
Disertación Doctoral Problemas de Regresión: … · Problemas de Regresión: Soluciones por...
147
Tecana American University PhD in System Engineering Disertación Doctoral Problemas de Regresión: Soluciones por Modelos Estadísticos y Redes Neuronales Artificiales Presentada para Optar por el Título de PhD in System Engineering Raúl Eduardo Roldán Quintero
Transcript of Disertación Doctoral Problemas de Regresión: … · Problemas de Regresión: Soluciones por...

Tecana American University PhD in System Engineering
Disertación Doctoral
Problemas de Regresión: Soluciones por Modelos Estadísticos y Redes
Neuronales Artificiales
Presentada para Optar por el Título de
PhD in System Engineering
Raúl Eduardo Roldán Quintero

Caracas, Diciembre 2002

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. i
RESUMEN
La aplicación de las redes neuronales artificiales ha capturado recientemente la atención de investigadores teóricos y prácticos, ya sea fortaleciendo los fundamentos matemáticos que las soportan o buscando cada vez más aplicaciones en el mundo real. Sin embargo, el uso de las técnicas estadísticas multivariadas goza de un espacio importante en la creación de modelos de fenómenos reales.
Ello ha creado, por así decirlo, una dialéctica que discierne sobre la calidad de los resultados de las unas sobre los otros. Este trabajo realiza un estudio comparativo entre las redes neuronales artificiales y los métodos estadísticos multivariados, específicamente en el tratamiento de problemas de regresión y correlación múltiple, regresión logística y series de tiempo, donde el común denominador estadístico es el Modelo de Regresión Lineal General.
Mediante una cuidadosa preparación y ubicación de muestras de datos, se desarrollan una serie de experimentos que, detectando condiciones de calidad de datos convergentes con el mundo real, demostrarán la complementariedad de ambas técnicas en la solución global de fenómenos alineados con las características exigidas por el Modelo de Regresión Lineal General.
Será concluyente el rendimiento de las redes neuronales en la aproximación de funciones, procesos de clasificación dicótoma y series de tiempo económicas. Pero así de contundente será también el valor y necesidad exploratoria de los métodos estadísticos multivariados en el proceso de estudio y arribo a una solución, específicamente en el análisis de datos, análisis de bondad de ajuste de los resultados y soporte en la preparación de la arquitecturas específicas de redes neuronales.
Finalmente, se sugerirán investigaciones que permitan comprender y desarrollar el proceso de extracción de autómatas a partir de las redes neuronales, con el objeto de salvar sus debilidades exploratorias, así como fortalecer los procesos metodológicos mediante la generalización y enriquecimiento, producto de su aplicación en la praxis.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. ii
TABLA DE CONTENIDO i. Introducción ..................................................................................................................... vii ii. Dedicatoria ..................................................................................................................... viii iii. Agradecimientos ............................................................................................................... ix
1. EL PROBLEMA DE LA INVESTIGACIÓN ................................................................ 1
1.1 PLANTEAMIENTO DEL PROBLEMA ................................................................................... 1 1.2 JUSTIFICACIÓN DE LA INVESTIGACIÓN ........................................................................... 4 1.3 OBJETIVOS ....................................................................................................................... 6 1.3.1 Objetivos Generales ............................................................................................................ 6
1.3.2 Objetivos Específicos.......................................................................................................... 7 1.4 ALCANCES ........................................................................................................................ 7 1.5 LIMITACIONES ................................................................................................................. 8
2. MARCO TEÓRICO ........................................................................................................ 9
2.1 MARCO REFERENCIAL Y ANTECEDENTES ....................................................................... 9 2.2 BASES TEÓRICAS. PARTE 1: ANÁLISIS ESTADÍSTICO MULTIVARIADO ......................... 15 2.2.1 La Distribución Normal Multivariada ............................................................................... 16
2.2.2 Análisis de Componentes Principales (PCA)...................................................................... 19
2.2.3 Análisis por Factores (FA) ................................................................................................ 23
2.2.4 Regresión y Correlación Múltiple ...................................................................................... 27
2.2.5 Regresión Logística .......................................................................................................... 30
2.2.6 Análisis Estadístico de Series de Tiempo ........................................................................... 34
2.2.7 Clasificación Estadística ................................................................................................... 42
2.2.8 Algunas Estadísticas Relevantes ....................................................................................... 44 2.3 BASES TEÓRICAS. PARTE 2: REDES NEURONALES ........................................................ 45 2.3.1 El Modelo de la Neurona Artificial, el Perceptron y los Filtros Lineales ............................. 46
2.3.2 El Perceptron Multicapa con Retropropagación ................................................................. 50
2.3.3 Redes de Base Radial........................................................................................................ 55

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. iii
2.3.4 Self-Organizing Feature Maps (SOFM) y Redes del tipo Learning Vector Quantization (LVQ) ............................................................................................................................. 59
2.3.5 La Red de Elman .............................................................................................................. 63
2.3.6 Filtros Adaptativos ........................................................................................................... 64
3. FORMULACIÓN DE HIPÓTESIS .............................................................................. 67
4. MARCO METODOLÓGICO....................................................................................... 70
4.1 TIPO DE INVESTIGACIÓN ............................................................................................... 70 4.2 DISEÑO Y SELECCIÓN DE LAS MUESTRAS ..................................................................... 70 4.3 INSTRUMENTOS .............................................................................................................. 77 4.4 PROCEDIMIENTO ............................................................................................................ 78 4.4.1 Experimento I: Regresión Multivariada de Origen no Lineal con bajo ruido ....................... 78
4.4.2 Experimento II: Regresión Multivariada de Origen Lineal con alto ruido ............................ 80
4.4.3 Experimento III: Regresión Logística con Datos Reales ..................................................... 82
4.4.4 Experimento IV: Análisis de Series de Tiempo Económicas ............................................... 84
4.4.5 Experimento V: Análisis de Señales .................................................................................. 86 4.5 ANÁLISIS E INTERPRETACIÓN DE DATOS ...................................................................... 87 4.5.1 Experimento I: Regresión Multivariada de Origen no Lineal con bajo ruido ....................... 87
4.5.2 Experimento II: Regresión Multivariada de Origen Lineal con alto ruido ............................ 93
4.5.3 Experimento III: Regresión Logística con Datos Reales ..................................................... 99
4.5.4 Experimento IV: Análisis de Series de Tiempo Económicas ..............................................107
4.5.5 Experimento V: Análisis de Señales .................................................................................124
5. CONCLUSIONES ........................................................................................................126
6. RECOMENDACIONES ..............................................................................................129
6.1 A NIVEL TEÓRICO ........................................................................................................129 6.2 A NIVEL PRÁCTICO .......................................................................................................129

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. iv
7. REFERENCIA DE INICIALES ..................................................................................131
8. BIBLIOGRAFÍA ..........................................................................................................133
9. REFERENCIAS ...........................................................................................................134

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. v
TABLA DE FIGURAS
Figura 1. Gráfico Scree para análisis de componentes principales..................................................... 22
Figura 2. Modelo de la Neurona Artificial ..................................................................................................... 46
Figura 3. Arquitectura de RNA de una capa. ............................................................................................... 47
Figura 4. Tipos más comunes de Funciones de Transferencia ..................................................................... 48
Figura 5. Modelo de Neuronas en Multicapa: ejemplo de tres capas ................................................. 50
Figura 6. Modelo de Neurona Artificial de Base Radial ........................................................................ 55
Figura 7. Arquitectura de Red Neuronal de Base Radial ..................................................................... 56
Figura 8. Arquitectura de Red Neuronal de Regresión Generalizada ................................................. 57
Figura 9. Arquitectura de Red Neuronal Probabilística ........................................................................ 58
Figura 10. Arquitectura de Red Neuronal de Competencia ................................................................. 59
Figura 11. Arquitectura de Red Neuronal SOFM .................................................................................. 61
Figura 12. Arquitectura de Red Neuronal LVQ ..................................................................................... 62
Figura 13. Arquitectura de Red Neuronal de Elman ............................................................................. 64
Figura 14. Modelo de Neurona Artificial Lineal...................................................................................... 65
Figura 15. Arquitectura de Red Neuronal de Filtro Adaptativo para predicción de señales .............. 66
Figura 16. Superficie de la Muestra A .......................................................................................................... 71
Figura 17. Superficie de la Muestra B .......................................................................................................... 72
Figura 18. PIB de los Estados Unidos. ........................................................................................................ 75
Figura 19. Diseño de Señal de la Muestra E ................................................................................................ 76
Figura 20. Aproximación de la superficie de la Muestra A por Regresión Lineal Múltiple ............................... 88
Figura 21. Aproximación de la superficie de la Muestra A por Red Neuronal MLP ........................................ 90
Figura 22. Regresión de los resultados de la red neuronal con el vector de entrenamiento en la Muestra A . 91
Figura 23. Convergencia de los errores de entrenamiento en la red neuronal MLP en la Muestra A. ............ 91
Figura 24. Aproximación de la superficie de la Muestra A por Red Neuronal GRNN ..................................... 92

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. vi
Figura 25. Regresión de resultados de la red neuronal GRNN con el vector de entrenamiento – Muestra A 92
Figura 26. Aproximación de la superficie de la Muestra B por regresión lineal múltiple .................................. 94
Figura 27. Aproximación de la superficie de la Muestra B por Red Neuronal MLP ........................................ 96
Figura 28. Regresión de los resultados de la red neuronal MLP con el vector de entrenamiento en Muestra B ......................................................................................................................................................... 97
Figura 29. Convergencia de los errores de entrenamiento en la red neuronal MLP en la Muestra B. ............ 98
Figura 30. Aproximación de la superficie de la Muestra B por Red Neuronal GRNN ..................................... 98
Figura 31. Regresión de resultados de la red neuronal GRNN con el vector de entrenamiento – Muestra B 99
Figura 32. Gráfico Scree de valores propios para las variables predictoras de la Muestra C. ...................... 101
Figura 33. Clasificación Jerárquica de la Muestra C. .................................................................................. 105
Figura 34. Rendimiento comparado de las soluciones del Experimento III .................................................. 107
Figura 35. Autocorrelación Parcial de la Serie del PIB de los Estados Unidos ............................................. 114
Figura 36. Autocorrelación de los residuales del Modelo ARIMA para la serie del PIB de los Estados Unidos ....................................................................................................................................................... 117
Figura 37. Autocorrelación Parcial de los residuales del Modelo ARIMA de la serie del PIB de los Estados Unidos ............................................................................................................................................. 118
Figura 38. Solución ARIMA para la serie del PIB de los Estados Unidos .................................................... 119
Figura 39. Correlación entre datos estimados vs. Neuronas en la Capa Oculta de la red que aproxima la Muestra D ....................................................................................................................................... 121
Figura 40. Comportamiento del Rendimiento de la Red Neuronal a medida que se agregan neuronas en la Capa Oculta en el procesamiento de la Muestra D. .......................................................................... 122
Figura 41. Comportamiento del Error durante el entrenamiento de la Red para procesar la Muestra D. ...... 122
Figura 42. Aproximación de la Muestra D con red neuronal. ..................................................................... 123
Figura 43. Señal aproximada en contraste con la señal original. ................................................................ 124
Figura 44. Comportamiento del error en el procesamiento de la Muestra E. ............................................... 125

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. vii
I. INTRODUCCIÓN La presente disertación desarrolla una investigación exploratoria, de naturaleza experimental pura, que busca analizar y proponer un espacio justo y apropiado a los métodos estadísticos multivariados y a las redes neuronales artificiales, en la creación de modelos de regresión y correlación múltiple, regresión logística y series de tiempo económicas.
El problema se justifica primariamente en los debates sobre la mejor calidad de los resultados de unas herramientas sobre las otras, cuando la propuesta fundamental de esta disertación será el discurso de complementariedad. Ello indudablemente implica abordar problemas relativos al método, donde el espacio arriba referenciado sea identificado, más allá de las discusiones teóricas o prácticas.
Por tal motivo, se hará una desarrollo teórico de los métodos estadísticos multivariados y sus fundamentos, para poder atacar los problemas mencionados. De igual modo, se recorrerán las arquitecturas de redes neuronales artificiales más usadas hoy en día, criterio obtenido de la investigación documental de diferentes estudios teóricos y prácticos, los cuales conforman las referencias obligadas de esta investigación.
Seguidamente, se prestará exhaustiva atención a las muestras, en cuanto a su apego a las imposiciones del Modelo de Regresión Lineal General, pero asignándoles condiciones que las acerquen más a las dificultades de calidad propias de los escenarios reales. Algunas de las muestras serán generadas experimentalmente, mediante simulación, y otras serán cuidadosamente seleccionadas, en la búsqueda de un reflejo de la realidad y sensibilidad a un proceso de investigación rico y metodológico.
Con base en esas muestras, se desarrollarán experimentos que tenderán no sólo a extraer bloques replicables de investigación, sino también a demostrar las hipótesis formuladas para validar el objeto de esta disertación.
Las conclusiones aclararán el espacio de solución de ambas técnicas en los problemas propuestos y permitirán desprender un ámbito de investigación y continuidad sobre los resultados obtenidos.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. viii
II. DEDICATORIA No es fácil la preparación de una disertación de doctorado, o al menos nunca lo fue para mí. Pero más allá de las dificultades inherentes a la misma, fue el TIEMPO la mayor de las dificultades.
TIEMPO que mis hijos, Raúl, Larry y Doris, me cedieron y que representa el tesoro de su alegría ... y que no se volverá a repetir. A ELLOS una especial dedicatoria por saber esperar y nunca dudar del amor que les profeso.
TIEMPO que mi esposa, Doris, dejó de disfrutar conmigo, enriqueciéndome con sus emociones y esa visión fresca y alegre de la vida ... que tanto me hizo falta en muchos momentos y que, cuando la necesité, siempre estuvo allí, consecuente y comprensiva, más allá de los límites racionales.
TIEMPO que mis padres, Irma y Víctor, preguntaban por mí con preocupación y espera paciente, siempre listos para aportarme un sabio y oportuno consejo, más allá del conocimiento ... pero así de valioso: sobre la vida.
TIEMPO que culmina con este paso de importante relevancia en mi carrera, y que espero disponerlo para retribuírselos con el mayor amor y dedicación del que sea capaz.
A todos ellos GRACIAS POR CONFIAR EN MI.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. ix
III. AGRADECIMIENTOS No es consecuente establecer una lista de las personas que pudieron colaborar conmigo en este proceso, y siempre es seguro que alguien se escapará. Pero me siento profundamente agradecido con cuatro personajes.
La visión estructurada y metodológica, que permita aclarar tanto el proceso de elaboración de una investigación formal, como la presentación de los resultados, a la luz de esta experiencia, requiere del juicio y madurez profesional de un experto. En este sentido, los aportes del Dr. Jesús Rivas Zabaleta y del Prof. Rubens Arizmendi han sido invalorables, y espero se encuentren, si no fielmente, reflejados a satisfacción.
El proceso de análisis de muestras y selección, así como su simulación fue ponderado con relativa ligereza al inicio del estudio. En este sentido, deseo expresar un particular agradecimiento al Prof. Dallas E. Jonson, de la Universidad Estatal de Kansas, quien, a través numerosos intercambios de correos electrónicos, me dedicó un tiempo valioso para la simulación de las muestras y selección de las fuentes de las restantes. Esto ha sido una piedra angular en el éxito de los experimentos desarrollados.
Finalmente, quiero agradecer al Dr. Alexander Tsyplakov, autor y desarrollador del software Matrixer, quien gentilmente le cedió una licencia a un perfecto desconocido en una latitud tan lejana de Rusia como lo es Venezuela, así como la validación de los modelos ARIMA que aquí están contenidos.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 1
1. EL PROBLEMA DE LA INVESTIGACIÓN
1.1 Planteamiento del Problema
Uno de los aspectos que buscan respuesta en la estadística es estimar los parámetros necesarios para ajustar un modelo dado a un conjunto de datos. Diferentes métodos existen para este fin, que parten de los más simples modelos univariados, tales como, máximo de verosimilitud, mínimos cuadrados y algunos métodos no paramétricos, entre otros, hasta técnicas multivariadas más especializadas, dedicadas a resolver modelos en espacios de n dimensiones, enfocándose en casos ya sea de regresión o de clasificación.
De todo el rango de problemas que cubren los métodos estadísticos, en esta disertación se hace énfasis en modelos de regresión. En investigación aplicada es muy común encontrar situaciones en las que se debe estimar o analizar la estructura del comportamiento de una variable criterio, en función de una o más variables predictoras. Cuando el criterio es una variable cuantitativa, se suele hablar de problemas de predicción o estimación, mientras que cuando la variable criterio es cualitativa o categórica, se habla entonces de problemas de clasificación.
Aún cuando existen otros métodos, tradicionalmente la solución de estos problemas se ha abordado desde la óptica de modelos estadísticos de regresión. Típicamente, para que estos modelos sean aplicables, los datos deben cumplir una serie de condiciones, entre las que destacan: normalidad e igualdad de varianzas, independencia, linealidad, normalidad de los residuales y tamaño muestral suficiente, entre otros, y cuando se disponen de funciones sobre las que aplicar los modelos, ellas deberán ser, además, continuas y diferenciables. El uso de estas técnicas descansa sobre el Modelo de Regresión General Lineal (MRGL).
El rendimiento de las soluciones dependerá del patrón de correlaciones que mantengan las predicciones entre sí, las cuales óptimamente deberán ser bajas, y entre cada predictor con la variable criterio, que deberán altas; al contrario, mientras las primeras correlaciones aumenten (lo que implicaría colinealidad) y las segundas desciendan, el rendimiento será cada vez peor.
En su naturaleza más genérica, este tipo de problema plantea el uso de tres técnicas bien específicas, a saber: regresión múltiple y correlación, la cual establece relaciones entre una variable y un conjunto de datos muestrales en un espacio de tres o más dimensiones; la regresión logística, la cual es un caso específico de clasificación basado en el MRGL, y las series de tiempo, como caso

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 2
particular de regresión, donde los datos predictores están ubicados en el tiempo y la predicción se concentra en un evento futuro, por supuesto asociado al tiempo.
Ahora bien, el problema surge cuando los supuestos de los métodos estadísticos paramétricos no se cumplen, o no se pueden demostrar, o cuando los supuestos de linealidad no pueden ser razonablemente mantenidos. En estos casos, hacen falta métodos no paramétricos que permitan relajar los supuestos que necesitan los datos muestrales o predictores, y que no se apoyen en una premisa de linealidad, al tiempo en que puedan mantener una buena calidad en estimar un valor, con base en una serie de variables muestrales. En estos casos surgen las técnicas de Redes Neuronales Artificiales (RNA) como alternativa para resolver problemas de regresión en las condiciones indicadas.
De esta forma, se dispone en principio de dos enfoques diferentes para la resolución de problemas de regresión, ya sea mediante la aplicación de Métodos Estadísticos Multivariados (MEMV) o por RNA, lo que deja escapar la pregunta: ¿cuál de ambos enfoques será mejor?
A efectos del desarrollo de esta disertación, se puede considerar apropiado suponer que no existe un método absolutamente mejor que otro; sin embargo, será válido suponer que, bajo ciertas condiciones, los MEMV serán mejores que las RNA y en otros casos, será a la inversa, sin dejar de considerar el escenario en que, a efectos experimentales, ambas pueden considerarse indiferentes.
Pitarque et. al. (1998) refiere un conjunto de trabajos empíricos que no encuentran diferencias entre los resultados hallados por la aplicación de MEMV y RNA, y otros trabajos que hablan de un mejor comportamiento de los últimos sobre los primeros. Así mismo, Chartejee y Laudato (1995) refieren un conjunto de aplicaciones de RNA a una diversidad de problemas, dada su facultad de relajar condiciones preliminares sobre los datos muestrales y agregar la flexibilidad de la no linealidad en los modelos a ser generados. Por su parte, Embrechts y Devogalaere (2000) han planteado la combinación de algoritmos de clustering (técnica basada en análisis de proximidad con fundamento estadístico) con algoritmos genéticos, como una alternativa a la aplicación de las RNA, reportando resultados favorables a su método. También, Santín González y Valiño Castro (2001) hicieron análisis sobre funciones de producción aplicando métodos de mínimos cuadrados (ordinario y corregido), análisis estocástico en frontera, y RNA del tipo Multilayer Perceptron (MLP) con retropropagación1, donde concluyen que las técnicas de RNA aplicadas proveen una alternativa viable a los métodos tradicionales.
1 Del inglés backpropagation.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 3
En el campo económico y financiero, Zekic – Susac (1999), compila una serie importante de referencias sobre la aplicación de RNA a la resolución de problemas económicos y financieros (con énfasis en predicción del movimiento de tasas de cambio y variaciones en la bolsa, fundamentados en la aplicación de la Teoría de Eficiencia del Mercado), con resultados prominentes. Mientras, González (2000) hace un estudio específico de la aplicación de RNA para predicciones macroeconómicas, donde cita una cantidad importante de referencias empíricas de la aplicación de estos métodos (en áreas tales como estimación de tasas de cambio, predicciones de movimiento en bolsa, comportamiento del producto interno bruto y funciones de producción industriales, entre otras) y su desempeño por encima de los métodos tradicionales estadísticos. De esta disciplina no escapan las predicciones basadas en series de tiempo y, a apropósito, Allende et. al. (1999) logran determinar modelos de RNA para estimar comportamientos no lineales de series de tiempo, en contraposición a los métodos tradicionales, que fundamentalmente se basan en modelos lineales.
Por otra parte, tanto la evidencia empírica como los estudios más teóricos, muestran dos aspectos que no se pueden pasar por alto con respecto a las RNA:
No hay una fórmula clara y unívoca en cuanto a la arquitectura general para el diseño de una red neuronal. Este será un problema que, por el fundamento teórico que las soporta, no será posible resolver de manera definitiva. Sin embargo, será necesario determinar métodos para analizar tales arquitecturas, sin quedar circunscritos a la simple aplicación de un modelo individual, de manera que no se elimine la posibilidad de conformar arquitecturas de múltiples RNA para modelar los fenómenos de regresión. Así, Haykin (1999) dedica un capítulo completo de su trabajo al análisis de Máquinas en Comité2, lo que permite ensamblar varias arquitecturas de RNA para la solución de problemas que puedan especializar módulos de una solución neuronal en áreas específicas. También, el trabajo empírico de Jiménez (1998) demuestra que, la combinación de salidas de varias RNA en un agregado, frecuentemente brinda mejores resultados que una red neuronal simple o individual.
Existe una debilidad metodológica para modelar fenómenos con RNA. Michie y Spiegelhalter (1994) han reportado deficiencias metodológicas en estudios comparativos de RNA y MEMV, sobre todo en el tratamiento y la preparación de la muestra, y el sesgo en la selección de los conjuntos de datos que han de ser usados en los experimentos, favoreciendo un método sobre otro, de manera implícita.
2 Del inglés, Comitee Machines.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 4
Estas referencias presentan un problema muy importante a considerar, sea el de determinar las condiciones en que la aplicación de RNA puede exceder el desempeño de los MEMV, e identificar la línea que define el nivel en que las segundas técnicas complementan a las primeras, en caso que así sea. En este sentido, no se demostraría necesariamente la supremacía de alguna técnica sobre la otra, sino que se definirían espacios de acción para cada una y un nivel adecuado de integración que conlleve a modelos aún más eficientes en la resolución de problemas de regresión.
En particular, se deberá dar respuesta a las siguientes preguntas:
¿Cuándo se deben usar técnicas de RNA o MEMV en la creación de modelos de fenómenos de regresión?
¿Cuál es una metodología que permita enfrentar el modelado de fenómenos de regresión?
¿Existe efectivamente una complementariedad entre los MEMV y las RNA?
1.2 Justificación de la Investigación
El problema planteado presenta una dualidad de enfoques. En primer lugar, los métodos estadísticos plantean la necesidad de un exhaustivo análisis de los datos, el proceso y los resultados: el modelo es explícitamente definido. Por su parte, las RNA plantean el problema a la manera de la ingeniería, es decir, la solución proviene de una caja negra que realiza el procesamiento de unos datos que son preparados de una manera específica: el modelo es implícito a la definición de la red neuronal.
En adición, y según Pitarque et. al. (1998), se ha recopilado información sobre las discrepancias entre las evidencias empíricas. Los estadísticos explican tales discrepancias empíricas aduciendo una incorrecta aplicación de las técnicas estadísticas: análisis inadecuado de los supuestos teóricos en los que se basan (homogeneidad de la matriz de covarianza y normalidad, entre otros), utilización de matrices de datos sesgadas, ausencia de procesamiento previo de los datos (ya sea en la identificación de outliers o datos faltantes), transformación de las variables, etc. Por su parte, los expertos en RNA aducen que, pese a que las redes neuronales a priori son capaces de asociar cualquier patrón de entrada con cualquier otro de salida, su rendimiento depende del ajuste heurístico de sus parámetros, a saber: número de unidades de entrada, de salida y ocultas, si procede; funciones de activación (lineal, sigmoidal, tangencial, etc.), reglas de aprendizaje (Hebb, delta, retropropagación, etc.), coeficientes de aprendizaje y momentum, entre otros; ajuste que no siempre garantiza la solución deseada, dada además la estructura de “caja negra” de este tipo de modelos, que según Pitarque et. al., reportan Cherkassky, Friedman y Wechler (1994). Esta dialéctica

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 5
también es documentada por Michie y Spiegelhalter (1994), quienes, como fue indicado más arriba, han reportado deficiencias metodológicas en estudios comparativos de RNA y MEMV, que tienden, así sea implícitamente, a favorecer un método sobre el otro.
Los estudios referenciados de naturaleza empírica, y soportados en buena medida por Haykin (1999) y Bishop (1995) de manera más formal, llevan a perfilar las siguientes asunciones y supuestos:
Las RNA han tenido una reciente popularidad en la resolución de problemas de regresión y clasificación, sobre todo en espacios de datos multivariados y funciones no lineales.
La arquitectura de las RNA es ambigua si bien genérica, sin poder determinarse un método que permita unívocamente establecer cuál es la mejor de todas las posibilidades.
La interpretación de los resultados, tanto de MEMV como de RNA, no es simple, y se opina que depende en buena medida del investigador.
Los MEMV se han podido definir de manera más genérica que las RNA: estas últimas se presentan aplicadas a problemas específicos, aunque las bases conceptuales que definen su arquitectura sean genéricas e independientes del problema que se pretende resolver. Ello genera una consecuencia aún mayor y es que metodológicamente, sólo se definen bloques muy grandes y genéricos para la construcción de las RNA, y es el análisis particular el que demuestra una aplicación específica.
Tanto las RNA como los MEMV se enfocan en problemas de regresión, correlación y clasificación estadística.
Las RNA resuelven, por su naturaleza, problemas que tienen tendencias no lineales; sin embargo, los MEMV tienden a linearizar las soluciones de los problemas que modela. Estos planteamientos son ampliamente discutidos y expuestos por Haykin (1999) y Bishop (1995).
La aplicación de RNA implica un conocimiento previo del problema que se va resolver, cosa que no necesariamente es un requerimiento para la aplicación de MEMV. Aún así, el tiempo necesario para preparar y entrenar las RNA es considerable en comparación con los MEMV. Tal planteamiento está desarrollado con cierto detalle por Statsoft (2002) y también presentado por Berson y Smith (1997), concluyendo ambos que tal conocimiento inicial es el que permite, de manera heurística, establecer los parámetros de definición de la red neuronal, y que de otra manera, sería más difícil su aplicación.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 6
Otros elementos adicionales a los escenarios descritos es que, en una muy buena medida, las técnicas de análisis estadístico son necesarias en los procesos de preparación de datos, ya sea para la aplicación de otras técnicas estadísticas o para el uso de RNA. Entre las técnicas estadísticas aplicadas en el análisis preliminar de datos, tal como lo expresa Johnson (1997), existen, entre otras:
Análisis de Componentes Principales: muy útil para cribado de datos y reducción de dimensionalidad, así como en análisis de agrupamientos.
Análisis por Factores: permite identificar relación entre variables y colabora en la reducción de dimensionalidad.
Análisis Discriminante Canónico, Análisis de Variables Canónicas y Análisis de Correlación Canónica: son técnicas que permiten la reducción de dimensionalidad.
Las propuestas de Johnson (1997), se ven reforzadas mediante otros postulados, reportados por Statsoft (2002) y Berson y Smith (1997), quienes específicamente expresan que la aplicación de las RNA exige un conocimiento preliminar del problema y que el uso de técnicas estadísticas pueden proveer los elementos básicos para obtener ese conocimiento preliminar para que, de manera heurística, se establezca la primera aproximación de los parámetros iniciales de la red neuronal.
Tanto la discusión sobre la eficiencia de los MEMV y las RNA, así como la necesidad de acudir a técnicas estadísticas básicas para las actividades de preparación y procesamiento previo de datos, presenta una arista interesante para abordar el problema y es que, en lugar de suponer la preeminencia de un método sobre el otro, resulta al menos razonable, identificar cómo unas técnicas complementan a las otras.
Esta tesis representa la base sobre la que se sustenta el desarrollo abordado por la presente disertación, y es la búsqueda de un enfoque que permita brindar un espacio adecuado a los MEMV y a las RNA en la solución de problemas de regresión específicamente, obteniendo así lo mejor de ambos mundos en la elaboración de modelos regresivos.
1.3 Objetivos
1.3.1 Objetivos Generales Con base en lo expuesto anteriormente, el objetivo de la disertación será hacer un análisis complementario y comparativo de la eficiencia de las Redes Neuronales

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 7
Artificiales y los Métodos Estadísticos Multivariados en la creación de modelos de regresión y correlación.
1.3.2 Objetivos Específicos El objetivo general propuesto lleva implícito el logro de los siguientes objetivos específicos:
Identificar las condiciones en las cuales se debe hacer uso único de métodos estadísticos multivariados y los casos que mejor son resueltos usando redes neuronales artificiales.
Determinar los métodos estadísticos multivariados que han de ser aplicados en la preparación y procesamiento previo de los datos muestrales, ya sea para continuar con redes neuronales artificiales o con otros métodos estadísticos multivariados. Esto permitirá determinar la complementariedad de ambas técnicas y el ámbito en que puede producirse la misma.
Desprender una metodología que permita abordar problemas que impliquen la elaboración de modelos de regresión y análisis de series de tiempo, usando tanto redes neuronales artificiales como métodos estadísticos multivariados.
Dado el carácter heurístico de la definición de la arquitectura de las redes neuronales artificiales, identificar criterios que puedan ser usados para acercarse al menos a una definición razonable de la misma.
1.4 Alcances
El desarrollo de la disertación estará circunscrito a la comparación de métodos estadísticos multivariados de regresión, y en particular a los siguientes:
Regresión Múltiple y Correlación.
Regresión Logística.
Series de Tiempo.
Por su parte, en cuanto a técnicas estadísticas multivariadas que apoyen la preparación y procesamiento previo de los datos, se hará uso de las siguientes técnicas, cuando apliquen:
Análisis de Componentes Principales.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 8
Análisis por Factores.
Análisis de Clasificación.
Todas estas últimas técnicas están principalmente asociadas con la reducción de dimensionalidad de los espacios muestrales, factor que, como será explicado dentro del marco teórico, es de fundamental importancia para simplificar los modelos resultantes de MEMV o RNA.
1.5 Limitaciones
Dada la complejidad para obtener muestras reales, y en virtud de la naturaleza teórica que se desea dar al estudio que busca establecer una generalización para el análisis del problema propuesto, las muestras que se utilizarán serán generadas por métodos de simulación o provendrán de muestras sensibles a estudios de investigación. Esto permite una ventaja adicional y es que se puede disponer de muestras que cumplan condiciones apropiadas y no apropiadas para aplicar los métodos, sean MEMV o RNA, brindando así criterios controlados para establecer el uso adecuado de una técnica u otra. Ello también abre el compás para investigaciones posteriores, que básicamente consistirían en tomar problemas del mundo real y aplicar las conclusiones y análisis a las que llegue el desarrollo de esta disertación; sin embargo, el análisis de datos reales, a no ser que provengan de muestras sensibles a experimentos de investigación controlada, no está contemplado en el alcance del presente estudio.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 9
2. MARCO TEÓRICO
2.1 Marco Referencial y Antecedentes
Básicamente, el problema de regresión presenta la problemática de identificar modelos que puedan analizar o predecir un conjunto de datos sobre fenómenos reales. Desde el punto de vista analítico, se pretende analizar la estructura de los datos para determinar sus características y, por decirlo de alguna manera, identificar las “leyes” que rigen su comportamiento. En esta línea de ideas, el análisis de datos para determinar grupos, la identificación de características de correlación y problemas de reducción de dimensionalidad, entre otros, caen en esta categoría.
Por la otra parte, los problemas predictivos buscan, a partir de la comprensión de la estructura subyacente en los datos muestrales, determinar las predicciones ya sea en valor o en cambio. Por ejemplo, las predicciones sobre si una acción subirá de precio, bajará o se mantendrá igual, así como determinar si una persona puede ser buen pagador en el caso de tramitación de crédito, presentan un problema de regresión, muy semejante al de clasificación, que mide cambios o categorizaciones. Pero, cuando se trata de estimar un valor en particular a partir de una muestra, como es el caso del valor de una acción, se tiene un problema completo de predicción basado en regresión.
Los tipos de problemas planteados presentan las siguientes características:
1. Buscar la significancia estadística de las diferencias entre grupos a fin de determinar si las predicciones que puedan hacerse de una variable dependiente, o criterio, con base en el conocimiento de un grupo de variables independientes, o predictoras, es significativo. Este problema puede ser visto de dos maneras: aquel que busca predecir eventos o comportamientos con el fin práctico de soportar procesos de toma de decisiones, y el otro que pretende entender y explicar la naturaleza de un fenómeno con el simple propósito de probar o desarrollar teorías. Este es el ámbito de los Modelos de Regresión y Correlación Múltiple (MRCM en lo adelante).
2. Modelar la probabilidad de que una unidad experimental caiga en un grupo particular, con base en la información medida en la propia unidad, es decir, construir modelos que se usen con fines de discriminación. Tales problemas se resuelven mediante Modelos de Regresión Logística (MRL en lo adelante). Aunque este problema luce semejante al de MRCM, tiene la particularidad de que la variable dependiente, en lugar de ser continua, toma valores discretos específicos y finitos. Muchas veces este método es

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 10
preferido sobre el Análisis Discriminante, dada las restricciones que este último modelo impone, tal como la condición de normalidad sobre cada categoría de variables de agrupación y que los predictores deben tener la misma varianza y covarianza, sin olvidar el principio de que la discriminación ocurre contra fronteras lineales.
3. Finalmente, cuando la variable tiempo juega un papel fundamental en los datos objeto de análisis, entonces los Modelos de Series de Tiempo (MST en lo adelante) son la solución tradicionalmente aplicada. Aquí se busca entender o predecir el comportamiento de una variable cuyos cambios están sujetos a su comportamiento en el tiempo. Este es un caso específico de regresión, donde la variable predictora es la misma variable dependiente, sólo que los valores predictores están dados en momentos previos al tiempo en que se desea analizar al criterio.
Antecedentes en la aplicación de estos métodos estadísticos multivariados en la resolución de esos tipos de problemas son simplemente tan innumerables que, cuando se aplican a las ciencias del comportamiento económico, se compilan en una disciplina en sí misma: la econometría. Por otra parte, las ciencias sociales y de comportamiento, así como análisis biológicos han hecho uso extensivo de estas técnicas a lo largo de los últimos 25 años. Grim y Yarnold (1995 y 2000) así como Johnson (1998) han reportado suficientes ejemplos de la aplicación de estos modelos.
Sin embargo, estos modelos estadísticos multivariados tienen importantes premisas que han de ser consideradas al momento de realizar el diseño del experimento, muchas de las cuales no siempre pueden ser satisfechas:
La más importante de todas es que, en todos los casos citados, siempre se aproxima la solución por un modelo lineal, lo cual evidentemente no siempre, por no decir casi nunca, representa la realidad.
Sobre las variables predictoras también se imponen condiciones relevantes que, al no cumplirse, los resultados no pueden ser considerados como valederos. En el MRCM se han de considerar las siguientes premisas:
o La multicolinealidad entre los predictores representa un problema importante en la aplicación del MRCM. Se entenderá por multicolinealidad las interrelaciones, medidas en términos de correlación, entre los predictores. En este caso, los coeficientes de estos predictores no necesariamente explican el grado de contribución que tienen sobre los cambios de la variable dependiente. Pero al mismo tiempo que se desea baja correlación entre los predictores, es altamente deseable que exista una alta correlación entre cada predictor y el criterio (o variable dependiente).

