
Nicolás Lagos Ruizrepository.udistrital.edu.co/bitstream/11349/4077/1/COMPARACIÓN … · Bases de...
63
1 ______________________________________________________________________________ _____________________________________________________________________________ COMPARACIÓN DEL FUNCIONAMIENTO DEL ALGORITMO C4.5 EN UN MODELO DE PERSISITENCIA RELACIONAL CONTRA UN MODELO NO RELACIONAL Nicolás Lagos Ruiz _____________________ Facultad de Ingeniería, Proyecto Curricular de Ingeniería de Sistemas Bogotá D.C., Colombia 2016
Transcript of Nicolás Lagos Ruizrepository.udistrital.edu.co/bitstream/11349/4077/1/COMPARACIÓN … · Bases de...

1
______________________________________________________________________________
_____________________________________________________________________________
COMPARACIÓN DEL FUNCIONAMIENTO DEL ALGORITMO C4.5 EN
UN MODELO DE PERSISITENCIA RELACIONAL CONTRA UN
MODELO NO RELACIONAL
Nicolás Lagos Ruiz
_____________________
Facultad de Ingeniería, Proyecto Curricular de Ingeniería de Sistemas
Bogotá D.C., Colombia
2016

2
______________________________________________________________________________
COMPARACIÓN DEL FUNCIONAMIENTO DEL ALGORITMO C4.5 EN
UN MODELO DE PERSISITENCIA RELACIONAL CONTRA UN
MODELO NO RELACIONAL
Nicolás Lagos Ruiz
Trabajo de grado presentado como requisito para optar al
Título de:
Ingeniero de Sistemas
Director:
M.Sc. NANCY GELVEZ GARCÍA
Codirector:
ESP. JOHN FREDDY PARRA PEÑA
Línea de Investigación:
Ingeniería de Software
Universidad Distrital Francisco José de Caldas
Facultad de Ingeniería
Bogotá D.C, Colombia
2016

3
______________________________________________________________________________
Nota de aceptación:
________________________________
________________________________
________________________________
________________________________
________________________________
_______________
Firma del Director del Trabajo de Grado
_________________________________
Firma del jurado
_________________________________
Bogotá, 2016

4
______________________________________________________________________________
Dedicatoria
A mis padres y mis hermanos del alma por estar siempre.
Por su apoyo incondicional, su ayuda y amor
Nicolás Lagos Ruiz

5
______________________________________________________________________________
Agradecimientos
A Dios por darme la oportunidad de concretar este importante proyecto y paso en mi vida.
A mis padres por su paciencia, acompañamiento, consejo, compresión, amor y guía infinitos.
A mi hermano Andrés por el acompañamiento y ayuda durante el proceso de elaboración.
A mi directora de Tesis el M.Sc. Nancy Gelvez Garcia y mi codirector ESP. John Freddy Parra
Peña por sus enseñanzas y su acompañamiento.
A Andrés Hamir Cobos Prada por su asesoría técnica y acompañamiento.
A Daniel Felipe Garzón Triana por su ayuda en la redacción.
A mis hermanos del alma por su apoyo incondicional.
A la universidad Distrital Francisco José de Caldas por la educación y formación recibidas a lo
largo de mi carrera.
Quiero darles mis más sinceros agradecimientos.

6
______________________________________________________________________________
Resumen
La minería de datos ha tomado relevancia en los últimos años, lejos de ser un tema nuevo,
es un tema que gana popularidad por ciertos periodos de tiempo, haciéndose evidente la necesidad
que tienen las organizaciones por convertir en información útil la gran cantidad de datos que
reciben en la actualidad.
Dentro de las herramientas existentes en el espectro de la minería de datos existe un
enfoque llamado árboles de decisión, usado para construir un árbol de relaciones entre diferentes
conjuntos de datos de manera probabilística, y haciendo uso de la entropía de la información y
otras técnicas.
En este documento se implementa un algoritmo generador de árboles de decisión,
utilizando dos enfoques similares pero con distinto propósito; modelos de persistencia relacional
y no relacional, ambos modelos considerados dentro de un ambiente clusterizado.
Dentro de la implementación del algoritmo C4.5, algoritmo generador, se construyó un
modelo de persistencia relacional utilizando PostgreSQL como motor de base de datos y Pgpool
como gestor del clúster. En contraparte, la implementación del modelo de persistencia no
relacional se construyó utilizando Hadoop, solución clusterizada por definición y su sistema de
archivos HDFS.
Finalmente, se ejecutan ambas implementaciones sobre un conjunto de datos de control y
un conjunto de datos “real”, comparando sus resultados por medio de una métrica, mostrándolos
y proponiendo posibles trabajos futuros.
Palabras clave: Minería de datos, Arboles de decisión, Persistencia, C4.5, Hadoop, HDFS,
PostgreSQL, Pgpool, Clúster.

7
______________________________________________________________________________
Abstract
Data mining has been a trending topic in recent years, but far from being a new trend, it
gains some popularity by time to time, making evident that data analytics’ and data storage is a
must today for every organization.
There are a lot of tools for data mining. One of them is decision trees, used to make a
relationship tree among different data sets in a probabilistic way and making use of entropy of
information and another informatics tools.
This document shows two different approaches of decision tree, using the relational model
and the non-relational model; both of them using a clustered environment.
Using C4.5 as the algorithm to make the decision tree, PostgreSQL, a free source database,
was selected as the relational solution, and Pgpool as cluster manager. On the other hand, Hadoop
was used as non-relational solution, clustered by default and its powerful data processor HDFS as
storage technique.
Finally, the results of running both implementations, using a test set and another with “real
life data”, making a comparison by the use of a metric were shown, besides future works.
Key words: Data mining, Decision tree, Data storage, C4.5, Hadoop, HDFS, PostgreSQL,
Pgpool, Cluster.

8
______________________________________________________________________________
Tabla de contenido Introducción .................................................................................................................................. 13
Formulación del Problema ........................................................................................................ 14
Justificación ............................................................................................................................... 15
Objetivos ................................................................................................................................... 16
Objetivo General.................................................................................................................... 16
Objetivos Específicos ............................................................................................................ 16
Estado del arte y marco de referencia ....................................................................................... 16
Bases de datos relacionales.................................................................................................... 16
Comparación de algunas bases de datos relacionales ............................................................ 19
Bases de datos no relacionales............................................................................................... 19
Comparación de algunas bases de datos no relacionales ....................................................... 20
Comparación bases de datos relacionales contra bases de datos no relacionales .................. 21
Hadoop................................................................................................................................... 22
MapReduce ............................................................................................................................ 23
PgPool II ................................................................................................................................ 25
Algoritmo C4.5 ...................................................................................................................... 26
Implementación C4.5 .................................................................................................................... 31
Precondiciones y Postcondiciones ............................................................................................ 31
Procesamiento Hadoop .............................................................................................................. 32
Procesamiento PostgreSQL ....................................................................................................... 34
Cálculo entropía y llamado recursivo........................................................................................ 35
Diagrama de clases algoritmo C4.5........................................................................................... 37
Universidad.distrital.c45 ........................................................................................................ 38
Universidad.distrital.c45.estructura ....................................................................................... 38
Universidad.distrital.c45.mapper ........................................................................................... 39
Universidad.distrital.c45.reducer ........................................................................................... 39
Universidad.distrital.c45.sql .................................................................................................. 39
Elaboración Clúster ....................................................................................................................... 39
Clúster Hadoop .......................................................................................................................... 40
Core-site................................................................................................................................. 41
Hdfs-site................................................................................................................................. 41

9
______________________________________________________________________________
Mapred-site ............................................................................................................................ 42
Yarn-site ................................................................................................................................ 43
Clúster PostgreSQL ................................................................................................................... 45
Elaboración Conjunto de Datos .................................................................................................... 46
Elaboración Métrica ...................................................................................................................... 49
Pruebas y Resultados .................................................................................................................... 52
Conjunto Depurado ................................................................................................................... 53
Weather ..................................................................................................................................... 57
Conclusiones y Trabajo Futuro ..................................................................................................... 59
Bibliografía ................................................................................................................................... 62

10
______________________________________________________________________________
Lista de Figuras
Figura 1 Esquema MapReduce. Fuente: elaboración propia ........................................................ 24
Figura 2 Estructura MapReduce. Fuente: elaboración propia ...................................................... 24
Figura 3 Algoritmo C4.5. Fuente: elaboración propia .................................................................. 27
Figura 4 Diagrama MapReduce operación inicial. Fuente: elaboración propia ........................... 33
Figura 5 Diagrama MapReduce operación final. Fuente: elaboración propia .............................. 34
Figura 6 Estructura datos C4.5 Fuente: elaboración propia .......................................................... 36
Figura 7 Diagrama de clases implementación Hadoop. Fuente: elaboración propia .................... 38
Figura 8 Diagrama de clases implementación PostgreSQL. Fuente: elaboración propia ............. 38
Figura 9 Configuración core-site.xml. Fuente: elaboración propia .............................................. 41
Figura 10 Configuración hdfs-site.xml Fuente: elaboración propia ............................................ 42
Figura 11 Configuración mapred-site.xml Fuente: elaboración propia ....................................... 42
Figura 12 Configuración yarn-site.xml Fuente: elaboración propia ............................................ 43
Figura 13 Archivo de configuración Hosts. Fuente: Elaboración propia ..................................... 44
Figura 14 Información Nodos. Fuente: Elaboración propia ......................................................... 44
Figura 15 Información Datanode. Fuente: Elaboración propia .................................................... 45
Figura 16 Configuración PgPool. Fuente: Elaboración propia .................................................... 46
Figura 17 Resultado Conjunto Depurado-2, implementación Hadoop. Fuente: Elaboración propia
....................................................................................................................................................... 53
Figura 18 Resultado Conjunto Depurado-2, implementación Pgpool. Fuente: Elaboración propia
....................................................................................................................................................... 54
Figura 19 Resultado Conjunto Depurado-2, Hadoop vs Pgpool. Fuente: Elaboración propia ..... 54
Figura 20 Resultado Conjunto Depurado-4, implementación Hadoop. Fuente: Elaboración propia
....................................................................................................................................................... 55
Figura 21 Resultado Conjunto Depurado-4, implementación Pgpool. Fuente: Elaboración propia
....................................................................................................................................................... 56
Figura 22 Resultado Conjunto Depurado-4, Hadoop vs Pgpool. Fuente: Elaboración propia ..... 57
Figura 23 Resultado Conjunto Weather, implementación Hadoop. Fuente: Elaboración propia . 57
Figura 24 Resultado Conjunto Weather, implementación Pgpool. Fuente: Elaboración propia .. 58
Figura 25 Resultado Conjunto Weather, Hadoop vs Pgpool. Fuente: Elaboración propia ........... 59

11
______________________________________________________________________________
Lista de ecuaciones
Ecuación 1 Entropía ...................................................................................................................... 28
Ecuación 2 Ganancia..................................................................................................................... 28

12
______________________________________________________________________________
Lista de tablas
Tabla 1 Comparación de bases de datos relacionales. Fuente: elaboración propia ...................... 19
Tabla 2 Comparación bases de datos no relacionales. Fuente: elaboración propia ...................... 21
Tabla 3 Bases relacionales VS No relacionales, tomada de mongoDB.com adaptada por el autor
....................................................................................................................................................... 22
Tabla 4 Ejemplo archivo de entrada. Fuente: elaboración propia ................................................ 32
Tabla 5 Ejemplo tabla Atributos PostgreSQL. Fuente: elaboración propia.................................. 35
Tabla 6 Características clúster. Fuente: elaboración propia ......................................................... 40
Tabla 7 Atributos conjunto de datos. Fuente: Elaboración propia................................................ 47
Tabla 8 Conjunto de datos depurado. Fuente: Elaboración propia ............................................... 48
Tabla 9 Conjunto de datos Weather. Fuente: http://storm.cis.fordham.edu/~gweiss/data-
mining/weka-data/weather.nominal.arff ....................................................................................... 49
Tabla 10 Tamaños muestras. Fuente: Elaboración propia ............................................................ 50
Tabla 11 Esquema de pruebas a realizar métrica. Fuente: Elaboración propia ............................ 52

13
______________________________________________________________________________
Introducción
Los temas relacionados con las tecnologías de la información están a la orden del día, cuando
se habla de innovación y el mejoramiento de los procesos productivos en ámbitos, tanto
académicos como empresariales, es un tema imperdible, todos quieren sacar provecho de estas
tecnologías y desean tener la vanguardia de las mismas, buscando obtener ventajas estratégicas
sobre sus pares.
De la mano de las tecnologías de la información, necesariamente se trata el tema de la
persistencia, empezando por el ya clásico enfoque relacional hasta llegar a enfoques más recientes
como Big Data, Minería de Datos, bases de datos no relacionales, entre otros.
En lo referente a la persistencia, el solo hecho de guardar datos, mantener su integridad y
seguridad ya no es suficiente. Dentro de estos datos se esconde información valiosa que no se
puede ver “a simple vista” y se hace necesaria la utilización de herramientas para extraer la misma,
recordando que la información es el activo más valioso para cualquier organización. [1]
Gracias al uso de ambas tecnologías de persistencia relacional y no relacional, las
organizaciones cuentan con herramientas para almacenar datos, recopilar información, y tomar
decisiones.
Con este trabajo se pretende mostrar ambos modelos, ofreciendo una comparación en aspectos
muy específicos de tecnologías de persistencia; esperando dar al lector una idea del potencial de
la persistencia relacional y la persistencia no relacional.

