
Conceptos)básicos)de)teoríade)la información)lucamartino.altervista.org/TeoriaInformacion.pdf ·...
31
Conceptos básicos de teoría de la información Luca Mar8no Apuntes no revisados Cuidado!
Transcript of Conceptos)básicos)de)teoríade)la información)lucamartino.altervista.org/TeoriaInformacion.pdf ·...

Conceptos básicos de teoría de la información
Luca Mar8no Apuntes no revisados
Cuidado!

Información
• La información asociada a un evento con probabilidad p(x) se define
• Un evento POCO frecuente 8ene MUCHA información. • Un evento MUY frecuente 8ene POCA información.
€
I(x) = −log p(x)[ ] Unidad de medida: bit

Entropía (discreta)
• Es el valor medio de la información
• ES UN NUMERO (un escalar). Se puede considerar una MEDIDA DE DISPERSIÓN de la densidad p(x).
• A veces se le indica como H(X) donde con X se indica la variable aleatoria con densidad p(x).
• Representa la incer8dumbre sobre el valor que puede tomar la variable aleatoria X.
€
HX = − p(x = i)i=1
N
∑ log p(x = i)[ ]

Entropía (discreta) • La entropía se puede considerar una medida de dispersión
porque por ejemplo es máxima cuando la p(x) es uniforme y minima cuando p(x) es una delta.
• La entropía diferencial (caso con8nuo) es máxima en el caso de la densidad Gaussiana.
….
Entropía DISCRETA máxima
Entropía DISCRETA minima (nula). Se asume que la forma indeterminada sea nula (por razones de con8nuidad).
€
1N
€
1N
€
1N
€
1N
€
1
€
HX = log2 N
€
HX = 0
€
0log2 0 = 0

Relación con la varianza • Otra medida de dispersión es, por ejemplo, la varianza. Pero la
varianza depende del soporte de la densidad, del orden de las deltas (de donde están posicionada las deltas)
• La entropía discreta es “simétrica” respecto a permutaciones de las probabilidades, es invariante bajo traslaciones y escalados.
En estas 2 densidades: la entropía es igual, pero la varianza no!
€
HaX +b = HX

