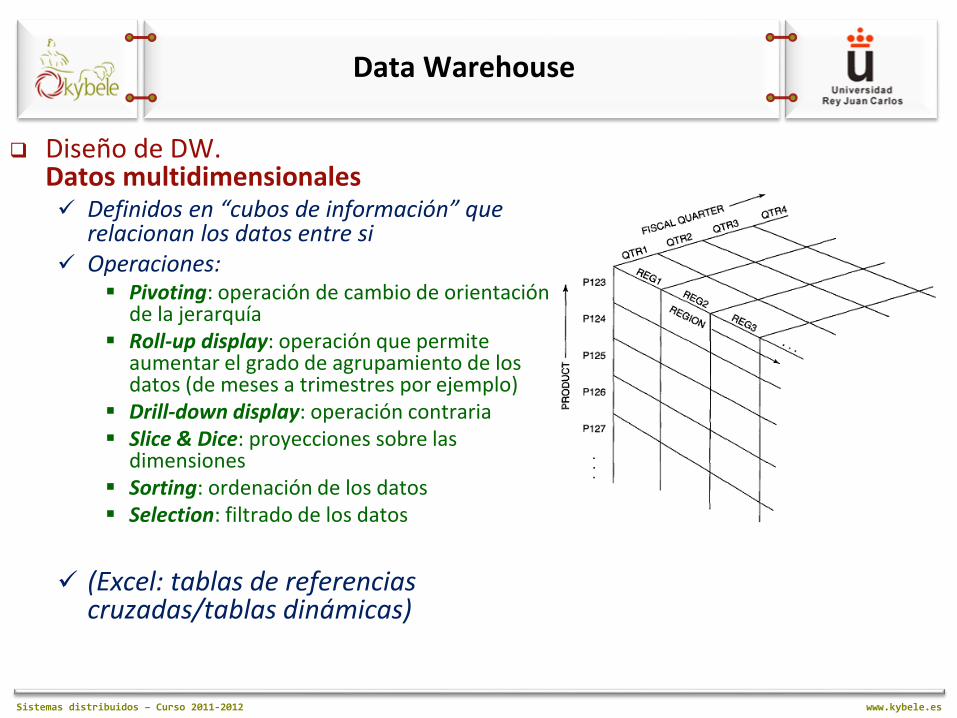
Diseño de DW. Datos multidimensionales Definidos en “cubos de información” que
relacionan los datos entre si Operaciones:
Pivoting: operación de cambio de orientación de la jerarquía
Roll-up display: operación que permite aumentar el grado de agrupamiento de los datos (de meses a trimestres por ejemplo)
Drill-down display: operación contraria Slice & Dice: proyecciones sobre las
dimensiones Sorting: ordenación de los datos Selection: filtrado de los datos
(Excel: tablas de referencias
cruzadas/tablas dinámicas)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Diseño de DW. Tipos de tablas
Tabla dimensión: Conjunto de formas en las que los datos pueden ser agregados, vistos, ordenados o entendidos (producto, tiempo, cliente, etc.) jerarquías de datos
Tabla de hechos (‘facts’): contiene una tupla por cada elemento de interés almacenado y consisten en conjuntos de valores de las medidas de negocio. Cada medida se toma mediante la intersección de las dimensiones que la definen

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Diseño de DW. Tipos de tablas
Obtenido de Wikipedia. http://es.wikipedia.org/wiki/Tabla_de_hechos

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Diseño de DW. Tipos de esquemas multidimensionales Esquema en estrella
Una tabla de hechos Varias tablas de dimensiones Características:
• Estructura simple Esquema fácil de entender • Alta eficiencia de consultas Pocas tablas que unir • Alto tiempo de carga de datos en las tablas de dimensiones
desnormalización, datos redundantes, gran tamaño de la tabla… • Estrategia más utilizada en implementaciones de DW ampliamente
soportada por herramientas de BI
Esquema en “copo de nieve” Una tabla de hechos Varias tablas de dimensiones jerarquizadas y normalizadas
Esquema en “constelación de hechos” Varias tablas de hechos Varias tablas de dimensiones compartidas

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Diseño de DW. Tipos de esquemas multidimensionales Esquema en estrella

