Material del curso “Recursos metodológicos y estadísticos...
69
©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-1 1 UNIVERSIDAD DE JAÉN Material del curso “Recursos metodológicos y estadísticos para la docencia e investigación” Manuel Miguel Ramos Álvarez Índice M M M A A A T T T E E E R R R I I I A A A L L L I I I I I I “ “ “ B B B A A A S S S E E E S S S C C C O O O M M M P P P U U U T T T A A A C C C I I I O O O N N N A A A L L L E E E S S S ” ” ” 2.1. Bases informáticas para el análisis estadístico ..................................................... 2 2.1.1. Programas de utilidad según la etapa de análisis ............................................ 3 2.1.2. Focalización en el programa SPSS ................................................................ 5 2.1.2.1. Ventanas básicas del programa SPSS......................................................... 6 2.1.2.2. Sistema de Menús en el programa SPSS................................................... 10 • Generales .................................................................................................... 10 • Procesamiento de Datos ................................................................................. 10 • Analizar ....................................................................................................... 11 • Gráficos ....................................................................................................... 18 • Utilidades (Herramientas automatización) ......................................................... 19 • Ayudas ........................................................................................................ 19 2.1.3. El programa Statistica .............................................................................. 20 2.1.3.1. Ventanas básicas del programa Statistica ................................................. 20 2.1.3.2. Sistema de Menús en el programa Statistica ............................................. 24 • Generales .................................................................................................... 24 • Procesamiento de Datos ................................................................................. 25 • Analizar ....................................................................................................... 26 • Gráficos ....................................................................................................... 34 • Utilidades (Herramientas automatización) ......................................................... 35 • Ayudas ........................................................................................................ 35 2.1.4. El entorno R............................................................................................ 36 2.1.4.1. Ventanas básicas del programa R ............................................................ 36 2.1.4.2. Bases del programa R ............................................................................ 37 2.1.4.3. Mejoras del programa R para los usuarios de Windows ............................... 38 2.2. Procesamiento inicial de los datos para una primera comprensión de los mismos .... 40 2.2.1. Introducción a la Codificación de variables................................................... 41 2.2.2. Estructura del fichero de datos .................................................................. 43 2.2.3. Ejemplificación de la introducción de datos a partir del Supuesto 2 mediante el programa Excel .................................................................................................... 44 2.2.4. Ejemplificación de la introducción de datos a partir del Supuesto 1 mediante programas de Análisis estadístico ........................................................................... 48 2.2.5. Ejemplificación de la introducción de datos a partir del Supuesto 3 mediante programas de Análisis estadístico ........................................................................... 50 2.2.6. Almacenamiento y edición de los ficheros de datos ....................................... 51 2.2.7. Importación de ficheros de datos a partir del Supuesto 2............................... 53 2.2.8. Incorporación de nueva información a partir de los datos básicos ................... 57 2.2.9. Selección de información (aplicación de un filtro de datos) ............................. 62 2.2.10. Manipulación de ficheros en el Entorno R .................................................. 67 2.3. Casos prácticos ............................................................................................. 69
Transcript of Material del curso “Recursos metodológicos y estadísticos...

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-1
1
UNIVERSIDAD DE JAÉN
Material del curso “Recursos metodológicos y estadísticos para la
docencia e investigación” Manuel Miguel Ramos Álvarez
Índice
MMMAAATTTEEERRRIIIAAALLL IIIIII “““BBBAAASSSEEESSS CCCOOOMMMPPPUUUTTTAAACCCIIIOOONNNAAALLLEEESSS”””
2.1. Bases informáticas para el análisis estadístico ..................................................... 2 2.1.1. Programas de utilidad según la etapa de análisis ............................................ 3 2.1.2. Focalización en el programa SPSS ................................................................ 5 2.1.2.1. Ventanas básicas del programa SPSS......................................................... 6 2.1.2.2. Sistema de Menús en el programa SPSS................................................... 10 • Generales .................................................................................................... 10 • Procesamiento de Datos................................................................................. 10 • Analizar ....................................................................................................... 11 • Gráficos ....................................................................................................... 18 • Utilidades (Herramientas automatización)......................................................... 19 • Ayudas ........................................................................................................ 19 2.1.3. El programa Statistica .............................................................................. 20 2.1.3.1. Ventanas básicas del programa Statistica ................................................. 20 2.1.3.2. Sistema de Menús en el programa Statistica ............................................. 24 • Generales .................................................................................................... 24 • Procesamiento de Datos................................................................................. 25 • Analizar ....................................................................................................... 26 • Gráficos ....................................................................................................... 34 • Utilidades (Herramientas automatización)......................................................... 35 • Ayudas ........................................................................................................ 35 2.1.4. El entorno R............................................................................................ 36 2.1.4.1. Ventanas básicas del programa R ............................................................ 36 2.1.4.2. Bases del programa R............................................................................ 37 2.1.4.3. Mejoras del programa R para los usuarios de Windows ............................... 38
2.2. Procesamiento inicial de los datos para una primera comprensión de los mismos.... 40 2.2.1. Introducción a la Codificación de variables................................................... 41 2.2.2. Estructura del fichero de datos .................................................................. 43 2.2.3. Ejemplificación de la introducción de datos a partir del Supuesto 2 mediante el programa Excel.................................................................................................... 44 2.2.4. Ejemplificación de la introducción de datos a partir del Supuesto 1 mediante programas de Análisis estadístico ........................................................................... 48 2.2.5. Ejemplificación de la introducción de datos a partir del Supuesto 3 mediante programas de Análisis estadístico ........................................................................... 50 2.2.6. Almacenamiento y edición de los ficheros de datos ....................................... 51 2.2.7. Importación de ficheros de datos a partir del Supuesto 2............................... 53 2.2.8. Incorporación de nueva información a partir de los datos básicos ................... 57 2.2.9. Selección de información (aplicación de un filtro de datos)............................. 62 2.2.10. Manipulación de ficheros en el Entorno R.................................................. 67
2.3. Casos prácticos............................................................................................. 69

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-2
2
2.1. Bases informáticas para el análisis estadístico o Programas de utilidad según la etapa de análisis. o Focalización en el programa SPSS.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-3
3
2.1.1. Programas de utilidad según la etapa de análisis
• Una de las contribuciones más importantes de los ordenadores a la ciencia en general: el gran impulso a la difusión de las técnicas de análisis de datos.
• El crecimiento de los paquetes estadísticos y su abaratamiento ha tenido consecuencias beneficiosas en cuanto a la ampliación del número de técnicas de análisis disponibles
• Un inconveniente: los paquetes estadísticos han impuesto unas determinadas maneras de realizar los análisis. Por ejemplo, algunos paquetes, como SPSS no permiten realizar pruebas no planeadas en variables manipuladas intra-sujetos.
Guía de los Programas de Análisis
Programa Ámbito Información Dispon. Excel Procesam.
inicial datos http://www.microsoft.com/spain/support/ http://www.ujaen.es/sci/invdoc/soft/microinf/acuespe/officeXP/officeXP.html
Sí
BMDP Win General http://www.statsol.ie/bmdp/bmdp.htm
-------
SAS SAS/JMP (SAS/INSIGHT*)
General, Salud
http://www.sas.com/technologies/analytics/statistics/
-------
SPSS General, Educativa
http://www.spss.com/ Sí
Statistica General, Experimen.
http://www.statsoft.com/ Sí-
SYSTAT Autosignal Peakfit TableCurve 2D, 3D Sigmaplot
EDA, Educativa
http://www.systat.com/
-------
STAT-GRAPHICS General, Experimen.
http://www.statgraphics.com http://www.ujaen.es/sci/invdoc/soft/microinf/acuespe/statg/statg5esp.html
Sí
S-Plus No Lineal-EDA, Economía
www.insightful.com Sí-
Minitab Modelización-EDA
www.minitab.com Sí-
Stata Propósito general
http://www.stata.com/
-------
EQS Ecuaciones estructurales
http://www.mvsoft.com/products.htm
-------
LISREL HLM
Ecuaciones estructurales y Modelos Jerárquicos
http://www.ssicentral.com/sp.html
-------
RATS Series Temporales
http://www.estima.com/
-------
TSP Series Temporales
http://www.tspintl.com/
-------
GAUSS
Programación matemática/ estadística
http://www.aptech.com/
-------
R Programación estadística y análisis especilizados
http://www.r-project.org/ http://cran.es.r-project.org/bin/windows/base/R-2.8.1-win32.exe
Sí (gratis)