14
______________________________________________________________________________
Formulación del Problema Actualmente se generan grandes volúmenes de información de fuentes muy diversas, como
lo son las transacciones de las organizaciones, las redes sociales, los sensores de los diferentes
aparatos electrónicos, el internet de las cosas, entre muchos otros. Estos datos deben ser capturados
y almacenados, dependiendo de su fuente se puede crear su persistencia de diferentes maneras, si
los datos son estructurados, se pueden almacenar fácilmente en un sistema de bases de datos
relacional, pero si por el contrario carecen de estructura, será recomendable usar alguna de las
múltiples tecnologías no relacionales, no solo para reducir los costos de persistencia, sino que
también para no perder información en la restructuración de los datos.
Cuando se trabaja con cualquier modelo, sin duda lo más importante es la información que
se puede adquirir del mismo. Esta información puede ser utilizada de diferentes maneras,
dependiendo la lógica con la que trabaje el negocio. Existen diferentes técnicas para adquirir,
organizar y explotar los datos usando herramientas muy variadas.
Dentro de las técnicas de procesamiento de la información, existe una con el fin de realizar
predicciones, conocida como árboles de decisión. Esta busca, partiendo de un conjunto de datos,
de los cuales se conocen sus entradas y salidas, llamado conjunto de entrenamiento, poder predecir
la salida de otro conjunto de datos de los cuales solo se conoce la entrada. Dentro de esta categoría
existe un algoritmo llamado C4.5 [2].
Al trabajar con el algoritmo C4.5 surge la pregunta ¿en qué modelo de persistencia se
obtendrán mejores resultados para el algoritmo C4.5?, ¿relacional o no relacional?
Este trabajo tiene como objeto verificar el funcionamiento del algoritmo de generación de
árboles de decisión C4.5, tanto para el modelo relacional como el no relacional, sobre un mismo

15
______________________________________________________________________________
conjunto de datos, y bajo una misma implementación, para después, por medio de una métrica
verificar en qué tipo de estructura de datos se obtuvieron los mejores resultados.
Justificación En el contexto de la persistencia es necesario llegar más allá que el simple hecho de capturar
y almacenar datos, aunque con esto se puede llegar a satisfacer las necesidades del negocio, es
necesario aprovechar el potencial de la información, considerado por muchos autores como el
activo más importante con el que cuentan las organizaciones hoy en día [1]. Para esto, además de
la infraestructura para capturar los datos y almacenarlos, es necesario utilizar técnicas que permitan
extraer de los mismos, información que se escape a simple vista o a la lógica del negocio de la
organización. Con esto se busca inferir patrones y comportamientos que escapen a la intuición
humana.
En el caso concreto de esta problemática, se encuentran ejemplos como: realizar
predicciones con datos que permitan facilitar la toma de decisiones, realizar predicciones de
esparcimiento de una epidemia, patrones de comportamiento humano, entre un sinfín más de
aplicaciones que tiene el campo en mención.
Sin embargo, utilizar el algoritmo para operar un conjunto de datos no garantiza su éxito,
es necesario evaluar las características del conjunto de entrada y la forma en la que fueron
indexadas y almacenadas en la tecnología de persistencia que se utilizó para posteriormente
comparar y verificar su efectividad contra un conjunto de prueba, evaluando a su vez que tan
sensible es el proceso con respecto al origen y la forma en la que se almacenaron los datos.
El resultado será comparado para observar el rendimiento de ambos modelos con respecto
a un conjunto de datos, logrando esto por medio de una métrica para homogenizar el problema.

16
______________________________________________________________________________
Finalmente, con los resultados obtenidos y evaluados por medio de la métrica se expondrán
las conclusiones y se harán recomendaciones en lo referente al tema.
Objetivos
Objetivo General
Implementar el algoritmo de clasificación de árboles de decisión C4.5 basado en un modelo
de datos relacional y en uno no relacional en un clúster, para posteriormente, por medio de una
métrica, evaluar su efectividad sobre un conjunto de datos.
Objetivos Específicos
Implementar el algoritmo C4.5 basado en un modelo de persistencia relacional.
Implementar el algoritmo C4.5 basado en un modelo de persistencia no relacional.
Aplicar una métrica para evaluar los resultados en ambos modelos de persistencia.
Estado del arte y marco de referencia El siguiente apartado contiene conceptos y definiciones claves para ayudar al lector a
comprender el contenido de este trabajo.
Bases de datos relacionales
Una base de datos relacional [3] sigue el modelo relacional que tiene su base en el álgebra
de conjuntos y almacena su información en tablas con columnas y filas. Una tabla es una relación
que tiene sentido en las columnas para objetos del mismo tipo, en este caso las filas. Este modelo
cuenta con un alto grado de madurez y es el modelo más popular de persistencia.
Las bases de datos relacionales cumplen con reglas de integridad que hacen la información
precisa y siempre disponible, las filas en una base de datos relacional deben ser únicas, ya que en
caso de existir filas repetidas pueden existir problemas distinguiendo una fila de la otra, la mayoría
de motores de bases de datos no permiten por este motivo la existencia de filas duplicadas. Una
segunda regla de integridad de este modelo impide que las columnas sean repetidas en grupos o

17
______________________________________________________________________________
colecciones de grupo. Una tercera regla de integridad involucra el concepto de valor nulo, el cual
indica que el valor no existe y que es diferente de un valor en blanco o en cero, donde dos valores
nulos no son considerados iguales.
Las reglas de Codd [4] son un conjunto de reglas que, de acuerdo a Edgar Codd, debe
cumplir un sistema de bases de datos relacional para serlo. A continuación las reglas de Codd.
Regla 1 (regla de la información): Toda la información contenida en la base de datos
debe estar almacenada en tablas y filas, tanto la información del usuario como la
meta información del sistema de bases de datos.
Regla 2 (acceso garantizado): Para cada elemento atómico de datos debe ser
garantizado el acceso lógico con una combinación de tabla, llave primaria y nombre
del atributo.
Regla 3 (tratamiento sistemático del valor nulo): Los valores nulos deben recibir un
tratamiento sistemático y uniforme.
Regla 4 (Catalogo activo): La descripción de la estructura de la base de datos debe
estar almacenada en un catálogo conocido como el diccionario de datos, el cual solo
puede ser accedido por usuarios autorizados, los usuarios pueden acceder al
catálogo por un lenguaje de consultas, que se usa para también para acceder a la
base de datos.
Regla 5 (Lenguaje de datos comprensivo): A la base de datos solo se puede acceder
usando un lenguaje con una sintaxis lineal que soporte definición, manipulación y
transacciones de datos, este lenguaje puede ser usado directamente o por alguna

18
______________________________________________________________________________
aplicación, si se accede a la base de datos sin ayuda de este lenguaje se considera
una violación.
Regla 6 (Regla de la actualización): Todas las vistas de la base de datos que puedan
ser actualizadas deben ser actualizables también por el sistema.
Regla 7 (Inserción, actualización y eliminación de alto nivel): El sistema de bases
de datos debe soportar las operaciones de alto nivel y no deben estar limitadas a una
sola fila, deben soportar los operadores de unión, intersección entre otras
operaciones de conjuntos.
Regla 8 (Independencia física de los datos): El almacenamiento de los datos debe
ser independiente del acceso a las aplicaciones, ningún cambio en la estructura
física de la base de datos debe tener efectos en como son accedidos los datos por
aplicaciones externas.
Regla 9 (Independencia lógica de los datos): La composición lógica de los datos
debe ser independiente del punto de vista de la aplicación, cualquier cambio en la
lógica de los datos no debe afectar las aplicaciones que las usan.
Regla 10 (Independencia de la integridad): La base de datos debe ser independiente
de la aplicación que la usa, su estructura debe poder modificarse sin necesidad de
modificar la aplicación.
Regla 11 (Independencia de distribución): Debe ser transparente para el cliente la
distribución física de los datos, para el usuario debe verse como si todo estuviera
ubicado en un solo sitio.
19
______________________________________________________________________________
Regla 12 (No subversiones): No se debe poder modificar el sistema de bases de
datos accediendo con lenguajes de más bajo nivel.
Comparación de algunas bases de datos relacionales
En la tabla 1 se muestra una comparación de las características de algunos motores de bases
de datos relacionales. [5]
Microsoft SQL
Server
PostgreSQL Oracle
Licencia Propietaria Open source Propietaria
Sistema Operativo Windows Windows, OS X,
Linux, BSD, Unix,
Android
Windows, OS X ,
Linux, Unix, Z/OS
Características
relacionadas con el
modelo relacional
ACID, integridad
referencial,
transacciones,
bloqueo de grano fino,
unicode
ACID, integridad
referencial,
transacciones,
bloqueo de grano fino,
unicode
ACID, integridad
referencial,
transacciones (no
DDL), bloqueo de
grano fino, unicode
Acceso GUI, SQL API, GUI, SQL API, GUI, SQL
Tablas y vistas Tablas temporales,
vistas materializadas
Tablas temporales,
vistas materializadas
Tablas temporales,
vistas materializadas
Objetos Cursor, Trigger,
Funciones,
Procedimientos
almacenados
Cursor, Trigger,
Funciones,
Procedimientos
almacenados
Cursor, Trigger,
Funciones,
Procedimientos
almacenados
Tabla 1 Comparación de bases de datos relacionales. Fuente: elaboración propia
Bases de datos no relacionales
Las bases de datos no relacionales [6] hacen referencia a una gran variedad de bases de
datos desarrolladas con el propósito de almacenar una gran cantidad de volumen de datos
relacionados con personas, objetos, productos, mediciones, etc., a los que se necesita acceder con
gran velocidad y frecuencia con la tecnología de procesamiento actual.