Entropías conjunta, condicional e información mutua
• Otras entropías y la información mutua
€
HXY = − p(x = i,y = j)i=1
N
∑ log p(x = i,y = j)[ ]j=1
L
∑
€
IXY = − p(x = i,y = j)i=1
N
∑ log p(x = i)p(y = j)p(x = i,y = j)
⎡
⎣ ⎢
⎤
⎦ ⎥
j=1
L
∑ €
p(x,y) = p(y | x)p(x)p(x,y) = p(x | y)p(y)
Recordemos que:
€
HX |Y = − p(x = i,y = j)i=1
N
∑ log p(x = i | y = j)[ ]j=1
L
∑
HX |Y = − p(x = i,y = j)i=1
N
∑ log p(y = j | x = i)[ ]j=1
L
∑
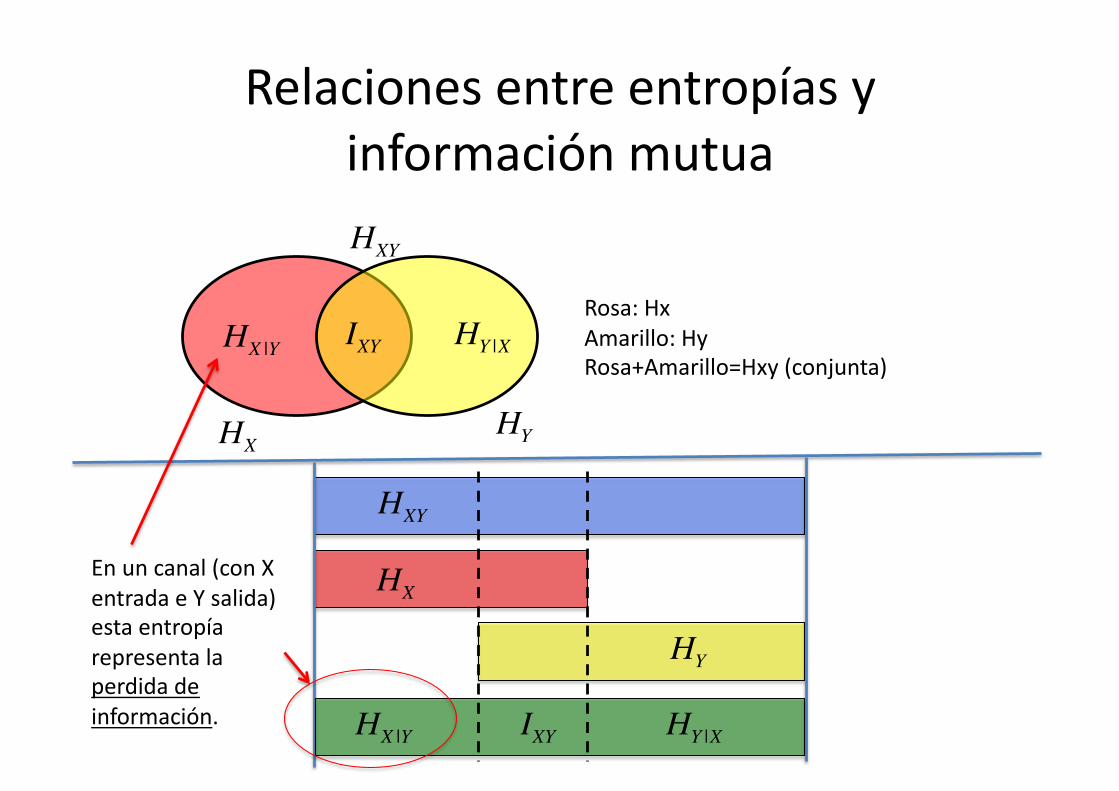
Relaciones entre entropías y información mutua
€
HX
€
HY
€
IXY
€
HX |Y
€
HY |X
€
HXY
Rosa: Hx Amarillo: Hy Rosa+Amarillo=Hxy (conjunta)
€
HXY
€
HX
€
HY
€
IXY
€
HX |Y
€
HY |X
En un canal (con X entrada e Y salida) esta entropía representa la perdida de información.

Relaciones entre entropías y información mutua
€
HXY
€
HX
€
HY
€
IXY
€
HX |Y
€
HY |X
Este diagrama es ú8l para escribir desigualdades o relaciones entre estas can8dades:
€
HXY ≤ HX +HY
HXY = HX +HY − IXYHXY = HX |Y +HY |X + IXYHXY = HX +HY |X
HXY = HY +HX |Y€
HX = HX |Y + IXYHY = HY |X + IXY
€
IXY = HX −HX |Y
IXY = HY −HY |X
IXY = HX +HY −HXY
IXY = IYX
€
HX ≤ HXY ≤ HX +HY
HY ≤ HXY ≤ HX +HY

Variables independientes
€
HXY
€
HX
€
HY
€
IXY = 0
€
HX |Y
€
HY |X
€
HX
€
HY
€
HX |Y
€
HY |X€
HXY
€
HX = HX |Y
HY = HY |X
HXY= HX +HY

Variables coincidentes X=Y (totalmente dependientes)
€
HXY
€
HX
€
HY
€
IXY = HX = HY = HXY
€
IXY
€
HXY = HX = HY = IXY
€
HX |Y = 0HY |X = 0€
IXY = HX = HY

Relaciones importantes
• Hay que recordar bien que
€
0 ≤ HX ≤ log2 M
€
0 ≤ HY ≤ log2 L
€
(HY =)HX ≤ HXY ≤ HX +HY
p(x) delta p(x) uniforme
X=Y Variables independientes
€
0 ≤ IXY ≤ HX (= HY )Variables independientes
X=Y
€
0 ≤ HX |Y ≤ HX
€
0 ≤ HY |X ≤ HY
Variables independientes Variables independientes
X=Y
X=Y

