
Guillermo Ayala Gallego 2 26 de marzo de 2014 - uv.es · An alisis de datos con R 1 Guillermo Ayala...
163
An´ alisis de datos con R 1 Guillermo Ayala Gallego 2 26 de marzo de 2014 1 Unom´as. 2 .
Transcript of Guillermo Ayala Gallego 2 26 de marzo de 2014 - uv.es · An alisis de datos con R 1 Guillermo Ayala...

Analisis de datos con R 1
Guillermo Ayala Gallego 2
26 de marzo de 2014
1Uno mas.2.

2

Indice general
1. Probabilidad: lo bueno si . . . 9
1.1. Experimento y probabilidad . . . . . . . . . . . . . . . . . . . . . . . 9
1.2. Variable aleatoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.2.1. Funcion de distribucion . . . . . . . . . . . . . . . . . . . . . 11
1.2.2. Media y varianza . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.2.3. Teorema de Bayes . . . . . . . . . . . . . . . . . . . . . . . . 19
1.3. Vectores aleatorios . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
1.4. Distribucion normal multivariante . . . . . . . . . . . . . . . . . . . 20
2. Un muy breve repaso a la Estadıstica 25
2.1. Algo de Estadıstica Descriptiva, poco . . . . . . . . . . . . . . . . . 25
2.2. Verosimilitud . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.3. Estimacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.3.1. Estimacion insesgada de media y varianza . . . . . . . . . . . 29
2.3.2. Estimacion insesgada del vector de medias y la matriz de co-varianzas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.4. Estimador maximo verosımil . . . . . . . . . . . . . . . . . . . . . . 32
2.5. Contraste de hipotesis . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.5.1. Test del cociente de verosimilitudes . . . . . . . . . . . . . . 35
2.5.2. Test de Wald . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.5.3. Intervalos de confianza . . . . . . . . . . . . . . . . . . . . . 35
3. Componentes principales 37
3.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.2. Componentes principales . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.3. Componentes principales de los datos golub . . . . . . . . . . . . . . 45
3.4. Un poco de teorıa ⇑ . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4. Analisis cluster 51
4.1. Algunos ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.2. Disimilaridades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.2.1. Disimilaridades entre observaciones . . . . . . . . . . . . . . 55
4.2.2. Disimilaridades entre grupos de observaciones . . . . . . . . 58
4.3. Cluster jerarquico . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
4.4. Metodos de particionamiento . . . . . . . . . . . . . . . . . . . . . . 65
4.4.1. Metodo de las k-medias . . . . . . . . . . . . . . . . . . . . . 65
4.4.2. Particionamiento alrededor de los mediodes . . . . . . . . . . 70
4.5. Silueta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
4.6. Un ejemplo completo . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
3

5. Analisis discriminante o de como clasificar con muestra de entre-namiento 835.1. Un problema de probabilidad sencillo . . . . . . . . . . . . . . . . . 865.2. Dos poblaciones normales . . . . . . . . . . . . . . . . . . . . . . . . 875.3. Dos normales multivariantes . . . . . . . . . . . . . . . . . . . . . . 875.4. Dos poblaciones normales multivariantes con parametros desconoci-
dos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 885.5. Analisis discriminante con mas de dos poblaciones normales . . . . 915.6. Valoracion del procedimiento de clasificacion . . . . . . . . . . . . . 925.7. Variables discriminantes canonicas o discriminantes lineales . . . . . 965.8. Algunos ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
6. Regresion 1036.1. Regresion lineal simple . . . . . . . . . . . . . . . . . . . . . . . . . . 1066.2. Regresion lineal multiple . . . . . . . . . . . . . . . . . . . . . . . . . 1086.3. Estimacion de β . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1086.4. Algunos casos particulares . . . . . . . . . . . . . . . . . . . . . . . . 1106.5. Verosimilitud . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1116.6. Algunos ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1116.7. Distribucion muestral de β . . . . . . . . . . . . . . . . . . . . . . . 1146.8. Bondad de ajuste . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1156.9. Valoracion de las hipotesis del modelo . . . . . . . . . . . . . . . . . 1166.10. Inferencia sobre el modelo . . . . . . . . . . . . . . . . . . . . . . . . 1346.11. Seleccion de variables . . . . . . . . . . . . . . . . . . . . . . . . . . 140
6.11.1. Procedimientos que comparan modelos . . . . . . . . . . . . . 1406.11.2. Procedimientos basados en criterios . . . . . . . . . . . . . . 143
6.12. Algunos ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 146
7. De como usar R en un tiempo razonable (no facil, no) 1597.1. Instalacion y como trabajar con R . . . . . . . . . . . . . . . . . . . 160
7.1.1. R y Windows . . . . . . . . . . . . . . . . . . . . . . . . . . 1607.1.2. R y Linux . . . . . . . . . . . . . . . . . . . . . . . . . . . . 160
7.2. ¿Como instalar un paquete? . . . . . . . . . . . . . . . . . . . . . . . 1607.3. ¿Como fijar el directorio de trabajo? . . . . . . . . . . . . . . . . . . 1617.4. Etiquetas de valor y de variable . . . . . . . . . . . . . . . . . . . . . 161
7.4.1. ¿Como etiquetar una variable? . . . . . . . . . . . . . . . . . 1617.5. Elaboracion de un informe a partir del codigo R . . . . . . . . . . . 161
7.5.1. Sweave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1617.6. R y Octave/Matlab . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
4

Prologo
Cada vez hay mas datos. Tenemos mas datos introducidos en ficheros. Y estoes lo peor. Si los datos estuvieran en hojas sueltas y perdidas pues no pasa nada.Se archivan los papeles y los datos no molestan. No, ahora los propios ordenadoreso bien muchas personas accediendo desde distintos lugares, tienen el mal gusto decrear unas bancos de datos cada vez mayores. Cada vez con mas casos y con masvariables. El problema no es conseguir datos. Los tienes a precio de saldo. Te los dansin que los pidas. Si tienes conocidos biologos, medicos, quımicos, psicologos seguroque tienen datos para analizar. Si trabajais en un hospital, tendreis una legion demedicos (y cada vez mas enfermeros) con datos. Todo el mundo tiene datos. A losque tienen carino. Que creen que tienen mucho valor. Pero que no saben que hacercon ellos. En el mejor de los casos algun dibujo estilo pastel (bueno, se le llamadiagrama de sectores pero es un pastel) o histograma. ¡Que Dios nos libre de tantodibujo que solo sirve para gastar papel y tinta!
En estas notas se pretende (solo se pretende) partiendo de unos conocimientosinformaticos que no sean basicos y de unos conocimientos probabilısticos y estadısti-cos mas bien basicos, llegar a poder hacer algo decente con un banco de datos.
La parte de analisis descriptivo de datos se obvia. Simplemente a lo largo delcurso se va utilizando y recordando. Ya esta bien de perder el tiempo explicandocomo hacer un histograma si luego lo hace un programa.
El tono de estas notas pretende ser ameno pues bastante toston es lo que secuenta. No inutil. Pero sı toston. Hay que asumirlo desde un principio. Esto no es”Sexo en Nueva York”.1 Son unas notas de Estadıstica con R ?. 2
Este documento contiene unas notas de clase para la asignatura de Analisis deDatos de Ingenierıa Informatica de la Universidad de Valencia. Pretende en cadatema empezar desde un nivel basico de contenidos para llegar al uso de la tecnicacorrespondiente. Es una realidad que el informatico acaba realizando analisis dedatos. Entre otras cosas porque suele ser la persona mas a mano o bien porque ya haprogramado el resto de la aplicacion que tambien incorporar algun tipo de analisismas o menos sencillo. Y es una pena ver como se desaprovecha la informacion.Por ello en estas notas pretendo tratar rapidamente muchos temas y, ademas, quepodamos utilizarlas. Por ello se recurre a R. Por su potencia y por su disponibilidad.Incluso en su propia casa y con una conexion a Internet no demasiado rapida puedeel estudiante instalarse R y cualquier paquete que se necesite. Esto ya es bastantedesde el punto de vista docente. Ademas, cualquier procedimiento estadıstico esta enR. Casi se puede decir, que si no lo esta, no merece la pena de utilizarse.
Se proponen distintos apendices como apoyo a conceptos anteriores necesarios.Se hace un repaso rapido de los conceptos basicos de la Probabilidad en el tema
1Sin duda, la mejor serie de television de la historia. Hay que verla. Las pelıculas de despuesno. En cualquier caso ahora es mas recomendable Girls.
2Un anuncio de la radio (Cadena Ser para mas senas) hablaba de una persona que no entendıaporque su profesor de Estadıstica lo habıa suspendido. Es de suponer que la persona que escribio elanuncio estudiarıa Periodismo. Allı hay una asignatura de Estadıstica. Claramente le ha servido.Ha hecho un anuncio y le habran pagado por ello.
5

1. Las ideas basicas de la Estadıstica que utilizamos en el resto del curso aparecenen el tema 2. Ambos capıtulos con meros resumenes que no sustituyen el repasode muchos de los conceptos en algunos de los textos que se citan en los capıtuloscorrespondientes.
Estas notas estan orientadas para estudiantes de Ingenierıa Informatica y porello en muchas ocasiones se incluyen definiciones y conceptos basicos que dichoestudiante no tiene. Una introduccion generica a la Probabilidad y la Estadısticaque es adecuado hojear pues cubre los conceptos previos es el libro de texto deDougherty [1990].
El interes fundamental de estas notas es dar una vision muy amplia sin perderdemasiado tiempo en detalles de cada tecnica. En este sentido se intenta ir directoal grano con lo que eso supone de dificultad anadida. Sin embargo, tiene la com-pensacion de ver como muchos de los conceptos que se estudian son reescritura unode otro.
Por fin, un signo de edad es tener que escribir las cosas para que no se nosolviden. Quizas para que uno mismo lo aprenda y para no olvidarlo despues. En elfondo, todos vamos aprendiendo segun lo explicamos y lo escuchamos.
Sin duda, unas notas como las que siguen solo se pueden hacer utilizando LATEXpara escribir y el programa R ? 3 para realizar el analisis de los datos. Son dosherramientas imprescindibles que se complementan perfectamente. Un tratamientoestadıstico no acaba con un codigo o con unos dibujos aislados. Acaba con uninforme. Con frecuencia, se dedica mas tiempo a explicar lo que se ha hecho, aescribir el informe, que a la preparacion y tratamiento de los datos, al analisis delos datos. En este sentido, creo que una herramienta como LATEX es fundamentalutilizada con R. En este texto hablamos de analisis de datos. No de LATEX. Sinembargo, uno aprende a veces cosas importantes mientras estudia otras que creeque lo son mas. En este sentido, habra referencias a LATEX.
Finalmente veamos una guıa de lectura del documento. Es muy habitual quesi uno empieza a leer un texto por el principio nunca pase mas alla del primer osegundo capıtulo, y eso con suerte. Las notas estan escritas de manera que se leancada tema por separado sin mas conexiones entre ellos. De modo que si quieres unpequeno repaso de Probabilidad consulta el tema 1. Si patinas un poco en lo basicode la Estadıstica pues entonces hay que leer el tema 2. Son los unicos temas decaracter basico. Los demas van al grano. En particular si te interesa como reducirla dimension del banco de datos lee el tema 3. Si el problema que te quita el suenoes como dadas unas variables sobre un individuo clasificarlo en uno de g posiblesgrupos conocidos a priori y de los cuales tienes ejemplos entonces no lo dudes ylee el tema 5. Si tienes datos y no saben si se disponen formando grupos y ni tansiquiera del numero de grupos que tienes entonces has de acudir sin remision altema 4. Finalmente en los temas 6, ?? y ?? viene la artillerıa pesada. Como todossabemos los modelos lineales son el corazon de la Estadıstica, sin ellos, otras tecnicasde analisis de datos se la hubieran ventilado. Los modelos lineales es un esfuerzocolectivo que ha construido una teorıa redonda, util, facil de aprender y aplicar.Parece que casi todo esta previsto y bien resuelto. Los modelos lineales generalizadossurgen de la envidia que todo lo corroe. Cuando la variable respuesta, en lugar deser continua, como en los modelos lineales, es una respuesta binaria, o multinomial,o bien un conteo. ¿Que hacer? La teorıa de modelos lineales no se puede aplicarni con calzadores. Sin embargo, con unos cuantos cambios tecnicamente simplessurgen unos modelos probabilısticos para analizar estos datos que son absolutamentepreciosos.
3La primera leccion sobre R es como citar el programa. En la lınea de comandos escribimoscitation y nos devuelve la referencia bibliografica. Del mismo modo lo podemos hacer si utilizamosotro paquete. Por ejemplo tecleando citation(“cluster”) nos indica como citar el paquete clusterque utilizamos en el tema 4.
6

Un detalle practico de enorme interes. Para programar con R en el sistema ope-rativa Windows lo mas comodo es utilizar RWinEdt (?) mientras que si trabajamosen Linux la opcion mas comoda es utilizar emacs con el paquete ESS. Se puedenencontrar detalles adicionales R.
R es libre. ¿Esto significa que es malo? ¿Tiene pocas funciones? ¿Lo que tieneno es de fiar? Hay una idea muy extendida de que el precio de las cosas esta ınti-mamente relacionado con la calidad. No se si en general es cierto. En el caso de Rno lo es. Algunos artıculos de prensa que apoyan el comentario son NYT.06.01.09,NYT.07.01.09, The New York Times, 16 de febrero de 2009.
Tambien podeis encontrar algunas empresas que, basandose en R, desarrollanproductos comerciales como Revolution Computing.
Finalmente algunas direcciones de interes sobre R son las siguientes: http://www.r-bloggers.com/.
7

8

Capıtulo 1
Probabilidad: lo bueno si . . .
Empezamos por donde hay que empezar. Con la Probabilidad. Temida, odiada.Despreciada porque habla de juegos. Por encima de todo, util, de una utilidadextrana. Da verguenza hablar de Estadıstica sin citar algo de Probabilidad. 1 Yno lo vamos a hacer. Vamos a cumplir con la papeleta. En cualquier caso, si note manejas bien con los conceptos basicos probabilısticos (variable aleatoria, vectoraleatorio, distribucion conjunta y marginal, . . .) hay que leer algun texto. Uno muybueno, pero no facil de encontrar, es ?.
1.1. Experimento y probabilidad
Dadas un conjunto de condiciones, un experimento, no siempre podemos predecirexactamente lo que va a ocurrir. La Probabilidad es la disciplina matematica queestudia estos experimentos.
En primer lugar determinamos el conjunto de posibles resultados que se puedeproducir en la experiencia, es el espacio muestral, Ω. Los posibles subconjuntosde A ⊂ Ω son los sucesos aleatorios y la probabilidad no nos dice si cada sucesosi va a producir o no sino que se limita a cuantificar para cada experimento lamayor o menor certidumbre que tenemos en la ocurrencia de A antes de realizar laexperiencia. P (A) es como se suele denotar habitualmente la probabilidad del sucesoA. Obviamente cada suceso tiene asignada una probabilidad. Han de darse unascondiciones de consistencia mınimas que han de verificar las distintas probabilidadesde los sucesos aleatorios. Son las siguientes
Definicion 1 (Medida de probabilidad) P funcion de conjunto definida sobrelos sucesos es una medida de probabilidad si:
1. (No negativa) P (A) ≥ 0 para todo A ⊂ Ω.
2. (La probabilidad del espacio muestral es uno) P (Ω) = 1.
3. (Numerablemente aditiva o σ aditiva) Si Ann≥1 es una sucesion de sucesosdisjuntos entonces
P (∪n≥1An) =∑n≥1
P (An).
1De hecho, hay una teorıa muy extendida que dice que podemos saber Estadıstica sin ningunconocimiento de Probabilidad. Esta creencia se considera un nuevo tipo de enfermedad mental. Sibien en una version leve de dicha enfermedad.
9