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 11
o A efectos de no caer en errores de especificación, debe evitarse violar cualquiera de las siguientes tres condiciones: todos los predictores relevantes para el criterio han de ser incluidos en el MRCM, las relaciones entre las variables han de ser lineales3 y predictores irrelevantes no pueden ser incluidos4.
o Los errores de medición muchas veces son consecuencia de un inadecuado modelo del fenómeno empírico. Muchas veces se tiende a incluir factores atenuantes, pero siempre es preferible que se realicen ajustes en las variables que son tomadas, e incluso reemplazarlas, a fin de asegurarse que ellas representen realmente lo que se desea medir.
o Los MRCM sólo pueden predecir o analizar (en el contexto descrito anteriormente) criterios continuos, es decir, no pueden tratar con criterios categóricos ni nominales, aunque ello puede ser resuelto por la vía de codificación.
o Finalmente, los residuales, es decir la diferencia entre el valor real del criterio y el obtenido por la aplicación del modelo, han de cumplir ciertas condiciones: deben tener media cero, deben cumplir con el principio de homoscedasticidad5 entre ellos, no estar correlacionados entre ellos si, ni con los predictores, y estar normalmente distribuidos.
La aplicación del MRL también tiene sus asunciones:
o La variable criterio ha de tomar valores discretos finitos. Generalmente se trata de unos pocos valores: 2, 3 o 4. Cada uno de esos valores tiene una probabilidad de ocurrencia.
o Los resultados del experimento deben ser estadísticamente independientes.
o El modelo debe ser definido de forma tal que no ocurran errores de especificación, en el sentido en que fue definido previamente para el MRCM.
3 Aún más allá: esas relaciones han de estar representadas por funciones continuas y diferenciables.
4 Sólo un caso permite incluir variables irrelevantes y es cuando se incluyen supresores en el modelo de regresión, tal y como lo exponen Grim y Yarnold (1995).
5 Homoscedasticidad entre variables se refiere a que debe existir la misma varianza en los errores.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 12
o Las categorías bajo análisis deben ser mutuamente excluyentes.
o Las pruebas de hipótesis del MRL requiere muestras grandes, entendido esto como de un mínimo de 50 casos por predictor, según lo reportan Grim y Yarnold (1995)6. Ello induce un problema importante de dimensionalidad, que implica un cuidadoso análisis sobre las variables predictores antes de formular el experimento y consecuente MRL.
El caso de las series de tiempo ha de ser analizado fundamentalmente para pasar las pruebas de estacionariedad, ya sea por el criterio de la función de autocorrelación o por el de raíces unitarias, los problemas de cointegración y los problemas de regresión espuria.
Estas premisas y criterios se traducen en un mensaje importante: ser cuidadosos al momento de estructurar el experimento e interpretar los resultados; sin embargo, las limitaciones de linealidad y condiciones estadísticas pueden ser difíciles de salvar en la práctica.
Es por ello que se han planteado métodos alternativos para la resolución de estos problemas, que permitan eliminar muchas de las premisas y poder ser más efectivos en la obtención de modelos para, particularmente, los problemas descritos.
Diferentes investigaciones han comenzado a recorrer este camino y es principalmente porque el fundamento de la RNA es su capacidad de aprender. Este fundamento ha sido estudiado formalmente desde McCulloch y Pitts en 1943, quienes proponen el primer modelo para una red neuronal. Este fue el principio sobre el cual Hebb desarrolla, en 1949, la primera regla formal de aprendizaje basada en la modificación de las sinapsis entre las neuronas, mediante la exposición a casos que contenían la pregunta y la respuesta, es decir, para un evento dado, se entrenaba un red neuronal a partir del resultado de ese caso. Esta fue la base sobre la cual se desarrollaron los modelos computacionales para sistemas adaptativos y de aprendizaje, que quizá consigue su mejor exponente en los trabajos de Rochester, Holland, Haibt y Duda en 1956. En ese mismo año, Uttley demostró que una red neuronal con sinapsis modificables podía aprender a clasificar patrones binarios en sus clases correspondientes.
Luego Rosenblatt en 1958 introdujo el concepto del perceptron, que luego dio lugar a las redes de múltiples capas o Multilayer Perceptron (MLP), una de las
6 Este valor es reportado por Grimm y Yarnold (1995, pág. 221) al referirse a una investigación realizada por Aldrich, J. H. Y Nelson, F. D., y documentada en Linear propability, logit and probit models, Beverly Hills, CA: Sage, 1984.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 13
más populares y difundidas hoy en día. Este planteamiento fue respondido en 1960 cuando Widrow y Hoff introducen el Algoritmo de Mínimos Cuadrados, que se diferencia del perceptron básicamente en la manera en que es entrenado.
Luego, en 1976, van der Malsburg y Willshaw introducen el modelo de Self-organizing Maps, como otro método alternativo para la gestión de RNA, el cual evolucionó al modelo de Kohonen en 1982, entre los más usados hoy día.
Fue más recientemente, en 1988, cuando Bromead y Lowe desarrollan redes neuronales basadas en funciones de base radial (Radial Basis Functions - RBF) las cuales surgen como una alternativa al MLP.
Estos eventos, por sólo indicar unos pocos de los más significativos, y gracias a las capacidades de cálculo de hoy día, han generado suficiente investigación teórica y empírica sobre el uso de las RNA en diferentes campos, entre ellos, el estadístico.7
Haykin (1999) compila algunos de los beneficios más importantes que se desprenden del uso de RNA, entre los que resaltan:
No Linealidad. Las neuronas artificiales pueden ser lineales o no lineales Esta propiedad es de suma importancia por la cantidad de fenómenos reales que se presumen no lineales.
Mapa entre las entradas y salidas. Este es el principio fundamental del aprendizaje en una red neuronal bajo una estrategia supervisada, gracias a la cual, cada impulso tiene asociado su respuesta, lo cual permite modificar las sinapsis entre la neuronas artificiales para adaptar su respuesta y aprender de los ejemplos. Este proceso, que parece partir del concepto de los métodos estadísticos no paramétricos, es muy poderoso, puesto que, virtualmente, una RNA puede ser entrenada para resolver prácticamente cualquier tipo de problema, dadas las condiciones apropiadas de arquitectura.
Adaptabilidad. De la característica anteriormente descrita deviene la capacidad de las RNA de adaptar los pesos de sus sinapsis a medida que se exponen a cada vez más casos, con lo que su aprendizaje, y por ende sus respuestas, es adaptable.
Calidad de la Respuesta. Las RNA no sólo proveen una respuesta a un estímulo, sino que además pueden proveer el grado de confianza en la
7 Una exposición bastante detallada de la evolución histórica de la RNA es presentado por Haykin (1999)

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 14
decisión. Cuando la clasificación de un patrón es dudosa, y ello puede efectivamente ser conocido, se enriquecen nuevos casos para re-entrenar posteriormente la RNA para que aprenda a responder a los mismos.
Información de Contexto. Como todas las neuronas de una RNA están de una forma u otra interconectadas, los efectos que los datos producen sobre la red para que puedan producir información, afectan a virtualmente todo el sistema, con lo que ese efecto queda diseminado a lo largo de toda la red.
Uniformidad de Análisis y Diseño. Las RNA son, por definición, procesadores universales de información, dado que los principios, terminología y principios de arquitectura de las RNA son independientes del problema propuesto para ser resuelto. El principio básico y universal es la neurona, contra la cual se definen teorías y reglas de aprendizaje de aplicación en cualquier RNA. Además, el concepto de construcción modular parte de la neurona propiamente dicha, hasta diferentes modelos de RNA.
Estos beneficios han sido observados por investigadores en el análisis de problemas que, tradicionalmente, eran abordados con MEMV y se han reportado resultados que no dejan de llamar la atención.
Chatterjee y Laudato (1995), precisamente basándose en las capacidades de las RNA para eliminar las imposiciones de linealidad y otras de índole estadística, analizaron entre otros, problemas de aproximación de funciones, lo cual generó la ventaja de que no era necesario acometer el problema de seleccionar la función, puesto que ello fue dejado implícitamente a la arquitectura de la RNA. Utilizando una arquitectura de red MLP retro-propagada lograron resultados importantes en aproximación de funciones. Finalmente, llegan a la conclusión de que las RNA no deben ser consideradas una panacea sino un complemento a los métodos regresivos, pero resaltan sus bondades cuando se disponen de muestras de datos grandes de alta dimensionalidad, sin que se conozca un modelo subyacente a los datos.
En el trabajo de Kilmer y Smith (1999), se aplicaron MEMV y RNA para el análisis del tamaño de lote óptimo en un problema de inventarios, que se traduce en un problema de regresión, hallando que las RNA exceden el comportamiento de los MEMV para el análisis de modelos regresivos de primero y segundo orden.
Uno de las estudios más curiosos, ya citado anteriormente, es el de Pitarque et. al. (1998), donde se crean muestras para comparar MEMV y RNA. Ellos obtuvieron que, sólo en tareas de predicción cuantitativa y bajo condiciones óptimas de aplicabilidad, los MEMV se comportaron mejor que las RNA. Este resultado efectivamente plantea un estudio cuidadoso de las características de las muestras antes de decidirse por un método u otro en problemas de regresión.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 15
Sin embargo, en problemas de clasificación discriminante, por regresión logística, las RNA produjeron siempre mejores resultados.
Otro estudio realizado por Giles et. al (2000) llega a la conclusión de que, mediante la aplicación de RNA lograron cubrir los problemas de predicciones de series de tiempo con datos que presentaban ruido significativo, así como condiciones de no estacionariedad, probado en el análisis de tendencia en el tipo de cambio de cinco monedas diferentes con respecto al dólar.
También, y específicamente en el campo de la regresión logística, Schumacher et. al. (1995), llegan a una conclusión más bien de complementariedad entre las técnicas de regresión logística y RNA, y que el uso de una sobre la otra dependerá de las condiciones específicas de la muestra y adecuación a las exigencias de cada método.
Para concluir esta lista de antecedentes, Zekic-Susac (1999) reporta casos de aplicación exitosa de RNA en análisis de problemas de regresión financiera, y específicamente, hace un estudio de aplicación de RNA a un problema predictivo de tasas de cambio, con resultados satisfactorios.
Sin embargo, todos los estudios hacen un énfasis importante en los esfuerzos necesarios para entender y preparar los datos, para lo cual, el análisis de correlación, análisis de componentes principales, así como estudios característicos de la muestra, son necesarios a fin de preparar un experimento adecuado y sobre todo, trabajar en un orden de dimensionalidad que subsane los problemas propios, tanto de los MEMV como de las RNA.
Esta muestra de antecedentes son los que han llevado al autor a realizar un estudio que cubra los objetivos propuestos en esta disertación y que, finalmente, pretenden brindar un curso de acción de cuándo escoger un MEMV o un RNA en problemas de regresión y correlación, y cómo pueden ellos complementarse.
2.2 Bases Teóricas. Parte 1: Análisis Estadístico Multivariado
Esta sección presenta y describe los elementos de análisis multivariado que son aplicables tanto en labores de preparación de datos como en análisis derivados del Modelo de Regresión General Lineal.
El objeto principal de establecer estos conceptos es fijar la base metodológica para los experimentos que serán desarrollados en los capítulos posteriores, a fin de efectuar las comparaciones entre el rendimiento de estos métodos y los que se basan en redes neuronales.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 16
2.2.1 La Distribución Normal Multivariada Los métodos de análisis multivariado funcionan muy bien cuando el vector de variables aleatorias proviene de muestras de datos normales multivariadas. Para ello, se dice que un vector de variables aleatorias:
px
xX
1
tiene distribución normal multivariada si en la expresión:
p
iiipp
p
p xaxaxax
xaa
111
1
1 xa (2.2.1.1)
para todos los conjuntos de valores seleccionados de los elementos del vector a, cada xi tendrá una distribución normal univariada. Nótese que parece muy sensato pensar que si todas las variables del vector X tienen distribución normal univariada, el vector tendría distribución normal multivariada. Sin embargo, esto no ha sido demostrado matemáticamente y de hecho existen contraejemplos8.
El vector de medias se denotará con la letra µ y la matriz de varianzas y covarianzas de X se denotará con la letra Σ , y quedan definidas de la siguiente manera:
ppxE
xEE
11
)(
)()x(µ (2.2.1.2)
ppp
p
ECov
1
111
µxµx)x(Σ (2.2.1.3)
donde )( iii xVar y ),( jiij xxCov
El coeficiente de correlación entre dos variables será definido como:
8 Ver Hogg and Craig, quienes suministraron un ejemplo en que cada variable está normalmente distribuida pero todas en conjunto no lo están.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 17
jjii
ijij
(2.2.1.4)
por lo que matriz de correlación P del vector X será:
1
1P
1
1
p
p
(2.2.1.5)
Si dos variables se distribuyen de manera independiente entonces su correlación y covarianza será igual a cero. La inversa de esta proposición no será siempre verdadera, y se cumplirá si las dos variables tienen distribución normal bivariada conjunta.
Si se toma el coeficiente de correlación de una muestra, la matriz de correlación muestral se denotará como R y las letras se sustituyen por “r”, donde este último es calculado con base en las estimaciones muestrales de varianza y covarianza. En fórmulas:
n
rxn1µ (2.2.1.6)
µxµx1
1Σ rrnn
(2.2.1.7)
21
1ˆ
niriii xx
n (2.2.1.8)
n
jrjiriij xxxxn 1
1 (2.2.1.9)
jjii
ijijr
ˆˆˆ
(2.2.1.10)
Cuando se calcula la correlación entre dos variables se está midiendo la relación lineal entre ellas. De esta manera, cuando el coeficiente de correlación es cercano a cero, sólo indica que no existe una relación lineal entre las variables, aunque pueda existir una relación no lineal entre ellas; sólo significará que no hay relación si ambas variables tienen una distribución normal bivariada conjunta.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 18
Por otra parte, para probar que el cálculo de correlación es significativamente distinto de cero, y partiendo de que las variables involucradas tienen una distribución normal bivariada, se acude al estadístico:
21
2
ij
ijij
r
nrt
(2.2.1.11)
Este estadístico tiene distribución t de Student con n – 2 grados de libertad, por supuesto cuando i es diferente de j. Sin embargo, la validez de estas pruebas está más dada por el tamaño de la muestra que por la magnitud del coeficiente de correlación.
En este caso se deben tomar ciertas consideraciones:
Cuando se manejan datos en un ambiente controlado, por ejemplo, en un laboratorio, se pueden obtener correlaciones del orden de 0.9; pero si se está trabajando con datos prácticos, puede ser difícil obtener valores de 0.7. Incluso, correlaciones que en valor absoluto estén en el orden de 0.6 son muy buenas generalmente, y si se trata con personas, 0.5 puede ser un resultado aceptable9.
No se deben calcular correlaciones con muestras de tamaño menor que 12. Nótese que se pueden esperar correlaciones significativamente distintas de cero sólo por azar en un orden del 5 al 10%. Esta consideración es también relevante al momento de analizar la cantidad de correlaciones significativamente distintas de cero.
Fisher encontró una forma más exacta de calcular intervalos de confianza para coeficientes de correlación cuando la muestra es de tamaño mayor que 25 de dos variables que tienen distribución normal bivariada. Específicamente, la variable
)(tanh rinvU tiene distribución aproximadamente normal con media )(tanh rinv y varianza 31 n con n mayor que 25. De esta forma un intervalo
de confianza para está dado por:
31
tanhtanh3
1tanhtanh 22 n
zrinvn
zrinv (2.2.1.12)
Ahora bien, como técnica de clasificación, la correlación puede ser utilizada para identificar relaciones subyacentes entre grupos de variables. Aunque es un
9 Estos criterios son propuestos por Jonson (2000).

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 19
método relativamente poco especializado, permite tener una visión preliminar de la muestra de datos que se analiza, por lo que se considera exploratorio.
De esta forma, cuando se tienen numerosas variables en un experimento, se puede estudiar la correlación existente entre grupos de variables e identificar reglas que permitan simplificar los análisis, considerando grupos más pequeños de variables correlacionadas.
2.2.2 Análisis de Componentes Principales (PCA) Es un procedimiento matemático que transforma un conjunto de variables correlacionadas en un conjunto menor de variables no correlacionadas llamadas componentes principales. Es útil realizarlo en diferentes circunstancias:
Permite cribar datos, identificando grupos correlacionados, ayudando a determinar outliers y otras anormalidades muestrales.
Permite ejecutar agrupamiento de variables compatibles entre sí, en subgrupos.
Es un paso preliminar que puede ayudar en gran medida al momento de realizar análisis factorial.
Cuando existe alta correlación entre las variables predictoras en un proceso de regresión, caso conocido como multicolinealidad de las variables, el análisis de componentes principales puede ayudar a determinar esta situación.
Dos son los objetivos fundamentales al realizar un análisis de esta índole:
Descubrir la verdadera dimensionalidad de los datos. Aún cuando se disponga de p variables en un experimento dado, es importante determinar si la dimensión real es p o menor. En caso que sea menor, el problema de análisis de las variables puede ser simplificado a un número menor de variables subyacentes, que describen el comportamiento de todas las variables, sin perder información.
El análisis de componentes principales siempre implicará la creación de nuevas variables. Pero estas variables han de ser entendidas en el contexto de proveer información adicional o pistas de agrupamiento de variables, más que la generación de nuevas variables significativas en sí mismas, caso que es el menos frecuente. La interpretación de las componentes principales no es necesariamente el objetivo primordial, y si se puede lograr tal interpretación, eso ha de ser considerado un caso excepcional.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 20
El proceso de selección de componentes principales, en general, sigue los pasos que se indican a continuación:
1. Las componentes principales no han de estar correlacionadas.
2. La primera componente principal debe explicar la variabilidad de los datos tanto como sea posible.
3. Cada componente principal subsiguiente debe tomar en cuenta tanta variabilidad en los datos como sea posible.
Para lograr la definición de las componentes principales hará falta acudir al álgebra lineal10.
La primera componente principal se define por µxa11 y en donde a1 se elige de forma tal que la varianza de µxa1 se maximice para todos los vectores a1 que satisfagan 1aa 11 . Ese valor máximo de la varianza es el eigenvalor11 1 más grande de , el cual ocurre cuando a1 es un eigenvector de correspondiente con 1 y que satisface que 1aa 11 .
De manera análoga se identifican las siguientes componentes principales, siempre haciendo referencia a todas las combinaciones lineales del vector de variables restantes.
De esta forma p 21 representan los eigenvalores ordenados de , y
p21 a,,a,a denotan los eigenvectores normalizados correspondientes de . Ante estos principios se puede afirmar que:
Dos componentes principales no están correlacionadas si y sólo si sus eigenvectores de definición son ortogonales entre sí.
La varianza de la j-ésima componente es el j-ésimo eigenvalor ordenado.
La traza de , pptr 2211)( . Mide la variación total de las variables originales.
10 Se recomienda el texto Álgebra Lineal de Keneth Hoffman y Ray Kunze. En él se podrá observar una exposición extensa sobre álgebra de matrices, y en particular, sobre valores propios y vectores propios, denominados en algunos textos como eigenvalores y eigenvectores, respectivamente.
11 También conocido con el nombre de Valor Propio. Los eigenvectores se conocen también como Vectores Propios.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 21
Por definición, ptr 21)( , por lo que la variación total de las componentes principales explica en igual medida la variación total de las variables originales.
En consecuencia a lo anterior, la relación trj mide la proporción de
variabilidad total en las variables originales que es explicada por la j-ésima componente principal.
Sea rx el vector correspondiente a las variables medidas en la r-ésima unidad experimental. Entonces, la calificación de la j-ésima componente principal de la r-ésima unidad experimental será µxa j rjy .
Los valores de un eigenvector no pueden ser comparados con los de otro, dado que todos ellos son normalizados, y en consecuencia tienen una longitud de 1.
Los valores necesarios de la matriz de varianzas y covarianzas, así como de la media, se toman de sus estimaciones muestrales.
Parta seleccionar el número de componentes principales existen dos métodos que se indican seguidamente.
Supóngase que se desea tomar en cuenta %100 de la variabilidad total de las variables originales y dígase que d es el número de componentes principales que se deben utilizar para lograr esa variabilidad. Entonces, calcúlese
trV k 21 , donde k < p, y d será el menor valor de k para el cual, por
primera vez se sobrepase el valor de . Recuérdese que un 95% de variabilidad puede ser fácilmente alcanzable en datos de laboratorio, pero un 70% de variabilidad puede ser difícil de alcanzar si se trata con datos de personas. Además, mientras más componentes principales, menos útil es el análisis.
El segundo método parte de la gráfica de SCREE12. En este método se grafican los números de los eigenvalores ordenados de mayor a menor sucesivamente en el eje de las absisas, contra sus valores en el eje de las ordenadas. Cuando los puntos de la gráfica tienden a nivelarse, estos eigenvalores tendrán valores suficientemente cercanos a cero como para poder ignorarse., incluso porque pueden estar midiendo simplemente ruido aleatorio.
12 Scree, geológicamente, significa los restos que aparecen en las partes más bajas de una ladera rocosa.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 22
De esta manera la dimensionalidad estará medida por el eigenvalor más pequeño de los valores grandes. En la gráfica de SCREE que se muestra más abajo, la dimensionalidad del espacio de variables sería de tres, en función de los valores que allí aparecen reflejados.
Figura 1. Gráfico Scree para análisis de componentes principales
Hay un conjunto de observaciones que se debe agregar al estudio de componentes principales, según se indica a continuación:
En primer lugar, el objeto del PCA no es eliminar variables, sino lograr un entendimiento de la verdadera dimensionalidad del experimento. Cuando las variables originales están poco correlacionadas, no tiene mucho sentido aplicar este tipo de análisis y siempre las variables originales son necesarias para calificar o evaluar las componentes principales.
Las variables que intervienen en el PCA deben estar medidas en las mismas unidades, o en el peor de los casos, comparables.
Las variables que intervienen en el PCA deben tener una varianza en magnitudes muy semejantes.
Estas últimas dos condiciones es lo que se define como evaluar las variables “sobre un fundamento igual”. Si ello no ocurre, se aplica un PCA sobre la matriz de correlaciones R, lo cual asume que las variables están normalizadas. Los cálculos se realizan de manera análoga a la forma como se realizaron sobre la matriz de varianzas y covarianzas, con la única excepción que la calificación de las componentes principales se realiza sobre el vector de variables normalizado y no sobre el vector de variables original.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 23
Para seleccionar la cantidad de componentes principales se aplican los mismos métodos descritos anteriormente. Además se puede usar uno adicional, que consiste en seleccionar los eigenvalores que sean mayores que 1. La razón de esto es que si un componente principal no puede explicar más variación que una variable por sí misma, entonces es probable que no sea importante. Nótese que esto aplica sólo cuando las variables están normalizadas, por lo que su varianza es 113.
Otro aspecto importante es determinar si efectivamente, en caso que los datos provengan de una distribución normal multivariada, las variables respuesta son independientes, es decir, no están correlacionadas. Esta prueba es importante puesto que si las variables no están correlacionadas no aplica un PCA. Tal situación ocurriría si P = I. Para probar esta hipótesis nula, se calcula el estadístico V, de alguna de las siguientes maneras:
RV
**2
*1V p ,es decir, el producto de los eigenvalores de la matriz de
correlación.
pp
p
2211
21V
, donde los lambda son los eigenvalores de la matriz de
varianzas y covarianzas.
Para valores grandes de n (mayores que 25), se rechaza la hipótesis nula (es decir, se puede aplicar un PCA) si:
2)1(,Vlog ppa donde 6/)52(1 pna
Si no se puede rechazar la hipótesis nula, no se debe aplicar un análisis de componentes principales.
2.2.3 Análisis por Factores (FA) Se pudo observar que el PCA busca explicar la variabilidad de las variables involucradas en un experimento. El Análisis por Factores (FA de sus iniciales en inglés Factor Análisis) se enfoca en explicar la covarianza o correlación entre las variables, a fin de identificar un nuevo conjunto de variables no correlacionadas, denominadas factores subyacentes, con el objeto de explicar de mejor manera las
13 Este es el método que utiliza SPSS 9.0 para hacer el análisis de componentes principales.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 24
variables del experimento. Esas nuevas variables han de ser evaluadas o calificadas para cada unidad experimental.
La resolución de un modelo FA no es única, por lo cual ejerce importante influencia el criterio del investigador en la interpretación y selección de los factores. Ello trae consigo una de las críticas más serias a esta técnica de análisis, puesto que el juicio puede sesgar los resultados finales del análisis.
Las metas del análisis por factores incluyen las siguientes:
Determinar si existe un conjunto de variables no correlacionadas más pequeño, que explique las relaciones entre las variables originales.
Determinar el número de variables subyacentes.
Interpretar las nuevas variables.
Evaluar las unidades experimentales con base en las nuevas variables subyacentes.
Usar estas variables en otros análisis de datos posteriores.
El modelo FA se expresa matricialmente de la siguiente manera:
ηfx (2.2.3.1)
donde:
pxxx ,,,x 21
mfff ,,,f 21 , con I0,f , es decir, normal con media 0 y varianza 1, representada por la matriz Identidad. Se denominan factores comunes.
p ,,,η 21 , con Ψ0,η en donde pdiag ,,, 21 . jη representa la variación residual específica de la j-ésima variable y se denominan factores específicos. jΨ es la varianza de esa j-ésima variable.
pmp
p
1
111
Λ . Esta matriz de multiplicadores, denominados cargas
factoriales jkλ , mide la contribución del k-ésimo factor común (f), a la j-ésima variable respuesta.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 25
f y η son independientes.
La ecuación principal de FA se puede determinar de manera equivalente como:
ΨΛΛΣ (2.2.3.2)
ó también:
ΨΛΛR 14 (2.2.3.3)
En caso que se tome R debe recordarse que se está trabajando sobre la base normalizada de las variables originales.
Para empezar a establecer una hipótesis sobre el número de factores, es conveniente comenzar con el número de componentes principales. Otros criterios para determinar el número definitivo de factores son:
1. Descartar los factores triviales, es decir, aquellos que tienen una y sólo una de las variables originales cargando sobre el factor. Esto carecería de sentido, pues se está explicando con un factor una variable, en cuyo caso, es mejor acudir a la variable original.
2. Analizar las Comunidades. La proporción de la varianza de xj que se explica por los factores comunes se llama comunidad de la j-ésima variable respuesta. Muchos investigadores creen que se debe hacer que las comunidades tengan valores cercanos a uno, lo cual equivale a que las varianzas Ψ sean cercanas a cero. No hay nada en el modelo que implique ello, y si se busca este objetivo, entonces se acercará el FA al PCA.
3. Si se dispone de una matriz de diferencias entre las correlaciones observadas entre las variables y las que se producen por la solución FA, se pueden obtener algunos criterios. Si las diferencias son pequeñas, podría existir la posibilidad de disminuir el número de factores; si algunas diferencias son grandes (muchas mayores que 0,25 y algunas mayores que 0,4), entonces podría ser necesario incrementar el número de factores.
4. Si se dispone de las correlaciones parciales entre las variables después de hacer el ajuste respecto a los factores comunes, y si alguna de las correlaciones parciales es grande, entonces debe considerarse el incremento de la cantidad de factores; en caso contrario, si todas las
14 R representa la matriz de correlación muestral, equivalente a P.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 26
correlaciones parciales son pequeñas, entonces se podría intentar la reducción del número de factores.
Existen diferentes métodos para análisis de FA, de los cuales son los más normales:
El método de factores principales sobre R, el cual calcula los PCA y sigue con el análisis de agrupación.
El método de máxima verosimilitud.
Dado que finalmente se desea identificar las variables tipificadas por un factor, es normal que sea necesario refinar el análisis. Ello se logra mediante los métodos de rotación, donde se busca que tantas cargas de los factores como se pueda estén cercanas a cero, maximizando tanto como sea posible las demás. Con ello se busca que las variables no se carguen mucho sobre más de un factor. Los métodos de rotación pueden ser ortogonales u oblicuos.
Existen diferentes pruebas y criterios que aplican en la realización de un FA. El primer elemento que lo apoya es el valor del determinante de la matriz de correlación, cuyo valor, si es muy cercano a 0, permite concluir que no se trata de una matriz identidad y que en últimas significa que existe correlación entre las variables estudiadas.
Dos estadísticos adicionales son usados para probar la validez de correlación de variables. El test de Bartlett se obtiene de una transformación ji-cuadrada del determinante de la matriz de correlación. Mientras más alto sea su valor, y menor su significancia, más improbable es que la matriz de correlación sea una matriz identidad, en cuyo caso se aconseja a proceder con un FA.
La otra prueba, el test KMO (Kaiser – Meyer – Olkin), compara los coeficientes de correlación de Pearson con los coeficientes de correlación parcial entre las variables. Valores cercanos a la unidad, obtenidos de la aplicación de una prueba KMO, recomiendan un FA. La interpretación de KMO propuesta por Kaiser es como sigue:
KMO > 0,9: excelente
KMO > 0,8: bueno
KMO > 0,7: aceptable
KMO > 0,6: mediocre o regular
KMO > 0,5: malo

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 27
KMO < 0,5: inaceptable.
Otro instrumento de análisis es la matriz de componentes. Esta matriz presenta los coeficientes utilizados para expresar cada variable en términos de los factores del modelo. Estos resultados son interesantes pues permiten identificar cuáles de los factores explican mejor la variabilidad de las variables, buscando con mayor énfasis que el primer factor explique la mayor cantidad de variables posibles. Ello ayudará a determinar la cantidad de factores que se está seleccionando.
Otro instrumento de análisis es la matriz de correlaciones reproducidas. Esta matriz muestra en su primera parte, la capacidad de los factores en explicar cada variable, es decir, las comunidades. En su parte inferior, muestra los residuales de las correlaciones observadas y las correlaciones estimadas, las cuales, según se dijo, se espera que estén cercanas a cero. Si hay muchas correlaciones cercanas a cero, es una sugerencia que se debe disminuir el número de factores hasta una proporción que no contradiga la regla práctica ya explicada.
El paso final en un FA consiste en la determinación de las puntuaciones factoriales, es decir, la generación de las nuevas variables, basadas en los factores, que explica el comportamiento de las restantes, y a partir de las cuales se procedería con los análisis posteriores.
Es importante recordar que, cuando se hace FA sobre la matriz de correlaciones, se trabaja con las variables normalizadas, por lo que las nuevas variables estarán dadas de esa manera.
Con estas puntuaciones se generan las nuevas variables del modelo a evaluar, las cuales siempre serán menos que las iniciales, con lo que se logra una simplificación importante del análisis de datos dada una reducción en la dimensionalidad de la muestra.
2.2.4 Regresión y Correlación Múltiple El Modelo de Regresión General Lineal (MRGL) está definido mediante la ecuación siguiente:
kkxxxy xxxk
22110,,,| 21 (2.2.4.1)
En este caso, Y es la variable aleatoria que se desea predecir en términos de los valores dados kxxx ,,, 21 , donde k ,,,, 210 son los coeficientes de regresión múltiple.
Este mismo modelo puede ser definido de manera más compacta y conveniente usando notación matricial. Sean:

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 28
nknn
k
k
xxx
xxxxxx
21
22221
11211
1
11
X ,
ny
yy
2
1
Y y
k
ˆ
ˆˆ
1
0
B
X es una matriz n x (k + 1) que contiene los valores dados de las ijx , a la cual se le agrega una columna de 1s para dar cabida a los valores constantes s. Y es un vector n-dimensional, que consiste de los valores observados de y, los cuales siguen una distribución normal multivariada, y B es un vector (k + 1)-dimensional que consiste de las estimaciones de mínimos cuadrados de los coeficientes de regresión.
Entonces, las estimaciones de mínimos cuadrados de los coeficientes de regresión están dados por:
B = ( X’X )-1 X’Y (2.2.4.2)
donde X’ es la transpuesta de X y ( X’X )-1 es la inversa de X’X.
Por otra parte, el estimador de máxima verosimilitud para la varianza será:
nYXBYY
(2.2.4.3)
Además.
1ˆ
ˆ
kncn
tij
ii
para i = 0, 1, 2, ..., k, (2.2.4.4)
es el valor de una variable aleatoria que tiene distribución t con n – k – 1 grados de libertad, donde ijc es el valor que se encuentra en la celda correspondiente a la i-ésima fila y j-ésima columna de la matriz (X’X)-1. Con esta base se pueden probar hipótesis acerca de uno de los múltiples coeficientes de regresión.
También,
1
1ˆ
0
knn
yt0
10
0
XX)(X'X'XB'
(2.2.4.5)

