
Síntesis Concatenativa -...
26
Síntesis Concatenativa Introducción a las Tecnologías del Habla 2 o cuatrimestre 2014 – Agustín Gravano
-
Upload
phamkhuong -
Category
Documents
-
view
214 -
download
0
Transcript of Síntesis Concatenativa -...

Síntesis Concatenativa
Introducción a las Tecnologías del Habla2o cuatrimestre 2014 – Agustín Gravano

Sistema text-to-speech (TTS)● Front end
– Input: Texto en algún formato: HTML, email, etc.● Procesamiento del texto de entrada:
tokenización, segmentación, normalización.● Análisis fonético: grafemas → fonemas.● Análisis lingüístico: clase de palabra, parsing.● Análisis prosódico: asignación de prosodia (F0, dur, int).
– Output: Secuencia de fonemas + prosodia deseada.
● Back end– Input: Secuencia de fonemas + prosodia deseada.
● Síntesis del habla propiamente dicha:Articulatoria, de formantes, contatenativa, etc.
– Output: Archivo de audio.

Síntesis concatenativa
1) Entrenamiento:
a) Grabar a una persona diciendo oraciones preparadas.
b) Recortar unidades de habla (frases, palabras, sílabas, sonidos, etc.).
2) Síntesis:
a) Elegir las unidades de la base de datos.
b) Concatenarlas, con algo de procesamiento de señales en los extremos de cada una.
c) [Usar procesamiento de señales para cambiar la prosodia (f0, duración, intensidad) de la secuencia.]

Síntesis concatenativa
Método más común hoy en día.– 1936 – Speaking Clock del Reino Unido.
“At the third stroke, it will be eight fifty-seven, precisely.” “El vuelo número N N N N de AEROLINEA con destino a
CIUDAD se encuentra ESTADO.”
Muy barato, fácil de implementar, de rápido desarrollo.
Ejemplo: tts-tiempo.wav “Cielo CIELO, temperatura NUM grado[s] NUM decima[s],
humedad NUM por ciento, visibilidad NUM kilómetros, vientos VIENTO_INT del sector VIENTO_DIR.”
Creado en pocas horas con Festival:http://www.cstr.ed.ac.uk/projects/festival/

Síntesis concatenativa
Dominio abierto (sintetizar cualquier oración): Unidad = difono (desde el medio de un fono hasta el medio
del siguiente)
Síntesis de difonos: Guardar una sola instancia de cada difono. Modificar la secuencia para cambiar la prosodia.
Selección de unidades:– Guardar varias instancias de cada difono.
– Elegir difonos cercanos a la prosodia deseada.

Difonos
● Difono: Desde la región estable de un fono hasta la región estable del siguiente fono.
● Los difonos capturan la coarticulación (influencia de un fono sobre sus vecinos) y evitan saltos en la señal.
● Ejemplo: difonos-ai.{wav,TextGrid}
o
sa ap po o--s
ooaa ppss

● Seleccionar un objeto Sound en la lista.● Annotate → To TextGrid... (Point vs. interval tiers)● Crear un TextGrid con dos capas: una de puntos y otra de
intervalos (usar cualquier nombre para identificarlas).● Seleccionar objetos Sound y TextGrid; View & Edit.● Agregar etiquetas de tipos punto e intervalo.
– Punto: click en un círculo para agregar.
– Intervalo: click en un círculo para definir un extremo.
– Una vez seleccionada la etiqueta, tipear un texto.● No olvidar guardar antes de cerrar Praat.
Anotación en Praat. TextGrid
( )

Síntesis de difonos
1) Preparar un inventario de difonos.
2) Armar frases que contengan todos los difonos.
3) Grabar a un/a locutor/a leyendo las frases.
4) Segmentar y etiquetar los difonos.
5) Cortar los difonos.

Inventario de difonos
Cantidad de difonos = O(fonos2)
No todos los difonos son válidos en un lenguaje. Restricciones fonotácticas. Ejemplos en español: /pf/ /kg/ /pp/ ...
● Ejemplo:
– Sistema en inglés (AT&T, Olive et al. 1998).
– 43 fonos. 432 = 1849 difonos posibles. Sólo 1162 difonos válidos.

