
TEMA 1 PARALELISMO A NIVEL DE INSTRUCCIONES (ILP) … · 2012-11-05 · TEMA 3.ILP BASADO EN...
30
TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 1 TEMA 1 PARALELISMO A NIVEL DE INSTRUCCIONES (ILP) BASADO EN TÉCNICAS DINÁMICAS ÍNDICE 3.1. Técnicas de Planificación dinámica: Algoritmo del marcador, Implementación del Algoritmo de Tomasulo, Renombrado dinámico de registros. 3.2. Enfoques del paralelismo: procesadores superescalares y supersegmentados (superpipeline). 3.3. El problema de las excepciones: interrupciones precisas. 3.4. Especulación hardware: buffer de reordenación. 3.5. Paralelismo de instrucciones disponible: en las aplicaciones: programas enteros, científicos y multimedia. 3.6. Procesadores reales encadenados y superescalares. 3.7. Organización y gestión de la memoria en procesadores avanzados.
Transcript of TEMA 1 PARALELISMO A NIVEL DE INSTRUCCIONES (ILP) … · 2012-11-05 · TEMA 3.ILP BASADO EN...

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 1
TEMA 1 PARALELISMO A NIVEL DE INSTRUCCIONES (ILP)
BASADO EN TÉCNICAS DINÁMICAS
ÍNDICE 3.1. Técnicas de Planificación dinámica: Algoritmo del marcador, Implementación del
Algoritmo de Tomasulo, Renombrado dinámico de registros.
3.2. Enfoques del paralelismo: procesadores superescalares y supersegmentados
(superpipeline).
3.3. El problema de las excepciones: interrupciones precisas.
3.4. Especulación hardware: buffer de reordenación.
3.5. Paralelismo de instrucciones disponible: en las aplicaciones: programas enteros,
científicos y multimedia.
3.6. Procesadores reales encadenados y superescalares.
3.7. Organización y gestión de la memoria en procesadores avanzados.

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 2
CONCEPTOS FUNDAMENTALES • Objetivo:
o Aumentar ILP
o Reducir bloqueos de datos y de control dinámicamente
• Dinámicas: en tiempo de ejecución.
• Principales algoritmos hardware (muy sofisticados):
o Predicción de saltos: BTB
o Planificación, secuenciamiento o reordenamiento (scheduling)
o Especulación dinámica de instr.: ejecutar instr. sin saber aún si son correctas
�Dinámicamente se pueden “cruzar” saltos
• Procesadores actuales son muy sofisticados
o se acercan al data flow limit o fases “accesorias” se ocultan.
o Sólo operaciones ALU se “ven”

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 3
CPI: tipos y bloqueos
• CPIdatos debido a dependencias de datos (típicamente RAW o RAW en
memoria) • CPIestructural debido a dependencias estructurales (típicamente UF no
segmentada, falta de recursos como UF, etc.) • CPIcontrol debido a saltos (típicamente saltos condicionales, fallos de
predicción de BTB) • CPImemoria debido a fallos de caché (de L1, L2, L3, acceso a RAM, fallos
de página, es decir, acceso a disco)
Memoria B.Control B.lEstructura B.Datos B.Bloqueo
BloqueoIdealReal
CPI CPI CPI CPI CPI
CPI CPI CPI
+++=
+=

