
APOSTILA DE CÁLCULO NUMÉRICO
101
A POS T I LA DE CÁ L CULO NUMÉRICO 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 x y 0.5 0.0 0 150 50 100 y 0.5 0.0 −0.5 1.0 1.0 −0.5 −1.0 x −1.0 −2.0 −1.5 −1.0 −0.5 0.5 1.0 1.5 −2 −1 1 2 x y 1 2 3 4 5 6 7 8 9 10 −0.6 −0.4 −0.2 0.0 0.2 0.4 0.6 0.8 1.0 x y Wanderson José Lambert Seropédica Maio de 2014
-
Upload
victor-almeida-bressiani -
Category
Documents
-
view
15 -
download
0
description
1 Introdução 51.1 Série de Taylor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2 Exercícios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82 Solução de sistema lineares 92.1 Método de Gauss . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.1.1 Implementação do Método de Gauss . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.2 Método de Gauss com pivoteamento parcial . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.2.1 Implementação do Método de Gauss com Pivoteamento . . . . . . . . . . . . . . . . 182.3 Decomposição LU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.3.1 Implementação do Método da Decomposição LU para matrizes . . . . . . . . . . . 232.4 Métodos iterativos: Ponto fixo, erros, norma de matriz e outras coisas mais . . . . . . . . 242.4.1 Método do Ponto fixo linear e erros . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.4.2 Norma de Vetores e Matrizes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 282.5 Método de Jacobi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.5.1 Implementação do Método de Jacobi . . . . . . . . . . . . . . . . . . . . . . . . . . . 342.6 Método de Gauss-Seidel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362.6.1 Implementação do Método de Gauss-Seidel . . . . . . . . . . . . . . . . . . . . . . . 382.7 Exercícios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 402.8 Projeto: Sistemas lineares . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 433 Métodos para o cálculos de raízes de funções 453.1 Método da Bisecção . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 463.1.1 Implementação do Método da Bisecção . . . . . . . . . . . . . . . . . . . . . . . . . . 513.2 Método de Newton . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 533.2.1 Taxa de Convergência do Método de Newton: Assumindo convergência . . . . . . . 553.2.2 Implementação do Método de Newton . . . . . . . . . . . . . . . . . . . . . . . . . . 573.3 Método da Secante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 593.3.1 Implementação do Método da Secante . . . . . . . . . . . . . . . . . . . . . . . . . . 603.4 Extensão do Método de Newton para funções vetoriais . . . . . . . . . . . . . . . . . . . . . 633.4.1 A implementação do Método de Newton p-dimensional . . . . . . . . . . . . . . . . 653.5 Exercícios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 683.6 Projeto: Encontrar raízes de funções . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 694 Interpolação Polinomial 714.1 Unicidade da expansão polinomial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 754.2 Método de Lagrange . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 764.3 Diferenças Divididas de Newton . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 804.4 Splines Cúbicas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 824.5 Exercícios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 834.6 Projeto: Interpolação de Funções Polinomiais . . . . . . . . . . . . . . . . . . . . . . . . . . 845 Ajuste de Curvas e Otimização 855.1 Exercícios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 865.2 Projeto: Ajuste de Curvas e Otimização . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 876 Derivação Numérica 896.1 Exercícios . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Transcript of APOSTILA DE CÁLCULO NUMÉRICO

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 1/101
APOSTILA DE CÁLCULO NUMÉRICO
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.00.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
x
y
0.50.0
0
150
50
100
y0.5
0.0
−0.51.0
1.0−0.5−1.0
x
−1.0
−2.0 −1.5 −1.0 −0.5 0.5 1.0 1.5
−2
−1
1
2
x
y
1 2 3 4 5 6 7 8 9 10
−0.6
−0.4
−0.2
0.0
0.2
0.4
0.6
0.8
1.0
x
y
Wanderson José Lambert
Seropédica
Maio de 2014

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 2/101
2
Vaaaaai Curintia!!!!

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 3/101
Sumário
1 Introdução 5
1.1 Série de Taylor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2 Exercícios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2 Solução de sistema lineares 9
2.1 Método de Gauss . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.1.1 Implementação do Método de Gauss . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.2 Método de Gauss com pivoteamento parcial . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.2.1 Implementação do Método de Gauss com Pivoteamento . . . . . . . . . . . . . . . . 18
2.3 Decomposição LU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.3.1 Implementação do Método da Decomposição LU para matrizes . . . . . . . . . . . 23
2.4 Métodos iterativos: Ponto fixo, erros, norma de matriz e outras coisas mais . . . . . . . . 242.4.1 Método do Ponto fixo linear e erros . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.4.2 Norma de Vetores e Matrizes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.5 Método de Jacobi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.5.1 Implementação do Método de Jacobi . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.6 Método de Gauss-Seidel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362.6.1 Implementação do Método de Gauss-Seidel . . . . . . . . . . . . . . . . . . . . . . . 38
2.7 Exercícios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 402.8 Projeto: Sistemas lineares . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3 Métodos para o cálculos de raízes de funções 45
3.1 Método da Bisecção . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 463.1.1 Implementação do Método da Bisecção . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.2 Método de Newton . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 533.2.1 Taxa de Convergência do Método de Newton: Assumindo convergência . . . . . . . 553.2.2 Implementação do Método de Newton . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.3 Método da Secante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 593.3.1 Implementação do Método da Secante . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.4 Extensão do Método de Newton para funções vetoriais . . . . . . . . . . . . . . . . . . . . . 63
3.4.1 A implementação do Método de Newton p-dimensional . . . . . . . . . . . . . . . . 653.5 Exercícios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 683.6 Projeto: Encontrar raízes de funções . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
4 Interpolação Polinomial 71
4.1 Unicidade da expansão polinomial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 754.2 Método de Lagrange . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 764.3 Diferenças Divididas de Newton . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 804.4 Splines Cúbicas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 824.5 Exercícios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 834.6 Projeto: Interpolação de Funções Polinomiais . . . . . . . . . . . . . . . . . . . . . . . . . . 84
3

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 4/101
4 SUMÁRIO
5 Ajuste de Curvas e Otimização 855.1 Exercícios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 865.2 Projeto: Ajuste de Curvas e Otimização . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
6 Derivação Numérica 89
6.1 Exercícios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 906.2 Projeto: Derivação Numérica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
7 Integração Numérica 93
7.1 Exercícios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 947.2 Projeto: Integração Numérica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
8 Equações Diferenciais Ordinárias 978.1 Exercícios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 988.2 Projeto: Equações Diferenciais Ordinárias . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 5/101
Capítulo 1
Introdução
Um curso de cálculo numérico talvez não seja a primeira oportunidade que o aluno tem de utilizar-sedo computador para resolver aspectos importantes dos problemas que aparecem no cálculo e álgebralinear, mas é o curso que torna tais conceitos numéricos mais organizados e é uma primeira tentativaa fim de tornar este processo rigoroso.
Neste curso, não pretendemos nos aprofundar em nenhum tópico especificamente, mas procura-remos cobrir os principais aspectos do cálculo numérico, introduzindo os métodos e fazendo algumasdemonstrações intuitivas a cerca dos mesmos. Apesar do curso ser organizado para um público geral:matemáticos, físicos, químicos, engenheiros, e afins, acreditamos que um certo rigor é necessário nomomento da introdução dos métodos, sem, entretanto, que tal rigor tire o foco do material que é deser introdutório e tratar o cálculo numérico como uma ferramenta a ser utilizada para resolver proble-mas práticos. Na seção de bibliografia são listados várias referências que discorrem esses conceitos demaneira mais rigorosa e aprofundada.
Como matemático, aprendi a não acreditar em tudo que eu vejo; aprendi a desconfiar da beleza dassoluções; aprendi a não confiar, cegamente, no método que se coloca a minha frente. Como cientistas ouusuários de ferramentas numéricas para o cálculo de problemas exatos, temos que ter perfeita confi-
ança na solução que encontramos, para tanto conhecermos, pelo menos rudimentos, das demonstraçõese rigor é realmente bastante importante.
Neste texto, não farei nenhuma menção à questão de erros de arredondamento como uma sessãoparticular. Entretanto, quando trabalhamos com questões numéricas tais erros de arredondamentodevem ser levados em conta. Devemos ter ciência disso, pois muitas vezes tais erros podem prejudicarsobremaneira nossa solução dando-nos respostas bastante erradas.
Hoje em dia, os computadores servem-se de uma memória bastante grande de modo que todos oscálculos são feitos com muitos dígitos significativos e os erros de arredondamento são, para a maioriados problemas práticos, bastante reduzidos. Mas seria uma temeridade dizer que eles não existem.
Ao longo do texto, procurarei chamar atenção desses aspectos em alguns momentos quando neces-sário, sem, no entanto, me alongar por demasia nessas questões.
Vale lembrar que para cada uma dos assuntos a seguir, existem muitos outros métodos. Seria
impossível num cursos de um semestre atingir todos os métodos e tratá-los com todo o rigor necessário.Dessa forma fizemos uma escolha: apresentar os métodos principais em cada seção.Fizemos a opção de ao invés de trazermos os algoritmos, em cada subsessão, que descreve cada
um dos métodos, trazemos o algoritmo implementado em Matlab. O mesmo contém instruções de usoatravés de um pequeno tutorial como utilizá-lo.
O texto é organizado como segue:
1. Capítulo 1. Discutimos a solução de sistemas lineares quadrados. Admitimos que a matriz doscoeficientes associada ao sistema linear é não singular, ou seja, o sistema possua solução única.
Apresentaremos métodos diretos, de decomposição de matrizes e métodos iterativos.
2. Capítulo 2. Discutimos métodos para se encontrar raízes de funções reais e de funções vetoriais.
5

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 6/101
6 CAPÍTULO 1. INTRODUÇÃO
Todos os métodos apresentados são, basicamente, iterativos. Aqui discutiremos, brevemente, ométodo de Taylor para a linearização de funções reais.
3. Capítulo 3. Neste capítulo discutimos os métodos usados para a interpolação de pontos, ou seja,dado um conjunto de n pontos qual o melhor polinômio ou função que melhor se ajusta a essespontos. Discutimos polinômio e splines. Note que os métodos de interpolação servem para nosdar condições de fazermos previsões sobre valores que estão dentro do domínio dos pontos deinterpolação, entretanto, tal técnica é muito ruim para querermos fazer previsões sobre pontosque estão fora do domínio do domínio, ou seja, de extrapolarmos os pontos, fato este que é discutidono capítuloa seguir.
4. Capítulo 4. Neste capítulo, desenvolvemos, brevemente, o conceito, bastante importante, dedado um conjunto de pontos, qual a curva, de um determinado grau, que se ajusta melhor aestes pontos. Observe que este conceito é diferente do estudado no Capítulo 3, pois aqui nãohá necessidade das curvas interpolarem os pontos, apenas de ser uma melhor aproximação. Talconceito é chamado mais geralmente de Métodos dos Mínimos Quadrados. Ele é a técnica maisusada em problemas experimentais pois através do ajuste de curvas é possível extrapolar forado domínio dos pontos, diferentemente dos métodos de interpolação que não permitem uma boa
extrapolação.5. Capítulo 5. Discutimos aqui a derivação e a aproximação de derivadas numericamente. As
técnicas são particularmente baseadas no método de Taylor para a linearização de função.
6. Capítulo 6. Neste capítulo, seguindo a mesma linha do capítulo anterior iremos aplicar o métodode Taylor para a linearização das funções a proposição dos métodos numéricos. Também utiliza-remos métodos de quadratura que constituem-se métodos de uma melhor precisão e aparecemde modo mais refinado. Neste capítulo, fazemos uma breve introdução sobre a ideia teórica daintrodução do conceito de integral, bem como a ideia de partição que será particularmente útilpara o estudo da resolução de equações diferenciais ordinárias.
7. Capítulo 7. Aqui, fazemos a solução de Equações Diferencias Ordinárias (inclusive para siste-mas) através de técnicas aproximativas. Utilizamos de uma modelação matemática para trans-formar equações diferenciais ordinárias de ordem mais alto em sistemas de equações afim deaplicarmos as técnicas desenvolvidas anteriormente.
Vale notar que o texto está sendo organizado aos poucos, portanto, alterações podem ocorrer ao longodo semestre. Em todas as sessões e subsessões são dados algoritmos implementados em matlab paracada um dos métodos introduzidos. Estude adequadamente os métodos para obter-se os algoritmos.
A cada final de capítulo, coloquei uma breve lista de exercícios, que foram retiradas, basicamenteda referência [1]. Caso queira, poderá procurar, em livros de cálculo numérico, mais exercícios paraaprofundamento da matéria que mais lhe interessar.
No final de cada sessão também é colocado um projeto a ser desenvolvido. O aluno poderá entregartodos os projetos. Cada projeto vale um ponto na prova, além da nota, na prova que corresponde. Épara ser feito em grupo, os detalhes constam em cada projeto.
Como sequência do texto, aqui, discutimos um método bastante útil em cálculo numérico que aexpansão de Taylor. Não nos aprofundaremos muito em tal técnica, mas discutiremos brevementesua aplicação.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 7/101
1.1. SÉRIE DE TAYLOR 7
1.1 Série de Taylor
A ideia principal da série de taylor é a seguinte questão:Será que é possível escrever uma função f : D ⊂ R −→ R , em séries de potências em torno de um
ponto c ∈ D , ou seja,
f (x) =∞
∑i=0
an(x − c)n? (1.1)
Queremos que essa série de potência seja convergente para um raio de convergência R, ou seja, admi-
timos que a série∞
∑i=0
an(x − c)n converge para |x − c| < R.
Definição 1. O valor positivo R é dito raio de convergência para a série de potência
∞
∑i=0
an(x − c)n. (1.2)
Se a série converge para todo
|x
−c
|< R e não converge para nenhum
|x
−c
|> R.
Vamos tentar e ver quais condições temos que impor sobre a função f para que a mesma possaser escrita como uma série do tipo (1.1). Olhando para (1.1) sabemos que f deve satisfazer para todox ∈ D.
f (x) = a0 + a1(x − c) + a2(x − c)2 + a3(x − c)3 + a4(x − c)4 + · · · . (1.3)
Como (1.3) é válido para todo x, em particular é válido para x = c, ou seja, :
f (x) = a0 + a1(c − c) + a2(c − c)2 + a3(c − c)3 + a4(c − c)4 + · · · ,
entãoa0 = f (c).
É sabido, que uma série de potências pode ser derivada (ou integrada) quantas vezes necessárias sobreo seu raio de convergência, então, derivando (1.3) uma vez, obtemos:
f ′(x) = a1 + 2a2(x − c) + 3a3(x − c) + 4a4(x − c)3 + · · · . (1.4)
Substituindo x = c em (1.4), nós obtemos:
f ′(c) = a1 + 2a2(c − c) + 3a3(c − c) + 4a4(c − c)3 + · · · ,
entãoa1 = f ′(c).
Procedendo com o mesmo algoritmo, podemos derivar (1.4) uma vez. Observe que o grau do polinômiovai caindo:
f ′′(x) = 2a2 + 2 · 3a3(x − c) + 3 · 4a4(x − c)2 + 4 · 5a5(x − c)3 · · · . (1.5)
Substituindo x = c em (1.4), nós temos, após os cálculos: então
a2 = f ′′(c)
2! .
Sendo bastante reduntante, com o mesmo algoritmo, podemos derivar (1.5) uma vez. Observe que ograu do polinômio vai caindo que os coeficientes multiplicando cada ai são decrescentes e da formai(i − 1)(i − 2) · · · (2)(1) = i !:
f ′′′(x) = 3!a3 + 2 · 3 · 4a4(x − c) + 3 · 4 · 5a5(x − c)2 + 4 · 5 · 6a6(x − c)3 · · · . (1.6)

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 8/101
8 CAPÍTULO 1. INTRODUÇÃO
Substituindo x = c em (1.6), nós temos, após os cálculos: então
a3 = f ′′′(c)
3! .
Apresentando este algoritmo, indutivamente, conseguimos descobrir que
an = f n(c)
n! , no qual f n(c) =
dn
dxn f
(c). (1.7)
Note que se n = 0, então a função não fazemos nenhuma derivação.Então a série de Taylor (1.1) em torno do ponto c pode ser escrita como:
f (x) =∞
∑i=0
f n(c)
n! (x − c)n = f (c) + f ′(c)(x − c) +
f ′′(c)
2! (x − c)2 + · · · . (1.8)
Entretanto, muitas vezes queremos apenas uma aproximação da série de Taylor, pois é muito difícilrepresentarmos, em problemas cotidianos, todos os termos da série. Então truncamos a série e expan-dimos apenas até um certo índice k . A pergunta é: Qual o erro cometido?
É possível mostrar,( veja referências [1], [2]), que uma série de Taylor pode ser escrita da seguinteforma:
f (x) =k
∑i=0
f n(c)
n! (x − c)n + Rk , (1.9)
no qual Rk é o erro cometido. Tal erro é dado por:
Rk = f n+1(ξ(x))
(n + 1)! (x − c)n+1. (1.10)
Vale observar que não temos condições, em geral, de dizer quem é ξ(x). Quando estudamos erro, emgeral utilizamos o pior caso possível para fazer uma estimativa (o maior erro possível que poderiaaparecer).
Dessa forma, a série de Taylor é escrita, contabilizando tal erro, como:
f (x) =k
∑i=0
f n(c)
n! (x − c)n +
f n+1(ξ(x))
(n + 1)! (x − c)n+1. (1.11)
Observação 1. Note que a o erro é bem pequeno para valores de x bem próximos de c. Portanto, paravalores de x próximos de c precisamos reter apenas poucos termos da série e erro tende a zero da ordemde |x − c|n+1 , ou seja, vai para zero bem rapidamente.
A série de Taylor pode ser facilmente extendida para dimensão espacial n qualquer, entretanto,quando for necessário (se for necessário) faremos a apresentação da série de Taylor para a respectivadimensão.
1.2 Exercícios
Exercício 1: Encontre a série de Taylor das funções em torno dos pontos indicados:a) f (x) = e x, em torno de c = 1.b) f (x) = xex3
, em torno de c = 0.c) f (x) = cos(x), em torno de c = π .d) f (x) = x4 + 2x3 + x2 + 1, em torno de c = 10.e) f (x) = x4sen(x), em torno de c = 0. f ) f (x) = l n(x), em torno de c = 1.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 9/101
Capítulo 2
Solução de sistema lineares
Inicialmente estamos interessados na resolução de sistema lineares. Sistemas lineares aparecem mui-tas vezes na nossa rotina de matemáticos, físicos, engenheiros, geólogos, etc. Em geral, tais sistemassão muito grandes e cálculos manuais tornam-se impraticáveis, portanto, a solução numérica é indis-pensável.
Existem muitos pacotes fechados (ou seja, programas nos quais o usuário não tem condições demodificar a estrutura do programa, entra apenas com o que se quer resolver) tais como Matlab, Mathe-matica, Scilab, etc; e calculadoras científicas como HP. Entretanto, conhecer-se a arquitetura de comotais programas são estruturados é bastante importante, além disso, muitas vezes precisamos de fatoimplementar tais métodos para resolver problemas grandes ou que exibam particularidades que, atra-vés de uma análise mais crítica, possam ter sua solução facilitada.
Definição 2. Um sistema linear consiste-se de um grupo de m equações com n incógnitas. Tais incóg-nitas são definidas como x1 , x2 , · · · , xn. O grupo de equações é escrito como:
a11 x1 + a12 x2 + · · · + a1nxn = b1,
a21
x1 + a
22x
2 +
· · ·+ a
2nx
n = b
2,
... ... · · · ... =
..., (2.1)
am1x1 + am2x2 + · · · amn xn = bm,
(2.2)
O sistema linear (2.1) pode ser escrito na forma matricial como:
AX = B , (2.3)
no qual A é a matriz dos coeficientes:
A =
a11 a12 · · · a1n
a21 a22
· · · a1n
... . . . · · · ...am1 am2 · · · amn
(2.4)
X = (x1, x2, · · · , xn)T é o vetor de incógnitas (observe que o sobreescrito T indica que o vetor estátransposto, ou seja, está de pé. Lembre-se T (tesão) deixa tudo que está deitado de pé...), e B =(b1, b2, · · · , bn)T .
Em nosso curso, iremos tratar apenas do caso em que o sistema linear é quadrado.
Definição 3. Dizemos que um sistema linear é quadrado se a quantidade de equações é exatamenteigual a quantidade de incógnitas, o que quer dizer que n = m. Note que neste caso a matriz doscoeficientes A é quadrada, ou seja, o número de linhas é igual o número de colunas.
9

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 10/101
10 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
Além disso, vamos admitir que o sistema linear (2.1) possua solução única. Os casos em que osistema não possua nenhuma solução ou possua infinitas soluções estão fora do escopo desse primeirocurso introdutório de cálculo numérico. Uma análise mais detalhada pode ser encontrada em livrosmais avançados de cálculo numérico, listados nas referências.
Sabemos de álgebra linear que para um sistema quadrado ter solução única, basta que a matriz dos
coeficientes A seja não singular. Há várias formas de verificar se uma matriz é não singular, todas elas,igualmente dificeis e a verificação, basicamente, depende de técnicas de decomposição e fatoração dematrizes. Algumas propriedades que exibem as matrizes quadradas não singulares são: determinanteda matriz A é não zero; a matriz A pode ser invertida; a matriz A pode ser fatorada numa matriztriangular com os elementos da diagonal principal todos diferentes de zero; etc..
Existem vários métodos para utilizados para a solução de sistemas lineares.Neste curso, estudaremos três diferentes tipos mais utilizados:
1. Método de Gauss - Método direto para a solução do sistema. Um dos métodos mais utilizados,inclusive em cursos de álgebra linear.
2. Método de Gauss com pivoteamento parcial - O pivoteamento é uma técnica utilizada para evitarque os erros de arredodamento se propagem muito para o sistema. Pode ser usado em sistemas
de equações para os quais as equações tenham ordens muito diferentes.3. Método de decomposição LU - Neste método decompomos a matriz A = LU , no qual L é uma
matriz triangular inferior e U é uma matriz triangular superior, basicamente, neste método uti-lizamos o método de Gauss acima. Existem muitas outras formas de decompor uma matriz, taiscomo decomposição A = PLU . Decomposição de Cholesky, caso a matriz seja definida positiva.Mas aqui nos concentraremos apenas na decomposição LU que é a mais usada e que serve, inclu-sive, para o caso em que a matriz seja singular.
4. Métodos iterativos de Jacobi e Gauss-Seidel - Estes métodos são bastante lentos para seremaplicados a sistemas pequenos, entretanto são bem interessantes para sistemas grandes para osquais a matriz dos coeficientes é diagonalmente dominante e esparsa. Daremos tais definiçõesnas seções que se seguem.
Vale ressaltar que existem muitos outros métodos para a resolução de sistemas lineares. Algunsdeles levando-se em conta particularidades da matriz dos coeficientes, tais como: positividade, sime-tria, esparsidade, tridiagonalidade, etc. Sugerimos que quando o leitor deparar-se com a resolução desistemas lineares grandes e com particularidades que ele procure as boas referências dadas no finaldo texto e procure lá métodos mais adequados as suas necessidades. A área do cálculo numérico ébastante rica e bem desenvolvida.
A parte de sistema linear está organizada em Seções: Método de Gauss; método de Gauss compivoteamento parcial; decomposição LU. Para a introdução dos métodos iterativos construimos umaseção no qual damos a ideia do ponto fixo para métodos iterativos e discutimos, brevemente, a noçãode norma de vetores e de matrizes. Posteriormente discutimos os métodos de Jacobi e Gauss-Seidel.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 11/101
2.1. MÉTODO DE GAUSS 11
2.1 Método de Gauss
Este método consiste em transformar a matriz dos coeficientes A numa matriz triangular superioratravés de operações elementares.
Definição 4. Uma matriz A é dita triangular superior se os elementos abaixo da diagonal principalsão todos nulos. Uma matriz A é dita triangular inferior se os elementos acima da diagonal principalsão todos nulos. Caso os únicos elementos não nulos da matriz estejam ao longo de sua diagonal ela étanto triangular superior quanto triangular inferior. Neste caso dizemos que a matriz é diagonal.
Definição 5. Operações elementares são aquelas operações feitas sobre matrizes para os quais po-demos substituir uma linha (ou coluna, mas neste caso iremos trabalhar apenas com linhas) por umacombinação linear de outras linhas ou permutação entre linhas. Tal processo não modifica a naturezada matriz, ou seja, se a matriz for não singular inicialmente ela continuará não singular. Caso sejasingular ela continuará singular. Note-se apenas que não é possível nessas operações multiplicar umalinha ou coluna pelo número zero, pois ele torna a matriz singular.
A ideia é transformar a matriz quadrada numa matriz do tipo triangular superior da forma:
a11 a12 a13 · · · a1n−1 a1n0 a22 a23 · · · a2n−1 a2n
0 0 a33 · · · a3n−1 a3n
0 0 0 a44 · · · a4n
0 0 0 0 . . .
...0 0 0 · · · 0 ann
(2.5)
no qual os ai j (com i , j variando de 1 até n com i ≤ j) são os coeficientes obtidos apartir das operaçõeselementares sobre a matriz.
Para aplicar o algoritmo de Gauss, os passos são simples: Primeiro passo: Construção da matriz aumentada do sistema (2.1):
Definição 6. A matriz aumentada é a matriz formada pela matriz dos coeficientes A e com a ultima
coluna formada pelo vetor do lado direito de (2.1) B = (b1 , b2, · · · , bn)T , da seguinte forma:
A =
a11 a12 · · · a1n | b1
a21 a22 · · · a2n | b2...
. . . · · · ...an1 an2 · · · ann | bn
(2.6)
Segundo passo: Inicialmente devemos zerar todos os elementos da primeira coluna que estão abaixoda primeira linha. Para isto vamos utilizar um pivô.
Definição 7. Dada uma matriz A qualquer da forma (2.4) , chamamos de pivô da i-ésima linha , o primeiro elemento não nulo da linha a partir da esquerda. No texto, usaremos apenas a palavra pivô ,a linha estará subentendida.
Caso o elemento a11 seja diferente de zero, este será o nosso pivô. Caso ele seja zero, devemos trocara posição entre a primeira linha e alguma linha que não tenha um elemento não nulo. Sempre existiráesta linha com elemento não nulo, pois a matriz é não singular. Uma dica, quando for fazer esta troca,procure trocar pela linha que possui o elemento de maior módulo, pois o método utilizado será maisestável.
Após as devidas trocas de linha, caso necessário e admitindo que a11 seja diferente de zero, procede-mos com a eliminação dos elementos a i1 para i = 2,3, · · · , n (ou seja, os elementos abaixo da primeiralinha). Para isto basta procedermos assim, para i = 2,3, · · · , n:
Li −→ L i −
a1i
a11
L1 , (2.7)