20
______________________________________________________________________________
Tipos de bases no relacionales
Documentos: Relaciona cada llave con una compleja estructura de datos conocida
como documento, un documento contiene varias tuplas de llaves que son
almacenadas en documentos.
Almacenamiento en grafos: Son usadas para almacenar información relacionada
con redes, como por ejemplo conexiones sociales o redes de epidemias.
Almacenamiento de llave: Cada tupla tiene una llave asociada, donde el tipo de
valor puede ser de diferente tipo de dato.
Columnas horizontales: Son bases de datos optimizadas para almacenamiento en
grandes conjuntos de datos utilizando columnas en vez de filas.
Tipos de bases no relacionales
Comparadas con las bases de datos relacionales, las bases de datos no relacionales ofrecen
más escalabilidad y tienen un rendimiento mejor, su modelo de datos resuelve problemas que las
bases de datos relacionales no pueden. Permiten almacenar grandes volúmenes de datos
estructurados, semiestructurados y no estructurados, además de iteraciones rápidas, agilidad
superior; programación nativa orientada a objetos flexible y fácil de usar; eficiente, escalamiento
fuera de la arquitectura, haciéndolas más eficientes que el modelo monolítico arquitectural del
modelo relacional.
Comparación de algunas bases de datos no relacionales
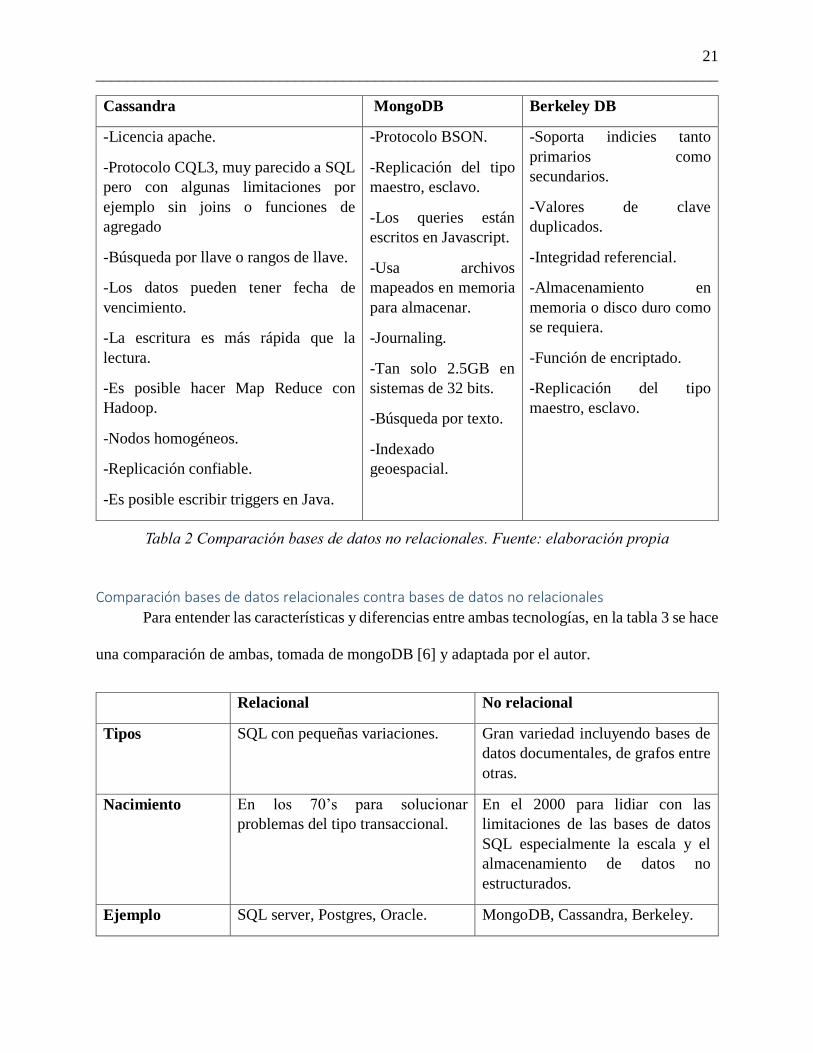
Ya que las bases de datos no relacionales no poseen características homogéneas para
comparar directamente, en la tabla 2 se muestra un cuadro con las características principales de
algunas de estas bases. [7]
21
______________________________________________________________________________
Cassandra MongoDB Berkeley DB
-Licencia apache.
-Protocolo CQL3, muy parecido a SQL
pero con algunas limitaciones por
ejemplo sin joins o funciones de
agregado
-Búsqueda por llave o rangos de llave.
-Los datos pueden tener fecha de
vencimiento.
-La escritura es más rápida que la
lectura.
-Es posible hacer Map Reduce con
Hadoop.
-Nodos homogéneos.
-Replicación confiable.
-Es posible escribir triggers en Java.
-Protocolo BSON.
-Replicación del tipo
maestro, esclavo.
-Los queries están
escritos en Javascript.
-Usa archivos
mapeados en memoria
para almacenar.
-Journaling.
-Tan solo 2.5GB en
sistemas de 32 bits.
-Búsqueda por texto.
-Indexado
geoespacial.
-Soporta indicies tanto
primarios como
secundarios.
-Valores de clave
duplicados.
-Integridad referencial.
-Almacenamiento en
memoria o disco duro como
se requiera.
-Función de encriptado.
-Replicación del tipo
maestro, esclavo.
Tabla 2 Comparación bases de datos no relacionales. Fuente: elaboración propia
Comparación bases de datos relacionales contra bases de datos no relacionales
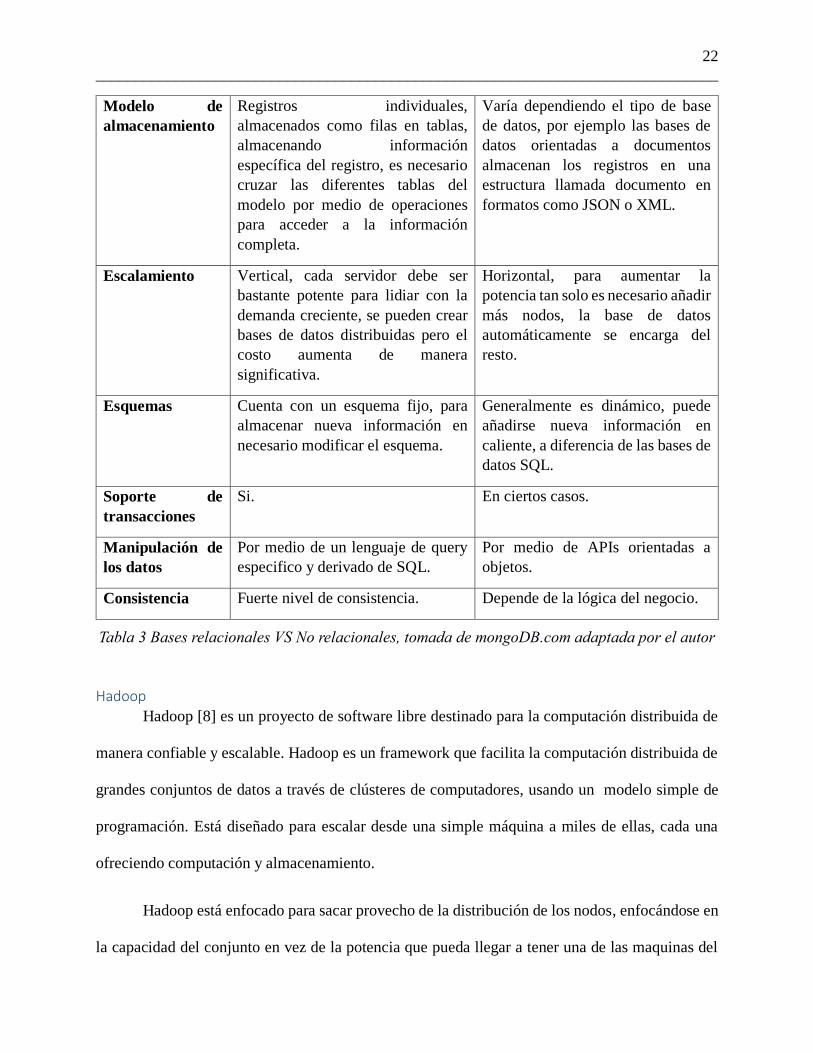
Para entender las características y diferencias entre ambas tecnologías, en la tabla 3 se hace
una comparación de ambas, tomada de mongoDB [6] y adaptada por el autor.
Relacional No relacional
Tipos SQL con pequeñas variaciones. Gran variedad incluyendo bases de
datos documentales, de grafos entre
otras.
Nacimiento En los 70’s para solucionar
problemas del tipo transaccional.
En el 2000 para lidiar con las
limitaciones de las bases de datos
SQL especialmente la escala y el
almacenamiento de datos no
estructurados.
Ejemplo SQL server, Postgres, Oracle. MongoDB, Cassandra, Berkeley.
22
______________________________________________________________________________
Modelo de
almacenamiento
Registros individuales,
almacenados como filas en tablas,
almacenando información
específica del registro, es necesario
cruzar las diferentes tablas del
modelo por medio de operaciones
para acceder a la información
completa.
Varía dependiendo el tipo de base
de datos, por ejemplo las bases de
datos orientadas a documentos
almacenan los registros en una
estructura llamada documento en
formatos como JSON o XML.
Escalamiento Vertical, cada servidor debe ser
bastante potente para lidiar con la
demanda creciente, se pueden crear
bases de datos distribuidas pero el
costo aumenta de manera
significativa.
Horizontal, para aumentar la
potencia tan solo es necesario añadir
más nodos, la base de datos
automáticamente se encarga del
resto.
Esquemas Cuenta con un esquema fijo, para
almacenar nueva información en
necesario modificar el esquema.
Generalmente es dinámico, puede
añadirse nueva información en
caliente, a diferencia de las bases de
datos SQL.
Soporte de
transacciones
Si. En ciertos casos.
Manipulación de
los datos
Por medio de un lenguaje de query
especifico y derivado de SQL.
Por medio de APIs orientadas a
objetos.
Consistencia Fuerte nivel de consistencia. Depende de la lógica del negocio.
Tabla 3 Bases relacionales VS No relacionales, tomada de mongoDB.com adaptada por el autor
Hadoop
Hadoop [8] es un proyecto de software libre destinado para la computación distribuida de
manera confiable y escalable. Hadoop es un framework que facilita la computación distribuida de
grandes conjuntos de datos a través de clústeres de computadores, usando un modelo simple de
programación. Está diseñado para escalar desde una simple máquina a miles de ellas, cada una
ofreciendo computación y almacenamiento.
Hadoop está enfocado para sacar provecho de la distribución de los nodos, enfocándose en
la capacidad del conjunto en vez de la potencia que pueda llegar a tener una de las maquinas del

23
______________________________________________________________________________
clúster, adicionalmente, manejando el control de fallos de los diferentes nodos, ofreciendo un
mejor desempeño.
Hadoop incluye las siguientes funcionalidades:
Hadoop Common: Núcleo del framework en el cual se basan las demás
funcionalidades.
Hadoop Distributed File System: Sistema de archivos que proporciona gran
flexibilidad sobre conjuntos de datos grandes.
Hadoop YARN: Agente encargado del manejo de las diferentes tareas y su
distribución en los diferentes componentes del clúster.
Hadoop MapReduce: Sistema basado en YARN para el procesamiento de grandes
cantidades de datos.
MapReduce
Es un algoritmo creado por Google [9] para procesar grandes conjuntos de datos por medio
de computación distribuida, usando computadores de bajo costo, siendo de los más populares. Este
modelo está compuesto de dos funciones: Map y Reduce. La labor principal de MapReduce es
dividir los datos en diferentes bloques lógicos; como entrada y salida se utilizan tuplas del tipo
llave/valor.
La función Map toma cada entrada llave/valor y produce una lista intermediaria de estos
mismos pares, luego se reúnen todos estos pares intermedios y son procesados por la función
Reduce para obtener los resultados finales. Las funciones son expresadas como se muestra en la
Figura 1.