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 29
es el valor de una variable aleatoria que tiene distribución t con n – k – 1 grados de libertad, y permite probar hipótesis acerca de las predicciones.
En adición, la Prueba de Durbin Watson es quizá la más conocida y popular para detectar correlación lineal. Este estadístico está dado por la expresión:
n
tt
n
ttt
u
uud
1
2
2
21
(2.2.4.6)
Esta prueba se basa en los siguientes supuestos:
El modelo de regresión incluye el término intercepto, es decir, el coeficiente de corte con el eje de las ordenadas.
Las variables explicativas se mantienen fijas en el muestreo repetido, es decir, no son estocásticas.
Las perturbaciones se generan mediante un esquema autorregresivo de primer orden.
No aplica en modelos autorregresivos.
No hay observaciones faltantes en los datos.
Bajo estas premisas, se muestran a continuación las reglas de decisión. Se parte entonces de calcular la regresión, bajo las premisas dadas, y determinar el valor del estadístico d, obteniendo también los límites dL y dU dado en las tablas de Durbin – Watson. La regla de decisión se expresa como sigue:
Hipótesis Nula Decisión Si y sólo si
No autocorrelación positiva Rechazar 0 < d < dL
No autocorrelación positiva No tomar decisión dL<= d <= dU
No correlación negativa Rechazar 4 – dL <= d <= 4
No correlación negativa No tomar decisión 4 – dU <= d <= 4 - dL
No autocorrelación, positiva o negativa
No rechazar dU < d < 4 - dU

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 30
Finalmente, es necesario resaltar algunas propiedades y consideraciones generales al MRCM, según se muestra a continuación:
A efectos predictivos, el MRCM es prácticamente hecho a la medida de la muestra que se usa en el estudio, por lo que la validez de sus predicciones no son necesariamente apropiadas en otras muestras de la misma población. Por ello, como parte del diseño experimental, se usan validaciones cruzadas a fin de probar la validez del modelo. En este caso, se toma otra muestra de la misma población y se evalúa el comportamiento del modelo con la misma.
Existen dos formas de proponer la ecuación de regresión: contra los datos originales en sus unidades de medición o en su forma normalizada o z. A efectos predictivos es mejor la primera; sin embargo, la forma z es mejor para efectos exploratorios. Nótese que si se usa esta última forma, los datos deben ser desnormalizados para poder tener una predicción con sentido en el experimento que se realiza. Por otra parte, cuando se usa la forma z, el intercepto es 0, y por ende, no aparece en la ecuación.
Cuando se usa la forma natural de la ecuación de regresión, la relación se mide entre los coeficientes de los predictores contra el criterio, pero no se puede establecer una relación comparativa entre el aporte de cada predictor con respecto al criterio. Es por ello, que la forma z es más apropiada para efectos exploratorios.
A efectos predictivos, no se puede esperar que la forma z de la ecuación de regresión se comporte bien con una muestra distinta a la que fue usada; es mejor el comportamiento de la ecuación natural.
Tal como fue indicado anteriormente, la multicolinealidad no es deseable en MRCM. Sin embargo, existe una excepción y es por la aplicación de variables supresoras. Estos son predictores que están altamente correlacionados con otras variables independientes, pero no tienen correlación (o es muy baja) con el criterio. De esta forma, las variables supresoras minimizan la varianza de otros predictores que ciertamente están relacionados con el criterio, lo cual resulta en unos coeficientes de correlación parcial más significativos en los predictores asociados con el criterio, con una mejor predicción sobre el mismo. Desafortunadamente, la obtención de supresores normalmente no es exitosa.
2.2.5 Regresión Logística El problema de regresión logística surge cuando se quiere expresar una variable dependiente en función de un conjunto de variables independientes, pero el

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 31
criterio toma valores enteros. Si la variable toma dos valores excluyentes, se denomina dicótoma; si toma más de dos valores será polítoma o multinomial.
En esencia, la regresión logística es una técnica de clasificación que puede parecer semejante al análisis discriminante; sin embargo, este último requiere condiciones más restrictivas que las impuestas a la regresión logística. Principalmente, la regresión logística rompe la necesidad de que las variables predictoras tengan una distribución normal multivariada15 y que las mismas sean continuas.
Al igual que el MRCM, el MRL relaciona una variable dependiente con varias variables predictoras; sin embargo:
Las variables predictoras pueden ser continuas o discretas.
La relación entre las variables predictoras y el criterio se asume como no lineal.
El MRCM se basa en estimaciones de mínimos cuadrados, mientras que el MRL se basa en estimaciones de máxima verosimilitud.
El principio predictivo del MRL siempre podrá ser interpretado como una probabilidad. Cuando la variable es dicótoma, se busca entonces la probabilidad de que una observación pertenezca a uno de los dos grupos.
Ciertas condiciones son necesarias para aplicación de un MRL:
Las variables aleatorias asumirán valores discretos con una probabilidad dada, y la suma de ellas sumará 1.
Los resultados del experimento con las observaciones son estadísticamente independientes.
El modelo debe ser correctamente especificado, es decir, se cuenta con todas la variables necesarias para predecir el criterio, y no está involucrada ninguna variable irrelevante. En la práctica, esta condición rara vez es lograda.
Las categorías bajo análisis, es decir, los valores categóricos que toma el criterio, son mutuamente excluyentes y colectivamente exhaustivas: no hay
15 Nótese que, según Jonson (2000) se puede usar análisis discriminante de la vecina más cercana si los datos predictores no siguen una distribución normal multivariada, pero aún así, deberán ser variables continuas.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 32
valores que puedan ser tomados al mismo tiempo por una variable y cada resultado debe ser miembro de una de las categorías bajo análisis.
Se requieren muestras grandes para poder probar hipótesis en modelos de regresión logística. Grim y Yarnold (2000) hacen referencia a un estudio de Aldrich y Nelson, quienes recomiendan que la muestra debe contener al menos 50 casos por cada una de las variables predictoras.
La especificación del MRL parte del mismo principio del MRCM. Sea primero:
X 10ˆ bbg (2.2.5.1)
Para obtener la estimación del MRL, tómese el valor calculado e introdúzcase en la siguiente expresión:
g
g
ee
ˆ
ˆ
1 (2.2.5.2)
De esta forma, el modelo brinda una probabilidad para la observación realizada. El resultado será asignado a la categoría que corresponda con la probabilidad asignada.
Nótese que esa expresión se traduce en que, gráficamente, los resultados se las observaciones serán ajustados por una curva sigmoidal (forma de S) con un valor mínimo en cero y máximo en uno. Ello facilita la interpretación de los resultados como probabilidades.
Las pruebas de hipótesis del MRL son análogos a los del MRCM. Por análogos se quiere significar su razonamiento mas no los estadísticos usados para las pruebas. Una de las formas de probar que el coeficiente de los predictores es 0 es a través del estadístico de la razón de verosimilitud G: un valor grande de este estadístico significa que el coeficiente de la población difiere de cero, rechazando la hipótesis nula. Los grados de libertad son iguales a la cantidad de predictores del modelo en cuestión. Particularmente, cuando el modelo tiene una sola variable predictora, la probabilidad para el estadístico de la razón de verosimilitud se toma de una distribución ji-cuadrada con 1 grado de libertad.
Otra prueba equivalente es la prueba z. Para obtener el estadístico z se divide el coeficiente del predictor entre su error estándar estimado.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 33
La elección de un método sobre otro es casi indiferente: ambos asumen muestras grandes, son ampliamente reportados y típicamente dan resultados paralelos cuando se aplican sobre la misma muestra16.
Un aspecto que no debe dejarse de lado es la estimación de intervalos de confianza para los coeficientes de regresión, los cuales serán más precisos (en el sentido de pequeños) a medida que el tamaño de la muestra aumente. Un solo detalle es que cuando un intervalo al, por ejemplo, 95% incluye el 0, entonces el coeficiente es no significativo al 5% (el nivel alfa del intervalo).
Existen diferentes medidas que giran en torno al MRL que han de ser consideradas con cierta atención:
Uno de ellos es el concepto de ventaja17. Indica qué tan sensible es una observación de pertenecer a un grupo y no a otro. Nótese que esto es diferente al concepto de probabilidad. Además, la probabilidad asume valores entre 0 y 1, mientras que la ventaja asume valores mayores que cero. Derivado de este concepto está la razón de la ventaja, la cual estima el cambio en la ventaja de pertenecer a un grupo a consecuencia de aumentar una unidad al predictor.
Referidos a MRL dicótomos, se tienen cuatro medidas:
o La Sensitividad se refiere al porcentaje de que un grupo esté clasificado con precisión, es decir, la correcta identificación de los ciertos positivos.
o El Valor Predictivo Positivo es el porcentaje de los individuos que el modelo clasifica correctamente en su grupo positivo.
o La Especificidad se refiere a que el otro grupo (el negativo) sea correctamente clasificado, es decir, que el modelo identifique correctamente a los verdaderos negativos.
o El Valor Predictivo Negativo es el porcentaje de individuos que el modelo clasifica correctamente en el otro grupo.
Los valores predictivos positivos y negativos son los de mayor significación en la evaluación del MRL, puesto que ellos indican el orden en que las clasificaciones se realizan correctamente.
16 Esta afirmación es reportada por Grimm y Yarnold (2000) haciendo referencia a un estudio de Hauck & Donner en 1977.
17 Del inglés odds.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 34
Una última consideración consiste en que, las propiedades del MRCM que no varían con respecto al MRL, se mantienen generalmente invariantes.
2.2.6 Análisis Estadístico de Series de Tiempo En los análisis de series de tiempo se persiguen dos metas principales:
Identificación de la naturaleza del fenómeno presentado por la secuencia de valores en el tiempo.
Predicción de valores futuros, con base en las observaciones disponibles.
Informalmente, esto requiere la identificación de patrones sobre los valores observados en las series de tiempo y que al mismo tiempo, puedan ser, en cierta medida, formalmente descritos.
En consecuencia, un análisis de series de tiempo asume que los datos siguen un patrón sistemático y que existe un ruido aleatorio, el error, el cual hace que ese patrón pueda ser difícil de identificar. Por lo tanto, muchas técnicas de análisis de estas series envuelven el filtrado de ese ruido aleatorio, para identificar el patrón que se esconde en los datos observados de la serie.
De esta forma, una serie de tiempo puede ser descrita en términos de dos clases de componentes: tendencia y estacionariedad. Por tendencia se entiende el componente sistemático, lineal o no, que implica un cambio en el tiempo y que no es repetitivo, al menos dentro de la muestra de datos observados. La estacionariedad se entiende como el patrón sistemático de repetición en el tiempo. Ambos componentes pueden coexistir en datos reales. Por ejemplo, no es de extrañar que una tienda muestre una tendencia secular ascendente en sus ventas y que al mismo tiempo muestre un patrón de estacionariedad en los meses de Agosto y Diciembre, donde las ventas pueden presentar incrementos significativos con respecto a las ventas observadas en una año, y este patrón puede ser observado sistemáticamente año tras año.
Seguidamente, se analizarán algunas técnicas que permiten el estudio de las series de tiempo, a fin de identificar su tendencia y estacionariedad.
Se dice que un proceso estocástico es estacionario si su media y su varianza son constantes en el tiempo y el valor de la covarianza entre dos períodos depende sólo de la distancia o rezago entre esos dos períodos y no del momento (instante de tiempo) en que es calculada la covarianza. En este sentido, en una serie de tiempo tY estocástica se cumple:
Media: )( tYE (2.2.6.1)

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 35
Varianza: 22 )()var( tt YEY (2.2.6.2)
Covarianza: kttk YYE (2.2.6.3)
Si 0k entonces 0 es simplemente la varianza de la serie de tiempo. Si 1k , entonces 1 es la covarianza entre dos términos adyacentes.
Así, si una serie de tiempo es estacionaria, la media, la varianza y la covarianza (o autocovarianza) son siempre iguales, sin importar el momento en el cual se midan.
Una de las pruebas más comunes para determinar la estacionariedad de una serie de tiempo es la que se base en la Función de Autocorrelación y el Correlograma. En términos generales, la Función de Autocorrelación (ACF) al rezago k está definida como el cociente de la covarianza al rezago k entre la
varianza, es decir: 0
k
k . La gráfica de k contra k se denomina Correlograma.
En un correlograma se distinguen varios aspectos:
Se muestra la secuencia de una serie de rezagos preseleccionados (lag).
Para cada rezago se muestra el correspondiente valor de su ACF.
El error estándar aparece a continuación para cada uno de los rezagos mostrados, el cual es calculado siguiendo la premisa de estacionariedad definida, conocida normalmente como un proceso estocástico débilmente estacionario de ruido blanco.
Seguidamente se muestra el correlograma, mostrando al mismo tiempo el límite de los intervalos de confianza al 95%, situación normalmente asumida en estas pruebas.
Luego se muestra el valor de la estadística de Box-Ljung (BL), definida
como
m
k
k
knnnBL
1
2
2 , la cual tiene aproximadamente una
distribución 2m . Aquí, n representa el tamaño de la muestra (o la cantidad
de datos disponibles en la serie de tiempo) y m representa la longitud del rezago. Si el valor del estadístico BL es mayor que el ji-cuadrado correspondiente con el nivel de significación requerido, entonces se rechaza una hipótesis nula de que la serie de tiempo es estacionaria.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 36
Si un proceso estocástico es puramente aleatorio, entonces los valores de ACF para cualquier rezago mayor que cero es estadísticamente cero18. Si una serie de tiempo presenta estacionariedad, entonces se podría observar valores de la ACF altos contrastando con una serie de valores estadísticamente iguales a cero, y ello debería ocurrir cada k rezagos.
Otra prueba, basada en la Raíz Unitaria, parte de la ecuación de regresión de primer orden AR(1), es decir, aquella en la cual el valor al rezago t depende del valor en el rezago t – 1 más un término de error, normalmente conocido como error de ruido blanco. Bajo esta definición, la ecuación genérica de regresión se escribe como:
ttt uYY 1 (2.2.6.4)
Si se efectúa la regresión y se encuentra que 1 entonces se dice que la variable estocástica tY tiene una raíz unitaria.
En la ecuación de regresión general XY 21 , normalmente se prueba la hipótesis nula 0: 20 H contra la alternativa de que es distinto de cero. Esta prueba de hipótesis busca determinar si la variable X está o no relacionada con Y. En efecto, si la hipótesis nula es cierta, la recta que relaciona la variable dependiente con la independiente sería una recta de pendiente 0, con lo cual no
habría ninguna relación. Esta prueba se hace con un estadístico )( 2
2
eet ,
valor que ha de tener una distribución 2,2 nt . En general, si el número de grados de libertad es mayor que 20 (lo que implica una muestra mayor que 22) y
05,0 , entonces se puede establecer como regla práctica que si 2t se rechaza la hipótesis nula, es decir, las variables en estudio están correlacionadas19. Si el número de grados de libertad es menor que 20, entonces hay que proceder con el procedimiento normal de prueba de hipótesis.
18 Estadísticamente significa que pasaría las pruebas estadísticas que permiten asumir que la diferencia de cero se debe sólo al impacto de factores aleatorios o a errores en la muestra.
19 Normalmente, los paquetes estadísticos ofrecen una estadística t. Esta estadística es calculada para ejecutar la prueba de hipótesis que se acaba de plantear. En general, si se quiere probar la hipótesis de que el coeficiente que acompaña a la variable independiente tiene un valor particular,
digamos k, el estadístico se calcularía de la siguiente manera )( 2
2
ee
kt . De aquí se obtiene la
expresión mostrada. Sin embargo, lo que normalmente se desea probar es que existe una relación entre ambas variables, lo que se logra verificando la hipótesis de que la recta que las relacione no es horizontal.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 37
Este razonamiento se hace puesto que entonces ya se dispone de una prueba de hipótesis comúnmente aplicada a una fórmula de regresión. Ello nos lleva a rescribir la ecuación de autorregresión de la siguiente manera:
ttttttt uYuYYYY 111 1 (2.2.6.5)
Representado de esta forma, se debe probar la hipótesis nula 0:0 H , lo cual si resulta cierta, se tiene una raíz unitaria y por lo tanto, la serie sería una caminata aleatoria, definida como no estacionaria.
Algunas consideraciones adicionales deben realizarse cuando se analiza la estacionariedad de una serie de tiempo, según se indica a continuación.
Consideraciones Genéricas sobre el estadístico “t” en análisis de correlación.
En primer lugar, la tabla de resultados muestra la significancia del estadístico t. Mientras ese valor esté más cercano a cero, se deberá rechazar la hipótesis nula y aceptar la alternativa.
Consideraciones de la validez del estadístico “t”: la prueba Dickey-Fuller (DF)
Hay que hacer notar, sin embargo, que la prueba t es útil cuando se pretende rechazar la hipótesis nula, pero cuando no puede ser rechazada, es necesario acudir a la Prueba de Dickey-Fuller, o también llamada prueba tau, dado que se cuestiona que en esta situación, el estadístico t siga una distribución t Student.
Existen programas estadísticos que proveen este valor tau, los cuales normalmente usan las tablas de James MacKinnon generadas mediante métodos de simulación.
La prueba DF considera dos parámetros:
Determinación del tipo de ecuación de regresión utilizada (G), ya sea sin constante (G = 0), con constante (G = 1), con constante y tendencia (G = 2) y con estas últimas más la tendencia cuadrada (G = 3). Evidentemente, todos estos casos consideran la inclusión de la variable independiente rezagada para estimar la variable dependiente.
Determinación de diferenciación de la variable dependiente (L): si la serie de valores no es diferenciada, entonces L = 0, si se trata de la primera diferencia, L = 1.
Consideraciones sobre ANOVA en análisis de correlación.
Por otra parte, se puede aplicar un ANOVA al modelo de regresión para determinar si efectivamente los factores de la ecuación afectan o no el

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 38
comportamiento de la variable dependiente. ANOVA permite medir el grado de impacto que tienen los residuales y la variable explicativa sobre la variable independiente. Mientras mayor sea el valor del estadístico F de ANOVA, mayor será el impacto de la variable explicativa (puesto que el numerador representa la suma explicada de los cuadrados), y viceversa, si F es menor, el denominar, que representa la suma de los cuadrados de los residuales, el impacto de los factores de ruido blanco será mayor, con lo que la serie será no estacionaria. Nótese además que, mientras mayor es el valor de F menor será la significancia asociada y se deberá rechazar la hipótesis nula, pero si F es pequeño, mayor será la significancia y se deberá aceptar la hipótesis nula.
En condiciones normales, no es necesario aplicar una prueba F si hace una prueba t cuando sólo están involucradas dos variables. Sin embargo, ANOVA en análisis de regresión múltiple aportará elementos de análisis adicionales.
Consideraciones sobre el Coeficiente de Correlación.
Para entender la importancia de R2 , es necesario observar su cálculo en series de datos, el cual se expresa a continuación:
Totales Cuadrados de SumaResiduales Cuadrados de Suma1R 2 (2.2.6.6)
Bajo esta definición, mientras más pequeño sea R2 , mayor será el impacto de los residuales en la explicación de la variación de la variable dependiente, por lo que la serie será menos estacionaria.
Nótese sin embargo, que este valor no depende de la cantidad de variables independientes que intervengan en la ecuación de regresión. A mayor cantidad de variables explicativas, menor será el impacto de los residuales. Por lo tanto, se ha de ser muy cuidadoso al momento de comparar dos regresiones que tengan una composición de variables explicativas distinta, sólo con base en R2.
A tal fin se usa el coeficiente de determinación ajustado, o R2 ajustado, el cual se ve afectado por características de la muestra y número de variables explicativas, y se calcula de la siguiente manera:
1Total cuadrados de Suma
)1(residual cuadrados de Suma1
11
RR2
22a
n
pnpn
Rp (2.2.6.7)
Aquí, n es el tamaño de la muestra y p el número de variables independientes. De esta forma se puede comparar la efectividad de ecuaciones alternativas de regresión.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 39
Debe ser claro que el R2 ajustado será siempre menor que R2 y cuando el R2 ajustado sea negativo (cosa que puede ocurrir aún cuando R2 siempre es necesariamente positivo), debe tomarse como cero.
Existen casos de regresiones que, aún cuando muestran muy buenos resultados, no se obtienen consistentemente en ensayos repetidos. La correlación espuria sucede cuando las variables en cuestión tienen una tendencia semejante, pero tal correlación se debe más al efecto del tiempo (u otra variable) que a la propia relación existente entre ellas. La inclusión de la variable de tendencia (tiempo) permite suprimir este efecto, dado que la tendencia asume su propio coeficiente y el coeficiente de la variable independiente mostrará su efecto neto.
Una característica de este tipo presenta normalmente unos coeficientes de correlación, normal y ajustado, que muestran una fuerte correlación entre las muestras de datos que se están analizando, lo cual debe ser objeto de mayor análisis. Lo recomendable entonces es estudiar el valor del estadístico de Durbin-Watson para determinar si existe correlación positiva; en particular, si el estadístico de Durbin-Watson (d) es bajo, se sugiere una correlación serial positiva entre ambas variables, atribuible a factores diferentes a su propia correlación. Como regla práctica se establece que un buen criterio para sospechar que la regresión estimada sufre de regresión espuria es que R2 > d20.
Para determinar si existe cointegración entre dos variables, y partiendo de las premisas de que ambas series son estacionarias en el mismo nivel de diferenciación, se establece la siguiente ecuación:
ttt XYu 20 (2.2.6.8)
Si la serie de los residuales resulta ser estacionaria sin necesidad de diferenciación, entonces, las variables están cointegradas.
Para ello, y siguiendo el método de prueba propuesto por Engle-Granger (EG), se toman los residuales resultantes de la regresión de la ecuación
iii uXY 10 , y se resuelve la regresión:
1 tt uu (2.2.6.9)
A esta regresión se le aplica la prueba DF para los residuales y se continúa con los estándares de esta prueba. En caso positivo se puede aplicar la ecuación de regresión arriba indicada.
20 Esta regla fue propuesta por Granger y Newbold, “Spurious Regressions in Econometrics”, Journal of Econometrics, vol. 2, 1974. Se encuentra reportada en Gujarati (1997).

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 40
A continuación se describirán diferentes maneras de modelar series de tiempo, siempre y cuando sean estacionarias
Sea la siguiente formulación:
ptpttt YYYY 22110 (2.2.6.10)
Se dice que la variable dependiente sigue un Proceso Autorregresivo de orden p, o AR(p). En este caso, el valor de la variable dependiente es una función de diferentes valores de ella misma en tiempos anteriores.
También se puede estimar una serie de tiempo en función de sus errores estocásticos de ruido blanco presentes y pasados. Sea la siguiente formulación:
qtqttt uuuY 110 (2.2.6.11)
Se dirá que la variable dependiente sigue un Proceso de Media Móvil de orden q MA(q).
Es muy probable que una variable dependiente refleje el efecto de sus valores anteriores en el tiempo y de sus errores de ruido blanco (residuales) presente y pasado. En este caso se estará en presencia de un Proceso Autorregresivo y de Media Móvil de orden p y q ARMA(p, q). Por ejemplo, un proceso ARMA(1,1), se formularía como:
11011 tttt uuYY (2.2.6.12)
Los procesos AR(p) y MA(q) asumen que las series de tiempo son estacionarias, es decir, son integradas de orden 0 o I(0). Cuando las series necesitan ser diferenciadas d veces para ser estacionaria, es decir son I(d), entonces no se puede aplicar directamente AR o MA. En este caso se aplica un proceso ARIMA(p,d,q). Nótese que cuando d = 0, se tiene un proceso ARMA (p,q). Asimismo, si d = 0 y q = 0 se tiene un AR(p). Lo mismo se obtendría para un proceso MA(q), cuando d = 0 y p = 0.
Para aplicar un modelo ARIMA(p,d,q) se sigue la Metodología de Box-Jenkins (BJ) la cual consta de cuatro pasos:
1. Identificación, paso en el cual se determinan los valores p, d, y q. Para ello se utiliza la función de autocorrelación (ACF) y la función parcial de autocorrelación (PACF).
2. Estimación, paso que consiste en determinar los parámetros de la regresión.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 41
3. Verificación, paso en el que se selecciona el modelo ARIMA más apropiado. Ello implica que la metodología BJ es iterativa y de prueba de diferentes modelos. La verificación más simple consiste en validar que los residuales del modelo resultante son de ruido blanco.
4. Predicción, paso en el que estiman los valores de tendencia, en función del modelo de regresión seleccionado. Es importante hacer notar que con esta metodología, si la serie es diferenciada, las estimaciones corresponderán a datos compatibles con la serie original, razón por la cual este proceso se llama integrado.
La ecuación de regresión obtenida de la aplicación de ARIMA, también puede tener una constante en su ecuación, la cual tendrá un significado dependiendo del modelo aplicado:
Si no hay parámetros autorregresivos en el modelo, la constante será la media de la serie de datos. Si la serie es diferenciada en este caso, la constante será la media de la serie diferenciada.
Si hay parámetros autorregresivos en la serie, entonces la constante será el intercepto. Si la serie es diferenciada en este caso, la constante será el intercepto de la serie diferenciada.
El estudio de PACF permite obtener el correlograma parcial. Este identifica la correlación entre observaciones que están separadas k periodos (rezagos) en el tiempo, manteniendo constantes las correlaciones en los rezagos intermedios. Si k = 1, entonces PACF = ACF.
En cualquier análisis de este tipo se debe hacer un estudio conjunto de ACF y PACF para determinar el modelo a construir.
En general se tiene:
Tipo de Modelo Patrón Típico de ACF Patrón Típico de PACF
AR(p) Decrece exponencialmente, o presenta un patrón sinusoidal, o ambos.
Picos grandes a lo largo de los p rezagos
MA(q) Picos grandes a lo largo de los q rezagos.
Decrece exponencialmente.
ARMA(p, q) Decrece exponencialmente. Decrece exponencialmente.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 42
Existe evidencia práctica de que los procesos se resumen principalmente a valores de 1 y 2 para p y q, según se indica en la siguiente tabla, equivalente a la anterior21:
Tipo de Modelo Patrón Típico de ACF Patrón Típico de PACF
AR(1) Decrece exponencialmente. Pico grande en el primer rezago.
AR(2) Decrece exponencialmente, o presenta un patrón sinusoidal.
Picos en los rezagos 1 y 2, sin correlación en los restantes rezagos.
MA(1) Pico grande en el primer rezago, sin correlación en los restantes.
Decrece exponencialmente.
MA(2) Picos grandes en los primeros dos rezagos, sin correlación en los restantes
Decrece exponencialmente, o presenta un patrón sinusoidal.
ARMA(1, 1) Decrece exponencialmente a partir del primer rezago.
Decrece exponencialmente a partir del primer rezago.
Dado que los parámetros están en 1 y 2, no es difícil probar diferentes modelos. Entonces el proceso implica la construcción y evaluación de varios modelos de predicción que combinen los valores indicados de los parámetros p y q, y la selección del más apropiado.
La Metodología de Box-Jenkins es bastante laboriosa y no produce un modelo único de predicción. Se requiere la prueba de diferentes modelos y múltiples análisis para simplificar los cálculos. Sin embargo, se ha demostrado en la práctica muy buenas capacidades de estimación, con lo que su uso es bastante difundido.
2.2.7 Clasificación Estadística Conocido también como Cluster Analysis (CA), es un conjunto de técnicas tendentes a clasificar datos que inicialmente no están clasificados, por lo que su foco está en medir semejanzas (o desemejanzas) entre dos observaciones
21 Estas recomendaciones fueron hechas por Pankratz (1983) y están reportadas por Gujarati (1997).

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 43
separadas y, a continuación, medir la semejanza (o desemejanza) entre dos agrupamientos de observaciones.
Los criterios de semejanza normalmente están basados en medidas de distancia, donde la distancia euclidiana es la medida fundamental, ya sea sobre medidas estandarizadas como no estandarizadas.
Para lograr fijarse criterios de semejanza, el uso de gráficas puede ser de gran ayuda, sólo si miden hasta tres variables (más cómodo si sólo son dos variables). Cuando ya se dispone de tres o más variables puede ser conveniente realizar un PCA, tratando de llevar la dimensionalidad de la muestra a dos y efectuar las clasificaciones sobre las calificaciones de las dos primeras componentes principales. También puede ser recomendable aplicar las técnicas de clasificación a las calificaciones de las componentes principales, tomando en cuenta que no deben estar normalizadas, puesto que si éstas están estandarizadas no ilustran de manera realista las distancias reales entre parejas de puntos.
Los métodos de clasificación pueden ser jerárquicos o no. En el primer caso, normalmente se hace uso de un árbol de clasificación para identificar los grupos. En el otro caso, se parte de un centro de los grupos potenciales y se procede a refinar los agrupamientos.
Los métodos de agrupamiento jerárquicos hacen uso de un árbol de agrupación conocido con el nombre de dendograma. Este diagrama muestra el resultado de las agrupaciones realizadas a lo largo de las iteraciones llevadas a cabo durante la creación del modelo. El objeto es producir finalmente un solo grupo; sin embargo, la observación de este gráfico permite determinar la cantidad de grupos a definir.
Por su parte, la agrupación no jerárquica utiliza principalmente la técnica denominada K-Medias, donde se asigna un miembro a un clúster minimizando la distancia del mismo al centro del clúster. Para ello, la clasificación se puede realizar conociendo el centro de los agrupamientos o no. El caso que se expone identifica primero la cantidad de agrupamientos, determina los centros de cada grupo y luego ubica nuevos casos en los agrupamientos identificados, una de las razones básicas para definir agrupamientos.
También las agrupaciones pueden ser de diferente tipo. Por ejemplo, se puede usar el criterio de vecino más cercano o vecino más lejano. El primero tiende a maximizar lo conexo de una pareja de agrupamientos y tienen la tendencia a crear menos grupos que el segundo, el cual tiende a minimizar las distancias de los agrupamientos, hallando grupos más compactos.
La aplicación de estas técnicas implica ejecutar agrupamientos por varios métodos y, si los resultados son similares, se puede concluir que existe un agrupamiento natural.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 44
2.2.8 Algunas Estadísticas Relevantes Estadística T2 de Hotelling
Con el fin de extender la estadística t de Student al caso multivariado, supóngase que nxxx ,,, 21 es una muestra aleatoria proveniente de una distribución normal multivariada con p variables Σµ,Np , con la media y matriz de varianza y covarianza conocidas.
Considere probar la hipótesis nula 00 µµ: H contra la alternativa de que sean diferentes.
Sea 01
02 µµΣµµ nT . Este estadístico se conoce como T2 de
Hotelling22.
También se sabe que 2
1T
nppn
tiene distribución pnpF , `.
De esta forma, esta estadística permite probar hipótesis concernientes a medias y regiones de confianza parta la media.
En la prueba de la media al %1001 de significación, se rechazaría la
hipótesis nula si pnpFTnp
pn
,,2
1 .
Así mismo se puede determinar una región de confianza para la media. Sean p ˆ,,ˆ,ˆ
21 y p21 a,,a,a los eigenvalores y eigenvectores, respectivamente de Σ . Una región de confianza %1001 para la media es un elipsoide con centro en
µ . El i-ésimo de los p ejes del elipsoide están dados por pnnFnp pnpi
,,
ˆ)1(2
en la dirección de ia
Esta estadística es interesante puesto que al permitir comparar las medias de dos poblaciones normales multivariadas, también permite determinar si las medias de dos agrupamientos son estadísticamente diferentes como para que continúen existiendo dos clúster separados. Si se rechaza la hipótesis nula de igualdad de medias, entonces se deben tener dos clúster, de lo contrario se mantendría uno unificado.
22 Cuando p = 1 , la estadística T2 de Hotelling es igual a la estadística t de Student al cuadrado.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 45
Prueba para la tendencia lineal
Si se miden p variables en períodos igualmente espaciados y se quiere probar una tendencia lineal, significaría que todas las medias caen sobre una misma recta. Por lo tanto, la hipótesis nula a probar es
121342323120 ,,,: ppppH .
Esta hipótesis nula pueda ser expresada como 02,,02: 211230 pppH .
La expresión anterior es equivalente a probar la hipótesis nula 0Hµ:0 H , donde
1210000
00012100000121
H
2.3 Bases Teóricas. Parte 2: Redes Neuronales
Los modelos basados en RNA normalmente cumplen propósitos predictivos y de clasificación, mas no exploratorios. Su carencia de realizar análisis exploratorios es por su misma característica de “caja negra”: a diferencia de los MRCM y sus derivados, los cuales establecen ecuaciones descriptivas del comportamiento de los datos muestrales que son analizados; este modelo es oculto en las RNA. Es por ello que las mismas surten un efecto sobre el resultado, el cual, luego de que la red es entrenada para aprender un patrón, puede brindar resultados sobre muestras obtenidas de la misma población. Giles et. al. (2000) estudiaron el proceso de extracción de un autómata en un experimento de predicción de series de tiempo con redes neuronales; sin embargo, el proceso es específico a la red y no produce resultados exploratorios contundentes.
Esta característica hace que los resultados de los modelos RNA produzcan predicciones sobre valores dados, o clasifiquen nuevos valores, en ambos casos, con base en el aprendizaje efectuado.
Ello inducirá un elemento adicional a los experimentos que serán efectuados y es que los mismos se concentrarán en ensayos predictivos, sean en comparación con el MRCM o con las Series de Tiempo, o en ensayos de clasificación, en comparación con los MRL. Cuando el modelo de red neuronal sea más apropiado para problemas de clasificación se indicará explícitamente; de lo contrario, se asumirá que la red es fundamentalmente predictiva.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 46
Por otra parte, el énfasis en esta exposición es metodológico, a fin de satisfacer las necesidades de la presente disertación.
2.3.1 El Modelo de la Neurona Artificial, el Perceptron y los Filtros Lineales
En su idea más simple, una neurona artificial, o simplemente neurona, realiza una transformación de un valor en otro, en función de unos pesos y una función de transferencia. Esta facultad de tener pesos asignados es lo que permite que las neuronas puedan aprender, es decir, ajustar su comportamiento, o pesos, a los casos a los que es expuesta. La conformación de una red de múltiples neuronas es lo que constituye la red neuronal artificial, o RNA. La siguiente figura es una representación gráfica del modelo de la neurona.
Figura 2. Modelo de la Neurona Artificial
En el modelo de la neurona, donde k representa la k-ésima neurona en una red de muchas de ellas, se distinguen cuatro elementos básicos:
1. Hay un conjunto de sinapsis o enlaces de conexión cada uno de los cuales está caracterizado por un pesos w. Cuando una señal xi es expuesta a la neurona, su valor es multiplicado por el correspondiente peso wki.
2. Hay un sumador que agrega todas las señales de entrada ya multiplicadas por su correspondiente peso.
3. Hay una función de activación que limita la amplitud de la salida de la neurona. Normalmente la salida de una neurona es tipificada por un intervalo cerrado [0,1] o [-1,1].
x1
x2
xm
wk1
wk2
wkm
fvk
y
bk
x1
x2
xm
wk1
wk2
wkm
fvk
y
bk

