
Tópicos de base de datos U1
72
Tópicos de base de datos 7º Semestre
-
Upload
amet-lopez-lopez -
Category
Documents
-
view
445 -
download
0
Transcript of Tópicos de base de datos U1

Tópicos de base de datos7º Semestre

1. Sistemas de bases dedatos distribuidas
1.1. Conceptos de base de datos distribuidas
1.2. Diseño de base de datos distribuidas
1.3. Procesamiento de operaciones de actualización distribuidas
1.4. Procesamiento de consultas distribuidas
1.5. Manejo de transacciones.

2. Sistemas de bases de datos orientadas a objetos
2.1. El modelo de datos orientado a objetos.
2.1.1. Características de los SGBDOO.
2.1.2. Tipos de SGBDOO.
2.1.3. Productos.
2.2. El estándar ODMG.
2.3. Identidad y estructura de objetos
2.4. Encapsulamiento, herencia y polimorfismo en BDOO.
2.5. Persistencia, concurrencia y recuperación en BDOO.

3. Sistemas de multibase de datos
3.1. Características y clasificación.
3.2. Arquitectura de un sistema de multibase de datos.
3.3. Procesamiento de operaciones de actualización.
3.4. Procesamiento de consultas.
3.5. Aplicaciones de Multibase de Datos.

4. Sistemas de gestión de contenidos
4.1. Definición Introducción y conceptos.
4.2. Clasificación de contenidos.
4.3. Arquitectura de un CMS.
4.4. Tipos de CMS en el mercado.
4.5. Modelado y Aplicación de CMS.

Bibliografía
1. Ramez A. Elmasri, Shamkant B. Navathe, Fundamentos de Sistemas de Bases de Datos, 3ª. Edición, Addison Wesley, 2002.
2. Practical Application of Object-Oriented Techniques to Relational Databases. Donald K. Burleson. OMG, 1994.
3. C. J. Date, Introducción a los Sistemas de Bases de Datos, 7a. edición, Prentice Hall.
4. Object-Oriented Information Systems: Planning and Implementation. David A. Taylor. Wiley, 1992.

5. Silberschatz, Korth, Sudarshan, Fundamentos de Bases de Datos, 4ª. Edición, Mc Graw Hill.
6. Batini Ceri Navathe, Diseño Conceptual de Base de Datos, Edición Adiso Wessley/Diaz de Santos.
7. Principles of distributed data bases systems, M.Tamer Ozsu, Prentice Hall, 2003, 3a.edición.
8. Miguel A. Rodríguez, “Bases de datos “, Mc Graw Hill, España 1992.

Políticas
• Asistir a clases
• Los celulares en vibrador, sin sonido o apagarlos.
• Las tareas, casos prácticos, trabajos y exposiciones serán entregados o presentados únicamenteen fechas acordadas.
• Tener el respeto a sus compañeros, así sea muy insignificante lo que se exponga, pregunte uopine.
• En caso de no presentar un examen en la fecha, no habrá otra fecha de presentación a menosque se justifique la falta y este a tiempo.
• El rango aprobatorio en el examen de regularización es de 70 como mínimo y 90 como máximo

Evaluación
Participación 15%
Tareas 25%
Proyecto/Practicas/Exposiciones 30%
Examen 30%
Total 100%

Exámenes
• Unidad 1
• 10 de Septiembre
• Unidad 2
• 8 de Octubre
• Unidad 3
• 5 de Noviembre
• Unidad 4
• 3 de Diciembre

Base de datos
Una BDD, permitirá que ya no un usuario, sino un número muy alto de usuariosaccedan a la información, de una manera ordenada, consistente y coherente.
Este tipo de BD, permiten que los datos queden repartidos en más de unordenador, lo cual es lo más interesante ya que surge la necesidad de obtenerun programa que maneje todas estas “partes” de la BDD, como si fuese unasola, y le den al usuario la impresión de cómo si él tuviese una BD centralizada.

Definición de BDD
• Una Base de Datos Distribuida (BDD) es un conjunto de múltiples bases de datos lógicamente relacionadas las cuales se encuentran distribuidas entre diferentes sitios interconectados por una red de comunicaciones, los cuales tienen la capacidad de procesamiento autónomo lo cual indica que puede realizar operaciones locales o distribuidas.

