
SNMP GERENCIA DE OPERACIONES ADEXUS - … de Tesis/Proyectos de Titulo Duoc/2... · 3.5.2 Ventajas...
74
DUOCUC ESCUELA DE INFORMATICA Y TELECOMUNICACIONES SNMP GERENCIA DE OPERACIONES ADEXUS Trabajo de Titulación presentado en conformidad a los requerimientos para optar al Título de Ingeniero de Ejecución en Conectividad y Redes. Profesor Guía: JAIME VALENZUELA. DAMARIS PAZ FUENTES DELGADO Santiago de Chile, 2013
Transcript of SNMP GERENCIA DE OPERACIONES ADEXUS - … de Tesis/Proyectos de Titulo Duoc/2... · 3.5.2 Ventajas...

DUOCUC
ESCUELA DE INFORMATICA Y TELECOMUNICACIONES
SNMP GERENCIA DE
OPERACIONES
ADEXUS
Trabajo de Titulación presentado en conformidad a los
requerimientos para optar al Título de Ingeniero
de Ejecución en Conectividad y Redes.
Profesor Guía:
JAIME VALENZUELA.
DAMARIS PAZ FUENTES DELGADO
Santiago de Chile, 2013

DUOCUC
ESCUELA DE INFORMATICA Y TELECOMUNICACIONES
MONITOREO CON SNMP ADEXUS
DAMARIS PAZ FUENTES DELGADO
Santiago de Chile, 2013

ii
Dedicado a mis Padres, hermanos
amigos, y familia en general que me
otorgaron su apoyo incondicional en
cada etapa de mis estudios superiores
y en esta etapa final tan importante.
ii

ii
AGRADECIMIENTOS
Agradezco la oportunidad de realizar este proyecto en ADEXUS S.A en
especial a Eduardo Guzmán molina, quien fue mi principal contacto en la empresa,
ya que estuvo a cargo de la supervisión de mis prácticas, las cuales fueron: Practica
profesional y Practica laboral.
También es de suma importancia dar los reconocimientos a mi profesor
tutor Jaime Valenzuela, quien ha guiado mis pasos para evaluar cada idea que
alguna vez se imaginó como la mejor. Ha sido de suma importancia para lograr
desarrollar el proyecto final. Gracias a todo ese apoyo y al análisis exhaustivo se
logra optar por una buena idea, el proceso no termina ahí, ya que luego en el
desarrollo del proyecto aparecen un sinfín de dudas y detalles que por muy pequeños
que parezcan son realmente de gran importancia para desarrollar una buen proyecto
con miras a que más temprano que tarde finalmente se lleve a la instancia en la cual
se defiende.
Se agradece a la institución por los conocimientos técnicos y
tecnológicos aportados por el resto de los docentes que forman parte de esta gran
institución llamada DUOC UC.
iii iii

INDICE GENERAL
DEDICATORIA ...................................................................................................... ii
AGRADECIMIENTOS ......................................................................................... iii
INDICE DE TABLAS……………………………………………………………….iv
INDICE DE FIGURAS...…………………………………………………………….v
RESUMEN…………………………………………………………………………..vi
ABSTRACT………………………………………………………………………...vii
I. INTRODUCCIÓN. .......................................................................................... 1
1.1 Antecedentes. ......................................................................................... 1
1.2 Historia. .................................................................................................. 2
1.2.1 Misión. ......................................................................................... 2
1.2.2 Visión. .......................................................................................... 2
1.3 Presencia empresarial. ............................................................................ 3
1.3.1 Organigrama empresarial ADEXUS S.A. ..................................... 4
1.4 Servicios y soluciones. ............................................................................. 4
1.4.1 Servidores. .................................................................................... 5
1.4.2 Soluciones y servicios de almacenamiento. ................................... 5
1.4.3 En comunicaciones y multimedia. ................................................. 6
1.4.4 Movilidad. .................................................................................. 6
1.4.5 Seguridad. .................................................................................. 6
1.4.6 Operaciones. ................................................................................ 6
1.4.7 Proyecto y Desarrollo. ................................................................. 6
1.4.8 Integración de soluciones. ............................................................ 7
1.4.9 Servicios técnicos para plataformas. ............................................ 7
1.4.10 BPO. ............................................................................................. 7
1.4.11 Proyectos especiales. .................................................................... 7
1.4.12 Soluciones de biometría. ............................................................... 7
1.4.13 Soluciones terminales POS. .......................................................... 8
1.5 Alianza de negocios y certificaciones....................................................... 8

1.5.1 Aliados Tecnológicos. ............................................................................. 8
5.1.2 Certificaciones. ............................................................................. 9
5.1.3 Certificaciones de Calidad. ......................................................... 10
II. SITUACIÓN ACTUAL CGSI ADEXUS. ...................................................... 11
2.1 Organigrama de la Gerencia de Operaciones. ....................................... 11
2.1.2 Funciones de la gerencia. ............................................................ 12
2.2 Sub-Gerencia de ERP-Center. ............................................................... 12
2.2.1 Área de Automatización (Flujos). ............................................... 13
2.2.2 HP Operations Orchestration (HPOO). ....................................... 14
2.2.3 Componentes de HPOO. ............................................................ 14
2.2.4 Ambientes de HPOO. ................................................................. 15
2.2.5 Chequeo de Conexión. ................................................................ 15
2.2.6 Terminología del área. ................................................................ 17
2.2.7 Servidores HPOO y bases de datos. ............................................ 18
2.2.8 Consideraciones. ......................................................................... 19
2.2.6 Ambientes de trabajo. ................................................................. 20
2.3 Problemática o Necesidad. ..................................................................... 21
2.3.1 Ejemplo de flujo (Check List Router CISCO). ............................. 21
2.3.2 Despliegue del flujo. ................................................................... 23
3.3.3 Explicación del flujo. .................................................................. 23
2.3.4 Despliegue final del flujo. ........................................................... 26
III. MARCO TEORICO. ..................................................................................... 27
3.1 Administración de red. .......................................................................... 27
3.2 SNMP.................................................................................................... 27
3.2.1 Componentes del Modelo de Administración de SNMP. ............. 29
3.2.2 Detalles del protocolo. ................................................................ 29
3.3 Arquitectura de SNMP. .......................................................................... 30
3.3.1 La base de Información de gestión (MIB). .................................. 30
3.3.2 Consola de administración (NMS). .............................................. 31
3.3.3 Agente. ........................................................................................ 31
3.4 Mensajes................................................................................................ 31
3.4.1 Get-request. ................................................................................. 31

3.4.2 Get-next-request. ......................................................................... 31
3.4.3 Response. .................................................................................... 32
3.5 SNMP PRTG. ....................................................................................... 33
3.5.1 Versiones SNMP. ........................................................................ 34
3.5.2 Ventajas de monitoreo SNMP. .................................................... 35
3.5.3 Ejemplos de sensores. .................................................................. 35
IV. OPCIONES DE SOLUCIÓN. ....................................................................... 38
4.1 CACTI................................................................................................... 38
4.1.1 Base de datos. .............................................................................. 38
4.1.2 Gráficos. ...................................................................................... 39
4.1.3 Gestión de usuarios. .................................................................... 39
4.2 PRTG Network Monitor. ....................................................................... 40
4.2.1 Conceptos claves. ........................................................................ 40
4.2.2 SNMP y WMI. ............................................................................ 40
4.2.3 Monitorización de Disponibilidad y Rendimiento. ....................... 41
4.2.4 Evitar periodos de inactividad. ..................................................... 41
4.2.5 Red entera en pantalla. ................................................................. 42
4.2.6 Monitorización. .......................................................................... 42
4.2.7 Cómo trabaja el monitor SNMP de PRTG................................... 43
4.3 OP Manager.......................................................................................... 44
4.3.1 Amplias prestaciones. .................................................................. 44
4.3.2 Funcionalidades. ......................................................................... 45
V. SOLUCION PROPUESTA. .......................................................................... 47
5.1 Características. ...................................................................................... 47
5.1.2 Monitorización de tráfico, uso, rendimiento y disponibilidad. ...... 47
5.1.3 Clasificar el uso de la banda ancha según IP, protocolo o conexión.47
5.1.3 Gestión jerárquica de equipos y sensores. .................................... 48
5.1.4 Alarmas, advertencias y alertas por estados inusuales. ................ 48
5.1.5 Listas Top 10. .............................................................................. 48
5.1.6 Informes exhaustivos. .................................................................. 49
5.1.7 Crear mapas con datos de monitoreo en directo............................ 49
5.1.8 PRTG es adecuado para redes con 100 o 10.000 sensores ............ 50

5.2 Versatilidad. .......................................................................................... 50
5.2.1 Interfaces de usuario. ................................................................... 50
5.2.2 Tipos de monitoreo. ..................................................................... 51
5.2.3 Sistema de alertas. ...................................................................... 52
5.2.4 Alta disponibilidad. .................................................................... 53
5.2.5 Monitoreo distribuido. ................................................................. 54
5.2.6 Informes detallados. ..................................................................... 54
BIBLIOGRAFIA .................................................................................................... 55
A N E X O S ........................................................................................................... 56
Anexo A: Servidor (Requerimientos) ...................................................................... 57
Anexo B: Ejemplos de monitoreo (PRTG) .............................................................. 58

INDICE DE TABLAS
Pág.
Tabla 1: HPOO clientes. ............................................................................................ 19
Tabla 2: HPOO servidores. ........................................................................................ 20
Tabla 3: HPOO acceso. .............................................................................................. 20
Tabla 4: HPOO de trabajo. ......................................................................................... 20
Tabla 5: Datos del flujo. ............................................................................................ 22
iv

INDICE DE FIGURAS
Figura 1 Mapa ADEXUS. ............................................................................................. 1
Figura 2 Presencia empresarial. ..................................................................................... 2
Figura 3 Organigrama ADEXUS.................................................................................... 3
Figura 4 Alinaza de negocios. ........................................................................................ 8
Figura 5 Certificaciones nivel empresa. .......................................................................... 9
Figura 6 Organigrama Gerencia de Operaciones. ......................................................... 11
Figura 7 Organigrama sub-gerencia de ERP CENTER. ................................................ 12
Figura 8 Ambientes de HPOO. ..................................................................................... 15
Figura 9 Tipos de conexiones HPOO. .......................................................................... 17
Figura 10 Ejemplo de automatización. ......................................................................... 23
Figura 11 Iteración de credenciales .............................................................................. 24
Figura 12 Comandos del flujo. ..................................................................................... 25
Figura 13 Resultado del flujo. ..................................................................................... 25
Figura 14 Despliegue final del flujo. ........................................................................... 26
Figura 15 Modelo de administración de SNMP. ........................................................... 29
Figura 16 Conponentes de mensaje SNMP. .................................................................. 32
Figura 17 Monitorización SNMP con PRTG. ............................................................... 58
Figura 18 Monitoreo de uso de banda ancha. ................................................................ 58
Figura 19 Grupo con varios equipos y sensores para una monitorización. ..................... 59
Figura 20 Alarmas y advertencias. ............................................................................... 59
Figura 21 Informe de uso de banda ancha..................................................................... 60
Figura 22 Mapa de red creado con el editor de maps interno de PRTG. ........................ 61
v

