
Universidad Autónoma Metropolitana Iztapalapa148.206.53.84/tesiuami/UAM3614.pdf · 1. Filtrado...
49
Universidad Autónoma Metropolitana Iztapalapa .. División de Ciencias Básicas e Ingeniería Licenciatura de Ingeniería en Electrónica Reporte de Proyecto Terminal Simulación de un filtro adaptable a través delalgoritmo NLMS Asesor: Dr. Fausto Casco Sanchez Participantes Rendón Nava Adrián Eduardo Rodriguez Gómez José Luis Valladares Solis Silvia Patricia México D.F. a 27 de julio de 2000
Transcript of Universidad Autónoma Metropolitana Iztapalapa148.206.53.84/tesiuami/UAM3614.pdf · 1. Filtrado...

Universidad Autónoma Metropolitana Iztapalapa
..
División de Ciencias Básicas e Ingeniería Licenciatura de Ingeniería en Electrónica
Reporte de Proyecto Terminal
Simulación de un filtro adaptable a través del algoritmo NLMS
Asesor: Dr. Fausto Casco Sanchez
Participantes Rendón Nava Adrián Eduardo Rodriguez Gómez José Luis
Valladares Solis Silvia Patricia
México D.F. a 27 de julio de 2000

Índice 225919
Capitulo I . Filtrado Adaptable I
1.1 Introducción ................................................................................. 1 Filtros FIR ................................................................................. 1 Filtros IIR ..................................................................... : .......... . 2
1.2 Ecuaciones normales ?.L.L.. "....?................... .................................... 4 . . / I . . I _ I
Capitulo 2 . Algoritmo NLMS 6
2.1 Estructura y operación del algoritmo LMS ................................. 2.2 Algoritmo de adaptación LMS ......................................................... 2.3 Algoritmo Normalizado LMS .........................................................
2.3.1 Algoritmo Normalizado LMS como la solución al Problema de Optimización Restringida .........................................................
Capitulo 3 . Algoritmo LMS con paso variable 3.1 Algoritmo LMS de paso variable ............................................. 3.2 Convergencia el vector medio ponderado ................................. 3.3 Comportamiento del error cuadrático medio ................................. 3.4 El estado estático de desajuste .............................................
Capitulo 4 . Matlab
4.1 ¿Qué es Matlab? ......................................................... 4.2 Herramientas utilizadas .........................................................
Comandos de propósito general ............................................. Procesamiento de señales ............................................. Control de flujo ..................................................................... Control de gráficos 2D elementales ............................................. Análisis matricial y funciones matemáticas elementales ......... Propósito específico ......................................................... Manipulación de matrices ......................................................... Creación de arreglos ......................................................... Direccionamiento de arreglos .............................................
6 9 11
11
16 16 18 19 22
28
28 29 29 30 30 31 31 32 32 33 33

Capitulo 5 . Resultados y Conclusiones
5.1 Síntesis de los algoritmos (Pseudocódigos) ................................. 0 Algoritmo NLMS ..................................................................... O Algoritmo VSSLMS .....................................................................
5.2 Transcripción al lenguaje de Matlab ............................................. 0 NLMS ................................................................................. 0 VSSLMS .................................................................................
5.3 Resultados y conclusiones de las simulaciones .................................
35
35 35 36 36 37 37 39

1. Filtrado Adaptable
1.1 Introducción
Antes de adentrarse en lo que es el filtrado adaptable, sería conveniente primero definir que es un filtro, y en lo particular, un filtro de señales eléctricas y/o electromagnéticas.
Un filtro es un dispositivo que realiza un proceso mediante el cual el espectro en frecuencia de una señal puede ser modificado o manipulado acorde con alguna especificación deseada. Dicho dispositivo podrá ampliar o atenuar un rango de componentes de frecuencia, rechazar o aislar una componente de frecuencia específica, etc.
El estudio que se lleva a cabo en el área de filtros no tendría razón de ser si no tuviese alguna justificación; es decir, una causa por la cual se hace. A continuación se presentan algunas aplicaciones que justifican el estudio de los filtros:
m m
m
m m m
Para eliminar el ruido que contamina a una señal. Para remover la distorsión de una señal causada por un canal de transmisión imperfecto o por fallas en la medición. Para separar dos o más distintas señales que fueron mezcladas a propósito maximizar la utilización del canal. Para demodular señales. Para convertir señales discretas en tiempo en señales continuas en tiempo. Para limitar señales en .banda, etc.
para
Por la forma en la cual una señal que entra un filtro es tratada, los filtros se pueden clasificar en dos tipos: analógicos y digitales. En este proyecto, se trabajó con filtros digitales.
Un filtro digital es un sistema digital que puede ser usado para filtrar señales discretas en tiempo. Una ventaja muy importante de los filtros digitales es la facilidad con la que los parámetros del filtro pueden ser cambiados para modificar las características del filtro. Una aplicación de la situación anterior es el desarrollo del filtrado adaptable.
La respuesta que presentan los filtros puede ser de dos tipos:
FIR (Finite Impulse Response), o I IR (Infinite Impulse Response)
Filtros FIR
La respuesta de un filtro FIR en el instante nT es de la forma:
1

m
y (nT) = aix(nT - iT ) I = -m
donde ai representa Constantes. Si ahora se asume causalidad, se puede mostrar que
a-l = a.2 = ... = O
y así m
y(n7') = z a x ( n T - iT) r=O
Si, además, x(nT) = O para n<O y ai= O para i>N
n W
y(n7') = x a x ( n T - iT) + x a x ( n T - iT)
= x a x ( n T - i T ) + x a x ( n T - i T ) I=o r=N+l N
= x a x ( n T - i T ) I=o
donde N es el orden del filtro.
La respuesta de un filtro IIR es función de los elementos de excitación así como de la sucesión de salida. En el caso de un filtro lineal, causal e invariante en tiempo
N N
y(nT) = ax(nT - iT) - xbT(nT - ir> r=O 1 = I
Si el instante nT se toma como el presente, la presente respuesta es función de los N valores presentes y pasados de la excitación así como de los N valores pasados de la respuesta. Es importante mencionar que la ecuación (1.4) se simplifica a la ecuación (1.3) si bi = O, así que esencialmente, el filtro FIR es un caso especial del filtro IIR.
El principio de un filtro adaptable se muestra en la figura r.1 La salida de un filtro digital programable con coeficientes variables se resta de una señal de referencia y(n) para producir una señal de error e(n), la' cual es usada en combinación con elementos de la sucesión de entrada x(n), para actualizar los coeficientes del filtro, siguiendo un criterio el
2

cual debe ser minimizado. Los filtros adaptables se pueden clasificar según las opciones que se tomen en las siguientes áreas:
. Criterio de optimización. . Algoritmo para actualización de coeficientes. . Estructura del filtro programable. O Tipo de señales procesadas - un¡ - o multidimensional.
Fig. 1.1 Principio de un Filtro Adaptable
Existe una alta dependencia de los algoritmos con el criterio de optimización, y frecuentemente es el algoritmo el que decide el criterio de optimización, y no al revés.
El filtro programable puede ser de tipo FIR o IIR y, en principio, puede tener cualquier estructura: forma directa, en cascada, en escalera, en enrejado o filtro de onda.
Los efectos de la longitud de palabra y la complejidad computacional varían con la estructura y con los coeficientes del filtro. Pero el punto peculiar con los filtros adaptables es que la estructura incide en la complejidad del algoritmo. Resulta que la forma directa FIR, es la estructura más simple de estudiar e implementar, y por ende la más popular.
Las señales multidimensionales pueden usar el mismo algoritmo y estructura que sus contrapartes monodimensionales. Sin embargo, la complejidad computacional y las limitaciones del hardware generalmente reducen las opciones a las más simples aproximaciones.
3

"
1.2 Ecuaciones Normales
Sea H(n) el vector de N coeficientes hi (n) del filtro programable al tiempo n, y sea X(n) el vector de las N muestras más recientes de la señal de entrada:
H(n) = X(n) = .. .......
X ( n + l - N )
La señal de error E(n) es
E(n) = y(n) - H' (n)X(n) (1.6) l
. - , .. - . .*
El procedimiento de optimización consiste en minimizar una función de costo j(n), la cual es tomada como una suma de errores cuadráticos, comenzando después del tiempo cero:
' y 1 *.'
5 ,i: 2 I:;!
n
p= 1
El factor W, es tomado generalmente cercano a 1 (O << W I 1). Ahora el problema es encontrar los coeficientes del vector H(n) el cual minimizará a j(n). La solución se obtiene igualando a cero las derivadas de j(n) con respecto a las entradas hi (n) del vector H(n), lo cual nos lleva a
En forma concisa, (1.8) es
(1.9)
(1.10)
4

