
práctica nº 2 de introducción a la psicometría: construcción de un ...
23
UNIVERSIDAD AUTÓNOMA DE MADRID FACULTAD DE PSICOLOGÍA CURSO 2002/03 Carmen García Julio Olea Vicente Ponsoda Javier Revuelta Carmen Ximénez Francisco J. Abad PRÁCTICA Nº 2 DE INTRODUCCIÓN A LA PSICOMETRÍA: CONSTRUCCIÓN DE UN TEST Y ANÁLISIS DE SUS PROPIEDADES PSICOMÉTRICAS
Transcript of práctica nº 2 de introducción a la psicometría: construcción de un ...

UNIVERSIDAD AUTÓNOMA DE MADRID FACULTAD DE PSICOLOGÍA CURSO 2002/03 Carmen García Julio Olea Vicente Ponsoda Javier Revuelta Carmen Ximénez Francisco J. Abad
PRÁCTICA Nº 2 DE INTRODUCCIÓN A LA PSICOMETRÍA:
CONSTRUCCIÓN DE UN TEST Y ANÁLISIS DE SUS PROPIEDADES PSICOMÉTRICAS

ÍNDICE
1. OBJETIVOS 1
2. PROCEDIMIENTO 1
2.1 Composición del grupo de prácticas 1
2.2 Definición del rasgo a medir y generación de ítems 1
2.3 Procedimiento de aplicación del test 2
2.4 Creación del fichero de datos 2
2.5 Estudio psicométrico del test 5
2.5.1. Análisis de los ítems 5
2.5.2. Estudio de las propiedades psicométricas del test definitivo 6
2.6 El análisis de datos con el programa SPSS 6
2.7 Elaboración del informe 18
3. EVALUACIÓN 19
4. HOJA DE VALORACIÓN 20

1
1. OBJETIVOS
Con la realización de esta práctica se pretende que el alumno aplique los contenidos de
la Teoría Clásica de los Tests realizando todos los pasos que requiere la construcción de un
test de rendimiento típico: generación de los ítems, aplicación a un grupo normativo,
selección de ítems, cálculo de la fiabilidad y validez, y baremación. El análisis de datos se
llevará a cabo con el programa SPSS en el aula de informática de la Facultad.
Una vez concluido el análisis de datos, los alumnos deberán confeccionar un informe
que detalle el procedimiento seguido para la creación de su test.
Se dedicarán varias clases a la orientación y supervisión del proceso anterior, desde el
análisis de datos hasta la elaboración del informe.
2. PROCEDIMIENTO
2.1. COMPOSICIÓN DEL GRUPO DE PRÁCTICAS.
Cada grupo de prácticas estará integrado por un mínimo de 3 personas y un máximo de
5. Se procurará que al menos uno de los integrantes tenga conocimientos básicos de
informática (DOS, Windows, procesadores de textos, etc.).
2.2. DEFINICIÓN DEL RASGO A MEDIR Y GENERACIÓN DE ÍTEMS
Cada grupo deberá elegir (libremente) y definir el rasgo que desee medir, siempre
teniendo en cuenta que el test debe de ser de rendimiento típico. A continuación se
procederá a generar ítems adecuados al mismo. Hemos fijado el número de ítems y el formato
de respuesta. El TEST INICIAL debe estar formado por 13 ítems y el TEST FINAL por 8
ítems. El formato de respuesta será de 5 CATEGORÍAS ORDENADAS.

2
2.3. PROCEDIMIENTO DE APLICACIÓN DEL TEST.
La aplicación de los tests se llevará a cabo durante horas lectivas. Cada clase deberá
responder a los tests de sus grupos. Esto permitirá disponer a cada grupo de una muestra de
unas 100 personas.
Para la aplicación del test, cada grupo deberá venir provisto de 110 copias de su test
que entregará a sus compañeros para ser debidamente cumplimentadas. Se sugiere que el test
quepa en una hoja. Si se considera necesario, el test puede incluir unas breves instrucciones.
2.4. CREACIÓN DEL FICHERO DE DATOS.
Después de aplicar el test tenemos que construir un fichero de datos, en el Editor de
Datos del SPSS, que denominaremos FICHERO.SAV. En dicho fichero se incluirán las
respuestas de la muestra a todos los ítems.
Lo primero que tenemos que tener en cuenta es el procedimiento de cuantificación de
las respuestas, siguiendo las pautas indicadas en clase:
a) Los ítems tienen un formato de respuesta de 6 categorías ordenadas. Deberemos decidir
si la cuantificación de un ítem va de 1 a 6 ó de 6 a 1 dependiendo, como hemos visto en
clase, de si el ítem mide de manera directa o inversa el rasgo que interesa.
c) Si una persona no responde a un ítem o marca dos alternativas, le asignaremos el valor
9 en ese ítem. Ésta va a ser la manera de codificar los valores perdidos (o “missings”)
en el SPSS.
FICHERO.SAV es un fichero SPSS de datos donde los sujetos son las filas y los ítems
las columnas o variables, de tal manera que cada fila recoge las respuestas de una persona a
todos los ítems. Por tanto, el fichero tiene tantas filas como sujetos hayan respondido el test.
La columna relativa a cada ítem debe reflejar las respuestas de todos los sujetos a ese ítem.
Cada fila debe empezar por el número de codificación del sujeto a que corresponda. Después
del número de codificación, se van grabando las respuestas a los ítems. Por ejemplo,
supóngase que disponemos de las respuestas de tres sujetos a un test de 15 ítems:
Sujeto 1: 1 3 3 4 3 4 3 3 4 3 4 2 4 4 3 2 Sujeto 2: 2 1 1 3 3 2 2 3 3 1 3 9 2 3 3 2 Sujeto 3: 3 2 2 9 2 1 3 4 2 2 4 5 2 2 3 2
Este ejemplo se refiere a las respuestas dadas por los tres primeros sujetos a los 15 ítems de