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 47
x1
x2
xm
w11
wsm
fv1y1
w10 = b1
fv2y2
fvsys
w20 = b2
ws0 = bs
x1
x2
xm
w11
wsm
fv1y1
w10 = b1
fv2y2
fvsys
w20 = b2
ws0 = bs
4. Existe una entrada bk que representa el sesgo23 de la neurona, el cual es opcional. Su efecto es incrementar o reducir la entrada a la función de activación de la neurona
En términos matemáticos, las ecuaciones de la neurona k son las siguientes:
m
jjkjk xwu
1
(2.3.1.1)
kkk buv (2.3.1.2)
kk vfy (2.3.1.3)
Si se asume que el sesgo es la entrada 0 de la neurona, se puede escribir la ecuación (2.3.1.2) como:
m
jjkjk xwv
0
(2.3.1.4)
donde x0 es equivalente a bk, y wk0 es el peso correspondiente al sesgo, y en forma matricial esta ecuación es equivalente a:
xwk kv (2.3.1.5)
Nótese la analogía matemática entre el MRCM y el modelo de la neurona cuando se asume que el peso del sesgo es igual a 1: efectivamente, representa un MRCM expresado en la forma z, es decir, normalizado, siempre y cuando la función de transferencia se defina sobre un intervalo apropiado.
Las neuronas se agrupan por capas. El modelo más simple es la agrupación de una serie de neuronas en una única capa.
Figura 3. Arquitectura de RNA de una capa.
Dentro de estos modelos es importante definir qué es la función de transferencia. Normalmente, esta función asume uno de tres tipos básicos:
23 Del inglés bias.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 48
Función de Salto24, la cual genera valores 0 o 1 y dicho cambio se produce en un umbral definido.
Función Lineal, la cual produce resultados en un rango dado con variaciones lineales.
Función Sigmoidal, la cual tiene forma de S y genera un comportamiento amortiguado. Normalmente pueden ser de dos tipos: log sigmoidal, que produce salidas entre 0 y 1, y tan sigmoidal que produce salidas entre –1 y 1.
Figura 4. Tipos más comunes de Funciones de Transferencia
Cuando se usa una función de salto en un modelo de RNA de una capa, se obtiene lo que se conoce con el nombre de Perceptron.
Esta arquitectura es entrenada de forma iterativa y supervisada, es decir, la red se expone secuencialmente a un conjunto de entradas con sus correspondientes valores de salida correctos t (en efecto un vector) y se realiza un ajuste de pesos cada vez que se obtiene una salida de la red. Si W es la matriz de pesos, x es el vector de entrada, y es el vector de salidas calculadas por la red y r representa la iteración, la regla de aprendizaje se puede resumir como:
Tr1r xeWW (2.3.1.6)
ebb r1r (2.3.1.7)
y-te (2.3.1.8)
El Perceptron de una capa es aplicable básicamente como elemento de clasificación, cuando las siguientes características se cumplen:
24 Del inglés Hard-Limit Function.
1
-1
1
-1
1
-1
Función de Salto Función Lineal Función Log Sigmoidal
1
-1
1
-1
1
-1
Función de Salto Función Lineal Función Log Sigmoidal

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 49
Los vectores de entrada deben ser linealmente separables. Este no es normalmente el caso, pero se puede aplicar procesamiento previo en algunos casos para que tal condición se cumpla. Si la muestra es linealmente separable, la convergencia es garantizada. Esta condición se debe a que la función de transferencia es de salto, por lo que las salidas tomarán valores 0 o 1.
Los datos de entrada han de ser cuidadosamente analizados a fin de identificar y eliminar los outliers.
Problemas de clasificación en varios grupos lineales pueden ser abordados cuando se diseña una arquitectura de varios perceptrones, pero existen otras arquitecturas que aplican mejor en estos casos.
Pese a sus limitaciones, el Perceptron jugó un papel importante en el desarrollo de algoritmos y arquitecturas más complejas de RNA.
Cuando la función de transferencia se cambia a una función lineal, se obtiene una Arquitectura de Filtro Lineal, la cual es sensible a aproximar funciones lineales. La regla de aprendizaje en este caso usa el método del Error Mínimo Cuadrático Medio (LMS de sus siglas en inglés Least Mean Square Error)25.
Se aplica la misma lógica iterativa y supervisada para el entrenamiento del Perceptron, pero, debido a la aplicación de LMS, las formulas de aprendizaje se reducen a:
T(r)(r)(r)1r xeWW 2 (2.3.1.9)
rr1r ebb 2 (2.3.1.10)
Aquí es obtenido de la derivación de la aplicación de LMS y representa la rata de aprendizaje. Si este valor es grande, la red aprende rápido pero podría llevar a inestabilidad y errores incrementales, obstaculizando la convergencia del algoritmo. Para asegurar un aprendizaje estable, la rata de aprendizaje debe ser menor que el recíproco del valor propio más grande de la matriz de correlación
xxT de los vectores de entrada26.
Normalmente, todo problema en el cual la red lineal tiene al menos tantos grados de libertad como restricciones, podrá ser resuelto. Los grados de libertad es el número de pesos y sesgos (S*M + M, o lo que el igual, la dimensión de los 25 Conocido también como el algoritmo de aprendizaje de Widrow-Hoff.
26 Afortunadamente, los paquetes que apoyan la construcción de RNA proveen esos cálculos en la mayoría de los casos.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 50
vectores de entrada S por la cantidad de neuronas M, que representa el número de pesos, más la cantidad de neuronas) y las restricciones es el número de pares de vectores de entrada / salida. La única excepción es que los vectores de entrada sean linealmente dependientes y no se aplique sesgo a la red.
Finalmente, esta arquitectura de red no resuelve problemas de asociación no lineal entre vectores de entrada y salida; en este caso, realizaría la aproximación de mínimos cuadrados de la suma de los errores.
2.3.2 El Perceptron Multicapa con Retropropagación27 Esta arquitectura de RNA es muy popular gracias a su capacidad de simular prácticamente cualquier comportamiento no lineal. Corresponde con una generalización del algoritmo de aprendizaje de Widrow-Hoff (LMS) para redes de múltiples capas con funciones de transferencia no lineales y diferenciables.
Figura 5. Modelo de Neuronas en Multicapa: ejemplo de tres capas
Estas redes normalmente usan funciones de transferencia log sigmoidales, aunque pueden hacer uso de funciones tan sigmoidales o lineales. Pero ciertamente se debe prestar atención al tipo de función de transferencia que se aplica a las neuronas de la capa de salida: si se usa alguna forma de función sigmoidal, entonces se limita la salida de la red a un rango pequeño de valores; si se desea mayor amplitud en el rango del intervalo de salida, será necesario usar una función lineal, lo cual representa el caso más normal.
27 El título viene de su denominación en inglés Feddforward Multilayer Perceptron with Backpropagation, y es comúnmente usado en español
11 bf xIWa 1,11 212 bf aLWa 2,12 323 bf aLWya 3,23
f 1 f 2
IW1,1
b1
LW2,1
b2
x
1
R x 1
f 3
LW1,1
b2
S1 x R
S1 x 1
n1
S1 x 1
a1
S1 x 1
1
S2 x 1
S2 x S1
S2 x 1
S2 x 1
1
n2 n3
S3 x 1
S3 x 1
a3
S3 x S2
y
123 fff y
11 bf xIWa 1,11 212 bf aLWa 2,12 323 bf aLWya 3,23
f 1 f 2
IW1,1
b1
LW2,1
b2
x
1
R x 1
f 3
LW1,1
b2
S1 x R
S1 x 1
n1
S1 x 1
a1
S1 x 1
1
S2 x 1
S2 x S1
S2 x 1
S2 x 1
1
n2 n3
S3 x 1
S3 x 1
a3
S3 x S2
y
123 fff y

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 51
Normalmente, estas redes se crean a partir de cuatro parámetros28:
Una matriz R x 2 que contiene los valores mínimos y máximos de los R elementos del vector de entrada.
Un vector que contiene el número de neuronas de cada una de las capas.
Un vector que indica las funciones de transferencia de cada una de las capas de neuronas.
Un parámetro que indica la función de entrenamiento a ser utilizada.
De relevante importancia en la aplicación de estas redes neuronales son los métodos de entrenamiento de la red. El método básico es el de retropropagación, del cual se hacen una serie de variantes que apuntan a lograr rapidez o a lograr una mejor utilización de la memoria.
La implantación más simple de este algoritmo de aprendizaje consiste en una actualización de los pesos y el sesgo en la dirección en la cual la función de rendimiento decrece más rápidamente, es decir, el negativo del gradiente. Una iteración puede ser escrita como:
kkk gww 1 (2.3.2.1)
En esta expresión wk es el vector de los pesos y sesgo actual, gk es el gradiente y k es la rata de aprendizaje.
Los datos de entrada pueden ser suplidos de manera incremental, ajustando los pesos y el sesgo luego que cada entrada es aplicada a la red, o por lotes, ajustando los mismos luego que todas las entradas han sido aplicadas.
Una variación, de naturaleza heurística, radica en el problema de la rata de aprendizaje. Si es muy grande, el algoritmo puede oscilar y volverse inestable, pero si es muy pequeña, puede tardar mucho en lograr convergencia. Aún así, no hay forma práctica de estimar la rata de aprendizaje antes del proceso de entrenamiento. De esta forma, el método de Rata de Aprendizaje Variable29, permite que la misma varíe durante la evolución del algoritmo, ajustando su valor al más grande posible, mientras que se mantiene la estabilidad; así, la rata de aprendizaje se hace sensible a la superficie del error local.
28 Esta es la convención que usa el módulo de Redes Neuronales de MATLAB. Mayor referencia puede ser encontrada en el Manual de Referencia de “Neural Network Toolbox” versión 4, publicado por MathWorks (2002).
29 Del inglés Variable Learning Rate.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 52
Otra variación trata de resolver el problema de valores grandes en la función del rendimiento de la red, cuando se usan funciones de transferencia sigmoidales. En estos casos, la pendiente tenderá a cero y el gradiente tendrá un valor muy pequeño, causando cambios muy pequeños en los pesos y el sesgo, independientemente de qué tan lejos se esté de la solución. En este caso, se toma el signo de la derivada para determinar la dirección del cambio, y los valores de cambio se calculan de manera separada. Este algoritmo es denominado Resilient Backpropagation, y es considerado también de naturaleza heurística.
Otros algoritmos de entrenamiento están basados en técnicas de optimización numérica. Los algoritmos de gradiente conjugados agrupan los métodos de Fletcher-Reeves, Polak- Ribiére, Powel-Beale y la conjugada escalada. Se usan también los algoritmos de búsqueda lineal, destacando, la búsqueda de la sección dorada, la búsqueda de Brent, búsqueda híbrida de bisección cúbica y en retroceso. Otras formas usan los métodos cuasi-Newton, basados en el cálculo de la matriz Hessian, y el método de Levenberg-Marquardt, que no usa el Hessian.
Algunas consideraciones para la aplicación de los algoritmos se suple a continuación30:
Gradiente Básico Descendente, es lento en su convergencia y se usa en modalidad de entrenamiento incremental.
Gradiente Descendente con Momento, es usualmente más rápido que el anterior y se usa también en entrenamiento de modo incremental.
Rata de Aprendizaje Adaptable, es más rápido que el gradiente básico decreciente, pero se usa sólo en modalidad de entrenamiento por lotes.
Resilient Backpropagation, es simple, funciona en modalidad por lotes, es de rápida convergencia y consume poca memoria.
Algoritmo de Gradiente Conjugada de Fletcher-Reeves, tiene los menores requerimientos de memoria de la familia de algoritmos de este tipo.
Algoritmo de Gradiente Conjugada de Polak- Ribiére, consume un poco más de memoria pero en algunos casos converge más rápidamente.
Algoritmo de Gradiente Conjugada de Powell-Beale, aún requiere más memoria que el anterior pero generalmente converge más rápido.
30 Para establecer esta comparación, se corrieron varios experimentos sugeridos en “Neural Networks Toolbox”, haciendo uso de Matlab, a fin de validar los principios aquí expresados.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 53
Algoritmo de Gradiente Conjugada Escalada, es muy bueno para propósitos generales y no requiere búsqueda de línea recta.
Método Cuasi-Newton BFGS31, sus requerimientos de memoria están directamente relacionados con el cálculo de la matriz de Hessian, lo cual induce operaciones relevantes en cada iteración, pero converge usualmente en menor cantidad de iteraciones que los métodos de gradiente conjugada.
Método de la Secante de un paso, es un intermedio en rendimiento entre el método anterior y los métodos de gradiente conjugada.
Algoritmo de Levenberg-Marquardt, es el de más rápida convergencia en redes de tamaño moderado. Debido a que no calcula la matriz de Hessian, sus requerimientos de memoria no son tan exigentes.
Regularización Bayesiana, es una modificación del algoritmo anterior y produce redes que generalizan bien, reduciendo al mismo tiempo la dificultad de determinar la arquitectura óptima de la red.
Además del entrenamiento de estas redes, otro problema que se debe trabajar es el de sobreajuste32, el cual ocurre cuando el error en el entrenamiento es muy pequeño pero, cuando nuevos datos son presentados a la red, su rendimiento es inapropiado. Esto ocurre debido a que la red “memoriza” los datos de entrenamiento pero generaliza mal.
Una de las formas de evitar este problema es usando una red sólo lo suficientemente grande como para obtener un ajuste adecuado: mientras más grande la red, más compleja la función que puede manejar pero más probabilidad de sobreajuste. La reducción del tamaño de la RNA evita este problema; sin embargo, no es nada fácil saber a priori el “tamaño” adecuado” de la red.
Una de las formas, llamada regularización, consiste en ajustar la función de rendimiento de la red, la cual es normalmente la suma de los cuadrados de los errores del entrenamiento de la red, agregándole un término que consiste en la media de la suma de los cuadrados de los errores. De esta forma, los pesos y sesgos de la red serán más pequeños y la respuesta de la red será más uniforme y menos proclive al sobreajuste. Otra método en esta familia es mediante Regularización Bayesiana, el cual brinda normalmente excelentes resultados, y es muy útil puesto que no requiere separación de los datos disponibles.
31 BFGS viene de sus autores Broyden, Fletcher, Goldfarb y Shanno.
32 Del Inglés overfitting.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 54
Otra forma de mejorar la generalización es mediante Detención Temprana33, la cual consiste en dividir los datos disponibles en tres conjuntos:
Datos de Entrenamiento, usados para calcular el gradiente y actualizar los pesos y sesgos.
Datos de Validación, usados para hacer seguimiento al error durante el proceso de entrenamiento. Normalmente, el error de validación decrece en las fases iniciales de entrenamiento, al igual que el error de entrenamiento. Sin embargo, cuando la red comienza a sobreajustarse, el error de validación comienza a crecer. Es en este momento cuando las iteraciones se detienen y se obtienen los pesos y sesgos al momento del error mínimo.
Datos de Prueba, los cuales no son usados durante el entrenamiento y sirven para comparar diferentes modelos de red. Es interesante graficar el error durante el proceso de entrenamiento puesto que, si el error en los datos de prueba alcanza un mínimo en un número significativamente distinto de iteraciones que el error de validación, puede significar una inadecuada o pobre división de los datos.
Con esta metodología no es apropiado usar algoritmos de entrenamiento que converjan muy rápidamente (como sería el caso del algoritmo de Leveberg-Marquardt). En este caso, los algoritmos de entrenamiento de Gradiente Conjugada Escalada o el de Resilient Backpropagation suelen ser apropiados. Así mismo hay que notar la dificultad de aplicar esta metodología cuando no se dispone de una muestra de datos grande, aspecto normal en problemas prácticos.
Finalmente, un par de consideraciones. A efectos de preparación de datos, es conveniente que los mismos sean llevados a escala, normalmente entre –1 y 1, facilitando así el rango de trabajo. Evidentemente ello requiere que los datos sean de nuevo convertidos a su escala original después del procesamiento. Alternativamente, es usual trabajar con los datos normalizados.
Cuando la dimensión de los datos de la muestra es grande, y existe correlación, es muy útil realizar Análisis de Componentes Principales, a fin de reducir la dimensionalidad y ganar tiempo de proceso en la red.
Luego, como actividad a posteriori , puede ser recomendable realizar una análisis de regresión entre la respuesta de la red y los resultados reales. Ello ayudará a determinar el ajuste de las aproximaciones.
33 Del Inglés Early Stopping.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 55
2.3.3 Redes de Base Radial34 Este tipo de redes puede requerir más neuronas que un perceptron multicapa (MLP) del tipo estudiado en la sección anterior; sin embargo, pueden ser diseñadas en una fracción del tiempo de lo que toma entrenar al perceptron. Hay que notar que ellas trabajarán bien cuando se dispone de muchos vectores de entrenamiento.
Figura 6. Modelo de Neurona Artificial de Base Radial
En las neuronas de estas redes, la entrada a la función de transferencia es el vector distancia entre el vector de pesos (w) y el vector de entrada (x).
La función de transferencia para una neurona de base radial está dada por la función:
2
)( nenf (2.3.3.1)
34 Del inglés Radial Basis Networks.
X f
x1
x2
xR
w1,1 w1,R
ny
b
||distancia||
2
)( nenf
1
X f
x1
x2
xR
w1,1 w1,R
ny
b
||distancia||
2
)( nenf
1

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 56
Esta función tiene un máximo cuando la entrada es cero, es decir, el vector de entrada es idéntico al de pesos. A medida que la distancia entre w y x decrece, la salida se incrementa. El sesgo b permite ajustar la sensibilidad de la neurona.
Partiendo de aquí, la arquitectura de un Red Neuronal de Base Radial (RBN de sus siglas en inglés) tiene una capa oculta de neuronas de base radial y una capa de salida de neuronas lineales.
Figura 7. Arquitectura de Red Neuronal de Base Radial
Si un vector de entrada es presentado a una red de estas características, cada neurona de la capa de base radial producirá un valor de acuerdo a qué tan cerca está el vector de entrada al vector de los pesos de las neuronas. Cuando los valores son muy cercanos a cero, su efecto sobre la capa lineal será ínfimo.
Los parámetros que permiten definir una red de base radial son los siguientes:
Vectores x que contienen los valores de entrada. Esta cantidad de vectores determinará una cantidad igual de neuronas en la primera capa de la red
Vectores t que contienen los valores de salida provistos para el entrenamiento.
El Spread, el cual representa el tamaño del área en el espacio de entrada al cual responderá cada neurona. Este valor debe ser suficientemente grande para que las neuronas respondan certeramente a regiones del espacio de entrada que se sobrepongan, pero no tan grande para que las neuronas respondan de la misma manera.
Radial Función
xIWa 1,11
1
11
f
bf Lineal Función
aLWy 2,1
2
212
f
bf
f 1 f 2
||dist||
b1
.*
LW2,1
b2
+
x
1
R x 1S1 x 1
S1 x 1
n1
S1 x 1
a1
S1 x 1
1
S2 x 1
S2 x S1
S2 x 1
n2
y
IW1,1
R
S1 x R
S2 x 1
Capa de Base Radial Capa Lineal
S1 S2 Radial Función
xIWa 1,11
1
11
f
bf Lineal Función
aLWy 2,1
2
212
f
bf
f 1 f 2
||dist||
b1
.*
LW2,1
b2
+
x
1
R x 1S1 x 1
S1 x 1
n1
S1 x 1
a1
S1 x 1
1
S2 x 1
S2 x S1
S2 x 1
n2
y
IW1,1
R
S1 x R
S2 x 1
Capa de Base Radial Capa Lineal
S1 S2

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 57
Hay casos en que se puede suplir un parámetro adicional, usualmente llamado Goal, el cual representa el umbral contra el que se comparará la suma de los errores cuadráticos de la red. De esta forma, las neuronas se añadirían una a una hasta que se alcance un error cuadrático por debajo del valor Goal, o se llegue al máximo número de neuronas. El diseño de la red cuando se suple este parámetro, es incremental.
De nuevo es importante hacer notar que, aunque es muy simple diseñar este tipo de red en comparación con el tiempo que toma el entrenamiento de redes del tipo perceptron multicapa con retropropagación, el número de neuronas que implica es mucho mayor. Ello se debe principalmente a que las funciones de transferencia log sigmoidales o tan sigmoidales responden a regiones grandes del espacio de entrada, mientras que las funciones de transferencia de base radial responden a espacios mucho más reducidos.
Un tipo particular de red neuronal de base radial es la Red de Regresión Generalizada35 (GRNN de sus siglas en inglés), la cual es frecuentemente usada para aproximación de funciones.
Figura 8. Arquitectura de Red Neuronal de Regresión Generalizada
Al igual que la red de base radial, esta arquitectura propone una capa de neuronas de base radial y otra de capa de neuronas con función de transferencia
35 Del inglés Generalized Regression Neural Network.
Radial Función
xIWa 1,11
1
11
f
bf Lineal Función
ny 2
2
2
ff
f 1 f 2
||dist||
b1
.*
LW2,1
nprod
x
1
R x 1Q x 1
Q x 1
n1
Q x 1
a1
Qx 1
Q x 1
Q x Q
Q x 1
n2
y
IW1,1
R
Q x R
Q x 1
Q Q
Capa de Base Radial Capa Lineal
Radial Función
xIWa 1,11
1
11
f
bf Lineal Función
ny 2
2
2
ff
f 1 f 2
||dist||
b1
.*
LW2,1
nprod
x
1
R x 1Q x 1
Q x 1
n1
Q x 1
a1
Qx 1
Q x 1
Q x Q
Q x 1
n2
y
IW1,1
R
Q x R
Q x 1
Q Q
Capa de Base Radial Capa Lineal

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 58
lineal. Sin embargo, la entrada a la capa de neuronas lineales es calculada como el producto escalar de la matriz de pesos de la capa de neuronas lineales LW2,1 y el vector de salida de capa de base radial a1, todo normalizado por la suma de los elementos de este último vector.
Este tipo de red neuronal puede, según se ha demostrado, aproximar cualquier función continua a un nivel de precisión arbitrario.
Existe un tipo adicional de red neuronal del tipo de base radial denominada Red Neuronal Probabilística36 (PNN de sus siglas en inglés). Esta es también una red de dos capas. Cuando una entrada es presentada a la red, la primera capa calcula las distancias entre el vector de entrada y los vectores de entrenamiento. La segunda capa suma esas contribuciones para cada clase de entradas para producir un vector de probabilidades. Finalmente, una función de transferencia competitiva se aplica sobre la salida, en la segunda capa, a fin de seleccionar el máximo de las probabilidades obtenidas, produciendo 1 para esa clase y 0 para las restantes.
Figura 9. Arquitectura de Red Neuronal Probabilística
Las PNN generalizan muy bien y, provista una suficiente cantidad de datos de entrenamiento, es prácticamente garantizado que converge a un clasificador Bayesiano.
36 Del inglés Probabilistic Neural Networks.
Radial Función
xIWa 1,11
1
11
f
bf aCompetenci de Función
aLWy 12,1
2
2
f
f
f 1 f 2
||dist||
b1
.* LW2,1
x
1
R x 1Q x 1
Q x 1
n1
Q x 1
a1
Qx 1K x Q
Q x Q
K x 1
n2
y
IW1,1
R
Q x R
K x 1
Q Q
Capa de Base Radial Capa de Competencia
Radial Función
xIWa 1,11
1
11
f
bf aCompetenci de Función
aLWy 12,1
2
2
f
f
f 1 f 2
||dist||
b1
.* LW2,1
x
1
R x 1Q x 1
Q x 1
n1
Q x 1
a1
Qx 1K x Q
Q x Q
K x 1
n2
y
IW1,1
R
Q x R
K x 1
Q Q
Capa de Base Radial Capa de Competencia

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 59
Nótese que todas las categorías de redes neuronales de base radial tienen muchas ventajas, principalmente la facilidad de diseño. Sin embargo, son lentas en su operación dado que usan mayor cantidad de cálculos que otras redes.
2.3.4 Self-Organizing Feature Maps (SOFM) y Redes del tipo Learning Vector Quantization (LVQ)37
Las redes del tipo SOM aprenden a detectar regularidades y correlaciones en los vectores de entrada y adapta su respuesta a esos patrones, aprendiendo a reconocer grupos de entradas similares; por lo tanto es una red de clasificación.
Su fundamento descansa sobre el principio de Aprendizaje Competitivo. En este tipo de aprendizaje el vector de entrada x es presentado a la neurona y se produce un vector que representa el negativo de las distancias entre ese vector de entrada y la matriz de pesos IW, a cuyo resultado se le suma el sesgo b. Si todos los sesgos fuesen 0, el máximo valor que puede producir esta sección de la neurona es 0, lo cual ocurriría cuando el vector de entrada iguala el vector de pesos de la neurona.
Figura 10. Arquitectura de Red Neuronal de Competencia
37 Se eligió utilizar los nombres en inglés sin traducción dado que normalmente la literatura en español hace referencia a estos tipos de redes por su nombre en inglés.
aCompetenci de Función
xIWya 1,11
1
11
f
bf
f 1
||dist||
b1
+
x
1
R x 1S1 x 1
S1 x 1
n1
S1 x 1
a1 = y
S1 x 1
IW1,1
R
S1 x R
Capa de Competencia
S1 aCompetenci de Función
xIWya 1,11
1
11
f
bf
f 1
||dist||
b1
+
x
1
R x 1S1 x 1
S1 x 1
n1
S1 x 1
a1 = y
S1 x 1
IW1,1
R
S1 x R
Capa de Competencia
S1

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 60
Luego, el vector entrante n a la función de transferencia es procesado y retorna cero para todas las neuronas, excepto para la ganadora, la cual está asociada al elemento más positivo de la entrada a esta capa. La salida de la ganadora es 1 y, en el caso particular en que el sesgo es nulo, ganará la neurona con el valor menos negativo producto de su primera capa.
Existen dos reglas de aprendizaje asociadas a estas neuronas competitivas. La primera de ellas es la Regla de Aprendizaje de Kohonen. Supóngase que la i-ésima neurona gana, entonces los elementos de la i-ésima fila de la matriz de pesos IW son ajustados como se muestra a continuación:
))(q-iqqiqi 1(1 1,11,11,1 IWxIWIW (2.3.4.1)
Esta regla permite que los pesos de la neurona aprendan un vector de entrada y, en consecuencia, es útil en aplicaciones de reconocimiento y clasificación.
Una de las limitaciones de las redes competitivas es que algunas de las neuronas pueden no siempre ser activadas, o lo que es igual, algunas neuronas nunca resultarán ganadoras y no tendrán ningún aporte en la red, por lo que se denominan neuronas muertas. Como una alternativa, el método de la Regla de Aprendizaje del Sesgo, usa el sesgo para aventajar a las neuronas que sólo ganan una competencia rara vez.
Esta capacidad no sólo elimina el problema de las neuronas muertas sino que además permite ser más preciso en el proceso de clasificación cuando los vectores de entrada se encuentran muy concentrados en un área del espacio de solución.
Haciendo uso de las redes competitivas, se dispone de una arquitectura muy particular que se denomina Self-organizing Feature Map (SOFM), redes tales que aprenden a clasificar vectores de entrada de acuerdo con la forma en que son agrupados en el espacio de entrada. Se diferencian de las capas competitivas en que la vecindad de neuronas del SOFM aprende a reconocer secciones vecinas del espacio de entrada; por lo tanto, estas redes aprenden tanto la distribución como la topología de los vectores de entrada que sirven de entrenamiento.
Las neuronas en un SOFM son arregladas originalmente en posiciones físicas de acuerdo con una función de topología, que normalmente son en malla, hexagonal y aleatoria. Las distancias entre las neuronas son calculadas partiendo de sus posiciones en el arreglo topológico. Este arreglo implica las maneras en que las distancias se calculan, de las cuales la más usual es la distancia entre las neuronas medidas en número de nodos de la topología que las separa.
El SOFM también identifica la neurona ganadora al igual que en las capas competitivas, pero la actualización ocurre en la neurona ganadora y en una vecindad en torno a ella, a un radio dado.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 61
Figura 11. Arquitectura de Red Neuronal SOFM
El entrenamiento de una red tipo SOFM ocurre presentándose un vector a la vez y en dos fases:
Fase de Ordenamiento de la Red. La distancia entre las neuronas comienza a una distancia máxima y decrece hasta una distancia de vecindad entonada.
Fase de Entonación. Esta fase se extiende por el resto del entrenamiento y busca un ajuste más preciso de las distancias en las vecindades.
En adición a los SOFM existen las redes del tipo Learning Vector Quantization (LVQ). Estas redes tienen una primera capa competitiva de neuronas y una segunda capa lineal. La capa competitiva clasifica los vectores de entrada de la misma manera en que fue introducido al inicio de esta sección. Sin embargo, la capa de transformación lineal transforma las salidas de la capa competitiva en las clases que sean definidas por el investigador. Por lo tanto, esta es una arquitectura de red neuronal dedicada a resolver problemas de clasificación.
El número de neuronas en cada capa corresponde con las sub-clases y clases en que se desean clasificar las entradas. La primera capa, la competitiva, identifica las sub-clases del espacio de entrada, las cuales estarán relacionadas con la función de transferencia lineal de la segunda capa, la cual asociará cada sub-clase con las clases objetivo.
aCompetenci de Función
xIWn 1,11
1f
f 1||dist||x
R x 1
n1
S1 x 1a1 = y
S1 x 1
R
Capa SOFM
IW1,1S1 x R
S1aCompetenci de Función
xIWn 1,11
1f
f 1||dist||x
R x 1
n1
S1 x 1a1 = y
S1 x 1
R
Capa SOFM
IW1,1S1 x R
S1

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 62
La regla de aprendizaje de estas redes, denominada también LVQ, toma una vector de entrada x y le asocia un vector de salida t que contiene tantos elementos como clasificaciones deseadas por el investigador, colocando un 1 en el elemento que corresponde con la clase de x, y los valores en 0.
Figura 12. Arquitectura de Red Neuronal LVQ
Para entrenar a la red, se presenta el vector x y se calcula la distancia entre él y la matriz de pesos IW. Supóngase que el i-ésimo elemento del vector resultante n es el más positivo, entonces la neurona i gana la competencia. Luego la función de transferencia produce un 1 en el i-ésimo elemento del vector de salida a y todos los demás valores reciben 0.
Cuando a es presentado a la segunda capa se multiplica por la matriz de pesos LW de esta capa, con lo que un 1 en a selecciona la clase de salida k del vector original de entrada x.
Si el vector x es clasificado correctamente, entonces:
1 kk ta (2.3.4.2)
En este caso, el valor de la i-ésima fila de IW se ajusta de la siguiente manera:
))(q-iqqiqi 1(1 1,11,11,1 IWxIWIW (2.3.4.3)
Lineal Función
aLWy 12,1
2
2
f
f
f 1 f 2||dist|| .* LW2,1
x
R x 1
n1 a1 n2
y
IW1,1
R
Capa de Competencia Capa Lineal
S1 x R
S1 x 1 S1 x 1 S2 x 1S2 x S1
S2 x 1
S2S1
aCompetenci de Función
xIWn 1,11
1f
Lineal Función
aLWy 12,1
2
2
f
f
f 1 f 2||dist|| .* LW2,1
x
R x 1
n1 a1 n2
y
IW1,1
R
Capa de Competencia Capa Lineal
S1 x R
S1 x 1 S1 x 1 S2 x 1S2 x S1
S2 x 1
S2S1
aCompetenci de Función
xIWn 1,11
1f

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 63
La misma forma de actualización ocurre si la clasificación de x es errada, pero dará diferentes valores.
La creación de una red LVQ requiere los siguientes parámetros:
Una matriz Rx2 que contiene los valores mínimos y máximos de los R elementos de entrada a la red.
El número de neuronas ocultas en la primera capa de la red, que representa el número de sub-clases que puede aprender la red.
El número de elementos de un vector que corresponde con cada clase objetivo.
La rata de aprendizaje que usualmente se establece en 0.0138.
La función de aprendizaje.
La gran característica y ventaja de las redes LVQ es que pueden clasificar grupos de entradas que no estén necesariamente separadas linealmente, como es el caso del perceptron simple.
2.3.5 La Red de Elman Esta red es un tipo de Red Recurrente, las cuales se caracterizan porque las salidas de una capa de neuronas retroalimentan la capa nuevamente. Un tipo de estas redes es la Red de Elman39, cuya capacidad principal, la cual es consecuencia de su diseño recursivo, es que puede aprender a detectar y generar patrones temporales; de allí se desprende su aplicación en procesamiento de señales y otros modelos donde el tiempo juega un papel determinante.
Esta es una red de dos capas con una retroalimentación que proviene de la salida de la primara capa a su propia entrada. En la capa oculta recurrente, la red usa neuronas con función de transferencia tan sigmoidal. Ello le permitirá aproximar cualquier tipo de función con un número finito de discontinuidades con una precisión arbitraria. Sólo una consideración y es que la cantidad de neuronas en la capa oculta aumentará en la medida en que se incremente la complejidad de la función a ser aproximada. El rezago, por así decirlo, que es tomado por el efecto 38 Este es el valor sugerido en MatLab para estas redes.
39 Otro tipo de red recurrente es la red de Hopfield, la cual tiene interés fundamentalmente teórico y es porque, aún en sus mejores diseños puede tener puntos estables que son espurios, lo que puede guiar a resultados incorrectos. Su uso está orientado como corrector de errores y categorización de vectores.
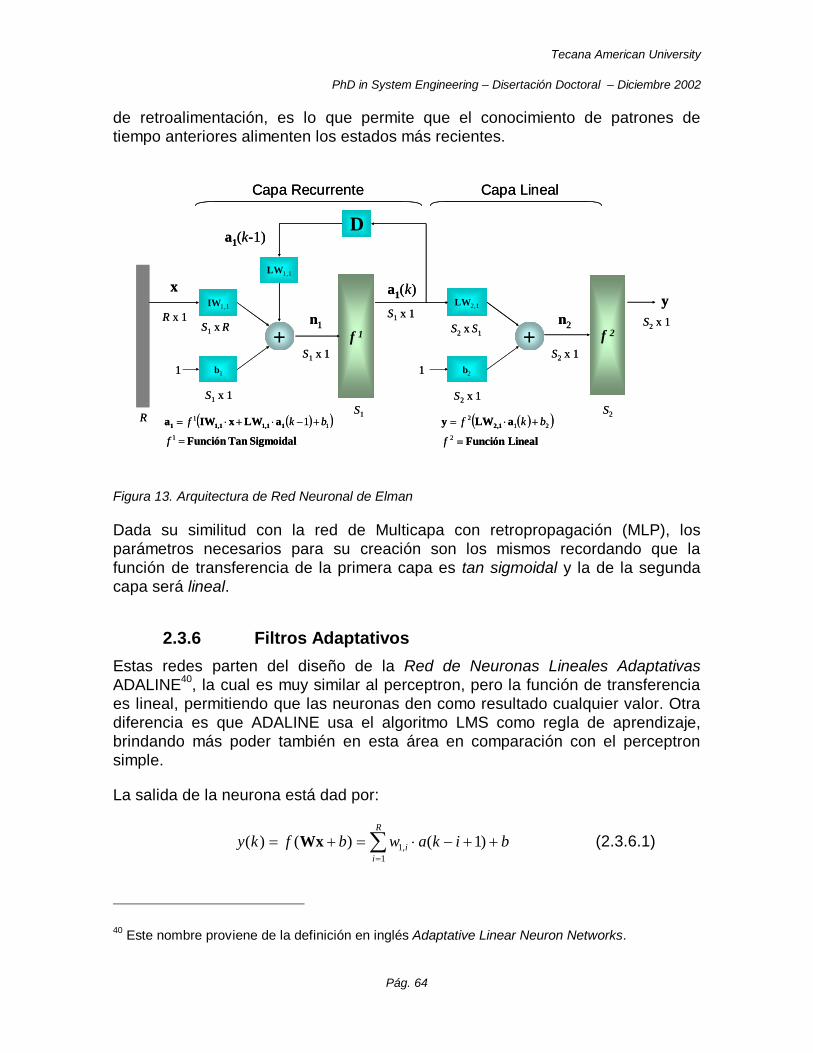
Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 64
de retroalimentación, es lo que permite que el conocimiento de patrones de tiempo anteriores alimenten los estados más recientes.
Figura 13. Arquitectura de Red Neuronal de Elman
Dada su similitud con la red de Multicapa con retropropagación (MLP), los parámetros necesarios para su creación son los mismos recordando que la función de transferencia de la primera capa es tan sigmoidal y la de la segunda capa será lineal.
2.3.6 Filtros Adaptativos Estas redes parten del diseño de la Red de Neuronas Lineales Adaptativas ADALINE40, la cual es muy similar al perceptron, pero la función de transferencia es lineal, permitiendo que las neuronas den como resultado cualquier valor. Otra diferencia es que ADALINE usa el algoritmo LMS como regla de aprendizaje, brindando más poder también en esta área en comparación con el perceptron simple.
La salida de la neurona está dad por:
R
ii bikawbfky
1,1 )1()()( Wx (2.3.6.1)
40 Este nombre proviene de la definición en inglés Adaptative Linear Neuron Networks.
Sigmoidal Tan Función
aLWxIWa 11,11,11
1
11 1
f
bkf Lineal Función
aLWy 2,1
2
212
f
bkf
f 1 f 2
IW1,1
b1
+
LW2,1
b2
+
x
1
R x 1
S1 x 1
n1
S1 x 1
a1(k)S1 x 1
1
S2 x 1
S2 x S1
S2 x 1
n2
y
LW1,1
R
S1 x R S2 x 1
Capa Recurrente Capa Lineal
S1 S2
Da1(k-1)
Sigmoidal Tan Función
aLWxIWa 11,11,11
1
11 1
f
bkf Lineal Función
aLWy 2,1
2
212
f
bkf
f 1 f 2
IW1,1
b1
+
LW2,1
b2
+
x
1
R x 1
S1 x 1
n1
S1 x 1
a1(k)S1 x 1
1
S2 x 1
S2 x S1
S2 x 1
n2
y
LW1,1
R
S1 x R S2 x 1
Capa Recurrente Capa Lineal
S1 S2
Da1(k-1)

