
Unidad 3 Abd
35
Unidad 3 Configuración y Administración del Espacio en Disco Instituto Tecnológico de Villahermosa Integrantes: •Luis Fernando Cámara Ayala •Aldo Pérez Maldonado •Cristian de Jesús Pérez Sánchez
description
Unidad 3 Abd
Transcript of Unidad 3 Abd

Unidad 3Configuración y Administración del
Espacio en Disco
Instituto Tecnológico de Villahermosa
Integrantes:
•Luis Fernando Cámara Ayala•Aldo Pérez Maldonado•Cristian de Jesús Pérez Sánchez

3.1 Estructuras Lógicas de Almacenamiento
Para la gestión del almacenamiento de una base de datos existen 4 conceptos bien definidos que deben ser conocidos para poder comprender la forma en la que se almacenan los datos. Vamos a ver la diferencia entre bloque, extensión, segmento y espacio de tablas.
Bloques: Se tratan de la unidad más pequeña. Generalmente debe múltiple del tamaño de bloque del sistema operativo, ya que es la unidad mínima que va a pedir Oracle al sistema operativo. Si no fuera múltiple del bloque del sistema se añadiría un trabajo extra ya que el sistema debería obtener más datos de los estrictamente necesarios. Se especifica mediante DB_BLOCK_SIZE
Extensiones: Se forma con uno o más bloques. Cuando se aumenta tamaño de un objeto se usa una extensión para incrementar el espacio.
Segmentos: Grupo de extensiones que forman un objeto de la base de datos, como por ejemplo una tabla o un índice.
Espacio de Tablas: Formado por uno o más datafiles, cada datafile solo puede pertenecer a un determinado tablespace

En general, el almacenamiento de los objetos de la base de datos no se realiza sobre el archivo o archivos físicos de la base de datos, sino que se hace a través de estructuras lógicas de almacenamiento que tienen por debajo a esos archivos físicos, y que independizan por tanto las sentencias de creación de objetos de las estructuras físicas de almacenamiento.
Esto es útil porque permite que a esos "espacios de objetos " les sean asociados nuevos dispositivos físicos (es decir, más espacio en disco) de forma dinámica cuando la base de datos crece de tamaño más de lo previsto. Posibilita además otra serie de operaciones como las siguientes:
•Asignar cuotas específicas de espacio a usuarios de la base de datos.
•Controlar la disponibilidad de los datos de la base de datos, poniendo fuera de uso alguno de esos espacios de tablas individualmente.
•Realizar copias de seguridad o recuperaciones parciales de la base de datos.
•Reservar espacio para almacenamiento de datos de forma cooperativa entre distintos dispositivos.
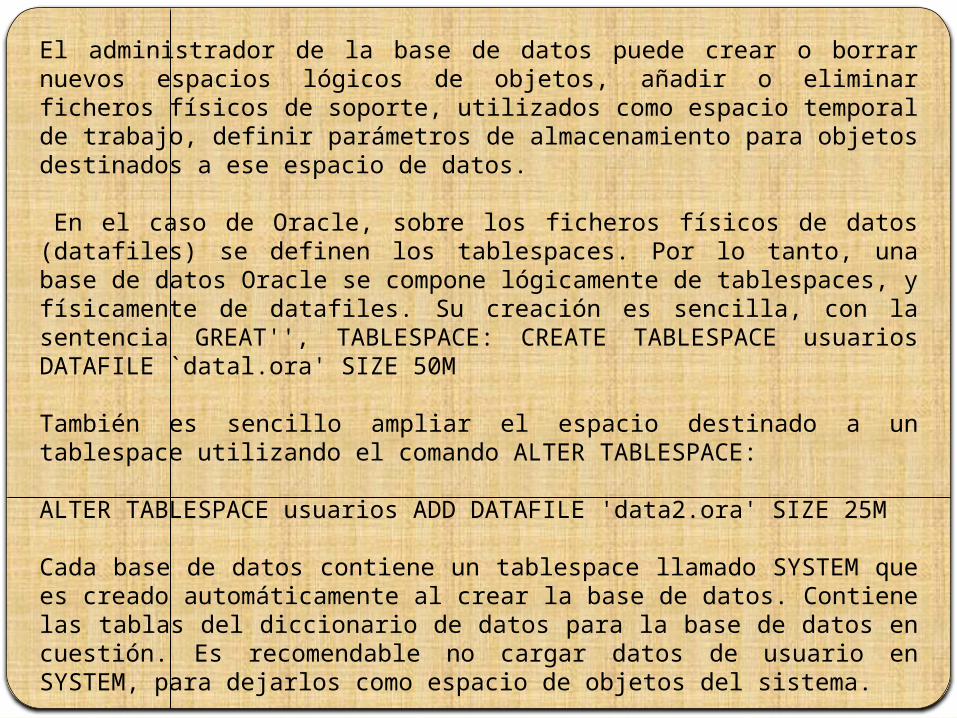
El administrador de la base de datos puede crear o borrar nuevos espacios lógicos de objetos, añadir o eliminar ficheros físicos de soporte, utilizados como espacio temporal de trabajo, definir parámetros de almacenamiento para objetos destinados a ese espacio de datos.
En el caso de Oracle, sobre los ficheros físicos de datos (datafiles) se definen los tablespaces. Por lo tanto, una base de datos Oracle se compone lógicamente de tablespaces, y físicamente de datafiles. Su creación es sencilla, con la sentencia GREAT'', TABLESPACE: CREATE TABLESPACE usuarios DATAFILE `datal.ora' SIZE 50M
También es sencillo ampliar el espacio destinado a un tablespace utilizando el comando ALTER TABLESPACE:
ALTER TABLESPACE usuarios ADD DATAFILE 'data2.ora' SIZE 25M
Cada base de datos contiene un tablespace llamado SYSTEM que es creado automáticamente al crear la base de datos. Contiene las tablas del diccionario de datos para la base de datos en cuestión. Es recomendable no cargar datos de usuario en SYSTEM, para dejarlos como espacio de objetos del sistema.