Ejemplo 1 Si el espacio muestral es finito y consideramos que todos los elementosque lo componen son equiprobables entonces la probabilidad de un suceso A vendrıadada como
P (A) =#(A)
#(Ω)(1.1)
siendo # el cardinal del conjunto. Se comprueba con facilidad que es una medidade probabilidad que verifica la axiomatica previa. Es el modelo que corresponde alconcepto intuitivo de resultados equiprobables. Practicamente todos los juegos deazar siguen un modelo como este donde varıan los resultados posibles.
Nota de R 1 (Muestreo con y sin reemplazamiento) Consideramos un con-junto finito y numeramos sus elementos de 1 a n. Nuestro espacio muestral es1, . . . , n. Veamos como extraer k elementos (con k ≤ n) sin reemplazamientode este conjunto. La funcion sample es la funcion basica. En el siguiente codigotenemos k = 6.
n <- 30
omega <- 1:n
sample(omega, size = 6, replace = FALSE)
## [1] 4 14 5 9 25 15
Ahora lo repetimos con reemplazamiento.
sample(omega, size = 6, replace = TRUE)
## [1] 28 2 6 26 2 7
1.2. Variable aleatoria
Supongamos el experimento consistente en elegir a una individuo al azar de laComunidad Valenciana. Obviamente el espacio muestral esta formado por los dis-tintos individuos. Si los numeramos tendrıamos Ω = ωiNi=i donde N es el numerototal de personas de la Comunidad. Eleccion al azar supone que cada individuotiene la misma probabilidad de ser elegido y viene dada por P (ωi) = 1
N . Obvia-mente cuando se elige una muestra de personas pensamos en alguna caracterısticanumerica de la misma por ejemplo su edad. Denotemos por X → R la aplicaciontal que X(ω) es la edad de la persona ω. Puesto que el individuo ω es seleccionadode un modo aleatorio, tambien sera aleatoria la cantidad X(ω). La aplicacion Xrecibe el nombre de variable aleatoria. Si B es un subconjunto arbitrario de numerosreales entonces cualquier afirmacion de interes sobre la variable aleatoria X suelepoderse expresar como P (ω : X(ω) ∈ B). Por ejemplo, si nos interesa la pro-porcion de personas que tienen 37 o mas anos esto supone plantearse el valor deP (ω : X(ω) ∈ [37,+∞)).
Dos son los tipos de variables de mayor interes practico, las variables aleatoriasdiscretas y las continuas. Una variable aleatoria se dice discreta si toma un conjuntode valores discreto, esto es, finito o si infinito numerable. Si el conjunto de valoresque puede tomar lo denotamos por D entonces se define la funcion de probabilidadde X como P (X = x). En estas variables se tiene que
P (a ≤ X ≤ b) =∑a≤x≤b
P (X = x), (1.2)
para cualesquiera valores reales a ≤ b.
10

Una variable aleatoria se dice continua cuando
P (a ≤ X ≤ b) =
∫ b
a
f(x)dx, (1.3)
para cualesquiera valores reales a ≤ b. La funcion f recibe el nombre de funcionde densidad (de probabilidad) de la variable X.
De un modo generico cuando se habla de la distribucion de una variable aleatoriaX hablamos de las probabilidades P (X ∈ B) para cualquier subconjunto B de R.Obviamente, para variables discretas,
P (X ∈ B) =∑x∈B
P (X = x) (1.4)
y para variables continuas
P (X ∈ B) =
∫A
f(x)dx. (1.5)
En resumen, si conocemos la funcion de probabilidad o la de densidad conocemosla distribucion de la variable.
1.2.1. Funcion de distribucion
Se define la funcion de distribucion de una variable aleatoria X como la funcionreal de variable real dada por
F (x) = P (X ≤ x) con x ∈ R. (1.6)
1.2.2. Media y varianza
Una variable suele describirse de un modo simple mediante su media y su va-rianza. La media nos da una idea de alrededor de que valor se producen los va-lores aleatorios de la variable mientras que la varianza cuantifica la dispersionde estos valores alrededor de la media. Se definen para variables discretas co-mo: la media es EX = µ =
∑x∈D xP (X = x); mientras que la varianza es
var(X) = σ2 = E(X − µ)2 =∑x∈D(x − µ)2P (X = x). Habitualmente ademas
de la varianza se suele utilizar para medir variabilidad la desviacion tıpica dada porσ =
√var(X).
En variables continuas las definiciones de media y varianza son las analogas susti-tuyendo sumatorios por integrales, de modo que la media se define como EX = µ =∫ +∞−∞ xf(x)dx mientras que la varianza sera var(X) = σ2 =
∫ +∞−∞ (x− µ)2f(x)dx.
En tablas 1.1 y 1.2 presentamos un breve resumen de las distribuciones quevamos a utilizar en este curso.
Nota de R 2 (Manejo de la distribucion binomial) En R se trabaja con lasdistribuciones de probabilidad mediante grupos de cuatro funciones. Por ejemplo,supongamos que estamos trabajando con la binomial. Entonces la funcion de pro-babilidad es dbinom, la funcion de distribucion es pbinom, la inversa de la funcionde distribucion que nos da los percentiles es qbinom y, finalmente, podemos gene-rar datos con distribucion binomial mediante la funcion rbinom. Consideramos unabinomial con 10 pruebas y una probabilidad de exito en cada prueba de 0.23.
dbinom(0:10, size = 10, prob = 0.23)
## [1] 7.327e-02 2.188e-01 2.942e-01 2.343e-01 1.225e-01 4.390e-02 1.093e-02 1.865e-03
## [9] 2.089e-04 1.387e-05 4.143e-07
11

Cu
ad
ro1.1
:D
istribu
cion
esd
iscretas
Distrib
ucio
nF
un
cion
de
pro
bab
ilidad
Med
iaV
arianza
Bern
ou
llif
(x|p)
=px(1−p)1−x
six
=0,1
pp(1−p)
Bin
om
ialf
(x|n,p
)= (
nx )px(1−p)n−x
six
=0,1
,...,nnp
np(1−p)
Hip
ergeometrica
f(x|A
,B,n
)=
Ax B
n−x
A
+B
n
six
=0,...,n
.nA
A+B
nAB
(A+B−n
)(A
+B
)2(A
+B−
1)
Geom
etricaf
(x|p)
=p(1−p)x
six
=0,1,2,...
1−pp
1−p
p2
Bin
om
ialN
egativa
f(x|r,p
)= (
r+x−
1x
)pr(1−p)x
six
=0,1
,2,...
r(1−
p)
pr(1−
p)
p2
Poisson
f(x|λ
)=
e−λλx
x!
six
=0,1,...
λλ
12

Cu
ad
ro1.2
:D
istr
ibu
cion
esco
nti
nu
as
Dis
trib
uci
onF
un
cion
de
den
sid
ad
Med
iaV
ari
an
za
Un
ifor
me
f(x|α,β
)=
1β−α
siα<x<β
α+β
2(β−α
)2
12
Nor
mal
,N
(µ,σ
2)
f(x|µ,σ
2)
=1
σ√
2πe−
1 2(x−µ
σ)2
x∈R
µσ
2
Gam
maGa(α,β
)f
(x|α,β
)=
βα
Γ(α
)xα−
1e−
βx
six>
0a
α βα β2
Exp
onen
cialExpo(λ
)f
(x|λ
)=
1 λex
p−x λ
six≥
0λ
λ2
Ji-
Cu
adra
doχ
2(ν
)X∼χ
2(ν
)siX∼Ga(ν 2,
1 2)
ν2ν
Bet
aBe(α,β
)f
(x|α,β
)=
Γ(α
+β
)Γ
(α)Γ
(β)xα−
1(1−x
)β−
1si
0<x<
1α
α+β
αβ
(α+β
)2(α
+β
+1)
t-S
tud
entt(ν
)f
(x)
=Γ
(ν+
12
)√νπ
Γ(ν 2
)
( 1+
x2 ν
) −ν+1
2
∀x∈R
0siν>
1νν−
2siν>
2
F-S
ned
ecorF
(m,n
)f
(x)
=Γ
(m
+n
2)
Γ(m 2
)Γ(n 2
)mm/2nn/2
xm/2−
1
(mx
+n
)(m
+n)/2
six>
0n
(n−
2)
sin>
22n2(m
+n−
2)
m(n−
2)2
(n−
4)
sin>
4
Wei
bu
ll(α,β
)f
(x|α,β
)=αβ−αxα−
1ex
p−
(x β
)αsix>
0β α
Γ(
1 α)
β2 α(2
Γ(
2 α)−
1 αΓ
2(
1 α))
Log
nor
mal
X∼N
(µ,σ
2)→eX∼LN
(µ,σ
2)
aL
afu
nci
on
gam
ma
sed
efin
eco
mo
Γ(α
)=
∫ +∞ 0xα−1
exp−xdx
,qu
eex
iste
yes
fin
ita∀α
>0
13
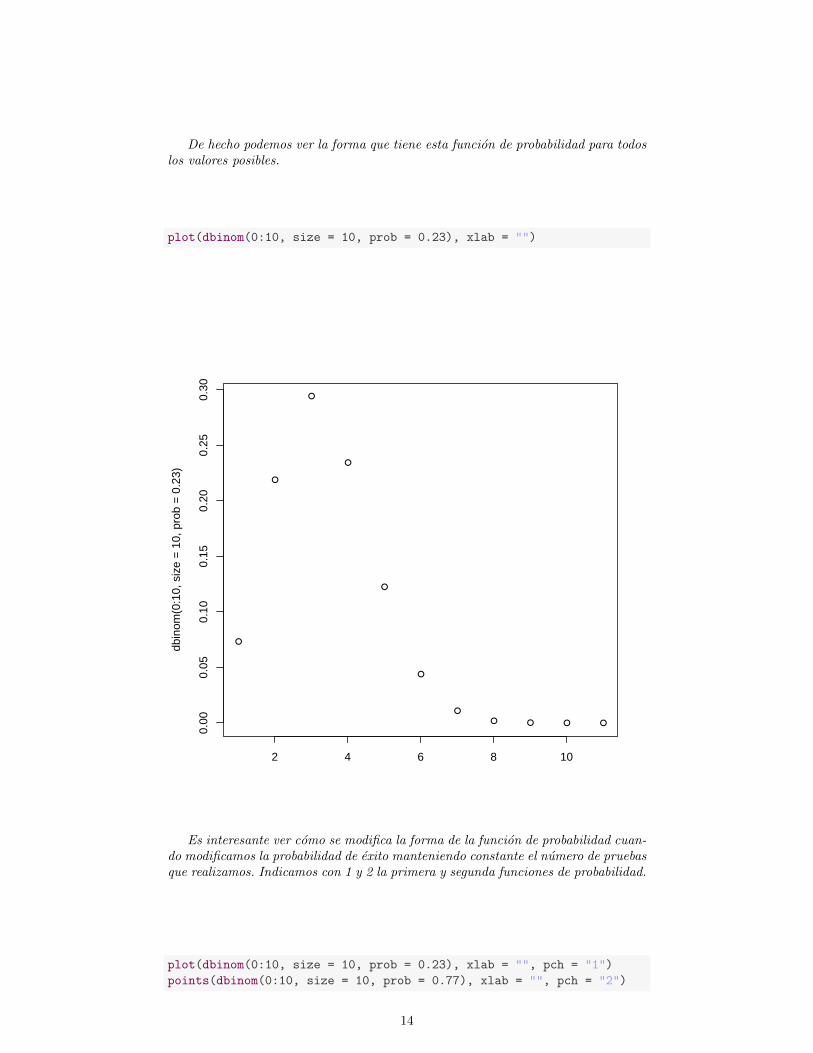
De hecho podemos ver la forma que tiene esta funcion de probabilidad para todoslos valores posibles.
plot(dbinom(0:10, size = 10, prob = 0.23), xlab = "")
2 4 6 8 10
0.00
0.05
0.10
0.15
0.20
0.25
0.30
dbin
om(0
:10,
siz
e =
10,
pro
b =
0.2
3)
Es interesante ver como se modifica la forma de la funcion de probabilidad cuan-do modificamos la probabilidad de exito manteniendo constante el numero de pruebasque realizamos. Indicamos con 1 y 2 la primera y segunda funciones de probabilidad.
plot(dbinom(0:10, size = 10, prob = 0.23), xlab = "", pch = "1")
points(dbinom(0:10, size = 10, prob = 0.77), xlab = "", pch = "2")
14

