
TEMA 3: Gestión de la Disponibilidad · Implementación y Mantenimiento ... ♦ITIL contempla...
54
E.T.S. de Ingeniería Informática CIMSI – Configuración, Implementación y Mantenimiento de Sistemas Informáticos Daniel Cascado Caballero Rosa Yáñez Gómez Mª José Morón Fernández TEMA 3: Gestión de la Disponibilidad
Transcript of TEMA 3: Gestión de la Disponibilidad · Implementación y Mantenimiento ... ♦ITIL contempla...

E.T.S. de Ingeniería Informática
CIMSI – Configuración, Implementación y Mantenimiento
de Sistemas Informáticos
Daniel Cascado CaballeroRosa Yáñez Gómez
Mª José Morón Fernández
TEMA 3: Gestión de la Disponibilidad

E.T.S. I. Departamento ATC
Contenidos
Introducción
Confiabilidad
Eliminación de Fallos
Predicción de Fallos
Tolerancia a Fallos
Prevención de Fallos
Ejemplos de Disponibilidad

E.T.S. I. Departamento ATC
Gestión de la Disponibilidad
Mejora Continua: 1 Proceso de 7 pasos
¿Qué medir?¿Qué se puede
medir?Medir Procesar Analizar Informar
Operación: 5 Procesos
Eventos Incidencias Problemas Peticiones Accesos
Transición: 7 Procesos
Planificación y Apoyo
CambioActivos y
ConfiguraciónVersiones
Validación y Prueba
Evaluación Conocimiento
Diseño: 6 Procesos
CatálogoNiveles de Servicio
Capacidad Disponibilidad Continuidad Seguridad
Estrategia: 3 Procesos
Financiero Demanda Portfolio

E.T.S. I. Departamento ATC
PROVEEDORES(Acuerdos y contratos)
Servicio: Elementos
PRODUCTOS (Infraestructura)
PROCESOS(Procedimientos)
PERSONAS (RRHH)

E.T.S. I. Departamento ATC
SIS
TE
MA
Sistema: Definición
Inte
rfaz Hardware
Software
Comunicaciones
Documentación

E.T.S. I. Departamento ATC
Introducción
Un servicio realiza una función mediante un determinado sistema, que se puede ver como la sucesión de sus estados de funcionamiento.
♦ ITIL contempla además los acuerdos con el cliente.
♦ El sistema tiene un estado interno y otro externo, que ve el cliente.
♦ La frontera entre el cliente y el sistema es el interfaz de proveedor de servicio
Cliente
• Estado externo
Cliente
• Estado externo
Sistema
• Estado interno
Sistema
• Estado interno

E.T.S. I. Departamento ATC
Definiciones (I)
♦ Fallo: Evento que interrumpe el correcto funcionamiento de un servicio.
� Es una incidencia, según ITIL.
� Incumple especificaciones funcionales.
� Puede ocurrir porque las especificaciones funcionales no estén bien definidas (los umbrales de servicio no están bien definidos, p.ej.)
♦ Parada (outage) o interrupción del servicio: Periodo de tiempo en el que el servicio no se ofrece correctamente.
♦ Restauración del servicio: Transición de servicio incorrecto a correcto.

E.T.S. I. Departamento ATC
Definiciones (II)
♦ Modos de fallo: Forma en la que el servicio sealeja de su correcto funcionamiento.
� Se clasifica en función de la severidad del fallo.
♦ Error: Funcionamiento incorrecto de todo o partedel servicio.
� Se debe a una falta (fault). Una falta no siempredesencadena un error.
• Internas al sistema o externas al sistema
• A su vez, pueden ser latentes, si no dan lugar a error, oactivas en caso contrario.
♦ Cuando el fallo no afecta a todo el sistema seconsidera que funciona en modo degradado,pudiendo ofrecer aún algunas de las funcionalidadesdel mismo que no han sido afectadas por el fallo

E.T.S. I. Departamento ATC
Ejemplos (I)
♦ La presencia de una vulnerabilidad de seguridad en un sistema es una falta interna
♦ Si dicha falta no desencadena un error, no afecta al estado interno del servicio.
� No desencadena un fallo
� La falta se considera latente
♦ Si causa un error, afectará al estado externo del servicio.
� Se la considera como una falta activa.

