
MEDIDAS ESTADÍSTICAS- CURSO BÁSICO UNIVERSITARIO
15
NOTA: Esta guía sólo presenta lo esencial del contenido sobre medidas estadísticas y no sustituye la amplia ayuda que puedes encontrar en la bibliografía suministrada al inicio del curso. UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANA Ciudad Guayana - Venezuela Prof. Zoraida Pérez Sánchez [email protected] ESTADÍSTICA Y PROBABILIDAD GUÍA 2 Medidas Estadísticas Zoraida Pérez Sánchez
-
Upload
zoraida-perez-s -
Category
Education
-
view
384 -
download
2
Transcript of MEDIDAS ESTADÍSTICAS- CURSO BÁSICO UNIVERSITARIO

NOTA: Esta guía sólo presenta lo esencial del contenido sobre medidas estadísticas y no sustituye la amplia ayuda que puedes encontrar en la bibliografía suministrada al inicio del curso.
UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANA
Ciudad Guayana - Venezuela
Prof. Zoraida Pérez Sánchez
ESTADÍSTICA
Y
PROBABILIDAD
GUÍA 2
Medidas Estadísticas
Zoraida Pérez Sánchez

UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANA ESTADÍSTICA Y PROBABILIDAD
PROFESORA ZORAIDA PÉREZ SÁ�CHEZ
DESCRIPCIO�ES ESTADÍSTICAS
2
DESCRIPCIONES ESTADÍSTICAS
Hasta ahora hemos visto que, según la pertinencia y la necesidad del caso, podemos agregar valor al análisis de datos (en una variable) cuando realizamos algunas de las siguientes acciones:
• Ordenando los datos de forma ascendente o descendente.
• Presentando los datos sin agrupar en una Tabla de Distribución de Frecuencias.
• Cuando la variable toma muchos valores diferentes es necesario agrupar los datos en clases y construir una Tabla de Distribución de Frecuencias.
• Graficando los resultados de las Tablas de Distribución de Frecuencias. Sin embargo, podemos resumir aún más la información utilizando las Descripciones Estadísticas, las cuales, son medidas que resumen, en un valor, características del conjunto de datos. De estas características, hay dos que son muy importantes:

UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANA ESTADÍSTICA Y PROBABILIDAD
PROFESORA ZORAIDA PÉREZ SÁ�CHEZ
DESCRIPCIO�ES ESTADÍSTICAS
3
Cuáles son las medidas estadísticas?

UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANA ESTADÍSTICA Y PROBABILIDAD
PROFESORA ZORAIDA PÉREZ SÁ�CHEZ
DESCRIPCIO�ES ESTADÍSTICAS
4
Además de comprender el significado de cada una de estas medidas, vamos a aprender a calcularlas: manualmente, con la calculadora y con la computadora, utilizando Excel y/o los programas estadísticos (por ejemplo: SPSS, MINITAB, otros)
1. MEDIDAS DE TENDENCIA CENTRAL: Coloquialmente, la información que dan es hacia qué valor se amontona la mayoría de los datos, cuál es el valor que puede ser el representante del colectivo. El objetivo de estas medidas es describir de alguna manera el centro o mitad de un conjunto de datos, buscar un valor que sea representativo de todos los valores incluidos en el conjunto de datos.
1.1. MEDIA ARITMÉTICA: Es la más conocida y la más usada de las medidas de tendencia central. También se le llama
promedio, pero en Estadística existen otros tipos de promedio, por lo cual se considera conveniente denominarla “media aritmética” Se define como la suma de los valores dividida entre el número de valores.
Media Aritmética de una MUESTRA )(x
La media aritmética de un conjunto de datos que corresponden a una muestra se calcula por la siguiente ecuación:
n
xx i∑
= Donde: muestra la de tamañon
observados valoreslos todosde
=
=∑ sumaxi
Media Aritmética de una POBLACIÓN: La media aritmética se calcula de igual forma, solo que N= número de elementos de la población, y se designa de la siguiente forma:
�
x∑=µ Donde:
población la de tamañoN
población la de valoreslos todosde
=
=∑ sumaxi
Propiedades de la media aritmética:
• Es un concepto muy conocido y muy aplicado.
• Siempre existe y es única: A cualquier conjunto de datos numéricos se le puede calcular la media aritmética y este valor resultante será único.
• Es útil para comparar medias de varios conjuntos de datos.
• Es relativamente confiable: Si tomamos varias muestras de una misma población y a cada una le calculamos su media aritmética, por lo general, éstas no varían significativamente.
• Toma en cuenta todos y cada uno de los elementos de los datos. Desventajas de la media aritmética:
• A veces las muestras pueden contener valores aberrantes (que se apartan de los demás datos por ser muy grandes o muy pequeños). Al promediar estos valores con los demás, se afecta el valor de la media hasta tal punto que no se pueda tomar como una medida que represente el centro de los datos.
• Cuando se trata de muchas observaciones o datos, el cálculo de la Media es tedioso, a menos que busquemos una aproximación de la misma, agrupando los datos en clases.
• Cuando los datos están agrupados en clases, la media no se puede calcular para un conjunto de clases de extremo abierto.
1.2. MEDIANA ( x~ ó Me ): Es el valor que divide los datos en dos partes iguales. El 50% de los datos son menores
a la mediana, y el otro 50% son mayores que ella. Si ordenamos los datos en forma ascendente o descendente, la mediana se define como:

UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANA ESTADÍSTICA Y PROBABILIDAD
PROFESORA ZORAIDA PÉREZ SÁ�CHEZ
DESCRIPCIO�ES ESTADÍSTICAS
5
• El valor que se encuentra en el centro del conjunto de datos cuando el total de elementos es un número impar. Ejemplo: Si el tamaño de la muestra es 75, la mediana será el valor que ocupe la posición Nº 38 en los datos ordenados.
• El promedio de los dos valores centrales cuando el total de elementos es par. Ejemplo: si n= 600 la mediana será el promedio de los dos datos que ocupan la posición 300 y 301.
Ventajas de la mediana:
• Los valores extremos no afectan a la Mediana como afectan a la Media.
• Es fácil de entender y se puede calcular tanto en datos no agrupados como agrupados.
• Podemos usar la mediana cuando los datos son expresiones cualitativas y los podemos expresar en escala ordinal (rangos) Ejemplo: Deficiente, Regular, Bueno, Eficiente, Excelente. Cuál será la Mediana?
• Cuando el rango es muy grande (es decir, existen grandes variaciones en los datos) la mediana puede ser mucho más significativa que la media aritmética.
Desventajas de la mediana:
• Se deben ordenar los datos antes de calcular la Mediana.
• Algunos procedimientos estadísticos que utilizan la Mediana son más complejos que aquellos que usan la Media
• No se puede calcular cuando los datos están agrupados y la clase medianal cae en un intervalo abierto.
1.3. MODA (Mo): Es el valor que más se repite en un conjunto de datos. Es decir aquel valor que posee la máxima
frecuencia. Puede existir más de una moda. Cuando hay dos modas se habla de Distribución Bimodal. Ventajas de la moda:
• Se puede usar para datos cualitativos y cuantitativos
• No se ve afectada por los valores extremos
• Se puede usar cuando existen clases de extremo abierto. Desventajas de la moda:
• No siempre existe. Nos podemos encontrar conjuntos de datos que no repiten valores, por lo que no existe valor modal.
• Si existe, no siempre es única, por lo que resulta difícil de interpretar y comparar.
• Puede darse el caso de que un solo elemento no representativo se repita y sea el valor con mayor frecuencia. Es por ello que la moda rara vez se usa. Se recomienda que cuando se vaya a usar la Moda como medida de tendencia central se calcule la Moda para Datos Agrupados.
1.4. MEDIA PONDERADA (O PROMEDIO PONDERADO): Es la media aritmética que toma en cuenta la importancia que tiene cada valor en relación con el total. Por lo tanto para calcular esta medida, es preciso asignarle un “peso” (importancia relativa) que se le llamará factor de ponderación “p”. Entonces se multiplica cada valor por el factor de ponderación asignado, se suman estos resultados y se divide por la suma de todos los factores de ponderación. Las fórmulas para la media ponderada muestral y poblacional son idénticas, como sigue:
∑
∑=
p
xipx p
).(
∑∑
=p
xp i
p
).(µ
1.5. MEDIA GEOMÉTRICA: Se utiliza para medir la tasa promedio de cambio o de crecimiento de alguna variable
nxxxxG ⋅⋅⋅⋅∗∗∗= 321
1.6. MEDIA ARMÓNICA: Es la recíproca de la media aritmética de los recíprocos de los datos. Se utiliza
frecuentemente para promediar velocidades, donde las distancias para cada velocidad son las mismas

UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANA ESTADÍSTICA Y PROBABILIDAD
PROFESORA ZORAIDA PÉREZ SÁ�CHEZ
DESCRIPCIO�ES ESTADÍSTICAS
6
∑∑==
x
n
n
x
xH 11
1
1.7. FRACTILES: Son los llamados estadísticos de orden. Exceptuando la mediana (que es un fractil también porque divide en dos al conjunto de datos), no son medidas de tendencia central sino de posición. Estos son: Mediana, Cuartiles, Quintiles, Deciles, percentiles.
nc
i *4
=
nd
i *10
=
np
i *100
=
i= la ubicación del dato requerido n= tamaño de la muestra c= cuartil. (Ej.: c=1 si buscamos el 1º cuartil) d= decil. (Ej.: d=2 si buscamos el 2º decil) p= percentil (Ej.: p=34 si buscamos el 34º percentil)
� Si “i” resulta número entero el fractil será el valor promedio entre xi y x(i+1) .
� Si “i” resulta número no entero el fractil será el valor que ocupe la posición
“i+1”. Es decir: x(i+1)
Recurrimos a ejemplos para calcular cualquier fractil: Hallar el 3º cuartil , el 6º decil y el 85º percentil del siguiente conjunto de datos:
Sueldos mensuales iniciales para una muestra de

UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANA ESTADÍSTICA Y PROBABILIDAD
PROFESORA ZORAIDA PÉREZ SÁ�CHEZ
DESCRIPCIO�ES ESTADÍSTICAS
7
12 egresados de una escuela de Administracion:
2210 2380 2420 2550
2255 2380 2440 2630
2350 2390 2450 2825
Fuente: Anderson,7ºEd. P.69
Tercer Cuartil -> 912*4
3*
4
3=== ni
Como “i” resultó ser un número entero (9) entonces el tercer cuartil será el promedio entre la novena y la décima (10º) posición: Tercer Cuartil = (2450+2550)/2 = 2500
Sexto Decil -> 2,712*10
6*
10
6=== ni
Como “i” resultó no ser un número entero (7,2) entonces el sexto decil será el dato que ocupe la octava (8º) posición: Sexto Decil=2440
85º Percentil -> 2,1012*100
85*
100
85=== ni
Como “i” resultó no ser un número entero (10,2) entonces el 85ºpercentil será el dato que ocupe la décimo primera (11º) posición. 85º percentil = 2630
2. MEDIDAS DE DISPERSIÓN: ¿Por qué es necesario analizar medidas de dispersión?
Un valor pequeño en una medida de dispersión indica que los datos están amontonados alrededor de la media. En este caso la media se considera representativa de los datos. Si pasa lo contrario, un valor grande en la medida de dispersión indica que los datos están más alejados de la media y no sería ésta tan representativa como en el primer caso. Podría darse el caso de que dos o más conjuntos de datos tengan el mismo valor de la media, sin embargo, la distribución de los mismos puede ser distinta en cada uno de los casos. Las razones más importantes son:
� Las medidas de dispersión proporcionan información adicional que permite juzgar la confiabilidad de la medida de tendencia central.
� Cuando los datos están muy dispersos existen problemas característicos, por lo que se debe saber distinguir estos casos observando la dispersión.
� Es útil cuando se desea comparar las dispersiones de diferentes muestras con promedios similares.

UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANA ESTADÍSTICA Y PROBABILIDAD
PROFESORA ZORAIDA PÉREZ SÁ�CHEZ
DESCRIPCIO�ES ESTADÍSTICAS
8
MEDIDAS DE DISPERSIÓN NO REFERIDAS A LA MEDIA ARITMÉTICA
2.1. Alcance o Recorrido: Es la diferencia entre el mayor valor y el menor valor de los datos:
mínmáxxxR −=
� Esta medida es fácil de entender y de encontrar, pero su utilidad es limitada. � Se ve influida por los valores extremos. � Tiene muchas posibilidades de cambiar de una muestra a otra, para una población dada. � Las distribuciones de extremo abierto no tienen alcance.
2.2. Alcance Interfractil: Es la diferencia entre los valores de dos fractiles. Ejemplos:
2080 PPntilInterperceAlcance −=
13 QQilIntercuartAlcance −=
MEDIDAS DE DISPERSIÓN REFERIDAS A LA MEDIA ARITMÉTICA
Estas medidas están referidas a la media aritmética porque informan "qué tan desviados están los datos respecto a la media aritmética. Para ello necesitamos definir lo que es Desviación Estadística.
DESVIACIÓN: Es la diferencia entre el valor de un dato y la media aritmética. µ−= ixe
2.3. Desviación Media: Es el promedio de las desviaciones en su valor absoluto.
�
xMD
i∑ −=
||.
µ
Ventaja: Se usan todos los datos para calcularla. Es fácil de interpretar. Desventaja: La desviación media no se presta a transformaciones algebraicas debido a que los signos son ajustados en su definición.
2.4. Varianza: Se define como el promedio de las desviaciones al cuadrado. Al elevar al cuadrado cada una de las
desviaciones se logra que todas ellas sean positivas y a su vez, que las desviaciones más grandes tengan más peso
Para una población: �
xi∑ −=
2
2)( µ
σ
Para una Muestra: 1
)( 2
2
−
−=∑
n
xxs
i

UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANA ESTADÍSTICA Y PROBABILIDAD
PROFESORA ZORAIDA PÉREZ SÁ�CHEZ
DESCRIPCIO�ES ESTADÍSTICAS
9
• Observa que para una muestra ya no sería “n” sino “n-1” porque en la práctica se ha encontrado que el valor resultante da una mejor estimación de la varianza de la población total. Para grandes valores de “N” no existe mucha diferencia entre una u otra.
• La varianza se puede usar para comparar dos o más conjuntos de datos.
• DESVENTAJA: Para un solo conjunto de datos las unidades de la Varianza no son manejables o fáciles de interpretar, ya que son unidades elevadas al cuadrado (dolares2,por ejemplo). Por esa razón debemos recurrir a la raíz cuadrada de la varianza que se define como DESVIACIÓN ESTANDAR o DESVIACIÓN TÍPICA.
2.5. Desviación Estándar: Se define como la raíz cuadrada de la Varianza. La Desviación estándar nos permite calcular
con un buen grado de precisión dónde están localizados los valores de una distribución de frecuencias con respecto a la media.
Para una población: �
xi∑ −=
2)( µσ
Para una Muestra: =−
−=∑
1
)( 2
n
xxs
i
2.6. Resultado Estándar: Da el número de desviaciones estándar que una observación en particular ocupa por debajo
o por encima de la media.
σ
µ−= ixz
Ejemplo: Queremos saber a cuantas desviaciones se encuentra de la media el dato xi = 0,12
79,0058,0
166,012,0Re 12,0 −=
−=
Este dato está a menos de una desviación estándar por debajo de la media.
2.7. Coeficiente de Variación: Sirve para comparar la media con la Desviación Estandar. Es una medida relativa muy útil para comparar el grado de variación en conjuntos de datos que posean diferentes medias.
100*Estandar
Media
DesviaciónVariacióndeeCoeficient =
2.8. Teorema de Chevyshev: Para cualquier conjunto de datos:
• Al menos el 75% de los datos caen dentro de σ2± (más o menos dos desviaciones estándar) a
partir de la media
• Al menos el 89% de los datos caen dentro σ3± a partir de la media

UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANA ESTADÍSTICA Y PROBABILIDAD
PROFESORA ZORAIDA PÉREZ SÁ�CHEZ
DESCRIPCIO�ES ESTADÍSTICAS
10
2.9. Regla Práctica: Cuando la curva de frecuencias es simétrica, con forma de campana y “n” es grande, se puede decir que:
• Aproximadamente el 68% de los valores de la población cae dentro de σ1± a partir de la
media.
• Aproximadamente el 95% de los datos caen dentro de σ2± (más o menos dos desviaciones
estandar) a partir de la media
• Aproximadamente el 99% de los datos caen dentro σ3± a partir de la media
EJEMPLO: A una muestra de 15 frascos se realizó un estudio de impurezas (% de impurezas)
0.04 0.06 0.12 0.14 0.14 0.15 0.17 0.17 0.18 0.19 0.21 0.21 0.22 0.24 0.25
Los resultados los podemos expresar por medio de los siguientes estadísticos: Media=0,166% ;Desviación Estándar= 0,058. DE ACUERDO CON EL TEOREMA DE CHEVYSHEV, PODEMOS DECIR QUE: Al menos el 75% de los datos (15 * 0,75= 11 frascos) están entre 0,05% Y 0,282%.
• 0,166 - (2 * 0,058) = 0,050 %
• 0,166 + (2 * 0,058) = 0,282 % Comprobemos si se cumple: ¿Cuántos de los datos caen dentro del intervalo 0.050–0.282? Catorce de los quince. Es decir el 93% de las observaciones están realmente dentro de este intervalo. Entonces sí se cumple el Teorema de Chebyschev. Es más, observamos que 93% se acerca mucho al valor de 95% (regla práctica). Por ello podemos concluir que esta distribución se aproxima a una distribución simétrica.
MEDIDAS DE FORMA
2.10. Asimetría: E grado de asimetría de una Distribución se determina:
s
Mox
estándarDesviación
amediaAsimetría
−=
−=
mod

UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANA ESTADÍSTICA Y PROBABILIDAD
PROFESORA ZORAIDA PÉREZ SÁ�CHEZ
DESCRIPCIO�ES ESTADÍSTICAS
11
2.11. CURTOSIS: Mide cuán puntiaguda es una distribución, en general, por referencia a la distribución normal.
• Leptocúrtica: Si tiene un pico alto.
• Platicúrtica: Si es aplastada.
• Mesocúrtica: Forma intermedia (como la distribución Normal)
EJERCICIO:. Como verás ya el ejercicio trae la respuesta. Pero tu tarea es hacerlo por tu cuenta, manualmente, con Excel y con el Statgraphics, y comprobar que te da igual que acá. Halla las otras medidas que no se piden acá.

UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANA ESTADÍSTICA Y PROBABILIDAD
PROFESORA ZORAIDA PÉREZ SÁ�CHEZ
DESCRIPCIO�ES ESTADÍSTICAS
12
Frecuencia = 30
Mínimo = 226
Máximo = 270
230 250 252 259 236 249 Media = 249,133
249 243 256 230 250 252 Desviación típica = 11,8051
243 269 226 249 255 240 Varianza = 139,361
260 231 261 268 252 259 Mediana = 250,0
252 261 242 240 270 240 Primer cuartil = 240,0
Percentil 90=
Moda = 252,0
PESO (en gramos)
Muestra de 30 paquetes de café
"EL NEGRITO"
FUENTE: DptoControl de calidad Cafetalera
Grano de Oro
3. CÓMO DETERMINAR LAS MEDIDAS ESTADÍSTICAS CUANDO SE NOS PRESENTAN LOS DATOS YA AGRUPADOS? Cuando se tiene una distribución de frecuencias cuyos datos YA ESTÁN AGRUPADOS EN CLASES, como el caso que a continuación se presenta, no se sabe el valor de cada observación, solo se sabe que cada dato se encuentra en una clase determinada. ¿Cómo hacer para estimar las medidas estadísticas? CASO: A continuación se presenta el consumo de gasolina que tuvo una muestra de 160 carros que tienen un kilometraje de 1000 KM de recorrido
Lim inf - Lim sup frecuencia
13 - 19 12
19 - 25 35
25 - 31 40
31 - 37 48
37 - 43 15
43 - 49 10
3.1. MEDIA ARITMÉTICA CUANDO LOS DATOS YA NOS LOS DAN AGRUPADOS: Solo se puede calcular una aproximación de la media, pues no tenemos el valor de cada uno de los 160 carros. Asumiendo que el punto medio de cada clase (o marca de clase) representará a todos los valores contenidos en cada una de las clases. Los pasos a seguir para calcular la media son:
• Se determina el punto medio de cada clase. Se redondean las cantidades, en caso de que no resulten cifras cerradas.
• Se multiplica el punto medio de cada clase por la frecuencia correspondiente a dicha clase.
• Se suman todos los resultados de las multiplicaciones.
• Se divide el total de la suma entre el número total de observaciones (“n” o “N”, según el caso) La media de una Muestra, para datos agrupados, se calcula:
n
xfx
m∑ ∗=
).( Donde:
clase cada de Marca
muestra la de Tamaño n
=
=
=
imx
clasecadadefrecuenciaif
La media de una Población, para datos agrupados, se calcula igual, lo que cambia es la notación:
�
xf m∑=
)*(µ

UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANA ESTADÍSTICA Y PROBABILIDAD
PROFESORA ZORAIDA PÉREZ SÁ�CHEZ
DESCRIPCIO�ES ESTADÍSTICAS
13
3.2. MEDIANA CUANDO LOS DATOS YA NOS LOS DAN AGRUPADOS: Cuando no se tiene acceso al conjunto de datos, sino que SE PRESENTAN YA AGRUPADOS, no se podrá indicar exactamente cuál será el valor que divide los datos en dos partes. Lo que sí se puede hacer se explicará con un ejemplo: Hallar la mediana para los siguientes datos agrupados
Saldos mensuales promedio en miles de Bs
Clases (miles de Bs)
Frecuencia Frecuencia Acumulada
0,00 - 50,00 78 78
50.00 - 100,00 123 201
100,00 - 150,00 187 388
150,00 - 200,00 82 470
200.00 - 250,00 51 521
250,00 - 300,00 47 568
300,00 - 350,00 13 581
350,00 - 400,00 9 590
400.00 - 450,00 6 596
450,00 - 500,00 4 600
Total 600
Fuente: Levin/Rubin , 6ªEd. P.99
• Se toma la mediana como n/2 , es decir 600 / 2=300.
• Sumando las frecuencias 78+123=201 se observa que el dato que ocupa la posición 300 se encuentra en la tercera clase.
• Se hace la suposición que en esta tercera clase, cuya amplitud es de 50$ (150$ menos100$) se distribuyen uniformemente sus 187 datos. Se aplica una regla de tres:
50$ ------------- 187
x $ ------------- (300 - 201) 126,47$ 50*187
)201300( $ 100 $ =
−+=x
Este resultado se interpreta como sigue: ”Se estima que la mitad de los 600 clientes analizados tienen un saldo menor o igual a 126,47$”
En forma general se puede calcular la mediana para Datos agrupados utilizando la siguiente fórmula
A* 2 L ~i
−
+==me
antes
f
Fn
xMe donde:
medianal clase la de Amplitud A
medianal clase absoluta frecuenciame
f
medianal clase la aanterior Acum. Absoluta Frecuenciaantes
F
muestra la de tamañon
medianal clase la deInferior Límite i
L
~
=
=
=
=
=
== MedianaxMe
3.3. MODA CUANDO LOS DATOS YA NOS LOS DAN AGRUPADOS:
A*
)()(
)( iL
−+−
−+=
despfmofantesfmof
antesfmofMo
modal clase la de Amplitud A
modal clase absol. frec.mo
f
modal clase aposterior absol frec.desp
f
modal clase la aanterior absol. rec.antes
f
muestra la de tamañon
modal clase la deInferior Límite i
L
=
=
=
=
=
=
=
f
ModaMo

UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANA ESTADÍSTICA Y PROBABILIDAD
PROFESORA ZORAIDA PÉREZ SÁ�CHEZ
DESCRIPCIO�ES ESTADÍSTICAS
14
3.4. FRACTILES CUANDO LOS DATOS YA NOS LOS DAN AGRUPADOS:
De la misma manera que se calcula la mediana para datos agrupados se ubican los fractiles:
Primer cuartil: A*
1
4
1
inferior
exactoL 1
−
+=
Qf
antesFn
Q Tercer Cuartil: A* 4
3
L
3inferiorexacto3
−
+=Q
antes
f
Fn
Q
:
Octavo Decil: A* 10
8
L
8inferiorexacto8
−
+=D
antes
f
Fn
D Segundo Decil: A* 10
2
L
2inferiorexacto2
−
+=D
antes
f
Fn
D
Noventa percentil: A* 100
90
L 90
inferiorexacto90
−
+=P
antes
f
Fn
P Décimo percentil: A* 100
10
L 10
inferiorexacto10
−
+=P
antes
f
Fn
P
3.5. VARIANZA CUANDO LOS DATOS YA NOS LOS DAN AGRUPADOS:
Para una población: �
xf mi∑ −=
2
2)(* µ
σ
Para una Muestra: 1
)(* 2
2
−
−=∑
n
xxfs
mi
3.6. DESVIACIÓN ESTÁNDAR CUANDO LOS DATOS YA NOS LOS DAN AGRUPADOS:
Para una población: �
xf mi∑ −=
2)(* µσ
Para una Muestra: =−
−=∑
1
)(* 2
n
xxfs
mi
Una Tabla nos facilita el cálculo manual. Pero también debes aprender a utilizar las herramientas tecnológicas. CON LA CALCULADORA, CON EXCEL Y CON PAQUETES COMO EL SPSS Y EL STATGRAPHICS:
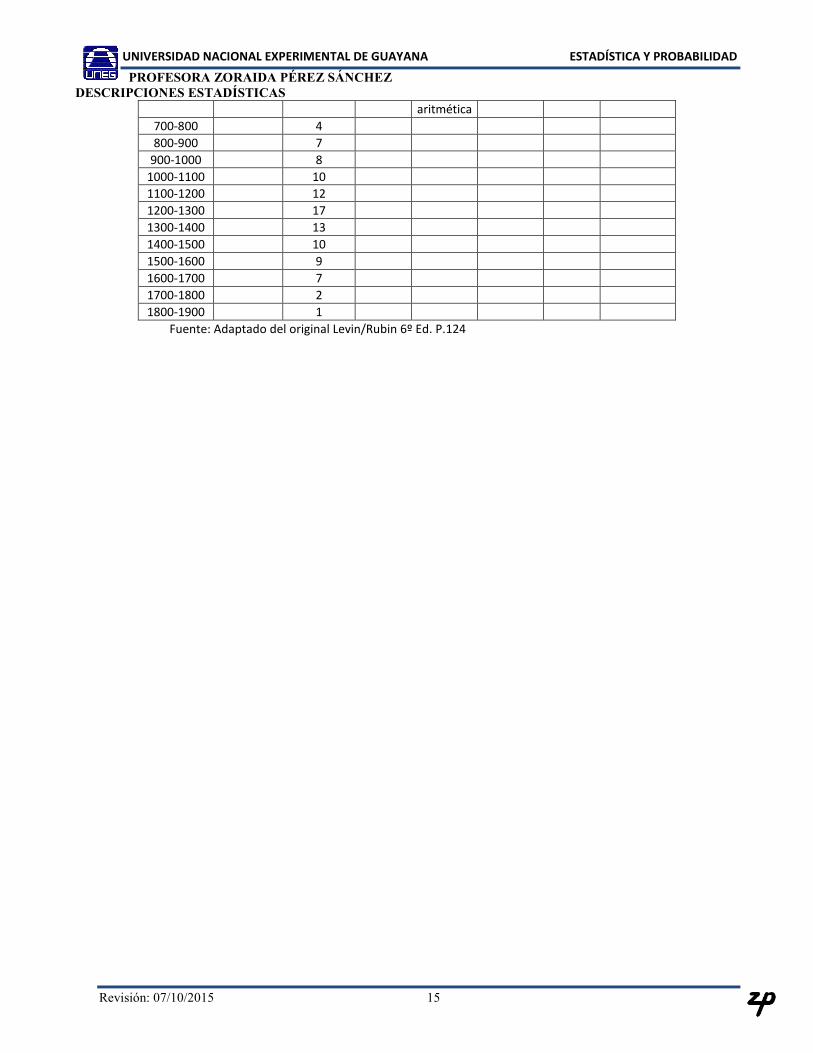
Ventas Semanales de 100 establecimientos de comida rápida (en miles de bolívares)
Clase Marca de Clase (xm)
Frecuencia (f)
f*xm
Media
(Xi - µ)
(Xi - µ)2
f * (Xi - µ)2
UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANA ESTADÍSTICA Y PROBABILIDAD
PROFESORA ZORAIDA PÉREZ SÁ�CHEZ
DESCRIPCIO�ES ESTADÍSTICAS
Revisión: 07/10/2015 15
aritmética
700-800 4
800-900 7
900-1000 8
1000-1100 10
1100-1200 12
1200-1300 17
1300-1400 13
1400-1500 10
1500-1600 9
1600-1700 7
1700-1800 2
1800-1900 1
Fuente: Adaptado del original Levin/Rubin 6º Ed. P.124


