Frases, grabación y segmentación
● Tono, intensidad y duración constantes.
● Frases portadoras: aportan consistencia.
/ba/ → #tabama#
/pa/ → #tapama#
/sa/ → #tasama#
# = silencio● Antes de grabar cada frase, escuchar una frase fija.
● Segmentación semi-automática de difonos.1) Alineación forzada con sistema de reconocimiento de habla.
2) Corrección manual.
/-a/ → #ama#
/-e/ → #ema#
/-o/ → #oma#
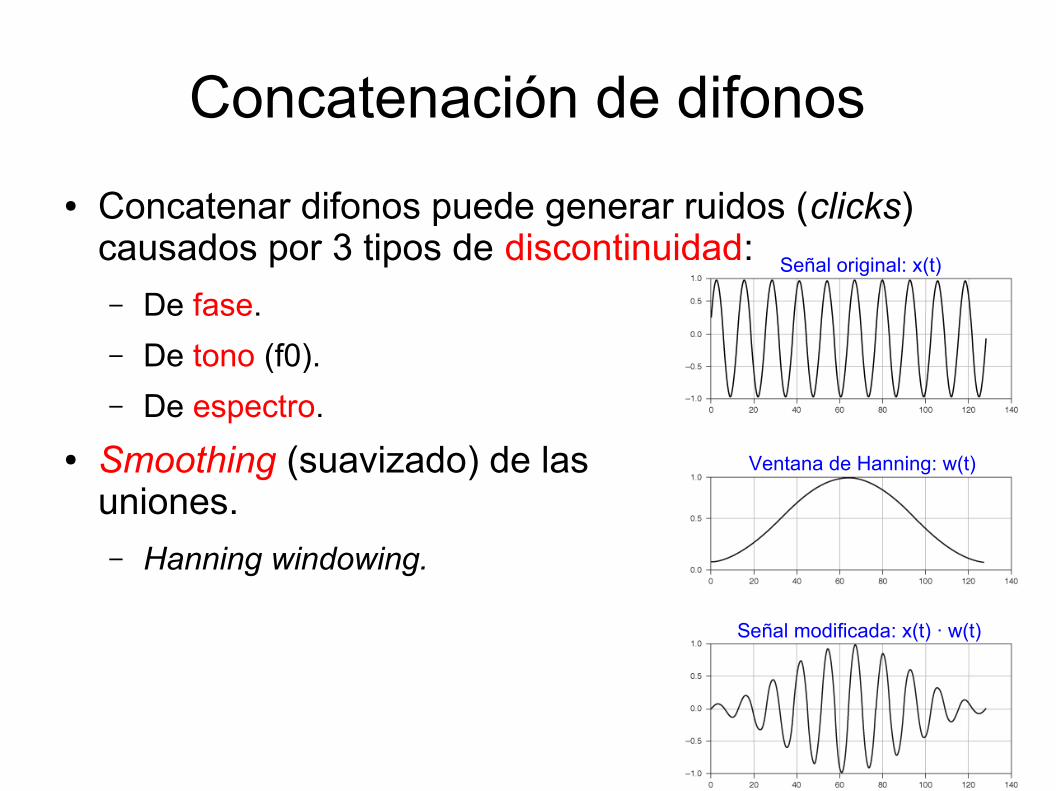
Concatenación de difonos
● Concatenar difonos puede generar ruidos (clicks) causados por 3 tipos de discontinuidad:– De fase.
– De tono (f0).
– De espectro.
● Smoothing (suavizado) de lasuniones.– Hanning windowing.
Señal original: x(t)
Ventana de Hanning: w(t)
Señal modificada: x(t) · w(t)

Modificación de la prosodia
● Todos los difonos tienen la misma prosodia (f0, int, dur). ● La prosodia deseada se consigue con proc. de señales.● La intensidad se puede modificar fácilmente.● ¿Cómo modificar tono y duración?
– Aumentar la duración de una señal disminuye el tono.● TD-PSOLA:
– Time-Domain Pitch-Synchronous Overlap-and-Add– Identificar ciclos básicos de la señal.– Para cambiar la duración: duplicar/borrar ciclos.– Para cambiar el tono: juntar o separar ciclos.