E.T.S. I. Departamento ATC
Ejemplos (II)
♦ Un cortocircuito en un chip es un fallo (respecto a la función del circuito)
♦ La consecuencia, es una falta, que permanecerá inactiva mientras no se active el circuito
♦ Cuando se active, la falta se vuelve activa y produce un error, que es probable que produzca otros errores
♦ Si el error afecta a la entrega correcta del servicio se produce un fallo

E.T.S. I. Departamento ATC
Ejemplos (III)
♦ El resultado del error de un programador lleva a un fallo en la escritura de la instrucción o dato correcto en el soft
♦ En cambio, todo esto es una falta inactiva hasta que se llame a la parte incorrecta del programa o al dato incorrecto y producirá un error
♦ Si el error afecta a la prestación correcta del servicio, producirá un fallo en el servicio
♦ A veces el fallo en el código es intencionado (bomba lógica) programada por un hacker
� Sólo producirá un fallo si al activarse se produce una denegación, o degradación de la prestación del mismo

E.T.S. I. Departamento ATC
Contenidos
Introducción
Confiabilidad• Definición
• Atributos
• Amenazas
• Recursos
Eliminación de Fallos
Predicción de Fallos
Tolerancia a Fallos
Prevención de Fallos
Ejemplos de Disponibilidad

E.T.S. I. Departamento ATC
Confiabilidad (Dependability): Definición
♦ Es la capacidad de un sistema para dar un servicio correctamente y con una fiabilidad justificada.
� La confiabilidad de un sistema A en otro B es el grado en el que la confiabilidad de A se ve afectada por la confiabilidad de B, es decir, el grado de dependencia aceptada de B.
♦ Tres componentes:
� Atributos
� Amenazas
� Recursos
Router de salida
Router de salida
Servidor CServidor CDistribuidor
LVSDistribuidor
LVS
Servidor AServidor A
Servidor BServidor BEste servidor tiene
alta confiabilidad en el LVS

E.T.S. I. Departamento ATC
Confiabilidad (Dependability): Componentes (I)
♦ Disponibilidad: Percepción del servicio correcto
♦ Fiabilidad: Continuidad del servicio correcto
♦ Seguridad: Ausencia de consecuencias dañinas para el usuario, el cliente o el entorno
♦ Integridad: Ausencia de alteraciones impropias del sistema
♦ Mantenibilidad: Capacidad de tolerar las reparaciones o modificaciones
♦ Confidencialidad: Bloqueo de accesos indebidos

E.T.S. I. Departamento ATC
FaltaFalta ErrorError FalloFallo Parada Parada RestauraciónRestauración
Confiabilidad (Dependability): Componentes (II)
♦ Falta: Causa subyacente de un error
♦ Error: Parte del estado del sistema que es responsable de provocar un fallo
♦ Fallos: Servicio entregado ≠ Servicio especificado

E.T.S. I. Departamento ATC
Confiabilidad (Dependability): Componentes (III)
♦ Medios para romper la cadena falta-error:
� Eliminación de fallos (fault removal): Trata de reducir el número y severidad de los fallos
� Predicción de fallos (fault forecasting): Se orienta a estimar el número presente de fallos, su futura incidencia y las consecuencias más probables.
� Tolerancia a fallos (fault tolerance): Trata de evitar los fallos que alteran el servicio en presencia de faltas
� Prevención del fallos (fault prevention): Trata de prevenir la ocurrencia o introducción de fallos

E.T.S. I. Departamento ATC
Contenidos
Introducción
Confiabilidad
Eliminación de Fallos
Predicción de Fallos
Tolerancia a Fallos
Prevención de Fallos
Ejemplos de disponibilidad

E.T.S. I. Departamento ATC
FaltaFalta ErrorError FalloFallo Parada Parada RestauraciónRestauración
Eliminación de Fallos
♦ Objetivo: Reducir el número y severidad de los fallos
♦ Mecanismos: 1. Eliminación de faltas activas o latentes
2. Gestión de faltas: amortiguar o eliminar el impacto de las faltas ⇒ No provoquen errores
3. Eliminación de errores
4. Gestión de errores: amortiguar o eliminar el impacto de las errores ⇒ No provoquen fallos

E.T.S. I. Departamento ATC
Eliminación de Faltas (I)
♦ Es el proceso que se lleva a cabo para eliminar las faltas (activas o inactivas) que pueden llevar a errores y/o fallos
♦ Durante el desarrollo:VerificaciónVerificación
•Si no cumple con las condiciones de verificación entonces….
Diagnóstico, para averiguar cuál es la faltaDiagnóstico, para averiguar cuál es la falta
•Si se encuentran faltas…
Corrección: se corrije la/s falta/sCorrección: se corrije la/s falta/s
•Y después se realiza una verificación regresiva, para garantizar la ausencia de consecuencias adversas de la eliminación
Validación:Validación:
•El sistema cumple con las especificaciones. Sino, se repite el proceso
♦ La verificación puede hacerse sobre el sistema o sobre un modelo del mismo
� Estática: se realiza sin poner en marcha el sistema
• Recorridos, análisis de flujo de datos, de complejidad, compilando, buscando vulnerabilidades, chequeo de máquinas de estado…
� Dinámica: se realiza poniéndolo en marcha = testing
• Por patrones de entrada
• Por valores de entrada aleatorios