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 12/101
12 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
ou seja, trocamos a linha i pela linha i subtraída da linha 1 multiplicada por a1i/a11. Após este primeiro passo a matriz fica da forma:
A =
a11 a12 · · · a1n | b1
0 a(1)22 · · · a
(1)2n | b
(1)2
.
.. .
. . · · ·...
0 a(1)n2 · · · a
(1)nn | b
(1)n
, (2.8)
no qual o sobrescrito (1) indica que o coeficiente não é o original e sim aquele trocado por aquelesomado, ou seja, os novos elementos são dados por
a(1)i j = a i j −
a1i
a11
a1 j.
Próximos passos: O processo é repetido. Note que após a primeira rodada de operações são introdu-zidos os zeros da primeira coluna. No segundo passo será necessário fazer operações para introduzir oszeros na segunda coluna abaixo da segunda linha. Caso a
(1)22 seja não nulo este será o pivô, entretanto,
caso este seja zero, deveremos, novamente, buscar um elemento diferente de zero na segunda coluna,sempre existirá pois, por hipótese, estamos admitindo que a matriz A é não singular. Procedendo comoanteriormente, para i = 3,4, · · · , n fazemos:
Li −→ L i −
a(1)2i
a(1)22
L2 , (2.9)
o que nos dá uma matriz da forma:
A =
a11 a12 a13 · · · a1n | b1
0 a(1)22 a
(1)23 · · · a
(1)2n | b
(1)2
0 0 a(2)33 · · · a
(2)3n | b
(2)3
... . . . · · · ...
0 0 a(2)
n3 · · · a
(2)nn
| b
(2)n
, (2.10)
no qual temos, como anteriormente,
a(2)i j = a
(1)i j −
a
(1)1i
a(1)11
a
(1)1 j .
Esse passo é feito no máximo n − 1 vezes. Após a aplicação desses para as n − 1 colunas (note quea última não precisará ser modificada), encontramos uma matriz aumentada que é da forma:
a11 a12 a13 · · · a1n−1 a1n | b1
0 a22 a23 · · · a2n−1 a2n | b2
0 0 a33 · · · a3n−1 a3n | b3
0 0 0 a44 · · · a4n | b4
0 0 0 0 .
. . .
.. .
..0 0 0 · · · 0 ann | bn
(2.11)
ou seja, o sistema linear torna-se:
a11 x1 + a12 x2 + a13x3 + · · · + a1n−1xn−1 + a1nxn = b1
a12 x2 + a23x3 + · · · + a2n−1xn−1 + a2nxn = b2
a33x3 + · · · + a3n−1xn−1 + a3nxn = b3 (2.12)... · · · . . .
... =...
ann xn = bn.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 13/101
2.1. MÉTODO DE GAUSS 13
O subescrito em cada coeficiente indica que esta matriz foi operada quantas vezes necessária paratorná-la uma matriz triangular superior. O sistema (2.12) é exatamente equivalente ao sistema origi-nal (2.1).
Definição 8. Para encontrar a solução basta resolvê-lo debaixo para cima, tal técnica é chamada de
retrossubstituição. Note que é fácil obter a solução desta forma, pois:
xn =bn
ann, (2.13)
xn−1 =bn−1 − an−1nxn
ann, (2.14)
... =..., (2.15)
x1 =b1 − a1nxn − · · · − a12 x2
a1. (2.16)
Exemplo 1. Resolva o sistema
x1 − 3x2 + 4x3 + 2x4 = 8
2x1 + x2 + 3x3 − x4 = 2
3x1 + 2x2 + 2x3 + 2x4 = −3 (2.17)
2x1 − x2 − x3 + x4 = 7
pelo método de Gauss. Para resolver, inicialmente criamos a matriz dos coeficientes C , com a matriz aumentada, M
C =
1 −3 4 22 1 3 −1
3 2 2 22 −1 −1 1
, M =
1 −3 4 2 82 1 3 −1 2
3 2 2 2 −32 −1 −1 1 7
, (2.18)
Procedendo para tornar a matriz C , uma matriz triangular superior, operamos sobre a matriz au-mentada M. A primeira coisa a fazer é introduzir zeros na primeira coluna abaixo da primeira linha.
Note que o pivô (que é o elemento da primeira linha e primeira coluna) a ser usado para tornar os ele-mentos abaixo da primeira linha da primeira coluna todos zero é 1. Não será necessário fazer nenhuma
permutação de linhas. Então procedendo as operações fazemos:
L2 − 2L1 −→ L2, L3 − 3L1 −→ L3 and L4 − 2L1 −→ L4. (2.19)
obtemos a matriz aumentada M como:
M =
1 −3 4 2 80 7 −5 −5 −140 11 −10 −4 −270 5 −9 −3 −9
(2.20)
Como próximo passo, introduzimos zeros abaixo da segunda linha e segunda coluna. O pivô a serutilizado para o segundo passo será 7.
Note que não mexemos mais na linha 1. Então procedendo as operações fazemos:
L3 − (11)
(7) L2 −→ L3 and L4 − (5)
(7)L2 −→ L4. (2.21)

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 14/101
14 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
obtemos a matriz aumentada M como:
M =
1 −3 4 2 80 7 −5 −5 −14
0 0
−
15
7
15
7 −5
0 0 −387
47
1
(2.22)
Finalmente, devemos introduzir zeros abaixo da terceira linha e terceira coluna. Observe que o pivô
agora será −15
7 . Dessa forma procedemos com o seguinte cálculo:
L4 − −(38)/(7)
−(15)/(7)L3 −→ L4, ou seja, L4 − 38
15L3 −→ L4 (2.23)
o que nos fornece:
M =
1 −3 4 2 8
0 7 −5 −5 −140 0 −15
7
27
7 −5
0 0 0 −46
5
41
3
(2.24)
Após estes cálculos, o sistema equivalente pode ser escrito como:
x1 − 3x2 + 4x3 + 2x4 = 8
7x2 − 5x3 − 5x4 = −14
−15
7 x3 +
27
7 x4 = −5
−46
5
x4 = 41
3 Aplicando retro-substituição encontramos:
x4 = −205
138, x3 =
5 + 27
7 x4
15
7
−→ x3 = − 47
138,
x2 = −14 + 5x3 + 5x4
7 −→ x2 = −76
23,
x1 = 8 + 3x2 − 4x3 − 2x4 −→ x1 = 167
69 .
2.1.1 Implementação do Método de Gaussfunction x = Gauss(A, b)
% Resolve o sistema linear Ax = b
% usando eliminação de Gauss
% A é u ma m atriz n p or n
% b é o vetor do lado direito da forma b=(b1,b2,...,bn)^T
% x é o vetor a ser encontrado
[n, n] = size(A); % Descobre a ordem da matriz A
x = zeros(n,1); % Inicializa x

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 15/101
2.2. MÉTODO DE GAUSS COM PIVOTEAMENTO PARCIAL 15
for i = 1:n-1
m = -A(i+1:n,i)/A(i,i); % Encontra a razão entre os elementos divididos pelo pivo.
A(i+1:n,:) = A(i+1:n,:) + m*A(i,:);
b(i+1:n) = b(i+1:n) + m*b(i);
end;
% Usando retro-substituicao para encontrar a solucao.x(n) = b(n)/A(n,n);
for i = n-1:-1:1
x(i) = (b(i) - A(i,i+1:n)*x(i+1:n))/A(i,i);
end
2.2 Método de Gauss com pivoteamento parcial
O método de Gauss com pivoteamento é o mesmo método de Gauss, entretanto, é utilizado quandoexistem diferenças muito grande entre as linhas e equações do problema. Por exemplo, suponha quevocê queiramos resolver um sistema linear simples 2x2:
0,003x1 + 59, 14x2 = 59, 17 (2.25)5,291x1 − 6, 130x2 = 46, 78 (2.26)
Verifique que este sistema possui como solução exata x1 = 10 e x2 = 1. Para tanto basta substituiresses valores em (2.25) e (2.26).
Entretanto, suponhamos que queiramos resolver pelo método de Gauss. Dessa forma a matrizaumentada do sistema acima será:
0, 003 59, 1 4 59, 1 75,291 −6, 130 46, 78
. (2.27)
Note que o pivô para da primeira linha é 0, 003, que apesar de pequeno é diferente de zero. Paraproceder os cálculos, imaginemos que queiramos ao invés de utilizar os valores exatos, que usemos
uma aproximação do valor. Para a aproximação temos dois tipos de formas de aproximar um número:truncamento e arredondamento.
Definição 9. Uma operação de truncamento de três dígitos significativos é aquela para o qual são pegados apenas 3 dígitos após a vírgula, desconsiderando-se o valor do quarto dígito após a vírgula. Exemplo: Truncamento do número 0, 0346843 será de 0, 034.
Definição 10. Uma operação de arredondamento de três dígitos significativos é aquela para o qualsão pegados os 2 primeiros dígitos significativos e o terceiro dígito depende do valor do quarto dígitoapós a vírgula, se o quarto dígito for maior ou igual a 5, será acrescido um ao terceiro dígito, caso oquarto dígito seja menor do que 5 o terceiro dígito é mantido inalterado. Exemplo: Arredondamento donúmero 0, 0346843 será de 0, 035.
Vamos utilizar um arredodamento de 3 casas após a vírgula. Então procedendo a decomposição deGauss, devemos fazer a seguinte operação:
L2 − 5, 291
0, 003L1 −→ L2.
Neste caso, a segunda linha fica dada por:
L2 = (0; −104289, 6633333333 · · · ; 104383, 2133333333 · · ·)T
Usando três casas decimais após a vírgula para o arredondamento, aproximamos L2 por:
L2 = (0; −104289, 663 · · · ; 104383, 213 · · ·)T

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 16/101
16 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
Note que esta aproximação, a nossos olhos, parece muito boa. Então o sistema linear, com as aproxi-mações, fica da forma:
0, 003x1 + 59, 14x2 = 59, 17 (2.28)
−104289, 663x2 = 104383, 213 (2.29)
Então da Eq. (2.29), encontramos
x2 = −104383, 663
104289, 213 ∼ 1.000897020829380,
o qual pode ser aproximado, com 3 casas decimais após a vírgula, por x2 = 1.001. Observe que estevalor está bem próximo do valor exato x2 = 1 que é a solução exata do nosso sistema.
Então, substituindo x2 = 1.001 em (2.28) obtemos:
0, 003x1 + 59, 14(1, 001) = 59, 17, −→ x1 = 59, 17− 59,199
0,003 = −9.667. (2.30)
Note que a solução x1 =
−9.667 é totalmente diferente da solução original do problema que é x1 = 10.
A questão que surge é: Por que isto aconteceu? Veja a Figura (2.1.a), no qual fazemos o desenho decada uma das retas definidas por (2.25) e (2.26). A reta azul é obtida de (2.25), escrevendo-se x 1 emfunção de x2. A reta vermelha é obtida de (2.26), escrevendo-se também x 1 em função de x2. Note quehá uma variação muito grande na reta azul, a vermelha está, nesta escala, praticamente sobre o eixox.
Isto ocorreu porque o pivô utilizado no primeiro nível de cálculo foi (em módulo) muito pequeno(0,003) comparado com os outros números do sistema. Note que na primeira operação dividimos L2 poreste valor. Isto introduz erros numéricos que podem se acumular e acabamos não tendo controle sobreisto.
Como devemos proceder? Como na primeira coluna o número 5, 291 é maior do que o número0, 003 permutamos a L1 com L2 para obtermos a seguinte matriz (note que o sistema é o mesmo a serresolvido):
5,291 −6, 130 46, 780, 003 59, 1 4 59, 1 7
. (2.31)
Vamos utilizar um arredodamento de 3 casas após a vírgula. Então procedendo, como anteriormente,a decomposição de Gauss, devemos fazer a seguinte operação:
L2 − 0, 003
5, 291L1 −→ L2.
Neste caso, a segunda linha fica dada por:
L2 = (0; 59, 143475713475716 · · · ; 59, 143475713475716 · · ·)T
Surpreendentemente, os valores com 15 casas decimais após a vírgula é exatamente o mesmo. Usando
três casas decimais após a vírgula para o arredondamento, aproximamos L2 por:
L2 = (0; 59, 1 43 · · · ; 59, 1 43 · · · )T
Então o sistema linear, com as aproximações, fica da forma:
5,291x1 − 6, 130x2 = 46, 78
59, 143x2 = 59, 143,
então, imediatamente, temos que x2 = 1. Substituindo na primeira equação, nos dá:
5, 291x1 − 6, 130(1) = 46, 78 −→ 5, 291x1 = 52, 91 −→ x1 = 10.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 17/101
2.2. MÉTODO DE GAUSS COM PIVOTEAMENTO PARCIAL 17
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1
−2000
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
x2
x1
1 2 3 4 5 6 7 8 9 10 11
−7
−6
−5
−4
−3
−2
−1
0
1
x1
x2
Figura 2.1: a)- Esquerda. A reta azul é obtida de (2.25), escrevendo-se x1 em função de x2. A reta ver-melha é obtida de (2.26), escrevendo-se também x1 em função de x 2. Note que há uma variação muitogrande na reta azul, a vermelha está, nesta escala, praticamente sobre o eixo x. b)- Direita. A reta azulé obtida de (2.25), escrevendo-se x2 em função de x1. A reta vermelha é obtida de (2.26), escrevendo-
se também x2 em função de x1. Nesta estratégia, as duas retas tem um crescimento praticamenteparecido e bem melhor comportado.
Note que a solução encontrada foi exata. Veja a Figura (2.1.b), no qual fazemos o desenho de cada umadas retas definidas por (2.25) e (2.26). A reta azul é obtida de (2.25), escrevendo-se x 2 em função dex1. A reta vermelha é obtida de (2.26), escrevendo-se também x2 em função de x1. Note que agorahouve um comportamento bem menos abrupto da solução, e as retas tem uma ordem de crescimento,praticamente igual.
Por que agora o método de Gauss funcionou? Funcionou pois foi aplicado o que chamamos dePivoteamento Parcial O Pivoteamento parcial é uma técnica muito simples. Basta em cada nível
de fatoração, sempre fazermos as permutações necessárias para tornarmos o pivô como sendo o maiorelemento, em módulo, de cada coluna.
Neste caso o algoritmo de Gauss ficará modificado para os seguintes passos:
Primeiro passo: Como no método de Gauss, inicialmente construímos a matriz aumentada do sis-tema (2.1), dada por (2.6).
Segundo passo: Inicialmente devemos zerar todos os elementos da primeira coluna que estão abaixoda primeira linha. Para isto vamos utilizar um pivô. Entretanto antes de zerar esses elementos,devemos escolher um pivô bem adequado. Para isto queremos o maior número (em módulo) possível.Então fazemos uma busca, na primeira coluna, do maior elemento em módulo. Se este maior elemento(em módulo) está na k -ésima linha (,ou seja, |a1 j| ≤ |a1k | para j = 1,2, · · · , n), trocamos a L1 com Lk ,mantendo as outras linhas originais sem mudar de lugar.
Após as devidas trocas de linhas, o sistema que temos é equivalente ao sistema original. Para fa-cilitar nossa notação renomeamos os elementos novamente como elementos da linha 1 como a1i parai = 1,2, · · · , n, elementos da linha 2 como a2i para i = 1,2, · · · , n e assim sucessivamente. Para pro-cedemos com a eliminação dos elementos a1i para i = 2,3, · · · , n (ou seja, os elementos da primeiracoluna abaixo da primeira linha). Para isto basta procedermos assim, para j = 2,3, · · · , n:
Li −→ L i −
a1i
a11
L1 , (2.32)
ou seja, trocamos a linha i pela linha i subtraída da linha 1 multiplicada por a1i/a11.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 18/101
18 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
Após este primeiro passo a matriz fica da forma:
A =
a11 a12 · · · a1n | b1
0 a(1)22 · · · a
(1)2n | b
(1)2
... . . .
· · ·...
0 a(1)n2 · · · a
(1)nn | b
(1)n
, (2.33)
no qual o sobrescrito (1) indica que o coeficiente não é o original e sim aquele trocado por aquelesomado, ou seja, os novos elementos são dados por
a(1)i j = a i j −
a1i
a11
a1 j.
Próximos passos: O processo é repetido. Note que após a primeira rodada de operações são introdu-zidos os zeros da primeira coluna. No segundo passo será necessário fazer operações para introduzir oszeros na segunda coluna abaixo da segunda linha. Entretanto antes de zerar esses elementos, devemosproceder como anteriormente e escolher um pivô bem adequado. Para isto queremos o maior número
(em módulo) possível. Então fazemos uma busca, na segunda coluna, do maior elemento em módulo.Se este maior elemento (em módulo) está na k -ésima linha (,ou seja, |a2 j| ≤ |a2k | para j = 2,3, · · · , n),trocamos a L2 com Lk , mantendo as outras linhas originais sem mudar de lugar.
Após as devidas trocas de linhas, o sistema que temos é equivalente ao sistema original. Parafacilitar nossa notação renomeamos os elementos novamente elementos da linha 2 como a2i para i =2,3, · · · , n, elementos da linha 3 como a3i para i = 2,3, · · · , n e assim sucessivamente. Note que aposição a1i = 0 para i = 2,3, · · · , n em todas as linhas.
Para procedemos com a eliminação dos elementos a2i para i = 3,4, · · · , n (ou seja, os elementosda segunda linha coluna abaixo da segunda linha). Para isto basta procedermos assim, para i =3,4, · · · , n:
Li
−→ L i
−a
(1)2i
a(1)22 L2 , (2.34)
o que nos dá uma matriz da forma (2.10). Esse passo é feito no máximo n − 1 vezes. Após a aplicaçãodesses para as n − 1 colunas (note que a última não precisará ser modificada), encontramos uma matrizaumentada que é da forma (2.11) que nos fornece o sistema da forma (2.12). Aqui não há diferençado processo do método de Gauss, pois o pivoteamento parcial foi utilizado apenas para tornar a matrizdos coeficientes uma matriz diagonal superior. A solução é obtida por retrossubstituição dada peladefinição 8.
2.2.1 Implementação do Método de Gauss com Pivoteamento
function x = GaussPP(A,b)
% Resolve o sistema linear Ax = b usando eliminação de Gauss com pivoteamento
% A é u ma m atriz n p or n
% b é o vetor do lado direito da forma b=(b1,b2,...,bn)^T
% x é o vetor a ser encontrado
n = size(A,1); %obtendo o tamanho da matriz A;
A = [A,b]; %Cria a matriz aumentada.
%Processo de eliminação inicia

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 19/101
2.2. MÉTODO DE GAUSS COM PIVOTEAMENTO PARCIAL 19
for i = 1:n-1
p = i ;
%Comparação para selecionar o pivo, observe que faz-se uma comparação
%entre os elementos que são maiores em valores absolutos.
for j = i+1:n
if abs(A(j,i)) > abs(A(i,i))U = A(i,:);
A(i,:) = A(j,:);
A(j,:) = U;
end
end
%verificando se os pivos não são nulos.
while A(p,i)== 0 & p <= n
p = p+1;
end
if p == n+1
disp(’Sem solução unica’); % neste caso o método para, pois não está adequado p
% matriz que não tenham solução unica.
break
else
i f p ~ = i
T = A(i,:);
A(i,:) = A(p,:);
A(p,:) = T;
end
end
for j = i+1:n
m = A(j,i)/A(i,i);
for k = i+1:n+1
A(j,k) = A(j,k) - m*A(i,k);
endend
end
%Checando se a ultima entrada é não zero. (isto serve para garantir que o método tenha
if A(n,n) == 0
disp(’Solucao nao unica’);
return
end
%Retro-substituicao
x(n) = A(n,n+1)/A(n,n);
for i = n - 1:-1:1sumax = 0;
for j = i+1:n
sumax = sumax + A(i,j)*x(j);
end
x(i) = (A(i,n+1) - sumax)/A(i,i);
end

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 20/101
20 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
2.3 Decomposição LU
Queremos fator a matriz A como um produto de duas outras matrizes na forma A = LU no qual L éuma matriz triangular inferior U é uma matriz triangular superior, ou seja,
a11 a12 · · · a1n
a21 a22 · · · a2n...
... . . .
...an1 an2 · · · ann
=
1 0 0 · · ·
0 0l21 1 0 · · · 0 0l31 l32 1 · · · 0 0...
... ... 1 · · · 0
... ... · · · . . .
...ln1 ln2 ln3 · · · 1
u11 u12 u13 · · · u1n−1 u1n0 u22 u23 · · · u2n−1 u2n
0 0 u33 · · · u3n−1 u3n
0 0 0 u44 · · · u4n
0 0 0 0 . . .
...0 0 0 · · · 0 unn
(2.35)
Observe que a vantagem de poder quebrar A = LU é que o sistema (2.3) poderá ser resolvido paraqualquer b diferente, sem que haja necessidades de se aplicar o método de Gauss toda vez. Então, pararesolver o sistema basta:
Ax = b,
−→LUx = b. (2.36)
Quebramos a solução em duas. Primeiro definimos y = U x e resolvemos, por substituição o sistema:
Ly = b, −→
1 0 0 · · · 0 0l21 1 0 · · · 0 0l31 l32 1 · · · 0 0...
... ... 1 · · · 0
... ... · · · . . .
...ln1 ln2 ln3 · · · 1
y1
y2
y3...
yn−1
yn
=
b1
b2
b3...
bn−1
bn
(2.37)
da seguinte forma:
y1 = b1,
y2 = b2 − y1l21 , (2.38)...
yn = bn − y1ln1 − y2ln2 − · · · − yn−1lnn−1.
Encontrado o vetor y, podemos encontrar o vetor x resolvendo o sistema por retrossubstituição
Ux = y, −→
u11 u12 u13 · · · u1n−1 u1n
0 u22 u23 · · · u2n−1 u2n
0 0 u33 · · · u3n−1 u3n
0 0 0 u44 · · · u4n
0 0 0 0 . . .
...
0 0 0 · · · 0 unn
x1
x2
x3...
xn−1
xn
=
y1
y2
y3...
yn−1
yn
(2.39)
da seguinte forma:
xn = yn
unn,
xn−1 = yn−1 − xnun−1n
un−1n−1,
... (2.40)
x1 = xn − xnu1n − xn−1u1n−1 − · · · − x2u12
u11.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 21/101
2.3. DECOMPOSIÇÃO LU 21
A decomposição da matriz segue os mesmos princípios da decomposição de Gauss. Isso ocorre, pois,é possível através de operações elementares (ou seja, operações sobre as linhas da matriz) transformar A numa matriz triangular superior através do método de Gauss. Cada operação elementar pode serexpressa através de uma matriz chamada de matriz de operações elementares o qual é denotadapor M(i). Por exemplo, para deixar a matriz A da forma (2.8) basta multiplicar a matriz A pela matriz
elementar M(1) como M(1) A = A(1), e obtemos a matriz A (1):
1 0 · · · 0− a21
a111 · · · 0
... · · · . . . ...
− an1a11
0 · · · 1
a11 a12 · · · a1n
a21 a22 · · · a2n...
. . . · · · ...an1 an2 · · · ann
, =
a11 a12 · · · a1n
0 a(1)22 · · · a
(1)2n
... . . . · · · ...
0 a(1)n2 · · · a
(1)nn
, (2.41)
Multiplicando a matriz A(1) pela matriz M(2) como M(2) A(1) = A(2) , temos:
1 0 · · · 0 00 1
· · · 0 0
0 − a(1)32
a(1)22
1 ... ...
... ... 0
. . . ...
0 − a(1)n2
a(1)22
· · · 0 1
a11 a12 · · · a1n0 a
(1)22 · · · a
(1)2n
... . . . · · · ...
0 a(1)n2 · · · a
(1)nn
, =
a11 a12 a13
· · · a1n
0 a(1)22 a(1)23 · · · a(1)2n
0 0 a(2)33 · · · a
(2)3n
... . . . · · · ...
0 0 a(2)n3 · · · a
(2)nn
, (2.42)
Note que a matriz M(i), para a i-esima operação, esta associada a i-esima coluna e tem a sempre aforma:
1 0 · · · 0 00 1 · · · 0 0... 0
. .. · · · 0 0
0 · · · − a(i−1)i+1i
a(i−1)ii
1...
...
... · · · ... 0 . . .
...
0 · · · − a(i−1)ni
a(i−1)ii
· · · 0 1
(2.43)
Através dessa análise, como devemos colocar zeros abaixo da primeira linha e primeira coluna, abaixoda segunda linha segunda coluna, abaixo da terceira linha e terceira coluna e assim, sucessivamente,teremos n − 1 matrizes (pois a última coluna não mexemos). Então para conseguirmos escrever amatriz A como uma matriz triangular superior U , basta multiplicar A pelas matriz M(i) e temos:
M(n−1) M(n−2) · · · M(1) A = U . (2.44)
Como sabemos que toda matriz de transformação elementar é invertível, podemos inverter o produto( M(n−1) M(n−2) · · · M(1))−1 = ( M(1))−1( M(2))−1 · · · ( M(n−1))−1, que é uma matriz triangular inferior,desta forma a matriz A pode ser escrita como:
A = ( M(1))−1( M(2))−1 · · · ( M(n−1))−1U , (2.45)
então a matriz definimos a matriz L = ( M(1))−1( M(2))−1 · · · ( M(n−1))−1. Note que é muito simples deencontrar a matriz inversa ( M(i))−1 para todo i, pois basta pegar a mesma matriz ( M(i)) e inverter o