3
un test de rendimiento típico formado por ítems con formato de respuesta de categorías
ordenadas que se valoran de 1 a 5 ó de 5 a 1 según si el ítem mide de manera directa o inversa
el rasgo que interesa. Observamos que el sujeto 2 tiene un 9 en el ítem número 11, lo que
significa que, o bien no lo ha respondido o ha seleccionado más de una opción de respuesta.
Veamos cómo se introducen los datos de este ejemplo en el SPSS. En primer lugar nos
situamos con el cursor en la primera casilla del Editor de Datos. Tenemos que crear un
fichero con 3 filas (nº sujetos) y 16 columnas (codificación del sujeto y sus respuestas en los
15 ítems). Para ello, simplemente se escriben las puntuaciones correspondientes a cada caso.
Para moverse de una celda a otra se pulsan las teclas marcadas con flechas. Los datos para los
diez primeros ítems se colocan del siguiente modo:
Figura 1. Editor de datos del SPSS
Una vez escritos los datos es necesario dar nombre a las variables. Como muestra la
Figura 1, el SPSS ha dado por defecto los nombres var00001, var00002, etc. y ha escrito los
valores numéricos con dos decimales. Si se desea personalizar el nombre de alguna variable y
definir sus características (por ejemplo: nivel de medida, número de decimales, etiquetas de
valores, formato de columna, definición de valores perdidos, etc.) hay que pulsar con el ratón
en la solapa “Vista de variables”. A continuación aparece una ventana que contiene tantas
filas como variables hay definidas en el editor de datos:
Pulsar para ver los datos
Pulsar para ver la definición de las variables
Aquí se muestra el contenido de la casilla donde está situado el cursor.

4
Figura 2.
En cada fila se da la posibilidad de modificar el nombre de la variable (teniendo en cuenta
que no puede tener más de 8 caracteres) además de otras propiedades como el tipo
(numérico, cadena, etc.), la anchura, el número de decimales (por defecto son dos), la
etiqueta (aquí se puede escribir, por ejemplo, la afirmación que incluye el ítem), el
significado de los valores que admite (p.e.: 1 = poco, ..., 5 = mucho), los valores perdidos,
la alineación del texto, etc. Basta situar el ratón o el cursor en cada casilla y escribir la
información deseada. En nuestro ejemplo, llamemos a las variables: sujeto, item1, item2, ...
item15.
Algunas de las casillas de la ventana ‘Vista de variables’ incorporan su propio cuadro
de diálogo que se activa al seleccionarlas. Por ejemplo, al pulsar en ‘Perdidos’ aparece el
siguiente cuadro de diálogo:

5
Desde este cuadro de diálogo se puede definir el valor o valores que designa valores perdidos (“missings”) en una variable. La opción por defecto es ‘no hay valores perdidos’. Se pueden definir hasta tres valores perdidos discretos y el rango donde se encuentran los valores perdidos de la variable. En nuestro ejemplo el valor 9, implica que el sujeto o bien no ha respondido o ha seleccionado más de una opción de respuesta.
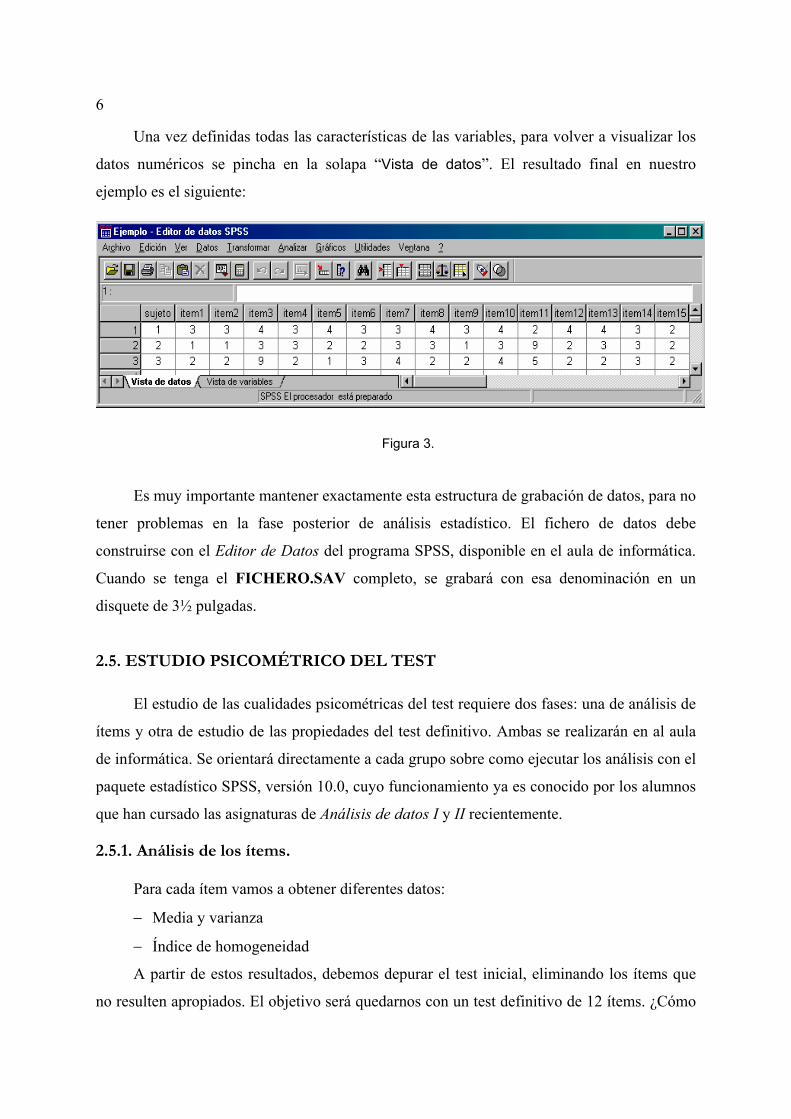
6
Una vez definidas todas las características de las variables, para volver a visualizar los
datos numéricos se pincha en la solapa “Vista de datos”. El resultado final en nuestro
ejemplo es el siguiente:
Figura 3.
Es muy importante mantener exactamente esta estructura de grabación de datos, para no
tener problemas en la fase posterior de análisis estadístico. El fichero de datos debe
construirse con el Editor de Datos del programa SPSS, disponible en el aula de informática.
Cuando se tenga el FICHERO.SAV completo, se grabará con esa denominación en un
disquete de 3½ pulgadas.
2.5. ESTUDIO PSICOMÉTRICO DEL TEST
El estudio de las cualidades psicométricas del test requiere dos fases: una de análisis de
ítems y otra de estudio de las propiedades del test definitivo. Ambas se realizarán en al aula
de informática. Se orientará directamente a cada grupo sobre como ejecutar los análisis con el
paquete estadístico SPSS, versión 10.0, cuyo funcionamiento ya es conocido por los alumnos
que han cursado las asignaturas de Análisis de datos I y II recientemente.
2.5.1. Análisis de los ítems.
Para cada ítem vamos a obtener diferentes datos:
− Media y varianza
− Índice de homogeneidad
A partir de estos resultados, debemos depurar el test inicial, eliminando los ítems que
no resulten apropiados. El objetivo será quedarnos con un test definitivo de 12 ítems. ¿Cómo