E.T.S. I. Departamento ATC
Eliminación de Faltas (II)
♦ Durante el uso del sistema: se realiza…
� Mantenimiento correctivo: Para faltas que han producido un error y han sido registradas
• Aislamiento de la falta
• Eliminación
� Mantenimiento predictivo: Orientado a eliminar faltas latentes, antes de que produzcan un error
• Faltas físicas que han ocurrido desde el último mantenimiento
• Faltas de desarrollo que han producido errores en otros componentes similares

E.T.S. I. Departamento ATC
Gestión de Faltas
♦ Evita que las faltas se activen de nuevo y puedan provocar errores
♦ Técnicas:
� Diagnóstico: Identifica y registra las causas del error en términos de localización y tipo
� Aislamiento: Excluye componentes fallidos del funcionamiento del servicio
� Reconfiguración: Reasigna tareas a componentes que no fallan o componentes redundantes
� Reinicialización: Comprueba, actualiza y registra la nueva configuración y actualiza las tablas del sistema y sus registros

E.T.S. I. Departamento ATC
Eliminación de Errores
♦ Es imposible eliminar todos los errores, así como prevenirlos al 100%
♦ La detección se convierte en una tarea continua dentro del funcionamiento del servicio.
♦ Dos formas de llevarla a cabo:
� Concurrentemente: tiene lugar durante el funcionamiento normal del servicio
� Preventiva: tiene lugar cuando no se presta normalmente el servicio, comprueba el sistema en busca de errores latentes y faltas inactivas.

E.T.S. I. Departamento ATC
Gestión de Errores
♦Elimina los errores del estado del sistema.
♦Técnicas:
� Rollback: Echar hacia atrás al sistema para que se vuelva a un estado estable
� Rollforward: Avanzar el estado del sistema para que salga del estado de error a un estado estable
� Compensation: Ocultar el error mediante la redundancia del sistema

E.T.S. I. Departamento ATC
Gestión de Errores: Estrategias
♦ Poner imagen del artículo

E.T.S. I. Departamento ATC
Gestión de Errores: Ejemplos
♦ Los motores de bases de datos suelen implementar rollback para que la base de datos vuelva al estado anterior a una transacción en caso de que no se haya realizado en su totalidad
♦ Un servicio web puede hacer compensación en caso de un error en uno de sus servidores, si la función de ese servidor está replicada en otro
♦ Nagios implementa scripts de rollfordwarden su base de datos para sacarla de estados inestables

E.T.S. I. Departamento ATC
Contenidos
Introducción
Confiabilidad
Eliminación de Fallos
Predicción de Fallos
Tolerancia a Fallos
Prevención de Fallos
Ejemplos de Disponibilidad

