Canción :Gracias, María Autor : Carchenilla Sincronizada Composición : Juan Braulio Arzoz.
Upload
percy-darwin-apaza-aguilarCategory
view
80download
0
Método de puntos interiores Primal Dualpara programación lineal
Braulio Gutiérrez Pari
Universidad Peruana UniónFacultad de Ingeniería y Aquitectura
Ingeniería Civil
Chullunquiani - PerúJunio del 2012

Índice general
Prólogo I
Introducción II
1. El Problema de Programación Lineal: Conceptos Básicos 11.1. El Problema de Programación Lineal . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2. Teoremas de convergencia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.3. Dualidad y Condiciones de Optimalidad . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.3.1. Dualidad . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121.3.2. Condiciones de Optimalidad de Karush-Kuhn-Tucker (KKT) . . . . . . . . . . 13
2. El Método de Newton, Lagrange y Penalización interna 142.1. El Método de Newton . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.2. El Método de Lagrange . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.3. El Método de Barrera Logarítmica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3. Método de Puntos interiores Primal-Dual 303.1. Método de puntos interiores Primal-Dual basado en barrera logaritmica . . . . . . . . 30
3.1.1. Construcción del método . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303.1.2. El Algoritmo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 363.1.3. Implementación y Experimentos . . . . . . . . . . . . . . . . . . . . . . . . . . 36
Conclusiones 52
Bibliografía 53
i

Prólogo
El siguiente trabajo es un resumen de uno de los capítulos a adicionarse al curso de Métodosnuméricos y programación dictado en 2012 en la escuela profesional de Ingeniería Civil. Curso quese imparte a los alumnos de quinto semestre
Como este trabajo está en su primera versión, probablemente existan algunos errores que seráncorregidos en las proxímas oportunidades, todo con la finalidad de otorgar una herramienta prácticade consulta.
ii

Introducción
Los algoritmos de Puntos interiores surgen, con el trabajo de Karmarkar, como una alternativade complejidad polinomial al bién establecido método simplex para el caso de programación lineal.En 1987 Kojima-Misuno-Yoshise presentan un algoritmo de Puntos interiores, llamado Primal-Dual,que seguido del trabajo de Mehrotra en 1992, fundamentan las bases de algunos de los algoritmosexistentes más eficientes para programación lineal.
El método de Puntos interiores Primal-Dual para programación lineal (1994). Este método es elmás eficiente y elegante dentro de la gran variedad de métodos que surgieron despues de la publicaciónformal del primer método de puntos interiores, el método de los Elipsoides (1978).
La literatura sobre los algoritmos de puntos interiores tipo Primal-Dual es extensa y variada,existen diferentes formulaciones, diversos resultados de convergencia y complejidad. Además de lasbuenas propiedades teóricas, los algoritmos Primal-Dual han demostrado poseer buen comportamien-to práctico y se han utilizado en distintas aplicaciones de manera satisfactoria.
El trabajo fue dividido en tres capítulos, en el primer capítulo tratamos el problema de progra-mación lineal junto con algunos conceptos básicos utilizados en la optimización lineal y no lineal,.enel capítulo 2 se describe el Método de Newton, Lagrange y penalización interna los cuales nos permi-tirán construir el método de puntos interiores Primal-Dual para programación lineal en el siguientecapítulo,. en el tercer capítulo construiremos el método de puntos interiores Primal-Dual para pro-gramación lineal, con la debida fundamentación matemática. Como un resumen del método, daremosel algoritmo el método. Finalmente los experimentos que corroboren la eficacia del método.
iii

Capítulo 1
El Problema de Programación Lineal:Conceptos Básicos
Dentro de la optimización, es indiscutible que el Método Simplex (1947) representa un clásico enla resolución de problemas de programación lineal. Más aún, el Simplex ha servido como fuente en laconstrucción de métodos especializados en la resolución de otros problemas, tales como programaciónentera. No obstante, cuando se realiza un análisis teórico con respecto a su eficiencia, el MétodoSimplex es considerado de tiempo de ejecución en el orden exponencial1, y por tanto, teóricamenteineficiente. Por otro lado, los resultados obtenidos en la práctica han mostrado que este método tieneun desempeño razonable y, frecuentemente, apenas requiere pocas iteraciones para resolver problemasde la vida real con un número de variables no muy grande.
El motivo para el mal comportamiento del método Simplex frente a pro-blemas particulares,tales como los propuestos por V. Klee y J. Minty, es que se desplaza por los vértices del poliedrodefinido por la región de factibilidad. A esto se le suman algunas otras desventajas, tales como laimplementación computacional sofisticada, peligro de ciclaje ante degeneración e ineficiencia anteproblemas de gran tamaño.
En los últimos cuarenta años surgieron otros tipos de métodos con una filosofía diferente, de-splazarse por el interior de la región factible. Los resultados teóricos fueron sorprendentes, puesmostraron que el problema de programación lineal podía ser resuelto en un tiempo de ejecuciónpolinomial. Dentro de los más representativos están el Método de las Elipsoides de Khachian y elMétodo de Karmarkar.
Por los años noventa surgieron métodos con la misma estrategia, des-plazarse por el interior delpoliedro de factibilidad, pero con la diferencia que éstos usaban tanto el primal como el dual pararesolver el problema de programación lineal. Estos métodos estaban fundamentados además en elMétodo de Newton, el Método de Barrera y el Método de Lagrange, estas herramientas matemáticasfusionadas produjeron lo que hoy en día se denomina Método de Puntos Interiores Primal-Dual,y actualmente, es considerada la manera más eficiente que se conoce para resolver el problema deprogramación lineal. Existen varias versiones de este método, una de ellas constituirá justamente elmotivo de este trabajo.
En la primera sección definiremos los concepto más importantes relacionados con el problema deprogramación lineal.en la forma estándar. así como sus propiedades más generales.
En la segunda sección veremos algunos teoremas de convergencia, y en la última sección analizare-mos la Dualidad y las Condiciones de Optimalidad, en esta sección veremos que para cada problema
1Es decir, que para problemas de programación lineal en espacios n dimensionales, puede realizar en el peor de loscasos, alrededor de 2n iteraciones.
1

CAPÍTULO 1. EL PROBLEMA DE PROGRAMACIÓN LINEAL: CONCEPTOS BÁSICOS 2
de Programación lineal existe otro problema de programación lineal denominado dual, la verdaderautilidad del dual está justamente en las relaciones que existen entre ambos problemas.
1.1. El Problema de Programación Lineal
Un problema de programación lineal es un modelo matemático que describe algún sistema ofenómeno de la vida real en términos matemáticos, donde todas las funciones involucradas son lineales.
El Problema de Programación Lineal en la forma estándar corresponde
Minimizar ctxAx = b
x ≥ 0(1.1)
donde A ∈ Rm×n (m < n) es de rango m, c ∈ Rn, x ∈ Rn y b ∈ Rm .La expresión ctx se llamafunción objetivo La expresión Ax = b se denomina las restricciones y x ≥ 0 condiciones de nonegatividad. El conjunto Ω = x ∈ Rn : Ax = b, x ≥ 0 se llama región de factibilidad y sus elementossoluciones factibles.
En resumen un problema de programación lineal se dice que está en forma estandar si y sólo si
Es de minimización
Solo incluye restricciones de igualdad.
El vector b es no negativo
Las variables x son no negativos.
Resolver el Problema de Programación Lineal consiste en hallar x∗ ∈ Ω tal que ctx∗ ≤ ctx, paratodo x ∈ Ω. Al vector x∗ se le denomina solución óptima . Consideremos un problema muy general.
Minimizar ctxAx = b
x ≥ 0
Si xk satisface las recciones Ax = b, x ≥ 0, entonces xk se llama punto factible. Del gráfico adjuntopodemos visualizar que ∇(ctx) = c es un vector que apunta en la dirección, donde la función objetivomás crece. Por lo tanto, −c estará apuntando hacia la dirección en cual la función objetivo alcanzasu mejor decrecimiento.

CAPÍTULO 1. EL PROBLEMA DE PROGRAMACIÓN LINEAL: CONCEPTOS BÁSICOS 3
x3
x1
c xt
x*
c x = kt
Obviamente maximizar una función es equivalente a minimizar el negativo de la función
Maximizarx∈Ω
f(x) = −Minimizarx∈Ω
(−f(x))
Existen otras formas de colocar el problema de programación lineal, por ejemplo, la forma canóni-ca.
Minimizar ctxAx ≥ bx ≥ 0
(1.2)
Es posible transformar el problema (1.2) en uno de la forma (1.1) mediante la introducción de unvector cuyas componentes son denominados variables auxiliares, del siguiente modo:
Minimizar ctxAx− s = b
x, s ≥ 0(1.3)
donde s ∈ Rm, tal que s = Ax− b, estas variables auxiliares se denominan variables de exceso.
Debemos resaltar aquí que con la introducción de variables auxiliares, el problema original dadoen (1.2) es transformado en otro problema de mayor dimensión, pues fueron añadidas m nuevasvariables, que corresponden a las componentes del vector s. En estas condiciones, resolver (1.3) noes lo mismo que resolver (1.2), pero si conseguimos resolver y encontrar una solución [x s]t para elproblema en (1.3), entonces x será una solución para (1.2).
En los párrafos anteriores asumimos que fueron introducidas exactamente m variables auxil-iares de exceso al problema (1.2), pero en realidad no siempre es necesario tal número de variables,pudiéndose añadir variables auxi-liares sólo donde se requiera, es decir, donde las restricciones seande desigualdad.

CAPÍTULO 1. EL PROBLEMA DE PROGRAMACIÓN LINEAL: CONCEPTOS BÁSICOS 4
Por otro lado, para transformar un problema del tipo
Minimizar ctxAx ≤ bx ≥ 0
(1.4)
a la forma estándar, podemos introducir un vector auxiliar de variables de holgura, del siguientemodo:
Minimizar ctxAx+ h = b
x, h ≥ 0(1.5)
Finalmente, debemos aclarar que la función objetivo en el problema (1.5) es diferente a la funciónobjetivo del problema original, debido a que ahora es de la forma ctx + 0h. Análogamente para elproblema dado en (1.3).
Cuando formulamos un problema de programación lineal, algunas veces las variables pueden nosatisfacer las condiciones de no negatividad, entonces podemos reemplazar por otras variables nonegativas mediante las siguientes sustituciones:
Si xi es una variable de tipo irrestricta (xi ∈ R), entonces podemos cambiarla por xi = x0i − x00i ,donde, x0i, x
00i ≥ 0.
Si xj ≥ lj, entonces hacemos xj = xj − lj, claramente ahora xj ≥ 0.
Si xj ≤ uj, entonces hacemos xj = uj − xj, observe que xj ≥ 0.
En lo sucesivo y por defecto, asumiremos también que siempre trabajamos con un problema linealen la forma estándar, salvo se aclare lo contrario.
Conjunto Convexo: Un conjunto K es convexo, si la combinación convexa de dos elementos cua-lesquiera del conjunto está en K. Es decir, si dados x1, x2 ∈ K, para todo λ ∈ [0, 1] , se verificaque
λx1 + (1− λ)x2 ⊂ K
Región Factible: Para el problema de programación lineal en la forma estándar, la región factiblees el conjunto P = x ∈ Rn : Ax = b, x ≥ 0
Solución Factible: En un punto situado en la región factible. Es decir, x es solución factible si x∈ P.
Solución Factible Óptima: Para el caso de minimización, es una solución factible óptima x∗ ∈ P,tal que ctx∗ ≤ ctx, para todo x ∈ P.

CAPÍTULO 1. EL PROBLEMA DE PROGRAMACIÓN LINEAL: CONCEPTOS BÁSICOS 5
Hiperplano: Un hiperplano en Rn es un conjunto de la forma©h = x ∈ Rn : ptx = k
ªdonde p ∈ Rn, p 6= 0, es un vector columna y k es una constante escalar. Un hiperplano es laextensión de lo que significa una recta en R2 o un plano en R3. Debmos notar que el vector pes normal al hiperplano h.
Semiespacio: Un hiperplano divide el espacio Rn en dos subregiones, llamadas semiespacios. Así,un semiespacio es el conjunto
h1 =©x ∈ Rn: ptx ≥ k
ªdonde p es un vector columna diferente de cero y k es un escalar. El otro semiespacio es elconjunto de puntos
h2 =©x ∈ Rn: ptx ≤ k
ªdonde h1 ∪ h2 = Rn
Poliedro: Región definida por la intersección de un conjunto finito de semiespacios. Un poliedro esun conjunto convexo.
Politopo: Poliedro no vacío y acotado
Restricción Activa: Dada la desigualdad ptx ≥ k, donde p ∈ Rn y k es un escalar. Si x0 ∈ Rnes tal que satisface ptx0 = k, entonces se dice que x0 hace activa la desigualdad ptx ≥ k. Enprogramación lineal, estas desigualdades constituyen las restricciones, en esas condiciones, sedice entonces que x0 hace activa dicha restricción. Para el caso de una restricción de igualdadptx = k, es claro que cualquier x que satisfaga dicha restricción hará activa ésta.
Punto extremo: Consideremos una región factible en programación lineal. Un punto extremo x ∈Rn es la intersección de n hiperplanos linealmente independientes. Es decir, x es un puntoextremo si hace activa n restricciones linealmente independientes. Si x fuera también factible,entonces se dice que es un punto extremo factible.
Punto Extremo No Degenerado: Un punto extremo no degenerado x se dice no degenerado, siexactamente hace activa n restricciones. Cuando más de n restricciones son activas con respectoa x, entonces el punto se denomina extremo degenerado.
El problema (1.1) no es degenerado. Esto significa que todo punto x factible para (1.1) tiene comomínimo m componentes diferentes de 0

CAPÍTULO 1. EL PROBLEMA DE PROGRAMACIÓN LINEAL: CONCEPTOS BÁSICOS 6
Solución Básica: Consideremos el problema de programación lineal en la forma estándar definidaen (1.1) donde existe n variables ym restricciones, conm < n, además asumiremos inicialmenteque el rango de A es completo:
Minimizar z = ctx (1.6)
Ax = b (1.7)
x ≥ 0 (1.8)
Una solución básica n−dimensional se obtiene eligiendo desde A una submatriz cuadrada Bde rango m, a esta submatriz cuadrada e inversible se le llama matriz básica. Reordenando lascolumnas de A, si fuera necesario, y también las componentes de x, particionamos la matriz Ay el vector de x de modo que se mantenga la compatibilidad:
A = [B N] (1.9)
x =
∙xBxN
¸(1.10)
Al vector xN se le denomina vector no básico y a sus n−m componentes se les llama variablesno básicas. y a sus m componentes se les llama variables básicas. Reemplazando (1.9) y (1.10)en (1.7) y despejando xB en función de xN , desde
[B N]
∙xBxN
¸= b
obtenemosBxB + NxN = b
B−1BxB + B−1NxN = B−1b
xB + B−1NxN = B−1b
xB = B−1b− B−1NxN (1.11)
Obsérvese que si damos valores arbitrarios a las variables del vector xN, y evaluamos xB según
(1.11), el vector x =∙xBxN
¸satisface automáticamente (1.7), pero aún no satisface (1.8). Si
hacemos xN = 0 y calculamos nuevamente xB según (1.11), el vector
x =
∙xBxN
¸=
∙xB0
¸=
∙B−1b
0
¸además será un punto extremo, pués n restricciones linealmente independientes son activas enx. Esto es, n−m restricciones activas a causa de xN = 0 y m restricciones activas a causa deAx = b. Este último vector x, calculando de ese modo, se denomina solución básica. Es decir,en programación lineal, una solución básica es un punto extremo.
Solución Básica factible (SBF): Haciendo xN = 0 y calculando xB según (1.11), si xB = B−1b ≥0, entonces la solución básica
x =
∙xBxN
¸=
∙B−1b
0
¸será además factible, pues satisface (1.7) pero ahora también (1.8). En este caso, la soluciónbásica se denomina solución básica factible. En programación lineal, una solución básica factiblees un extremo factible.
Solución Básica Factible No degenerada: Es una solución básica factible donde xB > 0. Ob-serve que una solución básica factible no degenerada hace exactamente n restricciones activas,por lo que es un punto extremo no degenerado. Cuando una o más variables básicas tomanel valor de cero, la solución básica factible se denomina degenerada. Note que una soluciónbásica factible degenerada hace más de n restricciones activas, lo que significa que es un puntoextremo degenerado.

