
Genetica humana
302
Texto multimedia Incluye CD-ROM Genética Humana Conceptos, mecanismos y aplicaciones de la Genética en el campo de la Biomedicina Francisco Javier Novo Villaverde www.FreeLibros.me
description
Â
Transcript of Genetica humana

Texto multimedia
Incluye CD-ROM
Genética HumanaConceptos, mecanismos y aplicaciones dela Genética en el campo de la Biomedicina
Francisco Javier Novo Villaverde
genetica humana 28/3/07 17:50 Página 1
www.FreeLibros.me

00-Portadillas 5/12/06 06:44 Página i
www.FreeLibros.me

Genética HumanaConceptos, mecanismos y aplicacionesde la Genética en el campo de la Biomedicina
00-Portadillas 5/12/06 06:44 Página i
www.FreeLibros.me

C E L L A N D M O L E C U L A R B I O L O G Y I N A C T I O N S E R I E S
Genética HumanaConceptos, mecanismosy aplicaciones de la Genéticaen el campo de la Biomedicina
Texto multimedia
Francisco Javier Novo VillaverdeDepartamento de GenéticaUniversidad de Navarra
Madrid • México • Santafé de Bogotá • Buenos Aires • Caracas • Lima • Montevideo • San JuanSan José • Santiago • São Paulo • White Plains
00-Portadillas 5/12/06 06:44 Página iii
www.FreeLibros.me

GENÉTICA HUMANA. Conceptos, mecanismos y aplicaciones de la Genética en el campo de la BiomedicinaFrancisco Javier Novo Villaverde
PEARSON EDUCACIÓN, S. A., Madrid, 2007
ISBN: 9788483223598Materia: Genética, 575
Formato 170 × 240 Páginas: 000
Datos de catalogación bibliográfica
Todos los derechos reservados. Queda prohibida, salvo excepción prevista en la Ley, cualquier formade reproducción, distribución, comunicación pública y transformaciónde esta obra sin contar con autorización de los titulares de propiedad intelectual.La infracción de los derechos mencionados puede ser constitutiva de delitocontra la propiedad intelectual (arts. 270 y sgts. Código Penal).
DERECHOS RESERVADOS© 2007 PEARSON EDUCACIÓN, S. A.Ribera del Loira, 2828042 Madrid
GENÉTICA HUMANA. Conceptos, mecanismos y aplicaciones de la Genética en el campo de la BiomedicinaFrancisco Javier Novo Villaverde
ISBN: 9788483223598Deposito Legal: M-
PEARSON PRENTICE HALL es un sello editorial autorizado de PEARSON EDUCACIÓN, S. A.
Equipo editorial Editor: Miguel Martín-RomoTécnico editorial: Marta Caicoya
Equipo de producción:Director: José Antonio ClaresTécnico: María Alvear
Diseño de cubierta: Equipo de diseño de Pearson Educación, S. A.Composición: Claroscuro Servicio Gráfico, S. L.Impreso por:
IMPRESO EN ESPAÑA - PRINTED IN SPAIN
Este libro ha sido impreso con papel y tintas ecológicos
00-Portadillas 5/12/06 06:44 Página iv
www.FreeLibros.me

Utilización de este texto
Las figuras son un elemento fundamental en este texto multimedia. Por lo tanto,se aconseja vivamente seguir a la vez el texto y las figuras.
El método habitual de estudio comenzará con la lectura de un apartado para in-tentar comprender los conceptos y mecanismos mostrados. A continuación, el lectordeberá observar atentamente las figuras correspondientes a ese apartado, volviendodespués al texto para repasar y fijar los contenidos que no hubiesen quedado clarosen la primera lectura.
En la página web www.unav.es/genetica/GH/ estarán disponibles actualizacio-nes, noticias, enlaces, etc., relacionados con este texto.
00-Portadillas 5/12/06 06:44 Página v
www.FreeLibros.me

Índice de contenido
Prólogo IX
A) Introducción
1. El flujo de la información genética 31.1 Los ácidos nucleicos 31.2 Visión general del proceso de expresión génica 51.3 La transcripción 61.4 Regulación de la transcripción en eucariotas 81.5 Maduración del ARN mensajero 91.6 El ayuste (splicing) y su regulación 101.7 Traducción y código genético en eucariotas 13
2. El ADN en el núcleo de la célula eucariota 172.1 La cromatina durante el ciclo celular 172.2 Replicación de la cromatina en interfase 192.3 Formación y segregación de los cromosomas durante la mitosis 232.4 Gametogénesis y meiosis 252.5 Recombinación a nivel molecular 29
3. Técnicas básicas de genética molecular 333.1 Tecnología del ADN recombinante: métodos y usos más frecuentes 333.2 Enzimas de restricción 373.3 Técnicas básicas de hibridación de ácidos nucleicos 383.4 Amplificación in vitro de ADN (PCR) 403.5 Secuenciación del ADN 443.6 Microarrays 47
B) El genoma humano
4. La geografía del genoma humano 514.1 Historia y desarrollo del Proyecto Genoma Humano 51
0-INDICE CONTENIDO 5/12/06 06:46 Página VII
www.FreeLibros.me

4.2 Estructura del genoma humano y variación inter-individual 584.3 El ADN repetitivo 624.4 El genoma mitocondrial 66
5. El genoma humano en acción 695.1 La secuencia influye en el estado funcional de la cromatina 695.2 Modificaciones epigenéticas y su importancia en la regulación
del estado funcional de la cromatina 715.3 Relación entre secuencia, estructura y función de la cromatina:
territorios cromosómicos 78
6. Origen de la variación genética en humanos 816.1 Variación en el ADN: polimorfismos y mutaciones 816.2 Mecanismos de reparación del ADN en humanos. Enfermedades
causadas por alteraciones en los mecanismos de reparación 82
C) La transmisión de los caracteres hereditarios
7. Genética mendeliana 937.1 Planteamiento experimental de Mendel 947.2 Monohíbridos: primera Ley de Mendel 957.3 Segunda Ley de Mendel: dihíbridos y trihíbridos 997.4 Redescubrimiento del trabajo de Mendel 1027.5. ¿Dónde están los «factores unitarios»? La teoría cromosómica
de la herencia 103
8. Herencia relacionada con el sexo 1078.1 Cada sexo tiene distinta constitución cromosómica 1078.2 Los genes situados en el cromosoma X muestran un modo especial
de herencia 1088.3 Determinación genética del sexo en humanos 1098.4 Compensación de dosis: hipótesis de Lyon 1118.5 Estructura de los cromosomas sexuales humanos 114
9. Modificaciones de las proporciones mendelianas 1179.1 Modo de estimar si se cumplen las proporciones mendelianas
esperadas 1179.2 Modificaciones de las proporciones mendelianas al estudiar
un carácter 1209.3 Modificaciones del dihibridismo. Interacción génica y epistasia 123
10. Genética de los caracteres cuantitativos 12910.1 Genética de los caracteres cuantitativos: experimentos
de Johannsen, Nilsson-Ehle y East 12910.2 Modelo poligenes-ambiente y enfermedades multifactoriales 13310.3 Heredabilidad en sentido amplio y en sentido restringido. Cálculo
de la heredabilidad en Genética Humana 135
VIII
Genética Hum
ana
0-INDICE CONTENIDO 5/12/06 06:46 Página VIII
www.FreeLibros.me

11. Ligamiento genético en humanos 13911.1 El concepto de ligamiento genético: fracción de recombinación y
distancia genética 13911.2 Informatividad de los marcadores utilizados en estudios de
ligamiento 14211.3 El cálculo del LOD score 14411.4 Ligamiento no paramétrico y su utilización en Genética Humana 147
12. Los genes en las poblaciones 15312.1 El equilibrio de Hardy-Weinberg 15312.2 Cambios en las condiciones que mantienen el equilibrio:
cruzamientos no aleatorios 15512.3 Cambios en las condiciones que mantienen el equilibrio: efectos
del tamaño poblacional 15812.4 Cambios en las condiciones que mantienen el equilibrio: migración
o flujo genético 16012.5 Cambios en las condiciones que mantienen el equilibrio:
recombinación y mutación 16012.6 Cambios en las condiciones que mantienen el equilibrio: selección 16112.7 Aplicaciones en Genética Humana 16512.8 Formación de la Teoría Sintética de la Evolución 16712.9 Explicación actual del proceso evolutivo y sus limitaciones 169
D) Patología genética
13. Citogenética 17713.1 El estudio de los cromosomas humanos 17713.2 Anomalías del número de los cromosomas 18013.3 El fenómeno de no disyunción meiótica 18313.4 Anomalías estructurales de los cromosomas 185
14. Mutaciones simples como causa de enfermedad 18914.1 Características generales de las mutaciones 18914.2 Mutaciones simples: tipos y nomenclatura 19014.3 Potencial patogénico de las mutaciones en el ADN codificante
y en el ADN no-codificante intragénico e intergénico 19014.4 Potencial patogénico de las mutaciones en el ADN no-codificante 19214.5 Nomenclatura general de mutaciones 195
15. Potencial patogénico de las secuencias repetidas 19915.1 Mutaciones en secuencias que están repetidas en tándem 19915.2 Expansión de trinucleótidos: neuropatías por expansiones de CAG
y enfermedades por expansión de otros trinucleótidos 20015.3 Neuropatías por expansiones de CAG 20115.4 Enfermedades por expansión de otros trinucleótidos 20215.5 Otras enfermedades por expansión de secuencias repetidas 20415.6 Mutaciones debidas a repeticiones dispersas 20515.7 Desórdenes genómicos 206
IX
Índice de contenido
0-INDICE CONTENIDO 5/12/06 06:46 Página IX
www.FreeLibros.me

16. Efectos fenotípicos de las mutaciones 21116.1 Pérdida de función, fenotipos recesivos y haploinsuficiencia 21216.2 Fenotipos dominantes por ganancia de función 21316.3 Alteraciones de la impronta genómica 21516.4 Mutaciones que afectan a la morfogénesis 221
17. Diagnóstico de enfermedades genéticas 22717.1 Estrategias generales de diagnóstico de enfermedades genéticas 22717.2 Métodos de detección de mutaciones 22817.3 Aplicación del ligamiento genético al diagnóstico: el proceso de
diagnóstico indirecto de enfermedades genéticas 234
18. Genética clínica 23718.1 Genética clínica y consejo genético 23718.2 Enfermedades de herencia autosómica 23918.3 Enfermedades de herencia ligada al cromosoma X 24318.4 Teorema de Bayes y su aplicación al cálculo de riesgos genéticos 24618.5 Enfermedades por alteración del ADN mitocondrial 24818.6 Diagnóstico prenatal 252
E) Nuevas herramientas de la genética moderna
19. Terapia génica 25719.1 Componentes de un sistema de terapia génica y vías de
administración 25719.2 Naturaleza del ácido nucleico terapéutico 25819.3 Tipos de vectores y su utilización en distintas estrategias
de transferencia génica 26019.4 Aplicaciones clínicas de la terapia génica en el momento actual 270
20. Bioinformática del genoma humano 27320.1 La Bioinformática 27320.2 Bases de datos en Genética Humana: bases de datos de secuencias 27420.3 Bases de datos en Genética Humana: bases de datos relacionadas
con enfermedades 27620.4 Búsquedas en bases de datos con BLAST 27720.5 Navegadores del genoma humano 279
Índice analítico 281
X
Genética Hum
ana
0-INDICE CONTENIDO 5/12/06 06:46 Página X
www.FreeLibros.me

Prólogo
La generalización del uso de Internet y de las computadoras domésticas permite con-cebir libros de texto cada vez más interactivos, con tutoriales multimedia y enlaces alos abundantísimos sitios educativos disponibles en la Red. Esto es especialmente útilen una materia como la Genética, en la que la percepción gráfica de los procesos esimprescindible para la adecuada comprensión de los conceptos y mecanismos impli-cados. Este libro de texto es fruto de mi reflexión acerca del modo de impartir la do-cencia de Genética a alumnos de disciplinas biomédicas que se enfrentan por pri-mera vez con el apasionante mundo de los genes. Durante años he venidoimpartiendo la asignatura de Genética Humana a alumnos de las licenciaturas deBiología y Bioquímica de la Universidad de Navarra, y esto me ha permitido prepa-rar poco a poco un manual detallado y abundante material gráfico que han consti-tuido el esqueleto del presente texto. Sobre este esqueleto inicial he añadido nuevoscapítulos y gran cantidad de material multimedia que han dado como resultado estetexto de «Genética Humana: conceptos, mecanismos y aplicaciones de la Genéticaen el campo de la Biomedicina».
Quizás lo que más llame la atención sobre este texto es que se presenta en un for-mato novedoso: sólo se incluyen algunas tablas e ilustraciones que ayudan a mante-ner la fluidez de la lectura, pero todos los materiales gráficos se han incluido en unCD que contiene todas las figuras a las que se hace referencia en el texto. El CD estácompuesto por una serie de páginas web que se pueden visualizar con cualquier na-vegador, y que van guiando al alumno paso a paso a través de tutoriales propios o deenlaces a vídeos o figuras de especial interés para comprender algún concepto. Portanto, el mayor aprovechamiento se conseguirá si el alumno va estudiando el texto ysiguiendo al mismo tiempo, con calma, las figuras del CD. Este método permitirá, oal menos eso espero, una comprensión rápida de los conceptos y mecanismos, ya queéste es el enfoque que he pretendido dar al texto. En mi opinión, ninguna figura «es-tática» puede suplir la información aportada por un video o una animación comen-tada, y por ello la mayoría de los tutoriales están grabados con una voz en «off» que
0-INDICE CONTENIDO 5/12/06 06:46 Página XI
www.FreeLibros.me

Genética Hum
ana
XII explica lo que se está viendo. Esto supone que el alumno debe utilizar una computa-dora con tarjeta de sonido y altavoces (o auriculares); para los enlaces externos ne-cesita también conexión a Internet. Confío en que la mayoría de los hogares cuentanhoy en día con esta tecnología. Una ventaja (no despreciable) de esta estructura esque permite abaratar significativamente el coste final del producto, al no requerir fi-guras a color dentro del propio texto; espero que esto ayude también a conseguir unaamplia difusión del libro.
Sin duda, algunos de los que han leído las líneas precedentes (en especial, cole-gas en la docencia universitaria de Genética) habrán pensado que este libro de textosupone una especie de «autotexto» que podría hacer innecesarias las clases teóricas.Nada más lejos de mi intención. De todas formas, al elaborar este método he tenidoen mente las directrices sobre el nuevo Espacio Europeo de Educación Superior, yen especial el sistema de transferencia de créditos europeos (ECTS) de reciente im-plantación en la Unión Europea. Este sistema está basado en la cantidad de trabajoque —a juicio del profesor— debe invertir un alumno para la adecuada comprensióny aprendizaje de la materia respectiva, y por eso el concepto de crédito incluye tam-bién las horas de trabajo personal del alumno. El presente libro, que exige al alumnouna inversión sustancial de tiempo mientras «navega» por las figuras al tiempo queestudia el texto, se adapta especialmente bien a este nuevo concepto. En cualquiercaso, como es lógico, las clases presenciales siguen siendo un pilar básico de la do-cencia universitaria, puesto que en ellas el alumno recibe una visión diferente de losmismos conceptos que se exponen en el libro, puede además aclarar las dudas que lehayan surgido (si ha leído el capítulo correspondiente antes de la clase, como esaconsejable) y puede también fijar los conceptos clave que poco a poco le irán ayu-dando a «pensar» como un genetista.
Como he dicho, el principal destinatario de este texto es el alumno que cursa unaasignatura general de Genética en una licenciatura biomédica (Medicina, Farmacia),y que se enfrenta por primera vez con esta materia. De todas formas, también puedeser útil para alumnos de la licenciatura de Biología que ya hayan cursado una asig-natura de Genética General (y, quizás, Ingeniería Genética) y se enfrentan con unaasignatura más específica de Genética Humana, especialmente los capítulos inclui-dos en los bloques B, D y E. En este caso, los capítulos correspondientes al bloque Ay al bloque C ya habrán sido estudiados con mucho más detalle en esas otras asig-naturas, pero lo presentado aquí puede servir como resumen que ayude a recordarlos conceptos fundamentales. Lógicamente, espero que este texto también resulte útila médicos y otros profesionales del mundo biomédico que quieran ponerse al día, oque necesiten un compendio claro, actualizado y moderno de los conceptos, meca-nismos y aplicaciones que ofrece la Genética en el siglo XXI.
0-INDICE CONTENIDO 5/12/06 06:46 Página XII
www.FreeLibros.me

CAPITULO 1 5/12/06 06:52 Página 1
www.FreeLibros.me

A) Introducción
Se incluyen en esta sección tres temas que servirán para repasarlos aspectos fundamentales de la estructura de los ácidos nucleicos
y la biología molecular del gen, así como la estructura básica de la cromatina y sus cambios durante el ciclo celular.
CAPITULO 1 5/12/06 06:52 Página 1
www.FreeLibros.me

C A P Í T U L O 1
El flujo de la información genética
Contenidos
1.1 Los ácidos nucleicos
1.2 Visión general del proceso de expresión génica
1.3 La transcripción
1.4 Regulación de la transcripción en eucariotas
1.5 Maduración del ARN mensajero
1.6 El ayuste (splicing) y su regulación
1.7 Traducción y código genético en eucariotas
1.1 Los ácidos nucleicos
La información genética se transmite a través de unas moléculas llamadas ácidos nu-cleicos, polímeros formados por unidades denominadas nucleótidos. Un nucleótido esuna molécula formada por una pentosa, una base nitrogenada y un grupo fosfato. Al con-junto formado por la pentosa y la base nitrogenada se le denomina nucleósido. Por tan-to, un nucleótido es el éster fosfato de un nucleósido. Dependiendo de la naturaleza dela pentosa, se distinguen dos tipos de ácidos nucleicos: el ácido ribonucleico (ARN) lle-va D-ribosa, y el ácido desoxi-ribonucleico (ADN) contiene 2-desoxi-D-ribosa. Las basesnitrogenadas que forman parte de los ácidos nucleicos pueden ser monocíclicas (pirimi-dinas) o bicíclicas (purinas). Las bases que intervienen en la formación del ADN se de-nominan Adenina (A), Citosina (C), Guanina (G) y Timina (T). El ARN contiene las tresprimeras y Uracilo (U) en vez de Timina.
Fue Friedrich Miescher el primero en identificar, en 1869, un material que llamó nu-cleína. Estudios posteriores fueron caracterizando progresivamente la naturaleza quími-
CAPITULO 1 5/12/06 06:52 Página 3
www.FreeLibros.me

ca de esta sustancia, así como su importancia biológica. Después de bastante con-troversia, Avery, MacLeod y McCarthy demostraron en 1944 que la introducción deADN purificado en bacterias hace que éstas cambien su fenotipo y es, por tanto, lamolécula transmisora de la información genética. En 1953, Rosalind Franklin, Mau-rice Wilkins, James Watson y Francis Crick describieron la estructura tridimensio-nal del ADN.
La Figura 1.1 contiene enlaces a los artículos originales de estos autores.
El ADN y el ARN son cadenas de polinucleótidos. Como los nucleótidos tienendireccionalidad debido a la posición del grupo fosfato en el carbono 5’ y del grupohidroxilo en el carbono 3’ de la pentosa, las moléculas de ADN y ARN también tie-nen una polaridad concreta que viene definida por la dirección 5’→3’. El ADN es unamolécula formada por dos cadenas antiparalelas, es decir, con polaridad contraria.Cada cadena está formada por un esqueleto desoxi-ribosa-fosfato, en el que alternanmoléculas de desoxi-ribosa unidas a los grupos fosfato mediante enlaces fosfo-diéster.De este esqueleto «protruyen» las bases nitrogenadas, unidas a la pentosa medianteenlaces glucosídicos. Además, la molécula de ADN está formada por dos cadenascomplementarias, lo que significa que la secuencia de bases nitrogenadas de una ca-dena es complementaria a la de la otra cadena. Esto se debe al hecho de que las ba-ses nitrogenadas forman sólo dos tipos de parejas: Citosina se empareja con Guani-na y Adenina se empareja con Timina. Erwin Chargaff fue el primero en demostraren 1950 que el ADN de doble cadena tiene relaciones equimolares de purinas y piri-midinas; la cantidad total de desoxi-adenina (dA) es igual a la de desoxi-timina (dT),y la de desoxi-guanina (dG) igual a la de desoxi-citosina (dC). Por tanto, una conclu-sión derivada de esto es que siempre se emparejan una purina con una pirimidina delmismo modo, siendo los pares dA con dT y dG con dC. Watson y Crick, en su mo-delo de doble hélice, establecieron el modo exacto en que se forman los enlaces encada par de bases, con tres puentes de hidrógeno en un par dG·dC y dos puentesde hidrógeno en un par dA·dT. Aunque hay muchos más tipos posibles de enlaces en-tre cada uno de estos nucleótidos, los enlaces tipo Watson-Crick tienen una propie-dad importante: ocupan el mismo espacio dentro de la doble cadena y pueden in-tercambiarse sin distorsionar la molécula. Finalmente, el hecho de que sólo se formendos tipos de pares de bases explica que las dos cadenas sean complementarias, ya quela secuencia de bases de una puede convertirse fácilmente en la secuencia de bases dela otra cadena sustituyendo cada base por su complementaria.
La Figura 1.2 contiene un enlace a animaciones en las que se explica la estructura de los ácidosnucleicos y de la doble hélice.
Por tanto, en la molécula completa de ADN, las cadenas polinucleotídicas semantienen unidas entre sí gracias a los puentes de hidrógeno que se forman entre ba-ses pertenecientes a cada una de las cadenas. Además, esta doble hebra no es lineal(como una escalera de mano), sino que adopta una configuración helicoidal en laque las bases nitrogenadas ocupan el interior y se disponen perpendicularmente a lascadenas laterales. Este fenómeno se denomina «apilamiento» de las bases (base stac-
4
El flujo de la información genética
CAPITULO 1 5/12/06 06:52 Página 4
www.FreeLibros.me

king) y es muy importante para mantener la estabilidad global de la doble hélice.Existen distintos tipos de configuraciones que puede adoptar la doble hélice depen-diendo de las condiciones del medio, pero la más relevante desde el punto de vistabiológico es la forma B, ya que es la más frecuente en condiciones fisiológicas. Enesta configuración, la hélice es dextrógira, con un diámetro de 2 nm, tiene 10 paresde bases por vuelta y una distancia de 0,34 nm entre cada par de bases. Las dos mo-léculas de desoxi-ribosa a las que se unen cada una de las bases del mismo par for-man dos «surcos» en la superficie externa de la hélice. Además, como estas dos des-oxi-ribosas no están situadas simétricamente, sino que miran hacia la misma cara dela doble hélice, los dos surcos que se forman no son iguales: uno de ellos es más an-cho (surco mayor) y otro más estrecho (surco menor).
La Figura 1.3 permite visualizar la forma B del ADN en tres dimensiones.
1.2 Visión general del proceso de expresión génica
La secuencia de nucleótidos de determinados fragmentos del ADN contiene infor-mación para la fabricación de proteínas, que son los principales elementos estructu-rales y funcionales de las células. De hecho, la secuencia de nucleótidos determinael tipo de aminoácidos y el orden en que se añaden en el proceso de síntesis de pro-teínas, y esa información está contenida de un modo codificado en la secuencia debases del ADN. El proceso por el que dicha información es descodificada y «tradu-cida» para dar lugar a la síntesis de proteínas específicas se conoce como expresióngénica. Este proceso comprende varios pasos de descodificación, que en líneas ge-nerales son la transcripción y la traducción. En lenguaje coloquial, transcribir signi-fica pasar algún tipo de información de un medio a otro. Por ejemplo, se transcribeuna conversación al ponerla por escrito. El primer paso en la lectura de la informa-ción contenida en la secuencia de nucleótidos consiste en la síntesis de una cadenade ARN a partir de un segmento de ADN. Este proceso de copia de una secuencia«molde» de ADN en un ARN se denomina transcripción. El ARN mantiene la in-formación que estaba contenida en el ADN precisamente porque lleva la misma se-cuencia de nucleótidos (con la excepción de las timinas, que son sustituidas por ura-cilos). Esta cadena de ARN puede intervenir directamente en algún proceso celular,pero lo más habitual es que transmita la información al siguiente elemento de la ca-dena de descodificación, y por eso se llama ARN mensajero (abreviado comoARNm). El ARNm es, por tanto, la molécula que va a llevar la información conteni-da en un segmento concreto de ADN (es decir, un gen) hasta la maquinaria de fa-bricación de proteínas. Como esta maquinaria está en el citoplasma, el ARNm debesalir del núcleo celular a través de los poros nucleares y llegar a los ribosomas. Allí,mediante un proceso denominado traducción, la información genética contenidaoriginalmente en la secuencia de nucleótidos del ADN será finalmente traducida enuna serie de instrucciones que permiten al ribosoma sintetizar una proteína concre-ta. En los siguientes apartados veremos con detalle cada uno de estos procesos.
La Figura 1.4 contiene un vídeo en el que se ve el proceso general de expresión génica.
5
Visión general del proceso de expresión génica
CAPITULO 1 5/12/06 06:52 Página 5
www.FreeLibros.me

1.3 La transcripción
El proceso general de transcripción consiste en la síntesis de una cadena de ARN porla acción de una polimerasa de ARN, que lee la secuencia de nucleótidos contenidaen el ADN molde y sintetiza la nueva cadena de ARN utilizando nucleótidos libres.En este proceso, la polimerasa se desliza por la cadena molde de ADN. La transcrip-ción es un proceso cíclico que se repite, en el que hay varias fases esenciales: i) de-terminar la región molde de ADN que ha de ser copiada, ii) iniciar la síntesis de ARN,iii) estabilizar y modular la elongación del ARNm naciente, iv) terminar el proceso.
En eucariotas, la molécula encargada de la síntesis es una polimerasa de ARNdependiente de ADN, es decir una polimerasa que usa un molde de ADN para sin-tetizar un ARN. Este enzima es en realidad un complejo enzimático formado pormúltiples subunidades proteicas al que se unen también factores accesorios sin loscuales no puede reconocer el lugar correcto de inicio de la síntesis. En eucariotas sedistinguen tres tipos de ARN polimerasas en función del tipo de genes que transcri-ben. Los genes tipo I de eucariotas son los que codifican los ARN ribosomales queveremos más adelante, y la polimerasa encargada de transcribir estos genes es laARN polimerasa I. La mayoría de los genes son genes tipo II, que codifican proteí-nas y algunos ARN pequeños con funciones concretas; su transcripción corre a car-go de la ARN polimerasa II. Finalmente, otros ARN pequeños, algunos ARN riboso-males y los ARN transferentes son sintetizados por la ARN polimerasa III.
El primer paso en la transcripción es determinar en qué punto comienza. Esto vie-ne determinado por la existencia de unas secuencias que definen la región del gen enla que se une el complejo enzimático responsable de la síntesis. Estas secuencias sellaman promotores, y son necesarios para que la transcripción pueda tener lugar. Unpromotor consta de varios pequeños motivos de secuencia, dispersos a lo largo de va-rios cientos de pares de bases, a los que se unen los distintos factores proteicos ne-cesarios para la transcripción. De hecho, la ARN polimerasa no se une al promotordirectamente, sino a través de otro complejo proteico denominado complejo de prei-niciación. Por ejemplo, una de las secuencias más constantes en promotores de eu-cariotas es la caja TATA, cuya secuencia consenso es 5’-TATATAAAT-3’; a esta se-cuencia se une un factor proteico llamado «proteína de unión a TATA» (en inglésTATA-binding protein, abreviado TBP). Sobre este factor se unen otros factores ac-cesorios y dan lugar a un factor de transcripción llamado TFIID. De modo similar,se forman otros factores de transcripción, que en el fondo no son más que proteínascon algún dominio de unión al ADN, que reconocen específicamente las secuenciaspresentes en los promotores y se unen a ellas. En el promotor eucariota típico de ge-nes tipo II se forma un complejo con TFIID, TFIIA, TFIIB y TFIIF, al que se une laARN polimerasa II. La unión posterior de TFIIH y TFIIE añade otras actividades alcomplejo, como la actividad helicasa necesaria para abrir la doble hélice y permitirel copiado de una cadena, y hace que comience la transcripción. Por tanto, la for-mación del complejo de preiniciación sobre promotores específicos es la forma decontrolar que la ARN polimerasa comience a sintetizar en el lugar correcto. Además,los promotores eucariotas están también modulados por otros elementos más lejanosdel punto de inicio de la transcripción, llamados «potenciadores» (enhancers en in-glés) o «silenciadores». Estos elementos son secuencias de ADN sobre las que se
6
El flujo de la información genética
CAPITULO 1 5/12/06 06:52 Página 6
www.FreeLibros.me

unen factores proteicos que contribuyen a estabilizar y potenciar el complejo de prei-niciación, en el caso de los potenciadores, o a impedir la transcripción en el caso delos silenciadores. Existen muchos otros elementos de secuencia que forman parte depromotores y que permiten regular dónde o cuándo se transcribe un gen. Muchos deestos elementos tienen una localización precisa respecto al inicio de la transcripción:por ejemplo, la caja TATA suele estar 25 nucleótidos en dirección 5’ al inicio de latranscripción (es decir, en posición –25, ya que se considera como posición +1 la delnucleótido donde se inicia la síntesis). Otros elementos frecuentes son la caja GC (se-cuencia consenso GGGCGG) o la caja CAAT (CCAAT) en posición –100, a las quese unen factores de transcripción específicos.
Con la fosforilación del extremo carboxilo-terminal de la ARN polimerasa II,comienza el desplazamiento de la misma por la cadena molde de ADN y la síntesisdel ARN naciente. En este proceso, la polimerasa lee la secuencia de nucleótidos deuna de las cadenas de la doble hebra de ADN y sintetiza un polinucleótido comple-mentario, reemplazando las timinas del ADN por uracilos. De este modo, se conser-va perfectamente la información que estaba contenida en el ADN. En este sentido,tiene importancia saber cuál es la hebra de la doble hélice que es utilizada como mol-de, y a veces existe cierta confusión sobre la nomenclatura de las dos hebras del ADNbicatenario. Es importante recordar que los polinucleótidos se sintetizan en dirección5’→3’, y lo mismo sucede con la síntesis del ARN mensajero. Por tanto, la hebra mol-de se lee en sentido 3’→5’ (es decir, antisentido) al tiempo que la transcripción pro-cede en sentido 5’→3’. Por eso, el convenio es llamar «hebra codificante» o «hebrasentido» a la hebra de la doble cadena de ADN que contiene exactamente la mismasecuencia de nucleótidos que el futuro ARNm transcrito (excepto por los uracilos).A la hebra complementaria, que es la que se utiliza como molde, se le llama «hebramolde» o «hebra antisentido».
DOBLE CADENA DE ADN(GEN)
5’—ACGtataaGATCTCGATCGAGACTAGCTAGCTAGCTAgCGATCGAGCTA-3’ |||||||||||||||||||||||||||||||||||||||||||||||||
3’-TGCTAGCTAGATAGCTAGCTCTGATCGATCGATCGATCGCTAGCTCGAT-5’
INICIO DE LATRANSCRIPCIÓNCAJA TATA
PROMOTOR Exon 1
7
La transcripción
La Figura 1.5 muestra una secuencia de ADN en la que se representan las principalessecuencias implicadas en la transcripción de un gen.
CAPITULO 1 5/12/06 06:52 Página 7
www.FreeLibros.me

El proceso de elongación del transcrito naciente, al menos en eucariotas, está su-jeto a numerosas pausas o paradas, debido a diversos obstáculos que la polimerasase puede encontrar al avanzar por el ADN molde. Como veremos en el siguiente ca-pítulo, la doble hélice está empaquetada en forma de cromatina, y esto crea obstá-culos importantes a los procesos de transcripción; además, el ADN puede haber su-frido daños que a veces impiden el paso del complejo transcripcional. Por eso, esimportante la presencia de factores que favorecen la elongación, tales como algunosfactores de transcripción (TFIIF y TFIIS) o la elongina. La fosforilación de la ARNpolimerasa también favorece significativamente el proceso de elongación. La últimafase del proceso de transcripción es la terminación de la síntesis. Así como en pro-cariotas la terminación está mediada por unas secuencias específicas en el ADN mol-de, en eucariotas la terminación no sigue este modelo, sobre todo en el caso de laARN polimerasa tipo II. La síntesis habitualmente sigue hasta que se ha sobrepasa-do el punto que constituirá el extremo 3’ del ARN mensajero, y la terminación estáligada a los procesos de maduración del transcrito que se describen a continuación.
La Figura 1.6 contiene un enlace a un vídeo que muestra esquemáticamente el proceso de transcripción.
1.4 Regulación de la transcripción en eucariotas
Así como los mecanismos que regulan la expresión génica son bastante bien conoci-dos en procariotas, y se han identificado distintos tipos de ARN polimerasas y de fac-tores de transcripción implicados en el inicio de la transcripción, el panorama en eu-cariotas es mucho más complejo. Sólo en los últimos años ha comenzado aconocerse con cierto detalle el modo en que se regula la intensidad de la expresióngénica, su restricción a determinados tejidos y su variación en respuesta a estímulosextracelulares. Aunque esta regulación se puede dar a varios niveles de complejidad,en este apartado estudiaremos únicamente el nivel basal, que es el compuesto por lassecuencias promotoras, potenciadoras y silenciadoras del inicio de la transcripción ylos factores proteicos que se unen a ellas. El complejo basal de iniciación es una ma-quinaria molecular gigante, con distintas actividades, cuyo ensamblaje es necesariopara la transcripción correcta tanto de genes constitutivos como de genes que se ex-presan sólo en determinados tejidos.
Hasta hace unos 10 años, se conocían seis factores generales de iniciación de latranscripción de genes clase II en eucariotas, llamados TFIIA, TFIIB, TFIID, TFIIE,TFIIF y TFIIH. Éstos, junto con la ARN polimerasa II, son suficientes para iniciar latranscripción de algunos genes in vitro, es decir, en el tubo de ensayo. Pronto se vioque algunos de estos factores generales eran en realidad complejos formados por va-rios componentes, y se identificaron un total de 23 proteínas además de las 12 sub-unidades de la ARN polimerasa II; con esto, se propuso un modelo por el que todosestos factores se ensamblan durante la iniciación de la transcripción. Los progresosde los últimos años han revelado que en realidad el transcriptosoma es un complejomucho mayor de lo que se creía, con muchos otros componentes proteicos que llevana cabo otras funciones, como la remodelación de la cromatina o la reparación del
8
El flujo de la información genética
CAPITULO 1 5/12/06 06:52 Página 8
www.FreeLibros.me

ADN. La regulación de la expresión génica se ejerce, a este nivel basal, mediante laregulación del ensamblaje de la maquinaria proteica necesaria para la transcripción,y en este sentido se ha estudiado especialmente el papel de los potenciadores y los ac-tivadores. Los potenciadores (enhancers en inglés) son pequeños elementos de se-cuencia del ADN a los cuales se unen unos factores proteicos llamados activadores,y dicha unión estimula la transcripción. Dado que distintos genes tienen distintos ele-mentos potenciadores y que no todas las células poseen los mismos activadores, estesistema permite cierta especificidad en la respuesta a estímulos fisiológicos que reci-be las células de distintos tejidos. Además, los activadores son proteínas modulares,es decir, poseen distintos dominios de unión a potenciadores diferentes, lo cual regu-la la afinidad y especificidad de las interacciones con los elementos de ADN.
El modo en que la unión de los activadores a los potenciadores es capaz de pro-mover la trancripción, ha sido estudiado con profundidad en los últimos años. Estosestudios han permitido aislar otro complejo proteico llamado mediador, constituidotambién por varias subunidades, que interacciona con los activadores y con la ARNpolimerasa II y así transduce las señales proporcionadas por los potenciadores alpromotor basal de la transcripción. Se han identificado varios mediadores en huma-nos, como TRAP, DRIP y otros; además de ayudar a estabilizar el complejo de ini-ciación gracias a las interacciones con los activadores y los factores generales detranscripción, los mediadores también pueden regular directamente la actividad de laARN polimerasa II.
La Figura 1.7 muestra el ensamblaje del complejo basal de transcripción por la acción de activadores y mediadores.
1.5 Maduración del ARN mensajero
En los genes transcritos por la ARN polimerasa tipo II, que en su inmensa mayoríason genes codificantes de proteínas, el ARN mensajero primitivo debe ser procesadopara mejorar su estabilidad y para eliminar las regiones que no son codificantes. Ade-más, en algunos casos es sometido a un proceso de corrección de errores o «edición».
En primer lugar, el ARN naciente es estabilizado mediante la adición de distin-tos grupos en sus extremos 5’ y 3’, ya que los extremos libres de la molécula de ARNson los más vulnerables a la degradación por unas enzimas llamadas exonucleasas.El extremo 5’ es modificado mediante la adición del capuchón o caperuza (cap eninglés), que consiste en la adición al primer nucleótido del ARN de una guanina mo-dificada. Podemos representar el extremo 5’ de un ARN recién transcrito por 5’-pppNpN…-3’, siendo cada p un grupo fosfato y N un nucleótido cualquiera (como eshabitual, el primer nucleótido de la cadena tiene tres grupos fosfato unidos al carbo-no 5’ de la ribosa). La caperuza consiste en una guanina metilada en posición 7, quese une por su carbono 5’ al primer grupo fosfato de la cadena. Por tanto, el enlaceentre la 7-metil-guanina y el primer nucleótido es atípico, ya que es un enlace 5’→5’en vez del enlace 5’→3’ habitual.
El otro tipo de modificación del ARN mensajero tiene lugar en el extremo 3’ delmismo, y consiste en el corte por un punto concreto y la posterior adición de una
9
Maduración del ARN m
ensajero
CAPITULO 1 5/12/06 06:52 Página 9
www.FreeLibros.me

cola de poli-adeninas. Es importante recordar que dicha cola no se añade al extremofinal del transcrito primario, sino que previamente tiene lugar un corte interno. Elpunto de corte viene definido por la presencia de una señal de poli-adenilación enel ARNm (cuya secuencia consenso es 5’-AAUAAA-3’) y un tracto rico en guaninasy uracilos (tracto GU) localizado unos 30-40 nucleótidos por debajo de la señal depoli-adenilación (es decir, en dirección 3’). El proceso está mediado por unos facto-res proteicos que se unen a cada una de estas señales, cortan al ARN mensajero unos20 nucleótidos por debajo de la señal de poli-adenilación, y comienzan a añadir ade-ninas. La formación de esta cola poli(A) es muy importante para mantener la esta-bilidad del ARNm y asegurar que éste pueda seguir siendo procesado y llegue a tra-ducirse correctamente.
La Figura 1.8 contiene un enlace a un vídeo educativo que muestra esquemáticamente la adición de la caperuza y la formación de la cola poli(A).
Un último tipo de modificación que pueden sufrir algunos ARNm es la correccióno «edición». La edición del ARN es un mecanismo de modificación co- o post-trans-cripcional mediante el cual se cambian uno o varios nucleótidos de un ARNm, conel resultado de que la secuencia del mensajero es ligeramente distinta de la que ve-nía codificada en la secuencia genómica. Este fenómeno, bastante común en otras es-pecies pero más raro en humanos, permite generar diversos ARNm a partir de unmismo gen. Por ejemplo, la apolipoproteína ApoB48, que se produce en el intestinopara entrar a formar parte de los quilomicrones, se origina por efeco de un cambioC→U en el que una citosina se des-amina para dar lugar a un uracilo; este cambiocrea un codón de parada en el ARNm de la ApoB100 y se produce una proteína máscorta de lo que sería esperado según la secuencia inicial. Un mecanismo similar estáimplicado en el origen de enfermedades como la neurofibromatosis tipo I o el tumorde Wilms, debidas a alteraciones en los genes NF1 y WT1, respectivamente.
La Figura 1.9 muestra esquemáticamente la edición del ARN que da lugar a la ApoB48.
1.6 El ayuste (splicing) y su regulación
Los ARN mensajeros de eucariotas tienen una característica muy importante: no soncodificantes en su totalidad, desde el principio al fin, sino que las regiones codifi-cantes están interrumpidas por otras regiones no-codificantes. Es decir, no todos losnucleótidos del ARN mensajero son leídos para sintetizar proteínas, sino que existenregiones codificantes llamada exones que alternan con otras regiones no-codifican-tes llamadas intrones. Debido a esta configuración, el siguiente paso en la madura-ción de un ARNm consiste en eliminar los intrones y pegar los exones para formarun mensajero maduro que pueda ser traducido desde el principio hasta el fin y sin in-terrupciones. Este proceso de corte y eliminación de intrones con empalme de losexones se denomina en inglés splicing, término naútico que corresponde al castella-no ayuste: la unión de dos cabos por sus chicotes. El ayuste es un proceso comple-jo, porque hay que tener en cuenta que el número de exones e intrones de un gen
10
El flujo de la información genética
CAPITULO 1 5/12/06 06:52 Página 10
www.FreeLibros.me

puede ser muy grande, y requiere una maquinaria proteica bastante sofisticada. Enprimer lugar, es importante definir el punto exacto que delimita la frontera entre unexón y un intrón, para que la maquinaria encargada del ayuste pueda actuar. Estospuntos vienen determinados por secuencias específicas del ARNm. Por ejemplo, losintrones de eucariotas comienzan en la práctica totalidad de los casos por los nu-cleótidos Guanina-Uracilo (secuencia 5’ de ayuste, GU) y terminan enAdenina–Guanina (secuencia 3’ de ayuste, AG). Estas secuencias se localizan dentrode unas regiones más amplias que cumplen un consenso de secuencia concreto. Porejemplo, la secuencia de ayuste 5’ está formada por el consenso 5’-AG|GU[A/G]AGU-3’ (la barra vertical indica el sitio de corte donde termina el exónprecedente y comienza el intrón; [A/G] significa que en esa posición puede haberuna A o una G). Por su parte, la secuencia de ayuste 3’ se ajusta al consenso 5’-NCAG|G-3’ (siendo N cualquier nucleótido). Además, es importante la presencia deuna adenina 20-40 nucleótidos por arriba (es decir, en dirección 5’) de la secuencia3’ de ayuste. Esta adenina se encuentra en la secuencia consenso 5’-CU[A/G]A[C/U]-3’ (es la adenina en negrita y subrayada), es decir, precedida por Ao G y seguida por C o U, y se denomina punto de ramificación (en inglés, branchpoint). Entre el punto de ramificación y la secuencia de ayuste 3’ se encuentra untracto rico en pirimidinas, es decir, formado casi exclusivamente por timinas o cito-sinas. Finalmente, se han identificado pequeños elementos de secuencia en exones oen intrones que actúan como potenciadores o silenciadores del proceso de ayuste, yque tienen gran importancia en la modulación y regulación fina del proceso.
Exón 1 Exón 2
Intrón 1
GUC CAUUCA
ARNn p U1
AGU
…UGAC…..….[C/T] [C/T][C/T][C/T] [C/C/T]AG G
CAG GUA
11
El ayuste(splicing)
y su regulación
La Figura 1.10 muestra esquemáticamente las distintas secuencias que son importantesen el proceso de ayuste.
CAPITULO 1 5/12/06 06:52 Página 11
www.FreeLibros.me

El proceso de ayuste implica varias reacciones enzimáticas que realizan cortesendonucleolíticos y unión de extremos libres. El primer paso del proceso es el corteen el sitio de ayuste 5’, justo por delante de la guanina del GU inicial del intrón. Esteextremo libre se une a la Adenina del punto de ramificación mediante un enlace fos-fo-diéster 5’-2’, creando una estructura en lazo. Finalmente, se corta la secuencia deayuste 3’ por detrás de la guanina del sitio AG, lo que resulta en la liberación del in-trón; los extremos libres de los dos exones flanqueantes son entonces religados. Lasmoléculas que llevan a cabo estos procesos son unas ribonucleoproteínas nuclearespequeñas (RNPnp), formadas por un ARN nuclear pequeño (ARNnp) y varias su-bunidades proteicas. Aunque hay varios tipos de ARNnp, los que participan en elproceso de ayuste se llaman U1, U2, U4, U5 y U6, y además dan su nombre a las co-rrespondientes RNPnp. La RNPnp U1 se une a la secuencia de ayuste 5’ por com-plementariedad de bases, ya que uno de sus extremos es complementario a la se-cuencia consenso que rodea a la GU del extremo 5’ del intrón.
Las otras ribonucleoproteínas implicadas actúan en los siguientes pasos del pro-ceso. La RNPnp U2 se une al punto de ramificación y esto hace que ambas RNP en-tren en contacto y facilita la formación del lazo. A continuación, un complejo for-mado por la RNPnp U4/6 y la RNPnp U5 se une a la región de ayuste 3’ y estabilizala formación de todo el complejo, llamado ayusteosoma (spliceosome en inglés), ylleva a cabo el corte 3’ y la unión de los exones.
La Figura 1.11 contiene un enlace a un vídeo educativo que muestra esquemáticamente el procesode ayuste.
Como se puede suponer, en un genoma eucariota hay miles de sitios que cumplenel consenso de secuencia necesario para funcionar como sitios de ayuste, pero sinembargo sólo unos pocos participan en el procesamiento normal de los genes. De he-cho, uno de los temas más interesantes en la regulación del ayuste es cómo se defi-nen exactamente los límites de exones e intrones, de modo que la maquinaria deayuste los reconozca como tales. Aunque todavía quedan incógnitas por resolver, hoyen día sabemos que hay otros elementos que cooperan para estabilizar el ayusteoso-ma y permitir que se lleve a cabo el proceso. Entre estos elementos destacan la pro-teínas SR (llamadas así por ser ricas en los aminoácidos Serina y Arginina), queinteraccionan con distintos componentes del ayusteosoma y se unen a secuenciasmoduladoras como son los potenciadores exónicos del ayuste. Todas estas interac-ciones tienen lugar antes de la unión de las RNPnp U4/6 y RNPnp U5, y son muyimportantes para definir los límites de exones e intrones y para regular el ayuste al-ternativo, que es el fenómeno por el cual un mismo gen puede sufrir distintos patro-nes de ayuste dependiendo del tejido o del tipo celular en que se lleva a cabo. El ayus-te alternativo es un fenómeno muy común en humanos, y hace que los ARNmresultantes de los distintos tipos de ayuste sean diferentes y por tanto tengan la ca-pacidad de codificar proteínas distintas, lo que añade un nivel más de complejidaden la función del genoma.
La Figura 1.12 muestra esquemáticamente los complejos que intervienen en la definición de los exones e intrones, así como el fenómeno de ayuste alternativo.
12
El flujo de la información genética
CAPITULO 1 5/12/06 06:52 Página 12
www.FreeLibros.me

1.7 Traducción y código genético en eucariotas
El paso final en el proceso de la expresión génica es la fabricación de una proteína apartir de la información contenida en la secuencia del ARNm. Conceptualmente, esteproceso es parecido a la interpretación de unas instrucciones escritas en un idioma,siguiendo un código de interpretación concreto. Por eso, el proceso se denomina tra-ducción. Si queremos traducir un lenguaje, en primer lugar necesitamos conocer eldiccionario para entender el significado de las palabras. En este caso, el diccionariose conoce como código genético, que es la correspondencia entre la informacióncontenida en el ARNm y el tipo de aminoácido que se añade a la proteína durantesu síntesis. En el ARNm, las instrucciones están compuestas por palabras de tres le-tras, es decir, cada tres nucleótidos forman una palabra que instruye a la maquinariade síntesis proteica a añadir un aminoácido concreto. Estas palabras de tres letras sedenominan codones. Es fácil calcular el número posible de palabras de tres letras quese pueden formar con un alfabeto de cuatro letras (A, C, G y T): 43, es decir 64 pa-labras distintas. Sin embargo, sólo hay 20 aminoácidos esenciales en las proteínas,por lo que en teoría sólo serían necesarios 20 codones. Teniendo en cuenta las pala-bras necesarias para la instrucción de iniciar la transcripción (AUG) y de terminarla(UAG, UAA, UGA), todavía tenemos la posibilidad de codificar un mismo ami-noácido con varios codones distintos. Para indicar este fenómeno se dice que el có-digo genético es degenerado, en el sentido de que varias palabras a veces codificanel mismo aminioácido. Por ejemplo, algunos aminoácidos como la leucina están co-dificados por seis codones diferentes.
La Figura 1.13 muestra el código genético, con la tabla de equivalencias entre los distintosaminoácidos y los codones que los codifican.
El hecho de que el código genético utilice palabras de tres letras implica que cual-quier secuencia anónima, cuyo significado no conocemos, podría dar lugar al menosa tres proteínas distintas dependiendo del punto de inicio de la traducción. En efec-to, cualquier secuencia (supongamos la secuencia 5’-ACGACTGCGTACACGTC-3’,por ejemplo) puede dividirse en bloques de tres palabras que configurarán instruc-ciones distintas si comenzamos a contar desde el primer nucleótido (ACG, ACT,GCG, etc. en nuestro ejemplo), desde el segundo (CGA, CTG, CGT, etc.) o desde eltercero (GAC, TGC, GTA, etc.). Como puede observarse, las proteínas codificadas encada caso tienen una secuencia de aminoácidos diferente. Cada una de estas posiblesformas de leer una secuencia codificante se denomina marco de lectura, y siempreexisten tres marcos de lectura posibles (en secuencias de una sola hebra) porque elcuarto marco de lectura es idéntico al primero, el quinto al segundo, etc. Esto plan-tea el problema de cómo reconoce la célula cuál es el marco de lectura que debe usarpara sintetizar la proteína correcta. Esto se soluciona de dos formas: en primer lugar,por la existencia de un codón de inicio (AUG, que codifica para el aminoácido me-tionina), y en segundo lugar porque sólo uno de los tres marcos de lectura (llamadopor eso «abierto») da lugar a una proteína de longitud adecuada, ya que en los otrosdos marcos de lectura aparecen codones de parada y las proteínas codificadas resul-tarían muy cortas y sin funcionalidad. En eucariotas, el codón de inicio está inclui-
13
Traducción y código genético en eucariotas
CAPITULO 1 5/12/06 06:52 Página 13
www.FreeLibros.me

do en una secuencia consenso definida por Marilyn Kozak, que es 5’-C[A/G]CCAUGG-3’. El marco de lectura abierto quedará definido, por tanto, cuan-do el codón de inicio vaya seguido por un número suficiente de codones codifican-tes hasta llegar a un codón de parada. Es importante tener en cuenta que latraducción no comienza al principio del ARNm, y tampoco termina al final del men-sajero. De hecho, en el gen y en el ARNm se pueden definir dos regiones no-tradu-cidas, una en dirección 5’ al inicio de la traducción y otra desde el codón de paradahasta el final, que flanquean la región codificante (el marco de lectura abierto). Laregión no traducida 5’ (RNT-5’, en inglés UnTranslated Region o 5’-UTR) se extien-de desde el inicio del ARNm (la caperuza) hasta el inicio de la traducción (codón deiniciación); la RNT-3’ (en inglés 3’-UTR) se extiende desde el codón de parada has-ta el inicio de la cola poli(A).
La maquinaria que lleva a cabo la traducción está constituida básicamente pordos elementos: los ribosomas y los ARN de transferencia. El ribosoma es una partí-cula compleja formada por subunidades de naturaleza ribonucleoproteica. En euca-riotas, el ribosoma consta de una subunidad pequeña (coeficiente de sedimentación40S) formada por un ARN y unas 30 proteínas, y otra subunidad grande (60S) for-mada por 3 ARN y unas 50 proteínas. Los ARN transferentes (ARNt) son pequeñasmoléculas de ARN que llevan en uno de sus extremos un aminoácido, y actúan comolos adaptadores que leen la información de cada codón y la transforman en un ami-noácido específico. Aunque se representan habitualmente con forma de trébol, enrealidad están doblados en forma de L. Las dos regiones más importantes de unARNt son el anticodón y el extremo 3’, que termina en los nucleótidos 5’-CCA-3’ ylleva el aminoácido correspondiente. El anticodón está formado por los tres nucleó-tidos que se emparejan con el codón por complementariedad, ya que la secuencia delcodón y la del anticodón son complementarias (ambas en dirección 5’→3’). Este em-parejamiento no necesita ser siempre perfecto, sino que en ocasiones se permite un
70 80 90 100 110 120----:----|----:----|----:----|----:----|----:----|----:----|atgTGGTTTTCTGTCCACTTCCCCTatgCAGGTGTCCAACGGATGTGTGAGTAAAATTCTM W F S V H F P Y A G V Q R M C E * N S C G F L S T S P M Q V S N G C V S K I L V V F C P L P L C R C P T D V * V K F W
130 140 150 160 170 180----:----|----:----|----:----|----:----|----:----|----:----|GGGCAGGTATTACGAGACTGGCTCCATCAGACCCAGGGCAATCGGTGGTAGTAAACCGAGG Q V L R D W L H Q T Q G N R W * * T E G R Y Y E T G S I R P R A I G G S K P R A G I T R L A P S D P G Q S V V V N R E
14
El flujo de la información genética
La Figura 1.14 muestra una secuencia de ADN con los distintos marcos de lectura posibles en el ARNm, señalando además las regiones no traducidas.
CAPITULO 1 5/12/06 06:52 Página 14
www.FreeLibros.me

cierto «tambaleo» cuando uno de los tres nucleótidos no forma un emparejamientoperfecto tipo Watson-Crick; precisamente, esto es lo que permite que varios codonessean leídos por un mismo anticodón.
La Figura 1.15 muestra un ARNt, señalando el anticodón unido al codón.
El proceso de traducción comienza con la fase de iniciación, mediante la uniónde la subunidad pequeña del ribosoma a la caperuza del ARNm maduro que provie-ne del proceso de ayuste. A continuación, la misma subunidad ribosomal se despla-za por el ARNm hasta encontrar el codón de iniciación apropiado, momento en quese unen el ARNtMet (el ARN transferente que lleva el aminoácido Metionina) y la su-bunidad ribosomal grande. El bolsillo del ribosoma donde está unido este primerARNt se llama sitio A (aminoacil). En este proceso participan también varios facto-res de iniciación (eIF1 a eIF6, del inglés eukaryotic initiation factor). La segunda fasede la traducción se llama elongación, y consiste en un proceso cíclico por el que elribosoma se desplaza tres nucleótidos y el ARNt que ocupaba el sitio A pasa a ocu-par otra región del ribosoma llamada sitio P (peptidil). Gracias a este movimiento, elsiguiente codón del ARNm queda dentro del sitio A, a donde acude otro ARNt conun anticodón complementario al nuevo codón. A continuación, la cadena peptídicaque «cuelga» del ARNt que ocupa el sitio P es transferida al aminoácido del ARNtque ocupa el sitio A, con lo que la cadena polipeptídica se alarga en un aminoácido.Estos procesos están ayudados y catalizados por los propios ARN ribosomales y pordos factores de elongación (eEF1 y eEF2, del inglés eukaryotic elongation factor). Laterminación de la traducción tiene lugar cuando alguno de los tres codones de pa-rada ocupa el sitio A, porque en vez de unirse un ARNt acude un factor de termina-ción (eRF1 y eRF3 en eucariotas, del inglés eukaryotic release factor).
La Figura 1.16 contiene un enlace a un vídeo que muestra el proceso de traducción.
La traducción completa el proceso de expresión génica. Aunque actualmente seestá reconociendo el papel de los ARN no codificantes, que se transcriben y son pro-cesados pero no se traducen en proteínas, el aforismo «un gen, una proteína» siguesiendo válido en la mayoría de los casos. Igualmente, el «dogma central de la bio-logía molecular» (es decir, la vía ADN→ARN→Proteína) no siempre se cumple, por-que algunos virus y otros organismos tienen un genoma con ARN que se retro-trans-cribe a ADN. En cualquier caso, las nociones y mecanismos que se han repasado eneste capítulo constituyen el punto básico de arranque para comprender la naturale-za molecular de los genes y su función como portadores de información biológica.
15
Traducción y código genético en eucariotas
CAPITULO 1 5/12/06 06:52 Página 15
www.FreeLibros.me

CAPITULO 1 5/12/06 06:52 Página 15
www.FreeLibros.me

C A P Í T U L O 2
El ADN en el núcleo de la célula eucariota
Contenidos
2.1 La cromatina durante el ciclo celular
2.2 Replicación de la cromatina en interfase
2.3 Formación y segregación de los cromosomas durante la mitosis
2.4 Gametogénesis y meiosis
2.5 Recombinación a nivel molecular
2.1 La cromatina durante el ciclo celular
En las células somáticas que tienen núcleo, la molécula de ADN está presente en una for-ma peculiar llamada originalmente cromatina. Por la estructura de la doble hélice delADN, sabemos que la distancia entre nucleótidos es de 0,34 nm; si el genoma humanohaploide tiene 3 × 109 pares de bases, la longitud total del genoma en forma de doble hé-lice lineal sería algo superior a un metro, y además cada núcleo contiene dos copias delgenoma. Todo este material debe entrar en el núcleo de una célula eucariota, cuyo diá-metro medio es de 5 µm. Esto significa que el ADN ha de adoptar un alto grado de em-paquetamiento para poder alojarse dentro del núcleo. Este empaquetamiento se lleva acabo mediante la unión de la doble hélice con varios tipos de proteínas para dar lugar auna estructura que es, precisamente, la cromatina.
Las células eucariotas, al proliferar, siguen una serie de etapas en las que se llevan acabo los procesos necesarios para dar lugar a dos células hijas: duplicar los componen-tes celulares, segregarlos espacialmente y dividir la célula de modo que las dos células re-sultantes lleven todos los ingredientes necesarios para su correcto funcionamiento. Estasetapas deben completarse en orden, de un modo altamente regulado, y constituyen lo que
CAPITULO 2 5/12/06 06:54 Página 17
www.FreeLibros.me

se llama ciclo celular. En cada ciclo celular se distinguen por tanto varias fases: lainterfase (etapa en la que la célula duplica su contenido), la mitosis (etapa en la quelos componentes se separan a polos opuestos de la célula) y citoquinesis (separaciónfísica de las dos células hijas). Probablemente sea la cromatina el componente celu-lar en el que es más importante la duplicación y segregación correctas, ya que estova a asegurar que la información genética se transmita sin alteraciones. Por tanto, esimportante saber cómo se comporta la cromatina en las distintas etapas del ciclo ce-lular.
La Figura 2.1 muestra las distintas fases del ciclo celular de una célula eucariota y los cambios quesufre la cromatina.
Durante la interfase, que es la etapa más larga del ciclo, la cromatina está sujetaa un grado de empaquetamiento de unas 2 000 veces, es decir, lo que en su estadonatural ocuparía un tamaño de 2 000 mm se reduce a un tamaño de 1 mm. Esto seconsigue por la unión de la doble hebra de ADN con unas proteínas básicas llama-das histonas, cuyos grupos positivos interaccionan con los grupos negativos del es-queleto fosfato del ADN. Hay cinco tipos principales de histonas, llamadas H1, H2A,H2B, H3 y H4, que se asocian entre sí para formar un octámero: dos moléculas deH3 junto con dos moléculas de H4 forman un tetrámero, y dos dímeros H2A/H2Bforman otro tetrámero; ambos tetrámeros se asocian para formar un núcleo proteico(octámero) alrededor del cual se enrolla la molécula de ADN. En concreto, 146 pa-res de bases de ADN dan 1,65 vueltas alrededor del octámero, y sobre este com-plejo se une la histona H1. Esta estructura, de unos 10 nm de diámetro, es lo que seconoce con el nombre de nucleosoma, y es la unidad básica de organización de lacromatina. Los nucleosomas están unidos entre sí por el filamento de ADN que se vaenrollando a su alrededor, como bolas en una cuerda, y esto da lugar a la fibra decromatina de 10 nm. En esta estructura, unos 200 pares de bases ocupan 10 nm, loque significa un grado de empaquetamiento de unas seis veces respecto al tamañolineal que ocuparía un fragmento de ADN de esa longitud (200 × 0,34 nm = 64 nm).
La Figura 2.2 muestra algunos modelos tridimensionales de un nucleosoma.
En condiciones fisiológicas, la fibra de 10 nm sufre un segundo grado de enrolla-miento sobre sí misma para dar lugar a una estructura en forma de solenoide, conseis nucleosomas por vuelta. Esta configuración constituye la fibra de 30 nm, en laque el grado de empaquetamiento del ADN es de unas 40 veces. La fibra de 30 nmsufre diferentes grados de empaquetamiento durante interfase y, especialmente, en lamitosis, en la que la cromatina alcanza su empaquetamiento máximo (unas 10 000veces) y da lugar a las estructuras visibles que llamamos cromosomas. Estos tipos dealto grado de enrollamiento se consiguen porque la fibra de 30 nm forma asas que seunen por su base a una estructura proteica que sirve como andamio. El andamio(scaffold en inglés) está constituido por proteínas no histonas, de las que las princi-pales son la Sc1 (idéntica a la topoisomerasa II) y la Sc2 o SMC2, que pertenece auna familia de proteínas llamada SMC (Structural Maintenance of Chromosomes, eninglés). Estas proteínas cumplen también un papel importante en el mantenimiento
18
El ADN en el núcleo de la célula eucariota
CAPITULO 2 5/12/06 06:54 Página 18
www.FreeLibros.me

de la condensación de la cromatina (de ahí que también se les llame condensinas).Las asas de la fibra de 30 nm se unen al andamio mediante unas secuencias ricas enAdeninas y Timinas llamadas SAR (Scaffold Attachment Region en inglés), que tie-nen gran afinidad por las proteínas del andamio. La estructura que resulta de este en-rollamiento da lugar a una fibra de unos 300 nm de grosor, en la que el grado totalde empaquetamiento del ADN es de unas 2 000 veces. Las SAR son regiones impor-tantes, dispersas por el genoma, que flanquean genes y a menudo se asocian con losorígenes de replicación que veremos más adelante, por lo que se piensa que puedenjugar un papel importante en la función y estructura de la cromatina. Finalmente, elempaquetamiento máximo de la cromatina durante la mitosis se consigue al espira-lizarse la fibra de 300 nm para dar lugar a una estructura de 600 nm de grosor (unacromátide) en la que el ADN alcanza ya un grado de empaquetamiento de 10 000veces.
2.2 Replicación de la cromatina en interfase
La interfase se subdivide en tres fases, de las que la más importante es la fase de sín-tesis (fase S). En esta fase tiene lugar la duplicación de los componentes celulares,incluyendo la cromatina. La fase S viene precedida y seguida por dos breves fases G(de gap, hueco o hiato), fase G1 y fase G2 respectivamente. Uno de los principalesprocesos que tienen lugar durante la fase S es la duplicación del contenido total deADN del núcleo, que se lleva a cabo mediante la replicación del ADN y el ensam-blaje en nucleosomas para dar lugar a la nueva cromatina. El proceso de replicacióndel ADN ya había sido sugerido por Watson y Crick en su descripción del ADN, aldarse cuenta de que la estructura de la doble hélice y la complementariedad de ba-ses permitía un mecanismo sencillo de copia. Aunque durante algunos años se dis-cutió cómo podría funcionar este mecanismo, Matthew Meselson y Franklin Stahldemostraron que el ADN se replica de modo semi-conservativo, es decir, que cada
Doble hélice (2 nm)
Fibra de 30 nm
Nucleosoma
Fibra de 10 nm
Solenoide
19
Replicación de la cromatina en interfase
La Figura 2.3 muestra los distintos grados de empaquetamiento de la cromatina.
CAPITULO 2 5/12/06 06:54 Página 19
www.FreeLibros.me

una de las nuevas moléculas lleva una cadena de la molécula original y otra cadenanueva, sintetizada tomando como molde la cadena complementaria. Posteriormentese fueron descubriendo los detalles del proceso, e identificando los distintos compo-nentes que lo llevan a cabo.
La Figura 2.4 muestra esquemáticamente la replicación semiconservativa, y contiene un enlace a un sitio educativo que explica los experimentos de Meselson y Stahl.
En eucariotas, la replicación comienza en múltiples sitios de una misma molécu-la de ADN a la vez, llamados orígenes de replicación. Dada la velocidad de copiade las polimerasas, una sola molécula de ADN polimerasa tardaría varios días en re-plicar un cromosoma completo, por lo que de hecho la replicación de la cromatinase lleva a cabo en varios miles de orígenes de replicación a la vez. De todas formas,aunque todos los orígenes funcionan durante la fase S, no todos se ponen en marchaa la vez: en algunos orígenes la replicación comienza al principio de la fase S (repli-cación temprana) y en otros comienza hacia el final (replicación tardía). En cadaorigen de replicación se forma una burbuja de replicación, por acción de unas heli-casas que abren la doble hélice para permitir la unión de las enzimas que llevarán acabo la síntesis, que son las polimerasas de ADN. Este primer paso está sujeto a unafina regulación, ya que un mismo origen sólo se replica una vez en cada ciclo ce-lular. De hecho, aunque la replicación a partir de un origen ya haya terminado y ésemismo origen pudiese volver a iniciar otro ciclo de replicación en la misma fase S,esto nunca sucede. Esta regulación se lleva a cabo por la acción de varios complejosproteicos como el ORC (del inglés Origin Recognition Complex), el complejo de pro-teínas MCM, y la geminina.
En cada burbuja se forman dos horquillas de replicación, apuntando en direc-ciones contrarias. Como los eventos que tienen lugar en cada horquilla son idénticos,basta estudiar lo que sucede en una de ellas. En primer lugar, una proteína de unióna ADN mono-catenario, llamada RPA (Replication Protein A, en inglés) se une a lascadenas que han sido separadas por las helicasas, y esto ayuda a mantener la burbu-ja de replicación abierta. A continuación, a cada una de las cadenas se une una en-zima llamada primasa, que es una ARN polimerasa dependiente de ADN (es decir,sintetiza ARN tomando como molde ADN). La primasa sintetiza un pequeño ARNque actúa como cebador (primer, en inglés, de ahí su nombre) para iniciar la síntesisde ADN. Las polimerasas de ADN dependientes de ADN llevan a cabo la síntesisde ADN elongando la cadena a partir del cebador de ARN generado previamente.Esta síntesis tiene lugar de modo diferente en cada una de las cadenas, debido a ladistinta orientación que tienen. En la cadena que discurre en sentido 3’→5’, el ceba-dor y la nueva cadena sintetizada sobre ella discurrirán en sentido 5’→3’, que es elúnico modo en que pueden sintetizar ADN las polimerasas. Por tanto, en esta cade-na, llamada cadena guía (leading strand en inglés) se puede sintetizar el nuevo ADNde modo continuo. Por el contrario, la otra cadena de la molécula original discurreen sentido 5’→3’, por lo que la nueva cadena sintetizada a partir de ésta (cadena re-trasada, o lagging strand en inglés) debería crecer en sentido 3’→5’. Como esto no esposible, ya que las polimerasas son incapaces de sintetizar ADN de esta forma, lo quesucede es que se generan varios cebadores de ARN a pequeñas distancias, sinteti-
20
El ADN en el núcleo de la célula eucariota
CAPITULO 2 5/12/06 06:54 Página 20
www.FreeLibros.me

zándose el ADN a partir de cada uno de ellos en sentido 5’→3’. El resultado neto esla síntesis semi-discontinua de la cadena retrasada en sentido 3’→5’ gracias a la sín-tesis de pequeños fragmentos (cada uno de los cuales fue sintetizado en sentido5’→3’). Estos fragmentos se denominan fragmentos de Okazaki, y tienen una longi-tud entre 100 y 1 000 nucleótidos en eucariotas. A medida que la horquilla de repli-cación avanza, las helicasas continúan abriendo la doble hélice (ayudadas por otrasenzimas llamadas topoisomerasas, que relajan la tensión generada por delante de lahorquilla). Tras la síntesis en ambas cadenas, otras enzimas eliminan los fragmentosde ARN que habían servido de cebadores, rellenan los huecos que quedan, y final-mente unas ligasas sellan los últimos enlaces fosfo-di-éster para obtener una cadenasin solución de continuidad.
Figura 2.5. En estas animaciones se muestra esquemáticamente el proceso de síntesis de la cadenaguía y de la cadena retrasada durante la replicación del ADN.
Aunque los complejos proteicos que intervienen en la replicación del ADN en eu-cariotas no han sido caracterizados con tanta profundidad como en procariotas, hoyen día se conocen bastantes detalles. De entre las diferentes ADN polimerasas iden-tificadas en eucariotas, la síntesis de los cebadores de ARN es obra de la primasa,que actúa junto con la ADN polimerasa αα. Ésta prolonga el cebador de ARN unospocos nucleótidos. El factor C de la replicación (RFC) desplaza la polimerasa α-pri-masa, una vez que se ha formado el cebador de ARN, y trae consigo otra proteínallamada PCNA (Proliferating Cell Nuclear Antigen, en inglés), que a su vez es la res-ponsable de reclutar la polimerasa que lleva a cabo la síntesis de ADN. Éstas son laADN polimerasa δδ (en la cadena retrasada) y la ADN polimerasa εε (en la cadenaguía). El complejo PCNA-Polimerasa también incluye una endonucleasa (FEN1 eneucariotas) que es la responsable de degradar los cebadores de ARN que son despla-zados por la polimerasa. Finalmente, la ligasa que culmina el proceso en eucariotases la ADN ligasa I.
La Figura 2.6 contiene un vídeo que explica el proceso de replicación de la cadena retrasada, con los distintos complejos proteicos implicados.
Es importante entender que la replicación del ADN no se refiere sólo a la dupli-cación de la doble cadena, sino que implica también el ensamblaje de la cromatinaa medida que el ADN se va replicando. De hecho, durante la replicación sólo se al-tera el empaquetamiento de la cromatina en una pequeña región: se estima que sólolos dos nucleosomas por delante de la horquilla de replicación se ven afectados porel avance de la maquinaria replicativa, y que unos 300 nucleótidos por detrás de lahorquilla ya se vuelven a ensamblar los nuevos nucleosomas para comenzar a formarlas dos nuevas fibras de cromatina. Este re-ensamblaje de la cromatina se produce envarias etapas, comenzando con la unión del tetrámero H3-H4 en primer lugar, se-guida de la deposición del tetrámero H2A/H2B; finalmente se añade la histona H1.Lógicamente, es muy importante mantener la «memoria» acerca del estado en queestaba una región de cromatina, para que las fibras hijas que se producen tras la re-plicación mantengan el mismo estado que tenía la fibra original. Como veremos, esto
21
Replicación de la cromatina en interfase
CAPITULO 2 5/12/06 06:54 Página 21
www.FreeLibros.me

se consigue por modificaciones químicas de algunos aminoácidos de las histonas, quese distribuyen por igual desde los nucleosomas de la fibra original a los nucleosomasde las fibras recién formadas.
En el caso de moléculas lineales de ADN, como los cromosomas, la replicaciónde los extremos terminales presenta un problema particular, puesto que el cebadorde ARN localizado en el extremo de la cadena retrasada no puede ser reemplazadopor ADN (como ocurre en la replicación normal). Por tanto, los cromosomas estarí-an sujetos a una degradación progresiva de sus extremos con cada división celular, yesto sería letal en células que se dividen muchas veces a lo largo de la vida de un in-dividuo. Para evitar esto, los cromosomas de eucariotas tienen en sus extremos unasestructuras especiales, llamadas telómeros, que protegen los extremos libres y evitanla erosión asociada con la replicación. Estas estructuras están formadas por la repe-tición una pequeña secuencia que está repetida múltiples veces al final del extremo3’ de una de las cadenas de la doble hélice, cadena que por tanto será más larga quela otra. Estas repeticiones, que en humanos están formadas por el hexanucleótidoTTAGGG, son añadidas por la acción de un enzima denominado telomerasa, queconsta de un componente ARN y de un componente enzimático con actividad poli-merasa de ADN dependiente de ARN. Usando el componente ARN como molde, latelomerasa va añadiendo nuevas repeticiones TTAGGG al extremo 3’ de una de lascadenas del cromosoma. Esto posibilita que, durante la replicación, se sintetice el ce-bador de ARN sobre las repeticiones teloméricas y no se pierda material genéticopropio del cromosoma. Las repeticiones que se pierden por causa de la replicación,son después añadidas por acción de la telomerasa, lo que asegura la integridad de loscromosomas durante toda la vida de la célula.
La Figura 2.7 incluye un vídeo que ilustra el problema de la replicación de los extremos y la acciónde la telomerasa.
Una consecuencia importante de la replicación es que el contenido total de ADNde la célula se duplica antes de que los cromosomas se hagan visibles y se sepa-ren en la mitosis, como veremos a continuación. Esto es precisamente lo que haceque cada cromosoma, durante la mitosis, esté compuesto por dos cromátides herma-nas pegadas. En este sentido, es importante evitar la confusión entre el número decromosomas y el contenido total de ADN de una célula. El número haploide de cro-mosomas (número de cromosomas distintos, que es característico de cada especie) serepresenta por la letra n; una célula somática tiene un número diploide (2n) de cro-mosomas, ya que tiene dos copias de cada cromosoma (n parejas de cromosomashomólogos). Antes de entrar en la fase S, una célula somática tiene un número 2n decromosomas (aunque no se ven en su forma típica, por estar la cromatina poco con-densada) y un contenido total de ADN correspondiente a una cromátide por cro-mosoma: esto se representa por la cantidad de ADN 2C. Al final de la replicación delADN, esa célula sigue teniendo 2n cromosomas (todavía invisibles) pero ahora tieneun contenido de ADN igual a 4C, ya que tenemos dos cromátides por cromosoma.Tras la mitosis, la segregación de las cromátides hermanas tiene como resultado quecada una de las células hijas lleva otra vez 2n cromosomas y un contenido de ADN
22
El ADN en el núcleo de la célula eucariota
CAPITULO 2 5/12/06 06:54 Página 22
www.FreeLibros.me

igual a 2C. De este modo, se mantiene el número de cromosomas y la cantidad totalde ADN tras las sucesivas divisiones celulares.
2.3 Formación y segregación de los cromosomas durante 2.3 la mitosis
La cromatina es una estructura dinámica cuyo grado de empaquetamiento es máximodurante la mitosis, y por eso en esta fase del ciclo celular se puede ver en una formaespecialmente condensada que da lugar a los cromosomas. Como hemos visto, estacondensación se produce porque la fibra de cromatina de 300 nm se enrolla en for-ma de espiral, proporcionando un grado de empaquetamiento unas cinco veces ma-yor al observado durante la interfase. La mitosis es el proceso de división de las cé-lulas somáticas, fundamental en la proliferación celular que tiene lugar durante eldesarrollo embrionario, el crecimiento y el mantenimiento de los tejidos. Supone unareorganización drástica de todos los componentes celulares, pero muy especialmentede los cromosomas, cuya segregación a cada una de las células hijas debe ser muy pre-cisa y estar finamente regulada y coordinada con la separación física de las nuevas cé-lulas (citoquinesis). Durante la mitosis, la maquinaria celular se especializa en llevara cabo los distintos procesos que tienen lugar en la célula: condensación de la cro-matina, formación del huso mitótico, segregación de los componentes y fisión celular.
La primera fase de la mitosis (profase), comienza con la condensación de la cro-matina, la ruptura de la envuelta nuclear y el desarrollo del huso mitótico. Es im-portante recordar que la cromatina ha sido replicada en la fase S de la interfase pre-via, por lo que cada cromosoma está ahora formado por dos cromátides hermanas.Los microtúbulos se unen a los quinetocoros, estructuras proteicas formadas sobrelos centrómeros de cada cromosoma, y comienzan a transportar a los cromosomashacia el plano ecuatorial del huso.
En la fase siguiente (metafase) cada cromosoma está unido a microtúbulos proce-dentes de los dos polos de la célula, de modo que todos los cromosomas están en elecuador del huso mitótico sometidos a fuerzas tensionales opuestas. Los mecanismosmoleculares que regulan la cohesión de cromátides hermanas comienzan a conocersecada vez mejor, y su implicación en patología humana está adquiriendo mayor rele-vancia. Por ejemplo, se han identificado las proteínas cromosómicas necesarias paramantener la cohesión de cromátides hermanas, que se denominan cohesinas. En eu-cariotas funcionan como cohesinas al menos cuatro miembros de la familia SMC(Structural Maintenance of Chromosomes), y en Xenopus (sapo) se ha identificado uncomplejo que es necesario para la cohesión y que está formado por SMC1 y SMC3junto con SCC1 (Sister Chromatid Cohesion 1). La cohesión se establece en la fase Sdel ciclo celular, durante la replicación del ADN, aunque las cohesinas estaban ya pre-sentes en la cromatina. Al replicarse el ADN, ambas cromátides quedan unidas por lascohesinas en toda su longitud, distinguiéndose dos tipos de cohesión: la cohesión enlos centrómeros y la cohesión en los brazos cromosómicos. Ambos tipos de cohe-sión están mediados por cohesinas, pero los procesos que los regulan son algo dife-rentes. El mantenimiento de esta cohesión durante metafase es muy importante, por-que es precisamente el balance entre las fuerzas de los microtúbulos y la cohesión de
23
Formación y segregación de los crom
osomas durante la m
itosis
CAPITULO 2 5/12/06 06:54 Página 23
www.FreeLibros.me

ambas cromátides lo que permite el alineamiento de los cromosomas en el plano ecua-torial: la tendencia de los microtúbulos a separar las cromátides se ve contrarrestadapor la cohesión que las mantiene unidas, y gracias a esta cohesión se genera la ten-sión necesaria para formar la placa metafásica. Es precisamente la pérdida brusca decohesión lo que permite la separación de las cromátides. Lógicamente, un compo-nente fundamental en estos procesos es el quinetocoro, que en definitiva es el puntode cada cromosoma donde se anclan los microtúbulos. Existe en células eucariotas unsistema que comprueba que todos los quinetocoros estén unidos a microtúbulos y ac-tiva un punto de control que impide la separación de las cromátides antes de conse-guir la perfecta unión de todos los quinetocoros a sus microtúbulos respectivos.
La metafase va seguida por la anafase, en la que tiene lugar la segregación de lascromátides hermanas de cada cromosoma hacia polos opuestos de la célula. La se-paración simultánea de 46 pares de cromátides hermanas en la transición metafase-anafase es un momento crucial del ciclo celular, y por tanto está finamente regulado.Por ejemplo, es crítico que la cohesión se pierda en el momento adecuado, para quecada cromátide pueda migrar a una célula hija sin errores. En general, se observa queprimero se pierde la cohesión en los centrómeros, y a medida que los microtúbulosvan «tirando» de los quinetocoros se va perdiendo la cohesión en los brazos. La se-paración se lleva a cabo mediante la degradación de las cohesinas.
La última fase de la mitosis es la telofase, en la que los cromosomas vuelven adescondensarse y se forma la envoltura nuclear alrededor de cada uno de los nuevosnúcleos que se han formado en cada polo de la célula. Terminada la mitosis, el pro-ceso de división celular se completará con la citoquinesis, en la que los componen-tes celulares se reordenan y se reorganiza el citoesqueleto para facilitar la divisón fí-sica de la célula en dos células hijas.
La Figura 2.8 contiene un vídeo que ilustra las principales fases de la mitosis.
Dada la importancia de la separación de las cromátides hermanas en anafase, seha investigado mucho en torno a su regulación. Se sabe que la degradación de las co-hesinas se lleva a cabo por dos mecanismos distintos: fosforilación (mediada por laquinasa Polo) de algunos componentes, y proteolisis de otros. Las proteínas implica-das en la proteolisis de la cohesinas se llaman separinas (o separasas). Se ha com-probado que las separinas son capaces de romper el complejo cohesina porque de-gradan la proteína SCC1 (una cohesina) durante el comienzo de la anafase,permitiendo la separación de las cromátides por la fuerza que ejercen los microtúbu-los. ¿Cómo se activan las separinas en el momento exacto de la anafase? Esto se haresuelto gracias a la identificación de las securinas, proteínas que inhiben la acciónproteolítica que ejercen las separinas sobre las cohesinas. Por tanto, durante la mito-sis las securinas están unidas a las separinas y así inhiben su acción, de modo que elcomplejo cohesina permanece intacto y las cromátides permanecen unidas. La diso-ciación de las cohesinas se produce por la degradación súbita de las securinas al co-mienzo de la anafase, de manera que las separinas quedan libres y pueden cortar porproteolisis el complejo cohesina. El evento crucial, por tanto, es la degradación de se-curinas, degradación que está mediada por un complejo proteico llamado APC (Ana-phase Promoting Complex) que posee actividad ubiquitina-protein-ligasa y promueve
24
El ADN en el núcleo de la célula eucariota
CAPITULO 2 5/12/06 06:54 Página 24
www.FreeLibros.me

la degradación de diversas proteínas al comienzo de la anafase. Lógicamente, estosprocesos no deben comenzar hasta que todos los quinetocoros están correctamenteunidos a los microtúbulos del huso, pues de lo contrario la segregación de las cromá-tides no sería correcta. Por tanto, existe también un mecanismo de señalización quedetecta si todos los quinetocoros han sido correctamente unidos por microtúbulos yenvía una señal de activación del APC, para que dé comienzo la pérdida de cohesión.
En la Figura 2.9 se explica el mecanismo de degradación de las cohesinas.
2.4 Gametogénesis y meiosis
En organismos de reproducción sexual, la formación de los gametos implica unmodo de división celular diferente al de las células somáticas. Los gametos deberánposeer una sola copia de cada cromosoma, de modo que el cigoto resultante de launión del gameto masculino y del gameto femenino en la fertilización sea diploide(con un cromosoma de origen paterno y otro cromosoma de origen materno en cadapar cromosómico). Para obtener un número haploide (n) de cromosomas en los ga-metos, el proceso de formación de los mismos (gametogénesis) tiene unas caracte-rísticas especiales. La principal peculiaridad es la existencia de un tipo distinto de di-visión celular en el que una célula diploide (2n) replica su ADN una vez (duplicandosu contenido total en ADN de 2C a 4C) pero experimenta dos divisiones cromosó-micas; esto tiene como consecuencia que los gametos masculino (espermatozoide) yfemenino (oocito) llevan un número haploide de cromosomas (n) y un contenido to-tal de ADN igual a C (una cromátide por cromosoma). Este modo de división celu-lar se denomina meiosis, y tiene además otras características muy importantes parala transmisión de la variabilidad genética. En ambas líneas germinales, masculina ofemenina, la gametogénesis comienza cuando los gonocitos experimentan una seriede divisiones mitóticas típicas en las que las células van madurando hasta llegar a for-mar las gonias (espermatogonias u oogonias, respectivamente) y los gametocitos pri-marios, que son células diploides (2n). A partir de este momento, las células repli-can su ADN en la fase S y a continuación entran en meiosis, en vez de dividirse pormitosis.
La meiosis incluye en realidad dos distintas divisiones cromosómicas, por lo quesuele separarse en dos fases llamadas meiosis I (o primera división meiótica) y meio-sis II (segunda división meiótica). La meiosis I es la más importante de las dos, y co-mienza con una profase larga, complicada y claramente distinta de la profase de lamitosis. Esta profase de la meiosis I (llamada, por tanto, profase I) comienza con lacondensación de la cromatina que, no lo olvidemos, se había replicado en la fase Sprecedente. Ambas cromátides están íntimamente unidas formando un único fila-mento, que se une por sus extremos a la membrana nuclear. Esta primera parte de laprofase I se llama leptoteno. En la siguiente etapa, llamada cigoteno, los cromoso-mas homólogos se emparejan longitudinalmente con gran exactitud, de manera quelas secuencias de cada uno de los dos homólogos quedan perfectamente alineadas.La unión entre los cromosomas de cada par se hace progresivamente más fuerte, dan-do lugar a un fenómeno que se conoce como sinapsis. La sinapsis se mantiene gra-
25
Gametogénesis y m
eiosis
CAPITULO 2 5/12/06 06:54 Página 25
www.FreeLibros.me
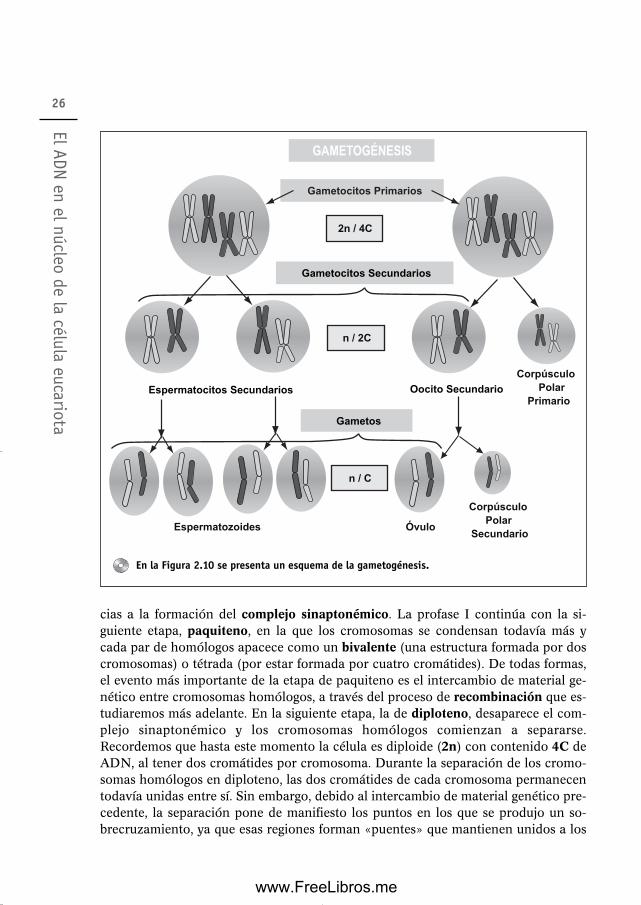
cias a la formación del complejo sinaptonémico. La profase I continúa con la si-guiente etapa, paquiteno, en la que los cromosomas se condensan todavía más ycada par de homólogos apacece como un bivalente (una estructura formada por doscromosomas) o tétrada (por estar formada por cuatro cromátides). De todas formas,el evento más importante de la etapa de paquiteno es el intercambio de material ge-nético entre cromosomas homólogos, a través del proceso de recombinación que es-tudiaremos más adelante. En la siguiente etapa, la de diploteno, desaparece el com-plejo sinaptonémico y los cromosomas homólogos comienzan a separarse.Recordemos que hasta este momento la célula es diploide (2n) con contenido 4C deADN, al tener dos cromátides por cromosoma. Durante la separación de los cromo-somas homólogos en diploteno, las dos cromátides de cada cromosoma permanecentodavía unidas entre sí. Sin embargo, debido al intercambio de material genético pre-cedente, la separación pone de manifiesto los puntos en los que se produjo un so-brecruzamiento, ya que esas regiones forman «puentes» que mantienen unidos a los
26
El ADN en el núcleo de la célula eucariota
Corpúsculo Polar
Primario
Espermatozoides Óvulo
Corpúsculo Polar
Secundario
Gametocitos Secundarios
Gametos
2n / 4C
n / 2C
n / C
Espermatocitos Secundarios Oocito Secundario
GAMETOGÉNESIS
Gametocitos Primarios
En la Figura 2.10 se presenta un esquema de la gametogénesis.
CAPITULO 2 5/12/06 06:54 Página 26
www.FreeLibros.me

dos homólogos de cada par e impiden la separación total. Estos puntos se denomi-nan quiasmas, y han de resolverse de algún modo para que la separación de los cro-mosomas pueda completarse. Por tanto, la profase I termina con una etapa corta de-nominada diaquinesis, en la que la cromatina alcanza su grado máximo decondensación y los cromosomas aparecen más cortos y gruesos.
Tras la profase I, los espermatocitos primarios entran ahora en metafase I, en lacual desaparece la membrana nuclear, se forma el huso y los microtúbulos traccio-nan por los quinetocoros. Esto hace que los bivalentes, que llevan los cromosomasparcialmente separados (unidos únicamente por los quiasmas), se orienten en elecuador de la célula. Debido a esta configuración, los cromosomas homólogos se si-túan en la placa metafásica con los centrómeros apuntando cada uno hacia uno delos polos de la célula. En la anafase I, la tracción de los microtúbulos y la activacióndel Complejo Promotor de la Anafase permiten la separación total de cada cromo-soma homólogo hacia uno de los polos, fenómeno llamado disyunción. Finalmente,en la telofase I se han formado ya dos grupos de cromosomas en cada polo de la cé-lula: cada uno de estos grupos consta de un número haploide (n) de cromosomas,cada uno de los cuales posee dos cromátides (contenido total de ADN igual a 2C).La meiosis I termina con la citoquinesis, la división física de las dos células hijas.Esta última fase es diferente en la línea germinal masculina y femenina, porque asícomo las células hijas del espermatocito primario son iguales, en el caso de la líneafemenina una de las dos células hijas se lleva casi todo el citoplasma mientras que laotra es mucho menor. Por tanto, en la espermatogénesis cada esperamatocito pri-mario da lugar a dos espermatocitos secundarios, mientras en la oogénesis cada oo-cito primario da lugar a un oocito secundario y a un corpúsculo polar de primerorden.
La segunda división meiótica, o meiosis II, es prácticamente igual a una mitosis.La única diferencia estriba en que la célula que se divide es haploide, mientras queen el caso de la mitosis la célula es diploide. Por tanto, esta división celular va a se-parar las dos cromátides que componen cada cromosoma de un gametocito secun-dario, para generar gametos con un número haploide de cromosomas (n), cada unode los cuales está formado por una sola cromátide (contenido total de ADN igual aC). Como decíamos al principio, esto asegura que la fecundación da lugar a un cigo-to diploide (2n) con contenido de ADN igual a 2C, al recibir un complemento cro-mosómico de cada gameto. El modo en que se completa la meiosis es también dife-rente en ambos sexos. Así como la espermatogénesis discurre de un modo continuodesde que se alcanza la madurez sexual, la oogénesis se detiene en profase I, de ma-nera que un alto número de oocitos primarios permanecen en un estado prolongadode diploteno, llamado dictioteno. Estos oocitos sólo proseguirán su maduración alllegar la madurez sexual, cuando con cada ciclo menstrual un oocito culmina lameiosis I y completa también la meiosis II para dar un oocito secundario (óvulo) yun segundo corpúsculo polar.
La Figura 2.11 incluye un vídeo en el que se muestran esquemáticamente las distintas fases de la meiosis.
27
Gametogénesis y m
eiosis
CAPITULO 2 5/12/06 06:54 Página 27
www.FreeLibros.me

Es importante fijarse en un hecho distintivo de la anafase de la meiosis I, queno comparten ni la anafase de la meiosis II ni la anafase de la mitosis. Este hechoconsiste en que los cromosomas homólogos se separan pero, al mismo tiempo, lasdos cromátides de cada cromosoma, por la acción de unas moléculas llamadas shu-goshinas, deben permanecer unidas por los centrómeros. Esto se consigue porque lascohesinas centroméricas no son degradadas por las separasas. Las shugoshinas seunen específicamente a los centrómeros y, por su asociación con una fosfatasa, im-piden la fosforilación de las cohesinas a ese nivel, lo cual a su vez impide que las co-hesinas sean degradadas por las separasas. Después, en la meiosis II, la ausencia deshugoshinas permite una segunda ola de activación de separasas que finalmente lle-vará a la separación completa de las dos cromátides de cada cromosoma homólogo.
Al margen de lo dicho en relación con la reducción del número total de cromo-somas en los gametos, la gran importancia de la meiosis reside en que es uno de losprincipales mecanismos de creación de variabilidad genética. Esto sucede a dos ni-veles, primero por la segregación aleatoria de los cromosomas de cada progenitor alos gametos, y en segundo lugar por el intercambio de material genético que tiene lu-gar durante los procesos de recombinación.
Respecto a lo primero, es fácil comprender que cada división meiótica producirágametos con distintas combinaciones de los cromosomas que estaban en la céluladiploide original, ya que la segregación se produce al azar. Para entender esto es útilimaginarse todos los cromosomas de una célula diploide como la suma de dos con-juntos haploides, el paterno y el materno. Así, cada pareja de cromosomas homólo-gos consta de un homólogo de origen paterno y otro de origen materno. Cuando loshomólogos se separan en la meiosis, no pasan todos los de origen paterno a una delas células hijas, y todos los de origen materno a la otra; por el contrario, se distri-buyen aleatoriamente. Como los homólogos pueden tener pequeñas diferencias enlos alelos presentes para algunos genes, el resultado es que cada gameto lleva unacombinación única de cromosomas de origen paterno y materno mezclados. La va-riabilidad que se puede generar por este sencillo mecanismo es altísima, porque con23 parejas de cromosomas el número de combinaciones posibles es igual a 223, o loque es lo mismo 8.388.608.
Por lo que respecta al segundo tipo de variabilidad introducida durante la meiosis,en la especie humana se ha calculado que se producen unos 55 sobrecruzamientos porcélula, porque ese es el número medio de quiasmas que se observan. Esto supone unamedia de al menos dos sobrecruzamientos por par cromosómico, incluidos los cro-mosomas sexuales. La presencia de estos quiasmas es importante para mantener losbivalentes unidos hasta anafase I, y asegurar que la disyunción se produce de modocorrecto. Pero además, es probable que el número total de eventos de recombinaciónsea todavía mayor al número de quiasmas, porque no todas las recombinaciones pro-ducen un sobrecruzamiento (como se verá en el apartado siguiente). Por tanto, el gra-do de intercambio de material genético entre cromátides de cromosomas homólogoses bastante alto, y hace que los cromosomas que finalmente llegan a un gameto seanligeramente distintos a los cromosomas que estaban presentes en la célula inicial.Como resultado de esto, la variabilidad genética generada durante la meiosis es alta,y por eso la probabilidad de que dos individuos tengan dos descendientes genética-mente idénticos es prácticamente nula. Esto es precisamente lo que persigue la repro-ducción sexual: generar descendientes distintos a sus progenitores y distintos entre sí.
28
El ADN en el núcleo de la célula eucariota
CAPITULO 2 5/12/06 06:54 Página 28
www.FreeLibros.me

2.5 Recombinación a nivel molecular
Uno de los temas más importantes en genética es la caracterización de los mecanis-mos moleculares por los que se produce intercambio de material genético entre cro-mátides durante la meiosis. Distintos modelos han intentado explicar cómo dos mo-léculas de ADN homólogas pueden entrecruzarse e intercambiar material genético.El paso inicial común a todos los modelos propuestos es el alineamiento preciso deambas moléculas, precisamente debido a que son cadenas de ADN homólogas, esdecir, pertenecientes a cromosomas homólogos y por tanto con la misma secuenciade nucleótidos. En realidad, hoy sabemos que ambas moléculas no son absoluta-mente idénticas, ya que pueden existir diferencias alélicas en su secuencia (por ejem-plo, pequeñas diferencias de un nucleótido). En cualquier caso, el alineamiento dedos secuencias homólogas es un requisito imprescindible para que se inicie el proce-so de recombinación, que se denomina por eso recombinación homóloga. Dicho ali-neamiento, como es lógico, se produce durante la profase I de la meiosis merced alcomplejo sinaptonémico que mantiene estrechamente unidos los cromosomas ho-mólogos en toda su longitud. Es lógico pensar que dicha configuración permite quedos moléculas de ADN de secuencia homóloga se mantengan en contacto.
Los primeros modelos de recombinación proponían que, tras el alineamiento, am-bas moléculas de ADN sufren una mella en una de sus cadenas, exactamente en lamisma posición, y esto deja dos cadenas «libres» que se intercambian entre sí y seunen a la molécula homóloga por complementariedad de bases. Dado que la gene-ración de dos mellas simultáneas en la misma posición es un evento muy improba-ble, Meselson y Radding propusieron otro modelo en el que una sola mella en unade las dos moléculas es suficiente para iniciar el proceso de recombinación, ya quela cadena libre puede invadir la doble hélice homóloga. Los estudios llevados a caboen distintas especies de eucariotas en los últimos años han demostrado que la re-combinación se inicia por la aparición de una rotura completa de una de las dos mo-léculas homólogas, es decir, una rotura bi-catenaria (de las dos cadenas de una do-ble hélice). Dichas lesiones, llamadas DSB (Double-Strand Break, en inglés), segeneran con cierta frecuencia en el ADN celular en respuesta a diversas causas; pa-rece comprobado que la creación específica de un DSB durante profase I es el pro-ceso iniciador de la recombinación.
Según el modelo actual de recombinación homóloga, en este proceso intervienenuna serie de complejos proteicos:
• Complejo RAD50, formado por las moléclulas MRE11, RAD50 y NBS1.
• El complejo RAD52, que incluye varios componentes (RAD51, RAD52,RAD54, RAD55 y RAD57 entre otros).
• La molécula RPA (la misma proteína A de la replicación).
Tras la creación de un DSB, los extremos libres son procesados mediante la activi-dad exonucleasa del complejo RAD50, que actúa en dirección 5’→3’ y, por tanto, ge-nera extremos libres más largos en la hebra 3’. Este extremo protruyente se recubrede RPA, RAD51 y otras moléculas del complejo RAD52 para formar un filamentonucleo-proteico. Este filamento tiene la capacidad de invadir la doble hebra homó-loga, abriendo en ella una burbuja, y se empareja a la cadena complementaria que
29
Recombinación a nivel m
olecular
CAPITULO 2 5/12/06 06:54 Página 29
www.FreeLibros.me

discurre en dirección antiparalela. A partir de este extremo 3’ se extiende la cadenausando la hebra complementaria como molde, al tiempo que se extiende también elotro extremo que había quedado libre. Tras una corta extensión, los extremos libresse unen por acción de una ligasa y esto genera dos estructuras en las que una hebrasalta de una molécula de ADN a la molécula homóloga. Dichas estructuras se deno-minan estructuras de Holliday, que fue el primero en proponer su existencia. Es im-portante tener en cuenta que si las dos moléculas de ADN no son inicialmente idén-ticas en su secuencia, durante el proceso de recombinación se pueden formarmoléculas híbridas, en las que ambas cadenas no son idénticas. Dichas moléculas deADN se llaman heteroduplex, y son muy importantes porque los desemparejamien-tos son corregidos por un mecanismo de reparación que se estudiará en otro capítu-lo; dicha corrección hace que una de las dos cadenas se modifique para hacerse per-fectamente complementaria a la otra, en un proceso llamado conversión génica.Como veremos en otras partes de este texto, la conversión génica es un mecanismoque da lugar a varias enfermedades genéticas en humanos.
Las estructuras de Holliday dan lugar unas estructuras cruciformes formadas pordos moléculas de ADN, llamadas también estructuras chi, que han de resolverse dealgún modo para permitir la separación de las dos cromátides. La resolución de lasestructuras de Holliday puede hacerse según un plano vertical o según un plano ho-rizontal, y es precisamente el tipo de resolución que se lleva a cabo lo que determi-na el tipo de moléculas que se generan. Por ejemplo, si las dos estructuras de Holli-day se resuelven según el mismo plano, las moléculas resultantes van a dar lugar aun sobrecruzamiento (la configuración que da lugar a los quiasmas que se ven en lameiosis); en cambio, cuando las dos estructuras de Holliday se resuelven según pla-nos distintos se producirá recombinación sin sobrecruzamiento. A su vez, cada unade estas dos posibilidades puede darse con o sin conversión génica, dependiendo dela presencia de heteroduplex y del modo en que se reparan.
Curiosamente, el modelo de recombinación iniciado por una rotura bicatenariaen una cadena es fruto de los estudios de reparación de este tipo de lesiones en eu-cariotas. Como veremos en otro capítulo, las roturas bicatenarias son un tipo fre-cuente de agresión al ADN, y son reparados en células somáticas precisamente porun mecanismo de recombinación homóloga que tiene lugar durante la fase S del ci-clo celular. En los últimos años se ha visto que este mismo mecanismo explica tam-bién las predicciones acerca de la recombinación durante la meiosis, y que de hechola maquinaria proteica responsable es básicamente la misma. Por tanto, hoy en díase considera como un mismo mecanismo que se ha adaptado a dos funciones ce-lulares importantes como la reparación del ADN y la generación de variabilidadgenética durante la formación de los gametos. Más recientemente, se ha sugeridoque la recombinación homóloga también puede tener otra función importante: la rei-niciación de la replicación del ADN. A menudo, la horquilla de replicación se paraprematuramente durante la síntesis de ADN y toda la maquinaria replicativa se des-ensambla; antes se pensaba que estas horquillas interrumpidas se reinician por el en-samblaje de un nuevo complejo de replicación en ese punto, pero cada vez hay másdatos a favor de la hipótesis de que la replicación se reinicia en esas horquillas porun fenómeno de recombinación homóloga. Dicha recombinación podría darse entrelas dos cromátides hermanas idénticas (la cromátide con la horquilla interrumpida y
30
El ADN en el núcleo de la célula eucariota
CAPITULO 2 5/12/06 06:54 Página 30
www.FreeLibros.me

SI sobrecruzamientoNO sobrecruzamiento
NO conversión
SI conversión
NO conversión
SI conversión
T
AG
C
G
C
G
C
T
AG
C
G
C
G
C
h/hh/h
T
G
A
C
G
C
G
C T
G
A
C
G
C
G
C
h
v
h
v
h/vh/v
T
AG
C
G
C
G
C
T
AG
C
G
C
G
C
la que se ha originado por la replicación hasta ese punto), que sería lo normal, o bienpuede darse entre cromátides de cromosomas homólogos, en cuyo caso se originaríaun fenómeno de recombinación homóloga con posible sobrecruzamiento. De hecho,algunos autores han sugerido que, originalmente, la principal función del mecanismode recombinación fue precisamente la reparación de horquillas de replicación inte-rrumpidas.
31
Recombinación a nivel m
olecular
La Figura 2.12 muestra esquemáticamente el modelo de recombinación iniciado por una roturabicatenaria en uno de los cromosomas homólogos, así como la resolución de las estructuras de Holliday y los posibles resultados de los procesos de recombinación.
CAPITULO 2 5/12/06 06:54 Página 31
www.FreeLibros.me

