Genetica Anexos
23
BASES GENÉTICAS DE LA CONDUCTA Material complementario Autor: Jordi Silvestre Soto
-
Upload
gimena-martos -
Category
Documents
-
view
221 -
download
0
description
Genetica
Transcript of Genetica Anexos

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto Presentación anexos El objetivo de los siguientes anexos es el de proporcionar información y material útil para complementar la información ofrecida en los distintos módulos del material de Bases genéticas de la conducta. Éstos tratarán sobre las bases moleculares de la genética de la conducta, así como sobre distintos conceptos útiles para entender e interpretar los resultados obtenidos mediante la aplicación de los diferentes métodos y técnicas que más habitualmente son utilizados en genética de la conducta. La información contenida en los genes es la que en mayor medida determinará el funcionamiento celular, así como la apariencia externa de un organismo. En realidad, los genes no hacen nada por sí mismos. Toda su influencia y efectos están intervenidos por las proteínas que éstos codifican. En general, cualquier modificación en la información genética tendrá como consecuencia una alteración en el producto que ésta codifica. Eso conducirá casi invariablemente a alteraciones a nivel orgánico y comportamental.
Los diferentes mecanismos que permiten la expresión, la funcionalidad y la modulación de las proteínas constituyen habitualmente intrincados y complejos procesos biológicos, por lo cual hasta que no se entiendan todos los pasos en la producción y funcionamiento de una determinada proteína, difícilmente será posible una explicación plausible para la expresión del rasgo en el que la mencionada proteína se encontraría involucrada.
Por otra parte, los métodos y estrategias de la genética de la conducta se encuentran fundamentalmente dirigidos a dilucidar la contribución relativa de los factores genéticos y ambientales a un rasgo o enfermedad. Se discutirán los conceptos y herramientas fundamentales para la interpretación de los resultados que se obtienen en los estudios de genética de la conducta con seres humanos. De esta manera, describiremos de forma general los conceptos de heredabilidad y de ambientalidad, de genotipo y de ambiente compartido y no compartido. Asimismo, veremos cómo la interacción entre los factores genéticos y ambientales es crucial para la expresión de la mayor parte de los rasgos y enfermedades humanas. Finalmente, se verá de forma resumida las características de los principales diseños utilizados en estudios en humanos.
En general, el principal objetivo de los estudios en humanos es el de poder discriminar las influencias genéticas de las ambientales, así como el de estudiar el papel que desarrolla la interacción entre ambos factores. Para llevar a cabo este objetivo, es necesario establecer y entender una serie de conceptos que proporcionarán las herramientas necesarias para la utilización e interpretación de los resultados derivados de estos estudios.

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto
Anexo 1. Los inicios de la genética: las leyes de la herencia de Mendel La transmisión de los caracteres hereditarios siguen unas leyes relativamente simples que fueron descritas
por primera vez a mediados del siglo XIX por el monje agustino Gregor Mendel (1822-1884) a partir de sus estudios con la planta del guisante en el pequeño huerto de su convento, gracias a los cuales fue capaz de deducir los principios por los que se rige la herencia. De hecho, Mendel está considerado el padre de la genética a causa de los conocimientos que aportó para entender los mecanismos de la transmisión de los caracteres hereditarios. No obstante, aunque intuyó que la información heredable tenía que estar contenida en unidades básicas de la herencia y que él llamó 'elementos' o 'factores' de herencia, a causa de las limitaciones de los conocimientos científicos y técnicos de la época fue incapaz de identificarlos como lo que ahora sabemos que constituye el soporte físico de la herencia (ADN, cromosomas, genes). En la actualidad, y tal como veremos más adelante, podemos no sólo identificar secuencias concretas y específicas de genes, sino que somos capaces ya de modificarlos, alterando la información que estos fragmentos de ADN contienen, para intentar actuar sobre la causa misma de algunas de las enfermedades producidas por alteraciones genéticas.
1.1. Experimentos de Mendel: las leyes de la herencia
Mendel estudió, mediante cruces sucesivos de la planta del guisante, la transmisión intergeneracional de diferentes rasgos o caracteres observables de esta planta (características fenotípicas). Mendel decidió considerar rasgos dicotómicos, es decir, rasgos que se presentaban de una u otra forma pero nunca mezclados1. Una segunda característica de las plantas que estudió fue la que podían ser representantes de lo que él llamó 'líneas puras' para un rasgo determinado (homocigóticos), en contraposición con las líneas híbridas (heterocigóticos)2.
A partir de los resultados de sus experimentos, Mendel dedujo una serie de leyes o principios que explicaban la transmisión de los caracteres hereditarios. De esta manera, concluyó que cada rasgo estaba determinado por dos 'elementos' de heredabilidad3 (lo que ahora conocemos como genes o, más concretamente, alelos) formando parejas y que cada uno de estos dos elementos se separan (se segregan) al azar durante la formación de los gametos (células sexuales), de manera que, para cada rasgo determinado, cada progenitor aporta uno de los 'elementos' al par de descendientes[4]. Además, Mendel llegó a la conclusión de que uno de estos dos 'elementos' dominaba sobre el otro, de manera que un individuo con uno solo de los elementos dominantes mostrará el rasgo determinado por este 'elemento', mientras que el rasgo determinado por un 'elemento' no dominante (recesivo) sólo se manifestará si ambos 'elementos' son también recesivos[5]. Finalmente, constató que cada uno de los caracteres estudiados (p. ej. color, forma, textura) se transmitían siguiendo los principios anteriormente apuntados y con independencia de la presencia o no del resto de los caracteres. Es decir, en la formación de los gametos, las parejas de 'elementos' segregados para un rasgo dado se transmiten independientemente de aquéllos para otro rasgo diferente. En otras palabras, la herencia de un gen no está afectada por la herencia de otro gen[6].
Actualmente se conocen muchas excepciones a las leyes de transmisión de los caracteres hereditarios tal como fueron formuladas por Mendel (p. ej., ved los conceptos de ligamiento, heterogeneidad genética, alelomorfismo múltiple, pleiotropía, etc. en este mismo módulo). No obstante, los principios mendelianos de la transmisión hereditaria continúan siendo básicamente válidos y explican correctamente una gran parte de la transmisión de las
1 Por ejemplo, uno de los rasgos estudiados fue el color de las semillas (guisantes: éstos podían presentarse o bien en color amarillo o bien en color verde, pero nunca en un color 'verde-amarillento'. En realidad, Mendel estudió seis rasgos dicotómicos de las plantas aparte del color de los guisantes (amarillos o verdes), tales como la forma o textura del guisante (liso o rugoso), la longitud del tallo de la planta (corto o largo), o la posición de la flor (axial o terminal). 2 Las primeras se caracterizan porque, al cruzarse entre sí, siempre producen plantas con las mismas características de los progenitores, mientras que las segundas, como productos de entrecruzamiento de dos plantas representantes de dos 'líneas puras' diferentes, al cruzarse entre sí pueden producir plantas cuyas características pueden diferir de las de sus progenitores directos. 3 Mendel supuso que los caracteres, tanto los dominantes como los recesivos, venían determinados por lo que él denominó 'elementos'. Hoy día sabemos que la localización física que contiene la información para este tipo de rasgos son fragmentos de ADN (ácido desoxirribonucleico) que llamamos genes, y que constituyen la unidad básica de la herencia. Cuando el mismo gen se presenta en formas diferentes al "original" (formas alternativas), cada una de estas formas recibe el nombre de alelo. El alelo cuya información prevalece sobre la del otro sería el alelo dominante, en contraposición con el 'dominado' o recesivo (ved la 'Ley de la dominancia/recesividad'). De esta manera, y tomando el ejemplo del color, estaríamos hablando de que el gen del color presentaría un alelo para el color amarillo y otro para el color verde, de los cuales el alelo para el color amarillo sería el alelo dominante. La combinación particular de alelos de un individuo es lo que llamamos genotipo, mientras que a los rasgos observables fruto de esta combinación particular lo llamaremos fenotipo. 4 Ley de los factores por parejas y de la segregación. 5 Ley de la dominancia/recesividad. 6 Ley de la transmisión independiente.

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto enfermedades hereditarias, sobre todo las originadas por la alteración de un solo gen (enfermedades unifactoriales). Veamos con más detalle los experimentos de los que Mendel dedujo las leyes fundamentales de la transmisión de rasgos hereditarios:
Ley de los factores por parejas: La herencia se basa en parejas de unidades particulares, determinando cada una de ellas un rasgo específico. Como explicación más plausible para justificar los resultados de los experimentos que veremos a continuación, Mendel dedujo que cada rasgo o carácter tenía que estar determinado por la combinación de dos 'elementos' o 'factores', cada uno de ellos aportado por cada uno de los progenitores. Estos elementos son los que ahora conocemos como genes.
Principio de uniformidad: Ley de la dominancia/recesividad: Al cruzar dos líneas puras que difieren en un carácter, todos los miembros de la primera generación F1 exhiben el mismo fenotipo para este carácter en coincidencia con uno de los progenitores. Además, desde un punto de vista fenotípico, cuando dos elementos diferentes, responsables de un rasgo determinado, se encuentran simultáneamente emparejados, uno de los dos elementos domina (elemento dominante) sobre el otro (elemento recesivo). Dado un carácter, al cruzar dos líneas puras (homocigóticas) diferentes, todos los descendientes de la primera generación (F1) serán fenotípicamente idénticos para una de las variaciones de este carácter, e iguales en el de uno de los progenitores (rasgo o carácter dominante). Es decir, mostrarán todas las mismas características externas, e iguales a la de uno de los progenitores. Por otra parte, el rasgo del otro progenitor (rasgo recesivo) no se manifestará en ningún caso, quedando enmascarado o escondido. Posteriormente, Mendel cruzó entre sí plantas híbridas (heterocigóticas) de la primera generación F1, fruto del cruce entre dos líneas puras, observando que el 25% de la descendencia de segunda generación (F2) producía semillas verdes mientras que el 75% continuaba produciendo semillas amarillas (relación fenotípica 1:4). Si se hubiera repetido este experimento con cualquiera de los otros rasgos (p. ej. textura, longitud del tallo, o características de la flor), se habrían obtenido los mismos resultados. Al rasgo que sólo se observaba en los miembros de la F2 después del cruce de miembros de la F1, pero nunca si se cruzaban dos plantas de líneas puras, lo denominó rasgo recesivo.
Figura 1. Consideremos el ejemplo del color de las semillas (guisantes). Mendel cruzó plantas que producían siempre guisantes de color amarillo con plantas que siempre producían guisantes de color verde, es decir, cruzó plantas homocigóticas para el rasgo color (él las denominó 'líneas puras'). El resultado de estos entrecruzamientos fue que siempre se obtenían plantas (plantas de primera generación, F1 en genética) que siempre producían guisantes amarillos. Cuando lo repitió para plantas homocigóticas para los rasgos textura, longitud del tallo o posición de la flor, observó que siempre había un carácter que prevalecía sobre el otro, el cual se manifestaba en todos los miembros de primera generación F1; por ejemplo, la forma lisa prevalecía sobre la rugosa, el tallo largo sobre el corto, y flor en posición terminal sobre el axial. Mendel denominó a estos rasgos caracteres dominantes (fijaos en que a lo largo de la asignatura, cuando hablemos de rasgos específicamente humanos, también consideraremos que los hay dominantes o recesivos). En el cruce entre plantas de la generación F1, de cada 4 descendientes 3 muestran un fenotipo dominante (en este caso, guisantes de color amarillo) por 1 con el fenotipo recesivo (guisante de color verde). Es decir, la relación del fenotipo de la F2 es de 1:4. Como podéis observar en la tabla del ejemplo, el genotipo de las plantas no coincide forzosamente con el fenotipo: el guisante del cuadro superior izquierdo es fenotípicamente amarillo y su genotipo es también 'amarillo' (AA), es decir, es homocigótico para el rasgo 'color amarillo' (tal como lo eran los de la línea pura). Podríamos decir que es una planta 'completamente dominante', tanto desde un punto de vista genotípico como fenotípico, ya que el amarillo es la característica dominante. Lo mismo sucede con los guisantes de color verde (recuadro inferior derecha): es homocigótico para los alelos de color verde y, por lo tanto, fenotipícamente de color verde. En cambio, los dos restantes son genotípicamente heterocigóticos o híbridos 'no puros', ya que contienen un alelo 'amarillo' (a) y un alelo 'verde' (a). Como la característica dominante es el amarillo, estas plantas son fenotípicamente de color amarillo.