E.T.S. I. Departamento ATC
Predicción de Fallos
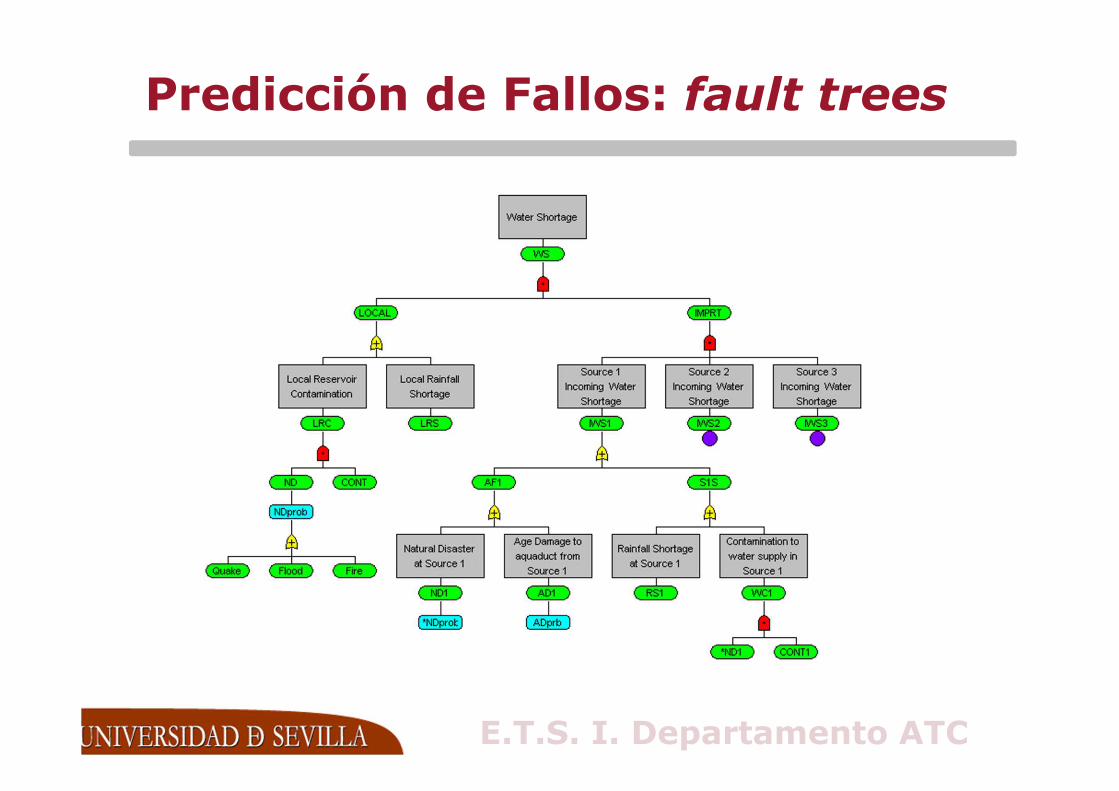
♦ Se realiza mediante la evaluación del comportamiento del sistema ante la ocurrencia de faltas o su activación. Dos aspectos:
� Cualitativo: Identificar y clasificar los modos de fallo y las condiciones para que se produzca un error
• Reliability block diagrams, fault trees
� Cuantitativo o probabilístico: Evaluar la probabilidad de que se satisfagan ciertos atributos del sistema (medidas)
• Modelado matemático, test de sistemas

E.T.S. I. Departamento ATC
Predicción de Fallos: RBDs
FR= tasa de fallos por millón de horas
RR= tasa de reparación por millón de horas
E.T.S. I. Departamento ATC
Predicción de Fallos: fault trees

E.T.S. I. Departamento ATC
Contenidos
Introducción
Confiabilidad
Eliminación de Fallos
Predicción de Fallos
Tolerancia a Fallos• Objetivo. Factores Claves. • Técnicas
• Recuperación de sistemas
Ejemplos de Disponibilidad

E.T.S. I. Departamento ATC
Tolerancia a Fallos (FTo)
♦ Objetivo: Que la ocurrencia de faltas ⇏ Fallos del servicio ⇒ ↑confianza en el servicio
♦ Factores claves:
� Detección temprana ⇒ Monitorización proactiva
� Tratamiento ⇒ Enmascaramiento del fallo para que no se refleje en el estado externo del sistema
♦ Técnicas:
� Escalado
� Replicación
� Distribución
� Evitar los puntos únicos de fallo (SPOF)

E.T.S. I. Departamento ATC
Contenidos
Introducción
Confiabilidad
Eliminación de Fallos
Predicción de Fallos
Tolerancia a Fallos• Objetivo. Factores Claves.
• Técnicas• Recuperación de sistemas
Prevención de Fallos
Ejemplos de Disponibilidad

E.T.S. I. Departamento ATC
Tolerancia a Fallos: Escalado
♦ Mantener un control de la capacidad del sistema permite conocer el punto en el que comienzan los fallos por saturación
♦ Se pueden establecer controles de admisión a partir de ciertos niveles de carga.
0,00
200,00
400,00
600,00
800,00
1.000,00
1.200,00
1.400,00
1.600,00
1.800,00
2.000,00
1 18 36 72 108 144 216
Th
rou
gh
pu
t
Virtual Users
Capacity Modeled
Measured