RESUMEN
En el presente informe se desarrolla una idea de proyecto de título, el
cual se encuentra enfocado a desarrollarse en una de las empresas más prestigiosa
en el ámbito de las tecnologías de la información, ADEXUS.
Actualmente la gerencia de operaciones cuenta con un sistema de
monitorización o checklist de máquinas que cumplen un rol fundamental ya que en
ellas se encuentran alojados los servicios o servidores, que son en donde se
administran, respaldan o ejecutan los datos de los clientes o de la misma empresa,
así también los equipos que ayudan a lograr todas las comunicaciones dentro y
fuera de ADEXUS, estos son los equipos de red routers, switchs, etc. También se
realizan chequeos a las herramientas de trabajo que se utilizan en ADEXUS,
muchas veces para hacer los reportes a los mismos clientes (Oracle, SAP, MySQL,
SQL, etc.).
El proceso para llevar a cabo un flujo de automatización resulta
desafortunadamente bastante tedioso, en el cual se pierde una cantidad de tiempo
considerable en el proceso de obtención de datos.
Con la implementación de un sistema de monitoreo de red, se lograra
cambiar la forma en que se obtengan los datos de los dispositivos o servicios, ya que
desde ese instante las maquinas darán cuenta de sus estados por si solas, ya no
habrá que ingresar a ella mediante un programa para consultarlas.
vi

ABSTRACT
This report develops a project idea of title, which is focused to develop
into one of the most prestigious companies in the field of information technology,
ADEXUS.
Operations management currently has a monitoring system or checklist
of machines that play a fundamental role since they are housed in the services or
servers, which are in which they are administered, endorse or execute customer data
or same company, so the teams that help achieve all communications in and out of
ADEXUS, these are the routers network equipment, switches, etc.. Checks are also
conducted to the working tools used in ADEXUS often reports to the same
customers (Oracle, SAP, MySQL, SQL, etc).
The process for conducting a flow of automation is unfortunately quite
tedious, which lose a considerable amount of time in the process of obtaining data.
With the implementation of a network monitoring system, was achieved
to change the way the data are devices or services, and that from that moment the
machines will realize their states by themselves, and not have to enter it through a
program to query them.
vii

vii vii

1
I. INTRODUCCIÓN.
Debido a la cantidad de equipamiento de red que se está administrando
hoy en día, en este caso, en un DATA CENTER es importante mantener un control
total de la red. Se necesita de una herramienta que ayude a encontrar problemas en el
menor tiempo posible, ya que un defecto técnico, genera un impacto en la red y a la
misma vez también en los datos o información que se almacena en el data center, por
consecuente la importancia de la administración de redes más allá de su
conocimiento global lógico es primordial. Existen plataformas de gestión integradas
con aplicaciones en común como el protocolo SNMP, Protocolo Sencillo de
Administración de Redes, que define la comunicación de un administrador con un
agente, lo que significa que define el formato y el significado de los mensajes que
intercambian el administrador y el agente. SNMP tiene la capacidad de integrarse en
productos de diferentes fabricantes que permite al administrador mantener una base
de datos con todas las configuraciones de los dispositivos de red.
1.1 Antecedentes.
Empresa chilena, de familia, integradora de sistemas computacionales,
líder en el país, con el transcurso de los años se han ido abriendo paso en países tales
como Perú y Ecuador, sus oficinas centrales en chile se encuentran ubicadas en
Miraflores #383, Santiago.
Figura 1 Mapa ADEXUS.

2
1.2 Historia.
Desde 1990 ADEXUS, empresa chilena integradora de sistemas, provee
soluciones abiertas y servicios especializados en las áreas de tecnología de la
información y comunicaciones, con una importante participación en el mercado
tecnológico y reconocida por sus pares como un gran aliado en el desarrollo y
posicionamiento de soluciones tecnológicas de integración.
Representa a más de 40 marcas y compañías internacionales de
tecnología de punta, lo que ha permitido concretar soluciones corporativas
multiplataforma en todos los sectores del país, entre los que destacan: finanzas,
telecomunicaciones, gobierno, educación superior, industria y comercio, además de
servicios.
ADEXUS es reconocida por sus clientes como un gran aliado en el
desarrollo y posicionamiento de soluciones tecnológicas de integración. En este
sentido, un aspecto que la ha diferenciado en el mercado de las TI constituye el
hecho de poseer el primer Centro Global de Servicios Informáticos (CGSI) en el
país, con altos niveles de seguridad y equipamiento de última generación.
1.2.1 Misión.
ADEXUS pretende ser una organización de asesorías, proyectos y
servicios, que genera relaciones de largo plazo con sus clientes, agregando valor a
sus negocios mediante el uso e integración de la tecnología.
1.2.2 Visión.
Ser una corporación regional, reconocida dentro de los principales
proveedores de consultoría, tecnología y servicios de alta calidad, integrada por un
equipo de profesionales altamente calificados.

3
1.3 Presencia empresarial.
Figura 2 Presencia empresarial.
ADEXUS Chile encuentra ubicado en tres puntos: Santiago, Valparaíso y
Antofagasta.
ADEXUS Perú se encuentra ubicado en Lima, en el Centro Empresarial
San Isidro.
ADEXUS Ecuador cuenta con dos puntos: Quito y Guayaquil.

4
1.3.1 Organigrama empresarial ADEXUS S.A.
La organización cuenta con un aproximado de 1200 personas, que se
encuentran distribuidas en las gerencias y subgerencias con sus respectivos cargos.
Figura 3 Organigrama ADEXUS.
1.4 Servicios y soluciones.
Adexus es una empresa que cumple con la función de proveer un servicio
tal como un integrador de sistemas y proveedor de soluciones de comercio
electrónico chileno que opera en Chile, Ecuador y Perú, además de EEUU. La
empresa ofrece servicios en las áreas de las tecnologías de la información y
comunicaciones, conexión de redes e internet. Asimismo, provee servicios
subcontratados como tele marketing, servicio al cliente, mesa de ayuda, plataformas
computacionales y respaldo a la biotecnología. Adexus atiende a clientes de los
sectores como banca y finanzas, telecomunicaciones, instituciones de gobierno,
educación superior, industria militar, comercio, industria y compañías de servicios y
de negocios estratégicos y de gran escala. Adexus se estableció en 1990 y tiene su
sede en Santiago de Chile.

5
1.4.1 Servidores.
Virtualización: Implica hacer que un recurso físico, como un servidor,
un sistema operativo o un dispositivo de almacenamiento, aparezca como si fuera
varios recursos lógicos a la vez, o que varios recursos físicos, como servidores o
dispositivos de almacenamiento, aparezcan como un único recurso lógico, todo esto
con fines de maximizar la utilización de los recursos.
Hpc: Se utiliza este sistema de procesamiento paralelo, capaz de hacer
súper cómputos complejos en el menor tiempo posible, se utilizan servidores o
grupos de servidores de bajo costo y alto rendimiento , que funcionan entre sí como
una única computadora sustentada por redes de alta velocidad, aportando una mejor
relación costo - beneficio.
Grid: Permite utilizar de forma coordinada todo tipo de recursos (entre
ellos cómputo, almacenamiento y aplicaciones específicas) que no están sujetos a un
control centralizado. En este sentido es una nueva forma de computación distribuida,
en la cual los recursos pueden ser heterogéneos (diferentes arquitecturas,
supercomputadores, clúster, etc. ) y se encuentran conectados mediante redes de área
extensa (por ejemplo Internet).
Cloud Computing: Consiste en servidores que desde internet están
capacitados para atender las peticiones de un cliente en cualquier momento. Este
puede tener acceso a su información o servicio, mediante una conexión a internet
desde cualquier dispositivo móvil o fijo ubicado en cualquier lugar. Sirven a sus
usuarios desde varios proveedores de alojamiento frecuentemente repartidos. Esta
medida reduce los costos, garantiza un mejor tiempo de actividad y que los sitios
web sean invulnerables a los hackers, a los gobiernos locales y a sus redadas
policiales.
1.4.2 Soluciones y servicios de almacenamiento.
- Almacenamiento.
- Librerías Virtuales.
- VTL.
- SAN y NAS.
- Software de administración y virtualización.

6
1.4.3 En comunicaciones y multimedia.
- Telepresencia y Videoconferencia.
- Telefonía IP.
- Redes Virtuales.
- Videostreaming.
- Comunicaciones Unificadas.
- IPTV y Carteleria Digital.
1.4.4 Movilidad.
- Hardware disponible: PC, PDA, Blackberry, Celular.
- Aplicaciones: Colaboración, Telefonía, E-mail, ERP.
- Redes disponibles: En escritorio, En la oficina, En casa, En la ciudad,
En viajes, En el aire.
1.4.5 Seguridad.
- Firewall. - Encriptación.
- Antispam. - Normativas y Consultoría.
- Antimalware.
1.4.6 Operaciones.
CGSI y ERP CENTER. CARACTERISTICAS.
- Software como Servicio. - Alta Seguridad Física.
- Consolidación y Virtualización. - Alta Disponibilidad en
- Acceso de alta velocidad a la Red. Climatización, Energía,
- Seguridad SOC. Servicios, Comunicaciones,
- Administración y Operación TI. y Seguridad Lógica.
- Almacenamiento en Demanda.
- Automatización.
1.4.7 Proyecto y Desarrollo.
SOA / SW:
- Arquitectura.
- Middleware.
- Aplicaciones World Class.
- Desarrollo de aplicaciones a la medida.

7
1.4.8 Integración de soluciones.
- Administración de Proyectos.
- Consultoría.
- Implantaciones.
- Diseño de Soluciones y Transversales.
1.4.9 Servicios técnicos para plataformas.
- Instalación y mantenimiento.
- Soporte.
- Ingeniería de Sistemas.
- Garantías y Servicios de Rendimiento.
- Análisis de Evaluación de Rendimiento.
1.4.10 BPO.
- Mesa de Ayuda.
- Documentación Técnica.
- Administración y Operación TI.
- Impresión.
- Administración de Activos.
1.4.11 Proyectos especiales.
- Monitoreo y control de corrientes catódicas (Mc3).
- Movilidad.
- Eficiencia Energética.
- Control de Combustible.
- Servicio de Comunicaciones Unificadas.
1.4.12 Soluciones de biometría.
- Soluciones de Reconocimiento Facial.
- Sistemas de Reconocimiento por Voz.
- Sistemas lectores de huella digital.