1
1
1
1
1
1
11 1 1 1
2 4 6 8 10
0.00
0.05
0.10
0.15
0.20
0.25
0.30
dbin
om(0
:10,
siz
e =
10,
pro
b =
0.2
3)
2 2 2 22
2
2
2
2
2
2
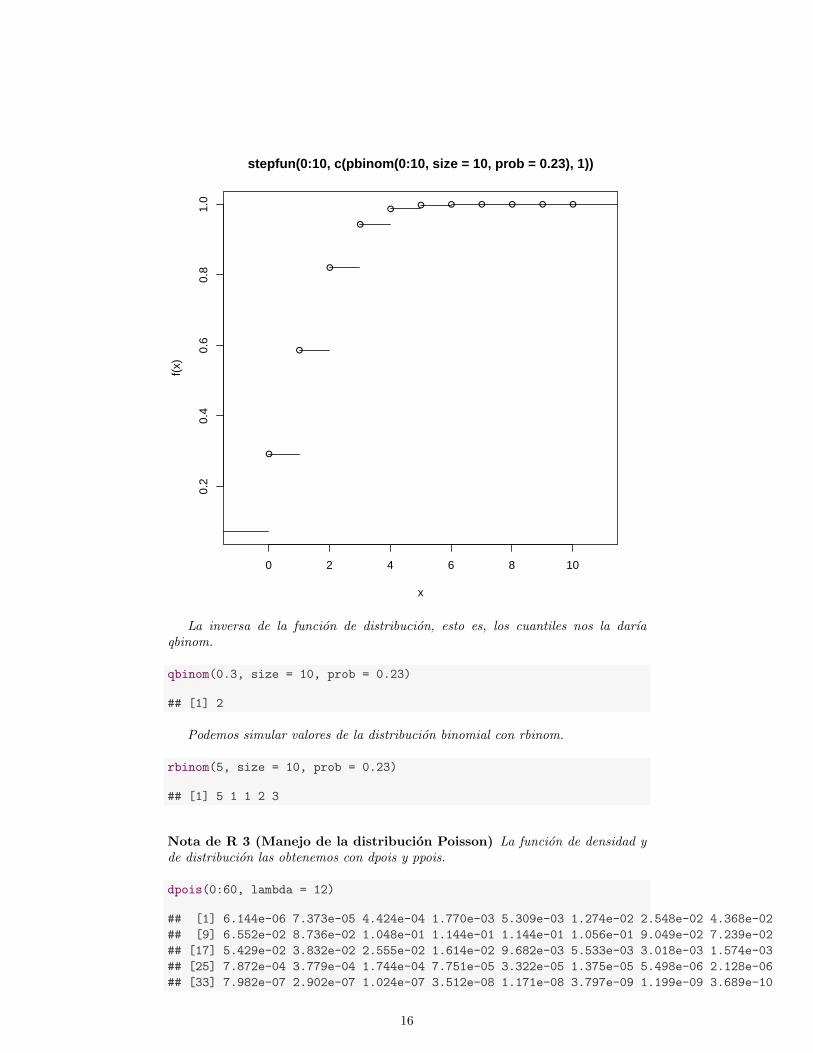
La funcion de distribucion la podemos conseguir con pbinom.
pbinom(0:10, size = 10, prob = 0.23)
## [1] 0.07327 0.29212 0.58628 0.82060 0.94308 0.98698 0.99791 0.99978 0.99999 1.00000
## [11] 1.00000
plot(stepfun(0:10, c(pbinom(0:10, size = 10, prob = 0.23), 1)), verticals = F)
15
0 2 4 6 8 10
0.2
0.4
0.6
0.8
1.0
stepfun(0:10, c(pbinom(0:10, size = 10, prob = 0.23), 1))
x
f(x)
La inversa de la funcion de distribucion, esto es, los cuantiles nos la darıaqbinom.
qbinom(0.3, size = 10, prob = 0.23)
## [1] 2
Podemos simular valores de la distribucion binomial con rbinom.
rbinom(5, size = 10, prob = 0.23)
## [1] 5 1 1 2 3
Nota de R 3 (Manejo de la distribucion Poisson) La funcion de densidad yde distribucion las obtenemos con dpois y ppois.
dpois(0:60, lambda = 12)
## [1] 6.144e-06 7.373e-05 4.424e-04 1.770e-03 5.309e-03 1.274e-02 2.548e-02 4.368e-02
## [9] 6.552e-02 8.736e-02 1.048e-01 1.144e-01 1.144e-01 1.056e-01 9.049e-02 7.239e-02
## [17] 5.429e-02 3.832e-02 2.555e-02 1.614e-02 9.682e-03 5.533e-03 3.018e-03 1.574e-03
## [25] 7.872e-04 3.779e-04 1.744e-04 7.751e-05 3.322e-05 1.375e-05 5.498e-06 2.128e-06
## [33] 7.982e-07 2.902e-07 1.024e-07 3.512e-08 1.171e-08 3.797e-09 1.199e-09 3.689e-10
16
## [41] 1.107e-10 3.239e-11 9.256e-12 2.583e-12 7.044e-13 1.878e-13 4.900e-14 1.251e-14
## [49] 3.128e-15 7.660e-16 1.838e-16 4.326e-17 9.983e-18 2.260e-18 5.023e-19 1.096e-19
## [57] 2.348e-20 4.944e-21 1.023e-21 2.080e-22 4.161e-23
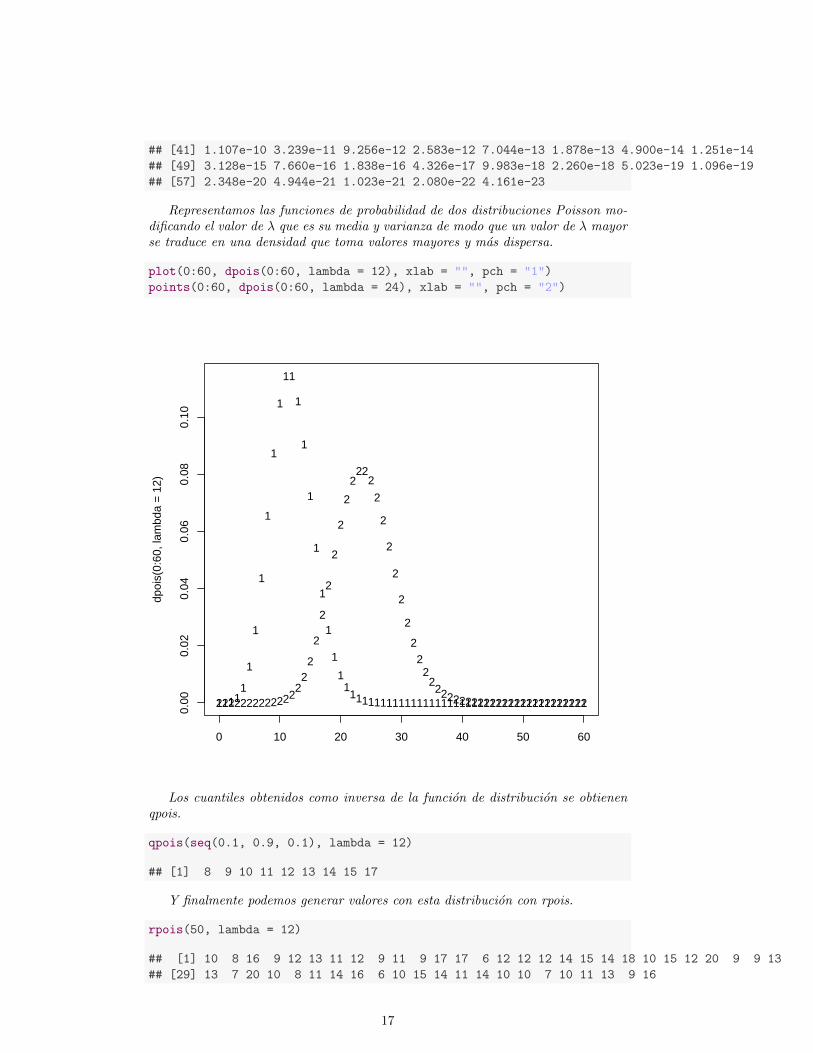
Representamos las funciones de probabilidad de dos distribuciones Poisson mo-dificando el valor de λ que es su media y varianza de modo que un valor de λ mayorse traduce en una densidad que toma valores mayores y mas dispersa.
plot(0:60, dpois(0:60, lambda = 12), xlab = "", pch = "1")
points(0:60, dpois(0:60, lambda = 24), xlab = "", pch = "2")
11111
1
1
1
1
1
1
11
1
1
1
1
1
1
1
11111111111111111111111111111111111111111
0 10 20 30 40 50 60
0.00
0.02
0.04
0.06
0.08
0.10
dpoi
s(0:
60, l
ambd
a =
12)
2222222222222222
2
2
2
2
2
2
222
2
2
2
2
2
2
2
22222222222222222222222222222
Los cuantiles obtenidos como inversa de la funcion de distribucion se obtienenqpois.
qpois(seq(0.1, 0.9, 0.1), lambda = 12)
## [1] 8 9 10 11 12 13 14 15 17
Y finalmente podemos generar valores con esta distribucion con rpois.
rpois(50, lambda = 12)
## [1] 10 8 16 9 12 13 11 12 9 11 9 17 17 6 12 12 12 14 15 14 18 10 15 12 20 9 9 13
## [29] 13 7 20 10 8 11 14 16 6 10 15 14 11 14 10 10 7 10 11 13 9 16
17

Nota de R 4 La funcion de densidad y de distribucion las obtenemos con dpois yppois.
dpois(0:60, lambda = 12)
## [1] 6.144e-06 7.373e-05 4.424e-04 1.770e-03 5.309e-03 1.274e-02 2.548e-02 4.368e-02
## [9] 6.552e-02 8.736e-02 1.048e-01 1.144e-01 1.144e-01 1.056e-01 9.049e-02 7.239e-02
## [17] 5.429e-02 3.832e-02 2.555e-02 1.614e-02 9.682e-03 5.533e-03 3.018e-03 1.574e-03
## [25] 7.872e-04 3.779e-04 1.744e-04 7.751e-05 3.322e-05 1.375e-05 5.498e-06 2.128e-06
## [33] 7.982e-07 2.902e-07 1.024e-07 3.512e-08 1.171e-08 3.797e-09 1.199e-09 3.689e-10
## [41] 1.107e-10 3.239e-11 9.256e-12 2.583e-12 7.044e-13 1.878e-13 4.900e-14 1.251e-14
## [49] 3.128e-15 7.660e-16 1.838e-16 4.326e-17 9.983e-18 2.260e-18 5.023e-19 1.096e-19
## [57] 2.348e-20 4.944e-21 1.023e-21 2.080e-22 4.161e-23
Representamos las funciones de probabilidad de dos distribuciones Poisson mo-dificando el valor de λ que es su media y varianza de modo que un valor de λ mayorse traduce en una densidad que toma valores mayores y mas dispersa.
plot(0:60, dpois(0:60, lambda = 12), xlab = "", pch = "1")
points(0:60, dpois(0:60, lambda = 24), xlab = "", pch = "2")
11111
1
1
1
1
1
1
11
1
1
1
1
1
1
1
11111111111111111111111111111111111111111
0 10 20 30 40 50 60
0.00
0.02
0.04
0.06
0.08
0.10
dpoi
s(0:
60, l
ambd
a =
12)
2222222222222222
2
2
2
2
2
2
222
2
2
2
2
2
2
2
22222222222222222222222222222
Los cuantiles obtenidos como inversa de la funcion de distribucion se obtienencon qpois.
18

qpois(seq(0.1, 0.9, 0.1), lambda = 12)
## [1] 8 9 10 11 12 13 14 15 17
Y finalmente podemos generar valores con esta distribucion con rpois.
rpois(50, lambda = 12)
## [1] 10 16 11 13 8 13 14 12 13 6 7 12 10 14 13 15 12 17 10 10 12 7 10 16 16 5 6 11
## [29] 11 15 14 6 13 13 13 10 14 8 13 12 7 11 17 14 18 18 11 14 14 20
1.2.3. Teorema de Bayes
Tenemos el espacio muestral Ω y una particion de dicho espacio, B1, . . . , Bk, estoes, sucesos disjuntos dos a dos y tales que su union cubren todo el espacio muestral.Entonces se tiene que, para cualquier suceso A,
P (Bi | A) =P (A | Bi)P (Bi)∑kj=1 P (A | Bj)P (Bj)
(1.7)
1.3. Vectores aleatorios
Supongamos X = (X1, . . . , Xd) un vector aleatorio con d componentes. Tantosi el vector es discreto (todas sus variables aleatorias componentes son discretas)como si es continuo denotaremos la correspondiente funcion de probabilidad o dedensidad conjunta mediante f(x1, . . . , xn). SiX es discreto entonces f(x1, . . . , xn) =P (X1 = x1, . . . , Xn = xn) y hablamos de funcion de probabilidad. En lo que siguehablamos del caso continuo. Todas las expresiones son analogas en el caso discretosustituyendo la integral por el sumatorio correspondiente.
Si X = (X1, . . . , Xd) es un vector continuo entonces
P (a1 ≤ X1 ≤ b1, . . . , ad ≤ X1 ≤ bd) =
∫ b1
a1
. . .
∫ bd
ad
f(x1, . . . , xd)dx1 . . . dxn, (1.8)
para cualesquiera ai ≤ bi con i = 1, . . . , d.En particular la distribucion del vector suele venir descrita mediante el vector
de medias y por la matriz de covarianzas.Si para la i-esima variable Xi consideramos la media µi = EXi entonces el
vector de medias µ viene dado por
µX =
µ1
...µd
Si no hace falta indicar el vector X entonces denotaremos simplemente µ en lugarde µX .
Para cada par de variables Xi y Xj podemos considerar su covarianza definidacomo σij = cov(Xi, Xj) = E(Xi − EXi)(Xj − EXj) = E(XiXj)− EXiEXj .
Obviamente si Xi = Xj entonces cov(Xi, Xi) = var(Xi), es decir, la covarianzade una variable consigo misma es la varianza de la variable, es decir, σii = var(Xi).Dado el vector aleatorio X podemos consider la covarianza de cada par de variablesy construir la matriz que en la posicion (i, j) tiene dicha covarianza. Es la matriz
19

de covarianzas, tambien llamada en la literatura matriz de varianzas, matriz devarianzas-covarianzas o matriz de dispersion. La denotaremos por Σ, es decir,
Σ =
σ11 . . . σ1d
......
...σd1 . . . σdd
En general si consideramos dos vectores aleatorios X = (X1, . . . , Xd)
′ e Y =(Y1, . . . , Yp) denotaremos
cov(X,Y ) =
cov(X1, Y1) . . . cov(X1, Yp)...
......
cov(Xd, Y1) . . . cov(Xd, Yp)
y sera la matriz de covarianzas entre dichos vectores.
Si los vectores X e Y son independientes se verifica que cov(X,Y ) = 0.Dado el vector X = (X1, . . . , Xd)
′ podemos considerar la matriz de correla-ciones que en la posicion (j, k) tiene el coeficiente de correlacion entre las variablesXi y Xj , ρjk =
σjk√σjjσkk
, es decir,
Pρ =
1 ρ12 . . . ρ1d
......
......
ρd1 ρd2 . . . 1
Obviamente, como la matriz de covarianzas, la matriz de correlaciones es simetricaya que ρjk = ρkj . Si denotamos por Dσ = diag(σ11, . . . , σdd) entonces tenemos que
Pρ = D− 1
2σ ΣD
− 12
σ . (1.9)
Propiedades del vector de medias y la matriz de covarianzas
Supongamos que tenemos una matriz A de dimensiones p×d con p ≤ d y de rangop (tiene pues p filas y p columnas que son linealmente independientes). Tenemos unvector aleatorio X con d componentes y consideramos el vector Y = Ax, esto es,consideramos la transformacion lineal del vector X asociada a la matriz A. Entoncesse tiene que
µY = E[Y ] = AE[X] = AµX . (1.10)
ycov(Y ) = cov(AX) = Acov(X)A′. (1.11)
1.4. Distribucion normal multivariante
Veamos dos definiciones equivalentes.
Definicion 2 Sea Y = (Y1, . . . , Yd)′ un vector aleatorio d-dimensional. Se dice que
el vector Y tiene una distribucion normal multivariante si tiene por funcion dedensidad conjunta
f(y|µ,Σ) =1
(2π)d2 |Σ| 12
exp
(− 1
2(y − µ)′Σ−1(y − µ)
), (1.12)
donde −∞ < yj < +∞, j = 1, . . . , d y Σ = [σjk] es una matriz definida positiva(Σ > 0).
20

Se puede probar que EY = µ y var(Y ) = Σ y por ello se suele denotar
Y ∼ Nd(µ,Σ). (1.13)
Se tiene que si Y1, . . . , Yd son variables aleatorias con distribucion normal indepen-dientes con medias nulas y varianza comun σ2 entonces se tiene que Y ∼ Nd(0, σ2Id).
Teorema 1 Supongamos Y ∼ Nd(µ,Σ) y sea
Y =
[Y (1)
Y (2)
], µ =
[µ(1)
µ(2)
], Σ =
[Σ11 Σ12
Σ21 Σ22
],
donde Y (i) y µ(i) son vectores di × 1 y Σii es una matriz di × di (con d1 + d2 = d).Se verifican las siguientes propiedades:
1. Si C es una matriz q × d de rango q entonces CY ∼ Nq(Cµ,CΣC ′).
2. Cualquier subvector de Y tiene una distribucion normal multivariante. Enparticular, se tiene que Y (1) ∼ Nd1(µ(1),Σ11).
3. Y (1) e Y (2) son independientes si cov(Y (1), Y (2)) = 0.
4. Si Ui = AiY (i = 1, . . . ,m) y cov(Ui, Uj) = 0 para i 6= j entonces los distintosvectores Ui son independientes.
5. (Y − µ)′Σ−1(Y − µ) ∼ χ2d.
6. La distribucion condicionada de Y (2), dado Y (1) = y(1) es Nd2(µ(2)+Σ21Σ−111 [y(1)−
µ(1)],Σ22,1) donde Σ22,1 = Σ22 − Σ21Σ−111 Σ12.
Una segunda manera en que podemos definir la distribucion normal multiva-riante es del siguiente modo.
Definicion 3 Y tiene una distribucion normal multivariante si a′Y =∑di=1 aiYi
tiene una distribucion normal univariante para cualquier vector a = (a1, . . . , ad)′.
Si EY = µ and cov(Y ) = Σ > 0 entonces Y ∼ Nd(µ,Σ).
Nota de R 5 El paquete [?] nos permite trabajar con la normal multivariante.
library(mvtnorm)
En concreto, veamos un ejemplo de la normal bivariante con vector de medias ymatriz de covarianzas dada por
mu <- c(4.5, 7.3)
Sigma <- matrix(c(7.097258, 3.885963, 3.885963, 3.371314), 2, 2)
Elegimos los puntos donde vamos a calcular la densidad bivariante
npuntos <- 50
x <- seq(mu[1] - 3 * sqrt(Sigma[1, 1]), mu[1] + 3 * sqrt(Sigma[1, 1]), len = npuntos)
y <- seq(mu[2] - 3 * sqrt(Sigma[2, 2]), mu[2] + 3 * sqrt(Sigma[2, 2]), len = npuntos)
y calculamos los valores.
21

z <- NULL
for (i in 1:npuntos) for (j in 1:npuntos)
z <- rbind(z, c(x[i], y[j], dmvnorm(c(x[i], y[j]), mean = mu, sigma = Sigma)))
Vamos a representarlos.
persp(z)
contour(z)
z
Y
Z
22

−2 0
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
4
4
4
4
4
4 4
4
4
4
4
4
4
4 4
4 4
4
4 4
4 4
4 4
6
6
6
6
6 6
6
6
6
6
6 6
6 6
6
6 6
6
6 6
6 6
6 6
6 6
6 6
6 6
8
8
8
8
8
8 8 8 8
8
8 8
8
8
8
8 8
8 8
8
8
8
8 8
8 8
8 8
8 8
8 8
8
10 10
10
10
10
10
10
10
10
10
10 1
0
10
10
10
10
10
10
10 10
10 10
10 10
10 10
10
10
12 12
12
12 12
12 12
12
12
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
¿Como generar valores normales multivariantes? Consideramos el vector de me-dias y la matriz de covarianzas siguiente.
mu <- c(4.5, 7.3, 6.2, 8.4, 7.3)
Sigma <- matrix(c(7.097258, 3.885963, 2.658114, 4.036412, 2.698515, 3.885963, 3.371314, 2.275973,
3.713151, 1.601078, 2.658114, 2.275973, 5.996727, 7.333165, 5.564751, 4.036412, 3.713151,
7.333165, 10.970678, 7.80342, 2.698515, 1.601078, 5.564751, 7.80342, 6.742381), 5, 5)
Y generamos los datos.
x <- rmvnorm(10, mean = mu, sigma = Sigma)
@
23