(1.11)
Ahora
Así, b(n) es un estimado de la matriz de autocorrelación de la señal de entrada, y r,(n) es un estimado de la correlación cruzada entre la entrada y las señales de referencia.
El vector óptimo Hopt es alcanzado cuando n tiende al infinito:
Las ecuaciones (1.14) y (1.9) son las ecuaciones normales (Yule-Walker) para señales estacionarias y evolutivas respectivamente. En filtros adaptables, pueden ser implementados recursivamente.
5

2. Algoritmo NLMS
2.1 Estructura y Operación del algoritmo LMS
€1 algoritmo LMS es un algoritmo de filtrado adaptable lineal que consiste en dos procesos básicos:
1. Un proceso de filtrado, que involucra (a) el procesamiento de una señal de salida de un filtro producida por una serie de taps de entrada y (b) generar una estimación de error comparando est3 señal de salida con una respuesta deseada.
2. Un proceso adaptivo, que involucra el ajuste automático de los taps ponderados del filtro acorde con la estimación del error.
La combinación de estos dos procesos trabajando juntos constituye un proceso de retroalimentación a través del algoritmo LMS, como se ilustra en el diagrama a bloques de la figura 2.1(a). Primero, se tiene un filtro transversal, alrededor del cual se construye el algoritmo LMS; este componente es responsable de realizar el proceso de filtrado. Segundo, se tiene un mecanismo para realizar el proceso de control adaptable en los taps ponderados del filtro transversal.
E
Los detalles del componente del filtro transversal se presentan en la figura 2.1(b). Los taps de entrada u(n), u(n - l), ... , u(n - M + 1) forman los elementos del vector de entrada u(n) de tamaño MX1, donde M-1 es el número de elementos de retardo; estos
6

Durante el proceso de filtrado la respuesta deseada d(n) es proporcionada procesando el vector de entrada u(n) . Dada esta entrada, el filtro transversal produce una salida
& n l [ ~ n ) usada como una estimación de la respuesta deseada d(n). De esta manera se puede definir una estimación de error e(n) como la diferencia entre la respuesta deseada Y la salida actual del filtro, como se indica en la salida de la figura 2.1(b).
La estimación de error e(n) y el vector de entrada u(n) se introducen en el mecanismo de control, y el proceso de retroalimentación a través de los coeficientes se cierra. La figura 2.l(c) presenta detalles del mecanismo de control adaptable.
"3 " U + 1 ) a tL , ln l (Cl.
Específicamente, una versión escalar del producto interno de la estimación del error e(n) y el tap de entrada u(n - k) son procesados para k = Orl,2,...,M-2,M-1. El resultado obtenido define la corrección S Gk(n) aplicada al tap ponderado G,(n) en la iteración
7

A 10 largo del capítulo, se asume que el vector de entrada u(n) y la respuesta deseada d(n) se dan en un medio estacionario. Para este medio, el método de steepest descent procesa un vector de ponderación w(n) que baja la superficie del desempeño de error en conjunto a lo largo de una trayectoria determinística, que termina en la solución de Wiener, wo. El algoritmo LMS se comporta de manera distinta por la presencia del ruido de gradiente.
Más que terminar en la solución de Wiener, el vector G ( n ) [diferente de w(n)] procesado por el algoritmo LMS ejecuta una moción aleatoria alrededor del mínimo punto de la superficie de desempeño del error.
Anteriormente se señaló que el algoritmo LMS involucra retroalimentación en su operación, la cual eleva la estabilidad. En este contexto, un criterio significativo es requerir que
J ( n ) -+ J( m) mientras n + 00
donde J ( n ) es el error cuadrático medio producido por el algoritmo LMS al tiempo n, y su valor final J ( m ) es una constante. Un algoritmo que satisface este requerimiento se dice que es convergente en el cuadrado medio. Para que el algoritmo LMS satisfaga este criterio, el tamaño de paso ,u tiene que satisfacer cierta condición relacionada a la estructura propia de la matriz de correlación en los taps de entrada. La diferencia entre el valor final J ( m ) y el valor mínimo J,,, alcanzado por la solución de Wiener es llamado el error cuadrático medio de exceso J,(m). Esta diferencia representa el precio pagado por usar el mecanismo adaptivo (estocástico) para controlar los taps ponderados en el algoritmo LMS en lugar de una aproximación determinística como en el método de steepest descent La razón de J,(m) a J,,, es llamado el desajuste, el cual es una medida de que tan lejos está la solución del estado estático calculada por el algoritmo LMS de la solución de Wiener. Es importante darse cuenta, sin embargo, que el desajusteM está bajo el control del diseñador. En particular, la retroalimentación de los taps ponderados se comporta como un filtro pasabajos, cuya constante promedio de tiempo es inversamente proporcional al tamaño de pasop. Sin embargo, asignando un valor pequeño a p el prpceso adaptivo se hace más lento, y los efectos del ruido de gradiente en los taps ponderados son filtrados. Esto tiene el efecto de reducir el desajuste. Se puede decir entonces, justificablemente, que el algoritmo LMS es simple en la implementación, capaz de entregar un alto desempeño adaptándose a su ambiente
8

2.2 Algoritmo de adaptación LMS
V J ( n ) = -2p + 2RW(n) (2.1)
La elección más simple para estimar R y p es usar estimados instantáneos que están basados en valores de muestra del vector de entrada y la respuesta deseada, definidos como, respectivamente,
k(n) = u(n)u"(n)
Y b( 7 2 ) = Zl(tZ)d*(n)
Así, el estimado instantáneo del vector gradiente es
GJ(n) = -2u(n)d'(n) + 2u(n)uH(n)G(n) (2.4)
Generalmente, este estimado es imperfecto porque el vector de ponderación estimado G(n) es un vector aleatorio que depende del vector de entrada u(n). Nótese que el estimado ?.I(.) puede ser visto también como el operador gradiente V aplicado al error cuadrático instantáneo I e(n)I2 .
Sustituyendo el estimado de la eq. (2.4) por el vector gradiente VJ(n) en el algoritmo steepest descent, se obtiene una nueva relación recursiva para actualizar el vector de ponderación:
G(n + 1) = G(n) + pl(n)[d'(n) - u"(n)*(n)] (2.5)
9

Aquí se usó un “sombrero” sobre el símbolo del V e d O r de ponderación para distinguirlo del valor obtenido usando el algoritmo steepest descent. En forma equivalente, se puede
el resultado en la forma de tres relaciones básicas como sigue:
1. Filtro de salida:
2 . Estimación de error:
3. Adaptación de taps:
Las ecuaciones (2.6) y (2.7) definen el error de estimación e(n), el proceso en el cual está basado la estimación actual del vector de ponderación,t;(n). Nótese también que el segundo término, pu(n)e*(n), del lado derecho de la eq. (2.8) representa la corrección que es aplicada al actual estimado del vector de ponderación,G(n). El procedimiento iterativo se comienza con un valor inicial $(O).
El algoritmo descrito por las eqs. (2.6) a (2.8) es la forma compleja del algoritmo LMS. En cada iteración 6 tiempo de actualización, también se requiere conocimiento de los valores más recientes: u(n),J(n), y G ( n ) : El algoritmo LMS es miembro de la familia de algoritmos estocásticos gradiente. En particular, cuando el algoritmo LMS opera sobre entradas estocásticas, el conjunto de direcciones permitidas mediante las cuales se pasa de un ciclo de iteración al siguiente es muy aleatorio y no puede ser pensado como direcciones gradiente verdaderas.
La figura 2.2 muestra una representación gráfica del flujo de señal del algoritmo LMS en la forma de un modelo de retroalimentación. El flujo de señal de la fig. 2.2 ilustra claramente la simplicidad del algoritmo LMS. En particular, se ve de la figura que el algoritmo LMS requiere solo 2M+l multiplicaciones complejas y 2M sumas complejas por iteración, donde M es el número de taps usados en el filtro transversal. En otras palabras, la complejidad computacional del algoritmo LMS es q M ) .
10