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto
Ley de la segregación: En la formación de los gametos (células sexuales) los elementos emparejados se separan (segregan) al azar, de manera que cada gameto recibe con la misma probabilidad (50%) uno de los dos elementos de la pareja. De esta manera, los elementos de la herencia (o genes) constituidos en parejas, se transmiten de generación en generación de manera inalterable, separándose en el momento de formar las células sexuales para seguidamente volver a formar nuevas parejas después de la fecundación7.
Ley de la transmisión independiente: Las leyes de la herencia se aplican a cada rasgo separadamente y de forma independiente y según las leyes comentadas anteriormente. Es decir, cada uno de los caracteres (color, forma, textura...) se transmite con independencia de la presencia del resto de los caracteres. Esta ley hace referencia a los casos en los que se consideran dos caracteres diferentes de forma simultánea, como por ejemplo el color (amarillo/verde) y la textura (lisa/rugosa) del guisante. Mendel descubrió que las diferentes características de los organismo (color, forma o textura, longitud del tallo...) se transmitían a la descendencia de forma independiente, favoreciendo la presencia de múltiples cruces y de diversidad fenotípica (ved la figura de la página siguiente).
Figura 2. En este ejemplo se muestra el cruce entre dos líneas puras (homocigóticas) para los rasgos color (amarillo/verde) y textura (liso/rugoso) de plantas (amarillo-liso, AABB) y plantas verde-rugosas (aabb). Al cruzar plantas de guisantes homocigóticas o 'líneas puras' para los rasgos de color y textura (amarillo: AA y liso: BB; verde: aa y rugoso: bb), Mendel observó que todos los guisantes de la primera generación (F1) eran amarillos y lisos, cumpliéndose de esta manera la segunda ley y revelando que los caracteres dominantes eran el color amarillo y la textura lisa, y los recesivos el color verde y la textura rugosa. Las plantas de esta primera generación F1 son dihíbridas, es decir, heterocigóticas para dos caracteres (AaBb). Cuando Mendel cruzó estas semillas entre sí, observó, tal como describe también su segunda ley, que en la segunda generación filial (F2) aparecían todas las combinaciones posibles entre los dos rasgos: guisantes amarillos-rugosos, verdes-lisos, amarillos-lisos y verdes-rugosos. Las letras A y a hacen referencia al color de la planta. La letra mayúscula simboliza el carácter dominante (amarillo) y la letra minúscula el recesivo (verde). Tal como se ha explicado anteriormente, siempre que haya como mínimo una forma con letra mayúscula (o alelo dominante, en términos de genética actual) se manifestará la característica, en cambio es necesaria la presencia de los dos alelos recesivos para que se manifieste el rasgo determinado por éstos. Las letras B y b de la tabla hacen referencia a la textura del guisante. El carácter dominante (B) es la textura lisa mientras que el recesivo es el rugoso (b). Si tenéis en cuenta las características de los caracteres recesivos y dominantes entenderéis por qué en la tabla, a pesar de seguirse la ley de la transmisión independiente de los caracteres y aparecer todas las combinaciones posibles, la mayoría de los guisantes son o bien lisos o bien amarillos (o ambas cosas al mismo tiempo).
1.2. Más allá de las leyes de Mendel
7 Este fenómeno, que Mendel sólo pudo deducir a partir de sus observaciones, está hoy en día muy bien descrito tanto a nivel celular como nivel molecular: la meiosis (ved el punto 3 de estos materiales). Recordemos que la meiosis es el proceso de división celular por el cual se obtienen los gametos o células sexuales (gametogénesis).

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto Lo que debe recordarse de Mendel es que fue capaz de elaborar una teoría válida a partir a partir de datos empíricos para explicar la transmisión de una serie de caracteres hereditarios. Todo ello lo hizo partiendo de la suposición de que la manifestación observable de cada rasgo está determinada por la combinación de dos 'elementos' heredables y que hoy en día reciben el nombre de genes (alelos, en caso de presentarse bajo formas alternativas), los cuales establecen relaciones de dominancia/recesividad, transmitiéndose de forma independiente en relación con aquellos que determinan otro rasgo.
Las consecuencias de las aportaciones de Mendel han sido muy importantes para el desarrollo de la genética. Aparte de las leyes de la herencia, de una manera más general, algunas de las conclusiones de los trabajos de Mendel podrán ser resumidas de esta manera:
1. No son las características físicas de los individuos lo que se transmite generación tras generación, sino los factores o 'elementos' heredables, que nosotros hoy día llamamos genes.
2. El fenotipo resulta de la cooperación de los factores de los organismos progenitores. 3. Los factores genéticos son de la misma naturaleza en el organismo progenitor macho y en el organismo progenitor
hembra, y se localizan en las células sexuales o gametos. 4. En el momento de la fecundación, la célula sexual masculina aporta uno de los factores y la célula sexual femenina aporta
el otro factor (hoy diríamos que aportan uno de los dos alelos del mismo gen).
A medida que avancéis en la asignatura, veréis la enorme influencia de las ideas de Mendel en la genética actual. De forma exagerada podríamos decir que mucho de lo que se ha escrito en genética después de los experimentos de Mendel ha consistido en descubrir las bases biológicas o celulares (los cromosomas) y moleculares (el ADN) de lo que él llamó 'elementos' o 'factores'. Aunque hoy en día se sabe que existen excepciones a las leyes de Mendel, los principios básicos de la transmisión hereditaria permanecen fieles a lo que él publicó en 1865.
1.3. Las características del material hereditario
Mendel murió sin que su trabajo fuera reconocido por la comunidad científica de la época. De esta manera, Charles Darwin no pudo (o no supo) relacionar su teoría de la evolución con los conocimientos que Mendel aportaba en su trabajo. No es hasta a finales del año 1900 cuando los trabajos de tres botánicos (Vries, Torrens, y Von Tchermak) señalan los mismos resultados y conclusiones que 35 años antes había publicado Mendel. Sin embargo, el avance tecnológico del siglo XX permite hoy el desarrollo de la genética. Johanssen introduce el término 'gen' para referirse a los elementos o factores de Mendel, y Bateson y Cuénot extienden los principios mendelianos a las especies animales. Anteriormente, Fleming (1882) había observado los cromosomas de anfibios en el microscopio, y Sutton (1902) descubre que éstos, durante el proceso de creación de células sexuales o gametos (la meiosis), se comportan de forma compatible con lo que Mendel había intuido. Finalmente, el equipo de Morgan, Sturtevant, Bridge y Muller, de la Universidad de Columbia, establece la relación definitiva entre genes y cromosomas a partir de los estudios con la mosca del vinagre (o de la fruta), Drosophila melanogaster, y proponía la teoría cromosómica de la herencia.
En la época de Mendel, Miescher (1869) había observado ya en esperma de peces una sustancia a la que llamó 'nucleína' y que correspondía con lo que ahora conocemos como cromatina; es decir, la sustancia que contiene el ácido desoxirribonucleico (ADN) dentro del núcleo de la célula. Los bioquímicos de entonces ya habían establecido los componentes químicos de esta sustancia, pero en aquel momento se creía que eran las proteínas y no el ADN el material responsable de la herencia. No fue hasta mediados del siglo XX cuando se pudo mostrar por primera vez la importancia del ADN en la genética. Así, en 1952 Hershey y Chase aportan la prueba definitiva estudiando virus capaces de infectar bacterias, tras lo cual liberan a su muerte centenares de nuevos virus que se reproducen de nuevo en otras bacterias. Estos investigadores observaron que los virus sólo tienen dos elementos: ADN y una capa proteica externa recubriéndolo. A partir de la utilización de marcadores con isótopos radiactivos, fueron capaces de demostrar que es el ADN el responsable de la generación de nuevos virus después de ser introducido dentro de la bacteria. Es decir, el ADN es el material de la herencia. En 1953, Watson y Crick propusieron el modelo molecular de la estructura en doble hélice antiparalelo del ADN, el cual podía explicar los mecanismos que a nivel molecular justificaban una de las propiedades más característica e importante del ADN: la capacidad de replicación, y que es básica para entender los mecanismos íntimos de la herencia. Posteriormente, tuvo lugar una serie de descubrimientos que ayudaron a conocer cuál es la relación entre el material hereditario y la función que éste desarrolla en el organismo mediante la replicación, transcripción, y la síntesis de proteínas. Estos conceptos son también desarrollados en el anexo siguiente.

