
NOCIONES DE ESTAD STICA - …iesrecesvinto.centros.educa.jcyl.es/sitio/upload/... · En...
69
NOCIONES DE ESTADÍSTICA NOCIONES DE ESTADÍSTICA NOCIONES DE ESTADÍSTICA NOCIONES DE ESTADÍSTICA
Transcript of NOCIONES DE ESTAD STICA - …iesrecesvinto.centros.educa.jcyl.es/sitio/upload/... · En...

NOCIONES DE ESTADÍSTICANOCIONES DE ESTADÍSTICANOCIONES DE ESTADÍSTICANOCIONES DE ESTADÍSTICA

INDICE 1. Usos de la Estadística y conceptos básicos...... ...................................................... 1 2. Estadística Descriptiva y Estadística Inferencia l..................................................... 3 3. Métodos básicos de la Estadística Descriptiva. .. .................................................... 4
3.1. Recogida de datos ............................................................................................. 4 3.2. Ordenación y tabulación de datos...................................................................... 5 3.3. Representación de datos ................................................................................... 7 3.4. Parámetros estadísticos................................................................................... 14
3.4.1. Medidas de posición o centralización.................................................... 14 3.4.2. Medidas de dispersión .......................................................................... 20 3.4.3. Medidas de forma.................................................................................. 23
4. Métodos básicos de la Estadística Inferencial... .................................................... 25
4.1. Muestreo .......................................................................................................... 25 4.2. Estimación estadística ..................................................................................... 32 4.3. Contrastes de hipótesis.................................................................................... 33
5. Aplicaciones de la estadística ................. ............................................................... 35 6. Series estadísticas bidimensionales. ............ ......................................................... 40
6.1. Variables estadísticas bidimensionales: tablas estadísticas. ........................... 40 6.2. Representaciones gráficas............................................................................... 42 6.3. Distribuciones marginales y condicionadas ..................................................... 44
6.3.1. Distribuciones marginales ..................................................................... 44 6.3.2. Distribuciones condicionadas................................................................ 44 6.3.3. Independencia y dependencia funcional ............................................... 45 6.3.4. Características marginales y condicionadas ......................................... 47
6.4. Covarianza....................................................................................................... 48 7. Regresión y correlación lineal.................. ............................................................... 49
7.1. El problema del ajuste...................................................................................... 49 7.2. Regresión lineal ............................................................................................... 50
8. Coeficiente de correlación...................... ................................................................. 53
8.1. Correlación lineal ............................................................................................. 53 8.2. Coeficiente de correlación lineal: propiedades................................................. 54
9. Significado de la regresión y aplicaciones...... ....................................................... 58

Estadística unidimensional
1
1 - USOS DE LA ESTADÍSTICA Y CONCEPTOS BÁSICOS
A pesar de los distintos usos de la Estadística, históricamente se la conocía con el único objetivo de recopilar datos, y así fue hasta el siglo XVII, momento en que los matemáticos comenzaron a abordar los problemas relacionados con el recuento de datos analizando las tendencias que se pueden presentar en los sucesivos resultados.
El hecho de entender y usar la Estadística únicamente como colección de datos se debía a
que tradicionalmente la Estadística la usaban los gobiernos para establecer registros de nacimientos, defunciones, impuestos,... De hecho, la palabra Estadística tiene el mismo origen que la palabra estado y como puede verse en multitud de documentos históricos, los estados ya sabían como recoger y organizar los datos mucho antes que los métodos científicos les permitiesen un estudio de ellos.
Es a los matemáticos del s. XIX a los que les debemos el uso de la palabra Estadística en
todo su sentido técnico ya que fueron ellos los que posibilitaron el paso de la estadística deductiva a la estadística inductiva o inferencial, que es la que actualmente tiene mayor influencia en todos los campos de la ciencia.
La ciencia de la Estadística se divide en dos partes: Estadística descriptiva y Estadística
inferencial. - La estadística descriptiva se encarga de la recogida, ordenación y tabulación de los datos
obtenidos en las diferentes observaciones. - La estadística inferencial cuya función es la de establecer conclusiones y tomar decisiones
basadas en ese análisis descriptivo. Conceptos básicos en un proceso estadístico
Es obvio que toda investigación estadística debe estar necesariamente referida a un
conjunto o colección de personas o cosas (realmente existentes o posibles) que verifiquen una definición bien determinada.
Recibe el nombre de población el conjunto de individuos o elementos que tienen unas
características comunes. Las personas o cosas que componen una población reciben el nombre de elementos y pueden tener existencia real: un coche, una casa, …, o bien referirse a algo mucho más abstracto: un intervalo de tiempo, un voto, etc..
El tamaño de una población viene dado por el número de elementos que componen dicha
población. Puede ser finito o infinito. No siempre es posible analizar cada elemento de una población, ya sea por razones económicas, de tiempo, de personal disponible, por destrucción de los elementos tras el análisis... Por eso, en muchos estudios estadísticos se estudia solo una parte de la población, que denominamos muestra. La operación de tomar una muestra de la población se denomina muestreo.
Es necesario que seleccionemos adecuadamente los elementos que integran la muestra,
eliminando criterios personales. Es decir, los elementos de una muestra han de ser elegidos al azar. Si operamos así estamos haciendo un muestreo probabilístico a partir del cual obtenemos muestras representativas. Cuando la selección de los elementos de la muestra se

Estadística unidimensional
2
hace por criterios personales no aleatorios, estamos ante un muestreo no probabilístico que nos da una muestra no representativa.
Las propiedades o cualidades que poseen los elementos de una población se denominan
caracteres. Los caracteres de los elementos que componen una población los dividiremos en: - Cuantitativos o variables. - Cualitativos o atributos. Los caracteres cualitativos o atributos son los que se describen mediante palabras, tal como
el sexo, estado civil, nacionalidad, etc. Un atributo adopta diversas modalidades. Por ejemplo el sexo: hombre o mujer.
Los caracteres cuantitativos o variables son los que se describen mediante números, es
decir, son medibles; tales como la estatura, la edad,... Las variables se expresan con símbolos (x, y, z...) que pueden tomar un valor numérico de entre un conjunto de valores posibles que se denomina dominio de la variable.
Distinguimos dos tipos de variables: - Variable discreta: cuando sus posibles valores son finitos o numerables - Variable continua: cuando sus posibles valores son infinitos no numerables. La representación de un carácter mediante un número no es un indicador infalible de que se
trate de una variable, pues a unos atributos se les asigna un número para indicar la modalidad. Por ejemplo para sexo: 1 para indicar hombre, 2 para indicar mujer. La verdadera diferencia entre un carácter cuantitativo y otro cualitativo es que si se trata de un atributo carece de sentido realizar operaciones algebraicas con los números que representan las modalidades. Además, los atributos se pueden ordenar por modalidades pero no jerarquizar.
Los resultados que se obtienen tras la observación de atributos y variables se denominan
datos u observaciones. En el caso de las variables también se les suele llamar valores. Los métodos de observación de los caracteres de los elementos se denominan: - Observación exhaustiva: cuando observamos todos los elementos de la población. - Observación parcial: cuando sólo observamos los elementos de una muestra. - Observación mixta: en este tipo de observación se combinan la observación exhaustiva
y la observación parcial, de tal manera que los caracteres que se consideran básicos para la investigación se observan exhaustivamente, y los restantes, mediante muestras.

Estadística unidimensional
3
2 - ESTADÍSTICA DESCRIPTIVA Y ESTADÍSTICA INFERENCI AL Cuando se observan exhaustivamente todos los elementos de la población (se supone que la
observación se efectúa sin errores), entonces se dispone de todos los datos posibles para aquel estudio. Con tales datos, es posible describir exactamente las regularidades, el comportamiento o las características de la población.
• Estadística descriptiva
La Estadística descriptiva no es otra cosa, pues, que la ciencia dedicada a descubrir las regularidades o características existentes en un conjunto de datos. Pero si la observación no es exhaustiva, sino que se parte de una muestra con la finalidad de conocer, mediante ella, las características de la población, entonces nos enfrentamos con un proceso de inducción, en virtud del cual se aprovecha la información suministrada por la muestra para conocer, aunque sea aproximadamente, aquellas características.
• Estadística inferencial
La Estadística Inductiva, también llamada Inferencia Estadística, tiene, por tanto, como función, generalizar los resultados de la muestra para estimar las características de la población. No obstante, el conjunto de datos muestrales puede describirse o analizarse de la misma forma que una población. Por tanto, el conjunto de observaciones o datos de una muestra puede manejarse en un doble sentido. Primero, para describir el propio conjunto de observaciones, y segundo, para inferir lo que ocurre en la población. En consecuencia, la fase descriptiva es común a cualquier conjunto de observaciones o
datos, ya se refieran éstos a toda la población, a una muestra o incluso a una subpoblación. La Estadística descriptiva, por otro lado, es la parte más clásica y elemental de la ciencia estadística.
Como ya hemos mencionado, una población está constituida por todos los elementos que
poseen unos caracteres por cuyo estudio estamos interesados. Una muestra, en cambio, es una parte de los elementos de la población, que, lógicamente, será representativa del total.
Cuando el estadístico puede observar todos los elementos de la población (observación
exhaustiva), entonces su tarea se reduce a describir las características y regularidades de la población. Pero si la observación no puede ser exhaustiva, entonces aquellas características hay que estudiarlas a través de una muestra representativa. La información suministrada por la muestra sirve para inducir o inferir, con mayor o menor exactitud, las características de la población.
Conviene que subrayemos, y esto es muy importante, que los conceptos de población y
muestra están subordinados al uso que se piensa hacer del conjunto de observaciones disponibles. Si lo único que se pretende es describir las características de dicho conjunto, entonces éste constituye, ciertamente, una población, aun cuando sea una parte de un total más general. Pero si se desea extender la información obtenida de él a otro conjunto mayor para inferir sus características, entonces, evidentemente, el conjunto de observaciones constituye una muestra (se supone que con todas las garantías).
La fase de descripción es (o puede ser) común a cualquier conjunto de observaciones,
mientras que la de inferencia sólo tiene efectividad cuando se trabaja con muestras.

Estadística unidimensional
4
3 - MÉTODOS BÁSICOS DE LA ESTADÍSTICA DESCRIPTIVA Como hemos indicado, la estadística descriptiva es la que estudia los datos resultantes de
una experiencia. En este caso con el término "estudia" nos referimos a recoger los datos, clasificarlos, representarlos y resumirlos en informaciones que ayuden a los interesados en su análisis para poder sacar conclusiones que ayuden a comprender algo o a la toma de decisiones. Por tanto, los métodos básicos que utiliza la Estadística descriptiva para describir e interpretar numéricamente la información obtenida de una gran cantidad de datos son:
- Recogida de datos. - Ordenación y tabulación datos. - Representación de los datos. - Calculo de los parámetros estadísticos.
Es importante tener en cuenta que en la estadística descriptiva no nos preguntamos si los
datos provienen de una muestra de la población o de toda la población. Con los datos obtenidos tras la observación y suponiendo ausencia de errores, tanto de
medición como de manipulación, trascripción y cálculo, podemos describir perfectamente cuanto acontece en la población o muestra objeto de estudio. La estadística descriptiva es una fase necesaria para luego realizar inferencia.
3.1 - Recogida de datos Por técnicas de obtención de datos entendemos el conjunto de métodos empleados para
recoger una información determinada de una población o muestra. La obtención de datos se realizará de forma que facilite guardar la información con un orden lógico para su posterior estudio y minimizando los errores entre la información inicial dada y el dato final que se analizará. Son justamente el coste de estas técnicas de recogidas de datos, el tiempo necesario para ejecutarlas y el personal disponible, algunos de los motivos que inducen a realizar un muestreo en lugar de analizar cada elemento de la población. Una vez definidas, exactamente, la población, el tipo de muestreo y la muestra se elaborará un documento que permita recoger las respuestas a las preguntas de una manera sencilla y precisa.
Por las razones económicas, de tiempo y de personal antes comentadas, lo primero que se
realiza para obtener los datos es buscar si la información que necesitamos ya ha sido trabajada, es decir, si existe alguna fuente que ya la haya estudiado. Una fuente importante son los registros administrativos en donde la información se recoge a nivel de gestión pero que luego se depura de manera que sea una información válida a distintos niveles. Estos trabajos se recogen a nivel oficial en el inventario de operaciones estadísticas del Estado.
En el supuesto de que no exista documentación estadística apropiada y suficiente para el
estudio que pretendemos realizar es cuando se lleva a cabo los distintos métodos de recogida, siendo los más usuales:
• Por correo Es el que suele utilizarse cuando se dispone de la lista y direcciones de los elementos de
la población. Una buena práctica consiste en adjuntar, junto con el cuestionario a rellenar e instrucciones para su cumplimentación, el sobre con la dirección de retomo ya impresa y convenientemente franqueado; así las molestias son menores.

Estadística unidimensional
5
• Por agentes distribuidores Se encarece notablemente el método anterior si hay que investigar a una gran masa de
población. Este método se realiza mediante agentes debidamente acreditados que recogen el cuestionario una vez efectuado. En esencia, es el mismo método que el anterior. • Por encuestadores
Son ahora personas especializadas las que formulan las preguntas que aparecen en el cuestionario y anotan las respuestas. Lógicamente, este sistema es el más apropiado, aunque no elimina totalmente los errores, pues pueden darse algunas influencias en las respuestas. Su inconveniente es que puede resultar más caro que los dos primeros métodos. • Por teléfono
Evidentemente mucho más barato que por encuestadores aunque menos fiable. • Por Internet
Método cada vez más generalizado ya que permite minimizar costes, tiempo y personal necesario.
Hoy en día, los estadísticos siguen estudiando formas de mejorar algunos problemas
relacionados con las técnicas de recogidas de datos. Estos problemas se centran en conseguir que los elementos de la población o muestra cumplimenten las encuestas necesarias y conseguir que las realicen de un modo que resulte más fiable.
El primero de los problemas, la "participación", se está consiguiendo de dos maneras:
compensando de alguna forma al encuestado (regalos, vales descuentos ... ) o haciendo que las encuestas sean de obligado cumplimiento (como son algunas encuestas que el Estado realiza a distintas empresas).
El segundo de los problemas, la fiabilidad, se intenta mejorar implicando al encuestado en la propia encuesta, por ejemplo, enviando los estudios y resultados que se obtienen tras el análisis de los datos de la encuesta que ha realizado o de otras encuestas que lleve la misma empresa y que puedan ser interesantes para el encuestado.
Una de las formas de clasificar los datos para depurarlos y prepararlos para la realización
de tablas es organizarlos en montones según una característica determinada aunque actualmente se suelen organizar y representar geográficamente (si los elementos estudiados pertenecen a una provincia, por pueblos; si pertenecen a una ciudad, por barrios ... ) Esta forma de organizar y representar los datos se denomina S.I.G. (Sistema de Información Georeferenciada).
3.2 - Ordenación y tabulación de datos Todos los datos obtenidos mediante las distintas técnicas de recogida de datos se resumen
en tablas, las cuales constituyen una parte fundamental de una investigación estadística. Toda tabla debe ir acompañada de una ficha técnica en donde se especifica el tipo y ámbito de la encuesta, el tipo de muestreo y tamaño de la muestra, el periodo de la referencia de la información, el método de obtención de datos utilizado y los fines de la investigación.
En las tablas estadísticas se introducen las siguientes magnitudes: • Frecuencia absoluta
Denominamos frecuencia absoluta al número de repeticiones que presenta dato. Representaremos por ni a la frecuencia absoluta referente al dato i.

Estadística unidimensional
6
• Frecuencia relativa Es la frecuencia absoluta dividida por el número total de datos, que denominamos
tamaño de la muestra y representaremos por N. Se suele expresar en tanto por uno, siendo el valor correspondiente al dato i -ésimo, f i, es decir:
N
nf i
i =
La suma de todas las frecuencias relativas es igual a la unidad.
• Frecuencia absoluta acumulada Es la suma de los distintos valores de la frecuencia absoluta tomando como
referencia un individuo dado. La última frecuencia absoluta acumulada es el tamaño de la muestra. Si representamos su valor i-ésimo por Ni tenemos:
N1= n1 N2 = n1+n2 ...................
Ni = n1 + n2 + ... + ni
• Frecuencia relativa acumulada Se obtiene al dividir cada frecuencia absoluta acumulada por el tamaño de la
muestra, la representaremos por F, y también se puede definir, al igual que la frecuencia absoluta acumulada, como la suma de los distintos valores de la frecuencia relativa, tomando como referencia un individuo dado.
F1= f1 F2 = f1+f2
................... Fi = f1 + f2 + ... + fi
La última frecuencia relativa acumulada es igual a la unidad.
Una tabla estadística contiene los datos observados y las distintas frecuencias absolutas y
relativas de éstos. Una vez los datos están tabulados, la tabla obtenida ofrece una visión de conjunto de los caracteres que se estudian. Un ejemplo de una tabla estadística para una variable discreta es:
Datos xi
Frecuencia absoluta
ni
Frecuencia absoluta
acumulada Ni
Frecuencia relativa
fi
Frecuencia relativa
acumulada Fi
x1 n1 N1 f1 F1
x2 n2 N2 f2 F2
… … … … …
xn nn Nn = N fn Fn = 1
∑ = Nni ∑ = 1if
Cuando queremos realizar una tabla de frecuencias para una distribución con un número
elevado de variables o con una distribución cuyas variables son continuas, éstas se suelen

Estadística unidimensional
7
agrupar en intervalos [Li-1, Li) para facilitar la elaboración de la tabla y la comprensión de los datos.
Antes de ver como se ordenan las frecuencias en una tabla para una variable continua
veamos brevemente algunas definiciones propias de la tabla de frecuencia para variables continuas:
• Denominaremos recorrido a la resta entre el valor mayor de los datos y el valor menor
y lo representaremos por Re. • Para operar utilizaremos la marca de clase, el punto medio de un intervalo. La marca
de clase se define como la semisuma de los valores extremos del intervalo, esto es, si la marca de clase del intervalo [Li-1, Li) la representamos por xi, entonces:
21 ii
i
LLx
+= −
• Denominaremos amplitud del intervalo a la diferencia entre el extremo superior del intervalo y el extremo inferior, es decir, a la longitud del intervalo, y se representa por:
ai = Li – Li-1 • El número de intervalos que formarán la tabla se obtendrá a partir de la raíz cuadrada
del número de datos.
Número de intervalos el número de datos=
• Si los intervalos no son de la misma amplitud para trabajar con ellos obtendremos la densidad de frecuencia del intervalo i-ésimo, como el cociente entre el número total de observaciones de un intervalo, esto es , la frecuencia absoluta, y la amplitud del mismo:
a
nd i
i =
Teniendo en cuenta esto, la ordenación de la tabla será la siguiente:
Intervalo : [Li-1, Li)
Marca de clase: xi
ni Ni fi Fi
3.3 - Representación de datos
Una vez que la masa inicial de datos está tabulada, la tabla obtenida ofrece una visión de
conjunto de los caracteres que se están estudiando. Un modo de poner de relieve dicha visión de conjunto consiste en utilizar representaciones gráficas de la tabla obtenida, lo que permite que el impacto visual proporcione una visión global del reparto de las observaciones.
No obstante, las representaciones gráficas no deben considerarse como un medio definitivo
para extraer conclusiones, sino como un medio auxiliar de la investigación estadística, que será fundamentalmente numérica, y esto siempre que el impacto visual provocado por la gráfica corresponda a la realidad, por lo que se debe recurrir a sistemas geométricos capaces de describir los datos de manera correcta para no inducir a conclusiones erróneas. Por lo tanto, se