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 65
Figura 14. Modelo de Neurona Artificial Lineal
Lo más interesante de esta propuesta es que, cuando las entradas son sujetas a retrasos transferidos a una serie de neuronas, entonces se puede lograr una simulación de patrones que responden a procesos estacionarios aleatorios, con lo que se dispone de un excelente modelo para simulación de series de tiempo en procesamiento de señales. Esa es la razón por la cual, aún cuando estas redes, al igual que el perceptron, trabajan sobre estaciones linealmente separables, son de uso muy difundido41.
Supóngase que se tiene una señal de entrada la cual pasa a través de N – 1 retrasos. La salida de este proceso es un vector N-dimensional compuesto por la señal de entrada en el momento actual, el momento anterior, y así sucesivamente en retroceso.
Si esta construcción es luego sumarizada, de acuerdo con el modelo ADALINE, y pasada a una función de transferencia lineal, se obtiene entonces la estructura de un filtro adaptativo.
Si esta salida es comparada con la señal que se esté recibiendo actualmente, se puede entonces ajustar los pesos en función de la corrección de error con lo cual
41 Construcciones similares pueden ser aplicadas a problemas de cancelación de errores, procesamiento de señales y sistemas de control, entre otros.
x1
x2
xR
w1,1
w,1,2
w1,R
fn
y
1
b
Lineal FunciónxW
fbfy )(
x1
x2
xR
w1,1
w,1,2
w1,R
fn
y
1
b
Lineal FunciónxW
fbfy )(

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 66
se obtiene un modelo de red que puede atender procesos estacionarios aleatorios de series de tiempo en procesamiento de señales.
Figura 15. Arquitectura de Red Neuronal de Filtro Adaptativo para predicción de señales
Por supuesto esta construcción puede ser extendida a múltiples filtros adaptativos de neuronas, donde la salida de cada rezago es pasado a una neurona especializada en esa salida, con su correspondiente función de transferencia (lineal, por supuesto)
f
x1(t) = x(t)
x2(t) = x(t-1)
x3(t) = x(t-2)
w1,2
w1,3
n(t) y(t)
1
b
Lineal FunciónxW
fbfy )(
D
+
D
Ajustar Pesos
e(t)
y(t) es la aproximación a x(t)
Filtro Lineal Adaptativo
f
x1(t) = x(t)
x2(t) = x(t-1)
x3(t) = x(t-2)
w1,2
w1,3
n(t) y(t)
1
b
Lineal FunciónxW
fbfy )(
D
+
D
Ajustar Pesos
e(t)
y(t) es la aproximación a x(t)
Filtro Lineal Adaptativo

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 67
3. FORMULACIÓN DE HIPÓTESIS
El Marco Conceptual desarrollado en el capítulo anterior ha brindado una serie de elementos – ya sea empíricos, teóricos o producto de investigaciones previas - para abordar el problema planteado. Recuérdese las preguntas iniciales propuestas en el planteamiento del problema (ver Capítulo 1, Sección 1.1):
¿Cuándo se deben usar técnicas de RNA o MEMV en la creación de modelos de fenómenos de regresión?
¿Cuál es una metodología que permita enfrentar el modelado de fenómenos de regresión?
¿Existe efectivamente una complementariedad entre los MEMV y las RNA?
A fin de dar respuesta a esas preguntas, se han planteado las siguientes hipótesis que serán demostradas a través de los experimentos que serán diseñados, desarrollados y descritos en el siguiente capítulo – Marco Metodológico42.
1. Las técnicas estadísticas multivariadas son útiles para procesar una muestra de datos multivariada y prepararla apropiadamente para realizar análisis basados en Métodos Estadísticos o Redes Neuronales Artificiales.
H0: Las técnicas estadísticas multivariadas permiten preparar los datos para futuros experimentos, sin importar las técnicas que serán utilizadas.
H1: es invariante el rendimiento de experimentos de la preparación de datos maestrales que sea realizada.
2. Las Redes Neuronales Artificiales permiten aproximar funciones multivariadas tan bien o mejor que los métodos estadísticos multivariados basados en el Modelo de Regresión General Lineal, específicamente en problemas de regresión y correlación.
H0: los resultados de experimentos con Redes Neuronales o con Métodos Estadísticos Multivariados, en igualdad de muestras, son indiferentes para problemas de regresión y correlación.
42 Aquí se usará la notación estadística para establecer las hipótesis. H0 indica la hipótesis nula, la cual plantea en positivo la hipótesis que se pretende mostrar, mientras que H1 refuta la hipótesis nula.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 68
H1: los resultados de experimentos con Redes Neuronales Artificiales y Métodos Estadísticos Multivariados son sensiblemente distintos para problemas de regresión y correlación.
3. Las Redes Neuronales Artificiales permiten clasificar datos multivariados tan bien o mejor que los métodos estadísticos multivariados basadas en el Modelo de Regresión Logística.
H0: los resultados de experimentos con Redes Neuronales o con Modelos de Regresión Logística, en igualdad de muestras, son indiferentes para problemas de clasificación.
H1: los resultados de experimentos con Redes Neuronales Artificiales y Modelos de Regresión Logística son sensiblemente distintos para problemas de clasificación.
4. Las Redes Neuronales Artificiales permiten aproximar series de tiempo tan bien o mejor que los métodos basados en la Metodología de Box-Jenkins (ARIMA) y regresión múltiple.
H0: los resultados de experimentos con Redes Neuronales o con Modelos ARIMA, en igualdad de muestras, son indiferentes para problemas de análisis de series de tiempo, como caso de procesamiento de señales.
H1: los resultados de experimentos con Redes Neuronales Artificiales y con Modelos ARIMA son sensiblemente distintos para problemas de análisis de series de tiempo, como caso de procesamiento de señales.
5. El uso de métodos estadísticos multivariados es importante para explorar sobre las características de los datos a ser modelados, ya sea por métodos de esa misma naturaleza o por la aplicación de Redes Neuronales Artificiales, por lo que su complementariedad es inherente al análisis de muestras multivariadas.
H0: el uso de Métodos Estadísticos Multivariados provee información importante en el análisis de experimentos e interpretación de resultados cuando se aplican Redes Neuronales Artificiales en problemas de regresión, correlación y análisis de series de tiempo.
H1: el uso de Métodos Estadísticos Multivariados no provee información adicional de valor en el análisis de experimentos e interpretación de resultados cuando se aplican Redes Neuronales Artificiales en problemas de regresión, correlación y análisis de series de tiempo.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 69
6. El rendimiento de las Redes Neuronales Artificiales difiere dependiendo del tipo y la arquitectura usada para una misma muestra de datos.
H0: los mejores resultados de cada Red Neuronal Artificial son siempre comparables, bajo la misma muestra de datos.
H1: al menos una de las arquitecturas de Red Neuronal Artificial tiene mejor o peor rendimiento que las otras, bajo la misma muestra de datos.
Las pruebas y conclusiones de las hipótesis citadas están circunscritas al alcance dado a la presente disertación, tal como se estableció en la Sección 1.4 del Capítulo 1.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 70
4. MARCO METODOLÓGICO
4.1 Tipo de Investigación
A fin de cumplir con los objetivos propuestos en esta disertación, así como buscar la aceptación o rechazo de las hipótesis planteadas, se ha diseñado una investigación que cumple básicamente con las siguientes características:
Desde el punto de vista del Nivel de la Investigación, se ha estructurado la disertación de manera Exploratoria. Esta arista permite un acercamiento comparativo entre los métodos estadísticos multivariados y las redes neuronales artificiales, a fin de presentar horizontes que determinen el espacio de acción de cada una de estas disciplinas y comprender en qué medida las unas complementas a las otras, y cuál es el espacio en que cada una de ellas pueda ser excluyente de la otra.
El Diseño de la Investigación es de naturaleza Experimental Pura. A fin de dar consistencia a los análisis, se ha considerado recomendable que las variables que compongan las muestras que alimentan a los experimentos sean controladas, por lo que los consecuentes experimentos satisfarán esta misma característica. Con ello, se busca identificar los principios teóricos que permitan desprender conclusiones que posteriormente, en otras investigaciones, puedan llevar a conformar experimentos sobre datos prácticos en escenarios reales. Por ello, algunas muestras serán simuladas y otras serán obtenidas de fuentes académicas o de investigadores, con características muy particulares, pudiendo de esta forma controlar, en un nivel muy adecuado, las características de los experimentos.
Finalmente, y dado que se busca confrontar un conjunto de investigaciones teóricas mediante experimentos controlados, la investigación, desde la visión de su propósito, será Aplicada. Mediante esta disertación, se busca contrastar diferentes resultados de investigaciones, unas orientadas a los métodos estadísticos multivariados y otras a las redes neuronales artificiales, y determinar las condiciones en que cada disciplina complementa a la otra, así como los escenarios en que su rendimiento pueda ser sensiblemente superior.
4.2 Diseño y Selección de las Muestras
A fin de realizar la pruebas comparativas de redes neuronales y métodos estadísticos multivariados, se diseñaron, en unos casos, y se investigaron en fuentes académicas y de investigación, en otros, algunas muestras que cumplen
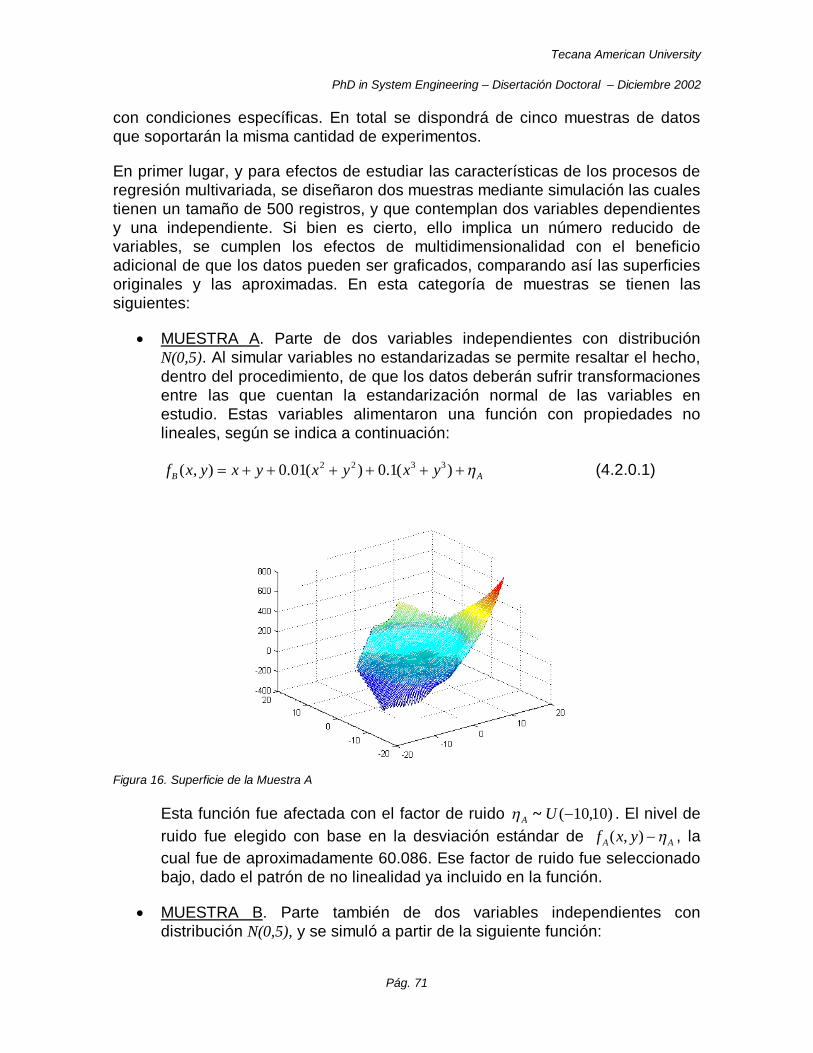
Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 71
con condiciones específicas. En total se dispondrá de cinco muestras de datos que soportarán la misma cantidad de experimentos.
En primer lugar, y para efectos de estudiar las características de los procesos de regresión multivariada, se diseñaron dos muestras mediante simulación las cuales tienen un tamaño de 500 registros, y que contemplan dos variables dependientes y una independiente. Si bien es cierto, ello implica un número reducido de variables, se cumplen los efectos de multidimensionalidad con el beneficio adicional de que los datos pueden ser graficados, comparando así las superficies originales y las aproximadas. En esta categoría de muestras se tienen las siguientes:
MUESTRA A. Parte de dos variables independientes con distribución N(0,5). Al simular variables no estandarizadas se permite resaltar el hecho, dentro del procedimiento, de que los datos deberán sufrir transformaciones entre las que cuentan la estandarización normal de las variables en estudio. Estas variables alimentaron una función con propiedades no lineales, según se indica a continuación:
AB yxyxyxyxf )(1.0)(01.0),( 3322 (4.2.0.1)
Figura 16. Superficie de la Muestra A
Esta función fue afectada con el factor de ruido )10,10(UA ~ . El nivel de ruido fue elegido con base en la desviación estándar de AA yxf ),( , la cual fue de aproximadamente 60.086. Ese factor de ruido fue seleccionado bajo, dado el patrón de no linealidad ya incluido en la función.
MUESTRA B. Parte también de dos variables independientes con distribución N(0,5), y se simuló a partir de la siguiente función:

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 72
BB yxyxf 37.02),( (4.2.0.2)
Figura 17. Superficie de la Muestra B
Esta función fue alterada con un factor de ruido )20,20(~ UB , el cual es significativo en comparación con la desviación estándar de BB yxf ),( , cuyo valor es de aproximadamente 10.43, dado que esta función sí tiene un comportamiento lineal.
Estas muestras fueron subdivididas en tres grupos: uno de entrenamiento, otro de validación y el último de prueba, en una proporción 50% – 25% – 25%. Estas dos muestras serán usadas para analizar los casos de regresión multivariada.43
Para la realización del experimento de regresión logística, se acudió a una muestra de datos que es el resultado de una encuesta de Orientación hacia el Trabajo realizada en España y publicada por el Centro de Investigaciones sobre la Realidad Social en 199444. La muestra es de 1200 encuestas realizadas a personas de más de 18 años y extraída de un modo aleatorio estratificado por Comunidades Autónomas y Municipios, de acuerdo con su tamaño.
La muestra fue ponderada por sexo y edades de los individuos de acuerdo con la siguiente distribución:
43 Una de las razones de usar muestras experimentales en estos casos fue la poca disponibilidad de muestras de suficiente tamaño y condiciones como para hacer las pruebas. La falta de muestras de tamaño adecuado es una de las razones para no llegar a resultados que posean sentido.
44 Esta muestra fue tomada de B. Visauta Vinacua (1998).

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 73
EDAD HOMBRE MUJER
18 - 29 0.13743 0.12836
30 - 44 0.16978 0.17034
50 - 64 0.10424 0.11145
más de 65 0.07538 0.10798
La encuesta contiene en total 86 variables y, para efectos del experimento, se tomó un subconjunto compuesto sólo por 5 variables más la identificación del número de encuesta. A la muestra obtenida se le denomina MUESTRA C. Estas variables serán referidas como:
ENC: Identificación de la encuesta. Es un número consecutivo entero de 1 a 1200.
B1: Situación laboral
o 1 – Laboralmente activo para el momento de la encuesta
o 5 – Laboralmente inactivo para el momento de la encuesta
o 9 – No contestó (todos los individuos contestaron a esta pregunta)
C1: Sexo
o 1 – Hombre
o 2 - Mujer
C2: Edad en años. Valor entero mayor o igual a 18.
C3: Estado Civil:
o 1 – Soltero
o 2 – Casado
o 3 - Viviendo en pareja
o 4 - Separado
o 5 - Divorciado

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 74
o 6 - Viudo
o 9 - No Contesto
C6: Estudios del entrevistado
o 0 – Menos de estudios primarios, no sabe leer.
o 1 – Menos de estudios primarios, sabe leer.
o 2 – Estudios primarios completos.
o 3 – Formación Profesional de primer nivel
o 4 – Formación profesional de segundo nivel
o 5 – Bachiller Elemental
o 6 – Bachiller Superior
o 7 – Estudios de grado medio (Escuela Universitaria)
o 8 – Universitarios o Técnicos de Grado Superior
o 9 – Sin responder
Nótese que casi todas las variables son categóricas y en esta muestra se considerará a B1, la cual es dicótoma, como el criterio, y las 4 variables restantes (C1, C2, C3 y C6) como predictoras, excluyendo a ENC, que sólo se comportará como un identificador del caso.
Existen diferentes razones para haber escogido esta muestra, pero principalmente resaltan dos:
La muestra proviene de un estudio real y ha sido muy útil para efectos de investigación, dada la rigurosidad con que fue obtenida.
Presenta suficiente cantidad de casos, y de hecho en exceso45, para poder realizar una regresión logística y los experimentos con redes neuronales artificiales.
45 Recuérdese que en la Sección 2.2.5 se indicaba que debe existir un mínimo de 50 casos por variable predictora. En este caso particular, siendo 4 las variables predictoras, sería necesario disponer como mínimo de 200 casos, cantidad que es mucho menor al número de casos que serán usados en el experimento, que, como será explicado más adelante, será de 973, aunque la muestra sea de 1200 encuestas.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 75
Luego, para desarrollar el experimento relativo a Series de Tiempo se tomó una muestra trimestral del PIB de los EEUU, desde el primer trimestre de 1970 hasta el cuarto de 1991. Esta muestra será denominada MUESTRA D.
Los períodos se numeran consecutivamente de 1 a 88, donde el primero de ellos corresponde con el valor del PIB en EEUU para el primer trimestre de 1970. Los datos, procesados con SPSS 9.0 se grafican a continuación:
Figura 18. PIB de los Estados Unidos.
Los datos fueron tomados de Damodar Gujarati (1997), y la razón fundamental para tomar esta muestra respondió a:
Corresponde a un caso real que ha servido como base de investigación en estudios de esta naturaleza.
La serie de tiempo presenta un comportamiento que requiere un análisis completo antes de poder llegar a una conclusión, tal y como podrá ser apreciado en el experimento respectivo. Esta faceta de la muestra permite desarrollar un experimento que contemple los pasos en el análisis de una serie de tiempo compleja.
Finalmente, la siguiente muestra de datos, referida como MUESTRA E, está diseñada para demostrar la aplicación de redes neuronales artificiales en la detección de señales en series de tiempo. Este es un problema diferente al de series de tiempo económicas y es la razón por la cual se incluye en la disertación, a fin de establecer las diferencias entre cada caso.
Se diseño una señal que dura 6 segundos con una rata de muestreo de 20 muestras por segundo, con la particularidad de que en el segundo 4 la frecuencia de la señal se duplica. Las ecuaciones usadas para generar esta muestra son las siguientes:
PIB de los Estados Unidos
Trimestre I de 1970 - Trimestre IV de 1991
Períodos trimestrales numerados de 1 - 88
Case Number
8681767166615651464136312621161161
Valu
e PI
B_U
SA
6000
5000
4000
3000
2000

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 76
segundos 4 primeros los para )4sin(1 ty (4.2.0.3)
segundos 4 cumplidos de luego )8sin(2 ty (4.2.0.4)
Esta función, donde t representa el tiempo, generó la siguiente señal:
Figura 19. Diseño de Señal de la Muestra E
Esta muestra permitirá:
Demostrar cómo la red neuronal puede identificar el patrón.
Demostrar la capacidad de la red neuronal para detectar el cambio de patrón en la señal.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 77
4.3 Instrumentos
Dado que las muestras de datos sobre las que se realizaron los experimentos, o fueron simuladas o fueron tomadas de fuentes académicas y de investigación, no se aplicaron instrumentos específicos para obtenerlas. Sin embargo, se usaron diferentes productos de software para simular, procesar y analizar los resultados.
MS-Excel 2000 (en adelante referido como Excel) fue intensamente utilizado para realizar las simulaciones de las Muestras A y B referidas en la Sección 4.2. Asimismo, fue usado para realizar análisis comparativos entre los resultados de los diferentes experimentos para cada muestra. Dada la capacidad de enlace de Excel con MatLab, a través de la facilidad ExcelLink de MatLab, Excel fue utilizado como herramienta de preparación de datos e interfaz con los comandos de MatLab, facilitando así la interacción con este último producto.
Todos los procesos asociados con Redes Neuronales fueron ejecutados con MatLab versión 6 release 12. Sobre este producto se programaron las características de las redes neuronales, así como los procesos de preparación de datos y post-procesamiento apropiados en cada caso. Cada uno de los experimentos fueron programados y sus resultados fueron transferidos a Excel para realizar los análisis comparativos. Es necesario resaltar que MatLab provee una serie de herramientas de productividad (o tool boxes) que permiten desarrollar muchos experimentos; sin embargo, ellos limitan la flexibilidad de los experimentos, y fue la razón por la cual se decidió preparar los programas que atendiesen los requerimientos específicos de la investigación.
Matrixer 4.446 fue utilizado para apoyar los procesos de análisis de series de tiempo, basados en la técnica ARIMA.
SPSS versión 9 fue utilizado para realizar la mayoría de los procesos estadísticos. Con excepción de las regresiones multivariadas que se aplicaron a las Muestras A y B descritas en la Sección 4.2, las cuales fueron realizadas en Excel, los demás procesos estadísticos fueron ejecutados en SPSS. Otra excepción fue la normalización de los datos para alimentar las redes neuronales MLP, así como la desnormalización de los resultados. La razón es que estos procesos están íntimamente ligados a las actividades de pre y post procesamiento de este tipo de redes en MatLab.47
46 La licencia del producto fue gentilmente cedida por su autor Alexander Tsyplakov.
47 Todos los nombres de los productos son marcas registradas de sus respectivas casas de software.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 78
4.4 Procedimiento
Los procedimientos utilizados tienen características particulares para cada uno de los experimentos realizados. Esto no debe sorprender puesto que en cualquier estudio estadístico o de redes neuronales, las soluciones son diseñadas, y por ende responden, en función de las características del espacio de datos en cuestión. Si bien es cierto que los procedimientos, como marco metodológico, existen y son definidos de manera genérica, el análisis es específico a cada caso y la construcción del experimento es igualmente consecuente. Por ello, los procedimientos serán descritos para cada uno de los experimentos. Luego, el análisis e interpretación de los resultados corresponderá con cada una de esos experimentos.
En términos generales, siempre se observarán actividades para el pre-procesamiento de los datos, el proceso estadístico o de red neuronal artificial, y actividades post-procesamiento, que servirán para presentar los resultados y efectuar comparaciones entre los diferentes procesos aplicados en el experimento.
Un aspecto que se debe resaltar, y siguiendo las recomendaciones del fabricante del producto, fue de seleccionar los parámetros por defecto contenidos en MatLab para la generación de las redes neuronales, sobre todo en lo que a error objetivo y rata de aprendizaje, en los casos que aplique, se refiere.
4.4.1 Experimento I: Regresión Multivariada de Origen no Lineal con bajo ruido
Este experimento está basado en la Muestra A descrita en la Sección 4.2 y busca analizar el comportamiento de la aproximación de la función bajo estudio, producto de la aplicación de una regresión lineal múltiple y de redes neuronales artificiales, en condiciones de bajo ruido pero no linealidad del espacio de datos.
El primer paso consistió en simular la mencionada Muestra A para que cumpliese con las siguientes características, razonablemente apropiadas para aplicación del MRGL:
Los datos provienen de una distribución normal.
La correlación existente entre los predictores es baja, mientras que se dispone de una correlación razonable entre ellos y el criterio. Tal razonabilidad implica que esa correlación esté en el entorno de 0.6, lo que permite simular condiciones que se apegan más a situaciones prácticas que experimentales, tal y como fue descrito en la Sección 2.2.1, y con apego a las explicaciones de Jonhson (2000).

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 79
La función escogida cumple dos condiciones:
o Es definida en el espacio, lo que permite graficar tanto la función original como la aproximación, aportando no sólo criterios matemáticos sino también visuales.
o Es de carácter polinómico, de manera tal que es diferenciable y continua en todo su dominio, evitando también interferencias armónicas que puedan ser producto de la aplicación de funciones trascendentales.
Se indujo un ruido uniforme al criterio originalmente obtenido de la función relativamente bajo, si se compara con la desviación estándar de los resultados de la función original. De esta forma, se hace énfasis en las capacidades de los modelos en aproximar el patrón no lineal más que en la eliminación de ruido en la muestra.
La muestra fue generada mediante simulación usando para ello Excel. El proceso fue iterativo y exploratorio hasta lograr las condiciones que se consideraron adecuadas para este procedimiento.
Cumpliendo el doble propósito de validar las condiciones de la muestra y de demostrar el proceso que sería seguido en un experimento sobre un escenario real, el primer paso fue validar los coeficientes de correlación entre predictores y criterio.
Luego se procedió a realizar la regresión lineal múltiple, la cual fue ejecutada en Excel. El 75% de los datos fueron usados para identificar el modelo de regresión y el 25% restante para determinar el error que comete el modelo de regresión lineal en sus aproximaciones. Estos resultados fueron graficados a fin de obtener una vista de la superficie aproximada a la función originalmente regresada. El proceso de graficación implica realizar una interpolación de la superficie de los predictores y la proyección del criterio. La interpolación siguió el método cúbico y fue realizada, en conjunto con la graficación, usando rutinas de MatLab.
En cuanto a la parte del experimento relativa a la aplicación de redes neuronales artificiales, se decidió por la popular arquitectura de Multilayer Perceptron con backpropagation. En este caso, se escogió desde el inicio una arquitectura de una capa oculta, siguiendo las recomendaciones de Demuth y Beale (2002), y se probaron diferentes cantidades de neuronas.
Siguiendo las recomendaciones de Estévez Valencia (1999), se partió con una cantidad de neuronas en esa capa oculta dada por:
2oi
hNNN
(4.4.1.1)

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 80
Aquí, Nh es el número de neuronas en la capa oculta, Ni es el número de variables de entrada y No es el número de variables de salida. En el caso de este experimento se tienen dos variables de entrada y una de salida, lo que daría un número de neuronas iniciales de 2 (por aproximación hacia arriba). Ese número inicial fue incrementado hasta obtener un rendimiento adecuado con 5 neuronas.
Antes de aplicar la red neuronal, se realizó la normalización de los datos y se seccionó la muestra en tres partes: 50% para entrenamiento, 25% para validación y 25% para prueba, a fin de aplicar un entrenamiento con Detención Temprana, evitando sobre-ajuste en los resultados de la red.
Dado que los datos de entrada fueron normalizados, los resultados tuvieron que ser desnormalizados a la misma desviación estándar originalmente calculada.
Finalmente, se muestra la regresión lineal entre el vector de entrenamiento y los resultados dados por la red y el modelo de regresión, como una evaluación de la bondad de ajuste del modelo.
En adición al uso de una red neuronal MLP, se aplicó otra arquitectura de tipo Regresión Generalizada (GRNN), basada en funciones de base radial, cuyo proceso de preparación es mucho más expedito que la MLP y se obtuvieron resultados que fueron pasados también por un proceso de regresión entre sus valores y los originales de la función sometida a ruido.
Fuera del proceso de simulación de la muestra, el procedimiento refleja las actividades típicas que se recomiendan observar en un proceso de regresión, incluyendo las actividades preparatorias y de análisis posterior.
4.4.2 Experimento II: Regresión Multivariada de Origen Lineal con alto ruido
Este experimento está basado en la Muestra B descrita en la Sección 4.2 y busca analizar el comportamiento de la aproximación de la función original, producto de regresión lineal múltiple y de la aplicación de redes neuronales artificiales, en condiciones de linealidad y alto ruido. Estas condiciones de ruido generan una superficie con muchas alteraciones o irregularidades, pero aún continua y diferenciable.
El primer paso consistió en simular la mencionada Muestra B para que cumpliese con las siguientes características, poco apropiadas para aplicación del MRGL:
Los datos provienen de una distribución normal.
La correlación existente entre los predictores es baja, mientras que se dispone de una correlación mixta entre ellos y el criterio. Tal razonabilidad implica que esa correlación esté en el entorno de 0.6 para uno de los casos

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 81
y muy bajas, en el entorno de 0.2, para el otro predictor con el criterio. Esto induce condiciones de baja calidad en la muestra, pero razonablemente característica de casos reales, lo que permite simular condiciones que se apegan más a situaciones prácticas que experimentales, tal y como fue descrito en la Sección 2.2.1.
La función escogida cumple dos condiciones:
o Es definida en el espacio, lo que permite graficar tanto la función original como las aproximaciones.
o Es de base lineal, de manera tal que es diferenciable y continua en todo su dominio, evitando también interferencias armónicas que puedan ser producto de la aplicación de funciones trascendentales.
Se indujo un ruido uniforme al criterio originalmente obtenido de la función relativamente alto, si se compara con la desviación estándar de los resultados de la función original. De esta forma, se hace énfasis en las capacidades de los modelos en aproximar el patrón irregular en una configuración de alto ruido en la muestra.
La muestra fue generada mediante simulación usando para ello Excel. El proceso fue iterativo y exploratorio hasta lograr las condiciones que se consideraron adecuadas para este procedimiento.
Los pasos seguidos en este experimento replican los del experimento anterior, buscando al mismo tiempo probar dicho procedimiento como método de análisis de muestras en procesos de regresión multivariada.
Asimismo, hay que notar que se usaron los mismos tipos de redes neuronales, pero se realizó un análisis previo para determinar la arquitectura de la red MLP. Dado el nivel de irregularidad de la superficie, lo cual indudablemente le agrega un importante componente de complejidad a la función a ser aproximada, se hizo necesario agregar un capa adicional oculta a la red. De nuevo, ello implicó un proceso heurístico de pruebas de diferentes números de capas y neuronas en cada capa con el propósito de:
Identificar al número de capas que permite una mejor aproximación a las irregularidades.
Identificar el número de neuronas por capa que busque el mismo objetivo anterior.
Evitar un proceso de sobre-ajuste a la red que erosione sus capacidades de generalización.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 82
4.4.3 Experimento III: Regresión Logística con Datos Reales
En términos de la MUESTRA C, descrita en la Sección 2.2, el objeto de este experimento es construir un modelo que identifique la propensión del estado laboral de una persona (activo – 1, o inactivo – 5, según valores de la variable B1) en función de los predictores disponibles, que son: edad, sexo, nivel de educación y estado civil. Nótese que tanto las tres últimas variables predictoras como el criterio son categóricas en su naturaleza, independientemente que tengan valores numéricos asignados48.
En buena medida, muchos de los análisis preliminares de los datos que serán realizados responden a razones específicas de los modelos que serán aplicados. En este sentido, lo primero que hay que resaltar es que el experimento comparará el rendimiento de modelos obtenidos por tres fuentes, propios de problemas de clasificación dicótoma:
Modelo de Regresión Logística
Modelo de Red Neuronal basada en Funciones de Base Radial, específicamente de tipo Probabilístico (PNN).
Modelo de Red Neuronal basada en Self Organized Features Maps, específicamente del tipo Learning Vector Quantization (LVQ).
El último tipo de red requiere que se disponga de una aproximación a la cantidad de sub-clases existentes en la muestra, puesto que ello determina el número de neuronas que tendrá la capa de competencia de la red LVQ (ver Sección 2.3.4). Ello corresponde con un análisis inicial de clases de los datos.
Luego, y por ser una muestra no experimental, será necesario entender la configuración de la misma.
Como parte de las actividades preparatorias lo primero que será necesario es determinar los casos que participarán en la muestra. Ello implica seleccionar las personas que tienen menos de 65 años (no incluido 65), puesto que a partir de 65 años, las personas se encontrarán jubiladas, según la ley española. Este proceso de filtrado se realiza tanto en SPSS, herramienta que permitirá procesar los análisis estadísticos preliminares y el modelo de regresión logística, como en Excel, herramienta que suplirá la muestra de datos a MatLab para correr los modelos de redes neuronales de los tipos PNN y LVQ, así como realizar los análisis comparativos. 48 Es una práctica normal asignar valores numéricos a las variables categóricas para así facilitar el procesamiento matemático de cualquier índole.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 83
Después, será necesario investigar la matriz de correlación entre todas la variables involucradas en el estudio. Ello permitirá determinar si cada una de las variables tiene peso suficiente en la participación del modelo final y la calidad existente en la muestra.
En todo estudio que implique análisis multivariado por la vía de métodos estadísticos o redes neuronales, siempre será necesario aplicar un análisis de componentes principales, a fin de detectar la dimensionalidad más apropiada de la muestra de datos. Nótese que ello, de tener éxito, permite simplificar mucho los modelos al reducir la cantidad de variables participantes.
La decisión para soportar si se toman componentes principales o no, que significaría seguir con la identificación de los factores (con base en las técnicas FA), estará basado en la evaluación de:
Determinante de la Matriz de Correlación.
El estadístico de KMO
La prueba de Barlett
El análisis de la varianza explicada
El gráfico Scree
La identificación clusters iniciales se hará con base en el Dendograma producto de un análisis de clasificación jerárquica, para luego proceder con un análisis de clasificación de tipo K-Means, que requiere una definición inicial de la cantidad de clusters. Allí será determinante el análisis de la varianza para tomar decisiones sobre el número de clusters que pudiesen manejarse.
La cantidad de clusters que se decida determinará el número de neuronas que tendrá la capa de competencia de la red neuronal LVQ, tal que sea múltiplo mayor o igual que la cantidad de resultados esperados de la red, que en este caso será la discriminación entre dos valores, es decir, dos variables de salida. Así se podrá al menos disponer de un par de valores candidatos de cantidad de neuronas en la capa de competencia de la red LVQ.
Nótese que estos análisis no son requeridos para la aplicación de la red tipo PNN, puesto que la red se auto-ajusta al espacio de datos introducido.
Una transformación interesante requerida para el procesamiento de cada red es la transformación del vector de entrenamiento, visto como índices, en vectores de dos dimensiones, es decir, colocar 1 o 0 dependiendo si la combinación correspondiente de valores de entrada produce una resultado u otro. Luego entonces será necesario tomar la salida de las redes y transformarlas a su