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 22/101
22 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
sinal, ou seja, a inversa da matriz ( M(i)) dada por (2.43) é:
1 0 · · · 0 00 1 · · · 0 0... 0
. . . · · ·
0 0
0 · · · a(i−1)i+1i
a(i−1)ii
1 ... ...
... · · · ... 0 . . .
...
0 · · · a(i−1)ni
a(i−1)ii
· · · 0 1
(2.46)
Fazendo o produto ( M(1))−1( M(2))−1 · · · ( M(n−1))−1, então a matriz L é finalmente dada por:
1 0 · · · 0 0a21a11
1 · · · 0 0...
a(1)32
a
(1)
22
. . .
· · · 0 0
ai+11a11
· · · a(i−1)i+1i
a(i−1)ii
1...
...
... · · · ... . . .
...an1a11
· · · a(i−1)ni
a(i−1)ii
· · · a(n−2)nn−1
a(n−2)n−1n−1
1
(2.47)
E a matriz U é a matriz triangular superior obtida através da decomposição de Gauss. Acabamos de provar o seguinte teorema:
Teorema 1. Se uma matriz quadrada A pode ser colocada na forma triangular superior através dométodo de Gauss sem que haja necessidade de pivoteamento e nenhum elemento da diagonal principal
é nulo, então A pode ser decomposta na forma A = LU , no qual L é uma matriz triangular inferior com elementos todos iguais a 1 na diagonal principal e U é uma matriz triangular superior.
Exemplo 2. Vamos decompor a matriz C dada por (2.18) como um produto C = LU . Para fazer isto,basta notar que já fizemos a decomposição de Gauss. Então a matriz L será formada pelos números que
foram multiplicados pelas linhas com os sinais trocados. A primeira coluna da matriz L será formada pelos números que usados em (2.19) com o sinal trocado, ou seja, a primeira coluna será (1 , 2 , 3 , 2)T . Asegunda coluna da matriz L será formada pelos números usados em (2.21) com o sinal trocado, ou seja,(0,1,11/7, 5/7)T . A terceira coluna da matriz L será formada pelo número usado em (2.23) com o sinaltrocado, ou seja, (0 , 0 , 1 , 3 8/15)T . A matriz U será a matriz resultante da operação, ou seja:
L =
1 0 0 02 1 0 0
3 117
1 0
2 5
7
38
15 1
, U =
1 −3 4 20 7 −5 −5
0 0 −157
277
0 0 0 −46
5
(2.48)
Se quisermos resolver o sistema (2.17) utilizando esta técnica resolvemos inicialmente:
1 0 0 02 1 0 0
3 11
7 1 0
2 5
7
38
15 1
y1
y2
y3
y4
=
82
−37
(2.49)

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 23/101
2.3. DECOMPOSIÇÃO LU 23
que, através de (2.38) nos dá como solução:
y1 = 8,
y2 = 2 − 8 · 2 = −14,
y3 =
−3
−3
·8 + 14(11/7) =
−5,
y4 = 7 − 8 (2) + 14
5
7
+ 5
38
15 =
41
3 .
Agora devemos resolver U x = y , ou seja,
1 −3 4 20 7 −5 −5
0 0 −15
7
27
7
0 0 0 −46
5
x1
x2
x3
x4
=
8−14−5413
(2.50)
Resolvendo (2.50) por retrossubstituição temos:
− 46
5 x4 =
41
3 −→ x4 = −205
138, x3 =
5 + 2 7
7 x4
15
7
−→ x3 = − 47
138,
x2 = −14 + 5x3 + 5x4
7 −→ x2 = −76
23,
x1 = 8 + 3x2 − 4x3 − 2x4 −→ x1 = 167
69 .
2.3.1 Implementação do Método da Decomposição LU para matrizes
function [L,U]=LUfactor(A)
% Método de fatoração para uma matriz A
% de nxn.
% A é fatorada como A = L*U
% Saída
% L é uma matriz triangular inferior com os elementos da diagonal
% principal todos valendo 1.
% U é a matriz triangular superior obtida através do sistema.
[n,n]=size(A);
L=eye(n);
for k=1:n
if (A(k,k) == 0) Error(’Pivoteamento é necessário’); end
L(k+1:n,k)=A(k+1:n,k)/A(k,k);
for j=k+1:n
A(j,:)=A(j,:)-L(j,k) *A(k,:);
end
end
U=A;

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 24/101
24 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
2.4 Métodos iterativos: Ponto fixo, erros, norma de matriz e
outras coisas mais
Suponhamos que queiramos resolver a seguinte equação bastante simples:
10x = 10. (2.51)
Todo mundo sabe que a resposta para esta equação é x = 1, não há segredo. Entretanto, podemospropor um método numérico iterativo dado recursivamente através da seguinte manipulação:
Metodo 1.
9x + x = 10, definimos a iteração 9x(n+1) = 10 − x(n) ou x(n+1) = 10
9 − x(n)
9 . (2.52)
Para começar a iteração é necessário um chute inicial. Caso este chute seja bem dado a solução podeou não convergir rapidamente. Vamos, inicialmente fornecere como chute inicial x(0) = 0. Dessa forma,através da relação estabelecida acima (2.52) encontramos x(1) como:
x(1) = 10
9 − x(0)
9 , −→ x(1) =
10
9 . (2.53)
A distancia entre x(0) e x(1) é dada por:
|x(0) − x(1)| =
0 − 10
9
= 10
9 . (2.54)
Aplicando sucessivamente, temos, x(2) como:
x(2) = 10
9 − x(1)
9 , −→ x(2) =
10
9 − 10
92 =
80
92 . (2.55)
A distancia entre x(1) e x(2) é dada por:
|x(1) − x(2)| =
10
9 − 80
92
= 10
92 . (2.56)
Aplicando sucessivamente, temos, x(3) como:
x(3) = 10
9 − x(2)
9 , −→ x(3) =
10
9 − 80
93 =
730
93 . (2.57)
A distancia entre x(2) e x(3) é dada por:
|x(2) − x(3)| =80
92 − 730
93
= 1093
. (2.58)
Observe que podemos aplicar, sucessivamente este critério e teremos que x(n) tenderá a 1 quando n vai para o infinito pois a distância entre termos consecutivos xn−1 e x(n) satisfaz a seguinte lei:
|xn−1 − x(n)| = 10
9n . (2.59)
E a pergunta relevante é: Quando devemos parar a iteração? A iteração deve ser feita até você encontrar o número necessário com a precisão exigida. Por exemplo,
se vc quer obter a solução do problema acima tal que a distância entre dois termos consecutivos seja de

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 25/101
2.4. MÉTODOS ITERATIVOS: PONTO FIXO, ERROS, NORMA DE MATRIZ E OUTRAS COISAS MAIS 25
10−4 , perceba que na n-ésima iteração o erro entre termos consecutivos é dado por 10/9n. Portanto, parasaber até quando vc irá iteragir basta então encontrar n tal que |xn−1 − x(n)| < 10−4| , ou seja, :
10
9n < 10−4, −→ 105 < 9n −→ 5
log(9) < n. (2.60)
A última desigualdade foi obtida passando logaritmo e log(9) é o logaritmo de 9 na base 10 que éaproximadamente 0.9542. Então basta iterar 6 ≤ n , para atingir a precisão exigida.
Metodo 2. Vamos pensar no mesmo problema, só que mudando o método:
9x + x = 10, definimos a iteração x(n+1) = 10 − 9x(n). (2.61)
Vamos, inicialmente fornecer como chute inicial x(0) = 0. Dessa forma, através da relação estabelecidaacima (2.61) encontramos x(1) como:
x(1) = 10 − 9x(0), −→ x(1) = 10. (2.62)
A distancia entre x
(0) e x
(1) é dada por:
|x(0) − x(1)| = |0 − 10| = 10. (2.63)
Aplicando mais uma vez temos, x(2) como:
x(2) = 10 − 9x(1), −→ x(2) = 10 − 90 = −80. (2.64)
A distancia entre x(1) e x(2) é dada por:
|x(1) − x(2)| = |10 − (−80)| = 90. (2.65)
Aplicando sucessivamente, temos, x(3) como:
x(3) = 10 − 9(−80), −→ x(3) = 730. (2.66)
A distancia entre x(2) e x(3) é dada por:
|x(2) − x(3)| = |−80 − 730| = 810. (2.67)
Observe que podemos aplicar, sucessivamente este critério e teremos que x(n) nunca tenderá a 1 quando nvai para o infinito pois a distância entre termos consecutivos xn−1 e x(n) está cada vez mais aumentando.
E a pergunta relevante é: Por que o Método 1 funcionou e o Método 2 não funcionou ?
2.4.1 Método do Ponto fixo linear e erros
Tais métodos são casos particulares de problemas iterativos chamados de método do ponto fixo. Ométodo do ponto fixo está baseado numa metodologia bastante utilizada em cálculo numérico que édo cálculo recursivo. Imagine que tenhamos uma sequência de pontos x(n) para n = 1 ,2,3, · · · dadarecursivamente através da relação
x(n+1) = f (x(n)), (2.68)
no qual f : D ⊂ R −→ R é uma função qualquer (o argumento é válido se a função f : D ⊂ Rm −→ R(n)),observe que D é o domínio da função. Caso f seja uma contração uniforme, ou seja, para todo x , y ∈ Dexista uma constante 0 ≤ K < 1 tal que
| f (x) − f ( y)| < K |x − y|, (2.69)

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 26/101
26 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
é possível mostrar que (2.68) possui um ponto fixo, ou seja, existe um x∗ tal que satisfaça:
x∗ = f (x∗). (2.70)
Neste caso, dizemos que a sequência x(n) dada por (2.68) é convergente, ou seja,
x∗ = limn−→∞ x(n+1) = lim
n−→∞ f (x(n)) = f ( limn−→∞ x(n)) = f (x∗), (2.71)
Para o caso linear, consideremos uma função f (x(n)) = T x(n) + c, no qual T e c são números (mais tardefaremos a extensão para T sendo uma matriz).
Neste caso o nosso método iterativo torna-se:
x(n+1) = T x(n) + c, (2.72)
Aplicando x(n) de modo iterativo acima temos:
xn+1 = T x(n) + c = T (Txn−1 + c) + c = T (T (Txn−2 + c) + c) + c = · · ·x(n+1) = T n+1x(0) + T n+1c + T nc + T n−1c +
· · ·+ Tc + c
x(n+1) = T n+1x(0) + (T n+1 + T n + T n−1 + · · · + T + 1)c. (2.73)
Observe que (T n+1 + T n + T n−1 + · · · + T + 1) é uma soma de termos geométricos de razão T . A somados n+1 primeiro termos é dada pela fórmula:
n+1
∑i=0
T i = T n+1 + T n + T n−1 + · · · + T + 1 = 1 − T n+1
1 − T (2.74)
Então temos de (2.73) a seguinte identidade:
x(n+1) = T n+1x(0) + 1 − T n+1
1
−T
c. (2.75)
Note que so podemos tomar n −→∞ se |T | < 1. Caso 1 ≤ |T | a série não converge. Tomando limitede n −→∞ em (2.74) temos que limn−→∞ T n+1 = 0 e:
∞
∑i=0
T i = 1
1 − T . (2.76)
Então se |T | < 1 e tomando limite n −→∞, temos que o método converge e vale:
limn−→∞ x(n+1) = x∗ = lim
n−→∞ T n+1x(0) + limn−→∞
n
∑i=0
T ic = 1
1 − T c, −→ x∗(1 − T ) = c −→ x∗ = T x∗ + c,
(2.77)
ou seja, x∗ é um ponto fixo do método iterativo (2.72). Acabamos de provar o seguinte teorema:
Teorema 2. Dado um sistema iterativo da forma (2.72) ele convergirá para um ponto fixo x∗ , i.e.,x∗ = T x∗ + c somente se |T | < 1. Caso |T | > 1 então o método divergirá.
O teorema 2) explica porque o Método 1 converge e o Método 2 diverge. Note que no Método 1T = −1/9 e no Método 2 T = −9.
Definição 11. O método iterativo deverá ser realizado até uma tolerância ou erro máximo sejamatingidos. Por tolerância, entendemos, o máximo erro admitido para encontrar-se a raiz. E denotamostal tolerância como tol. Note que tol > 0.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 27/101
2.4. MÉTODOS ITERATIVOS: PONTO FIXO, ERROS, NORMA DE MATRIZ E OUTRAS COISAS MAIS 27
Definição 12. Definimos como erro absoluto o valor numérico para o qual a solução encontrada difereda solução exata. Note que se x∗ é a solução exata então o erro, denotado por Er
(n)abs na i-ésima iteração é
definido como:
Er(i)abs = ||x∗ − x(i)||. (2.78)
Entretanto, é muito mais útil trabalhar com o erro relativo. Se ||x∗|| > 0 , então
Er(i)rel =
||x∗ − x(i)||||x∗|| , (2.79)
pois, se por exemplo, x∗ for muito grande e o valor de tol > 0 muito pequeno, o valor demorará muito aser obtido. Vamos considerar um caso ilustrativo.
Suponha, para um problema, que a solução correta seja x∗ = 10000000 , e coloquemos como tolerân-cia tol = 0,01 , então o método irá parar apenas quando x(i) estiver dentro do intervalo (9999999, 99; 10000000, 01).
Entretanto, para métodos aproximativos isso poderá ser muito demorado. uma Uma solução do tipo100000001 já é uma excelente aproximação, o erro relativo, será em torno de 10 ( − 7).
O erro relativo também funciona bem se x∗ é bem pequeno. Imagine se a solução correta x∗ é (0,0001) ,
e colocamos uma tolerância de 0,01 , então a solução a ser atingida é menor do que o próprio erro.Como, muitas vezes, não temos controle sobre este fato, sempre preferimos utilizar o erro relativo.
Através do método acima podemos provar o seguinte teorema:
Teorema 3. O método iterativo Eq. (2.77) , fornece uma sequência de pontos x(i) tal que dois valoresconsecutivos da sequência tem a distância dada por |x(i+1) − x(i)| = |T |n(|1 − T ||x(0)| + |c|) (Eq. (2.80)
abaixo). Se x(0) = 0 , então a distância reduz-se a |x(i+1) − x(i)| = |T |n(|1 − T ||x(0)| + |c|). Além disso
|x(i) − x∗| = |T n|x(0) +
c
1 − T
e se x(0) = 0 , então |x∗ − x(i)| =
cT n
1 − T
.Prova: Note pelo método iterativo de (2.77)
x(i+1) − x(i) = T n+1x(0) + 1 − T n+1
1 − T c − (T nx(0) + 1 − T n
1 − T c) = (T n+1 − T n)x(0) + T n − T n+1
1 − T c
x(i+1) − x(i) = T n
(T − 1)x(0) + 1 − T
1 − T c
= T n
(T − 1)x(0) + c
|x(i+1) − x(i)| = |T |n(|(1 − T )x(0) + c|). (2.80)
Note de (2.80) que se o chute inicial x(0) for 0, então temos que |x(i+1) − x(i)| = |T |n|c|. Agora o erro, dado por |x(i) − x∗| satisfaz:
|x∗ − x(i)| =
1
1 − T − (T nx(0) +
1 − T n
1 − T c)
= |T n|x(0) +
c
1 − T
. (2.81)
Note que se x (0) = 0, então o erro é dado por |x∗ − x(i)| =
cT n
1 − T
.
Definição 13. O número de iterações para se atingir a precisão desejada, é entendido como o númerode vezes que devemos fazer os cálculos tal que o erro, seja menor do que uma determinada tolerância,tol , ou seja,
Eriabs =
||x∗ − x(i)||||x∗|| < tol
Dessa forma qualquer x ∈ (x∗ − tol ||x∗||, x∗ + tol ||x∗||) é admitido como solução do problema.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 28/101
28 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
Observação 2. Todo algoritmo iterativo deve ser colocado um número máximo de iterações para o qualo método pode ser executado. Isso é necessário, pois, caso o método não convirja os cálculos poderão ser
feitos sem parar (por exemplo,se T > 1 ) e o método nunca irá atingir nenhum valor. Dessa forma defi-nimos Número máximo de iterações como sendo o maior número de iterações admitido no processoiterativo. Muitas vezes, caso esse número seja atingido o método não converge. Caso haja confiança no
método, basta aumentar esse número de iterações. Para métodos não convergentes, o número máximode iterações sempre será atingido para uma tolerância dada.
Observação 3. Então note pelo Teorema 3 que a diferença entre x∗ , x(i) , que é o erro, tem como valor
numérico |x(i) − x∗| = |T n|x(0) +
c
1 − T
e que a distância entre dois termos consecutivos x(i) e x (i+1) é
|x(i+1) − x(i)| = |T |n(|1 − T ||x(0)| + |c|) , ou seja, tais diferenças são bastante similares. Entretanto, do ponto de vista computacional é muito mais fácil quantificar a distância entre dois pontos consecutivos. Então como vamos admitir que uma raiz satisfaz uma tolerância exigida tol sempre que tivermos doistermos consecutivos distando no máximo de tol||x(i+1)|| (erro relativo) um do outros, ou seja, se tivermosi tal que
||x(i+1) − x(i)||
||x
(i+1)
||< tol , (2.82)
então dizemos que atingimos a tolerância exigida. Note que xi+1 é diferente de zero, pois a única possibilidade desse termo ser zero é caso c também fosse zero, aí a única solução seria a trivial.
2.4.2 Norma de Vetores e Matrizes
Tal ideia pode ser extendida para o caso de matrizes. Entretanto, será necessário generalizar a noçãode módulo de um número. Como uma matriz pode ser entendida como um vetor de vetores, então, anoção natural de distância que surge para matriz é a noção de norma. Por exemplo, se tivermos umvetor da forma x = (x1, x2, · · · , xn a norma euclidiana do vetor x, denotada como ||x||2 é dada porque
||x
||2 =
n
∑i=1
x2
i
= x2
1
+ x2
2
+· · ·
+ x2n. (2.83)
Existem outras normas que podem ser consideradas no caso de vetores. Temos uma norma que échamada de norma 1, e é denotada como ||x||1, dada por:
||x||1 =n
∑i=1
|xi| = |x1| + |x2| + · · · + |xn|. (2.84)
E uma norma que é chamada de norma infinito (ou norma do máximo), denotada como ||x||∞, dadapor:
||x||∞ = max1≤i≤n
|xi|. (2.85)
Todas essas normas são equivalentes e igualmente importante e possuem suas respectivas aplicações.Na verdade, a norma é uma estrutura matemática bastante rica e uma descrição mais detalhada dissoé encontrada em
Exemplo 3. Seja x = (5,2,3, −3,5, −8,7, −4). Vamos calcular ||x||2 , ||x||1 e ||x||∞. Pela definição dasnormas acima temos:
||x||2 =
(5)2 + (2)2 + (3)2 + (−3)2 + (5)2 + (−8)2 + (7)2 + (−4)2 =√
201. (2.86)
||x||1 = |5| + |2| + |3| + | − 3| + |5| + | − 8| + |7| + | − 4| = 37. (2.87)
||x||∞ = max1≤i≤8
(|5|, |2|, |3|, | − 3|, |5|, | − 8|, |7|, | − 4|) = 8. (2.88)

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 29/101
2.4. MÉTODOS ITERATIVOS: PONTO FIXO, ERROS, NORMA DE MATRIZ E OUTRAS COISAS MAIS 29
Para o nosso caso, precisamos definir apenas uma norma adequada para uma matriz A quadrada.Sem muito aprofundamento nesse conceito, é possível mostrar que para uma matriz A da forma (2.4),como m = n, uma norma é dada como sendo o máximo valor da soma do modo dos elementos de umalinha, ou seja,
|| A
||∞ = max
1≤i≤n
n
∑ j=1 |
ai j|
(2.89)
Note que para encontar o máximo valor, somamos o módulo dos elementos de cada linha e pegamos omaior valor dessa soma.
Exemplo 4. Seja a matriz A
A =
1 −3 4 22 1 3 −13 2 2 22 −1 −1 1
,
soma modulo linha 1 |1| + | − 3| + |4| + |2| = 10,soma modulo linha 2 |2| + |1| + |3| + | − 1| = 7,
soma modulo linha 3 |3| + |2| + |2| + |2| = 9,soma modulo linha 4 |2| + | − 1| + | − 1| + |1| = 5.
(2.90)
Portanto, || A||∞ = 10 , pois a maior das somas é a da linha 1, que é 10.
Abaixo, utilizaremos as técnicas acima para apresentação dos métodos iterativos de Jacobi e Gauss-Seidel. Para tanto vamos admitir que a matriz seja diagonalmente dominante.
Definição 14. Uma matriz A da forma (2.4) é diagonalmente dominante se para cada linha, o elementoda diagonal é maior do que a soma dos módulos de todos os outros elementos da respectiva linha, ouseja, para a i-ésima linha o elemento da diagonal é dado por a ii , então
|aii | >n
∑ j=1, j=i
|ai j|. (2.91)
Exemplo 5. A matriz A
A = 15 −3 6 22 10 3
−1
3 2 −11 22 −1 −1 −15
(2.92)
é diagonalmente dominante, pois:
1. Em L1 o elemento da diagonal é 15 e |15| > | − 3| + |6| + |2|. 2. Em L2 o elemento da diagonal é 10 e |10| > |2| + |3| + | − 1|. 3. Em L3 o elemento da diagonal é −11 e | − 11| > |3| + |2| + |2|. 4. Em L4 o elemento da diagonal é −15 e | − 15| > |2| + | − 1| + | − 1|.
Observação 4. É possível provar, veja [1] que uma matriz diagonalmente dominante é invertível. Então se o sistema linear da forma (2.1) tiver A como uma matriz quadrada diagonalmente dominante
o sistema tem solução única.Observação 5. Os métodos iterativos são, em geral, bastante demorados para convergirem. A veloci-dade de convergência está associada ao valor absoluto de T . Se ||T || << 1 , então os métodos convergembem rapidamente, por outro lado se ||T || é um valor menor do que 1 , mas bem próxima a 1 o métodoconverge lentamente.
Por outro lado, os métodos iterativos são bastante úteis para a resolução de matrizes esparsas
Definição 15. Uma matriz A é dita esparsa se somente poucos dos seus elementos forem diferente de zero. Numa matriz esparsa a maioria dos elementos é zero.
e também são úteis para sistemas lineares que não são quadrados, para a aproximação de soluções.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 30/101
30 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
2.5 Método de Jacobi
Este é um método iterativo, baseado na metodologia do ponto fixo descrito acima. Então, qualquer queseja o algoritmo iterativo proposto, temos que ter garantia de que o método numérico convirja.
Para tanto, podemos mostrar, que se a matriz for diagonalmente dominante então o método de
Jacobi, que será definido a seguir, é convergente.Seja o sistema a ser resolvido:
a11 x1 + a12 x2 + · · · + a1nxn = b1,
a21 x1 + a22 x2 + · · · + a2nxn = b2,
... ... · · · ... =
..., (2.93)
an1x1 + an2x2 + · · · ann xn = bn,
(2.94)
Então propomos como método iterativo o seguinte método, para i = 1,2, · · · :
x(i+1)1 =
b1 − a12 x(i)2 − a13 x
(i)3 − · · · − a1nx
(i)n
a11,
x(i+1)2 =
b2 − a21 x(i)1 − a23 x
(i)3 − · · · − a2nx
(i)n
a22,
... =..., (2.95)
x(i+1)n =
bn − an1x(i)1 − an2x
(i)2 − · · · − ann−1x
(i)n
ann,
(2.96)
Note que o método dado por (2.95) é da forma (2.72), com T igual a matriz e c o vetor :
T =
0 − a12
a11· · · − a1n
a11
− a21
a220 · · · − a2n
a22...
. . . · · · ...
− an1
ann− an2
ann· · · 0
e c =
b1
a11b2
a22...
bn
ann
. (2.97)
Note que a matriz dos coeficientes do sistema (2.93) pode ser escrita como (2.4) com m = n. Notetambém que é possível decompor a matriz A em três diferentes matriz L que é uma matriz diagonal
inferior com elementos da diagonal todos nulos D que é uma matriz diagonal e U que é uma matriztriangular superior com todos os elementos da diagonal nulos:
L =
0 0 · · · 0a21 0 · · · 0
... . . . · · · ...
an1 an2 · · · 0
, D =
a11 0 · · · 00 a22 · · · 0...
. . . · · · ...0 0 · · · ann
, U =
0 a12 · · · a1n
0 0 · · · a2n...
. . . · · · ...0 0 · · · 0
(2.98)
Observe que a matriz A dos coeficientes pode ser decomposta em A = L + D + U . Por que isso érelevante? Pois podemos escrever a matriz T e o vetor c, em função de tais matrizes. Note que paraobtermos a matriz T usamos apenas os elementos acima e abaixo da diagonal da matriz A, divididos

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 31/101
2.5. MÉTODO DE JACOBI 31
pelos respectivos elementos da diagonal, todos com sinal negativo, ou seja,
T = −D−1(L + U ) e c = D−1b no qual D−1 =
1a11
0 · · · 0
0 1a22
· · · 0...
. .. · · ·
..
.0 0 · · · 1ann
. (2.99)
Admitindo que a matriz A seja diagonalmente dominante podemos provar o seguinte teorema.
Teorema 4. Seja um sistema linear da forma (2.1) com A uma matriz quadrada, diagonalmentedominante. Então o método iterativo de Jacobi pode ser escrito como x(i+1) = T x(i) + c será convergente
e o erro absoluto pode ser medido como:
||x(i+1) − x(i)||2. (2.100)
Observação 6. Pelo teorema acima, o método deverá ser iterado até que se atinja a tolerância, tol , exigida, ou seja, devemos iterar até que o erro absoluto satisfaça, para algum i
||x(i+1) − x(i)||2
||x(i+1)||2
< tol . (2.101)
Prova do Teorema 4. Para fazer a prova deste fato, basta apenas mostrar que a matriz T , satisfaz||T ||∞ < 1, pois aí podemos usar o Teorema 2 e concluir que o esquema da forma x(i+1) = T x(i) + c, sejaconvergente.
Então vamos provar ||T ||∞ < 1. Usando a definição da norma da matriz (2.89), então ||T ||∞ é dadapor:
||T ||∞ = max1≤l≤n
n
∑ j=1
|al j|. (2.102)
Admita que o valor máximo acima é atingido para uma linha k qualquer, então ||T ||∞ satisfaz:
||T ||∞ =
ak 1
akk
+
ak 2
akk
+ · · · +
akk −1
akk
+
akk +1
akk
+ · · · akn
akk
. (2.103)
Note que como A é diagonalmente dominante, para toda linha o módulo do elemento da diagonal émaior que o módulo da soma dos outros elementos da matriz da mesma linha, em particular, para alinha k tenhos:
|akk | > |ak 1| + |ak 2| + · · · + |akk −1| + |akk +1| + · · · |akn | . (2.104)
Dividindo ambos os lados de (2.104) por |akk |, (que é positivo pois a matriz é diagonalmente dominante),temos, após ajeitar os termos, que
ak 1akk
+ ak 2
akk
+ · · · + akk −1
akk
+ akk +1
akk
+ · · · aknakk
< 1. (2.105)
Portanto, comparando (2.103) e (2.105), chegamos a conclusão que ||T ||∞ < 1, e portanto o método éconvergente.
Exemplo 6. Aplique o método de Jacobi para resolver o sistema linear:
20x1 − 3x2 + 4x3 = 8
x1 − 30x2 + 3x3 = 2
3x1 + 2x2 + 20x3 = −3,