8
1.4.13 Soluciones terminales POS.
- Transaccionales de tipo cajero Corresponsal, Pago de Cuentas,
Recarga de Pre-pagos.
- Desarrollo de soluciones de negocio ligadas a la captura de
transacciones de tarjetas de crédito.
- Transacciones de tipo dial-up, LAN y GMS/GPRS, cubriendo
ambientes de negocio de tipo fijo y móvil.
- Tecnología que cubre autorizadores de transacciones de crédito, para
bancos, empresas de recaudaciones, hasta empresas de retail.
1.5 Alianza de negocios y certificaciones
1.5.1 Aliados Tecnológicos.
ADEXUS ha establecido alianzas tecnológicas y acuerdos de distribución
con más de 40 proveedores líderes en tecnologías de la información y
comunicaciones, cubriendo ampliamente los campos de la computación,
administración de información, comunicaciones, Internet, seguridad, multimedia y
televisión, identificación biométrica, reconocimiento de voz, sistemas de eficiencia
energética, y otros.
Figura 4 Alianza de negocios.

9
5.1.2 Certificaciones.
ADEXUS para mantener su nivel de liderazgo en el mercado, se ha
sometido en el transcurso de los años a una serie de certificaciones, las cuales
certifican a la empresa en sí, a sus personas y también cuenta con certificaciones que
están netamente ligadas a los servicios.
Figura 5: Certificaciones nivel empresa.

10
5.1.3 Certificaciones de Calidad.
En su constante preocupación por otorgar servicios de alta confiabilidad
y calidad a sus Clientes, ADEXUS ha realizado una importante inversión en la
estandarización de sus servicios, adoptando metodologías y aplicando las mejores
prácticas a sus procesos de operación. Es así, que las principales áreas de Servicio,
han emprendido proyectos tendientes a lograr certificaciones de calidad exigidas por
un mercado cada vez más dependiente de los servicios tecnológicos para el apoyo y
continuidad de sus operaciones.
.
CERTIFICACIÓN ISO/IEC 20000-1:2005.
CERTIFICACIÓN ISO/IEC 27001:2005.
METODOLOGÍA ITIL PARA SOPORTE DE SERVICIOS
(BS15000).
CERTIFICACIÓN DEL MODELO DE MADUREZ EN EL
DESARROLLO DE SOFTWARE (CMMI L3).
CERTIFICACIÓN QUALIFIED SAP IT PROVIDER.
SIX SIGMA.

11
II. SITUACIÓN ACTUAL CGSI ADEXUS.
ADEXUS, a través de su Centro Global de Servicios Informáticos ofrece
a sus clientes una infraestructura robusta y flexible, capaz de entregar servicios que
permiten a sus clientes externalizar sus procesos informáticos, optimizando sus
costos y su calidad de servicios gracias a la externalización de estos. Las
dependencias de la Gerencia de Operaciones se encuentran en Miraflores #383, Piso
#3, Santiago.
2.1 Organigrama de la Gerencia de Operaciones.
Figura 6: Organigrama Gerencia de Operaciones.
Subgerencia Producción
Jefe de Sala
Operación
Explotación de Sistemas
Service Desk
Monitoreo
BOC
Subgerencia Tecnología
Comunicaciones.
ADM.
Proyectos
ADM.
Compartida
Ingeniería y
Proyectos
ADM.
Proyectos
ADM.
Compartida
Storage y Respaldos
ADM.
Proyectos
ADM.
Compartida
ADM.
de Servicios
ADM. De Servicios
Provisión
Subgerencia Customer
Service
Subgerencia Infraestructu
ra
Subgerencia
Gestión
Subgerencia
ERP Center
SAP Center
Consultoría
Técnica
Automatización
Gerente
Operaciones CGSI
Seguridad Asistente

12
2.1.2 Funciones de la gerencia.
Esta gerencia se compone de una serie de subgerencia las cuales al
trabajar en conjunto llevan a que la empresa como un todo, ADEXUS, logre prestar
una serie de servicios, entre los cuales se destacan:
2.2 Sub-Gerencia de ERP-Center.
Figura 7: Organigrama subgerencia de ERP CENTER.
Subgerencia de
ERP Center
SAP Center
Consultoría
Administración BASIS
Automatización
Servicios de housing.
Servicios de hosting.
Servicios de comunicaciones.
Servicios de monitoreo de
redes y servicios.
Servicios de respaldo local o
remoto.
Servicios de almacenamiento.
Servicios web.
Servicios ISP Internet.
Servicios de operaciones y
explotación.

13
La subgerencia de ERP1 center o SAP center, es el área en donde se
encuentran los administradores de sistemas y servicios, los especialistas ya sea de
SAP, MySQL, SQL, Oracle, Web login, en ERP center también se encuentra el área
de automatización, la cual es de vital importancia dentro de la gerencia de
operaciones, ya que es en donde se desarrollan todo tipo de sistemas ya sean páginas
web, o mantenedores para otras áreas o también para los clientes. En automatización
como el nombre lo dice, se realizan los llamados FLUJOS, con el programa de la
compañía HP: Hp-Orchestrator, el cual sirve para automatizar todo tipo de
actividades realizadas por personas de otras áreas.
2.2.1 Área de Automatización (Flujos).
Al momento de desarrollar un flujo se debe tener en cuenta en primer
lugar hacia quien va orientado. Como regla, los flujos siempre deben ir orientados a:
un cliente, una máquina o todas las máquinas.
Cuando se requiere de la creación de un flujo, esta tarea debería ser
asignada a través de una OT2. Cuando llega una OT, en el caso del área de
automatización, esta va dirigida al Subgerente de SAP CENTER (Eduardo Guzmán).
El Subgerente la visualiza y se la asigna a un analista de automatización. De esta
forma se lleva cierto control sobre el área. Al finalizar la tarea, el ejecutor de la OT
deberá redactar algún tipo de documentación que deje constancia de los pasos que
siguió y como se realizó el flujo. Por lo general esto se realiza en el cgsiportal en el
sector: “Sis. Flujos Ingreso Flujos”.
Importante: Cualquier flujo que se suba a producción o afecte algún
sistema tiene que incorporar dentro de su funcionamiento los correos de
contingencia: [email protected], [email protected].
1 ERP (Enterprise Planing Resource): Planificador de recursos de la empresa.
2 OT: Orden de trabajo, constancia de lo que el especialista solicita.

14
2.2.2 HP Operations Orchestration (HPOO).
Es un sistema para la creación y el uso de acciones en secuencias
estructuradas (llamados flujos) que mantienen, solucionan problemas, reparan, y
provisionan los recursos de tecnología de la información (TI), a través de:
Comprobación del estado, diagnóstico y reparación de redes, servidores,
servicios, aplicaciones de software, o estaciones de trabajo individuales.
Comprobación de los equipos cliente, servidores y máquinas virtuales
para el software necesario y actualizaciones, si es necesario, realiza las instalaciones
necesarias, actualizaciones o distribuciones.
Realización de tareas repetitivas, como comprobar el estado de sitio en
las páginas Web internas o externas.
2.2.3 Componentes de HPOO.
HP Operations Orchestration Central, es una interfaz basada en web en
la que los usuarios pueden:
• Ejecutar flujos.
• Administrar el sistema.
• Extraer y analizar los datos resultantes de la ejecución de un flujo.
HP Operations Orchestration Studio, es un programa de edición
independiente en la que los autores de flujo pueden:
• Crear, modificar, y probar flujos.
• Crear nuevas operaciones.
• Especificar qué tipo de usuarios pueden ejecutar flujos o partes de los
flujos.

15
2.2.4 Ambientes de HPOO.
Los flujos se desarrollan en automatización según los requerimientos
previos adquiridos y luego se entrega al área de producción para que sea subido al
sistema de producción en donde se le asigna los días y el horario en el cual el flujo
deberá ejecutarse en el sistema.
Figura 8 : Ambientes de HPOO
2.2.5 Chequeo de Conexión.
Al momento de trabajar con flujos y equipos externos, en primer lugar se
debe chequear la conexión con esos equipos. Para ello se puede realizar un ping con
la(s) maquina(s), para verificar si existe conectividad. Tener en cuenta además que
por lo general las máquinas poseen dos IP (una IP productiva y una de respaldo). En
el caso de no poder conectarse con la IP productiva, se debe intentar establecer
conexión con la de respaldo. Para interactuar con equipos Windows, se necesita tener
habilitados los puertos RPC3 (rango de puertos) para efectuar la conexión y la
3 RPC (Remote Procedure Call): Técnica para la comunicación entre procesos en una o
más computadoras conectadas a una red.

16
realización de consultas WMI4 (servicio que tiene que estar habilitado, por lo general
viene habilitado por defecto).
Para los servidores Linux por lo general se utilizan los puertos 22 (SSH)
y 23 (Telnet) y en el caso de trabajar con equipos RAS se debe verificar si hay
comunicación entre este y el aplicativo HPOO (Servidor). El puerto de conexión es
el 9004.
Al momento de ingresar en el cgsiportal (Sistema Flujos) se debe
verificar si se tienen los permisos necesarios para hacer el ingreso de flujos HPOO en
el sistema. En el caso de no estar autorizado para ingresar flujos, dirigirse con el
encargado del área de Automatización ya que es el único usuario autorizado para dar
permisos.
4 WMI (Windows Management Instrumentation): Instrumental de administración de
Windows, establece normas para tener acceso y compartir información de administración de la red.

17
Figura 9: Tipos de conexiones de HPOO.
2.2.6 Terminología del área.
RFC: Sirve para dar aviso de un cambio o una modificación de un CI5.
Es un control de cambio. Debe ser autorizado para poder realizarse y en
algunos casos requiere de CAB6.
5 CI: Es un insumo de la empresa.
6 CAB (Change Advisory Board): Comité de cambios de ITIL.

18
Warning: Aviso que se produce cada vez que hay un incidente que
afecta a un ambiente productivo o a un cliente.
BSC: Herramienta de cambio.
CMDB: Administración de BD7 de configuración.
CAB: Comité asesor de cambio.
Incidente: Evento que saque un CI de su operación normal (sin
perjudicar Sub servicios).
ITIL: conjunto de buenas prácticas para la entrega de servicio de
tecnología CI.
Procesos ITIL (Biblioteca de infraestructura TI): Procesos dentro de
una organización, para la gestión y operación de la infraestructura TI
para promover una prestación de servicio óptimo a los clientes a un
costo justificable.
2.2.7 Servidores HPOO y bases de datos.
En el ambiente de producción existen dos servidores, uno Windows que
tiene el aplicativo HPOO y el servidor Linux que posee la Base de Datos.
(10.180.236.27).
Ambiente de desarrollo (HPOO y BD SQL Server), Windows:
10.180.236.14 - IP respaldo: 10.181.0.14.
Sada, Portal de Clientes, Panel de Control. (CentOS): 10.180.236.29
CGSI PORTAL (Sitio y BD SQL Server), Windows: 172.30.2.207 - IP
respaldo: 10.181.0.202.
CGSIWEB: 172.30.2.204.
Base de Datos MYSQL HPOO (ambiente de producción): 10.180.236.31.
7 BD: Base de dato.