24
______________________________________________________________________________
Figura 1 Esquema MapReduce. Fuente: elaboración propia
Por lo general, la función Reduce tiene una salida binaria, los programas que implementan
MapReduce se pueden ejecutar en los siguientes modos.
Autónomo: se ejecuta en tan solo un solo equipo, es decir un clúster con solo un nodo.
Pseudo-distribuido: se crean nodos virtuales en una sola máquina, es un clúster con nodos
virtuales.
Distribuido: modo completamente funcional con múltiples maquinas funcionando como
nodos dentro del clúster.
Finalmente la estructura de MapReduce es mostrada en la Figura 2.
Figura 2 Estructura MapReduce. Fuente: elaboración propia

25
______________________________________________________________________________
PgPool II
PgPool, según la wiki oficial de los desarrolladores [10], es un middleware que funciona
entre los servidores de PostgreSQL y los clientes de la base de datos. Cuenta con licencia BSD y
provee las siguientes características.
Pool de conexiones: Pgpool almacena las conexiones utilizadas para acceder a los
diferentes servidores PostgreSQL, y en caso de que las credenciales de conexión
de otra solicitud sean idénticas a las existentes, reutiliza las existentes, evitando la
creación innecesaria de conexiones.
Replicación: PgPool puede manejar múltiples servidores de PostgreSQL, usando
la función de replicación se tiene la posibilidad de replicar dos o más discos físicos,
evitando de esta manera la interrupción del servicio en caso de falla de algún disco
en los nodos.
Balance de carga: En caso de que la base de datos sea replicada, al ejecutar una
operación de tipo SELECT se deben obtener los mismos resultados. Aprovechando
este hecho, PgPool distribuye las operaciones SELECT en los diferentes servidores
PostgreSQL para mejorar la velocidad con la que se realizan las consultas, este
beneficio se ve más claramente si la consulta regresa gran cantidad de tuplas y si
se cuenta con gran número de nodos.
Limite en el número de conexiones: PostgreSQL tiene un máximo número de
conexiones simultáneas, una vez alcanzado este tope regresa un error impidiendo
el acceso a la base de datos. PgPool mejora esta característica y en caso de que se

26
______________________________________________________________________________
logre el máximo número de conexiones, la solicitud se pone en esperar en vez de
generar error.
PgPool funciona como un puente entre el cliente y los diferentes servidores PostgreSQL,
estableciendo un canal de comunicación entre los dos. Adicionalmente los clientes y los servidores
no hacen distinción entre PgPool y una instancia más de PostgreSQL, por lo que no es necesario
ningún desarrollo adicional en ninguna de las plataformas implicadas.
Algoritmo C4.5
El algoritmo C4.5 [2] desarrollado por Ross Quinlan es un algoritmo para generar árboles
de decisión, es una mejora del algoritmo ID3 del mismo autor. El algoritmo C4.5 usa un conjunto
de entrenamiento para construir el árbol de decisiones, usando el concepto de entropía de la
información. El conjunto de entrenamiento está compuesto por n instancias ya clasificadas, donde
cada instancia es un vector de Xn características, donde cada x1, x2,…, xn es un atributo o atributos
de la instancia. A cada vector c1, c2,…, cn de características se le conoce como la clase a la cual
pertenece cada instancia.
En cada nodo del árbol, el algoritmo elige un atributo de los datos que los divida de la
manera más efectiva en un subconjunto, buscando diferenciar de la mejor manera las diferentes
clases, el criterio que usa es la ganancia de información de los resultados de elegir un atributo u
otro, el atributo con la mayor ganancia será escogido para realizar la división.
Adicionalmente, el algoritmo maneja algunos casos base:
Todas las muestras pertenecen a la misma clase: en este caso simplemente se crea
una hoja para el árbol eligiendo esa clase.

27
______________________________________________________________________________
Ninguna de las características proporciona ganancia de información: en este caso
se crea un nodo hacia arriba del árbol con el valor esperado.
Se encuentra una clase no vista antes: en este caso se crea un nodo hacia arriba del
árbol usando el valor esperado.
A continuación en la Figura 3 el pseudocódigo del algoritmo.
Figura 3 Algoritmo C4.5. Fuente: elaboración propia
Cálculo de la entropía y la ganancia
Una de las partes cruciales del algoritmo C4.5 es el cálculo de la entropía [11] y la ganancia
de información, ya que esta determina cuál de las posibles divisiones genera mayor ganancia en
términos de información, y determina si la ganancia de información es suficientemente grande
para continuar con las ramificaciones o si por el contrario ya no vale la pena seguir ramificando y
el algoritmo pasa a un estado de detenido.

28
______________________________________________________________________________
El cálculo de la entropía y de la ganancia de información se hace como se enseña en las
Ecuaciones 1 y 2.
E:(S)= ∑ - Pr(Ci) * log2 Pr(Ci)
n
i=1
Ecuación 1 Entropía
G:(S,A)= E(S) - ∑ Pr(Ai) E(𝑆𝐴𝑖)
𝑚
i=1
Ecuación 2 Ganancia
Donde los valores son los siguientes:
S – conjunto de datos.
E(S) – entropía de S.
G(S,A) – ganancia de S después de hacer un división en el atributo A.
n – número de clases en S.
Pr(Ci) – frecuencia de la clase Ci en S.
m – número de valores del atributo A en S.
Pr(Ai) – frecuencia de los casos que tiene Ai en S
E(SAi) – subconjunto de S que contiene el valores de Ai.

29
______________________________________________________________________________
El cálculo de estos valores junto con el llamado recursivo del algoritmo constituye la parte
esencial del C4.5.
Casos de éxito del algoritmo C4.5
A continuación se citan algunos trabajos realizados con el algoritmo C4.5.
Reconocimiento facial con el algoritmo C4.5 extendido. [12]
El reconocimiento facial es un ejemplo típico de evaluación de datos basados en la
sensibilidad, uno de los mayores problemas son las dificultades con la ambigüedad
y el procesamiento de los objetivos en la búsqueda de una clave de identificación
efectiva. En este trabajo se propuso un mecanismo de reconocimiento de imágenes
con una versión extendida del algoritmo C4.5 como mecanismo de identificación,
utilizando una métrica para verificar las salidas con buenos resultados.
Procesamiento de diabetes tipo 2 con maximización de la expectativa y el algoritmo
C4.5. [13]
Está investigación utilizó el algoritmo C4.5 y EM para elaborar un sistema de
procesamiento de datos de diabetes tipo 2. Tomando como fuente de datos casi
14000 muestras de múltiples fuentes, de varias dimensiones y una serie de
experimentos de minería de datos anteriores. Con esa cantidad de datos se descubrió
un comportamiento patológico de la diabetes tipo 2, donde se puede corroborar que
el árbol de decisión obtenido es casi idéntico con la lista clínica de factores de riesgo
de la diabetes. Adicionalmente, los positivos positivos, (personas sanas), fue del
80.9% y los negativos positivos, (personas con la enfermedad), fueron 92.05%, este
es un rango de efectividad bastante alto.

30
______________________________________________________________________________
Conservación de la privacidad sobre datos particionados de manera horizontal con
el algoritmo C4.5. [14]
La conservación de la privacidad en un entorno de computación distribuida es lo
que se busca con la implementación del algoritmo C4.5. En un escenario donde se
busca elaborar un árbol de decisión con datos distribuidos en diferentes nodos de
una plataforma de computación distribuida, el objetivo es que los nodos no
compartan información sensible, utilizando técnicas de seguridad multi-party de
computación, permitiendo elaborar el árbol de decisión, tanto con valores discretos
como continuos, y garantizando la privacidad al mismo tiempo.
Minería de datos con el algoritmo C4.5 y virtualización de cartografía interactiva.
[15]
Considerando la utilización de técnicas del descubrimiento del conocimiento en
bases de datos, se busca combinar varias de estas técnicas para crear clasificación
de objetos espaciales por medio de mapas. Con los mapas se busca tanto la
preparación de los datos como la interpretación de los mismos.
Detectando errores de software con el algoritmo C4.5. [16]
Las métricas de detección de defectos en el software generalmente están
relacionadas con el proceso de creación del mismo, en vez de enfocarse al momento
de puesta en producción. Sin embargo, aún existe el problema de utilizar una técnica
de predicción de fallos en este tipo de ambiente. En este trabajo se propone un una
técnica de predicción de errores por medio del algoritmo C4.5, con pruebas
realizadas en entornos experimentales llegando a un performance de 52.65%.

31
______________________________________________________________________________
Implementación C4.5
Este capítulo abarca todo lo relacionado con el desarrollo del algoritmo C4.5, usando como
lenguaje base Java™ y combinándolo con las diferentes tecnologías de persistencia propuestas
para llevar a cabo este proyecto. Es importante destacar que ambas implementaciones, Hadoop,
PostgreSQL, no se utilizan tan solo para guardar datos, sino que también buscan entrelazarse con
la funcionalidad del algoritmo, buscando tanto beneficios como desventajas que ofrecen las
tecnologías mencionadas anteriormente.
Precondiciones y Postcondiciones Para el caso de las dos implementaciones se contempla que tengan tanto la misma entrada
como la misma salida, esto con el fin de darle homogeneidad al problema y facilitar de esta manera
cálculos en tiempos de ejecución y otros aspectos a tener en cuenta en el momento de evaluar el
algoritmo.
La fuente de entrada de información de la implementación del algoritmo será un archivo
plano (.txt) que contiene información de los diferentes atributos asociados y su valor de clase
correspondiente, cada valor se da en una línea, para que de esa manera se interprete cada una de
las líneas del archivo como un valor de atributo asociado a su vez a un valor de clase. De igual
forma, los valores de cada línea contendrán el valor de atributo y su posición indicará a que atributo
hace referencia, los valores de los distintos atributos están separados por coma (,) y el valor final
de cada línea será el valor de clase asociado a la combinación de valores de atributo que le
anteceden, esta manera de organizar el conjunto de entrada fue inspirada en la manera en la que se
realiza en Weka. En la Tabla 4 se muestra un ejemplo del conjunto de entrada.
Ejemplo Conjunto de datos Convenciones

32
______________________________________________________________________________
sunny,hot,high,FALSE,no
sunny,hot,high,TRUE,no
overcast,hot,high,FALSE,yes
rainy,mild,high,FALSE,yes
rainy,cool,normal,FALSE,yes
Atributo 1: outlook, posibles valores (sunny, overcast,
rainy).
Atributo 2: temperature, posibles valores (hot, mild,
cool).
Atributo 3: humidity, posibles valores (high, normal).
Atributo 4: windy posibles valores (TRUE, FALSE).
Valor de clase: posibles valores (yes, no)
Tabla 4 Ejemplo archivo de entrada. Fuente: elaboración propia
La salida del algoritmo, en ambos casos, es un árbol de decisión creado con base en los
datos del conjunto de entrada. Este árbol se presenta de manera plana como una estructura de datos,
sin representación visual.
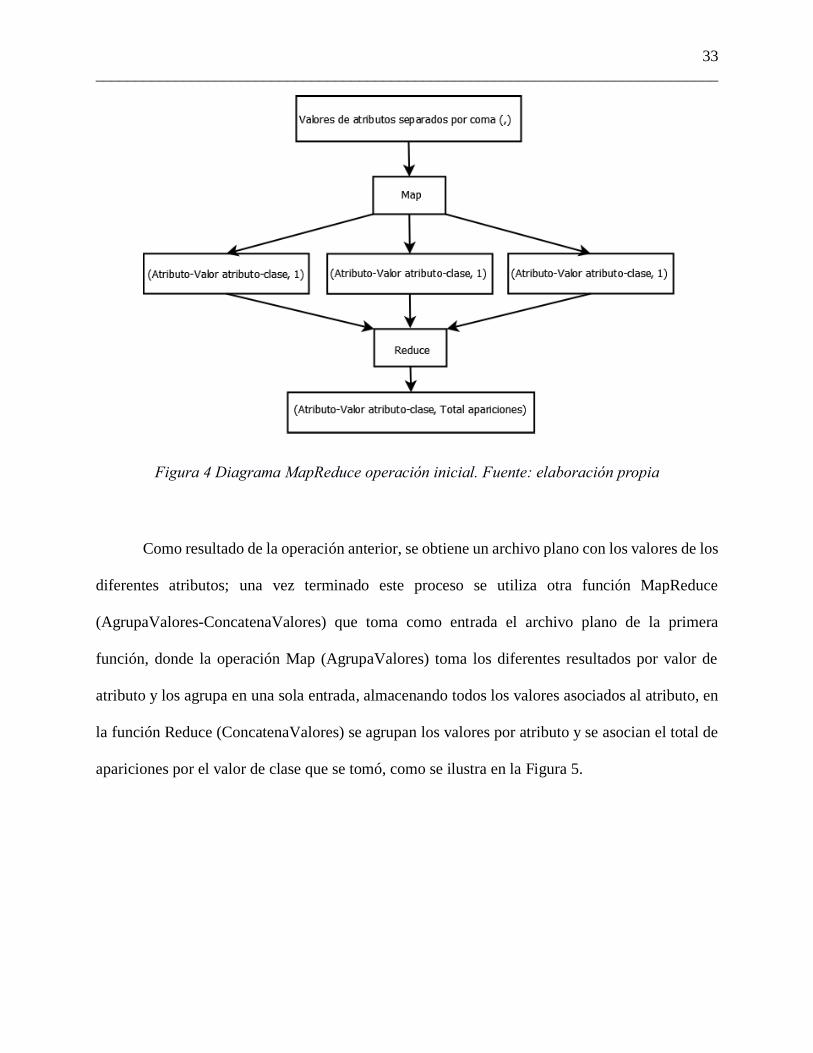
Procesamiento Hadoop Adicionalmente a la ejecución de los pasos del algoritmo C4.5, la implementación en
Hadoop debe tener en cuenta otras condiciones que buscan sacar provecho de las funciones Map
y Reduce de Hadoop. Para lograr esto, se transforma el conjunto de datos inicial aplicando una
función MapReduce (MapearAtributos-SumarAtributos) que toma los datos de entrada, agrupando
los valores de los atributos con la función Map (MapearAtributos), creando una entrada llave-
valor, donde la llave es el nombre del atributo junto con el valor que tomó y su respectivo valor de
clase; y el valor es un contador estático que adiciona uno (1) por cada repetición del valor. En el
proceso de Reduce (SumarAtributos) se asocian las entradas con el mismo valor de llave y se
suman los valores para generar de salida un mapa con los valores anteriormente mencionados
como se ilustra en la Figura 4.
33
______________________________________________________________________________
Figura 4 Diagrama MapReduce operación inicial. Fuente: elaboración propia
Como resultado de la operación anterior, se obtiene un archivo plano con los valores de los
diferentes atributos; una vez terminado este proceso se utiliza otra función MapReduce
(AgrupaValores-ConcatenaValores) que toma como entrada el archivo plano de la primera
función, donde la operación Map (AgrupaValores) toma los diferentes resultados por valor de
atributo y los agrupa en una sola entrada, almacenando todos los valores asociados al atributo, en
la función Reduce (ConcatenaValores) se agrupan los valores por atributo y se asocian el total de
apariciones por el valor de clase que se tomó, como se ilustra en la Figura 5.

