SEGMENTACION DE FORMAS USANDO MODELOS DEFORMABLES MEMORIA...
178
SEGMENTACION DE FORMAS USANDO MODELOS DEFORMABLES MEMORIA QUE PRESENTA ANTONIO GARRIDO CARRILLO 1996 DIRECTOR NICOLAS PEREZ DE LA BLANCA CAPILLA
Transcript of SEGMENTACION DE FORMAS USANDO MODELOS DEFORMABLES MEMORIA...

!"#$%#&!'%( ! )*!')*#+ ! ,# )(&"-%#)*.'! *'%!,*/!')*# #$%*0*)*#,
!1%1+1 ! *'/!'*!$2# *'0($&3%*)# -'*4!$+* # ! /$#'# #
SEGMENTACION DE FORMAS USANDO MODELOS DEFORMABLES
MEMORIA QUE PRESENTAANTONIO GARRIDO CARRILLO
1996
DIRECTORNICOLAS PEREZ DE LA BLANCA CAPILLA

Indice general
1. Introduccion 1
1.1. El problema. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2. Planteamiento. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2.1. Segmentacion: aproximaciones. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2.2. Modelizacion de deformaciones: aproximaciones. . . . . . . . . . . . . . . . . . . . 5
1.2.2.1. Metodos sin informacion a priori. . . . . . . . . . . . . . . . . . . . . . . 5
1.2.2.2. Metodos con informacion a priori. . . . . . . . . . . . . . . . . . . . . . . 6
1.2.3. Fusion de informacion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.2.3.1. Informacion de las aristas de una imagen. . . . . . . . . . . . . . . . . . . 8
1.2.4. Deteccion de formas: representacion. . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.2.4.1. Descripcion de un contorno: Modelo propuesto. . . . . . . . . . . . . . . . 9
1.2.4.2. Ejemplo ilustrativo: Un enfoque simbolico. . . . . . . . . . . . . . . . . . 10
1.3. Objetivo y estructura del trabajo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.3.1. Objetivo General. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.3.2. Organizacion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.3.3. Imagenes test. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2. El espacio de escalas. 15
2.1. Representacion multiescala de las imagenes. . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.2. Obteniendo informacion multiescala. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3. El espacio de escalas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3.1. Definicion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.3.2. Derivacion en el espacio de escalas. . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.4. Propiedades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.5. Estructura a traves del parametro de escala. . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.5.1. Comportamiento de los puntos crıticos en el esp. de esc. . . . . . . . . . . . . . . . 22
3. Contornos: Descripcion y aproximacion 25
3.1. El contorno y su alisamiento. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.1.1. Contraccion del contorno . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.2. Curvatura y espacio de escalas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2.1. Curvatura: Definicion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2.2. Aplicacion del espacio de escalas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.3. Representacion multiescala del contorno 2D. . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.3.1. Calculo del valor absoluto de las curvas de curvaturas. . . . . . . . . . . . . . . . . 32
3.3.2. Construccion de las trayectorias de los maximos. . . . . . . . . . . . . . . . . . . . 32
3.3.3. Localizacion de los maximos en el contorno original. . . . . . . . . . . . . . . . . . 33
3.4. Algoritmo de deteccion de puntos dominantes. . . . . . . . . . . . . . . . . . . . . . . . . 34
i

pag.ii INDICE GENERAL
3.4.1. Idea basica. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.4.2. Formulacion general del algoritmo. . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.4.3. Algoritmo detallado. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.4.3.1. Algoritmo Ap. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.4.3.2. Algoritmo Af . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.4.3.3. Valor U . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.4.3.4. Minimalidad del resultado. . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.4.4. Discusion y resultados. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.4.4.1. Discusion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.4.4.2. Resultados. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4. Fronteras y Preprocesamiento de Aristas. 51
4.1. Deteccion de fronteras. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.1.1. Seleccionando un detector de aristas. . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.1.2. Mejorando los resultados desde la interpretacion multiescala. . . . . . . . . . . . . 52
4.1.2.1. Movimiento de las fronteras a traves de la escala. . . . . . . . . . . . . . 53
4.1.2.2. Relacionando aristas: Multihisteresis. . . . . . . . . . . . . . . . . . . . . 54
4.1.3. Algoritmo multiescala de deteccion de fronteras. . . . . . . . . . . . . . . . . . . . 56
4.1.3.1. Proyeccion sobre una imagen con maxima precision. . . . . . . . . . . . . 59
4.2. Preprocesamiento y extraccion de cadenas. . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.2.1. Deteccion de Puntos Multiples. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.2.1.1. Algoritmo para puntos multiples. . . . . . . . . . . . . . . . . . . . . . . 61
4.2.2. Busqueda, corte y orientacion de cadenas. . . . . . . . . . . . . . . . . . . . . . . . 62
4.2.2.1. Busqueda y extraccion de una cadena. . . . . . . . . . . . . . . . . . . . . 62
4.2.2.2. Corte y Orientacion de las cadenas. . . . . . . . . . . . . . . . . . . . . . 62
4.2.2.3. Criterio para orientacion. . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4.3. Ejemplos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
5. Modelizacion de deformaciones 69
5.1. Aproximacion propuesta. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
5.1.1. Planteamiento. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
5.1.2. Derivacion de las ecuaciones de equilibrio del elemento finito. . . . . . . . . . . . . 71
5.1.2.1. Notacion y relaciones. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
5.1.2.2. El elemento finito en equilibrio. . . . . . . . . . . . . . . . . . . . . . . . 72
5.1.3. Solucionando la ecuacion de equilibrio: Analisis modal. . . . . . . . . . . . . . . . . 73
5.1.3.1. Transformacion de la ecuacion de equilibrio. . . . . . . . . . . . . . . . . 73
5.1.3.2. Modos de vibracion libre. . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
5.1.4. Calculo de los modos naturales de deformacion. . . . . . . . . . . . . . . . . . . . . 75
5.1.4.1. Calculo de la matriz de masas. . . . . . . . . . . . . . . . . . . . . . . . . 76
5.1.4.2. Calculo de la matriz de rigidez. . . . . . . . . . . . . . . . . . . . . . . . . 76
5.2. Seleccion de deformaciones. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
5.2.1. Deformaciones modales. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
5.2.2. Componentes principales. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
6. Localizacion inicial de contornos deformables 81
6.1. La transformada de Hough generalizada. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
6.1.1. Formulacion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
6.1.2. El caso mas simple: deformaciones rıgidas. . . . . . . . . . . . . . . . . . . . . . . . 82
6.1.3. Caso general. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
ii

INDICE GENERAL pag.iii
6.2. Manejo de ruido y pequenas deformaciones. . . . . . . . . . . . . . . . . . . . . . . . . . . 84
6.2.1. Cambio en la votacion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
6.2.1.1. Zona de incertidumbre. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
6.2.1.2. T. Hough modificada. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
6.2.2. Uso de otro tipo de informacion desde el template. . . . . . . . . . . . . . . . . . . 86
6.2.2.1. Niveles de informacion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
6.2.2.2. Construccion de informacion de nivel superior. . . . . . . . . . . . . . . . 87
6.2.3. Reformulacion de la Transformada de Hough. . . . . . . . . . . . . . . . . . . . . . 88
6.2.3.1. Un ejemplo ilustrativo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
6.3. Disminucion del tamano del acumulador. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
6.3.1. Muestreo del espacio de parametros. . . . . . . . . . . . . . . . . . . . . . . . . . . 92
6.4. Integracion de informacion multicanal. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
6.4.1. Una solucion directa. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
6.4.2. Integracion por medio de la transformada de Hough modificada. . . . . . . . . . . 96
6.5. Resultados. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
6.5.1. Ejemplos sobre citologıas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
6.5.2. Ejemplos sobre nematodos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
6.5.3. Ejemplos sobre manos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
7. Optimizacion de la localizacion 111
7.1. Mejora de la localizacion inicial. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
7.1.1. Incremento de la precision. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
7.1.2. Extraccion de la informacion para cada objeto. . . . . . . . . . . . . . . . . . . . . 112
7.1.3. Uso de un modelo geometrico. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
7.1.4. Un algoritmo de enfoque. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
7.1.4.1. Un ejemplo ilustrativo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
7.2. Optimizacion final de la solucion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
7.2.1. Definicion de las funciones. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
7.2.2. Funcion de energıa externa desde las fronteras. . . . . . . . . . . . . . . . . . . . . 117
7.2.2.1. Energıa desde las aristas. . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
7.2.2.2. Mejora a partir de la direccion del gradiente. . . . . . . . . . . . . . . . . 119
7.2.3. Funcion de energıa externa desde otras fuentes. . . . . . . . . . . . . . . . . . . . . 121
7.2.4. Delimitando el espacio de deformacion. . . . . . . . . . . . . . . . . . . . . . . . . 122
7.2.5. Un problema de regularizacion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
7.2.6. Un modelo probabilıstico. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
7.3. Resultados. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126
7.3.1. Ejemplos sobre citologıas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
7.3.2. Ejemplos sobre nematodos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
7.3.3. Ejemplos sobre manos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
Conclusiones y trabajos futuros 139
Discusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
Desarrollos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
A. Calculo de los modos naturales de vibracion. 143
B. Vibraciones naturales de un nematodo. 147
iii

pag.iv INDICE GENERAL
C. Aproximacion elıptica de una nube de puntos. 151
D. Modelo de Grenander: Distribucion a priori. 153
Bibliografıa 159
Indice de Materias 165
iv

Indice de figuras
1.1. Ejemplo de imagen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2. Descripcion cualitativa de distintos patrones. . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.3. Imagenes test. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.1. Funcion gaussiana. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.2. Derivadas de gaussiana 1D. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.3. Derivadas de gaussiana 2D. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.1. Contornos: Imagenes test. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.2. Contorno geografico con distintos grado de alisamiento. . . . . . . . . . . . . . . . . . . . 27
3.3. Correccion global de la contraccion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.4. Angulo de contingencia. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.5. Curva de curvaturas con sigma 16 y 45.25. . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.6. Espacio de escalas de la curvatura para el contorno de Espana. . . . . . . . . . . . . . . . 31
3.7. Contorno cuasi-triangular. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.8. Curvatura del contorno cuasi-triangular. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.9. Optimalidad de dos puntos y una curva. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.10. Trayectorias de maximos de Espana, italia y G. Bretana. . . . . . . . . . . . . . . . . . . . 40
3.11. Trayectorias de maximos del Grupo celular, mano y hoja. . . . . . . . . . . . . . . . . . . 41
3.12. Puntos obtenidos de contorno celular. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.13. Puntos obtenidos en el contorno de Espana. . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.14. Puntos obtenidos de una mano. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.15. Puntos obtenidos en el contorno de Italia. . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.16. Puntos obtenidos de la hoja. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.17. Puntos obtenidos de Inglaterra. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3.18. Minimizacion del numero de puntos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.19. Interpolacion desde el numero de puntos minimal. . . . . . . . . . . . . . . . . . . . . . . 49
4.1. Funcion laplaciana de gaussiana. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.2. Histeresis. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.3. Multihisteresis (ver texto). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.4. Proyeccion en una imagen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.5. Eliminacion de Puntos triples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
4.6. Imagen sin puntos multiples. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
4.7. Corte y Orientacion de cadenas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4.8. Criterio de Orientacion de cadenas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4.9. Fronteras(Ejemplo 1) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
4.10. Fronteras(Ejemplo 2) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
v

pag.vi INDICE DE FIGURAS
4.11. Fronteras(Ejemplo 3) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
5.1. Deformaciones modales de un cuadrado. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
6.1. Zona de incertidumbre. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
6.2. Niveles informacionales de un contorno. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
6.3. Descripcion de un objeto. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
6.4. Rachas de una circunferencia. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
6.5. Resultados de la localizacion de celulas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
6.6. Nematodos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
6.7. Localizacion de nematodos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
6.8. Resultados multi-histeresis de la localizacion de celulas. . . . . . . . . . . . . . . . . . . . 95
6.9. Cooperacion entre escalas en la deteccion. . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
6.10. Integracion de informacion multicanal. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
6.11. Citologıas(Ejemplo 1): original y parametros . . . . . . . . . . . . . . . . . . . . . . . . . 100
6.12. Citologıas(Ejemplo 1): Celulas detectadas . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
6.13. Citologıas(Ejemplo 1): Situacion de las celulas detectadas . . . . . . . . . . . . . . . . . . 101
6.14. Citologıas(Ejemplo 1): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
6.15. Citologıas(Ejemplo 2): original y parametros . . . . . . . . . . . . . . . . . . . . . . . . . 102
6.16. Citologıas(Ejemplo 2): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
6.17. Nematodos(Ejemplo 1): original y parametros . . . . . . . . . . . . . . . . . . . . . . . . . 103
6.18. Nematodos(Ejemplo 1): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
6.19. Nematodos(Ejemplo 2): original y parametros . . . . . . . . . . . . . . . . . . . . . . . . . 104
6.20. Nematodos(Ejemplo 2): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
6.21. Manos(Ejemplo 1): original y fronteras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
6.22. Manos(Ejemplo 1): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
6.23. Manos(Ejemplo 2): original y fronteras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
6.24. Manos(Ejemplo 2): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
6.25. Manos(Ejemplo 3): original y fronteras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
6.26. Manos(Ejemplo 3): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
6.27. Manos(Ejemplo 4): original y fronteras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
6.28. Manos(Ejemplo 4): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
6.29. Manos(Ejemplo 5): original y fronteras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
6.30. Manos(Ejemplo 5): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
6.31. Manos(Ejemplo 6): original y fronteras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
6.32. Manos(Ejemplo 6): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
7.1. Extraccion de informacion para cada objeto. . . . . . . . . . . . . . . . . . . . . . . . . . . 112
7.2. Estimacion elıptica de la localizacion de celulas. . . . . . . . . . . . . . . . . . . . . . . . . 113
7.3. Aristas y espacio de parametros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
7.4. Histograma y umbralizacion del espacio de parametros. . . . . . . . . . . . . . . . . . . . 116
7.5. Distancia a la arista mas cercana. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
7.6. Uso de la direccion del Gradiente. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
7.7. Ejemplo de funcion h(x, θ). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
7.8. Deformaciones locales sobre un modelo elıptico. . . . . . . . . . . . . . . . . . . . . . . . . 125
7.9. Citologıas(Ejemplo 1): original y parametros . . . . . . . . . . . . . . . . . . . . . . . . . 128
7.10. Citologıas(Ejemplo 1): Celulas detectadas . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
7.11. Citologıas(Ejemplo 2): original y parametros . . . . . . . . . . . . . . . . . . . . . . . . . 129
7.12. Citologıas(Ejemplo 2): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
vi

INDICE DE FIGURAS pag.vii
7.13. Nematodos(Ejemplo 1): parametros y objeto detectado . . . . . . . . . . . . . . . . . . . . 130
7.14. Nematodos(Ejemplo 1): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
7.15. Nematodos(Ejemplo 2): original y localizacion inicial . . . . . . . . . . . . . . . . . . . . 131
7.16. Nematodos(Ejemplo 2): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
7.17. Manos(Ejemplo 1): original y localizacion inicial . . . . . . . . . . . . . . . . . . . . . . . 132
7.18. Manos(Ejemplo 1): Resultado usando fronteras . . . . . . . . . . . . . . . . . . . . . . . . 132
7.19. Manos(Ejemplo 1): original y fronteras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
7.20. Manos(Ejemplo 1): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
7.21. Manos(Ejemplo 2): original y fronteras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
7.22. Manos(Ejemplo 2): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
7.23. Manos(Ejemplo 3): original y fronteras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
7.24. Manos(Ejemplo 3): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
7.25. Manos(Ejemplo 4): original y fronteras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
7.26. Manos(Ejemplo 4): Resultado final . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
7.27. Manos(Ejemplo 5) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
vii

pag.viii INDICE DE FIGURAS
viii

Capıtulo 1
Introduccion
1.1. El problema.
LA deteccion y extraccion automatica de los objetos presentes en una escena es un problema cuya
complejidad si se plantea en sus terminos mas generales hace muy difıcil el estudio de soluciones
globales para todo tipo de imagenes, no habiendose obtenido hasta ahora mas que soluciones parciales para
determinadas aplicaciones y/o condiciones de las imagenes. Los problemas mas importantes asociados a
la segmentacion de imagenes que son objeto de nuestro estudio, son debidos en primer lugar al ruido y a
la aparacion de multiples objetos en la imagen.
Entenderemos por ruido cualquier proceso que haga crecer la incertidumbre sobre los posibles objetos
presentes en la imagen. Existen por tanto distintos tipos de ruidos que pueden afectar al analisis de la
informacion presente en una imagen:
Un tipo de ruido aparece en el proceso de captacion de la imagen, que introduce sobre esta un ruido
de tipo estocastico que es usualmente modelizado por una distribucion Gaussiana o de Poisson.
Aunque este ruido puede ser importante en algunos tipos de detectores y alterar considerablemente
los valores de los pixeles, los sistemas de captacion que hemos usado, basados en sensores de tipo
CCD, producen imagenes con una calidad razonable en terminos de S/N .
Otro tipo de ruido que afecta aun de forma mas considerable es el que denominaremos de tipo no
estocastico y se caracteriza por la falta de contraste entre los valores de gris de los pıxeles exteriores
e interiores a un objeto junto con un rango corto de niveles de gris de la imagen. Este tipo de ruido
viene dado por el tipo de material u objetos que estamos analizando y es por tanto muy difıcil
de modelizar matematicamente. La unica solucion factible para paliar la falta de informacion que
este segundo tipo de ruido introduce en la imagen es el uso de hipotesis sobre el comportamiento y
formas de los objetos presentes en la imagen.
Un tercer tipo proviene de la multiplicidad de objetos en la imagen. Ademas de la confusion que
ocasiona el considerar que existe mas de un objeto en la imagen, debemos considerar problemas tales
como el solapamiento (dificulta la segmentacion al hacer que la informacion con la que segmentar
la imagen sea unicamente parcial).
Ademas del proceso de ruido existe otro mecanismo natural que hace aumentar la incertidumbre: las
variaciones geometricas de la forma1. Estas hacen imposible la aplicacion de metodos de deteccion de
objetos que superando problemas de ruido se limitan a la deteccion de contornos rıgidos sin contemplar
posibles deformaciones. Un ejemplo de imagen con este tipo de problematica se puede ver en la figura 1.1.
1Un problema que afecta especialmente a objetos en la naturaleza.
1

pag.2 Introduccion
Figura 1.1: Ejemplo de imagen.
Cuando se pretende resolver el problema de segmentacion de objetos, es decir, ir desde la captacion
de una imagen hasta la clasificacion de los objetos que se encuentran en ella, la metodologıa a seguir es
ir realizando cada una de las etapas necesarias desde las de mas bajo nivel semantico e ir subiendo hasta
la comprension de la imagen de manera que en cada una de ellas fijamos los siguientes pasos:
Una informacion a procesar: procedente de la etapa anterior.
Una tecnica para el proceso.
Una informacion procesada: destinada a la siguiente etapa.
Bajo el paradigma de Marr ([Marr y Nishahara 78]), cada uno de estos pasos han sido convencional-
mente tratados de forma independiente provocando un estudio separado en muchos campos tal y como
muestra la literatura ([Gonzalez y Woods 92], [Jain 89], [Sonka et al. 93]). Un enfoque clasico de detec-
cion de contornos (boundary detection) para resolver nuestro problema en analisis de imagenes podrıa
ser el siguiente: captacion de la imagen, preprocesamiento, extraccion de fronteras, union de fronteras,
deteccion del contorno y clasificacion del contorno. Es claro que el flujo unidireccional de esta informacion
perjudica a los resultados obtenidos por dos razones:
La informacion que se pierde en un nivel ya no puede ser utilizada en los niveles semanticamente
superiores.
El error cometido en un nivel es arrastrado y posiblemente amplificado en posteriores tareas.
Estos dos puntos son contrapuestos ya que evitar arrastrar errores implica una perdida mayor de
informacion y el intentar pasar de una etapa a otra un volumen superior de informacion implica cometer
mas errores.
Para resolver este problema, podemos plantear como solucion un estudio mas profundo y detallado
de cada una de las etapas intentando obtener en cada una de ellas una informacion mayor y mas exacta.
Para este planteamiento existe amplia bibliografıa que trata cada uno de estos puntos en gran detalle
([Gonzalez y Woods 92], [Jain 89], [Sonka et al. 93]). Estos estudios aunque de gran ayuda aportando
soluciones a muchos problemas tienen la clara desventaja de no combinar las informaciones de distintas
fuentes a la vez que no aprovechan la posibilidad de recuperar nueva informacion de bajo nivel una vez
que se conocen nuevos hechos en un nivel superior. Considerese el hecho de reconocer objetos unicamente
Capıtulo 1

Planteamiento. pag.3
usando la informacion de una imagen gradiente (la informacion debe provenir de distintos canales) o
el hecho de determinar la existencia de bordes en una zona de bajo gradiente una vez que ha intuido
la familia de objetos a la que posiblemente pertenecera el objeto en estudio (reafirma informacion de
bajo nivel una vez concluidos ciertos hechos a nivel superior). Es por ello por lo que es necesario el
replanteamiento de una metodologıa para llevar a cabo esta segmentacion intentando recoger los aspectos
positivos de los trabajos realizados hasta ahora e intentando evitar los aspectos negativos que se han
resaltado.
El presente trabajo esta organizado de forma que describe una metodologıa de resolucion de problemas
de segmentacion basada en las fronteras de una forma que recuerda la division del problema realizada
en las teorıas de Marr([Marr 82]) en el sentido de que obtenemos informacion a nivel mas bajo (pixel) y
subimos a partir de ella hacia la interpretacion de la imagen. Por otro lado, el enfoque realizado puede ser
clasificado dentro de la vision basada en el modelo ya que asumimos la presencia de objetos particulares
e intentamos localizarlos en la imagen.
1.2. Planteamiento.
Como es de esperar, y tal como muestra la literatura, el exito de muchas tecnicas y algoritmos se basa
en gran medida en el tipo de informacion y la forma eficiente en que se maneja. Si pretendemos resolver
un problema es recomendable considerar que:
Un incremento en la informacion usada debe traducirse en mejores resultados. Un algoritmo sera mas
eficaz si favorecemos el uso de una mayor cantidad de informacion.
Es conveniente usar la informacion de forma correcta, es decir, se deben disenar sistemas que sepan
relacionar informacion de distinto tipo e incluso sepan ponderar informaciones mas o menos seguras.
En este sentido es necesario tener en cuenta la informacion que nos ofrece la imagen y la forma en
que podemos relacionarla con las caracterısticas que describen el objeto a segmentar.
Adicionalmente, es necesario obtener metodos eficientes que permitan disenar algoritmos que resuel-
van el problema en un tiempo aceptable. En este sentido resultan muy convenientes metodos que per-
mitan incorporar caracterısticas tales como un planteamiento multiresolucion, facil pararelizacion,
etc.
1.2.1. Segmentacion: aproximaciones.
Existen distintas aproximaciones para intentar resolver el problema de segmentacion de imagenes. A
partir de los trabajos realizados hasta el momento podemos distinguir tres grandes lıneas:
Basadas en deteccion de contornos desde la informacion de gradiente. En este caso podemos distin-
guir varias alternativas. La solucion mas inmediata que podemos plantear si usamos este tipo de
tecnicas es realizar un proceso de deteccion de fronteras mas un proceso de union de estas.
• Deteccion de fronteras. En esta etapa cobra especial interes las condiciones de las imagenes de
que disponemos puesto que un alto nivel de ruido hace necesaria una tecnica o deteccion de
aristas de baja sensibilidad a este.
Por otro lado, los algoritmos tradicionales usan una unica escala o nivel de resolucion para
extraer las aristas por lo que solo tienen en cuenta las caracterısticas que se ven realzadas en
ellas obviando otras que hubieran sido obtenidas si el nivel de escala cambia. Para conseguir
mejores resultados necesitaremos obtener un nivel de informacion alto de la imagen y por
tanto hara falta considerar una interpretacion multiresolucion de la imagen([Lindeberg 94a],
[Rosenfeld 84]).
Seccion 1.2

pag.4 Introduccion
• Union de fronteras. Este tipo de operacion se puede realizar a dos niveles distintos:
Bajo nivel o de forma no supervisada: Corresponde a metodos para unir las fronteras
sin ningun tipo de informacion acerca del contorno que se busca. Por lo tanto se pre-
sentan como metodos recomendables para un postprocesamiento de las fronteras desde
algun tipo de detector. Ejemplos pueden ser la histeresis que es usada en el algoritmo de
Canny([Canny 86]), metodos de relajacion([Hancock y Kittler 90a], [Hancock et al. 92],
[Hancock y Kittler 90b], [Kittler y Hancock 89]) o de busqueda en el entorno ([Farag y
Delp 95]).
Alto nivel o de forma supervisada: Usan informacion del contorno a buscar. Este tipo de
union es la que realmente nos permite la deteccion del objeto buscado. En la literatura
existe una amplia variedad de tecnicas entre las que podemos destacar tecnicas basadas
en una descripcion sintactica del objeto([Bunke 92], [Fu 82], [Garrido et al. 95]) o tecnicas
basadas en la transformada de Hough ([Ballard 81], [Illingworth y Kittler 88], [Kalvianen
et al. 94]), la cual nos permite la localizacion de contornos rıgidos y es relativamente
insensible a la fluctuacion por el ruido y partes ocultas de los objetos.
Es necesario destacar que la estimacion de contornos desde imagenes ruidosas sin un modelo de
objeto es un problema ill-posed([Poggio y Torre 84]), es decir, mal condicionado y cuyas soluciones
no son unicas. De esta forma, nos centraremos en los metodos que combinan deteccion y modelado
del contorno.2.
Basadas en deteccion de regiones. En este tipo podemos englobar un amplio repertorio de tecnicas,
entre las que podemos destacar segmentacion por crecimiento de regiones, por division y union de
regiones ([Pavlidis 80], [Sonka et al. 93]) o tecnicas derivadas a partir de la Morfologıa Matematica
propuesta por Serra ([Serra 82]) que han sido y son de amplio uso en aplicaciones de tipo biomedi-
co. Sin embargo, dichas tecnicas son muy exigentes con la calidad de las imagenes en terminos
de alto contraste de los objetos sobre el fondo de la imagen. El uso de estas tecnicas sobre este
tipo de imagenes y otros con problemas (tales como solapamiento, abundancia de objetos, etc.)
obtiene un grado de exito parcial (vease por ejemplo [Fdez-Valdivia et al. 95c]) dado que consiguen
segmentaciones en las que pueden aparecer algunas regiones que contienen uno o mas objetos3.
Modelos deformables: Es necesario separar del resto las tecnicas que se basan en el uso de modelos
deformables dada por un lado la gran importancia que han tomado estas tecnicas en la deteccion
de objetos con deformaciones y por otro lado dada la difıcil clasificacion en las tecnicas descritas
anteriormente si consideramos los template deformables como un modelo de objeto que puede sufrir
de mas o menos deformacion. Es importante destacar que con el uso de modelos deformables no
podemos en absoluto obviar las tecnicas concernientes a la deteccion de fronteras o regiones dado
que los contornos deben ser deformados segun la informacion que se obtenga de la imagen (ya sea
proveniente de las fronteras [Cohen y Cohen 93], [Garrido et al. 95], [Kass et al. 87a], [Kass et
al. 87b], o basada en regiones [Grenander et al. 91], [Ronfard 94]) ası como otras como colores,
texturas, etc que pueden ser usadas para determinar el grado de acoplamiento del template a la
imagen. Los modelos deformables seran de especial interes en nuestro trabajo ya que los contornos
de los objetos son especialmente sensibles a presentar caracterısticas de deformacion.
Teniendo en cuenta las cualidades y defectos que podemos observar en los metodos anteriores y dado
que algunas imagenes son especialmente difıciles de segmentar por:
2Un claro ejemplo de esta tecnica es la transformada de Hough generalizada.3Considerese por ejemplo que dos objetos se encuentran solapados (a este tipo de tecnicas les resultara practicamente
imposible la separacion).
Capıtulo 1

Planteamiento. pag.5
Falta de homogeneidad (ruidos de tipo no aleatorio).
Objetos solapados.
Formas muy variables debido a deformaciones naturales.
Multiples objetos con caracterısticas a distintas escalas.
Sera deseable, si queremos obtener informacion segura y estable, resolver este problema haciendo uso
de tecnicas o ideando alguna tecnica con caracterısticas tales como:
Incorporar un modelo de contorno a buscar.
Reconstruir o inferir informacion inexistente a partir de informacion parcial.
Manejar casos de deformacion del contorno buscado.
Manejar la informacion a distintas escalas.
1.2.2. Modelizacion de deformaciones: aproximaciones.
En la literatura existen muchas y distintas formas de tratar la localizacion de contornos deformados.
Podrıamos realizar una primera clasificacion de estos metodos en:
Metodos SIN informacion a priori o no supervisados. No se posee ninguna informacion acerca del
modelo de contorno que se intenta localizar. Referencias a metodos de este tipo son por ejemplo
[Cohen y Cohen 93], [Kass et al. 87b], [Ronfard 94].
Metodos CON informacion a priori o supervisados.Se posee un modelo de objeto que contrastar
con la imagen para obtener su posible localizacion. Referencias a metodos de este tipo son por
ejemplo [Amit y Kong 96], [Cootes et al. 95], [Dubuisson et al. 96], [Grenander et al. 91], [Jain y
Lakshmanan 96], [Knoerr 88], [Yuille et al. 92].
1.2.2.1. Metodos sin informacion a priori.
Este tipo de metodos comienzan a tener un gran auge a partir de [Kass et al. 87a] donde se proponen
los modelos de contornos activos o snakes al problema de deteccion de contornos planteandolo como un
problema de regularizacion.
Desde un punto de vista continuo, un Snake puede considerarse una funcion:
f : [0, 1] ⇒ ℜ2 (1.1)
que puede implementarse como un conjunto de puntos ordenados (llamados snaxels)
S = p1, p2, · · · , pn (1.2)
definidos sobre el grid rectangular.
Sobre esta funcion se define una funcion de energıa que se compone de dos partes:
Energıa interna: Hace referencia a la curva que define el contorno. Cuanto mas “suave” sea, tanta
menos energıa tiene. Se puede implementar algun criterio de suavidad y continuidad para medir
esta energıa.
Seccion 1.2

pag.6 Introduccion
Energıa externa: Hace referencia a las fuerzas externas desde la imagen. Cuanto mas cerca este la
curva del contorno que determina la localizacion en la imagen, tanta menos energıa externa tiene.
Un criterio para ello puede ser considerar el gradiente para medir la optimalidad del snake en cuanto
a energıa externa se refiere.
Como es de esperar, el problema consiste en encontrar un equilibrio entre ambas energıas (problema
de regularizacion) definiendo un punto de energıa mınima global que determina la solucion al problema
de segmentacion.
Aunque constituye una aproximacion muy potente debido a su gran eficacia, especialmente en con-
tornos que sufren de deformaciones difıciles de controlar como son los contornos biomedicos, e incluso en
problemas de seguimiento de formas en imagenes en movimiento (por ejemplo, Kalman Snakes en [Blake
y Yuille 92]), sufre de varios inconvenientes entre los que conviene destacar:
Requieren de un proceso previo de localizacion aproximada del contorno, que en muchos casos se
soluciona mediante un posicionamiento manual por parte del usuario.
El no tener mas que una restriccion referente a caracterısticas como suavidad y continuidad en lo que
al contorno buscado se refiere, provoca que problemas como falta de homogeneidad, solapamientos,
etc. compliquen el proceso de deteccion.
1.2.2.2. Metodos con informacion a priori.
En estos metodos englobamos aquellos que definen un tipo particular de forma a localizar, es decir,
un modelo a priori de lo que se busca. Al contrario que el caso discutido en el punto anterior en el que
las condiciones que definen un posible contorno se refieren a propiedades de suavidad, continuidad, etc.
en este caso se posee la informacion que define una familia de posibles deformaciones del contorno a
segmentar.
El metodo mas basico y obviamente mas limitado de deteccion de una forma puede ser formulado como
una convolucion de una plantilla con una imagen (mediante una operacion de correlacion) que obtiene
los puntos de mayor correspondencia, los cuales si poseen un valor suficientemente alto determinan la
existencia de esta plantilla (vease por ejemplo [Ballard y Brown 82], pag. 65). Obviamente, este metodo
aunque trabaja con un modelo a priori no contempla el problema de las deformaciones.
El uso de modelos deformables propiamente dichos intentan resolver este problema definiendo un
modelo a priori mediante un template4 y un conjunto de deformaciones sobre el. La solucion del problema
se plantea de manera muy similar al caso anterior:
Tenemos un modelo de forma parametrizado y por tanto una forma de decidir si un contorno
corresponde al conjunto de posibilidades que pretendemos manejar. Una manera de definirlo, serıa
por ejemplo fijar una probabilidad a priori sobre los posibles contornos.
Tenemos una forma de medir el grado de fijacion de ese contorno a la imagen. Para definirlo,
podemos especificar una funcion de energıa o una probabilidad correspondiente a esta.
La localizacion en la imagen del objeto deseado se realiza por tanto sin mas que anadir un algoritmo
que use esas dos informaciones y localice el optimo.
Aunque estos metodos presentan un enfoque mucho mas rico que el anterior, siguen existiendo difi-
cultades en su aplicacion:
4En principio, aunque el caso mas sencillo es la definicion de un contorno, no es necesario definir esta plantilla en base a
este sino que podrıamos definirla en base a otro tipo de informaciones, por ejemplo, referentes a regiones con determinados
contrastes de gris.
Capıtulo 1

Planteamiento. pag.7
Aun no se ha resuelto de forma general el problema de la localizacion automatica de la posicion
inicial del objeto sobre la que aplicar el algoritmo de optimizacion (por ej. [Cootes et al. 95], [Jain
y Lakshmanan 96], [Knoerr 88], [Grenander et al. 91], [Kass et al. 87b], etc...).
En algunos trabajos se han conseguido resultados muy buenos que resuelven el problema de la
localizacion inicial y la optimizacion pero que a cambio, han necesitado un modelo de objeto muy
especıfico (por ej. [Yuille et al. 92]).
No resuelven el problema de que existan varias instanciaciones de la forma que buscamos que pueden
presentar dificultades adicionales como solapamientos y ruido no aleatorio.
Existen algunas aproximaciones que pretenden resolver estos problemas, como los g-snakes o snakes
basados en el modelo que se definen a partir de los snakes([Kass et al. 87a]) mediante la adicion de
un modelo de contorno y la definicion de un problema de estimacion de MAP([Lai y Chin 95]). En
ellos se consiguen buenos resultados pero careciendo de una forma de manejar fuertes deformaciones y
proponiendo como metodo de inicializacion la transformada de Hough generalizada.
Existen algunas aproximaciones que pretenden resolver estos problemas, como la generalizacion de
los snakes, es decir, los g-snakes o snakes basados en el modelo fruto de anadir un modelo de contorno
y definir un problema de estimacion de MAP([Lai y Chin 95]). En ellos se consiguen buenos resultados
proponiendo como metodo de inicializacion la transformada de Hough generalizada pero careciendo de
una forma de manejar fuertes deformaciones y altos niveles de ruido.
1.2.3. Fusion de informacion.
Si intentamos clasificar el tipo de informacion que se usa en los algoritmos de segmentacion de objetos
podrıamos determinar dos grandes grupos:
Basada en regiones: Utiliza caracterısticas referentes a la homogeneidad de zonas en la imagen.
Los interiores de las regiones de un objeto se caracterizan por ser homogeneos ya sea en niveles de
gris, en la presencia de una estructura que determina el tipo de textura, el color, etc. Es decir, si
consideramos una imagen f en la que f(x, y) = g indica que el pixel en la posicion (x, y) tiene un
valor g (p.e. nivel de gris, una tupla RGB indicando el color, un vector que mide las componenentes
de una imagen multibanda, etc.) detectar zonas homogeneas no es mas que localizar las regiones
de valor constante en alguna imagen o funcion T (x, y) que se evalua en funcion del valor de f en la
posicion (x, y) y su entorno.
Basada en fronteras: Utiliza la informacion de gradiente para determinar los bordes del objeto. Al
contrario que las anteriores, en este caso se usa la informacion de las zonas de mayor variacion
para delimitar el contorno del objeto. A pesar de ello, no podemos considerar esta informacion
independiente de la anterior pues son dos caras de un mismo problema, tengase en cuenta que la
deteccion de aristas no es mas que realzar los puntos de separacion entre regiones.
En el tipo de problemas que intentamos resolver el uso de tecnicas basadas unicamente en regiones
plantea mayores dificultades. Considerese por ejemplo que dos objetos se encuentran solapados, la homo-
geneidad de la union de ambos puede producir una unica region y por consiguiente un resultado erroneo
o la existencia de ruido no aleatorio que introduce falta de homogeneidad en la imagen puede determinar
que un objeto quede dividido en varias regiones. Por ello, en este trabajo nos vamos a centrar principal-
mente en la deteccion de objetos basandonos en informaciones de gradiente aunque sin descartar que el
modelo puede enriquecerse con la incorporacion de nuevas informaciones a partir de regiones, texturas u
otras caracterısticas como veremos mas adelante.
Seccion 1.2

pag.8 Introduccion
Una forma de llevar a cabo el uso de informaciones de distintas fuentes es plantear un enfoque
multiresolucion de la imagen. Efectivamente, si consideramos dos escalas distintas de una misma imagen,
la informacion gradiente de ambas difiere de tal forma que considerar distintas escalas nos da mayores
garantıas de exito.
Ahora bien, si usamos la informacion de las aristas de una imagen, debemos de plantearnos la forma en
que vamos a obtener a partir de estas la localizacion de los objetos. Para ello es necesario que consideremos
la informacion que de estos nos dan las aristas. Es en base a ella como definiremos una modelizacion del
objeto orientada a su localizacion.
1.2.3.1. Informacion de las aristas de una imagen.
Desde un punto de vista semantico podemos distinguir varios niveles de informacion en una imagen
de aristas. En nuestro trabajo vamos a presentar un determinado enfoque de esta idea a fin de modelizar
los objetos. Nuestro objetivo por tanto en este punto es determinar el tipo de informacion que se puede
obtener desde el gradiente de la imagen.
Una posible division de estos niveles podrıa ser la siguiente:
El nivel mas basico es el del pixel. Es posible construir metodos que utilizando la informacion a este
nivel consigan determinar la localizacion de los objetos. Dado que la informacion es pobre (dado
su nivel), estos metodos deberan de compensar con un aporte fuerte acerca del contorno que se
pretende detectar. Ası, podemos distinguir la transformada de Hough ([Illingworth y Kittler 88],
[Kalvianen et al. 94]) como una tecnica eficiente que usa la informacion del pixel independientemente
de su entorno.
Por encima del pixel podemos distinguir un nivel informacionalmente mas relevante, compuesto por
el pixel y su entorno. En este caso tenemos mas informacion acerca de la frontera del objeto. En
este punto por tanto podemos aplicar metodos que sepan explotar este contenido. Ası, podemos
distinguir los metodos de relajacion (por ej. [Hancock y Kittler 90b]) como una tecnica que intenta
la deteccion o realce de los contornos en base a este tipo de informacion.
Finalmente, el nivel superior viene determinado por las cadenas, es decir, la concatenacion de pıxeles
adyacentes segun el 8-entorno del grid rectangular. En este punto estamos englobando un amplio
conjunto de posibilidades, desde pequenas cadenas de dos o tres pıxeles descritas en el punto anterior
hasta un contorno completo describiendo la forma y localizacion de un objeto. Es por ello por lo
que se hace necesario una subdivision:
• La forma mas simple de una cadena viene determinada por un segmento rectilıneo. En este
caso, se posee una informacion contextual muy superior considerando la localizacion relativa
de unos pıxeles respecto de otros a lo largo de toda la cadena. Obviamente, debido al ruıdo y
la discretizacion, los puntos no se encuentran sobre una lınea ideal sino que pueden sufrir de
perturbaciones aunque en general y dentro de ciertos lımites definan una tendencia.
• Subiendo en la escala informacional que estamos definiendo, el siguiente nivel viene deter-
minado por la yuxtaposicion de cadenas rectilıneas, es decir, por una multilınea. Es intere-
sante destacar aquı la importancia de los metodos de deteccion basados en puntos domi-
nantes([Douglas y Peucker 73], [Fdez-Valdivia et al. 95a], [Teh y Chin 89], etc...) que podemos
considerar coincidentes con los puntos de union de dos cadenas rectilıneas y especialmente los
que clasifican estos mediante algun criterio de importancia ([Perez de la Blanca et al. 93]).
• Obviamente, el ultimo punto hace referencia a una multilınea cerrada que define el contorno
del objeto, es decir a un polıgono que determina aproximadamente la localizacion y forma de
las fronteras del objeto.
Capıtulo 1