Canal discreto sin memoria (DMC)
• En una formula se puede escribir
• En estos casos o se da la formula arriba, o la VEROSIMILITUD (en el caso discreto, es una matriz….MATRIZ DE CANAL)
€
Y (t) = X(t) + E(t)t= 8empo Y(t)=variable aleatoria (recepción) al 8empo t X(t)=variable aleatoria (transmisión) al 8empo t E(t)= ruido, variable aleatoria al 8empo t
€
Y = X + E
€
p(yt | xt )
€
p(y | x)
Flujo de bits
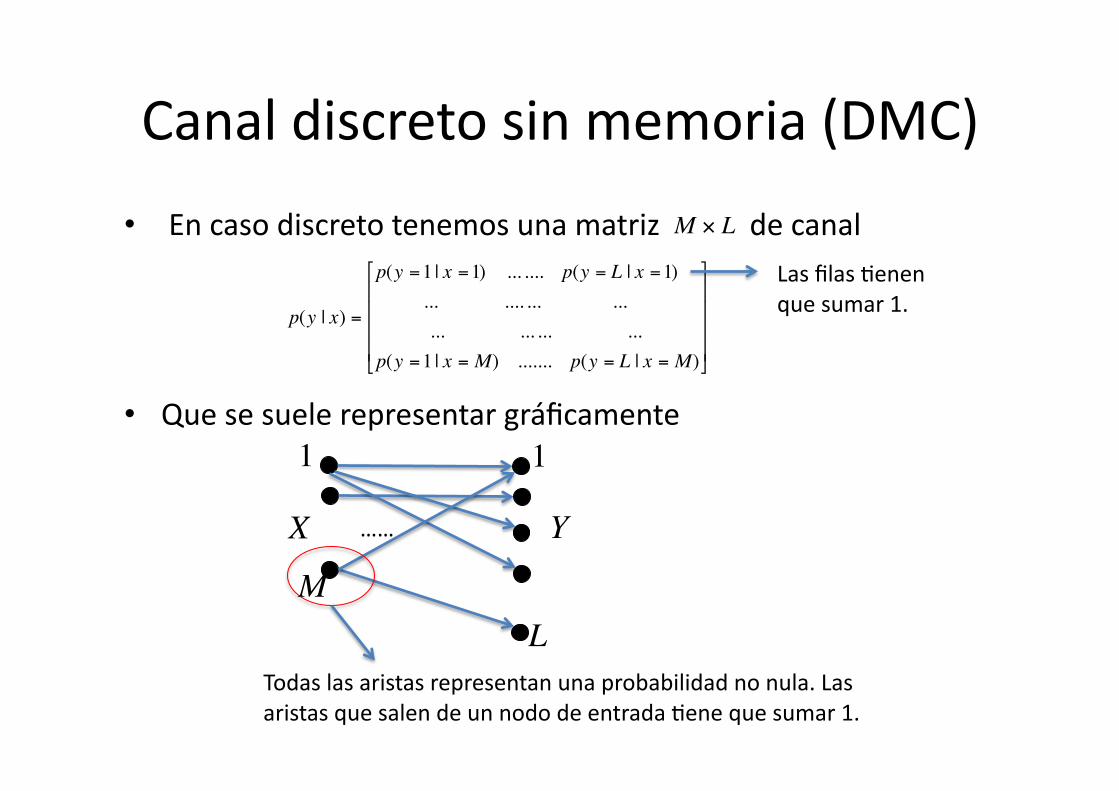
Canal discreto sin memoria (DMC)
• En caso discreto tenemos una matriz de canal
• Que se suele representar gráficamente €
p(y | x) =
p(y =1 | x =1) ...... ....
.... p(y = L | x =1)... ...
... ...p(y =1 | x = M) ....
... ...
... p(y = L | x = M)
⎡
⎣
⎢ ⎢ ⎢ ⎢
⎤
⎦
⎥ ⎥ ⎥ ⎥
€
M × L
……
€
X
€
Y
Todas las aristas representan una probabilidad no nula. Las aristas que salen de un nodo de entrada 8ene que sumar 1.
€
1
€
M €
1
€
L
Las filas 8enen que sumar 1.