24

Capıtulo 2
Un muy breve repaso a laEstadıstica
Solo pretendemos fijar notacion y recordar algunos de los conceptos basicos. Esmas que recomendable consultar algun texto de introduccion a la Estadıstica. Haytantos y, muchos, tan buenos que es casi un pecado recomendar alguno. El que setenga a mano sera bueno. Teniendo en cuenta que este texto esta muy orientadoal uso de la Estadıstica con R ? serıa bueno consultar Verzani [2005] en donde sepresenta la estadıstica basica con el programa.
2.1. Algo de Estadıstica Descriptiva, poco
Cuando tenemos un banco de datos lo primero y conveniente es describir de unmodo sencillo dichos datos, bien mediante unos resumenes numericos o bien median-te unos resumenes graficos. Esto es lo que se conoce como Estadıstica descriptiva.Veamos algun ejemplo para recordar estos conceptos.
Nota de R 6 (Analisis descriptivo de unos datos de hospitalizacion ambulatoria)Vamos a realizar un analisis descriptivo de unos datos relativos a hospitalizacionambulatoria. Empezamos cargando el fichero de datos.
load("../data/scoremaster")
Lo que acabamos de cargar es un data frame cuyo nombre es scoremaster. Hemosde saber cuales son las variables que lo componen.
names(scoremaster)
## [1] "score" "eg1" "d1" "t1" "s1"
## [6] "score2" "eg2" "d2" "t2" "s2"
## [11] "score3" "eg3" "d3" "t3" "s3"
## [16] "score4" "score5" "especialidad" "intensidad" "tipoanes"
## [21] "asa" "sexo" "T.TOTALP" "T.QUIRUR" "edad"
Para poder trabajar con los nombres de las variables hemos de adjuntar el bancode datos
attach(scoremaster)
Podemos ver los primeros diez valores de la variable score.
25

score[1:10]
## [1] 6 4 5 6 7 6 7 8 6 5
## Levels: 3 < 4 < 5 < 6 < 7 < 8
De las variables consideradas algunas son categoricas como puede ser la especia-lidad o tipoanes (tipo de anestesia), otras son ordinales como score, score2, score3,. . . mientras que otras son continuas como T.TOTALP o T.QUIRUR. Es intere-sante utilizar la funcion extractora summary sobre un data frame.
summary(scoremaster)
## score eg1 d1 t1 s1 score2 eg2 d2 t2
## 3: 13 0: 18 0: 18 0: 50 0: 17 3 : 7 0 : 27 0 : 36 0 : 11
## 4: 89 1:545 1:360 1:359 1:307 4 : 33 1 :377 1 :359 1 : 59
## 5:199 2:359 2:544 2:513 2:598 5 :133 2 :359 2 :366 2 :691
## 6:276 6 :234 NA's:159 NA's:161 NA's:161
## 7:219 7 :192
## 8:126 8 :162
## NA's:161
## s2 score3 eg3 d3 t3 s3 score4
## 0 : 3 3 : 2 0 : 9 0 : 10 0 : 0 0 : 0 Min. :5.0
## 1 :237 4 : 3 1 : 78 1 : 76 1 : 9 1 : 45 1st Qu.:6.0
## 2 :522 5 : 34 2 : 51 2 : 51 2 :127 2 : 92 Median :6.5
## NA's:160 6 : 45 NA's:784 NA's:785 NA's:786 NA's:785 Mean :6.4
## 7 : 34 3rd Qu.:7.0
## 8 : 20 Max. :8.0
## NA's:784 NA's :902
## score5 especialidad intensidad tipoanes asa sexo T.TOTALP
## Min. :4.0 1 :325 1:168 General:746 1:555 0 :329 Min. : 900
## 1st Qu.:5.5 2 :163 2:426 Plexo :108 2:332 1 :590 1st Qu.: 6060
## Median :6.5 4 :136 3:328 CAM : 65 3: 35 NA's: 3 Median : 8790
## Mean :6.0 5 : 55 NA's : 3 Mean : 9881
## 3rd Qu.:7.0 7 :157 3rd Qu.:12420
## Max. :7.0 8 : 74 Max. :35160
## NA's :918 NA's: 12
## T.QUIRUR edad
## Min. : 600 Min. : 4.0
## 1st Qu.: 2640 1st Qu.:31.0
## Median : 3600 Median :43.0
## Mean : 3903 Mean :43.5
## 3rd Qu.: 4860 3rd Qu.:56.0
## Max. :16200 Max. :84.0
## NA's :194
En el resumen anterior vemos que cuando se trata de una variable categoricanos muestra los conteos asociados a cada uno de los valores posibles (si hay muchascategorıas solo pone algunas y las demas las agrupa en una ultima categorıa). Enlas variables numericas saca unas descriptivas numericas. Observemos la descriptivanumerica de T.TOTALP.
summary(T.TOTALP)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 900 6060 8790 9880 12400 35200
26
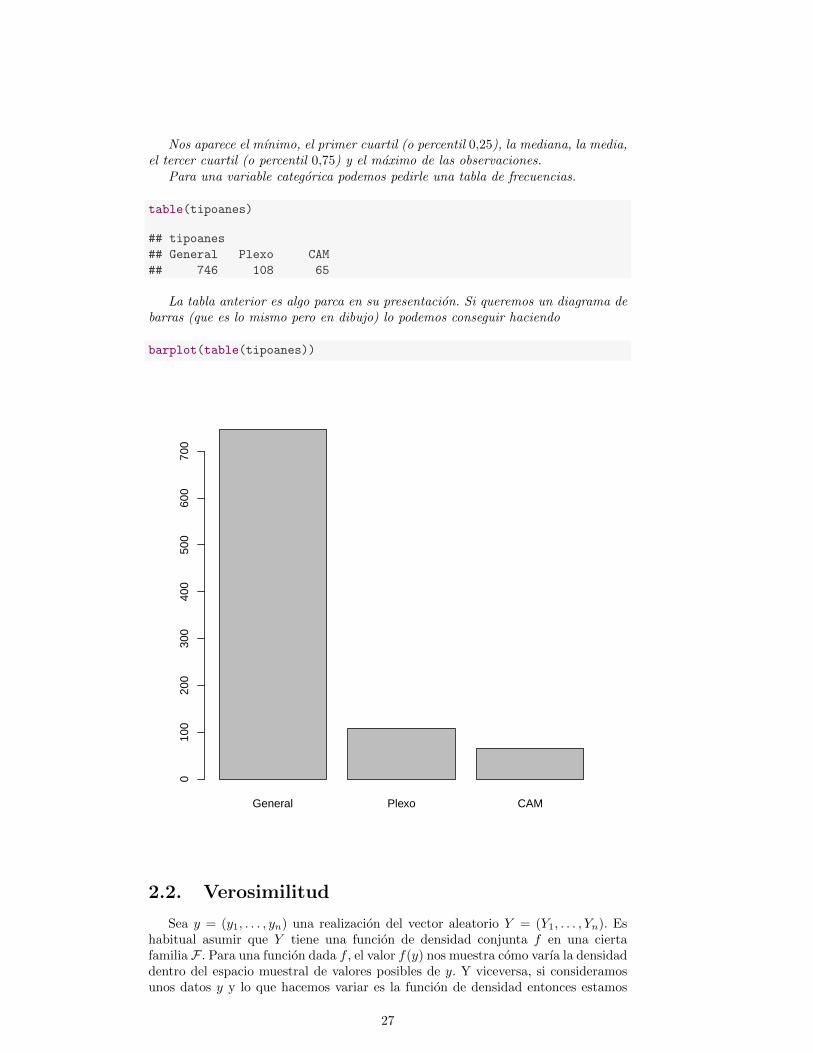
Nos aparece el mınimo, el primer cuartil (o percentil 0,25), la mediana, la media,el tercer cuartil (o percentil 0,75) y el maximo de las observaciones.
Para una variable categorica podemos pedirle una tabla de frecuencias.
table(tipoanes)
## tipoanes
## General Plexo CAM
## 746 108 65
La tabla anterior es algo parca en su presentacion. Si queremos un diagrama debarras (que es lo mismo pero en dibujo) lo podemos conseguir haciendo
barplot(table(tipoanes))
General Plexo CAM
010
020
030
040
050
060
070
0
2.2. Verosimilitud
Sea y = (y1, . . . , yn) una realizacion del vector aleatorio Y = (Y1, . . . , Yn). Eshabitual asumir que Y tiene una funcion de densidad conjunta f en una ciertafamilia F . Para una funcion dada f , el valor f(y) nos muestra como varıa la densidaddentro del espacio muestral de valores posibles de y. Y viceversa, si consideramosunos datos y y lo que hacemos variar es la funcion de densidad entonces estamos
27

viendo como de verosımil es cada una de las funciones dados los datos y. Esta funcionrecibe el nombre de verosimilitud de f dados los datos y y se suele denotar como
V erosimilitud[f ; y] = L(f ; y) = f(y). (2.1)
Con frecuenica, es conveniente trabajar con el logaritmo natural de la funcion an-terior y hablaremos de la log-verosimilitud.
l[f ; y] = log f(y). (2.2)
Una simplificacion adicional (que es habitual en las aplicaciones) supone que lafuncion de densidad f pertenece a una familia parametrica F , esto es, cada elementode la familia es conocido completamente salvo un numero finito de parametrosθ = (θ1, . . . , θp) de modo que denotaremos f(y; θ) o fY (y; θ). Al conjunto de valoresposibles de θ se le llama espacio parametrico y lo denotaremos por Θ. En estecaso, la logverosimilitud es una funcion de θ y denotaremos
V erosimilitud[θ; y] = l(θ; y) = log f(y; θ). (2.3)
Supongamos una transformacion 1-1 de Y a Z, Z = g(Y ). Las densidades deambos vectores se relacionan segun la siguiente relacion
fZ(z) = fY (y)
∣∣∣∣∂y∂z∣∣∣∣,
donde
∣∣∣∣∂y∂z ∣∣∣∣ es el jacobiano de la transformacion de z a y. Se tiene la siguiente relacion
entre las verosimilitudes
LZ(θ; z) =
∣∣∣∣∂y∂z∣∣∣∣LY (θ; y).
Esto sugiere que es mejor trabajar con el cociente de las verosimilitudes para dosvectores de parametros θ1 y θ2 en lugar de los valores aislados.
Si asumimos que los distintos Y1, . . . , Yn son independientes entonces
LY (θ; y) = fY (y) =
n∏i=1
fYi(yi),
y
ly(θ; y) =
n∑i=1
log fYi(yi) =
n∑i=1
LYi(θ; yi).
Veamos algunos ejemplos de verosimilitud.
Ejemplo 2 (Pruebas Bernoulli) Y1, . . . , Yn son independientes y con la mismadistribucion (i.i.d.) P (Yi = yi) = θyi(1− θ)1−yi y
L(θ; y) = θ∑ni=1 yi(1− θ)n−
∑ni=1 yi
Ejemplo 3 (Numero de exitos en n pruebas Bernoulli) Nuestros datos sonahora el numero total de exitos en un numero dado de pruebas de Bernoulli, r. En-tonces la variable correspondiente R tiene una distribucion binomial con n pruebasy una probabilidad de exito θ. La verosimilitud viene dada por
L(θ; r) =
(n
r
)θr(1− θ)n−r
28

Ejemplo 4 (Muestreo Bernoulli inverso) Nuestros datos son ahora el numerototal de pruebas necesarias para alcanzar un numero previamente especificado deexitos. La variable aleatoria correspondiente N tendra una distribucion binomialnegativa con r exitos y una probabilidad de exito θ. La funcion de verosimilitudcorrespondiente viene dada por
L(θ;n) =
(n− 1
r − 1
)θr(1− θ)n−r
Consideremos los tres ejemplos anteriores 2, 3 y 4. Si consideramos dos valores delparametro θ1 y θ2 entonces el cociente de las verosimilitudes calculados en ambosvalores tiene el mismo valor en los tres ejemplos.
2.3. Estimacion
Denotamos por Θ el espacio formado por los valores que puede tomar θ o espacioparametrico. Un estimador del parametros o vector parametrico θ es cualquierfuncion de la muestra X1, . . . , Xn que toma valores en el espacio parametrico.
Si δ(X1, . . . , Xn) es un estimador del parametro θ entonces se define el errorcuadratico medio como
MSE(δ) = E[δ(X1, . . . , Xn)− θ]2 (2.4)
En el caso en que se verifique que Eδ(X1, . . . , Xn) = µδ = θ, es decir, que elestimador sea insesgado entonces:
MSE(δ) = E[δ(X1, . . . , Xn)− θ]2 = E[δ(X1, . . . , Xn)− µδ]]2 = var(δ).
Y el error cuadratico medio no es mas que la varianza del estimador.Consideremos la siguiente cadena de igualdades. Denotamos
MSE(δ) = E[δ − θ]2 = E[δ − µδ + µδ − θ]2 = E[δ − µδ]2 + [µδ − θ]2 (2.5)
La diferencia entre la media del estimador y el parametro, µδ − θ, recibe el nombrede sesgo. Finalmente lo que nos dice la ecuacion anterior es que el error cuadraticomedio MSE(δ) lo podemos expresar como la suma de la varianza del estimador,E[δ − µδ]2, mas el sesgo al cuadrado, [µδ − θ]2.
A la raız cuadrada de la varianza de un estimador, es decir, a su desviaciontıpica o estandar se le llama error estandar. La expresion error estandar se usaen ocasiones indistintamente para referirse o bien dicha desviacion tıpica o bien alestimador de la misma.
2.3.1. Estimacion insesgada de media y varianza
Dada una muestra Y1, . . . , Yn de una variable. Un estimador habitualmente uti-lizado para estimar µ = EYi es la media muestral dada por
Y =1
n
n∑i=1
Yi. (2.6)
Notemos que
EY = E[1
n
n∑i=1
Yi] =1
n
n∑i=1
EYi =1
n
n∑i=1
µ = µ.
En definitiva, la media muestral es un estimador que no tiene ningun sesgo cuandoestima la media de Yi (la media poblacional) o, lo que es lo mismo, es un estimadorinsesgado.
29