Planteamiento. pag.9
1.2.4. Deteccion de formas: representacion.
Los algoritmos de reconocimiento clasicos se basan fundamentalmente en la distincion de algun tipo
de caracterısticas sobre el objeto a detectar que son comparadas con las obtenidas a partir de un conjunto
de posibles candidatos (de un posible conjunto de formas previamente almacenadas en una base de datos)
o con las detectadas en una imagen (si queremos segmentar los objetos que contiene) mediante alguna
funcion de distancia para dar lugar a una determinada clasificacion o localizacion. Obviamente, la forma
de resolver este problema varıa mucho de unas soluciones a otras en:
La caracterizacion del objeto. Existen muchas posibilidades para registrar esta caracterizacion us-
ando informacion de texturas, colores, contornos, etc.
La funcion de distancia, es decir, el grado de correspondencia entre el objeto que queremos detectar
y las distintas posibilidades de clasificacion o localizacion. Por ejemplo, si deseamos clasificar un
contorno para reconocer la familia de objetos a la que pertenece, esta funcion nos indica la distancia
a cada una de las clases que se posean o, si deseamos localizar un objeto en una imagen, nos indica
la bondad de cada una de las posibles localizaciones.
El metodo para resolver el problema de obtener el optimo en esta funcion de distancia.
La deteccion de una forma en una imagen no es mas que determinar un punto en un espacio de
localizaciones que contendra ejes tales como desplazamientos, rotaciones, homotecias y otros ejes de
deformacion no rıgida en el caso de sean objetos deformables.
Han sido muchos los trabajos que han estudiado el problema de la caracterizacion de formas con el ob-
jetivo de construir algoritmos que fueran eficaces en el reconocimiento de estas. Para ello, se han disenado
multitud de caracterizaciones que se destacan por sus buenas propiedades como: dar lugar a algoritmos
de reconocimiento muy eficientes como los algoritmos de parsing de deteccion sintactica ([Bunke 92],[Fu
82], etc), invariancia frente a grupos de transformaciones ([Wood 96]), simplificacion en gran medida del
numero de datos que procesar manteniendo un grado de significacion muy alto(caracterizacion por puntos
dominantes), facilidad de calculo desde la imagen, etc. Por otro lado, muchas de ellas tambien sufren de
varios inconvenientes como son: sensibilidad al ruido, variacion limitada a deformaciones rıgidas, imposi-
bilidad de obtener resultados a partir de informacion parcial, aplicabilidad en un conjunto limitado de
problemas, algoritmos de deteccion dedicados a familias de objetos con caracterısticas especiales, etc.
1.2.4.1. Descripcion de un contorno: Modelo propuesto.
Si consideramos la descripcion anterior acerca de los distintos niveles que podemos distinguir en la
informacion de aristas de una imagen unida a la descripcion de una forma por medio de una cadena
cerrada, podremos distinguir varios niveles similares a la hora de modelizar un objeto. Efectivamente,
una forma puede ser descrita usando desde la especificacion de la posicion de cada uno de los puntos
que componen su contorno (considerese la transformada de Hough que usa esta descripcion) hasta la
descripcion lineal a trozos, es decir, mediante un polıgono5.
Un metodo que pretenda obtener conclusiones a partir de las aristas de una imagen debera recibir
unas entradas a partir de estas y obtener unos resultados que seran tanto mejores como la informacion
de entrada que se le proporcione. Es de esperar que sera mas sencillo concluir un hecho semanticamente
relevante cuanto mayor sea el contenido semantico de las entradas.
En el presente trabajo necesitaremos una modelizacion de los objetos a un nivel lo suficientemente
relevante como para que los metodos que se van a proponer sean capaces de obtener salidas bastante
5Tengase en cuenta que aunque simple, la descripcion es completa, es decir, cualquier forma puede ser descrita mediante
la aproximacion de un polıgono con una calidad que dependera del numero de lados de este. En el caso concreto de una
cadena, podemos describir la cadena de forma exacta mediante una enumeracion de los codigos Freeman que la componen.
Seccion 1.2

pag.10 Introduccion
seguras acerca de la localizacion de las formas. Esta forma de enfocar el problema conlleva dos problemas
asociados a los dos pasos subyacentes respectivamente:
Debemos desarrollar un algoritmo para obtener, a partir de la informacion de fronteras del detector
propuesto, la descripcion de estas a un nivel informacional superior.
Debemos desarrollar un metodo que sepa concluir hechos referentes a la localizacion de las formas
a partir de la descripcion obtenida en el paso anterior.
Ahora bien, ¿Que tipo de informacion podemos obtener a partir de las aristas para que nuestro metodo
sea eficaz?. En este trabajo, los resultados se presentaran a partir de algoritmos que trabajaran sobre una
descripcion en base a las distintas subcadenas (“aproximadamente” lineales) en que se puede describir el
contorno de la forma buscada (tendencias o rachas de la forma), es decir, en base a una aproximacion
poligonal. De todas formas aquı y mas adelante insistiremos en la posibilidad de adaptar el metodo (de
una forma directa) al uso de informacion de distinto nivel e incluso al uso simultaneo de informaciones
de distintos niveles que se obtienen de forma natural al considerar distintas formas de describir nuestro
contorno como son:
Informacion de pıxeles aislados.
Informacion de tendencias o rachas.
Informacion de concatenacion de distintas tendencias6.
1.2.4.2. Ejemplo ilustrativo: Un enfoque simbolico.
Si construimos una descripcion en base a las tendencias de un objeto, tendremos que:
Hacer una particion en subcadenas del contorno original de forma que cada una de estas cumpla
algun criterio de linealidad.
Asignar a cada subcadena obtenida un valor de tendencia.
Para un ejemplo simple de un cuadrado, en el primer punto podrıamos ocuparnos de detectar que
esta compuesto de 4 subcadenas correspondientes a cada uno de los 4 lados. En el segundo, debemos
asignar una tendencia a cada lado, por ejemplo, tendencias correspondientes a los angulos 0, π/2, π y
3π/2 o considerando un modelo invariante frente a rotaciones asignando las diferencias entre tendencias
consecutivas de π/2,π/2,π/2 y π/2. Obviamente estamos considerando el caso continuo, es decir, la
diferencia entre tendencias consecutivas puede tomar cualquier valor en el intervalo [−π, π].
Un ejemplo ilustrativo es el que se presenta en la figura 1.2 en la que se considera una discretizacion
de las tendencias en 8 valores distintos correspondientes a los 8 codigos Freeman. Para modelizar las
formas, se consideran las diferencias entre codigos Freeman consecutivos (modulo 8) obteniendose valores
enteros del intervalo [−3,+4].
1.3. Objetivo y estructura del trabajo.
1.3.1. Objetivo General.
El presente trabajo desarrolla un procedimiento de segmentacion automatica de objetos en imagenes
que presentan la problematica anteriormente expuesta mediante la localizacion de los contornos cerrados
que separan la zona interior y exterior del objeto.
Para poder conseguir este objetivo:
6Los puntos dominantes pueden considerarse un caso particular de este tipo ya que pueden hacerse corresponder con los
puntos de union de distintas tendencias.
Capıtulo 1

Objetivo y estructura del trabajo. pag.11
Tendencias:
4,5,6,7,0,1,2,3,4
Modelo:
+1,+1,+1,+1,+1,+1,+1,+1
Tendencias:
Modelo:
5,6,5,4,3,2,3,4,5,6,7,0,1,2,3,4
+1,-1,-1,-1,-1,+1,+1,+1,+1,+1,+1,+1,+1,+1,+1
Tendencias:
Modelo:
6,5,3,2,3,4,7,6,5,0,1,2,1,7,6,7,0,3,2,1,4
-1,-2,-1,+1,+1,+3,-1,-1,+3,+1,+1,-1,-2,-1,+1,+1,+3,-1,-1,+3,+2
Códigos
Freeman
4
5
3
6
2
0
7
1
(A)
(B)
(C)
Figura 1.2: Descripcion cualitativa de distintos patrones.
Es necesario realizar una busqueda supervisada. Debemos de conocer un modelo de la forma que
se desea localizar (por ejemplo, un modelo de contorno) de manera que necesitamos metodos de
descripcion y aproximacion de dichos contornos con el fin de introducir dicha informacion en
un formato util para nuestros algoritmos, es decir, en un formato que facilite la busqueda en un
espacio de localizaciones.
Para conseguir la localizacion de los contornos debemos de disponer de un modelo que nos pueda
fijar el contorno estimado sobre la frontera exacta aunque el objeto que deseamos detectar pueda
sufrir de variaciones geometricas o de algun tipo de deformacion. Necesitaremos por tanto definir
un espacio de localizaciones posibles sobre el que poder aplicar un modelo de objeto deformable.
Debido a los problemas que se presentan, es especialmente recomendable realizar un estudio mul-
tiescala para obtener informacion de mas de una escala ya que centrandonos solo en una de ellas,
la informacion que podemos obtener es menor.
Debemos de desarrollar una solucion que nos permita la fusion de informacion, ya sea desde
distintas escalas o desde distintas fuentes, facilitando ası la generalizacion del metodo a distintos
problemas.
Las tecnicas que se disenan para obtener informacion desde la imagen pueden ofrecer unicamente
Seccion 1.3

pag.12 Introduccion
parte de esta (por ejemplo, trozos de frontera). Para llevar a cabo una estimacion del contorno a
localizar, debemos de construir un modelo de descripcion de objetos orientado a la reconstruccion
a partir de informacion parcial.
Es necesario saber distinguir la informacion mas relevante para que los resultados sean correctos.
Habra de formularse un metodo robusto frente a informacion ruidosa.
1.3.2. Organizacion.
Organizaremos esta tesis de la siguiente forma:
En el capıtulo dos introducimos el espacio de escalas como un concepto fundamental en el proce-
samiento de imagenes tal y como describio Marr en sus trabajos ya que nos permitira obtener informa-
cion a distintas escalas (recordemos que los objetos en una imagen pueden aparecer a distintas escalas e
incluso como veremos, distintos segmentos de la frontera del objeto son captados de una forma optima
en distintas escalas). Deberemos tener en cuenta este concepto en el estudio de cualquier senal, ya sea
2-D (por ejemplo: imagenes de grises, gradientes, etc...) como en 1-D (por ejemplo: estudio de contornos
y su curvatura).
El objetivo principal en este trabajo es localizar los objetos presentes en una imagen disponiendo de
una descripcion del contorno que lo determina. Por lo tanto deberemos caracterizar la curva que describe
dicho objeto a partir del estudio de este con el objetivo de obtener una descripcion que pueda ser usada en
una posterior etapa de reconocimiento. Es en el capıtulo tres donde se presenta una discusion y estudio de
la forma en que pueden caracterizarse y aproximarse los contornos desde una representacion multiescala
de estos.
En el capıtulo cuatro nos centraremos en el procesamiento a mas bajo nivel, es decir, en la forma
en que vamos a obtener las fronteras y que es lo que pretendemos obtener a partir de ellas. Para esta
discusion plantearemos dos objetivos: en primer lugar obtener un conjunto de aristas completo en el
sentido de que deben de representar la mayor parte de la informacion en la imagen (en lo que a fronteras
se refiere) y robusto en el sentido de que no deben ser especialmente sensibles a ruido, y en segundo lugar
debemos determinar el preprocesamiento que aplicaremos sobre estas aristas para que puedan ser usadas
en los algoritmos de posterior localizacion.
En el capıtulo cinco se presenta la metodologıa general de modelizacion de deformaciones. Dado
que nuestros contornos pueden presentarse con deformaciones, deberemos disponer de un metodo para
caracterizar tales deformaciones de forma que podamos localizar un objeto a pesar de que se presente
deformado, como es natural en la deteccion a partir de imagenes de tipo biomedico. Como resultado de
esta parte deberemos disponer de un sistema de ejes coordenados que parametrizen las deformaciones
que pueden presentar los objetos a localizar.
En el capıtulo seis nos centraremos en la primera gran etapa de la deteccion de contornos deformables:
la localizacion aproximada del objeto a detectar, problema que intentaremos abordar en un marco tan
general como sea posible intentando de esta forma ampliar el conjunto de casos en los que es posible
aplicar esta metodologıa. Deberemos considerar dicha localizacion a partir de informacion de aristas
teniendo especial interes en la importancia de un estudio multiescala de la imagen que permite disponer
de una cantidad mucho mayor de informacion garantizandonos por consiguiente resultados mas completos
a partir de algoritmos mas robustos.
En el capıtulo siete completaremos la deteccion del contorno optimizando los resultados obtenidos
desde la aproximacion inicial. Para ello, se propondra un metodo de fijacion de la curva que tenga en cuenta
las posibles deformaciones locales del contorno pero que a la vez sea capaz de preservar la informacion
a priori que se posee sobre la forma de este. Un problema que se resolvera se refiere a la definicion
de funciones de potencial planteando una solucion que permitira el uso simultaneo de informaciones de
gradiente y de regiones a fin de dotar de mayor robustez al metodo frente a la variedad de problemas que
Capıtulo 1

Objetivo y estructura del trabajo. pag.13
se pueden presentar (considerese la falta de homogeneidad, solapamiento, informacion parcial, ruido no
aleatorio, etc).
Por ultimo se realizara una breve discusion junto con la exposicion de las conclusiones y lıneas futuras
que se establecen a partir de este trabajo.
1.3.3. Imagenes test.
En el estudio que se realiza en este trabajo las imagenes biomedicas son de especial relevancia ya
que presentan muchos de los problemas que hemos comentado. Ya que las imagenes que usaremos en
este trabajo estan orientadas a ilustrar el comportamiento de la metodologıa que se propone sobre los
distintos problemas, nos centraremos principalmente en este tipo de imagenes. El rango de niveles de gris
de las estas es de 256 y sus tamanos 256x256 pıxeles.
De especial interes son las imagenes de citologıas de mama captadas a traves de microscopios opticos
con una camara de vıdeo de tipo CCD adosada a su tubo. El principal problema que se presenta para
la segmentacion automatica de las celulas presentes en dichas imagenes es la ausencia de contraste y
homogeneidad en muchas regiones de la imagen ası como la abundancia y solapamiento de celulas. El
problema se ve agravado especialmente ya que las imagenes han sido tomadas a partir de preparaciones
tenidas con la tecnica de Papanicolau, que ofrece poca calidad provocando ruido no aleatorio debido a la
falta de homogeneidad en la absorcion o fijacion de la tincion.
Por otro lado se usaran otras imagenes que permitan manejar casos de objetos mas complejos como son
los nematodos que tienen una alta variabilidad geometrica, o casos de manos que constituyen una forma
muy interesante desde el punto de vista de los trabajos previos que lo usan como ejemplo ilustrativo.
Ademas, se usaran puntualmente otras imagenes a fin de destacar la generalidad del modelo que
se propone y permitir la comparacion de metodos. Una muestra de dichas imagenes se presenta en la
figura 1.3. Como podemos ver, usaremos imagenes de citologıas, otras imagenes biologicas e incluso
contornos cartograficos.
Seccion 1.3

pag.14 Introduccion
Figura 1.3: Imagenes test.
Capıtulo 1

Capıtulo 2
El espacio de escalas.
MUCHAS tecnicas de procesamiento de imagenes trabajan a nivel local considerando la relacion
entre los pıxeles y su entorno1. El concepto que subyace debajo de este tamano de entorno es el
de escala. Nosotros usaremos este concepto mediante el llamado espacio de escalas, una teorıa con fuerte
sustento matematico que nos va a permitir manejar con mayor facilidad senales a diferentes escalas.
En este capıtulo nos limitaremos a realizar un estudio centrandonos en los distintos puntos que
tendremos en cuenta en los siguientes capıtulos:
1. Que es el espacio de escalas y como podemos usarlo.
2. Definicion formal.
3. Propiedades basicas que nos permitiran un manejo mas sencillo y eficaz de las senales a distintas
escalas.
4. Estructura a traves de la escala destacando el comportamiento de los puntos crıticos como puntos
destacados que luego usaremos en distintos algoritmos.
2.1. Representacion multiescala de las imagenes.
Los objetos en el mundo real presentan caracterısticas que son observables a distintas escalas. En el
sistema visual humano, el reconocimiento de objetos se realiza a distintas escalas utilizando solo algunas
de ellas donde estan las caracterısticas mas relevantes o mezclando la informacion que proviene de distintas
escalas para describir completamente la forma. El aspecto multiescala tiene especial interes en el caso en
que para obtener cierta caracterıstica de un objeto haya que obtener informacion de distintas escalas.
Aunque en los ultimos anos se estan estudiando en profundidad estas tecnicas, los primeros trabajos
que podemos relacionar con algun tipo de representacion multiescala son los quad tree , introducidos por
Klinger[Klinger 71]2(para mas informacion, consultar [Rosenfeld 84], [Samet 90a], [Samet 90b], [Tanimo-
to y Klinger 80]). Otros trabajos que comenzaron posteriormente son las representaciones piramidales
(introducidas por Burt[Burt 81] y Crowley[Crowley 81]) de rapida aceptacion por las posibilidades de
mejora en eficiencia de muchos algoritmos (vease por ej. [Ng et al. 93]). En esta representacion, el primer
nivel consiste en la imagen original, y cada nivel se obtiene del inmediatamente inferior con una operacion
1Es abundante la literatura donde aparecen los conceptos de 4-entorno, 8-entorno, etc...2En este caso, se divide de forma recursiva la imagen en zonas o regiones cada vez mas pequenas (cada zona que se
decide a dividir queda dividida en 4 subregiones) obteniendose una informacion de nivel mas fino cuanto mas se desciende
en la estructura de arbol asociada
15

pag.16 El espacio de escalas.
de muestreo (numero de pıxeles inferior) mediante la union de la informacion en varios pıxeles vecinos
del nivel inferior a traves de una operacion de alisamiento.
Un tipo especial de representacion multiescala (en el que fundamentalmente nos centraremos) con
un parametro de escala continuo y preservando en todas las escalas un muestreo espacial identico es la
representacion en el espacio de escalas introducida por Witkin([Witkin 83]) y Koenderink([Koenderink
84], [Koenderink y Van Doorn 86]) con la que podemos obtener estructuras dentro de la imagen que
suceden a diferentes escalas, generarando a partir de la senal original (en nuestro caso, la imagen a
estudiar) una familia de senales derivadas en las que se van eliminando sucesivamente caracterısticas
desde las escalas mas finas hasta las menos finas.
2.2. Obteniendo informacion multiescala.
Dada una senal n-dimensional, disponemos de varias formas de realizar un estudio basado en la
informacion de las distintas escalas:
Trabajar con una escala solamente. Es muy comun determinar un valor de un parametro para
realizar alguna operacion sobre la imagen (usar una tecnica de alisamiento con un determinado
tamano de entorno, usar un tamano de operador, etc), es decir, seleccionar una determinada escala.
En algunos casos se puede estimar el valor del parametro de forma automatica pero para otros no
es posible o no se conoce la manera de hacerlo. El objetivo de esta forma de trabajo es localizar
la informacion que aparece en la escala definida por el tamano del parametro a partir de la que
obtenemos los resultados que se desean eliminando la informacion de las demas (lo que indica que
las caracterısticas buscadas aparecen en una sola escala); un problema clasico que se ha tratado
de esta forma es la eliminacion de ruido, el cual aparece a las escalas mas finas y que puede ser
eliminado con filtros de paso bajo alisando la senal (vease por ejemplo [Canny 86]). En esta forma
de trabajo cobra especial interes el problema de calcular el parametro correspondiente a la escala
cuando se desconoce la escala interna (es decir, la correspondiente a la resolucion del pıxel) de la
imagen a procesar(vease [Lindeberg 93a],[Rosin 92]).
Trabajar con varias escalas independientes y a partir de ellas unir los resultados dado que las
estructuras en la imagen pueden aparecer en distintas escalas. Pero aparece un problema adicional:
hay que estudiar la forma en que se deben de mezclar los resultados de las distintas escalas, los
cuales pueden ser distintos e incluso pueden dar lugar a una aparente contradiccion puesto que es
posible realizar distintas interpretaciones.
Trabajar con la representacion multiescala (por ejemplo, espacio de escalas como una senal n+ 1-
dimensional considerando la funcion continua a lo largo del parametro de escala). En este caso,
podemos no solo utilizar la informacion de distintas escalas sino que podemos utilizar la relacion
entre ellas a traves del parametro de la escala. (Vease por ejemplo [Asada y Brady 86],[Lindeberg
93b], [Mokhtarian y Mackworth 86],[Rattarangsi y Chin 92]). En este punto es interesante hacer
referencia a trabajos que tratan a la senal particionada en partes que deben ser tratadas a distintas
escalas (Vease por ejemplo [Garcıa et al. 94],[Garcıa et al. 95],[Fdez-Valdivia et al. 95a]) resultado
de una discretizacion de los valores de las escalas que aparecen en cada uno de los puntos de la
senal.
2.3. El espacio de escalas.
Como se ha mencionado, la representacion en el espacio de escalas no es mas que un tipo de repre-
sentacion multiescala en el que a una funcion n-dimensional se le anade un nuevo parametro (parametro
Capıtulo 2
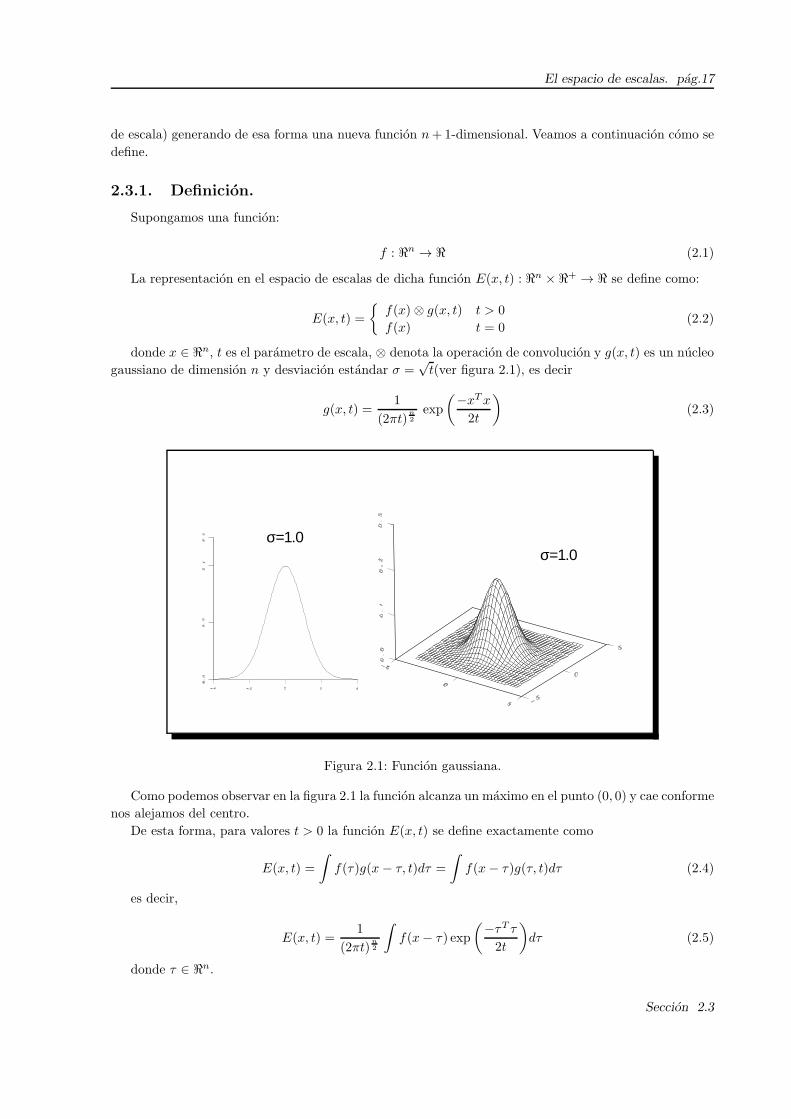
El espacio de escalas. pag.17
de escala) generando de esa forma una nueva funcion n+1-dimensional. Veamos a continuacion como se
define.
2.3.1. Definicion.
Supongamos una funcion:
f : ℜn → ℜ (2.1)
La representacion en el espacio de escalas de dicha funcion E(x, t) : ℜn ×ℜ+ → ℜ se define como:
E(x, t) =
f(x)⊗ g(x, t) t > 0
f(x) t = 0(2.2)
donde x ∈ ℜn, t es el parametro de escala, ⊗ denota la operacion de convolucion y g(x, t) es un nucleo
gaussiano de dimension n y desviacion estandar σ =√t(ver figura 2.1), es decir
g(x, t) =1
(2πt)n2
exp
(−xTx
2t
)(2.3)
σ=1.0σ=1.0
Figura 2.1: Funcion gaussiana.
Como podemos observar en la figura 2.1 la funcion alcanza un maximo en el punto (0, 0) y cae conforme
nos alejamos del centro.
De esta forma, para valores t > 0 la funcion E(x, t) se define exactamente como
E(x, t) =
∫f(τ)g(x − τ, t)dτ =
∫f(x− τ)g(τ, t)dτ (2.4)
es decir,
E(x, t) =1
(2πt)n2
∫f(x− τ) exp
(−τT τ
2t
)dτ (2.5)
donde τ ∈ ℜn.
Seccion 2.3

pag.18 El espacio de escalas.
Igualmente, si queremos darle un sentido fısico a la definicion anterior podemos usar la ecuacion de
difusion del calor:
∂E
∂t=
1
22 E (2.6)
para la cual, la temperatura a tiempo cero es E(x, 0) = f(x).
2.3.2. Derivacion en el espacio de escalas.
El hecho de que la representacion en el espacio de escalas de una funcion pueda ser definida como la
convolucion con un nucleo gaussiano, y basandonos en la conocida propiedad de la conmutatividad de
las operaciones de derivacion y de convolucion
∂nf(x)⊗ g(x, σ)
∂xn= f(x)⊗ ∂ng(x, σ)
∂xn(2.7)
al ser la funcion gaussiana infinitamente diferenciable, podemos tratar a la funcion E(x, t) igualmente
de clase C∞ 3. Por consiguiente, cuando deseemos conocer la derivada de cierto orden y cierta direccion
de la funcion vista en un valor de escala t = σ2 no tendremos mas que convolucionar la funcion original
con el nucleo resultado de la derivacion de la funcion gaussiana. Por ejemplo, en caso 1-Dimensional,
resultan nucleos (ver figura 2.2)
De orden cero:
g(x, σ) =1√2πσ
exp
(−x2
2σ2
)(2.8)
Con primera, segunda y tercera derivadas:
g′(x, σ) = 1√2πσ3
− x exp
(−x2
2σ2
)= g1(x, σ) (2.9)
g′′(x, σ) = 1√2πσ3
exp
(−x2
2σ2
) (x2
σ2− 1
)= g2(x, σ) (2.10)
g′′′(x, σ) = 1√2πσ5
exp
(−x2
2σ2
) (3x− x3
σ2
)= g3(x, σ) (2.11)
En el caso 2-Dimensional, las derivadas que aparecen obviamente son parciales a partir de la siguiente
igualdad
G(x, y, σ) =1
2πσ2exp
−(x2 + y2)
2σ2(2.12)
que como podemos comprobar son resultado del producto de 2 funciones gaussianas 1-Dimensionales
evaluadas en las variables x e y respectivamente, por lo tanto, podemos englobar el calculo de sus derivadas
en la igualdad
∂nG
∂xp∂yn−p= gp(x, σ) gn−p(y, σ) (2.13)
Representaciones graficas de algunas de estas derivadas parciales pueden observarse en la figura 2.3,
las cuales corresponden a:
∂G
∂x
∂2G
∂x∂y
∂2G
∂y2
Capıtulo 2

Propiedades pag.19
Figura 2.2: Derivadas de gaussiana 1D.
Debido a que cualquier derivada de orden n satisface la ecuacion de difusion (ecuacion 2.6), es decir,
la igualdad
∂(∂nE∂xn
)
∂t=
1
22 ∂nE
∂xn(2.14)
las propiedades y resultados que se apliquen a E(x, t) tambien son igualmente validos para dichas
derivadas.
2.4. Propiedades
El espacio de escalas ha sido ampliamente estudiado y no es nuestra intencion realizar un exahustivo
estudio de sus propiedades (vease por ejemplo [Lindeberg 94a] para un amplio y profundo estudio). En
esta seccion veremos unicamente una rapida formulacion de las propiedades basicas que necesitaremos
tener en cuenta en el resto de esta memoria.
Semigrupo conmutativo.
La representacion del espacio de escalas tiene una estructura de semigrupo conmutativo con respecto
al parametro de escala. Esto indica que si consideramos dos nucleos gaussianos de parametros t1 y
3Obviamente las derivadas que nos aparecen con respecto a la variable x deben ser entendidas como derivadas parciales
que pueden estar mezcladas, es decir con respecto a posiblemente distintas dimensiones de la variable.
Seccion 2.4
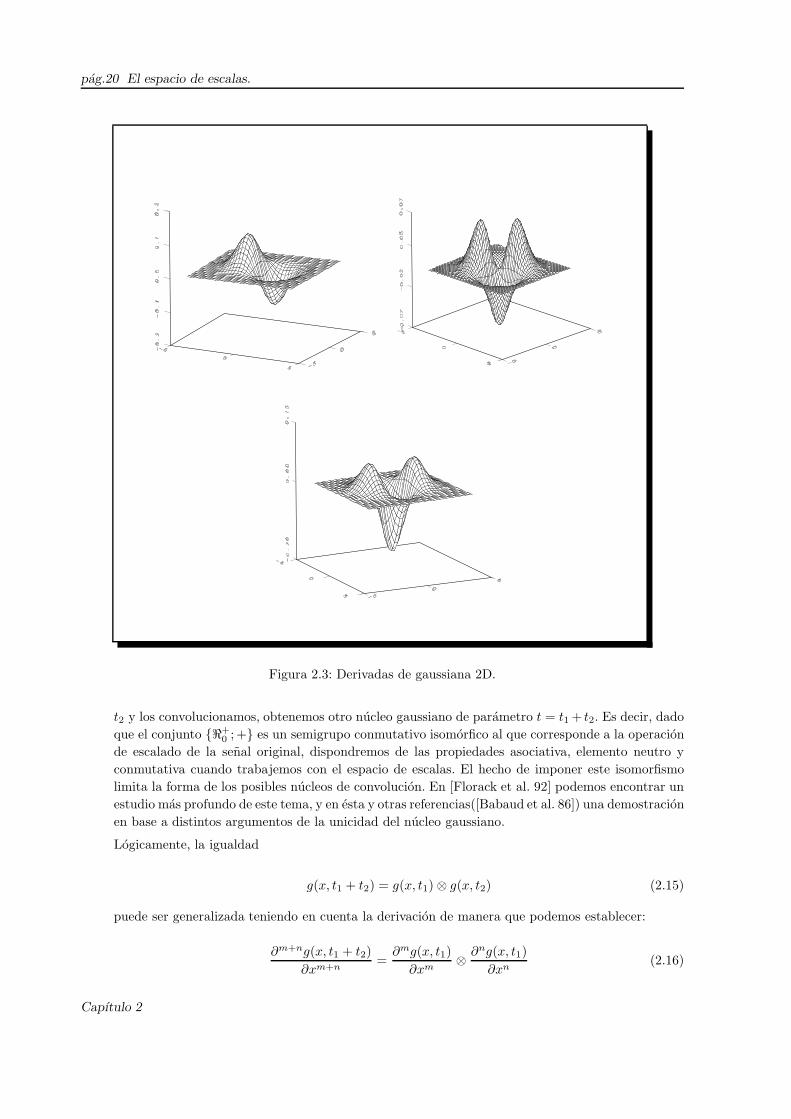
pag.20 El espacio de escalas.
Figura 2.3: Derivadas de gaussiana 2D.
t2 y los convolucionamos, obtenemos otro nucleo gaussiano de parametro t = t1+ t2. Es decir, dado
que el conjunto ℜ+0 ; + es un semigrupo conmutativo isomorfico al que corresponde a la operacion
de escalado de la senal original, dispondremos de las propiedades asociativa, elemento neutro y
conmutativa cuando trabajemos con el espacio de escalas. El hecho de imponer este isomorfismo
limita la forma de los posibles nucleos de convolucion. En [Florack et al. 92] podemos encontrar un
estudio mas profundo de este tema, y en esta y otras referencias([Babaud et al. 86]) una demostracion
en base a distintos argumentos de la unicidad del nucleo gaussiano.
Logicamente, la igualdad
g(x, t1 + t2) = g(x, t1)⊗ g(x, t2) (2.15)
puede ser generalizada teniendo en cuenta la derivacion de manera que podemos establecer:
∂m+ng(x, t1 + t2)
∂xm+n=
∂mg(x, t1)
∂xm⊗ ∂ng(x, t1)
∂xn(2.16)
Capıtulo 2

Propiedades pag.21
Causalidad.
Koenderink ([Koenderink 84]) introdujo el concepto de causalidad que nos dice que cualquier car-
acterıstica que se encuentre en un nivel de escala alto, debe poseer una o varias causas en un nivel
de escala inferior4.
Este concepto de causalidad puede ser reescrito para dimensiones concretas:
• En el caso 1-dimensional no pueden ser creados nuevos maximos en la representacion del
espacio de escalas cuando el parametro de escala se incrementa.
• En el caso 2-dimensional no pueden ser creados nuevos niveles de superficie en la representacion
del espacio de escalas cuando el parametro de escala se incrementa5.
Como podemos ver, en el caso 1-dimensional no es posible la creacion de nuevos maximos a traves
del espacio de escalas. Igualmente en base a dicho concepto, el hecho de que exista un maximo a un
nivel de escala implica que debe al menos existir uno en las escalas mas finas que haya dado lugar
al primero. El que existan varios maximos a un nivel de escala inferior nos lleva a la conclusion
de que los maximos pueden tanto desaparecer como unirse en uno solo. Este hecho hace incorrecta
la operacion de recorrido de un camino descrito por un maximo a traves del espacio de escalas
desde un nivel alto a un nivel bajo ya que dicho camino se encontrara con bifurcaciones([Witkin
83],[Asada y Brady 86]). La estructura que se refleja en ese recorrido es una estructura jerarquica
uno-a-muchos, lo que indica que puede ser representada por una estructura de arbol, hecho que ha
sido utilizado por algunos autores como una forma de caracterizar la funcion representada en el
espacio de escalas (ver [Asada y Brady 86], [Witkin 83], [Rattarangsi y Chin 92]).
Muestreo del espacio de escalas. Funcion de escala efectiva.
En un caso practico no podemos trabajar con un parametro de escala que es continuo, es decir, si
queremos estudiar el espacio de escalas generado en base a la teorıa que se presenta, tendremos que
muestrear distintos valores de escala.
Intuitivamente, ya podemos sospechar que las caracterısticas que se presentan a altos niveles de
escala desapareceran mas lentamente que en bajas escalas. En este sentido, un muestreo uniforme
en el parametro t de escala parece no recomendable. A lo largo de los ultimos anos hay una amplia
bibliografıa([Florack et al. 92], [Koenderink 84], [Lindeberg y Eklundh 92a],etc...) que muestra la
necesidad de un muestreo no uniforme.
Definimos la funcion de escala efectiva τ(t) como una funcion de t de forma que la seleccion no
uniforme de escalas en este parametro, se convierte en un muestreo uniforme sobre τ . Estudios sobre
la invarianza en el espacio de escalas, nos indican que la forma de la funcion es:
τ(t) = A+B log t (2.17)
Puede verse el uso de esta forma de muestreo del espacio de escala en distintos trabajos ([Lowe
88], [Garcıa et al. 94], [Rosin 92], etc...) donde se observa la conveniencia de esta ası como otros
argumentos que la apoyan.
Ası por ejemplo, Lindeberg realiza un estudio para senales discretas desde la densidad de estructuras
y la probabilidad de que desaparezcan llegando a resultados que en base condiciones generales
se ajustan a esta expresion. Es de destacar que Lindeberg apunta que para senales discretas, el
4Tengase en cuenta que no ocurre al contrario ya que hay caracterısticas que existen en un nivel bajo y desaparecen en
los niveles altos5Notese que no se hace referencia a nuevos maximos. De hecho en dimensiones 2 o superiores, pueden crearse nuevos
maximos.
Seccion 2.4

pag.22 El espacio de escalas.
comportamiento de τ(t) es aproximadamente lineal para escalas finas y se aproxima asintoticamente
al comportamiento logarıtmico cuando la escala aumenta.
Dicha funcion logarıtmica hace conveniente realizar un muestreo uniforme sobre un eje logarıt-
micamente escalado o equivalentemente, realizar el muestreo sobre t de valores que aumentan de
forma exponencial.
2.5. Estructura a traves del parametro de escala.
El estudio del comportamiento de la senal a traves del parametro de escalas, es decir, la relacion
entre las estructuras a diferentes niveles de escala que podemos llamar estructura en profundidad (del
termino deep structure acunado por Koenderink en [Koenderink 84]) es muy importante para un estudio
completo del espacio de escalas. Ya en los trabajos de Witkin ([Witkin 83]) se destaca la importancia de
esta relacion cuando observa experimentalmente que los intervalos definidos sobre el arbol de intervalos6
son tanto mas perceptualmente detectables cuanto mayor es su estabilidad, es decir, las estructuras mas
estables a lo largo de la escala son detectadas por el ojo humano. Desde entonces en la literatura se pueden
encontrar distintos trabajos que tratan sobre este tema ([Koenderink y Van Doorn 86]), [Bergholm 87],
[Lindeberg 94a], etc...).
El comportamiento de las estructuras en el espacio 2-dimensional es mas complejo que en el caso
1-dimensional. Koenderink y Van Doorn ([Koenderink y Van Doorn 86]) y mas profundamente Lindeberg
([Lindeberg 92b]) destacan que en el caso 2-D existen nuevos fenomenos a tener en cuenta. Los llamados
blobs (regiones de la imagen mas oscuras o mas claras asociadas con al menos un extremo local7) pueden
unirse, separarse y desaparecer. Estos sucesos (usalmente llamados bifurcaciones) ocurren de forma similar
para fronteras, cruces por cero de la laplaciana, etc.
2.5.1. Comportamiento de los puntos crıticos en el esp. de esc.
Un punto x0 ∈ ℜn es un punto crıtico de una funcion f : ℜn → ℜ si el gradiente en este punto es
cero. Si la matriz Hessiana en este punto es no singular entonces este punto es no degenerado.
Con un un estudio formal de la trayectoria de los puntos crıticos a traves del espacio de escalas podemos
deducir su comportamiento y en particular como pueden variar las fronteras8. Mas concretamente, la
derivada con respecto al parametro de escala de la trayectoria r(t) que sigue un punto crıtico no degenerado
(x0,y0) en la escala t0 viene dada por la siguiente expresion:
dr
dt(t0) = −1
2(HE)(x0)
−1(∇2(∇E))(x0) (2.18)
es decir,
dr
dt(t0) = −1
2
(∂2E∂x2
∂2E∂y∂x
∂2E∂x∂y
∂2E∂y2
)−1
(x0,y0)
[(∂2
∂x2+
∂2
∂y2
)(∂E∂x∂E∂y
)]
(x0,y0)
(2.19)
Si eliminamos las referencias a 2 dimensiones (eliminamos y) podemos obtener la derivada en caso
1-D:
dr
dt(t0) = −1
2
∂3E∂x3 (x0; t0)∂2E∂x2 (x0; t0)
(2.20)
6Obtenido a partir de las trayectorias y uniones de los maximos a traves del espacio de escalas de una senal 1-Dimensional.7Para una definicion precisa puede consultarse [Lindeberg 93b].8Consultense los trabajos de Lindeberg acerca del comportamiento a traves del espacio de escalas para mas detalles del
desarrollo matematico y una ampliacion de este estudio.
Capıtulo 2

Estructura a traves del parametro de escala. pag.23
Por lo tanto, la velocidad de un punto crıtico corresponde a la expresion 2.19 en el caso de 2 dimensiones
y a la expresion 2.20 en el caso de 1 dimension.
Seccion 2.5

pag.24 El espacio de escalas.
Capıtulo 2

Capıtulo 3
Contornos: Descripcion y
aproximacion
UNA consecuencia directa del uso de informacion de aristas para la localizacion de objetos es el estudio
de los contornos que los definen. Como se ha indicado anteriormente, el procesamiento de las aristas
de la imagen nos llevara a estructurar la informacion en distintos niveles. Dado que nuestro planteamiento
es realizar una localizacion supervisada, si nuestro objetivo es localizar un determinado contorno en la
imagen usando cierto tipo de caracterısticas, deberemos disponer de un metodo para extraerlas a partir de
dicho contorno. Por tanto es necesario obtener una descripcion y caracterizacion de estos. Obviamente, el
enfoque multiescala que usamos en el tratamiento de la informacion a lo largo de este trabajo se traduce
en algoritmos que estudian la curva que describe el contorno a distintas escalas.
Para ilustrar el funcionamiento de los algoritmos que se describen en este capıtulo usaremos tanto
contornos de tipo biologico como geografico a fin de mostrarlos sobre formas muy variables. Dichos
contornos se muestran en la figura 3.1 y corresponden a los contornos de un grupo de celulas, Espana,
una mano, italia, una hoja y Gran Bretana.
3.1. El contorno y su alisamiento.
El contorno de la imagen esta compuesto por una serie de n pıxeles (xi, yi) con i = 0 · · ·n − 11.
Expresaremos la curva C a estudiar de forma parametrica:
C = x(s), y(s) (3.1)
donde s es un parametro continuo que se mueve a lo largo de la longitud de la curva2(s ∈ [0, L]). En
nuestro caso, la curva que estudiamos la tenemos descrita con una serie de puntos y por tanto disponemos
a efectos practicos de un muestreo de ambas funciones, x(s) e y(s)3.
El representar el contorno a distintas escalas no es mas que convolucionar las funciones x(s) e y(s)
con un nucleo gaussiano 1-Dimensional (ecuacion 2.8) con σ acorde con la escala requerida. Es decir, el
contorno a una escala σ viene dado por
Cσ = C ⊗ gσ = (x(s) ⊗ g(s, σ), y(s)⊗ g(s, σ)) (3.2)
1El contorno suponemos cerrado y por tanto el primer y ultimo punto estan a distancia maxima√2.
2Como el contorno es cerrado, estas dos funciones en el parametro s son periodicas3Considerese la posibilidad de interpretar la curva de forma continua sin mas que interpolar por ejemplo mediante rectas.
25

pag.26 Contornos: Descripcion y aproximacion
Figura 3.1: Contornos: Imagenes test.
Un ejemplo de dicha operacion se muestra en la figura 3.2, en la que vemos un mismo contorno
geografico con distintos grados de alisamiento (σ = 0,σ = 5,7,σ = 16,σ = 45,25).
3.1.1. Contraccion del contorno
Como es de esperar, al realizar un alisamiento sobre el contorno, dicho contorno se contrae. [Lowe 88]
estudia este problema suponiendo una circunferencia centrada en el punto (r, 0) de radio r (pasa por el
origen). En este caso la funcion x(s) es
x(s) = r(1− cos
s
r
)(3.3)
y determina que la contraccion en un punto viene dada por
r
(1− e−
σ2
2r2
)(3.4)
donde el valor de r se determina a partir de la segunda derivada de la funcion x(s)
x′′(s) = e−σ2
2r2
r(3.5)
Capıtulo 3