Propiedades de una BDDAutonomía Local
No dependencia de un sitio central
Operación Continua
Independencia con respecto a lalocalización
Independencia con respecto a lafragmentación
Independencia de réplica
Procesamiento Distribuido de Consultas
Independencia con respecto al equipo
Independencia con respecto al SistemaOperativo
Independencia con respecto a la red
Independencia con respecto al DBMS

Centralizado VS Distribuido
Centralizado
Control centralizado
Independencia de Datos
Reducción de redundancia
Estructuras complejas y accesoseficientes
Seguridad
Distribuido
Control jerárquico
Transparencia en la Distribución
Replicación de Datos
No hay estructuras intersitios
Problemas de seguridad intrínsecos

Control centralizado
• En las bases de datos distribuidas es posible identificar una estructura decontrol jerárquico basado en un Administrador global de bases de datos, elcual tiene la principal responsabilidad de la totalidad de la base de datos, yel Administrador local de bases de datos, quien tiene la responsabilidad desu respectiva base de datos local.

Independencia de datos
• La independencia de datos quiere decir, que la organización actual de losdatos es transparente a las aplicaciones. Los programas son escritosteniendo una vista conceptual de los datos, llamada esquema conceptual.
• La independencia de datos es que los programas no son afectados por loscambios en la organización física de los datos.

Reducción de la redundancia
• En las bases de datos distribuidas, se tienen varias razones para considerar laredundancia de los datos como una característica necesaria:
• Las aplicaciones pueden verse favorecidas si los datos son replicados en todos los sitiosdonde la aplicación las necesita
• La razón de disponibilidad del sistema puede incrementarse por este medio, debido a que siel sitio en el que se encuentran los datos fallara, la ejecución de la aplicación no se detieneporque existe una copia en algún otro sitio.

Estructuras complejas y acceso eficiente• Es conveniente tomar en cuenta dos cuestiones muy
importantes en el momento de accesar a una base dedatos distribuida, la optimización local y laoptimización global de los accesos.
• La optimización global consiste en determinar qué datos seránaccesados en qué sitios y qué archivos de datos serántransmitidos entre sitios.
• La optimización local consiste en decidir como llevar acabo elacceso a la base de datos local en cada sitio.

Seguridad
• Los dueños de los datos locales pueden proteger de diferentes maneras suinformación, esto dependiendo del DBMS local; y segundo, los problemasde seguridad son intrínsecos en los sistemas de bases de datos en general,esto debido a que las comunicaciones en las redes es su punto débil conrespecto a la protección

Ventajas de las bases de datosdistribuidas sobre las bases de datoscentralizadas
• Razones organizacionales
• Interconexión de las bases de datos existentes
• Desarrollo incremental
• Reducción de la sobrecarga de la comunicación
• Consideraciones en el desempeño
• Confiabilidad y disponibilidad

Razones organizacionales
• Las bases de datos distribuidas se acercan más a las necesidades de laestructura de la organización distribuida.

Interconexión de las bases de datos existentes
• Las bases de datos distribuidas son la solución natural cuando se tienenvarias bases de datos existentes en la organización. En este caso, las basesde datos distribuidas son creadas utilizando una estrategia de diseño tipobottom-up a partir de las bases de datos locales existentes.

Desarrollo incremental
• Si una organización agrega una nueva unidad, relativamente autónoma,entonces las bases de datos distribuidas soportarían este crecimiento con elmenor grado de impacto a las unidades ya existentes.

Reducción en la sobrecarga de la comunicación
• En el máximo de que las aplicaciones sean locales es uno de los objetivosprimarios en el diseño de las bases de datos distribuidas.

Consideraciones en el desempeño
• La existencia de varios procesadores autónomos dan como resultado unincremento en el desempeño por medio de un alto grado de paralelismo

Confiabilidad y disponibilidad
• Las fallas en una base de datos distribuida pueden ser más frecuentes queen las centralizadas, debido al gran número de componentes, pero el efectode cada falla es considerado por cada aplicación que usa los datos en sitioque falló, y por lo tanto es raro que el sistema en su totalidad falle.