Estadística unidimensional
8
deben considerar las representaciones gráficas como medios útiles de presentación de los datos que, junto con otras medidas numéricas, permitirán un estudio correcto de la masa de datos inicial y, por tanto, de los caracteres de la población que nos interesan.
En general, las representaciones gráficas más utilizadas se basan en un sistema de ejes
cartesianos, de forma que en el eje horizontal (o de abscisas) se toman los distintos valores de la variable, y en el eje vertical (o de ordenadas) las frecuencias. Así, el plano queda determinado por cuatro cuadrantes, si bien en estadística la mayor parte de los gráficos pertenecen al primer cuadrante. Debe advertirse también que la graduación de los ejes puede obtenerse aplicando la escala aritmética o de números reales o la escala logarítmica. En el último caso, si se aplica a un solo eje, se dice escala semilogarítmica, y si se aplica a las dos, escala doblemente logarítmica.
Una posible clasificación de los distintos gráficos es respecto al tipo de variable que
representa. Esta es la clasificación por la que optamos aunque los gráficos que veremos no tienen que ser exclusivos de un tipo variable concreta, como indicaremos en cada caso. En principio distinguimos dos tipos de gráficos independientemente se trate de una variable discreta o continua, estos gráficos dependen de que queramos representar las frecuencias (absolutas o relativas) o las frecuencias acumuladas.
Se denominan diagramas diferenciales a aquellos gráficos en los que se representan
frecuencias absolutas o relativas y se denominan diagramas integrales a aquellos que se realizan a partir de las frecuencias acumuladas, lo que da lugar a gráficos crecientes, y es obvio que este tipo de gráficos no tiene sentido para variables cualitativas.
• Gráficos para variables cualitativas:
Los gráficos más usuales para representar este tipo de variable son los siguientes:
a) Diagramas de barras.
Se realizan representando en el eje de ordenadas las variables y en el eje abscisas las frecuencias absolutas relativas.
Si, mediante el gráfico, se intenta comparar varias poblaciones entre sí, existen otras
modalidades del diagrama de barras como por ejemplo:
Solteros 4
Casados 5
Viudos 7
Divorciados 3

Estadística unidimensional
9
Cuando los tamaños de las dos poblaciones son diferentes, es conveniente utilizar las frecuencias relativas, ya que en otro caso podrían resultar engañosas.
b) Diagrama de sectores
Para realizar estos diagramas, también llamados coloquialmente tartas, se divide un círculo en tantos sectores circulares como clases existan, de modo que el área de cada sector sea proporcional a la frecuencia que se quiera representar.Para calcularlo podemos decir que el área depende del ángulo central, mediante la siguiente proporción:
360
α=N
ni
Así, siguiendo el ejemplo anterior:
Este diagrama se utiliza para cualquier tipo de variable.
c) Pictogramas
Expresan con dibujos relativos al tema que se quiera representar las frecuencias de las variables. Se realizan representado a diferentes escalas un mismo dibujo. Las escalas de los dibujos se realizan de forma que el área de cada uno sea proporcional a la frecuencia que representan. Este tipo de gráficos suele usarse en los medios de comunicación, para que sean comprendidos por el público no especializado, sin que sea necesaria una explicación compleja.
Muestra 1 Muestra 2
Solteros 4 5
Casados 5 6
Viudos 7 6
Divorciados 3 2

Estadística unidimensional
10
d) Cartogramas
Para las distribuciones de tipo geográfico se suelen usar mapas, que se colorean con
diferentes tonalidades, cuyas frecuencias equivalentes se explican al margen, o bien se colocan dibujos alusivos si se están estudiando los lugares en que se producen o se encuentran los bienes correspondientes. Estos gráficos se denominan cartogramas y la forma de construirlos se basa en la proporcionalidad con las frecuencias de la misma forma que los pictogramas.
• Gráficos para variables cuantitativas discretas: a) Diagrama de barras
Para representar las frecuencias absolutas o relativas, acumuladas o no, de una variable cuantitativa discreta se utiliza principalmente el diagrama de barras, aunque se utiliza también para representar otros tipos de variables, como indicaremos en el apartado correspondiente.
En este caso, las barras deben ser estrechas para representar que los valores que toma la variable son discretos. En el eje de abcisas, situaremos los diferentes valores de la variable. En el eje de ordenadas la frecuencia que queramos representar. Levantaremos barras o columnas de altura correspondiente a la frecuencia adecuada.
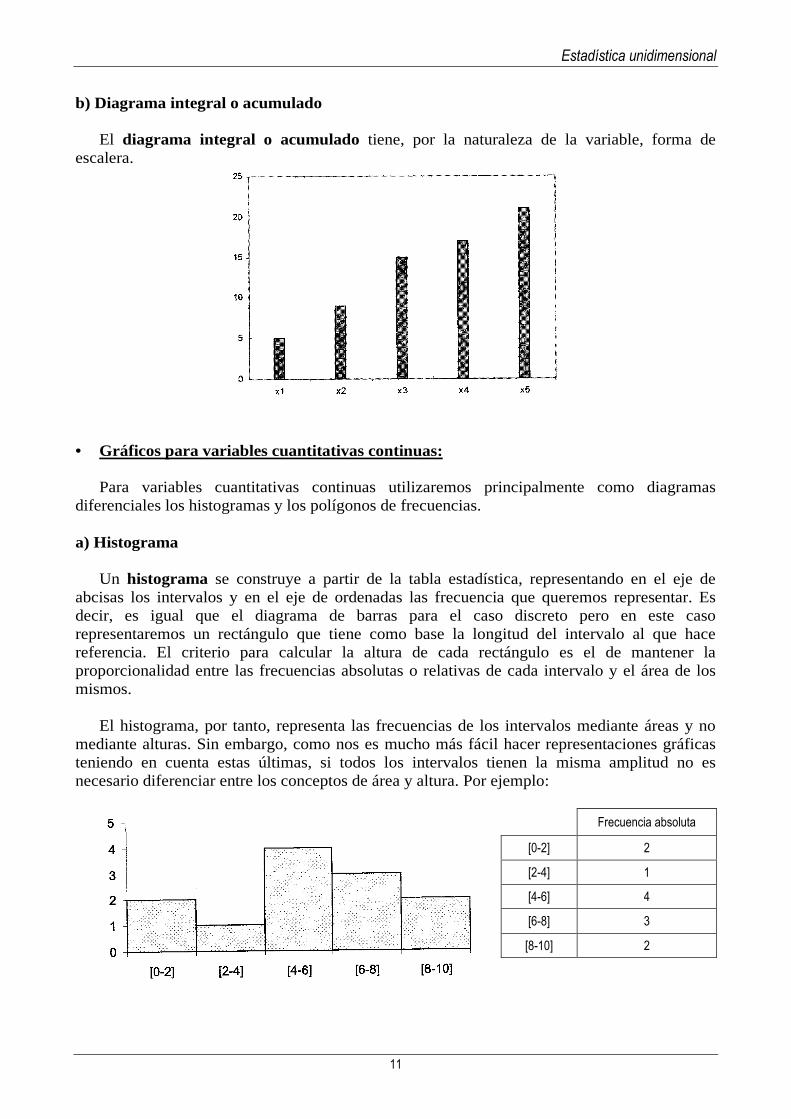
Así, un ejemplo de diagrama diferencial de barras es:
Variables Frecuencia
absoluta
Frecuencia absoluta
acumulada X1 5 5 X2 4 9 X3 6 15 X4 2 17 X5 4 21
Estadística unidimensional
11
b) Diagrama integral o acumulado
El diagrama integral o acumulado tiene, por la naturaleza de la variable, forma de escalera.
• Gráficos para variables cuantitativas continuas: Para variables cuantitativas continuas utilizaremos principalmente como diagramas
diferenciales los histogramas y los polígonos de frecuencias.
a) Histograma Un histograma se construye a partir de la tabla estadística, representando en el eje de
abcisas los intervalos y en el eje de ordenadas las frecuencia que queremos representar. Es decir, es igual que el diagrama de barras para el caso discreto pero en este caso representaremos un rectángulo que tiene como base la longitud del intervalo al que hace referencia. El criterio para calcular la altura de cada rectángulo es el de mantener la proporcionalidad entre las frecuencias absolutas o relativas de cada intervalo y el área de los mismos.
El histograma, por tanto, representa las frecuencias de los intervalos mediante áreas y no
mediante alturas. Sin embargo, como nos es mucho más fácil hacer representaciones gráficas teniendo en cuenta estas últimas, si todos los intervalos tienen la misma amplitud no es necesario diferenciar entre los conceptos de área y altura. Por ejemplo:
Frecuencia absoluta
[0-2] 2
[2-4] 1
[4-6] 4
[6-8] 3
[8-10] 2
Estadística unidimensional
12
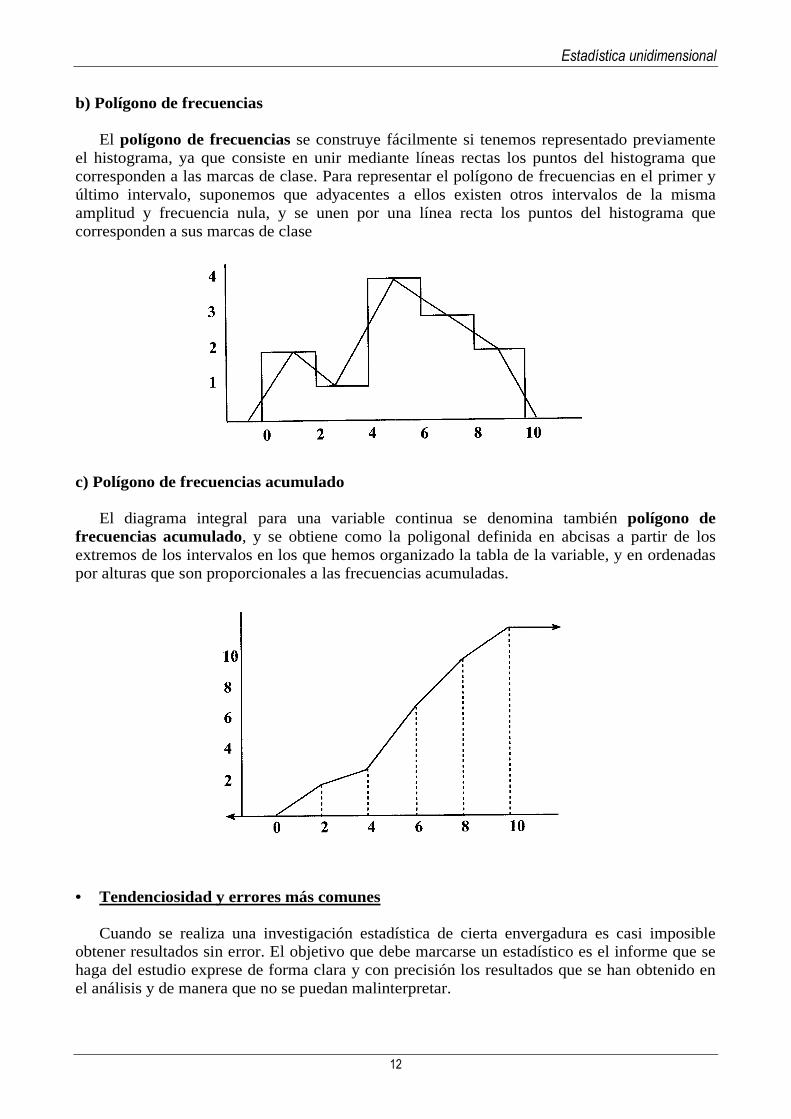
b) Polígono de frecuencias
El polígono de frecuencias se construye fácilmente si tenemos representado previamente el histograma, ya que consiste en unir mediante líneas rectas los puntos del histograma que corresponden a las marcas de clase. Para representar el polígono de frecuencias en el primer y último intervalo, suponemos que adyacentes a ellos existen otros intervalos de la misma amplitud y frecuencia nula, y se unen por una línea recta los puntos del histograma que corresponden a sus marcas de clase
c) Polígono de frecuencias acumulado
El diagrama integral para una variable continua se denomina también polígono de
frecuencias acumulado, y se obtiene como la poligonal definida en abcisas a partir de los extremos de los intervalos en los que hemos organizado la tabla de la variable, y en ordenadas por alturas que son proporcionales a las frecuencias acumuladas.
• Tendenciosidad y errores más comunes Cuando se realiza una investigación estadística de cierta envergadura es casi imposible
obtener resultados sin error. El objetivo que debe marcarse un estadístico es el informe que se haga del estudio exprese de forma clara y con precisión los resultados que se han obtenido en el análisis y de manera que no se puedan malinterpretar.

Estadística unidimensional
13
Los errores más comunes y no significativos (por errores no significativos nos referimos a los errores no muestrales) podemos hablar de los siguientes tipos:
1. Errores de planteamiento, que se deben a una investigación mal estructurada o
planificada, a definiciones ambiguas o incompletas que no permiten localizar perfectamente los elementos que han de ser observados.
2. Errores de respuesta, originados por un cuestionario poco pensado, por un método de
recogida de datos inapropiado, por unos agentes mal instruidos O por no haber previsto el control y depuración de respuestas. Dentro de los errores de respuesta se incluye el «no consta», es decir, el cuestionario no contestado.
3. Errores de manipulación, provocados fundamentalmente por los defectos de
organización, pudiendo suceder, incluso, que se pierdan cuestionarios antes de llegar al centro de tabulación.
4. Errores de tabulación y de cálculo, debidos, lógicamente, a la inexistencia de controles
de operaciones. 5. Errores en la expresión de los datos, debidos principalmente a la forma como se realiza
las gráficas. Es por ejemplo cuando la presentación de la gráfica no es legible. 6. Tendenciosidad, intencionada o no, es probablemente el principal problema que se puede
presentar en un estudio estadístico. Consiste en presentar la información, información verdadera, de forma que pueda ser malinterpretada e inducir a error. Un ejemplo es el producido al no tener una escala predeterminada:
Aunque las dos tablas están realizadas con los mismos datos, el crecimiento de la
primera parece mucho mayor que el de la segunda. Esto se ha debido, simplemente, al haber utilizado distintas escalas.
Otro ejemplo común es presentar un diagrama de barras con el eje de ordenadas no
completo (en vez de comenzar en 0 comenzar en otro valor) mostrando un resultado tendencioso ya que da la impresión de que la diferencia entre las barras es diferente a la real.
Otro ejemplo tendencioso es el de agrupar los datos según interese o mostrar
únicamente los datos que se quieran; por ejemplo, si tras es estudio de los habitantes de una determinada ciudad se obtiene que el 86% de los menores de 30 años consumen una marca A y que el 92% de los mayores de 30 años no la consumen, se puede omitir este segundo dato e indicar únicamente que el 86% de los menores de 30 años la consumen, dando a entender que el consumo es elevado.

Estadística unidimensional
14
3.4 - Parámetros estadísticos
Las tablas estadísticas y la representación gráfica nos dan una idea cualitativa de conjunto
de una distribución de frecuencias que no es suficiente, por ejemplo, para comparar dos distribuciones.
Con el fin de obtener un resumen cuantitativo se sustituye el conjunto de valores por números llamados parámetros estadísticos o medidas descriptivas de los datos, que son unos números que nos permitirán, con objetividad y precisión, tener una visión más completa del fenómeno estudiado, comparar distintas distribuciones de frecuencias y valorar con números sus distintas características. Los parámetros estadísticos se clasifican en diversos tipos:
- Medidas de posición o centralización. - Medidas de dispersión. - Medidas de asimetría y curtosis.
3.4.1 - MEDIDAS DE POSICIÓN O CENTRALIZACIÓN.
Las medidas de centralización son valores que están medidos en las mismas unidades que las observaciones y que nos indican en torno a qué posición se distribuyen las observaciones que disponemos, es decir, cómo se agrupan los datos observados.
Se clasifican en medidas de posición central (medias mediana y moda) y en medidas de posición no central (cuartiles, deciles , percentiles) dependiendo de que estos valores nos orienten sobre el lugar central de la distribución o sobre la posición de una parte cualquiera previamente determinada de la misma.
Todas ellas verifican que su valor está comprendido entre el menor y el mayor valor de los datos disponibles. 1.- Media aritmética de una variable.
Lo que se busca con este parámetro es determinar la posición central de una distribución cualquiera, de modo que su valor represente su centro de gravedad en el sentido de compensar las desviaciones con respecto a él de los valores de la variable en un sentido u otro.
Se define por tanto la media aritmética como la suma de todos los valores de la distribución dividida por el número total de datos y se representa por x . Así pues,
1 2
1
1 NN
ii
x x xx x
N N =
+ + += = ∑…
Si el valor xi de la variable Xi se repite ni veces, hay que considerar estas repeticiones en la
suma, de modo que 1
ki i
i
x nx
N=
⋅=∑ ; con 1
k
ii
n N=
=∑ .
La frecuencia relativa del valor xi queda determinada por ii
nf
N= , por lo que podemos poner
1
k
i ii
x x f=
= ⋅∑
En el caso de que tuviéramos una distribución con datos agrupados, los valores individuales de
la variable serían desconocidos y por tanto no se podría utilizar la expresión anterior. En este

Estadística unidimensional
15
supuesto se formulan las hipótesis de que el punto medio del intervalo de clase (marca de clase) representa adecuadamente el valor medio de dicha clase, y se aplicaría la fórmula original de la media simple para dichos valores. Ventajas e inconvenientes • Ventajas:
- se utilizan en el cálculo todos los valores de que se dispone en la distribución - está perfectamente determinada de forma objetiva y es única - es calculable - es el centro de gravedad de la distribución
• Inconvenientes: - los valores extremos muy dispares influyen de manera notable en su valor, por este motivo
puede perder valor representativo
No obstante, la media aritmética, como medida de posición es la forma más adecuada para el resuman estadístico en el caso de distribuciones en escala de intervalos o de proporción, con los cuales dicha medida alcanza su máximo sentido. 2.- Media ponderada.
Cuando es conocido que los valores de la variable no tienen todos la misma importancia con respecto al tratamiento que deben dárseles, suele ser bastante útil utilizar una variable de la media aritmética denominada media ponderada.
Para calcularla se le asocia a cada valor de la variable xi un peso wi que mide su grado de importancia en la distribución. Dichos pesos wi son valores positivos y representan el número de veces que sus correspondientes valores xi son más representativos que un valor que tuviese peso asociado a la unidad.
Se define la media aritmética ponderada de una distribución de valores 1 2, , , kx x x… , de pesos
1 2, , , kw w w… a
1
1
k
i ii
p k
ii
x wx
w
=
=
⋅=∑
∑
Notar que los pesos wi pueden ser números reales positivos cualesquiera. 3.- Media geométrica.
En muchas situaciones los valores de la distribución no son de naturaleza propiamente aditiva, como en el caso de precios o salarios. En estos casos la media aritmética deja de ser fácilmente interpretable. Así, si tenemos una serie de índices de precios durante un periodo de años, el índice medio anual de precios debe ser aquel que manteniéndose constante durante todos esos años, produzca la misma degradación final de los precios en el último año con respecto del año inicial que los índices originales.