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-4
4
Especialmente recomendables:
• http://www.statsoft.com/textbook/stathome.html • http://www.stat.ucla.edu/textbook/ • Documentación de Software estadístico para programación, de libre distribución:
http://www.r-project.org/ • Páginas Web de autores destacados, que incluyen la implementación de pruebas
específicas mediante programas gratuitos. o Meta-análisis: http://www.powerandprecision.com/ o Potencia estadística: http://www.mvsoft.com/ o Rand Wilcox, Professor of Psychology at USC, has developed a set of S-Plus (as
well as R) macros to accompany his book (and the upcoming new edition): Introduction To Robust Estimation and Hypothesis Testing Academic Press, 2005 and other. Los Macros: http://www-rcf.usc.edu/~rwilcox/
Enfocados en el análisis cualitativo:
Se puede acceder a los mismos a través de una de las siguientes direcciones: www.provalisresearch.com ó http://socserv.mcmaster.ca/w3virtsoclib/software.htm
• Annotape. Is a system for recording, analysing and transcribing audio data for qualitative research
• ATLAS/ti. Is a software product for qualitative data analysis • CAQDAS. Is the Computer Assisted Qualitative Data Analysis Software Networking
Project • HyperResearch. Is qualitative data analysis software package enabling you to code and
retrieve, build theories, and conduct analyses of your data • ITALASSI. Interaction Viewer for Regression Models • Leximancer. Identifies key themes, concepts and ideas from unstructured text • LOGISTIC. Logistic regression program (DOS) • MVSP. Multivariate statistical analysis package • ORIANA. Circular data statistical software • PRACTICEMILL. Authoring and Testing Tool for Teachers and Trainers • QDA MINER. Text management and qualitative analysis program • QSR International offer three software products for qualitative data analysis. One of
these is the most widely used QDA software product called NUD*IST (or N6), another is NVivo.
• Qualrus. Is a general-purpose qualitative analysis program which supports text and multimedia sources
• SIMSTAT. Statistical Analysis software • TextAnalyst. Is a system for semantic text analysis and navigation. • The Ethnograph. Is the second most widely used software for qualitative data analysis
in the world. • WordStat. Is a content analysis / qualitative analysis software product. Content
Analysis & Text Mining module for Simstat or QDA Miner.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-5
5
2.1.2. Focalización en el programa SPSS
1. Sin duda uno de los paquetes que más amplia aceptación tiene es SPSS, un paquete cuyo interfaz de usuario ha mejorado considerablemente en las últimas versiones.
2. Sus ventajas fundamentales son incuestionables: o Facilidad de manejo, marcos y ventanas cuya organización facilita la comprensión
del análisis y su gran abanico de técnicas estadísticas. En la mayoría de los temas nuestra exposición viene acompañada por los comandos de SPSS que son necesarios para lograr los objetivos de análisis, acompañados por la salida que ofrece.
o Además se ha impuesto en el mercado, lo que contribuye a la unificación (comparable a Windows como sistema operativo) y la continua actualización.
o Unido a lo anterior, es previsible que proporcione cobertura técnica a los usuarios en el futuro y que depure las ayudas y documentación.
3. Desventajas: o La organización de las técnicas de análisis y de las opciones gráficas deja que
desear puesto que mezcla la aproximación estadística clásica con la más modera, lo que desemboca en un gran solapamiento de las opciones y técnicas.
o Impone estilos de análisis que no están justificados en la literatura estadística especializada, como por ejemplo para los diseños de medidas repetidas o para el cálculo de errores globales en el análisis detallado tipo ANOVA.
o Su elevado coste. La licencia básica es muy costosa y además expira en un año. o Unido a lo anterior, gran cantidad de técnicas de análisis especializados hay que
adquirirlas con un coste adicional que sigue siendo elevado. o Desde el punto de vista del software resulta un programa pobre, puesto que es
lento en muchas ocasiones y además aborta los procesos con elevada frecuencia. 4. Disponibilidad en la Universidad Jaén:
http://www.ujaen.es/sci/invdoc/soft/microinf/acuespe/spss/spss11.html http://www.ujaen.es/sci/invdoc/soft/microinf/acuespe/spss/amos50.html Donde por un coste muy bajo se puede adquirir una licencia para ordenador personal y renovar los códigos todos los años, gracias a la cobertura del servicio central de informática.
5. Menús de ayuda y tutoriales: C:\Archivos de programa\SPSS\tutorial\spsstut\introtut2.htm

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-6
6
2.1.2.1. Ventanas básicas del programa SPSS Ventana Inicial del Programa

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-7
7
Ventana Principal del Programa
Título
Menús
Herramientas
Edición
Desplazamientos Área Datos:
Matricial
Opciones Datos
Barra Estado

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-8
8
Ventana Análisis Prototípica del Programa
Área Variables
Disponibles
Área Definición Variables
Área Comandos y Opciones del
Módulo análisis
Área Comandos y Opciones generales

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-9
9
Ventana Resultados Prototípica del Programa
Área Resultados según título
elegido
Área Títulos
Área Opciones Edición

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-10
10
2.1.2.2. Sistema de Menús en el programa SPSS
• Generales Menús: Archivo, Edición y Ver
• Procesamiento de Datos Menús: Datos y Transformar

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-11
11
• Analizar A) Resumen de la información: Análisis descriptivo-exploratorio
Para Ayudar en la creación de tablas resumen del apartado de resultados, cuando se desea tantear los resultados con la lógica de ANOVA.
La Opción de Resumen Descriptivo más importante. • Para Distribución de
Frecuencias (aprox. clásica), • la opción de descripción, • EDA, • Tablas de Contingencia para
Diseños Categóricos • Análisis especializados de
escala de medida fuerte (Tipo Razón).
Generación más sofisticada de Tablas de Contingencia.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-12
12
Para Ayudar nuevamente en la creación de tablas resumen del apartado de resultados, pero cuando interesa agrupar según muchas categorías más que tantear los resultados.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-13
13
B) Análisis inferencial básico: Modelo Lineal General: ANOVA y Regresión
Contraste de Hipótesis sobre la Media (Lineal-ANOVA) con enfoque clásico.
Análisis del Modelo Lineal General. • Una única variable
Dependiente. • Más de una variable
dependiente. • Diseños Intrasujetos o de
medidas repetidas. • Diseños especializados de
Efectos Mixtos (algunas vv, independientes son de efectos fijos y algunas de efectos aleatorios).
Análisis del Modelo Lineal General para diseños especializados como por ejemplo Covariados o Factoriales Mixtos Complejos.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-14
14
Análisis de tipo Regresión con enfoque clásico. • Dos variables • Controlando el influjo de
terceras variables. • Distancias que intervienen en
cálculos de residuales y sobre todo del tipo Multivariado (como la Distancia Euclídea).
Análisis de tipo Regresión según el enfoque del Modelo Lineal para diseños correlaciones (Cuadrante 1º) pero mezcla también el Modelo Lineal Generalizado para diseños categóricos espacialmente para regresión logística (Cuadrantes 2º y 4º), así como opciones No Lineales (Cuadrante 3º).

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-15
15
C) Análisis de los supuestos del Modelo y pruebas alternativas No Paramétricas
Compendio de pruebas No paramétricas con distinta finalidad (ver el cuadro clasificatorio de pruebas No Paramétricas).
D) Generalización al diseño categórico
Análisis de diseños categóricos desde el punto de vista del enfoque del Modelo Lineal, permitiendo obtener el Modelo Óptimo que mejor ajusta a los datos.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-16
16
E) Análisis avanzado: Técnicas Multivariantes
Análisis del tipo Clúster y Discriminante para clasificar datos según los casos o las variables. Por ejemplo se extraen 5 agrupaciones a partir de insectos de diferentes tipos.
Análisis del Factorial con un objetivo descriptivo avanzado. Por ejemplo, un conjunto de 100 indicadores de calidad se resume (reduce) a partir de 6 factores.
Análisis de escalas de utilidad en Ciencias de corte comportamental, social y educativo Por ejemplo, análisis de la fiabilidad o exactitud de una medida.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-17
17
Análisis de series temporales (muchas medidas a través del tiempo), especialmente con aproximación ARIMA basada en autorregresión. Por ejemplo abstraer el modelo que subyace al patrón de las medidas de una sustancia contaminante a través de los registros de todo un año.
Análisis de supervivencia, de aplicación en el ámbito de Ciencias de la Salud en el que interesa estudiar los datos que van quedando con el transcurso del tiempo o tras la aplicación de programas de tratamiento.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-18
18
• Gráficos Los tipos de representaciones Gráficas en SPSS
A
A
D
B
B
E
E
C
B
E
A
F
F
E
F
A) Tipo Histograma (Barras-Columnas-Histograma, Pareto) B) Tipo Polígono Frecuencias (Líneas, Secuencia, Superficie) C) Tipo Diagrama Simbólico (Sectores, Iconos, Imágenes)
D) Tipo Diagrama Dispersión E) Tipo EDA (Max-Min, Cajas, P-P y Q-Q Normal)
F) Fines Específicos: Para Series Temporales (Autocorrelaciones, Correlaciones Cruzadas, Espectral),
Barras de Error –Rangos- o para Control Calidad.
©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-19
19
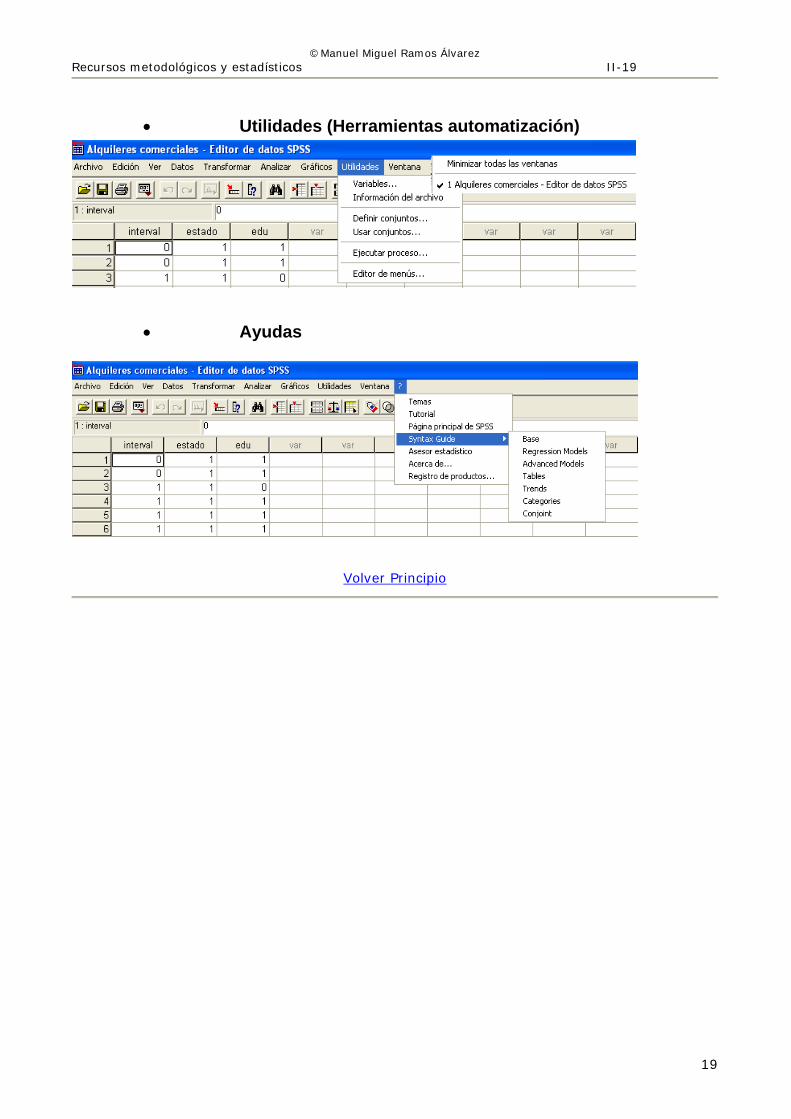
• Utilidades (Herramientas automatización)
• Ayudas
Volver Principio