LOS estimados instantáneos de R y p dados en las eqs. (2.2) y (2.3), respectivamente, tienen varianzas relativamente grandes. A primera vista, pudiera parecer que el algoritmo LMS es incapaz de un buen desempeño dado que el algoritmo usa estimados instantáneos. Sin embargo, se debe recordar que el algoritmo LMS es recursivo por naturaleza, con el resultado que el algoritmo mismo promedia efectivamente estos estimados, en algún sentido, durante el curso de la adaptación.
2 2 5 9 1 9 2.3 Algoritmo Normalizado LMS
En la forma estándar del algoritmo LMS, la corrección de pa(n)e'(n) aplicada al vector de ponderación G(n) en la iteración n + l es directamente proporcional al vector de entrada ~ ( n ) , Así, cuando u(n) es grande, el algoritmo LMS experimenta un problema de amplificación de ruido de gradiente. Para superar esta dificultad, se usará el algoritmo LMS Normalizado. En particular, la corrección aplicada al vector de ponderación G(n) en la iteración n + l es "normalizada" con respecto al cuadrado de la norma Euclidiana del vector de entrada u(n) en la iteración n. $ *. Pb;
" P I . . I
,F.. 4:;.
Se formulará al algoritmo normalizado LMS como una modificación natural al algoritmo .a ,_. r*.t ,%<
LMS ordinario. Alternativamente, se derivará al algoritmo normalizado LMS en su propia manera. c;'
2.3.1 Algoritmo Normalizado LMS como ¡a solución al Problema de Optimización Restringida.
El algoritmo NLMS puede ser visto como la solución al problema de optimización h z (minimización) restringida. Específicamente, el problema de interés puede ser descrito ' m: como sigue: Srl!
:y Y n: ,*" r, ,;* '
c", 5
r i g P (3
2 07
:I. . m z "
v
c'
SEA: ;3 2 Dado un vector de entrada u(n) y la correspondiente respuesta d(n), determinar el h{ h h E
vector G ( n + 1) para minimizar la norma Euclidiana cuadrática del cambio I;' L' k " u;
&(?I + 1) = G(n + 1) - G(n) (2.9)
en el vector G(n + 1) con respecto a su valor anterior G(n) , sujeto a la restricción
G (n + l)u(n) = d(n) (2.10)
Para resolver este problema de optimización restringida, se usará el método de los Multiplicadores de Lagrange.
La norma cuadrada del cambio &(n + 1) en el vector G(n + 1) puede ser expresado como
IIG(n + 1)11' = ¿%H((Iz + 1 ) s (n + 1) = [G(n + 1) - G(n)]"[G(n + 1) - G(n)]
11

"
(2.11)
Entonces se tiene
(2.13)
(2.14) (2.15)
Así, la restricción compleja puede ser reescrita de la eq. (2.10) como un par de restricciones reales equivalentes:
A l - l
(ak (n + I)!, (n - k ) + b, (n + l)zr, (n - k ) = dl (n) (2.16) k=I)
Y ( k - 1
C ( a k ( n + l ) t 1 2 ( n - k ) + b k ( n + l ) u l ( n - k ) = d , ( n ) (2.17) k=O
Ahora se puede formular una función de costo real J(n) para el problema de optimización restringida. Particularmente, se combinan las eqs. (2.13), (2.16), y (2.17) en la siguiente relación:
(2.18)
donde A, y ;1, son multiplicadores de Lagrange. Para encontrar los valores óptimos de (n + 1) y 6, (n + 1) , se diferencia la función de costoJ(n) con respecto a estos dos
parámetros y se establece el resultado a cero. De esta forma, el uso de la eq. (2.18) en la ecuación
12

(2.19)
De forma similar, el uso de la eq. (2.18) en la ecuación complementaria
= o ak (n + 1)
lleva al resultado complementario
2[b, (n + 1) - h, (n)] - (n - k) - 421, (n - k) = o (2.20)
A continuación, se usarin las definiciones de las eqs. (2.12) y (2.15) para combinar estos dos resultados en uno solo, como lo muestra
2[Gk (n + 1) - Ck (n)] = A*y(n - k) , k = O, 1, ... , M-1 (2.21)
donde R es un multiplicador complejo de Lagrange:
2 = .2, +.iA (2.22)
La solución para e l l * desconocido: se multiplican ambos lados de la eq. (2.21) por u*(n - k ) y se suma sobre todos los posibles valores enteros de k desde O hasta "1. Se obtiene entonces
k=O
(2.23)
donde Ilu(n)ll es la norma Euclidiana del vector de entrada u(n) . A continuación, se usa la restricción compleja de la eq. (2.10) en (2.23) para formular-2'. como se muestra:
13
(2.24)

Sin embargo, de la definición de la estimación del error e(n), se tiene
e(n) = d(n) - 6 (n)u(n)
Finalmente, se sustituye la eq. (2.25) en la eq. (2.21), obteniendo
&$ (Y1 + 1) = Gk (n + 1) - Gk (TI)
En forma de vector, se puede escribir de manera equivalente
&(n + 1) = t;(n + 1) - G ( n )
(2.25)
(2.26)
(2.27)
Para ejercer el control sobre el cambio en el vector de ponderación de una iteración a otra sin cambiar su dirección, se introduce un factor de escala real positivo denotado por ,íi . Esto es, simplemente redefinir el cambio &(n + 1)como
Equivalentemente, se puede escribir como
(2.28)
(2.29)
De hecho, esta es la recursión deseada para procesar el vector ponderado de tamaño M X l en el algoritmo LMS Normalizado.
La ecuación (2.29) muestra claramente la razón para usar el término "Normalizado". Se observa que el producto del vector u(n)e'(n) está normalizado con respecto al cuadrado de la norma Euclidiana para el vector de entrada u(n) . H punto importante de notar del análisis presentado anteriormente es que dada nueva información de entrada (al tiempo n) representada por el vector de entrada u(n) y la respuesta deseada d(n), el algoritmo LMS Normalizado actualiza al vector de ponderación de t a l modo que el valor G(n + 1)
14

al tiempo n + l exhibe un cambio mínimo (en el sentido de la norma Euclidiana) con respedo al valor conocido $(n) al tiempo n; por ejemplo, ningún peso puede representar un cambio mínimo. Sin embargo, el algoritmo LMS Normalizado (y para este propósito el algoritmo LMS convencional) es una manifestación del principio de
mínima. El principio de perturbación mínima establece que, en el umbral de nueva información de entrada, los parámetros de un sistema adaptive deben ser perturbados en una minima relación.
Mas aún, comparando la recursión de la eq. (2.29) para el algoritmo NLMS con la ecuación (2.8) del algoritmo LMS convencional, se pueden hacer las siguientes observaciones:
La adaptación constante de ,íi para el algoritmo NLMS es adimensional, mientras la adaptación constante dep para el algoritmo LMS tiene las dimensiones de potencia-'.
0 Estableciendo
(2.30)
se puede ver al algoritmo NLMS como un algoritmo LMS con el tamaño de paso variando en el tiempo.
0 El algoritmo NLMS converge en el cuadrado medio si la adaptación constante,íi satisface la siguiente condición:
O<,í i<2 (2.31)
De manera más importante, el algoritmo NLMS exhibe un rango de convergencia que es potencialmente más rápido que cualquier otro algoritmo LMS para los datos de entrada correlacionados y sin correlacionar. Otro punto de interés es que al superar el problema de amplificación del ruido de gradiente asociado con el algoritmo LMS, el algoritmo NLMS introduce un problema por sí mismo. Específicamente, cuando el vector de entrada u(n) es pequeño, las dificultades numéricas pueden surgir porque entonces es necesario dividir por un pequeño valor para la norma al cuadrado Il~(n)11~. Para resolver este problema, se modifica ligeramente la recursión de la eq. (2.29) como sigue:
(2.32)
donde a>O, y como antes O < ji < 2 . Para a = O, la eq. (2.32) se reduce a la forma previa dada en la eq. (2.29).
15

3. Algoritmo LMS con paso variable
En este capítulo se propone un algoritmo LMS con un paso de tamaño variable donde el ajuste para el tamaño del paso es controlado por la predicción del error al cuadrado. La motivación para hacer esto, es que una predicción de error grande causará que el tamaño del paso se incremente para proporcionar un seguimiento más rápido mientras que una predicción de error pequeña resultará en un decremento del tamaño del paso para alcanzar un menor desajuste.
3.1 Algoritmo LMS de paso variable
El problema en el filtrado adaptable, es tratar de ajustar el conjunto de coeficientes del fittro de tal suerte que la salida del sistema siga a una señal deseada. Sea el vector de entrada al sistema denotado por x k y la salida escalar deseada dk. Se asume que estos procesos están relacionados por la ecuación
donde e, es una secuencia independiente Gaussiana, independiente del proceso de entrada X,. Se van a considerar dos casos: %* es igual a una constante W * , y Wk* esta variando aleatoriamente acorde con la ecuación
donde LI es menor que, pero cercano a 1, y Z, es una secuencia independiente, independiente de X, y de e , , con covarianza E(Z,Zf } = ofI¿&, siendo Sb la función delta de Kronecker. El primer caso se referirá a un ambiente estacionario, el segundo a un ambiente no estacionario. Se asume que el proceso de entrada X, es una secuencia independiente de media cero, con covarianza E(X,Xf ) = R, una matriz positiva definida. Lo asumido anteriormente se hace con frecuencia en la literatura y aunque usualmente esto no se da en la práctica, los análisis basados en lo asumido con anterioridad arrojan predicciones que son frecuentemente validadas en aplicaciones y simulaciones.
El algoritmo LMS de tipo adaptable es un algoritmo de búsqueda de gradientes el cual computa una serie de coeficientes W, que buscan minimizar E(d, - X,'W,)', El algoritmo es de la forma
16

donde
E, = J , - x,'rv, (3.4)
Y p k es el tamaño de paso. En el algoritmo LMS estándar pk es una constante, Aquí, se propone un nuevo algoritmo, al Cual nos referiremos como algoritmo de paso variable 0 algoritmo VSS (Variable Step 9ze) por sus siglas en inglés. Para ajustar el paso variable
pk
donde 0 < Pmm < Pm,. El tamaño inicial del paso p0 se toma usualmente como pm,, aunque el algoritmo no es sensible a la elección. Como se puede ver de (3.5), el tamaño del paso , u k es siempre positivo y es controlado por el tamaño de la predicción del error y los parámetros a y y . Intuitivamente hablando, una predicción de error grande incrementa el tamaño del paso para lograr una convergencia mayor. Si la predicción del error decrementa, el tamaño del paso disminuirá para reducir el desajuste. La constante
el límite, Una condición suficiente que garantiza que el error cuadrático medio permanezca dentro de los límites es
Pmar es escogida para asegurar que el error cuadrático medio del algoritmo permanezca en
p,, 5 2 f 3tr(R)
17