Estadística unidimensional
16
En estas circunstancias, la medida de posición central más utilizada es la media geométrica. Entonces, dada una distribución de frecuencias (xi, ni), se define la Media Geométrica y se representa por G a la raíz n-ésima del producto de los N valores de la distribución:
1 21 2
1
k i
kn nn nN Nk i
i
G x x x x=
= ⋅ ⋅ ⋅ = ∏…
Notar que 1
k
ii
n N=
=∑ . El cálculo de G se facilita empleando logaritmos:
1
1log log
k
i ii
G n xN =
= ⋅∑
Ventajas e inconvenientes • Ventajas:
- está definida de forma objetiva y es única. - considera en su cálculo todos los valores de la distribución. - los valores extremos tiene menos influencia que en la media aritmética.
• Inconvenientes: - cálculo complicado - sólo deba aplicarse cuando los valores de la distribución sean todos positivos, ya que si
alguno fuese cero anularía la media geométrica y si hubiese valores negativos, se obtendrían valores imaginarios.
Su empleo más frecuente es el de promediar datos de tipo multiplicativo tales como
porcentajes, tasas, números índices, etc., es decir, en los casos en que se supone que la variable presenta variaciones acumulativas. 4.- Media Armónica.
Se define la media armónica de una distribución de frecuencias (xi, ni) y se representa por H como:
1 2
11 2
kk i
ik i
N NH
nn n nx x x x=
= =+ + + ∑⋯
Como puede verse, la inversa de la media armónica es la media aritmética de los inversos de los valores de la variable. Se suele utilizar para promediar velocidades, tiempos, rendimientos. Ventajas e inconvenientes • Ventajas:
- en su cálculo intervienen todos los valores de la distribución. - cálculo sencillo. - está definida de forma objetiva y es única.
• Inconvenientes: - no debe usarse con valores próximos a cero pues sus inversos pueden crecer en demasía
haciendo despreciables frente a ellos la información aportada por valores mayores. - no es posible su determinación en distribuciones con algunos valores iguales a cero.
Estadística unidimensional
17
5.- Mediana
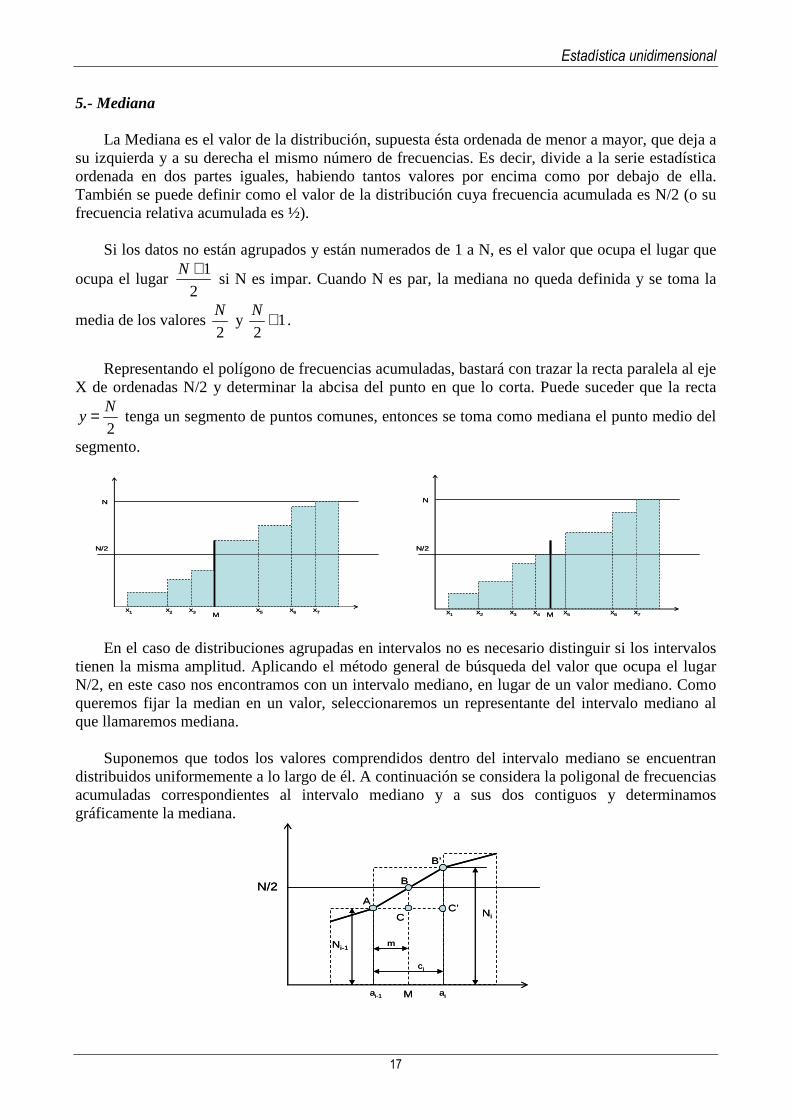
La Mediana es el valor de la distribución, supuesta ésta ordenada de menor a mayor, que deja a su izquierda y a su derecha el mismo número de frecuencias. Es decir, divide a la serie estadística ordenada en dos partes iguales, habiendo tantos valores por encima como por debajo de ella. También se puede definir como el valor de la distribución cuya frecuencia acumulada es N/2 (o su frecuencia relativa acumulada es ½).
Si los datos no están agrupados y están numerados de 1 a N, es el valor que ocupa el lugar que
ocupa el lugar 1
2
N + si N es impar. Cuando N es par, la mediana no queda definida y se toma la
media de los valores 2
N y 1
2
N + .
Representando el polígono de frecuencias acumuladas, bastará con trazar la recta paralela al eje
X de ordenadas N/2 y determinar la abcisa del punto en que lo corta. Puede suceder que la recta
2
Ny = tenga un segmento de puntos comunes, entonces se toma como mediana el punto medio del
segmento.
N
N/2
Mx1 x2 x3 x5 x6 x7
N
N/2
Mx1 x2 x3 x5 x6 x7
N
N/2
Mx1 x2 x3 x5 x6 x7x4
N
N/2
Mx1 x2 x3 x5 x6 x7x4
En el caso de distribuciones agrupadas en intervalos no es necesario distinguir si los intervalos tienen la misma amplitud. Aplicando el método general de búsqueda del valor que ocupa el lugar N/2, en este caso nos encontramos con un intervalo mediano, en lugar de un valor mediano. Como queremos fijar la median en un valor, seleccionaremos un representante del intervalo mediano al que llamaremos mediana.
Suponemos que todos los valores comprendidos dentro del intervalo mediano se encuentran
distribuidos uniformemente a lo largo de él. A continuación se considera la poligonal de frecuencias acumuladas correspondientes al intervalo mediano y a sus dos contiguos y determinamos gráficamente la mediana.
N/2
Mai-1 ai
A
B
B’
CC’ Ni
Ni-1
ci
m
N/2
Mai-1 ai
A
B
B’
CC’ Ni
Ni-1
ci
m

Estadística unidimensional
18
Vemos que 1iM a m−= + . Determinamos m en base a la hipótesis fijada, que nos permite
escribir ' '
AC BC
AC BC= , ya que los triángulos ABC y AB’C’ son semejantes. Por tanto AC m= ,
' iAC c= , 1( / 2) iBC N N−= − y 1' ' i i iB C N N n−= − = .
Sustituyendo en la relación anterior se tiene que: 1( / 2) i
i i
N Nm
c n−−= ,
y por tanto despejando tenemos 1( / 2) ii
i
N Nm c
n−−= ⋅ ,
de modo que: 11
( / 2) ii i
i
N NM a c
n−
−−= + ⋅
Ventajas e inconvenientes • Ventajas:
- es sencilla de calcular - no influyen en ella más que los datos centrales de la distribución. - se puede calcular aún desconociendo los valores extremos de la distribución siempre que
contemos con suficiente información respecto de sus frecuencias.
• Inconvenientes: - no puede expresarse mediante una fórmula matemática sencilla a efectos de realizar con ella
grandes desarrollos matemáticos.
A pesar de la fórmula vista para el caso de distribuciones en escala por intervalos, la mediana tiene un mayor sentido en casos de distribuciones en escala ordinal (susceptibles de ser ordenados), de la cual es la medida más representativa por describir la tendencia central de la misma. 6.- Moda
Se llama Moda de una distribución de frecuencias al valor (o valores) de la variable al que corresponde mayor frecuencia. Una distribución de frecuencias puede tener una o varias modas. Si tiene una se llama unimodal, si tiene dos, bimodal, etc.
El cálculo de la Moda resulta sencillo en el caso de datos simples y datos agrupados, pero
cuando los datos están agrupados en intervalos no obtendremos el valor exacto de la Moda, sino una aproximación que dependerá de las hipótesis que realicemos sobre las observaciones de cada intervalo considerado. Las hipótesis de partida son: − Hay una moda en cada intervalo cuya densidad de frecuencia no es superada por ningún otro. − Dentro de los intervalos, la moda es aquel punto que equilibra las densidades de frecuencia de
los intervalos adyacentes, suponiendo que los valores se reparten en el interior de los mismos de manera uniforme.
Sea pues 1[ , )i ia a− un intervalo cuya densidad de frecuencia no es superada por ningún otro.
Estre intervalo recibe el nombre de intervalo modal o clase modal. La densidad de frecuencia hi de
un intervalo i-ésimo es el cociente entre la frecuencia absoluta asociada ni y su amplitud ei: ii
i
nh
e= .

Estadística unidimensional
19
M0ai-1 ai
ei
b
ai+1ai-2
hi
hi+1
hi-1
a
M0ai-1 ai
ei
b
ai+1ai-2
hi
hi+1
hi-1
a
En la representación gráfica el equilibrio debe darse en el sentido de ser 1
1
i
i
ha
b h+
−
=
Como la moda M0 será 0 1iM a b−= + , tenemos 1 11 1
ii i
i i
e bab h h
h h+ +− −
−= ⋅ = ⋅ .
Despejando 1 1 1i i i ib h e h b h− + +⋅ = ⋅ − ⋅ , y así 1
1 1
ii
i i
hb e
h h+
+ −
= ⋅+
. Por tanto la expresión de M0 es
10 1
1 1
ii i
i i
hM a e
h h+
−+ −
= + ⋅+
Si las amplitudes de los intervalos fuesen constantes, la expresión de la moda será
10 1
1 1
ii i
i i
nM a e
n n+
−+ −
= + ⋅+
Ventajas e inconvenientes • Ventajas:
- fácil interpretación - cálculo sencillo
• Inconvenientes: - no tiene una expresión matemática sencilla para el cálculo algebraico. - no intervienen en su determinación todos los valores de la distribución. - los cambios en la distribución que se produzcan ajenos al valor modal no son detectados.
La obtención de las modas de una distribución tienen una importancia propia derivada del
hecho de que sirve para detectar posibles fusiones de distintas poblaciones unidimensionales en la masa de datos. A veces avisa de la necesidad de dividir dicha masa de datos en partes distintas para que el fenómeno que estamos tratando se estudie mejor. 7. - Medidas de posición no centrales.
Otros valores notables, pero que no reflejan ninguna tendencia central son los Cuantiles. Son valores de la distribución que la dividen en partes iguales, es decir, en intervalos que comprenden el mismo número de valores. Entre los Cuantiles de uso más frecuente están los Cuartiles, los Deciles y los Percentiles.

Estadística unidimensional
20
• Cuartiles: son tres valores de la distribución que la dividen en cuatro partes iguales, es decir, en
cuatro intervalos dentro de los cuales están el 25% de los valores de la distr5ibución. Se representan por Ci con i=1,2,3.
• Deciles: son los nueve valores de la distribución que la dividen en 10 partes iguales. Cada parte
contendrá el 10% de la distribución. Se representan por Di, con i=1,2,…,9. • Percentiles: son los 99 valores que dividen a la distribución en 100 partes iguales. Se
representan por Pi, con i=1,2,…,99.
Notar que P25=C1; P50=C2=M ; P75=C3; P10=D1; P20=D2; …; P90=D9. Su cálculo es análogo al de la mediana y en general se aplica la expresión
1
/ 1
i
r k i ii
rN N
kQ a cn
−
−
⋅ −= + ⋅ donde
1) para k = 4 y r = 1,2,3 obtenemos los cuarteles 2) para k = 10 y r = 1,2,…,9 obtenemos los deciles 3) para k = 100 y r = 1,2,…,99 obtenemos los percentiles
3.4.2 - MEDIDAS DE DISPERSIÓN.
Las medidas de dispersión tienen por objeto dar una idea de la mayor o menor concentración de los valores de una distribución alrededor de los valores centrales. Las medidas de tendencia central tienen como objetivo sintetizar toda la información de la que se dispone. Por tanto, medir la representatividad de estas medidas equivale a cuantificar la separación de los valores de la distribución con respecto de dicha media. La mayor o menor separación de los valores entre si se llama Dispersión o Variabilidad. Por tanto las medidas de dispersión nos miden el grado de dispersión de la distribución de la variable. 1 - Recorrido
Se llama recorrido a la diferencia entre el mayor y el menor de los valores de la variable y se
representa por R: 1nR x x= −
Por su sencillez de cálculo se utiliza sobre todo en el control de fabricación industrial, aunque es muy sensible a los valores erróneos.
El recorrido intercuartílico es la diferencia entre los valores P75 y P25 y nos indica el intervalo
de longitud RI donde están comprendidos el 50% central de los valores. 2 - Desviaciones
Consideremos un valor central C y un valor de la variable xi. Al valor xi - C se llama
desviación de xi respecto de C. Al valor ix C− , desviación absoluta.
Se define la desviación media, D, de una distribución de frecuencias con respecto al valor
central C a

Estadística unidimensional
21
1
1 k
i ii
D x C nN =
= − ⋅∑ (en caso de datos agrupados).
Las desviaciones medias más utilizadas son respecto a la media y a la mediana, que se obtienen sustituyendo C por x y M, respectivamente.
Las desviaciones medias tienen un significado preciso como promedio de las desviaciones,
aunque tienen el inconveniente de no ser adecuadas para el cálculo algebraico. 3 - Varianza y desviación típica
La varianza de una distribución de frecuencias es la media aritmética de los cuadrados de las
desviaciones respecto a la media. Es el índice de dispersión más usado y se designa por σ2. Su expresión viene dada por:
( )22
1
1 k
i ii
x x nN
σ=
= − ⋅∑
para datos agrupados y xi marcas de clase, siendo x la media aritmética de la distribución de frecuencias (xi, ni).
A la raíz cuadrada positiva de la varianza se llama desviación típica y se obtiene como
( )2
1
1 k
i ii
x x nN
σ=
= − ⋅∑
Cálculo abreviado de la varianza y la desviación típica
Desarrollando la expresión anterior:
( ) ( )2
22 2 2 2
1 1 1 1 1
2 2 2 2 2
1 1
1 1 1 22
1 12
k k k k k
i i i i i i i i i ii i i i i
k k
i i i ii i
x xx x n x x x x n x n n x n
N N N N N
x n x x x n xN N
σ= = = = =
= =
= − ⋅ = + − ⋅ = ⋅ + − ⋅ =
= ⋅ + − = ⋅ −
∑ ∑ ∑ ∑ ∑
∑ ∑
Disponiendo los cálculos en forma de tabla:
ix in i in x⋅ 2i in x⋅
1x 1n 1 1n x⋅ 21 1n x⋅
⋮ ⋮ ⋮ ⋮
ix in i in x⋅ 2i in x⋅
⋮ ⋮ ⋮ ⋮
kx kn k kn x⋅ 2k kn x⋅
iN x=∑ i in x⋅∑ 2
i in x⋅∑
2
2 2
1 1
1 1k k
i i i ii i
n x x nN N
σ= =
= ⋅ − ⋅
∑ ∑

Estadística unidimensional
22
La varianza medirá la mayor o menor dispersión de los valores respecto a la media aritmética.
Si la dispersión es muy grande, la media no será representativa. Propiedades de la desviación típica • No tiene un sentido muy concreto en sí misma y tiene significado para comparar dos
distribuciones. Dividiendo las desviaciones típicas de ambas se puede obtener cuántas veces una distribución es más dispersa que otra.
• Es más sensible que la media a los valores erróneos, puesto que intervienen al cuadrado. Su cálculo puede resultar pesado, por lo que a veces se prefiere el recorrido.
• Es la menor de todas las desviaciones cuadráticas respecto a un promedio. • Para distribuciones simétricas o moderadamente asimétricas se cumple de forma aproximada
que: 1. Entre x σ− y x σ+ están aproximadamente el 68% de las observaciones. 2. Entre 2x σ− y 2x σ+ están aproximadamente el 95% de las observaciones. 3. Entre 3x σ− y 3x σ+ están aproximadamente el 98% de las observaciones.
También podemos utilizar como medida de dispersión respecto a la media la denominada
Cuasivarianza: *2 2
1
NS
Nσ=
−
4 - Medidas de dispersión relativas.
Supongamos que se tienen dos distribuciones de frecuencias cuyos promedios son P1 y P2 y queremos saber cuál de los dos es más representativa. Esta comparación no la podemos efectuar por sus respectivas medidas de dispersión ya que las distribuciones , en general, no vendrán dadas en las mismas unidades de medida. Tampoco, aunque sus unidades de medida sean las mismas, si los promedios son numéricamente diferentes. Por tanto es necesario construir medidas adimensionales. Estas medidas de dispersión, llamadas relativas, siempre vendrán dadas en forma de cociente. Entre ellas destacan: • Coeficiente de apertura
Es la relación por cociente entre el mayor y el menor valor de una distribución: 1
n
xA
x= . Es
muy fácil de calcular pero presenta inconvenientes: − Mide la dispersión de la distribución, pero no hace referencia a ningún promedio por lo que no
resuelve el problema de comparación entre estos. − Sólo tiene en cuenta dos valores de la distribución (los extremos), lo que dará gran dispersión en
el caso de que estén muy separados. • Recorrido relativo.
Es el cociente entre el recorrido y la media aritmética r
RR
x= . Nos indica el número de veces
que el recorrido contiene a la media aritmética.