3.1.1 Definición de Almacenamiento de Bases de Datos
Las bases de datos suelen ser creadas para almacenar grandes cantidades de datos de forma permanente. Por lo general, los datos almacenados en éstas suelen ser consultados y actualizados constantemente.
La mayoría de las bases de datos se almacenan en las llamadas memorias secundarias, especialmente discos duros, aunque, en principio, pueden emplearse también discos ópticos, memorias flash, etc.
Las razones por las cuales las bases de datos se almacenan en memorias secundarias son:
•En general, las bases de datos son demasiado grandes para entrar en la memoria primaria.
•La memoria secundaria suele ser más barata que la memoria primaria (aunque esta última tiene mayor velocidad).
•La memoria secundaria es más útil para el almacenamiento de datos permanente, puesto que la memoria primaria es volátil.

3.1.2.- Definición y Creación del Espacio Asignado para cada Base de Datos
Las bases de datos se almacenan en ficheros o archivos. Existen diferentes formas de organizaciones primarias de archivos que determinan la forma en que los registros de un archivo se colocan físicamente en el disco y, por lo tanto, cómo se accede a éstos.Las distintas formas de organizaciones primarias de archivos son:
•Archivos de Montículos (o no Ordenados): esta técnica coloca los registros en el disco sin un orden específico, añadiendo nuevos registros al final del archivo.
•Archivos Ordenados (o Secuenciales): mantiene el orden de los registros con respecto a algún valor de algún campo (clave de ordenación).
•Archivos de Direccionamiento Calculado: utilizan una función de direccionamiento calculado aplicada a un campo específico para determinar la colocación de los registros en disco.
• Árboles B: se vale de la estructura de árbol para las colocaciones de registros.
•Organización Secundaria o Estructura de Acceso Auxiliar: Estas permiten que los accesos a los registros de un archivo basado en campos alternativos, sean más eficientes que los que han sido utilizados para la organización primaria de archivos.

El DBMS asigna espacio de almacenamiento a las bases de datos cuando los usuarios introducen create database o alter database. El primero de los comandos puede especificar uno o más dispositivos de base de datos, junto con la cantidad de espacio en cada uno de ellos que será asignado a la nueva base de datos.
Si se utiliza la palabra clave default o se omite completamente la cláusula on, el DBMS pone la base de datos en uno o más de los dispositivos predeterminados de base de datos especificados en master.sysdevices.
Para especificar un tamaño (por ejemplo, 4MB) para una base de datos que se va a almacenar en una ubicación predeterminada, se utiliza: on default = size de esta forma:
create database newpubs on default = 4

3.1.3.- Bitácoras
Son estructuras ampliamente utilizadas para grabar las modificaciones de la base de datos.Cada registro de la bitácora escribe una única escritura de base de datos y tiene lo siguiente:
•Nombre de la Transacción: Nombre de la transacción que realizó la operación de escritura.
•Nombre del Dato: El nombre único del dato escrito.
•Valor Antiguo: El valor del dato antes de la escritura.
•Valor Nuevo: El valor que tendrá el dato después de la escritura.