I
3.2 Convergencia del Vector Medio Ponderado
El algoritmo VSS dado por las ecuaciones (3.3) a (3.6) es difícil de analizar exactamente. Para hacer el análisis más Sencillo, se introduce la siguiente simplificación. Se asumirá que
X, Ek 1 = E(& )E( x, E, )
LO anterior es Cierto Si , u k es una constante, pero no puede darse para el algoritmo vss. Sin embargo, se puede decir que es casi cierto. Esto es por que si y es pequeño, ,U, variará lentamente alrededor de su valor medio. Escribiendo
se ve que para una y suficientemente pequeña, el segundo término del lado derecho de (3.7) será pequeño comparado con el primero, La simplificación hecha permite derivar resultados teóricos cuyas predicciones nacen de las simulaciones. Hacer simplificaciones corno esta es una práctica común en la literatura del procesamiento adaptable de señales.
primero se estudiará la convergencia del vector de pesos medio. Como el caso estacionario puede ser derivado del caso no estacionario igualando a = 1, O! = O
(resultando en Z, = O con probabilidad uno), y Wk* = W*, se dará la derivación para el caso no estacionario solamente. De la simplificación anterior,
El vector de los coeficientes de error = W, - &* satisface la ecuación
La ecuación (3.8) es estable si y solo si
Una condición suficiente que debe mantener (3.9) es
E(Pk ) < 2 + Ama (R)
18
(3.9)
!

donde /Znlnr(R) es et máximo valor propio de la matriz R. Para cualquier 1, E(&*) >O. Aún así con la eq. (3.91, E ( % ) >O. EI caso estacionario
donde Wk* = W' es incluso más simple por el hecho de que la eq. (3.8) se vuelve una ecuación diferencial homogénea. La eq. (3.9) es entonces necesaria y suficiente para que E(K.) &?ir > W * .
Una condición más poderosa y a la vez más simple para que E(Wk ) converja a W* es que
LMS. P",, < (2 / Anla(R)). Esta condición es la misma que aquella para el algoritmo de paso fijo
La convergencia del vector medio ponderado no es suficiente para garantizar la convergencia del error cuadrático medio. En la siguiente sección, se derivarán las ecuaciones que describen el comportamiento del error cuadrático medio,
3.3 Comportamiento del error cuadrático medio
Como es el caso para el algoritmo regular LMS, la covarianza del vector de coeficientes está relacionada directamente con el error cuadrático medio. Por eso se analizará primero la covarianza para el vector de coeficientes. Sea el vector de coeficientes de error
m, = w, - Wk*
En el caso no estacionario, mk satisface la ecuación
Dado que R, la matriz de covarianza de X,, es simétrica, existen las matrices Q y A , con A diagonal, tal que
R = QAQ' y Q'Q = I. Sea
Vk = Q'%,X; = Q'X, ,
Wk*' = Q'Wk*, y Z; = Q'Z,.
Entonces,
19

+ E(Z,Z;) + E ( p ; X ; X ; e ; ) .
para poder continuar, se asumirá lo siguiente.
l. 2.
EI tamaño de paso pk es independiente de X, y de Vk . LOS componentes de Vk son independientes, condicionando variables aleatorias Gaussianas dado , u k - ¡ . Lo asumido en 1') es básicamente un refuerzo de lo asumido en 1). La justificación para lo que se asumió en 2) será discutido al final de esta sección. Ahora, asumiendo que a es cercano a la unidad de tal suerte que todos los términos (1 - a) pueden ser descartados, se tiene que
(3.11)
(3.12)
Se puede usar ahora el teorema de factorización de momentos Gaussiano para simplificar algunas de las expresiones de las ecuaciones mostradas anteriormente. Se tiene
Sustituyendo (3.13) en (3.10) lleva a
De la definición de E, , y de la independencia de e , ,
(3.13)
(3.14)
(3.15)
Realizando algunas operaciones, se deriva a la siguiente expresión aproximada para E(&;):
20

(3.17)
(3.19)
Nótese que al asumir que E@,) < 2 / Amm(R), E@&) >O, el último término del lado derecho de la ea. (3.19) será asintóticamente cero. El exceso del error cuadrático medio teX(k) = g(k) - t,,,,, está dado por
5,:(k) = lT G,. (3.20)
El comportamiento del error cuadrático medio está ahora descrito completamente por las eqs. (3.17) a (3.20).
El uso del teorema de factorización Gaussian0 fue posible 'por lo asumido en 2). Lo asumido en 2) se usa sólo en la evaluación de E(&:). Dado que E(&:) es multiplicado por la pequeña cantidad de y' , sólo se necesita mostrar que lo asumido en 2) se mantiene. Se mostrará que bajo condiciones requeridas para la convergencia del error cuadrático medio, Io asumido en 2) se mantendrd asintóticamente, para , u k pequeño.
Supongamos que
Entonces los elementos no diagonales de E(YkV:) son determinados por una ecuación homogénea de la forma
21

p,, = 1 - j i (A , + A j ) +2p54A1
(3.21)
(3.22)
p,,p, - p; = (1 - 2p4 + 2 p 2 # ) ( 1 - 2 j i 4 + 2p'Q
-[I-ji(A +;1,)+2p'&tl]2
= [(l- j i A l ) 2 + (2p2 - ji2)l;][(l - j q 2
+(2$ - p 2 ) A ; ] - [ ( 1 - j i 4 ) ( 1 - j i 4 )
+ (2p' - j 2 ) A , A j ] 2
-
= (2p2 - j i " ? ) [ ; l , (1 -$A1) - A] (1 - jiA,)I2 2 o. (3.23)
En la siguiente sección, se muestra que una de las condiciones para la convergencia del error cuadrático medio es que p,, < 1,VZ = 1, ..., n. Así, bajo esta condición y usando la eq. (3.23)
Plj < 1. (3.24)
esto significa que las componentes no diagonales de E(VkVr) decrecerán a cero, t a l que las componentes de V, no están correlacionadas asintóticamente. Finalmente, para i 3t , j
la expectación condicional [E(V,Vl Ip,-, )I,, satisface aproximadamente la ecuación
y así, las componentes de V, no están correlacionadas asintóticamente.
! 3.4 El estado estático de desajuste
I En esta sección se examinará el desempeño del algoritmo con tamaño de paso variable. La figura de mérito que se usará es el estado estático de desajuste M, el cual se define como
S M = tal L,"
22

Definase también
La matriz de la eq. (3.17) para G, converge a F mientras k -+ OO. resultados obtenidos en la' estabilidad muestran que la eq. (3.17) es exponencialmente estable si los valores propios de F yacen estrictamente dentro del círculo unitario. Ahora,
' det(F - 6 Z) = det[diug(p, - 6,. . . , p, - <)I 1 1
det[l + dug(- ) . p'A2 11'1 PI - ~ " " pn - <
(3.26)
Se concluye que las condiciones necesarias y suficientes para que los valores propios de F estén dentro del círculo unitario son
pl < 1, j = 1,2 ,...., n
Estas son equivalentes a las condiciones
23

i (3.27)
Asumiendo que estas dos condiciones se mantienen entonces, la solución para (jL converge a G, donde G está dado por lo siguiente:
(; = [ 2 , Z - Ap'(2Z+ 11')]"(0,2 1 + p5A2 1Ll,,). (3.29)
Aplicando el lema de inversión de matriz a (3.29) se obtiene
.[o:'l+ p'Al&,,,]. (3.30)
Despues de un poco de álgebra, se obtienen las siguientes ecuaciones:
Para valores de desajuste pequeños, 2G'G << (Ll,, + I' G)' , por lo que
2ayji(cm1,,, + 1'G) + 3y' (LI, + 1' G)' 1 - a '
p - %
(3.31)
(3.32)
(3.33)
(3.34)
La elección de a y y son muy importantes para la convergencia de G, . Aquí se da una condición suficiente de a y y para garantizar la convergencia de G, cuando 4k, I cm,,, , Io cual es una situación usual.
La condición suficiente para garantizar que (3.27) y (3.28) son satisfechas es:
g 5
1 2 j i 3tr(R)
I- (3.35)
24