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 32/101
32 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
com erro máximo igual a 0.01. Note que podemos usar o erro dado pela distância entre dois termos
consecutivos, então devemos iterar até que ||x(1) − x(0)||2
||x(1)||2
< 0,01 seja atingido. A solução do sistema
linear corresponde a intersecção dos três planos definidos por cada uma das equações, veja Figura 2.2.
Note que a matriz dos coeficientes A é diagonalmente dominante, então o método iterativo de Jacobi
pode ser escrito como:
x(i+1)1 =
8 + 3x(i)2 − 4x
(i)3
20
x(i+1)2 =
−2 + x(i)1 + 3x
(i)3
30
x(i+1)3 =
−3 − 3x(i)1 − 2x
(i)2
20 .
A solução exata desse problema pode ser provada ser, com 4 casas decimais de precisão, (0, 4305; −0, 0730; −0, 2073).
Nos cálculos que se seguem, usarei arredondamento apenas na iteração em que atingir a precisão exigida, entretanto, o aluno já pode proceder com arredondamentos com 4 casas decimais desde o iníciodo cálculo.
Para iniciar a iteração precisamos de um chute inicial. Vamos começar com a iteração tomandox(0) = (0 , 0 , 0). Dessa forma podemos achar x(1) como:
x(1)1 =
8 + 3x(0)2 − 4x
(0)3
20 =
4
5
x(1)2 =
−2 + x(0)1 + 3x
(0)3
30 = − 1
10
x
(1)
3 = −3
−3x
(0)1
−2x
(0)2
20 = − 3
20 .
Note que ||x(1) − x(0)||2
||x(1)||2
é
||x(1) − x(0)||2
||x(1)||2
=
45 − 0
2+− 1
10 − 02
+− 3
20 − 02
45
2+− 1
10
2+− 3
20
2= 1.
Como a precisão exigida não foi atingida, ou seja, ||x(1)
−x(0)
||2
||x(1)||2> 0,01 , continuamos o processo. Para
encontrar x(2) usamos x(1) obtido anteriormente no esquema de Jacobi e obtemos:
x(2)1 =
8 + 3x(1)2 − 4x
(1)3
20 =
89
200
x(2)2 =
−2 + x(1)1 + 3x
(1)3
30 = − 11
200
x(2)3 =
−3 − 3x(1)1 − 2x
(1)2
20 = − 7
25.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 33/101

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 34/101
34 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
encontrar x(5) usamos x(4) obtido anteriormente no esquema de Jacobi e obtemos:
x(5)1 =
8 + 3x(4)2 − 4x
(4)3
20 =
517087
1200000
x(5)2 = −2 + x
(4)
1 + 3x
(4)
330 = − 175781
2400000
x(5)3 =
−3 − 3x(4)1 − 2x
(4)2
20 = − 497411
2400000.
Note que ||x(5) − x(4)||2
||x(5)||2
é
517087
1200000 − 1721140000
2+− 175781
2400000 + 109315000
2+− 497411
2400000 + 50203240000
2
5170871200000
2+
− 175781
24000002
+
− 497411
24000002
=
√ 301718
√ 16639907718
16639907718 ∼ 0, 0042.
Agora a precisão foi atingida, pois o erro relativo na quinta iteração é ||x(5) − x(4)||2
||x(5)||2
∼ 0,0042 < 0,01.
Portanto a solução será, com 4 casas de aproximação (0, 4309, −0, 0732, −0.207). Do erro estabelecido,sabemos que podemos ter confiança na solução apenas até a terceira casa decimal, ou seja, a solução aser dada será (0,431; −0,073; −0,207).
2
x−0.20.2 0.0 −0.4
−4
y0.4
0
4−2
0.40.0
0.2
Figura 2.2: a)- Esquerda. Intersecção de cada uma das equações lineares do sistema acima. b)- Di-reita.Zoom próximo a solução.
2.5.1 Implementação do Método de Jacobi
function jacobi(A, b, N)
%
% O método de Jacobi(A, b, N) resolve um sistema linear iterativo
%A é matriz dos coeficientes, e b é o vetor coluna.
%N é o número máximo de iterações.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 35/101
2.5. MÉTODO DE JACOBI 35
%O método implementado é o Jacobi iterativo.
% O vetor inicial é um vetor nulo, mas pode ser ajustado até um de acordo
% com a necessidades.
% A forma iterativa é baseado na matriz de transição de Jacobi.
% Tj = (D)^(-1)*(L+U) e o vetor constante cj=D^(-1)*b.
% A saída é o vetor solucao x.
n = size(A,1);
% Separando a matriz A em três matrizes L, U e D
% A=L+D+U, no qual L é uma matriz triangular inferior, D é a matriz
% diagonal e U é a matriz triangular superior
D = diag(diag(A));
L = tril(-A,-1);
U = triu(-A,1);
% matriz de transicao e vetor constante usado para iteracoes
Tj = inv(D)*(L+U);
cj = inv(D)*b;
tol = 1e-05; % Tolerancia de 10^(-5)
k = 1 ;
x = zeros(n,1); %vetor inicial
while k <= N
x(:,k+1) = Tj*x(:,k) + cj;
if (norm(x(:,k+1)-x(:,k))/(norm(x(:,k+1)))) < tol
disp(’O procedimento foi um sucesso’)
disp(’Condicao ||x^(k+1) - x^(k)|| < tol foi encontrada após k iterações’)
disp(k); disp(’x = ’);disp(x(:,k+1));k=k+1;
break
end
k = k+1;
end
if (norm(x(:,k)-x(:,k-1))/(norm(x(:,k)))) > tol || k > N
disp(’Numero maximo de iteracoes foi atingido sem satisfazer a condicao:’)
disp(’||x^(k+1) - x^(k)|| < tol’); disp(tol);
disp(’Por favor, examine um sistema de iterações’)
disp(’No caso em que você possa observar que a matriz é convergente, aumente o numer
disp(’No caso de divergencia, a matriz pode não ser diagonalmente dominante’)disp(x’);
end

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 36/101
36 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
2.6 Método de Gauss-Seidel
Uma pergunta imediata é: Será que não podemos melhorar o método? Observe que, do método deJacobi, sempre esperamos que x(i+1) esteja mais próxima da solução do sistema linear x∗ do que x(i).Observe, de (2.95), também, que supondo que conheçamos x(i), vamos calcular x
(i+1)1 . Observe de (2.95)
que precisamos saber x (i) j para j = 2,3, · · · , n. Para calcular x (i+1)
2 , do método de Jacobi precisamos de
x(i)1 , x
(i)3 , · · · x
(i)n , entretanto, já conhecemos x
(i+1)1 , será que não seria mais vantajoso trocarmos x
(i)1 por
x(i+1)1 ?
O mesmo se sucede para o cálculo de x(i+1)3 , do método de Jacobi precisamos de x
(i)1 , x
(i)2 , x
(i)4 , · · · x
(i)n ,
entretanto, já conhecemos x(i+1)1 e x
(i+1)2 , será que não seria mais vantajoso trocarmos x
(i)1 por x
(i+1)1 e
x(i)2 por x
(i+1)2 ?
Este é justamente o método de Gauss-Seidel. Tal método consiste-se em perceber que para o cál-culo do elemento x
(i+1)k , todos os elementos x
(i+1)l , para l = 1,2, · · · , k − 1 são conhecidos e podem ser
substituidos no algoritmo de Jacobi (2.95), dando-nos o seguinte algoritmo:
x(i+1)1 = b1 − a12 x
(i)2 − a13 x
(i)3 − a14 x
(i)4 − · · · − a1nx
(i)n
a11,
x(i+1)2 =
b2 − a21 x(i+1)1 − a23 x
(i)3 − a24x
(i)4 − · · · − a2nx
(i)n
a22,
x(i+1)3 =
b2 − a31 x(i+1)1 − a32 x
(i+1)2 − a34 x
(i)4 − · · · − a2nx
(i)n
a22, (2.106)
... =...,
x(i+1)n =
bn − an1x(i+1)1 − an2x
(i+1)2 − an3x
(i+1)3 − · · · − ann−1x
(i+1)n
ann,
Tal método pode ser escrito como, na forma matricial, usando as matrizes L, D e U definidas em (2.98)como:
Dx(i+1) = b − Lx(i+1) − Ux (i) −→ (D + L)x(i+1) = b − Ux(i) −→ x(i+1) = (D + L)−1(b − Ux(i)), (2.107)
Então T = −(D + L)−1U e c = (D + L)−1b. É possível mostrar que se A é diagonalmente dominante,então, ||T ||∞ < 1, no entanto, é bem mais trabalhoso, veja as referências do texto.
O critério de erro a ser usado será exatamente o critério dado em (2.101). Vamos resolver o mesmo sistema dado no Exemplo 6.
Exemplo 7. O método iterativo de Gauss-Seidel pode ser escrito como:
x(i+1)
1
= 8 + 3x
(i)2 − 4x
(i)3
20
x(i+1)2 =
−2 + x(i+1)1 + 3x
(i)3
30
x(i+1)3 =
−3 − 3x(i+1)1 − 2x
(i+1)2
20 .
A solução exata desse com 4 casas decimais de precisão, (0, 4305; −0, 0730; −0, 2073). Vamos resolver,como no exemplo 6 , com precisão de 0.01.
Nos cálculos que se seguem, usarei arredondamento apenas na iteração em que atingir a precisão exigida, entretanto, o aluno já pode proceder com arredondamentos com 4 casas decimais desde o iníciodo cálculo.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 37/101
2.6. MÉTODO DE GAUSS-SEIDEL 37
Para iniciar a iteração precisamos de um chute inicial. Vamos começar com a iteração tomandox(0) = (0 , 0 , 0). Dessa forma podemos achar x(1) como:
x(1)1 =
8 + 3x(0)2 − 4x
(0)3
20 =
2
5
x(1)2 =
−2 + x(1)1 + 3x
(0)3
30 = − 4
75
x(1)3 =
−3 − 3x(1)1 − 2x
(1)2
20 = − 307
1500.
Note que ||x(1) − x(0)||2
||x(1)||2
é
||x(1) − x(0)||2
||x(1)
||2
=
25 − 0
2+− 4
75 − 02
+− 307
1500 − 02
252
+− 475
2
+− 3071500
2= 1.
Como a precisão exigida não foi atingida, ou seja, ||x(1) − x(0)||2
||x(1)||2
> 0,01 , continuamos o processo. Para
encontrar x(2) usamos x(1) obtido anteriormente no esquema de Gauss-Seidel e obtemos:
x(2)1 =
8 + 3x(1)2 − 4x
(1)3
20 =
3247
7500
x(2)2 =
−2 + x(1)1 + 3x
(2)3
30 = − 8179
112500
x(2)3 = −3 − 3x
(2)1 − 2x
(2)2
20 = − 467257
2250000.
Note que ||x(2) − x(1)||2
||x(2)||2
é
||x(2) − x(1)||2
||x(2)||2
=
32477500 − 2
5
2+− 8179
112500 + 475
2+− 467257
2250000 + 3071500
2
32477500
2+− 8179
112500
2+− 467257
2250000
2=
√ 7435683449
√ 1193958330449
1193958330449 ∼ 0, 078
Como a precisão exigida não foi atingida, ou seja, ||x
(2)
− x
(1)
||2||x(2)||2> 0,01 , continuamos o processo. Para
encontrar x(3) usamos x(2) obtido anteriormente no esquema de Gauss-Seidel e obtemos:
x(3)1 =
8 + 3x(2)2 − 4x
(2)3
20 =
1211143
2812500
x(3)2 =
−2 + x(3)1 + 3x
(2)3
30 = − 24664283
337500000
x(3)3 =
−3 − 3x(3)1 − 2x
(3)2
20 = − 699591457
3375000000.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 38/101
38 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
O erro nesse passo, medido por ||x(3) − x(2)||2
||x(3)||2
é
=
12111432812500 − 3247
75002
+ − 24664283337500000 + 8179
1125002
+ − 6995914573375000000 + 467257
22500002
12111432812500
2
+− 24664283
337500000
2
+− 699591457
3375000000
2 =
11√
527257438469√
num
num ∼ 0, 0049,
onde num = 2662549899984351749. Agora a precisão foi atingida, pois o erro relativo na quinta iteração
é ||x(3) − x(2)||2
||x(3)||2
∼ 0,0049 < 0,01. Portanto a solução será, com 4 casas de aproximação (0, 4306, −0, 0730, −0.2072).
Do erro estabelecido, sabemos que podemos ter confiança na solução apenas até a terceira casa decimal,ou seja, a solução a ser dada será (0, 431; −0, 073; −0,207).
Observação 7. Em todos os calculos acima, poderíamos ter calculado o erro usando a norma ||x||∞ ,ou seja,
||x(i+1) − x(i)||∞||x(i+1)||∞
=max j∈[1,2,3](|x(i+1)
j − x(i) j |
max j∈[1,2,3](|x(i+1) j |. (2.108)
A utilização dessa norma diminui bastante os cálculos, pois, por exemplo se tivéssemos
(x(2)1 , x
(2)2 , x
(2)3 ) =
3247
7500, − 8179
112500, − 467257
2250000
.
e
(x(3)1 , x
(3)2 , x
(3)3 ) =
1211143
2812500, − 24664283
337500000, − 699591457
3375000000
.
Então ||x(i+1) − x(i)||∞
||x(i+1)
||∞ é dada por:
max 1211143
2812500 − 32477500
,− 24664283
337500000 + 8179112500
,− 699591457
3375000000 + 4672572250000
max
12111432812500
,− 24664283
337500000
,− 699591457
3375000000
=
12111432812500 − 3247
7500
12111432812500
= 0,0053
Refaça a solução do sistema acima usando o método de Jacobi e Gauss-Seidel com a norma ||x||∞acima.
2.6.1 Implementação do Método de Gauss-Seidel
function GaussSeidel(A, b, N)
%
% O metodo de GaussSeidel(A, b, N) resolve um sistema linear iterativo
% A = matriz dos coeficientes, e b é o vetor coluna.
% N = o número máximo de iteracoes.
% O método implementado é o Gauss Seidel iterativo.
% O vetor inicial é um vetor nulo, mas pode ser ajustado de acordo
% com a necessidades.
% A forma iterativa é baseado na matriz de transicao de Gauss.
% Tj = (D)^(-1)*(L+U) e o vetor constante cj=D^(-1)*b.
% no qual

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 39/101
2.6. MÉTODO DE GAUSS-SEIDEL 39
% L= matriz triangular inferior obtida atraves de A (diagonal zero).
% U= matriz triangular superior obtida atraves de A (diagonal zero).
% D= matriz diagonal
% A matriz A=L+D+U.
% A de saída é o vetor solucao x.
n = size(A,1);
% Separando a matriz A em tres matrizes L, U e D
% A=L+D+U, no qual L e uma matriz triangular inferior, D e a matriz
% diagonal e U e a matriz triangular superior
D = diag(diag(A));
L = tril(A,-1);
U = triu(A,1);
% matriz de transicao e vetor constante usado para iteracoes
Tmej = -inv(D)*
(L);
Tmaj = -inv(D)*U;
cj = inv(D)*b;
Tj=Tmej+Tmaj;
tol = 1e-05; % Tolerancia de 10^(-5)
k = 1 ;
x = zeros(n,1); %vetor inicial
while k <= N
auxiliar=x(:,k);
x(:,k+1) = Tj*x(:,k) + cj;
for st=1:n
x(st,k+1) =( Tmej(st,:)*x(:,k+1)+ Tmaj(st,:)*x(:,k)) + cj(st);auxiliar(st)=x(st,k+1);
end
if ((norm(x(:,k+1)-x(:,k)))/(norm(x(:,k+1)))) < tol
disp(’O procedimento foi um sucesso’)
disp(’Condicao ||x^(k+1) - x^(k)|| < tol foi encontrada apos k iteracoes’)
disp(k); disp(’x = ’);disp(x(:,k+1));
k=k+1;
break
end
k = k+1;
end
if ((norm(x(:,k)-x(:,k-1)))/(norm(x(:,k)))) > tol || k > N
disp(’Numero maximo de iteracoes foi atingido sem satisfazer a condicao:’)
disp(’||x^(k+1) - x^(k)|| < tol’); disp(tol);
disp(’Por favor, examine um sistema de iterações’)
disp(’No caso em que voce possa observar que a matriz é convergente, aumente o numer
disp(’No caso de divergencia, a matriz pode nao ser diagonalmente dominante’)
disp(x’);
end

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 40/101
40 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
2.7 Exercícios
Exercício 1 Em cada um dos problemas abaixo utilize eliminação de Gauss com substituição retroa-tiva e (caso necessário) operações com arredondamento de 2 dígitos (ou seja, duas casas após a vírgula)
4x1 − x2 + x3 = 8, 4x1 + x2 + 2x3 = 9,2x1 + 5x2 + 2x3 = 3, 2x1 + 4x2 − x3 = −5,
x1 + 2x2 + 4x3 = 11, x1 + x2 − 3x3 = −9,
Exercício 2 Utilize o Algoritmo da eliminação de Gauss para resolver os sistemas lineares a seguir,se possível, determine onde a substituição de linhas é necessária
x1 − x2 + 3x3 = 2, 2x1 − 1, 5x2 + 3x3 = 1, 2x1 = 3,
3x1 − 3x2 + x3 = −1, −x1 + 2x3 = 3, x1 + 1, 5x2 = 4,5,
x1 + x2+ = 3 , 4x1 − 4, 5x2 + 5x3 = 1, x1 − 2x2 + 3x3 = 1,
x1 + x2 + x4 = 2, 2x1 = 3 x1 + x2 + x4 = 2,
2x1 + x2 − x3 + x4 = 1, x1 + 1, 5x2 = 4, 5, 2x1 + x2 − x3 + x4 = 1,
4x1 − x2 − 2x3 + 2x4 = 0, −3x2 + 0, 5x3 = −6,6, −x1 + 2x2 + 3x3 − x4 = 4,
3x1 − x2 − x3 + 2x4 = 3, 2x1 − 2x2 + x3 + x4 = 0, 8, 3x1 − x2 − x3 + 2x4 = −3,
Exercicio 3 Dado o sistema linear
2x1 − 6α x2 = 3,
α x1 − x2 = 3
2.
a)- Encontre os valores de α para os quais o sistema não tem soluções.b)- Encontre os valores de α tenha infinitas soluções.
c)- Assumindo que existe uma única solução para um valor de α dado, encontre essa solução.Exercicio 4 Dado o sistema linear
x1 − x2 +α x3 = −2,
− x1 + 2x2 −α x3 = 3.
α x1 + x2 + x3 = 2. (2.109)
a)- Encontre os valores de α para os quais o sistema não tem soluções.b)- Encontre os valores de α tenha infinitas soluções.c)- Assumindo que existe uma única solução para um valor de α dado, encontre essa solução.Exercício 5 Existe um método para a resolução de sistemas lineares, chamado de Método de
Gauss-Jordan que consiste-se em transformar a matriz aumentada numa matriz diagonal da forma:
a11 0 0 · · · 0 0 | b1
0 a22 0 · · · 0 0 | b2
0 0 a33 · · · 0 0 | b3
0 0 0 a44 · · · 0 | b4
0 0 0 0 . . .
... ...
0 0 0 · · · 0 0 | bn
, (2.110)
Dessa forma a solução obtida não exige substituição retroativa e é dada por:
xi =bi
aii. (2.111)

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 41/101
2.7. EXERCÍCIOS 41
a)- Desenvolva um algoritmo para tal método de resolução.b)- Desenvolva o algoritmo para a resolução dos sistemas lineares do exercício 1 e 2. Note que o
número de cálculo aumenta consideravelmente.Exercício 6 Encontre o intercâmbio de linhas que são necessários para se utilizar o método de
Gauss sem pivoteamento.
x1 − 5x2 + x3 = 7, x1 + x2 − x3 = 1, 2x1 − 3x2 + 2x3 = 5, x2 + x3 = 6,
10x1 + 20x3 = 6 , x1 + x2 + 4x3 = 2, −4x1 + 2x2 − 6x3 = 4,5, x1 − 2x2 − x3 = 4,
5x1 − x3 = 4, 2x1 − x2 + 2x3 = 3, 2x1 + 2x2 + 4x3 = 8, x1 − x2 + x3 = 5,
Exercício 7 Repita o exercício anterior utilizando o método de Gauss com pivoteamento parcial.Exercício 8 Use eliminação de Gauss e operações aritméticas com aproximação de três dígitos por
truncamento (veja definição 9) para resolver os seguintes sistemas lineares, e compare as aproxima-ções com as soluções reais.
0,03x1 + 58, 9x2 = 59, 2, 58, 9x1 + 0,03x2 = 59, 2, 3, 03x1 − 12,1x2 + 14x3 = −119,
5,31x1
−6,10x2 = 47, 0,
−6,10x1 + 5,31x2 = 47, 0,
−3,03x1 + 12, 1x2
−7x3 = 120, 5,
Solução real (10,1)T , Solução real (1,10)T , 6, 11x1 − 14,2x2 + 21x3 = −139,
Solução real (0,10,1/7)T
Exercício 9 Repita o exercício anterior com operações aritméticas com arredondamento (vejadefinição 10) de 3 dígitos.
Exercício 10 Repita o exercício 8 utilizando a eliminação de Gauss com pivoteamento parcial.Exercício 11 Repita o exercício 9 utilizando a eliminação de Gauss com pivoteamento parcial.Exercício 12 Repita o exercício 5 utilizando um arredondamento de um dígito significativo.Exercício 13 Repita o exercício 6 utilizando um arredondamento de um dígito significativo.Exercício 14 Resolva os seguintes sistemas lineares:
1 0 0
2 1 0−1 0 1
2 3 −1
0 −2 10 0 3
x3
x2
x1
=
2
−11
,
2 0 0
−1 1 03 2 −1
1 1 1
0 1 20 0 1
x3
x2
x1
=
−1
30
Exercício 15 Fatore as matrizes a seguir utilizando decomposição LU .
2 −1 1
3 3 93 3 5
,
1 2 −1
2 4 7−1 2 5
,
1 1 −1 2−1 −1 1 5
2 2 3 72 3 4 5
,
1 1 −1 22 2 4 51 −1 1 72 3 4 6
Exercício 16 Use o método da fatoração LU para resolver cada um dos sistemas lineares abaixo:
2x1 − x2 + x3 = −1, 1, 012x1 − 2,132x2 + 3, 104x3 = 1, 984, 2x1 = 3,
3x1 + 3x2 + 9x3 = 0 , −2, 132x14,096x2 − 7, 013x3 = −5,049, x1 + 1, 5x2 = 4,5,
3x1 + 3x2 + 5x3 = 4, 3, 104x1 − 7,013x2 + 0, 014x3 = −3,895, x1 − 2x2 + 3x3 = 1,
2x1 = 3, 2, 1756x1 + 4, 0231x2 − 2, 1732x3 + 5, 1967x4 = 17, 102,
x1 + 1, 5x2 = 4,5, −4,0231x1 + 6x2 + 1, 1973x4 = −6, 1593,
− 3x2 + 0, 5x3 = 6,6, −1x1 − 5, 2107x2 + 1, 1111x3 = −3, 0004,
2x1 − 2x2 + x3 + x4 = 0.8, 6, 0235x1 + 7x2 − 4, 1561x4 = 0,