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto
Anexo 2. Genes, proteínas y expresión genética
2.1. Síntesis proteica
En este apartado y a lo largo de los tres subapartados de los que consta, veremos en qué consiste y cómo se realiza la síntesis proteica.
Básicamente, un gen puede definirse como la unidad funcional de la herencia y, por lo tanto, como la unidad básica capaz de almacenar y transmitir información8. Un gen consiste en definitiva en un fragmento de ADN que codifica para una molécula funcional –principalmente proteínas–9. El proceso por el cual un gen acaba codificando para una proteína consta de dos etapas básicas: la transcripción y la traducción. La transcripción consiste básicamente en hacer un molde de ARN (ARN mensajero, ARNm) de una secuencia determinada de bases nitrogenadas del ADN, para seguidamente y mediante el ARN de transferencia (ARNt) "traducir" la secuencia codificada en el ARNm en una sucesión de aminoácidos, cuyo conjunto constituirá la proteína. Así pues, el proceso de la síntesis proteica puede resumirse en los siguientes puntos:
1. Transcripción: Este proceso tiene lugar en su primera fase en el núcleo celular. La doble hélice del ADN de los cromosomas es
separada en sus dos hélices simples dejando al descubierto las bases nitrogenadas de una porción correspondiente a un gen. Esta porción es usada por la enzima ARN polimerasa como plantilla para fabricar el ARN mensajero (ARNm) mediante el principio de complementariedad de bases (A-O, T-A, C-G, G-C). Este ARNm saldrá del núcleo celular al citoplasma. Pero durante este periodo, el ARNm será objeto de diferentes tipos de maduración, incluido el llamado splicing o de empalme, por el cual todas o algunas de las secuencias no codificantes del gen o intrones son eliminadas para seguidamente unir (empalmar, splice) las secuencias restantes de exones. Así, la secuencia final del ARNm puede ser descrita por una sucesión de unidades de tres nucleótidos (codón). Un codón es, pues, la secuencia de tres nucleótidos (triplete) en el ARNm que codifican para un determinado aminoácido, mientras que el triplete complementario de aquél, asociado al ARN de transferencia (ARNt), se denomina anticodón.
2. Traducción: El conjunto de tripletes o codones del ARNm se traducen en aminoácidos que se reconocen mediante el anticodón
(o triplete complementario) asociado al ARNt, según lo establecido por el código genético. Por lo tanto, se ha pasado de un lenguaje basado en la complementariedad de bases individuales (transcripción) a uno basado en aminoácidos. Es decir, se ha traducido de un lenguaje basado en la complementariedad de bases individuales a otro lenguaje basado en la relación entre tripletes de bases y aminoácidos. Este proceso tiene lugar en los ribosomas, donde el ARNr (de varios tamaños y estructuras) sería uno de los componentes estructurales junto con proteínas específicas asociadas (los ribosomas están formados por ARNr acoplados a proteínas). El ribosoma se une al ARNm por el codón (start) o de iniciación (AUG), el cual es reconocido sólo por el ARN de transferencia (ARNt) de iniciación acoplado al aminoácido metionina. Durante este proceso, complejos formados por un aminoácido unido a un ARNt específico con el correspondiente anticodón (triplete complementario al del ARNm) se unen al codón apropiado del ARNm al formar pares de bases complementarias con el anticodón del ARNt.
3. Formación de proteínas: El ribosoma se va moviendo a lo largo de la molécula de ARNm de codón a codón, mientras los
aminoácidos son acoplados uno a uno formando las secuencias polipeptídicas dictadas originariamente por el ADN y representadas por el ARNm. Finalmente, un factor de liberación se une a uno de los codones que señalan la parada (codón 'stop' que puede ser del tipo UAA, UAG o UGA), acabando la traducción y liberando el polipéptido completo (proteína) del ribosoma. La molécula de ARNm queda libre para volver a ser utilizada y repetir el proceso tantas veces como sea necesario.
De hecho, este proceso constituye un dogma central de la genética, según el cual el flujo de información y de actividad es A→DNARN→proteína. Sólo en casos muy determinados y especiales la información puede fluir del ARN al ADN10.
2.2. ¿Un gen, una proteína?
Por otra parte, parece que tampoco es del todo acertada la asunción de "un gen, una proteína". En efecto, un gen puede originar de hecho diferentes tipos de proteínas. Para entender cómo puede ocurrir eso debe saberse en primer lugar que
8 Un gen se define como la unidad hereditaria elemental con una función específica. 9 En efecto, se puede destacar que no todos los genes funcionales acaban sintetizando una proteína. Por ejemplo, los genes que codifican para el ARNt o para el ARN ribosómico (ARNr, uno de los componentes estructurales del ribosoma), se transcriben pero no se traducen. Por lo tanto, a veces una molécula de ARN, y no una proteína, es el producto acabado de la información codificada en un gen funcional. De esta manera, los genes se podrían clasificar en función de si son o no transcritos y/o traducidos en los: (a) que codifican proteínas o enzimas (se transcriben y traducen); (b) de ARNs específicos (se transcriben y no se traducen); y genes reguladores (no se transcriben ni traducen). Por otra parte, recientemente se ha comprobado cómo determinados transcritos (ARNm) y/o proteínas derivadas de éstos pueden ser el producto de la combinación de dos genes adyacentes. A estos transcritos y/o proteínas fruto de la combinación de diferentes genes se los ha denominado quimera. Se cree que, como mínimo, un 2-5% de los genes del genoma humano estarían involucrados en este fenómeno. 10 Un ejemplo lo encontramos en el mecanismo de acción de los retrovirus. Un retrovirus (p. ej., el VIH causante del sida), está constituido básicamente por un solo filamento de ARN, el cual utiliza el ADN de la célula anfitrión (infectada) para su replicación. El ARN vírico, después de entrar en la célula anfitrión, es capaz de sintetizar una réplica en ADN de doble filamento, el cual se inserta en el ADN celular. Los mecanismos de transcripción de la propia célula son utilizados después para producir más ARNm vírico, el cual es interpretado para producir las proteínas necesarias para la 'fabricación' de más virus.

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto
la mayoría de los genes son compuestos por partes alternativas: los intrones y los exones, y que después de la transcripción de un determinado transcrito primario o ARNp (la cadena original de ARN complementaria a la secuencia de ADN que determina un gen), este ARNp está sujeto a un proceso de maduración necesario para que pueda ser funcional una vez fuera del núcleo celular. El proceso de maduración consiste básicamente en la eliminación de los intrones seguido del empalme de los exones restantes del ARN precursor (ARNp, transcrito primario) dando lugar al ARNm. Este proceso de eliminación de intrones y empalme (splicing) de exones en el ARN (RNA splicing) es el proceso principal de maduración, y se inicia inmediatamente después de la transcripción (de ADN a ARN). Eso significará que los intrones son partes del gen que no serán utilizados en la síntesis de proteínas. Seguidamente, el ARNm maduro que contiene exones y regiones reguladoras abandona el núcleo para unirse a los ribosomas e iniciar la traducción. No obstante, es importante destacar que durante el proceso de maduración y empalme pueden tener lugar procesamientos alternativos del ARN: el empalme alternativo y la edición, cuya consecuencia es la obtención de diferentes ARNm a partir de una misma secuencia original de ADN (gen). Mediante el proceso de empalme alternativo (alternative splicing), las posiciones de los intrones y exones pueden ser cambiadas con respecto a la cadena original del ADN. Este fenómeno puede generar diferentes transcritos o ARNm a partir de un mismo gen (ADN) dependiendo de cómo el ARNp sea 'procesado' en un momento determinado. Eso hace que un mismo gen pueda generar más de un producto proteico (isomorfismo proteico). Por otra parte, la secuencia del ARNm puede ser modificada también al añadírsele nucleótidos individuales en un proceso denominado edición del ARN. El resultado de ambos procesos (empalme alternativo y edición) es que se pueden generar diferentes ARNm a partir de un solo gen, los cuales darán lugar posteriormente a diferentes proteínas11.
Los principales tipos de ARN (ARNm, ARNt, ARNr) son básicamente intermediarios para facilitar la transmisión de la información contenida en el ADN para la formación de las proteínas (síntesis proteica). Sin embargo, existen otros tipos de ARN involucrados en otras funciones diferentes. En efecto, recientemente se ha comprobado cómo moléculas de ARN pueden actuar también como factores de regulación o como catalizadores (enzimas) en procesos diferentes a los de la síntesis de proteínas. Sería lo que se ha llamado ARN no codificante o funcional. En la actualidad se considera, pues, que podría haber una multitud de genes específicos que codificarían ya no para proteínas, sino para una gran variedad de moléculas ARN no codificante cuya función no estaría relacionada directamente con la síntesis de proteínas, sino con otras funciones celulares específicas12. 2.3. El código genético Una proteína es una cadena de aminoácidos, los cuales vienen a su vez definidos por tripletes de bases nitrogenadas (uracil, citosina, adenina, guanina). Cada triplete de nucleótidos del ARNm correspondiente a un aminoácido recibe el nombre de codón (ya que es la unidad mínima que codifica), mientras que al triplete complementario del anterior relacionado con el ARNt se le denomina anticodón. Diferentes combinaciones de las bases nitrogenadas en grupos de tres codificarán unos 20 aminoácidos, constituyendo el código genético. Es fácil ver, pues, que hay más codones que aminoácidos13; cosa por la cual algunos de éstos pueden estar codificados por más de un triplete o codón. Este hecho constituye la base de lo que se conoce como degeneración del código genético. Eso tiene una extraordinaria importancia, ya que la degeneración del código genético disminuye el efecto de las mutaciones puntuales que puedan producirse.
El hecho de que un mismo aminoácido pueda ser codificado por codones diferentes es lo que se denomina 'degeneración del código genético'. La principal ventaja es que la degeneración del código amortigüe (disminuya) el efecto de mutaciones puntuales que afecten a bases o nucleótidos individuales, los cuales, sin este mecanismo alternativo, provocarían mutaciones fatales. Las mutaciones silenciosas o sinónimas son claros ejemplos de este fenómeno. Como hay más codones que aminoácidos (20), algunos de éstos tienen que estar codificados por más de un triplete o codón. Tal como hemos mencionado, la degeneración del código genético se refiere al hecho de que un mismo aminoácido puede estar codificado por diferentes tripletes combinaciones de nucleótidos (redundancia; p. ej., el aminoácido alanina puede estar codificado por cuatro tripletes o codones distintos: GCA, GCC, GCG y GCU). Por lo tanto hay tripletes 'sinónimos' para un mismo aminoácido. Eso se conoce como 'degeneración genética' o 'degeneración del código genético'. Eso tiene gran importancia, ya que este hecho hace que se amortigüe o disminuya el efecto de mutaciones puntuales que afecten a bases o nucleótidos individuales, las cuales, si no existiera el mecanismo alternativo de la degeneración, darían lugar a
11 Por otra parte, recientemente se ha comprobado cómo determinados transcritos (ARNm) y/o proteínas derivadas de éstos pueden ser el producto de la combinación de dos genes adyacentes. A estos transcritos y/o proteínas fruto de la combinación de diferentes genes se los ha denominado quimera. Se cree que, como mínimo, un 2-5% de los genes del genoma humano estarían involucrados en este fenómeno. 12 Se cree que el ARN no codificante podría constituir los vestigios de un código genético primitivo donde las proteínas, como moléculas especializadas, todavía no existían, y cuya función la realizarían los fragmentos de ARN. Éstos se habrían conservado hasta los organismos presentes en forma de ARN sin, en principio, funcionalidad aparente. Entre las moléculas de ARN "funcional" podríamos destacar el ARN de interferencia (ARNi), que estaría involucrado en la regulación genética inhibiendo la expresión de genes. 13 Cada codón viene determinado por la combinación de tres nucleótidos de los cuatro disponibles, por lo tanto: 43=64 posibilidades de codones diferentes.

