SISTEMA DE SÍNTESIS DE IMÁGENES DE TRAZADO DE RAYOS EN …
75
1 SISTEMA DE SÍNTESIS DE IMÁGENES DE TRAZADO DE RAYOS EN UNA PLATAFORMA DE DESARROLLO PARA HARDWARE EMBEBIDO Pontificia Universidad Javeriana Noviembre 15, 2012 Luisa Fernanda García, M.Sc. Director Carlos Albero Parra, Ph.D. Director Julián Andrés Guarín Reyes Autor
Transcript of SISTEMA DE SÍNTESIS DE IMÁGENES DE TRAZADO DE RAYOS EN …

1
SISTEMA DE SÍNTESIS DE IMÁGENES DE TRAZADO DE RAYOS EN UNA
PLATAFORMA DE DESARROLLO PARA HARDWARE EMBEBIDO
Pontificia Universidad Javeriana
Noviembre 15, 2012
Luisa Fernanda García, M.Sc. Director
Carlos Albero Parra, Ph.D.
Director
Julián Andrés Guarín Reyes
Autor

2
A mi padre, Luis Eduardo Guarin Sepulveda, quien es la síntesis de que la verdad convence pero el ejemplo arrastra, el mejor padre, amoroso lider de
nuestra familia y el hombre que más admiro.
A mi madre, Amanda Reyes, que con su increible forma se ser y su manera sui generis de mirar el mundo, me hacen entender que madre solo hay una,
pero la mía es la mejor .
A mi hermano Alejandro , “Monchi”, que siempre ha sido el mejor hijo y hermano, de quien siempre estaré orgulloso y a quien siempre trataré de
emular.
A Héctor Morales, a quien no solo considero mi amigo, sino también mi hermano y quien además es el mejor ingeniero electrónico que conozco y
del que seguir su ejemplo es apenas una aspiración.
Y por supuesto con cariño para mi primo hermano Mauricio Guarín, constante aliado y testigo fiel de este trabajo.
Este trabajo es para ustedes, porque ustedes siempre estuvieron ahí.

3
AGRADECIMIENTOS A los profesores del Departamento de Electrónica, en especial a los profesores Salguero, Maldonado, Jaquenod, Pariguan y López. A los profesores Luisa Fernanda García y Carlos Alberto Parra, por la dirección y asesoría, muchas, muchas gracias. Agradezco también a los ingenieros Carlos Carrasco, Oscar Daniel Molina y a mi gran amigo Gonzalo Hernández Prieto -por su incondicional apoyo-, pues facilitaron recursos físicos y de tiempo durante la realización de esta investigación. Gracias amigos. A todos los que me empujan, me apoyan, me piden, me demandan y me exigen, que sea un mejor ingeniero todos los días, muchas gracias.

4
TABLA DE CONTENIDO. AGRADECIMIENTOS ........................................................................................................................... 3 TABLA DE CONTENIDO. .................................................................................................................... 4 1 INTRODUCCIÓN AL PROBLEMA ............................................................................................. 5 2 ESTADO DEL ARTE EN TRAZADO DE RAYOS ................................................................... 7 3 INTRODUCCIÓN TRAZADO DE RAYOS.............................................................................. 17
3.1 Intersección Rayos y Esferas. ....................................................................................... 19 3.2 Shading Model (Modelo de coloración) .................................................................... 22
4 DESCRIPCIÓN GENERAL DE LA SOLUCIÓN .................................................................... 23 4.1 Componentes de hardware utilizado. ....................................................................... 23 4.2 Componente de software. .............................................................................................. 24 4.3 Herramientas de Desarrollo. ........................................................................................ 25 4.4 Otras Herramientas. ......................................................................................................... 25
5 ARQUITECTURA DE SOFTWARE ......................................................................................... 27 5.1 Escenario 3D y enlaces seriales. .................................................................................. 27 5.2 Intersección geométrica y oclusión. .......................................................................... 28 5.3 Display y framebuffer driver. ....................................................................................... 28
6 ARQUITECTURA DE HARDWARE ....................................................................................... 29 6.1 Descripción de la arquitectura de procesamiento de flujo de datos. ............ 29 6.2 Elementos de la arquitectura. ...................................................................................... 30
6.2.1 Interconexión decodificada de datos. ............................................................... 31 6.2.2 Componentes Aritméticos. .................................................................................... 31 6.2.2.3. Inversor, 32 Bits en Punto Flotante IEEE 754, Precisión Sencilla. .... 36 6.2.2.4. Raíz Cuadrada IEEE 754, 32 Bits Floating Point, Single Precision. ... 37
6.2.3. Adaptadores de formato. ........................................................................................... 38 7. INTERFAZ DE PROGRAMACIÓN, MÁQUINA DE ESTADOS Y SINCRONIZACIÓN DEL RAYTRAC .................................................................................................................................... 40
7.1 Interfaz de programación. ................................................................................................. 40 7.2 Mecanismos de sincronización del RayTrac............................................................... 45
7.2.1. Interfaz Avalon Memory Mapped Master. ...................................................... 45 7.2.2. Interfaz Avalon Memory Mapped Slave ............................................................... 48
7.2.3. Interfaz Avalon Interrupt Out ............................................................................. 51 7.3. Mecanismos de sincronización del RayTrac.............................................................. 51
8. RESULTADOS ............................................................................................................................. 55 8.1. Verificación: Resultados. ............................................................................................... 55 8.2. Validación: Resultados del sistema como herramienta para la realización de rendering. .................................................................................................................................. 58 8.3. Problemas en la generación de imágenes con RayTrac .................................... 64 8.3. Recursos Utilizados, simulaciones y análisis de tiempos. ................................ 64
9. CONCLUSIONES ......................................................................................................................... 69 9.1. Trabajo a futuro. ............................................................................................................... 71
10 BIBLIOGRAFÍA ............................................................................................................................. 72

5
1 INTRODUCCIÓN AL PROBLEMA
Rendering es el proceso computacional en el que los elementos e interacciones de un
modelo representado en 3 dimensiones espaciales (polígonos, fuentes de luz, etc.),
son proyectados contra un plano arbitrario que también pertenece al modelo, para
formar en él una imagen sintetizada.
Existen varias clases de algoritmos, siendo los principales el algoritmo de rasterización
y el algoritmo de trazado de rayos.
El algoritmo del trazado de rayos se considera cualitativamente, en términos de
calidad de las imágenes y otros criterios, muy superior, ya que básicamente, simula el
comportamiento óptico de la luz, ejecutando el cálculo de los fenómenos físicos de
absorción, refracción y reflexión.
El problema del algoritmo de trazado de rayos es la carga computacional que asume el
procesador al ejecutarlo. El desempeño de dicha ejecución es siempre menor que la de
un algoritmo de raster para la misma escena, por lo tanto es más probable que sea
elegido para ser implementado.
Por ejemplo, un desarrollador de videojuegos, optará por ejecutar un algoritmo de
raster cuyo desempeño le brinda una tasa de refresco mínimo, así no tenga las
prestaciones de calidad visual que el algoritmo de trazado de rayos ofrece.
Para que el algoritmo de trazado de rayos no sea desechado, su desempeño debe ser
mayor, en comparación con los algoritmos cuyo desempeño los convierte en la opción
para elegir.
Dada la falta de desempeño en imágenes por segundo, de cualquier aplicación que
aplique un algoritmo de trazado de rayos, comparada con el desempeño que la misma
obtendría al aplicar rasterización, se propone una solución que aborda el problema
desde el hardware en el que se ejecuta el algoritmo.
La solución consiste en el diseño e implementación de un procesador vectorial, que
acelere los cálculos vectoriales críticos en la ejecución de un algoritmo de trazado de
rayos, aumentando la posibilidad de elegirlo, por encima de otros algoritmos
convencionales de rendering. A este procesador se le denomina RayTrac.

6
Objetivo General.
Diseñar e implementar una arquitectura de trazado de rayos para síntesis de
imágenes.
Objetivos Específicos.
● Diseñar, simular e implementar los circuitos aritméticos que soporten la
resolución geométrica de un sistema de trazado de rayos.
● Implementar una interfaz operativa, sirviendose de herramientas de software
propietarias y abiertas, de terceros.
● Evaluar la implementación de la arquitectura de trazado de rayos, a partir de
software.
Para el cumplimiento de estos objetivos se implementó una plataforma de trazado de
rayos llamado RtEngine (A), y está compuesta por un procesador vectorial llamado
RayTrac (B) y una aplicación de rendering a la que se llama JART (Just Another Ray
Tracer) (C) .
La implementación de los componentes RayTrac y Jart, dan como resultado la
implementación del componente RtEngine. En el capítulo 4 Descripción General del
Sistema se hace referencia al RtEngine sus componentes y características.

7
2 ESTADO DEL ARTE EN TRAZADO DE RAYOS Sobre el desempeño…. En los últimos 10 años se han visto ejemplos de aplicaciones, en los que se ejecutan algoritmos de trazado de rayos con un desempeño de rendering mayor o igual a 30 imágenes por segundo (nivel de desempeño interactivo). Sin embargo, las aplicaciones que en la actualidad se ejecutan a niveles interactivos, dependen de sofisticadas arquitecturas paralelas, granjas de render en la nube, etc. Se puede resumir, sobre el estado del arte en trazado de rayos, que para obtener un desempeño de nivel interactivo y adoptar la técnica, es necesario un poder computacional costoso, lejos del presupuesto de un usuario final. Rasterización vs. Trazado de Rayos. La otra técnica para realizar rendering o síntesis de imágenes es rasterización. Desde que la industria tecnológica, en cualquiera de sus áreas, adoptó las imágenes por computador, rasterización ha sido la técnica de facto implementada. En comparación con trazado de rayos, rasterización es en términos computacionales más eficiente. A pesar de dicha adopción, se considera que la técnica de trazado de rayos es más precisa, pues simula el comportamiento de la luz mediante modelos físicos, lo que deriva en síntesis de imágenes de mejor calidad que las producidas por programas que utilizan rasterización. Durante los últimos 10 años, ha existido la discusión abierta, acerca de si en algún momento el poder computacional accesible por un usuario final permitirá que la técnica de trazado de rayos reemplace totalmente la técnica de rasterización, por supuesto con un desempeño de refresco de imágenes interactivo. Hay quienes están en contra y a favor de la idea, sin embargo existen opiniones moderadas que reconocen las dificultades y prestaciones de la técnica de trazado de rayos, así como el avance mayor en el desarrollo de software y hardware especializado para rasterización. Por lo anterior, es difícil concluir si la técnica de rasterización será reemplazada en algún momento por trazado de rayos. Esta discusión se ha realizado sin tener en cuenta el surgimiento de la tendencia de cloud computing, la cual se ha visto como una opción interesante para mejorar el desempeño de algoritmos que necesitan poder de cómputo en alta demanda y a la que se ha puesto atención a partir del año 2011, como alternativa para implementar trazado de rayos interactivo. Los argumentos de la discusión, se han enunciado en diversos trabajos de los últimos años. Estos llevan a la conclusión de que hay efectos, operaciones y elementos de la síntesis de imágenes, en los que se desempeña mejor el algoritmo de trazado de rayos (sombras, reflejos, refracción) y otros en los que lo hace el algoritmo de rasterización (oclusión y partículas para humo, niebla, explosiones, fuego etc.). Dado lo anterior se espera que lo que ocurra en los próximos años sea la implementación de algoritmos híbridos, resultados de la fusión entre las dos técnicas, más que la imposición definitiva de alguna, por ejemplo, la resolución visual se

8
ejecutarán de manera eficiente usando rasterización, mientras que los efectos de reflexión y refracción, usando trazado de rayos. Inicios de la técnica de trazado de rayos. En 1978 Turner Whitted presenta su trabajo titulado “Un modelo de iluminación mejorado para coloración de imágenes”. En el resumen introductorio del trabajo, explica el algoritmo de trazado de rayos:
“Para sintetizar con precisión una imagen bidimensional a partir de una escena tridimensional, se debe conocer la información con la que la iluminación global afecta
la intensidad de cada pixel en la imagen, en el momento en que dicha intensidad se calcula. De manera simplificada, esta información se almacena en un árbol de rayos
que se proyectan desde el observador a la primera superficie encontrada y desde ahí a otras superficies y hacia las fuentes de luz.”
Turner describe en este trabajo, cómo la intensidad de cada pixel es una función de las fuentes emisoras de luz y las propiedades de los materiales de aquellas superficies afectadas por dichas fuentes. Turner cita los métodos expuestos por Arthur Appel en su ensayo “Algunas técnicas de coloreado con maquinas para síntesis de imágenes de solidos.”, de 1968, para saber si cualquier punto de impacto en la intersección de un rayo con alguna superficie es visible ó no, si está afectado por alguna fuente de luz (visible por una fuente de luz) ó no y de esta manera saber si dicho punto de impacto es visible por el observador y de serlo, saber si está en la sombra ó afectado por una o varias fuentes de luz. Aunque Appel no le llama explícitamente Trazado de Rayos, si enuncia lo que sería de ahí en adelante el problema principal de la técnica: el desempeño.
“Este método consume mucho tiempo, usualmente requiere para un resultado útil, miles de veces el cálculo que requiere una imagen wireframe1.”
Para Turner la técnica de trazado de rayos más que una técnica de síntesis, era un complemento a un modelo de iluminación, que le permitía establecer si había línea de vista entre las superficies y el observador o las fuentes de luz, pero más importante, le permitía modelar los fenómenos de refracción y reflexión de la luz. Este complemento consistió en el modelamiento de las leyes de Fresnel y Snell. A partir de este trabajo, se realizó el corto animado “The Compleat Angler”, donde ilustra los fenómenos de reflexión, refracción, absorción, resolución geométrica de la
1 Wireframe: Síntesis de un modelo 3D, en el que solo se tiene en cuenta las aristas de las superficies que componen los solidos en el modelo y no la coloración de estas.