34
______________________________________________________________________________
Figura 5 Diagrama MapReduce operación final. Fuente: elaboración propia
El archivo plano generado después de aplicar las funciones de Hadoop será el utilizado
para realizar el cálculo de la entropía.
Procesamiento PostgreSQL De manera similar al procesamiento en Hadoop, PostgreSQL toma el conjunto de datos
inicial y los transforma para realizar las operaciones del algoritmo, tomando los datos del archivo
plano y pasándolos a la base de datos.
Para el procesamiento de los valores de los diferentes atributos y sus clases asociadas, (ver
sección Precondiciones y Postcondiciones), se crea una tabla que contiene en cada tupla la
información asociada a cada valor que el atributo puede tomar. Su identificador, el valor que tomó
ese atributo, la fila asociada al valor (haciendo referencia al archivo plano) y el valor de clase
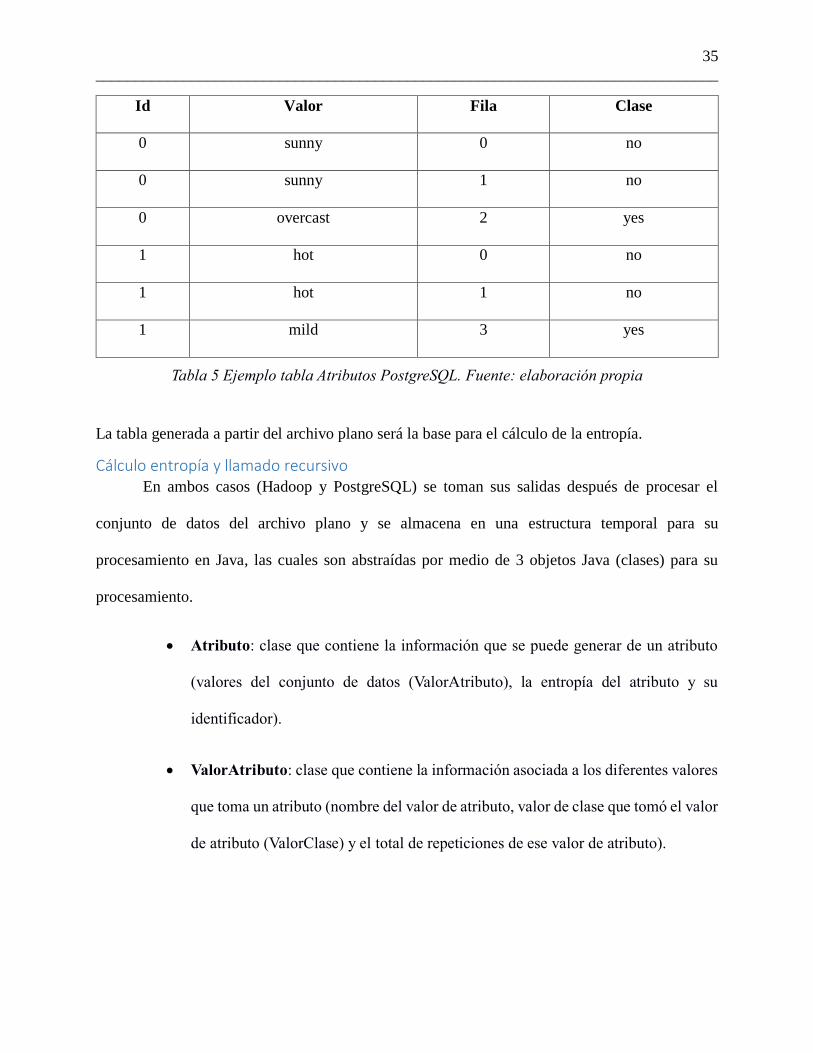
asociado a la misma, como se ilustra en la Tabla 5.
35
______________________________________________________________________________
Id Valor Fila Clase
0 sunny 0 no
0 sunny 1 no
0 overcast 2 yes
1 hot 0 no
1 hot 1 no
1 mild 3 yes
Tabla 5 Ejemplo tabla Atributos PostgreSQL. Fuente: elaboración propia
La tabla generada a partir del archivo plano será la base para el cálculo de la entropía.
Cálculo entropía y llamado recursivo En ambos casos (Hadoop y PostgreSQL) se toman sus salidas después de procesar el
conjunto de datos del archivo plano y se almacena en una estructura temporal para su
procesamiento en Java, las cuales son abstraídas por medio de 3 objetos Java (clases) para su
procesamiento.
Atributo: clase que contiene la información que se puede generar de un atributo
(valores del conjunto de datos (ValorAtributo), la entropía del atributo y su
identificador).
ValorAtributo: clase que contiene la información asociada a los diferentes valores
que toma un atributo (nombre del valor de atributo, valor de clase que tomó el valor
de atributo (ValorClase) y el total de repeticiones de ese valor de atributo).

36
______________________________________________________________________________
ValorClase: clase que contiene la información asociada al valor de clase que
pueden tomar los valores de atributo (nombre clase, cantidad de ocurrencias de ese
valor de clase).
Toda la abstracción necesaria para ejecutar el algoritmo C4.5 de manera correcta se logra
utilizando listas de los 3 tipos de clases mencionados anteriormente, donde la clase Atributo
contiene listas de la clase ValorAtributo y esta a su vez contiene listas de la clase ValorClase como
se ilustra en la Figura 6.
Una vez generada la estructura de datos con base en la salida, se procede a iterar cada uno
de los valores para calcular su entropía como se describe en la sección cálculo de la entropía, lo
cual genera un valor de ganancia por atributo y una entropía general del conjunto de atributos,
donde se procederá a hacer una comparación de las diferentes ganancias para elegir el atributo que
Atributo
•<Lista> ValorAtributo
• Identificador
•Nombre
ValorAtributo
•<Lista> ValorClase
•Nombre
• Total Apariciones
ValorClase
•Nombre Clase
•Apariciones
Figura 6 Estructura datos C4.5 Fuente: elaboración propia

37
______________________________________________________________________________
aporte más información. Una vez elegido el atributo de mayor ganancia se procede a comparar con
un límite de ganancia aceptable, el cual es parametrizable. De ser mayor al límite aceptable, el
Atributo elegido se toma para realizar la siguiente partición.
El proceso anterior se repite de manera recursiva a medida que se eligen los atributos
ganadores, creando un subconjunto del conjunto de entrada original, tomando como divisor los
valores que puede tomar el atributo ganador en cada división y repitiendo los pasos con este
subconjunto; en caso de que la ganancia aceptable sea mayor que la ganancia de todos los atributos
del conjunto o no sea posible seguir haciendo subconjuntos, se detiene el proceso recursivo y se
da por terminado el algoritmo.
Diagrama de clases algoritmo C4.5 El preprocesamiento y el posterior cálculo de la entropía, y el llamado recursivo se
representan en los diagramas de clases expuestos en las Figuras 7 y 8.

38
______________________________________________________________________________
Figura 7 Diagrama de clases implementación Hadoop. Fuente: elaboración propia
Figura 8 Diagrama de clases implementación PostgreSQL. Fuente: elaboración propia
Universidad.distrital.c45
Paquetería general y contenedora de las clases C4.5 y Entropía encargadas de realizar las
tareas del algoritmo como se explicó en la sección cálculo de la entropía y llamado recursivo.
Universidad.distrital.c45.estructura
Incluye las clases que representan la estructura de datos que contiene la información
obtenida después del preprocesamiento. Adicionalmente contiene la clase Nodo con la cual se crea
un árbol que almacena el resultado de cada iteración para su posterior utilización.

39
______________________________________________________________________________
Universidad.distrital.c45.mapper
Contiene las clases que realizan las actividades de map en la implementación de Hadoop
explicadas en la sección prepocesamiento Hadoop.
Universidad.distrital.c45.reducer
Contiene las clases que realizan las actividades de reduce en la implementación de Hadoop
explicadas en la sección prepocesamiento Hadoop.
Universidad.distrital.c45.sql
Contiene las clases que realizan las actividades de mapeo en la implementación de Hadoop
explicadas en la sección prepocesamiento PostgreSQL y una clase conexión encargada de manejar
la conexión del algoritmo a la base de datos.
Elaboración Clúster
Adicionalmente a la implementación del algoritmo C4.5, el objetivo general de este trabajo
involucra la ejecución del mismo en un clúster, en este caso, compuesto por tres nodos conectados
en una red LAN. Realizar la ejecución en un ambiente clusterizado proporciona mayor fiabilidad
y velocidad de procesamiento al momento de ejecución, ventaja que se hace más evidente a medida
que aumenta el conjunto de datos a procesar.
Una de las ventajas que ofrecen las soluciones en clúster es tener mayor capacidad de
procesamiento con diferentes tipos de hardware, facilitando de esta manera el escalamiento de
soluciones sin necesidad de un presupuesto amplio. Para la ejecución del algoritmo C4.5 se usó un
clúster con las siguientes características, mostradas en la Tabla 6:
Nombre Equipo Procesador RAM Almacenamiento

40
______________________________________________________________________________
Maestro Intel Core i7-
2670QM @2.20GHz
6 GB 500 GB
Esclavo1 Intel Core i7 i7-
2670QM @2.00GHz
8 GB 500 GB
Esclavo2 Intel Core 2 Duo
E7400 @2.80GHz
4 GB 500 GB
Tabla 6 Características clúster. Fuente: elaboración propia
Aunque ambas soluciones (Hadoop, PostgreSQL) usan el mismo hardware, la
configuración del clúster no es la misma para ambos casos, en el caso de Hadoop se debe
configurar un ambiente distribuido y en el de PostgreSQL se utilizará PgPool II, como se explica
en las siguientes secciones. Sin embargo, ciertas configuraciones son comunes, es necesario contar
con Java 7 o superior, (ya que la implementación está construida en esta versión del lenguaje), y
como medio de comunicación en ambas soluciones se usa el protocolo SSH, siendo este un medio
seguro y confiable de comunicación entre los diferentes nodos del clúster.
Clúster Hadoop Adicionalmente a la instalación de Hadoop es necesaria la configuración de sus diferentes
nodos donde varía la configuración dependiendo si el nodo es esclavo o maestro, donde el nodo
maestro tendrá la responsabilidad de gestionar los recursos del clúster y si se desea también, el
procesamiento de datos, de lo contrario, se delega el procesamiento de datos a los nodos esclavos
del clúster. Esta decisión se toma dependiendo de los recursos con los que se cuente. En el caso de
esta implementación el nodo maestro también procesará datos.
Hadoop cuenta con diferentes archivos .xml de configuración, cada uno asociado a
diferentes tareas que ejecuta el framework. En caso de que no se encuentren especificadas las