Canal discreto sin memoria (DMC)
• En los problemas nos suelen dar la matriz de canal y la probabilidad sobre las entradas
• Teniendo estas dos densidades, realmente tenemos la densidad conjunta, es decir, toda la información.
……
€
X
€
Y
€
1
€
M €
1
€
L
€
p(y | x)€
p(x)
€
p(x,y) = p(y | x)p(x)

Canal discreto sin memoria (DMC)
• Podemos calcular todo
• Tenemos los 5 elementos
……
€
X
€
Y
€
1
€
M €
1
€
L
€
p(y | x)€
p(x)
€
p(x,y) = p(y | x)p(x)
€
p(y) = p(x = i,y)i=1
M
∑ = p(y | x = i)p(x = i)i=1
M
∑
€
p(x | y) =p(x,y)p(y)
=p(y | x)p(x)
p(y)=
p(y | x)p(x)
p(y | x = i)p(x = i)i=1
M
∑
€
p(x)
€
p(y | x)
€
p(y)
€
p(x | y)
€
p(y,x)

Canal discreto sin memoria (DMC)
• Nota que esta formula,
• es fácil de resumir, recordar y entender gráficamente
€
Y = j
€
p(y = j | x = k)
€
p(y = j) = p(x = i,y = j)i=1
M
∑ = p(y = j | x = i)p(x = i)i=1
M
∑
€
p(y = j | x = s)€
p(y = j | x = i)
€
X = k€
X = s€
X = i
Hay que considerar todas las ramas que entran en el nodo j.
€
p(y = j | x) = 0
Si no hay otras ramas, las demás probabilidades son nulas

Lo que nos gustaría: Canal ideal.
• a nosotros nos gustaría claramente que X=Y (caso ideal).
• Es decir obtener la máxima información mutua ( ).
• en otra forma queremos que la perdida de información en el canal sea nula ( : si conozco Y, conozco perfectamente X, no tengo incer8dumbre, no tengo sorpresas!) €
IXY = HX = HY
€
HX |Y = 0
……
€
X
€
YCANAL IDEAL

Lo peor: X e Y independientes.
• Si X e Y son independientes cualquier información sobre Y no me aporta nada sobre X.
• En este caso (minima información mutua). • La perdida de información es máxima ( : si conozco Y,
la incer8dumbre sobre X no disminuye).
€
IXY = 0
€
HX |Y = HX
€
p(y | x) =p(x,y)p(x)
=p(y)p(x)p(x)
= p(y)€
p(x,y) = p(x)p(y)

Lo peor: X e Y independientes.
• Cuando un canal genera esta independencia entre X e Y? • Cuando
……
€
X
€
Y
€
p(x)
€
p(y)€
p(y | x) = constante = 1num. ramas que salen de una entrada
PEOR CANAL POSIBLE
Todas las entradas 8enen el mismo numero de ramas.

Otros casos interesantes • Hemos dicho que cuando Y=X tenemos
• Puede haber casos donde una entropía condicional sea nula pero la otra no, y . Por ejemplo
€
IXY = HX = HY
€
HX |Y = 0
€
X
€
Y
€
HY |X = 0
€
Y ≠ X
€
1
€
2
€
3
€
4 €
1
€
2€
HY |X = 0
€
HX |Y ≠ 0
¿qué incer8dumbre tengo sobre Y si conozco X? Ninguna.

Otros casos interesantes • El caso simétrico seria
• Nota que , pero también este canal se podría considerar “ideal” (la perdida de información en el canal es nula).
€
X
€
Y
€
Y ≠ X
€
1
€
2
€
3
€
4€
1
€
2
€
HX |Y = 0
€
HY |X ≠ 0
¿qué incer8dumbre tengo sobre X si conozco Y? Ninguna.
Perdida info en el canal