9
oclusión e implementa modelos de coloreo e iluminación propuestos por Phong, Blinn y Newell. Cada frame del corto tomó 74 minutos para ser sintetizado y el render fue llevado a cabo en una máquina VAX-11/780, con una resolución de 640x480 pixeles y utilizando 9 bits por pixel. En el tiempo total de ejecución en promedio se empleo en un 75% en calcular intersecciones, 12% en coloreo y 13% en sobrecarga. Desarrollo de la computación gráfica y adopción de trazado de rayos en la industria. El trabajo de Turner Whitted establece el marco teórico de referencia, como punto de partida, para el avance en el desarrollo de trazado de rayos como técnica de síntesis de imágenes. Sin embargo muchas compañías de principios de los años 80 se rehusaron a colocar el algoritmo de trazado de rayos en sus aplicaciones, pues era computacionalmente costoso. La situación no era mejor para la técnica de rasterización: para el momento las aplicaciones interactivas en 3D estaban lejos del mercado de usuarios finales, los cuales se encontraban consumiendo productos en el mercado 2D, correspondiente a consolas de videojuegos como Atari, Magnavox Oddisey, Nintendo etc. y el naciente mercado del computador personal, con contadas excepciones, aplicaciones como simuladores de vuelo, que eran rasterizadores de triángulos que no superaban las decenas de triángulos en la pantalla y no implementaban modelos de iluminación. Aquellas aplicaciones que utilizaban rasterización como algoritmo de síntesis de imágenes y complejos modelos de iluminación, ya fuera interactiva u off line estaban reservadas para corporaciones, instituciones militares, productoras de cine etc., pues tenían el presupuesto que les permitía obtener el poder computacional suficiente. Disney produciría la película “TRON” de 1982. Esta película fue crucial para la técnica de trazado de rayos, pues sería utilizada parcialmente para sintetizar escenas que en conjunto durarían 30 minutos. Sin embargo, solo se implementó una parte del algoritmo llamada ray casting, que realiza la resolución geométrica de la oclusión y simula el efecto de absorción de la luz, descartando los fenómenos de refracción, reflexión y cálculo de sombras. Es importante destacar esta película porque fue la primera vez que la técnica de trazado de rayos, se utilizaría para la producción de una aplicación real y no solo sería una demostración, como había sido hasta el momento. Desafortunadamente no se prestó mucha atención a la técnica de síntesis usada en la película, porque sus ventas en taquilla fueron muy malas. Sin embargo en 1982 Industrial Light and Magic (Lucas Films), produjo una secuencia para la película “Start Trek II: The Wrath of Khan”, usando un programa especializado en síntesis de imágenes para trazado de rayos, REYES (Renders Everything You Ever Saw), llamada The Genesis Effect.

10
En 1986 Industrial Light and Magic, se separa de Lucas Films y se convierte en Pixar. Pixar toma el programa de Loren Carpenter, REYES y desarrolla un lenguaje para colorear superficies llamado RSL (Reyes Shading Language), el cual se presentó en el SIGGRAPH de 1989. Pixar entra a la historia en ese mismo año al ganar un premio OSCAR a mejor corto animado por Tin Toy. Habían transcurrido 10 años desde que Turner Whitted había escrito el trabajo en el que basó The Compleat Angler. Adicionalmente, Pixar establece la arquitectura de trazado de rayos usada por la industria durante los años 90, Renderman, una continuación de REYES. El primer largometraje totalmente animado fue creado en Renderman y se llamó Toy Story. Optimización y aceleración por Hardware. A finales de los años 80 y comienzos de los 90, los juegos 3D interactivos ya estaban en la escena del mercado de computadores personales. Sin embargo eran las consolas como Nintendo, Sega etc., las plataformas de mayor consumo y los juegos que en ellas se ejecutaban eran aplicaciones 2D. Si en los años 80 la presión por rendering foto realista se había ejercido principalmente en la industria del cine, no fue sino hasta los años 90 en que la industria de los videojuegos se consolidó y empezó a presionar a los fabricantes de hardware para obtener tasas interactivas de refresco mayores. Esta presión contribuyó a la adopción definitiva de la técnica de rasterización como técnica de síntesis de imágenes a niveles de refresco interactivos, pues la técnica de trazado de rayos aún era una técnica de síntesis offline y demandaba mucho poder computacional para el hardware de la época. De 1989 a 1991 aparecen los primeros juegos en 2.5D2 de primera persona para computadores personales (Wing Commander, Hovertank, Wolfenstein 3D) y fueron escritos usando una aproximación del algoritmo de Ray Casting3. Para poder obtener niveles interactivos y una sensación geométrica 3D correcta, con las arquitecturas del momento, 386DX(25 MHZ) y 486SX (800 nm / 500 MHz / 41 MIPS), se debía utilizar una técnica distinta: rasterización. Se comenzó a trabajar en optimizaciones, para mejorar el desempeño de los algoritmos de síntesis de imágenes, tanto para trazado de rayos, como para rasterización. Se implementó mejores tipos de los datos abstractos usados para almacenar la información de las escenas 3D, dando origen a las particiones espaciales, disminuyendo de manera considerable la cantidad de primitivas geométricas que se debían leer desde la memoria, para ser posteriormente proyectadas en la pantalla, si
2 Visualmente se imita la sensación de 3D, pero geométricamente no lo es. 3 Se usó exclusivamente para resolver el problema de línea de vista entre el observador y una superficie.

11
es que eran visibles para el observador. La subdivisión de la geometría en particiones espaciales, fue un aspecto muy estudiado en el momento, dando lugar a una buena cantidad de trabajos en el tema. En 1991 Dan Gordon y Shuhong Cheng, publican un método de partición binaria del espacio, que aceleraba los algoritmos de síntesis de imágenes de rasterización a niveles interactivos: Front to Back Display of BSP Trees. Esto fue definitivo para el desarrollo y consolidación de la técnica, pues mejoraba y hacia mas eficiente el recorrido de los tipos abstractos de datos que almacenaban las escenas 3D. En aquel año la empresa ID Software, pionera en los videojuegos 3D de primera persona en PC (Doom, Wolfenstein 3D etc), preparaba la primera versión del videojuego DOOM. Jhon Carmack, programador líder del proyecto intentaba proyectar las texturas en las caras de las superficies o primitivas de los solidos en el juego, sin embargo este proceso es computacionalmente pesado y Carmack no lograba obtener un desempeño mayor a 15 imágenes por segundo. Leyó el trabajo de Gordon y Cheng y no tardó en implementarlo para DOOM, acelerando 4 veces el desempeño. A pesar que esta optimización era perfecta para rasterización, no lo era para trazado de rayos, puesto que la carga computacional en el algoritmo de trazado de rayos radica en el número de rayos que se deben calcular por segundo y no en el número de primitivas geométricas en una escena. En 1992, Nieh y Levoy implementan Volume Rendering on Scalable Shared Memory MIMD architectures (Síntesis de imágenes de volúmenes en arquitecturas escalables MIMD de memoria compartida), con varios procesadores, utilizando memoria compartida y trazado de rayos. Sin embargo estos volúmenes se describen mediante ecuaciones analíticas y no son prácticos para aplicaciones interactivas como videojuegos. Finalmente en 1995 se empieza a trabajar en arquitecturas de hardware que permitían acelerar directamente las operaciones cruciales con la que se calcula el algoritmo de trazado de rayos. Se comienza a simular en computadores paralelos virtuales la ejecución del algoritmo. Los resultados indicaban que las características del algoritmo de trazado de rayos, se podían implementar de manera natural en arquitecturas de hardware que utilizaran recursos de cómputo en paralelo. En 1996 Humphreys y Ananian publican: TigerShark: A Hardware Accelerated Ray Tracing Engine, donde se implementaba un trazador de rayos en una tarjeta de la empresa Texas Instruments usando una arquitectura de DSPs distribuidos con el fin de que fuera escalable. En 1997 la empresa Advanced Rendering Technology lanza al mercado el chip AR250. Este chip poseía 64 unidades en punto flotante operando a 50 MHz y su tarea específica era ejecutar trazado de rayos. Su sucesor el AR350 aparecería en la tarjeta PCI Renderdrive, el chip poseía capacidad para hacer trazado de rayos en paralelo con otros chips AR350, gran poder computacional, procesaba modelos de iluminación

12
complejos, profundidad de campo, etc., y más importante aún, utilizaba el lenguaje de shaders, totalmente compatible con Renderman, la arquitectura de trazado de rayos en software que Pixar había impuesto en la industria. Las tarjetas con el chipset AR250/350 eran las tarjetas aceleradoras 3D para trazado de rayos, sin embargo eran costosas y se utilizaban en servidores, no en computadores de usuario final. Era usada por grupos de animadores, modeladores, artistas y no por individuos. Si estos grupos eran demasiados grandes, el desempeño caería de nuevo. Tarjetas aceleradoras para 3D Raster. En 1994/1995 el costo de las memoria RAM bajó significativamente, lo que permitió la comercialización de tarjetas de aplicación especifica para los buses industriales, de las motherboard del momento, ISA, PCI y AGP, promoviendo la aparición de las primeras tarjetas GPU para 3D. Las primeras se incorporaron en las consolas de videojuegos de manera masiva (Play Station y Nintendo 64) y poco a poco fueron penetrando el mercado de los computadores personales. Las primeras GPU ejecutaban única y exclusivamente uno o varios pipeline gráficos para rasterización: poseían varias unidades de hardware que ejecutaban las operaciones de vértices, calculaba en qué pixel se proyectaba qué triángulo, las tarjetas poseían una memoria para texturas (Texture Cache) que inciden en el cálculo final del color de los pixeles. Estas primeras GPU no eran programables y no contaban con una interfaz de programación de aplicaciones comunes. Un problema serio con el que contaron las primeras GPU fue la falta de una interfaz de programación estándar, además en aquel momento OpenGl y Direct3D, eran muy jóvenes y poco el soporte que ofrecían para estas nuevas tarjetas. En general las aplicaciones debían ofrecer soporte para cada tarjeta GPU en particular. Para el final de los años 90 las GPU no eran programables y no soportaban lenguajes de coloreo, comparado con las tarjetas para trazado de rayos AR250/350, en este aspecto las GPU iban perdiendo terreno (aunque ganaban en interactividad y eso era más importante), pero existían al menos varias compañías dedicadas al desarrollo y manufactura de GPU para rasterización y solo Advanced Rendering Technology estaba en el mercado para trazado de rayos. Hoy en día no existen compañías dedicadas a la fabricación de chip sets para trazado de rayos y solo dos compañías dedicadas a la creación de chip sets para rasterización y cómputo general: ATI4 y NVIDIA. En el momento en que las GPU ofrecen compatibilidad con OpenGl y Direct3D en 1997, avanzaron definitivamente para dejar establecida a la técnica de rasterización como la
4 ATI fue adquirida por AMD en el 2006.

13
técnica de síntesis de imágenes estándar. El gran poder computacional y la programabilidad que ofrecían dio lugar al nacimiento de un nuevo paradigma computacional, no solo para gráficos sino en general, GPGPU Computing o por sus cifras en inglés, Cómputo de Propósito General en Unidades de Procesamiento Gráfico. Trazado de Rayos en Hardware Gráfico Programable Aunque en los 90 los procesadores AR250, AR350 y la implementación TigerShark habían sido ejemplos de trazado de rayos acelerado por hardware, no fue sino hasta la primera década del siglo 21 que comenzó a haber mayor cantidad de implementaciones. Una vez que las GPU incrementan su fuerza de adopción debido a la tendencia GPGPU, empezaron a surgir trabajos de diferente áreas que utilizaban el poder computacional que estas ofrecían. Este fue el caso de trazado de rayos como aplicación “general” que usaba dicho poder de cómputo. En 2002, Carr, Hall y Hart, implementaron The Ray Engine en la universidad de Illinois. Sus trazador de rayos utilizaba pixel shader processors (procesadores para coloreo), los cuales venían dentro de las GPU, para ejecutar un algoritmo de intersección de rayos y triángulos. Sin embargo su implementación solo llegaba a 0.3 imágenes por segundo5. A pesar del bajo desempeño, el haber implementado un algoritmo de trazado de rayos fue un hito, pues habían dudas si era posible hacerlo dado que una arquitectura GPU no soporta instrucciones de control de flujo que le permita hacer branching. Branching es el tipo de instrucción que decide mediante la evaluación de una expresión cual es la siguiente instrucción a ejecutar, por ejemplo “si el valor de una expresión es esto, ejecute esto de lo contrario ejecute esto otro”, lo anterior no es posible en una GPU y una algoritmo de trazado de rayos, así como muchos otros algoritmos, utilizan ese tipo de instrucciones. A pesar de estas limitantes, el trabajo de Carr, Hall y Hart, demostró la posibilidad de implementar algoritmos de trazado de rayos en una GPU. El mismo año, 2002, Purcell, Buck, Mark y Hanrahan, publican Ray Tracing on Programmable Graphics Hardware. En él comparan el desempeño del algoritmo de trazado de rayos en un arquitectura CPU/branching convencional contra el de una GPU/non branching, simulando la ejecución del algoritmo de trazado de rayos en una GPU y en una SIMD CPU. Demuestran que la arquitectura GPU, resulta ser varias veces mas rápida que la arquitectura CPU. La implementación de Carr, Hall y Hart era distinta que la de Purcell, Buck, Mark y Hanrahan, básicamente porque la primera utilizaba la CPU para el coloreo y otras 5 El valor es estimado, puesto que la fuente solo provee información acerca del número de rayos por segundo que la implementación estaba en capacidad de realizar. Para el cálculo se asume una resolución estándar para la época de 10x24x768 pixeles.

14
tareas mientras que la GPU solo para la intersección de triángulos y rayos, la segunda utilizaba la GPU para hacer todo el rendering, desde la resolución geométrica hasta el coloreo eliminando el cuello de botella GPU-CPU. Otros trabajos similares por Purcell fueron publicados en 2003, Photon Mapping on Programmable Graphics Hardware y Ray Tracing on a Stream Processor. Donde se aborda no solo el tema de trazado de rayos, sino también el de iluminación global utilizado photon mapping que es una técnica que utiliza el algoritmo de trazado de rayos para resolver la ecuación de transporte de la luz de Kajiya. Sin embargo el desempeño no mejoró y fue del mismo orden que el desempeño exhibido por los trabajos del año 2002. Finalmente dos años después, en el 2005, Christen publica Ray Tracing on GPU. Esta implementación se hace utilizando la API que expone Direct3D, los lenguajes de coloreo GLSL (OpenGl) y HLSL (Direct3D), para programar los fragment/vertex processors de los que disponía la familia GeForce 6x00. La implementación utilizaba todo el conocimiento disponible por el estado del arte en aquel entonces: aceleración mediante optimizaciones con arboles de subdivisión espacial, se eliminó la recurrencia de las operaciones de intersección mediante rutinas iterativas, evitando el llamado a funciones y localización en memoria de varias pilas; adicionalmente se utilizó el vertex processor que en las anteriores implementaciones con GPU no se había utilizado, simplemente porque la GPU no lo traía. Así como un fragment processor es un procesador para calcular operaciones de coloreo de pixeles, un vertex processor es un procesador para calcular operaciones con vértices. Adicionalmente adoptaron una arquitectura de stream processing, en la que flujos de datos se procesan a través de un kernel, que no es más que una función especializada. Sin embargo esto ya lo había hecho Purcell en su trabajo Ray Tracing on a Streaming Processor. El resultado fue muy interesante, se obtuvo un performance de 12.5 imágenes por segundo en una imagen de 256 x 256. Aunque no era un nivel interactivo, si despertaba mucho interés porque finalmente se estaba empezando a ver desempeños nunca antes vistos en el campo de trazado de rayos. NVIDIA presentó en el año 2010 un motor para realizar trazado de rayos y lo público bajo el título Optix: A General Purpose Ray Tracing Engine. Los resultados en performance son los mismos que los reportados 5 años atrás por Christen, pero con imágenes de mayor resolución, detalle y elementos foto realistas. Trazado de Rayos en FPGAs y arquitecturas paralelas En 2002 Meissner publica VIZARD II: a reconfigurable interactive volume rendering system, y el algoritmo de síntesis es ray casting, la versión reducida de trazado de rayos que no tiene en cuenta los fenómenos de refracción y reflexión de la luz, ni hace