Para estimar de un modo insesgado la varianza σ2 a partir de una muestraY1, . . . , Yn se utiliza la varianza muestral dada por
S2 =1
n− 1
n∑i=1
(Yi − Y )2. (2.7)
La razon de la division por n − 1 en lugar de dividir por n viene de las siguientesigualdades.
E
n∑i=1
(Yi − Y )2 =
E
n∑i=1
[(Yi − µ)− (Y )2 − µ)]2 =
n∑i=1
E(Yi − µ)2 − nE(Y − µ)2, (2.8)
pero E(Yi − µ)2 = σ2 y E(Y − µ)2 = var(Y ) = σ2/n. En consecuencia,
E
n∑i=1
(Yi − Y )2 = nσ2 − σ2
n= nσ2 − σ2 = (n− 1)σ2,
de donde,
ES2 = E1
n− 1
n∑i=1
(Yi − Y )2 = σ2,
es decir, S2 estima la varianza σ2 sin sesgo.
Nota de R 7 (Estimacion insesgada de media y varianza) Vamos a estimarla media y la varianza de un modo insesgado. Empezamos leyendo los datos score-master.
load("../data/scoremaster")
attach(scoremaster)
La media muestral del tiempo total quirurgico (en segundos) lo obtenemos con
mean(T.QUIRUR)
## [1] 3903
Mientras que la varianza y desviacion tıpica muestral vienen dadas por
var(T.QUIRUR)
## [1] 3107898
sd(T.QUIRUR)
## [1] 1763
2.3.2. Estimacion insesgada del vector de medias y la matrizde covarianzas
Ahora consideramos una muestra de un vector de dimension d, Y1, . . . , Yn i.i.d.con vector de medias µ = EYi y matriz de covarianzas Σ = cov(Yi). Los estima-dores insesgados de µ y Σ son las versiones multivariantes de la media y varianza
30

muestrales. Si
Yi =
Yi1...Yip
Entonces podemos representar toda la muestra como la siguiente matriz
Y =
Y′1...Y ′n
=
Y11 . . . Y1d
......
...Yn1 . . . Ynd
mientras que los datos observados, la matriz de datos, vendrıa dada por
y =
y′1...y′n
=
y11 . . . y1d
......
...yn1 . . . ynd
El vector de medias muestral viene dado por la siguiente expresion en terminos dela matriz Y ,
Y =1
n
n∑i=1
Yi =1
nY ′1n. (2.9)
siendo 1n el vector n× 1 con todos los valores iguales a uno. Tambien denotaremos
Y =
Y·1...Y·p
El estimador de la matriz de covarianzas (poblacional) Σ serıa la matriz de co-varianzas muestral que tiene en la posicion (j, k) la covarianza muestral entre lascomponentes j y k,
Sjk =1
n− 1
n∑i=1
(Yij − Y·j)(Yik − Y·k),
de modo que
S =
S11 . . . S1d
......
...Sd1 . . . Sdd
=1
n− 1
n∑i=1
(Yi − Y )(Yi − Y )′ =1
n− 1Q.
Es inmediato que EY = µ porque componente a componente hemos visto que severifica la igualdad. A partir de los vectores Yi consideramos Xi = Yi − µ de modoque se verifica X = X − µ. Se sigue que
n∑i=1
(Yi − Y )(Yi − Y )′ =n∑i=1
(Xi − X)(Xi − X)′ =n∑i=1
XiX′i − nXX ′.
Los vectores X1, . . . , Xn tienen vector de medias nulo y matriz de covarianzas Σ, lamisma que los Yi. En consecuencia, EXX ′ = Σ y
EQ =
n∑i=1
cov(Yi)− n cov(Y ) = nΣ− n cov(Y ) = nΣ− nΣ
n= (n− 1)Σ.
31

Tenemos pues que S es un estimador insesgado de la matriz Σ.Finalmente, si denotamos por rjk el coeficiente de correlacion entre las variables
j y k, es decir,
rjk =
∑ni=1(Yij − Y·j)(Yik − Y·k)√∑n
i=1(Yij − Y·j)2∑ni=1(Yik − Y·k)2
=Sjk√SjjSkk
(2.10)
Denotaremos por R la matriz de correlaciones muestrales R = [rjk].
Nota de R 8 (Matrices de covarianza y correlacion muestrales) Vamos a es-timar la media y la varianza de un modo insesgado. Empezamos leyendo los datosscoremaster.
load("../data/scoremaster")
attach(scoremaster)
La covarianza y la correlacion muestrales entre el timepo total quirurgico y eltiempo total postquirurgico los obtenemos con
cov(T.QUIRUR, T.TOTALP)
## [1] 2308272
cor(T.QUIRUR, T.TOTALP)
## [1] 0.2365
La matriz de covarianzas muestral vendrıa dada por
cov(cbind(T.QUIRUR, T.TOTALP))
## T.QUIRUR T.TOTALP
## T.QUIRUR 3107898 2308272
## T.TOTALP 2308272 30659874
y la de correlaciones serıa
cor(cbind(T.QUIRUR, T.TOTALP))
## T.QUIRUR T.TOTALP
## T.QUIRUR 1.0000 0.2365
## T.TOTALP 0.2365 1.0000
2.4. Estimador maximo verosımil
El metodo de estimacion que vamos a utilizar en este curso el metodo demaxima verosimilitud. El estimador maximo verosımil de θ, que denotaremospor θ, se obtienen maximizando la funcion de verosimilitud o, equivalentemente,la transformacion monotona de dicha funcion que es la funcion de logverosimilitud.Utilizaremos para denotar el estimador maximo verosımil la notacion inglesa MLE.
L(θ) = maxθ∈Θ
L(θ), (2.11)
o tambienθ = argmaxθ∈ΘL(θ), (2.12)
32

Ejemplo 5 (Bernoulli) Se puede comprobar sin dificultad que p =∑ni=1 xin .
Una propiedad importante de los estimadores maximo verosımiles consiste enque si θ∗ = f(θ) siendo f una biyeccion entonces el estimador maximo verosımil deθ∗ es verifica que
θ∗ = f(θ). (2.13)
Ejemplo 6 (Normal) En este caso se comprueba que µ = Xn y que σ2 = n−1n S2 =
1n
∑ni=1(Xi − Xn)2. Teniendo en que cuenta la propiedad enunciada en 2.13 ten-
dremos que σ =√
n−1n S2.
En muchas situaciones la funcion L(θ) es concava y el estimador maximo ve-
rosımil θ es la solucion de las ecuaciones de verosimilitud ∂L(θ∂θ = 0. Si cov(θ)
denota la matriz de covarianzas de θ entonces, para un tamano muestral grande ybajo ciertas condiciones de regularidad (ver Rao [1967], pagina 364), se verifica que
cov(θ) es la inversa de la matriz de informacion cuyo elemento (j, k) viene dadopor
− E(∂2l(θ)
∂θj∂θk
)(2.14)
Notemos que el error estandar de θj sera el elemento que ocupa la posicion (j, j)en la inversa de la matriz de informacion. Cuanto mayor es la curvatura de lalogverosimilitud menores seran los errores estandar. La racionalidad que hay detrasde esto es que si la curvatura es mayor entonces la logverosimilitud cae rapidamentecuando el vector θ se aleja de θ. En resumen, es de esperar que θ este mas proximoa θ.
Ejemplo 7 (Binomial) Supongamos que una muestra en una poblacion finita yconsideremos como valor observado el numero de exitos. Entonces la verosimilitudserıa
L(p) =
(n
y
)py(1− p)n−y, (2.15)
y la logverosimilitud viene dada como
l(p) = log
(n
y
)+ y log p+ (n− y) log(1− p), (2.16)
La ecuacion de verosimilitud serıa
∂l(p)
∂p=y
p− n− y
1− p=
y − npp(1− p)
. (2.17)
Igualando a cero tenemos que la solucion es p = yn que no es mas que la proporcion
muestral de exitos en las n pruebas. La varianza asıntotica serıa
− E[∂2l(p)
∂p2
]= E
[y
p2+
n− y(1− p)2
]=
n
p(1− p). (2.18)
En consecuencia asintoticamente p tiene varianza p(1−p)n lo cual era de prever pues
si consideramos la variable Y que nos da el numero de exitos entonces sabemos queEY = np y que var(Y ) = np(1− p).
33

2.5. Contraste de hipotesis
Genericamente vamos a considerar situaciones en donde particionamos el espacioparametrico Θ en dos conjuntos Θ0 y Θ1, es decir, Θ0 ∩ Θ1 = ∅ (son disjuntos) yy Θ0 ∪Θ1 = Θ (cubren todo el espacio parametrico). Consideramos el contraste dehipotesis siguiente.
H0 :θ ∈ Θ0 (2.19)
H1 :θ ∈ Θ1 (2.20)
Basandonos en una muestra aleatoria X1, . . . , Xn hemos de tomar una decision.Las decisiones a tomar son una entre dos posibles: (i) Rechazar la hipotesis nula obien (ii) no rechazar la hipotesis nula. Notemos que, una vez hemos tomado unadecision, podemos tener dos posibles tipos de error como recoge la siguiente tabla.En las columnas indicamos la realidad mientras que en las filas indicamos la decisionque tomamos.
H0 H1
Rechazamos H0 Error tipo INo rechazamos H0 Error tipo II
Supongamos que Rn es el conjunto de valores que puede tomar el vector aleatorio(X1, . . . , Xn). Entonces el contraste de hipotesis se basa en tomar un estadıstico ofuncion de la muestra que denotamos δ(X1, . . . , Xn) de modo que si δ(X1, . . . , Xn) ∈C entonces rechazamos la hipotesis nula mientras que si δ(X1, . . . , Xn) /∈ C entoncesno rechazamos la hipotesis nula. Notemos que simplemente estamos particionandoel espacio muestral (que suponemos) Rn en dos partes, C y Cc, de modo que to-mamos una decision basandonos en si el estadıstico δ esta en C o bien esta en elcomplementario de C. Al conjunto C se le suele llamar la region crıtica. La funcionpotencia se define como
π(θ) = P (δ ∈ C|θ). (2.21)
Contraste de la media en la poblaciones normales
Si tenemos una muestra X1, . . . , Xn de una poblacion normal con media µ yvarianza σ2 donde ambos parametros se asumen desconocidos un test habitualmenteconsiderado es si la media toma un valor dado. El test formalmente planteado serıa:
H0 :µ = µ0, (2.22)
H1 :µ 6= µ0. (2.23)
Siendo S2 =∑ni=1(Xi−X)2
n−1 , el estadıstico habitualmente utilizado es el siguiente
T =X − µ0
S/√n.
Bajo la hipotesis nula este estadıstico sigue una distribucion t de Student con n− 1grados de libertad,
T ∼ t(n− 1).
Si suponemos que trabajamos con un nivel de significacion α la region crıtica en lacual rechazamos la hipotesis nula serıa
|T | > tn−1,1−α2 .
34

2.5.1. Test del cociente de verosimilitudes
El cociente de verosimilitudes para contrastar estas hipotesis se define como
Λ =maxθ∈Θ0
L(θ)
maxθ∈Θ L(θ)(2.24)
Es razonable pensar que en la medida en que Λ tome valores menores entoncesla hipotesis alternativa sea mas plausible que la hipotesis nula y por lo tanto re-chacemos la hipotesis nula. Realmente se suele trabajar con −2 log Λ pues bajola hipotesis nula tiene una distribucion asintotica ji-cuadrado donde el numero degrados de libertad es la diferencia de las dimensiones de los espacios parametricosΘ = Θ0∪Θ1 y Θ0. Si denotamos L0 = maxθ∈Θ0
L(θ) y L1 = maxθ∈Θ L(θ) entoncesΛ = L0
L1y
− 2 log λ = −2 logL0
L1= −2(l0 − l1) (2.25)
siendo l0 y l1 los logaritmos de L0 y L1 respectivamente que tambien correspondencon los maximos de la logverosimilitud sobre Θ0 y sobre Θ.
2.5.2. Test de Wald
Supongamos que el θ es un parametro y θ denota su estimador maximo verosımil.Supongamos que queremos contrastar las siguientes hipotesis:
H0 :θ = θ0, (2.26)
H1 :θ 6= θ0. (2.27)
Denotamos por SE(θ) el error estandar bajo la hipotesis alternativa de θ. Entoncesel estadıstico
z =θ − θ0
SE(θ)(2.28)
tiene, bajo la hipotesis nula, aproximadamente una distribucion normal estandar,z ∼ N(0, 1). Este tipo de estadısticos donde se utiliza el error estandar del estimadorbajo la hipotesis alternativa recibe el nombre de estadıstico de Wald.
Supongamos que θ es un vector de parametros y queremos contrastar las hipote-sis dadas en 2.26. La version multivariante del estadıstico dado en 2.28 viene dadapor
W = (θ − θ0)′[cov(θ)]−1(θ − θ0), (2.29)
donde cov(θ) se estima como la matriz de informacion observada en el MLE θ. Ladistribucion asintotica de W bajo la hipotesis nula es una distribucion ji-cuadradodonde el numero de grados de libertad coincide con el numero de parametros noredundantes en θ.
2.5.3. Intervalos de confianza
Empezamos recordando el concepto de intervalo de confianza con un ejemplomuy conocido como es la estimacion de la media en poblaciones normales.
Ejemplo 8 (Intervalo de confianza para la media de una normal) Veamos-lo con un ejemplo y luego planteamos la situacion mas general. Tenemos una mues-tra aleatoria X1, . . . , Xn i.i.d. tales que Xi ∼ N(µ, σ2). Entonces es conocido que
Xn − µS/√n∼ tn−1. (2.30)
35

Vemos como Xn−µS/√n
depende tanto de la muestra que conocemos como de un parame-
tro (la media µ) que desconocemos. Fijamos un valor de α (habitualmente tomare-mos α = 0,05) y elegimos un valor tn−1,1−α/2 tal que
P (−tn−1,1−α/2 ≤Xn − µS/√n≤ tn−1,1−α/2) = 1− α. (2.31)
La ecuacion anterior la podemos reescribir como
P (Xn − tn−1,1−α/2S√n≤ µ ≤ Xn + tn−1,1−α/2
S√n
) = 1− α. (2.32)
Tenemos una muestra aleatoria X1, . . . , Xn y por lo tanto tenemos un intervalo alea-torio dado por [Xn − tn−1,1−α/2
S√n, Xn + tn−1,1−α/2
S√n
]. Este intervalo tiene una
probabilidad de 1−α de contener a la verdadera media. Tomemos ahora la muestray consideremos no los valores aleatorios de Xn y de S2 sino los valores observadosxn y s. Tenemos ahora un intervalo [xn− tn−1,1−α/2
s√n, xn+ tn−1,1−α/2
s√n
] fijo. Es
posible que µ este en este intervalo y es posible que no lo este. Sabemos que antesde tomar la muestra tenıamos una probabilidad de 1−α de contener a la verdaderamedia pero despues de tomar la muestra tenemos una confianza de 1− α de con-tener a la verdadera media. Al intervalo [xn− tn−1,1−α/2
s√n, xn + tn−1,1−α/2
s√n
] se
le llama intervalo de confianza para µ con nivel de confianza 1− α.
Vamos a ver un planteamiento mas general del problema.Supongamos que tenemos un test para contrastar la hipotesis simple H0 : θ = θ0
frente a la alternativa H1 : θ 6= θ0. Supongamos que elegimos un nivel de significa-cion α para contrastar las hipotesis anteriores y consideramos el siguiente conjuntoformado por todos los θ0 tales que no rechazamos la hipotesis nula al nivel α. Es-te conjunto es un conjunto de confianza al nivel 1 − α. Cuando el conjunto deconfianza es un intervalo hablamos de intervalo de confianza.
Supongamos que consideramos el test del cociente de verosimilitudes. Denotemospor χ2
k(1 − α) el percentil 1 − α de una distribucion ji-cuadrado con k grados delibertad. Entonces el intervalo de confianza al nivel 1− α serıa el conjunto
θ0 : −2[l(θ0)− l(θ)] < χ2k(1− α) (2.33)
Consideremos ahora un test de Wald. En este caso, el intervalo de confianza deWald vendrıa dado por el siguiente conjunto:
θ0 :|θ − θ0|SE(θ)
< Z1−α/2 (2.34)
donde SE(θ) es el error estandar estimado de θ bajo la hipotesis alternativa.
36

Capıtulo 3
Componentes principales
3.1. Introduccion
En este tema nos ocupamos de problemas de reduccion de dimension. ¿Que sig-nifica reducir la dimension? Responder a esta pregunta es obvio si nos fijamos en losdatos que tenemos. Trabajando con expresion de genes tenemos tantas filas comogenes y tantas columnas como muestras. En resumen miles de filas y decenas o cen-tenares de columnas. En temas anteriores hemos visto como seleccionar filas, estoes, seleccionar genes es una tarea incluso previa. Hemos de quedarnos con genes quetengan una expresion diferencial si consideramos alguna caracterıstica fenotıpicao bien con genes que tengan una expresion mınima o bien con genes que tenganun cierto nivel de variacion. ¿Que hacemos con las columnas? O de otro modo:¿que hacemos con las muestras? Quizas la respuesta natural serıa: si tenemos milesde filas, ¿por que preocuparse de unas decenas de filas? No es una buena respuesta.Realmente tener 50 o 100 columnas son muchas a la hora de visualizar resultados obien de aplicar tratamientos estadısticos. En este tema tratamos el tema de comoreducir el numero de columnas.
3.2. Componentes principales
Para ilustrar los conceptos vamos a considerar unos datos sencillos. Tomamoslos datos golub y nos fijamos en los genes que tienen que ver con “Cyclin” (tienenesta palabra en su nombre). Vamos a considerar las dos primeras muestras, esto es,las dos primeras columnas.
library(multtest)
data(golub)
sel <- grep("Cyclin", golub.gnames[, 2])
golub.red <- golub[sel, 1:2]
Los datos aparecen en el siguiente dibujo. Cada punto corresponde con uno delos genes seleccionados.
plot(golub.red)
37