41
______________________________________________________________________________
configuraciones en estos archivos, Hadoop tomará las configuraciones por defecto, su
configuración se muestra a continuación.
Core-site
Contiene la configuración asociada al core de Hadoop como la configuración de entrada y
salida, entre otras configuraciones comunes a HDFS y a MapReduce, en este caso se especifica
que el core se encuentra en el nodo maestro como se ve en la Figura 9.
Hdfs-site
Contiene la configuración de los demonios del HDFS, el NameNode, el Seconday
NameNode y los DataNodes. En este archivo de configuración se puede especificar el número de
bloques de replicado, los permisos sobres HDFS, el número de replicaciones entre otros. Para el
clúster se especificó el factor de replicación (3), la ruta donde se encuentra el DataNode y la ruta
donde se encuentra el NameNode como se ve en la figura 10.
Figura 9 Configuración core-site.xml. Fuente: elaboración propia

42
______________________________________________________________________________
Figura 10 Configuración hdfs-site.xml Fuente: elaboración propia
Mapred-site
Contiene la configuración de los demonios del MapReduce, el JobTracker y los
TaskTrackers. Para el clúster se indica que el JobTracker será el del nodo maestro y que el
framework del MapReduce será Yarn como se ve en la figura 11.
Figura 11 Configuración mapred-site.xml Fuente: elaboración propia

43
______________________________________________________________________________
Yarn-site
Contiene toda la configuración asociada al manejo del yarn. En el caso del clúster se
establecen los servicios auxiliares, la ruta del JobTracker, la ruta del scheduler y la ruta del
ResourceManager, en ese caso todas apuntan al nodo maestro como se muestra en la figura 12.
Figura 12 Configuración yarn-site.xml Fuente: elaboración propia
Finalmente es necesario configurar el archivo hosts para que la comunicación de los nodos
sea posible, ya que Hadoop busca los diferentes nodos por su nombre. Adicionalmente, es
necesario agregar el nombre que le asigne HDFS a los diferentes DataNodes como se muestra en
la Figura 13.

44
______________________________________________________________________________
Figura 13 Archivo de configuración Hosts. Fuente: Elaboración propia
Si se realizó de manera correcta la configuración Hadoop, se debe ver todos los nodos del
clúster cuando se acceda al administrador del sitio como se muestra en la Figura 14.
Figura 14 Información Nodos. Fuente: Elaboración propia
Del mismo modo, los DataNodes deben salir en el administrador del HDFS como se
muestra en la Figura 15.

45
______________________________________________________________________________
Figura 15 Información Datanode. Fuente: Elaboración propia
Clúster PostgreSQL La configuración para el clúster se realiza por medio de PgPool, configurando el archivo
pgpool.conf, indicando el tipo de alguno de los modos de funcionamiento de PgPool. En tal caso,
se utiliza el modo de replicación, el cual mantiene el esquema de datos igual y síncrono en todos
los nodos del clúster. Adicional a lo mencionado, se debe desactivar la conexión SSL de todos los
nodos del clúster y se debe habilitar la conexión por medio de SSH. La configuración se muestra
en la Figura 16.

46
______________________________________________________________________________
Elaboración Conjunto de Datos
El conjunto de datos se creó buscando que fuera homogéneo para las dos implementaciones
del algoritmo C4.5. También se buscó que fueran tan solo datos nominales (pues la
implementación no soporta entradas del tipo numérico aunque el algoritmo original sí) y
adicionalmente, que un valor del conjunto de datos fuera destacado, de tal manera que se pudiera
elegir como valor de clase al cual estarán referenciados los demás valores.
Se decidió utilizar un conjunto de datos del servicio general de administración de los
Estados Unidos (Data.gov) [17] debido a la gran variedad de datos con los que cuenta y
adicionalmente la cantidad de los mismos. El conjunto de datos usado lleva por nombre Consumer
Complaint Database (base de datos de quejas de consumidores), el cual contiene datos de las quejas
de los usuarios del servicio bancario en Estados como se muestra en la Tabla 7.
Figura 16 Configuración PgPool. Fuente: Elaboración propia

47
______________________________________________________________________________
Dato Tipo
Fecha recibido Fecha
Producto Texto
Subproducto Texto
Problema Texto
Subproblema Texto
Información del cliente Texto
Respuesta publica de la entidad Texto
Entidad Texto
Estado (USA) Texto
Código Zip Texto
Tags Texto
Consentimiento del cliente Texto
Medio por el cual se realizó la queja Texto
Día envió queja Fecha
Respuesta de la entidad Texto
Respuesta efectuada a tiempo Booleano
Replicación del cliente Booleano
Id Numérico
Tabla 7 Atributos conjunto de datos. Fuente: Elaboración propia
El conjunto de datos crudo no es de utilidad, ya que tiene algunos datos no aptos para
clasificar como atributos (como la fecha o el id). Además, algunos campos están vacíos, por lo que
es necesario realizar una depuración de los mismos. Finalmente, es necesario elegir un atributo
que actúe como valor de clase con el cual se hagan asociaciones a los demás atributos.

48
______________________________________________________________________________
Se eligió como valor de clase el campo Entidad porque los valores que puede tomar se
repiten con regularidad sin perder la variedad de valores posibles, y adicionalmente, se ve como
una asociación natural de los demás campos, debido a que los demás atributos se pueden
representar como características asociadas al servicio que prestan las diferentes entidades
bancarias. En adición, los campos Fecha Recibido, Subproducto, Subproblema, Información
Cliente, Tags, Consentimiento del Cliente, Día envío de la Queja, e Id, fueron removidos ya que
no cumplían con las condiciones necesarias para ser procesados por el algoritmo, o estaban
incompletos, o no aportaban ganancia de información. El conjunto de datos depurado es como se
indica en la Tabla 8.
Dato Tipo
Producto Texto
Problema Texto
Estado (USA) Texto
Código Zip Texto
Medio por el cual se realizó la queja Texto
Respuesta de la entidad Texto
Respuesta efectuada a tiempo Booleano
Replicación del cliente Booleano
Entidad Texto
Tabla 8 Conjunto de datos depurado. Fuente: Elaboración propia
En complemento a la remoción de atributos, algunos valores de atributo que se encontraban
vacíos se reemplazaron por “NA”, ya que la utilización del espacio vacío no está permitida como

49
______________________________________________________________________________
entrada valida en la implementación. El conjunto de datos cuenta con 569.495 tuplas de los valores
mencionados en la Tabla 8 y asociaos a Entidad como valor de clase.
Por otra parte, se utiliza el conjunto de datos Weater, disponible en los conjuntos de muestra
de Weka, el cual tiene una serie de factores climáticos que determinan si es posible o no salir a
jugar. El conjunto se muestra en la Tabla 9. El conjunto cuenta con 14 tuplas.
Dato Tipo
Outlook Texto
Temperature Texto
Humidity Texto
Windy Texto
Play Texto
Tabla 9 Conjunto de datos Weather. Fuente: http://storm.cis.fordham.edu/~gweiss/data-
mining/weka-data/weather.nominal.arff
Elaboración Métrica
Una vez creadas las implementaciones y verificado su correcto funcionamiento, es
necesario definir un mecanismo por el cual se pueda comparar el rendimiento de ambos algoritmos
con base en los elementos comunes, con la finalidad de identificar las ventajas y desventajas entre
las implementaciones. Para efectuar la comparación, se plantea la métrica expuesta a continuación.
Dentro de la métrica no se considera verificar la eficacia del algoritmo de manera empírica
o teórica, ya que ha sido demostrada en otros trabajos con ese fin, tan solo se evalúa el performance
de las implementaciones realizadas. Para tal fin, se verificará el tiempo de ejecución del algoritmo
50
______________________________________________________________________________
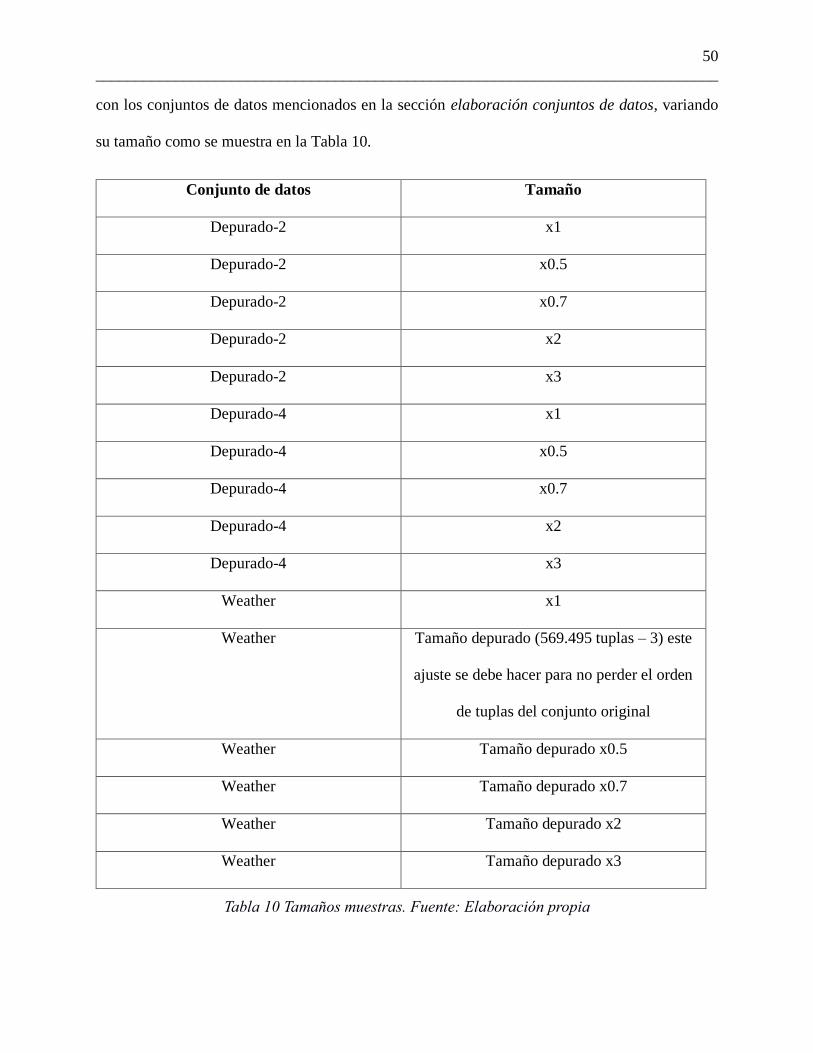
con los conjuntos de datos mencionados en la sección elaboración conjuntos de datos, variando
su tamaño como se muestra en la Tabla 10.
Conjunto de datos Tamaño
Depurado-2 x1
Depurado-2 x0.5
Depurado-2 x0.7
Depurado-2 x2
Depurado-2 x3
Depurado-4 x1
Depurado-4 x0.5
Depurado-4 x0.7
Depurado-4 x2
Depurado-4 x3
Weather x1
Weather Tamaño depurado (569.495 tuplas – 3) este
ajuste se debe hacer para no perder el orden
de tuplas del conjunto original
Weather Tamaño depurado x0.5
Weather Tamaño depurado x0.7
Weather Tamaño depurado x2
Weather Tamaño depurado x3
Tabla 10 Tamaños muestras. Fuente: Elaboración propia

51
______________________________________________________________________________
El nombre Depurado-4 y Depurado-2 hace referencia al conjunto Depurado original
restando ciertas filas, en el caso de - 2 se removió Estado (USA), Código Zip, y en el caso de - 4
se removió Estado (USA), Código ZIP, Respuesta de la Entidad, Respuesta efectuada a tiempo y
Replicación del Cliente; debido a que la ejecución del conjunto total tomaba más de 72 horas y no
era viable la realización de prueba con ese tiempo de ejecución, pues no se podía garantizar la
estabilidad de la red y el suministro eléctrico del clúster por tanto tiempo.
En adición a estos valores, se varía el número de nodos del clúster (1, 2, 3), con el fin de
medir la diferencia de rendimiento entre las implementaciones a medida que aumenta el tamaño
del conjunto de datos y varían los nodos del clúster. La variación de los nodos se hace quitando
primero el Esclavo2 (máquina con menos potencia), luego el Esclavo1 y por ultimo con solo el
nodo maestro. Finalmente, la variación del conjunto depurado de datos se hará tomando alguna
porción al azar del conjunto y dividiéndola según se crea conveniente, las siguientes subdivisiones
se tomarán del mismo conjunto de datos para conservar uniformidad en el proceso, mientras que
con el conjunto Weather se amplió al tamaño del conjunto depurado y se modificó acorde al
mismo.
En el caso de usarse una muestra más grande que el conjunto de datos, se multiplicara el
mismo obteniendo n veces el conjunto de datos. Es importante resaltar que al ampliar el conjunto
de datos no se afecta el resultado del algoritmo, ya que al estar repetidas las tuplas se llega a un
sesgo donde no se aporta más información que en el caso del conjunto original.
Se harán pruebas con base en lo anteriormente mencionado, como se muestra en la Tabla
11.
Cantidad de Nodos Cantidad de datos (en base al tamaño original)