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto
cadenas polipeptídicas alteradas o a la interrupción del proceso de síntesis proteica. Aunque pueda haber un cambio (sustitución) de una de las bases del triplete, este triplete modificado (mutante) puede codificar para el mismo aminoácido que el normal, por lo que la proteína resultante será la misma y no habrá consecuencias observables. Así pues, las mutaciones a pequeña escala, como la mutación silenciosa o sinónima (mutación de sustitución) son, por tanto, un claro ejemplo de las ventajas que comportaría el fenómeno de la degeneración genética.
Figura 3. La unión de dos nucleótidos forma un par de bases. En el ADN, la citosina (pirimidinas) siempre está unida a la guanina (purina) mediante tres puentes de hidrógeno, mientras que la adenina (purina) siempre se encuentra unida a la timina (pirimidinas) por dos puentes de hidrógeno.
La unión de aminoácidos constituirá cadenas polipeptídicas o proteínas, elementos esenciales para el funcionamiento del organismo, las cuales estarán caracterizadas por el número y orden de esos aminoácidos. Así pues, el código genético puede ser considerado como un diccionario que establece una equivalencia entre las bases nitrogenadas del ARN y el lenguaje de las proteínas, establecido por los aminoácidos.
Todas las células del organismo tienen básicamente los mismos genes. Sin embargo, es obvio que la mayor parte de los organismos pluricelulares no son una masa uniforme, sino que ésta formada por grupos diferenciados de células con funciones determinadas que constituyen órganos. El conjunto de diferentes órganos constituirá el organismo. Lo que diferencia a unas células de las otras sería la combinación particular de genes activos e inactivos, lo cual permitiría, a su vez, la regulación diferencial de la síntesis proteica. En definitiva, lo que caracteriza a una célula determinada es el tipo de proteínas que son sintetizadas en ella y para qué. Como veremos (ved punto 2.5. Epigenética), esta regulación puede tener lugar a diferentes niveles.
2.4. Estructura y función de los cromosomas
En este apartado estudiaremos lo que ya se había empezado a explicar en el apartado anterior: cómo se estructura y organiza la molécula básica de la herencia, el ADN. A modo de resumen, la molécula de ADN está constituida por cadenas de nucleótidos. Cada nucleótido está conformado por un grupo fosfato y un nucleósido, formado a su vez por un azúcar (2-desoxirribosa) y una base nitrogenada: adenina (a), citosina (C), guanina (G), timina (T)14.
A modo de resumen:
14 En el caso del ARN, el azúcar sería la ribosa, mientras que en relación con las bases nitrogenadas presentaría, en lugar de la timina (T), el uracil (U).
BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto
• ADN = Cadena de nucleótidos
o Nucleótido = Nucleósido + Fosfato
Nucleósido = Azúcar + Base nitrogenada
• Bases nitrogenadas en ADN: adenina (A), citosina (C), guanina (G), timina (T)
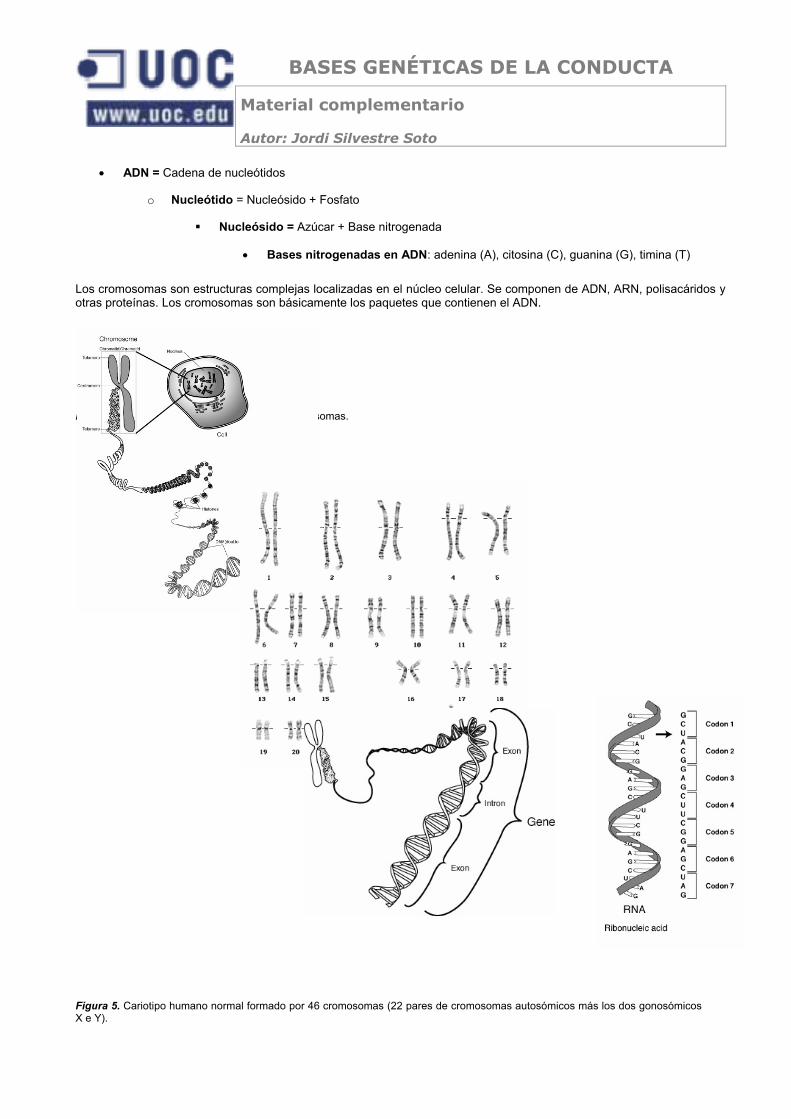
Los cromosomas son estructuras complejas localizadas en el núcleo celular. Se componen de ADN, ARN, polisacáridos y otras proteínas. Los cromosomas son básicamente los paquetes que contienen el ADN.
Figura 4. Estructura básica del ADN, de los cromosomas.
Figura 5. Cariotipo humano normal formado por 46 cromosomas (22 pares de cromosomas autosómicos más los dos gonosómicos X e Y).

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto Anexo 3. Epigenética: la regulación de la expresión génica
Básicamente, la epigenética estudia los mecanismos condicionados de forma externa por los cuales se regula la expresión genética y de los efectos asociados a éstos. Es decir, los mecanismos que hacen que un gen se exprese o no, de qué forma la expresión génica se ve afectada por éstos y cómo la expresión génica se encuentra diferencialmente afectada en un mismo individuo en función del estadio de desarrollo o bien cómo ésta determina también las diferencias entre distintos individuos.
Una de las definiciones más correcta que se pueden encontrar de epigenética (del griego epí, 'en' o 'sobre') sería aquella que no la define como el estudio de "la herencia de patrones de expresión genética que no vienen determinados por los genes, sino por otros factores bioquímicos relacionados". La epigenética hace referencia, pues, a los cambios reversibles del ADN así como de las proteínas asociadas que hacen que unos genes se expresen o no en función de las condiciones externas.
El hecho de que estos cambios sean heredables implica que el ambiente en el que un individuo vive y se desarrolla puede de hecho influir sobre su descendencia. Por lo tanto, un rasgo ya no dependería tanto sólo del tipo de gen heredado, sino también de los condicionantes que hacen que éste se pueda o no expresar.
Lo que hace tan interesante a la epigenética es que, hoy por hoy, es muy complejo y difícil cualquier tipo de actuación directa sobre una mutación genética con aplicaciones terapéuticas. No obstante, cuando la alteración viene dada por factores epigenéticos, la intervención terapéutica sería en principio mucho más sencilla, por medio, por ejemplo, de terapias farmacológicas.
Ahora bien, hay que notar que, si bien la epigenética viene regulada por factores que no son estrictamente genéticos, y dada la tendencia a considerar todo lo que no es genético como ambiental, conviene no confundir "factores epigenéticos" con "factores ambientales". Lo que sí es verdad es que, al igual que pasa con los genes, los factores ambientales pueden influir sobre los factores epigenéticos, de igual forma como también lo hacen sobre los factores genéticos (p. ej., mutaciones), aunque parece que los factores ambientales i/o el estilo de vida (hábitos) pueden "moldear" de forma más fácil el epigenoma que los genes. Así, por ejemplo, la epigenética explicaría cómo, de idénticos genotipos (gemelos MZ), pueden resultar diferentes fenotipos. Se sabe ya que los factores epigenéticos desempeñan un papel importante en las diferencias individuales entre miembros de una misma especie, incluso entre miembros próximos de una misma familia (p. ej., diferencias entre gemelos MZ), así como entre diferentes especies (humanos frente a chimpancés). Por lo tanto, es evidente que la profundización en los conocimientos de la implicación y funcionamiento de los factores epigenómicos en las diferentes psicopatologías será crucial para entender cómo éstas se desarrollan diferencialmente entre individuos (por ejemplo, por qué, de dos gemelos MZ, uno desarrolla esquizofrenia y el otro no) y, por lo tanto, en una mejor terapéutica individualizada para su tratamiento.
3.1. Mecanismos epigenéticos
Cualquier modificación del ADN que altere la estructura de un gen y por lo tanto su potencial capacidad de expresión, sin modificar su secuencia básica, puede considerarse un cambio epigenético. Los diferentes procesos bioquímicos epigenéticos (de tipo extragenéticos) implicados de forma más importante en la regulación génica serían la metilación del ADN y la metilación y/o acetilación de las histonas.
De hecho, el equipo del Manuel Esteller ha demostrado que factores epigenéticos, concretamente la metilación del ADN así como la acetilación de las histonas, explicarían el por qué individuos con idéntico material genético, como sería el caso de los gemelos MZ, no son fenotípicamente idénticos, o por qué dos individuos con la misma alteración genética asociada a una determinada enfermedad desarrollan y sufren ésta en momento y modo diferentes.
A. Metilación y acetilación de las histonas: Por otra parte, las histonas son las proteínas en torno a las que se enrolla el ADN y que regulan y rodean el ADN. Estas histonas pueden también ser objeto de metilación o acetilación. El hecho de que una histona esté o no metilada o acetilada y que este hecho se encuentre asociado a un determinado rasgo o enfermedad podría ser de utilidad en el diagnóstico y predicción de la efectividad de un determinado tratamiento. Eso es como un biomarcador preciso.
B. Metilació i acetilació de les histones: D’altra banda, les histones son les proteïnes al voltant de les quals s'enrotlla l’ADN i que regulen i envolten l’ADN. Aquestes histones poden també ser objecte de metilació o acetilació. El fet de que una histona estigui o no metilada o acetilada i que aquest fet es trobi associat a un determinat tret o malaltia podria ser d’utilitat en el diagnòstic i predicció de l’efectivitat d’un determinat tractament. Això és com a un biomarcador precís.
Por otra parte, y como ya hemos mencionado, los cambios epigenéticos están causados por enzimas. Como las enzimas son buenas dianas terapéuticas para los fármacos, es relativamente sencillo encontrar fármacos que inhiban estas enzimas. Por lo tanto, es de esperar que muchas alteraciones debidas a factores epigenéticos sean susceptibles de

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto tratamientos farmacológicos, ya sea para inhibir la metilación o para inducir la acetilación. De hecho, la principal ventaja de la epigenética es su reversibilidad. Todo lo contrario que el caso de una mutación genética.