15
cálculo de sombras. La implementación fue hecha en una FPGA XILINX Virtex PCI CARD, El algoritmo de ray casting es usado bastante en aplicaciones de imágenes médicas, pues la visualización de órganos no requiere de los fenómenos de refracción ni reflexión. Esta implementación usó subdivisión espacial mediante voxels, imágenes a una resolución de 256x256 pixeles y un performance de 16 imágenes por segundo en promedio. En 2003 Fender publica A high-speed ray tracing engine built on a field-programmable system, sin embargo solo implementa ray casting como algoritmo de síntesis, pero obteniendo 40 imágenes por segundo con una resolución de 512x384. Un trabajo similar, en 2002, lo realizó Srinivasan al publicar Hardware Accelerated Ray Tracing, en él se implementaba trazado de rayos utilizando una FPGA Altera Apex PCI CARD. No se implementaba refracciones en este trabajo, pero si reflexiones y las únicas primitivas que se implementaban eran esferas. En el mismo año se realizaron trabajos para acelerar el cálculo de iluminación global en FPGAS y se logró obtener desempeños de 5 imágenes por segundo. En 2004 Slusallek, publica el primer trabajo de trazado de rayos a nivel interactivo conocido como RPU, el titulo del proyecto es Realtime ray tracing of dynamic scenes on a FPGA chip. En este proyecto se obtuvieron desempeños de 24 o más imágenes por segundo con implementación full de trazado de rayos (sombras, reflexiones, refracción, etc.). Es un hito para el estado del arte en trazado de rayos. En 2007 Hanika, publica Fixed Math Ray Tracing con el objetivo de reducir la lógica necesaria para implementar un algoritmo de trazado de rayos en Hardware. Al no utilizar punto flotante como el marco de referencia para representar cantidades aritméticas, se reduce el tamaño en silicio, número de transistores, etc., necesario para implementar operaciones entre estas cantidades, como suma, resta, multiplicación etc. Aunque los resultados demostraron que era posible implementar un sistema en punto fijo, no se continuó investigando en este tema, posiblemente porque los niveles de integración cada vez eran mayores: en 2007 Intel anuncio una compuerta NAND de 22 nm así que el tamaño de las operaciones aritméticas no era lo que más le preocupa a la comunidad que desarrollaba trazado de rayos. Sin embargo Agarwal en su ensayo Clock Rate vs. IPC, predice que el tamaño reducido de los transistores no hará desaparecer el uso de instrucciones segmentadas, o sea instrucciones que emplean mas de un ciclo de reloj para ser ejecutadas, debido a que las uniones/caminos de silicio que conectan a los transistores, comenzarán a ser más lentas que estos últimos, requiriendo la segmentación, reduciendo la frecuencia de instrucciones por segundo, e inutilizando la optimización que se pudiera lograr en una implementación de punto fijo. A partir de 2006 se empezaron a ver trazadores de rayos con desempeños no interactivos pero relevantes, implementados sobre arquitecturas paralelas. Bigler, Stephens y Parker, implementaron Manta, un trazador de rayos paralelo en el marco del trabajo A Design for Parallel Interactive Ray Tracing Systems, obtuvieron un desempeño de 3 imágenes por segundo.

16
Para 2011 Ize, Brownlee y Hansen, publican Real-Time Ray Tracer for Visualizing Massive Models on a Cluster. El sistema consiste en un sistema en paralelo, con un plano de memoria virtual compartido, sobre una infraestructura de red de alto desempeño InfiniBand. El sistema logra un desempeño mayor a 100 imágenes por segundo en resolución full HD, equivalente a 1080p, o sea 1080 líneas no entrelazadas. Sin embargo se usaron 64 nodos cada uno Quad Core Xeon X5550s corriendo a 2.67 GHz con 24GB de memoria RAM, algo no muy “usuario final”. Demostraciones de Ray Tracing Interactivo. Desde 2004 hasta 2009 una serie de ejemplos, del juego de ID software fueron implementados por Daniel Pohl con una particularidad: el sistema de síntesis de imágenes era trazado de rayos. Finalmente en 2009 Pohl publica: Light It Up! Quake Wars* Gets Ray Traced. Se logró con 4 máquinas Intel quad-socket 2.66 GHz Dunnington, un desempeño de 20-35 imágenes por segundo. En 2011 Pohl mplementó el juego Wolfenstein usando trazado de rayos en una granja de servidores Intel® Multicore Integrated Architecture (MIC). Sin embargo esto se llevo a cabo usando un esquema de cloud computing, pues las imágenes y gameplay, se llevaba a cabo en una máquina de escritorio de prestaciones normales.

17
3 INTRODUCCIÓN TRAZADO DE RAYOS
Trazado de Rayos, es una técnica de síntesis de imágenes. Simula un conjunto de
fenómenos ópticos relacionados: reflexión, refracción, absorción de la luz, etc.
Utilizando modelos de iluminación y coloreo combinados con la técnica, se reproducen
efectos visuales como, sombras, iluminación global, radiación lumínica, etc.
El algoritmo original de trazado de rayos consiste en simular el lanzamiento de varios
rayos de luz desde una o varias fuente de irradiación, dentro de una escena 3D. Estos
rayos eventualmente atraviesan la escena. Algunos rayos impactarán las superficies
que conforman los solidos de la escena y otros no. Aquellos que intersectan las
superficies, rebotarán de superficie en superficie hasta que salgan de la escena o hasta
que impacten al observador. Debido a que en cada rebote del rayo se le adjunta
información de la superficie intersectada, aquellos que llegan al observador poseen
suficiente data para sintetizar una imagen 2D.
Esta versión inicial del trazado de rayos es la versión hacia adelante, en la que los
rayos van desde las fuentes de luz al observador. Esta versión es ineficiente debido a
que una gran cantidad de rayos no intersectará al observador, compilando con
aquellos rayos que no lo hace una gran cantidad de información superflua.
La técnica se debe implementar usando el algoritmo en su versión hacia atrás, como lo
muestra la Ilustración 1 donde los rayos se trazan desde el observador hacia las
fuentes de luz. Algunos rayos no intersectarán alguna superficie en el modelo, pero los
rayos que si lo hacen adquieren información acerca del material que compone las
superficies intersectadas. Esta información le permite al algoritmo reconocer si el
punto de impacto está bajo la sombra, si es translucido o reflexivo, el color del
material y la intensidad con que refleja luz. En el caso de translucidez o reflexión el
algoritmo traza de nuevo rayos para obtener información, pues la data reunida a partir
del impacto original no es suficiente.

18
Ilustración 1. Técnica de trazado de rayos, hacia atrás, del observador hacia las fuentes de luz.
El algoritmo de trazado de rayos es el siguiente:
Para cada pixel en la pantalla.
Ri = Trazar un rayo desde el observador al pixel y normalizarlo (magnitud =
1).
Para cada superficie, Si, que compone los solidos de la escena 3D.
Si el rayo Ri intersecta la superficie Si.
Si la distancia, Di, del observador al punto de impacto es
menor que Dmin (la minima distancia del observador al punto
de impacto para cualquier Ri)
Almacenar impacto, [Si,Ri]
Trazar otro conjunto de rayos desde el punto de impacto [Si,Ri] hacia las
fuentes de luz y averiguar si hay sombra.
A partir de las características del material de la superficie en la dupla [Si,Ri]
calcular el color y la intensidad Ci, con que las fuentes de luz afectan la
superficie Si basándose en un modelo de iluminación. Si el material es
reflexivo o transparente, trazar los rayos necesarios los cuales son una
función de Ri y completar la información faltante de intensidad y color.

19
Con la información recopilada formar la dupla [Ri, Ci], en la que se asocia el
rayo Ri al color en calculado Ci.
Compilar la imagen y tratarla con el conjunto de valores C = {C0, .., Cn-1}.
En negrilla aparecen dos procedimientos, uno que verifica la intersección de los rayos
con las superficies y otra que utiliza un modelo de iluminación y coloreo, al que
llamaremos Shading Model, para calcular la intensidad y el color en cada impacto.
La intersección que se implementó en este trabajo es entre rayos y esferas. El Shading
Model es un modelo simple en el que se abstrae el color de un material como una
tupla de tres valores, rojo, verde y azul.
Adicionalmente el algoritmo implementado no calcula los fenómenos de reflexión o
refracción, lo que simplificó su implementación en software.
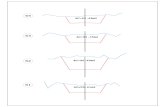
3.1 Intersección Rayos y Esferas.
Una esfera está determinada por un vector de posición central de la esfera V y radio r.
En la Ilustración 2, se muestran los elementos geométricos que describen una esfera y
su posición en un espacio cartesiano.
Ilustración 2. Elementos descriptivos de una esfera: Posición centro de esfera V y radio de esfera r.
En la Ilustración 3 se proyectan 2 rayos, Ri y Rj, que impactan justo el perfil de la
circunferencia:

20
Ilustración 3. Elementos de relación entre el observador y la esfera.
Los rayos Ri y Rj son unitarios. Al tomar el rayo Ri y proyectar el vector V sobre él, se
forma un triángulo rectángulo con el segmento formado por el vector V como
hipotenusa, los segmentos de longitud r y V.Ri forman los catetos opuestos y
adyacentes respectivamente. El ángulo de referencia será α, que es el formado entre
los vectores V y Ri.
El ángulo α es crítico, dado que su apertura es la máxima justo antes que el rayo Ri y la
esfera de posición V y radio r, se tiene:
Pero como Ri es un vector unitario:
La ecuación corresponde a la multiplicación de la hipotenusa por el coseno
del ángulo α, obteniendo la longitud del cateto adyacente equivalente a V.Ri. Por lo
tanto se puede escribir la ecuación pitagórica en la que intervendría el cateto opuesto:
Tomando V.Ri y cambiándolo con r2 se tiene:
Cómo cambia la ecuación, si Ri cambiará de dirección?. Se ha colocado V.Ri sola al lado
derecho, puesto que Ri es un vector que representa el rayo y su magnitud siempre

21
será igual a 1, dependiendo de su dirección, se obtienen 3 escenarios con respecto a la
esfera:
La proyección V.Ri cae en la superficie de la esfera, Ilustración 3.
La proyección V.Ri cae dentro de la esfera, Ilustración 4.
La proyección V.Ri cae fuera de la esfera, Ilustración 5.
En la Ilustración 4, la proyección cae dentro de la esfera:
Ilustración 4. El segmento que va desde V hasta la proyección V.Ri posee una longitud menor que la del radio de
la esfera cuando dicha proyección cae dentro de la esfera.
Es evidente que el segmento formado por la proyección de la hipotenusa V, sobre el
rayo Ri, forma un cateto opuesto cuya longitud es menor que r, por lo tanto podemos
reescribir la ecuación:
E intercambiando de nuevo los lados:
De la desigualdad podemos afirmar que si el valor de la longitud del segmento
resultante al proyectar V sobre Ri es menor que cierto valor característico que
relaciona a la esfera y el observador, entonces dicha proyección intersectará la esfera.
La Ilustración 5, muestra una proyección de los rayos Ri y Rj que caen por fuera de la
esfera:

22
Ilustración 5. El segmento que va desde V hasta la proyección V.Ri posee una longitud mayor que la del radio de
la esfera cuando dicha proyección cae fuera de la esfera.
En conclusión cuando hay una intersección entre el la proyección formada por el
vector V sobre el rayo Ri y la esfera, ya sea dentro de la esfera ó en la superficie de la
esfera y se satisface la desigualdad:
La expresión del lado derecho de la esfera será llamado constante de relación
observador esfera K:
3.2 Shading Model (Modelo de coloración)
El modelo de coloración es muy simple, no tiene en cuenta fuentes de luz o si el
material de la superficie modelada es transparente o reflexivo, únicamente se tiene en
cuenta el componente difuso del material, es decir, el color nominal del material.
El componente difuso del material estará representado por 3 componentes rojo, verde
y azul. Se utilizará 8 bits por componente y 32 bits por pixel. Dado que son 3
componentes se necesitan 24 bits por pixel, al implementar 32 bits sobrarán 8 bits, los
cuales por lo general tienen una función de indicar la opacidad/transparencia del
material, pero en este caso no se usará.
Los 8 bits bajos, de los 16 bits más altos, almacenarán el valor del componente rojo.
Los 8 bits altos de los 16 bits más bajos, almacenarán el valor del componente verde y
los 8 bits bajos el valor de azul.

23
4 DESCRIPCIÓN GENERAL DE LA SOLUCIÓN
El RtEngine es un conjunto de componentes que en conjunto realizan síntesis de
imágenes. Los componentes son un grupo de elementos conformados por un
elemento de software y varios de hardware.
El componente de software se llama Jart, que es el programa de trazado de rayos que
se ejecutará sobre el RayTrac, para realizar la síntesis de imágenes. Adicionalmente
Jart expone una interfaz de programación de aplicación o como sus siglas en inglés API,
correspondiente al driver del procesador RayTrac.
Uno de los componentes de hardware se llama RayTrac, es un procesador vectorial y
su objetivo es ejecutar las operaciones geométricas que normalmente utiliza el
algoritmo de trazado de rayos, más rápido de lo que lo haría un procesador
convencional.
4.1 Componentes de hardware utilizado.
Para la implementación del RtEngine, se utilizó una tarjeta Nios II Embedded
Evaluation Kit. Es una tarjeta de la empresa Terasic y el chipset principal es Altera
Cyclone III EP3C25F24.
A continuación, la Ilustración 6, contiene una imagen de la tarjeta usada en el
proyecto.
Ilustración 6. Tarjeta de desarrollo embebido NEEK, Nios II Embedded Evaluation Kit.

24
La tarjeta cuenta con los siguientes componentes usados en la implementación del
RtEngine:
16 MB Flash.
1 MB Static RAM.
32 MB DDR RAM.
800 x 480 VGA, TOUCHSCREEN LCD.
JTAG Interface Port.
RS232 Serial Interface Port.
NIOS II 32 Bit RISC Processor.
Procesador vectorial RayTrac.
FPGA Cyclone III EP3C25F24.
La FPGA Cyclone III posee 24624 celdas lógicas, 66 bloques de 1024 bytes y 66
multiplicadores de 18x18 bits. El procesador NIOS II, está implementado usando lógica
programable en la FPGA, así como el procesador vectorial RayTrac.
La Ilustración 7, muestra el diagrama de bloques y la manera cómo se relacionan los
componentes de hardware que componen el RtEngine.
Ilustración 7. Diagrama de Bloques de los componentes de hardware del RtEngine.
Todos los componentes son implementaciones de Altera y se integran dentro del
RtEngine. El único componente cuyo diseño e implementación hace parte del alcance
de este trabajo es el componente RayTrac.
4.2 Componente de software.
Jart es el programa que realiza la síntesis de imágenes usando el algoritmo de trazado
de rayos, cuyos detalles se explican en el capítulo 3, Introducción Trazado de Rayos.