52
______________________________________________________________________________
3
Tamaños conjunto depurado
Tamaños conjunto Weather
2
Tamaños conjunto depurado
Tamaños conjunto Weather
1
Tamaños conjunto depurado
Tamaños conjunto Weather
Tabla 11 Esquema de pruebas a realizar métrica. Fuente: Elaboración propia
Pruebas y Resultados
Una vez realizadas las pruebas, se obtuvieron los siguientes resultados separados por
número de nodos del clúster y por la cantidad del conjunto de datos, el elemento de comparación
es el tiempo de ejecución en segundos.
53
______________________________________________________________________________
Conjunto Depurado
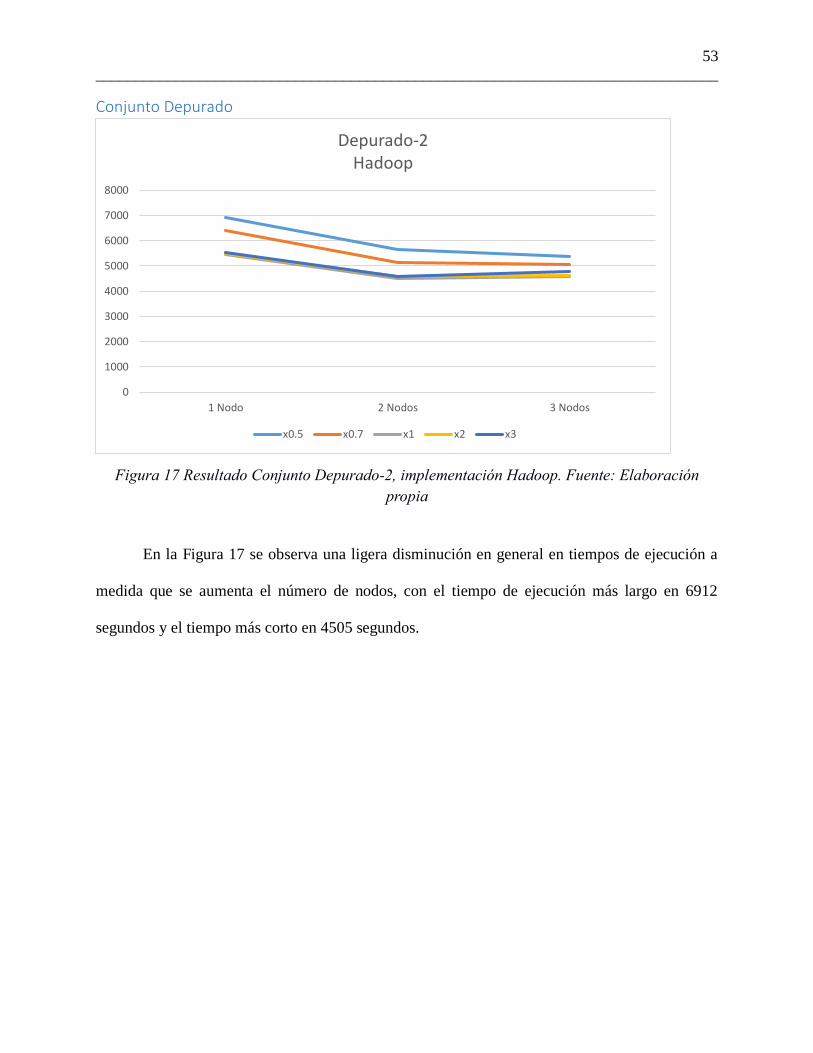
Figura 17 Resultado Conjunto Depurado-2, implementación Hadoop. Fuente: Elaboración
propia
En la Figura 17 se observa una ligera disminución en general en tiempos de ejecución a
medida que se aumenta el número de nodos, con el tiempo de ejecución más largo en 6912
segundos y el tiempo más corto en 4505 segundos.
0
1000
2000
3000
4000
5000
6000
7000
8000
1 Nodo 2 Nodos 3 Nodos
Depurado-2 Hadoop
x0.5 x0.7 x1 x2 x3
54
______________________________________________________________________________
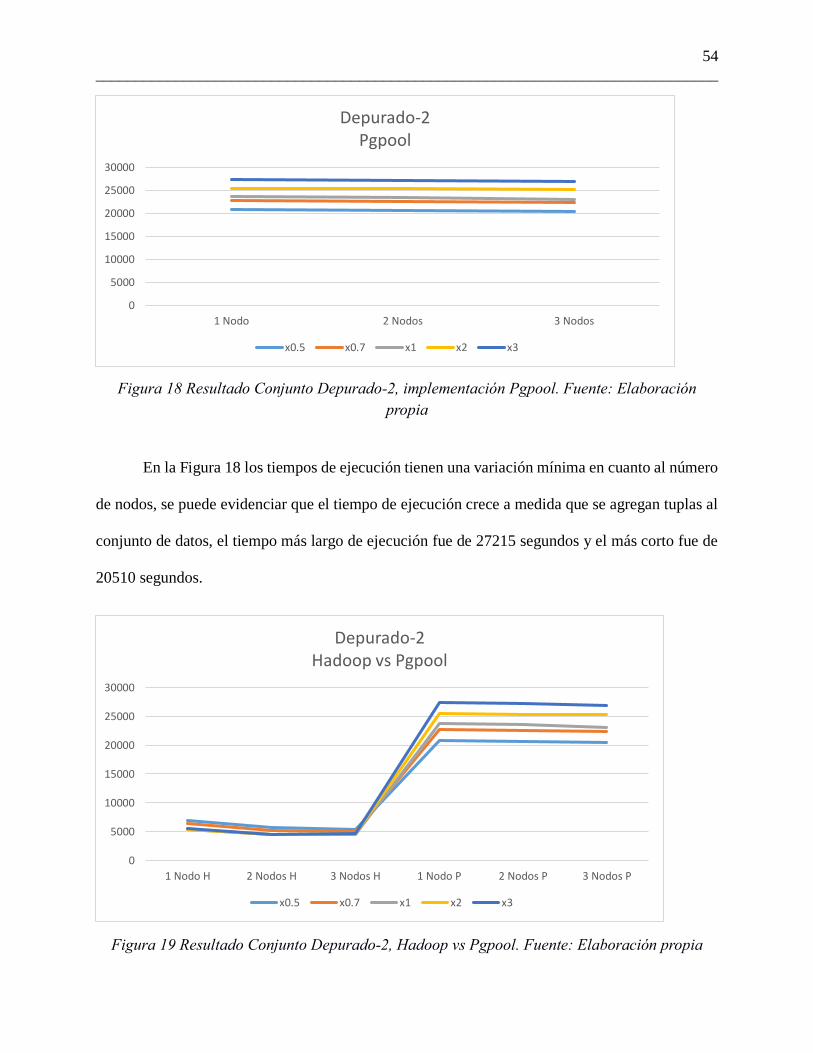
Figura 18 Resultado Conjunto Depurado-2, implementación Pgpool. Fuente: Elaboración
propia
En la Figura 18 los tiempos de ejecución tienen una variación mínima en cuanto al número
de nodos, se puede evidenciar que el tiempo de ejecución crece a medida que se agregan tuplas al
conjunto de datos, el tiempo más largo de ejecución fue de 27215 segundos y el más corto fue de
20510 segundos.
Figura 19 Resultado Conjunto Depurado-2, Hadoop vs Pgpool. Fuente: Elaboración propia
0
5000
10000
15000
20000
25000
30000
1 Nodo 2 Nodos 3 Nodos
Depurado-2 Pgpool
x0.5 x0.7 x1 x2 x3
0
5000
10000
15000
20000
25000
30000
1 Nodo H 2 Nodos H 3 Nodos H 1 Nodo P 2 Nodos P 3 Nodos P
Depurado-2 Hadoop vs Pgpool
x0.5 x0.7 x1 x2 x3

55
______________________________________________________________________________
En la Figura 19, la comparación entre ambas implementaciones se puede observar una
diferencia considerable entre los tiempos de ejecución en general, tomando más tiempo para
realizar la ejecución la solución en Pgpool.
Figura 20 Resultado Conjunto Depurado-4, implementación Hadoop. Fuente: Elaboración
propia
En la Figura 20 nuevamente se evidencia un cambio en tiempos de ejecución donde la
tendencia a disminuir es notable en a medida que aumentan los nodos, el tiempo más largo fue de
5119 segundos y el tiempo más corto fue de 3495 segundos.
0
1000
2000
3000
4000
5000
6000
1 Nodo 2 Nodos 3 Nodos
Depurado-4Hadoop
x0.5 x0.7 x1 x2 x3