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-20
20
2.1.3. El programa Statistica
Teniendo en cuenta los pros y contras que se expusieron respecto al programa SPSS, el programa Statistica de la compañía StatSsoft quizás constituye una de las mejores opciones alternativas puesto que aventaja al primero en la mayoría de los inconvenientes expuestos. Recientemente se ha adaptado al castellano, aunque cuesta bastante obtenerla. Un inconveniente es su precio, que ha incrementado considerablemente en el último año.
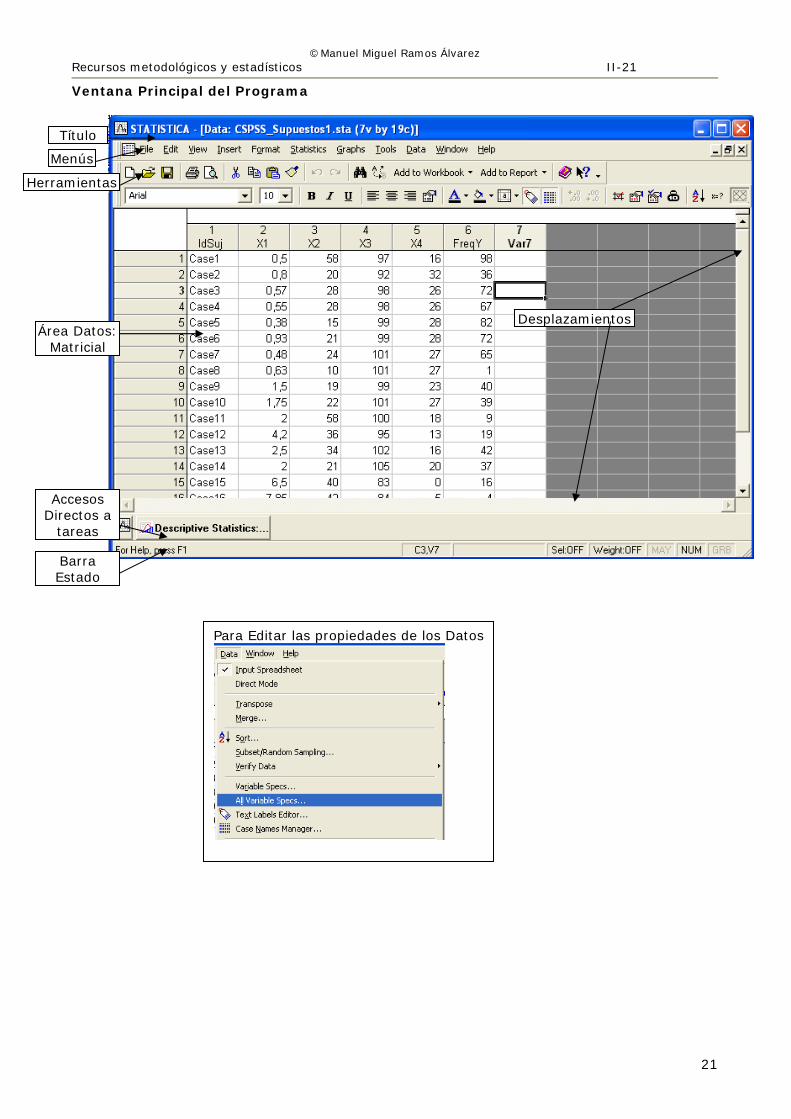
2.1.3.1. Ventanas básicas del programa Statistica
Ventana Inicial del Programa
©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-21
21
Ventana Principal del Programa
Título
Menús
Herramientas
Área Datos: Desplazamientos
Matricial
Accesos Directos a
tareas
Barra Estado
Para Editar las propiedades de los Datos

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-22
22
Ventana Análisis Prototípica del Programa
La lógica es la contraria a la del programa SPSS puesto que en Statistica, primero se le indica al programa cuál es el diseño para un tipo particular de opción analítica y posteriormente es cuando se pueden plantear los cálculos adicionales relevantes al módulo analítico en cuestión.
2.1.Área Variables
Disponibles
2.2.Área Definición Variables
[1] Área Comandos y Opciones generales
3.1. Opciones adicionales del Módulo análisis
[2] Definir Diseño
2.3. Parámetros Diseño estadístico
[3] Área Comandos y Opciones del Módulo análisis

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-23
23
Ventana Resultados Prototípica del Programa
Área Títulos Área Resultados según título
elegido
Área Opciones Edición
Pestañas para seleccionar resultados
consultados recientemente
Botón de retorno al análisis que se está efectuando
©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-24
24
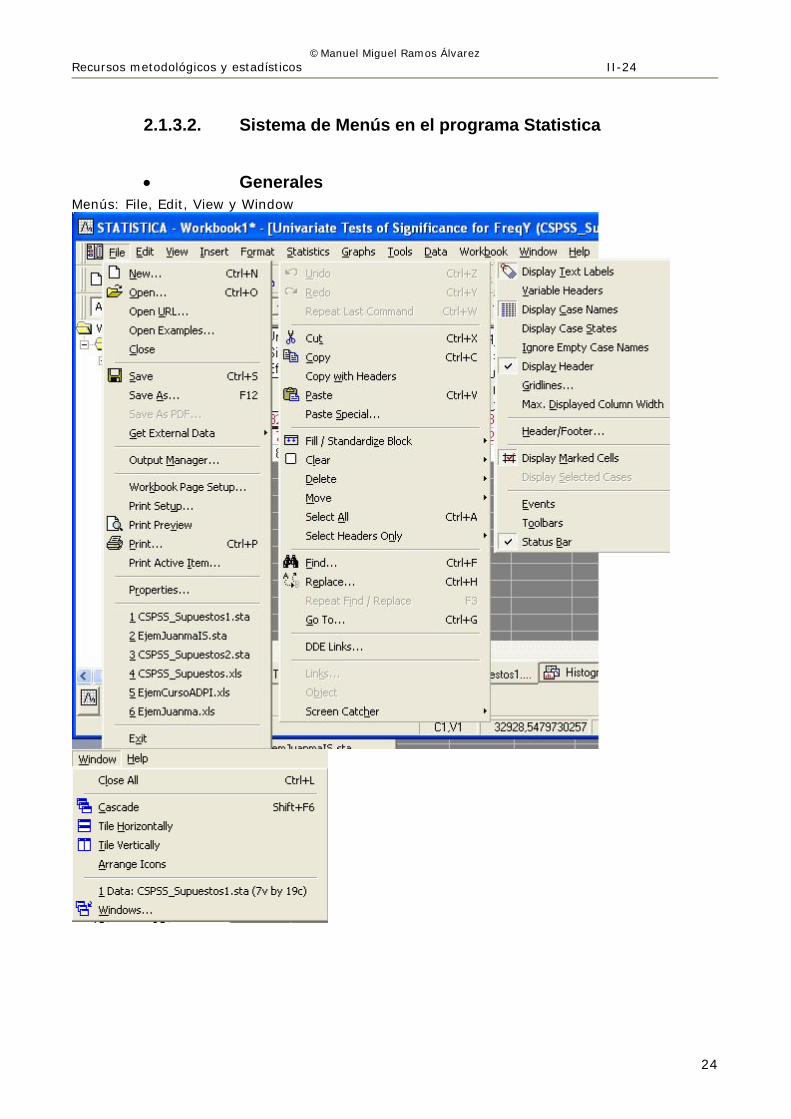
2.1.3.2. Sistema de Menús en el programa Statistica
• Generales Menús: File, Edit, View y Window

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-25
25
• Procesamiento de Datos Menús: Insert, Format y Data

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-26
26
• Analizar En general:

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-27
27
A) Resumen de la información: Análisis descriptivo-exploratorio
Incluye varias opciones. • Estadísticos descriptivos
básicos variable a variable tanto clásicos como robustos (con EDA).
• Descriptivos en el contexto de estudios correlacionales/ covariacionales.
• Descriptivos para diseños Entregrupos tanto simples como factoriales como anidados
• Para Distribución de Frecuencias y Tablas de Contingencia tanto en Diseños Categóricos simples como factoriales (múltiples).

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-28
28
B) Análisis inferencial básico: Modelo Lineal General: ANOVA y Regresión
Contraste de Hipótesis sobre la Media (Lineal-ANOVA), sobre la Correlación (Lineal-Regresion) y sobre las Proporciones, con enfoque clásico y para diseños simples.
• Distancias que intervienen en cálculos de residuales y sobre todo del tipo Multivariado (como la Distancia Euclídea).
• Dos variables • Controlando el influjo de
terceras variables.
Análisis de tipo Regresión con enfoque clásico.
• Diseños Factoriales Mixtos que incluyen ambos tipos de manipulación (repeated measures).
• Diseños Intrasujetos o de medidas repetidas (repeated measures).
• Diseños Entregrupos ya unifactoriales (one-way) o Factoriales (Factorial).
Análisis de tipo ANOVA con enfoque clásico.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-29
29
Análisis del Modelo Lineal General. • Ya en el contexto de
regresión (continuous). • Ya en el contexto ANOVA
(cetegoriacal). • Más de una variable
dependiente (Multivariate) versus Intrasujetos (within Effects).
• Diseños especializados: de Efectos Mixtos (algunas vv, independientes son de efectos fijos y algunas de efectos aleatorios), Covariados o Factoriales Mixtos Complejos, Anidados o Jerárquicos, etc.
Análisis de tipo Regresión No Lineal (i.e. curva de crecimiento exponencial o regresión regional - piecewise regression models-).