19
2.2.8 Consideraciones.
En el caso de trabajar con clientes y sus respectivos nemos y equipos, la
Base de Datos para obtener esa información se encuentra en la máquina 172.30.2.202
(Estructura - MySQL).
Dentro de la Base de Datos Estructura (172.30.2.202), se encuentra dos
tablas que hacen referencia a los clientes: “Clientes” y “Clientes_ITIL”. Solo se debe
ocupar la tabla “Clientes”. “Clientes_ITIL” no es válida como tabla.
Al Momento de trabajar con HPOO y desarrollar un flujo se debe tener
en cuenta las siguientes tablas correspondientes a la base de datos “Checklist”
alojada en 10.180.236.18 (Desarrollo) y 10.180.236.194\PRD (Producción):
HPOOCLIENTES:
Tabla 1: HPOO clientes.
HPOOSERVIDORES:
Esta tabla contiene los datos de los servidores, entre ellos están la IP de
administración, el sistema operativo, el nombre, el puerto y protocolo de acceso, etc.

20
Tabla 2: HPOO servidores.
HPOOACCESO:
Esta tabla contiene la información de los usuarios y password de todos
los servidores de Adexus.
Tabla 3: HPOO acceso.
2.2.6 Ambientes de trabajo.
Se puede ver el ambiente de desarrollo, la base de datos e ip de los
sistemas utilizados en el área.

21
Ambiente Base de Datos Máquina Sistema
Desarrollo SQL SERVER 10.180.236.14 HPOO-Desarrollo
Producción SQL SERVER 172.30.2.205 CGSIPORTAL (DDN)
Producción MySQL 172.30.2.206 CGSIPORTAL (CLOUD)
Producción SQL SERVER 10.180.236.194\PRD -
Producción MySQL 172.30.2.207 CGSIWEB
Producción MySQL 172.30.2.27 SADA, Panel de control
Tabla 4: Ambientes de trabajo.
2.3 Problemática o Necesidad.
Actualmente con el sistema de automatizar mediante flujos, trae consigo
una serie de desventajas, comenzando por la petición del desarrollo en sí, ya que el
área que requiere el flujo debe solicitarlo al sub-gerente de ERP 8Center y luego, el
destina el desarrollo del flujo a un integrante del área, luego el especialista debe
acudir al área solicitante y tomar las peticiones específicas y los datos necesarios
para poder desarrollar el flujo, en todo este proceso se pierde bastante tiempo ya que
todos esto va apoyado por una orden de trabajo, la cual debe ser aceptada por ambas
áreas (la solicitante y automatización), otro problema es que en el ambiente de
desarrollo el flujo tiene un cierto tiempo de ejecución y al subirlo al ambiente
productivo el tiempo asciende al doble, lo que a veces lleva a que el flujo se salga de
su ejecución y se termine con error.
2.3.1 Ejemplo de flujo (Check List Router CISCO).
Necesidad / Solicitud: El área de comunicaciones solicita al área de
automatización, un desarrollo en HPOO, para así lograr automatizar una tarea que se
realiza todos los días en la mañana.
8 ERP (Planing Resource Enterprise): Administrador de recursos de la empresa.

22
Definición del flujo: Se debe automatizar diferentes chequeos de dos
router CISCO, los cuales están encargados de realizar la conexión externa de
telefonía convencional, con la telefonía IP implementada en ADEXUS. Los
nombres de las maquinas son: GWADX-1 y GWADX-2.
Chequeo: la información que se debe proveer del flujo es la siguiente:
*Mostrar el tiempo que llevan operativos ambos equipos.
*Mostrar el porcentaje de CPU utilizada, libre y total.
*Mostrar los datos de la memoria del procesador (total, libre y utilizada).
*Mostrar las tramas y la descripción de su estado (Up – Down).
Datos: El área de comunicaciones provee una serie de datos, los cuales
son de total necesidad, para poder desarrollar el flujo dentro de los datos aportados se
encuentran:
Tabla 4: Datos del flujo.
Nombre del equipo: GWADZ-1 / GWADZ-2.
Ip de los equipos: 10.2.105.x / 10.2.105.x
User: xxxx.
Password: xxxxx.

23
2.3.2 Despliegue del flujo.
Figura10: Ejemplo de automatización.
3.3.3 Explicación del flujo.
A continuación se realiza una detallada explicación de la función que
cumple cada uno de los objetos que son participes del flujo.
Formateo de credenciales: Aquí se contienen las variables necesarias
para poder conectarse a los equipos GWADX1 – GWADX2. Estas son: las ip, el
puerto de conexión, username y password.
24
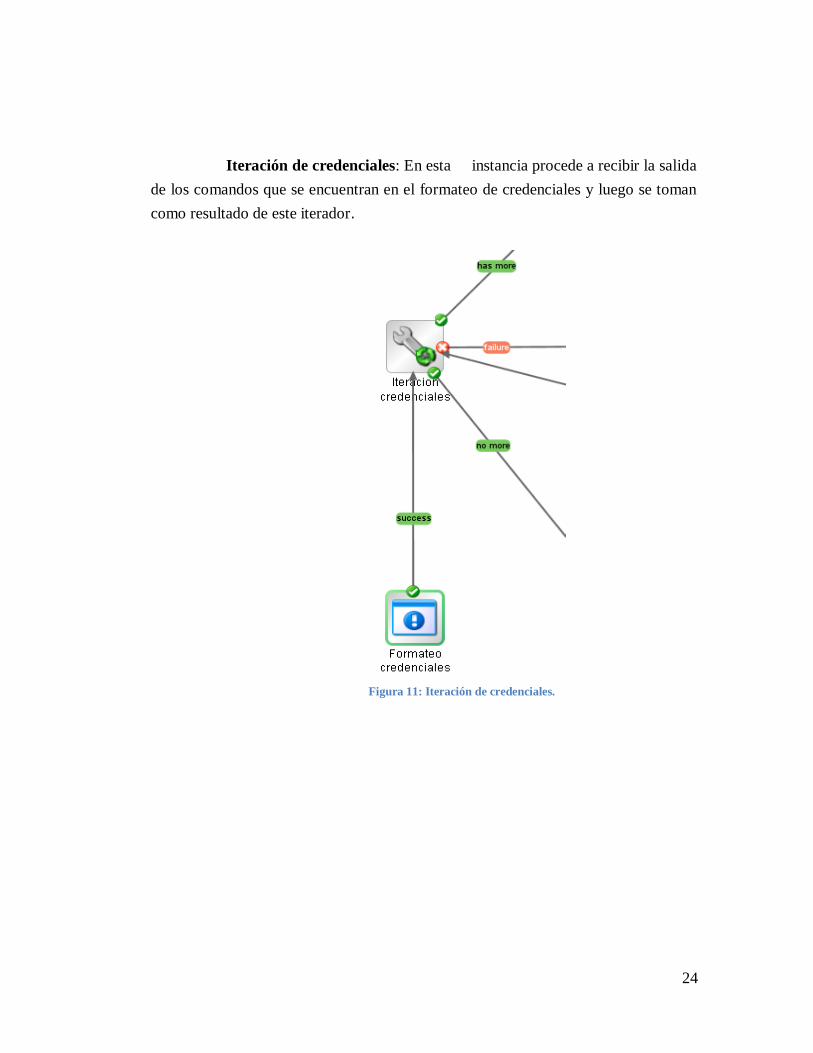
Iteración de credenciales: En esta instancia procede a recibir la salida
de los comandos que se encuentran en el formateo de credenciales y luego se toman
como resultado de este iterador.
Figura 11: Iteración de credenciales.

25
Figura 12: Comandos del flujo.
En estos cuatro pasos se realizan la recepción de las variables de
conexión de los dos equipos a revisar, luego de obtener estos resultados, se procede a
realizar la consulta o ejecución del comando, que en este caso tiene total
concordancia con el nombre de cada objeto, es decir, que el objeto Uptime, despliega
el estado de actividad de ambos dispositivos, el objeto Cpu muestra el porcentaje de
utilización de la cpu de los equipos, el objeto Processor despliega la memoria total,
utilizada y libre, y finalmente el objeto Tramas, nos muestra los enlaces y su
correspondiente descripción.
Resultado chequeo dispositivo: En este paso se juntan los resultados de
los comandos ejecutados anteriormente, estos se acoplan en una tabla, la cual se
utilizara para realizar él envió de correo electrónico con estos datos.
Figura 4: Resultado del chequeo.
26
Send mail: En este objeto se introducen los datos necesarios para que se
realice él envió de correo electrónico, también se encuentra el código HTML de la
tabla final, la cual será enviada al correo electrónico que también está estipulado en
este objeto.
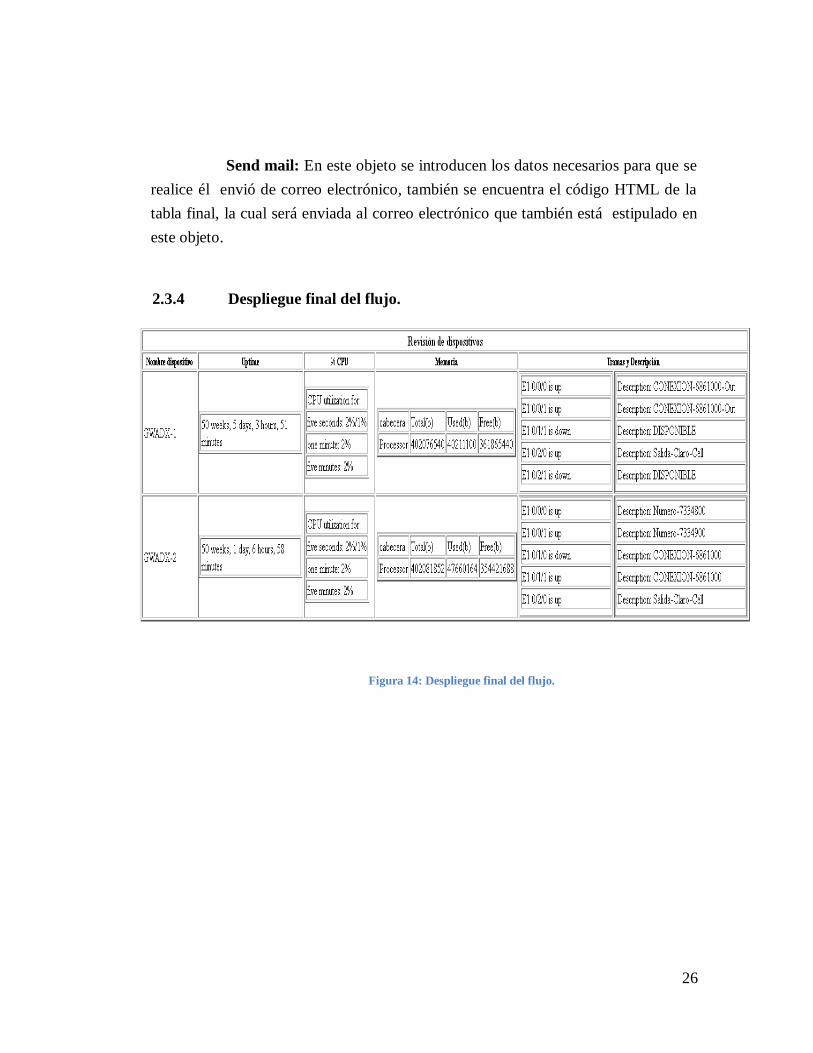
2.3.4 Despliegue final del flujo.
Figura 14: Despliegue final del flujo.