25
Sin embargo el programa implementa otras funcionalidades necesarias para
implementar una interfaz que permita manipular el procesador vectorial RayTrac,
dichas funcionalidades son:
Driver para el RayTrac orientado a procesamiento de flujos.
Capa de comunicación que permita la entrada de escenas 3D para ser
sintetizadas por el sistema.
4.3 Herramientas de Desarrollo.
Para descripción de hardware se usó el lenguaje VHDL. Quartus II, SOPC Builder y
Model Sim, es la suite de herramientas con la que se compilan, simulan e incluyen en la
micro arquitectura los diseños descritos en dicho lenguaje.
Quartus II compila y sintetiza los archivos de descripción de hardware y genera los
archivos para programar las FPGA. Model Sim es una herramienta que sirve para
realizar test benches, simulaciones programadas para verificar funcionalmente los
diseños. Finalmente SOPC Builder sirve para diseñar y configurar micro arquitecturas,
como la mostrada en la Ilustración 7.
Adicionalmente, se utiliza NIOS II EDS para compilar y enlazar código nativo para el
procesador Nios II. Adicionalmente NIOS II EDS provee herramientas de depuración y
descarga de código.
4.4 Otras Herramientas.
Para generar los escenarios 3D que van a servir de entrada para el RtEngine, se usó
Blender3D.6 Esta herramienta es una suite de modelado 3D y animación, además
posee la característica de ejecutar scripts en Python, un lenguaje de script
interpretado. Usando esta característica se pueden establecer enlaces seriales entre el
RtEngine y la suite de animación, de esta forma se puede ingresar modelos 3D en el
sistema. La Ilustración 8 muestra la idea anterior:
6 www.blender.org

26
Ilustración 8. Uso de la herramienta de modelamiento 3D Blender y el RtEngine. El enlace serial comunica el
RtEngine con Blender.

27
5 ARQUITECTURA DE SOFTWARE
El componente de software JART es el programa de trazado de rayos implementado,
para realizar síntesis de imágenes, fue implementado anteriormente para correr en
sistema operativo Linux, se rescribió en el marco de este proyecto, para NIOS II.7 El
programa está escrito en lenguaje C.
Sus siglas significan Just Another Ray Tracer, y su objetivo es ejecutar y medir el
desempeño del algoritmo de trazado de rayos, cuando este ejecuta las operaciones
vectoriales en hardware y en software.
La entrada de datos al sistema, el escenario 3D, se hace desde la herramienta Blender
mediante un protocolo tipo Xmodem, implementado en un script en Python. Este
script no pertenece a Jart, pues este está implementado sobre el procesador Nios II y
reside en la memoria Flash de la tarjeta de desarrollo NEEK. Este script es la única
porción de código implementado que no hace parte de Jart.
Un código de recepción de datos Xmodem se implementó en el Jart, para recibir los
datos de la escena 3D, desde Blender. Una vez se recibe el escenario, Jart comenzará el
proceso de resolución geométrica.
El proceso de resolución geométrica comenzará con el cálculo de los rayos que se
lanzarán hacia la escena. Por cada pixel en la pantalla se debe disparar y normalizar un
rayo. Con los rayos creados y el escenario 3D recibido, comienza el proceso de cálculo
de intersección entre dichos rayos y las superficies del mencionado escenario. Con la
información calculada a partir de las intersecciones se procede a construir la imagen.
5.1 Escenario 3D y enlaces seriales.
Desde el programa Blender3D, se modelaron las escenas usadas en con el sistema. Así
mismo se implemento un script secuencial, para transmitir datos seriales usando la
capacidad que Blender3D posee como entorno integrado para desarrollar en python.
Se utilizó la biblioteca pyserial, de fácil instalación y uso. Esta biblioteca, posee un set
de funciones y módulos que permiten administrar enlaces de comunicación serial en la
capa de aplicación y que permiten administrar el tipo de conexión en la capa de enlace
de datos (RS232, ETHERNET, ETC.)
7 https://sourceforge.net/projects/jagtracer/

28
5.2 Intersección geométrica y oclusión.
Utilizando el driver orientado a kernel se escribió un conjunto de funciones y procedimientos que realizaba las funciones propias del Jart. Dichas funciones son:
1. Recepción de los materiales y primitivas esféricas desde Blender3D utilizando el driver de comunicación serial del NIOS II.
2. Cálculo de la constante K, para todas las esferas recibidas. (Ver Capitulo 3.1). 3. Cálculo y normalización de los rayos primarios. 4. Cálculo de intersección combinatorio entre rayos y primitivas. 5. Selección de aquellas primitivas que intersecta cada rayo y discernimiento de
aquellas primitivas más cercanas por rayo. Para eso se calcula la distancia de impacto.
Todas estas operaciones son geométricas y son la base del algoritmo de trazado de rayos. La operación que más tarde en ser ejecutada es la 4, que consiste en el cálculo de intersección de rayos y esferas.
5.3 Display y framebuffer driver.
Una vez se calculan las intersecciones y se sabe a que primitiva impacta cada rayo, se genera la imagen utilizando la información geométrica calculada. El driver que provee Altera para acceder a la pantalla mediante un buffer de memoria, se utiliza para escribir los cálculos de color que se hacen. Realmente no se calcula mucho, pues lo único que se hace es tomar el color difuso del material de la primitiva que se quiere dibujar y transformarlo a un numero de 32 bits que entiende el driver del framebuffer.

29
6 ARQUITECTURA DE HARDWARE
El RayTrac es un procesador de flujos, puesto que su operación consiste en la
configuración de una función especializada o kernel de procesamiento, en el que se
opera un conjunto de datos extenso8. En este documento se usará la palabra kernel
para hacer referencia a la función especializada, que ejecutaría el RayTrac.
Este conjunto de datos de entrada corresponde a un flujo de entrada (FE) y el conjunto
de resultados calculados por el kernel son un flujo de salida(FS). Estos flujos de datos,
vienen y van hacia la memoria DDR RAM con que cuenta la tarjeta NEEK. Las
operaciones de lectura y escritura de los datos que residen en la memoria, se hacen a
través de un bus de datos Avalon de Altera. El bus tiene capacidad para realizar
operaciones de transferencia un dato a la vez.
El término flujo de entrada en general hará referencia a un conjunto de datos de
entrada (operandos, vectores, parámetros, etc.) y la dirección donde están
almacenados; el término flujo de salida hará referencia a un conjunto de datos de
salida (como por ejemplo resultados) y la dirección inicial donde se almacenarían.
Dado que solo se dispone de un bus de datos compartido, se modelará la arquitectura
de procesamiento como un Stream Processor, con un flujo de entrada y un flujo de
salida.
6.1 Descripción de la arquitectura de procesamiento de flujo de datos.
El RayTrac se comunica e interactúa con 2 componentes de hardware: el procesador
Nios II y la memoria DDR RAM. La comunicación con el procesador es en una sola
dirección, del procesador al RayTrac. El RayTrac posee un banco de registros, los
cuales se encuentran mapeados en el pool de direcciones del procesador. La
comunicación con la memoria se hace a través del bus Avalon. La comunicación se
hace mediante transacciones de lectura y escritura, desde y hacia la memoria.
El RayTrac se configura usando el banco de registros, principalmente para cumplir 3
funciones:
Configurar el kernel, para ejecutar una operación aritmética particular. Una
especie de opcode identifica la operación aritmética a ejecutar, el cual se
escribe en un registro designado para tal fin.
8 Purcell, T. J. 2004.Ray Tracing on a Stream Processor.

30
Configurar el flujo de entrada de datos, con los operandos a ejecutar. En el
banco de registros del RayTrac existen dos en particular, uno donde se escribe
la dirección con el origen del flujo de entrada y otro con el tamaño de dicho
flujo.
Configurar el flujo de salida de datos, con los resultados de la ejecución de los
operandos en el flujo de entrada, utilizando el kernel seleccionado.
La Ilustración 9, muestra los 3 elementos que se configuran en el banco de registros
del RayTrac, la función especializada o kernel, la dirección de donde provienen los
operandos de entrada o flujo de entrada y la dirección a donde se escribirán los
resultados de las operaciones ejecutadas
Ilustración 9. A través del flujo de entrada, vienen los operandos que se transforman mediante el kernel en
resultados, los cuales salen a través del flujo de salida de datos.
6.2 Elementos de la arquitectura.
Internamente el RayTrac posee ciertos elementos en su arquitectura que le permiten
tener la funcionalidad descrita en la sección anterior, 6.1. Estos elementos son: La
interconexión decodificada de datos, los componentes aritméticos y los adaptadores de
entrada/salida. Estos elementos son descritos en las secciones a continuación, 6.2.1,
6.2.2. y 6.2.3.
La Ilustración 10, muestra un pipeline aritmético, elemento esencial del RtEngine. El
pipeline, se forma cuando al interconectar los bloques aritméticos (bloques de colores)
usando, la interconexión decodificada de datos (Cuadro en Azul).
Ilustración 10. Diagrama de bloques del RayTrac. Bloques aritméticos y un mecanismo de interconexión
conforman un pipeline aritmético, elemento principal del RayTrac.

31
6.2.1 Interconexión decodificada de datos.
El RayTrac puede ser configurado para ejecutar un conjunto de operaciones
vectoriales. Sin embargo, solo una operación puede ser ejecutada al tiempo por cada
flujo de datos de entrada.
El RayTrac posee varios bloques aritméticos internos entre sumadores,
multiplicadores, inversor y radicación. Adicionalmente las entradas y salidas de estos
bloques, están conectadas por una serie de circuitos de multiplexación, controladas
por el registro donde se configura el opcode. El valor del opcode decodifica el camino
de datos, usando los circuitos de multiplexación.
Cada valor de opcode determina una manera nueva en que el camino se forma,
componiendo operaciones distintas según su valor. Para más información sobre el
funcionamiento del banco de registros del RayTrac, consulte el capítulo 7.
Una interconexión decodificada de datos, a lo largo de su extensión conecta circuitos
aritméticos para formar de manera compuesta una operación vectorial. Este camino
de circuitos es segmentado por registros dentro de los bloques aritméticos.
6.2.2 Componentes Aritméticos.
Los componentes o bloques aritméticos del RayTrac son adición, substracción,
multiplicación, inversión y raíz cuadrada. El formato de representación numérico es
IEEE 754. Se escogió este formato de representación en punto flotante, por encima de
un formato en punto fijo, por la precisión y porque el formato de los resultados de las
operaciones es el mismo que el de los operandos, lo que no ocurre con punto fijo.
6.2.2.1 Suma IEEE 754, 32 Bits, Punto Flotante de Precisión Simple.
Se tiene los valores F0 y F1 cuya representación es en punto flotante:
F0 = s0 2e0 f0
F1 = s12e1 f1
Donde si toma el valor de -1 o 1 dependiendo del signo, ei es un valor entero y fi es una
fracción en el rango [1.0,2.0).

32
F0 + F1 = s0 2e0 f0 + s12e1 f1
Por razones prácticas en la ilustración de este ejemplo, se supone que e0 > e1. Se tiene
entonces:
Se puede reemplazar el valor de la diferencia de los exponentes, multiplicando y
dividiendo al mismo tiempo por una potencia de 2 elevada a :
Y reemplazando e0 en la expresión:
Finalmente multiplicar por una potencia de 2 elevada a un numero negativo, en
representación binaria, significa hacer un corrimiento de bits a la derecha:
Sin embargo la fracción resultado fres’ puede que no haya quedado normalizada, dentro
del rango [1.0,2.0). Así que se debe normalizar, realizando corrimientos a la izquierda o
a la derecha, los bits de fres’ para obtener la fracción final y restando o sumando
respectivamente, a e0, el número de corrimientos hechos, obteniendo finalmente 2res.

33
La Tabla 1 representa el diagrama de flujo de datos de la suma y la ilustración 11 el
diagrama de bloques.
Etapa 0
Cálculo del signo del segundo operando (s1).
Cálculo de la diferencia de los exponentes
(delta).
Si el exponente e0 es menor e1, se
intercambian todos los operandos.
Etapa 1
Decodificación “One Hot” de la diferencia de
exponentes (deltaOneHot).
Correr los bits de la mantisa de menor
exponente.
Signar la mantisa de mayor exponente.
Etapa 2 Signar la mantisa corrida.
Etapa 3 Sumar las mantisas.
Etapa 4 Sacar el signo de la mantisa resultante.
Etapa 5
Calcular el corrimiento que requerirá la
mantissa (delta).
Tabla 1. Diagrama de flujo de la suma flotante. La columna de la izquierda ilustra el diagrama, la columna en la
derecha, detalla los bloques correspondientes en la columna izquierda. Cada etapa se encuentra precedida o
sucedida por registros. La Ilustración 11 muestra el diagrama de bloques de la suma.

34
Ilustración 11. Diagrama de Bloques de la suma en punto flotante de 32 bits. Archivo RTL: fadd32.vhd
6.2.2.2 Multiplicación 32 Bits, Punto Flotante IEEE 754 Precisión Simple.
Abstracción Algebraica de la operación.
Se tiene los valores F0 y F1 cuya representación es en punto flotante:
F0 = s0 2e0 f0
F1 = s12e1 f1
Donde si toma el valor de -1 o 1 dependiendo del signo, ei es un valor entero y fi es una
fracción en el rango [1.0,2.0).
El producto de los dos valores será el siguiente:
Si el valor de la fracción calculada fres es mayor o igual a 2.0, entonces se debe dividir
por 2 y el valor del exponente se le debe sumar 1.

35
La Tabla 2, ilustra el diagrama de flujo de datos de la multiplicación.
Etapa 0
Suma de Exponentes
Multiplicación de Signos
Multiplicación de Mantisas
Etapa 1
Normalización de la mantisa
resultante.
Etapa 2
Normalización del exponente
resultante.
Tabla 2. Diagrama de flujo que describe las etapas combinatorias del multiplicador en punto flotante.
La Ilustración 12, muestra el diagrama de bloques de la multiplicación.
Ilustración 12. Diagrama de bloques del circuito de multiplicación en punto flotante IEEE754.