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 42/101
42 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
Exercício 17 Para cada uma das matrizes A abaixo, calcule a norma e diga quais são diagonal-mente dominantes.
2 −1 13 11 9
3 3 15 ,
12 2 −12
−14 7
−1 2 −5 ,
11 1 −1 2−1 −11 1 5
2 2 32 72 3 4 15
,
1 1 −1 22 2 4 5
1 −1 1 72 3 4 6
21 −1 1
3 32 93 3 52
,
13 2 −1
23 14 7−1 2 51
,
9 12 −1 2−1 −17 1 5
2 2 18 72 3 4 9
,
11 1 −1 22 11 4 51 −1 11 72 3 4 16
Exercício 18 Faça as duas primeiras iterações do método de Jacobi para os sistemas (use x(0) = 0):
3x1 − x2 + x3 = 1, 10x1 − x2 = 9 , 4x1 + x2 − x3 = 5, −2x1 + x2 + 1
3x3 = 4,
3x1 + 6x2 + 2x3 = 0, −x1 + 10x2 − 2x3 = 7 , −x1 + 3x2 + x3 = −4, x1 − 2x2 − 0, 5x3 = −4,
3x1 + 3x2 + 7x3 = 4, −2x2 + 10x3 = 3 , 2x1 + 2x2 + 5x3 = 1, x2 + 2x3 = 0,
10x1 + 5x2 = 6, 4x1 + x2 − x3 + x4 = −2 4x1 + x2 + x4 = 2,
5x1 + 10x2 − 4x3 = 25, x1 + 4x2 − x3 − x4 = −1, 2x1 + 8x2 − x3 + x4 = 1,
− 4x2 + 8x3 − x4 = −11, −x1 − x2 + 5x3 + x4 = 0, −x1 + 2x2 − 10x3 − x4 = 4,
− x3 + 5x4 = −11, x1 − x2 + x3 + 3x4 = 1, 3x1 − x2 − x3 + 20x4 = −3,
Exercício 19 Repita o Exercício 18 usando o método de Gauss-Seidel.Exercício 20 Resolva o Exercício 18, usando o método de Jacobi com erro máximo de x = 0.01. O
erro aqui pode ser o medido na norma ||x||2 ou ||x||∞ descrito na observação 7.Exercício 21 Resolva o Exercício 18, , usando o método de Gauss com erro máximo de x = 0.01. O
erro aqui pode ser o medido na norma ||x||2 ou ||x||∞ descrito na observação 7.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 43/101
2.8. PROJETO: SISTEMAS LINEARES 43
2.8 Projeto: Sistemas lineares
Uma quantidade bastante importante para uma matriz é a noção de determinante. Em geral o cálculodo determinante é bastante complicado, entretanto, caso seja possível reduzir uma matriz numa formatriangular (superior ou inferior) o determinante transforma-se no produto dos elementos da diagonal
principal. A primeira parte do projeto consiste-se em desenvolver um método numérico para encontrar-se odeterminante de uma matriz baseado em tornar a matriz triangular superior ou triangular inferior.Note que operações elementares podem modificar o determinante da matriz, portanto, o algoritmo temque levar este fato em conta.
Como referência consulte o livro [1] no capítulo 6.Observação: O Algoritmo deve funcionar se o determinante for zero. Observe que isso vai aconte-
cer se em algum momento de transformar a matriz em triangular inferior (ou superior) for impossívelencontrar um pivô não nulo.
O trabalho deve conter:
1. A argumentação matemática.
2. O Algoritmo (implementado em qualquer linguagem ou software. Podem ser usados os programasque eu implementei em matlab para ajudar a transformar a matriz numa matriz triangular.Entretanto, note que será necessário guardar as operações feitas pois existem algumas operaçõeselementares que estragam o determinante da matriz).
3. Um exemplo de uma matriz 7x7, implementado na linguagem para mostrar rodando.
O grupo deverá conter no máximo 4 alunos. A avaliação do trabalho será feita grupo a grupo. A nota será dada em função do conhecimento do trabalho e será dada pela nota menor entre os 4 alunos.Se no dia de apresentar o trabalho para o professor um aluno do grupo não estiver presente, tire onome do aluno ou todos receberão zero.
Lembrando que não vale a pena colocar um aluno apenas por amizade ou porque ele é o famoso paga lanche , pois isso não contribuirá em nada para ninguém. Se não sabe explicar o trabalho, todos
ganharão zero.Outra coisa importante, não adianta copiar o que está escrito (no livro, wikipedia, etc..etc), porquede bobo só tenho a cara e o jeito de andar, ou seja, descobrirei. E sim, eu leio o que me entregam. Esim, eu confiro e procuro na net para ver se não copiaram de alguém.
Caso tenha uma frase inteira que seja copiada o trabalho todo será anulado. O mesmo vale paradois trabalhos com uma frase inteira igual ou uma linha de código igual. Os dois serão anulados. Econheço todos os truques do tipo: trocar uma palavra por um sinônimo dela, inverter a ordem daspalavras, picar o texto para parecer diferente, etc...
Observação:O trabalho valerá até 1 ponto na primeira avaliação do dia 17 de junho.Não será contabilizado caso o aluno decida fazer segunda chamada, ou seja, se o aluno perder a
primeira prova, implicitamente, estará dizendo que não quer que o trabalho seja avaliado.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 44/101
44 CAPÍTULO 2. SOLUÇÃO DE SISTEMA LINEARES
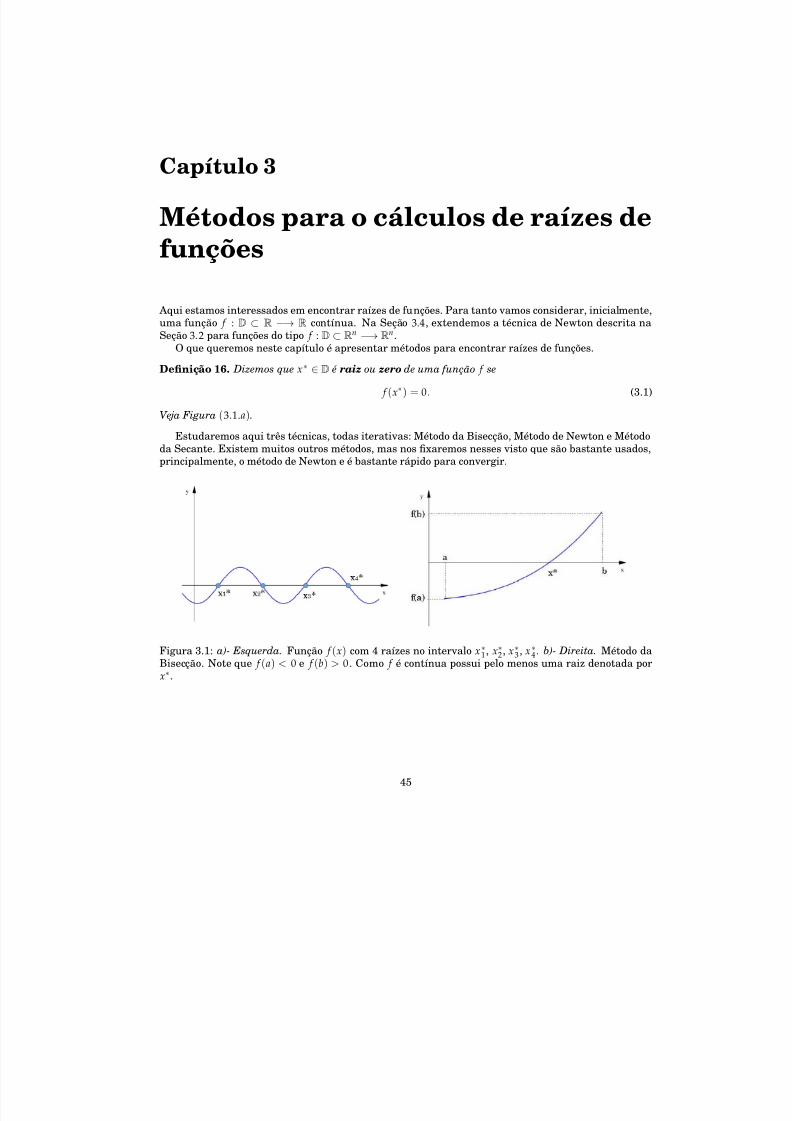
7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 45/101
Capítulo 3
Métodos para o cálculos de raízes de
funções
Aqui estamos interessados em encontrar raízes de funções. Para tanto vamos considerar, inicialmente,uma função f : D ⊂ R −→ R contínua. Na Seção 3.4, extendemos a técnica de Newton descrita naSeção 3.2 para funções do tipo f : D ⊂ Rn −→ Rn.
O que queremos neste capítulo é apresentar métodos para encontrar raízes de funções.
Definição 16. Dizemos que x∗ ∈ D é raiz ou zero de uma função f se
f (x∗) = 0. (3.1)
Veja Figura (3.1.a).
Estudaremos aqui três técnicas, todas iterativas: Método da Bisecção, Método de Newton e Métododa Secante. Existem muitos outros métodos, mas nos fixaremos nesses visto que são bastante usados,principalmente, o método de Newton e é bastante rápido para convergir.
Figura 3.1: a)- Esquerda. Função f (x) com 4 raízes no intervalo x∗1, x∗
2, x∗3, x∗
4. b)- Direita. Método daBisecção. Note que f (a) < 0 e f (b) > 0 . Como f é contínua possui pelo menos uma raiz denotada porx∗.
45

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 46/101
46 CAPÍTULO 3. MÉTODOS PARA O CÁLCULOS DE RAÍZES DE FUNÇÕES
3.1 Método da Bisecção
O método da Bisecção baseia-se no teorema do valor intermediário para funções contínuas, o qual podeser reformulado da seguinte forma.
Teorema 5. Seja f : [a, b] −→
R uma função contínua, tal que f (a) < 0 < f (b) , então existe umd ∈ (a, b) tal que f (d) = 0 , ou seja, d é uma raiz da função, veja Figura (3.1.b).
Observação 8. O teorema 5 continua válido de tivermos f (a) > 0 > f (b). Como exercício, refaça ademonstração do Teorema 5 que é dada abaixo.
Para provar o Teorema 5 utilizamos o seguinte resultado, sem prova.
Teorema 6. Seja an uma sequência de números reais, monótona e limitada, então an é convergente.
Definição 17. Dizemos que uma sequência de números reais an é monótona crescente (respectiva-mente, monótona não decrescente ) se
an+1 > an (respectivamente, an+1 ≥ an) ∀ n ∈ N.
Definição 18. Dizemos que uma sequência de números reais an é monótona decrescente (respectiva-mente, monótona não crescente ) se
an+1 < an (respectivamente, an+1 ≤ an) ∀ n ∈ N.
Definição 19. Dizemos que uma sequência de números reais an é limitada superiormente (respecti-vamente, limitada inferiormente ) se existe um L1 ∈ R (respectivamente, L2 ∈ R ) tal que
an ≤ L1 (respectivamente, an ≥ L2) ∀ n ∈ N.
Se an for limitada inferiormente e superiormente é dita, simplesmente, sequência limitada.
Prova do Teorema 5. A demonstração é bem simples e construtivo. A própria demonstração é o
algoritmo. Como vamos criar uma sequência de números, vamos denotar a0 = a e b0 = b.
1. Calculamos o ponto médio do intervalo [a0, b0] o qual denotamos por x(1)m , ou seja,
x(1)m =
a0 + b0
2 .
Avaliamos a função f em x(1)m e temos 3 possibilidades:
• f
x(1)m
= 0. Se isto acontecer x∗ = x
(1)m e o algoritmo finaliza pois encontramos a raiz.
• f x(1)m < 0. Se isto acontecer, quer dizer que a raiz está entre [x
(1)m , b0], então definimos a1
e b1 como:a1 = x
(1)m e b1 = b0.
• f
x(1)m
> 0. Se isto acontecer, quer dizer que a raiz está entre [a0, x
(1)m ], então definimos: a1
e b1 como:a1 = a0 e b1 = x
(1)m .
• Note que o tamanho do intervalo [a1, b1] é a metade do tamanho anterior, ou seja,
b1 − a1 = b − a
2 .

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 47/101
3.1. MÉTODO DA BISECÇÃO 47
2. Note que agora a raiz está no novo intervalo [a1, b1]. E procedemos como anteriormente. Calcula-
mos o ponto médio do intervalo [a1, b1] o qual denotamos por x(2)m , ou seja,
x(2)m =
a2 + b2
2 .
Avaliamos a função f em x(2)m e temos 3 possibilidades:
• f
x(2)m
= 0. Se isto acontecer x∗ = x
(2)m e o algoritmo finaliza pois encontramos a raiz.
• f
x(2)m
< 0. Se isto acontecer, quer dizer que a raiz está entre [x
(2)m , b1], então definimos a2
e b2 como:a2 = x
(2)m e b2 = b1.
• f
x(2)m
> 0. Se isto acontecer, quer dizer que a raiz está entre [a1, x
(2)m ], então definimos: a2
e b2 como:a2 = a1 e b2 = x
(2)m .
• Note que o tamanho do intervalo [a2, b2] é a metade do tamanho anterior, ou seja,
b2 − a2 = b1 − a1
2 =
b − a
22 .
3. E este processo é continuado. Note que dessa forma geramos duas sequências de pontos ai e bi talque i ∈ N. Além disso a sequência ai é não decrescente, pois, pelo algoritmo acima, se temos ai
podemos encontrar a i+1 e, note que a i+1 ou será ai + bi
2 , que é maior que a i, caso f
ai + bi
2
< 0,
ou será o próprio a i se f
ai + bi
2
> 0. E qualquer caso temos que a i é uma sequência monótona
não decrescente. Pelo mesmo argumento, temos que bi é uma sequência monótona não crescente,
ou seja, a1 ≤ a2 ≤ a3 · · · ≤ ai · · · e b1 ≥ b2 ≥ b3 · · · ≥ bi · · · .
Além disso o tamanho do intervalo [ai, bi] satisfaz:
bi − ai = b − a
2i . (3.2)
As sequências ai e bi são limitadas (tanto inferiormente por a, quando superiormente por b), entãopelo Teorema 6 as sequências são convergentes, ou seja, existem l1 e l2 tais que
limi−→∞
ai = l1 e limi−→∞
bi = l2. (3.3)
Para mostrar que l1 é igual a l2, basta usar (3.2) e tomar o limite de i indo para o∞.
limi−→∞
(bi − ai) = limi−→∞
(bi) − limi−→∞
(ai) = l2 − l1 = limi−→∞
b − a
2i
= (b − a) lim
i−→∞
1
2i
= 0 . (3.4)
Chamando l = l1 = l2, só falta mostrar que l é a raiz. Note que como a função f é contínua então
f (ai) < 0 −→ limi−→∞
f (ai) = f
limi−→∞
ai
= f (l) ≤ 0 (3.5)
e
f (bi) > 0 −→ limi−→∞
f (bi) = f
limi−→∞
bi
= f (l) ≥ 0. (3.6)
Então de (3.5) e (3.6) temos que f (l) = 0. E o teorema é demonstrado.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 48/101
48 CAPÍTULO 3. MÉTODOS PARA O CÁLCULOS DE RAÍZES DE FUNÇÕES
Function 1: x^2 − 1
−1 .4 −1.2 −1.0 −0.8 −0.6 −0.4 −0.2 0.2 0 .4 0.6 0 .8 1.0 1 .2 1.4
−1.0
−0.5
0.5
1.0
x
y
Function 1: x^2
−1.4 −1.2 −1 .0 −0.8 −0 .6 −0.4 −0 .2 0 .0 0 .2 0 .4 0 .6 0 .8 1 .0 1 .2 1 .4
0.5
1.0
1.5
2.0
x
y
Figura 3.2: a)- Esquerda. A função f (x) = x 2 − 1 tem duas raízes em x = −1 e x = 1, entretanto, comonão muda de sinal no intervalo [−1.5, 1.5]. Caso o intervalo seja restringido para [0, 1.5] é possívelaplicar o método. b)- Direita. A função f (x) = x 2 tem um zero em x = 0, mas a função nunca muda desinal, portanto o método não funciona.
Function 1: x − 2
Function 2: 4*x^2*cos(x)
−1.4 −1.2 −1.0 −0.8 −0.6 −0.4 −0.2 0.2 0.4 0.6 0.8 1.0 1.2 1.4
−3
−2
−1
1
2
x
y
Figura 3.3: A função descontínua é dada por f (x) = x − 2 se x ≤ 0.3 e f (x) = 4x2cos(x) se x > 0.3,muda de sinal no intervalo [−1 , 3 ; 1 , 3] entretanto, não possui nenhuma raiz pois é descontínua nesseintervalo.
Observação 9. Pode acontecer da função ter raízes, mas o método só pode ser aplicado se a funçãomuda de sinal no intervalo. Por exemplo, f (x) = x2 − 1 , possui duas raízes no intervalo [−1.5, 1.5] ,
entretanto, o método não pode ser aplicado pois a função não muda o sinal no intervalo. Veja Figura3.2. Caso o intervalo seja restrito, por exemplo, [0, 1.5] o método pode ser aplicado. Entretanto, há
funções que mesmo restringindo o intervalo não é possível encontrar a raiz, pois a função é zero num
ponto mas nunca troca de sinal, por exemplo, a função f (x) = x
2
possui uma raiz em x = 0 , mas nuncamuda de sinal, então o método nunca pode ser aplicado.
Observação 10. Caso a função f seja descontínua pode acontecer de f (a) < 0 e f (b) > 0 , mas a funçãonão ter nenhuma raiz, veja Figura 3.3.
Definição 20. Para uma tolerância, tol, (ou erro máximo) fornecida, O método deve iterar até que o erro para encontrar raízes , ou seja, o método deve ser iterado i vezes até que
| f (x(i+1)m )| < tol , (3.7)
onde x(i+1)m é a o ponto médio do intervalo [ai, bi].

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 49/101
3.1. MÉTODO DA BISECÇÃO 49
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
−1.0
−0.8
−0.6
−0.4
−0.2
0.0
0.2
0.4
0.6
0.8
1.0
x
y
x^2
cos(x)
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
−1.0
−0.5
0.0
0.5
1.0
x
y
Figura 3.4: a)- Esquerda. Função f (x) = x2 − cos(x) no intervalo [0, 1]. b)- Direita. f (x) = x 2 − cos(x)tem um zero quando as funções x2 e cos(x) se encontram, ou seja, a raiz x∗ satisfaz (x∗)2 = cos(x∗).
Exemplo 8. Use o método da bisecção para mostrar que a função
f (x) = x 2 − cos(x)
possui uma raiz no intervalo [0, 1]. Encontre a solução com erro de 0.01. Note que f (0) = 02 − cos(0) = −1 e que f (1) = 12 − cos(1) ∼ 0.4597 (lembre-se que cos(1) é medido
em radianos). Então existe um zero entre [0, 1]. Aplicando o algoritmo:
1. O ponto médio do intervalo [0, 1] é x(1)m = 0.5. Avaliando a função f em x
(1)m temos:
f
x(1)m
= (0, 5)2 − cos(0, 5) ∼ −0, 6276,
ou seja, a raiz está entre [0 , 5 ; 1] e substituímos a1 = 0, 5 e b1 = 1. Note que a tolerância ainda não foi atingida pois f x
(1)m
= | − 0, 6276| = 0,6276 > 0, 01.
2. O ponto médio do intervalo [0 , 5 ; 1] é x(2)m = 0,75. Avaliando a função f em x
(2)m temos:
f
x(2)m
= (0,75)2 − cos(0,75) ∼ −0, 1692,
ou seja, a raiz está entre [0,75,1] e substituímos a 2 = 0,75 e b2 = 1. Note que a tolerância aindanão foi atingida pois
f
x
(2)
m ∼ | − 0, 1692|
= 0,1692
>0, 01.
3. O ponto médio do intervalo [0,75;1] é x(3)m = 0, 875. Avaliando a função f em x
(3)m temos:
f
x(3)m
= (0,875)2 − cos(0, 875) ∼ 0, 1246,
ou seja, a raiz está entre [0,75,0,875] e substituímos a3 = 0,75 e b3 = 0, 875. Note que a tolerânciaainda não foi atingida pois
f
x(3)m
= |0, 1246| = 0, 1246 > 0, 01.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 50/101
50 CAPÍTULO 3. MÉTODOS PARA O CÁLCULOS DE RAÍZES DE FUNÇÕES
4. O ponto médio do intervalo [0,75,0,875] é x(4)m = 0,8125. Avaliando a função f em x
(4)m temos:
f
x(4)m
= (0, 8125)2 − cos(0, 8125) ∼ −0, 0275,
ou seja, a raiz está entre [0,8125,0,875 ] e substituímos a4 = 0, 8125 e b4 = 0, 875. Note que a
tolerância ainda não foi atingida pois f x(4)m
∼ | − 0, 0275| = 0,0275 > 0, 01.
5. O ponto médio do intervalo [0,8125,0,875 ] é x(5)m = 0, 84375. Avaliando a função f em x
(5)m temos:
f
x(5)m
= (0, 84375)2 − cos(0, 84375) ∼ 0, 0472,
ou seja, a raiz está entre [0, 8125, 0, 84375] e substituímos a5 = 0, 8125 e b5 = 0, 84375. Note que atolerância ainda não foi atingida pois
f
x(5)m
∼ |0, 0472| = 0, 0472 > 0, 01.
6. O ponto médio do intervalo [0, 8125, 0, 84375] é x(6)m = 0, 828125. Avaliando a função f em x(6)
m
temos: f
x(6)m
= (0, 828125)2 − cos(0, 828125) ∼ 0, 0095,
A tolerância foi atingida, pois f x(6)m
∼ |0, 0095| = 0, 0095 < 0, 01.
Logo a raiz da função é aproximada por x∗ = 0,8281.
Observação 11. Existem funções que possuem variação muito rápida em torno de sua raiz, Veja Figura(3.5) , de modo que impor condições de erro apenas sobre o módulo de f (x(i)) pode fazer com que o métodonão convirja, mesmo estando com um valor de solução bastante próxima do valor de raiz no domínio.
X
y
−0.10 −0.08 −0.06 −0.04 − 0.02 0.02 0.04 0.06 0.08 0.10
−20
−10
10
20
X
y
Figura 3.5: a)- Esquerda. Variação bastante rápida em torno da raiz. b)- Direita. Função f (x) = 2000xem torno de x = 0, observe que para termos uma tolerância sobre | f (x)| < 0,01, devemos ter quex ∈ (−0, 000005; 0, 000005) o que em geral está fora do arredondamento que utilizamos com 4 casadecimais.
Por exemplo, para a função f (x) = 2000x , x = 0 é uma raiz da função, entretanto, se tivermos encontrado na nossa aproximação um valor aproximado de xaprox = 0.001 , tal valor é bastante próximode x = 0 , entretanto, se fossemos o valor dessa função teríamos
f (xaprox) = 2000(0.001) = 2,

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 51/101
3.1. MÉTODO DA BISECÇÃO 51
que seria estaria bem fora da tolerância, em geral, estabelecida, Veja Figura (3.5). Neste caso, se qui-séssemos que | f (x)| < 0,01 , deveriamos ter:
| f (x)| = 2000|x| < 0,01 −→ |x| < 0, 000005,
ou seja, x
∈(
−0, 000005; 0, 000005) , ou seja, tal número estaria inclusive fora do nosso arredondamento
utilizado até agora que está sendo de 4 casas decimais. Então, para contornar tal caso, como critério de convergência estabelecemos um dos 3 casos:
1. Se | f (x(i))| < tol1 é satisfeita para alguma tol1 sobre a imagem da função estabelecida, dizemosque o método numérico convergiu para a raiz com erro máximo tol 1. Isto é o que desejamosque aconteça em geral. Tomamos x∗ = x(i).
2. Se | f (x(i)| não for menor do que tol 1 , estabelecido como a tolerância da imagem, mas |x(i+1) −x(i)| < tol2 , no qual tol2 é a tolerância que colocamos sobre pontos do domínio, dizemos que a araiz não atingiu a tolerância exigida da imagem, mas atingiu a tolerância exigida nodomínio. Tomamos x∗ = x(i+1).Este caso contempla justamente o exemplo acima dado. Note, poroutro lado, que é possível encontrar |x(i+1) − x(i)| < tol2 , mas tal que f (x∗) seja um valor bemdistante de zero. Entretanto, o erro relativo, neste caso é bem pequeno em geral. item Se nem
| f (x(i+1))| < tol1 , nem |x(i+1) − x(i)| < tol2 são satisfeitas, mas o número de iterações excedeu ummáximo estabelecido. Dizemos que o método não convergiu. É, muitas vezes, possível aumentaro número máximo de iterações permitido fazendo com que o método convirja.
3.1.1 Implementação do Método da Bisecção
function [xr, k] =biseccao
a=input(’Entre com a funcao ’,’s’);
f=inline(a);
xl=input(’Entre com o valor inferior do intervalo ’) ;xu=input(’Entre com o valor superior do intervalo ’);
tol=input(’Entre com a tolerancia exigida ’);
N= input(’Entre com o maximo numero de iteracoes possiveis ’);
if f(xu)*f(xl)<=0
else
fprintf(’Erro. O metodo so funciona se vc entrar se a funcao mudar de sinal. Tente nova
xl=input(’Entre com o valor inferior do intervalo’) ;
xu=input(’Entre com o valor superior do intervalo’);
end
k=0;
xr= xu;
xx=linspace(xl,xu,100);
plot(xx,f(xx));
hold on
plot(xr,f(xr),’*’)
hold off
pause
while (abs(f(xr))>=tol)

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 52/101
52 CAPÍTULO 3. MÉTODOS PARA O CÁLCULOS DE RAÍZES DE FUNÇÕES
xr=(xu+xl)/2;
if f(xr)==0
str = [’A raiz foi’, num2str(xr), ’’]
it = [’O numero de iteracoes foi ’, num2str(k), ’’]
break
endif f(xu)*f(xr)<=0
xl=xr;
else
xu=xr;
end
if f(xl)*f(xr)<=0
xu=xr;
else
xl=xr;
end
xnew(1)=0;
k=k+1;
xnew(k+1)=xr;
xx=linspace(xl,xu,100);
plot(xx,f(xx));
hold on
xrr=(xl+xu)/2;
plot(xr,f(xr),’*’)
%hold off
pause
if (k>=N)fprintf(’O metodo nao convergiu com as iteracoes exigidas’);
break,
end
%if abs((xnew(i)-xnew(i-1))/xnew(i))<tol,
% break,end
end
if(k<N)
str = [’A raiz foi’, num2str(xr), ’’]
it = [’O numero de iteracoes foi ’, num2str(k), ’’]end
if (k>=N)
it = [’O numero de iteracoes foi ’, num2str(k), ’ E o metodo nao convergiu’]
end

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 53/101
3.2. MÉTODO DE NEWTON 53
3.2 Método de Newton
O método da Bisecção é bom, entretanto, é bastante lento. Há métodos iterativos que, na vizinhançada raiz e sob certas condições, convergem muito rápido.
Um desses métodos é o método de Newton. Tal método surge através de uma observação geométrica
interessante para algumas funções. Veja Figura (3.6.a).
15.3 15.4 15.5 15.6 15.7 15.8 15.9 16.0
−20
−10
0
10
X
y
Figura 3.6: a)- Esquerda. Método de Newton. b)- Direita. Função x 2 − 250 na vizinhança de sua raiz,note que a função se comporta de modo muito parecido a de uma função afim com coeficiente angularpositivo, por isso o método converge muito rapidamente.
Suponha que conheçamos o ponto x(n) e queiramos encontrar, através de um método, um pontox(n+1) . O algoritmo é tal que a partir de x(n) traçamos uma reta que é tangente a função f (x) no ponto(x(n), f (x(n))). O ponto x(n+1) é corresponde ao valor do domínio para o qual a tangente partindo de
(x(n), f (x(n))) atinge o eixo x.Note, da Figura (3.6.a) que temos um triângulo com vértices (x(n), f (x(n))), (x(n+1), 0) e (x(n), 0). O
valor da numérico da reta tangente no ponto (x(n), f (x(n))) é a derivada da função avaliada em x(n+1) eé igual a tangente do triângulo acima descrito, ou seja, temos que:
f ′(x(n)) = f (x(n)) − 0
x(n) − x(n+1), −→ x(n+1) = x(n) − f (x(n))
f ′(x(n)). (3.8)
O algoritmo (3.8) é chamado de Método de Newton.Para começar a iteração do método de Newton é necessário um chute inicial, se o chute inicial for
bom o método pode iterar rapidamente.
Exemplo 9. Use o método de Newton para estimar a raiz f (x) = √ 250. Para utilizar o método de Newton neste caso, precisamos criar uma função adequada, para o qual√
250 seja uma raiz. Note que
f (x) = x2 − 250,
tem como raiz, justamente,√
250. Para aplicar o método de Newton, precisamos calcular a derivada de f (x) a qual é dada por f ′(x) =
2x , então o método é escrito como:
x(n+1) = x(n) − ( x(n))2 − 250
2x(n) . (3.9)