E.T.S. I. Departamento ATC
Tolerancia a Fallos: Replicación (I)
♦ La replicación actúa compensando los errores al aumentar la redundancia.
E.T.S. I. Departamento ATC
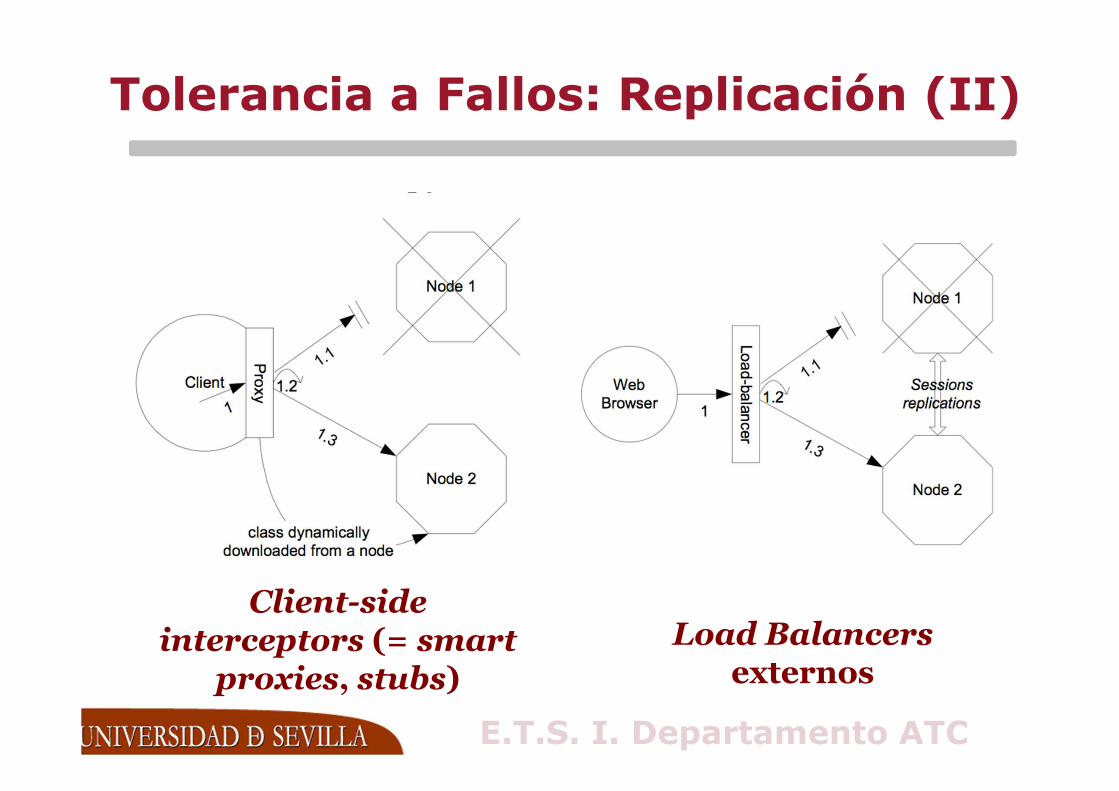
Tolerancia a Fallos: Replicación (II)
Client-side interceptors (= smart
proxies, stubs)
Load Balancersexternos

E.T.S. I. Departamento ATC
Tolerancia a Fallos: Distribución (I)
Es necesario establecer mecanismos de distribución que no sólo se encarguen de repartir la carga sino también de sortear nodos en modos de fallo determinado.

E.T.S. I. Departamento ATC
Tolerancia a Fallos: Distribución (II)

E.T.S. I. Departamento ATC
Tolerancia a Fallos: Distribución (III)

E.T.S. I. Departamento ATC
Tolerancia a Fallos: SPOF
♦ OBJETIVO: Evitar los puntos únicos de fallo (SPOF) a todos los niveles:
� Replicación del hard de los servidores (Ej: tarjetas de red dobles)
� Replicación de los propios servidores a nivel hard
� Replicación de la lógica soft y coherencia
� Replicación de los repositorios de datos
� Replicación de las comunicaciones
� Replicación del personal (!)
� Redundancia de los procedimientos (!)