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Diseño de DW. Tipos de esquemas multidimensionales Esquema en estrella (extraído de IronBridge SW Inc. 2006)
Regions
EAST
CTRL
East
Central
Beverages
1000
2000
Snap Soda
Crackle Pop
Weeks
2006W01
2006W02
2006W03
Week ending 7 Jan 2006
Week ending 14 Jan 2006
Week ending 21 Jan 2006
Weeks
2006W01
2006W01
2006W01
2006W01
2006W02
2006W02
2006W02
2006W02
2006W03
2006W03
2006W03
2006W03
Dollar Sales
10
12
14
9
12
16
10
15
15
10
15
20
Regions
EAST
EAST
CTRL
CTRL
EAST
EAST
CTRL
CTRL
EAST
EAST
CTRL
CTRL
Beverages
1000
2000
1000
2000
1000
2000
1000
2000
1000
2000
1000
2000
Unit sales
5
6
7
3
6
8
4
6
6
4
6
8
Price
2.00
2.00
2.00
3.00
2.00
2.00
2.50
2.50
2.50
2.50
2.50
2.50
© IronBridge Software Inc.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Diseño de DW. Tipos de esquemas multidimensionales Esquema en “copo de nieve” (snowflake)

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Diseño de DW. Tipos de esquemas multidimensionales Esquema en “constelación de hechos”

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Construcción de un DW 70% de la carga de procesamiento en un DW “Extracción, Transformación y Carga” (proceso ETL)
Extracción: • Orígenes: OLTP, SAP, ERP, sistemas operacionales, legacy • Los datos son extraídos (ad-hoc querying) para su posterior integración
Transformación: • Mapeo de datos a un formato común (renombrado de atributos y tipos de
datos) • “Limpieza” de los datos: validación y análisis de la calidad • “Enriquecimiento” de los datos: p.ej. geolocalización y otros metadatos • Conversión al modelo del DW
Carga: • Tareas de carga en segundo plano • Temporización y monitorización del proceso • Importancia de la distribución de los datos:
» DW federado. Confederación de DW autónomos. » DW distribuido. Repositorio de metadatos replicado en cada DW.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Construcción de un DW
Herramientas ETL:
Microsoft Access / SSIS / SQL Server BCP
IBM DB2 Bulk /DataStage
Oracle Data Pump
Sybase BCP (Bulk Copies Data)
SAS ETL Studio
Jitterbit (opensource)
Pentaho Data Integrator (opensource)
Talen Open Studio (opensource)
http://infogoal.com/datawarehousing/etl_tool_selecti.htm

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Construcción de un DW
Extraído de Datawarehouse4u.info

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Construcción de un DW. Metadatos Metadatos que describen tablas:
Nombre físico Nombre lógico Tipo: hecho, dimensión, otros (‘puente’) Rol: OLTP, sistema heredado (legacy), intermedio SGBD: DB2, Informix, SQL Server, Oracle, Sybase Localización Definición Observaciones
Metadatos que describen columnas de tablas Nombre físico Nombre lógico Orden en la tabla Tipo de datos Longitud Posiciones decimales Requerido/Admite null Valor por defecto Definición Observaciones

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Construcción de un DW. Metadatos Metadatos:
Necesarios para simplificar y automatizar la obtención de la información desde los sistemas operacionales a los sistemas de toma de decisiones
Objetivos que deben cumplir los metadatos, según el colectivo al
que va dirigido (www.sinnexus.com): Dar soporte al usuario final:
• Ayudándole a acceder al DW con su propio lenguaje de negocio • Indicando qué información hay y qué significado tiene • Ayudar a construir consultas, informes y análisis, mediante herramientas de BI
Dar soporte a los responsables técnicos del DW: • Aspectos de auditoría • Gestión de la información histórica • Administración del DW • Elaboración de programas de extracción de la información • Especificación de las interfaces para la realimentación a los sistemas
operacionales de los resultados obtenidos... • Etc.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Data Warehouse
Data mining ¿Business Services?
Extraído de Connolly & Begg. Database Systems: A Practical Approach to Design, Implementation and Management . 6th Ed.

Sistemas distribuidos – Curso 2011-2012 www.kybele.es
Ejercicios
Estudiar la taxonomía de sistemas distribuidos de almacenamiento descrita en: http://www.cloudbus.org/reports/DistributedStorageTaxonomy.pdf
Encontrar y describir las operaciones permitidas del protocolo NFS (versión 4)
Estudiar cómo NFS cumple las características de transparencia, replicación de ficheros, heterogeneidad SW y de Sist. Op., tolerancia a fallos, consistencia, seguridad y eficiencia
Buscar información acerca de las técnicas de read-ahead y write-delay en entornos distribuidos. ¿Qué relación tienen con la definición de transacciones?
Buscar ejemplos de bases de datos distribuidas y estudiar la forma en que gestionan los diferentes esquemas definidos en la arquitectura ANSI/SPARC
¿Por qué los algoritmos de optimización se centran en la ordenación de joins/semijoins?
¿Qué relación hay entre un CPD y un Data Warehouse?


