CAPITULO 2 5/12/06 06:54 Página 31
www.FreeLibros.me

C A P Í T U L O 3
Técnicas básicas de genéticamolecular
Contenidos
3.1 Tecnología del ADN recombinante: métodos y usos más frecuentes
3.2 Enzimas de restricción
3.3 Técnicas básicas de hibridación de ácidos nucleicos.
3.4 Amplificación in vitro de ADN (PCR)
3.5 Secuenciación del ADN
3.6 Microarrays.
3.1 Tecnología del ADN recombinante: métodos y usos 3.1 más frecuentes
A principios de los años 1970 se desarrollaron una serie de técnicas que dieron lugar a loque se llamó «ingeniería genética», «clonación molecular» o «tecnología del ADN re-combinante». Básicamente, esta tecnología nació como respuesta a la necesidad de obte-ner grandes cantidades de un gen o genes, o incluso genomas completos, para poder lle-var a cabo los estudios que permitiesen obtener la secuencia de nucleótidos de un genconcreto, estudiar sus mutaciones, analizar su función, etc. El nombre de clonación mo-lecular sugiere precisamente la idea de un número grande de copias idénticas, y se utili-zaba ya en biología para designar poblaciones de bacterias o células idénticas («clones»).Al aplicarlo a la obtención de copias idénticas de un ácido nucleico, se convirtió en clo-nación molecular. El primer experimento que mostró la posibilidad de propagar un frag-mento de ADN de eucariotas en una bacteria fue la clonación de fragmentos del ADN ri-bosomal de Xenopus laevis dentro de la bacteria E. coli. Desde entonces, la tecnología del
CAPITULO 3 5/12/06 07:02 Página 33
www.FreeLibros.me

ADN recombinante se ha utilizado con éxito en muchos campos, desde aplicacionescon fines industriales (dando lugar a la Biotecnología), hasta la detección de altera-ciones genéticas, pasando por la modificación genética de organismos, la terapia gé-nica y un largo etcétera. En este capítulo recordaremos los principios generales de lastécnicas básicas de biología molecular; otras tecnologías más específicas utilizadas enGenética Humana, como el diagnóstico molecular de alteraciones genéticas o la tera-pia génica, se verán con más detalle en los capítulos correspondientes.
En líneas generales, la obtención de grandes cantidades de un fragmento específicode ADN (es decir, de un gran número de copias idénticas) se lleva a cabo en varios pa-sos: i) obtención de un pequeño número de copias de dicho fragmento, habitualmentemediante la digestión del ADN celular con algún enzima que corte específicamente elgenoma en el punto deseado; ii) la inserción de esas copias en un «vector de clona-ción», que es un fragmento de ADN con unas propiedades especiales que le permitenmultiplicarse dentro de un huésped apropiado; iii) la propagación del nuevo fragmen-to «recombinante» (es decir, el fragmento híbrido formado por la unión del inserto y elvector) dentro del huésped, obteniendo un gran número de copias del mismo.
Esta metodología puede también aplicarse a genomas completos, de forma que esposible cortar un genoma en pequeños fragmentos y clonar cada uno de esos frag-mentos por separado; la colección completa de clones que representan un genoma sedenomina genoteca (o biblioteca genómica). Aunque las genotecas pueden representargenomas completos, también es habitual crear genotecas de fragmentos genómicos (uncromosoma, por ejemplo, o una región cromosómica de interés) cuando no sea posibleclonar ese fragmento debido a su gran tamaño. También es posible construir genotecasespecializadas, en las que los fragmentos insertados en los vectores tienen una natura-leza específica; por ejemplo, son muy comunes las genotecas de ADNc, en las que cadaclon lleva un ADN complementario (una copia en ADN de un ARN mensajero).
Figura 3.1. Estrategia general de clonación molecular de un fragmento de ADN en un vector para supropagación en bacterias.
Por tanto, en toda estrategia de clonación molecular son necesarios tres elementosbásicos: un inserto, un vector y un huésped. Como hemos dicho, el inserto es el frag-mento de ADN que queremos obtener en grandes cantidades, para después procedera estudiarlo. Por lo que respecta al huésped, lo más habitual es que se trate de algunacepa de la bacteria Escherichia coli, especialmente modificada para permitir el creci-miento de vectores con gran eficacia y fidelidad.
Respecto a los vectores de clonación, existe una gran variedad de posibilidades,cada una con características distintas que los hacen adecuados para aplicacionesconcretas. Los primeros vectores utilizados fueron los plásmidos, que son elementosbacterianos extracromosómicos, circulares, que se replican dentro de la bacteriahuésped con independencia de la replicación del cromosoma bacteriano. Los plás-midos utilizados en clonación molecular son variaciones de plásmidos nativos, quehan sido modificados con el objeto de conseguir que se repliquen con mayor eficacia(hasta cientos de copias por bacteria). Además, también se ha creado en ellos una re-gión que se puede cortar fácilmente con enzimas de restricción (ver más adelante)para introducir en ella el fragmento de ADN de interés (es decir, el inserto). Tambiénse ha introducido en ellos el gen de resistencia a algún antibiótico, que permita se-
34
Técnicas básicas de genética molecular
CAPITULO 3 5/12/06 07:02 Página 34
www.FreeLibros.me

leccionar las bacterias que llevan el plásmido dentro: cuando al cultivo en el que cre-cen las bacterias se añade el antibiótico, sólo crecerán aquellas que tienen el plásmi-do y expresan los genes del mismo. Los plásmidos tienen una capacidad limitada, yaque permiten albergar insertos de unas 5-10 kilobases de tamaño, como máximo.
La necesidad de clonar fragmentos de mayor tamaño hizo que se desarrollasenotros tipos de vectores derivados del genoma del fago lambda, un virus bacteriófagoque infecta bacterias introduciendo en ellas el genoma viral. Modificando el genomanativo del fago lambda, se han creado diversos vectores de clonación con una capa-cidad mayor que la de los plásmidos (permiten albergar insertos de tamaños en tor-no a las 15 kilobases), que también se replican en bacterias con gran eficacia. La ne-cesidad de clonar fragmentos todavía mayores llevó a desarrollar otros tipos devectores. Por ejemplo, los cósmidos son vectores artificiales con características deplásmidos y de fagos, y tienen una capacidad de unas 40 kilobases. Posteriormenteaparecieron vectores derivados de los cromosomas de levaduras, incluyendo secuen-cias necesarias para la replicación y la estabilidad de los brazos cromosómicos. Es-tos vectores se denominan Cromosomas Artificiales de Levaduras (en inglés YAC,Yeast Artificial Chromosome), crecen dentro de levaduras y tienen una gran capaci-dad porque pueden albergar insertos de hasta dos megabases (2 × 106 pares de ba-ses). Como veremos más adelante, los vectores tipo YAC fueron muy importantespara crear los primeros mapas del genoma humano, pero tienen algunos inconve-nientes en su manejo ya que los insertos a veces sufren alteraciones a medida que semultiplican dentro de las levaduras. Por tanto, se desarrollaron otros vectores conmenos capacidad pero mucho más estables y de manejo más fácil, como son los vec-tores derivados del fago P1 o del mismo cromosoma bacteriano. Estos vectores se de-nominan, respectivamente PAC (del inglés, P1-phage Artificial Chromosome) y BAC(Bacterial Artificial Chromosome); crecen también dentro de bacterias y son capacesde albergar insertos de tamaños entre 100-150 kilobases. Aunque existen muchosotros tipos de vectores que se utilizan en técnicas de clonación molecular, estos sonlos más usados en Genética humana, y aparecerán en otros capítulos de este texto.
El proceso general de clonación molecular se desarrolla en varios pasos. En primerlugar, es necesario preparar el inserto y el vector de modo adecuado. Esto supone cor-tarlos de modo que los extremos libres del inserto puedan unirse a los extremos del vec-tor. De hecho, como los vectores suelen ser circulares es necesario abrirlos en un lugarespecífico en el que introducir el inserto. Todos estos cortes se llevan a cabo con unasenzimas especiales llamadas enzimas de restricción, cuya característica principal esprecisamente la capacidad de cortar el ADN en regiones específicas. Debido a la im-portancia de las enzimas de restricción en ingeniería genética, les dedicaremos el si-guiente apartado de este capítulo; por ahora, es suficiente comprender que constituyenlas «tijeras» moleculares que nos permiten realizar cortes específicos en el inserto y enel vector para que ambos tengan extremos compatibles que se puedan unir.
El siguiente paso es, precisamente, la unión de inserto y vector para formar la mo-lécula «recombinante» o híbrida. Esta unión la realiza un enzima denominada ADNligasa, habitualmente procedente del fago T4. Este enzima tiene la capacidad de ca-talizar la formación de enlaces fosfo-di-éster entre el grupo 5’ fosfato y el grupo 3’ hi-droxilo de dos cadenas nucleotídicas yuxtapuestas, y por tanto puede unir dos molé-culas de ADN bicatenario cuyos extremos sean compatibles. Tras la reacción deligación se obtiene una molécula circular de ADN conteniendo el inserto dentro del
35
Tecnología del ADN recombinante: m
étodos y usos más frecuentes
CAPITULO 3 5/12/06 07:02 Página 35
www.FreeLibros.me

GENOTECA
ADN GENÓMICO
vector, y capaz de replicarse dentro de un huésped apropiado merced a las secuen-cias específicas del vector.
Por tanto, el siguiente paso del proceso de clonación molecular consiste en la in-troducción de la molécula recombinante en el huésped, habitualmente E. coli. Esteproceso se denomina transformación, y puede hacerse por métodos químicos o físi-cos. El método químico más empleado es el «golpe de calor» en una solución de clo-ruro de calcio, tras el cual las bacterias son capaces de permitir el acceso de molé-culas de ADN a su interior. Este proceso es muy ineficaz, ya que sólo una bacteriade cada 500 o cada 1000 incorporará la molécula de ADN recombinante con éxito;sin embargo, las bacterias se multiplican varios órdenes de magnitud cuando crecenen cultivo, por lo que en teoría basta que la transformación sea eficaz en tan sólounas pocas bacterias para que podamos crecerlas en condiciones de selección (utili-zando antibióticos específicos dependiendo del tipo de vector que usemos) y obteneruna población en la que todas las bacterias contienen la molécula de ADN recombi-nante. Los métodos físicos son más eficaces que los químicos, y se basan en la aper-tura de poros en la pared bacteriana mediante la aplicación de un shock eléctrico,por lo que la técnica se denomina electroporación.
Al final del proceso, por tanto, contamos con una población bacteriana com-puesta por millones de bacterias, cada una de las cuales lleva varios cientos de co-pias de una molécula recombinante que contiene un fragmento específico de ADN(el inserto original). Utilizando métodos sencillos de extracción de ADN de las bac-terias, es posible obtener preparaciones muy puras que contienen millones de copiasdel fragmento, y esto nos permite llevar a cabo cualquier tipo de análisis o de estu-dios funcionales.
36
Técnicas básicas de genética molecular
La Figura 3.2 incluye enlaces a animaciones que muestran el proceso de transformación y la obtención de alto número de copias de moléculas recombinantes.
CAPITULO 3 5/12/06 07:02 Página 36
www.FreeLibros.me

3.2 Enzimas de restricción
En los años 1950 se descubrió que algunos bacteriófagos (virus que infectan y des-truyen bacterias) podían infectar algún tipo concreto de bacterias pero no otros, de-bido a que algunas bacterias eran capaces de digerir el ADN del fago y por tanto im-pedían su crecimiento. Como el fago ve «restringido» el rango de huéspedes quepuede infectar, a dicho sistema se le llamó sistema de restricción. Posteriormente sedescubrió que dicha restricción se lleva a cabo gracias a unas enzimas del tipo en-donucleasas, que digieren el ADN de doble cadena tras el reconocimiento y unión asecuencias específicas en el genoma «invasor». Por tanto, dichas enzimas reciben elnombre genérico de enzimas de restricción. Las enzimas de restricción tienen granimportancia para la supervivencia de las bacterias, y por ello son muy abundantes yaparecen en todos los géneros de bacterias que se han estudiado. El descubrimientode las primeras enzimas de restricción de tipo II en los años 1970 fue clave para eldesarrollo de las tecnologías del ADN recombinante.
Las enzimas de restricción se clasifican en tres tipos: tipo I, tipo II y tipo III. Lasenzimas de tipo I y las de tipo III son complejos multiproteicos que reconocen se-cuencias específicas de ADN asimétricas, y digieren al ADN en otra región inespe-cífica alejada de la secuencia de reconocimiento, bastante alejadas en el caso de lastipo I (desde 50 hasta varios miles de pares de bases) o menos alejadas en el caso delas tipo III (unos 25 pares de bases). De todas formas, las enzimas de restricción deinterés en ingeniería genética son las de tipo II, que están codificadas por un únicogen bacteriano y que suelen actuar en forma de dímeros. Su característica principales que el corte endonucleolítico tiene lugar dentro de la misma secuencia de reco-nocimiento por la que se unen al ADN, llamadas también «dianas» o «sitios» de res-tricción. Hoy en día se conocen más de 3 000 endonucleasas de restricción de tipo II,que reconocen más de 200 dianas distintas.
Las enzimas que reconocen la misma diana pero proceden de bacterias distintasse denominan isosquizómeros; es importante conocer su existencia para no confun-dir endonucleasas que tienen la misma secuencia de reconocimiento. En este senti-do, es importante conocer la nomenclatura de estas enzimas, que depende del nom-bre de la cepa bacteriana de la que se aíslan. Por ejemplo, las enzimas de restricciónpurificadas a partir de Escherichia coli se denominan «EcoXX»: las tres primeras le-tras (en cursiva) designan la especie, y uno o más caracteres en mayúscula (letras onumeros romanos, nunca en cursiva) designan la cepa o distinguen varias enzimasde una misma bacteria. Por lo general, las dianas de reconocimiento de las enzimastipo II tienen una longitud de cuatro a ocho pares de bases.
Lógicamente, el número de posibles sitios de corte para una endonucleasa de res-tricción varía inversamente a la longitud de la diana de reconocimiento, ya que porazar es más fácil encontrar secuencias de cuatro nucleótidos que de ocho, por ponerun ejemplo. Esto es importante a la hora de predecir si un enzima concreto presen-tará muchas o pocas dianas en un fragmento de ADN. Una característica importan-te de las enzimas de tipo II es que las secuencias de reconocimiento son idénticascuando se leen en dirección 5’→3’ en cada una de las dos cadenas de la doble héli-ce. Es decir, las dianas de reconocimiento de las enzimas tipo II son secuencias pa-lindrómicas. Existen algunas excepciones a esta regla general, sobre todo cuando lasdianas de reconocimiento tienen alguna posición degenerada, es decir, que puede serocupada por dos o más nucleótidos indistintamente.
37
Enzimas de restricción
CAPITULO 3 5/12/06 07:02 Página 37
www.FreeLibros.me

Finalmente, una característica común a la mayoría de las enzimas tipo II es quecortan la cadena de ADN dentro de la secuencia de reconocimiento. Dependiendodel sitio exacto donde corten, los extremos libres generados por el corte pueden serde varios tipos. En primer lugar, si la secuencia de reconocimiento está constituidapor un número par de nucleótidos y el corte se produce exactamente en el centro, losextremos serán «romos», es decir, las dos cadenas de la molécula de ADN tendrán lamisma longitud. En cambio, en otras enzimas el punto de corte está desplazadorespecto del eje de simetría de la secuencia de reconocimiento; dada la naturalezapalindrómica de dicha secuencia, esto genera extremos libres en los que una de lasdos cadenas de la doble hélice es más larga que la otra, que se denominan extremoscohesivos. En las enzimas que generan extremos cohesivos, se distinguen además dostipos según cuál de las dos cadenas de la molécula de ADN es más larga, la cadena5’ o la 3’; así se habla de extremos cohesivos con «salientes» 5’ o 3’, respectivamente.El tipo de extremos que genera cada enzima es un factor importante en losexperimentos de clonación molecular, porque las ligasan sólo pueden unir extremosque sean compatibles, y además los extremos cohesivos habitualmente son ligadoscon mucha mejor eficacia que los extremos romos.
3.3 Técnicas básicas de hibridación de ácidos nucleicos
El desarrollo del concepto de hibridación entre moléculas de ácidos nucleicos ha te-nido gran importancia en el desarrollo de la ingeniería genética, como veremos al ha-
38
Técnicas básicas de genética molecular
TCGACAGCTGACGCATGTATAGCTAGCGATCTAGCAluI NlaIII Sau3AI
AGCTGTCGACTGCGTACATATCGATCG CTAGATCG |||||||||||||||||||||||||||||||||||
5’
5’
…GACAG CTGAC…
…CTGTC GACTG… ||||| |||||
Extremos romos
5’
5’
…ACGCATG TAT…
…TGC GTACATA… ||| |||
Extremos cohesivos
(salientes 3’)
5’
5’
…AGC GATCTAG…
…TCGCTAG ATC… ||| |||
Extremos cohesivos(salientes 5’)
En la Figura 3.3 se muestran ejemplos de dianas de restricción con extremos romos y cohesivos,así como una animación del proceso de corte.
CAPITULO 3 5/12/06 07:02 Página 38
www.FreeLibros.me

blar de algunas técnicas concretas en otros apartados de este capítulo. En sentido ge-neral, hibridación se refiere al proceso por el que dos cadenas de ácidos nucleicosque son complementarias se unen para dar una molécula bicatenaria. Las cadenasoriginales pueden ser de ADN o de ARN, de modo que la hibridación puede serADN-ADN o ADN-ARN (es más infrecuente trabajar con dobles cadenas de ARN).
La hibridación es un proceso con una cinética que se puede estudiar por las cur-vas de desnaturalización del ADN. Cuando una doble hélice se desnaturaliza hasta laseparación completa de ambas cadenas y se retiran las condiciones desnaturalizantes,las cadenas vuelven a reasociarse buscando las regiones complementarias: a mayor nú-mero de nucleótidos complementarios, la renaturalización es más rápida (y la desna-turalización más difícil). Como hemos visto, la desnaturalización se realiza habitual-mente por calor; si medimos el porcentaje de moléculas desnaturalizadas a medida queaumentan la temperatura, obtenemos una curva sigmoidea que permite calcular latemperatura a la cual el 50 por ciento de las moléculas están desnaturalizadas. Di-cha temperatura se conoce como temperatura de fusión, abreviada Tm (de melting eninglés). Un fragmento de ADN tendrá una Tm característica que dependerá de su ta-maño y de la composición de bases: como los pares entre citosina y guanina formantres puentes de hidrógeno frente a los dos que forman los pares adenina-timina, unfragmento con muchos pares G:C será más estable y más difícil de desnaturalizar, porlo que su Tm será más alta que la de un fragmento rico en pares A:T.
Estas propiedades de desnaturalización e hibridación de dobles hélices de ADNhan sido explotadas para desarrollar métodos de laboratorio que permitan identificarla naturaleza de fragmentos de ácidos nucleicos en mezclas complejas. Por ejemplo,la digestión de ADN celular total con un enzima de restricción produce miles de frag-mentos de distintos tamaños en el tubo de reacción; en esas circunstancias, es posi-ble identificar cuál de esos fragmentos es portador de una secuencia específica utili-zando técnicas de hibridación. Para ello, se añade a la mezcla otro pequeñofragmento de ADN que represente la región que queremos identificar, se desnatura-lizan todos los fragmentos y se dejan hibridar libremente. La mayor parte de las ca-denas complementarias se reasociarán para reconstruir los fragmentos originales; encambio, la presencia de pequeñas cadenas que son perfectamente complementariascon una región de un fragmento grande permitirá la formación de híbridos entre lacadena pequeña y la correspondiente cadena larga complementaria. De hecho, estareacción se ve favorecida respecto de la reasociación de cadenas largas entre sí, pre-cisamente porque los fragmentos pequeños hibridan más rápidamente.
Por tanto, un pequeño fragmento de ADN es capaz de identificar los fragmentosde una mezcla compleja que contienen secuencias complementarias al mismo. Poreste motivo, estos pequeños fragmentos se denominan sondas (probe en inglés), y sue-len estar constituidas por moléculas de ADN de varios cientos de pares de bases. Detodas formas, en un tubo de ensayo no se ven las moléculas de ADN, por lo que unasonda de ADN no será de gran utilidad si no es fácilmente detectable. Por este moti-vo, las sondas utilizadas en biología molecular llevan algún tipo de marcaje que per-mita detectar su presencia: marcaje con algún isótopo radioactivo, con un fluorocro-mo o con una molécula con actividad enzimática detectable por alguna reacciónquímica. La utilización de sondas de ADN marcadas ha sido uno de los pilares bási-cos de la ingeniería genética en los últimos decenios, y su utilización sigue estando
39
Técnicas básicas de hibridación de ácidos nucleicos
CAPITULO 3 5/12/06 07:02 Página 39
www.FreeLibros.me

muy extendida; de hecho, algunas de las tecnologías más recientes, como los microa-rrays de ADN, se basan todavía en la hibridación de sondas con fragmentos «diana».
La Figura 3.4 muestra el proceso de hibridación de una sonda sobre una molécula complementariade ADN.
Aunque los fenómenos de hibridación se dan en solución, la utilización más habi-tual de sondas de ADN es la detección de fragmentos de ácidos nucleicos que han sidopreviamente inmovilizados sobre un soporte sólido. El ejemplo más sencillo es la de-tección de un fragmento específico de ADN celular que ha sido digerido con un enzi-ma de restricción. La separación de los fragmentos generados por la digestión puedehacerse fácilmente mediante electroforesis en gel de agarosa o de acrilamida, sustan-cias porosas en las que la velocidad de migración electroforética varía en función deltamaño de los fragmentos. Una vez que los fragmentos han sido separados, el uso deuna sonda marcada nos permitirá detectar el fragmento o fragmentos que contienenla secuencia de la sonda, ya que ésta hibridará específicamente en esas regiones.
Para llevar a cabo de modo sencillo la reacción de hibridación entre la sonda ylos fragmentos digeridos que se han separado en el gel, Edwin Southern ideó un mé-todo sencillo para transferir todos los fragmentos del gel a un soporte sólido de ni-trocelulosa o de nylon, más resistente y fácilmente manejable que un gel. La transfe-rencia crea una réplica del gel en el soporte sólido (llamado filtro, por utilizarseinicialmente papel de filtro), ya que mantiene la posición relativa que tenían los frag-mentos en el gel. Tomando nombre de su creador, la transferencia de fragmentos deADN de un gel a un filtro se denomina transferencia southern; cuando los frag-mentos son de ARN, en vez de ADN, las condiciones en que se realiza la transfe-rencia cambian un poco, y se denomina transferencia northern (juego de palabrascon Southern, que significa «sureño»; northern es «norteño»). Posteriormente, estatécnica también se aplicó a las proteínas, tomando entonces el nombre de transfe-rencia western («occidental»).
La Figura 3.5 ilustra el proceso de electroforesis en gel de agarosa, así como la transferencia de fragmentos a una membrana rígida.
Los métodos de transferencia de ácidos nucleicos a soporte sólido junto con la hi-bridación con sondas marcadas han sido y siguen siendo muy utilizados en biologíamolecular. Estos mismos principios se han combinado también con las técnicas clá-sicas de citogenética para el estudio de cromosomas, dando lugar a las técnicas de ci-togenética molecular que veremos en un capítulo posterior. Otras aplicaciones de es-tas técnicas al diagnóstico de alteraciones genéticas en Genética humana seránabordadas en los capítulos correspondientes.
3.4 Amplificación in vitro de ADN (PCR)
Aunque las técnicas de clonación molecular proporcionan altas cantidades de unfragmento de ADN, son técnicas laboriosas, con incubaciones largas: un experimen-
40
Técnicas básicas de genética molecular
CAPITULO 3 5/12/06 07:02 Página 40
www.FreeLibros.me

to típico de clonaje lleva unos dos días. Hacia finales de los años 1980 se describióuna metodología nueva que permitía amplificar selectivamente una región concretade ADN, de modo que partiendo de cantidades iniciales pequeñísimas (teóricamen-te, una sola copia del fragmento) podrían obtenerse varios miles de millones de co-pias. El método se desarrolla en un periodo de pocas horas y no incluye ningún pasode digestión, ligación ni transformación, sino que se basa en la acción cíclica de unapolimerasa de ADN que amplifica selectivamente la región de interés y ninguna otra.Por este motivo, el método se conoce como reacción en cadena de la polimerasa(abreviado PCR, en inglés Polymerase Chain Reaction).
El punto central de la técnica de PCR es la síntesis de ADN desde un punto con-creto, repetida durante un número elevado de veces (ciclos). Por tanto, hay dos ele-mentos esenciales de la técnica: i) conseguir que la amplificación se limite exclusiva-mente a la región genómica de interés, y ii) utilizar algún tipo de polimerasa quepermita repetir el proceso de síntesis de ADN muchas veces.
Por lo que respecta al primer punto, la técnica utiliza algo que ya era conocido,como es la capacidad de las polimerasas de ADN de catalizar la síntesis de ADN apartir del extremo 3’ libre de un oligonucleótido que está unido a una cadena com-plementaria más larga, la cual actúa como molde de la síntesis. Este proceso, habi-tual en la replicación del ADN celular, puede reproducirse en el laboratorio utili-zando pequeñas moléculas de ADN complementarias a una región concreta de unadoble cadena más larga. Como es sabido, una de las formas de desnaturalizar elADN (es decir, separar las dos cadenas de una doble hélice) es mediante calor; comosabemos, la temperatura necesaria para alcanzar dicha desnaturalización depende dela secuencia de la molécula, pero a partir de los 92-94 ºC la práctica totalidad de lasmoléculas estarán desnaturalizadas.
Si se desnaturaliza una molécula de ADN, obtendremos dos cadenas libres; al de-jar enfriar la preparación, ambas moléculas vuelven a unirse por complementariedadde bases hasta que el ADN se re-naturaliza por completo. Este proceso es lento, porlo que si la re-naturalización se lleva a cabo en presencia de pequeños oligonucleó-tidos cuya secuencia es complementaria a alguna porción de la molécula larga origi-nal, estas pequeñas moléculas se unirán rápidamente a la región complementaria dela molécula larga antes de que ésta llegue a re-naturalizarse. El resultado es que cadauna de las cadenas originales se mantiene monocatenaria excepto en la región en quese ha unido el oligonucleótido. En esa región, una polimerasa de ADN puede sinte-tizar a partir del extremo 3’ libre de la molécula pequeña, usando como molde la se-cuencia de la molécula grande. Por este motivo, las moléculas cortas que inician lasíntesis de ADN se llaman cebadores (primers, en inglés). Si utilizamos dos cebado-res, cada uno de ellos complementario a cada una de las dos cadenas de la molécu-la original de ADN, habrá dos procesos de síntesis simultáneos en direcciones opues-tas, y al final tendremos dos cadenas bicatenarias de ADN con la misma secuenciaque la molécula original. Es fácil ver que, precisamente, es la posición de los ceba-dores la que determina qué región de la molécula larga se va a amplificar, ya que sólola secuencia que queda comprendida entre los dos cebadores va a ser amplificada.
El vídeo de la Figura 3.6 muestra la desnaturalización, unión y extensión de un cebador sobre una región específica de ADN.
41
Amplificación
in vitrode ADN (PCR)
CAPITULO 3 5/12/06 07:02 Página 41
www.FreeLibros.me

Los elementos necesarios para llevar a cabo una reacción de PCR, por tanto, sonel ADN molde original que se quiere amplificar, los cebadores, la polimerasa de ADNy nucleótidos libres que se incorporan a la cadena naciente durante la síntesis. Por loque respecta al ADN molde, una de las grandes ventajas de la PCR es que puede uti-lizarse ADN relativamente impuro, e incluso es posible usar células o bacterias com-pletas, sangre impregnada en papel de filtro, etc. En cualquier caso, la pureza delADN molde asegura un buen funcionamiento de la reacción. Además, las cantidadesnecesarias son pequeñas, no deben superar los 100-200 ng por reacción; se estimaque con estas cantidades de ADN genómico total se puede amplificar un gen que estéen una sola copia en el genoma. Los cebadores son oligonucleótidos sintéticos mo-nocatenarios, con un grupo hidroxilo 3’ a partir del que se sintetiza la nueva cadenade polinucleótidos. La característica más crucial de un cebador es su especificidad,es decir, que sólo se pueda unir a una región concreta del ADN molde. Esto va a ase-gurar que sólo se amplifique la región de interés; por el contrario, si los cebadores seunen inespecíficamente en zonas distintas a la deseada, la PCR produce resultadosdifícilmente interpretables. Esto es especialmente importante cuando el ADN molderepresenta un genoma completo, o fragmentos cromosómicos grandes. Para asegurareste parámetro, se utilizan cebadores con una tamaño mínimo de 17 nucleótidos, yaque se estima que esta longitud es suficiente para reconocer una sola secuencia en ungenoma eucariota. En efecto, la probabilidad de encontrar por azar una secuencia de17 nucleótidos es 417 = 1,7 × 1010. Como los genomas de mamíferos tienen en tornoa 3 × 109 nucleótidos, esto supone que un cebador de 17 nucleótidos en teoría pue-de identificar una secuencia única dentro de un genoma de ese tamaño. Evidente-mente, pueden utilizarse cebadores más largos, dependiendo de otros factores que secomentarán más adelante, pero los cebadores utilizados en reacciones de PCR típi-cas están en un rango de tamaños entre los 17 y 25 nucleótidos.
La polimerasa de ADN utilizada es la responsable de la extensión de la nueva ca-dena de ADN a partir de un cebador. El tipo de polimerasa utilizado viene determi-nado por las características de la propia reacción de PCR. Como la reacción ha desometerse a numerosos ciclos de desnaturalización-renaturalización, la actividad en-zimática de la polimerasa se destruye con cada etapa de calentamiento para desna-turalizar el ADN, por lo que sería necesario añadirla nuevamente al comienzo decada ciclo. Esta dificultad se ha superado por el descubrimiento de polimerasas deADN que son termoestables, es decir, pueden soportar elevadas temperaturas du-rante largo tiempo sin perder su actividad. Las bacterias que viven en aguas terma-les, como la especie Thermus aquaticus, sobreviven en temperaturas cercanas a los100 ºC y contienen polimerasas termoestables. De ahí que la polimerasa más fre-cuentemente utilizada en las reacciones de PCR se denomine polimerasa Taq, paraindicar su origen. La polimerasa Taq requiere la presencia de ión magnesio como co-factor, por lo que todas las soluciones utilizadas deben llevar este elemento. La tem-peratura óptima de polimerización de la Taq es de 72 ºC: a esa temperatura se in-corporan unos 100 nucleótidos por segundo. Además, la Taq carece de la actividadexonucleasa 3’→5’ que tienen otras polimerasas. Finalmente, los nucleótidos libres,necesarios para sintetizar las nuevas cadenas, tienen una buena resistencia al calor ysu vida media es de más de 40 ciclos de calentamiento. Como se trata de sintetizar
42
Técnicas básicas de genética molecular
CAPITULO 3 5/12/06 07:02 Página 42
www.FreeLibros.me

ADN, se utilizan desoxi-nucleótidos trifosfato (dATP, dCTP, dGTP y dTTP), que pue-den incorporarse al extremo 3’ de una cadena creciente por su grupo fosfato 5’.
Teniendo en cuenta todo lo dicho hasta el momento, podemos esquematizar unareacción de PCR como un proceso cíclico, repetitivo, en el que cada uno de los ci-clos está constituido por tres fases: desnaturalización, hibridación y extensión. Lafase de desnaturalización, como su nombre indica, consiste en someter la reaccióna una temperatura de 94 ºC durante un minuto, para asegurar que todas las molécu-las de ADN molde se han desnaturalizado y están en estado monocatenario. Real-mente, la desnaturalización es prácticamente instantánea cuando toda la mezcla al-canza esa temperatura, pero la inercia térmica hace que haya que mantener latemperatura de desnaturalización durante unos segundos. No es bueno prolongarlademasiado, porque esto daña el ADN molde y reduce la actividad de la Taq.
La siguiente fase de cada ciclo debe permitir la hibridación de los cebadores consus secuencias complementarias en el ADN molde, y por eso se llama fase de hibri-dación. En este sentido, «hibridar» es formar una molécula bicatenaria de ADN apartir de la unión de dos moléculas monocatenarias que tienen secuencias comple-mentarias. Para llevar esto a cabo, es necesario disminuir la temperatura de la reac-ción, de modo que los cebadores se unan a sus dianas pero las cadenas largas de lamolécula original no lleguen a reasociarse entre sí. La temperatura a la que se reali-za la hibridación depende de la secuencia de los cebadores, pero suele estar entre55 ºC y 65 ºC, y se mantiene en torno a un minuto.
La última etapa de un ciclo típico se denomina fase de extensión, porque en ellala polimerasa extiende los dos cebadores tomando como molde las secuencias de lascadenas originales, incorporando los desoxi-nucleótidos que están presentes en lamezcla de reacción. Por la temperatura óptima de la polimerasa, esta fase se realizaa 72 ºC, durante un tiempo variable dependiendo de la longitud del fragmento am-plificado (entre 30 segundos y dos minutos, en condiciones estándar). Una reaccióntípica de PCR consta de 30-35 ciclos como el descrito. Además, suele ir precedidapor un breve periodo de desnaturalización de unos tres a cinco minutos, para asegu-rar que todo el ADN está desnaturalizado antes del primer ciclo, y una fase final deextensión (unos cinco a 10 minutos a 72 ºC) para extender todas las moléculas quehayan quedado incompletas.
Es fácil ver que, teóricamente, en cada ciclo se duplica el número de moléculasde ADN de la región específica que queremos amplificar; por tanto, el número demoléculas presentes en un ciclo dado es 2n, siendo n el número de ciclo. Por ejem-plo, si partimos de una sola molécula inicial de ADN, tras 10 ciclos tendremos 1 024copias, tras 20 ciclos tendremos 1 048 576 copias, y tras 30 ciclos tendremos1 073 741 824 de copias de la molécula original. De todas formas, no todas las molé-culas serán idénticas, porque en cada ciclo se generan moléculas que llevan cadenaslargas que sobrepasan el límite de uno de los cebadores. Estas moléculas aumentanen progresión aritmética (se crean dos con cada ciclo), mientras que los fragmentosespecíficos comprendidos por los dos cebadores aumentan exponencialmente a par-tir del tercer ciclo. Por ejemplo, en una PCR de 35 ciclos tendremos 34 359 738 368copias (235), de las que 70 corresponden a moléculas largas y el resto correspondenal fragmento de interés. Este aumento exponencial se observa también experimen-talmente, cuando se cuantifica la cantidad de ADN total después de cada ciclo; tras
43
Amplificación
in vitrode ADN (PCR)
CAPITULO 3 5/12/06 07:02 Página 43
www.FreeLibros.me

una fase inicial más lenta, tiene lugar una fase de aumento exponencial (una línearecta cuando se representa en escala logarítmica), y una fase final (a partir del ciclo32-35, más o menos) en la que se alcanza una meseta y la amplificación se detienepor agotamiento de los reactivos y pérdida de actividad de la polimerasa.
La Figura 3.7 lleva a una animación que muestra los primeros ciclos de una PCR y permite calcularel número de moléculas que se generan por ciclo.
Lógicamente, la realización de una reacción de PCR requiere un equipamientoapropiado que permita llevar a cabo los ciclos de modo automático. Inicialmente, seutilizaban baños separados, cada uno a una temperatura distinta (desnaturalización, hi-bridación y extensión) y los investigadores debían pasar los tubos de reacción de unbaño a otro a los tiempos apropiados. Pronto se desarrollaron máquinas que tienen unaplaca metálica, con capacidad para un alto número de tubos, cuya temperatura puedevariarse con gran rapidez y precisión, estando todo el proceso controlado por un mi-croprocesador. Estas máquinas, llamadas termocicladores (o cicladores térmicos), per-miten programar las condiciones de tiempo, temperatura, número de ciclos, etc, demodo que el operador sólo tiene que introducir los tubos y esperar al final de la reac-ción, que suele durar en torno a los 60-90 minutos con los termocicladores modernos.
Las aplicaciones de la técnica de PCR han sido múltiples desde su aparición; a lolargo de este libro veremos su uso en la detección de alteraciones genéticas que cau-san enfermedades. La descripción de los posibles usos en diferentes estrategias deanálisis genético y en biotecnología, está más allá del objetivo de este apartado, en elque se ha pretendido únicamente introducir en esta técnica a aquellos que no la co-nocen. En cualquier caso, es importante reseñar una de las variantes más utilizadas,como es la amplificación de fragmentos de ARN mensajero. En este caso, en vez deutilizar ADN como molde para la amplificación, se usa una molécula de ADN quees copia de un ARNm, obtenida por un proceso que se llama retrotranscripción: gra-cias a la actividad transcriptasa reversa de la polimerasa de algunos virus (una ADNpolimerasa dependiente de ARN), se puede sintetizar una molécula de ADN com-plementaria a una molécula de ARN. Por tanto, si queremos amplificar selectiva-mente un ARNm, es preciso obtener primero un ADN complementario (llamadoADNc) haciendo una retrotranscripción del ARNm, y después ese ADNc ya se pue-de amplificar por PCR como cualquier otro fragmento de ADN. Por este motivo, estavariante de la técnica se llama RT-PCR (retrotranscripción-PCR). Es una técnicamuy utilizada y de gran interés cuando se quiere trabajar con las secuencias de losgenes ya procesados, prescindiendo de los intrones, y supuso un gran avance porquehasta su aparición era muy difícil estudiar ARN mensajeros.
3.5 Secuenciación del ADN
Desde el descubrimiento de la estructura del ADN y del código genético, una de lasherramientas más importantes para identificar genes y predecir su función ha sido ladeterminación de la secuencia de nucleótidos que constituye cada gen. En las últimasdécadas, la tecnología de secuenciación del ADN ha sido determinante para poder
44
Técnicas básicas de genética molecular
CAPITULO 3 5/12/06 07:02 Página 44
www.FreeLibros.me

llevar a cabo los distintos «proyectos genoma», cuya finalidad es obtener la secuen-cia completa de nucleótidos del genoma completo de una especie. Hoy en día, ade-más, un aspecto crucial de la investigación genética es la determinación de pequeñasvariaciones interindividuales, lo que requiere la secuenciación de una misma regiónen distintos individuos. Por tanto, los métodos actuales de determinación de la se-cuencia de nucleótidos de un fragmento de ADN son muy variados, y los desarrollostecnológicos recientes han dado lugar a un gran abanico de técnicas diseñadas pararesponder a distintas necesidades. De todas formas, todas las tecnologías son de al-gún modo tributarias del método original ideado por Fred Sanger y Alan Coulson afinales de los años 1970. Este método se conoce como el método de «terminación decadenas» o «di-desoxi», porque se basa en la interrupción del proceso de extensiónde un cebador, dando lugar a cadenas de todas las posibles longitudes, puesto quecada una ha sido interrumpida en una posición distinta; la separación de las cadenasde distintos tamaños y la detección de qué nucleótido llevan en su extremo 3’ nospermite deducir la secuencia de la molécula original.
El primer elemento de toda reacción de secuenciación es, lógicamente, el frag-mento de ADN cuya secuencia queremos leer; precisamente, este fragmento sirvecomo molde para la síntesis de ADN a partir de un cebador específico que se une a élpor complementariedad de bases, y esto es lo que nos va a permitir deducir la se-cuencia de nucleótidos del fragmento. Aunque inicialmente era necesario convertir elfragmento de ADN a su forma monocatenaria, clonándolo en un tipo especial de vec-tores, hoy en día puede utilizarse ADN de doble cadena, bien sea en forma de plás-midos (cuyo inserto queremos secuenciar) o como productos de PCR. Al igual que enel caso de la PCR, otro elemento necesario es el cebador que va a iniciar la síntesis deADN desde el punto donde queremos empezar a leer la secuencia del fragmento ori-ginal. Nótese que aquí sólo vamos a utilizar un cebador (en vez de dos, como en laPCR) ya que no queremos amplificar una región, sino simplemente sintetizar nuevascadenas de ADN a partir de un punto concreto. Como toda reacción de síntesis deADN, también es necesaria la presencia de una polimerasa de ADN que tenga bue-na procesividad y fidelidad (es decir, que no introduzca errores en la nueva cadena).
El punto clave de este método de secuenciación está en los nucleótidos libres pre-sentes en la reacción, que se van a ir incorporando a la nueva cadena sintetizada porla polimerasa a partir del extremo 3’ del cebador; además de 2’-desoxi-nucleótidos tí-picos en su forma tri-fosfato, este método incorpora a la mezcla de reacción unos nu-cleótidos especiales que actúan como «terminadores» de la síntesis. Los terminado-res son nucleótidos modificados químicamente que carecen además del grupohidroxilo 3’ por el que crece la cadena, de ahí su nombre de di-desoxi-NTP (abre-viado como ddNTP), ya que corresponden a la forma 2’,3’-di-desoxi de cada nucleó-tido tri-fosfato.
La Figura 3.8 contiene enlaces a animaciones que ilustran el método original de secuenciación deSanger.
La reacción de secuenciación, una vez que tenemos los distintos componentesmezclados en cantidades adecuadas, procede del siguiente modo. En primer lugar, elfragmento a secuenciar se desnaturaliza para separar las dos cadenas y permitir que
45
Secuenciación del ADN
CAPITULO 3 5/12/06 07:02 Página 45
www.FreeLibros.me

el cebador acceda a su región complementaria específica. Tras permitir la hibridacióndel cebador con la cadena molde respectiva, la polimerasa comienza a extender el ce-bador incorporando nucleótidos complementarios a los de la cadena molde. Como enla reacción están presentes desoxi-NTPs y didesoxi-NTPs, en cada posición es posibleincorporar uno u otro. En el caso de incorporar un dNTP, la cadena seguirá exten-diéndose normalmente, ya que el nuevo nucleótido proporciona el grupo hidroxilo 3’necesario para formar un nuevo enlace fosfo-di-éster con el grupo fostato de un nue-vo nucleótido; en cambio, si el nucleótido incorporado es un ddNTP, la síntesis dela cadena terminará en esa posición, ya que no existe el grupo hidroxilo 3’ necesa-rio para continuar la elongación. Lógicamente, esto sucederá para cada posición, demodo que mientras la síntesis avanza (porque se han incorporado dNTPs) en cadanueva posición existe la posibilidad de que la cadena se termine en ese punto. Al fi-nal, tendremos una colección de fragmentos de todos los posibles tamaños, con unadiferencia de longitud de un nucleótido; cada fragmento estará terminado por el nu-cleótido complementario al que estaba en la cadena molde original en esa posición.
Cuando la reacción de secuenciación ha sido completada, sólo nos resta separarde alguna forma todos los fragmentos de los distintos tamaños y ver en qué nucleó-tido está terminado cada uno de ellos, de modo que así podremos reconstruir la se-cuencia original. Los métodos para separar los fragmentos y leer el nucleótido ter-minal han cambiado bastante desde la descripción original del método. Hoy en día,lo más habitual es utilizar terminadores marcados con algún fluorocromo específi-co: se trata de ddNTPs que llevan unido un grupo químico que produce fluorescen-cia cuando es excitado por una luz de una determinada longitud de onda. Como cadaterminador lleva un fluorocromo distinto, es fácil saber en qué nucleótido terminóuna cadena concreta, dependiendo del tipo de fluorescencia que produzca. Para laseparación de los fragmentos se utilizan técnicas de electroforesis capilar, en la quela mezcla de reacción va pasando por unos finos capilares que contienen una matrizporosa capaz de resolver fragmentos de ADN que se diferencian en tamaños de tansólo un nucleótido. De este modo, cuando la reacción de secuenciación ya comple-tada pasa por el capilar, los fragmentos más pequeños pasan más facilmente y salendel capilar antes que los fragmentos mayores, que tienen más dificultad para atrave-sar los poros y por eso quedan retenidos temporalmente. El resultado es que todoslos fragmentos de la mezcla de reacción van saliendo del capilar ordenados por ta-maños, comenzando por el más corto, con diferencias de tamaño un solo nucleóti-do. A la salida del capilar se sitúa una fuente de luz (habitualmente un láser) que ex-cita los fluorocromos y produce un tipo de fluorescencia específico de cada ddNTP,lo cual es detectado por un dispositivo especial. Así, viendo el orden en que van apa-reciendo los cuatro distintos colores correspondientes a los cuatro nucleótidos, po-demos saber la secuencia de la cadena que se ha sintetizado, que será exactamentela secuencia complementaria a la cadena molde original.
El vídeo de la Figura 3.9 muestra con detalle el método moderno de secuenciación conterminadores fluorescentes y separación de los fragmentos mediante electroforesis capilar.
Aunque en la actualidad se están desarrollando metodologías nuevas más rápidasy baratas, en dispositivos miniaturizados que permiten determinar la secuencia de un
46
Técnicas básicas de genética molecular
CAPITULO 3 5/12/06 07:02 Página 46
www.FreeLibros.me

fragmento en segundos, el método de secuenciación de Sanger ha tenido una in-fluencia crucial en el desarrollo de la biología molecular y la genética moderna.
3.6 Microarrays
La cuantificación del nivel de expresión de un gen, la intensidad con la que se trans-cribe, puede medirse utilizando las técnicas explicadas en los apartados precedentes.Inicialmente se utilizaba la técnica de Northern blot, en la que la intensidad de la se-ñal obtenida es proporcional a la cantidad de ARNm presente en la muestra. Más re-cientemente se han desarrollado técnicas de PCR cuantitativa que consiguen cuanti-ficar la cantidad de ARNm presente en la muestra: utilizando ADNc (ADNcomplementario) como molde, se puede realizar RT-PCR cuantitativa para determi-nar la abundancia relativa del ARNm y comparar varios tejidos o condiciones expe-rimentales.
Con la llegada de los grandes proyectos de secuenciación, se planteó la posibili-dad de determinar la expresión génica a nivel genómico, es decir, analizar el perfilde expresión de todos los genes de un genoma en distintas situaciones, para así iden-tificar los genes implicados en distintos procesos fisiológicos o en el desarrollo de en-fermedades. La cuantificación de la expresión de miles de genes es impracticable porlos métodos tradicionales, por lo que se desarrolló una metodología nueva que per-mitiese hacer este tipo de experimentos a bajo coste y en poco tiempo. Dicha tecno-logía se conoce como la tecnología de microarrays, también llamados a veces«chips» de ADN, porque se basa en la utilización de unos dispositivos sólidos mi-niaturizados en los que se puede medir la expresión de miles de genes a la vez.
Aunque existen distintos tipos de microarrays en función de la tecnología de fa-bricación, el fundamento de todos ellos es la hibridación de una mezcla de dos cla-ses de ADNc, marcados con fluorocromos distintos, sobre una fase sólida que con-tiene miles de sondas inmobilizadas, cada una de ellas específica para un gendistinto. Por tanto, a diferencia de los experimentos tradicionales de hibridación so-bre filtros, en los que el ADN está fijado sobre la fase sólida y la sonda está presen-te en la solución de hibridación, en la tecnología de microarrays son las sondas lasque están inmovilizadas sobre el soporte sólido, y son los ADNc los que «buscan» lassondas complementarias a su secuencia e hibridan con ellas. De modo general, unmicroarray es un portaobjetos de vidrio al que se han adherido, por métodos físicoso químicos, sondas de ADN en posiciones fijas y ordenadas, cada una ocupando unpunto o «spot». Cada punto contiene entre 107-108 moléculas de una sonda concre-ta, que puede ser de distintos tamaños y que debería reconocer específicamente unsolo gen del genoma.
La Figura 3.10 muestra ejemplos de varios tipos de microarrays, cómo se fabrican y una imagen de hibridación.
Aunque los microarrays fueron originalmente diseñados para realizar estudios deexpresión génica a escala genómica, también se pueden utilizar para detectar peque-ñas deleciones o duplicaciones en un genoma. En este caso se habla de microarrays
47
Microarrays
CAPITULO 3 5/12/06 07:02 Página 47
www.FreeLibros.me

genómicos, en los que las sondas son fragmentos de un genoma. Por ejemplo, un mi-croarray genómico humano tendrá varios miles de sondas que representan todo el ge-noma humano ordenado en los distintos puntos del array; la hibridación se realizacon una mezcla de dos ADN genómicos, con la finalidad de detectar regiones genó-micas que estén en distinto número de copias en uno de los genomas respecto al otro.
En cualquier caso, la metología experimental es similar en los distintos tipos demicroarrays. En primer lugar es necesario obtener los ADN que se van a hibridar so-bre el microarray (ADNc si se van a hacer estudios de expresión génica o ADN ge-nómico total si se trata de microarrays genómicos). Cada una de las dos muestras quese van a comparar es marcada con un fluorocromo distinto, habitualmente uno queda fluorescencia verde y otro con fluorescencia roja. A continuación se realiza lareacción de hibridación y se detecta la fluorescencia que emite cada punto del mi-croarray. Dependiendo de la intensidad de la fluorescencia de cada color en cadapunto, es posible deducir si el gen representado por esa sonda se expresa o no en lasmuestras.
Lógicamente, un experimento con microarrays genera cantidades masivas de da-tos, al tratarse de miles de puntos analizados simultáneamente; por ello, las herra-mientas de análisis de imagen y de procesamiento de los datos son bastante sofisti-cadas. Gracias a esto, los estudios de microarrays están permitiendo avanzar en eldiagnóstico de enfermedades, ya que permiten detectar «firmas» de expresión espe-cíficas para enfermedades concretas. Estas «firmas» son patrones característicos for-mados por los genes que tienen su expresión más alterada en un proceso concreto;al detectar el subgrupo de genes que se alteran con mayor intensidad, podemos uti-lizar esa información para diagnosticar si un individuo sufre ese mismo proceso. Enalgunos casos, la utilización de estas «firmas» moleculares ha ayudado a distinguirprocesos que antes se agrupaban juntos, identificando enfermos que tienen distintasposibilidades de respuesta a tratamientos, distinta supervivencia, etc.
La Figura 3.11 nos lleva a unas animaciones que muestran cómo se lleva a cabo y se interpreta un experimento con microarrays.
Actualmente se están generando bases de datos que archivan los resultados demúltiples estudios de microarrays, con lo que es posible acceder a esos datos y ela-borarlos para obtener información sobre los niveles de expresión de un gen en dis-tintos tipos celulares y en distintas condiciones experimentales. El análisis de estosdatos permitirá establecer cómo varían los patrones de expresión génica de un geno-ma en distintos procesos metabólicos y fisiológicos, así como también en diversas si-tuaciones patológicas. Así podremos identificar las variaciones típicas de los distin-tos tipos de cáncer, de enfermedades cardiovasculares, neurodegenerativas, etc; esto,a su vez, permitirá identificar nuevas dianas terapéuticas para restablecer esos patro-nes de expresión alterados.
48
Técnicas básicas de genética molecular
CAPITULO 3 5/12/06 07:02 Página 48
www.FreeLibros.me

CAPITULO 4 5/12/06 07:06 Página 49
www.FreeLibros.me

B) El genoma humano
En tres temas se cubre la organización general del genomahumano y la relación entre estructura y función, además de prestar
atención a las bases moleculares del cambio genético y a losmecanismos correctores de los errores introducidos en la secuencia.
CAPITULO 4 5/12/06 07:06 Página 49
www.FreeLibros.me

C A P Í T U L O 4
La geografía del genomahumano
Contenidos
4.1 Historia y desarrollo del Proyecto Genoma Humano
4.2 Estructura del genoma humano y variación inter-individual
4.3 El ADN repetitivo
4.4 El genoma mitocondrial
4.1 Historia y desarrollo del Proyecto Genoma Humano
En 1986, el Departamento de Energía de los Estados Unidos lideró la Iniciativa del Ge-noma Humano, tras varios años de contactos y reuniones, y puso en marcha el mayorproyecto biomédico de la historia con el objetivo final de conseguir la secuencia com-pleta del genoma humano en el año 2005. El Proyecto Genoma Humano comenzó ofi-cialmente en Estados Unidos en octubre de 1990, siguiendo un plan a cinco años paradesarrollar las herramientas que permitiesen conseguir esa meta. Estas herramientas eranprincipalmente la construcción de mapas genéticos (de ligamiento) y de mapas físicos(de clones) de todo el genoma humano, al tiempo que se desarrollaba la tecnología ne-cesaria para realizar secuenciación a gran escala. La estrategia general consistió en cons-truir mapas genéticos y físicos e integrarlos, para aumentar cada vez más en resolucióndesde el cromosoma hasta la secuencia de ADN.
Los mapas genéticos describen la organización cromosómica de caracteres (un rasgofenotípico, una enfermedad) o de marcadores genéticos, mediante estudios de ligamien-to genético.
CAPITULO 4 5/12/06 07:06 Página 51
www.FreeLibros.me

El concepto de ligamiento genético y la forma en que se cuantifica son objeto del Capítulo 11. Si el lector no está familiarizado con la construcción de mapas de ligamiento, se aconseja estudiarel Capítulo 11 antes de seguir leyendo.
Los primeros éxitos de mapeo genético en humanos fueron los que consiguieronasociar un carácter a un cromosoma, como por ejemplo el ligamiento del daltonis-mo al cromosoma X, o ligamiento del grupo sanguíneo Duffy al cromosoma 1. Esteúltimo fue el primer rasgo hereditario mapeado a un autosoma (en 1968) gracias aque, en una familia concreta, se observó que este rasgo se heredaba junto con un he-teromorfismo del cromosoma 1. Esto puso de manifiesto la utilidad de contar conmarcadores de ADN que estuviesen distribuidos por todo el genoma, fuesen fácilesde estudiar en un número alto de individuos y tuviesen una posición cromosómicaconocida, ya que así se podrían realizar estudios de ligamiento genético en familiasque padecen una determinada enfermedad genética para determinar si esa enferme-dad está en ligamiento con alguno de estos marcadores, lo que facilitaría la identifi-cación del gen responsable.
Los tipos de marcadores más utilizados en estudios de ligamiento en GenéticaHumana son:
• Polimorfismos de Longitud de Fragmentos de Restricción (en inglés, las siglasson RFLP). Un RFLP es un polimorfismo originado por un cambio de un nu-cleótido que crea o destruye una diana de restricción, de manera que en-contraremos alelos con esa diana y alelos sin ella. Por tanto, un RFLP es pordefinición un marcador bialélico (sólo hay dos alelos posibles). La presencia
52
La geografía del genoma hum
ano
STS 8 STS 6 STS 4 STS 2 STS 7 STS 5
STS 3 STS 1 MAPA FÍSICO
8 marcadores tipo STS cuya posición es conocida
MAPA GENÉTICO DE LIGAMIENTO 4 marcadores posicionados por
estudios de ligamiento
Distancia en centimorgans (cM)
Distancia física en pares de bases (bp)
DS16C4 DS16B3 DS16A2 DS16A1
La Figura 4.1 explica cómo son los mapas físicos y los mapas de ligamiento genético, y su utilización en el Proyecto Genoma Humano.
CAPITULO 4 5/12/06 07:06 Página 52
www.FreeLibros.me

o ausencia de esa diana hace que los fragmentos originados por la digestióndel ADN con esa enzima de restricción sean de distinto tamaño. En general,un polimorfismo tipo RFLP puede detectarse de dos modos: a) digerir direc-tamente el ADN genómico, separar los fragmentos en un gel, hacer un Sou-thern blot e hibridarlo con una sonda específica para detectar cada uno de losfragmentos polimórficos; b) amplificar la región del polimorfismo mediantePCR y digerir directamente el producto de PCR para separar los fragmentosen un gel.
• Los marcadores tipo VNTR (acrónimo inglés de «Número Variable de Repe-ticiones en Tándem») son polimorfismos originados por pequeñas secuenciasde ADN que están repetidas en tándem. El número de repeticiones es dife-rente en los distintos individuos de la población, por lo que en principio pue-den existir más de dos alelos distintos para cada marcador (aunque cada in-dividuo sólo lleve dos alelos, en la población general pueden existir más). Losmarcadores en los que la secuencia repetida es corta (dos a cuatro nucleóti-dos) se denominan también microsatélites o STR («Short Tandem Repeats»,Repeticiones Cortas en Tandem), y están homogéneamente distribuidos portodo el genoma. Los marcadores en los que la secuencia repetida es más lar-ga (decenas a cientos de nucleótidos) se denominan minisatélites, y han sidomuy importantes en los estudios de genética forense ya que permiten estable-cer una huella genética única para cada individuo. Los minisatélites son másabundantes hacia las regiones teloméricas de los cromosomas, y —debido a sutamaño— en principio deben detectarse mediante Southern blot e hibridación.En cambio, los marcadores de tipo microsatélite pueden detectarse mediantePCR y están distribuidos uniformemente por el genoma, por lo que su análi-sis es más rápido y sencillo y proporcionan mayor información.
• Los SNP (pronunciado snip) son polimorfismos de un solo nucleótido (Sin-gle Nucleotide Polymorphisms) en los que el simple cambio de un nucleótidoen una secuencia genómica da lugar a distintos alelos. Lógicamente, para cadaposición sólo puede haber cuatro alelos como máximo (A, C, G o T), aunquelo habitual es que un SNP tenga dos alelos en la población general. Se estimaque, como promedio, hay al menos un SNP cada 500-1 000 pares de bases,de los cuales un porcentaje importante son polimorfismos codificantes (es de-cir, cambian un aminoácido en la proteína codificada por el gen) y constitu-yen la principal fuente de variabilidad genética inter-individual, puesto quedos individuos cualesquiera tienen alrededor de un 0,1 por ciento de sus nu-cleótidos distintos. La gran ventaja de los SNP sobre los demás tipos de mar-cadores, además de ser tan abundantes y estar muy uniformemente distribui-dos por todo el genoma humano, es la posibilidad de analizarlos mediantemétodos automatizables a gran escala, como los microarrays, de manera quese pueden determinar cientos o miles de SNPs a la vez en un mismo experi-mento.
La Figura 4.2 ilustra los tipos de marcadores más utilizados en la construcción de mapas de ligamiento genético en humanos.
53
Historia y desarrollo del Proyecto Genom
a Hum
ano
CAPITULO 4 5/12/06 07:06 Página 53
www.FreeLibros.me

El objetivo inicial del PROYECTO GENOMA era crear un mapa genético (de li-gamiento) con marcadores distribuidos por todo el genoma con una distancia me-dia de 1 cM entre marcadores. Los mapas genéticos se basaron en un primer mapapublicado en 1987, hecho con 393 marcadores tipo RFLP agrupados en 23 gruposde ligamiento, con una distancia media entre marcadores superior a 10 cM. El pri-mer mapa genético de todo el genoma fue el realizado por un centro de investiga-ción francés llamado Généthon en 1992, e incluía 803 marcadores tipo microsa-télite.
Los mapas físicos, en cambio, reconstruyen la estructura de un segmento deADN, determinando los tipos y orden relativo de las distintas secuencias que lo com-ponen, sus tamaños, y las distancias entre ellas. Para la construcción de mapas físi-cos se utiliza un tipo de marcador distinto, que veremos más adelante. Lógicamente,el mapa físico de mayor resolución posible es la secuencia completa de ese segmen-to (resolución de un nucleótido), pero también es posible realizar mapas de menorresolución (un ejemplo, mapas de restricción). El tipo de marcador utilizado en lacreación de mapas físicos se denominó STS (Sequence-Tagged Site = Sitio Etiqueta-do por su Secuencia). Un STS es un pequeño fragmento de ADN (unos pocos cien-tos de pares de bases) de secuencia y localización genómica conocidas, fácilmenteamplificable mediante PCR. Durante años se habían identificado un buen número demarcadores STS, mediante la secuenciación parcial de clones previamente mapeadospor otros métodos. Además, los microsatélites utilizados en la creación de mapas deligamiento también pueden convertirse fácilmente en STS, leyendo la secuencia queflanquea las repeticiones del microsatélite. Gracias a esto, hoy contamos con una lis-ta ordenada de STS que están distribuidos por todo el genoma humano, cuya se-cuencia y condiciones de amplificación mediante PCR son fácilmente accesibles atodo investigador. El PROYECTO GENOMA se propuso inicialmente conseguir ma-pas de marcadores tipo STS distribuidos por todo el genoma y con una distancia me-dia entre marcadores en torno a 0,1 Mb (es decir, 100kb).
Utilizando estos marcadores STS, se pudieron construir mapas físicos, es decirmapas compuestos por clones de bibliotecas genómicas, capaces de albergar insertosde gran tamaño. Existen distintos vectores de este tipo, entre los que destacan losvectores tipo YAC (Yeast Artificial Chromosome), PAC (P1-phage Artificial chromo-some) y BAC (Bacterial Artificial Chromosome). Cada uno de estos vectores de clo-nación tiene características específicas, ventajas e inconvenientes. En concreto, losYAC son los vectores que permiten albergar un mayor tamaño de inserto (hasta dosmegabases), pero son bastante inestables (tienden a perder fragmentos del insertocuando se replican) y tienen un porcentaje relativamente alto de clones quiméricos(es decir, clones en los que el inserto está en realidad formado por dos fragmentosprocedentes de cromosomas distintos). Los PACs y BACs, en cambio, sólo permitenclonar insertos de unas 100 a 150 kilobases de tamaño (por lo que son necesariosmuchos más clones para cubrir completamente un segmento genómico determina-do), pero en cambio son muy estables y el porcentaje de quimerismo es muy peque-ño. Aunque los YACs han sido el vector principalmente utilizado al principio de losaños 90, hoy en día han sido desplazados por PACs y BACs.
54
La geografía del genoma hum
ano
CAPITULO 4 5/12/06 07:06 Página 54
www.FreeLibros.me

La Figura 4.3 explica la utilización de marcadores STS para crear un contig de clones que cubranuna región del genoma.
Los primeros mapas físicos del genoma humano estaban compuestos por con-tigs de YACs que cubrían parcialmente el genoma humano, siendo el mejor ejemploel mapa creado también por Généthon en 1993. Este mapa supuso un avance enor-me porque —aunque sólo cubría algunas regiones genómicas— sirvió como punto departida para elaborar mapas más completos con vectores más fiables y manejables,como BACs y PACs.
El PROYECTO GENOMA hizo una revisión de sus objetivos en 1993, teniendoen cuenta los progresos realizados en los tres años anteriores, y estableció nuevasmetas para los siguientes cinco años (1993-1998). En resumen, estos nuevos objeti-vos fueron:
• Conseguir un mapa genético con resolución de dos a cinco cM entre marca-dores.
• Conseguir un mapa físico con STS espaciados regularmente cada 0,1 Mb (loque significaba identificar y localizar la posición de —como mínimo— unos30 000 STS).
• Desarrollar nuevas tecnologías para la identificación de genes a partir deADN genómico.
• Desarrollar nuevas tecnologías de secuenciación y completar 80 Mb de se-cuencia confirmada para todos los organismos que estaban siendo secuencia-dos por los distintos proyectos.
• Potenciar la genómica comparada: completar las secuencias de E. coli, S. ce-revisiae y C. elegans, y comenzar los proyectos de secuenciación de los geno-mas de Drosophila y de ratón.
55
Historia y desarrollo del Proyecto Genom
a Hum
ano
GGAGACTACGGAGATTACCTACGGGACTACAGAAGGAGACTACGGAGAGTACCTACGGGACTGTCT
DS16C4 DS16B3 DS16A2 DS16A1
STS 8 STS 6 STS 4
STS 2STS 7 STS 5
STS 3 STS 1
CONTIG: conjunto de clones solapantesque cubren una región del genoma
La secuenciación de cada clon permite reconstruir la secuencia original de esa región genómica
CONTIG: conjunto de clones solapantesque cubren una región del genoma
La secuenciación de cada clon permite reconstruir la secuencia original de esa región genómica
CAPITULO 4 5/12/06 07:06 Página 55
www.FreeLibros.me

Cuando en 1998 se revisaron los avances realizados en esos cinco años, con el fin dediseñar un nuevo plan quinquenal, los resultados habían sido realmente prometedo-res: en septiembre de 1994 se publicó un mapa genético de todo el genoma humanointegrado por 4 000 marcadores tipo microsatélite y 1 800 marcadores tipo RFLP,con una distancia media entre marcadores de 0,7 cM. Esto superaba en más de tresaños el objetivo propuesto inicialmente. Por su parte, Généthon publicó en 1995 otromapa físico de YACs que estaba formado por 255 contigs (con un tamaño medio de10 Mb cada contig) y cubría el 75 por ciento del genoma humano. Durante esos añosse continuaron desarrollando nuevos marcadores tipo STS, hasta llegar en 1998 a unmapa que contenía 52 000 STS (casi el doble de los inicialmente propuestos).
Por lo que respecta a la secuenciación, en octubre de 1998 se había obtenido untotal de 180 Mb de secuencia del genoma humano (6 por ciento del total), ademásde 111 Mb de secuencia de otros organismos, muy por encima de lo previsto en elplan 1993-1998. Además, se había completado la secuencia de E. coli y de S. cerevi-siae, éste último el primer organismo eucariota en ser secuenciado totalmente. Estofue posible gracias a importantes avances en la tecnología de secuenciación, que sehizo progresivamente más rápida, fiable y barata. Posteriormente, en diciembre de1998, se completó la secuencia de C. elegans, el primer organismo multicelular se-cuenciado en su totalidad con un genoma de unas 97 Mb.
Por tanto, en 1998 el PROYECTO GENOMA se fijó un nuevo plan de objetivoshasta el año 2003, en el que se incluían ocho metas concretas:
1. Completar la secuencia del genoma humano para 2003 (año que coincidíacon el 50º aniversario del descubrimiento de la doble hélice por Watson yCrick), creando un primer borrador de trabajo en 2001. Este objetivo se ace-leró enormemente por la competencia de la empresa privada Celera Geno-mics, que se propuso secuenciar todo el genoma humano, utilizando una es-trategia distinta al consorcio internacional del PROYECTO GENOMA, conel fin de obtener la propiedad intelectual y poder explotar esa informacióncon fines comerciales. A pesar de los problemas suscitados inicialmente porla fuerte competencia entre ambos proyectos, el 26 de junio de 2000 se pro-dujo el anuncio oficial de que se había alcanzado un primer borrador del 87por ciento de la secuencia del genoma humano. Este primer borrador fue pu-blicado el 15 de febrero de 2001 en las revistas Nature (el mapa del Consor-cio Internacional) y Science (el mapa de Celera Genomics).
La Figura 4.4 muestra el proceso general utilizado por el Consorcio Internacional para la secuenciación del Genoma Humano.
2. Continuar el desarrollo y la innovación de las tecnologías de secuenciación.Como ya se ha comentado, éste ha sido un factor determinante en el avancedel PROYECTO GENOMA.
3. Estudiar la variación en el genoma humano. Como hemos visto, los SNP seencuentran en el genoma humano a razón de uno por cada kilobase, comopromedio, y representan las diferencias genéticas entre individuos de unamisma especie. Como se verá en el Capítulo 11, la creación de mapas densosde SNP permitirá llevar a cabo estudios de asociación para detectar los genes
56
La geografía del genoma hum
ano
CAPITULO 4 5/12/06 07:06 Página 56
www.FreeLibros.me

que están implicados en enfermedades complejas, debidas a alteraciones enmuchos genes —siendo la contribución de cada gen a la enfermedad peque-ña— y, por tanto, difíciles de detectar por otros métodos de ligamiento.
4. Desarrollar tecnología para la «genómica funcional», es decir, identificar to-dos los genes y determinar cuál es la función de cada gen. La gran revoluciónen las estrategias de identificación de regiones codificantes (es decir, genes)comenzó con la idea de Craig Venter de secuenciar al azar y a gran escalafragmentos de ADNc de bibliotecas obtenidas a partir de diversos tejidos. Es-tos fragmentos de secuencia se denominaron «Etiquetas de Secuencia Expre-sada» (EST, Expressed Sequence Tags), ya que —en el fondo— cada una repre-senta un fragmento de un ARNm (una secuencia expresada en un tejidoconcreto). En pocos años, la base de datos de EST creció de manera expo-nencial, con cientos de miles de secuencias expresadas procedentes de dis-tintas bibliotecas de ADNc. Como algunos de estos EST proceden de un mis-mo ARNm, se creó una colección no redundante llamada UNIGENE queagrupa los EST por familias, siendo cada familia representativa de un únicoARNm. Poco después comenzaron también proyectos internacionales paramapear secuencias de UNIGENE, de manera que en 1994 se publicó un pri-mer mapa con la localización de 16 000 EST correspondientes a genes dis-tintos, y en 1998 se publicó un segundo mapa de 41 664 EST, que represen-taban 30 181 genes distintos. Cuando se conozca el catálogo completo degenes de nuestro genoma, será necesario estudiar la expresión de cada gen endistintos tejidos y en distintas situaciones fisiológicas y patológicas, en res-puesta a distintos factores ambientales, etc. Lógicamente, esto será el objetode la investigación biomédica de buena parte del siglo XXI.
5. Genómica Comparada. El análisis comparado de los genomas de varias es-pecies es de gran utilidad para identificar mecanismos biológicos conserva-dos durante la evolución (por lo que son especialmente importantes), es-tructura y función de genes ortólogos, etc. Aunque el plan para 1998-2003se propuso conseguir la secuencia completa del genoma de Drosophila parael año 2002, esta meta se cumplió en abril del año 2000 gracias a la colabo-ración de laboratorios y Universidades con Celera Genomics, descifrandounas 120 Mb de secuencia que comprenden la práctica totalidad de la eu-cromatina de este insecto. El nuevo gran reto ahora es conseguir la secuen-cia completa del genoma de otras especies de mamíferos: el primer borradorcompleto del genoma de ratón se obtuvo en 2002 y el del genoma de chim-pancé en 2005.
6. Implicaciones éticas, legales y sociales del PROYECTO GENOMA. Es im-portante tener consciencia de la influencia que va a tener el Proyecto Geno-ma y sus aplicaciones sobre los individuos y las sociedades. Cuestiones comoel diagnóstico de enfermedades que no tienen tratamiento, la extensión deuna mentalidad eugenésica que lleve a la discriminación por razón de defi-ciencias genéticas, el diagnóstico prenatal de alteraciones genéticas que con-fieren predisposición a sufrir enfermedades que se manifestarán en la edadadulta, la detección de rasgos psicológicos con base genética, la confidencia-lidad de la información genética de los individuos (y la posible discriminación
57
Historia y desarrollo del Proyecto Genom
a Hum
ano
CAPITULO 4 5/12/06 07:06 Página 57
www.FreeLibros.me

laboral) serán una constante en los debates sociales de este siglo, y es impor-tante llevar a cabo una labor de divulgación seria para que la sociedad pue-da discutir de modo sosegado y bien fundamentado las bases éticas sobre lasque sostener las aplicaciones biomédicas de la biotecnología en los años quese avecinan.
7. Desarrollo de herramientas bioinformáticas (bases de datos y herramientasde análisis de datos) que puedan ser compartidas por la comunidad científica.Será especialmente importante el desarrollo de herramientas informáticas quepermitan identificar exones y predecir la estructura de genes en grandes se-cuencias genómicas, así como plataformas de genómica funcional para el aná-lisis de la expresión de miles de genes a la vez.
8. Formación en genómica: favorecer que científicos y académicos se dediquena la investigación genómica y a divulgar y aumentar el conocimiento públicode los distintos aspectos del PROYECTO GENOMA.
Finalmente, la primera versión esencialmente completa del genoma humano fueanunciada oficialmente el 14 de abril de 2003, cubriendo un total de 3 069 Mb (92,3por ciento del total estimado del genoma humano) con un 99,99 por ciento de fiabi-lidad en cada posición secuenciada. El análisis de la secuencia publicada permite ha-cerse una idea bastante aproximada de la estructura de nuestro genoma, su compo-sición y algunas de sus características funcionales, como se explica a continuación.
4.2 Estructura del genoma humano y variación inter-individual
El genoma humano nuclear tiene un tamaño aproximado de 3 200 Mb (megabases),es decir tres mil doscientos millones de pares de bases. Esta cifra total incluye unas2 950 Mb de eucromatina y unas 250 Mb de heterocromatina (formada, como vere-mos, por ADN satélite). Esta cifra se refiere al genoma haploide, de manera que lascélulas somáticas (diploides) contienen el doble.
La Figura 4.5 muestra una visión general de los distintos tipos de secuencias que constituyen el genoma humano.
Una primera clasificación del genoma humano distingue, por un lado, los genes ysecuencias relacionadas con genes (exones, intrones, regiones no traducidas que con-tienen elementos reguladores, etc.), y por otro todo el ADN que está entre los genes,llamado ADN extragénico o «de relleno» y que no codifica ninguna proteína ni con-tiene ningún elemento funcional. Curiosamente, la mayor parte del genoma humano(un 70 por ciento) está formada por este último, de forma que sólo un 30 por cientodel genoma humano incluye secuencias relacionadas con genes. Lo más sorprenden-te es que de este 30 por ciento sólo un cinco por ciento está constituído por ADNcodificante (exones), siendo el resto ADN no-codificante asociado a genes. Por tan-to, resulta que sólo un 1,5-2 por ciento del total del genoma humano es ADN co-dificante. El ADN extragénico está formado, sobre todo, por los componentes repe-titivos del genoma humano que se explicarán más adelante, aunque también haysecuencias únicas o en bajo número de copia.
58
La geografía del genoma hum
ano
CAPITULO 4 5/12/06 07:06 Página 58
www.FreeLibros.me

Desde la publicación del primer borrador del Genoma Humano en febrero de2001, podemos dar unos valores promedio estimados a partir de los datos publicados:
• Se estima que el genoma humano contiene en torno a los 20 000-25 000 genes.
• Alrededor de un 50 por ciento del genoma humano está constituido por ADNrepetitivo.
• Se puede estimar que la densidad media de genes es de un gen cada 100 kb,aunque existen regiones ricas en genes (algunas zonas del cromosoma 19, porejemplo) y otras regiones que son muy pobres en genes (como el cromoso-ma Y). Por tanto, se puede deducir una frecuencia media de 10 genes por cadaMb de secuencia.
• El tamaño promedio de un gen humano es de 20-30 kb, aunque hay grandesdiferencias de unos genes a otros.
• El número de exones que forman un gen es muy variable (desde genes que tie-nen un solo exón hasta algunos genes con 100 exones o más), pero podemosestablecer un valor promedio de siete-ocho exones por gen.
• El tamaño medio de un exón es de 150 nucleótidos. Por lo que respecta a losintrones, en cambio, existe una enorme variabilidad de tamaños, y no es in-frecuente encontrar en casi todos los genes algún intrón de gran tamaño.
• El tamaño medio de un ARNm es de 1,8-2,2 kb incluyendo las regiones no-tra-ducidas flanqueantes. La longitud media de una región codificante es de 1,4 kb.
Una de las características más evidentes del borrador de nuestro genoma es su hete-rogeneidad. En efecto, la secuencia no es uniforme, sino que muchas de sus caracte-rísticas (riqueza en C+G frente a A+T, riqueza en genes, etc.) se distribuyen hetero-géneamente, con regiones de gran abundancia flanqueadas por regiones en que esosparámetros son más escasos. Así por ejemplo, el contenido medio de G+C del ge-noma humano es del 41 por ciento, menor de lo teóricamente esperado. Además, siel genoma se divide en «ventanas» de 20 kb se observan regiones con valores muyalejados del promedio, con una dispersión 15 veces mayor de lo que sería esperablesi la distribución fuese uniforme. La distribución de %G+C de estas ventanas no seajusta a una distribución normal, sino que está desviada hacia valores bajos.
Además, se ha comprobado que los genes tienden a concentrarse en las ventanasmás ricas en G+C. Esto se conocía ya de antiguo, y de hecho se había acuñado el tér-mino isocoro para designar las regiones genómicas que son homogéneas en cuanto alcontenido en G+C y que pueden separarse mediante gradientes de densidad. Se dis-tinguen isocoros L e isocoros H, según su contenido en G+C sea bajo (Low) o alto(High), y dentro de cada isocoro hay varios subgrupos. La tabla que se presenta a con-tinuación resume algunas características importantes de los distintos isocoros:
Isocoro % GC % del genoma Contenido Genes % Mb ADN Densidad de genes
L1 38 30 48 1,860 1 cada 130 kbL2 41 32H1 44 19 27 870 1 cada 100 kbH2 49 10H3 53 9 25 270 1 cada 35 kb
59
Estructura del genoma hum
ano y variación inter-individual
CAPITULO 4 5/12/06 07:06 Página 59
www.FreeLibros.me

Como puede apreciarse, existe una relación directa entre el contenido de unaregión genómica en nucleótidos G+C y su riqueza en genes. Es decir, hay en elgenoma humano unas regiones con mayor riqueza de genes, regiones que a su vezson las que tienen un mayor porcentaje de nucleótidos G+C.
Otro hallazgo inesperado en nuestro genoma ha sido la presencia de mayor nú-mero de duplicaciones del que se había estimado hasta entonces. De hecho, el aná-lisis muestra alrededor de un cinco por ciento de duplicaciones segmentarias, defi-nidas como dos o más segmentos cromosómicos >1 kb con >90 por ciento deidentidad de secuencia; dicho nivel de homología corresponde a una antigüedad deunos 40 millones de años. Las duplicaciones intracromosómicas (las copias están enel mismo cromosoma) tienen un tamaño medio de unas 100 kb, mientras que las du-plicaciones intercromosómicas (entre cromosomas distintos) son más pequeñas (10-50 kb). Las duplicaciones segmentarias son más frecuentes en regiones centroméri-cas y cerca de los telómeros (donde pueden llegar a constituir un 25 por ciento dela secuencia). Los centrómeros, en concreto, están flanqueados por regiones ricas enduplicaciones intercromosómicas procedentes de regiones eucromáticas de otroscromosomas, que se han ido transponiendo a zonas pericentroméricas a una veloci-dad de seis-siete eventos por millón de años durante la evolución de primates. Lasduplicaciones intracromosómicas pueden dar lugar a alteraciones genómicas, comoveremos más adelante.
La Figura 4.6 muestra esquemáticamente los tipos de duplicaciones segmentarias.
El análisis de la secuencia también ha mostrado la alta cantidad de pseudogenesque hay en el genoma humano. Como su nombre indica, los pseudogenes son ver-siones «incorrectas» de genes, que contienen diversos tipos de mutaciones y habi-tualmente no se transcriben. Se dividen en pseudogenes no procesados y pseudoge-nes procesados. Los primeros son copias de un gen, habitualmente originadas porduplicación del gen original y posteriores mutaciones que hacen que la copia pierdasu capacidad codificante. Contienen exones e intrones, pero carecen de promotor yhabitualmente tienen codones de parada prematuros. En cambio, los pseudogenesprocesados son copias del ARN mensajero de un gen, que se ha retrotranscrito e in-sertado en otra posición del genoma (de ahí que se denominen también retropseu-dogenes). No tienen intrones, y tampoco tienen capacidad codificante por la ausen-cia de promotor y por la presencia de codones de parada. Se han identificado unos11 000 pseudogenes en el genoma humano, de los que la mayor parte (unos 8 000)son pseudogenes procesados. En total, se estima que el número de pseudogenes ennuestro genoma puede llegar a unos 20 000. De todas formas, todos los pseudogenesdetectados se originan a partir de tan sólo unos 2 500 genes funcionales, de modoque la mayor parte de los genes no tienen ningún pseudogen en el genoma.
La Figura 4.7 muestra la estructura de los distintos tipos de pseudogenes.
Recientemente se han encontrado 481 segmentos >200 pares de bases totalmen-te conservados (100 por ciento de identidad sin gaps) en regiones ortólogas de hu-mano, rata y ratón, y la gran mayoría están también conservados en pollo y perro (95
60
La geografía del genoma hum
ano
CAPITULO 4 5/12/06 07:06 Página 60
www.FreeLibros.me

y 99 por ciento de identidad, respectivamente). Muchas también están conservadasen pez. Estos «elementos ultraconservados» se solapan con exones de genes impli-cados en el procesamiento de ARN, y también son abundantes en intrones de genesrelacionados con el desarrollo o con la regulación de la transcripción. Junto con lasmás de 5 000 secuencias >100 nucleótidos que están totalmente conservadas en lostres mamíferos secuenciados, estos fragmentos constituyen una nueva clase de ele-mentos genéticos cuya función está por determinar, pero el hecho de que están másconservados que las proteínas indica que deben jugar algún papel importante.
También es importante dedicar unas líneas a describir la presencia de genes quedan lugar a microARN. Como es sabido, el estudio del mecanismo de interferenciade ARN ha llevado a la identificación de ARN interferentes endógenos en los geno-mas de eucariotas, incluido el genoma humano. Estos ARN se denominan micro-ARN (miARN) y se transcriben a partir de genes con un promotor de ARN-polime-rasa II. Estos genes tienen un segmento palindrómico, de modo que el ARNmprimario forma un pri-miARN que contiene una horquilla de ARN bicatenario; estepri-miARNm es procesado dentro del núcleo de la célula por una ARNasa tipo IIIllamada DROSHA y esto da lugar a un pre-miARN, una ARN bicatenario con for-ma de horquilla de unos 70 nucleótidos de tamaño. El pre-miARN sale del núcleo yes procesado en el citoplasma por Dicer, originando un miARN de unos 22 nucleó-tidos. Éste entra a formar parte del complejo RISC (denominado miRISC para losmiARN) y regula la expresión de genes diana mediante degradación de sus mensaje-ros o por represión de la traducción. Actualmente se han identificado más de 300 ge-nes de miARN en el genoma humano, y se calcula que puede haber en torno a 500.La mayoría de estos genes se localizan en intrones de genes codificantes, y ademásestán bastante conservados en primates. Dado que cada uno de estos miARN pue-de regular la expresión de varios genes diana, se estima que hasta un 20-30 por cien-to de todos los genes del genoma humano pueden estar regulados por miARN, loque les confiere una extraordinaria importancia.
La secuenciación del genoma humano ha permitido también estudiar la variacióngenética inter-individual, es decir, las diferencias genéticas que están en la base de lasdiferencias fenotípicas entre individuos. Esto tiene gran relevancia médica, porquemuchas de estas variantes pueden ser también causa de la distinta susceptibilidad adesarrollar enfermedades o la diferente respuesta a fármacos que tienen personas dis-tintas. Uno de los tipos más importantes de variabilidad genética es el constituido porlos cambios en un nucleótido de la secuencia, conocidos con el nombre de SNP. Unode los objetivos del PROYECTO GENOMA HUMANO era el estudio de la diversi-dad genética, y esto ha cristalizado en otro proyecto internacional denominado Pro-yecto HapMap que se propone precisamente identificar los SNP más frecuentes en elgenoma humano en individuos de diferentes grupos étnicos. En octubre de 2005, elProyecto Hapmap publicó un primer mapa que contiene 1 007 329 SNP con una dis-tancia media entre ellos de cinco kb, con una frecuencia del alelo menos frecuenteigual o superior al cinco por ciento (es decir, presentes en al menos el cinco por cien-to de la población). Todos estos SNP fueron genotipados en 269 individuos de cua-tro grupos raciales: 90 de raza yoruba, de Nigeria; 90 caucasianos de Utah; 45 de razahan, de China; y 44 japoneses. La segunda fase de este Proyecto se propone genotiparotros cinco millones de SNP. La inspección de estos mapas permite hacerse una idea
61
Estructura del genoma hum
ano y variación inter-individual
CAPITULO 4 5/12/06 07:06 Página 61
www.FreeLibros.me

de la variación en el genoma, tanto entre individuos como entre distintos grupos ra-ciales. Además, estos datos han permitido comprobar que esta variación se agrupa enbloques, de modo que todos los SNP de un mismo bloque se heredan juntos. En uncapítulo posterior veremos la importancia de estos bloques para estudiar la asociaciónde SNP concretos con la susceptibilidad a padecer enfermedades.
La Figura 4.8 muestra la estructura de los haplotipos formados por los alelos de varios SNP cercanos.
Otro tipo de variación que se ha descubierto al analizar la secuencia del genomahumano es la originada por diferencias en el número de copias de grandes seg-mentos genómicos. Al analizar genomas de distintos individuos, se ha visto que exis-ten unas 200-300 regiones genómicas de tamaño grande (entre 10 y 50 kilobases)cuyo número de copias en el genoma es diferente de unos individuos a otros. Estetipo de variaciones, llamadas LCV (Large-scale Copy number Variations) o CNP(Copy Number Polymorphisms) pueden ser deleciones o repeticiones en tándem. Unacaracterística de todas estas regiones es que están flanqueadas por duplicacionessegmentarias, y esto hace pensar que la variación en el número de copias es el re-sultado de reordenaciones entre esos elementos flanqueantes. Aunque su papel bio-lógico todavía no está claro, los CNP pueden tener importancia en la variación ge-nética inter-individual que explica las diferencias en la predisposición a desarrollarenfermedades.
Finalmente, se ha catalogado también otro tipo de variación consistente en poli-morfismos de inserción/deleción pequeños (de tamaños entre un nucleótido a10 kb). Se han detectado varios cientos de miles, y se estima que en total hay alre-dedor de 1,5 millones de estos polimorfimos en el genoma humano. Aunque se dis-tribuyen por todo el genoma, se ha visto que en algunas regiones son especialmentefrecuentes. Muchos de ellos están dentro de genes, y pueden causar alteracionescuando afectan al promotor o a la región codificante (exones).
4.3 El ADN repetitivo
Como hemos visto al principio de este capítulo, hasta un 50 por ciento del genomahumano está constituido por ADN repetitivo, antiguamente conocido como «ADNbasura». Por su importancia, a continuación estudiamos con mayor detalle su com-posición y los distintos tipos de secuencias que lo forman. Ya se ha mencionado quepodemos encontrar ADN repetitivo tanto en el ADN codificante (en los genes y se-cuencias relacionadas) como en el ADN no-codificante, pero la mayor parte se en-cuentra en el ADN no-codificante. Quizás el único ejemplo de ADN repetitivo codi-ficante que merece la pena reseñar es el correspondiente al ADN ribosomal, que seconcentra en los brazos cortos de los cromosomas acrocéntricos (13, 14, 15, 21 y 22)y está formado por tres genes que dan lugar a los tres ARN ribosomales de 5,8S, de18S y de 28S. Los tres genes están juntos formando un bloque que mide unas 13 ki-lobases. Estos bloques se encuentran repetidos unas 50 veces, separados entre sí porun espaciador intergénico que mide unas 30 kilobases. En conjunto, el ADN riboso-mal ocupa un tamaño de unas dos megabases.
62
La geografía del genoma hum
ano
CAPITULO 4 5/12/06 07:06 Página 62
www.FreeLibros.me

En el ADN no-codificante, tanto intragénico (es decir, intrones y otras regionesno-codificantes relacionadas con genes) como extragénico, podemos encontrar di-versos tipos de elementos repetidos. En general, se trata de una secuencia de ADNque se repite en el genoma cientos o miles de veces. Estas repeticiones pueden en-contrarse en tándem (es decir, seguidas una detrás de otra) o dispersas.
El ADN repetido en tándem se divide en varios grupos según el tamaño total queorigina la repetición:
• El genoma humano contiene en total unas 250 Mb de ADN satélite (llama-do así porque al separar el ADN genómico en gradientes de densidad apare-ce como tres bandas «satélites» de la banda principal). El ADN satélite estáformado por la repetición de una secuencia de ADN miles de veces en tán-dem, es decir unas copias pegadas a otras. Esto da lugar a regiones repetidascon tamaños que van desde 100 kb hasta varias megabases. Por ejemplo, elADN Satélite 1 es una secuencia de 42 nucleótidos, mientras que en el Saté-lite 2 la secuencia repetida es (ATTCCATTCG) y en el Satélite 3 se repite elpentámero (ATTCC). Un tipo de ADN satélite muy importante es el ADN al-foide o Satélite alfa, en el que la secuencia repetida tiene un tamaño de 171nucleótidos, y que forma parte del ADN de los centrómeros de los cromoso-mas humanos. Otros tipos de ADN satélite son el Satélite beta (repetición de68 nucleótidos) y el Satélite gamma (repetición de 220 nucleótidos), que tam-bién se encuentran en la cromatina centromérica de varios cromosomas.
• El ADN de tipo Minisatélite está formado por secuencias de 6-25 nucleótidosque se repiten en tándem hasta dar un tamaño total entre 100 nucleótidos y20 kb. Un ejemplo de ADN Minisatélite es la repetición que forma los teló-meros de los cromosomas humanos, en los que el hexanucleótido (TTAGGG)se repite miles de veces en tándem dando lugar a bloques de 5-20 kb de ta-maño. Algunas repeticiones de este tipo son polimórficas, y dan lugar a losmarcadores de tipo VNTR que hemos mencionado en un apartado anterior.
• El ADN de tipo Microsatélite está formado por secuencias de dos, tres o cua-tro nucleótidos que se repiten hasta dar bloques con un tamaño total habi-tualmente no superior a 150 nucleótidos. Hay repeticiones de este tipo portodo el genoma humano, y muchas de ellas son muy útiles como marcadoresgenéticos porque el número de repeticiones varía entre individuos. Ejemplosde ADN microsatélite son los dinucleótidos (CA), o las repeticiones de trinu-cleótidos (CAG).
El ADN repetido disperso está formado por secuencias que se repiten miles de ve-ces en el genoma humano, pero no en tándem sino de manera dispersa. Este tipo derepeticiones constituyen un 45 por ciento de todo el genoma humano y se clasificanen función del tamaño de la unidad repetida:
• Los SINE (Short Interspersed Nuclear Elements, elementos nucleares dispersoscortos) suponen un 13 por ciento del genoma humano. Son secuencias cortasrepetidas miles de veces en el genoma humano de forma dispersa. El principalSINE es la familia de elementos Alu, que es específica de primates y constitu-ye un 10 por ciento de nuestro genoma. Un elemento Alu está formado por unasecuencia de 250-280 nucleótidos, con unas 1 500 000 copias por genoma y
63
El ADN repetitivo
CAPITULO 4 5/12/06 07:06 Página 63
www.FreeLibros.me

una repetición cada cuatro kb como promedio. Es un elemento relativamenterico en guaninas+citosinas (56 por ciento de contenido en CG, mientras queel contenido promedio del genoma humano es del 41 por ciento). Se localizapredominantemente en la bandas R de los cromosomas humanos. Está flan-queado por pequeñas repeticiones directas (en la misma orientación). Su es-tructura es la de un dímero no idéntico, ya que el segundo monómero es 30 nu-cleótidos mayor que el primero. Contiene colas poli-A al final de cadamonómero, y se transcribe por la ARN polimerasa III a partir de un promotorinterno, pero no codifica ninguna proteína. Actúa como un retrotransposón,ya que puede copiarse e insertarse en otras regiones del genoma.
• Los LINE (Long Interspersed Nuclear Elements, o elementos nucleares dis-persos largos) constituyen un 20 por ciento del genoma humano. Son se-cuencias con un tamaño de varias kilobases, agrupados en distintas familias.El principal LINE es el llamado LINE-1 o L1, formado por una secuenciade unas seis kb repetida unas 800 000 veces en el genoma (aunque muchosde estos elementos no están completos, sino truncados y les falta la parte 5’),llegando a constituir alrededor de un 15 por ciento del genoma. Estos ele-mentos, al contrario que los SINE, no son ricos en guaninas+citosinas (tie-nen un 42 por ciento de citosinas+guaninas, que es cercano al contenidopromedio del genoma humano) y se localizan predominantemente en lasbandas G de los cromosomas. Un elemento L1 codifica dos proteínas: unaARN-binding protein en el marco de lectura ORF1 y una proteína con ac-tividad endonucleasa y retrotranscriptasa en el marco de lectura ORF2.Está flanqueado por unas pequeñas repeticiones directas (en la mismaorientación) y termina en una cola poli-A. Los elementos LINE son retro-transposones, puesto que pueden copiarse a sí mismos a través de un inter-mediario ARN y transponerse a otras localizaciones genómicas. Según elmodelo más aceptado, el elemento se transcribe por la ARN polimerasa IIa partir de un promotor interno, sus productos proteicos se unen a la colapoli-A de su propio ARN mensajero y el complejo se inserta en el ADN ge-nómico por la acción combinada de la endonucleasa (que corta dentro deregiones ricas en AT que llevan la secuencia TTTT↓A) y de la retrotrans-criptasa. Las proteínas codificadas por los LINE son utilizadas también parala retrotransposición de elementos SINE y de pseudogenes procesados, porlo que pueden jugar un importante papel como elemento modificador delgenoma. De hecho se ha visto que la secuencia propia de los L1 tiene lapropiedad de inhibir la transcripción, de ahí que los niveles de ARNm yproteínas codificadas por los L1 en las células sea muy bajo. Lo más intere-sante es que también pueden modificar la transcripción de los genes encuyos intrones hay abundancia de estos elementos: un 80 por ciento de losgenes humanos tienen L1 en sus intrones, y la densidad en L1 correlacionanegativamente con los niveles de expresión de estos genes. Por tanto, su pa-pel tanto en la evolución de genomas como en la regulación génica le con-fiere una gran importancia. Se acabó el mito del «ADN basura».
• Los HERV (retrovirus endógenos humanos), representan copias de los retro-virus humanos que se han ido integrando en el genoma humano en el curso
64
La geografía del genoma hum
ano
CAPITULO 4 5/12/06 07:06 Página 64
www.FreeLibros.me

de la evolución y con frecuencia son el origen de proto-oncogenes celulares.Habitualmente representan copias truncadas del genoma de estos virus, yconstituyen alrededor de un ocho por ciento del genoma (hay unas 450 000copias). Como habitualmente conservan alguna de las repeticiones terminaleslargas de estos genomas, se denominan también repeticiones tipo LTR (LongTerminal Repeat).
• Nuestro genoma también contiene unas 300 000 copias de elementos repeti-dos originados por transposones ADN, lo que supone un tres por ciento deltotal del genoma. Estos elementos contienen el gen (habitualmente truncado)de la transposasa, flanqueado por repeticiones invertidas. De entre las distin-tas familias que existen cabe destacar el tipo MER1 o MER2 y los elementosmariner (Hsmar2), responsables de algunas reordenaciones cromosómicasimportantes en patología humana.
La Figura 4.10 muestra la estructura de los distintos tipos de repeticiones dispersas del genomahumano.
Es importante hacer algún comentario sobre la movilidad de los retroelementos dis-persos. Tanto los LINE como los Alu que estén completos pueden, en teoría, copiar-se e insertarse en otra posición del genoma a través de un intermediario ARNm. Dehecho, esto sucede habitualmente, aunque por fortuna con muy baja frecuencia. Secalcula que uno de cada 100-200 nuevos nacimientos lleva una inserción nueva deun Alu o de un L1, que pueden ser causa de enfermedades por diversos mecanismos.
65
El ADN repetitivo
LINE
transcripción
traducciónUnión de las proteínas a su propio ARNm
ARNm
Rotura endonucleolítica
Retrotranscripción
Reparación
Nuevo LINE (copia en
otra localización)
La Figura 4.9 ilustra el mecanismo de retrotransposición de los LINE.
CAPITULO 4 5/12/06 07:06 Página 65
www.FreeLibros.me

Esta tasa de nuevas inserciones es mucho más baja que en otros mamíferos. Por loque respecta a los L1, se calcula que existen actualmente unos 5 000 elementos com-pletos en el genoma humano, de los cuales unos 90 son activos (capaces de retro-transposición). El potencial patogénico de estos elementos viene dado por la propiacapacidad de insertarse aleatoriamente en el genoma (e interrumpir genes), por ladesregulación de la expresión de genes cercanos (por los elementos promotores delos LINE y SINE), pero sobre todo por recombinación ilegítima entre copias de Aluo L1 que están en localizaciones cromosómicas distintas. Curiosamente, los elemen-tos Alu causan este tipo de recombinación con más frecuencia que los L1, especial-mente en algunos genes que sufren duplicaciones o deleciones por recombinaciónentre secuencias Alu.
Para finalizar, es interesante tener una visión de conjunto de la localización de losdistintos tipos de elementos repetidos en el genoma humano, representados sobre uncariotipo convencional. Como ya se ha dicho, el ADN ribosomal se localiza en elbrazo corto de los cromosomas acrocéntricos. El satélite alfa puede verse en todoslos centrómeros. El satélite beta, en cambio, está en localización pericentroméricaen los cromosomas acrocéntricos y en la constricción secundaria del cromosoma 1.El satélite gamma es pericentromérico en los cromosomas 8 y X. El satélite 1 estáen los centrómeros de los cromosomas 3 y 4, además de encontrarse también en elbrazo corto de los cromosomas acrocéntricos (distal al ADN ribosomal). El satélite2 es pericentromérico en los cromosomas 2 y 10, además de formar la constricciónsecundaria de los cromosomas 1 y 16. Finalmente, el satélite 3 está en la constric-ción secundaria de los cromosomas 9 e Y, así como en el brazo corto de los cromo-somas acrocéntricos (proximal al ADN ribosomal). Los elementos dispersos se en-cuentran distribuidos por todo el genoma, siendo los LINE más abundantes enbandas G y los elementos SINE más abundantes en bandas R (bandas claras); mi-crosatélites y minisatélites también están dispersos, aunque éstos últimos tienden aconcentrarse en torno a los telómeros.
En la Figura 4.11 se ven dos ejemplos de la distribución de elementos repetidos de tipo satélite en cromosomas humanos.
4.4 El genoma mitocondrial
La mitocondria es un orgánulo de probable origen endosimbióntico que se ha adap-tado a su nicho intracelular: para aumentar su tasa de replicación y asegurar la trans-misión a las células hijas después de cada división mitótica, el genoma de las mito-condrias de mamíferos se ha ido reduciendo de tamaño hasta alcanzar las 16 569 kben el caso del genoma mitocondrial humano. Las mitocondrias son las verdaderascentrales térmicas de nuestro organismo ya que en ellas tiene lugar la fosforilaciónoxidativa (OXPHOS), es decir, la respiración celular acoplada a la producción deenergía en forma de ATP. El funcionamiento del sistema OXPHOS tiene, además, im-portancia médica por la generación de especies reactivas de O2 (Reactive OxygenSpecies, ROS) y por la regulación de la muerte celular programada o apoptosis. Lasproteínas incluidas en el OXPHOS se localizan dentro de la membrana mitocon-
66
La geografía del genoma hum
ano
CAPITULO 4 5/12/06 07:06 Página 66
www.FreeLibros.me

drial interna, e incluyen: (1) componentes de la cadena transportadora de electro-nes (Cadena respiratoria mitocondrial, CRM); (2) ATPasa de membrana; (3) Trans-locador de nucleótidos de Adenina (ANT).
El ADNmt humano es una molécula circular de 16 569 pares de bases. El núme-ro de moléculas de ADNmt por célula varía entre unos pocos cientos en los esperma-tozoides a unas 200 000 copias en el oocito, pero en la mayor parte de los tejidos elrango está comprendido entre unas 1 000 y 10 000 copias por célula, con 2-10 molé-culas de ADN por mitocondria. Este genoma contiene información para 37 genes:
• Genes que codifican las dos subunidades 12S y 16S del ARNr (ARN ribo-somal) de la matriz mitocondrial.
• Los genes para los 22 ARNt (ARN transferente), requeridos para la síntesis deproteínas mitocondriales en la misma matriz mitocondrial.
• Genes que codifican 13 polipéptidos que forman parte de los complejos mul-tienzimáticos del sistema OXPHOS. En concreto, en el genoma mitocondrialse codifican siete subunidades del Complejo I, una subunidad del ComplejoIII, tres subunidades del Complejo IV, y dos subunidades de la ATPasa (Com-plejo V).
Es importante no perder de vista que el resto de las subunidades polipeptídicas de es-tos complejos, así como el Complejo II completo, están codificados en el genoma nu-clear, de manera que no todas las enfermedades mitocondriales están necesariamen-te causadas por alteraciones en el ADN mitocondrial.
La Figura 4.12 muestra los complejos proteicos de la membrana de la mitocondria que estáncodificados por genes del propio genoma mitocondrial.
La característica estructural más sorprendente del ADNmt es que los genes se en-cuentran situados uno a continuación del otro, sin apenas intrones ni regiones no co-dificantes entre los genes. Al contrario que el genoma nuclear, en el que las regionesno codificantes son mayoritarias, el ADN mitocondrial sólo posee un tres por cien-to de secuencias no codificantes. Veintiocho de los genes mitocondriales (dos ARNr,14 ARNt y 12 polipéptidos) se encuentran en una de las cadenas (cadena H o pesada),mientras que los nueve genes restantes (un polipéptido y ocho ARNt) están en la ca-dena complementaria (cadena L o ligera). La única zona del ADNmt que no codificaningún gen es la región del bucle de desplazamiento (bucle-D), localizada alrededordel origen de replicación de la cadena H. Esta región contiene también los promoto-res de la transcripción y los elementos reguladores de la expresión génica. Otra de laspeculiaridades de la organización genética del ADNmt es que los genes de los ARNtse distribuyen entre los genes de los ARNr y los codificantes de proteínas; esta dis-posición tiene consecuencias muy importantes para el procesamiento del ARN.
Para la replicación del ADNmt hacen falta dos orígenes diferentes, uno paracada cadena (OH y OL). Ambos orígenes de replicación están muy separados, ha-ciendo que el proceso sea unidireccional y asimétrico. La síntesis del ADN se iniciaen OH y es realizada por una polimerasa específica de la mitocondria, la ADNpol γγ,que alarga un ARN iniciador fruto del procesamiento de un transcrito primario quese sintetiza a partir del promotor L. La replicación continúa de modo unidireccional
67
El genoma m
itocondrial
CAPITULO 4 5/12/06 07:06 Página 67
www.FreeLibros.me

hasta alcanzar OL, momento en el cual comienza la síntesis de la segunda cadena delADN, alargando también un pequeño iniciador de ARN.
La Figura 4.13 muestra la estructura del ADN mitocondrial.
En la transcripción del ADNmt intervienen una polimerasa de ARN, al menos unfactor de transcripción implicado en la iniciación (mtTFA), y uno de terminación(mTERF). Las dos cadenas del ADNmt se transcriben completamente a partir de trespuntos de iniciación diferentes, dos para la cadena pesada (H1 y H2) y uno para lacadena ligera (L), originando tres moléculas policistrónicas que se procesan poste-riormente por cortes endonucleolíticos precisos en los extremos 5´ y 3´ de las secuen-cias de los ARNt, para dar lugar a los ARNr, ARNt y ARNm maduros. De esta formalos ARNt, situados entre los genes de los ARNr y ARNm, actúan como señales de re-conocimiento para los enzimas de procesamiento. En particular, la cadena H se trans-cribe mediante dos unidades de transcripción solapadas en la región de los ARNr: laprimera de estas unidades comienza delante del gen para el ARNtPhe (lugar de ini-ciación H1), termina en el extremo 3´ del gen para el ARNr 16S y es responsable dela síntesis de los ARNr 12S y 16S, del ARNtPhe y del ARNtVal. El factor de termina-ción (mTERF) se une a una secuencia situada en el gen del ARNtLeu y provoca la ter-minación de esta unidad. La segunda unidad de transcripción comienza cerca del ex-tremo 5´ del gen del ARNr 12S (lugar de iniciación H2) y transcribe la casi totalidadde la cadena pesada; el procesamiento de este ARN policistrónico origina los ARNmde 12 péptidos y los otros 12 ARNt codificados en esta cadena. La transcripción de lacadena ligera comienza cerca del extremo 5´ del ARN 7S (en el bucle-D) y da lugar aliniciador de la replicación de la cadena pesada, ocho ARNt y un péptido (ND6).
La síntesis de las proteínas mitocondriales tiene lugar en ribosomas específicosde la mitocondria, cuyos componentes están codificados en el ADNmt (ARNr 12S y16S) y en el genoma nuclear (84 proteínas ribosomales). En este sistema de traduc-ción se sintetizan las trece proteínas codificadas en el ADNmt utilizando un códigogenético que difiere ligeramente del código genético universal. Así, UGA codificael aminoácido triptófano (Trp) en vez de ser un codón de terminación, y los codonesAUA y AUU se utilizan también como codones de iniciación.
La biogénesis de la mitocondria depende de la expresión coordinada de los ge-nomas mitocondrial y nuclear, pero hasta ahora se conoce muy poco acerca de losmecanismos que regulan la interacción de ambos sistemas genéticos. La expresióndel ADNmt parece estar regulada por el factor de iniciación de la transcripciónmtTFA, codificado en el genoma nuclear. Este factor podría ser el responsable tantode los niveles de ARN como del número de copias de ADNmt, ya que la replicacióndepende de la síntesis de un iniciador de ARN a partir del promotor de la cadena li-gera. La regulación de la relación entre los ARNr y los ARNm mitocondriales se rea-liza fundamentalmente mediante la selección del lugar de iniciación de la transcrip-ción de la cadena pesada, que a su vez está relacionada con el factor mtTERF (quecausa terminación de la transcripción después de la síntesis de los ARNr) y con elprocesamiento de los ARN primarios. Asimismo, la actividad transcripcional puedeestar regulada por estímulos hormonales, especialmente por hormonas tiroideas queactúan tanto de un modo indirecto (por activación de genes nucleares) como direc-tamente sobre el propio ADNmt.
68
La geografía del genoma hum
ano
CAPITULO 4 5/12/06 07:06 Página 68
www.FreeLibros.me