El contorno y su alisamiento. pag.27
Figura 3.2: Contorno geografico con distintos grado de alisamiento.
El metodo por lo tanto consiste en a partir de la segunda derivada, determinar el radio de la circun-
ferencia correspondiente y a partir de este calcular la contraccion sustrayendo tal valor a la coordenada
alisada, para obtener ası el valor corregido.
Es una tecnica efectiva aunque el valor de correccion es local, es decir, es distinto para cada uno
de los valores de la curva dependiendo de la derivada segunda. Este hecho lo hace poco recomendable
en el caso de que queremos mantener no solo una localizacion espacial cercana a la original sin alisar
sino tambien otros valores (como valores de derivadas) relacionados con los originales de la curva alisada
(por ejemplo, derivadas proporcionales a las originales). Si no es de esta forma, el realizar una correccion
espacial puede dar como resultado una curva que presenta por ejemplo un punto de inflexion mientras
que en las derivadas no encontramos ese punto.
Otra forma simple aunque interesante es realizar una medida del tamano global de la forma y hacer que
la forma alisada aumente hasta dicho tamano. Ejemplos de esta correccion se presentan en la figura 3.3.
En la fila superior se observan los alisamientos sin correccion y en la inferior con correcion. La forma de
representacion de cada imagen consiste en dibujar cada curva con un gris proporcional al logaritmo de la
escala. La curva original se presenta en negro, y conforme aumenta la escala, aumenta el valor de gris.
Si al igual que Lowe ([Lowe 88]) suponemos una circunferencia, la operacion de alisamiento im-
plicara una disminucion del radio de dicha circunferencia. Es obvio que si medimos el radio de la original
sin alisar y realizamos un escalado de la alisada hasta dicho radio, el efecto de contraccion se habra elim-
inado. Se define el punto medio de la curva como:
pmedio(C) = (px, py) =1
L
(∫ L
0
x(s)ds,
∫ L
0
y(s)ds
)(3.6)
y a partir de este punto medio el radio medio de la curva
Rmedio(C) =1
L
∫ L
0
√(x(s) − px)2 + (y(s)− py)2ds (3.7)
Seccion 3.1

pag.28 Contornos: Descripcion y aproximacion
Figura 3.3: Correccion global de la contraccion.
La correccion por consiguiente consistira en escalar la curva alisada por un factor correspondiente al
cociente del radio medio de la curva original y la alisada, logicamente con respecto al punto medio de la
curva alisada. Es decir
xcorregida(s) = px + (x(s)− px)Rmedio(C)
Rmedio(Cσ)(3.8)
ycorregida(s) = py + (x(s) − py)Rmedio(C)
Rmedio(Cσ)
3.2. Curvatura y espacio de escalas.
3.2.1. Curvatura: Definicion.
Uno de los elementos que caracterizan la forma de una curva es el grado de curvatura. Supongamos que
tenemos una curva en la que tomamos dos puntos arbitrarios, p y q. Se define el angulo de contingencia
del arco pq como el angulo de giro de la tangente a la curva cuando pasa del punto p al punto q(ver
figura 3.4).
La curvatura media del arco pq se define como la razon del angulo de contingencia α respecto a la
longitud del arco
Kmed =α
pq(3.9)
Capıtulo 3

Curvatura y espacio de escalas. pag.29
p
α q
Figura 3.4: Angulo de contingencia.
La curvatura en un punto p se define como el lımite de la curvatura media cuando q tiende a p o dicho
de otra forma, cuando la longitud del arco tiende a cero.
Kp = lımq→p
Kmed (3.10)
La curvatura de una curva puede ser definida
K(x,y) =∂2y∂x2√[
1 +(
∂y∂x
)2]3(3.11)
Si denotamos
x =∂x
∂sy =
∂y
∂sx =
∂2x
∂s2y =
∂2y
∂s2
entonces
∂y
∂x=
y
x
∂2y
∂x2=
xy − yx
x3
y por lo tanto nos resulta la igualdad siguiente
K(x,y) =xy − yx√(x2 + y2)
3(3.12)
que sera la que usaremos en el calculo de la curvatura.
3.2.2. Aplicacion del espacio de escalas.
Volviendo a los contornos, disponemos de dos funciones discretas x(s) e y(s), de un metodo de al-
isamiento (convolucion con gaussiana) y queremos calcular la curvatura de la curva Cσ, es decir, la
curvatura de la curva alisada con una gaussiana de parametro t = σ2. Como vimos (pagina 18) para cal-
cular las derivadas necesarias para el calculo de la curvatura, solo necesitamos convolucionar directamente
con las derivadas primera y segunda de la funcion gaussiana (ecuaciones 2.9 y 2.10).
Usando esta tecnica, se obtienen curvas como las presentadas en la figura 3.5 que corresponden al
contorno y alisamientos presentados en la figura 3.2.
Seccion 3.2

pag.30 Contornos: Descripcion y aproximacion
Figura 3.5: Curva de curvaturas con sigma 16 y 45.25.
Una vez que tenemos representado el contorno a distintas escalas, podemos realizar el estudio a traves
del espacio de escalas de la curva de curvaturas. Como es de esperar, la curva sera mas suave cuanto mayor
sea el alisamiento, es decir, a escala superior. Si hacemos una representacion 3D de la forma en que la
curvatura se va suavizando conforme va en aumento la escala, obtenemos una grafica como la presentada
en la figura 3.6 que corresponde a alisamientos del contorno geografico presentado en la figura 3.2.
Asada y Brady ([Asada y Brady 86]) propusieron el curvature primal sketch para representar los
cambios en la curvatura del contorno conforme se incrementa la escala. Basicamente consiste en estudiar
a distintas escalas la curva de curvaturas detectando ciertas discontinuidades. La forma de construccion
de esta representacion multiescala consiste en ir alisando la curva de curvaturas con un nucleo gaussiano
de distinta anchura como se ha visto anteriormente.
Ademas de esta representacion multiescala, podemos estudiar el espacio de escalas del contorno 2D
que se genera convolucionando una gaussiana de escala variable con las funciones del contorno x(t), y(t)
de forma separada. El resultado de este sucesivo alisamiento del contorno se llama el espacio de escalas
de la curvatura que ha sido usado en [Mokhtarian y Mackworth 86] para el reconocimiento y en otros
trabajos (vease por ejemplo [Rattarangsi y Chin 92]).
3.3. Representacion multiescala del contorno 2D.
Dado que nuestro interes se centra inicialmente sobre los puntos dominantes, y estos los relacionamos
directamente con los puntos de maxima curvatura, aplicaremos el algoritmo desarrollado en este trabajo
Capıtulo 3

Representacion multiescala del contorno 2D. pag.31
Vis
ta fr
onta
l
Vista posterior
Figura 3.6: Espacio de escalas de la curvatura para el contorno de Espana.
sobre el espacio de escalas de la curvatura aunque su formulacion permite aplicar exactamente los mis-
mos pasos sobre cualquier tipo de representacion multiescala en la que podamos establecer una relacion
de causalidad (ver pagina 21) y podamos realizar un seguimiento de los puntos relevantes en cada es-
cala a traves del espacio de escalas. De esta forma podemos obtener a partir del contorno la funcion
correspondiente a la curva de curvaturas, calcular su valor absoluto y realizar dicho seguimiento de los
maximos.
Por lo tanto, si deseamos construir esta representacion multiescala del contorno, deberemos resolver:
1. Calculo de las funciones fα1, fα2
, · · · , fαd correspondientes al valor absoluto de las curvas de
curvaturas.
2. Determinar los maximos en cada funcion fαiy enlazarlos, es decir, determinar la trayectoria de
estos a traves de los distintos alisamientos de la curva.
3. Para cada uno de los maximos en cada una de las escalas, localizar su situacion en la curva original.
Seccion 3.3

pag.32 Contornos: Descripcion y aproximacion
3.3.1. Calculo del valor absoluto de las curvas de curvaturas.
En primer lugar, debemos determinar los valores de αi correspondientes a cada una de las escalas
que se van a considerar. Obviamente, para distintas curvas C = (x(s), y(s)) habra una localizacion de
caracterısticas en distintas escalas, e incluso para una misma curva dependiendo de la escala interna
(pagina 16). Este hecho no implica ningun parametro adicional ya que es una cuestion de muestreo del
espacio de escalas asegurando simplemente que el valor mınimo α1 es suficientemente pequeno y el valor
maximo αd es suficientemente alto. Es los experimentos disenados el valor mınimo ha sido de 2 (un valor
que solo alisa el ruido consecuencia de la discretizacion, es decir, por encima de la escala interna)4 y
el valor maximo aquel que nos garantiza que el contorno ha sido suficientemente alisado (por ejemplo,
considerando la escala externa de la senal). Obviamente disminuir el valor mınimo o aumentar el valor
maximo no influye en los resultados y por tanto estas cotas se determinan facilmente. Por otra parte, el
muestreo se ha realizado con valores equidistantes en una escala logarıtmica (ver pagina 21).
Los valores que se han usado para el muestreo de las curvas de curvaturas a distintas escalas son:
2, 2√2, 4, · · · , 64
√2
Que a efectos practicos se hacen independientes del contorno a estudiar. Una vez determinados estos
valores, el calculo de las funciones fαino es mas que aplicar el metodo descrito en la pagina 29. Dado
que para realizar dicho calculo es necesario realizar sucesivos alisamientos a valores de escala crecientes,
es interesante destacar en este punto que en base a las propiedades de semigrupo conmutativo y mas
concretamente usando la ecuacion 2.16 obtener una curva mas alisada (por ejemplo a valor σ2 = kσ1) del
mismo orden puede llevarse a cabo mediante un nuevo alisamiento sobre la curva obtenida a nivel σ1.
Es facil ver que para obtener una curva alisada a valor σ2 = kσ1 disponiendo de la curva a valor σ1
basta alisar esta con un nucleo gaussiano de valor
σ =√k2 − 1σ1 (3.13)
3.3.2. Construccion de las trayectorias de los maximos.
Para determinar los puntos mas importantes del contorno, debemos realizar un seguimiento de los
maximos del valor absoluto de la curva de curvaturas a traves del parametro de escala. Esta operacion
por tanto requiere de las trayectorias de estos teniendo en cuenta que:
Los maximos pueden desaparecer a medida que aumentamos el valor de la escala.
Varios maximos pueden unirse en uno al incrementar el valor de escala.
Como se ha mencionado anteriormente, el algoritmo dispondra de un muestreo del espacio de escalas
sobre un conjunto finito de valores de escala. El problema por tanto radica en que un maximo a una
determinada escala puede estar desplazado en la siguiente escala o incluso puede no existir. El algorit-
mo de construccion de trayectorias que necesitamos consistira en determinar para cada valor de escala
muestreado αi la correspondencia entre los maximos a dicha escala y los maximos a escala αi+1.
El problema del camino de un maximo cuando cambiamos de escala ha sido estudiado por distinto
autores ([Bergholm 87], [Lindeberg 94a]). En este trabajo se presenta un algoritmo sencillo y eficiente
que a efectos practicos resulta suficiente. Nos basamos en la idea de que los efectos de un alisamiento
gaussiano con valor de desviacion estandar σ pretende5 suprimir o unir las caracterısticas (lease para
nuestro problema, maximos) en la senal que distan menos de σ.
4De hecho, a efectos practicos se ha interpretado esta curva alisada (y reescalada hasta el radio medio inicial) como la
curva original.5Usamos la palabra “pretende” ya que esta propiedad realmente no se cumple siempre como puede verse por ejemplo en
[Lindeberg 94a] o como podremos observar en los resultados que obtendremos en este trabajo.
Capıtulo 3

Representacion multiescala del contorno 2D. pag.33
Sea Mαiel conjunto de los maximos a nivel αi
Mαi= pαi
| pαimaximo fαi
∪ −1 (3.14)
donde pαi∈ [0, L] y el valor −1 sera usado para indicar que un maximo no tiene continuidad.
El problema de enlazar los maximos no es mas que determinar las aplicaciones:
ξ : Mαi−→ Mαi+1
(3.15)
Donde los conjuntos origen y final se definen segun la igualdad 3.14 y la funcion ξ se define como:
ξ(pαi) =
pαi+1
dist(pαi, pαi+1
) < αi+1
−1 en otro caso(3.16)
definiendo la funcion dist(p, q) considerando que el contorno es cerrado, es decir
dist(p, q) =
minq − p, p+ L− q p ≤ q
dist(q, p) p > q(3.17)
En el caso de que haya varios puntos que cumplen la condicion de que la distancia sea menor que
αi+1 logicamente se seleccionara el de menor distancia.
3.3.3. Localizacion de los maximos en el contorno original.
Debido al desplazamiento que sufre la localizacion de los maximos despues de aplicar un alisamiento,
no serıa correcta una operacion en la que usaramos el punto donde hemos encontrado un maximo a
una escala alta para localizar un punto en la curva. Es decir, si tenemos una curva C = (x(t), y(t)) y
localizamos un maximo de curvatura en el punto t = d en una escala alta σ, tendremos un punto de
maxima curvatura de la curva Cσ = (xσ(t), yσ(t)) en (xσ(d), yσ(d)) pero no es correcto inferir que dicha
caracterıstica se situa en (x(d), y(d)) en la curva original C ya que dicho maximo a podido sufrir una
desviacion que habra que corregir para localizarlo en C.
Por otro lado, podemos pensar que el problema esta ya resuelto dado que hemos construido las
trayectorias de los maximos a traves del parametro de escala. Efectivamente, estos caminos nos ayudan a
resolver el problema pero no de forma directa ya que recordemos que un maximo puede producirse como
union de varios, es decir, a una escala alta distinguimos un punto dominante que a escalas inferiores se
traduce en varios maximos. De esta forma, no es correcto usar un algoritmo que siga un maximo a traves
del parametro de escala hasta la localizacion en la curva original. Obviamente, si el maximo no surge
como union de varios maximos no hay problema pues su localizacion no tiene ninguna ambiguedad.
Para ilustrar este problema, consideremos la figura 3.7 en la que aparece un polıgono de 4 lados y
por tanto con cuatro puntos destacados si consideramos una escala cercana a cero. En la figura tambien
aparecen dos perfiles aproximados de las funciones correspondientes a las curvas de curvaturas con dos
alisamientos distintos (una representacion 3-D de las curvaturas a traves del espacio de escalas se puede
observar en la figura 3.8). Como hemos mencionado a un valor de parametro de escala bajo se distinguen
los 4 puntos del polıgono, en cambio a un valor alto solo se distinguen 3 puntos.
En una aplicacion real, si necesitaramos localizar contornos triangulares, este serıa un buen candidato
dandose por valido si el pequeno segmento puede obviarse, es decir, si la figura es considerada a una
escala superior. Ahora bien, si queremos aproximar la curva mediante un triangulo, es decir, si queremos
determinar sobre el contorno original 3 puntos que indican la localizacion del triangulo, dos de ellos
quedan claros pero el tercero no tiene una localizacion clara. Desde un punto de vista intuitivo, parece
conveniente que la eleccion sea el punto medio del segmento pequeno aunque si uno de los dos puntos
tuviese un valor de curvatura mayor parece mas interesante que el punto elegido se encuentre mas cerca
Seccion 3.3

pag.34 Contornos: Descripcion y aproximacion
0 L0
Curvatura a escala baja.
Contorno original
0 L
Curvatura a escala alta
Figura 3.7: Contorno cuasi-triangular.
de este. En el algoritmo que se presenta la localizacion considerada corresponde a una media ponderada
por el valor de curvatura, es decir, la localizacion de un punto pαi+1∈ Mαi+1
es
Loc(pαi+1) =
∑
pαi∈O
fαi(pαi
)Loc(pαi)
∑
pαi∈O
fαi(pαi
)(3.18)
Donde el conjunto O se define como
O = pαi| ξ(pαi
) = pαi+1 (3.19)
Logicamente esta recurrencia se aplicara siempre que queramos recuperar la localizacion del maximo
a una escala mas pequena. Si αi+1 es suficientemente pequeno como para obviar la desviacion, definimos
Loc(pαi+1) = pαi+1
.
3.4. Algoritmo de deteccion de puntos dominantes.
3.4.1. Idea basica.
El algoritmo de deteccion de puntos dominantes que se propone a continuacion se basa en una vision
multiescala del contorno. La idea consiste en detectar las caracterısticas mas relevantes a una escala
superior y si no es suficiente para describir el contorno (usando por ejemplo una medida de error residual),
ir disminuyendo el valor de escala y por tanto ir detectando las caracterısticas mas finas en una operacion
de enfocado. El enfocado a traves del espacio de escalas no es novedoso en lo que se refiere a seguimiento
de los maximos a traves del parametro de escala. En [Bergholm 87] se estudia la localizacion de los
maximos del gradiente a un valor de escala alto para mediante una operacion de enfocado localizarlos
Capıtulo 3

Algoritmo de deteccion de puntos dominantes. pag.35
Dos máximos se unenen uno a escala superior
Vista posterior de las curvas de curvaturas
Figura 3.8: Curvatura del contorno cuasi-triangular.
a un valor de escala bajo. Esta operacion nos permite seleccionar fronteras de alta relevancia en una
escala alta y evitar el problema de la localizacion de estas fronteras (recordemos que los maximos tienen
una localizacion mas exacta a escalas mas bajas). Aunque el trabajo se presenta muy util para ciertas
aplicaciones que requieren una mejor localizacion de las fronteras, se presenta el problema de determinar
mediante dos parametros cuales seran las fronteras a enfocar por lo que los resultados solo nos permiten
obtener las mismas fronteras que otros operadores aunque con un nivel de localizacion mas exacto. Por
otro lado, la operacion de enfocado que se presenta en este trabajo es bastante distinta ya que se pretende
no solo localizar los maximos a una escala baja (vease apartado anterior) sino que el enfocado que se
realiza es local (en unas regiones se enfoca mas que en otras) ademas de que debemos tener en cuenta que
un maximo a un nivel de escala alta puede provenir de la union de varios maximos a una escala inferior.
Basicamente, el enfocado consiste en que a partir de un conjunto de puntos que describen el contorno
evaluar si son suficientes de manera que si lo son no es necesario un mejor enfoque y en caso contrario
evaluar la zona del contorno que no queda bien descrita y en ella enfocar, es decir, obtener los puntos
dominantes a un nivel de escala mas bajo que contiene las mismas o mas caracterısticas de las que
disponıamos en el nivel superior (recuerdese el concepto de causalidad, pagina 21).
Es importante destacar la necesidad de una representacion multiescala del contorno de manera que
habra partes que seran bien caracterizadas a una escala alta mientras otras necesitaran de una escala
inferior. Este hecho nos lleva a la construccion de un algoritmo en el que los puntos detectados son
hallados a distintas escalas segun las necesidades de representacion.
Seccion 3.4

pag.36 Contornos: Descripcion y aproximacion
3.4.2. Formulacion general del algoritmo.
En esta seccion vamos a formular el algoritmo mas general de manera que aunque se concreta el
algoritmo de forma unica en las siguientes secciones donde se exponen distintas variantes, pueda ser
considerado cualquier otro criterio de calculo en base a otras funciones de ajuste (vease Af mas adelante)
y de caracterizacion (vease Ap mas adelante) siempre recogiendo la misma filosofıa en cuanto a la vision
multiescala de la funcion a estudiar. A continuacion se describen los distintos pasos en una version
recursiva del algoritmo propuesto.
Los datos previos a la ejecucion del algoritmo son:
1. Sea C el contorno a estudiar, y a partir del cual debemos localizar un conjunto P de puntos en el
contorno que nos permitan caracterizarlo.
2. Sean Ap y Af dos algoritmos que resuelven respectivamente:
Ap obtiene un conjunto de puntos dominantes a partir de un contorno C′ representado a una
escala α.
Af a partir de un contorno C′ y un conjunto de puntos P ′ devuelve una medida de ajuste de
P ′ para describir C′ en funcion de algun error residual.
3. Obtener una representacion multiescala del contornoC a valores de escala crecientes α1, α2, · · · , αd.
El ALGORITMO recursivo Puntos(C,α1, · · · , αd, U) es:
1. Obtener un conjunto PC = Ap(C,αd) = p1, p2, · · · , pn.
2. temp = ∅
3. Para i = 1 hasta i = n
a) Si (Af (C(pi,pi+1), pi, pi+1) > U)
temp = temp⋃
Puntos(C(pi,pi+1), α1, · · · , αd−1, U).
4. Devolver (PC ∪ temp).
Donde C(pi,pi+1) denota el contorno que recorre C desde el punto pi al punto pi+16. Y el valor U es
un umbral que indica un valor de error residual maximo para el conjunto de puntos final.
3.4.3. Algoritmo detallado.
Una vez descrito el algoritmo general, es interesante destacar que la instanciacion a un algoritmo
concreto de este puede tener distintas soluciones. Veamos una de sus posibilidades determinando Ap, Af ,
y U .
3.4.3.1. Algoritmo Ap.
Recordemos que uno de los pasos del algoritmo general consiste en la localizacion de una serie de
puntos dominantes a una escala αd mediante el algoritmo Ap. La eleccion de un metodo para resolverlo
tiene una amplia gama de posibilidades considerando que la literatura contiene una extensa coleccion
de ellos(vease por ejemplo [Teh y Chin 89] que contiene un breve resumen de varios algoritmos y otras
referencias como [Ansari y Huang 91], [Fdez-Valdivia et al. 95b], [Perez de la Blanca et al. 93], etc.).
Obviamente, el algoritmo a aplicar debe de obtener los puntos de una unica escala (αd) con lo cual el
6Los subındices se entienden modulo n.
Capıtulo 3

Algoritmo de deteccion de puntos dominantes. pag.37
problema quedarıa directamente resuelto, o bien, deberıa ser un algoritmo que obtenga los puntos de
forma directa desde el contorno (a la escala en que este representado dicho contorno) de manera que Ap
no serıa mas que representar a escala αd el contorno y aplicar dicho metodo. Notemos que algoritmos
como el de Teh y Chin que son muy sensibles al ruido aumentan en interes cuando se plantea la posibilidad
de aplicarlos habiendolo suprimido (ver por ejemplo [Ansari y Huang 91]). Esta eliminacion del ruido se
garantiza en niveles suficientemente altos de escala.
En los experimentos disenados, la eleccion para dicho algoritmo ha sido la mas natural, es decir, el
calculo de los puntos dominantes a escala αd no es mas que determinar los maximos del valor absoluto
de la curva de curvaturas del contorno alisado a dicha escala.
Por consiguiente, la representacion multiescala del contorno que hemos usado viene dada por d fun-
ciones 1D fα1, fα2
, · · · , fαd correspondientes al valor absoluto de las curvas de curvaturas generadas
mediante los d alisamientos del contorno.
3.4.3.2. Algoritmo Af .
Recordemos que Af consiste en un algoritmo que tomando una curva y un conjunto de 2 o mas puntos
en ella, devuelve un valor indicando la optimalidad de dichos puntos para la representacion de la curva.
En nuestro caso intentamos decidir si dos puntos (p1 y p2) aproximan correctamente un segmento de
curva, de esta forma usaremos como medida la mayor distancia d de cada punto de la curva a la recta que
interpola los puntos([Fdez-Valdivia et al. 95b]) , es decir, si aplicamos Af a una curva C(s) = (x(s), y(s))
donde 0 ≤ s ≤ L el valor devuelto sera
Af (C, p1, p2) = max0≤s≤L
| C(s), p1, p2 | (3.20)
donde | p, r(x) | denote la distancia del punto p a la recta r(x) dicha medida puede verse representada
graficamente en la figura 3.9.
p1
p2d
Figura 3.9: Optimalidad de dos puntos y una curva.
Logicamente esta eleccion no es unica y pueden considerarse multitud de variantes como puede ser la
medida del area entre la recta y la curva, la distancia del punto mas distante a la cuerda normalizado
por la longitud de esta([Perez de la Blanca et al. 93]), u otras mas complejas como la distancia maxima
entre la curva y una interpolacion de los puntos dominantes usando metodos como splines([Fdez-Valdivia
et al. 95b]).
3.4.3.3. Valor U .
El valor umbral U para determinar el error maximo en la aproximacion es un parametro del algoritmo.
Para las curvas que tratamos, vendra dado por un valor de 0 a 1 indicando un factor del radio medio de la
curva(ecuacion 3.7) a fin de que el algoritmo sea independiente del tamano del contorno. Es posible que
Seccion 3.4

pag.38 Contornos: Descripcion y aproximacion
en algunas aplicaciones, este valor sea directamente determinado por las necesidades de representacion,
como por ejemplo, en aplicaciones donde se intenta aproximar un contorno con un mınimo de puntos
usando un criterio de distancia maxima.
3.4.3.4. Minimalidad del resultado.
Una vez obtenido un conjunto de puntos que representan un contorno determinado, tal vez sea in-
teresante la eliminacion de algunos de ellos con respecto al algoritmo Af . Uno de los motivos por los
que esta posibilidad surge se debe a que cuando se realiza un enfoque de un segmento de la curva, es
posible que se creen varios puntos dominantes(tengase en cuenta que cuando bajamos el parametro de
escala lo hacemos segun el muestreo realizado y por tanto si de un nivel a otro desaparecen varios puntos,
cuando se enfoque a ese nivel surgen varios simultaneamente). En aplicaciones como la aproximacion de
un contorno con un mınimo numero de puntos puede ser interesante afinar el algoritmo para obtener un
conjunto de puntos menor.Una forma de realizar este afinamiento es realizar un enfoque de manera que
se obtenga un punto en cada paso del enfoque.
Aunque se realice un enfoque punto a punto no se garantiza que el conjunto de puntos resultante sea
minimal aunque si es una muy buena aproximacion en lo que respecta a calidad dado que todos los puntos
que aparecen intentan representar una estructura significativa del contorno. El motivo de ello proviene de
que puntos que son maximos a una escala alta son obtenidos a pesar de que tienen curvatura cercana a
cero. Obviamente, siempre podremos replantear el algoritmo para considerar unicamente puntos maximos
por encima de un umbral mınimo de curvatura.
Una solucion muy sencilla para evitar este conjunto sobrante de puntos es considerar la posibilidad
de tras obtener los puntos dominantes poder eliminar el maximo numero posible de ellos sin perder
logicamente la calidad de la aproximacion. Es claro que podemos seleccionar distintas formas de realizar
esta eliminacion para llegar al valor minimal deseado, por ejemplo intentando realizar una eliminacion
segun el valor de curvatura (de menor a mayor) o usando alguna otra funcion que nos permita seleccionar
los puntos segun su importancia (vease por ejemplo el criterio de optimo definido en [Perez de la Blanca
et al. 93] y usado en [Fdez-Valdivia et al. 95b]). En los resultados que se presentan se ha optado por
la solucion mas coherente con el algoritmo presentado, es decir, la importancia de un punto pi viene
determinada por Af (C(pi−1,pi+1), pi−1, pi+1). Mas concretamente, el Algoritmo Minimo(C,P ) es el
siguiente:
1. Seleccionar pi desde P con minimo Af (C(pi−1,pi+1), pi−1, pi+1).
2. Si Af (C(pi−1,pi+1), pi−1, pi+1) ≤ U
a) P = P − pib) Ir a 1.
3. Devolver P.
Se puede comprobar que considerando criterios como la eliminacion de maximos con valores cercanos a
cero o refinamiento del algoritmo presentado se obtienen resultados similares a la aplicacion del algoritmo
Minimo(C,P ).
3.4.4. Discusion y resultados.
3.4.4.1. Discusion.
Aunque la formulacion del algoritmo puede sugerir al lector que el objetivo de este es la aproximacion
mediante una polilınea del contorno en estudio con una cantidad de puntos minimal, es necesario destacar
Capıtulo 3

Algoritmo de deteccion de puntos dominantes. pag.39
que a partir del algoritmo propuesto obtenemos principalmente dos ventajas frente a algoritmos que
simplemente aproximan poligonalmente el contorno (vease por ejemplo [Douglas y Peucker 73]):
Los puntos obtenidos son de maxima curvatura, es decir, correspondientes a puntos dominantes
en alguna de las escalas y por tanto perceptualmente de alta relevancia. Es por ello por lo que la
ganancia no viene unicamente determinada en terminos cuantitativos (numero de puntos menor
para caracterizar el contorno) sino tambien en terminos cualitativos (un conjunto de puntos que
recogen las caracterısticas mas relevantes del contorno). Considerese por ejemplo una aplicacion
en la que se desea almacenar una serie de contornos con un mınimo de informacion y ademas se
pretende reconocer posteriormente contornos que se encuentran almacenados de esta forma.
El metodo de interpolacion es escogido a priori y puede ser usado en el calculo de los puntos dom-
inantes. Este posibilidad hace al algoritmo mas eficaz en el momento de seleccionar un numero
mınimo de puntos. Si el metodo de interpolacion es suficientemente bueno, la cantidad de infor-
macion necesaria para realizar la aproximacion puede reducirse considerablemente, teniendo obvi-
amente en cuenta siempre que los puntos de mayor relevancia deben ser escogidos en primer lugar.
Ademas, debemos tener en cuenta que el algoritmo puede ser modificado mas profundamente segun
las necesidades de nuestra aplicacion determinando una forma de construir una curva de corte sobre
los graficas de las trayectorias de los maximos (veanse figuras 3.10 y 3.11)7. Considerese por ejemplo
una seleccion de puntos guiada por un criterio de duracion o estabilidad a traves del parametro
de escala en la que se obtendrıa un conjunto de puntos de alta relevancia tal como indican las
observaciones de Witkin en sus trabajos (vease pagina 22).
3.4.4.2. Resultados.
En esta seccion vamos a presentar los resultados y datos intermedios que se producen para varios
casos concretos de imagenes. Los contornos sobre los que se aplicara el algoritmo son los que se presentan
en la figura 1.3. Las curvas estan parametrizadas desde cero al valor de la longitud de la curva, es decir,
en el intervalo [0, L] localizando el punto (x(0), y(0)) recorriendo las columnas de la imagen de arriba
hacia abajo y de izquierda a derecha. Una vez localizado ese punto se recorre la curva cerrada en el
sentido contrario a las agujas del reloj. El punto de comienzo se encuentra senalizado con una flecha en
los contornos que se muestran.
En las siguientes figuras se presenta:
Las 2 primeras (la figura 3.10 y la figura 3.11) representan las trayectorias de los maximos del valor
absoluto de la curvatura a lo largo del espacio de escalas.
Las 6 siguientes (desde la figura 3.12 a la figura 3.17) representan los puntos que se han obtenido
al enfocar para conseguir una buena descripcion. En la parte superior encontramos de nuevo las
trayectorias de los maximos a las que se ha anadido una lınea quebrada que une los puntos local-
izados en la imagen inferior a la altura de escala en la que han sido fijados, es decir, el resultado
final de la operacion de enfoque.
Finalmente, en las figuras 3.18 y 3.19 se representan los 6 ejemplos desarrollados con los puntos que
representan el contorno como conjunto minimal, es decir, la seleccion de puntos final eliminando
parte de los puntos dominantes obtenidos en nuestro algoritmo ası como la interpolacion lineal
desde estos puntos.
7En este trabajo, obviamente se ha propuesto una forma simple y eficaz que es suficiente para nuestros objetivos.
Seccion 3.4

pag.40 Contornos: Descripcion y aproximacion
45.25
2
2.82
4
5.65
8
11.31
16
22.62
32
64
90.5
0 968.6
45.25
2
2.82
4
5.65
8
11.31
16
22.62
32
64
90.5
0 918
45.25
2
2.82
4
5.65
8
11.31
16
22.62
32
64
90.5
0 1238.97
(A)
(B)
(C)
Figura 3.10: Trayectorias de maximos de Espana, italia y G. Bretana.
Capıtulo 3

Algoritmo de deteccion de puntos dominantes. pag.41
45.25
2
2.82
4
5.65
8
11.31
16
22.62
32
64
90.5
845.3490
45.25
2
2.82
4
5.65
8
11.31
16
22.62
32
64
90.5
0 1378.71
45.25
2
2.82
4
5.65
8
11.31
16
22.62
32
64
90.5
0 1044.38
(A)
(B)
(C)
Figura 3.11: Trayectorias de maximos del Grupo celular, mano y hoja.
Seccion 3.4

pag.42 Contornos: Descripcion y aproximacion
0 845.349
Figura 3.12: Puntos obtenidos de contorno celular.
Capıtulo 3

Algoritmo de deteccion de puntos dominantes. pag.43
0 968.603
Figura 3.13: Puntos obtenidos en el contorno de Espana.
Seccion 3.4

pag.44 Contornos: Descripcion y aproximacion
0 1378.71
Figura 3.14: Puntos obtenidos de una mano.
Capıtulo 3

Algoritmo de deteccion de puntos dominantes. pag.45
0 918
Figura 3.15: Puntos obtenidos en el contorno de Italia.
Seccion 3.4

pag.46 Contornos: Descripcion y aproximacion
0 1044.38
Figura 3.16: Puntos obtenidos de la hoja.
Capıtulo 3

Algoritmo de deteccion de puntos dominantes. pag.47
0 1238.97
Figura 3.17: Puntos obtenidos de Inglaterra.
Seccion 3.4

pag.48 Contornos: Descripcion y aproximacion
Figura 3.18: Minimizacion del numero de puntos.
Capıtulo 3

Algoritmo de deteccion de puntos dominantes. pag.49
Figura 3.19: Interpolacion desde el numero de puntos minimal.
Seccion 3.4

pag.50 Contornos: Descripcion y aproximacion
Capıtulo 3

Capıtulo 4
Fronteras y Preprocesamiento de
Aristas.
MARR propone en sus teorıas la creacion o deteccion del llamado primal sketch que nos es mas que
el primer paso desde la informacion mas basica (las aristas) hacia la interpretacion de la imagen,
distinguiendo entes de mayor contenido semantico. Si hemos distinguido varios niveles informacionales
provenientes de las fronteras para realizar la modelizacion de nuestros objetos, necesitamos elegir un
algoritmo para la deteccion de estas aristas ası como un preprocesamiento de estas a fin de prepararlas
para que puedan ser usadas en el algoritmo de localizacion de contornos. Obviamente, las imagenes
de aristas, resultado de la deteccion de fronteras no pueden ser consideradas como resultados de la
segmentacion sino como indicios indicadores de las posibles localizaciones de los objetos.
4.1. Deteccion de fronteras.
4.1.1. Seleccionando un detector de aristas.
Existe una gran variedad de algoritmos de deteccion de fronteras ([Sonka et al. 93]) desde los mas
simples que consisten en pequenos nucleos de convolucion (2x2, 3x3) como son los operadores de Roberts,
Laplace, Prewitt, Sobel, Robinson o Kirsch hasta los mas complejos en los que los nucleos se complican
llegando a variar dependiendo de la zona de la imagen ([Garcıa et al. 95]) o el algoritmo es completado
con una etapa de postprocesamiento para mejorar las aristas obtenidas desde el operador ([Canny 86],
[Kittler y Hancock 89], [Hancock y Kittler 90b]).
Podrıa plantearse la conveniencia de metodos que tras una primera deteccion de fronteras intentaran
unir en lo posible las aristas resultantes en vistas de unos resultados de mas calidad para etapas pos-
teriores. Como podemos comprobar, estos metodos resultan difıciles de aplicar si consideramos la gran
cantidad de ruido que contienen las imagenes, y especialmente la naturaleza de este ruido que lo hace
imposible de tratar con ningun modelo aleatorio. Un ejemplo de estas tecnicas puede ser la relajacion,
con la que podemos comprobar la inoperancia de esta solucion.
La razon de que los resultados obtenidos sea pobre se debe especialmente a dos razones:
Tal y como se ha indicado, el ruido confunde al metodo y es recomendable metodos que se comporten
mejor frente a este. Si se realiza alguna etapa de mejora de las aristas debe ser con mayor seguridad
(por ejemplo, solo donde haya gradientes altos) y en ultima instancia en base al modelo de objeto
que se quiere localizar.
51

pag.52 Fronteras y Preprocesamiento de Aristas.
Es necesaria una interpretacion multiescala de la imagen. En gran medida el ruido aparece en unas
escalas distintas a los objetos y por otro lado es posible que distintas evidencias que se intentan
localizar se pongan de relieve solo en caso de eliminar otras caracterısticas menos relevantes.
De los primeros filtros que tratan formalmente el problema de detectar fronteras a distintas escalas
son los basados en Laplaciana de Gaussiana1, es decir, la laplaciana de una imagen previamente alisada
por una gaussiana:
∇2(G(x, y, σ) ⊗ f(x, y)) (4.1)
O equivalentemente la convolucion con un filtro laplaciana de gaussiana (ver figura 4.1)
∇2(G(x, y, σ)) ⊗ f(x, y) (4.2)
Laplaciana de Gausiana (invertida)Laplaciana de Gausiana
Figura 4.1: Funcion laplaciana de gaussiana.
Aunque en la lınea del tipo de operador que deseamos, esta opcion tiene la desventaja de que nos
da una respuesta sin ninguna referencia al vector gradiente, es decir, a la magnitud y la direccion de la
frontera detectada que como veremos seran fundamentales para la interpretacion de las aristas.
De una forma similar a este operador, podemos realizar la convolucion de la imagen con una funcion
gaussiana y en lugar de aplicar un operador de segundo orden como es el laplaciano aplicar operadores de
primer orden para obtener la orientacion de la frontera. Si estudiamos la derivada parcial en la direccion del
eje de abcisas y en el eje de ordenadas obtendremos efectivamente una estimacion del vector gradiente.
Estas observaciones nos llevan al filtro de Canny ([Canny 86]) como una excelente opcion ya que nos
permiten una interpretacion multiescala de la imagen y por otro lado nos ofrece un excelente metodo de
umbralizacion de la imagen gradiente, como es la histeresis, a fin de obtener las fronteras de la imagen.
4.1.2. Mejorando los resultados desde la interpretacion multiescala.
Es conveniente tener en cuenta que si asumimos un enfoque segun el espacio de escalas la informacion
de fronteras desde la que pretendemos obtener informacion acerca de los objetos en la imagen es una
1Abreviado como LoG por algunos autores
Capıtulo 4

Deteccion de fronteras. pag.53
senal que esta definida sobre 3 dimensiones: las correspondientes a las dos dimensiones del plano mas la
correspondiente a la escala (ver pagina 17). Por tanto nuestro sistema dispone de un nuevo eje a traves
del cual podemos relacionar y transmitir informacion.
4.1.2.1. Movimiento de las fronteras a traves de la escala.
Como hemos visto anteriormente (pag. 22), es posible determinar el camino que seguira un punto
crıtico cuando la escala cambia2. Serıa optimo que pudieramos determinar el movimiento que pueden
sufrir las fronteras entre dos niveles adyacentes de un muestreo del espacio de escalas o al menos poder
acotar dicho movimiento a fin de construir algoritmos que hagan corresponder las estructuras de las
imagenes a nivel de las aristas. La teorıa nos indica que no es posible.
Efectivamente si consideramos el caso en que tenemos un punto frontera (x0, y0) sobre una larga linea
recta y asumimos que el sistema de coordenadas esta alineado con la frontera de forma que el eje de abcisas
es perpendicular a esta y que la derivada tercera con respecto a x es distinta de cero, la ecuacion 2.20 nos
indica que la velocidad de este punto frontera cuando el parametro de escala cambia viene dado por:
dr
dt(t0) = −1
2
∂4E∂x4 (x0; t0)∂3E∂x3 (x0; t0)
(4.3)
simplemente cambiando E por ∂E∂x
que corresponde al gradiente de la imagen y por tanto, sus maximos
a las fronteras.
De esta expresion podemos derivar que no es posible ninguna acotacion acerca de la velocidad de
las aristas. Si consideramos dos fronteras paralelas adyacentes, cuando se acercan para unirse en una al
incrementar el parametro de escala, la velocidad tiende a infinito ya que la derivada tercera tiende a cero
([Lindeberg 92b], [Griffin y Colchester 95]).
Bergholm construye un algoritmo de enfoque de fronteras ([Bergholm 87]) en el que hace un seguimien-
to de las aristas a traves del espacio de escalas (hasta las escalas mas finas). Desde los resultados teoricos
que hemos planteado, esta operacion no es totalmente satisfactoria si, como hace Bergholm, nos basamos
en acotar el maximo movimiento que puede sufrir una frontera al movernos de un nivel al adyacente en
el muestreo de las escalas. A pesar de ello, relacionar estos niveles adyacentes mediante un criterio de
cercanıa de las fronteras es una operacion recomendable por varias razones:
Bergholm demuestra para un conjunto aceptable de casos que la operacion de enfocado funciona
correctamente.
Los resultados obtenidos indican que el metodo en la practica tiene un buen comportamiento.
El no poder relacionar estructuras de dos escalas ocurre solo en casos muy concretos (ver [Lindeberg
92b]) por lo que el comportamiento general del metodo es bueno.
Si nuestra intencion es relacionar una a una las fronteras, los casos de bifurcacion pueden ser
obviados.
El metodo es simple y por lo tanto muy eficiente.
Es de destacar el trabajo desarrollado en [Goshtasby 94] en el que se desarrolla un algoritmo de
seguimiento de fronteras obtenidas a partir del operador Laplaciana de Gaussiana estudiando de forma
local el valor del incremento en el parametro de escala para asegurar un desplazamiento maximo. Como
veremos mas adelante, el algoritmo propuesto se usara para obtener una informacion mas completa
de las aristas en una imagen. Es posible plantearse la posibilidad de un estudio profundo acerca del
2Obviamente cuando el punto sea no degenerado.
Seccion 4.1

pag.54 Fronteras y Preprocesamiento de Aristas.
comportamiento de las fronteras a fin de optimizar aun mas los resultados pero no es recomendable
debido a que:
La cantidad de informacion es bastante grande y estando en una etapa temprana del metodo
podemos esperar a obtener informacion de mas alto nivel para volver a afinar en las aristas que
intervienen en el contorno del objeto buscado.
El intentar obtener mayor numero de fronteras sin un modelo de contorno y especialmente en las
imagenes que manejamos se traduce en una cantidad mayor de ruido.
4.1.2.2. Relacionando aristas: Multihisteresis.
La doble umbralizacion de la imagen gradiente es un procedimiento muy eficaz para obtener una
imagen de aristas. Garantiza por un lado la obtencion de fronteras muy seguras y por otro ayuda a
la union de fronteras a traves de aristas con un nivel de gradiente no demasiado elevado. Por este
motivo, se presenta como un procedimiento ideal para la umbralizacion. Canny, propone que tras la
obtencion del gradiente y la supresion de no maximos, sea aplicada la histeresis o doble umbralizacion a
la imagen obtenida. Nuestro caso es distinto pues no manejamos un unico canal de informacion sino que
nuestra imagen gradiente esta definida sobre 3 dimensiones, dos correspondientes al plano XY sobre el
que esta definida la imagen original y una a la escala.
En la histeresis tradicional, es decir, con un solo tamano de gaussiana, se determinan dos umbrales:
El umbral alto: Cualquier punto en la imagen con un gradiente por encima de este valor es un punto
frontera con un grado de seguridad muy alto.
El umbral bajo: De forma similar, cualquier punto en la imagen con un gradiente por debajo de
este valor no es un punto frontera.
Cualquier punto con un gradiente entre el umbral bajo y el alto sera o no un punto frontera en funcion
de que este conectado (en un 8-entorno) a un punto frontera o no lo este, respectivamente.
En la figura 4.2 se representa graficamente esta idea. En esta grafica, aparece en la parte superior una
imagen de celulas para la cual se ha calculado el gradiente. Para la zona delimitada por un cuadrado se
ha representado de forma ampliada la magnitud del gradiente y una representacion 3D de esta. Como
se puede observar en la figura existen dos zonas con un gradiente muy alto y que por consiguiente seran
marcadas como fronteras directamente al sobrepasar el umbral alto en la primera fase de la histeresis.
La zona intermedia, es decir, la cresta que une estas fronteras seguras tiene un nivel de gradiente que se
situa entre el umbral bajo y el alto y sera marcada como frontera en la segunda fase de la histeresis.
En nuestro algoritmo, dado que la entrada en una senal 3-dimensional, ya no tiene sentido hablar de
un 8-entorno sino de un 26-entorno. Es decir, dado un pıxel debemos de tener en cuenta su 8-entorno en
el mismo nivel, y sus 9-entornos en el nivel superior e inferior.
Una cuestion importante que hay que considerar es la referente a los umbrales que se seleccionan para
la multihisteresis. Canny propone como umbral alto la magnitud de gradiente correspondiente al 90 por
ciento del histograma acumulado y el umbral bajo como la mitad del alto. Si realizamos una histeresis
multinivel hara falta seleccionar umbrales para cada nivel. Cada umbral de nuestro algoritmo sera una
n-tupla si consideramos un muestreo de n niveles3. Como puede intuir el lector, se abre un amplio abanico
de posibilidades a la hora de determinar estos valores: desde calcular umbrales independientemente para
cada nivel hasta en base a alguna medida de relevancia de las escalas ponderar las mas importantes
ası como una umbralizacion adaptativa en cada zona de un determinado nivel.
Antes de comentar el metodo y resultados que se han usado en este trabajo es muy interesante
considerar el calculo de un unico umbral doble para todas las escalas. El problema de hacer un calculo a
3En el caso continuo, la n-tupla se traduce en una funcion definida sobre ℜ+, es decir, para cualquier valor de escala.
Capıtulo 4