Es fundamental que siempre se cree un registro en la bitácora cuando se realice una escritura antes de que se modifique la base de datos.
También tenemos la posibilidad de deshacer una modificación que ya se ha escrito en la base de datos, esto se realizará usando el campo del valor antiguo de los registros de la bitácora.
Los registros de la bitácora deben residir en memoria estable como resultado el volumen de datos en la bitácora puede ser exageradamente grande.
La instrucción en MySQL para crear una bitácora en .txt se crea antes de acceder a la base de datos con la instrucción:
"xampp>mysql>bin>mysql -hlocalhost -uroot --tee=C:bitacora.txt“
La bitácora debe registrar todos los movimientos (insertar, eliminar y modificar) que se realicen en las tablas de la base de datos. Para lograr lo anterior es necesario crear un trigger para que se ejecute después de la operación de insertar, otro para después de eliminar y el último para después de modificar para cada una de las 3 tablas de la base de datos.

3.1.4.- Particiones
Cuando alguna de las tablas de una base de datos llega a crecer tanto que el rendimiento empieza a ser un problema, es hora de empezar a conocer algo sobre optimización. Una característica de MySQL son las particiones.
Particionar tablas en MySQL nos permite rotar la información de nuestras tablas en diferentes particiones, consiguiendo así realizar consultas más rápidas y recuperar espacio en disco al borrar los registros. El uso más común de particionado es según la fecha.
Para ver si nuestra base de datos soporta particionado simplemente ejecutamos:
SHOW VARIABLES LIKE '%partition%';

Se puede particionar una tabla de 5 maneras diferentes:
Por Rango: para construir las particiones se especifican rangos de valores.
ALTER TABLE contratos PARTITION BY RANGE (YEAR (fechaInicio)) ( PARTITION partDecada80 VALUES LESS THAN (1990), PARTITION partDecada90 VALUES LESS THAN (2000), PARTITION partDecada00 VALUES LESS THAN (2010), PARTITION partDefault VALUES LESS THAN MAXVALUE );
La última partición (partDefault) tendrá todos los registros que no entren en las particiones anteriores. De esta manera nos aseguramos que la información nunca dejará de insertarse en la tabla.

Por Listas: para construir nuestras particiones especificamos listas de valores concretos.
ALTER TABLE contratos PARTITION BY LIST (YEAR (fechaInicio)) ( PARTITION partDecada80 VALUES IN (1980, 1981, 1982, 1983, 1984, 1985, 1986, 1987, 1988, 1989), PARTITION partDecada90 VALUES IN (1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999), PARTITION partDecada00 VALUES IN (2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009), PARTITION partDecada10 VALUES IN (2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019) );

Por Hash: MySQL se encarga de distribuir las tuplas automáticamente usando una operación de módulo. Sólo hay que pasarle una columna o expresión que resulte en un entero (el hash) y el número de particiones que queramos crear.
ALTER TABLE contratos PARTITION BY HASH (YEAR (fechaInicio)) PARTITIONS 7;
Por Clave: similar a la partición por hash, pero en este caso no necesitamos pasarle un entero; MySQL utilizará su propia función de hash para generarlo. Si no se indica ninguna columna a partir de la que generar el hash, se utiliza la clave primaria por defecto.
ALTER TABLE contratos PARTITION BY KEY () PARTITIONS 7;
Compuesta: podemos combinar los distintos métodos de particionado y crear particiones de particiones