7
los eliminamos?
− Sobre todo atendiendo a los índices de homogeneidad. Eliminaremos los que menor
Hj manifiesten.
− También puede eliminarse algún ítem que presente una varianza muy pequeña.
− Si el test fuese de rendimiento óptimo, podríamos eliminar los ítems con medias
extremas; es decir, con índices de dificultad próximos a 0 ó a 1.
2.5.2 Estudio de las propiedades psicométricas del test definitivo.
A partir de FICHERO.SAV, estudiaremos las garantías que ofrece el test definitivo.
En concreto, considerando únicamente las respuestas a los 12 ítems que forman este test
definitivo, vamos a obtener:
a) Su coeficiente de fiabilidad, por la técnica de dos mitades.
b) Su coeficiente α de Cronbach.
c) Un análisis factorial para conocer la validez factorial del test.
d) Un baremo en centiles.
2.6. EL ANÁLISIS DE DATOS CON EL PROGRAMA SPSS.
Para obtener todos los indicadores psicométricos que acabamos de mencionar
utilizaremos el paquete estadístico SPSS versión 10.0.
El análisis de datos requiere la construcción de dos tipos de ficheros:
1). Un fichero de datos FICHERO.SAV cuyo proceso de construcción ya hemos detallado.
2). Un fichero de resultados FICHERO.SPO, en el que aparezcan los resultados de todos los
análisis realizados. Este fichero tiene que incluir los resultados de los análisis para la
selección de ítems y los resultados de los análisis para el test definitivo.
A continuación se presenta un ejemplo a partir del cual veremos los procedimientos y
menús del SPSS que se necesitan para llevar a cabo los análisis. El ejemplo se refiere a un
test inicialmente compuesto por 15 ítems de 5 alternativas de los que se han seleccionado 12.
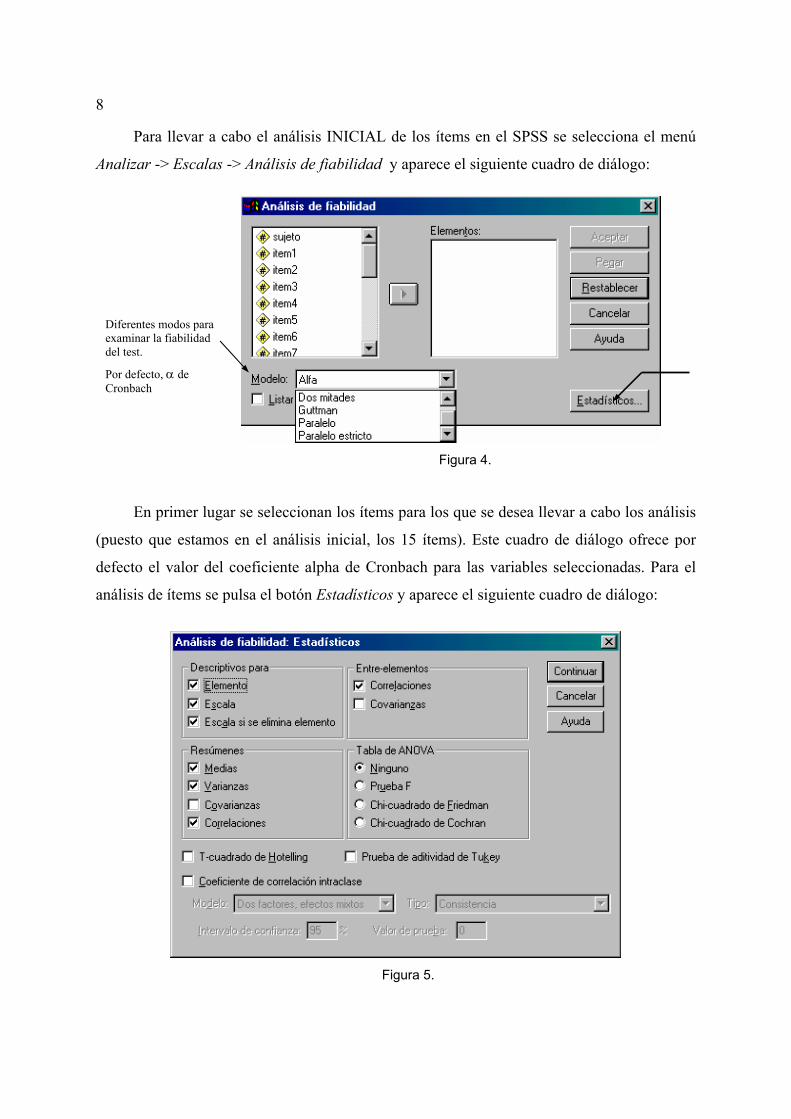
8
Para llevar a cabo el análisis INICIAL de los ítems en el SPSS se selecciona el menú
Analizar -> Escalas -> Análisis de fiabilidad y aparece el siguiente cuadro de diálogo:
Figura 4.
En primer lugar se seleccionan los ítems para los que se desea llevar a cabo los análisis
(puesto que estamos en el análisis inicial, los 15 ítems). Este cuadro de diálogo ofrece por
defecto el valor del coeficiente alpha de Cronbach para las variables seleccionadas. Para el
análisis de ítems se pulsa el botón Estadísticos y aparece el siguiente cuadro de diálogo:
Figura 5.
Diferentes modos para examinar la fiabilidad del test.
Por defecto, α de Cronbach