56
______________________________________________________________________________
Figura 21 Resultado Conjunto Depurado-4, implementación Pgpool. Fuente: Elaboración
propia
En la Figura 21 se hacen más marcadas las diferencias en tiempos de ejecución con respecto
al conjunto anterior sin embargo no es un diferencia considerable a medida que varían los nodos
del clúster, siendo el tiempo de ejecución más corto de 19745 segundos y el más largo de 23201
segundos.
18000
19000
20000
21000
22000
23000
24000
1 Nodo 2 Nodos 3 Nodos
Depurado-4Pgpool
x0.5 x0.7 x1 x2 x3
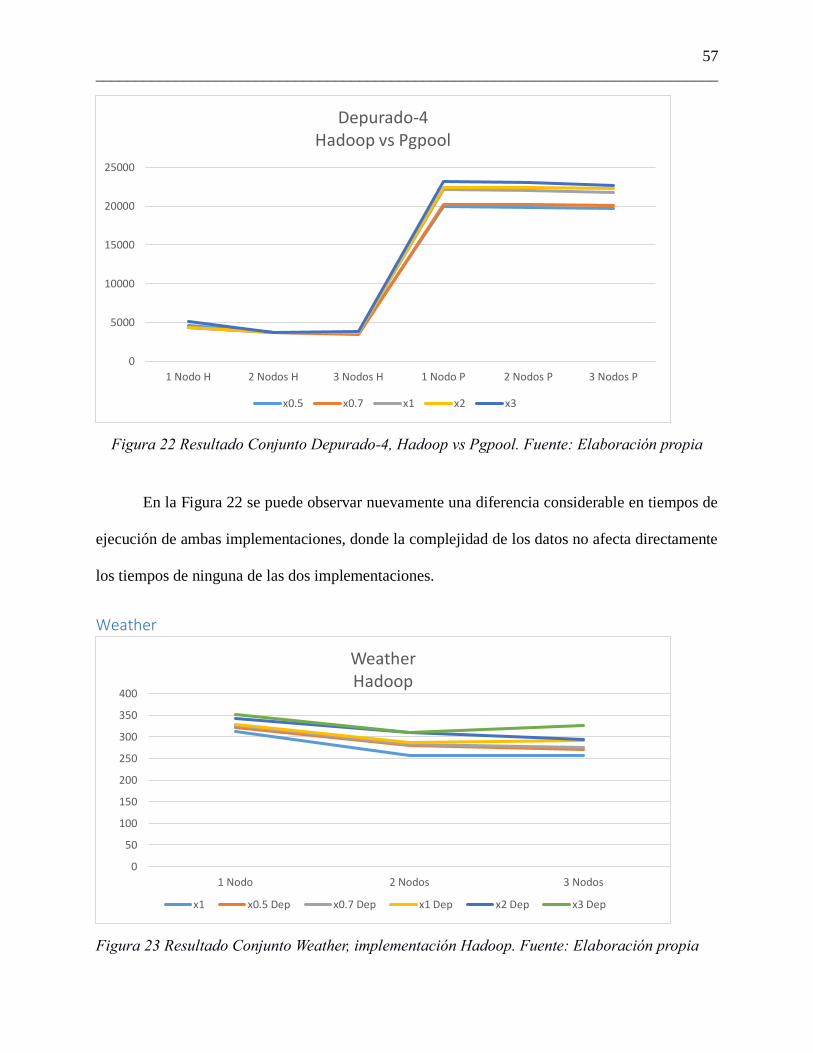
57
______________________________________________________________________________
Figura 22 Resultado Conjunto Depurado-4, Hadoop vs Pgpool. Fuente: Elaboración propia
En la Figura 22 se puede observar nuevamente una diferencia considerable en tiempos de
ejecución de ambas implementaciones, donde la complejidad de los datos no afecta directamente
los tiempos de ninguna de las dos implementaciones.
Weather
Figura 23 Resultado Conjunto Weather, implementación Hadoop. Fuente: Elaboración propia
0
5000
10000
15000
20000
25000
1 Nodo H 2 Nodos H 3 Nodos H 1 Nodo P 2 Nodos P 3 Nodos P
Depurado-4Hadoop vs Pgpool
x0.5 x0.7 x1 x2 x3
0
50
100
150
200
250
300
350
400
1 Nodo 2 Nodos 3 Nodos
Weather Hadoop
x1 x0.5 Dep x0.7 Dep x1 Dep x2 Dep x3 Dep
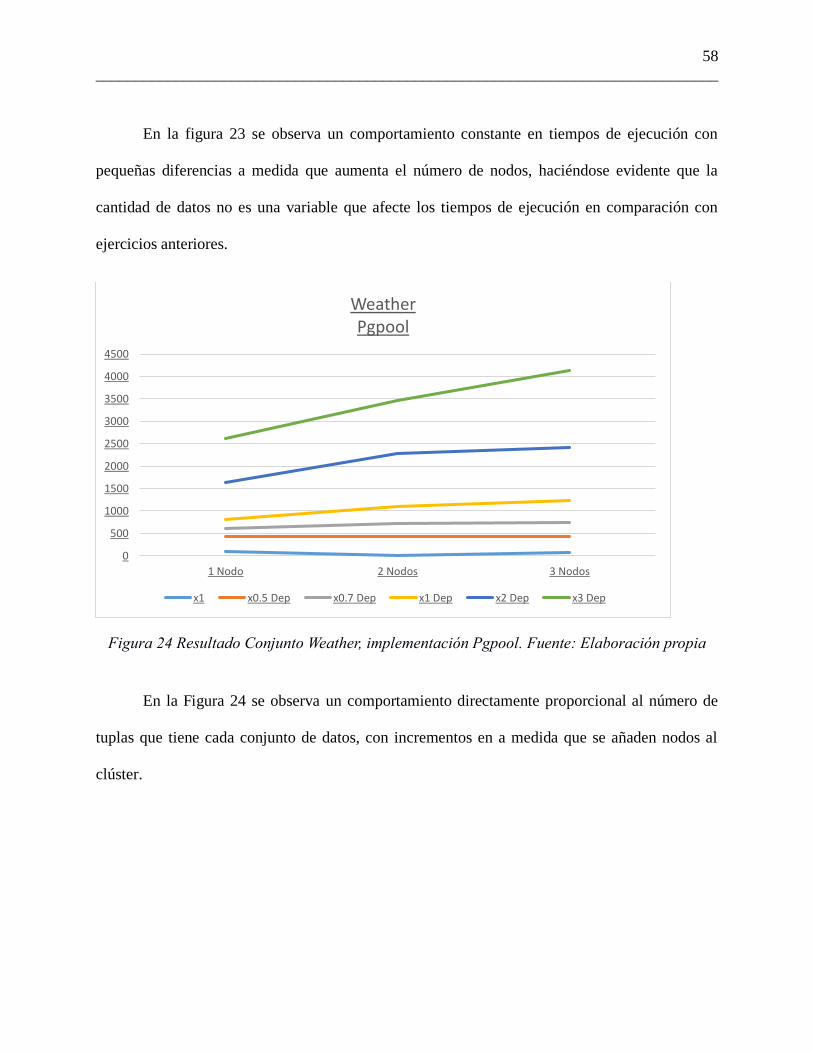
58
______________________________________________________________________________
En la figura 23 se observa un comportamiento constante en tiempos de ejecución con
pequeñas diferencias a medida que aumenta el número de nodos, haciéndose evidente que la
cantidad de datos no es una variable que afecte los tiempos de ejecución en comparación con
ejercicios anteriores.
Figura 24 Resultado Conjunto Weather, implementación Pgpool. Fuente: Elaboración propia
En la Figura 24 se observa un comportamiento directamente proporcional al número de
tuplas que tiene cada conjunto de datos, con incrementos en a medida que se añaden nodos al
clúster.
0
500
1000
1500
2000
2500
3000
3500
4000
4500
1 Nodo 2 Nodos 3 Nodos
Weather Pgpool
x1 x0.5 Dep x0.7 Dep x1 Dep x2 Dep x3 Dep

59
______________________________________________________________________________
Figura 25 Resultado Conjunto Weather, Hadoop vs Pgpool. Fuente: Elaboración propia
En la figura 25 se puede observar que la implementación en Pgpool logra ser más veloz
con el menor número de datos, sin embargo una vez sobre pasa el tiempo de Hadoop
(aproximadamente 470 segundos) se hace más lento a medida que se aumenta el conjunto de datos.
Conclusiones y Trabajo Futuro
Con base en el trabajo realizado y con los resultados obtenidos, se llegó a las siguientes
conclusiones.
La solución que usa Hadoop no experimenta cambios drásticos en tiempos de ejecución a
medida que aumenta el conjunto de datos, lo anterior por la utilización de HDFS como
sistema de almacenamiento y teniendo en cuenta que incluso el conjunto más grande
utilizado como muestra no es considerado de gran tamaño en el enfoque Big Data.
0
500
1000
1500
2000
2500
3000
3500
4000
4500
1 Nodo H 2 Nodos H 3 Nodos H 1 Nodo P 2 Nodos P 3 Nodos P
Weather Hadoop vs Pgpool
x1 x0.5 Dep x0.7 Dep x1 Dep x2 Dep x3 Dep

60
______________________________________________________________________________
El conjunto de datos no es lo suficientemente grande para ejecutar el paralelismo de manera
óptima en Hadoop, no se logró paralelismo total ni realizando las configuraciones indicadas
por el proveedor (forzando los bloques de datos de HDFS a tamaño de 16 megas y forzando
la ejecución de múltiples tareas por pequeñas que sean en todos los nodos del clúster).
Usando un conjunto de datos considerado pequeño en Big Data, no se evidencia mejora en
tiempos de ejecución a medida que aumentan los nodos del clúster.
El algoritmo C4.5 en la solución de Hadoop, ve afectados sus tiempos de ejecución
directamente por la cantidad de información que posee el conjunto de datos.
En la solución que usa Pgpool se observa un incremento en tiempos de ejecución a medida
que se incrementa el número de tuplas.
A medida que aumenta el número de nodos en Pgpool el costo de mantener los nodos
sincronizados aumenta, resultando en tiempos de ejecución más largos.
La utilización de Pgpool como software de clusterización mejora los tiempos de ejecución
de consultas. Sin embargo, mantener los diferentes nodos del clúster sincronizado es muy
costoso en tiempos de ejecución.
La utilización de Pgpool resulta útil como solución para infraestructura de persistencia. Sin
embargo, para obtener mejores resultados se requiere de un hardware más potente.
La solución que utiliza Pgpool presenta mejor rendimiento con pocas tuplas
independientemente de la información que posean los datos, pero a medida que aumenta el
número de tuplas, la solución que utiliza Hadoop presenta mejor rendimiento.

61
______________________________________________________________________________
La solución que usa Pgpool toma más tiempo pre procesando los datos que la solución que
usa Hadoop.
Ninguna de las dos soluciones presenta mejoras en tiempos de ejecución a medida que
aumenta el número de nodos del clúster, en medida por el conjunto de datos elegido
(tamaño vs complejidad).
Como trabajo futuro se podría adicionar valores continuos al algoritmo C4.5 para observar
los cambios en tiempos de ejecución que requiere este procesamiento adicional. Así mismo,
adicionar más nodos para evaluar un conjunto de datos mayor y variando los modelos de
almacenamientos; a manera de ejemplo usando Oracle en vez de Pgpool.

62
______________________________________________________________________________
Bibliografía
[1] R. Federico, «medium.com,» 2016. [En línea]. Available:
https://medium.com/@fg_rega/the-age-of-data-and-why-information-is-the-most-valuable-
asset-d5d9c57620e1#.fsrye6b0n. [Último acceso: 11 junio 2016].
[2] Q. Roos, C4.5: Programs for Machine Learning, Kluwer Academic Publishers, 1993.
[3] Oracle, «A Relational Database Overview (The Java™ Tutorials > JDBC(TM) Database
Access > JDBC Introduction),» 19 Agosto 2015. [En línea]. Available:
https://docs.oracle.com/javase/tutorial/jdbc/overview/database.html. [Último acceso: 14
Junio 2016].
[4] «tutorials point,» 19 Agosto 2015. [En línea]. Available:
http://www.tutorialspoint.com/dbms/dbms_codds_rules.htm.
[5] «Wikipedia,» 20 Agosto 2015. [En línea]. Available:
https://en.wikipedia.org/wiki/Comparison_of_relational_database_management_systems.
[6] «mongoDB,» 15 Agosto 2015. [En línea]. Available: https://www.mongodb.com/nosql-
explained.
[7] K. Kovacs, «kkovacs,» 26 Agosto 2015. [En línea]. Available: http://kkovacs.eu/cassandra-
vs-mongodb-vs-couchdb-vs-redis.
[8] S. h. R. Shankar Ganes h Manikandan, «Big Data Analysis using Apache Hadoop».
[9] S. G. Jeffrey Dean, «Google Research Publications,» Diciembre 2004. [En línea].
Available: http://research.google.com/archive/mapreduce.html. [Último acceso: 14 junio
2016].
[10] «Pgpool Wiki,» 2016 Junio 17. [En línea]. Available:
http://www.pgpool.net/mediawiki/index.php/Main_Page. [Último acceso: 1 Julio 2016].
[11] «octavian's blog,» 25 03 2011. [En línea]. Available:
https://octaviansima.wordpress.com/2011/03/25/decision-trees-c4-5/. [Último acceso: 2016
junio 16].
[12] K. Yamada, A. Ohuchi y M. Oda, «Face image retrieval method using extended C4.5,» de
Systems, Man, and Cybernetics, 1997. Computational Cybernetics and Simulation., 1997
IEEE International Conference, Orlando, FL, 1997.
[13] G. Juan, L. Sen-Lin, J. Hong-bo, Z. Tie-mei y H. Yi-wen, «Type 2 diabetes data processing
with EM and C4.5 algorithm,» de Complex Medical Engineering, 2007. CME 2007.
IEEE/ICME International Conference, Beijing, 2007.
[14] X. Ming-Jun, K. Han y H. Liu-Sheng, «Privacy Preserving C4.5 Algorithm Over
Horizontally Partitioned Data,» de Grid and Cooperative Computing, 2006. GCC 2006.

63
______________________________________________________________________________
Fifth International Conference, Hunan, 2006.
[15] G. Andrienko y N. Andrienko, «Data mining with C4.5 and interactive cartographic
visualization,» de User Interfaces to Data Intensive Systems, 1999. Proceedings, Los
Alamitos, CA, 1999.
[16] B. Li, B. Shen, J. Wang, Y. Chen, T. Zhang y J. Wang, «A Scenario-Based Approach to
Predicting Software Defects Using Compressed C4.5 Model,» de Computer Software and
Applications Conference (COMPSAC), 2014 IEEE 38th Annual, Vasteras, 2014.
[17] «Data.gov,» 2015 Septiembre 26. [En línea]. Available:
https://catalog.data.gov/dataset/consumer-complaint-database. [Último acceso: 4 Julio
2016].


