Borrar ParticionesLo bueno de trabajar con particiones es que podemos borrar rápidamente registros sin tener que recorrer toda la tabla e inmediatamente recuperar el espacio en disco utilizado por la tabla.
Por ejemplo si queremos borrar la partición más antigua simplemente ejecutamos:
ALTER TABLE reports DROP PARTITION p201111;
Añadir particionesEn el ejemplo anterior las 2 últimas particiones creadas han sido:
PARTITION p201205 VALUES LESS THAN (TO_DAYS ("2012-06-01")),PARTITION pDefault VALUES LESS THAN MAXVALUE
El problema es que todos los INSERT que se hagan después de mayo de 2012 se insertarán en pDefault. La solución sería añadir particiones nuevas para cubrir los próximos meses:
ALTER TABLE reports REORGANIZE PARTITION pDefault INTO (PARTITION p201206 VALUES LESS THAN (TO_DAYS ("2012-07-01")),PARTITION pDefault VALUES LESS THAN MAXVALUE);
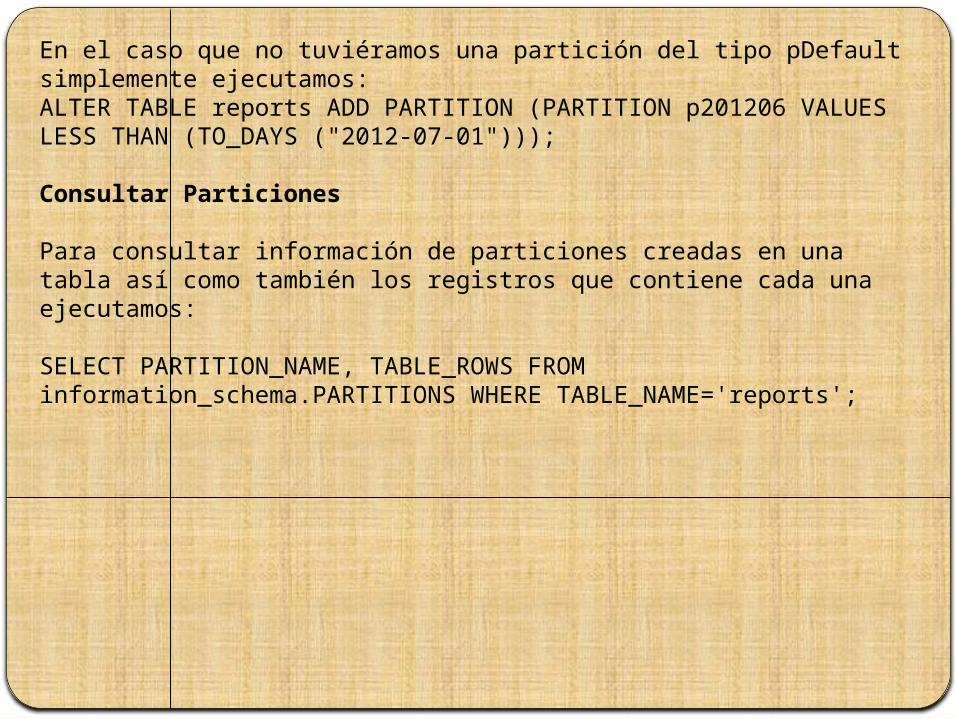
En el caso que no tuviéramos una partición del tipo pDefault simplemente ejecutamos:ALTER TABLE reports ADD PARTITION (PARTITION p201206 VALUES LESS THAN (TO_DAYS ("2012-07-01")));
Consultar Particiones
Para consultar información de particiones creadas en una tabla así como también los registros que contiene cada una ejecutamos:
SELECT PARTITION_NAME, TABLE_ROWS FROM information_schema.PARTITIONS WHERE TABLE_NAME='reports';

3.1.5.- Espacios Privados
Un “espacio privado” permite que los administradores y redactores gestionen el conjunto de datos del sitio. Algunas bases de datos tienen estos espacios privados llamados comúnmente paneles de control, que son formularios que aparecen al abrir la base de datos.
Los paneles de control sirven de "puerta principal" o "recibidor" de una base de datos en el sentido de que dirigen a las personas hacia determinadas tareas, como introducir o buscar datos. Sirven también para mantener alejados a los usuarios de las tablas que contienen los datos en tiempo real.
Cuando se recibe una base de datos, se averiguar cómo están estructurados los datos, revisar de manera general el panel de control. Puede ofrecer algún indicio sobre las tareas que el diseñador de la base de datos consideró que realizarían los usuarios habitualmente con los datos.