TD-PSOLA: Cómo identificar ciclos básicos
● Pitch marking
– Electroglotógrafo (EGG) durante la grabación.
– Automáticamente: algoritmos aproximados (ej: autocorrelación).

TD-PSOLA: Cómo modificar la duración
● Duplicar ciclos para alargar la señal.● Eliminar ciclos para acortar la señal.

TD-PSOLA: Cómo modificar el tono
● Juntar ciclos para aumentar la frecuencia (y el tono); separarlos para disminuir la frecuencia.
● Agregar ciclos cuando sea necesario para mantener la duración deseada.
overlap-and-add
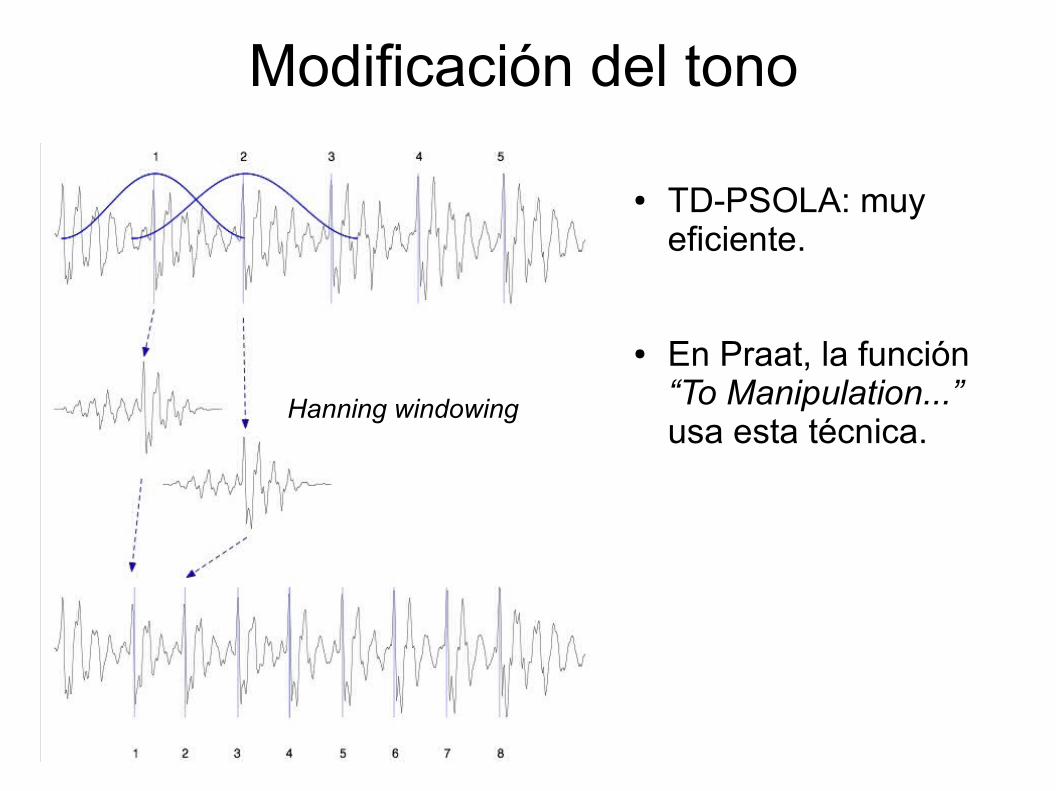
Modificación del tono
● TD-PSOLA: muy eficiente.
● En Praat, la función “To Manipulation...” usa esta técnica.
Hanning windowing

● Seleccionar un objeto de tipo 'Sound'● Manipulate → To manipulation... (Usar rango tonal 100-400Hz.)
● View & Edit. ● Pitch → Stylize pitch (2st)● Para modificar el tono, en la capa “Pitch manip”:
– Arrastrar los puntos. Agregar puntos con: click, CTRL+T.
● Para modificar la duración, en la “Duration manip”:
– Arrastrar los puntos. Agregar puntos con: click, CTRL+D. Ejercicio 1: Abrir /home/ith50/clase07/cena.wav. Modificar su prosodia
para que suene a una pregunta (mejor aún si suena indignada).
Ejercicio 2: Abrir /home/ith50/clase07/lamparita.wav. Modificar su prosodia para que diga “alcanza” en lugar de “alcanzá”.
Ejercicio: Manipulación de prosodia