CAPÍTULO 1. EL PROBLEMA DE PROGRAMACIÓN LINEAL: CONCEPTOS BÁSICOS 7
Dirección Factible: Consideremos el problema de programación lineal.
Minimizar ctxAx ≤ bx ≥ 0
Un vector d ∈ Rn, d 6= 0, es denominado una dirección factible, si dado un punto factible x,para todo λ > 0,se tiene
A(x+ λd) ≤ bx+ λd ≥ 0
Para el caso de un problema programación lineal en la forma estándar, nosotros decimos que unvector d ∈ Rn, d 6= 0, es una dirección factible, si dado un punto factible x, para todo λ > 0,setiene
A(x+ λd) = b
x+ λd ≥ 0En estas condiciones, podemos decir que si d ∈ Rn tal que d > 0, entonces d es una direcciónfactible para el problema PL estándar si, y solo si, Ad = 0 y x + λd ≥ 0, para todo λ > 0.Debemos observar que esta definición de dirección factible es válida sólo en programación lineal,para el caso general de programación no lineal la definición es diferente.
Dirección Extrema: Una dirección extrema de un conjunto convexo es una dirección factible, lacual no puede ser representada como una combinación lineal positiva de dos direcciones factiblesdistintas (linealmente independientes). por lo tanto, en programación lineal podemos decir queel conjunto de direcciones extremas generan todas las direcciones factibles.
Dirección de Decrecimiento: Dado x factible y d ∈ Rn, d 6= 0, d es una dirección de decrec-imiento partiendo de x, si existe ² > 0 tal que, para todo t ∈ h0, ²]
ct(x+ td) < ctx
Para el caso de minimización, una dirección es de decrecimiento si, y solo si, ctd < 0. Obvia-mente, si para un x factible no existe direcciones de decrecimiento d, tal que el punto x + tdsea factible, entonces x es una solución óptima.
Claramente, podemos verificar que el vector d = −∇(ctx) = −c 6= 0, obtenido de la función objetivo,es una dirección de decrecimiento. Esto se debe a que.
ctd = ct(−c) = − kck2 < 0
El vector −c no sólo es un vector de decrecimiento, sino que es el vector que proporciona elmáximo decrecimiento. Es decir, si consideramos otra dirección de decrecimiento d, tal quek−ck =
°°d°° , entonces partiendo de un punto factible x y desplazándonos en las direcciones −cy d, el punto x− tc es mejor que el punto x+ td, en otras palabras
ct(x− td) ≤ ct(x+ td)
Función Convexa: Si K conjunto convexo no vacío y f: K ⊂ Rn −→ R es una función, se dice quef es convexa si.
f(λx1 + (1− λ)x2) ≤ λf(x1) + (1− λ)f(x2)

CAPÍTULO 1. EL PROBLEMA DE PROGRAMACIÓN LINEAL: CONCEPTOS BÁSICOS 8
x1
f
xλ 1 2=λx +(1-λ)x
f(x )1 f(x )2
λf(x )+(1-λ)f(x )1 2
1.2. Teoremas de convergencia
En esta sección presentamos algunos teoremas que garantizan la convergencia del método depuntos interiores Primal-Dual.
Teorema 1.1 La región factible P del problema (1.1) es un conjunto convexo.
Prueba. Sea P la región factible del problema (1.1), sea x1, x2 ∈ P arbitrarios, definamos x =λx1 + (1− λ)x2 con λ ∈ [0, 1] , queremos probar que x ∈ P y x ≥ 0.
i) Como Ax1 = b y Ax2 = b, entonces.
Ax = A(λx1 + (1− λ)x2) = λAx1 + (1− λ)Ax2 = λb+ (1− λ)b = b
ii) Ahora, x1 ≥ 0, x2 ≥ 0, λ ≥ 0, entonces (1− λ) ≥ 0, de aquí se tiene que λx1 ≥ 0, (1 − λ)x2 ≥ 0.En consecuencia P es un conjunto convexo.
Definición 1.1 Sea P ⊂ Rn un conjunto convexo y f : Rn → R una función convexa. La siguienteformulación matemática dada por.
Minimizar f(x)
x ∈ P (1.12)
se denomina problema de programación convexa.
El problema de programación convexa tiene importantes propiedades que lo distingue de proble-mas más generales, uno de los resultados más interesantes está dado en el siguiente teorema.
Teorema 1.2 En un problema de programación convexa:a) Todo minimizador local es minimizador global.b) El conjunto de minimizadores es convexo.c) Si f es estrictamente convexa, no puede haber más de un mininizador.
Prueba. Para mostrar (a) supongamos que x∗ sea un minimizador local pero no global del problemade programación convexa dado en (1.12)entonces existe un x ∈ P, x 6= x∗, tal que f(x) < f(x∗).Ahora, para λ ∈ [0, 1] , consideremos la combinación convexa xλ = (1− λ)x∗ + λx, por la convexidadde P, tenemos que xλ ∈ P, y por la convexidad de f
f(xλ) = f((1− λ)x∗ + λx) ≤ (1− λ)f(x∗) + λf(x)
= f(x∗) + λ(f(x)− f(x∗)) < f(x∗)

CAPÍTULO 1. EL PROBLEMA DE PROGRAMACIÓN LINEAL: CONCEPTOS BÁSICOS 9
Ahora, para λ > 0 suficientemente próximo de 0, xλ se torna arbitrariamente próximo pero diferentede x∗, pero además f(xλ) < f(x
∗). Esto significa que para cualquier vecindad V(x∗, ε) es posibleencontrar un xλ ∈ V(x∗, ε) tal que f(xλ) < f(x∗), lo cual contradice el hecho que x∗ es un minimizadorlocal.
Para mostrar (b) nosotros llamamos de S al conjunto de todos los minimizadores del problemade programación convexa. sea x, y ∈ S, entonces
f(x) = f(y) ≤ f(λx+ (1− λ)y), ∀ λ ∈ [0, 1]
Por la convexidad de f tenemos
f(λx+ (1− λ)y) ≤ λf(x) + (1− λ)f(y)
= f(y) + λ(f(x)− f(y))
= f(y) = f(x), ∀ λ ∈ [0, 1]
Entonces f(x) = f(y) = f(λx + (1 − λ)y) ≤ f(x) = f(y), ∀ λ ∈ [0, 1] , este último significa queλx+ (1− λ)y también es un minimizador y por tanto λx+ (1− λ)y ∈ S, de donde S es convexo.
Para la parte (c), supongamos que existe x, y ∈ S con x 6= y, entonces para λ ∈ [0, 1] se tieneque f(x) = f(y) = f(λx+ (1 − λ)y), debido a que x, y son minimizadores globales. Ahora, como f esestrictamente convexa se verifica
f(λx+ (1− λ)y) < f(x) = f(y)
con lo que tenemos la contradicción deseada y la prueba está concluida.
Teorema 1.3 El problema de programación lineal en la forma estándar es un problema de progra-mación convexa.
Prueba. Dado el siguiente problema de programación lineal
Minimizar f(x) = ctx
sujeto a Ax = b
x ≥ 0
debido a la linealidad de f, satisface la siguiente condición
ct(λx+ (1− λ)y) = λctx+ (1− λ)cty, ∀x, y ∈ Rn, λ ∈ [0, 1]
Luego, f es una función convexa. Falta sólo verificar que la región de factibilidad es un conjuntoconvexo. Para esto, definamos Ω = x ∈ Rn : Ax = b, x ≥ 0 . Dado x1, x2 ∈ Ω, luego Ax1 = b,
x1 ≥ 0, Ax2 = b, x2 ≥ 0. Sea x = λx1 + (1− λ)x2 y λ ∈ [0, 1]
Ax = A(λx1 + (1− λ)x2) = λAx1 +Ax2 − λAx2 = b
Ademásλx1 + (1− λ)x2 ≥ 0
Por lo tanto x ∈ Ω, y Ω es convexo.
Corolario 1.1 En un problema de programación lineal en la forma estándar se cumple:Todo minimizador local de f es global.
CAPÍTULO 1. EL PROBLEMA DE PROGRAMACIÓN LINEAL: CONCEPTOS BÁSICOS 10
Consideremos ahora el problema de programación lineal en la forma estándar
Minimizar ctx
x ∈ P (1.13)
donde P = x ∈ Rn : Ax = b, x ≥ 0 , b ∈ Rm, A ∈ Rm×n es de rango m, con m < n.
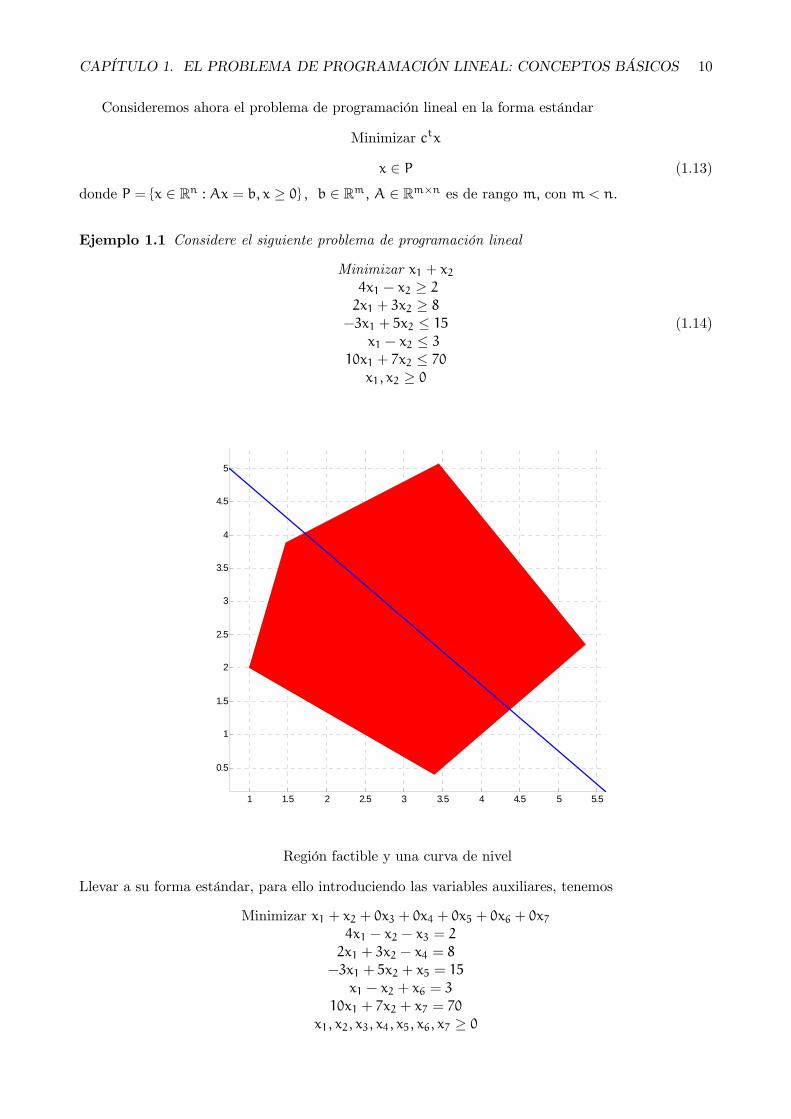
Ejemplo 1.1 Considere el siguiente problema de programación lineal
Minimizar x1 + x24x1 − x2 ≥ 22x1 + 3x2 ≥ 8
−3x1 + 5x2 ≤ 15x1 − x2 ≤ 3
10x1 + 7x2 ≤ 70x1, x2 ≥ 0
(1.14)
1 1.5 2 2.5 3 3.5 4 4.5 5 5.5
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
Región factible y una curva de nivel
Llevar a su forma estándar, para ello introduciendo las variables auxiliares, tenemos
Minimizar x1 + x2 + 0x3 + 0x4 + 0x5 + 0x6 + 0x74x1 − x2 − x3 = 2
2x1 + 3x2 − x4 = 8
−3x1 + 5x2 + x5 = 15
x1 − x2 + x6 = 3
10x1 + 7x2 + x7 = 70
x1, x2, x3, x4, x5, x6, x7 ≥ 0

CAPÍTULO 1. EL PROBLEMA DE PROGRAMACIÓN LINEAL: CONCEPTOS BÁSICOS 11
Curvas de nivel de f sobre RLos datos que a introducir en el computador son
A =
⎡⎢⎢⎢⎢⎣4 −1 −1 0 0 0 0
2 3 0 −1 0 0 0
−3 5 0 0 1 0 0
1 −1 0 0 0 1 0
10 7 0 0 0 0 1
⎤⎥⎥⎥⎥⎦ , b =
⎡⎢⎢⎢⎢⎣2
8
15
3
70
⎤⎥⎥⎥⎥⎦ , c =
⎡⎢⎢⎢⎢⎢⎢⎣
1
1
0
0
0
0
⎤⎥⎥⎥⎥⎥⎥⎦al resolver con una implementación computacional básica en Matlab nos otorga;
x(12) =
⎡⎢⎢⎢⎢⎢⎢⎢⎢⎣
1.002.000.000.008.004.0046.00
⎤⎥⎥⎥⎥⎥⎥⎥⎥⎦Después de 12 iteraciones principales ejecutadas por el programa, proyectando x12 sobre el x1x2-espacio, podemos ver lo que sucedió en el problema original. Así, la solución aproximada de (1.14)es ∙
x1x2
¸=
∙1.002.00
¸el valor óptimo es: z = 3.00, y la solución óptima es x = [1 2]t

CAPÍTULO 1. EL PROBLEMA DE PROGRAMACIÓN LINEAL: CONCEPTOS BÁSICOS 12
1.3. Dualidad y Condiciones de Optimalidad
Por lo general, la dualidad y las condiciones de optimalidad son usadas para la construcción demétodos que son variaciones del Simplex, tal como veremos en el capítulo 3 el método Primal-Dualde Puntos Interiores para programación Lineal.
Uno de los aspectos teóricos más importantes asociado a la programación lineal es la dualidad.Mediante esto, es posible caracterizar al problema de programación lineal desde otro punto de vista.
1.3.1. Dualidad
Dado el problema de programación lineal en la forma estándar
Minimizar ctxAx = b
x ≥ 0(1.15)
Definiendo el dual de un problema de Programación lineal en la forma estándar
Maximizar btyAty+ z = c
z ≥ 0(1.16)
donde z ∈ Rn.
Cualquier problema de programación lineal (LP) denominado primal tiene asociado a él otroproblema también LP llamado dual, Para cualquier problema primal y su dual, todas las relacionesentre ellos son simétricas porque el dual de su dual es el primal.
Las variables del problema de maximización se relacionan con la restricción del problema deminimización del siguiente modo.
Problema de Minimización[coeficientes]
número de variablesnúmero de restricciones
Variable≥ 0≤ 0
IrrestrictaRestricción
≥≤=
⇔⇔⇔⇔⇔⇔⇔⇔⇔
Problema de Maximización[coeficientes]t
número de restriccionesnúmero de variables
Restricción≤≥=
Variable≥ 0≤ 0
Irrestricta
Relación variable-restricción entre el primal y su dual
Ejemplo 1.2
PrimalMaximizar 3x1 + 5x2
x1 ≤ 42x2 ≤ 12
3x1 + 2x2 ≤ 18x1, x2 ≥ 0
⇔Dual
Minimizar 4y1 + 12y2 + 18y3y1 + 2y3 ≥ 3
2y2 + 2y3 ≥ 5y1, y2, y3 ≥ 0.