3.1.6.- Espacios para Objetos
Los DBMS se basan en archivos para almacenar datos, y estos archivos, o conjuntos de datos, residen en medios de almacenamiento, o dispositivos. Una buena parte del trabajo del DBA implicará la planificación para el almacenamiento real de la base de datos.
El rendimiento de la base de datos depende de la entrada y salida a disco. La cantidad de datos almacenados es mayor que nunca antes, y los datos son almacenados por más tiempo.
Algunos DBMS permiten al tamaño de los archivos temporales de expandirse y contraerse de forma automática. Dependiendo del tipo y la naturaleza de las operaciones de base de datos en proceso, esta fluctuación puede provocar picos de uso del disco.
Hay muchos problemas de almacenamiento que deben ser resueltos antes de que un DBA pueda crear una base de datos. Uno de los temas más importantes es la cantidad de espacio para permitir la base de datos.

El cálculo espacial debe tener en cuenta no sólo tablas, índices, sino también, y dependiendo del DBMS, el registro de transacciones. Cada una de estas entidades probablemente requerirá un archivo separado o conjunto de datos, para el almacenamiento persistente.
El DBA debe separar en diferentes discos a los archivos para:
•Mejorar el rendimiento
•Separar índices de datos
•Aislar los logros en otro disco

3.2 Segmentos
Los datos en la BD son almacenados físicamente en bloques Oracle: la mínima unidad de espacio físico, y es un múltiplo del bloque del SO (2 Kb usualmente). El tamaño del bloque Oracle se fija por el parámetro DB_BLOCK_SIZE del fichero init.ora. Un tamaño grande de bloque mejora la eficiencia del cache de E/S, pero el tamaño de la SGA aumentará para contener los mismos DB_BLOCK_BUFFERS, lo que significa un problema de memoria.
Una serie de bloques contiguos es una extensión, que es una unidad lógica de almacenamiento. Una serie de extensiones es un segmento. Cuando un objeto es creado, se reserva una extensión en su segmento. Cuando el objeto crezca, necesitará más espacio y se reservarán más extensiones.

Cada segmento tiene un conjunto de parámetros de almacenamiento que controla su crecimiento:
initial: tamaño de la extensión inicial (10k).
next: tamaño de la siguiente extensión a asignar (10k).
minextents: número de extensiones asignadas en el momento de la creación del segmento (1).
maxextents: número máximo de extensiones (99).
pctincrease: Porcentaje en el que crecerá la siguiente extensión antes de que se asigne, en relación con la última extensión utilizada (50).

pctfree: porcentaje de espacio libre para actualizaciones de filas que se reserva dentro de cada bloque asignado al segmento (10).
pctused: porcentaje de utilización del bloque por debajo del cual Oracle considera que un bloque puede ser utilizado para insertar filas nuevas en él.
tablespace: nombre del espacio de tablas donde se creará el segmento.
Cuando se diseña una BD se ha de tener mucho cuidado a la hora de dimensionar la BD y prever el crecimiento de las tablas. A continuación se hacen algunas consideraciones sobre la gestión del espacio para los diferentes segmentos.

Segmentos de Datos
El espacio del diccionario de datos se suele mantener más o menos constante, aunque es crítico que tenga suficiente espacio para crecer en el espacio de tablas SYSTEM. Así, hay que tener cuidado de colocar las tablas de usuario, los índices, segmentos temporales y los segmentos de rollback en otros espacios de tablas.
Además, es recomendable que el espacio de tablas SYSTEM esté al 50% o 75% de su espacio disponible. Finalmente, asegurarse que los usuarios no tienen privilegios de escritura en el espacio de tablas SYSTEM.
Las tablas crecen proporcionalmente con el número de filas, ya que se puede suponer que la longitud de las filas es constante.
Segmentos de Índice
Los índices crecen en tamaño en mayor proporción que las tablas asociadas si los datos en la tabla son modificados frecuentemente. La gestión del espacio es mejor si se mantienen los índices de tablas grandes en espacios de tablas separados.