C A P Í T U L O 5
El genoma humano en acción
Contenidos
5.1 La secuencia influye en el estado funcional de la cromatina
5.2 Modificaciones epigenéticas y su importancia en la regulación del estado funcional de la cromatina
5.3 Relación entre secuencia, estructura y función de la cromatina: territorios cromosómicos
5.1 La secuencia influye en el estado funcional de la cromatina
Como ya se ha dicho, el grado de empaquetamiento no es uniforme a lo largo de todo elgenoma. De hecho, en el núcleo en interfase siempre se distinguió una cromatina deno-minada eucromatina, poco condensada, y otra llamada heterocromatina, con un mayorgrado de condensación. Hoy sabemos que estas categorías morfológicas tienen un corre-lato funcional, ya que la eucromatina es transcripcionalmente más activa mientras quelos genes incluidos en heterocromatina tienen un bajo nivel de expresión. La heterocro-matina, a su vez, puede ser de dos tipos: constitutiva, que nunca se transcribe y se loca-liza en los centrómeros y en la constricción secundaria de algunos cromosomas; o fa-cultativa, que en el fondo es un tipo de eucromatina que se heterocromatiniza ensituaciones concretas, como es el caso del cromosoma X inactivo en las mujeres.
Además de estas dos grandes categorías de cromatina, es importante comprender quedentro de las regiones eucromáticas la cromatina tampoco es totalmente homogénea,como queda reflejado, por ejemplo, en su distinta repuesta a varias tinciones. Este com-portamiento es precisamente la base del patrón de bandas característico de cada cromo-soma y que permite la creación del cariotipo convencional. Como veremos en un capí-tulo posterior, la tinción con un colorante llamado Giemsa produce unas bandas oscuras(bandas G) separadas por bandas claras (bandas R). La tinción con otra sustancia lla-mada Quinacrina (que se une específicamente a regiones ricas en adeninas y timinas)produce un patrón de bandas similar a las bandas G, mientras que la tinción con Cro-momicina-A (que se une preferentemente a regiones ricas en guaninas y citosinas) gene-ra un patrón similar a las bandas R.
CAPITULO 5 5/12/06 07:08 Página 69
www.FreeLibros.me

Por tanto, las peculiaridades morfológicas de la cromatina son debidas, al menosen parte, a diferencias en la secuencia de nucleótidos del genoma; el modelo del an-damio (scaffold) que vimos en el Capítulo 2 permite explicar esta relación, ya que lasbandas G representan regiones con un mayor grado de empaquetamiento del ADN,lo que implica una mayor densidad de las regiones de unión al andamio (llamadasSAR). Como las SAR son relativamente ricas en adenina y timina, esto explica queestas regiones genómicas se tiñan más intensamente por Quinacrina y Giemsa, mien-tras las bandas R, más ricas en guanina y citosina, tienen un menor grado de empa-quetamiento, menor densidad de SAR y se tiñen débilmente por estos colorantes. Portanto, las distintas bandas del cariotipo reflejan no sólo diferencias en la condensa-ción de la cromatina, sino también diferencias en su composición: ya hemos vistoque el genoma humano tiene un contenido medio en G+C del 41 por ciento, peroque esto no se distribuye de manera uniforme por todo el genoma.
A su vez, las diferencias en condensación y en composición de las distintas re-giones de cromatina se correlacionan con otra variable importante: la riqueza en ge-nes y su actividad transcripcional. Por ejemplo, se estima que un 80 por ciento delos genes se localizan en bandas R (las más ricas en nucleótidos G+C), que son lasmenos condensadas. También se ha observado que, en general, las bandas R son dereplicación temprana, mientras que las bandas G son de replicación más tardía.Como se recordará del Capítulo 2, la replicación del ADN en eucariotas comienzaen muchos orígenes de replicación durante la fase S del ciclo celular, pero no todoslos orígenes de replicación comienzan a funcionar a la vez: hay unos orígenes quesiempre comienzan al principio de la fase S (replicación temprana) y otros que vancomenzando a funcionar más tarde (replicación tardía). Asimismo, se sabe que losgenes constitutivos (housekeeping en inglés), que son los que se expresan en todoslos tejidos, se replican temprano; por el contrario, los genes que están en regiones he-terocromáticas (el cromosoma X inactivo, por ejemplo) son de replicación más tar-día. Parece —por tanto— que regiones con alta densidad de genes, ricas en C+G y des-condensadas se replican antes que regiones silenciadas o con baja densidad de genes.
Otro aspecto que diferencia los distintos tipos de bandas es la acetilación de lashistonas. Como se verá a continuación, se ha podido comprobar que la acetilaciónde las histonas que forman los nucleosomas lleva a la formación de una cromatinamás abierta, que permite mejor el acceso de factores de transcripción y la expresiónde los genes contenidos en esas regiones. Esto se debe a que las colas amino-termi-nales de las histonas interaccionan con más fuerza entre sí y con el ADN cuando losgrupos épsilon-amino de las lisinas están en su forma des-acetilada; la acetilación re-laja esas interacciones y descondensa parcialmente la fibra de 30 nm y la unión delADN con los nucleososmas. Curiosamente, se ha comprobado que las histonas de lasbandas G están menos acetiladas que las histonas de las bandas R. Esto ayudaríatambién a explicar la menor condensación de la cromatina en las bandas R, y nosproporciona un mecanismo para entender por qué las bandas R se replican antesy son más activas transcripcionalmente: por un lado, no necesitan descondensarsepara que se lleve a cabo la replicación, y por otro constituyen unos dominios en losque el ADN es más accesible a los factores de transcripción.
Figura 5.1 La acetilación de colas amino-terminales de las histonas influye en la condensación dela cromatina.
70
El genoma hum
ano en acción
CAPITULO 5 5/12/06 07:08 Página 70
www.FreeLibros.me

En resumen, es importante darse cuenta de que los mecanismos básicos de regu-lación de la expresión génica estudiados en el Capítulo 1 están sometidos a un nivelsuperior de regulación, dependiente de la situación de un gen dentro del genoma ydel estado funcional de la cromatina en que se encuentra, que a su vez está influidopor el tipo de secuencias que la componen. Generalizando, podemos resumir lasprincipales características de los dos estados de cromatina más frecuentes, represen-tados por los dos tipos principales de bandas citogenéticas (banda G, oscuras, y ban-das R, claras):
Bandas G Bandas R
Densidad en genes Baja AltaPorcentaje de G+C Bajo AltoReplicación Tardía TempranaComposición Ricas en A+T Ricas en G+CAcetilación Histonas Baja AltaRepeticiones predominantes LINE SINE
5.2 Modificaciones epigenéticas y su importancia 5.2 en la regulación del estado funcional de la cromatina
Es muy importante comprender que los aspectos estructurales y funcionales se inte-gran en un modelo «dinámico», según el cual una región de cromatina estará en unestado más o menos favorable a la expresión génica dependiendo del tipo de se-cuencias que la forman y también de las modificaciones epigenéticas a ese nivel. Pormodificaciones epigenéticas se entienden todos aquellos cambios que sufre la cro-matina pero que no afectan a la secuencia de nucleótidos: por eso no son modifica-ciones «genéticas», sino que están «por encima» (que es lo que significa epi en grie-go). En los últimos años se ha comprobado experimentalmente la gran importanciaque tienen los mecanismos que regulan la actividad de la cromatina mediante cam-bios epigenéticos.
Para entender esto, es importante recordar que la actividad transcripcional basalen eucariotas es esencialmente restrictiva, en el sentido de que los promotores estánen estado inactivo hasta que se ponen en marcha por la acción de los elementos lla-mados «activadores» y el ensamblaje del complejo basal de transcripción. Para queestos factores proteicos se unan a sus dianas en el ADN es necesario que la croma-tina de esa región esté relativamente descondensada, para exponer más fácilmente ladoble hélice y permitir el acceso de factores proteicos. De hecho, los genes que sontranscripcionalmente activos se asocian habitualmente con sitios hipersensibles aDNAsa I, regiones cortas (unos pocos cientos de pares de bases) formadas por ADNque no está asociado a nucleosomas, precisamente porque se encuentra unido a fac-tores de transcripción.
La Figura 5.2 ilustra esquemáticamente la distinta accesibilidad a una región de cromatinadependiendo del grado de condensación.
71
Modificaciones epigenéticas y su im
portancia en la regulación del estado funcional …
CAPITULO 5 5/12/06 07:08 Página 71
www.FreeLibros.me

Los nucleosomas son, por tanto, un elemento fundamental para mantener este es-tado basal restrictivo, al impedir el acceso de la maquinaria transcripcional a los pro-motores. La represión transcripcional mediada por nucleosomas se debe tanto a lasinteracciones directas del octámero de histonas con el ADN, como a las interaccio-nes que se originan entre nucleosomas vecinos para dar lugar a la fibra de cromati-na. Como hemos visto más arriba, las colas N-terminales de las histonas de los nu-cleosomas quedan libres hacia fuera, y son las regiones más susceptibles de sermodificadas químicamente para variar su carga y alterar las interacciones, tanto en-tre histonas y ADN como entre nucleosomas vecinos. Por tanto, si conseguimos re-lajar alguna de estas interacciones conseguiremos favorecer la transcripción de losgenes que están incluidos en esas regiones. Esta relajación se puede conseguir gra-cias a que las colas N-terminales de las histonas tienen una serie de aminoácidos (li-sinas y serinas, principalmente) que pueden sufrir modificaciones covalentes deltipo acetilación, metilación o fosforilación, y que van a ser cruciales en la regula-ción de estos fenómenos. A su vez, estos cambios se coordinan con otras modifica-ciones epigenéticas que sufre la propia cadena de ADN en forma de metilación de al-gunos nucleótidos concretos, y en su conjunto ambos procesos constituyen unimportante mecanismo de regulación de la actividad transcripcional. A continuaciónveremos por separado las modificaciones epigenéticas que sufre la cromatina, poruna parte, y el ADN por otra.
A. Modificación de la cromatina. Para superar la represión basal debida a la pre-sencia de nucleosomas y facilitar la expresión de un gen, los activadores de la trans-cripción pueden potenciar la actividad transcripcional alterando, en primer lugar, lapropia estructura de la cromatina: aunque el activador no se una directamente al pro-motor de un gen, puede reclutar distintas actividades modificadoras de la cromati-na cuya acción sea conferir a esa región un estado que facilite la transcripción. Estasactividades pueden ser de varios tipos:
• Complejos proteicos implicados en el remodelamiento nucleosomal: son ca-paces de mover los nucleosomas de su posición para dejar expuesta una regiónpromotora y permitir la expresión génica. Este tipo de actividad está mediadapor complejos multiproteicos con actividad ATPasa, de los cuales el primeroen ser aislado fue el complejo SWI/SNF (primero se identificó en levaduras,después en humanos). Este complejo desestabiliza el nucleosoma al romper loscontactos del ADN con el octámero, que queda libre para moverse y asociar-se con una región vecina de la molécula de ADN. Todos los remodeladores denucleosomas pertenecen a la familia SNF2 de ATPasas, y pueden dividirse ensiete subgrupos dependiendo de los dominios proteicos que contienen.
En la Figura 5.3 se ilustra el movimiento de nucleosomas por la acción de remodeladoresde la cromatina.
• Complejos implicados en la acetilación de histonas: el factor Gcn5 de leva-dura fue el primer activador transcripcional con actividad acetilasa de histo-nas descubierto, en 1996. Posteriormente se vio que otros co-activadores dela transcripción de mamíferos también poseían actividad acetil-transferasa,
72
El genoma hum
ano en acción
CAPITULO 5 5/12/06 07:08 Página 72
www.FreeLibros.me

factores tales como p300, CBP (CREB-BP) y P/CAF, de ahí que hoy se co-nozcan en conjunto con el nombre de HAT (Histone AcetylTransferase). És-tos actúan como factores de transcripción integradores de diversas vías detransducción de señales implicadas en el control del ciclo celular y de los pro-cesos de diferenciación, reparación y apoptosis. Otros activadores transcrip-cionales con actividad HAT son el factor de transcripción TAFII250 (que for-ma parte del complejo TFIID), SRC-1 y ACTR (coactivadores de receptoresnucleares). Al igual que la acetilación de las histonas conduce a la activacióntranscripcional, la des-acetilación de las histonas crea una estructura cro-matínica más condensada que impide la transcripción de los genes incluidosen la esa región genómica. En este sentido, se ha comprobado que los facto-res HDAC1 y HDAC2 (Histone De-Acetylase), cuya función es des-acetilar lashistonas, están presentes en el complejo Sin3-NcoR, un co-represor trans-cripcional que regula la expresión de genes importantes en el ciclo celular yen el desarrollo embrionario.En conjunto, acetilasas y des-acetilasas actúan sobre los mismos aminoácidosde las colas amino-terminales de las histonas H3 y H4, especialmente las lisi-nas 9, 14, 18 y 23 de la histona H3 y las lisinas 5, 8, 12 y 16 de la histonaH4. En la Figura 5.1 ya se ha visto el posible mecanismo por el que la des-ace-tilación de las histonas favorece la compactación de nucleosomas vecinos e im-pide la transcripción en esa región. De hecho, se ha comprobado que la des-acetilación de la lisina 16 en la histona H4 provoca la condensación de la fibrade 10 nm, mientras que la acetilación de este residuo impide la formación de lafibra de 30 nm y permite la interacción con co-activadores de la transcripción.
• Otras modificaciones muy importantes son la fosforilación de la histona H3en la serina 10 y la metilación de las lisinas 4, 9, 27, 36 y 79 en la histonaH3 y de la lisina 20 de la histona H4, metilación catalizada por unos com-plejos proteicos que tienen actividad metil-transferasa. Se ha comprobado queestas modificaciones actúan en coordinación con la acetilación, establecien-do lo que ahora se conoce como el «Código de Histonas». Según este códi-go, una región se comportará como eucromatina o como heterocromatina de-pendiendo de las modificaciones epigenéticas de las histonas que conformanlos nucleosomas de la región; las regiones limítrofes, en las que se da una tran-sición de un tipo de cromatina al otro, muestran características propias de am-bos tipos de cromatina, y son capaces de unir complejos proteicos llamadosaisladores (en inglés insulator), que forman una especie de barrera física e im-piden que un tipo de cromatina se extienda más allá del límite de la región einvada la región vecina.De modo general, el código de histonas establece que una región de eucro-matina se caracteriza por tener la lisina 4 de la histona H3 metilada (con uno,dos o tres grupos metilo), y las lisinas 9 y 14 de la misma histona acetiladas.Se ha comprobado que esta configuración tiene la propiedad de unirse a undominio proteico llamado «bromodominio», que está presente en muchos ac-tivadores de la transcripción. Una región con estas características puede he-terocromatinizarse si sufre una cascada de alteraciones: la pérdida de la me-tilación de la lisina 4, la desacetilación progresiva de las lisinas 9 y 14, y
73
Modificaciones epigenéticas y su im
portancia en la regulación del estado funcional …
CAPITULO 5 5/12/06 07:08 Página 73
www.FreeLibros.me

finalmente la metilación de la lisina 9 constituyen una marca de heterocro-matina, a la que se unen proteínas que contienen un dominio de silencia-miento llamado «cromodominio» que recluta factores de silenciamientocomo la proteína HP1 (proteína de heterocromatina-1). Estas interaccionesestán influidas también por la fosforilación de la serina 10 de la histona H3;por ejemplo, dicha fosforilación —generada por la quinasa Aurora B— inhíbela unión de HP1 con la lisina 9 metilada durante la mitosis.
La Figura 5.4 ilustra el concepto del «Código de histonas» y su utilidad para definir distintasregiones de cromatina.
B. La metilación del ADN juega un papel fundamental en el mantenimiento delsilenciamiento transcripcional. El ADN de vertebrados se metila en el carbono 5 de las citosinas que están en el dinucleótido CpG (la «p» indica el grupo fosfato queune una citosina con una guanina, en dirección 5’→3’). Curiosamente, la abundanciade este dinucleótido en el genoma de vertebrados es sólo un 25 por ciento de lo es-perado, es decir, el porcentaje normalizado de este dinucleótido es de 0,25. En efec-to, si el contenido en C+G del genoma es del 41 por ciento, la probabilidad espera-da de encontrar un dinucleótido CpG es (0,205 × 0,205) = 0,042 (o sea, 4,2 porciento); en cambio, la frecuencia observada de este dinucleótido está en torno al unopor ciento en el genoma humano, de ahí que el porcentaje normalizado sea 1/4 = 0,25.Además, los dinucleótidos CpG no están distribuidos homogéneamente a lo largodel genoma, sino que son más abundantes en los genes, tanto en los exones como,sobre todo, alrededor del inicio de la transcripción. Pues bien, los dinucleótidosCpG que tienen metilada la citosina son los que están distribuidos a lo largo dela secuencia de genes. Por el contrario, los dinucleótidos CpG que no están me-tilados tienden a concentrarse en regiones que se denominan islas CpG.
Aunque estas islas se han definido tradicionalmente como las regiones de un ta-maño igual o superior a 500 pb, con un contenido total de G+C superior a 50 porciento y con un cociente de dinucleótidos CpG observados frente a esperados supe-rior a 0,6, hoy en día se pueden definir por su porcentaje normalizado de CpG. De
74
El genoma hum
ano en acción
Bromo
Ac
T-K-Q-T-A-R-K-S T-G-G-K-A9
14Me
4
Me Ac
AcAc
T-K-Q-T-A-R-K- -T G-G-K-A9
14MeMe
4
MeMe AcAc
Chromo
P
CAPITULO 5 5/12/06 07:08 Página 74
www.FreeLibros.me

hecho, el análisis de todos los promotores del genoma humano identifica dos tiposde genes: los que tienen un promotor con un porcentaje normalizado de CpG en tor-no al 0,61 y los que tienen un promotor con un porcentaje normalizado de CpG entorno al 0,23. Los primeros constituyen un 70 por ciento de todos los promotores, ycorresponden a los genes constitutivos o «domésticos» (housekeeping, en inglés). Porel contrario, los promotores con bajo porcentaje normalizado de CpG constituyen un30 por ciento del total de los promotores, y corresponden a los genes que se expre-san en tejidos específicos. Los promotores que contienen una isla CpG están habi-tualmente hipometilados en la línea germinal, lo cual les protege frente a las transi-ciones C→T que sufren las citosinas metiladas.
En la Figura 5.5 se representa la distribución de dinucleótidos CpG a lo largo de un gen, mostrandoel concepto de «isla CpG».
La metilación del ADN está catalizada por unas metil-transferasas específicas delas citosinas que forman parte de dinucleótidos CpG, y se conocen básicamente dostipos de estas metil-transferasas de ADN. Las DNMT3A y DNMT3B son responsa-bles de la metilación de novo, es decir, la metilación de dinucleótidos CpG que noestaban previamente metilados. En cambio, la DNMT1 (ADN-metil-transferasa-1) esresponsable de mantener la metilación durante la replicación. En efecto, dado que enla doble cadena de ADN un dinucleótido CpG tiene realmente dos citosinas metila-bles (ya que existe un CpG en cada una de las cadenas de la doble hélice), un sitiototalmente metilado tendrá realmente dos citosinas metiladas. Tras la replicación delADN, ambas dobles hélices conservarán una cadena con el CpG metilado (la prove-niente de la molécula original), mientras que la cadena de nueva síntesis estará sinmetilar. Esto genera dinucleótidos CpG hemi-metilados, es decir, metilados en unade las citosinas pero no en la otra; la DNMT1 tiene la función de re-metilar precisa-mente estos dinucleótidos para restablecer el estado inicial de metilación completaque tenía la molécula original.
La Figura 5.6 muestra el proceso de re-metilación de dinucleótidos CpG que han quedado hemi-metilados tras la replicación.
Numerosos estudios han mostrado el significado biológico de la metilación delADN: 1) es un importante mecanismo epigenético de silenciamiento génico a niveltranscripcional, y permite mantener el silenciamiento de ciertos genes durante losprocesos de diferenciación celular; 2) la metilación es un mecanismo de defensafrente a elementos móviles del genoma, cuyos promotores están habitualmente si-lenciados por metilación; y 3) la metilación es un mecanismo estabilizador de lacromatina, especialmente de la heterocromatina pericentromérica, ya que la des-me-tilación de este tipo de cromatina conduce a la aparición de reordenamientos cro-mosómicos severos.
Los mecanismos moleculares por los que la metilación conduce al silenciamien-to transcripcional pueden ser múltiples:
• Impidiendo la unión de factores de transcripción al promotor. Por ejemplo,algunos factores de transcripción generales como Sp1, CREB, E2F o NF-kB
75
Modificaciones epigenéticas y su im
portancia en la regulación del estado funcional …
CAPITULO 5 5/12/06 07:08 Página 75
www.FreeLibros.me

se unen a dominios que contienen CpG, y esta unión disminuye cuando es-tos dominios están metilados. Sin embargo, este mecanismo no se puede apli-car de modo general a todos los genes.
• Mediante la unión específica de represores transcripcionales al ADN metila-do. Existen varias proteínas de unión a los dinucleótidos CpG metilados, de-nominadas genéricamente MeCP (Methyl-Cytosine binding Protein) o MDB(Methyl Binding Domain), que forman parte de complejos con actividad re-presora de la transcripción. Por ejemplo, MeCP-2 es una proteína que con-tiene un dominio de unión a dinucleótidos CpG metilados, así como otro do-minio por el que se une a un represor transcripcional llamado Sin3.Curiosamente, Sin3 reprime la transcripción a través de su unión con HDAC2(que, como ya hemos visto, des-acetila las lisinas de la histona H3). De estamanera, la represión transcripcional debida a la metilación de los dinucleóti-dos CpG se produce gracias a la asociación entre metilación del ADN y ace-tilación de la cromatina, ya que el dominio de represión transcripcional deMeCP-2 es capaz de reclutar el complejo Sin3-NCoR-HDAC2 y así iniciar unfoco de cromatina hipoacetilada en una región específica del genoma. Esto ex-plica que las regiones en las que el ADN está metilado sean capaces de silen-ciar genes cercanos (aunque éstos no tengan sus dinucleótidos CpG metila-dos), al englobarlos en una región genómica silenciada por des-acetilación.
El vídeo incluido en la Figura 5.7 ilustra la interacción entre metilación del ADN y modificación delas histonas.
Una propiedad muy importante del silenciamiento por metilación es que es reversi-ble: se ha comprobado que los promotores que han sido silenciados por metilaciónpueden reactivarse si se des-metila esa región. Un mecanismo posible para explicaresta reactivación es la pérdida de la metilación durante la replicación: esto sucede-ría si ciertos factores de transcripción o activadores nucleares consiguieran unirse asus promotores inmediatamente después de la replicación y antes de que actúe laDNMT1 de mantenimiento en los sitios hemi-metilados. Una vez que se estabiliza elcomplejo basal de transcripción sobre esa región, éste atraería algunos componentescon actividad HAT, que a su vez actuarían manteniendo la cromatina abierta y per-mitiendo la transcripción. Esto, además, impediría la acción de la DNMT1 y termi-naría por eliminar la metilación en esa región tras varios ciclos de replicación. Estemecanismo se conoce como des-metilación pasiva. Otro mecanismo alternativopara explicar la re-expresión de genes silenciados por metilación, sobre todo en cé-lulas diferenciadas que ya no se replican, es la desmetilación activa, aunque todavíano se ha aislado de modo concluyente ninguna des-metilasa de ADN.
En resumen, la metilación del ADN constituye un importantísimo mecanismoepigenético de regulación de la expresión génica, debido a su interacción con los me-canismos que modifican la estructura de la cromatina. El mantenimiento de los pa-trones de metilación explica también que las modificaciones epigenéticas sean here-dadas establemente tras la replicación del ADN. Además, como ya se hamencionado, la metilación tiene importantes implicaciones biológicas, y por tanto laalteración de los procesos normales de metilación de la cromatina puede pertur-
76
El genoma hum
ano en acción
CAPITULO 5 5/12/06 07:08 Página 76
www.FreeLibros.me

bar procesos fisiológicos importantes. En primer lugar, por ser un mecanismo funda-mental en el silenciamiento de retrovirus endógenos, transposones y ADN satélite,las alteraciones en la metilación de estos elementos puede provocar numerosas ano-malías genéticas.
Además, la metilación es la base molecular de los fenómenos de impronta genó-mica (imprinting) que se estudiarán más adelante, y es un mecanismo fundamentalen la regulación de la expresión génica durante el desarrollo embrionario. De hecho,el embrión sufre una onda de des-metilación genómica global en la fase de mórulade ocho células, seguida por la re-metilación gradual que vuelve a fijar los patronesde metilación en la fase de blastocisto. También la inactivación del cromosoma X enmujeres es un proceso básicamente controlado por procesos de metilación, acetila-ción y silenciamiento.
Por tanto, cada vez está más claro que la des-regulación de las modificaciones epi-genéticas de la cromatina está en la base de algunas enfermedades humanas. El casomás claro es una enfermedad neurológica hereditaria llamada Síndrome de Rett, en elque se han identificado mutaciones en el gen que codifica la proteína de unión a metil-citosinas MECP2. Probablemente, esto origine un exceso de «ruido transcripcional»por falta de silenciamiento global de muchos genes, con efectos más marcados en el ce-rebro que en otros órganos. Por otra parte, el papel de la metilación en cáncer tam-bién está cobrando cada vez más importancia, ya que se ha visto que muchos tipos detumores tienen alteraciones importantes en los procesos de metilación de la cromatina:
• La desaminación de citosinas metiladas (debida habitualmente a la acciónde una citidín-desaminasa, o bien por desaminación hidrolítica espontánea)provoca un cambio de Citosina por Timina, haciendo que los dinucleótidosCpG metilados sean puntos calientes (hotspots) para la generación de muta-ciones de este tipo. De hecho, se ha estimado que el 30 por ciento de las mu-taciones encontradas en tumores en el gen TP53 (que codifica la proteína p53,un supresor tumoral importante) son transiciones C→T que tienen lugar den-tro de dinucleótidos CpG.
• Se ha comprobado que durante el proceso de iniciación tumoral hay una hi-pometilación global del genoma de la célula pre-maligna, lo que provoca unaumento en la inestabilidad genómica y la aparición de anomalías cromosó-micas. Por ejemplo, los ratones en los que el gen DNMT1 ha sido inactivadomuestran una elevada tasa de deleciones o duplicaciones de regiones cromo-sómicas. Además, algunos oncogenes concretos se sobreexpresan en algunostumores por des-metilación de sus promotores (por ejemplo el oncogénBCL2). Del mismo modo, se ha identificado una enfermedad (Síndrome ICF,siglas de Inmunodeficiencia, inestabilidad Centromérica y defectos Faciales)en la que los pacientes tienen mutaciones en el gen DNMT3B, que codificauna metil-transferasa que metila específicamente los satélites centroméricos 2y 3; la desmetilación de esas regiones de heterocromatina provoca fusionesentre cromosomas. En conjunto, estos datos sugieren que la metilación es unmecanismo muy importante para mantener la estabilidad del genoma.
• Al mismo tiempo, la hipermetilación puntual de algunos genes supresorestumorales, con el consiguiente silenciamiento y pérdida de función, es un me-canismo muy frecuente de generación de distintos tipos de cáncer. Por ejem-
77
Modificaciones epigenéticas y su im
portancia en la regulación del estado funcional …
CAPITULO 5 5/12/06 07:08 Página 77
www.FreeLibros.me

plo, el gen RB1 está frecuentemente metilado en un tipo de tumores llamadosretinoblastomas esporádicos. También es frecuente la hipermetilación (y si-lenciamiento) del gen supresor tumoral p16 en varios tipos de tumores; la hi-permetilación del gen VHL (Von Hippel-Lindau) en 20 por ciento de los car-cinomas de células renales esporádicos; la inactivación, por hipermetilación,del gen de reparación de desemparejamientos hMLH1 en tumores de colonesporádicos que muestran inestabilidad de microsatélites. En conjunto, se es-tima que en tejido tumoral hasta un 10 % de las islas CpG están metiladas, encontraste con células normales en las que este porcentaje es mucho más bajo.
• Por su parte, algunos complejos con actividad modificadora de la cromatinase han asociado también con el desarrollo de cáncer. Por ejemplo, el genAIB1, que tiene actividad acetilasa de histonas, está amplificado en cáncer demama y por tanto se expresa a niveles más altos de lo normal. Por otro lado, elco-activador transcripcional CBP, que también funciona como una acetilasa dehistonas, está fusionado con el gen MOZ o con el gen MLL en pacientes conleucemia mieloide aguda; esta fusión hace que la actividad acetilasa esté au-mentada en determinadas células de la médula ósea y esto desencadena la leu-cemia. Además, otro co-activador transcripcional con actividad acetilasa de his-tonas (la proteína p300) está mutado en cáncer colorrectal y delecionado en el80 por ciento de los glioblastomas, un tipo de tumor cerebral. Lo mismo puededecirse de los complejos con actividad des-acetilasa de histonas (HDAC): yahemos visto que la supresión de Myc y la unión de Rb con el factor de trans-cripción E2F dependen en gran medida de su unión con complejos que tienenactividad des-acetilasa. Además, se ha demostrado que algunas oncoproteinas
78
El genoma hum
ano en acción
La Figura 5.8 muestra la regulación de la transcripción de un gen que responde al ácidoretinoico, mostrando la importancia de los complejos modificadores de la cromatina y sualteración en un tipo de leucemia.
Ac Ac
• Ausencia de ligando
• Desacetilación
(Represión)
• Unión del ligando
(ácido retinoico )
• Acetilación
(Transcripción )
• Forma anómala
del receptor
• Impide unión del
ligando
AcAc
AcAc AcAc
• Ausencia de ligando
• Desacetilación(Represión)
• Unión del ligando (ácido retinoico))
• Acetilación(Transcripción )
• Forma anómala del receptor
• Impide unión del ligando
AcAcAcAc
HDACNCOR NCOR
Sin3
HAT
PML/RAR
HDACNCOR
Sin3
HDAC
Sin3
RX
R
RX
R
RX
R RA
R
RA
R
Translocación con
Proteína de fusión
PML/ RARa
Gen que responde
al Ácido Retinoico
Translocación conProteína de fusión
PML/ RARa
Gen que responde al Ácido Retinoico
CAPITULO 5 5/12/06 07:08 Página 78
www.FreeLibros.me

virales como HPV E7 o el antígeno T de SV40 inactivan el gen RB1 al impedirsu unión con complejos que tienen actividad HDAC. Finalmente, las transloca-ciones asociadas con la leucemia promielocítica producen fusiones entre facto-res de transcripción que interaccionan con diversas acetilasas y des-acetilasasde histonas, con complejos remodeladores de la cromatina y con proteínas quetienen actividad metil-transferasa de histonas.
Considerando todos los ejemplos citados en los párrafos anteriores, podemos con-cluir que los procesos que regulan la metilación de la cromatina están implicados enla iniciación y progresión tumoral; esto, además, abre nuevas posibilidades terapéu-ticas en muchos tipos de cáncer, ya que el estado de metilación es potencialmentemodificable mediante fármacos.
5.3 Relación entre secuencia, estructura y función 5.3 de la cromatina: territorios cromosómicos
Al ocuparnos de los mecanismos que regulan la función del genoma a nivel global,es importante tener en cuenta el nivel superior de organización de un genoma den-tro del núcleo. En los últimos años se ha puesto en evidencia que distintas regionesde la fibra de cromatina tienden a ocupar posiciones concretas en el núcleo, de-pendiendo de la secuencia subyacente, del estado transcripcional de los genes de esaregión y de sus modificaciones epigenéticas, del tiempo de replicación del ADN im-plicado, etc. Por tanto, cada vez está más claro que si queremos tener una imagencompleta de cómo se regula la función del genoma, no podemos ignorar aspectos es-tructurales tales como la composición en nucleótidos o la posición dentro del núcleo.
Uno de los aspectos más intrigantes de la biología genómica de los últimos años esla organización espacial de la cromatina dentro del núcleo de la célula eucariota, dan-do lugar a lo que se han denominado «territorios cromosómicos». Este concepto havenido a completar la imagen del núcleo eucariota como una estructura compartimen-talizada, en la que distintas regiones contienen maquinarias específicas que llevan acabo funciones concretas. Esta noción debe integrarse con la presencia de dominioscromatínicos definidos y más o menos estables a lo largo de la vida de una célula.
Diversos estudios han mostrado de forma convincente que la cromatina corres-pondiente a cada uno de los cromosomas tiende a ocupar unas posiciones concretasen el núcleo en interfase, y que esas posiciones tienden a mantenerse durante el ci-clo celular. Por ejemplo, la posición de un cromosoma concreto dentro del núcleoestá relacionada con el tamaño del cromosoma y con su riqueza en genes, que —comohemos visto— se correlaciona también con la secuencia de nucleótidos subyacente.En general, se considera que los cromosomas pequeños tienden a localizarse hacia elinterior del núcleo; igualmente, cromosomas ricos en genes tienden a ocupar posi-ciones centrales. También existen datos que muestran que las regiones pobres en ge-nes y en secuencias Alu se asocian con la periferia del núcleo, dejando la cromatinarica en genes en el interior. De todas formas, todavía se desconoce cómo se estable-cen estos territorios y cómo se mantienen tras la mitosis.
En la Figura 5.9 se ilustra el concepto de «territorio cromosómico».
79
Relación entre secuencia, estructura y función de la cromatina: territorios crom
osómicos
CAPITULO 5 5/12/06 07:08 Página 79
www.FreeLibros.me

La replicación del ADN y la transcripción génica son dos procesos que tienen lu-gar dentro del núcleo y que exigen una remodelación importante de la fibra de cro-matina para permitir el acceso de las maquinarias proteicas que los llevan a cabo.Además, se ha visto que ambos procesos no tienen lugar al azar, en cualquier lugardel núcleo, sino en compartimentos especializados a los que acuden las fibras de cro-matina que están en la vecindad. Se habla así de «fábricas de replicación» o de «fa-bricas de transcripción», regiones nucleares ocupadas por regiones genómicas quese replican o transcriben simultáneamente aunque pertenezcan a territorios cromo-sómicos distintos.
Lógicamente, las asas de cromatina que ocupan una fábrica determinada tendránuna configuración similar, en cuanto al grado de condensación de la cromatina, la se-cuencia de nucleótidos, la riqueza en genes, etc.; esto explica que el genoma se orga-nice como un mosaico de regiones que comparten características similares, ya que esasregiones podrían interaccionar dentro del núcleo al situarse en una misma fábrica dereplicación o de transcripción. Por ejemplo, se ha visto que en el genoma humano exis-ten unas regiones llamadas RIDGES (Regions of IncreaseD Gene Expression, en in-glés) en las que son más abundantes los genes que se transcriben activamente, y sonregiones ricas en G+C, pobres en repeticiones tipo LINE y con densidad génica alta.Junto a éstas, se observan también regiones con poca densidad en genes, bajo niveltranscripcional y relativamente pobres en G+C, que se llaman por tanto anti-RID-GES. Pues bien, los genes presentes en RIDGES tienden a localizarse, dentro del nú-cleo, en torno a las fábricas de transcripción. Lo mismo sucede con los genes de repli-cación temprana, que se asocian significativamente con las fábricas de replicaciónnucleares. Por tanto, los modelos actuales postulan que los genes que son replicados otranscritos residen en regiones cromatínicas relativamente descondensadas, las cualessalen de sus propios territorios cromosómicos hacia fábricas de replicación o trans-cripción vecinas. En esas fábricas, por tanto, pueden interaccionar regiones alejadasde un mismo cromosoma, o incluso asas de cromatina de territorios cromosómicos dis-tintos; esto permite explicar, en el caso de la transcripción, la acción de potenciadoresde la expresión que actúan a larga distancia o incluso en trans.
Como es lógico, en todas estas interacciones son importantes las modificacionesepigenéticas de la cromatina y del ADN que hemos estudiado en este capítulo, queen el fondo constituyen la base molecular que permite los fenómemos de condensa-ción y descondensación necesarios para la replicación, transcripción y desplaza-miento físico de las asas de cromatina. Conjugando todos estos elementos, obtene-mos una visión dinámica de la cromatina nuclear en la que la estructura del núcleose integra con la función y secuencia del genoma. Esta visión es mucho más rica quelos modelos anteriores, que no tenían en cuenta todos estos factores, y además per-mite explicar mucho mejor la regulación fina de la expresión génica durante el des-arrollo embrionario o la diferenciación celular. La otra cara de la moneda es que setrata de procesos tremendamente complicados y, por ello, potencialmente frágiles, demodo que pequeñas perturbaciones en estos mecanismos pueden dar lugar a altera-ciones genéticas y enfermedades humanas. En este sentido, el cáncer es un ejemplotípico de proceso complejo de des-regulación de la diferenciación celular, en el quese observan importantes alteraciones epigenéticas y una fuerte desorganización de laestructura nuclear.
80
El genoma hum
ano en acción
CAPITULO 5 5/12/06 07:08 Página 80
www.FreeLibros.me

C A P Í T U L O 6
Origen de la variacióngenética en humanos
Contenidos
6.1 Variación en el ADN: polimorfismos y mutaciones
6.2 Mecanismos de reparación del ADN en humanos. Enfermedades causadas por alteraciones 6.3 en los mecanismos de reparación
6.1 Variación en el ADN: polimorfismos y mutaciones
La variación observable en los individuos se debe en gran medida a la variación genéti-ca, sobre la que se añade la variación producida por la influencia del ambiente. La va-riación genética se debe a la presencia de cambios genéticos heredables (de una célula asus células hijas), que además son transmitidos a la siguiente generación si afectan a lalínea germinal (pero no son transmitidos si solamente afectan a células somáticas). Comoes sabido, un gen —localizado en un locus— puede presentarse en formas diferentes de-bidas a variaciones en la secuencia. Cada forma alternativa se denomina alelo, y el por-centaje de ese alelo en la población general se denomina frecuencia alélica. Cuando unlocus se presenta, al menos, en dos formas alélicas y la frecuencia alélica del alelo másraro es del uno por ciento o mayor, ese locus se llama locus polimórfico, y esa variaciónse denomina polimorfismo. La variación inter-individual garantiza la adaptación de unaespecie a condiciones ambientales cambiantes, a expensas de producir algunos indivi-duos con mutaciones más graves, que desencadenan una enfermedad.
En humanos, la variación entre individuos se genera principalmente durante el pro-ceso de reproducción sexual (por recombinación meiótica). Además, durante la vida deun individuo se van introduciendo muchas nuevas mutaciones en el genoma de sus cé-lulas, aunque sólo un pequeño porcentaje de estos cambios afectan a las células germi-nales y quedan fijados en el genoma de la especie. La tasa de nuevas mutaciones es re-
CAPITULO 6 5/12/06 07:10 Página 81
www.FreeLibros.me

sultado del equilibrio entre mutación y reparación de las mutaciones. En efecto, encada división celular se incorporan 6x109 nucleótidos, y se estima que se producenunas 1017 divisiones celulares durante la vida media de un individuo: por tanto, unsistema sin errores debería tener una exactitud de 6x1026, lo que es virtualmente im-posible.
De hecho, se sabe que la ADN polimerasa produce un error cada 104 nucleóti-dos incorporados, aunque está dotada de un sistema de «edición» que mejora estatasa hasta 107. Además, los sistemas de detección y reparación de errores consiguenque, al final, la replicación del ADN celular sólo origine un error cada 1010 nucleó-tidos. De hecho, se estima que en una célula somática aparecen unas 10-7 mutacio-nes por gen por división, es decir, una mutación por cada 300 divisiones celulares(asumiendo un total de 30 000 genes). Esta es una tasa extremadamente baja (insu-ficiente para explicar todas las mutaciones que se producen en cáncer, por ejemplo),lo que implica la existencia de sistemas celulares de reparación del ADN que se ocu-pan de reparar la inmensa mayoría de las mutaciones introducidas en el genoma,contribuyendo a mantener una fidelidad alta. Además, muchas de estas mutacionesserán silenciosas porque no afectan a ADN codificante; otras, las más dañinas, sufri-rán una fuerte presión selectiva y su frecuencia alélica será muy baja. Como se ve, lapresencia de polimorfismos y mutaciones en las poblaciones humanas es resultadodel juego entre mutación-reparación-selección.
6.2 Mecanismos de reparación del ADN en humanos. 6.2 Enfermedades causadas por alteraciones 6.2 en los mecanismos de reparación
A) Reparación de desemparejamientos entre nucleótidos normales
Los mecanismos de reparación mencionados actúan reparando tipos específicos dedaño al ADN. Los desemparejamientos entre bases normales pueden originarse porla tautomería de las bases (la forma imina de Citosina empareja con Adenina, o laforma enólica de Timina empareja con Guanina), por desaminación de citosinas me-tiladas (las citosinas metiladas de los dinucleótidos CpG se desaminan a Timina), yprincipalmente por los errores de la ADN polimerasa durante la replicación delADN. También se producen desemparejamientos durante la formación de heterodu-plexes en los procesos de recombinación. Además, el deslizamiento de la cadenanueva sobre la cadena molde durante la replicación también puede producir buclesde inserción/deleción (IDLs↓).
Todos estos tipos de desemparejamiento se corrigen por el sistema MMR (mis-match repair), cuyos componentes conocidos en humanos son hMLH1, hMSH2,hMSH3, hMSH6, hPMS1, hMLH3 y hPMS2 (homólogos de MutS y MutL de E.coli). Estas subunidades actúan como heterodímeros hMSH2/hMSH6, que recono-cen tanto los bucles (loops) de inserciones/deleciones de uno a ocho nucleótidoscomo los desemparejamientos simples de una base; o bien actúan como heterodíme-ros hMSH2/hMSH3, que reconoce sólo bucles. Cada uno de estos dímeros, a su vez,
82
Origen de la variación genética en humanos
CAPITULO 6 5/12/06 07:10 Página 82
www.FreeLibros.me

actúa junto con los homólogos de MutL, que son hMLH1/hPMS2 y hMLH1/hPMS1(recientemente se ha descrito también hMLH1/hMLH3). En concreto, los heterodí-meros hMSH2/hMSH6 junto con hMLH1/hPMS2 reparan los desemparejamientossimples, mientras que cualquiera de los dos complejos (hMSH2/hMSH3 ohMSH2/hMSH6) en combinación con hMLH1/hPMS2 son capaces de repararstem-loops (tallo-bucle) producidos por IDLs, como se muestra en la figura.
La Figura 6.1 muestra algunos ejemplos de desemparejamientos entre nucleótidos normales y elfuncionamiento del sistema de reparación de desemparejamientos MMR.
En E. coli, este sistema actúa uniéndose al desemparejamiento y a una base me-tilada adyacente, corta la cadena no metilada (recién sintetizada) hasta una distan-cia de 1-2 kb del mismatch, una endonucleasa corta los nucleótidos contenidos en elasa, y la polimerasa rellena el hueco. En mamíferos el mecanismo no está todavía to-talmente explicado, pero se ha encontrado una proteína (MBD4 o MED1) que seune a metil-citosinas, tiene actividad N-glicosilasa y forma complejos con MLH1,además de modular el sistema de MMR.
Cuando hay defectos en este proceso de reparación aparecen errores durante la re-plicación del ADN, errores que se pueden ver al analizar secuencias repetidas cortastipo microsatélite. Por tanto, los defectos en el sistema de reparación de desempareja-mientos dan lugar al fenómeno conocido como Inestabilidad de Microsatélites(MIN = Microstallite INstability) o «fenotipo mutador». Se conocen algunas enferme-dades debidas a mutaciones en componentes de estos sistemas de reparación. Porejemplo el 90 por ciento de los pacientes con cáncer colo-rectal no-polipósico heredi-tario (HNPCC o Síndrome de Lynch) tienen mutaciones en uno de los genes hMSH2,hMLH1, hPMS1, hPMS2 o hMSH6, de forma que los individuos que han heredadouna mutación tienen una alta probabilidad de sufrir una segunda mutación en el otroalelo en alguna de sus células somáticas, por lo que el riesgo global de desarrollar estetipo de cáncer es del 80-85 por ciento (o del 75 por ciento a los 55 años) en estos su-jetos. Estos tumores muestran inestabilidad de microsatélites, pero además la inestabi-lidad también afecta a genes que tienen repeticiones en sus secuencias codificantes(BAX, TGFBRII). Son las mutaciones en estos genes las que a menudo llevan al des-arrollo de neoplasias. Curiosamente, los pacientes homocigotos para mutaciones enMLH1 (dos mutaciones en la línea germinal) desarrollan en la infancia neoplasias he-matológicas además de otros tumores (neurofibromatosis, meduloblastoma), lo que su-giere la existencia de genes implicados en la hematopoyesis y en el control del creci-miento celular que son dianas del sistema MMR.
B) Reparación de nucleótidos dañados
Otros sistemas detectan la presencia de bases anormales tales como, por ejemplo, losuracilos que aparecen por la des-aminación de una citosina. En general, estas mo-dificaciones están debidas a la acción de mutágenos: benzopirenos del tabaco, agen-tes alquilantes, diversos agentes químicos de la dieta, el daño causado por especiesreactivas de oxígeno, así como las alteraciones debidas a la radiación ultravioleta.Los procesos químicos que con mayor frecuencia provocan mutaciones son 1) las
83
Mecanism
os de reparación del ADN en humanos…
CAPITULO 6 5/12/06 07:10 Página 83
www.FreeLibros.me

oxidaciones por radicales libres, especialmente la formación de 8-oxoguanina, que seempareja con T en vez de C (se calcula que se forman unas 10 000 al día en cada cé-lula) y 2) las reacciones hidrolíticas, ya que la molécula de ADN sufre una hidrólisisespontánea lenta que hace que se pierdan unas 10 000 purinas al día en un genomahumano, con la consiguiente creación de otros tantos sitios apurínicos. También laradiación UV produce sitios apurínicos, pero sobre todo provoca dímeros de pirimi-dinas.
La Figura 6.2 muestra la estructura de algunos nucleótidos anormales y la formación de lesionespor acción de la luz ultravioleta.
En general, todas estas lesiones son graves, ya que impiden la replicación correc-ta del ADN y, a la larga, llevan a la muerte celular. Podemos generalizar diciendo quelas lesiones del ADN producidas por la presencia de nucleótidos anormales se corri-gen por cuatro mecanismos: reversión directa, BER (Base Excision Repair), NER(Nucleotide Excision Repair) o por polimerasas capaces de pasar por encima de lalesión.
Figura 6.3. Visión general de los mecanismos de reparación de lesiones que incluyen nucleótidosdañados.
A continuación se ve con más detalle cada uno de estos mecanismos:
1. Al contrario que otras especies, la reversión directa por enzimas fotoreacti-vadoras no existe en humanos. Nuestro único recurso en este sentido consis-te en un enzima llamado MGMT (metil-guanina metil-transferasa), que pue-de eliminar el metilo introducido por agentes alquilantes en la guanina (elcual daría lugar a transiciones GàA, pues la O6-metilguanina se empareja conTimina).
2. La reparación por escisión de bases (BER) elimina las bases que han sufridoataques hidrolíticos (des-aminación, por ejemplo) por ROS o la 8-oxo-guani-na producida por el tabaco. El paso crítico en este tipo de reparación es la ro-tura del enlace N-glicosídico que une la base al esqueleto desoxi-ribosa-fos-fato, catalizado por ADN glicosilasas (específicas para determinados tipos delesión: UDG, OGG, etc.). Posteriormente, el sitio AP (apurínico o apirimidí-nico) es roto por una AP endonucleasa que cataliza la incisión del enlace fos-fodiester en posición 5’ al sitio AP. La escisión del azúcar se completa con laeliminación del residuo desoxi-ribosa-fosfato por la acción de una desoxi-ri-bosa-fosfodiesterasa que corta el otro enlace fosfodiéster. Finalmente, se re-llena el hueco mediante la acción de ADN pol ββ y una ADN ligasa. Este me-canismo de reparación parece necesario para la viabilidad, ya que el ratónknock-out para ADN pol β es letal embrionario. Un proceso paralelo es cru-cial en la diversificación de los genes de las inmunoglobulinas, ya que loslinfocitos B expresan un enzima llamado AID (Activation-Induced Deami-nase) que desamina citosinas y las convierte en uracilos; dichos uraciloscrean sitios AP que pueden ser procesados por un complejo llamado RAD50
84
Origen de la variación genética en humanos
CAPITULO 6 5/12/06 07:10 Página 84
www.FreeLibros.me

(que veremos más adelante) cuya actividad liasa rompe el esqueleto desoxi-ribosa-fosfato y rompe el ADN. Dichas roturas son necesarias para que losgenes de la inmunoglobulinas se reordenen y puedan dar lugar a la diversi-dad necesaria para una adecuada respuesta inmune.
El vídeo de la Figura 6.4 muestra el funcionamiento del sistema de reparación por escisión debases (BER).
3. La reparación por escisión de nucleótidos (NER) elimina fotoproductos pro-ducidos por UV y otros aductos que confieren estructuras anormales a la ca-dena de ADN. El mecanismo de actuación de este sistema de reparación noestá totalmente claro, pero se sabe que requiere la formación de un complejoentre XPC (proteína que es esencial para NER) y RPA (proteína de unión aADN monocatenario) con la región lesionada. Sobre este foco también seunen XPA y el complejo TFIIH (que contiene, entre otras, las proteínas XPB(ERCC3) y XPD (ERCC2), ambas con actividad helicasa necesaria para llevara cabo NER). El paso clave es la creación de dos incisiones, flanqueando lalesión, en la cadena de ADN que está dañada: una incisión tiene lugar tres anueve bases en dirección 3’ de la lesión y la otra incisión se produce 16 a 25bases en dirección 5’ de la lesión, comprendiendo unas 25-30 bases en total.En mamíferos, la incisión 3’ la lleva a cabo una nucleasa llamada XPG, y laincisión 5’ la realiza el heterodímero XPF/ERCC1. Tras las incisiones y eli-minación de la región dañada, tiene lugar la resíntesis de esa región mediantela acción de un holoenzima que contiene PCNA y DNApol δδ o εε.
La Figura 6.5 incluye un video que muestra esquemáticamente el funcionamiento del sistema dereparación por escisión de nucleótidos (NER).
3. Un aspecto especialmente interesante es la relación del NER con la trans-cripción, a través de la presencia de XPB y XPD en TFIIH (que es uno de losfactores de transcripción generales), dando lugar al concepto de Reparaciónacoplada a la transcripción (TCR = Transcription-Coupled Repair). De he-cho, se ha comprobado que el daño por UV se repara con más eficacia y másrápido en la cadena que se transcribe y en genes transcripcionalmente acti-vos. También se ha visto que ciertos tipos de daño oxidativo pueden reparar-se por TCR incluso cuando el NER no funciona. Además de los citados XPBy XPD, otras dos proteínas con actividad helicasa (CSA y CSB) son respon-sables de TCR, y también se ha implicado a hMLH1 en TCR. Las mutacionesque destruyen el sistema TCR dan lugar a una enfermedad llamada Síndro-me de Cockayne. Las mutaciones en genes que codifican otras proteínas aso-ciadas con NER dan lugar a varias enfermedades (Xeroderma pigmentosum,Tricotiodistrofia), que en su conjunto cursan con fotosensibilidad e inestabi-lidad cromosómica, y aumento del riesgo de aparición de melanoma (un tipode cáncer de piel). Finalmente, algunos pacientes tienen una variante de Xe-roderma Pigmentosum sin defectos en NER (llamada XP variante, o XP-V),
85
Mecanism
os de reparación del ADN en humanos…
CAPITULO 6 5/12/06 07:10 Página 85
www.FreeLibros.me

que está debida a mutaciones en el gen humano homólogo del gen RAD30 delevadura. Este gen codifica la polimerasa eta (Polη), que puede replicar elADN correctamente incluso en la presencia de dímeros de pirimidinas.
4. Respecto al último mecanismo de reparación de nucleótidos dañados (es de-cir, las polimerasas capaces de «saltarse» la lesión), recientemente se ha vis-to que Pol ζ (polimerasa zeta) o Pol η (polimerasa eta) son capaces de sinte-tizar ADN frente a dímeros TT. Sin embargo, así como Pol η suele introducirdos Adeninas, Pol ζ introduce bases incorrectas y por tanto es un mecanismode reparación de baja fidelidad.
C) Reparación de roturas de la doble hebra del ADN
La creación de roturas bicatenarias del ADN (DSB=Double-Strand Breaks) es unpaso necesario para la recombinación homóloga en meiosis y mitosis, y para la reor-denación V(D)J de genes de las inmunoglobulinas y receptores de células T. Además,este tipo de roturas aparecen durante la replicación del ADN y también son causa-das por diferentes agentes genotóxicos: radiación ionizante (rayos X), ROS origina-dos por el metabolismo celular. Los DSB se reparan por dos vías principales, en di-ferentes fases del ciclo celular: Fusión no homóloga de extremos (NHEJ), quefunciona sobre todo en G1/S (antes de la replicación del ADN) y Recombinaciónhomóloga (HR), que teóricamente actuaría en S/G2, cuando ya hay dos cromátideshermanas (de manera que se utiliza la doble hebra homóloga como molde para la re-paración).
La Figura 6.6 muestra las posibilidades de respuesta celular a la aparición de roturas bicatenariasen el ADN (DSB) y sus efectos.
1. Recombinación Homóloga: como ya hemos comentado en el Capítulo 2, lamaquinaria responsable del mecanismo molecular de recombinación meióti-ca se utiliza también para reparar DSB a partir de una cromátide hermana.El mecanismo general es bien conocido, e incluye el procesamiento de los ex-tremos mediante una exonucleasa 5’→3’ para dejar extensiones 3’ libres, in-vasión de la doble hebra homóloga por parte del filamento de ADN mono-catenario recubierto de proteínas, síntesis de nuevo ADN usando la cadenahomóloga como molde, ligación y resolución de la recombinación. Da lugara conversión génica con o sin sobrecruzamiento, según sea la resolución delas estructuras de Holliday.
1. RAD51 (homólogo del gen RecA, que en E. coli es fundamental en la res-puesta SOS) forma filamentos sobre el extremo monocatenario de ADNque resulta de la digestión de los extremos libres, y es necesario para quese pueda realizar la invasión de la cadena libre a la doble cadena homóloga.RAD51 es indetectable en G1 y se expresa en S/G2. Los ratones RAD51-/-
son letales embrionarios y sus células muestran inestabilidad cromosómica.Una línea celular de pollo, en la que RAD51 está bajo el control de un pro-motor represible, muestra inestabilidad cromosómica y muerte celular cuan-
86
Origen de la variación genética en humanos
CAPITULO 6 5/12/06 07:10 Página 86
www.FreeLibros.me

do se reprime la expresión de RAD51, lo que muestra la necesidad de este genpara la viabilidad celular. Hay otros genes implicados en reparación de DSBque tienen cierta homología con RAD51 y que podrían modular la acción deéste. Por ejemplo, se ha visto que la ausencia del gen XRCC2 (20 por cientode homología con Rad51) disminuye la eficacia de la recombinación homó-loga en la reparación de DSB, pero no es letal; lo mismo podría suceder conRAD55 o RAD57. Por otra parte, se ha comprobado en levadura que la pro-teína RPA altera la eficacia con la que se forman los filamentos de RAD51.
1. RAD52 parece actuar como el «portero» del mecanismo de recombinaciónhomóloga. Esta proteína interacciona con RPA y con RAD51, favoreciendola formación del filamento de RAD51 en presencia de RPA. Como el ratónRAD52-/- no es letal (sólo se observa una ligera disminución en la eficacia derecombinación homóloga), se postula la existencia de genes homólogos deRAD52 que complementen la ausencia de éste.
1. La expresión del complejo RAD50 no varía durante el ciclo celular, por loque debe regularse post-traduccionalmente (mediante fosforilación o porcompartimentalización en el núcleo). Este complejo tiene actividad 5’→3’exonucleasa, y parece transducir señales de daño de ADN hacia la paradadel ciclo celular. Experimentos de irradiación «en bandas» han mostrado,mediante anticuerpos monoclonales contra un componente de este comple-jo, que RAD50 se asocia a los DSB muy pronto tras la irradiación. En hu-manos, los pacientes con el llamado «Síndrome de Roturas de Nimega» tie-nen mutaciones en un componente de este complejo llamado NBS1,muestran sensibilidad a radiación ionizante e inestabilidad cromosómica, ylas células de estos pacientes no son capaces de formar focos después de lairradiación con rayos X ultrablandos; por tanto, lo más probable es que laproteína NBS1 sea responsable de dirigir el complejo RAD50 a los lugaresde daño del ADN.
1. Una observación muy interesante es la implicación de BRCA1 y BRCA2 (ge-nes mutados en ciertos tipos de cáncer de mama familiar) con la reparaciónde DSB, ya que se ha visto que las proteínas codificadas por estos genes inter-accionan con RAD51, bien directamente (BRCA2) o de manera indirecta(BRCA1). Ambas son proteínas nucleares que se expresan en S/G2, funcio-nan como activadores transcripcionales, y los ratones knock out de ambasson letales embrionarios. En cambio, un ratón que lleva una copia de BRCA2truncada (BRCA2tr/tr) sufre linfomas del timo, alta inestabilidad cromosómi-ca y estimulación de la vía de señalización de p53. BRCA1 se fosforila trasdaño al ADN, y se ha descrito la asociación de BRCA1 con el complejoRAD50 en el momento del ciclo celular en que BRCA1 está fosforilado(S/G2). Por otra parte, en estudios de colocalización tras irradiación simila-res a los descritos arriba, se ha visto que BRCA1 está presente en focos nu-cleares que contienen RAD50 en unas células o en focos que contienenRAD51 en otras células, pero no hay células en las que se asocie con am-bos a la vez. Una hipótesis atractiva es que durante la reparación de DSB porrecombinación homóloga BRCA1 coopera con RAD50 en el procesamientode los extremos del ADN dañado y que, mediante la interacción entre
87
Mecanism
os de reparación del ADN en humanos.
CAPITULO 6 5/12/06 07:10 Página 87
www.FreeLibros.me

BRCA1 y BRCA2 (que se asocia físicamente a RAD51), facilita el acopla-miento con los procesos de recombinación mediados por RAD51.
La Figura 6.7 ilustra la presencia de focos de reparación en células que han sido previamenteirradiadas para generar roturas bicatenarias (DSB) en el ADN.
2. Fusión no homóloga de extremos (NHEJ): el proceso general de reparaciónes similar pero sin recombinación, ya que en este caso no existe una doble ca-dena homóloga: simplemente se fusionan los extremos libres. Tras la genera-ción del DSB, los extremos libres también son procesados por una nucleasa;posteriormente se procede a la unión de los mismos y a la ligación, perdién-dose siempre algunas bases en la región de unión.
1. Este mecanismo tiene lugar fisiológicamente en linfocitos, donde es respon-sable de la reordenación de segmentos V(D)J de los genes de inmunoglobuli-nas. Un componente principal de este sistema es el complejo ADN-PK(DNAPK), una serina/treonina kinasa nuclear que consta de una subunidadcatalítica (DNAPKcs) y de un heterodímero de unión a ADN llamado KU(que a su vez se compone de KU70 y KU80). El complejo ADN-PK se asociaa los extremos rotos, ayuda al alineamiento de los extremos y facilita su liga-ción. Este sistema de reparación es importante, sobre todo en células del sis-tema inmune, y de hecho las mutaciones en el gen que codifica la DNAPKcsprovocan la enfermedad llamada Inmunodeficiencia Combinada Severa(SCID). Además, el complejo ADN-PK fosforila y activa una nucleasa llama-da Artemis, que es la responsable de llevar a cabo el procesamiento de los ex-tremos libres para que se puedan religar. Este último paso, la unión de los ex-tremos ya procesados, es realizado por una ligasa (ADN ligasa IV) que actúajunto con XRCC4, una fosfoproteína nuclear que también es sustrato deADN-PK in vitro.
El vídeo de la Figura 6.8 muestra, paso a paso, el funcionamiento del sistema de reparación porfusión de extremos (NHEJ).
1. Es muy interesante la asociación que se ha encontrado en levaduras entreKu70 y proteínas silenciadoras de la transcripción de telómeros (Sir2, Sir3 ySir4), sugiriendo la posibilidad de que Ku reclute proteínas Sir a los DSBpara inducir un estado de cromatina condensada que evite la transcripción oreplicación y facilite el proceso de reparación, o bien evite que los extremoslibres de ADN puedan interaccionar con otras moléculas de ADN. Dado quela disrupción de Ku o del complejo RAD50 lleva al acortamiento de telóme-ros en levaduras, es lógico pensar que Ku se una al ADN telomérico e inter-accione con Sir4 para inhibir la replicación a ese nivel.
1. Tradicionalmente se ha considerado que el principal mecanismo de repara-ción de DSB en mamíferos es la fusión de extremos (NHEJ), ya que se ha vis-to que la frecuencia de recombinación homóloga en mitosis es muy baja. Estoes lo contrario de lo que sucede en levaduras, donde el principal mecanismode reparación de DSBs es la recombinación homóloga. Actualmente, en cam-
88
Origen de la variación genética en humanos
CAPITULO 6 5/12/06 07:10 Página 88
www.FreeLibros.me

bio, esto está en discusión. Por un lado, parece que la recombinación mitóti-ca en mamíferos es más alta de lo que se creía: del orden de 10-4 a 10-5; porotro lado, los ratones incapaces de llevar a cabo NHEJ (DNAPK -/-) no sonletales, mientras que los ratones incapaces de recombinación homóloga(RAD51-/- o los RAD54-/-) sí son letales. Esto indica que HR puede de al-guna forma complementar la ausencia de NHEJ, pero en cambio NHEJ nopuede complementar la ausencia de HR en células somáticas.
D) Mecanismos de reparación presentes en mitocondrias
Un tema reciente en patología genética humana es la alteración de los mecanismosde reparación del ADN mitocondrial. Tradicionalmente se ha considerado que lasmitocondrias de mamíferos no son capaces de llevar a cabo ningún tipo de repara-ción, ya que los dímeros de pirimidinas no son reparados con eficacia. Esto explica-ría además la mayor tasa de mutaciones del ADN mitocondrial (ADNmt) respecto alADN nuclear. Hoy se sabe que hay ciertos tipos de daño que sí pueden repararse enmitocondrias (por ejemplo, los sitios AP originados por daño oxidativo) y en generalparece que las mitocondrias de organismos superiores son capaces de llevar a caboBER pero no NER ni MMR. El tipo de daño que puede repararse mediante BER vaa estar limitado por la presencia de ADN glicosilasas en la mitocondria, y hasta elmomento se ha demostrado la presencia de uracil-ADN-glicosilasa (UDG) y de 8-oxo-guanina-glicosilasa (OGG). Además, otras glicosilasas tienen señales de locali-zación mitocondrial en sus extremos N-terminal. Una diferencia del BER que se lle-va a cabo en mitocondrias con el BER nuclear es que la polimerasa presente enmitocondrias es la ADN pol γγ, que además posee actividad liasa (fosfodiesterasa).También existe dentro de la mitocondria una actividad ADN ligasa, que se origina apartir del gen de la ADN ligasa III por un codón de iniciación alternativo que creauna señal de localización mitocondrial.
89
Mecanism
os de reparación del ADN en humanos…
CAPITULO 6 5/12/06 07:10 Página 89
www.FreeLibros.me

00-Portadillas 5/12/06 06:44 Página i
www.FreeLibros.me

C) La transmisión de los caracteres hereditarios
Esta sección incluye seis temas en los que se tratan los aspectosfundamentales del mendelismo y sus principales excepciones, dando
paso al estudio del ligamiento genético, la genética de caracterescuantitativos y de las enfermedades multifactoriales, así como unas
nociones de genética de poblaciones y evolución.
CAPITULO 7 5/12/06 07:12 Página 91
www.FreeLibros.me

00-Portadillas 5/12/06 06:44 Página i
www.FreeLibros.me

C A P Í T U L O 7
Genética mendeliana
Contenidos
7.1 Planteamiento experimental de Mendel
7.2 Monohíbridos: primera Ley de Mendel
7.3 Segunda ley de Mendel: dihíbridos y trihíbridos
7.4 Redescubrimiento del trabajo de Mendel
7.5 ¿Dónde están los «factores unitarios»? La teoría cromosómica de la herencia
A finales del siglo XIX, las observaciones de Gregor Mendel sentaron las bases biológicasde la herencia, dando lugar a lo que hoy conocemos como Genética. Es muy importan-te estudiar el desarrollo histórico de las ideas en torno a la herencia, para poner en elcontexto adecuado las ideas propuestas por Mendel y comprender la gran novedad quesupusieron en su momento.
Ya los antiguos habían observado que muchos caracteres pasan de padres a hijos, y sehabían preguntado cómo podría ser esto. Hipócrates fue el primero en elaborar una teo-ría, llamada «pangénesis», según la cual cada parte del cuerpo produce algún tipo departícula que es recogida en lo que él denominó «semen» (hoy diríamos gametos) y trans-mitida a la descendencia. La pangénesis fue criticada por Aristóteles, que la desechó porvarias razones. En primer lugar, constató que en ocasiones unos individuos tienen rasgosmás parecidos a abuelos o ancestros remotos que a sus padres, lo que no encaja bien conel hecho de que la herencia se transmita únicamente de padres a hijos. Además, tambiénobservó que a veces se transmiten caracteres que aún no se poseen en el momento de te-ner descendencia (como la tendencia a tener canas o la calvicie, por ejemplo). Por otrolado, apuntó el hecho fácilmente comprobable de que las mutilaciones en animales yplantas no se heredan. Esto es algo fundamental, porque Aristóteles admitía como hechocierto la herencia de los caracteres adquiridos, algo universalmente aceptado hasta mu-chos siglos después. Como la pangénesis no podía explicar estas discrepancias, el filóso-fo propuso que lo que se hereda no son los rasgos en sí mismos, sino la potencialidad
CAPITULO 7 5/12/06 07:12 Página 93
www.FreeLibros.me

de producirlos. Hoy en día esto nos parece un concepto evidente, y se asemeja ex-traordinariamente a la idea de gen que actualmente tenemos, pero en su tiempo fueuna propuesta revolucionaria a la que no se le dio toda la importancia que requería.No hay que olvidar que algunas nociones básicas como la existencia de gametos, lameiosis o la reproducción sexual eran totalmente desconocidas, por lo que era difí-cil formular teorías que explicasen la transmisión de caracteres a lo largo de genera-ciones sucesivas.
Mendel no podría haber explicado sus resultados sin comprender un concepto bá-sico que hoy expresaríamos diciendo que, tanto en animales como en plantas, un ga-meto masculino y un gameto femenino se unen para formar un cigoto. En este sen-tido, un avance fundamental fue la demostración de que las plantas superiores tienenreproducción sexual, siendo el polen el elemento masculino. Fue un botánico llama-do Kölreuter, un siglo antes de Mendel, el que elaboró y sistematizó el trabajo sobrehíbridos en plantas: modos de polinización, la obtención de híbridos con caracteres«intermedios» entre los progenitores (aunque un pequeño porcentaje de la descen-dencia expresa un rasgo que sólo se encuentra en uno de los progenitores), etc. Ade-más, pocos años antes de Mendel ya se había propuesto la idea de que un solo gra-no de polen es suficiente para fecundar una planta, aunque este concepto todavíasería objeto de debate durante algún tiempo.
En 1859, Charles Darwin publica El Origen de las especies, proponiendo la evo-lución de las especies mediante un proceso de selección natural. Sin embargo, Dar-win no pudo proponer una explicación biológica coherente porque no conocía lasbases biológicas de la variación y de la herencia. Darwin aceptaba la pangénesis por-que era la teoría que mejor explicaba la herencia de caracteres adquiridos (lo cual leayudaba a explicar la selección natural) y llamó «gémulas» a las partículas somáticasque un individuo transmite a su descendencia. En su libro The Variation in Animalsand Plants under Domestication, de 1868, Darwin recoge las ideas más prevalentesen ese momento, y reconoce la existencia de dos tipos de variación: variación conti-nua (caracteres cuantitativos) y variación discontinua (caracteres cualitativos). Sinembargo, consideraba que esta última era relativamente rara y no tenía tanta impor-tancia como la variación continua, que podía modificarse mediante selección y portanto era más útil para explicar el concepto de selección natural. Aunque parece queDarwin llegó a recibir una copia de los trabajos de Mendel publicados dos años an-tes, nunca llegó a leerlos y por tanto no pudo comprender la importancia de la va-riación discontinua.
7.1 Planteamiento experimental de Mendel
Gregor Mendel nació el 22 de julio de 1822 en Heinzendorf. Hijo de labradores, sehizo sacerdote agustino en 1847. En 1850 suspendió el examen que le permitiría en-señar ciencias naturales, por lo que se marchó a Viena a estudiar física, química, zoo-logía y botánica durante dos años. En 1853 se traslada al monasterio de los agusti-nos en Brno (en lo que hoy es la república Checa) y allí comienza a hacer susexperimentos con plantas. En 1865 presenta sus resultados y conclusiones en la reu-nión de la Sociedad de Historia Natural de Brno, que son publicadas un año después
94
Genética mendeliana
CAPITULO 7 5/12/06 07:12 Página 94
www.FreeLibros.me

en las Actas de dicha Sociedad en un artículo que lleva el título de «Versuche überPflanzenhybriden» (Experimentos sobre Híbridos de Plantas). En 1868 fue nombra-do abad del monasterio, por lo que desde entonces no pudo dedicar tanto tiempo asus experimentos. Murió el 6 de enero de 1884 a causa de una glomerulonefritis.
Fruto de sus observaciones trabajando con híbridos de plantas, Mendel llegó alconvencimiento de que el único modo de comprender las bases biológicas de latransmisión de caracteres hereditarios era mediante el estudio de variaciones dis-continuas, es decir, aquellos caracteres que se presentan únicamente en dos formasalternativas. Como explica en su artículo, considera que es necesario: 1) determinarcon exactitud el número de las diferentes formas que aparecen en la descendencia delos híbridos; 2) agrupar estas formas por separado en las distintas generaciones;3) describir sus relaciones matemáticas exactas. Por ejemplo, en el artículo originalde 1866 dice «...Entre los numerosos experimentos hechos hasta el momento, nin-guno ha sido realizado de manera que sea posible determinar el número de las dife-rentes formas en que aparecen los descendientes de híbridos, o agrupar estas formascon certeza según generaciones separadas, o determinar exactamente sus relacionesestadísticas…». Gracias a esta aproximación metodológica, que le supuso analizarunas 28 000 plantas, Mendel pudo observar que las proporciones obtenidas en la des-cendencia de las distintas clases de híbridos se mantenían y se repetían para varioscaracteres distintos. Esto le permitió elaborar una teoría que explicase cómo podríandarse esas proporciones y llevar a cabo experimentos concretos que validasen las pre-dicciones formuladas por dicha teoría. Veamos con más detalle la manera en que de-sarrolló sus experimentos.
7.2 Monohíbridos: primera Ley de Mendel
Mendel escogió la planta del guisante Pisum sativum (aunque había cultivado y es-tudiado también otras especies) porque es fácilmente cultivable, tiene un ciclo cortoy los cruzamientos son fáciles de controlar. Seleccionó siete caracteres que mostra-ban variación claramente discontinua, es decir, representados cada uno por dos for-mas alternativas en líneas puras. Estas líneas puras eran el resultado de autofecun-dar plantas durante varias generaciones, hasta conseguir que esos caracteres semantuviesen constantes. Los siete caracteres fueron:
• Guisantes rugosos/lisos.
• Guisantes amarillos/verdes.
• Vainas en posición axial/terminal.
• Vainas hinchadas/arrugadas.
• Vainas verdes/amarillas.
• Flores violetas/blancas (o la envuelta de la semilla gris/blanca, respectiva-mente).
• Tallo de la planta alto/enano.
La Figura 7.1 contiene enlaces a recursos educativos que ilustran los conceptos básicos del mendelismo.
95
Monohíbridos: prim
era Ley de Mendel
CAPITULO 7 5/12/06 07:12 Página 95
www.FreeLibros.me

En primer lugar, Mendel llevó a cabo cruces monohíbridos, es decir, para cadauno de los siete caracteres por separado cruzó plantas que se comportaban como va-riedades puras. Observó que sólo una de las dos formas alternativas estaba presen-te en el 100 por ciento de la F1 (la primera generación filial), mientras que la otraforma había «desaparecido». Curiosamente, al autofecundar individuos de la F1, ob-servó que esa forma desaparecida volvía a aparecer en la F2. Lo más importante, yesta fue la aportación más novedosa de Mendel, estableció las proporciones en quese daba cada una de las formas en cada generación (en la F1 y en la F2). Por ejemplo,al analizar la forma del guisante, cruzó la variedad pura que producía guisantes rugo-sos con la variedad pura que producía guisantes lisos. En la F1 todas las plantas pro-ducían guisantes lisos, pero al autofecundar estas plantas de la F1 observó que en laF2 resultante había 5.474 guisantes lisos y 1.850 guisantes rugosos, lo que supone unarelación de 2,96:1 lisos frente a rugosos. Al repetir esto para los siete caracteres, ob-servó que se repetía el mismo fenómeno, siendo las proporciones obtenidas muy pa-recidas y siempre en torno a una relación 3:1, por lo que Mendel concluyó que se tra-taba de un fenómeno general que debía tener una explicación coherente.
Mendel razonó que estos datos numéricos podrían explicarse suponiendo que cadacarácter está controlado por un «factor» que puede presentarse en dos formas alter-nativas. Por ejemplo, habría un factor responsable de la forma del guisante, con unaforma que produce guisantes lisos y otra forma que produce guisantes rugosos. Ade-más, cada planta debería tener dos copias de ese «factor», que podrían ser idénticaso distintas (por ejemplo, podría haber plantas con dos copias de la forma que produ-ce plantas rugosas, o con una copia de cada forma). En las variedades puras iniciales,cada planta tendría dos copias idénticas: las plantas con guisantes lisos tendrían doscopias de la forma que produce guisantes lisos, las plantas con guisantes rugosos ten-drían dos copias de la forma que produce guisantes rugosos. Con estos presupuestos,si cada planta pasa a la descendencia sólo una de sus copias, todas las plantas dela F1 tendrían una copia de cada progenitor, por lo que todas tendrían una copia delfactor que produce guisantes lisos y otra copia del factor que produce guisantes rugo-sos. Ahora bien, si una de las formas domina sobre la otra, todas las plantas de estageneración serían iguales (por ejemplo, si la forma que produce guisantes lisos domi-na sobre la forma que produce guisantes rugosos, todos los guisantes de la F1 seríanlisos, como de hecho sucedía). Así pues, si estos factores se transmiten a la descen-dencia de forma totalmente aleatoria, la F2 resultante de autofecundar plantas de laF1 (que tienen dos copias distintas del factor), estaría compuesta por 25 por ciento deplantas con las dos copias idénticas e iguales a las de una de las variedades puras ini-ciales, 25 por ciento de plantas con dos copias idénticas iguales a las de la otra varie-dad pura inicial, y el 50 por ciento de plantas con dos copias distintas (como las plan-tas de la F1). Como una copia domina sobre la otra, realmente veríamos 75 por cientode las plantas con la conformación de una de las variedades inciales (la que estabapresente en la F1) y 25 por ciento de las plantas con la conformación de la otra va-riedad inicial (la que había «desaparecido» en la F1). Es decir, veríamos una propor-ción 3:1 tal y como Mendel había encontrado experimentalmente.
Como hemos visto, para que esta explicación sea coherente han de darse variascondiciones que se han marcado en negrita en el párrafo anterior. Estas condicionesconstituyen los tres principios que Mendel propuso que debían cumplirse para poder
96
Genética mendeliana
CAPITULO 7 5/12/06 07:12 Página 96
www.FreeLibros.me

explicar las proporciones encontradas, y que a veces se agrupan en lo que se conocecomo Primera Ley de Mendel: i) los factores que determinan la herencia se en-cuentran en dos formas alternativas y cada individuo lleva dos copias (idénticas odistintas), de las cuales sólo una se transmite a la descendencia; ii) cada una de esasdos copias tiene la misma probabilidad de pasar a la descendencia, es decir, se trans-miten de modo totalmente aleatorio; iii) una de las formas de cada factor domina so-bre la otra, de modo que cuando las dos copias son distintas, el carácter se manifies-ta como si las dos copias fuesen iguales para la forma dominante.
Lógicamente, en la nomenclatura moderna podemos expresar estos conceptos deun modo mucho más preciso, pero en la época de Mendel esta nomenclatura todavíano existía. Hoy podemos decir que los «factores unitarios» de los que hablaba Men-del son lo que llamamos genes; las formas distintas que puede presentar cada gen sellaman alelos (o formas alélicas); la transmisión de uno de los dos alelos a la descen-dencia se conoce como segregación; los distintos tipos de parejas que se pueden darson los tres posibles genotipos (dos homocigotos y un heterocigoto). Por tanto, hoydiríamos que un carácter fenotípico está controlado por un gen que se presenta en dosformas alélicas alternativas, una dominante y otra recesiva. Las variedades puras ini-ciales son homocigotos para cada uno de los alelos, las plantas de la F1 son todas he-terogicotos y sólo manifiestan el carácter determinado por el alelo dominante; lasplantas de la F2 son 25 por ciento homocigotos dominantes, 50 por ciento heteroci-gotos y 25 por ciento homocigotos recesivos (es decir, hay una relación genotípica1:2:1). Los homocigotos dominantes y los heterocigotos son fenotípicamente idénti-cos, por lo que encontraremos una relación fenotípica 3:1 en la F2.
Para expresar esto de un modo más gráfico, hoy en día usamos una letra para in-dicar cada forma alélica y representamos los cruces de manera esquemática. Porejemplo, podemos designar el alelo que produce guisantes lisos como R y el alelo queproduce guisantes rugosos como r, siendo R dominante sobre r. Las dos variedadespuras iniciales serían homocigotos, RR en el caso de las que producen guisantes li-sos y rr las que producen guisantes rugosos. El cruce inicial se puede representarcomo RR X rr. Si cada alelo segrega al azar, cada alelo R puede combinarse con unalelo r, pero en la descendencia (generación F1) todas las plantas tendrán genoti-po Rr. Como R es dominante, su fenotipo será de guisantes lisos. Al cruzar plantasde la F1 entre sí, tendremos cruces del tipo Rr X Rr. Ahora tenemos cuatro posiblescombinaciones de alelos en la descendencia (RR, Rr, rR y rr), cada una de ellas conla misma probabilidad de producirse. Es decir, en la F2 tendremos 25 por ciento deplantas con genotipos RR, 25 % con genotipo Rr, 25 por ciento con genotipo rR y 25por ciento con genotipo rr. Como los genotipos Rr y rR son iguales desde el punto devista funcional (heterocigotos, da igual el orden), tendremos un 25 por ciento de ho-mocigotos dominantes (RR), 50 por ciento de heterocigotos (Rr) y 25 por cientode homocigotos recesivos (rr). Como R es dominante, los heterocigotos y los ho-mocigotos RR son idénticos (todos producen guisantes lisos), y por tanto el 75 porciento de las plantas producirán guisante lisos y el 25 por ciento rugosos.
Es muy útil utilizar métodos gráficos para representar los cruzamientos, porqueeso simplifica el cálculo de las proporciones genotípicas en la descendencia. El mé-todo más sencillo es quizás el de los cuadrados de Punnett (ideados por ReginaldPunnett), que consisten en representar los alelos de un progenitor en horizontal y los
97
Monohíbridos: prim
era Ley de Mendel
CAPITULO 7 5/12/06 07:12 Página 97
www.FreeLibros.me

del otro progenitor en vertical, formando unas cuadrículas que se rellenan con los ge-notipos resultantes.
Los enlaces de la Figura 7.2 ayudan a comprender gráficamente las proporciones genotípicas y fenotípicas del cruce monohíbrido.
También se puede utilizar un método ramificado, tanto para calcular los genoti-pos como los fenotipos. Por ejemplo, en un cruce del tipo Rr X Rr estableceríamosla probabilidad de cada alelo de uno de los progenitores (1/2 R y 1/2 r, en este caso) ydespués, para cada uno de ellos, establecemos la probabilidad de cada alelo del otroprogenitor. Al tratarse de sucesos independientes, las probabilidades se multiplicanpara calcular la probabilidad de cada genotipo en la descendencia. Así, en nuestroejemplo, 1/2 R (del primer progenitor) puede combinarse por igual con cualquiera delos alelos del segundo progenitor (con 1/2 R o con 1/2 r). Por tanto, podríamos repre-sentarlo esquemáticamente de modo ramificado:
1/2 R = 1/2 X 1/2 = 1/4 RR1/2 R
1/2 r = 1/2 X 1/2 = 1/4 Rr
1/2 R = 1/2 X 1/2 = 1/4 rR1/2 r
1/2 v = 1/2 X 1/2 = 1/4 rr
Como Rr y rR son iguales, tenemos las proporciones genotípicas 1/4 RR, 1/2 Rr y1/4 rr, o lo que es lo mismo 1:2:1.
Impresiona bastante seguir el razonamiento de Mendel, cómo a partir de una sim-ple proporción fenotípica deduce los principios generales que la explican. De todasformas, esto no era más que una hipótesis plausible, por lo que Mendel se propusodiseñar los experimentos que pudiesen confirmar las predicciones que se derivabande su teoría. Para ello hizo dos tios de experimentos. Por un lado, llevó a cabo cru-zamientos prueba, que es un tipo de retrocruzamiento (cruzar una planta con unode sus progenitores). El cruzamiento prueba consiste en fecundar una planta de la F1con el progenitor homocigoto recesivo, es decir, con la variedad pura cuyo fenotipodesaparecía en la F1.
Si los postulados son ciertos, este cruzamiento entre un heterocigoto y un homo-cigoto recesivo debería dar descendencia con 50 % de plantas heterocigotos y 50 %homocigotos recesivos. Siguiendo con el ejemplo de la forma del guisante, si r es elalelo recesivo y R el dominante, tendríamos que todas las plantas de la F1 son Rr. Sihacemos el cruzamiento prueba con plantas rr, tendríamos un cruce Rr X rr en elque el 50 % de la descendencia será Rr y el 50 % será rr: es decir, la mitad de losguisantes serán lisos (R domina sobre r) y la mitad rugosos. La otra comprobaciónque hizo Mendel fue autofecundar plantas de la F2. Como hemos visto, 25 % de és-tas deberían ser RR (guisantes lisos), 50 % Rr (también lisos) y 25 % rr (rugosos). Alautofecundar plantas rugosas (rr), todos los guisantes resultantes deberían ser tam-bién rugosos. En cambio, de todas las plantas de la F2 con guisantes lisos un terciodeberían ser homocigotos y dos tercios heterocigotos. Por eso, al autofecundar plan-
98
Genética mendeliana
{{
CAPITULO 7 5/12/06 07:12 Página 98
www.FreeLibros.me

tas con guisantes lisos, un tercio de los cruces deberían ser RR X RR y dar descen-dencia con 100 % de guisantes lisos en la F3; dos tercios de los cruces deberían serdel tipo Rr X Rr y dar descendencia en las proporciones fenotípicas 3:1 típicas deeste cruce. Pues bien, en todos los casos Mendel encontró que las proporciones en-contradas experimentalmente se ajustaban perfectamente a lo esperado, para todoslos caracteres estudiados. Con esto, concluyó que los principios propuestos eran co-rrectos y explicaban la transmisión hereditaria de la variación discontinua.
La Figura 7.3 ilustra las pruebas utilizadas para confirmar la validez de los postulados de laprimera Ley de Mendel.
7.3 Segunda Ley de Mendel: dihíbridos y trihíbridos
No contento con lo que había encontrado al analizar cada uno de los caracteres porseparado, Mendel se preguntó qué sucedería al estudiarlos conjuntamente. En primerlugar llevó a cabo cruces dihíbridos, es decir, entre plantas que se comportabancomo variedades puras para dos caracteres distintos a la vez. Por ejemplo, estudió elcolor y la forma del guisante, obteniendo plantas con guisantes amarillos y lisos si-multáneamente, y plantas con guisantes verdes y rugosos. Estas plantas podían con-siderarse variedades puras para ambos caracteres, porque siempre se daban esas mis-mas combinaciones de forma y color. Al cruzar plantas de ambas variedades puras,Mendel observó que en la F1 todos los guisantes eran iguales: amarillos y lisos a lavez; es decir, manifestaban los dos caracteres dominantes. La autofecundación de
99
Segunda Ley de Mendel: dihíbridos y trihíbridos{ {
{{50% Tt 25% TT 25% tt
Tt X Tt TT X TT tt X tt
100% tt
ALTAS ENANAS
autofecundación
100% TT
F2
3 : 1
F3
3 : 1
50% Tt 25% TT 25% tt
CAPITULO 7 5/12/06 07:12 Página 99
www.FreeLibros.me

estas plantas de la F1 dio como resultado una F2 con proporciones de 9/16 de doblesdominantes (amarillos/lisos), 3/16 para cada una de las dos combinaciones de undominante con un recesivo (3/16 amarillos/rugosos y 3/16 verdes/lisos) y 1/16 de do-bles recesivos (verdes/rugosos). Al analizar estos resultados, Mendel se dio cuentade que éste sería precisamente el resultado esperado si consideramos el cruce dihí-brido como dos cruces monohíbridos independientes. En estas circunstancias, cadaplanta de la F1 produciría cuatro posibles tipos de gametos: si denominamos R/r alos alelos liso/rugoso y V/v a los alelos amarillo/verde, las plantas de la F1 (con gui-santes amarillos y lisos) serían heterocigotos para ambos caracteres, con genotipoVvRr. Por tanto, cada una de estas plantas puede transmitir cuatro posibles combi-naciones alélicas: VR, Vr, vR y vr. De este modo, al cruzar dos plantas de la F1 ten-dríamos 16 posibles tipos de cruces:
VR X VR Vr X VR vR X VR vr X VRVR X Vr Vr X Vr vR X Vr vr X VrVR X vR Vr X vR vR X vR vr X vRVR X vr Vr X vr vR X vr vr X vr
Podemos calcular fácilmente los genotipos resultantes de cada cruce usando cua-drados de Punnett o con el método ramificado genotípico (VR X VR tendrá descen-dencia con genotipo VVRR, etc.). Como algunos cruces son idénticos (por ejemplo, losdos que están en negrita), podemos agrupar los genotipos resultantes y obtenemos nue-ve posibles genotipos distintos en la descendencia, en las siguientes proporciones: 1/16VVRR, 2/16 VVRr, 2/16 VvRR, 4/16 VvRr, 1/16 VVrr, 2/16 Vvrr, 1/16 vvRR, 2/16 vvRr y 1/16 vvrr.Debido a la dominancia del liso y del amarillo, estos nueve genotipos dan lugar sola-mente a cuatro fenotipos en las siguientes proporciones: 9/16 amarillos/lisos, 3/16 ama-rillos/rugosos, 3/16 verdes/lisos y 1/16 verdes/rugosos. Esto lo vemos muy bien usando elmétodo ramificado fenotípico: si la probabilidad de amarillos:verdes en la F2 es de 3:1,observaremos 3/4 amarillos y 1/4 verdes. Ahora bien, si de cada uno de estos hay 3/4 li-sos y 1/4 rugosos, al final las probabilidades de cada fenotipo se pueden calcular:
3/4 lisos = 9/16 amarillos y lisos1/4 amarillos
1/4 rugosos = 3/16 amarillos y rugosos
3/4 lisos = 3/16 verdes y lisos1/4 verdes
1/4 rugosos = 1/16 verdes y rugosos
Pues bien, éstas fueron precisamente las proporciones que Mendel encontró alrealizar estos cruces, la proporción fenotípica 9:3:3:1 de dobles dominantes : domi-nante/recesivo : recesivo/dominante : doble recesivo. Dado que sus resultados seajustaban al modelo teórico, Mendel formuló su cuarto principio —también conoci-do hoy como la Segunda Ley— que establece que las parejas de factores segreganno sólo al azar, sino además de manera independiente para caracteres distintos.
La Figura 7.4 contiene un enlace que ayuda a comprender los cruces dihíbridos.
100
Genética mendeliana
{{
CAPITULO 7 5/12/06 07:12 Página 100
www.FreeLibros.me

Mendel también quiso comprobar este postulado realizando cruzamientos pruebade las plantas de la F2 con el progenitor doble homocigoto recesivo. Por ejemplo, los9/16 de plantas con guisantes amarillos y lisos de la F2 son el resultado de sumar todaslas plantas con cuatro genotipos distintos: VVRR (1/16), VVRr (2/16), VvRR (2/16) y VvRr(4/16). Es decir, de todas las plantas de la F2 con guisantes amarillos y lisos, 1/9 seránVVRR, 2/9 serán VVRr, 2/9 serán VvRR y 4/9 serán VvRr. ¿Cómo saber los genotipos deestas plantas? Al igual que en el monohibridismo, mediante los cruzamientos pruebade cada una de ellas con una variedad pura doble homocigota recesiva (vvrr).
Mendel predijo cómo debería ser la descendencia resultante de cada uno de estoscruces. Por ejemplo, al cruzarse los dobles homocigotos dominantes de la F2 (VVRR)con una planta vvrr darán un 100 por ciento de descendencia de tipo doble hetero-cigoto VvRr y por tanto con fenotipo amarillo y liso. Las plantas con genotipo VVRren la F2 darán, en cambio, dos tipos posible de gametos (VR y Vr), por lo que el cru-ce prueba VVRr X vvrr dará como resultado un 50 por ciento de plantas VvRr y un50 por ciento de plantas Vvrr (o, lo que es lo mismo, 50 por ciento con guisantesamarillos y lisos y 50 por ciento con guisantes amarillos y rugosos). Lo mismo pue-de hacerse para los otros dos cruzamientos prueba, los de plantas VvRR y VvRr y cal-cular las proporciones fenotípicas esperadas en la descendencia. Pues bien, cuandoMendel hizo todos estos cruces de prueba, comprobó que los resultados obtenidoscoincidían con las predicciones de su modelo, por lo que concluyó que este cuartopostulado era también cierto.
Mendel todavía fue más lejos y demostró que estos principios se cumplían tam-bién al cruzar plantas que se comportaban como variedades puras para tres factoresa la vez (cruce trihíbrido). El cruce de una variedad pura triple dominante con otratriple recesiva dará como resultado 100 por ciento de triples heterocigotos en la F1(todos manifiestan los tres fenotipos dominantes). Para calcular la descendencia re-sultante de la autofecundación de éstos, hay que tener en cuenta que cada planta pro-ducirá ocho tipos posibles de gametos. Por ejemplo, para tres genes A, B y C conalelos dominante (mayúscula) o recesivo (minúscula), cada triple heterocigoto(AaBbCc) dará lugar a gametos del tipo ABC, ABc, AbC, Abc, aBC, aBc, abC, o abc.Si hacemos un cuadrado de Punnett para calcular los genotipos resultantes y sus pro-porciones, vemos que el cruce AaBbCc X AaBbCc origina 64 combinaciones dife-rentes. Usando el método ramificado genotípico o fenotípico, vemos que todas estasposibles combinaciones se pueden agrupar en 27 genotipos distintos, que dan lugara ocho fenotipos diferentes en proporciones 27:9:9:9:3:3:3:1. Una vez más, lo queMendel encontró se correspondía exactamente con lo que debería suceder de acuer-do con sus postulados.
La Figura 7.5 muestra el diagrama ramificado genotípico de un cruzamiento trihíbrido.
Lógicamente, es fácil darse cuenta de que la interpretación de los resultados au-menta notablemente al estudiar varios caracteres a la vez, ya que las posibles combi-naciones de genotipos (y, por tanto, de fenotipos) son mayores. En cualquier caso,hay una regla sencilla para calcular el número de posibles gametos, genotipos y fe-notipos que se pueden generar al estudiar cualquier número de genes simultánea-mente. Si n es el número de caracteres distintos que estudiamos, cada uno de ellos
101
Segunda Ley de Mendel: dihíbridos y trihíbridos
CAPITULO 7 5/12/06 07:12 Página 101
www.FreeLibros.me

controlado por un gen con dos alelos, el número de gametos posible será 2n, el nú-mero de posibles genotipos es 3n, y el número de posibles fenotipos es también 2n.Así, para tres genes tendríamos ocho gametos posibles que originan 64 combinacio-nes agrupadas en 27 genotipos y ocho fenotipos distintos.
7.4 Redescubrimiento del trabajo de Mendel
Como hemos visto, Mendel comenzó sus experimentos en 1856, leyó los resultadosen la reunión de la Sociedad de Historia Natural de Brno en 1865, y el trabajo fuepublicado el año siguiente. En el período que transcurre entre 1866 y el 1900, la fi-gura más influyente fue sin duda August Weismann, un discípulo de Darwin. En pri-mer lugar, Weismann creía que la pangénesis no era correcta, y diseñó experimentospara probarlo. Por ejemplo, cortó la cola de ratones durante 22 generaciones sucesi-vas, comprobando que el tamaño de la cola no disminuía al nacer. Además, tenien-do en cuenta los avances científicos de esos años, Weismann reconoció la existenciade células germinales, la importancia del núcleo y la existencia de cromosomas. Sugran contribución fue la elaboración de la teoría del germoplasma como material he-reditario. Frente a la creencia en las gémulas de origen somático, Weismann propu-so que la herencia se transmite únicamente a través de las células germinales y quelas unidades hereditarias residen en los cromosomas. Lógicamente, esas ideas eranbastante teóricas y no tenían comprobación experimental, pero prepararon el cami-no para que a principios del siglo XX pudiesen comprenderse los trabajos de Mendel.
Se sabe que del artículo original de Mendel se imprimieron 40 copias, aunque sólohay constancia de tres que fueron enviadas a sus maestros y colegas. De todas formas,la Sociedad de Historia Natural de Brno enviaba sus Actas a unas 130 bibliotecas detoda Europa y América, por lo que sus hallazgos tuvieron una difusión adecuada. Sinembargo, llama la atención que durante años nunca fuesen citados, probablementeporque no fueron comprendidos del todo. La clave para que se prestase atención altrabajo original de Mendel fue una referencia de Focke en 1881, que en una revisiónde la literatura sobre hibridaciones en plantas cita el artículo de Mendel (bajo el epí-grafe «Pisum») y dice que «Mendel creyó haber encontrado relaciones numéricasconstantes». Esta frase llamó la atención de Karl Correns, que había llegado inde-pendientemente a las conclusiones «mendelianas» en 1899 haciendo hibridacionesen varias especies. Al leer la alusión de Focke a las «relaciones numéricas constan-tes», Correns citó el trabajo original de Mendel y fue probablemente el primero encomprender su verdadero alcance. Al mismo tiempo, en el año 1900, Hugo de Vriespublicó tres artículos en los que también llegaba a conclusiones parecidas, encon-trando la relación 3:1 en varias especies distintas. En uno de esos trabajos se cita tam-bién el artículo de Mendel (aunque no se citaba en la versión original francesa, se citaen la versión posterior en alemán: parece que de Vries no había tenido noticia del tra-bajo de Mendel, pero incluyó la referencia al saber que Correns lo citaba en su artí-culo). Tshermak también publicó dos artículos en 1900 llegando a conclusiones men-delianas, pero con resultados más limitados que los dos anteriores.
William Bateson era un zoólogo de Cambridge que ya en 1894 era consciente dela importancia de estudiar la variación discontinua con una aproximación más ma-
102
Genética mendeliana
CAPITULO 7 5/12/06 07:12 Página 102
www.FreeLibros.me

temática. En mayo de 1900 dio una conferencia en la Royal Horticultural Societyen Londres, describiendo los resultados de Mendel y su confirmación por De Vries,y se convirtió en el defensor más entusiasta del mendelismo. Junto a Reginald Pun-nett fue desarrollando los principios de la herencia según las leyes mendelianas. Pocoa poco los principios de Mendel se fueron confirmando en otras plantas y en anima-les, y así se fue introduciendo y fijando la nomenclatura que utilizamos hoy en día.Por ejemplo, Bateson acuñó el término «genética» (del griego genetikos) al usarlopor vez primera en una carta del 18 de abril de 1905, dirigida a Adam Sedgewick.También inventó los términos homocigoto, heterocigoto o alelomorfo (hoy reempla-zado por alelo). Johannsen, otro botánico del que hablaremos más adelante, intro-dujo en 1909 los términos gen, genotipo y fenotipo.
7.5 ¿Dónde están los «factores unitarios»? La teoría 7.5 cromosómica de la herencia
La aceptación de las leyes de Mendel a principios del siglo XX supuso que se inicia-ra la búsqueda de las bases celulares de la herencia, es decir, dónde residen los «fac-tores» que controlan los caracteres hereditarios, cuál es la naturaleza de los distintosalelos, en qué estructuras se transmiten de una generación a la siguiente, etc. Haciael año 1900, los conocimientos de Citología en plantas y animales permitían aventu-rar alguna hipótesis al respecto. Por ejemplo, se sabía que el núcleo de las célulascontiene una sustancia (cromatina) que se condensa en forma de cromosomas. Seaceptaba que cada especie tiene un número fijo de cromosomas, definido por el nú-mero de cromosomas presente en los gametos, y que en especies de reproducción se-xual los gametos tienen una copia de cada cromosoma, mientras que las células so-máticas tienen dos copias. También se había observado (al menos en plantas) que lareducción en el número de cromosomas se produce en las últimas fases de la forma-ción de los gametos.
En esos primeros años del siglo, por tanto, era generalmente aceptado que el ma-terial hereditario residía en los cromosomas, aunque la naturaleza amorfa y «está-tica» de la cromatina no permitía explicar cómo podría ser esto. De hecho, algunascuestiones citológicas que entonces se creían ciertas distaban mucho de la realidad.Por ejemplo, existía la creencia general de que los cromosomas formaban un largo fi-lamento continuo (el «espirema») que se dividía transversalmente al final de la in-terfase, de modo que todos los cromosomas eran esencialmente iguales unos a otrosexcepto por su tamaño. Aunque también se había observado la meiosis, se pensabaque en la división reductora los cromosomas se dividían transversalmente, estandounidos por los extremos. En general, la mecánica de estos procesos no estaba clara yesta falta de detalle no permitía establecer las bases citológicas de los principios men-delianos de transmisión de la herencia. Aunque ya Correns y Cannon habían pro-puesto en los primeros años del siglo XX la hipótesis de que los genes (los «factores»de Mendel) residen en los cromosomas, sus modelos eran poco claros.
El citólogo que dio mayor impulso a este campo fue sin duda Theodor Bovery,que en 1902 llegó a la conclusión de que los cromosomas no son equivalentes, sinoque son distintos unos de otros y todos son necesarios para dar lugar a un embrión
103
¿Dónde están los «factores unitarios»? La teoría cromosóm
ica de la herencia
CAPITULO 7 5/12/06 07:12 Página 103
www.FreeLibros.me

viable. En sus estudios con embriones monospérmicos y polispérmicos de erizo demar, pudo observar formas anormales de desarrollo embrionario cuando el númerode cromosomas no era el adecuado. Además, esto le llevó a formular la teoría cro-mosómica del cáncer, que tanta influencia tendría en años posteriores.
Pero la mayor evidencia experimental de que los procesos citológicos permitíanexplicar las leyes de Mendel la produjo Walter Sutton en 1902. Sutton era un estu-diante de Medicina que dedicó sus primeros años a estudiar cromosomas de célulassomáticas de saltamontes, demostrando irrefutablemente por primera vez que loscromosomas se presentan en pares homólogos en las células somáticas y que losgametos tienen una sola copia, procedente de uno de los progenitores. En un tra-bajo de 1903 (The chromosomes in heredity) elabora más esta teoría mostrando quedistintos pares cromosómicos se orientan al azar en el huso meiótico, y así sugirióque la división reduccional no era transversal sino longitudinal. Todos estos pro-cesos permitían explicar perfectamente lo que Mendel había propuesto: la segrega-ción al azar de factores que están en parejas, de las que sólo una copia pasa a la des-cendencia. De hecho, Sutton escribió en uno de sus trabajos: I may finally callattention to the probability that the association of paternal and maternal chromoso-mes in pairs and their subsequent separation during the reducing division… mayconstitute the physical basis of the Mendelian law of heredity. A pesar de la clarivi-dencia de sus afirmaciones y de su evidente interés por la ciencia, Sutton no terminósu doctorado, sino que se hizo médico y se dedicó a la cirugía. En cualquier caso, sucontribución permitió explicar la base física de la herencia y el comportamiento delos «factores» mendelianos, dando lugar a la teoría cromosómica de la herencia.
De todas formas, no todos aceptaban fácilmente que los factores mendelianos«viajasen» en los cromosomas. La demostración formal no llegaría hasta años mástarde gracias al trabajo de Morgan, Sturtevant, Muller y Bridges en la mosca Dro-sophila melanogaster. Durante años, estos genetistas fueron estableciendo la posi-ción de los genes responsables de distintos caracteres en los cromosomas de la mos-ca. Vieron que algunos caracteres se comportaban como si «viajasen» juntos, porqueno segregaban al azar, y llamaron a este fenómeno «ligamiento». Establecieron asívarios grupos de ligamiento y demostraron que coincidían con los tres pares de au-tosomas que tiene la Drosophila, es decir, que los genes se localizan en los cromoso-mas y se agrupan de modo lineal. En 1916 publicaron The Mechanism of MendelianHeredity, que se conviertió en el primer tratado detallado de las leyes mendelianas,sus excepciones y sus bases citológicas.
Aun así, la aceptación no fue unánime, y mendelistas tan brillantes como Batesonmostraban sus reservas. Por ejemplo, en una revisión sobre The Mechanism of Men-delian Heredity que hace el propio Bateson en 1916, dice: … it is inconceivable thatparticles of chromatin or of any other substance, however complex, can possess tho-se powers which must be assigned to our factors… The supposition that particles ofchromatin, indistinguisable from each other and indeed almost homogeneous underany known test, can by their material nature confer all the properties of life surpas-ses the range of even the most convinced materialism. Evidentemente, en aquellosaños no se conocía la naturaleza química de la cromatina y era impensable que pu-diese estar compuesta por una molécula como el ADN, tan simple en su estructurapero tan rica en su capacidad codificante y en sus funciones.
104
Genética mendeliana
CAPITULO 7 5/12/06 07:12 Página 104
www.FreeLibros.me