Deteccion de fronteras. pag.55
Frontera inicalmente dudosa
de fronteras seguras
hecha segura por la unión
del área seleccionada
Magnitud del gradiente
Magnitud del gradiente del área seleccionada
Imagen Original
segurasFronteras
Figura 4.2: Histeresis.
partir de todas las escalas surge dado que los valores de distintas escalas deben ser comparables. Para ello
podemos normalizar a fin de conseguir la invarianza en la escala ([Florack et al. 92]). Aun ası, considerar
un umbral comun para todo el espacio ocasionarıa una preferencia en las escalas mas altas. Efectivamente,
considerando la respuesta a la senal ([Lindeberg 93a])
f(x′) =∫ x
−∞
g(x, t0) dx (4.4)
la magnitud del gradiente normalizado incrementa con la escala (como era de esperar ya que conforme
la escala tiende a infinito la frontera tiende a un salto ideal).
En los resultados que se presentan en este trabajo, la umbralizacion ha sido la mas obvia, es decir, el
calculo para cada uno de los niveles de los umbrales propuestos en el algoritmo de Canny (de esta forma
no se determina ninguna preferencia por ninguna de las escalas) que como veremos ofrece resultados
bastante buenos. Otra posibilidad interesante puede ser determinar valores que decrecen conforme la
escala aumenta debido a que la informacion de escalas superiores sufre de menos ruido y tiene mayor
estabilidad.
Seccion 4.1

pag.56 Fronteras y Preprocesamiento de Aristas.
4.1.3. Algoritmo multiescala de deteccion de fronteras.
Una vez discutidos los distintos aspectos acerca de la construccion de un algoritmo de deteccion de
aristas desde un enfoque multiescala de la imagen, veamos concretamente cuales serıan los distintos pasos
que en definitiva se proponen.
Supongamos que se desean detectar las fronteras considerando el intervalo [σmin, σmax] del espacio de
escalas con una muestra de n canales. Tengase en cuenta que el numero de muestras debe ser obtenido
a partir de la amplitud del intervalo para considerar un ancho entre dos muestras consecutivas suficien-
temente pequeno (recordemos por ejemplo que en [Bergholm 87] se recomienda un ancho de 12 ). En este
trabajo se ha usado la expresion:
n = 4(σmax − σmin) + 1 (4.5)
para determinar el numero de muestras a tratar. Ademas supongamos los valores para el calculo de
los umbrales en la multihisteresis pb y pa (0 ≤ pb, pa ≤ 1) que como anteriormente se comento, Canny
propone valores aproximados de 0,5 y 0,9. Los pasos del algoritmo son los siguientes:
1.- Obtencion de la imagen gradiente para cada escala σi (1 ≤ i ≤ n) desde la imagen original f(x, y),
es decir, para cada i hacer:
1.1.- Obtener la componente X de la imagen gradiente como (ver pag. 18)
Gxi(x, y) =∂(f(x, y)⊗ gσi
(x, y))
∂x= f(x, y)⊗ ∂gσi
(x, y)
∂x(4.6)
1.2.- Obtener la componente Y de la imagen gradiente como (ver pag. 18)
Gyi(x, y) =∂(f(x, y)⊗ gσi
(x, y))
∂y= f(x, y)⊗ ∂gσi
(x, y)
∂y(4.7)
1.3.- Obviamente la magnitud y direccion del gradiente para cada imagen vienen determinados por:
Mi(x, y) =√Gx2
i (x, y) +Gy2i (x, y) (4.8)
Di(x, y) = arctanGyi(x, y)
Gxi(x, y)(4.9)
2.- Calcular las tuplas correspondientes a los umbrales bajos (Ub1 · · ·Ubn) y umbrales altos (Ua1 · · ·Uan),
es decir, para cada i hacer:
2.1.- Calcular el histogramaHi(x) de la imagen magnitudMi(x, y) normalizado en el intervalo [0, 1].
2.2.- Hacer Uai = H−1i (pa).
2.3.- Hacer Ubi = pb · Uai.
3.- Inicializar las etiquetas de las imagenes resultado Eti(x, y), es decir, para cada valor i y cada pareja
(x, y) hacer:
3.1.- SiMi(x, y) NO ES un maximo en la direccionDi(x, y), entoncesEti(x, y) = NO FRONTERA.
3.2.- En caso contrario:
3.2.1.- Si Mi(x, y) < Ubi entonces Eti(x, y) = NO FRONTERA.
3.2.2.- en caso contrario Eti(x, y) = POSIBLE FRONTERA.
4.- Aplicar multihisteresis sobre las imagenes Eti(x, y), es decir, para cada valor de i y cada pareja
(x, y) hacer:
Capıtulo 4

Deteccion de fronteras. pag.57
4.1.- Si Mi(x, y) ≥ Uai y Eti(x, y) = POSIBLE FRONTERA entonces
4.1.1.- Eti(x, y) = FRONTERA.
4.1.2.- Seguir asignando la etiqueta FRONTERA recursivamente por cada uno de los vecinos
del punto (x, y) del canal i mientras esten etiquetados como POSIBLE FRONTERA y
la magnitud del gradiente sea mayor que el umbral bajo.
Los resultados de este algoritmo se pueden ver para un ejemplo ilustrativo en la figura 4.3.
Seccion 4.1

pag.58 Fronteras y Preprocesamiento de Aristas.
Um
bral
alto
Um
bral
sim
ple
His
tére
sis
Mul
tihis
tére
sis
Figura 4.3: Multihisteresis (ver texto).
Capıtulo 4

Deteccion de fronteras. pag.59
En esta figura se presentan en cada fila los resultados obtenidos en los canales σ = 1, σ = 1,5 y σ = 2
para una misma imagen. Cada una de las columnas contiene:
En la primera columna se presenta una umbralizacion simple usando como umbral la media del
umbral bajo y el alto. En ella se observan algunas fronteras importantes pero tambien se detecta
un incremento de ruido, es decir, de fronteras incorrectas. Un decremento del umbral usado aunque
mejorarıa las fronteras buscadas empeorarıa el resultado con la introduccion de incorrecciones.
En la segunda columna se ilustra la eficacia de usar doble umbral. Se presentan unicamente las
fronteras que estan por encima del valor alto. Como se puede observar, estas son un subconjunto
suficientemente pequeno como para asegurar un nivel de seguridad muy alto.
En la tercera columna se presentan los resultados de la histeresis. En este caso vemos como las
cadenas que han empezado a detectarse por encima del umbral alto se ven alargadas y unidas en
gran medida.
En la cuarta columna se observan los resultados del algoritmo propuesto. Como podemos ver,
en los 3 canales presentados se ha mejorado sustanciamente la informacion dado que cadenas que
presentaban ambiguedad para la segmentacion ahora si consiguen delimitar el contorno de la celula.
Es interesante destacar que los umbrales que se estan usando para la multihisteresis son identicos
que los que se presentan para el algoritmo de Canny por lo que la existencia de nuevas cadenas
no esta asociada con la modificacion de estos sino con la introduccion adicional de informacion de
contexto a traves del parametro de escala.
4.1.3.1. Proyeccion sobre una imagen con maxima precision.
Como hemos visto anteriormente, un problema asociado a la deteccion de fronteras usando valores
altos de escala es el desplazamiento de su posicion real. En [Bergholm 87] y [Goshtasby 94] se desarrollan
algoritmos para solventar este problema obteniendose buenos resultados. Se abre por tanto la posibilidad
de integrar la informacion obtenidas en las distintas escalas mediante el seguimiento de las fronteras
de cada una de ellas hasta la escala mas baja. Es necesario destacar varios comentarios acerca de esta
operacion:
En los citados trabajos, los algoritmos se desarrollan a fin de optimizar la localizacion de las aristas
detectadas a un valor alto de escala. En nuestro caso, deseamos obtener la informacion conjunta de
todas las escalas.
Es posible construir un algoritmo para representar en una sola imagen y con alta precision la cadenas
obtenidas en todos los canales uniendo los distintos resultados.
En imagenes con alto nivel de ruido y especialmente en el caso de que sea de tipo no estocastico, es
conveniente considerar las aristas obtenidas a una escala alta debido a que se ven menos afectadas
por estos problemas y facilitando por tanto el proceso de segmentacion.
Para poder ilustar este “enfocado” de fronteras se ha implementado el siguiente algoritmo:
1.- Obtencion del conjunto de aristas Ai para cada escala σi (1 ≤ i ≤ n).
2.- Inicializar R = ∅.
3.- Desde i = n hasta i = 1
2.1.- R = R− Ai ∪ E(Ai)
Seccion 4.1

pag.60 Fronteras y Preprocesamiento de Aristas.
2.2.- R = R ∪ Ai
donde E(Ai) son el conjunto de puntos en la imagen que tienen al menos un vecino (considerando el
8-entorno) en el conjunto Ai. Un ejemplo de la aplicacion de este se puede ver en la figura 4.4.
ba
Figura 4.4: Proyeccion en una imagen.
Como se puede observar, aunque se obtiene un grado muy alto de fronteras y con una buena precision,
el nivel de ruido ocasiona distorsiones en las aristas que pueden dificultar el proceso de segmentacion. Mas
adelante desarrollaremos por tanto un metodo en base al modelo de objeto a localizar para integrar las
distintas cadenas obtenidas a partir de cada uno de los canales considerados que pueda ser generalizado
para la integracion de informacion de distintas fuentes. Antes deberemos describir como procesar cada
imagen de aristas a fin de obtener una lista de las cadenas presentes.
4.2. Preprocesamiento y extraccion de cadenas.
Los resultados obtenidos mediante el detector de fronteras no pueden ser usados de forma directa.
Para poder ser usados deberemos de transformarlos a una descripcion en base a cadenas de puntos
consecutivos. Para poder hacerlo, necesitamos resolver dos problemas:
Procesar los puntos multiples en la imagen.
Buscar las cadenas y orientarlas apropiadamente segun la descripcion del objeto a localizar.
4.2.1. Deteccion de Puntos Multiples.
La informacion de la imagen de aristas que debemos obtener consiste inicialmente en un conjunto de
cadenas en las que cada punto tiene como maximo 2 vecinos. Logicamente, antes de extraer las cadenas
de la imagen, se presenta el primer problema: los puntos que tienen mas de dos vecinos. Estos puntos son
los que llamamos puntos multiples.
Para borrarlos de la imagen seguimos el siguiente proceso:
Recorremos la imagen de forma secuencial buscando los puntos multiples. Cuando detectamos uno de
ellos, si el punto se encuentra en la primera fila (columna) o ultima fila(columna) se elimina directamente
(borrando el entorno) y en caso contrario se realiza una busqueda recursiva a traves de las distintas
ramas que se unen en el punto multiple que se esta tratando, para obtener su longitud. En caso de que
Capıtulo 4

Preprocesamiento y extraccion de cadenas. pag.61
la longitud llegue a un determinado valor Max Recursivo (umbral previamente fijado), se devuelve este
y termina la recursividad. Debido a que las ramas pueden ampliarse en forma de arbol (por existencia
de mas puntos multiples), la longitud devuelta sera la longitud de la rama mas larga. Una vez que se
conocen las longitudes de las ramas se borra el entorno del punto y se restablece este junto con las dos
ramas mas largas. Su efecto por tanto es el que se muestra en la figura 4.5.
Figura 4.5: Eliminacion de Puntos triples
En el caso de que las ramas sean de tamanos grandes no se tiene informacion (en este punto del
proceso) para indicar la rama optima a eliminar. Se cortan todas y se deja el problema de realizar la
eleccion correcta para una etapa posterior en la que se dispondra de mas informacion del modelo.
4.2.1.1. Algoritmo para puntos multiples.
Para todo punto (k,l) dentro de la imagen hacer
1. Si el punto (k,l) tiene mas de dos vecinos hacer
1.1 Para todo (i,j) del 8-entorno de P
1.1.1 Si (i,j) es frontera hacer
longitud(i,j) = 1 + computar((k, l) → (i, j))
1.1.2 en caso contrario
longitud(i,j) = 0
1.2 Eliminar el 8-entorno de P
1.3 Si 2 puntos del 8-entorno tienen longitud estrict. mayor que las demas
Recuperar los dos puntos (i,j) del 8-entorno con longitud(i,j) maximo.
Donde el algoritmo computar((k, l) → (i, j)) consiste en:
1. Inicializar max= 0
2. Marcar como visitado (i,j)
3. Para d=-1 hasta 1 hacer
3.1 Para e=-1 hasta 1 hacer
3.1.1 Si No esta marcado (i+d,j+e) y
Seccion 4.2

pag.62 Fronteras y Preprocesamiento de Aristas.
(i + d− k)2 + (j + e− l)2 > 2 y
(d 6= 0 o e 6= 0)
3.1.1.1 aux= 1 + computar((i, j) → (i+ d, j + e))
3.1.1.2 max= (max > aux?)max:aux
4. Devolver max
4.2.2. Busqueda, corte y orientacion de cadenas.
Una vez eliminados los puntos multiples, las cadenas que quedan en la imagen son:
Cadenas cerradas: Todos sus puntos tienen 2 vecinos.
Cadenas abiertas: Todos sus puntos tienen 2 vecinos excepto los extremos que solamente tienen
uno.
En la figura 4.6 se presenta un ejemplo de imagen fronteras a la que se le han eliminado los puntos
multiples.
Con puntos triples Sin puntos triples
Figura 4.6: Imagen sin puntos multiples.
4.2.2.1. Busqueda y extraccion de una cadena.
El algoritmo consiste en recorrer la imagen hasta encontrar un pıxel frontera en ella, tras lo cual se
recorre la imagen en busca del extremo de la cadena o en su caso del punto de comienzo de esta (cadena
cerrada).
Una vez localizado el extremo de la cadena se recorre almacenando los codigos en un array.
4.2.2.2. Corte y Orientacion de las cadenas.
Las cadenas de la imagen son orientadas (recorridas) en el sentido contrario a las agujas del reloj
asumiendo que los objetos que queremos segmentar son de un nivel de grıs mas oscuro que el fondo.
Graficamente la operacion a realizar en esta fase es solucionar los problemas de la figura 4.7(la flecha
indica sentido del recorrido) donde podemos observar:
Capıtulo 4

Preprocesamiento y extraccion de cadenas. pag.63
1
2
3
Caso 1
1 1
2
P
3
4
5
Caso 3
2
4
5
3.1
3.2
Solución Caso 3
1
2
3
Caso 2
Figura 4.7: Corte y Orientacion de cadenas.
Caso 1.- La celula es recorrida correctamente por lo tanto no es necesaria ninguna operacion. Las 3
cadenas permanecen igual.
Caso 2.- Las cadenas 1 y 2 son correctas. La cadena 3 debe ser invertida para quedar en la situacion del
caso 1.
Caso 3.- Las cadenas 1,2,4 y 5 son correctas pero la cadena 3 es la union de dos cadenas:
La superior antes del punto P la cual pertenece a la celula de la derecha (cadena 3.1).
La inferior despues del punto P la cual pertenece a la celula de la izquierda (cadena 3.2).
El resultado del algoritmo en el caso 3 es mostrado en la parte inferior derecha de la figura,
el cual implica cortar la cadena 3 por el punto P, e invertir la 3.2 para hacer el sentido
conforme a las agujas del reloj.
4.2.2.3. Criterio para orientacion.
El criterio para determinar que una cadena (cada punto P) esta bien orientada se realiza de la siguiente
forma:
Seccion 4.2

pag.64 Fronteras y Preprocesamiento de Aristas.
Se obtiene una estimacion de la recta tangente a cada punto P usando la recta tangente a P ( 4.8 A)
y el vector gradiente en P ( 4.8 B).
1
2
3
1
2
3
PP
(A) (B)
Figura 4.8: Criterio de Orientacion de cadenas
Salvo precision y ruido, el vector gradiente en P y la recta tangente a la cadena y con sentido identico
forman aproximadamente un angulo recto.
Decidiremos que el punto P esta bien orientado si el producto vectorial del vector gradiente y el vector
que determina la recta tangente tiene un signo determinado (negativo o positivo dependiendo del orden
de los factores).
En la orientacion, dado que el modulo del producto vectorial no es importante y nos podemos permitir
el lujo de que los vectores implicados sean poco precisos, el vector tangente se aproxima con el vector
delimitado por dos puntos:
El primero de ellos, Alcance codigos Freeman antes del punto P y
El segundo Alcance codigos Freeman posteriores a P.
donde Alcance es un parametro que se ha fijado a 2. Logicamente esto provoca que los puntos de los
extremos no sean tratados y se consideren de igual orientacion que los de su entorno.
De esta forma, la cadena tiene el siguiente tratamiento:
La cadena es correcta si todos sus puntos tienen el signo predeterminado como correcto.
Una cadena hay que invertirla si todos sus puntos tienen el signo predeterminado como incorrecto.
Una cadena hay que dividirla si esta constituida por rachas de puntos con distinto signo de forma
que cada una de esas subcadenas debera ser orientada segun los dos puntos anteriores.
4.3. Ejemplos.
En este apartado ilustramos con 3 ejemplos la deteccion de fronteras sobre imagenes de citologıas
que, como destacamos anteriormente, sufren de un nivel de ruido muy alto que dificulta la obtencion de
aristas. Para cada uno de ellos, se presentan las siguientes imagenes:
Imagen original.
Capıtulo 4

Ejemplos. pag.65
Fronteras obtenidas en los canales σ = 1, σ = 1,5, σ = 2, σ = 2,5 tras realizar la multihisteresis.
Union de los canales. El resultado de realizar la operacion logica OR con las imagenes de fronteras.
Esta imagen nos da una idea de la cantidad de informacion total que podemos obtener a partir de
las distintas escalas consideradas.
Seccion 4.3

pag.66 Fronteras y Preprocesamiento de Aristas.
Ejemplo 1
(f)(e)
(d)
(b)(a)
(c)
Figura 4.9: (a) Original. (b) σ = 1. (c) σ = 1,5. (d) σ = 2. (e) σ =
2,5. (f) Union de los distintos canales.
Capıtulo 4

Ejemplos. pag.67
Ejemplo 2
(f)(e)
(d)
(b)(a)
(c)
Figura 4.10: (a) Original. (b) σ = 1. (c) σ = 1,5. (d) σ = 2.
(e) σ = 2,5. (f) Union de los distintos canales.
Seccion 4.3

pag.68 Fronteras y Preprocesamiento de Aristas.
Ejemplo 3
(f)(e)
(d)
(b)(a)
(c)
Figura 4.11: (a) Original. (b) σ = 1. (c) σ = 1,5. (d) σ = 2.
(e) σ = 2,5. (f) Union de los distintos canales.
Capıtulo 4

Capıtulo 5
Modelizacion de deformaciones
EL tipo de contornos que pretendemos localizar tienen la particularidad de que pueden sufrir de un
alto grado de deformacion. Este hecho obliga a que cualquier tecnica desarrollada a fin de segmentar
nuestras imagenes debe de contemplar la existencia de estas deformaciones.
En nuestro caso, si consideramos la necesidad de ofrecer una informacion a priori desde el contorno
que se busca junto con la posibilidad de que este contorno sufra de deformaciones, deberemos de proponer
una modelizacion de estas a fin de poder parametrizar y de esta manera considerar las deformaciones que
se pueden presentar.
Existen distintas formas de realizar la modelizacion de deformaciones (vease pagina 5). Si consider-
amos las caracterısticas positivas y negativas de los metodos descritos en la literatura podemos exponer
brevemente cuales son los aspectos que pretendemos contemplar con nuestro modelo:
Debemos de presentar un modelo que maneje informacion a priori acerca del contorno a detectar.
El metodo debe ser capaz de localizar las posiciones iniciales del objeto a localizar.
Debemos poder parametrizar las distintas deformaciones procurando que dicha parametrizacion sea
generalizable a otras formas.
Una vez detectada la posicion inicial del objeto, debemos definir un potencial que guıe al template
mediante un metodo de optimizacion considerando el tipo de imagenes que tenemos, es decir, con
abundancia de objetos, solapamiento, etc.
Por lo tanto para ello, en primer lugar, es necesario contar con alguna tecnica que nos permita manejar
las distintas deformaciones que puede presentar nuestro contorno, y que sera presentada a lo largo de
este capıtulo.
5.1. Aproximacion propuesta.
El sistema de descomposicion de deformaciones que se va a presentar corresponde al analisis modal
usado en ingenierıa para la simulacion del comportamiento dinamico de un objeto a fin de estudiar sus
movimientos y deformaciones. Una introduccion a estas tecnicas puede encontrarse en [Livesley 88] y un
amplio y profundo estudio en [Bathe 82] aunque nosotros obviamente solo usaremos parte de ello en una
adaptacion a nuestro problema.
Esta modelizacion ha sido propuesta por Pentland y Sclaroff ([Pentland y Sclaroff 91], [Sclaroff y
Pentland 95]) aunque a fin de resolver un problema muy distinto: Realizar una correspondencia de un
contorno con otro de entre una base de datos de posibilidades, considerando los contornos ya segmentados.
Este modelo que se propone tiene las siguientes ventajas:
69

pag.70 Modelizacion de deformaciones
1. Puede ser aplicado a un conjunto amplio de contornos, es decir, no es especıfico para ninguna forma
ni aplicacion.
2. Como otros metodos en la literatura se basa en deformar una forma estandar pero con la ventaja
de que los distintos ejes de deformacion pueden obtenerse desde su geometrıa en base a propiedades
fısicas.
3. Permite una clasificacion de las deformaciones desde las mas globales a las mas locales.
4. Esta basada en una interpretacion fısica de la forma que nos permite:
Entender y manejar el metodo con mayor facilidad.
Incluir nuevas mejoras considerando nuevos aspectos fısicos en la forma como son: distinta
densidad de masa, rigidez variable a lo largo de la forma, etc...
5. Nos ofrece la posibilidad de aplicar algoritmos muy potentes para disenar procedimientos de apren-
dizaje como son: determinar correspondencias entre contornos, alineamiento de formas, etc ([Sclaroff
y Pentland 95]).
6. Modelizamos en base a un metodo de elementos finitos(FEM) que nos permite disponer de una
caracterizacion mas estable numericamente que los metodos de diferencias finitas y ademas con
funciones continuas a pesar de trabajar con el grid rectangular posibilitando por tanto el obtener
medidas en cualquier punto del plano y no solamente en los puntos discretos que manejarıan metodos
de diferencias finitas.
5.1.1. Planteamiento.
Consideremos una forma descrita por medio de un vector X:
X =
x1
...
xn
y1...
yn
(5.1)
que esta compuesto por los n puntos (xi, yi) que provienen de un muestreo a lo largo del contorno
estandar, es decir, del prototipo de contorno que sufrira las deformaciones1. Consideraremos un contorno
deformado Xd:
Xd = X +Φv (5.2)
donde Φ es una matriz compuesta por 2n vectores de longitud 2n correspondientes a los 2n grados de
libertad de deformacion de la forma X . Como es obvio, v corresponde a los pesos de cada uno de esos
vectores, es decir, es el vector que determina la deformacion en el espacio vectorial definido por la base
de 2n vectores:
φ1 · · ·φ2n (5.3)
Ahora bien, ¿Que matriz Φ es la mas util para caracterizar las deformaciones?. El caso mas sencillo
es la base ortonormal canonica, es decir, con cada vector i compuesto por valores cero excepto el valor
1El contorno estandar corresponde a aquel que resulta de aplicar una deformacion nula a la forma que se intenta localizar.
Capıtulo 5

Aproximacion propuesta. pag.71
unidad de la posicion i-esima. En este caso, los vectores de deformacion son poco informativos. Serıa
mucho mas interesante una descomposicion de forma que pudieramos clasificar cada eje de manera que
distinguieramos caracterısticas tales como globalidad o no de la deformacion, si es una deformacion
afectada de ruidos y las componentes rıgidas de dicha deformacion.
El analisis modal desde una interpretacion fısica de la forma nos da las herramientas para esta descom-
posicion en una base definida como los modos de vibracion libre de la forma que surgen de la geometrıa
y la asignacion de propiedades fısicas tales como masa y rigidez a cada uno de los puntos.
5.1.2. Derivacion de las ecuaciones de equilibrio del elemento finito.
El problema que resuelve la ingenierıa consiste en dada la geometrıa, de un cuerpo, las fuerzas o
cargas que se aplican a este, las condiciones de soporte, la ley de tension deformacion del material y las
tensiones iniciales calcular los desplazamientos, tensiones y deformaciones que sufre dicho cuerpo. Para
poder realizar este calculo sobre un objeto arbitrario es necesario un analisis basado en elementos finitos.
Nuestro objetivo en esta seccion sera formular las ecuaciones del elemento finito obviando los problemas
adicionales como el posterior ensamblaje de las matrices de los elementos dado que interpretaremos
nuestro contorno como un unico elemento finito. La mayor parte de esta seccion se ha obtenido de [Bathe
82] por lo que se remite al lector a esta referencia para una ampliacion de cualquier punto de esta breve
introduccion.
5.1.2.1. Notacion y relaciones.
Supongamos un elemento finito con n puntos nodales definidos sobre un sistema coordenado XY Z.
Denotamos:
Desplazamiento sufrido por un punto (x, y, z) como u(x, y, z) = (UVW )t.
El tensor de deformacion correspondiente a un desplazamiento u(x, y, z) como
ǫ =
ǫXX
ǫY Y
ǫZZ
ǫXY
ǫY Z
ǫZX
=
∂U∂X∂V∂Y∂W∂Z
∂U∂Y
+ ∂V∂X
∂V∂Z
+ ∂W∂Y
∂W∂X
+ ∂U∂Z
(5.4)
Las tensiones correspondientes a las deformaciones ǫ como
τ =
τXX
τY Y
τZZ
τXY
τY Z
τZX
= Cǫ+ τI (5.5)
donde C es la matriz de tension deformacion o matriz de elasticidad y τI denota tensiones ini-
ciales. El valor de C depende del problema. Para un material elastico isotropico en condiciones de
deformacion plana se puede establecer:
C =E(1 − ν)
(1 + v)(1− 2ν)
1 ν1−ν
0ν
1−ν1 0
0 0 1−2ν2(1−ν)
(5.6)
Seccion 5.1

pag.72 Modelizacion de deformaciones
donde E es el modulo de Young y ν el ratio de Poisson (para mayor profundidad ver [Bathe 82]
pagina 193 y siguientes).
Para interpolar los desplazamientos en cualquier punto del objeto, dispondremos de una matriz
H(x, y, z) de dimensiones 3x3n, es decir
u(x, y, z) = H(x, y, z)U (5.7)
donde U denota una matriz de 3nx1 correspondiente a los desplazamientos de los n nodos definidos
en el elemento finito.
Una vez definida la matriz H podemos determinar la relacion que hay entre los desplazamientos U
y el tensor deformacion ǫ
ǫ(x, y, z) = B(x, y, z)U (5.8)
donde B es la matriz de desplazamiento deformacion y sus filas se obtienen por diferenciacion y
combinacion de las de H .
Denotaremos R al conjunto total de fuerzas aplicadas sobre el objeto.
5.1.2.2. El elemento finito en equilibrio.
La situacion mas sencilla de equilibrio de un elemento corresponde al equilibrio estatico y se formula:
K · U = R (5.9)
Donde U corresponde a los desplazamientos nodales, R son las fuerzas sobre el cuerpo y K es la matriz
de rigidez que se define de la siguiente forma
K =
∫
V
BtCBdV (5.10)
Ahora bien, las fuerzas pueden variar con el tiempo y la igualdad KU = R es valida como ecuacion de
equilibrio en cada punto a lo largo del tiempo. El problema surge si estas variaciones son suficientemente
rapidas como para tener en cuenta las fuerzas de inercia. Entonces la ecuacion de equilibrio debe de
formularse
MU +KU = R (5.11)
donde U es el vector aceleracion y M es la matriz de masas definida
M =
∫
V
ρHtHdV (5.12)
siendo ρ la densidad de masa.
Por ultimo, si el objeto se encuentra en movimiento tambien hay una disipacion de energıa que se
incluye en el analisis mediante la introduccion de un termino dependiente de la velocidad, es decir, la
ecuacion de equilibrio finalmente viene determinada por:
MU +DU +KU = R (5.13)
donde U es el vector velocidad y D puede denotarse como la matriz de amortiguacion definida como
D =
∫
V
κHtHdV (5.14)
Capıtulo 5

Aproximacion propuesta. pag.73
En general es practicamente imposible calcular D y se suele construir a partir de las matrices M y
K. Una solucion usual es la asuncion de Rayleigh
D = αM + βK (5.15)
es decir, D es una combinacion lineal de la matriz de masas y de rigidez (para mas detalles, vease
[Bathe 82] pagina 796)
5.1.3. Solucionando la ecuacion de equilibrio: Analisis modal.
Una solucion a la ecuacion de equilibrio formulada en el apartado anterior es realizar un cambio de
base. La idea de la superposicion modal consiste en cambiar la base de forma que la nueva base permita
estudiar los efectos de las fuerzas en cada eje de forma independiente de manera que la solucion al sistema
venga determinada por la suma de estas respuestas.
5.1.3.1. Transformacion de la ecuacion de equilibrio.
Para transformar la ecuacion de equilibrio, usamos la siguiente transformacion desde los desplaza-
mientos U(t) a los desplazamientos generalizados X(t)
U(t) = PX(t) (5.16)
Si aplicamos esta transformacion a la ecuacion 5.13 y premultiplicamos por P t obtenemos
P tMPX + P tDPX + P tKPX = P tR (5.17)
que cambiando de notacion se transforma en
MX + DX + KX = R (5.18)
con las correspondencias obvias
M = P tMP
D = P tDP
K = P tKP
R = P tR
En esencia se ha realizado un cambio de base desde los desplazamientos generalizados para obtener
nuevas matrices K, M y C que simplifiquen el problema expresandose los desplazamientos de los elementos
en funcion de los desplazamientos generalizados como
u(x, y, z, t) = HPX(t) (5.19)
5.1.3.2. Modos de vibracion libre.
Una transformacion efectiva en la practica se consigue usando las soluciones de la ecuacion de equilibrio
suponiendo desplazamientos de libre vibracion con R = 0. Obviamente, si el sistema debe estabilizarse,
deberemos hacer D = 0 para que no haya perdida de energıa y la ecuacion resulta
MU +KU = 0 (5.20)
con una solucion en forma de
Seccion 5.1

pag.74 Modelizacion de deformaciones
U = φ sinw(t− t0) (5.21)
en la que podemos distinguir que φ es un vector que indica la amplitud de la vibracion y w es su
frecuencia (radianes/seg).
Si sustituimos la solucion en forma de armonico en la ecuacion expuesta, obtenemos como resultado
un autoproblema generalizado a partir del que se debe de determinar φ y w
Kφ = w2Mφ (5.22)
La solucion a este problema([Press et al. 92]) esta compuesta por 3n autosoluciones:
(w21 , φ1), (w
22 , φ2) · · · (w2
3n, φ3n) (5.23)
donde los autovectores son M-ortonormalizados, es decir,
φtiMφj =
1 Si i = j
0 Si i 6= j(5.24)
y los autovalores estan ordenados de menor a mayor
0 ≤ w21 ≤ · · · ≤ w2
3n
El vector φi se denomina el vector del i-esimo modo de la forma y wi es la correspondiente frecuencia
de vibracion.
Si definimos una matriz Φ cuyas columnas son los autovectores φi y una matriz diagonal Ω2 que tiene
los autovalores w2i como su diagonal, es decir:
Φ = [φ1|φ2| · · · |φ3n] Ω2 =
w21
. . .
w23n
(5.25)
las 3n soluciones se pueden escribir
KΦ = MΦΩ2 (5.26)
y como los autovectores son M-ortonormales, se cumplen las siguientes igualdades
ΦtKΦ = Ω2 ΦtMΦ = I (5.27)
Por lo tanto, la matriz Φ sera una buena matriz de transformacion (anteriormente denotada P )
U(t) = ΦX(t) (5.28)
Obteniendose ecuaciones de equilibrio correspondientes a desplazamientos generalizados modales
X(t) + ΦtDΦX(t) + Ω2X(t) = ΦtR(t) (5.29)
con condiciones iniciales
X(0) = ΦtMU(0) X(0) = ΦtMU(0) (5.30)
Por ultimo, es necesaria la diagonalizacion de la matriz D para lo que debe de ser de una forma
especial. Lo normal es restringir su forma suponiendo que se construye a partir de las series de Caughey
Capıtulo 5

Aproximacion propuesta. pag.75
D = M
r−1∑
k=0
ak[M−1K]k (5.31)
Lo que es equivalente a suponer que la amortiguacion que describe la disipacion de energıa es pro-
porcional a la respuesta del sistema. Si tomamos r = 2 se reduce a la forma de Rayleigh comentada
anteriormente
D = ΦtDΦ = a0I + a1Ω2 (5.32)
obteniendose 3n ecuaciones independientes:
Xi(t) + diXi(t) + w2i xi(t) = ri(t) (5.33)
en las que di es el parametro de amortiguacion modal.
5.1.4. Calculo de los modos naturales de deformacion.
Como hemos visto en los apartados anteriores, podemos caracterizar las distintas deformaciones de un
objeto de una forma natural mediante los ejes definidos por cada modo de vibracion libre. Ahora bien, es
aun necesario detallar el metodo concreto de analisis definiendo el tipo de funciones que usaremos para
interpolar en todos los puntos de la forma. En esta seccion veremos un metodo concreto (que sera usado
en esta memoria) propuesto en [Sclaroff y Pentland 95] detallando la forma en que pueden calcularse los
modos de vibracion aunque, como el lector puede intuir, pueden usarse otros metodos y/o variaciones
([Bathe 82], [Pentland y Sclaroff 91]).
Necesitamos definir un conjunto de funciones de interpolacion o funciones de forma a fin de obtener la
matriz H de la ecuacion 5.7 pero en 2-D, es decir, de dimensiones 2x2n siendo n el numero de elementos
nodales denotados (xi, yi) con 1 ≤ i ≤ n. La matriz H(x, y) por tanto tendra la forma:
H(x, y) =
(h1(x, y) · · · hn(x, y) 0 · · · 0
0 · · · 0 h1(x, y) · · · hn(x, y)
)(5.34)
Donde hi son las funciones de forma que definen nuestro elemento finito isoparametrico y que deben
de cumplir:
El valor en cada nodo del elemento finito debe cumplir
hi(x, y) =
1 Si (x, y) = (xi, yi)
0 Si (x, y) 6= (xi, yi)(5.35)
El cualquier otro punto (x, y) del objeto debe de cumplirse
n∑
i=1
hi(x, y) = 1 (5.36)
Es decir, al interpolar el valor de una medida en un punto que coincide con un nodo se debe de obtener
el mismo valor de ese nodo y si no coincide, el valor puede obtenerse a partir de todos normalizando como
es obvio la suma de los pesos a 1.
Usaremos como funciones de interpolacion las propuestas en [Sclaroff y Pentland 95] basadas en la
suma ponderada de n gaussianas,
hi(x, y) =n∑
k=1
aikgk(x, y) (5.37)
Seccion 5.1

pag.76 Modelizacion de deformaciones
donde gk es una gaussiana 2-D de desviacion σ y centrada en el punto (xk, yk).
Para poder garantizar la igualdad 5.35 en cada punto (x, y) correspondiente a un nodo, los pesos aikpueden ser obtenidos desde la matriz A, inversa de la matriz
G =
g1(x1, y1) · · · g1(xn, yn)...
...
gn(x1, y1) · · · gn(xn, yn)
(5.38)
y si queremos que se cumpla la igualdad 5.36 para cualquier punto que no sea un punto nodal,
deberıamos normalizar
hi(x, y) =
∑n
k=1 aikgk(x, y)∑m
j=1
∑n
k=1 ajkgk(x, y)(5.39)
aunque para los objetivos de este trabajo, no sera necesario tenerlo en cuenta simplificando de esta
manera el calculo de la matrices de masas y rigidez.
5.1.4.1. Calculo de la matriz de masas.
La matriz de masas de dimensiones 2n por 2n se calcula a partir de:
M =
∫
V
ρHtHdV =
(Maa 0
0 Mbb
)(5.40)
donde Maa = Mbb y cada elemento (i, j) de estas matrices se calcula planteando una doble integral
que podemos resolver haciendo uso de las igualdades de [Gradshteyn y Ryzhik 88] (pag. 337) referentes
a la solucion de integrales infinitas de exponenciales. Como resultado obtenemos:
Maa = Mbb = ρπσ2G−1RGG−1 (5.41)
donde los elementos de la matriz RG son las raıces cuadradas de los elementos de G.
5.1.4.2. Calculo de la matriz de rigidez.
La matriz de rigidez de dimensiones 2n por 2n se calcula a partir de:
K =
∫
V
BtCBdV =
(Kaa Kab
Kba Kbb
)(5.42)
con Kba = Kab y donde la matriz C esta definida en la ecuacion 5.6 y la matriz B es
B(x, y) =
∂∂x
h1(x, y) · · · ∂∂x
hn(x, y) 0 · · · 0
0 · · · 0 ∂∂y
h1(x, y) · · · ∂∂y
hn(x, y)∂∂y
h1(x, y) · · · ∂∂y
hn(x, y)∂∂x
h1(x, y) · · · ∂∂x
hn(x, y)
(5.43)
si notamos α, β y ξ a las expresiones
α =ν
1− ν, β =
E(1− ν)
(1 + v)(1 − 2ν), ξ =
1− 2ν
2(1− ν)(5.44)
cada elemento (i, j) de estas matrices se resuelve de una forma similar al calculo de la matriz de masas
obteniendose
kaaij= πβ
∑
k,l
aikajl
[1 + ξ
2− (xk − xl)
2 + ξ(yk − yl)2
4σ2
]rGkl
(5.45)
Capıtulo 5