1. Distribución: Los datos no están residentes en el mismo sitio(procesador). Esto permite distinguir una base de datos distribuida de unabase de datos centralizada.
2. Correlación lógica: Los datos tienen algunas propiedades que losrelacionan, de tal manera que se puede distinguir una base de datosdistribuida de un conjunto de bases de datos locales o archivos residentesen diferentes sitios de una red de computadores
Dos puntos importantes en una BDD

Diseño de bases de datos
distribuidas

El Modelo relacional
El modelo relacional hace uso del álgebra relacional, la cual utiliza estrategiasde acceso a la base de datos mientras que las herramientas como SQL sonprogramas de aplicación directamente.

• Selección
• Proyección
• Unión
• Diferencia
• Producto cartesiano
• Join
• Join Natural
• Semijoin
• Semijoin Natural
• Agrupamiento

Selección
Produce una relación con el mismo esquema de la relación operando y unsubconjunto de tuplas del mismo que satisfacen un predicado.

Proyección
• Genera un conjunto de tuplas derivadas de la relación operando al proyectarun subconjunto de atributos de esta. Si hay tuplas repetidas, estas seeliminan

Unión
• Produce una relación con el mismo esquema de cada uno de los operandos yun conjunto de tuplas resultante de unir las de las relaciones operando.

Diferencia
• Está formada por las tuplas de la primera relación que no se encuentran enla segunda

Producto cartesiano
• Produce una relación con todas los atributos de los dos relaciones, dondecada tupla de la primera se combina con todas las tuplas de la segunda

Join
• El join de dos relaciones se basa en una fórmula que especifica el predicadodel join.
• Normalmente está dada por conjunciones de comparaciones entreatributos tomados de los dos operandos. Un join se deriva del productocartesiano y de la selección.

Join Natural
• También denominado equijoin, el join natural genera unarelación en la que de cada par de atributos idénticos sedescarta uno. Las tuplas resultantes son las quesatisfacen la igualdad en dichos atributos.

Semijoin
• Es el resultante de aplicar proyección sobre los atributos del primeroperando después de haber hecho join a los dos operandos. Debe tener encuenta un predicado, igual que con el join.

Semijoin Natural
• Es el resultante de aplicar proyección sobre los atributos del primeroperando después de haber hecho join natural a los dos operandos.

Agrupamiento
• Operación definida por un conjunto de atributos que determinan elagrupamiento y unas funciones agregadas a ser evaluadas en cada grupo dela relación.

• Modelo de datos que representa un esquema de base dedatos mediante entidades y asociaciones
• Describe una base de datos de una forma sencilla y global
• Se realiza a partir de los requisitos de datos que debe cumpliruna base de datos

Modelo E-RDescriben el esquema de una base de datos
• Entidades: Rectángulos, representan objetos reales
• Atributos: Óvalos, representan propiedades de estos objetos
• Relaciones: Rombos, representan enlaces

Ejemplo

Cardinalidad de una relación
1:1 Uno a uno
1:N Uno a muchos
N:M Muchos a muchos


Cardinalidad1:1
PERSONA dirige DEPTO
1:N
PERSONA trabaja DEPTO
N:N
ALUMNO inscrito CURSO

SQL
• El lenguaje de consulta estructurado (SQL) es un lenguaje de base de datosnormalizado, utilizado por el motor de base de datos de Microsoft Jet. SQLse utiliza para crear objetos QueryDef, como el argumento de origen delmétodo OpenRecordSet y como la propiedad RecordSource del control dedatos.

• El lenguaje SQL está compuesto por comandos, cláusulas, operadores yfunciones de agregado. Estos elementos se combinan en las instruccionespara crear, actualizar y manipular las bases de datos.

Existen dos tipos de comandos SQL:
• DLL: permiten crear y definir nuevas bases de datos, campos e índices.
• DML: permiten generar consultas para ordenar, filtrar y extraer datos de labase de datos.

CREATE Utilizado para crear nuevas tablas, campos e índices
DROP Empleado para eliminar tablas e índices
ALTER Utilizado para modificar las tablas agregando campos o cambiando ladefinición de los campos.