CAPÍTULO 1. EL PROBLEMA DE PROGRAMACIÓN LINEAL: CONCEPTOS BÁSICOS 13
PrimalMinimizar 3x1 + 5x2 − 4x3
x1 + 2x2 − 4x3 ≥ 63x1 − 2x2 + x3 = −10
x1 ≤ 0, x2 ≥ 0, x3 irrestricta.
⇔Dual
Maximizar 6y1 − 10yy1 + 3y2 ≥ 32y1 − 2y2 ≤ 5−4y1 + y2 = −4
y1 ≥ 0, y2 irrestricto
Lema 1.1 Si x, y son soluciones factibles del problema de minimización y maximización, respecti-vamente, entonces
bty ≤ ctx
Prueba. Consideremos la forma canónica del primal y el dual, sean x e y soluciones factibles delproblema de minimización y maximización, respectivamente. Veamos que
Ax ≥ b, x ≥ 0 (1.17)
ademásAty ≤ c, y ≥ 0 (1.18)
de (1.17) se tiene que b ≤ Ax ahora multiplicando por y ≥ 0
bty ≤ xtAty
≤ xtc = ctx
≤ ctx
Corolario 1.2 Si x∗ e y∗ son soluciones factibles del pro-blema de minimización y maximización,respectivamente, tal que ctx∗ = bty∗, entonces x∗ e y∗ son soluciones factibles óptimas.
Prueba. Haremos una prueba indirecta. Sea x∗ no es una solución óptima del problema de mini-mización, entonces para algún x factible tenemos
ctx < ctx∗
usando el Lema anterior, se tienebty ≤ ctx < ctx∗
y en consecuencia bty∗ 6= ctx∗
1.3.2. Condiciones de Optimalidad de Karush-Kuhn-Tucker (KKT)
Los puntos x∗, y∗, z∗ son soluciones óptimas para el Primal y el Dual del problema de progra-mación lineal respectivamente, si juntos satisfacen:
Ax = b, x ≥ 0 (Factibilidad Primal)
Aty+ z = c, y irrestricto, z ≥ 0 (Factibilidad Dual)
ztx = 0 (C. de Complementariedad)
Estas condiciones de Karush Kunh Tucker respresentan condiciones necesarias y suficientes para unminimizador global del problema.

Capítulo 2
El Método de Newton, Lagrange yPenalización interna
En este capítulo describiremos las tres herramientas numéricas que nos permitirán la construccióndel método de puntos interiores Primal-Dual para Programación Lineal.
El método de Newton. Este método numérico es aplicado para resolver sistemas de ecuaciones nolineales y es aplicado en la resolución de problemas de optimización sin la presencia de restricciones.
El método de Lagrange. Este método numérico es aplicado frecuentemente para resolver problemasde optimización con restricciones de igualdad.
El método de Penalización interna. Este método numérico es aplicado frecuentemente para re-solver problemas de optimización con restricciones de desigualdad.
los cuales nos permitirán construir el método de Puntos interiores Primal dual para programaciónlineal.
En general, los métodos de puntos interiores están soportados básicamente por una fusión deestas tres técnicas numéricas, el método de Newton, Lagrange y penalización interna.
2.1. El Método de Newton
Este método numérico es aplicado con mayor frecuencia en la resolución de problemas de opti-mización sin restricciones. y será modificado antes de poderlo utilizar en puntos lejanos de la solución,añadiendo en un inicio una longitud de paso α.
Recordemos inicialmente el método de Newton para hallar un cero de una función de una variable,es decir resolver f(x) = 0 con primera derivada contínua f ∈ C1(R). Dado un punto inicial xk, conf0(xk) 6= 0 para todo k = 0, 1, 2, 3, ..., .
Partiendo de un punto xk, como en la figura adjunta, trazamos la recta tangente a la curvay = f(x) recordemos la ecuación punto pendiente y−y0 =m(x−x0) en el punto inicial (xk, f(xk).Lacual es f(x)− f(xk) = f0(xk)(x− xk) despejando f(x) tenemos
f(x) = f(xk) + f0(xk)(x− xk) (Recta tangente a la curva)
El próximo punto,xk+1, está definido como la solución de f(x) = 0
0 = f(xk) + f0(xk)(xk+1 − xk)
14
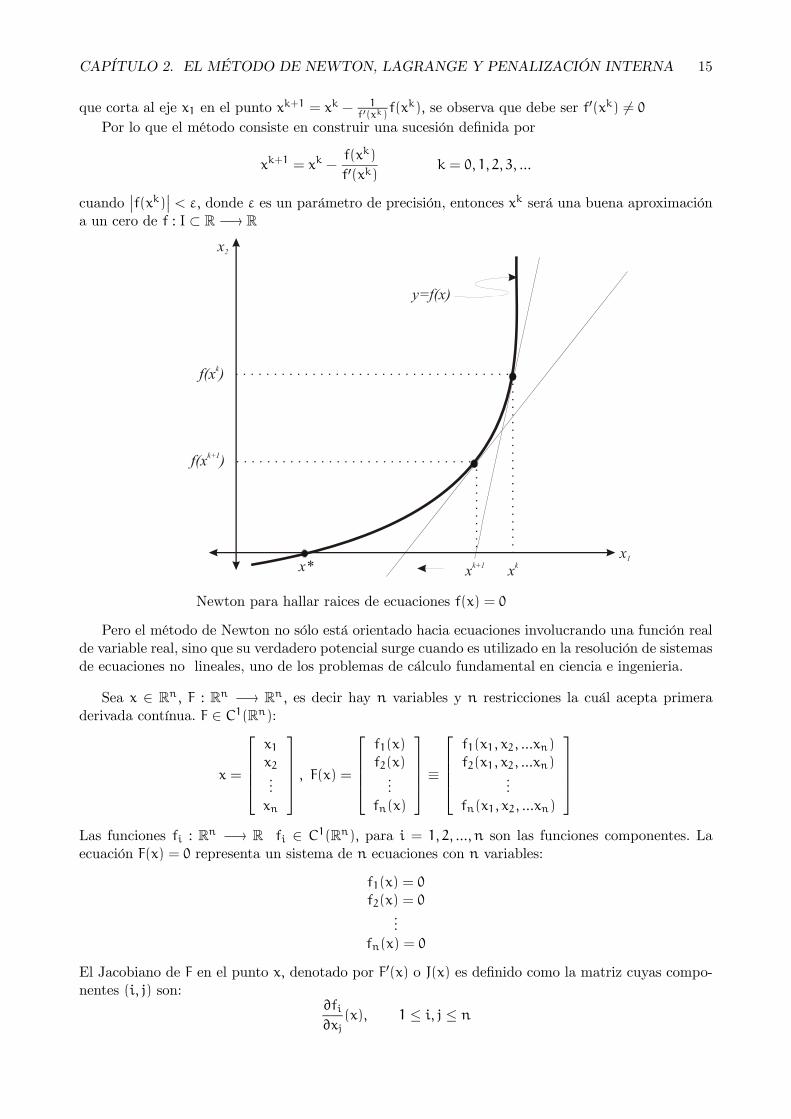
CAPÍTULO 2. EL MÉTODO DE NEWTON, LAGRANGE Y PENALIZACIÓN INTERNA 15
que corta al eje x1 en el punto xk+1 = xk − 1f0(xk )
f(xk), se observa que debe ser f0(xk) 6= 0Por lo que el método consiste en construir una sucesión definida por
xk+1 = xk −f(xk)
f0(xk)k = 0, 1, 2, 3, ...
cuando¯f(xk)
¯< ε, donde ε es un parámetro de precisión, entonces xk será una buena aproximación
a un cero de f : I ⊂ R −→ R
Newton para hallar raices de ecuaciones f(x) = 0
Pero el método de Newton no sólo está orientado hacia ecuaciones involucrando una función realde variable real, sino que su verdadero potencial surge cuando es utilizado en la resolución de sistemasde ecuaciones no lineales, uno de los problemas de cálculo fundamental en ciencia e ingenieria.
Sea x ∈ Rn, F : Rn −→ Rn, es decir hay n variables y n restricciones la cuál acepta primeraderivada contínua. F ∈ C1(Rn):
x =
⎡⎢⎢⎢⎣x1x2...xn
⎤⎥⎥⎥⎦ , F(x) =⎡⎢⎢⎢⎣f1(x)
f2(x)...
fn(x)
⎤⎥⎥⎥⎦ ≡⎡⎢⎢⎢⎣f1(x1, x2, ...xn)
f2(x1, x2, ...xn)...
fn(x1, x2, ...xn)
⎤⎥⎥⎥⎦Las funciones fi : Rn −→ R fi ∈ C1(Rn), para i = 1, 2, ..., n son las funciones componentes. Laecuación F(x) = 0 representa un sistema de n ecuaciones con n variables:
f1(x) = 0
f2(x) = 0...
fn(x) = 0
El Jacobiano de F en el punto x, denotado por F0(x) o J(x) es definido como la matriz cuyas compo-nentes (i, j) son:
∂fi
∂xj(x), 1 ≤ i, j ≤ n

CAPÍTULO 2. EL MÉTODO DE NEWTON, LAGRANGE Y PENALIZACIÓN INTERNA 16
explícitamente
J(x) = F0(x) =
⎡⎢⎢⎢⎣f01(x)f02(x)...
f0n(x)
⎤⎥⎥⎥⎦ =⎡⎢⎢⎢⎣∇ft1(x)∇ft2(x)...
∇ftn(x)
⎤⎥⎥⎥⎦El método de Newton es de caracter iterativo y está basado en la aproximación lineal de la funciónF en torno al punto actual xk
F(x) ≈ Lk(x) = F(xk) + J(xk)(x− xk)
siguiendo el principio descrito anteriormente, el siguiente punto xk+1 es una solución de
Lk(x) = 0 (2.1)
Si J(xk) es no singular de (2.1), entonces tiene solución única, esto es
0 = F(xk) + J(xk)(xk+1 − xk)
despejando el punto actual xk+1
xk+1 = xk −1
J(xk)F(xk)
xk+1 = xk − J−1(xk)F(xk) (2.2)
Empezando de un punto inicial x0. Si x0 está suficientemente cerca a la solución x∗ satisfaciendoF(x∗) = 0, entonces bajo las condiciones apropiadas, podemos esperar que la sucesión converga a lasolución x∗; es decir
lımk→∞xk = x∗
Obtener xk+1 directamente de (2.2) debería ser evitado para fines computacionales, ya que calcularJ−1(xk) es considerado costoso. Entonces una i-teración de Newton consiste en resolver un sistemalineal:
J(xk)dk = −F(xk) (2.3)
xk+1 = xk + dk (2.4)
lo que nos indica (2.4) es que una vez conocido el paso de newton dx, es posible calcular xk+1.
Aunque el método de Newton es muy atractivo en función de sus propiedades de convergenciacerca de la solución, ha de modificarse antes de poderlo utilizar en puntos más lejados de la solución,una primera modificación es añadir una longitud de paso (α).a la dirección de newton.
Vale recalcar que el método de newton elige como dirección de búsqueda
dx = −J(xk)−1F(xk)
Es importante notar que la dirección dx no se puede calcular si J(xk) es una matriz singular. Inclusoen el caso de que no lo fuese, dx no sería necesariamente una dirección de descenso cuando la matrizJ(xk) no es definida positiva. La programación convexa es un caso importante para que la direcciónde newton sea de descenso.
Resumiendo este método más popular para resolver sistemas de ecuaciones no lineales. Dadauna función Fn : Rn 7→ Rn y un sistema Fn(x) = 0. El Método de Newton consiste en repetirconsecutivamente, para k = 0,1,2,.., hasta que
°°Fn(xk)°° < ε, donde ε > 0, la siguiente regla:
xk+1 = xk −Fn(x
k)
F0n(xk)

CAPÍTULO 2. EL MÉTODO DE NEWTON, LAGRANGE Y PENALIZACIÓN INTERNA 17
Note que xk denota un vector de aproximación de la solución del sistema de ecuaciones Fn(x) = 0,además, x0 es el vector inicial y F0n(x
k) es el Jacobiano de Fn en xk.
El siguiente programa en Matlab resuelve el sistema F(x) = 0, si prec representa el parámetrode presición, J = F0(x) como el Jacobiano del sistema de ecuaciones. y x0 un punto inicial.
function x=newton(x)iter=0; prec=0.000001;while norm(Fn(x))>prec
iter=iter+1;x=x-inv(Jn(x))*Fn(x);fprintf(’iter= %2i; x = [ %7.4f %7.4f]\n’, iter,x);if iter>1000
error(’parece que newton no converge’);end
end
Veamos algunos ejemplos
Ejemplo 2.1 Se quiere resolver el sistema de ecuaciones no lineales
−x+ 2y− 4 = 0
(x− 6)2 − y+ 4 = 0
Ejecutando Newton, con los siguientes puntos iniciales∙12
¸y∙610
¸tenemos, pero primero defi-
namos el sistema de ecuaciones y el Jacobiano
F(x) =
∙−x1 + 2x2 − 4
(x1 − 6)2 − x2 + 2
¸;
F0n(xk) = J(x) =
"dfdx1
dfdx2
dgdx1
dgdx2
#=
∙−1 2
2(x1 − 6) −1
¸