Estadística unidimensional
23
• Recorrido semiintercuartílico Es el cociente entre el recorrido intercuartílico y la suma del primer y tercer cuartil:
3 1
3 1s
C CR
C C
−=+
• Coeficiente de variación de Pearson
Con él podemos comparar las medias aritméticas de dos distribuciones que vengan dadas en unidades diferentes. Se define como el cociente entre la desviación típica y la media aritmética:
. .S
C Vx x
σ= =
Es una medida adimensional y representa el número de veces que σ contiene a x . Cuanto mayor sea C.V., más veces contendrá σ a x , por lo que a mayor C.V., menor representatividad de x . El coeficiente se suele expresar en tanto por ciento.
Como tanto en σ como en x han intervenido todos los valores de la distribución, C.V. presenta la garantía de que utiliza toda la información.
La cota inferior de σ es cero (el menor valor que puede tomar σ) y es el valor de C.V. que indica la máxima representatividad de x . 3.4.3 - MEDIDAS DE FORMA
Se han visto hasta ahora las medidas de centralización o posición y las medidas de dispersión, de modo que tenemos una idea de las “forma” que tiene la distribución objeto de nuestro estudio. Pero es necesario definir otra serie de medidas que permitan cuantificar la forma de la distribución en dos sentidos: la mayor o menor simetría y la concentración más o menos acusada de los valores centrales de la distribución en torno a las medidas de posición central que ya conocemos.
Las medidas de forma de una distribución se pueden clasificar en dos grandes grupos: medidas de asimetría y medidas de curtosis. 1 - Medidas de asimetría
Las medidas de asimetría se dirigen a elaborar un indicador que permita establecer el grado de
simetría (o asimetría) que presenta una distribución sin necesidad de llevar a cabo su representación gráfica. Diremos que una distribución es simétrica si al representarla gráficamente y trazada una vertical que pase por la media aritmética, deja a ambos lados el mismo número de valores.
Pearson define su índice de simetría como 1
x Mof
σ−= . Así si se verifica que f1 = 0, entonces
x Mo Me= = y la distribución es simétrica. Si f1 > 0 se dice que es asimétrica a la derecha, pues Mo < x , y si f1 < 0, asimétrica a la izquierda, pues Mo>x .
Estadística unidimensional
24
Otro índice de simetría más general es el de Fisher, que vale
( )3
11 2
1 k
i ii
x x nN
gσ
=
− ⋅=
∑
Análogamente como ocurría con el de Pearson, si g1 = 0 la distribución es simétrica, si g1 > 0 presenta asimetría a la derecha y si g1 < 0, asimetría a la izquierda. 2 - Medidas de apuntamiento o Curtosis
Estas medidas se aplican a distribuciones acampanadas, es decir, unimodales, simétricas o con ligera asimetría. Tratan de estudiar la distribución de frecuencias alrededor de la media y en la zona central de la distribución dará lugar a una distribución más o menos apuntada.
Para estudiar la curtosis de una distribución es necesario definir previamente una distribución “tipo” que se toma como modelo de referencia. Esta distribución es la llamada distribución normal, que corresponde a fenómenos muy corrientes en la naturaleza y cuya representación gráfica es una campana de Gauss dada por la fórmula
( )2
2
1
21( )
2
x x
f x e σ
σ π
−−
=
Se trata de ver la deformación existente entre una distribución, en sentido vertical y la normal.
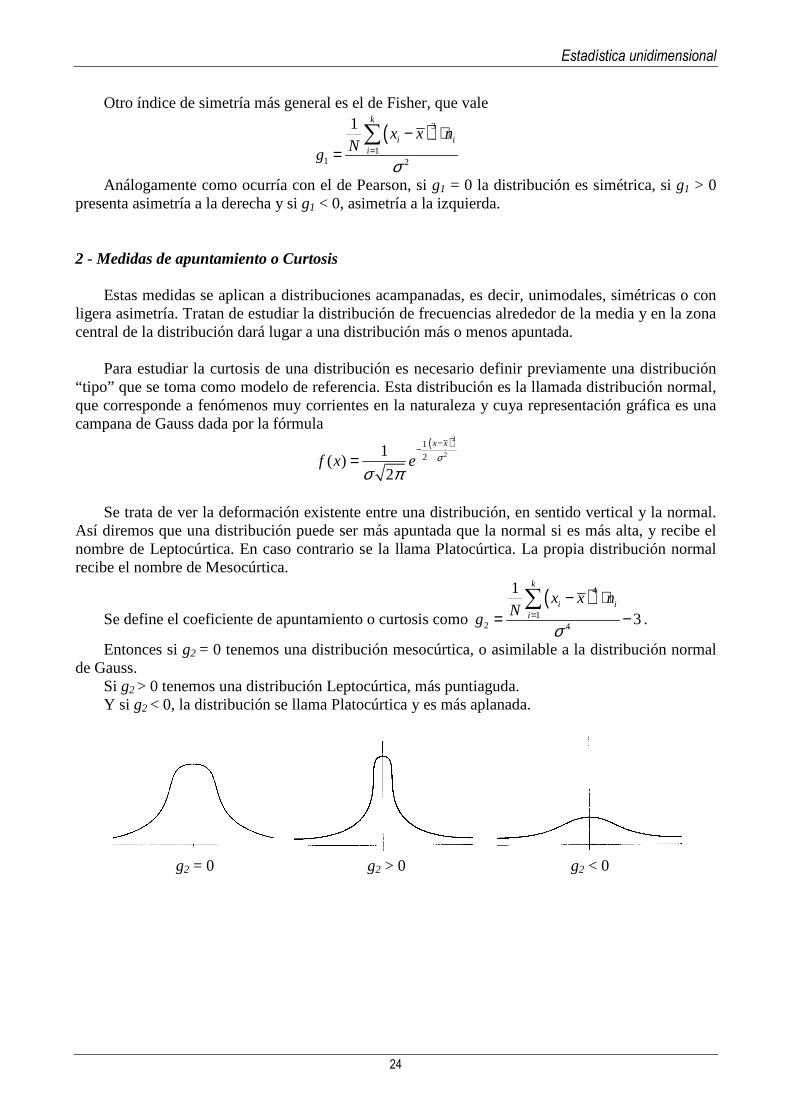
Así diremos que una distribución puede ser más apuntada que la normal si es más alta, y recibe el nombre de Leptocúrtica. En caso contrario se la llama Platocúrtica. La propia distribución normal recibe el nombre de Mesocúrtica.
Se define el coeficiente de apuntamiento o curtosis como ( )4
12 4
1
3
k
i ii
x x nN
gσ
=
− ⋅= −
∑.
Entonces si g2 = 0 tenemos una distribución mesocúrtica, o asimilable a la distribución normal de Gauss.
Si g2 > 0 tenemos una distribución Leptocúrtica, más puntiaguda. Y si g2 < 0, la distribución se llama Platocúrtica y es más aplanada.
g2 = 0 g2 > 0 g2 < 0

Estadística unidimensional
25
4 - MÉTODOS BÁSICOS DE LA ESTADÍSTICA INFERENCIAL La estadística inferencial establece previsiones y conclusiones sobre la población a partir de
los datos obtenidos de una muestra, siguiendo un método basado fundamentalmente en el cálculo de probabilidades. Dicho cálculo busca crear modelos estadísticos teóricos que se ajusten lo más posible a la realidad y cuya función es generalizar los resultados de la muestra para estimar características de la población. Los métodos en los que se basa la Estadística inferencial para poder establecer sus conclusiones son:
- Muestreo. - Estimación estadística. - Contraste de hipótesis.
4.1. Muestreo
Como ya se ha indicado, en estadística se llama Población o Universo, a cualquier conjunto o
colección de individuos o elementos que tienen una característica común. Así son ejemplos de Población los habitantes de una provincia, los árboles de un bosque o los establecimientos comerciales de una ciudad. Lo que interesa en la Población es medir o contar uno o varios caracteres cuantitativos. Por tanto se hace necesario que la Población esté definida para saber qué elementos la componen.
Cuando se pueden observar todos los elementos de la Población, diremos que se está realizando un censo. En este caso la tarea a realizar es describir las características y regularidades de la Población con los métodos de la Estadística Descriptiva y construir el modelo de Distribución de Probabilidad para que pueda ser utilizado en posteriores investigaciones
Pero no siempre es posible analizar cada elemento de la Población debido a diferentes razones como: - que sea inviable económicamente estudiar la población, - que el estudio implique la destrucción del elemento (ensayos destructivos) - que la población sea muy difícil de controlar - que se desea conocer rápidamente ciertos datos de la Población (p.e. encuestas de intención de
voto) por lo que las características de la Población deben ser estudiadas a partir de un subconjunto de esta.
Hemos definido muestra de una Población como un subconjunto de elementos de dicha Población. El número de elementos que la componen se llama tamaño de la muestra y el proceso de escoger una muestra de una población, muestreo. Como ya se ha indicado, si la investigación se dirige a toda la población se estará haciendo un censo u observación exhaustiva. Si lo que se recoge es la información de una muestra, una encuesta.
Al efectuar una observación exhaustiva se conoce el valor que toma una característica X en
cada uno de los individuos de la Población, por lo que se conoce la distribución de la variable haciéndose innecesarios los métodos de Inferencia estadística. Si la característica X se observa en una muestra de la Población, para poder utilizar adecuadamente la Inferencia estadística hay que prescindir de las muestras seleccionadas según un criterio u opinión personal. De este modo surge de forma natural la necesidad de cuantificar los errores de muestreo y de conocer los aspectos fundamentales para que una muestra sea representativa de la Población.

Estadística unidimensional
26
Para obtener conclusiones razonables a partir de una muestra, esta debe estar bien elegida, debe ser representativa de la Población. Esta cualidad depende de dos aspectos fundamentales: el tamaño de la muestra y de cómo se realiza la selección de los individuos que la componen.
Por lo que respecta al tamaño, si la muestra es demasiado pequeña, no se obtendrían
conclusiones relevantes y precisas salvo en el caso de poblaciones homogéneas, en las que cualquier subconjunto tiene características análogas al conjunto (p.e. una muestra de sangre). Por otra parte, un aumento del tamaño de la muestra no supone un aumento significativo de la representatividad.
Considerando la selección de los elementos, al sustituir el estudio de la población por el estudio
de una muestra se comenten errores. Si la muestra está seleccionada al azar éstos se pueden controlar, pero si está mal elegida, no es representativa y aparecen errores imprevistos e incontrolados. Un ejemplo de estos errores se pueden ver en los estudios de intención de voto en las elecciones a la presidencia de los EEUU en 1936: una revista realizó la encuesta a más de 4 millones de sus lectores obteniendo el resultado de fracaso electoral de Roosevelt. Por otro lado, otra encuesta a 4500 personas adelantó el éxito del Roosevelt con bastante exactitud. La explicación es que el segundo estudio contaba con una muestra más homogénea de la sociedad americana de entonces.
Los integrantes de una muestra han de ser elegidos al azar, eliminando criterios personales. En este caso estamos ante un muestreo probabilístico al que se pueden aplicar métodos de inferencia estadística. Obtenemos así muestras representativas. En caso contrario estamos ante el muestreo opinático o no probabilístico (p.e. encuestas de Internet).
Hay dos tipos de errores en la selección de la muestra. 1. Errores muestrales, que se encuentran latentes en toda muestra representativa pues no
proporciona una medida exacta de las características de la población, aun siendo representativa.
2. Sesgos, ocasionados por la falta de representatividad de la muestra, o a errores de observación debidos a definiciones defectuosas, medidas mal efectuadas, etc.
Por este motivo es importante conocer los tipos de muestreo así como la garantía de su
representatividad. Para aumentar la representatividad sin necesidad de aumentar el tamaño de la muestra se recurre al muestreo o técnicas de muestreo. En la práctica resuelven el problema de la representatividad. Pero antes de pasar a estudiar los diferentes tipos de muestreo, se presentarán algunos conceptos básicos en el muestreo. Distribución poblacional
Supongamos que en una Población dada nos interesa estudiar la característica numérica x, y tenemos para cada uno de sus elementos los valores x1, x2,…, xN. Su distribución queda definida principalmente por los parámetros poblacionales que son:
N : tamaño de la Población;
Media poblacional: 1
N
ii
x
Nµ ==∑
;

Estadística unidimensional
27
Varianza poblacional:
2
2 21 1
( )N N
i ii i
x x
N N
µσ µ= =
−= = −∑ ∑
;
Desviación típica poblacional: 2σ σ= +
Proporción poblacional: AA
pN
= ,
con A= nº de elementos de la población con la característica A. Destacar que estos parámetros son valores numéricos
Distribución de la muestra
Medimos en la muestra la característica numérica x que nos interesa. Ahora x es una variable
estadística, y se estudia la distribución de sus frecuencias con los métodos de la Estadística Descriptiva. Si x1, x2,…, xn son los valores obtenidos, a partir de estos se calculan los parámetros estadísticos o muestrales:
n : tamaño de la muestra;
Media muestral: 1
n
ii
xx
n==∑
;
Varianza muestral:
2
2 21 1
( )n n
i ii i
x x xS x
n n= =
−= = −∑ ∑
;
Desviación típica muestral: 2S S= + ;
Proporción poblacional: pn
α= ,
con α = nº de individuos de la muestra con la característica A. Destacar que ahora estos parámetros son funciones, pues dependen de la muestra escogida.
Nuestro objetivo es obtener información sobre la Ley de Probabilidad que rige la característica x de la Población a partir de las observaciones de la misma elegidas para formar la muestra, es decir, queremos estimar los parámetros poblacionales a partir de los datos muestrales. Así, se define como estadístico a cualquier función que depende sólo de los valores de la muestra x1, x2,…, xn, y estimador a aquel estadístico que se utiliza para estimar el valor de un parámetro desconocido de la Población.
Como para cada muestra considerada el estimador toma un valor, este es una variable aleatoria, y por tanto, cada estimador tendrá una distribución que llamaremos Distribución muestral del estimador considerado. Los estadísticos más utilizados son 2, ,x S S y un parámetro muestral que se llama Cuasivarianza muestral, definido como:
2
2 1
( )
1
n
ii
C
x xS
n=
−=
−
∑. (Notar que 2 21
C
nS S
n
−= , y 2 2
1C
nS S
n=
−)
El muestreo probabilístico se caracteriza porque puede calcularse de antemano la probabilidad de obtener cada una de las posibles muestras, para lo cual es necesario que la selección de la muestra pueda considerarse como un experimento aleatorio. Así cada observación xi es una variable aleatoria que tiene la distribución de probabilidad de la Población: E[xi]=µ, V[x i]=σ2, para todo i = 1,2,…0.

Estadística unidimensional
28
Este tipo de muestreo es el único que tiene rigor científico y el único que puede darnos el error que cometemos en la inferencia. Dentro del muestreo aleatorio hay varios tipos que se verán a continuación. I) Muestreo aleatorio simple
Se realiza en poblaciones en las que los datos son homogéneos, es decir, no existen factores que produzcan variabilidad sistemática. En este tipo de muestreos los elementos de la población homogénea se eligen al azar. La representatividad de una muestra obtenida por el muestreo aleatorio simple (MAS) viene garantizada por tener cada elemento la misma probabilidad de ser elegido. Así, si un 40% de la población tiene la característica xi, se obtendrá, por término medio, un 40% de elementos de la muestra con esa característica.
Se distinguen a su vez dos casos de MAS, dependiendo de que los elementos de la población se
selecciones con o sin reemplazamiento.
I.1 - MAS sin reemplazamiento
Cuando las sucesivas extracciones de elementos se realizan sin reemplazamiento tenemos un número de muestras posibles dado por N combinaciones tomadas de n en n, por lo que la
probabilidad de seleccionar una de ellas es ( ) 1/i
NP X
n
=
, con Xi muestra cualquiera de n
elementos de las N
n
posibles. De este modo, la probabilidad de que la unidad ui pertenezca a la
muestra es1
( ) /1i
N N nP u
n n N
− = = −
.
La distribución que sigue la media muestral x , tiene por esperanza y varianza:
Esperanza: 1 1
1 1 1[ ] [ ]
n n
i ii i
E x E x E x nn n n
µ µ= =
= = = ⋅ ⋅ = ∑ ∑
Varianza: [ ]( )2
2[ ]
1
N nV x E x E x
N n
σ− = − = ⋅ −
, donde 1
N n
N
−− se llama factor de corrección
para poblaciones finitas.
I.2 - MAS con reemplazamiento
Cuando las sucesivas extracciones de elementos se realiza con reemplazamiento, entonces tenemos un n-upla x1, x2,…, xn de variables aleatorias independientes e idénticamente distribuidas según la distribución de la población.
Como tenemos Nn muestras posibles, la probabilidad de seleccionar una de ellas es por tanto 1/Nn. En este caso la distribución de la media muestral es:
1 1
1 1 1[ ] [ ]
n n
i ii i
E x E x E x nn n n
µ µ= =
= = = ⋅ ⋅ = ∑ ∑
22 2
2 2 21 1 1
1 1 1 1[ ] [ ]
n n n
i ii i i
V x V x V x nn n n n n
σσ σ= = =
= = = ⋅ = ⋅ = ∑ ∑ ∑ , (notar que xi son v.a.i.)
La distribución de la varianza muestral es:

Estadística unidimensional
29
2 2 2
1
1 1( )
n
ii
nE S E x x
n nσ
=
− = − =
∑
En consecuencia, el valor medio de S2 es menor que σ2 , aunque la diferencia tiende a cero al aumentar el tamaño de la muestra. Por eso se define la Cuasivarianza muestral Sc
2, que verifica E[Sc
2]=σ2, lo que se demuestra sencillamente. Notar que en el caso de ser la población infinita, o el tamaño N muy grande, es prácticamente
igual hacer el muestreo con o sin reemplazamiento pues:
2 2
[ ] [ ]1
nN nV x V x
N n n
σ σ→∞−= ⋅ → =−
22 2 2( 1) ( 1)
[ ] [ ]1
nN n nE S E S
N n n
σ σ→∞− −= ⋅ → = ⋅−
Como regla práctica se suele adoptar que si la fracción de muestreo n/N es menor que 5/100,
entonces se hace el muestreo aleatorio simple con reemplazamiento, que es el que se utiliza con mayor frecuencia, y al ser variables aleatorias e independientes e idénticamente distribuidas, el estudio de las distribuciones de x y S2 queda mucho más sencillo.
En el estudio de la distribución de la proporción muestral, definimos en la Población la variable aleatoria Y de Bernouilli: Y ≡ B(1, pA). Sabemos que E[Y] = pA, V[Y] = pA·qA, donde qA=1-pA. Si tomamos una muestra aleatoria simple de tamaño n, Y1,Y2,…,Yn, la proporción
muestral de A es:1
1 n
ii
p Yn =
= ∑ . Entonces su esperanza y varianza serán:
1 1
1 1 1[ ] [ ]
n n
i i A Ai i
E p E Y E Y n p pn n n= =
= = = ⋅ ⋅ = ∑ ∑
2 21 1
1 1 1[ ] [ ]
n nA A
i i A Ai i
p qV p V Y V Y n p q
n n n n= =
⋅ = = = ⋅ ⋅ ⋅ = ∑ ∑ , por ser v.a.i.
Distribuciones de probabilidad en el muestreo
Conocer las distribuciones de probabilidad en el muestreo de los estadísticos estudiados es clave en la Inferencia Estadística. A partir de estos resultados, suponiendo una muestra aleatoria simple con reemplazamiento se tiene que:
A) Caso de poblaciones normales X≡N(µ,σ)
1) Si σ es conocido, ,x Nn
σµ ≡
2) Si σ es desconocido, 1/
n
c
xt
S n
µ−
− ≡
3) 22
2 21 12 2
( 1) cn n
n Sn S
σ σ− −− ⋅⋅ ≡ ℵ ⇔ ≡ ℵ , y además es independiente dex .
B) Caso de poblaciones no normales
1) Cuando no se sabe la distribución de la población y n≥30, podemos aplicar el teorema central del Límite y tenemos que