Lo que queremos: maximizar
• Pues queremos maximizar la información mutua.
• Dado que el canal es dado (no se puede cambiar!), lo único que podemos variar son las probabilidades de las entradas.
• Es decir buscaremos la que maximiza la .
€
IXY
……
€
X
€
Y
€
p(x)
€
IXY
€
p(y | x)
€
p(x)
Matriz de canal: está dada.
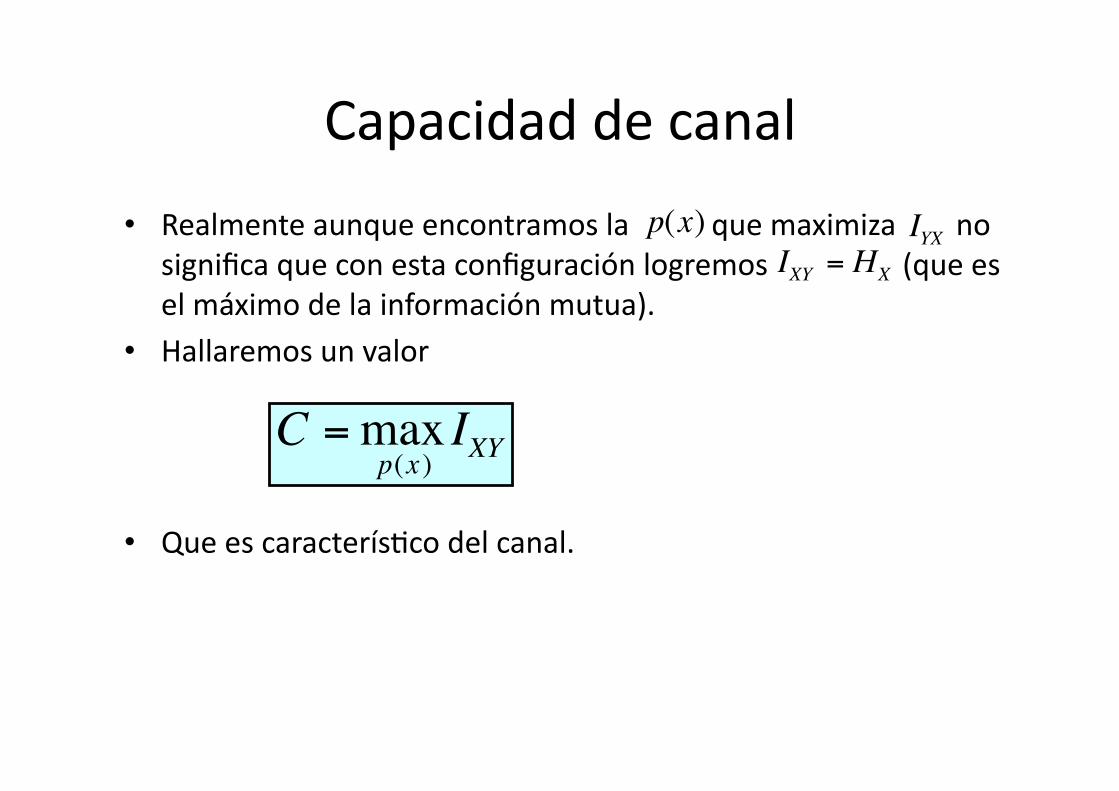
Capacidad de canal
• Realmente aunque encontramos la que maximiza no significa que con esta configuración logremos (que es el máximo de la información mutua).