• SELECT Utilizado para consultar registros de la base de datos que satisfagan un criterio determinado
• INSERT Utilizado para cargar lotes de datos en la base de datos en una única operación.
• UPDATE Utilizado para modificar los valores de los campos y registros especificados
• DELETE Utilizado para eliminar registros de una tabla de una base de datos

• FROM Utilizada para especificar la tabla de la cual se van aseleccionar los registros
• WHERE Utilizada para especificar las condiciones que deben reunirlos registros que se van a seleccionar
• GROUP BY Utilizada para separar los registros seleccionados engrupos específicos
• HAVING Utilizada para expresar la condición que debe satisfacercada grupo
• ORDER BY Utilizada para ordenar los registros seleccionados deacuerdo con un orden específico

• AND Es el "y" lógico. Evalúa dos condiciones y devuelve unvalor de verdad sólo si ambas son ciertas.
• OR Es el "o" lógico. Evalúa dos condiciones y devuelve unvalor de verdad si alguna de las dos es cierta.
• NOT Negación lógica. Devuelve el valor contrario de laexpresión.

• < Menor que
• > Mayor que
• <> Distinto de
• <= Menor ó Igual que
• >= Mayor ó Igual que
• = Igual que
• BETWEEN Utilizado para especificar un intervalo de valores.
• LIKE Utilizado en la comparación de un modelo
• In Utilizado para especificar registros de una base de datos

• AVG Utilizada para calcular el promedio de los valores de un campodeterminado
• COUNT Utilizada para devolver el número de registros de la selección
• SUM Utilizada para devolver la suma de todos los valores de un campodeterminado
• MAX Utilizada para devolver el valor más alto de un campo especificado
• MIN Utilizada para devolver el valor más bajo de un campo especificado

Transformaciones equivalentes
Hay dos aspectos que deben tenerse en cuenta: la semántica y la secuencia de operaciones.
La semántica: la cual se entiende con el significado del programa, es decir, lo que debe hacer
Secuencia de operaciones: la que se entiende con la forma de lograrlo. Lo que quiere decirque dos expresiones con la misma semántica pueden tener dos secuencias de operacionesdiferentes.

Join
La sentencia join en SQL permite combinar registros de dos o más tablas enuna base de datos relacional. En el Lenguaje de Consultas Estructurado (SQL),hay tres tipo de JOIN: interno, externo, y cruzado.
Matemáticamente, JOIN es composición relacional, la operación fundamentalen el álgebra relacional, y generalizando es una función de composición.

Combinación interna (INNER JOIN)
• Con esta operación se calcula el producto cruzado de todos los registros; asícada registro en la tabla A es combinado con cada registro de la tabla B;pero sólo permanecen aquellos registros en la tabla combinada quesatisfacen las condiciones que se especifiquen.

Combinación Cruzada (CROSS JOIN)
• Presenta el producto cartesiano de todos los registros de las dos tablas. Elcódigo SQL para realizar este producto cartesiano enuncia las tablas queserán combinadas, pero no incluye algún predicado que filtre el resultado.

Combinación externa (OUTER JOIN)
• Mediante esta operación no se requiere que cada registro en las tablas atratar tenga un registro equivalente en la otra tabla. El registro esmantenido en la tabla combinada si no existe otro registro que lecorresponda.
• Este tipo de operación se subdivide dependiendo de la tabla a la cual se leadmitirán los registros que no tienen correspondencia, ya sean de tablaizquierda, de tabla derecha, o combinación completa.

De tabla izquierda (LEFT OUTER JOIN o LEFT JOIN)
• El resultado de esta operación siempre contiene todos los registros de latabla de la izquierda (la primera tabla que se menciona en la consulta), auncuando no exista un registro correspondiente en la tabla de la derecha, parauno de la izquierda.
• La sentencia LEFT JOIN retorna la pareja de todos los valores de la tablaizquierda con los valores de la tabla de la derecha correspondientes, oretorna un valor nulo NULL en caso de no correspondencia.

Ejemplo de aprendizaje
• Show databases: Muestratodas las bases de datos.
Para nuestro práctica usaremosla base de datos ejercicio.

• Use ejercicio; = nos permite poner ejecución la base de datos llamada “ejercicio”.
• Show tables; = Muestra las tablas que contiene la base de datos que estemos utilizando.

• Describe orden; =Imprime en pantallalos atributos quecorresponden a cadatabla, así como lainformación quedetalla al atributo.

• Las consultas a los registro podemos hacerla con la sentencia:
• Select * fromNombre_tabla;

Inner Join
Nos permite unir dos tablas en este caso la tabla personasy orden, esta primera consulta asocia a todas las personasque tienen una orden. Este tipo de sentencia se le llamaexplícita debido a que lleva la palabra Join.