Segmentos de Rollback
Los segmentos de rollback almacenan la imagen anterior a una modificación de un bloque. La información en el segmento de rollback se utiliza para asegurar la consistencia en lectura, el rollback (el valor en el segmento de rollback se copia en el bloque de datos) y la recuperación.
Es importante comprender cuál es el contenido de un segmento de rollback. No almacenan el bloque de datos modificado entero, sólo la imagen previa de la fila o filas modificadas. La información del segmento de roolback consiste en varias entradas llamadas undo.
Por ejemplo, si se inserta una fila en una tabla, el undo necesitará sólo el rowid de la fila insertada, ya que para volver atrás la insercion sólo hay que realizar un delete. En las operación de actualización, se almacenará el valor antiguo de las columnas modificadas. El segmento de rollback asegura que la información undo se guardan durante la vida de la transacción.
Un segmento de rollback como cualquier otro segmento consiste en una serie de extensiones. Sin embargo, la mayor diferencia entre un segmento de datos y otro rollback es que en este último las extensiones se utilizan de manera circular. Así, habrá que tener cuidado a la hora de fijar el tamaño del segmento de rollback para que la cabeza no pille a la cola.

Segmentos Temporales
Los segmentos temporales se crean cuando se efectuan las siguientes operaciones:
Create Index
Select con distinct, order by, union, intersect y minus.
uniones no indexadas.
Ciertas subconsultas correlacionadas.
Si las tablas a ordenar son pequeñas la ordenación se realiza en memoria principal, pero si la tabla es grande se realiza en disco. El parámetro SORT_AREA_SIZE determina el lugar donde se hace la ordenación. Incrementándole se reduce la creación de segmentos temporales.

3.3 Definición de Memoria Compartida
Un servidor Oracle es un sistema que permite administrar bases de datos y que ofrece un medio de gestión de información abierto, completo e integrado.Un servidor Oracle está constituido de una instancia y una base de datos.
Instancia de Oracle
Una instancia de Oracle permite acceder a la base de datos Oracle y permite abrir únicamente una sola base de datos.
La instancia de Oracle está compuesta de:
Procesos en segundo plano que administran y aplican las relaciones entre las estructuras físicas y las estructuras de memoria. Existen dos categorías:
•Procesos en Segundo Plano Obligatorios: DBWN, PMON, CKPT, LGWR, SMON•Procesos en Segundo Plano Facultativos: ARCn, LMDn, RECO, CJQ0, LMON, Snnn, Dnnn, Pnnn, LCKn, QMNn

Estructuras de Memoria: compuestas básicamente de dos áreas de memoria: el área de memoria asignada a la SGA (System Global Area): asignada al inicio de la instancia y representa un componente fundamental de una instancia de Oracle.
Está compuesta de varias áreas de memoria:•Área de memoria compartida•Buffer caché de la base de datos•Log buffer
Área de Memoria Asignada a la PGA (Program Global Area): Ésta es asignada al inicio del proceso de servidor. Es reservada a cada proceso de usuario que se conecte a la base de datos Oracle y liberada al final del proceso.
El Proceso de Usuario: Es el programa que solicita una interacción con la base de datos iniciando una conexión. Se comunica únicamente con el proceso de servidor correspondiente.
El Proceso de Servidor: Representa el programa que entra directamente en interacción con el servidor Oracle. Responde a todas las peticiones y envía los resultados. Puede estar dedicado a un servidor cliente o compartido por varios.

3.4 Definición de Múltiples Instancias de un DBMS
Cuando comenzamos a trabajar con Oracle una de las primeras cosas que aprendemos es a diferenciar entre estos conceptos: base de datos, instancia e instancia de base de datos.Una instancia es el conjunto de procesos que se ejecutan en el servidor así como la memoria que comparten para ello.Cuando se habla de base de datos, nos referimos a los archivos físicos que componen nuestra base de datos.Si queremos referirnos a los procesos que se ejecutan en memoria como a los archivos de base de datos tendremos que utilizar el término instancia de base de datos.
La instancia en Oracle describe varios procesos residentes en la memoria del computador(es) y un área de memoria compartida por aquellos procesos. En arquitecturas de bases de datos tales como, Microsoft SQL Server e IBM BD2, la palabra instancia indica una colección de bases de datos que comparten recursos de memoria en común, o sea, la relación entre instancia y bases de datos es 1 a N. Pero la relación entre la instancia de Oracle y la base de datos es 1 a 1 o n a 1. Cuando hay una relación N a 1, la configuración es llamada RAC (Real Application CLuster), donde la base de datos reside en discos compartidos y las instancias en múltiples computadores anexados a la base de datos.