9
Si se ejecutan las selecciones que aparecen señaladas en el cuadro de diálogo de la
figura 5, el SPSS proporciona una salida de resultados. Estos resultados contienen toda la
información necesaria para realizar el análisis de los ítems y determinar los ítems que
constituyen el test definitivo. Los resultados correspondientes a los datos del ejemplo se
muestran en las tablas primera a quinta.
Como puede verse en la tabla 1, en primer lugar se obtienen una serie de estadísticos
descriptivos para cada ítem: la media, la desviación típica y el número de personas que han
respondido al ítem. Las medias de nuestro ejemplo están comprendidas entre 2,1860 del ítem
13 y 3,7558 del ítem 10. El ítem 8 tiene la mayor desviación típica, 1,5169.
Tabla 1. Estadísticos descriptivos univariados para los 15 ítems del test inicial. R E L I A B I L I T Y A N A L Y S I S - S C A L E (A L P H A) Mean Std Dev Cases 1. ITEM1 3.1977 .9433 86.0 2. ITEM2 2.7442 .9602 86.0 3. ITEM3 2.2907 1.2354 86.0 4. ITEM4 2.4070 1.1311 86.0 5. ITEM5 2.6628 .9281 86.0 6. ITEM6 3.4186 1.1216 86.0 7. ITEM7 2.3488 .9045 86.0 8. ITEM8 2.8721 1.5169 86.0 9. ITEM9 2.8023 .9557 86.0 10. ITEM10 3.7558 .9933 86.0 11. ITEM11 2.4767 1.3610 86.0 12. ITEM12 2.6977 .8821 86.0 13. ITEM13 2.1860 1.1009 86.0 14. ITEM14 2.6628 .9281 86.0 15. ITEM15 2.7093 .8659 86.0
Los coeficientes de correlación entre los ítems se muestran en la tabla 2. Nótese que
para el ítem 4 muchos coeficientes son bajos y/o negativos.
La tabla 3 muestra algunos estadísticos adicionales para todo el test. La media en el test
es 41,2326 y su desviación típica 5,3549. También se ofrecen la media de las varianzas y de
las correlaciones entre los ítems, así como su rango. Por ejemplo, la media de las varianzas es
1,1473. La varianza más pequeña es 0,7498 y la mayor 2,3011.
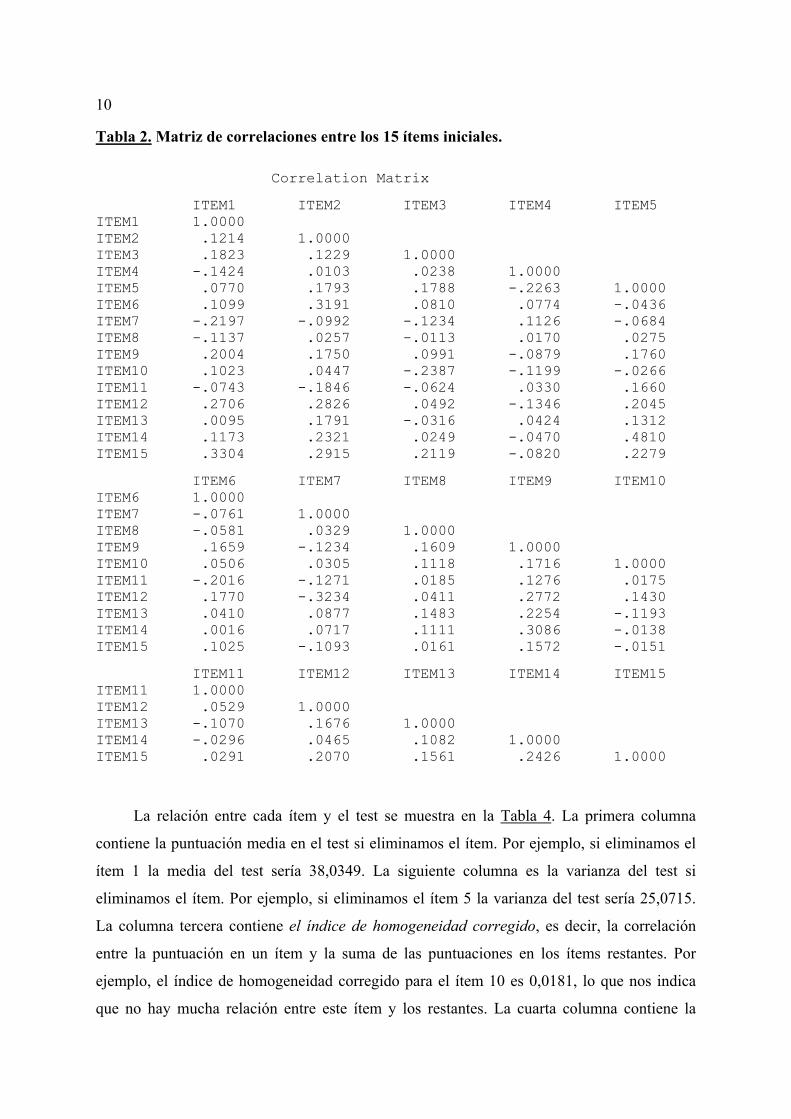
10
Tabla 2. Matriz de correlaciones entre los 15 ítems iniciales. Correlation Matrix
ITEM1 ITEM2 ITEM3 ITEM4 ITEM5 ITEM1 1.0000 ITEM2 .1214 1.0000 ITEM3 .1823 .1229 1.0000 ITEM4 -.1424 .0103 .0238 1.0000 ITEM5 .0770 .1793 .1788 -.2263 1.0000 ITEM6 .1099 .3191 .0810 .0774 -.0436 ITEM7 -.2197 -.0992 -.1234 .1126 -.0684 ITEM8 -.1137 .0257 -.0113 .0170 .0275 ITEM9 .2004 .1750 .0991 -.0879 .1760 ITEM10 .1023 .0447 -.2387 -.1199 -.0266 ITEM11 -.0743 -.1846 -.0624 .0330 .1660 ITEM12 .2706 .2826 .0492 -.1346 .2045 ITEM13 .0095 .1791 -.0316 .0424 .1312 ITEM14 .1173 .2321 .0249 -.0470 .4810 ITEM15 .3304 .2915 .2119 -.0820 .2279
ITEM6 ITEM7 ITEM8 ITEM9 ITEM10 ITEM6 1.0000 ITEM7 -.0761 1.0000 ITEM8 -.0581 .0329 1.0000 ITEM9 .1659 -.1234 .1609 1.0000 ITEM10 .0506 .0305 .1118 .1716 1.0000 ITEM11 -.2016 -.1271 .0185 .1276 .0175 ITEM12 .1770 -.3234 .0411 .2772 .1430 ITEM13 .0410 .0877 .1483 .2254 -.1193 ITEM14 .0016 .0717 .1111 .3086 -.0138 ITEM15 .1025 -.1093 .0161 .1572 -.0151
ITEM11 ITEM12 ITEM13 ITEM14 ITEM15 ITEM11 1.0000 ITEM12 .0529 1.0000 ITEM13 -.1070 .1676 1.0000 ITEM14 -.0296 .0465 .1082 1.0000 ITEM15 .0291 .2070 .1561 .2426 1.0000
La relación entre cada ítem y el test se muestra en la Tabla 4. La primera columna
contiene la puntuación media en el test si eliminamos el ítem. Por ejemplo, si eliminamos el
ítem 1 la media del test sería 38,0349. La siguiente columna es la varianza del test si
eliminamos el ítem. Por ejemplo, si eliminamos el ítem 5 la varianza del test sería 25,0715.
La columna tercera contiene el índice de homogeneidad corregido, es decir, la correlación
entre la puntuación en un ítem y la suma de las puntuaciones en los ítems restantes. Por
ejemplo, el índice de homogeneidad corregido para el ítem 10 es 0,0181, lo que nos indica
que no hay mucha relación entre este ítem y los restantes. La cuarta columna contiene la
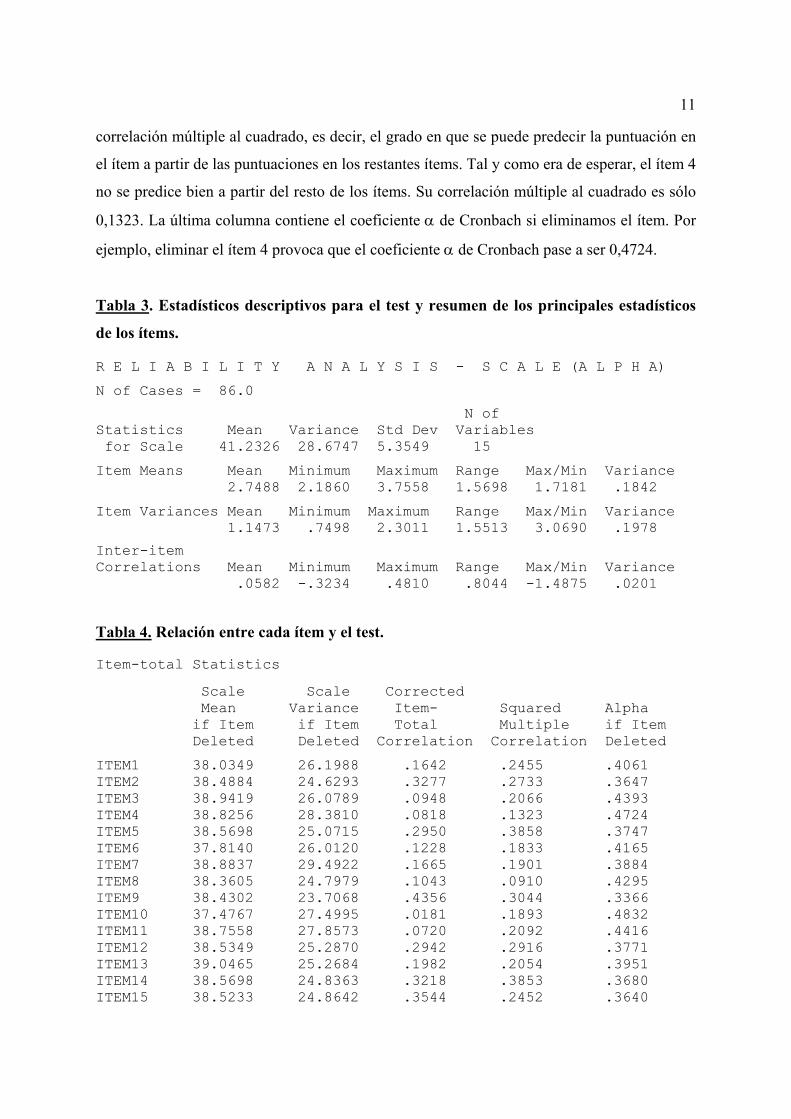
11
correlación múltiple al cuadrado, es decir, el grado en que se puede predecir la puntuación en
el ítem a partir de las puntuaciones en los restantes ítems. Tal y como era de esperar, el ítem 4
no se predice bien a partir del resto de los ítems. Su correlación múltiple al cuadrado es sólo
0,1323. La última columna contiene el coeficiente α de Cronbach si eliminamos el ítem. Por
ejemplo, eliminar el ítem 4 provoca que el coeficiente α de Cronbach pase a ser 0,4724.
Tabla 3. Estadísticos descriptivos para el test y resumen de los principales estadísticos
de los ítems.
R E L I A B I L I T Y A N A L Y S I S - S C A L E (A L P H A)
N of Cases = 86.0
N of Statistics Mean Variance Std Dev Variables for Scale 41.2326 28.6747 5.3549 15
Item Means Mean Minimum Maximum Range Max/Min Variance 2.7488 2.1860 3.7558 1.5698 1.7181 .1842
Item Variances Mean Minimum Maximum Range Max/Min Variance 1.1473 .7498 2.3011 1.5513 3.0690 .1978
Inter-item Correlations Mean Minimum Maximum Range Max/Min Variance .0582 -.3234 .4810 .8044 -1.4875 .0201 Tabla 4. Relación entre cada ítem y el test.
Item-total Statistics
Scale Scale Corrected Mean Variance Item- Squared Alpha if Item if Item Total Multiple if Item Deleted Deleted Correlation Correlation Deleted
ITEM1 38.0349 26.1988 .1642 .2455 .4061 ITEM2 38.4884 24.6293 .3277 .2733 .3647 ITEM3 38.9419 26.0789 .0948 .2066 .4393 ITEM4 38.8256 28.3810 .0818 .1323 .4724 ITEM5 38.5698 25.0715 .2950 .3858 .3747 ITEM6 37.8140 26.0120 .1228 .1833 .4165 ITEM7 38.8837 29.4922 .1665 .1901 .3884 ITEM8 38.3605 24.7979 .1043 .0910 .4295 ITEM9 38.4302 23.7068 .4356 .3044 .3366 ITEM10 37.4767 27.4995 .0181 .1893 .4832 ITEM11 38.7558 27.8573 .0720 .2092 .4416 ITEM12 38.5349 25.2870 .2942 .2916 .3771 ITEM13 39.0465 25.2684 .1982 .2054 .3951 ITEM14 38.5698 24.8363 .3218 .3853 .3680 ITEM15 38.5233 24.8642 .3544 .2452 .3640

