
IDENTIFICACION AUTOMATICA DEL LENGUAJE …villasen/index_archivos/cursoTL/...automática del...
39
IDENTIFICACION AUTOMATICA DEL LENGUAJE HABLADO SIN RECONOCIMIENTO FONÉTICO DE LA SEÑAL DE VOZ AVANCE DE TESIS DOCTORAL 4to. SEMESTRE ENERO 2006 Realizado por: Ana Lilia Reyes Herrera Director: Dr. Luis Villaseñor Pineda Laboratorio de Tecnologías del Lenguaje Coordinación de Ciencias Computacionales. Instituto Nacional de Astrofísica Óptica y Electrónica, Luis E. Erro 1, Tonantzintla, Puebla, 72840, México Enero 2006 1 de 39
Transcript of IDENTIFICACION AUTOMATICA DEL LENGUAJE …villasen/index_archivos/cursoTL/...automática del...

IDENTIFICACION AUTOMATICA DEL LENGUAJE HABLADO SIN RECONOCIMIENTO FONÉTICO DE LA SEÑAL DE VOZ
AVANCE DE TESIS DOCTORAL
4to. SEMESTRE ENERO 2006
Realizado por: Ana Lilia Reyes Herrera
Director: Dr. Luis Villaseñor Pineda
Laboratorio de Tecnologías del Lenguaje Coordinación de Ciencias Computacionales.
Instituto Nacional de Astrofísica Óptica y Electrónica, Luis E. Erro 1, Tonantzintla, Puebla, 72840, México
Enero 2006
1 de 39

Contenido Pág.
Resumen..........................................................................................................................................3 1. Introducción..................................................................................................................................4
1.1. La naturaleza del problema...................................................................................................5 1.2. Las dificultades en la identificación del lenguaje hablado.....................................................6
2. La propuesta ................................................................................................................................7 2.1 Preguntas de Investigación ....................................................................................................7 2.2 Aportaciones ..........................................................................................................................7
3. Metodología..................................................................................................................................8 3.1 Procesamiento acústico de la señal de voz ...........................................................................8 3.2 Método de aprendizaje.........................................................................................................10
4. Estado del arte ...........................................................................................................................10 4.1. Enfoque con representación fonética..................................................................................10 4.2. Enfoque sin representación fonética ...................................................................................11
5. Avances de la investigación .......................................................................................................13 5.1. Corpus.................................................................................................................................14 5.2. Proceso de aprendizaje.......................................................................................................14 5.3. Paso 2: Obtención de más características en MFCC..........................................................15
5.3.1 Experimento 1: Vector directo de 16MFCC...................................................................17 5.3.2 Experimento 2: Aplicando ganancia de información al vector de 16MFCC ..................17 5.3.3 Experimento 3: La identificación automática de lenguas sin trascripción fonética: Náhuatl y Zoque de México....................................................................................................18 5.3.3 Conclusiones.................................................................................................................20
5.4. Paso 3: Caracterización independiente del tiempo .............................................................20 5.4.1 Experimento 4: Nuevo conjunto de características acústicas de 192 atributos ............21 5.4.2 Experimento 5: Nuevo conjunto de características con ganancia de información ........24 5.4.3 Conclusiones.................................................................................................................27
5.5 Paso 4: Procesamiento acústico basado en Wavelets.........................................................28 5.5.1 Conceptos básicos de Wavelets ...................................................................................28 5.5.2 Experimento 6: El uso de la transformada Daubechies. ...............................................30 5.5.3 Conclusiones.................................................................................................................34
Cronograma de Actividades ...........................................................................................................37 Referencias ....................................................................................................................................38
2 de 39

Resumen La identificación automática del lenguaje hablado consisten en identificar el idioma de quien habla basándose sólo en una simple muestra de voz sin considerar al hablante o lo que está diciendo por medios computacionales. La identificación automática del lenguaje hablado tiene muy diversas aplicaciones. Por ejemplo, las compañías de teléfono quisieran tener un eficiente identificador de idiomas para los hablantes extranjeros y así poder reenviar sus llamadas a un operador capaz de comprender dicho idioma; un sistema de traducción multilingüe con más de dos o tres idiomas necesita un sistema de identificación de lenguaje hablado como primer paso para seleccionar el sistema de traducción apropiado; y por supuesto, los gobiernos alrededor del mundo han estado interesados por mucho tiempo en un sistema identificador de idiomas para propósitos de monitoreo. En la actualidad, los mejores sistemas automáticos de identificación de lenguaje hablado utilizan información lingüística para la tipificación del idioma, es decir, dependen de la representación fonética de la señal de voz. A pesar de los buenos resultados de estos métodos, se depende de un estudio lingüístico previo para cada uno de los lenguajes a identificar; y en base a este estudio, se pueden establecer los valores de los parámetros de identificación. La presente investigación doctoral propone la creación de un método para la identificación del lenguaje hablado basado en información extraída directamente de la señal acústica sin requerir de un módulo de tratamiento fonético. En este documento se exponen los avances y resultados alcanzados durante el segundo año de investigación.
3 de 39

1. Introducción La identificación del lenguaje hablado es el problema de identificar el idioma de quien habla basándose sólo en una simple muestra de voz sin considerar al hablante, lo que está diciendo y el tamaño de la muestra de señal de voz. De acuerdo a esto, la identificación automática del lenguaje hablado es el proceso de usar un sistema computacional para identificar el lenguaje de un hablante a partir de la señal acústica producida al hablar. Con la creciente globalización del comercio en el mundo, existen muchas compañías con sociedades en diferentes países, las cuales demandan una comunicación entre ellos, siendo ésta afectada por los límites del idioma, por otro lado, las compañías de teléfono quisieran tener un eficiente identificador de idiomas para los hablantes extranjeros y poder enviar sus llamadas a los operadores que pueden hablar su idioma. Por otro lado, un sistema de traducción multilingüe con más de dos o tres idiomas necesita un sistema de identificación de lenguaje hablado como primer paso de su sistema para poder reenviar la voz al sistema de traducción apropiado. Lo que es más, un identificador de lenguaje hablado puede salvar vidas; en Estados Unidos de Norteamérica, existen muchos casos reportados al 911 (número telefónico de emergencias) de los cuales no fueron resueltos rápidamente porque el operador al no reconocer el idioma de hablantes extranjeros. Ya que sin importar que se trate de un hablante bilingüe, la lengua materna es utilizada inconscientemente en condiciones de alto estrés. Estos son sólo algunos de los ejemplos que muestran el interés en la identificación automática del lenguaje. Actualmente lo sistemas automáticos de identificación de lenguaje varían en sus enfoques. Los sistemas con mejores resultados, son los que basan la identificación del lenguaje hablado al emplear las características lingüísticas propias de cada lenguaje. Este tipo de sistemas trabaja básicamente en dos pasos. Primero, se segmenta la señal acústica en sus correspondientes fonemas, de igual forma que un reconocer del habla [1]. Posteriormente, la secuencia de fonemas se mide contra uno o varios modelos de lenguaje [3] [4]. Un modelo de lenguaje captura las combinaciones posibles de los fonemas de un lenguaje específico. Así, el modelo de lenguaje que mejor cubra la muestra en cuestión será considerado el lenguaje de la muestra. Desafortunadamente, este enfoque requiere de recursos lingüísticos para realizar estas dos tareas. Por un lado, para reconocer los fonemas se necesita de grandes cantidades datos (grabaciones) previamente etiquetados. Cada grabación debe etiquetarse manualmente a nivel fonético, para después calcular el modelo acústico de cada fonema del lenguaje en cuestión. Por otro lado, para construir el modelo de lenguaje es necesario recopilar grandes cantidades de texto y voz. Con estos datos se calculan las probabilidades de las diversas secuencias de los fonemas. Así, este enfoque depende de una gran cantidad de trabajo previo orientado a caracterizar el lenguaje ó lenguajes a identificar. Como es de imaginar, bajo este esquema, agregar un nuevo lenguaje al sistema de identificación es muy costoso. Desafortunadamente, para las lenguas que no tienen trascripción a texto (ni trascripción fonética), como muchas de las lenguas indígenas de México; este enfoque no es de utilidad.
4 de 39

Además, existe la necesidad real de crear un sistema de asistencia lingüística a emigrantes indígenas monolingües en México [2]; el cual permita la asistencia inmediata a los hablantes indígenas monolingües que se encuentran en la necesidad de interactuar con las autoridades, en México o en EE.UU., cuando no conoce su lengua o procedencia, como en un caso de detención o tratamiento médico de emergencia. Otro enfoque, que trata de eliminar la etiquetación fonética es aquel que usa un sistema de segmentación automática sobre las grabaciones de entrenamiento [5]. En este caso, no reconocemos estrictamente fonemas sino “tokens”. De esta manera, caracterizamos un lenguaje a partir de estos “tokens”, pero este enfoque se mantiene muy cercano al anterior enfoque, pues la identificación del lenguaje hablado se basa, en un reconocedor de “tokens” junto con modelos de lenguaje basados en dichos “tokens”. Por último, un tercer enfoque trata de explotar directamente la señal acústica para identificar el lenguaje hablado. En este caso, se trata de explotar las características de la señal acústica, como la prosodia, la entonación, etc. Hasta este momento, este enfoque no obtiene resultados comparables a los obtenidos con los enfoques anteriores sin embargo no depende de ningún estudio lingüístico, ya sea para la construcción del reconocedor como para la creación de los modelos de lenguaje.
1.1. La naturaleza del problema
Teóricamente las diferencias entre los idiomas son múltiples y enormes. A pesar de que esas diferencias son evidentes a diferentes niveles (léxico, sintáctico, etc.) la identificación del lenguaje hablado es aún un reto. Los sonidos que se generan cuando hablamos pueden ser descritos en términos de un conjunto de unidades lingüísticas abstractas llamadas fonemas. Cada fonema corresponde a una única configuración del tracto vocal. Diferentes combinaciones de fonemas constituyen diferentes palabras. Por lo que, diferentes palabras están formadas de diferentes secuencias de fonemas que corresponden a diferentes movimientos del tracto vocal. Y mas aún, diferentes combinaciones de palabras producen un infinito número de oraciones que contienen toda la información que uno quiere transmitir. La fonética analiza los fonemas en términos de las características lingüísticas de esos sonidos y los relaciona con la posición y movimientos de las articulaciones. Los fonemas pueden ser clasificados en:
• Modo de articulación, el cual describe diferentes fonemas de acuerdo a la forma que el tracto vocal restringe el aire que sale de los pulmones. Los idiomas tienen diferentes categorías de fonemas: nasal, vocal, fricativa, etc.
• Características de los formantes, las consonantes pueden ser formadas dependiendo si las cuerdas vocales están o no están involucradas en su producción.
• Lugar donde se hace la articulación, es decir, el lugar donde se estrecha el tracto vocal durante la pronunciación.
5 de 39