27
III. MARCO TEORICO.
3.1 Administración de red.
La administración de una red puede ser difícil por dos razones:
• Primera, la mayor parte de las redes son heterogéneas, es decir, la red
consta de componentes de hardware y software fabricado por varias compañías. Los
pequeños errores de un proveedor pueden hacer incompatibles los componentes.
• Segunda, las redes en su mayor parte son grandes. La detección de las
causas de un problema de comunicación puede ser muy difícil si el problema sucede
entre computadoras de sitios diferentes.
3.2 SNMP.
Es un protocolo utilizado para intercambiar información de gestión entre
los dispositivos de la red. Su idea original es monitorizar y gestionar redes
manteniendo un esquema de simplicidad y efectividad.
Hasta la llegada de SNMP, la gestión de red había sido propietaria y los
productos desarrollados por cada fabricante, lo que complicaba enormemente los
centros de control de la redes heterogéneas, además, dada la dificultad de desarrollar
este tipo de productos y el mercado restringido al que iban dirigido, los productos
eran caros y complejos. Con el crecimiento de la popularidad de TCP/IP, apareció un
mercado lo suficientemente atractivo para que la IETF9 propusiera un estándar de
gestión. Un aspecto potencial de estos sistemas es que pueden generar tanto tráfico
en la red y tanta información para gestionarse a sí mismos que pueden llegar a
convertirse en una carga significativa para la red. Para que una gestión estándar tenga
éxito debe basarse en software simple, pequeño y de bajo costo para poder instalarlo
en la gran cantidad de pequeños dispositivos que constituyen la red.
9 IETF (Internet Engineering Task Force): Fuerza de Tareas de Ingeniería de Internet,
organización internacional abierta de normalización, su objetivo, contribuir a la ingeniería de Internet.

28
SNMP fue publicado inicialmente en 1989 pero las primeras aplicaciones
no aparecieron hasta 1990. SNMP V2 apareció en Mayo de 1993 añadiendo nuevos
comandos para reducir el tráfico de red, especialmente en redes grandes, ofrece
además nuevas capacidades de notificación de errores, introduce la definición de
nuevos objetos, más contadores y mejores herramientas de gestión. Finalmente se
han introducido añadidos para garantizar la seguridad y la autenticación, que
finalmente se implementaron en SNMP V3.
SNMP funciona con el protocolo de transporte UDP10
. El protocolo UDP
es un protocolo no orientado a conexión de la capa de transporte del modelo TCP/IP.
Este protocolo es muy simple ya que no proporciona detección de errores (no es un
protocolo orientado a conexión).
El gestor implementa un esquema de temporización y retransmisión para
contemplar el hecho de la pérdida de los mensajes y solventar la falta de fiabilidad de
UDP.
SNMP hace uso de dos puertos UDP, el 161 y el 162 para la recepción en
el agente y el gestor respectivamente, de esta forma es posible que en una estación
operen simultáneamente el software de gestor y agente.
10 UDP (User Datagram Protocol): protocolo del nivel de transporte basado en el
intercambio de datagramas en la red, sin establecer una previa conexión.

29
3.2.1 Componentes del Modelo de Administración de SNMP.
Figura 15: Modelo de administración de SNMP.
3.2.2 Detalles del protocolo.
SNMP trabaja en la capa de aplicación. El agente SNMP recibe
peticiones por el puerto UDP 161. Él debe enviar peticiones desde cualquier puerto
disponible de la fuente hacia el puerto 161 del agente. La respuesta del agente será
enviada de regreso por el puerto fuente del gestor. El gestor recibe notificaciones
(Traps e InfofmRequests), sobre el puerto 162. El agente puede generar
notificaciones desde cualquier puerto disponible.
La idea es que SNMP sea un componente integral y esencial de todos los
sistemas TCP/IP, por ello, todos los protocolos por debajo del nivel de aplicación
tienen sus componentes SNMP. SNMP también se ha extendido para cubrir equipos

30
no TCP/IP y algunos protocolos propietarios, constituyéndose en el estándar más
ampliamente utilizado para la recogida de información de gestión de red.
La idea básica es que la recogida y gestión de la información de la red se
haga en las llamadas estaciones de gestión de red que se comunicarán con el resto de
los elementos de red. Estas estaciones de gestión de red serán normalmente
estaciones de trabajo que muestran gráficamente aspectos relevantes acerca de los
elementos que está monitorizando. La aplicación que se encarga de la comunicación
con los elementos de red es el gestor que es la implementación en la estación del
protocolo SNMP.
Los elementos de red pueden ser cualquier dispositivo de la red
(clásicamente que use parte del conjunto de protocolos TCP/IP) como un router, un
terminal, una impresora, etc. Tendremos un software en el elemento de red
monitorizado que se denominará agente y cuya función es, por un lado, recoger
información de los eventos que se producen en el dispositivo, y por otro comunicarse
con el gestor.
La comunicación puede producirse de dos maneras:
1. El gestor puede preguntar al agente acerca del valor de alguna variable
2. El agente puede informar al gestor acerca de algún hecho importante.
3.3 Arquitectura de SNMP.
Para funcionar SNMP consta de tres elementos:
3.3.1 La base de Información de gestión (MIB).
Es una base de datos de objetos administrados que son accesibles por el
agente y manipulados vía SNMP para lograr la administración de la red. La MIB se
encuentra dividida en cuatro áreas:
a- Atributos del sistema.
b- Atributos privados.
c. Atributos experimentales.
d- Atributos de directorio.

31
3.3.2 Consola de administración (NMS).
Es un programa encontrado en una estación de trabajo y tiene la
habilidad de indagar los agentes utilizando SNMP. Básicamente la consola se
encarga de ejecutar las aplicaciones que ayudan a analizar el funcionamiento de la
red, normalmente provee una interfaz gráfica que muestra un mapa de los agentes
encontrados en la red.
3.3.3 Agente.
Es un programa encontrado en un dispositivo de red, ya sea una estación,
un switch o un router o cualquier dispositivo administrable mediante SNMP. Posee
una vista de la MIB que incluye la MB estándar de internet más otras extensiones.
En la MIB no se tiene porque implementar todos los grupos de variables definidas en
la especificación de las MIB. Gracias a esto se puede simplificar significativamente
la implementación de SNMO en dispositivos pequeños de una red (debido a su
limitación de memoria y procesamiento). Básicamente tiene las funciones de
inspeccionar las variables de la MIB (consultar valores de las variables) y alterar
variables en la MIB (cambiar valores de las variables), para lograr algún efecto en el
dispositivo.
3.4 Mensajes.
SNMP Define cinco tipos de mensajes de intercambio entre gestor y
agente que se denominan PDUs (Unidad de datos de Protocolo):
3.4.1 Get-request.
Utilizado por la estación de gestión para obtener el valor de una o más
variables MIB del agente SNMP de la estación remota.
3.4.2 Get-next-request.
Es similar a la anterior, con la diferencia que se obtiene el valor de una
variable sin definir ésta explícitamente. De hecho se obtiene el valor de la variable
que sigue a la especificada dentro de la ordenación de la MIB.

32
3.4.3 Response.
Es la respuesta del agente a una petición del gestor devolviendo el valor
de una o más variables.
3.4.4 Set-request.
Constituye el mecanismo para que el gestor modifique los valores de las
variables MIB de la estación remota.
3.4.5 Trap.
Cuando se produce un determinado evento o condición en la estación
remota, el agente envía un trap para notificarlo al gestor. Dado que el mensaje se
envía de forma síncrona y en cualquier momento, la estación de gestión debe
monitorizar la red en todo instante.
El mensaje comienza con el campo Versión, que puede tomar los valores
0 o 1 para SNMPV1 y SNMPv2 respectivamente.
Figura16: Componentes de mensaje de SNMP.
El campo comunidad define un nivel de autenticación del emisor del
mensaje de forma que puede determinarse si tiene permiso de modificación e incluso
de lectura sobre las variables de la MIB.
En cada sistema remoto se aplica una política de acceso de manera que
existan varios perfiles con diferentes privilegios; para ello se crean distintas vistas de
la MIB con diferentes modos de acceso sobre los objetos de esta: Sólo lectura,
Lectura y escritura, etc.

33
La asignación de un modo de acceso a una determinada vista constituye
lo que se conoce como perfil de comunidad, y la política de acceso consiste en
asignar a cada comunidad definida en el agente un perfil. De este modo, el gestor
identificará una comunidad en cada PDU enviada al agente y éste atenderá la
petición en función de que la comunidad disponga de privilegios para realizarla o no.
SNMP en su última versión (SNMPv3) data de 2002 y posee cambios
significativos con relación a sus predecesores, sobre todo en aspectos de seguridad,
sin embargo no ha sido mayoritariamente aceptado en la industria.
3.5 SNMP PRTG.
Las redes de gran tamaño son difíciles de manejar. Utilizar un monitor
SNMP como el PRTG Network Monitor de Paessler le ayuda a vigilar el uso de
ancho de banda y parámetros importantes del sistema. Y le permite reaccionar ante
posibles complicaciones antes de que causen periodos de inactividad.
El Protocolo de Gestión de Red Básica (SNMP por sus siglas en inglés)
es un conocido protocolo para la gestión de redes. Se utiliza para recopilar
información de los dispositivos de redes, como servidores, impresoras, hubs,
switches y routers y configurarlos en una red de protocolo de Internet (IP).
Utilizando un monitor SNMP, puede monitorizar el rendimiento de red,
auditar el uso de la red, detectar errores en la red o accesos inadecuados. El monitor
SNMP de PRTG puede comunicar e interactuar con cualquier dispositivo compatible
con SNMP. La sencilla e intuitiva interfaz del monitor SNMP permite a los usuarios
llevar a cabo varias funciones con pocos clics del ratón.