12
El coeficiente α de Cronbach del test inicial, compuesto por 15 ítems, aparece en la
tabla 5. En nuestro ejemplo alcanza un valor de 0,4284.
Tabla 5. Coeficiente α de Cronbach del test inicial.
Reliability Coefficients 15 items
Alpha = .4284 Standardized item alpha = .4812
Para obtener el test definitivo de 12 ítems deberemos eliminar los 3 ítems que peor se
comporten a partir de los datos de las tablas 1, 2, 3 y 4. En nuestro ejemplo eliminaríamos los
ítems 10, 11 y 4 ya que, como se puede ver en la tabla 4, estos son los ítems que poseen los
índices de homogeneidad más bajos. En nuestro ejemplo no consideramos las medias al
eliminar los ítems, ya que nuestro test es de rendimiento típico. El test definitivo de nuestro
ejemplo estará compuesto, por lo tanto, por los ítems 1, 2, 3, 5, 6, 7, 8, 9, 12, 13, 14 y 15.
Entrando de nuevo en el menú Analizar -> Escalas -> Análisis de fiabilidad (ver figura
4) obtendremos los estadísticos para el test definitivo (seleccionar sólo los ítems 1, 2, 3, 5, 6,
7, 8, 9, 12, 13, 14 y 15). Ahora sólo solicitaremos los descriptivos para ‘Escala’ (ver figura 5
y desactivar las opciones restantes).
La tabla 6 contiene la media, varianza y el coeficiente α del test final. En el test inicial
el coeficiente α era de 0.4284. En el test final, a pesar de ser más corto, el coeficiente α
alcanza un valor de 0.5437. Por lo tanto, al eliminar estos ítems hemos mejorado la
consistencia interna del test.
Tabla 6. Media, varianza y coeficiente α de Cronbach del test final. R E L I A B I L I T Y A N A L Y S I S - S C A L E (A L P H A)
N of Statistics for Mean Variance Std Dev Variables SCALE 32.5169 26.0935 5.1082 12 Reliability Coefficients
N of Cases = 89.0 N of Items = 12
Alpha = .5437