En cualquier caso, hacia 1920 la citología y la genética se habían encontrado de-finitivamente. El mendelismo podía ya explicarse sobre la base de la teoría cromo-sómica, es decir: i) los dos alelos de cada gen se localizan en la misma posición (lo-cus) en cromosomas homólogos, y segregan al azar a los gametos gracias a laseparación de los cromosomas durante la meiosis; ii) genes distintos segregan de ma-nera independiente (4º postulado de Mendel) porque se localizan en cromosomasdistintos. Además, estos conceptos se fueron ampliando progresivamente con las no-ciones de recombinación e intercambio de material genético entre cromosomas ho-mólogos, ligamiento, etc.
105
¿Dónde están los «factores unitarios»? La teoría cromosóm
ica de la herencia
CAPITULO 7 5/12/06 07:12 Página 105
www.FreeLibros.me

CAPITULO 7 5/12/06 07:12 Página 105
www.FreeLibros.me

C A P Í T U L O 8
Herencia relacionadacon el sexo
Contenidos
8.1 Cada sexo tiene distinta constitución cromosómica
8.2 Los genes situados en el cromosoma X muestran un modo especial de herencia
8.3 Determinación genética del sexo en humanos
8.4 Compensación de dosis: hipótesis de Lyon
8.5 Estructura de los cromosomas sexuales humanos
8.1 Cada sexo tiene distinta constitución cromosómica
En 1891, Hermann Henking describió un corpúsculo en el núcleo de las células de in-sectos machos de la especie Pyrrhocoris (un tipo de chinche). Dicho corpúsculo se for-maba durante la meiosis, y Henking lo denominó «cuerpo X» por su naturaleza desco-nocida. Cuando se observó la meiosis con detenimiento, se comprobó que 22 de los 23cromosomas de esta especie se emparejaban durante la meiosis para formar 11 parejas,pero otro cromosoma quedaba condensado y daba lugar al «cuerpo X» en uno de lospolos en algunas células. Al reconocerse que se trataba de un cromosoma, dicho cor-púsculo pasó a llamarse cromosoma X.
A principios del siglo XX, en 1905, Edmund B. Wilson y una de sus estudiantes de doc-torado, Nettie M. Stevens, comprobaron que el número de cromosomas X difiere entremachos y hembras. Estudiando insectos del género Protenor (saltamontes) y el Lygaeusturicus, observaron que cada sexo tiene configuraciones cromosómicas distintas, y llega-ron a la conclusión de que el sexo está determinado por el número de cromosomas X pre-sentes en las células. En Protenor comprobaron que las hembras tienen dos ejemplares deeste cromosoma (XX) y en cambio los machos sólo tienen uno (XO). A este tipo de de-
CAPITULO 8 5/12/06 07:14 Página 107
www.FreeLibros.me

terminación cromosómica del sexo le llamaron modo XX/XO. En Lygaeus, en cam-bio, vieron que la situación era ligeramente distinta, ya que las hembras son XX y losmachos tienen —además de un cromosoma X— otro cromosoma más pequeño llama-do cromosoma Y. A este tipo de configuración le llamaron modo XX/XY.
Estas observaciones pusieron de manifiesto el hecho fundamental de que uno delos sexos produce dos clases distintas de gametos: con o sin cromosoma X en elcaso del modo Protenor; con cromosoma X o con cromosoma Y, en el modoLygaeus. Al sexo que produce gametos distintos se le llama, por tanto, sexo hetero-gamético. Aunque lo más habitual es que el sexo heterogamético sea el masculino,como en la especie humana, esto no siempre es así. Por ejemplo, en muchas espe-cies de aves el sexo heterogamético es el femenino, y siguen un modo distinto de de-terminación cromosómica del sexo, que se llama ZZ/ZW. En humanos se sigue elmodo XX/XY, mientras que en la mosca Drosophila melanogaster, a pesar de quetiene un cromosoma Y, se sigue el modo XX/XO.
8.2 Los genes situados en el cromosoma X muestran un modo8.2 especial de herencia
Como hemos visto, en el laboratorio de Tomas H. Morgan, conocido como la «FlyRoom» («Habitación de las Moscas»), se establecieron los principios del mendelis-mo estudiando diversos caracteres y mutaciones en Drosophila. Morgan observó en1910 que en el caso de la mutación white del ojo de Drosophila a veces no se cum-plían las proporciones mendelianas esperadas. Observó que el patrón de herenciade esta mutación dependía del sexo del progenitor que transmitía la mutación.Así, el cruce entre un mutante white macho y una hembra silvestre daba una F1 con100 por cien de ojos silvestres (rojo ladrillo) y una F2 con la proporción 3:1(rojo:blanco), que sería la proporción esperada si el alelo silvestre (rojo) es domi-nante sobre el mutante white. En cambio, el cruce recíproco, en el que la mutaciónwhite estaba en el progenitor hembra, daba una F1 con una proporción 1:1 en laque todos los machos tenían ojos blancos. Además, esta misma proporción se re-petía en la F2, teniendo el 50 por ciento de los machos ojos blancos.
Basándose en la teoría cromosómica de la herencia de Sutton y Boveri y, sobretodo, en la hipótesis propuesta por Stevens y Wilson pocos años antes, Morgan con-cluyó que el gen de esta mutación (el locus white) estaba localizado en el cro-mosoma X de Drosophila. Si esto era cierto, las hembras llevarían dos copias delgen y sólo manifiestarían el fenotipo cuando ambos alelos están mutados (es decir,la mutación sería recesiva y sólo se manifestaría en homocigosis). Los machos, encambio, sólo llevan un cromosoma X; esta situación se describe como hemicigosis(un solo alelo, en vez de los dos que suele ser habitual en genes autosómicos), y poreso se dice que los machos son hemicigotos para todos los genes del cromosoma X.En estas circunstancias, los machos siempre manifestarán el fenotipo aunque sea re-cesivo, ya que el único alelo que tienen es el alelo mutante.
108
Herencia relacionada con el sexo
CAPITULO 8 5/12/06 07:14 Página 108
www.FreeLibros.me

La Figura 8.1 ilustra los cruces entre moscas con ojos de color silvestre (rojo ladrillo) y moscas conla mutación white (ojos blancos). También se muestra un ejemplo de herencia ligada al cromosomaX en humanos.
Este hallazgo constituyó el primer ejemplo de ligamiento de un carácter a un cro-mosoma concreto, y además fue decisivo para respaldar la teoría cromosómica de laherencia. Todos los caracteres controlados por genes situados en el cromosoma Xsiguen este tipo de herencia, que pasó a llamarse «ligada al sexo». Sin embargo, unnombre más adecuado es el de «ligada al cromosoma X», ya que hay caracterescuya herencia está influida por el sexo sin estar controlados por genes situados enninguno de los cromosomas sexuales. Por ejemplo, existen rasgos controlados porgenes autosómicos que sólo se expresan en un sexo por razones hormonales. Dichoscaracteres, influidos o limitados por el sexo, pueden confundirse a veces con ca-racteres ligados al cromosoma X. Aunque la herencia ligada al X puede ser de tiporecesivo o dominante, lo más frecuente es la de tipo recesivo, que se caracteriza por-que sólo los individuos hemicigotos (XY) manifiestan el fenotipo recesivo, ya quelas hembras (XX) son habitualmente heterocigotos. Como veremos más adelante, laherencia ligada al X recesiva es muy importante en Genética Humana, y tiene unascaracterísticas que permiten reconocerla y proporcionar un consejo genético muyvalioso.
8.3 Determinación genética del sexo en humanos
El hallazgo de que el sexo está determinado por el tipo de cromosomas sexuales quese heredan puso en marcha la búsqueda de los mecanismos por los que estos cro-mosomas influyen en la determinación del sexo. Estos mecanismos se fueron cono-ciendo gracias a los trabajos de Calvin Bridges, un discípulo de Morgan. Bridges de-mostró que el sexo de Drosophila viene determinado por el número total decromosomas X que están presentes, o más exactamente por el cociente entre el nú-mero de cromosomas X y el número de autosomas. Esta especie tiene tres paresde autosomas y un par de cromosomas sexuales, por lo que habitualmente el co-ciente X/autosomas de las moscas hembra es igual a 1 (dos copias del cromosomaX y dos copias de cada autosoma) y el de los machos es igual a 0,5 (un cromosomaX y dos copias de cada autosoma). Sin embargo, Bridges estudió el sexo de moscascon diferentes composiciones cromosómicas y encontró que las moscas XXY sonhembras normales (cociente = 1), mientras que las moscas XO son machos estéri-les (cociente = 0,5). Esto le llevó a concluir que el cromosoma Y en Drosophila notiene genes necesarios para la determinación del sexo masculino, pero sí genes ne-cesarios para la fertilidad de los machos. Esta misma conclusión se confirmaba alestudiar la progenie de moscas con tres cromosomas X y con un número variable deautosomas. Bridges observó que un cociente X/autosomas = 1 produce hembrasnormales y fértiles; un cociente >1 produce metahembras infértiles; uncociente = 0,5 corresponde a machos; un cociente = 0,33 produce metamachosinfértiles. Otros cocientes intermedios producen moscas con genitales ambiguos yestériles, denominados intersex. Por tanto, la conclusión fue que los genes que de-
109
Determinación genética del sexo en hum
anos
CAPITULO 8 5/12/06 07:14 Página 109
www.FreeLibros.me

terminan el sexo en Drosophila están en los autosomas, pero el cromosoma X debetener algún gen necesario para determinar el sexo femenino cuando está en dobledosis génica. Aunque no es el momento de explicar a fondo el proceso genético dedeterminación del sexo en Drosophila, nos sirve para introducir esta cuestión en re-lación con nuestra propia especie.
En mamíferos, la determinación del sexo tiene su origen embriológico en la di-ferenciación de la gónada primitiva, bien hacia la gónada femenina (ovario) o ha-cia la gónada masculina (testículo). En el caso de que se inicie la vía de diferencia-ción testicular, este órgano comienza a producir Sustancia Inhibitoria Mülleriana(en las células de Sertoli) y andrógenos (en las células de Leydig), que determinanel desarrollo de los caracteres sexuales secundarios. Lo fundamental, por tanto, esla diferenciación inicial de la gónada primitiva en los primeros momentos del de-sarrollo embrionario. Desde que se conoció la implicación del cromosoma Y en ladeterminación del sexo por el modo XX/XY, se postuló que el cromosoma Y debíacontener algún factor necesario para la diferenciación de la gónada primitiva haciatestículo, y se denominó TDF (testis-determining factor) a ese hipotético factor cuyaidentidad permaneció oculta durante años. Posteriormente se descubrió ZFY (Zinc-finger on the Y), un gen del cromosoma Y que codifica un factor de transcripcióndel tipo dedo de zinc, y se pensó que podía ser el buscado TDF.
Sin embargo, la búsqueda del gen responsable del desarrollo sexual masculinoconcluyó en 1993, al comprobarse que ratones hembras en los que se había inser-tado en uno de los cromosomas X una copia de un gen llamado Sry (localizado enel cromosoma Y) eran fenotípicamente machos. SRY (Sex-determining Region onthe Y) es el gen iniciador de una cascada en la que también participan otros genesdel cromosoma Y junto con otros genes localizados en autosomas.
Básicamente, el proceso comienza cuando la cresta genital es poblada por cé-lulas del mesonefros y del saco vitelino, que aportan las células somáticas y germi-nales respectivamente. La cresta genital se desarrolla hacia la gónada indiferencia-da por acción de dos factores de transcripción llamados WT1 (Wilms Tumor 1) ySF1 (Steroidogenic Factor 1). A partir de este momento, la diferenciación hacia ova-rio o testículo será fruto de la acción de diversos genes. Si SRY está presente (comosucede en individuos con un cromosoma Y) la acción de éste factor de transcrip-ción y de otro llamado SOX9 hace que la gónada primitiva se desarrolle hacia tes-tículo. Éste, a su vez, producirá factores que inhiben el desarrollo de los conductosde Müller, estabilizan el desarrollo de los conductos de Wolff y promueven el desa-rrollo de los genitales externos masculinos. Otros genes implicados son MIS-R, elreceptor de andrógenos, INSL3 y LGR8. En ausencia de SRY, como ocurre enmujeres con dos cromosomas X, los genes DAX1 y WNT4 promueven la diferen-ciación de la gónada primitiva hacia tejido ovárico; la ausencia del receptor andro-génico y la presencia de WNT4 promueven la regresión de los conductos de Wolffy el desarrollo de las estructuras derivadas de los conductos de Müller. Por tanto,en el desarrollo sexual intervienen gran cantidad de genes que actúan a distintos ni-veles de la vía, y mutaciones en cualquiera de ellos puede dar lugar a alteracionesen el desarrollo sexual y por tanto a varones con cariotipo XX o a mujeres conconstitución cromosómica XY.
110
Herencia relacionada con el sexo
CAPITULO 8 5/12/06 07:14 Página 110
www.FreeLibros.me
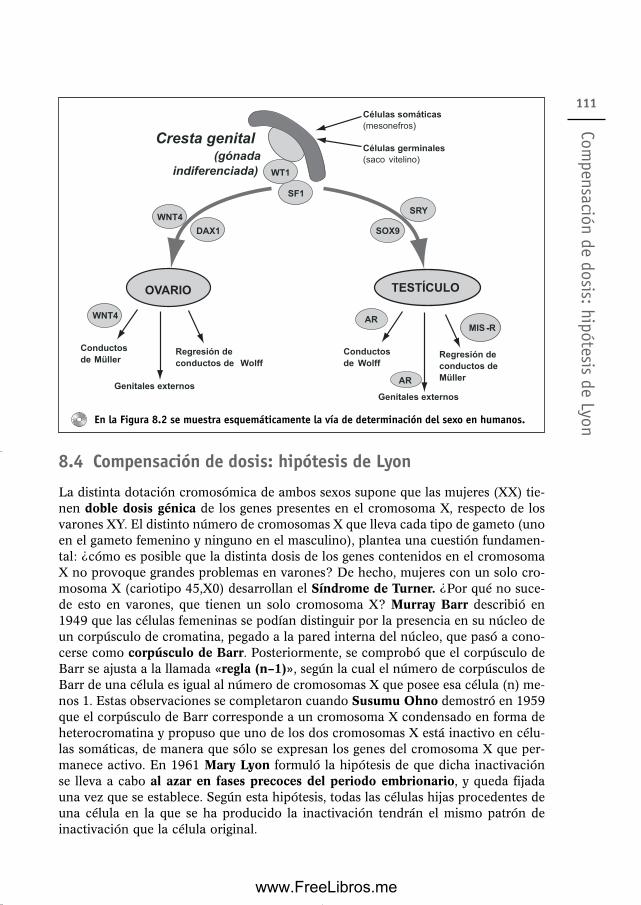
En la Figura 8.2 se muestra esquemáticamente la vía de determinación del sexo en humanos.
8.4 Compensación de dosis: hipótesis de Lyon
La distinta dotación cromosómica de ambos sexos supone que las mujeres (XX) tie-nen doble dosis génica de los genes presentes en el cromosoma X, respecto de losvarones XY. El distinto número de cromosomas X que lleva cada tipo de gameto (unoen el gameto femenino y ninguno en el masculino), plantea una cuestión fundamen-tal: ¿cómo es posible que la distinta dosis de los genes contenidos en el cromosomaX no provoque grandes problemas en varones? De hecho, mujeres con un solo cro-mosoma X (cariotipo 45,X0) desarrollan el Síndrome de Turner. ¿Por qué no suce-de esto en varones, que tienen un solo cromosoma X? Murray Barr describió en1949 que las células femeninas se podían distinguir por la presencia en su núcleo deun corpúsculo de cromatina, pegado a la pared interna del núcleo, que pasó a cono-cerse como corpúsculo de Barr. Posteriormente, se comprobó que el corpúsculo deBarr se ajusta a la llamada «regla (n–1)», según la cual el número de corpúsculos deBarr de una célula es igual al número de cromosomas X que posee esa célula (n) me-nos 1. Estas observaciones se completaron cuando Susumu Ohno demostró en 1959que el corpúsculo de Barr corresponde a un cromosoma X condensado en forma deheterocromatina y propuso que uno de los dos cromosomas X está inactivo en célu-las somáticas, de manera que sólo se expresan los genes del cromosoma X que per-manece activo. En 1961 Mary Lyon formuló la hipótesis de que dicha inactivaciónse lleva a cabo al azar en fases precoces del periodo embrionario, y queda fijadauna vez que se establece. Según esta hipótesis, todas las células hijas procedentes deuna célula en la que se ha producido la inactivación tendrán el mismo patrón deinactivación que la célula original.
111
Compensación de dosis: hipótesis de Lyon
Cresta genital(gónada
indiferenciada) WT1
SF1
OVARIO
DAX1
WNT4
Conductos de Müller
Genitales externos
Regresión de conductos de Wolff
WNT4
TESTÍCULO
SOX9
SRY
Conductos de Wolff
Genitales externos
Regresión de conductos de Müller
AR
AR
MIS -R
Células somáticas(mesonefros)
Células germinales(saco vitelino)
-
CAPITULO 8 5/12/06 07:14 Página 111
www.FreeLibros.me

Esta hipótesis permitía explicar la expresión de algunos rasgos ligados al cromo-soma X, tales como el color del pelaje en los gatos, en el que las gatas (que se cono-cen como gatas calico) muestran a veces manchas o bandas de color negro, naranja yblanco, mientras los gatos macho son de color totalmente negro o totalmente naran-ja. El proceso de inactivación también explicaría el patrón en mosaico de algunas en-fermedades dermatológicas causadas por genes que están en el cromosoma X, comola displasia ectodérmica anhidrótica (fenómeno ya descrito por Darwin en 1875). Elestudio de las isoformas de glucosa-6-fosfato deshidrogenasa en fibroblastos aisla-dos de mujeres permitió confirmar la hipótesis de Lyon, al observarse la presencia deuna sola isoforma en las células de mujeres heterocigotas (que deberían tener dos iso-formas distintas).
Hoy en día, el fenómeno de inactivación temprana y aleatoria de un cromoso-ma X en mujeres es universalmente aceptado, y se conoce también con el nombre de«Lyonización» en honor a Mary Lyon. Mediante este mecanismo, las células somáti-cas femeninas tienen uno de sus cromosomas X en estado inactivado, es decir, trans-cripcionalmente silenciado y altamente compactado en forma de heterocromatina. Lainactivación del X se realiza al azar mediante un mecanismo de recuento que deter-mina el cociente entre el número de cromosomas X y el número de autosomas. Si sedetecta más de un cromosoma X, el proceso continúa con la inactivación, inicial-mente temporal e inestable, de todos los cromosomas X menos uno. Finalmente, elproceso termina con el silenciamiento estable y definitivo de esos cromosomas. Aun-que los mecanismos moleculares que regulan estos procesos no se entienden comple-tamente, se conocen las regiones cromosómicas implicadas y los genes más impor-tantes en el proceso de inactivación, como se describe a continuación.
Los procesos de inactivación se ejecutan gracias un locus multifuncional deno-minado XIC, que está localizado en Xq13 y que contiene los elementos necesariospara el recuento del número de cromosomas X, para la elección del X que será si-lenciado y para el propio mecanismo de silenciamiento. Este locus incluye el genXIST, un gen de 32 kb que se transcribe en un ARN de 19 kb, es procesado y polia-denilado pero no se traduce. XIST es necesario para iniciar el silenciamiento delcromosoma X, pero no para los mecanismos de contaje, elección ni para el posteriormantenimiento del estado silenciado. En XIC también se encuentra el mecanismo decontaje y posiblemente un mecanismo de elección, que dependen del locus XCE.
La Figura 8.3 muestra un ejemplo del fenómeno de inactivación del X. También se incluye unesquema del locus XIC.
112
Herencia relacionada con el sexo
Tsx Brx Cdx4
TsiXXce
XIC
Xist Tsx Brx Cdx4
TsiXXce
XIC
Xist
CAPITULO 8 5/12/06 07:14 Página 112
www.FreeLibros.me

Todos estos procesos comienzan en los estadios iniciales del desarrollo embrio-nario. Así, en la mórula de cuatro-ocho células se detecta expresión de XIST a bajonivel en ambos cromosomas X, tanto en el de origen paterno (Xp) como en el deorigen materno (Xm). A partir de ese momento, XIST deja de expresarse en uno delos cromosomas X (en el caso de embriones XX), o en el único cromosoma X (en em-briones XY). Por tanto, la expresión inicial de XIST es transitoria y sólo se estabilizaen torno a la fase de blastocisto en uno de los dos cromosomas X (en aquél que que-dará finalmente inactivado). Recientemente se ha descubierto un gen antisentido, de-nominado TSIX, cuyo transcrito se solapa parcialmente con el ARN codificado porXIST. Curiosamente, TSIX sigue un patrón de expresión similar a XIST: inicialmen-te se expresan ambos alelos, pero al comienzo de la inactivación únicamente se ex-presa el alelo del cromosoma X que permanecerá activo. Esto sugiere que la expre-sión de TSIX juega un papel importante en la expresión transitoria de XIST y en laelección del cromosoma que finalmente será inactivado. En este proceso participa elfactor CTCF, que se une a la región de metilación diferencial cercana a TSIX. Dichaunión sólo se produce cuando esa región está des-metilada, y tiene dos posibles efec-tos: o bien impide la acción de un enhancer sobre XIST (porque CTCF es un ele-mento aislador o insulator); o bien estimula la transcripción de TSIX, con el consi-guiente silenciamiento de XIST.
Tras la elección, tiene lugar el proceso de iniciación del silenciamiento, seguidade otros cambios que permiten mantener el estado silenciado. En este proceso, elARN codificado por XIST recubre todo el cromosoma y desencadena los cambiosque caracterizarán al cromosoma X inactivo: metilación de las islas CpG, desacetila-ción de las histonas, replicación tardía en la fase S, presencia de una histona espe-cial (macroH2A) en vez de H2A. Recientemente también se ha visto que la lisina 27de la histona H3 está metilada en el cromosoma X inactivo. En cambio, el ARN co-dificado por XIST no llega a estabilizarse en el X que permanecerá activo, y final-mente el propio gen XIST se silencia y deja de expresarse. Lógicamente, en un em-brión XY sólo hay expresión baja y transitoria de XIST en el cromosoma X de origenmaterno, que nunca se inactiva porque el mecanismo de contaje detecta la presenciade un solo cromosoma X.
El vídeo de la Figura 8.4 sirve para ilustrar el proceso de inactivación del cromosoma X.
Mary Lyon también ha propuesto que la propagación del estado inactivado a par-tir del XIC se ve facilitada por la presencia de elementos distribuidos a lo largo detodo el cromosoma X y que actuarían como «estaciones repetidoras» del proceso deinactivación. Unos elementos que podrían cumplir esta función son los LINE, queson especialmente abundantes en el cromosoma X respecto a los autosomas (formanun 30 por ciento de la secuencia de este cromosoma). Además, al estudiar pacientescon translocaciones entre el cromosoma X y un autosoma, se ha comprobado que lainactivación del X se propaga a los autosomas pero sólo parcialmente, y que esta pro-pagación es directamente proporcional a la riqueza en LINEs de cada autosoma. Lasecuenciación del cromosoma X apoya esta hipótesis, ya que se ha comprobado quelos LINE se distribuyen a lo largo del X de manera coherente con la inactivación:son especialmente abundantes en las zonas que flanquean el XIC y disminuyen en
113
Compensación de dosis: hipótesis de Lyon
CAPITULO 8 5/12/06 07:14 Página 113
www.FreeLibros.me

abundancia en las regiones más distales del brazo corto, precisamente la región don-de la inactivación es más débil.
Es muy importante tener claro que la inactivación del cromosoma X no es com-pleta, es decir, no afecta a todos los genes del cromosoma. De hecho, se estima quesólo un 65 por ciento de los genes presentes en el cromosoma X se inactivan; un20 por ciento de los genes se inactivan sólo parcialmente (es decir, no están inacti-vados en todas las células) y un 15 por ciento escapan totalmente al proceso deinactivación. Esto quiere decir que, para esos genes, existen dos copias funcionalesen mujeres XX pero sólo existe una copia en varones XY. Para evitar las diferenciasde dosis génica en estos casos, algunos de estos genes que escapan a la inactivacióntienen un gen homólogo funcional en el cromosoma Y, lo que hace que ambos sexostengan la misma dosis génica funcional. Se piensa que el fenotipo de mujeres X0 conSíndrome de Turner se debe precisamente a la disminución de dosis de todos o al-gunos de los genes que escapan la inactivación, ya que estas pacientes sólo tienenuna dosis funcional de estos genes (cuando deberían tener dos).
8.5 Estructura de los cromosomas sexuales humanos
Lo que ahora conocemos como cromosomas X e Y, formaban una pareja de autoso-mas hace aproximadamente 300 millones de años. Los datos más recientes apoyan la«ley de Ohno» (formulada por Susumu Ohno en 1967), que dice que el primer pasoen el proceso de creación del dimorfismo de los cromosomas sexuales fue la fijacióndel gen responsable del desarrollo del sexo masculino en uno de los cromosomas (elque se convertiría en el futuro cromosoma Y) y su pérdida en el otro cromosoma delpar (el futuro X). Después, la limitación progresiva de recombinación entre ellos con-dujo a una evolución separada de ambos cromosomas: el Y perdió material rápida-mente por la falta de recombinación, sufrió varias duplicaciones y se quedó con pocos genes, de los cuales un gran porcentaje tienen homólogos en el X. El cromoso-ma X, en cambio, se conservó mejor gracias a la existencia de recombinación entre lasdos copias presentes en mujeres, y fue evolucionando progresivamente desde metate-rios (mamíferos sin placenta, como los marsupiales) a euterios (mamíferos con pla-centa). Al final, en el cromosoma X actual conserva una región del autosoma ances-tral de prototerios (mamíferos que ponen huevos), además de otra región «añadida»después de la separación de los metaterios. Actualmente, ambos cromosomas sexua-les sólo se recombinan entre ellos en las dos pequeñas regiones pseudoautosómicasque están en los extremos de cada brazo. La reciente secuenciación completa del cro-mosoma X en el año 2005 ha aclarado la estructura de los cromosomas X e Y:
En el cromosoma X se pueden distinguir:
• Dos regiones pseudoautosómicas PAR1 y PAR2, por las que se recombinan loscromosomas X e Y (al menos una recombinación en PAR1 es necesaria en lameiosis masculina). PAR1 (en Xp e Yp) tiene un tamaño de 2,7 Mb, mientrasque PAR2 (en el extremo del brazo largo de ambos cromosomas) mide 330 kb.
• Una gran región conservada (XCR, X-conserved region) que ocupa la mayorparte del brazo largo del cromosoma X. Esta es la secuencia más antigua y re-presenta los restos del autosoma original de prototerios del que se originaron
114
Herencia relacionada con el sexo
CAPITULO 8 5/12/06 07:14 Página 114
www.FreeLibros.me

los cromosomas X e Y actuales. Una pequeña porción de esta región se en-cuentra transpuesta al cromosoma Y (XTR, X-transposed region), calculán-dose que dicha transposición tuvo lugar hace 5 millones de años, después dela separación de humanos y chimpancés.
• Una región «añadida» (XAR, X-added region) más joven que XCR, al parecerincorporada al cromosoma X a partir de otro autosoma hace unos 100 millo-nes de años en mamíferos placentarios (euterios). Esta región representa lamayor parte del brazo corto del cromosoma X actual. Algunos fragmentos dela porción más distal de este brazo, cercanos a la PAR1, están también pre-sentes en el cromosoma Y, distinguiéndose hasta 12 bloques de homología en-tre ambos cromosomas.
De los aproximadamente 1 000 genes que hay en el cromosoma X, 54 tienen un ho-mólogo funcional en el Y: 24 de ellos están en PAR1, cinco en PAR2 y 25 en las re-giones no-recombinantes de ambos cromosomas. De éstos 25, 15 están en la XAR ytres en XTR; los siete genes restantes se localizan en la XCR y por eso se piensa quedescienden del autosoma ancestral.
La Figura 8.5 muestra la estructura de los cromosomas X e Y humanos.
El cromosoma Y es el más peculiar de todos los cromosomas humanos, ya quesólo 23 megabases (de un total estimado de 50 Mb) están formadas por eucromatina.Por ello, este cromosoma es también el más pobre en genes. La peculiar estructura delcromosoma Y actual se debe a su comportamiento durante la meiosis: lógicamente,no puede quedar sin emparejar durante la meiosis, y de hecho se empareja con el cro-
115
Estructura de los cromosom
as sexuales humanos
XTR
XTR
PAR2
PAR1
XTR
PAR1
PAR2
PAR1
XA
RX
CR
Gen
es q
ue
esca
pan
a la
inac
tiva
ció
n
XTRXTR
CAPITULO 8 5/12/06 07:14 Página 115
www.FreeLibros.me

mosoma X a través de las dos regiones pseudoatosómicas que contiene en los extre-mos del brazo corto y del brazo largo, respectivamente. El resto del cromosoma Y nose recombina nunca, y por esto ha ido acumulando mutaciones y degenerando con eltiempo. La región eucromática del Y comprende unas 22 Mb (el resto del cromoso-ma es heterocromatina) y está constituida por tres tipos de secuencias: i) un bloquede 3,4 Mb fruto de una transposición procedente del X (XTR, región transpuesta des-de el X); ii) un total de 8,6 Mb de secuencias derivadas del cromosoma X, que repre-sentan las regiones derivadas del cromosoma ancestral; y iii) un total de 10,2 Mb deregiones palindrómicas, distribuidas en siete bloques.
En total, en el cromosoma Y sólo se han encontrado 158 unidades transcripcio-nales, entre las que destacan 27 genes que tienen homólogos claros en el cromoso-ma X. De éstos, 13 están degenerados y se han convertido en pseudogenes; los 14 res-tantes son auténticos genes que se expresan en varios tejidos, con la excepción de SRY(que sólo se expresa en células germinales masculinas). Todos estos genes se localizanfundamentalmente en las regiones derivadas del X. Por el contrario, en las regionespalindrómicas hay unos 60 genes, agrupados en nueve familias, que sólo se expresanen el tejido testicular y que no tienen un homólogo claro en el cromosoma X: estosgenes parecen codificar proteínas necesarias para la fertilidad masculina. Por lo querespecta al papel de las regiones palindrómicas, parecen tener una importancia claveen el mantenimiento de la secuencia y estructura del cromosoma Y: la recombinaciónentre los brazos de cada palíndromo y la conversión de secuencias entre ellos evita larápida degeneración que tendría lugar por la ausencia de recombinación entre los cro-mosomas X e Y en esta región.
116
Herencia relacionada con el sexo
CAPITULO 8 5/12/06 07:14 Página 116
www.FreeLibros.me

C A P Í T U L O 9
Modificaciones de las proporciones mendelianas
Contenidos
9.1 Modo de estimar si se cumplen las proporciones mendelianas esperadas
9.2 Modificaciones de las proporciones mendelianas al estudiar un carácter
9.3 Modificaciones del dihibridismo. Interacción génica y epistasia
Ya desde el inicio de los experimentos con plantas, diversos naturalistas habían encon-trado proporciones fenotípicas en la F2 de monohíbridos o dihíbridos que no se corres-pondían con lo que cabría esperar según las leyes mendelianas (3:1 y 9:3:3:1, respectiva-mente). Como acabamos de ver, la búsqueda de las causas de estas desviaciones permitiódescubrir la herencia ligada al sexo en los caracteres controlados por genes situados enel cromosoma X. Además, se descubrieron fenómenos como el multialelismo o la inter-acción génica en aquellos caracteres que están controlados por más de un gen. Aunquetodas estas situaciones dan lugar a proporciones fenotípicas distintas a las esperadas porlas leyes de Mendel, el análisis detallado de lo que sucede viene a confirmar que, efecti-vamente, los postulados mendelianos también explican estas situaciones.
9.1 Modo de estimar si se cumplen las proporciones 9.1 mendelianas esperadasAntes de pasar al estudio de estas cuestiones, es imprescindible estudiar la metodologíaempleada para poder afirmar con fiabilidad si unas proporciones fenotípicas dadas seapartan significativamente de lo esperado según las leyes mendelianas. Lógicamente, los
CAPITULO 9 5/12/06 07:16 Página 117
www.FreeLibros.me

porcentajes esperados nunca se cumplen perfectamente porque el tamaño de lasmuestras no es lo suficientemente grande. Por ejemplo, en un cruce moníbrido típi-co en el que analizamos 100 plantas en la F2, esperaríamos encontrar 75 con el fe-notipo dominante y 25 con el fenotipo recesivo. Sin embargo, lo más probable es quenunca encontremos exactamente estos números, sino 74 y 26, o 77 y 23, por ejemplo.En el caso de especies con generaciones menos numerosas, como sucede en las fa-milias humanas, las desviaciones pueden ser todavía mayores debido al pequeño nú-mero de individuos que se estudia. Por tanto, es imprescindible contar con un méto-do cuantitativo que nos permita concluir con certeza estadística si los porcentajesencontrados se ajustan a lo esperado.
El método utilizado es el cálculo del Chi cuadrado, un estadístico que se ajustaa una distribución concreta y que permite calcular la bondad del ajuste de unas pro-porciones a un modelo teórico. El método calcula la probabilidad de que la dife-rencia observada entre las proporciones experimentales y las proporciones teóricassea atribuible al azar. La hipótesis nula es que las proporciones teóricas se cum-plen y la diferencia es explicable por el azar, sobre todo cuando el tamaño de lamuestra es pequeño. Si el estadístico χ2 (chi cuadrado) supera un cierto valor, sepuede rechazar la hipótesis nula con una fiabilidad específica (5 por ciento, 1 porciento, 0,1 por ciento) y por tanto se puede afirmar que las proporciones fenotípi-cas experimentales se alejan significativamente de las esperadas según el modeloteórico.
Es fácil comprender la mecánica de este razonamiento con un ejemplo. En uncruce monohíbrido típico analizamos 1 000 individuos de la F2 y encontramos 760con el fenotipo dominante y 240 con el fenotipo recesivo. Esto se aparta de los750:250 que esperaríamos encontrar si este carácter se heredase de forma mendelia-na, pero tenemos que comprobar si esta desviación es atribuible al azar (de modo quesi hubiésemos analizado 10 000 individuos las proporciones hubiesen sido más cer-canas al 3:1 teórico), o si efectivamente este carácter no sigue las leyes de Mendel. Elprimer paso es el cálculo del estadístico χ2 con arreglo a la fórmulaχ2 = Σ [ (O – E)2/E], siendo O el número de casos observados y E el número de ca-sos esperados para cada categoría. En nuestro ejemplo, para el fenotipo dominanteesperaríamos encontrar 750 casos, pero hemos encontrado 760. Así, calculamos(760 – 750)2/750 = 0,133. Hacemos lo mismo para el fenotipo recesivo:(240 – 250)2/250 = 0,4. Ahora podemos obtener el sumatorio, de modo queχ2 = 0,133 + 0,4 = 0,533. El último paso es comprobar este valor en una tabla que re-presente los valores máximos del χ2 a los que se puede rechazar la hipótesis nula condistintos niveles de probabilidad y para varios grados de libertad. Si buscamos en unade estas tablas, vemos que —para un grado de libertad— se puede rechazar la hipóte-sis nula, con un error del cinco por ciento, cuando el valor del χ2 es igual o superiora 3,841. Como el valor calculado por nosotros es inferior, no podemos rechazar lahipótesis nula y, por tanto, las proporciones experimentales no se apartan significa-tivamente de lo esperado según un modelo mendeliano de herencia. En cambio, sihubiésemos obtenido 780 dominantes y 220 recesivos, el χ2 resultante sería de 4,8.Como este valor rebasa el valor de la tabla para un grado de libertad y p = 0,05(3,841) pero es inferior al valor de la tabla para p = 0,025 (5,024), podríamos recha-zar la hipótesis nula con un nivel de confianza del 95 por ciento (p < 0,05) y afirmar
118
Modificaciones de las proporciones m
endelianas
CAPITULO 9 5/12/06 07:16 Página 118
www.FreeLibros.me

que las proporciones obtenidas no se ajustan a un modelo mendeliano de herencia.El número de grados de libertad siempre es igual al número total de clases menosuno: como en nuestro caso sólo teníamos dos clases fenotípicas, hemos utilizado ungrado de libertad. En el caso de un cruce dihíbrido, en el que tendremos cuatro cla-ses fenotípicas distintas en la F2, deberíamos calcular el χ2 total y buscar en la tablael valor correspondiente para tres grados de libertad.
La Figura 9.1 muestra el uso del χχ2 para estimar si unas proporciones fenotípicas se ajustan a las esperadas según las leyes mendelianas.
Otra consideración previa a los temas que vamos a tratar en este capítulo hacereferencia a la manera de nombrar los diferentes alelos de cada gen. Es bastante evi-dente que al principio cada genetista utilizaba distintas nomenclaturas, y se tardóun tiempo en alcanzar un consenso sobre la notación de los alelos. Aunque hoy endía se pueden utilizar distintas formas de denominar los alelos, podemos dar unasreglas generales. Como ya vimos al explicar los experimentos de Mendel, lo más ha-bitual es denominar los alelos con la letra inicial del carácter recesivo (por ejem-plo, vimos que los alelos para el color del guisante se llamaban V y v por ser éstala inicial de «verde», que es el carácter recesivo). Así, podemos utilizar una sola le-tra tanto para el alelo dominante (poniéndola en mayúscula) como para el recesi-vo (en minúscula). En otros casos, se estudian mutaciones respecto a un carácternormal, y hay que establecer nombres para los alelos que causan las mutaciones ypara el alelo normal. Un buen ejemplo es el color del ojo de Drosophila, para el quehay un alelo que causa el color normal rojo ladrillo y otros alelos mutantes que danlugar a ojos de distintos colores. En general, a los alelos normales se les denominaalelos «silvestres» o «salvajes», porque son los que se encuentran en la naturaleza.Cada alelo mutante se representa por una o varias letras que describen la mutación(br para «brown», ojos marrones, por ejemplo) y el alelo salvaje se representa en-tonces por esas mismas letras añadiendo el superíndice +. Por ejemplo, una moscaheterocigota para la mutación «brown» tendría un genotipo br+/br. En ocasionesse eliminan las letras del alelo silvestre, dejando únicamente el +. Así, el genotipoanterior también podría representarse como +/br. Dependiendo del estado domi-nante o recesivo del alelo mutante, éste se representa con mayúsculas o minúscu-las, respectivamente.
En los casos en que no hay dominancia o en las series alélicas (en las que hay va-rios alelos para un mismo carácter y las relaciones de dominancia entre ellos soncomplejas) se suelen utilizar superíndices para designar los distintos alelos, como porejemplo en el color del plumaje de patos «Mallard». Para este carácter hay tres ale-los denominados M, MR y md, siendo la dominancia: MR (Restricted) > M (Mallard)> md (Dusky). En el caso concreto de la Genética Humana, las recomendaciones ac-tuales indican que los alelos se designen mediante un número o una letra, precedidopor un asterisco, a continuación del símbolo del gen. Por ejemplo, la variante Cons-tant Spring de la hemoglobina alfa-2 se puede denominar HBA2*0001 (alelo 0001del gen HBA2).
119
Modo de estim
ar si se cumplen las proporciones m
endelianas esperadas
CAPITULO 9 5/12/06 07:16 Página 119
www.FreeLibros.me

9.2 Modificaciones de las proporciones mendelianas 9.2 al estudiar un carácter
Como hemos visto, tras los trabajos de Bateson, Morgan y muchos otros genetistas losprincipios mendelianos se aceptaron como algo de aplicación general. Sin embargo,también desde el principio se reconocieron excepciones que no podían ser explicadaspor estos principios, al menos aparentemente. Por ejemplo, observaciones en plantashabían revelado casos en los que la F1 de un cruce monohíbrido tenía un fenotipointermedio entre el dominante y el recesivo de los progenitores, y ese fenotipo in-termedio estaba presente también en el 50 por ciento de la F2. Este era el caso del co-lor de la flor en algunas especies, en las que al cruzar una variedad pura de flores ro-jas con otra variedad pura de flores blancas se obtenía en la F1 un 100 por ciento deflores rojas (color intermedio entre el rojo y el blanco). En la F2 resultante de la au-tofecundación de flores de la F1 se obtenían 25 por ciento de flores rojas, 50 por cien-to de flores rosas y 25 por ciento de flores blancas. Es fácil darse cuenta de que estasproporciones fenotípicas de la F2 (1:2:1) coinciden con las proporciones genotípicasesperadas, en vez de las proporciones fenotípicas 3:1 que son habituales en este tipode cruces. Estos resultados sugieren que no se está cumpliendo la condición de do-minancia completa de un alelo sobre el otro, de modo que los heterocigotos muestranun fenotipo distinto (un poco menos «fuerte») que los homocigotos dominantes.
La explicación para esta dominancia «débil» está en que el carácter fenotípico obe-dece a efectos de dosis, es decir, el fenotipo depende de la dosis en que aparece el ale-lo dominante. En el ejemplo del color de las flores, podemos imaginar que el alelo re-cesivo da lugar a flores blancas (cuando se trata de plantas homocigotos recesivos)porque no produce ninguna cantidad de pigmento rojo; el alelo que da lugar al colorrojo hace que se produzca una cantidad determinada de pigmento rojo, y por tanto lapresencia de dos alelos rojos (homocigoto dominante) tendrá como resultado floresmás rojas que la presencia de un solo alelo rojo (heterocigoto rojo/blanco), en cuyocaso las flores serán de un color rojo débil o rosa. Este fenómeno se denomina domi-nancia incompleta o semidominancia, y es muy común en caracteres fenotípicos queson el resultado de la acción de algún enzima, ya que la actividad enzimática totaldependerá del número de alelos capaces de producir el enzima correspondiente.
Otra circunstancia que puede modificar las proporciones fenotípicas mendelianaspor relaciones anómalas entre alelos es la co-dominancia, en la que cada uno de losalelos da lugar a un producto funcional que se expresa con independencia del otro.En estas condiciones, el heterocigoto tendrá un fenotipo distinto a cualquiera de losdos homocigotos, que también serán distintos entre sí. Por eso, las proporciones fe-notípicas de la F2 serán también del tipo 1:2:1, como en el caso anterior. Un ejemplotípico de co-dominancia en un carácter codificado por un gen es el grupo sanguíneoMN en la especie humana. El locus que codifica este carácter puede presentarse endos formas alélicas llamadas LM y LN, las cuales codifican unas glicoproteínas de lamembrana de los eritrocitos que dan lugar a los antígenos M y N respectivamente. Losindividuos homocigotos LM/LM tienen fenotipo M, los homocigotos LN/LN tienen fe-notipo N, y los heterocigotos LM/LN tienen fenotipo MN. Por tanto, un cruzamientoentre heterocigotos LM/LN X LM/LN producirá proporciones fenotípicas 1:2:1 (25 porciento MM, 50 por ciento MN, 25 por ciento NN). En el fondo, se trata de la misma
120
Modificaciones de las proporciones m
endelianas
CAPITULO 9 5/12/06 07:16 Página 120
www.FreeLibros.me

situación que veíamos para la dominancia incompleta, con la diferencia de que aquílos dos alelos producen una proteína funcional y por tanto ambos son igualmentedominantes. Poniéndolo en los mismos términos del ejemplo anterior, sería como unaplanta con un alelo que produce un pigmento que genera flores de color rojo y otroalelo que produce un pigmento para el color amarillo: todas las plantas de la F1 seránde color naranja (heterocigotos) y en la F2 se producirán 25 por ciento de flores ro-jas, 50 por ciento naranjas y 25 por ciento amarillas.
Los vídeos de la Figura 9.2 ilustran los conceptos de codominancia y dominancia incompleta.
Aunque en especies diploides cada individuo sólo tiene dos alelos en cada locusautosómico, esto no quiere decir que esos dos alelos sean los dos únicos alelos posi-bles que se pueden encontrar en la naturaleza para ese carácter. De hecho, para mu-chos rasgos fenotípicos es habitual que haya más de dos alelos posibles, sobre todosi se incluyen todos los alelos mutantes que se pueden encontrar. Este fenómeno seconoce como alelismo múltiple y el conjunto de alelos se denomina serie alélica. Lapresencia de alelos múltiples es otro motivo por el que en ocasiones las proporcio-nes mendelianas no se cumplen. El ejemplo más ilustrativo en genética humana es eldel grupo sanguíneo ABO, originado por unos antígenos de la membrana de los eri-trocitos. Estos antígenos están derivados de la sustancia H, que es una glicoproteínade membrana que termina con los residuos N-acetil-Glucosamina—Galactosa—Fuco-sa (–NacGlu—>Gal—>Fucosa). El antígeno 0, codificado por el alelo IO o i, mantie-ne intacta la sustancia H; el antígeno A, codificado por el alelo IA, añade un restoN-acetil-Galactosamina a la Galactosa de la sustancia H, y el antígeno B, codifica-
121
Modificaciones de las proporciones m
endelianas al estudiar un carácter
A A
A a
a a
A AA A
A aA a
a aa a
CAPITULO 9 5/12/06 07:16 Página 121
www.FreeLibros.me

do por el alelo IB, añade una Galactosa a la Galactosa de la sustancia H. Los alelosIA e IB son codominantes entre sí, pero lógicamente ambos son dominantes sobreIO ya que éste no produce ningún antígeno distinto a la sustancia H.
Teniendo en cuenta estas relaciones de dominancia, esta serie alélica puede dar lu-gar a cuatro posibles fenotipos (A, B, AB y O) a partir de una gran variedad de ge-notipos. Por ejemplo, el cruce entre un individuo de fenotipo A y otro de fenotipo Bpuede dar lugar a distintos tipos de descendencia, dependiendo de los genotipos delos progenitores. Si el cruce es del tipo IA IA X IB IB toda la descendencia serán he-terocigotos IA IB con fenotipo (grupo sanguíneo) AB. Sin embargo, si se trata de uncruce IA IO X IB IO (en el que los progenitores también son de grupo sanguíneo A yB respectivamente) la descendencia tendrá proporciones fenotípicas 1/4 A, 1/4 B, 1/4 ABy 1/4 O. Estos porcentajes, a primera vista, pueden confundir y llevar a pensar que estecarácter no se hereda de forma mendeliana. El análisis detallado de cada tipo de cru-zamiento confirma que también se cumplen los postulados de Mendel, aunque la pre-sencia de más de dos alelos distintos, con diferentes relaciones de dominancia entresí, puede confundir la interpretación de las proporciones halladas en la descendencia.
La Figura 9.3 muestra la estructura de los grupos sanguíneos ABO y las consecuencias delalelismo múltiple.
La última situación en la que no se obtienen las proporciones mendelianas espe-radas cuando se estudia un carácter fenotípico es aquella en la que uno de los aleloses letal, es decir, impide el desarrollo embrionario de los individuos que llevan una odos copias de ese alelo. Cuando la letalidad se produce sólo en individuos homocigo-
122
Modificaciones de las proporciones m
endelianas
Fucosa Galactosa
Sustancia H
N -Acetilgalactosamina
Galactosa
Alelo IA
(añade N-acetilgalactosamina)
Alelo IB
(añade galactosa)
Alelo i(no añade nada)
FENOTIPO A
FENOTIPO O
FENOTIPO B
Fucosa Galactosa N - Acetilglucosamina
Sustancia H
N -AcetilgalactosaminaN-Acetilgalactosamina
GalactosaGalactosa
A
B
FENOTIPO A
FENOTIPO O
FENOTIPO B
CAPITULO 9 5/12/06 07:16 Página 122
www.FreeLibros.me

tos para ese alelo, se habla de un alelo letal recesivo, mientras que si basta con la pre-sencia de un solo alelo para causar letalidad se habla de letal dominante.
Un ejemplo típico de alelos letales es el del locus que controla el pelaje amarillode ratones, estudiado por Cuenot en 1904. Al alelo que produce un pelaje normal sele llama agouti (o agutí) en referencia a un roedor de ese nombre que vive en Sud-américa. El pelaje agutí normal se debe a que cada pelo tiene pequeñas bandas trans-versales negras y amarillas, de modo que la apariencia final es de un pelaje castaño.Además del alelo agutí normal (A) y de su correspondiente recesivo a, existe un aleloque origina un pelaje de color completamente amarillo (AY), que es dominante res-pecto al alelo agutí A. Por tanto, los cruces entre un ratón agutí y otro amarillo, o en-tre dos ratones agutí, producen las proporciones mendelianas esperadas en al descen-dencia. Por ejemplo, el cruce AA X AYA (ratón agutí con ratón amarillo) tendrá unadescendencia con 50 por ciento de ratones agutí y 50 por ciento amarillos. En cam-bio, los cruces entre ratones amarillos tienen descendencia con 1/3 de ratones agu-tí y 2/3 de ratones amarillos, lo cual no se corresponde con las proporciones fenotí-picas esperadas. Si el cruce fuese del tipo AYA X AYA, en la descendencia deberíamosencontrar 1/4 AA, 1/4 AYAY y 1/2 AYA, lo cual se debería traducir en 3/4 amarillos y 1/4
agutí (proporción 3:1 típica). La explicación reside precisamente en que el alelo AY
es letal recesivo, y provoca la muerte embrionaria de ratones homocigotos AYAY. Poreso, al descontar el 25 por ciento de ratones AYAY nos quedamos sólo con descen-dencia de genotipos AA o AYA y de ahí las proporciones encontradas. El alelo ama-rillo (AY) es, por tanto, un ejemplo de un alelo letal, recesivo en cuanto a la letali-dad pero dominante en cuanto al carácter fenotípico que controla (el color amarillodel pelaje). En el caso de humanos es más difícil descubrir genes con alelos letales,porque habitualmente no tienen otro efecto fenotípico que permita reconocerlos. Aveces se ven proporciones ligeramente distintas a las esperadas, y en esos casos sesospecha que uno de los alelos es subvital o subletal, es decir, que causa cierta mor-talidad durante el desarrollo embrionario.
Al llegar al final de este apartado, es muy importante recordar que todas las posi-bles desviaciones de las proporciones fenotípicas mendelianas que hemos visto has-ta ahora están causadas por problemas en los alelos de un único gen que controlaun carácter fenotípico, bien por falta de dominancia completa, por la existencia demúltiples alelos o por la presencia de alelos letales. Por eso las hemos agrupado bajoel epígrafe de modificaciones del monohibridismo, porque son situaciones que surjenal analizar un único gen.
9.3 Modificaciones del dihibridismo. Interacción génica 9.3 y epistasia
En ocasiones, cuando se estudian dos caracteres fenotípicos también se obtienen pro-porciones distintas a las esperadas según los principios mendelianos, que predicenuna descendencia con proporciones 9:3:3:1 al cruzar dos individuos heterocigotospara cada uno de los caracteres. Lógicamente, las circunstancias estudiadas en elapartado anterior también afectarán a estas proporciones si uno de los genes queanalizamos está sujeto a codominancia, dominancia incompleta, letalidad, etc. Por
123
Modificaciones del dihibridism
o. Interacción génica y epistasia
CAPITULO 9 5/12/06 07:16 Página 123
www.FreeLibros.me

ejemplo, podemos considerar dos caracteres distintos tales como el grupo sanguíneoABO (cuyo sistema alélico ya ha sido explicado) y el albinismo. Éste último es un ca-rácter mendeliano controlado en ratones por un solo gen, con un alelo silvestre A yun alelo recesivo a que provoca albinismo en homocigotos aa. Si cruzamos ratonesdobles heterocigotos Aa/IAIB, la descendencia no se ajustará a las proporciones tí-picas 9:3:3:1, sino que obtendremos ratones pigmentados con grupo sanguíneo A, Bo AB, y también ratones albinos con cualquiera de los tres grupos sanguíneos. Lasproporciones fenotípicas serán 3:6:3:1:2:1, que en el fondo es una modificación de larelación 9:3:3:1. La razón de este fenómeno es que los alelos que determinan el gru-po sanguíneo son co-dominantes (los alelos IA y IB) y por eso distorsionan las pro-porciones fenotípicas esperadas.
Habitualmente, las anomalías en las proporciones del dihibridismo se detectancuando se estudia un carácter fenotípico que está controlado por dos o más genes,debido a un fenómeno llamado interacción génica. En efecto, aunque cada gen porseparado se comporte de acuerdo a los principios mendelianos y los genotipos seanlos esperados, puede suceder que las proporciones fenotípicas sean aberrantes por-que ambos genes están controlando un mismo carácter y la acción de uno enmasca-ra los genotipos del otro. La interacción génica no significa que ambos genes o susproductos interaccionen directamente, sino que participan en una misma vía o pro-ceso biológico (como puede ser la generación de un pigmento en varios pasos meta-bólicos, por ejemplo). Si cada gen actúa a distintos niveles de esa vía, uno de ellospuede afectar la expresión del otro y dar lugar a proporciones fenotípicas inespera-das en la descendencia.
El principal obstáculo que nos encontramos para interpretar las proporciones esque, si únicamente estamos analizando un carácter fenotípico, es imposible saber apriori si dicho carácter está controlado por un gen o por varios. En efecto, en el casode dos caracteres era fácil porque podíamos agrupar la descendencia en las cuatroposibles categorías fenotípicas que surjen al considerar dos caracteres a la vez, peroaquí estamos observando un carácter solamente. La pista que nos indica el númerode genes implicados es el denominador de las proporciones fenotípicas encontra-das: si éstas se expresan en dieciseisavos, podemos suponer que nos encontramosante un carácter fenotípico controlado por dos genes, si son sesentaycuatroavos setratará de tres genes, etc.
Los efectos de la interacción génica pueden ser básicamente de dos tipos: la apa-rición de fenotipos nuevos (que no estaban presentes en los progenitores) y la mo-dificación de las proporciones típicas del dihibridismo. Por lo que respecta al pri-mero, recordemos que según los principios mendelianos el carácter recesivo de unode los progenitores desaparece en la F1 y reaparece en el 25 por ciento de la F2. Encambio, si un carácter está controlado por dos genes distintos, a veces el resultado esque en la F2 aparecen fenotipos nuevos que no estaban presentes en la F1 ni enlos progenitores. Tal es el caso, por ejemplo, del color del pimiento Capsicum an-nuum, que es un rasgo fenotípico determinado por dos loci: uno de ellos determinala producción o no de pigmento rojo, con un alelo R que produce pigmento rojo y esdominante sobre el alelo r que no produce pigmento. El otro gen controla la degra-dación de la clorofila (de color verde), con un alelo dominante C que degrada la clo-rofila para dar un color amarillento (sin pigmento), y un alelo recesivo c que no de-
124
Modificaciones de las proporciones m
endelianas
CAPITULO 9 5/12/06 07:16 Página 124
www.FreeLibros.me

grada la clorofila y por tanto da el color verde típico. En estas circunstancias, un cru-ce de variedades puras RRCC (de color rojo) X rrcc (de color verde) da lugar al 100por cien de plantas RrCc (de color rojo) en la F1. Hasta aquí todo parecería indicarque el color del pimiento está controlado por un solo gen. En cambio, el cruce RrCcX RrCc produce en la F2 unas proporciones genotípicas con 9/16 R_C_ de color rojo,3/16 R_cc de color marrón (por la presencia simultánea del rojo y el verde), 3/16 rrC_de color amarillento por la ausencia de pigmentos y 1/16 rrcc de color verde. Esto vacontra los principios del monohibridismo mendeliano típico, ya que tenemos cuatrofenotipos distintos. Aunque esto podría sugerir la presencia de alelos múltiples paraun solo locus, las proporciones encontradas para las cuatro clases fenotípicas (ex-presadas en dieciseisavos) sugieren que este carácter está controlado por dos loci.
Otro ejemplo de este fenómeno es el color de los ojos de la Drosophila, en el queel tipo silvestre de color rojo ladrillo está controlado por dos genes: brown (marrón)y scarlet (escarlata). El locus brown tiene un alelo silvestre bw+ dominante sobre elrecesivo marrón (br) y el locus scarlet tiene un alelo silvestre st+ dominante sobre elrecesivo (st) que produce ojos de color rojo escarlata. Las moscas con ojos de colorsilvestre tienen un genotipo bw+bw+/st+st+. Al cruzar una mosca mutante con ojosde color marrón (bwbw/st+st+) con otra de ojos escarlata (bw+bw+/stst), toda la F1es doble heterocigótica (bw+bw/st+st) y por tanto con ojos del color silvestre rojo la-drillo. En la F2 resultante del cruce entre moscas de la F1, se obtiene un nuevo fe-notipo (ojos de color blanco) en 1/16 del total, y proporciones 9:3:3:1 de los fenoti-pos silvestre, marrón, escarlata y blanco respectivamente. Nuevamente, la presenciade 4 clases fenotípicas expresadas en dieciseisavos nos alerta sobre la presencia dedos loci controlando este carácter. De hecho, lo que sucede es que el locus browncontrola la producción de un pigmento de color rojo brillante llamado drosopterina,mientras que el locus scarlet controla la producción de otro pigmento de color ma-rrón llamado xantomatina. En situaciones normales, el color silvestre es el resultadode la mezcla de ambos pigmentos. En cambio, mutaciones en el locus brown hacenque no se produzca drosopterina y el único pigmento del ojo sea la xantomatina (deahí el color marrón del ojo). Las mutaciones en el locus scarlet hacen que no se pro-duzca xantomatina, siendo el color del ojo rojo escarlata por la presencia de dro-sopterina. Los dobles mutantes recesivos (1/16) del total de la F2, carecen de ambospigmentos y por tanto tienen ojos de color blanco.
El otro efecto de la interacción génica es la distorsión de las proporciones men-delianas esperadas al analizar un carácter. Dicha distorsión puede ser debida a lapresencia de dos genes que controlan dicho carácter, de modo que uno de los genesenmascara la expresión del otro. Este fenómeno se conoce con el nombre de epis-tasia y puede ser de distintos tipos, como veremos a continuación. Al gen que modi-fica la expresión del otro se le denomina gen epistático, y al gen cuya expresión esmodificada se le denomina gen hipostático. Un buen ejemplo para entender la epis-tasia, utilizando los grupos sanguíneos humanos, es el llamado fenotipo Bombay.Como se recordará, los isoantígenos A y B resultan de la adición de N-acetil-galac-tosamina o de galactosa, respectivamente, a la sustancia H. Por tanto, sólo los indi-viduos que tienen sustancia H en la membrana de los eritrocitos pueden expresar an-tígenos A o B. La producción de sustancia H (la adición de la última fucosa a lacadena glicosídica) está controlada por otro locus distinto que presenta un alelo do-
125
Modificaciones del dihibridism
o. Interacción génica y epistasia
CAPITULO 9 5/12/06 07:16 Página 125
www.FreeLibros.me

minante H (produce sustancia H completa) y otro alelo recesivo h (no la produce).Por tanto, los individuos homocigotos hh no producirán sustancia H y no podránexpresar ningún isoantígeno aunque tengan alelos IA o IB para el locus del siste-ma ABO.
Este fenómeno se encontró por primera vez en una mujer del grupo O hija de pa-dres A y AB, lo cual es imposible según la herencia del sistema ABO. Esta mujer, ca-sada con un individuo del grupo A (genotipos posibles Iai o IAIA) tuvo descendenciadel grupo A, B y AB, lo cual también es imposible si ella fuese realmente del grupoO (genotipo ii). La explicación es que la mujer en realidad tenía genotipo IBi y portanto debería ser del grupo B, pero como es homocigota para el alelo recesivo h yno produce sustancia H su fenotipo es del grupo O. Podemos imaginar un cruce en-tre individuos dobles heterocigotos para el grupo ABO y para la sustancia H, del tipoIAIB/Hh X IAIB/Hh. Según el locus ABO, la descendencia debería ser 1/4 del grupoA, 1/4 del grupo B y 1/2 del grupo AB. Sin embargo, al tener en cuenta el locus H ve-mos que 1/4 de cada una de esas categorías serán homocigotos hh (sin sustancia H) ypor tanto del grupo O. Al considerar ambos loci, las proporciones fenotípicas serán3/16 del grupo A, 6/16 del grupo AB, 3/16 del grupo B y 4/16 del grupo O, lo cual sedesvía de las proporciones esperadas 9:3:3:1. Como vemos, la presencia de un genepistático (el que controla la producción de sustancia H) enmascara la expresión dellocus ABO (que en este ejemplo es el gen hipostático) porque ambos genes están im-plicados en procesos bioquímicos que interaccionan en un mismo carácter fenotípi-co. Como las proporciones fenotípicos se expresan en dieciseisavos, esto nos aler-taría inmediatamente sobre la presencia de dos genes interactuando de modoepistático aunque no supiésemos nada de la existencia de la sustancia H.
La Figura 9.4 muestra un ejemplo del fenotipo Bombay.
En general, la epistasia puede ser recesiva o dominante, según el gen epistáticodeba estar en homocigosis o no, respectivamente, para enmascarar la expresión delgen hipostático. A su vez, la epistasia puede ser simple (uno de los genes es epistáti-co sobre el otro) o doble (ambos loci son epistásicos el uno sobre el otro). Veamosalgunos ejemplos de los tipos de epistasia más comunes:
Epistasia simple recesiva: ya vimos que el color del pelaje de ratones estácontrolado por el gen agutí, con un alelo A dominante sobre a, de forma que losratones A- (AA o Aa) son de fenotipo agutí y los ratones aa tienen pelaje negro(carecen de las pequeñas bandas amarillas). Existe otro gen que controla la pre-sencia o no de pigmentación, con alelo dominante C (pigmentación) y un alelorecesivo Ca que impide cualquier tipo de pigmentación. Los ratones de genotipohomocigoto recesivo CaCa son, por tanto, albinos, mientras que los ratones C–(CC o CCa) son del color especificado por el locus agutí. La F1 de un doblehomocigoto dominante AA/CC (agutí) con un doble homocigoto recesivoaa/CaCa (albino) son todos heterocigotos dobles de pelaje agutí (genotipoAa/CCa). La F2 resultante de cruzar ratones de la F1 muestra una proporción9:4:3 (agutí:albino:negro) por epistasia de C sobre A. En este caso, hablamos deepistasia recesiva porque el alelo Ca es recesivo (sólo CaCa modifica el fenotipo
126
Modificaciones de las proporciones m
endelianas
CAPITULO 9 5/12/06 07:16 Página 126
www.FreeLibros.me

determinado por A). El ejemplo anterior del fenotipo Bombay es también unaepistasia de este tipo, pero al ser codominantes los grupos sanguíneos los 9/16 sedescomponen en 6/16 y 3/16 (de ahí las proporciones 3:6:4:3 que veíamos). La epis-tasia simple recesiva es muy común entre genes que actúan a distintos pasos deuna misma vía metabólica, y por eso es frecuente en enfermedades del metabo-lismo. Por ejemplo, cuando la producción de un pigmento se lleva a cabo en dospasos metabólicos, de modo que el producto de la primera reacción es el sustra-to de la segunda reacción, las mutaciones que afectan al enzima responsable dela primera reacción serán epistáticas sobre el gen que controla el segundo paso.
Epistasia simple dominante: en este caso el alelo del gen epistático es do-minante, y basta con una sola copia para que enmascare el efecto del gen hi-postático. Un ejemplo típico es el color de la calabaza común, en el que inter-viene un gen que controla el primer paso metabólico en la producción de unpigmento. El alelo normal (w) permite la reacción química, pero es recesivofrente al alelo W que impide dicha reacción. El producto de este primer paso esel sustrato de una segunda reacción controlada por otro gen (con alelos Y e y)que da lugar al color final de la calabaza. Las plantas con genotipo ww para elprimer gen (es decir, se lleva a cabo el primer paso de la vía) pueden ser ama-rillas (genotipos YY o Yy para el segundo gen) o verdes (genotipo yy). En cam-bio, basta la presencia de un alelo W en el primer locus para que todas lasplantas sean blancas, porque no se completa la primera reacción y no hay pig-mentación. En este tipo de espistasia, la F2 resultante del cruce de dobles hete-rocigotos muestra proporciones fenotípicas 12:3:1, con 12/16 del fenotipo deter-minado por el alelo dominante del gen epistático.
Epistasia doble recesiva: este tipo de epistasia fue observada por primeravez por Bateson y Punnett al estudiar el color de las flores de Lathyrus odora-tus (guisante oloroso). Vieron que al cruzar dos flores blancas todas las plantasde la F1 eran púrpuras y en la F2 aparecía una proporción 9:7 de púrpuras:blan-cas. Las proporciones en dieciseisavos confirman la presencia de dos loci P y Qque controlan este carácter. La proporción 9:7 se puede explicar si considera-mos que ambos genes tienen un alelo dominante (P o Q) y otro recesivo (p o q)y actúan sobre dos pasos sucesivos en la vía metabólica que genera el pigmen-to de las flores. Si el pigmento que da el color púrpura sólo se produce cuandoestán presentes al menos un alelo dominante de cada uno de los genes im-plicados, la descendencia de un cruce del tipo PPqq x ppQQ (en el que ambasplantas tienen flores blancas), será del 100 por ciento de dobles heterocigotosPpQq en la F1 (todas con flores púrpuras, pues tienen un alelo dominante decada par génico). El cruce de estas plantas dará en la F2 9/16 de plantas con ge-notipo homocigoto recesivo para alguno de los dos genes (blancas); el resto se-rán púrpuras por tener genotipos con un alelo dominante para ambos genes. Sedenomina doble recesiva porque la presencia de cualquiera de los dos homoci-gotos recesivos para uno de los genes es epistático sobre el otro gen.
Otros tipos de espistasia. Se conocen muchos otros ejemplos de epistasiaen las que las relaciones entre el gen epistático y el hipostático pueden ser dis-tintas. Por ejemplo, cuando un fenotipo requiere la presencia de al menos unalelo dominante para cualquiera de los dos loci que controlan un carácter, el fe-
127
Modificaciones del dihibridism
o. Interacción génica y epistasia
CAPITULO 9 5/12/06 07:16 Página 127
www.FreeLibros.me

notipo alternativo aparecerá únicamente en individuos dobles homocigotos, ylas proporciones obtenidas en la F2 de un cruce entre dobles heterocigotos se-rán 15:1. Este tipo de epistasia se denomina doble dominante porque los dosalelos epistáticos son dominantes de modo recíproco, y es típica de genes quese han originado por duplicación a partir de un gen ancestral y controlan unmismo carácter fenotípico. Otra situación distinta es la que origina epistasia do-ble dominante/recesiva, debida a la supresión dominante de un gen sobre elefecto del otro y que produce proporciones fenotípicas 13:3.
El vídeo de la Figura 9.5 ilustra el concepto de epistasia.
Como conclusión a este capítulo, conviene recordar que todas las desviacionesque hemos visto de las proporciones fenotípicas esperadas según los principios men-delianos no invalidan las conclusiones de Mendel, sino que en el fondo las confir-man. Sin embargo, estas excepciones sirven para recordarnos que los caracteres he-reditarios que están controlados por un solo locus con dos alelos son, en realidad,una minoría. Curiosamente, los siete caracteres descritos por Mendel en su artículooriginal cumplían estos requisitos, pero la mayor parte de los rasgos genéticos sonmás complejos y están sometidos a alguno de los fenómenos descritos (codominan-cia, alelismo múltiple, interacción, etc.). Como veremos más adelante, los rasgos demayor importancia en Genética Humana están controlados por dos o más genes,y generan muchas veces variación fenotípica continua. Aunque las leyes de Mendelson todavía aplicables incluso en estos casos, la interpretación se complica tremen-damente al aumentar el número de loci, al aparecer alelos mutantes y al añadirse losefectos de la interacción entre los genes y el ambiente.
128
Modificaciones de las proporciones m
endelianas
CAPITULO 9 5/12/06 07:16 Página 128
www.FreeLibros.me

C A P Í T U L O 1 0
Genética de los caracterescuantitativos
Contenidos
10.1 Genética de los caracteres cuantitativos: experimentos de Johannsen, Nilsson-Ehle y East
10.2 Modelo poligenes-ambiente y enfermedades multifactoriales
10.3 Heredabilidad en sentido amplio y en sentido restringido. Cálculo de la heredabilidad en Genética10.3 Humana
10.1 Genética de los caracteres cuantitativos: experimentos 10.1 de Johannsen, Nilsson-Ehle y East
Hemos visto que Mendel se centró en el estudio de caracteres cualitativos (es decir, ca-racteres que sólo aparecen en dos posibles formas alternativas), que generan un tipo devariación llamada variación discontinua. Sin duda alguna, la gran intuición de Mendelfue que sólo el estudio de la variación discontinua le permitiría desentrañar las leyes dela herencia y los factores implicados en la misma. Sus experiencias le habían mostradoque este tipo de caracteres eran los únicos que reaparecían en la F2 después de haberdesaparecido en la F1. Por el contrario, los caracteres cuantitativos o continuos (que ad-miten muchos valores posibles y en los que los valores individuales se agrupan en tornoa una media, como el caso la altura de una planta, el peso de los frutos, etc.) no mostra-ban este comportamiento. La importancia de esta decisión fue extraordinaria, sobre todoteniendo en cuenta que la teoría prevalente en ese momento era contraria a esta mane-ra de pensar. Por ejemplo, Darwin daba preferencia a los caracteres cuantitativos res-pecto a los cualitativos (que consideraba de menor importancia) y aceptaba una teoríallamada «pangénesis». Según esta teoría, la herencia sería el resultado de la mezcla de«gémulas», unas partículas somáticas que de algún modo llegarían a la descendencia y
CAPITULO 10 5/12/06 07:18 Página 129
www.FreeLibros.me

determinarían que los caracteres de la descendencia fuesen intermedios a lo encon-trado en ambos progenitores.
Es curioso que Darwin no se fijase en la importancia de la variación discontinua,porque de hecho un modelo de herencia basado en caracteres cualitativos favorecíamás su teoría evolutiva. Probablemente fue muy importante la influencia del pensa-miento de Francis Galton, que estaba convencido de que los caracteres cuantitativosconstituyen la base de la variación entre individuos y no entendía que éstos pudiesenser explicados por medio de variaciones discontinuas. De hecho, Galton había estu-diado el tamaño de la planta del guisante y había encontrado evidencias de variacióncontinua (una F1 con altura intermedia a la de ambos progenitores). Estos experi-mentos tenían sus antecedentes en Kölreuter, un botánico que en 1766 había hechonumerosos cruces en plantas y había encontrado caracteres (como la altura de laplanta Nicotiana, por ejemplo) que mostraban variación continua. No es de extrañar,pues, que se generase una fuerte controversia a principios del siglo XX entre los par-tidarios del mendelismo y los biometricistas (discípulos de Galton, defensores de lavariación continua).
Por desgracia, la influencia de Galton y la aplicación de las ideas de los biometri-cistas a sujetos humanos ocasionaron una de las páginas más oscuras de la Genéticaa principios del siglo XX, ya que cristalizaron en el movimiento eugenésico, que flo-reció en los Estados Unidos de la mano de Charles Davenport en el laboratorio deCold Spring Harbor. Con la idea de mejorar la raza humana mediante apareamientosselectivos, los eugenistas pretendían eliminar de la sociedad rasgos «negativos» comola criminalidad, el analfabetismo o la prostitución; su presión fue suficiente para queel gobierno de los Estados Unidos aprobase —entre 1910 y 1939– legislación eugené-sica en tres áreas: restricción de la inmigración europea; impedir matrimonios entreindividuos de razas distintas; esterilización de los individuos «genéticamente infrado-tados». El auge del movimiento nazi con la aplicación de la «solución final» contri-buyó al descrédito del movimiento eugenista americano, llevando al cierre de su prin-cipal laboratorio en 1939. Por desgracia, muchas de las leyes aprobadas siguieronvigentes durante años, y la esterilización de los deficientes mentales continuó en Es-tados Unidos hasta los años 1970; para entonces, unos 60 000 norteamericanos ha-bían sido esterilizados sin consentimiento propio o de los responsables legales.
En la Figura 10.1 se puede encontrar un enlace a los archivos del movimiento eugenésicoamericano.
Las disputas en torno a las bases genéticas de la variación continua se resolvieronpor los experimentos de varios genetistas en las primeras décadas del siglo XX. El pri-mero en abordar la utilización de metodología estadística en el estudio de la variacióncontinua fue el botánico danés Johannsen, que tuvo una gran importancia en la Ge-nética (a él se deben los términos gen, genotipo y fenotipo, por ejemplo). En sus tra-bajos, que se extendieron de 1903 a 1909, intentó estudiar el efecto de la herencia ydel ambiente sobre la variación, siguiendo la idea inicial de Galton de «nature versusnurture». Johannsen estudió sobre todo el peso de las alubias de Phaseolus vulgarisen una cepa comercial y detectó la presencia de variación continua, con alubias de dis-tintos pesos que se agrupaban en torno a un valor medio. Autopolinizando durante va-
130
Genética de los caracteres cuantitativos
CAPITULO 10 5/12/06 07:18 Página 130
www.FreeLibros.me

rias generaciones, consiguió líneas puras para minimizar el efecto genético y estudióla F1. A pesar de tratarse de líneas puras, los pesos de las semillas de cada una de es-tas líneas siguen una distribución normal, con valores ligeramente distintos. Al plantarsemillas de pesos diferentes (pero todas procedentes de una misma línea pura y portanto genéticamente iguales), encontró que el peso medio de la progenie de las distin-tas semillas era idéntico (no significativamente distinto) y coincidía con la media depesos de la línea pura original.
Por ejemplo, en su línea pura número 13 las semillas se distribuían en torno a unpeso medio de 0,45 g, pero había semillas de pesos mayores y menores a esta media,como es lógico. Al plantar algunas de estas semillas y estudiar el peso de la alubia enla progenie, encontró que una semilla de 0,28 g producía alubias con un peso mediode 0,45 g, una semilla de 0,48 g producía alubias con un peso medio de 0,43 g, y unasemilla de 0,58g producía plantas que daban alubias con un peso medio de 0,46 g. Estodemostraba la presencia de factores genéticos (responsables de que el peso medio delas alubias sea igual a la media del peso de las semillas originales, como es de esperaren una línea pura); pero además también demostraba la presencia de otros factores(presumiblemente ambientales) que hacen que las semillas no sean todas idénticas,sino que el peso varíe en torno a un valor medio. Además, cada línea pura tenía unpeso medio de alubia característico, con una media que se repetía en la F1 aunque seplantasen semillas con pesos dispares. Fue, por tanto, Johannsen el primero en sugerirexperimentalmente que la variación continua podría explicarse por una combinaciónde factores genéticos y ambientales.
La Figura 10.2 explica los experimentos de Johannsen.
De todas formas, esto no demostraba que los factores genéticos implicados en laherencia de caracteres continuos fuesen de tipo mendeliano. Algunos biometricis-tas, sobre todo el matemático Pearson, seguían negando la posibilidad de que los fac-tores mendelianos pudiesen explicar la variación continua. Sin embargo, Bateson yYule elaboraron en 1906 una argumentación matemática para explicar que la presen-cia de varios factores mendelianos con dominancia incompleta puede originar la va-riación continua propia de los caracteres cuantitativos. De todas formas, la demostra-ción experimental de esto no llegaría hasta los estudios de Herman Nilsson-Ehle en1909. Nilsson-Ehle tenía varias líneas puras de trigo, en las que estudió caracterescuantitativos con variación continua, tales como el color de las espigas. En sus líneas,las espigas tenían colores que iban desde el blanco al rojo oscuro pasando por estadí-os intermedios (rojo claro, rojo). Cruzó en primer lugar una planta de espiga blancacon una de color rojo claro y obtuvo F1 en la que todas las espigas eran de color in-termedio («rosa»); en la F2 obtuvo tres clases fenotípicas con proporciones 1:2:1,siendo 1/4 de plantas con espigas blancas, 1/2 espigas rosas y 1/4 espigas de color rojoclaro. En principio, como ya hemos visto al hablar del mendelismo, estas proporcio-nes pueden explicarse perfectamente mediante un modelo mendeliano de dominanciaincompleta del rojo sobre el blanco. Sin embargo, cuando cruzó plantas de espigasblancas con plantas de espigas rojas (más oscuras que el «rojo claro») obtuvo cincoclases de plantas: 1/16 rojas, 4/16 intermedio entre rojo y rojo claro, 6/16 rojo claro, 4/16rosa y 1/16 blancas. Estas proporciones (1:4:6:4:1) sugieren un modelo de dos pares gé-
131
Genética de los caracteres cuantitativos
CAPITULO 10 5/12/06 07:18 Página 131
www.FreeLibros.me

nicos con epistasia doble dominante (15:1) y dominancia incompleta (todos los ro-jos suman 15). De hecho, el cruce de plantas de espiga blanca con plantas de colorrojo oscuro dio lugar a siete clases fenotípicas, con proporciones expresadas en se-sentaycuatroavos: 1/64 de plantas con espigas blancas y el resto de las plantas con es-pigas de seis clases de rojos (rojo claro, rojo y rojo oscuro más las categorías interme-dias entre cada una de estas tres). Estas proporciones y el número de clases fenotípicassugieren un modelo de epistasis triple dominante: tres loci con dominancia incom-pleta (y efecto aditivo de dosis), y el resultado fenotípico es la distribución del co-lor de la espiga como una variable continua. Esta fue la primera demostración ex-perimental de que un carácter controlado por varios genes puede mostrar variacióncontinua aunque cada uno de los genes se herede de forma mendeliana, si cada unode ellos tiene un pequeño efecto aditivo sobre el carácter fenotípico.
Faltaba por demostrar que la variación debida a efectos ambientales puede ser res-ponsable de las diferencias observadas entre individuos con genotipos idénticos. Lademostración formal no llegaría hasta los estudios de Edward East en 1916, nueva-mente con plantas. Estudiando la longitud de la corola en dos líneas puras de Nico-tiana longiflora, vio que la F1 mostraba un tamaño intermedio a los fenotipos paren-tales, con arreglo a una distribución normal. En la F2, el valor medio se mantenía perola varianza se ampliaba notablemente, aunque sin llegar a los valores extremos que seveían en las clases parentales. Esto se explica porque las plantas de la F1 son hetero-cigotos para todos los genes que intervienen en el tamaño de la flor, de modo que lasplantas de la F2 tendrán varias combinaciones distintas de genotipos y de ahí la ma-yor dispersión de los resultados. De hecho, East observó que la F3 resultante de cru-ces seleccionados (entre plantas de la F2 que tenían el mismo tamaño de corola) re-producía exactamente el tamaño de las plantas cruzadas, con una dispersión detamaños debida a factores ambientales. Por ejemplo, cruzó inicialmente dos varieda-des puras de 40 mm y 93 mm de media, respectivamente. En la F1, el tamaño mediode corola fue de 64 mm (con valores entre 61 y 67 mm). En la F2 resultante de cru-zar dos plantas de la F1 se mantuvo el tamaño medio de corola (67 mm) pero au-mentó la dispersión (valores entre 52 y 82 mm), indicando la presencia de nuevos ge-notipos que están originando tamaños distintos. Al cruzar dos plantas de esta F2 quetenían corolas del mismo tamaño (58mm), vio que la descendencia tenía un tamañomedio cercano a 58 mm; al cruzar dos plantas de 70 mm obtuvo una descendenciacon tamaño medio cercano 70 mm, etc. Es decir, comprobó que efectivamente hayfactores genéticos responsables de los distintos tamaños medios en los distintos cru-ces, al tiempo que los factores ambientales son los responsables de la dispersión devalores que se observa en las plantas que tienen un mismo genotipo. Con estos expe-rimentos, East pudo demostrar el efecto simultáneo de la variación genética y la va-riación ambiental, cuyos efectos combinados contribuyen a crear variación continua.
Por tanto, un par de décadas después del re-descubrimiento de Mendel se habíallegado a la explicación de cómo los principios mendelianos, que afectan a caracte-res discretos (variación discontinua) pueden dar lugar a variación continua de ca-racteres cuantitativos: cuando un carácter fenotípico está controlado por dos o másgenes y los efectos de cada gen sobre ese carácter se suman. Esto se conoce como he-rencia poligénica. En estos casos, es de gran interés determinar el número de locique intervienen. Lo más habitual es determinar el porcentaje de individuos de la F2
132
Genética de los caracteres cuantitativos
CAPITULO 10 5/12/06 07:18 Página 132
www.FreeLibros.me

que tienen valores en torno a cualquiera de los dos parentales. Así, para un sologen esto sería 1/4, para dos loci sería 1/16, para tres loci sería 1/64, etc. Se puede ver queesto es igual a (1/4)
n, donde n es el número de loci distintos. Por ejemplo, ya vimosque el experimento de Nilsson-Ehle sugería tres loci (1/64 = [1/4]
3), mientras que en elexperimento de East ninguna de las 444 flores de la F2 tenía una corola de tamañosimilar a la media de los progenitores, por lo que el número de poligenes debe ser almenos superior a 4 ([1/4]
4 = 1/256).
10.2 Modelo poligenes-ambiente y enfermedades 10.1 multifactoriales
Hemos visto cómo se llegó a explicar la variación continua por la acción de variosgenes sobre un mismo carácter (herencia poligénica), y cómo la existencia de varia-ción ambiental añadida hace que las diferencias entre las clases fenotípicas se suavi-cen y la variación sea más gradual. A la combinación de herencia poligénica con lavariación introducida por factores ambientales se le llama herencia multifactorial,para indicar la multiplicidad de factores que intervienen en la expresión del carácterfenotípico. En el campo de la Genética Humana la herencia multifactorial es de gran
133
Modelo poligenes-am
biente y enfermedades m
ultifactoriales
Línea pura A Línea pura B
Longitud corola (x): 40 mm 94 mm
61 64 67
52 67 82
54 72 79
F1
F2
F3
−
El vídeo de la Figura 10.3 ilustra los experimentos de H. Nilsson-Ehle y de E. East.
CAPITULO 10 5/12/06 07:18 Página 133
www.FreeLibros.me

importancia, porque la mayoría de los fenotipos y muchas enfermedades, llamadastambién enfermedades complejas, siguen este tipo de herencia. De hecho, las enfer-medades multifactoriales o complejas son las más importantes desde el punto de vis-ta epidemiológico, por lo que actualmente son objeto de investigación con el fin deidentificar los factores genéticos y ambientales implicados. Fruto del trabajo de estosúltimos años, se ha detectado un alto número de loci relacionados con el desarrollode enfermedades como cáncer, diabetes, hipertensión, esquizofrenia, enfermedadesneuro-degenerativas, etc.
Algunas de las enfermedades multifactoriales se manifiestan en rasgos fenotípicosclaramente cuantitativos, como por ejemplo la presión arterial o los niveles de glu-cosa en sangre. Como hemos visto en el apartado anterior, se puede demostrar quelos rasgos cuantitativos que se encuentran en la población mostrando una distribu-ción normal pueden explicarse por la interacción de varios genes (cada uno de loscuales se heredaría de forma mendeliana). Por ejemplo, podemos imaginar un mo-delo sencillo de dos loci que regulan la presión sanguínea, de forma que cada uno deellos se hereda de modo mendeliano y provoca un aumento de 20 mm de presión ar-terial cuando se encuentra en estado homocigoto para el alelo dominante (mayúscu-la), 10 mm en los heterocigotos o no provoca ningún aumento en los homocigotospara el alelo recesivo (minúscula). Representando estos valores en un gráfico de ba-rras, se puede comprobar que 1/16 de la población tendrá un genotipo AA/BB (au-mento de 40 mm de presión arterial), 4/16 de la población tendrá genotipos que pro-vocan un aumento de 30 mm, 6/16 tendrá genotipos con 20 mm, 4/16 con 10 mm y 1/16
serán genotipo aa/bb (0 mm de aumento). Como se ve, estos valores se aproximan auna distribución normal. Lógicamente, la presencia de más loci hace que aparezcanmás categorías (más barras) y que la curva de distribución se «suavice» cada vez más.La variación debida a factores ambientales (ingesta de sal, ejercicio físico, etc.) so-breañadidos a los factores genéticos producirá la curva gaussiana típica de muchosde estos rasgos cuantitativos.
La Figura 10.4 incluye un vídeo que ilustra la importancia de la herencia poligénica en lasenfermedades complejas.
Hay otro tipo de enfermedades que no tienen una herencia mendeliana recono-cible, sino que se ajustan al modelo de enfermedades multifactoriales, y sin embargono se presentan como rasgos cuantitativos típicos, sino que originan fenotipos cua-litativos. Por ejemplo, algunas malformaciones frecuentes, como el labio leporino,forman parte de esta categoría. Una explicación bastante aceptada de estos rasgospropone que es la predisposición a manifestar la enfermedad o malformación lo quetiene un origen multifactorial (mezcla de factores genéticos mendelianos y de facto-res ambientales). Por tanto, aunque esta predisposición sí que se ajusta a una distri-bución normal en la población, la enfermedad sólo se desarrolla cuando se supera uncierto umbral de predisposición. En estos casos se presupone que los familiares di-rectos de estos enfermos comparten con ellos algunos factores genéticos y/o am-bientales, por lo que tendrán mayor predisposición que la población general a sufrirla misma enfermedad. Esto explica que el riesgo de recurrencia de la enfermedad
134
Genética de los caracteres cuantitativos
CAPITULO 10 5/12/06 07:18 Página 134
www.FreeLibros.me

(probabilidad de que haya otro miembro afectado en una misma familia) sea mayoren los familiares de un enfermo que en la población general.
Ejemplos clásicos de este tipo de enfermedades son la estenosis pilórica, que ade-más muestra diferencias en cuanto al sexo (hay más varones que mujeres afectadospor la enfermedad, lo que sugiere que el umbral de predisposición es más bajo en va-rones), o el paladar hendido (fisura del paladar/labio leporino). Para calcular el ries-go de recurrencia en estas enfermedades (la aparición de otro caso en una familia enla que ya hay un enfermo) se utilizan siempre riesgos empíricos, basados en la obser-vación de los datos de prevalencia de la enfermedad en la población, datos que pue-den variar considerablemente de una población a otra. Una propiedad a tener encuenta es que en estos casos el riesgo es variable, al contrario de lo que ocurre en en-fermedades con herencia mendeliana simple, en las que el riesgo es fijo. Así, cuandohay varios miembros de una misma familia afectados por una enfermedad multifacto-rial, el riesgo de que aparezca un nuevo caso en la misma familia es mayor que si hayun solo miembro enfermo; igualmente, cuando el individuo enfermo es del sexo quese afecta con menor frecuencia, el riesgo también aumenta. Esto se explica porque, enestos casos, se supone que en esa familia concreta concurren más factores genéticosy/o ambientales y su curva de predisposición está desplazada a la derecha.
El vídeo de la Figura 10.5 ilustra la herencia poligénica de algunos rasgos cualitativos.
10.3 Heredabilidad en sentido amplio y en sentido restringido.10.2 Cálculo de la heredabilidad en Genética Humana
La determinación de la influencia de factores genéticos en caracteres cuantitativostiene consecuencias importantísimas en la explotación de especies vegetales o ani-males (tamaños, pesos, producción de leche, de huevos, de uvas, etc.). La aplicaciónmás importante en Genética Humana es la posibilidad de determinar la importanciarelativa de los factores genéticos y de los factores ambientales en las enfermeda-des multifactoriales, por las implicaciones que esto tiene para la prevención y trata-miento de estas dolencias.
Una forma de resolver este problema es estimar la parte de la variación total deuna variable que es debida a factores ambientales, para de ahí deducir la variaciónatribuíble a factores genéticos. En el caso de los caracteres cuantitativos, esto es re-lativamente sencillo porque pueden estudiarse con métodos estadísticos, analizan-do los parámetros que definen las variables poblacionales y sus relaciones (media, va-rianza, covarianza, regresión). De todos éstos, la varianza es el parámetro que mejordefine la dispersión de una variable continua en torno a la media y por tanto pode-mos estimar la variación fenotípica calculando la varianza total de ese rasgo en la po-blación. Esta varianza fenotípica total (VP) será la suma de la varianza debida a fac-tores genéticos (VG), más la varianza debida a factores ambientales (VE), más lavarianza debida a las interacciones entre genes y ambiente (VGE). A su vez, la varia-ción genética viene determinada por tres componentes: la varianza debida a efectosaditivos (VA), la varianza debida a efectos de dominancia (VD) y la varianza debidaa efectos de interacción génica (VI). Usando esta metodología podemos estimar la
135
Heredabilidad en sentido am
plio y en sentido restringido. Cálculo de la heredabilidad…
CAPITULO 10 5/12/06 07:18 Página 135
www.FreeLibros.me

heredabilidad (H 2) de un rasgo fenotípico cuantitativo. En sentido amplio, la he-redabilidad indica qué proporción de la variación fenotípica total VP de una varia-ble continua es atribuible a factores genéticos. Siguiendo las definiciones preceden-tes, esta heredabilidad en sentido amplio se calcula con arreglo a la fórmula:
H 2 = VG/VP
siendo VP = VG + VE + VGE (aunque VGE suele despreciarse). Para calcular H2 ne-cesitamos usar especies puras (genotipos iguales), que nos permiten calcular la va-rianza ambiental VE variando las condiciones ambientales de forma que toda la va-riación sea debida al ambiente. Además de esta dificultad de tipo práctico, esteconcepto de heredabilidad en sentido amplio es poco útil porque no nos indica exac-tamente el porcentaje de la variación que es debida a factores genéticos aditivos, queson los más interesantes. Por eso, otra forma más habitual de calcular la heredabili-dad (heredabilidad en sentido estricto, h2) se basa en calcular específicamente laparte de la varianza genética que es debida a factores aditivos (VA), respecto a la de-bida a diferencias en la dominancia (VD) y a efectos de interacción (VI). Habitual-mente, esta última es despreciable y se considera que la varianza genotípica total esVG = VA + VD.
En especies que lo permiten, el cálculo se realiza mediante experimentos de se-lección artificial, para evaluar el posible beneficio derivado de tal selección. Porejemplo, en una población en la que una variable continua tiene una media M, setoma una submuestra de individuos con una media significativamente diferente(esa diferencia se denomina «diferencial de selección», D), y se determina la me-dia en la progenie de esos individuos seleccionados. La diferencia de la media en ladescendencia con la media poblacional inicial se denomina «ganancia» G (o «res-puesta» R). La heredabilidad en sentido estricto h2 se calcula como G/D, e incluyeúnicamente los factores genéticos aditivos. Se puede comprobar que con la selecciónprolongada, la heredabilidad va disminuyendo progresivamente, al haber cada vezmenos factores genéticos aditivos que puedan seguir modificando el fenotipo.
En la Figura 10.6 se incluye un vídeo y varias ilustraciones que muestran el concepto de heredabilidad y su cuantificación en Genética Humana.
Lógicamente, este tipo de aproximación experimental no es posible en el caso dela Genética Humana. Sin embargo, la enorme importancia socio-sanitaria de las en-fermedades multifactoriales hace que sea de gran utilidad determinar cuánto influyeel ambiente y cuánto la herencia en la génesis de esas enfermedades. Para cuantifi-car la magnitud del componente genético de una enfermedad, concepto análogo a laheredabilidad, se utilizan actualmente dos procedimientos:
• Cálculo del riesgo relativo. Si calculamos el riesgo relativo de padecer la en-fermedad que tienen distintos grupos de personas relacionadas genéticamen-te, como por ejemplo los hermanos de individuos enfermos, y vemos que elriesgo de padecer la enfermedad en ese grupo es significativamente mayor queen la población general, podemos deducir que existen factores genéticos quedeterminan la aparición de esta enfermedad. El riesgo relativo se calcula
136
Genética de los caracteres cuantitativos
CAPITULO 10 5/12/06 07:18 Página 136
www.FreeLibros.me

como λR, en el que el subíndice R indica el grado de parentesco del grupo queestamos estudiando con los individuos enfermos. Por ejemplo lo (la «O» vie-ne del inglés offspring, que significa «descendencia») indicaría la prevalenciade la enfermedad en los hijos e hijas de individuos enfermos; λs (la «S» vienedel inglés sibs, que significa «hermanos y hermanas») sería la prevalencia dela enfermedad en los hermanos y hermanas de individuos enfermos, etc. Cal-culando el cociente de cada uno de estos riesgos entre el riesgo poblacionalgeneral podemos calcular el riesgo relativo. Un concepto similar al de riesgorelativo es el de odds ratio (cociente del producto cruzado), que se calcula deotro modo pero nos da prácticamente la misma información. La interpreta-ción de estos cálculos es la misma: si los parientes de los individuos enfermostienen un riesgo significativamente aumentado de padecer la enfermedadfrente al riesgo de la población general, se puede suponer que la enfermedadtiene un componente genético importante.
• Cálculo de las tasas de concordancia en parejas de gemelos. Si una enfer-medad tiene un componente genético significativo, aparecerá con mayor fre-cuencia en individuos con mayor parecido genético que en individuos genéti-camente más distantes. Un modo elegante de estudiar esto en la práctica escomparar los gemelos dicigóticos (cuyo grado de identidad genética es igualal de una pareja cualquiera de hermanos) y los gemelos monocigóticos, ya queéstos son prácticamente idénticos desde el punto de vista genético. Este tipode estudios, que han dado abundantes frutos en Genética Humana, se basanen el cálculo de las tasas de concordancia, es decir, el porcentaje de parejasde gemelos que concuerdan para un mismo rasgo fenotípico (una enfermedad,en este caso), de manera que simplemente calculamos el porcentaje de pare-jas de gemelos en las que ambos padecen la misma enfermedad. Estas parejasserían «concordantes» para esa enfermedad, mientras que las parejas en lasque un gemelo está enfermo pero el otro está sano serían parejas «discordan-tes». Pues bien, si una enfermedad tiene un fuerte componente genético, latasa de concordancia en parejas de gemelos monocigóticos (MC) será clara-mente más alta que en parejas de gemelos dicigóticos (DC), pues aquelloscomparten mayor número de genes que éstos. Además, este tipo de análisistiene la ventaja de que corrige la influencia de los factores ambientales, ya queen la mayoría de los casos ambos hermanos gemelos —tanto MC como DC—han estado sometidos a las mismas influencias ambientales.
• En el caso de rasgos cuantitativos (la presión arterial, por ejemplo) la esti-mación de la concordancia puede realizarse mediante el cálculo del coefi-ciente de correlación intraclase (correlación de los valores de presión arterialde un hermano con su gemelo respectivo), de forma que un coeficiente de co-rrelación R = 1 equivale al 100 por cien de concordancia. La comparación deconcordancias entre gemelos MC y DC se hace del mismo modo que se com-paran dos coeficientes de correlación. En el caso de rasgos cualitativos (pre-sencia o ausencia de una enfermedad) simplemente calculamos el porcentajede parejas de gemelos que concuerdan para esa enfermedad y así obtenemosla tasa de concordancia (porcentaje de parejas concordantes respecto al to-tal de parejas). Con estos datos podemos estimar la heredabilidad (h), me-
137
Heredabilidad en sentido am
plio y en sentido restringido. Cálculo de la heredabilidad…
CAPITULO 10 5/12/06 07:18 Página 137
www.FreeLibros.me
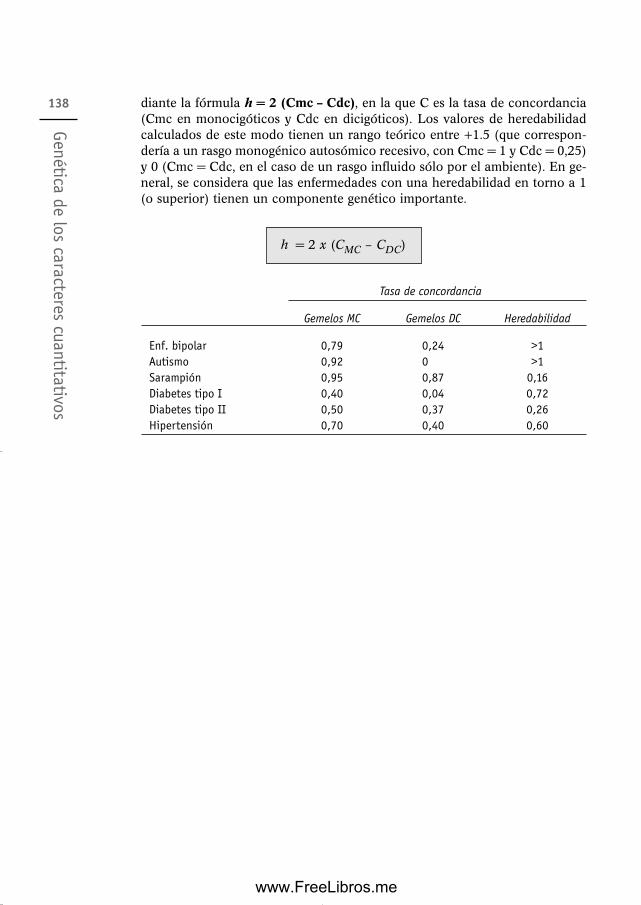
diante la fórmula h = 2 (Cmc – Cdc), en la que C es la tasa de concordancia(Cmc en monocigóticos y Cdc en dicigóticos). Los valores de heredabilidadcalculados de este modo tienen un rango teórico entre +1.5 (que correspon-dería a un rasgo monogénico autosómico recesivo, con Cmc = 1 y Cdc = 0,25)y 0 (Cmc = Cdc, en el caso de un rasgo influido sólo por el ambiente). En ge-neral, se considera que las enfermedades con una heredabilidad en torno a 1(o superior) tienen un componente genético importante.
h = 2 x (CMC – CDC)
Tasa de concordancia
Gemelos MC Gemelos DC Heredabilidad
Enf. bipolar 0,79 0,24 >1Autismo 0,92 0,24 >1Sarampión 0,95 0,87 0,16Diabetes tipo I 0,40 0,04 0,72Diabetes tipo II 0,50 0,37 0,26Hipertensión 0,70 0,40 0,60
138
Genética de los caracteres cuantitativos
CAPITULO 10 5/12/06 07:18 Página 138
www.FreeLibros.me