36
6.2.2.3. Inversor, 32 Bits en Punto Flotante IEEE 754, Precisión Sencilla.
Se tiene el valor Fi cuya representación es en punto flotante:
Fi = si 2ei fi
Donde si toma el valor de -1 o 1 dependiendo del signo, ei es un valor entero y fi es una
fracción en el rango [1.0,2.0).
El valor elevado a la -1 potencia sería:
Dado que si es 1 o -1, el valor de si-1 es si. El valor de el inverso de Fi es entonces:
Si el valor de la fracción calculada fi-1 es menor a 1, entonces se debe multiplicar por 2
y el valor del exponente se le debe restar 1.
El circuito está calculado usando lógica combinatoria, excepto las expresiones y
, las cuales utilizan una tabla de búsqueda, implementada en una memoria ROM
de 1024 direcciones y 18 bits de ancho de palabra. El direccionamiento de esa tabla es
con una palabra de 10 bits de ancho, que corresponden a los 10 bits más altos de la
mantisa fi. Se ignoran los 13 bits restantes de la mantisa y por lo tanto habrá una
pérdida de precisión. Usar mas bits habría requerido memorias más grandes y es
posible aumentar la precisión aumentar la precisión mediante este método.
Ilustración 13. Diagrama de Flujo Inversor 32 bits punto flotante IEEE754. Se cambia de signo al exponente y
direccionando con los primeros 10 bits de la mantissa se calcula el valor de la fracción invertida.
er = -er
fr = memsqrimpar(fr[22..13])

37
Ilustración 14. Diagrama de bloques del multiplicador flotante en 32 bits IEEE754. RTL: invr32.vhd
La Ilustración 13 y la Ilustración 14, muestra el diagrama de flujo y de bloques del
inversor en punto flotante.
6.2.2.4. Raíz Cuadrada IEEE 754, 32 Bits Floating Point, Single Precision.
Se tiene el valor F0 cuya representación es en punto flotante:
Fi = si 2ei fi
Al calcular la raíz cuadrada se asume que si vale 1, puesto que el dominio de la función
raíz cuadrada es [0,) ei es un valor entero y fi es una fracción en el rango [1.0,2.0).
El valor elevado a la -1 potencia sería:
El valor del exponente resultante ei/2 debe ser un valor entero. Por lo tanto el valor de
ei debe ser un número par. Si ei no es un número par, se requerirá de una
normalización del exponente y la fracción. Finalmente el valor de la raíz cuadrada se
calculará así:
El circuito está calculado usando lógica combinatoria, excepto las expresiones
o
y , las cuales utilizan una tabla de búsqueda, implementada en una memoria ROM
de 1024 direcciones y 18 bits de ancho de palabra. El direccionamiento de esa tabla es

38
con una palabra de 10 bits de ancho, que corresponden al bit menos significativo del
exponente y a los 9 bits más altos de la mantisa fi. Se ignoran los 14 bits restantes de la
mantisa y por lo tanto habrá una pérdida de precisión. Usar mas bits habría requerido
memorias más grandes y es posible aumentar la precisión mediante este método. La
Ilustración 15 y la Ilustración 16, muestran lo explicado.
Ilustración 15. Diagrama de Flujo Operación Raíz Cuadrada en formato IEEE754. El exponente se divide entre dos
mediante el corrimiento de un bit a la derecha. Usado una de dos memorias, en función de la paridad del
exponente de entrada, se cálcula la mantissa.
Ilustración 16. Diagrama de bloques del multiplicador en 32 bits de punto flotante IEEE754.RTL: sqrt32.vhd
6.2.3. Adaptadores de formato.
El procesador vectorial, RayTrac tiene una interfaz de entrada y salida: los bloques de
adaptación de formato (Ver Ilustración 10). Los flujos de datos de entrada ingresan al
Expr, fr
Expsq = Expr >> 1
fsq = memsqrimpar(fr[22..14])
Sqr = Expsq,
fsq
Exp0 impar
?
fsq = memsqrpar(fr[22..14])

39
RayTrac de manera serial, uno tras otro en valores que son cantidades en punto
flotante de 32 bits. El kernel configurado en el RayTrac recibe vectores (3 valores de 32
bits en paralelo) o pares de vectores (6 valores de 32 bits en paralelo). De manera
similar los datos de salida se escriben en el bus Avalon de manera serial, valores de 32
bits uno tras otro y al menos que el kernel que este configurado entregue resultados
escalares, por ejemplo el producto punto, o la magnitud de un vector, el valor
resultante de las operaciones será un vector compuesto de 3 resultados escalares.
Los elementos de adaptación de flujos que posee el RayTrac son 2:
Adaptador 32:192 o 32:96 (Flujo de Entrada).
Adaptador 128:32 (Flujo de Salida).
Ambos adaptadores en el flujo de salida o de entrada, están controlados por máquinas
de estado muy simples, que toman los valores de 32 bits que llegan en serie y
componen los vectores de entrada o que toman los vectores resultantes y los
convierte en una serie de valores, para ser escritos en el bus Avalon.

40
7. INTERFAZ DE PROGRAMACIÓN, MÁQUINA DE ESTADOS Y
SINCRONIZACIÓN DEL RAYTRAC
En el RayTrac, se puede programar el kernel o función especializada, que se quiera
ejecutar, la dirección y tamaño de un flujo de datos de entrada y la dirección de un
flujo de datos de salida. Utilizando la dirección mapeada en el pool de direcciones del
procesador Nios II y la librería que provee Altera para programar el RayTrac
escribiendo en su banco de registros de control y estado.
Para facilitar el desarrollo de aplicaciones que usan el RayTrac se ha implementado un
driver orientado a procesamiento de flujos. El objetivo de este driver es que el
desarrollador programe las operaciones vectoriales, utilizando el paradigma de flujos
de entrada/salida y kernels.
El RayTrac es programable siempre que se encuentre en el estado idle. El RayTrac
tiene distintos estados, idle, source y sink, en los que se configura, lee operandos y
escribe resultados respectivamente.
En el momento de ejecución de las operaciones, se utiliza los mecanismos que provee
el bus Avalon para sincronizar la operación del RayTrac con el exterior.
7.1 Interfaz de programación.
Para programar el RayTrac se debe utilizar el driver orientado a procesamiento de
flujos, este driver sin embargo se implemento utilizando una interfaz de programación
de “bajo” nivel9. El código del driver se anexa. La interfaz de bajo nivel consiste en un
banco de registros, que consiste en un conjunto de 16 registros de 32 bits de ancho,
que sirven para programar y controlar el RayTrac.
En la Tabla 3 a continuación se enumera y describe dichos registros.
Nombre/s Descripción Dirección
Reg_ctrl Registro de control: En este registro se llevan
a cabo las configuraciones que definen la
operación o kernel a ejecutar, la operación de
el adaptador de formato de flujos de salida,
la operación del adaptador de flujos de datos
BASE+0
9 Bajo “nivel” no hace referencia al lenguaje de programación, que en este caso fue C, realmente hace referencia a que se interactua con el RayTrac a nivel de registros.

41
de entrada y se almacenan algunas banderas
para soportar el control de flujo.
Más adelante se detalla este registro.
Reg_Vx/Reg_Vy/Reg_Vz/
Reg_Sc
Estos registros almacenan el último vector
registrado en el adaptador de formato de
flujos de salida.
BASE+4 /
BASE+8 /
BASE+12 /
BASE+16
Reg_Scratch00 Registro Scratch, para realizar pruebas
almacenar datos etc. En general se utiliza
para depuración del hardware.
BASE + 20
Reg_OutputCounter Registro que cuenta el número de datos que
han salido hacia el bus de datos externo. El
programador puede escribir cualquier valor
en este registro, perdiendo la cuenta que el
sistema lleve.
BASE + 24
Reg InputCounter Registro que al igual que OutputCounter,
cuenta datos, pero de entrada. Es escribible
por el programador.
BASE + 28
Reg FetchStart Registro en el que se programa la dirección
externa donde se almacena el bloque de flujo
de datos de entrada.
BASE + 32
Reg SinkStart Registro en el que se programa la ubicación
externa a donde se direccionará el flujo de
salida de datos
BASE + 36
Reg_Ax/Reg_Ay/Reg_Az /
Reg_Bx/Reg_By/Reg_Bz
Registros en los que se almacena el último
flujo de entrada “formateado” por el
adapatador de formatos de flujo de entrada,
es decir en estos registros se cargan el último
par de vectores que entraron en el sistema.
BASE + 40/
BASE + 44/
BASE + 48/
BASE + 52/
BASE + 56/
BASE + 60 Tabla 3. Nombre, descripción y direcciones del los registros del bloque de registros de programación y control de
flujo.
Los registros que se utilizan para programar el kernel usando la interconexión
decodificada de circuitos aritméticos son el registro de control, reg_ctrl, el registro de
dirección de fuente de flujo de datos de entrada, reg_fetchstart y el registro de
dirección de escritura de resultados del flujo de datos de salida, reg_sinkstart.
Para ordenar el camino que los datos recorren desde la entrada, hasta la salida y por el
cual se van transformando, el sistema utiliza la interconexión decodificada de circuitos

42
aritméticos. Este circuito decodifica función especializada o kernel configurado por el
programador y está decodificación determina entonces el camino de datos dentro del
pipeline aritmético.
Haciendo uso del registro de control, el programador configura el kernel o función
especializada a ejecutar. A continuación la Tabla 4 detalla los campos de este registro.
Bit No. Nombre (rw) Descripción
0 cmb (rw) Este bit describe la manera en que el adaptador de flujos de entrada carga o formatea los flujos de entrada. Este campo aplica para operaciones que requieren dos vectores A y B. Se ignora para operaciones unarias como la normalización de vectores o el cálculo de magnitud de vectores. 0: Todos los flujos de entrada se cargan secuencialmente en seis componentes, que conforman los 2 vectores A y B, de la siguiente manera: Ax, Ay, Az, Bx, By, Bz, Ax, Ay ….. y así sucesivamente. Una vez exista otro dato disponible entrante, empieza de nuevo la secuencia. 1: Todos los flujos de entrada se cargan secuencialmente en los 3 componentes que conforman el vector B, salvo los primeros 3 datos del flujo de entrada que se cargarán en el vector A, de la siguiente manera: Ax, Ay, Az, Bx, By, Bz, Bx, By, Bz, Bx, By, Bz, Bx…… y así sucesivamente.
[3:1] dcs (rw) Kernel o función especializada a ejecutar. El valor de estos 3 bits codifica la operación a realizar y es función de la interconexión decodificada de circuitos aritméticos decodificarlos, para interconectar las operaciones aritméticas que definen un kernel. 000: Suma de Vectores. A+B. 001: Resta de Vectores. A-B. 011: Producto Cruz. AxB. 100: Producto Punto. A.B. 110: Magnitud y Normalización de Vectores. |A| y A*1/|A|. 111: Multiplicación Simple Componente a Componente.
[5:4] vtsc (rw) Este campo define la tasa de adaptación de flujos de salida. 00 ó 10: Solo leer el componente vectorial de la cola de resultados 96:32. Se debe usar este valor cuando se quiere configurar un kernel cuyos resultados solo sean vectores, ejemplo: Producto Cruz. 01: Solo leer el componente escalar de la cola de resultados 32:32. Se debe usar este valor cuando se quiere configurar un kernel cuyos resultados son exclusivamente valores escalares, por ejemplo el producto punto o la magnitud vectorial. 11: Leer el componente vectorial y escalar de la cola de resultados 128:32. Cuando se selecciona la operación Magnitud y Normalización Vectorial (dcs=110), se debe tener en cuenta que en la cola de resultados se almacenaran cuatro valores por resultados: Los 3 componentes del vector normalizado y la magnitud del vector original. Es deseable leer los cuatro datos y en ese caso se utiliza el valor vtsc=11.

43
6 dma (rw) 0: El sistema funciona como un stream processor, al que se le configura un kernel o función especializada para ejecutar y una fuente de flujos de entrada y un destino para los flujos de salida. A este modo de le llama modo RayTrac. 1: El sistema funciona como un direct memory access, escribiendo bulks de datos utilizando los registro REG_FETCHSART como dirección externa de lectura de datos y REG_SINKSTART como dirección externa de escritura de datos. El tamaño del bulk se escribe en el campo de bits nfetch de este mismo registro.
[13:7] Banderas: (r) [ap : dp : pl : pp : wp : dc : fc] Consultar el capítulo V. Control de flujo de datos y sincronización externa. Para información más detallada sobre las banderas a continuación. ap: address pending flag. 1: Está pendiente por ser enganchada la dirección y tamaño del bulk programado del flujo de datos de entrada. 0: No hay pendientes en el momento enganches de dirección de flujos de entrada. dp: data pending flag. 1: En el momento hay una transmisión de flujos de datos de entrada y no ha terminado. 0: En el momento está pendiente la entrada de flujos de entrada al sistema. pl: parameter loading flag. 0: La máquina de estados del adaptador de formato de flujos de entrada se encuentra en el estado Ax. 1: La máquina de estados del adaptador de formato de flujos de entrada se encuentra en la mitad de la carga de algún vector, por lo tanto puede estar en cualquier estado menos en Ax. pp: pipeline pending flag. 0: No se encuentra en el momento dato alguno transitando entre los circuitos aritméticos ni la interconexión decodificada de circuitos aritméticos en el momento. 1: Existen datos transitando en las etapas de los circuitos aritméticos o en la interconexión decodificada de circuitos aritméticos. wp: write on memory pending flag. 0: No existen flujos de salida para ser direccionados hacia una dirección en el exterior del RayTrac. 1: Hay flujos de salida ya formateados pendientes por ser escritos en una dirección externa al RayTrac.