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 4
PREDICCIÓN DINÁMICA: BTB • Caché de predicción de saltos (comportamiento y destino) (Branch Target Buffer)
o Se Indexa en fase IF por el PC (como instrucción)
• Predictor local
o Predictor en función de las últimas K ocurrencias de cada salto individualmente.
• Predictor por correlación
o Predictor en función de las comportamientos de los últimos P saltos del
programa.
• Predictor por torneo (Tournament predictor):
o Combina el Predictor local con el de correlación
o Elige uno de los dos comportamientos en función de un selector de 2 bits con
saturación.
• Si falla la predicción
o Vacía la cadena (afecta al rendimiento) � Penalidad de control
o Actualiza la predicción (modifica los bits de predicción)
o Reinicia la cadena con la instrucción correcta
TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 5
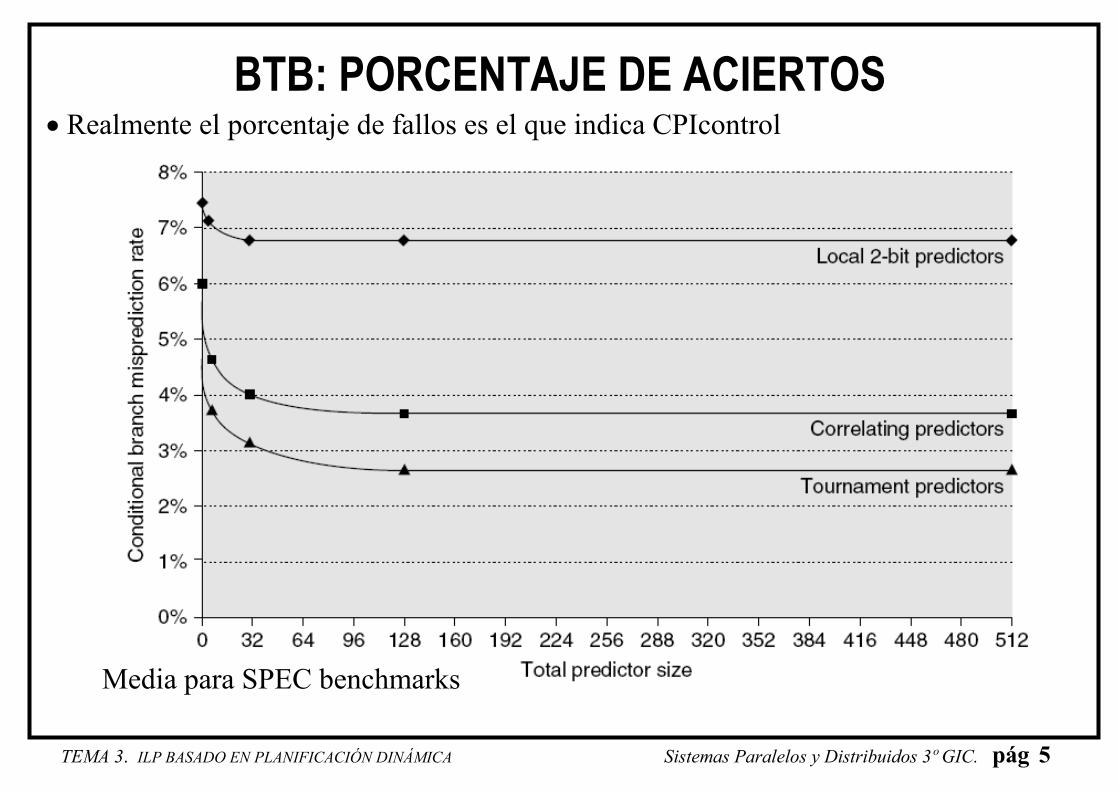
BTB: PORCENTAJE DE ACIERTOS • Realmente el porcentaje de fallos es el que indica CPIcontrol
Media para SPEC benchmarks

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 6
Enfoques del paralelismo de instrucciones: superescalar, VLIW, supersegmentado.
tejecución = Ninst × CPI × τ·
• Tres Modelos teóricos según factor que se reduce:
o Reducir Ninst : LIW o VLIW (“Very Long Instruction Word”).
- instrucciones más densas
o Reducir CPI : Superescalares. - CPI puede ser menor que 1 ciclo/ inst
o Reducir τ : “superpipeline”, supersegmentado o superencadenado.
- etapas supersegmentadas.
- CPI >= 1
• Procesadores reales: combinación de ellos.

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 7
Máquina Superescalar • Emisión Dinámica � Compatibilidad software (ISA normal)
� éxito comercial � Típicos en GPP (General Purpose Processors)
• Recordar cuasi máxima: las técnicas dinámicas acaban imponiéndose a
las estáticas en máquinas de propósito general, por la compatibilidad
del sw.
Instrucciones IF ID EX ME WB
IF ID EX ME WB
IF ID EX ME WB
IF ID EX ME WB
Tiempo
• DEF: m = grado de superescalaridad (Issue Width). • DEF: IPC = (CPI)-1= Número de instrucciones por ciclo. • IPCideal = m>1 , CPIideal =1/m <1 o Bloqueos (datos, estructurales, control) => IPCreal <= IPCideal, CPIreal >= CPIideal
No mezclar CPI con IPC
¿Ninstr. en vuelo?

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 8
Implementación de Procesadores Superescalares • La idea teórica es fácil si se tienen varias U.F.
RISC ENCADENADO CON VARIAS U.F.
IF ID WB
EX Enteros
EX FP/Ent MUL
EX FP ADD
EX FP/Ent DIV
MEM
IF ID WB
EX Enteros
EX FP/Ent MUL
EX ADD FP
EX FP/Ent DIV
IF ID WB
? ? ? ?
? ? ? ?
IDEA DE RISC SUPERESCALAR
MEM
• Emisión (ID o IS) ���� complejidad de implementación � Hay que detectar muchas RAW en ella (de m instrucciones)
� Hay que decidir qué instrucciones se pueden emitir
� Hay que leer muchos registros a la vez (2m lecturas +m escrituras en la fase WB)
• grado superescalaridad m ¡ atascado desde 1996 en m=3~4 !