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 54/101
54 CAPÍTULO 3. MÉTODOS PARA O CÁLCULOS DE RAÍZES DE FUNÇÕES
Como chute inicial, vamos dar uma raiz exata próxima de√
250 que conhecemos, por exemplo, x(0) = 16 ,que é a raiz exata de 256. Então podemos achar x(1) como:
x(1) = x (0) − ( x(0))2 − 250
2x(0) = 16 − (16)2 − 250
2 ∗ 250 = 15, 8125. (3.10)
Avaliando a função f em x(1) para calcular o erro, obtemos:
| f (x)| = |(x(1))2 − 250| ∼ 0, 0352.
O erro é, aproximadamente, 0.0352 , o que não é ruim com apenas uma iteração. Entretanto, vamositerar mais uma vez para melhorar essa aproximação, para x(1) = 15, 8125 , encontramos
x(2) = x (1) − (x(1))2 − 250
2x(1) =∼ 15.8114. (3.11)
Avaliando a função f em x(2) para calcular o erro, obtemos:
| f (x)| = |(x(2))2 − 250| ∼ 0, 0000012.
que é uma excelente aproximação. Tivemos que colocar aqui mais do que 4 casas decimais significativasapós a vírgula, pois o método deu um erro menor do que 0, 0001. Um excelente método.
Exemplo 10. Use o método de Newton para encontrar a raiz de f (x) = x2 − cos(x) , com erro de 0,01. Esta é exatamente a função do exemplo 8 , a qual foi encontrada na sexta iteração.
Para resolver, precisamos calcular a derivada de f (x) = 2x + sen(x) , então o método é escrito como:
x(n+1) = x(n) − (x(n))2 − cos(x(n))
x(n) + sen(x(n)). (3.12)
Como chute inicial, x(0) = 1 , então podemos achar x(1) como:
x(1)
= x(0)
− (x(0))2
−cos(x(0))
2x(0) + sen(x(0)) = 1 − (1)2
−cos(1)
2 ∗ 1 + sen(1) ∼ 0, 8382. (3.13)
Avaliando a função f em x(1) para calcular o erro, obtemos:
| f (x)| = |(x(1))2 − cos(x(1))| ∼ 0, 0338.
A precisão não foi atingida, mas está muito próximo da tolerância dada que foi de 0,01. Iterando maisuma vez, para x(1) = 0,8382 , encontramos
x(2) = x(1) − ( x(1))2 − cos(x(1))
2x(1) + sen(x(1))=∼ 0.8242. (3.14)
Avaliando a função f em x(2) para calcular o erro, obtemos:
| f (x)| = |(x(2))2 − cos(x(2))| ∼ 0, 0003.
O erro, surpreendentemente, é menor que 0, 001 na segunda iteração. O método converge rapidamente.
Uma pergunta, o que aconteceria, se no Exemplo 10 tivéssemos escolhido como chute inicial o pontox(0) = 0. Observe neste caso que teríamos um problema bastante sério, pois quando fóssemos calculara derivada teríamos
f ′(x(0)) = f ′(0) = 2(0) − sen(0) = 0,
note do algoritmo de Newton, que teríamos divisão por zero!!!De fato isto é um problema para o método de Newton, como este fato é sério, tecemos uma observa-
ção:

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 55/101
3.2. MÉTODO DE NEWTON 55
Observação 12. O método de Newton não deve ser usado para raízes x∗ tais que f ′(x∗) = 0 , o problema é que quase nunca sabemos desse fato. Então é útil não usar o método para funções para osquais a derivada começa a atingir valores próximos a zero, pois a solução, muito provavelmente, nãoirá convergir.
Veja a Figura (3.7.a) , para um estado x (n−1) , através da reta por este ponto, encontramos x(n) como
sendo o valor de x para o qual a reta tangente à função f em (x(n−1), f (x(n−1) ) atinge o eixo x. Note que,visualmente, x(n) está mais longe da raiz x∗ do que x(n−1).
A partir de x (n) , aplicamos novamente o método de Newton para encontrarmos x(n+1). Tal ponto é ovalor de x para o qual a reta tangente à função f em (x(n), f (x(n) ) atinge o eixo x. Note que aqui é bemclaro que O método está se afastando da solução raiz do problema. E por que isto aconteceu?
Aconteceu, pois em x(n) a derivada da função está muito próxima de zero, o que, por uma análisecriteriosa do método de Newton, através da Equação (refnewtonmeth) , podemos ver que o mesmo secomporta muito mal.
A convergência do método de Newton é uma questão difícil de estabelecer, pois não é sempre que omesmo converge. Entretanto, para chutes iniciais perto da raiz, e se não houver pontos que tornem aderivada com valores muito próximos de zero (ou zero) o método, em geral, converge.
Por outro lado, caso o método convirja, podemos estabelecer um resultado interessante que diz quãorápido o método de Newton converge, que o que chamamos de taxa de convergência, Seção 3.2.1.
Figura 3.7: a)- Esquerda. Método de Newton. b)- Direita. Função x 2 − 250 na vizinhança de sua raiz,note que a função se comporta de modo muito parecido a de uma função afim com coeficiente angularpositivo, por isso o método converge muito rapidamente.
3.2.1 Taxa de Convergência do Método de Newton: Assumindo convergên-cia
Vamos assumir que o método de Newton encontre uma raiz, a qual denotamos como x∗, vamos estimarquão rápido dois pontos da sequência x(n) e x(n+1) se aproximam de x∗.
Para isto, vamos usar a fórmula de Taylor (1.11), expandida em torno de x (n), com trucamento desegunda ordem, ou seja (1.11)
f (x) = f (x(n)) + f ′(x(n))(x − x(n)) + f ′′(ξ)
2! (x − (x(n))2. (3.15)
no qual ξ é uma função que depende de x o qual, em geral, não sabemos fornecer precisamente.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 56/101
56 CAPÍTULO 3. MÉTODOS PARA O CÁLCULOS DE RAÍZES DE FUNÇÕES
Vamos fazer x = x∗, raiz da equação. Para este valor f (x∗) = 0 e a equação acima (3.15) nos dá arelação:
0 = f (x(n)) + f ′(x(n))(x∗ − x(n)) + f ′′(ξ)
2! (x∗ − (x(n))2,
− f ′(x(n))(x∗ − x(n)) = f (x(n)) + f ′′(ξ)2!
(x∗ − (x(n))2, (3.16)
Admitindo que f ′(x(n)) = 0, podemos dividir ambos os lados de (3.16) por − f ′(x(n)) e obtemos:
x∗ − x(n) = − f (x(n))
f ′(x(n))− f ′′(ξ)
f ′(x(n))2!(x∗ − (x(n))2. (3.17)
De (refnewtonmeth) podemos escrever
− f (x(n))
f ′(x(n))
= x (n+1) − x(n)
o que substituindo em (3.17) nos dá:
x∗ − x(n) = x (n+1) − x(n) − f ′′(ξ)
f ′(x(n))2!(x∗ − (x(n))2,
x∗ − x(n+1) = − f ′′(ξ)
f ′(x(n))2!(x∗ − (x(n))2. (3.18)
De (3.18) podemos ver como se aproximam os pontos da sequência da raiz x∗:
|x∗
−x(n+1)
|= f ′′(ξ)
f ′(x(n))2! (
|x∗
−(x(n)
|)2. (3.19)
Note de (3.19) que | f ′(x(n))| << 1, então a solução pode, de fato, se distanciar da solução. Por outrolado, se | f ′(x(n))| e (x(n) é está suficientemente próximo da solução, então o método de Newton dá umaconvergência que chamamos de convergência quadrática
Definição 21. Um método iterativo para encontrar uma solução x∗ tem ordem de convergência (ourazão de convergência) k , para algum k ∈ R+ se satisfaz:
|x∗ − x(n+1)| ≤ M|x∗ − x(n+1)|k , (3.20)
para alguma constante M > 0. Denotamos isso como O(
|x∗
−x(n+1)
|k ) , ou, simplesmente,O(k ). Se, por
outro lado, M = M(x) e lim x−→x∗ M(x) = 0 , denotamos tal fato como o(|x∗ − x(n+1)|k ) , ou, simplesmente,⋊(k ).
Então temos estabelecido o seguinte teorema:
Teorema 7. Caso o método de Newton seja convergente para uma raiz x∗ , então a taxa de convergência é quadrática, ou seja, satisfaz (3.19)
Observação 13. O método de bisecção também possui uma taxa de convergência, mas a demonstração é bem mais complicada do que este caso. Se o aluno tiver interesse da demonstração dessa convergência e da de outros métodos recomendamos como uma excelente leitura [1].

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 57/101
3.2. MÉTODO DE NEWTON 57
3.2.2 Implementação do Método de Newton
function [ x, ef, ex, iter ] = newton
a=input(’Entre com a funcao ’,’s’);
f=inline(a);
b=input(’Entre com a derivada da funcao ’,’s’);
df=inline(b);
x0=input(’Entre com o chute inicial ’) ;
tol1=input(’Entre com a tolerancia exigida para o erro de f(^{n+1})’);
tol2=input(’Entre com a tolerancia exigida para o erro |x^{n+1}-x^{n}|’);
N= input(’Entre com o maximo numero de iteracoes possiveis ’);
% Metodo de Newton.
% Descobre as raizes sucessivamente.
%
% Output:
% x - aproximacao da raiz
% ef - |f(x^n)| (ou seja, o erro de $f$.
% ex - erro estimado emvalor absoluto dno dominio
% iter=numero de iteracoes.
%
% Example:% [ x, ex ] = newton( ’exp(x)+x’, ’exp(x)+1’, 0, 0.5*10^-5, 10 )
x(1) = x0 - (f(x0)/df(x0));
ef(1)=abs(f(x(1));
ex(1) = abs(x(1)-x0);
k = 2 ;
% Comando para fazer o gráfico (apenas cosmetico).
xxx=linspace(x(1),x0,100);
plot(xxx,f(xxx))
hold on
plot(x0,f(x0), ’*’)
plot(xxx,((f(x0))/(x0-x(1))) *xxx-((f(x0))/(x0-x(1))) *x(1))
%
pause
while (ef(k-1) >= tol1) && (ex(k-1) >= tol2) && (k <= N)
x(k) = x(k-1) - (f(x(k-1))/df(x(k-1)));
ef(k)=abs(f(x(k));
ex(k) = abs(x(k)-x(k-1));
% Comando para fazer o gráfico (apenas cosmetico).
xxx=linspace(x(k),x(k-1),100);

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 58/101
58 CAPÍTULO 3. MÉTODOS PARA O CÁLCULOS DE RAÍZES DE FUNÇÕES
plot(xxx,f(xxx))
hold on
plot(x(k-1),f(x(k-1)), ’*’)
plot(xxx,((f(x(k-1)))/(x(k-1)-x(k))) *xxx-((f(x(k-1)))/(x(k-1)-x(k))) *x(k))
%
k = k+1;
pause
end
%
% Verificação quanto ao erro e ao número de iterações atingidas.
%
%
% Erro maximo da imagem foi atingido. Raiz encontrada
%
if(k<N)&& (ef(k-1) < tol1)
str = [’A raiz atingiu |f(x^n)|<tol1. O valor da raiz eh ’, num2str(x(k-1)), ’’]
efinalimagem=[’Com erro da imagem, |f(x^n)| ’ num2str(ef(k-1)), ’’]
efinaldominio=[’Com, |x^{n}-x^{n-1}| dado por ’ num2str(ex(k-1)), ’’]
it = [’O numero de iteracoes foi ’, num2str(k-1), ’’]
end
%
% Erro maximo da imagem nao foi atingido, mas do dominio foi.
%
if(k<N)&& (ef(k-1) >= tol1)
[’A raiz nao atingiu |f(x^n)|<tol1, mas |x^{n}-x^{n-1}| <tol2’]
str = [ ’O valor da raiz eh ’, num2str(x(k-1)), ’’]it = [’O numero de iteracoes foi ’, num2str(k-1), ’’]
efinalimagem=[’Com erro da imagem, |f(x^n)| ’ num2str(ef(k-1)), ’’]
efinaldominio=[’Com, |x^{n}-x^{n-1}| dado por ’ num2str(ex(k-1)), ’’]
end
%
% Numero de iterações nao foi suficiente para o metodo convergir.
%
if (k>=N)
[’O metodo nao convergiu. Aumente a tolerancia’]
it = [’O numero de iteracoes foi ’, num2str(k-1). ’]
enditer=k-1;
end

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 59/101
3.3. MÉTODO DA SECANTE 59
3.3 Método da Secante
O método da secante é uma leve modificação do método de Newton. Para este método aproximamos aderivada em x(n) por uma reta secante, conforme a Figura (3.7.b).
Note que isto pode ser facilmente obtido através da expansão de Taylor, pois, expandindo até n = 1,
em torno de um ponto c, temos uma aproximação do tipo: f (x) = f (c) + f ′(c)(x − c) +O(|x − c|2). (3.21)
onde temos O(|x − c|2) indica que o erro vai a zero quadraticamente quando x tende a c, conforme aDefinição 21.
Tomando x = x(n−1) e c = x(n) temos, de (3.21)
f (x(n−1)) = f (x(n)) + f ′(x(n))(x(n−1) − x(n)) +O(|x(n−1) − x(n)|2)
f ′(x(n)) = f (x(n)) − f (x(n−1))
(x(n) − x(n−1))+ O(|x(n) − x(n−1)|2)
x(n) − x(n−1) . (3.22)
Como O(hk ), para algum h e k genéricos, diz que taxa de convergência e hk , quando dividimos tal
ordem por h p
, então a taxa de convergência (ou ordem de convergência) torna-seO
(hk
)/h p
= O
(hk
− p
),portanto, de Eq. (3.22) temos, finalmente:
f ′(x(n)) = f (x(n)) − f (x(n−1))
(x(n) − x(n−1))+O(|x(n) − x(n−1)|). (3.23)
Portanto, podemos adaptar o método de Newton, substituindo f ′(x(n)) por uma aproximação. Dessaforma, para se obter o estado x(n+1), são necessários os dois estados anteriores x(n−1) e x(n). O métododa Secante é escrito como:
x(n+1) = x (n) − f (x(n)) f (x(n))− f (x(n−1))
(x(n)−x(n−1))
−→ x(n+1) = x (n) − f (x(n))(x(n) − x(n−1))
f (x(n)) − f (x(n−1)). (3.24)
Vamos repetir os mesmos exemplos usados para o método de Newton. Note que para a inicialização dométodo da secante são necessários dois chutes iniciais, os quais vamos chamar de x(−1) e x(0).
Exemplo 11. Use o método da secante para estimar a raiz f (x) =√
250. Para utilizar o método de secante, como em Newton, temos que
√ 250 é raiz de f (x) = x 2 − 250. Então
o método da secante, (3.24) , fica escrito como:
x(n+1) = x(n) − ((x(n))2 − 250)(x(n) − x(n−1))
(x(n))2 − (x(n−1))2 . (3.25)
Precisamos dar dois chutes iniciais para a raiz a fim de inicializar o método. Vamos fornecer as duasraízes exatas mais próximas da raiz de
√ 250 que conhecemos que são 15 e 16 x(−1) = 15 e x(0) = 16.
Então, usando (3.25) , podemos achar x(1) como:
x(1) = x(0) − ((x(0))2 − 250)(x(0) − x(−1))
(x(0))2 − (x(−1))2 ∼ 15, 8064. (3.26)
Avaliando a função f em x(1) para calcular o erro, obtemos:
| f (x(1))| = |(x(1))2 − 250| ∼ 0, 1561.
O erro não está tão satisfatório quanto o do método de Newton, pois um dos chutes, 15 , estava longe dasolução. Vamos continuar iterando x(1) = 15, 8064 , encontramos para o próximo ponto
x(2) = x(1) − ((x(1))2 − 250)(x(1) − x(0))
(x(1))2 − (x(0))2 =∼ 15.8114. (3.27)

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 60/101
60 CAPÍTULO 3. MÉTODOS PARA O CÁLCULOS DE RAÍZES DE FUNÇÕES
Avaliando a função f em x(2) para calcular o erro, obtemos:
| f (x)| = |(x(2))2 − 250| ∼ 0, 0009.
que é uma excelente aproximação, menos boa do que de Newton, mas com duas iterações já encontramos
uma raiz com erro menor que 0, 001.Exemplo 12. Use o método da Secante para encontrar a raiz de f (x) = x2 − cos(x) , com erro de 0,01.
o método da secante, (3.24) , fica escrito como:
x(n+1) = x(n) − ((x(n))2 − cos(x(n)))(x(n) − x(n−1))
(x(n))2 − cos(x(n)) − (x(n−1))2 − cos(x(n−1)). (3.28)
Precisamos dar dois chutes iniciais para a raiz a fim de inicializar o método. Vamos fornecer os dois extremos 0 e 1 , ou seja, x(−1) = 0 e x(0) = 1 , note que neste caso não teremos divisão por zero.
Então x(1) , de (3.28) , é obtido satisfazendo:
x(1) = x (0)
− ((x(0))2 − cos(x(0)))(x(0) − x(−1))
(x(0))2 − cos(x(0)) − (x(−1))2 − cos(x(−1)) ∼0, 6851. (3.29)
Avaliando a função f em x(1) para calcular o erro, obtemos:
| f (x(1))| = |(x(1))2 − cos(x(1))| ∼ 0,3050
A precisão de 0,01 não foi atingida. Iterando mais uma vez, para x(1) = 0, 6851 , encontramos
x(2) = x(1) − ((x(1))2 − cos(x(1)))(x(1) − x(0))
(x(1))2 − cos(x(1)) − (x(0))2 − cos(x(0))∼ 0, 8107. (3.30)
Avaliando a função f em x(2) para calcular o erro, obtemos:
| f (x(2))| = |(x(2))2 − cos(x(2))| ∼ 0, 0318.
A precisão de 0,01 não foi atingida, diferentemente do método de Newton que nos deu a convergênciacom apenas duas iterações. Iterando mais uma vez, para x(2) = 0, 8107 , encontramos
x(3) = x(2) − ((x(2))2 − cos(x(2)))(x(2) − x(1))
(x(2))2 − cos(x(2)) − (x(1))2 − cos(x(1))∼ 0, 8253. (3.31)
Avaliando a função f em x(3) para calcular o erro, obtemos:
| f (x(3))| = |(x(3))2 − cos(x(3))| ∼ 0, 0028.
A tolerância foi atingida, entretanto, com 3 iterações o método da secante deu um erro maior do que ométodo de Newton apenas com duas iterações. O método da secante tem vantagens, pois, mesmo pararegiões em que temos uma derivada nula, as vezes ele pode ser aplicado, diferentemente do método de
Newton, fazendo com que o método da secante seja mais robusto em certas situações.
3.3.1 Implementação do Método da Secante
function [ x, ef, ex,iter ] = secante
a=input(’Entre com a funcao ’,’s’);
f=inline(a);

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 61/101
3.3. MÉTODO DA SECANTE 61
xm1=input(’Entre com o primeiro chute inicial ’) ;
x0=input(’Entre com o segundo chute inicial ’) ;
tol1=input(’Entre com a tolerancia exigida para o erro de f(^{n+1})’);
tol2=input(’Entre com a tolerancia exigida para o erro |x^{n+1}-x^{n}|’);
N= input(’Entre com o maximo numero de iteracoes possiveis ’);
% Metodo da Secante
% Descobre as raizes sucessivamente.
%
% Output:
% x - aproximacao da raiz
% ef - |f(x^n)| (ou seja, o erro de $f$.
% ex - erro estimado emvalor absoluto dno dominio
% k=numero de iteracoes.
%
% Example:
% [ x, ex ] = secante( ’exp(x)+x’, ’exp(x)+1’, 0, 0.5*10^-5, 10 )
x(1)=x0;
x(2) = x0 - ((f(x0)(x0-xm1))/(f(x0)-f(xm1)));
ef(1)=abs(f(x(1));
ex(1) = abs(x(1)-x0);
k = 3 ;
% Comando para fazer o gráfico (apenas cosmetico).
xxx=linspace(x(1),x0,100);
plot(xxx,f(xxx))
hold on
plot(x0,f(x0), ’*’)
plot(xxx,((f(x0))/(x0-x(1))) *xxx-((f(x0))/(x0-x(1))) *x(1))
%
pause
while (ef(k-2) >= tol1) && (ex(k-2) >= tol2) && (k <= N)
x(k) = x(k-1) - ((f(x(k-1))(x(k-1)-x(k-2)))/(f(x(k-1))-f(x(k-2))));
ef(k-1)=abs(f(x(k));ex(k-1) = abs(x(k)-x(k-1));
% Comando para fazer o gráfico (apenas cosmetico).
xxx=linspace(x(k),x(k-1),100);
plot(xxx,f(xxx))
hold on
plot(x(k-1),f(x(k-1)), ’*’)
plot(xxx,((f(x(k-1)))/(x(k-1)-x(k))) *xxx-((f(x(k-1)))/(x(k-1)-x(k))) *x(k))
%

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 62/101
62 CAPÍTULO 3. MÉTODOS PARA O CÁLCULOS DE RAÍZES DE FUNÇÕES
k = k+1;
pause
end
%
% Verificação quanto ao erro e ao número de iterações atingidas.%
%
% Erro maximo da imagem foi atingido. Raiz encontrada
%
if(k-1<N)&& (ef(k-2) < tol1)
str = [’A raiz atingiu |f(x^n)|<tol1. O valor da raiz eh ’, num2str(x(k-1)), ’’]
efinalimagem=[’Com erro da imagem, |f(x^n)| ’ num2str(ef(k-2)), ’’]
efinaldominio=[’Com, |x^{n}-x^{n-1}| dado por ’ num2str(ex(k-2)), ’’]
it = [’O numero de iteracoes foi ’, num2str(k-2), ’’]
end
%
% Erro maximo da imagem nao foi atingido, mas do dominio foi.
%
if(k-1<N)&& (ef(k-2) >= tol1)
[’A raiz nao atingiu |f(x^n)|<tol1, mas |x^{n}-x^{n-1}| <tol2’]
str = [ ’O valor da raiz eh ’, num2str(x(k-1)), ’’]
it = [’O numero de iteracoes foi ’, num2str(k-2), ’’]
efinalimagem=[’Com erro da imagem, |f(x^n)| ’ num2str(ef(k-2)), ’’]
efinaldominio=[’Com, |x^{n}-x^{n-1}| dado por ’ num2str(ex(k-2)), ’’]
end
%% Numero de iterações nao foi suficiente para o metodo convergir.
%
if (k-1>=N)
[’O metodo nao convergiu. Aumente a tolerancia’]
it = [’O numero de iteracoes foi ’, num2str(k-2). ’]
end
iter=k-2;
end

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 63/101
3.4. EXTENSÃO DO MÉTODO DE NEWTON PARA FUNÇÕES VETORIAIS 63
3.4 Extensão do Método de Newton para funções vetoriais
O método de Newton pode ser facilmente extendidos para funções vetoriais.
Definição 22. Entendemos por funções vetoriais (ou aplicações , ou ainda campos vetoriais ) fun-ções com domínio sendo um subconjunto denso do R p e o contradomínio um subconjunto denso de Rq
para p e q inteiros maiores do que 1. Para a obtenção das raízes, vamos assumir que p = q. Dessa forma a função f , a qual encontraremos as raízes, satisfaz f : D ⊂ R p −→ R p , ou seja,
f ( x) = ( f 1( x), f 2( x), · · · , f ( x))T , no qual x = (x1, x2, · · · , x p)T
De fato, através de (3.8), podemos verificar que a extensão é bastante simples. Entretanto, nométodo de Newton precisamos de calcular a derivada da função para a qual queremos encontrar a raiz.O equivalente neste caso é a matriz Jacobiana
Definição 23. Seja f : D ⊂ R p −→ R p , com, f ( x) = ( f 1( x), f 2( x), · · · , f ( x))T , e x = (x1, x2, · · · , x p)T ,uma função vetorial contínua que admite todas as derivadas parciais em relação a x , então a matriz
Jacobiana é a matriz quadrada definida como:
J (x) =
∂ f 1∂x1
∂ f 1∂x2
· · · ∂ f 1∂x p
∂ f 2∂x1
∂ f 2∂x2
· · · ∂ f 2∂x p
... · · · . . . ...
∂ f p
∂x1
∂ f p
∂x2· · · ∂ f p
∂x p
(3.32)
Assumindo que a matriz Jacobiana admite inversa em pontos adequados, o método de Newton (3.8)fica escrito como:
x(n+1) = x
(n) −
J ( x(n))−1
f ( x(n)), (3.33)
no qual
J ( x(n))−1
é a inversa da matriz Jacobiana avaliada no ponto x(n).
Lembrando que conhecemos x(n) e queremos encontrar o ponto x
(n+1) da nossa sequência aproxi-mativa.
Para sistemas de equações pequenos, o cálculo da inversa é imediato, mas para sistemas grandes,o cálculo da matriz inversa é bastante custoso, entretanto, nestes casos, podemos reescrever (3.33)como um sistema linear e aplicar os métodos desenvolvidos no Capítulo 2, para a resolução do sistemaproveniente.
Passando x(n) para o lado esquerdo na igualdade (3.33) e multiplicando ambos os lados do resultado
por J ( x(n)), nós obtemos: J ( x(n))( x(n+1) − x
(n)) = f ( x(n)). (3.34)
Definindo ∆x(n) = ( x(n+1) − x(n)), então o sistema (3.34) fica escrita como
J ( x(n))∆x(n) = f ( x(n)), (3.35)
o qual é resolvido, como já dito anteriormente, utilizando-se as técnicas desenvolvidas no Capítulo 2.Encontrado ∆x(n), para obter x(n+1) basta proceder:
∆x(n) = ( x(n+1) − x(n)) −→ x
(n+1) = ∆x(n) + x(n). (3.36)
Para o próximo exemplo precisamos definir:
Definição 24. Seja f : D ⊂ R p −→ R , uma função contínua que admite todas as derivadas parciais de primeira ordem, o gradiente de f , o qual é denotado por ∇ f (ou grad( f ) ), é definido como a aplicação∇ f : D ⊂ R p −→ R p , escrita como o vetor:
∇ f =
∂ f
∂x1, ∂ f
∂x2, · · · ,
∂ f
∂x p
T
. (3.37)