E.T.S. I. Departamento ATC
Contenidos
Introducción
Confiabilidad
Eliminación de Fallos
•Eliminación de Faltas
•Gestión de Faltas
•Eliminación de Errores
•Gestión de Errores
Predicción de Fallos
Tolerancia a Fallos•Objetivo. Factores Claves.
•Técnicas
•Recuperación de sistemas
Prevención de Fallos
Ejemplos de Disponibilidad
E.T.S. I. Departamento ATC
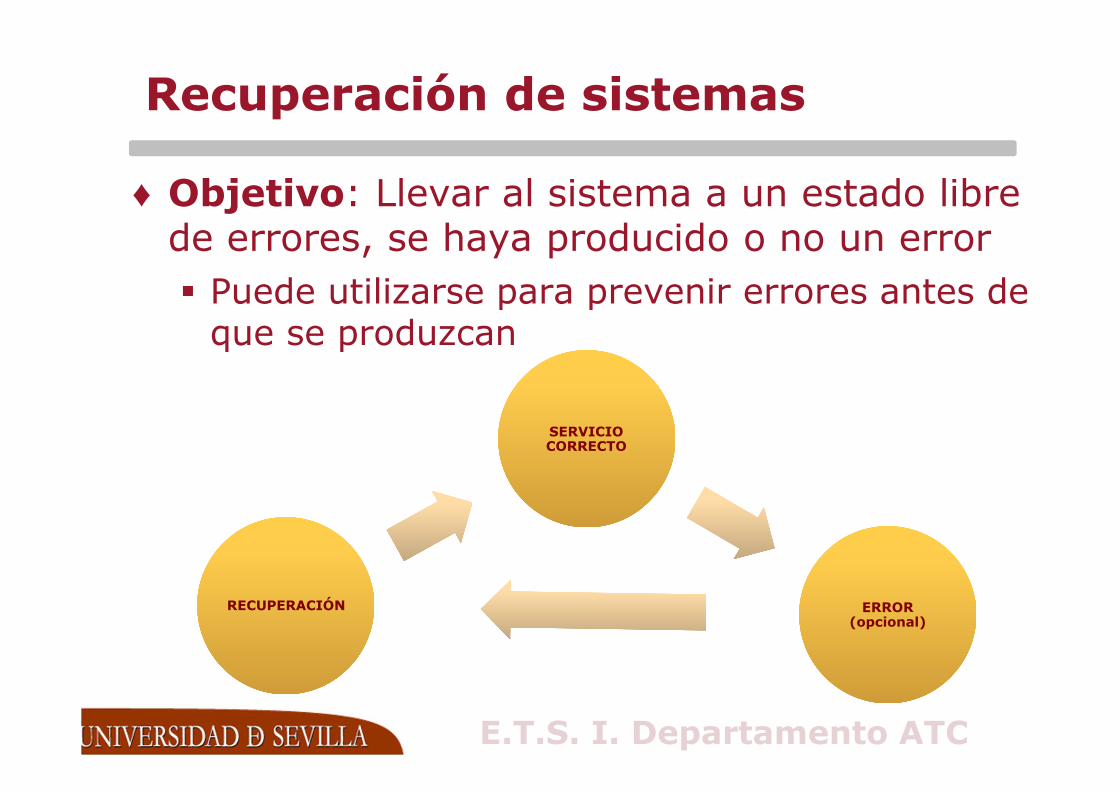
Recuperación de sistemas
♦ Objetivo: Llevar al sistema a un estado libre de errores, se haya producido o no un error
� Puede utilizarse para prevenir errores antes de que se produzcan
SERVICIO CORRECTOSERVICIO CORRECTO
ERROR (opcional)
ERROR (opcional)
RECUPERACIÓNRECUPERACIÓN

E.T.S. I. Departamento ATC
Contenidos
Introducción
Confiabilidad
Eliminación de Fallos
Predicción de Fallos
Tolerancia a Fallos
Prevención de Fallos•Diseño del Sistema•Hardware FTo
Ejemplos de Disponibilidad

E.T.S. I. Departamento ATC
FTo: Diseño del sistema (I)
♦ Modularidad: Descomposición jerárquica del sistema en módulos. Cada módulo es:� Unidad de servicio
� Contenedor de los fallos
� Unidad mantenible y reparable por sí misma
♦ Fallo rápido (fail-fast): Un módulo debería o funcionar correctamente o fallar por completo. Los estados intermedios son difíciles de detectar y tratar
♦ Fallos independientes: Si un módulo falla, dicho fallo no debe afectar al resto de módulos

E.T.S. I. Departamento ATC
FTo: diseño del sistema (II)
♦ Fallos independientes: Si un módulo falla, dicho fallo no debe afectar al resto de módulos
♦ Redundancia: Disponibilidad de módulos de repuesto (spare) instalados y configurados previamente, para sustituir a otro en caso de fallo. Entretanto, se puede reparar el módulo que falló
♦ Replicación: aumenta la disponibilidad. Pero cuidado…
� Puede llevar al sistema a un estado degradado
� O a una interrupción, si las réplicas no pueden absorber la capacidad total requerida

E.T.S. I. Departamento ATC
Contenidos
Introducción
Confiabilidad
Eliminación de Fallos
Predicción de Fallos
Tolerancia a Fallos
Prevención de Fallos•Diseño del Sistema
•Hardware FTo
Ejemplos de Disponibilidad

E.T.S. I. Departamento ATC
FTo: Hardware FTo
♦ Además de las directrices de diseño de un sistema Fto, suelen aplicarse:
� Auto-chequeo: Capacidad del componente para saber su estado de funcionamiento
� Watchdogs: Un flag que debe de ser borrado cada cierto tiempo. Si no se hace el sistema se resetea, o da un error
� Comparación: La función del componente está replicada, de manera que un árbitro puede avisar del error del componente en caso de respuestas discordantes.
• El árbitro también puede ser redundante
• La disponibilidad se incrementa notablemente si además de redundancia es posible hacer reparaciones en el componente.