Diferentes combinaciones de modo de articulación, formantes y lugar de articulación resultan en diferentes fonemas. Generalmente un lenguaje no usa todas las posibles combinaciones de formantes, de articulación y de lugar de articulación. Es decir, un lenguaje usa sólo un subconjunto de todos los posibles fonemas que el ser humano puede producir. Así diferentes lenguajes tienen diferentes fonemas, por ejemplo el francés tiene 15 vocales mientras que el español sólo tiene cinco, el alemán tiene vocales unidas mientras que en el inglés no están permitidas, etc. Por otro lado, la manera en que dichos fonemas se unen para formar una palabra debe respetar ciertas reglas propias de cada lenguaje, de la misma forma que cada lenguaje tiene su propia gramática. Los métodos tradicionales de identificación automática del lenguaje aprovechan estas características (los fonemas de un lenguaje y sus combinaciones permitidas) para reconocer un lenguaje. Sin embargo, cuando hablamos no sólo generamos fonemas, también existen otros aportes de información dentro de la señal acústica tal como la entonación, la duración, el acento, el ritmo, etc. Estos elementos comúnmente son agrupados por los lingüistas bajo el concepto de prosodia. Este tipo de información también es distintiva en los lenguajes humanos.
1.2. Las dificultades en la identificación del lenguaje hablado
La identificación del lenguaje hablado por medios automáticos es una tarea difícil que inevitablemente debe limitarse en diversos aspectos. Por ejemplo, el tipo de locutores esperados (i.e. niños, adultos, hombres, mujeres, etc.); el tipo de conversación (palabra aislada, frases claves, habla espontánea, etc.); el canal de transmisión de la señal de voz (micrófono, teléfono, etc.); el nivel de ruido en la señal; el número de idiomas a identificar, etc. En particular, nuestro trabajo aborda la problemática de la identificación del lenguaje hablado cuando:
(i) la señal acústica es muestreada en frecuencias bajas en particular para el teléfono (El canal del teléfono ésta limitado a anchos de banda bajos aproximadamente de 3.2 Khz., con una frecuencia de muestreo de 8kHz, por lo que, la información en las altas frecuencias de la señal de voz se pierde, dando como resultado menos información para la discriminación);
(ii) el tipo de conversación sea continuo (el habla continua introduce co-articulación y pausas);
(iii) se tiene una situación independiente del locutor (el tracto vocal en cada persona es diferente, entonces las variaciones de los hablantes en la realización de fonemas puede ser substancial).
Las primeras dos condiciones limitan el alcance de nuestro trabajo. Por el contrario, un
sistema independiente del locutor es más difícil que uno dependiente del locutor pero esta característica es fundamental si deseamos construir un sistema práctico. Los humanos no tenemos problemas en identificar un lenguaje cuando lo entendemos. Similarmente, no hay duda que un sistema de identificación de lenguaje parecido al humano debería conseguir resultados impecables, si pudiera tener un gran vocabulario almacenado con el
6 de 39

cual es preciso reconocer y adquirir el conocimiento de las reglas sintácticas y semánticas para cada lenguaje en esta tarea. Con las recientes técnicas y recursos computacionales, el desarrollo de un sistema de este tipo es imposible. Las razones son las siguientes:
• La ejecución de sistemas de reconocimiento del habla está aún muy lejos de los niveles de ejecución humanos. Los actuales sistemas de reconocimiento del habla trabajan mejor con grandes restricciones en el tamaño del vocabulario. Pero para los sistemas de identificación del lenguaje hablado, tales restricciones no pueden ser hechas.
• Recolectar y seleccionar el suficiente conocimiento de los múltiples lenguajes no es una tarea trivial. Para obtener una representación robusta de esta información, se requiere de una cantidad grande de datos de entrenamiento.
2. La propuesta Nuestra investigación está orientada a no depender de la representación fonética de la señal de voz para la identificación del lenguaje hablado, por lo tanto la investigación consiste en desarrollar un nuevo método que, obteniendo información directamente de la señal de voz, nos permita obtener mejores porcentajes de identificación del lenguaje hablado que los métodos propuestos hasta ahora bajo este mismo enfoque.
2.1 Preguntas de Investigación
El desarrollo de la investigación doctoral busca dar respuesta a las siguientes preguntas: • ¿Se podrá hacer la identificación del lenguaje hablado utilizando sólo las características
acústicas de la onda de señal de voz? • En este caso, ¿Cuál es el conjunto de características acústicas más adecuadas para la
identificación del lenguaje hablado? • ¿Se puede hacer la identificación automática del lenguaje hablado en tiempos
comparables a los empleados por el ser humano? • ¿Qué método o combinación de métodos de clasificación será el más adecuado bajo
estas condiciones en la identificación del lenguaje hablado?
2.2 Aportaciones
Nuestro trabajo aportará: • Un método para extracción de características acústicas especializado en la identificación
del lenguaje hablado. • Un método de identificación del lenguaje hablado sin utilizar reconocimiento fonético.
7 de 39

3. Metodología
En base al diagrama de componentes básicos para la identificación del lenguaje hablado sin representación fonética (ver figura 3.0), realizaremos nuestro trabajo en dos pasos principales: el primero dedicado al procesamiento acústico de la señal de voz y el segundo al proceso de aprendizaje. Lenguaje
Clasificador
Extracción de Características Acústica
Señal de voz Figura 3.0. Componentes básicos para la identificación del lenguaje sin representación fonética.
3.1 Procesamiento acústico de la señal de voz
Al no depender de la representación fonética de la señal de voz, el peso del método recae en el procesamiento acústico, necesitamos un nuevo proceso acústico que extraiga las características más representativas para una mejor discriminación de los lenguajes. Por ello, realizaremos los siguientes pasos:
1. Observar las diferencias que se obtienen de utilizar procesos acústicos basados en características de articulación -como producimos el habla- contra los basados en la percepción -cómo escuchamos. Existen varios algoritmos para cada uno de ellos, pero utilizaremos los que actualmente han obtenido mejores resultados:
• Para la obtención de características de articulación, utilizaremos el de coeficientes de predicción lineal LPC (Linear Predictive Coefficients).
• Para la obtención de características perceptuales, utilizaremos el de coeficientes cepstrales de frecuencia Mel MFCC (Mel Frequency Cepstral Coefficients).
2. Observar el resultado que se obtiene de utilizar más coeficientes cepstrales Mel, que los
que comúnmente se utiliza en el estado del arte (12 como máximo), ya que el uso de 12 coeficientes ha dado buenos resultados para la segmentación de fonemas [7], pero como nosotros deseamos eliminar esa segmentación fonética, pensamos obtener más detalle de las frecuencias al aumentar el número de coeficientes centrales Mel a 16.
8 de 39

• Obtener el vector de características acústicas sin aplicar ningún método de reducción de dimensionalidad.
• Obtener un nuevo vector de características acústicas aplicando un método de reducción de dimensionalidad.
• Obtener un nuevo conjunto de características acústicas, tales como el promedio de coeficientes MFCC, y los deltas a diferentes intervalos (1, 2 y 3),
3. Obtener nuevas características acústicas de la señal de voz utilizando Wavelets., El uso
de wavelets no se ha realizado hasta ahora en la problemática de la identificación del lenguaje, sin embargo, éstos han sido utilizados en el reconocimiento del habla obteniendo buenos resultados [8][9]. Por otro lado, los wavelets son funciones capaces de representar señales con una muy buena resolución en los dominios del tiempo y la frecuencia [6]. La transformada wavelet permite una buena resolución en las bajas frecuencias que es donde están la prosodia y el ritmo que hacen posible la discriminación de lenguajes.
• Obtener el vector completo de características obtenido por la transformada wavelet.
• Reducir el vector de características utilizando un método de reducción de dimensionalidad.
• Obtener un nuevo conjunto de características más pequeño, utilizando promedios, desviación estándar, etc.
4. Desarrollar un método para la identificación de los intervalos vocálicos y consonánticos
[10]. • Observar la sonoridad en la señal de voz, como base para la discriminación de las
clases rítmicas.
5. Obtener nuevas características para la discriminación de los lenguajes en base a la desviación estándar de la duración de los intervalos vocálicos y consonánticos.
6. Observar los resultados con estas nuevas características con el corpus OGI multi-
language telephone speech OGI_TS [11]. • Realizando pruebas con los lenguajes utilizados en el estado del arte, Cummins et
al. y Rouas et al, para poder compararnos. • Realizando pruebas con lenguas indígenas de México que no tienen trascripción
fonética. • Realizar pruebas con un conjunto de idiomas rítmicamente semejantes.
7. Observar los resultados con diferentes tamaños de muestras de señal de voz: • Primero con muestras de señal de voz del mismo tamaño que las que utilizaron en
el estado del arte Cummins et al. con 50 segundos, y Rouas et al., 45 segundos.
9 de 39

• Posteriormente variar a 30 y 7 segundos de muestras de señal de voz, para observar su comportamiento al usar menos señal de voz.
3.2 Método de aprendizaje
Realizar un estudio para definir cual es la representación y algoritmo o algoritmos de aprendizaje, que nos ayude con la tarea de identificación del lenguaje hablado, teniendo como conocimiento previo (entrada) las características acústicas producidas en el primer paso. Para ello será necesario:
• Realizar experimentos con diferentes clasificadores, de acuerdo a diferentes representaciones: estocásticos, máquinas de vectores de soporte y redes neuronales.
• Observar el uso de análisis de componentes principales (PCA) y ganancia de información, para reducir la dimensionalidad de los vectores de características acústicas.
• Realizar experimentos con la combinación de clasificadores para después unirlos por medio de un torneo de pares de lenguajes con mejores porcentajes.
4. Estado del arte Antes de presentar propiamente los resultados durante este segundo año de trabajo, presentamos una breve descripción de los dos enfoques mencionados anteriormente así como los resultados reportados hasta ahora por los sistemas actuales.
4.1. Enfoque con representación fonética
Este enfoque utiliza dos tipos de información: la fonética y la fonotáctica. Este enfoque consta de dos pasos básicos:
• Reconocimiento fonético. En este enfoque se utilizan para cada lenguaje a identificar un conjunto de modelos acústicos (uno para cada fonema) para transformar la señal acústica en la secuencia de fonemas más probable. Para la construcción de dichos modelos acústicos es necesario contar con un gran número de grabaciones. Estas grabaciones deben cubrir todos los fonemas del idioma así como sus alófonos (variantes de los fonemas dado su contexto, el acento regional, etc.). Ahora bien, dichas grabaciones deben estar etiquetadas manualmente por expertos a nivel fonético, es decir, cada grabación debe ser escuchada por el experto para determinar las fronteras entre los fonemas. Esta segmentación manual de la señal es una tarea muy costosa. Por otro lado, damos por hecho, que el idioma en cuestión ha sido previamente sistematizado por lingüistas definiendo claramente su conjunto de fonemas.
• Modelado del lenguaje. Es a partir de la secuencia de fonemas que propiamente se realiza la tarea de identificación. Para ello se comparan las proporciones de los fonemas en la secuencia contra los modelos de los lenguajes a identificar. Un modelo de lenguaje
10 de 39