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 64/101
64 CAPÍTULO 3. MÉTODOS PARA O CÁLCULOS DE RAÍZES DE FUNÇÕES
Definição 25. Seja f : D ⊂ R p −→ R , um ponto crítico de f , são os valores x ∈ R p tal que o gradientede f , ou seja, x ∈ R p tal que ∇ f ( x) = 0.
Os pontos críticos são candidatos a pontos de: máximo, mínimo ou sela.
Exemplo 13. Encontre os pontos críticos da função f (x) = x2 + y 2 , com precisão de 0, 001. Para encontrar tais pontos críticos precisamos derivar a função f para encontrar o gradiente:
∇ f =
∂ f
∂x, ∂ f
∂ y
T
= (2x, 2 y).
a solução pra este sistema é bem fácil, x = y = 0 , entretanto, vamos aplicar o método de Newton.Observe que ∇ f D ⊂ R2 −→ R2. A Jacobiana dessa aplicação é a matriz:
2 00 2
, cuja a inversa é
1
2 0
0 12
Então o método de Newton (3.33) é escrito, na forma vetorial, como:
x(n+1)
y(n+1) = x(n)
y(n) −
12 0
0
1
2 2 x(n)
2 y(n) = x(n)
y(n) −
x(n)
y(n) = 0
0 . (3.38)
Para qualquer valor de (x(0), y(0))T fornecido, o método de Newton dá solução exata para o ponto críticoque é (0, 0)T . Veja Figura (3.8.a).
4
6
82
0
y1
0 1
0
x
−2
22−1
−1
−2
yy
0.0
0.5
0.2
0.4
1.0
0.6
0.0
1.0−0.5
−1.0
0.5
1.00.0
−0.5
xx−1.0
0.8
Figura 3.8: a)- Esquerda. Função f (x) = x2 + y2 tendo ponto crítico em (x, y) = (0, 0), note queeste ponto crítico é ponto de mínimo. b)- Direita. Função f (x) =
1 − x2 − y2, com ponto crítico em
(x, y) = (0, 0), note que este ponto crítico é ponto de máximo.
Exemplo 14. Encontre os pontos críticos da função f (x) =
1 − x2 − y2 , com precisão de 0, 001.
Para encontrar tais pontos críticos precisamos derivar a função f para encontrar o gradiente:
∇ f =
∂ f
∂x, ∂ f
∂ y
T
= − x√
−x2− y2+1− y√
−x2− y2+1
T . (3.39)
Geometricamente (veja Figura (3.8.b) ) e por intuição, podemos ver que a solução para este sistema éx = y = 0 , entretanto, vamos aplicar o método de Newton. Observe que ∇ f : D ⊂ R2 −→ R2. A
Jacobiana e a sua inversa dessa aplicação são as matrizes:
y2−1
(−x2− y2+1)32
− x y
(−x2− y2+1)32
− x y
(−x2− y2+1)32
x2−1
(−x2− y2+1)32
,
x2 −x2 − y2 + 1 − −x2 − y2 + 1 x y
−x2 − y2 + 1
x y −x2 − y2 + 1
y2 − 1
−x2 − y2 + 1

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 65/101
3.4. EXTENSÃO DO MÉTODO DE NEWTON PARA FUNÇÕES VETORIAIS 65
Então o método de Newton (3.33) é escrito, depois de alguns cálculos, na forma vetorial, como:
x(n+1)
y(n+1)
=
x(n)
y(n)
−
−x(n)
(x(n))2 + ( y(n))2 − 1
− y(n)
(x(n))2 + ( y(n))2 − 1
=
x(n)
(x(n))2 + ( y(n))2
y(n)
(x(n))2 + ( y(n))2
(3.40)
Vamos fornecer, inicialmente, valor de (x(0), y(0))T = (0 , 5 ; 0 , 5)T , então na primeira iteração, utilizando(3.40) , temos:
x(1)
y(1)
=
x(0)
(x(0))2 + ( y(0))2
y(0)
(x(0))2 + ( y(0))2
=
=
0,25
0,25
. (3.41)
Substituindo no gradiente da função, dado por (3.39) , obtemos:
||∇ f (x(1), y(1))||2 ∼
(−0.2672612419)2 + (−0.2672612419)2 ∼ 0.377964473.
Estamos longe do valor da raiz, pois o erro ainda é bem grande. Vamos iterar mais uma vez, usando ovalor (x(1), y(1))T = (0,25;0,25)T , na segunda iteração, temos:
x(2)
y(2)
=
x(1)
(x(1))2 + ( y(1))2
y(1)
(x(1))2 + ( y(1))2
=
=
0, 03125
0, 03125
. (3.42)
Substituindo no gradiente da função, dado por (3.39) , obtemos:
||∇ f (x(2), y(2))||2 ∼
(−0, 03128056235)2 + (−0, 03128056235)2 ∼ 0, 04423739552
Ainda não atingimos a tolerância exigida, mas estamos bem próximos dela. Vamos iterar pela terceiravez, obtendo:
x(3)
y(3) = x(2)
(x(2))2 + ( y(2))2
y(2)
(x(2))2 + ( y(2))2
= ∼ 0, 000061
0, 000061 . (3.43)
Substituindo no gradiente da função, dado por (3.39) , obtemos:
||∇ f (x(2), y(2))||2 ∼
(−0, 000061)2 + (−0, 000061)2 ∼ 0, 000086.
Atingimos a raiz na terceira iteração com erro de, aproximadamente, 0, 00009 , bem menor que o erro exigido de 0,01.
Observação 14. Existem outros métodos que podem ser usados para aproximar as raízes da função ve-torial, entretanto, sua dedução é bem mais trabalhosa e está fora do objetivo desse material introdutóriode cálculo numérico. Para mais detalhes veja Capítulo 11 de [1].
3.4.1 A implementação do Método de Newton p-dimensional
function [ x, ex,iter ] = newtonpdimensional(x0,tol)
% Metodo de Newton.
% Descobre as raizes sucessivamente.
%
%
% Diferentemente do metodo anterior, nao podemos
% entrar com a função $f$ e a matriz $jacobiana$

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 66/101
66 CAPÍTULO 3. MÉTODOS PARA O CÁLCULOS DE RAÍZES DE FUNÇÕES
% Vamos defini-la num a função separada (abaixo)
% a qual chamamos de $funcaof$ e $Jacobianaf$
% Entrada do método
% x0 = chute inicial como vetor COLUNA
% tol = tolerancia maxima admitida para o erro.%
% Output:
% x - aproximacao da raiz
% ex - erro estimado em valor absoluto.
%
% k=numero de iteracoes.
% Calcula a dimensão para o qual
% estamos querendo encontrar a raiz.
nn=length(x0);
%
% Neste método iremos utilizar o comando de inversao de matrizes do matlab
%
%Avalie a matriz Jacobiana no ponto x0
J= Jacobiana(x0);
%Inverte a Jacobiana
A= inv(J);
x(:,1) = x0 - A*(funcaof(x0));
calculaf1(:,1)=f(x(:,1));
%
% Calcula os erros absolutos para o dominio e a imagem% Estamos usando a norma 2.
%
auxiliar1=0
auxiliar2=0;
for ii=1:nn
auxiliar1=(x(ii,1)-x0(ii))^2+auxiliar;
auxiliar2=(calculaf1(ii))^2+auxiliar2;
end
ef(1)=sqrt(auxiliar2);
ex(1) = sqrt(auxiliar1);
k=2;
pause
while (ef(k-1) >= tol1) && (ex(k-1) >= tol2) && (k <= N)
J= Jacobiana(x(:,k-1));
%Inverte a Jacobiana
A= inv(J);
x(:,k) = x(:,k-1) - A*(calculaf1(:,k-1));
calculaf1(:,k)=f(x(:,k));

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 67/101
3.4. EXTENSÃO DO MÉTODO DE NEWTON PARA FUNÇÕES VETORIAIS 67
%
% Calcula os erros absolutos para o dominio e a imagem
% Estamos usando a norma 2.
%
auxiliar1=0
auxiliar2=0;for ii=1:nn
auxiliar1=(x(ii,k)-x(ii,k-1))^2+auxiliar;
auxiliar2=(calculaf1(ii))^2+auxiliar2;
end
ef(k)=sqrt(auxiliar2);
ex(k) = sqrt(auxiliar1);
k = k+1;
pause
end
%
% Verificação quanto ao erro e ao número de iterações atingidas.
%
%
% Erro maximo da imagem foi atingido. Raiz encontrada
%
if(k<N)&& (ef(k-1) < tol1)
str = [’A raiz atingiu |f(x^n)|<tol1. O valor da raiz eh ’, num2str(x(:,k-1)), ’’]
efinalimagem=[’Com erro da imagem, |f(x^n)| ’ num2str(ef(k-1)), ’’]
efinaldominio=[’Com, |x^{n}-x^{n-1}| dado por ’ num2str(ex(k-1)), ’’]
it = [’O numero de iteracoes foi ’, num2str(k-1), ’’]
end
%
% Erro maximo da imagem nao foi atingido, mas do dominio foi.
%
if(k<N)&& (ef(k-1) >= tol1)
[’A raiz nao atingiu |f(x^n)|<tol1, mas |x^{n}-x^{n-1}| <tol2’]
str = [ ’O valor da raiz eh ’, num2str(x(:,k-1)), ’’]
it = [’O numero de iteracoes foi ’, num2str(k-1), ’’]
efinalimagem=[’Com erro da imagem, |f(x^n)| ’ num2str(ef(k-1)), ’’]
efinaldominio=[’Com, |x^{n}-x^{n-1}| dado por ’ num2str(ex(k-1)), ’’]
end
%
% Numero de iterações nao foi suficiente para o metodo convergir.
%
if (k>=N)
[’O metodo nao convergiu. Aumente a tolerancia’]
it = [’O numero de iteracoes foi ’, num2str(k-1). ’]
end
iter=k-1;
end

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 68/101
68 CAPÍTULO 3. MÉTODOS PARA O CÁLCULOS DE RAÍZES DE FUNÇÕES
3.5 Exercícios
Observação 15. Nos exercícios abaixo, caso o intervalo possua extremos sendo números com vírgula,utilizarei o símbolo “;” para indicar a separação entre dois números distintos.
Exercício 1 Use o método o teorema do valor intermediário para cada uma das funções para provarque elas possuem raízes no intervalo selecionado e o use o método da Bisecção iterando o método 3 vezese calcule o erro encontrado.
f (x) =√
x − cos(x) x ∈ [0, 1], f (x) = 3(x + 1)(x − 0.5)(x − 1) x ∈ [−2 ; 1 , 5] e x ∈ [−1, 3]
Exercício 2. Prove que cada função f (x) possui raiz no intervalo dado através do teorema do valorintermediário, e use o método a bisecção para encontrar raiz com tolerância de 0,01 em cada caso:
f (x) = x3 − 7x2 + 14x − 6, para x ∈ [0; 1], x ∈ [1 ; 3 , 2] e x ∈ [3 , 2 ; 4].
f (x) = x4 − 2x3 − 4x2 + 4x + 4, para x ∈ [−2; −1], x ∈ [0, 2], x ∈ [2, 3] e x ∈ [−1, 0].
f (x) = x − 2−x, para x ∈ [0, 1], f (x) = ex − x2 + x − 2, para x ∈ [0, 1]
f (x) = 2xcos(2x) − (x + 1)2
, para x ∈ [−3, −2], e x ∈ [−1; 0]. f (x) = xcos(x) − 2x2 + 3x − 1, para x ∈ [0 , 2 ; 0 , 3], e x ∈ [1 , 2 ; 1 , 3].

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 69/101
3.6. PROJETO: ENCONTRAR RAÍZES DE FUNÇÕES 69
3.6 Projeto: Encontrar raízes de funções

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 70/101
70 CAPÍTULO 3. MÉTODOS PARA O CÁLCULOS DE RAÍZES DE FUNÇÕES

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 71/101
Capítulo 4
Interpolação Polinomial
Muitas vezes, em problemas práticos cotidianos, deparamo-nos com um grupo de dados (que podemser obtidos experimentalmente ou através de fórmulas) e queremos encontrar uma função que passaconecta todos esses dados.
Como uma primeira aproximação, a ideia é encontrar um polinômio de grau adequado conectandoesses pontos.
Por exemplo, imagine que tenhamos obtido, através de algum experimento os pontos (x0, y0) = (0, 1)e (x1, y1) = (1, 3). A pergunta é: “Qual o polinômio de menor grau que conecta esses dois pontos?”.Desde o pré de 6, sabemos que dois pontos determinam de modo único uma reta.
Uma reta é encontrada através da Equação:
y = ax + b,
no qual devemos encontrar os valores de a (que é o coeficiente angular, ou seja, a inclinação da reta) e b(que é o coeficiente linear, ou seja, o ponto no qual a reta corta o eixo y). Note que precisamos de duasinformações para encontrar a e b, as quais foram fornecidas através dos pontos dados.
De modo genérico, para pontos (x0, y0) e (x1, y1) dados, tal que x0
= x1, podemos encontrar os
valores a e b através do seguinte algoritmo.Quando x = x0, temos que y = y0; quando x = x1, temos que y = y1. Dessa forma encontramos o
seguinte sistema linear nas incógnitas a e b:
y0 = ax0 + b, (4.1)
y1 = ax1 + b. (4.2)
Tem como solução
a = y1 − y0
x1 − x0e b =
x0 y1 − x1 y0
x0 − x1, (4.3)
portanto, a equação da reta y = ax + b é escrita como:
y = y1
− y0
x1 − x0x +
x0 y1
−x1 y0
x0 − x1. (4.4)
Para o exemplo acima, tomando (x0, y0) = (0, 1) e (x1, y1) = (1, 3), encontramos a reta, veja Figura(4.1.a):
y = 3 − 1
1 − 0x +
0 · 3 − 1 · 1
0 − 1 = 2x + 1.
Observe que a necessidade de x0 = x1 aconteceu pois apenas nesse caso y é função. Caso x0 = x1 e y0 = y1 a reta é paralela ao eixo y e não é uma função, deveria ser dada por uma curva parametrizada.
Seguindo nosso raciocínio, imaginemos agora que nos sejam dados 3 pontos (x0, y0) = (0, 1), (x1, y1) =(1, 3) e (x2, y2) = (2, 8). A pergunta é: “Qual o polinômio de menor grau que conecta tais pontos”? Caso
71
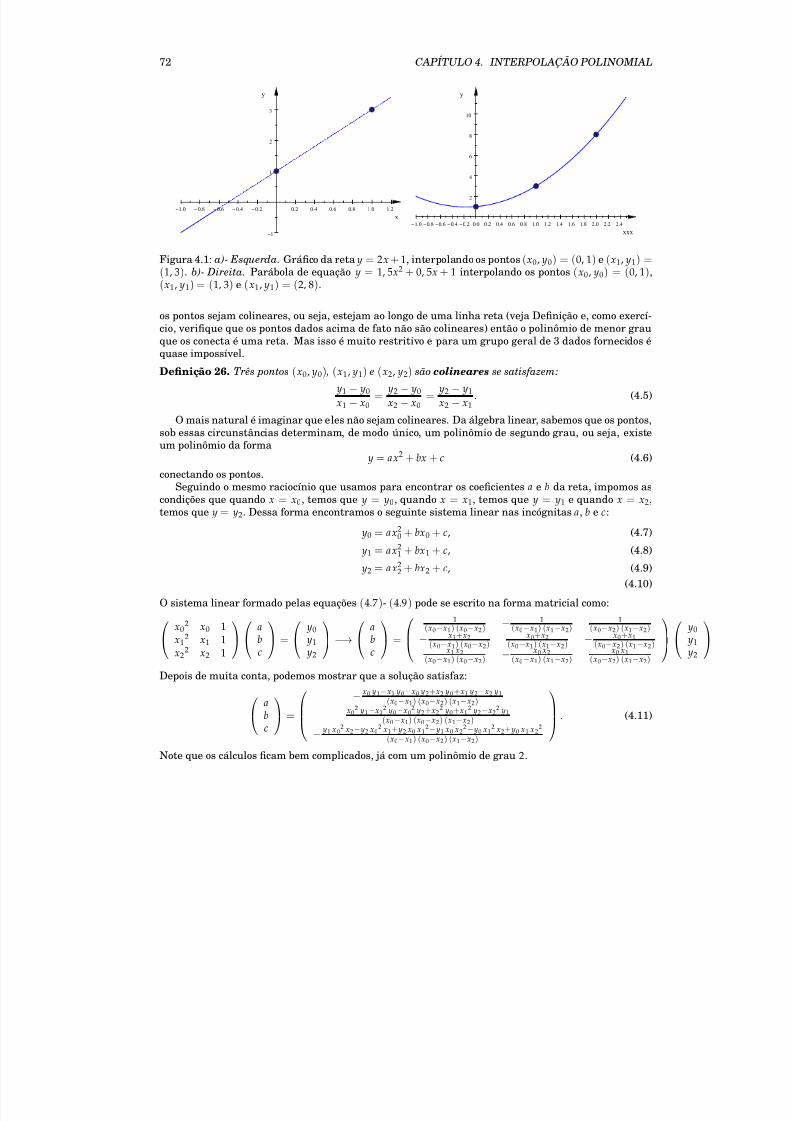
7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 72/101
72 CAPÍTULO 4. INTERPOLAÇÃO POLINOMIAL
−1.0 −0.8 −0.6 −0.4 −0.2 0.2 0.4 0.6 0.8 1.0 1.2
−1
1
2
3
x
y
−1.0 −0.8 −0.6 −0.4 −0.2 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0 2.2 2.4
2
4
6
8
10
xxx
y
Figura 4.1: a)- Esquerda. Gráfico da reta y = 2x + 1, interpolando os pontos (x0, y0) = (0, 1) e (x1, y1) =(1, 3). b)- Direita. Parábola de equação y = 1, 5x2 + 0, 5x + 1 interpolando os pontos (x0, y0) = (0, 1),(x1, y1) = (1, 3) e (x1, y1) = (2, 8).
os pontos sejam colineares, ou seja, estejam ao longo de uma linha reta (veja Definição e, como exercí-cio, verifique que os pontos dados acima de fato não são colineares) então o polinômio de menor grauque os conecta é uma reta. Mas isso é muito restritivo e para um grupo geral de 3 dados fornecidos équase impossível.
Definição 26. Três pontos (x0, y0) , (x1, y1) e (x2, y2) são colineares se satisfazem:
y1 − y0
x1 − x0=
y2 − y0
x2 − x0=
y2 − y1
x2 − x1. (4.5)
O mais natural é imaginar que eles não sejam colineares. Da álgebra linear, sabemos que os pontos,sob essas circunstâncias determinam, de modo único, um polinômio de segundo grau, ou seja, existeum polinômio da forma
y = ax2 + bx + c (4.6)
conectando os pontos.Seguindo o mesmo raciocínio que usamos para encontrar os coeficientes a e b da reta, impomos as
condições que quando x = x0, temos que y = y0, quando x = x1, temos que y = y1 e quando x = x2,temos que y = y2. Dessa forma encontramos o seguinte sistema linear nas incógnitas a, b e c:
y0 = ax20 + bx0 + c, (4.7)
y1 = ax21 + bx1 + c, (4.8)
y2 = ax22 + bx2 + c, (4.9)
(4.10)
O sistema linear formado pelas equações (4.7)- (4.9) pode se escrito na forma matricial como:
x02 x0 1x1
2 x1 1x2
2 x2 1
abc
=
y0
y1
y2
−→ a
bc
=
1
(x0−x1) (x0−x2) − 1
(x0−x1) (x1−x2)1
(x0−x2) (x1−x2)
− x1+x2(x0−x1) (x0−x2)
x0+x2(x0−x1) (x1−x2)
− x0+x1(x0−x2) (x1−x2)
x1 x2(x0−x1) (x0−x2)
− x0 x2(x0−x1) (x1−x2)
x0 x1(x0−x2) (x1−x2)
y0
y1
y2
Depois de muita conta, podemos mostrar que a solução satisfaz:
a
bc
=
− x0 y1−x1 y0−x0 y2+x2 y0+x1 y2−x2 y1
(x0−x1) (x0−x2) (x1−x2)x0
2 y1−x12 y0−x0
2 y2+x22 y0+x1
2 y2−x22 y1
(x0−x1) (x0−x2) (x1−x2)
− y1 x02 x2− y2 x0
2 x1+ y2 x0 x12− y1 x0 x2
2− y0 x12 x2+ y0 x1 x2
2
(x0−x1) (x0−x2) (x1−x2)
. (4.11)
Note que os cálculos ficam bem complicados, já com um polinômio de grau 2.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 73/101
73
Observação 16. Note que se os pontos forem colineares, ou seja, satisfizerem (4.5) , então a = 0 (prove esse fato, usando (4.5) em (4.11) ). Portanto, não precisamos nos preocupar inicialmente em verificar seos pontos são ou não colineares, basta que x i = x j se i = j para qualquer conjunto de pontos e é possível
encontrar tal polinômio. Caso seja colinear, os coeficientes de graus mais altos irão, naturalmente,anularem-se.
Em geral, para um exemplo específico, é muito mais fácil calcular a solução diretamente, ou seja,para encontrarmos o polinômio passando por (x0, y0) = (0, 1), (x1, y1) = (1, 3) e (x2, y2) = (2, 8),precisamos resolver o sistema linear:
1 = a(0)2 + b(0) + c, −→ c = 1
3 = a(1)2 + b(1) + c, −→ a + b + c = 3
8 = a(2)2 + b(2) + c, −→ 4a + 2b + c = 8 ,
que tem como solução bastante simples a = 1 , 5, b = 0, 5 e c = 1, portanto o polinômio passando pelostrês pontos dados é y = 1, 5x2 + 0, 5x + 1, veja Figura (4.1.b).
Agora imagine que tenhamos um grupo de m + 1 pontos (x0, y0), ( x2, y2), · · · , ( xm, ym). Generica-mente (desconsiderando casos em que os pontos estejam todos sobre uma curva de grau menor que m),o polinômio de menor grau que interpola esses pontos é um polinômio de grau m da forma:
y = amxm + am−1xm−1 + · · · + a1x1 + a0. (4.12)
Observe que existem m + 1 incógnitas, que são os m + 1 coeficientes ai para i = 0,1, · · · , m e m + 1informações, que são os pontos para os quais o polinômio passa.
Usando a mesma estratégia anterior, iremos admitir que y = y0, quando x = x0, que y = y 1 quandox = x2 e assim sucessivamente até que y = yn quando x = xn. Dessa forma encontramos o seguintesistema linear nas incógnitas am, am−1, · · · , a0:
y0 = amxm0 + am−1xm−1
0 + · · · + a1x0 + a0,
y1 = amxm1 + am−1xm−11 + · · · + a1x1 + a0, (4.13)... =
...
ym = amxmm + am−1xm−1
m + · · · + a1xm + am,
o qual pode ser escrito na forma matricial como:
AX = Y −→
xm0 xm−1
0 · · · 1
xm1 xm−1
1 · · · 1... · · · . . .
...xm
m xm−1m · · · 1
am
am−1...
a0
=
y0
y1...
ym
(4.14)
A matriz dos coeficientes A é um tipo de matriz, chamada de matriz de Vandermonde. É possívelmostrar que se xi = x j para i = j a matriz é não singular. Então quer dizer que o sistema (4.14) temsolução e única.
Exemplo 15. Encontre o polinômio de grau 4 passando pelos pontos (0, 1) , (1, 3) , (2, 7) , (3, 5) , (4,11). Para encontrar o polinômio, basta resolvermos o sistema:
0 0 0 0 11 1 1 1 1
24 23 22 2 134 33 32 3 144 43 42 4 1
a4
a3
a2
a1
a0
=
1375
11
(4.15)