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto Anexo 3. Meiosis: implicaciones en la generación y transmisión de alteraciones genéticas y cromosómicas Cómo ya sabéis, el ser humano tiene una constitución de 461 cromosomas organizados en 23 pares: 22 pares de autosomas y 1 par de cromosomas sexuales XY. El cariotipo de 46 cromosomas constituye la condición de euploidía (o número normal de cromosomas). Los cromosomas son aparejados en cromosomas homólogos, por lo cual la información contenida en cada uno de los cromosomas está duplicada. El cariotipo humano normal consta, pues, de 23 pares de cromosomas en cada una de sus células (constitución diploide, 46 cromosomas), excepto en las células sexuales o gametos, que tienen la mitad (23 cromosomas, constitución haploide)2. El par de cromosomas sexuales es idéntico en mujeres (XX), mientras que en los hombres (XY) éstos difieren tanto en medida y morfología como en contenido génico. Pero algunos individuos pueden presentar una dotación cromosómica numéricamente mayor o menor (aneuploidía o anomalías numéricas), mientras que otros pueden presentar anomalías cromosómicas de tipo estructural (alteraciones en la morfología y/o estructura del cromosoma). Ambos tipos de anomalías cromosómicas suelen reflejarse claramente en un cariotipo anómalo, dando lugar, en el caso de ser viables, a cromosomopatías que cursan habitualmente con afectación conductual y cognitiva. Normalmente, las aneuploidías son el resultado de errores en la meiosis, esto es, en el proceso de formación de los gametos femeninos u óvulos (ovogénesis) o masculinos o espermatozoides (espermatogénesis). La meiosis, recordemos, es el proceso de división celular a partir del cual se obtienen los gametos haploides a partir de células diploides. Durante la meiosis los cromosomas homólogos se aparejan (sinapsis cromosómica), intercambian partes de segmentos (entrecruzamiento y recombinación) y finalmente se separan (segregación o disyunción). La importancia de la meiosis como proceso biológico se puede simplificar en dos puntos fundamentales: (A) reducir el material genético a la mitad, de tal manera que cada célula hija reciba un juego cromosómico haploide completo; (B) aumentar la variabilidad aumentando las combinaciones alélicas de los gametos mediante el entrecruzamiento, y produciendo nuevas combinaciones como resultado del proceso de segregación independiente (primera ley de Mendel) por el cual cromosomas maternos y paternos se combinan en forma independiente en cada gameto. El proceso por el cual se generan nuevas combinaciones alélicas, ya sea por entrecruzamiento o por segregación independiente, recibe el nombre de recombinación, y es de gran importancia para la evolución de las especies
Figura 5. Meiosis normal: La mayor parte de las aneuploidías se originan por errores en la meiosis en los procesos de espermatogénesis o de ovogénesis, ya sea por errores en la primera división meiótica (meiosis I) al no separarse correctamente los cromosomas homólogos, ya sea en la segunda división meiótica (meiosis II) al no separarse correctamente las cromátidas hermanas del cromosoma. Observad el entrecruzamiento entre homólogos en la primera división meiótica y el resultado final de cuatro células hija diferentes, con dotación haploide, como consecuencia de la segregación independiente. Una separación (disyunción) anormal de los pares de cromosomas homólogos o de las cromátidas de los cromosomas de la célula germinal diploide (durante las anafases de la primera o segunda división meiótica, respectivamente) será la causa usual de que las cuatro células hijas o gametos resultantes presenten una dotación no haploide (con un cromosoma adicional, gameto disómico; o bien con uno de menos, gameto nulisómico). Al ser fertilizados, los gametos
1 46=2n, donde n es el número haploide (23 en humanos). 2 Al genoma mitocondrial se lo denomina también cromosoma 25.

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto disómicos resultarán trisomías mientras que los gametos nulisómicos producirán monosomías. Dependiendo del número de cromosomas implicados (ya sea por exceso o por defecto), pueden ser: (a) nulisòmics: falta de un cromosoma y de su homólogo (2n–2), inviable; (b) monosómicos completos: falta de uno de los cromosomas homólogos (2n–1), inviable excepto la del cromosoma X (síndrome de Turner); (c) monosómicos parciales: falta de una parte de uno de los cromosomas homólogos (2n–<1), usualmente a causa de deleciones; (d) trisómicos: duplicación completa de uno de los cromosomas homólogos (2n+1); (e) etc.

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto
Anexo 4. Cálculo de probabilidades: nociones básicas Como podéis haber observado en la anterior exposición de las diferentes leyes de Mendel, en la metodología que él utilizó para llegar a éstas, el cálculo de probabilidades desempeñó un papel importante en el momento de poder establecer cómo un determinado alelo o gen podía llegar a distribuirse en la descendencia en función de cómo éste afectara o estuviera presente en los progenitores. Una situación análoga es la que encontramos en los casos de enfermedades hereditarias monogénicas o unifactoriales. De hecho, el cálculo de probabilidades de acontecimientos genéticos cobra particular importancia con una clara funcionalidad práctica en el caso del proceso del consejo o asesoramiento genético. Por consejo genético podríamos entender el proceso de comunicación mediante el cual se pretende dar a los individuos y/o a las familias que sufren o tienen el riesgo de sufrir una enfermedad genética la información sobre su condición, proporcionando, asimismo, la información necesaria que permitiera a éstos tomar las decisiones oportunas según el caso. Es evidente, pues, que el proporcionar la información sobre el riesgo de sufrir y/o transmitir una determinada alteración genética, así como el del riesgo asociado de sufrir y/o transmitir una determinada enfermedad asociada a una alteración genética, se constituye como un punto crucial en el proceso del consejo genético y, por lo tanto, en una herramienta que todo profesional relacionado con el consejo genético (y aquí se incluye el psicólogo) tendría que dominar a la perfección. Los métodos para calcular el mencionado riesgo varían según sea el tipo de enfermedad objeto del consejo. Por ello, el cálculo de probabilidades sí tiene sentido en el caso de que la enfermedad genética sea de tipo monogénica o unifactorial, es decir, producida por un único gen, o bien en las producidas por anomalías cromosómicas (para más detalles, ved módulo 4) que se manifiestan como "todo o nada". Al contrario, en el caso de las enfermedades poligénicas o multifactoriales (no causadas por múltiples genes), el cálculo del riesgo no sería aplicable en el sentido estricto de poder calcular la probabilidad utilizando métodos matemáticos. En este caso lo que se proporciona son los riesgos empíricos basados en lo que se observa a nivel poblacional. Aquí, sin embargo, nos limitaremos a proporcionar las nociones básicas de cálculo de probabilidades que presumimos os pueden ser de más utilidad para el cálculo de riesgo de una enfermedad monogénica. 4.1. Espacio muestral, acontecimientos y probabilidad El concepto de probabilidad es un concepto familiar, pero que para una definición más precisa requiere necesariamente considerar su naturaleza matemática. De hecho, se podría definir probabilidad como el concepto que permite expresar de forma cuantitativa el carácter aleatorio de un acontecimiento con posibilidades de ocurrir. De forma más práctica, la probabilidad de un determinado acontecimiento se define como la proporción de veces que ocurre este determinado acontecimiento en relación con el total de todos los acontecimientos posibles15. Tomemos el caso de un experimento. En estadística, un experimento es cualquier proceso que proporciona datos, numéricos o no numéricos. Al conjunto de todos los resultados posibles en un determinado experimento se le denomina espacio muestral (S). Los elementos que constituyen el espacio muestral S serían, pues, los diferentes acontecimientos que pueden tener lugar dentro de este espacio muestral; es decir, los diferentes resultados a los que un experimento concreto puede dar lugar. S es, pues, el conjunto de todos los acontecimientos posibles (resultados) de un determinado experimento. A cada uno de los posibles resultados de un experimento lo llamaremos acontecimiento (A). Un acontecimiento A es, por lo tanto, un subconjunto del espacio muestral S. Teniendo en cuenta eso, podríamos definir la probabilidad de un acontecimiento A, P(A), considerando en primer lugar todos los resultados posibles de un experimento (S); después se contabilizan todos los resultados en los que el experimento resulta en un acontecimiento determinado (A); finalmente, suponiendo que todos los resultados son igualmente posibles, se define la probabilidad como el número de casos favorables a A dividido por el número de casos posibles: P(A)=A/S. De esta manera, por definición, la probabilidad se mide por un número entre 0 y 1. Si un acontecimiento no ocurre nunca (acontecimiento imposible), su probabilidad asociada es 0, mientras que si ocurriera siempre (acontecimiento cierto) su probabilidad asociada sería 1. Las probabilidades, pues, suelen expresarse como decimales (entre valores 0 y 1), fracciones o porcentajes (al multiplicar por 100 los anteriores valores).
15 Esta definición, y lo que de ella se derivará, corresponde a lo que se conoce como enfoque tradicional o frecuentista de la probabilidad (para basarse en frecuencias). No obstante, existe también otro enfoque que interpreta de forma diferente el concepto de probabilidad basándose en los métodos bayesianos (por el matemático del siglo XVIII Thomas Bayes, 1702-1761). Estos métodos se diferencian del concepto tradicional por incorporar información externa al estudio para, con esta información y los datos ya observados, estimar la distribución de probabilidad para el efecto que se esté investigando. Por lo tanto, en esencia, la metodología bayesiana nos permite calcular la probabilidad de un acontecimiento dado (a posteriori) conociendo la probabilidad primera de que suceda (probabilidad a priori) en función de las modificaciones que el sistema (espacio muestral) pueda sufrir a posteriori. Así pues, si en la metodología clásica (frecuentista) se calcula la probabilidad suponiendo que la realidad sea determinada de una manera (hipótesis nula), en el enfoque bayesiano la probabilidad calculada viene dada, además de por la realidad esperada, en función de los datos reales observados; es decir, por los resultados condicionados a un resultado determinado previamente observado. La metodología bayesiana se utiliza para "actualizar" un determinado valor a priori de la probabilidad en función de los datos reales obtenidos en un determinado experimento, para así obtener una determinada probabilidad "real", denominada función de probabilidad a posteriori. En otras palabras, nos permite, conociendo la probabilidad de que ocurra un acontecimiento dado, modificar el valor de la mencionada probabilidad cuando se dispone de nueva información. No obstante, en esta asignatura la metodología que se utilizará será la frecuentista, por ser ésta, hoy por hoy, la más extendida.