Seleccion de deformaciones. pag.77
kbbij = πβ∑
k,l
aikajl
[1 + ξ
2− (yk − yl)
2 + ξ(xk − xl)2
4σ2
]rGkl
(5.46)
kabij = kbaij= −πβ(α+ ξ)
4σ2
∑
k,l
aikajl(xk − xl)(yk − yl)rGkl(5.47)
5.2. Seleccion de deformaciones.
Una vez que las deformaciones las expresamos en funcion de los modos de vibracion libre vamos a
estudiar la forma en que vamos a seleccionar las principales deformaciones que presenta nuestro objeto.
Para ello, en primer lugar veremos las caracterısticas de nuestra nueva base y como a partir de ella
podemos directamente obtener los primeros resultados.
5.2.1. Deformaciones modales.
En nuestro caso 2-D la nueva base de deformaciones esta compuesta por 2n vectores φi correspondi-
entes a 2n frecuencias de vibracion wi (vease 5.23) que supongamos estan ordenadas de menor a mayor.
Un ejemplo simple de esta nueva base se presenta en la figura 5.1.
vector 5
vector 1 vector 2 vector 3 vector 4
vector 8vector 7vector 6
Figura 5.1: Deformaciones modales de un cuadrado.
En esta figura se presentan graficamente las 8 deformaciones correspondientes a los modos de vi-
bracion libre ordenadas de menor frecuencia a mayor2. Como se puede observar en ella, este sistema de
representacion nos permite distinguir:
Los 3 primeros modos corresponden a los movimientos rıgidos, es decir, traslacion y rotacion.
Los 2n−3 ultimos modos son deformaciones no rıgidas. Este conjunto de deformaciones se presenta
desde las mas globales correspondientes a las frecuencias de vibracion mas bajas hasta las mas
locales y sensibles al ruido en las frecuencias altas.
2En la pagina 147 se puede observar un ejemplo mas complejo.
Seccion 5.2

pag.78 Modelizacion de deformaciones
De este primer paso podemos obtener descartando tanto los 3 primeros modos que no deforman el
objeto hasta los ultimos que corresponden a deformaciones locales, las principales deformaciones que
puede llegar a sufrir nuestro contorno. La eliminacion de los ultimos modos nos facilita:
Evitar los efectos del ruido y las deformaciones locales. Es esta etapa de la segmentacion nos interesa
especialmente encontrar los objetos en la imagen sin atender a los detalles o cambios locales.
Eliminar la sobre-dimensionalidad del problema ocasionada por un excesivo muestreo de los puntos
que caracterizan al contorno. Si al modelizar el objeto se han seleccionado un numero excesivo de
puntos, el tipo de deformaciones que se obtienen se veran afectadas especialmente a las correspon-
dientes a cambios locales3.
5.2.2. Componentes principales.
La forma mas sencilla y efectiva de delimitar el conjunto de vectores significativos para nuestro modelo
es en base a un conjunto de ejemplos que ilustren cuales son las posibilidades de deformacion de nuestro
contorno. En este sentido se plantea la posibilidad de obtencion de componentes principales. Este estudio
nos beneficiara en varios sentidos:
Podremos determinar facilmente los vectores de alta vibracion a eliminar.
Puede ocurrir que aunque desde el punto de vista fısico sea natural una determinada deformacion
de nuestro contorno correspondiente a una frecuencia baja, en la practica no nos la encontremos
para nuestro objeto en particular (al igual que una descomposicion Fourier no tiene por que tener
contribuciones en todas las frecuencias). El disponer de un conjunto de posibilidades nos puede
permitar realizar las correspondientes simplificaciones.
Por ultimo, no solo es posible eliminar vectores que no se presenten en nuestra aplicacion sino que
podemos realizar un estudio de posibles correlaciones entre los valores reales de manera que registrar
dichas variaciones puede realizarse de una forma mas optima.
Supongamos que disponemos de un conjunto de m ejemplos Ei (1 ≤ i ≤ m) correspondientes a m
posibilidades de deformacion de un contorno. Supongamos T el contorno de deformacion cero. El proceso
puede ser el siguiente:
1. Alinear cada contorno Ei con el contorno T , es decir, realizar la correspondencia de puntos desde
Ei a T calculando para ello la traslacion, rotacion y deformaciones no rıgidas correspondientes.
Un metodo eficaz de realizar esta alineacion esta descrito en [Sclaroff y Pentland 95] en base a la
descripcion modal del contorno. Aunque no entraremos a detallar este proceso, si conviene destacar
que se realiza en dos fases:
a) Calculo de las transformaciones rıgidas. En este punto, la problematica viene planteada por
el calculo de la rotacion necesaria en la alineacion. Aunque el tercer vector obtenido en la
descomposicion modal corresponde a un movimiento rotativo, no podemos olvidar que es una
trasformacion lineal y por tanto no es posible resolverla de esta forma. Pese a ello, la transfor-
macion es necesaria unicamente cuando se debe realizar una rotacion grande para la alineacion
y basta una rotacion aproximada pues la descripcion modal permite recoger pequenas defor-
maciones.
b) Una vez determinadas de forma aproximada las transformaciones rıgidas, se usan las deforma-
ciones modales para determinar la forma definitiva de alineacion de los contornos (incluyendo
la correccion de las traslaciones y de la rotacion).
3En caso de que el numero de puntos sea cercano al optimo sera recomendable obviar la eliminacion.
Capıtulo 5

Seleccion de deformaciones. pag.79
2. De esta forma, si T y cada muestra estan descritos en base a n puntos y disponemos de m muestras
X1, X2 · · · , Xm
donde Xi tiene la forma de la ecuacion 5.1, la alineacion de cada una de ellas con T nos permite
calcular los m vectores Ui correspondientes a los desplazamientos nodales que llevan desde T a cada
ejemplo:
Ui = Xi − T (5.48)
y si consideramos que
Ui = ΦUi ΦtMΦ = I
donde Ui son los desplazamientos generalizados modales, la transformacion a coordenadas modales
es
Ui = Φ−1Ui = ΦtMUi (5.49)
y cada ejemplo puede ser descrito
Xi = ΦUi + T (5.50)
de manera que Ui1 ,Ui2 y Ui3 corresponden a las traslaciones y la rotacion cuyos valores son nulos a
causa de la alineacion previa.
3. A partir de las m muestras podemos calcular la media y matriz de covarianzas de los vectores Vi
mV =1
m
m∑
j=1
Vi CV =1
m
m∑
j=1
VkVtk −mV m
t
V(5.51)
donde Vi = (Ui3 , · · · , Ui2n)t. La matriz CV es real y simetrica por lo que pueden calcularse 2n− 3
autovectores ortonormales y 2n− 3 autovalores correspondientes al autoproblema
CV ei = λiei
Si denotamos A a la matriz
A = (e1, e2, · · · , e2n−3)t (5.52)
la transformacion Vi = A(Vi −mV ) se denomina la transformada de Hotelling y se caracteriza por
tener una media y matriz de covarianzas
mV = 0 CV =
λ1 0. . .
0 λ2n−3
(5.53)
Seccion 5.2

pag.80 Modelizacion de deformaciones
4. Los nuevos vectores Vi definidos por la transformada de Hotelling se caracterizan por tener ele-
mentos no correlados y ademas, las varianzas de dichos elementos coinciden con los autovalores λi.
Basta con seleccionar los elementos correspondientes a los valores mas altos de estos autovalores
para seleccionar las coordenadas de mayor variacion y por lo tanto las de mayor informacion. Los
vectores Vi correspondientes a este nuevo sistema simplificado se pueden obtener haciendo uso de
la transformacion
Vi = AtVi +mV (5.54)
y por tanto, cada ejemplo Xi puede escribirse
Xi = Φ ·((0, 0, 0) | (AtVi +mV )
t)t
+ T (5.55)
Capıtulo 5

Capıtulo 6
Localizacion inicial de contornos
deformables
SE pueden distinguir muchos y variados modelos de objetos deformables a lo largo de la literatura.
Estos modelos pueden variar en distintos aspectos:
Aproximacion de los contornos.
Definicion de potenciales y funciones de energıa.
Tecnicas de optimizacion.
Pero todos comparten un mismo aspecto: no poseen una etapa previa que permita determinar de forma
automatica las localizaciones iniciales de las soluciones. Existen algunas aproximaciones al problema,
ası en [Lai y Chin 95] se propone la transformada de Hough como un metodo de inicializacion aunque con
la unica garantıa de que es un caso particular de la metodologıa propuesta que como es obvio sufrira de
una disminucion en la calidad de los resultados conforme aumenta el grado de deformacion llegando a ser
de difıcil utilizacion en imagenes tales como las presentadas aquı. En otros casos, si el modelo se desarrolla
para una aplicacion especıfica permite desarrollar algoritmos de inicializacion pero que son difıcilmente
generalizables, ası por ejemplo en [Yuille et al. 92] se utiliza informacion de picos, valles y fronteras para
localizar los objetos aunque, a pesar de ser muy eficaz, si trasladamos el problema a otros objetos y/o
imagenes resulta una tecnica de difıcil aplicacion(si no imposible)1.
En este capıtulo se propone un metodo para la localizacion de contornos en imagenes que pueden
sufrir de los siguientes problemas:
Multitud de objetos.
Solapamientos.
Informacion parcial.
Ruido no aleatorio.
obteniendose resultados validos para la inicializacion de contornos deformables que contemplan un
conjunto de deformaciones muy grande.
1Aunque no debemos de olvidar la eficacia de combinar distintas informaciones de la imagen para optimizar los resultados
como ilustra la aplicacion de Yuille en la deteccion de contornos desde caras.
81

pag.82 Localizacion inicial de contornos deformables
En este capıtulo vamos a desarrollar un metodo para la localizacion aproximada de objetos en la
imagen como un metodo de inicializacion. Nuestra intencion sera obtener un conjunto de valores para
los parametros que definen la localizacion (traslacion, rotacion y deformaciones no rıgidas) del contorno
buscado lo que nos sugiere el uso de la transformada de Hough. El hecho de que la dimensionalidad del
problema y el ruido en los datos de entrada sean altos nos obliga a una reformulacion de esta.
6.1. La transformada de Hough generalizada.
6.1.1. Formulacion.
Supongamos la curva
C(t) = (fx(t), fy(t)) (6.1)
donde el parametro t se mueve en el intervalo 0 ≤ t ≤ L y la curva C esta centrada en el punto (0, 0),
es decir,
∫ L
0
fx(t)dt =
∫ L
0
fy(t)dt = 0 (6.2)
Supongamos ademas un conjunto de ejes de deformacion
D = ex, ey, er, ed1, · · · , edn
(6.3)
correspondientes a traslaciones (ex en abcisas y ey en ordenadas), rotaciones (er) y un numero inde-
terminado n (variando segun el objeto a localizar) de deformaciones no rıgidas.
El conjunto de posibles localizaciones de la curva C(t) sobre el conjunto de deformaciones D viene
determinada por (3 + n)-tuplas de valores. La transformada de Hough construye un espacio discreto de
dimension 3 + n asignando a cada uno de los puntos de este el numero de pıxeles frontera que aparecen
en la imagen de aristas y que corresponden a dicha localizacion del contorno.
6.1.2. El caso mas simple: deformaciones rıgidas.
Tradicionalmente la transformada de Hough generalizada se ha formulado para formas que sufrıan
unicamente de traslaciones y de rotaciones debido a la inmanejabilidad del espacio de parametros que
resulta de un aumento del numero de dimensiones.
Si consideramos una curva C(t) que puede sufrir de deformaciones rıgidas, una localizacion de dicha
forma en una imagen viene determinada por 3 valores:
(x,y,r)
con x ∈ [xmin, xmax], y ∈ [ymin, ymax] e r ∈ [0, 2π] que corresponden a la curva:
C′(t) = (x+ fx(t) cosr − fy(t) sinr,y + fx(t) sinr + fy(t) cosr) (6.4)
Construir la transformada de Hough de una imagen I sobre un espacio de parametros discreto
E(x,y,r) (es decir, sobre una matriz de acumulacion) consiste en2:
1. Calcular el conjunto de aristas A de I.
2. Para toda tupla (px, py,r, t), tal que (px, py) ∈ A, r ∈ [0, 2π], t ∈ [0, L] hacer
2Obviamente haciendo uso de una conveniente discretizacion de los parametros que aparecen.
Capıtulo 6

La transformada de Hough generalizada. pag.83
a) x = px − (fx(t) cosr − fy(t) sinr)
b) y = py − (fx(t) sinr + fy(t) cosr)
c) Incrementar en un voto la posicion E(x,y,r).
Una mejora obvia de este procedimiento consiste en tener en cuenta el gradiente del punto (px, py)
de manera que los valores de t que se necesitan muestrear se ven disminuidos en gran medida ya que
solo sera necesario usar aquellos puntos de la curva tales que tras la rotacion pudieran resultar con un
gradiente aproximado al del punto[Ballard 81].
El problema mas importante para la aplicacion de esta tecnica surge de su ineficiencia debida al
tamano del espacio de parametros por dos razones:
Espacio: El tamano de la matriz de votos crece exponencialmente con el numero de ejes, es decir,
con el numero de parametros necesarios para describir la forma.
Tiempo: El numero de posiciones que hay que recorrer por cada uno de los pıxeles frontera crece
de la misma forma.
A lo largo de la literatura han aparecido muchas variaciones del algoritmo que han derivado en mejoras
de tiempo y espacio. No es nuestra intencion presentar aquı las posibles variaciones (para ello, el lector
se puede remitir por ejemplo a [Davies 90], [Illingworth y Kittler 88] y [Kalvianen et al. 94], donde
aparece un rapido repaso de las diversas aportaciones). A pesar de ello, no se ha formulado el algoritmo
para manejar casos de formas como las estudiadas en este trabajo. Dado que la T.H. es una tecnica
muy potente para manejar condiciones de ruido, solapamiento e informacion parcial, a lo largo de este
capıtulo propondremos distintas aportaciones sobre el algoritmo general que nos permitiran reducir la
impracticabilidad de este. Para ello, antes formularemos el caso general.
6.1.3. Caso general.
En el caso general consideraremos ademas de las traslaciones y rotaciones, las deformaciones no
rıgidas que modelizaremos segun la ecuacion 5.1 y siguientes. Segun esta aproximacion nuestro contorno
sera manejado usando solo los puntos nodales mientras que las deformaciones en los demas puntos podran
ser obtenidas por interpolacion.
Si consideramos n vectores de deformacion no rıgida (φd1, · · · , φdn
), denotaremos
Cd(t) = (fdx (t), f
dy (t)) (6.5)
a la curva resultado de aplicar una deformacion d = (d1, · · · ,dn) a la curva original C(t) (d
perteneciente a un conjunto D de posibles deformaciones del contorno).
De esta manera, la localizacion de una curva viene determinada por una (3 + n)-tupla
(x,y,r,d1, · · · ,dn)
que consideraremos durante lo que resta de capıtulo, esta compuesta por
Deformaciones rıgidas: traslacion y rotacion.
Deformaciones no rıgidas: ordenadas desde las mas globales a las mas locales, es decir, desde las que
pueden provocar una mayor variacion en la forma hasta las que provocan pequenas perturbaciones.
de una forma similar al caso de la deformaciones rıgidas, construir la transformada de Hough de una
imagen I sobre una matriz de acumulacion E(x,y,r,d) consiste en:
Seccion 6.1

pag.84 Localizacion inicial de contornos deformables
1. Calcular el conjunto de aristas A de I.
2. Para toda tupla (px, py,r,d, t), tal que (px, py) ∈ A, r ∈ [0, 2π], d ∈ D, t ∈ [0, L], hacer
a) x = px − (fdx (t) cosr − fd
y (t) sinr)
b) y = py − (fdx (t) sinr + fd
y (t) cosr)
c) Incrementar en un voto la posicion (x,y,r,d1, · · · ,dn) del acumulador E.
6.2. Manejo de ruido y pequenas deformaciones.
La existencia de ruido en la imagen provoca un desplazamiento en las aristas que se obtienen desde el
detector de fronteras. Por otro lado, el uso de filtros paso-bajo (como es nuestro caso) aunque evita hasta
cierto nivel parte del ruido, provoca una desviacion en la localizacion exacta de la frontera ([Bergholm
87], [Lindeberg 92b]).
La transformada de Hough inicialmente se formulo para la localizacion de contornos de los que se
disponıa de una precisa descripcion. A lo largo de la literatura se ha mantenido en general esta formu-
lacion. Es interesante distinguir la transformada de Hough difusa (fuzzy Hough transform) que permite
la deteccion de contornos que no se conocen de forma exacta aunque se ha desarrollado unicamente como
una etapa de postprocesamiento (despues de la aplicacion de la transformada de Hough generalizada) en
la que solo se realiza una correccion del contorno localizado en funcion del gradiente del entorno(vease
[Sonka et al. 93], pag. 159).
Por consiguiente, es necesario describir un procedimiento mas estable para poder procesar informacion
de aristas que pueden haberse desplazado de su localizacion real. Para poder conseguirlo planteamos dos
contribuciones:
Si las aristas se encuentran desplazadas de su posicion real, la votacion de la T.H. tradicional se
realizara en posiciones incorrectas del acumulador. Esta situacion sugiere una adaptacion de la
forma de votacion al problema.
En imagenes con una cantidad de ruido muy alta, no solo nos encontramos con aristas desplazadas
sino que ademas existen muchas aristas que no corresponden a estructuras que nos interesen. Para
eliminar los efectos de estas ası como estabilizar la informacion de las aristas de nuestro contorno
podemos hacer que los datos de entrada a la transformada de Hough sean de mayor contenido
semantico.
6.2.1. Cambio en la votacion.
6.2.1.1. Zona de incertidumbre.
Si consideramos la formulacion de la transformada de Hough presentada en los apartados anteriores,
la votacion en el acumulador se realiza mediante el calculo del punto correspondiente al centro de la
curva3. Esta operacion no es mas que solucionar un sistema de ecuaciones, es decir, la votacion desde un
pıxel frontera corresponde a resolver el problema de encontrar todas las tuplas de deformacion tal que
un punto de la curva resulte en la posicion de la arista. Ası, para una determinada arista y un punto en
la curva, se calcula el desplazamiento sufrido por este punto a causa de todas las deformaciones excepto
las traslaciones calculandose el desplazamiento en funcion de la posicion de esta arista y la variacion de
este punto.
3Este punto central corresponde al punto situado en la posicion (0,0) del un objeto con desplazamiento y deformacion
cero. Obviamente, es un punto arbitrario que se escoge a priori y que en nuestro caso se hace coincidir con el punto central
calculado a partir del contorno segun se expuso en el capıtulo de contornos.
Capıtulo 6

Manejo de ruido y pequenas deformaciones. pag.85
Consideremos la figura 6.1(A). En ella podemos distinguir el punto C (centro de la curva) y el punto
p (un punto en la curva).
C
pp’
C’ C
p
x
y
(A) (B)
Figura 6.1: Zona de incertidumbre.
Si el punto p esta sujeto a desviaciones (por ejemplo, desde p a p′), un desplazamiento de este induce
un desplazamiento en el calculo del posible centro de la forma (desde C a C′). Si estudiamos los posibles
desplazamientos que puede sufrir un punto p, obtenemos como resultado una zona alrededor de este en
la que podra situarse; zona que inducira igualmente una zona de incertidumbre4 acerca de la posicion del
centro (vease figura 6.1(B)).
6.2.1.2. T. Hough modificada.
En la T.H. que se formulo anteriormente, para cada posible deformacion y punto en la curva se
calculaba un posible centro de esta. Si incluimos la variacion del punto, realmente calcularemos la posicion
de una zona de incertidumbre. La T.H. puede ser modificada para incluir esta posibilidad, es decir, en
lugar de realizar un incremento de un voto en el posible centro, incrementar en un voto todos los posibles
valores determinados por dicha zona.
Es conveniente destacar algunos aspectos de esta aproximacion:
Aunque la zona de incertidumbre de un punto sea desconocida, basta con considerar una zona que
la contenga. De esta manera garantizamos que el centro real es votado. Logicamente, es posible
construir algoritmos que aproximen (por exceso) dicha zona. Un ejemplo de estos podrıa ser el
calculo de la capsula convexa que contiene un conjunto de puntos de posibles centros obtenidos a
partir de una muestra.
Un aumento en el tamano de la zona de incertidumbre redunda en una disminucion de la precision.
Podrıa considerarse la posibilidad de realizar una votacion ponderada, es decir, votar en unas
posiciones con un valor de 1 voto mientras que en las menos probables anadir un valor menor a fin
de considerar las probabilidades de deformacion. Es este trabajo, se realizara una votacion uniforme
que como veremos es suficiente para localizar las formas de manera aproximada.
4En la literatura referente a la transformada de Hough se puede distinguir el concepto de PSF para indicar el conjunto
de puntos a votar a partir de la localizacion de una arista (vease por ejemplo [Davies 90], [Jeng y Tsai 91]).
Seccion 6.2

pag.86 Localizacion inicial de contornos deformables
La zona de incertidumbre puede variar dependiendo del punto del contorno que se intenta localizar.
Por ejemplo, en un determinado objeto, es posible que unas zonas puedan varias mas que otras, ya
sea por problemas de captacion o por la propia naturaleza del objeto a detectar. Se puede definir
una zona de incertidumbre para cada punto o para cada zona del objeto de manera que se obtenga
una informacion mas estable.
6.2.2. Uso de otro tipo de informacion desde el template.
6.2.2.1. Niveles de informacion.
Como se ha visto anteriormente, podemos distinguir distintos niveles informacionales en las aristas
de una imagen (vease pag. 8). De la misma forma podemos clasificar los distintos tipos de informacion
que definen un contorno. Una posible division de estos se presenta en la figura 6.2
Objeto Mayor contenido semántico
Relación 1 a muchos
Relación 1 a muchos
Relación 1 a muchos
Píxel Menor contenido semántico
Tendencia (Freeman)
Racha
Relación 1 a muchos
Relación 1 a muchos
Estructura
Punto dominante Incremento del nivelinformacional
Figura 6.2: Niveles informacionales de un contorno.
En dicha figura podemos distinguir los niveles:
1. Pıxel: Es el nivel inferior y constituye la unidad basica informacional sobre la que se construye
cualquier contorno.
2. Tendencia (Freeman): Constituye el nivel generado por la tendencia o codigo Freeman desde 2
pıxeles adyacentes. Es de mayor nivel informacional que el pıxel5.
3. Racha: Corresponde a la generalizacion del punto anterior. Definiremos una racha como un segmento
de curva que cumple condiciones de linealidad dentro de un rango de posible variacion.
5Por ejemplo, en condiciones de ausencia de ruido, determina una aproximacion a la perpendicular del gradiente.
Capıtulo 6

Manejo de ruido y pequenas deformaciones. pag.87
4. Punto Dominante: La union de dos rachas determina un punto de alta variacion que podemos hacer
corresponder a los puntos de maxima curvatura muy usados a lo largo de la literatura (vease el
capıtulo dedicado a los contornos).
5. Estructura: Esta compuesta por la yuxtaposicion de varias rachas en una misma curva. La deteccion
de estructuras en una imagen puede resultar un metodo de localizacion importante especialmente
en casos en que la curva a localizar posea alguna estructura significativa que la distinga.
6. Objeto: Descrito por la curva cerrada. Su localizacion es, obviamente, nuestro objetivo.
Logicamente, aunque no entra dentro de nuestros objetivos el desarrollarlas, las distintas caracteri-
zaciones y representaciones de las formas que se han desarrollado hasta el momento abren un conjunto
mucho mas amplio de posibilidades. En este trabajo, destacamos las mas relevantes con respecto a la
representacion e informacion que estamos usando.
6.2.2.2. Construccion de informacion de nivel superior.
Si pretendemos usar informacion mas estable en nuestros algoritmos, el problema mas complejo e
inmediato surge de la necesidad de definir un metodo para construirla.
Considerando los niveles anteriormente expuestos, los tipos de informacion que pueden ser usados
son: Tendencias(Freeman), Rachas, Puntos dominantes y Estructuras. Es interesante destacar algunas
soluciones:
Racha.
Podemos usar un amplio numero de algoritmos que a lo largo de la literatura se han propuesto
para la aproximacion de una curva por una polilınea. Ası podrıamos usar un detector de fronteras para
localizar las curvas de nuestra imagen y procesar estas para obtener la localizacion de estas tendencias
generalizadas.
Es interesante destacar la solucion presentada en [Garrido et al. 95] donde se usa la informacion de
los codigos Freeman que componen la cadena para determinar una racha de entre un conjunto discreto
de posibilidades.
Puntos dominantes.
En los trabajos que se han realizado en referencia a este tipo de informacion, los esfuerzos se han
centrado en el problema de la obtencion de los puntos de una curva determinada, es decir, segmentada.
Una forma de obtenerla por consiguiente es con el estudio de las cadenas de aristas en la imagen (vease
el capıtulo de contornos).
Otra forma con la que podemos localizar en la imagen posibles candidatos es mediante el estudio de
los puntos de union correspondientes a maximos en la curvatura de curvas de nivel. Usando el espacio
de escalas introducido en los capıtulos anteriores, la curvatura de curvas de nivel puede ser obtenida
mediante la expresion([Koenderink 84], [Florack et al. 92])
κ =E2
yExx − 2ExEyExy + E2xEyy
(E2x + E2
y)32
(6.6)
donde denotamos
Ex =∂E
∂xEy =
∂E
∂yExx =
∂2E
∂x2Eyy =
∂2E
∂y2(6.7)
Obviamente, es posible que puntos de bajo gradiente y que por tanto no corresponden a contornos
de los objetos obtengan un nivel de curvatura muy destacado. Para poder seleccionar los puntos que
Seccion 6.2

pag.88 Localizacion inicial de contornos deformables
nos interesan, una tecnica usual es multiplicar por la magnitud del gradiente elevada a alguna poten-
cia([Lindeberg 93a]). Si la potencia es 3 resulta
κ = E2yExx − 2ExEyExy + E2
xEyy (6.8)
Por otro lado, es de destacar la deteccion de este tipo de puntos en base a la transformada de Hough
(vease [Davies 90], pag. 323).
Estructura.
Si usamos informacion de un detector de aristas, la forma mas natural es aplicar un metodo de
matching de las cadenas de puntos con zonas de nuestro contorno. Para hacerlo:
Podemos usar informacion de menor nivel tal como puntos dominantes o rachas y determinar alguna
tecnica para combinarla formando estructuras.
Aplicar un metodo directo. Por ej. Podemos usar la funcion de la curva de curvaturas de la cadena
detectada a fin de realizar una correspondencia con alguna zona de la funcion de curvaturas de
nuestra curva o caracterizar las curvas que describen los objetos en base a un conjunto de primitivas
(arcos, zonas de concavidad y convexidad, etc.).
6.2.3. Reformulacion de la Transformada de Hough.
Una vez que disponemos de una forma de manejar las deformaciones y de informacion estable podemos
reformular el algoritmo para la deteccion de posibles localizaciones. Aunque para nuestras imagenes
bastara con una version mas simple basada unicamente en la deteccion de rachas, aquı formularemos el
algoritmo en su forma mas general.
Característica 1.1 Característica 1.m
Característica 1 Característica 2
Objeto
Característica n
Figura 6.3: Descripcion de un objeto.
Supongamos un objeto a detectar descrito segun se observa en la figura 6.3. En esta figura, el objeto se
describe por medio de una jerarquıa determinada por los distintos niveles informacionales que se observan
para las distintas caracterısticas desde las de mas alto nivel hasta las de mas bajo nivel. Ası por ejemplo,
la primera caracterıstica puede hacer referencia a informacion de contornos, la segunda de texturas, la
Capıtulo 6

Manejo de ruido y pequenas deformaciones. pag.89
tercera de color, etc. Obviamente dentro de cada una de estas se podran distinguir otras de manera
recurrente6.
Como se ha comentado anteriormente, todas las posibles localizaciones de nuestra forma vienen de-
scritas por una (3 + n) − tupla. Para poder evaluar la posicion donde se encuentra el objeto, podemos
construir un acumulador de evidencias E de dimension 3 + n abarcando todas las posibles localizaciones
y que es evaluado una forma similar a la transformada de Hough, teniendo en cuenta que:
Cada posicion en el acumulador no corresponde al numero de evidencias detectadas en la imagen.
Debera construirse un metodo que acumule las evidencias y sea capaz de comparar dos valores
acumulados para determinar el que indica de forma mas probable la existencia del objeto contemp-
lando si es necesario la mezcla de evidencias de distinto tipo (ej. colores con fronteras). El metodo
de acumulacion permite tener en cuenta aspectos como:
• Ponderar unas evidencias frente a otras. Por ej. unas evidencias pueden ser mas significativas
que otras.
• Tener en cuenta el grado de fiabilidad en la deteccion de la evidencia. Por ej. podemos encontrar
en una zona de la imagen la existencia de una evidencia con una baja probabilidad.
• etc.
Habra de determinarse para cada caracterıstica en el objeto la zona de incertidumbre producida por
las posibles desviaciones que a causa del ruido y deformaciones puedan producirse de manera que
el acumulador sera modificado en todas las posiciones de esta zona para cada evidencia detectada
en la imagen.
6.2.3.1. Un ejemplo ilustrativo.
Consideremos la localizacion de contornos celulares en una imagen de citologıas. El contorno a localizar
puede ser modelizado como una circunferencia que puede sufrir de deformaciones.
(B)
Racha 2
detectada
r
R
(A)
l 6
5 3
2
10
7
R
4
Figura 6.4: Rachas de una circunferencia.
6Tengase en cuenta que no es un objetivo en este trabajo el determinar una estructura de representacion de un objeto.
Son muchos los trabajos que se pueden encontrar acerca de esta. El objetivo de esta representacion no es mas que destacar
la importancia de dos cosas: existen distintas informaciones para poder determinar la localizacion de un objeto y estas se
presentan ordenadas segun su contenido semantico
Seccion 6.2

pag.90 Localizacion inicial de contornos deformables
En la figura 6.4 se puede observar:
(A) La circunferencia puede ser modelizada mediante 8 rachas consecutivas que corresponden a los lados
de un octogono. Supongamos que R determina el radio del contorno celular y l la longitud de la
racha.
(B) Detectar una racha en la imagen implica determinar una posible localizacion del centro. En esta
localizacion podemos aplicar una zona de incertidumbre que asumiremos de forma circular con radio
r.
Ahora bien, ¿Como podemos definir el acumulador de evidencias?. Supongamos una forma con n
rachas ri de longitudes li (1 ≤ i ≤ n). Supongamos ademas que se han detectado en la imagen mi rachas
de longitudes Lij (1 ≤ j ≤ mi) evidenciando la existencia de la racha ri para una determinada posicion
p del acumulador. El valor para esta posicion puede ser calculado de una forma natural como:
E(p) =n∑
i=1
ai max1≤j≤mi
mınLij , li
li
(6.9)
donde
n∑
i=1
ai = 1 (6.10)
de forma que ai pondera cada una de las rachas considerando por tanto la importancia de detectar
una zona u otra del contorno. El resultado de la evaluacion es un valor en el intervalo [0, 1] que representa
la fraccion de curva localizada.
En el ejemplo que nos ocupa, realizaremos la ponderacion obvia
ai =1
n∀i (6.11)
para evaluar un acumulador definido sobre 2 dimensiones correspondientes a las traslaciones. Una
vez calculado, habra de escogerse el conjunto de puntos con valores superiores correspondientes a las
posiciones de mayor probabilidad y por tanto a las posiciones de los objetos a localizar. Como es de
esperar, la zona de incertidumbre provoca que estos maximos no se encuentren aislados sino que pueden
situarse en mesetas. La forma de escoger una aproximacion a la localizacion sera:
1. Seleccionar el punto central de la meseta. Es una operacion sencilla que se puede realizar mediante
una media de los puntos que pertenecen a esta.
2. Eliminar todos los puntos que se situen dentro del objeto detectado como puntos candidatos a
una nueva localizacion. Es una operacion necesaria pues el ruido, las deformaciones, y la forma de
votacion provocan una dispersion de votos a lo largo de las posiciones cercanas a las localizaciones
de los objetos.
Para ilustrar el proceso, consideremos los resultados ofrecidos en la figura 6.5. Cada una de las imagenes
consiste en:
(a) Imagen original.
(b) Imagen de aristas obtenida desde la imagen original a traves del filtro de Canny7 con σ = 1,0 y
valores de histeresis 0,5 y 0,9.
7Las aristas no se han obtenido con ningun enfoque multiescala. En este resultado solo se usa la informacion procedente
de una escala aunque como veremos mas adelante los resultados pueden ser mejorados.
Capıtulo 6

Disminucion del tamano del acumulador. pag.91
a c
d
b
e f
Figura 6.5: Resultados de la localizacion de celulas.
(c) Espacio de parametros. Resultado del calculo de E(p) superpuesto al conjunto de aristas. Como
se puede observar, los valores mas altos corresponden a situaciones cercanas a los centros de las
celulas.
(d) Umbralizacion del espacio de parametros. El valor umbral usado corresponde al 50% del valor
maximo (0,5 en el rango de posibles valores [0, 1]). Para este valor, todos los puntos obtenidos
corresponden a celulas en la imagen.
(e) Localizaciones. Posiciones de las celulas obtenidas en la imagen.
(f) Localizaciones sobre original. El lector puede observar como existen celulas que no han sido obtenidas
a causa de la falta de informacion desde la imagen de aristas. Como veremos posteriormente, us-
ar varias escalas permitira un manejo de mayor informacion que repercute en una mejora de los
resultados.
6.3. Disminucion del tamano del acumulador.
El problema mas importante en la solucion que se presenta procede del tamano tan grande que puede
llegar a tener el acumulador en caso de que el objeto a localizar pueda presentar grandes y variadas
deformaciones. Por ejemplo, considerese el caso de que en las imagenes de citologıas presentadas hasta
ahora pudieran encontrarse celulas muy achatadas, es decir, facilmente modelizables con una elipse pero
muy difıciles de representar con un contorno circular. En estos casos sera necesario contemplar estas
deformaciones pero para ello, deberemos aumentar la dimensionalidad del espacio de parametros (En el
Seccion 6.3

pag.92 Localizacion inicial de contornos deformables
caso de contornos celulares la nueva dimension del espacio es 5). Ahora bien, ¿Como podrıamos eliminar
este problema?. Podemos plantear dos soluciones8:
1. Eliminar los modos de deformacion local.
2. Muestrear el espacio de parametros de forma mas gruesa.
Como puede intuir el lector, el primer punto hace referencia a eliminar los modos de deformacion
menos importantes, es decir, aquellos que provocan una variacion menor en la localizacion del contorno
y que por tanto pueden ser asimilados por la zona de incertidumbre. En gran medida, esta solucion se
ha presentado en los resultados hasta ahora expuestos. Tengase en cuenta por ejemplo que las celulas
de la figura 6.5 pueden presentar cierto nivel de deformacion sin que los resultados se vean afectados.
Es claro, que esta solucion es solo parcial puesto que cuanto mayor sea esta zona, mayor ambiguedad se
presenta en la solucion y mayor sensibilidad al ruido (estructuras ruidosas en la imagen pueden localizarse
como contornos detectados). Por consiguiente, habra siempre un conjunto de modos de deformacion
que no podran ser eliminados puesto que provoca la creacion de una zona de incertidumbre de tamano
inaceptable. A pesar de ello, estos ejes de deformacion podran ser muestreados para obtener la disminucion
deseada.
6.3.1. Muestreo del espacio de parametros.
Para ilustrar el funcionamiento del metodo propuesto, consideraremos un contorno de mayor dificultad
que las formas elıpticas: El contorno de un nematodo. Determinaremos 14 nodos para la modelizacion de
deformaciones que induciran 28 ejes de deformacion (en la pagina 147 y siguientes se muestran los modos
de vibracion naturales) calculados segun se presento en el capıtulo anterior.
ba
Figura 6.6: Nematodos.
Para ilustrar la robustez del metodo a problemas tales como solapamientos, ruidos no aleatorios, etc.,
se detectaran dichas formas en imagenes construidas a tal efecto (vease figura 6.6)
Para conseguir un numero de posibles deformaciones manejable, consideraremos que disponemos de
una clasificacion de estas desde las mas globales a las mas locales denotadas segun la ecuacion 6.3. La
reduccion en el espacio de los parametros viene determinada por:
8Por supuesto, aplicar ambas soluciones permite el grado maximo de simplificacion del espacio de parametros.
Capıtulo 6

Disminucion del tamano del acumulador. pag.93
Eliminacion de los n−m ejes de deformacion menor.
Muestreo de los 3 +m ejes restantes.
En funcion del tamano de la zona de incertidumbre deseada. Podrıamos seleccionar muchas formas
de realizar este muestreo. Por ejemplo, un metodo muy simple de realizar este muestreo a partir de un
conjunto de muestras del objeto a localizar consiste en:
Determinar un tamano maximo de la zona de incertidumbre.
Eliminar ejes de deformacion comenzando desde el menos relevante hasta el mas importante mien-
tras la variacion de las muestras reconstruidas sin estos ejes sea menor que dicho valor maximo.
Muestrear los ejes restantes.
Bajar el nivel de muestreo de los ejes seleccionados mientras la variacion en las nuevas muestras
reconstruidas se encuentre dentro del rango permitido.
El resultado de esta operacion es un diccionario de posibles deformaciones base que pueden sufrir de
traslaciones y rotaciones. En el problema que nos ilustra el funcionamiento se ha llegado a determinar 7
ejes de deformacion:
Las 3 primeras correspondientes a las deformaciones rıgidas, es decir, a traslaciones y rotaciones.
Las 4 restantes a deformaciones no rıgidas. El muestreo realizado para conseguir un buen diccionario
de deformaciones base ha sido de (7, 3, 3, 3) respectivamente, es decir, desde el eje principal se han
obtenido 7 muestras equidistantes en el rango de posibles valores, del segundo eje, 3 muestras, etc.
Es conveniente resaltar la manejabilidad de este diccionario. Efectivamente, es sencillo una vez con-
struido realizar modificaciones tales como eliminacion o inclusion de nuevas posibilidades.
Los resultados obtenidos para las imagenes presentadas en la figura 6.6 se pueden ver en la figura 6.7.
En esta podemos distinguir:
Primera columna: Las imagenes de aristas. Para ilustrar el funcionamiento de estos algoritmos se
usara unicamente una escala. En esta columna se presenta el resultado del algoritmo de Canny
sobre una escala σ = 1,0 y umbrales de histeresis 0,5 y 0,9. Como puede verse, el resultado es un
conjunto de cadenas con una cantidad de ruido muy alta a partir de las cuales es muy difıcil obtener
buenos resultados si usamos algun algoritmo tradicional.
Segunda columna: Es difıcil si no imposible mostrar todo el espacio de parametros. Es necesario co-
mentar que, debido a la dimensionalidad, las imagenes correspondientes al espacio de los parametros
han sido construidas asignando a cada punto un nivel de gris g(x, y) proporcional al valor maximo
a lo largo de los ejes de rotacion y deformacion no rıgida, es decir,
g(x, y) ∝ maxr,d1,···,dn
E(x, y,r,d1, · · · ,dn) (6.12)
Tercera columna: Se representan los contornos solucion (maximos del espacio de parametros) sobre
la imagen original. Es de destacar como en la primera imagen (c), se ha detectado el contorno a
pesar de que el tamano de este no es correcto.
Es interesante observar, que al igual que se puede definir una zona de incertidumbre para cada pun-
to o zona del contorno, en general es posible definirla para cada deformacion base. Ademas, una vez
seleccionada la localizacion, es posible recuperar las cadenas que han votado en favor de esta.
Seccion 6.4

pag.94 Localizacion inicial de contornos deformables
a c
d
b
e f
Figura 6.7: Localizacion de nematodos.
6.4. Integracion de informacion multicanal.
En primer lugar, la forma de comunicacion entre canales mas inmediata ya ha sido comentada anterior-
mente: usar un espacio de escalas para la deteccion de aristas. Efectivamente, solo con los resultados de la
multihisteresis obtenemos mejores localizaciones (figura 6.8) que estudiando una unica escala (figura 6.5).
Es de destacar en los resultados que se presentan sobre la multihisteresis que:
1. Se han usado exactamente los mismos parametros. El incremento de las aristas de la imagen no es
debido a un cambio en los parametros(por ejemplo, los umbrales) sino a una mejora del metodo
de obtencion de aristas y por tanto garantiza mayor informacion sin tener que incluir una gran
cantidad de ruido.
2. Como se puede observar en los resultados, se han obtenido mejoras en:
a) Se han detectado dos nuevas celulas.
b) La informacion del espacio de los parametros es mas estable. Como podemos ver en la imagen
umbralizada (tambien al 50% al igual que en la figura 6.5) los puntos obtenidos localizan mejor
los centros de las celulas.
3. No se han detectado todas las celulas. Efectivamente, una de ellas no se ha localizado a pesar de
que parece ser muy clara. Si el lector comprueba las aristas que se han obtenido, se puede observar
que no son en absoluto suficientes aunque en estos ultimos resultados se posee mayor informacion.
Ademas una de las nuevas celulas se ha localizado con informacion bastante inestable (compruebese
que solo uno o dos pıxeles se han obtenido en la umbralizacion). Estas limitaciones se deben a:
Capıtulo 6

Integracion de informacion multicanal. pag.95
ed
cba
f
Figura 6.8: Resultados multi-histeresis de la localizacion de celulas.
a) La informacion no es suficiente. Sera conveniente estudiar la forma en que podemos manejar
un nivel superior de esta sin introducir una cantidad excesiva de ruido.
b) El contorno del objeto a localizar esta excesivamente deformado. Es posible que la zona de
incertidumbre sea demasiado pequena o sea necesario contemplar algun eje mas de deformacion.
Logicamente, una forma de mejorar la informacion que se posee consiste en usar varios canales si-
multaneamente para lo que debemos de plantear alguna solucion al problema de la integracion de infor-
macion.
6.4.1. Una solucion directa.
Una vez obtenidos los resultados del detector de aristas la forma mas simple de obtener las localiza-
ciones deseadas es aplicar los algoritmos anteriores a cada una de las escalas. El resultado por tanto es
un conjunto de posibles localizaciones para cada escala cada una de ellas provocada por un determinado
conjunto de aristas de la imagen.
Ahora bien, ¿Como podemos integrar la informacion del conjunto de canales?. Una forma inmediata
consiste en los siguiente pasos:
Particion del conjunto total de contornos localizados. Consiste en clasificar los subconjuntos de
contornos que se refieren a un mismo objeto a partir del conjunto total de contornos localizados en
todos los canales. Este paso no es de gran dificultad y para resolverlo existen diversos metodos que
funcionaran sin problema dado que la distancia entre los contornos que delimitan un mismo objeto
es pequena en relacion con la distancia de contornos que delimitan distintos objetos.
Seccion 6.4

pag.96 Localizacion inicial de contornos deformables
Para cada subconjunto de contornos que delimitan un mismo objeto hay que calcular una unica
curva que integre dicha informacion. Como el lector puede intuir, la forma mas obvia para obtener
esta es a traves de una media de los contornos. Para ello podemos realizar un alineamiento punto
a punto de los objetos y calcular la media o podemos establecer una correspondencia de los puntos
dominantes, realizar la media de estos e interpolar el conjunto resultante.
Aunque este solucion es simple y eficiente tiene la desventaja de que no es mas que obtener una
aproximacion que resume las distintas soluciones obtenidas a lo largo de las escalas. Es conveniente que
la informacion desde distintas fuentes coopere para obtener un resultado mejor.
6.4.2. Integracion por medio de la transformada de Hough modificada.
En el apartado anterior hemos visto una solucion simple al problema de combinar informacion desde
distintos canales. Ahora bien, la integracion de informacion se ha realizado con posterioridad a la deteccion
de los contornos. Esta forma de actuacion provoca que si en un determinado canal no se consigue detectar
cierto objeto, aunque se posea informacion parcial de dicha localizacion, esta informacion se perdera con
la posibilidad incluso de no localizar la curva.
Escala 2 Escala 3Escala 1
Localización de la formaUnión de información
Figura 6.9: Cooperacion entre escalas en la deteccion.
Efectivamente, considerese la situacion de la figura 6.9.En esta se muestra un caso ilustrativo de las
limitaciones de la metodologıa anterior. Como se observa, el intento de localizacion de la elipse en cada
uno de los 3 canales fallarıa debido a la falta de informacion. En cambio, como vemos en la union de los
tres canales, hay suficientes cadenas si se realiza un estudio de las 3 escalas simultaneamente localizando
la elipse como se muestra en la figura.
El algoritmo que proponemos en este trabajo usa los distintos canales a la vez resolviendo la co-
operacion entre escalas. El metodo consiste en tratarlas conjuntamente, es decir, en lugar de considerar
Capıtulo 6