E.T.S. I. Departamento ATC
Triple Modular Redundancy
♦ Tres módulos redundantes. Un árbitro decide cuál da la salida (por mayoría).
♦ Si un módulo falla, se puede desconectar
� Puede asumir como mucho un fallo en un módulo
♦ El árbitro también puede fallar (no tiene redundancia)

E.T.S. I. Departamento ATC
N-Modular Redundancy
♦ N módulos activos (N impar)
� Tiene un primer procesamiento de las entradas, y otro posterior a las salidas
� Se garantiza tanto la entrada al módulo como la salida (dos etapas de árbitros)
� Asumirá hasta floor(N/2) fallos
E.T.S. I. Departamento ATC
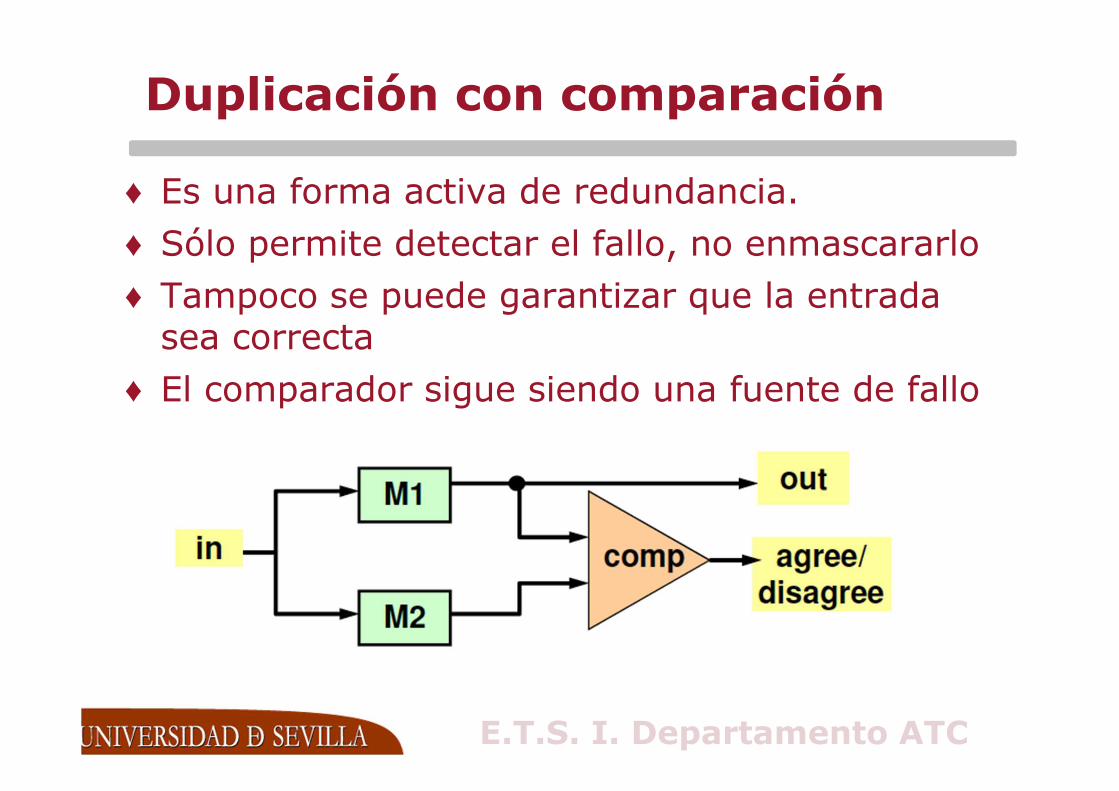
Duplicación con comparación
♦ Es una forma activa de redundancia.
♦ Sólo permite detectar el fallo, no enmascararlo
♦ Tampoco se puede garantizar que la entrada sea correcta
♦ El comparador sigue siendo una fuente de fallo
E.T.S. I. Departamento ATC
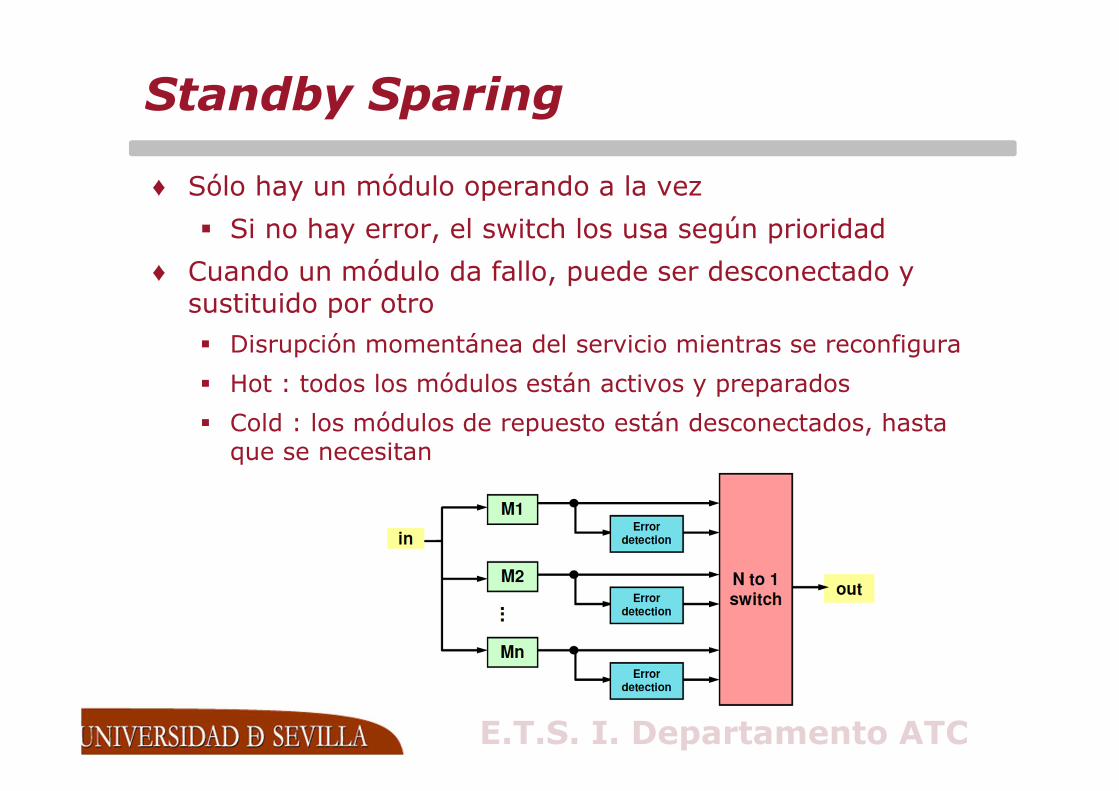
Standby Sparing
♦ Sólo hay un módulo operando a la vez
� Si no hay error, el switch los usa según prioridad
♦ Cuando un módulo da fallo, puede ser desconectado y sustituido por otro
� Disrupción momentánea del servicio mientras se reconfigura
� Hot : todos los módulos están activos y preparados
� Cold : los módulos de repuesto están desconectados, hasta que se necesitan