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto
De hecho, todo el cálculo de probabilidades y, con éste, toda la estadística se basan en tres propiedades que se asignan a las probabilidades, denominadas axiomas de Kolmogorov:
1. 0≤ P(A)≤ 1. Esto es: la probabilidad de un acontecimiento A es siempre mayor o igual que cero (0) y menor o igual que uno (1). En efecto, tal como ya indicábamos, la probabilidad del acontecimiento A, P(A)=A/S. Por lo tanto, el valor de la probabilidad siempre estará entre 0 (A=0; acontecimiento imposible) y 1 (A=S; siempre el mismo acontecimiento).
2. P(S)=1. Esto es: la probabilidad del espacio muestral S es igual a uno (1).
Evidentemente, al realizar un experimento siempre sucede algo. Esta propiedad se expresa como que la probabilidad de un acontecimiento cierto es igual a uno (1). Si S tiene un único elemento (siempre el mismo acontecimiento), éste es un acontecimiento cierto. A=S; P(S)=1. Se dice acontecimiento imposible de aquél cuya probabilidad vale cero (0): A es imposible si P(A)=0.
3. P(A o B)=P(A)+P(B). Esto es: si A y B son dos acontecimientos diferentes mutuamente excluyentes, es decir, nunca ocurren simultáneamente (sería el caso de, por ejemplo, tirar una moneda al aire: o bien sale cara o bien cruz, pero nunca puede salir cara y cruz al mismo tiempo), la probabilidad de que ocurra uno u otro es la suma de sus probabilidades. En general, si un fenómeno determinado presenta dos posibles resultados, la probabilidad de que una de estas dos ocurra se determina por: P(A o B)=P(A)+P(B)–P(A y B), es decir, la suma de sus probabilidades individuales y restándole la probabilidad de que ocurran de forma simultánea. En este caso se trata de fenómenos mutuamente excluyentes P(A y B)=0, por lo tanto P(A o B)=P(A)+P(B).
Otras propiedades importantes de las probabilidades serían:
1. Se llama acontecimiento contrario del acontecimiento A al acontecimiento A', que se define como A'=S–A. En este caso, la probabilidad del acontecimiento contrario es P(A')=1–P(A).
2. Se llama probabilidad condicional del acontecimiento B respecto del acontecimiento A a la probabilidad de que, dado un
resultado A, éste se dé simultáneamente a B. Este valor se representa como P(B|A). P(B|A) es igual al resultado de decidir la probabilidad de que se den A y B simultáneamente, P(A y B), dividido por la probabilidad de A, P(A). Esto es: P(B|A)=P(A y B)/P(A). Entonces, la correspondiente a la probabilidad condicional del acontecimiento A respeto del acontecimiento B sería: P(A|B)=P(A y B)/P(B).
3. Al contrario, dos acontecimientos, A y B, son independientes (esto es: no están condicionados el uno del otro) si y sólo si la probabilidad de que éstos se den simultáneamente, P(A y B), es igual al producto de sus probabilidades. Esto es: P(A y B)=P(A)·P(B). En efecto, para el caso de acontecimientos independientes P(B|A)=P(B), ya que P(B|A)=P(A)·P(B)/P(A)=P(B); y P(A|B)=P(A), ya que P(A|B)=P(A)·P(B)/P(B)=P(A).
Una vez que se tienen claros estos principios del cálculo de probabilidades, nos podríamos preguntar: ¿y todo eso, cómo se puede aplicar de forma práctica para solucionarnos problemas directamente relacionados con nuestra asignatura?16. Lo podemos ver con algunos ejemplos: 4.2. La ley de la suma Tal como indicábamos, dos acontecimientos (A y B) son excluyentes cuando la ocurrencia de uno impide la del otro. Es decir, cuando la P(A y B)=0; después, la probabilidad de que se dé uno u otro, P(A o B) es igual a la suma de sus probabilidades individuales: P(A o B)=P(A)+P(B). Por ejemplo, suponed el caso de dos progenitores, ambos Aa, donde "a" representa" un alelo recesivo del gen "A" para una enfermedad genética. ¿Cuál sería la probabilidad de que la descendencia fuera portadora de este alelo recesivo? Lo que se pide es que calculemos la probabilidad de que la descendencia sea aa o Aa. La probabilidad de que sea aa es de ¼, mientras que la de que sea Aa es de ½. Por lo tanto, la probabilidad de que sea aa o Aa será de ¼+½=¾ (75%). 4.3. La ley del producto Es de utilidad para calcular la probabilidad de que dos o más acontecimientos independientes17 los unos de los otros se presenten de forma simultánea. En este caso, la probabilidad será igual al producto de sus probabilidades individuales. Esto es: P(A y B)= P(A)·P(B). Por ejemplo, al igual que en el caso anterior, suponed dos progenitores, ambos Aa, donde a representa un alelo recesivo para una enfermedad genética. ¿Cuál sería la probabilidad de que la descendencia fuera portadora de este alelo recesivo
16 Para ejemplos específicos, podéis ver el apartado dedicado al cálculo de la probabilidad de acontecimientos genéticos del manual de Klug (págs. 65-73) recomendado en la bibliografía. 17 Recordemos que dos acontecimientos son independientes cuando la probabilidad de que se dé un acontecimiento no está condicionada a la ocurrencia del otro. Es decir, cuando el resultado de uno no afecta al resultado del otro y viceversa.

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto pero del sexo masculino? La respuesta de qué probabilidad había de que fueran portadores ya la sabemos de antes (¾ ó 75%). La probabilidad de que sean descendientes masculinos es de ½. Por lo tanto, la probabilidad de que sean portadores y del sexo masculino es de ¾*½=3/8 (37,5%). Otro ejemplo: suponed el caso de dos progenitores, ambos AaBb, donde a y b representan alelos recesivos para dos enfermedades genéticas diferentes. ¿Cuál sería la probabilidad de que la descendencia no esté afectada por ninguna de las dos enfermedades? Como los alelos (genes) se transmiten de forma independiente, estamos calculando la probabilidad de que sean AA o Aa (1/4+1/2=3/4), o bien BB o Bb (1/4+1/2=3/4). Por lo tanto, ésta es de 3/4 para cada una de ellas. Así, la probabilidad de no estar afectado por ninguna de las dos es de ¾* ¾=9/16 (56,25%). 4.4. Probabilidad condicional Consideremos dos acontecimientos diferentes A y B. Llamemos P(A) a la probabilidad de que ocurra un acontecimiento A, y P(A y B) a la probabilidad de que ocurran ambos acontecimientos A y B de forma simultánea. A la probabilidad de que ocurra A cuando sabemos que ya ha ocurrido B se la denomina probabilidad condicional y, como ya hemos visto, se expresa como P(A|B), donde P(A|B)=P(A y B)/P(B).
Por ejemplo, queremos saber la probabilidad de que, dada la unión de dos progenitores portadores de un alelo recesivo, uno de los descendientes sea portador heterocigótico [Aa] sabiendo que un hermano de éste no está afectado. Como hay un descendiente no afectado sabemos que los progenitores tienen que ser heterocigóticos por este alelo (Aa). Las posibilidades de portador (Aa) son de ½, mientras que las de no estar afectado (ser normal [AA] o ser heterocigótico para el alelo recesivo [Aa]) son de ¾. Entonces, considerando las condiciones antes expuestas, la probabilidad sería de (½)/(¾)=2/3=0,6666... (o del 66,67%). 4.5. Teorema del binomio Un caso especial lo constituye el teorema del binomio. A diferencia de la ley del producto, la ley del binomio se aplica para calcular la probabilidades de la ocurrencia de una serie concreta de acontecimientos dentro de un espacio muestral específico y finito; es decir, con un número fijo de resultados. Por lo tanto, en principio nos proporciona la herramienta para calcular la probabilidad de cualquier combinación de acontecimientos alternativos en una serie concreta de acontecimientos. El teorema del binomio se expresa de forma general como (a+b+…+z)n=1. Donde a, b... son la probabilidades a priori de cada uno de los respectivos acontecimiento (resultados), y n es igual al número total de acontecimientos de la muestra. Por ejemplo, en una familia con cuatro hijos podríamos calcular la probabilidad de que dos sean del sexo femenino y los otros dos del sexo masculino. En este caso, como sólo son posibles dos resultados mutuamente excluyentes (a=niño o b=niña) y el número total de la muestra es 4, la fórmula quedaría: (a+b)4=1. El desarrollo de la ecuación daría: a4+4a3b+6a2b2+4ab3+b4=1. En cada término del desarrollo, los exponentes representan el número del acontecimiento en cuestión (a o b). En este caso, el término que indicaría la probabilidad de dos niños y dos niñas sería el 6a2b2. La probabilidad inicial, al menos teórica, de que un hijo sea niño es de ½, en este caso igual a la de que sea niña, también ½ (ya que se tratan de sucesos mutuamente excluyentes). Entonces, la probabilidad de que en una familia con cuatro hijos dos sean niños y dos sean niñas es de 0,375 (o de un 37,5%), resultado que se obtiene al sustituir a=1/2 y b=1/2 en el término anterior 6a2b2 [6·(1/2)2·(1/2)2=6·1/4·1/4=0,375.
Otro sistema más rápido para calcular este tipo de probabilidades es el que proporciona la expresión: ( )ts bats
n•
• !!!
(fórmula adaptada para al caso del ejemplo anterior), donde n es el número total de acontecimientos, a y b son igualmente las probabilidades de que se den, a priori y respectivamente, los acontecimiento A o B (en este caso niño o niña), mientras que s y t denotan el número de veces que se da uno u otro acontecimiento18. A raíz de lo que antes hemos expuesto, puedes plantearte para qué podría aplicarse la siguiente expresión:
( uts cbauts
n••
•• !!!! )
. Trata de imaginar un ejemplo genético donde podría aplicarse.
18 Si hacéis los cálculos, veréis que el resultado que se obtiene es el mismo que aplicando la ecuación anterior.