• Hallaremos un valor
• Que es caracterís8co del canal.
€
p(x)
€
IYX
€
IXY = HX
€
C =maxp(x )
IXY
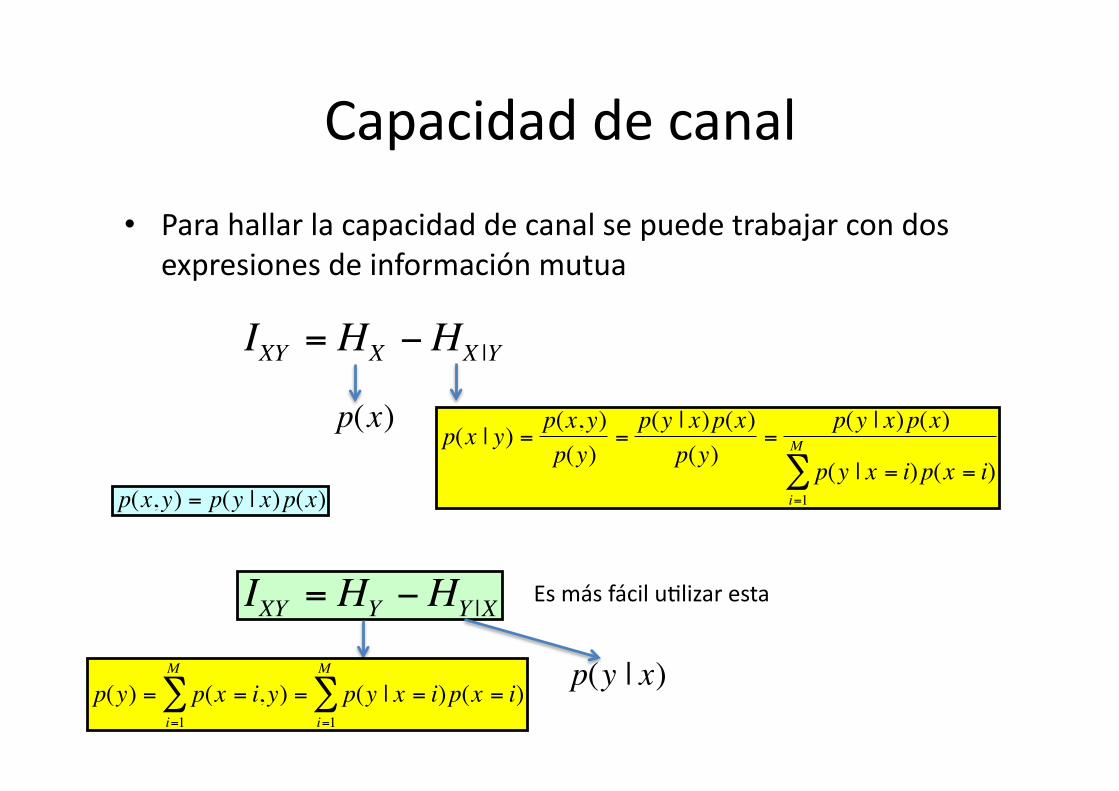
Capacidad de canal
• Para hallar la capacidad de canal se puede trabajar con dos expresiones de información mutua
€
p(x)
€
IXY = HX −HX |Y
€
IXY = HY −HY |X€
p(x | y) =p(x,y)p(y)
=p(y | x)p(x)
p(y)=
p(y | x)p(x)
p(y | x = i)p(x = i)i=1
M
∑
€
p(x,y) = p(y | x)p(x)
€
p(y | x)
€
p(y) = p(x = i,y)i=1
M
∑ = p(y | x = i)p(x = i)i=1
M
∑
Es más fácil u8lizar esta