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 84
formato original. Como parte de esta transformación será necesario, para disminuir la dimensionalidad del vector a dos, transformar el valor de entrenamiento 5 en 2, de manera que dichos sean contiguos (en este caso 1 y 2), y al simular cada red, se deberá aplicar la transformación inversa.
Otro aspecto interesante en la construcción del modelo es considerar la cantidad de empleados y desempleados de la muestra. Ello determinará la probabilidad a priori de que una persona se encuentre empleada o no y, en consecuencia, provee el valor umbral para asignar una probabilidad u otra a cada caso. Este aspecto es relevante en todos los modelos de solución que se desarrollarán, excepto para la red de tipo PNN.
Finalmente, se realizará un análisis comparativo entre los tres métodos, basado en la capacidad para clasificar como ciertos los casos que realmente son ciertos, y como falsos, los casos que efectivamente lo son.
4.4.4 Experimento IV: Análisis de Series de Tiempo Económicas
Este experimento está orientado a hacer una comparación entre los resultados de la aproximación de una serie de tiempo por el modelo ARIMA, siguiendo la metodología de Box-Jenkins, y por una Red Neuronal MLP con Backpropagation.
El proceso de análisis preliminar de la serie de tiempo contempla los siguientes pasos:
Análisis del correlograma y la función de autocorrelación ACF, incluyendo las pruebas de Box-Ljung.
Análisis de las raíces unitarias de la serie de tiempo.
Análisis del estadístico t de Student y las pruebas de Dickey-Fuller, y prueba alternativa con las tablas de MacKinnon.
Análisis de la Varianza.
Estos elementos preliminares están orientados a evaluar la estacionariedad de la serie. Luego se procede con el análisis propio para comenzar un ARIMA:
Análisis de la Función Parcial de Autocorrelación PACF.
Diferenciación de la serie en caso que sea necesario.
Análisis conjunto del ACF y PACF para determinar los parámetros del modelo ARIMA.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 85
Determinar alternativas de parámetros ARIMA y correr los diferentes modelos alternativos.
Evaluar cada uno de los modelos en función de:
o Significancia de los coeficientes del modelo.
o Estadísticos AIC y BIC
o Coeficiente de Correlación R2 ajustado
o Prueba F
o Evaluación de la autocorrelación de los residuales del modelo
Graficación del modelo ARIMA e identificación del rango de error en el gráfico.
Para el procesamiento de la red neuronal se comenzará con el análisis del correlograma de la primera diferencia de la serie de tiempo, a fin de identificar los rezagos que impactan los cambios en el valor que se está analizando.
Luego, el modelo de red neuronal es corrido contra la serie original, para lo cual será necesario preparar la muestra de entrenamiento y modelo siguiendo los siguientes criterios:
La cantidad de variables de entrada será igual a la cantidad de rezagos que impacten la diferencia en el valor corriente del PIB.
La muestra de datos deberá ordenarse de forma tal que, para un valor dado en el vector de entrenamiento, se corresponderá una columna en la matriz de datos que contenga tantas filas como variables de entrada y que cada una refleje, en orden, los rezagos identificados en el análisis de la función ACF de la primera diferencia de la serie.
Nuevamente, se seccionará la muestra en tres partes de 50%, 25% y 25% para entrenamiento, validación y prueba, respectivamente, dado que se utilizará Detección Temprana como estrategia de entrenamiento de la red.
En este experimento se incluirá un análisis más exhaustivo de la heurística asociada a la selección de la arquitectura de la red, mediante:
o Incremento escalonado de la cantidad de neuronas en la capa oculta.
o Análisis del rendimiento de la red neuronal en cada caso.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 86
o Análisis de la correlación entre los valores aproximados por la red y los reales, para cada caso.
o Análisis de la convergencia de los errores de entrenamiento, validación y prueba, en cada caso.
En la mayor medida posible, y para la red nueronal, se está replicando conceptualmente la arquitectura y el proceso que se siguió en el Experimento I, a fin de probar el proceso metodológico.
4.4.5 Experimento V: Análisis de Señales Este experimento está diseñado para demostrar la capacidad de una red neuronal en la identificación de señales que dependen del tiempo. Nótese que este es un problema muy distinto al de la serie de tiempo del experimento anterior. Si bien es cierto que el tiempo determina el comportamiento, la señal toma una patrón que se mantiene uniforme.
Hay que resaltar que las redes neuronales tipo Elman han sido utilizadas en arquitecturas de solución de análisis de series de tiempo económicas, como lo reporta Giles et. al (2000). Sin embargo, los mayores esfuerzos en la identificación de patrones de series de tiempo económicas, y Zekic-Susac (1999) reporta diversas investigaciones que lo soporta, se basan en redes neuronales del tipo MLP.
El procesamiento de señales es comúnmente analizado usando Filtros Lineales Adaptativos, y esa será la arquitectura de red que será usada.
El único elemento a ser considerado en el diseño de la arquitectura de la red es la cantidad de rezagos que serán utilizados para determinar el siguiente valor.
No se realizarán procesos estadísticos puesto que no aplican en este caso. Sólo se busca diferenciar el procesamiento de señales de la series de tiempo económicas.
La totalidad del experimento fue desarrollado sobre MatLab.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 87
4.5 Análisis e Interpretación de Datos
El análisis e interpretación de datos será presentado por cada uno de los experimentos desarrollados. El proceso seguido corresponde con la descripción del procedimiento de cada experimento, según se presentó en la Sección 4.4.
4.5.1 Experimento I: Regresión Multivariada de Origen no Lineal con bajo ruido
Los resultados del análisis de correlación en la muestra se muestran en la siguiente tabla:
X1 X2 Y + Noise
X1 1
X2 0.02178468 1
Y + Noise 0.55566488 0.64593149 1
Las variables X1 y X2 corresponden con los predictores y Y+Noise es el criterio. Nótese que efectivamente la correlación entre los predictores es muy baja mientras que la correlación entre cada predictor y el criterio es razonable, respondiendo a una muestra de calidad media, apegada a los perfiles de situaciones prácticas.
Seguidamente, se muestra el resultado de aplicar un modelo de regresión lineal múltiple sobre estos datos para determinar el criterio.
Estadísticas de la regresión
Coeficiente de correlación múltiple 0.84302446
Coeficiente de determinación R2 0.71069024
R2 ajustado 0.70913481
Error típico 32.7370032
Observaciones 375

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 88
Nótese que el coeficiente de correlación múltiple provee un resultado muy bueno, y ambas categorías del coeficiente de determinación son muy consistentes entre sí, con lo que pudiese esperarse una buena calidad en la aproximación proveniente del modelo.
Aún así se realizó un análisis de varianza, que arrojó un valor F de 456.9 con un nivel de significación prácticamente de cero, reforzando la calidad esperada en la aproximación del modelo.
La superficie aproximada por este modelo se muestra gráficamente a continuación:
Figura 20. Aproximación de la superficie de la Muestra A por Regresión Lineal Múltiple
Nótese que la superficie aproximada, como tal, representa un plano inclinado, sin caracterizar las curvaturas propias de la superficie original.
Al realizar la regresión de los resultados del modelo de regresión lineal contra los valores de la función con ruido agregado, se obtuvieron los siguientes resultados:
Estadísticas de la regresión
Coeficiente de correlación múltiple 0.74485522
Coeficiente de determinación R2 0.5548093
R2 ajustado 0.55118986
Error típico 36.7410239
Observaciones 125

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 89
En este caso, los resultados son de una calidad mediana, aún considerando que el valor F de 153.28 a una significancia de prácticamente cero producto del análisis de la varianza, permite cierto nivel de confianza sobre la estimación.
Es interesante observar los resultados de los coeficientes de regresión de este modelo lineal y las correspondientes pruebas, los cuales son los siguientes:
Coeficientes Error típico Estadístico t Probabilidad
Intercepción 1.58792964 1.69079706 0.9391604 0.34825778
X1 6.81645309 0.350907 19.4252411 1.5665E-58
X2 8.0490604 0.35406401 22.73334811 2.3782E-72
Mientras que las pruebas t de Student proveen unos resultados buenos para los coeficientes de los regresores, no lo es así para el intercepto, lo cual demuestra de alguna forma la fuente de error en la aproximación del modelo lineal.
Se pasa ahora a analizar los resultados de la aplicación de una red neuronal tipo MLP con backpropagation cuya arquitectura es de dos variables de entrada, una capa oculta de 5 neuronas y una variable de salida. Nótese que el espacio de aproximación es continuo, ello implicó que las funciones de transferencia fuesen continuas: para la capa oculta se usó una función de activación tan sigmoidal, mientras que para la capa de salida se uso una función lineal, permitiendo simular el rango de salida continuo de la función.
El primer elemento interesante de observar es la aproximación que realiza esta red neuronal sobre la superficie original, tal y como se muestra en la siguiente gráfica:

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 90
Figura 21. Aproximación de la superficie de la Muestra A por Red Neuronal MLP
Esta superficie presenta características más similares a la superficie de la función original, lo que sugiere una mejor aproximación. Pero, véanse los resultados de la regresión entre los valores de la función y los valores obtenidos de la red:
Estadísticas de la regresión
Coeficiente de correlación múltiple 0.97699215
Coeficiente de determinación R2 0.95451367
R2 ajustado 0.95442233
Error típico 14.052894
Observaciones 500
Estos resultados son definitivamente superiores a los logrados por el modelo de regresión lineal múltiple, tomando en cuenta además el valor sumamente alto de F, el cual fue de 10450.344, con una significancia de cero, al aplicar análisis de varianza.
Estos resultados fueron graficados para mostrar el ajuste entre los resultados de la red neuronal y los valores de entrenamiento, según se muestra a continuación:

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 91
Figura 22. Regresión de los resultados de la red neuronal con el vector de entrenamiento en la Muestra A
Esta arquitectura de red fue escogida luego de observar la convergencia entre los diferentes errores de entrenamiento, siguiendo los criterios de Detención Temprana. La convergencia del error en la red puede ser observada en la siguiente gráfica:
Figura 23. Convergencia de los errores de entrenamiento en la red neuronal MLP en la Muestra A.
Aún cuando estos resultados pueden ser considerados muy alentadores, se probó con una red de tipo Función de Base Radial, específicamente de Regresión Generalizada (GRNN). El uso de esta arquitectura responde a dos razones:
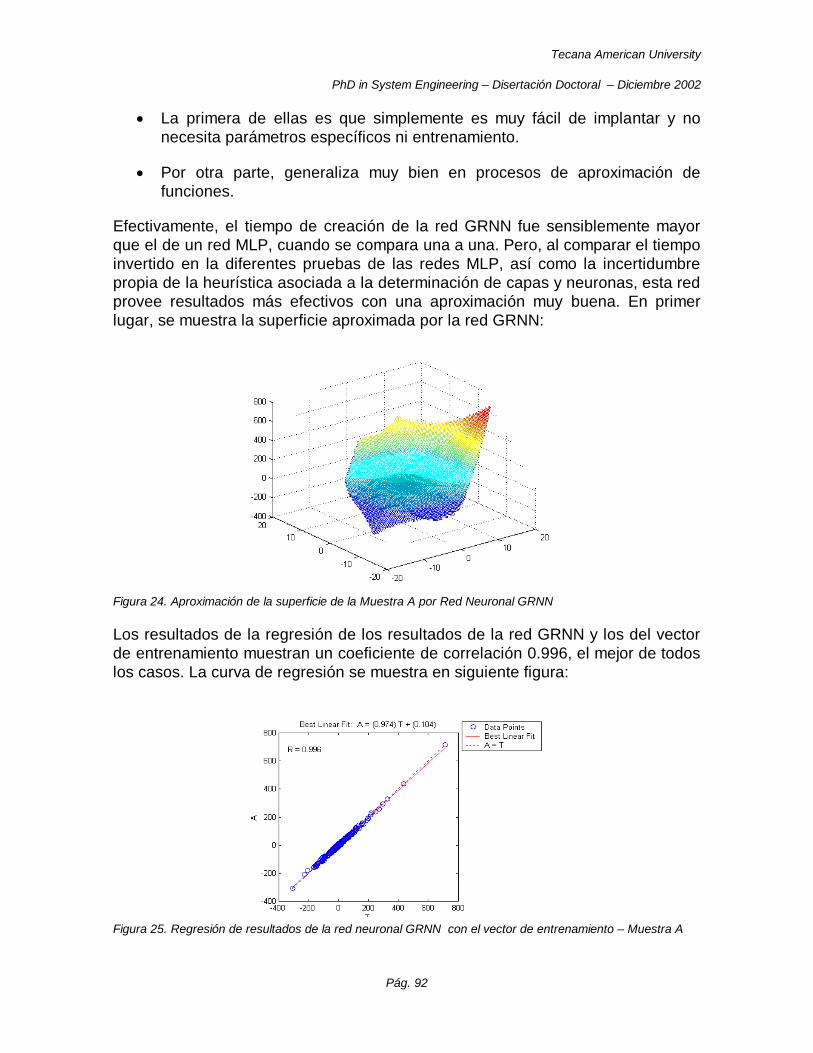
Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 92
La primera de ellas es que simplemente es muy fácil de implantar y no necesita parámetros específicos ni entrenamiento.
Por otra parte, generaliza muy bien en procesos de aproximación de funciones.
Efectivamente, el tiempo de creación de la red GRNN fue sensiblemente mayor que el de un red MLP, cuando se compara una a una. Pero, al comparar el tiempo invertido en la diferentes pruebas de las redes MLP, así como la incertidumbre propia de la heurística asociada a la determinación de capas y neuronas, esta red provee resultados más efectivos con una aproximación muy buena. En primer lugar, se muestra la superficie aproximada por la red GRNN:
Figura 24. Aproximación de la superficie de la Muestra A por Red Neuronal GRNN
Los resultados de la regresión de los resultados de la red GRNN y los del vector de entrenamiento muestran un coeficiente de correlación 0.996, el mejor de todos los casos. La curva de regresión se muestra en siguiente figura:
Figura 25. Regresión de resultados de la red neuronal GRNN con el vector de entrenamiento – Muestra A

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 93
Estos resultados pueden ser considerados los más apropiados en los procesos de aproximación de la función original aplicados, pese a que esta arquitectura es una de las menos populares, quizá por el tiempo que toma su puesta en operación. Otro aspecto, es el consumo de recursos, el cual cada vez se hace menos sensible, en virtud de las capacidades de procesamiento disponibles.
Los resultados de este experimento muestran una mejora progresiva en la aproximación de la superficie original, con condiciones razonablemente aceptables para aplicar un proceso de regresión lineal múltiple, donde la heurística asociada al proceso al MLP crea cierta incertidumbre sobre los resultados, y el mejor resultado se logra con la red GRNN, para este tipo de experimento.
Un aspecto que será constante en todos los experimentos con redes neuronales será la problemática de identificación del autómata asociado a la solución, que sería equivalente a la detección de los coeficientes de regresión. De esta forma, no hay una capacidad exploratoria trivial real sobre la muestra y más bien el uso es sólo predictivo.
4.5.2 Experimento II: Regresión Multivariada de Origen Lineal con alto ruido
Al igual que en el experimento anterior, se comienza con un examen de los resultados del análisis de correlación en la muestra, según se muestra en la siguiente tabla:
X1 X2 Y + Noise
X1 1
X2 0.0031738 1
Y + Noise 0.62372594 0.17473713 1
Las variables X1 y X2 corresponden con los predictores y Y+Noise es el criterio. Nótese que efectivamente la correlación entre los predictores es muy baja así como la correlación entre cada predictor y el criterio es mixta, es decir, en un caso razonable y en otro baja, respondiendo a una muestra de calidad baja, apegada a los perfiles de situaciones prácticas de naturaleza más bien extrema.
Seguidamente, se muestra el resultado de aplicar un modelo de regresión lineal múltiple sobre estos datos para determinar el criterio.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 94
Estadísticas de la regresión
Coeficiente de correlación múltiple 0.64720903
Coeficiente de determinación R2 0.41887953
R2 ajustado 0.41575522
Error típico 11.6169308
Observaciones 375
Nótese que el coeficiente de correlación múltiple provee un resultado razonablemente bueno, y ambas categorías del coeficiente de determinación son muy consistentes entre sí pero con valores mucho más bajos que el coeficiente de correlación múltiple, con lo que pudiese esperarse una calidad media en la aproximación proveniente del modelo.
Aún así se realizó un análisis de varianza, que arrojó un valor F de 134.07 con un nivel de significación prácticamente de cero. Siendo que este nivel de aceptación es razonable, los valores F no son sensiblemente altos (para tener un criterio compárese con los resultados de este mismo estadístico en los análisis del Experimento I).
La superficie aproximada por este modelo se muestra gráficamente a continuación:
Figura 26. Aproximación de la superficie de la Muestra B por regresión lineal múltiple
Nótese que la superficie aproximada como tal representa un plano inclinado, sin caracterizar las irregularidades propias de la superficie original.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 95
Al realizar la regresión de los resultados del modelo de regresión lineal contra los valores de la función con ruido agregado, se obtuvieron los siguientes resultados:
Estadísticas de la regresión
Coeficiente de correlación múltiple 0.67992056
Coeficiente de determinación R2 0.46229197
R2 ajustado 0.45792036
Error típico 7.46709952
Observaciones 125
En este caso, los resultados son de una calidad media - baja, aún considerando que el valor F de 105.75 a una significancia de prácticamente cero producto del análisis de la varianza, lo que permitiría cierto nivel de confianza sobre la estimación.
Es interesante observar los resultados de los coeficientes de regresión de este modelo lineal, los cuales son los siguientes:
Coeficientes Error típico Estadístico t Probabilidad
Intercepción 1.59871673 0.60016414 2.66379917 0.00806235
X1 1.92000055 0.12177364 15.7669633 2.9627E-43
X2 0.54578151 0.12486514 4.37096773 1.6071E-05
Las pruebas t de Student proveen unos resultados buenos para todos los coeficientes de regresión, lo que permitiría inducir que, aunque el modelo de regresión lineal múltiple no aproxima las irregularidades de la superficie, en cierta medida equilibra las mismas a través de un plano, produciendo un resultado que refleja más el comportamiento amortiguado de la función que la propia función. Esto es interesante si se busca identificar el patrón subyacente a la superficie con ruido.
Se pasa ahora a analizar los resultados de la aplicación de una red neuronal tipo MLP con backpropagation cuya arquitectura es de dos variables de entrada, dos capas ocultas, de 20 neuronas cada una, y una variable de salida. Nótese que el espacio de aproximación es continuo, lo cual implicó, al igual que en el Experimento I, que las funciones de transferencia fuesen continuas: para las

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 96
capas ocultas se usó una función de activación tan sigmoidal, mientras que para la capa de salida se uso una función lineal, permitiendo simular el rango de salida continuo de la función.
El arribo a las dos capas ocultas y la cantidad de neuronas en cada capa fue de nuevo heurístico; pero es importante resaltar algunos aspectos de ese proceso:
En primer lugar, agregar capas y neuronas aumenta la capacidad de la red para aproximar irregularidades.
Mientras se agregan capas y neuronas, también se puede caer en un problema de sobre-ajuste, generando más irregularidades de las que realmente puedan existir.
A mayor cantidad de capas y neuronas, en búsqueda de detectar el patrón irregular, se pierde progresivamente rendimiento en el entrenamiento, indicador clave para determinar que se han agregado capas o neuronas adicionales innecesarias.
El balance entre capas / neuronas y rendimiento de la red es lo que determina en buena medida un punto de equilibrio en la identificación de la arquitectura de la red MLP.
El primer elemento interesante de observar es la aproximación que realiza esta red neuronal sobre la superficie original, tal y como se muestra en la siguiente gráfica:
Figura 27. Aproximación de la superficie de la Muestra B por Red Neuronal MLP
Esta superficie presenta características más próximas a las irregularidades de la superficie de la función original, lo que sugiere una mejor aproximación que el
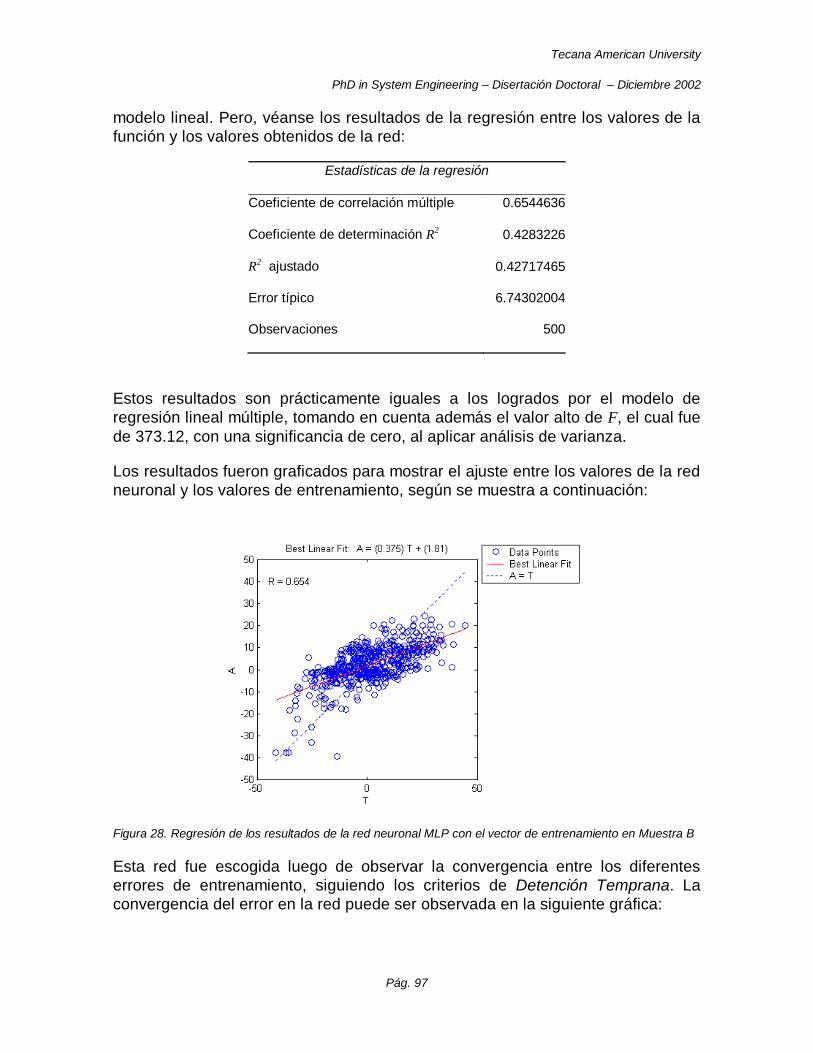
Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 97
modelo lineal. Pero, véanse los resultados de la regresión entre los valores de la función y los valores obtenidos de la red:
Estadísticas de la regresión
Coeficiente de correlación múltiple 0.6544636
Coeficiente de determinación R2 0.4283226
R2 ajustado 0.42717465
Error típico 6.74302004
Observaciones 500
Estos resultados son prácticamente iguales a los logrados por el modelo de regresión lineal múltiple, tomando en cuenta además el valor alto de F, el cual fue de 373.12, con una significancia de cero, al aplicar análisis de varianza.
Los resultados fueron graficados para mostrar el ajuste entre los valores de la red neuronal y los valores de entrenamiento, según se muestra a continuación:
Figura 28. Regresión de los resultados de la red neuronal MLP con el vector de entrenamiento en Muestra B
Esta red fue escogida luego de observar la convergencia entre los diferentes errores de entrenamiento, siguiendo los criterios de Detención Temprana. La convergencia del error en la red puede ser observada en la siguiente gráfica:

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 98
Figura 29. Convergencia de los errores de entrenamiento en la red neuronal MLP en la Muestra B.
Ante la evidencia poco alentadora de los resultados obtenidos con ese tipo y arquitectura de red, se probó con una red de tipo Función de Base Radial, específicamente de Regresión Generalizada (GRNN).
Efectivamente, el tiempo de creación de la red fue, al igual que en el Experimento I sensiblemente mayor que el de un red MLP, haciendo válidas las mismas observaciones allá indicadas. En primer lugar, se muestra la superficie aproximada por la red GRNN:
Figura 30. Aproximación de la superficie de la Muestra B por Red Neuronal GRNN
Los resultados de la regresión de los valores arrojados por la red GRNN y los del vector de entrenamiento muestran un coeficiente de correlación 0.762, el mejor de todos los casos. La curva de regresión se muestra en siguiente figura:

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 99
Figura 31. Regresión de resultados de la red neuronal GRNN con el vector de entrenamiento – Muestra B
Estos resultados pueden ser considerados los más apropiados en los procesos de aproximación de la función original.
Los resultados de este experimento muestran una mejora progresiva en la aproximación de la superficie original, con condiciones razonablemente aceptables para aplicar un proceso de regresión lineal múltiple, donde la heurística asociada al proceso de la red MLP crea cierta incertidumbre sobre los valores obtenidos, y el mejor resultado se logra con la red GRNN, para este tipo de experimento.
4.5.3 Experimento III: Regresión Logística con Datos Reales
El primer paso en el procesamiento preliminar de la muestra fue filtrarla para quedarse únicamente con las personas estrictamente menores de 65 años; no fue necesario fijar una cota inferior puesto que las personas encuestadas tenían, para ese momento, mínimo 18 años. Esto fue realizado tanto en SPSS como en Excel, y produjo como resultado una muestra filtrada de 973 casos.
Luego se procedió con un análisis de correlación entre la variables que intervienen en el problema. En general, los coeficientes de correlación son bajos, pero arrojaron un nivel de significancia adecuado con un nivel de confianza para el Error Tipo I de 0.01, producto de una prueba t de dos colas, que en últimas provee un intervalo de confianza para dichos coeficientes.
Sin embargo, ciertos aspectos llaman la atención. En primer lugar, el valor del determinante de la matriz de correlación de las variables predictoras arrojó un valor de 0.676, el cual puede considerarse bajo para aceptar una hipótesis de que no exista correlación entre la variables, aunque no definitivo. Esto es un indicador
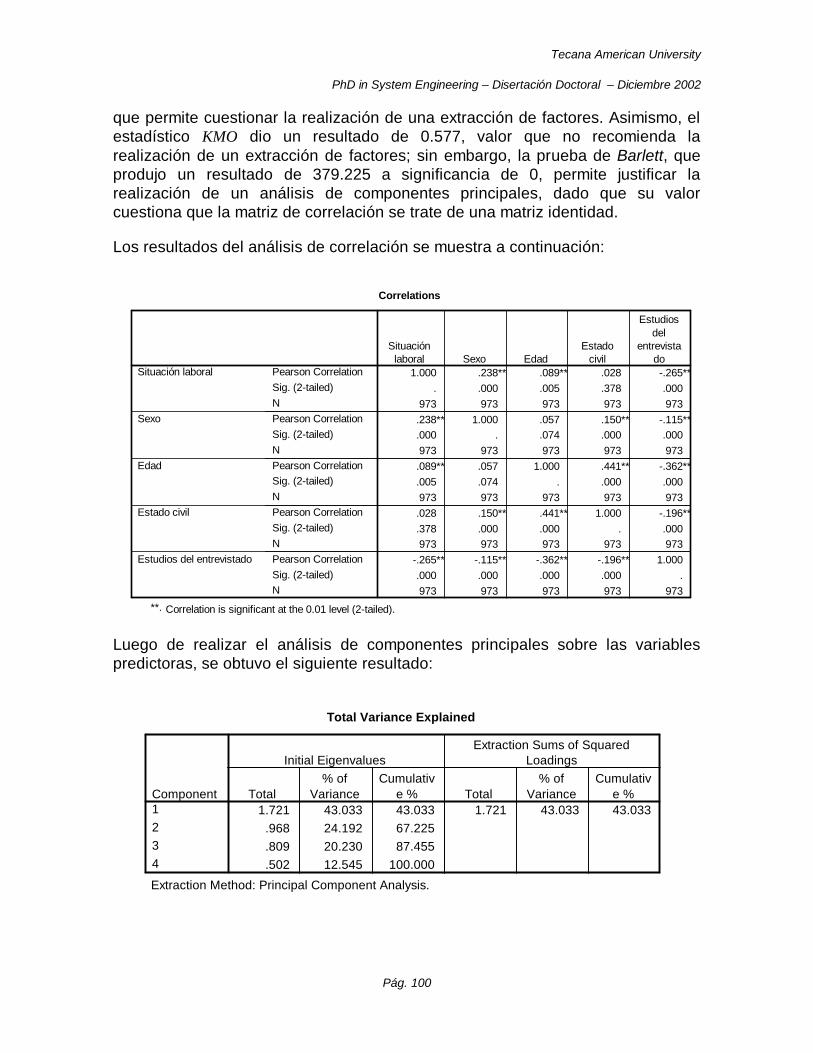
Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 100
que permite cuestionar la realización de una extracción de factores. Asimismo, el estadístico KMO dio un resultado de 0.577, valor que no recomienda la realización de un extracción de factores; sin embargo, la prueba de Barlett, que produjo un resultado de 379.225 a significancia de 0, permite justificar la realización de un análisis de componentes principales, dado que su valor cuestiona que la matriz de correlación se trate de una matriz identidad.
Los resultados del análisis de correlación se muestra a continuación:
Luego de realizar el análisis de componentes principales sobre las variables predictoras, se obtuvo el siguiente resultado:
Correlations
1.000 .238** .089** .028 -.265**. .000 .005 .378 .000
973 973 973 973 973.238** 1.000 .057 .150** -.115**.000 . .074 .000 .000973 973 973 973 973.089** .057 1.000 .441** -.362**.005 .074 . .000 .000973 973 973 973 973.028 .150** .441** 1.000 -.196**.378 .000 .000 . .000973 973 973 973 973
-.265** -.115** -.362** -.196** 1.000.000 .000 .000 .000 .973 973 973 973 973
Pearson CorrelationSig. (2-tailed)NPearson CorrelationSig. (2-tailed)NPearson CorrelationSig. (2-tailed)NPearson CorrelationSig. (2-tailed)NPearson CorrelationSig. (2-tailed)N
Situación laboral
Sexo
Edad
Estado civil
Estudios del entrevistado
Situaciónlaboral Sexo Edad
Estadocivil
Estudiosdel
entrevistado
Correlation is significant at the 0.01 level (2-tailed).**.
Total Variance Explained
1.721 43.033 43.033 1.721 43.033 43.033.968 24.192 67.225.809 20.230 87.455.502 12.545 100.000
Component1234
Total% of
VarianceCumulativ
e % Total% of
VarianceCumulativ
e %
Initial EigenvaluesExtraction Sums of Squared
Loadings
Extraction Method: Principal Component Analysis.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 101
Completando el análisis, también se proceso el gráfico Scree, tal y como se muestra a continuación:
Figura 32. Gráfico Scree de valores propios para las variables predictoras de la Muestra C.
Con estos resultados, sólo se obtuvo un valor propio por encima de uno y, aunque los tres primeros valores propios explican 87.45% de la variación de las variables, se decidió no extraer factores principales, puesto que la muestra contiene sólo cuatro variables predictoras. Es de hacer notar que la decisión es algo subjetiva, puesto que los valores de correlación y el análisis de componentes principales pudiese sugerir débilmente el uso de tres factores; sin embargo, se concluyó no extraerlos puesto que sólo se eliminaría una variable en un entorno dudoso, la cual no facilitaría sensiblemente el manejo de la dimensionalidad de la muestra.
Finalmente esta decisión fue definitiva al analizar la matriz de correlaciones reproducidas y observar que el 100% de los residuales tiene un valor por encima de 0.05, lo que determina el buen ajuste del modelo con las cuatro variables. De esta forma, el análisis de componentes principales permitió concluir que es razonable mantener las cuatro variables predictoras originales y no extraer factores.
Sólo un aspecto quedará aún pendiente para análisis posterior y es que el estado civil tiene una correlación no significativa con el criterio, lo cual implicará probar el modelo de regresión logística con esa variable y sin ella, para observar los resultados y determinar la cantidad real de variables a ser usada en el modelo
Scree Plot
Component Number
4321
Eig
enva
lue
1.8
1.6
1.4
1.2
1.0
.8
.6
.4