Estadística unidimensional
30
Si σ es conocida, ,x Nn
σµ →
, y si σ es desconocida, , cSx N
nµ →
2) Si Y≡B(1,p) y n≥30, también por el teorema central del Límite,
, A AA
p qp N p
n
⋅≡
II - Muestreo aleatorio estratificado
Si en la población existe variabilidad, entonces se divide en grupos homogéneos denominados estratos y posteriormente se extrae una MAS de cada estrato. Se deben coger como estratos aquellos factores que producen variabilidad de los datos. Si N es el tamaño de la población y denominamos N1 ,N2,…,Nk el tamaño de cada estrato, tenemos que N=N1+…+Nk. El número de elementos de cada estrato a seleccionar será nj, proporcional al número de elementos de cada estrato, es decir
jj
Nn n
N= , donde n es el número de elementos que queremos que tenga la muestra. Por ejemplo, si
se tiene una población en el que el 60% son mujeres y el 40% hombres, para escoger una muestra de 2.000 personas se divide la población en dos estratos, hombres y mujeres, y se escoge al azar una muestra proporcional de cada estrato, que en este caso son 1.200 mujeres y 800 hombres.
La representatividad de una muestra obtenida por muestreo aleatorio estratificado viene garantizada por el hecho de que
• el número de elementos de cada estrato es proporcional al tamaño del estrato • el número de elementos seleccionados de cada estrato es proporcional a la variabilidad de
cada estrato. Una vez determinado el número de individuos que deben pertenecer a cada estrato se procede a
la selección de individuos de cada estrato por MAS. III - Muestreo aleatorio sistemático
Se emplea cuando los elementos de la población están ordenados en listas. Si k es el entero más próximo a N/n, la muestra sistemática se toma eligiendo al azar un elemento entre los k primeros. Sea n1 el orden del elegido. A continuación se toman los elementos n1+k, n1+2k,…, a intervalos fijos de k hasta completar la muestra.
Si el orden de los elementos de la lista es al azar, este procedimiento es equivalente al MAS, aunque resulta más fácil llevarlo a cabo sin errores. La representatividad de una muestra aleatoria sistemática es la misma que la de un MAS. Si el orden es tal que los individuos próximos tienden a ser más semejantes que los alejados, el muestreo sistemático tiende a ser más preciso que el MAS, al cubrir más homogéneamente toda la Población. El muestreo sistemático puede utilizarse con el muestreo estratificado para seleccionar la muestra dentro de cada estrato. IV - Muestreo aleatorio polietápico, por áreas o conglomerados
Si a Población presenta heterogeneidad, se utiliza este tipo de muestreo. Para llevarlo a cabo de divide a la Población en diferentes secciones o conglomerados y se eligen al azar unas cuantas secciones para formar la muestra. En un primer paso se descompone al a Población en clases llamadas conglomerados, de forma que dentro de cada conglomerado haya la misma dispersión o heterogeneidad, de tal forma que todos los conglomerados se parezcan entre si. El segundo paso

Estadística unidimensional
31
consiste en elegir la muestra realizando un muestreo aleatorio de conglomerados. Cuando se elige un conglomerado, todos los elementos del mismo pasan a formar parte de la muestra.
La representatividad de una muestra por áreas viene garantizada por el hecho de haber elegido los conglomerados por un método aleatorio. V - Muestreo secuencial o muestreo sobre calidad
Este tipo de muestreo se utiliza sobre todo para realizar controles de calidad en los que debe estudiar una característica de una Población cuyo estudio implica la destrucción del elemento que se selecciona. Las unidades de muestreo son examinadas progresivamente hasta llegar al punto en que se tiene suficiente información como para dar el resultado con las probabilidades de error previamente establecidas. Por tanto, primeramente se establecen unas propiedades que debe de cumplir el elemento que se seleccione y se toma la decisión de rechazarlo o aceptarlo y de continuar o no la inspección.
Con este tipo de muestreo se requiere una muestra de menor tamaño que en los muestreos estudiados anteriormente, aunque puede haber una ligera pérdida de representatividad respecto a ellos. VI - Métodos indirectos de muestreo
Si podemos estimar una recta de regresión entre dos variables de una Población con una muestra de una variable (independiente,.que obtendremos por métodos directos ya vistos), podemos estimar los valores de otra variable (dependiente). La representatividad de la muestra dependerá del coeficiente de correlación entre las dos variables que se estudien y de la representatividad de la muestra de la variable independiente.
Tamaño de la muestra Hasta ahora se ha respondido a la pregunta ¿cómo se debe seleccionar una muestra para que sea
representativa? Queda por contestar la otra cuestión planteada ¿qué tamaño debe de tener la muestra?
En el diseño del estudio estadístico, antes de realizar el muestreo, se ha de fijar el tamaño de la
muestra con el fin de que los gastos económicos para su realización estén dentro del presupuesto fijado, que el tiempo necesario para realizar el muestreo sea corto y que los resultados sean fiables.
En primer lugar se establecerá el tamaño de la muestra dependiendo del grado de precisión que se quiera alcanzar, pues en función del tamaño de la muestra se obtienen los gastos que requiere y el tiempo necesario. Destacar que el coste y el tiempo hace que muchos estudios no se realicen con la precisión determinada inicialmente.
Se partirá, por tanto, de un determinado error e y de un nivel de confianza para obtener el
tamaño adecuado. Se define el nivel de confianza como la probabilidad de que la diferencia entre el estimador y el parámetro que se quiere estimar sea menor que la cota de error. Podemos
enunciarlo como ( ) 1P x eµ α− < = − , y para que esta probabilidad sea elevada, α tiene que ser
muy pequeño. Si se considera además el error de la formae kn
σ= , queda

Estadística unidimensional
32
1P x kn
σµ α − < = −
.
Suponiendo una Población normal con µ desconocida, pero conocida σ, tipificando queda
( ) 1/
xz P z k
n
µ ασ
−= ⇒ < = − , y por tanto /2k zα= , por lo que el error vendrá dado por
/2e zn
ασ= . A partir de aquí se despeja n, resultando
2
/2zn
eα σ⋅ =
.
Esta expresión se aplica directamente porque conocemos /2zα y e lo fijamos. Observamos que el
tamaño de la muestra será mayor cuanto mayor sea /2zα , es decir, mayor el nivel de confianza 1-α,
y será mayor también cuanto menor sea e2, pues la estimación es más precisa en el intervalo.
La fórmula anterior sólo sirve para muestreos sobre poblaciones infinitas o finitas con
reemplazamiento. Para las poblaciones finitas se tomará /2 1N
N ne z
N nα
σ−= ⋅−
, es decir añadiéndole
el factor de corrección.
Despejando queda 1
1N
nn
n
N
∞
∞= −+
, con2
/2zn
eα σ
∞⋅ =
.
En el caso de no tener información sobre la población se utilizará la desigualdad de Markov,
que dice que dad una función no negativa g de la variable aleatoria x, para todo λ>0 se verifica:
[ ] [ ]( )( )
E g xP g x λ
λ> ≤ .
Tomando ( ) [ ] ( ) [ ]2
2 2( ) 0 ( )g x x E g x E x V x
n
σµ µ = − > ⇒ = − = = , y fijando 2 0λ ε= > ,
( )2 2
2 22 2
P x P xn n
σ σµ ε µ εε ε
− > ≤ ⇔ − > ≤ ⋅ ⋅
lo que permite determinar el tamaño de la muestra necesario para asegurar con determinada probabilidad que la media muestral no se alejará más de una determinada cantidad de la media poblacional.
4.2 - Estimación estadística La estimación estadística, que se basa fundamentalmente en el cálculo de probabilidades,
tiene por objeto inferir el valor de un parámetro desconocido de una distribución en base a los datos de una muestra.
La estimación de parámetros se realiza mediante:
• Estimación puntual En la que se aproxima el valor del parámetro a partir de un estadístico calculado en
la muestra. No hay un único criterio para determinar el mejor estimador puntual pero

Estadística unidimensional
33
para ser un buen estimador se desea que sea insesgado (cuando su distribución está centrada en el parámetro a estimar), consistente (si la probabilidad de que la estimación y el parámetro estén próximos aumenta y tiende a 1 al aumentar el tamaño de la muestra) y eficiente (un parámetro es más eficiente que otro si tiene menor varianza).
• Estimación por intervalos de confianza En la que en lugar de un solo punto se da un intervalo para estimar el valor de un
parámetro. Los extremos del intervalo se calculan en base a los datos de la muestra y la probabilidad de que el verdadero valor del parámetro desconocido esté en el intervalo debe ser alta. Para ello, primeramente se debe fijar la probabilidad con la que se pretende que el intervalo contenga al parámetro. Esta probabilidad, 1-a, se denomina nivel de confianza y al valor a se le llama nivel de significación.
4.3 - Contraste de hipótesis El contraste de hipótesis, también llamado test de hipótesis, es un procedimiento que
permite verificar si un conjunto de afirmaciones sobre la población son o no ciertas y si los datos nos ofrecen evidencia estadística para poder aceptar o rechazar una hipótesis que se plantea.
El contraste de hipótesis es, por tanto, un método numérico para comprobar una teoría o
hipótesis sobre una población. Dicho método consta de los siguientes pasos:
1. Enunciar la hipótesis H0. Consiste en darle un valor a un parámetro de cierta población.
2. Construir la zona de aceptación en función del nivel de significación. Si la hipótesis es cierta, el parámetro de la muestra se distribuirá de forma conocida. En
primer lugar se considera un nivel de significación siendo los más comunes α = 0,10; α = 0,05; α = 0,01. A continuación se construye la zona de aceptación que es el intervalo fuera del cual sólo se encuentran el α · 100 % de los casos "más raros".
3. Verificar la hipótesis
Obtener el correspondiente parámetro en una muestra cuyo tamaño es el que se ha decidido en el paso 2.
4. Decidir si se acepta la hipótesis
Se decide si se acepta la hipótesis con un nivel de significación a dependiendo de que el valor del parámetro esté dentro de la zona de aceptación. Si no lo está, se rechaza la hipótesis.
Veamos un ejemplo concreto: ¿Podemos suponer que es correcta una moneda que, al arrojarla 100 veces, da 25 caras?
1. Enunciamos la hipótesis: "la moneda es correcta"
5,02
1][:0 === caraPpH
2. Construimos la zona de aceptación: si la hipótesis fuera cierta, entonces las proporciones de caras en una muestra de tamaño 100 seguirían una distribución normal, esto es:

Estadística unidimensional
34
( )05,0;5,0100
5,05,0;5,0, NN
n
pqpN =
⋅=
3. Elegimos un nivel de significación α = 0,05; por tanto el 95% de las proporciones muestrales de caras estarían en el intervalo característico:
(0,5 - 1,96 . 0,05; 0,5 + 1,96 . 0,05) = (0,402; 0,598)
denominada zona de aceptación.
4. Decidimos si aceptamos o no la hipótesis: puesto que la proporción obtenida en la
muestra es 0,25 que no está en la zona de aceptación se rechaza la hipótesis y consideramos que la moneda no es correcta.

Estadística unidimensional
35
5 - APLICACIONES DE LA ESTADÍSTICA.
La estadística es una ciencia de aplicación práctica casi universal en todos los campos científicos. En este apartado vamos a ver algunas aplicaciones en campos concretos tanto de la Estadística Descriptiva como de la Estadística Inferencial
Aplicación en las Ciencias Sociales El papel de la estadística en el proceso de investigación sociológica está claramente
determinado: las consideraciones estadísticas se introducen tan sólo en la fase analítica del proceso de investigación, después de haber obtenido los datos, frecuentemente a partir de una muestra. La estadística es, pues, un instrumento auxiliar en el proceso de investigación.
1.- El análisis comparativo en sociología El análisis comparativo es una de las parcelas estudiadas por la Estadística Descriptiva. La
Sociología hace constantemente uso de las comparaciones para avanzar el pensamiento sociológico (ejemplo: comparación sobre las actitudes de colectivos, comparación de tasas brutas de natalidad para analizar la tendencia general del censo, comparación de la situación económica de una zona determinada en diferentes años).
Para una correcta comparación es preciso formular e identificar claramente los objetos o
fenómenos que se van a medir, para que se puedan contrastar consistentemente grupos comparables. Son tres los tipos de comparación que se pueden realizar:
• Comparación entre grupos.
El modelo de comparación será el realizado entre un grupo experimental al que se le ha sometido a un tratamiento conocido, como podría ser un grupo de alumnos al que se le enseña un programa educativo especial, y un grupo de control no sometido a dicho tratamiento (grupo de alumnos que continúa con el programa tradicional). Se trata, pues, de una comparación entre un grupo experimental y un grupo de control en dos momentos en el tiempo, es decir, antes y después de someter al grupo experimental al tratamiento. Los grupos que se comparan pueden estar constituidos por individuos o por cosas u objetos no personales, tales como grupos de organizaciones o instituciones sociales.
• Comparaciones entre un grupo y un caso individual de dicho grupo. Así, se pueden comparar los resultados escolares de un estudiante con los
correspondientes a la media de su clase. Lo importante será siempre delimitar y definir las características del grupo que se compara con las correspondientes al individuo.
• Comparaciones entre los resultados de un estudio y unos resultados estandarizados que bien han sido establecidos a partir de investigaciones previas o provienen de un modelo teórico formulado por el investigador.
Un ejemplo sería contrastar determinadas características demográficas de un grupo social objeto de estudio con las correspondientes tasas que ofrecen los resultados del censo general de la población. Otras veces el estándar es simplemente un estudio anterior que sirve de referencia a una nueva investigación (ejemplo: un antropólogo que estudia una

Estadística unidimensional
36
comunidad rural ya estudiada anteriormente). También las comparaciones se podrán realizar a partir de teorías conocidas. Un ejemplo sería el siguiente: la teoría de la transición demográfica de las sociedades que pasan del estado preindustrial al industrial predice un cambio en las tasas de natalidad y mortalidad, de forma que los valores altos de tales tasas se reducen significativamente.
2.- Recogida de datos estadísticos La descripción estadística de un fenómeno sociológico se hace mediante datos numéricos.
La recogida de datos puede realizarse utilizando fuentes internas (ejemplo: datos intrínsecos a la propia actividad de la empresa y que son facilitados por ella misma) y externas (ejemplo: información ajena a la propia empresa y que es facilitada por otros organismos o individuos).
Existen muchas entidades públicas y privadas (ministerios, cámaras de comercio, entidades
bancarias, revistas especializadas, el Instituto Nacional de Estadística, etc.) que publican periódicamente datos e informes estadísticos de tipo general o especializados: finanzas, asuntos sociales y económicos, educación, etc. Dichas publicaciones son importantes fuentes externas.
La recogida de datos es una tarea delicada pues un error en esta fase falsea todo el
tratamiento posterior, de ahí que, una vez concluida, haya de hacerse un detenido escrutinio de los números conseguidos, a fin de revisar datos sospechosos o rechazar los claramente inadmisibles.
3.- Aplicaciones en la estimación del tamaño o cara cterísticas de una población La estimación del tamaño o características de una población se realiza en base a: Censos y recuentos
Cuando tanto el tamaño de la población a estudiar y los recursos necesarios para el estudio no sean excesivos se puede someter a análisis la población total dada la exactitud que se obtendrá. Los censos de población tienen gran tradición y fueron las primeras manifestaciones estadísticas.
Estudios actuales que implican la utilización de censos y recuentos son: los estudios sobre características demográficas, los de fecundidad comparativa en diferentes grupos socio-económicos y étnicos, los de actitudes y opiniones, los del efecto de la movilidad física y social, de la sanidad, del empleo y desempleo, analfabetismo y educación.
Aplicaciones del muestreo
En muchos casos se recurre a la utilización de la inferencia estadística para inferir a toda una población las conclusiones sacadas a través del estudio de una muestra de la misma. Ejemplos que actualmente han adquirido gran importancia son:
• Investigaciones de mercado El sondeo o medición de la opinión pública, tradicionalmente importante por su relación
con objetivos no sólo sociales, sino también económicos o políticos, ha adquirido actualmente una gran relevancia. Investigadores del mercado, trabajadores sociales, doxólogos, psefólogos y analizadores de la opinión pública constituyen parte de un nuevo colectivo que utiliza el muestreo de opinión pública como herramienta de trabajo. Es

Estadística unidimensional
37
interesante, así mismo, el empleo del material recogido en las encuestas para el análisis y simulación de votaciones y otras reacciones políticas y sociales.
Ciertos investigadores (Stephan y McCarthy) incluyen entre los estudios de la opinión
pública los relacionados con votaciones, matrimonio y vida familiar, lectura y uso de bibliotecas, empleo del teléfono, radio y televisión, moral y comportamiento de los militares en campaña y en tiempo de paz, reacciones de un país ante una calamidad pública, propaganda y rumores e influencia personal de ciertos individuos. Se han efectuado muestreos, igualmente, para medir preferencias y evaluar el prestigio de personalidades, partidos, profesionales, etc. y las relaciones entre diferentes razas y países.
En los sondeos de opinión pública aparecen como problemas principales la negativa a
proporcionar información o a facilitarla de forma incompleta y no verídica por parte de los individuos seleccionados en la muestra. Serán varias las técnicas para paliar estos efectos negativos: asignación de agentes de recogida de datos de las mismas características que los individuos de la muestra (raza, clase social), explicación clara de los fines del sondeo, fijación de entrevistas en lugar y hora preferentes para los entrevistados, etc.
• Distribuciones por estratos o clases Se trata del problema de la determinación de estratos o clases y la asignación o
atribución de individuos a tales clases, problema que se relaciona con cuestiones taxonómicas y con el análisis discriminante.
• Número óptimo de las diferentes profesiones En relación con programas de desarrollo, nos encontramos con los problemas socio-
económicos de la determinación del número óptimo de las diferentes profesiones o actividades con relación a los objetivos señalados. Tiene interés la clasificación de las ocupaciones por diversos criterios. Entre éstos está el del tiempo discrecional, tiempo máximo que puede trabajarse sin que la imperfección en la tarea desempeñada llegue al conocimiento de un superior. Se pueden establecer clasificaciones por prestigio y estratos a los que corresponden las diferentes profesiones o actividades. Algunos problemas sociológicos de movilidad y otros con aplicación particular a la permanencia en puestos de trabajo han sido estudiados por Goodman (1961).
4.- La teoría de la población Los demógrafos y sociólogos utilizan las técnicas de la Estadística (tanto descriptiva como
inferencial) para realizar sus investigaciones. Para la Teoría de la Población han desarrollado un esquema conceptual para describir los cambios demográficos que se producen en los países al pasar por diversos estados de industrialización y urbanización.
Tres son los tipos que se utilizan para describir países: de alto crecimiento potencial, de
crecimiento transaccional y de decadencia incipiente. Tales tipos se definen en términos de tasas de natalidad, de mortalidad y de crecimiento negativo, respectivamente.
5.- Aplicaciones de la teoría de la decisión estadí stica La Teoría de la Decisión y la Teoría de Muestras son los dos grandes temas que trata la