• Esta consulta ejecuta lo mismo que la sentencia anterior, estetipo de Join es conocido como implícito, otro dato a observar esque “Order by” permite ordenar según el atributo que escojamos.

NATURAL JOIN
Podemos realizar también un Natural Join, este caso en particular permite comparar todas las columnas que tengan el mismo nombre en ambas tablas.

CROSS JOIN
• Cross Join al igual que Inner Join, tiene una manera implícita yexplícita. Esta que esta mostrada representa la maneraExplícita.
• Es un producto cartesiano que menciona las tablas que seráncombinadas, pero no incluye algún predicado que filtre elresultado.

La siguiente sentencia es la forma de expresar la manera implícita de un CROSS JOIN, el resultado es el mismo que el de la forma explícita.

OUTER JOINCon el OUTER JOIN no esnecesario que losregistros en las tablas atratar tenga un registroequivalente en la otratabla. El registro esmantenido en la tablacombinada si no existeotro registro que lecorresponda.
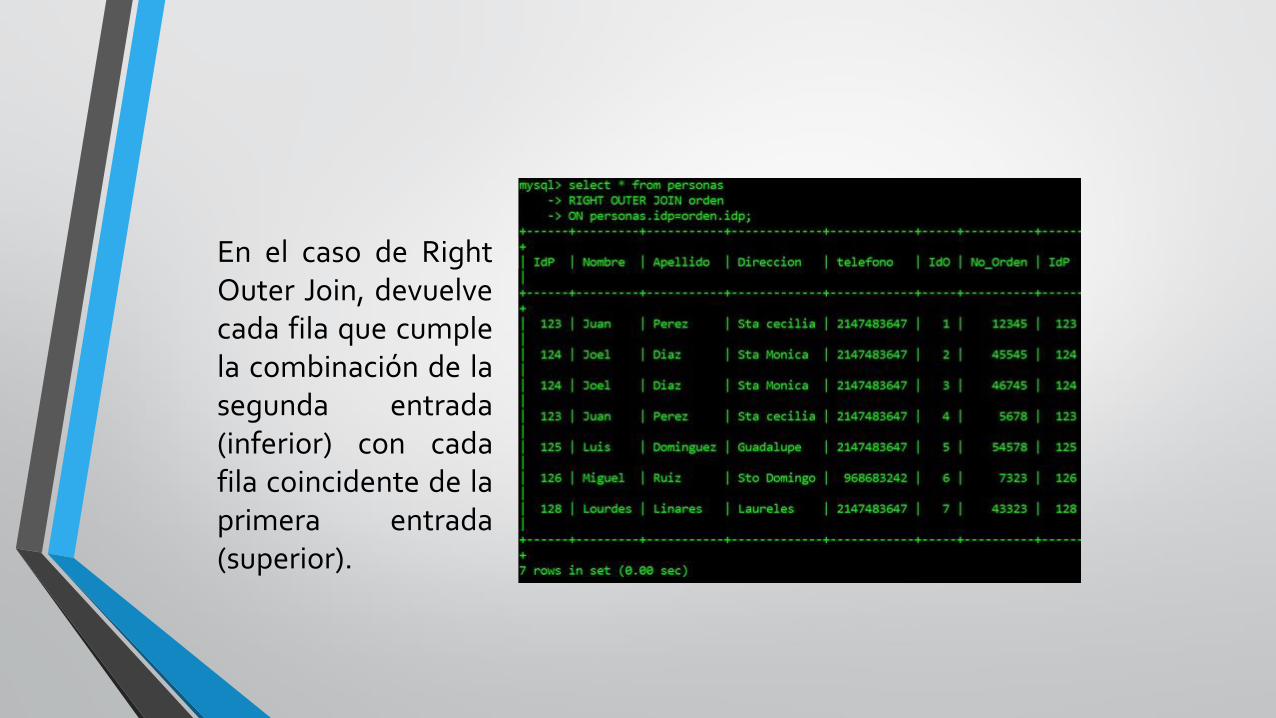
En el caso de RightOuter Join, devuelvecada fila que cumplela combinación de lasegunda entrada(inferior) con cadafila coincidente de laprimera entrada(superior).


