34
3.5.1 Versiones SNMP.
SNMP Versión 1: La versión más antigua y más básica de SNMP.
Ventajas: Con el apoyo de la mayoría de los dispositivos compatibles con SNMP.
Desventajas: la seguridad limitada ya que sólo se utiliza una contraseña simple
("community string") y los datos se envían como texto sin cifrar (encriptar). Debe
por lo tanto, sólo se puede utilizar dentro de las LAN detrás de un cortafuegos, no en
WANs; sólo es compatible con contadores de 32 bits que no es suficiente para el
control de ancho de banda de alta carga (gigabits/segundo).
SNMP versión 2c: Añade contadores de 64 bits.
Ventajas: Soporta contadores de 64 bits para controlar el uso de ancho de banda en
redes. de gigabits/segundo.
Desventajas: La seguridad es limitada (igual que con SNMP V1).
SNMP versión 3: Añade la autenticación y el cifrado.
Ventajas: Se pueden crear cuentas, con autenticación para usuarios múltiples y la
encriptación de paquetes de datos opcional, el aumento de la seguridad disponible,
además de todas las ventajas de la versión 2c.
Desventajas: Difícil de configurar. No es adecuado para redes grandes.
Es importante saber que si se selecciona una versión SNMP que no es
compatible con el servidor o el dispositivo que desea controlar, recibirá un mensaje
de error. Desafortunadamente, la mayoría de las veces estos mensajes de error no
mencionan explícitamente la posibilidad de que usted podría estar utilizando la
versión de SNMP incorrecta. Estos mensajes proporcionan una información mínima,
como "no se puede conectar" o similar. La misma situación si las cadenas de
comunidad, nombres de usuario o contraseñas son correctos.

35
3.5.2 Ventajas de monitoreo SNMP.
Conocer el consumo de ancho de banda y de los recursos es clave para
mejorar la gestión de red. Un monitor SNMP ayuda a
Evitar bloqueos del ancho de banda y del rendimiento de los servidores.
Descubrir qué aplicaciones o servidores están consumiendo el ancho de
banda.
Proporcionar una mejor calidad de servicio a los usuarios de una manera
proactiva.
Reducir costes adquiriendo ancho de banda y hardware en función de la
carga actual.
3.5.3 Ejemplos de sensores.
PING: (Packet Internet Groper), significa "Buscador o rastreador de
paquetes en redes".
Ping es una utilidad que diagnóstica en redes el estado de la
comunicación de dispositivos ya sean localmente o con uno o varios equipos remotos
de una red TCP/IP por medio del envío de paquetes ICMP de solicitud y de
respuesta. Mediante esta utilidad puede diagnosticarse el estado, velocidad y calidad
de una red determinada.
El sensor de ping realiza una o más pings para supervisar la
disponibilidad de un dispositivo. Cuando se utiliza más de un ping por intervalo, sino
que también mide la pérdida de paquetes se producen en por ciento.

36
HTTP: (Hypertext Transfer Protocol) protocolo de transferencia de
hipertexto, es el protocolo usado en cada transacción de la WWW (World Wide
Web).
PRTG ofrece los siguientes sensores basados en HTTP:
HTTP: Supervisa un servidor web para controlar si un sitio web (o un
elemento web específico) es alcanzable.
HTTP avanzada: Supervisa un servidor web a través del protocolo HTTP
con diferentes configuraciones avanzadas (por ejemplo, para comprobar el contenido
de una página web o para utilizar la autenticación o un servidor proxy).
HTTP Transacción: Monitores de un servidor web con un conjunto de
direcciones URL para supervisar si los inicios de sesión o carritos de compras están
trabajando muy bien.
HTTP Content: Supervisa un valor de retorno proporcionada por una
solicitud HTTP. Este sensor solicita un URL HTTP y, a continuación analiza el
resultado devuelto por uno o más valores entre paréntesis cuadrados.
SMTP: (Simple Mail Transfer Protocol), Protocolo para la transferencia
simple de correo electrónico), es un protocolo de la capa de aplicación. Protocolo de
red basado en texto, utilizado para el intercambio de mensajes de correo electrónicos.
El sensor SMTP monitoriza un servidor de correo mediante el Protocolo
simple de transferencia de correo (SMTP) y muestra el tiempo de respuesta del
servidor. Puede enviar opcionalmente un mensaje de prueba con cada chequeo.

37
POP 3: (Post Office Protocol), Protocolo de Oficina de Correo o
"Protocolo de Oficina Postal" en clientes locales de correo para obtener los mensajes
de correo electrónico almacenados en un servidor remoto. Es un protocolo de nivel
de aplicación en el Modelo OSI.
POP3 está diseñado para recibir correo, no para enviarlo; le permite a los
usuarios con conexiones intermitentes o muy lentas (tales como las conexiones por
módem), descargar su correo electrónico mientras tienen conexión y revisarlo
posteriormente incluso estando desconectados. Cabe mencionar que la mayoría de
los clientes de correo incluyen la opción de dejar los mensajes en el servidor, de
manera tal que, un cliente que utilice POP3 se conecta, obtiene todos los mensajes,
los almacena en la computadora del usuario como mensajes nuevos, los elimina del
servidor y finalmente se desconecta.
FTP: (File Transfer Protocol), Protocolo de Transferencia de Archivos,
se utiliza en Internet para el intercambio de archivos (por ejemplo, para cargar
contenido de una página web o para descargar archivos de un servidor).
Al igual que la mayoría de los sensores de protocolo, el sensor FTP
ofrece varios niveles de control:
Conectar: Sólo tiene que conectar y enviar SALIR (comprueba si el
servidor está en ejecución y aceptar solicitudes en todos).
Usuario: Enviar USUARIO la sesión prevista (servidor comprueba si
reacciona según el protocolo).
PASS: Enviar PASS con la contraseña para el usuario (comprueba si un
usuario realmente puede Entrar). Los parámetros incluyen: PORT, el número de
puerto del servicio de correo que desea controlar (normalmente el puerto 21).

38
IV. OPCIONES DE SOLUCIÓN.
Actualmente se está automatización para realizar chequeos de máquinas,
servicios, archivos, etc. La forma de cómo lo hace HPOO es consultándole a las
maquina a través del flujo. Se pretende cambiar el sistema, para mejorar los tiempos
muertos que se generan en desarrollar un flujo, reducir los tiempos para recaudar los
datos finales que se solicitan, y que definitivamente las maquinas por si solas se
reporten y entreguen su estado actual y el de sus archivos, carpetas o servicios, no
que un programa, en este caso HPOO, ingrese a la máquina para indagar en ella.
4.1 CACTI.
Cacti es una completa herramienta que proporciona la solución perfecta
para la generación de gráficos en red, diseñada para aprovechar el poder de
almacenamiento y la funcionalidad para gráficas que poseen las aplicaciones
RRDtool. Esta herramienta, desarrollada en el lenguaje de programación web PHP,
provee un pooler ágil, plantillas de gráficos avanzadas. Además de ser capaz de
mantener los gráficos, orígenes de datos y Round Robin Archivos en una base de
datos, y manejo de usuarios. Tiene una interfaz de usuario fácil de usar, que resulta
conveniente para instalaciones del tamaño de una LAN, así como también para redes
complejas con cientos de dispositivos.
4.1.1 Base de datos.
Para manejar la recopilación de datos, se le puede pasar a Cacti la ruta a
cualquier script o comando junto con cualquier dato que el usuario necesitare
ingresar; Cacti reunirá estos datos, introduciendo este trabajo en el cron (para el caso
de un sistema operativo Linux) y cargará los datos en la BD (base de datos) MySQL
y los archivos de Planificación 11
Round-Robin que deba actualizar.
11 Round-Robin: Método para seleccionar todos los elementos en un grupo de manera
equitativa y en un orden racional.

39
Una fuente de datos también puede ser creada. Por ejemplo, si se quisiera
representar en una gráfica los tiempos de ping de un host, se podría crear una fuente
de datos, utilizando un script que haga ping a un host y devuelva el valor en
milisegundos. Después de definir opciones para la RRDtool12
, como ser la forma de
almacenar los datos, uno puede definir cualquier información adicional que la fuente
de entrada de datos requiera, en este caso, la IP del host al cual hacer el ping. Luego
que una fuente de datos es creada, automáticamente se mantiene cada 5 minutos.
4.1.2 Gráficos.
Una vez que una o más fuentes de datos se definen, un gráfico de
RRDtool se puede crear con los datos. Cacti le permite crear casi cualquier gráfico
RRDtool, utilizando todos los tipos de gráficos RRDTool estándar y funciones de
consolidación. Un área de selección de colores y la función de relleno automático de
texto también ayudan en la creación de gráficos para hacer el proceso más amigable.
Existen diversas formas de desplegar los gráficos, no sólo se puede crear gráficos
basados en la RRDtool, sino que también hay varias formas de mostrarlas. Junto con
una “lista de vistas” estándar y una “vista preliminar”, también existe una “vista en
árbol”, la cual permite colocar gráficos un árbol jerárquico.
4.1.3 Gestión de usuarios.
Debido a las variadas funciones de cacti, existe una herramienta de
gestión basada en el usuario consiste en que se puede añadir usuarios y darles
permisos a ciertas áreas de cacti. Esto permitirá que algunos usuarios puedan
cambiar parámetros en los gráficos o en las configuraciones de este, así como
también existirán usuarios que solo puedan visualizar los gráficos.
Cacti puede escalar a un gran número de fuentes de datos y gráficos
mediante el uso de plantillas. Esto permite definir las capacidades de un host
.
12 RRDTool (Round Robin Database Tool): Herramienta que trabaja con una base de
datos que maneja planificación según Round-Robin.

40
4.2 PRTG Network Monitor.
PRTG Network Monitor es una potente herramienta de monitorización
de la Paessler AG. Asegura la disponibilidad de componentes de red y mide el tráfico
y el uso de la red. Ahorra costos ayudando a evitar fallos, optimizar conexiones,
economizando tiempo de implementación y controlando acuerdos de nivel de
servicio (SLAs).
4.2.1 Conceptos claves.
Sensor: Es un instrumento encargado de monitorear individualmente
cada aspecto de un dispositivo de red.
Aparato: Es un instrumento lógico que se ubica en cada punto de red
(dirección IP) en donde se realiza el monitoreo. Cada aparato puede tener uno o más
sensores.
Grupo: Es el conjunto de aparatos que se pueden clasificar según sus
características, las cuales ayudan al monitoreo más fácil y efectivo.
Después de instalar el programa en la computadora en la que se va a
realizar el monitoreo de la red, se crea automáticamente un acceso directo en el
escritorio en el cual hacemos doble clic para acceder a la interfaz de usuario para el
registro.
4.2.2 SNMP y WMI.
SNMP (Simple Network Management Protocol) y WMI (Windows
Management Instrumentation) son usados para adquirir datos acerca del uso y el
rendimiento de todos los sistemas que componen su red, incluyendo el uso de puertos
individuales de switches y enrutadores.