Integracion de informacion multicanal. pag.97
todas las cadenas de una escala para la votacion en un determinado espacio de parametros, consideraremos
todas las cadenas de todas las escalas para esta votacion.
ed
cba
f
Figura 6.10: Integracion de informacion multicanal.
El resultado obtenido con este metodo se puede observar en la figura 6.10. En ella podemos distinguir
las siguientes imagenes:
(a) Imagen original sobre la que aplicar el metodo.
(b) Resultado de la union a traves de la proyeccion en una imagen de maxima precision de las distintas
imagenes de aristas de cada uno de los canales(vease capıtulo de obtencion de fronteras). Como
podemos ver, se posee informacion de todas las celulas completas que aparecen en la imagen.
(c) Union de las imagenes de aristas con el espacio de parametros. Efectivamente, tal como se observa
en la imagen, la mayor acumulacion de votos se localiza aproximadamente en los centros de las
celulas.
(d) Espacio de parametros sobre el que se realiza la busqueda de las localizaciones de las celulas.
(e) Resultado de la umbralizacion de la imagen (d) al valor correspondiente al 75% (0,75 en el rango
[0, 1] de posibles valores). Como el lector puede observar, directamente con este umbral bastante
alto obtenemos donde se encuentran las celulas menos deformadas (mas circulares) y con mayor
informacion (cadenas mas completas).
(f) Resultado de la umbralizacion de la imagen (d) al valor correspondiente al 50%(0,5 en el rango [0, 1]
de posibles valores). En este umbral se localizan todas las celulas de las que se posee informacion
suficiente como para delimitar su posicion y deformacion.
Seccion 6.4

pag.98 Localizacion inicial de contornos deformables
Por ultimo, es necesario destacar que aunque en este trabajo se ha realizado una integracion de infor-
macion a partir de las distintas imagenes gradiente obtenidas en cada escala considerada, los algoritmos
desarrollados pueden ser perfectamente aplicables a casos en que la informacion proceda de otras fuentes
(nivel de gris, texturas, color, etc.).
6.5. Resultados.
A continuacion se presentan los resultados obtenidos en la inicializacion de distintos contornos. Las
distintas imagenes que se presentan son:
Tipo I. Ejemplos sobre citologıas.
Ej.1.- Presenta un caso de multiples objetos donde su cercanıa puede ocasionar confusion en
el espacio de parametros.
En la primera figura (6.11) se observa la imagen original junto con el espacio de paramet-
ros que se obtiene desde la aproximacion octogonal del contorno elıptico. En el espacio
de parametros podemos observar como se han podido segmentar las multiples celulas
sin ningun tipo de ambiguedad.
En la siguiente figura (6.12) se presentan en primer lugar (imagen a) el resultado de
operar el espacio de parametros normalizado al rango [0−255] con la imagen original por
medio de la operacion maximo confirmando ası la correcta localizacion de los maximos
detectados, y en segundo lugar las celulas localizadas a partir de los maximos que se
extraen considerando una umbralizacion en 0,5 (de un rango posible [0, 1]).
Por ultimo, en las figuras 6.13 y 6.14 podemos ver la correspondencia entre la localizacion
de cada celula y las zonas de maximo ası como la situacion sobre la imagen original de
los contornos detectados (desde los 10 primeros maximos correspondientes a las celulas
mas seguras, hasta las 30 celulas que se obtienen con la umbralizacion de 0,5).
Ej.2.- Corresponde a una imagen con varias celulas, aunque en este caso de una variabilidad
mayor. Podemos observar como aunque el contorno a localizar es de un tamano fijo, la
localizacion de las celulas se determina correctamente a pesar de que alguna de ellas
corresponde a un tamano considerablemente distinto. Es interesante destacar (vease
el espacio de parametros, figura 6.15.a) que hemos tenido que incrementar el radio de
la zona de incertidumbre para contemplar una mayor variabilidad del contorno que,
como podemos ver en la figura 6.16, ahora corresponde a un polıgono de ocho lados con
algunas deformaciones (se ha incorporado un eje de deformacion no rıgida).
Tipo II. Ejemplos sobre nematodos. En esta forma es necesario contemplar varios ejes de deformacion
no rıgida9. Las imagenes que se muestran han sido construidas a partir de dos imagenes: una
de celulas para introducir ruido y la imagen del nematodo a detectar10.
Ej.1.- En este ejemplo se segmenta un nematodo que a pesar de que se encuentra parcialmente
oculto, se obtiene si ningun tipo de ambiguedad como se puede observar en el espacio
de parametros umbralizado (figura 6.18.a) con un valor de 0.75.
Ej.2.- En este caso, mostramos un ejemplo interesante en el que el contorno a detectar tiene un
grado de correspondencia muy alto a pesar de que pueda estar desviado de su localizacion
real mediante una rotacion de 180 grados. Si se observa en la figura 6.20, en la imagen
9Se han considerado 4 ejes de deformacion no rıgida con un muestreo de 7,3,3,3 respectivamente10El procedimiento ha consistido en primero dibujar el nematodo sobre la imagen de celulas y segundo dibujar de nuevo
los puntos por debajo de un umbral de la imagen de celulas sobre ese resultado.
Capıtulo 6

Resultados. pag.99
(a) podemos ver el resultado de umbralizar al valor de 0.75 el espacio de parametros;
se obtienen 2 localizaciones que corresponden a la real (parte inferior) y a otra desde
un contorno similar rotado. Obviamente, la de mayor valor establece la segmentacion
correcta como se puede ver en la ultima imagen.
Tipo III. Ejemplos sobre manos.
Ej.1.- En este ejemplo (y siguientes) se muestra como el metodo consigue realizar una primera
aproximacion a la solucion a pesar de que se dispone unicamente de informacion parcial.
Como veremos mas adelante en la parte de optimizacion, en esta imagen se dispone
realmente de muy poca informacion para localizar los dos dedos que se encuentran casi
ocultos. Es interesante observar que la mano en el primer plano se ha aproximado en
gran medida y que la segunda, aunque no tan perfectamente, posee una localizacion
bastante cercana a la deseada.
Ej.2.- Este caso es similar al anterior aunque con un solapamiento en una direccion distinta.
Ahora, en la mano posterior, la informacion en uno de los dedos es nula, y las dos manos
se situan paralelamente de forma que pueden provocarse confusiones. A pesar de ello,
el metodo consigue una buena aproximacion para ambas manos.
Ej.3.- Un ultimo ejemplo de este tipo de problematica refleja un comportamiento similar a
los dos anteriores. La localizacion aproximada es buena aunque necesitara de una opti-
mizacion final para localizar definitivamente la forma.
Ej.4.- En este ejemplo se han cambiado las condiciones de la imagen. Ahora contemplamos
no solo problemas de solapamiento sino que anadimos una fuerte componente ruidosa.
La imagen ha sido generada mediante la adicion de ruido de sal y pimienta de forma
aleatoria en un 50% de los puntos de la imagen produciendo una relacion senal-ruido
R =S
S +N= 0,4996 ≈ 0,5 (6.13)
Como podemos ver en la figura 6.27 (imagen b), el mapa de aristas se ve fuertemente
degradado de forma que pocas aristas quedan estables lo que obviamente afecta al espa-
cio de parametros que refleja una situacion de mayor ruido que en los casos anteriores.
Sin embargo, la inicializacion que refleja la figura 6.28 (imagen b) es bastante buena.
Ej.5.- De nuevo ilustramos una situacion ruidosa en las mismas condiciones que el ejemplo
anterior para concluir que efectivamente, el metodo obtiene unos resultados igualmente
bastante buenos a pesar de que la imagen se vea afectada por un nivel de ruido bastante
alto (relacion senal-ruido R = 0,5024 ≈ 0,5).
Ej.6.- Por ultimo se muestra un ejemplo mas complejo en lo que a solapamiento y falta de
informacion se refiere, considerando una imagen que contiene 3 manos.
Seccion 6.5

pag.100 Localizacion inicial de contornos deformables
6.5.1. Ejemplos sobre citologıas.
Ejemplo 1
(b)(a)
Figura 6.11: (a) Original. (b) Espacio de parametros.
(b)(a)
Figura 6.12: (a) Situacion de los maximos. (b) Celulas detectadas.
Capıtulo 6

Resultados. pag.101
Ejemplo 1 (continuacion)
(b)(a)
Figura 6.13: (a) Celulas detectadas. (b) Las 10 primeras celulas.
(b)(a)
Figura 6.14: (a) Las 20 primeras celulas. (b) Celulas detectadas.
Seccion 6.5

pag.102 Localizacion inicial de contornos deformables
Ejemplo 2
(b)(a)
Figura 6.15: (a) Original. (b) Espacio de parametros.
(b)(a)
Figura 6.16: (a) Celulas detectadas. (b) Celulas detectadas sobre la imagen original.
Capıtulo 6

Resultados. pag.103
6.5.2. Ejemplos sobre nematodos.
Ejemplo 1
(b)(a)
Figura 6.17: (a) Original. (b) Espacio de parametros.
(b)(a)
Figura 6.18: (a) Esp. de parametros umbralizado a 0.75. (b) Resultado.
Seccion 6.5

pag.104 Localizacion inicial de contornos deformables
Ejemplo 2
(b)(a)
Figura 6.19: (a) Original. (b) Espacio de parametros.
(b)(a)
Figura 6.20: (a) Espacio de parametros umbralizado a 0.75. (b) Resultado.
Capıtulo 6

Resultados. pag.105
6.5.3. Ejemplos sobre manos.
Ejemplo 1
(b)(a)
Figura 6.21: (a) Original. (b) Fronteras.
(b)(a)
Figura 6.22: (a) Espacio de parametros. (b) Resultado sobre la imagen original.
Seccion 6.5
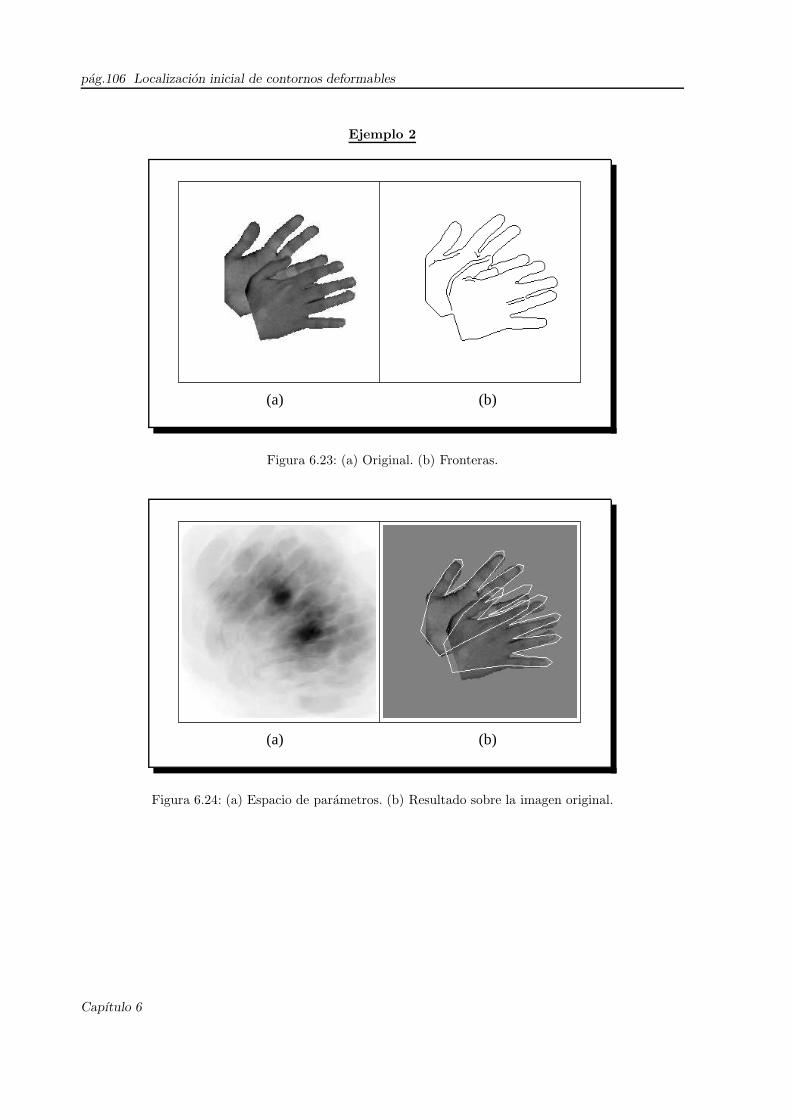
pag.106 Localizacion inicial de contornos deformables
Ejemplo 2
(b)(a)
Figura 6.23: (a) Original. (b) Fronteras.
(b)(a)
Figura 6.24: (a) Espacio de parametros. (b) Resultado sobre la imagen original.
Capıtulo 6

Resultados. pag.107
Ejemplo 3
(b)(a)
Figura 6.25: (a) Original. (b) Fronteras.
(b)(a)
Figura 6.26: (a) Espacio de parametros. (b) Resultado sobre la imagen original.
Seccion 6.5

pag.108 Localizacion inicial de contornos deformables
Ejemplo 4
(b)(a)
Figura 6.27: (a) Original. (b) Fronteras.
(b)(a)
Figura 6.28: (a) Espacio de parametros. (b) Resultado sobre la imagen original.
Capıtulo 6

Resultados. pag.109
Ejemplo 5
(b)(a)
Figura 6.29: (a) Original. (b) Fronteras.
(b)(a)
Figura 6.30: (a) Espacio de parametros. (b) Resultado sobre la imagen original.
Seccion 6.5

pag.110 Localizacion inicial de contornos deformables
Ejemplo 6
(b)(a)
Figura 6.31: (a) Original. (b) Fronteras.
(b)(a)
Figura 6.32: (a) Espacio de parametros. (b) Resultado sobre la imagen original.
Capıtulo 6

Capıtulo 7
Optimizacion de la localizacion
PARA obtener la localizacion exacta de un objeto en la imagen necesitamos un metodo adicional que
ajuste las aproximaciones obtenidas segun los algoritmos propuestos en el tema anterior sobre los
maximos de la imagen gradiente, es decir, en la posicion de las aristas de la imagen.
Este problema se traduce en la determinacion de un metodo de optimizacion de las aproximaciones.
Existen multitud de tecnicas en la literatura que tratan este problema considerando tanto informacion del
modelo (vease pag. 5) como restricciones acerca de la forma del contorno; ası como distintos algoritmos
de optimizacion: ascension de colinas, algoritmos geneticos, simulate annealing, modelizaciones fısicas,
etc. Logicamente, en estos trabajos ha sido necesario definir algun tipo de funcion de energıa o funcion de
potencial sobre las distintas realizaciones del contorno buscado que junto con un posible modelo a priori
nos determine la superficie de optimizacion.
En este capıtulo vamos a tratar de resolver el problema de optimizar la solucion inicial obtenida
planteando distintas posibilidades sobre alguna funcion de energıa que se adapte al tipo de informacion
que nos proporciona una imagen de aristas, sin descartar (como mas adelante veremos) que sea enriquecida
con informacion adicional desde un planteamiento basado en regiones. Ademas se propondra una algoritmo
de optimizacion que generaliza el metodo de deteccion expuesto en el tema anterior a fin de obtener una
localizacion mucho mas exacta y cercana a la solucion que se desea encontrar.
7.1. Mejora de la localizacion inicial.
Uno de los mayores problemas del uso de modelos deformables para la deteccion de objetos en una
imagen es realizar una inicializacion incorrecta. Efectivamente, la funciones de potencial que son usadas
en estos algoritmos no son convexas y el exito en la deteccion de optimos depende de forma directa
del punto inicial usado en el algoritmo de optimizacion. Debido a su gran importancia, es necesario
replantearse si la localizacion inicial de la forma puede ser mejorada de manera que se pueda garantizar
un resultado correcto en la optimizacion sin necesidad de recurrir a algoritmos de un coste computacional
excesivamente alto, y en el caso de que esto sea necesario, partir de una localizacion suficientemente
buena como para que estos algoritmos requieran pocos pasos.
7.1.1. Incremento de la precision.
La solucion mas inmediata y mas exigente con las condiciones del problema a resolver consiste en
contemplar una mayor precision en el algoritmo de inicializacion por medio de un incremento en el
numero de ejes de deformacion y/o muestreo de estos.
Como hemos visto anteriormente, la gran dimensionalidad del espacio de parametros ası como una
111

pag.112 Optimizacion de la localizacion
amplitud grande en el rango de posibles valores en cada una de estas dimensiones nos obligaba ha
realizar una simplificacion en el dominio de la solucion que se traducıa en una mayor eficiencia hasta
niveles aceptables al calcular la primera aproximacion del contorno a la solucion.
Consideremos por ejemplo la localizacion de la formas circulares de las celulas. Como hemos visto,
ha sido posible resolver el problema simplificando el espacio de los parametros hasta las dos dimensiones
correspondientes al desplazamiento. Esta simplificacion hace el metodo de deteccion muy simple y efi-
ciente pero por otro lado ofrece resultados en los que la solucion final se encuentra bastante lejana a la
inicializacion y a pesar de que no existe ambiguedad con la celula detectada, un metodo de optimizacion
que opere con una funcion de potencial sensible al ruido en la imagen (considerese por ejemplo la imagen
gradiente con un valor de escala bajo) puede estancarse en un mınimo local. La solucion mas inmediata
que nos ocupa sera la inclusion de mas ejes de deformacion en esta inicializacion.
Obviamente, si incrementamos la precision en el algoritmo de inicializacion nos aproximamos a la
solucion mediante la transformada de Hough clasica aplicada sobre los ejes de deformacion determinados.
Con ello, haremos el algoritmo cada vez mas ineficiente ya que nos encontraremos con las dificultades
propias de la transformada de Hough y por tanto las condiciones que deberan ser exigidas al problema
llegaran a ser inaceptables para muchas aplicaciones.
7.1.2. Extraccion de la informacion para cada objeto.
Un primer paso para poder mejorar los resultados desde la informacion de aristas es seleccionar aque-
llas que estan directamente involucradas en la localizacion del objeto, es decir,si intentamos aplicar una
segunda fase de mejora de la localizacion inicial, una forma de simplificarla sera considerando unicamente
las cadenas de aristas que han votado en la seleccion de una determinada posicion.
ed
cba
f
Figura 7.1: Extraccion de informacion para cada objeto.
Capıtulo 7

Mejora de la localizacion inicial. pag.113
Una forma de realizar este procedimiento es almacenar para cada posicion del espacio de los parametros
las cadenas que van afectando a dicha posicion. Obviamente, este algoritmo sufre de una alta ineficiencia
respecto al espacio requerido. Por ello, es necesario realizar una segunda iteracion sobre las cadenas
(tengase en cuenta que es posible simplificar el numero de cadenas de esta vuelta ya que teniendo la
posicion del objeto muchas de ellas son directamente descartables) de forma que la eficiencia del algoritmo
no se ve afectada.
En la figura 7.1 se presenta un ejemplo de esta operacion. En las posiciones a y b se pueden observar
la imagen original y una imagen de aristas. En las restantes (c a f) se muestran las imagenes de aristas
que se han extraıdo para las 4 primeras celulas obtenidas.
7.1.3. Uso de un modelo geometrico.
Una vez que hemos determinado las cadenas que votan por una determinada localizacion, es posible
construir un algoritmo de mejora en la aproximacion si consideramos un posible modelo geometrico de
nuestro objeto (considerese por ejemplo que se dispone de un algoritmo de aproximacion del contorno
desde una nube de puntos mediante un enfoque por mınimos cuadrados).
Un ejemplo sencillo de esta opcion viene dado por las imagenes de citologıas. En este caso podemos
aproximar el contorno por medio de una elipse. El algoritmo de aproximacion consta de dos fases:
1. Obtencion de una primera estimacion
2. Minimizacion del error cometido.
Obteniendose un resultado como el mostrado en la figura 7.2
Figura 7.2: Estimacion elıptica de la localizacion de celulas.
Las expresiones que han sido usadas en esta estimacion se presentan en los apendices de esta memoria
(vease pagina 151) con las que se han estimado los parametros de la expresion
(r − a
c− b
)t(A B
B C
)(r − a
r − b
)= 1 (7.1)
Seccion 7.1

pag.114 Optimizacion de la localizacion
7.1.4. Un algoritmo de enfoque.
El tamano potencialmente alto del espacio de parametros nos sugiere el uso de un algoritmo que maneje
informacion multiresolucion. En la literatura podemos encontrar diversos algoritmos que representan el
espacio de parametros por medio de una estructura jerarquica (vease [Kalvianen et al. 94]) pero que
registran algunos inconvenientes:
El metodo tiene problemas si el maximo en el espacio de parametros esta cerca de la frontera de
un hipercubo a una baja resolucion.
Hay que determinar un metodo para seleccionar los hipercubos sobre los que hay que iterar a
mas baja resolucion. Si usamos un umbral, es posible que en un hipercubo haya pocos votos pero
corresponden a un unico punto del espacio de parametros a mas alta resolucion. En cambio, si hay
muchos votos es posible que esten dispersos a mayor resolucion.
Extraen las curvas una a una, repitiendo el proceso cada vez que se quiere obtener una nueva.
Algunos algoritmos estan disenados para un tipo particular de curvas. (Por ej. rectas).
La reformulacion de la transformada de Hough presentada en este trabajo nos permite formular un
algoritmo de enfoque que aprovecha una resolucion cada vez mas alta en cada iteracion para obtener la
localizacion de contornos sin sufrir los inconvenientes anteriormente expuestos.
Cada uno de los l niveles de resolucion se situan entre:
El nivel de menor resolucion(nivel 1). Contiene un muestreo grueso de los ejes de deformacion y
contempla incluso la eliminacion de los menos relevantes (es decir, un muestreo de 0 puntos). Cal-
cular la localizacion de los contornos buscados en este nivel implica usar una zona de incertidumbre
de tamano maximo que dependera del problema y la resolucion seleccionada. Obtener un valor alto
en el espacio de parametros de este nivel corresponde a una localizacion aproximada de la forma.
El nivel de mayor resolucion(nivel l). Se construye en base a un muestreo fino de los ejes de defor-
macion que puede incluso incluir los ejes de deformacion local en el caso extremo. Obviamente, la
zona de incertidumbre que se crea a este nivel es de menor tamano que en los anteriores y permite
la localizacion mas exacta.
El algoritmo por tanto consiste en iterar desde el nivel 1 hasta el nivel l estudiando en cada iteracion
solo las zonas del nivel anterior que han sobrepasado cierto umbral (en el nivel 1 la zona a estudiar
abarca todas las posibilidades). Obviamente, en los primeros niveles se obtendran muchos puntos que no
corresponden a localizaciones del contorno pero a su vez se eliminaran muchos otros en los que tendremos
garantıa de que no existe el contorno a localizar y muchas aristas que no participan en la votacion de las
zonas seleccionadas para la siguiente iteracion.
Este algoritmo no solo nos permite localizar un objeto con posibles deformaciones de una manera
eficiente sino que ademas, puede obtener formas con un grado de desviacion asociado. Efectivamente,
supongamos la deteccion de elipses en una imagen. Podemos seleccionar varios niveles de resolucion,
desde el mas grueso que podrıa consistir en el algoritmo mostrado para obtener los resultados de la
figura 6.5 hasta el mas fino que determina traslacion, eje mayor, eje menor y rotacion. Una vez localizado
una zona de posible localizacion en el nivel i, puede ocurrir:
El contorno tambien es detectado en una localizacion mas fina en el nivel i + 1. En este caso nos
interesa esta nueva posicion pues es mas exacta.
El contorno no se localiza en el nivel i+ 1 y por tanto su mejor localizacion esta situada a nivel i.
Capıtulo 7

Mejora de la localizacion inicial. pag.115
La situacion de la mejor localizacion determina el grado de desviacion asociado al contorno. Si es
el nivel l la desviacion al contorno teorico es mınima. Cuanto menor sea el nivel, mayor desviacion del
contorno teorico poseera.
7.1.4.1. Un ejemplo ilustrativo.
Veamos un ejemplo sencillo aplicado a las formas elıpticas que aparecen en una imagen de celulas. La
imagen test que se propone se caracteriza por una gran cantidad de ruido, solapamiento y variabilidad
de formas (particularmente en lo que respecta a tamano de las celulas).
cba
Figura 7.3: Aristas y espacio de parametros.
En la figura 7.3 se puede ver la imagen original junto con un posible mapa de aristas (que corresponde
a un nivel de escala σ = 2) y el espacio de parametros, resultado de aplicar el algoritmo descrito en el
capıtulo anterior considerando solo desplazamientos de un contorno a localizar de deformacion cero.
El hecho de usar unicamente dos ejes de deformacion hace necesaria una zona de incertidumbre de un
tamano considerable a fin de que los valores que se obtienen en el espacio de parametros para localizaciones
correctas de celulas sean suficientemente altos como para que se obtengan en la umbralizacion(vease
figura 7.4). Obviamente, si usamos estos resultados para plantear las posibles posiciones iniciales de
nuestros contornos deformables, las celulas son fijadas en unas posiciones bastante inexactas.
Ahora bien, estos resultados pueden ser mejorados mediante el algoritmo de enfoque, es decir, usando
las zonas de posible localizacion que se obtienen de la umbralizacion del espacio de parametros en una
segunda iteracion, en la que el numero de ejes de deformacion se aumenta a fin de mejorar los resultados.
Las principales ventajas que obtenemos en esta segunda vuelta son:
Se puede aplicar el algoritmo de forma independiente a cada una de las zonas(o hipercubos si ası se
delimitan) que se han obtenido en el primer paso favoreciendo por tanto la implementacion paralela.
El numero de puntos en los que hay que realizar la busqueda se ve enormemente disminuido y por
tanto permite la incorporacion de nuevos ejes de deformacion sin degradar la eficiencia del sistema
(vease la figura 7.4 en la que se observa que la gran mayorıa de puntos en el espacio de parametros
se concentran en los valores mas bajos del histograma).
Ademas, los datos a usar tambien disminuye si hacemos una seleccion de las aristas que han con-
tribuido a cada una de las regiones.
Seccion 7.2
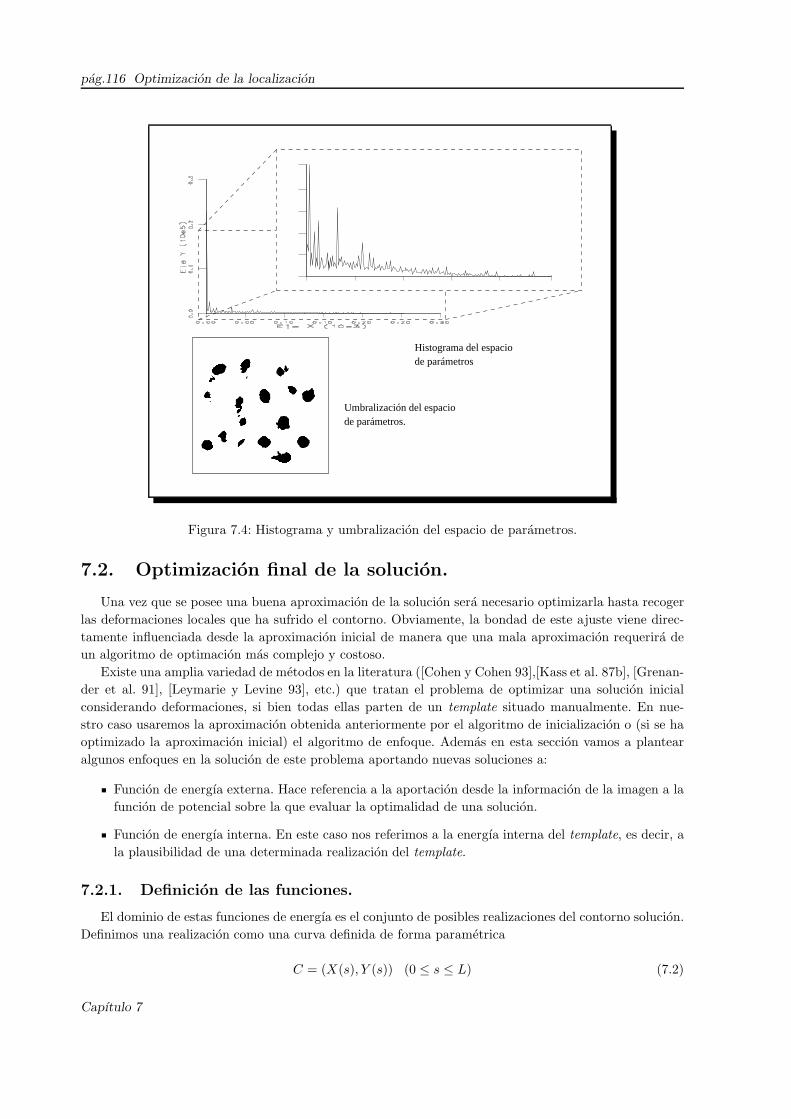
pag.116 Optimizacion de la localizacion
Umbralización del espacio
de parámetros
de parámetros.
Histograma del espacio
Figura 7.4: Histograma y umbralizacion del espacio de parametros.
7.2. Optimizacion final de la solucion.
Una vez que se posee una buena aproximacion de la solucion sera necesario optimizarla hasta recoger
las deformaciones locales que ha sufrido el contorno. Obviamente, la bondad de este ajuste viene direc-
tamente influenciada desde la aproximacion inicial de manera que una mala aproximacion requerira de
un algoritmo de optimacion mas complejo y costoso.
Existe una amplia variedad de metodos en la literatura ([Cohen y Cohen 93],[Kass et al. 87b], [Grenan-
der et al. 91], [Leymarie y Levine 93], etc.) que tratan el problema de optimizar una solucion inicial
considerando deformaciones, si bien todas ellas parten de un template situado manualmente. En nue-
stro caso usaremos la aproximacion obtenida anteriormente por el algoritmo de inicializacion o (si se ha
optimizado la aproximacion inicial) el algoritmo de enfoque. Ademas en esta seccion vamos a plantear
algunos enfoques en la solucion de este problema aportando nuevas soluciones a:
Funcion de energıa externa. Hace referencia a la aportacion desde la informacion de la imagen a la
funcion de potencial sobre la que evaluar la optimalidad de una solucion.
Funcion de energıa interna. En este caso nos referimos a la energıa interna del template, es decir, a
la plausibilidad de una determinada realizacion del template.
7.2.1. Definicion de las funciones.
El dominio de estas funciones de energıa es el conjunto de posibles realizaciones del contorno solucion.
Definimos una realizacion como una curva definida de forma parametrica
C = (X(s), Y (s)) (0 ≤ s ≤ L) (7.2)
Capıtulo 7

Optimizacion final de la solucion. pag.117
La definicion de estas funciones sera:
Para la funcion de energıa externa Eext(C) construiremos una funcion de potencial P (x, y) que
asocia a cada punto de la imagen una valor que sera tanto mas pequeno cuanto mas probable sea
su pertenencia al conjunto de puntos que describen la solucion optima. Como consecuencia de ello,
la funcion de energıa externa se puede definir en terminos del valor acumulado de energıa en todos
los puntos de la curva C normalizado por la longitud de esta, es decir:
Eext(C) =1
L
∫ L
0
P (X(s), Y (s))ds (7.3)
Logicamente es posible anadir nuevos terminos correspondientes a aportaciones que provienen de
distintas fuentes:
Eext(C) =
n∑
i=1
kiEiext(C) (7.4)
O en general como
Eext(C) = H(E1ext(C), · · · , En
ext(C)) (7.5)
donde H es una funcion que integra la informacion desde las n fuentes que deseamos tener en
cuenta.
Para definir la funcion de energıa interna Eint(C) debemos de establecer un criterio que nos mida
el grado de pertenencia del contorno C a la familia de objetos deformados que modelizamos, y que
podemos formular en terminos de una distancia entre la realizacion concreta C y esta familia (o
una curva media que la represente).
7.2.2. Funcion de energıa externa desde las fronteras.
Dado que el enfoque realizado en este trabajo esta centrado en el uso de informacion proporcionada
por las aristas para obtener la localizacion del objeto, la primera opcion que podrıamos considerar para
definir la funcion de energıa externa es la magnitud del gradiente, es decir,
P (x, y) = −‖∇g(x, y)‖ (7.6)
Una solucion mas robusta frente al ruido que esta consiste en determinar una familia de funciones de
potencial ordenadas por la escala de forma que se realiza una optimizacion desde las escalas mas altas
hasta las mas finas ([Burt 81], [Leymarie y Levine 93]).
Los problemas de esta solucion son:
La funcion correspondiente a la magnitud del gradiente puede tener un nivel muy alto de ruido.
Efectivamente, en ella apareceran nuevos maximos locales en direccion del gradiente que puede
confundir al metodo por lo que es mas recomendable usar este tipo de informacion cuando queramos
realizar un ultimo ajuste una vez asegurada la cercanıa a la solucion.
No se usa toda la informacion que nos ofrece el gradiente ya que obviamos la componente de
direccion.
Desperdiciamos la informacion obtenida en las etapas anteriores referente a las principales aristas
que determinan la localizacion del objeto.
Seccion 7.2

pag.118 Optimizacion de la localizacion
Veamos la forma en que podemos resolver estos problemas formulando una funcion de energıa que sea
robusta al ruido y que facilite el problema al algoritmo de optimizacion.
7.2.2.1. Energıa desde las aristas.
Una forma de construir un potencial desde las aristas obtenidas en la deteccion de fronteras es estable-
cer que los puntos correspondientes a estas tengan un potencial mınimo (p. e. cero) y vaya aumentando
en los puntos conforme se alejan de estas aristas.
Una forma muy eficiente de construir esta funcion es obteniendo la funcion d(x, y) correspondiente a
la distancia entre el punto (x, y) y el punto frontera(del conjunto de aristas A) mas cercano a el1(vease
figura 7.5):
d(x, y) = mın(r,s)∈A
‖(x, y)− (r, s)‖ (7.7)
Aristas Distancia a la arista más cercana
Figura 7.5: Distancia a la arista mas cercana.
A partir de ella, el potencial en un punto (x, y) se puede definir como dicha distancia, determinando
de esta forma un potencial 0 en los aristas y creciente conforme nos alejamos de estas. Obviamente, se
pueden construir un conjunto infinito de funciones ([Cohen y Cohen 93]) a partir de esta estableciendo:
P (x, y) = f(d(x, y)) (7.8)
donde f(x) es una funcion creciente que determina la forma en que varıa el potencial con respecto a
la distancia al punto frontera mas cercano y por lo tanto la forma del gradiente de la funcion potencial
(∇P = f ′(d(x, y))∇d(x, y)).
La desventaja en el uso de este potencial es que no se pondera la importancia de las cadenas dado
que cualquiera de ellas determina igualmente puntos de energıa mınima (de valor cero). Una forma de
tener en cuenta este aspecto consiste en ponderarlas con la magnitud del gradiente de cada punto. En
este caso la funcion P (x, y) viene dada por la expresion:
P (x, y) = mın(r,s)∈A
I(r, s) + f(‖(x, y)− (r, s)‖) (7.9)
donde la funcion I es la funcion de ponderacion que en el caso que nos ocupa se define como
I(r, s) = −‖∇g(r, s)‖ (7.10)
1Esta operacion se puede implementar eficientemente realizando unicamente 4 pasadas sobre la imagen binaria.
Capıtulo 7

Optimizacion final de la solucion. pag.119
.
Notese que la funcion P (x, y) = f(d(x, y)) es un caso particular de esta en la que la funcion de
ponderacion es la funcion constante cero.
Es interesante destacar dos comentarios acerca de esta nueva funcion:
Un punto (x, y) que es arista no tiene que permanecer con un nivel de potencial −‖∇g(x, y)‖ ya
que si se situa suficientemente cerca de un punto con mucho menor potencial el valor resultante en
(x, y) se vera disminuido. Esta consecuencia es muy razonable ya que la funcion de energıa debe de
guiar el contorno que se esta fijando hacia los puntos arista de mayor relevancia.
La funcion f(x) cobra especial relevancia en este caso ya que puede ser usada para ponderar
la importancia de la magnitud del gradiente en relacion con la distancia al punto frontera. Si
consideramos una funcion f(x) que crece muy rapidamente (por ej, f(x) = mx con m muy alto)
las aristas de la imagen seran muy independientes ya que dos puntos frontera cercanos podran
permanecer con un potencial correspondiente a la magnitud de su gradiente. Si por el contrario el
valor de m es muy pequeno el radio de accion de una arista sera mucho mas amplio de manera que
una arista puede sobrevalorarse frente a otra a pesar de que esten distantes.
7.2.2.2. Mejora a partir de la direccion del gradiente.
Aunque usar la magnitud del gradiente permite introducir nueva informacion en la funcion de energıa,
todavıa es posible mejorar los resultados mediante el uso de la direccion del gradiente2. El sistema se
vera mejorado en dos aspectos:
Si la imagen de aristas contiene diferentes cadenas cercanas (ya sea de un mismo objeto, de objetos
cercanos o incluso solapados) la informacion de la direccion del gradiente puede evitar que la
solucion se acerque hacia cadenas que serıas erroneas ya que la curva que describe el objeto se
vera influenciada de igual forma por cadenas de una direccion como de otra. Por ejemplo, en la
parte superior de la figura 7.6 se observa un caso en el que el punto p se vera atraıdo hacia los
puntos a, b, c si no se usa la direccion del gradiente (en cuyo caso unicamente sera atraıdo por el
punto a).
La funcion de energıa se ve modificada de manera que la solucion se dirige de forma mas directa
hacia la solucion mejorando su comportamiento en situaciones que hasta ahora eran mucho mejor
tratadas en un enfoque basado en regiones([Ronfard 94]). Por ejemplo, en la parte inferior de la
figura 7.6 se observa un caso en el que el punto p de la curva a optimizar se vera atraıdo hacia los
lados. En caso de que contemplemos la direccion del gradiente o un enfoque orientado a regiones
las fuerzas que actuaran sobre el contorno seran las reflejadas en la parte derecha.
Debemos por tanto definir una funcion que tenga en cuenta este aspecto. La solucion que se ha
adoptado en este trabajo ha sido anadir una nuevo eje a la funcion de potencial P que se mueve en el
intervalo [−π, π]:
P (x, y, θ) = mın(r,s)
I(r, s) + h(‖(x, y)− (r, s)‖, θ) (7.11)
de forma que la funcion de energıa establecida en la ecuacion 7.3 queda como sigue:
Eext(C) =1
L
∫ L
0
P (X(s), Y (s), θ(s))ds (7.12)
2Recordemos que los resultados en el procesamiento de las cadenas a lo largo de los capıtulos anteriores ha sido mucho
mas fructıfero considerando esta informacion (tanto en la etapa de preprocesamiento como en la etapa de inicializacion)
Seccion 7.2

pag.120 Optimizacion de la localizacion
Imagen original Aristas Curva a fijar
a b c p
p
Localización inicial Fuerzas de atracción
Figura 7.6: Uso de la direccion del Gradiente.
donde θ(t) se define como el angulo formado por los vectores:
∇g(X(t), Y (t)) y
(−dy
ds(t),
dx
ds(t)
)(7.13)
La definicion mas sencilla para la funcion h(x, θ) y que solucionarıa los casos expuestos en la figura 7.6
es:
h(x, θ) =
f(x) Si −π
2 ≤ θ ≤ π2
+∞ en caso contrario(7.14)
En la figura 7.7 se muestran los resultados para esta funcion h(x, θ) usando las funciones f(x) = x e
I(r, s) = 0. En esta figura se representa la imagen de aristas obtenida desde un circulo y las proyecciones
sobre dos valores concretos del angulo θ (el blanco corresponde a valores cero y el negro a valores positivos).
Capıtulo 7