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-30
30
C) Análisis de los supuestos del Modelo y pruebas alternativas No Paramétricas
Compendio de pruebas No paramétricas con distinta finalidad (ver el cuadro clasificatorio de pruebas No Paramétricas). Hay un módulo especializado en el ajuste de Modelos de distribución, de gran utilidad en cuanto al análisis de los supuestos y otro para estimar probabilidades directamente a partir de diferentes modelos de distribución.
D) Generalización al diseño categórico
Análisis de diseños categóricos desde el punto de vista del enfoque del Modelo Lineal, permitiendo obtener el Modelo Óptimo que mejor ajusta a los datos.
Dentro del contexto de Análisis de tipo Regresión según el enfoque del Modelo Lineal para diseños correlaciones pero mezcla también el Modelo Lineal Generalizado para diseños categóricos espacialmente para regresión logística.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-31
31
E) Análisis avanzado: Técnicas Multivariantes
Análisis del tipo Clúster y Discriminante para clasificar datos según los casos o las variables. Por ejemplo se extraen 5 agrupaciones a partir de insectos de diferentes tipos.
Análisis Factorial, con un objetivo descriptivo avanzado. Por ejemplo, un conjunto de 100 indicadores de calidad se resume (reduce) a partir de 6 factores.
Análisis de escalas de utilidad en Ciencias de corte comportamental, social y educativo Por ejemplo, análisis de la fiabilidad o exactitud de una medida.
Análisis de supervivencia, de aplicación en el ámbito de Ciencias de la Salud en el que interesa estudiar los datos que van quedando con el transcurso del tiempo o tras la aplicación de programas de tratamiento.
Análisis de series temporales (muchas medidas a través del tiempo), especialmente con aproximación ARIMA basada en autorregresión. Por ejemplo abstraer el modelo que subyace al patrón de las medidas de una sustancia contaminante a través de los registros de todo un año.
Análisis de ecuaciones estructurales (relaciones de predicción secuenciales en las que se pone a prueba una cadena causal de acontecimientos). Por ejemplo intentar predecir la inteligencia general (medida con las Matrices Progresivas de Raven), a partir de la capacidad de memoria operativa.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-32
32
F) Análisis avanzado: Técnicas Específicas
El programa incluye módulos especializados (que se comercializan de manera individual y que no se incluyen en la licencia básica del programa), los cuales permiten implementar análisis estadísticos bastante sofisticados, la mayoría relacionados con modelización:
Análisis de control de calidad. Cuando la salida de un proceso (i.e. gráfico) tiene que reflejar cambios inmediatos de manera dinámica.
Teoría matemática de optimización de diseños (DOE). Para deducir diseños óptimos cuando se desea simplificar el modelo (i.e. está justificado que se prescinda de las interacciones complejas, como en los diseños anidados o jerárquicos).
Módulo especializado para estimaciones relacionadas con la potencia estadística y el tamaño del efecto del tratamiento.
Módulo especializado para la modelización de redes neuronales, como las del tipo conexionista (i.e. Regla LMR de aprendizaje).

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-33
33
Módulo especializado (“Data mining”) para abstraer patrones, modelar grandes masas de datos y hacer predicciones, donde destaca la aplicación de Control de Calidad (Quality Control), algunas de las cuales sirven para el análisis de datos en diseños del tipo cualitativo.
Módulo especializado para la para el análisis cualitativo de textos.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-34
34
• Gráficos Los tipos de representaciones Gráficas en Statistica
A E F D
F C
B
Mezcla
E
C A
B
E C
E
A) Tipo Histograma (Barras-Columnas-Histograma, Pareto) B) Tipo Polígono Frecuencias (Líneas, Secuencia, Superficie) C) Tipo Diagrama Simbólico (Sectores, Iconos, Imágenes)
D) Tipo Diagrama Dispersión E) Tipo EDA (Max-Min, Cajas, P-P y Q-Q Normal)
F) Fines Específicos: Para Series Temporales (Autocorrelaciones, Correlaciones Cruzadas, Espectral),
Barras de Error –Rangos- o para Control Calidad

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-35
35
• Utilidades (Herramientas automatización)
• Ayudas
Especialmente recomendable la opción “Electronic Statistics Textbook”
Volver Principio

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-36
36
2.1.4. El entorno R
Hoy por hoy, este entorno constituye una de las mejores opciones de análisis estadístico especializado, básicamente porque su coste es cero y además la calidad técnica de los análisis supura con creces a la de los programas comerciales. Esto es así ya que se trata de un programa de libre distribución bajo licencia GNU y además porque el número de librerías especializadas va creciendo exponencialmente en los últimos años. El inconveniente más importante es que el investigador tiene que programar los análisis, de manera que en realidad el programa no incluye ningún tipo de menú que guíe los análisis. De hecho no siquiera está pensado para el sistema operativo Windows, aunque veremos como manejarlo desde el mismo a través de una consola de interacción.
2.1.4.1. Ventanas básicas del programa R Para interactuar con este entorno a través de Windows tenemos que efectuar la instalación oportuna del mismo (ver la página Web: http://cran.es.r-project.org/bin/windows/base/R-2.8.1-win32.exe). Ventana Principal del Programa
Título
Menús
Herramientas
Área Interacción
Desplazamientos
Línea de Comandos (>) Y de resultados [1]

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-37
37
2.1.4.2. Bases del programa R Y eso es todo. Es decir, introduciríamos nuestras instrucciones en la línea de comandos y tras pulsar [Enter], el programa ofrece el resultado de las mismas. Para facilitar su manejo se proponen algunas consideraciones. A) Comandos básicos
X1 <- c(3, 4, 5, 7); X1 [Enter] Asignación, definición y verificación básica de variables (“;” para incluir más de un cmd misma línea).
Verificación objeto Teclear su nombre rm() Borra objetos en memoria. help() ?
Obtención de ayuda
“” Para invocar var según caracteres B) Tipos de datos
Vectores x <- c(3,4,2) Factores Para variables categóricas Series array (data_vector, dim_vector), de
dimensión k Matrices matrix(0, n, b), como series pero para k=2 Marcos data.frame, Marco o base de datos que
permite diferentes tipos de información asociados a una variable
serie temporal ts() listas cualquier tipo de mezclas de datos
C) Lectura/Escritura de datos a partir de ficheros
read.table, read.fwf, scan Leer data.frames en ASCII write.table Almacenarlos
D) Sistema de Ayudas
A partir de linea cmd help(mean) A partir del Menú Ayuda
Documentación Web actualizada en diversos idiomas
http://cran.es.r-project.org/manuals.html
E) Ampliación de posibilidades de análisis cargando paquetes de librerías
A partir del servidor http://cran.es.r-project.org/web/packages/
A partir de direcciones propias de autores o de revistas científicas
http://www-rcf.usc.edu/~rwilcox/ http://brm.psychonomic-
journals.org/content/38/3/532/suppl/DC1
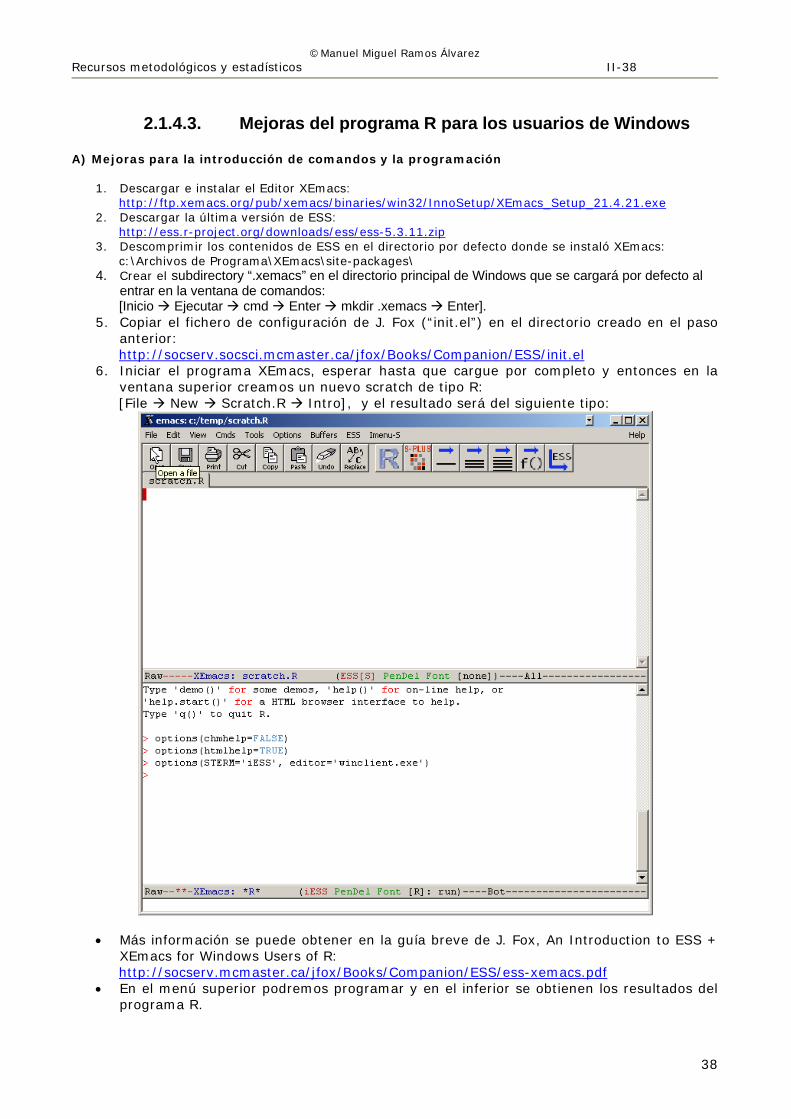
F) Aportaciones técnicas Se pueden aportar librerías, siguiendo el estándar de programación (ver ), así como documentos técnicos (ver ) y artículos concretos (ver ). G) Opcional. Creación de un script para la introducción de comandos: [Archivo Nuevo script le damos un nombre y lo almacenamos]. De esta manera tenemos un sencillo editor en el que emplear las funciones del portapapeles de Windows y para ejecutar partes concretas, la seleccionamos y pulsamos [Crtl + R].
©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-38
38
2.1.4.3. Mejoras del programa R para los usuarios de Windows A) Mejoras para la introducción de comandos y la programación
1. Descargar e instalar el Editor XEmacs: http://ftp.xemacs.org/pub/xemacs/binaries/win32/InnoSetup/XEmacs_Setup_21.4.21.exe
2. Descargar la última versión de ESS: http://ess.r-project.org/downloads/ess/ess-5.3.11.zip
3. Descomprimir los contenidos de ESS en el directorio por defecto donde se instaló XEmacs: c:\Archivos de Programa\XEmacs\site-packages\
4. Crear el subdirectory “.xemacs” en el directorio principal de Windows que se cargará por defecto al entrar en la ventana de comandos: [Inicio Ejecutar cmd Enter mkdir .xemacs Enter].
5. Copiar el fichero de configuración de J. Fox (“init.el”) en el directorio creado en el paso anterior: http://socserv.socsci.mcmaster.ca/jfox/Books/Companion/ESS/init.el
6. Iniciar el programa XEmacs, esperar hasta que cargue por completo y entonces en la ventana superior creamos un nuevo scratch de tipo R: [File New Scratch.R Intro], y el resultado será del siguiente tipo:
• Más información se puede obtener en la guía breve de J. Fox, An Introduction to ESS + XEmacs for Windows Users of R: http://socserv.mcmaster.ca/jfox/Books/Companion/ESS/ess-xemacs.pdf
• En el menú superior podremos programar y en el inferior se obtienen los resultados del programa R.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-39
39
B) Mejoras en la salida del programa A través del paquete R2HTML se puede lograr una salida que se asemeja al visor de resultados de los programas comerciales. A continuación se propone un fragmento de código que sirve para conseguir este tipo de salida con formato.
library(R2HTML) HTMLStart(outdir = "c:/",filename="BrainTrain",echo=FALSE) as.title("Este es el visor del estudio de BarinTraining en HTML") Memoria <- c(9,8,7,8,5,5,7,7,8,1,8,7) NivGrupos <- c("BrainT", "VideoJ", "RepVideoJ") gl(3, 4, label=NivGrupos) Grupos <- gl(3, 4, label=NivGrupos) BrainTrain <- data.frame(Grupos, Memoria) tapply(Memoria, Grupos, mean) modelo <- lm(Memoria ~ Grupos) summary(modelo) anova(modelo) HTMLStop() #En versiones posteriores a la 2.6.x hay que cargar el paquete expresamente: #Paquetes Instalar paquetes seleccionar un CRAN mirror Aceptar
Para más información se puede consultar: http://www.stat.ucl.ac.be/ISdidactique/Rhelp/library/R2HTML/doc/R2HTML.pdf