Combinando (3.32) Y (3.34) se obtiene
(3.36)
(3.37)
Usando las ecuaciones de arriba, se puede ahora derivar la expresión para el desajuste.
Desajuste estacionario: para sistemas estacionarios (i.e.,az2 = O ), se puede escribir a como
donde
Sea y = 1'Y. Entonces
El desajuste M puede entonces ser escrito como
Y M=- 1-Y
(3.38)
(3.39)
(3.40)
La ecuación (3.40) no da una expresión explícita para el desajuste, ya quey depende de
M a través de ii y p 2 . La solución para la ecuación no lineal de 5, se discutirá más tarde en conexión con el caso no estacionario. Sin embargo, nótese que si pk es constante, digamos 2p' , entonces y está dado por
-
25

"" __.
Para valores de desajuste pequeños, las componentes de Y son mucho menores que 1 así que
Se tiene entonces la siguiente expresión aproximada para Y :
2py = p%(R). (3.41)
Sustituyendo la eq. (3134) para p ' , la (3.32) para ,E, y el hecho de que
en la eq. (3.41), se ecuaci6n cuadt-ática:
encuentra tras un poco de álgebra, que y satisface la siguiente
Ya que y << 1, la raíz que debe tomarse es
(3.42)
Finalmente, se llega a la siguiente expresión aproximada para el desajuste de M, válida para desajustes pequeños en el caso estacionario:
(3.43)
26

De la eq. (3.31), tenemos que
(3.45)
Las ecuaciones (3.32), (3.44) y (3.45) pueden ser resueltas por iteración para encontrar a
ecuación para G, también garantiza la convergencia de la iteración, comenzando, digamos en 5, = O.
5cx z Nótese que la condición requerida de la ecuación (3.28) para la estabilidad de la
Se puede observar nuevamente que paia un tamaño de paso constante pk = p Y valores propios iguales, (3.45) se simplifica a
También, si se asume que p' A, << ,E, y que p'fr(R) << 2 j i , la eq. (3.31) se reduce a
Y si ahora pk es constante, digamos 2p' , la ecuación de arriba se transforma en
27
(3.46)

t i 4. MATLAB
4.1. ¿Qué es Matlab?
En resumen, MATLAB es a la vez un ambiente matemático interactivo y un lenguaje de programación que permite la visualización numérica del cómputo y de datos.
MATLAB ha demostrado ser muy versátil y capaz de ayudar en la solución de problemas
aplicación en donde se requieran cálculos numéricos complejos.
i
1 en matemáticas aplicadas, física, química, ingeniería, finanzas y/o casi cualquier área de !
Así, Matlab es un ambiente de programación de alto nivel para el cómputo matemático y científico usado extensamente en la educación, investigación e industria. El sistema de Matlab deriva mucha de su capacidad de cómputo a partir de dos componentes principales. El primero es un conjunto de rutinas numéricas de alta calidad de álgebra lineal. El segundo componente es su compatibilidad con los gráficos. Los gráficos 2D y 3D de Matlab se basan en la representación geométrica de matrices y vectores, por lo tanto trabaja independientemente del resto del sistema.
Partiendo de esta base altamente optimizada de las matemáticas y gráficos, Matlab se extiende mediante una familia de paquetes de aplicación específica llamados “toolbox& Cada “tm/hx”contiene una colección de rutinas en Matlab y de los programas escritos en FORTRAN y C (con interface de Matlab). Con el tiempo, Mathworks’ y otros han desarrollado los “too/hxes“con apkaciones que se extienden desde análisis numérico y estadístico a redes neuronales, lógica difusa, y modelos financieros. Este proceso dinámico de desarrollo ha hecho de Matlab un sistema en continua expansión, reflejando las ideas y esfuerzos de investigadores en muchos campos de la ciencia y de la ingeniería.
Esta herramienta computacional de alto desempeño es complementado por un ambiente de programación amigable. La interfaz de usuario de Matlab funciona mediante comandos. Los objetos básicos de los datos tales como matrices y vectores se pueden construir y manipular fácilmente con una sintaxis funcional semejante a la manera que se hace en papel. Puesto que muchos problemas se pueden solucionar con una simple llamada a un procedimiento o función, Matlab se puede utilizar con absoluta eficacia sin el recurso a la escritura extensa del código. Matlab tiene su propio lenguaje de programación de alto nivel que el sistema interpreta, por lo tanto es mucho más fácil programar en éI que en muchos lenguajes de nivel inferior comunes tales como FORTRAN, PASCAL, o C, puesto que el programador puede concentrarse en la lógica y la eficacia de un algoritmo sin
I The Mathworks Inc. Creador de Matlab.
20

E
por tareas tales como declaración y asignación de memoria variables. Por su P '' uesto, esta facilidad de empleo tiene un precio. Como en muchos lenguajes, hay a
una pérdida de desempeño en el tiempo de ejecución, especialmente si el
P' ograma contiene bucles. Sin embargo, para Matlab, el tiempo extra necesario para correr el programa (posiblemente hasta diez veces más) se compensa por la poca cantidad de tiempo que lleva su programación.
para los proyectos en los cuales el desempeño es la prioridad, hay dos maneras de alcanzar la eficacia en el tiempo de ejecución dentro del ambiente de programación de Matlab. El primero es usar al compilador de Matlab, que traduce un archivo *.m a código en c y genera un archivo binario accesible para Matlab *.ma. El método más tradicional es optimizar la escritura a partir de la vectorización, que significa convertir operaciones con datos escalares a operaciones con datos matriciales.
Este ambiente de programación flexible e intuitivo, ha hecho de Matlab una herramienta de desarrollo de gran alcance. Por ejemplo, un nuevo usuario con conocimiento básico en algebra lineal puede hacer programas eficientes y fáciles de entender en poco tiempo. Un usuario experimentado de Matlab, con la suficiente comprensión de las matemáticas subyacentes de un campo de la aplicación determinado, puede construir un ambiente modificado para requisitos particulares con nuevos comandos y nuevos too/boxes.
Debido a esta poderosa combinación de ambiente de desarrollo amigable para el usuario y alto rendimiento de computo numérico, Matlab se ha convertido en el software preferido por miles de investigadores e ingenieros alrededor del mundo. Sin embargo la elección de cada usuario por algún softwzre en particular depende en gran medida del campo de aplicación del que se trate. En nuestro caso, para la simulación de un filtro digital
. adaptable, Matlab resultó el lenguaje y ambiente ideal, permitió la optimización de recursos tales como tiempo, eficiencia, rapidez, simplicidad, etc.
4.2. Herramientas utilizadas
Como se mencionó en el apartado anterior Matlab, contiene una amplísima gama de funciones, comandos y operadores disponibles. Para este trabajo se utilizaron algunas de ellas. A continuación se mencionarán cada una con una breve explicación acerca de su funcionamiento y uso.
Comandos de propósito general
dear Función: Elimina elementos de la memoria. Sintaxis: clear all Descripción: Quita todas las variables, funciones y archivos mex de la memoria. Deja el espacio de trabajo vacío, como si Matlab a penas fuera invocado.
29

procesamiento de señales O sinc
Función: Sinc o sen(nt)/xt Sintaxis: y = sinc (x) Descripción: CalCUla la función sinc de una matriz 0 vector de entrada, donde la función sinc está dada por:
r 1 para t = O
para t # O
filter Función: Filtra datos con un filtro FIR o IIR. Sintaxis: y = filter (b, a, x ) Descripción: Filtra los datos contenidos en el vector x con el filtro descrito por 10s vectores a y b (coeficientes del numerador y denominador de la función de transferencia del filtro en el dominio Z, respectivamente). Si a(1) es cero filter regresa un error. Esto se esquematiza en la siguiente figura:
Control de flujo for Función: Repite instrucciones un número de veces específico. Sintaxis: f o r variable = expresión
Instrucciones end
Descripción: Las columnas de la expresión se almacenan una a la vez en la variable mientras las siguientes instrucciones, de arriba hacia abajo, son ejecutadas. En la Práctica casi siempre dichas expresiones son escalares. El tope de la instrucción for siempre termina con la sentencia end.
if Función: Ejecución condicional de instrucciones.
30