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 9
PLANIFICACIÓN DINÁMICA: CONCEPTO. � Proc. de planif. estática ejecuta instrucciones en orden.
o Si una instrucción no puede ejecutarse, la cadena se para completamente:
Tiempo
DIVF
ADDF
SUBF
ADDI
DIVF F0, F2, F4
ADDF F10,F0,F8
SUBF F8, F8, F14
ADDI R1, R1, 4
…
c.bq.datos
_ _ _ _ _ _ _
_ _ _ _ _ _ _
Cronograma sin planificación dinámica
� ADDF debe esperar � muchos bloqueos CPI datos
o Pero SUBF, ADDI, etc., podría ejecutarse…
� Superescalares “comprimen” la ejecución (más instr. /ciclo) � aún más bloqueos
por CPI datos
� Necesitan técnicas dinámicas “agresivas”
TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 10
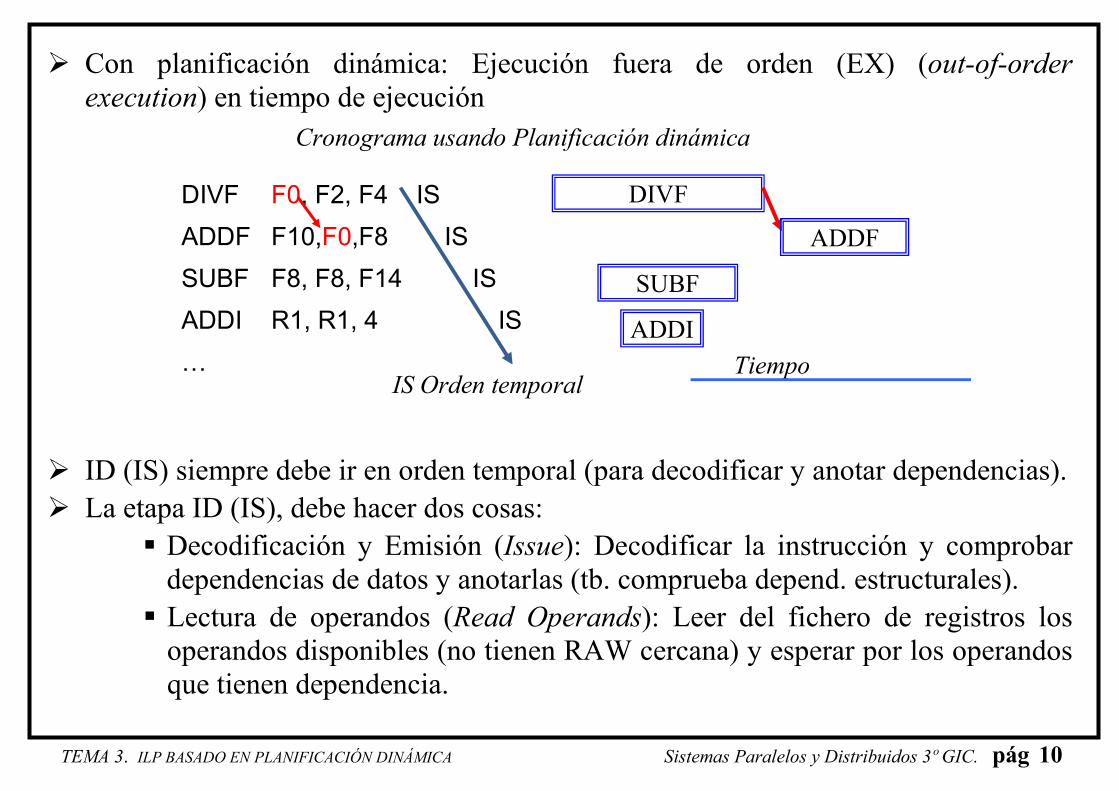
� Con planificación dinámica: Ejecución fuera de orden (EX) (out-of-order execution) en tiempo de ejecución
Tiempo
DIVF
ADDF
SUBF
ADDI
DIVF F0, F2, F4 IS
ADDF F10,F0,F8 IS
SUBF F8, F8, F14 IS
ADDI R1, R1, 4 IS
…
Cronograma usando Planificación dinámica
IS Orden temporal