13
También podemos informar sobre la consistencia interna del test calculando el
coeficiente de fiabilidad por el método de las dos mitades. Para ello, se selecciona el menú
Analizar -> Escalas -> Análisis de fiabilidad. Desde este cuadro de diálogo se puede obtener el
coeficiente de fiabilidad por el método de dos mitades (ver figuras 4 y 5).
La tabla 7 contiene un resumen de los estadísticos que obtendríamos, si dividiésemos la
escala en dos partes. La parte 1 está formada por los 6 primeros ítems y la parte 2 por los 6
últimos.
Tabla 7. Estadísticos para la escala dividida en dos mitades.
R E L I A B I L I T Y A N A L Y S I S - S C A L E (S P L I T) N of Statistics for Mean Variance Std Dev Variables PART 1 16.5618 8.0672 2.8403 6 PART 2 15.9551 11.7252 3.4242 6 SCALE 32.5169 26.0935 5.1082 12
El coeficiente de fiabilidad obtenido por este procedimiento se muestra en la tabla 8. La
correlación entre las dos mitades del test vale 0.3239. El coeficiente de fiabilidad de nuestro
test vale 0.4894.
Tabla 8. Coeficientes de fiabilidad obtenidos por el método de dos mitades.
Reliability Coefficients N of Cases = 89.0 N of Items = 12 Correlation between forms=.3239 Equal-length Spearman-Brown = .4894 Guttman Split-half =.4830 Unequal-length Spearman-Brown = .4894 6 Items in part 1 6 Items in part 2 Alpha for part 1 = .2761 Alpha for part 2 = .4961