44
fc: fetch condition flag. 0: No existen direcciones de flujos de entrada pendientes por ser enganchadas o la tasa de tránsito de datos por el RayTrac es muy alta y no se deben traer dentro más flujos de datos de entrada. 1: Existen direcciones de flujos de datos de entrada pendientes por ser enganchadas y la tasa de tránsito de datos por el RayTrac es baja. dc: drain condition flag. 0: No es prioritario escribir flujos de salida, afuera del RayTrac. 1: En el momento las condiciones del RayTrac en general indican que es prioritario escribir flujos de salida, afuera del RayTarc.
14 rlsc (rw) 0: Una vez se escribe el ultimo flujo de datos de salida entonces no se reinicia el adaptador de formato de flujos de entrada. Esto quiere decir que sin importar en que estado se encuentre la máquina de estados del adaptador de formato de flujos de entrada, conservará su estado. 1: Una vez se escribe el último flujo de datos de salida entonces se reiniciaría el adaptador de formato de flujos de entrada. Esto quiere decir que sin importar en que estado se encuentre la máquina de estados del adaptador de formato de flujos de entrada, volverá al estado AX.
15 rom(r) 0: Todos los registros se encuentran en modo lectura y escritura donde aplique. 1: Algunos registros se encuentran en modo escritura. Esto ocurre cuando el kernel está ejecutando operaciones. Los registros en dicha condición son:
Reg_OutputCounter
Reg_InputCounter
Reg_FetchStart
Reg_SinkStart
Reg_Ctrl
[30:16] Nfetch (rw) Número de datos que posee el siguiente flujo de entrada. Este valor se encuentra en cero todo el tiempo. Una vez se le asigne un valor distinto a cero, el bit rom se colocará en cero y el sistema comenzará a ingresar los flujos de entrada procesarlos y sus resultados escribirlos. Max Bulk Size=2
15-1.
31 Irq(rw) Una vez se escriba el último dato del último flujo de resultados de salida, este bit se colocará en uno para señalar el evento del fin del procesamiento del flujo. La escritura de este bit SOLO es posible una vez se haya activado la interrupción y SOLO se puede escribir en él el valor cero. Esto sirve como mecanismo para acusar recibo desde el proceso al que se le notifica la

45
interrupción.
Tabla 4. Registro de Control y Programación REG_CTRL.
7.2 Mecanismos de sincronización del RayTrac. El RayTrac posee varios mecanismos de sincronización para operaciones internas cómo escritura en fifos (colas) internas para mantenimiento de datos intermedios en pipelines y también para la lectura de los mismos. Sin embargo esa sincronización es mas un detalle de la descripción de hardware, es decir, es un detalle del código fuente con el que se describió el hardware. Para más información consulte el código fuente, el cual se anexó a este trabajo. Sin embargo el RayTrac trabaja en conjunto con el procesador Nios II y las memorias. Para sincronizar el funcionamiento entre estos elementos se utiliza el bus Avalon de Altera.
Ilustración 17. Interfaces RayTrac, 1. Master port, 2. Slave port, 3. Interruption sender port.
La Ilustración 17, muestra las interfaces que utiliza el RayTrac para sincronizarse y comunicarse con la CPU y la memoria. Dichas interfaces son:
1 Interfaz Avalon Memory Mapped Master: Transacciones de lectura y escritura
con la memoria DDRAM.
2 Interfaz Avalon Memory Mapped Slave: Operaciones de configuración del
RayTrac.
3 Interfaz Interrupt Sender: Sincronización del evento de final de operación con el
procesador NIOS II.
7.2.1. Interfaz Avalon Memory Mapped Master. Esta interfaz es usada por el RayTrac para ejecutar transacciones de escritura y lectura
de flujos de datos de salida y de entrada respectivamente. La interfaz Master, es usada

46
cuando se desea escribir o leer datos a un elemento Slave. En este caso el RayTrac es
un dispositivo con una interfaz Master, que solicitará la escritura y lectura de datos a
un dispositivo con una interfaz Slave como el controlador de memoria DDRAM.
Los operandos de las operaciones aritméticas que se ejecutan en el RayTrac y sus
resultados, se leen y escriben exclusivamente usando esta interfaz, cualquier valor de
configuración y/o programación del RayTrac será escrito o leído a través de la interfaz
Avalon Memory Mapped Slave.
Operación de Lectura de Datos.
La lectura de datos utiliza los datos configurados en el registro REG_FETCHSTART y el
campo de bits nfetch de REG_CTRL.
El registro REG_FETCHSTART contiene la dirección de inicio de la transacción de
lectura. Esta dirección es de 32 bits y el espacio de direccionamiento es externo al
RayTrac. El campo de bits nfetch, contiene el numero de datos que se desea transferir
hacia el RayTrac.
La transacción de lectura de datos funciona en modo burst o ráfaga. Esto significa que
al bus Avalon se le informará el tamaño de la transacción y en que dirección se
encuentran los datos a leer.
Las señales utilizadas para efectuar la transacción son:
Master_waitrequest (in)
Master_read (out)
Master_burstcount (out)
Master_address (out)
Master_readdata (in)
Master_readdatavalid (in)
La Ilustración 18 detalla un ejemplo de transacción de lectura en ráfaga.

47
Ilustración 18. Transacción de lectura en ráfaga.
La interfaz inicia la transacción de lectura colocando en la señal read, en 1 y
escribiendo la dirección que se encuentra almacenada en REG_FETCHSTART en la
salida address y escribiendo el tamaño de la ráfaga en burstcount. Inmediatamente la
interconexión Avalon coloca la señal waitrequest en 1, para indicar que el bus de datos
se encuentra ocupado. Mientras que la señal waitrequest se encuentre en 1, las
señales read, address y burstcount deben permanecer fijas y sin cambio.
Cuando la interconexión coloca la señal waitrequest en 0, estará indicando que la fase
de direccionamiento de la transacción habrá terminado. Al siguiente ciclo de reloj se
debe colocar en 0 la señal read.
Una vez quedan enganchadas las direcciones en la interconexión comienza la fase de
datos de la transacción de lectura. Cada vez que la interconexión coloca en 1 la señal
readdatavalid, se debe enganchar dentro del RayTrac el dato readdata.
Operación de Escritura de datos.
La escritura de datos utiliza los datos configurados en el registro REG_SINKSTART. Este
registro contiene la dirección de inicio de la transacción, a donde serán escritos los
datos. Esta dirección es de 32 bits y el espacio de direccionamiento es externo al
RayTrac.
La transacción de escritura de datos funciona en modo burst o ráfaga. Esto significa
que al bus Avalon se le informará el tamaño y en qué dirección se escribirán estos
datos.
Master_waitrequest (in)
Master_write (out)
Master_burstcount (out)
Master_address (out)

48
Master_writedata (out)
La Ilustración 19 detalla un ejemplo de transacción de una escritura en ráfaga.
Ilustración 19. Transacción de escritura en ráfaga.
La interfaz inicia la transacción de lectura colocando en la señal write, en 1 y
escribiendo la dirección que se encuentra almacenada en REG_SINKSTART en la salida
address, escribiendo el tamaño de la ráfaga en burstcount y el primer dato a escribir en
writedata.
Inmediatamente la interconexión Avalon coloca la señal waitrequest en 1, para indicar
que el bus de datos se encuentra ocupado. Mientras que la señal waitrequest se
encuentre en 1, las señales write, address, writedata y burstcount deben permanecer
fijas y sin cambio.
Cuando la interconexión coloca la señal waitrequest en 0, estará indicando que el dato
a escribir fue enganchado por la interconexión al siguiente ciclo de reloj se debe
colocar el siguiente dato a escribir en writedata.
Las señales write, address, burstcount deben mantenerse constantes durante toda la
transacción. Pero cuando waitrequest sea cero y no queden mas datos por escribir la
señal write debe quedar en 0, terminando la transacción de escritura.
7.2.2. Interfaz Avalon Memory Mapped Slave La Interfaz de programación de bajo nivel del RayTrac, provee al programador con un
banco de 16 registros para la configuración, programación y depuración del mismo.
Ese banco se accede desde el procesador Nios II usando el pool de direcciones , el cual
asigna una dirección al RayTrac. En realidad esa dirección referencia la interfaz Slave
en el RayTrac.

49
Las señales utilizadas por esta interfaz son:
Slave_read (in)
Slave_readdata(out)
Slave_write(in)
Slave_writedata(in)
Slave_address(in).
La dirección de entrada corresponde a un espacio de direccionamiento nativo, esto
significa que la interconexión traduce las direcciones planas externas al espacio de
direcciones nativo del RayTrac, haciendo que el direccionamiento sea transparente e
independiente del exterior para interfaz slave.
Operación de lectura y escritura
Ilustración 20. Transacciones de escritura y lectura en la interfaz Avalon Slave. Fuente: ALTERA.
10
La implementación de la interfaz Avalon Memory Mapped Slave, no implementa el
drive o lectura de todas las señales en la Ilustración 20. La razón es porque la
interconexión externamente las maneja y hace que el manejo de las mismas sea
transparente para la interfaz implementada. Dichas señales son:
Slave_byteenable : Esta señal enmascara el conjunto de bits que desean ser
leídos de los 32 bits posibles. Sin embargo el diseño de la interfaz de
programación exige que sean leídos y escritos todos los bits cuando se
configuran o leen registros.
10 Altera, Avalon Interface Specifications.

50
Slave_begintransfer : Esta entrada señaliza el comienzo de una transacción de
escritura ó lectura. Se implementa por defecto en la interconexión y es
transparente para la implementación de la interfaz slave.
Slave_waitrequest : Esta señal le indica a la interconexión que el RayTrac no
está disponible para ser accedido a través de la interfaz slave. Sin embargo este
mecanismo no será implementado, porque la sincronización entre la interfaz de
programación del RayTrac y el proceso que lo controla se hará mediante la
señal de interrupción.
El diagrama de bloques en la Ilustración 21, muestra la implementación de la
interfaz slave:
Ilustración 21. Implementación de la Intefaz Avalaon Memory Mapped Slave en el RayTrac.
La lectura de registros tiene una latencia de 2 ciclos de reloj, distribuidos en una etapa
de decodificación de dirección y otra de multiplexación. La interconexión notifica la
solicitud de lectura colocando la señal read en uno, dicha señal se engancha junto con
la dirección del registro que se quiere leer, en el primer ciclo de reloj. La interconexión
coloca la señal read en 0 y espera al siguiente ciclo por el dato.
La escritura de registros tiene una latencia de 2 ciclos de reloj, distribuido en una etapa
de enganche de decodificación de dirección y otra etapa de escritura del registro
seleccionado. La transacción de escritura comienza cuando la interconexión coloca la
señal write en 1. Una vez se engancha el dato y la dirección se da por concluida la
transacción para la interconexión y esta coloca la señal write en 0.
La interfaz Avalon Memory Mapped Slaved solo sirve para configurar el kernel y las
direcciones fuente y destino, de los flujos de entrada y salida, respectivamente.

51
Estos registros están disponibles para lectura en todo momento. Sin embargo solo en
el Estado IDLE, estarán disponibles para escritura.
7.2.3. Interfaz Avalon Interrupt Out La interfaz de interrupción tiene la función de sincronizar el RayTrac con el programa
que se ejecuta sobre el procesador Nios II, JART. La interrupción se genera cuando la
ejecución de una operación vectorial ha terminado y el flujo de resultados se ha
terminado de escribir en la memoria. Desde el momento en que comienza la
operación, hasta que se genera la interrupción los registros de configuración solo se
pueden leer.
Una vez la interrupción es generada se le debe indicar al RayTrac que la interrupción
fue atendida, para ello se debe escribir un cero en el bit mas alto del registro de
configuración y programación REG_CTRL.
Opción de Polling.
Existe la opción de no utilizar la interfaz de interrupción, en caso de que la detección
del final de ejecución de operación en el RayTrac no sea una operación crítica. Para
detectar el final de la ejecución se puede leer el bit más significativo del registro de
control, el cual solo se puede leer hasta que este en 1, lo que significa el fin de la
ejecución.
7.3. Mecanismos de sincronización del RayTrac. El RayTrac opera en 3 modos principales: IDLE, SOURCE y SINK. IDLE es el estado en
que el RayTrac se encuentra ocioso, sin tareas por realizar.
SOURCE es el estado en el que el RayTrac verifica las condiciones para comenzar una
transacción de carga de direcciones y descarga de datos. El estado SINK es el estado en
el que el RayTrac comienza una transacción de carga de datos con resultados de
operaciones en una memoria externa.
Una vez se escribe en el campo nfetch del registro de control, el tamaño del flujo de
entrada, la máquina pasará al estado SOURCE, porque la condición Zero Transit, deja
de cumplirse.
El diagrama de Ilustración 22 muestra la operación del Estado Idle.

52
Ilustración 22. Estado IDLE.
El estado IDLE prioriza la escritura en el registro de control, sobre cualquier otra
operación que se lleve a cabo en el RayTrac.
Si no se está llevando a cabo una operación de escritura en los registros de
configuración, se verifica el tránsito de datos en los bloques aritméticos RayTrac. Si
hay datos la condición Zero Transit es falsa y el siguiente estado será SOURCE.
El siguiente diagrama, Ilustración 23, muestra la operación del estado SOURCE:
Ilustración 23. Estado SOURCE.

53
El Estado SOURCE prioriza si se está ejecutando un enganche de direcciones durante el
ciclo de reloj. Si se está realizando la operación de enganche se verifica si ya se terminó
y dar por finalizada la fase de enganche de dirección.
En caso de que no se este ejecutando un enganche de dirección, se verifica si la
condición Flood Condition, la cual verifica que no haya datos pendientes por descargar
desde la memoria, se da, pues de hacerlo se inicia una transacción de lectura de datos
Cada vez que se engancha una dirección se reduce en uno el valor de ocupación de la
cola de direcciones pendientes por enganchar.
El Estado SINK tiene dos funciones: transmitir los resultados del pipeline aritmético a la
dirección de memoria externa y notificar mediante una interrupción, si la ejecución de
la operación ha terminado.
El siguiente diagrama de flujo ilustra el funcionamiento del Estado SINK:
Ilustración 24. Estado SINK.
En la Ilustración 24, muestra que el estado SINK le da prioridad a cualquier transacción
de escritura de datos que se esté ejecutando, verificando si el dato a escribir se
engancho en el bus de datos de lo contrario enganchará el dato.
Cuando se engancha el dato, se verifica si ese era el último por transmitir, dando por
terminada la transacción de escritura.

54
El otro caso es que no hayan transacciones de escritura llevándose a cabo. En ese caso
se verifica la condición Drain Condition, que cual verfiica que haya resultados listos por
ser escritos en la memoria, comenzando dicha transacción.
Cuando las condiciones no se dan, la máquina de control de flujo pasará al Estado
SOURCE si hay datos transitando en el RayTrac, sino, se genera una señal de
interrupción para indicar que la operación terminó y el siguiente estado sería IDLE.