CAPÍTULO 2. EL MÉTODO DE NEWTON, LAGRANGE Y PENALIZACIÓN INTERNA 18
que cuya gráfica correspondiente se observa.
gráfica de z = −x1 + 2x2 − 4 y z = (x1 − 6)2 − x2 + 2
Al ejecutar el programa newton, primero con el punto inicial∙1
2
¸con un parámetro de precisión
0,000001 tenemos:
>> x = newton([1 2]0)iter = 1 ; x = [ 3.3333 3.6667]iter = 2 ; x = [ 4.2667 4.1333]iter = 3 ; x = [ 4.4863 4.2431]iter = 4 ; x = [ 4.4999 4.2500]iter = 5 ; x = [ 4.5000 4.2500]
x =
4,5000
4,2500
Converge a la raíz∙4,5000
4,2500
¸proyectando en el plano x1x2 podemos observar todo los puntos de
iteración, desde el punto inicial, hasta la raíz

CAPÍTULO 2. EL MÉTODO DE NEWTON, LAGRANGE Y PENALIZACIÓN INTERNA 19
0 1 2 3 4 5 6 7 8 9 100
1
2
3
4
5
6
7
8
9
10
Newton con punto inicial x0 = [1 2]t
Ahora ejecutando newton con el otro punto inicial∙9
3
¸tenemos:
>> x = newton([9 3]0)iter = 1 ; x = [8.1818 6.0909]iter = 2 ; x = [8.0086 6.0043]iter = 3 ; x = [8.0000 6.0000]iter = 4 ; x = [8.0000 6.0000]
x =
8,0000
6,0000

CAPÍTULO 2. EL MÉTODO DE NEWTON, LAGRANGE Y PENALIZACIÓN INTERNA 20
que también converge a otra raíz∙8,0000
6,0000
¸, y también podemos observar los puntos de iteración.
0 1 2 3 4 5 6 7 8 9 100
1
2
3
4
5
6
7
8
9
10
Newton con punto inicial x0 = [9 3]t
Problema 2.1 Se quiere resolver el sistema de ecuaciones no lineales
5x21 + 6x1x2 + 5x22 − 4x1 + 4x2 − 4 = 0
x21 + x22 − 1 = 0
Ejecutando el programa newton con punto inicial∙11
¸.
Sean
F(x) =
∙5x21 + 6x1x2 + 5x
22 − 4x1 + 4x2 − 4
x21 + x22 − 1
¸
J(x) =
"dfdx1
dfdx2
dgdx1
dgdx2
#=
∙10x1 + 6x2 − 4 6x1 + 10x2 + 4
2x1 2x2
¸ejecutando el programa de newton, se puede hallar una raíz en cinco iteraciones.
>> x = newton([1 1]0)iter = 1 ; x = [1,2500 0,2500]
iter = 2 ; x = [0,9917 0,2917]
iter = 3 ; x = [0,9575 0,2904]
iter = 4 ; x = [0,9569 0,2903]
iter = 5 ; x = [0,9569 0,2903]
x =
0,9569
0,2903
Ejemplo 2.2 Considere el sistema de ecuaciones no lineales
x22 − (x1 − 1)3 = 0
ln(1+ x22) + e−x1 − 3x1 + 2x2 = 0

CAPÍTULO 2. EL MÉTODO DE NEWTON, LAGRANGE Y PENALIZACIÓN INTERNA 21
Observe que:
F(x) =
∙x22 − (x1 − 1)
3 = 0
ln(1+ x22) + e−x1 − 3x1 + 2x2 = 0
¸y
J(x) =
"−3(x1 − 1)
2 2x1
−e−x1 − 3 2x11+x2
2
+ 2
#Al ejecutar Newton con punto inicial x0 = [1 1]t y con un parámetro de precisión ε = 0,000001 nosotorga:
x(1) =0.572736078175030.50000000000000
x(2) =0.15438003883215-0.05711721521426
x(3) =0.417146044288710.33025949727142
(4) =3.409549320170674.48252254203493
x(5) =3.309779310475063.60789101090839
x(6) =3.419416638033053.75489556515174
x(7) =3.412338776984853.74673397345497
x(8) =3.412304377195203.74669341650677
Ejemplo 2.3 Se requiere resolver el sistema
x31 + x32 − 2x
23 + x
24 + 3 = 0
x1x2 − x3x4 + 2 = 0
x1 + x22 + x3 + x4 = 0
x1x3 + x2x4 = 0
Al ejecutar Newton con punto inicial x0 = [1 2 3 4]t y con un parámetro de precisión ε = 0,000001
nos otorga:
x(15) =
-1.688209053943051.40864292542700-0.780486462819910.48442062541582
Al ejecutar Newton con punto inicial x0 = [−1 −1 − 1 − 1]t y con un parámetro de precisión² = 0,000001 nos otorga:
x(6) =
0.30104099749255-1.49799619587565-1.00745590938951-1.53757769093631

CAPÍTULO 2. EL MÉTODO DE NEWTON, LAGRANGE Y PENALIZACIÓN INTERNA 22
2.2. El Método de Lagrange
Este método numérico transforma un problema de optimización con restricciones de igualdad enun problema irrestricto.
Si intentamos resolver el problema
Minimizar f(x)Sujeto a:
gi(x) = 0, i = 1, ...,m
He aquí tenemos un problema de optimización con restricciones de igualdad, formando la funciónLagrangiana tenemos.
L(x, y) = f(x)−
mXi=1
yigi(x)
y entonces teniendo esta función irrestricta nos toca minimizar la función L(x, y), para ello podemosutilizar el método de Newton expuesta anteriormente.
∂L
∂xj=
∂f
∂xj(x)−
mXi=1
yi∂gi
∂xj(x) = 0 j = 1, ..., n
∂L
∂xi= −gi(x) = 0 i = 1, ...,m
Este sistema de ecuaciones constituye las condiciones de optimalidad de primer orden para el prob-lema de minimización con restricciones de igualdad (Karush Kuhn Tucker), las cuales son necesariaspara un minimizador local. Pero cuando este problema es un problema de programación convexa,es decir, que tanto la función objetivo como el conjunto definido por las restricciones son convexos,entonces las condiciones son además suficientes y un minimizador local es global. O sea, resolver elúltimo sistema nos otorga un minimizador global del problema de optimización con restricciones deigualdad.
Curvas de niveles, ∇(f) y ∇g(x)
Ilustración de las condiciones de Karush-Kuhn-Tucker para el caso de una restricción de igualdady dos variables, y también podemos observar que el mínimo se alcanza en un punto en el que elgradiente de la función objetivo y el de la restricción son linealmente dependientes. Esto es lo querepresenta las condiciones de optimalidad de primer orden. Recordando además que las variables deLagrange son irrestrictas en el signo.

CAPÍTULO 2. EL MÉTODO DE NEWTON, LAGRANGE Y PENALIZACIÓN INTERNA 23
Ejemplo 2.4Minimizar f(x1, x2) = x1 + 2x2
s.ag(x1, x2) = x
21 − 6x1 + x
22 − 8x2 + 20 = 0
formando la función Lagrangiana
L(x1, x2,λ) = x1 + 2x2 + λ³x21 − 6x1 + x
22 − 8x2 + 20
´entonces el sistema a resolver es:
∂L
∂x1= 1+ (2x1 − 6)λ = 0
∂L
∂x2= 2+ (2x2 − 8)λ = 0
∂L
∂λ= x21 − 6x1 + x
22 − 8x2 + 20 = 0
donde λ es la variable lagrangiana asociada a la restricción del problema. Definimos
F(x, λ) =
⎡⎣ 1+ (2x1 − 6)λ
2+ (2x2 − 8)λ
x21 − 6x1 + x22 − 8x2 + 20
⎤⎦y calculando su respectivo Jacobiano
J(x,λ) =
⎡⎣ 2λ 0 2x1 − 6
0 2λ 2x2 − 8
2x1 − 6 2x2 − 8 0
⎤⎦Para resolver este problema haremos una modificación al programa de newton, e implementaremosen el lenguaje de programación (Matlab) a la que denominamos newton_2. Teniendo en cuenta quex es la variable, y λ que es la variable lagrangiana irrestricta en signo, que lo denotaremos por y.
function [x,iter]=newton_2(x,y)n=length(x);m=length(y);iter=0;
while norm(Fn(x,y))>0.0001d=-inv(Jn(x,y))*Fn(x,y);dx=d(1:n); dy=d(n+1:n+m);a=-1/min(min(dx./x),-1);x=x+0.95*a*dx; y=y+0.95*a*dy;iter=iter+1;
end
.a.es el criterio de la razónEjecutando el programa de newton_2, para un punto inicial de [1 2 ]t y variable lagrangiana
λ = 3
>> x = [1 2 ]t, y = 3,

CAPÍTULO 2. EL MÉTODO DE NEWTON, LAGRANGE Y PENALIZACIÓN INTERNA 24
Obtenemos
x(1) =
∙1.43542.2771
¸, y(1) =
£1.0406
¤x(2) =
∙1.69672.1546
¸, y(2) =
£0.5294
¤x(3) =
∙1.95631.9981
¸, y(3) =
£0.4964
¤x(4) =
∙1.99791.9994
¸, y(4) =
£0.4997
¤x(5) =
∙1.99992.0000
¸, y(5) =
£0.5000
¤x(6) =
∙2.00002.0000
¸, y(6) =
£0.5000
¤Después de 6 iteraciones principales jecutadas por el programa, proyectando x(6) sobres x1x2−espacio,podemos ver lo que sucedió en el problema original. Asi como la solución es∙
x1x2
¸=
∙2.00002.0000
¸
Cuya gráfica corresponde:
Del gráfico podemos observar que el mínimo se alcanza en un punto en el que, gradiente de la funciónobjetivo y el de la restricción son linealmente dependientes.
2.3. El Método de Barrera Logarítmica
Este método numérico transforma un problema de optimización con restricciones de desigualdaden un problema irrestricto.
Dada un problema de la forma.
Minimizar f(x)Sujeto a: xj ≥ 0 j = 1, 2, ...n
(2.5)

CAPÍTULO 2. EL MÉTODO DE NEWTON, LAGRANGE Y PENALIZACIÓN INTERNA 25
añadiendo la función barrera −μnPj=1
log(xj) a la función objetivo. El problema equivalente e irrestricto
asociado a (2.5) está dado por
Minimizar B(x | μ) = f(x)− μ
nXj=1
log(xj) (2.6)
mientras que si μ −→ 0, entonces x(μ) −→ x∗. Añadiendo log(xj) a la función objetivo ocasionaráque la función objetivo se incrementará infinitamente cuando xj −→ 0 (Cuando xj se aproxima a lafrontera de Ω). Pero la solución óptima está justamente sobre el vértice de la región factible, por esose hace necesario la introducción del parámetro de penalización μ ∈ R+ que equilibre la verdaderacondición de la función objetiva contra el de la función barrera.
El conjunto de minimizadores x(μ) es llamado trayectoria central. La siguiente figura adjuntamuestra el comportamiento de la función logarítmica cuando decrece el parámetro μ. Se puede ob-servar que a medida que este parámetro tiende a cero, la función se acerca cada vez más a los ejes.
El parámetro μ1 < μ2
La siguiente figura muestra el comportamiento de la barrera logarítmica en relación a variasrestricciones cuando μ −→ 0. A medida que esto ocurre la pared que forma la barrera logarítmica seasemeja cada vez más a las paredes del polítopo, de modo que en el límite, coincidirán.
Barrera logarítmica con várias restricciones
CAPÍTULO 2. EL MÉTODO DE NEWTON, LAGRANGE Y PENALIZACIÓN INTERNA 26
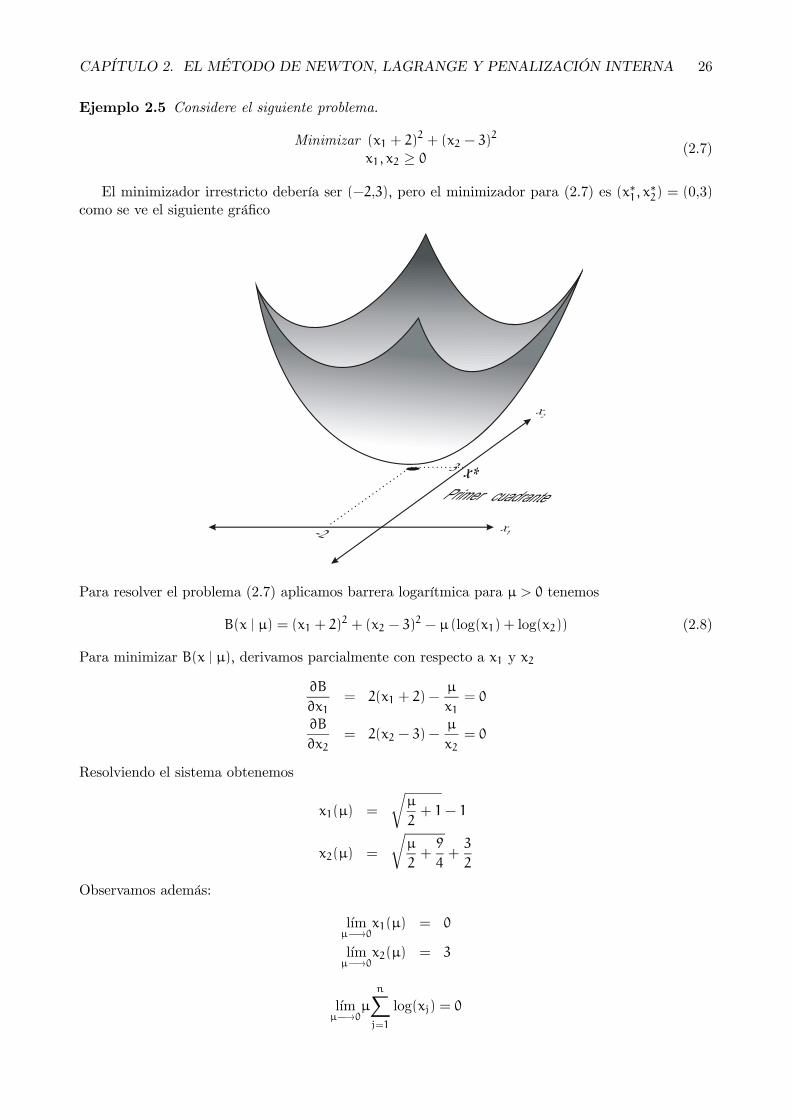
Ejemplo 2.5 Considere el siguiente problema.
Minimizar (x1 + 2)2 + (x2 − 3)
2
x1, x2 ≥ 0(2.7)
El minimizador irrestricto debería ser (−2,3), pero el minimizador para (2.7) es (x∗1, x∗2) = (0,3)
como se ve el siguiente gráfico
Para resolver el problema (2.7) aplicamos barrera logarítmica para μ > 0 tenemos
B(x | μ) = (x1 + 2)2 + (x2 − 3)
2 − μ (log(x1) + log(x2)) (2.8)
Para minimizar B(x | μ), derivamos parcialmente con respecto a x1 y x2
∂B
∂x1= 2(x1 + 2)−
μ
x1= 0
∂B
∂x2= 2(x2 − 3)−
μ
x2= 0
Resolviendo el sistema obtenemos
x1(μ) =
rμ
2+ 1− 1
x2(μ) =
rμ
2+9
4+3
2
Observamos además:
lımμ−→0x1(μ) = 0
lımμ−→0x2(μ) = 3
lımμ−→0μ
nXj=1
log(xj) = 0
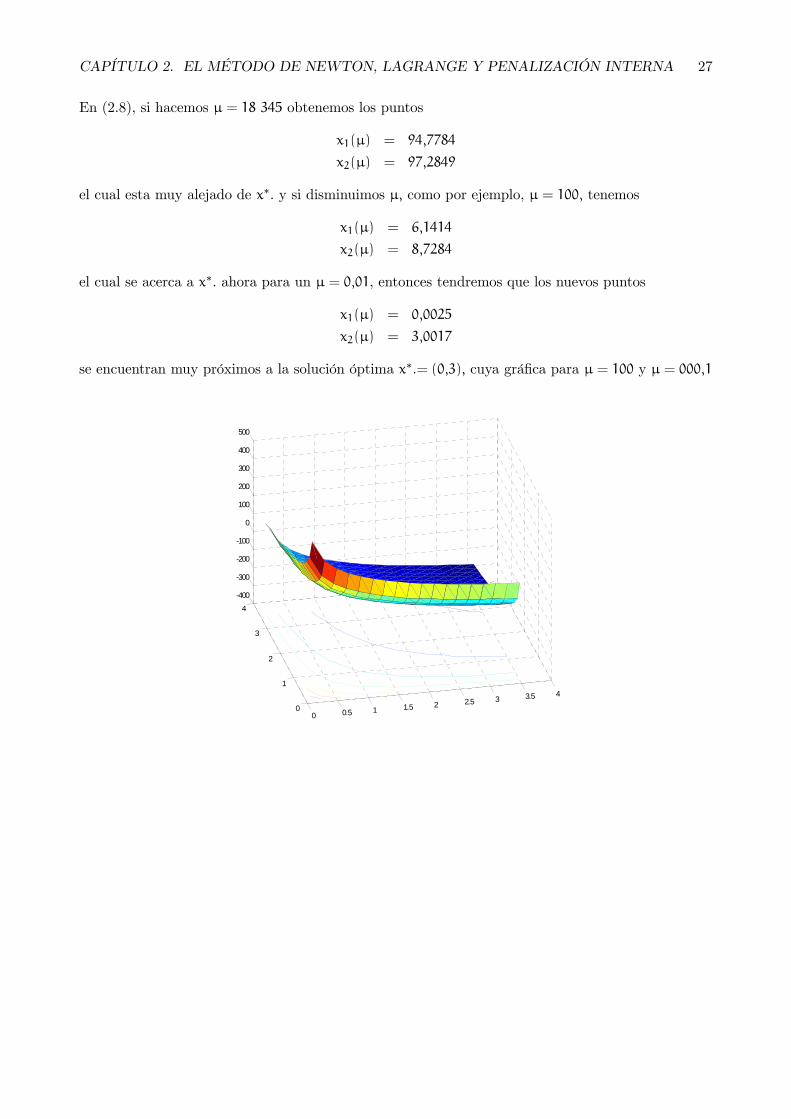
CAPÍTULO 2. EL MÉTODO DE NEWTON, LAGRANGE Y PENALIZACIÓN INTERNA 27
En (2.8), si hacemos μ = 18 345 obtenemos los puntos
x1(μ) = 94,7784
x2(μ) = 97,2849
el cual esta muy alejado de x∗. y si disminuimos μ, como por ejemplo, μ = 100, tenemos
x1(μ) = 6,1414
x2(μ) = 8,7284
el cual se acerca a x∗. ahora para un μ = 0,01, entonces tendremos que los nuevos puntos
x1(μ) = 0,0025
x2(μ) = 3,0017
se encuentran muy próximos a la solución óptima x∗.= (0,3), cuya gráfica para μ = 100 y μ = 000,1
0 0.5 1 1.5 2 2.5 3 3.5 4
0
1
2
3
4
-400
-300
-200
-100
0
100
200
300
400
500