� ID (IS) siempre debe ir en orden temporal (para decodificar y anotar dependencias).
� La etapa ID (IS), debe hacer dos cosas:
� Decodificación y Emisión (Issue): Decodificar la instrucción y comprobar
dependencias de datos y anotarlas (tb. comprueba depend. estructurales).
� Lectura de operandos (Read Operands): Leer del fichero de registros los
operandos disponibles (no tienen RAW cercana) y esperar por los operandos
que tienen dependencia.
TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 11
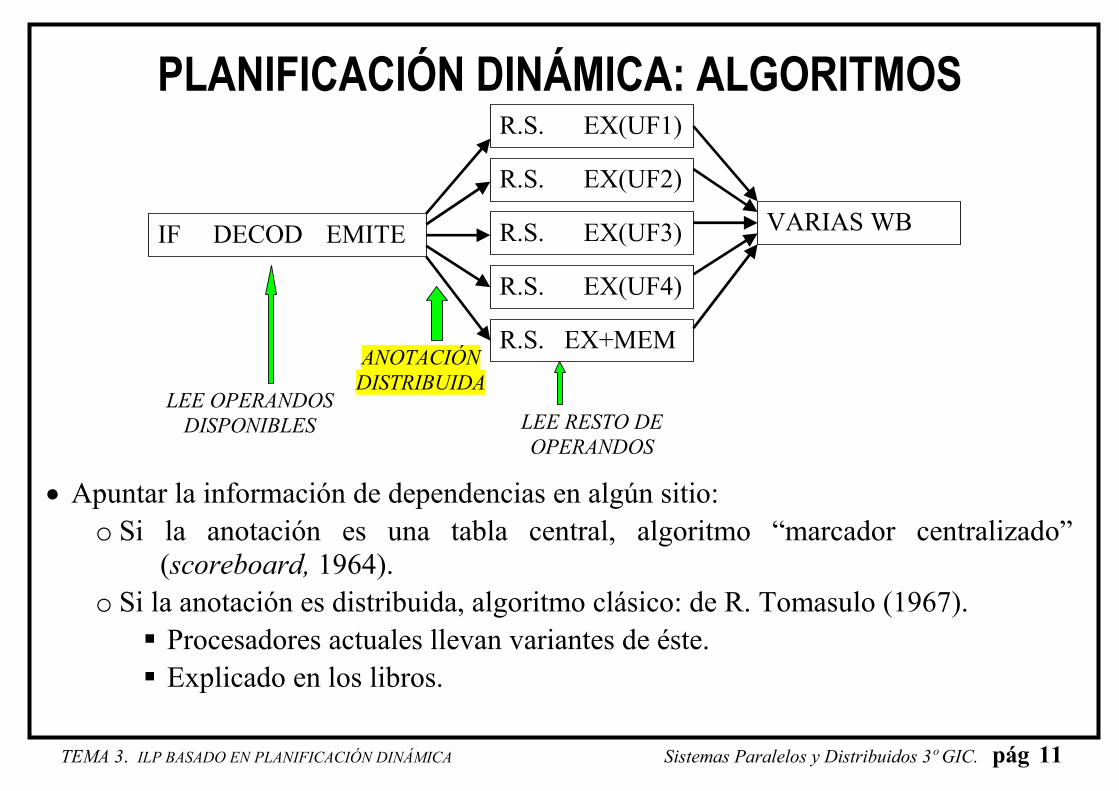
PLANIFICACIÓN DINÁMICA: ALGORITMOS
ANOTACIÓN DISTRIBUIDA
IF DECOD EMITE
R.S. EX(UF1)
R.S. EX(UF2)
R.S. EX(UF3)
R.S. EX(UF4)
R.S. EX+MEM
LEE OPERANDOS DISPONIBLES LEE RESTO DE
OPERANDOS
VARIAS WB
• Apuntar la información de dependencias en algún sitio:
o Si la anotación es una tabla central, algoritmo “marcador centralizado”
(scoreboard, 1964).
o Si la anotación es distribuida, algoritmo clásico: de R. Tomasulo (1967).
� Procesadores actuales llevan variantes de éste.
� Explicado en los libros.