55
8. RESULTADOS Las pruebas realizadas se realizaron en dos niveles, verificación y validación. Los
resultados de estas prueban confirman el logro de los objetivos, en mayor o menor
media, propuestos en el Capítulo 0.
Las pruebas de verificación consisten en la medición del desempeño del RayTrac, al
ejecutar las diferentes operaciones que este puede ejecutar. Estas pruebas buscan
confirmar el funcionamiento y medir el desempeño de los circuitos aritméticos que
ejecutan operaciones vectoriales.
Las pruebas de validación confirman el funcionamiento del sistema como arquitectura
de trazado de rayos y síntesis de imágenes. El sistema tiene obtuvo resultados
distorsionados en las imágenes producidas por hardware, debido a problemas de
precisión aritmética con la operación raíz cuadrada.
Adicionalmente se hace un recuento de los recursos de fpga utilizados, simulaciones
hechas y cálculo de máxima frecuencia.
8.1. Verificación: Resultados. Se realizó la medición del tiempo de ejecución en Hardware y Software de las
siguientes operaciones:
Producto Punto
Producto Cruz
Producto Simple
Suma Vectorial
Normalización de Vectores.
Las pruebas fueron hechas por cada operación. Se realizaron las mismas pruebas en
hardware y en software, usando el RayTrac y el Nios II respectivamente.
A continuación se muestran los resultados de las pruebas de desempeño por cada
operación. Las Ilustraciones 29 a 32 el eje X es tiempo en microsegundos y el eje Y
número de operaciones ejecutadas. El eje Y está dividió logarítmicamente en base 10 y
representa el tiempo en microsegundos que en promedio tomó cada etapa de 5
repeticiones. El eje X representa el número de ejecuciones en cada etapa. Finalmente
se representa mediante esferas los resultados, donde el radio de cada esfera
representa el tiempo promedio de ejecución de cada etapa (lo mismo que su ubicación

56
en el eje Y). El color de la esfera representa el tipo de ejecución: azul para hardware y
violeta para software.
Producto Punto
Operación Número de Iteraciones Hardware (RayTrac) Software (Nios II)
Tiempo de Ejecución Promedio (µsecs)
Producto
Punto
10 103,415 1153,1908
100 647,8 10760,0678
1000 6443 107059,097
Tabla 5. Resultado de desempeño para la operación producto punto.
En la tabla 5 se observan los tiempos promedios de ejecución de 10, 100 y 1000
ejecuciones de la operación producto punto.
Ilustración 25. Comparativo de los tiempos por tipo de ejecución. En Violeta los tiempos de ejecución en software y en azul los
tiempos de ejecución en hardware.
Producto Cruz
Operación Número de Iteraciones Hardware (RayTrac) Software (Nios II)
Tiempo de Ejecución Promedio (µsecs)
Producto
Cruz
10 99,1008 2896,4072
100 660,794 29266,7532
1000 6468 255011,1938
Tabla 6. Resultado de desempeño para la operación producto cruz.
100
1000
10000
100000
1000000
1 10 100 1000 10000
Hardware (RayTrac) Software (Nios II)

57
Ilustración 26. Comparativo de los tiempos por tipo de ejecución. En Violeta los tiempos de ejecución en software y en azul los
tiempos de ejecución en hardware.
Suma Vectorial.
Operación Número de Iteraciones Hardware (RayTrac) Software (Nios II)
Tiempo de Ejecución Promedio (µsecs)
Suma Vectorial
10 103,6482 1137,5804
100 650,6 10778,499
1000 6466,2 107008,3562
Tabla 7. Resultado de desempeño para la operación suma vectorial.
Ilustración 27. Comparativo de los tiempos por tipo de ejecución. En Violeta los tiempos de ejecución en software y en azul los
tiempos de ejecución en hardware.
Producto Simple
Operación Número de Iteraciones Hardware (RayTrac) Software (Nios II)
Tiempo de Ejecución Promedio (µsecs)
Producto Simple
10 102,23 2939,9638
100 656,8 29150,4946
1000 6465 291959,025
Tabla 8. Resultado de desempeño para la operación producto simple.
100
1000
10000
100000
1000000
1 10 100 1000 10000
Hardware (RayTrac) Software (Nios II)
100
1000
10000
100000
1000000
1 10 100 1000 10000
Hardware (RayTrac) Software (Nios II)

58
Ilustración 28. Comparativo de los tiempos por tipo de ejecución. En Violeta los tiempos de ejecución en software y en azul los
tiempos de ejecución en hardware.
Normalización de Vectores.
Operación Número de Iteraciones Hardware (RayTrac) Software (Nios II)
Tiempo de Ejecución Promedio (µsecs)
Normalización
10 99,8436 183,7848
100 653,4 1431,2
1000 6485,9376 14120,5224
Tabla 9. Resultado de desempeño para la operación normalización vectorial.
Ilustración 29. Comparativo de los tiempos por tipo de ejecución. En Violeta los tiempos de ejecución en software
y en azul los tiempos de ejecución en hardware.
8.2. Validación: Resultados del sistema como herramienta para la realización de rendering.
El JART se implementó hasta el punto que dispara rayos hacia la escena y forma la
imagen sin hacer cálculos de iluminación complejos. Las primitivas que compusieron
las escenas de prueba eran esferas. La Ilustración 30 y la Ilustración 31, muestran un
100
1000
10000
100000
1000000
1 10 100 1000 10000
Hardware (RayTrac) Software (Nios II)
100
1000
10000
100000
1 10 100 1000 10000
Hardware (RayTrac) Software (Nios II)

59
ejemplo de una escena sintetizada, de 16 esferas, en software y hardware
respectivamente.
Ilustración 30. Imagen sintetizada utilizando unicamente la CPU para calcularla (NIOS II).

60
Ilustración 31. Imagen sintetizada utilizando únicamente el RayTrac. El ruido aparente de la imagen, las
inexactitudes de los bordes, se deben a un problema en el calculo de la dirección de los rayos disparados hacia la escena.
Cada imagen tiene una resolución de 800x480 pixeles, esto significa que se disparan
384000 rayos hacia cada escena.
El tiempo operacional11 de cada escena se ilustra a continuación:
11 El tiempo que tomo realizar las operaciones vectoriales, se descartan los tiempos de sobrecarga.

61
Ilustración 32. Tiempo operacional de cada escena.
El sistema escala linealmente conforme aumenta el número de esferas en la escena. Se
observa que la escena más compleja (32 esferas) tiene problemas se demora casi 3
minutos, un desempeño lento, sin embargo el resultado era el esperado, dado que no
se implementó ningún tipo de optimización en el algoritmo de síntesis.
Es interesante notar que estos tiempos serían mayores al menos en un orden
aproximadamente, si las escenas se hubieran calculado en software.
Ilustración 33. Tiempo Operacional de Ejecución vs. Número de esferas en la escena. (Clasificación por tipo de
operación vectorial)
La ilustración 33 revela los tiempos de ejecución operacional por cada tipo de escena.
Cuando el número de esferas es 1, el tiempo operacional más importante corresponde
0
50
100
150
200
0 5 10 15 20 25 30 35
Se
gu
nd
os
Numero de Esferas
Tiempo Operacional vs. Número de Esferas
0
20
40
60
80
100
1
2
4
8
1
3
Se
gu
nd
os
Número de Esferas
Tiempo Operacional vs. Número de Esferas
(Clasificado por tipo de operación)
Producto Punto Suma/Resta Normal
Prod Simple

62
a la suma/resta. En un escenario más real el tiempo más representativo corresponde
de nuevo a la suma/resta y adicionalmente al producto punto.
La ilustración 34 revela la tasa relativa de ejecución por operación:
Ilustración 34. Tiempo Operacional Relativo vs. Número de Esferas. (Clasificado por tipo de operación)
Las ilustraciones 55 y 54 revelan el desempeño del RayTrac en relación con el número
de esferas que hay en cada escena. Esto es importante para el análisis del hardware
con respecto al problema.
0
0,1
0,2
0,3
0,4
0,5
0,6
1 2
4
8
16
32
Po
rce
nta
je d
e E
jecu
ció
n R
ela
tiv
o
Número de Esferas
Tiempo Operacional Relativo vs. Número de Esferas
(Clasificado por tipo de operación)
Producto Punto Suma/Resta

63
Las ilustraciones 56 y 57 muestra el desempeño con respecto al algoritmo de trazado
de rayos, donde las clases son distintas etapas de este.
Ilustración 35. Tiempo Operacional vs. Número de Esferas (Clasificado por etapa de ejecución en el algoritmo de
trazado de rayos)
Ilustración 36. Tiempo Operacional Relativo vs. Número de Esferas (Clasificado por etapa de ejecución en el
algoritmo de trazado de rayos)
0
50
100
150
200
1
2
4
8
1
3
Se
gu
nd
os
Número de Esferas
Tiempo Operacional vs. Número de Esferas
(Clasificado por etapa de ejecución en el algoritmo de trazado de rayos)
Test Rayo Esfera
Pre Calculo Esfera
Calculo Distancia Objetos Impactados
0
0,2
0,4
0,6
0,8
1
1 2
4 8
16
32
Po
rce
nta
je d
e E
jecu
ció
n R
ela
tiv
o
Número de Esferas
Tiempo Operacional Relativo vs. Número de Esferas
(Clasificado por etapa de ejecución en el algoritmo de trazado de rayos)
Test Rayo Esfera
Conjunto Primario de Rayos
Pre Calculo Esfera

64
Las ilustraciones 56 y 57, muestran la importancia que tiene la etapa de intersección
entre rayos y esferas. Conforme crece el número de esferas por escenario,
prácticamente el RayTrac ejecuta operaciones para calcular la intersección entre rayo
y esfera.
8.3. Problemas en la generación de imágenes con RayTrac
Las imágenes sintetizadas en hardware tuvieron problemas debido a un problema con
los rayos disparados hacia la escena. Una vez se ha calculado el vector del rayo, se
realizan 3 operaciones con este para considerarlo disparado, se calcula la magnitud del
rayo, se invierte el valor calculado y se multiplica por cada componente del vector. El
resultado es un rayo de magnitud uno y la misma dirección.
Al verificar y comparar los valores de los rayos generados en software y en hardware
se encontró un error del +-3% en la dirección de los rayos generados por hardware, lo
que genera la distorsión en las imágenes generadas. Al observar la Ilustración 31, el
error en la dirección de los rayos es evidente, pues no hay distorsión en los bordes de
la esfera que se encuentra cerca del observador, pero conforme las esferas se
encuentran más alejadas, la distorsión se hace evidente.
El problema ocurre con la precisión de la operación raíz cuadrada en punto flotante.
Dado que la raíz cuadrada de la mantisa se calcula utilizando una memoria de 1024
palabras de 18 bits, significa que se usa los diez bits más altos de la misma para
direccionar en la memoria y obtener un resultado. Sin embargo se está desconociendo
la información residente en los otros 13 bits restante de la mantisa y resolución en la
función raíz cuadrada. Sin embargo para poder implementar una función raíz cuadrada
de 23 bits de direccionamiento, se necesita una memoria de 8 millones de palabras,
cada una de 18 bits al menos. No se cuenta con esa clase de memoria.
A pesar de los problemas que ocurren con la distorsión de la imagen, se puede asegurar que una vez, se corrija el defecto de la raíz cuadrada, los tiempos comparativos no van a cambiar, pues la arquitectura es en pipeline y para resolverlo, se cambiaría una etapa combinatoria existente o se añadirían etapas combinatorias adicionales, que siendo los suficientemente segmentadas, no afectarán la frecuencia máxima de funcionamiento que se logró (133 MHz según la herramienta Altera TimeQuest).
8.3. Recursos Utilizados, simulaciones y análisis de tiempos. Recursos utilizados
El sistema generado se compiló en Quartus II y produjo el siguiente reporte:

65
Ilustración 37. Recursos usados por el RtEngine. Fuente: ALTERA QUARTUS II, Fitter Report.
El sistema generado permite a la FPGA quedar holgada en recursos y se puede pensar
en aumentar las prestaciones del RayTrac incluso en instanciar otro más.
Ilustración 38. Recursos usados por el RayTrac. Fuente: ALTERA QUARTUS II, Fitter: Resources Used By Entity
Report.
Resumiendo la información en la tabla se tiene:
Interconexión decodificada de circuitos aritméticos: Utiliza 490 celdas lógicas.
Adaptador de formato de flujos de salida: Utiliza en la lógica de las colas de
resultados y de salida, 109 celdas lógicas y 4 bloques de memoria m9k.

66
Sumadores pipeline aritmético. En promedio, cada uno utiliza 363.33 celdas
lógicas, 1 multiplicador de 9x9 bits y 1 multiplicador de 18x18 bits, para realizar
corrimientos.
Multiplicadores pipeline aritmético. En promedio, cada multiplicador utiliza
173.5 celdas lógicas y 3 multiplicadores de 18x18 bits.
Raíz Cuadrada pipeline aritmético: En promedio utiliza 7 celdas lógicas y 2
bloques de memoria m9k.
Inversor pipeline aritmético: En promedio utiliza 23 celdas lógicas y 2 bloques
de memoria m9k.
Colas de sincronización pipeline aritmético q0 y q2: en promedio cada cola
utiliza 221 celdas lógicas. (un costo alto, se sugiere utilizar bloque m9k).
Cola de sincronización pipeline aritmético q1: utiliza 36 celdas lógicas, mucho
menos que q0 y q2, pero requiere de 3 m9ks, para ser implementada.
Un circuito RayTrac requiere 4527 celdas lógicas, 12 bloques de memoria m9k y 45
multiplicadores 9x9 bits.
Simulaciones.
Las simulaciones se llevan a cabo con la entrada y salida de archivos, hacia y desde un
testbench, el cual es ejecutado por el programa MODELSIM Altera Starter Edition.
Adicionalmente se crea una herramienta utilizando el lenguaje de programación
PYTHON, cuyo objetivo es analizar los códigos fuente de los RTL que describen el
RAYTRAC y compilar el código VHDL con el testbench.
Para generar la entrada de la simulación, la cual es una escena en 3D, se utiliza el
programa Blender3D, en el que se puede modelar esta escena con esferas y mediante
un script se genera un archivo de entradas para la simulación.
Para visualizar los resultados de la simulación se utilizan 2 herramientas:
1. Testbench Compiler: script para hacer observables en el testbench aquellas
señales que no son puertos de salida en el DUT.

67
2. Posterior a la ejecución del testbench, en un archivo CSV (Comma Separated
Values) de valores separados por comas, se escriben los resultados de la
simulación. Las filas poseerán señales o puertos de observación y las columnas
avanzan hacia la derecha conforme la simulación avanza.
Para la generación de esta simulación funcional se desarrollaron 2 herramientas
concretas:
1. Script de generación de testbench: Cuando se realiza una simulación funcional
haciendo uso de un testbench es usual encontrar dos entidades en el testbench,
la primera es la DUT (Device Under Test) o Dispositivo Bajo Test y la segunda es
la entidad que controla y genera los estímulos o entradas para la simulación.
El problema que surge es que la entidad que controla los estímulos solo puede
acceder a los puertos de entrada y salida de la DUT, para escribirlos y leerlos
respectivamente. Dado que la DUT es por lo general la entidad top en el
circuito entero, las señales y puertos que se encuentran más abajo dejan de ser
visibles para la simulación, lo que supone un problema para entender los
posibles errores de diseño que surjan en aquellas entidades bottom.
El script de generación testbench analiza todas las entidades instanciadas en el
top entity y mediante reglas de comentarios (al estilo doxygen12), detecta
señales que el diseñador desea observar en la simulación y modifica los RTL de
tal manera que esa señal sea visible en los puertos del top entity y de esta
manera hacerlos observables para la entidad que controla y genera las
entradas para la simulación.
2. El testbench compilado adicionalmente genera instrucciones para que en la
ejecución de la simulación se genere un archivo con la imagen del render.
Las simulaciones funcionales, fueron consignadas en archivos .csv, en un formato
separado por comas. Se anexan con este documento.
Analisis de Tiempos.
Se realizó el análisis de tiempos para el RayTrac. El sistema posee un solo dominio de
reloj de una frecuencia de 60 MHz, lo que simplifica el cuidado que se debe tener en el
momento en que se realiza el diseño de los circuitos y la definición de restricciones o
constraints, al momento de realizar el análisis de tiempos.
12 www.doxygen.org

68
Sin embargo los circuitos externos al RayTrac, funcionan en un dominio de reloj de 100
MHz, por lo tanto en el capítulo de integración con los sistemas externos se realizará el
análisis de tiempos, con restricciones y dominios de reloj adicionales.
Los reportes de tiempos fueron generados una vez realizada la compilación y el fitting
del circuito en Quartus II.
El reporte de frecuencia máxima da por resultado 137.61 MHz. Este resultado indica
que el periodo mínimo que puede tener el reloj del sistema es de 7.2 ns, tiempo
satisfactorio para un sistema que se diseñó pensando para un reloj de 50 MHz cuyo
periodo es de 20 ns.
El reporte de restricciones y fmax arrojado por la herramienta TimeQuest es el
siguiente:
Fmax Restricted Fmax Clock Name
137.61 MHz 137.61 MHz clko Tabla 10. Frecuencia máxima calculada para el RayTrac.
SDC Command Name Period Waveform Targets
create_clock clko 20 { 0.000 10.000 } [get_ports {clk}] Tabla 11. Restricciones creadas para el análisis de tiempo posterior a la operación de fitting que realiza Quartus
II, que sirve como entrada para el TimeQuest Analyzer.
El reporte de tiempos se anexa13 al documento.
13 Ver lista de anexos al final del documento.