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 102
definitivo. Esto es además interesante puesto que con el análisis de regresión logística se podrá confirmar la cantidad de variables que serán consideradas en los modelos de red neuronal, ya sea PNN o LVQ.
De cualquier manera, se incluye a continuación el análisis de correlaciones reproducidas de la Muestra C.
Con estos resultados ya se puede realizar un análisis del modelo de regresión logística. Dado que existe la duda de incluir la variable estado civil en el modelo, se hicieron dos corridas, una con el estado civil incluido y otra sin contemplarlo. En el primer caso se obtuvo un rendimiento general del modelo del orden del 68.45%, y en el segundo ese valor fue de 64.03%, razón por la cual se decidió por el modelo de regresión logística que contempla la totalidad de las variables predictoras, es decir, incluyendo el estado civil. Por lo tanto, se observarán detalladamente estos resultados.
Reproduced Correlations
.104b .259 .237 -.211
.259 .647b .592 -.526
.237 .592 .543b -.482-.211 -.526 -.482 .428b
-.202 -8.66E-02 9.553E-02-.202 -.151 .165
-8.66E-02 -.151 .2869.553E-02 .165 .286
SexoEdadEstado civilEstudios del entrevistadoSexoEdadEstado civilEstudios del entrevistado
Reproduced Correlation
Residual a
Sexo EdadEstado
civil
Estudiosdel
entrevistado
Extraction Method: Principal Component Analysis.Residuals are computed between observed and reproduced correlations. There are 6 (100.0%)nonredundant residuals with absolute values > 0.05.
a.
Reproduced communalitiesb.
Classification Table for B1 The Cut Value is .41 Predicted Sí No Percent Correct S N Observed Sí S 146 256 36.32% No N 51 520 91.07% Overall 68.45%

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 103
En primer lugar, considérese el resultado global del modelo, el cual muestra un elevado nivel de acierto para los casos en que la persona no trabaja, y sensiblemente inadecuado para las personas que se encuentran trabajando. Ello por una parte está influenciado por las probabilidades a priori, y por otro, por la ausencia de linealidad en el modelo. Véase los parámetros de regresión del modelo logístico a continuación:
La prueba de hipótesis sobre los coeficientes de la ecuación se realiza usando el Estadístico de Wald, el cual prueba la hipótesis nula de si los coeficientes son iguales a cero, y que sigue una distribución ji-cuadrada. De nuevo, valores grandes de este estadístico con significancia muy cercana a cero, hacen rechazar
----------------- Variables in the Equation ------------------ Variable B S.E. Wald df Sig R C1(1) -1.0469 .1467 50.8981 1 .0000 -.1925 C2 .0152 .0073 4.3548 1 .0369 .0422 C6 73.5897 8 .0000 .2089 C6(1) 2.2629 .6588 11.7974 1 .0006 .0862 C6(2) 2.5525 .3680 48.1024 1 .0000 .1869 C6(3) 2.0066 .3299 37.0012 1 .0000 .1629 C6(4) 1.2283 .4248 8.3599 1 .0038 .0694 C6(5) .9486 .4111 5.3244 1 .0210 .0502 C6(6) 1.3794 .3733 13.6563 1 .0002 .0940 C6(7) 1.5077 .3478 18.7889 1 .0000 .1128 C6(8) .6694 .3940 2.8871 1 .0893 .0259 C3 30.5775 5 .0000 .1249 C3(1) .2824 .6957 .1648 1 .6848 .0000 C3(2) -.7264 .6614 1.2060 1 .2721 .0000 C3(3) 1.4287 1.0903 1.7170 1 .1901 .0000 C3(4) -.8316 .9167 .8229 1 .3643 .0000 C3(5) -.8838 1.1551 .5854 1 .4442 .0000 Constant -.8937 .8043 1.2345 1 .2665 95% CI for Exp(B) Variable Exp(B) Lower Upper C1(1) .3510 .2633 .4680 C2 1.0153 1.0009 1.0300 C6(1) 9.6113 2.6423 34.9616 C6(2) 12.8392 6.2412 26.4123 C6(3) 7.4376 3.8963 14.1978 C6(4) 3.4154 1.4854 7.8533 C6(5) 2.5820 1.1536 5.7792 C6(6) 3.9723 1.9113 8.2559 C6(7) 4.5163 2.2841 8.9299 C6(8) 1.9531 .9024 4.2273 C3(1) 1.3263 .3392 5.1853 C3(2) .4837 .1323 1.7683 C3(3) 4.1731 .4925 35.3610 C3(4) .4354 .0722 2.6252 C3(5) .4132 .0429 3.9756

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 104
la hipótesis nula y, por ende, los valores de los coeficientes son diferentes de cero estadísticamente. Otro elemento es el coeficiente de correlación parcial R el cual mide la contribución de la variable predictora al modelo, separando el efecto de las restantes; así, mientras más cercano a cero sea su valor, menor contribución parcial tendrá la variable en el modelo, siendo al contrario si su valor está más cerca de 1 o –149.
Por otra parte, y dado que las variables son categóricas, el modelo de regresión logística calcula coeficientes para cada caso de las variable categórica. Esta división era imperativa, puesto que esas variables categóricas, que tienen valores numéricos, no toman valores continuos.
Con este preámbulo y observando la tabla anterior, se concluye que el Estado Civil (variable C3) tiene muy poca contribución al modelo, confirmado tanto por R como por el estadístico de Wald para cada una de sus componentes categóricas. Esto es consistente con el análisis de correlación inicial. Nótese además que habría que hacer un análisis para cada categoría del Nivel de Estudios (variable C6), de donde se desprende que en algunos casos el nivel de estudio es más impactante en la situación laboral que en otros.
Finalmente, los estadísticos de verosimilitud logarítmica (-2LL) y de bondad de ajuste, con valores respectivos de 1150.252 y 984.069, los cuales son sensiblemente altos, hablan de un mal ajuste del modelo a los datos. Sin embargo, es importante resaltar el aporte exploratorio que brindaron los resultados para el entendimiento del problema50.
Con estos resultados, se justifica aún más la aplicación de redes neuronales artificiales, a fin de estimar modelos que predigan la clasificación cuando las separaciones de clases no son lineales.
La primera prueba se hizo con la red neuronal tipo LVQ, la cual fue sensiblemente lenta para realizar sus cálculos. Pero antes de ver sus resultados, recuérdese que se debe realizar el análisis de cluster para determinar la cantidad tentativa de neuronas que existirá en la capa de competencia.
49 Nótese que este es el mismo criterio que aplica en el Modelo General de Regresión Lineal.
50 Sólo como comentario, no incluido en el desarrollo por su poco valor agregado al estudio, se corrió un modelo adicional que asumía una probabilidad a priori igual para ambas condiciones laborales y los estadísticos no mejoraron; sin embargo, el modelo, aún sin alterar su rendimiento global significativamente, mejoró la clasificación de los casos que se encuentran laborando, en detrimento de los casos que no laboraban, lo cual es consistente con un enfoque lineal de la solución del problema.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 105
Inicialmente se corrió una análisis de cluster jerárquico para identificar una cantidad preliminar de clases con las cuales trabajar, obteniéndose el siguiente dendograma:
Figura 33. Clasificación Jerárquica de la Muestra C.
Adicionalmente, el reporte de corridas en la clasificación arroja los siguientes resultados:
Estos resultados pueden ser interpretados de forma tal que, según el dendograma, pudiese existir entre 2 y 4 clusters, aunque el análisis de corridas sugiere 3 clusters. Debido a que el resultado puede tomar dos valores, el número de neuronas que podrán ser incluidos será de dos o cuatro.
* * * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * * Dendrogram using Average Linkage (Between Groups) Rescaled Distance Cluster Combine C A S E 0 5 10 15 20 25 Label Num +---------+---------+---------+---------+---------+ C1 1 C3 3 C6 4 C2 2
Vertical Icicle
X X X X X X XX X X X X XX X X X X
Number of clusters123
Eda
d
Est
udio
s de
l ent
revi
stad
o
Est
ado
civi
l
Sex
o
Case

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 106
Cuando se realizó un análisis de clasificación por el método de K-Means, dado que ya se tiene una aproximación al número inicial de clusters, se ejecutaron los experimentos con 2 y cuatro clusters, siendo relevantes los resultados con 4 de ellos, según se muestra a continuación:
Con este experimento, la distribución de los casos quedó tal y como se muestra a continuación:
En general, tal clasificación es apropiada y equilibrada, haciendo la salvedad que la variable Sexo (C1) no contribuye a la definición de clases en la muestra.
De esta forma, la red tipo LVQ quedó con una arquitectura que contempla 4 neuronas en la capa de competencia y dos neuronas en la capa lineal, donde las probabilidades a priori de las clases fueron asignadas como 0.4 y 0.6 para la condición laborable y no laborable, respectivamente.
Los resultados de aplicar esta red neuronal fueron:
61.07% de aciertos para la condición laboral
65.96% de aciertos para la condición no laboral
Aún cuando los resultados son más equilibrados, no se puede considerar un ajuste adecuado a la muestra de datos.
ANOVA
.187 3 .250 969 .745 .52557261.844 3 11.457 969 4997.831 .000
47.918 3 .581 969 82.438 .000240.593 3 4.766 969 50.481 .000
SexoEdadEstado civilEstudios del entrevistado
MeanSquare df
ClusterMean
Square df
Error
F Sig.
The F tests should be used only for descriptive purposes because the clusters have been chosen tomaximize the differences among cases in different clusters. The observed significance levels are notcorrected for this and thus cannot be interpreted as tests of the hypothesis that the cluster means areequal.
Number of Cases in each Cluster
283.000276.000203.000211.000973.000
.000
1234
Cluster
ValidMissing

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 107
La red tipo PNN logró estar operativa en menos tiempo que la red LVQ, considerando además que no requirió preparaciones adicionales al análisis estadístico preliminar. Sus resultados fueron los siguientes:
84.73% de aciertos para la condición laboral
91.52% de aciertos para la condición no laboral
Indudablemente este ajuste es muy bueno para la muestra de datos y muy superior a los modelos anteriores.
La siguiente gráfica muestra el rendimiento comparado entre los tres modelos:
Figura 34. Rendimiento comparado de las soluciones del Experimento III
Es resaltante que nuevamente un modelo de solución basado en una arquitectura de red de función de base radial logra los mejores resultados también en un problema de clasificación, indudablemente adaptándose mejor a las condiciones no lineales de la muestra con una correlación que puede ser baja entre los predictores y el criterio.
4.5.4 Experimento IV: Análisis de Series de Tiempo Económicas
Este experimento fue desarrollado para demostrar las técnicas de análisis de estacionariedad en series de tiempo, así como identificación de características espurias. En él, se demuestra la aplicación de la Metodología Box – Jenkins para desarrollar un modelo ARIMA, para luego hacer una aproximación usando un modelo de redes neuronales artificiales del tipo MLP con Backpropagation. Para el procesamiento estadístico de la MUESTRA D, base de este experimento, se
0%
20%
40%
60%
80%
100%
MRL Red LVQ Red PNN
LaboraCesante

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 108
utilizó SPSS y Matrixer, este último complementando el análisis de modelos específicos de series de tiempo. Los modelos de redes neuronales artificiales se corrieron usando MatLab. Algunos cálculos adicionales, así como la preparación de datos para MatLab, se realizaron en Excel.
Con base en el producto SPSS se obtiene el correlograma de la serie de tiempo, a fin de determinar si la serie es estacionaria o no. Este gráfico se muestra a continuación:
En este correlograma se distinguen varios aspectos:
Se muestra la secuencia de los primeros 25 rezagos (lag).
Para cada rezago se muestra el correspondiente valor de su ACF.
Autocorrelations: PIB_USA Auto- Stand. Lag Corr. Err. -1 -.75 -.5 -.25 0 .25 .5 .75 1 Box-Ljung 1 .969 .105 . ***.*************** 85.464 2 .935 .104 . ***.*************** 166.015 3 .901 .104 . ***.************** 241.705 4 .866 .103 . ***.************* 312.364 5 .830 .102 . ***.************* 378.052 6 .791 .102 . ***.************ 438.492 7 .752 .101 . ***.*********** 493.743 8 .712 .101 . ***.********** 543.969 9 .675 .100 . ***.********* 589.596 10 .638 .099 . ***.********* 630.911 11 .601 .099 . ***.******** 668.086 12 .565 .098 . ***.******* 701.376 13 .532 .097 . ***.******* 731.244 14 .499 .097 . ***.****** 757.944 15 .467 .096 . ***.***** 781.639 16 .437 .095 . ***.***** 802.609 17 .405 .095 . ***.**** 820.895 18 .374 .094 . ***.*** 836.749 19 .343 .093 . ***.*** 850.270 20 .312 .093 . ***.** 861.628 21 .279 .092 . ***.** 870.824 22 .246 .091 . ***.* 878.060 23 .213 .091 . **** 883.610 24 .182 .090 . **** 887.691 25 .152 .089 . ***. 890.610 Plot Symbols: Autocorrelations * Two Standard Error Limits . Total cases: 88 Computable first lags: 87

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 109
El error estándar aparece a continuación para cada uno de los rezagos mostrados, el cual es calculado siguiendo la premisa de estacionariedad definida, conocida normalmente como un proceso estocástico débilmente estacionario de ruido blanco.
Seguidamente se muestra el correlograma, mostrando al mismo tiempo el límite de los intervalos de confianza al 95%, situación normalmente asumida en estas pruebas.
Luego se muestra el valor de la estadística de Box-Ljung (BL).
Este correlograma presenta las siguientes características:
El valor inicial de ACF es muy grande.
En lo sucesivo, decrece progresivamente.
Aún en el rezago 14, ACF tienen un valor considerable de 0,499.
Sólo en el rezago 25, ACF presenta un valor lo suficientemente bajo como para que se considere estadísticamente cero al 95% de confianza (esta es la razón por la cual se grafica el correlograma hasta el valor del rezago 25).
El correlograma de la serie de tiempo del PIB de los Estados Unidos demuestra una dependencia muy fuerte de los valores previos.
Además, partiendo del estadístico BL se puede llegar a la misma conclusión. Observando el gráfico del correlograma, BL para el rezago 25 presenta un valor de 890,61. El valor de ji-cuadrado con 25 grados de libertad y 05,0 es de 37,6525. El valor de BL es muchísimo mayor que 2
25,05.0 , por lo tanto se rechaza la hipótesis de que la serie sea estacionaria, puesto que no todos los k son cero, que es el objeto de la prueba.
Para evaluar la prueba de la raíz unitaria de la serie del PIB en los EEUU, evalúese primero la ecuación de regresión:
ttt uPIBPIB 1 (4.5.4.1)
El cálculo de la regresión arroja los siguientes resultados, donde se notará que el valor del coeficiente de la variable independiente es muy cercano a 1, y el intervalo de confianza también se encuentra en esa cercanía.
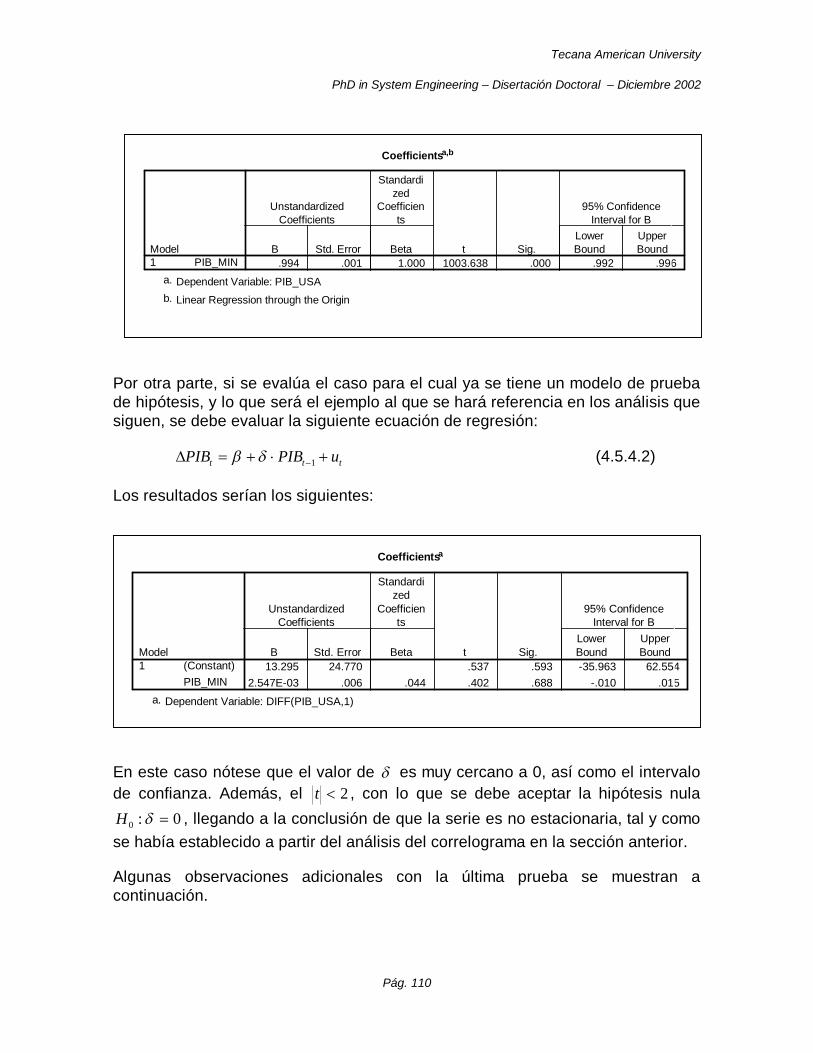
Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 110
Por otra parte, si se evalúa el caso para el cual ya se tiene un modelo de prueba de hipótesis, y lo que será el ejemplo al que se hará referencia en los análisis que siguen, se debe evaluar la siguiente ecuación de regresión:
ttt uPIBPIB 1 (4.5.4.2)
Los resultados serían los siguientes:
En este caso nótese que el valor de es muy cercano a 0, así como el intervalo de confianza. Además, el 2t , con lo que se debe aceptar la hipótesis nula
0:0 H , llegando a la conclusión de que la serie es no estacionaria, tal y como se había establecido a partir del análisis del correlograma en la sección anterior.
Algunas observaciones adicionales con la última prueba se muestran a continuación.
Coefficientsa,b
.994 .001 1.000 1003.638 .000 .992 .996PIB_MINModel1
B Std. Error
UnstandardizedCoefficients
Beta
Standardized
Coefficients
t Sig.LowerBound
UpperBound
95% ConfidenceInterval for B
Dependent Variable: PIB_USAa.
Linear Regression through the Originb.
Coefficientsa
13.295 24.770 .537 .593 -35.963 62.5542.547E-03 .006 .044 .402 .688 -.010 .015
(Constant)PIB_MIN
Model1
B Std. Error
UnstandardizedCoefficients
Beta
Standardized
Coefficients
t Sig.LowerBound
UpperBound
95% ConfidenceInterval for B
Dependent Variable: DIFF(PIB_USA,1)a.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 111
Consideraciones Genéricas sobre el estadístico “t” en análisis de correlación.
En primer lugar, la tabla de resultados muestra la significancia del estadístico t. Mientras ese valor esté más cercano a cero, se deberá rechazar la hipótesis nula y aceptar la alternativa. En este caso, la significancia para el coeficiente de la variable independiente es más cercana a 1, con lo cual se debe rechazar la hipótesis alternativa.
Consideraciones de la validez del estadístico “t”: la prueba Dickey-Fuller (DF)
Hay que hacer notar sin embargo, que la prueba t es útil cuando se debe rechazar la hipótesis nula, pero cuando no puede ser rechazada, como en este caso, es necesario acudir a la prueba de Dickey-Fuller, o también llamada prueba tau, dado que se cuestiona que en esta situación, el estadístico t siga una distribución t Student.
Existen programas estadísticos que proveen este valor tau, los cuales normalmente usan las tablas de James MacKinnon generadas mediante métodos de simulación. En el caso que se ha venido desarrollando, se utiliza el producto Matrixer51, el cual hace uso de las tablas de MacKinnon para hacer la prueba tau.
En el ejemplo, la ecuación (4.5.4.1) es no diferenciada y no contiene término constante; la ecuación (4.5.4.2) es diferenciada y tiene término constante. Si se incluyese tendencia, lo que implica incluir la variable tiempo, se obtendría una ecuación de la siguiente forma:
ttt uPIBtPIB 110 (4.5.4.3)
Si, adicionalmente se consideran términos autorregresivos adicionales en la ecuación de regresión, se obtendría una ecuación de la siguiente forma:
t
m
iititt uPIBPIBtPIB
1110 (4.5.4.4)
Este modelo implicaría la aplicación de una prueba DF aumentada (denominada comúnmente ADF). En este caso, se obtendrían los coeficientes tau para la variable independiente y cada uno de los rezagos adicionales considerados. Sin embargo, asintóticamente los valores DF para la variable independiente son iguales, por lo que los resultados de las pruebas DF y la ADF, en lo referente a
51 Esta es una de las debilidades encontradas en SPSS hasta la versión 10, el cual no provee el valor crítico tau para la prueba de Dickey-Fuller. Matrixer también ejecuta modelos ARIMA (que serán expuestos más adelante), funcionalidad disponible sólo en SPSS Trends, el cual se adquiere de manera separada al producto SPSS Básico.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 112
los valores críticos tau de la variable independiente, pueden considerarse iguales. Por esta razón, en el caso particular de Matrixer, sólo provee la prueba ADF, dado que si la ecuación de regresión no es del tipo (4.5.4.4), entonces sólo se toma el valor DF de la variable independiente y se hace caso omiso sobre los demás estadísticos tau.
Cuando se aplica la prueba ADF a la ecuación (4.5.4.2), con G = 0 y L = 0, entonces se obtiene un estadístico tau = 5.838585 con un nivel de significancia de 1.0000. Si se aplica la misma prueba a (4.5.4.2), con G = 1 y L = 1, se obtiene que el estadístico tau es igual a -6.484377 con nivel de significancia 0.0000. Si el nivel de significancia del resultado excede 0.05, debe aceptarse la hipótesis nula, de lo contrario se rechaza. Tal y como se esperaba, (4.5.4.1) representa una serie con raíces unitarias y (4.5.4.2) ya no tiene raíces unitarias, con lo cual la diferenciación genera una serie de tiempo del PIB de USA estacionaria.
Otra forma de aplicar la prueba es a partir de las tablas de MacKinnon . Para una muestra de tamaño 100 y al nivel de significancia del 5%, el valor crítico tau según MacKinnon es 3,17, el cual será utilizado como aproximación del valor crítico en esta muestra de tamaño 86. Si el valor absoluto del estadístico t es mayor que el valor crítico tau de MacKinnon, entonces se acepta la hipótesis nula (existencia de raíz unitaria). Nótese que el valor absoluto de t (1003) para el análisis de la ecuación (4.5.4.1) excede enormemente al valor absoluto crítico de tau; por el contrario, el valor absoluto de t (0.402) para el análisis de la ecuación (4.5.4.2) es menor que le valor absoluto crítico de tau. Estos resultados son consistentes con las conclusiones alcanzadas.
Consideraciones sobre ANOVA en análisis de correlación.
Se muestra a continuación el resultado de ANOVA para el ejemplo en cuestión
Se observa que el valor de F es pequeño y la significancia es relativamente cercana a 1, factor que está alineado con la prueba de hipótesis t. Como
ANOVAb
211.026 1 211.026 .162 .688a
109483.9 84 1303.379109694.9 85
RegressionResidualTotal
Model1
Sum ofSquares df
MeanSquare F Sig.
Predictors: (Constant), PIB_MINa.
Dependent Variable: DIFF(PIB_USA,1)b.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 113
observación adicional, nótese la desproporción entre la suma de cuadrados del coeficiente de regresión y de los residuales.
Tal y como se indicó en el desarrollo teórico, en condiciones normales, no es necesario aplicar una prueba F si hace una prueba t cuando sólo están involucradas dos variables y sólo se incluye aquí a efectos ilustrativos.
Consideraciones sobre el Coeficiente de Correlación.
Otros aspectos del análisis de regresión incluyen el estudio del coeficiente de correlación (R) y el coeficiente de determinación (R2). Se muestran a continuación los resultados para el caso que se está analizando:
Nótese que el coeficiente de correlación es casi cero, y al ser el coeficiente de correlación ajustado menor que cero, se asume que es cero a los efectos de análisis. En este caso, el análisis de estos coeficientes muestra la no estacionariedad de la serie del PIB en los EEUU.
A fin de analizar la tendencia del PIB en los Estados Unidos, se aplicará la Metodología de Box – Jenkins para desarrollar un ARIMA con el PIB en EEUU.
Model Summaryb
.044a .002 -.010 36.1023 1.321Model1
R R SquareAdjustedR Square
Std. Errorof the
EstimateDurbin-W
atson
Predictors: (Constant), PIB_MINa.
Dependent Variable: DIFF(PIB_USA,1)b.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 114
Para ello, se estudiará la PACF, para obtener el correlograma parcial, según gráfico que se muestra a continuación.
Figura 35. Autocorrelación Parcial de la Serie del PIB de los Estados Unidos
Los valores de PACF se muestran en el siguiente correlograma parcial:
PIB_USA
Lag Number
252321191715131197531
Par
tial A
CF
1.0
.5
0.0
-.5
-1.0
Confidence Limits
Coefficient

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 115
Nótese que PACF tiene un pico representativo en el primer rezago y luego es estadísticamente cero. Este hecho reafirma la necesidad de diferenciación de primer orden.
Siguiendo las sugerencias indicadas en el desarrollo teórico de este informe, para el análisis de la serie de tiempo del PIB de los EEUU y con base en los resultados del correlograma (el cual decrece exponencialmente) y el correlograma parcial (que presenta un pico sólo en el primer rezago), se diría que esta serie sigue un proceso AR(1), con lo que el modelo a determinar es ARIMA(1,1,0).
Utilizando Matrixer para correr el modelo se obtiene:
Partial Autocorrelations: PIB_USA Pr-Aut- Stand. Lag Corr. Err. -1 -.75 -.5 -.25 0 .25 .5 .75 1 1 .968 .108 . ***.*************** 2 -.054 .108 . * . 3 -.047 .108 . * . 4 -.077 .108 . ** . 5 -.008 .108 . * . 6 -.031 .108 . * . 7 -.022 .108 . * . 8 -.029 .108 . * . 9 .004 .108 . * . 10 -.006 .108 . * . 11 -.016 .108 . * . 12 -.005 .108 . * . 13 .017 .108 . * . 14 -.007 .108 . * . 15 -.023 .108 . * . 16 .005 .108 . * . 17 -.033 .108 . * . 18 -.009 .108 . * . 19 -.042 .108 . * . 20 -.036 .108 . * . 21 -.068 .108 . * . 22 -.028 .108 . * . 23 .012 .108 . * . 24 -.002 .108 . * . 25 .015 .108 . * . Plot Symbols: Autocorrelations * Two Standard Error Limits . Total cases: 88 Computable first lags: 85

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 116
Dado que PACF presenta cierto patrón sinusoidal, aunque sólo presenta un pico en el primer rezago, se puede probar un modelo ARIMA (0,1,2), obteniéndose:
La simple observación del nivel de significancia del segundo parámetro en este modelo haría que se descartara para un nivel de significancia del 5% (0.05), por lo cual este modelo no se tomaría en cuenta.
También se puede probar un modelo ARIMA(0,1,1) como un derivado del anterior, dado que el pico se obtiene sólo en el primer rezago, obteniéndose:
ARIMA (Box-Jenkins model) Dependent variable: USA_PIB[PIBC] 1 differences Number of observations: 85 Variable Coefficient St. Error t-statistic Sign. 1 Constant 15.83879115 4.3934659843 3.6050788163 [0.0005] 2 %ar1 0.333402486 0.1028005414 3.2431977634 [0.0017] R^2adj. = 99.691055118% DW = 2.0367 R^2 = 99.694733033% S.E. = 34.047562943 Residual sum of squares: 96216.633018 AIC = 9.9166421556 BIC = 9.9741163028 F(1,83)= 10.51833 [0.0017]
ARIMA (Box-Jenkins model) Dependent variable: USA_PIB[PIBC] 1 differences Number of observations: 86 Variable Coefficient St. Error t-statistic Sign. 1 Constant 22.988337088 5.4324538279 4.2316672753 [0.0001] 2 %ma1 0.3027678684 0.1079064419 2.8058368256 [0.0063] 3 %ma2 0.1839449194 0.1083241371 1.6980972517 [0.0932] R^2adj. = 99.696053585% DW = 1.9735 R^2 = 99.703205266% S.E. = 36.354486188 Residual sum of squares: 109696.83928 AIC = 9.9314125649 BIC = 10.017029331 F(2,83)= 5.635963 [0.0051]
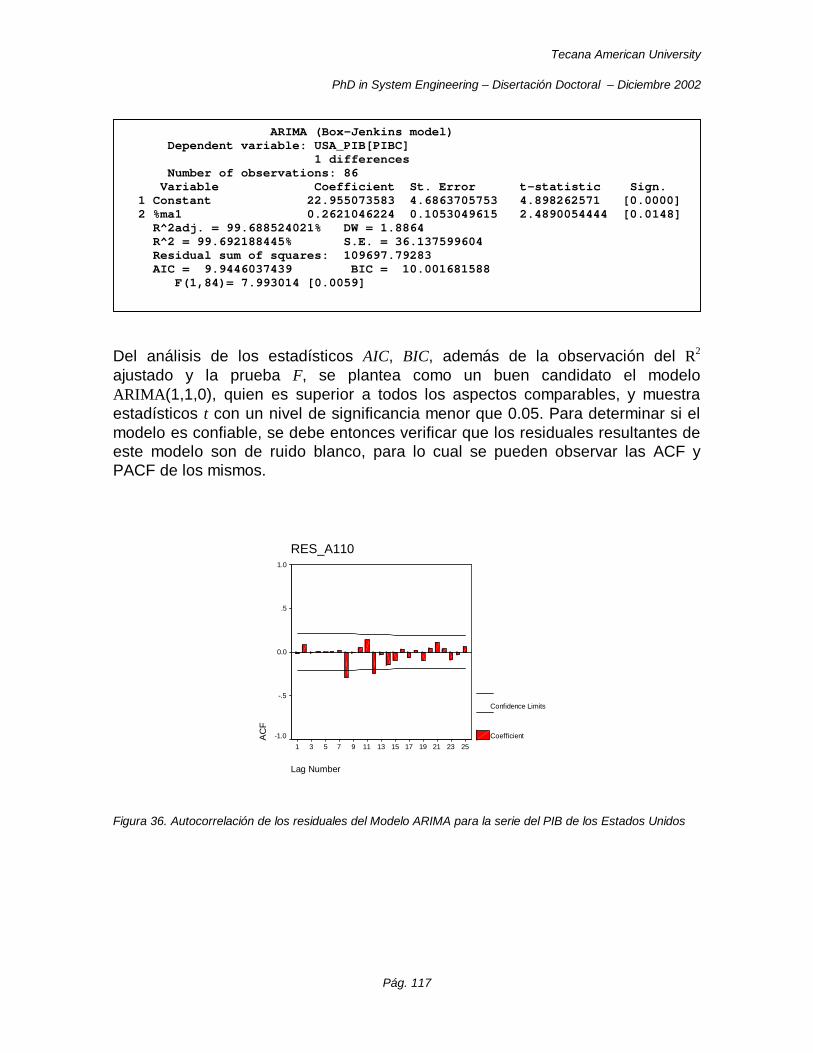
Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 117
Del análisis de los estadísticos AIC, BIC, además de la observación del R2 ajustado y la prueba F, se plantea como un buen candidato el modelo ARIMA(1,1,0), quien es superior a todos los aspectos comparables, y muestra estadísticos t con un nivel de significancia menor que 0.05. Para determinar si el modelo es confiable, se debe entonces verificar que los residuales resultantes de este modelo son de ruido blanco, para lo cual se pueden observar las ACF y PACF de los mismos.
Figura 36. Autocorrelación de los residuales del Modelo ARIMA para la serie del PIB de los Estados Unidos
ARIMA (Box-Jenkins model) Dependent variable: USA_PIB[PIBC] 1 differences Number of observations: 86 Variable Coefficient St. Error t-statistic Sign. 1 Constant 22.955073583 4.6863705753 4.898262571 [0.0000] 2 %ma1 0.2621046224 0.1053049615 2.4890054444 [0.0148] R^2adj. = 99.688524021% DW = 1.8864 R^2 = 99.692188445% S.E. = 36.137599604 Residual sum of squares: 109697.79283 AIC = 9.9446037439 BIC = 10.001681588 F(1,84)= 7.993014 [0.0059]
RES_A110
Lag Number
252321191715131197531
AC
F
1.0
.5
0.0
-.5
-1.0
Confidence Limits
Coefficient