es un listado de todas las posibles combinaciones de dos, tres o n fonemas con sus respectivas probabilidades (v. g. las características fonotácticas del idioma). Para la creación de los modelos de lenguaje son necesarios grandes corpus de texto (y/o transcripciones ortográficas de grabaciones) para la estimación de dichas probabilidades. Los modelos pueden ser entrenados usando modelos ocultos de Markov (HMM´s) o redes neuronales. Por supuesto, se da por hecho que se trata de un idioma con convenciones claramente establecidas para su escritura. Situación que no es del todo cierta para todas las lenguas humanas, por ejemplo, algunas de las lenguas indígenas mexicanas.
En [12] se han conseguido buenos resultados con el corpus OGI_TS [11] usando una
pequeña variación a este enfoque: ellos explotan el factor de que un reconocedor fonético, para un lenguaje, puede ser desarrollado reutilizando los modelos acústicos de un lenguaje diferente. Esto tiene la ventaja de que los reconocedores fonéticos no necesitan ser desarrollados para todos los lenguajes a identificar. Estos sistemas obtienen un 79% precisión en la identificación de 11 lenguajes usando 50 segundos de señal de voz y 70% usando 10 segundos de señal de voz. En [3] se han conseguido los mejores resultados hasta hoy con el corpus SpeechDat-M (un esfuerzo europeo), este trabajo utilizó un sólo idioma, el portugués, para obtener los modelos de los otros lenguajes; dichos modelos están basados en una interpolación de las probabilidades de un fonema tipo bigrama. Sus resultados fueron 85% usando 10 segundos de señal de voz, para 6 lenguajes a identificar.
4.2. Enfoque sin representación fonética
Los siguientes trabajos resumen los principales enfoques para la identificación del lenguaje sin representación fonética de la señal de voz hablada:
German Spanish Japanase Mandarin
English 52 62 57 58
German - 51 58 65 Spanish - - 66 47
Japanese - - - 60
Tabla 4.2.1. Porcentajes de discriminación obtenido por Cummins et al. [15 ].
• Cummins [15] utilizó la prosodia (frecuencia fundamental F0) en el procesamiento acústico para extraer las características de la señal de voz de cada uno de los lenguajes a identificar. El trabajo recae en que las variaciones de amplitud en la frecuencia fundamental son importantes para percibir el ritmo en el habla (para ello utilizó el filtro pasa-bandas de bajo orden Butterworth). A partir de esta caracterización usó una red neuronal para clasificar pares de idiomas. Para la red neuronal usó el modelo LSTM (Long Short-Term Memory) y para el entrenamiento utilizó una combinación de backpropagation
11 de 39
truncada a través del tiempo y aprendizaje recurrente en tiempo real. Sus pruebas fueron hechas con el corpus OGI_TS [11] tomando cinco idiomas, con 50 hablantes diferentes por idioma para entrenamiento y 20 para prueba. Sus resultados se muestran en la tabla 4.2.1, para pares de lenguajes en señales de voz de 50 segundos.
• Samouelian [14] para el procesamiento acústico realizó los siguientes pasos: fragmentó la señal, obtuvo 12 coeficientes cepstrales de frecuencia Mel, calculó su delta (el cambio de cada coeficiente entre dos segmentos contiguos en el tiempo), y finalmente aplicó la derivada de normalización de energía, llamada energía delta. Para el proceso de aprendizaje usó el algoritmo C4.5 para generar un árbol de decisión a partir de un corpus de entrenamiento de 50 hablantes de tres idiomas obtenidos del corpus OGI_TS [11] con muestras de señal de 45 segundos. Las pruebas se realizaron con muestras de 45 segundos y de 10 segundos obteniendo 53% y 48.6% respectivamente.
• Rouas [16] propone un método para identificar los lenguajes en base a su entonación y ritmo, retoma las teorías lingüísticas y trata de caracterizar el ritmo en función de intervalos vocálicos y consonánticos. Los lingüistas describen agrupan los lenguajes de acuerdo a su entonación, como por ejemplo el Chino Mandarin ó el Vietnamita, usan la entonación para diferenciar entre silabas con diferente significado, en cambio en el inglés se utiliza la entonación para saber si es una pregunta o afirmación. Su modelo parte de segmentar la señal de voz en intervalos formados por vocales e intervalos formados por consonantes, para obtener los parámetros del ritmo. Para obtener los parámetros de entonación utilizó la frecuencia fundamental F0 de cada segmento, obteniendo cuatro parámetros, la media, la desviación estándar, el F0 skewness y el F0 kurtosis. Dichos parámetros son modelados usando Gaussian Mixture Models (GMM). Sus experimentos fueron hechos con el corpus OGI_TS y sus resultados se muestran en la tabla 4.2.2.
German Spanish Mandarin Vietnamese Japanese Korean Tamil Farsi
English 59.5 67.7 75.0 67.7 67.6 79.4 77.4 76.3
German _ 59.4 62.2 65.7 65.8 71.4 69.7 71.8
Spanish _ _ 80.6 62.1 62.5 75.9 65.4 66.7
Mandarin _ _ _ 50.0 50.6 73.5 74.2 76.3 Vietname
se _ _ _ _ 68.6 56.2 71.4 66.7
Japanese _ _ _ _ _ 65.7 59.4 66.7
Korean _ _ _ _ _ _ 62.1 75.0
Tamil _ _ _ _ _ _ _ 69.7
Tabla 4.2.2. Porcentajes de discriminación obtenido por Rouas et al. [16].
12 de 39

A manera de resumen, la tabla 4.1 muestra un concentrado de los resultados obtenidos por los diferentes trabajos usando los diferentes enfoques.
Recursos lingüísticos Resultados Autor /año
Tipo de procesamiento
acústico
Tiempo de muestra
(segundos)
Cantidad de idiomas
reconocidosRecono-cimiento fonético
Modelos de lenguaje Otros
Método de clasificación Tamaño de
Corpus
Porcentaje de identifica-
ción
Casseiro 2000 12 DMFCC 10
6:inglés, español, francés, italiano, alemán,
portugués
Sólo uno (para el portu-gués)
Uno para cada
lenguaje a reconocer
No
Interpolación de probabilida-des de los bi-
gramas
SpeechDat corpus 6000
hablantes 79.6%
Torres/ Singer 2002
GMM-SDC Delta-cepstral
coeficientes 45 12 lenguajes
Si, (tokens en lugar
de fonemas)
Uno para cada
lenguaje a reconocer
No GMM-Tokenization
OGI_TS 45 hablantes c/idioma
45s: 75% 10s: 70%
Cummins 1999 Delta F0 50
5:ingles, japonés español, alemán
mandarín.
No No pro-sodia
Red neuronal back-
propagation LSTM
OGI_TS 50 hablantes c/idioma
Ver tabla 4.2.1
Samouelian 1998
12 MFCC 12 DMFCC 1 DEnergía
45 entrena-miento; 10
prueba
3:inglés, japonés alemán
No No No Inferencia
inductiva árbol de decisión
50 hablantes OGI_TS
45s: 53% 10s: 48.6%
Rouas 2003
Ritmo: intervalos de vocales y consonantes,
cuatro parámetros F0
45 10 lenguajes No No No GMM-modelo prosódico, con
Bayes OGI_TS Ver tabla
4.2.2
Tabla 4.1. Comparativo de métodos para la identificación del lenguaje
5. Avances de la investigación De acuerdo a nuestros objetivos y metodología, los experimentos realizados hasta ahora cubren los primeros cuatro puntos. El primer paso, fue reportado en la propuesta de tesis. Ese paso consistió en observar las diferencias en utilizar procesos acústicos basados en características de articulación (como producimos el habla), contra los basados en la percepción de cómo escuchamos. En resumen, la variabilidad del habla producida por la co-articulación y otros factores hacen del análisis de la voz extremadamente difícil. La facilidad del humano en superar estas dificultades sugiere que un sistema basado en la percepción auditiva podría ser un buen enfoque. Desafortunadamente nuestro conocimiento de la percepción humana es incompleto. Lo que sabemos es que el sistema auditivo está adaptado a la percepción de la voz. El oído humano detecta frecuencias de 20Hz a 20,000 Hz, pero es más sensible entre 1000 y 6000 Hz. También es más sensible a cambios pequeños en la frecuencia en el ancho de banda
13 de 39

crítico para el habla. Para representar mejor el patrón de percepción del oído humano, se desarrollo una escala llamada Mel, una escala logarítmica. Estudios recientes muestran que el humano no procesa frecuencias individuales independientemente, como lo sugiere el análisis acústico. En su lugar escuchamos grupos de frecuencias y somos capaces de distinguirlas de ruidos de alrededor.
Durante ese primer paso se probó al caracterizar la señal usando un método con un enfoque en la articulación: el algoritmo de LPC (Linear Predictive Coefficients); y un método con un enfoque basado en la percepción: el algoritmo MFCC (Mel Frequency Cepstral Coefficients). Los mejores resultados se obtuvieron al usar el algoritmo MFCC (para más detalle del experimento véase la propuesta de tesis). Por otro lado, dado que no se contaba con un corpus adecuado los resultados no pudieron compararse contra los métodos reportados en el estado del arte. Sin embargo, dicho experimento sentó las bases para buscar otras alternativas de caracterización de la señal de voz, tales como el uso de wavelets (enfocándonos en las bajas frecuencias) y reafirmar el uso de MFCC pero con un número más alto de coeficientes, así como el reducir el tamaño de ventana de 50 milisegundos a 20 milisegundos. Además de agrandar el tamaño de la muestra de señal de 3 segundos a 7, 30 y 50 segundos.
A partir de estas primeras conclusiones se realizaron otros experimentos con resultados interesantes. En las figuras 5.1 y 5.2 se muestran los pasos de los experimentos que en las siguientes secciones se describen.
5.1. Corpus
Para tener la misma base de evaluación se adquirió el corpus OGI_TS. De este corpus e tomaron nueve idiomas: Inglés, Alemán, Español, Japonés, Chino Mandarin, Coreano, Tamil, Vietnamita y Farsi; no se pudo probar con Francés porque recientemente fue eliminado del Corpus OGI_TS [11], utilizamos estos idiomas para poder compararnos contra los trabajos de Cummins et al.[15 ] y Rouas et al. [16 ]. Para cada idioma se tomaron 50 hablantes diferentes; se trata de conversaciones telefónicas, es decir, a 8Khz, donde las personas hablaron espontáneamente, respondiendo a preguntas tales como, ¿Describe el trayecto a tu trabajo?, ¿Describe como es tu casa?, ¿Cómo es el clima en tu país?, etc. Al tratarse de habla espontánea se presentan fenómenos de co-articulación así como pausas. Las pruebas fueron hechas con dos diferentes tamaños de muestras de 30 y 50 segundos, tanto para entrenamiento como para prueba. Teniendo en total 450 hablantes diferentes y 13500 segundos de señal de voz, para el experimento de 30 segundos y 22500 para el de 50 seg.
5.2. Proceso de aprendizaje
El algoritmo de aprendizaje para todos los experimentos fue el mismo, ya que en esta etapa de la investigación dedicamos todo el esfuerzo a la caracterización acústica, obteniendo 4 diferentes formas de obtener las características acústicas, las cuales pasan al proceso de aprendizaje. Los experimentos de aprendizaje y clasificación fueron realizados con el algoritmo
14 de 39

Sequential Minimal Optimization (SMO) que es una máquina de vectores de soporte instrumentado por Platt [19] en la herramienta WEKA [20]. Para la evaluación se utilizó 10-fold-cross-validation. Se realizaron pruebas para pares de idiomas como en Cummins [15] y Rouas[16]. Se utilizaron máquinas de soporte, porque se ha reportado que dan buenos resultados para esta tarea, como se observó en Torres et al. [21].
5.3. Paso 2: Obtención de más características en MFCC.
El objetivo de este experimento era observar los resultados que se obtenían al utilizar más coeficientes cepstrales Mel, que los que comúnmente se han estado utilizando en el estado del arte, para la identificación de los idiomas. Samouelian [14] para el procesamiento acústico utilizó 12 coeficientes cepstrales Mel, porque se ha mostrado que para la segmentación de fonemas [7], el uso de más coeficientes no mejora los resultados, pero nosotros no vamos a realizar segmentación fonética, por lo tanto si aumentamos el número de coeficientes obtendremos más detalle de las frecuencias secundarias. Sabemos que la mayoría de los sonidos incluyendo el habla tienen una frecuencia dominante llamada frecuencia fundamental (F0), la percibimos como el tono (“pitch”) combinado con frecuencias secundarias. En el habla, la frecuencia fundamental es la velocidad a la que vibran las cuerdas vocales al producir un fonema sonoro. Sumadas a la frecuencia fundamental hay otras frecuencias que contribuyen al timbre del sonido. Son las que nos permiten distinguir una trompeta de un violín o las voces de diferentes personas. Algunas bandas de la frecuencia secundarias juegan un rol importante en la distinción de un fonema de otro. Se les llama formantes y son producidas por la resonancia. La garganta, boca y nariz son cámaras de resonancia que amplifican las bandas o frecuencias formantes contenidas en el sonido generado por las cuerdas vocales. Estas formantes amplificadas dependen del tamaño y forma de la boca, y si el aire pasa o no por la nariz. Como se mencionó en el estado del arte Cummins et al, basa el procesamiento acústico solamente en el uso de la frecuencia fundamental, nosotros al ampliar el número de coeficientes cepstrales capturamos además de la frecuencia fundamental F0, las frecuencias secundarias que pueden ser importantes en la tarea de discriminar lenguajes. Se automatizó por medio de un programa hecho en la herramienta PRAAT [18], la fragmentación del tamaño de la muestra de 7, 30 y 50 segundos; además este programa obtiene las características acústicas de la señal de voz aplicando a cada una de esas muestras el modelado de señales de análisis local en la frecuencia por medio del método MFCC, dando como resultado 16 coeficientes; el método MFCC fue aplicado con ventanas de 20 milisegundos, sin traslapes entre ventanas. Finalmente el programa obtiene una matriz y una tabla de valores reales de las características acústicas de la señal de voz, para su posterior proceso.
15 de 39