14
Para determinar la validez factorial de nuestro test realizamos un análisis factorial por
el método del Componente Principal. Para llevar a cabo dicho análisis se selecciona el menú
Analizar -> Reducción de datos -> Análisis factorial y aparece el siguiente cuadro de diálogo:
Lo primero es seleccionar las variables que constituyen el test definitivo de 12 ítems y
transportaras a la casilla Variables. Dentro de este cuadro de diálogo veremos dos opciones:
Extracción y Rotación. Si se pulsa en el botón Extracción aparece el siguiente cuadro de
diálogo:
Desde aquí puede elegirse el método que se seguirá para la extracción de factores,
obtener un diagrama de sedimentación, controlar cuántos factores son extraídos, o especificar
el máximo de iteraciones para la convergencia. En nuestro caso, nos interesa el método de
Componentes principales que es el que aparece por defecto.
15
Si pulsamos el botón Rotación aparece el siguiente cuadro de diálogo:
La rotación es un método general para facilitar la interpretación de una solución
factorial. Existen varios métodos diferentes para la rotación. Nosotros escogeremos la
rotación Varimax. Este cuadro de diálogo permite incluir los resultados de la solución rotada.
Los resultados que ofrece el SPSS con las selecciones realizadas se ofrecen de la tabla
novena a la decimoprimera.
Tabla 9. Factores obtenidos (método del Componente Principal).
Varianza total explicada
2.628 21.901 21.901 2.628 21.901 21.901 1.781 14.841 14.8411.504 12.531 34.431 1.504 12.531 34.431 1.730 14.414 29.2551.242 10.353 44.784 1.242 10.353 44.784 1.482 12.351 41.6061.096 9.135 53.919 1.096 9.135 53.919 1.478 12.313 53.919.970 8.083 62.002.882 7.349 69.352.822 6.847 76.198.760 6.331 82.529.598 4.985 87.514.551 4.592 92.106.520 4.333 96.439.427 3.561 100.000
Componente123456789
101112
Total% de lavarianza
%acumulado Total
% de lavarianza
%acumulado Total
% de lavarianza
%acumulado
Autovalores inicialesSumas de las saturaciones al
cuadrado de la extracciónSuma de las saturaciones al
cuadrado de la rotación
Método de extracción: Análisis de Componentes principales.

16
Tabla 10. Matriz factorial con los cuatro factores retenidos.
Matriz de componentesa
.518 -.374 -.175 -.208
.598 -5.76E-02 .135 .488
.317 -.191 -.414 -.154
.523 .362 -.450 -3.70E-02
.354 -.334 .348 .585-.347 .501 -9.94E-02 .452.102 .483 .371 -.371.583 .199 .292 -.171.600 -.224 .328 -.209.292 .446 .429 -4.36E-02.467 .553 -.317 .165.607 -4.63E-02 -.270 5.231E-02
ITEM1ITEM2ITEM3ITEM5ITEM6ITEM7ITEM8ITEM9ITEM12ITEM13ITEM14ITEM15
1 2 3 4Componente
Método de extracción: Análisis de componentes principales.4 componentes extraídosa.
Tabla 11. Matriz factorial rotada.
Matriz de componentes rotados a
.232 .636 .120 -9.48E-02
.287 9.853E-02 .718 .103
.360 .381 -6.61E-02 -.230
.767 9.076E-02 -3.77E-02 .105-.113 7.817E-02 .825 -3.19E-02.131 -.753 1.499E-02 -3.06E-02
-2.10E-03 -3.58E-02 -.229 .682.226 .297 .197 .562
1.727E-02 .589 .299 .3558.714E-02 -8.81E-02 .141 .660
.752 -.170 8.780E-02 .222
.522 .339 .241 -1.71E-02
ITEM1ITEM2ITEM3ITEM5ITEM6ITEM7ITEM8ITEM9ITEM12ITEM13ITEM14ITEM15
1 2 3 4Componente
Método de extracción: Análisis de componentes principales.
Método de rotación: Normalización Varimax con Kaiser.La rotación ha convergido en 7 iteraciones.a.
En la tabla 9, desde la columna segunda hasta la cuarta se muestran los autovalores o
varianza de cada factor, el porcentaje de varianza que cada factor explica y el porcentaje de
varianza acumulado. Por ejemplo, la varianza del factor 1 es 2.628 lo que supone un 21.90%
de la varianza total. Las columnas 5 a 7 contienen las varianzas, porcentajes y porcentajes

17
acumulados de los factores con varianza superior a uno, que son los factores que se retienen
(en nuestro ejemplo los cuatro primeros). Las tres últimas columnas contienen esta misma
información (varianza, porcentaje y porcentaje acumulado) de los cuatro factores retenidos
tras su rotación ortogonal. Como se observa, los cuatro factores explican el 53.92% de la
variabilidad total.
La matriz factorial se ofrece en la tabla 10 y la matriz factorial resultado de efectuar
una rotación Varimax en la tabla 11. Ésta es la matriz que debemos interpretar para juzgar la
validez factorial de nuestro test. Por ejemplo, en nuestro test el primer factor viene definido
sobre todo por los ítems número 5, 14 y 15 cuyas saturaciones son respectivamente 0.767,
0.752 y 0.522.
Para terminar, se ofrece la distribución de frecuencias a partir de la cual podemos
calcular el baremo en centiles. Esta distribución de frecuencias se obtiene a partir de la
puntuación total de cada sujeto en el test. Para obtener dicha puntuación hay que crear una
nueva variable que es el resultado de sumar las puntuaciones en los 12 ítems del test
definitivo. Llamaremos a la nueva variable Total. Para crearla se selecciona el menú
Transformar -> Calcular que sólo está disponible en el Editor de datos del SPSS. Con los
datos de nuestro ejemplo, el cuadro de diálogo tendría el siguiente aspecto:
Una vez definida la variable Total, para obtener su distribución de frecuencias se
selecciona el menú Analizar -> Estadísticos descriptivos -> Frecuencias del SPSS cuyo
cuadro de diálogo tiene el siguiente aspecto:

18
Los resultados obtenidos con esta selección aparecen en la tabla 12. La última columna
contiene los porcentajes acumulados que nos permiten conocer los centiles. Por ejemplo, en
nuestro test C73 = 44.
Tabla 12. Centiles y distribución de frecuencias de nuestro test.
TOTAL
1 1.0 1.2 1.23 3.0 3.5 4.71 1.0 1.2 5.82 2.0 2.3 8.18 8.0 9.3 17.46 6.0 7.0 24.48 8.0 9.3 33.73 3.0 3.5 37.26 6.0 7.0 44.26 6.0 7.0 51.210 10.0 11.6 62.86 6.0 7.0 69.83 3.0 3.5 73.37 7.0 8.1 81.43 3.0 3.5 84.92 2.0 2.3 87.22 2.0 2.3 89.52 2.0 2.3 91.91 1.0 1.2 93.03 3.0 3.5 96.51 1.0 1.2 97.72 2.0 2.3 100.086 86.0 100.014 14.0
100 100.0
31323334353638394041424344454647484950515354
Total
Válidos
SistemaPerdidosTotal
Frecuencia PorcentajePorcentaje
válidoPorcentajeacumulado

19
Una vez obtenidos todos los resultados deberán guardarse en el fichero FICHERO.SPO
utilizando para ello el menú Archivo -> Guardar.
2.7 ELABORACIÓN DEL INFORME.
Una vez realizados todos los análisis, los grupos redactarán un trabajo en el que se
describa el proceso seguido, comentando los resultados más importantes.
La primera hoja de cada trabajo TIENE QUE SER LA HOJA DE VALORACIÓN.
Una hoja idéntica a la que se adjunta en la página 17. Cada grupo DEBE conservar una copia
de su trabajo, ya que tras la corrección solamente se devolverá la hoja de valoración con la
evaluación y comentarios oportunos.
En la segunda hoja debe constar el título del test Y LOS INTEGRANTES DEL GRUPO. Es
obligatorio adjuntar al informe un disco, debidamente identificado, con el fichero de datos y
el fichero de resultados. El trabajo en sí debe incluir los siguientes apartados:
1. Objetivos de la prueba.
En este apartado debe especificarse el rasgo que se pretende medir, con una
definición lo más operativa posible del mismo y de sus componentes.
2. Redacción de ítems.
Se deben especificar los ítems que miden cada componente y, en su caso, si lo hacen
de modo directo o inverso. Aclarar el formato de respuesta elegido y el modo de
cuantificación de las respuestas.
3. Análisis de ítems.
Para cada ítem hay que especificar su varianza, media y su índice de homogeneidad.
Comentar los resultados indicando los 3 ítems eliminados y los motivos por los que
se eliminan.
4. Fiabilidad del test.
Adjuntar y comentar el coeficiente de fiabilidad y el coeficiente alfa obtenidos, este
último tanto del test inicial como del test final.
5. Validez del test.
Comentar los resultados del análisis factorial para establecer qué dimensiones mide
el test. Se debe presentar una tabla con las saturaciones y las varianzas de los factores

20
retenidos. También hay que proponer algún procedimiento para estudiar la validez de
constructo del test. El procedimiento propuesto NO DEBE SER UNA DEFINICIÓN
de la validez de constructo. Se deben concretar las hipótesis, indicando qué
resultados aportarían información a favor de la validez de constructo del test. Por
ejemplo, si el rasgo que midiese nuestro test fuese el autocontrol, sería de esperar
que, según lo que apunta la teoría, éste fuese mayor en la población normal que en
otras poblaciones psicopatológicas. Si no se encontrasen tales diferencias la validez
de las puntuaciones de nuestro test se vería seriamente amenazada.
6. Baremos.
Incluir una tabla que muestre los baremos por centiles obtenidos.
7. Apéndice.
En un apéndice debe incluirse el test y los archivos FICHERO.SAV y
FICHERO.SPO con los datos y los análisis realizados.
Cada grupo debe incluir en su informe toda esta información, aunque la puede
organizar de otra forma y realizar los comentarios adicionales pertinentes. Se ruega
paginar el trabajo.
3. EVALUACIÓN
La realización de esta práctica es obligatoria. La fecha tope para entregar el informe es
31 de mayo. La práctica se valorará desde 0 hasta 1 punto. Esta puntuación se sumará a la
calificación final del examen.

21
HOJA DE VALORACIÓN (A RELLENAR POR LOS ALUMNOS)
EL TEST MIDE: ___________________________________________________________ INTEGRANTES:
Nombre y apellidos (en mayúsculas) GRUPO
1 2 3 4 5
(A RELLENAR POR EL PROFESOR)
¿Está toda la información solicitada? SÍ NO . Información que falta: ¿Se informa de manera correcta sobre la redacción, el análisis y la selección de ítems? SÍ NO . Información que falta: ¿Se informa adecuadamente de los dos indicadores de fiabilidad? SÍ NO . Información que falta: ¿Se interpreta adecuadamente el análisis factorial? SÍ NO . Información que falta: ¿Son adecuadas las sugerencias sobre la validez de constructo? SÍ NO . Información que falta: ¿Se ha establecido bien el baremo centil? SÍ NO . Información que falta:
Aspectos destacables:
Principales deficiencias: CALIFICACIÓN: _________________________________


