Optimizacion final de la solucion. pag.121
Aristas Angulo .π/2Angulo 0
Figura 7.7: Ejemplo de funcion h(x, θ).
7.2.3. Funcion de energıa externa desde otras fuentes.
En la seccion anterior nos hemos centrado en proponer una funcion de energıa que se base en la
informacion obtenida a partir de un detector de aristas. Obviamente, el tipo de informacion que podemos
usar para medir la optimalidad de la fijacion de nuestro contorno puede provenir de muchas y muy distintas
fuentes. Supongamos por ejemplo que manejamos imagenes de niveles de gris, es deseable que el nivel
en el interior del objeto que estamos segmentando sea lo mas homogeneo posible, o si usamos imagenes
en color (con tres bandas RGB o su equivalente HSV) sera una aproximacion aun mejor cuanto menos
heterogeneidad de colores exista. Un razonamiento similar puede ser aplicado a otro tipo de caracterısticas
tales como imagenes multibanda, texturas, etc. Ası, es interesante destacar la posibilidad de usar otro
tipo de informacion que de forma mas natural se incorpora desde un planteamiento basado en regiones.
Tradicionalmente, la naturaleza de la aplicacion a disenar ha determinado el tipo de funcion de energıa
que se podrıa usar para optener una solucion mas eficaz, ya sea basada en gradientes o en regiones. Ası por
ejemplo, en aplicaciones donde existe una distorsion alta del gradiente (por ejemplo, provocada por el
ruido), los metodos basados en regiones se presentan mas convenientes. Por otro lado, si se presentan otros
problemas tales como solapamientos, los metodos basados en fronteras pueden resultar mas efectivos.
Considerando la lınea que hemos seguido a lo largo de esta memoria, es interesante tener en cuenta una
colaboracion entre la informacion de fronteras y regiones a fin de conseguir un metodo de optimizacion
mas eficaz. Para ello consideremos primero que tipo de medidas podemos realizar sobre las imagenes que
nos ocupan para obtener el grado de optimalidad (en lo que a regiones se refiere) de una determinada
realizacion del contorno a fijar.
Si planteamos la homogeneidad del interior del contorno como la medida que nos indica si la region
contenida en el objeto es mas o menos optima, el calculo mas sencillo para considerar este tipo de
informacion es una medida de dispersion de los datos en la region interior (Rin). Por ejemplo, el cuadrado
de las desviaciones de los niveles de gris I(x, y)
V =
∫
Rin
(I(x, y)− µ)2
∫
Rin
dxdy
µ =
∫
Rin
I(x, y)dxdy
∫
Rin
dxdy
(7.15)
que determina la region optima como la de valor constante (varianza nula), aunque se pueden plantear
situaciones mas complejas como por ejemplo considerar que la regıon optima puede contener valores que
varıan conforme un plano3([Beaulieu y Goildberg 89]) de manera que la energıa puede ser medida como
los cuadrados de los errores (distancia al plano) o en esta misma lınea, calcular
3Pensemos en una escena donde la iluminacion se va degradando de un punto a otro de forma que un mismo objeto
puede presentar zonas brillantes y oscuras simultaneamente
Seccion 7.2

pag.122 Optimizacion de la localizacion
V =
∫
Rin
∇2I(x, y)dxdy (7.16)
El problema de usar estas medidas en un metodo de optimizacion de objetos deformables se plantea
cuando consideramos que los contornos tienden a contraerse ya que cuanto menor sea la superficie que
recoja la curva, mayor homogeneidad presenta. Esto nos lleva a considerar que la optimalidad de una
region no viene determinada unicamente por su interior, sino tambien por su exterior ([Grenander et al.
91], [Ronfard 94]) de forma que la contraccion del contorno redundara en una degradacion de la medida
exterior. Ası por ejemplo, en [Grenander et al. 91] se define la energıa como la suma de las varianzas
interna y externa al objeto para segmentar imagenes ruidosas de manos. Tambien es interesante destacar
el trabajo presentado en [Ronfard 94] en el que plantea una solucion para el uso de informacion de regiones
sobre contornos activos (inicialmente formulados usando imagenes gradiente) mediante el estudio de la
distancia de Ward([Ward 63]) entre dos regiones Rin y Rout
D(Rin, Rout) = W region(Rin +Rout)−W region(Rin)−W region(Rout) (7.17)
donde W region(R) se define como la funcion de energıa sobre una region.
Otra solucion muy interesante para usar informacion de regiones es construir una funcion de energıa
Eext(C) = H(EFext(C), ER
ext(C)) (7.18)
que simultaneamente use las fronteras (EFext(C)) y regiones(ER
ext) de manera que el procedimiento
sea capaz de optimizar la solucion inicial correctamente a pesar de que alguna de estas informaciones
sea pobre. El problema de esta solucion es determinar la forma en que pueden integrarse en una unica
funcion varias medidas de distinta naturaleza. Para solventar este problema, es necesario realizar una
normalizacion de las funciones de forma que las haga comparables.
Como veremos mas adelante en la parte de resultados, en algunas aplicaciones sera recomendable el
uso de informacion de fronteras, el uso de informacion de regiones o el de ambos simultaneamente. Para
ilustrar el funcionamiento de un algoritmo que maneje ambos tipos a la vez, la solucion seleccionada para
evitar el problema de mezclar medidas de distinta naturaleza ha sido normalizar los vectores gradiente
de ambas funciones de forma que un procedimiento de optimizacion que seleccione una direccion para
buscar el optimo avanzara hacia la solucion del problema usando para ello una suma ponderada de las
direcciones indicadas por cada una de las fuentes. Es decir, la direccion viene determinada por:
−(λ
∇EFext(C)
‖∇EFext(C)‖ + (1 − λ)
∇ERext(C)
‖∇ERext(C)‖
)(7.19)
donde λ indica la relevancia asignada a cada una de las funciones usadas en la optimizacion.
7.2.4. Delimitando el espacio de deformacion.
Si aplicamos un contorno sobre una imagen en una posicion inicial y dejamos que se mueva con com-
pleta libertad en direccion de maximo gradiente hacia un optimo, es decir, sin ningun tipo de informacion
acerca de las posibilidades de deformacion del objeto, en el caso de que la funcion de energıa que se define
desde la imagen no sea suficientemente buena (considerese por ejemplo la existencia de optimos locales
producidos por ruido, falta de informacion en la imagen, etc.) o en el caso de que la inicializacion no
este suficientemente cerca del punto que buscamos, el resultado de la optimizacion no sera el deseado
o incluso peor aun recogera unas deformaciones que no son posibles para la familia de objetos que de-
seamos segmentar. La solucion mas sencilla a este problema es determinar un hipercubo en el espacio de
deformacion que delimita el conjunto de posibilidades de variacion.
Capıtulo 7

Optimizacion final de la solucion. pag.123
Podemos obtener una solucion al problema realizando un estudio estadıstico ([Cootes et al. 95]) sobre
la variacion de las muestras en cada una de las componentes de deformacion y determinar un subespacio
a partir de la media y la varianza en cada uno de ellos. Por ejemplo, si hemos realizado un estudio de
componentes principales (ecuaciones de 5.51 a 5.54), tenemos los valores de las varianzas (autovalores) y
valores medios para cada una de estas. El subespacio puede ser delimitado por la variacion maxima de 3
veces la desviacion estandar alrededor de la media.
Tambien es posible seguir la interpretacion fısica que se realizo en la modelizacion de deformaciones.
Para ello, podemos calcular la energıa de deformacion como ([Sclaroff y Pentland 95]):
Edefor =1
2U tΩ2U (7.20)
que determina mayor energıa cuanto mayor sea la frecuencia de vibracion. Obviamente, podemos
introducir informacion del modelo aplicando pesos a cada uno de los ejes de deformacion.
En definitiva, todas estas soluciones nos ofrecen formas sencillas y comodas de delimitar el conjunto
de posibles formas del contorno sin mas que acotar la cantidad de energıa maxima que puede ser utilizada
para optimizar la solucion.
Independientemente de la solucion adoptada, es conveniente no acotar la posibilidad de variacion en
lo que respecta a traslacion, rotacion y escala a fin de que los resultados obtenidos sean invariantes frente
a estas transformaciones.
7.2.5. Un problema de regularizacion.
En muchas situaciones aunque el objeto no aparezca de forma natural con ciertas deformaciones, es
posible que sea conveniente admitir una gran variacion a causa de las fuertes evidencias que ofrece la
imagen. Este hecho sugiere una solucion que admita un equilibrio entre la informacion desde el contorno
y la informacion desde la imagen. Una forma de introducir informacion del modelo de esta forma es
plantear un problema de regularizacion para la busqueda del optimo. Para ello es necesario definir las
funciones de energıa interna y externa para plantear la ecuacion de energıa total (la funcion sobre la que
buscar el optimo) de la siguiente forma:
Etotal(C) = λEint(C) + (1− λ)Eext(C) = Eint(C) +1− λ
λEext(C) (7.21)
En el modelo de snakes([Kass et al. 87a]), la energıa interna se define en terminos de la primera y
segunda derivadas de la curva como:
Eint(C) = w1(s)
∣∣∣∣∂C
∂s
∣∣∣∣2
+ w2(s)
∣∣∣∣∂2C
∂s2
∣∣∣∣2
(7.22)
que impone condiciones locales de tension y rigidez que no informan acerca de la variabilidad del
modelo y aunque permiten modelizar eficazmente muchas situaciones con la variacion de las funciones
de peso wi, no son suficientes para incluir la informacion que podemos poseer del contorno. Por ello, es
conveniente definir la funcion de energıa interna en otros terminos (sin descartar obviamente el introducir
informacion del tipo de la ecuacion 7.22). Usar una funcion de distancia entre el contorno de deformacion
cero y el deformado o usar una funcion de energıa de deformacion en una interpretacion fısica (ecuacion
7.20) son distintas posibilidades para definir la solucion.
7.2.6. Un modelo probabilıstico.
Otra solucion al problema de conseguir un equilibrio entre la informacion de la imagen y la del objeto
es definir un modelo probabilıstico ([Yuille et al. 92]) para el que debemos de establecer:
Seccion 7.2

pag.124 Optimizacion de la localizacion
Una probabilidad a priori: Corresponde a la funcion de energıa interna definida anteriormente y
establece la probabilidad de cada una de las realizaciones de nuestro modelo.
Un modelo de ruido: establece la probabilidad de las observaciones de forma que junto con la
probabilidad a priori podemos establecer la probabilidad a posteriori.
Es razonable determinar que si hemos obtenido una aproximacion a la solucion del problema de
segmentacion en una etapa anterior, la localizacion exacta se situa con mayor probabilidad en las cercanıas
de esta primera aproximacion.
Por otro lado, las deformaciones locales no son normalmente contempladas en el modelo de objeto
que se maneja ya que son resultado de algun tipo de ruido en la imagen (recuerdese la eliminacion
de los ejes modales de mayor vibracion o los ejes de menor desviacion tıpica de la transformada de
hotelling). A pesar de ello, es posible que sea conveniente contemplar en el reconocimiento una ultima
etapa de determinacion de pequenas variaciones en la cadena de puntos que define el contorno del objeto
manteniendo un equilibrio entre la informacion global que se ha obtenido y la informacion que la imagen
nos ofrece.
Un modelo de objeto deformable que se ajusta al enfoque que realizamos es el propuesto por Grenan-
der, Chow y Keenan ([Grenander et al. 91]). Los elementos basicos de la aproximacion de Grenander
son:
un espacio de generadores (G=segmentos sobre el plano).
un grafo conector (σ=grafo cıclico).
condiciones de regularidad sobre σ (R=poligonos cerrados).
un grupo de transformaciones (T , T :G → G, T=Grupo Euclıdeo x Escala).
Sea C el espacio de configuraciones, es decir
C = c|c = σ(g0, g1, · · · , gn−1), (g0, g1, · · · , gn−1) ∈ Gn (7.23)
donde gi denota los generadores, n es el numero de generadores usados para definir una figura par-
ticular y σ es el grafo que define las conexiones entre los generadores. Si C(R) denota el conjunto de
configuraciones que verifican la condiciones de regularidad (R), el objetivo es conocer que subconjunto
de C(R) representa la forma que esta siendo considerada. Para generar los elementos de C(R) que define
la forma de interes, comenzamos desde un template S ∈ Gn y aplicamos transformaciones Tj ∈ T a sus
generadores bajo la condicion de que las configuraciones resultantes caigan dentro de C(R),
E(S) = c|c = σ(T0g0, T1g
1, · · · , Tn−1gn−1) ∈ C(R), (T0, T1, · · · , Tn−1) ∈ T n (7.24)
Se observa que no todos los vectores (T0, T1, · · ·-, Tn−1) ∈ T n generan configuraciones que representan
bien la forma. Para restringir el conjunto de posibles configuraciones desde un template, Grenander
([Grenander y Keenan 89]) introduce una medida de probabilidad sobre el espacio T de valores que
definen el grupo de transformaciones. En nuestro caso tan solo consideraremos transformaciones del
tipo homotecias y giros. Se usa un proceso de Markov valuado en T sobre el grafo frontera tal que los
componentes de las matrices T0, T1, ..., Tn−1
Ti =
(1 + t0i t1i−t1i 1 + t0i
)(7.25)
son un proceso de Markov independiente de primer orden (vease [Grenander et al. 91], [Knoerr 88])
donde t0i esta asociado a la homotecia y t1i esta asociado al angulo de giro (vease [Knoerr 88]). Dado
Capıtulo 7

Optimizacion final de la solucion. pag.125
que nosotros estamos interesados solamente en pequenas deformaciones, asumimos que (t0i, t1i) son
conjuntamente una gaussiana. En este caso, la distribucion sobre las deformaciones locales del template
es una distribucion gaussiana 2n-variante.
Por otro lado, podemos definir una distribucion a posteriori anadiendo el factor p(I | C) si disponemos
de una funcion de energıa E(C) definida sobre cada posible realizacion C que mide la bondad de la esta
curva para segmentar el objeto de la imagen I. Esta funcion puede ser definida como una distribucion de
Gibbs
p(I | C) =1
ctee−E(C) (7.26)
Un ejemplo del posible resultado obtenido en esta etapa de postprocesamiento puede observarse en la
figura 7.8, la cual se ha obtenido a partir de la deformacion de las curvas correspondientes a las elipses
que se muestran en la figura 7.2.
Figura 7.8: Deformaciones locales sobre un modelo elıptico.
Es interesante realizar varios comentarios sobre este modelo:
La division de la curva que define el contorno del objeto en segmentos rectilıneos debe hacerse
suficientemente fina como para aceptar la hipotesis de la dependencia markoviana de primer orden
([Knoerr 88]). Como es de esperar, si los segmentos definidos son demasiado grandes, es posible que
las variaciones de uno de ellos no dependa unicamente de los adyacentes (considerese por ejemplo,
la existencia de simetrıas en la forma).
Es necesario aplicar un algoritmo de optimizacion sobre la funcion de probabilidad a posteriori.
Considerando que la funcion a optimizar no es convexa y si deseamos obtener un optimo global,
no tendremos mas remedio que recurrir a un costoso algoritmo como el simulate annealing4. Un
intento de mejorar esta situacion pudiera ser definir un conjunto de posibles divisiones de la curva
(desde la mas gruesa hasta la mas fina). Esta solucion es unicamente parcial ya que no podemos
obviar el punto anterior.
Para que el metodo tenga exito, es necesario disponer de una aproximacion suficientemente buena
a la solucion del problema ([Grenander et al. 91]).
4Es necesario destacar que Grenander propone el muestreo de la probabilidad a posteriori determinando como solucion
al problema la media de las ultimas realizaciones.
Seccion 7.2

pag.126 Optimizacion de la localizacion
Dado la limitacion de este modelo como solucion global al problema de localizar un objeto deformado
y por otro lado la complejidad matematica para su exposicion en este trabajo, no daremos mas detalles
teoricos.
7.3. Resultados.
A continuacion se presentan los resultados obtenidos en la optimizacion final de algunos contornos.
Los localizaciones iniciales que se muestran para la aplicacion del proceso de optimizacion, corresponden
a ejemplos presentados en el capıtulo de inicializacion. El metodo de optimizacion sobre las funciones de
energıa usado ha sido el de ascension de colinas.
Las distintas imagenes que se presentan son:
Tipo I. Ejemplos sobre citologıas.
Ej.1.- Presenta una imagen de celulas que aparecio en el capıtulo de inicializacion. En este
caso, se ha realizado un muestreo mas fino de los ejes de deformacion de manera que la
zona de incertidumbre usada en la deteccion es menor y por consiguiente el resultado
es mas exacto.
Ej.2.- Este ejemplo es similar al anterior. De igual forma se ha optimizado el resultado mediante
un muestreo mas fino del espacio de parametros. Es interesante observar en esta imagen
como el metodo consigue segmentar objetos que se situan con un grado de solapamiento
bastante alto.
Tipo II. Ejemplos sobre nematodos.
Ej.1.- En este caso se presenta la imagen del ejemplo anterior en la que se localiza el nematodo
que aparece en ella. En la imagen b de la figura 7.13 se puede ver la localizacion inicial
que se optimiza hasta la imagen a de la figura 7.14 despues de 30 iteraciones usando
informacion de fronteras. Son de destacar los resultados presentados en la ultima imagen
que corresponden a la segmentacion tanto del nematodo como de las celulas presentes.
Ej.2.- Este ejemplo es similar al anterior. Ilustramos la optimizacion de la localizacion de un
nematodo presentando la inicializacion, el resultado tras 10 iteraciones, y el resultado
final despues de 30 iteraciones.
Tipo III. Ejemplos sobre manos.
Ej.1.- En este ejemplo se muestra la necesidad de integrar informacion de fronteras y regiones.
En la figura 7.17 se muestra la inicializacion obtenida a partir de las cadenas que apare-
cen en la figura 7.18 y que son las usadas para la optimizacion que da lugar al resultado
que se presenta en esta. Como podemos observar, la informacion de la que se dispone no
es suficiente para llegar a una buena localizacion. Una primera solucion para resolverlo
es usar informacion de regiones y obviar las fronteras que delimitan el objeto. A fin
de garantizar un metodo mas robusto y tal como explicamos anteriormente (vease pag.
122) se han usado las fronteras (de la misma forma que en los ejemplos anteriores) junto
con las regiones (minimizando el valor de la varianza) haciendo uso de la ecuacion 7.19
(el valor usado para λ es 0,5). Los resultados se pueden ver en las figuras 7.19 y 7.20 en
las que podemos ver que tras 30 iteraciones la fijacion final es claramente mejor.
Ej.2.- En este caso, la localizacion inicial esta mucho mas lejos de la solucion que en el caso
anterior. Por ello el numero de iteraciones debe ser superior y como podemos observar,
tras 75 iteraciones, el algoritmo encuentra igualmente la solucion.
Capıtulo 7

Resultados. pag.127
Ej.3.- En este ejemplo se introduce la distorsion provocada por el ruido de tipo sal y pimienta
que afecta aproximadamente a un 50% de los puntos de la imagen (recordemos que
posee una relacion senal-ruido aproximadamente de 0,5). En esta imagen se presenta
mas clara la necesidad de introducir informacion de regiones (se ha usado un valor
de λ de 0,4.) dado que las fronteras obtenidas (figura 7.23, imagen b) estan aun mas
deterioradas.
Ej.4.- De nuevo planteamos una inicializacion mas distante unida al ruido del mismo tipo que
en el ejemplo anterior. Ahora, al igual que en el caso anterior, con solo 50 iteraciones
obtenemos la solucion.
Ej.5.- Por ultimo, presentamos la segmentacion de dos manos (figura 7.3.3). Es interesante
destacar que en la mano inferior (imagenes e y f) la informacion de regiones es mas
problematica ya que el exterior de la mano no corresponde a fondo. En caso de que
en las imagenes a segmentar podamos encontrar este tipo de problemas, es necesario
ponderar favoreciendo a la informacion de tipo fronteras (se ha usado un valor de λ de
0,6).
Seccion 7.3

pag.128 Optimizacion de la localizacion
7.3.1. Ejemplos sobre citologıas.
Ejemplo 1
(b)(a)
Figura 7.9: (a) Original. (b) Espacio de parametros.
(b)(a)
Figura 7.10: Celulas detectadas.
Capıtulo 7

Resultados. pag.129
Ejemplo 2
(b)(a)
Figura 7.11: (a) Original. (b) Espacio de parametros.
(b)(a)
Figura 7.12: Resultado final.
Seccion 7.3

pag.130 Optimizacion de la localizacion
7.3.2. Ejemplos sobre nematodos.
Ejemplo 1
(b)(a)
Figura 7.13: (a) Original. (b) Localizacion inicial.
(b)(a)
Figura 7.14: (a) Resultado (30 iteraciones). (b) Resultado conjunto.
Capıtulo 7

Resultados. pag.131
Ejemplo 2
(b)(a)
Figura 7.15: (a) Original. (b) Localizacion inicial.
(b)(a)
Figura 7.16: (a) Resultado tras 10 iteraciones. (b) Resultado (30 iteraciones).
Seccion 7.3

pag.132 Optimizacion de la localizacion
7.3.3. Ejemplos sobre manos.
Ejemplo 1
(b)(a)
Figura 7.17: (a) Original. (b) Localizacion inicial.
(b)(a)
Figura 7.18: (a) Fronteras usadas en la optimizacion. (b) Resultado tras 50 iteraciones.
Capıtulo 7
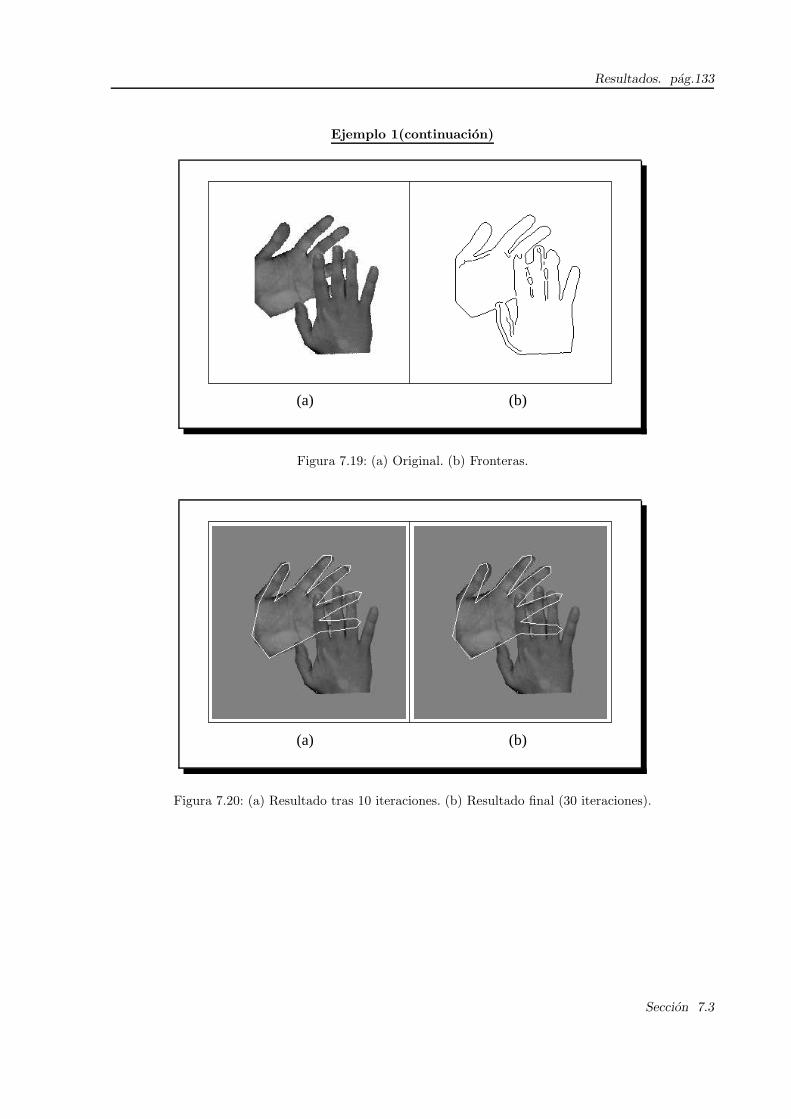
Resultados. pag.133
Ejemplo 1(continuacion)
(b)(a)
Figura 7.19: (a) Original. (b) Fronteras.
(b)(a)
Figura 7.20: (a) Resultado tras 10 iteraciones. (b) Resultado final (30 iteraciones).
Seccion 7.3

pag.134 Optimizacion de la localizacion
Ejemplo 2
(b)(a)
Figura 7.21: (a) Original. (b) Fronteras.
(b)(a)
Figura 7.22: (a) Localizacion inicial. (b) Resultado final (75 iteraciones).
Capıtulo 7

Resultados. pag.135
Ejemplo 3
(b)(a)
Figura 7.23: (a) Original. (b) Fronteras.
(b)(a)
Figura 7.24: (a) Localizacion inicial. (b) Resultado final (50 iteraciones).
Seccion 7.3

pag.136 Optimizacion de la localizacion
Ejemplo 4
(b)(a)
Figura 7.25: (a) Original. (b) Fronteras.
(b)(a)
Figura 7.26: (a) Localizacion inicial. (b) Resultado final (50 iteraciones).
Capıtulo 7

Resultados. pag.137
Ejemplo 5
(f)(e)
(d)
(b)(a)
(c)
Figura 7.27: (a) Original. (b) Fronteras. (c) Localizacion inicial. (d) Resultado
(50 iteraciones). (e) Localizacion inicial. (f) Resultado (50 iteraciones).
Seccion 7.3

pag.138 Optimizacion de la localizacion
Capıtulo 7

Discusion, conclusiones y trabajos
futuros.
Discusion.
Es esta memoria se ha expuesto una metodologıa de trabajo para solucionar el problema de la seg-
mentacion supervisada de objetos deformables. Para conseguirlo, hemos establecido varios principios
(vease el capıtulo de introduccion) a partir de los cuales se han desarrollado una serie de algoritmos que
han dado lugar a excelentes resultados en diferentes aplicaciones. Para poder construirlos, hemos tenido
que resolver varios puntos:
1. Estudiar la caracterizacion del objeto. Fundamentalmente nos hemos centrado en la descricion de
formas 2D a traves de su contorno. Para estudiar dicho contorno se ha usado el espacio de escalas
de la curvatura, proponiendo un algoritmo para la construccion de las trayectorias de maximos y
permitiendo por tanto manejar una representacion multiescala del contorno que puede ser usada
para una amplia variedad de problemas. Como un ejemplo de ello, se ha considerado una aplicacion
sencilla a la deteccion de puntos relevantes en un contorno a partir de un valor maximo de error U
que da lugar a una aproximacion poligonal.
2. Estudiar un modelo deformable de objeto. Para resolverlo se ha usado la descomposicion en base a
los modos de vibracion libre del objeto. Desde ellos e incorporando informacion desde ejemplos se
han obtenido las componentes principales que dan lugar a los ejes de deformacion que se usan en
la localizacion.
3. Estudiar un algoritmo que nos permite obtener la localizacion inicial del objeto a partir de la
informacion de la imagen y del modelo de deformacion.
La informacion de la imagen puede provenir desde distintos canales tal como hemos podido com-
probar en la interpretacion multiescala que daba lugar a varios mapas de aristas. Es de destacar
dos comentarios acerca de esta:
a) Se pueden distinguir varios niveles semanticos. En los algoritmos desarrollados se ha usado un
nivel superior al del pıxel, lo que provoca una mayor estabilidad y eficacia del metodo.
b) La integracion de informacion se ve facilitada desde la coherencia de esta. Una solucion mas
compleja y que permitirıa una ampliacion del metodo se plantea si consideramos informaciones
de distinta naturaleza (aristas mas colores mas texturas, etc...).
Por otro lado, la informacion que se posee del modelo de deformacion plantea un sistema de ejes
que parametrizan las distintas instancias del contorno a localizar.
Para obtener las localizaciones deseadas se plantea un sistema de votacion en el espacio de de-
formaciones desde las caracterısticas detectadas en la imagen. Logicamente, la construccion de un
139

pag.140 Optimizacion de la localizacion
sistema generico que use distintas fuentes de informacion (de igual o distinta naturaleza) se centra
en la definicion de una funcion de integracion que sepa unir los distintos indicios de localizacion en
el espacio de localizaciones, es decir, que sepa acumular los votos teniendo en cuenta la naturaleza
de las informaciones.
Este proceso de votacion es el mas costoso en tiempo dada la cantidad de informacion que se procesa
y el tamano de los acumuladores. En esta memoria se ha resuelto este problema pasando desde
una solucion impracticable hasta algoritmos que garantizan la aplicabilidad del metodo. A pesar
de ello, las implementaciones actuales requieren aun una cantidad alta de recursos para algunas
aplicaciones5. Si deseamos algoritmos mas rapidos debemos tener en cuenta que:
a) Existen multitud de aportaciones referentes a la mejora en tiempo y espacio de la transformada
de Hough (vease mas adelante desarrollos futuros).
b) Los algoritmos formulados son altamente paralelizables.
c) Se han establecido aportaciones para acelerar el proceso (vease el algoritmo de enfoque).
d) La formulacion presentada sobre el tratamiento de la informacion a distinto nivel permite una
simplificacion muy alta en el numero de datos de entrada al algoritmo6.
de forma que se pueden construir sistemas eficaces desde un punto de vista practico.
4. Estudiar un metodo de optimizacion para fijar la solucion final. Para resolverlo hemos usado un
algoritmo de ascension de colinas sobre una funcion de energıa coherente con las informaciones
usadas en la localizacion y el modelo deformable que se ha establecido. La fijacion correcta de
la solucion final a pesar de usar un algoritmo simple de optimizacion muestra la bondad de las
funciones definidas. Ademas se ha mostrado como el uso de distintas informaciones (fronteras y
regiones) enriquece el metodo dando lugar a mejores resultados. Por ultimo se ha propuesto un
metodo probabilıstico como refinamiento final a fin de fijar, si procede, las deformaciones locales7.
Conclusiones.
1. El flujo de informacion hacia la interpretacion de la imagen debe ser bidireccional:
En una direccion concluimos nuevos hechos desde la informacion que poseemos.
En otro usamos los hechos concluidos para descartar o rescatar nueva informacion.
2. La segmentacion de imagenes con una fuerte componente ruidosa requiere de un modelo de objeto
que en caso de que pueda sufrir variaciones geometricas debera ser un modelo deformable.
3. Es conveniente el estudio multiescala de la senal mediante el que podemos:
Considerar una cantidad superior de informacion. Efectivamente, como hemos podido com-
probar, realizar un estudio multiescala de la senal, facilita el manejo de informaciones que se
localizan a distintas escalas.
Concluir nuevos hechos desde el establecimiento de relaciones entre las informaciones que se
obtienen en distintas escalas.
5Por ejemplo, en la localizacion de las manos se ha usado un muestreo de (5,4,3) en los ejes de deformacion no rıgida
que da lugar a un tiempo requerido del orden de 60 veces la ejecucion de la transformada de Hough generalizada.6Recordemos que en la transformada de Hough tradicional el numero de entradas es del orden del numero de pıxeles
obtenidos por el detector de aristas.7Una aplicacion muy interesante de este modelo es la segmentacion de citologıas de mama en las que se mide si el
contorno (la membrana celular) esta bien definido (las celulas cancerıgenas rompen la membrana celular)
Conclusiones y trabajos futuros

Resultados. pag.141
4. La descomposicion en los modos naturales de deformacion es una excelente opcion para la parametrizacion
de las deformaciones de un objeto en imagenes biomedicas. Con esta, conseguimos un sistema de
ejes coordenados que clasifican las deformaciones y nos permiten un estudio eficaz y jerarquico de
la deformacion de un contorno.
5. La trasformada de Hough puede ser usada como inicializacion para modelos deformables a pesar
de que los objetos posean un alto grado de variacion. Obviamente, la T.H. clasica no es capaz de
manejar dichas situaciones aunque la reformulacion presentada en este trabajo permite la construc-
cion de algoritmos que junto con tecnicas de optimizacion basadas en modelos deformables consigue
una correcta localizacion.
6. Existen diferentes fuentes de informacion que colaboran en la determinacion de la localizacion del
objeto. El uso simultaneo de estas nos permite obtener un metodo mas robusto y eficaz especialmente
en casos de fuerte inestabilidad (ruido no estocastico, solapamiento, multiples objetos).
7. El espacio de localizaciones definido por los principales ejes de deformacion establece una superficie
de optimizacion muy robusta frente a problemas de ruidos e informacion parcial.
Desarrollos Futuros.
Estudio de contornos 2D. Una vez que disponemos de un algoritmo que nos ofrece una repre-
sentacion multiescala del contorno, se ha abierto la posibilidad de construccion de otros algoritmos.
Considerese por ejemplo la generacion de una familia de polıgonos multiresolucion que puede ser
obtenida variando el valor de U desde un valor maximo de alta resolucion hasta un valor mınimo
de mas baja resolucion y que pueden ser usados en problemas de alineamiento de formas.
Aprendizaje.
• De los puntos nodales que representan la aproximacion poligonal (algoritmo de puntos dom-
inantes desde una muestra). En este trabajo se ha presentando un algoritmo que obtiene los
puntos principales desde un contorno representativo. Para objetos deformables puede ser mas
interesante describir dichos puntos desde varias curvas para las que una misma zona se presenta
con distintas curvaturas.
• De la zona de incertidumbre. En los ejemplos desarrollados en esta memoria se ha fijado una
zona de incertidumbre circular y por exceso. Si se desea desarrollar un mecanismo totalmente
automatico para el reconocimiento de formas, es necesario determinar un modulo de apren-
dizaje que sea capaz de inferir que parametros son los mas optimos.
Eficiencia.
• Estudio de la aplicacion de metodos jerarquicos que consideran distintas resoluciones (vease
por ejemplo [Ben Yacoub y Jolion 95], [Meer et al. 90], [Jain y Lakshmanan 96]).
• Integracion multicanal previa a la localizacion. En este punto es interesante destacar la posibil-
idad de localizar la mejor escala para cada zona de la imagen (vease por ejemplo [Brunnstrom y
otros 90], [Garcıa et al. 95], [Lindeberg 93a]) aunque resulta mas efectivo para nuestro problema
localizar varias escalas significativas y limitarnos a la eliminacion de informacion redundante
([Garcıa-Silvente et al. 96]). Un planteamiento interesante es el estudio de algoritmos para
reducir el conjunto de aristas original eliminando las cadenas redundantes obtenidas desde
distintas escalas.
Conclusiones y trabajos futuros

pag.142 Optimizacion de la localizacion
• Mejora con aportaciones realizadas para la T.H. clasica. (vease por ejemplo [Davies 90], [Jeng
y Tsai 91], [Kalvianen et al. 94], [Ser y Siu 95], [Yip et al. 95], etc.). Este punto resulta de
los de mayor interes ya que un amplio conjunto de estudios realizados sobre la T.H. clasica
consiguen una mejora muy importante en eficiencia y el estudio de la aplicacion de estos sobre
el enfoque desarrollado en este trabajo puede dar lugar a tiempos aceptables incluso para
problemas complejos.
Informacion desde el objeto: Introduccion de informacion a priori sobre el espacio de deformacion
(por ejemplo, una probabilidad). Soluciona casos como falta de informacion (veanse los ejemplos
sobre manos).
Informacion desde la imagen: Mezcla de informaciones.
• Otro tipo de informacion. La metodologıa que se ha desarrollado esta abierta a la incorporacion
de otro tipo de informacion para determinar la localizacion de un objeto. Para ello habra que
estudiar como se define la funcion que integra dicha informacion para actualizar una posicion
del espacio de parametros. Logicamente, en este punto pueden considerarse distintas tecni-
cas de Inteligencia Artificial (Redes neuronales, redes causales, tecnicas de propagacion de la
incertidumbre,...).
• Otras funciones. (Incluye por ejemplo dar peso a las cadenas con criterios como nivel de ruido
en el contorno, estabilidad a traves del espacio de escalas, etc).
Generalizacion mediante la aplicacion a otros problemas. Podemos considerar por ejemplo:
• Objetos compuestos. El considerar que el objeto no se define a partir de una unica curva que
lo delimita cae fuera de los objetivos de este trabajo. A pesar de ello, es posible desarrollar
algoritmos que segmenten objetos complejos definidos a partir de subobjetos o subestructuras
([Yuille et al. 92]).
• Caracteres escritos. Este campo es muy interesante ya que aunque en principio parece un
problema que puede estar distante de los desarrollos en esta memoria, no podemos olvidar que
en esencia no es mas que un objeto deformable aunque las funciones que se deban definir sean
de distinta naturaleza ([Lai y Chin 95]).
• Registrado de imagenes ([Amit y Kong 96]).
• Movimiento (seguimiento de un objeto que varıa en posicion y deformacion en una secuencia
de imagenes).
Aplicacion a 3D.
Conclusiones y trabajos futuros

Apendice A
Calculo de los modos naturales de
vibracion.
En este apendice se presenta la parte mas relevante del codigo utilizado para el calculo de los modos
naturales de vibracion (vease pagina 75). En primer lugar se ofrece el listado completo del fichero principal
con la funcion main. Aunque existen funciones que se usan y no se presentan, el codigo esta escrito en
C++ y es facilmente legible sin necesidad de informacion adicional.
El fichero principal es:
#include <general.hh>
#include <stream.h>
#include <math.h>
#include <stdio.h>
#include <matriz.hh>
#include <modal.hh>
#include <parametros.hh>
/∗ ∗/
/∗ —————— Estructura de los parametros ——————- ∗/
const char ∗plantilla= ’’i?Sk?Sm?Sv.SV.S’’;
const char ∗descripcion[]= ’’poligono: Nombre del fichero con la matriz nx2’’,
’’f Rigidez: nombre del fichero para almacenar la matriz K’’,
’’f Masa: nombre del fichero para almacenar la matriz M’’,
’’f Valores: nombre del fichero para almacenar los autovalores’’,
’’f Vectores: nombre del fichero para almacenar los autovalores’’
;
/∗ ∗/
int main(int argc, char ∗argv[])
143

pag.144 Calculo de los modos naturales de vibracion.
double SIGMA;
char nom[250]=’’-’’,nomk[250]=’’’’, nomm[250]=’’’’, nomv[250]=’’’’, nomV[250]=’’’’;
Matriz p,K,M,val,vec;
double alfa,beta,xi;
buscar parametros(argc,argv,plantilla,descripcion,nom,
nomk,nomm,nomv,nomV);
p.leer matriz(nom);
if (p.columnas()!=2)
ErrorFin(’’main->La matriz entrada tiene que tener 2 columnas’’);
SIGMA= CalculaSigmaDistanciaMedia(p);
cerr ≪ ’’Puntos: \n’’≪ p.t();
cerr ≪ ’’\nSigma: ’’ ≪ SIGMA ≪ ’’\n’’;cerr ≪ ’’Calculamos las matrices K,M\n’’;
alfa= POISSON RATIO/(1-POISSON RATIO);
beta= STIFFNESS∗(1-POISSON RATIO)/
((1+POISSON RATIO)∗(1-2∗POISSON RATIO));
xi= (1-2∗POISSON RATIO)/(2∗(1-POISSON RATIO));
mass stiffness(M, K, p, SIGMA, DENSIDAD, alfa, beta, xi);
if (nomk[0]!=’\0’)K.grabar matriz(nomk);
if (nomm[0]!=’\0’)M.grabar matriz(nomm);
cerr ≪ ’’Calculamos los autovectores y autovalores.\n’’;
vec=M;
K.generalizado autoV(val,vec);
val.grabar matriz(nomv);
vec.grabar matriz(nomV);
return 0;
Es necesario detallar el calculo de la matriz de masas y de rigidez que se obtienen por medio de la
siguiente funcion:
/∗∗∗ Function name : mass stiffness
∗∗∗∗ Description : Calcula M,K como propone Sclaroff
Apendice A

Calculo de los modos naturales de vibracion. pag.145
∗∗ Input : puntos=(x1,x2,....,xm,y1,y2,...,ym)∧t∗∗ Output : Matriz M y K
∗/void mass stiffness(Matriz& M, Matriz& K, const Matriz& p, const double sig,
const double ro, const double alfa, const double beta,
const double xi)
register i,j,k,l;
double sig cuad,sumaa,sumab,sumbb,aikjlg;
double xi12= (xi+1)/2,xkl,ykl;
int m=p.filas();
Matriz G(m,m),invG(m,m),Kaa(m,m),Kbb(m,m),Kab(m,m);
/∗ ————————– Construimos G ————————– ∗/
sig cuad=2∗sig∗sig;for (i=1;i<=m;i++)
for (j=1;j<=m;j++) //en i,j ponemos funcion g sub i del punto j
xkl= p[j][1]-p[i][1]; // (vx,vy)= xj-xi;
ykl= p[j][2]-p[i][2];
G[i][j]= exp(-(xkl∗xkl+ykl∗ykl)/sig cuad);
invG= G. 1();
G= G.aplica funcion(sqrt); // G contiene las raices cuadradas
/∗ ————————- Matriz de masas ————————- ∗/
M= (ro∗M PI∗sig∗sig)∗(invG∗G∗invG);
M= ( M | Matriz(m,m,0))/
(Matriz(m,m,0) | M );
/∗ ———————— Matriz de rigidez ———————— ∗/
sig cuad= 4∗sig∗sig;
for (i=1;i<=m;i++)
for (j=1;j<=m;j++) sumaa=sumab=sumbb=0;
for (k=1;k<=m;k++)
for (l=1;l<=m;l++) xkl= p[k][1]-p[l][1]; // xkl= xk-xl;
ykl= p[k][2]-p[l][2]; // ykl= yk-yl
aikjlg= invG[i][k]∗invG[j][l]∗G[k][l];
sumab+=aikjlg∗xkl∗ykl;
Apendice A

pag.146 Calculo de los modos naturales de vibracion.
sumaa+=aikjlg∗(xi12-(xkl∗xkl+xi∗ykl∗ykl)/sig cuad);
sumbb+=aikjlg∗(xi12-(xi∗xkl∗xkl+ykl∗ykl)/sig cuad);
Kaa[i][j]=sumaa;
Kab[i][j]=sumab;
Kbb[i][j]=sumbb;
Kaa∗ =M PI∗beta;Kbb∗ =M PI∗beta;Kab∗ =(-M PI∗beta∗(alfa+xi)/sig cuad);
K= ( Kaa | Kab )/
( Kab | Kbb );
Y por ultimo, el autoproblema generalizado se ha resuelto de la siguiente forma:
/∗ ∗/
//
// Method name : generalizado autoV
//
// Description : Resuelve Ax=Lambda B x. Recipes pg 462;
// Input : A es ∗this y B es vec
// Output : En val los autovalores y en vec los autovectores
//
void Matriz::generalizado autoV(Matriz& val, Matriz& vec, int ord) const
Matriz L,L 1,C;
L= vec.cholesky(); // L∗Lt=B
L 1= L. 1(); // L 1 es la inversa de L
L= L 1.t(); // L ahora contiene L∧(-1)∧t == L∧t∧(-1)C=L 1∗(∗this)∗L; // C=L∧(-1)∗a∗(L∧(-1))∧tC.autoV(val,vec); // Calcula los autovalores y autovectores de C
vec= L∗vec; // vec= L∧t∧(-1)∗ vec
if (ord)
vec.ordena autoV(val);
Para mayor informacion acerca de los calculos realizados puede ser consultada la referencia [Press et
al. 92].
Apendice A