Análisis LPC
Análisis utilizando Wavelets trasformada de Daubechies db2, 4 coeficientes
Análisis MFCC con 16 coeficientes
Extracción de bajas frecuencias por medio de Hard-threshold Con un valor de .01
Obtención de promedios y Deltas 1,2, y 3
Conversión a Formato ARFF
Vector de características directo
Conjunto características LPC
Conjunto características 16MFCC
Conjunto características Promedios y ∆1, ∆2 y ∆3 de 16MFCC
Conjunto características Wavelets
Señal de voz
Fig. 5.1. Diagrama de los diferentes métodos de obtención de características acústicas.
Clasificación de los pares de lenguajes en base a las características Acústicas obtenidas, utilizando maquinas de vectores de soporte (SMO)
Vector de características acústicas directo
Reducir dimensionalidad método Ganancia de Información
Conjunto características LPC
Conjunto características 16MFCC
Conjunto características Promedios y ∆1, ∆2 y ∆3 de 16MFCC
Conjunto características Wavelets
Identificación del idioma
Fig. 5.2. Diagrama de proceso de aprendizaje utilizando los nuevos conjuntos de características acústicas.
16 de 39

5.3.1 Experimento 1: Vector directo de 16MFCC Sin utilizar ningún método de reducción de dimensionalidad se probó solo para 7
segundos de señal de voz, porque los vectores de 30 y 50 segundos tuvieron 23984 y 39984 atributos respectivamente, por lo que su manejo en la herramienta WEKA[20] no fue posible. Aún para 7 segundos los resultados fueron muy buenos, superando al estado del arte, Cummins et al y Rouas et al. En la tablas 5.3.1.1, se muestran los resultados contra Cummins y en la tabla 5.3.1.2 se muestran los resultados contra Rouas.
Ger Spa Jap Man
Eng 91 (52) 91 (62) 92 (57) 67 (58)
Ger - 62 (51) 69 (58) 77 (65) Spa - - 60 (66) 74 (47) Jap - - - 76 (60)
Tabla 5.3.1.1 Porcentajes de discriminación con muestras de señal de voz de 7 segundos, entre
paréntesis el porcentaje obtenido por Cummins [15].
German Spanish Mandarin Vietnamese Japanese Korean Tamil Farsi
English 86(59.5) 78 (67.7) 59 (75.0) 72 (67.7) 68 (67.6) 69 (79.4) 83 (77.4) 81 (76.3)
German _ 58 (59.4) 71 (62.2) 68 (65.7) 72 (65.8) 64 (71.4) 71 (69.7) 67 (71.8) Spanish - - 72 (80.6) 53 (62.1) 62 (62.5) 58 (75.9) 52 (65.4) 64 (66.7) Mandarin - - - 66 (50.0) 66 (50.6) 60 (73.5) 78 (74.2) 66 (76.3)
Vietnamese - - - - 61 (68.6) 53 (56.2) 66 (71.4) 58 (66.7) Japanese - - - - - 62 (65.7) 62 (59.4) 63 (66.7) Korean - - - - - - 66 (62.1) 65 (75.0) Tamil - - - - - - - 57 (69.7)
Tabla 5.3.1.2 Porcentajes de discriminación con muestras de señal de voz de 7 segundos, entre paréntesis el porcentaje obtenido por Rouas [16].
5.3.2 Experimento 2: Aplicando ganancia de información al vector de 16MFCC Utilizando la ganancia de información como método de reducción de dimensionalidad los
resultados mejoraron y se redujo el número de atributos a procesar. Los resultados se muestran en las tablas 5.3.2.1 y 5.3.2.2.
Ger Spa Jap Man
Eng 93 (52) 96 (62) 96 (57) 81 (58)
Ger - 76 (51) 85 (58) 82 (65) Spa - - 79 (66) 91 (47) Jap - - - 83 (60)
Tabla 5.3.2.1 Porcentajes de discriminación con muestras de señal de voz de 7 segundos, utilizando
ganancia de información; entre paréntesis el porcentaje obtenido por Cummins [15].
17 de 39

German Spanish Mandarin Vietnamese Japanese Korean Tamil Farsi
English 85(59.5) 83 (67.7) 67 (75.0) 81 (67.7) 79(67.6) 76 (79.4) 85 (77.4) 86 (76.3)
German 71 (59.4) 83 (62.2) 85 (65.7) 69(65.8) 70 (71.4) 77 (69.7) 68 (71.8) Spanish 83 (80.6) 71 (62.1) 70(62.5) 63 (75.9) 54 (65.4) 64 (66.7) Mandarin 80 (50.0) 73(50.6) 65 (73.5) 79 (74.2) 75(76.3)
Vietnamese 72(68.6) 68(56.2) 63(71.4) 72(66.7) Japanese - 62(65.7) 67(59.4) 61(66.7) Korean - - 66(62.1) 65(75.0) Tamil - - 66(69.7)
Tabla 5.3.2.2 Porcentajes de discriminación con muestras de señal de voz de 7 segundos, utilizando
ganancia de información; entre paréntesis el porcentaje obtenido por Rouas [16].
5.3.3 Experimento 3: La identificación automática de lenguas sin trascripción fonética: Náhuatl y Zoque de México.
Actualmente en México 6 de cada 100 habitantes (de 5 años y más) hablan alguna lengua indígena, lo que representa el 7.3% de la población total de México [22]. La mayoría de ellos son indígenas monolingües, los cuales tienen la necesidad de interactuar con médicos y autoridades tanto en México como en EE. UU, por casos de emergencias médicas o detecciones ó simplemente estén perdidos. Además de las aproximadamente 69 lenguas indígenas en México la gran mayoría no tienen trascripción a texto. El único sistema que existe hasta hoy, es “Que Lenguas Hablas” [http://cdi.gob.mx/ini/lenguahablas/], el cual identifica la lengua indígena en forma manual, es decir, se hace escuchar a la persona monolingüe todas las posibles grabaciones de lenguas que hay en el sistema, que son alrededor de 39 divididas en cinco grandes grupos: Mayas, Oaxaca, Nahuas, Región centro y Región Norte; y hasta que entienda la frase que se le dice, entonces tenemos identificado que lengua indígena habla. Este proceso es muy tardado y cansado para la persona monolingüe. Por ello, existe la necesidad de crear un sistema automático de identificación de lenguas indígenas de México; con los objetivos de automatizar la identificación mediante el procesamiento de la voz, permitiendo el uso remoto del sistema, mediante teléfono o un portal Internet; integrar más lenguas al sistema de manera eficiente y rápida; y establecer mecanismos de interacción comunicativa con los hablantes monolingües. Dicho sistema permitirá a las autoridades la identificación automática de la lengua del hablante monolingüe, y proporcionará intérpretes adecuados y una lista de instrucciones y derechos fundamentales.
Como mencionamos anteriormente, los sistemas con mejores resultados, son los que basan la identificación del lenguaje hablado en el empleo de las características lingüísticas propias de cada lenguaje. Desafortunadamente, para las lenguas que no tienen trascripción a texto, como muchas de las lenguas indígenas de México; este enfoque no es de utilidad.
En este experimento se tomaron dos de las lenguas indígenas, una de ellas de las más representativas de México, el Náhuatl con el 24% de hablantes de lenguas indígenas en todo el
18 de 39

país y la el Zoque de Oaxaca con el 1% de hablantes; y el idioma español, el cual es el idioma oficial en México. Las grabaciones de Zoque de Oaxaca y Náhuatl fueron tomadas del corpus [23], y el español fue tomado del corpus OGI_TS [11]. Se tomaron de cada una de las lenguas indígenas y el idioma español 20 hablantes diferentes, sin restricciones en la forma de hablar y que decir; con co-articulación y pausas. Las grabaciones de las lenguas indígenas están hechas a 44kHz, por lo que fueron re-muestreadas a 8kHz, y las del idioma español fueron hechas vía telefónica, es decir, a 8Khz; ya que el corpus fue hecho en base a llamadas telefónicas. En total se obtienen 60 muestras de señal de voz hablada, con diferentes duraciones 3 seg, 7seg y 10 seg.
La caracterización de la señal como el proceso de aprendizaje fue igual al descrito en las secciones anteriores. Para la evaluación se utilizó 10-fold-cross-validation. El primer experimento se realizó con datos sin aplicar ninguna técnica de reducción de dimensionalidad, el segundo aplicando ganancia de información. Los dos experimentos fueron realizados con los 3 diferentes tamaños de muestras de señal de voz de 3,7 y 10 segundos, generados por el procesamiento acústico de la señal de voz, previamente descrito. Los resultados se muestran en las tablas 5.3.3.2, 5.3.3.3. Estos dos experimentos fueron hechos para pares de idiomas. Posteriormente se realizaron pruebas para los tres idiomas juntos, los resultados se muestran en la tabla 5.3.3.4.
3 segundos 7 segundos 10 segundos
Náhuatl Español Náhuatl Español Náhuatl Español Zoque 85 95 79 93 84 95
Náhuatl - 94 - 93 - 94
Tabla 5.3.3.5. Porcentaje de discriminación entre las lenguas indígenas: Náhuatl y Zoque de Oaxaca y el español. Sin utilizar ganancia de información.
3 segundos 7 segundos 10 segundos
Náhuatl Español Náhuatl Español Náhuatl Español Zoque 94 98 94 98 97 98
Náhuatl - 97 - 97 - 94
Tabla 5.3.3.5. Porcentaje de discriminación entre las lenguas indígenas: Náhuatl y Zoque de Oaxaca y el español. Utilizando ganancia de información
Los tres idiomas Sin gananciade información
Con Ganancia de información
3 segundos 82 91
7 segundos 87 93 10 segundos 86 92
Tabla 5.3.3.5. Comparativo de las tres lenguas de acuerdo a sus diferentes tamaños de muestras.
19 de 39

5.3.3 Conclusiones Como puede observarse los resultados son muy alentadores y con esto podemos sentar
las bases para un identificador automático de lenguas sin trascripción fonética como las lenguas indígenas de México, es claro que el corpus utilizado fue muy pequeño, y será necesario realizar experimentos más completos en cuanto contemos con corpus grandes de las lenguas indígenas de México. Aún así, pudimos observar que el Náhuatl es más rítmico que el Zoque de Oaxaca el cual es más tonal, como el Chino Mandarin, por ello los porcentajes de discriminación son muy altos, habrá que realizar pruebas con otras lenguas más parecidas entre ellas, pero nos enfrentamos a la no existencia de corpus.
En general, con estos experimentos nos dimos cuenta que al aumentar el número de coeficientes a 16, la discriminación de los pares de lenguajes mejoró y superó el estado del arte. Aunque los resultados son buenos tenemos el factor tiempo, es decir, el vector de características acústicas obtenido de esta manera depende del tiempo. Con este método es posible que estemos generando un buen clasificador pero sólo para un conjunto cerrado de muestras. Por ello, es que decidimos experimentar con un nuevo conjunto de características acústicas que no dependieran del tiempo, resumiendo la información que tenemos en los coeficientes a través de sus promedios y sus variaciones.
5.4. Paso 3: Caracterización independiente del tiempo
El objetivo de este experimento fue proponer una nueva caracterización más real al hacerla independiente del tiempo. Además, se consiguió un nuevo conjunto de características acústicas que más manejable, al ser más pequeño. Sabemos que los cambios temporales en el espectro juegan un papel muy importante en la percepción humana. Una de las maneras de capturar esta información es el uso de los cambios o delta ∆ en los coeficientes cepstrales. Con ellos es posible describir el cambio de cada coeficiente en el tiempo. Estos se definen de la siguiente manera:
• Se obtienen los coeficientes cepstrales Mel de orden 16 (16MFCC) para obtener los Ck
• Con ventanas de 20mseg se obtienen los deltas 16MFCC de primer orden calculando de la siguiente manera:
o El delta ∆1 16MFCC: ∆1Ck = Ck – Ck-1 o El delta ∆2 16MFCC: ∆2Ck = Ck – Ck-2 o El delta ∆3 16MFCC: ∆3Ck = Ck – Ck-1 o Los promedios de los deltas ∆1, ∆2 y ∆3
• El promedio de los coeficientes Promedio-Ck = Σ Ck / N • El máximo y mínimo de Ck • El máximo y mínimo de de los deltas ∆1, ∆2 y ∆3
20 de 39