C A P Í T U L O 1 1
Ligamiento genéticoen humanos
Contenidos
11.1 El concepto de ligamiento genético: fracción de recombinación y distancia genética
11.2 Informatividad de los marcadores utilizados en estudios de ligamiento
11.3 El cálculo del LOD score
11.4 Ligamiento no paramétrico y su utilización en Genética Humana
11.1 El concepto de ligamiento genético: fracción 11.1 de recombinación y distancia genética
Aunque algunos autores ya habían sugerido la presencia de determinados genes en cro-mosomas concretos, no hubo evidencia clara de esto hasta el descubrimiento del liga-miento del locus white de Drosophila al cromosoma X (como se ha explicado en el Capí-tulo 8), descubrimiento hecho por Morgan en torno a 1910. Poco después, Morganidentificó nuevos mutantes, entre ellos otro llamado rudimentary, que también mostrabaligamiento al cromosoma X. Esto llevó a Morgan a estudiar la segregación simultánea deestos dos genes: si siempre se heredan juntos, esto sugeriría que están cerca en el mismocromosoma, ya que no ha habido recombinación entre ellos. En efecto, según las leyes dela herencia mendeliana dos loci que están en cromosomas distintos segregarán de mane-ra independiente, es decir, los dos alelos de cada locus se distribuirán en los gametos demodo aleatorio. En cambio, cuando los dos loci están en el mismo cromosoma (se dice en-tonces que son sinténicos), cabe pensar que siempre se heredará la misma combinaciónde alelos y un miembro de la descendencia que herede un alelo concreto de uno de los locitambién heredará el alelo del otro locus que estaba en el mismo cromosoma parental. Porel contrario, si se produce una recombinación (con sobrecruzamiento) en algún punto in-
CAPITULO 11 5/12/06 07:19 Página 139
www.FreeLibros.me

termedio entre ambos loci durante la meiosis, los gametos llevarán combinaciones alé-licas que no estaban presentes en ninguno de los progenitores, es decir, se formen ga-metos recombinantes.
Morgan comprobó que podía darse recombinación entre el locus white y el locusrudimentary en Drosophila, pero al estudiar otras mutaciones (especialmente el coloramarillo del cuerpo y el color blanco de los ojos) observó que nunca se detectaba re-combinación con otros loci localizados en el mismo cromosoma, y llamó ligamientoa ese fenómeno. Alfred Sturtevant, un estudiante de Morgan, demostró que la proba-bilidad de que haya una recombinación entre dos loci depende de la distancia físicaque los separa, y por tanto la frecuencia con que aparecen recombinantes puede utili-zarse para deducir la distancia que separa dos genes que están en el mismo cromoso-ma; Sturtevant construyó en una noche el primer mapa genético de ligamiento, en elque se representaba el orden y la distancia de cinco genes localizados en el cromoso-ma X de Drosophila. Poco después, Calvin Bridges detectó los primeros casos de li-gamiento entre genes localizados en autosomas, y poco a poco se fueron describiendodistintos grupos de ligamiento. El concepto de ligamiento genético, por tanto, va in-trínsecamente unido al de distancia física entre genes, que es la que origina distintasproporciones de individuos recombinantes en la descendencia.
Cuando ambos loci están suficientemente alejados (aunque estén en el mismo cro-mosoma) existe una probabilidad tan alta de que haya un sobrecruzamiento entreellos que segregarán de manera similar a una segregación independiente, producien-do gametos recombinantes en la mitad de la descendencia (50 por ciento de gametosrecombinantes y 50 por ciento de gametos no-recombinantes). En este sentido, esimportante recordar que el sobrecruzamiento tiene lugar entre dos cromátides, cadauna perteneciente a un cromosoma homólogo; las otras dos cromátides no se recom-binan, de ahí que un sobrecruzamiento da lugar a cuatro gametos de los cuales dosson recombinantes y los otros dos son idénticos a los cromosomas originales. Sin em-bargo, a medida que dos loci sinténicos se sitúan más cerca uno del otro, la probabi-lidad de que haya un sobrecruzamiento entre ellos es cada vez menor, y por tanto laprobabilidad de formación de gametos recombinantes también va decreciendo.Puede llegarse a un punto en que los loci estén tan juntos que nunca se dé un so-brecruzamiento entre ellos, de modo que no se originarán gametos recombinantes yno se encontrarán individuos recombinantes en la descendencia. Por tanto, la cuanti-ficación del número de eventos de recombinación entre dos loci nos permite estimarla distancia genética entre ellos: a mayor proximidad, menor probabilidad de recom-binación y por tanto el porcentaje de individuos recombinantes será menor.
La Figura 11.1 ilustra por qué la probabilidad de recombinación entre dos loci es función de sudistancia física.
En Genética Humana, la cuantificación de la frecuencia de recombinación sehace estudiando la segregación de dos secuencias de ADN en los individuos de unafamilia, e identificando aquellos individuos cuyo genotipo sólo pueda explicarse poruna recombinación en la meiosis de uno de los progenitores. Las secuencias que seutilizan en estudios de ligamiento se denominan marcadores genéticos, que son se-cuencias que se encuentran en distintas formas (distintos alelos) en la población ge-neral, ya que para detectar si ha habido recombinación debemos ser capaces de dis-
140
Ligamiento genético en hum
anos
CAPITULO 11 5/12/06 07:19 Página 140
www.FreeLibros.me

tinguir los distintos alelos. Además, los estudios de ligamiento entre marcadores sir-ven para establecer mapas de ligamiento en los que estos marcadores están en un or-den determinado, separados por distancias precisas. Por tanto, los marcadores utili-zados en estudios de ligamiento son polimorfismos genéticos, es decir, secuenciasque se encuentran en la población en varias formas posibles. Diferentes individuosde la población pueden tener, por tanto, distintos genotipos (distintas combinacio-nes de alelos) para un marcador concreto. Los principales tipos de polimorfismos ge-néticos que se utilizan como marcadores en estudios de ligamiento han sido explica-dos con detalle al hablar del genoma humano en el Capítulo 4.
Para realizar mapas de ligamiento entre marcadores, es necesario ante todo ge-notipar cada uno de los marcadores en todos los miembros de una o varias familias.Al analizar los genotipos de cada individuo y la segregación de los diferentes alelos,se pueden identificar los individuos recombinantes, aquellos cuyo genotipo sólopuede explicarse por una recombinación en uno de sus progenitores. La cantidad deindividuos recombinantes en la descendencia nos permite calcular la fracción de re-combinación (representada por la letra griega θ), que se define como el número deindividuos recombinantes dividido por el número total de individuos en la descen-dencia. Además de estudiar la distancia entre marcadores, en los estudios de liga-miento que se realizan en Genética Humana es frecuente buscar cuál es la distanciaentre un marcador y el locus responsable de una enfermedad genética. En estos ca-sos, el análisis de ligamiento nos permitirá calcular la distancia entre el marcador yel gen responsable de una enfermedad. Utilizando esta metodología se han identi-ficado los genes responsables de muchas enfermedades genéticas, mediante una es-trategia denominada clonaje posicional: al conocer la distancia que separa el locusresponsable de una enfermedad de varios marcadores genéticos concretos, se simpli-fica enormemente la tarea de identificar el gen causal.
La Figura 11.2 muestra el modo de calcular la fracción de recombinación entre el locusresponsable de una enfermedad autonómica dominante y un marcador genético.
141
El concepto de ligamiento genético: fracción de recom
binación y distancia genética
1-2
2-4 1-2
1-4 1-4
θ = 1/6 = 0,17 = 17%
DISTANCIA GENÉTICA = 17 cM
2-2 2-4 1-4
CAPITULO 11 5/12/06 07:19 Página 141
www.FreeLibros.me

La fracción de recombinación, calculada tal y como se ha explicado en la figura an-terior, nos permite estimar la distancia genética entre dos loci, distancia que se mideen centimorgans (cM): cuando entre dos loci se detecta una fracción de recombina-ción θ = 0,01 (uno por ciento de individuos recombinantes), se dice que ambos loci es-tán a una distancia genética de 1 cM. Esta distancia genética (1 cM) equivale aproxi-madamente a 1 Mb (megabase) de distancia física, aunque esta equivalencia varía a lolargo del genoma y hay funciones matemáticas más exactas para convertir la distanciagenética en distancia física. En cualquier caso, es importante comprender que la frac-ción de recombinación nunca podrá ser mayor a 0,5 (50 por ciento), ya que éste esprecisamente el porcentaje de individuos recombinantes que se producen en ausenciade ligamiento (cuando siempre hay una recombinación, como se ha explicado másarriba) o en el caso de que ambos loci estén situados en cromosomas distintos.
11.2 Informatividad de los marcadores utilizados en estudios11.2 de ligamiento
Como acabamos de explicar, para poder realizar estudios de ligamiento es necesarioidentificar los individuos recombinantes para determinar la fracción de recombina-ción. Por desgracia, en ocasiones es imposible establecer si un individuo de la des-cendencia es recombinante o no, bien porque el individuo que transmite la enferme-dad es homocigoto para el marcador analizado, o bien porque es heterocigotoidéntico al otro progenitor; estas situaciones dan lugar a lo que denominamos fami-lias no-informativas o semi-informativas, respectivamente.
La Figura 11.3 muestra algunos ejemplos de falta de informatividad de un marcador.
Lo posibilidad de perder informatividad subraya la importancia de usar marcado-res para los que todos los árboles analizados sean informativos, lo cual dependerá di-rectamente de la informatividad de los marcadores utilizados. La informatividad deun marcador refleja la probabilidad de encontrar individuos heterocigotos para esemarcador en la población general, y es función del número de alelos posibles para elmarcador y de las frecuencias relativas de cada alelo en la población. Teniendo encuenta las características de cada tipo de marcador, es posible calcular dos parámetrosque definen la informatividad de un marcador genético: el índice de heterocigosidady el PIC (contenido de información de un polimorfismo, Polymorphism InformationContent en inglés). Estos parámetros se calculan mediante la siguiente fórmula:
• El primer miembro (1 - Σ pi2) es la heterocigosidad, es decir, el porcentaje de
individuos de la población general que son heterocigotos para ese marcador.
142
Ligamiento genético en hum
anos
PIC = 1 – Σ pi2 – Σ Σ 2 pi
2 pj2
n nn – 1
i = 1 i = 1 j = i + 1
heterocigosidad % heterocigotosidénticos
CAPITULO 11 5/12/06 07:19 Página 142
www.FreeLibros.me

Ya hemos visto que si el individuo que transmite la enfermedad es homocigo-to para un marcador, esa familia no será informativa para ese marcador, deahí que la heterocigosidad sea una medida de la informatividad de un marca-dor genético. Como pi
2 es la frecuencia de homocigotos para cada alelo delmarcador, el sumatorio de todos los posibles homocigotos se le resta a 1 y seobtiene así el porcentaje de heterocigotos. Como criterio general, se puede de-cir que la heterocigosidad de un marcador aumenta: (a) con el número de ale-los que ese marcador presenta en la población general; y (b) cuanto más pa-recidas son las frecuencias de los distintos alelos de ese marcador.
• El segundo miembro de la ecuación le resta a la heterocigosidad la probabili-dad de que una familia no sea informativa debido a que ambos padres son he-terocigotos idénticos (en cuyo caso, como hemos visto antes, la mitad de ladescendencia será informativa (homocigotos) y la mitad será no-informativa(los heterocigotos). Como es sabido, para dos alelos i y j con frecuencias alé-licas pi y pj la frecuencia de heterocigotos es 2pipj. Por tanto, la probabilidadde que dos individuos sean heterocigotos idénticos es 2pipj × 2pipj = 4 (pi
2pi2),
pero como sólo se pierde informatividad en la mitad de la descendencia, en laecuación se resta sólo 2 (pi
2pi2).
Algunos ejemplos del cálculo del PIC ilustrarán la informatividad de los distintos ti-pos de marcadores genéticos. Por ejemplo, un marcador bialélico (el caso típico se-ría un RFLP) con frecuencias alélicas iguales (p1 = p2 = 0,5) tendría:
Heterocigosidad = [1 – (p12 + p2
2)] = [1 – (0,52 + 0,52)] = 1– 0,5 = 0,5
PIC = 1 – (p12 + p2
2) – 2 (p12 × p2
2) = 1 – (0,52 + 0,52) – 2 (0,52 × 0,52) = 0,375
En cambio, un marcador con cuatro alelos (alelos 1, 2, 3 y 4) en el que cada ale-lo tiene una frecuencia p = 0,25, presentará en principio seis posibles combinacionesde heterocigotos, con genotipos (1-2), (1-3), (1-4), (2-3), (2-4) y (3-4). Por tanto, paracalcular todos los posibles casos de heterocigotos idénticos en la población, habráque sumar [2 (p1
2 p22)] + [2 (p1
2 p32)] + [2 (p1
2 p42)] + [2 (p2
2 p32)] + … hasta completar
las seis posibles combinaciones de heterocigotos. Aplicando la fórmula general:
Heterocigosidad = [1 – (0,252 + 0,252 + 0,252 + 0,252 )] = 0,75
PIC = 1 – (0,252 + 0,252 + 0,252 + 0,252 ) – 6 [2 (0,252 × 0,252 )] = 0,703
Como se ve, el hecho de que un marcador tenga cuatro posibles alelos en vez dedos aumenta su informatividad casi al doble. De hecho, un marcador con 10 alelosarrojaría, aplicando la fórmula anterior, un PIC de 0,891 si las frecuencias alélicasson iguales. Por tanto, de los distintos marcadores que se han mencionado más arri-ba, los más informativos son los de tipo microsatélite, seguidos por SNP y RFLP.De todas formas, como ya se ha comentado, la posibilidad de estudiar a la vez milesde SNPs de forma automatizada (algo que no es posible con los microsatélites), jun-to con su alta densidad a lo largo del genoma, hace que los SNP sean hoy en día losmarcadores de mayor utilidad en la construcción de mapas de ligamiento genético detodo el genoma.
Sea cual sea el tipo de marcador utilizado, los estudios de ligamiento requieren ge-notipar a todos los miembros de una familia para detectar la presencia de individuos
143
Informatividad de los m
arcadores utilizados en estudios de ligamiento
CAPITULO 11 5/12/06 07:19 Página 143
www.FreeLibros.me

recombinantes y así poder calcular la fracción de recombinación. En el ejemplo de lafamilia con una enfermedad autosómica dominante presentado en la Figura 11.2, he-mos podido establecer que el individuo transmisor de la enfermedad transmitía a lavez el alelo 2 del marcador, ya que ambos se localizan a poca distancia en el mismocromosoma. Sabemos esto porque este individuo, a su vez, heredó la enfermedad desu padre, que también le transmitió el alelo 2 del marcador. Cuando en un individuoque transmite una enfermedad podemos determinar inequívocamente el origen pa-rental tanto del alelo que causa la enfermedad como de los alelos del marcador —esdecir, podemos determinar qué alelos de cada uno de los dos loci van en el mismocromosoma— se dice que conocemos la fase de ligamiento de ese individuo. Precisa-mente es el hecho de conocer la fase de ligamiento en el individuo transmisor lo quehace que todas las meiosis de este individuo sean informativas, y nos permite deter-minar con certeza si los individuos de la descendencia son recombinantes o no.
Se recordará que en el caso concreto de esta familia había un individuo recombi-nante de un total de seis, lo que sugiere que ambos loci (el marcador y el gen de la en-fermedad) están en ligamiento a una distancia que produce un recombinante de cadaseis individuos (fracción de recombinación θ = 1/6 = 0,17, es decir a una distancia ge-nética de 17 cM). El principal problema es que este resultado podría haberse dadopor azar: teóricamente es posible que no haya ligamiento y que una descendencia másnumerosa nos mostrase una fracción de recombinación más cercana al 50 por cientode individuos recombinantes. Frente a esta «hipótesis nula» (no ligamiento) tenemosuna hipótesis alternativa de que existe ligamiento entre ambos loci, a una distancia talque origina una θ = 0,17. ¿Cómo podemos determinar cuál de las dos hipótesis es laverdadera o, al menos, la que mejor explica los datos obtenidos en esta familia?
11.3 El cálculo del LOD score
Para cuantificar la significación de cada una de estas hipótesis, los estudios de liga-miento utilizan un método llamado «Estimación de la Máxima Verosimilitud» («ve-rosimilitud» es la traducción del término inglés likelihood). Este método consiste enestimar la verosimilitud de cada hipótesis, calculando la probabilidad de encontrar-nos con esa fracción de recombinación cuando se verifica esa hipótesis. Por ejemplo,para estimar la verosimilitud de la hipótesis de ligamiento, calculamos la probabili-dad de obtener un recombinante de cada seis individuos en el caso de que exista li-gamiento a una distancia de 17 cM; para estimar la verosimilitud de la hipótesis nula,calculamos la probabilidad de obtener un recombinante de cada seis individuos en elcaso de que no exista ligamiento, y así sucesivamente. El razonamiento matemáticopara estimar estas probabilidades se puede ilustrar con un ejemplo del lanzamientode monedas.
La Figura 11.4 ilustra el modo de estimar la verosimilitud de una hipótesis.
Aplicando esta forma de proceder al árbol que hemos venido estudiando, recor-damos que hay cinco individuos no-recombinantes y un recombinante, luego formu-lamos la hipótesis H1 de que la distancia entre el locus de la enfermedad y el locus
144
Ligamiento genético en hum
anos
CAPITULO 11 5/12/06 07:19 Página 144
www.FreeLibros.me

del marcador es tal que producen una frecuencia de recombinación θ = 1/6. Por tan-to, bajo esta hipótesis, la probabilidad de encontrar un individuo recombinante esP(R) = 1/6, y la probabilidad de encontrar un no-recombinante es P (NR) = 5/6. La ve-rosimilitud de que esta hipótesis (H1, θ = 1/6) explique nuestros datos experimentales(5 no-recombinantes y 1 recombinante) se calcula aplicando la fórmula general:
L (H1) = θR × (1 – θ)NR
Por el contrario, la verosimilitud de la hipótesis nula para explicar nuestros datossería:
L (H0) = θ(R + NR)
Para calcular cuántas veces más verosímil es nuestra hipótesis que la hipótesisnula, hallamos el cociente de verosimilitudes (likelihood ratio). En Genética Huma-na, para que este cociente sea significativo al 95 % se requiere que sea mayor o iguala 1 000. Es fácil darse cuenta de que uno de los principales problemas que nos en-contramos es el tamaño pequeño de las generaciones, al contrario de los estudios deligamiento que se hacen en otras especies. Una forma de solventar este problema esrepetir el análisis en varias familias distintas, y combinar los resultados obtenidos encada una de ellas con el fin de aumentar la potencia estadística de los estudios de li-gamiento. Para poder combinar resultados de familias distintas, Newton Morton ideóel concepto del Lod score (que podría traducirse como «puntuación lod» y se repre-senta por la letra Z), que es el log
10del cociente de verosimilitudes. Por tanto, un co-
ciente de verosimilitudes = 1 000 equivale a un lod score igual a 3 (Z = 3), y éste esprecisamente el valor mínimo de Z que se requiere para poder afirmar que existe li-gamiento significativo entre dos loci.
Para hallar el lod score máximo de todos los posibles, es habitual utilizar progra-mas informáticos que calculan directamente el lod score que se obtiene para variashipótesis de ligamiento y a distintos valores de θ. Además, como los resultados deuna sola familia raras veces serán significativos, necesitamos combinar los resultadosobtenidos a partir de los datos de varias familias. Para ello, se suman los lod scores(Z) obtenidos para cada θ en las distintas familias que estamos analizando, hastaidentificar la fracción de recombinación θ a la que obtenemos el lod score máximoen el conjunto de las familias analizadas. Éste es el valor que finalmente nos per-mitirá afirmar si existe o no ligamiento significativo entre el gen de la enfermedad yeste marcador. Además, como la Z máxima se obtiene a una fracción de recombina-ción concreta, podemos también estimar la distancia genética más probable entreambos loci, expresada —como siempre— en centimorgans. Por ejemplo, si la Z máxi-ma se obtuvo a una θ = 0,16, la distancia genética entre ambos loci estará en tornode 16 cM, con un intervalo de confianza cuyo cálculo es también sencillo.
La Figura 11.5 incluye un vídeo y varios gráficos que explican el modo de calcular el LOD store.
Un problema muy importante en los estudios de ligamiento es que muchas vecesno podemos deducir la fase de ligamiento en el progenitor que transmite la enfer-
145
El cálculo del LOD score
CAPITULO 11 5/12/06 07:19 Página 145
www.FreeLibros.me

medad, al no poder establecer con exactitud si un alelo concreto del marcador estáen el mismo cromosoma que lleva el alelo mutado o si está en el cromosoma homó-logo. Lógicamente, esto impide establecer si un individuo de la descendencia es re-combinante o no, y por tanto complica mucho el cálculo de la fracción de recombi-nación. De hecho, hay dos posibles fases de ligamiento que tienen la mismaprobabilidad, y esto ha de tenerse en cuenta a la hora de estimar la verosimilitud decada hipótesis. Así, se calcula el cociente de verosimilitudes para cada una de las fa-ses de ligamiento alternativas y se halla el lod score promedio de ambas:
Z (θ) = log10[1/2[θR(1 – θ)NR/0,5(R + NR)] + 1/2[θNR(1 – θ)R/0,5(R + NR)]]
Lógicamente, el desconocimiento de la fase de ligamiento en el individuo quetransmite la enfermedad hace que el valor final del lod score sea más bajo, por lo que–si los loci estudiados están realmente en ligamiento— será necesario estudiar un ma-yor número de familias para poder alcanzar el valor umbral de Z = 3.
Es muy útil representar los valores que adopta el lod score Z en función de losdistintos valores de la fracción de recombinación θ. Cuando se hace esto, podemosobservar varios tipos posibles de curva:
• Si no se ha encontrado ningún individuo recombinante en ninguna de las fa-milias estudiadas, esto quiere decir que los dos loci que estamos estudiando(el locus de la enfermedad y el del marcador) están en ligamiento y tan cer-canos entre sí que no se producen sobrecruzamientos entre ellos. El lod sco-re es máximo a θ = 0, para ir bajando hasta Z = 0 para una θ = 0,5.
• Cuando existe ligamiento, lo más habitual es hallar una curva de forma para-bólica, con un pico máximo de lod score a una determinada fracción de re-combinación. En estos casos el lod score a la fracción de recombinación θ = 0debe ser (– ∞), ya que hemos encontrado individuos recombinantes en algu-na de las familias y esto hace imposible la hipótesis de que la fracción de re-combinación sea cero. El intervalo de confianza de la fracción de recombina-ción máxima se calcula trazando una horizontal una unidad de lod score pordebajo de la Z máxima, y viendo dónde corta ambas ramas de la curva. Comosiempre, el lod score Z se hace 0 para una fracción de recombinación θ = 0,5,pues en este caso el cociente de verosimilitudes L(H1)/L(H0) = 1, y el log10de 1 es igual a 0.
• En ocasiones, la curva alcanza valores de Z inferiores a –2. En estas circuns-tancias podemos afirmar que NO existe ligamiento por debajo de una deter-minada fracción de recombinación θ y por tanto ambos loci necesariamenteestán a una distancia genética superior a la indicada por esa fracción de re-combinación (si es que efectivamente están en ligamiento).
• Finalmente, hay ocasiones en que no encontramos ligamiento significativo,pero tampoco podemos excluirlo para ninguna de las θ estudiadas, puesto queno hay ningún valor de lod score que sea superior a +3 o inferior a –2. En es-tos casos no podemos extraer ninguna información útil de los datos obtenidosde estas familias.
146
Ligamiento genético en hum
anos
CAPITULO 11 5/12/06 07:19 Página 146
www.FreeLibros.me

11.4 Ligamiento no paramétrico y su utilización 11.4 en Genética Humana
Como acabamos de ver, uno de los requisitos para poder hacer estudios de liga-miento mediante el cálculo de lod score es conocer el tipo de herencia de la enfer-medad que estamos estudiando, ya que sin esta información es imposible detectar lapresencia de individuos recombinantes. De hecho, los programas informáticos querealizan los cálculos para el análisis de ligamiento exigen que se introduzcan variosparámetros indicando el tipo de herencia (autosómica dominante, recesiva, etc.). Pordesgracia, la mayoría de las enfermedades complejas (aquellas que están determina-das por varios genes y por factores ambientales) no siguen un patrón hereditariomendeliano típico, por lo que los estudios de ligamiento clásicos que se han estudia-do hasta ahora no se pueden aplicar. En estos casos hay que acudir a métodos de li-gamiento que no requieren ajuste de la muestra a un modelo concreto de herencia,llamados por tanto métodos no-paramétricos o independientes de modelo.
Hay básicamente dos tipos de pruebas, las que detectan ligamiento y las que de-tectan asociación alélica. Es muy importante darse cuenta de la diferencia entre am-bos conceptos: el ligamiento es un fenómeno que afecta a loci —se dice, por ejemplo,que dos loci están en ligamiento a una distancia determinada— pero el alelo del mar-cador que «viaja» con el alelo de la enfermedad puede ser diferente en familias dis-tintas. Por ejemplo, en una familia concreta podemos detectar ligamiento porque laenfermedad siempre segrega junto con el alelo A1 de un marcador, pero en otra fa-milia distinta (con la misma enfermedad) el alelo mutado puede viajar con el aleloA5 de ese mismo marcador. Ambos loci (el marcador y el gen de la enfermedad) es-tán en ligamiento pero en cambio no siempre se dan las mismas asociaciones de ale-los en todas las familias. Esto es así porque existe una situación de equilibrio deHardy-Weinberg entre ambos loci, de manera que cada alelo de uno de los locus pue-de encontrarse con cualquiera de los alelos del otro locus. Los métodos de análisisde ligamiento no paramétricos que detectan asociación alélica buscarán precisamen-te desviaciones de esta situación de equilibrio, detectando la presencia de un haplo-tipo (una determinada combinación de alelos para dos loci distintos, en nuestro casoserían el alelo mutado y un alelo concreto del marcador) que se encuentre con ma-yor frecuencia de la que cabría esperar si esos loci estuviesen en equilibrio. Si de-mostramos que, incluso en familias distintas, la enfermedad se asocia significativa-mente con un alelo concreto del marcador, podemos decir que existe asociaciónalélica; como la principal causa de asociación alélica es el desequilibrio de liga-miento por cercanía física de ambos loci (están tan cercanos uno al otro que no seha alcanzado todavía el equilibrio de Hardy-Weinberg entre ellos), la asociación alé-lica se traduce en cercanía física. Por tanto, podemos servirnos de la asociación alé-lica para localizar genes responsables de enfermedades complejas.
A continuación se explica brevemente cómo funciona cada uno de estos métodos:
1. Los métodos que detectan ligamiento buscan alelos compartidos por todoslos individuos que están enfermos en una misma familia. Para comprendercómo se hace esto, es importante aprender a distinguir los alelos que son
147
Ligamiento no param
étrico y su utilización en Genética Hum
ana
CAPITULO 11 5/12/06 07:19 Página 147
www.FreeLibros.me

idénticos por descendencia (situación que se denomina IBD: identical bydescent) de los alelos que son idénticos por estado (IBS: identical by state).
En la Figura 11.6 se intenta mostrar el concepto de alelos IBD y alelos IBS.
1. Los estudios de alelos idénticos por descendencia entre individuos enfermosde una misma familia se basan en el hecho de que los hermanos que padecenuna misma enfermedad tienen mayor probabilidad de compartir el segmentogenómico que contiene el gen causante de esa enfermedad. En ese segmentotambién habrá, en la vecindad del gen, algunos marcadores (polimorfismos), ypor tanto esas parejas de hermanos también serán idénticos por descenden-cia para los alelos de esos marcadores. En general, se puede demostrar quedos hermanos tienen una probabilidad del 25 por ciento de tener dos aleloscualesquiera idénticos por descendencia (probabilidad de 1/4), una probabili-dad del 50 por ciento de compartir un alelo IBD (dos de cuatro posibilidades)y una probabilidad del 25 por ciento de no compartir ningún alelo IBD. Encambio, si ambos hermanos han heredado la enfermedad, compartirán el seg-mento genómico que contiene el gen causal, incluidos los marcadores cerca-nos, por lo que encontraremos alelos IBD de esos marcadores en una fre-cuencia superior a la esperable por el azar. Por ejemplo, en una enfermedadautosómica dominante el 50 por ciento de los hermanos enfermos comparti-rán en promedio dos alelos IBD, y el 50 por ciento restante compartirán unalelo IBD; en el caso extremo de una enfermedad autosómica recesiva, todoslos hermanos afectados compartirán como promedio dos alelos IBD.
1. Por tanto, para realizar estas pruebas es preciso analizar miles de marcado-res dispersos por todo el genoma en un número bastante grande de parejasde hermanos enfermos, y así detectaremos una frecuencia de alelos IBD sig-nificativamente superior a lo que sería esperable por el azar para aquellosmarcadores cercanos al gen de la enfermedad. Por esta razón, este método sedenomina frecuentemente ASP (affected sib-pair, parejas de hermanos afec-tados), porque busca regiones que sean idénticas por descendencia en pare-jas de hermanos afectados por la misma enfermedad. Como a veces no es fá-cil contar con el número suficiente de parejas de hermanos enfermos, otra
148
Ligamiento genético en hum
anos
3-41-2
1-3 1-3
3-41-2
1-3 1-31-42-32-4
3-41-2
1-3 1-31-4
2 IBD
1 IBD
0 IBD
2 IBD1 IBD 2 IBD
-1-
}
CAPITULO 11 5/12/06 07:19 Página 148
www.FreeLibros.me

variante de este método estudia miembros más distantes de una misma fami-lia, conocido como APM (affected pedigree member, miembro afectado del ár-bol familiar). Como se ha mencionado, para poder detectar ligamiento utili-zando estos métodos es necesario genotipar un número elevado demarcadores distribuidos por todo el genoma y detectar aquellos cuyos alelosson compartidos por parientes enfermos en proporciones significativamentemayores a lo esperable por azar. Estos análisis se realizan utilizando progra-mas informáticos, tales como SIBPAL o GENEHUNTER. Además, Hase-man y Elston desarrollaron un algoritmo para aplicar esto mismo a variablescuantitativas (cualquier variable cuantificable numéricamente), haciendo unagráfica que representa la diferencia entre hermanos para esa variable elevadaal cuadrado (en ordenadas), frente al porcentaje de alelos IBD compartidospor hermanos (en abscisas). Si la pendiente de la recta de ajuste es significa-tivamente negativa, esto indica que hay ligamiento, ya que en ausencia de li-gamiento los valores deben distribuirse alrededor de una línea vertical cen-trada en torno al 50 por ciento de alelos IBD.
2. Detección de asociación alélica. Cuando no se dispone de parejas de her-manos para estudios que buscan alelos idénticos por descendencia, se puedenhacer estudios de asociación alélica para detectar un marcador muy cercanoal gen que causa una enfermedad. Aunque los estudios de asociación alélicapueden emplearse también en cualquier situación, resultan especialmente úti-les en poblaciones aisladas sometidas a cierto efecto fundador, en las que to-davía no han pasado el número suficiente de generaciones para que todos losalelos presentes en la población hayan llegado a una equilibrio de Hardy-Weinberg. Por ejemplo, la identificación del gen que está mutado en una en-fermedad llamada Hemocromatosis Hereditaria se identificó gracias a que lamutación específica se originó en una región geográfica concreta, y hoy en díase encuentra especialmente en poblaciones de origen celta.El tipo de familia que se necesita para los estudios de asociación es muy sen-cillo: ambos padres y un solo descendiente enfermo. El cálculo puede hacer-se mediante dos pruebas: TDT (Transmission-Disequilibrium Test, prueba detransmisión del desequilibrio) o HRR (Haplotype Relative Risk, riesgo rela-tivo de un haplotipo), aunque el más popular y más usado es el método delTDT. Para realizar este test, se analiza un mismo marcador en varias familiasdistintas, escogiendo un marcador para el que los progenitores sean hetero-cigotos; a continuación se compara la frecuencia con la que se transmite cadaalelo de los padres al hijo afectado. Al hacer esto en varias familias, podemosdetectar si hay algún alelo concreto del marcador que se transmita preferen-cialmente a los hijos afectados sobre lo que sería esperable por el azar. Porejemplo, si a es el número de veces que un progenitor transmite el alelo A1de un marcador, y b es el número de veces que transmite un alelo distinto aA1, se puede demostrar que el estadístico (a – b)2/(a + b) sigue una distribu-ción chi-cuadrado con un grado de libertad. Si la frecuencia de transmisiónde este alelo a hijos enfermos es significativamente más alta de lo esperablepor azar, podemos concluir que existe asociación alélica y que, por tanto, elgen de la enfermedad está muy cercano a este marcador. Lógicamente, como
149
Ligamiento no param
étrico y su utilización en Genética Hum
ana
CAPITULO 11 5/12/06 07:19 Página 149
www.FreeLibros.me

a priori no sabemos dónde está localizado el gen, hay que hacer el análisisutilizando miles de marcadores distribuidos por todo el genoma, hasta darcon uno que muestre asociación con la enfermedad.
La Figura 11.7 ilustra el Test de Transmisión de Desequilibrio (TDT) como medida de asociaciónalélica.
Como resumen, a la hora de escoger un método para la detección de genes res-ponsables de enfermedades complejas hemos de tener en cuenta el tipo de familiasde que disponemos, así como factores de tipo material y económico (derivados delaltísimo número de genotipajes que es necesario realizar). Aunque los tests de ASPrequieren menos genotipajes, la región genómica compartida que detectan es bas-tante grande, por lo que la identificación posterior del gen que causa la enfermedadsería más laboriosa. Por eso, lo ideal es complementar un estudio de ASP con es-tudios de asociación alélica, que requieren el genotipaje de muchos más individuos,pero revelan regiones genómicas habitualmente menores a 1 megabase. Aunque losestudios que utilizan ligamiento no-paramétrico o asociación alélica suelen dar re-sultados cuya significación es difícil de cuantificar, y a menudo los resultados obte-nidos en estudios distintos no concuerdan entre sí, son los únicos métodos válidospara localizar genes implicados en el desarrollo de enfermedades complejas (poligé-nicas y multifactoriales). Precisamente son estas enfermedades las que tienen mayorrepercusión socio-sanitaria, por afectar a gran parte de la población.
Las nuevas tecnologías de genotipaje que utilizan marcadores tipo SNP (SingleNucleotide Polymorphisms, ya vistos anteriormente) han acelerado enormemente laidentificación de genes que confieren susceptibilidad a enfermedades comunes. Porejemplo, en los últimos años se ha demostrado asociación entre el gen CAPN10 y lasusceptibilidad a desarrollar diabetes tipo 2, así como también entre un polimorfismoen el gen de la interleuquina 12 y la diabetes tipo 1. Es previsible que en los próximosaños se identifiquen las principales variantes que confieren susceptibilidad a las en-fermedades más frecuentes. Por ejemplo, podemos pensar que en un futuro no muylejano un paciente hipertenso que acuda a la consulta genética será estudiado para de-tectar variantes de susceptibilidad en varios genes, y gracias a los resultados se le cla-sificará dentro de un grupo molecular determinado que permitirá asignarle un trata-miento dietético o farmacológico específico. Desde este punto de vista, el genotipajede polimorfismos concretos puede convertirse en un análisis de rutina en el diagnós-tico de un número creciente de enfermedades humanas en el próximo decenio.
En este sentido, es importante detectar los SNP que pueden ser más informativosen estos estudios: se estima que en toda la población mundial se encuentran unos 10millones de SNPs en los que ambas variantes alélicas tienen una frecuencia mayor oigual a uno por ciento. A pesar del indudable interés que tienen estos polimorfismospara realizar estudios de asociación alélica, genotipar todos estos SNPs en un nú-mero grande de individuos es, hoy por hoy, impracticable. Podemos salvar este obs-táculo gracias a que muchos SNP, por estar muy cerca físicamente, se heredan jun-tos en pequeños bloques en los que todavía no se ha alcanzado el equilibrio deHardy-Weinberg. Es decir, se pueden identificar bloques de desequilibrio de liga-miento en el genoma, puesto que los alelos de los SNP que están en un mismo blo-
150
Ligamiento genético en hum
anos
CAPITULO 11 5/12/06 07:19 Página 150
www.FreeLibros.me

que están en desequilibrio de ligamiento. La combinación concreta de alelos de losdistintos SNP que están en un mismo bloque constituye un haplotipo característicode ese bloque. Por tanto, un grupo reducido de SNPs de cada haplotipo pueden serrepresentativos de todo ese haplotipo (por lo que reciben el nombre de tag-SNPs, oSNP-etiqueta); de este modo, no es necesario genotipar todos los SNPs del genoma,sino sólo los SNP-etiqueta. De hecho, se estima que bastaría con analizar unos200 000 para cubrir todos los haplotipos del genoma humano, y esa es una cifra quese puede estudiar con la metodología actual. Recientemente se ha publicado un mapade 1,6 millones de SNPs que han sido genotipados en 71 individuos estadounidensesde ascendencia europea, asiática y africana. Este mapa fue completado por el Pro-yecto Internacional Hapmap, que publicó en 2005 un mapa con todos los haploti-pos de SNPs presentes en diversas poblaciones humanas, como se ha explicado en elCapítulo 4. Este mapa permite identificar la estructura y el tamaño de los bloques dedesequilibrio de ligamiento del genoma, y hará posible la realización de estudios deasociación para identificar las regiones donde residen los genes que confieren sus-ceptibilidad a enfermedades comunes.
151
Ligamiento no param
étrico y su utilización en Genética Hum
ana
CAPITULO 11 5/12/06 07:19 Página 151
www.FreeLibros.me

CAPITULO 11 5/12/06 07:19 Página 151
www.FreeLibros.me

C A P Í T U L O 1 2
Los genes en las poblaciones
Contenidos
12.1 El equilibrio de Hardy-Weinberg
12.2 Cambios en las condiciones que mantienen el equilibrio: cruzamientos no aleatorios
12.3 Cambios en las condiciones que mantienen el equilibrio: efectos del tamaño poblacional
12.4 Cambios en las condiciones que mantienen el equilibrio: migración o flujo genético
12.5 Cambios en las condiciones que mantienen el equilibrio: recombinación y mutación
12.6 Cambios en las condiciones que mantienen el equilibrio: selección
12.7 Aplicaciones en Genética Humana
12.8 Formación de la Teoría Sintética de la Evolución
12.9 Explicación actual del proceso evolutivo y sus limitaciones
La evolución biológica es el resultado de los cambios en los tipos y frecuencias de los ale-los existentes en una población de individuos, siempre y cuando dichos cambios sontransmitidos a la generación siguiente. En otras palabras, la evolución es el cambio enla constitución genética de una población a lo largo del tiempo. Es importante com-prender que: i) el hecho de que los cambios sean heredables quiere decir que la base mo-lecular de la evolución está en los genes; ii) la evolución no afecta a individuos, sino apoblaciones.
12.1 El equilibrio de Hardy-WeinbergLa elaboración del concepto actual de evolución se remonta a los orígenes de la genéti-ca de poblaciones, que describe la estructura genética de una población de individuos ypredice sus cambios en el tiempo. G. H. Hardy y W. Weinberg demostraron en 1908 queen una población sometida a unas condiciones determinadas se observa que: i) las fre-cuencias de los alelos se mantienen estables durante sucesivas generaciones, y ii) las fre-cuencias genotípicas también se mantienen constantes, debido a que dependen exclusi-
CAPITULO 12 5/12/06 07:22 Página 153
www.FreeLibros.me

vamente de las frecuencias alélicas. Estos postulados se conocen como la Ley delequilibrio de Hardy-Weinberg. Cuando no se dan las condiciones necesarias paraque se cumplan estos presupuestos, aparecen alelos nuevos en la población o bien lasfrecuencias alélicas cambian. Esto, a su vez, crea las condiciones básicas necesariaspara que pueda darse evolución. Las condiciones que deben cumplirse para que unapoblación se encuentre en equilibrio genético, es decir, para que se cumpla la Ley deHardy-Weinberg, son:
• Población de tamaño grande en la que todos los individuos se reproducen.
• Los cruzamientos entre individuos de la población se producen al azar.
• Ausencia de mutación.
• Ausencia de selección natural.
• Ausencia de flujos migratorios.
Lógicamente, en la práctica es muy improbable encontrar una población en la que secumplan todas estas condiciones, por lo que la evolución es un hecho tan frecuenteen la naturaleza.
La gran aportación metodológica de Hardy y Weinberg es que permite abordar elestudio de los cambios en la estructura genética de una población en términos mate-máticos precisos. En primer lugar, dedujeron una ecuación que permite predecir las fre-cuencias genotípicas a partir de las frecuencias alélicas, y por tanto saber si una pobla-ción se encuentra en equilibrio. Según la ecuación del equilibrio de Hardy-Weinberg,
p2 + 2pq + q2 = 1
siendo p y q las frecuencias de los dos alelos A y a de un gen que controla un carác-ter fenotípico. En estas circunstancias, en una especie diploide, encontraremos in-dividuos con tres posibles genotipos: AA, aa y Aa. Por tanto, es fácil establecer la re-lación entre frecuencias alélicas y frecuencias genotípicas:
p = AA + 1/2 Aaq = aa + 1/2 Aa
Lógicamente, al haber sólo dos alelos se cumple que
p + q = 1p = 1 – qq = 1 — p
De aquí se puede deducir que las frecuencias de los genotipos de los individuosde la población se distribuyen según la expansión del binomio:
(p + q)2 = p2 + 2pq + q2
es decir, p2 es la frecuencia de individuos con el genotipo AA, q2 es la frecuencia deindividuos con el genotipo aa, y 2pq es la frecuencia de individuos heterocigotosAa. Lógicamente, el total es el 100 por cien de los individuos de la población, luego
p2 + 2pq + q2 = 1
Llegados a este punto es importante recalcar una serie de conceptos fundamenta-les. En primer lugar, las frecuencias alélicas son en sí mismas estables. Este concep-to es muy importante y fue revolucionario en su momento, porque hasta Hardy y
154
Los genes en las poblaciones
CAPITULO 12 5/12/06 07:22 Página 154
www.FreeLibros.me

Weinberg se pensaba que los alelos dominantes van desplazando a los alelos recesivosde la población con el transcurso del tiempo, hasta eliminarlos por completo. Hardyy Weinberg demostraron que esto no es así, siempre que se cumplan las condicionesbásicas de equilibrio. De hecho, no todas las desviaciones del equilibrio producenevolución, porque muchas veces se alteran las frecuencias genotípicas sin que cambienlas frecuencias alélicas. Como veremos a lo largo de este capítulo, cuando no se cum-ple alguna de las condiciones necesarias para el equilibrio genético podemos tenercambios en las frecuencias alélicas, en las frecuencias genotípicas, o en ambas.
12.2 Cambios en las condiciones que mantienen el equilibrio:12.2 cruzamientos no aleatorios
Hardy y Weinberg demostraron que, en una población que no esté sometida a nin-guna fuerza evolutiva, las frecuencias alélicas se mantendrán constantes en genera-ciones sucesivas siempre que los cruzamientos entre individuos sean aleatorios.Por ejemplo, para un carácter determinado por un gen que tiene dos alelos A y a, demodo que la mitad de los alelos sean A y la otra mitad sean a (frecuencias alélicasde 0,5 para cada alelo), las frecuencias genotípicas serán 0,25 AA, 0,5 Aa y 0,25 aa.Si los individuos de esta población se reproducen al azar, encontraremos teórica-mente nueve tipos de cruzamientos, todos en la misma proporción:
AA × AA Aa × AA aa × AAAA × Aa Aa × Aa aa × AaAA × aa Aa × aa aa × aa
Si ahora calculamos los genotipos de la descendencia que resulta de cada cruza-miento, asignando cuatro descendientes por pareja, tendremos los resultados que semuestran en la siguiente tabla:
Cruzamiento aleatorio
Cruzamientos posibles Genotipos esperados en la descendenciaAA Aa aa
AA × AA 4AA × Aa 2 2AA × aa 4Aa × AA 2 2Aa × Aa 1 2 1Aa × aa 2 2aa × AA 4aa × Aa 2 2aa × aa 4
Total 9 (25 %) 18 (50 %) 9 (25 %)
Como se puede comprobar, en la descendencia se mantienen las frecuencias ge-notípicas que existían en la generación anterior: 25 por ciento de individuos AA, 50
155
Cambios en las condiciones que m
antienen el equilibrio: cruzamientos no aleatorios
CAPITULO 12 5/12/06 07:22 Página 155
www.FreeLibros.me

por ciento de individuos Aa y 25 por ciento de individuos aa. Si contamos el nú-mero de alelos A y a que hay en la nueva población, vemos que también las fre-cuencias alélicas se han mantenido estables (50 por ciento de alelos A y 50 por cien-to de alelos a).
En la naturaleza es bastante frecuente que los cruzamientos no se realicen to-talmente al azar. En muchas especies, los individuos se cruzan preferencialmente conotros que tienen ciertas características fenotípicas (y, por tanto, determinados genoti-pos). Esto rompe las condiciones de equilibrio y cambia las proporciones genotípicasesperadas. En los procesos de mejora animal y vegetal se utilizan a veces cruzamien-tos dirigidos, con el fin de obtener individuos que tengan determinadas característi-cas fenotípicas (tamaño de la flor, cantidad de carne, etc.). En humanos tampoco esraro que se den cruzamientos preferenciales por razones culturales, sociales, étnicas,geográficas, etc. Se distinguen varios tipos de cruzamientos preferenciales:
Cruzamiento preferencial positivo: en este caso, los individuos tienden a cru-zarse con otros que comparten sus mismas características fenotípicas. En el casomás extremo, sólo tendremos cruzamientos de individuos genotípicamente iguales, esdecir AA X AA, Aa X Aa y aa X aa. Por tanto, habrá un incremento en el porcenta-je de homocigotos y una disminución en la proporción de heterocigotos:
Cruzamiento Preferencial Positivo
Cruzamientos posibles Genotipos esperados en la descendenciaAA Aa aa
AA × AA 4AA × Aa 1 2 1aa × aa 4
Total 5 2 5(42 %) (17 %) (42 %)
Nótese que en una sola generación las frecuencias genotípicas han variado sus-tancialmente apartándose del equilibrio, aunque las frecuencias alélicas se mantie-nen en 50 por ciento A y 50 por ciento a.
Cruzamiento preferencial negativo: es muy raro en humanos, y se da cuando losindividuos se cruzan preferencialmente con otros que tienen características fenotípi-cas distintas a las suyas. Teóricamente, se producirían seis tipos de cruzamientos, conun aumento en la proporción de heterocigotos y un descenso en las proporciones dehomocigotos:
Cruzamiento Preferencial Negativo
Cruzamientos posibles Genotipos esperados en la descendenciaAA Aa aa
AA × Aa 2 2
156
Los genes en las poblaciones
(continúa)
CAPITULO 12 5/12/06 07:22 Página 156
www.FreeLibros.me

AA × aa 4Cruzamiento Preferencial Negativo
Cruzamientos posibles Genotipos esperados en la descendenciaAA Aa aa
Aa × AA 2 2Aa × aa 2 2aa × AA 4aa × Aa 2 2
Total 4 16 4 (17 %) (67 %) (17 %)
Nótese que, nuevamente, las frecuencias genotípicas se apartan del equilibriopero las frecuencias alélicas se mantienen constantes (50 por ciento A y 50 porciento a).
Endogamia: la endogamia (o consanguinidad, como se denomina en poblacioneshumanas) es el cruzamiento entre individuos que guardan algún tipo de parentesco,es decir, que comparten un ancestro común. Constituye una forma extrema de cru-zamiento preferencial positivo, ya que los individuos comparten una gran proporciónde sus alelos (1/2 en el caso de hermanos, 1/8 en el caso de primos hermanos, etc.). Laendogamia se puede cuantificar mediante el coeficiente de endogamia (F), que midela probabilidad de que dos alelos en dos individuos de una población procedan deun ancestro común (es decir, sean idénticos por descendencia). El cociente de en-dogamia F puede variar entre 0 (cruzamiento aleatorio) y 1 (todos los alelos son idén-ticos porque proceden del mismo progenitor). Cuando nos encontramos en una si-tuación de endogamia, las frecuencias genotípicas van a cambiar de tal forma que lafrecuencia de homocigotos AA = p2 + Fpq, la frecuencia de heterocigotos Aa = 2pq– 2Fpq y la frecuencia de homocigotos aa = q2 + Fpq. Es decir, con cada generaciónde cruces endogámicos, la frecuencia de heterocigotos disminuye y la de homocigo-tos aumenta. En el caso de retrocruzamientos con un progenitor (como suele hacer-se para conseguir líneas puras de ratones, por ejemplo), F = 0,5 y la frecuencia deheterocigotos disminuye a la mitad con cada generación. En general, el cruza-miento preferencial puede hacer que en pocas generaciones aumente enormementela proporción de individuos que son homocigotos para un genotipo. El problema esque a veces un carácter resulta deletéreo y los individuos homocigotos tienen su via-bilidad o su fertilidad reducidas, por lo que toda la población se ve afectada. Este fe-nómeno se conoce como depresión endogámica. Lógicamente, la endogamia es unfenómeno más grave que el apareamiento preferencial, ya que en este último sólo sealteran las frecuencias genotípicas para uno o varios genes (aquellos que controlanel carácter que condiciona la preferencia del apareamiento). La endogamia, por elcontrario, afecta a todo el genoma y tiene consecuencias más severas.
Aunque la gente piensa que los hijos de matrimonios consanguíneos tienen unaalta probabilidad de sufrir anomalías, esto no es necesariamente así. Únicamente
157
Cambios en las condiciones que m
antienen el equilibrio: cruzamientos no aleatorios
(continuación)
CAPITULO 12 5/12/06 07:22 Página 157
www.FreeLibros.me

cuando en la familia hay algún alelo recesivo deletéreo, habrá mayor frecuencia dehomocigotos para ese alelo como fruto de la consanguinidad. Un ejemplo de lo an-terior es el de la comunidad Amish de Pennsylvania y Ohio, que llevan varios siglosviviendo aislados por razones culturales y religiosas. Los matrimonios repetidos en-tre miembros de la misma comunidad han provocado una situación de endogamia enla que han aflorado algunas enfermedades recesivas que son mucho más frecuentesen esta población que en la población general. En este sentido, estudios hechos enniños japoneses han encontrado que cada aumento del 10 por ciento de F conllevauna disminución de seis puntos del cociente intelectual; además, en ese mismo estu-dio se vio que la descendencia de primos hermanos (en la que F = 0,0625) sufrió unamortalidad 40 por ciento superior a la de niños de matrimonios no endogámicos. Detodas formas, estudios hechos en varias poblaciones han determinado que la descen-dencia de primos hermanos sólo tiene un riesgo de sufrir malformaciones congénitasaproximadamente dos por ciento superior al que existe en la población general, y dehecho los matrimonios entre primos hermanos son relativamente frecuentes en cier-tas culturas, como en la hindú o la árabe.
Hemos visto qué sucede cuando no se cumple una de las condiciones necesariaspara mantener el equilibrio de Hardy-Weinberg en una población. Recordemos quela ausencia de cruzamientos aleatorios provoca un desvío del equilibrio, con cambiosmarcados en las frecuencias genotípicas pero sin afectar a las frecuencias alélicas. Acontinuación estudiaremos otras situaciones que, además de alterar las frecuen-cias genotípicas, también producen cambios en las frecuencias alélicas en la po-blación.
12.3 Cambios en las condiciones que mantienen el equilibrio: 12.3 efectos del tamaño poblacional
Con cierta frecuencia se producen cambios aleatorios en el número de alelos que pa-san de una generación a la siguiente, por un efecto de error de muestreo. Dicho errorse debe a que en una población no siempre se reproducen todos los individuos, porlo que en la siguiente generación sólo tendremos un subgrupo de los alelos que esta-ban presentes en la generación anterior, y esto da lugar a oscilaciones aleatorias enlas frecuencias alélicas de una generación a la siguiente.
Este fenómeno se conoce como deriva genética aleatoria, y es equivalente a sa-car bolas de un saco que contiene, por ejemplo, 50 bolas blancas y 50 bolas negras(100 bolas en total). Si sacamos 40 bolas para formar 20 parejas (lo que sería equi-valente a sacar alelos de una población para generar individuos diploides en la ge-neración siguiente), lo normal es observar pequeñas desviaciones respecto a la pro-porción teórica esperada de 20 bolas blancas y 20 bolas negras. De este modo, concada generación (cada vez que sacamos bolas de una bolsa), las frecuencias alélicasoscilan por efecto del azar. Además, estas oscilaciones serán mayores cuanto menorsea el tamaño de la población. Por ejemplo, si de la bolsa que contiene 100 bolas sa-camos sólo 10 bolas, no sería de extrañar que obtuviésemos grupos de 10 bolas enlos que la mayoría fuesen de un mismo color. Incluso, por mero azar, podríamos sa-car 10 bolas blancas, en cuyo caso el color blanco se habría fijado en la nueva po-
158
Los genes en las poblaciones
CAPITULO 12 5/12/06 07:22 Página 158
www.FreeLibros.me

blación ya que habría desaparecido la posibilidad de sacar bolas negras en sucesivasgeneraciones. Por tanto, en el caso de poblaciones con un pequeño número de indi-viduos que se reproducen, la deriva genética aleatoria puede tener efectos muy mar-cados sobre las frecuencias alélicas, pudiendo incluso hacer que uno de los alelossustituya completamente al otro (se dice entonces que un alelo ha quedado fijado yel otro ha sido «barrido» de la población).
La Figura 12.1 ilustra el error de muestreo y la deriva genética aleatoria.
La deriva genética se puede estimar a partir de la variación alélica existente en lapoblación, que se cuantifica mediante la varianza estadística. En una población detamaño N con frecuencias alélicas p y q, la varianza de la frecuencia alélica (sp
2) sepuede calcular mediante la fórmula sp
2 = pq/2N. En otras palabras, la deriva obser-vada en una población depende de las frecuencias alélicas y del tamaño poblacional.Por el numerador, podemos deducir que la deriva será mayor si las frecuencias aléli-cas son iguales que si son muy dispares. De la fórmula se desprende también que laderiva será más acusada en poblaciones de pequeño tamaño. La deriva genética tie-ne dos efectos principales: origina cambios en las frecuencias alélicas, y puede tam-bién reducir la variabilidad genética cuando alguno de los alelos se fija en la po-blación. Además, como es un fenómeno aleatorio, encontramos que diferentespoblaciones pueden derivar de modo distinto, aunque al principio del proceso ten-gan el mismo tamaño y las mismas frecuencias alélicas.
Dos circunstancias afectan especialmente a poblaciones humanas y provocancambios en las frecuencias alélicas de la población por deriva genética aleatoria. Enprimer lugar, algunas poblaciones humanas actuales han sido fundadas por un pe-queño núcleo inicial de pobladores que han dado lugar a la población actual. Puedesuceder que en el grupo inicial de pobladores existiese algún alelo concreto (porejemplo, una mutación que causa una enfermedad genética) en baja frecuencia. Si to-dos los individuos se reproducen, incluyendo los enfermos, el resultado tras muchasgeneraciones será que ese alelo (y la enfermedad causada por él, en nuestro ejemplo)serán muy frecuentes en la población actual. Este fenómeno se conoce como efectofundador. Hay muchos ejemplos de enfermedades o rasgos genéticos cuya alta fre-cuencia en determinadas poblaciones se puede explicar por un efecto fundador. Porejemplo, la alta frecuencia del grupo sanguíneo 0 entre los indios de América delSur y Central parece deberse a que todos proceden de un pequeño número de po-bladores que entraron por el estrecho de Behring al final de la última glaciación, en-tre los que ese grupo sanguíneo debía ser predominante. Quizás el caso más extremode efecto fundador es el de la enfermedad de Huntington, un desorden neurológicoque se encuentra con una frecuencia mucho más alta de lo normal en una pequeñapoblación del lago Maracaibo, en Venezuela. Parece que la gran mayoría de los po-bladores actuales de esa región, unos 20 000, proceden de una misma mujer que lle-gó a la zona en el siglo XIX y que sufría la enfermedad.
Otro fenómeno similar que perturba las frecuencias alélicas por deriva genéticaaleatoria es el efecto de cuello de botella. En este caso, alguna causa (un desastrenatural, epidemias, guerras) lleva a reducir drásticamente el tamaño de una pobla-ción en una generación, por lo que las frecuencias alélicas de la generación siguien-
159
Cambios en las condiciones que m
antienen el equilibrio: efectos del tamaño poblacional
CAPITULO 12 5/12/06 07:22 Página 159
www.FreeLibros.me

te serán muy distintas a las de la generación anterior. En casos de cuello de botellamuy acentuados, puede llegarse a la pérdida de algún alelo, y a menudo los cuellosde botella provocan una reducción importante en la diversidad genética de la pobla-ción que sobrevive.
Hasta ahora hemos visto situaciones que alteran el equilibrio de Hardy-Weinbergen una población, produciendo cambios en las frecuencias genotípicas y alélicas pordiversos mecanismos. De todas formas, los mecanismos más importantes para gene-rar evolución son los que introducen nuevos alelos en una población (trasladándo-los desde otras poblaciones o generando alelos nuevos a partir de los ya existentes)y la selección natural, que elimina o favorece aquellos alelos que permiten la mejoradaptación de la especie a su medio. En primer lugar veremos los procesos que creannuevos alelos en una población determinada.
12.4 Cambios en las condiciones que mantienen el equilibrio:12.4 migración o flujo genéticoSin duda, los fenómenos migratorios son actualmente la principal causa de entradade alelos nuevos en poblaciones humanas. La llegada de individuos con una consti-tución genética distinta (flujo genético), en la medida en que los nuevos individuosse mezclan con la población existente, hace que las frecuencias alélicas de la pobla-ción receptora cambien o que aparezcan nuevos alelos que antes no estaban presen-tes. Del mismo modo, la población que sufre la emigración también puede verse so-metida a cambios en las frecuencias alélicas, si los individuos que la abandonan noson totalmente representativos del acervo genético de la población.
Por ejemplo, si m individuos de una población 1 en la que un alelo tiene una fre-cuencia q1 migran a otra población 2 en la que ese alelo está en una frecuencia q2,la frecuencia del alelo en la población que resulta después de la migración será q’ =q1m + q2 (1-m). De esta ecuación es fácil deducir que el cambio en la frecuencia alé-lica en la población 2 (la población receptora) es igual a m (q1 – q2), lo que quieredecir que los efectos sobre las frecuencias alélicas dependerán del número de indivi-duos que migran (m) y de la diferencia inicial en las frecuencias alélicas entre ambaspoblaciones. Aunque el efecto de la migración es homogeneizar las diferencias ge-néticas entre poblaciones (al contrario que la deriva o la selección natural, como ve-remos más adelante), es una causa importante de entrada de nuevos alelos y de au-mento de la variabilidad en una población concreta.
12.5 Cambios en las condiciones que mantienen el equilibrio:12.4 recombinación y mutaciónLos fenómenos moleculares capaces de crear nuevos alelos o nuevas combinacionesde alelos ya existentes son la mutación y la recombinación, respectivamente. La re-combinación tiene lugar en las células germinales, durante la meiosis. En el caso dela especie humana, los 23 cromosomas procedentes del gameto masculino se alineancon los procedentes del gameto femenino e intercambian segmentos de material ge-nético. Esto hace que los cromosomas resultantes lleven combinaciones de alelos
160
Los genes en las poblaciones
CAPITULO 12 5/12/06 07:22 Página 160
www.FreeLibros.me

(haplotipos) que no estaban presentes en ninguno de los progenitores. Aunque nose crean nuevos alelos sino nuevas combinaciones de los ya existentes, la recombi-nación constituye un importantísimo mecanismo de creación de diversidad genética.
La mutación es el cambio introducido en el material genético a nivel molecular,alterando la secuencia de nucleótidos. Las mutaciones pueden ser puntuales (si afec-tan únicamente a un nucleótido) o pueden alterar segmentos más o menos grandesdel genoma (alteraciones cromosómicas, por ejemplo). Desde el punto de vista evo-lutivo, las únicas mutaciones que interesan son las que afectan a las células germi-nales, pues son las únicas que se transmitirán a la generación siguiente. Lógicamen-te, además es necesario que la mutación se exprese en un fenotipo, es decir, que alterealguna función biológica. Esto no es lo habitual, ya que la mayoría de las mutacionesson silenciosas (no alteran la secuencia de aminoácidos de la proteína codificada porel gen) y, por tanto, son «neutras» desde el punto de vista evolutivo. Las mutacionesdeletéreas suelen ser eliminadas por selección, aunque a veces quedan en el acervogenético en forma recesiva y pueden aflorar en generaciones futuras (esto es lo quese conoce como «lastre genético»).
En definitiva, cuando la mutación es la única fuerza evolutiva que actúa sobre unapoblación, los cambios en las frecuencias alélicas son muy pequeños y serían nece-sarias muchas generaciones para producir variaciones significativas. Aunque la tasamutacional (el número de mutaciones que se introducen por generación) varía deuna especie a otra y en general es bastante baja, la mutación es la «materia prima»sobre la que actúa la principal fuerza evolutiva: la selección.
Los enlaces de la Figura 12.2 permiten simular el efecto de la migración y la mutación sobre las frecuencias alélicas.
12.6 Cambios en las condiciones que mantienen el equilibrio:12.4 selección
La principal intuición de Charles Darwin, fruto de las observaciones que le llevarona escribir El origen de las especies, fue que el principal mecanismo evolutivo es la se-lección natural. El concepto de selección natural es simple, y podría definirse comola diferente eficacia biológica (entendida como viabilidad o capacidad reproductiva)que confieren alelos distintos. Así, los alelos que permiten una mejor adaptación almedio tienden a ser favorecidos, mientras que los alelos deletéreos tienden a ser eli-minados de la población. Según esto, los alelos neutros, que no confieren ningunaventaja ni desventaja, no estarán sometidos a selección. Un ejemplo muy citado es elde la polilla Biston betularia, estudiada por H. B. D. Kettlewell en la segunda mitaddel siglo XIX en Manchester. Kettlewell observó que antes de 1848 esta especie se en-contraba con dos colores distintos, claro u oscuro, y que las polillas oscuras eran me-nos del dos por ciento de la población de polillas de la zona. Durante los años si-guientes, la proporción de polillas oscuras fue creciendo hasta llegar a constituir el95 por ciento del total en el año 1898. Esto se observaba en las zonas industrializa-das, mientras que en las zonas rurales el aumento de polillas oscuras era menos acu-sado. Como el color de las polillas es un rasgo codificado por un gen, el cambio en
161
Cambios en las condiciones que m
antienen el equilibrio: selección
CAPITULO 12 5/12/06 07:22 Página 161
www.FreeLibros.me

los colores era el resultado de cambios en las frecuencias alélicas. Kettlewell atribu-yó el cambio al hecho de que la industrialización de la región hizo que el hollín sedepositase en los abedules donde se posaban las polillas, y esto hacía que las de co-lor claro destacasen más y fuesen presa más fácil de los pájaros depredadores. Laspolillas oscuras, en cambio, tenían una mayor probabilidad de pasar desapercibidasy sobrevivir. Por tanto, las polillas oscuras sobrevivían más que las claras y se repro-ducían con más frecuencia, haciendo que los alelos que generan el color oscuro pa-saran preferentemente a las generaciones sucesivas. La mejor adaptación al medio delas polillas oscuras, simplemente por un mecanismo de selección, provocó la evolu-ción de esta especie en esa región.
Para cuantificar los efectos de la selección, es necesario calcular la eficacia bio-lógica relativa o «fitness», que es el éxito reproductivo relativo de un genotipo con-creto. La eficacia se representa por la letra w y su valor varía entre 0 y 1. Por ejem-plo, para dos alelos A y a, se puede calcular la descendencia media que produce cadagenotipo. Supongamos que los individuos con genotipo AA tienen una media de 10descendientes, los Aa cinco descendientes y los aa dos descendientes. La eficacia decada genotipo se calcula como el número de descendientes de ese genotipo respectoal genotipo más eficaz: wAA = 10/10 = 1; wAa = 5/10 = 0,5; waa = 2/10 = 0,2.
Una variable relacionada con la eficacia biológica relativa es el coeficiente de se-lección (s), que indica la intensidad de la selección frente a un genotipo determina-do. El cálculo se hace con arreglo a la fórmula s = 1 – w, luego en el ejemplo ante-rior tendríamos que sAA = 0; sAa = 0,5; saa = 0,8. Este modelo permite predecir que,en ausencia de otros factores, la diferente eficacia biológica de cada genotipo provo-cará cambios en las frecuencias alélicas con cada generación. Estos cambios depen-derán únicamente de las frecuencias alélicas iniciales y de la eficacia biológica rela-tiva de cada genotipo. Así, para genotipos AA, Aa y aa que estén en frecuencias p2,2pq y q2 respectivamente, con eficacias wAA, wAa y waa, las frecuencias genotípicastras selección durante una generación serán:
f(AA) = p2 wAAf(Aa) = 2pq wAaf(aa) = q2 waa
Es importante darse cuenta de que la selección, en sí misma, no tiene memoriani es un proceso guiado hacia un fin, no «piensa» lo que va a suceder dos o tresprocesos de selección después. Simplemente consigue la mejor adaptación a las con-diciones ambientales que se dan en un momento dado, pero si esas condiciones cam-bian los rasgos que habían sido seleccionados pueden volver a perderse. Por eso, laselección no es un proceso progresivo de «mejora» de una población, porque los in-dividuos mejor adaptados en un momento concreto no tienen por qué ser bioló-gicamente más perfectos.
En los enlaces de la Figura 12.3 se puede estudiar el efecto de la selección en distintascondiciones.
Existen varios tipos de selección que tienen distintos efectos sobre las frecuenciasalélicas y la variabilidad genética de la población. Si consideramos un rasgo fenotí-
162
Los genes en las poblaciones
CAPITULO 12 5/12/06 07:22 Página 162
www.FreeLibros.me

pico controlado por un gen con dos alelos, podemos distinguir cuatro tipos princi-pales de selección:
i) selección contra uno de los homocigotos. En este caso, uno de los genoti-pos homocigóticos (AA o aa, en los ejemplos que venimos viendo) tiene des-ventaja adaptativa y por eso la selección actúa en su contra. La consecuen-cia es la disminución progresiva de la frecuencia del alelo presente en esegenotipo. Por ejemplo, en el caso extremo de selección completa en contradel genotipo aa, los individuos aa no llegarán a reproducirse y los únicosemparejamientos posibles serán los que se muestran en la siguiente tabla:
Selección contra un homocigoto (aa)
Posibles cruzamientos Genotipos esperados en la descendenciaAA Aa aa
AA × AA 4AA × Aa 2 2Aa × AA 2 2Aa × Aa 1 2 1
Total 9 6 1(56 %) (38 %) (6 %)
i) Como se observa, en la siguiente generación la frecuencia del alelo a habrácaído al 25 por ciento (ocho alelos a de un total de 32), y esta tendencia semantendrá mientras dure la selección. De todas formas, es importante darsecuenta de que el alelo a nunca llegará a desaparecer de la población, porquesiempre será transmitido por individuos heterocigotos Aa.
i) En las poblaciones humanas, los rasgos recesivos se ven sometidos a este tipode selección, aunque de un modo mucho más leve. Por una parte, algunosrasgos recesivos, como el albinismo, no suponen una gran desventaja selecti-va. Otras enfermedades más severas, en las que hace años había una alta mor-talidad antes de llegar a la edad reproductiva, cuentan hoy en día con trata-mientos más eficaces y se consigue que los enfermos vivan más años y puedanreproducirse, por lo que el efecto de la selección sobre las frecuencias aléli-cas es menor. Si se conocen los valores de eficacia biológica relativa (w) decada genotipo (y por tanto los del coeficiente de selección s), se puede cal-cular el cambio que se producirá en la frecuencia alélica utilizando diversasfórmulas para fenotipos recesivos, dominantes o sin dominancia.
i) En la historia reciente de las poblaciones humanas encontramos un ejemplomuy ilustrativo de selección contra un homocigoto. Un alelo concreto delgen que codifica el receptor cinco de quimioquinas (alelo denominadoCCR5delta32) confiere a las células resistencia frente a la invasión por labacteria causante de la peste bubónica. Los individuos homocigotos para esealelo son inmunes a la peste, y los heterocigotos tienen cierta inmunidad.Los homocigotos sin ese alelo, en cambio, son los más susceptibles. Dado
163
Cambios en las condiciones que m
antienen el equilibrio: selección
CAPITULO 12 5/12/06 07:22 Página 163
www.FreeLibros.me

que las poblaciones europeas fueron sometidas a varias epidemias de pesteen los siglos XIV a XVIII, durante las que murieron millones de personas, elalelo CCRdelta32 aumentó mucho en su frecuencia, y hoy se encuentra entorno al 10 por ciento en poblaciones europeas, muy superior a otras zonasdel planeta. Recientemente se ha visto que este alelo también protege frentea la infección por el virus VIH causante del SIDA.
ii) selección contra ambos homocigotos. En este caso, ambos homocigotos es-tán en desventaja selectiva en comparación con los heterocigotos (wAA <wAa > waa), de ahí que se llame selección a favor de heterocigotos o tam-bién sobredominancia. En el caso más extremo, los individuos AA y aa nun-ca llegan a reproducirse, por lo que sólo hay cruzamientos Aa X Aa. Aunqueeste tipo de cruzamientos produce 1/4 de homocigotos AA y 1/4 de homoci-gotos aa, éstos no llegan a reproducirse y sólo los heterocigotos Aa pasansus alelos a la generación siguiente. El efecto neto es que en pocas genera-ciones se estabilizan las frecuencias de los dos alelos (equilibrio polimórfi-co estable), por lo que este tipo de selección se llama también selección es-tabilizante.
ii) El ejemplo más ilustrativo de selección contra ambos homocigotos es la re-lación entre la anemia falciforme y la malaria en el África sub-sahariana.La anemia falciforme es una enfermedad recesiva rara, en la se produce untipo de hemoglobina anormal (hemoglobina S) que hace que sus hematíesadquieran una conformación anómala. Los homocigotos sufren una formagrave de la enfermedad y mueren en la infancia, por lo que habitualmenteno llegan a reproducirse. Los heterocigotos, en cambio, sufren una formaleve que no compromete su viabilidad. Curiosamente, la anemia falciformeprotege frente a la infección por Plasmodium falciparum, el organismo cau-sante de la malaria. El parásito crece dentro de los hematíes, pero no puedeentrar en hematíes que están deformados como consecuencia de la hemo-globina S. Por tanto, los individuos con hemoglobina normal son muchomás susceptibles a la infección que los individuos con anemia falciforme: losindividuos heterocigotos para la hemoglobina S están relativamente protegi-dos frente al Plasmodium, aunque no tanto como los homocigotos. Por tan-to, tenemos una situación en la que tanto ambos tipos de homocigotos tie-nen comprometida su viabilidad: los individuos con dos alelos dehemoglobina S, debido a la anemia falciforme, y los individuos con hemo-globina normal, debido a que son más fácilmente infectados y mueren demalaria. En cambio, los heterocigotos con un solo alelo falciforme están re-lativamente protegidos frente a la malaria y no padecen la forma mortal deanemia, de modo que se ven favorecidos respecto a los homocigotos. El efec-to neto es que en las zonas de África donde hay malaria la frecuencia del ale-lo falciforme es mucho más alta que en el resto del planeta.
iii) Selección contra heterocigotos y uno de los homocigotos. Esto equivale ala selección a favor de uno de los genotipos homocigotos (wAA > wAa > waa,por ejemplo). En este caso, los cambios en las frecuencias alélicas serán muyrápidos a favor del alelo presente en el genotipo más eficaz. De hecho, en elcaso extremo en que los heterocigotos y un tipo de homocigotos no se re-
164
Los genes en las poblaciones
CAPITULO 12 5/12/06 07:22 Página 164
www.FreeLibros.me

produzcan, en una sola generación puede perderse un alelo y quedar fijadoel otro. Por ejemplo, si la selección actúa contra heterocigotos Aa y homo-cigotos aa, sólo llegarán a reproducirse los individuos AA, con lo que el ale-lo a estará ausente en la siguiente generación. Lógicamente, esta forma ex-trema de selección no es frecuente en poblaciones humanas, aunque lasenfermedades dominantes en las que tanto los heterocigotos como los ho-mocigotos sufren la enfermedad podrían estar sujetas a este tipo de selecciónsiempre que estos individuos vean reducida su viabilidad.
iv) selección contra heterocigotos. Finalmente, si la selección actúa únicamen-te en contra de los heterocigotos (wAA > wAa < waa) ocurrirá que la pobla-ción se polarizará hacia los homocigotos, y esto se conoce como infradomi-nancia. En el caso de alelos A y a con frecuencias p = q = 1/2, únicamentehabrá cruzamientos entre homocigotos de ambos tipos, que producirán unadescendencia típica con proporciones 25 por ciento AA, 50 por ciento Aa y25 por ciento aa.
Selección contra heterocigotos (Aa)
Posibles cruzamientos Genotipos esperados en la descendenciaAA Aa aa
AA × AA 4AA × Aa 4aa × AA 4aa × aa 4
Total 4 8 4(25 %) (50 %) (25 %)
ii) De todas formas, como los individuos Aa fallecen antes de reproducirse, lasfrecuencias alélicas se reajustarán rápidamente hacia 50 por ciento A y 50por ciento a. Por tanto, la subdominancia también produce un equilibriopolimórfico, pero al contrario que en el caso de la sobredominancia, aquí elequilibrio es inestable. Cualquier perturbación por alguna otra fuerza evo-lutiva hará que las frecuencias alélicas cambien rápidamente hasta fijar unode los alelos en la población.
12.7 Aplicaciones en Genética HumanaAunque ya hemos visto algunos ejemplos en los que las nociones básicas de la Ge-nética de poblaciones se aplican a poblaciones humanas, podemos hacer otras con-sideraciones de gran interés práctico. La más inmediata es que la Ley de Hardy-Wein-berg permite calcular las frecuencias de los alelos mutantes que causanenfermedades humanas. Esto es especialmente útil en el caso de enfermedades rece-sivas, en las que sólo los homocigotos desarrollan la enfermedad. Si se conocen lascifras de prevalencia de la enfermedad en una población podemos calcular las fre-cuencias alélicas, la tasa de portadores en la población y las tasas de incidencia pre-
165
Aplicaciones en Genética Hum
ana
CAPITULO 12 5/12/06 07:22 Página 165
www.FreeLibros.me

vistas en generaciones futuras. Por ejemplo, si la prevalencia de una enfermedad re-cesiva es de 25 enfermos por cada 100 000 habitantes, entonces q2 = 0,00025 yq = 0,016. Por tanto, p = 0,984 y 2pq = 0,031. En otras palabras, en esa población latasa de portadores es del 3,1 por ciento y se mantendrá estable si no se alteran sig-nificativamente las condiciones del equilibrio.
También es importante hacer algunas consideraciones respecto a la eficacia de lascampañas de detección prenatal de enfermedades recesivas. La finalidad de estascampañas es evitar que nazcan individuos enfermos, es decir, homocigotos; sin em-bargo, esto no hace que disminuya la frecuencia alélica ni el porcentaje de individuosportadores (heterocigotos). En efecto, tal y como hemos visto al hablar de selecciónfrente a un homocigoto (en este caso, recesivo), el alelo deletéreo nunca desaparece.Esto significa que las campañas eugenésicas son totalmente ineficaces para eliminaralelos recesivos de una población. Por ejemplo, se ha calculado que si la frecuencia delalelo recesivo causante del albinismo en Noruega es del 1 por ciento, un programa eu-genésico dirigido a eliminar el alelo albino de la población noruega (esterilizando, porejemplo, a todos los albinos) tardaría 100 generaciones en reducir la frecuencia alé-lica a la mitad de su valor actual (0,005) y llevaría 9 900 generaciones reducirla al0,0001. En este sentido, el parámetro más importante para saber si es factible aplicaruna campaña de detección prenatal en una enfermedad recesiva es el cociente entreheterocigotos y homocigotos: cuanto menor es la frecuencia del alelo mutante (q),mayor es el cociente 2pq/q2 y la frecuencia alélica q apenas bajará debido al alto nú-mero de portadores en la población. En cambio, estas campañas resultan más eficacespara hacer disminuir el número de nuevos enfermos en el caso de enfermedades rece-sivas más frecuentes, en las que q es más alto y el cociente 2pq/q2 menor.
Las enfermedades ligadas al cromosoma X constituyen un caso especial para elcálculo de frecuencias alélicas y genotípicas, ya que los enfermos son habitualmentevarones hemicigotos que sólo llevan una copia del alelo mutante. Por tanto, la pre-valencia de la enfermedad en la población (varones enfermos por 100 000 habitan-tes) es igual a q (la frecuencia del alelo mutante). El porcentaje de mujeres homoci-góticas (y, por tanto, enfermas) es q2, y suele ser muy bajo.
Aunque en otras especies es relativamente sencillo calcular la tasa de mutaciones,la eficacia biológica relativa y el coeficiente de selección, en poblaciones humanassólo podemos obtener aproximaciones. Por ejemplo, la tasa de nuevas mutacionesen enfermedades dominantes puede estimarse utilizando la fórmula µ = n/2N, sien-do n el número de enfermos que nacen de padres sanos (los cuales deben ser homo-cigotos sanos si la enfermedad tiene penetrancia completa) y N el número total denacimientos. Los cálculos de µ varían de unas enfermedades a otras, lo que reflejaque las tasas de mutación no son iguales para todos los genes.
Finalmente, podemos fijarnos en cómo mutación y selección natural actúan endirecciones opuestas, en especial sobre los alelos deletéreos. Éstos aumentan porefecto de la mutación, pero la selección tiende a eliminarlos de la población. Cuandoambas fuerzas alcanzan un equilibrio en el que todos los nuevos alelos mutados soneliminados por selección, la frecuencia de un alelo deletéreo dominante es igual alcociente µ/s, siendo µ la tasa de mutaciones y s el coeficiente de selección. En el casode un alelo recesivo, su frecuencia es igual a la raíz cuadrada del cociente µ/s. Si co-nocemos la tasa de mutación y la frecuencia alélica, podemos calcular la eficacia bio-
166
Los genes en las poblaciones
CAPITULO 12 5/12/06 07:22 Página 166
www.FreeLibros.me

lógica o viceversa. Por ejemplo, se sabe que la acondroplasia, una enfermedad auto-sómica dominante, tiene una eficacia w = 0,74, ya que los individuos con acondro-plasia son fértiles pero tienen en promedio un 74 por ciento de la descendencia quetienen los individuos sin acondroplasia. Por tanto, s = 1 – W = 0,26. Si la tasa muta-cional calculada para este gen (usando la fórmula del párrafo anterior) es de 3 × 10-5
mutaciones por generación, podemos deducir que la frecuencia alélica es q = 0,0003/0,26= 0,0012, que corresponde con la frecuencia de la enfermedad en la población.
Una última consideración es la que hace referencia al papel de la selección natu-ral en poblaciones humanas en la actualidad. Así como a lo largo de nuestra historiala selección ha jugado un papel importante en los cambios de frecuencias alélicas, yen gran parte del mundo todavía es así (recuérdese el ejemplo de la malaria en Áfri-ca), en el mundo industrializado el papel de la selección es cada vez menor. Estoes consecuencia de las mejoras en la calidad de vida y en los cuidados sanitarios, quehacen posible que individuos enfermos (que, de otro modo, fallecerían antes de laedad reproductiva) vivan más y puedan llegar a reproducirse y pasar los alelos mu-tantes a la siguiente generación. Esto es especialmente claro en el caso de tumoreshereditarios de la infancia, como el retinoblastoma, que es una enfermedad de he-rencia autosómica dominante. También sucede con enfermedades recesivas comunes,como la fibrosis quística, que hace años tenía una alta mortalidad durante la infan-cia y en cambio hoy en día los enfermos suelen vivir hasta la edad adulta. Lógica-mente, no debemos renunciar a los logros alcanzados en el tratamiento de las enfer-medades, pero hemos de ser conscientes de que las poblaciones humanas vanacumulando un lastre genético cada vez mayor.
12.8 Formación de la Teoría Sintética de la Evolución
En sentido biológico amplio, la evolución es un concepto universalmente aceptado:a lo largo de la historia natural del planeta, unas especies han ido desapareciendo ydando paso a otras que se derivan de las anteriores. Lamarck, al comienzo del si-glo XIX, fue el primer naturalista en proponer el concepto de que unas especies se hanido transformando en otras, aunque en aquel momento esto no pasaba de ser una in-tuición, sin el respaldo de datos experimentales convincentes. En la Encyclopedia ofGenetics, se define evolución como «el proceso mediante el cual, según unos indi-viduos se diferencian gradualmente de otros al irse reproduciendo, los organismoscambian en otros nuevos a lo largo del tiempo». El diccionario de la RAE, en su22.ª edición, define la evolución (biológica) como «el proceso constante de transfor-mación de las especies a través de cambios producidos en sucesivas generaciones».El Diccionario del Español Actual (edición de 1999) la define como «cambio gra-dual y progresivo de las especies a lo largo de sucesivas generaciones».
Este concepto de evolución es el que está en el imaginario popular, pero no debeser confundido con la Teoría General de la Evolución, o evolución tal y como se en-tiende en ámbitos científicos, que es la teoría que intenta explicar los mecanismos quedan lugar a evolución. La Teoría de la Evolución arranca de las observaciones de Dar-win, publicadas en El origen de las especies, y del descubrimiento de las leyes de la he-rencia por Mendel, a finales del siglo XIX. Darwin usó inicialmente la expresión «des-
167
Formación de la Teoría Sintética de la Evolución
CAPITULO 12 5/12/06 07:22 Página 167
www.FreeLibros.me

cent with modification» para indicar que pequeños cambios heredados de una genera-ción a la siguiente podían explicar la transformación de unas especies en otras. Pero entiempos de Darwin todavía no se habían descubierto los principios de la Genética, porlo que no se podían describir los mecanismos que producían esos cambios ni cómo seheredaban de una generación a la siguiente. La gran intuición de Darwin fue que elprincipal mecanismo por el que opera la evolución es la selección natural, aunque nopudo demostrarlo experimentalmente por las razones apuntadas. El redescubrimientode las leyes de Mendel en el año 1900 y la elaboración de la genética de poblacionesen las primeras décadas del siglo XX dieron lugar a la Teoría Sintética de la Evoluciónen torno a 1940. Posteriormente, los datos aportados por la biología molecular y la bio-logía del desarrollo han completado y matizado algunos aspectos de la Teoría General.
Por tanto, actualmente la evolución se define en términos científicos como el pro-ceso mediante el cual una población de individuos adquiere cambios que son he-redados a generaciones sucesivas. Por ejemplo, podemos citar la definición de evo-lución que propone Douglas J. Futuyma en su libro Evolutionary Biology (SinauerAssociates, 1986): Biological evolution (...) is change in the properties of populationsof organisms that transcend the lifetime of a single individual. The ontogeny of anindividual is not considered evolution; individual organisms do not evolve. Thechanges in populations that are considered evolutionary are those that are inherita-ble via the genetic material from one generation to the next. Es decir, la evoluciónbiológica es el resultado de los cambios, pequeños o grandes, en los tipos y fre-cuencias de alelos existentes en una población de individuos, ya que esos cambiosson transmitidos a las generaciones siguientes.
Es interesante ver con un poco más de detalle el desarrollo histórico de las ideasque han dado lugar al concepto moderno de evolución. En las primeras décadas delsiglo XX, como hemos visto, Hardy y Weinberg establecieron las bases de la genéticade poblaciones. Los genetistas de principios de siglo pensaban que los alelos domi-nantes deberían ir desplazando poco a poco a los alelos recesivos de la población, has-ta reemplazarlos por completo. Hardy (matemático) y Weinberg (físico) demostraronmatemáticamente que esto no tenía por qué ser así, sino que —en determinadas con-diciones— las frecuencias genotípicas deberían mantenerse estables y depender exclu-sivamente de las frecuencias alélicas. En los años posteriores, Ronald Fisher, J. B. S.Haldane y Sewall Wright desarrollaron estas ideas y elaboraron los conceptos quedieron lugar a la genética de poblaciones. Fisher, creador de la estadística moderna ydel concepto de varianza, aportó entre otras muchas cosas lo que se conoce como elteorema fundamental de la selección natural: el cambio en la eficacia biológica (fit-ness) depende de la varianza genética aditiva (en otras palabras, a mayor variación enla población, mayor capacidad adaptativa). Sewall Wright, por su parte, hizo más hin-capié en los efectos del tamaño poblacional, desarrollando el concepto de deriva ge-nética y proponiendo la existencia de paisajes adaptativos. Todas estas ideas fueronsistematizadas y popularizadas por T. Dobzhansky, que en 1937 publicó Genetics andthe Origin of Species. En este libro se exponía una teoría unificadora que explicaba demodo razonablemente satisfactorio las leyes por las que opera la evolución, la TeoríaSintética o «síntesis moderna». En torno a 1970 surgieron nuevas hipótesis para ex-plicar aspectos evolutivos concretos, de manera que la Teoría Sintética fue matizaday ampliada para dar lugar a lo que hoy llamamos Teoría General de la Evolución.
168
Los genes en las poblaciones
CAPITULO 12 5/12/06 07:22 Página 168
www.FreeLibros.me

Todo lo anterior sirve para subrayar la idea que se ha expuesto al principio de estecapítulo: la evolución es fundamentalmente un fenómeno que afecta a la consti-tución genética de una población (el «acervo genético», es decir, el conjunto de ale-los que están presentes en una población) y sus cambios en el tiempo. Por tanto, esnatural que la evolución deba ser estudiada con un enfoque eminentemente genéti-co y utilizando las metodologías propias del análisis genético. No se puede afrontarel estudio de la evolución sin comprender todos los conceptos explicados en la sec-ción dedicada a la Genética de Poblaciones. Los métodos cuantitativos de análisis dela variabilidad genética y de la selección natural son imprescindibles en cualquier dis-cusión científica en torno a la evolución. De hecho, algunos autores resumen el pro-ceso evolutivo en una expresión sencilla pero llena de significado: «los genes mutan,los individuos son seleccionados, las poblaciones evolucionan».
12.9 Explicación actual del proceso evolutivo y sus limitaciones
El proceso evolutivo se divide habitualmente en tres fases: microevolución, especia-ción y macroevolución. La primera se refiere a los cambios relativamente pequeñosque surgen en una población de individuos de una misma especie, y es la más fácilde observar y de estudiar experimentalmente. La especiación es el proceso por el queuna especie da lugar a otra u otras mediante un proceso ramificado (cladogénesis) olineal (anagénesis). Macroevolución se refiere a los cambios observados durante lar-gos periodos de tiempo, que dan lugar a organismos muy diversos. La teoría moder-na de la evolución explica satisfactoriamente la microevolución y la especiación,pero los mecanismos de macroevolución son más hipotéticos y sujetos a discusión,ya que la evidencia experimental es más fragmentaria y menos sólida. Una idea cen-tral a todos estos procesos es el concepto de especie, que en sí mismo es objeto debastante controversia. Ernst Mayr fue el taxonomista que más ha contribuido a darforma al concepto moderno de especie: en organismos de reproducción sexual, unaespecie es un grupo de poblaciones naturales que de hecho o en potencia se repro-ducen entre sí y que están aisladas reproductivamente de otros grupos similares. Esteconcepto de especie, que puede aplicarse con bastante generalidad a los animalespero con menos fiabilidad a las plantas, ha sido matizado más recientemente por lagenética molecular y el concepto filogenético de especie: teniendo en cuenta carac-terísticas taxonómicas –basadas en diferencias morfológicas y funcionales– así comodiferencias genéticas cuantificables por métodos moleculares, una especie es unarama claramente definida en un árbol filogenético.
La teoría de la evolución explica satisfactoriamente cómo se producen la micro-evolución y la especiación. Una idea central en estos procesos, ya presente en la de-finición original de especie, es el aislamiento: para que pueda surgir una especie nue-va, parte de la población original ha de quedar aislada del resto de los individuos deesa población. De hecho, los ejemplos mejor documentados de especiación se hanverificado en condiciones de aislamiento: por ejemplo, hay evidencias de especiaciónespecialmente intensa en archipiélagos, en los que es frecuente encontrar situacionesde aislamiento geográfico de poblaciones. Cuando dos poblaciones de una especiequedan separadas reproductivamente por razones geográficas, seguirán rumbos evo-
169
Explicación actual del proceso evolutivo y sus limitaciones
CAPITULO 12 5/12/06 07:22 Página 169
www.FreeLibros.me

lutivos distintos con el paso del tiempo, tanto si los ambientes a los que están some-tidas son distintos o no. Este tipo de especiación se llama especiación alopátrica, yes el más fácil de explicar y para el que se han encontrado más ejemplos en la natu-raleza. Por el contrario, dos poblaciones pueden diverger sin estar aisladas geográfi-camente, fenómeno que se conoce como especiación simpátrica. Aunque ésta últi-ma es más difícil de explicar y está menos documentada, hay algunos ejemplos enplantas.
El proceso de especiación es explicado por la teoría moderna de la evolución uti-lizando los conceptos de variabilidad, selección natural y deriva genética. El requisi-to necesario para que haya microevolución y especiación es la presencia de variacióngenética. Si no existe variación, no puede haber evolución. Como hemos visto, yaFisher había postulado que la variación genética es directamente proporcional a lavelocidad con la que opera la selección adaptativa. Al explicar los principios de laGenética de Poblaciones hemos visto que la mutación es el principal mecanismo porel que aumenta la variación genética, mientras que la selección natural habitualmen-te disminuye la variabilidad existente en la población, aunque en algunos casos lamantiene (selección a favor de heterocigotos y equilibrio polimórfico estable). En ge-neral, en el caso de dos poblaciones aisladas sometidas a condiciones ambientalesdistintas, la principal fuerza microevolutiva será la selección. El coeficiente de selec-ción y la eficacia biológica (fitness) permiten predecir la magnitud de los cambios enlas frecuencias alélicas con las sucesivas generaciones.
La teoría moderna de la evolución también permite predecir que dos poblacionesen condiciones de aislamiento geográfico sufrirán evolución aunque no estén some-tidas a presiones ambientales diferentes. Sewall Wright fue el primero en predecirque si el tamaño poblacional es pequeño, las frecuencias alélicas pueden cambiar rá-pidamente por deriva genética aleatoria, sin estar determinadas por la selección na-tural. Un mecanismo frecuente de especiación es el aislamiento de una población pe-queña que contiene un pequeño grupo de los alelos presentes en la población originalde partida (efecto fundador). En estas condiciones, la deriva genética puede fijar rá-
170
Los genes en las poblaciones
escarabajos
avispas
mariposas
moscas
esca
raba
jos
avis
pas
mar
ipos
as
mos
cas
La Figura 12.4 explica qué es un árbol filogenético.
CAPITULO 12 5/12/06 07:22 Página 170
www.FreeLibros.me

pidamente ciertos alelos en la población y producir evolución sin selección. El papelde la deriva genética en la evolución adquirió especial protagonismo tras los traba-jos de Motoo Kimura en 1968. Durante los años precedentes, los avances en biolo-gía molecular habían hecho posible, por primera vez, cuantificar las diferencias ge-néticas que se observan entre especies distintas definidas por el concepto clásico deespecie. Estas comparaciones confirmaron que los grupos taxonómicos se corres-pondían extraordinariamente bien con los grupos filogenéticos derivados de la com-paración de secuencias de ADN. Kimura observó que la mayor parte de los cambiosmoleculares en el ADN eran «neutros» desde el punto de vista de la selección, ya queafectan a nucleótidos que no alteran la secuencia de aminoácidos de la proteína co-dificada. El descubrimiento de que los genomas de mamíferos están formados en sumayor parte por ADN no-codificante, así como la presencia de numerosos polimor-fismos silenciosos y selectivamente neutros ha supuesto un respaldo de la teoría neu-tral de la evolución, que así complementó la Teoría Sintética prevalente hasta losaños 70. La teoría neutral hace predicciones importantes, ya que postula que la granmayoría de las mutaciones son neutras y, por tanto, la tasa de cambio evolutivo (anivel molecular) viene determinada exclusivamente por la tasa de mutación, inde-pendientemente del tamaño de la población. Esto introdujo el concepto de «relojmolecular», tan importante en los estudios actuales de evolución molecular. Por otraparte, la teoría neutral también predice que la probabilidad de fijación de un alelo enla población dependerá exclusivamente del tamaño de la misma. Estas prediccionesse han confirmado en bastantes casos, aunque actualmente la teoría neutral se hamodificado para incluir los efectos de alelos deletéreos sometidos a selección débil.
Dado que la teoría sintética explicaba satisfactoriamente la microevolución y laespeciación, hasta los años 70 era común aceptar que la macroevolución sería el re-sultado de estos mismos mecanismos operando durante grandes periodos de tiempo.Este modelo de pequeños cambios graduales a lo largo del tiempo se conoce comogradualismo, y supone que las especies están constantemente evolucionando a unavelocidad lenta. En 1972, Stephen Jay Gould y Niles Eldredge propusieron la hipó-tesis del equilibrio puntuado, para intentar explicar el hecho de que el registro fósilmuestra que muchas especies han estado durante millones de años básicamente sincambios y en poco tiempo sufrieron transformaciones drásticas. Según estos autoresy otros paleontólogos no es necesario que la evolución actúe constantemente, por-que muchas especies están bien adaptadas y no necesitan cambiar si no se alteran lascondiciones ambientales. Es precisamente en periodos de cambios ambientales brus-cos (glaciaciones, sequías, cambios en el clima o en los recursos alimenticios, depre-dadores, etc.) cuando la selección natural puede favorecer variedades que estabanpresentes en la población en baja frecuencia, dando lugar a cambios adaptativos rá-pidos.
Por otro lado, los estudios de evolución molecular, sobre todo en la comparaciónde genomas, han mostrado que muchos genes reguladores y genes implicados en eldesarrollo embrionario están muy conservados en la naturaleza. En concreto, la bio-logía del desarrollo estudia los genes responsables de los patrones corporales, la po-laridad, las extremidades y la organogénesis. Los genes implicados en estos procesosson extraordinariamente similares entre especies evolutivamente distantes, lo que hallevado a generar una nueva disciplina llamada biología del desarrollo evolutiva
171
Explicación actual del proceso evolutivo y sus limitaciones
CAPITULO 12 5/12/06 07:22 Página 171
www.FreeLibros.me

(«evo-devo», del inglés evolutionary developmental biology). La idea que se extrae deestos análisis es que pequeños cambios en genes clave, que regulan la expresión deun número elevado de genes distintos, puede producir alteraciones morfológicas im-portantes en un periodo corto de tiempo.
La Figura 12.5 muestra la organización de los genes homeobox en humanos y en Drosophila.
En esta misma línea, los estudios comparativos de los genomas de distintas espe-cies muestran que la duplicación de genes, la duplicación de genomas y los reor-denamientos cromosómicos han sido frecuentes en diversos momentos evolutivos.Susumu Ohno publicó en 1970 el libro Evolution by gene duplication, proponiendola idea de que la duplicación de genomas ha sido una de la fuerzas evolutivas quehan permitido crear complejidad y aumentar la variación genética. Aunque en esosaños no había mucha evidencia experimental para apoyar esta hipótesis, Ohno pos-tuló que los cambios macroevolutivos no pueden explicarse por la acción lenta de laselección sobre la variedad alélica presente en la población, sino que es necesario quehaya suficiente redundancia en el genoma para que la selección pueda actuar por se-parado sobre distintas copias de los mismos genes. Esa redundancia se habría alcan-zado mediante duplicaciones genómicas parciales o totales.
Los estudios moleculares de familias y superfamilias de genes, y la reciente se-cuenciación de genomas completos han ido confirmando algunas de las prediccionesde Ohno. Hoy en día se acepta que grandes segmentos de los genomas de eucariotasestán formados por regiones duplicadas y que la mayor parte de las familias génicashan surgido por duplicación y divergencia separada de las distintas copias, o inclusopor duplicaciones genómicas completas. La comparación de familias de genes mues-tra que, en general, los genes ortólogos (copias de un gen en especies distintas) tie-nen mayor homología entre sí que los genes parálogos (copias duplicadas de un gendentro de una misma especie), lo cual sugiere que la duplicación inicial es muy anti-gua. En cuanto a la duplicación de genomas, se ha sugerido que durante la evoluciónde los vertebrados han tenido lugar dos duplicaciones genómicas (hipótesis 2R), yaque muchos genes importantes (genes homeobox, genes del complejo mayor de his-tocompatibilidad, etc.) tienen una sola copia en invertebrados pero tres o cuatro co-pias en vertebrados. Los análisis más recientes del genoma humano muestran la exis-tencia de muchos más genes duplicados de los que cabría esperar por azar, y cuandose compara con los genomas de Drosophila y de C. elegans parece que hubo al me-nos una duplicación genómica completa entre invertebrados y vertebrados.
En el caso concreto de los mamíferos, los genomas analizados en los últimosaños permiten constatar la presencia de gran cantidad de reordenaciones cromosó-micas, de mayor o menor tamaño. Esto se ve especialmente bien al comparar geno-mas de especies muy similares: por ejemplo, si se alinean los genomas de primates,se observa que la sintenia es casi total, aunque varias translocaciones e inversionesdan lugar a los 46 autosomas del chimpancé frente a los 44 de la especie humana.Al comparar especies más separadas, como humano y ratón, los bloques de sinteniason más pequeños y están más dispersos (hay 342 bloques de un tamaño promediode unas 10 Megabases cada uno). Esto sugiere que ambos genomas se han origina-do a partir de un genoma ancestral mediante complejos eventos de duplicación, in-versión y translocación.
172
Los genes en las poblaciones
CAPITULO 12 5/12/06 07:22 Página 172
www.FreeLibros.me

Como conclusión, parece bastante claro que la historia evolutiva de la vida delplaneta es tremendamente complicada. Aunque los mecanismos básicos, sobre todolos que originan microevolución y especiación, son bastante bien comprendidos, loscambios macroevolutivos son más difíciles de analizar. Diferentes especies han evo-lucionado a distintas velocidades, en respuesta a factores ambientales muy cambian-tes y a interacciones complejas con otras especies. Estos factores han propiciado,además, la extinción de la inmensa mayoría de las especies, por lo que el cuadro ge-neral macroevolutivo es fragmentario y no es fácil proponer explicaciones satisfacto-rias. En cualquier caso, la teoría sintética, que explicaba cambios pequeños, ha sidomatizada y completada por aportaciones importantes como la teoría neutral de Ki-mura, la teoría del equilibrio puntuado y la hipótesis de Ohno. Con estas aportacio-nes, se ha rebajado algo la importancia de la selección natural gradual en los cam-bios macroevolutivos y en cambio se tiende a dar más importancia a alteracionesgenómicas o a cambios ambientales bruscos que pueden haber provocado fases deevolución acelerada. Sobre los cambios adquiridos durante estos periodos, la selec-ción habría proporcionado el «ajuste fino» adaptativo.
La conciliación de la teoría moderna de la evolución con las convicciones filosó-ficas o religiosas de los individuos no debería ofrecer problemas, al tratarse de ámbi-tos del conocimiento diferentes. La mayor parte de los problemas han surgido cuan-do uno de esos ámbitos ha intentado invadir el otro. En el ámbito protestanteanglosajón, especialmente en los Estados Unidos, se originó un movimiento llamadocreacionismo al advertir que la teoría de la evolución estaba siendo utilizada paraatacar los fundamentos de las creencias religiosas de los ciudadanos. Las disputas en-tre creacionistas y evolucionistas son todavía hoy muy acentuadas en ese país; pordesgracia, algunos intentos recientes de deslegitimar ideas propias del ámbito filosó-fico-teológico en nombre de la ciencia no han ayudado en absoluto a conciliar am-bas visiones. Un ejemplo muy claro fue la publicación en 1986 de «El relojero ciego»por Richard Dawkins. En ese libro el autor se propone refutar, recurriendo al me-canismo de la evolución y en particular a la selección natural, el «argumento del di-seño» que había sido propuesto por el teólogo protestante William Paley en 1802.Obviamente, este planteamiento traspasa los límites de la ciencia experimental, yaque ésta responde a preguntas sobre mecanismos biológicos pero no puede respon-der a argumentos teológicos ni a preguntas sobre las causas primeras y el origen on-tológico del mundo material; estas cuestiones pertenecen más al ámbito de la filoso-fía y escapan al propio método experimental. En cualquier caso, la publicación de eselibro dio lugar a una fuerte respuesta que cristalizó en un movimiento que hoy se co-noce como «Diseño Inteligente», una reformulación moderna de la quinta vía de To-más de Aquino (como lo era también, en el fondo, el argumento del diseño de Paley).El Diseño Inteligente intenta utilizar la ciencia actual (sobre todo a nivel molecular,proponiendo el concepto de «complejidad irreductible») para demostrar la existen-cia de un diseño en la naturaleza, y por tanto la existencia de un ser inteligente crea-dor de dicho diseño. Nuevamente nos encontramos ante un intento de utilizar laciencia con fines que no son los suyos, ya que el argumento del diseño inteligente,aunque basado en observaciones de la naturaleza, es básicamente un argumento decarácter filosófico más que científico. La particular situación de la sociedad america-na ha hecho que el debate en torno al Diseño Inteligente y su posible inclusión en
173
Explicación actual del proceso evolutivo y sus limitaciones
CAPITULO 12 5/12/06 07:22 Página 173
www.FreeLibros.me

las escuelas (en las asignaturas de ciencias naturales) sea especialmente agrio y hayallegado a las instancias políticas del país. Por suerte, los círculos científicos son cadavez más conscientes de la magnitud del problema, y estamos asistiendo a grandesavances en todo lo que rodea a las relaciones entre conocimiento científico y con-vicciones filosóficas personales.
En la Figura 12.6 se puede leer un artículo de opinión acerca de las relaciones entre ciencia y fe.
En este sentido, un editorial de la revista Nature en abril de 2005 decía: …scien-tists would do better to offer some constructive thoughts of their own. For religiousscientists, this may involve taking the time to talk to students about how they per-sonally reconcile their beliefs with their research. Secular researchers should talk toothers in order to understand how faiths have come to terms with science. All scien-tists whose classes are faced with such concerns should familiarize themselves withsome basic arguments as to why evolution, cosmology and geology are not compe-ting with religion. When they walk into the lecture hall, they should be prepared totalk about what science can and cannot do, and how it fits in with different religiousbelief s». Estas frases indican ciertamente una nueva sensibilidad hacia las creenciasreligiosas de los científicos, y un intento de mantener las conclusiones de las cienciasexperimentales dentro del ámbito que les es propio.
Un magnífico ejemplo reciente en el que se pone en práctica el consejo del pá-rrafo citado, es la publicación de The language of God: a scientist present s eviden-ce for belief, escrito por Francis Collins. El autor es un genetista de gran reputación,por haber identificado el gen responsable de la fibrosis quística y por haber dirigidoel Proyecto Genoma Humano. En este libro, Collins describe su trayectoria intelec-tual personal hacia la fe en un Dios personal origen del Universo, creador tambiéndel mecanismo evolutivo para generar diversidad.
Además, en Internet se pueden encontrar varios sitios de asociaciones de cientí-ficos cristianos, como la American Scientific Affiliation (www.asa3.org) o Christiansin Science (www.cis.org.uk), que ilustran muy bien cómo el conocimiento científico ylas creencias religiosas de los individuos ofrecen dos visiones del mundo que no sonopuestas, sino que se armonizan y complementan mutuamente.
174
Los genes en las poblaciones
CAPITULO 12 5/12/06 07:22 Página 174
www.FreeLibros.me