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 74/101
74 CAPÍTULO 4. INTERPOLAÇÃO POLINOMIAL
Usando algum método desenvolvido no Capítulo 2 , encontramos a solução de (a4, a3, a2, a1, a0) como(11/12, −41/6, 181/12, −43/6, 1) , então o polinômio de grau 4 fica escrito como:
y = 11
12x4 − 41
6 x3 +
181
12 x2 − 43
6 x + 1.
Veja a Figura (4.2.a).
0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0
2
4
6
8
10
12
xxx
y
−1.0 −0.8 −0.6 −0.4 −0.2 0.0 0 .2 0 .4 0 .6 0 .8 1 .0 1 .2 1 .4 1 .6 1 .8 2 .0 2 .2
3.0
3.1
3.2
3.3
3.4
3.5
3.6
3.7
3.8
3.9
4.0
x
y
Figura 4.2: a)- Esquerda. Gráfico do polinômio y = 11
12x4 − 41
6 x3 +
181
12 x2 − 43
6 x + 1, interpolando os
pontos (0, 1), (1, 3), (2, 7), (3, 5), (4,11). b)- Direita. Reta de equação y = 1
3x +
10
3 passando pelos
pontos (−1, 3), (2, 4).
Poderíamos entar estar satisfeitos e dizer que esse capítulo está acabado e podemos passar para opróximo. Bem, mas vamos entar imaginar um caso exemplo, nada absurdo.
Imagine que tenhamos 101 pontos para serem interpolados. Vamos imaginar que os valores de xsão da forma x0 = 0, x1 = 1, · · · , x i = i · · · x100 = 100. Como estudado até agora, sabemos que podemosencontrar um polinômio de grau 100 conectando esses pontos. Bastante grande, mas bem possível determos que interpolar essa quantidade de pontos.
Portanto, a matriz dos coeficientes A ficaria escrita como:
x1000 x99
0 · · · 1x100
1 x991 · · · 1
... · · · . . . ...
x100m x99
m · · · 1
−→
0 0 · · · 0 11 1 · · · 1 1
2100 299 . . . 2 1... · · · . . .
...100100 (100)99 · · · 100 1
Observe que da primeira linha para a centésima linha, a ordem da matriz fica extremamentegrande, pois passa de 1 para (o absurdo) 100100. Qualquer método utilizado para a solução, poderáencontrar muitos problemas e os erros podem aumentar tanto a ponto de estragar definitivamente asolução do sistema.
Uma questão se coloca: Como tentar contornar esse fato? Como conseguir interpolar esses pontosutilizando um algoritmo que seja estável e nos dê uma solução adequada?
Isso tem que acontecer, pois sabemos ser possível interpolar esses pontos. Para tanto surgem algu-mas técnicas interessantes, tais como o método de Lagrange que descreveremos a seguir. Na Seção 4.4discutiremos a spline-cúbica, que é uma técnica de interpolação um pouco diferente da de encontrar po-linômios, mas particularmente, muito útil. Em geral, os programas que constroem gráficos, baseiam-sena técnica de spline cúbica para desenhar as curvas.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 75/101
4.1. UNICIDADE DA EXPANSÃO POLINOMIAL 75
4.1 Unicidade da expansão polinomial
Na próxima seção, iremos propor um método diferente para encontrar um polinômio de grau m pas-sando por m + 1 pontos. Uma pergunta bastante relevante é: Este polinômio será único ou existemoutros polinômios de grau m que interpolam os pontos?.
Definição 27. Dizemos que um polinômio p(x) interpola um conjunto pontos (xi, yi) , para i = 0,1, · · · , mdados, se
p(xi) = y i, ∀i = 0 ,1,2, · · · , m.
Definição 28. Dado um polinômio qualquer p(x) , definimos como o grau de um polinômio o maior expoente (inteiro e positivo) de suas potências. Representamos tal grau como grau( p(x))
A resposta a essa pergunta é: Sim, o polinômio é único e é dado pelo seguinte Teorema:
Teorema 8. Existe um único polinômio de grau menor ou igual a m interpolando m + 1 pontos (xi, yi) , para i = 0,1, · · · , m dados.
Prova: Suponhamos que existam dois polinômios, denotados por p1(x) e p2(x), de grau menor ou
igual a m interpolando os pontos (xi, yi), para i = 0,1, · · · , m dados, ou seja, para i = 0,1, · · · , m
p1(xi) = y i e p2(xi) = y i. (4.16)
Definimos um polinômio P(x) como sendo a diferença de p1(x) e p 2(x):
P(x) = p1(x) − p2(x),
Sabemos que a soma ou diferença de polinômios não podem aumentar o seu grau (podem diminuir,desde que pode haver cancelamento do termo de maior expoente entre os polinômios). Portanto ouP(x) ≡ 0, ou seja, P(x) é identicamente zero, ou grau(P(x)) ≤ m.
Se P(x) não é identicamente nulo note que temos cada xi, para i = 0,1, · · · , m, é uma raiz dopolinômio P(x) pois
P(xi) = p1(xi) − p2(xi) = yi − yi = 0,no qual a última igualdade é obtida de (4.16).
Quer dizer que P(x) tem m + 1 raízes, neste caso P(x) poderia ser decomposto em suas raízes como:
P(x) = h(x)(x − x0)(x − x1) · · · (x − xm), (4.17)
no qual o grau de h(x) seria maior ou igual a zero (o polinômio constante, exceto o identicamente nulo,tem grau 0). Mas isto é um absurdo, pois se P(x) pudesse ser decomposto como (4.17) o grau(P(x)) > m.O absurdo esteve em supor que P(x) não era identicamente nulo. Portanto, a única possibilidade paraP(x) ≡ 0 e, portanto,
p1(x) − p2(x) ≡ 0 −→ p1(x) ≡ p2(x), (4.18)
e o Teorema está provado.
Observação 17. Como o polinômio de grau m é único, então não importa da forma que calculemoso polinômio. O método de Lagrange dará o mesmo polinômio que seria obtido pelo método anterior,
entretanto, de forma bem mais estável, pois não há crescimento rápido dos termos, como no caso damatriz de Vandermonde anteriormente descrita.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 76/101
76 CAPÍTULO 4. INTERPOLAÇÃO POLINOMIAL
4.2 Método de Lagrange
O método de Lagrange é um método bastante simples, mas poderoso e que torna possível a obtenção deum polinômio de grau m interpolando m + 1 pontos qualquer que seja o valor de m (inclusive o exemploacima que tornou-se insolúvel).
Ele baseia-se numa ideia que vamos começando a construir paulatinamente. Primeiro para equa-ções lineares, depois para polinômios de segundo grau até sua generalização para um caso de m-ésimograu.
Polinômio de Grau 1
Como na Seção anterior, suponhamos que queiramos interpolar os pontos (x0, y0) e (x1, y1) com x0 = x1. Vamos propor um polinômio p(x) dado por:
p(x) = L0(x) y0 + L1(x) y1, (4.19)
no qual L0(x) e L1(x) são funções a serem determinadas. Vamos determiná-la do modo mais simplesque pudermos. Primeiro, note que se impusermos a condição sobre L0(x) e L1(x) satisfazendo:
L0(x) =
1, se x = x0,
0, se x = x1,e L1(x) =
0, se x = x 0,
1, se x = x 1,(4.20)
temos de (4.19) que o polinômio p(x) satisfaz:
p(x0) = L0(x0) y0 + L1(x0) y1 = y0 e p(x1) = L0(x1) y0 + L1(x1) y1 = y1,
o que indica que o polinômio p(x) realmente interpola (x0, y0) e (x1, y1).Precisamos encontrar uma função razoável para L0(x) e L1(x) de modo que eles retenham as pro-
priedades (4.20) e continuem simples. A melhor forma de propor tal função é olhando para os valoresque ela se anula.
Começando por L0(x), note que este anula-se para x = x1, então já temos uma boa indicação decomo proceder e desenvolver um algoritmo simples. Vamos propor, inicialmente,
L0(x) = x − x1, (4.21)
Observe que (4.21) é a função mais simples que se anula em x1 e não é constante. Mas note que elaainda não satisfaz a segunda propriedade, ou seja, que L0(x0) = 1. Para chegar em tal propriedade,basta normalizarmos (4.21), dividindo-o por (x0 − x1) e temos:
L0(x) = x − x1
x0 − x1, (4.22)
o qual é um polinômio de grau um bem simples que satisfaz as propriedades (4.20).Usando o mesmo argumento construtivo para L1(x) (refaça os passos), propomos a seguinte função:
L1(x) = x − x0
x1 −
x0
. (4.23)
Usando (4.22) e (4.23), o polinômio p(x) dado por (4.19) é escrito como:
p(x) = x − x1
x0 − x1 y0 +
x − x0
x1 − x0 y1, (4.24)
Exemplo 16. Encontre, pelo método de Lagrange, o polinômio passando por (−1, 3) , (2, 4). Para encontrar o polinômio, basta substituir (−1, 3) , (2, 4) em (4.24):
p(x) = x − 2
−1 − 23 +
x + 1
2 + 14 =
x
3 +
10
3 ,
que é uma reta, veja Figura (4.2.b)

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 77/101
4.2. MÉTODO DE LAGRANGE 77
Polinômio de Grau 2
Seguindo nosso raciocínio, suponhamos que queiramos interpolar os pontos (x0, y0), (x1, y1) e (x2, y2)com x0 = x 1 = x2. Vamos propor um polinômio p (x) dado por:
p(x) = L0(x) y0 + L1(x) y1 + L2(x) y2, (4.25)
no qual L0(x), L1(x) e L2(x) são funções a serem determinadas. Vamos determiná-la do modo maissimples que pudermos. Primeiro, note que se impusermos a condição sobre L0(x), L1(x) e L2(x) satis-fazendo:
L0(x) =
1, se x = x0,
0, se x = x1,
0, se x = x2,
L1(x) =
0, se x = x 0,
1, se x = x 1,
0, se x = x 2,
e L2(x) =
0, se x = x 0,
0, se x = x 1,
1, se x = x 2,
(4.26)
temos de (4.25) que o polinômio p(x) satisfaz:
p(x0) = L0(x0) y0 + L1(x0) y1 + L2(x0) y2 = y 0,
p(x1) = L0(x1) y0 + L1(x1) y1 + L2(x1) y2 = y 1
p(x2) = L0(x2) y0 + L1(x2) y1 + L2(x2) y2 = y 2,
o que indica que o polinômio p(x) realmente interpola (x0, y0), (x1, y1) e (x2, y2).Precisamos encontrar uma função razoável para L0(x), L1(x) e L2(x) de modo que eles retenham
as propriedades (4.26) e continuem simples. A melhor forma de propor tal função é olhando para osvalores que ela se anula, como no caso linear.
Vamos fazer para L0(x), os outros são iguais. Note que L0(x) se anula para x = x1 e x = x2, fatoque nos dá uma boa indicação de como proceder e desenvolver um algoritmo simples. A função maissimples que satisfaz essa propriedade que podemos pensar é:
L0(x) = (x − x1)(x − x2), (4.27)
Para obter que L0(x0) = 1, basta normalizarmos (4.27), dividindo-o por (x0 − x1)(x0 − x2) e temos:
L0(x) = (x − x1)(x − x2)
(x0 − x1)(x0 − x2), (4.28)
o qual é um polinômio de grau dois bem simples que satisfaz as propriedades (4.26).Usando o mesmo argumento construtivo para L1(x) e L2(x) (refaça os passos), propomos as seguin-
tes funções:
L1(x) = (x − x0)(x − x2)
(x1 − x0)(x1 − x2) t exte L2(x) =
(x − x0)(x − x1)
(x2 − x0)(x2 − x1). (4.29)
Usando (4.28) e (4.29), o polinômio p(x) dado por (4.25) é escrito como:
p(x) = (x − x1)(x − x2)(x0 − x1)(x0 − x2)
y0 + (x − x0)(x − x2)(x1 − x0)(x1 − x2)
y1 + (x − x0)(x − x1)(x2 − x0)(x2 − x1)
y2, (4.30)
Exemplo 17. Encontre, pelo método de Lagrange, o polinômio passando por (0, 2) , (1, 6) , (2, 4). Para encontrar o polinômio, basta substituir esses pontos em (4.30):
p(x) = (x − 1)(x − 2)
(0 − 1)(0 − 2)2 +
(x − 0)(x − 2)
(1 − 0)(1 − 2)6 +
( x − 0)(x − 1)
(2 − 0)(2 − 1)2 = 7 x − 3 x2 + 2,
que é uma parábola, veja Figura (4.3.b)
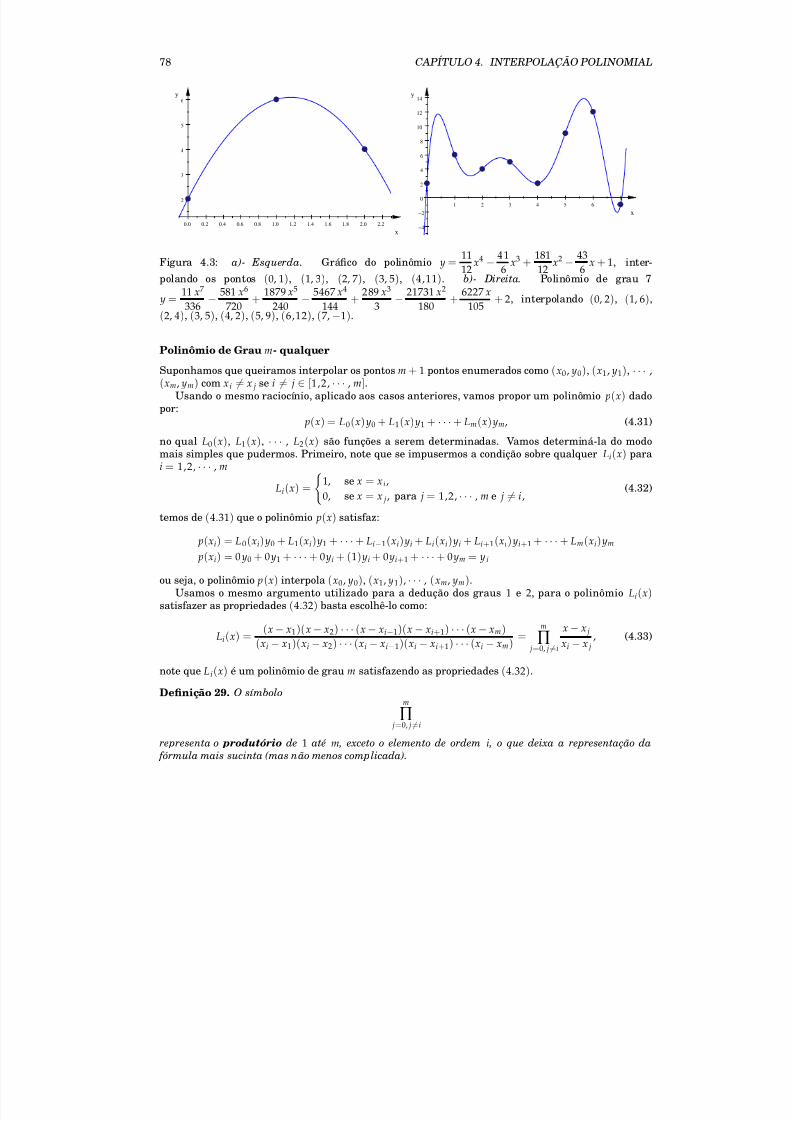
7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 78/101
78 CAPÍTULO 4. INTERPOLAÇÃO POLINOMIAL
0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0 2.2
2
3
4
5
6
x
y
1 2 3 4 5 6 7
−4
−2
0
2
4
6
8
10
12
14
x
y
Figura 4.3: a)- Esquerda. Gráfico do polinômio y = 11
12x4 − 41
6 x3 +
181
12 x2 − 43
6 x + 1, inter-
polando os pontos (0, 1), (1, 3), (2, 7), (3, 5), (4,11). b)- Direita. Polinômio de grau 7
y = 11 x7
336 −
581 x6
720
+ 1879 x5
240 −
5467 x4
144
+ 289 x3
3 −
21731 x2
180
+ 6227 x
105
+ 2, interpolando (0, 2), (1, 6),
(2, 4), (3, 5), (4, 2), (5, 9), (6,12), (7, −1).
Polinômio de Grau m- qualquer
Suponhamos que queiramos interpolar os pontos m + 1 pontos enumerados como (x0, y0), (x1, y1), · · · ,(xm, ym) com x i = x j se i = j ∈ [1,2, · · · , m].
Usando o mesmo raciocínio, aplicado aos casos anteriores, vamos propor um polinômio p(x) dadopor:
p(x) = L0(x) y0 + L1(x) y1 + · · · + Lm(x) ym, (4.31)
no qual L0(x), L1(x), · · · , L2(x) são funções a serem determinadas. Vamos determiná-la do modomais simples que pudermos. Primeiro, note que se impusermos a condição sobre qualquer Li(x) para
i = 1,2, · · · , m
Li(x) =
1, se x = x i,
0, se x = x j, para j = 1,2, · · · , m e j = i ,(4.32)
temos de (4.31) que o polinômio p(x) satisfaz:
p(xi) = L0(xi) y0 + L1(xi) y1 + · · · + Li−1(xi) yi + Li(xi) yi + Li+1(xi) yi+1 + · · · + Lm(xi) ym
p(xi) = 0 y0 + 0 y1 + · · · + 0 yi + (1) yi + 0 yi+1 + · · · + 0 ym = y i
ou seja, o polinômio p(x) interpola (x0, y0), (x1, y1), · · · , (xm, ym).Usamos o mesmo argumento utilizado para a dedução dos graus 1 e 2, para o polinômio Li(x)
satisfazer as propriedades (4.32) basta escolhê-lo como:
Li(x) = (x − x1)(x − x2) · · · (x − xi−1)(x − xi+1) · · · (x − xm)(xi − x1)(xi − x2) · · · (xi − xi−1)(xi − xi+1) · · · (xi − xm)
=m
∏ j=0, j=i
x − x j
xi − x j, (4.33)
note que L i(x) é um polinômio de grau m satisfazendo as propriedades (4.32).
Definição 29. O símbolom
∏ j=0, j=i
representa o produtório de 1 até m , exceto o elemento de ordem i , o que deixa a representação da fórmula mais sucinta (mas não menos complicada).

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 79/101
4.2. MÉTODO DE LAGRANGE 79
Usando (4.33) o polinômio (4.31) é escrito como:
p(x) =m
∏ j=1
x − x j
xi − x j y0 +
m
∏ j=0, j=1
x − x j
xi − x j y1 + · · · +
m
∏ j=0, j=m−1
x − x j
xi − x j ym−1 +
m−1
∏ j=0
x − x j
xi − x j ym. (4.34)
Exemplo 18. Encontre, pelo método de Lagrange, o polinômio de grau 7, passando pelos pontos 8 (0, 2) ,(1, 6) , (2, 4) , (3, 5) , (4, 2) , (5, 9) , (6,12) , (7, −1).
Para encontrar o polinômio, basta substituir esses pontos em (4.34) , com m = 7. Como o polinô-mio é bastante grande, iremos calcular cada um dos L0 até L7 separadamente. Após alguma álgebra,
encontramos:
L0(x) = − (x − 1) (x − 2) (x − 3) (x − 4) (x − 5) (x − 6) (x − 7)
5040 ,
L1(x) = x (x − 2) (x − 3) (x − 4) (x − 5) (x − 6) (x − 7)
720 ,
L2(x) = −x (x − 1) (x − 3) (x − 4) (x − 5) (x − 6) (x − 7)
240 ,
L3(x) = x (x − 1) (x − 2) (x − 4) (x − 5) (x − 6) (x − 7)
144 ,
L4(x) = −x (x − 1) (x − 2) (x − 3) (x − 5) (x − 6) (x − 7)
144 ,
L5(x) = x (x − 1) (x − 2) (x − 3) (x − 4) (x − 6) (x − 7)
240 ,
L6(x) = −x (x − 1) (x − 2) (x − 3) (x − 4) (x − 5) (x − 7)
720 ,
L7(x) = x (x − 1) (x − 2) (x − 3) (x − 4) (x − 5) (x − 6)
5040 .
Então o polinômio p(x) , dado por (4.34) e usando os valores de L0(x) , L1(x),
· · · , L7(x) , acima encon-
tramos:
p(x) = 11 x7
336 − 581 x6
720 +
1879 x5
240 − 5467 x4
144 +
289 x3
3 − 21731 x2
180 +
6227 x
105 + 2.
Veja a Figura 4.3.b).
Só a título de lembrança, do Teorema 8, sabemos que esta expansão é única. Portanto podemosestabelecer nossos cálculos acima através do seguinte:
Teorema 9. (Teorema de Lagrange) O único polinômio de grau m interpolando m + 1 pontos ( xi, yi) , para i = 0,1, · · · , m , é dado por (4.31) com os L i(x) , para i = 0,1, · · · , m satisfazendo (4.33).
Tal fato irá motivar uma forma mais simples de encontrarmos os coeficientes da expansão de La-
grange.Observação 18. Neste material não provaremos a convergência, nem o erro cometido pela interpolaçãode polinômios aproximando funções, pois está fora do escopo desse curso introdutório. Em [1] tal análise
é feita detalhadamente.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 80/101
80 CAPÍTULO 4. INTERPOLAÇÃO POLINOMIAL
4.3 Diferenças Divididas de Newton
Como sabemos, através dos Teoremas 8 e 9 que o polinômio de grau menor ou igual a m interpolandom + 1 pontos é único, podemos procurar formas alternativas de encontrar tais coeficientes de modomais rápido e adequado.
Dessa forma, se considerarmos tais pontos como ( xi, yi), para i = 0,1, · · · , m, podemos propor umpolinômio de grau m da forma:
P(x) = a0 + a1(x − x0) + a2(x − x0)(x − x1) + · · · + am(x − x0)(x − x1) · · · (x − xm−1), (4.35)
no qual os ai, para i = 0,1, · · · , m são desconhecidos. O nosso objetivo é, justamente, obter meiospara encontrá-los. Como nos algoritmos desenvolvido anteriormente, vamos construir o mecanismode encontrar os ai de modo intuitivo, para tanto, vamos começar com polinômios de grau 1, depoispolinômios de grau 2, até chegarmos aos polinômios de grau m qualquer e estabelecermos a teoria.
Diferenças Divididas para polinômios de grau 1
Já sabemos que um polinômio de grau 1 será obtido da interpolação de dois pontos (x0, y0) e (x1, y1).
Neste caso o polinômio P(x) dado por (4.35) é escrito como:P(x) = a0 + a1(x − x0). (4.36)
Queremos encontrar a0 e a1 de modo que P(x0) = y0 e P(x1) = y 1. Impondo essas condições obtemos:
1. Para x = x0, podemos obter a0 como:
y0 = P(x0) = a0 + a1(x0 − x0) = a0 −→ a0 = P(x0) = y 0.
2. Para x = x1, já conhecemos a0, através do cálculo anterior, portanto a1 é dado por:
y1 = P(x1) = a0 + a1(x1 − x0) = y0 + a1(x1 − x0) −→ a1 = P(x1) − P(x0)
x1
−x0
= y1 − y0
x1
−x0
.
Note que os coeficientes são os mesmos que encontramos com os métodos anteriores, o polinômio ficada (não surpreendente) forma:
P(x) = y0 + y1 − y0
x1 − x0(x − x0).
Diferenças Divididas para polinômios de grau 2
Para o polinômio de grau 2 precisamos de três pontos (x0, y0), (x1, y1) e (x2, y2). Neste caso o polinômioP(x) dado por (4.35) é escrito como:
P(x) = a 0 + a1(x − x0) + a2(x − x0)(x − x1). (4.37)
Queremos encontrar a0, a1 e a2 de modo que P(x0) = y0, P(x1) = y1 e P(x2) = y2. Impondo essascondições obtemos:
1. Para x = x0, podemos obter a0 como:
y0 = P(x0) = a0 + a1(x0 − x0) + a2(x0 − x0)(x0 − x1) = a0 −→ a0 = P(x0) = y0.
2. Para x = x1, já conhecemos a0, através do cálculo anterior, portanto a1 satisfaz:
y1 = P(x1) = a0 + a1(x1 − x0) + a2(x1 − x0)(x1 − x1) = y0 + a1(x1 − x0) −→a1 =
P(x1) − P(x0)
x1 − x0=
y1 − y0
x1 − x0.

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 81/101
4.3. DIFERENÇAS DIVIDIDAS DE NEWTON 81
item Para x = x 2, já conhecemos a0 e a1, através dos cálculos anteriores, para obter a2 temos:
P(x2) = a0 + a1(x2 − x0) + a2(x2 − x0)(x2 − x1) = P(x0) + P(x1) − P(x0)((x2 − x0))
x1 − x0+ a2(x2 − x0)(x2 − x1)
a2
= P(x2) − P(x0)
(x2 − x0)(x2 − x1) − P(x1) − P(x0)
(x1 − x0)(x2 − x1) =
1
(x2 − x1)P(x2) − P(x0)
(x2 − x0) − P(x1) − P(x0)
(x1 − x0)

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 82/101
82 CAPÍTULO 4. INTERPOLAÇÃO POLINOMIAL
4.4 Splines Cúbicas

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 83/101
4.5. EXERCÍCIOS 83
4.5 Exercícios

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 84/101
84 CAPÍTULO 4. INTERPOLAÇÃO POLINOMIAL
4.6 Projeto: Interpolação de Funções Polinomiais

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 85/101
Capítulo 5
Ajuste de Curvas e Otimização
85

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 86/101
86 CAPÍTULO 5. AJUSTE DE CURVAS E OTIMIZAÇÃO
5.1 Exercícios

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 87/101
5.2. PROJETO: AJUSTE DE CURVAS E OTIMIZAÇÃO 87
5.2 Projeto: Ajuste de Curvas e Otimização

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 88/101
88 CAPÍTULO 5. AJUSTE DE CURVAS E OTIMIZAÇÃO

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 89/101
Capítulo 6
Derivação Numérica
89

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 90/101
90 CAPÍTULO 6. DERIVAÇÃO NUMÉRICA
6.1 Exercícios

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 91/101
6.2. PROJETO: DERIVAÇÃO NUMÉRICA 91
6.2 Projeto: Derivação Numérica

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 92/101
92 CAPÍTULO 6. DERIVAÇÃO NUMÉRICA

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 93/101
Capítulo 7
Integração Numérica
93

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 94/101
94 CAPÍTULO 7. INTEGRAÇÃO NUMÉRICA
7.1 Exercícios

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 95/101
7.2. PROJETO: INTEGRAÇÃO NUMÉRICA 95
7.2 Projeto: Integração Numérica

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 96/101
96 CAPÍTULO 7. INTEGRAÇÃO NUMÉRICA

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 97/101
Capítulo 8
Equações Diferenciais Ordinárias
97

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 98/101
98 CAPÍTULO 8. EQUAÇÕES DIFERENCIAIS ORDINÁRIAS
8.1 Exercícios

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 99/101
8.2. PROJETO: EQUAÇÕES DIFERENCIAIS ORDINÁRIAS 99
8.2 Projeto: Equações Diferenciais Ordinárias

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 100/101
100 CAPÍTULO 8. EQUAÇÕES DIFERENCIAIS ORDINÁRIAS

7/18/2019 APOSTILA DE CÁLCULO NUMÉRICO
http://slidepdf.com/reader/full/apostila-de-calculo-numerico-5696e06843bbe 101/101
Referências Bibliográficas
[1] R. L. Burden, J. D. Faires, Numerical Analysis, Ninth Edition, Brooks/COLE Cengange Learning,Canada, 2011.
[2] E. L. Lima, Análise Real, 2a. Edição, IMPA, Rio de Janeiro.


