Con estos deltas obtenemos un nuevo vector de características acústicas perceptivas. A partir de estos vectores calculamos los promedios, así como sus máximos y mínimos alcanzando una nueva caracterización que resume en un sólo vector las variaciones de toda una grabación. En resumen este nuevo vector queda confirmado de la siguiente manera:
Promedio-Ck
Máximo-Ck
Mínimo-Ck
Promedio ∆1Ck
Promedio ∆2Ck
Promedio ∆3Ck
Xk = Máximo ∆1Ck
Máximo ∆2Ck
Máximo ∆3Ck
Mínimo ∆1Ck
Mínimo ∆2Ck
Mínimo ∆3Ck
Para las pruebas se utilizaron la misma cantidad de idiomas que los usados por Cummins
[15] y Rouas [16], obteniendo por medio de MFCC 16 coeficientes, obteniendo 5584 valores, a estos valores se les obtiene el promedio de cada coeficiente, los deltas ∆1, ∆2 y ∆3, así como los promedios de dichos deltas. Por lo que obtenemos un nuevo conjunto de características acústicas reducido de 5584 a 192 para muestras de 7 segundos, de 23984 a 192, para muestras de 30 segundos y de 39984 a 192 para muestras de 50 segundos. Las pruebas se realizaron en diferentes tamaños de muestras de 7, 30 y 50 segundos. Se realizaron las mismas comparaciones de parejas de idiomas que Cummins [15] y obteniendo mejores resultados. Como mencionamos anteriormente las diferencias con Cummins son: utilizó la delta F0 y delta Energía, para el tamaño de muestra utilizó 50 segundos de señal de voz, y finalmente utilizó para la discriminación de lenguajes la Red neuronal LSM. Los resultados se muestran en las siguientes secciones.
5.4.1 Experimento 4: Nuevo conjunto de características acústicas de 192 atributos Sin utilizar ningún método de reducción de dimensionalidad, sólo en base a la obtención
del nuevo conjunto de características de 192 atributos, se obtuvieron mejores resultados que los obtenidos por Cummins [15] y Rouas [16]; los resultados comparándonos contra Cummins se muestran en las tablas 5.4.1.1, 5.4.1,2 y 5.4.1.3, y una gráfica a manera de resumen se muestra en la tabla 5.4.1.4. En observamos que obtenemos mejores resultados con este nuevo conjunto de características acústicas contra lo obtenido por Cummins, nuestra única dificultad es la pareja de español y japonés, pero definitivamente la pareja inglés y alemán que son dos idiomas del tipo rítmico strees-timed, se discriminaron con un muy buen porcentaje.
21 de 39

Ger Spa Jap Man
Eng 86 (52) 78 (62) 68 (57) 59 (58) Ger - 58 (51) 72 (58) 71 (65) Spa - - 62 (66) 72 (47) Jap - - - 66 (60)
Tabla 5.4.1.1 Porcentajes de discriminación con muestras de señal de voz de 7 segundos, sin utilizar ganancia de información, entre paréntesis el porcentaje obtenido por Cummins [15].
Ger Spa Jap Man
Eng 61 (52) 73 (62) 62 (57) 70 (58)
Ger - 54 (51) 61 (58) 58 (65) Spa - - 57 (66) 74 (47) Jap - - - 68 (60)
Tabla 5.4.1.2. Porcentajes de discriminación con muestras de señal de voz de 30 segundos, sin utilizar ganancia de información, entre paréntesis el porcentaje obtenido por Cummins [15].
Ger Spa Jap Man
Eng 71 (52) 88 (62) 74 (57) 62 (58)
Ger - 52 (51) 64 (58) 69 (65) Spa - - 63 (66) 71 (47) Jap - - - 68 (60)
Tabla 5.4.1.3. Porcentajes de discriminación con muestras de señal de voz de 50 segundos, sin utilizar ganancia de información, entre paréntesis el porcentaje obtenido por Cummins [15].
40
50
60
70
80
90
100
Eng-G
er
Eng-S
pa
Eng-Ja
p
Eng-M
an
Ger-Spa
Ger-Ja
p
Ger-Man
Spa-Ja
p
Spa-M
an
Jap-M
an
porc
enta
je d
e di
scri
min
ació
n
CummisMFCC-7SegMFCC-30segMFCC-50seg
Tabla 5.4.1.4. Comparativo de los porcentajes de discriminación con muestras de señal de voz de 7,30 y 50 segundos, sin utilizar ganancia de información, contra el porcentaje obtenido por Cummins [15].
22 de 39

Los resultados comparándonos contra Rouas [16 ] se muestran en las tablas 5.4.1.5,
5.4.1,6 y 5.4.1.7, y una gráfica a manera de resumen se muestra en la tabla 5.4.1.8. De igual forma, se obtienen en general mejores resultados. Rouas et al. encontraron problemas en la identificación de la pareja de inglés y alemán, que en nuestro caso fue muy superior a ellos, es decir ellos usaron las características de entonación y cantidad de intervalos vocálicos y consonánticos. No nos fue tan bien para las parejas contra el coreano.
Tabla 5.4.1.5 Porcentajes de discriminación con muestras de señal de voz de 7 segundos, sin utilizar ganancia de información, entre paréntesis el porcentaje obtenido por Rouas [16].
German Spanish Mandarin Vietnamese Japanese Korean Tamil Farsi
English 86(59.5) 78 (67.7) 59 (75.0) 72 (67.7) 68(67.6) 69 (79.4) 83 (77.4) 81 (76.3)
German _ 58 59.4) 71 (62.2) 68 (65.7) 72(65.8) 64 (71.4) 71 (69.7) 67 (71.8)
Spanish - - 72 (80.6) 53 (62.1) 62(62.5) 58 (75.9) 52 (65.4) 64 (66.7)
Mandarin - - - 66 (50.0) 66(50.6) 60 (73.5) 78 (74.2) 66 (76.3)
Vietnamese - - - - 61(68.6) 53(56.2) 66(71.4) 58(66.7)
Japanese - - - - - 62(65.7) 62(59.4) 63(66.7)
Korean - - - - - - 66(62.1) 65(75.0)
Tamil - - - - - - - 57(69.7)
Tabla 5.4.1.6. Porcentajes de discriminación con muestras de señal de voz de 30 segundos, sin utilizar ganancia de información, entre paréntesis el porcentaje obtenido por Rouas [16].
German Spanish Mandarin Vietnamese Japanese Korean Tamil Farsi
English 61(59.5) 73 (67.7) 70 (75.0) 73 (67.7) 62(67.6) 59 (79.4) 83 (77.4) 66 (76.3) German _ 54 (59.4) 58 (62.2) 68 (65.7) 61(65.8) 50 (71.4) 65(69.7) 55 (71.8) Spanish - - 74 (80.6) 66 (62.1) 57(62.5) 59 (75.9) 54 (65.4) 55 (66.7) Mandarin - - - 68 (50.0) 68(50.6) 56 (73.5) 74 (74.2) 64(76.3)
Vietnamese - - - - 63(68.6) 60(56.2) 67(71.4) 66(66.7) Japanese - - - - - 66(65.7) 73(59.4) 63(66.7) Korean - - - - - - 64(62.1) 63(75.0) Tamil - - - - - - - 72(69.7)
23 de 39

German Spanish Mandarin Vietnamese Japanese Korean Tamil Farsi
English 71(59.5) 88 (67.7) 62 (75.0) 82 (67.7) 74(67.6) 75 (79.4) 91 (77.4) 77(76.3) German _ 52 (59.4) 69 (62.2) 68 (65.7) 64(65.8) 57 (71.4) 73 (69.7) 60 (71.8) Spanish - - 71 (80.6) 63 (62.1) 63(62.5) 61 (75.9) 63 (65.4) 60 (66.7)
Mandarin - - - 57 (50.0) 68(50.6) 57 (73.5) 77 (74.2) 79(76.3) Vietnamese - - - - 57(68.6) 58(56.2) 66(71.4) 75(66.7) Japanese - - - - - 65(65.7) 61(59.4) 65(66.7)
Korean - - - - - - 70(62.1) 69(75.0) Tamil - - - - - - - 69(69.7)
Tabla 5.4.1.7. Porcentajes de discriminación con muestras de señal de voz de 50 segundos, sin utilizar
ganancia de información, entre paréntesis el porcentaje obtenido por Rouas [16].
40
50
60
70
80
90
100
Eng-G
er
Eng-Spa
Eng-M
an
Eng-V
iet
Eng-Ja
p
Eng-K
or
Eng-T
am
Eng-Far
Ger-Spa
Ger-Man
Ger-Viet
Ger-Jap
Ger-Kor
Ger-Tam
Ger-Far
Spa-M
an
Spa-V
iet
Spa-Ja
p
Spa-K
or
Spa-T
am
Spa-F
ar
Man-V
iet
Man-Ja
p
Man-K
or
Man-T
am
Man-Far
Viet-Ja
p
Viet-K
or
Viet-T
am
Viet-F
ar
Jap-K
or
Jap-T
amJap
-Far
Kor-Tam
Kor-Fa
r
Tam-Far
Rouas MFCC-7seg MFCC-30seg MFCC50seg
Tabla 5.4.1.8. Comparativo de los porcentajes de discriminación con muestras de señal de voz de 7,30 y 50 segundos, sin utilizar ganancia de información, contra el porcentaje obtenido por Rouas [16].
5.4.2 Experimento 5: Nuevo conjunto de características con ganancia de información
Utilizando ganancia de información sobre el nuevo conjunto de características de 192 atributos, se obtuvieron mejores resultados que los obtenidos por Cummins [15] y Rouas [16]. En las tablas 5.4.2.1., 5.4.2.2. y 5.4.2.3, se muestran los resultados contra Cummins y una gráfica a manera de resumen se muestra en la tabla 5.4.4.
24 de 39