Estadística unidimensional
38
Estadística Inferencial. Son dos las técnicas principales que la Teoría de la Decisión pone a disposición de las Ciencias Sociales.
• Decisiones estadísticas
Después de sacar una muestra de cierta población, y obtener los datos referentes a la muestra, podemos usarlos para ayudarnos a tomar una decisión sobre la población. Un ejemplo sería analizar las necesidades de vivienda en una muestra particular para tomar una decisión en cuanto a la construcción de un número determinado de viviendas en una ciudad.
Es importante observar que estas decisiones están tomadas sobre una base probabilística. Esto es, hay siempre una probabilidad calculada de que una decisión particular sea mala. El acierto de la decisión estadística es que el grado de riesgo correspondiente a cualquier decisión particular se mide objetivamente en términos de probabilidades.
• Hipótesis estadística El procedimiento a seguir para llegar a una decisión será primero suponer la hipótesis
que se quiere decidir, después estudiar los resultados del experimento para ver si son consecuentes o no con la hipótesis y, finalmente, rechazar o aceptar dependiendo de si son consecuentes o no.
Un ejemplo sería la determinación del nivel de delincuencia de una ciudad específica. Una de las hipótesis podría ser que el nivel de delincuencia es mayor en la mitad norte que en la mitad sur. Para ello se procede al análisis mediante el estudio de una muestra concreta aleatoria sobre la que se contrasta la hipótesis, siguiéndose la veracidad o falsedad de la misma.
Aplicaciones en la biología, las ciencias experimen tales y las ciencias de la salud
Como se ha ido viendo a lo largo del tema, la estadística descriptiva es la que estudia los
datos resultantes de una experiencia. En este caso con el término "estudia" nos referimos a recoger los datos, clasificarlos, representarlos y resumirlos en informaciones que ayuden a los interesados en su análisis para poder sacar conclusiones que ayuden a comprender algo o a la toma de decisiones. Aplicaciones de la estadística descriptiva se encuentran en numerosos ámbitos.
Un ejemplo podría ser la aplicación de la estadística descriptiva en la denominada Ciencias
de la Salud. La recogida de datos referentes a la población, como pueden ser las enfermedades de las personas, los tratamientos aplicados o los métodos de diagnóstico, clasificando esta información teniendo en cuenta datos tan dispares como la situación económica, la edad o el color de la piel, aportará numerosos indicadores al campo de la Medicina que mejorarán sin duda el diagnóstico más rápido de enfermedades o ayudarán a encontrar nuevos antídotos en las investigaciones. Los mismo sucede en campos como la Química, la Biología o la Veterinaria.
En lo referente a las Ciencias Experimentales la estadística juega un papel fundamental.
Sobre todo a la hora de analizar las diferencias entre los datos obtenidos de los experimentos y los datos esperados según el sistema supuesto. En el campo de la Física existen multitud de aplicaciones de la estadística, que pueden ir desde control de errores de medida hasta el cálculo

Estadística unidimensional
39
de enlaces necesarios para la no saturación de las líneas telefónicas. Algo muy parecido sucede en las Ingenierías tanto Electrónicas, de Telecomunicaciones, Industriales o Informática.
Otras aplicaciones Tras todo 1o comentado se puede observar la dificultad de encontrar algún ámbito, tanto a
nivel empresarial como tecnológico o científico que no utilicen la estadística como valor añadido a su actividad. Algunos ámbitos que no se han nombrado directamente, pero dónde también deben tenerse en cuenta las aplicaciones de la estadística, podrían ser, entre otros muchos, la Publicidad, ayudando a prever o a entender la influencia de una campaña sobre un sector de la población, la Lingüística, ayudando a analizar dos obras literarias muy semejantes, las Matemáticas, dónde se utilizan numerosos modelos estadísticos, las Compañías de Seguros, utilizando las tablas de mortalidad para calcular las tarifas de sus clientes, o la Informática , tanto en algoritmos complejos como en distribuciones de tráficos por las redes de ordenadores.

Estadística bidimensional. Regresión
40
6. SERIES ESTADÍSTICAS BIDIMENSIONALES
Una estadística de una característica de la población pretende ofrecer información cuantitativa de la misma, para poder ser analizada. Normalmente no se lleva a cabo el estudio de una sola variable, sino que al analizar la población se suelen estudiar numerosas variables relacionadas entre sí. Un ejemplo sería la edad, las calificaciones de diferentes materias, los días de falta de asistencia y las horas de estudio de un alumno de cuarto de ESO. Hay que tener en cuenta que, en ocasiones, la información no la proporcionan los datos, sino las relaciones entre los datos que muchas veces son los objetivos reales de los estudios.
A lo largo del presente tema se estudia la forma de utilizar de forma conjunta las diferentes variables y la forma de analizar las relaciones que se dan entre ellas. La regresión trata de dar los medios necesarios para calcular aproximadamente el valor de una variable conocida otra. La correlación lineal nos indicará el grado de dependencia que hay entre las variables. 6.1. Variables estadísticas bidimensionales: tablas estadísticas
En múltiples problemas estadísticos, la observación de un fenómeno da lugar a la obtención de medidas de dos caracteres. Así, se pueden observar el peso y la talla de un conjunto de personas o la velocidad y el recorrido de frenado de un automóvil. Consideremos una población de N individuos descritos simultáneamente por dos variables X e Y. Tendremos entonces una variable estadística bidimensional (X, Y).
En el caso de variables bidimensionales, podemos distinguir tres tipos principales de tablas. • Primer tipo
Se origina cuando el número de datos bidimensionales N es pequeño. En este caso, los datos se disponen en dos columnas sobre las que se emparejan los correspondientes valores unidimensionales de una misma realización de la variable bidimensional, como puede verse en la siguiente tabla:
Variable X Variable Y
x1 y1 x2 y2 … … xn yn
• Segundo tipo
Se utiliza cuando el número de datos N es grande pero, sin embargo, existe un número pequeño (k) de parejas de valores distintos. Es decir, cuando entre los N datos existan k realizaciones (x1,y1), (x2, y2), .... (xk, yk) distintas que se repiten n1, n2, … , nk, veces, respectivamente, siendo
n1 + n2 + ... + nk = N.
En este caso la tabulación se realiza en tres columnas, enfrentando los valores xi, yi y ni en cada fila, es decir, valores unidimensionales de cada realización con su frecuencia absoluta correspondiente, según se expresa en la siguiente tabla:

Estadística bidimensional. Regresión
41
Variable X Variable Y Frecuencia
x1 y1 n1 x2 y2 n2 … … … xk yk nk N
Hay que hacer notar que las tablas del primer tipo pueden considerarse como de segundo
tipo, en donde las frecuencias valen 1 para la totalidad de los pares de los valores observados. • Tercer tipo
Se utiliza este tipo de tabulación cuando el número de observaciones es elevado y el número de distintas parejas de valores observadas también. En este caso se utiliza una tabla de doble entrada, que recibe el nombre de tabla de correlación, y que tiene la forma que puede verse:
Intervalos Totales
de clase X (a0, a1) (al, a2) .... (ai-1, ai) .... (ak-l, ak)
horizontales
Intervalos Marcas de
de clase Y de clase xl x2 .... xi .... xk
(b0, bl) y1 n11 n21 .... ni1 .... nkl n·1
(b1, b2) y2 n12 n22 .... ni2 .... nk2 n·2
.... .... .... .... .... .... .... .... ....
(bj-l, bj) yj n1j n2j .... nij .... nkj n·j
.... .... .... .... .... .... .... .... ....
(bp-1, bp) yp n1p n2p .... nip .... nkp n·p
Totales verticales n1· n2· .... ni· .... nk· n·· = N
Como se ve, la tabla es de doble entrada, figurando en las columnas las modalidades o valores de X y en las filas los de Y. En la intersección de la columna del valor xi, y la fila correspondiente al valor yj se encuentra la frecuencia absoluta del par (xi, yj), que designamos por nij. En la última fila aparecen los totales de las frecuencias de las columnas; ni· es la suma de frecuencias de todos los pares cuyo primer elemento es x1·. En general:
∑=
=p
jiji nn
1·
En la última columna aparecen los totales de las frecuencias de las filas; n·1 es la suma de frecuencias de todos los pares cuyo segundo elemento es y1. En general:
∑=
=k
iijj nn
1·
Por último:
∑∑∑∑=== =
====p
jj
k
ii
k
i
p
jij Nnnnn
1·
1·
1 1··
Se define la frecuencia relativa del par (xi, yj) como el cociente entre su frecuencia absoluta
y el número total de pares. Se designa por f ij

Estadística bidimensional. Regresión
42
N
nf ij
ij =
fi· es la frecuencia (relativa) de los pares cuyo primer elemento es xi, independientemente de cual sea el segundo valor. Se define por:
∑=
==p
jij
ii f
N
nf
1
··
Del mismo modo f·j es la frecuencia relativa de los pares cuya segunda componente es yj
siendo la primera cualquier valor de X, se define por:
∑=
==k
iij
jj f
N
nf
1
··
Es evidente que:
∑ ∑∑∑= = ==
===p
j
k
i
p
jijj
k
ii fff
1 1 1·
1· 1
Nota:
Si las variables no están agrupadas en clases, se pueden suprimir la primera fila y la primera columna de la tabla. Una representación gráfica se puede obtener asignando a cada par (xi, yj) un punto del plano.
6.2. Representaciones gráficas
Las principales representaciones gráficas que se adoptan para variables bidimensionales (cuantitativas) son las siguientes: • Si X e Y son variables discretas
Sobre los ejes de abcisas y ordenadas se presentan los valores de X e Y, respectivamente, y sobre cada punto (xi, yj) se dibuja un círculo con ese centro y superficie proporcional a su frecuencia nij. Por tanto, cuanto mayor sea la frecuencia asociada a un par, mayor será el círculo centrado en él.
Otra representación equivalente a esta y que recibe el nombre de nube de puntos o diagrama de dispersión, consiste en representar cada pareja de valores mediante un punto en un sistema de ejes coordenados. Cuando una pareja de valores está repetida, junto a la representación del punto correspondiente se indica el valor de su frecuencia.
Veamos un ejemplo. Sea la distribución de frecuencias:

Estadística bidimensional. Regresión
43
entonces, su representación gráfica será la siguiente:
• Si X es variable continua e Y es variable discreta.
Si X es por ejemplo una variable continua e Y discreta, o viceversa, entonces la representación se suele llevar a cabo a través del conjunto de histogramas que podemos trazar para las distribuciones condicionadas de la variable de tipo continuo a los distintos valores de la variable discreta, presentándose de forma conjunta. • Si las variables X e Y son ambas continuas
La representación más utilizada es la que se conoce con el nombre de estereograma, que es en realidad una generalización del histograma para tres dimensiones. El proceso es el siguiente: sobre un plano se trazan los ejes sobre los que tomaremos los valores de las variables X e Y, respectivamente, y perpendicularmente a ellos, sobre cada rectángulo, resultante del cruce de dos clases o intervalos de las dos variables, se levanta un paralepípedo, cuyo volumen es proporcional a la frecuencia absoluta conjunta asociada a dicho rectángulo. Puede demostrarse que el volumen total del estereograma es l.
Veamos un ejemplo: las edades de los esposos y esposas de 20 matrimonios fueron las indicadas en la siguiente tabla:
Edad esposa 18 - 26 26 - 34 34 - 42
Edad
esposo 22 30 38
20-26 23 2 3 5
26-32 29 3 4 6
32-38 35 5 6 8
Observemos que en este caso todos los rectángulos de cruce tienen la misma área 6 × 8 = = 48, luego bastará tomar como referencia de altura sus frecuencias, con lo cual el estereograma que obtenemos es el siguiente:

Estadística bidimensional. Regresión
44
6.3. Distribuciones marginales y condicionadas 6.3.1. Distribuciones marginales
Sea la variable bidimensional (X, Y). Si considerarnos la variable X con sus valores x1, x2, …, xi, …, xk y sus frecuencias absolutas, independientes del valor de Y, n1·, n2·, ..., ni·, ..., nk· obtenemos lo que se llama distribución marginal de la variable X. La frecuencia (relativa)
marginal de xi esN
nf i
i·
· = . Del mismo modo, llamaremos distribución marginal de la variable
Y, a sus valores y1, ..., yj, …, yp con sus frecuencias absolutas n·1, …, n·j, …, n·p. La frecuencia
marginal de yj es N
nf j
j·
· = .
Es evidente que: ∑ ∑= =
==k
i
p
jji ff
1 1·· 1
En la tabla, la distribución marginal de X está formada por la primera y la última fila. La
distribución marginal de Y la forman la primera y la última columna. 6.3.2. Distribuciones condicionadas
Consideremos los n·j individuos que presentan el valor yj. De todos estos, nij toman el valor xi. Entonces se define corno frecuencia del valor xi condicionado por el valor yj a j
if , siendo:
j
ijji n
nf
·
=
Llamaremos distribución condicionada de la variable X por el valor yj a la representada en la tabla siguiente:
Valores de X Frec. absolutas Frec. relativas
x1 n1j jf1
xi nij j
if
xk nkj j
kf
Total n·j 1

Estadística bidimensional. Regresión
45
Como se ve, en la tercera columna figuran las frecuencias de los distintos valores de X condicionadas por yj. Según lo dicho hasta ahora y teniendo en cuenta que hay p valores posibles para Y, existen p distribuciones condicionadas para la variable X.
Del mismo modo, la frecuencia condicionada de yj por xi es:
·i
ijij n
nf =
donde ijf representa la proporción de pares (xi, yj) sobre los que tienen como primer elemento xi.
Las tablas de distribuciones condicionadas de yj por xi son:
Valores de Y Frec. absolutas Frec. relativas
Y1 ni1 if1
yi nij ijf
yk nip ipf
Total ni· 1
6.3.3. Independencia y dependencia funcional
Puede suceder que las variables X e Y tengan un cierto grado de dependencia. De momento, nos limitaremos a definir los dos casos extremos: la ausencia de dependencia, llamada independencia, y la dependencia total o dependencia funcional. Definición de independencia funcional
Diremos que la variable X es independiente de Y cuando las frecuencias relativas de las distribuciones condicionadas de X por yj son idénticas entre sí. Según esto las p distribuciones condicionadas de X son iguales. j
if no depende de j, es decir:
p
ip
j
ijii
n
n
n
n
n
n
n
n
··2·
2
1·
1 ===== ⋯⋯
Aplicando la conocida propiedad de las proporciones:
··
·
··2·1·
21
· n
n
nnnn
nnnn
n
ni
pj
ipijii
j
ij =++++++++++
=⋯⋯
⋯⋯ de donde ·i
ji ff =
Las frecuencias condicionadas son iguales a las frecuencias marginales y las distribuciones condicionadas iguales a la distribución marginal.
Por otra parte:
N
n
N
n
n
n
N
n
n
n ijj
i
ijiij ⋅=⋅= ·
·
·
··
o bien jij
ijiij fffff ⋅=⋅= ··
y cuando X es independiente de Y, ·ij
i ff = ; sustituyendo ijiijij fffff ⋅=⋅= ··· por lo que
jij ff ·= , que nos indican que las frecuencias de Y condicionadas por xi, no dependen de i. Por
tanto, cuando X es independiente de Y también Y es independiente de X, y se dice que la independencia es recíproca.
A continuación damos un ejemplo de dos variables independientes:

Estadística bidimensional. Regresión
46
x1 x2 x3 TOTAL
y1 3 6 12 21
y2 5 10 20 35
y3 2 4 8 14
y4 4 8 16 28
TOTAL 14 28 56 98
Veamos que las frecuencias condicionadas son iguales a las frecuencias marginales y las
distribuciones condicionadas iguales a la distribución marginal. Las distribuciones marginales de X e Y son:
X F.Abs
ni· F.Rel
fi·
Y F.Abs
n·j F.Rel
f·i x1 14 14/98 = 1/7 y1 21 21/98 = 3/14 x2 28 28/98 = 2/7 y2 35 35/98 = 5/14 x3 56 56/98 = 4/7 y3 14 14/98 = 2/14
TOTAL 98 1 y4 28 28/98 = 4/14 TOTAL 98 1
Las distribuciones condicionadas son:
X F.Abs
ni· F.Rel
ijf
Y
F.Abs n·j
F.Rel ijf
x1 14 14/98 = 1/7 y1 21 21/98 = 3/14 x2 28 28/98 = 2/7 y2 35 35/98 = 5/14 x3 56 56/98 = 4/7 y3 14 14/98 = 2/14
TOTAL 98 1 y4 28 28/98 = 4/14 TOTAL 98 1
Definición de dependencia funcional
Se dice que la variable X depende funcionalmente de Y si a cada valor yj corresponde un único valor de X. Para todo j la frecuencia absoluta es nula salvo para un valor de i, siendo nij = n·j. En cada fila todas las frecuencias son nulas excepto una, aunque puede haber varias frecuencias no nulas en la misma columna. Esta dependencia funcional se expresa por x = f(y). En general, la representación gráfica de x = f(y) será una curva llamada de dependencia. A cada ordenada (y) le corresponderá, en este caso, un único valor de x.
A continuación damos un ejemplo donde X depende funcionalmente de Y.
xl x2 x3 TOTAL
y1 4 0 0 4
y2 0 6 0 6
y3 7 0 0 7
y4 0 0 9 9
y5 0 2 0 2
TOTAL 11 8 9 28

Estadística bidimensional. Regresión
47
Cuando la variable Y también depende funcionalmente de X, se dice que la funcionalidad es recíproca. En este caso la tabla es cuadrada y en cada fila y en cada columna hay un único valor distinto de cero. 6.3.4. Características marginales
Consideremos la distribución marginal de X. Sus características más importantes son: • Media
∑ ∑ ∑∑= = = =
⋅=⋅=⋅=k
i
k
i
k
i
p
jiijiiii xfxfxn
Nx
1 1 1 1··
1
• Varianza
( ) ( )∑ ∑= =
−⋅=−⋅==k
i
k
iiiiix xxfxxn
NXV
1 1
2·
2·
2 1)( σ
• Desviación típica: xσ
Para la variable marginal Y. • Media
∑ ∑ ∑∑= = = =
⋅=⋅=⋅=p
j
p
j
k
i
p
jjijjjjj yfyfyn
Ny
1 1 1 1··
1
• Varianza
( ) ( )∑ ∑= =
−⋅=−⋅==p
j
p
jjjjjy yyfyyn
NYV
1 1
2·
2·
2 1)( σ
• Desviación típica: yσ
6.3.5. Características condicionadas
Consideremos la distribución condicionada de X al valor yj, dada por la tabla de más abajo. Al definir las características de esta distribución, media y varianza, las asignaremos el subíndice j, donde j puede tomar valores desde 1 hasta p.
X Frec. Absoluta Frec. Relativa
xl n1j jf1
xi nij j
if
xk nkj j
kf
TOTAL n·j 1
Definimos la media jx y la varianza Vj(x) de esta distribución por:
• Media: ∑ ∑= =
⋅=⋅=k
i
k
ii
jiiij
jj xfxn
nx
1 1·
1