CAPÍTULO 2. EL MÉTODO DE NEWTON, LAGRANGE Y PENALIZACIÓN INTERNA 28
0 0.5 1 1.5 2 2.5 3 3.5 4
01
23
40
5
10
15
20
25
30
35
40
Ejemplo 2.6 dada el problema
Minimizar¡x1 −
52
¢2+ 2 (x2 − 2)
2
3x1 + 2x2 ≤ 6(2.9)
podemos observar que el minimizador irrestricto debería ser (52, 2) aplicando barrera logarítmica al
problema (2.9) para μ > 0 se tiene
B(x | μ) =
µx1 −
5
2
¶2+ 2 (x2 − 2)
2 − μ log(6− 3x1 − 2x2) (2.10)
los puntos estacionarios de B(x | μ) en función de μ son:
∂B
∂x1= 2(x1 −
5
2) +
3μ
6− 3x1 − 2x2= 0
∂B
∂x2= 2(x2 − 2) +
2μ
6− 3x1 − 2x2= 0
y resolviendo este sistema de ecuaciones obtenemos:
x1(μ) =77−
p99(11+ 8μ)
44
x2(μ) =77−
p11(11+ 8μ)
44

CAPÍTULO 2. EL MÉTODO DE NEWTON, LAGRANGE Y PENALIZACIÓN INTERNA 29
donde (x1(μ), x2(μ)) se aproximan a (1,32 ) a medida que μ −→ 0.
En general, no podemos dar una solución directa para (2.7) y (2.9) como en los dos ejemplos ante-riores, pero podemos usar el siguiente algoritmo:
Dados x0 > 0, μ0 > 0, ε > 0 y k = 0
Paso 1. Hallar xk(μk), el minimzador de B(x | μ)
Paso 2. Parar si μk < ε. Caso contrario, elegir un μk+1, tal que0 < μk+1 < μk
Paso 3. Hacer k = k+ 1 y volver al paso 1.
Entonces xk(μk) −→ x∗ cuando μk −→ 0
El parámetro de penalización μk debe aproximarse iterativamente hacia cero, en general consisteen hacer μ0 = 1 y μk+1 =
μk10para k = 1, 2, ...
En el paso 1, para hallar x(μ) usamos el método de Newton para resolver el sistema de n ecuacionescon n variables:
∂B
∂xj(x | μ) =
∂f(x)
∂xj−
μ
xj= 0, j = 1, ..., n

Capítulo 3
Método de Puntos interioresPrimal-Dual
Se denomina métodos de puntos interiores precisamente porque los puntos generados por estosalgoritmos se hallan en el interior de la región factible. Esta es una clara diferencia respecto delmétodo Simplex, el cual avanza por la frontera de dicha región moviéndose de un punto extremo aotro
Un punto interior para problemas de programación lineal en la forma estándar en un vector quesatisface las restricciones de igualdad, pero sus componentes deben ser estrictamente positivas.
Si Ω = x ∈ Rn : Ax = b, x ≥ 0 denota la región de factibilidad para un problema de progra-mación lineal en la forna estándar, entonces ,nosotro decimos que el punto x es un punto interior deΩ, o que se encuentra en el interior de Ω, si x ∈ Ω0 = x ∈ Rn : Ax = b, x ≥ 0 .
3.1. Método de puntos interiores Primal-Dual basado en barreralogaritmica
La construcción de este método está soportada por tres técnicas numéricas muy utilizadas enoptimización: Penalización interna, Lagrange y el método de Newton. Un Newton para minimizaciónirrestricta, y los métodos de Penalización interna y de Lagrange para convertir problemas con re-stricciones en problemas irrestrictos..
3.1.1. Construcción del método
Consideremos los problemas Primal y Dual para programación lineal en forma estándar
Minimizar ctx
Sujeto a:Ax = b
x ≥ 0
(P)
Donde c, x ∈ Rn, b ∈ Rm y A ∈ Rm×n (m < n)
Maximizar bty
Sujeto a:Aty+ z = c
z ≥ 0
(D)
Donde z ∈ Rn, y ∈ Rm.irrestricta. Pero debemos tener en cuenta lo siguiente
30

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 31
H1. El conjunto P = x ∈ Rn : Ax = b, x > 0 no vacío
H2. El conjunto T =©y ∈ Rm, z ∈ Rn : Aty+ z = c, z > 0
ªno vacío
H3. La matriz A es de rango m
En estas condiciones, de acuerdo con el teorema de la adualidad, los problemas (P) y (D) tienensolución óptima, coincidiendo los valores de sus funciones objetivo Además el conjunto desoluciones óptimas de ambos problemas están acotados..
La estratégia de este método resuelve ambos problemas en forma simultánea.
Para x factible y (y, z), el duality gap (intervalo de dualidad)
duality gap = ctx− bty
= xtc− xtAty (Ax = b)
= xt(c−Aty)
= xtz (c−Aty = z)
≥ 0 (x, z ≥ 0)
duality gap es cerrado en el óptimo x∗
ctx∗ − bty∗ = (x∗)t z∗ = 0
por lo que las condiciones de complementaridad son:
x∗j z∗j = 0, j = 1, 2, ..., n
Las condiciones de no negatividad serán manejadas por el método de Ba-rrera logaritmica, y lasrestricciones de igualdad por Lagrange. La función irrestricta resultante por el método de Newton.
Introduciendo primeramente la función Barrera a los (P) y (D)
Minimizar ctx− μnPj=1
log(xj)
Ax− b = 0
(3.1)
Maximizar bty+ μnPj=1
log(zj)
Aty+ z− c = 0
(3.2)
Vale recalcar que las barreras, −nPj=1
log(xj) y +nPj=1
log(zj), no permiten que los puntos interiores
de (P) y (D) se aproximen a la frontera de la región factible. Las barreras al estar presentes en lafunción objetivo del problema de minimización aumentan la función objetivo infinitamente a medidaque el punto x se acerca a la frontera. Pero en programación lineal el óptimo x∗ esta en un extremo,y aparentemente la barrera nos impediría de llegar a x∗. Para contrarrestar este efecto usamos unparámetro de penalización equilibrante μ > 0.
A continuación formando las funciones lagrangianas correspondiente de (3.1) y (3.2) tenemos:
LP(x, y) = ctx− μ
nXj=1
log(xj)− yt(Ax− b) (3.3)
LD(x, y) = bty+
nXj=1
log(zj)− xt(Aty+ z− c) (3.4)

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 32
Calculando las derivadas parciales respectivas de (3.3) y (3.4), tenemos:
∂LP
∂x= c−
μ
xj−Aty = 0 (3.5)
∂LP
∂y= b−Ax = 0 (3.6)
∂LD
∂x= Aty+ z− c = 0 (3.7)
∂LD
∂y= b−Ax = 0 (3.8)
∂LD
∂z=
μ
zj− x = 0;−→ xjzj = μ (3.9)
De (3.7) despejamos c = Aty+ z y sustituimos en (3.5) se tiene
Aty+ z−μ
xj−Aty = 0
xjzj = μ j = 1, ..., n
estas expresiones después de simplificar las expresiones algebraicas tenemo
Ax = b
Aty+ z = c
xjzj = μ, j = 1, ...n
(3.10)
Se observa que cuando μ = 0, las condiciones de OPtimalidad son satisfechas, pero por cuestionesnuméricas debemos fijar un μ > 0 y aproximarlo iterativamente hacia cero
Dados los puntos x, z ∈ Rn. definamos e = [1 1 1 ... 1]t ∈ Rn (n-vector de unos) y
X =
⎡⎢⎢⎢⎣x1 0 · · · 0
0 x2 · · · 0...
.... . .
...0 0 · · · xn
⎤⎥⎥⎥⎦ y Z =
⎡⎢⎢⎢⎣z1 0 · · · 0
0 z2 · · · 0...
.... . .
...0 0 · · · zn
⎤⎥⎥⎥⎦notando que
X−1 =
⎡⎢⎢⎢⎣1x1
0 · · · 0
0 1x2
· · · 0...
.... . .
...0 0 · · · 1
xn
⎤⎥⎥⎥⎦ y Z−1 =
⎡⎢⎢⎢⎣1z1
0 · · · 0
0 1z2
· · · 0...
.... . .
...0 0 · · · 1
zn
⎤⎥⎥⎥⎦Es decir, las condiciones de optimalidad simultáneas, para un mismo μ de los problemas (P) y (D)están dadas por:
Ax = b
Aty+ z = c
XZe = μe
(3.11)
Si la solución del problema del sistema de ecuaciones lineales (3.11) se designa mediante [x(μ), y(μ), z(μ)]t ,para cada μ > 0. El duality gap es
g(μ) = ctx(μ)− bty(μ)
= xt(μ)c− xt(μ)Ay(μ) (Ax(μ) = b)
= xt(μ) (c−Ay(μ))
= xt(μ)z(μ)¡c−Aty(μ) = z(μ)
¢= μ

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 33
Al tender μ→ 0, g (μ) converge a cero, lo que implica que x(μ) y y(μ) converge a la solución de losproblemas (P) y (D), respectivamente.
μ es una aproximación del intervalo de dualidad, y debemos aclarar, que si su valor decrece muyrápidamente se puede perder convergencia. El intervalo de dualidad puede incluso aumentar. Si suvalor disminuye muy lentamente se requiere muchas iteraciones.
Pero, por cuestiones numéricas, nosotros debemos comenzar fijando un μ > 0 inicial y aproximarloiterativamente hacia cero.
Definamos la trayectoria central como:
C = (xμ, yμ, zμ); μ > 0
La trayectoria central C es un arco de puntos estrctamente factibles, que juegan un rol importanteen la teoria de algoritmos Primal-Dual. Para cada μ > 0 se tiene los puntos (xμ, yμ, zμ) ∈ C.
Otra manera de definir C es
F(xμ, yμ, zμ) =
⎛⎝ 00
XZe-μe
⎞⎠ , (xμ, zμ) > 0
Se muestra de manera intuitiva la trayectoria central
xµ
x*
x 0xµ
x*
x 0
El método de puntos interiores Primal-Dual, encuentra soluciones Óptimas (x∗, y∗, z∗), aplicandovariantes del método de Newton a las tres condiciones de igualdad (3.11) y modificando las direc-ciones de búsqueda y longitud de paso, de manera que las desigualdades (x, z) ≥ 0 sean satisfechasestrictamente en cada iteración.
Cálculo de la dirección de movimiento (Paso de Newton)