La instancia de Oracle es el motor que procesa los requerimientos de datos desde la base de datos. Está compuesta por procesos en primer plano, en segundo plano y un área de memoria compartida (SGA).
Una instancia de Oracle es un conjunto de estructuras de memoria que están
asociadas con los archivos de datos (datafiles) en una máquina. Una base de datos es una colección de archivos físicos.

Instancia de OracleLa integran los procesos 'background' y la SGA. Abre una y sólo una BDO, y permite acceder a ella.Nota: con Oracle Real Application Cluster (RAC), más de una instancia usarán la misma BD.En la máquina donde reside el servidor Oracle, la variable ORACLE_SID identifica a la instancia con la que estamos trabajando.
VistasV$DATABASE (Base de datos).V$INSTANCE (Instancia).V$SGA (SGA).V$SGAINFO (Gestión dinámica de la SGA).V$SGASTAT (SGA detallada).V$BUFFER_POOL (Buffers en la caché de datos)V$SQLAREA (Sentencias SQL).V$PROCESS (Procesos).V$BGPROCESS (Procesos background).V$DATAFILE (Ficheros de datos de la BD).V$CONTROLFILE (Ficheros de control de la BD).V$LOGFILE (Ficheros redo log de la BD).DBA_TABLESPACES (Tablespaces de la BD).

DBA_SEGMENTS (Segmentos que hay en los tablespaces).DBA_EXTENTS (Extensiones que componen los segmentos).DBA_USERS (Usuarios de la BD).
Oracle RAC(Real Application CLuster).En un Rac de Oracle, múltiples instancias permiten el acceso a una única Base de datos. En un RAC las instancias corren en múltiples Nodos (servidores), y acceden a un conjunto común de datafiles que comprender a una 'Única' Base de datos.“
En contraste, en un ambiente de una única instancia, una base de datos Oracle es usada por sólo UNA Instancia corriendo en el servidor. Por lo Tanto, los usuarios accediendo a la base de datos pueden conectarse a ésta, sólo a través de ese 'Único' servidor.
En un Oracle RAC, una base de datos puede ser montada por más de una instancia, y en cualquier punto, una instancia será parte de sólo una Base de datos. El almacén no volátil para archivos de datos que comprende la Base de datos es igualmente disponible a todos los nodos, para el acceso de lectura y escritura. De lo anterior se desprende que un RAC de Oracle necesita coordinar y regular el acceso “simultaneo” a los datos desde múltiples servidores (nodos), por ende, debe existir una red privada que sea eficiente, confiable y de alta rapidez, entre los nodos del clúster para enviar y recibir datos

Crear Instancias MySQLTener dos instancias o más tiene entre otras las siguientes justificaciones. Una se dedicará a desarrollo, para hacer las modificaciones y pruebas necesarias y otra al de producción.ProcesoCopiar la carpeta data que se encuentra en nuestro caso en c:\MySQL, como data2