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-40
40
2.2. Procesamiento inicial de los datos para una primera comprensión de los mismos
o Creación de ficheros de datos: codificación de variables, gestión, importación, almacenamiento
o Incorporación de nueva información a partir de los datos básicos
Antes de comenzar sería conveniente que almacenase los ficheros con los que va a trabajar en alguna carpeta personal. Si intenta abrir ficheros de SPSS o de Excel directamente a través de un Navegador (i.e. Explorer), el enlace al programa puede que funcione inadecuadamente. Es preferible que abra el programa (i.e. SPSS) y desde él acceda al fichero concreto. Los ficheros están todos incluidos en un fichero comprimido de la plataforma que se denomina “RMEDI_Supuestos.zip”.
Tenga presente que hay 3 supuestos que servirán para ejemplificar los contenidos de este tema, así como de los dos temas que vienen a continuación: análisis descriptivo y análisis basado en Diferencias mediante ANOVA.
Puede trabajar de dos maneras, o bien divide la pantalla en dos mitades, de manera que
en una de ellas tenga el tutorial y en la otra el programa informático para ir aplicando los comandos.
o Otra opción es imprimir el tutorial y así poder dedicar la ventana completa del PC al manejo del programa informático.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-41
41
2.2.1. Introducción a la Codificación de variables
• La medición de variables métricas o cuantitativas requiere fundamentalmente de la
asignación de códigos (casi siempre numéricos) que reflejen los cambios cuantitativos. • En comparación, cuando se mide una variable categórica el proceso no es tan directo
puesto que tenemos que codificar dicha variable mediante valores numéricos, aunque la codificación no puede ser cualquiera.
• Puede utilizarse cualquier esquema de codificación siempre que se emplee de manera sistemática. El esquema es una cuestión realmente arbitraria. Sin embargo, hay esquemas que son preferibles, puesto que facilitan la comprensión de los datos, evitan errores interpretativos y además son más sólidos a efectos del cálculo numérico.
• Se han impuesto tres sistemas de codificación: sistema de efectos, ficticio (dummy) y de
contrastes. Hay autores que manifiestan sus preferencias por el de contrastes (v.gr. los manuales enfocados a regresión), otros por el de efectos (v.gr. enfocados al ANOVA) y otros al sistema ficticio (v.gr. los que tienen un enfoque al análisis categórico).
• El sistema no afectará a los estadísticos finales del análisis inferencial pero sí a la interpretación de los parámetros.
• Principios generales que nos serán de utilidad: o La suma de los coeficientes adjudicados tiene que ser cero. o El sistema incluirá tantos contrastes como grados de libertad tenga la variable a
codificar, es decir número de niveles menos uno. o Para la interacción basta con multiplicar entre sí los coeficientes adjudicados a
cada una de las variables implicadas en la configuración.
• Ejemplos destacados: o Si tenemos un grupo de control que deseamos comparar con el resto entonces
podríamos decantarnos por el sistema ficticio, de forma que la categoría de referencia coincida precisamente con el nivel neutral.
o El mejor sistema (y el único) para abordar el análisis de tendencias o funciones polinómicas es el de contrastes.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-42
42
Sistema de Efectos Sistema ficticio (dummy) Sistema de contrastes
El cambio de cada nivel con respecto a la gran media del diseño. Se fija un nivel y se le asigna el coeficiente unitario. Posteriormente vamos comparando dicha categoría con las restantes una a una, asignando a la otra categoría el valor -1. En consecuencia habrá siempre un nivel con el valor cero y por lo tanto su efecto se puede deducir a partir de los otros.
El cambio de cada nivel con respecto a alguno que se fija como punto de referencia. Se fija un nivel y se le asigna el coeficiente nulo. Posteriormente vamos asignando el coeficiente unitario a los niveles restantes. De nuevo habrá siempre un nivel con el valor cero y por lo tanto su efecto se puede deducir a partir de los otros.
Descomponer las variables de manera ortogonal. Se ha impuesto el de Helmert, tomando nuevamente como punto de referencia el primer nivel de la variable. Obtenemos comparabilidad directa entre los niveles pero de manera que en algunos contrastes se promedian diferentes niveles. Nuevamente, si deseamos deshacer dichas agrupaciones entonces tenemos que ir sumando contrastes para deducir unos a partir de los otros.
Dos Niveles
φA
a1 1
a2 -1
Tres Niveles
φA1 φA2
a1 1 1
a2 -1 0
a3 0 -1
Dos Niveles
φA
a1 0
a2 1
Tres Niveles
φA1 φA2
a1 0 0
a2 1 0
a3 0 1
Dos Niveles
φA
a1 1
a2 -1
Tres Niveles
φA1 φA2
a1 2 0
a2 -1 1
a3 -1 -1

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-43
43
2.2.2. Estructura del fichero de datos • Los datos se deben de organizar según una estructura particular que es la que
actualmente emplean la mayoría de los programas de análisis estadístico. • En general, cada unidad de análisis (sujetos, casos) ocupa una fila diferente y
sólo una. • Los valores que se han medido en las variables dependientes se introducen en
sendas columnas. o Además, las variables manipuladas Entregrupos (caso de muestras
independientes) se codifican en columnas, una por cada variable. o Finalmente los niveles de las variables manipuladas Intrasujetos (caso de
muestras relacionadas) ocupan diferentes columnas, una por cada nivel de dicha variable y en ellas aparecerán los valores medidos en las variables dependientes.
• De manera equivalente, si se mide en más de una variable dependiente, entonces cada una de las mismas se corresponde con una columna.
Supuesto-1
Supuesto-2 Supuesto-3

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-44
44
2.2.3. Ejemplificación de la introducción de datos a partir del Supuesto 2 mediante el programa Excel
Casos en filas
Columna A: Var.Indep Mes
Columna B: Var.Indep Tipo
Columna C: Var. Dep
Frecuencia
Columnas D a F: Codifica Mes
Columna G: Codifica Tipo
Columnas H a J: Codifica Interacc
La Interacción se refiere al efecto
conjunto de las dos variables
independientes
©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-45
45
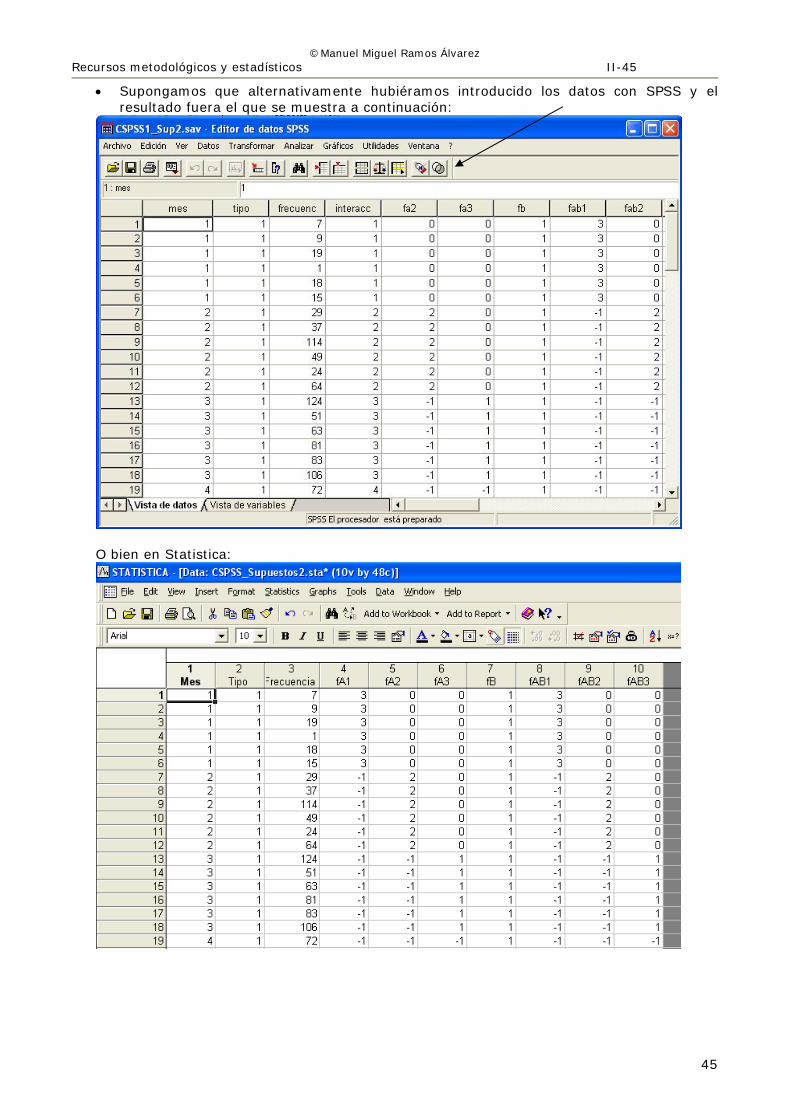
• Supongamos que alternativamente hubiéramos introducido los datos con SPSS y el resultado fuera el que se muestra a continuación:
O bien en Statistica:

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-46
46
• Ahora el objetivo es definir el significado de la codificación de una variable
nominal como es el caso del “mes”. Para ello podemos cambiar la definición de variables pulsando sobre la pestaña inferior [Vista de variables], entonces indicamos que la variable mes es del tipo Numérico y procedemos a definir el significado de las etiquetas nominales, lo que nos llevaría a la ventana en SPSS:
o Así procederíamos con lo 4 valores e iríamos añadiendo hasta obtener:
En Statistica: Data Text/Labels Editor:

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-47
47
• Finalmente indicar que en la ventana principal de Edición de datos existe un botón de
herramienta ( ) que nos permite visualizar los códigos o bien sus etiquetas y que aparecía indicado con una flecha en las imágenes precedentes.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-48
48
2.2.4. Ejemplificación de la introducción de datos a partir del Supuesto 1 mediante programas de Análisis estadístico
• En la ventana del editor de datos procedemos como en Excel, de manera matricial y el resultado quedaría como sigue:
En Statistica:

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-49
49
• Además, si pulsamos en la pestaña inferior de Vista de variables (o elegimos Data All
Variable Specs), podemos definir las características de las mismas, tal y como en la imagen:
Ejemplo para Humanidades:
Ejemplo para Ciencias:
• Fundamentalmente resaltar las opciones de valores y Medida. La última hace referencia a la escala de medida según la taxonomía de Stevens y el campo de valores nos permite definir la significación de los códigos numéricos empleados para la codificación, como en el ejemplo del apartado precedente.
Las variables y la escala de medida (CUADRO 2.5. Esquema resumen del proceso de medición, tomado de Ramos et al., 2004)
NOMINAL ORDINAL INTERVALO RAZÓN
DEFINICIÓN Esquema clasificación Ordenación
Comparación de Intervalos
(agrupaciones de la misma longitud) o
distancia que existe entre las ordenaciones.
Exige un valor de referencia o cero
relativo (arbitrario).
Comparación entre razones, lo
que exige la existencia de un
cero real o absoluto.
PROPIEDAD O TIPO DE RELACIÓN
Igualdad/
Desigualdad Mayor que/ Menor que Diferencia / Suma Multiplicación/
División
EJEMPLOS
Diagnóstico en
Psicopatología Sexo
Rasgo Personalidad
Dureza minerales
Inteligencia en Z. Temperatura (ºC-F)
Tiempo Reacción Longitud

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-50
50
2.2.5. Ejemplificación de la introducción de datos a partir del Supuesto 3 mediante programas de Análisis estadístico
• En la ventana del editor de datos procedemos como en los dos supuestos precedente y
el resultado quedaría ahora como sigue:
• De nuevo editamos la vista de variables y obtenemos lo siguiente: Ejemplo para Humanidades:
Ejemplo para Ciencias:
• En el campo dedicado a las etiquetas hemos introducido el significado de las mismas, 80 vs 90 vs 100.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-51
51
2.2.6. Almacenamiento y edición de los ficheros de datos • Una vez introducidos los datos y definidas las variables, procedemos a almacenarlas en
un fichero tal y como se haría en cualquier programa del entorno Windows: [Archivo|Guardar (File|Save)] o bien [Archivo|Guardar como…(File|Save As …)]. En el ejemplo los ficheros se han denominado “CADIPI1_Sup*.sav” (“CADIPI1_Sup*1.sta”), es decir:
o CADIPI1_Sup1E.sav, CADIPI1_Sup1E.sta, CADIPI1_Sup1C.sav ó CADIPI1_Sup1C.sta,
o CADIPI1_Sup2E.sav, CADIPI1_Sup2E.sta, CADIPI1_Sup2C.sav ó CADIPI1_Sup2C.sta,.
o CADIPI1_Sup3E.sav, CADIPI1_Sup3E.sta, CADIPI1_Sup3C.sav ó CADIPI1_Sup3C.sta,
o CADIPI1_Sup4.sav, CADIPI1_Sup4.sta.
• Por otro lado, podemos añadir casos en filas o variables en columnas en cualquier momento que lo deseemos, basta con seleccionar con el ratón la fila o columna correspondiente y pulsar el botón secundario del ratón.
Por ejemplo para intercalar añadir un caso:
Y para intercalar una variable:

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-52
52
En Statistica:
Por ejemplo para intercalar un caso:
Y para intercalar una variable:

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-53
53
2.2.7. Importación de ficheros de datos a partir del Supuesto 2 • Una buena costumbre es trabajar en un programa de propósito general, como por
ejemplo Excel, para introducir los datos y poder inspeccionarlos. Entonces posteriormente se llevarán al programa SPSS mediante la opción de importación automática de la que dispone.
• Puesto que los datos del fichero para el supuesto 2 se crearon en Excel, nos servirá como ejemplo. El fichero de Excel se llama “CADIPI1_Sup.xls” y contiene en realidad cuatro hojas de cálculo, de las cuales ahora únicamente nos interesa la del 2º supuesto.
• Con el editor de datos del programa de análisis (bien SPSS bien Statistica) en blanco, pulsamos [Archivo|Abrir|Datos ó File|Open], entonces especificamos el tipo de datos para Excel y el nombre del fichero:
Especificar aquí que es del tipo Excel
• Posteriormente seleccionamos la hoja de trabajo y le indicamos que lea el nombre de las variables en el primera fila de datos:

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-54
54
En Statistica:
• Con el editor de datos del programa de análisis (bien SPSS bien Statistica) en blanco, pulsamos [File|Open], entonces especificamos el tipo de datos para Excel y el nombre del fichero:
• Posteriormente le indicamos que importe el fichero como una Hoja, seleccionamos la hoja de trabajo que nos interesa y le indicamos que lea el nombre de las variables en el primera fila de datos:

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-55
55
• Alternativamente, supongamos que los datos en realidad se encontraban en un fichero de texto sencillo tipo ASCII (que se puede editar meramente con el Bloc de Notas de Windows) y además con los datos divididos en dos ficheros: “CADIPI1_Sup2a.txt” y “CADIPI1_Sup2b.txt”, uno por cada tipo de riachuelo. Pues bien, empezamos importando el primero de los ficheros como antes, lo único que cambia es el formato (ahora texto) y el hecho de que los datos se encuentran separados mediante el carácter “;” pero evidentemente podríamos haber elegido otro tipo de separador. En definitiva:

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-56
56
• Y ya podemos pulsar en el comando [Finalizar]. • Guardamos el fichero resultante con formato de SPSS y realizamos exactamente la
misma operación con el otro fichero de texto que contiene la segunda parte de los datos, con lo cual llegamos a los ficheros “CADIPI1_Sup2a.sav” y “CADIPI1_Sup2b.sav”. Ahora procedemos a la fusión, mediante el comando [Datos|Fundir archivos|Añadir casos…].
• Entonces, si teníamos activo el fichero “CADIPI1_Sup2b.sav”, le decimos al programa que fusione el otro fichero, es decir “CADIPI1_Sup2a.sav”. Obviamente también se puede efectuar a la inversa. Lo más importante es especificar (si las hubiera) cuáles son las variables que no coinciden en ambos ficheros. El resultado:
En Statistica se hace de manera muy similar y por este motivo no se especifican los detalles.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-57
57
2.2.8. Incorporación de nueva información a partir de los datos básicos
• Aunque hemos simplificado tremendamente las opciones de gestión de ficheros, centrando lo más importante, se ha indicado lo más relevante para poder tener una base razonable.
• Hasta aquí hemos vistos todo lo que atañe a los datos originales, pero con frecuencia es necesario incluir nuevas variables que surgen a partir de otras originales, mediante alguna transformación.
• En lo que sigue ejemplificaremos esta tarea para el Supuesto 1. Supongamos que nuestro objetivo es transformar la variable X1 en otra nueva que corresponda con su inversa, es decir queremos aplicar la transformación:
1 11' ; 11 1
X InvXX X
= =
• Pues bien, con el fichero oportuno “CADIPI1_Sup1.sav” activo, primero creamos una nueva variable y le damos incluso un nombre, “InvX1”, entonces pulsamos [Transformar|Calcular…] y nos aparece la ventana principal de transformaciones que constituye un asistente:
Ejemplo para Humanidades:

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-58
58
Ejemplo para Ciencias:
• A la izquierda se expresa la variable destino y a la derecha la expresión adecuada. • Esta opción es bastante poderosa y el investigador debe familiarizarse con ella. Tenemos
operadores algebraicos básicos, operadores lógicos por ejemplo para aplicar una transformación únicamente a una parte de los datos (i.e. a un solo grupo), así como funciones estadísticas y matemáticas bastante sofisticadas (en la parte derecha bajo funciones). En los módulos posteriores, al hablar de las transformaciones de los datos volveremos sobre esta opción.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-59
59
En Statistica:
• Con el fichero oportuno “CADIPI1_Sup1.sta” activo, primero creamos una nueva variable y le damos incluso un nombre, “InvX1”, entonces pulsamos con el botón secundario del ratón sobre la variable recién creada y entonces introducimos la función en la ventana inferior o bien activamos el asistente de funciones en el menú [Data|Batch Transfomrmation Formulas…] y nos aparece la ventana principal de transformaciones que constituye un asistente (Botón Functions):
• También en este programa, esta opción es bastante poderosa. Tenemos operadores algebraicos básicos, operadores lógicos por ejemplo para aplicar una transformación únicamente a una parte de los datos (i.e. a un solo grupo), así como funciones estadísticas y matemáticas bastante sofisticadas (en la parte derecha bajo funciones). En los módulos posteriores, al hablar de las transformaciones de los datos volveremos sobre esta opción.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-60
60
Recodificación de diversas variables en una única variable. En ocasiones puede interesarnos juntar los niveles de diversas variables en una única variable. Por ejemplo, si tenemos un diseño factorial de 2 variables del tipo 4x2, podríamos crear una nueva variable con 8 niveles. Lo ilustraremos a partir del supuesto 2. En SPSS:
• Con el fichero oportuno (MEFCS.Sup2.sta) elegimos como antes, primero creamos una nueva variable y le damos un nombre, “Combina”, entonces pulsamos [Transformar|Calcular…] y nos aparece la ventana principal de transformaciones:
• Entonces, en la ventana inferior para establecer una condición (“Si …”) vamos definiendo cada nuevo valor a partir de la combinación de las variables que deseamos recodificar, i.e. el valor 1 de “Combina” se corresponde con Estrategia=1 (ó v1=1) y Genero=1 (ó v2=1), y así sucesivamente hasta completar los seis valores.
©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-61
61
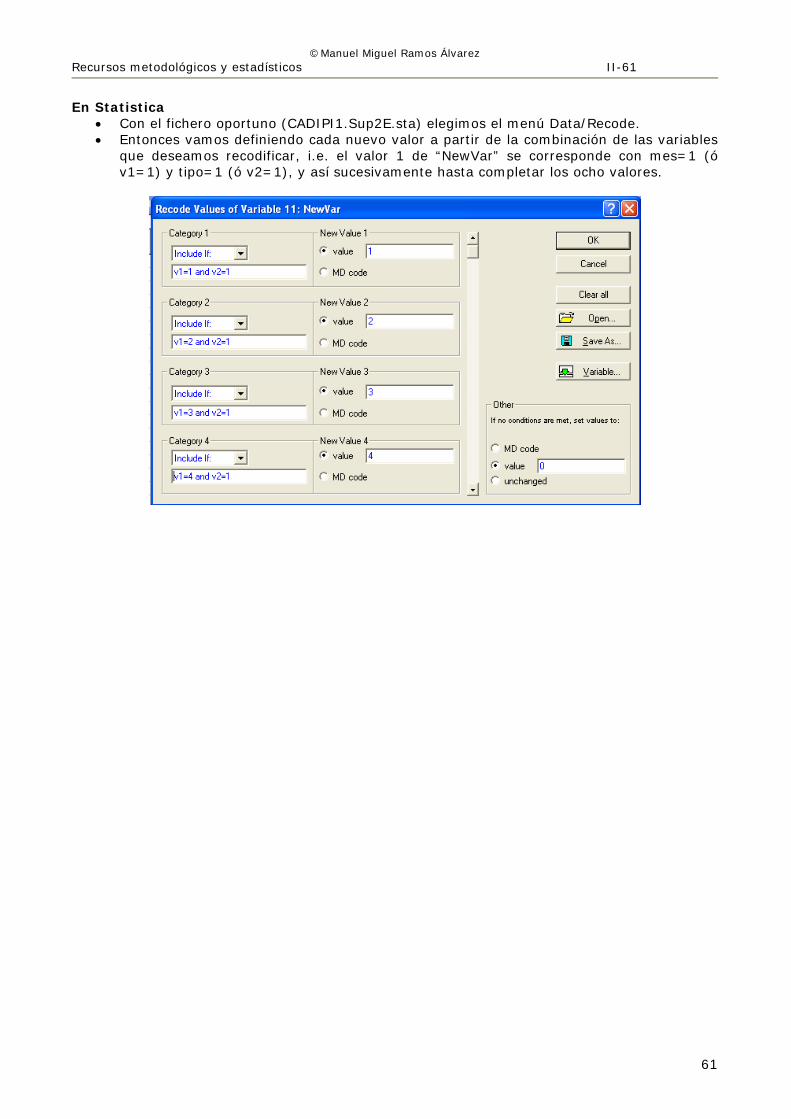
En Statistica
• Con el fichero oportuno (CADIPI1.Sup2E.sta) elegimos el menú Data/Recode. • Entonces vamos definiendo cada nuevo valor a partir de la combinación de las variables
que deseamos recodificar, i.e. el valor 1 de “NewVar” se corresponde con mes=1 (ó v1=1) y tipo=1 (ó v2=1), y así sucesivamente hasta completar los ocho valores.
©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-62
62
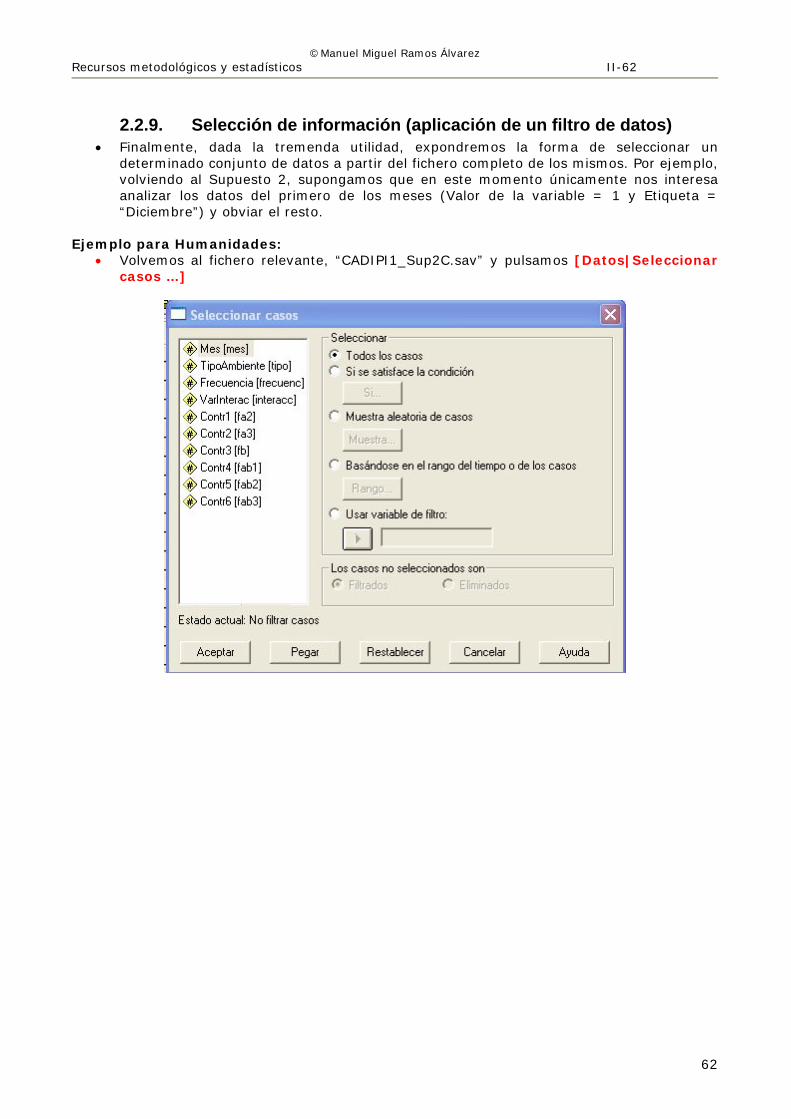
2.2.9. Selección de información (aplicación de un filtro de datos) • Finalmente, dada la tremenda utilidad, expondremos la forma de seleccionar un
determinado conjunto de datos a partir del fichero completo de los mismos. Por ejemplo, volviendo al Supuesto 2, supongamos que en este momento únicamente nos interesa analizar los datos del primero de los meses (Valor de la variable = 1 y Etiqueta = “Diciembre”) y obviar el resto.
Ejemplo para Humanidades:
• Volvemos al fichero relevante, “CADIPI1_Sup2C.sav” y pulsamos [Datos|Seleccionar casos …]
©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-63
63
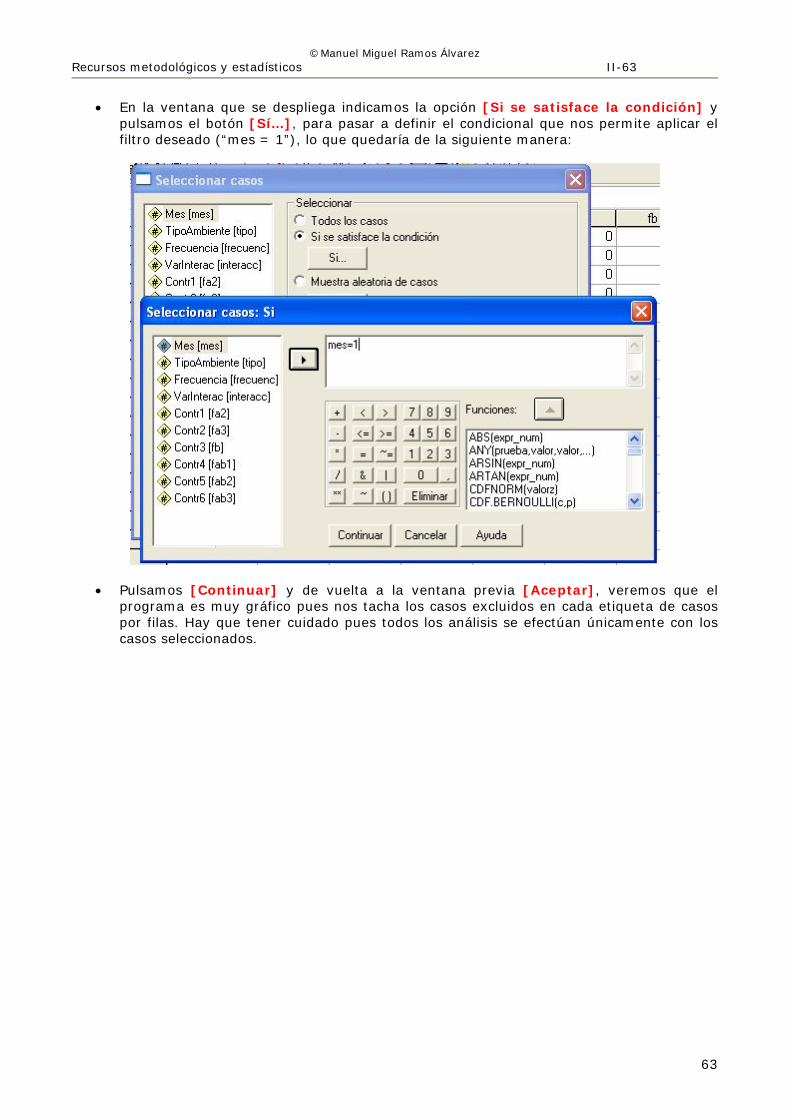
• En la ventana que se despliega indicamos la opción [Si se satisface la condición] y
pulsamos el botón [Sí…], para pasar a definir el condicional que nos permite aplicar el filtro deseado (“mes = 1”), lo que quedaría de la siguiente manera:
• Pulsamos [Continuar] y de vuelta a la ventana previa [Aceptar], veremos que el programa es muy gráfico pues nos tacha los casos excluidos en cada etiqueta de casos por filas. Hay que tener cuidado pues todos los análisis se efectúan únicamente con los casos seleccionados.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-64
64
Ejemplo para Ciencias:
• Volvemos al fichero relevante, “CADIPI1_Sup2E.sav” y pulsamos [Datos|Seleccionar casos …]