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 12
ALGORITMO DE TOMASULO. • Técnica de planificación dinámica de instrucciones con gestión distribuida.
• En el IBM/360 (1967, Robert Tomasulo) era sólo para operaciones de FP.
• Hoy se aplica a todas las instrucciones, y la mayoría de procesadores avanzados
llevan un algoritmo similar al clásico.
• Este algoritmo se puede aplicar a otro tipo de sistemas donde hay ciertos recursos
compartidos por diversos agentes, y se quieren gestionar los recursos de forma
distribuida. La implementación que veremos aquí es hardware.
• Se puede definir la especificación exacta (en lenguaje C, con simuladores, en
VHDL) del algoritmo de Tomasulo. Esto se implementa luego en hardware.
ETAPAS O FASES: IF IS EX WB • Fetch (IF): Acceso a caché de instrucciones para leer instrucción apuntada por PC
• Issue (IS): Emisión de la instrucción.
• Execution (EX): ejecución de la operación (o acceso a memoria).
• Write (WB): Escritura de resultado

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 13
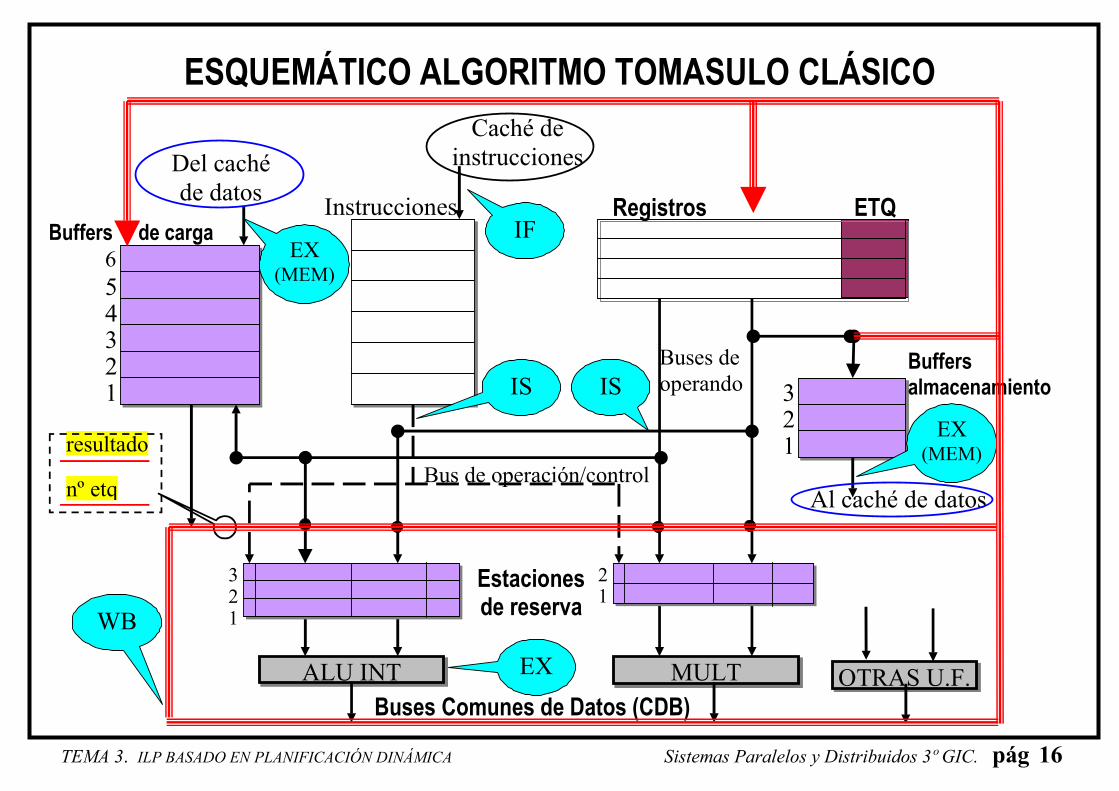
ALGORITMO TOMASULO: COMPONENTES • Estación de Reserva (Reservation Stations, R.S.):
• Pequeños búferes dónde esperan las instrucciones emitidas junto a las U.F. hasta
que pueden ejecutarse
• Forman una pequeña cola de instrucciones, sin orden estricto de salida (se sirve
primero a la que tenga disponibles todos sus operandos fuentes).
• Las R.S. para instr. de carga/almacenamiento se llaman Buffers de Memoria
• Bus Común de Datos (Common Data Bus, CDB):
• Une la salida de las UF con el fichero de registros y las estaciones de reserva.
• Las UF mandan el dato de salida a través de él para que lo lean el resto de
elementos de la CPU
• Se trata de un recurso común por el que hay que competir.
• Los proc. suelen tener más de un CDB
• Contiene dos buses: uno para el resultado y otro para la etiqueta asociada.
• Etiqueta (tag):
• Identificadores que se asocian a los registros destino cada vez que se emite una
instrucción. Así se evitan dependencias ficticias (WAR, WAW)
• Cada registro del fichero de registros tiene un campo para la etiqueta.

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 14
ALGORITMO TOMASULO: FUNCIONAMIENTO • En algoritmo clásico y en los actuales, podemos decir que los nombre de las RS y
etiquetas son los mismos.
• En cada fase de emisión (IS) se envían m instr. a las R.S. de la UF correspondiente,
junto con sus operandos disponibles (leídos del fichero de registros)
- Se renombra cada registro destino con una etiqueta: desde entonces, es ésta la
que circula por toda la CPU
• Cada R.S. está a la “escucha” de los CDBs para capturar los operandos que necesite.
• Cuando un RS contiene todos los operandos, se ejecuta.
• Tras la escritura (WB) la RS (y etiqueta) se libera (se usará para otra instr.)
- Los resultados se envían a los CDBs (junto con la etiqueta) para que sean leídos
por todas las R.S. y el fichero de registros.
- Como tales resultados nuevos llegan a las R.S., podría haber alguna (o varias)
que ahora ya tengan sus operandos y pasen a ejecutarse.