Sintaxis: if expresión Instrucciones
end Descripción: Las instrucciones se ejecutan si expresión tiene elementos distintos de cero.
2 2 5 9 1 9 Control de gráficos 2D elementales a plot
Función: Grafica en 20. Sintaxis: p l o t (X, y) Descripción: Grafica el vector y vs. el vector X. Si X o y son una matriz, entonces el vector se grafica contra las raíces o columnas de la matriz en forma ordenada,
title Función: Título de la gráfica. Sintaxis: title ( ‘texto’ ) Descripción: Escribe t e x t o como título superior de la gráfica.
zoom Función: Acercamiento hacia afuera o hacia adentro de una gráfica en 20. Sintaxis: zpom Descripción: Cada vez que se hace click sobre la gráfica actual, zoom cambia los límites de los ejes en un factor de 2.
xlabel Función: Etiqueta para el eje x. Sintaxis: xlabel ( ‘texto’ ) Descripción: Agrega t e x t o a la gráfica actual de 2D debajo del eje X o a un lado o al fondo de la gráfica actual 30.
figure Función: Abre una nueva ventana gráfica. Sintaxis: figure
Descripción: Cuando se crea una nueva figura se crea una nueva ventana cuyas características son controladas por un número de factores incluidos en el sistema de ventaneo y propiedades de la figura.
Análisis matricial y funciones matemátidas elementales norm Función: Obtiene la norma de vectores o matrices. Sintaxis: n= norm (x )
31

Descripción: La norma de una matriz es un escalar n que da una medida de la magnitud de los elementos de la matriz X .
propósito específico o tic tot
Función: Cronómetro. Sintaxis: t i c
Instrucción toc
Descripción: tic inicializa el cronómetro y toc por si mismo imprime el lapso de tiempo desde que tic inició,
wavread Función: Carga archivos de sonido de formato *.wav. Sintaxis: y = wavread ( ‘ar.chivo’ )
Descripción: Carga los archivos *.wav en la variable especificada regresando los datos muestreados en y. Si el archivo no incluye la extensión .wav, éSta se asume.
Manipulación de matrices 0 (operador)
Función: Caracter especial que expresa la matriz transpuesta. Sintaxis: y = X , .
Descripción: El operador \ transpone la matriz sobre la que se encuentra operando.
Ejemplo:
x = O 1 3 4
>> X’
ans =
O
32

1 3 4
zeros Función: Puros ceros. Sintaxis: y= z e r o s (m/n) Descripción: Define una matriz de [m x n] llena de ceros. Requiere menos tiempo para definirla que mediante un bucle de asignaciones a cero.
Dado que Matlab es un lenguaje de programación fundamentado en el manejo de arreglos y matrices, resulta de primordial importancia el conocer las distintas manipulaciones, construcciones y direccionamientos que se pueden realizar sobre los mismos.
Creación de arreglos De la siguiente manera se pude generar muy fácilmente un arreglo de tamaño n:
>>X = [O 1 3 4 1
x =
O 1 3 4
o también (utilizando lo anterior)
>> y = s i n (X)
O 0.8415 O. 1411 - 0 . 7 5 6 8
Direccionamiento de arreglos Los elementos dentro de un arreglo se accesan utilizando paréntesis de la siguiente forma:
>> X ( 3 )
33

a n s =
3
a n s =
O
a n s =
1 3 4
>> X(3:-1:1)
ans =
3 1 O
34

I I 5, Resultados y Conclusiones
5.1, Síntesis de los Algoritmos (Pseudocódigos)
Algoritmo NLMS RESUMEN POR PASOS
Dado un sistema a identificar con una funci6n de transferencia H con un numero de N taps (orden del filtro) dado:
l. Se inicializa el sistema identificador W con el mismo número de taps, a cero.
2. Se inicializa el tamaño de paso a ( l l a > O )
Para cada n (iteracicín), realizar los pasos 3 a 6.
3. Tomar N muestras de la entrada X,
4. Obtener el error de la salida del sistema W con respecto a la salida del sistema deseado d, = H,J:
e, = d, - W,J:
5. Actualizar el filtro adaptable NLMS.
6. Insertar una muestra mis al nuevo paquete de N muestras de la entrada.
35

Algoritmo VSSLMS RESUMEN POR PASOS
Dado un sistema a identificar con una función de transferencia H con un numero de N taps (orden del filtro) dado:
l. Se inicializa el sistema identificador W con el mismo número de taps, a cero.
2. Se inicializan los parámetros del tamaño de paso máximo y mínimo (haX y bin), p=kax , así C O ~ O y y a ( O<a<l y y>O )
Para cada n (iteración), realizar los pasos 3 a 7.
3. Tomar N muestras de la entrada X, 4. Obtener el error de la salida del sistema W con respecto a la
salida del sistema deseado d, = HJS(,'
e, = d, - WJS(,'
5. Actualizar el f i l t r o adaptable VSSLMS.
Wn+, = W n + P n Xnen 6. Actualizar el paso pn con
p'n+l= a p n + yen
Y
2
1 &ax si P ' k + l ' Pmax
Pn+ l = Pmn si P ' k + l < Pmn
p tk+ , para cualquier otro
7. Insertar una muestra más al nuevo paquete de N muestras de la entrada.
5.2 Transcripción al lenguaje de MATLAB
Por las cualidades del programa que se mencionaron en el capítulo anterior, la . transcripción del algoritmo a MATLAB fue relativamente sencilla:
36

VSSLMS
. 1 "?I .::; % l i m p i a m o s c u a l q u i e r v a r i a b l e a n t e r i o r (de l a memoria
% Numero d e i t e r a c i o n e s % E l o r d e n d e l f i l t r o % Pdr.6metro d e l a l g o r i t m o %E'arámetro del dlgori tmo
% E s c a l a s m6xima y mínimas para m u
% C o n s i d e r a c i 3 n i n i c i a l p a r a e l VSS % C o n s t a n t e p d r a c o n t r o l a r l a forma d e l a función Sampllng
I
:.: = r d m i ( 1 , N i ) - 0 . 5 ; % L a rntrar ja e rgódica a l s i s t e m a , (oscila a l rededor d? Oi
r = ! r L ~ t ~ c i ( l , N i ) - 0 . 5 1 * 0 . 0 1 ; % E l ruido a l a s a l i d a
l ~ , = .,l!-,L-( ? , ( ( - N / & ) : ( N / L - 1 ) ) * o m e g a ) ; % E l ::i:;tama deseado
37

para poder observar gráficamente la eficiencia del algoritmo, se utilizó el error de identificaciÓn (expresado en decibeles), que nos da una medida del error en la salida del sistema adaptable con respecto a la salida deseada en presencia de ruido:
el. cual se va graficando conforme k va creciendo. Su implementación en MATLAB es igualmente simple que su expresión analítica. Queda como sigue:
Para poder visualizar los resultados del filtro final y del error de aproximación se ejecutó el siguiente listado para despliegue de gráficos:
38