−1.5 −1.0 −0.5 0.0 0.5 1.0 1.5 2.0
−1.
5−
1.0
−0.
50.
00.
51.
01.
5
golub.red[,1]
golu
b.re
d[,2
]
Para la fila i (para el gen i) denotamos las expresiones observadas en las dosmuestras como xi = (xi1, xi1). Tenemos n filas y por lo tanto nuestros datos son xicon i = 1, . . . , n.
Vamos a repetir el dibujo anterior mostrando el nombre del gen.
38

−1.5 −1.0 −0.5 0.0 0.5 1.0 1.5 2.0
−1.
5−
1.0
−0.
50.
00.
51.
01.
5
Primera muestra
Seg
unda
mue
stra
CCND2 Cyclin D2
CDK2 Cyclin−dependent kinase 2
CCND3 Cyclin D3
CDKN1A Cyclin−dependent kinase inhibitor 1A (p21, Cip1)
CCNH Cyclin H
Cyclin−dependent kinase 4 (CDK4) gene
Cyclin G2 mRNA
Cyclin A1 mRNA
Cyclin−selective ubiquitin carrier protein mRNA
CDK6 Cyclin−dependent kinase 6
Cyclin G1 mRNA
CCNF Cyclin F
Centramos los datos. Esto es, le restamos a cada columna la media de la columna.Para ello, primero calculamos las medias. El vector de medias lo vamos a denotarpor x = (x1, x2) donde
xj =
n∑i=1
xijn
es decir, cada componente es la media de las componentes. En resumen el primervalor es la expresion media en la primera muestra para todos los genes. Podemoscalcular facilmente el vector de medias. Una funcion especıfica es la siguiente.
medias <- colMeans(golub.red)
Tambien podemos usar la funcion generica apply que nos hace lo mismo.
medias <- apply(golub.red, 2, mean)
Le restamos a cada columna su media.
golub.red <- sweep(golub.red, 2, medias)
En la siguiente figura reproducimos los datos centrados. Mostramos los ejes decoordenadas en rojo.
39

plot(golub.red)
abline(v = mean(golub.red[, 1]), col = "red")
abline(h = mean(golub.red[, 2]), col = "red")
−1.5 −1.0 −0.5 0.0 0.5 1.0 1.5
−1.
0−
0.5
0.0
0.5
1.0
1.5
golub.red[,1]
golu
b.re
d[,2
]
Hemos trasladado los datos de modo que las medias de cada variable valen ceroahora. Esto es lo que se conoce como centrar los datos. Hemos centrado los datos.Podemos comprobar que los nuevos datos tienen una media nula.
colMeans(golub.red)
## [1] -3.007e-17 1.070e-17
Nuestros datos (filas) corresponden a las expresiones correspondientes a los ge-nes. Los datos originales tienen dimension 2 (dos variables correspondientes a lasdos muestras) y supongamos que pretendemos reducir la dimension a solo una, estoes, representar cada gen mediante un unico numero. La idea de las componentesprincipales es considerar una combinacion lineal de los valores originales. Es decir,se pretende elegir un vector (de dimension dos) a1 = (a11, a12) de modo que enlugar de utilizar xi consideremos (el resumen) ui = a11xi1 + a12xi2. ¿Que a1 elegi-mos? La idea es lograr que los valores ui tengan la mayor variabilidad que se puedacon objeto de no perder informacion. Mantener la variabilidad original indica quemantenemos la informacion que los datos originales tienen. En concreto se elige a1
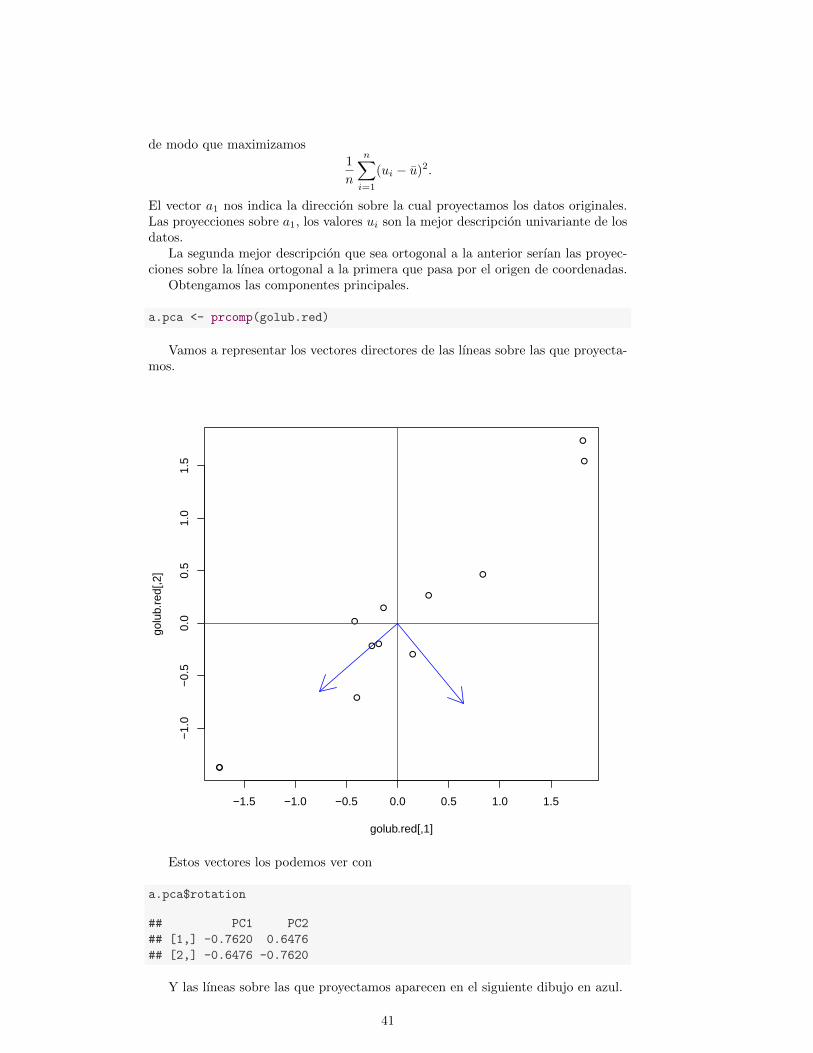
40
de modo que maximizamos
1
n
n∑i=1
(ui − u)2.
El vector a1 nos indica la direccion sobre la cual proyectamos los datos originales.Las proyecciones sobre a1, los valores ui son la mejor descripcion univariante de losdatos.
La segunda mejor descripcion que sea ortogonal a la anterior serıan las proyec-ciones sobre la lınea ortogonal a la primera que pasa por el origen de coordenadas.
Obtengamos las componentes principales.
a.pca <- prcomp(golub.red)
Vamos a representar los vectores directores de las lıneas sobre las que proyecta-mos.
−1.5 −1.0 −0.5 0.0 0.5 1.0 1.5
−1.
0−
0.5
0.0
0.5
1.0
1.5
golub.red[,1]
golu
b.re
d[,2
]
Estos vectores los podemos ver con
a.pca$rotation
## PC1 PC2
## [1,] -0.7620 0.6476
## [2,] -0.6476 -0.7620
Y las lıneas sobre las que proyectamos aparecen en el siguiente dibujo en azul.
41
−1.5 −1.0 −0.5 0.0 0.5 1.0 1.5
−1.
0−
0.5
0.0
0.5
1.0
1.5
golub.red[,1]
golu
b.re
d[,2
]
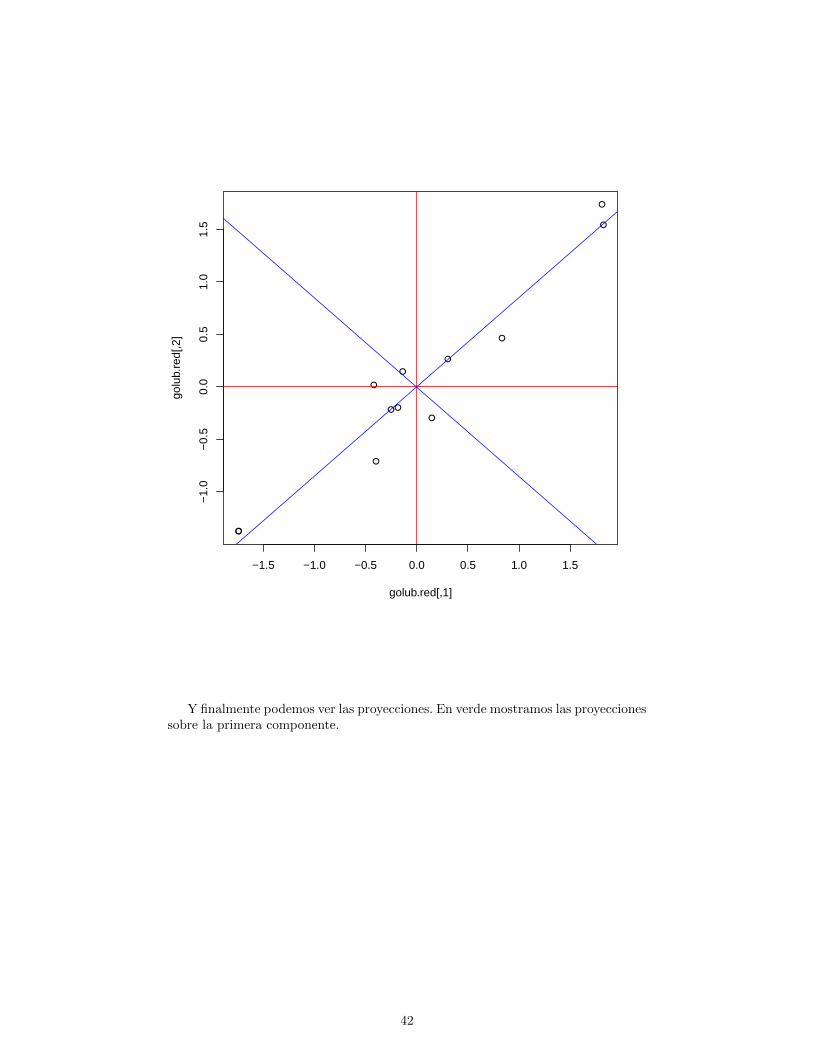
Y finalmente podemos ver las proyecciones. En verde mostramos las proyeccionessobre la primera componente.
42

−1.5 −1.0 −0.5 0.0 0.5 1.0 1.5
−1.
0−
0.5
0.0
0.5
1.0
1.5
golub.red[,1]
golu
b.re
d[,2
]
Y ahora consideremos la proyeccion sobre la segunda componente.
43
−1.5 −1.0 −0.5 0.0 0.5 1.0 1.5
−1.
0−
0.5
0.0
0.5
1.0
1.5
golub.red[,1]
golu
b.re
d[,2
]
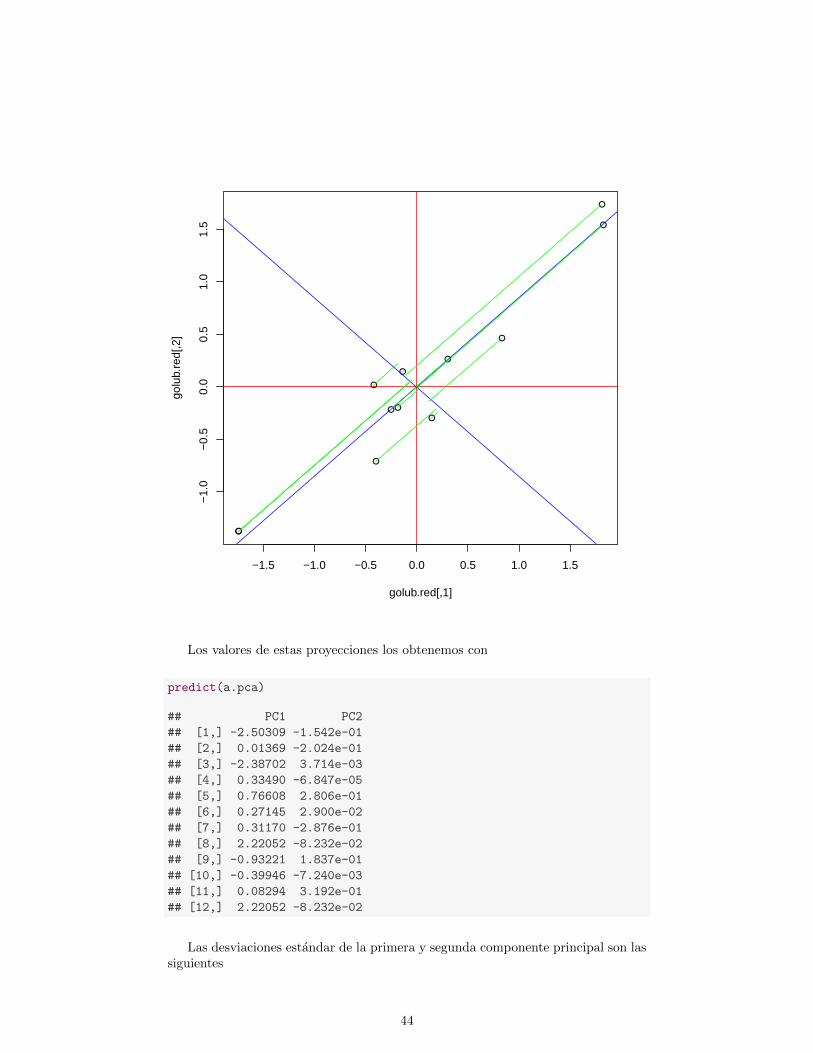
Los valores de estas proyecciones los obtenemos con
predict(a.pca)
## PC1 PC2
## [1,] -2.50309 -1.542e-01
## [2,] 0.01369 -2.024e-01
## [3,] -2.38702 3.714e-03
## [4,] 0.33490 -6.847e-05
## [5,] 0.76608 2.806e-01
## [6,] 0.27145 2.900e-02
## [7,] 0.31170 -2.876e-01
## [8,] 2.22052 -8.232e-02
## [9,] -0.93221 1.837e-01
## [10,] -0.39946 -7.240e-03
## [11,] 0.08294 3.192e-01
## [12,] 2.22052 -8.232e-02
Las desviaciones estandar de la primera y segunda componente principal son lassiguientes
44

## [1] 1.469 0.185
Y las varianzas son los cuadrados de las desviaciones estandar.
a.pca$sdev^2
## [1] 2.15730 0.03421
¿Como de variables son nuestros datos? Podemos cuantificar el total de la va-riacion de los datos sumando las varianzas de cada una de las dos coordenadas
var(golub.red[, 1])
## [1] 1.267
var(golub.red[, 2])
## [1] 0.9246
cuya suma es
var(golub.red[, 1]) + var(golub.red[, 2])
## [1] 2.192
Las nuevas coordenadas tienen la misma varianza total.
sum(a.pca$sdev^2)
## [1] 2.192
¿Y que proporcion de la varianza es atribuible a la primera componente? ¿Y ala segunda? Podemos dividir la varianza de cada componente por la suma total.
variacion.total <- sum(a.pca$sdev^2)
a.pca$sdev^2/variacion.total
## [1] 0.98439 0.01561
La primera componente explica un 98.44 % de la variacion total. ¿Para que ne-cesitamos utilizar dos numeros por gen si con uno tenemos esencialmente la mismainformacion.
3.3. Componentes principales de los datos golub
Hemos visto las componentes principales con dos variables (en nuestro casodos muestras) con efecto de poder ver el significado geometrico de las componentesprincipales. Vamos a trabajar con el banco de datos completo: todos los datos golubque tienen 38 muestras (27 de un tipo de leucemia y 11 de otro tipo).
Obtengamos las componentes principales.
golub.pca <- prcomp(golub, scale = TRUE, center = TRUE)
45