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 34
El método Primal-Dual se basa en tomar como direcciones de movimiento las de Newton, resul-tantes de resolver el sistema (3.11). Dada los puntos iniciales x0, z0 ∈ Rn, y0 ∈ Rm, donde x0 > 0 yz0 > 0. Fijemos adecuadamente un valor inicial para el parámetro de penalización μ = μ0. El sistema(3.11) lo podemos respresentar por F(x0, y0, z0) = 0.
F(x0, y0, z0) =
⎡⎣ Ax0 − b
Aty0 + z0 − c
XZe− μ0e
⎤⎦ = 0 (3.12)
La matriz Jacobiana de F(x0, y0, z0) es
J(x0, y0, z0) =
⎡⎣ A 0 00 At I
Z 0 X
⎤⎦para realizar una iteración de Newton, resolvamos el sistema J(x0, y0, z0)dw = −F(x0, y0, z0) dondedw = [dx, dy, dz]t es el paso de Newton.⎡⎣ A 0 0
0 At I
Z 0 X
⎤⎦⎡⎣ dx
dy
dz
⎤⎦ = −
⎡⎣ Ax0 − b
Aty0 + z0 − c
XZe− μ0e
⎤⎦=
⎡⎣ b−Ax0
c−Aty0 − z0
μ0e− XZe
⎤⎦definamos los vectores residuales Primal y Dual
rp = b−Ax0
rd = c−Aty0 − z0
rc = μ0e− XZe
Es decir, se resuelve el sistema ⎡⎣ A 0 00 At I
Z 0 X
⎤⎦⎡⎣ dx
dy
dz
⎤⎦ =⎡⎣ rprdrc
⎤⎦ (3.13)
Obsérvamos que si xk ∈ P y£yk, zk
¤t ∈ T. k = 0, 1, 2, ...., entonces rp = 0 y rd = 0.El sistema (3.13) puede ser resuelto indirectamente, y puede ser visto como
Adx = rp (3.14)
Atdy+ dz = rd (3.15)
Zdx+ Xdz = rc (3.16)
multiplicando (3.15) por X y restando con (3.16), obtenemos
XAtdy− Zdx = Xrd − rc (3.17)
multiplicando la ecuación (3.17) por AZ−1 e involucrando (3.14) llegamos a un sistema cuadradopara dy esto es
AZ−1XAtdy = AZ−1(Xrd − rc) + rp
calculada dy se puede calcular fácilmente dz y dx,de (3.15) y (3.16), en conjunto tenemos.
dy = (AZ−1XAt)−1(AZ−1(Xrd − rc) + rp)
dz = rd −Atdy
dx = Z−1 (rc − Xdz)
(3.18)

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 35
Amplitud de movimiento (Longitud de paso)
El algoritmo básico seguido por el método de Puntos interiores consiste en, comenzando por xo,generar una sucesión de puntos xk que nos lleve hasta el punto óptimo x∗
Cada nuevo punto se obtendrá del anterior, siguiendo el procedimiento iterativo.
x(k+1) = x(k) + βαdx
Mediante (3.18) tenemos calculada el paso de Newton (dx, dy, dz)t. Ahora usamos dx como unadirección en el x−espacio y (dy, dz) como una dirección en el (y, z)−espacio. Seguidamente debemoselegir la longitud de los pasos en los dos espacios de modo que podamos desplazarnos prudentemente,manteniendo x > 0, z > 0, esto es posible utilizando:
αP = mın1≤j≤n
¯−xj
dxj: dxj < 0
°αD = mın
1≤j≤n
¯−zj
dzj: dzj < 0
°Ahora podemos dezplazarnos prudentemente, el siguiente punto (x1, y1, z1) será calculado mediante
x1 = x0 + βαPdx
y1 = y0 + βαDdy
z1 = z0 + βαDdz
donde β ∈ h0, 1i es un parámetro que nos permite controlar que las posibles soluciones no lleguen ala frontera de la región factible, ni mucho menos salgan de la región. En la práctica se obtuvieronbuenos resultados usándo β = 0.95 y/o β = 0.98, esto completa una iteración de Newton. La técnicasólo resuelve el sistema (3.11) con respecto a un μ0, para obtener una aproximación a la soluciónóptima, deberíamos reducir μ0, en cada iteración.
Los puntos (x1, y1, z1)t son utilizados como iniciales para la segunda iteración de newton, al
repetir esto, el método genera una sucesión¡xk, yk, zk
¢t®que converge sólo hacia una solución del
sistema (3.11).
Ajuste del Parámetro Penalizador (μ)
Ahora debemos establecer un criterio para determinar cuando el punto actual x(k) está lo suficien-temente próximo a x∗. Penalización sugiere la disminución iterativa de μ con la finalidad de obteneruna solución para el problema de programación lineal estándar, y nada impide la disminución delparámetro de penalización en cada iteración de newton, dado μk, el siguiente parámetro penalizadores elegido mediante:
μk+1 =
¯ctxk − btyk
¯n2
, k = 0, 1, 2, ..
donde n es el número de variables, esto produce una reducción substancial en μ a cada paso denewton, las iteraciones continúan hasta que la diferencia¯
ctxk − btyk¯
sea suficientemente pequeña, esto se consigue controlando el error relativo¯ctxk − btyk
¯1+ |btyk |
< ε (3.19)

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 36
de (3.19), el denominador 1+¯btyk
¯nos permite mantener una proporción acerca de la aproximación
entre los valores objetivos primal y dual, se le sumó 1 para evitar problemas de precisión cuandoel costo óptimo se acerca a cero. Por ejemplo, si para cada cierta iteración k, ctxk = 100000001 ybtyk = 100000000, el error absoluto es ctxk − btyk = 1. Sin embargo, el error relativo ctxk−btyk
1+btyk
tendrá una aproximación con una precisión de 8 dígitos, con lo cual ya es razonable parar el algorímo.Donde ε > 0 es la precisión deseada. En la práctica se utiliza valores ε =
£10−6, 10−8
¤.
3.1.2. El Algoritmo
Inicialización: Dados y ∈ Rm y x, z ∈ Rn, donde x, z > 0. Definir la precisión requerida ε > 0,el n−vector columna e = [1 1..,1]t y el valor inicial de μ > 0.
Paso 1: Mientras |ctx(k)−bty(k) |1+|bty(k) |
< ε, no satisface, HACER
Paso 2: Definir las matrices diagonales X = diag(x) y Z = diag(z)
Paso 3: Calcular
⎧⎨⎩rp = b−Ax
rd = c−Aty− z
rc = μ0e− XZe
Paso 4: Calcular
⎧⎨⎩dy = (AZ−1XAt)−1(AZ−1(Xrd − rc) + rp)
dz = rd −Atdy
dx = Z−1 (rc − Xdz)
Paso 5: CalcularαP = min
1≤j≤n
−xjdxj
: dxj < 0®
αD = min1≤j≤n
−zjdzj
: dzj < 0®
Paso 6: Asignar
⎧⎨⎩x← x+ (0.95)(αP)dxy← y+ (0.95)(αD)dyz← z+ (0.95)(αD)dz
Paso 7: Hacer μk+1 =|ctx−bty|
n2y volver al paso 1.
3.1.3. Implementación y Experimentos
La implemetación está hecha de un modo particular y con fines experimentales. hemos utilizadoMatlab 6.0, esto se justifica debido a la interface gráfica y matricial que Matlab otorga
Método de puntos interiores Primal-Dual[m,n]=size(A); x=ones(n,1); y=ones(m,1); z=x; u=100; e=x iter=0;
while abs(c’*x-b’*y)/(1+abs(b’*y)) > 0.000001;X=diag(x); Z=diag(z);rp=b-A*x; rd=c-A’*y+z; rc=u*e-X*Z*e;dy=(A*inv(Z)*X*A’)\(A*inv(Z)*(X*rd-rc)+rp);dz=rd-A’*dy;dx=Z\(rc-X*dz);aP=-1/min(min(dx./x),-1); aD=-1/min(min(dz./z),-1);x=x+0.95*aP*dx; y=y+0.95*aD*dy; z=z+0.95*aD*dz;u=abs(c‘*x-b’*y)/n^2; iter=iter+1;
endv=c’*x;

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 37
Ejemplo 3.1 Consideremos en siguiente problemas
Minimizar x1 + x2 + x3
x1 + 2x2 + 3x3 ≥ 102x1 + x2 − x3 ≥ 20
x3 ≥ 4x1, x2, x3 ≥ 0
llevando a su forma estándar tenemos
Minimizar x1 + x2 + x3
x1 +2x2 +3x3 −x4 = 10
2x1 +x2 −x3 −x5 = 20
x3 −x6 = 4
x1, x2, x3, x4, x5, x6 ≥ 0
A =
⎛⎝ 1 2 3 -1 0 02 1 -1 0 -1 00 0 1 0 0 -1
⎞⎠ , b =
⎛⎝ 10204
⎞⎠ , c =
⎛⎜⎜⎜⎜⎜⎜⎝
111000
⎞⎟⎟⎟⎟⎟⎟⎠La solución factible para este problema dado por (puntos iniciales):
x(0) =
⎛⎜⎜⎜⎜⎜⎜⎝
30
5
15
75
30
11
⎞⎟⎟⎟⎟⎟⎟⎠ , y(0) =
⎡⎣ 1/4
1/4
1/4
⎤⎦ , z(0) =
⎛⎜⎜⎜⎜⎜⎜⎝
1/4
1/4
1/4
1/4
1/4
1/4
⎞⎟⎟⎟⎟⎟⎟⎠con estos vectores iniciales se procede a aplicar el algoritmo para una i-teración.
Iteración 1dado el vector de solución, x(0) y z(0), y las matrices, X y Z, para la primera iteración están
disponibles a través de:
X =
⎡⎢⎢⎢⎢⎢⎢⎣
30 0 0 0 0 00 5 0 0 0 00 0 15 0 0 00 0 0 75 0 00 0 0 0 30 00 0 0 0 0 11
⎤⎥⎥⎥⎥⎥⎥⎦
Z =
⎡⎢⎢⎢⎢⎢⎢⎣
1/4 0 0 0 0 00 1/4 0 0 0 00 0 1/4 0 0 00 0 0 1/4 0 00 0 0 0 1/4 00 0 0 0 0 1/4
⎤⎥⎥⎥⎥⎥⎥⎦

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 38
e =
⎡⎢⎢⎢⎢⎢⎢⎣
111111
⎤⎥⎥⎥⎥⎥⎥⎦Las funciones objetivo del primal y dual, así como la brecha de dualidad (duality gap) y la barrera
de parámetros μ para estos vectores de inicio están dados por
ctx = 50.00 ; bty = 8.50;¯ctx− bty
¯= 41.50
MIENTRAS
¯ctx− bty
¯1+ |bty|
= 4,3684 < ε, HACER
calculando
dy =³AZ−1XAt
´−1(AZ−1(Xrd − rc) + rp)
dz = rd −Atdy
dx = Z−1(rc − Xdz)
Pues
rp = b−Ax(0) =
⎡⎣ 000
⎤⎦
rd = c−Aty(0) − z(0) =
⎡⎢⎢⎢⎢⎢⎢⎣
000000
⎤⎥⎥⎥⎥⎥⎥⎦tenemos
dy =
⎡⎣ -2.830.315.11
⎤⎦ ; dz =
⎡⎢⎢⎢⎢⎢⎢⎣
2.215.353.68-2.830.315.11
⎤⎥⎥⎥⎥⎥⎥⎦ ; dx =
⎡⎢⎢⎢⎢⎢⎢⎣
104.59288.06164.171173.23333.06164.17
⎤⎥⎥⎥⎥⎥⎥⎦Usando el criterio de la razón, se encuentra el tamaño del paso del vector primal
αp = min¯−xj(k)
dxj(k): ∀ dxj(k) < 0, 1 ≤ j ≤ n
°αp = mın 1.00 = 1.00
de igual manera para el vector dual.
αd = min¯−zj(k)
dzj(k): ∀ dzj(k) < 0, 1 ≤ j ≤ n
°
αd = mın 0.09 = 0.09

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 39
Usando un factor de tamaño de paso del 95%, para las nuevas iteraciones al final de la primeraiteración, para el vector primal x, el vector dual y, y el vector reducción de costo z se obtiene
x(1) =
⎛⎜⎜⎜⎜⎜⎜⎝
30
5
15
75
30
11
⎞⎟⎟⎟⎟⎟⎟⎠+ (0.95) (1)⎡⎢⎢⎢⎢⎢⎢⎣
104.59288.06164.171173.23333.06164.17
⎤⎥⎥⎥⎥⎥⎥⎦ =⎛⎜⎜⎜⎜⎜⎜⎝
129.36278.66170.971189.57346.41166.97
⎞⎟⎟⎟⎟⎟⎟⎠
y(1) =
⎛⎝0.250.250.25
⎞⎠+ (0.95) (0.09)⎡⎣ -2.830.315.11
⎤⎦ =⎛⎝0.010.280.68
⎞⎠
z(1)=
⎛⎜⎜⎜⎜⎜⎜⎝
0.250.250.250.250.250.25
⎞⎟⎟⎟⎟⎟⎟⎠+ (0.98) (0.09)⎡⎢⎢⎢⎢⎢⎢⎣
104.59288.06164.171173.23333.06164.17
⎤⎥⎥⎥⎥⎥⎥⎦ =⎛⎜⎜⎜⎜⎜⎜⎝
0.440.700.560.010.280.68
⎞⎟⎟⎟⎟⎟⎟⎠reduciendo el valor del parámetro u
ctx =578.98 , bty =8.36
μ(1) = 0,1 ∗|ctx−bty|
n2=0.1∗570.6236 =1.59
Con las nuevas iteraciones disponibles para el vector de costo reducido z, y el vector dual y, unnuevo ciclo de iteración se puede empezar. Las primeras diez iteraciones se muestran en las siguientestablas. El resumen para el vector dual y, y el valor objetivo del dual se muestra en la tabla 1; parael vector solución del primal y el valor objetivo del primal se muestra en la tabla 2; y para el vectorde costo reducido z, y el parámetro de barrera, μ, se muestra en la tabla 3.
el proceso de convergencia del algoritmo Primal-Dual aplicado a este ejemplo después de 10iteraciones podemos observar el las siguientes tablas
iteración y1 y2 y3 Objetivo1 0.2123 0.2888 0.3754 9.40002 0.0897 0.4442 1.1094 14.21903 0.0166 0.4887 1.4166 15.60634 0.0015 0.4986 1.4903 15.94805 0.0002 0.4998 1.4984 15.99116 0.0000 0.5000 1.4997 15.99847 0.0000 0.5000 1.4999 15.99978 0.0000 0.5000 1.5000 15.99999 0.0000 0.5000 1.5000 16.000010 0.0000 0.5000 1.5000 16.0000Tabla 1
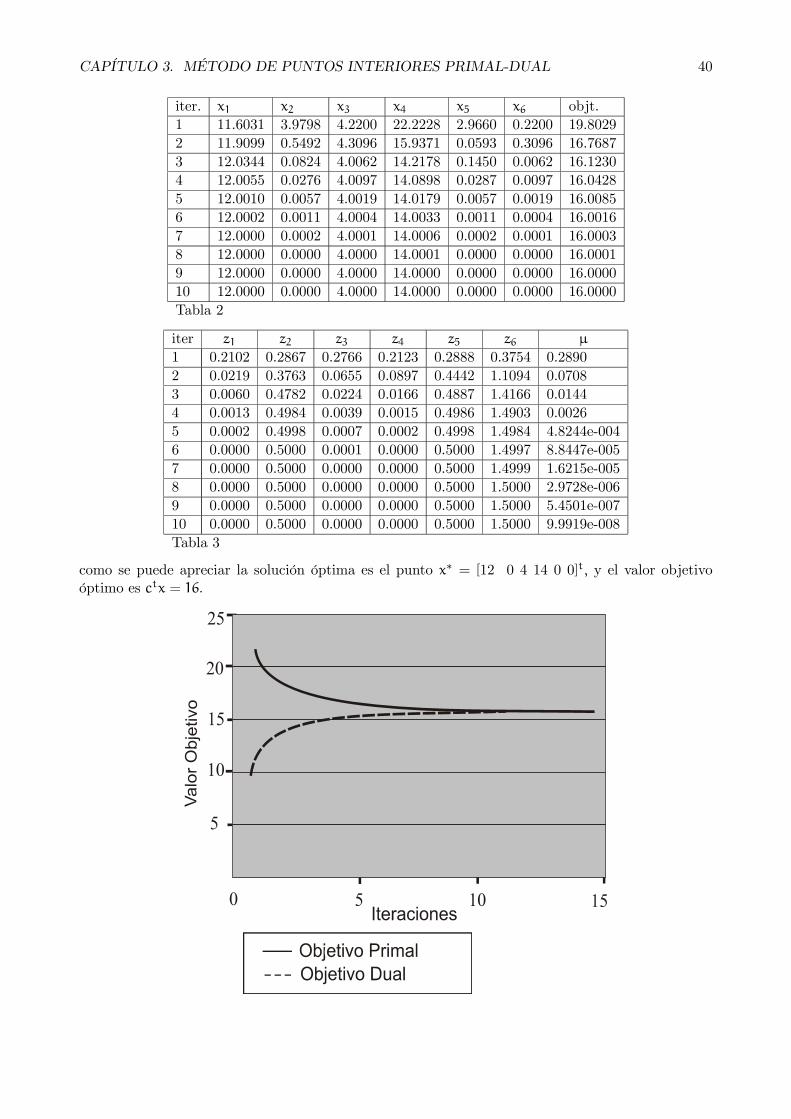
CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 40
iter. x1 x2 x3 x4 x5 x6 objt.1 11.6031 3.9798 4.2200 22.2228 2.9660 0.2200 19.80292 11.9099 0.5492 4.3096 15.9371 0.0593 0.3096 16.76873 12.0344 0.0824 4.0062 14.2178 0.1450 0.0062 16.12304 12.0055 0.0276 4.0097 14.0898 0.0287 0.0097 16.04285 12.0010 0.0057 4.0019 14.0179 0.0057 0.0019 16.00856 12.0002 0.0011 4.0004 14.0033 0.0011 0.0004 16.00167 12.0000 0.0002 4.0001 14.0006 0.0002 0.0001 16.00038 12.0000 0.0000 4.0000 14.0001 0.0000 0.0000 16.00019 12.0000 0.0000 4.0000 14.0000 0.0000 0.0000 16.000010 12.0000 0.0000 4.0000 14.0000 0.0000 0.0000 16.0000Tabla 2
iter z1 z2 z3 z4 z5 z6 μ
1 0.2102 0.2867 0.2766 0.2123 0.2888 0.3754 0.28902 0.0219 0.3763 0.0655 0.0897 0.4442 1.1094 0.07083 0.0060 0.4782 0.0224 0.0166 0.4887 1.4166 0.01444 0.0013 0.4984 0.0039 0.0015 0.4986 1.4903 0.00265 0.0002 0.4998 0.0007 0.0002 0.4998 1.4984 4.8244e-0046 0.0000 0.5000 0.0001 0.0000 0.5000 1.4997 8.8447e-0057 0.0000 0.5000 0.0000 0.0000 0.5000 1.4999 1.6215e-0058 0.0000 0.5000 0.0000 0.0000 0.5000 1.5000 2.9728e-0069 0.0000 0.5000 0.0000 0.0000 0.5000 1.5000 5.4501e-00710 0.0000 0.5000 0.0000 0.0000 0.5000 1.5000 9.9919e-008Tabla 3
como se puede apreciar la solución óptima es el punto x∗ = [12 0 4 14 0 0]t, y el valor objetivoóptimo es ctx = 16.