41
4.2.3 Monitorización de Disponibilidad y Rendimiento.
PRTG Network Monitor incluye más de 40 tipos de sensores, de cada
tipo de servicio de red común (Ejemplos: PING, HTTP, SMTP, POP3, FTP, etc.),
permitiendo monitorizar velocidad y fallos de su sistema de red. Tan pronto un fallo
haya sido detectada el software le alerta enviando correos electrónicos, SMS,
mensajes de radiolocalizador y otros métodos de notificación.
Los Tiempos de respuesta y tiempos sin conexión son constantemente
guardados en una base de datos de la cual puede compilar reportes de rendimiento,
tiempo sin conexión y SLAs en cualquier momento.
4.2.4 Evitar periodos de inactividad.
Las Empresas dependen cada vez más de sus redes para transferir datos,
proveer servicios de comunicación y habilitar operaciones básicas. Perdidas de
rendimiento o fallas del sistema pueden impactar el resultado final del negocio. La
monitorización continua de redes y servidores facilita discernir y resolver problemas
antes de que se conviertan en una amenaza al negocio:
Evitar estrangulamientos de ancho de banda y de rendimiento de servidor.
Proporcionar una mejor calidad de servicio a sus usuarios de manera
proactiva.
Reducir costos comprando el ancho de banda y el equipo necesario
basándose en cargas efectivas.
Incrementar ganancias evitando pérdidas causadas por fallos de sistema no
descubiertos.
Ganar tranquilidad: mientras PRTG no se comunique con usted mediante
correo electrónico, SMS, radiolocalizador, etc. Puede estar seguro que todo
está funcionando correctamente y de esta manera se puede dedicar a otros
negocios importantes.

42
4.2.5 Red entera en pantalla.
PRTG Network Monitor cubre todos los aspectos de la monitorización de
redes: monitorización de disponibilidad, monitorización de tráfico y de uso, SNMP,
NetFlow, esnifer de paquetes y muchos más, al igual que funciones de reporte y de
análisis - una solución simple y clara para toda su red.
4.2.6 Monitorización.
El programa opera 24 horas, 7 días a la semana en una maquina basada
en Windows, monitorizando parámetros de uso de red. Los datos de monitorización
son guardados en una base de datos para poder generar reportes históricos.
La interfaz de usuario permite configurar el equipo y los sensores que
desea monitorizar. Además, puede generar reportes de uso y proveer colegas y
clientes con acceso a gráficos y tablas de datos.
Este programa nos permite cualidades de monitorización tales como:
Más de 150 tipos de sensores cubren todos los aspectos de monitoreo de red.
Supervisión del tiempo de funcionamiento y periodos de inactividad
(uptime / downtime).
Monitorización del ancho de banda utilizando SNMP, WMI, NetFlow,
sFlow, jFlow, packet sniffing.
Monitoreo de aplicaciones.
Monitoreo web.
Monitoreo de servidores virtuales.
Monitoreo de SLA (acuerdo de nivel de servicio).
Monitorización QoS (Calidad de servicio, por ejemplo para monitorizar
VoIP).
Monitoreo ambiental.
Monitorización de LAN, WAN, VPN, y sitios distribuidos.
Registro extenso de eventos (Extensive event logging).
Soporte de IPv6.

43
4.2.7 Cómo trabaja el monitor SNMP de PRTG.
PRTG es un eficiente monitor SNMP por diferentes motivos:
Monitorización de datos de tráfico estándar. PRTG busca
automáticamente todas las interfaces de un dispositivo que sacan a la luz los anchos
de banda entrantes y salientes, paquetes unidifusión/sin unidifusión o los fallos. A
continuación, el sistema proporciona una lista con los puertos identificados que
simplifica la configuración de los sensores.
Asistente SNMP para la monitorización de datos de Windows.
Windows vía SNMP suministra una gran cantidad de datos de monitorización. Al
utilizar el asistente SNMP, se pueden generar listas para un acceso sencillo a miles
de contadores de rendimiento en máquinas con Windows. Basándose en estos
indicadores de rendimiento, con un solo clic es posible configurar los sensores para
la monitorización de los parámetros específicos del sistema.
Monitorización adecuada para datos registrados. Los fabricantes de
dispositivos compatibles con SNMP normalmente dan información de acceso (OID)
a los datos requeridos para la monitorización en forma de archivos de Base de
Información de Gestión (MIB por sus siglas en inglés). Con este fin, Paessler ha
desarrollado el importador MIB que convierte fácilmente estos archivos en las
denominadas "bibliotecas OID" para PRTG. El importador MIB se puede descargar
de manera gratuita. Además, numerosas bibliotecas OID preconfiguradas ya se han
incorporado a PRTG (p. ej. routers Cisco, servidores Dell, carga de la CPU, usos del
disco, número de páginas de impresión, monitorización medioambiental y mucho
más).
Creación directa de un sensor en caso de OID conocido. Si se conoce
la dirección específica (OID) de datos SNMP, esta se puede introducir manualmente
en PRTG, creando un sensor de manera rápida y sencilla.

44
4.3 OP Manager.
OpManager es una solución de monitorización de servidores,
aplicaciones y dispositivos de red. Optimizada para empresas de todos los tamaños,
la potente solución de monitorización de redes e infraestructuras es escalable y
modular. Ofrece monitorización general de redes, sistemas y aplicaciones,
monitoriza tecnologías específicas como entornos virtuales VMWare, Hyper-V,
Directorio Activo, MS Exchange, MS SQL, Telefonía Voz IP, así como el análisis
del flujo de tráfico de Red y ancho de banda.
4.3.1 Amplias prestaciones.
OpManager 9 ofrece una interfaz de usuario mejorada con una consola
centralizada más intuitiva, automatización de flujos de trabajo, monitorización
avanzada en entornos virtualizados, integración con aplicaciones de terceros y
mucho más.
OpManager 9 hace que gestionar la red sea muy sencillo gracias a su
fácil despliegue, uso y mantenimiento, ofreciendo monitorización sin agentes y
soporte out-of-the-box para más de 100 fabricantes y más de 650 tipos de
dispositivos.
A continuación se detallan algunas de las características de OpManager.
Monitorización de redes y servidores.
Recogida de traps SNMP, syslog y logs de eventos.
Medición de tiempos de respuesta (WAN RTT).
Detección e identificación automática de dispositivos de red.
Monitorización de aplicaciones críticas: Exchange, VMware, SQL, Active
Directory.
Análisis de tráfico y monitorización de ancho de banda (NetFlow).
Módulo para la configuración centralizada de dispositivos de red.
Módulo para la monitorización de redes VOIP.
Arquitectura distribuida capaz de monitorizar más de 50.000 interfaces o
5000 servidores a través de una única consola de gestión.

45
Amplia reducción del tiempo de respuesta por parte de los administradores
gracias a su intuitiva consola y al soporte “out of the box”.
Soporte para Microsoft Hyper-V, con más de 70 indicadores de
disponibilidad y rendimiento de Hyper-V, extendiendo la monitorización de
entornos virtualizados a entornos de VMware y Microsoft.
APIs que facilitan la integración con el help desk y/o soluciones de gestión
TI de la empresa.
Capacidad de convertir instancias independientes de OpManager en sondas
de monitorización remotas, para mayor escalabilidad en redes grandes.
Entre todas sus grandes características, también es destacable la
capacidad de ir más allá de las funciones de los protocolos de SNMP o WMI,
permitiendo a los administradores automatizar procesos utilizando sus propios scripts
de monitorización de red con la consola de gestión. Los scripts soportados incluyen
PowerShell, Linux shell script, VBScript, JavaScript, CScript, Perl y Python.
Permite una visualización gráfica, de mapas de red, de notificaciones
automáticas, de más de 100 informes.
4.3.2 Funcionalidades.
Descubrimiento automático de dispositivos: Descubre automáticamente
los Routers, Switches, Servidores, impresoras de red, y otros dispositivos de red,
incluyendo servidores y máquinas virtuales. OpManager acelera el proceso de
descubrimiento generando una lista de dispositivos potencialmente activos leyendo
las tablas ARP a la vez que hace ping para estar seguro de que no queden
dispositivos sin detectar. También descubre servicios (como HTTP, etc.) que están
habilitados en un dispositivo.
IT Workflow para automatización de procesos “drag & drop”: Conjunto
de rutinas predefinidas para llevar a cabo comprobaciones y acciones durante
situaciones de fallo en la red, tareas de mantenimiento o eventos. Para configurarlo
no es necesaria la introducción de código alguno (mecanismo “drag & drop”).

46
Fácil de instalar y usar: Elimina la complejidad en las tareas de
monitorización, muy fácil de usar y no requiere la instalación de agentes remotos,
por lo que el retorno de la inversión es casi inmediato.
Monitorización en tiempo real: OpManager monitoriza su red de 3
formas diferentes: Polling de dispositivos y servidores, para confirmar,
disponibilidad; Monitorización de parámetros críticos a través de SNMP, WMI y
Telnet / SSH; y recepción de traps SNMP de dispositivos.
Alertas instantáneas: Tan pronto detecta un problema, puede notificar a
los administradores a través de correo electrónico o vía SMS a móviles. La función
de alerta incluye la posibilidad de ejecutar aplicaciones, comandos de sistema o la
ejecución de un fichero de sonido, para alertas audibles.
Mapa intuitivo de los dispositivos de red: Genera automáticamente
mapas de infraestructura de sus servidores, routers, impresoras, switches y
cortafuegos. También permite generar vistas personalizadas para agrupar
dispositivos según necesidad de negocio.
Informes completos: Generación de informes completos a nivel de
detalle de dispositivos o vista de pájaro de toda la red, para analizar disponibilidad,
tiempos de respuesta, tráfico, utilización de interfaz o tiempo de respuesta de
aplicaciones.
Herramientas de Networking: Incluye útiles herramientas de networking
que ayudan a solucionar problemas de los dispositivos de red como Ping, Trace
Route, etc. Destaca el explorador de MIBs, una sencilla utilidad SNMP que facilita la
administración de la red, y el Switch Port Mapper que ayuda a encontrar rápidamente
lo que está conectado a cada puerto del switch, su dirección mac y otros parámetros
críticos.

47
V. SOLUCION PROPUESTA.
Se considera una buena opción a implementar el programa de monitoreo
PRTG Network Monitor, es una herramienta que puede ser instalado en Windows
Server 2003 y 2008, y también en XP, Vista y Windows 7 y permite monitorizar
sistemas Windows, Linux, Unix y MacOS.
5.1 Características.
Este programa es de gran utilidad y posee un sin fin de características en
su administración a continuación se detallan algunas de las cualidades de esta
herramienta.
5.1.2 Monitorización de tráfico, uso, rendimiento y disponibilidad.
Mediante las estadísticas que muestran los totales (disponibilidad, ancho
de banda / tráfico, carga CPU, alertas) nos podemos informar rápidamente sobre el
estado actual de toda la red. Los estados se pueden mostrar para todos los sensores, y
por grupo. De este modo, podemos tener una vista general de toda la red y de cada
dispositivo.
5.1.3 Clasificar el uso de la banda ancha según IP, protocolo o conexión.
Para saber qué aplicaciones o direcciones IP están causando el tráfico en
la red, se puede utilizar packet sniffing (PRTG analiza cada paquete de datos que
pasa por la red) o el monitoreo basado en NetFlow/jFlow/sFlow. Usando cualquiera
de estas tecnologías, PRTG puede analizar el uso de la banda ancha y atribuirlo a
protocolos u ordenadores en la red. (Anexo B, figura 32).