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 15
ALGORITMO TOMASULO: CPI bloqueos - La cadena no se bloqueará por las RAW: Teóricamente CPIdatos = 0
- Los cachés son no bloqueantes (non-blocking caches). Teóricamente CPImemoria = 0
- Solamente si no hay RS libre, no se hace IS y la CPU se bloqueará hasta que se
libere alguna. Aumenta el CPI bloqueo estructural: CPIestruct ≠ 0
- NOTA: aunque teóricamente sólo existe CPIestruct ≠ 0, estos bloqueos provienen de
otras causas: muchos fallos de caché, muchas RAW, etc.
o Ej: un acceso a memoria principal son del orden de:
� (sólo latencia RAM) 40 ns * 3 Gciclos/s = 120 ciclos CPU
� Durante esos 120 ciclos, si no se pueden ejecutar instr. (esperan al dato de
RAM), se ocuparían 120*m RS ¡!!!
� Como no van a existir tantas � teóricamente CPIestruct ≠ 0, pero realmente
debido a acceso a RAM
TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 16
ESQUEMÁTICO ALGORITMO TOMASULO CLÁSICO
nº etq
1 2 3
ALU INT MULT
Del caché
de datos
Caché de
instrucciones
Buffers de carga
Instrucciones Registros ETQ
Buffers almacenamiento
Buses de
operando
Bus de operación/control
Estaciones de reserva
Buses Comunes de Datos (CDB)
1 2 3 4 5
6
1 2 3
1 2
Al caché de datos
IF
EX
EX (MEM)
WB
IS
EX (MEM)
IS
OTRAS U.F.
resultado

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 17
ALGORITMO TOMASULO: Ejemplo de renombrado • Las etiquetas se llaman como R.S.
• sólo quedan las RAW reales, que van formando el grafo de dependencias.
LD F0, 0(R1) LD F2, 0(R3) MULTD F4, F0, F2 LD F6, 0(R2) ADDD F4, F6, F4 ADDD F4, F10, F4 ADDI R1, R1, 16 LD F0, 8(R1) SD 0(R1), F4
LD Carga1, 0(R1) LD Carga2, 0(R3) MULTD Multfp1, Carga1, Carga2 LD Carga3, 0(R2) ADDD Addfp1, Carga3, Multfp1 ADDD Addfp2, F10, Addfp1 ADDI Ent1, R1, 16 LD Carga1, 0(Ent1); el buffer Carga1 ya está libre
SD 0(Ent1), Addfp2 ; sin oper destino

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 18
Ejemplo 1: cronograma Tomasulo Cronograma de IS EX WB para el siguiente fragmento de código. Veáse el
reordenamiento dinámico de fases EX. Las INT se anticipan a las FP.
m = grado de superescalaridad = 3
- Ld/St: 2 ciclos (como E1+E2).
- MULTD: 4 ciclos,
- ADDD: 2 ciclos, operaciones enteras y saltos: 1 ciclo.
Suponer infinitas R.S., excepto sólo 2 R.S. de carga. (Carga3 no existe, deberá
bloquearse y esperar a que esté libre Carga1 para usarla)
LD F0, 0(R1)
LD F2, 0(R3)
MULTD F4, F0, F2
LD F6, 0(R2)
ADDD F4, F6, F4
ADDD F4, F10, F4
ADDI R1, R1, 16
LD F0, 8(R1)
SD 0(R1), F4
Hallar también el número de R.S. consumidas en cada ciclo

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 19
Ejemplo 2: Bucles con Tomasulo Sea el procesador con algoritmo de Tomasulo con las siguientes duraciones:
m = grado de superescalaridad = 1
- Ld/St: 2 ciclos (como E1+E2).
- MULTD: 4 ciclos,
- ADDD: 2 ciclos
- operaciones enteras y saltos: 1 ciclo.
Cronograma de IS EX WB para 2 iteraciones del bucle.
(ver croquis en página siguiente, donde “conviven” varias iteraciones)
Loop: LD F0, 0(R1)
MULTD F4, F0, F2
SD 0(R1), F4
SUBI R1, R1, 8
BNEZ R1, Loop