5.3 Resultados de las simulaciones
mG{+;~ El algoritmo en general lanzó una buena respuesta y una buena adaptación al sistema deseado H. Inicialmente el
d(n) sistema H a identificar se propuso como una función sampling
e(n) y eficacia del algoritmo frente a otros sistemas, se probó cambiando la función sampling por una función cuadrada, también se sustituyó al ruido blanco por una señal sintetizada
de audio en la entrada. Recordemos que en general, el algoritmo puede reconocer cualquier sistema lineal invariante en tiempo, así que, aunque los sistemas propuestos son relativamente comunes y fáciles de generar, éstos no limitan las capacidades del algoritmo.
T' con entrada x(n) de ruido blanco. Para verificar el desempeño
0 3 , Señal de audio
.03""-.""""".""-,""-."""""""-."""""-
-o 4 O 0 2 0 4 O6 0 8 1 1 2 1 4 1 6 1 8 2
Muestra x lo4
Para todos los casos que se presentarán a continuación, el numero de taps u orden del filtro es N=32.
Así para la propuesta inicial se tienen los datos y resultados que se presentan a continuación:
I
39
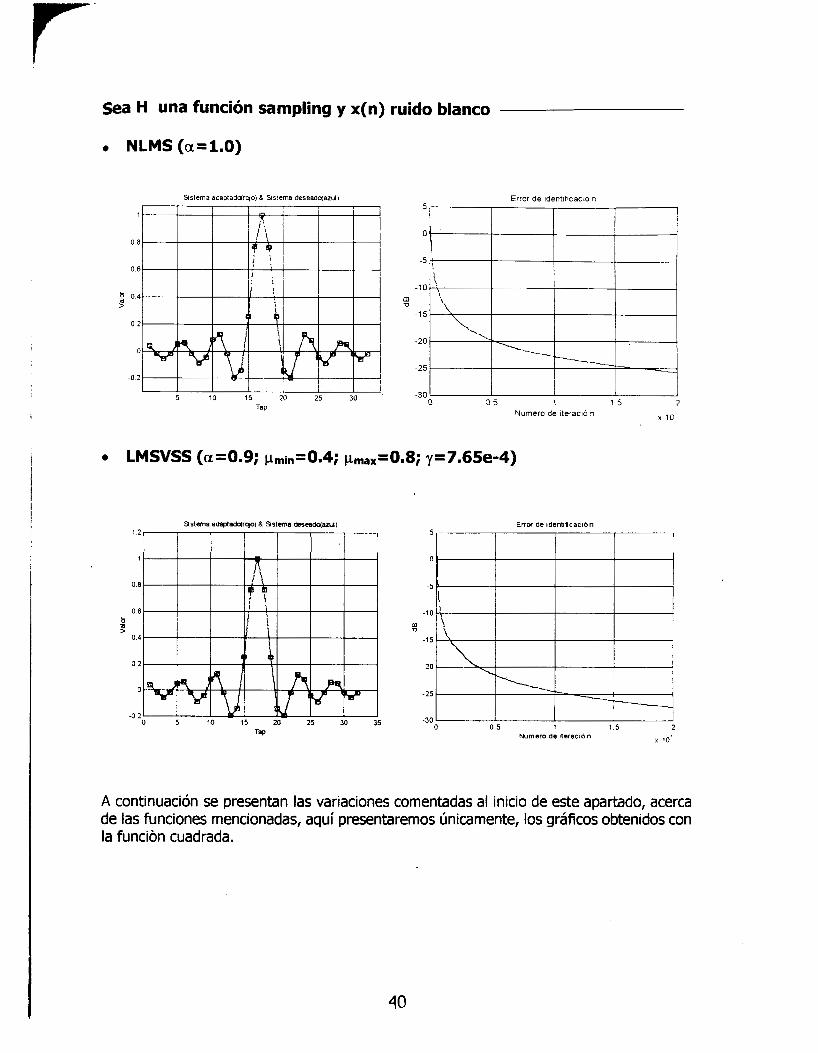
*a H una función sampling y x(n) ruido blanco
o NLMS (a=l.O)
Sistema adaptadarqo) 8 Slstenm deseadaazltl
1 5
Error de ldenttftcacio n
O 8 O
0 6 -5
b o 4 -1 o
9 m D
-1 5 0 2
-20 O
-25 -0 2
5 10 15 20 25 30 -30 Tap
O 0 5 1 1 5 2 Numero de iteraclo n x 10-
0 LMSVSS (a=O.9; pmin=0.4; pmax=0.8; y=7.65e-4)
1 2
1
O8
0 6 b >
04
0 2
O
4 2 5 10 15 20 25 M 35
Error de ldenhficacldn 5
O
-5
-10
m
-15
-20
-25
-m "
O 0 5 1 1 5 2 Numero de ~leraccdn x lo1
A continuación se presentan las variaciones comentadas al inicio de este apartado, acerca de las funciones mencionadas, aquí presentaremos únicamente, los gráficos obtenidos con la funcion cuadrada.
40
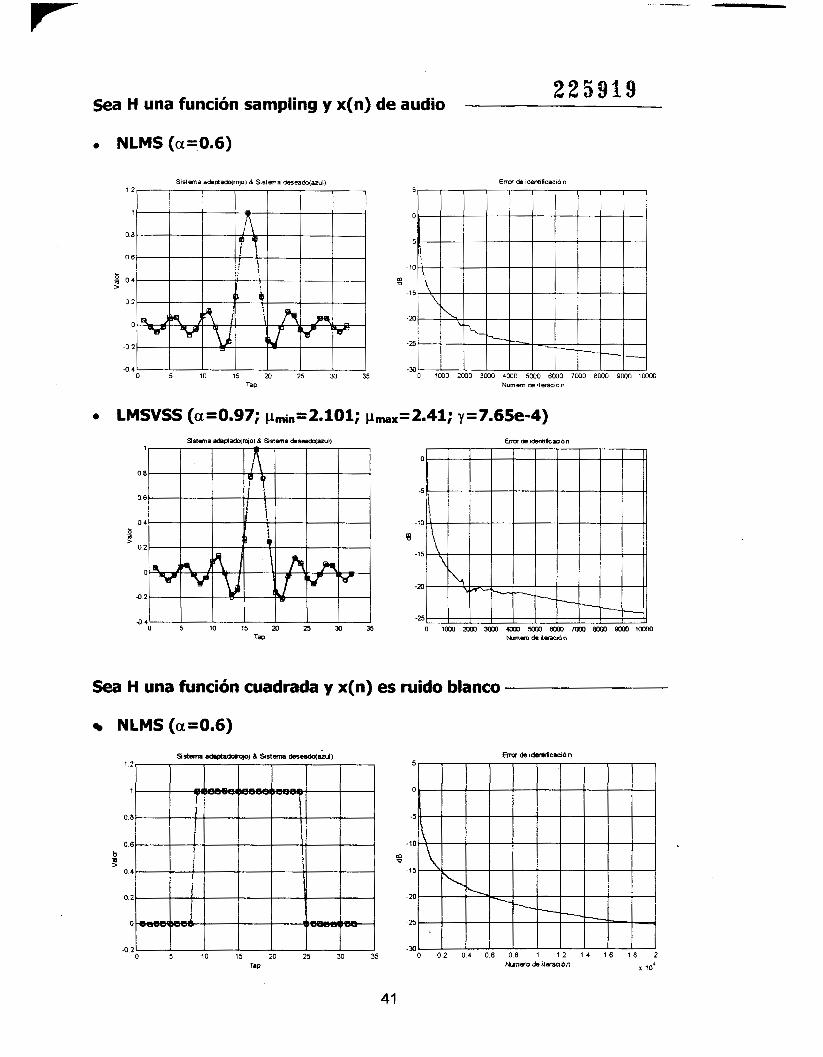
2 2 5 9 1 9 Sea H una función sampling y x(n) de audio
o NLMS (arO.6)
0 LMSVSS (01=0.97; p,,,i,=2.101; pmax=2.41; y=7.65e-4)
Sea H una función cuadrada y x(n) es ruido blanco
NLMS (az0.6)
Enu de 1 W I c a a 6 n
x lo1
41
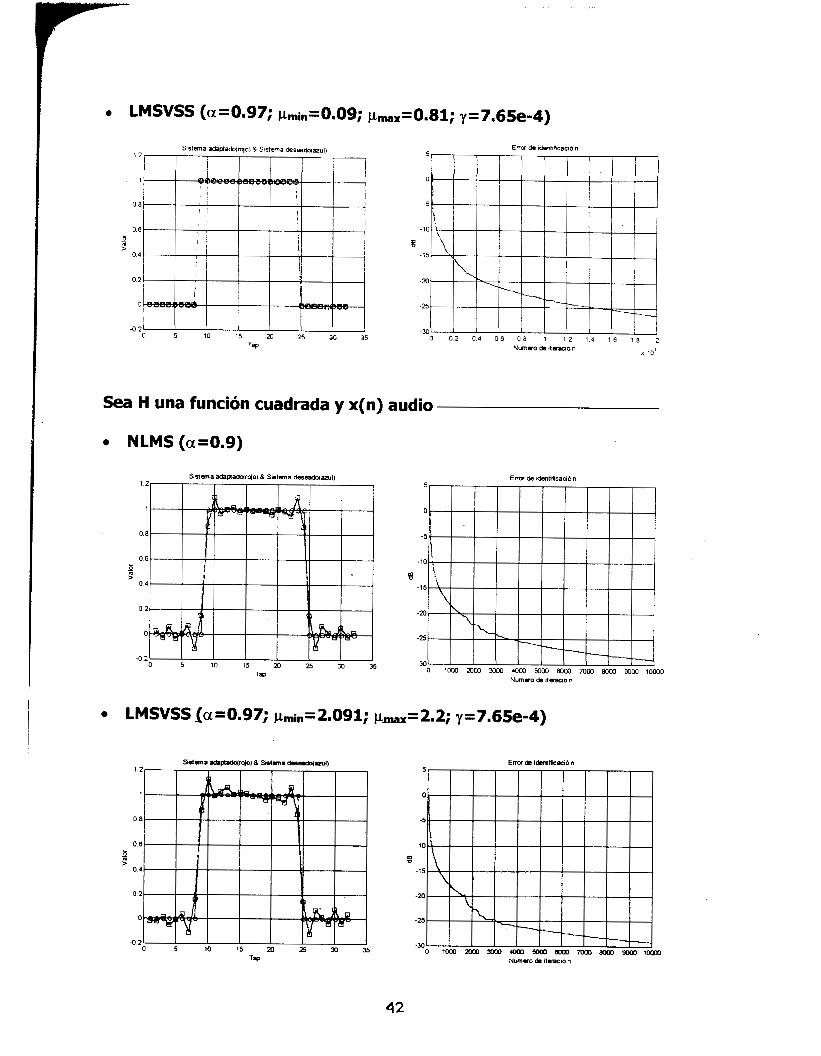
Sea H una función cuadrada y x(n) audio
0 NLMS (a=0.9)
Numero de lteracldn
42
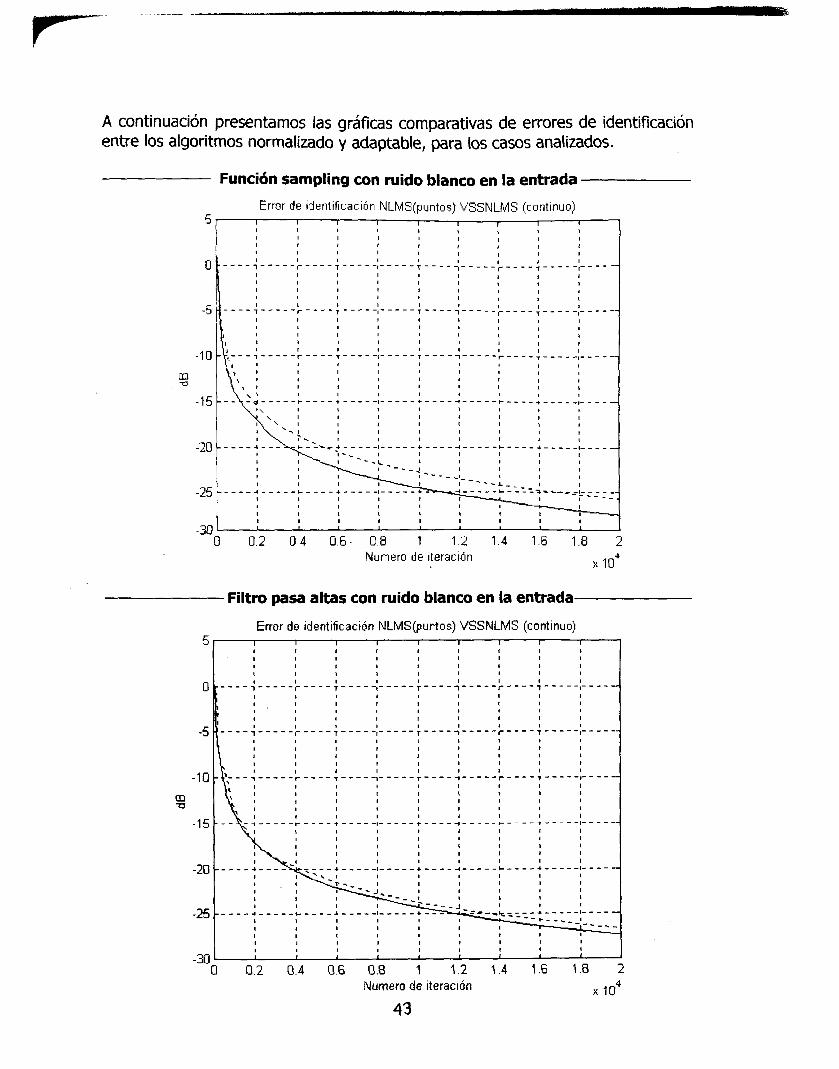
A continuación presentamos las gráficas comparativas de errores de identificación entre los algoritmos normalizado y adaptable, para 10s casos analizados.
Función sampling con ruido blanco en la entrada
5
O
-5
-1 o %
-15
Error de identif icaciin NLMS[puntosj VSSNLMS (continuo) I I I I I I I I I , , I L , I , I I I I I I I I I I
I I I I I I I I 1 8 I I I I I I I a l I I I I I I I I I
t 8 I I I I I I , I I 1 I I I I I I I I I I I I I I I
~ ~ " - T " " - l " - " T - " - ~ " - " - T " " ~ , " " ~ l " " -
I I I I I I I 1 I I I I I I I I
I I I I I I I 8 I , I I I
" ~ . , + " " - l " " - + " " ~ " " - c " " + " " - ] I""
'b"".! I I I"" , I I I I I I I""
I I I I -:--...:- I ""c""+""-l""-+- -4""-c-:==" "-= I ""_
, , 0
I I I I L , I I I I
-30 1 I I I I I I I I I 1
x lo4 O 0.2 0.4 13.6. 0.8 1 1.2 1.4 1.6 1.8 2
Numero de iteraci6n
Filtro pasa altas con ruido blanco en la entrada
Error de identificaciitn NLMS(puntos) VSSNLMS (continuo)
I I I 1 I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
I I I I I I I r""~""""" I I 1 , I ,
I I I I I I I
r - - - - 7 - - - - - T""T"""""
I I I I I I I i i -10
m -a
-15
-30 I 0 I , I I I I I I I I I I I I I I I I
x lo4 O 0.2 0.4 0 6 0.8 1 1.2 1.4 1.6 1.8 2
Numero de iteración
43