El argumento center=TRUE centra los datos restando la media de la columna demodo que las variables tengan medias nulas. El argumento scale=TRUE hace quelas variables originales sean divididas por su desviacion estandar de modo que lavarianza (y la desviacion estandar) de las nuevas variables sea la unidad.
Diferentes criterios podemos aplicar a la hora de decidir con cuantas componen-tes nos quedamos.
1. Uno puede ser la proporcion total explicada. Fijar un nivel mınimo y quedar-nos con el numero de componentes necesario para superar este valor mınimo.
2. El segundo puede ser que una componente no puede tener una desviacionestandar menor que una de las variables originales. Si hemos escalado cadavariable original dividiendo por su desviacion estandar entonces la desviacionestandar de cada componente ha de ser mayor que uno.
3. Otro criterio puede ser ver en que momento se produce un descenso de ladesviacion estandar muy notable. Quedarnos con las componentes previas.
Un resumen de las componentes nos puede indicar con cuantas nos quedamos.
summary(golub.pca)
## Importance of components:
## PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 PC9
## Standard deviation 5.044 1.4407 1.1173 1.0351 0.8582 0.7440 0.7210 0.6923 0.6382
## Proportion of Variance 0.669 0.0546 0.0328 0.0282 0.0194 0.0146 0.0137 0.0126 0.0107
## Cumulative Proportion 0.669 0.7240 0.7569 0.7851 0.8045 0.8190 0.8327 0.8453 0.8561
## PC10 PC11 PC12 PC13 PC14 PC15 PC16 PC17
## Standard deviation 0.6363 0.56700 0.55263 0.53868 0.52011 0.49568 0.48402 0.47719
## Proportion of Variance 0.0106 0.00846 0.00804 0.00764 0.00712 0.00647 0.00617 0.00599
## Cumulative Proportion 0.8667 0.87518 0.88321 0.89085 0.89797 0.90443 0.91060 0.91659
## PC18 PC19 PC20 PC21 PC22 PC23 PC24 PC25
## Standard deviation 0.47068 0.45421 0.43795 0.43410 0.42475 0.41582 0.40718 0.40066
## Proportion of Variance 0.00583 0.00543 0.00505 0.00496 0.00475 0.00455 0.00436 0.00422
## Cumulative Proportion 0.92242 0.92785 0.93290 0.93786 0.94260 0.94715 0.95152 0.95574
## PC26 PC27 PC28 PC29 PC30 PC31 PC32 PC33
## Standard deviation 0.3948 0.38731 0.38417 0.37882 0.37124 0.36957 0.3596 0.3593
## Proportion of Variance 0.0041 0.00395 0.00388 0.00378 0.00363 0.00359 0.0034 0.0034
## Cumulative Proportion 0.9598 0.96379 0.96767 0.97145 0.97508 0.97867 0.9821 0.9855
## PC34 PC35 PC36 PC37 PC38
## Standard deviation 0.35276 0.34218 0.33228 0.32572 0.30667
## Proportion of Variance 0.00327 0.00308 0.00291 0.00279 0.00247
## Cumulative Proportion 0.98875 0.99183 0.99473 0.99753 1.00000
Atendiendo al segundo criterio nos quedarıamos con las cuatro primeras compo-nentes. La quinta tiene una desviacion inferior a uno. Atendiendo al tercer criteriovemos que a partir de la quinta es muy estable la desviacion estandar. Si nos que-damos con las cinco primeras componentes estamos explicando un 80.44 % de lavariacion total. Puede ser una buena eleccion y una solucion intermedia. Los nuevosdatos los obtenemos con la funcion predict.
a <- predict(golub.pca)
Podemos ver todas las componentes para el primer gen (primera fila).
46
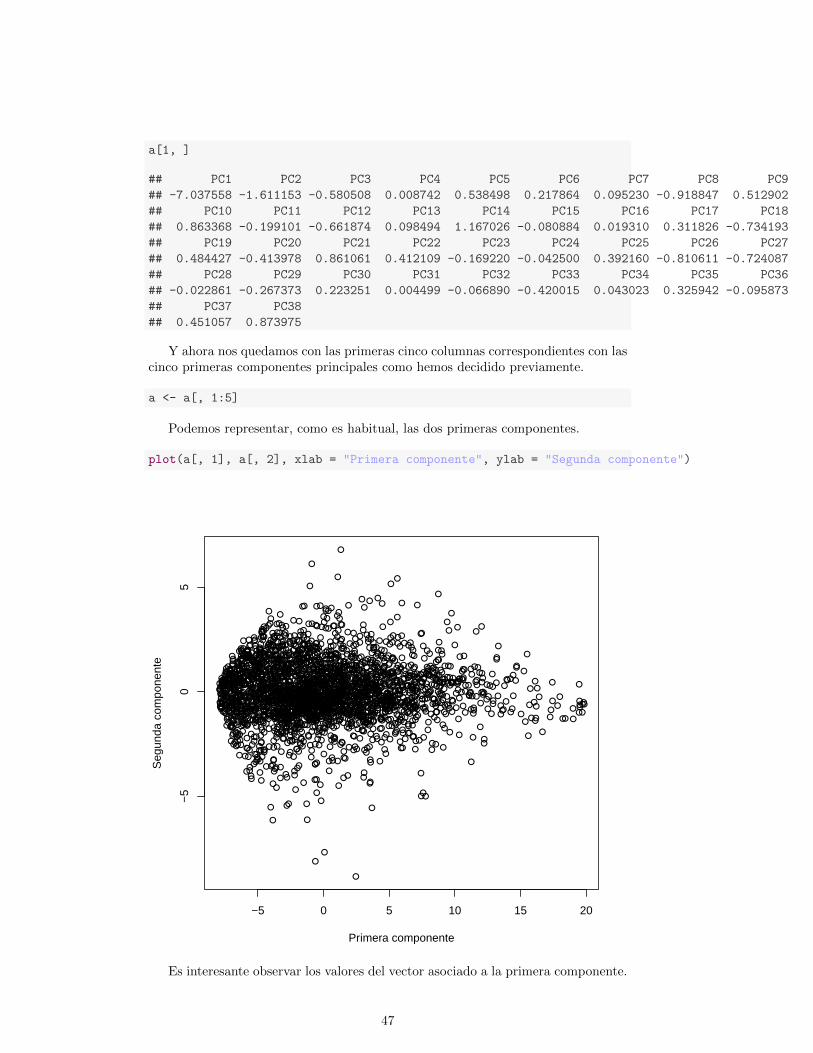
a[1, ]
## PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 PC9
## -7.037558 -1.611153 -0.580508 0.008742 0.538498 0.217864 0.095230 -0.918847 0.512902
## PC10 PC11 PC12 PC13 PC14 PC15 PC16 PC17 PC18
## 0.863368 -0.199101 -0.661874 0.098494 1.167026 -0.080884 0.019310 0.311826 -0.734193
## PC19 PC20 PC21 PC22 PC23 PC24 PC25 PC26 PC27
## 0.484427 -0.413978 0.861061 0.412109 -0.169220 -0.042500 0.392160 -0.810611 -0.724087
## PC28 PC29 PC30 PC31 PC32 PC33 PC34 PC35 PC36
## -0.022861 -0.267373 0.223251 0.004499 -0.066890 -0.420015 0.043023 0.325942 -0.095873
## PC37 PC38
## 0.451057 0.873975
Y ahora nos quedamos con las primeras cinco columnas correspondientes con lascinco primeras componentes principales como hemos decidido previamente.
a <- a[, 1:5]
Podemos representar, como es habitual, las dos primeras componentes.
plot(a[, 1], a[, 2], xlab = "Primera componente", ylab = "Segunda componente")
−5 0 5 10 15 20
−5
05
Primera componente
Seg
unda
com
pone
nte
Es interesante observar los valores del vector asociado a la primera componente.
47

golub.pca$rotation[, 1]
## [1] 0.1715 0.1691 0.1650 0.1727 0.1659 0.1669 0.1686 0.1602 0.1649 0.1688 0.1654 0.1694
## [13] 0.1629 0.1661 0.1648 0.1721 0.1559 0.1600 0.1677 0.1492 0.1273 0.1621 0.1644 0.1653
## [25] 0.1659 0.1690 0.1540 0.1689 0.1541 0.1517 0.1691 0.1682 0.1452 0.1675 0.1638 0.1509
## [37] 0.1476 0.1520
Podemos ver que son coeficientes muy parecidos, todos positivos. Basicamentetenemos la media muestral de todos los niveles de expresion en las 38 muestras. Laprimera componente es basicamente la media sobre las 38 muestras. ¿Y la segundacomponente?
golub.pca$rotation[, 2]
## [1] 0.104190 -0.036887 0.069109 0.100701 0.170952 0.028349 0.032391 0.000506
## [9] 0.093594 0.023533 0.075376 -0.089381 0.233400 0.077939 0.237951 0.184072
## [17] 0.078197 0.041608 0.114629 0.247148 0.201580 -0.014148 0.037859 0.210586
## [25] -0.044465 0.122287 0.021439 -0.189279 -0.174593 -0.243776 -0.165316 -0.150156
## [33] -0.344035 -0.157688 -0.130649 -0.277921 -0.344829 -0.222766
Si observamos los coeficientes vemos que las primeros 27 valores son positivos ylos 11 ultimos son negativos. Ademas no hay una gran diferencia entre los 27 prime-ros y tampoco entre los 11 ultimos. Basicamente estamos comparando, para cadagen, la media de los niveles de expresion sobre los datos ALL (leucemia linfoblasticaaguda) con la media sobre los datos AML (leucemia mieloide aguda).
3.4. Un poco de teorıa ⇑Cuando tomamos medidas sobre personas, objetos, empresas, unidades experi-
mentales de un modo generico, se tiende a recoger el maximo de variables posible.En consecuencia tenemos dimensiones del vector de caracterısticas X grandes.
Una opcion consiste en sustituir la observacion original, de dimension d, por kcombinaciones lineales de las mismas. Obviamente pretendemos que k sea muchomenor que d. El objetivo es elegir k de modo que expresen una proporcion razo-nable de la dispersion o variacion total cuantificada como la traza de la matriz decovarianza muestral, tr(S),
Sea X un vector aleatorio de dimension d con vector de medias µ y matrizde covarianzas Σ. Sea T = (t1, t2, . . . , td) (los ti indican la i-esima columna de lamatriz) la matriz ortogonal tal que
T ′ΣT = Λ = diag(λ1, . . . , λd), (3.1)
donde λ1 ≥ λ2 ≥ . . . ≥ λd ≥ 0 son los valores propios de la matriz Σ. Sea
Y = T ′(X − µ). (3.2)
Si denotamos la j-esima componente de Y como Yj entonces Yj = t′j(X − µ) conj = 1, . . . , d. A la variable Yj la llamamos la j-esima componente principal deY . La variable Zj =
√λjYj es la j-esima componente principal estandarizada
de Y .Estas componentes tienen algunas propiedades de gran interes.Notemos que el vector tj tiene longitud unitaria y, por lo tanto, Yj no es mas
que la proyeccion ortogonal de X − µ en la direccion tj .
Proposicion 1 1. Las variables Yj son incorreladas y var(Yj) = λj.
48

2. Las variables Zj son incorreladas y con varianza unitaria.
Demostracion.En cuanto al apartado primero tenemos que
var(Y ) = var(T ′(X − µ) = T ′var(Y )T = T ′ΣT = Λ.
El segundo apartado es directo a partir del primero.
Se verifica el siguiente resultado.
Teorema 2 Las componentes principales Yj = t′j(X − µ) con j = 1, . . . , d tienenlas siguientes propiedades:
1. Para cualquier vector a1 de longitud unitaria, var(a′1X) alcanza su valor maxi-mo λ1 cuando a1 = t1.
2. Para cualquier vector aj de longitud unitaria tal que a′jti = 0 para i =1, . . . , j − 1, se tiene que var(a′jX toma su valor maximo λj cuando aj = tj.
3.∑dj=1 var(Yj) =
∑dj=1 var(Xj) = traza(Σ).
La version muestral de las componentes principales la obtenemos sustituyendo enlo anterior µ y Σ por X y Σ respectivamente. Es importante considerar el estimadorde Σ que estamos utilizando (o bien el estimador insesgado donde dividimos porn− 1 o bien el estimador en donde dividimos por n).
Si denotamos por λ1 ≥ . . . ≥ λd los valores propios ordenados de Σ y la matrizT = (t1, . . . , td) es la matriz tal que cada columna es el correspondiente vector propioentonces tenemos las componentes principales muestrales dadas por yj = T ′(xi−x).La nueva matriz de datos viene dada por
Y ′ = (y1, . . . , yn) = T ′(x1 − x, . . . , xn − x) (3.3)
Finalmente, si las variables vienen dadas en unidades muy distintas puede serconveniente sustituir la matriz de covarianzas (poblacional o muestral) por la co-rrespondiente matriz de correlaciones. De hecho, una de los inconvenientes de lascomponentes principales como un modo de reducir la dimension de los datos es preci-samente que obtenemos resultados distintos si utilizamos las componentes principa-les obtenidas a partir de la matriz de covarianzas o bien las componentes principalesobtenidas a partir de la matriz de correlaciones.
A partir de las d variables originales podemos obtener hasta d componentes prin-cipales. Sin embargo, hemos dicho que pretendemos reducir la dimension del vectorde datos. La pregunta a responder es: ¿con cuantas componentes nos quedamos?
Supongamos que estamos trabajando con la matriz de covarianzas Σ. Hemosde recordar que var(yj) = λj y que
∑dj=1 var(xj) =
∑dj=1 var(yj) =
∑dj=1 λj . En
consecuencia se suelen considerar los siguientes cocientes∑kj=1 λj∑dj=1 λj
, con k = 1, . . . , d,
de modo que, cuando para un cierto valor de k, estamos proximos a la unidad nosquedamos con ese valor de k. En la version muestral trabajaremos o bien con losvalores propios de la matriz de covarianzas muestral o la matriz de correlacionesmuestrales.
Una referencia muy interesante sobre componentes principales es Abdi and Wi-lliams [2010].
49