CAPITULO 13 5/12/06 07:23 Página 175
www.FreeLibros.me

D) Patología genética
Consta de ocho temas en los que se aborda el núcleo principal deesta asignatura: los mecanismos genéticos de las enfermedades, eldiagnóstico de las alteraciones genéticas y el cálculo de los riesgos
de transmisión a la descendencia.
CAPITULO 13 5/12/06 07:23 Página 175
www.FreeLibros.me

C A P Í T U L O 1 3
Citogenética
Contenidos
13.1 El estudio de los cromosomas humanos
13.2 Anomalías del número de los cromosomas
13.3 El fenómeno de no disyunción meiótica
13.4 Anomalías estructurales de los cromosomas
13.1 El estudio de los cromosomas humanos
La citogenética constitucional se ocupa del análisis de los cromosomas en células querepresentan la línea germinal del individuo (habitualmente linfocitos de sangre periféri-ca), y se llama así para distinguirla de los estudios citogenéticos sobre poblaciones celu-lares concretas que no representan la constitución genética de todo el individuo (célulassomáticas, por ejemplo las células de un tumor). La citogenética constitucional refleja,por tanto, la estructura cromosómica que ha sido heredada y que, a su vez, se transmiti-rá a la descendencia.
La citogenética clásica se basa en la creación y análisis del cariotipo, que es la pre-sentación ordenada de los cromosomas cuando se hacen visibles en metafase. Hasta losaños 50 se creía que los humanos teníamos 48 cromosomas y que el sexo dependía delnúmero de cromosomas X, como sucede en Drosophila. En 1956 se determinó el núme-ro exacto de cromosomas de la especia humana, y en 1959 ya se habían identificado lasanomalías cromosómicas características de los Síndromes de Down, Turner y Klinefelter.Esto se debió a mejoras técnicas que permitieron cultivar leucocitos de sangre periférica(estimulando el crecimiento en cultivo con fitohemaglutinina y mitógenos), detener el ci-clo celular específicamente en metafase (utilizando sustancias como colchicina) y reali-zar tinciones específicas del ADN. En 1968 Caspersson introdujo las bandas Q, y en1971 se introdujeron las bandas G, que es el método más utilizado para generar carioti-pos.
CAPITULO 13 5/12/06 07:23 Página 177
www.FreeLibros.me

El método habitual de cariotipado incluye la adición de un mitógeno (habitual-mente fitohemaglutinina) a una suspensión de linfocitos, tras lo cual se cultivan lascélulas durante 48-72 horas; cuando hay suficiente número de células, se detiene elciclo celular en mitosis utilizando colchicina, de modo que todas las células se ha-brán parado en metafase (momento en que los cromosomas se hacen visibles). El tra-tamiento con una solución hipotónica rompe las células y separa los cromosomas,tras lo cual se procede a la fijación de la muestra. A continuación se aplican distin-tas tinciones, que producen patrones de bandas característicos en los distintos cro-mosomas. En el método de bandas Q, el primero en aparecer históricamente, loscromosomas se tiñen con un colorante fluorescente con afinidad por regiones ricasen adeninas y timinas, lo cual produce unas bandas características en los cromoso-mas cuando se observan con luz ultravioleta. El método de bandas G consiste en so-meter las preparaciones a una digestión suave con tripsina antes de teñirlas conGiemsa, un colorante con afinidad por el ADN; cuando se analizan las preparacio-nes al microscopio de luz, se observan unas bandas oscuras (bandas G) separadaspor unas bandas claras. Para teñir los cromosomas según el método de bandas R sesometen las preparaciones a un tratamiento de calor en solución salina antes de latinción con Giemsa, lo cual produce un patrón de bandas claras y oscuras que es jus-tamente el inverso al que se obtiene con el método de bandas G. Esto es así porqueel tratamiento por calor hace que se desnaturalicen las regiones ricas en adeninas ytiminas, por lo que las bandas R oscuras corresponden a las bandas G claras. El mé-todo de bandas C se utiliza para teñir la heterocromatina constitutiva (centrómeros),y consiste en la tinción con Giemsa tras la desnaturalización en una solución satu-rada de hidróxido de bario.
En conjunto, utilizando estos métodos, y otros que son menos utilizados, se pue-den ver cuatro tipos principales de estructuras:
• Bandas de heterocromatina constitutiva (bandas C) que corresponden a lasregiones que permanecen condensadas durante la interfase.
• Bandas de eucromatina, formando un patrón de bandas claras y oscuras al-ternas a lo largo de todo el cromosoma; se ven como bandas G, R o Q.
• Regiones organizadoras del nucleolo, correspondientes a las regiones cromo-sómicas donde residen los genes del ARN ribosomal; se tiñen con una tinciónespecial de plata.
• Quinetocoros, las estructuras centroméricas que aparecen en mitosis y meio-sis a las que se unen los microtúbulos del huso; se tiñen con tinciones espe-ciales que usan anticuerpos específicos.
Los patrones de bandas G que definen cada cromosoma humano se publican perió-dicamente en el International System for Cytogenetics Nomenclature (ISCN), mos-trando distintas resoluciones: desde 350-550 bandas por cariotipo cuando se estu-dian células en metafase, hasta 850 bandas por cariotipo cuando se analizan célulasen prometafase. Los cromosomas (22 pares de autosomas más los cromosomas se-xuales X e Y) se ordenan en parejas de cromosomas homólogos, cada uno de los cua-les tiene a su vez las dos cromátides que resultan de la replicación del ADN en la faseS previa, aunque en ocasiones las dos cromátides están pegadas y no se distinguen almicroscopio. La forma de ordenar los cromosomas responde a un convenio (París,
178
Citogenética
CAPITULO 13 5/12/06 07:23 Página 178
www.FreeLibros.me

1971) y se lleva a cabo teniendo en cuenta el tamaño del cromosoma y la posicióndel centrómero, asignando a cada uno un brazo corto (p) y un brazo largo (q). Asíse pueden distinguir cromosomas metacéntricos (ambos brazos de la misma longi-tud), submetacéntricos (con el brazo p más corto que el brazo q) o acrocéntricos(cuyo brazo corto está formado por ADN satélite con ADN ribosomal en el centro).Así, el cromosoma 1 es el de mayor tamaño, y el cromosoma 21 el más pequeño. Te-niendo en cuenta todas estas características, el cariotipo humano se divide en va-rios grupos (que van del grupo A hasta el grupo G), con los cromosomas sexuales Xe Y formando un grupo aparte.
La Figura 13.1 explica la nomenclatura de las regiones y bandas cromosómicas, y muestra un ejemplo de cariotipo convencional con bandas G.
Además de las técnicas convencionales de bandeo, hoy contamos con una seriede técnicas que se engloban bajo una nueva disciplina llamada Citogenética Mole-cular, que combina la citogenética clásica con la hibridación específica de sondasmarcadas con fluorocromos (FISH = Fluorescence In Situ Hybridisation). La técnicade FISH, muy utilizada hoy en día, consiste en la hibridación de sondas específicascon cromosomas metafásicos, que previamente han desnaturalizados como en cual-quier reacción de hibridación. Aunque inicialmente se utilizaban preparaciones demetafases, también se puede hacer FISH directamente en núcleos interfásicos, loque permite detectar anomalías numéricas o estructurales específicas (utilizando son-das específicas) incluso en poblaciones celulares que no pueden dividirse o que noproducen buenas metafases (células fijadas e incluídas en parafina, por ejemplo). Al-gunas variantes de la técnica de FISH incluyen el llamado pintado cromosómico(painting), que permite resaltar un cromosoma concreto, incluyendo los fragmentosdel mismo que se hayan translocado a otras posiciones. Igualmente, la técnica deSKY (Spectral Karyotyping) consiste en el pintado de cada cromosoma con un colordistinto, gracias a combinaciones de fluorocromos y técnicas interferométricas en ladetección de la fluorescencia emitida. A pesar de su complejidad y alto coste, el SKY-FISH es una técnica valiosísima para detectar pequeñas alteraciones cromosómicasque, de otra forma, pasarían totalmente desapercibidas. Otra variante es la técnica deCGH (Comparative Genomic Hybridisation, Hibridación Genómica Comparativa),que permite detectar ganancias o pérdidas de material genético en un ADN pruebacuando se compara con un ADN de referencia, y es muy utilizada en la búsqueda deregiones cromosómicas amplificadas o delecionadas en tumores.
Los vídeos de la Figura 13.2 muestran distintos ejemplos de técnicas de citogenética molecular.
El ISCN también es responsable de unificar la nomenclatura para la descripciónde cariotipos normales o alterados. Las reglas básicas más importantes que hay queconocer son las siguientes:
• Se especifica en primer lugar el número total de cromosomas, seguido de loscromosomas sexuales y, si las hay, las alteraciones que se encuentren. Estos
179
El estudio de los cromosom
as humanos
CAPITULO 13 5/12/06 07:23 Página 179
www.FreeLibros.me

datos van separados por comas, sin espacios antes ni después de la coma. Porejemplo, el cariotipo de un varón normal se expresaría como «46,XY».
• Los individuos denominados «mosaicos» (es decir, aquellos que tienen dos omás constituciones cromosómicas distintas) se describen separando cadaconstitución cromosómica por una barra «/».
• Las alteraciones que estudiaremos en este capítulo se describen utilizandoabreviaturas apropiadas. Por ejemplo, «del» significa deleción, «dup» dupli-cación, «inv» inversión, «ins» inserción, «t» translocación, «i» isocromoso-ma, «r» cromosoma en anillo. Después de cada una de estas alteraciones seindican los cromosomas implicados (entre paréntesis) y a continuación las re-giones implicadas (en otro paréntesis distinto).
• Las ganancias o pérdidas de cromosoma completos se indican con el signo +o – antes del número correspondiente al cromosoma implicado.
13.2 Anomalías del número de los cromosomas
Las anomalías cromosómicas (cromosomopatías) son un tipo muy importante de pa-tología genética. Los fenotipos provocados por las anomalías cromosómicas son muyvariables, pero podemos describir algunas características generales que se cumplenen casi todos:
• Se asocian a retraso en el desarrollo y retraso mental, frecuentemente contalla baja.
• Se asocian con alteraciones faciales y otras anomalías menores de cabeza ycuello.
• Se asocian a determinadas malformaciones congénitas (defectos cardíacos,malformaciones en manos y pies, etc.), que suelen seguir un patrón específicode cada síndrome.
Clásicamente las anomalías cromosómicas se dividen en dos grandes grupos: aque-llas debidas a un número anormal de cromosomas (anomalías numéricas) y las debi-das a alteraciones en la estructura de los cromosomas (anomalías estructurales). Porlo que respecta a las anomalías numéricas, en conjunto tienen una frecuencia en tor-no al 0,5 por ciento de nacidos vivos (1/200). A continuación se detalla la frecuen-cia de las anomalías numéricas más frecuentes:
Frecuencia de anomalías cromosómicas numéricas (por 1 000 nacidos vivos):
trisomía 21 1,5trisomía 18 0,12trisomía 13 0,07XXY 1,545,X 0,4XYY 1,5
180
Citogenética
CAPITULO 13 5/12/06 07:23 Página 180
www.FreeLibros.me

Las anomalías numéricas pueden ser de dos tipos:
Euploidías: constituciones cromosómicas con un número total de cromosomasque es múltiplo del número haploide (23 en humanos). Si un cariotipo normal esdiploide (46 cromosomas, 2n), es posible encontrar anomalías numéricas debidasa la presencia de otros múltiplos del número haploide: tri-ploidías (3n, 69 cromo-somas), tetra-ploidías (4n, 92 cromosomas), etc. La nomenclatura aprobada de es-tos transtornos consiste en especificar el número total de cromosomas seguido decoma (sin espacios) y el conjunto de cromosomas sexuales. Por ejemplo, una tri-ploidía en una mujer se representaría como 69,XXX. La triploidía es el tipo másfrecuente de poliploidía (se estima que un 2 por ciento de todas las concepcionesson triploides), pero la gran mayoría son letales y son muy raras en nacidos vivos.Las causas más frecuentes son la dispermia (fecundación de un óvulo por dos es-permatozoides), la fusión de un óvulo con un cuerpo polar (diginia), o un errormeiótico en la gametogénesis que dé lugar a un gameto diploide. La tetraploidía(4n) aparece normalmente en las células somáticas de algunos tejidos, y es el re-sultado de una reduplicación endomitótica, en la que hay dos duplicaciones cro-mosómicas con una sola división celular.
Aneuploidías: son alteraciones numéricas que no afectan a todo el comple-mento cromosómico, sino solamente a un par cromosómico. En ocasiones, la alte-ración no afecta a todo el cromosoma, sino sólo a un segmento cromosómico, encuyo caso suelen denominarse aneusomías segmentarias. Las aneuploidías son al-teraciones con distintos grados de severidad en cuanto a los fenotipos que provo-can, aunque en general se puede decir que son más graves cuando afectan a un au-tosoma que a un cromosoma sexual, y que son más severas las pérdidas decromosomas (monosomías) que las ganancias de cromosomas (trisomías). La au-sencia completa de un par cromosómico (nulisomía) es incompatible con la vida.A continuación veremos algunas de las aneuploidías más frecuentes en patologíahumana:
• Trisomía 21 (47,XX o XY,+21), Síndrome de Down. Es la causa más comúnde retraso mental congénito. Presentan una facies característica (en la quedestacan las fisuras palpebrales oblicuas, hipoplasia de la nariz y macroglo-sia), estatura baja, defectos cardíacos y retraso mental variable. Algunos ca-sos son mosaicos 46,XX/47,XX, ↓+21 (tienen dos poblaciones celulares, unacon la trisomía y otra normal) y son clínicamente más leves. Alrededor de uncinco por ciento de los casos de Síndrome de Down se deben a una translo-cación robertsoniana entre los cromosomas acrocéntricos 14 y 21. El resto delos casos –la gran mayoría– son debidos a no-disyunción durante la gameto-génesis, de los cuales el 75 por ciento son no-disyunciones en meiosis I. Porlas razones que se explicarán más adelante, existe una mayor incidencia deSíndrome de Down en mujeres de edad más avanzada. Así, aunque la inci-dencia global de la enfermedad es de uno por ciento por cada 650 nacidosvivos, las tasas de incidencia desglosada por tramos de edad materna mues-tran una clara tendencia, sobre todo a partir de los 30 años de edad:
181
Anomalías del núm
ero de los cromosom
as
CAPITULO 13 5/12/06 07:23 Página 181
www.FreeLibros.me

Edad materna Riesgo de S. de Down
15 1:157820 1:152825 1:135130 1:90935 1:38440 1:112
• El riesgo de recurrencia de la enfermedad en una pareja joven (la probabili-dad de tener un segundo hijo con Síndrome de Down) está en torno al unopor ciento. No hay suficiente información sobre el riesgo de transmisión de laenfermedad en individuos que son mosaicos.
La Figura 13.3 muestra el cariotipo de un Síndrome de Down.
• Recientemente se ha visto, en un modelo murino, que el funcionamiento deuna familia de factores de transcripción llamados NFATc (Nuclear Factor ofActivated T cells) es muy importante en el desarrollo de esta enfermedad. Es-tos factores de transcripción regulan la expresión de genes durante el des-arrollo, y viajan del núcleo al citoplasma (y viceversa) mediante una fosfori-lación que es regulada por dos genes que están en el cromosoma 21, en laregión crítica que causa el Síndrome de Down. En presencia de un númeroalto de copias de estos genes, los NFAT no funcionan adecuadamente y susgenes diana se expresan débilmente, lo que podría causar algunas de las ma-nifestaciones fenotípicas de la enfermedad.
• Trisomía 18 (47,XX o XY,+18), Síndrome de Edwards. La prevalencia de estaaneuploidía es de 1/6 000 nacidos vivos. Es la anomalía cromosómica que seencuentra más frecuentemente en abortos espontáneos. Muy pocos casos so-breviven el primer año de vida.
• Trisomía 13 (47,XX o XY,+13), Síndrome de Patau. Tiene una prevalencia de1/10 000 nacidos vivos. Son rasgos característicos de esta enfermedad las fi-suras orofaciales, polidactilia y microftalmia. El 90 por ciento de los nacidosvivos fallecen en el primer año de vida.
• Monosomía X (45,X), Síndrome de Turner. Los pacientes con S. de Turnersólo tienen un solo cromosoma X (es la única monosomía viable en huma-nos). La frecuencia de la enfermedad es 1/5 000 niñas recién nacidas. Las en-fermas son fenotípicamente mujeres, siendo sus características más comunesla talla corta, malformaciones (cuello corto, pecho en coraza) e inmadurezsexual por disgenesia gonadal. No suele estar asociado a retraso mental. Sepiensa que esta enfermedad se debe que el cromosoma X contiene genes queescapan a la inactivación fisiológica de uno de los cromosomas X, y que portanto se necesitan las dos copias para un correcto funcionamiento celular. Alexistir un solo cromosoma X en los sujetos con S. de Turner, estos genes es-tarían en dosis génica mitad de la normal (una sola copia), originando las al-teraciones propias de la enfermedad. También existen individuos con S. de
182
Citogenética
CAPITULO 13 5/12/06 07:23 Página 182
www.FreeLibros.me

Turner que son mosaicos 46,XX/45,X o tienen anomalías estructurales delcromosoma X (como el isocromosoma del brazo largo). Los individuos conesta enfermedad suelen padecer abortos espontáneos.
• Síndrome de Klinefelter, 47,XXY. Esta aneuploidía se encuentra con una fre-cuencia de 1/1 000 nacidos varones. Son individuos con talla alta, hipogona-dismo y ginecomastia, inteligencia ligeramente inferior a lo normal. Hasta un15 por ciento de los enfermos muestran mosaicismo. De los raros casos de en-fermos con S. de Klinefelter que tienen cariotipos 48,XXXY y 49,XXXXY sededuce que a mayor número de cromosomas X «extra», la gravedad de la en-fermedad y el retraso mental son también mayores.
13.3 El fenómeno de no disyunción meiótica
Se estima que hasta un cinco por ciento de todas las concepciones humanas sonaneuploides, aunque la gran mayoría de éstas terminan en abortos espontáneos y nose reconocen clínicamente. La incidencia de aneuploidías varía según el periodo ges-tacional, tal y como se muestra en la siguiente tabla:
Frecuencia de anomalías cromosómicas en:
Mortinatos (20 a 40 semanas de gestación): 4 %Abortos espontáneos detectables clínicamente
(7 a 8 semanas de gestación): 35 %Abortos espontáneos NO detectables clínicamente
(antes de 7 semanas): 20 %
También se ha visto que hasta un 20 por ciento de los oocitos humanos son por-tadores de aneuploidías, mientras que sólo el uno-dos por ciento de los espermato-zoides tienen alteraciones en el número de cromosomas. De estos datos se concluyeque la segregación de cromosomas durante la meiosis —especialmente durante laoogénesis— es un proceso que no se lleva a cabo de modo totalmente eficaz en hu-manos. La segregación cromosómica incorrecta origina alteraciones cromosómicasen el embrión, pero la mayoría de estos embarazos se pierden porque esas alteracio-nes son letales en estadíos iniciales del desarrollo embrionario.
Como se recordará, los cromosomas homólogos y las cromátides hermanas se separan en cada una de las dos divisiones que tienen lugar durante la meiosis. Lasaneuploidías se producen por una separación incorrecta (no-disyunción) en una de lasdos divisiones meióticas, aunque lo más frecuente es la falta de disyunción en meiosisI por la presencia de un sobrecruzamiento mal posicionado. Se ha visto en el Capítu-lo 2 que una gonia diploide da lugar a cuatro gametos haploides ya que, tras la repli-cación del ADN en el gonocito primario, la primera división meiótica genera célulascon un solo cromosoma de cada par (aunque cada uno tiene todavía dos cromátideshermanas); la segunda división meiótica separa las cromátides hermanas a cada unode los gametos. Teniendo este esquema en mente, es fácil comprender que los efectosde una no-disyunción en la meiosis I serán distintos a los efectos de una no-dis-yunción en la meiosis II. Si la no-disyunción ha tenido lugar en meiosis I, se produ-cirán dos gametos nulisómicos (sin ninguna copia de ese cromosoma) y dos gametos
183
El fenómeno de no disyunción m
eiótica
CAPITULO 13 5/12/06 07:23 Página 183
www.FreeLibros.me

disómicos (con dos copias), los cuales llevarán una copia de cada cromosoma homó-logo presente en la célula progenitora (es decir, son heterodisómicos). Por el contra-rio, si la no-disyunción sucede en la meiosis II, tendremos dos gametos normales, ungameto nulisómico y un gameto disómico con dos copias idénticas (isodisómico).
El vídeo de la Figura 13.4 muestra los tipos de gametos resultantes de la no-disyunción enmeiosis I o en meiosis II.
Como se ha mencionado más arriba, está comprobado que la mayoría de loserrores de disyunción tienen lugar durante la oogénesis, especialmente en meio-sis I. Esto se ha relacionado con el hecho de que la gametogénesis femenina –al con-trario de lo que sucede en la espermatogénesis– experimenta una meiosis I especial-mente larga (comienza en el periodo fetal y culmina individualmente con cadaovulación, entre 15 y 45 años después). Este hecho podría aumentar la sensibilidaddel oocito a sufrir no-disyunciones. Estudios recientes muestran que la aparición deno-disyunciones tiene que ver con la posición de los quiasmas durante la recom-binación, de modo que los quiasmas que están demasiado cerca de los centrómeroso de los telómeros favorecen los errores en la separación de los cromosomas homó-logos. Actualmente se piensa que la maquinaria que procesa los quiasmas va per-diendo eficacia con los años, por lo que los oocitos con quiasmas en localizaciones«subóptimas» originan errores de disyunción con mayor facilidad en oocitos «viejos»que en oocitos «jóvenes». Esto encaja bien con el hecho de que las aneuploidías sonmás frecuentes al aumentar la edad materna.
Respecto a las causas moleculares de la no-disyunción, es razonable pensar quela des-regulación de los procesos de recombinación, cohesión y separación decromátides sea responsable, en buena medida, de la segregación deficiente de loscromosomas a las células hijas. Como se recordará, durante la meiosis I cada pare-
184
Citogenética
No disyunción en Meiosis I No-disyunción en Meiosis II
CAPITULO 13 5/12/06 07:23 Página 184
www.FreeLibros.me

ja de quinetocoros hermanos es arrastrada hacia un extremo del huso; si ha habidoun sobrecruzamiento, la cohesión debida a la presencia de los quiasmas se opondráa la fuerza de los microtúbulos que tienden a separar los dos cromosomas homólo-gos. Por tanto, es fundamental que la cohesión entre cromosomas homólogos semantenga a nivel de los centrómeros mientras los homólogos se separan, para quelas cromátides se mantengan unidas hasta la llegada de la meiosis II. En el Capítu-lo 2 se han esbozado los mecanismos moleculares que regulan estos procesos, porlo que la alteración de cualquiera de las proteínas implicadas puede provocar la apa-rición de aneuploidías. Esto se ha visto corroborado por la detección de alteracio-nes en estos mecanismos en cáncer, que en la mayoría de los casos se asocia conaneuploidías muy marcadas. Se ha visto, por ejemplo, que en tumores colorrectalesaneuploides hay mutaciones en el gen BUB1, que codifica una proteína del com-plejo proteico que regula la cohesión en los quinetocoros. Además, se ha demostra-do que una securina denominada PTTG (pituitary tumour transforming gene) tienepropiedades de oncogén: muestra niveles altos de expresión en tumores pituitariosy es un factor de mal pronóstico en cáncer de colon, ya que los niveles de PTTG co-rrelacionan con la invasividad del tumor. Todo esto pone de manifiesto que los ge-nes implicados en los mecanismos que regulan la segregación de cromátides her-manas durante la división celular son muy importantes para mantener una correctasegregación cromosómica durante la mitosis, y es lógico pensar que lo mismo sepuede aplicar a la meiosis.
13.4 Anomalías estructurales de los cromosomas
Existen muchos posibles tipos de alteraciones en la estructura de los cromosomas. Sila alteración da lugar a la pérdida o ganancia de material genético, se habla de alte-raciones desequilibradas; en el caso contrario, se denominan equilibradas. Las alte-raciones equilibradas no suelen producir patología en el individuo que las lleva, aun-que determinadas alteraciones equilibradas pueden favorecer la formación deaneuploidías en la descendencia, como se verá más adelante. Se piensa que las alte-raciones estructurales se producen por errores durante la meiosis, bien porque loscromosomas homólogos no se alinean correctamente o bien porque se produce em-parejamiento entre secuencias homólogas que pertenecen a cromosomas distintos.La recombinación entre cromosomas que no están correctamente alineados o entrecromosomas que no son homólogos tiene como resultado la generación de duplica-ciones, deleciones, inversiones, translocaciones, isocromosomas o cromosomas enanillo.
La Figura 13.5 muestra distintos tipos de anomalías cromosómicas estructurales.
Las inversiones son alteraciones estructurales intracromosómicas debidas a laaparición de dos roturas dentro de un mismo cromosoma y la inversión completadel segmento que queda entre ellas. Hay básicamente dos tipos de inversiones: pe-ricéntricas (el centrómero del cromosoma queda incluido dentro de la región in-vertida) o paracéntricas (la región invertida está en uno de los brazos cromosómi-
185
Anomalías estructurales de los crom
osomas
CAPITULO 13 5/12/06 07:23 Página 185
www.FreeLibros.me

cos, sin incluir el centrómero). Habitualmente, las inversiones son equilibradas. Sinembargo, pueden originar problemas cuando se forman los bivalentes entre cromo-somas homólogos durante la recombinación en meosis: al formarse el bivalente, elcromosoma con la inversión puede formar un bucle para que todas las regionesqueden alineadas con las correspondientes secuencias del cromosoma homólogo. Sitiene lugar un sobrecruzamiento dentro del bucle de una inversión paracéntrica,se originará un cromosoma acéntrico (sin centrómero) y otro dicéntrico (con doscentrómeros). En anafase, cada centrómero del cromosoma dicéntrico migrará ha-cia cada uno de los polos, formándose un puente que se romperá al final de anafa-se. El resultado será la generación de gametos con diversas deleciones y/o duplica-ciones, dependiendo del punto donde se rompa el puente anafásico. En cambio, siel sobrecruzamiento se produce dentro de una inversión pericéntrica, los dos cro-mosomas resultantes llevarán un solo centrómero pero tendrán duplicada o dele-cionada la región distal a los límites de la inversión. Por tanto, aunque un individuoportador de una inversión sea fenotípicamente normal, es importante recordar queen su descendencia pueden aparecer individuos con reordenaciones des-equilibra-das (deleciones o duplicaciones), aunque no es posible calcular la probabilidad deque esto suceda.
La Figura 13.6 contiene un vídeo en el que se muestran esquemáticamente los tipos de gametosque se generan por una recombinación entre cromosomas homólogos, cuando uno de ellos lleva unainversión.
Los isocromosomas son cromosomas en los que ambos brazos son idénticos, y seoriginan por la pérdida total de uno de los brazos y la duplicación del otro brazo; elresultado final es un cromosoma simétrico. Los isocromosomas de cromosomas au-tosómicos son habitualmente letales; el isocromosoma más frecuente en humanos esel del cromosoma X, que aparece en algunos sujetos con Síndrome de Turner dandolugar a cariotipos 46,X,i(Xq).
Las deleciones pueden ser terminales (afectan a la región terminal o teloméri-ca de un cromosoma) o intersticiales. Si son lo suficientemente grandes como paraser visibles citogenéticamente suelen ser graves. Por ejemplo, la deleción denomi-nada 46,XY,del(5p), en la que se pierde un fragmento terminal del brazo corto delcromosoma 5, es causa del Síndrome de cri-du-chat (maullido de gato); la deleciónterminal 46,XY,del(4p) da lugar al Síndrome de Wolf-Hirschhorn. Desde que se hautilizado la técnica de FISH, se ha conseguido delimitar mejor las deleciones cro-mosómicas, e incluso se ha podido identificar algunos síndromes debidos a dele-ciones que no eran visibles por citogenética convencional (cariotipo de bandas G).Por esta razón, estas enfermedades se denominan «Síndromes por Microdele-ción», aunque también se les llama aneusomías segmentarias o síndromes de genescontiguos (ya que en las pequeñas deleciones se pierden habitualmente varios ge-nes). La siguiente tabla recoge algunos de los principales síndromes por microde-leción, indicando la región delecionada y el gen (o genes) implicados en esas dele-ciones:
186
Citogenética
CAPITULO 13 5/12/06 07:23 Página 186
www.FreeLibros.me

Síndrome Deleción (genes)
Wolf-Hirschhorn 4p16.3Williams-Beuren 7q11.23 (elastina)WAGR (Wilms, aniridia, genital defects, growth retardation) 11p13 (WT1 y PAX6)Prader-Willi/Angelman 15q11-q13Rubinstein-Taybi 16p13.3 (CBP)Miller-Diecker lisencefalia 17p13.3 (LIS1)Smith-Magenis 17p11.2 (KER)Alagille 20p12.1-p11.23 (Jagged1)DiGeorge (CATCH22) 22q11.21-q11.23
Las translocaciones consisten en el intercambio de fragmentos cromosómicos en-tre cromosomas no homólogos. Hablamos de translocaciones recíprocas cuando am-bos cromosomas son donantes y receptores de material cromosómico, de modo queparte de un cromosoma pasa a otro y, a su vez, parte de éste pasa al primero. Lastranslocaciones recíprocas desequilibradas, en las que se ha perdido o ganado ma-terial genético durante el proceso de formación de la translocación, son habitual-mente causa de enfermedad. Por el contrario, las translocaciones equilibradas noson necesariamente patogénicas, a no ser que los puntos de rotura en alguno de loscromosomas interrumpan algún gen concreto. En cambio, un individuo portador deuna translocación recíproca equilibrada puede tener descendencia con alteracionescromosómicas estructurales. Esto se debe a que, durante la meiosis, los cromosomastranslocados se alinean con los dos cromosomas normales respectivos, dando lugara la formación de un tetravalente en vez de un bivalente. La segregación de los cro-mosomas del cuadrivalente a cada gameto puede realizarse según un patrón adya-cente o alternante: mientras la segregación alternante puede generar gametos nor-males o equilibrados, la segregación adyacente da lugar a gametos nulisómicos odisómicos, que causarán monosomías o trisomías en el embrión.
La Figura 13.7 explica la segregación de cromosomas con una translocación recíproca equilibrada.
Otro tipo importante de translocación son las llamadas translocaciones Robertso-nianas (también denominadas «fusión céntrica»), en las que dos cromosomas acro-céntricos se fusionan por sus centrómeros. Al igual que en las translocaciones equili-bradas, los individuos portadores de una translocación robertsoniana no suelenpadecer ninguna patología, ya que llevan dos copias completas de cada uno de los cro-mosomas implicados (la copia normal más la copia presente en el cromosoma con latranslocación). En cambio, en la descendencia sí que pueden aparecer monosomías otrisomías de los segmentos implicados. Esto se debe a que durante la meiosis el cro-mosoma con la fusión céntrica se apareará con los dos cromosomas homólogos co-rrespondientes, formando un trivalente en vez de un bivalente. El resultado de esta es-tructura, dependiendo de cómo sea la segregación, será la formación de gametosnormales (segregación alternante) o de gametos nulisómicos o disómicos (segregacio-nes adyacentes), que a su vez provocarán monosomías o disomías en la descendencia.
En la Figura 13.8 se muestra la segregación de cromosomas con una translocación robertsoniana.
187
Anomalías estructurales de los crom
osomas
CAPITULO 13 5/12/06 07:23 Página 187
www.FreeLibros.me

CAPITULO 13 5/12/06 07:23 Página 187
www.FreeLibros.me

C A P Í T U L O 1 4
Mutaciones simplescomo causa de enfermedad
Contenidos
14.1 Características generales de las mutaciones
14.2 Mutaciones simples: tipos y nomenclatura
14.3 Potencial patogénico de las mutaciones en el ADN codificante y en el ADN no-codificante in-tragénico e intergénico
14.4 Potencial patogénico de las mutaciones en el ADN no-codificante
14.1 Características generales de las mutaciones
Ya se ha mencionado que el genoma humano está sujeto a variación genética y que estacapacidad de introducir modificaciones genéticas heredables supone una ventaja para laespecie, al permitir la adaptación a condiciones ambientales cambiantes. Sin embargo, laexistencia de una tasa mutacional basal tiene el peligro de introducir cambios genéticosdeletéreos en un individuo o una familia concreta, provocando enfermedades heredables.Por tanto, de modo general podemos decir que la presencia de mutaciones en una pobla-ción está sujeta al juego entre la tasa mutacional basal (la velocidad a la que se producen)y la presión selectiva frente a cada una de las mutaciones, de forma que aquellas muta-ciones que sean muy agresivas no se extenderán al resto de la población tan rápidamen-te como mutaciones con efectos fenotípicos más leves. Por ejemplo, ya hemos visto enotro capítulo que las aberraciones cromosómicas (trisomías, monosomías, etc.) son raraspero casi siempre patogénicas, mientras que los polimorfismos de secuencia —variantesalélicas que no causan ninguna enfermedad— son mucho más frecuentes. En cierto modo,lo mismo sucede con los distintos tipos de mutaciones: aquellas que provocan alteracio-nes graves del producto proteico, que están sometidas a una fuerte presión selectiva en sucontra, suelen ser menos frecuentes que mutaciones con efectos más leves.
CAPITULO 14 5/12/06 07:25 Página 189
www.FreeLibros.me

Antes de estudiar todos los posibles tipos de mutaciones, será de gran utilidad re-cordar la estructura y procesamiento de un gen típico, porque esto nos ayudará a com-prender cómo se clasifican y sus efectos. Recordemos que en el ADN genómico se pue-de distinguir una región 5’ no-traducida (desde el inicio de la transcripción hasta elATG que señala el inicio de la traducción), exones separados por intrones (que con-tienen las secuencias consenso de ayuste GT-AG), el codón de terminación (TAA enla figura) y la región 3’ no traducida, que incluye la señal de poliadenilación (AATAAA). La transcripción del gen y la posterior maduración del transcrito primariodan como resultado el ARNm maduro, que después es traducido en la proteína co-rrespondiente. En general, los distintos tipos de mutaciones que se encuentran en ungen pueden ser tanto mutaciones simples (deleciones, inserciones o substituciones queafectan a un nucleótido o a unas pocas bases) o reordenamientos grandes (delecionesparciales o reordenamientos que dan lugar a duplicaciones o deleciones del gen).
En la Figura 14.1 se muestran esquemáticamente los distintos tipos de mutaciones que se puedenencontrar en un gen, y cómo afectan a su función.
A lo largo de este capítulo, veremos con detalle los distintos tipos de mutacionesque provocan enfermedades humanas.
14.2 Mutaciones simples: tipos y nomenclaturaLas substituciones simples de un nucleótido por otro se denomi-nan transiciones o transversiones, según provoquen el cambio depurina por purina o pirimidina por pirimidina (transiciones), o elcambio de una purina por pirimidina o viceversa (transversiones).En el esquema adjunto, las transiciones se representan por flechasgrises y las transversiones por flechas negras. Como puede apre-
ciarse, las transversiones deberían ser el doble de frecuentes que las transiciones(ocho posibles transversiones por cuatro posibles transiciones). En cambio, al anali-zar las mutaciones presentes en enfermedades humanas encontramos que las transi-ciones son más frecuentes. Esto es debido a que —en general— las transiciones pro-vocan una alteración menos severa del producto proteico, por lo que la presiónselectiva contra ellas es menor. Además, el dinucleótido CpG suele estar metilado enla citosina, y la des-aminación espontánea de una metil-citosina da lugar a unatransición del tipo C→T. Como este cambio tiene lugar con relativa frecuencia en elgenoma de mamíferos, esto también contribuye a la alta frecuencia de transicionesque se observa en estas especies.
14.3 Potencial patogénico de las mutaciones en el ADN 14.3 codificante y en el ADN no-codificante intragénico 14.3 e intergénico
Cuando las substituciones simples tienen lugar en ADN codificante, sus efectospueden ser de varios tipos:
190
Mutaciones sim
ples como causa de enferm
edad A
G
C
T
CAPITULO 14 5/12/06 07:25 Página 190
www.FreeLibros.me

a) Substituciones silenciosas (llamadas sinónimas, sin cambio de sentido): nocambian ningún aminoácido en la proteína codificada, debido a que la mu-tación cambia un codón por otro codón sinónimo. Como son biológicamen-te neutras, no están sujetas a selección y por tanto son relativamente fre-cuentes en ADN codificante. Habitualmente se producen por cambios en latercera base de un triplete, ya que es habitualmente este nucleótido el quevaría entre codones sinónimos.
b) Substituciones no-sinónimas (el cambio de nucleótidos origina un cambio enla capacidad codificante del ARNm). Según el cambio introducido, podemosdistinguir:
• Mutaciones con cambio de sentido (mis-sense, en inglés), cuando el cam-bio de nucleótidos provoca un cambio de aminoácidos. Se habla de cam-bio conservativo cuando ambos aminoácidos (el original y el nuevo) per-tenecen al mismo grupos bioquímico, o no conservativo cuandopertenecen a grupo distintos. Estos últimos son —en general— más graves,puesto que alteran la estructura de la proteína en mayor grado. Tambiénson importantes los cambios que afectan a Cisteínas y Prolinas, que sonaminoácidos muy importantes en el mantenimiento de la estructura ter-ciaria de la proteína.
• Mutaciones sin sentido (non-sense), cuando un codón que codifica unaminoácido se convierte en un codón de parada (UAA, UAG o UGA).Estas mutaciones dan lugar a proteínas truncadas en la región C-termi-nal, además de disminuir la estabilidad del ARNm. En general son muygraves, por lo que son menos frecuentes que las mutaciones con cambiode sentido.
En la Figura 14.2 se muestran distintos tipos de mutaciones puntuales y su efecto sobre el producto proteico.
• Mutaciones con ganancia de sentido, cuando la mutación transforma uncodón de parada en un codón codificante. Son casos infrecuentes, entrelos que destaca el de una variante de la hemoglobina denominada He-moglobina Constant Spring (variante alélica HBA20001), originada porel cambio de UAA (codón de parada) a CAA. Esto tiene como resultadola adición de 30 aminoácidos a la secuencia de la hemoglobina alfa-2,que se hace más inestable y provoca una enfermedad de la sangre llama-da alfa-talasemia.
En la Figura 14.3 se esquematiza la mutación que origina la hemoglobina Constant Spring.
c) Deleciones e inserciones de uno o de unos pocos nucleótidos pueden intro-ducir o eliminar aminoácidos sin cambiar la pauta de lectura, siempre que setrate de inserciones o deleciones de tres nucleótidos (o múltiplos de tres).Cuando se insertan o delecionan nucleótidos en un número que no es múlti-plo de tres, se produce un frameshift (desplazamiento del marco de lectura)
191
Potencial patogénico de las mutaciones en el ADN codificante y en el ADN no-codificante…
CAPITULO 14 5/12/06 07:25 Página 191
www.FreeLibros.me

con un cambio muy importante en la estructura proteica. Para comprenderlas mutaciones con cambio del marco de lectura, es importante repasar esteconcepto, ya presentado en el Capítulo 1.
En la Figura 14.4 se recuerda el concepto de marco de lectura (frameshift) y se muestra sudesplazamiento por efecto de distintos tipos de inserciones.
LOS QUE VES SON LOS QUE SON ...
LOS QaU EVE SSO NLO SQU ESO N.. FRAMESHIFT +1LOS Qab UEV ESS ONL OSQ UES ON. FRAMESHIFT +2LOS Qab cUE VES SON LOS QUE SON INSERCIÓN 3bp
Al igual que las mutaciones sin sentido, las mutaciones con cambio del marco de lec-tura provocan alteraciones importantes del producto proteico y, por tanto, están so-metidas a mayor presión selectiva, por lo que suelen ser menos frecuentes en ADNcodificante que las mutaciones sinónimas. Además, los cambios del marco de lectu-ra suelen introducir codones de parada prematuros, por lo que habitualmente se pro-ducen también proteínas truncadas que ven muy comprometida su funcionalidad.
Otro mecanismo por el que puede perderse o recuperarse el marco de lectura esla edición del ARN, fenómeno que ya se explicó en el Capítulo 1. Una variedad cu-riosa de edición del ARN surge en unas ratas que tienen una deleción de un solo nu-cleótido en el gen de la vasopresina, haciendo que desarrollen hipertensión arterial.Estas ratas mejoran espontáneamente al envejecer, debido a un proceso de edicióndel ARNm mediante el cual se pierde el dinucleótido GA en un motivo GAGAGde ese mismo gen. La deleción de estos dos nucleótidos, añadida a la deleción de unnucleótido que ya tenían, hace que se recupere el marco de lectura original y que seproduzcan mayores niveles de vasopresina funcional. Recientemente, se ha encon-trado un motivo GAGAGA en el gen de la proteína precursora de amiloide-β (β-APP) y se ha visto que tiene lugar una edición similar, con deleción de dos bases enel ARNm y la interrupción del marco de lectura que produce una proteína truncaday es causa de algunos casos de enfermedad de Alzheimer en humanos.
14.4 Potencial patogénico de las mutaciones en el ADN 14.4 no-codificante
Las mutaciones simples que tienen lugar en ADN no codificante intragénico (es de-cir, en intrones y regiones no traducidas) son silenciosas, excepto cuando afectan alas secuencias de consenso para ayuste (splicing) de los extremos 5’ y 3’ de los in-trones. En este caso, podemos encontrar:
• Mutaciones que destruyen una de las secuencias de consenso. Si esto tienelugar en ausencia de secuencias de ayuste crípticas (escondidas) y en intro-nes pequeños, habitualmente se lee todo el intrón, que queda así incluido enel ARNm. Esto hace que se añadan aminoácidos a la proteína, aunque tam-
192
Mutaciones sim
ples como causa de enferm
edad
CAPITULO 14 5/12/06 07:25 Página 192
www.FreeLibros.me

bién es posible que se introduzca un cambio en el marco de lectura y se al-tere toda la secuencia de aminoácidos a partir de ese punto.
• Si la mutación que destruye la secuencia de ayuste tiene lugar en presencia deuna secuencia de ayuste críptica en ese mismo intrón, el exón vecino serámás largo; por el contrario, si la secuencia críptica está en el exón cercano ala mutación, dicho exón será más corto.
• En ocasiones, las mutaciones que destruyen una de las secuencias consensode ayuste hacen que se «salte» el exón adyacente (lo que en inglés se deno-mina skipping del exón), dando lugar a una proteína que ha perdido un cier-to número de aminoácidos, aunque también es posible que produzca un cam-bio en el marco de lectura. El exón afectado será el 5’ o el 3’ a la mutación,según se destruya el GT o el AG de un intrón, respectivamente.
En la Figura 14.5 se muestran distintas mutaciones que afectan a las secuencias consenso deayuste.
• Un caso especial de este tipo de mutaciones es la transición A → G en posi-ción + 3 de la secuencia donante de ayuste, una alteración que está asocia-da con desarrollo de enfermedades en –al menos– ocho genes humanos.Como se recordará, la secuencia donante de ayuste (la del extremo 5’ del in-trón) es complementaria a la secuencia del ARN nuclear pequeño U1(U1snRNA), cuya presencia es necesaria para que se lleve a cabo el procesode ayuste. Los dos primeros nucleótidos del intrón son siempre GT (comple-mentarios a CA en el U1snRNA), y el tercer nucleótido de la secuencia deayuste suele ser adenina (complementaria al uracilo correspondiente en elU1snRNA). En cambio, las posiciones + 4 a + 6 no siempre son perfecta-mente complementarias. De hecho, la adenina en posición +3 dota de ciertaflexibilidad a los nucleótidos de las posiciones + 4 a + 6, que pueden ser dis-
193
Potencial patogénico de las mutaciones en el ADN no-codificante
EXÓN 1 INTRÓN 1 EXÓN 2
EXÓN 2A
MUTACIÓN
GT
GT
TTAGG
TTAG G…
Lugar críptico de ayuste(intrónico)
AG
…AG
{
CAPITULO 14 5/12/06 07:25 Página 193
www.FreeLibros.me

cordantes de la secuencia del U1snRNA y aún así son capaces de funcionarcorrectamente como secuencia donante de ayuste. En cambio, si alguna de lasposiciones + 4 a + 6 no son complementarias a la secuencia del U1snRNA,una mutación en la posición + 3 tiene como resultado la falta de funcionali-dad de esta secuencia de ayuste, con lo que se salta el exon precedente.
La Figura 14.6 muestra una mutación de la posición +3, que provocará el skipping del exón 16 delgen COLQ.
• Finalmente, existen mutaciones que, sin afectar directamente a secuenciasconsenso de ayuste, pueden activar un lugar críptico en un intrón y produ-cir un exón más grande y posiblemente un cambio en el marco de lectura.
La Figura 14.7 muestra la creación de secuencias de ayuste crípticas intrónicas.
Como regla general, podemos afirmar que las mutaciones que afectan al meca-nismo de ayuste son más raras que las substituciones, aunque algunos genes tienenuna estructura exónica que les otorga una tendencia especial a sufrir mutacionesde este tipo: se trata, habitualmente, de genes con muchos intrones y con exones pe-queños, como sucede con los genes que codifican cadenas del colágeno (COL7A1,por ejemplo, tiene 118 exones), o bien genes con muchos sitios crípticos de ayuste(como es el caso del gen de la beta-globina).
Como se explicaba en el Capítulo 1, recientemente se ha descrito que ciertas se-cuencias exónicas o intrónicas pueden actuar como potenciadores o silenciadores delayuste. Estas secuencias se denominan ESE (Exonic Splicing Enhancers) o ESS (Exo-nic Splicing Silencers) cuando están en exones; ISE o ISS cuando están en intrones.A estas secuencias se unen proteínas llamadas proteínas SR (las que se unen a lospotenciadores de ayuste) o algunas hnRNP (las que se unen a los silenciadores). Portanto, estas proteínas regulan el proceso de ayuste y determinan si un exón va a es-tar presente en el transcrito final o, por el contrario, se va a saltar. Es importante te-ner en cuenta que algunas mutaciones en estos motivos, aunque sean silenciosasporque no cambian el aminoácido (o porque se localizan en intrones), pueden sinembargo tener efectos sobre el mensajero, haciendo que un exón se pierda y alteran-do así la estructura de la proteína o rompiendo el marco de lectura. De hecho, en al-gunos genes (ATM, NF1) se ha estimado que el 50 por ciento de las mutacionesque originan enfermedades afectan a regiones que cambian el patrón de ayustesin cambiar la secuencia de aminoácidos.
Un buen ejemplo para ilustrar esta situación es una enfermedad llamada AtrofiaMuscular Espinal, debida a deleciones y/o mutaciones del gen SMN1. Cerca de estegen hay un gen parálogo casi idéntico llamado SMN2, en el que un cambio C → Tmodifica el patrón de ayuste (sin cambiar la secuencia de aminoácidos) y hace queel exón 7 se pierda, dando lugar a una proteína truncada no funcional. De todas for-mas, un pequeño porcentaje de las moléculas siguen un ayuste normal (con el exón7) y producen proteína normal a partir del gen SMN2. Por tanto, aunque no hayaninguna copia funcional de SMN1 (como sucede en enfermos con atrofia muscularespinal) la enfermedad tiene distinta gravedad según el número de copias de SMN2
194
Mutaciones sim
ples como causa de enferm
edad
CAPITULO 14 5/12/06 07:25 Página 194
www.FreeLibros.me

presentes. De hecho, se piensa que esta circunstancia podría utilizarse para corregirla sintomatología de los pacientes con Atrofia Muscular Espinal.
La Figura 14.8 muestra la diferencia de ayuste entre los genes SMN1 y SMN2.
Otro tipo de mutaciones del ADN no-codificante intragénico son las que afectana la señal de poli-adenilación, que se encuentra en la región no traducida 3’ de ungen. Estas mutaciones pueden originar proteínas defectuosas y llevar a la degrada-ción del ARNm. Por ejemplo, una mutación en la señal de poliadenilación del genque codifica la hemoglobina alfa-2 (alelo HBA20024) convierte la señal AATAAAen AATGAA, con lo que el ARNm no se poli-adenila correctamente, el ARNm se de-grada y se desarrolla la enfermedad alfa-talasemia por ausencia de cadenas de he-moglobina alfa-2.
Finalmente, las substituciones en el ADN no codificante intergénico, serán si-lenciosas excepto cuando afectan a elementos reguladores de la expresión génica(promotores, potenciadores, etc.) o a otros elementos necesarios para el correcto pro-cesamiento del ARNm. Por ejemplo, mutaciones que afectan a la «Región de Con-trol del Locus» de las alfa- y beta-globinas (un conjunto de potenciadores situadosunas 40–60 kb en dirección 5’ de los genes respectivos) provocan unas enfermeda-des denominadas talasemias, debidas a la síntesis deficiente de globinas.
14.5 Nomenclatura general de mutaciones
Llegados a este punto, interesa estudiar la nomenclatura recomendada para descri-bir los distintos tipos de mutaciones que hemos visto hasta ahora. Aunque las reco-mendaciones van cambiando con el paso de los años, a continuación se resumen lasreglas principales:
1. Describir la mutación utilizando la numeración de nucleótidos de la se-cuencia genómica (g.) o del ADNc (c.) o la numeración de la secuencia de
195
Nomenclatura general de m
utaciones
6 8
CAGACAA
6 8
UAGACAA
SMN1
SMN2
SMN1
SMN1 ∆7
6 8
6 8
CAPITULO 14 5/12/06 07:25 Página 195
www.FreeLibros.me

aminoácidos, según los casos. Siempre la Adenina del codón de iniciaciónATG se toma como posición +1, de forma que el nucleótido anterior es laposición –1.
2. Describir las substituciones de nucleótidos según el esquema general:
2. Intervalo + secuencia antigua + tipo de cambio + secuencia nueva.
2. Utilizar una flecha o el signo «>» para las sustituciones, «del» para delecio-nes, «ins» para inserciones. Los rangos se indican con guión bajo (de subra-yado) para evitar confusiones con el signo negativo. Las combinaciones dedos o más alteraciones se separan con el signo + y se incluyen en corchetes.Algunos ejemplos:
2. g.12T>A (Cambio de timina por adenina en el nucleótido 12 de la secuenciagenómica)
2. [6T>C + 13_14del] (Dos cambios en el mismo alelo)2. [6T>C] + [13_14del] (Dos mutaciones, una en cada alelo)2. 14–15insT (Inserción de timina entre dos nucleótidos)2. 112_117delAGGTCAinsTG (Inserción de TG en vez de AGGTCA, también
se podría indicar como 112_117>TG)
3. En repeticiones en tándem, se asigna por convenio el cambio a la última re-petición (la que ocupa una posición más 3’): por ejemplo, la deleción de undinucleótido TG en la secuencia ACTGTGTGCC (siendo A el nucleótido1991) se describiría como 1997-1998del (o 1997-1998delTG).
4. La variabilidad en microsatélites se designa contando la posición de laprimera repetición. Si la secuencia del ejemplo anterior fuese polimórfica,se designaría 1993(TG)3-22, para indicar que en posición 1993 comienzaun dinucleótido TG que se encuentra en la población repetido entre 3 y 22veces.
5. En intrones (cuando no se conoce la secuencia genómica), se señala la posi-ción dentro del intrón con referencia al exón más cercano (utilizando núme-ros positivos comenzando con la G de la secuencia de ayuste GT donante, ynúmeros negativos contando desde la G de la secuencia AG aceptora). Sepuede usar tanto la sigla IVS como sinónimo de «intrón», como la numera-ción correspondiente a la secuencia del ADNc. Ejemplos:
2. IVS3+1G>T o c.621+1G>T (621 es el último nucleótido del exón 3, luego +1es la G de la secuencia donante GT del intrón 3).
2. IVS6-5C>A o c.1781–5C>A (1781 es el primer nucleótido del exón 7, luego–1 es la G de la secuencia aceptora AG del intrón 6, –2 es la A, y así sucesi-vamente hasta llegar a –5).
6. Para describir substituciones de aminoácidos, se indica el número del ami-noácido y el cambio operado, considerando la metionina iniciadora como
196
Mutaciones sim
ples como causa de enferm
edad
CAPITULO 14 5/12/06 07:25 Página 196
www.FreeLibros.me

+1. Se sigue el esquema general aminoácido cambiado + rango + aminoáci-do nuevo.
2. Se recomienda usar el código de aminoácidos de una letra, aunque tambiénpuede utilizarse el de tres letras, empleando la letra X para indicar un codónde parada. Ejemplos:
2. R117H (la Arg en posición 117 pasa a His)2. G542X (la Gly 542 se convierte en codón de parada)
T97del (deleción de la treonina 97) o T97_C102del (deleción de los ami-noácidos 97 a 102)
T97_W98insLK (inserción de leucina y lisina entre las posiciones 97 y 98,ocupadas por treonina y triptófano)
197
Nomenclatura general de m
utaciones
CAPITULO 14 5/12/06 07:25 Página 197
www.FreeLibros.me

CAPITULO 14 5/12/06 07:25 Página 197
www.FreeLibros.me

C A P Í T U L O 1 5
Potencial patogénicode las secuencias repetidas
Contenidos
15.1 Mutaciones en secuencias que están repetidas en tándem
15.2 Expansión de trinucleótidos: neuropatías por expansiones de CAG y enfermedades por expansiónde otros trinucleótidos
15.3 Neuropatías por expansiones de CAG
15.4 Enfermedades por expansión de otros trinucleótidos
15.5 Otras enfermedades por expansión de secuencias repetidas
15.6 Mutaciones debidas a repeticiones dispersas
15.7 Desórdenes genómicos
Además de las mutaciones simples estudiadas en el capítulo anterior, puede haber muta-ciones más complejas que afectan a secuencias repetidas, tanto repeticiones en tándem(mini- y micro-satélites) como repeticiones dispersas (elementos Alu, LINE, etc).
15.1 Mutaciones en secuencias que están repetidas en tándem
Un tipo de mutación que afecta con frecuencia a las repeticiones cortas en tándem detipo microsatélite es la expansión o contracción de la repetición. Como ya vimos al es-tudiar los mecanismos de reparación, este fenómeno se produce habitualmente por unmecanismo llamado «desemparejamiento por deslizamiento de cadenas» (slipped-strandmispairing en inglés). Dicho proceso puede tener lugar durante la replicación del ADNque contiene la repetición, si se da un deslizamiento hacia atrás o hacia delante de la ca-dena que está siendo sintetizada sobre la cadena molde. Este deslizamiento origina un
CAPITULO 15 5/12/06 07:27 Página 199
www.FreeLibros.me

bucle en una de las cadenas, cuyo resultado final es que la nueva cadena de ADNtendrá una repetición más o una repetición menos que la cadena original, según eldesplazamiento haya sido hacia atrás o hacia delante, respectivamente. Este meca-nismo explica los polimorfismos de longitud de los microsatélites, que ya hemos es-tudiado al hablar de estos marcadores en el Capítulo 1.
La Figura 15.1 muestra esquemáticamente el mecanismo de expansión de un trinucleótido pordeslizamiento de una cadena durante la replicación.
Lo importante ahora es darse cuenta de que sila expansión o contracción tiene lugar en la re-gión codificante de un gen que contiene repeticio-nes en tándem cortas, el resultado será la apari-ción de deleciones de aminoácidos (si sedelecionan tres nucleótidos) o cambios en el mar-co de lectura (si se delecionan repeticiones deuno, dos, cuatro o cinco nucleótidos). Se presen-tan a continuación dos ejemplos de lo dicho. En elcuadro superior observamos, arriba, la secuencianativa del gen CFTR (mutado en una enfermedadllamada «Fibrosis Quística del páncreas»), que
contiene una repetición en tándem del nucleótido Timina (hay cinco Timinas segui-das en los codones 142 y 143). La deleción de una T por el fenómeno que acabamosde describir provocará un cambio del marco de lectura, como se aprecia en la fila dedebajo. En el cuadro inferior vemos un ejemplo de deleción de un trinucleótido TTGen la región codificante del Factor IX de la coagulación: la secuencia nativa (fila su-perior) contiene dos repeticiones TTG en tándem, de modo que la deleción de unade ellas provoca la deleción de un aminoácido sin alterar el marco de lectura (fila in-ferior). Lógicamente, lo mismo que se ha ilustrado aquí con deleciones puede decir-se de las inserciones. Los microsatélites del tipo trinucleotídico pueden además su-frir expansiones mayores, dando lugar a un grupo de enfermedades conocidas como«enfermedades por expansión de trinucleótidos». Dada su importancia en patologíahumana, las estudiamos con más detalle en el siguiente apartado.
15.2 Expansión de trinucleótidos: neuropatías por expansiones15.2 de CAG y enfermedades por expansión 15.2 de otros trinucleótidos
Hay un grupo de enfermedades debidas a la expansión de repeticiones de trinucleóti-dos, que tienen una serie de rasgos en común. El descubrimiento del mecanismo porel que se desencadenan estas enfermedades ayudó a comprender un fenómeno clíni-co que se conocía con el nombre de «anticipación»: la aparición de la enfermedad auna edad cada vez más temprana y de forma más severa en sucesivas generaciones deuna misma familia. Como veremos, la presencia de secuencias trinucleotídicas inesta-bles, que aumentan de tamaño en cada generación, permitió explicar este fenómeno.
200
Potencial patogénico de las secuencias repetidas
141 142 143 144 145GCC ATT TTT GGC CTT
141 142 143 144 145GCC ATT TT*G GCC TT
329 330 331 332 333CCA CTT GTT GAC CGA
329 330 331 332CCA CTT G** *AC CGA
CAPITULO 15 5/12/06 07:27 Página 200
www.FreeLibros.me
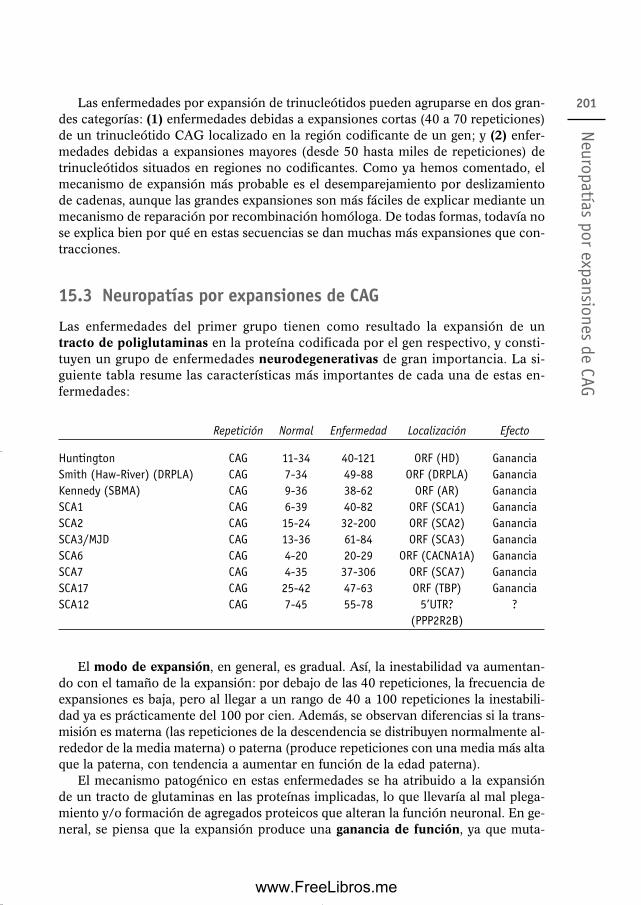
Las enfermedades por expansión de trinucleótidos pueden agruparse en dos gran-des categorías: (1) enfermedades debidas a expansiones cortas (40 a 70 repeticiones)de un trinucleótido CAG localizado en la región codificante de un gen; y (2) enfer-medades debidas a expansiones mayores (desde 50 hasta miles de repeticiones) detrinucleótidos situados en regiones no codificantes. Como ya hemos comentado, elmecanismo de expansión más probable es el desemparejamiento por deslizamientode cadenas, aunque las grandes expansiones son más fáciles de explicar mediante unmecanismo de reparación por recombinación homóloga. De todas formas, todavía nose explica bien por qué en estas secuencias se dan muchas más expansiones que con-tracciones.
15.3 Neuropatías por expansiones de CAG
Las enfermedades del primer grupo tienen como resultado la expansión de untracto de poliglutaminas en la proteína codificada por el gen respectivo, y consti-tuyen un grupo de enfermedades neurodegenerativas de gran importancia. La si-guiente tabla resume las características más importantes de cada una de estas en-fermedades:
Repetición Normal Enfermedad Localización Efecto
Huntington CAG 11-34 40-121 ORF (HD) GananciaSmith (Haw-River) (DRPLA) CAG 7-34 49-88 ORF (DRPLA) GananciaKennedy (SBMA) CAG 9-36 38-62 ORF (AR) GananciaSCA1 CAG 6-39 40-82 ORF (SCA1) GananciaSCA2 CAG 15-24 32-200 ORF (SCA2) GananciaSCA3/MJD CAG 13-36 61-84 ORF (SCA3) GananciaSCA6 CAG 4-20 20-29 ORF (CACNA1A) GananciaSCA7 CAG 4-35 37-306 ORF (SCA7) GananciaSCA17 CAG 25-42 47-63 ORF (TBP) GananciaSCA12 CAG 7-45 55-78 5’UTR? ?
(PPP2R2B)
El modo de expansión, en general, es gradual. Así, la inestabilidad va aumentan-do con el tamaño de la expansión: por debajo de las 40 repeticiones, la frecuencia deexpansiones es baja, pero al llegar a un rango de 40 a 100 repeticiones la inestabili-dad ya es prácticamente del 100 por cien. Además, se observan diferencias si la trans-misión es materna (las repeticiones de la descendencia se distribuyen normalmente al-rededor de la media materna) o paterna (produce repeticiones con una media más altaque la paterna, con tendencia a aumentar en función de la edad paterna).
El mecanismo patogénico en estas enfermedades se ha atribuido a la expansiónde un tracto de glutaminas en las proteínas implicadas, lo que llevaría al mal plega-miento y/o formación de agregados proteicos que alteran la función neuronal. En ge-neral, se piensa que la expansión produce una ganancia de función, ya que muta-
201
Neuropatías por expansiones de CAG
CAPITULO 15 5/12/06 07:27 Página 201
www.FreeLibros.me

ciones y deleciones que anulan la función de esos mismos genes no dan lugar a lamisma enfermedad que la expansión del trinucleótido. Por ejemplo, la expansión deun trinucleótido CAG en el gen del receptor de andrógenos da lugar a la Atrofia Mus-cular Espino-Bulbar (SBMA, Enfermedad de Kennedy), mientras que las mutacionesde ese mismo gen provocan el Síndrome de feminización testicular. Por otro lado, lalongitud de las expansiones correlaciona con la gravedad de la sintomatología, lo quehace pensar que estas enfermedades se deben a una ganancia de función con un efec-to tóxico que aumenta con el número de glutaminas que lleva la proteína, probable-mente a partir de un umbral de 35-40 residuos.
También se ha demostrado que, para provocar degeneración neuronal, las proteí-nas mutantes deben entrar en el núcleo, ya que cuando se envían al citoplasma nose observa efecto patogénico alguno. Esto sugiere que pueden interaccionar con fac-tores de transcripción ricos en glutamina y alterar la transcripción de genes nece-sarios para la supervivencia neuronal. De hecho, se ha demostrado que la acetilasade histonas CBP (co-activador transcripcional del que hemos hablado en el Capítu-lo 2) es secuestrada en presencia de proteínas con tractos de poli-glutaminas, con loque se altera la expresión de genes necesarios para la supervivencia neuronal. Dadoque las proteínas con tractos de poli-glutaminas pueden unirse entre sí por interac-ciones proteína-proteína, otros factores de transcripción con poli-glutaminas tam-bién podrían quedar secuestrados en estas enfermedades. De hecho, se ha visto re-cientemente que el factor de transcripción TAFII130, un componente de TFIID,interacciona con el factor de transcripción Sp1 a través de regiones con tractos deglutaminas; la presencia de una proteína con tractos largos de poliglutaminas podríaimpedir esta interacción y cancelar la expresión de los genes regulados por estos fac-tores. En el caso concreto de la huntingtina (la proteína codificada por el gen muta-do en la Enfermedad de Hutington) se ha demostrado, por ejemplo, que la presenciade huntingtina con expansión de glutaminas impide la expresión del gen que codifi-ca el receptor D2 de la dopamina, mediante un mecanismo como el descrito.
En la Figura 15.2 se esquematiza un posible mecanismo patogénico de la huntingtina que llevaexpansión de un tracto de glutaminas.
15.4 Enfermedades por expansión de otros trinucleótidos
El segundo grupo de enfermedades por expansión de trinucleótidos incluye enfer-medades más heterogéneas, aunque también se caracterizan por afectar al sistemanervioso. Sus características se resumen en la siguiente tabla, donde se muestra quela inestabilidad propia del rango de 40-100 repeticiones (llamado en estos casos«premutación») no causa la enfermedad, sino que favorece la aparición de una ex-pansión explosiva, llegando de golpe hasta varios miles de repeticiones («mutacióncompleta»), que ya causa la enfermedad. Esta «explosividad» no se produce cuan-do la repetición está interrumpida por un triplete distinto; por ejemplo, algunos ale-los del gen FRAXA tienen repeticiones del trinucleótido CGG que están interrum-pidas por el trinucleótido AGG cada 10 repeticiones CGG, y esos alelos no sufrenexpansión.
202
Potencial patogénico de las secuencias repetidas
CAPITULO 15 5/12/06 07:27 Página 202
www.FreeLibros.me

Repetición Normal Pre-mutación Mutación Localización
Distrofia Miotónica (DM1) CTG 5-37 50-80? 80-2000+ 3’ UTR (DMPK)X Frágil (FRAXA) CGG 6-52 59-230 230-2000+ 5’ UTR (FMRP)X Frágil (FRAXE) GCC 4-35 (35-61)? 200-900 5’ UTR (FMR2)Ataxia Friedreich GAA 6-32 (35-40)? 200-1700 Intron (FRDA)SCA8 CTG 16-37 ? 107-127 3’ UTR (SCA8)
En estas enfermedades, como regla general, el efecto patogénico es resultado dela pérdida de función de la proteína o de la alteración en la función del ARNm, yaque las expansiones están en regiones no codificantes. En este grupo destacan:
• Síndrome del X frágil. Es la causa más frecuente de retraso mental ligado alcromosoma X (un 40 por ciento de los casos) y la causa heredada más fre-cuente de retraso mental aislado. Inicialmente, esta enfermedad se detectabapor el cariotipo, que muestra una rotura en Xq27.3 cuando las células se cul-tivan en presencia de metrotexato o en ausencia de folato. Posteriormente, laidentificación en 1991 del gen FMR1 reveló la existencia de un gen de 38 kby 17 exones, con un trinucleótido CGG en una isla CpG de la región promo-tora del gen. Fue el primer ejemplo de una enfermedad originada por la ex-pansión de una repetición de trinucleótidos. Las mutaciones de la región co-dificante son raras, pero también provocan la enfermedad cuando implicandisminución de la proteína FMRP, lo que sugiere que la expansión del trinu-cleótido provoca una pérdida de función. La proteína codificada por el genes citoplasmática y se expresa en cerebro (por igual en todos los tipos de neu-ronas, aunque no se expresa en células no-neuronales), así como en testículo(en células germinales pero no en células de Sertoli o de Leydig). La proteínaposee dominios de unión al ARN y dominios de unión a otras proteínas, y seha comprobado que se une a su propio mensajero, a un cuatro por ciento detodos los ARNm de cerebro fetal, y también a la subunidad 60S de los ribo-somas. Podría por tanto entrar en el núcleo, capturar mensajeros y exportar-los al citoplasma como parte de la maquinaria traduccional, específicamenteaquellos mensajeros que son cruciales para el desarrollo de las dendritas ypara la función sináptica en las neuronas.
• Curiosamente, se ha visto que la mayor parte de los ARNm que se unen aFMRP forman estructuras secundarias llamadas «cuartetos-G», debido a lapresencia de Guaninas espaciadas regularmente; mediante estas estructuras, losmensajeros se unen al dominio RGG (arginina-glicina-glicina) de la FMRP.También se ha visto que, en Drosophila, la proteína FMRP forma parte delcomplejo de silenciamiento por interferencia de ARN (RISC), lo que abre laposibilidad de que dicho mecanismo también esté implicado en la fisiopatolo-gía del Síndrome del X frágil. Aunque el hallazgo del gen y la elucidación de laestructura de la proteína todavía no han permitido desvelar completamente elmecanismo fisiopatológico de la enfermedad, sí han servido para explicar elmodo inusual de transmisión de la misma, que se verá en un capítulo posterior.
La Figura 15.3 muestra la estructura de los cuartetos G.
203
Enfermedades por expansión de otros trinucleótidos
CAPITULO 15 5/12/06 07:27 Página 203
www.FreeLibros.me

• La distrofia miotónica se puede producir por alteraciones en 2 loci. La formamás frecuente es la DM1, debida a la expansión del trinucleótido CTG en laregión no traducida-3’ del gen DMPK, que codifica una proteín-quinasa.Como la enfermedad se hereda de forma autosómica dominante, parece queel complejo fenotipo de esta enfermedad (que incluye miotonía muscular, ca-taratas y arritmias cardíacas) debe ser el resultado de la alteración de algúnproceso celular importante. De hecho, se ha comprobado que la expansión deltrinucleótido CTG en el gen DMPK inhibe la expresión de un gen vecino lla-mado SIX5.
• Se ha visto que los ratones knock-out para el gen DMPK tienen una arritmiasimilar a la que se ve en los pacientes con distrofia miotónica, mientras que losratones knock-out para SIX5 sufren unas cataratas que recuerdan a las de losenfermos. La miopatía se produce por la presencia de ARN con largas expan-siones de repeticiones CUG (esto se ha comprobado también en ratones). Lahipótesis más aceptada es que la expansión da lugar a un ARN que es capazde unirse a varias proteínas de unión a ARN que regulan el fenómeno del ayus-te, alterando su función. Como resultado, se altera el ayuste correcto de otrosARNm, y de hecho se han identificado más de 10 genes cuyo ayuste y funciónestá alterada en esta enfermedad. Estos genes incluyen un canal de cloro, elpropio SIX5, el gen de la troponina T, el receptor de la insulina, genes con fun-ciones neuronales, etc. En conjunto, se piensa que la sintomatología de la en-fermedad es el resultado conjunto de la desregulación de todos estos genes porla presencia de un ARNm con la expansión de CTG.
• La ataxia de Friedreich, enfermedad autosómica recesiva que no muestra elfenómeno clínico de anticipación, parece también un buen ejemplo de pér-dida de función debida a la expansión, ya que los sujetos enfermos deben serhomocigotos (tener ambos alelos con la expansión) o heterocigotos compues-tos (un alelo con expansión y el otro alelo con una mutación puntual). El tri-nucleótido GAA que sufre la expansión está localizado en una secuencia Aludel primer intrón del gen FRDA, que codifica una proteína llamada frataxina.Los alelos normales están interrumpidos por la secuencia (GAGGAA)5-9 y notienen más de 32 repeticiones GAA. La expansión impide la transcripción delgen, al formar un intrón muy largo con estructuras de triple hélice en el ADNgenómico. Los niveles bajos de frataxina alteran la función mitocondrial, yaque esta proteína es importante en la homeostasis del hierro en la mitocon-dria, y dan lugar a una disminución en la producción de energía y a la forma-ción de especies reactivas de oxígeno.
15.5 Otras enfermedades por expansión 15.5 de secuencias repetidas
Recientemente se ha descrito un tipo de epilepsia mioclónica progresiva de he-rencia autosómica recesiva, debida a la expansión de una secuencia de 12 nucleó-tidos (CCCCGCCCCGCG). Este es el primer ejemplo de enfermedad por expan-sión de un minisatélite, que en este caso se encuentra en la región promotora del
204
Potencial patogénico de las secuencias repetidas
CAPITULO 15 5/12/06 07:27 Página 204
www.FreeLibros.me

gen CSTB (cistatina B, un inhibidor de proteasas). Los alelos normales tienen has-ta tres repeticiones, mientras que sujetos con «premutación» tienen 12 a 17 repeti-ciones y los enfermos tienen entre 30 y 75 copias (en total, un tamaño de 360-900nucleótidos). Un 14 por ciento de los individuos con esta enfermedad tienen muta-ciones en la región codificante del gen, por lo que el mecanismo patogénico pare-ce ser por pérdida de función. De hecho, la presencia de la expansión conduce adisminución de los niveles de ARNm, probablemente debido a la desorganizacióndel promotor del gen CSTB.
También se ha identificado un nuevo tipo de ataxia espino-cerebelosa (SCA10),de herencia autosómica dominante. La causa de esta enfermedad reside en la ex-pansión de un pentanucleótido (ATTCT) en el intrón 9 del gen SCA10. Los indivi-duos normales tienen 10 a 22 repeticiones, mientras que los sujetos con esta enfer-medad tienen alelos entre 500 y 4 500 repeticiones. Posteriormente a este hallazgo,se identificó la primera enfermedad debida a la expansión de un tetranucleótido: laDistrofia Miotónica tipo 2. Los individuos normales tienen menos de 26 repeticio-nes CCTG en el intrón 1 del gen ZNF9, mientras que las expansiones en pacientesvan desde 75 a 11 000 repeticiones.
15.6 Mutaciones debidas a repeticiones dispersas
Las repeticiones dispersas del genoma humano, estudiadas con detalle en el Capítu-lo 4, suelen dar lugar a reordenamientos cromosómicos por un mecanismo denomi-nado «sobrecruzamiento desigual» (en inglés, UnEqual Cross-over, UEC). Habi-tualmente, la recombinación homóloga durante la meiosis tiene como finalidadproducir nuevas combinaciones de alelos, ya que se recombinan cromosomas homó-logos. El sobrecruzamiento desigual consiste en la recombinación entre secuenciashomólogas pero no-alélicas (es decir, que tienen homología en su secuencia pero es-tán en localizaciones genómicas diferentes). Tal es el caso, por ejemplo, de los genesparálogos (miembros de una familia génica, con alto grado de homología entre ellos)o de las repeticiones dispersas tipo SINE o LINE (cuyos miembros tienen una se-cuencia muy homóloga). Un buen ejemplo que ilustra los efectos del sobrecruza-miento desigual es el mecanismo que origina varones con cariotipo XX o mujeres XY(con disgenesia gonadal y disfunción ovárica). Hasta un 30 por ciento de los casosde estas patologías son debidos a un sobrecruzamiento desigual entre los genesPRKX y PRKY, genes homólogos que están cerca de la Región Pseudoautosómica delos cromosomas sexuales X e Y, respectivamente. Fruto de esta recombinación des-igual, el gen SRY —gen que determina el sexo masculino, situado en el cromosomaY— acompaña al fragmento telomérico del cromosoma Y que se mueve al cromoso-ma X, dando como resultado un cromosoma X que contiene SRY y un cromosomaY sin SRY. Esto origina individuos que fenotípicamente son varones a pesar de serXX, así como mujeres con cariotipo XY.
La Figura 15.4 muestra el proceso de recombinación desigual entre los genes PRKX y PRKY.
205
Mutaciones debidas a repeticiones dispersas
CAPITULO 15 5/12/06 07:27 Página 205
www.FreeLibros.me

Además, los fenómenos de recombinación desigual son causa frecuente de dupli-caciones o deleciones cuando tienen lugar entre repeticiones no alélicas de gran ta-maño con un alto grado de homología, como son las duplicaciones segmentarias delgenoma humano, que ya mencionamos en el Capítulo 4. Habitualmente, esto sucedeentre secuencias que pertenecen a cromosomas distintos, pero en ocasiones la recom-binación o sobrecruzamiento desigual también puede tener lugar entre cromátideshermanas. En este caso se produce el llamado «intercambio desigual entre cromati-des hermanas» (en inglés, UnEqual Sister Chromatid Exchange, abreviado UESCE),que da lugar a alteraciones en ambas cromátides de un mismo cromosoma: habitual-mente se produce una duplicación en una cromátide y una deleción en la otra.
El vídeo de la Figura 15.5 ilustra el proceso de recombinación desigual entre secuencias decromosomas homólogos o de cromátides hermanas.
Otro posible efecto de la recombinación desigual entre secuencias homólogas esla conversión génica entre ellas. Como hemos visto en un capítulo anterior, durantelos procesos de recombinación homóloga se forma un heterodúplex que puede darlugar a un proceso de conversión génica, de modo que una de las secuencias se co-pia a la otra. Habitualmente, la conversión génica tiene lugar entre alelos de un mis-mo gen; sin embargo, la recombinación desigual entre dos secuencias no alélicas (ungen y un pseudogen no funcional, por ejemplo) puede provocar la conversión de lasecuencia del gen en la secuencia del pseudogen, lo que equivaldría a anular la fun-ción del gen. Un ejemplo clásico de este mecanismo es la enfermedad llamada «Hi-perplasia Suprarrenal Congénita» (déficit del enzima 21-hidroxilasa). Alrededor del75 por ciento de los casos de esta enfermedad están provocados por un fenómenode conversión génica entre el gen CYP21B (que codifica el enzima) y el pseudogenCYP21A (que no es funcional).
De modo general, hasta ahora hemos considerado que los elementos repetidos quese recombinan ilegítimamente están en la misma orientación. Puede suceder, sin em-bargo, que estén invertidos (en orientaciones contrarias uno respecto del otro). En estecaso, la recombinación entre elementos repetidos dará lugar a la inversión de la regiónque queda entre las repeticiones, como se verá en un ejemplo del siguiente apartado.
15.7 Desórdenes genómicosEn conjunto, los procesos de recombinación desigual dan lugar a un grupo de enfer-medades humanas que se conocen con el nombre de «Desórdenes Genómicos», yque incluyen –entre otros– los Síndromes por microdeleción que se han menciona-do estudiado en el Capítulo 13. Los Desórdenes Genómicos se pueden agruparcomo sigue:
A) Debidos a deleciones
• Los pacientes con Ictiosis ligada al X tienen una deleción del gen de la sul-fatasa esteroidea en Xp22, por reordenación entre elementos repetidos (sepa-rados por 1,9 Mb) que flanquean este gen.
206
Potencial patogénico de las secuencias repetidas
CAPITULO 15 5/12/06 07:27 Página 206
www.FreeLibros.me

• La deleción que produce el Síndrome de Williams-Beuren está originada porrecombinación entre duplicaciones segmentarias que flanquean el gen de laelastina en 7q11, repeticiones que están separadas por 1,6 Mb.
• La causa más frecuente de los Síndromes de Prader-Willi y de Angelman esuna deleción de 4 Mb por recombinación desigual entre duplicaciones en15q11-q13.
• La reordenación más frecuente en el cromosoma 22 es la deleción de unas 3Mb en 22q11.2, que se encuentra en el 90 por ciento de pacientes con Sín-drome de Di George o con Síndrome Cardio-velo-facial.
• Un caso especial de deleción de secuencias repetidas es la contracción de unaserie de repeticiones en tándem cerca del telómero 4q, que origina una enfer-medad llamada distrofia facio-escápulo-humeral. Recientemente se ha com-prendido el mecanismo molecular de dicha enfermedad. En la región subte-lomérica 4q existe un elemento llamado D4Z4 que está repetido en tándem.Los cromosomas normales tienen entre 10 y 100 repeticiones del elemento.Los cromosomas «contraídos», que tienen entre una y 10 repeticiones, pue-den dar lugar a la enfermedad si además ese cromosoma tiene un satélite betaa continuación de la repetición (lo que se conoce como variante 4qA); loscromosomas 4q sin el satélite beta no dan lugar a la enfermedad, aunque ten-gan sólo 1-10 repeticiones D4Z4 (variante 4qB). Esta contracción desencade-na la enfermedad mediante la des-regulación de genes cercanos a esa región,especialmente por sobre-expresión del gen FRG1.
En la Figura 15.6 se incluyen esquemas de los principales desórdenes genómicos debidos a deleciones.
B) Debidos a duplicaciones/deleciones
Los reordenamientos entre dos elementos llamados CMT1A-REP, localizados en17p12, dan lugar a individuos con la duplicación o con la deleción de la región com-
207
Desórdenes genómicos
Deleción de 3 Mb(90%)
Di George (22p)
Deleción de 1,5 Mb(5-10%) 4 Mb
15q11 -q13
Prader -Willi /Angelman
CAPITULO 15 5/12/06 07:27 Página 207
www.FreeLibros.me

prendida entre ambas repeticiones. Esta región incluye el gen PMP22, que codificauna proteína de la mielina, y la duplicación o deleción de esta región origina dos en-fermedades distintas (Charcot-Marie-Tooth o Neuropatía Hereditaria con Parálisispor Presión, respectivamente). Las repeticiones CMT1A-REP tienen un tamaño deunas 30 kb y están a una distancia de 1,5 Mb, de forma que el sobrecruzamiento des-igual entre ellas origina la deleción o duplicación de esa región. Estas repeticionestienen una región pequeña (1,7 kb) que es casi totalmente idéntica en todas ellas, ytambién contienen un elemento similar al transposón «mariner». Parece que la pre-sencia de éste último puede favorecer la acción de una transposasa a este nivel y fa-cilitar la recombinación desigual entre cromátides. Algo similar sucede en el Síndro-me de Smith-Magenis, debido a una deleción de unas 5 Mb en 17p11.2. Losindividuos con duplicación de esa región tienen un fenotipo distinto.
La Figura 15.7 ilustra el proceso de recombinación desigual que origina las enfermedades deCharcot-Marie-Tooth y la Neuropatía Hereditaria con Parálisis por Presión.
C) Debidos a inversiones
Cuando la recombinación desigual se produce entre repeticiones invertidas que es-tán en la misma cromátide, a menudo se originan inversiones cromosómicas. Estefenómeno es especialmente frecuente como causa de Hemofilia A, una coagulopatíadebida al déficit de Factor VIII de la coagulación. El gen que codifica el Factor VIIItiene un elemento llamado int22h que está repetido dos veces antes del exón 1 y otravez (en la orientación contraria) en el intrón 22 (entre los exones 22 y 23). Un so-brecruzamiento desigual entre uno de los elementos que están antes del exón 1 conel elemento del intrón 22 dará lugar a una inversión de toda la región comprendidaentre ambas repeticiones, rompiendo totalmente la capacidad codificante del gen.Este mecanismo es responsable de un 45 por ciento de los casos de Hemofilia A enhumanos, lo que subraya la gran importancia de este tipo de fenómenos en patolo-gía humana.
La Figura 15.8 muestra el proceso de recombinación desigual que origina la inversión del gen delFactor VIII, causante de Hemofilia A.
Otro ejemplo de inversión es la que da lugar a la distrofia muscular de Emery-Dreifuss, por recombinación entre repeticiones invertidas en Xq28. Este caso es es-pecialmente interesante porque se ha detectado la inversión de esta región en un ter-cio de las mujeres normales.
D. Otras anomalías
La recombinación desigual entre elementos duplicados del genoma humano originatambién otros procesos. Por ejemplo, la duplicación invertida del cromosoma 15 esel cromosoma marcador que se encuentra con mayor frecuencia en recién nacidos.También se encuentra un cromosoma marcador dicéntrico debido a una duplicacióninvertida en 22q en pacientes con Síndrome de Ojo de Gato, por reordenamientos
208
Potencial patogénico de las secuencias repetidas
CAPITULO 15 5/12/06 07:27 Página 208
www.FreeLibros.me

entre duplicaciones segmentarias. Estas mismas duplicaciones están implicadas en latranslocación t(11;22)(q23;q11), que es la única translocación recíproca equilibradarecurrente en humanos. Finalmente, se ha observado que hasta un uno por ciento delos casos de retraso mental esporádico pueden ser debidos a una microdeleción en17q21.31, por recombinación entre duplicaciones segmentarias flanqueantes. Curio-samente, esa región se presenta en humanos en dos configuraciones diferentes, yaque existe un polimorfismo de inversión debido también a la presencia de duplica-ciones segmentarias en orientación invertida; una de esas configuraciones, la llama-da H2, es la que puede dar lugar a la microdeleción.
La Figura 15.9 muestra la estructura de 17q21.31 y la microdeleción que se origina en esta región.
209
Desórdenes genómicos
700 kb
900 kb
H1(80%)
H2(20%)
microdeleción 17q21.31
CAPITULO 15 5/12/06 07:27 Página 209
www.FreeLibros.me

CAPITULO 15 5/12/06 07:27 Página 209
www.FreeLibros.me

C A P Í T U L O 1 6
Efectos fenotípicosde las mutaciones
Contenidos
16.1 Pérdida de función, fenotipos recesivos y haploinsuficiencia
16.2 Fenotipos dominantes por ganancia de función
16.3 Alteraciones de la impronta genómica
16.4 Mutaciones que afectan a la morfogénesis
Cuando un gen está mutado por cualquiera de los mecanismos que hemos visto en el ca-pítulo anterior, pueden suceder fundamentalmente dos cosas: (a) que esa mutación se si-lenciosa, no tenga ningún efecto pernicioso ni provoque ningún fenotipo anómalo; o (b)que esa mutación provoque la aparición de un fenotipo aberrante que conduzca al desarrollo de una enfermedad. En este segundo caso, que es el que nos ocupa en esta Ge-nética Humana, es importante darse cuenta de que la alteración de un gen puede provo-car un fenotipo anormal mediante dos mecanismos, fundamentalmente: la pérdida defunción o la ganancia de función. La pérdida de función de un gen equivale a su ausen-cia total, ya que el gen no codifica la proteína respectiva. En general, esto da lugar a fe-notipos que se heredan de manera recesiva, ya que es necesario que estén mutados losdos alelos para que se manifieste el fenotipo. Sin embargo, en aquellos casos en los quehay un efecto de dosis génica, en los que se producen fenotipos dominantes por un fe-nómeno llamado haploinsuficiencia, la pérdida de función genera fenotipos de herenciadominante. En el caso de las mutaciones que provocan una ganancia de función, los fe-notipos resultantes son generalmente de herencia dominante, porque la mutación facili-ta que el gen escape a los mecanismos que regulan su expresión, o bien crea una nuevafunción que tiene un efecto dominante negativo. Como regla general, podemos decir quecuando las mutaciones puntuales en un gen producen el mismo fenotipo que las dele-ciones de todo el gen, lo más probable es que esas mutaciones provoquen una pérdida
CAPITULO 16 5/12/06 07:29 Página 211
www.FreeLibros.me

de función; en cambio, las mutaciones que operan a través de una ganancia de fun-ción suelen provocar fenotipos distintos a los que genera la deleción o disrupción deese gen. A continuación veremos un poco más a fondo cada una de estas dos situa-ciones.
16.1 Pérdida de función, fenotipos recesivos 16.1 y haploinsuficiencia
Un gen puede perder su función de varias maneras:
• Mutaciones en el propio gen: cualquier tipo de mutación que interrumpa lacapacidad codificante del gen hará que se pierda su función. Como hemos vis-to en el capítulo precedente, puede tratarse de mutaciones puntuales, dele-ciones o inserciones que interrumpen el marco de lectura, así como alteracio-nes de las secuencias de ayuste (splicing). También podemos incluir aquellasmutaciones que no afectan a la secuencia del transcrito (ARNm) sino a su es-tabilidad, de forma que el mensajero se degrada rápidamente y no llega a tra-ducirse en la proteína correspondiente.
• Mutaciones que afectan a los elementos que regulan la expresión génica. Ungen puede dejar de expresarse por mutaciones que afectan al promotor, bienpor mutaciones que alteran las secuencias de unión a factores de transcrip-ción o bien provocando su metilación. Otro mecanismo que disminuye la ex-presión génica es el que se conoce como efectos de posición, es decir, una re-ordenación cromosómica que mueve un gen de su posición original a otraregión del genoma que está silenciada (una región de heterocromatina, porejemplo). En ocasiones, esto hace que el gen deje de expresarse. Hay variosejemplos de enfermedades humanas producidas por este mecanismo, como elcaso de la Distrofia Facio-Escápulo-Humeral que hemos estudiado en el ca-pítulo anterior. Otros ejemplos son la Aniridia (por alteraciones del genPAX6) o la Displasia Campomélica (alteraciones del gen SOX9), enfermeda-des en las que muchas veces se observan translocaciones que no interrumpendirectamente los genes respectivos, sino que los separan de su contexto genó-mico habitual y los colocan en una región de cromatina silenciada.
Aunque la pérdida de función de un gen suele desencadenar fenotipos recesivos, a ve-ces se obtienen fenotipos con herencia dominante. Esto sucede en aquellos casos enlos que la disminución de la dosis génica al 50 por ciento de lo que es habitual ya escapaz de provocar el fenotipo patológico. Como es sabido, los genes autosómicos y elcromosoma X en mujeres están en doble dosis génica (hay dos alelos para cada gen),lo que hace que en circunstancias normales se produzcan unos niveles determinadosde producto proteico. Habitualmente, la pérdida de uno de los alelos no tiene ningúnefecto patológico: aunque sólo se produce la mitad de proteína de lo que sería normal,la cantidad producida por el alelo normal es suficiente para realizar la función res-pectiva. Sin embargo, en algunos casos la simple disminución de la dosis génica a lamitad, por la inactivación de uno de los alelos mediante cualquier mecanismo muta-
212
Efectos fenotípicos de las mutaciones
CAPITULO 16 5/12/06 07:29 Página 212
www.FreeLibros.me

cional de los que se han estudiado, provoca el desarrollo del fenotipo patológico.Cuando esto sucede, se habla de enfermedades causadas por haploinsuficiencia o in-suficiencia haploide, que lógicamente se heredan con un patrón dominante. Aunquehay bastantes enfermedades humanas causadas por haploinsuficiencia, un buen ejem-plo es el Síndrome de Turner (45,X0), en el que basta la pérdida de una copia de losgenes implicados para que se desarrollen las características fenotípicas propias de estaenfermedad. En concreto, se ha visto que uno de los genes responsables de esta en-fermedad (SHOX) se localiza en la región pseudoautosómica del cromosoma X y ha-bitualmente escapa a la inactivación del cromosoma X, por lo que en condiciones nor-males está presente en doble dosis génica. Cuando se pierde una copia de este gen (porla ausencia de uno de los cromosomas X), la única copia que queda no es suficientepara llevar a cabo correctamente su función y esto parece ser la causa de la talla cor-ta de las mujeres con Síndrome de Turner.
16.2 Fenotipos dominantes por ganancia de función
Los mecanismos por los que las mutaciones pueden originar una ganancia de fun-ción que se manifieste en un fenotipo dominante son variados, pero podemos seña-lar tres:
• Una mutación que altera la proteína de forma que ésta adquiere una nuevafunción. El mejor ejemplo es el alelo «Pittsburgh» de alfa-1 antitripsina, unenzima con actividad anti-elastasa. Habitualmente, los alelos mutantes dealfa-1 antitripsina producen una pérdida de función, con la consiguiente dis-minución de la actividad enzimática y el desarrollo de una enfermedad deno-minada enfisema pulmonar. En cambio, el alelo «Pittsburgh» está debido auna mutación que cambia la metionina en posición 358 a una arginina(M358R). Esto hace que el enzima adquiera una actividad anti-trombina queantes no tenía, dando lugar a un transtorno de la coagulación en vez de pro-vocar enfisema pulmonar. Las mutaciones con ganancia de función son muyfrecuentes en cáncer, siendo uno de los principales mecanismos de activaciónde oncogenes. Por ejemplo, la fusión de los genes BCR y ABL, en pacientescon leucemia mieloide crónica, es el resultado de una translocación (9;22) enla que el gen ABL —una tirosina-quinasa— pierde su región reguladora y que-da fusionado con la región 5’ del gen BCR, que se expresa en células proge-nitoras hematopoyéticas. Esto provoca un nuevo gen de fusión que conducea una expresión constitutiva y des-regulada de la tirosina-kinasa ABL en cé-lulas de la serie mieloide en la médula ósea, lo que lleva el desarrollo de laleucemia.
• Ganancia de función también por la sobre-expresión de un gen, como re-sultado de duplicaciones o amplificaciones génicas: un segmento genómicoque se copia varias veces, de forma que los genes contenidos en ese segmen-to estarán en un número de copias muy superior al normal. Este también esun mecanismo frecuente en distintos tipos de cáncer. Por ejemplo, el onco-gén C-MYC está amplificado en varios tumores (sobre todo en neuroblasto-mas), C-ERBB2 en tumores de mama, etc. Aunque estas amplificaciones pue-
213
Fenotipos dominantes por ganancia de función
CAPITULO 16 5/12/06 07:29 Página 213
www.FreeLibros.me

den verse en un cariotipo convencional como regiones de tinción homogé-nea (Homogenous Staining Regions, HSR), o también como «Dobles Dimi-nutos» (cromosomas minúsculos), la técnica de FISH las detecta con muchamayor sensibilidad y permite además contar el número de veces que el gense ha amplificado.
La Figura 16.1 muestra algunos ejemplos de mutaciones que producen ganancia de función en cáncer.
• Por un efecto dominante-negativo. Consiste en que ciertos tipos de genes co-difican moléculas que funcionan como dímeros o forman parte de complejosmultiméricos, de modo que basta la mutación en uno de los alelos del genpara que las moléculas proteicas mutantes desestabilicen totalmente los com-plejos de los que forman parte. Un ejemplo típico es el de enfermedades queafectan a los genes que codifican alguna de las cadenas de colágeno. La mo-lécula de pro-colágeno es un trímero formado por distintos tipos de cadenas,cuya combinación da lugar a los diferentes tipos de colágeno que existen. Demodo general, una mutación en el gen de una de las cadenas provocará la de-sestabilización de todo el complejo trimérico, por lo que basta la mutación enun solo alelo para que se desarrolle la enfermedad. En estos casos, puede dar-se la circunstancia de que una mutación puede tener distinta gravedad en fun-ción del número de moléculas mutantes y nativas que se generan.
En la Figura 16.2 se ilustra el efecto dominante negativo de las mutaciones que provocan la desestructuración de las moléculas de procolágeno tipo I.
Todo lo dicho hasta ahora supone, en cierta medida, una simplificación con fines di-dácticos. De hecho, existen algunos genes en los que distintas mutaciones puedenoriginar tanto una pérdida como una ganancia de función, llevando al desarrollode fenotipos y enfermedades distintas según se trate de una pérdida o una ganancia.Ya hemos visto, por ejemplo, el caso del gen del receptor de andrógenos, en el quela expansión de un trinucleótido provoca la enfermedad de Kennedy (atrofia muscu-lar espino-bulbar) mientras que las mutaciones con pérdida de función dan lugar alllamado Síndrome de feminización testicular. Otro ejemplo es el de PMP22 (locali-zado en 17p11.2), un gen sensible a dosis en el que la duplicación de uno de los ale-los —lo que supone la existencia de tres copias funcionales del gen— provoca la en-fermedad de Charcot-Marie-Tooth (un tipo de neuropatía periférica). Por elcontrario, la pérdida de uno de los alelos por deleción o —menos frecuentemente—por mutación puntual provoca otra neuropatía distinta llamada «Neuropatía heredi-taria con parálisis por presión».
A continuación veremos otras dos situaciones especiales que sirven para ilustrarmuy bien la variedad de efectos fenotípicos que se obtienen por mutaciones. En pri-mer lugar estudiaremos el fenómeno de la impronta genómica y sus alteraciones; des-pués veremos algunas alteraciones en el desarrollo embrionario debidas a mutacio-nes en genes que codifican factores de transcripción y receptores de membrana.
214
Efectos fenotípicos de las mutaciones
CAPITULO 16 5/12/06 07:29 Página 214
www.FreeLibros.me

16.3 Alteraciones de la impronta genómica
El imprinting o impronta genómica es la marca epigenética que define una región ge-nómica como materna o paterna en el cigoto. La existencia de este fenómeno se des-cubrió al crear embriones de ratón por transferencia nuclear: cambiando un pronú-cleo masculino por un segundo pronúcleo femenino se obtiene un ginogenonte;reemplazando el pronúcleo femenino por un segundo pronúcleo masculino se obtie-ne un androgenonte. En teoría, estos embriones (excepto los androgenontes YY) de-berían ser viables, pero en cambio se observó que estas modificaciones son letales enel periodo embrionario, y que esa letalidad tiene dos formas diferentes: los ginoge-nontes muestran un embrión normal con falta de desarrollo de tejidos extraem-brionarios, mientras que los androgenontes muestran más alteraciones en el em-brión que en tejidos extraembrionarios. En humanos, las concepciones uniparentalesandrogenéticas, que se originan raramente por la pérdida de los cromosomas mater-nos poco después de la fertilización, se manifiestan en una estructura que se conocecomo mola hidatidiforme completa. Por el contrario, los oocitos que se dividen porpartenogénesis sólo contienen material materno, y dan lugar a quistes dermoides.Estos hallazgos se explican actualmente por la existencia en el genoma de genes «im-prontados» (sometidos al fenómeno de la impronta), en los que de algún modo se re-conoce el origen parental de cada alelo y se produce el silenciamiento selectivo deuno de ellos: en unos casos siempre se silencia el materno, en otros genes siempre sesilencia el alelo paterno. Por tanto, cuando el núcleo del cigoto sólo contiene mate-rial de uno de los progenitores, pero no una mezcla de ambos, los embriones resul-tantes son inviables. Esto sugiere la existencia de una asimetría de los genomas ma-terno y paterno, en cuanto a que ambos genomas tienen silenciados distintos gruposde genes. Esta asimetría es necesaria para el correcto desarrollo embrionario.
Dado que ambos alelos de los genes sometidos a imprinting son idénticos y capa-ces de interaccionar con los mismos factores de transcripción, el mecanismo que si-lencia uno de ellos de manera estable y heredable debe ser un mecanismo epigené-tico, que haga posible que el imprinting pueda borrarse durante la gametogénesis yre-establecerse tras la fecundación. La metilación, como mecanismo silenciador de laexpresión génica, cumple la mayor parte de estos requisitos, y hay bastantes líneas deevidencia que apoyan el papel de la metilación en el fenómeno de imprinting: 1) to-dos los genes improntados descritos hasta el momento —excepto uno— muestran re-giones con metilación diferencial (abreviadas DMR en inglés, regiones que estánmetiladas en uno de los alelos pero no en el otro), cuyos patrones de metilación seestablecen durante la gametogénesis y se mantienen gracias a la metilación específi-ca de ADN hemi-metilado; 2) los embriones de ratón dnmt1-/- (que carece de ADN-metiltransferasa-1) muestran expresión bi-alélica de genes improntados, es decir, enausencia de la metilasa de mantenimiento se re-expresa el alelo que estaba silencia-do; 3) se ha descrito el caso de una mujer con mutaciones en el gen DNMT3L (quecodifica una metilasa) que tiene infertilidad porque los embriones fallecen al im-plantarse en el útero; y 4) no se ha encontrado un fenómeno similar al imprinting enespecies incapaces de llevar a cabo metilación.
Igualmente, se ha comprobado que los genes sometidos a imprinting también sereplican de manera asincrónica: por FISH se suelen ver dos señales de hibridación
215
Alteraciones de la impronta genóm
ica
CAPITULO 16 5/12/06 07:29 Página 215
www.FreeLibros.me

correspondientes a las dos cromátides que se forman durante la fase S del ciclo ce-lular, pero en genes improntados se ve un cromosoma con dos señales y el otro cro-mosoma homólogo con una sola señal. Esto sugiere que el alelo específicamente si-lenciado se replica más tarde.
Existen varios modelos para explicar cómo la metilación diferencial da lugar a lasdiferencias de expresión entre alelos paterno y materno, y cómo se regulan genes ve-cinos que tienen patrones de imprinting opuestos. Parece claro que en algunos casoses muy importante la proteína CTCF (CTC-binding factor) una proteína que se unea la las regiones de metilación diferencial (DMR) únicamente cuando éstas no estánmetiladas. Por ejemplo, se ha visto que la regulación de los genes Igf2 y H19 en ra-tón (que tienen patrones de imprinting opuestos) se lleva a cabo por este mecanismo,ya que CTCF actúa como aislador (insulator) del promotor de Igf2 de unos poten-ciadores lejanos.
La Figura 16.3 muestra varios modelos de regulación de los genes que están sometidos a imprinting.
La importancia de la proteína CTCF se ha puesto de manifiesto gracias a un ha-llazgo sorprendente, al conseguir ratones partenogenéticos viables cuando se dele-ciona de su genoma el gen H19 y la región de metilación diferencial a la que seune CTCF. Inicialmente, un ratón partenogenético lleva dos copias del genoma ma-terno, por lo que tendrá expresión bialélica del gen H19 y silenciamiento de ambos
216
Efectos fenotípicos de las mutaciones Me
Me
Me
Alelo 1
Alelo 2
Alelo 1
Alelo 2
Alelo 1
Alelo 2
CAPITULO 16 5/12/06 07:29 Página 216
www.FreeLibros.me

alelos de Igf2, de ahí que sean inviables. La deleción de una de las copias del H19 re-establece la expresión monoalélica de este gen, pero todavía hay silenciamiento totalde Igf2 e inviabilidad embrionaria. En cambio, si además se deleciona la región demetilación diferencial a la que se une CTCF, ahora los potenciadores pueden pro-mover la expresión de Igf2 en este cromosoma, con lo que se reestablece la expresiónmonoalélica de Igf2. El resultado final es la expresión monoalélica de H19 de uno delos cromosomas y la expresión monoalélica de Igf2 del cromosoma homólogo, quees la situación normal. Esto ilustra la importancia que tiene la impronta genómica enel desarrollo embrionario, y sugiere que la ineficacia de los procesos de clonaciónde mamíferos probablemente se deba a que los núcleos somáticos utilizados para latransferencia nuclear no tienen los patrones de imprinting necesarios para la viabili-dad embrionaria.
El vídeo de la Figura 16.4 muestra la importancia del fenómeno del imprinting en el desarrolloembrionario.
En cada ciclo reproductivo, los patrones de imprinting han de establecerse denuevo, puesto que lo que en una meiosis fue material de origen paterno (transmisiónde un varón a su hija, por ejemplo) en la siguiente meiosis pasará a ser marcadocomo materno (cuando esa hija tenga descendencia). Para poder cambiar el imprin-ting es necesario borrar toda la información previa sobre cuál de los alelos debe si-lenciarse. Como el genoma está muy desmetilado en los gametos, el cambio en lospatrones de imprinting debe de tener lugar durante la gametogénesis. Con los datosactuales, la hipótesis más aceptada para explicar el borrado y re-establecimiento delos patrones de metilación durante la gametogénesis es la existencia de proteínas ca-paces de unirse a las DMR no-metiladas (y así protegerlas de la metilación), juntocon otros factores que se unen a las DMR metiladas y ayudan a mantener el estadosilenciado. Se piensa que sólo una de las líneas germinales (masculina o femenina)es capaz de producir los factores que protegen de la metilación a las regiones no-metiladas. Así, estas regiones se mantendrán des-metiladas en la línea germinal queproduzca estos factores. Por el contrario, estas regiones se metilarán y silenciarán enla línea germinal que no los produce. Por lo que respecta a la identidad de dichos fac-tores, los candidatos ideales son las proteínas que se unen específicamente a regio-nes metiladas (MeCP2, HDAC, etc.) o a regiones no metiladas (CTCF, factores detranscripción que se unen a CpGs no metilados, etc.).
La impronta es, por tanto, un mecanismo fisiológico normal. Sin embargo, algu-nas alteraciones genéticas que afectan a regiones sometidas a imprinting pueden darlugar a enfermedades. Este es el caso de la llamada disomía uniparental, situaciónen la que ambas copias de un cromosoma o de una región cromosómica procedendel mismo progenitor. Si esa región contiene genes «improntados», el resultado pue-de ser la presencia de dos copias «silenciadas» de un gen, con lo que el efecto vienea ser similar a una deleción homocigótica de ese locus. Hoy en día conocemos unalarga lista de enfermedades y tumores humanos debidos a disomía uniparental de locisometidos a impronta. Además, se han detectado regiones improntadas en los cro-mosomas 11, 15, 7 y 14, y actualmente se conocen unos 30 genes improntados en ra-tón y humanos.
217
Alteraciones de la impronta genóm
ica
CAPITULO 16 5/12/06 07:29 Página 217
www.FreeLibros.me