Capacidad de canal
• Esta es más fácil de u8lizar en la prac8ca
• Pero esta es más interesante en la teoría
€
IXY = HX −HX |Y€
IXY = HY −HY |X
Información que atraviesa en canal
Información a la entrada
Perdida de Información en el canal

Capacidad de canal
• Otra observación muy importante es que
• La can8dad puede interpretar como el numero de entradas (simbolos) que se pueden u8lizar al mismo 8empo sin cometer ningún error en comunicación.
€
2c = numero de entradas que puedo utilizar sin cometer errores
€
2capacidad
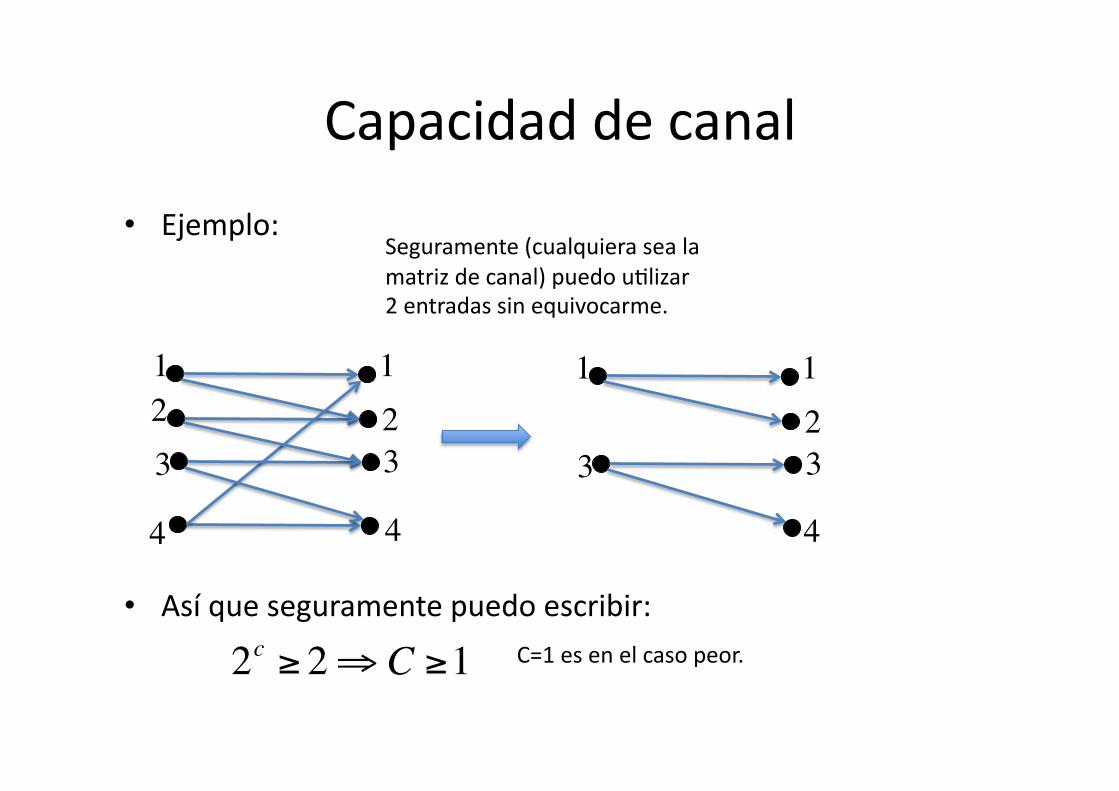
Capacidad de canal
• Ejemplo:
• Así que seguramente puedo escribir:
€
1
€
1
Seguramente (cualquiera sea la matriz de canal) puedo u8lizar 2 entradas sin equivocarme.
€
2
€
3
€
3
€
2
€
1
€
4€
1
€
3
€
3
€
2
€
2c ≥ 2⇒ C ≥1€
4
€
4
C=1 es en el caso peor.

Capacidad de canal
• Más en general con par:
• Así que seguramente puedo escribir:
€
1
€
M
€
M
€
1
Seguramente puedo u8lizar M/2 entradas sin equivocarme.
€
2
€
3
€
3
€
2€
1
€
4€
1
€
3
€
3
€
2
€
2c ≥ M2⇒ C ≥ log2
M2
= log2 M −1
……
€
M
€
M −1……
€
M −1
€
M

Capacidad de canal
• Hemos encontrado una cota inferior para la capacidad de este canal
• Pero también por el mismo razonamiento como mucho, en el caso ideal, podemos u8lizar todas las entradas es decir
€
C ≥ log2M2
€
1
€
M€
1
€
2
€
3
€
3
€
2
……
€
M
€
2C ≤ MC ≤ log2 M
€
log2M2≤ C ≤ log2 M
Cuidado: esta formula es siempre verdadera! No solo en este canal.
€
C ≤ log2 LTambién vale siempre esta desigualdad

Capacidad de canal
• Además si la probabilidad de transiciones son equiprobables ( )
• Se puede demostrar
€
1
€
M€
1
€
2
€
3
€
3
€
2
€
C = log2M2
……
€
M
1/2 1/2
1/2 1/2
1/2 1/2
1/2 1/2
1/2

Canales en paralelo
• Si tenemos 2 canales en paralelo, podemos encontrar la capacidad equivalente (total)
C1
C2
€
2ctot = 2c1 + 2c2
€
ctot = log2 2c1 + 2c2( )


