69
9. CONCLUSIONES
Los resultados de verificación muestran la ventaja de implementar la ejecución
de operaciones vectoriales complejas en hardware. La ejecución de hardware
es más rápida que la ejecución de software. Al comparar las operaciones se
encuentra que la ejecución en hardware es al menos un orden de magnitud
más rápida que la ejecución de software (10x).
Los tiempos de ejecución escalan linealmente conforme aumenta el número de
operaciones a realizar.
Aunque el sistema RayTrac corre a 65 MHz, este no puede entregar 65 millones
de resultados por segundos, el problema radica en que este comparte recursos
de memoria con el procesador Nios II, a través de el bus Avalon. A pesar de que
el RayTrac realiza transferencias tipo DMA, dicha transferencia está sometida al
arbitramento del Bus Avalon, por lo tanto los tiempos de acceso son variables y
no determinables. Analizando los resultados se estima que la perdida por cuello
de botella es de un orden de magnitud. Por lo tanto el throughput (numero de
resultados por segundo) pasaría de un ideal de 66 MHz a 6 MHz,
aproximadamente.
Una caída de throughput ideal supone que se podrían instanciar unidades
RayTrac que usen menos registros, o sea, menos segmentadas en sus pipeline y
con un reloj de menor frecuencia. Se ganaría en área de uso y consumo de
potencia.
El cuello de botella generado para acceder a los recursos de memoria desde el
RayTrac o el Nios II, es un problema desde la perspectiva del hardware, el cual
es un factor ponderante en la caída de desempeño del algoritmo. Sin embargo
este problema no es inherente del algoritmo de trazado de rayos,; este
problema es un problema normal de las arquitectura de computo
convencionales, en las que los periféricos comparten unos recursos, como por
ejemplo memoria haciendo uso del mismo bus.
No se realizó ningún tipo de optimización del algoritmo de trazado de rayos, se
implementó el más general de todos. Esto contribuye al bajo desempeño del
sistema. Lo anterior se hace evidente cuando en la ilustración 57 se observa la
tasa de test de rayos y esferas, comparado con el número de cálculos de
distancia de objetos impactados: se consumen recursos de computo muy
importantes solamente en tests de rayos y esferas cuyo resultado es negativo.

70
Los tiempos que realmente son relevantes para los resultados de este trabajo,
en la sección de validación de este capítulo son los tiempos operacionales, los
cuales hacen referencia a los tiempos en los que se empleo recursos de
cómputo exclusivamente para el cálculo de operaciones vectoriales. Los
tiempos de sobrecarga son aquellos periodos en los que los recursos de
computo se emplean para operaciones administrativas sobre los datos, esto es
moverlos de una dirección de memoria a la otra, cargar datos desde la
herramienta de modelado, interpretar comandos, sistema operativo, etc.
Sin embargo los tiempos de sobrecarga se pueden mejorar haciendo
optimizaciones en hardware, por ejemplo la escritura de operandos en
direcciones especificas de memoria sería mucho más rápida si se implementará
en la operación del DMA del RayTrac
Las operaciones de producto punto y suma vectorial, son las operaciones que
mas se ejecutan en el contexto hardware de la ejecución del algoritmo de
trazado de rayos.
Por otra parte el algoritmo de trazado de rayos es básicamente un algoritmo de
resolución de intersección entre rayos y primitivas.
Los resultados ilustran el peor de los casos en la versión más general del
algoritmo de trazado de rayos: pocos test de intersección positivos, 8% a 28%,
en peor y mejor de los casos respectivamente. Esto significa una cantidad de
procesamiento inútil que debe ser optimizado mediante software.
El resultado más relevante de este proyecto es que la falta de desempeño del
algoritmo de trazado de rayos, no se debe exclusivamente a su naturaleza o
planteamiento matemático intrínseco que lo conforma. En este proyecto el problema
de cuello de botella para el acceso a las memorias, la falta de recursos para
implementarlas localmente por ejemple memorias cache, fue el factor más importante
para obtener el bajo desempeño que se obtuvo.
A pesar de lo anterior el desempeño no era el objetivo, lo que se quería mostrar era la
alternativa que brindaba el implementar las operaciones vectoriales en hardware más
que ejecutarlas en software. Los resultados evidencian que se logra una aceleración en
el desempeño de ejecución cuando esta se realiza en hardware con respecto a
software, pero desafortunadamente para obtener un sistema de trazado de rayos, los
cuellos de botella de la arquitectura son más relevantes y resolverlos requiere de
soluciones novedosas.

71
9.1. Trabajo a futuro. Un trabajo menor es refinar la implementación de la raíz cuadrada para poder
corregir el problema de distorsión de las imágenes y de dirección del rayo.
Se propone generar trabajos que desde la perspectiva de hardware, propongan
arquitecturas más atractivas a este tipo de aplicaciones como los procesadores de
flujos, para ello se necesita contar con arquitecturas novedosas, en el aspecto de
acceso a los datos. En el caso de este proyecto se debe utilizar un diseño
completamente diferente para evitar la tasa de throughput caiga en promedio, lo que
se estima es una orden de magnitud.
Las operaciones de producto punto y suma vectoriales, son básicas en la
operación del algoritmo de trazado de rayos, la optimización de los diseños de estos,
que permitan una mayor segmentación sin consumir más recursos, de los que ya se ha
consumido, para generar un mejor diseño es un objetivo a cumplir.
Para implementar un algoritmo de trazado de rayos eficiente, es necesario
hacer implementaciones, como sub divisiones espaciales, pre cálculo de vértices y
entidades geométricas.
Adicional a la búsqueda de arquitecturas que superen el problema del cuello de
botella, sería importante proponer arquitecturas distribuidas y que en paralelo puedan
ejecutar el algoritmo de trazado de rayos de manera eficiente.

72
10 BIBLIOGRAFÍA
Agarwal, V., MS Hrishikesh, S. W. Keckler, and D. Burger. 2000. "Clock Rate Versus IPC: The End of the Road for Conventional Microarchitectures."IEEE, .
Altera Corporation. 2011. Avalon Interface Specifications.
Altera Corporation. 2012. Cyclone III Device HandBook.
Benthin, C. 2006. "Realtime Ray Tracing on Current Cpu Architectures." .
Bigler, J., A. Stephens, and S. G. Parker. 2006. "Design for Parallel Interactive Ray Tracing Systems."IEEE, .
Bingham, Scott and Donald YunFan. 2008. "Ray Tracing made Simple A Ray Tracer Implemented on an FPGA " .
Bishop, G. and D. M. Weimer. 1986. "Fast Phong Shading."ACM, .
Carr, N. A., J. D. Hall, and J. C. Hart. 2002. "The Ray Engine."Eurographics Association, .
Cassagnabere, C., F. Rousselle, and C. Renaud. 2004. "Path Tracing using the AR350 Processor."ACM, .
Christen, M. 2005. "Ray Tracing on GPU." Master's Thesis, Univ.of Applied Sciences Basel (FHBB).
Deschamps, J. P., G. J. A. Bioul, and G. D. Sutter. 2006. " Arithmetic Operations: Multiplication. Synthesis of Arithmetic Circuits: FPGA, ASIC, and Embedded Systems." In , 81.
Djeu, P., W. Hunt, R. Wang, I. Elhassan, G. Stoll, and W. R. Mark. 2011. "Razor: An Architecture for Dynamic Multiresolution Ray Tracing." ACM Transactions on Graphics (TOG) 30 (5): 115.
Dutré, P. "Global Illumination Compendium." .
Eldridge, M., H. Igehy, and P. Hanrahan. 2000. "Pomegranate: A Fully Scalable Graphics Architecture."ACM Press/Addison-Wesley Publishing Co., .
ERTÜRK, U. R. "Ray Tracing on Cell by using KD-Tree Acceleration Structure." .
Fender, J. and J. Rose. 2003. "A High-Speed Ray Tracing Engine Built on a Field-Programmable System."IEEE, .
Ferreira, H. S. 2008. "Ray Tracing in Electronic Games." .

73
Gordon, D. and S. Chen. 1991. "Front-to-Back Display of BSP Trees." Computer Graphics and Applications, IEEE 11 (5): 79-85.
Guigue, P. and O. Devillers. 2003. "Fast and Robust Triangle-Triangle Overlap Test using Orientation Predicates." Journal of Graphics Tools 8 (1): 25-32.
Hanika, J. 2007. "Fixed Point Hardware Ray Tracing." Aug 23: 1-61.
Howard J. 2007. "Real Time Ray Tracing, the End of Rasterization?" .
Humphreys, G. and C. S. Ananian. 1996. "Tigershark: A Hardware Accelerated Ray-Tracing Engine." Senior Independent Work, Princeton University.
Hurley, Jim. 2005. "Ray Tracing Goes Mainstream." 09 (02): 99.
Kajiya, J. T. 1986. "The Rendering Equation." ACM SIGGRAPH Computer Graphics 20 (4): 143-150.
Keates, MJ and RJ Hubbold. 1995. "Interactive Ray Tracing on a Virtual Shared-Memory Parallel Computer." .
Khailany, B., W. J. Dally, U. J. Kapasi, P. Mattson, J. Namkoong, J. D. Owens, B. Towles, A. Chang, and S. Rixner. 2001. "Imagine: Media Processing with Streams." Micro, IEEE 21 (2): 35-46.
Kim, S. S., S. W. Nam, D. H. Kim, and I. H. Lee. 2007. "Hardware-Accelerated Ray-Triangle Intersection Testing for High-Performance Collision Detection." Journal of WSCG 15.
Kobayashi, H., K. Suzuki, K. Sano, and N. Oba. 2002. "Interactive Ray-Tracing on the 3DCGiRAM Architecture."Citeseer, .
Kuchkuda, R. 1988. "An Introduction to Ray Tracing." Theoretical Foundations of Computer Graphics and CAD 40: 1039-1060.
Meißner, M., U. Kanus, G. Wetekam, J. Hirche, A. Ehlert, W. Straßer, M. Doggett, P. Forthmann, and R. Proksa. 2002. "VIZARD II: A Reconfigurable Interactive Volume Rendering System."Eurographics Association, .
Nieh, J. and M. Levoy. 1992. "Volume Rendering on Scalable Shared-Memory MIMD Architectures."ACM, .
Owens, J. D., M. Houston, D. Luebke, S. Green, J. E. Stone, and J. C. Phillips. 2008. "GPU Computing." Proceedings of the IEEE 96 (5): 879-899.
Parker, S., W. Martin, P. P. J. Sloan, P. Shirley, B. Smits, and C. Hansen. 1999. "Interactive Ray Tracing."ACM, .

74
Parker, S. G., J. Bigler, A. Dietrich, H. Friedrich, J. Hoberock, D. Luebke, D. McAllister, M. McGuire, K. Morley, and A. Robison. 2010. "Optix: A General Purpose Ray Tracing Engine." ACM Transactions on Graphics (TOG) 29 (4): 66.
Phong, B. T. 1975. "Illumination for Computer Generated Pictures." Communications of the ACM 18 (6): 311-317.
Pohl, D. 2011. "Experimental Cloud-Based Ray Tracing using Intel MIC Architecture for Highly Parallel Visual Processing." Intel Corp.
PohL, D. 2009. "Light it Up! Quake Wars Gets Ray Traced." Intel Visual Adrenaline (2).
Pohl, D. 2012. "Tracing Rays through the Clouds. Intel Visual Adrenaline." .
Purcell, T. J. 2004. "Ray Tracing on a Stream Processor." .
Purcell, T. J., I. Buck, W. R. Mark, and P. Hanrahan. 2002. "Ray Tracing on Programmable Graphics Hardware." ACM Transactions on Graphics (TOG) 21 (3): 703-712.
Purcell, T. J., C. Donner, M. Cammarano, H. W. Jensen, and P. Hanrahan. 2003. "Photon Mapping on Programmable Graphics Hardware."Eurographics Association, .
Reeves, W. T. 1983. "Particle systems—a Technique for Modeling a Class of Fuzzy Objects."ACM, .
Reinhard, E. and F. W. Jansen. 1997. "Rendering Large Scenes using Parallel Ray Tracing." Parallel Computing 23 (7): 873-885.
Schmittler, J., I. Wald, and P. Slusallek. 2002. "SaarCOR: A Hardware Architecture for Ray Tracing."Eurographics Association, .
Schmittler, J., S. Woop, D. Wagner, W. J. Paul, and P. Slusallek. 2004. "Realtime Ray Tracing of Dynamic Scenes on an FPGA Chip."ACM, .
Srinivasan, J. R. 2002. "Hardware Accelerated Ray Tracing.".
Styles, H. and W. Luk. 2002. "Accelerating Radiosity Calculations using Reconfigurable Platforms."IEEE, .
Tanenbaum, A. S. and A. S. Woodhull. 1997. Operating Systems: Design and Implementation. Vol. 68 Prentice Hall.
The Codermind Team. 2008. " Ray Tracing Tutorial by the Codermind Team." .
van der Ploeg, AJ. 2006. "Interactive Ray Tracing, the Replacement of Rasterization?" .

75
Wald, I., C. Benthin, and P. Slusallek. 2002. "A Flexible and Scalable Rendering Engine for Interactive 3D Graphics." Computer Graphics Group, Saarland University.
Wald, I., C. P. Gribble, S. Boulos, and A. Kensler. 2007. "SIMD Ray Stream Tracing-SIMD Ray Traversal with Generalized Ray Packets and on-the-Fly Re-Ordering." SCI Institute, University of Utah, Technical Report# UUSCI-2007-012 (Aug.2007): 1-8.
Wald, I. and P. Slusallek. 2001. "State of the Art in Interactive Ray Tracing." STAR, EUROGRAPHICS 2001: 21-42.
Whitted, T. 1980. "An Improved Illumination Model for Shaded Display." Communications of the ACM 23 (6): 343-349.
Woo, A. 1992. "Ray Tracing Polygons using Spatial Subdivision."Citeseer, .
Woop, S., J. Schmittler, and P. Slusallek. 2005. "RPU: A Programmable Ray Processing Unit for Realtime Ray Tracing."ACM, .
Yates, R. 2009. "Fixed-Point Arithmetic: An Introduction." Digital Signal Labs 81 (83): 198.