Ger Spa Jap Man Eng 85 (52) 83 (62) 79 (57) 67 (58)
Ger - 71 (51) 69 (58) 83 (65) Spa - - 70 (66) 83 (47) Jap - - - 73 (60)
Tabla 5.4.2.1. Porcentajes de discriminación con muestras de señal de voz de 7 segundos, utilizando ganancia de información, entre paréntesis el porcentaje obtenido por Cummins [15].
Ger Spa Jap Man
Eng 79 (52) 85 (62) 72 (57) 68 (58)
Ger - 69 (51) 62 (58) 71 (65) Spa - - 75 (66) 81 (47) Jap - - - 80 (60)
Tabla 5.4.2.2. Porcentajes de discriminación con muestras de señal de voz de 30 segundos, utilizando ganancia de información, entre paréntesis el porcentaje obtenido por Cummins [15].
Ger Spa Jap Man
Eng 78 (52) 85 (62) 77 (57) 75 (58) Ger - 71 (51) 66 (58) 79 (65) Spa - - 69 (66) 74 (47) Jap - - - 77 (60)
Tabla 5.4.2.3. Porcentajes de discriminación con muestras de señal de voz de 50 segundos, utilizando ganancia de información, entre paréntesis el porcentaje obtenido por Cummins [ ].
40
50
60
70
80
90
100
Eng-G
er
Eng-S
pa
Eng-Ja
p
Eng-M
an
Ger-Spa
Ger-Ja
p
Ger-Man
Spa-Ja
p
Spa-M
an
Jap-M
an
porc
enta
je d
e di
scri
min
ació
n
CummisMFCC-7SegMFCC-30segMFCC-50seg
Tabla 5.4.2.4. Comparativo de los porcentajes de discriminación con muestras de señal de voz de 7,30 y 50 segundos, utilizando ganancia de información, contra el porcentaje obtenido por Cummins [15].
25 de 39

Los resultados comparándonos contra Rouas [16] se muestran en las tablas 5.4.2.5, 5.4.2.6 y 5.4.2.7, y una gráfica a manera de resumen se muestra en la tabla 5.4.2.8.
German Spanish Mandarin Vietnamese Japanese Korean Tamil Farsi
English 85(59.5) 83 (67.7) 67 (75.0) 81 (67.7) 79(67.6) 76 (79.4) 85 (77.4) 86 (76.3)
German 71 (59.4) 83 (62.2) 85 (65.7) 69(65.8) 70 (71.4) 77 (69.7) 68 (71.8) Spanish 83 (80.6) 71 (62.1) 70(62.5) 63 (75.9) 54 (65.4) 64 (66.7)
Mandarin 80 (50.0) 73(50.6) 65 (73.5) 79 (74.2) 75(76.3) Vietnamese 72(68.6) 68(56.2) 63(71.4) 72(66.7) Japanese - 62(65.7) 67(59.4) 61(66.7)
Korean - - 66(62.1) 65(75.0) Tamil - - 66(69.7) Tabla 5.4.2.5. Porcentajes de discriminación con muestras de señal de voz de 7 segundos, utilizando
ganancia de información, entre paréntesis el porcentaje obtenido por Rouas [16].
German Spanish Mandarin Vietnamese Japanese Korean Tamil Farsi English 79(59.5) 85 (67.7) 68 (75.0) 81 (67.7) 72(67.6) 74 (79.4) 82 (77.4) 77 (76.3)
German 69 (59.4) 71 (62.2) 68 (65.7) 62(65.8) 54 (71.4) 68 (69.7) 65 (71.8) Spanish 81 (80.6) 70 (62.1) 75(62.5) 74 (75.9) 56 (65.4) 62 (66.7)
Mandarin 80 (50.0) 80(50.6) 68 (73.5) 84 (74.2) 73(76.3) Vietnamese 69(68.6) 72(56.2) 70(71.4) 78(66.7) Japanese - 61(65.7) 67(59.4) 71(66.7)
Korean - - 64(62.1) 54(75.0) Tamil - - 74(69.7) Tabla 5.4.2.6. Porcentajes de discriminación con muestras de señal de voz de 30 segundos, utilizando
ganancia de información, entre paréntesis el porcentaje obtenido por Rouas [16].
German Spanish Mandarin Vietnamese Japanese Korean Tamil Farsi
English 78(59.5) 85 (67.7) 75 (75.0) 76 (67.7) 77(67.6) 74 (79.4) 86 (77.4) 81 (76.3) German 71 (59.4) 79 (62.2) 75 (65.7) 66(65.8) 67 (71.4) 77 (69.7) 57 (71.8) Spanish 74 (80.6) 70 (62.1) 69(62.5) 74 (75.9) 66 (65.4) 62 (66.7)
Mandarin 72 (50.0) 77(50.6) 66 (73.5) 84 (74.2) 75(76.3) Vietnamese 70(68.6) 66(56.2) 68(71.4) 77(66.7) Japanese - 68(65.7) 66(59.4) 72(66.7)
Korean - - 75(62.1) 65(75.0) Tamil - - 75(69.7) Tabla 5.4.2.7. Porcentajes de discriminación con muestras de señal de voz de 50 segundos, utilizando
ganancia de información, entre paréntesis el porcentaje obtenido por Rouas [16].
26 de 39

40
50
60
70
80
90
100
Eng-Ger
Eng-Spa
Eng-Man
Eng-Viet
Eng-Jap
Eng-Kor
Eng-TamEng-Fa r
Ger-Spa
Ger-Man
Ger-Viet
Ger-Jap
Ger-Kor
Ger-TamGer-F
ar
Spa-Man
Spa-Viet
Spa-Jap
Spa-Kor
Spa-TamSpa-Fa r
Man-Viet
Man-Jap
Man-Ko r
Man-Tam
Man-Far
V iet-Jap
V iet-Ko r
V iet-TamV iet-F
ar
Jap-Kor
Jap-TamJap-Fa r
Kor-TamKor-F
ar
Tam-Fa r
Rouas MFCC-7seg MFCC-30seg MFCC50seg
Tabla 5.4.2.8. Comparativo de los porcentajes de discriminación con muestras de señal de voz de 7,30 y 50 segundos, sin utilizar ganancia de información, contra el porcentaje obtenido por Rouas [ ].
5.4.3 Conclusiones De lo anterior podemos concluir que el nuevo conjunto de características acústicas, a parte de ser de sólo 192 atributos, da mejores resultados. Esta caracterización supera a lo obtenido por Cummins [15], el cual sólo usó la frecuencia F0, eliminando las frecuentas secundarias, que en nuestro caso obtuvimos al incrementar el número de coeficientes cepstrales. Al hacer el cálculo de deltas ∆1, ∆2 y ∆3, capturamos los cambios de los coeficientes que son los formantes los cuales son cambios importantes que se realizan en la pronunciación de cada fonema, y hay que recordar que cada idioma tiene muy diferentes fonemas. No hay que olvidar la entonación y el ritmo que capturamos con la frecuencia fundamental F0.
Para el caso de Rouas [16] superamos la mayoría sus resultados, ellos tuvieron problemas en la identificación de la pareja de ingles y alemán, que en nuestro caso fue muy superior, el uso de las características de entonación y cantidad de intervalos vocálicos y consonánticos es bueno, como ellos lo mencionan, para la discriminación entre lenguajes stress-timed (como el ingles y alemán) contra los que utilizan la entonación como un marcador léxico (el chino-mandarin y vietnamita). En nuestro caso es interesante notar los bajos resultados en el caso del coreano. Para el japonés que es un lenguaje mora-timed, pudimos discriminarlo bien contra los stress-timed, los tonales y los que usan la entonación como marcador léxico.
Otra observación que tenemos es que con muestras pequeñas de señal de voz se obtuvieron mejores resultados, ya que las variaciones en los promedios de los deltas ∆1, ∆2 y ∆3, son de mayor ayuda para la tarea de discriminación. Desafortunadamente, este es un punto en contra de esta caracterización pues es de esperarse que los promedios tiendan a estabilizarse
27 de 39

con muestras de señal de voz más grandes, y al parecer, a acercarse mucho entre los diferentes idiomas.
Como conclusión general de este nuevo conjunto de características acústicas, es pertinente para la discriminación entre lenguajes de diferentes grupos: stress-timed, mora-timed y syllabed-timed. En el caso de Rouas [16], es bueno para los que utilizan la entonación como un marcador léxico, por lo que como trabajo futuro sería interesante combinar ambos métodos, para obtener un conjunto de características acústicas más robusto.
5.5 Paso 4: Procesamiento acústico basado en Wavelets
El objetivo de este experimento fue observar el comportamiento del uso de wavelets en la tarea de identificación de idiomas. Este método es completamente diferente a los usados anteriormente basados en la transformada de Fourier. Nosotros proponemos el uso de wavelets motivados por su capacidad de representar señales con una muy buena resolución en los dominios del tiempo y frecuencia [6]; Además, la transformada wavelet permite una buena resolución en las bajas frecuencias que es donde están la prosodia y el ritmo que hacen posible la discriminación de los lenguajes. Cabe mencionar que los wavelets han sido utilizadas en el reconocimiento del habla [8][9], pero hasta ahora no se ha reportado ningún trabajo aprovechando el uso de wavelets en la identificación de idiomas. El uso de coeficientes wavelets es motivado por modelos de procesamiento acústico humano y por su habilidad para capturar características de frecuencia importantes. La transformada wavelet descompone la señal de voz en lo que se conoce como multiresolución, lo que nos permite obtener un detalle de las frecuencias bajas en el tiempo. Por el estado del arte sabemos que los wavelet son robustos para el procesamiento de señales con ruido, esto nos ayuda cuando la señal de voz es espontánea. La transformada wavelet acentúa la información más sobresaliente acerca de la señal de lenguaje hablada y lo hace más robusto. A continuación se presentan los conceptos básicos de wavelets, para posteriormente describir los experimentos al usarla en nuestra tarea de identificación.
5.5.1 Conceptos básicos de Wavelets Morlet, desarrolló su propia forma de analizar las señales sísmicas para crear componentes que estuvieran localizados en el espacio, a los que denominó "wavelets de forma constante". Independientemente de que los componentes se dilaten, compriman o desplacen en el tiempo, mantienen la misma forma. Se pueden construir otras familias de wavelets adoptando una forma diferente, denominada wavelet madre, dilatándola, comprimiéndola o desplazándola en el tiempo. Morlet y Grossmann trabajaron para demostrar que las ondas se podían reconstruir a partir de sus descomposiciones en wavelets. De hecho, las transformaciones de wavelets resultaron funcionar mucho mejor que las transformadas de Fourier, porque eran mucho menos susceptibles a pequeños errores de cómputo. Un error o un truncamiento indeseados de los
28 de 39

coeficientes de Fourier pueden transformar una señal suave en una saltarina o viceversa; las wavelets evitan tales consecuencias desastrosas. La propiedad de ortogonalidad fue descubierta por Meyer, dicha propiedad matemática hacia que la manipulación y el trabajo con la transformación wavelet resultara más fácil. La idea del análisis multiresolución, es decir la observación de señales a distintas escalas de resolución, ya era familiar para los expertos en procesamiento de imágenes. Gracias al trabajo de Mallat, las wavelets se convirtieron en algo mucho más sencillo. Ya se podía hacer un análisis de wavelet sin necesidad de conocer la fórmula de una wavelet madre. Finalmente en 1987, Ingrid Daubechies descubrió una clase completamente nueva de wavelets, que no sólo eran ortogonales, sino que también se podían implementar mediante sencillas ideas de filtrado digital. Las nuevas wavelets eran casi tan sencillas de programar y utilizar como los wavelets de Haar, pero eran suevas, sin los saltos de las wavelet de Haar. En la figura 5.5.1 se muestran a la izquierda la wavelet Daubechies db4 y a la derecha la db8.
Figura 5.5.1. Wavelet Daubechies db4 del lado izquierdo y la db8 del lado derecho.
Las siguientes figuras (fig.5.5.1.2) muestran la descomposición y reconstrucción de la
señal, donde h1 es un filtro pasa-bajo y g1 es un filtro pasa-alta; aj+1 representa la aproximación, para voz son las bajas frecuencias donde esta la prosodia y el ritmo. Dj+1 representa el detalle, siendo las altas frecuencias.
29 de 39