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 41
Ejemplo 3.2 Considere el siguiente problema
Minimizar −2x1 − 7x2s.a 4x1 + 5x2 ≤ 40
2x1 + x2 ≥ 82x1 + 5x2 ≥ 20x1, x2 ≥ 0
su forma estándar, dada por
Minimizar −2x1 − 7x2 + 0x3 − 0x4 − 0x5s.a 4x1 + 5x2 + x3 = 40
2x1 + x2 −x4 = 8
2x1 + 5x2 −x5 = 20
x1, x2, x3, x4, x5 ≥ 0
y su correspondiente Dual del problema es
Maximizar 40y1 + 8y2 + 20y3s.a 4y1 + 2y2 + 2y3 + z1 = −2
5y1 + y2 + 5y3 +z2 = −7
y1 +z3 = 0
−y2 +z4 = 0
−y3 +z5 = 0
z1, z2, z3, z4, z5 ≥ 0
Comencemos tomando un punto inicial factitible x0 =
⎡⎢⎢⎢⎢⎣53555
⎤⎥⎥⎥⎥⎦ ,
y0 =
⎡⎣ -411
⎤⎦ y z0 =⎡⎢⎢⎢⎢⎣107411
⎤⎥⎥⎥⎥⎦ en esta condición también se puede observar que rp = 0 y rd = 0.

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 42
A partir de esta solución factible, la figura adjunta muestra la sucesión generada por el algoritmohasta llegar a la solución óptima factible, el punto [0 8]t .
0 1 2 3 4 5 6 7 8 9 100
1
2
3
4
5
6
7
8
Punto inicial factible [5 3]t
iter x0 = 5 31 x1 = 2.35 6.072 x2 = 2.27 6.123 x3 = 1.18 7.024 x4 = 0.12 7.905 x5 = 0.01 7.996 x6 = 0.00 8.00
Observamos ahora que, dada otro punto inicial infactible x0 =
⎡⎢⎢⎢⎢⎣11111
⎤⎥⎥⎥⎥⎦ ,
y0 =
⎡⎣ 111
⎤⎦ y z0 =⎡⎢⎢⎢⎢⎣11111
⎤⎥⎥⎥⎥⎦ , Aquí se observó que rp 6= 0 y rd 6= 0, pero en el punto óptima estosresiduos son rp = 0 y rd = 0.
Se observó aquí, a pesar que el punto inicial es infactible [1 1]t, también el algoritmo haceconverge a la misma solución óptima del problema la cual es [0 8]t , veamos la figura adjunta
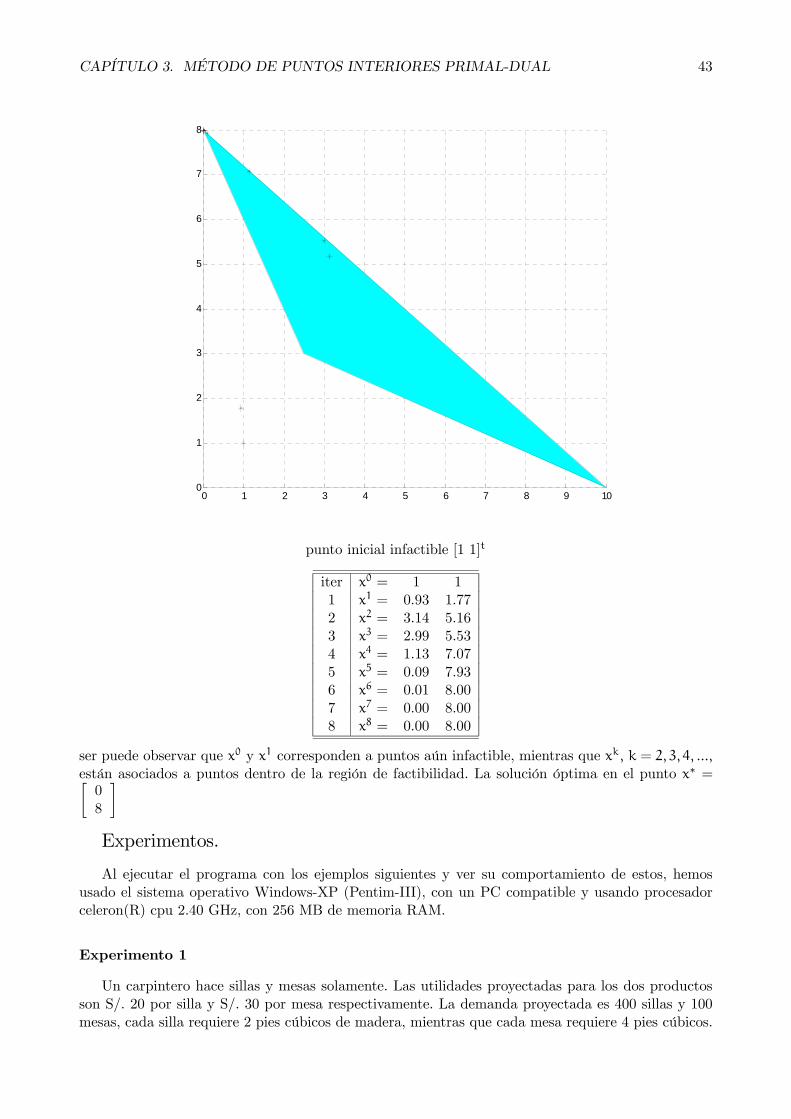
CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 43
0 1 2 3 4 5 6 7 8 9 100
1
2
3
4
5
6
7
8
punto inicial infactible [1 1]t
iter x0 = 1 11 x1 = 0.93 1.772 x2 = 3.14 5.163 x3 = 2.99 5.534 x4 = 1.13 7.075 x5 = 0.09 7.936 x6 = 0.01 8.007 x7 = 0.00 8.008 x8 = 0.00 8.00
ser puede observar que x0 y x1 corresponden a puntos aún infactible, mientras que xk, k = 2, 3, 4, ...,están asociados a puntos dentro de la región de factibilidad. La solución óptima en el punto x∗ =∙08
¸Experimentos.
Al ejecutar el programa con los ejemplos siguientes y ver su comportamiento de estos, hemosusado el sistema operativo Windows-XP (Pentim-III), con un PC compatible y usando procesadorceleron(R) cpu 2.40 GHz, con 256 MB de memoria RAM.
Experimento 1
Un carpintero hace sillas y mesas solamente. Las utilidades proyectadas para los dos productosson S/. 20 por silla y S/. 30 por mesa respectivamente. La demanda proyectada es 400 sillas y 100mesas, cada silla requiere 2 pies cúbicos de madera, mientras que cada mesa requiere 4 pies cúbicos.

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 44
El carpintero tiene un total de 1 000 pies cúbicos de madera en stock. ¿Cuántas sillas y mesasdebe construir para aumentear al máximo sus utilidades?
Sean
x1 el número de sillas
x2 el número de mesas
estas son las variables desconocidas, para éste problema.El carpintero quiere aumentar al máximo sus utilidades, esto es
20x1 + 30x2
sujeto a las restricciones que:
El importe total de madera para los dos productos no puede exceder los 1 000 pies cúbicosdisponibles
Los números de sillas y mesas a ser hechas, no deben exceder las demandas,
El número de sillas y mesas necesitan ser no negativos.por lo que tenemos:
Maximizar 20x1 + 30x2
2x1 + 4x2 ≤ 1 0000 ≤ x1 ≤ 4000 ≤ x2 ≤ 100
añadiendo las variables auxiliares x3, x4, x5 y llevando a su forma estandar, tenemos.
Minimizar − 20x1 − 30x2 + 0x3 + 0x4 + 0x5
2x1 + 4x2 + x3 + 0x4 + 0x5 = 1 000
x1 + 0x2 + 0x3 + x4 + 0x5 = 400
0x1 + x2 + 0x3 + 0x4 + x5 = 100
x1, x2, x3, x4, x5 ≥ 0Al introducir los datos en el computador
A =
⎡⎣ 2 4 1 0 01 0 0 1 00 1 0 0 1
⎤⎦
b =
⎡⎣ 1000400100
⎤⎦ ; c =⎡⎢⎢⎢⎢⎣-20-30000
⎤⎥⎥⎥⎥⎦Al resolver se obtuvo
x =
⎡⎢⎢⎢⎢⎣400.0050.000.000.0050.00
⎤⎥⎥⎥⎥⎦con valor Óptimo v = -9499.99, como em problema es de maximización v = 9499.99

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 45
Experimento 2:
Supongamos que tenemos que escribir un trabajo en un tiempo máximo de 40 horas, el trabajoconsta de 200 páginas de texto, 62 tablas y 38 figu-ras. Para realizar este trabajo fueron consultados4 trabajadores diferentes (tipeadores), los detalles de la rapidez, tarifa y disponibilidad de cadatrabajador son dados en la tabla adjunta. ¿Cuál será la estrategia para distribuir el trabajo entre loscuatro trabajadores de modo que el costo sea lo mínimo posible.
Tipo Trabajador 1 Trabajador 2 Trabajador 3 Trabajador 4
texto 8 0.50 10 0.55 9 0.60 14 0.65pág/h sol/pág pág/h sol/pág pág/h sol/pág pág/h sol/pág
tabla 12 0.60 11 0.60 10 0.50 11 0.55tab/h sol/tab tab/h sol/tab tab/h sol/tab tab/h sol/tab
figura 5 1.20 2 0.90 3 1.00 2 0.80fig/h sol/fig fig/h sol/fig fig/h sol/fig fig/h sol/fig
Disponibilidad 14 horas 16 horas 12 horas 10 horas
Para formular matemáticamente este problema, es decir para construir un modelo que representeeste problema, debemos primeramente definir las variables, esto es fundamental, pues la complejidadde la formulación depende de esta definición. Debemos aclarar que no existe una fórmula explícitapara el proceso de modelación, sino que depende de la práctica, sentido común y habilidad.
La variable. Sea xi,j la cantidad de unidades de trabajo del tipo i a ser realizada por el trabajadorj. Claramente, i = 1, 2, 3 y j = 1, 2, 3, 4.
La función objetivo. Note que 0,5x1,1 + 0,6x2,1 + 1,2x3,1 representa el costo que demanda eltrabajador 1 se le es encargado realizar x1,1 páginas de texto, x2,1 tablas y x3,1 figuras. El mismorazonamiento vale para el trabajador 2, el trabajador 3 y el cuarto trabajador. Asi, el costo totaldebido a los cuatro trabajadores estará dado por
0,5x1,1 + 0,6x2,1 + 1,2x3,1| z Trabajador 1
+ 0,55x1,2 + 0,6x2,2 + 0,9x3,2| z Trabajador 2
+
+0,6x1,3 + 0,5x2,3 + x3,3| z Trabajador 3
+ 0,65x1,4 + 0,55x2,4 + 0,8x3,4| z Trabajador 4
Esta función (objetivo) debemos minimizar tanto como sea posible.
Las restricciones. Como son 200 páginas de texto, entonces el total de páginas de texto digitadaspor los cuatro trabajadores debe satisfacer
x1,1 + x1,2 + x1,3 + x1,4 = 200
Como son 62 tablas, la suma total de tablas realizada por los cuatro trabajadores debe satisfacer
x2,1 + x2,2 + x2,3 + x2,4 = 62
Por otro lado, como son 38 figuras, el total de figuras hechas por los cuatro trabajadores debesatisfacer
x3,1 + x3,2 + x3,3 + x3,4 = 38
Además, cada trabajador no debe exceder su disponibilidad. Así, si el primer trabajador escribe 8páginas de texto en una hora, él realizará una página en 1/8 de hora, entonces digitar x1,1 páginas