● Base de datos relativamente pequeña: ~8MB para inglés (16Hz, 16 bits). – Ok para PC, pero para celular/tablet?
● Modificación de la prosodia con procesamiento de señales (e.g. TD-PSOLA): resultados poco naturales.
● Idea alternativa:
– Guardar muchas instancia de cada difono; al sintetizar, elegir la instancia con las características prosódicas más parecidas a las deseadas.
– Síntesis por selección de unidades.
Síntesis de difonos

Selección de unidades
● Las frases a grabar deben contener múltiples instancias de cada difono.
– Respetar la distribución de frecuencias del lenguaje.
– En español, muchas instancias de /la/; pocas de /pt/.● Varias horas de grabación.
● Segmentación semi-automática de fonemas.
1) Alineación forzada con sistema de reconocimiento.
2) Corrección manual.

Selección de unidades
● Síntesis = Encontrar en la base de datos la secuencia de difonos que mejor cumpla la especificación dada.
● ¿Qué significa “mejor”?
– Costo del objetivo (T): Cuán bien respetan los difonos las características especificadas (prosodia, contexto, etc.).
– Costo de unión (J): Cuán bien se concatenan los difonos adyacentes.
U=argminU
∑i
T (si , u i)+∑i
J (ui , u i+1)
donde si : especificación de la i-ésima unidad a sintetizar
ui : unidad de la base de datos

Costo del objetivo T(s, u)
● ¿Cuánto se parecen la unidad u (de la base de datos) y la especificación objetivo s?
● Ejemplos de especificaciones de difonos:/-t/, acentuado, principio frase, F0 alto, adverbio, .../la/, no acent., medio frase, F0 medio, artículo, ...
● Costo objetivo T = suma de P subcostos Tp:
– Acentuación, posición en la frase y en la palabra, F0, duración, intensidad, POS de la palabra, etc.
– Cada subcosto tiene un peso wp
– ¿Cómo se determinan los pesos wp?
T (s , u)=∑p=1
P
w p T p(s , u)

Costo de unión J(ui , u
i+1)
● ¿Cuán suave es la concatenación de dos unidades ui
y ui +1
(ambas de la base de datos)?
● Costo de unión J = suma de P subcostos Jp:
– Intensidad, F0, atributos espectrales, etc.
– Cada subcosto tiene un peso wp.
J (ui , u i+1)=∑p=1
P
w p J p(ui , u i+1)

Selección de unidades
-o
-o
ol
ol
ol
la
la
la
la
am mu un
un
un
nd
nd
nd
nd
do
do
do
o-
o-
o-
o-
am
S = -o ol la am mu un nd do o- (con sus especificaciones prosódicas y contextuales)
Base de datos de difonos:
Û
U=argminU
∑i
T (si , u i)+∑i
J (ui , u i+1)

Selección de unidades
● Algoritmo de Viterbi
– Programación dinámica.
– Encuentra en forma eficiente y exacta el camino con el costo más bajo.
– Complejidad: O(M * N2). ● M = Longitud de la secuencia objetivo.● N = Número de difonos en la base de datos.
– J&M: Capítulo 6.
– Reconocimiento automático del habla.

Selección de unidades
● Resultados más naturales que con otras técnicas.
● Base de datos muy grande: O(GB).
● Búsqueda de difonos: cara computacionalmente.
– Cuadrática en el tamaño de la base de datos!
– Técnicas de optimización: e.g. clustering de difonos.
● La calidad puede ser muy mala cuando no hay buenos candidatos en la base de datos.
– Problema: en interacciones humano-máquina suele ser muy molesto mezclar cosas muy buenas y muy malas.

Algunas demos
● Cepstral
– http://www.cepstral.com/en/demos
● Loquendo– http://www.nuance.com/for-business/by-solution/customer-service-solutions/solutions-
services/inbound-solutions/loquendo-small-business-bundle/tts-demo/spanish/index.htm
● LumenVox
– http://www.lumenvox.com/products/tts/
● AT&T
– http://www.research.att.com/~ttsweb/tts → att-demo.wav


