Apendice B
Vibraciones naturales de un
nematodo.
En este apendice se presenta un ejemplo de las deformaciones naturales correspondientes a los modos
naturales de vibracion de una forma de nematodo. Se han muestreado un total de 14 nodos en el contorno
que se traducen en un total de 28 vectores de deformacion cada uno de ellos presentados con una lınea
continua sobre el contorno de deformacion cero (lınea discontinua). El lector puede observar como se
pueden distinguir:
Los vectores 1 y 2 reflejan traslaciones en el eje Y y en el eje X respectivamente.
El vector 3 representa una rotacion. Aunque pueda parecer que puede modelizarse una rotacion
grande, recuerdese que estos vectores deforman por medio de una operacion lineal.
Los vectores 4-28 son deformaciones rıgidas. Como podemos ver, las deformaciones se clasifican
desde las mas globales a las mas locales.
Por ultimo, destacar que aunque algunas parezcan poco reales (vease por ejemplo, la numero 14), el
modulo del vector de deformacion no es el de la figura ya que se ha escalado para que el lector pueda
observar de una forma mas clara las deformaciones. Estas deformaciones se presentan a continuacion.
147

pag.148 Vibraciones naturales de un nematodo.
vector 1 vector 2 vector 3
vector 4 vector 5 vector 6
vector 7 vector 8 vector 9
vector 10 vector 11 vector 12
Apendice B

Vibraciones naturales de un nematodo. pag.149
vector 13 vector 14 vector 15
vector 16 vector 17 vector 18
vector 19 vector 20 vector 21
vector 22 vector 23 vector 24
Apendice B

pag.150 Vibraciones naturales de un nematodo.
vector 25 vector 26 vector 27
vector 28
Apendice B

Apendice C
Aproximacion elıptica de una nube
de puntos.
En este apendice se presentan las expresiones consideradas en la aproximacion mediante una elipse de
una nube de puntos. Supongamos (r1, c1) · · · (rN , cN ) el conjunto de puntos a los que aproximar la elipse.
Representamos la elipse mediante los parametros a, b, A,B,C en la ecuacion:
(r − a
c− b
)t(A B
B C
)(r − a
r − b
)= 1
La primera estimacion que se realiza es:
a =1
N
n∑
n=1
rn
b =1
N
n∑
n=1
cn
(A B
B C
)=
1
2(µrrµcc − µ2rc)
(µcc −µrc
−µrc µrr
)
donde:
µrr =1
N
N∑
n=1
(rn − a)2
µrc =1
N
N∑
n=1
(rn − a)(cn − b)
µrc =1
N
N∑
n=1
(cn − b)2
Y el error a minimizar es:
ǫ2 =
N∑
n=1
[d2(rn − a)2 + 2de(rn − a)(cn − b) + (e2 + f2)(cn − b)2 − 1
]2
151

pag.152 Aproximacion elıptica de una nube de puntos.
donde:
d =√A e =
B
df =
√c− e2
Y la derivada del error utilizada en la optimizacion es:
∂ǫ2
∂a= 4
N∑
n=1
(fn − 1)[−d2(rn − a)− de(cn − b)
]
∂ǫ2
∂b= 4
N∑
n=1
(fn − 1)[−de(rn − a)− (e2 + f2)(cn − b)
]
∂ǫ2
∂d= 4
N∑
n=1
(fn − 1)[d(rn − a)2 + e(rn − a)(cn − b)
]
∂ǫ2
∂e= 4
N∑
n=1
(fn − 1)[d(rn − a)(cn − b) + e(cn − b)2
]
∂ǫ2
∂f= 4
N∑
n=1
(fn − 1)[f(cn − b)2
]
Apendice C

Apendice D
Modelo de Grenander: Distribucion
a priori.
En este apendice se presenta la parte mas relevante del codigo utilizado para la simulacion de la
distribucion a priori del modelo probabilıstico de deformacion de Grenander. La funcion principal es
DeformarTemplate y el codigo es:
#include <math.h>
#include <stdlib.h>
#include <LEDA/list.h>
#include <fdiscreta1D.hh>
#include <deform.hh>
/∗ ———————– Variables globales ———————— ∗/
const int nr= 2; // Numero de restricciones
Matriz beta(1000,2,0.0); // 1000 es el maximo de vectores de un template
/∗ ∗/
static void ConstruirQ1Q2 (Matriz& Q1, Matriz& Q2, Matriz& abond, Matriz& sig,
int kiter, int nvectors)
register i,j,k;
int n= Q1.filas();
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
if(i==j) k=kiter+i-1;
k=(k>nvectors)?k-nvectors:k;
Q1[i][i] = abond[1][k]+abond[1][(k==nvectors)?1:k+1]+1/sig[1][k];
Q2[i][i] = abond[2][k]+abond[2][(k==nvectors)?1:k+1]+1/sig[2][k];
else if (i==j+1)
153

pag.154 Modelo de Grenander: Distribucion a priori.
k=kiter+i-1;
k=(k>nvectors)?k-nvectors:k;
Q1[i][j]= -abond[1][k];
Q2[i][j]= -abond[2][k];
else if (j==i+1)
k=kiter+j-1;
k=(k>nvectors)?k-nvectors:k;
Q1[i][j]= -abond[1][k];
Q2[i][j]= -abond[2][k];
else Q1[i][j]=Q2[i][j]=0;
/∗ ∗/
/∗∗∗ Function name : DeformarTemplate
∗∗∗∗ Description : Realiza una iteracion de la a priori de grenander
∗∗ Input : Antiguo template old, parametros abond y sig, numero de
∗∗ segmentos que deformar y situacion de estos en old(1..nvector).
∗∗ Output : Nuevo template deformado.
∗/Matriz DeformarTemplate (Matriz& parent, Matriz& oldchild,
Matriz& abond, Matriz& sig,
int n, int kiter)
register i,j;
Matriz parent relativo(parent.filas(),parent.columnas());
Matriz child relativo(oldchild.filas(),oldchild.columnas());
int n2= 2∗n;int index,index 1;
int nvectors= parent.filas();
/∗ ————— Preparamos los vectores parent y child ————— ∗/
Matriz child= oldchild;
for (i=2;i<=parent.filas();i++) parent relativo[i][1]= parent[i][1]-parent[i-1][1];
parent relativo[i][2]= parent[i][2]-parent[i-1][2];
parent relativo[1][1]= parent[1][1]-parent[parent.filas()][1];
parent relativo[1][2]= parent[1][2]-parent[parent.filas()][2];
for (i=2;i<=child.filas();i++)
Apendice D

Modelo de Grenander: Distribucion a priori. pag.155
child relativo[i][1]= child[i][1]-child[i-1][1];
child relativo[i][2]= child[i][2]-child[i-1][2];
child relativo[1][1]= child[1][1]-child[parent.filas()][1];
child relativo[1][2]= child[1][2]-child[parent.filas()][2];
Matriz L(nr,n2,0.0);
for(i=1;i<=n2;i+=2) // L= |1 0 1 ... 0 |L[1][i]=1; // |0 1 0 ... 1 |L[2][i+1]=1;
Matriz // H = / 1 0 0 ... 0 | 0 0 0 ... 0\H(n2,n2,0.0); // | 0 0 0 ... 0 | 1 0 0 ... 0|
for(i=1;i<=n;i++) // | 0 1 0 ... 0 | 0 0 0 ... 0|H[2∗i-1][i]=1.0; // | 0 0 0 ... 0 | 0 1 0 ... 0
H[2∗i][i+n]=1.0; // ...
Matriz subparent(n2,1,0.0);
for (index=kiter,i=1;i<n2;i+=2) subparent[i][1]=parent relativo[index][1];
subparent[i+1][1]=parent relativo[index][2];
index= (index==nvectors)?1:index+1;
Matriz Gamma(n2,n2,0.0);
for(i=1;i<n2;i+=2) Gamma[i][i]=subparent[i][1];
Gamma[i][i+1]=-subparent[i+1][1];
Gamma[i+1][i+1]=subparent[i][1];
Gamma[i+1][i]=subparent[i+1][1];
Matriz G;
G= Gamma∗H;
Matriz Q1(n,n,0.0),Q2(n,n,0.0);
ConstruirQ1Q2 (Q1, Q2, abond, sig, kiter, nvectors);
Q1= Q1. 1();
Q2= Q2. 1();
Apendice D

pag.156 Modelo de Grenander: Distribucion a priori.
Matriz Cov;
Cov = ( Q1 | Matriz(n,n,0)) /
(Matriz(n,n,0) | Q2 );
Matriz mb(n2,1,0.0),Gmb;
i= (kiter==1)?nvectors:kiter-1;
j= kiter+n;
j= (j>nvectors)?j-nvectors:j;
mb[1][1]= Q1[1][1]∗beta[i][1]/abond[1][(i==nvectors)?1:i+1];
mb[n][1]= Q1[1][n]∗beta[j][1]/abond[1][j];mb[n+1][1]= Q2[1][1]∗beta[i][2]/abond[2][(i==nvectors)?1:i+1];
mb[n2][1]= Q2[1][n]∗beta[j][2]/abond[2][j];
Gmb= G ∗ mb;
Matriz muz(n2,1), w(n2,1);
for (index=kiter,i=1;i<n2;i+=2) muz[i][1]=Gmb[i][1]+parent relativo[index][1];
muz[i+1][1]=Gmb[i+1][1]+parent relativo[index][2];
w[i][1]=child relativo[index][1];
w[i+1][1]=child relativo[index][2];
index= (index==nvectors)?1:index+1;
Matriz LLRL,z,Rz;
Matriz D,C,identidad(n2,n2),Gzt, X;
Rz= G ∗ Cov ∗ G.t();
LLRL= L.t() ∗ (L ∗ Rz ∗ L.t()). 1();
z= muz+ Rz ∗ LLRL ∗ (L∗w - L∗ muz);
D= Rz.cholesky();
identidad.identidad();
C= D∗ (identidad - D.t() ∗ LLRL ∗ L ∗ D );
X= Normal(n2);
z= z+C∗X;
Gzt= H.t()∗Gamma. 1()∗(z-subparent);
for(index=kiter,i=1;i<=n;i++) beta[index][1]=Gzt[i][1];
beta[index][2]=Gzt[n+i][1];
index= (index==nvectors)?1:index+1;
Apendice D

Modelo de Grenander: Distribucion a priori. pag.157
index=kiter;
index 1=(kiter==1)?nvectors:kiter-1;
for(i=1;i<=n-1;i++)child relativo[index][1]=z[2∗i-1][1];child relativo[index][2]=z[2∗i][1];child[index][1]=child relativo[index][1]+child[index 1][1];
child[index][2]=child relativo[index][2]+child[index 1][2];
index= (index==nvectors)?1:index+1;
index 1= (index 1==nvectors)?1:index 1+1;
child relativo[index][1]=child[index][1]-child[index 1][1];
child relativo[index][2]=child[index][2]-child[index 1][2];
return child;
donde la funcion Normal(n) genera un vector n-dimensional de una N(0,I). Para mayor informacion
acerca de los calculos realizados se pueden consultar las referencias [Grenander et al. 91] y [Knoerr 88].
Apendice D

pag.158 Modelo de Grenander: Distribucion a priori.
Apendice D

Bibliografıa
[Amit y Kong 96] Y. Amit y Augustine Kong, Graphical Templates for Model Registration, IEEE Trans.
Pattern Analysis and Machine Intell., vol. 18, no. 3, pp. 225-236, 1996.
[Ansari y Huang 91] N. Ansari y Kuo-Wei Huang, Non-Parametric Dominant Point Detection, Pattern
Recognition. Vol. 24. N. 9, pp 849-862. 1991.
[Asada y Brady 86] H. Asada y M. Brady, The curvature Primal Sketch, IEEE Trans. Pattern Analysis
and Machine Intell., vol. 8, n. 1, pp 2-14, 1986.
[Babaud et al. 86] J. Babaud, A. P. Witkin, M. Baudin, y R.O. Duda, Uniqueness of the Gaussian kernel
for scale-space filtering, IEEE Trans. Pattern Analysis and Machine Intell., vol.8, no. 1, pp. 26-33,
1986.
[Baddeley y Van Lieshout 92] A. Baddeley y M.N. Van Lieshout, Object recognition using markov spatial
processes, 11th IAPR International Conference on Pattern Recognition, vol B, pp. 136-139. 1992.
[Ballard 81] D.H. Ballard, Generalizing the Hough Transform to Detect Arbitrary Shapes, Pattern Recog-
nition, vol. 13, pp. 111-122, 1981.
[Ballard y Brown 82] D.H. Ballard y C.M. Brown, Computer Vision, Prentice Hall, 1982.
[Bathe 82] K. Bathe. Finite Element Procedures, Prentice-Hall, 1996.
[Beaulieu y Goildberg 89] J.M. Beaulieu y M. Goldberg, Hierarchy in Picture Segmentation: A Stepwise
Optimization Approach, IEEE Trans. Pattern Analysis and Machine Intell., vol. 11, n. 2, pp
150-163, 1989.
[Bengtsson y Eklundh 91] A. Bengtsson y J, Eklundh, Shape representation by multiscale contour aprox-
imation, IEEE Trans. Pattern Analysis and Machine Intell., vol. 13, no. 1, pp. 85-93, 1991.
[Ben Yacoub y Jolion 95] S. Ben Yacoub y J.M. Jolion, Characterizing the hierarchical Hough transform
through a polygonal approximation algorithm, Pattern Recognition Letters, vol. 16, pp. 389-397,
1995.
[Bergholm 87] Fredrik Bergholm, Edge Focusing, IEEE Trans. Pattern Analysis and Machine Intell., vol.
9, n. 6, pp 726-741, 1987.
[Blake y Yuille 92] A. Blake y Alan Yuille, Active Vision. MIT Press (1992).
[Bookstein 78] F. L. Bookstein, The Measurement of Biological Shape and Shape Change. Lectures Notes
in Biomathematics n.24, Springer-Verlag, 1978.
[Brunnstrom y otros 90] K. Brunnstrom, J.O. Eklundh y T. Lindeberg, On scale and resolution in active
analysis of local image structure, Imagen and Vision Computing, vol. 8, no. 4, pp. 289-296, 1990.
159

pag.160 BIBLIOGRAFIA
[Bunke 92] H. Bunke, Advances in structural and syntactic pattern recognition, World Scientific, 1992.
[Burt 81] J. Burt, Fast filter transforms for image processing, Computer Vision, Graphics, and Image
Processing, vol. 16, pp. 20-51, 1981.
[Canny 86] J. Canny,A computacional approach to edge detection, IEEE Trans. Pattern Analysis and
Machine Intell., vol. 8, n. 6, pp 679-698, 1986.
[Carmo 76] Manfredo Perdigao do Carmo, Differential geometry of curves and surfaces, Prentice-Hall
1976.
[Cohen y Cohen 93] L. D. Cohen y I. Cohen, Finite-Element Methods for Active Contour Models and
Balloons for 2-D and 3-D Images, IEEE Trans. Pattern Analysis and Machine Intell., vol. 15, no.
11, pp 1131-1147, 1993.
[Cootes et al. 95] T.F. Cootes, C.J. Taylor, D.H. Cooper y J. Graham,Active shape models - their training
and application, Computer vision and image understanding, vol. 61(1), 38-59, 1995.
[Crowley 81] J.L. Crowley, A Representation for Visual Information PhD thesis, Carnegie-Mellon Uni-
versity, Robotics Institute, Pittsburgh, Pennsylvania, 1981.
[Davies 90] E. Davies, Machine Vision: Theory, Algorithms, Practicalities, Academic Press, 1990.
[Douglas y Peucker 73] D.H. Douglas y T.K. Peucker, Algorithms for the reductions of the number of
points required to represent a digitised line or its caricature. Canadian Cartographer 10(2),pp.
112-122, 1973.
[Dubuisson et al. 96] M. P. Dubuisson, S. Lakshmanan y A.K. Jain, Vehicle segmentation and Classifi-
cation using Deformable templates, IEEE Trans. Pattern Analysis and Machine Intell., vol. 18,
no. 3, pp. 293-308, 1996.
[Farag y Delp 95] Aly A. Farag y Edward J. Delp, Edge linking by sequential search. Pattern Recognition,
Vol. 28, N. 5, pp 611-633, 1995.
[Fdez-Valdivia et al. 91] J. Fdez-Valdivia, N. Perez de la Blanca, Characterization of shapes in micro-
scopical digital images 7th. SCIA Procc, 701-708, 1991.
[Fdez-Valdivia et al. 95a] J. Fdez-Valdivia, J.A. Garcıa, M. Gcia-Silvente, A. Garrido y N. Perez de
la Blanca, A new edge-oriented approach to segment 2-D shapes VI Simposium Nacional de
Reconocimiento de Formas y Analisis de Imagenes, pp. 97-104, 1995.
[Fdez-Valdivia et al. 95b] J. Fdez-Valdivia, J.A. Garcıa, N. Perez de la Blanca, A. Garrido y J.M. Fuertes,
A new methodology to solve the problem of characterizing 2-D biomedical shapes, Computers
Methods and Programs in Biomedicine 46, pp. 187-205, 1995.
[Fdez-Valdivia et al. 95c] J. Fdez-Valdivia, J. Chamorro, J.A. Garcia, A. Garrido y E. Lozano, A
watershed-based algorithm to segment digital images, Actas del VI Simposium Nacional de Re-
conocimiento de formas y analisis de imagenes, pp. 105-111, 1995.
[Florack et al. 92] L.M.J. Florack, B.M. ter Haar Romeny, J.J. Koenderink, y M.A. Viergever, Scale and
the differential structure of images, Image and Vision Computing, vol. 10, pp. 376-388, 1992.
[Fu 82] K.S. Fu, Syntactic Pattern Recognition and Applications, Prentice Hall 1982.
[Garcıa et al. 94] J.A. Garcıa y J. Fdez-Valdivia, Representing planar curves by using a scale vector,
Pattern Recognition Letters. Vol 15 pp. 937-942, 1994.

BIBLIOGRAFIA pag.161
[Garcıa et al. 95] J.A. Garcıa, J. Fdez-Valdivia y A. Garrido, A scale-vector approach for edge detection,
Pattern Recognition Letters. Vol 16 pp. 637-646, 1995.
[Garcıa-Silvente et al. 96] M. Garcıa-Silvente, J.A. Garcıa y J. Fdez-Valdivia, The novel scale-spectrum
space for representing gray-level shape. Aceptado en Pattern Recognition.
[Garrido et al. 95] A. Garrido, N. Perez de la Blanca, J. Fdez-Valdivia y J.M. Fuertes, Segmenting non-
random noise biomedical images. Actas del VI Simposium Nacional de Reconocimiento de formas
y analisis de imagenes, pp. 434-442, 1995.
[Geman y Geman 84] D. Geman y S. Geman, Stochastic Relaxation, Gibbs Distributions, and the
Bayesian Restoration of Images, IEEE Trans. Pattern Analysis and Machine Intell., vol. 6,
721-741, 1984.
[Gonzalez y Woods 92] R. C. Gonzalez y R. E. Woods, Digital Image Processing, Addison-Wesley, 1992.
[Goshtasby 94] Ardeshir Goshtasby, On edge focusing, Image and Vision Computing, vol. 12, no. 4, 1994.
[Gradshteyn y Ryzhik 88] I.S. Gradshteyn y I.M. Ryzhik, Table of integrals, series, and products, Aca-
demic press, San Diego, 1988.
[Grenander 76] U. Grenander, Pattern Synthesis. Lectures in Pattern Theory Vol. 1. Applied Mathemat-
ical Sciences, vol. 18, Springer Verlag, 1976.
[Grenander y Keenan 89] U. Grenander y D.M. Keenan, Towards automated image understanding. Jour-
nal of Applied Probability, vol. 16, n.2, 207-221, 1989.
[Grenander et al. 91] U. Grenander, Y. Chow y D. M. Keenan, Hands: A Pattern Theoretic Study of
Biological Shapes, Springer Verlag, 1991.
[Griffin y Colchester 95] L.D. Griffin y A.C.F. Colchester, Superficial and deep structure in linear diffu-
sion scale space: isophotes, critical points and separatrices, Image and Vision Computing, vol.
13, no. 7, pp. 534-557, 1995.
[Hancock y Kittler 90a] E.R. Hancock y J. Kittler, Edge-labelling using dictionary-based relaxation, IEEE
Trans. Pattern Analysis and Machine Intell., vol. 12, 165-181, 1990.
[Hancock y Kittler 90b] E.R.Hancock y J. Kittler. Discrete Relaxation. Pattern Recognition, Vol. 23, No
7, pp . 711-733, 1990
[Hancock et al. 92] E.R. Hancock, M. Haindl y J. Kittler, Multiresolution edge labelling using hierarchical
relaxation, 11th IAPR International Conference on Pattern Recognition, vol B, 140-144, 1992.
[Haralick y Shapiro 92] R. Haralick y L. Shapiro, Computer and Robot Vision, vol-I, Addison-Wesley,
1992.
[Illingworth y Kittler 88] J. Illingworth, y J. Kittler, A Survey of the Hough transform, Comput. Vision,
Graph & Image Process., Vol 44, pp 87-116, 1988.
[Jain y Lakshmanan 96] A.K. Jain y Sridhar Lakshmanan, Objetc Matching Using Deformable Tem-
plates, IEEE Trans. Pattern Analysis and Machine Intell., vol. 18, no. 3, pp. 267-278, 1996.
[Jain 89] A.K. Jain, Fundamentals of digital image processing, Prentice-Hall, 1989.
[Jeng y Tsai 91] S.C. Jeng y W.H. Tsai, Scale and orientation invariant generalized hough transform- A
new approach, Pattern Recognition, vol. 24, No. 11, pp. 1037-1051, 1991.

pag.162 BIBLIOGRAFIA
[Kalvianen et al. 94] H. Kalvianen, P. Hirvonen, Lei Xu y Erkki Oja, Probabilistic and non-probabilistic
Hough transforms: overview and comparisons, Image and Vision Computing, Vol. 13 n. 4, May
1995.
[Kass et al. 87a] M. Kass, A. Witkin, y D. Terzopoulos.Snakes:Active contour models. In Proc. 1st Int.
Conf. on Computer Vision, 259-268, London, 1987.
[Kass et al. 87b] M. Kass, A. Witkin, y D. Terzopoulos.Snakes:Active contour models. Int. Journal of
Computer Vision, vol. 1, no. 4, 321-331, 1987.
[Kittler y Hancock 89] J.Kittler y E.R.Hancock. Combining evidence in probabilistic relaxation. Int. J.
Pattern Recognition Artif. Intell. 3. pp. 29-52, 1989.
[Klinger 71] A. Klinger, Pattern and search statistics. Optimizing Methods in Statistics (J.S. Rustagi,
ed.),(New York), Academic Press, 1971.
[Knoerr 88] A. Knoerr, Globals Models of Natural Boundaries: Theory and Applications. Report in Pat-
tern Theory 148. Brown University, 1988.
[Koenderink 84] J.J. Koenderink ,The structure of images Biological cybernetics 50:363-370, 1984
[Koenderink y Van Doorn 86] J.J. Koenderink y A.J. Van Doorn,Dynamic Shape Biological cybernetics
53:383-396, 1986
[Koenderink y Richards 88] J.J. Koenderink y W. Richards, Two-dimensional curvature operators, Jour-
nal of the Optical Society of America, vol.5, N. 7, pp. 1136-1141, Julio 1988.
[Lai y Chin 95] K.F. Lai y R.T. Chin, Deformable Contours: Modelling and Extraction. IEEE Trans.
Pattern Analysis and Machine Intell., vol. 17, N. 11, pp. 1084-1090, Noviembre 1995.
[Leavers 92] V.F. Leavers, Use of the radon transform as a methos of extracting information about shape
in two dimensions, Image and Vision Computing, vol 10, no. 2, 1992.
[Leymarie y Levine 93] F. Leymarie y M.D. Levine, Tracking Deformable Objects in the Plane Using
and Active Contour Model, IEEE Trans. Pattern Analysis and Machine Intell., vol. 15, N. 6, pp.
617-634, Junio 1993.
[Lindeberg 90] T. Lindeberg, Scale Space for Discrete Signalsm IEEE Trans. Pattern Analysis and Ma-
chine Intell., vol. 12, N. 3, pp. 234-254, Marzo 1990.
[Lindeberg y Eklundh 92a] T. Lindeberg y J.O. Eklundh, The scale-space primal sketch: Construction
and experiments, Image and Vision Computing, vol. 10, pp. 3-18, 1992.
[Lindeberg 92b] T. Lindeberg, Scale-space behaviour of local extrema and blobs, J. of Mathematical Imag-
ing and Vision, vol. 1, pp. 65-99, Mar 1992
[Lindeberg 93a] T. Lindeberg, On scale selection for differential operators., en Proc. 8th Scandinavian
Conf. on Image Analysis, pp. 857-866, Mayo 1993.
[Lindeberg 93b] T. Lindeberg, Detecting salient blob-like image strctures and their scales with a scale-
space primal sketch: A method for focus-of-attention, Int. J. of Computer Vision, vol.11, no. 3,
pp. 283-318, 1993.
[Lindeberg 93d] T. Lindeberg, Effective Scale: A Natural Unit for Measuring Scale-Space Lifetime, IEEE
Trans. Pattern Analysis and Machine Intell., vol. 15, N. 10, pp. 1068-1074, 1993.

BIBLIOGRAFIA pag.163
[Lindeberg 94a] T. Lindeberg, Scale-space theory in computer vision, Kluwer Academic Publishers. Dor-
drecht, Netherlands, 1994.
[Livesley 88] R. K. Livesley, Elementos finitos: introduccion para ingenieros, Limusa, Mexico, D.F., 1988.
[Lowe 88] D.G. Lowe, Organization of smoot image curves at multiple scales. Proc. 2nd International
Journal of Computer Vision, pp. 558-567, 1988.
[Marr y Nishahara 78] D.Marr y H.K. Nishahara, Visual Information Processing: Artificial Intelligence
and the Sensorium of Sight. Technology Review, V81 (1), pp 2-23, 1978.
[Marr 82] D. Marr. Vision - A Computational Investigation into the Human Representation and Process-
ing of Visual Information. W.H. Freeman and Co., San Francisco, 1982.
[Meer et al. 90] P. Meer, C.A. Sher y A. Rosenfeld, The chain pyramid: hierarchical contour processing,
IEEE Trans. Pattern Analysis and Machine Intell., vol. 12, 363-376, 1990.
[Mokhtarian y Mackworth 86] F. Mokhtarian y A. Mackworth, Scale-Based Description and Recognition
of Planar Curves and Two-Dimensional Shapes. IEEE Trans. Pattern Analysis and Machine
Intell., vol. 8, n. 1, pp 34-43, 1986.
[Ng et al. 93] I. Ng, J. Kittler y J. Illingworth, Supervised segmentation using a multiresolucion data
representation, Signal Processing vol. 31 no. 2, pp. 133-163, 1993.
[Pao et al. 92] Derek C. W. Pao, Hon F. Li, y R. Jayakumar, Shapes Recognition Using the Straight Line
Hough transform: Theory and Generalization, IEEE Trans. Pattern Analysis and Machine Intell.,
vol. 14, no. 11, noviembre 1992.
[Pavlidis 80] T. Pavlidis. Structural Pattern Recognition. Springer Series in Electrophysics. vol. 1.
Springer-Verlag, 1980.
[Pei y Horng 95] Soo-Chang Pei y Ji-Hwei Horng. Circular arc detection based on Hough transform,
Pattern Recognition Letters, vol. 16, pp. 615-625, 1995.
[Pentland y Sclaroff 91] A. Pentland y S. Sclaroff. Closed-form solutions for physically-based shape mod-
eling and recognition. IEEE Trans. Pattern Analysis and Machine Intell., 13(7), pp. 715-729, Julio
1991.
[Perez de la Blanca et al. 92] N. Perez de la Blanca y J. Fdez-Valdivia Building up templates for non-
rigid plane outlines. Proceedings ICPR-92, vol.3, pp. 575-578, 1992.
[Perez de la Blanca et al. 93] N. Perez de la Blanca, J. Fdez-Valdivia y J.A. Garcia Characterizing planar
outlines Pattern Recognition Letters. Vol 14. pp. 489-497. 1993.
[Perona y Malik 90] P. Perona y J. Malik, Scale-Space and Edge detection using anisotropic diffusion,
IEEE Trans. Pattern Analysis and Machine Intell., vol. 12, n. 7, pp. 629-639, Julio 1990.
[Poggio y Torre 84] T. Poggio y V. Torre, Ill-posed Problems and Regularization Analysis in Early Vision,
Proceedings of AARPA Image Understanding Workshop, pp. 257-263, 1984.
[Press et al. 92] W. Press, S. Teukolsky, W. Vetterling y B. Flannery, Numerical recipes in C, Cambridge
U.P., 1992.
[Rattarangsi y Chin 92] A. Rattarangsi y R.T. Chin, Scale-Based Detection of Corners of Planar Curves.
IEEE Trans. Pattern Analysis and Machine Intell., vol. 14, n. 4, abril 1992.

pag.164 BIBLIOGRAFIA
[Ronfard 94] R. Ronfard, Region-Based Strategies for Active Contour Models, International Journal of
Computer Vision, 13:2, 229-251, 1994.
[Rosenfeld 84] A.Rosenfeld,Multiresolution Image Processing and Analysis, Springer Series in Information
Sciences. vol. 12. Springer-Verlag, 1984.
[Rosin 92] P.L. Rosin, Representing curves at their natural scales. Pattern Recognition, Vol. 25, no. 11,
pp.1315-1325. 1992.
[Samet 90a] H. Samet, The design and analysis of spatial data structures. Addison Wesley, 1990.
[Samet 90b] H. Samet, Applications of spatial data structures. Addison Wesley, 1990.
[Sclaroff y Pentland 95] S. Sclaroff y A. Pentland. Modal Matching for Correspondence and Recognition,
IEEE Trans. Pattern Analysis and Machine Intell., vol 17, no. 6, pp 545-561, 1995.
[Sclaroff 95] S. Sclaroff.Modal Matching: A Method for Describing, Comparing, and Manipulating Digital
Signals. PhD Dissertation, MIT Media Laboratory, 1995.
[Ser y Siu 95] P.K. Ser y W.C. Siu, A new Generalized Hough Transform for the detection of irregular
objects. Journal of visual communication and image representation, Vol. 6, No. 3, pp 256-264,
Septiembre 1995.
[Serra 82] J. Serra, Image Analysis and Mathematical Morphology, Academic Press 1982.
[Sonka et al. 93] M. Sonka, V. Hlavac y R. Boyle, Image, processing, analysis and machine vision, Chap-
man & Hall, 1993.
[Staib y Duncan 92] L.H. Staib y J.S. Duncan, Boundary Finding with Parametrically Deformable Mod-
els, IEEE Trans. Pattern Analysis and Machine Intell., vol. 14, 1061-1075, 1992.
[Szeliski 89] Szeliski, R. Bayesian Modeling of Uncertainty in Low-Level Vision. Kluwer Academic Pub-
lishers, Boston. MA, 1989.
[Tanimoto y Klinger 80] Tanimoto y A. Klinger, eds, Structured Computer Vision. New York: Academic
Press, 1980.
[Teh y Chin 89] C.H. Teh y R. T. Chin, On the detection of dominant points on digital curves. IEEE
Trans. Pattern Analysis and Machine Intell., vol. 11, n. 8, pp 859-872, 1989.
[Ward 63] J.H. Ward, Hierarchical grouping to optimize and objective function, J. Amer. Stat. Ass., vol.
58, pp. 236-245, 1963.
[William y Shah 90] D.J William. y M. Shah, Edge contours using multiple scale, Computer Vision
Graphics and Image Processing,vol. 51, pp. 256-274, 1990.
[Witkin 83] A.P. Witkin, Scale-space filtering. Proc. 8th Intern. Joint Conf. Artif. Intell., Karlsruhe, West
Germany, pp. 1019-1022, 1983.
[Wood 96] J. Wood, Invariant pattern recognition: a review. Pattern Recognition, Vol. 29, no. 1, pp. 1-17,
1996.
[Yip et al. 95] R.K.K. Yip, P.K.S. Tam y D.N.K. Leung, Modification of Hough Transform for object
recognition using a 2-dimensional array. Pattern Recognition. vol 28, no. 11, pp. 1733-1744,
1995.
[Yuille et al. 92] A.L. Yuille, P.W. Hallinan y D.S. Cohen, Feature Extraction from faces using de-
formables templates, Int. Jour. Computer Vision, vol. 8, no. 2, 99-111, 1992.

Indice alfabetico
Aa posteriori, probabilidad, 124, 125
a priori
informacion, 5, 69
probabilidad, 124
aceleracion, vector de, 72
activo, contorno, 5
acumulador, 82, 83
de evidencias, 89
disminucion del tamanno, 91
representacion grafica del, 93
ajuste, funcion de, 36
algoritmo
Af , 37
Ap, 36
de enfocado de fronteras, 59
de enfoque, 114
de minimizacion de puntos, 38
de puntos dominantes, 34
multiescala detector de fronteras, 56
para puntos multiples, 61
alisamiento de contornos, 25, 29
amortiguacion, 75
matriz de, 72
parametro de, 75
analisis modal, 69, 73
angulo de contingencia, 28
aproximacion
elıptica, 151
aproximaciones
elıpticas, 113
modelos deformables, 5
no supervisados, 5
supervisados, 6
segmentacion, 3
aristas, vease fronteras
autoproblema
generalizado, 74
T. Hotelling, 79
Bbifurcaciones, 22, 53
blobs, 22
Ccadenas
corte y orientacion, 62
criterio para orientacion, 63
extraccion de, 60
informacion de, 8, 86
calor, difusion del, 18
Canny
filtro de, 52
caracterizacion, funcion de, 36
Caughey, series de, 74
causalidad, 21, 31
citologıas de mama, 13
codigos Freeman, 10, 86
contorno, 25
activo, 5
alisamiento de, 25, 29
contraccion del, 26
geografico alisado, 26
localizacion, 81
representacion multiescala de un, 30
representacion de un, 9
contraccion
correccion de la, 27
correccion global de la, 27
del contorno, 26
correlacion, 78
cota de error, 36, 37
curva
forma parametrica, 25, 116
punto medio, 27
radio medio de, 27
curvatura, 28
calculo de la, 32
curvas de nivel, 87
espacio de escalas de la, 30
165

pag.166 INDICE ALFABETICO
puntos de maxima, vease puntos dominantes
curvatura media, 28
curvature primal sketch, 30
Ddeformacion
base, 93
ejes (en T.H.) de, 82
global y local, 70, 77, 83, 124
limitacion de la, 122
modal, 77
no rıgida, 77, 83
plana
condiciones de, 71
principal, 78
rıgida, 77, 82, 83
seleccion, 77
tensor, 71
densidad de masa, 72
derivacion, espacio de escalas, 18
desplazamiento-deformacion
matriz de, 72
desplazamientos generalizados, 73
modales, 74
desviacion
de los maximos(correccion), 33
diccionario de deformaciones, 93
difusion del calor, 18
dimension
del espacio de localizaciones, 82, 83, 91, 111
dinamico, comportamiento, 69
distancia de Ward, 122
Eelasticidad, matriz, 71
elastico, material, 71
elemento finito
ecuaciones, 71
elemento finito en equilibrio, 72
eliminacion
de deformaciones, 78
de la zona de incertidumbre, 90
de modos de deformacion local, 92
de puntos multiples, 60
energıa
de deformacion, 123
disipacion, 72, 75
externa, 6, 116
desde fronteras, 117
desde regiones, 121
interna, 5, 116, 123
enfocado
algoritmo de, 114
de fronteras, 53, 59
operacion de, 34
entorno, informacion del, 8
equilibrio
ecuacion de, 71
transformacion de la, 73
elemento finito en, 72
estatico, 72
error mınimo, 36, 37
escala
efectiva, 21
espacio de, vease espacio de escalas
estructura a traves de la, 22
interna, 16, 32
seleccion de una, 16
espacio de escalas, 15
curvatura y, 29
de la curvatura, 30
definicion, 17
derivacion, 18
muestreo, 21, 32
normalizacion, 55
propiedades, 19
causalidad, 21
muestreo, 21
semigrupo conmutativo, 19
estatico, equilibrio, 72
estocastico
ruido, 1
ruido no, 1
estructura
en profundidad, 22
informacion de una, 87, 88
evidencias
acumulador de, 89
de cada cobjeto, 112
ponderacion de, 90
FFEM, 70
filtro de Canny, 52
fısica
energıa, 123
propiedad, 70
forma

INDICE ALFABETICO pag.167
alineamiento de una, 69, 78
deteccion de una, 9
funciones de, 75
modos de la, 74
representacion de una, 9, 89
propiedades de la, 9
codigos, 10, 86
fronteras
caminos de las, 53
de cada objeto, 112
deteccion de, 51, 56
energıa desde, 117
informacion basada en, 7
optimizacion desde, 111
proyeccion multiescala de, 59
segmentacion desde, 3
union de, 4
no supervisada, 4
supervisada, 4
Ggaussiana
2-D(derivadas), 18
derivadas de, 18, 29
distribucion, 125
graficas de, 19, 20
nucleo de, 17
para interpolacion, 75
Gibbs, distribucion de, 125
global, deformacion, vease deformacion global y lo-
cal
g-snakes, 7
Hhisteresis, 52, 54
homogeneidad
problema de, 1
regiones y, 121
Hotelling, transformada de, 79
Hough
transformada de
generalizada, 82
modificada, 85, 88
Iimagenes test, 13, 25
incertidumbre
zona de, vease zona de incertidumbre
inercia, fuerzas de, 72
informacion
de aristas, 8, 86
de cada objeto, 112
fusion de, 7
multicanal
integracion, 94, 117, 121, 122
multiescala, 16
niveles de la, 8, 86, 88
construccion, 87
tipos de, 7
interpolacion, 37, 96
matriz de, 72, 75
invarianza en la escala, 55
isotropico, material, 71
Llaplaciana de gaussiana, 52, 53
ley de tension-deformacion, 71
libre
modos de vibracion, vease vibracion libre
local, deformacion, vease deformacion global y local
LoG, 52
logarıtmico, muestreo, 22, 32
MMarkov, proceso de, 124
Marr
paradigma de, 2
primal sketch de, 51
masa, 71
calculo de la matriz de, 76
densidad de, 72
matriz de, vease matriz,masas
material elastico, 71
matriz
amortiguacion, vease amortiguacion
covarianzas, 79
de acumulacion, 82
de transformacion, 73, 74
desplazamiento-deformacion, 72
elasticidad, 71
fuerzas, 72
interpolacion, 72, 75
masas, 72
calculo, 76
rigidez, 72
calculo, 76
maximos
caminos de los, 21, 31

pag.168 INDICE ALFABETICO
construccion, 32
del acumulador de evidencias, 90
del valor absoluto, 32, 37
localizacion de los, 33
mesetas, en la acumulacion, 90
minimizacion
del conjunto de puntos, 38
del error cometido, 113, 151
mınimos cuadrados, 113
modal
analisis, 69, 73
coordenada, 79
deformacion, 77
desplazamiento generalizado, 74, 79
superposicion, 73
modelo
de ruido, 124
deformable
probabilıstico, 123
segmentacion con un, 4
geometrico, uso de un, 113
modulo de Young, 72
morfologıa, 4
M-ortonormalidad, 74
movimientos
no rıgidos, 77
rıgidos, 77
muestreo
de una curva, 25
del contorno, 70
del espacio de escalas, 32
del espacio de parametros, 92
en representacion piramidal, 16
espacio de escalas, 21
multicanal
informacion, vease informacion, multicanal
multiescala
informacion, 16
union de, 94
representacion, 15, 16, 52
multihisteresis, 54, 94
umbrales, 54
multiplicidad, ruido por, 1
multiresolucion
espacio de parametros, 114
imagen, 8
Nniveles
de la informacion, 8, 86
de resolucion, 114
Ooptimizacion
de la localizacion
de fronteras, 59
de objetos, 111
final de la solucion, 116
PPapanicolau, tecnica de, 13
parametro de escala, 17
particion de contornos localizados, 95
piramidal, representacion, 15
pıxel, informacion del, 8, 86
Poisson
distribucion de, 1
ratio de, 72
potencial, 116–122
precision, incremento de la, 111
preprocesamiento de aristas, 60
primal sketch, 51
principales, deformaciones, 78
profundidad, estructura en, 22
punto crıtico, 22
trayectoria, 22
velocidad, 23, 53
punto medio, 27
puntos dominantes, 30, 36, 87
deteccion de, 34
informacion basada en, 87
puntos multiples, 60
eliminacion, 62
Qquad-tree, 15
Rrachas, 10, 86, 87, 90
radio medio, 27, 37
ratio de Poisson, 72
Rayleigh, asuncion de, 73
regiones
caracterizacion de, 121
energıa desde, 121
informacion basada en, 7, 119
segmentacion por, 4
varianza interior de, 121

INDICE ALFABETICO pag.169
regularizacion, 123
relajacion, metodos de, 8, 51
representacion
de formas, 9, 89
de un contorno, 9
multiescala, 15
multiescala de un contorno 2D, 30
rigidez, 71
calculo de la matriz de, 76
matriz, 72
condiciones locales de, 123
rıgidos, movimientos, 77
ruido, 1
no aleatorio, 1, 13
por multiplicidad, 1
sal y pimienta, 99
tipos, 1
estocastico, 1
Ssegmentacion, 10
aproximaciones, 3
desde fronteras, 3
desde modelos deformables, 4
desde regiones, 4
semigrupo conmutativo, 19
senal-ruido, relacion, 99
series de Caughey, 74
snakes, 5, 123
snaxels, 5
solapamiento, ruido por, 1
soporte, condiciones de, 71
superposicion modal, 73
supervisados, metodos, 5
Ttamano global, medida de, 27
template deformables, segmentacion por, 4
tendencias, 10
discretizacion, 10, 87
generalizadas, 87
tension, 71
condiciones locales de, 123
tension-deformacion
ley, 71
matriz, 71
tensor de deformacion, 71
transformada
de Hotelling, 79
de Hough, 82
difusa, 84
modificada, 85, 88
trayectorias
de los maximos, vease maximos,caminos...
Uumbralizacion
usando histeresis, 52, 54
usando multihisteresis, 54
unicidad del nucleo gaussiano, 20
union
de informacion multicanal, 16, 94
usando la T.H., 96
de rachas, 87
fronteras, 4, 51
puntos de, 87
Vvelocidad, vector, 72
vibracion libre, modos de, 71, 73, 77
votacion, 85
WWard, distancia de, 122
YYoung, modulo de, 72
Zzona de incertidumbre, 84–86, 90, 114