Estadística bidimensional. Regresión
48
• Varianza: ( ) ( )∑ ∑= =
−⋅=−⋅=k
i
k
iji
jijiij
jj xxfxxn
nXV
1 1
22
·
1)(
Del mismo modo se definen para la distribución de la variable Y condicionada a xi:
• Media: ∑ ∑= =
⋅=⋅=p
j
p
jj
ijjij
ii yfyn
ny
1 1·
1
• Varianza: ( ) ( )∑ ∑= =
−⋅=−⋅=p
j
p
jij
ijijij
ii yyfyyn
nYV
1 1
22
·
1)(
6.4. Covarianza
Hemos visto anteriormente como asociadas a una variable estadística bidimensional que hay una serie de distribuciones unidimensionales (marginales y condicionadas). Evidentemente, la descripción numérica de una variable bidimensional pasa por una descripción numérica de dichas variables unidimensionales, aspecto este que ya sabemos manejar en base a temas anteriores. Para cada distribución puede estudiarse, por ejemplo, posición, dispersión, simetría y curtosis como ya vimos.
Ahora bien, existe sin embargo una medida general para la distribución bidimensional, que es de gran utilidad y está ligada a la independencia de las variables. Dicha medida se conoce con el nombre de covarianza y suele representarse por σσσσxy. Viene dada por la siguiente fórmula:
( ) ( )N
yyxxnk
i
p
jjiij
xy
∑∑= =
−⋅−⋅= 1 1σ
donde (xi, yj) es una observación conjunta y x e y las medias aritméticas de las distribuciones marginales de X e Y, respectivamente.
Puede comprobarse, además, sin dificultad, que la covarianza se puede poner en la forma:
yxN
yxnk
i
p
jjiij
xy ⋅−⋅⋅
=∑∑
= =1 1σ
Veamos que en caso de independencia entre las variables la covarianza en nula.
Demostración: La condición de independencia era:
N
n
N
n
N
n jiij ·· ⋅= , ∀ i,j
Calculemos, según esta condición, el valor de la covarianza:
0·
1 1
···
1 11 1
=⋅−⋅=⋅−=⋅−⋅⋅=⋅−⋅= ∑ ∑∑∑∑∑= == == =
yxyxyxN
ny
N
nxyx
N
n
N
nyxyx
N
nyx j
k
i
p
jj
ii
jik
i
p
jji
ijk
i
p
jjixyσ

Estadística bidimensional. Regresión
49
7. REGRESIÓN Y CORRELACIÓN LINEAL 7.1. El problema del ajuste
En algunas ocasiones, del estudio teórico de un fenómeno se puede deducir la fórmula matemática que liga las magnitudes consideradas. Por ejemplo, la fórmula de los gases perfectos es un resultado de la teoría cinética de los gases. Pero otras veces, para llegar a dicha fórmula sólo se dispone de un conjunto de pares de valores (xi, yi) obtenidos experimentalmente. Entonces se plantea el problema de hallar una función y = f(x; λl, ... , λk) perteneciente a una determinada familia, en cuya expresión figuran k-parámetros o constantes indeterminadas, de forma que se adapte lo mejor posible al conjunto de datos experimentales y permita predecir con éxito el resultado de futuras experiencias.
Este problema presenta analogías con el de la interpolación; es más, si el número de pares ( , )i ix y de valores experimentales es k, elegimos la familia de los polinomios y convenimos en
que la mejor aproximación sea: f(xi; λl, ... , λk) = yi (con i = 1, ... , k), ambos problemas coinciden.
Pero, en general, no sucede esto, pues f no es un polinomio y el número de parámetros es menor que el de los pares de valores experimentales, así el sistema antes planteado carece de solución. En tal caso la determinación de los parámetros se lleva a cabo imponiendo la condición de que la diferencia entre los valores observados y los que da la función f(x; λ1, ... , λk) sean los menores posibles.
En el problema del ajuste se distinguen, pues, dos partes: 1) Elección de la familia de funciones f(x; λ1, ... , λk), es decir, elección del tipo de función de
ajuste. 2) Determinación de los parámetros λ1, ... , λk .
Las funciones que más se utilizan para llevar a cabo el ajuste son polinomios, funciones exponenciales y potenciales, así como las funciones logarítmicas. Método de los mínimos cuadrados
Sean (xi, yi) los pares de valores observados, e y=f(x; λl, ... , λk) la fórmula con que representamos la relación que existe entre x e y. Para determinar los parámetros λ1, ... , λk que aparecen en dicha fórmula disponemos del sistema que resulta al imponer la condición:
f(xi; λl, ... , λk) = yi (con i = 1, ... , k) Si n = k, existe el número justo de condiciones que se requieren para fijar los parámetros.
Pero, en general, n > k y el sistema propuesto es imposible; el problema que entonces se plantea es cómo asignar a los parámetros λ1, ... , λk los valores adecuados.
Para resolverlo se definen las desviaciones de las observaciones: ei = yi - f(xi; λl, ... , λk)
o diferencias entre los valores observados y los valores teóricos que suministra la fórmula, y según cómo se comporten ciertas sumas formadas con estas desviaciones, así resultan diversos métodos para obtener valores de los k parámetros.

Estadística bidimensional. Regresión
50
Este método se establece sobre la hipótesis de que la suma ∑=
n
iie
1
2 de los cuadrados de las
desviaciones sea mínima. Tiene la ventaja de que los valores que asigna a los parámetros corresponden a la fórmula «más probable» en el sentido de que los valores de y que se deduzcan de ella son los valores más probables de las observaciones, supuesto que éstas cumplen la ley de Gauss de los errores. El desarrollo del método requiere conocimientos sobre la determinación de mínimos de funciones de varias variables. Se trata, pues, de hacer que la función
∑=
=n
iieE
1
2
sea mímima
El método de los mínimos cuadrados nos proporciona las condiciones que nos permiten, eligiendo una familia de funciones, determinar cuál de ellas ajusta mejor nuestra nube de puntos.
Dada una nube de puntos y considerando la familia de todas las funciones lineales, vamos a aplicar el método de los mínimos cuadrados para determinar cuál de todas ellas ajusta mejor nuestro diagrama de dispersión. Esta recta se denomina recta de regresión y su estudio lo desarrollamos en el siguiente apartado. 7.2. Regresión lineal
Sea una nube de puntos que se condensa alrededor de una recta. Llamaremos recta de regresión de Y sobre X a la que nos da los valores aproximados de Y conocidos los de X. Su ecuación será de la forma y = ax + b, y nuestro problema es calcular los coeficientes a y b.
Para ello utilizaremos el método de los mínimos cuadrados, descrito anteriormente, según el cual la recta que más se ajusta a la nube es aquella para la cual la media, ponderada por las frecuencias totales fij de los cuadrados de las desviaciones paralelas al eje OY entre los puntos P y la recta, sea mínima.
Para cada punto P(xi, yj) su desviación respecto a la recta y = ax + b es la cantidad que denotaremos dij y que se calcula: dij = yj - y = yj - (axi + b). Según el método de los mínimos cuadrados para que:
( )∑∑ ∑∑= = = =
−−==k
i
p
j
k
i
p
jijijijij baxyfdfD
1 1 1 1
22
sea mínima deben cumplirse las condiciones siguientes:

Estadística bidimensional. Regresión
51
0=∂∂
a
D y 0=
∂∂
b
D
Desarrollando obtenemos:
( )
( )bxayfbxfayf
baxyfb
D
k
i
p
j
k
i
k
i
p
jij
p
jiijiij
k
i
p
jijij
−−−=
−−−=
=−−−=∂∂
∑∑ ∑ ∑∑∑
∑∑
= = = = ==
= =
22
2
1 1 1 1 11
1 1
Como ( ) 02 =−−− bxay , esto implica que xayb −=
Despejando tenemos que bxay += , relación que nos indica que el punto ( )yx, está sobre la
recta. Al punto ( )yxG ,= se le llama centro de gravedad de la nube Pij y sus coordenadas son las medias de las variables marginales X e Y.
Sustituyendo b en D queda:
( ) ( )[ ]∑∑∑∑= == =
−−−=+−−=k
i
p
jijij
k
i
p
jijij xxayyfxayaxyfD
1 1
2
1 1
2
( ) ( )[ ]∑∑= =
=−−−−−=∂∂ k
i
p
jijiij xxayyxxf
a
D
1 1
02 , por lo que
( )[ ] ( ) ( )∑∑ ∑∑∑∑= = = == =
=−−−⇒=−−−k
i
p
ji
k
i
p
jijjij
k
i
p
jijij xxfayyfxxayyf
1 1 1 11 1
00
Despejando:
( )
( )xxf
yyf
a
i
k
i
p
jij
j
k
i
p
jij
−
−=
∑∑
∑∑
= =
= =
1 1
1 1
Si multiplicarnos numerador y denominador por ( )xxi −
( )( )
( )2
1 1
1 1
xxf
yyxxf
a
i
k
i
p
jij
ji
k
i
p
jij
−
−−=
∑∑
∑∑
= =
= =
Teniendo en cuenta que ( ) ( )∑ ∑∑= = =
−=−=k
i
k
i
p
jiijiix xxfxxf
1 1 1
22·
2σ podemos poner
( )( )22
1 1
x
xy
x
ji
k
i
p
jij yyxxf
aσσ
σ=
−−=∑∑
= =

Estadística bidimensional. Regresión
52
Como la recta y = ax + b tiene por pendiente 2x
xyaσσ
= , y pasa por el punto ( )yx, se obtiene:
( )xxyyx
xy −=−2σ
σ
Cambiando x por y, y tomando las desviaciones paralelas al eje OX, se obtiene la recta de
regresión de X sobre Y, cuya ecuación es:
( )xxyyy
xy −=−2σ
σ
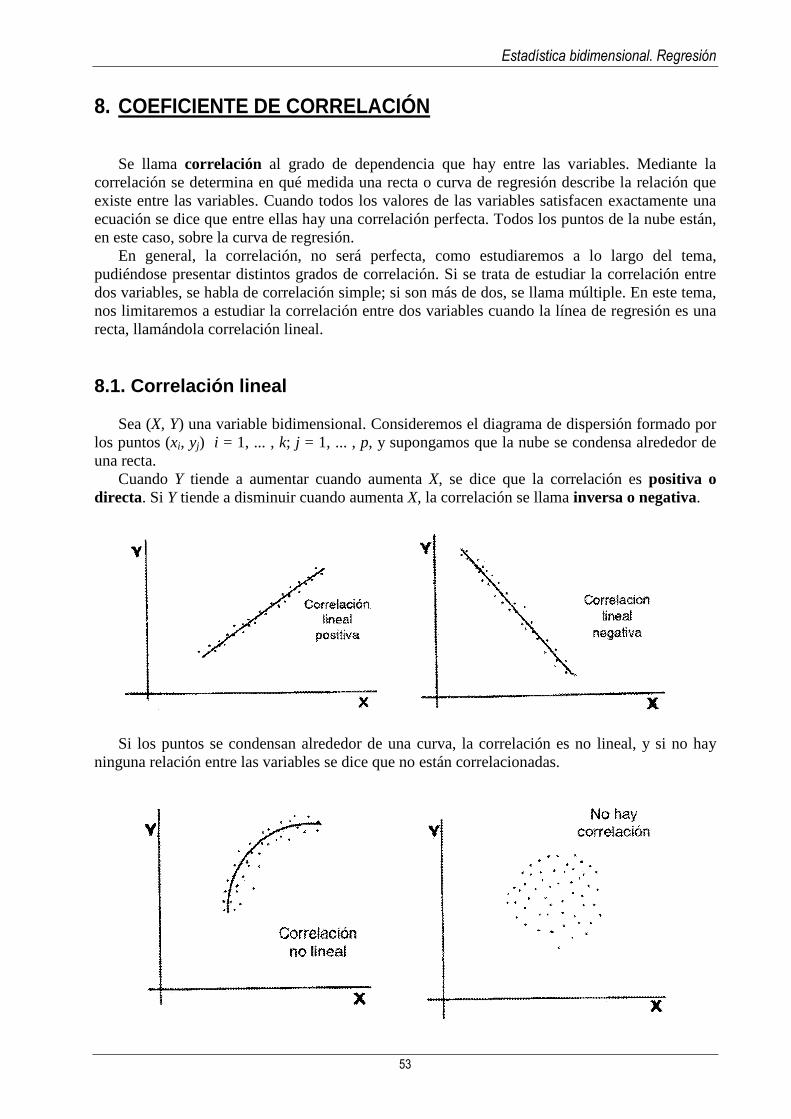
Estadística bidimensional. Regresión
53
8. COEFICIENTE DE CORRELACIÓN
Se llama correlación al grado de dependencia que hay entre las variables. Mediante la correlación se determina en qué medida una recta o curva de regresión describe la relación que existe entre las variables. Cuando todos los valores de las variables satisfacen exactamente una ecuación se dice que entre ellas hay una correlación perfecta. Todos los puntos de la nube están, en este caso, sobre la curva de regresión.
En general, la correlación, no será perfecta, como estudiaremos a lo largo del tema, pudiéndose presentar distintos grados de correlación. Si se trata de estudiar la correlación entre dos variables, se habla de correlación simple; si son más de dos, se llama múltiple. En este tema, nos limitaremos a estudiar la correlación entre dos variables cuando la línea de regresión es una recta, llamándola correlación lineal. 8.1. Correlación lineal
Sea (X, Y) una variable bidimensional. Consideremos el diagrama de dispersión formado por los puntos (xi, yj) i = 1, ... , k; j = 1, ... , p, y supongamos que la nube se condensa alrededor de una recta.
Cuando Y tiende a aumentar cuando aumenta X, se dice que la correlación es positiva o directa. Si Y tiende a disminuir cuando aumenta X, la correlación se llama inversa o negativa.
Si los puntos se condensan alrededor de una curva, la correlación es no lineal, y si no hay ninguna relación entre las variables se dice que no están correlacionadas.

Estadística bidimensional. Regresión
54
Para medir cualitativamente la correlación entre las variables basta con observar atentamente la distribución de los puntos alrededor de la recta o curva de regresión. Cuanto mayor sea el ajuste a la curva, mayor será la correlación.
La necesidad de medir cuantitativamente el grado de correlación entre las variables nos lleva a definir el coeficiente de correlación. 8.2. Coeficiente de correlación lineal: propiedades
Definimos por coeficiente de correlación lineal entre las variables X e Y a la razón:
( ) ( )
( ) ( )1 1
22
1 1 1 1
pk
ij i ii j
p pk k
ij i ij ji j i j
f x x y y
r
f x x f y y
= =
= = = =
− −=
− ⋅ −
∑∑
∑∑ ∑∑
Según la definición r es simétrico respecto a X e Y, por tanto: r = r xy = ryx
Para obtener una expresión más sencilla recordemos lo que conocemos hasta ahora:.
( )( )1 1
pk
xy ij i ii j
f x x y yσ= =
= − −∑∑
( )22
1 1
pk
x ij ii j
f x xσ= =
= −∑∑
( )22
1 1
pk
y ij ji j
f y yσ= =
= −∑∑
Sustituyendo en r se obtiene
xy
x y
rσ
σ σ=
⋅
Comparemos esta expresión con la encontrada al calcular los coeficientes de la recta de
regresión, para encontrar una relación entre ellos que nos permitirá luego deducir propiedades del coeficiente de correlación lineal.
Tenemos: xy
x y
rσ
σ σ=
⋅ y
2
xy
x
aσσ
= , por lo que despejando σxy e igualando expresiones queda:
y
x
a rσσ
= ⋅
Propiedades • El coeficiente de correlación lineal es un número comprendido entre -1 y 1, es decir, -1 ≤ r ≤
1.

Estadística bidimensional. Regresión
55
• Si r=1 entonces la correlación es total o funcional, pues todos los puntos están sobre la recta de regresión. La suma de los cuadrados de las desviaciones es nula, luego todos los puntos están sobre la recta de regresión. Las ecuaciones de las rectas de regresión de Y sobre X y de X sobre Y son, respectivamente:
( )1x
y
r y y r x xσσ
≡ − = ⋅ −
( )1
1 x
y
r y y x xr
σσ
≡ − = ⋅ −
a) Si r = 1, las dos rectas coinciden y toman la expresión: ( )x
y
y y x xσσ
− = −
Se dice en este caso que entre las dos variables existe una dependencia funcional.
b) Si r = -1, las rectas también coinciden y su ecuación es: ( )x
y
y y x xσσ
− = − −
Análogamente, en este caso, entre las dos variables también existe una dependencia funcional.
• Si r = 0, la correlación es nula. En este caso la suma de los cuadrados de las desviaciones es máxima y toma el valor σy. Se obtiene lo que se llama dispersión completa. Las rectas de regresión quedan:
0y y y y− = ⇒ = ; 0x x x x− = ⇒ =
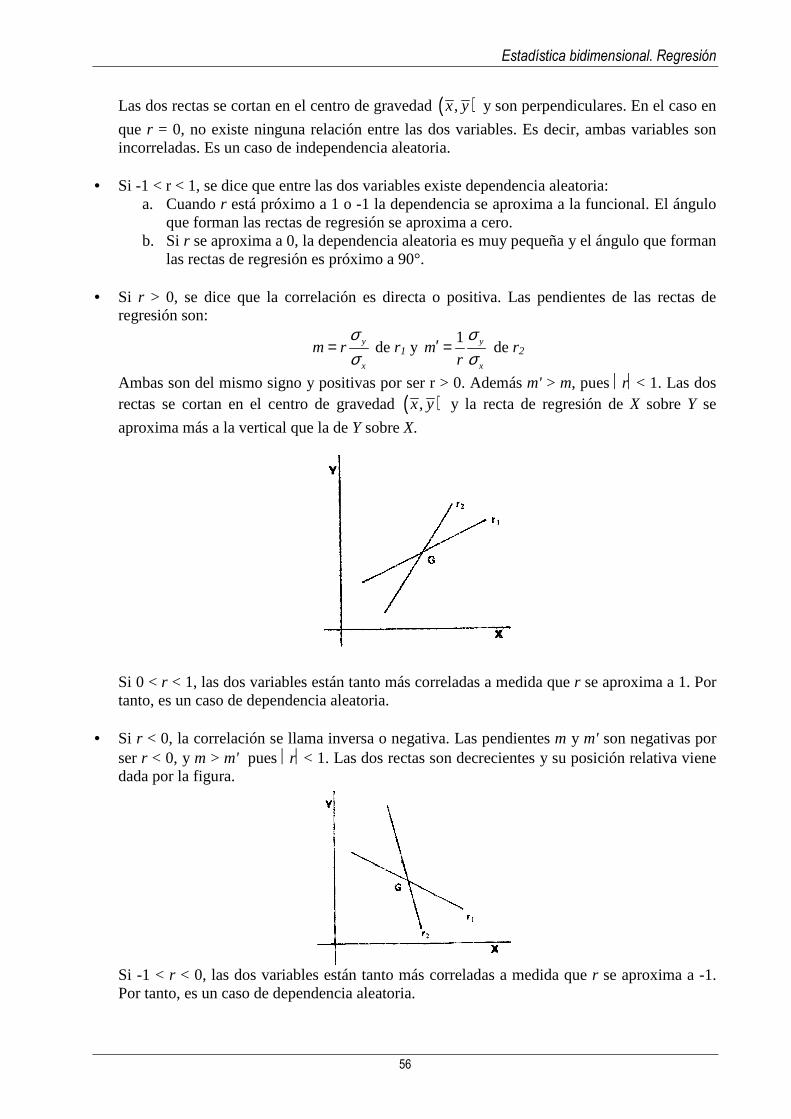
Estadística bidimensional. Regresión
56
Las dos rectas se cortan en el centro de gravedad ( ),x y y son perpendiculares. En el caso en
que r = 0, no existe ninguna relación entre las dos variables. Es decir, ambas variables son incorreladas. Es un caso de independencia aleatoria.
• Si -1 < r < 1, se dice que entre las dos variables existe dependencia aleatoria: a. Cuando r está próximo a 1 o -1 la dependencia se aproxima a la funcional. El ángulo
que forman las rectas de regresión se aproxima a cero. b. Si r se aproxima a 0, la dependencia aleatoria es muy pequeña y el ángulo que forman
las rectas de regresión es próximo a 90°.
• Si r > 0, se dice que la correlación es directa o positiva. Las pendientes de las rectas de regresión son:
y
x
m rσσ
= de r1 y 1 y
x
mr
σσ
′ = de r2
Ambas son del mismo signo y positivas por ser r > 0. Además m' > m, pues r< 1. Las dos rectas se cortan en el centro de gravedad ( ),x y y la recta de regresión de X sobre Y se
aproxima más a la vertical que la de Y sobre X.
Si 0 < r < 1, las dos variables están tanto más correladas a medida que r se aproxima a 1. Por tanto, es un caso de dependencia aleatoria.
• Si r < 0, la correlación se llama inversa o negativa. Las pendientes m y m' son negativas por ser r < 0, y m > m' pues r< 1. Las dos rectas son decrecientes y su posición relativa viene dada por la figura.
Si -1 < r < 0, las dos variables están tanto más correladas a medida que r se aproxima a -1. Por tanto, es un caso de dependencia aleatoria.