Descomposición
Reconstrucción
Figura 5.5.1.2. Proceso de descomposición y reconstrucción de la señal por medio de wavelets.
5.5.2 Experimento 6: El uso de la transformada Daubechies. A partir de la onda acústica de la señal de voz hablada, de cada uno de los hablantes, se
selecciona el tamaño de la muestra a procesar de 30 y 50 segundos; posteriormente a cada una de esas muestras se les aplica el proceso de wavelets. Se utilizó la transformada wavelet de Daubechies, con 4 coeficientes y normalizada a [-1,1]. Obteniendo las características acústicas para nuestra tarea, en las figuras 5.5.2.1 y 5.5.2.2 se muestran las descomposiciones de la señal de voz por medio de la transformada wavelet Daubechies db2, donde 2 es el orden. De esto obtenemos un conjunto de coeficientes wavelets. La descomposición nos genera bajas y altas frecuencias, que para nuestra tarea son más importantes las bajas frecuencias, porque como ya mencionamos anteriormente es donde se encuentra la prosodia y el ritmo. También sabemos que los coeficientes wavelet con valores altos representan las bajas frecuencias, por lo que para extraerlas aplicamos un hard-threshold [25] con un valor de .01; esto nos reduce la dimensionalidad de los coeficientes wavelets de 262,144 a 2623 (para muestras de señal de voz de 30 segundos) y de 524288 a 5244 (para muestras de 50 segundos), dándonos la información más relevante para la tarea. Este proceso se instrumento en la herramienta de proceso acústico PRAAT versión 4.0.5 [24].
El hard-threshold es utilizado para eliminar ruido, que se obtiene cuando la señal de voz es producida por teléfono, el medio ambiente y otros medios, los umbrales utilizados deben ser muy pequeños para no eliminar las bajas frecuencias, existen ya formulas probadas para los umbrales, de acuerdo al tipo de ruido que se quiere eliminar; en nuestro caso fue utilizado para eliminar las altas frecuencias. En la figura 5.5.2.3 se muestran los dos tipos: el hard-threshold y la
30 de 39
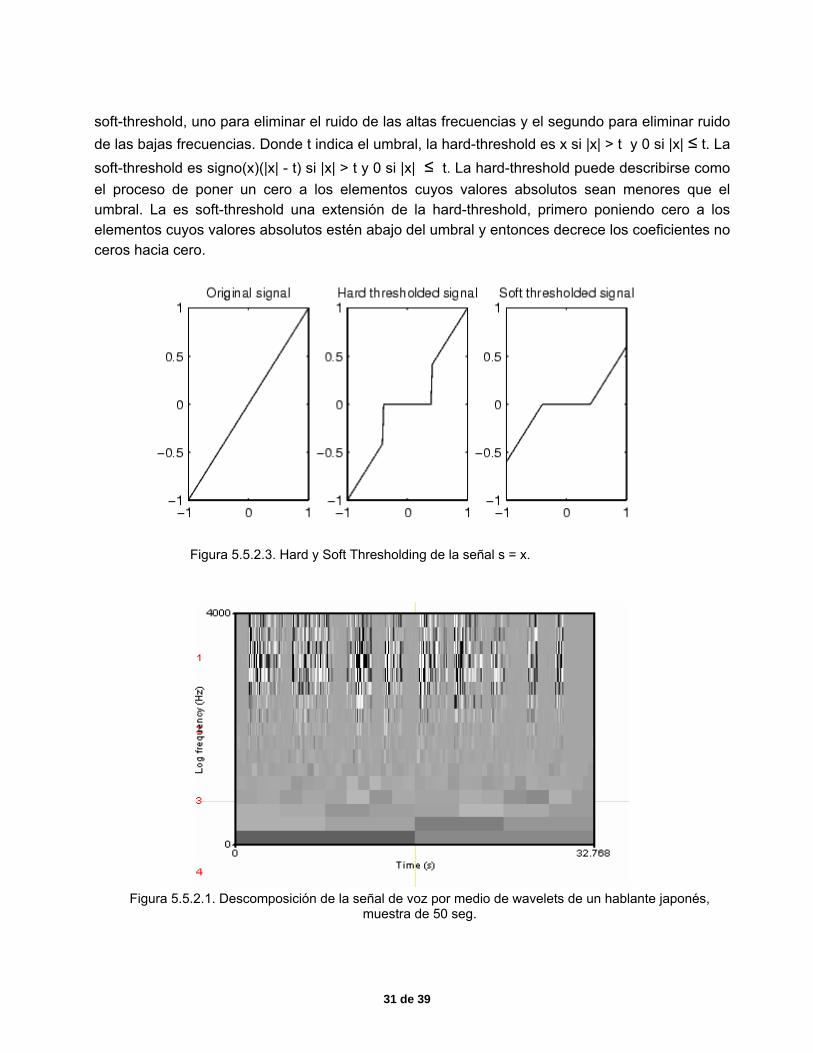
soft-threshold, uno para eliminar el ruido de las altas frecuencias y el segundo para eliminar ruido de las bajas frecuencias. Donde t indica el umbral, la hard-threshold es x si |x| > t y 0 si |x| ≤ t. La soft-threshold es signo(x)(|x| - t) si |x| > t y 0 si |x| ≤ t. La hard-threshold puede describirse como el proceso de poner un cero a los elementos cuyos valores absolutos sean menores que el umbral. La es soft-threshold una extensión de la hard-threshold, primero poniendo cero a los elementos cuyos valores absolutos estén abajo del umbral y entonces decrece los coeficientes no ceros hacia cero.
Figura 5.5.2.3. Hard y Soft Thresholding de la señal s = x.
Figura 5.5.2.1. Descomposición de la señal de voz por medio de wavelets de un hablante japonés,
muestra de 50 seg.
31 de 39
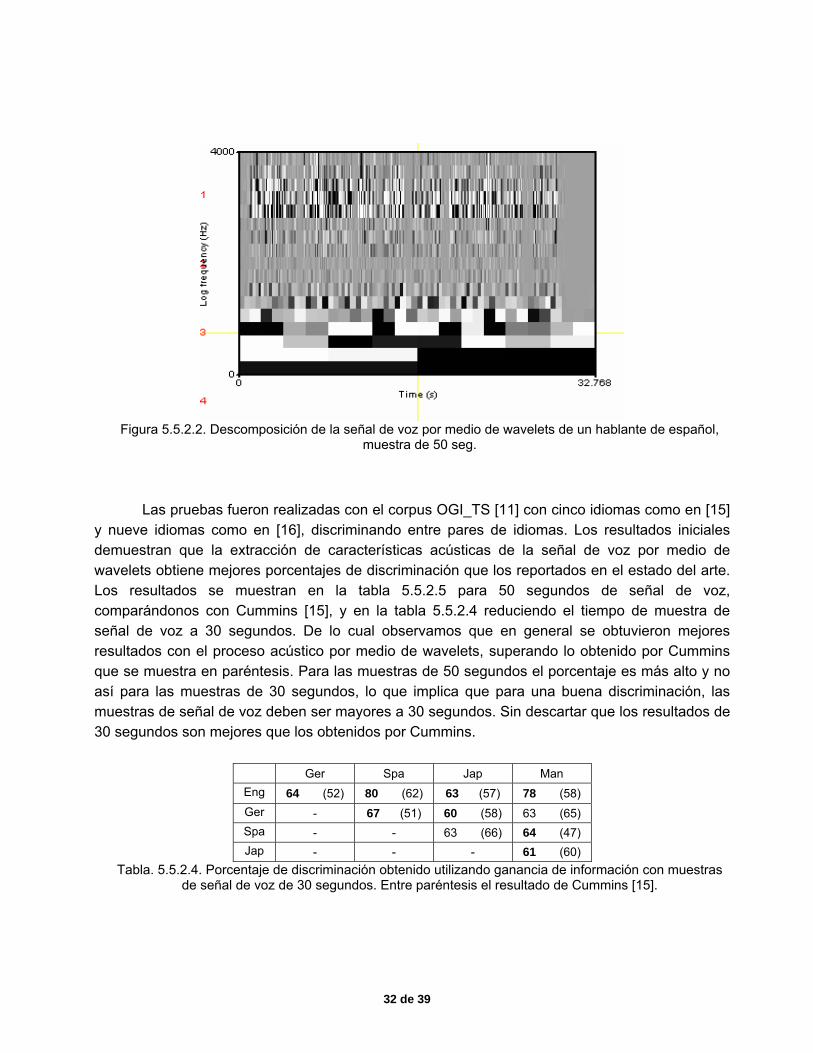
Figura 5.5.2.2. Descomposición de la señal de voz por medio de wavelets de un hablante de español,
muestra de 50 seg.
Las pruebas fueron realizadas con el corpus OGI_TS [11] con cinco idiomas como en [15]
y nueve idiomas como en [16], discriminando entre pares de idiomas. Los resultados iniciales demuestran que la extracción de características acústicas de la señal de voz por medio de wavelets obtiene mejores porcentajes de discriminación que los reportados en el estado del arte. Los resultados se muestran en la tabla 5.5.2.5 para 50 segundos de señal de voz, comparándonos con Cummins [15], y en la tabla 5.5.2.4 reduciendo el tiempo de muestra de señal de voz a 30 segundos. De lo cual observamos que en general se obtuvieron mejores resultados con el proceso acústico por medio de wavelets, superando lo obtenido por Cummins que se muestra en paréntesis. Para las muestras de 50 segundos el porcentaje es más alto y no así para las muestras de 30 segundos, lo que implica que para una buena discriminación, las muestras de señal de voz deben ser mayores a 30 segundos. Sin descartar que los resultados de 30 segundos son mejores que los obtenidos por Cummins.
Ger Spa Jap Man
Eng 64 (52) 80 (62) 63 (57) 78 (58) Ger - 67 (51) 60 (58) 63 (65) Spa - - 63 (66) 64 (47) Jap - - - 61 (60)
Tabla. 5.5.2.4. Porcentaje de discriminación obtenido utilizando ganancia de información con muestras de señal de voz de 30 segundos. Entre paréntesis el resultado de Cummins [15].
32 de 39

Ger Spa Jap Man
Eng 75 (52) 86 (62) 71 (57) 78 (58) Ger - 75 (51) 76 (58) 72 (65) Spa - - 70 (66) 71 (47) Jap - - - 79 (60)
Tabla 5.5.2.5. Porcentaje de discriminación obtenido utilizando ganancia de información con muestras de señal de voz de 50 segundos. Entre paréntesis el resultado obtenido por Cummins [15].
40
50
60
70
80
90
100
Eng-Ger
Eng-Spa
Eng-Jap
Eng-Man
Ger-Spa
Ger-Jap
Ger-Man
Spa-Jap
Spa-Man
Jap-Man
Cummis Wavelet-30seg Wavelets-50seg
Tabla 5.5.2.6. Comparativo de los porcentajes de discriminación con muestras de señal de voz de 30 y
50 segundos, utilizando ganancia de información, contra el porcentaje obtenido por Cummins [15]. Para el segundo grupo con nueve idiomas similar a lo que utilizó Rouas[16], los resultados
se presentan en la tabla 5.5.2.7, para 50 segundos de muestra de señal de voz a diferencia de lo que utilizó Rouas de 45 segundos, y en la tabla 5.5.2.8 se muestran los resultados con 30 segundos de señal de voz. Aun cuando se redujo el tamaño de muestra los resultados demuestran un buen porcentaje de discriminación. Entre paréntesis se muestra el porcentaje obtenido por Rouas [16]. Los resultados en general no fueron buenos para el lenguaje tamil, pero hemos de considerar que la mayoría de los lenguajes obtuvo buenos resultados de discriminación entre lenguajes. En este segundo grupo de idiomas al igual que en el primero, al aumentar el tamaño de muestra de 30 a 50 segundos los porcentajes de discriminación aumentan. Indicándonos que este tipo de procesamiento acústico por medio de wavelets debe ser con muestra grandes de señal de voz.
33 de 39