48
5.1.3 Gestión jerárquica de equipos y sensores.
En PRTG Network Monitor los "sensores", se encargan de la
monitorización. Los sensores se organizan en forma de árbol para crear una lista que
podemos navegar con facilidad y que nos permite agrupar equipos, sitios o servicios
similares. Los usuarios podemos crear grupos anidados: Cada grupo puede contener
varios equipos, y cada equipo varios sensores. (Anexo B, figura 33).
5.1.4 Alarmas, advertencias y alertas por estados inusuales.
Las alarmas (rojas) son sensores no disponibles (p.ej. debido a un fallo
del software o hardware) o que traspasan un valor definido (p.ej. espacio libre de
disco duro por debajo del 10%).
Las advertencias (amarillas) son causados por servicios lentos (p.ej. una
página web que carga demasiado lenta) o por recursos que están a punto de agotarse
(p.ej. baja memoria RAM o alta carga de CPU)
PRTG marca sensores con un estado inusual (naranja) si los valores
actuales discrepan mucho de los valores históricos (calculado a través de un análisis
estadístico) (Anexo B, Figura 34).
5.1.5 Listas Top 10.
Las listas "Top 10" son unas herramientas potentes para conseguir una
vista rápida de todos los sistemas en la red, y para encontrar posibles problemas. Las
listas Top 10 están disponibles para:
Disponibilidad más alta y más baja.
Los tiempos de PING más rápidos y más lentos.
Uso de la banda ancha más alto y más bajo.
Páginas webs más rápidas y más lentas.
Carga CPU más alta y más baja.
Más y menos espacio de disco duro libre.

49
5.1.6 Informes exhaustivos.
Los informes se usan para analizar los resultados del monitoreo durante
un tiempo específico, como por ejemplo un día, un mes o un año.
PRTG incluye una potente función de informes para generar informes
tanto en el momento o programados con anterioridad (p.ej. una vez al día). Se
pueden crear informes para uno o varios sensores. El contenido y el diseño dependen
de la plantilla de informes seleccionada y se aplican a todos los sensores en el
informe. (Anexo B, Figura35).
5.1.7 Crear mapas con datos de monitoreo en directo.
Los mapas combinan el estado de sensores, gráficos y tablas. Podemos
crear tantos mapas que queremos, y personalizar el diseño y los fondos con mapas de
la red, mapas geográficos, etc. Crear el diseño es fácil utilizando drag&drop desde la
misma interfaz web de PRTG.
Los mapas de PRTG se basan en un concepto innovador que nos permite
de crear páginas webs con información de estado del momento en un diseño
personalizado. Esto nos abre incontables posibilidades para la implementación de
mapas. Por ejemplo, se puede utilizar esta función para:
Diseñar mapas de redes sobreponiendo iconos de estado para cada equipo en el
mapa.
Crear paneles de control que podemos mostrar en las pantallas de nuestro centro
de datos.
Crear una vista rápida de la red para publicación en la Intranet para que la
dirección de la empresa y otros empleados puedan informarse.
Crear vistas personalizadas de los sensores más importantes de nuestra
monitorización de red.
Crear listas Top 10 para los sensores de un grupo o equipo determinado.

50
5.1.8 PRTG es adecuado para redes con 100 o 10.000 sensores
PRTG Network Monitor es apto para redes de todos los tamaños. Se
puede utilizar en redes pequeñas con pocos equipos (por ejemplo, utilizando la
versión gratuita, que permite monitorear hasta 10 sensores), o bien se puede integrar
en redes grandes con 10.000 sensores o más (del momento, el software puede
monitorizar hasta 20.000 sensores en una sola instalación).
5.2 Versatilidad.
La versatilidad de PRTG lo hace la herramienta perfecta para el
monitoreo de redes de todos los tamaños.
5.2.1 Interfaces de usuario.
Interfaz web con toda la funcionalidad: tecnología web moderna, basada en
AJAX.
Sólo HTML, interfaz web minimialista (funcionalidad limitada) para
navegadores antiguos y dispositivos móviles (funciona con IE6/7/8, iPhone,
Android, Blackberry).
Enterprise Console: aplicación Windows, especialmente diseñada para
grandes instalaciones. Se pueden ver los datos de monitoreo de varias
instalaciones de PRTG en una aplicación.
Apps para iOS (iPhone/iPad) y Android smartphones: Siga el estado de la
red aunque esté viajando (hay que descargarlo/comprarlo por separado).
Todas las interfaces permiten el acceso local y remoto protegido por SSL y
pueden ser utilizados simultáneamente.

51
5.2.2 Tipos de monitoreo.
Más de 150 tipos de sensores cubren todos los aspectos de monitoreo de
la red que se requiera monitorear.
Existe la supervisión del tiempo, en cuanto al funcionamiento y
periodos de inactividad (uptime / downtime).
Se puede realizar una monitorización de ancho de banda utilizando
SNMP, WMI, NetFlow, sFlow, jFlow, packet sniffing.
Existe una gran cantidad de monitoreos a continuación se detalla una
lista de los tipos que se pueden realizar:
Monitoreo de aplicaciones.
Monitoreo web.
Monitoreo de servidores virtuales.
Monitoreo de SLA (acuerdo de nivel de servicio).
Monitorización QoS (Calidad de servicio, por ejemplo para monitorizar
VoIP).
Monitoreo ambiental.
Monitorización de LAN, WAN, VPN, y sitios distribuidos.
Registro extenso de eventos (Extensive event logging).
Soporte de IPv6.
Monitoreo sin agentes (agentes opcionales (remote probes) permiten una
monitorización incluso más detallada).

52
5.2.3 Sistema de alertas.
Tecnologías de notificación: envío de mensajes de correo electrónico,
SMS/pager, syslog y SNMP Trap, HTTP request, event log entry, reproducir
archivos de audio, Amazon SNS y cualquier tecnología externa que pueda ser
ejecutado por un fichero EXE o batch.
Alertas de estado (up, down, aviso).
Alertas de límites (valor por debajo / encima de x).
Umbrales (por debajo / encima de x durante z minutos).
Alertas con múltiples condiciones (tanto x como z están inactivos).
Alertas de escalación (notificaciones adicionales cada x minutos durante el
tiempo de inactividad).
Dependencias (para evitar una ola de alertas).
Alertas reconocidas (no se mandan más notificaciones para esta alarma).
Programación de alertas (pare evitar alertas de baja prioridad durante la
noche).

53
5.2.4 Alta disponibilidad.
PRTG nos da la posibilidad de generar un cluster de alta disponibilidad
para un monitoreo de red sin interrupciones.
Las características son las siguientes:
En un cluster de PRTG, se pueden combinar hasta 5 instancias ("nodos")
para crear un sistema de cluster de alta disponibilidad.
Ni siquiera una actualización de software causa un periodo de inactividad
para un Cluster de PRTG.
El cluster automáticamente garantiza la alta disponibilidad: si un nodo
primario falla o pierde la conexión con el cluster, otro nodo en seguida toma el papel
del servidor principal ("master server") y se encarga de enviar las notificaciones. Así
se siguen mandando las notificaciones, incluso si el nodo primario ha perdido su
conectividad o ha fallado.
Además, puede implementar un monitoreo desde varios sitios ("múltiple
points-of-presence monitoring"): todos los nodos monitorizan todos los sensores
durante todo el tiempo. Eso significa que los tiempos de respuesta se miden desde
varios puntos en la red, y los resultados pueden ser comparados entre ellos. Así
también se pueden calcular tiempos totales de funcionamiento e inactividad.
Nos hemos guardado lo mejor para el final: Todas las licencias de PRTG
le permiten crear un cluster de alta disponibilidad de dos nodos con solamente una
clave de licencia (para 3 o más nodos, necesitará licencias adicionales).

54
5.2.5 Monitoreo distribuido.
Con las sondas remotas ("Remote Probes") PRTG Network Monitor
puede supervisar varias redes en diferentes lugares, por ejemplo para:
Monitorizar todas las sucursales desde la casa matriz.
Monitorizar redes separadas en un mismo lugar (p.ej. redes DMZ y LAN).
Los proveedores de servicios informáticos pueden monitorizar las redes de sus
clientes y aumentar la calidad de servicio.
Para ello, hace falta solamente una instalación núcleo de PRTG ("PRTG
Core Server"). Cada licencia de PRTG contiene un número ilimitado de sondas
remotas.
5.2.6 Informes detallados.
Informes en formato HTMO o PDF.
Los informes se pueden generar ad hoc o de forma programada (cada día,
semana, mes).
Los datos de monitorización históricos se pueden exportar a HTML, XML o
CSV.
PRTG incluye más de 30 plantillas para informes:
Gráficos y tablas de datos detallados para uno o más sensores.
Tiempo de funcionalidad / periodos de inactividad (% y
segundos).
Good/failed requests (% y total).
Top 100 Consumo de ancho de banda.
Top 100 Uso de CPU.
Top 100 Tiempos Ping.
Top 100 Espacio de disco.
Top 100 tiempo de funcionalidad / periodos de inactividades.

55
BIBLIOGRAFIA
[SNMP] http://librosnetworking.blogspot.com/2011/04/introduccion-snmp.html
http://www.net-snmp.org/
http://es.wikipedia.org
http://www.snmp.com
[CACTI] http://www.cacti.net/
http://es.wikipedia.org/wiki/Cact
[OP Manager] http://www. opmanager.com.es
http://www.manageengine.com/network-monitoring/
[PRTG] http://www.es.paessler.com/prtg
http://www.paessler.com/manuals/prtg7/snmp_sensors

56
A N E X O S

57
ANEXO A: SERVIDOR (Requerimientos)
Requerimientos.
Para instalar y trabajar con PRTG Network Monitor necesita:
Un computador, servidor o máquina virtual con la capacidad operativa
mínima de un ordenador promedio construido en 2007 con mínimo 1024 MB RAM.
Cualquier versión de Microsoft® Windows (a partir de XP, en versión
Server o Workstation, 32 o 64-bit).
Navegador de red tipo Google Chrome, Firefox, Safari o Internet
Explorer (a partir de versión 8) para proveer acceso a la interface web.

58
ANEXO B: EJEMPLOS DE MONITOREO (PRTG)
Figura 17: Monitorización SNMP con PRTG.
Figura 18: Monitoreo del uso de la banda ancha con packet sniffing.

59
Figura 19: Grupo con varios equipos y sensores para una monitorización.
Figura 20: alarmas y advertencias actuales.

60
Figura 21: Informe de uso de la banda ancha.

61
Figura 22: Mapa de red creado con el editor de mapas interno de PRTG.

















![Presentacion Adexus Versiones Con Ddll[1]](https://static.fdocuments.ec/doc/165x107/55cf9cca550346d033ab0d3d/presentacion-adexus-versiones-con-ddll1.jpg)