Copiar y pegar la configuración de MySQL. Es decir, del archivo my.ini (en linux my.cnf) generamos una copia que podría llamarse my2.ini.
Ahora con cuidado editamos my2.ini, procure no tocar my,ini a menos que este seguro de lo que hace.
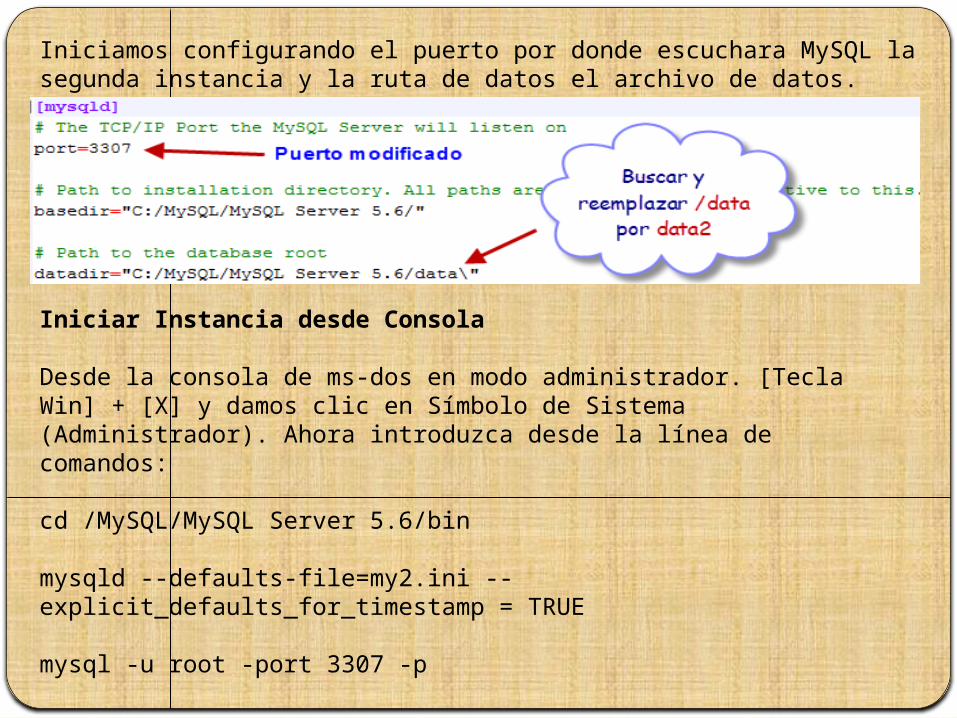
Iniciamos configurando el puerto por donde escuchara MySQL la segunda instancia y la ruta de datos el archivo de datos.
Iniciar Instancia desde Consola
Desde la consola de ms-dos en modo administrador. [Tecla Win] + [X] y damos clic en Símbolo de Sistema (Administrador). Ahora introduzca desde la línea de comandos:
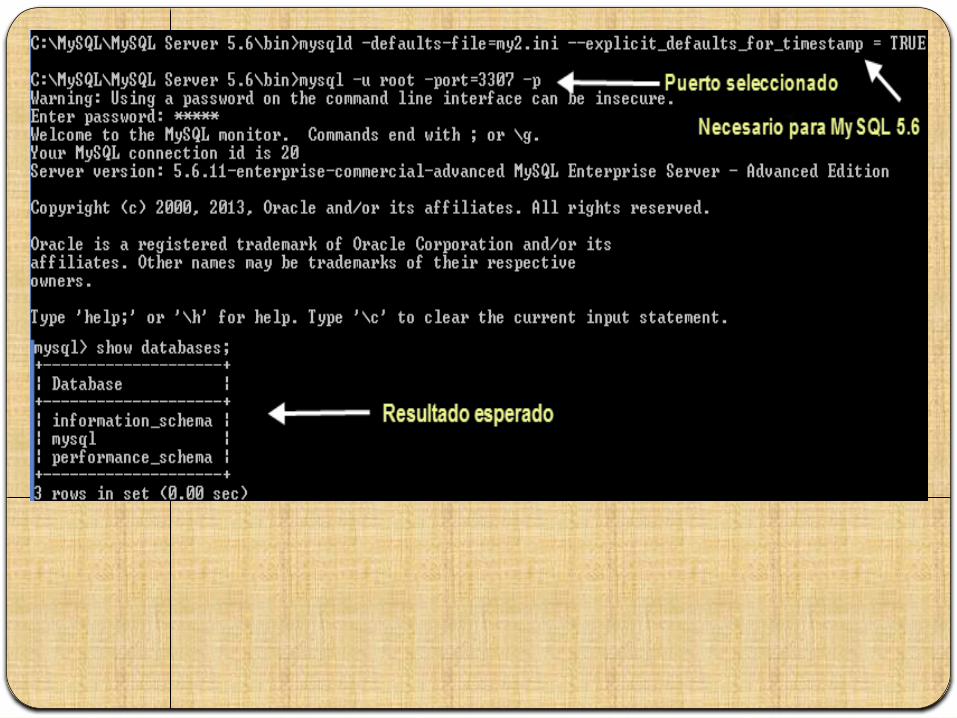
cd /MySQL/MySQL Server 5.6/bin
mysqld --defaults-file=my2.ini --explicit_defaults_for_timestamp = TRUE
mysql -u root -port 3307 -p

Establecer la Instancia como ServicioProcederemos a instalar la nueva instancia como servicio. Desde la consola de ms-dos en modo administrador. En windows 8 pulse la [Tecla Win] + [X] y damos clic en Símbolo de Sistema (Administrador):


