Tabla 5.5.2.7. Porcentaje de discriminación obtenido utilizando ganancia de información con muestras de señal de voz de 50 segundos. Entre paréntesis el resultado obtenido por Rouas [16].
German Spanish Mandarin Vietnamese Japanese Korean Tamil Farsi English 75(59.5) 86(67.7) 78 (75.0) 72 (67.7) 71(67.6) 76 (79.4) 60 (77.4) 78 (76.3) German - 75(59.4) 72 (62.2) 73 (65.7) 76(65.8) 72 (71.4) 64 (69.7) 64 (71.8) Spanish - - 71 (80.6) 81 (62.1) 70(62.5) 72 (75.9) 70 (65.4) 76 (66.7) Mandarin - - - 66 (50.0) 79(50.6) 75 (73.5) 73 (74.2) 62 (76.3)
Vietnamese - - - - 79(68.6) 76 (56.2) 68 (71.4) 71 (66.7) Japanese - - - - - 78 (65.7) 77 (59.4) 79 (66.7) Korean - - - - - - 62 (62.1) 73 (75.0) Tamil - - - - - - - 73 (69.7)
German Spanish Mandarin Vietnamese Japanese Korean Tamil Farsi English 64(59.5) 80 (67.7) 78 (75.0) 75 (67.7) 63(67.6) 73 (79.4) 65 (77.4) 76 (76.3)
German 67 (59.4) 63 (62.2) 72 (65.7) 60(65.8) 65 (71.4) 63 (69.7) 73 (71.8) Spanish 64 (80.6) 67 (62.1) 63(62.5) 55 (75.9) 73 (65.4) 51 (66.7) Mandarin 66 (50.0) 61(50.6) 71 (73.5) 66 (74.2) 60 (76.3) Vietnamese 57(68.6) 61 (56.2) 66 (71.4) 56 (66.7) Japanese - 68 (65.7) 63 (59.4) 65 (66.7) Korean - - 62 (62.1) 69 (75.0) Tamil - - 81 (69.7)
Tabla 5.5.2.8 Porcentaje de discriminación obtenido utilizando ganancia de información con muestras de señal de voz de 30 segundos. Entre paréntesis el resultado obtenido por Rouas [16].
5.5.3 Conclusiones El uso de wavelets para el procesamiento acústico de la señal de voz da resultados
alentadores en la identificación del lenguaje, ya que la transformada wavelet permite enfocarnos en las bajas frecuencias que es donde están la prosodia y el ritmo que hacen posible la discriminación de lenguajes. Con estos resultados nos estamos acercando a los porcentajes de discriminación que obtienen los sistemas que utilizan representación fonética, que como hemos dicho anteriormente son los que mejores resultados han obtenido hasta ahora. Para un trabajo futuro podríamos mezclar diferentes extracciones de características acústicas de la señal de voz, tales como el ritmo como en [16], los coeficientes wavelets y generar características híbridas más completas que nos ayuden a obtener un porcentaje igual o mejor que los sistemas que utilizan representación fonética.
A modo de resumen, en las siguientes graficas (fig. 5.5.3.1, 5.5.3.2, 5.5.3.3, 5.5.3.4, 5.5.3.5 y 5.5.3.6) se muestran los resultados al obtener el promedio de cada uno de los porcentajes que se obtuvieron por parejas de idiomas; tomando como base un idioma y obteniendo el promedio de sus porcentajes con los otros idiomas en pares. Aunque no es valido un promedio para nuestra
34 de 39

tarea, se simplifica para tener una idea global de los resultados obtenidos por los nuevos métodos de caracterización de la señal de voz.
40
50
60
70
80
90
100
Ingles Aleman Español Japones Mandarin
CummisMFCC-7SegMFCC-30segMFCC-50seg
Figura 5.5.3.1 Promedio de cada uno de los idiomas utilizando nueva caracterización independiente del
tiempo (deltas y promedios de 16MFCC), vector directo.
50
55
60
65
70
75
80
85
90
95
100
Ingles Aleman Español Japones Mandarin
CummisMFCC-7SegMFCC-30segMFCC-50seg
Figura 5.5.3.2 Promedio de cada uno de los idiomas utilizando nueva caracterización independiente del
tiempo (deltas y promedios de 16MFCC), con ganancia de información.
50
55
60
65
70
75
80
85
90
95
100
Ingles Aleman Español Japones Mandarin
CummisWavelets-30segWavelets-50seg
Figura 5.5.3.3 Promedio de cada uno de los idiomas utilizando wavelets con ganancia de información. De lo que podemos concluir que con los nuevos métodos de procesamiento acústico
superamos a Cummins et. al [15].
35 de 39

50556065707580859095
100
Ingles Aleman Español Mandarin Vietnamita Japones Coreano Tamil Farsi
Rouas MFCC-7seg MFCC-30seg MFCC50seg
Figura 5.5.3.4 Promedio de cada uno de los idiomas utilizando nueva caracterización independiente del tiempo (deltas y promedios de 16MFCC), vector directo.
50556065707580859095
100
Ingles Aleman Español Mandarin Vietnamita Japones Coreano Tamil Farsi
Rouas MFCC-7seg MFCC-30seg MFCC50seg
Figura 5.5.3.5 Promedio de cada uno de los idiomas utilizando nueva caracterización independiente del tiempo (deltas y promedios de 16MFCC), con ganancia de información.
50556065707580859095
100
Ingles Aleman Español Mandarin Vietnamita Japones Coreano Tamil Farsi
Rouas Wavelets-30seg Wavelets-50seg
Figura 5.5.3.6 Promedio de cada uno de los idiomas utilizando wavelets con ganancia de información.
36 de 39

Cronograma de Actividades 2 0 0 4 2 0 0 5 2 0 0 6 TAREAS 1 2 3 4 5 6 7 8 9 Investigación del estado del
arte en procesamiento
de la voz
Definición de tema y estudio del estado del arte especifico
Pruebas del procesamiento: articulación &
perceptual Pruebas clasificadores
con
Defensa de propuesta Realizar
pruebas con el corpus
OGI_TS Revisar teoria
Wavelets Desarrollar
nuevas caracteristicas
usando wavelets Vector
completo de wavelets Vector de
caracteristicas wavelets con ganancia de
info. Desarrollar
nuevas ar ac s
promedios,
acteristicde wavelets
usando
desviación estandar, varianza.
Desarrollar nuevas
caracteristicas usando 16
MFCC 16 MFCC con ganancia de
info. Desarrollar
nuevo conjunto de
caracteristicas
d promedios y eltas ∆1, ∆2 y
∆3 Desarrollar un
37 de 39

2 0 0 4 2 0 0 5 2 0 0 6 TAREAS 1 2 3 4 5 6 7 8 9
metodo para intervalo
vocalicos y los s
consonanticos Realizar
pruebas con
indigenas de
lenguas
México Realizar
pruebas con
muestras
diferentes tamaños de
Evaluación de
desarrollados los modelos
Documento de
Tesis Defensa de
esisT
Referencias ] . 9 5 ”L a d t c io based o a g -dep n e e o n io , h
Thesis, Oregon graduate institute of science and technology, USA. C. Rodríguez, (2003):”Proyecto multidisciplinario de asistencia monolingüe”.
www.iling.unam.mx/langid/ . e o I. r c (1998) L age Id t c o U in n Ling stic Info ion”, in
10th Portuguese on Pattern Recognition (RECPAD’98), Lisbon Portugal. . A , a 7) a g e if t n ed on Cross-L g a s c
models and Optimized Information Combination”, In EUROSPEECH-1997, 67-70. . . r s ra s il , . in M A l , R.J e . e d Deller. ( )
che to Language identificatio ssi odel ifted Delta Cepstral 02, Springer Verlag. sept. 2002, pp. 89-92.
] I. Daubechies, “Ten lectures on Wavelets”, Vol. 61, SIAM Press, Philadelphia, PA USA, 1992. ] X. Huang, A. Acero, H-W. Hon, (2001) “Spoken Language Processing”, Microsoft Research, Prentice
Hall. [8] R. Modic, B. Lindberg, B. Petek. (2003) “Comparative wavelet and MFCC speech recognition
the Slovenian and English speechDat2”, in NOLISP-2003, Le Croisic, France, paper
IEEE International
[1
[2]
Y Yan (1 9 ): angu ge i en ifi at n n l n uage e dent phon r c ng it n” P D.
[3]
[4]
D Cas ir , T an oso, “ angu en ifi ati n s g Mi imum ui rmat
O ndersen P. Dalsga rd (199 “L ngua e Id nt ica io bas an u ge Acou ti
[5] P A To re -Car s qu lo E S ger, . . Koh er . Gre ne, D.A R ynol s and J.R. 2002 “ApproaFeatures”, Proc. ICSLP 20
s n using Gau an Mixture M s and Sh
[6[7
experiments on 016.
[9] M. Gupta and A. Gilbert, (2001) “Robust speech recognition using wavelet coefficient features”, in IEEE Automatic Speech Recognition and Understanding Workshop, USA, pp. 445-448.
[10] F. Ramus, M. Nespor, J. Mehler, (1999) :”Correlates of linguistic rhythm in the speech signal”. Cognition, 73(3), pp. 265-293. Elsevier.
[11] Y.K. Muthusamy, R. Cole, B. Oshika (1992) ”The OGI multi-language telephone speech corpus”. International Conference on Spoken Language Processing (ICSLP’92), volumen 2, pp.895-998, Alberta, Canada.
[12] M. Zissman, E. Singer (1994) :”Automatic language identification of telephone speech messages using phoneme recognition and n-gram modeling”, in Proceedings of the
38 de 39

Conference on Acoustic, Speech and Signal Processing (ICASSP’94), Vol. 1, pp. 305-308, Adelaide, Australia. A. Samouelian, (1996) “Automatic Language Identification using th[14] Inductive Inference”, in 4
it Features“, Proc. EUROSPEECH’99, Budapest, Hungary, 1, pp. 371-374,
[17] Muthusamy, N. Jain, R. Cole (1994) :”Perceptual benchmarks for automatic language
msterdam. June 2004
[21] rt Vector Machines”. In Proc. Odyssey: The Speaker and Language Recognition Workshop
[22] oblacion/
International Conference on Spoken Language Processing (ICSLP 96), Philadelphia, USA. [15] F. Cummins, F. Gers, and J. Schmidhuber, (1999) “Language Identification from Prosody without
explic[16] J.-L. Rouas, J. Farinas, F. Pellegrino and R. André-Obrecht (2003) “Modeling prosody for language
identification on read and spontaneous speech” in Proc. IEEE ICASSP 2003, vol 1, pp. 40-43. Y.K. identification”, in Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP’94), Adelaide, Australia.
[18] P. Boersma, D. Weenink, Praat v 4.2.08. (2004). A system for doing phonetics by computer. Institute of Phonetic Sciences of the UniversityofA
[19] J. Platt: (1998) "Fast Training of Support Vector Machines using Sequential Minimal Optimization". Advances in Kernel Methods - Support Vector Learning, B. Schoelkopf, C. Burges, and A. Smola, eds., MIT Press.
[20] I. Witten, F. Eibe (2000): Weka (Waikato Environment for Knowledge Analysis).Data Mining, Practical Machine Learning Tools and Techniques with java Implementations, Academic Press, USA. 2000. W.M. Campbell, E. Singer, P.A. Torres-Carrasquillo, D.A. Reynolds (2004) : “Language Recognition with Suppoin Toledo, Spain, ISCA, pp. 41-44, 31 May - 3 June. INEGI.(2005)Indicadores sociodemográficos de México 2004 http://cuentame.inegi.gob.mx/p
[23] AILLA.(2005) Archivo de los idiomas indígenas de Latinoamérica, grabaciones de H. Johnson. http://www.ailla.utexas.org/site/welcome_sp.html
[24] P. Boersma, D. Weenink, “Praat v 4.0.5. (2002) A system for doing phonetics by computer”. Institute of honetic Sciences of the University of Amsterdam. June.
39 de 39


