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 20
Croquis: diferencia entre planificación estática y dinámica para bucle paralelizable (sólo flujo de datos)
Bypasses específicos entre UF LD
LD’
MULTD
MULTD’
SD
SD’
SUBI
BNEZ Tiempo
MULT
SD
LD
MULT’
SUB
SD’
BNEZ
LD’
Múltiples registros de usuario
LD
MULTD
SD
SUBI
BNEZ
Tiempo
MULT
SUB
SD
Bypass por el CDB
LD
BNEZ
LD
MULTD
SD
SUBI
BNEZ
MULT
SUB
SD
LD
BNEZ
Múltiples R.S.
Desenrollado estático Tomasulo: dinámicamente - Tb. “conviven” varias iteraciones a la vez
- Adelantar emisión de instr de 2ª iter ⇒ mejor

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 21
Variante actual más común del Alg. Tomasulo • Se renombran, dinámicamente y para todas las instr. emitidas, los registros lógicos
(de usuario, de las instr. de ensamblador) por registros físicos (internos, no visibles al
programador). Los registros físicos funcionan como etiquetas. Suele haber muchos
más registros físicos que lógicos.
Dependencias de Memoria • Los accesos a memoria (ejecutados en búferes de carga y de almacenamiento)
pueden tener dependencias entre los datos que leen o escriben en memoria. Ej:
- SW 20(R3), R9
- LW R1, 8(R4) Si ocurre que: 20+R3 = 8+R4 ⇒ RAW en memoria
• Evidentemente esta dependencia no se puede detectar en t. de compilación.
• Dinámicamente hay un buffer de comparación de direcciones: Antes de que un Load
acceda al caché, se debe comparar su dirección efectiva con todas las de los búferes
de almacenamiento. Si hay coincidencia ⇒ dependencia real en memoria.
• Los búferes de Store son como un buffer de escritura en caché (con dirección y dato)
• En procesadores con pocos registros de usuario (CISC) el código tendrá muchos
accesos a memoria. El riesgo es mayor y se necesita más hw para resolverlo.

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 22
Tomasulo en procesadores reales • micros con planif dinámica:
o capaces de emitir y ejecutar varias instrucciones a la vez,
o Cientos de R.S. Miles de comparadores.
• Uno de los primeros microprocesadores con planif dinámica fue Motorola PowerPC 620 (1995).
o Es un ejemplo similar a los actuales GPP
o Intenta emitir 4 instr. por ciclo
o cadena de 4 fases (IF ID IS EX) y arquitectura es muy similar al algoritmo
clásico Tomasulo.
- Poseía unas pocas R.S. por cada UF
- Dos unidades enteras simples (1 ciclo).
- Una unidad entera compleja (3 a 20 ciclos) para MULT y DIV enteras.
- Una unidad de carga-almacenamiento (1 ciclo si acierta en caché).
- Una unidad de punto flotante (31 ciclos DIVFP, 2 ciclos ADDFP y MULTFP).
- Y una unidad de saltos, que actualice BTB en caso de fallo de predicción.

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA
Ej: Power PC 620 (similar al Tomasulo clásico)
ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribui
Ej: Power PC 620 (similar al Tomasulo clásico)
Sistemas Paralelos y Distribuidos 3º GIC. pág 23
Ej: Power PC 620 (similar al Tomasulo clásico)

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 24
Máquinas reales: Alpha 21264 (Digital, COMPAQ) 1999 - 80 Registros INT de 64 bits. 72 Reg FP (es como un pequeño caché)
- Superescalar de grado m=4
- Primero renombran reg. Luego, R.S. (Integer y FP queue) se quedan a la espera de leer
operandos. Cuando están disponibles, los leen (etapa posterior)
- Los bancos de registros enteros están duplicados para permitir 4 UF enteros trabajando en
paralelo.

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 25
CONCLUSIONES: PLANIFICACIÓN ESTÁTICA VS. DINÁMICA. RESUMEN: PROS Y CONTRAS
PLANIFICACIÓN ESTÁTICA PLANIFICACIÓN DINÁMICA Menos Hardware Complicación hardware
Compilador más difícil Compilador no tiene que optimizar
Posibles problemas de herencia (compilador debe conocer endoarquitectura)
Transparente al usuario
Inconveniente: Dependencia compilación-rendimiento
El hardware extrae el rendimiento que puede en cada versión del microproc.
Tamaño de código estático puede crecer ⇒ más fallos de caché
Tamaño de código estático no se toca
Ventaja: Ventana de instrucciones infinita (análisis global)
Defecto: Ventana de instrucciones limitada (fase IF) (análisis local)
El compilador no puede conocer:
- valores de registros (dir. acceso)
- predicción dinámica, etc.
En tiempo de ejecución se conoce más:
- valores de registros (dir. acceso)
- predicción dinámica, etc.
Puede eliminar instrucciones (overhead u otras) No puede eliminar instrucciones
Puede necesitar muchos registros de usuario No necesita muchos registros de usuario (son internos, ocultos al usuario; ej. CISC)