Los loci sometidos a impronta tienden a aparecer agrupados en determinadas re-giones cromosómicas, de manera que —dentro de cada uno de estos grupos o clus-ters— unos genes muestran expresión materna y otros genes muestran expresión pa-terna. Esto se ilustra con el ejemplo de dos enfermedades llamadas Síndrome dePrader-Willi y Síndrome de Angelman, originados por alteraciones en el grupo degenes improntados que se encuentran en 15q11-q13. Todos los genes improntadosen esta región muestran expresión específica del alelo paterno excepto el genUBE3A, que muestra expresión materna en cerebro. Parece que la expresión deUBE3A depende de la expresión de un transcrito antisentido que comienza 6,5 kben dirección 3’ del codón de parada de UBE3A y que alcanza hasta la mitad 3’ deUBE3A, de manera que en la mayoría de los tejidos somáticos este transcrito no seexpresa y por tanto la expresión de UBE3A en estos tejidos es bialélica. Por el con-trario, el transcrito antisentido se expresa en células de Purkinje, neuronas del hipo-campo y células mitrales olfatorias, silenciando el alelo paterno y originando el im-printing de UBE3A en estos tejidos.
En la Figura 16.5 se muestra el cluster de genes sometidos a imprinting en 15q11, cuyas alteraciones causan los síndromes de Prader-Willi y de Angelman.
Por estudios en pacientes con microdeleciones, sabemos que el centro de imprin-ting de esta región es bipartito y cubre en total unas 100 kb. Dentro de esta región,el centro de imprinting para Angelman cubre 1,15 kb, mientras que el centro de im-printing Prader-Willi es más distal y cubre unas 4,3 kb (incluyendo el promotor y elexón 1 del gen SNRPN). Se postula que durante la gametogénesis estos centros fijanlos patrones de expresión de toda esta región, de forma que en la oogénesis se acti-va el centro de imprinting AS —que, a su vez, bloquea la función del centro de im-printing PW—. Como resultado, los gametos femeninos sólo expresan el gen UBE3A.En cambio, en la espermatogénesis el centro AS estaría bloqueado, de manera que
218
Efectos fenotípicos de las mutaciones
ZNF127
NECDINASNRPN
PAR -5IPW
PAR -1
UBE3A
Antisense
Paterno
Materno
CAPITULO 16 5/12/06 07:29 Página 218
www.FreeLibros.me

el centro de imprinting PW es ahora activo y promueve la expresión de todos los ge-nes de expresión paterna, incluido el gen antisentido que bloquea la expresión deUBE3A. De este modo se crean los epigenotipos paterno y materno que se manten-drán durante el desarrollo embrionario y en células somáticas adultas.
El Síndrome de Prader-Willi, cuya incidencia estimada es de 1/25 000, se carac-teriza por disminución de la actividad fetal, obesidad, hipotonía muscular, retrasomental, hipogonadismo hipogonadotrófico, manos y pies pequeños, hipopigmenta-ción, baja estatura y rasgos dismórficos. Se debe a la falta de expresión de los genesespecíficos del cromosoma paterno dentro de esta región. Por el contrario, el Sín-drome de Angelman tiene una incidencia de 1/15 000 nacimientos y está caracteri-zado por un fenotipo distinto al de Prader-Willi: retraso mental severo, temblor, ata-xia, marcha anormal, tendencia a la risa, trastornos del sueño y convulsiones. Estáprovocado por la falta de expresión del gen UBE3A, que se expresa específicamenteen el cromosoma materno. Las alteraciones de la impronta de todos estos genes pue-den tener lugar por varios mecanismos:
1. Deleciones grandes de la región: producirán Síndrome de Prader-Willi(SPW) si la deleción afecta al cromosoma paterno, o Síndrome de Angelman(AS) si la deleción afecta al cromosoma materno. Constituyen la principalcausa de estas enfermedades (70 por ciento de todos los casos).
2. Disomía uniparental (UPD), debida a no-disyunción durante una de lasmeiosis parentales. En efecto, la no-disyunción puede originar gametos disó-micos o nulisómicos, que originan cigotos trisómicos o monosómicos. En es-tas circunstancias, la disomía uniparental puede ser resultado tanto de la re-cuperación de un cigoto trisómico por pérdida de uno de los cromosomas,como de la duplicación completa de un cromosoma para recuperar un cigo-to monosómico. En este último caso vemos una isodisomía (ambos cromo-somas provienen de la duplicación de un mismo cromosoma parental), mien-tras que un 70 por ciento de los casos de reducción de cigotos trisómicos danlugar a heterodisomía (presencia de los dos cromosomas del mismo progeni-tor). La presencia de dos cromosomas 15 paternos da lugar a un dos por cien-to de los casos de Síndrome de Angelman, mientras que el 25 por ciento delos casos de Síndrome de Prader-Willi se deben a la presencia de dos cromo-somas 15 maternos.
3. Mutaciones puntuales en los genes responsables. En el Síndrome de Angel-man se detectan mutaciones en el gen UBE3A (que codifica la E6 ubiquitin-ligasa) hasta en un 20 por ciento de los enfermos. En el caso del Síndrome dePrader-Willi, en cambio, la búsqueda de un gen candidato no ha dado resul-tados, aunque el principal gen implicado es SNRPN. En el caso concreto deeste gen (SNRPN), se ha visto que existe otra secuencia codificante en direc-ción 5’ (SNURF por SNRPN Upstream Reading Frame) de manera que, dehecho, ambos forman un único gen bicistrónico: un solo transcrito del que setraducen dos proteínas. Con los datos actuales, hay que considerar el Sín-drome de Prader-Willi como un síndrome de microdeleción causado por lapérdida de varios genes contiguos.
4. Mutaciones o microdeleciones que afectan a los centros de imprinting, demanera que no se podrán re-establecer los patrones durante la gametogé-
219
Alteraciones de la impronta genóm
ica
CAPITULO 16 5/12/06 07:29 Página 219
www.FreeLibros.me

nesis en el caso de que haya transmisión de un sexo al opuesto (madre-hijo o padre-hija). El resultado funcional en el cigoto es idéntico a lo que su-cede en la disomía uniparental: ambos alelos llevan el mismo patrón de im-printing. Este tipo de alteraciones son responsables de un cinco por ciento delos casos de Síndrome de Prader-Willi o de Síndrome de Angelman. El ejem-plo típico es el de la abuela paterna portadora de una mutación en el centrode imprinting del cromosoma 15 que lleva marcado como materno. Al trans-mitir este cromosoma a un hijo varón, el cromosoma mutado pasará a su hijomarcado como materno, por lo que no es necesario reestablecer el imprintingy el hijo será normal (llevará un cromosoma marcado como paterno y otrocomo materno). En la siguiente generación, en cambio, este individuo varóndeberá pasar su cromosoma 15 marcado como paterno, por lo que la marcaque lo identificaba como materno deberá ser borrada durante la espermato-génesis y sustituida por la marca que lo identifique como paterno. En este in-dividuo dicho cambio será imposible, debido a la mutación en el centro deimprinting de su cromosoma 15 materno, por lo que su descendencia llevarádos cromosomas con epigenotipo materno y desarrollará Síndrome de Pra-der-Willi. Lo mismo puede suceder para el Síndrome de Angelman, cuando lamutación del centro de imprinting afecta al cromosoma paterno.
El diagnóstico genético en estas dos enfermedades va dirigido a la detección de de-leciones, de disomía uniparental o de alteraciones en el centro de imprinting, y se re-aliza por los siguentes procedimientos:
• Cariotipo convencional: es insuficiente para detectar la microdeleción típica,pero es útil en el probando y en los padres para detectar posibles translocacio-nes, ya que un pequeño porcentaje de las deleciones son fruto de translocacio-nes no equilibradas (casi siempre de novo). También detectará translocacionesequilibradas de novo o heredadas, aunque estos casos son excepcionales.
• FISH: detecta todas las deleciones, usando sondas frente al gen SNRPN encombinación con una sonda centromérica del cromosoma 15. La mayoría delas deleciones son intersticiales, siendo la más frecuente una pequeña dele-ción de unas 4 Mb de tamaño.
• Detección de Disomía Uniparental: se usan microsatélites del cromosoma 15para determinar el origen parental de cada cromosoma. Lógicamente, es ne-cesario descartar primero la presencia de deleción, y además este procedi-miento viene limitado por la necesidad de obtener muestras del probando yde ambos progenitores, así como por la posible falsa paternidad.
• Análisis de metilación: puede hacerse bien por Southern blot tras digestióndel ADN genómico con enzimas de restricción sensibles a metilación, o porPCR específica de metilación (MS-PCR). Si el exón 1 de SNRPN y el centrode imprinting adyacente están metilados en los dinucleótidos CpG, esto indi-ca un patrón materno; si no están metilados, podemos excluir el silencia-miento de SNRPN y los demás genes de expresión paterna. Es un análisis queno requiere muestras de los progenitores, y permite confirmar la existencia deSíndrome de Prader-Willi cuando se observa sólo el patrón de metilación ma-terno. Tiene la ventaja de que si el análisis es normal (es decir, si se observan
220
Efectos fenotípicos de las mutaciones
CAPITULO 16 5/12/06 07:29 Página 220
www.FreeLibros.me

dos patrones distintos de metilación, correspondientes a los cromosomas pa-terno y materno), esto automáticamente excluye la presencia de deleción o dedisomía uniparental. Cuando esta prueba es anormal (patrón únicamente ma-terno) y no se detecta deleción ni disomía uniparental, esto sugiere la exis-tencia de alteraciones en el centro de imprinting.
• En el caso concreto del Síndrome de Angelman también es necesario buscarmutaciones en UBE3A: aunque esto sólo supone un 20 por ciento de los pa-cientes, su detección es de gran importancia por el aumento dramático en elriesgo de recurrencia de la enfermedad en la misma familia. Se estima quehasta un tercio de los pacientes que tienen estudios de metilación normalestienen mutaciones en UBE3A, por lo que la estrategia diagnóstica recomen-dada es comenzar con estudios de metilación y después buscar mutaciones deUBE3A en aquellos sujetos con resultados de metilación normales.
La Figura 16.6 muestra la estrategia diagnóstica en los síndromes de Prader-Willi y Angelman.
En el Síndrome de Prader-Willi el riesgo de recurrencia (un segundo individuo en-fermo en la misma familia) es prácticamente cero en los casos de deleción y de diso-mía uniparental que no están asociados a reordenaciones cromosómicas. De todasformas, a efectos de consejo genético se considera un riesgo de recurrencia del unopor ciento, ya que en una muestra amplia de pacientes se detectó un riesgo de recu-rrencia en hermanos de probandos del 1,6 por ciento (aunque esto incluía todas lasposibles causas). El mayor riesgo de recurrencia se produce en los casos familiaresque están debidos a alteraciones en el centro de imprinting. En estos casos, el riesgode recurrencia es del 50 por ciento ya que volverá a suceder siempre que el padretransmita el cromosoma 15 que lleva la mutación. En el Síndrome de Angelman, elriesgo de recurrencia también se considera habitualmente del uno por ciento, excep-to en los casos de mutaciones del centro de imprinting y de mutaciones en UBE3A,en las que el riesgo de heredar el cromosoma materno mutado es del 50 por ciento(si el cromosoma mutado se hereda del padre no hay enfermedad porque en ese cro-mosoma el gen UBE3A no se expresaría en cualquier caso).
16.4 Mutaciones que afectan a la morfogénesis
El estudio comparativo del desarrollo embrionario en humanos, ratón y Drosophilaha permitido identificar los mecanismos genéticos por los que se generan varias en-fermedades congénitas de la morfogénesis. En general, estas mutaciones afectan so-bre todo a genes que codifican dos tipos de proteínas:
A) Factores de transcripción: son proteínas con actividad reguladora de la ex-presión génica gracias a que poseen dos propiedades principales: capacidad de unióna determinados elementos en el ADN y capacidad de transactivación de otros facto-res proteicos. Los factores de transcripción tienen, por tanto, un dominio de uniónal ADN y un dominio de transactivación por el que se une a los otros componentesde un complejo activador o represor de la transcripción. Hay cuatro tipos principa-
221
Mutaciones que afectan a la m
orfogénesis
CAPITULO 16 5/12/06 07:29 Página 221
www.FreeLibros.me

les de dominios de unión al ADN que se encuentran en la gran mayoría de factoresde transcripción: 1) HTH (helix-turn-helix o hélice-vuelta-hélice), presente sobretodo en factores de transcripción que intervienen en la regulación de la expresión gé-nica durante el desarrollo embrionario. El ejemplo mejor conocido es el homeodo-minio, que está presente en los genes homeobox que determinan la identidad posi-cional de las células a lo largo del eje craneo-caudal del embrión; 2) dedos de zinc,que suelen unirse a elementos de respuesta en el ADN; 3) cremalleras de leucina,con una hélice en la que hay una leucina cada siete aminoácidos de manera que que-dan en la misma cara de la hélice y dimerizan fácilmente; 4) HLH (helix-loop-helixo hélice-lazo-hélice) son similares a cremalleras de leucina y también forman homo-y heterodímeros; ambos son importantes en la regulación de procesos de diferencia-ción celular y desarrollo embrionario.
En la Figura 16.7 se muestra la estructura de algunos factores de transcripción.
Entre los síndromes malformativos debidos a alteraciones en factores de trans-cripción encontramos varios grupos:
• Las extremidades se organizan en torno a tres ejes (Antero-Posterior, Dorso-Ventral y Proximal-Distal), y se desarrollan a partir de un brote en el que hayuna intensa actividad mitótica en la llamada zona de progresión, actividadque es inducida por el repliegue apical ectodérmico. Esta actividad mitóticaestá en equilibrio con los procesos de apoptosis de células del mesénquima,que da lugar a los espacios interdigitales e interóseos. El principal mecanis-mo de formación del eje antero-posterior es la vía de señalización intrace-lular de las proteínas Hedgehog, integrada por SHH, los factores de trans-cripción GLI1, GLI2 y GLI3, y los receptores Patched (PTCH) y Smoothened(SMO). El gen llamado Sonic Hedgehog (SHH) se expresa en la línea mediadel Sistema Nervioso Central, en la notocorda y en la Zona de Actividad Po-larizante, que es la región que determina la «posterioridad» de un miembro.En general, la disregulación de este gen provoca sindactilia (fusión de dos omás dedos) y/o polidactilia, (aparición de uno o más dedos «extra») que tien-den afectar a los dedos cercanos al pulgar (preaxiales) en casos de sobre-ex-presión de SHH, o bien afectan a los dedos cercanos al meñique (centra-les/postaxiales) en casos de represión de este gen. Sin embargo, no se hanencontrado mutaciones de SHH en malformaciones de miembros, pero sí enpacientes con holoprosencefalia autosómica dominante. Esta enfermedad seorigina por el desarrollo defectuoso del cerebro anterior y de la cara, con unasmanifestaciones muy variables que van desde un incisivo único hasta indivi-duos con un solo ojo (cíclopes), pero es genéticamente heterogénea ya quemutaciones en otros genes como ZIC2, SIX3, TGIF y PATCHED también lacausan. Por otro lado, las mutaciones del gen PTCH (localizado en 9q22.3)causan el Síndrome de Gorlin autosómico dominante (carcinoma nevoidede células basales), que además cursa frecuentemente con polidactilia pre- opostaxial, o bien sindactilia del 3º y 4º dedos del pie. Finalmente, los factoresde transcripción GLI comparten el dedo de zinc de la proteína codificada por
222
Efectos fenotípicos de las mutaciones
CAPITULO 16 5/12/06 07:29 Página 222
www.FreeLibros.me

el gen cubitus interruptus de Drosophila, y actúan como activadores o repre-sores de la vía de transducción de señales de SHH. Por ejemplo, el Síndromede cefalopolisindactilia de Greig (polidactilia postaxial de manos, preaxial depies, macrocefalia, frente prominente con hipertelorismo leve), de herenciaautosómica dominante, se debe a haploinsuficiencia de GLI3 por mutacionesque destruyen el dedo de zinc de este gen, de manera que se produce expre-sión ectópica preaxial de SHH (GLI3 normalmente inhibe la expresión deSHH). En cambio, GLI3 también parece implicado en el Síndrome de Pa-llister-Hall (hamartomas hipotalámicos con malformaciones de extremida-des), por mutaciones que respetan el dedo de zinc y por tanto mantienenconstitutivamente la actividad represora sobre SHH. Un mecanismo similarparece implicado en la Polidactilia postaxial tipo A (en la que se ha identifi-cado una mutación de GLI3 que respeta el dedo de zinc). Por su parte, el Sín-drome de Rubinstein-Taybi (retraso psicomotor y del crecimiento, dismorfis-mo facial, anomalías de los pulgares y, raramente, polidactilia preaxial de lospies) se debe a mutaciones en CBP: como GLI se transactiva a través de undominio de unión a CBP, la ausencia de este factor provoca una expresiónbaja de GLI, seguida por la expresión anormalmente elevada de SHH.
La Figura 16.8 ilustra el desarrollo de los miembros y la función de varios genes en este proceso.
• Los genes que codifican proteínas con el homeodominio se denominan geneshomeobox (la homeobox es la «caja» o secuencia de ADN que codifica el ho-meodominio), y se agrupan en varias familias. En Drosophila, el plan corpo-ral se regula durante la embriogénesis por la expresión del grupo de genesHOM-C, organizados en un complejo Antennapedia (3’, estructuras anterio-res) y un complejo Bithorax (5’, estructuras posteriores). Los factores de trans-cripción que regulan la expresión de estos genes son el grupo trithorax (regu-lación positiva) y el grupo polycomb (regulación negativa). Los ortólogoshumanos de HOM-C son la familia de genes HOX, de los que hay cuatro gru-pos parálogos (cada grupo se denomina por una letra de la A a la D). Dentrode un grupo, cada gen se designa con un número del 1 al 13 en dirección 3’ a5’. Así, los parálogos 1 determinan regiones anteriores y los parálogos 13 lasregiones posteriores del eje corporal. El desarrollo de las extremidades tie-nen una fase inicial en la que es importante la expresión de genes HOX, y dehecho se ha descrito un tipo de sin-polidactilia en pacientes que tienen un au-mento de 7-14 alaninas en el gen HOXD13, expansión que provoca una ga-nancia de función de dicho gen. También se han encontrado mutaciones enHOXA13 en pacientes con Síndrome mano-pie-genital, caracterizado por hi-poplasia del quinto dedo de manos y pies y malformaciones genitourinarias(hipospadias o útero bicorne).
• Los genes de la familia Pax codifican factores de transcripción que contie-nen un dominio de unión al ADN de 128 aa con dos regiones de hélice-vuel-ta-hélice, llamado paired domain porque originalmente se encontró en el genpaired de Drosophila. Además, los factores Pax3, Pax4, Pax6 y Pax7 tambiéncontienen un homeodominio. Las mutaciones en el dominio paired de PAX6
223
Mutaciones que afectan a la m
orfogénesis
CAPITULO 16 5/12/06 07:29 Página 223
www.FreeLibros.me

1 2 3 4 5 6 7 8 9 10 11 12 13
3’ 5’
Antennapedia
Bithorax
HOX A
HOX B
HOX C
HOX D
causan anomalías oculares (aniridia, anomalía de Peters, distrofia corneal, ca-tarata congénita e hipoplasia de la fovea). En estos casos, la aniridia (o, a ve-ces, anoftalmia) no parece producirse por un efecto dominante negativo, sinopor haploinsuficiencia del gen PAX6, ya que los heterocigotos sólo tienen ani-ridia pero en cambio los homocigotos padecen anoftalmia, lo cual sugiere unefecto de dosis. Las mutaciones en PAX6 también son responsables de la ani-ridia del Síndrome WAGR, por una microdeleción en 11p13 que delecionatodo el gen. Por lo que respecta al gen PAX3, algunas mutaciones en el mis-mo producen el Síndrome de Waardenburg tipo 1 (distopia cantorum, pig-mentación anormal y sordera sensorioneural), mientras que otras mutacionesen este mismo gen dan lugar al Síndrome de Klein-Waardenburg (lo anteriormás camptodactilia y malformaciones de las extremidades). Otro miembro deesta familia, el gen PAX8, está mutado en casos familiares de disgenesia ti-roidea. Por su parte, las mutaciones que afectan al gen PAX2 causan una con-dición autosómica dominante que incluye colobomas del nervio óptico, ano-malías renales y reflujo vesico-ureteral.
• SRY es el gen que controla el desarrollo de la gónada masculina y, lógica-mente, se localiza en el cromosoma Y. La proteína codificada por SRY con-tiene una caja HMG (High Mobility Group), que es un motivo de 79 aas porel que la proteína se une al ADN y lo dobla hasta 130 grados, con lo que fa-vorece la activación de genes cercanos. Las mutaciones en SRY son causa dela aparición de individuos con cariotipo XY que fenotípicamente son muje-res. Otros genes relacionados con SRY son los genes de la familia SOX; porejemplo, SOX9 está mutado en una enfermedad autosómica dominante lla-mada Displasia campomélica (inversión de sexo en varones, arqueamientocongénito de huesos largos, paladar hendido, ausencia de costillas y tórax pe-
224
Efectos fenotípicos de las mutaciones
La Figura 16.9 muestra un esquema de los genes homeobox humanos.
CAPITULO 16 5/12/06 07:29 Página 224
www.FreeLibros.me

queño). Se piensa que las malformaciones esqueléticas de la displasia campo-mélica se deben a que SOX9 es un factor de transcripción que transactiva se-cuencias reguladoras que se encuentran en el primer intrón del gen COL2A1,que da lugar al colágeno tipo II. Por tanto, la falta de SOX9 lleva consigo unaproducción insuficiente de cadenas alfa-1 del colágeno tipo 2, con las consi-guientes malformaciones en huesos y cartílagos.
B) Receptores de las vías de transducción de señales: constituyen otro gran grupode proteínas que suelen dar lugar a fenotipos de herencia dominante, habitualmentepor un efecto dominante negativo de las moléculas mutadas. A continuación se se-ñalan dos de los ejemplos más ilustrativos:
El vídeo de la a 16.10 ilustra la estructura y funcionamiento de los receptores tirosina-quinasa, asícomo el efecto dominante negativo de las mutaciones que provocan la activación constitutiva de lavía de señalización.
• Los genes que codifican receptores para el factor de crecimiento fibroblás-tico (FGF). Tras la unión del ligando extracelular al receptor, unión mediadapor heparán-sulfato de la matriz extracelular, los receptores forman homo- oheterodímeros, se transfosforilan en el dominio quinasa intracelular y a con-tinuación fosforilan proteínas intracelulares implicadas en diversas vías detransducción de señales. Las mutaciones que afectan a los genes de estos re-ceptores (FGFR1, FGFR2 y FGFR3) causan varios síndromes de craniosinos-tosis y enanismo cuyas bases moleculares están comenzando a comprenderse.Por ejemplo, la Acondroplasia (un tipo de enanismo) es una enfermedad deherencia autosómica dominante debida a mutaciones en el gen del receptordel Factor de Crecimiento Fibroblástico-3 (FGF3). Este receptor forma un ho-modímero que se activa en respuesta a su ligando natural. En cambio, en lospacientes con acondroplasia se encuentran mutaciones en uno de los alelosdel gen, de forma que la molécula mutada conduce a la dimerización del re-ceptor incluso en ausencia de ligando. Como resultado, se obtiene una acti-vación constitutiva de la cascada de señales iniciada por el receptor, que enúltimo término provoca el cierre prematuro del cartílago de crecimiento de loshuesos largos y la baja talla característica de esta enfermedad. La mutaciónmás frecuente en casos de acondroplasia es la mutación G380R del genFGFR3, que afecta al dominio transmembrana del receptor. Curiosamente,mutaciones en otras regiones de este mismo gen causan fenotipos similarespero no idénticos, como por ejemplo la displasia tanatofórica (micromelia ehipoplasia de costillas con fallo respiratorio). Estas enfermedades son de he-rencia dominante por el efecto dominante negativo de estas mutaciones, quehace que con una sola molécula mutada se produzca la activación constituti-va del receptor en ausencia de ligando. Respecto a mutaciones en otros genesque codifican receptores de FGF (FGFR1 y FGFR2), también causan enfer-medades con alteraciones de huesos y cartílagos, como el Síndrome de Crou-zon (craniosinostosis, bien aislada o bien asociada con otros defectos esque-léticos), el Síndrome de Pfeiffer (pulgares y primer dedo del pie anchos con
225
Mutaciones que afectan a la m
orfogénesis
CAPITULO 16 5/12/06 07:29 Página 225
www.FreeLibros.me

anquilosis interfalángica), el Síndrome de Jackson-Weiss (lo anterior más co-alescencia tarso-metatarsiana) y el Síndrome de Apert (sindactilia severa).
• Mutaciones que afectan al gen RET. Este gen codifica un receptor tirosina-quinasa, cuyo ligando es el GDNF (Glial cell line-Derived Neurotrophic Fac-tor). Las mutaciones de RET son muy interesantes, ya que muestran cómo unmismo gen puede sufrir mutaciones que provocan pérdida o ganancia defunción, dando lugar a fenotipos diferentes. En el caso concreto de RET, al-gunas mutaciones con cambio de sentido afectan a aminoácidos del dominioextracelular o del dominio quinasa, y provocan la activación del receptor demanera independiente de ligando. Estas mutaciones carcinoma medular detiroides familiar u otros cuadros de cáncer familiar denominados MEN2(Multiple Endocrine Neoplasia), que son de herencia dominante porque unsolo alelo mutado desencadena la enfermedad por un efecto dominante ne-gativo. Por el contrario, algunas mutaciones de RET que llevan a la pérdidade función (mutaciones sin sentido, cambios del marco de lectura, deleciones,etc.) provocan la ausencia de las moléculas del receptor codificadas por el ale-lo mutado, con el resultado de que la intensidad de la señalización de esta víase ve disminuida. Esto provoca un déficit en la migración de precursores neu-rales al tubo digestivo durante el desarrollo embrionario, lo que da lugar a laEnfermedad de Hirschsprung (megacolon agangliónico: ausencia congénitade los plexos submucosos y mientérico del colon distal). Esta enfermedad sehereda con un patrón dominante, aunque también se han identificado muta-ciones en otros genes que causan la misma enfermedad con herencia recesi-va, como el gen EDNRB del receptor para endotelina B (receptor de protei-nas G) o también el gen de su ligando EDN3 (endotelina 3).
226
Efectos fenotípicos de las mutaciones
CAPITULO 16 5/12/06 07:29 Página 226
www.FreeLibros.me

C A P Í T U L O 1 7
Diagnóstico de enfermedadesgenéticas
Contenidos
17.1 Estrategias generales de diagnóstico de enfermedades genéticas
17.2 Métodos de detección de mutaciones
17.3 Aplicación del ligamiento genético al diagnóstico: el proceso de diagnóstico indirecto de enfer-17.3 medades genéticas
17.1 Estrategias generales de diagnóstico de enfermedades genéticas
Como en cualquier otro tipo de patologías, el diagnóstico de enfermedades genéticas serealiza mediante la identificación clínica de los síntomas y signos que caracterizan cadasíndrome concreto, apoyado en datos de laboratorio. Con los avances del Proyecto Ge-noma Humano, hoy en día es posible, en muchos casos, analizar directamente la altera-ción causal a nivel del ADN. De todas formas, en el entorno clínico nos encontramos va-rios problemas que pueden dificultar el diagnóstico correcto. En primer lugar, la posiblepresencia de heterogeneidad genética: varios genes pueden ser los responsables de unaúnica enfermedad. Esta circunstancia hace muy laborioso el estudio mutacional, ya quemultiplica el número de exones que hay que analizar. Incluso en aquellos casos en losque se sabe con exactitud qué gen está alterado, puede suceder que las mutaciones res-ponsables del cuadro clínico se distribuyan por todo el gen (fenómeno que algunos au-tores denominan heterogeneidad alélica), de manera que sería necesario analizar todala región codificante antes de poder descartar o confirmar que el gen en cuestión estámutado. Lógicamente, si se trata de un gen de gran tamaño, el análisis se hace extrema-damente laborioso. La situación opuesta vendría dada por aquellas enfermedades gené-ticas que están causadas, en la gran mayoría de familias, por una misma mutación, de
CAPITULO 17 5/12/06 07:31 Página 227
www.FreeLibros.me

manera que podemos centrarnos en el estudio de esa mutación concreta para con-firmar o descartar el defecto molecular que provoca esa enfermedad.
Por tanto, hemos de sopesar todas las circunstancias mencionadas para decidir sinos inclinamos por realizar lo que se denomina diagnóstico directo (análisis de unindividuo para ver si es portador de la mutación concreta que causa la enfermedaden esa familia), o si por el contrario aplicaremos el denominado diagnóstico indi-recto (análisis de marcadores genéticos en la familia para ver si el consultando ha he-redado el cromosoma que lleva la mutación). A continuación discutiremos las ven-tajas e inconvenientes de cada una de estas aproximaciones diagnósticas, así comolos métodos más habitualmente empleados.
La Figura 17.1 explica las dos estrategias diagnósticas para detectar alteraciones genéticas enenfermedades humanas.
17.2 Métodos de detección de mutaciones
Como hemos dicho, el diagnóstico directo consiste en el estudio de un gen —cuyaimplicación en el desarrollo de una enfermedad ya ha sido demostrada— para detec-tar la presencia de posibles mutaciones en el mismo. En aquellos casos en que lasmutaciones patogénicas pueden estar localizadas a lo largo de toda la secuencia co-dificante del gen (heterogeneidad alélica fuerte), se deben utilizar métodos «de ba-rrido», que examinan cada exón por separado para detectar simplemente si existeuna mutación o no. Estos métodos no identifican el tipo de mutación, pero nos per-miten descartar rápidamente todos aquellos exones normales, para centrarnos en elestudio de los exones mutados. En cambio, cuando queremos detectar una mutaciónconcreta, porque ya sabemos que es esta mutación la que origina la enfermedad enesa familia, utilizaremos métodos dirigidos a identificar únicamente esa mutación(métodos «de confirmación»). Estos últimos son quizás los métodos más utilizadosen el contexto de un laboratorio diagnóstico, especialmente en aquellas enfermeda-des que tienen una heterogeneidad alélica limitada, es decir, enfermedades en lasque un pequeño número de mutaciones causan la inmensa mayoría de los casos. Losejemplos más notorios son la mutación C282Y (que causa la mayoría de los casos deHemocromatosis Hereditaria en europeos); la mutación F508del, responsable dehasta el 80 por ciento de los casos de Fibrosis Quística en individuos nor-europeos;la inversión de los exones 1-22 del gen del Factor VIII de la coagulación (respon-sable de un 50 por ciento de los casos de hemofilia A); la mutación G380R del genFGFR3 (que causa la mayoría de los casos de Acondroplasia), las mutaciones N370Sy L444P (que detectan la mayoría de los casos de Enfermedad de Gaucher), o las en-fermedades por expansión de trinucleótidos (Enfermedad de Huntington, Síndromedel X Frágil, etc.). A continuación analizaremos algunos de los métodos más utiliza-dos en el diagnóstico directo, tanto métodos de barrido como de confirmación.
1. Métodos de barrido para la detección rápida de mutaciones (sin identificarel tipo concreto de mutación). Excepto en el primero (SSCP) estos métodosse basan en la detección de heteroduplexes, que se forman por la reasocia-ción lenta de las cadenas tras la desnaturalización del fragmento de ADN.
228
Diagnóstico de enfermedades genéticas
CAPITULO 17 5/12/06 07:31 Página 228
www.FreeLibros.me

Cuando el fragmento contiene una mutación y se mezcla con un ADN nor-mal, la desnaturalización-reasociación da lugar a moléculas heteroduplexportadoras de un desemparejamiento (mismatch) precisamente en el nucleó-tido donde está la mutación.
• SSCP (Single Strand Conformation Polymorphism, Polimorfismo de laConformación de Cadenas Sencillas). Un cambio en la secuencia provo-ca cambios conformacionales cuando el ADN se desnaturaliza (se sepa-ran las dos cadenas) y se deja que cada cadena se repliegue por separado.Estos cambios conformacionales se detectan porque alteran la migraciónelectroforética en geles de poliacrilamida no-desnaturalizantes. En elejemplo típico, se amplifica un exón mediante PCR, se desnaturaliza elproducto de PCR por calor, se cargan los productos desnaturalizados enun gel de acrilamida, se realiza la electroforesis y se tiñe el gel medianteuna tinción específica para el ADN (tinción de plata, por ejemplo). Si nohay mutaciones, se detectarán únicamente las bandas correspondientes alhomodúplex (resultado de la reasociación parcial de las dos cadenascomplementarias durante la electroforesis) y las bandas correspondientesa cada una de las cadenas sencillas que se han replegado adoptando unaconformación determinada. En cambio, la presencia de una mutacióndará lugar a nuevas bandas debidas al patrón de plegamiento de las ca-denas sencillas mutantes, que será diferente al de las cadenas nativas.Como hemos comentado, este análisis no nos dice de qué tipo de muta-ción se trata: para eso es necesario secuenciar este producto de PCR ycompararlo con la secuencia normal. La ventaja es que nos permite des-cartar la presencia de mutaciones rápidamente, lo que ahorra tiempo y re-cursos.
La Figura 17.2 explica gráficamente la técnica de SSCP.
• DGGE (Denaturing Gradient Gel Electrophoresis, Electroforesis en Gelcon Gradiente Desnaturalizante) y sus variantes, entre las que destacaTGGE (Temperature Gradient Gel Electrophoresis). Esta técnica se basaen someter una muestra de ADN a una electroforesis en geles de acrila-mida con un gradiente desnaturalizante químico o térmico, de maneraque la muestra se encuentra con condiciones cada vez más desnaturali-zantes a medida que avanza por el gel. Las muestras de ADN son pro-ductos de PCR (exones, habitualmente) en cuyo extremo hay una regióncorta muy rica en citosinas y guaninas (región llamada «clamp» o «pin-za» GC), de forma que la temperatura de desnaturalización de esta pe-queña región es mayor que la del resto del fragmento. Por tanto, cuandoel fragmento va avanzando por el gel, llegará un momento en que se des-naturaliza todo excepto la región del clamp-GC. El resultado es que elfragmento se frena y deja de avanzar por el gel. Cuando la muestra deADN es un heterodúplex que contiene un desemparejamiento, su puntode desnaturalización será distinto al del fragmento nativo, y por tanto se
229
Métodos de detección de m
utaciones
CAPITULO 17 5/12/06 07:31 Página 229
www.FreeLibros.me
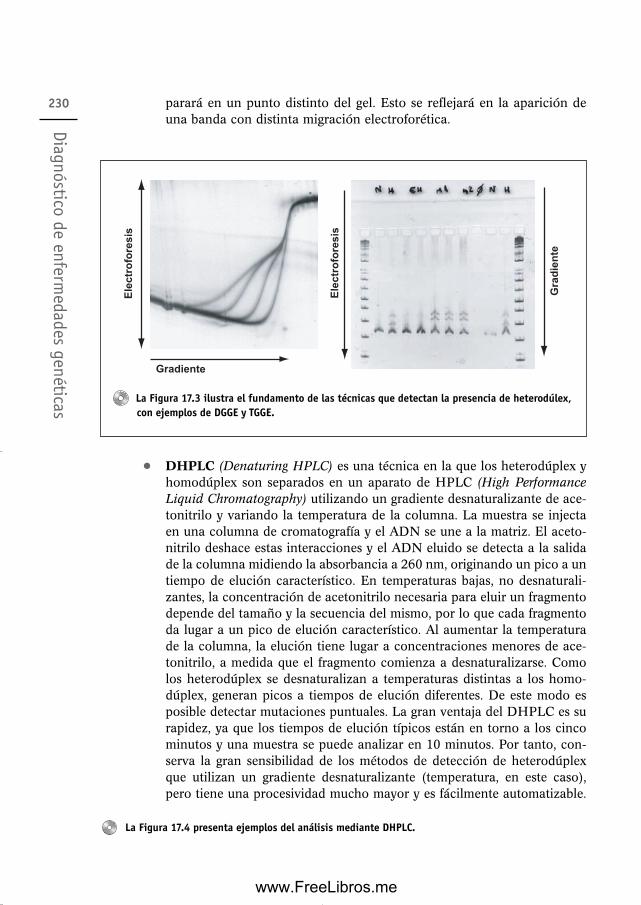
parará en un punto distinto del gel. Esto se reflejará en la aparición deuna banda con distinta migración electroforética.
La Figura 17.3 ilustra el fundamento de las técnicas que detectan la presencia de heterodúlex,con ejemplos de DGGE y TGGE.
• DHPLC (Denaturing HPLC) es una técnica en la que los heterodúplex yhomodúplex son separados en un aparato de HPLC (High PerformanceLiquid Chromatography) utilizando un gradiente desnaturalizante de ace-tonitrilo y variando la temperatura de la columna. La muestra se injectaen una columna de cromatografía y el ADN se une a la matriz. El aceto-nitrilo deshace estas interacciones y el ADN eluido se detecta a la salidade la columna midiendo la absorbancia a 260 nm, originando un pico a untiempo de elución característico. En temperaturas bajas, no desnaturali-zantes, la concentración de acetonitrilo necesaria para eluir un fragmentodepende del tamaño y la secuencia del mismo, por lo que cada fragmentoda lugar a un pico de elución característico. Al aumentar la temperaturade la columna, la elución tiene lugar a concentraciones menores de ace-tonitrilo, a medida que el fragmento comienza a desnaturalizarse. Comolos heterodúplex se desnaturalizan a temperaturas distintas a los homo-dúplex, generan picos a tiempos de elución diferentes. De este modo esposible detectar mutaciones puntuales. La gran ventaja del DHPLC es surapidez, ya que los tiempos de elución típicos están en torno a los cincominutos y una muestra se puede analizar en 10 minutos. Por tanto, con-serva la gran sensibilidad de los métodos de detección de heterodúplexque utilizan un gradiente desnaturalizante (temperatura, en este caso),pero tiene una procesividad mucho mayor y es fácilmente automatizable.
La Figura 17.4 presenta ejemplos del análisis mediante DHPLC.
230
Diagnóstico de enfermedades genéticas
Ele
ctro
fore
sis
Ele
ctro
fore
sis
Gradiente
Gra
die
nte
CAPITULO 17 5/12/06 07:31 Página 230
www.FreeLibros.me

• Rotura de Desemparejamientos (Mismatch Cleavage). Es un método ba-sado en el hecho de que determinados tratamientos químicos o enzimáti-cos son capaces de romper un fragmento de ADN específicamente en elpunto donde existe un desemparejamiento. Como hemos dicho, los hete-roduplexes son portadores de un desemparejamiento (mismatch) precisa-mente en el nucleótido donde está la mutación. Por tanto, el tratamientocon determinadas sustancias romperá el fragmento sólo en el caso de queexistan desemparejamientos, de forma que una electroforesis en gel serásuficiente para comprobar la presencia de una mutación.
• PTT (Protein Truncation Test, Prueba de truncamiento de proteínas). Esun método especialmente dirigido a la detección de mutaciones quecrean un codón de parada prematuro y provocan el truncamiento de laproteína. Para llevar a cabo esta prueba, se prepara ADNc mediante RT-PCR (PCR tras transcripción reversa del ARN del paciente) utilizando uncebador que contiene la secuencia del promotor del fago T7 y la secuen-cia consenso de inicio de la traducción (secuencia de Kozak). Esta cons-trucción permite realizar la transcripción y traducción in vitro, a partirdel producto de la RT-PCR. El análisis en un gel de acrilamida de los frag-mentos proteicos que resultan de la transcripción/traducción revelará lapresencia de una banda correspondiente al tamaño esperado para la se-cuencia nativa, o bien otras bandas de menor tamaño correspondientes atodas las posibles mutaciones que provoquen un truncamiento del pro-ducto proteico (mutaciones sin sentido, los cambios del marco de lecturay las mutaciones que afectan a las secuencias de ayuste).
La Figura 17.5 ilustra el fundamento de la técnica de PTT.
• Secuenciación. Hoy en día, con la aparición de equipos fluorescentes au-tomatizados y con bajo coste por reacción, la secuenciación directa deproductos de PCR (exones, o incluso la secuenciación directa de unADNc obtenido por RT-PCR) es un método cada vez más popular de de-tección de mutaciones. Tiene la ventaja de que identifica el tipo de muta-ción, y de hecho es un paso obligado para identificar las mutaciones de-tectadas por los métodos de barrido que acabamos de explicar. Sinembargo, sólo es realmente fiable cuando el ADN mutado está en unaproporción superior al 15-20 por ciento del total de ADN presente en lamuestra. Aunque esto se cumple en las enfermedades hereditarias, no esel caso de la detección de mutaciones en muestras procedentes de tumo-res, en las que con frecuencia la cantidad de células tumorales es baja yno todas son portadoras de una mutación concreta.
Cada uno de los métodos de barrido que hemos visto tiene sus ventajas e inconve-nientes, sobre todo en lo referente a la sensibilidad (porcentaje de mutaciones queson capaces de detectar), coste, complejidad técnica, capacidad de especificar la po-sición de la mutación, etc. Aunque las características de cada método se presentanresumidas en la siguiente tabla, la elección de un método u otro dependerá de las pe-
231
Métodos de detección de m
utaciones
CAPITULO 17 5/12/06 07:31 Página 231
www.FreeLibros.me

culiaridades de cada laboratorio, del gen que se quiera estudiar, los medios disponi-bles y la experiencia previa con cada uno de los métodos.
Método Ventajas Inconvenientes
Detecta todas y Excesiva información, costeSecuenciación especifica la posición. alto, laboriosa.
Sencillo. Secuencias <400bp.SSCP Buena sensibilidad. No especifica posición.
Cierta complejidad.DGGE y DHPLC Muy alta sensibilidad. No especifica posición.
Rotura de Muy alta sensibilidad. Gran dificultad técnica.Desemparejamientos Puede especificar posición. Toxicidad OsO4.
Alta sensibilidad. No todos los tipos de mutaciones.PTT Especifica la posición. Complejidad técnica, coste.
2. Métodos de comprobación para detectar de la existencia de una mutaciónespecífica:
• PCR-Digestión. El fundamento de esta técnica reside en el hecho de quela mutación crea o destruye una diana de restricción, de modo que la sim-ple digestión del producto de PCR con el enzima de restricción permitedeterminar, en un gel de agarosa, el patrón de digestión indicativo de lapresencia o ausencia de la mutación. Es un método que, por su sencillezy rapidez, es uno de los más utilizados en laboratorios clínicos. La prin-
232
Diagnóstico de enfermedades genéticas
La Figura 17.6 muestra una mutación detectada mediante secuenciación con terminadoresmarcados.
CAPITULO 17 5/12/06 07:31 Página 232
www.FreeLibros.me

cipal limitación, lógicamente, es que no todas las mutaciones alteran unadiana de restricción.
La Figura 17.7 explica el proceso de detección de una mutación específica mediante la digestión deun producto de PCR con enzimas de restricción.
• ASO (Allele Specific Oligonucleotide, Oligonucleótido Específico de Ale-lo). Una técnica bastante utilizada en los primeros años del diagnósticomolecular, aunque hoy en día ha caído en cierto desuso. Se basa en el di-seño de sondas específicas para el alelo mutado y para el alelo nativo, uti-lizando oligonucleótidos. El tamaño de las sondas hace que su Tm (tem-peratura de desnaturalización) sea lo suficientemente distinta para que—en determinadas condiciones de hibridación— la sonda específica delalelo normal hibride solamente con ADN normal, y la sonda específicadel alelo mutado hibride específicamente con ADN genómico que con-tiene la mutación. El ADN de los pacientes (puede ser tanto ADN genó-mico como un exón amplificado mediante PCR) se deposita en membra-nas de nylon haciendo un «dot-blot», y esas membranas se hibridan concada una de las sondas (oligonucleótidos marcados con radioactividad ocon fluorescencia). El análisis de la hibridación de cada sonda permiteidentificar si la muestra contiene un solo alelo mutado (heterocigoto), dosalelos mutados (homocigoto para la mutación), o ninguno (homocigotosano).
• ARMS (Amplification Refractory Mutation System, Sistema de MutaciónResistente a la Amplificación) está basada en el mismo principio queASO, es decir, la utilización de oligonucleótidos específicos para la se-cuencia normal y para la secuencia mutada. La diferencia estriba en que,en el caso del ARMS, estos oligonucleótidos son cebadores de PCR. Sediseñan, por tanto, dos reacciones de PCR que comparten un mismo ce-bador común pero se diferencian en los cebadores específicos para cadaalelo: un cebador amplificará sólo el alelo normal, el otro cebador ampli-ficará sólo el alelo mutado. Dada la rapidez y sencillez de la PCR, estatécnica está desplazando cada vez más a la técnica de ASO.
• OLA (Oligonucleotide Ligation Assay, Ensayo de Ligación de Oligonu-cleótidos). Se trata de un método algo más laborioso, pero que —una vezoptimizado— permite analizar gran número de muestras con rapidez y fia-bilidad. Se basa en la ligación de dos oligonucleótidos, uno de los cualesestá marcado con biotina y el otro con una molécula radioactiva o fluo-rescente. El punto crucial es el diseño de los oligonucleótidos a ambos la-dos de la base mutada. Por ejemplo, un diseño habitual es que ambos oli-gos hibriden sobre la secuencia normal, de modo que la mutación impidala hibridación de uno de ellos. Como consecuencia, la reacción de liga-ción sólo será efectiva en presencia de una secuencia normal. Cuando seseparan las sondas y se unen por los residuos de biotina a un soporte quecontiene estreptavidinas, sólo las moléculas completas (fruto de la liga-ción de los dos oligos) emitirán la señal correspondiente al marcador (ra-
233
Métodos de detección de m
utaciones
CAPITULO 17 5/12/06 07:31 Página 233
www.FreeLibros.me

dioactividad o fluorescencia). Por el contrario, el ADN de un sujeto ho-mocigoto para la mutación no dará ninguna señal. En principio, este mé-todo también permite detectar los individuos heterocigotos para la muta-ción, ya que la intensidad de la señal emitida será la mitad de la de unindividuo homocigoto normal. El método de OLA permite la automatiza-ción y la cuantificación de la señal cuando se utilizan marcadores fluo-rescentes, lo que le convierte en un buen método para el análisis de grancantidad de muestras.
• MLPA (Multiplex Ligation-dependent Probe Amplification) es una modi-ficación del OLA que permite determinar el número de copias de hasta 45genes en un solo ensayo, pudiendo discriminar secuencias que difieren enun solo nucleótido. MLPA utiliza, para cada gen, dos sondas: una de ellases complementaria a la secuencia que se quiere estudiar (21-30 nucleóti-dos), a la que se añade la secuencia de un cebador universal en el extremo5’; la otra sonda de la pareja tiene otra secuencia complementaria a la dia-na, un ADN de relleno —que puede ser de distintos tamaños— y la se-cuencia de otro cebador universal en el extremo 3’. Ambas sondas hibri-dan a ambos lados de la secuencia diana, y son ligadas por una ligasatermoestable. Con un solo cebador se pueden amplificar las sondas que sehan ligado correctamente. Utilizando secuencias de relleno de distintos ta-maños para cada gen, podemos amplificar en una misma reacción muchosfragmentos distintos, lo que ahorra mucho tiempo y reactivos. Además,como las condiciones de reacción son las mismas, la cantidad final de pro-ducto es proporcional a la cantidad inicial de ADN, por lo que los resul-tados de MLPA pueden ser cuantificados. Por tanto, MLPA permite de-tectar deleciones y amplificaciones, además de detectar mutaciones.
La Figura 17.8 resume los principios generales de varios métodos para la detección de mutacionesespecíficas, basados en la utilización de oligonucleótidos específicos.
Un comentario final a todas estas técnicas de análisis directo es que pueden aplicarsea ADN procedente de distintos tipos de muestra, ya que trabajan con secuencias am-plificadas mediante PCR. Por tanto, es posible detectar la presencia de mutaciones nosólo en ADN de sangre periférica, sino también en raspados bucales, vellosidades co-riales, cabello, biopsias, material incluido en bloques de parafina o incluso de tarjetasimpregnadas con manchas de sangre (tarjetas de Guthrie, por ejemplo).
17.3 Aplicación del ligamiento genético al diagnóstico: el proceso17.3 de diagnóstico indirecto de enfermedades genéticas
Como ya se ha mencionado al principio de este capítulo, hay ocasiones en las que noes posible, o resulta muy poco práctico, llevar a cabo diagnóstico directo. Esto suce-de en aquellos casos en los que no se conoce la secuencia del gen causante de unaenfermedad, o cuando éste es excesivamente grande y complejo (compuesto por mu-
234
Diagnóstico de enfermedades genéticas
CAPITULO 17 5/12/06 07:31 Página 234
www.FreeLibros.me

chos exones, por ejemplo). En estos casos todavía podemos predecir si un individuoha heredado la enfermedad, estudiando marcadores específicos que nos permitanidentificar cuál cromosoma de los progenitores es el que lleva la mutación. Una vezidentificado, simplemente hemos de ver qué cromosomas han heredado los hijos,para predecir la probabilidad de que también hayan heredado la mutación. Como noestudiamos directamente el gen, sino marcadores genéticos que nos ayudan a identi-ficar los cromosomas, se denomina a este proceso «Diagnóstico Indirecto». Paracomprender el diagnóstico indirecto es necesario repasar los conceptos generales deligamiento genético y su aplicación a familias humanas que han sido expuestos en elCapítulo 11.
A veces nos enfrentamos con una enfermedad genética cuyo gen causal no hasido todavía identificado, lo que obviamente impide realizar diagnóstico directo. Enotras ocasiones, aun conociendo el gen que debe estar mutado, resulta impracticablerealizar estudios de diagnóstico directo en la rutina de un laboratorio clínico, por lagran heterogeneidad alélica que muestra esa enfermedad (un gran número de posi-bles mutaciones pueden ser las responsables del cuadro clínico), o en genes con unaestructura exónica muy compleja. Un ejemplo bastante claro es la Distrofia Muscu-lar de Duchenne (DMD), debida a mutaciones en el gen de la distrofina. Este gen esmuy grande (ARNm de 14 kb) y tiene 79 exones distribuidos a lo largo de 2,3 mega-bases de ADN genómico, por lo que el estudio mutacional de cada exón sería exce-sivamente laborioso. En este tipo de situaciones, una alternativa muy utilizada es lade establecer si el probando ha heredado el cromosoma o los cromosomas parenta-les que llevan el gen mutado, o si por el contrario ha heredado los cromosomas pa-rentales normales. Para hacer esto se sigue un proceso denominado «gene tracking»,algo así como «seguir la pista» a los alelos enfermos en una familia concreta. Esto sehace utilizando marcadores polimórficos situados muy cerca o incluso dentro del genen cuestión, escogiendo aquellos marcadores que sean informativos en cada familiaconcreta. Los marcadores son del mismo tipo que los utilizados en el análisis de li-gamiento (RFLP, microsatélites). Utilizando esta estrategia podemos saber si un in-dividuo ha heredado una mutación de su progenitor enfermo simplemente determi-nando si ha heredado el cromosoma mutado de ese progenitor.
Lógicamente, esta estrategia es válida siempre que no haya habido ninguna re-combinación entre el locus de la enfermedad y el locus del marcador, de ahí que uti-licemos marcadores tan cercanos al gen que la frecuencia de recombinación seaprácticamente 0. De hecho, la metodología empleada es la misma que en los estu-dios de ligamiento, pero varía la manera de utilizar la información obtenida: mien-tras en los estudios de ligamiento queremos determinar la distancia entre dos loci, enel análisis indirecto ya sabemos cuál es esa distancia (y conocemos por tanto la fre-cuencia de recombinación) y simplemente utilizamos esa información para determi-nar qué cromosoma ha sido transmitido por cada progenitor a un individuo concre-to de la descendencia. El proceso general que se sigue en el diagnóstico indirecto esel siguiente:
a) Distinguir los dos cromosomas en cada uno de los progenitores: para esto esimprescindible encontrar un marcador para el que ambos progenitores seanheterocigotos (a poder ser no idénticos), de manera que esta familia sea to-talmente informativa.
235
Aplicación del ligamiento genético al diagnóstico: el proceso …
CAPITULO 17 5/12/06 07:31 Página 235
www.FreeLibros.me

b) Resolver la fase de ligamiento en el individuo transmisor: esto supone ser ca-paces de determinar cuál de los alelos del marcador segrega con el alelo dela enfermedad (y «viaja», por tanto, en el mismo cromosoma). Para esto hayque estudiar a los progenitores del individuo transmisor o a su descendenciay deducir la fase de ligamiento entre el marcador y el gen. Nuevamente, unarecombinación entre ambos loci (enfermedad y marcador) llevaría a resulta-dos erróneos, de ahí la importancia de usar marcadores cercanos al gen (o in-tragénicos) de modo que la frecuencia de recombinación entre ambos seadespreciable.
c) Determinar el alelo del marcador que ha sido transmitido al probando. Estonos dirá (con una fiabilidad mayor o menor dependiendo de la fracción derecombinación entre el marcador y el gen) si se ha transmitido el cromosomacon el alelo mutado o el alelo normal. Aquí se hace evidente la enorme utili-dad del diagnóstico indirecto: permite establecer si un individuo ha here-dado la mutación sin necesidad de detectar directamente la presencia dela misma. Como hemos comentado, su gran limitación viene dada porque enocasiones los marcadores están a cierta distancia del locus de la enfermedady las predicciones no son fiables al 100 por cien. Por ejemplo, si la distanciaentre el marcador y el locus de la enfermedad fuese de 5 cM (lo que suponeuna frecuencia de recombinación del cinco por ciento), la fiabilidad del aná-lisis sólo sería del 95 por ciento, ya que en un cinco por ciento de los casospodría haberse dado un sobrecruzamiento entre ambos loci que hubiese tras-ladado el alelo mutado al cromosoma homólogo. En la práctica, solventamosesta limitación mediante el uso de varios marcadores, preferiblemente situa-dos a ambos extremos del locus de la enfermedad. De esta forma, la única po-sibilidad de error sería un doble sobrecruzamiento entre el locus de la enfer-medad con cada uno de los marcadores, pero la probabilidad de que estosuceda es prácticamente despreciable. Lógicamente, a mayor número de mar-cadores, mayor fiabilidad de los resultados, sobre todo si además se incluyenmarcadores situados dentro del propio gen de la enfermedad.
La Figura 17.9 explica el proceso general del diagnóstico indirecto utilizando marcadorespolimórficos en ligamiento con el gen responsable de una enfermedad genética.
236
Diagnóstico de enfermedades genéticas
CAPITULO 17 5/12/06 07:31 Página 236
www.FreeLibros.me

C A P Í T U L O 1 8
Genética clínica
Contenidos
18.1 Genética clínica y consejo genético
18.2 Enfermedades de herencia autosómica
18.3 Enfermedades de herencia ligada al cromosoma X
18.4 Teorema de Bayes y su aplicación al cálculo de riesgos genéticos
18.5 Enfermedades por alteración del ADN mitocondrial
18.6 Diagnóstico prenatal
18.1 Genética clínica y consejo genético
La genética clínica se ocupa del diagnóstico y atención de las personas y familias en lasque aparece una enfermedad genética. Incluye varios aspectos, algunos de ellos algo di-ferentes de la práctica médica habitual:
• Diagnóstico correcto de la enfermedad, de lo contrario el cálculo de riesgos ge-néticos no tiene sentido. Para ello, además de los métodos clásicos de diagnósti-co, es importante realizar bien el diagnóstico molecular (estudiado en el capítuloanterior) y reconstruir la historia familiar detallada.
• La aplicación de los principios de la genética mendeliana permite calcular el ries-go de recurrencia de la enfermedad en la misma familia, establecer el pronóstico,iniciar medidas de diagnóstico precoz y de prevención en individuos de riesgo(antes de la aparición de los síntomas). Por todo esto, la genética clínica es un pi-lar básico de la «Medicina predictiva» del futuro.
• Un elemento fundamental es el consejo genético, que, según la definición de laSociedad Americana de Genética Humana (1975) «es un proceso de comunica-ción que trata de los problemas humanos asociados con la ocurrencia, o riesgo deocurrencia, de un transtorno genético en una familia. Este proceso requiere queuna o más personas adiestradas de forma apropiada ayuden al individuo o fami-
CAPITULO 18 5/12/06 07:33 Página 237
www.FreeLibros.me

lia a: 1) comprender los hechos médicos, incluyendo el diagnóstico, la evolu-ción probable del transtorno y el tratamiento disponible; 2) apreciar el modoen que la herencia contribuye al transtorno y el riesgo de recurrencia en pa-rientes concretos; 3) comprender las alternativas para enfrentarse al riesgo derecurrencia; 4) escoger un curso de acción que les parezca apropiado a la vis-ta de su riesgo, sus objetivos familiares y sus normas éticas y religiosas, y ac-tuar de acuerdo con la decisión tomada, y 5) procurar la mejor adaptación po-sible a la enfermedad en un miembro afectado de la familia y/o al riesgo deesta enfermedad». En contraste con el método médico tradicional, en el queel facultativo prescribe al paciente lo que debe hacer, entre profesionales dela Genética Clínica existe un amplio consenso a favor de que el consejo ge-nético sea un proceso no-directivo, es decir, que sea el propio paciente o lafamilia los que decidan qué acción tomar en función de la información pro-porcionada por el facultativo. En este sentido, es importante comprender quela carga de una enfermedad genética para el paciente y para la familia puedeser valorada de modo muy distinto de unos casos a otros, dependiendo de va-rias circunstancias. Es importante explicar bien las posibilidades de modificarla carga genética o el riesgo genético, y poner a las familias afectadas en con-tacto con servicios sociales de apoyo, organizaciones de afectados por la en-fermedad, etc.
Las dos herramientas básicas de la genética clínica, que el estudiante debe dominar,son la realización de la historia familiar y la estimación de riesgos genéticos. La his-toria familiar es la parte de la historia clínica en la que se reconstruye el árbol fami-liar y se intenta identificar otros miembros del mismo que puedan estar afectados porla enfermedad. Esto permitirá deducir el tipo de herencia y el riesgo de recurrencia.Se utilizan las reglas generales de construcción de árboles familiares, y además es im-portante:
• Preguntar acerca de nacidos muertos o abortos espontáneos.
• Indagar la existencia de posible consanguinidad.
• Tener en cuenta posibles casos de falsa paternidad.
• Recoger también información básica de las ramas del árbol que parezcan noestar afectadas.
• Siempre es mejor registrar la fecha de nacimiento que la edad.
• Tener en cuenta que el diagnóstico puede no ser acertado, sobre todo en elcaso de individuos ya fallecidos. Por tanto, es importante examinar directa-mente, siempre que sea posible, a los individuos afectados; examinar a los pre-sumiblemente «sanos», para excluir que en realidad tengan una forma pocosevera de la enfermedad; tratar de obtener toda la información posible deotros parientes más lejanos.
Por lo que respecta a la estimación del riesgo genético, se expresa siempre como unaprobabilidad, es decir en modo fraccional o en porcentaje (un riesgo de 1/2 es igual aun riesgo del 50 por ciento). El riesgo genético no es más que la probabilidad de pa-decer la enfermedad que tiene un individuo concreto de la familia, probabilidad es-timada a partir de los datos del árbol familiar que nos permiten deducir el tipo de he-rencia y aplicar las leyes mendelianas.
238
Genética clínica
CAPITULO 18 5/12/06 07:33 Página 238
www.FreeLibros.me

Los patrones hereditarios típicos se pueden reconocer al analizar el árbol genea-lógico de la familia en la que hay individuos enfermos, ya que cada tipo de herenciaproduce árboles familiares con unas características propias. Para la construcción deárboles familiares, llamados también «genealogías» o «pedigrís» (por influencia deltérmino inglés pedigree), se utilizan unos símbolos aceptados por convenio, y seconstruyen siguiendo unas reglas que hay que conocer.
La Figura 18.1 muestra los principales símbolos utilizados en la creación de árboles genealógicos(genealogías o pedigrís).
18.2 Enfermedades de herencia autosómica
Las enfermedades autosómicas dominantes suelen tener una frecuencia génica muybaja (la prevalencia de estas enfermedades es habitualmente inferior a 1/1 000 indi-viduos), y por tanto los individuos homocigotos son extremadamente infrecuentes;de hecho, la homocigosidad para estas enfermedades es muchas veces letal y provo-ca abortos espontáneos. El árbol típico de una enfermedad autosómica dominantemuestra individuos enfermos en todas las generaciones, afectando ambos sexos porigual. Cuando se ve una transmisión de padre enfermo a hijo varón, podemos des-cartar la presencia de una enfermedad ligada al cromosoma X. Para calcular el ries-go de padecer la enfermedad en la descendencia, se utilizan los cuadrados de Pun-net. Mediante el uso de estos diagramas es fácil concluir que la mitad de ladescendencia serán heterocigotos enfermos y la otra mitad homocigotos sanos. Dosindividuos sanos, si efectivamente son homocigotos (veremos alguna excepción másadelante), no pueden tener descendencia con la enfermedad.
Ya se ha mencionado antes que es muy poco frecuente encontrar enfermos ho-mocigotos (dos alelos mutados), pues esto exigiría la unión de dos heterocigotos en-fermos. Sin embargo, hay algunas enfermedades autosómicas dominantes en la queesto sucede con mayor frecuencia de lo habitual, debido a que tienen una frecuenciagénica más alta de lo habitual (no son letales, sino de comienzo tardío, por lo quepermiten llegar a la edad fértil, tener descendencia y propagar la mutación). Un buenejemplo de lo dicho es la Hipercolesterolemia familiar, una enfermedad autosómi-ca dominante debida a mutaciones en el receptor de las LDL (lipoproteínas de bajadensidad) que cursa con niveles altos de colesterol total y colesterol LDL, xantomastendinosos, xantelasmas y aterosclerosis precoz. La enfermedad afecta a uno de cada500 individuos de la población y es causa del cinco por ciento de los infartos de mio-cardio que se producen antes de los 60 años de edad. Como es una enfermedad queno altera la fertilidad, la frecuencia alélica es alta (en torno a uno de cada 1 000 ale-los presentes en la población están mutados) y no es raro encontrar individuos ho-mocigotos (en torno a uno por millón). Los homocigotos están afectados con másgravedad que los heterocigotos, mostrando niveles más altos de colesterol y mayorriesgo de enfermedad coronaria. El análisis molecular de los individuos enfermos yde los miembros de su familia permite predecir la gravedad de la enfermedad, esta-blecer el riesgo en la descendencia y comenzar el tratamiento preventivo con dieta ofármacos hipolipemiantes. También se pueden encontrar individuos homocigotos en
239
Enfermedades de herencia autosóm
ica
CAPITULO 18 5/12/06 07:33 Página 239
www.FreeLibros.me

enfermedades autosómicas dominantes en las que existe una cierta predisposición alas uniones entre individuos enfermos. Esto último sucede, por ejemplo, en una en-fermedad llamada acondroplasia. Los individuos que sufren esta enfermedad, dadasu baja estatura, tienden a formar matrimonios entre ellos, lo que eleva la probabili-dad de que aparezcan sujetos homocigotos.
Las enfermedades autosómicas recesivas requieren, por definición, que los indi-viduos afectados sean homocigotos (dos alelos mutados) y, por tanto, sus progenito-res son habitualmente portadores sanos heterocigotos. El árbol típico de un patrónautosómico recesivo muestra generaciones con algún miembro afectado, separadaspor generaciones en las que no hay ningún individuo enfermo, patrón muy pocoprobable en transtornos dominantes. Se encuentran individuos enfermos de ambossexos, y es muy frecuente la presencia de uniones con-sanguíneas (entre individuosque comparten un ancestro común, como primos, primos segundos, etc.).
Un buen ejemplo de enfermedad autosómica recesiva es la Fibrosis Quística delPáncreas, enfermedad debida a mutaciones en el gen CFTR (Cystic Fibrosis Trans-membrane Regulator), localizado en 7q31. La enfermedad afecta a uno de cada2 500 nacidos vivos de raza caucásica, lo que significa una frecuencia alélica del0,02 (dos por ciento de los alelos presentes en la población están mutados) y unafrecuencia de portadores del 0,04 (uno de cada 25 individuos de la población gene-ral son heterocigotos). La enfermedad surge por el mal funcionamiento de un canalde cloro, lo que provoca una mucoviscidosis (secreciones mucosas muy viscosas)que poco a poco conduce a la destrucción del tejido pulmonar y pancreático, ade-más de provocar obstrucción intestinal en algunos neonatos. Se conocen alrededorde 400 mutaciones diferentes en el gen CFTR, pero en poblaciones europeas un 70por ciento de los casos se deben a la deleción F508del, que deleciona tres bases sincambiar el marco de lectura:
SECUENCIA NORMAL GAA AAT ATC ATC TTT GGT GTTGluA Asn IleTC IleC Phe GlyT Val
F508del GAA AAT ATC AT- --T GGT GTTGluA Asn IleTCIle- --T GlyT Val
Además de F508del, hay otras mutaciones que causan Fibrosis Quística y que seencuentran con frecuencia alélica mayor a uno por ciento, de modo que el análisisde ocho mutaciones (incluyendo F508del) puede detectar hasta un 85-90 por cientode los casos en poblaciones de origen europeo.
Hay una serie de fenómenos —muchos de los cuales ya se han mencionado— quecomplican la evaluación de los árboles de enfermedades autosómicas dominantesy recesivas, y hacen que el cálculo de los riesgos en la descendencia sea menos fia-ble. A continuación se señalan los problemas más frecuentes:
• Heterogeneidad genética de locus. Ya se ha mencionado que muchas enfer-medades hereditarias pueden estar causadas por mutaciones en genes distin-tos, y se han visto algunos ejemplos. Esto se manifiesta, habitualmente, en laaparición de distintos patrones de herencia en familias diferentes. Así, porejemplo, hemos visto un tipo de enfermedad de Charcot-Marie-Tooth que si-
240
Genética clínica
CAPITULO 18 5/12/06 07:33 Página 240
www.FreeLibros.me

I
II
III
1 2 3 4 5 6 7 8
1 2 3 4 5 6 7 8
I
II
III
1 2 3
?
4
1 2 3 4
5
IV
1 2
1 2
??
gue un patrón autosómico dominante (por duplicaciones del gen PMP22),pero también existen familias en las que esta enfermedad sigue un patrón li-gado al sexo (por mutaciones en otro gen situado en el cromosoma X). Otroejemplo notable es el Síndrome de Ehlers-Danlos, que puede estar causadopor mutaciones en al menos ocho loci diferentes, dando lugar a familias conpatrón autosómico dominante, autosómico recesivo o ligado al sexo recesivo,dependiendo del gen implicado en cada caso. Lógicamente, la identificacióndel tipo de herencia en una familia concreta nos ayudará a predecir el genafectado (y buscar mutaciones en el mismo, si es posible) y a estimar el ries-go de padecer la enfermedad en la descendencia.
• Penetrancia incompleta. Hasta ahora hemos dado por supuesto que siempreque un gen está mutado se desarrollará la enfermedad correspondiente. Pordesgracia para el profesional de la Genética (pero por suerte para los pacien-tes), esto no se cumple en el 100 por cien de los casos. De hecho, no es infre-cuente encontrar árboles en los que un individuo ha transmitido una enfer-medad dominante sin haber estado él mismo afectado por dicha enfermedad.En la Figura 18.3 puede observarse una familia afectada por una enfermedadautosómica dominante en la que el individuo II-2 (señalado por la flecha) haheredado y transmitido la mutación, pero no ha llegado a desarrollar la en-
241
Enfermedades de herencia autosóm
ica
La Figura 18.2 muestra los árboles genealógicos típicos de las enfermedades con herenciaautonómica dominante y autonómica recesiva.
CAPITULO 18 5/12/06 07:33 Página 241
www.FreeLibros.me

fermedad. Descartando la posibilidad de que se trate de una nueva mutaciónque ha surgido en ese individuo, ya que esa misma enfermedad estaba ya pre-sente en los progenitores, hemos de concluir que este individuo es portadorde la mutación pero no expresa la enfermedad. Este fenómeno se denomina«penetrancia incompleta», y es característico de algunas enfermedades domi-nantes, como por ejemplo el Retinoblastoma hereditario.
• Expresividad variable. Muchas enfermedades hereditarias tienen manifesta-ciones clínicas complejas, con signos y síntomas que se pueden presentar endistintas combinaciones y con distinto grado de severidad. Se dice entoncesque estas enfermedades tienen expresividad clínica variable. En algunos casos,como por ejemplo la Neurofibromatosis tipo 1, distintos miembros de unamisma familia (todos con la misma mutación), pueden tener manifestacionesclínicas de la enfermedad muy dispares. No tenemos hoy en día una explica-ción clara para el fenómeno de la distinta expresividad de una misma muta-ción, pero es probable que esté originado por factores ambientales que influ-yen en el desarrollo de la enfermedad o por diferencias inter-individuales enotros genes que modifican la expresión del fenotipo.
En la Figura 18.3 se ilustran los conceptos de penetrancia incompleta y expresividad variable.
Por lo que respecta al cálculo de riesgos, podemos resumir:
• Las enfermedades de herencia autosómica dominante tienen, en general,frecuencias alélicas muy bajas (<0,001) y por eso los individuos homocigotos(ambos alelos mutados) son muy raros. Lo normal es encontrar cruces entreun heterocigoto y un homocigoto sano, por lo que el riesgo en la descenden-cia es de 50 por ciento heterocigotos enfermos y 50 por ciento homocigotossanos. Por eso, para cada hijo el riesgo de recurrencia es del 50 por ciento,aunque siempre hay que tener en cuenta los factores que pueden modificar es-tos riesgos (penetrancia incompleta, expresividad variable, tasa de nuevas mu-taciones).
• En enfermedades de herencia autosómica recesiva, ambos progenitores tie-nen que ser al menos portadores, por lo que en la descendencia habrá 25 porciento de enfermos (homocigotos con mutación), 25 por ciento de sanos (ho-mocigotos sin mutación) y 50 por ciento de portadores sanos (heterocigotos).Por tanto, el riesgo de recurrencia es inicialmente 1/4 (25 por ciento). Es im-portante recordar que la presencia de consanguinidad es un hecho muy fre-cuente en estas enfermedades. Más raramente hay matrimonios entre un por-tador sano y un enfermo homocigoto, en cuyo caso se produce un patrón deherencia cuasi-dominante con 50 por ciento de enfermos y 50 por ciento deportadores sanos en la descendencia. Una causa frecuente de consulta en elcaso de enfermedades de herencia autosómica recesiva es el matrimonio en-tre un portador y un individuo de otra familia distinta en la que no existe laenfermedad. Lógicamente, el riesgo final para la descendencia dependeráfundamentalmente de la probabilidad que tenga este individuo de ser porta-dor, lo cual, a su vez, depende de la tasa de portadores en la población ge-
242
Genética clínica
CAPITULO 18 5/12/06 07:33 Página 242
www.FreeLibros.me

neral. Como se recordará, la ley de Hardy-Weinberg permite estimar esta tasaen función de la prevalencia de la enfermedad en esa población.
En la Figura 18.4 se muestran los cuadrados de Punnet que ayudan a calcular el riesgo derecurrencia en enfermedades de herencia autonómica dominante y recesiva.
18.3 Enfermedades de herencia ligada al cromosoma X
Al igual que las enfermedades autosómicas, las enfermedades ligadas al sexo puedenser recesivas o dominantes. Lo más habitual es encontrar enfermedades de herencialigada al sexo recesivas, en las que las mujeres portadoras son sanas. El árbol típicomuestra únicamente varones enfermos, habitualmente sin transmisión de la enferme-dad de un padre a sus hijos varones. Se pueden dar tres situaciones, cuyos cuadradosde Punnet se presentan en la Figura 18.5. En primer lugar, la unión entre una mujerportadora (Aa) y un varón sano (A—) dará lugar a un 50 por ciento de hijas homoci-gotas sanas y un 50 por ciento de heterocigotas portadoras, mientras que el 50 porciento de los hijos varones serán sanos y el otro 50 por ciento serán enfermos. En elcaso de uniones entre una mujer portadora sana (Aa) y un varón enfermo (a—), los hi-jos varones tendrán los mismos riesgos que en el caso anterior (la mitad sanos y la mi-tad enfermos), pero las hijas serán homocigotas (enfermas, por tanto) en el 50 porciento de los casos y portadoras sanas en el otro 50 por ciento. Por último, las unio-nes entre un varón enfermo (a—) y una mujer homocigota sana (AA) dan lugar a unadescendencia en la que todos los hijos son sanos y todas las hijas son portadoras sa-nas. Como puede apreciarse, es importante distinguir las mujeres sanas que son ho-mocigotas de aquellas que son heterocigotas portadoras.
Ya hemos comentado que la inactivación del cromosoma X se realiza al azar encélulas somáticas, de forma que toda mujer es, en el fondo, un mosaico con pobla-ciones celulares en las que se ha inactivado un cromosoma X y poblaciones celula-res en las que se ha inactivado el otro. Sin embargo, en algunas circunstancias lainactivación puede ser preferencial, inactivándose el mismo cromosoma X en todaslas células. Esto sucede, por ejemplo, en casos de anomalías estructurales (delecioneso duplicaciones) que afectan a uno de los cromosomas X, en cuyo caso suele inacti-varse el cromosoma anormal. En cambio, en individuos con translocaciones equili-bradas entre el cromosoma X y un autosoma se inactiva preferencialmente el cro-mosoma normal, ya que de lo contrario se produciría a una monosomía parcial delautosoma implicado en la translocación. También se ha visto inactivación sesgada enalgunas familias con deleciones que afectan a XIST o a TSIX, así como en familiascon mutaciones que afectan al promotor de XIST. En algunos casos raros de enfer-medades ligadas al sexo recesivas, la inactivación preferencial del cromosoma X nor-mal en mujeres portadoras (que deberían ser fenotípicamente sanas) puede dar a lu-gar a la aparición de la enfermedad, aunque habitualmente con unas manifestacionesmás leves.
La Distrofia Muscular de Duchenne (DMD) es quizás uno de los mejores ejemplosde enfermedad ligada al sexo recesiva. Está causada por mutaciones en el gen de la dis-trofina, localizado en Xp21, y afecta a uno de cada 3 300 varones en todos los grupos
243
Enfermedades de herencia ligada al crom
osoma X
CAPITULO 18 5/12/06 07:33 Página 243
www.FreeLibros.me

étnicos. La ausencia de distrofina provoca la desestructuración del Complejo Asocia-do a la Distrofina (DAC) del sarcolema y conduce a la aparición de una degeneraciónmuscular progresiva que suele terminar con la vida del paciente alrededor de la terce-ra década de la vida. Como se recordará, el gen DMD es uno de los de mayor tamañoconocido, lo que condiciona una alta tasa de nuevas mutaciones (en torno a 10—4 nue-vas mutaciones por generación). Alrededor del 60 por ciento de las mutaciones son de-leciones (con tamaños que van desde varias kilobases hasta una megabase), con un«punto caliente» (hot spot) de aparición de deleciones en el exón 7. El resto de las mu-taciones son deleciones pequeñas y mutaciones puntuales que alteran el marco de lec-tura. La distrofia muscular de Becker es un fenotipo más leve causado por mutacio-nes en el mismo gen, pero en este caso las mutaciones NO rompen el marco de lectura(deleciones pequeñas y mutaciones puntuales con cambio de sentido).
El árbol típico de las enfermedades con herencia ligada al sexo dominante muestrauna estructura similar al de las enfermedades autosómicas dominantes, con la peculiari-dad de que nunca hay transmisión padre-hijo, pero en cambio todas las hijas de los va-rones enfermos son heterocigotas enfermas. Por el contrario, desarrollará la enfermedadel 50 por ciento de los hijos y el 50 por ciento de las hijas de una mujer portadora y unvarón normal. En general, los árboles suelen mostrar la presencia del doble de mujeresenfermas que de varones enfermos, excepto en aquellos casos en que la enfermedad esletal en varones. De todas formas, las mujeres suelen desarrollar formas más leves de laenfermedad, debido a que el 50 por ciento de sus células habrán inactivado el cromoso-ma X portador de la mutación y expresarán el alelo normal del gen implicado. Algunosejemplos de estas enfermedades son el Síndrome de Rett, el Raquitismo Hipofosfatasé-mico, o la Incontinencia Pigmentaria tipo 1 (enfermedad en la que sólo se ven mujeresafectadas, probablemente por letalidad embrionaria en varones).
En la Figura 18.5 se muestran los pedigrís típicos de enfermedades ligadas al sexo recesivas y dominantes.
Un patrón hereditario anómalo, dentro de las enfermedades ligadas al cromoso-ma X, es el que presentan las familias con Síndrome del X Frágil. El estudio del ár-bol de una familia con esta enfermedad pone de manifiesto un patrón de herencia
244
Genética clínica
I
II
III
1 2
4 5
4 5
1
2
1 2
3
1
2
IV
3
I
II
III
IV
CAPITULO 18 5/12/06 07:33 Página 244
www.FreeLibros.me

dominante con penetrancia reducida en mujeres, además de otros hechos que cons-tituyen lo que se conoce como «paradoja de Sherman»: 1) el riesgo de transmisiónde la enfermedad aumenta en sucesivas generaciones, y 2) se encuentran varonesnormales que transmiten la enfermedad a todas sus hijas, que serán por tanto porta-doras sanas. Como hemos comentado en otro capítulo, hoy en día sabemos que estaenfermedad está causada por la expansión de un trinucleótido en el gen FMR1, conalelos que varían en el número de veces que está repetido el trinucleótido. La pre-sencia de premutación (rango de 50 a 230 repeticiones) no provoca manifestacionesfenotípicas en los portadores (tanto varones como mujeres). La expansión de estosalelos premutados sólo se produce por vía materna, y la probabilidad de que esto su-ceda depende de la longitud del alelo premutado.
La Figura 18.6 ilustra la paradoja de Sherman, mostrando en un árbol los riresgos de expansión a mutación completa dependiendo del tamaño de la premutación y del sexo.
En general podemos afirmar que la expansión de pre-mutación a mutación com-pleta tiene lugar en menos del 20 por ciento de los alelos <70 repeticiones y en másdel 70 por ciento de los alelos >90 repeticiones. Como se recordará, la expansión a mu-tación completa va acompañada de hipermetilación del promotor del gen FMR1, loque provoca la ausencia de la proteína. Aunque la mutación provoca una pérdida defunción del gen, el fenotipo es dominante (basta un alelo con la mutación completapara desarrollar la enfermedad). De hecho, la presencia de un cromosoma con muta-ción completa e hipermetilación se asocia con retraso mental en todos los varones yen el 50-70 por ciento de las mujeres (por la inactivación del X, muchas células habráninactivado el cromosoma X mutado). Las mujeres que llevan un alelo con pre-muta-ción no suelen desarrollar la enfermedad, pero tienen riesgo de sufrir expansión en sudescendencia. Por el contrario, los varones con pre-mutación —denominados VaronesTransmisores Normales (NTM, Normal Transmitting Male)— transmiten el alelo pre-mutado, sin sufrir expansión, a todas sus hijas (que serán portadoras sanas), y —comoes lógico— no lo transmiten a ninguno de sus hijos. Recientemente se ha encontradoque estos varones desarrollan una enfermedad neurológica llamada FXTAS (síndromede temblor/ataxia asociado con el X-frágil) en las últimas décadas de la vida. Estos in-dividuos muestran inclusiones cerebrales con aumento del mRNA y de la proteínaFMRP, además de otras proteínas como laminina A/C. Esta enfermedad es un belloejemplo de cómo la identificación del mecanismo molecular genético ha permitido ex-plicar una serie de fenómenos clínicos y hereditarios de difícil comprensión.
El cálculo de riesgos en las enfermedades de herencia recesiva ligada al cromo-soma X, por tanto, debe hacerse teniendo en cuenta que las mujeres portadoras (he-terocigotas) son sanas pero los varones hemicigotos (con una mutación en su únicocromosoma X) son enfermos. En el caso de mujeres portadoras, la mitad de sus hi-jos varones serán enfermos y la otra mitad sanos; de sus hijas, la mitad serán porta-doras y la otra mitad homocigotas sanas. Es característico que nunca hay transmi-sión de padre enfermo a hijos varones, lo cual es muy importante para el consejogenético. En cambio, el 50 por ciento de las hijas de un varón enfermo serán porta-doras (sanas), pero ninguna será enferma. La excepción a esta regla general es el ma-trimonio de un varón enfermo con una mujer portadora, lo cual sucede a veces en
245
Enfermedades de herencia ligada al crom
osoma X
CAPITULO 18 5/12/06 07:33 Página 245
www.FreeLibros.me

casos de consanguinidad. En estos casos puede haber mujeres enfermas (heredan dosmutaciones) e incluso transmisión de padre enfermo a hijo varón (aunque, en reali-dad, el hijo hereda la enfermedad de su madre). Por lo que respecta a la herencia li-gada al X dominante, el matrimonio entre una mujer enferma (heterocigota) y unvarón normal produce una descendencia con riesgo de recurrencia en el 50 por cien-to de los hijos y en el 50 por ciento de las hijas. En cambio, el matrimonio entre unvarón afectado y una mujer normal da lugar a un riesgo del 100 por cien de recu-rrencia en las hijas (todas heredan el cromosoma X paterno, que transmite la muta-ción), pero todos los hijos varones serán sanos.
18.4 Teorema de Bayes y su aplicación al cálculo de riesgos18.4 genéticos
En algunas situaciones, los riesgos de recurrencia calculados según los principiosmendelianos pueden ser matizados y precisados por información adicional acerca deesa familia. Por este motivo, el consejo genético hace uso de la estadística bayesiana,derivada de la aplicación del teorema de Bayes. En su formulación general, el teo-rema de Bayes dice que:
P(A) × P(B|A)P(A|B) = ————–————––––——
Σ P(A) × P(B|A)
Esto significa que la probabilidad de un suceso A cuando se verifica una condi-ción B (eso se representa como «A sobre B») es igual a la probabilidad inicial del pri-mer suceso, multiplicado por la probabilidad de que la condición B se verifique enpresencia del suceso A, dividido por la probabilidad total de la condición B (que esel sumatorio de todos los posibles numeradores). Es decir, la probabilidad inicial oteórica de un suceso cualquiera puede ser modificada si se cumple alguna condiciónque afecta a ese suceso, dependiendo de la probabilidad de esa condición y de la pro-babilidad de que cuando tal condición se cumple se vea afectado el suceso inicial.Este tipo de análisis estadístico tiene aplicación en muchos campos, pero en el casoconcreto del consejo genético es especialmente útil en el cálculo de riesgos de recu-rrencia de enfermedades recesivas ligadas al cromosoma X, en las que podemos in-cluir información de tipo condicional. También es posible incorporar los datos deldiagnóstico molecular para matizar los riesgos de recurrencia calculados según losprincipios mendelianos, como veremos en algunos ejemplos.
Quizás el ejemplo más sencillo de cómo utilizar la información derivada de árbo-les genealógicos para modificar los riesgos iniciales sea el cálculo del riesgo de serportador de una enfermedad autosómica recesiva. Como sabemos por los principiosmendelianos, cualquier hermano o hermana de un afectado con una enfermedad au-tósomica recesiva, cuyos progenitores son portadores sanos, tiene una probabilidadinicial del 50 por ciento de ser portador sano, 25 por ciento de ser homocigoto sanoy 25 por ciento de ser homocigoto enfermo. En cambio, puede darse el caso de quenos encontremos una familia en la que uno de los hermanos es sano, y claramente noha desarrollado la enfermedad. En ese individuo, lógicamente, podemos despreciar el
246
Genética clínica
CAPITULO 18 5/12/06 07:33 Página 246
www.FreeLibros.me

25 % de probabilidad de ser enfermo, porque de hecho está sano. En efecto, sólo haydos posibilidades de ser hermano sano de un afectado por una enfermedad autosó-mica recesiva: o ser portador (probabilidad inicial del 50 por ciento) o ser homocigo-to sano (probabilidad inicial del 25 por ciento). De este 75 por ciento total, un 50 porciento corresponde a la probabilidad de ser portador, luego el riesgo que tiene un her-mano sano de ser portador de la enfermedad no es 50 por ciento, como inicialmentecabría suponer, sino realmente 2/3. Esto, que se comprende modo intuitivo, suponerealmente una aplicación del teorema de Bayes. En efecto, la probabilidad (P) inicialde ser portador sano es 1/2 y de ser homocigoto sano es 1/4, como acabamos de ver. Es-tablecemos la condición («si el individuo es SANO») y calculamos la probabilidadcondicional para cada estado posible: en este caso, la probabilidad condicional es 1(100 por cien) siempre, ya que tanto un portador sano como un homocigoto sano sonsanos. Si hacemos una tabla en la que indicamos las probabilidades bajo cada una delas dos posibles situaciones, obtenemos algo como lo que se muestra a continuación.Un individuo portador tiene una probabilidad inicial (a priori) del 50 % de ser sano,y si cumple la condición de estar sano su probabilidad condicional (estar sano) es del100 por cien (P = 1); lo mismo puede calcularse para un homocigoto sano (probabi-lidades inicial y condicional de 1/4 y 1, respectivamente). A continuación se calcula laprobabilidad combinada o conjunta de que ambos sucesos tengan lugar a la vez, es de-cir, se multiplican la probabilidad inicial y la condicional. La probabilidad conjuntacorresponde al término P(A) × P(B|A) de la ecuación anterior. Como vemos en la ta-bla, las probabilidades conjuntas son 1/2 y 1/4, respectivamente, para el caso de ser por-tador sano o de ser homocigoto sano:
Portador Homocigoto (sano)
Inicial 1/2 1/4Condicional («si es sano») 1 1Conjunta 1/2 1/4Final 2/4 ÷ 3/4 = 2/3 1/3
La suma de todas las posibles probabilidades conjuntas (el sumatorio que está enel denominador de la ecuación) es, en nuestro caso, 3/4 (1/2 + 1/4). Por tanto, la pro-babilidad final se calcula hallando el cociente entre la probabilidad conjunta de cadasituación y la suma de todas ellas. En nuestro ejemplo, la probabilidad final de queel hermano de un enfermo con una enfermedad autosómica recesiva sea portador dela misma, si es sano, es de (1/2) ÷ (3/4) = 2/3, y la probabilidad final de que sea homo-cigoto sano es 1/3. Como se puede ver, los riesgos no siempre son algo fijo, sino queen ocasiones pueden modificarse, a veces de manera sustancial, con la incorporaciónde nueva información.
El teorema de Bayes también se utiliza con frecuencia para calcular el riesgo de-rivado de pruebas diagnósticas bioquímicas o moleculares, y puede combinarse conla información obtenida del árbol genealógico. Por ejemplo, si se sabe que una enfer-medad tiene una prevalencia de 1/100 000 individuos, la probabilidad inicial de padecer-la es P(A) = 10-5. Si una prueba diagnóstica es positiva en el 80 por ciento de los in-
247
Teorema de Bayes y su aplicación al cálculo de riesgos genéticos
CAPITULO 18 5/12/06 07:33 Página 247
www.FreeLibros.me

dividuos enfermos y en un cinco por ciento de sanos (falsos positivos), podemos cal-cular la probabilidad de que un individuo en el que la prueba es positiva realmentepadezca la enfermedad. Para esto, calculamos la probabilidad de tener alterada laprueba si uno está enfermo: P(B|A) = 0,8. Igualmente, la probabilidad de tener alte-rada la prueba si uno está sano es 0,05 (obsérvese el uso del condicional para calcu-lar las probabilidades condicionales). La probabilidad final de que un sujeto tenga laenfermedad y además una prueba diagnóstica positiva es, por tanto, el producto de laprobabilidad inicial de enfermar multiplicado por la probabilidad condicional de te-ner alterada la prueba si está realmente enfermo, dividido por la probabilidad de queel marcador esté alterado en general (la suma de ambas probabilidades conjuntas):
Enfermo Sano
Inicial 10-5 0,99999Condicional 0,8 0,05Conjunta 0,8 × 10-5 0,0499995
Final (0,8 × 10-5) ÷ 0,0500075 = 1,6 × 10-4
Obsérvese que hemos multiplicado por más de 10 el riesgo inicial, en aquellos ca-sos en los que la prueba diagnóstica está alterada.
En cualquier caso, la situación en la que más se utiliza el teorema de Bayes enconsejo genético es para el cálculo del riesgo de ser mujer portadora en las enfer-medades con herencia ligada al X recesiva, ya que en estos casos el riesgo puedemodificarse sustancialmente. En estas familias es importante identificar correcta-mente la mujeres portadoras obligatorias (aquellas que han tenido al menos un hijoenfermo o una hija portadora) y asignar la información condicional correctamente,sobre todo en el caso de estudios moleculares de análisis indirecto.
La Figura 18.7 ilustra la aplicación del teorema de Bayes al cálculo de riesgos en enfermedades deherencia ligada al X recesiva, utilizando algunos ejemplos prácticos.
18.5 Enfermedades por alteración del ADN mitocondrial
El ADNmt presenta una serie de características genéticas que lo diferencian clara-mente del ADN nuclear:
• Alta tasa de mutación: la tasa de mutación espontánea del ADNmt es unas10 veces superior a la del ADN nuclear. Por tanto, hay una gran variación desecuencias entre especies e incluso entre individuos de una misma especie. Enel hombre se ha calculado que dos individuos escogidos al azar tienen comopromedio 50-70 nucleótidos diferentes en su genoma mitocondrial. Ademásde estas diferencias, en un individuo determinado se está produciendo conti-nuamente, a lo largo de la vida, una heterogeneidad en el ADNmt como con-secuencia de las mutaciones que se están dando en las células somáticas. Se
248
Genética clínica
CAPITULO 18 5/12/06 07:33 Página 248
www.FreeLibros.me

ha propuesto que una acumulación de este daño mitocondrial pudiera ser lacausa de la disminución en la capacidad respiratoria de los tejidos que tienelugar durante el envejecimiento.
• Poliplasmia y Segregación mitótica: en cada célula hay cientos o miles de mo-léculas de ADNmt. En principio, todas las células de un individuo normal tie-nen moléculas idénticas de ADNmt, situación que se denomina homoplas-mia. Si en una célula aparecen dos poblaciones de ADNmt, una normal y otramutada, se dice que estamos en una situación de heteroplasmia. Durante ladivisión celular, las mitocondrias —y, por tanto, las moléculas de ADNmt— sedistribuyen al azar entre las células hijas.
• Efecto umbral: el fenotipo de una célula en heteroplasmia dependerá del por-centaje de ADN dañado que exista en la célula; es decir, del grado de hete-roplasmia de una mutación. Cuando el número de moléculas de ADNmt mu-tadas es pequeño, el ADNmt normal es capaz de mantener la funciónmitocondrial. Sin embargo, cuando el número de copias de ADNmt mutadosobrepasa un umbral determinado, la producción de ATP puede llegar a estarpor debajo de los mínimos necesarios para el funcionamiento de los tejidos,llevando al desarrollo de patología mitocondrial. Es importante tener encuenta que los distintos tejidos pueden variar en el grado de homoplasmia oheteroplasmia para un ADNmt mutado, lo que origina una gran variabilidaden la expresividad clínica de las enfermedades mitocondriales. Por otra parte,los tejidos tienen distintas necesidades energéticas, y el número de orgánulosy de moléculas de ADNmt es también diferente en cada tejido. Por tanto, losórganos preferentemente afectados en las enfermedades mitocondriales sonaquellos que dependen en mayor grado de la producción de energía para sucorrecto funcionamiento.
• Herencia materna: el ADNmt se hereda exclusivamente por vía materna. Lapequeña cantidad de genoma mitocondrial contenido en el espermatozoideraramente entra en el óvulo fecundado, y cuando lo hace es eliminado acti-vamente. El tipo de herencia matrilineal es bastante fácil de reconocer al exa-minar un árbol genealógico, y tiene importantes consecuencias en el consejogenético (ver más adelante).
Por lo que respecta a las enfermedades humanas debidas a mutaciones del ADNmt,podemos dividirlas en dos grandes grupos: enfermedades asociadas a mutacionespuntuales y enfermedades debidas a alteraciones estructurales del ADNmt. Las en-fermedades asociadas a mutaciones puntuales son frecuentes, debido a la alta tasade mutación del ADNmt. Actualmente se han descrito más de 50 mutaciones pun-tuales, que se localizan en los tres tipos de genes codificados en el ADNmt (ARNr,ARNt y polipéptidos del OXPHOS). Según su efecto patogénico, distinguimos lasmutaciones que originan el cambio de un aminoácido por otro, afectando a algunode los 13 genes codificantes de proteínas, y las mutaciones que afectan a los genesde los ARNr o ARNt, que tienen efectos globales en la síntesis de las proteínas mi-tocondriales. Las enfermedades asociadas a alteraciones estructurales del ADNmtpueden ser tanto deleciones más o menos grandes como, menos frecuentemente, in-serciones y/o duplicaciones. Hasta el momento se han descrito varios cientos de re-ordenaciones del ADNmt, que —al contrario que las mutaciones puntuales— suelen
249
Enfermedades por alteración del ADN m
itocondrial
CAPITULO 18 5/12/06 07:33 Página 249
www.FreeLibros.me

ser esporádicas. Como regla práctica, podemos decir que en aquellos casos quemuestran herencia matrilineal ha de sospecharse la presencia de mutaciones pun-tuales del ADNmt; en casos esporádicos, en cambio, son más frecuentes las dele-ciones y/o duplicaciones. Si, por el contrario, se confirma un patrón de herenciaautosómico dominante, el estudio debe ir dirigido hacia la búsqueda de delecio-nes múltiples; si fuese autosómico recesivo, deben buscarse depleciones delADNmt.
La Figura 18.8 muestra las mutaciones puntuales más frecuentes del ADN mitocondrial.
La detección de mutaciones puntuales se realiza habitualmente por digestión defragmentos de PCR con enzimas de restricción sensibles al cambio de nucleótido in-troducido por la mutación. En cualquier caso, resulta más fiable la detección me-diante Southern del ADNmt digerido con enzimas de restricción específicas paracada una de las mutaciones concretas, pero esto no siempre es posible y, por otra par-te, es más laborioso.
Las deleciones se encuentran siempre en heteroplasmia, aunque pueden llegara constituir un porcentaje muy alto de la población de ADNmt. Su determinación sehace fundamentalmente en biopsias musculares, pero si la afectación es muy grave sepueden llegar a detectar también en sangre periférica. Las deleciones se detectan conrelativa facilidad por la técnica de Southern, que muestra poblaciones de ADNmt demenor tamaño que el normal (16.569 pb). Se emplea habitualmente ADNmt digeri-do con BamHI o con EcoRV, utilizando como sonda un gran fragmento de ADNmtobtenido mediante PCR de largo alcance.
El diagnóstico de depleción del ADNmt se realiza también por hibridación Sou-thern, comparando los niveles de ADNmt con los de ADN nuclear.
La confirmación molecular de una alteración del ADNmt ayuda a establecer eldiagnóstico de enfermedad mitocondrial y el patrón de herencia matrilineal. Esto tie-ne una importancia capital desde el punto de vista del consejo genético y el cálculodel riesgo de recurrencia de la enfermedad, ya que la herencia matrilineal está ca-racterizada por la transmisión exclusivamente por vía materna. Esto hace que tengaalgunas características especiales: se afectan ambos sexos, pero los varones —enfer-mos o no— nunca transmiten la enfermedad, y sus descendientes (hijos o hijas) noson portadores; por otro lado, las mujeres afectadas transmiten la enfermedad atoda su descendencia, de forma que todas sus hijas tienen riesgo de transmitir y/opadecer la enfermedad, y todos sus hijos tienen riesgo de padecerla.
Las enfermedades mitocondriales pueden deberse a defectos en genes nucleares oa alteraciones del propio genoma mitocondrial. La diferencia entre ambos tipos deprocesos es importante porque los tipos de herencia son diferentes y las implicacio-nes para el cálculo de riesgos pueden ser grandes. Dada la importancia del metabo-lismo oxidativo, las enfermedades mitocondriales presentan gran variedad de sínto-mas y signos, y suponen un problema diagnóstico importante. En generalencontramos afectación neuromuscular: neuropatía óptica, convulsiones, accidentescerebrovasculares, mioclonías, neuropatía periférica, ataxia, demencia, miopatías. Detodas formas, los pacientes con enfermedad del ADN mitocondrial pueden agrupar-se en tres categorías:
250
Genética clínica
CAPITULO 18 5/12/06 07:33 Página 250
www.FreeLibros.me