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 46
de texto le tomará 18x1,1 horas (el mismo razonamiento vale para las tablas y figuras), como su
disponibilidad es 14 horas, debemos tener
1
8x1,1 +
1
12x2,1 +
1
5x3,1 ≤ 14
Análogamente para el segundo trabajador
1
10x1,2 +
1
11x2,2 +
1
2x3,2 ≤ 16
Para el tercer trabajador1
9x1,3 +
1
10x2,3 +
1
3x3,3 ≤ 12
Para el cuarto trabajador1
14x1,4 +
1
11x2,4 +
1
2x3,4 ≤ 10
Finalmente, como la ejecución del trabajo no debe exceder las 40 horas, entonces la suma de todaslas horas utilizadas por los cuatro trabajadores no debe exceder esta cantidad, es decir
1
8x1,1 +
1
12x2,1 +
1
5x3,1| z
Trabajador 1
+1
10x1,2 +
1
11x2,2 +
1
2x3,2| z
Trabajador 2
+
+1
9x1,3 +
1
10x2,3 +
1
3x3,3| z
Trabajador 3
+1
14x1,4 +
1
11x2,4 +
1
2x3,4| z
Trabajador 4
≤ 40
Las condiciones de no negatividad. Observe que las variables no pueden ser negativas, es decir
xi,j ≥ 0, i = 1, 2, 3 j = 1, 2, 3, 4
La formulación matemática. La función objetivo, las restricciones y las condiciones de no negativi-dad, producen un modelo particular de problema de programación lineal, una de las representacionesque usaremos en este ejemplo corresponde a.
Minimizar 0,5x1,1+0,6x2,1+1,2x3,1+0,55x1,2+0,6x2,2+0,9x3,2+0,6x1,3+0,5x2,3+x3,3+0,65x1,4+0,55x2,4 + 0,8x3,4
x1,1 + x1,2 + x1,3 + x1,4 = 200
x2,1 + x2,2 + x2,3 + x2,4 = 62
x3,1 + x3,2 + x3,3 + x3,4 = 3818x1,1 +
112x2,1 +
15x3,1 ≤ 14
110x1,2 +
111x2,2 +
12x3,2 ≤ 16
19x1,3 +
110x2,3 +
13x3,3 ≤ 12
114x1,4 +
111x2,4 +
12x3,4 ≤ 10
(3.20)
18x1,1 +
112x2,1 +
15x3,1 +
110x1,2 +
111x2,2 +
12x3,2+
+19x1,3 +
110x2,3 +
13x3,3 +
114x1,4 +
111x2,4 +
12x3,4 ≤ 40
xi,j ≥ 0, i = 1, 2, 3 j = 1, 2, 3, 4
Llevando a su forma estándar se resolvió este problema, con valor objetivo Óptimo de 176.48 enun tiempo de 0.016 segundos
Formas GeneralesPrimer caso

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 47
Consideremos el siguiente problema Primal Dual en forma estándar
Minimizar ctx (P)
Ax = b
x+ s = u
x, s ≥ 0
donde c, x, s, u ∈ Rn, b ∈ Rm y A ∈ Rm×n. y su dual
Maximizar bty− utw (D)
Aty+ z−w = 0
z,w ≥ 0
donde y ∈ Rm y w ∈ Rn.asumiendo que el rango de A es m, las condiciones de no negatividad delas variables se sustituyen por un término en la función objetivo que se haga muy grande cuandoesas variables tomen valores nega-tivos. Un método del punto interior es un esquema reiterativo porresolver (P) y (D) en cada iteración satisfaciéndo las restricciones de no negatividad, aplicando labarrera logaritmica el problema primal queda
Minimizar ctx− μnPj=1
Ln(xj)− μnPj=1
Ln(sj)
Ax = b
x+ s = u
(P(u))
y el dual
Maximizar bty− utw+ μnPj=1
Ln(zj)− μnPj=1
Ln(wj)
Aty−w+ z = c
La representación geométrica del nuevo problema se muestra de manera intuituiva el funcionamientodel algoritmo.
Para cada μ el mínimo de la función objetivo correspondiente se alcanza en un interior de la región
factible modificada, al tender μ −→ 0, el óptimo interior de la región factible tiende al óptimo delproblema lineal original. El camino hasta alcanzarlo en el proceso iterativo resultante de ir cambiandoμ conforme el camino central.

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 48
Las restricciones de igualdad serán manejadas por el método de Lagrange, por lo que se tiene.
LP = ctx− μ
nXj=1
Ln(xj)− μ
nXj=1
Ln(sj)− yt(Ax− b) +wt(x+ s− u)
LD = bty− utw+ μ
nXj=1
Ln(zj)− μ
nXj=1
Ln(wj)− xt(Aty−w+ z = c)
continuando con el análisis se calcula las derivadas parciales respectivas, obteniéndose
∂LP
∂x= c− μX−1e−Aty+w = 0 (3.21)
∂LP
∂y= b−Ax = 0 (3.22)
∂LP
∂x= −μS−1e+w = 0 (3.23)
∂LP
∂x= x+ s− u = 0 (3.24)
∂LD
∂x= c−Aty+w− z = 0 (3.25)
∂LD
∂x= b−Ax = 0 (3.26)
∂LD
∂x= u+ μW−1e+ x = 0 (3.27)
∂LD
∂x= μZ−1e− x = 0 (3.28)
de (3.20) se tiene c−Aty+w = z esto en (3.16) tenemos:
z = μX−1e
multiplicando ambos lados por X tenemos
Xz = μe
XZe = μe
de la misma forma de (3.19)se tiene u − x = s, esto en (3.22) tenemos s = μW−1e, multiplicandoambos lados de esta última ecuación por W tenemos
sW = μe
SWz = μe
Las condiciones necesarias de primer orden, para un mismo μ de los pro-blemas primal y dualquedan.
Ax = b
x+ s = u
Aty+ z−w = c
XZe = μe
SWe = μe
x, s, z,w ≥ 0
(3.29)

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 49
donde X, S,Z yW son matrices diagonales con coeficientes xi, si,zi y wi, respectivamente, el n-vectorcolumna e = [1 1..,1]t y z = μX−1e, .Para resolver el sistema podemos usar el método de NewtonF(x) = 0.
F(x, s, y, z,w) =
⎡⎢⎢⎢⎢⎣Ax− b
Aty+ z−w− c
x+ s− μ
XZe− μe
SWe− μe
⎤⎥⎥⎥⎥⎦cuyo Jacobiano está dado por
J(x, s, y, z,w) =
⎡⎢⎢⎢⎢⎣A 0 0 0 0
0 0 At I −I
I I 0 0 0
Z 0 0 X 0
0 W 0 0 S
⎤⎥⎥⎥⎥⎦por lo que las tres primeras de estas condiciones de (3.29) son lineales y fuerzan la factibilidad delprimal y dual en la solución.
Las dos siguientes de (3.29) son no lineales y dependen del parámetro μ. para μ = 0, son lascondiciones de complementariedad de holguras.
El conjunto de soluciones x(μ), s(μ), y(μ), z(μ), w(μ) definen los puntos centrales de los proble-mas primal dual.
En un punto del proceso iterativo de estos métodos, [x, s, y, z, w] se resuelve el sistema J(xk)dx =−F(xk) ⎡⎢⎢⎢⎢⎣
A 0 0 0 0
0 0 At I −I
I I 0 0 0
Z 0 0 X 0
0 W 0 0 S
⎤⎥⎥⎥⎥⎦⎡⎢⎢⎢⎢⎣dx
ds
dy
dz
dw
⎤⎥⎥⎥⎥⎦ = −
⎡⎢⎢⎢⎢⎣Ax− b
Aty+ z− w− c
x+ s− μ
XZe− μe
SWe− μe
⎤⎥⎥⎥⎥⎦⎡⎢⎢⎢⎢⎣A 0 0 0 0
0 0 At I −I
I I 0 0 0
Z 0 0 X 0
0 W 0 0 S
⎤⎥⎥⎥⎥⎦⎡⎢⎢⎢⎢⎣dx
ds
dy
dz
dw
⎤⎥⎥⎥⎥⎦ =
⎡⎢⎢⎢⎢⎣b−Ax
c−Aty− z+ w
μ− x+ s
μe− XZe
μe− SWe
⎤⎥⎥⎥⎥⎦para encontrar una dirección (dx, ds, dy, dz, dw)⎡⎢⎢⎢⎢⎣
A 0 0 0 0
0 0 At I −I
I I 0 0 0
Z 0 0 X 0
0 W 0 0 S
⎤⎥⎥⎥⎥⎦⎡⎢⎢⎢⎢⎣dx
ds
dy
dz
dw
⎤⎥⎥⎥⎥⎦ =
⎡⎢⎢⎢⎢⎣rbrcru
τμe− XZe
τμe− SWe
⎤⎥⎥⎥⎥⎦ (3.30)
donde τ es un escalar entre 0 y 1, las matriz diagonales de X,Z, S,y W son definidos y
rb = b−Ax
rc = c−Aty− z+ w
ru = μ− x+ s
escogiendo diferentes valores de τ
Si τ = 0, la dirección será de descenso puro sin componente de centrado: dirección predictor

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 50
Si τ = 1 y μ = 12n(xtz+ stw) la dirección es de centrado puro dejando el gap primal dual sin
cambio: dirección corrector:
El sistema (3.30) puede convertirse en un sistema equivalente de ecuaciones con lo hecho de lassiguientes eliminaciones:
dz = X−1(τμe− XZe− Zdx)
ds = μ− x− s− dx
dw = S−1(τμe− SWe−Wru +Wdx)
el sistema queda∙−D−2 At
A 0
¸ ∙dx
dy
¸=
∙rc − X
−1(τμe− XZe) + S−1(τμe− SWe−Wru)
rb
¸donde D2 =
¡x−1Z+ S−1W
¢−1. esta ecuación se denomina sistema aumentado.
Todos los métodos de puntos interiores resuelven un sistema como éste. Se puede reducir máseliminando dx sin más que multiplicar el primer subconjunto de ecuaciones por AD2 y sumar elsegundo; resultan las siguientes ecuaciones normales,³
AD2At´dy = rb +AD
2(rc − X−1(τμe− XZe)
+S−1(τμe− SWe−Wru)
Lo único que resta del proceso iterativo es determinar la amplitud de paso en la dirección calculadapara que se mantenga la factibilidad del problema y adaptar el parámetro μ.
Los códigos más modernos centran sus esfuerzos, y diferencias, dentro de este esquema.
Segundo caso.Consideremos que el problema Primal original tiene acotaciones superio-res e inferiores en las
variables x, como el problemaMinimizar ctx (3.31)
Ax = b
` ≤ x ≤ u (3.32)
donde algunas de las componentes del vector u pueden ser infinitas y algunas de ` pueden ser cero.
Empleando las variables de holgura s y v, el problema anterior se puede escribir así:
Minimizar ctx (3.33)
Ax = b
x+ s = u
x− v = `
s ≥ 0v ≥ 0
(3.34)
Al problema (3.34) aplicaremos la técnica de la función barrera logaritmica para reemplazar lascondiciones de no negatividad y así llegar a considerar el siguiente problema de minimización
Minimizar ctx− μ
nXi=1
Ln(si)− μ
nXi=1
Ln(vi) (3.35)

CAPÍTULO 3. MÉTODO DE PUNTOS INTERIORES PRIMAL-DUAL 51
Ax = b
x+ s = u
x− v = `
(3.36)
y su función lagrangiana tiene la forma
L(x, y, z,μ) = ctx− μnPi=1
Ln(si)− μnPi=1
Ln(vi)− yt(Ax− b)+
+wt(x+ s− u)− zt(x− v− `)(3.37)
recordando que las restricciones lagrangianas son irrectrictas en signo, donde:
las variables duales asociadas a las restricciones Ax = b son y
las variables duales asociadas a las restricciones x+ s = u son w
las variables duales asociadas a las restricciones x− v = ` son z.
Las condiciones necesarias de primer orden que deben cumplir son
∂L∂x(x, y, z,μ) = 0 = Aty+ z−w− c
∂L∂y(x, y, z,μ) = 0 = Ax− b
∂L∂z(x, y, z,μ) = 0 = x− v− `
∂L∂s(x, y, z,μ) = 0 = SWe− μe
∂L∂v(x, y, z,μ) = 0 = VZe− μe
∂L∂w(x, y, z,μ) = 0 = x+ s− u
(3.38)
Para el caso de ` = 0, que implica x = v, estas condiciones pasan a ser
Ax = b
x+ s = u
Aty+ z−w = c
XZe− μe
SWe− μe
(3.39)
La dirección de búsqueda resultante de aplicar el método de newton al sistema anterior es
dy = (AΘA)−1£(b−Ax) +AΘ((c−Aty− z+w) + ρ(μ))
¤dx = Θ
£Atdy− ρ(μ)− (c−Aty− z+w)
¤dz = μX−1e− Ze− X−1Zdx
dw = μS−1e−We+ S−1Wdx
ds = −dx
(3.40)
dondeΘ = (X−1Z+ S−1W)−1
ρ(μ) = μ(S−1 − X−1)e− (W − Z)e(3.41)

Conclusiones
En este trabajo se construyó, detalladamente, el método más eficiente en la actualidad que nospermite resolver el problema de programación lineal a gran dimensión: El Método de puntos interioresPrimal-Dual para programación lineal.
Podemos concluir entonces que:
1. El método de puntos interiores Primal-Dual es relativamente nuevo, y constituye una alternativaal método Simplex.
2. Los métodos de puntos interiores son mecanismos que abordan el problema de un modo diferente:crean una sucesión de puntos por el interior de la región de factibilidad, la cual converge haciaun óptimo.
3. El método de puntos interiores Primal-Dual está basado en tres estrategias numéricas, El métodode Newton, Lagrange y Penalización interna.
4. El método de puntos interiores Primal-Dual es de fácil implementación computacional. En estecaso usamos el Matlab.
5. En la parte experimental, cuando el Método es sometido a problemas de grandes dimensiones,resultó tener un buen desempeño.
6. Fue posible ampliar el Método para formatos diferentes al de programación lineal estándar.
52

Bibliografía
[1] Martinez J., Santos A., Métodos Computacionales de Optimização. IMECC-UNICAMP, 1995
[2] Yin Zhang, A quick Introduction to Linear Programming,DRAFT, September 24, 2007
[3] David G. Luenberger, Programación Lineal y no lineal. ADDISON-WESLEY IBEROAMERI-CANA, 1 989
[4] Bazaraa M. S., Sherali H. D.,Shetty C. M. Nonlinear Programming, theory and Algorithms. SecondEdition John Wiley & Sons, 1993
[5] Mokhtar S. Bazaraa., John J. Jarvis. Programación Lineal y Flujo en Redes. EDITORIALLIMUSA, 1981
[6] Lima E. L. Curso de Análise, Volume 2. Terceira Edição. IMPA, 1989.
53