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 26
3.2 Tipos de Superescalares según Emisión • La planificación y emisión determinan la arquitectura interna.
• Emisión Dinámica siempre. Pero
- Flexible (Sin restricciones en el orden/tipo de instr.)
���� Más complejidad
- Rígida (Con Restricciones).
���� Menos complejidad
���� Casos usuales • Exigen cierto orden en las m instrucciones: Se parece a VLIW (pero
con emisión dinámica) • Deben ser de cierto tipo (en función de la UF, tipo INT o FP, etc.)
o Ejemplo m = 2: restricción una INT otra FP. Casos instr.:
INT IF ID
FP IF ID
FP IF ID
FP IF - ID
INT IF ID
INT IF - ID

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 27
Tipos de Superescalares según Planificación El rendimiento depende de la complejidad del superescalar
• Planificación Dinámica (Algor. Tomasulo o similar).
- No suele tener restricciones en el orden/tipo de instr.:
���� Toda instr. queda a la espera en la R.S.
- Más complejidad (y consumo)
• Planificación Estática.
- Si suelen tener restricciones en el orden/tipo de instr.:
- Menos complejidad (y consumo)
- Caso típico:
���� “Tuberías” independientes
���� Primeros superescalares (principios de los 90) y sistemas empotrados
actuales de m=2

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 28
Ejemplos: Impacto de c. bq. en prestaciones • Un bloqueo de toda la cadena:
muy caro en prestaciones.
• Más deceleración para mayor m. Ej: 2 c. bq.
Hallar A respecto caso ideal
• Hallar y comparar la deceleración
para Encadenado y para Superescalar grado m,
si CPIbloqueo_memoria =0.2 c/instr.
� “se amplifica” m veces.
Encadenado
Superescalar
• Hallar deceleración y CPIbloqueo para Superescalar m=4, si no hay ningún ciclo de
bloqueo total, pero sólo se emiten 3 de las m=4 instrucciones.
¿Cuál es correcto?:
IPCideal= 4, IPCreal=3, luego IPCbloqueo=4-3 = 1 instr/ciclo => CPIbloqueo= 1 cic/inst CPIideal= 1/4, CPIreal=1/3, luego CPIbloqueo= CPIreal - CPIideal=1/3-1/4=1/12 cic/inst
EJERCICIO: Calcular A si en ciclos pares se ejec. m instr, pero en los impares sólo 1.
Dibujar fases ID para m=4 con solo 3 ID por ciclo
IS
IS
- - IS
IS
IS
IS
- - IS
IS

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 29
Implementación Superescalares (Planif. Dinámica) (I) Arquitectura muy distinta a la de los superescalares con planif. estática.
Programador/Compilador en realidad siempre ayudan en más rendimiento.
Más complejidad ⇒ más consumo (peores para sist empotrados)
Normalmente una cola de instr. por cada etapa
IF
mIS
emitidas
IS
mEX
ejecutadas
EX
mWB
escritas
mIF
buscadas
WB
• ¿Cuál es el grado m de superescalaridad?:
� Buscar cuello de botella en la cadena
� Típicamente m suele ser mIS
> Nº máximo instr. en vuelo = suma de instrucc. o entradas de todos los búferes.
> Difícil ver el cronograma. Se ocultan esperas de cualquier tipo, llenando y
vaciando las colas (hasta que se bloquea por agotamiento de una de las colas).
> EJEMPLO: Dibujar Cronogr. Si los ritmos en ciclos pares/impares son: IF:4/2, IS: 3/3, EX: 1/5, WB: 2/4 (media 3 por ciclo para toda fase)
¿La cola de instr. en IF es FIFO?
¿La cola de instr. en IS es FIFO?
¿Qué cola son las R.S:?

TEMA 3. ILP BASADO EN PLANIFICACIÓN DINÁMICA Sistemas Paralelos y Distribuidos 3º GIC. pág 30
Implementación Superescalares (Planif. Dinámica) (II)
• Fase IF: IFU Instruction Fetch Unit. Cola independiente que - buscan m instr (o más) por ciclo
- siempre prepara las m instr. siguientes para IS.
• Fase IS más compleja (cuello de botella)
- Emite las m instr. (mientras haya R.S. libres).
- Actualmente casi ningún procesador de propósito general impone reglas o
restricciones sobre las m instrucciones.
• Fase EX: - Debe ser Nº total U.F. > m. (algunas UF pueden estar ociosas).
- Doble puerto (o doble banco) cada vez más habitual.
• Fase WB: Nº CDB’s y puertos del fichero de registros es proporcional a m.
¿Qué debe hacer la BTB?
¿Puede existir una BTB en L2?


