E.T.S. I. Departamento ATC
Pair and a Spare
♦ Combinación de duplicación y NMR
� Siempre operan dos módulos en paralelo
� Si uno da error se sustituye por un repuesto
� El comparador vigila si hay error, y los detectores averiguan cuál es

E.T.S. I. Departamento ATC
Contenidos
Introducción
Confiabilidad
Eliminación de Fallos
•Eliminación de Faltas
•Gestión de Faltas
•Eliminación de Errores
•Gestión de Errores
Predicción de Faltas
Tolerancia a Faltas
•Objetivo. Factores Claves.
•Técnicas
•Recuperación de sistemas
•Diseño del sistema
•Hardware FTo
Ejemplos de Disponibilidad

E.T.S. I. Departamento ATC
Ejemplos: fly-by-wire
♦ Utilizado para controlar las superficies de vuelo de aeronaves civiles y militares
♦ Redundancia cuádruple de todos los sistemas actuadores de las superficies de control (Pair-&-Spare, n=4)
� Líneas neumáticas de presión
� Líneas de datos
� Actuadores
♦ Cada elemento tiene su propio autochequeo y detección de fallo
♦ Suelen tener dos o más procesadores para generar las señales a los actuadores
♦ En los modelos antiguos, posibilidad de reversión a manual si el sistema falla por completo (F-15, en caso de proximidad a pulso magnético)
♦ En Cápsula Apollo, implementaba NMR, n=5

E.T.S. I. Departamento ATC
Ejemplos: RAID
♦ Nivel 0: sin redundancia
♦ Nivel 1: discos en espejo. Duplicidad de la información
♦ Nivel 2: Información intercalada a nivel de bytes entre los discos. Corrección de errores por ECC
♦ Nivel 3: Información intercalada a nivel de bytes entre los discos. Detección de errores por disco de paridad
♦ Nivel 4: Ficheros intercalados a nivel de bloques. Disco de Paridad
♦ Nivel 5: Ficheros intercalados a nivel de bloques. Paridad distribuida entre varios discos.


