• Raramente se presenta como un síndrome fácilmente identificable: MELAS(encefalopatía mitocondrial con acidosis láctica y episodios de accidentes ce-rebrovasculares) muestra estatura baja, sordera bilateral, diabetes, convulsio-nes, accidentes cerebrovasculares y encefalopatía en la 3.ª o 4.ª décadas de lavida. LHON (Leber hereditary optic neuropathy) muestran fallo visual bilate-ral en la 2ª-3ª décadas. Otras presentaciones clásicas son la oftalmoplegia ex-terna con o sin ptosis, que aparece junto con una miopatía proximal en CPEO(chronic progressvie external ophtalmoplegia) o con ataxia, sordera bilateral ydefectos de conducción cardíaca en el Síndrome de Kearns-Sayre. Otros sín-dromes son NARP (neurogenic weakness, ataxia, retinitis pigmentosa) yMERRF (epilepsia mioclónica y ragged-red-fibers o fibras musculares rojasdeshilachadas).
• Un segundo grupo de pacientes tienen una constelación de datos clínicos quesugieren enfermedad mitocondrial, pero no encajan en ninguno de los sín-dromes citados. Por ejemplo, son típicos los casos de estatura baja con sorde-ra neurosensorial bilateral, oftalmoplegia con ptosis, diabetes y migrañas. Esnecesario un estudio neurológico exhaustivo, y la asociación de cualquiera deestos datos con miopatía o signos de afectación neurológica central hace eldiagnóstico de enfermedad mitocondrial muy probable. Sin embargo, lo máshabitual es que estos pacientes sean estudiados para descartar gran cantidadde enfermedades neurológicas hereditarias autosómicas (alguna forma de ata-xia espinocerebelosa, estadíos iniciales de la enfermedad de Huntington, sín-drome de Usher, Charcot-Marie-Tooth) antes de que se llegue a pensar en en-fermedad mitocondrial. Un diagnóstico común en estos pacientes es el de«miastenia congénita».
• El último gran grupo de enfermos es el más difícil de definir, y está constitui-do por pacientes con síntomas aislados que —después de un estudio exhausti-vo— terminan achacándose a patología mitocondrial. Por ejemplo, un ciertoporcentaje de accidentes cerebrovasculares juveniles son resultado de patolo-gía mitocondrial, pero además la presentación a menudo es extra-neurológi-ca: cardiomiopatía hipertrófica, enfermedad tubular renal, hipoparatiroidis-
251
Enfermedades por alteración del ADN m
itocondrial
La Figura 18.9 muestra un árbol genealógico típico de herencia matrilineal.
CAPITULO 18 5/12/06 07:33 Página 251
www.FreeLibros.me

mo, insuficiencia suprarrenal, diabetes, disfagia. La sordera familiar neuro-sensorial progresiva es frecuentemente debida a patología mitocondrial, comodemostró el grupo de Xavier Estivill en 70 familias españolas con la mutacióndel nucleótido 1555.
Entre las pruebas diagnósticas que resultan útiles para llegar al diagnóstico de pa-tología mitocondrial, contamos con las siguientes:
• Investigaciones generales: habitualmente, estos pacientes han sido sometidosa gran catidad de tests. Es necesario ver la función cardíaca, test de toleran-cia a glucosa, nivel de lactato en sangre (es más específico en el líquido cefa-lo-raquídeo), electroencefalograma para detectar encefalopatía subaguda,TAC cerebral (es común la calcificación bilateral de ganglios basales).
• Investigaciones específicas: detección de alteraciones en el ADN mitocon-drial, tanto reordenamientos (deleciones, duplicaciones) como mutacionespuntuales. Lo más habitual es que las mutaciones estén en heteroplasmia, yesto determina la expresividad fenotípica (habitualmente es necesario >85 porciento de ADNmt mutado para que se manifieste la enfermedad). Las muta-ciones letales sólo pueden estar en heteroplasmia, pero en general el porcen-taje de heteroplasmia varía en distintos órganos en un mismo individuo e in-cluso también con la edad, de ahí la enorme variabilidad clínica. En algunasentidades es relativamente sencilla la detección molecular: por ejemplo, haytres mutaciones que en conjunto explican el 95 por ciento de los pacientescon LHON. En cambio, las deleciones responsables de los síndromes deCPEO o Kearns-Sayre no son detectables en sangre, por lo que los resultadosnegativos han de ser interpretados con cautela. En estos casos, la biopsia demúsculo esquéletico es la piedra angular para el diagnóstico de patología mi-tocondrial: por un lado, la detección histoquímica de fibras deficientes enCOX y en otros complejos de la cadena respiratoria confirma la afectaciónmitocondrial; además, los estudios moleculares en ADN muscular confirmanla presencia de deleciones o de mutaciones puntuales.
18.6 Diagnóstico prenatal
El avance de las técnicas diagnósticas genéticas permite hoy en día, para determina-dos procesos, realizar diagnóstico precoz dentro del útero. Esta modalidad diagnós-tica, llamada diagnóstico prenatal, es con frecuencia causa de la petición de conse-jo genético, y tiene unos matices especiales por las implicaciones emocionales fuertesque conlleva para la familia. El desarrollo de los métodos de diagnóstico prenatal haido parejo a la práctica del consejo genético, y por tanto se ha realizado de modo res-ponsable y adecuado. En cambio, el uso generalizado de nuevos métodos, especial-mente la ecografía, fuera del contexto del consejo genético (o incluso como sustitu-to del mismo) sin realizar adecuadamente el cálculo de riesgos, la detección deportadores ni otras medidas de apoyo, supone un descenso en la calidad de la asis-tencia que reciben las familias con enfermedades genéticas. El uso de pruebas de ba-rrido (screening) en el primer trimestre del embarazo significa que la mayor parte delas consultas de diagnóstico prenatal se realizan en situaciones en las que no exis-
252
Genética clínica
CAPITULO 18 5/12/06 07:33 Página 252
www.FreeLibros.me

tía riesgo previo de una enfermedad genética, lo cual genera situaciones especial-mente delicadas que es importante gestionar bien.
Dado que los procesos de diagnóstico prenatal suponen una cierta tensión emo-cional para la familia, especialmente para la madre, y pueden provocar una morbili-dad fetal significativa, se recomienda que sólo se realice diagnóstico prenatal cuan-do se cumplen una serie de condiciones y en aquellos casos en que está indicado. Enconcreto, sólo se debe plantear el diagnóstico prenatal en el caso de enfermedadesgraves para las que exista un método diagnóstico específico y fiable, y que sean sus-ceptibles de tratamiento o prevención. Las indicaciones principales, por tanto, sonlas cromosomopatías, los defectos del tubo neural, y la edad materna avanzada. Tam-bién se debe valorar la aceptación o no, por parte de la familia, del aborto eugénicocomo opción, ya que algunos autores desaconsejan iniciar los estudios de diagnósti-co prenatal cuando dicha opción no se acepta (por motivos éticos, religiosos o de ín-dole personal). En efecto, en estas circunstancias no está claro que el diagnósticoconlleve ningún beneficio, y por el contrario pueden generarse conflictos serios queson difíciles de resolver y a los que el facultativo no podrá dar respuesta. En estas cir-cunstancias, el diagnóstico prenatal sólo sería de utilidad si se pueden tomar medi-das preventivas o terapéuticas en el periodo fetal, lo cual sólo es posible en un nú-mero reducido de enfermedades.
Por tanto, antes de la puesta en marcha del proceso de diagnóstico prenatal es im-portante conocer las disposiciones de la pareja respecto a las posibles opciones tera-péuticas, además de considerar otros factores como la severidad de la posible enfer-medad, la posibilidad de tratamiento o medidas preventivas, y la fiabilidad de lastécnicas de diagnóstico prenatal. Este último punto es también de gran importancia,y debe ser explicado con claridad y ejemplos prácticos, porque el concepto de «ries-go» no siempre es correctamente entendido. Igualmente es importante que no se rea-lice diagnóstico prenatal sin una estimación previa del riesgo que tiene un feto con-creto de padecer la enfermedad: el diagnóstico prenatal no está exento decomplicaciones y supone en sí mismo un riesgo para el feto, por lo que no está justi-ficado realizarlo cuando el riesgo previo de padecer esa enfermedad es muy bajo. Estosupone, lógicamente, que el diagnóstico prenatal debe formar parte del proceso globalde consejo genético y ser realizado, siempre que sea posible, por especialistas en ge-nética clínica.
Los dos métodos más utilizados para la obtención de material fetal son la amnio-centesis y la toma de una biopsia de vellosidades coriónicas. La amniocentesis con-siste en la toma de una muestra de líquido amniótico, que contiene células fetales ensuspensión. Dichas células se pueden cultivar in vitro para después realizar estudioscromosómicos, bioquímicos o moleculares, lo cual requiere entre una y tres semanas.El procedimiento es, guiado por ultrasonidos y, en manos experimentadas, fiable. Susprincipales inconvenientes son el límite de edad fetal, ya que no puede realizarse an-tes de las 15 semanas de gestación, y los riesgos de pérdida fetal que conlleva (en tor-no al 0,5-1 por ciento). La biopsia de vellosidades coriónicas puede realizarse du-rante el primer trimestre del embarazo, en torno a la décima semana, y esespecialmente útil para realizar estudios moleculares y en la presencia de un riesgoalto de cromosomopatía. En cambio, es menos utilizada que la amniocentesis cuan-do el riesgo de alteraciones citogenéticas es bajo. El procedimiento se realiza me-
253
Diagnóstico prenatal
CAPITULO 18 5/12/06 07:33 Página 253
www.FreeLibros.me

diante punción a través de la pared abdominal (transabdominal) o a través del cue-llo del útero (transcervical), bajo guía ecográfica. En ese momento, el tejido corióni-co todavía no forma una placenta propiamente dicha, por lo que la biopsia se exa-mina bajo microscopio y se aíslan las vellosidades (que únicamente contienen tejidofetal). El material obtenido puede utilizarse directamente (sin necesidad de cultivo)para estudios moleculares o enzimáticos. En general, este procedimiento se reservapara embarazos de alto riesgo, ya que la probabilidad de pérdida fetal es mayor queen la amniocentesis (en torno al 2-3 por ciento).
Dado el riesgo relativamente alto de daño fetal que tienen la amniocentesis y, so-bre todo, la obtención de vellosidades coriónicas, desde hace años se están buscan-do métodos no invasivos que permitan realizar estudios moleculares o bioquímicosen material fetal. Entre éstos, estan siendo muy utilizados los métodos ecográficos, elanálisis bioquímico de sangre materna, el análisis de células fetales presentes en lasangre materna, o incluso la obtención de sangre fetal (aunque este procedimiento esmás invasivo y por tanto más peligroso que los otros mencionados). También en losúltimos años, con la proliferación de las técnicas de fertilización in vitro, es posiblerealizar diagnóstico genético preimplantatorio, obteniendo un blastómero a partirde un embrión de pocas células y realizando estudios moleculares a partir del ADNde esa única célula. Por desgracia, dicho procedimiento habitualmente no se realizaen el contexto del consejo genético, y todavía no existen datos claros acerca del po-sible daño fetal que pueda producir. Tampoco hay estudios abundantes sobre las ta-sas de error que se obtienen en el diagnóstico de las distintas enfermedades genéti-cas, y en cualquier caso su aplicación está limitada por la baja tasa de éxito de lafertilización in vitro.
254
Genética clínica
CAPITULO 18 5/12/06 07:33 Página 254
www.FreeLibros.me

CAPITULO 15 5/12/06 07:27 Página 209
www.FreeLibros.me

E) Nuevas herramientas de la genética moderna
Esta sección aborda los dos últimos temas del programa, que in-troducen al alumno en las cuestiones de más actualidad y le abren
perspectivas de futuro.
CAPITULO 19 5/12/06 07:35 Página 255
www.FreeLibros.me

C A P Í T U L O 1 9
Terapia génica
Contenidos
19.1 Componentes de un sistema de terapia génica y vías de administración
19.2 Naturaleza del ácido nucleico terapéutico
19.3 Tipos de vectores y su utilización en distintas estrategias de transferencia génica
19.4 Aplicaciones clínicas de la terapia génica en el momento actual
19.1 Componentes de un sistema de terapia génica y vías19.1 de administración
El desarrollo de la genética molecular durante los últimos años, y especialmente toda lainformación derivada del Proyecto Genoma Humano, han propiciado que podamosafrontar la modificación directa de las alteraciones genéticas o la utilización de ácidosnucleicos como agentes terapéuticos. La terapia génica es una nueva modalidad tera-péutica surgida a finales de los años 80, y que puede definirse como la transferencia deácidos nucleicos (ADN o ARN) con fines terapéuticos.
Toda estrategia de terapia génica se basa, por tanto, en la transferencia de ácidos nu-cleicos (transferencia génica) al interior de un grupo de células. Estas células pueden serlas células enfermas –cuyo daño se pretende reparar–, o bien un grupo de células nor-males que se modifican genéticamente para que sean las efectoras de una acción tera-péutica, por ejemplo sintetizando una proteína concreta. Por lo tanto, todo sistema de te-rapia génica es análogo a un sistema de transporte, en el que hay un agente que estransportado y un vehículo de transporte. En nuestro caso, el agente transportado es unácido nucleico y el vehículo encargado de llevarlo al interior de las células diana se de-nomina vector. Según el modo de hacer llegar el vector (conteniendo el agente terapéu-tico) a las células diana, es ya clásica la distinción entre terapia génica ex vivo y terapiagénica in vivo. En el primer caso, la administración del vector se realiza fuera del cuer-po: se obtiene una biopsia del órgano de interés, se expanden las células mediante culti-
CAPITULO 19 5/12/06 07:35 Página 257
www.FreeLibros.me
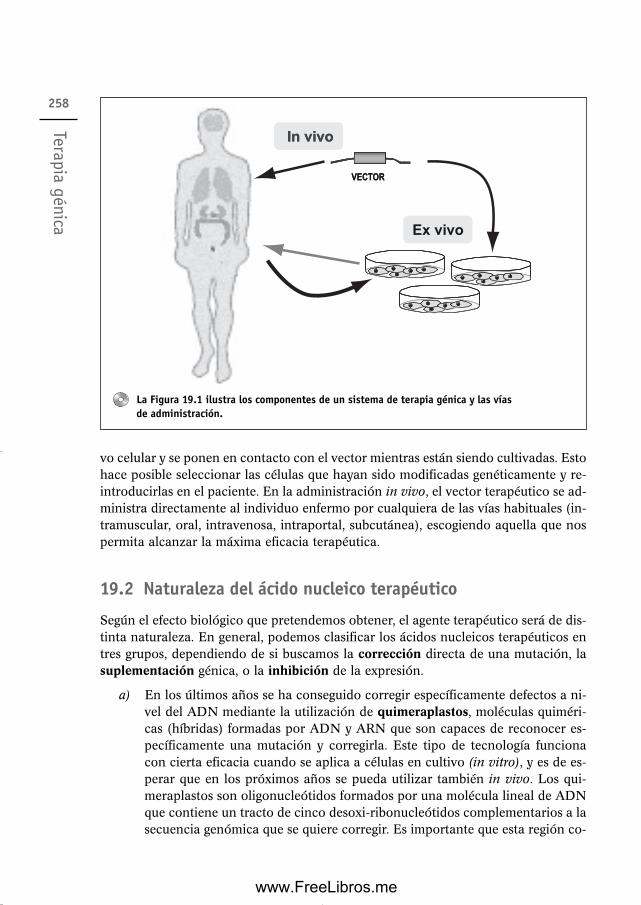
vo celular y se ponen en contacto con el vector mientras están siendo cultivadas. Estohace posible seleccionar las células que hayan sido modificadas genéticamente y re-introducirlas en el paciente. En la administración in vivo, el vector terapéutico se ad-ministra directamente al individuo enfermo por cualquiera de las vías habituales (in-tramuscular, oral, intravenosa, intraportal, subcutánea), escogiendo aquella que nospermita alcanzar la máxima eficacia terapéutica.
19.2 Naturaleza del ácido nucleico terapéutico
Según el efecto biológico que pretendemos obtener, el agente terapéutico será de dis-tinta naturaleza. En general, podemos clasificar los ácidos nucleicos terapéuticos entres grupos, dependiendo de si buscamos la corrección directa de una mutación, lasuplementación génica, o la inhibición de la expresión.
a) En los últimos años se ha conseguido corregir específicamente defectos a ni-vel del ADN mediante la utilización de quimeraplastos, moléculas quiméri-cas (híbridas) formadas por ADN y ARN que son capaces de reconocer es-pecíficamente una mutación y corregirla. Este tipo de tecnología funcionacon cierta eficacia cuando se aplica a células en cultivo (in vitro), y es de es-perar que en los próximos años se pueda utilizar también in vivo. Los qui-meraplastos son oligonucleótidos formados por una molécula lineal de ADNque contiene un tracto de cinco desoxi-ribonucleótidos complementarios a lasecuencia genómica que se quiere corregir. Es importante que esta región co-
258
Terapia génica
VECTOR
In vivo
VECTOR
In vivo
Ex vivo
La Figura 19.1 ilustra los componentes de un sistema de terapia génica y las vías de administración.
CAPITULO 19 5/12/06 07:35 Página 258
www.FreeLibros.me

rrectora esté flanqueada por fragmentos de 10 ribonucleótidos (ARN). El oli-gonucleótido se empareja específicamente con la región mutada y los siste-mas de reparación celulares llevan a cabo la reparación de la mutación to-mando como molde la base correspondiente del oligonucleótido terapéutico.Teóricamente, es posible diseñar oligonucleótidos ARN/ADN para corregirdirectamente las mutaciones puntuales que causan las enfermedades heredi-tarias más frecuentes.
b) En el caso de mutaciones que simplemente producen pérdida de función,puede ser suficiente la suplementación génica, es decir, suplementar las cé-lulas con copias normales del gen sin preocuparnos de corregir las mutacio-nes presentes en el ADN genómico. Lo más habitual en estos casos es que elagente terapéutico sea una unidad de expresión en la que la transcripción delgen en cuestión viene regulada por promotores virales potentes, por promo-tores regulables o por promotores específicos de un tipo celular concreto.
c) Cuando el defecto genético que tratamos de corregir origina una ganancia defunción, como suele suceder en mutaciones con efectos oncogénicos, lo lógi-co es intentar inhibir la expresión del gen que está causando el fenotipo abe-rrante. Los agentes terapéuticos más utilizados en estas circunstancias son lasmoléculas antisentido o los ribozimas. Los oligonucleótidos antisentido pue-den inhibir directamente la expresión de un gen al unirse a la doble hélice deADN mediante enlaces tipo Hoogsteen, formando una triple hélice que impi-de la transcripción mediada por la ARN polimerasa II. Estos oligonucleótidossuelen estar modificados químicamente para aumentar su estabilidad y efica-cia, siendo las principales modificaciones los grupos fósforo-tioato en el es-queleto desoxi-ribosa-fosfato de los oligonucleótidos, o bien los ácidos nuclei-cos en los que el enlace fosfo-diéster viene substituido por un enlace peptídico(denominados Acidos Nucleicos Peptídicos, PNA). Los ARNm antisentidoson capaces de emparejarse con los ARN sentido y formar moléculas bicate-narias de ARN que no pueden ser traducidas y son digeridas por la RNAsa Hcelular. Los ribozimas, pequeñas moléculas de ARN con actividad catalítica,pueden ser diseñados para reconocer un ARNm específico y degradarlo mer-ced a su actividad endonucleolítica específica. En general, la utilización demoléculas antisentido y ribozimas está limitada por la baja eficacia que mues-tran todavía en modelos in vivo. Hoy en día, las mejores perspectivas de inhi-bición eficaz y específica de la expresión génica se basan en la interferencia deARN, un mecanismo de silenciamiento génico post-transcripcional descrito enplantas y C. elegans que consiste en la degradación de ARN mensajeros endó-genos por la presencia de moléculas pequeñas de ARN de doble cadena ho-mólogas al mensajero que se destruye. Este proceso depende de una RNAasatipo III llamada DICER, responsable de la formación de los ARN pequeños, yde un complejo llamado RISC (RNA Induced Silencing Complex) que contie-ne unas proteínas del complejo ARGONAUTA y los ARN pequeños que diri-gen el complejo a la diana. Se ha visto que este mecanismo también juega unpapel importante en la regulación génica en humanos, ya que el análisis delgenoma ha revelado la presencia de genes que codifican ARN pequeños (apro-ximadamente 75 nucleótidos) que forman horquillas y que son procesados por
259
Naturaleza del ácido nucleico terapéutico
CAPITULO 19 5/12/06 07:35 Página 259
www.FreeLibros.me

DICER y proteínas del complejo Argonauta para generar ARN intereferentespequeños, de unos 21-22 nucleótidos. Estos genes endógenos se denominanmiRNA (microRNA), para diferenciarlos de los siRNA que provienen de mo-léculas bicatenarias de ARN de procedencia externa. Actualmente se piensaque ambos tipos de moléculas (miRNA y siRNA) tienen la misma vía efecto-ra, que actúa impidiendo la traducción (si la homología de la molécula inter-ferente con el ARN mensajero no es total), o bien eliminando los mensajerossi la homología es total. Sorprendentemente, también se ha visto que las repe-ticiones centroméricas y los transposones, cuando se transcriben, dan lugar aARN interferentes pequeños que utilizan este mecanismo para modificar lacromatina, induciendo metilación en las histonas o en el ADN y provocandola formación de heterocromatina o el silenciamiento transcripcional. En los úl-timos años se ha demostrado que se pueden utilizar siRNAs o microRNAspara inhibir la expresión de genes endógenos, generando moléculas interfe-rentes específicas para un gen concreto. Por ejemplo, se ha conseguido silen-ciar genes endógenos en células humanas mediante siRNAs dirigidos específi-camente frente a promotores concretos. Dicho silenciamiento se lleva a cabopor metilación de los dinucleótidos CpG de esos promotores y por metilaciónde la lisina 9 de la histona H3 de esa región. El avance más espectacular usan-do esta tecnología tuvo lugar en 2004, cuando un grupo consiguió reducir has-ta un 40 % los niveles de colesterol en ratón, usando unos siRNA sintéticosconjugados con colesterol que fueron injectados directamente en la vena de lacola. Los siRNA fueron captados eficazmente por receptores del hígado, ye-yuno y otros órganos y provocaron la degradación de los ARNm endógenosde apolipoproteína B, con el consiguiente descenso en los niveles de LDL ycolesterol total.
En la Figura 19.2 se muestran algunos ejemplos de moléculas utilizadas en distintas estrategias deterapia génica.
19.3 Tipos de vectores y su utilización en distintas estrategias19.3 de transferencia génica
Los ácidos nucleicos terapéuticos han de ser vehiculizados al interior de las célulasdiana por medio de vectores adecuados. Se distinguen dos tipos fundamentales devectores: los basados en virus (vectores virales) y los vectores sintéticos (vectores novirales) que intentan emular la capacidad natural que tienen los virus de introducirácidos nucleicos en las células.
1. Los vectores virales fueron los primeros en ser utilizados, dada su alta efica-cia como vehículos de ácidos nucleicos. Los virus están compuestos por unADN o un ARN rodeado de una cápside proteica y, en algunos casos, una en-vuelta lipoproteica. El ciclo biológico de los virus pasa por la introducción delgenoma viral en determinados tipos celulares, habitualmente por la presenciade receptores en la membrana de las células. Para poder utilizar un virus
260
Terapia génica
CAPITULO 19 5/12/06 07:35 Página 260
www.FreeLibros.me

como vector en terapia génica, es preciso insertar el ácido nucleico terapéu-tico en el genoma viral, y conseguir al mismo tiempo que el virus no se repli-que y, por tanto, no sea patogénico. Por esto, los virus utilizados en terapiagénica se denominan virus recombinantes y defectivos (carecen de algunafunción necesaria para su propio ciclo replicativo). A continuación se repa-san los principales vectores virales utilizados actualmente en terapia génica.
a) Vectores retrovirales. La familia Retroviridae está compuesta por lassubfamilias Spumaviridae, Lentiviridae y Oncoviridae. Los vectores re-trovirales utilizados en terapia génica están derivados de los oncovirusmurinos del tipo C, especialmente los que son anfitrópicos (que puedeninfectar tanto células murinas como humanas). Recientemente se handesarrollado vectores derivados de lentivirus, especialmente del HIV-1.
a) Los retrovirus son virus ARN que tienen una envuelta fosfolipídica, conglicoproteínas que determinan el tropismo del virus al ser reconocidaspor receptores celulares específicos. Dentro de esta envuelta hay unacápside proteica de estructura icosaédrica que contiene dos copias delgenoma viral, la transcriptasa inversa (RT), y la integrasa. El genoma deun retrovirus es una molécula de ARN de polaridad positiva en la que sedistinguen tres tipos de genes: genes gag (que codifican las proteínas dela cápside), genes pol (que codifican las enzimas necesarias para el cicloviral, como la proteasa y la integrasa) y genes env (que codifican las gli-coproteínas de la envuelta). El genoma está flanqueado por dos repeti-ciones terminales largas (LTR, Long Terminal Repeat), y contiene tam-bién una señal de empaquetamiento PSI mediante la cual las moléculasde ARN se unen a las proteínas de la cápside y son empaquetadas efi-cazmente. El LTR izquierdo contiene una región (U3) para el comienzode la transcripción, y un primer binding site (pbs) para el comienzo de laretrotranscripción. El LTR derecho contiene una secuencia de poli-puri-nas (ppt) para la replicación de la segunda cadena.
a) El ciclo replicativo de los retrovirus comienza cuando el virus es reco-nocido por receptores celulares, lo que lleva a la fusión de la envuelta vi-ral con la membrana celular y a la internalización del nucleoide. A con-tinuación tiene lugar la retrotranscripción del ARNm para formar unADNc bicatenario (este proceso tiene lugar dentro de la nucleocápside,
261
Tipos de vectores y su utilización en distintas estrategiasde transferencia génica
LTR gag pol envPSI LTR
U3 pbs ppt
La Figura 19.3 muestra la estructura del genoma de un retrovirus.
CAPITULO 19 5/12/06 07:35 Página 261
www.FreeLibros.me

antes de su llegada al núcleo de la célula), y después se desensambla lacápside al llegar a la membrana nuclear. El genoma viral se integra en elgenoma de la célula huésped (integración mediada por la propia integra-sa del virus), y entonces comienza la transcripción a partir del promotorU3 que está en el LTR izquierdo. Se producen distintos tipos de ARNm,fundamentalmente un transcrito que contiene gag y pol y otros transcri-tos que codificarán las proteínas de la envuelta. Los ARNm son exporta-dos al citoplasma y traducidos, dando lugar a poliproteínas gag-pol y alas proteínas de la envuelta. Estas últimas viajan a la membrana celular,mientras que las poliproteínas gag-pol forman nuevas nucleocápsides alunirse a la señal de empaquetamiento de los ARNm positivos. Tras el em-paquetamiento, que tiene lugar en el citoplasma, las cápsides salen de lacélula por gemación, quedando rodeadas de nuevo por una envueltacompuesta por la membrana celular y las glicoproteínas codificadas porel virus que habían llegado anteriormente a la membrana. Las nuevaspartículas retrovirales se activan cuando la proteasa rompe la polipro-teína gag-pol dentro de la propia partícula viral y da lugar a moléculas in-dependientes de proteasa, integrasa y retrotranscriptasa.
a) Es importante señalar que el nucleoide de un oncovirus es incapaz deatravesar la membrana nuclear, por lo que es necesario que la célula su-fra al menos una mitosis para que el genoma viral entre en contacto conel genoma de la célula huésped. En cambio, los retrovirus de la familia delos lentivirus sí que pueden atravesar la membrana nuclear, por lo quepueden infectar células que no están en división. Esta es una propiedadmuy importante a la hora de valorar las posibles aplicaciones de estos ti-pos de vectores.
a) Para generar un retrovirus recombinante defectivo, es necesario susti-tuir los genes de las proteínas virales por el gen terapéutico que se quie-re utilizar. Lógicamente, para producir estos virus defectivos debemosusar una línea célular (célula empaquetadora) que aporte los genes vira-les en trans. Estas células empaquetadoras tienen los genes virales in-sertados en el genoma celular, de modo que expresan establemente lasproteínas virales. Sin embargo, las copias de los genes virales que estánintegradas en el genoma celular carecen de la señal de empaquetamien-to, por lo que sus transcritos no pueden empaquetarse en las nuevas par-tículas virales. De este modo, una célula empaquetadora en condicionesnormales no produce viriones completos, sino sólo partículas vacías. Encambio, cuando transfectamos estas células con un plásmido recombi-nante que contenga el ADN terapéutico flanqueado por los LTR y por laseñal de empaquetamiento (además de otros elementos necesarios en ciscomo el primer binding site, y el tracto polipurínico necesario para la sín-tesis de la segunda cadena) se generarán partículas retrovirales recombi-nantes y defectivas, que pueden ser purificadas y concentradas a partir delos sobrenadantes del cultivo celular. En este proceso es muy importanteevitar la aparición de retrovirus con capacidad replicativa, que podríangenerarse por recombinación homóloga entre las secuencias virales que
262
Terapia génica
CAPITULO 19 5/12/06 07:35 Página 262
www.FreeLibros.me

están presentes en nuestro plásmido con las secuencias virales presentesen el genoma de la célula empaquetadora. Por este motivo, se utilizan cé-lulas empaquetadoras que tienen los genes virales separados entre sí, demodo que serían necesarias varias recombinaciones independientes paragenerar un virus replicativo, algo altamente improbable.
El vídeo de la Figura 19.4 explica el ciclo replicativo de los retrovirus y el proceso de generación deretrovirus defectivos recombinantes.
a) Los retrovirus recombinantes defectivos han sido muy utilizados en tera-pia génica. Por las limitaciones propias del tamaño del genoma viral, elADN terapéutico no puede ser mayor a 7-8 kb. Son vectores con buenainfectividad, un tropismo amplio, pero son bastante lábiles (lo que difi-culta su purificación) y sólo transducen eficazmente células que están endivisión. Además, son inactivados en el torrente sanguíneo por el sistemadel complemento, por lo que su principal uso ha estado reservado a es-trategias de terapia génica ex vivo. Su capacidad integrativa les permitealcanzar, en teoría, una duración muy larga de la expresión incluso en cé-lulas que estén dividiéndose activamente. Sin embargo, los promotoresvirales suelen silenciarse por metilación, por lo que la expresión no es tanprolongada como cabría esperar. Se está investigando la posibilidad demodificar el tropismo de estos vectores, mediante la creación de proteí-nas de la envuelta quiméricas que incluyan algún scFv (anticuerpo mo-nocatenario) u otros ligandos de receptores celulares conocidos.
a) Como se ha mencionado, recientemente se han desarrollado vectores re-trovirales basados en lentivirus, aprovechando la circunstancia de que elHIV-1 es uno de los virus mejor estudiados. El genoma de este virus con-tiene algunos genes (tat y rev, por ejemplo) que no están presentes en losoncoretrovirus y que son esenciales para la expresión de los genes virales.Algunas de las proteínas virales tienen señales de localización nuclear yfacilitan la entrada del virus por los poros nucleares, de ahí la capacidadque tienen estos virus de infectar células que no están en división. Aun-que los problemas de seguridad de los lentivirus están prácticamente su-perados, todavía hay que mejorar los sistemas de producción para poderutilizarlos en pacientes con total seguridad. Su principal aplicación está enla transferencia de genes a células del sistema nervioso in vivo, y a proge-nitores hematopoyéticos ex vivo, siendo esta última una propiedad espe-cialmente interesante por su inmenso potencial terapéutico, y porque es-tas células son prácticamente intransfectables por otros medios.
b) Vectores adenovirales. Se conocen gran cantidad de serotipos de adeno-virus humanos, pero los más utilizados en terapia génica han sido los se-rotipos 2 y 5. Los adenovirus son virus ADN sin envuelta, responsablesde las principales enfermedades de vías respiratorias altas (el «catarro»común), con muy buen tropismo por células humanas. La nucleocápsidede un adenovirus consta de una cápside icosaédrica que está compuestapor 720 proteínas hexona y 60 proteínas pentona. De las pentonas parte
263
Tipos de vectores y su utilización en distintas estrategiasde transferencia génica
CAPITULO 19 5/12/06 07:35 Página 263
www.FreeLibros.me

la proteína de la fibra (una proteína trimérica) que termina en una pro-teína «botón» (knob) mediante la cual el adenovirus se une a receptorescelulares específicos.
a) El genoma adenoviral es un ADN de doble cadena de aproximadamente35 kb de tamaño, flanqueado por repeticiones terminales invertidas(ITR) de 100-140 nucleótidos y una señal de empaquetamiento (psi) cer-ca del ITR izquierdo. Contiene gran cantidad de genes, que se agrupan enregiones tempranas (early) y tardías (late), según el momento en que setranscriben después de la infección. Así, las regiones tardías se transcri-ben tras la replicación del genoma viral, y contienen los genes que codi-fican las proteínas estructurales del virus. En cambio, las regiones tem-pranas se transcriben antes de la síntesis del ADN viral, y cumplen variasfunciones:
• Las proteínas codificadas en E1 incluyen, por ejemplo, E1A (proteí-na necesaria para transactivar la transcripción de los demás genes vi-rales) y E1B 55kd (que se une a E4). Además, estas proteínas inter-fieren con las funciones de la célula huésped: E1A es unaoncoproteína, E1B 19kd inhibe la apoptosis mediada por p53 y E1B55kd promueve la degradación de p53.
• La región E2 codifica proteínas necesarias para la replicación viral:ADN polimerasa, proteína terminal, etc.
• La región E3 codifica algunas proteínas que ayudan al adenovirus aescapar al sistema immune, como la proteína gp19kd que inhibe lapresentación de fragmentos antigénicos con moléculas de clase II delComplejo Mayor de Histocompatibilidad.
• La región E4 codifica diversas proteínas que silencian genes endóge-nos, regulando el transporte de ARN mensajeros fuera del núcleo.
b) El ciclo replicativo de un adenovirus es más sencillo que el de los retro-virus. El adenovirus se une a un receptor de membrana específico deno-minado CAR (CoxackieAdenovirusReceptor) mediante el botón de la fi-bra, y a continuación la pentona se une por un motivo RGD(arginina-glicina-aspártico) a integrinas cercanas para después ser inter-nalizado por endocitosis. La propia cápside adenoviral es capaz de de-sestabilizar el endosoma, que se rompe y libera las partículas virales al ci-toplasma. Las nucleocápsides llegan a la membrana nuclear y soncapaces de introducir el genoma viral a través de los poros nucleares.
b) Para generar adenovirus recombinantes defectivos (es decir, que llevenel ADN terapéutico pero no puedan replicarse) se sigue una estrategia si-milar a la que veíamos para los retrovirus: substituir algún gen viral porel gen terapéutico. Lo más habitual es delecionar el genoma viral en laregión E1, para lo que necesitaremos una célula empaquetadora que ex-prese de manera estable los genes contenidos en esa región. La línea ce-lular más utilizada como célula empaquetadora para construir adenovi-rus recombinantes se denomina célula 293. Para conseguir el adenovirusrecombinante, se cotransfectan células 293 con dos plásmidos distintos:
264
Terapia génica
CAPITULO 19 5/12/06 07:35 Página 264
www.FreeLibros.me

un plásmido en el que el gen terapéutico está flanqueado por parte delgen E1, la señal de empaquetamiento y los ITR virales, y otro plásmidoque contiene todo el genoma viral excepto la señal de empaquetamientoy la región de E1 que está presente en trans en el genoma de las células293. Una vez dentro de la célula, los mecanismos de recombinación soncapaces de generar un genoma viral recombinante que llevará el gen te-rapéutico dentro del genoma viral (al que le falta E1). Como el gen tera-péutico va unido a la señal de empaquetamiento PSI, únicamente estostranscritos se empaquetarán correctamente en las nuevas cápsides vira-les, mientras que los genomas virales producidos endógenamente carecende la señal PSI y por tanto no producen viriones infectivos. Los adeno-virus delecionados en E1 permiten insertar genes terapéuticos con un ta-maño máximo de 5 kb, por lo que posteriormente se han generado vec-tores que llevan además deleciones en E3 y E4, para conseguir llegar auna capacidad de 7-8 kb. La última generación de vectores adenoviralesconsiste en los llamados adenovirus gutless (vacíos), en los que todo elgenoma viral ha sido delecionado y por tanto tienen una capacidad teó-rica en torno a las 30 kb de ADN exógeno. Para producirlos hay queaportar en trans todas las funciones adenovirales necesarias, medianteplásmidos helper o por estrategias que utilizan el sistema Cre/loxP.
La Figura 19.5 muestra la estructura del genoma de un adenovirus y de una partícula adenoviral,así como el proceso general de producción de adenovirus recombinantes defectivos.
b) Los adenovirus comenzaron a usarse en terapia génica más tarde que losretrovirus, pero rápidamente ganaron en popularidad y hoy en día sonlos vectores más utilizados para aplicaciones in vivo. Infectan gran va-riedad de células, son relativamente estables y fáciles de purificar y con-centrar, y son eficaces tanto sobre células quiescentes como sobre célu-las en división. Como el genoma del vector no se integra en el genoma dela célula huésped, la duración de la expresión en células en división es li-mitada. Su principal inconveniente es la toxicidad que producen a dosisaltas, y la fuerte respuesta inmune celular y humoral que sigue a su ad-ministración, con la consiguiente disminución de eficacia terapéutica.Los nuevos vectores adenovirales «vacíos» superan algunos de estos in-convenientes.
c) Vectores Virales Adenoasociados. Se trata de Parvovirus que infectan alhombre pero no son patógenos. Pertenecen al grupo de los Dependovi-rus, virus ADN sin envuelta que necesitan de funciones helper para com-pletar su ciclo replicativo completo. Estas funciones helper las aporta unadenovirus o un herpesvirus que sobreinfecta las mismas células que pre-viamente habían sido infectadas por un dependovirus. El genoma de unvirus adenoasociado es un ADN monocatenario con un tamaño de 4,8kb y una estructura muy simple, con dos regiones codificantes: cap, quecodifica las tres proteínas de la cápside, y rep, que codifica cuatro proteí-nas necesarias para la replicación viral. El genoma está flanqueado por
265
Tipos de vectores y su utilización en distintas estrategiasde transferencia génica
CAPITULO 19 5/12/06 07:35 Página 265
www.FreeLibros.me

dos repeticiones terminales invertidas (ITR), que forman unas estructurasen horquilla y que son los únicos elementos necesarios en cis para poderllevar a cabo el ciclo vital del virus.
b) La infección por un virus adenoasociado comienza por la unión del vi-rus a receptores celulares y su entrada en la célula. El genoma viral es ca-paz de entrar en el núcleo incluso en células que no se dividen, y una vezallí se convierte a doble hebra y se integra en un locus específico locali-zado en el brazo largo del cromosoma 19 humano (banda 19q13). Todasestas funciones están mediadas por proteínas de la célula huésped, peroademás se ha comprobado que las proteínas virales Rep78/68 son nece-sarias para la integración específica del genoma viral en una secuenciallamada AAVS1 que está en 19q13. En ausencia de funciones helper, elgenoma viral integrado permanecerá como un provirus, en forma laten-te. Ante una sobreinfección por adenovirus o herpesvirus, el adenoaso-ciado comienza su fase lítica con la transcripción de los genes virales, lareplicación del genoma viral y el empaquetamiento en las cápsides paradar lugar a nuevos viriones.
b) Para obtener virus adenoasociados recombinantes como vectores en te-rapia génica, se construye un plásmido recombinante que contiene el genterapéutico flanqueado por los ITR virales. En el método clásico de pro-ducción de estos vectores, se cotransfectan células 293 con el plásmidorecombinante y con otro plásmido que aporta en trans las funciones capy rep, y después se infectan esas mismas células con un adenovirus. Elproblema de este procedimiento es que los preparados virales tienen unafuerte contaminación por adenovirus, por lo que es necesario inactivareste adenovirus contaminante mediante tratamiento con calor. Los mé-todos actuales de producción evitan este problema al aportar las funcio-nes helper del adenovirus en un tercer plásmido que se cotransfecta conlos otros dos, de forma que la generación de adenovirus maduros es prác-ticamente imposible.
b) Los vectores adenoasociados están ganando popularidad rápidamente porsus extraordinarias características: buena infectividad, integración en elgenoma de la célula huésped, muy baja toxicidad y ausencia de respuestainmune celular frente a las proteínas virales. Por desgracia, la especifici-dad de la integración en un locus concreto se pierde en los virus adenoa-sociados recombinantes, ya que no se produce Rep68/78 (que es absolu-tamente necesaria para que tenga lugar esta integración específica). Enconsecuencia, la integración se realiza al azar, como en el caso de los re-trovirus. Los virus adenoasociados pueden transducir células mitóticas océlulas en división, y están especialmente indicados en aplicaciones invivo en las que se requiere una expresión prolongada del gen terapéutico.
d) Otros vectores virales que actualmente están ganado en popularidad sonlos Herpesvirus, basados en el virus del herpes simplex (HSV), que tienenun marcado tropismo neuronal y por eso se emplean fundamentalmentepara la transferencia de genes al sistema nervioso. Los HSV son virus en-vueltos con un genoma lineal de 152 kb de ADN bicatenario, en el que se
266
Terapia génica
CAPITULO 19 5/12/06 07:35 Página 266
www.FreeLibros.me
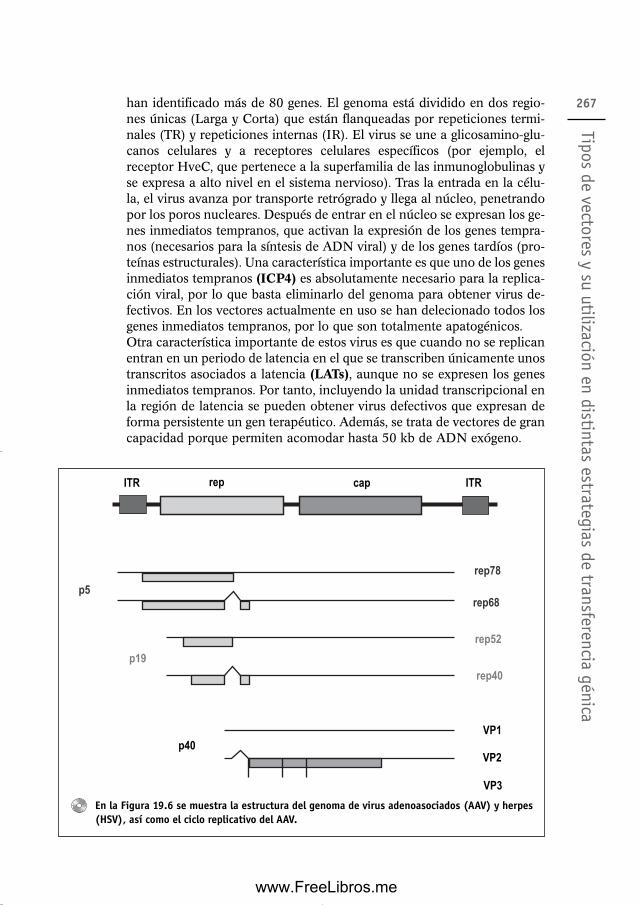
han identificado más de 80 genes. El genoma está dividido en dos regio-nes únicas (Larga y Corta) que están flanqueadas por repeticiones termi-nales (TR) y repeticiones internas (IR). El virus se une a glicosamino-glu-canos celulares y a receptores celulares específicos (por ejemplo, elreceptor HveC, que pertenece a la superfamilia de las inmunoglobulinas yse expresa a alto nivel en el sistema nervioso). Tras la entrada en la célu-la, el virus avanza por transporte retrógrado y llega al núcleo, penetrandopor los poros nucleares. Después de entrar en el núcleo se expresan los ge-nes inmediatos tempranos, que activan la expresión de los genes tempra-nos (necesarios para la síntesis de ADN viral) y de los genes tardíos (pro-teínas estructurales). Una característica importante es que uno de los genesinmediatos tempranos (ICP4) es absolutamente necesario para la replica-ción viral, por lo que basta eliminarlo del genoma para obtener virus de-fectivos. En los vectores actualmente en uso se han delecionado todos losgenes inmediatos tempranos, por lo que son totalmente apatogénicos.
b) Otra característica importante de estos virus es que cuando no se replicanentran en un periodo de latencia en el que se transcriben únicamente unostranscritos asociados a latencia (LATs), aunque no se expresen los genesinmediatos tempranos. Por tanto, incluyendo la unidad transcripcional enla región de latencia se pueden obtener virus defectivos que expresan deforma persistente un gen terapéutico. Además, se trata de vectores de grancapacidad porque permiten acomodar hasta 50 kb de ADN exógeno.
267
Tipos de vectores y su utilización en distintas estrategiasde transferencia génica
ITR ITR
p5
p19
rep78
rep68
rep52
rep40
VP1
VP2
VP3
p40
rep cap
En la Figura 19.6 se muestra la estructura del genoma de virus adenoasociados (AAV) y herpes(HSV), así como el ciclo replicativo del AAV.
CAPITULO 19 5/12/06 07:35 Página 267
www.FreeLibros.me

2. Los Vectores no-virales representan un intento de imitar las funciones de losvirus como vehículos de transferencia génica mediante sistemas sintéticos, deforma que en principio son vectores mucho más seguros desde el punto devista de su peligrosidad biológica y su patogenicidad. En este sentido, los vec-tores no-virales no se diferencian conceptualmente de los fármacos a los queestamos habituados. La principal limitación de este tipo de vectores es que,en la actualidad, su eficacia in vivo es mucho menor que la de los vectores vi-rales. Esto se debe a la inestabilidad propia de sistemas sintéticos complejosy a las diferentes barreras que han de superar:
• Los complejos entre el ácido nucleico y los demás componentes de es-tos sistemas han de ser estables tras su administración, y no desinte-grarse antes de alcanzar las células. Por otra parte, la biodistribución deestos preparados hace que la concentración efectiva en las células dia-na sea baja, por lo que es importante que lleven en su superficie algúntipo de ligando para receptores específicos de las células a las que loqueremos enviar.
• Habitualmente, estos complejos entran en las células por endocitosis, demanera que quedan expuestos al ataque de las enzimas lisosomales. Paraevitar esto, se intenta incluir en estos vectores algún tipo de molécula quealtere el pH del endosoma y consiga romperlo antes de su fusión con loslisosomas y liberar así el complejo intacto al citoplasma. Estas moléculassuelen ser péptidos o proteínas virales que cumplen esta misma funciónen algunos tipos de virus. Una vez en el citoplasma, estos complejos hande ser lo suficientemente estables como para llegar hasta el núcleo, puessi el ácido nucleico se libera muy pronto será degradado por nucleasas ci-toplasmáticas. Pero si son demasiado estables, el ácido nucleico no con-seguirá liberarse y por tanto no podrá entrar en el núcleo de la célula.Este compromiso entre protección y liberación es quizás uno de los retosmás importantes que tienen que superar los vectores no virales para au-mentar su eficacia actual.
• En cierta medida, la inclusión en estos complejos de alguna molécula ca-paz de dirigirlos al núcleo celular serviría para acelerar su tránsito cito-plasmático. Por tanto, otro componente habitual en los vectores no vira-les son las moléculas con señales de localización nuclear que ademáspermitan la entrada del ácido nucleico a través del complejo del poro nu-clear, pues de lo contrario sólo serán efectivos en células que estén en mi-tosis.
Como se ve, la tarea de construir un vector no-viral «ideal» equivale a intentar re-construir en el laboratorio lo que los virus consiguen de manera natural, lo cual noes en absoluto sencillo. En cualquier caso, son uno de los campos de investigaciónmás activa, sobre todo por parte de empresas farmacéuticas y de biotecnología, y esprevisible que los próximos años vean avances significativos en este terreno. Actual-mente, los vectores no-virales más utilizados son los siguientes:
a) Inyección Directa. Lógicamente, lo más sencillo es injectar directamente elácido nucleico (ADN desnudo) en el órgano de interés. Aunque poco eficaz,
268
Terapia génica
CAPITULO 19 5/12/06 07:35 Página 268
www.FreeLibros.me

este procedimiento funciona razonablemente en ciertas aplicaciones y en al-gunos órganos. Por ejemplo, el músculo esquelético es uno de los órganosque más eficazmente incorporan un plásmido inyectado, alcanzando nivelesde expresión suficientes para conseguir inmunización frente a proteínas vi-rales, tumorales, etc. En ocasiones se utiliza la inyección de ADN formula-do con diversos polímeros (sobre todo poli-vinil-pirrolidona) que lo prote-gen de la acción de las nucleasas y prolongan su vida media tras laadministración. También se utiliza el ADN encapsulado en microesferas depolímeros biodegradables (por ejemplo, copolímeros de ácido láctico y gli-cólico), que pueden inyectarse en un órgano y proporcionar liberación sos-tenida del ácido nucleico terapéutico durante un periodo de tiempo más omenos prolongado, dependiendo del tipo de polímero utilizado. Otra varie-dad es la transferencia génica balística (pistola génica o «gene gun»), en laque el ácido nucleico terapéutico se adsorbe sobre la superficie de una bo-las microscópicas de oro u otro metal inerte, que son disparadas a presiónsobre el órgano diana. Es una vía de administración utilizada en la piel (parainmunización génica) o a veces sobre otros órganos, pero las bolas no tie-nen un gran poder de penetración (raramente superior a unos pocos milí-metros).
b) Complejos formados por el ácido nucleico terapéutico y otros componentes.Son los sistemas más complicados de elaborar y optimizar, pero los más efi-caces dentro de los vectores no-virales. El principio que subyace a todos lossistemas de este tipo es la complejación del ADN (molécula grande con altonúmero de cargas negativas) con polímeros de naturaleza catiónica (concargas positivas), de manera que la neutralización de cargas da lugar a com-plejos más o menos estables, de pequeño tamaño, en los que el ADN estáprotegido de la acción de nucleasas. Suele distinguirse entre lipoplexos(cuando el ADN se compleja con lípidos catiónicos) y poliplexos (ADNcomplejado por policationes, habitualmente poli-lisina o poli-etilén-imina).Sobre la estructura básica de un lipoplexo o un poliplexo pueden añadirseotro tipo de moléculas que actúen como estabilizadores, ligandos para re-ceptores específicos, moléculas desestabilizadoras del endosoma, señales delocalización nuclear. Por ejemplo, se ha utilizado poli-etilén-glicol para au-mentar la estabilidad de lipoplexos en el torrente sanguíneo y evitar la inac-tivación por el suero. Asimismo, ha sido muy utilizada la unión de poli-lisi-na a transferrina o a orosomucoide, para conseguir unión específica areceptores hepáticos. Otra estrategia utilizada con bastante éxito ha sido laformación de lipoplexos que además incluyen partículas del virus hemaglu-tinante del Japón (virus Sendai) inactivados, lo que proporciona una entra-da en las células muy eficaz (por la fusogenicidad del virus Sendai) y buenescape endosomal.
En la Figura 19.7 se muestran algunos ejemplos de vectores no virales.
La siguiente tabla resume las principales características de los vectores que se hanmencionado:
269
Tipos de vectores y su utilización en distintas estrategiasde transferencia génica
CAPITULO 19 5/12/06 07:35 Página 269
www.FreeLibros.me
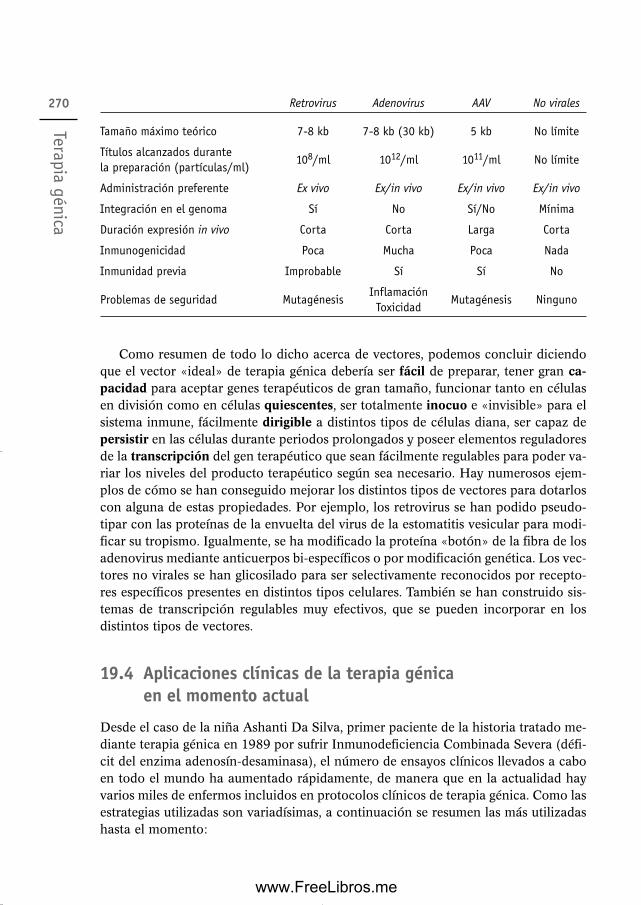
Retrovirus Adenovirus AAV No virales
Tamaño máximo teórico 7-8 kb 7-8 kb (30 kb) 5 kb No límite
Títulos alcanzados durante108/ml 1012/ml 1011/ml No límite
la preparación (partículas/ml)
Administración preferente Ex vivo Ex/in vivo Ex/in vivo Ex/in vivo
Integración en el genoma Sí No Sí/No Mínima
Duración expresión in vivo Corta Corta Larga Corta
Inmunogenicidad Poca Mucha Poca Nada
Inmunidad previa Improbable Sí Sí No
InflamaciónProblemas de seguridad Mutagénesis Mutagénesis Ninguno
Toxicidad
Como resumen de todo lo dicho acerca de vectores, podemos concluir diciendoque el vector «ideal» de terapia génica debería ser fácil de preparar, tener gran ca-pacidad para aceptar genes terapéuticos de gran tamaño, funcionar tanto en célulasen división como en células quiescentes, ser totalmente inocuo e «invisible» para elsistema inmune, fácilmente dirigible a distintos tipos de células diana, ser capaz depersistir en las células durante periodos prolongados y poseer elementos reguladoresde la transcripción del gen terapéutico que sean fácilmente regulables para poder va-riar los niveles del producto terapéutico según sea necesario. Hay numerosos ejem-plos de cómo se han conseguido mejorar los distintos tipos de vectores para dotarloscon alguna de estas propiedades. Por ejemplo, los retrovirus se han podido pseudo-tipar con las proteínas de la envuelta del virus de la estomatitis vesicular para modi-ficar su tropismo. Igualmente, se ha modificado la proteína «botón» de la fibra de losadenovirus mediante anticuerpos bi-específicos o por modificación genética. Los vec-tores no virales se han glicosilado para ser selectivamente reconocidos por recepto-res específicos presentes en distintos tipos celulares. También se han construido sis-temas de transcripción regulables muy efectivos, que se pueden incorporar en losdistintos tipos de vectores.
19.4 Aplicaciones clínicas de la terapia génica 19.4 en el momento actual
Desde el caso de la niña Ashanti Da Silva, primer paciente de la historia tratado me-diante terapia génica en 1989 por sufrir Inmunodeficiencia Combinada Severa (défi-cit del enzima adenosín-desaminasa), el número de ensayos clínicos llevados a caboen todo el mundo ha aumentado rápidamente, de manera que en la actualidad hayvarios miles de enfermos incluidos en protocolos clínicos de terapia génica. Como lasestrategias utilizadas son variadísimas, a continuación se resumen las más utilizadashasta el momento:
270
Terapia génica
CAPITULO 19 5/12/06 07:35 Página 270
www.FreeLibros.me

Terapia génica del cáncer: la estrategia más utilizada es, sin duda, la utilización delos llamados genes suicidas. Se trata de transferir a las células tumorales un gen quecodifique una proteína capaz de activar un pro-fármaco inactivo a su forma activa. Esmuy popular la utilización del gen de la timidín-kinasa del virus del Herpes Simplex(HSV-tk), que codifica una timidín-kinasa capaz de fosforilar el ganciclovir a ganci-clovir-trifosfato. El ganciclovir tri-fosfato es la forma activa capaz de interferir con lareplicación del ADN y provocar la muerte de las células que están dividiéndose acti-vamente. Por tanto, si somos capaces de transferir el gen de la HSV-tk a las células deun tumor, que tienen una alta tasa replicativa, la administración sistémica de ganci-clovir conseguirá matar selectivamente las células tumorales. Una ventaja añadida esel llamado efecto espectador (bystander), mediante el cual la timidín-kinasa produci-da en unas células puede pasar a las células vecinas, de forma que aunque no todaslas células tumorales hayan incorporado el gen terapéutico, el efecto citotóxico es bas-tante homogéneo en todo el tumor. Esta estrategia se ha empleado en tumores cere-brales, usando vectores retrovirales para transducir sólo células tumorales (en divi-sión) pero no neuronas (que no se dividen). También se ha empleado con éxito entumores hepáticos, usando en este caso vectores adenovirales.
Otra estrategia utilizada en terapia génica del cáncer se basa en la suplementa-ción de las células malignas con genes supresores tumorales (p53, por ejemplo). Seha utilizado también la transferencia al tumor de genes que inhiben la angiogénesis(endostatina, angiostatina, etc.) para eliminar el tumor por falta de aporte vascular.Por último, una de las estrategias que han tenido más éxito y que ofrecen mejoresperspectivas de futuro es la inmunopotenciación, es decir, favorecer la puesta enmarcha de una respuesta inmune frente a las células tumorales. En este sentido, sehan transferido los genes de gran variedad de citoquinas o moléculas inmunopoten-ciadoras (IL-2, IL-12, GM-CSF, IFN-γ, TNFα, etc.) tanto a células tumorales como acélulas presentadoras de antígeno (células dendríticas), o bien se han transferido alas células tumorales los genes de moléculas co-estimuladoreas del complejo mayorde histocompatibildad (por ejemplo, B7.1) para favorecer la presentación de los an-tígenos tumorales.
El vídeo de la Figura 19.8 muestra algunos ejemplos de utilización de terapia génica frente alcáncer.
Terapia génica de enfermedades hereditarias: la mayoría de las enfermedadesmetabólicas debidas a mutaciones inactivantes en genes que codifican proteínas conactividad biológica (un enzima, un factor de coagulación, una hormona, etc.) puedenabordarse mediante una estrategia de suplementación génica que restaure los nivelesde la proteína deficiente. Por ejemplo, se ha utilizado la transferencia génica almúsculo para conseguir la producción local de distrofina en casos de distrofia mus-cular de Duchenne. De manera similar, se han transferido genes al músculo o al hí-gado para que estos órganos secreten al torrente circulatorio un factor que está au-sente. En este sentido, ha tenido especial resonancia el éxito alcanzado con latransferencia mediada por virus adenoasociados del gen del factor IX de la coagula-ción al músculo esquelético, para producir niveles plasmáticos de este factor que pue-dan corregir los defectos en la coagulación que sufren animales hemofílicos.
271
Aplicaciones clínicas de la terapia génicaen el m
omento actual
CAPITULO 19 5/12/06 07:35 Página 271
www.FreeLibros.me

Inmunización frente a enfermedades infecciosas mediante transferencia génica,con el fin de que las células sinteticen péptidos inmunogénicos y estimulen al siste-ma inmune hasta eliminar el agente patógeno. Se están ensayando inmunizacionesgénicas frente a virus (virus B y virus C de la hepatitis, virus de la gripe) u otros agen-tes, como el parásito de la malaria. Es bastante eficaz la injección directa de un plás-mido en músculo o la transferencia intradérmica mediante pistola génica. En gene-ral, la eficacia de estos tratamientos reside en la capacidad de producir localmenteuna proteína que sea liberada y capturada por macrófagos y otras células presenta-doras de antígenos, que procesan esas proteínas a pequeños péptidos y los presentancon moléculas de clase II del sistema mayor de histocompatibilidad (MHC) para es-timular las células CD4+ (linfocitos T helper). Además, si las células transfectadas ex-presan moléculas de clase I del MHC también podrán presentar los péptidos reciénsintetizados y estimular células CD8+ (linfocitos T citotóxicos).
Una de las asignaturas pendientes de la terapia génica es la demostración de suutilidad clínica en humanos. En enero de 2006, el número de ensayos clínicos queincluían transferencia de genes ascendía a 1 145 en todo el mundo. El 80 por cientode estos estudios son ensayos clínicos en fase I (estudio de toxicidad) o fase I/II, elresto son ensayos en fase II (estudio de eficacia terapéutica) o en fase III. Estos da-tos se resumen a continuación:
Ensayos clínicos en enero de 2006: 1 145 en total
Distribuidos por el tipo de enfermedad:Cáncer: 67 %Monogénicas: 9%Marcaje: 4%Infecciosas: 7%Vasculares: 9%
Distribuidos por el tipo de vector utilizado:Retrovirus: 24 %Lipofección: 8%Adenovirus: 25%DNA desnudo: 17%HSV: 3%Virus adenoasociados: 3%
Distribuidos por el tipo de gen terapéutico:Citoquinas: 26 %Antígenos: 15 %Genes suicidas: 7 %Proteínas deficientes: 6 %Genes supresores tumorales: 12 %Genes antisentido y ribozimas: 1 %Receptores: 4 %
272
Terapia génica
CAPITULO 19 5/12/06 07:35 Página 272
www.FreeLibros.me

C A P Í T U L O 2 0
Bioinformática del genomahumano
Contenidos
20.1 La Bioinformática
20.2 Bases de datos en Genética Humana: bases de datos de secuencias
20.3 Bases de datos en Genética Humana: bases de datos relacionadas con enfermedades
20.4 Búsquedas en bases de datos con BLAST
20.5 Navegadores del genoma humano
20.1 La Bioinformática
Tradicionalmente, la investigación en Biología Molecular se ha realizado en el laborato-rio experimental, pero la inmensa cantidad de datos generados en los últimos años hapropiciado el desarrollo de herramientas computacionales para extraer, organizar y ana-lizar toda la información contenida en esos datos y así poder generar nuevo conoci-miento. Por eso, hoy en día es difícil entender la investigación en biología sin la utiliza-ción de herramientas informáticas más o menos sofisticadas.
La Bioinformática es la disciplina científica que combina biología, computación ytecnologías de la información. El objetivo de esta disciplina es facilitar nuevas percep-ciones biológicas y crear una perspectiva global que permita identificar los principiosunificadores de la biología. Inicialmente, la Bioinformática se ocupaba sobre todo de lacreación de bases de datos de información biológica, especialmente secuencias de nu-cleótidos y de proteínas, y del desarrollo de herramientas para la utilización y análisis delos datos contenidos en esas bases de datos. Sin embargo, cada vez es más claro que seránecesario unificar toda esta información si queremos alcanzar un cuadro completo de labiología de la célula, de forma que los investigadores puedan comprender cómo se alte-ran estos procesos en las distintas enfermedades. Por eso, la Bioinformática ha ido evo-
CAPITULO 20 5/12/06 07:37 Página 273
www.FreeLibros.me

lucionando para ocuparse cada vez con mayor profundidad del análisis e interpeta-ción de los distintos tipos de datos que se generan hoy en día (secuencias de geno-mas, proteomas, orfeomas, dominios y estructuras de proteínas, etc.). Estas formas deanálisis e interpretación de datos suelen denominarse Biología Computacional. Lasprincipales áreas de la Bioinformática y de la Biología Computacional son, por tan-to, 1) el desarrollo de herramientas que permitan el acceso, uso y actualización dedistintos tipos de información biológica; 2) el desarrollo de nuevos algoritmos y so-luciones estadísticas para analizar grandes conjuntos de datos y resolver problemasbiológicos complejos, tales como predecir la estructura de un gen en una secuenciagenómica, predecir la estructura de proteínas, identificar familias de proteínas a par-tir de sus secuencias, etc.
En este capítulo nos centraremos únicamente en algunas herramientas necesariaspara explorar el genoma humano desde el punto de vista biomédico, pero es impor-tante tener en cuenta que existen muchas otras áreas de la Bioinformática que no setocarán aquí.
La Figura 20.1 enlaza con algunos recursos educativos en Bioinformática.
20.2 Bases de datos en Genética Humana: bases de datos20.2 de secuencias
Las bases de datos biológicas son archivos de datos almacenados de modo eficaz yuniforme. Los datos provienen de las distintas áreas de la Biología Molecular. Las ba-ses de dados primarias contienen secuencias de ADN y de proteínas, estructuras deproteínas o perfiles de expresión de genes y proteínas. Cada registro de estas basesde datos contiene una secuencia y su correpondiente «anotación» (comentarios queincluyen información acerca de esa secuencia, habitualmente hechos de modo ma-nual por algún investigador). Las bases de datos secundarias archivan los datos queson fruto del análisis de las bases de datos primarias; por ejemplo, son bases de da-tos secundarias las que contienen familias de proteínas, motivos o dominios protei-cos, familias de genes, etc. Un aspecto crucial en las Bases de Datos es la necesidadde un interfaz que permita interrogar cada base de datos (o, mejor incluso, todas ala vez) de un modo intuitivo y sencillo, de manera que el investigador pueda obteneruna imagen global y completa del proceso biológico que se propone estudiar. Las dosherramientas principales de búsqueda que están disponibles hoy en día son SRS (Se-quence Retrieval System) para las bases de datos mantenidas en Europa por el Insti-tuto Europeo de Bioinformática (EBI, European Bioinformatics Institute en Hinx-ton, Reino Unido) y Entrez para las bases de datos mantenidas por el CentroNacional para la Información en Biotecnología de los Estados Unidos (NCBI, Na-tional Center for Biotechnology Information en Bethesda, Estados Unidos). En gene-ral, estos interfaces permiten extraer información mediante búsquedas por texto, yaque nos ofrecen una página de búsqueda donde introducimos la expresión que que-remos buscar y obtenemos todos los registros que contienen esa expresión en algunode sus campos. Este tipo de búsqueda es rápido y potente, ya que nos permite obte-ner gran cantidad de información (secuencias, descripciones, etc.) sobre una entidadconcreta.
274
Bioinformática del genom
a humano
CAPITULO 20 5/12/06 07:37 Página 274
www.FreeLibros.me

Las tres principales bases de datos primarias de secuencias de nucleótidos sonEMBL-Bank (en el EBI), DDBJ (en el CIB de Mishima, Japón) y GenBank (en elNCBI). Desde hace unos años, estas bases de datos firmaron un convenio de cola-boración por el que constituyeron el INSDC (International Nucleotide SequenceDatabase Collaboration), de modo que se sincronizan entre ellas cada 24 horas ycontienen exactamente la misma información. Además, son accesibles gratuitamen-te por Internet, y contienen todas las secuencias de nucleótidos que son de dominiopúblico. En febrero de 2006 estas bases de datos contenían unos 54 millones de re-gistros, con unos 60 000 millones de nucleótidos en total, y su crecimiento en los úl-timos años ha sido exponencial. Están divididas en varias secciones que reflejan gru-pos taxonómicos, además de otros grupos no taxonómicos como por ejemplo lassecuencias protegidas por patente. En estas bases de datos prima la cantidad sobrela calidad, en el sentido de que contienen todo lo que los investigadores depositanen ellas, y por tanto son bastante heterogéneas en cuanto al tipo de secuencias, sucalidad, su anotación, etc. Por este motivo son también redundantes, ya que la mis-ma secuencia puede encontrarse repetida en distintos registros procedentes de dis-tintos autores. Cada entrada en estas bases de datos es un registro que debe tener unidentificador único, formado por letras y/o números, conocido como «número deacceso» (accession number), que es estable (nunca cambiará en sucesivas versionesde ese registro). Por tanto, otro código indicará las sucesivas versiones de cada nú-mero de acceso, por lo que es importante conocer ambos. En febrero de 1999, el con-sorcio GenBank/Embl/DDBJ acordó un formato de versión consistente en el nú-mero de acceso seguido de un punto y un número. Además, GenBank incluye elindicador «GI».
La Figura 20.2 incluye algunos tutoriales para ilustrar el uso de Entrez y de SRS.
Entrez Gene es otra base de datos del NCBI, que podríamos calificar de secun-daria ya que contiene infromación derivada de GenBank. Se trata de una base de da-tos centrada en genes, más que en secuencias, y por eso reúne todas las secuencias(además de información de otro tipo) sobre un gen concreto, en todos los genomasen los que existen secuencias correspondientes a dicho gen. De hecho, Entrez Genees un interfaz único con gran cantidad de información descriptiva sobre loci genéti-cos (nomenclatura, nombres alternativos, números de acceso de las secuencias, in-formación sobre la posición y enlaces a otros recursos). Entrez Gene se basa en untipo especial de secuencias llamadas RefSeq, generadas por el propio NCBI a partirde secuencias contenidas en GenBank. RefSeq pretende ser una colección integrada,completa y no redundante de secuencias de ADN genómico, ARN y proteínas, paralos principales organismos. El NCBI genera secuencias RefSeq para más de 1 100 vi-rus y 150 bacterias además de organismos superiores (humano, ratón, rata, zebrafish,etc.). Las principales características de la colección RefSeq son la no-redundancia,la conexión entre secuencias nucleotídicas y sus correspondientes secuencias protei-cas, un formato constante, números de acceso específicos y mantenimiento (curationen inglés) a cargo del personal del NCBI y colaboradores externos. Los números deacceso de RefSeq tienen el formato: XX_123456 (dos letras, guión bajo y seis núme-ros). Las dos letras iniciales indican el tipo de secuencia. Por ejemplo, en el caso desecuencias que han sido revisadas manualmente podemos encontrar números de ac-ceso de estos tipos:
275
Bases de datos en Genética Hum
ana: basesde datos
de secuencias
CAPITULO 20 5/12/06 07:37 Página 275
www.FreeLibros.me

NC_123456 Moléculas genómicas completas (genomas, cromosomas, plásmidos)NG_123456 Región genómica incompletaNM_123456 ARN mensajeroNR_123456 ARN no codificante (ribosomal, pseudogenes, etc.)NP_123456 Proteína (en futuras versiones se añadirán dos números más)
En el caso de secuencias que todavía no han sido revisadas por el personal delNCBI, los números de acceso pueden ser:
NT_123456 Secuencias de clones usados para ensamblar genomas (BACs)NW_123456 Ensamblajes parciales de genomas (shotgun)XM_123456 ARN mensajero deducido de las anotaciones del ADN genómicoXR_123456 ARN no codificante deducido de las anotacionesXP_123456 Proteínas deducidas de las anotaciones del ADN genómico
La Figura 20.3 ilustra el uso de Entrez Gene para obtener información y secuencias de referenciade genes completos.
20.3 Bases de datos en Genética Humana: bases de datos20.3 relacionadas con enfermedades
Además de las bases de datos de secuencias, existen también muchos recursos de in-terés en Biomedicina, entre los que destacan las bases de datos relacionadas con en-fermedades. A continuación se describen las tres que pueden ser de más utilidad alestudiante o profesional de una disciplina biomédica, para encontrar información so-bre enfermedades genéticas y las mutaciones que las causan, descripción clínica, gru-pos de apoyo, etc.
Online Mendelian Inheritance in Man (OMIM) es un catálogo de genes y en-fermedades genéticas humanas, centrado especialmente en enfermedades heredita-rias. OMIM se basa en el texto escrito por Victor A. McKusick llamado MendelianInheritance in Man, cuya última edición es de 1998. Cada entrada en OMIM está ca-racterizada por un número de acceso que consiste en un número de seis dígitos; elprimer dígito es indicativo del modo de herencia de ese rasgo o gen. Así, los núme-ros OMIM que comienzan por 1, 2 ó 6 indican loci o fenotipos de herencia autosó-mica, los que empiezan por 3 indican loci o fenotipos de herencia ligada al cromo-soma X, los que empiezan por 4 indican herencia ligada al cromosoma Y y los queempiezan por 5 indican herencia mitocondrial. Además, las variantes alélicas se de-signan por el número OMIM seguido por un punto y un número de cuatro dígitos.Cada número de acceso suele ir precedido por un símbolo, que nos indica algo másacerca de ese locus o fenotipo. Así, un asterisco (*) indica que se trata de un gen cuyasecuencia es conocida; almohadilla (#) indica que es la descripción de un fenotipo,y no representa necesariamente un único locus; el símbolo «más» (+) indica que setrata de la descripción de un fenotipo y de un gen de secuencia conocida; el «tantopor cien» (%) indica que se trata de un fenotipo o locus con herencia mendelianacomprobada, del que se desconoce la base molecular. Cuando no hay ningún símbo-lo, quiere decir que esa entrada no tiene una base mendeliana confirmada, o bien quesu diferenciación de otra entrada en la base de datos no está clara. En ocasiones en-
276
Bioinformática del genom
a humano
CAPITULO 20 5/12/06 07:37 Página 276
www.FreeLibros.me

contraremos un acento circunflejo (^) para indicar que una entrada ha sido elimi-nada de la base de datos.
GeneClinics y GeneTests son una base de datos estadounidense de enfermedadesgenéticas, dirigida a enfermos y personal sanitario, cuyo fin es proporcionar infor-mación sobre análisis genéticos y su uso en el diagnóstico, tratamiento y consejo ge-nético. Contiene un listado de laboratorios de Estados Unidos y del resto del mundodonde se realizan pruebas genéticas diagnósticas y de investigación. Además, tieneun listado de centros donde se realiza consejo genético, una serie de revisiones he-chas por expertos sobre algunas de las enfermedades genéticas más frecuentes, y ma-teriales educativos como un glosario ilustrado de términos genéticos, presentaciones,etc. El equivalente europeo es EDDNAL (European Directory of DNA Laboratories),que contiene información sobre laboratorios de Europa que llevan a cabo pruebasmoleculares diagnósticas para enfermedades genéticas; sin embargo, no contiene unadescripción de las enfermedades ni ofrece apoyo a enfermos y sus familias.
Finalmente, otro tipo de bases de datos de gran importancia en Genética Huma-na son las que reúnen mutaciones que causan enfermedades. Aunque existen muchasbases de datos para genes o enfermedades concretas, Human Gene Mutation Data-base (HGMD) intenta recopilar todas las mutaciones publicadas que causan enfer-medades hereditarias humanas (no incluye, por tanto, mutaciones somáticas ni mu-taciones del genoma mitocondrial). Desde 1999, HGMD también incluyepolimorfismos asociados con enfermedades humanas, extraídos de la literatura cien-tífica. Estos polimorfismos sólo se incluyen si su relación con la enfermedad está de-mostrada de un modo convincente.
En la Figura 20.4 se pueden encontrar enlaces a OMIM, Geneclinics, EDDNAL y HGMD.
20.4 Búsquedas en bases de datos con BLAST
En las bases de datos que contienen secuencias, además de hacer búsquedas por tex-to también es posible interrogar directamente la base de datos con una secuenciaconcreta, con el fin de extraer todas las secuencias parecidas o idénticas que están enla base de datos. De esta forma, es posible conocer la identidad de una secuenciaanónima, bien porque ya está depositada en la base de datos (indicando a qué co-rresponde) o bien por su alto grado de similitud con otras secuencias conocidas. Parahacer este tipo de búsquedas, es necesario comparar directamente nuestra secuencia«pregunta» (query) con cada una de las secuencias de la base de datos, y extraer úni-camente las que superen un cierto grado de parecido. Lógicamente, si buscamos entodo GenBank, por ejemplo, hemos de comparar nuestra secuencia con varios mi-llones de secuencias, lo que podría llevar un tiempo excesivo. Por suerte, disponemosde herramientas bioinformáticas que realizan alineamientos de secuencias de modorápido y eficaz, por lo que una búsqueda típica en GenBank se completa en cuestiónde segundos.
Aunque no podemos entrar aquí en una descripción detallada de cómo funcionanlos algoritmos para alineamientos de secuencias, es importante describir con ciertodetalle el más utilizado hoy en día para búsquedas en bases de datos, que se llamaBLAST (siglas en inglés de Basic Local Alignment Search Tool). BLAST compara se-cuencias de modo «apareado» (pairwise), es decir, de dos en dos, y cada compara-
277
Búsquedas en bases de datos con BLAST
CAPITULO 20 5/12/06 07:37 Página 277
www.FreeLibros.me

ción da como resultado una puntuación (score) que es mayor cuanto mayor es el pa-recido entre las secuencias que se comparan. El algoritmo permite una implementa-ción en programas informáticos de ejecución rápida y al mismo tiempo con alta sen-sibilidad, que se realiza en varios pasos. En primer lugar, el programa rompe nuestrasecuencia «pregunta» (query) en pequeños fragmentos llamados «palabras» (words)y busca todas las palabras de la base de datos que se parezcan a cada una de las pa-labras de nuestra secuencia. Una vez que encuentra alineamientos entre palabras quesuperan una puntuación inicial determinada que viene definida por el parámetro«T», el programa extiende esos alineamientos iniciales en ambas direcciones hastagenerar un alineamiento. La rapidez y sensibilidad de la búsqueda viene determina-da por el parámetro T, mientras que W (el tamaño de palabra) puede ser modificadodependiendo del tipo de secuencias que estemos manejando. Al final, los posibles ali-neamientos se ordenan en función de la puntuación (score) final.
Es importante comprender que la puntuación de un alineamiento se obtiene uti-lizando matrices de substitución, que permiten asignar una puntuación a cada posi-ción del alineamiento. Inicialmente, las matrices se desarrollaron para los alinea-mientos entre secuencias de proteínas, en las que se puede calcular la probabilidadde que un aminoácido concreto (en una de las secuencias) esté substituido por otroaminoácido (en la otra secuencia). Las primeras matrices utilizadas fueron las matri-ces PAM, creadas por Margaret Dayhoff, y están basadas en alineamientos múltiplespara determinar la frecuencia con la que se producen sustituciones de unos ami-noácidos por otros. Examinando alineamientos globales de secuencias muy relacio-nadas y la frecuencia de las distintas sustituciones, Dayhoff construyó las matricesPAM (Point Accepted Mutation), matrices de probabilidad para cada sustitucióndada una distancia evolutiva concreta. De hecho, 1 PAM representa la matriz de sus-tituciones para una distancia evolutiva tal que han cambiado el uno por ciento de losaminoácidos. La matriz PAM más utilizada es la PAM250, que corresponde a unadistancia evolutiva tal que ha cambiado el 80 por ciento de los aminoácidos (aunquela mutabilidad varía para cada aminoácido dentro de una misma matriz). Por tanto,PAM250 es útil para alinear secuencias cuando no sabemos si son homólogas. Si lasimilitud entre las secuencias que queremos alinear es alta, deberemos utilizar otrasmatrices (habitualmente PAM30). Steven y Jorja Henikoff construyeron despuésotro tipo de matrices, llamadas matrices BLOSUM (Blocks Substitution Matrix),usando alineamientos locales múltiples de secuencias más divergentes que en el casode las matrices PAM. Agrupando las secuencias según distintos umbrales de identi-dad de aminoácidos obtuvieron distintas matrices: por ejemplo BLOSUM80 se deri-vó de los alineamientos que contenían un 80 por ciento de identidad. Por tanto, seutilizan matrices BLOSUM con valores bajos para secuencias más divergentes (BLO-SUM30) y matrices con valores altos (BLOSUM90) para secuencias muy similares.La más utilizada es BLOSUM62. En cualquier caso, las matrices se utilizan parapuntuar alineamientos de proteínas, mientras que en alineamientos de secuenciasde nucleótidos se utilizan matrices de sustitución unitarias en las que los únicos pa-rámetros importantes son la puntuación que se le asigna a un emparejamiento y lapenalización que se asignan a los desemparejamientos y a los huecos.
La Figura 20.5 muestra las dos matrices de sustitución más utilizadas para calcular la puntuaciónde alineamientos de secuencias.
278
Bioinformática del genom
a humano
CAPITULO 20 5/12/06 07:37 Página 278
www.FreeLibros.me

Para comparar la «calidad» de cada alineamiento, BLAST calcula la probabilidadde encontrar un alineamiento con esa misma puntuación en esa base de datos sim-plemente por azar, y a esa probabilidad le llama valor E (expectation), que es el pa-rámetro que mejor describe la significación de los alineamientos hallados por el pro-grama. En cualquier caso, todo alineamiento debe ser revisado para comprobar queefectivamente tiene relevancia biológica, ya que pequeñas regiones de baja compleji-dad, elementos repetidos, etc., suelen dar puntuaciones altas y significativas y con-fundir el alineamiento verdadero entre dos secuencias. Por esto, es importante utili-zar los filtros que incluye el programa, para eliminar regiones de poco interésbiológico que puedan interferir en la interpretación de los resultados. BLAST se ofre-ce como varios programas distintos, dependiendo del tipo de secuencias que se com-paran; blastn para dos secuencias de nucleótidos, blastp para dos secuencias de pro-teínas, blastx para comparar una secuencia de nucleótidos (traducida) con una basede datos de proteínas, tblastn para comparar una secuencia de proteínas con unabase de datos de nucleótidos (traducida), y tbalstx para comparar una secuencia denucleótidos (traducida) con una base de datos de nucleótidos (traducida).
La Figura 20.6 incluye enlaces a algunos tutoriales para aprender los fundamentos de la utilizaciónde BLAST.
20.5 Navegadores del genoma humano
Con la publicación del primer borrador de la secuencia completa del genoma huma-no en 2003, se desarrollaron varias herramientas informáticas para poder visualizarde modo gráfico la secuencia y todas las anotaciones hechas por distintos investiga-dores (por «anotación» se entiende cualquier elemento que se sitúa sobre la secuen-cia, en una posición concreta: genes, ARNm, SNP, los clones utilizados para la se-cuenciación, repeticiones, etc.). Las tres herramientas que acabaron por imponerse,por ser las de mayor envergadura y facilidad de uso, fueron ENSEMBL, creada porel EBI y el Instituto Sanger de Hinxton (Reino Unido), el Genome Browser de laUniversidad de California en Santa Cruz (Estados Unidos) y el Map Viewer delNCBI (Estados Unidos). Inicialmente, cada uno de estos sitios desarrollaba su pro-pio ensamblaje del genoma humano a partir de los fragmentos depositados en Gen-Bank, y después añadían todas las anotaciones sobre dicho ensamblaje. Regular-mente, cada tres o seis meses, se hacían nuevos ensamblajes incorporando las nuevassecuencias depositadas en GenBank, pero a partir de un momento dado el ensam-blaje pasó a ser realizado únicamente por el NCBI. En el momento de escribir estetexto, el ensamblaje utilizado es el llamado Build 36 del NCBI, correspondiente a la secuencia ya terminada, y realizado en noviembre de 2005. Genome Browser yENSEMBL utilizan este mismo ensamblaje para realizar sus propias anotaciones yhacerlas de dominio público en sus respectivos sitios web.
ENSEMBL y Genome Browser son, por tanto, similares en su concepción y ensu estructura, pero muy distintos en su apariencia y en algunas de las anotaciones queofrecen. En ambos casos, todas las anotaciones están almacenadas como entradas deuna base de datos relacional, que es interrogada utilizando formularios en páginasweb y que dispone la información en modo gráfico con elementos interactivos. Al-gunos aspectos importantes, como la predicción de genes y su estructura (exones,
279
Navegadores del genoma hum
ano
CAPITULO 20 5/12/06 07:37 Página 279
www.FreeLibros.me

transcritos alternativos, etc.) son elaborados siguiendo procesos distintos: por ejem-plo, Genome Browser muestra «Known Genes» (genes conocidos), basados en el ali-neamiento de todas las proteínas contenidas en Uniprot y de todos los ARNm de Ref-Seq sobre la secuencia genómica; ENSEMBL, por el contrario, genera sus propiosgenes utilizando un proceso similar pero totalmente automático. Otras anotacionesson idénticas, ya que ambos sistemas usan el mismo procedimiento. Por ejemplo,para anotar los elementos repetidos tanto ENSEMBL como Genome Browser utili-zan un programa llamado Repeatmasker, que detecta todas las repeticiones conoci-das que están contenidas en una base de datos específica llamada Repbase. Cada unode los sitios tiene también una herramienta de búsqueda rápida que realiza el aline-amiento de una secuencia «pregunta» sobre la secuencia del genoma. Ambos nave-gadores permiten ver a la vez el genoma de otras especies, y contienen infinidad deanotaciones y enlaces con otras bases de datos y con los registros originales de Gen-Bank. Todo estudiante o profesional que necesite explorar el genoma humano y loselementos que contiene debería aprender a manejar con soltura estas herramientas.
En la Figura 20.7 se incluyen tutoriales para utilizar navegadores del genoma humano.
280
Bioinformática del genom
a humano
CAPITULO 20 5/12/06 07:37 Página 280
www.FreeLibros.me

281
Índice analítico
Índice analítico
«chips» de ADN, 4745,X, 1808-oxoguanina, 84
aborto eugénico, 253acéntrico, 186acetilación, 72, 76acondroplasia, 225, 228, 240acrocéntricos, 187activadoresadaptación, 161adenovirus, 263
gutless, 265ADN, 1
codificante, 58, 190desnudo, 268extragénico, 58glicosilasas, 84forma B, 5mitocondrial, 89, 248repetitivo, 59, 62ribosomal, 62, 179satélite, 63, 179
ADNc, 34, 44, 47ADNmt, 67ADN-PK, 88agentes alquilantes, 84agutí, 123, 126
aislador, 73, 216albinismo, 124alelismo múltiple, 121alelo, 81, 97, 119, 120
letal, 123«silvestre», 119idéntico por descendencia, 148, 157
alfa-1 antitripsina, 213alfa-talasemia, 195algoritmos, 274Alu, 63amniocentesis, 253amplificaciones génicas, 213anafase, 24anagénesis, 169andamio, 18androgenonte, 215aneuploidías, 181aneusomías segmentarias, 181, 186Angelmananiridia, 212, 223anotación, 274, 279antennapedia, 223anticipación, 200, 204anticodón, 14antiparalelas, 4apolipoproteína ApoB48, 10apolipoproteína B, 260
21-INDICE ANALÍTICO 5/12/06 07:46 Página 281
www.FreeLibros.me

apoptosis, 66árbol familiar, 238árbol filogenético, 169ARGONAUTA, 259ARMS, 233ARN, 1
mensajero, 5ribosomal, 178transferentes, 14
ARNm antisentido, 259ARNnp, 12Artemis, 88ASO, 233asociación alélica, 147, 149ataxia
de Friedreich, 204espino-cerebelosa, 205
Atrofia MuscularEspinal, 194Espino-Bulbar, 202
ayuste, 192, 204(splicing), 10alternativo, 12
BAC, 35, 54bandas
C, 69, 178G, 177Q, 177R, 69, 178
bases de datos, 274Bateson, 131BER, 84, 89bioinformática, 58, 273biopsia de vellosidades coriónicas, 253bithorax, 223bivalente, 26, 27, 186, 187BLAST, 277BLOSUM, 278brazo
corto, 179largo, 179
BRCA1, 87BRCA2, 87bromodominio, 73
bucle-D, 67burbuja de replicación, 20, 82
cadenaguía, 20retrasada, 20
cajaCAAT, 6GC, 6TATA, 6
cálculo de riesgos, 242, 245, 246, 250caperuza, 9carcinoma medular de tiroides familiar,
226cariotipo, 177, 220CBP, 73, 78, 202, 223cebador, 20, 41, 42, 43, 45cefalopolisindactilia, 223célula empaquetadora, 262centimorgans, 142centro de imprinting, 218, 219centrómeros, 23, 60, 63, 178CFTR, 200, 240CGH, 179Charcot-Marie-Tooth, 208, 214chi-cuadrado, 118, 149ciclo celular, 18cigoteno, 25citogenética, 177
molecular, 40citoquinesis, 18, 24, 27cladogénesis, 169clamp-GC, 229clonación molecular, 33, 35clonaje posicional, 141C-MYC, 213CNP, 62cociente entre heterocigotos y homoci-
gotos, 166código
de Histonas, 73genético, 13, 68
co-dominancia, 120codón de
inicio, 13terminación, 8, 190
282
Índice analítico
21-INDICE ANALÍTICO 5/12/06 07:46 Página 282
www.FreeLibros.me

codones, 13coeficiente de
endogamia, 157selección, 162
cohesinas, 23, 24, 28colágeno, 214colchicina, 178Collins, 174complejo basal de iniciación, 8condensinas, 19consanguinidad, 242, 246consejo genético, 221, 237, 246, 252, 277contigs, 55conversión
génica, 30, 206corpúsculo de Barr, 111cósmidos, 35CPEO, 251creacionismo, 173cremalleras de leucina, 222cresta genital, 110cromátide, 22, 23, 25, 26, 27, 178
hermanas, 206cromatina, 17, 21, 23, 25, 69, 71, 79, 80,
103cromodominio, 74cromosoma, 23, 177, 180
submetacéntrico, 179X, 107, 111, 114Y, 108, 115
cruce trihíbrido, 101cruzamiento
preferencial, 156prueba, 98
CTCF, 216cuadrados de Punnett, 97, 239cuartetos-G, 203
Darwin, 94, 129, 167dedos de zinc, 222deleción, 180, 186, 191, 206, 207, 219,
220, 250depleción del ADNmt, 250depresión endogámica, 157deriva genética, 168
aleatoria, 158, 170
desemparejamiento, 82, 231por deslizamiento de cadenas, 199
desequilibrio de ligamiento, 147, 150desnaturalización, 43DGGE, 229DHPLC, 230diagnóstico, 227, 237, 252
directo, 228genético preimplantatorio, 254indirecto, 235prenatal, 252
diaquinesis, 27dicéntrico, 186Dicer, 61, 259dictioteno, 27diferencial de selección, 136diginia, 181dihibridismo, 124dihíbridos, 99dímeros de pirimidinas, 84dinucleótido CpG, 74, 190diploteno, 26diseño inteligente, 173disgenesia gonadal, 182, 205disomía uniparental, 217, 219, 220dispermia, 181Displasia
campomélica, 212, 224tanatofórica, 225
distrofiafacio-escápulo-humeral, 207, 212miotónica, 203, 204, 205muscular de Becker, 244muscular de Duchenne, 235, 243muscular de Emery-Dreifuss, 208
disyunción, 27DNMT1, 75Dobzhansky, 168dominancia incompleta, 120, 131dot-blot, 233drosopterina, 125DSB, 29, 86duplicación, 180, 206, 207duplicaciones
genómicas, 172segmentarias, 60, 62, 206
283
Índice analítico
21-INDICE ANALÍTICO 5/12/06 07:46 Página 283
www.FreeLibros.me

EBI, 274edición del ARN, 10, 192efecto
de cuello de botella, 159dominante-negativo, 211, 214, 225fundador, 149, 159umbral, 249
efectos dedosis, 120posición, 212
eficacia biológica, 161Ehlers-Danlos, 241electroforesis, 40, 46, 229electroporación, 36elementos ultraconservados, 61elongación, 8, 15EMBL, 275Endogamia, 157enfermedad de
Alzheimer, 192Gaucher, 228Hirschsprung, 226
enfermedadescomplejas, 133multifactoriales, 133por expansión de trinucleótidos, 200
enfisema pulmonar, 213ENSEMBL, 279enzimas de restricción, 35, 37epigenéticas, 71epilepsia mioclónica progresiva, 204epistasia, 125, 126equilibrio
de Hardy-Weinberg, 154, 158polimórfico, 165polimórfico estable, 164puntuado, 171
error de muestreo, 158especiación, 169
alopátrica, 170simpátrica, 170
EST, 57estenosis pilórica, 134estructuras de Holliday, 30eucromatina, 69, 178
euploidías, 181evo-devo, 172evolución, 153, 167exones, 10expresión génica, 5, 71expresividad variable, 242extensión, 43extremos
cohesivos, 38romos, 38
F1, 96F2, 96factor
C de la replicación, 21de crecimiento fibroblástico, 225IX de la coagulación, 200
factoresde transcripción, 6, 221unitarios, 97, 103
fase de ligamiento, 144, 146, 236fase S, 19fenotipo Bombay, 125Fibrosis
del páncreas, 200, 240FISH, 179, 220fitohemaglutinina, 178flujo genético, 160fluorocromo, 46FMR1, 203FMRP, 203fosforilación, 72fracción de recombinación, 141fragmentos de Okazaki, 21frameshift, 191frataxina, 204frecuencia de recombinación, 235frecuencias
alélicas, 154, 159genotípicas, 154
fusióncéntrica, 187no homóloga de extremos, 86, 88
FXTAS, 245
284
Índice analítico
21-INDICE ANALÍTICO 5/12/06 07:46 Página 284
www.FreeLibros.me

gametocitos primarios, 25gametogénesis, 25, 26, 181, 184, 215,
217, 218gametos, 27, 28
recombinantes, 140ganancia de
función, 201, 211sentido, 191
gatas calico, 112gemelos, 137gémulas, 94, 129gen hipostático, 125GenBank, 275gene tracking, 235genes, 97
constitutivos, 70, 75homeobox, 172, 222, 223HOX, 223suicidas, 270
genéticaclínica, 237de poblaciones, 153, 168
genoma mitocondrial, 66Genome Browser, 279genoteca, 34genotipos, 97germoplasma, 102Giemsa, 178ginogenonte, 215gónada primitiva, 110grados de libertad, 119gradualismo, 171
haploide, 22haploinsuficiencia, 211, 213, 223, 224haplotipo, 147, 151HapMap, 61Haseman y Elston, 149HAT, 73HDAC1, 73HDAC2, 73hebra
antisentido, 6codificante, 6molde, 6sentido, 6
Hedgehog, 222helicasas, 20hélice
-lazo-hélice, 222-vuelta-hélice, 222
hemicigosis, 108hemicigotos, 166Hemocromatosis Hereditaria, 149, 228Hemofilia A, 208, 228heredabilidad, 135, 136, 137herencia
autosómica, 239cuasi-dominante, 242ligada al X, 248matrilineal, 249, 250multifactorial, 133poligénica, 132, 133
herpesvirus, 266HERV, 65heterocromatina, 69, 111, 178, 260heterodisomía, 219heterodúplex, 30, 229heterogeneidad
alélica, 227genética, 227, 240
heteroplasmia, 249hibridación, 39, 43, 47, 179Hipercolesterolemia familiar, 239Hiperplasia Suprarrenal Congénita, 206hipótesis 2R, 172hipótesis de Lyon, 112histonas, 18, 72, 73historia familiar, 238hnRNP, 194holoprosencefalia, 222homeodominio, 222, 223homodúplex, 229homoplasmia, 249horquillas de replicación, 20Huntington, 159, 201, 228huso mitótico, 23, 27
Ictiosis, 206idénticos por descendencia, 148imprinting, 215impronta genómica, 77, 215
285
Índice analítico
21-INDICE ANALÍTICO 5/12/06 07:46 Página 285
www.FreeLibros.me

inactivación del cromosoma X, 77, 243índice de heterocigosidad, 142Inestabilidad de Microsatélites, 83informatividad, 142infradominancia, 165Inmunodeficiencia Combinada Severa,
88, 270inmunopotenciación, 271inserción, 180, 191inserto, 34interacción génica, 124interfase, 18, 18interferencia de ARN, 259International System for Cytogenetics
Nomenclature, 178intrones, 10inversión, 180, 185, 206, 208islas CpG, 74isocoro, 59isocromosoma, 180, 183, 186isodisomía, 219isosquizómeros, 37ITR, 264, 266
Johannsen, 130
Kimura, 171Kozak, 14KU70, 88KU80, 88
labio leporino, 134lastre genético, 161LCV, 62lentivirus, 262, 263leptoteno, 25leucemia mieloide crónica, 213ley de Ohno, 114LHON, 251ligamiento, 104, 109
genético, 51, 139, 234no paramétrico, 147
ligasa, 35ligasas, 21likelihood ratio, 145LINE, 63, 113, 205
línea germinal, 177lipoplexos, 269locus, 81, 105LOD score, 144LTR, 65, 261Lyonización, 112
macroevolución, 169macroH2A, 113mapa genético, 140mapas
de ligamiento, 141físicos, 53genéticos, 51
marcadores, 52, 148, 235genéticos, 140
marco de lectura, 191matrices de substitución, 278Máxima Verosimilitud, 144MDB, 76mediador, 9medicina predictiva, 237meiosis, 25, 28, 29, 140, 183, 187, 217MELAS, 251Mendel, 93, 94, 102MERRF, 251metacéntricos, 179metafase, 23, 178, 179metilación, 72, 74, 75, 77, 212, 215, 220,
260metil-transferasas de ADN, 75método ramificado, 98MGMT, 84MHC, 271microARN, 61, 260microarrays, 47, 53microdeleción, 219microevolución, 169microsatélite, 53, 63, 143, 200migración, 160minisatélites, 53, 63mis-sense, 191mitosis, 18, 22, 23, 24MLPA, 234MMR, 82mola hidatidiforme, 215
286
Índice analítico
21-INDICE ANALÍTICO 5/12/06 07:46 Página 286
www.FreeLibros.me

monohíbridos, 95monosomía, 181, 182, 187Morgan, 104, 108, 139mortinatos, 183mosaicos, 180, 181, 182movimiento eugenésico, 130mucoviscidosis, 240mutación, 82, 83, 160, 166, 189, 199,
211puntual, 250sinónima, 191
NARP, 251NCBI, 274NER, 85Neurofibromatosis tipo 1, 242no-disyunción, 183non-sense, 191nucleína, 1nucleósido, 1nucleosoma, 18, 72nucleótido, 1nulisomía, 181número de acceso, 275
octámero, 18, 72Ohno, 172OLA, 233oligonucleótidos antisentido, 259OMIM, 276oncovirus, 262orígenes de replicación, 20
PAC, 35, 54PAM, 278pangénesis, 93, 129paquiteno, 26paracéntricas, 185paradoja de Sherman, 245parálogos, 205PCNA, 21PCR, 41, 229, 232, 233, 250penetrancia incompleta, 241pérdida de función, 203, 211pericéntricas, 185PIC, 142
pintado cromosómico, 179pirimidinas, 1pistola génica, 268placa metafásica, 24plásmidos, 34polidactilia, 222polimerasa de
ADN, 20, 41, 42, 45ARN, 6
polimorfismo, 81, 141de inversión, 209
poliplasmia, 249poliplexos, 269polycomb, 223potenciadores, 6, 9, 11, 80, 194
exónicos del ayuste, 12Prader-Willipreiniciación, 6pre-miARN, 61premutación, 202, 245prevalencia, 165primasa, 20pri-miARN, 61probabilidad, 247
condicional, 247conjunta, 247final, 247inicial, 247
profase, 23promotor, 6proteínas
SR, 12, 194truncadas, 192
ProyectoGenoma, 51, 56, 57Internacional Hapmap, 151
pseudogen, 60, 206PTT, 231punto de ramificación, 11puntuación lod, 145purinas, 1
quiasmas, 27, 30, 184quimeraplastos, 258quinetocoro, 23, 23, 27, 178, 185quistes dermoides, 215
287
Índice analítico
21-INDICE ANALÍTICO 5/12/06 07:46 Página 287
www.FreeLibros.me

RAD50, 29, 84, 87RAD51, 86RAD52, 29, 87radiación UV, 84reacción en cadena de la polimerasa, 41receptor de andrógenos, 214recombinación, 26, 28, 30, 140, 160, 184
homóloga, 29, 86RefSeq, 275región
3’ no traducida, 1905’ no-traducida, 190
regionesno-traducidas, 14pseudoautosómicas, 114
relaciónfenotípica, 97genotípica, 97
reparación, 82acoplada a la transcripción, 85
Repeatmasker, 280replicación, 19, 30, 75, 76, 80, 82repliegue apical ectodérmico, 222retinoblastoma, 167, 242retrotranscripción, 44, 261retrovirus, 261RFLP, 52, 143, 235ribonucleoproteínas nucleares pequeñas,
12ribosoma, 14ribozimas, 259RIDGES, 80riesgo
de recurrencia, 135, 221, 237, 246relativo, 136
RISC, 61, 203, 259rotura bicatenaria, 29, 86RPA, 20, 29, 85, 87RT-PCR, 44, 231
SAR, 19, 70secuencia de ayuste críptica, 193secuenciación, 44, 55securina, 24, 185segregación, 28, 97, 139
adyacente, 187
alternante, 187selección, 161, 166
estabilizante, 164sensibilidad, 231señal de
empaquetamiento, 261poliadenilación, 10, 190, 195
separasas, 28separinas, 24serie alélica, 121sexo heterogamético, 108shugoshinas, 28silenciadores, 6, 11, 194sinapsis, 25sindactilia, 222Síndrome
de Angelman, 207, 218, 219, 221de Apert, 226de Cockayne, 85de cri-du-chat, 186de Crouzon, 225de Di George, 187, 207de Down, 181de Edwards, 182de Gorlin, 222de Kearns-Sayre, 251de Klein-Waardenburg, 224de Klinefelter, 183de Microdeleción, 186de Ojo de Gato, 208de Patau, 182de Pfeiffer, 225de Prader-Willi, 207, 218, 219de Rett, 244de Roturas de Nimega, 87de Rubinstein-Taybi, 187, 223de Smith-Magenis, 208de Turner, 111, 182, 213de Williams-Beuren, 187, 207de Wolf-Hirschhorn, 186del X frágil, 203, 228, 244
síndromes malformativos, 222SINE, 63, 205sinténicos, 139sitio A, 15sitio P, 15
288
Índice analítico
21-INDICE ANALÍTICO 5/12/06 07:46 Página 288
www.FreeLibros.me

sitiosapurínicos, 84hipersensibles a DNAsa I, 71
skipping, 193SKY, 179SNP, 53, 61, 143, 150sobrecruzamiento, 30, 139, 185, 186
desigual, 205sobredominancia, 164solenoide, 18sonda, 39, 47, 233sordera neurosensorial, 251Southern, 40, 250SOX9, 110SRY, 110, 205, 224SSCP, 229STR, 53STS, 54Sturtevant, 140substituciones, 190suplementación génica, 259sustancia H, 121, 125
tag-SNPs, 151tamaño poblacional, 159tasa
de portadores, 166mutacional, 161, 248mutacional basal, 189
tasas de concordancia, 137TDT, 149telofase, 24telomerasa, 22telómeros, 22, 63temperatura de fusión, 39teorema
de Bayes, 246fundamental de la selección natural,
168teoría
cromosómica de la herencia, 104General de la Evolución, 167neutral de la evolución, 171
terapia génica, 257terminadores, 45termocicladores, 44
tétrada, 26tetra-ploidías, 181tri-ploidías, 181trisomía, 21, 181, 187tetravalente, 187TGGE, 229topoisomerasas, 21tracto rico en pirimidinas, 11traducción, 5, 13, 14transcripción, 5, 6, 80transcriptosoma, 8transferencia
génica, 257southern, 40
transformación, 36transiciones, 190translocación, 180, 187
robertsoniana, 181, 187transposones, 65transversiones, 190trinucleótidos, 200triploidía, 181trisomía, 21, 180, 181trithorax, 223trivalente, 187TSIX, 113
UBE3A, 218, 219, 221UNIGENE, 57
VNTR, 53variación, 56, 81
continua, 130discontinua, 129genética, 61
varianzafenotípica, 135, 136genotípica, 136
vector, 257de clonación, 34no-viral, 267viral, 260
virusadenoasociado, 265hemaglutinante del Japón, 269
289
Índice analítico
21-INDICE ANALÍTICO 5/12/06 07:46 Página 289
www.FreeLibros.me

Walter Sutton, 104William Bateson, 102Williams-Beuren
xantomatina, 125xeroderma pigmentosum, 85XIC, 112XIST, 112
XRCC4, 88
XXY, 180
YAC, 35, 54
ZFY, 110
Zona de Actividad Polarizante, 222
290
Índice analítico
21-INDICE ANALÍTICO 5/12/06 07:46 Página 290
www.FreeLibros.me


