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-65
65
• En la ventana que se despliega indicamos la opción [Si se satisface la condición] y
pulsamos el botón [Sí…], para pasar a definir el condicional que nos permite aplicar el filtro deseado (“mes = 1”), lo que quedaría de la siguiente manera:
• Pulsamos [Continuar] y de vuelta a la ventana previa [Aceptar], veremos que el programa es muy gráfico pues nos tacha los casos excluidos en cada etiqueta de casos por filas. Hay que tener cuidado pues todos los análisis se efectúan únicamente con los casos seleccionados.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-66
66
En Statistica:
• Volvemos al fichero relevante, “CADIPI1_Sup2C.sta” y pulsamos [Tools|Selection Conditions | Edit …]
• En la ventana que se despliega indicamos la opción [Enable Selection Conditions] y pulsamos el botón [Specific, selected by:], para pasar a definir el condicional que nos permite aplicar el filtro deseado (“v1 = 1”), lo que quedaría de la siguiente manera:
• Pulsamos [Aceptar] y confirmamos la activación del filtro de vuelta a la ventana previa [Aceptar], veremos que existe la opción de visualizar [Display] la selección efectuada (i.e. por defecto el programa pone en itálica los casos seleccionados). Hay que tener cuidado pues todos los análisis se efectúan únicamente con los casos seleccionados.
• Dos son las herramientas asociadas a las selecciones de este tipo:
Editar Filtro Activa/Desactiva Filtro
• También se puede acceder al filtro pulsando sobre el botón “Select Cases” que figura en la parte Inferior Derecha de los módulos especializados de análisis, de manera que se defina a posteriori, una vez que se ha iniciado el análisis.

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-67
67
2.2.10. Manipulación de ficheros en el Entorno R 1. El procesamiento inicial de datos se realizará en una hoja de cálculo, con objeto de poder
manipular los datos con facilidad y de forma que después se puedan manipular o analizar con cualquier tipo de programa especializado de análisis. 1.1. Crear un fichero en Microsoft Office Excel ® con la estructura estándar de casos-en-filas
y variables-en-columnas, incluyendo el nombre de las variables:
En el ejemplo, la primera columna codifica el grupo, la segunda columna los valores medidos en una primera variable dependiente y la tercera columna los que se han medido en una segunda variable dependiente. La muestra está constituida por un total de 8 sujetos, de los cuales cada uno de los grupos tiene asignados 4 sujetos. Una vez introducidos los datos, los almacenamos en un fichero de Excel, en el ejemplo le llamamos “EjemR.xls” y estará ubicado en la raíz del disco duro C.
1.2. También es conveniente almacenar los datos en un fichero de texto, que únicamente contendrá caracteres ASCII. Para ello, se almacena el fichero del apartado precedente con el formato de texto, invocando en Excel los comandos: [Archivo Guardar Como
Nombre de archivo: EjemR, Guardar como tipo: Texto (MS-DOS) Guardar Aceptar Sí Archivo Salir].
2. En el entorno R-Software, se puede programar directamente en la Consola de comandos pero es mucho más cómodo abrir un script independiente en el que podemos escribir como en cualquier editor sencillo de texto y entonces ejecutar partes concretas del mismo seleccionándolas y pulsando [Ctrl+R]. Para hacer esto, ejecutamos los comandos: [Archivo
Nuevo script]. Para más comodidad las Ventanas se pueden organizar en forma de título. 3. Además, dicho script se puede almacenar para futuros análisis, mediante [Archivo
Guardar como Nombre: ComandEjem, Tipo: R files (*.R) Guardar], al que se puede acceder con [Archivo Abrir script Nombre: ComandEjem, Tipo: R files (*.R) Abrir].
4. Vistos los preliminares, nos centramos ahora en la definición de los datos en el entorno S.
Para ello disponemos de multitud de opciones, de las cuales optaremos por la que nos permite mantener mayor uniformidad con otros entornos estadísticos. Trabajaremos con objetos del tipo Data.Frame y además rellenándolo a partir de la importación del fichero de texto del tipo definido en los apartados precedentes. Para esto vinclulamos un nombre, i.e. DataEjem, a toda la información mediante el comando: [DataEjem <- read.table("c:/EjemR.txt", header=T). el comando header sirve para procesar las cabeceras de los datos, es decir los nombres de las variables, las cuales estaban incluidas en nuestro ejemplo (Grupo, VarDep1 y VarDep2).

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-68
68
4.1. Alternativamente, R incorpora algunos paquetes para facilitar la interacción con ficheros
de Excel (i.e. RODBC, RexcelInstaller). En el ejemplo siguiente se empleará RODBC: #------------------------------------------------------------------
#Ejemplo 1 .- Brain Training a partir de Excel library(RODBC) canal <- odbcConnectExcel("c:/ModGeneralAnalisis.xls") ActivFisXls <- sqlFetch(canal, "ASCII1") odbcCloseAll() ActivFisXls
#En versiones posteriores a la 2.6.x hay que cargar el paquete expresamente: #Paquetes Instalar paquetes seleccionar un CRAN mirror Aceptar RODBC
#------------------------------------------------------------------
5. También es recomendable enlazar los nombres de las columnas del fichero, es decir los
nombres de las variables, con objeto de acceder a la información con mayor comodidad: [attach(DataEjem)].
6. A partir de aquí se pueden seleccionar fragmentos de los datos a través de los valores y los
nombres de las variables. Por ejemplo: Grupo1 <- DataEjem[Grupo == 1, "VarDep1"]

©Manuel Miguel Ramos Álvarez Recursos metodológicos y estadísticos II-69
69
2.3. Casos prácticos 1. A continuación figura un nuevo supuesto de prácticas sobre el que podrá aplicar los
principales conceptos aprendidos en este tema. Enunciado: El objetivo de esta investigación fue evaluar los efectos de la Dieta tipo Mediterránea en la prevención de la enfermedad cardiovascular (ver un ejemplo en la dirección: http://www.med-estetica.com/Cientifica/Revista/n16/dietamediterranea.html), para lo cual se formaron al azar grupos de intervención con dieta mediterránea suplementada con aceite de oliva, frutos secos, o con vino, respectivamente. Además, un cuarto grupo sirvió como control. En los grupos de intervención, las cantidades se equilibraron con objeto de optimizar los efectos saludables sobre la dieta. A continuación se presentan los datos sobre la concentración sérica de los marcadores de inflamación vascular relacionados con la aparición y desarrollo de la arteriosclerosis, como marcador de trastornos cardiovasculares, para los individuos del estudio y según el grupo de pertenencia.
Oliva F.Secos Vino Control
7 19 62 124 9 27 77 51
19 104 90 63 1 39 58 81
18 14 57 83 15 54 1 106
Preguntas: 1.1. Introduzca los datos mediante el programa Excel y almacénelos en el fichero llamado
“PracticaT2.xls”. 1.2. En el programa SPSS, importe los datos a partir del fichero del apartado anterior, defina
adecuadamente las variables y entonces almacénelo en el fichero “PracticaT2.sav”. 1.3. Introduzca una transformación de la variable dependiente a partir de su inversa, en una
nueva variable que se llamará “InvInflama” y con el resultado, cree un nuevo fichero que se llamará PracticaT2Transf.sav
1.4. ¿Cómo se haría la codificación de la variable Grupo mediante el sistema de contrastes de tipo Helmert?
1.5. Intente obtener la media exclusivamente del Grupo de Control, para lo cual tendrá que seleccionar dicho grupo mediante un filtro y después obtener la media mediante los comandos [Analizar][Estadísticos Descritivos][Descriptivos][Variables: Inflamacion].
Volver Principio