Estadística bidimensional. Regresión
57
Nota: Tan importante es el valor del coeficiente r como el valor del coeficiente:
22
2 2
xy
x y
rσ
σ σ=
⋅
al que se denomina coeficiente de determinación ya que determina si el ajuste lineal es suficiente o se deben buscar ajustes o modelos alternativos. Teniendo en cuenta esto, si r2 = 1, la correlación es perfecta, y en el caso de que r2 = 0 (entonces r = 0) implica que la correlación es nula, es decir, en este caso X no nos sirve para describir el comportamiento de la variable Y.

Estadística bidimensional. Regresión
58
9. SIGNIFICADO Y APLICACIONES 9.1. Uso y abuso de la regresión
La aplicación de los métodos expuestos de regresión y correlación exige un análisis teórico previo de las posibles relaciones entre las variables. Puede ocurrir que se seleccionen dos variables cualesquiera al azar y que dé la casualidad de que, estadísticamente, la correlación es perfecta cuando no existe relación posible entre ellas. Por ejemplo, el hecho que, casualmente, la correlación lineal entre la tasa de natalidad en Nueva Zelanda y la producción de cereales en España a lo largo de un determinado período fuera perfecta no nos debería llevar a suponer que existe algún tipo de relación lineal entre estas variables.
Se deben seleccionar entre las que la fundamentación teórica avale algún tipo de relación, evitando, en lo posible, relaciones a través de otra variable principal. Por ejemplo, el consumo de bebidas puede variar en la misma dirección que el consumo de gasolina, pero no porque una variable dependa directamente de la otra, sino porque ambas van en el mismo sentido que las variaciones de la renta, que será la principal variable explicativa. 9.2. Predicción
El objetivo último de la regresión es la predicción o pronóstico sobre el comportamiento de una variable para un valor determinado de la otra. Así, dada la recta de regresión de Y sobre X, para un valor X = x0 de la variable, obtenemos y0.
Es claro que la fiabilidad de esta predicción será tanto mayor, en principio, cuanto mejor sea la correlación entre las variables. Por tanto, una medida aproximada de la bondad de la predicción podría venir dada por r. 9.3. Errores de medida en variables numéricas
Veamos un ejemplo práctico de aplicación del coeficiente de correlación en el campo de la medición.
La medida de parámetros fisiológicos está sujeta a error y a la propia variabilidad biológica. La presión arterial es un claro ejemplo: aunque la técnica es bastante simple, pueden aparecer errores debidos a defectos del aparato utilizado, a la aplicación del manguito, al estado del paciente y a la objetividad y preparación del observador. Es de desear que el proceso sea fiable: la repetición de las medidas de la misma magnitud producen resultados iguales o al menos similares. Hablamos entonces de fiabilidad de las mediciones, estabilidad o concordancia. Diremos que una medición es fiable si la variabilidad en mediciones sucesivas se mantiene dentro de cierto margen razonable.
En ocasiones pueden existir diferentes métodos de medida, siendo uno de ellos el que mejor determina la magnitud de la variable en estudio. A éste se le conoce como patrón de referencia y en principio sería el método a emplear preferentemente, salvo que presente serios inconvenientes, como pueden ser el coste, complicado de utilizar, etc. Es el caso de la medición de la tensión arterial mediante la introducción de un catéter flexible en una arteria periférica. Si se dispone de un método alternativo al método de referencia, más práctico de utilizar, interesa determinar la concordancia entre ambos sistemas.
El coeficiente de correlación se emplea como índice de concordancia entre los dos métodos.

Estadística bidimensional. Regresión
59
9.4. Otras aplicaciones
Para acabar, indicar que todos los conceptos tratados a lo largo del tema se aplican en muchos y diferentes campos.
En Sanidad por ejemplo en la comparación de medidas corporales (peso y talla, nivel de grasa y colesterol...). En Educación buscando la relación, por ejemplo, entre el nivel socioeconómico del alumnado y su rendimiento escolar. En Psicología, ya que en una investigación psicológica existen, además de los sujetos, otras unidades de análisis y es importante determinar la influencia de estos en el comportamiento del individuo. En distintas áreas de Economía como la econometría ...

Ejercicios
60
EJERCICIOS DE ESTADISTICA UNIDIMENSIONAL 1.- La puntuación de un test, de valores entre cero y diez, realizado a 20 personas es la siguiente:
2 5 6 9 7 8 9 6 3 4 1 8 3 4 2 7 5 8 5 5
a) Elabora una tabla estadística b) Construye un diagrama de barras
2.- El color favorito de 10 personas elegido entre azul, amarillo y rojo es:
azul rojo amarillo rojo amarillo azul rojo amarillo amarillo azul
a) Realiza una tabla de frecuencias b) Construye un diagrama de sectores
3.- En las elecciones al Parlamento de Cataluña del año 2006 en la ciudad de Reus se obtuvieron
los siguientes resultados: Censo electoral: 71.361 Votantes: 36.501 Abstención: 34.860 Resultado:
Partido político Votos CiU 11.645 PSC 9.079 ERC 5.844 PP 4.562 ICV 2.549 Otros 2.106
a) Calcula el porcentaje de votantes y de abstenciones b) El número de votos nulos c) Elabora una tabla estadística de frecuencias d) Representa los datos en un diagrama de sectores y en un diagrama de barras.
4.- Las edades de los 12 jugadores de la plantilla de baloncesto del equipo CB Tarragona en la
temporada 2006-2007 son:
29 36 19 28 28 20 24 21 24 30 23 27
a) Elabora la tabla estadística b) Calcula la media aritmética de las edades c) Halla la mediana d) Calcula la moda

Ejercicios
61
5.- Las calificaciones del examen de matemáticas Aplicadas a las Ciencias Sociales de 25 alumnos de 1º de Bachillerato son:
1 2 3 4 5 6 9 6 3 4 2 4 5 8 4 1 3 4 7 4 7 5 9 2 6
a) Elabora la tabla estadística b) ¿Cuál es el porcentaje de aprobados? ¿Y de suspensos? c) ¿Cuántos alumnos han obtenido una nota superior a 6? d) Calcula la media aritmética. e) Halla la mediana. f) Calcula la moda. g) Halla la desviación estándar de la distribución.
6.- Completa la tabla siguiente de una variable cuantitativa continua:
Valores ni Marca de clase (xi) Ni fi Fi % [260-270) 14 [270-280) 7 [280-290) 11 [290-300) 5 [300-310) 4 [310-320) 9
Total 50 7.- Completa la tabla siguiente de los m2 de 30 viviendas de una organización:
Valores ni Marca de clase (xi)
Ni xi·ni ix x− i ix x n− ⋅ 2( )ix x− 2( )i ix x n− ⋅
[50-100) 8 [100-150) 16 [150-200) 4 [200-250) 2
Total 30
a) Calcula la media aritmética b) Halla la mediana c) Halla la clase modal d) Calcula la desviación media e) Calcula la desviación estándar

Ejercicios
62
8.- Las alturas de 40 pasajeros de un avión son las siguientes expresadas en cm:
140 192 126 177 150 179 175 174 171 169 164 182 178 167 170 173 182 172 189 173 175 185 124 164 180 158 186 175 172 176 193 190 181 163 190 162 162 161 167 155
a) Calcula el recorrido b) Distribuye los datos en diez intervalos de siete unidades de amplitud c) Elabora una tabla como la del ejercicio anterior d) Calcula la media aritmética y la desviación estándar e) Calcula la desviación media f) ¿Cuál es el porcentaje de pasajeros que son más altos de 166 cm?¿Y más bajos de 152?
9.- El número de calzado de los alumnos de una clase de 1º de Bachillerato es:
39 35 45 42 40 43 37 35 39 41 37 40 42 39 41 39 36 40 42 39 42 45 41 44 43 38 38 37 40 41
Considerando la variable como discreta:
a) Elabora la tabla de frecuencias b) Calcula la media aritmética, la media y la moda c) Halla la varianza y la desviación estándar
10.- Las ganancias de una empresa durante los diez últimos años han sido las siguientes:
Años Beneficios
(millones de euros) 1997 1.248 1998 1.125 1999 972 2000 1.208 2001 1.110 2002 1.005 2003 1.102 2004 1.170 2005 1.250 2006 1.375 2007 1.382
a) Elabora un gráfico con la evolución de los beneficios b) Calcula la media de los beneficios de la empresa durante esa década c) Halla la desviación típica e interpreta el resultado.

Ejercicios
63
11.- El número de goles que un jugador ha marcado durante la primera ronda de la liga son:
Jornada 1 2 3 4 5 6 7 8 9 Goles 0 2 3 1 1 2 2 3 0 Jornada 10 11 12 13 14 15 16 17 18 Goles 0 1 2 2 1 0 0 0 1
a) Elabore un diagrama de barras en el que el eje de abcisas sea el número de goles y el de
ordenadas, el número de partidos b) Calcula la media y la desviación típica del número de goles.
12.- Un jugador de baloncesto ha conseguido los siguientes puntos en los primeros diez partidos de Liga:
Partidos 1 2 3 4 5 6 7 8 9 10 Puntos 12 20 15 8 10 11 15 7 9 17
a) Elabora un diagrama de barras en que el eje de abcisas sea el número del partido, y el de
ordenadas, el número de puntos. b) Calcula la media y la varianza del número de puntos.
13.- A las 4h de la madrugada, la policía realizó la prueba de alcoholemia a 50 conductores, y el resultado obtenido, agrupado por intervalos, fue:
Intervalos de tasas de alcoholemia (mg/l)
Frecuencia ni
[0; 0,2) 35 [0,2; 0,4) 7 [0,4; 0,6) 2 [0,6; 0,8) 3 [0,8; 1) 1 [1; 1,2) 0 [1,2; 1,4) 1 [1,4; 1,6) 1
a) Calcula el porcentaje de cada intervalo b) ¿Cual es el promedio de la tasa de alcoholemia? c) Encuentra la clase modal. d) Representa el correspondiente histograma y el polígono de frecuencias.

Ejercicios
64
EJERCICIOS DE ESTADISTICA BIDIMENSIONAL 1.- Dados los valores siguientes de las variables bidimensionales X(peso) e Y(altura):
Peso (kg): X 52 60 70 73 54 80 65 60 90 85 Altura (cm): Y 160 163 181 185 170 170 172 164 192 178
a) Elabora la tabla de doble entrada b) Elabora la nube de puntos c) Calcula la mediana y la desviación típica de cada variable. d) Calcula la covarianza.
2.- Con los datos de la siguiente tabla de doble entrada calcula los parámetros siguientes:
Y/X 0 1 2 3 4 Total
10 2 1 1 0 0
11 1 0 1 1 1
12 1 0 0 3 0
13 0 0 0 1 2
Total
a) Media aritmética de X e Y b) Desviación típica de X e Y. c) Covarianza. d) Coeficiente de correlación
3.- Dada la siguiente distribución bidimensional de covarianza 3,2xyσ = ; desviación típica de x
1,71xσ = y coeficiente de correlación r = 0,99; calcula la desviación típica de y σy.
4.- De una distribución bidimensional se conocen los siguientes parámetros:
1,7x = 2,3y = 1,1xyσ = 1,0yσ =
a) Calcula la recta de regresión de x sobre y b) Calcula la recta de regresión de y sobre x c) Calcula el coeficiente de correlación
Ejercicios
65
5.- Dada la siguiente tabla de doble entrada, donde X son las horas diarias que cada alumno dedica a los videojuegos e Y es el número de suspensos del último trimestre:
Y/X 0 1 2 3 4 5 Total
0 1 3 1 0 0 0
1 2 5 0 0 0 0
2 1 2 3 0 1 0
3 0 0 1 3 2 0
4 0 1 1 1 2 1
5 0 1 1 3 2 2
Total
a) completa la tabla de doble entrada b) Representa la nube de puntos c) Elabora la tabla siguiente: xi yi ni ni·xi ni·xi
2 ni·yi ni·yi2 ni·xi·yi
d) Calcula las medias y las desviaciones típicas de los datos anteriores. e) Calcula la covarianza e interpreta su signo.
6.- Con los datos de la actividad anterior:
a) Calcula el coeficiente de correlación y las rectas de regresión. b) ¿Cuántas asignaturas se prevé que suspenderá un alumno que juega 2,5h? c) ¿Cuántas horas debe de jugar un alumno que ha suspendido tres materias?
7.- Dada la siguiente tabla, donde X es el área de un bosque (ha) e Y es la madera que se extrae al año (kg):
xi yi ni ni·xi ni·xi2 ni·yi ni·yi
2 ni·xi·yi 100 29 1 150 38 2 200 47 0 250 63 3 300 74 1 350 82 1 400 90 2 450 111 1 500 129 2 550 136 1 600 150 1
Total 15

Ejercicios
66
a) Completa la tabla anterior b) Calcula las medias y las desviaciones c) Calcula la covarianza y el coeficiente de correlación.
8.- Se mide la altura y el número del calzado de diez personas adultas, y los resultados son:
Pie: X 39 46 45 41 38 44 42 39 41 45 Altura (cm): Y 163 194 185 172 170 180 177 160 165 183
a) Elabora la tabla de doble entrada b) Representa la nube de puntos c) Calcula la media y la desviación típica de cada variable d) Calcula la covarianza e) Calcula el coeficiente de correlación e interpreta el resultado.
9.- Se mide la concentración de calcio en diferentes aguas comerciales mediante un aparato que mide el área de la figura registrada. Por este motivo se realiza una recta de regresión:
Concentración (mg/ml): X
0 5 10 15 20 25 30 35 40
Area: Y 0 25 46 78 102 121 149 173 205
a) Calcula el coeficiente de correlación b) Encuentra la recta de regresión de Y sobre X c) Un pueblo lleva a analizar una muestra de agua cuya área es de 112. ¿Qué concentración
de calcio tiene el agua? 10.- En una clase de 20 alumnos de 4º de ESO, las notas del curso de ciencias naturales y matemáticas son las siguientes:
Nota ciencias naturales (X)
7 6 8 3 4 7 5 8 6 5
Nota matemáticas (Y)
6 6 7 7 5 7 6 8 5 5
Nota ciencias naturales (X)
2 1 10 2 8 6 4 9 7 8
Nota matemáticas (Y)
3 2 8 3 9 4 5 7 7 6
a) Calcular la covarianza y el coeficiente de correlación de la distribución anterior b) Encuentra las rectas de regresión c) ¿Qué nota de matemáticas obtendría un alumno que tenga un 6 en ciencias naturales?
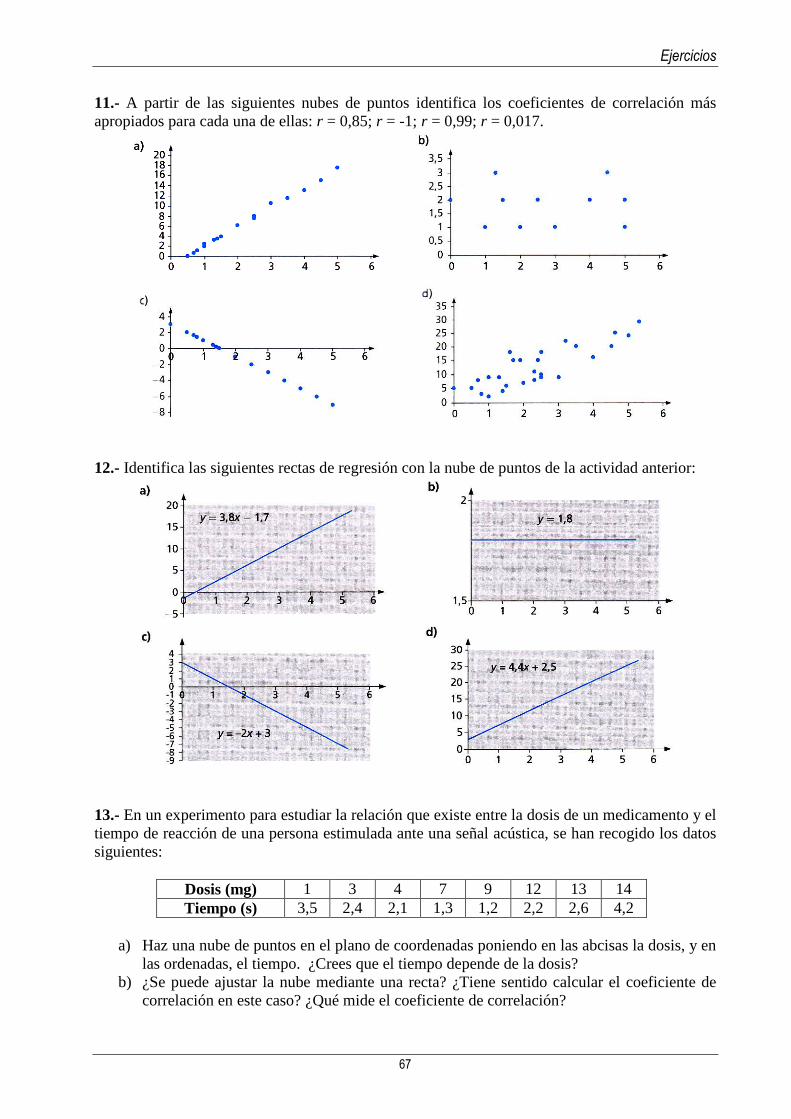
Ejercicios
67
11.- A partir de las siguientes nubes de puntos identifica los coeficientes de correlación más apropiados para cada una de ellas: r = 0,85; r = -1; r = 0,99; r = 0,017.
12.- Identifica las siguientes rectas de regresión con la nube de puntos de la actividad anterior:
13.- En un experimento para estudiar la relación que existe entre la dosis de un medicamento y el tiempo de reacción de una persona estimulada ante una señal acústica, se han recogido los datos siguientes:
Dosis (mg) 1 3 4 7 9 12 13 14 Tiempo (s) 3,5 2,4 2,1 1,3 1,2 2,2 2,6 4,2
a) Haz una nube de puntos en el plano de coordenadas poniendo en las abcisas la dosis, y en
las ordenadas, el tiempo. ¿Crees que el tiempo depende de la dosis? b) ¿Se puede ajustar la nube mediante una recta? ¿Tiene sentido calcular el coeficiente de
correlación en este caso? ¿Qué mide el coeficiente de correlación?


