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto
Anexo 5. Conceptos importantes para discernir los efectos genéticos de los ambientales 5.1. Genotipo, ambientes compartidos e independientes En la actualidad, se encuentra de forma ampliamente aceptado el hecho de que, en general, un fenotipo, ya sea físico o conductual, está en mayor o menor medida determinado por la interacción entre los factores genéticos y ambientales. En el caso del estudio de la conducta como fenotipo, es importante comprender el modelo poligénico que explica cómo diferentes genes pueden actuar de forma interactiva para modularla. De entre los factores genéticos, podemos distinguir en función del tipo y mecanismos subyacentes en la expresión genética los componentes aditivo, el de dominancia y el de epístasis. De estos tres factores genéticos, sólo se hereda de los progenitores el componente aditivo, es decir, el que resulta de la suma de los efectos genéticos de los diferentes alelos. El componente aditivo se identifica como componente genético compartido. Los otros dos (dominancia y epístasis) provienen de la interacción ya sea de genes dentro de un mismo locus (dominancia) o de alelos de distintos loci (epístasis). Cabe destacar que este tipo de interacciones, a pesar de que utilicen el material hereditario, no se heredan propiamente, ya que de cada uno de los progenitores sólo heredamos un cromosoma de cada par de homólogos, es decir, particulares de cada individuo, y por lo tanto se identifican con el componente genético no compartido. Se dice que los efectos no aditivos o el componente genético no compartido hacen que los sujetos de una misma familia se diferencien entre sí, mientras que los aditivos los hacen más similares. De esta manera, en primer lugar se debe tener claro el significado de los términos 'genotipo compartido' y 'genotipo no compartido'. A la proporción de genes comunes entre diferentes individuos con relación de parentesco (familia) la denominaremos genotipo compartido. Entre individuos de una misma familia, la proporción de genotipo compartido dependerá del grado de consanguinidad. En general, tal como ya indicábamos, el genotipo compartido hace 'iguales' a aquellos individuos que lo posean, mientras que el no compartido sería responsable de las desigualdades entre estos individuos. Lo mismo podríamos decir con respecto a los factores ambientales: mientras que un ambiente compartido tiende a hacer similares a los individuos de una misma familia, el no compartido tendería a diferenciarlos. El modelo poligénico integra todos estos componentes, genéticos y ambientales. 5.2. Heredabilidad y ambientalidad Estos dos conceptos se han establecido para estudiar la contribución relativa de los factores genéticos y ambientales en la manifestación de una conducta. Tal como ya se ha comentado, uno de los objetivos fundamentales de los estudios en genética de la conducta es el de determinar la proporción en la que los genes influyen en la manifestación de un determinado rasgo o enfermedad. Para ello se ha establecido el concepto de heredabilidad. Dada la importancia de este parámetro y la confusión que muchas veces provoca una mala interpretación, el significado preciso de este término, así como de sus posibles aplicaciones, será detallado de forma especial a continuación.
El heredabilidad es un concepto estadístico que estima la proporción de la variación de un carácter en una determinada población (diferencia entre individuos o variación fenotípica) que puede ser atribuible a diferencias en factores genéticos (variación genotípica). Es decir, intenta dar respuesta a la pregunta: ¿qué parte de las diferencias observadas para un determinado rasgo y población se debe a diferencias en la información genética de los individuos y qué parte a las diferencias en los ambientes a los que han estado expuestos los individuos? Para responder, debe tenerse en cuenta que la variabilidad de un rasgo concreto en una población determinada (la variación fenotípica o VF) depende de la variación genética (VG) por una parte y de la variación ambiental (VA) por otra, así como de la interacción entre genes y ambiente (GxA). A modo de modelo simple en donde no se tienen en cuenta las interacciones entre genética y ambiente, la VF podría expresarse de la siguiente forma:
VF=VG+VA+2CovGA, donde CovGA = covarianza que se establece entre genes y ambiente=0.
No obstante, cabe destacar que la heredabilidad es un parámetro con dos acepciones, una en un sentido amplio (H2) y la otra en un sentido estricto (h2)19. La heredabilidad en su sentido amplio indica la proporción de la varianza fenotípica (VF) debida a la variabilidad de todos los efectos genéticos. Por otra parte, la heredabilidad en su sentido estricto (h2) representa la proporción de la varianza fenotípica debida a la variabilidad de los factores aditivos de los genes (varianza aditiva, VAd). Tal como veremos más adelante, este último componente de la varianza genética es muy importante en el contexto evolutivo porque es la única varianza que actúa de forma efectiva sobre la evolución, al ser el único componente heredable (ved más adelante). Explicaremos este punto con mayor detalle. Como hemos dicho con anterioridad, la heredabilidad en el sentido amplio (H2) mide la proporción de la variación fenotípica (VF) que puede ser explicada por la variabilidad de los factores
19
A pesar de que la nomenclatura para designar la heredabilidad en su sentido amplio o estricto (H2 o h2) puede variar dependiendo del autor o manual, nosotros hemos optado por la notación H2 para designar la heredabilidad en su sentido amplio, y la de h2 para designar la heredabilidad en su sentido estricto.

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto genéticos con respecto a los ambientales. Considera la variabilidad genética como un todo (todo lo que no es ambiental), y es:
H2=VG/VF
La H2 no tendría ninguna aplicación práctica sino descriptiva. Es decir, sólo da información sobre cómo un determinado rasgo se distribuye en una determinada población, así como de la proporción debida a la variabilidad de factores no ambientales en las diferencias observadas para un rasgo y una población determinada. No obstante, sí que nos puede indicar en cierta manera hasta qué punto un determinado rasgo poligénico es susceptible de ser modificado por factores no genéticos y por lo tanto de intervenir sobre éste mediante la modificación del ambiente. Tal como se desprende directamente al observar la fórmula anterior, es importante notar que la heredabilidad es un término aplicable sólo a poblaciones y no a individuos concretos. Eso es una consecuencia inmediata del uso de las medidas de varianza para calcular la H2.
Por otra parte, tendríamos la heredabilidad en sentido estricto (h2). Ésta tiene en cuenta otros factores de varianza al considerar que la VG en realidad está compuesta por la variabilidad en dos de sus principales efectos, uno aditivo y el otro de dominancia (así como otro menos importante debido a efectos epistásicos). En este sentido, debe destacarse la importancia de la comprensión del modelo poligénico, el modelo que explica cómo una variedad de genes interactúan para afectar al fenotipo. El fenotipo viene determinado por la interacción entre los componentes genéticos y los ambientales. En el caso de los genéticos se distinguen el componente aditivo, el de dominancia y el de epístasis. De estos tres sólo se hereda de los progenitores el aditivo, es decir, el que resulta de la suma de los efectos genéticos de los alelos. Por otra parte, los otros dos aparecen si hay interacciones dentro de un mismo locus (dominancia) o entre los alelos de diferentes loci (epístasis) y surgen de las interacciones del que es heredado pero no se heredan propiamente, por lo cual son particulares del individuo, ya que de nuestros padres tanto sólo heredamos un cromosoma de cada par de homólogos, y por lo tanto sólo uno de los alelos. Se dice que los efectos no aditivos (dominancia y epístasis) hacen que los sujetos de una familia se diferencien entre sí, mientras que los aditivos los hacen más similares. Al contrario de lo que sucedía con la H2, en donde se consideraba la VG como un todo (variabilidad debida a todos los factores relacionados con los genes), en la h2 se han considerado de forma independiente los diferentes factores que la componen:
VG=VAd+VD+VI , donde :
VAd = varianza genética aditiva, debida a que el grado en el que un rasgo se expresa viene dado por la suma de los efectos de genes individuales (efecto medio de los caracteres aditivos).
VD = varianza de la dominancia, debida a que algunos alelos muestran dominancia sobre otros del mismo locus, enmascarando la acción del no dominante.
VI = varianza debida a las interacciones epistásicas, es decir, al enmascaramiento de un gen (epistásico) a otro gen (hipostásico), los cuales no son alelos uno del otro.
Entonces, como: VF=VG + VA
O, lo que es lo mismo: VF=[VAd+VD+VI]+VA
Dado que las variabilidades debidas a los efectos de dominancia y epistásicos no son factores heredados, sino que aparecen por la interacción entre diferentes genes una vez ya heredados, éstos pueden ser despreciados, quedando sólo la influencia de la variabilidad debida a los factores genéticos aditivos. De esta manera, la h2 quedaría como la proporción de la varianza fenotípica total (VF) que es explicada por la variabilidad genética aditiva VAd, esto es: h2=VAd/VF
Debe tenerse en cuenta que la heredabilidad en un sentido estricto (h2), ya que es una medida de la proporción de la varianza de un rasgo que puede ser transmitida de una generación a la otra, resulta en ocasiones de mayor utilidad que la H2 (por ejemplo para la selección de animales o plantas con características especiales). En este caso, si la h2 fuera elevada, eso indicaría que parte de la varianza fenotípica es debida a los efectos aditivos de los genes, no del ambiente, y por lo tanto, el carácter medido sería susceptible de ser seleccionado artificialmente. Así, también podemos comprender lo que comentábamos con anterioridad: que la VAd era el componente esencial para entender el papel de la heredabilidad en la evolución. Al contrario de lo que sucede con la H2 (medida puramente descriptiva), la h2 permitiría la predicción de los resultados en un proceso de selección (por ejemplo en la mejora de un rasgo concreto para el ganado o agricultura), es decir, expresa la mayor o menor posibilidad de que un rasgo pase a la descendencia. Mientras que la heredabilidad en el sentido amplio (H2), al hacer referencia sólo a la proporción de varianza fenotípica debida a factores no ambientales, sin tener en cuenta los efectos específicos aditivos ni de dominancia, no proporciona información precisa de la información de la varianza del rasgo que se transmite a la

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto
descendencia.
5.2.1. Cálculo de la heredabilidad La heredabilidad estricta es posible calcularla a partir de los coeficientes de correlación que se dan entre familiares de diferente grado. Por ejemplo, a partir de los datos de estudios con gemelos es posible la obtención de las correlaciones entre gemelos monocigóticos (rMZ) y gemelos dicigóticos para un determinado rasgo. A partir de los datos rMZ y rDZ hay dos fórmulas fundamentales que permiten el cálculo de la heredabilidad estricta (h ) 2
(1) h2 = 2(rMZ-rDZ) 20
(2) h2 = rMZ-rDZ/1-rDZ 21
A pesar de que hay cierta controversia sobre cuál de los dos métodos es más válido para calcular la aportación 'puramente' genética y, por lo tanto, la heredabilidad, las dos fórmulas son perfectamente válidas y, de hecho, muchos trabajos de investigación utilizan simultáneamente ambos métodos para calcular la h . Aunque los resultados numéricos suelen ser ligeramente diferentes, el sentido de las conclusiones finales que de ellos se derivan no tendría que divergir de modo significativo
2
22.
5.3. Interacción entre los factores genéticos y ambientales Como se ha expuesto anteriormente, otro concepto relevante para la comprensión e interpretación de los resultados que se obtienen con los estudios de genética es el de la interacción entre factores genéticos y ambientales (GxA). Actualmente se encuentra establecido que el fenotipo no sólo viene determinado de forma lineal por la suma de los aspectos ambientales y genéticos, sino que en la mayoría de los casos hay una interacción bidireccional que es la que explica la manifestación final de un rasgo o enfermedad. La interacción genes y ambiente (GxA) hace referencia a la manera en que los genes y el ambiente afectan al fenotipo, pudiendo definirse como el control genético de la sensibilidad a las diferencias del ambiente. De esta manera, un mismo gen puede manifestarse de forma diferente bajo la influencia de ambientes distintos. 5.3.1. Correlación entre los factores genéticos y los ambientales (covarianza) Por otra parte, los genes tienden, a su vez, a seleccionar o a modular el ambiente de modo que puedan expresarse de la forma más favorable. En este caso, la interacción entre los factores genéticos y los ambientales se explica por el concepto de correlación positiva entre genes y ambiente (covarianza). La correlación entre genes/ambiente se refiere a que un individuo con un determinado genotipo tiende a desarrollarse en aquellos ambientes que sean propensos a favorecer la expresión de este genotipo (hay una correlación entre genes y ambiente). Aunque se han propuesto varias taxonomías para la clasificación de los diferentes tipos de correlación o covarianza G/A, una de las más utilizadas en genética de la conducta es la que distingue tres tipos de covarianza G/A dependiendo básicamente de la manera en que los factores ambientales son aportados o seleccionados:
1. En primer lugar tenemos la correlación pasiva, la cual se refiere al hecho de que el ambiente en donde se desarrolla un individuo favorece la expresión de su genotipo. Este tipo se denomina pasiva porque ni el comportamiento ni el genotipo del individuo determinan el ambiente en el que éste se encuentra.
2. En segundo lugar, tenemos la correlación activa, que se refiere a aquella que se establece cuando es la propensión genética del individuo la que provoca que éste busque y eventualmente seleccione el ambiente o experiencias que más favorezcan la expresión de esta propensión genética.
3. Por último, la correlación evocativa o reactiva se refiere a aquella por la que se establece una relación 'evocada' entre los factores genéticos y ambientales, en la cual es la propia expresión del genotipo la que provoca situaciones (reacciones) que favorecen la aparición de factores ambientales propicios al desarrollo de aquéllas.
20
Para más detalles, ved el anexo del manual de Plomin sobre estos conceptos. 21
Método de Holzinger (1937). 22
Podéis también visitar la siguiente dirección http://www.evotutor.org/Selection/Sl4A.html, donde encontraréis un simulador de heredabilidad modificando los diferentes parámetros que intervienen en su estimación.