'Filtro Pasa Altas con audio en la entrada
Error de Identlfcact6n NLlmS(puntos) VSSNLMS (continuo) 5 I I I I I I I I
I I I I I I I I
I i w : : ! (-J ""I l""-,""-7""-,""-r"",""~,""~l""~,""-
-5 "" l""-r"""""""- T"",""-7 ""
T""-,""-
I I I I (-J ""I I M i ! ! ! ! ! l""-,""-7""-,""-r"",""~,""~l""~,""-
-5 "" l""-r"""""""- T"",""-7 ""
T""-,""-
-lot\"-: ""_; ""4 "" $"": "" :""-:""; " " _ ~ ""_ I I I I : - I
-25
-30 O 1 O00 2000 3000 4000 5000 6000 7000 8000 9000 IQOOO
Numero de rteraclbn
Observando las gráficas de comparación entre los algoritmos, podemos notar que el sistema encontrado con paso variable, para un número de iteración dado, ofrece. una mejor adaptación ya que presenta un menor error para todos los casos presentados. Esta disminución se aprecia mucho mejor en el caso original (función sampling y ruido blanco) ya que se observa que desde la iteración 400, existe una mejor adaptación de 2 dB aproximadamente por debajo del algoritmo normalizado.
Aunque este resultado concuerda con el deseado, esperábamos un mejor desempeño por parte del algoritmo con paso variable en las variantes propuestas, ya que aquí, la diferencia no es tan pronunciada. Esta diferencia pudo deberse a que la entrada de audio no presenta tanta varianza como el ruido blanco (totalmente aleatorio) mismo que puede ayudar a la adaptación del filtro, de hecho, en los casos de la función cuadrada con audio, se observa el fenómeno de Gibbs, generalmente resultante de una corta aproximación o por señales faltantes en una aproximación. El filtro resultante contrasta con el error de identificación obtenido en estos casos, ya que es prácticamente tan bajo como con ruido blanco a la entrada.
Otro factor posible para explicar este fenómeno contradictorio en los resultados gráficos del sistema rectangular con entrada de audio, podría ser el considerar la existencia de mínimos locales, en donde el algoritmo parecería estar convergiendo adecuadamente.
Es importante comentar que los parámetros del algoritmo que se presentan, fueron encontrados empíricamente, es decir a prueba y error, donde despul% de muchos cambios en los valores de estos parámetros se logra encontrar al mejor. Este hecho no es aislado
44

. . ".
ya que la documentación de los algoritmos ya existentes nos dicen que este comportamiento es común en la elaboración de &os. Así pues, es lógico pensar que todos estos algoritmos podrían tener un mejor desempeño con valores diferentes a los que tienen pero que no han sido probados aún. Un claro indicador de esto es el hecho de que siendo éste un tema muy estudiado, hasta la fecha siguen habiendo mejoras y nuevas propuestas (de algoritmos y de valores de los parámetros).
Hay que indicar, para nuestro caso en particular, que aunque se aumentó el número de iteraciones, el comportamiento del error de identificación nunca llegó a ser completamente constante.
45

Bibliografía
rpr Kwong, Raimond, A Variable SteD Size Alaorithm, IEEE Transactions on signal processing, 1992 rpr Sankaran, Sundar, Normalized LMS Alaorithm with orthoaonal correction factors, IEEE Article. r7p Haykin, Simon, AdaDtive Filter Theory, Ed. Prentice Hall. 1996 rpr The Mathworks inc., The Student Edition of Matlab (User’s Guide), Prenice Hall, 1995. rpr Andreas, Antoniov, Diaital Filters: Análisis and Desian, Mc. Graw Hill, 1979. ~h* Bellanger, Maurice G., AdaDtive Diaital Filters and Sianal Analysis, Marcel Dekker Inc., 1987.
46


