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 118
Figura 37. Autocorrelación Parcial de los residuales del Modelo ARIMA de la serie del PIB de los Estados Unidos
Nótese que ambos correlogramas muestran algunos valores fuera de los niveles de confianza al 5% de significancia. Sin embargo, obsérvese el resultado de ACF:
RES_A110
Lag Number
252321191715131197531
Par
tial A
CF
1.0
.5
0.0
-.5
-1.0
Confidence Limits
Coefficient
Auto- Stand. Lag Corr. Err. -1 -.75 -.5 -.25 0 .25 .5 .75 1 Box-Ljung 1 -.022 .107 . * . .041 . 2 .082 .106 . ** . .641 . 3 -.009 .105 . * . .649 . 4 .007 .105 . * . .654 . 5 -.003 .104 . * . .655 . 6 .008 .103 . * . .661 . 7 .014 .103 . * . .681 . 8 -.286 .102 **.*** . 8.549 . 9 -.009 .101 . * . 8.558 . 10 .051 .101 . * . 8.818 . 11 .143 .100 . ***. 10.851 . 12 -.246 .099 *.*** . 16.989 . 13 -.031 .099 . * . 17.087 . 14 -.143 .098 .*** . 19.230 . 15 -.096 .097 . ** . 20.198 . 16 .032 .097 . * . 20.309 . 17 -.068 .096 . * . 20.810 . 18 .025 .095 . * . 20.881 . 19 -.096 .094 . ** . 21.915 . 20 .047 .094 . * . 22.168 . 21 .113 .093 . ** . 23.655 . 22 .040 .092 . * . 23.838 . 23 -.086 .092 . ** . 24.724 . 24 -.031 .091 . * . 24.843 . 25 .057 .090 . * . 25.237 .
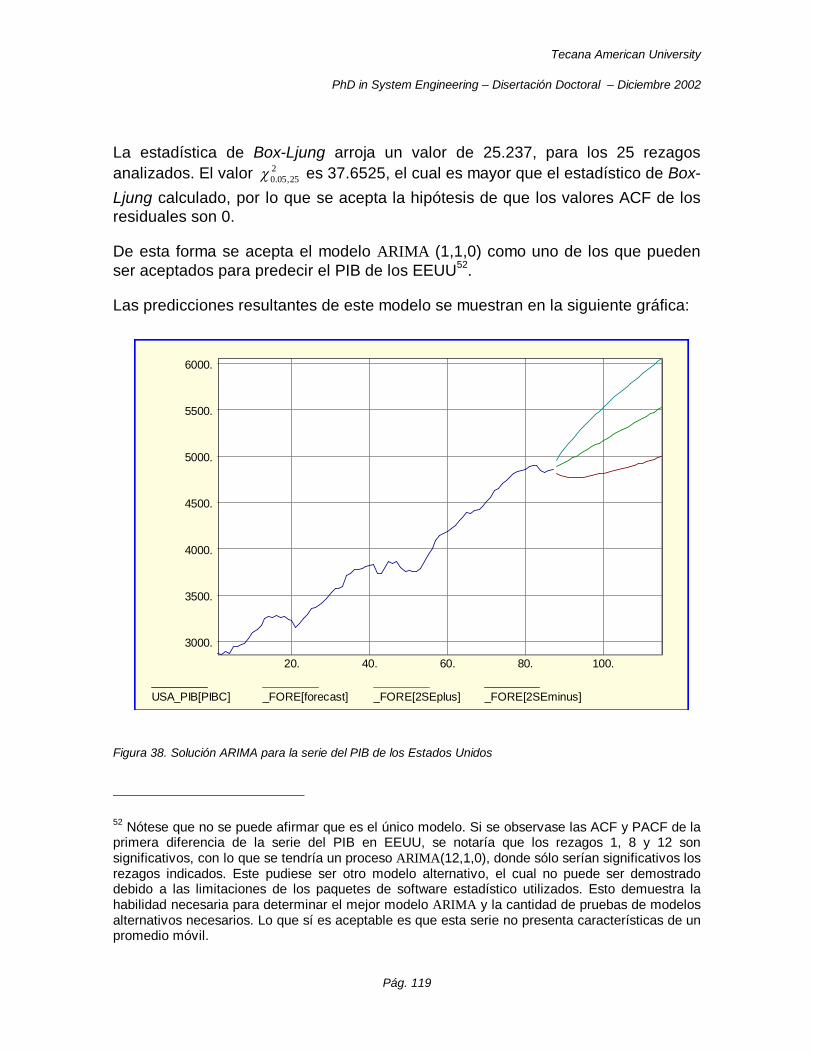
Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 119
La estadística de Box-Ljung arroja un valor de 25.237, para los 25 rezagos analizados. El valor 2
25,05.0 es 37.6525, el cual es mayor que el estadístico de Box-Ljung calculado, por lo que se acepta la hipótesis de que los valores ACF de los residuales son 0.
De esta forma se acepta el modelo ARIMA (1,1,0) como uno de los que pueden ser aceptados para predecir el PIB de los EEUU52.
Las predicciones resultantes de este modelo se muestran en la siguiente gráfica:
Figura 38. Solución ARIMA para la serie del PIB de los Estados Unidos
52 Nótese que no se puede afirmar que es el único modelo. Si se observase las ACF y PACF de la primera diferencia de la serie del PIB en EEUU, se notaría que los rezagos 1, 8 y 12 son significativos, con lo que se tendría un proceso ARIMA(12,1,0), donde sólo serían significativos los rezagos indicados. Este pudiese ser otro modelo alternativo, el cual no puede ser demostrado debido a las limitaciones de los paquetes de software estadístico utilizados. Esto demuestra la habilidad necesaria para determinar el mejor modelo ARIMA y la cantidad de pruebas de modelos alternativos necesarios. Lo que sí es aceptable es que esta serie no presenta características de un promedio móvil.
100.80.60.40.20.
6000.
5500.
5000.
4500.
4000.
3500.
3000.
USA_PIB[PIBC] _FORE[forecast] _FORE[2SEplus] _FORE[2SEminus]

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 120
La gráfica muestra los valores del PIB en USA y la predicción, resaltando también la banda de desviación en función del error del modelo.
La Metodología de Box-Jenkins es bastante laboriosa y no produce un modelo único de predicción. Se requiere la prueba de diferentes modelos y múltiples análisis para simplificar los cálculos. Sin embargo, se ha demostrado en la práctica muy buenas capacidades de estimación, con lo que su uso es bastante difundido.
La resolución del problema con la aplicación de redes neuronales acudirá de nuevo a una red MLP con Backpropagation, la cual ha sido utilizada previamente en este tipo de problemas.
En este caso se requiere una preparación adicional de los datos, pues hay que determinar los rezagos que son significativos al momento de determinar un valor de la serie. Pero dado que ya se pudo verificar la función ACF para la serie del PIB, se analizará la ACF para la primera diferencia, a fin de filtrar efectivamente las variaciones que son relevantes y, en consecuencia, identificar los valores que se tomarán de la serie original para tipificar un valor en particular.
El correlograma anterior demuestra que los coeficientes, en la primera diferencia, que son significativos son los correspondientes con los rezagos 1, 2, 8, 12 y 14,
MODEL: MOD_1. Variable: DELTAPIB Missing cases: 2 Valid cases: 86 Autocorrelations: DELTAPIB DIFF(PIB_USA,1) Auto- Stand. Lag Corr. Err. -1 -.75 -.5 -.25 0 .25 .5 .75 1 Box-Ljung Prob. 1 .333 .106 . ***.*** 9.897 .002 2 .192 .105 . **** 13.221 .001 3 .041 .105 . * . 13.373 .004 4 .028 .104 . * . 13.447 .009 5 .000 .103 . * . 13.447 .020 6 -.018 .103 . * . 13.477 .036 7 -.089 .102 . ** . 14.239 .047 8 -.284 .102 **.*** . 22.054 .005 9 -.087 .101 . ** . 22.797 .007 10 .020 .100 . * . 22.838 .011 11 .041 .100 . * . 23.004 .018 12 -.216 .099 **** . 27.791 .006 13 -.141 .098 .*** . 29.857 .005 14 -.196 .098 **** . 33.915 .002 15 -.127 .097 .*** . 35.627 .002 16 -.027 .096 . * . 35.709 .003 Plot Symbols: Autocorrelations * Two Standard Error Limits . Total cases: 88 Computable first lags: 85
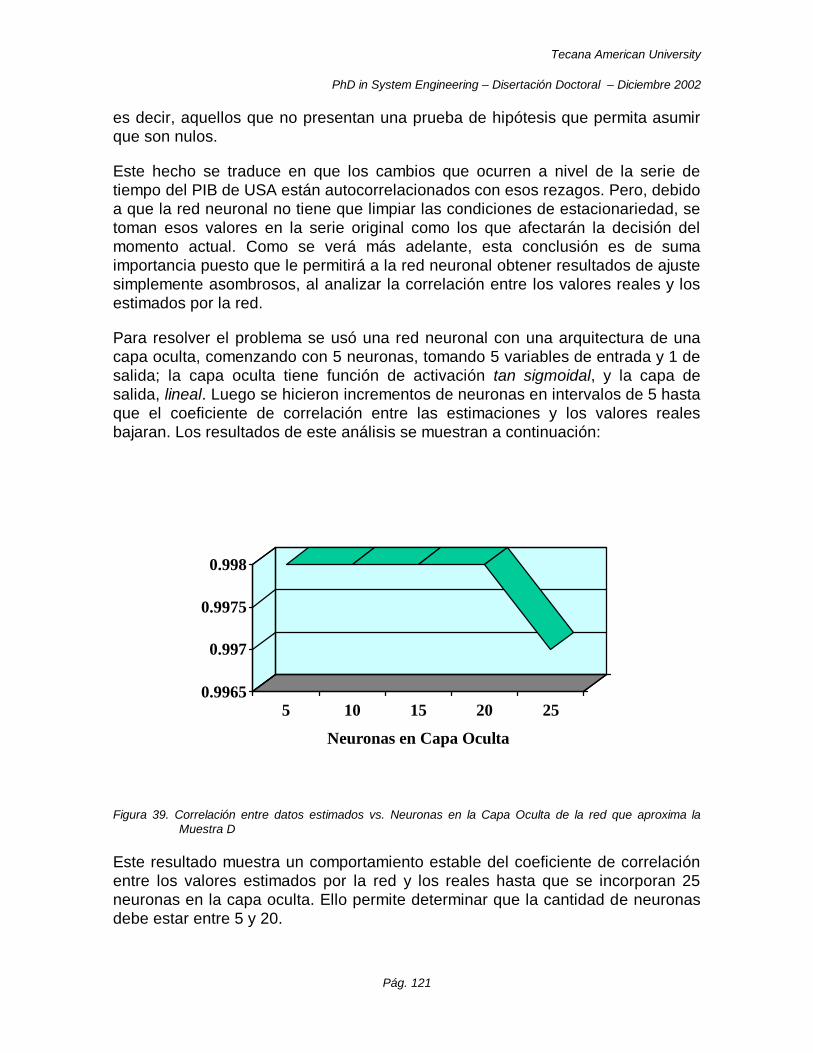
Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 121
es decir, aquellos que no presentan una prueba de hipótesis que permita asumir que son nulos.
Este hecho se traduce en que los cambios que ocurren a nivel de la serie de tiempo del PIB de USA están autocorrelacionados con esos rezagos. Pero, debido a que la red neuronal no tiene que limpiar las condiciones de estacionariedad, se toman esos valores en la serie original como los que afectarán la decisión del momento actual. Como se verá más adelante, esta conclusión es de suma importancia puesto que le permitirá a la red neuronal obtener resultados de ajuste simplemente asombrosos, al analizar la correlación entre los valores reales y los estimados por la red.
Para resolver el problema se usó una red neuronal con una arquitectura de una capa oculta, comenzando con 5 neuronas, tomando 5 variables de entrada y 1 de salida; la capa oculta tiene función de activación tan sigmoidal, y la capa de salida, lineal. Luego se hicieron incrementos de neuronas en intervalos de 5 hasta que el coeficiente de correlación entre las estimaciones y los valores reales bajaran. Los resultados de este análisis se muestran a continuación:
Figura 39. Correlación entre datos estimados vs. Neuronas en la Capa Oculta de la red que aproxima la Muestra D
Este resultado muestra un comportamiento estable del coeficiente de correlación entre los valores estimados por la red y los reales hasta que se incorporan 25 neuronas en la capa oculta. Ello permite determinar que la cantidad de neuronas debe estar entre 5 y 20.
0.9965
0.997
0.9975
0.998
5 10 15 20 25
Neuronas en Capa Oculta

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 122
Por otra parte, se muestra a continuación el rendimiento de la red a medida que se van agregando neuronas en la capa oculta.
Figura 40. Comportamiento del Rendimiento de la Red Neuronal a medida que se agregan neuronas en la Capa Oculta en el procesamiento de la Muestra D.
Véase a continuación el comportamiento del error cuando la red neuronal tenía 10 neuronas en la capa oculta.
Figura 41. Comportamiento del Error durante el entrenamiento de la Red para procesar la Muestra D.
0
0.0005
0.001
0.0015
0.002
5 10 15 20 25
Neuronas en Capa Oculta
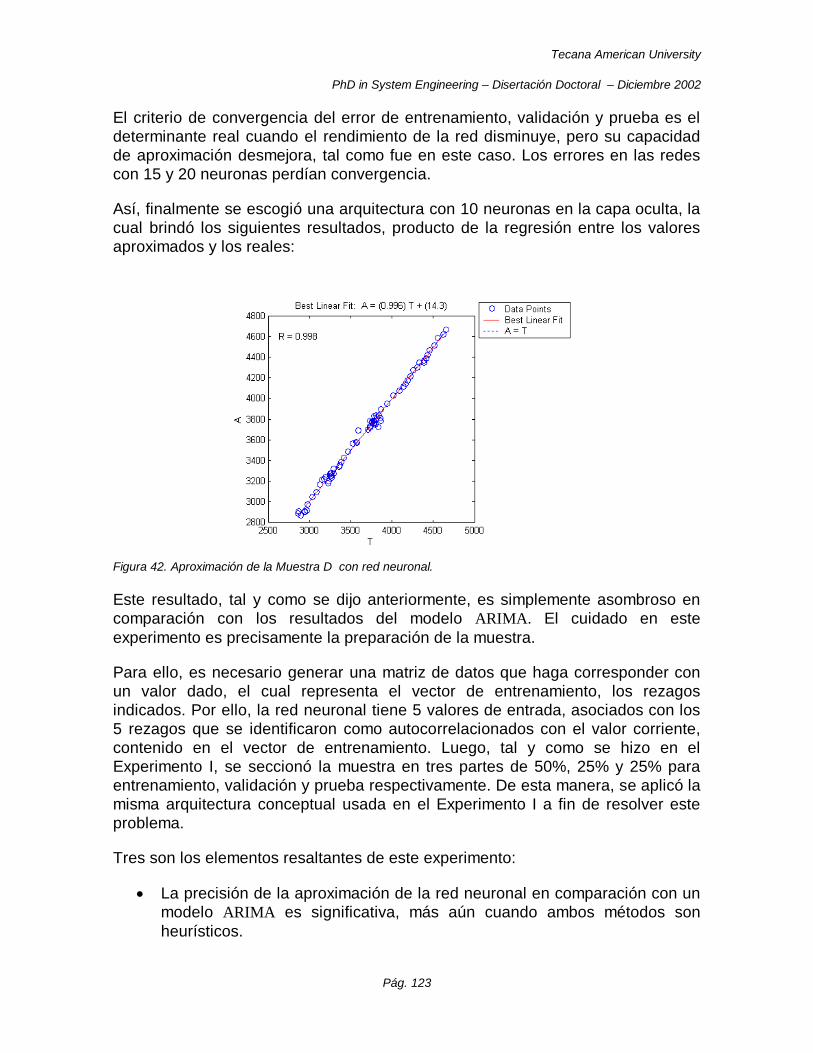
Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 123
El criterio de convergencia del error de entrenamiento, validación y prueba es el determinante real cuando el rendimiento de la red disminuye, pero su capacidad de aproximación desmejora, tal como fue en este caso. Los errores en las redes con 15 y 20 neuronas perdían convergencia.
Así, finalmente se escogió una arquitectura con 10 neuronas en la capa oculta, la cual brindó los siguientes resultados, producto de la regresión entre los valores aproximados y los reales:
Figura 42. Aproximación de la Muestra D con red neuronal.
Este resultado, tal y como se dijo anteriormente, es simplemente asombroso en comparación con los resultados del modelo ARIMA. El cuidado en este experimento es precisamente la preparación de la muestra.
Para ello, es necesario generar una matriz de datos que haga corresponder con un valor dado, el cual representa el vector de entrenamiento, los rezagos indicados. Por ello, la red neuronal tiene 5 valores de entrada, asociados con los 5 rezagos que se identificaron como autocorrelacionados con el valor corriente, contenido en el vector de entrenamiento. Luego, tal y como se hizo en el Experimento I, se seccionó la muestra en tres partes de 50%, 25% y 25% para entrenamiento, validación y prueba respectivamente. De esta manera, se aplicó la misma arquitectura conceptual usada en el Experimento I a fin de resolver este problema.
Tres son los elementos resaltantes de este experimento:
La precisión de la aproximación de la red neuronal en comparación con un modelo ARIMA es significativa, más aún cuando ambos métodos son heurísticos.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 124
El proceso aplicando una red neuronal es mucho más simple y expedito que el equivalente para aplicar un modelo ARIMA.
Independientemente del modelo a aplicar, es necesario hacer análisis estadístico preliminar, tanto para saber cómo preparar la muestra de datos de entrenamiento para la red neuronal, como para entender estructuralmente la serie de tiempo.
4.5.5 Experimento V: Análisis de Señales Este es un experimento muy simple asociado con la MUESTRA E, y sólo consistió en determinar una cantidad de 5 rezagos para entrenar las red neuronal, la cual será del tipo Filtro Lineal Adaptativo. Los resultados de la curva ajustada, donde se contrasta con la original, se muestra a continuación:
Figura 43. Señal aproximada en contraste con la señal original.
Inicialmente, la red toma 1.5 segundos en detectar el patrón de la señal y luego del cuarto segundo, sólo una onda completa para ajustarse al nuevo patrón de frecuencia. Esto puede ser apreciado mejor observando el error:

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 125
Figura 44. Comportamiento del error en el procesamiento de la Muestra E.
Este experimento permite diferenciar las características de los diferentes tipos de series de tiempo, y en este caso, el de los Filtros Lineales Adaptativos, se puede usar para aproximar señales o para ubicar el comportamiento del error en funciones no lineales.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 126
5. CONCLUSIONES
Luego de la realización de los experimentos, y con base en las muestras en ellos utilizadas, se dispone de criterios suficientes para evaluar las hipótesis propuestas en la presente disertación (ver Capítulo 3). De todos los experimentos realizados, el número V escapa al soporte de las hipótesis, pues fue incluido sólo con propósitos aclaratorios.
En primer lugar, en referencia a las Hipótesis 1 y 5, relativas a la aplicación de MEMV en la preparación y exploración de muestras de datos, definitivamente se demostró la necesidad de usar herramientas y métodos estadísticos para realizar el procesamiento preliminar y preparatorio de los experimentos. Aún más, siempre gracias a su gestión, se pudo tener una idea clara de la estructura de la muestra que aplicaba al experimento. Aspectos resaltantes son los siguientes:
Los análisis estadísticos básicos, así como de correlación, son fundamentales para cualquier proceso de involucre MEMV o RNA.
Es siempre recomendable realizar un PCA antes de aplicar un MEMV o RNA, a fin de simplificar la dimensionalidad del espacio muestral, de ser así posible. Si resulta positivo, procederá entonces y FA para extraer los factores de la muestra.
El caso específico de redes del tipo MLP requiere la normalización de los datos antes de ser procesados, y la desnormalización luego de obtener los resultados.
Cuando se realiza un experimento de clasificación del tipo de regresión logística, aún si se pretende aplicar un modelo de RNA, la primera técnica agrega elementos exploratorios que no deben ser rechazados en ningún caso.
La aplicación de una RNA del tipo LVQ exige el análisis de clusters para determinar la cantidad de neuronas en la capa de competencia.
En análisis de series de tiempo, indistintamente de la técnica a utilizar, se requiere un estudio de las funciones ACF y PACF, tanto en la serie original como en la diferenciada. Ello permite determinar los rezagos que afectan al valor corriente, aspecto relevante para la preparación de la muestra de datos y determinación de las variables de entrada a una red neuronal.
Independientemente del método usado, MEMV o RNA, es muy recomendable realizar una regresión lineal entre los valores de entrenamiento y los valores aproximados, lo cual funciona como una

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 127
prueba de bondad de ajuste, única en el caso de las RNA, y adicional en el caso de los MEMV.
Con respecto a la Hipótesis 2, la cual se formuló para evaluar funciones multivariadas, y tomando en cuenta que, aún cumpliendo criterios de muestras apropiadas para MEMV basados en el MRLG, las redes neuronales aprendieron mejor el ajuste a las funciones, sobre todo por sus características no lineales o de alto ruido. Sin embargo, y en el caso de funciones de alto ruido, el MRLG produce elementos suficientes para explorar el patrón lineal que subyace a la función con ruido. Es necesario apuntar que los resultados obtenidos con la red GRNN excedieron los obtenidos con las soluciones provenientes de MRLG y red MLP. Sin embargo, hay que notar el cuidado que se debe tener de no agregar complejidad a una red del tipo MLP, ya sea en capas o neuronas por capas, puesto que de lo contrario, se sobre-ajustaría la red, produciendo más irregularidades de las incluidas originalmente en una función de alto ruido.
En cuanto a la Hipótesis 3, referente a problemas de clasificación dicótoma, las redes neuronales artificiales produjeron resultados al menos comparables con un MRL, en condiciones donde la separación de los datos no se puede asumir lineal. Hay que resaltar que el modelo de red PNN superó en exceso todos los resultados de los modelos aplicados en este experimento, ya sea MRL o LVQ.
Al abordar la Hipótesis 4, referente a series de tiempo, fue indudable la calidad del resultado obtenido con una red tipo MLP, así como la simplificación de los cálculos y preparación de datos.
Finalmente, y en relación con la Hipótesis 6, es definitivo que la arquitectura de una red neuronal en particular, así como el tipo de red, afectan la calidad de las aproximaciones, manteniendo aún constantes las muestras de datos. Cada uno de los experimentos, con excepción del IV, utilizó dos tipos de redes neuronales y se pudo observar que alguna producía mejores resultados que otras. Asimismo, en todos los experimentos se probó con diferentes cantidades de capas y neuronas por capa oculta, exceptuando a las redes basadas en funciones radiales (GRNN y PNN), y se pudo observar cómo la convergencia de los errores, el rendimiento de la red y la calidad de los resultados variaba con los cambios de arquitectura. En función de esto es importante resaltar que, pese a la falta de popularidad, las redes de base radial usadas, específicamente GRNN y PNN, produjeron excelentes resultados cuando fueron aplicadas a aproximación de funciones y a clasificación, respectivamente. Si bien es cierto, su procesamiento es más lento que el de los otros tipos de red neuronal usados en los experimentos, ello se ve compensado por el ahorro de tiempo en su diseño, lo cual también elimina la heurística de determinar la arquitectura de la red, lo que puede ser considerado como ventaja o desventaja. El efecto inmediato de esta situación es que estas redes consumen más tiempo y memoria que las de otros tipos, pero la calidad de sus resultados y la practicidad en el diseño, compensan

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 128
esos aspectos, más aún hoy en día cuando los recursos de hardware son cada vez mayores y más económicos.
Un elemento relevante es la dificultad de extraer un perfil de la solución, como puede ser el caso en cualquiera de los MEMV estudiados en esta disertación. La extracción de autómatas de las redes neuronales para tipificar un perfil de la función aproximada es materia compleja. Ello indudablemente confirma las debilidades exploratorias de la redes neuronales.
Estas conclusiones efectivamente brindan un espacio a los modelos basados en Redes Neuronales Artificiales y Métodos Estadísticos Multivariados, demostrando que ambas técnicas no se excluyen, sino que coadyuvan a la resolución de problemas de regresión y correlación.
Si bien es cierto, extraer una metodología específica no fue una consecuencia contundente de los experimentos realizados, se observa cómo ciertos bloques genéricos de trabajo, así como técnicas específicas, se repiten invariablemente en la resolución de problemas de este tipo.
Una observación final es la heurística asociada a cada uno de los métodos, sean MEMV y RNA. Existe un importante nivel de análisis y decisión sobre los resultados que pueden incluso ser interpretados como subjetividad y hasta ambigüedad. Si bien es cierto que los fundamentos matemáticos de ambos tipos de modelos son rígidos, la naturaleza de los resultados es tan compleja, que sólo será el sano juicio del investigador el que permita extraer los componentes relevantes de un modelo u otro, así como las conclusiones pertinentes.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 129
6. RECOMENDACIONES
6.1 A Nivel Teórico
Esta disertación produjo resultados contundentes en cuanto al rendimiento de las redes neuronales artificiales en comparación con los método estadísticos multivariados. Sin embargo, también abrió un campo interesante de investigación en los siguientes temas:
Los aspectos metodológicos continúan siendo un factor de profunda investigación. Es irrefutable que se identificaron bloques de construcción en la elaboración de los experimentos, e incluso, se demostró la validez de los mismos a lo largo de su ejecución. Sin embargo, es también aceptable que existen aspectos de estilo investigativo que aún no confluyen en un proceso metodológico universal, si bien se puede aceptar la validez técnica de los pasos aplicados. Este es un aspecto que requerirá maduración y que probablemente es el reflejo del propio proceso evolutivo de ambas técnicas matemáticas.
La identificación de un perfil de la solución obtenida de una red neuronal artificial, por la vía de extracción de autómatas, es un campo relativamente poco investigado. El estudio de esta área de investigación podrá aportar elementos exploratorios a las soluciones de redes neuronales artificiales, que aún son sensiblemente débiles.
6.2 A Nivel Práctico
La naturaleza propia de esta disertación abre un universo de aplicaciones prácticas de los resultados obtenidos, tanto en la replicación de los métodos propuestos, como en el fortalecimiento de un proceso metodológico enriquecido y desarrollado por la praxis. Pero hay algunos aspectos que es necesario resaltar:
La investigación de estudios y aplicaciones de redes neuronales a problemas prácticos gira mucho en torno a las arquitecturas del tipo Multilayer Perceptron del tipo feedforward con backpropagation. Sin embargo, uno de los resultados más contundentes de los experimentos realizados en esta disertación fue la calidad de los resultados y la practicidad de aplicación de las Redes de Regresión Generalizada, para problemas de aproximación de funciones, y las Redes Probabilísticas, para el caso de clasificación. Ello entonces sugiere la aplicación más extensiva de estas arquitecturas, ambas basadas en funciones de base radial, para problemas del tipo citado.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 130
Un aporte interesante de esta disertación, en el estudio de las series de tiempo, es la identificación de los rezagos en la primera diferencia de la serie en cuestión, a fin de determinar las variables de entrada a la red MLP, pero aplicando el modelo de solución a la serie original. Esto abre un camino metodológico en la solución de problemas de este tipo basados en modelos con arquitecturas MLP, a la luz de la calidad de los resultados obtenidos.
El campo práctico propone una gran cantidad de problemas que son tipificados por las muestras y experimentos desarrollados en esta disertación, por lo que se esperaría una aplicación amplia de los mismos a casos reales, replicando y enriqueciendo el método propuesto.
Finalmente, es imperativo la demostración práctica de las técnicas y métodos propuestos en esta disertación, a fin de dar valor empírico a las posibilidades de predicción de las redes neuronales artificiales. Ello sólo es posible validando casos en el mundo real.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 131
7. REFERENCIA DE INICIALES
Durante el desarrollo de esta disertación, y con el objeto de simplificar la redacción, se usaron un conjunto de iniciales que se compilan a continuación, con su correspondiente significado:
ACF: Función de Autocorrelación (del inglés Autocorrelation Function).
AR(p): Proceso autorregresivo de orden p.
ARIMA: Proceso Autorregresivo Integrado de Media Móvil.
FA: Análisis por Factores (del inglés Factor Análisis).
GRNN: Red Neuronal de Regresión Generalizada (del inglés Generalized Regresión Neural Network).
LMS: Algoritmo de Error Medio Cuadrático (del ingés Least Mean Square).
LVQ: Learning Vector Quantization. Tipo de red neuronal de la clase SOFM.
MA(q): Proceso de Media Móvil de orden q.
MEMV: Métodos Estadísticos Multivariados.
MLP: Multilayer Perceptron del tipo FeedForward.
MRCM: Modelo de Regresión y Correlación Múltiple.
MRGL: Modelo de Regresión Lineal General.
MRL: Modelo de Regresión Logística.
MST: Modelo de Series de Tiempo.
PACF: Función de Autocorrelación Parcial (del inglés Partial Autocorrelation Function).
PCA: Análisis de Componentes Principales (del inglés Principal Component Análisis).
PNN: Red Neuronal Probabilística (del inglés Probabilistic Neural Network).
RBF: Función de Base Radial (del inglés Radial Basis Function).

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 132
RBN: Red de Base Radial (del inglés Radial Basis Network).
RNA: Red(es) Neuronal(es) Artificial(es).
SOFM: Self Organizing Feature Map. Tipo de red neuronal.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 133
8. BIBLIOGRAFÍA
Bishop, Christopher. Neural Networks for Pattern Recognition. Oxford University Press. 1995.
Chapra, Stephen y Canale, Raymond P. Métodos Numéricos para Ingenieros. Mc. Graw Hill. 1999.
Dalquist, Germund y Bjork, Ake. Numerical Methods. Prentice Hall. 1974.
Demuth, Howard & Beale, Mark. Neural Network Toolbox: User’s Guide. The MathWorks. 2002.
Feller, William. Introducción a la Teoría de Probabilidades y sus Aplicaciones. Volumen 1.1973.
Freund, John E. y Walpole, Ronald E. Estadística Matemática con Aplicaciones. Prentice may. 1990.
Grimm & Yarnold. Reading and Understanding more Multivariate Statistics. American Phycological Association. 2000.
Grimm & Yarnold. Reading and Understanding Multivariate Statistics. American Phycological Association. 1995.
Gujarati, Damodar. Econometría. Mc Graw Hill. 1997.
Haykin, Simon. Neural Networks: A comprehensive Foundation. Prentice Hall 1999.
Hoffman, Kenneth y Kunze, Ray. Algebra Lineal.Prentice Hall. 1973.
Hogg, Robert V. & Craig, Allen T.. Introduction to Mathematical Statistics. Collier MacMillan International Editions. 1970
Johnson, Dallas E. Métodos Multivariados Aplicados al Análisis de Datos. Internacional Thompson Editores. 2000.
Thomas, George. Cálculo Infinitesimal y Geometría Analítica. Aguilar. 1976.
Vinacua, Visauta. Análisis Estadístico con SPSS para Windows, volúmenes 1 y 2. B. Mc Graw Hill. 1998 y 1999, respectivamente.
Zikmund, William G. Investigación de Mercados. Prentice Hall. !995.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 134
9. REFERENCIAS
Allende, Héctor; Moraga, Claudio; Salas, Rodrigo. Artificial Neural Networks in Time Series Forecasting: A Comparative Analysis. Universidad Técnica Federico Santa María, Chile. 1999.
Chatterjee, Santig; Laudato, Matthew. Statistical Applications of Neural Networks. Northeastern University. 1995.
Choi, Chong-Ho; Choi, Jin Young. Constructive Neural Networks with Piecewise Interpolation Capabilities for Function Approximations. IEEE Transactions on Neural Networks. Vol. 5, Nº 6. 1994.
Combrink-Kuiters, C.J.M.; Van Enschot, M.H. Two Approaches to Analyzing Cases: Neural Networks And Linear Regression. 13th BILETA Conference: 'The Changing Jurisdiction'. Dublin, Ireland. 1998.
De Freitas, Joao F. G. Bayesian Methods for Neural Networks (PhD Dissertation). University of Cambridge. 2000.
De Freitas, Nando; Andrieu, Christophe. Sequential Monte Carlo for Model Selection and Estimation of Neural Networks. 2000.
Dybowsk, Richardi; Roberts, Stephen J. Confidence Intervals and Prediction Intervals for Feed-Forward Neural Networks. 1999.
Embrechts, Mark J.; Devogelaere Dirk. Supervised Scaled Regression Clustering: an Alternative to Neural Networks. Rensselaer Polytechnic Institute, Troy, NY & University of Leuven, Belgium. 2000.
Estévez Valencia, Pablo. Clasificación de Patrones mediante Redes Neuronales Artificiales. Anales del Instituto de Ingenieros de Chile, pp 24-31. 1999.
Estévez Valencia, Pablo. Selección de Características para Redes Neuronales. Anales del Instituto de Ingenieros de Chile, pp. 65-74. 1999.
Giles, C.Lee ; Lawrence, Steve; Tsoi, Ah Chung. Noisy Time Series Prediction using a Recurrent Neural Network and Grammatical Inference. University of Wollongong, Australia. 2000.
Gonzalez, Steven. Neural Networks for Macroeconomic Forecasting: A Complementary Approach to Linear Regression Models. Working Paper. 2000.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 135
Gupta, Vijay. Time Series Analysis.
Haselstaeiner, Ernst. Neural Based Method for Time Series Classification (PhD Dissertation). Graz University, Germany. 2000.
Herbert, K; Lee H. Model Selection for Neural Network Classification. Duke University. 2000.
Jiménez, Daniel. Dynamically Weighted Ensemble Neural Networks for Classification. The University of Texas Health Science Center at San Antonio. 1998.
John, George H. Enhancements to Data Mining Process (PhD Dissertation). Stanford University. 1997.
K. Ryan & d. Giles. Testing for Units Roots in Economic Time Series with Missing Observations. University of Victoria, Canada.
Kaiser y A. Maravall. Notes on Time Series Analysis ARIMA Models and Signal Extraction. R. Documento de Trabajo Nº 0012. Publicación del Banco de España.
Kilmer, Robert A.; Smith, Alice E. Using Artificial Neural Networks to Approximate a Discrete Event Stochastic Simulation Model. 1999.
Kuihan Lee, Herbert. A Framework for Non Parametric Regression Using Neural Networks. Duke University. 2000.
Kuihan Lee, Herbert. Model Selection and model Averaging for Neural Networks (PhD Dissertation). Carnegie Mellon University. 1999.
Lawrence, Steve; Back, Andrew; Tsoi, Ah Chung. Function Approximation with Neural Networks and Local Methods: Bias, Variance and Smoothness. Australian Conference on Neural Networks, ACNN, pp. 16-21. 1996.
Lawrence, Steve; Burns, Ian; Back, Andrew; Tsoi, Ah Chung; Giles, Lee. Neural Network Classification and Prior Class Probabilities. University of Wollongong. Australia. 1998.
Michie, D.; Spiegelhalter, D.J.; Taylor C.C. Machine Learning, Neural and Statistical Classification. 1994.
Paige, Robert L. Bayesian Inference in Neural Networks. University of Colorado. 2002.

Tecana American University
PhD in System Engineering – Disertación Doctoral – Diciembre 2002
Pág. 136
Papadopoulos ,G.; Edwards, P.J.; Murray, A.F. Confidence Estimation Methods for Neural Networks: A Practical Comparison. University of Edinburgh. 2000.
Parekh, Rajesh; Yang,Jihoon; Honavar, Vasant. Constructive Neural-Network Learning Algorithms for Pattern Classification. IEEE Transactions on Neural Networks,VOL.11,NO.2,March 2000.
Pitarque, Alfonso ; Roy, Juan Francisco; Ruiz, Juan Carlos. Redes Neuronales vs. Modelos Estadísticos: Simulación sobre tareas de predicción y clasificación. Universidad de Valencia, España. 1998.
Poland, Jan; Zell, Andreas. Different Criteria for Active Learning in Neural Networks: A Comparative Study. University of Tubingen. Germany. 1998.
Portegie. Introduction to the MatLab Neural Networks Toolbox 3.0. 2000.
Santín González, Daniel; Valiño Castro, Aurelia. Comparing neural networks and efficiency techniques in non-linear production functions. Universidad Complutense de Madrid. 2001.
Sarle, Warren S. Neural Networks and Statistical Models. SAS Institute Inc. 1994.
Schumacher, Martin; Robner, Reinhard; Vach, Werner. Neural Networks and Logistic Regression: Part I. University of Freiburg. Germany. 1995.
Shachmurove, Yochanan. Applying Artificial Neural Networks to Business, Economics and Finance. The City College of the City University of New York and The University of Pennsylvania. 2002.
Shapiro, Jonathan. Neural Networks in MatLab.2000.
Turmon, Michael J.; Fine Terrence L. Sample Size Requirements For Feedforward Neural Networks. Cornell University. NY. 1995.
Van Gorp, Jürgen; Schoukens, Johan; Pintelon Rik. Adding Input Noise to Increase the Generalization of Neural Networks is a Bad Idea. Intelligent Engineering Systems Through Artificial Neural Networks, Volume 8., pp. 127 - 132. 1998.
Vehtari, Aki; Lampinen, Jouko. Bayesian Neural Networks with Correlating Residuals. Helsinki University of Technology. 1999.
Zekic – Susac, Marijana. Neural Networks in Investment Profitability Predictions. Doctoral Dissertation. Varacdin. 1999.


