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto A pesar de ser conceptos parecidos, el de correlación (G/A) tiene que ser diferenciado claramente del de interacción (GxA). Si la interacción hace referencia a cómo el ambiente puede regular diferencialmente la expresividad de los genes, la correlación indica el hecho de que el ambiente que experimenta un individuo está determinado en cierta medida por su genotipo. Por lo tanto, mientras que la correlación G/A refleja una distribución no aleatoria de ambientes entre diferentes genotipos, es decir, la influencia de la predisposición genética a la exposición o no a un determinado ambiente, por otra parte la interacción GxA relaciona el modo real como los genes y el ambiente afectan al fenotipo, por lo cual estaríamos hablando de la respuesta (susceptibilidad o sensibilidad) del aspecto genético ante un determinado ambiente.
Resumiendo, tenemos por un lado que el ambiente puede modular la expresión de los genes y por otro que los genes pueden llegar a determinar a la vez el ambiente, de manera tal que éste sea favorable a la maximización de la expresividad genética. La interacción bidireccional entre genes y ambiente queda, pues, bien establecida.
1.6. Estudios de familias, de adopciones y de gemelos Tradicionalmente, las estrategias de investigación en genética de la conducta incluían estudios de gemelos y de adopciones, diseñados para discriminar las influencias biológicas de las ambientales, lo cual posibilita establecer la heredabilidad de un determinado rasgo o enfermedad. Como la mayoría de los estudios en genética, los estudios de genética de la conducta requieren también el análisis de familias y de poblaciones para averiguar qué individuos poseen o no una determinada forma de un gen o conjunto de genes y así obtener información sobre el tipo de herencia de un rasgo o enfermedad concreta, así como establecer los factores de riesgo asociados. En genética de la conducta, se establecen tres grandes tipos de estudios ('clásicos') en humanos dependiendo del tipo de muestra considerada:
a. estudios de familias,
b. estudios de adopciones,
c. estudios de gemelos.
En cada uno de estos tipos de estudios se puede aplicar una variedad de diseños experimentales que nos permitirán extraer conclusiones en referencia a la relación genética entre diferentes rasgos o patologías, el tipo de herencia, la expresividad de un gen, la heredabilidad del rasgo en cuestión y la interacción entre el gen y el ambiente.
Así destacamos que, de los últimos estudios, analizando los resultados más recientes en genética del comportamiento, se desprenden dos conclusiones principales:
1. Casi todos los rasgos de comportamiento y/o enfermedades mentales presentan una heredabilidad de moderada a alta (y en mayor grado que las enfermedades físicas comunes).
2. La contribución de los factores ambientales es máximamente relevante con respecto a la influencia del ambiente no compartido. Es decir, los factores ambientales que tienden a diferenciar, más que a hacer similares, a las personas.
Este tipo de estudios, y también aquellos que utilizan la aplicación de las técnicas de la genética molecular, han permitido la reciente identificación de fragmentos de ADN (loci) asociados a conductas y enfermedades conductuales que permiten hacer grandes avances en la localización de genes asociados a enfermedades graves tales como la esquizofrenia o el trastorno bipolar.

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto
Anexo 6. Estudios en animales y técnicas de ADN molecular 6.1. Métodos en animales El objetivo de estas técnicas es la creación de cepas de animales por experimentación con características fenotípicas y genotípicas concretas. Este tipo de estudios tienen unas grandes ventajas metodológicas, ya que permiten la manipulación controlada tanto de los factores genéticos como de los ambientales, lo cual permite estimar de forma relativamente sencilla la contribución relativa de cada uno de estos factores, así como determinar las interacciones que se establecen entre sí sobre una conducta estudiada en un entorno experimental. Los tres métodos fundamentales de obtención de cepas de animales útiles para los estudios de genética conductual son: la cría selectiva, las cepas consanguíneas, y las cepas recombinantes. Desde hace miles de años, los humanos se han esforzado por descubrir técnicas que permitan modificar las características de animales y plantas, fundamentalmente dirigidas a mejorar la producción de alimentos. Así, la cría selectiva, realizada hace miles de años, ya se puede considerar un tipo de manipulación genética, ya que mediante esta técnica se consigue acentuar algunos rasgos deseables tales como algunos colores en las flores, una mayor producción de leche en las vacas o una mayor docilidad en el caso de animales como las ovejas o los perros. La cría selectiva busca conseguir líneas de animales con los valores máximo y mínimo de un rasgo o característica fenotípica (por ejemplo, ratas de laboratorio con mucha/poca capacidad de aprendizaje); eso se consigue mediante el cruce entre sí de aquellos animales que presenten el rasgo por exceso de un lado y por defecto del otro (fijaos en las similitudes de la cría selectiva con la eugenesia). Por otra parte, lo que caracteriza el método de cepas consanguíneas es el tipo de apareamiento, que se inicia ya entre poblaciones genéticamente homogéneas (entre familiares). En este caso, lo que se pretende es la obtención de cepas de animales homocigóticos mediante el apareamiento entre sujetos consanguíneos, generalmente entre hermanos. Así se pueden obtener animales de una cepa que sean en la práctica totalidad homocigóticos para todos los loci. Por el contrario, las cepas consanguíneas distintas diferirán genéticamente entre sí. La detección de diferencias individuales dentro de cada una de las cepas revelará los efectos debidos a factores ambientales, mientras que la comparación de los efectos de un mismo ambiente sobre dos cepas diferentes de este tipo permitirá, por ejemplo, averiguar la influencia de los factores genéticos en la conducta estudiada. Finalmente, tenemos también la posibilidad de las cepas consanguíneas recombinantes. Éstas se obtienen a partir del cruce de dos cepas consanguíneas diferentes de forma repetida mediante el cruce de dos miembros consanguíneos (p. ej., hermanos y hermanas). Dado que durante los diferentes entrecruzamientos los cromosomas parentales se recombinarán varias veces, finalmente se originará un único patrón de recombinantes de los cromosomas de cada cepa. A partir de la utilización de esta técnica, se pueden hacer mapas genéticos de la localización de distintos genes utilizando enzimas de restricción y polimorfismos genéticos. 6.2. Técnicas de genética molecular En los últimos años, el avance de las técnicas en biología molecular ha permitido el desarrollo de la denominada ingeniería genética. Es decir, la disciplina que se basa en la manipulación de la molécula de ADN. Esta modificación se puede conseguir añadiendo o eliminando fragmentos o secuencias concretas de ADN. Las técnicas de ingeniería genética han despertado un gran interés por las perspectivas que ofrecen, ya que, por ejemplo, proporcionan las herramientas para la modificación in vivo de aquellos genes cuya alteración puede ser la responsable de una determinada enfermedad, de manera que, después de su localización y caracterización, podrá ser posible diseñar los instrumentos necesarios para la 'reparación' del defecto responsable de esa enfermedad. De hecho, la genética molecular ya ha sido aplicada con éxito para la modificación del material hereditario de plantas y animales, por ejemplo para la obtención de plantas resistentes a determinados agentes químicos o biológicos, o para la obtención de animales que no expresan un determinado gen (animales knock-out) o bien para que puedan expresar un gen que en principio no les corresponde (animales knock-in o transgénicos).

BASES GENÉTICAS DE LA CONDUCTA
Material complementario
Autor: Jordi Silvestre Soto Anexo 7. Consideraciones sobre el Proyecto Genoma Humano El genoma es todo el ADN de un organismo. El Proyecto Genoma Humano (PGH) ha permitido secuenciar todo el genoma, es decir, determinar la orden exacto en el que se organizan los aproximadamente 3.000 millones de pares de bases que configuran nuestro ADN. Un objetivo básico del PGH es el de identificar todos los genes del ADN humano (aproximadamente 30.000), por lo cual sus resultados tendrían que aportar información para la identificación de aquellos genes o conjuntos de genes involucrados en el comportamiento humano. La primera contribución práctica de este proyecto será un enorme progreso en el estudio de las enfermedades hereditarias, facilitando la identificación de sus bases genéticas concretas.
Sin duda, la secuenciación del genoma humano revolucionará la medicina en general y la psicología y la psiquiatría en particular. Al menos en teoría, uno de los principales impactos será el de poder entender de forma más precisa y con más profundidad las bases neurobiológicas de las diferencias individuales, permitiendo una mejor comprensión de la etiología (causa) de las enfermedades. Cabe destacar también que la dilucidación de las bases genético-moleculares involucradas en una determinada enfermedad proporcionará a la vez los cimientos para diseñar nuevos fármacos para su tratamiento, más específicos, efectivos y con un mayor índice de tolerabilidad.
Desde una perspectiva farmacológica, encontramos otras aplicaciones de los conocimientos sobre el genoma humano. Por ejemplo, muchos psicofármacos presentan una gran diversidad de respuestas individuales. Esta variabilidad es debida, en gran medida, a las diferencias interindividuales en el metabolismo de los fármacos, el cual llevan a cabo principalmente las enzimas. Las enzimas son proteínas catalizadoras que vienen codificadas por uno o varios genes. Las diferentes formas genéticas (alelos o mutaciones puntuales) para estos genes que presentan las personas se asocian a una diferente actividad de las enzimas que implica un efecto diferencial del fármaco en el organismo. Así, el estudio de las diferencias individuales de la sensibilidad en los fármacos a través del ADN del paciente tendría que permitir seleccionar las opciones terapéuticas más adecuadas a las características de un paciente particular. Pero el verdadero trabajo comenzará con el análisis de los mecanismos y modo de acción de los productos génicos, tanto de tipo proteico como de tipo estrictamente regulador (p. ej., ARN de interferencia), y también de cómo éstos afectan al crecimiento y desarrollo de las influencias ambientales sobre dichos procesos y el grado de individualidad de ambos. Es aquí, pues, donde los factores epigenéticos cobrarán toda su importancia. De hecho, ya se está considerando cómo realizar diferentes proyectos epigenómicos (proyecto epigenoma) para diferentes tipos celulares.