50

Capıtulo 4
Analisis cluster
En este tema vamos a tratar lo que en la literatura estadıstica recibe el nombre deanalisis cluster 1 o, en mejor castellano, analisis de conglomerados. En la literaturade Inteligencia Artificial se utiliza la expresion clasificacion no supervisada. Tenemosuna muestra de observaciones multivariantes de dimension d. ¿Que pretendemoshacer con ellos? Encontrar grupos. Muy breve la respuesta pero: ¿que son grupos?Imaginemos una imagen aerea fija de un patio de un colegio. En esta imagen losdatos son las posiciones de los ninos. ¿Se agrupan los ninos formando grupos otodos estan jugando con todos y los grupos son una consecuencia pasajera del juego(delanteros y defensas que aparecen agrupados en un ataque)?
Parece claro y simple el problema. Sı, lo parece. ¿Que es un grupo? ¿Comodefino un grupo? ¿Cuantos grupos distingo en los datos? Estamos viendo el efectodel ruido o realmente hay una estructura debajo que la vemos en un entorno conruido.
¿Que quiere decir encontrar grupos? Se trata de clasificar las observaciones engrupos de modo que las observaciones de un mismo grupo sean lo mas similares quepodamos y que los grupos entre sı sean muy distintos. El numero de procedimientosque se han propuesto en la literatura es muy grande. La mayor parte de ellos no tie-nen un modelo probabilıstico debajo, no son procedimientos basados en modelo. Sonmetodos que esencialmente utilizan el concepto de proximidad. Valoran de distintasformas lo proximos, lo cercanos que estan los puntos, dentro de un mismo grupoy entre distintos grupos. Es pues, el primer punto a tratar: ¿como cuantificamoslo cerca o lejos que estan los distintos puntos? En la seccion 4.2 nos ocupamos deeste punto. Tambien sera necesario, como veremos en el tema, valorar cuando dosconjuntos de puntos son mas o menos parecidos, proximos, similares. En la mismaseccion nos ocupamos de ello. Supongamos que ya hemos clasificado en distintosgrupos. ¿Hemos tenido exito al hacerla? Cuando tenemos un analisis discriminantetenemos una muestra donde sabemos a que grupo pertenece el individuo y dondelo hemos clasificado. Esto nos permitıa valorar si nuestro procedimiento clasificabien o no. Aquı no vamos a tener esta referencia que nos da la muestra de entrena-miento. ¿Como valorarlo? Un concepto conocido por silueta y debido a Rousseeuw[Kaufman and Rousseeuw, 1990] nos va a servir para ello. No es ni tan simple ni tansatisfactorio como en analisis discriminante (como es de esperar si tenemos menosinformacion para trabajar). Lo estudiamos en la seccion 4.5.
Entre los muchos procedimientos de obtener los grupos a partir de los datos,los mas utilizados son dos tipos: procedimientos jerarquicos y metodos de parti-cionamiento. De los jerarquicos nos ocupamos en la seccion 4.3. El metodo de lask-medias y el metodo de las k-mediodes (el castellano como siempre es muy sufrido
1Por cierto que la palabra cluster no existe en castellano
51

pues no existe la palabra) son metodos de particionamiento y los tratamos en laseccion 4.4.
Una referencia muy adecuada que se puede consultar es el texto de [Kaufmanand Rousseeuw, 1990]. Cualquier texto de reconocimiento de patrones es adecuado.
En lo que sigue vamos a basarnos fundamentalmente en la librerıa cluster [?] ydenotaremos los datos a agrupar con xi con i = 1, . . . n siendo xi = xi1, . . . , xid.
4.1. Algunos ejemplos
Empezamos viendo un conjunto de datos que nos sugieran el problema y comotratarlo.
Nota de R 9 (Un ejemplo de datos a agrupar) Generamos tres muestras co-rrespondientes a distribuciones bivariates normales. La matriz de covarianzas va-mos a suponer que es la matriz identidad. Los vectores de medias son µ1 = c(1, 1),µ2 = c(3, 3) y µ2 = c(7, 7). Es resumen un vector Xi ∼ Nd(µi, I2×2. Vamos a ge-nerar cien datos de cada grupo. Vamos a utilizar el paquete mvtnor ? para simularlas distintas normales bivariantes.
library(mvtnorm)
x1 <- rmvnorm(n = 100, mean = c(1, 1))
x2 <- rmvnorm(n = 100, mean = c(3.3, 4.1))
x3 <- rmvnorm(n = 100, mean = c(6, 5.5))
El siguiente dibujo muestra los datos generados.
limite.x <- c(-1, 8)
limite.y <- limite.x
plot(x1, xlim = limite.x, ylim = limite.y)
points(x2, pch = 2)
points(x3, pch = 3)
52
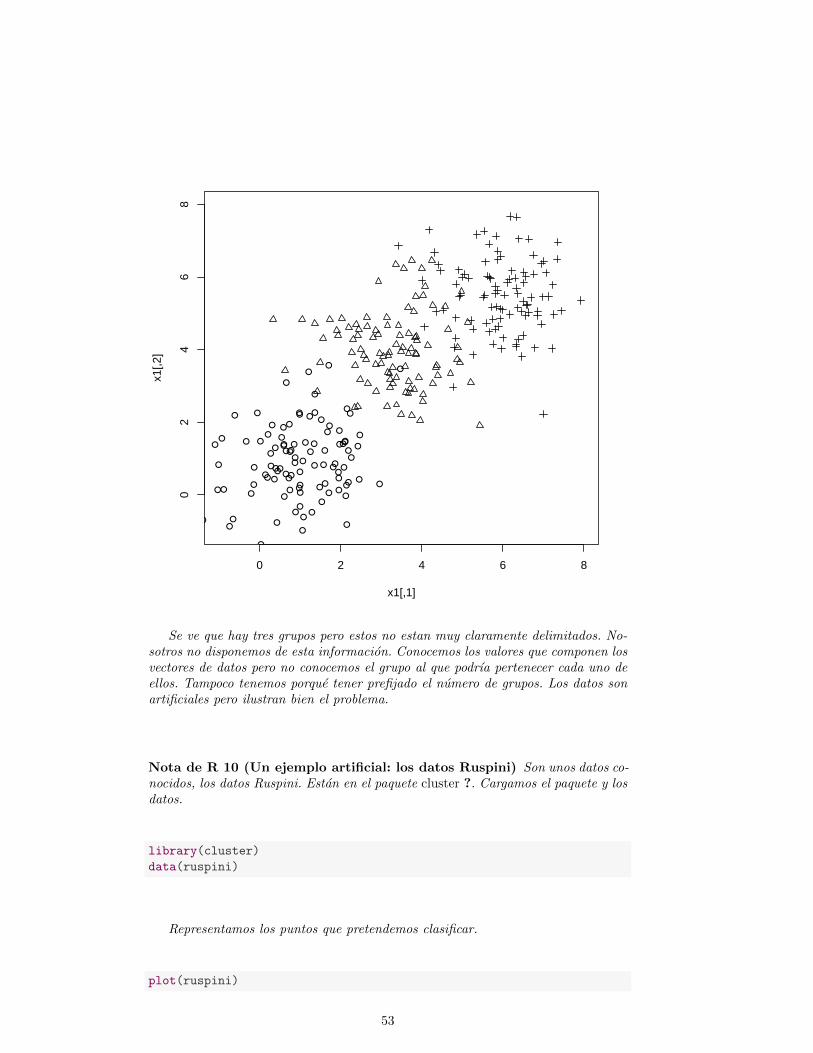
0 2 4 6 8
02
46
8
x1[,1]
x1[,2
]
Se ve que hay tres grupos pero estos no estan muy claramente delimitados. No-sotros no disponemos de esta informacion. Conocemos los valores que componen losvectores de datos pero no conocemos el grupo al que podrıa pertenecer cada uno deellos. Tampoco tenemos porque tener prefijado el numero de grupos. Los datos sonartificiales pero ilustran bien el problema.
Nota de R 10 (Un ejemplo artificial: los datos Ruspini) Son unos datos co-nocidos, los datos Ruspini. Estan en el paquete cluster ?. Cargamos el paquete y losdatos.
library(cluster)
data(ruspini)
Representamos los puntos que pretendemos clasificar.
plot(ruspini)
53

0 20 40 60 80 100 120
050
100
150
x
y
Son datos bivariantes. Visualmente vemos como se agrupan los puntos. Parececlaro que podemos distinguir cuatro grupos.
Nota de R 11 (Un ejemplo con los datos golub) Empezamos cargando los da-tos.
library(multtest)
data(golub)
Previamente hemos visto que los valores de expresion de los genes “CCND3Cyclin D3” y “Zyxin” permiten diferenciar entre ALL y AML. Localicemos las ex-presiones correspondientes a estos genes.
grep("CCND3 Cyclin D3", golub.gnames[, 2])
## [1] 1042
grep("Zyxin", golub.gnames[, 2])
## [1] 2124
Los datos aparecen en estas filas. Por lo tanto podemos construir la matriz dedatos correspondiente.
54

cz.data <- data.frame(golub[1042, ], golub[2124, ])
colnames(cz.data) <- c("CCND3 Cyclin D3", "Zyxin")
Este sera un segundo ejemplo para analizar. Veamos los datos.
plot(cz.data)
−0.5 0.0 0.5 1.0 1.5 2.0 2.5
−1
01
2
CCND3 Cyclin D3
Zyx
in
En este caso las observaciones corresponden a las muestras y las variables sonlos niveles de expresion de dos genes. ¿Hay grupos? Esto no son datos artificialescomo los de Ruspini y ya no es tan claro.
4.2. Disimilaridades
4.2.1. Disimilaridades entre observaciones
Empezamos tratando el problema de cuantificar el grado de proximidad, desimilaridad entre dos puntos en el espacio de dimension d. Tradicionalmente estetema en Matematicas se ha formalizado a traves del concepto de distancia o metrica.Una metrica es una funcion que a cada par de puntos x, y ∈ Rd le asocia un valorpositivo de modo que cuando mayor es mas distantes son, mas alejados estan. Comosiempre la formalizacion matematica de un concepto intuitivo ha de ser prudentey pedir que se verifiquen ciertos axiomas que resulten razonables y generalmente
55

admisibles. En concreto la funcion d definida en el espacio producto Rd×Rd se diceque es una metrica si verifica:
No negativa d(x, y) ≥ 0.
Un punto dista 0 de sı mismo d(x, x) = 0.
Simetrıa d(x, y) = d(y, x).
Desigualdad triangular d(x, z) ≤ d(x, y) + d(y, z), para todo x, y, z ∈ Rd.
Las distancias mas utilizadas en analisis cluster son la distancia euclıdea y la dis-tancia de Manhattan. Para dos vectores x e y (en Rd) entonces la distancia euclıdease define como
d(x, y) =
√√√√ d∑k=1
(xk − yk)2, (4.1)
con x, y ∈ Rd. La distancia de Manhattan viene dada por
d(x, y) =
d∑k=1
|xk − yk|. (4.2)
Las distancias euclıdea y de Manhattan son adecuadas cuando trabajamos convariables continuas y que ademas esten en una misma escala. 2 Notemos que cadauna de las componentes del vector pesan igualmente. Si tenemos variables que noestan igualmente escaladas estas distancias pueden pesar mas unas variables queotras no por lo diferentes que sean entre los individuos sino simplemente por suescala.
Con mucha frecuencia nos encontramos trabajando con variables que aun siendocontinuas estan medidas en escalas muy diversas o bien tenemos variables que soncontinuas, otras que son binarias, otras categoricas con mas de dos categorıas o bienvariable ordinales. En resumen, todos los posibles tipos de variables simultaneamen-te considerados. Es lo habitual. Una variable binaria la codificamos habitualmentecomo 1 y 0 indicando presencia o ausencia del atributo que estemos consideran-do. En una variable categorica la codificacion es completamente arbitraria y por lotanto no tiene sentido la aplicacion de una de estas distancias.
Todo esto plantea el hecho de que no es recomendable, ni tampoco facil, en unbanco de datos con distintos tipos de variables considerar una metrica o distancia,esto es, algo que verifique las propiedades anteriores. Son demasiado exigentes estaspropiedades. Lo que se hace es proponer medidas entre los vectores de caracterısti-cas que tienen algunas de las propiedades y son, ademas, razonables. Por ello nohablaremos, en general, de una distancia o una metrica, sino de una medida dedisimilaridad. Finalmente, valores grandes estaran asociados con vectores de carac-terısticas que tienen una mayor diferencia. Se han propuesto distintas medidas dedisimilaridad entre variables cualitativas (binarias simetricas o asimetricas, cuali-tativas, ordinales) y cuantitativas. En lo que sigue comentamos con algun detallela que lleva la funcion daisy de la librerıa cluster ?. Es una opcion muy generica yrazonable.
Consideramos el problema cuando solo tenemos un tipo de variable. Finalmentecombinaremos todo en una sola medida de disimilaridad.
Supongamos descrita al individuo o caso mediante d variables binarias. Es natu-ral construir la tabla de contingencia 2×2 que aparece en la tabla 4.1 donde las filascorresponden con el individuo i y las columnas con el individuo j. Segun la tabla
2La funcion dist de ? es una buena opcion para el calculo de estas y otras distancias. Tambienlo es la funcion daisy del paquete cluster ?.
56

Cuadro 4.1: Conteos asociados a dos casos descritos por variables binarias
1 01 A B A+B0 C D C+D
A+C B+D d=A+B+C+D
los individuos i y j coincidirıan en la presencia de A atributos y en la no presenciade D atributos. Tenemos B atributos en i que no estan en j y C atributos que noestan en i pero sı que estan en j.
El total de variables binarias es de d = A+B+C+D. Basandonos en esta tablase pueden definir distintas medidas de disimilaridad. Vamos a considerar dos situa-ciones distintas. En la primera trabajamos con variables binarias simetricas y otrapara variables binarias no simetricas. Una variable binaria es simetrica cuando lasdos categorıas que indica son intercambiables, cuando no tenemos una preferenciaespecial en que resultado lo codificamos como 1 y que resultado codificamos como0. Un ejemplo frecuente es el sexo de la persona. Si las variables son todas bina-rias simetricas es natural utilizar como disimilaridad el coeficiente de acoplamientosimple definido como
d(i, j) =B + C
A+B + C +D= 1− A+D
A+B + C +D.
La interpretacion de esta medida de disimilaridad es simple. Dos individuos sontanto mas disimilares cuantas mas variables binarias tienen distintas. Notemos quela presencia o ausencia de un atributo tienen el mismo peso.
Supongamos que las variable que describen al individuo son binarias asimetricas.Ejemplos de esto pueden ser la presencia o ausencia de un atributo muy pocofrecuente. Por ejemplo, tener o no tener sida. Dos personas que tienen el sida, tienenmas es comun, estan mas proximas, que dos personas que no lo tienen. Supongamosque codificamos el atributo menos frecuente como 1 y el mas frecuente como 0.Esta claro que un acoplamiento 1-1 o acoplamiento positivo es mas significativo queun acoplamiento negativo o acoplamiento 0-0 por lo que A, numero de acoplamientospositivos, ha de tener mas peso que d o numero de acoplamientos negativos. El masconocido es el coeficiente de Jaccard que se define como
d(i, j) =B + C
A+B + C= 1− A
A+B + C
en el que simplemente no consideramos los acoplamientos negativos.Consideremos ahora el caso de variables categoricas con mas de dos categorıas.
Si todas las variables son de este tipo y tenemos un total de d variables entonceslos individuos i y j son tanto mas disimilares cuanto mas variables categoricas sondistintas. Si denotamos por u el numero de variables en las que coinciden los dosindividuos entonces la medida de disimilaridad serıa
d(i, j) =d− ud
.
Finalmente veamos como tratar las variables ordinales. Lo que haremos para va-riables de este tipo es transformarlas al intervalo [0, 1]. Si xij denota la j-esimavariable del i-esimo individuo entonces consideramos la transformacion
yik =xik − 1
Mk − 1
57

siendo 1, . . . ,Mk los valores que puede tomar la j-esima variable ordinal. Lo queestamos haciendo con este procedimiento es transformar la variable ordinal es unavariable numerica con una escala comun. En la medida en que el numero de cate-gorıas sea mayor esta transformacion tendra mas sentido.
Hemos visto como tratar cada tipo de variable aisladamente. El problema escombinar todas ellas en una sola medida de disimilaridad. La funcion daisy delpaquete cluster ? utiliza la siguiente medida:
d(i, j) =
∑dk=1 δ
(k)ij d
(k)ij∑d
k=1 δ(k)ij
, (4.3)
donde:
δ(k)ij vale uno cuando las medidas xik y xjk no son valores faltantes y cero en
otro caso;
δ(k)ij vale 0 cuando la variable k es binaria asimetrica y tenemos entre los
individuos i y j un acoplamiento 0-0;
el valor d(k)ij es lo que contribuye a la disimilaridad entre i y j la variable k.
• Si la variable k es binaria o categorica entonces d(k)ij es definida como
d(k)ij = 1 si xik 6= xjk y 0 en otro caso.
• Si la variable k es numerica entonces
d(k)ij =
|xik − xjk|Rk
siendo Rk el rango de la variable k definido como
Rk = maxh
xhk −mınhxhk
donde h varıa entre todos los individuos con valor no faltante de la va-riable k.
Si todas las variables son categoricas entonces 4.3 nos da el numero de acoplamientosdel total de pares disponibles, en definitiva, el coeficiente de acoplamiento simple. Sitodas son variables binarias simetricas entonces obtenemos otra vez el coeficiente deacoplamiento simple. Si las variables son binarias asimetricas entonces obtenemosel coeficiente de Jaccard. Cuando todas las variables con las que trabajamos sonnumericas la medida de disimilaridad es la distancia de Manhattan donde cadavariable esta normalizada.
Dado un conjunto de datos xi con i = 1, . . . , n tendremos, utilizando algunasde las medidas de disimilaridades comentadas, una matriz de dimension n× n quetiene en la posicion (i, j) la disimilaridad entre xi y xj , d(i, j): [d(i, j)]i,j=1,...,n.
Con esta matriz cuantificamos la disimilaridad que hay entre los elementos ori-ginales de la muestra. Algunos de los procedimientos de agrupamiento que vamosa considerar en lo que sigue no necesitan conocer los datos originales. Pueden apli-carse con solo conocer esta matriz de disimilaridades. Otros no. Otros utilizan losdatos a lo largo de las distintas etapas de aplicacion del procedimiento.
4.2.2. Disimilaridades entre grupos de observaciones
En algunos procedimientos de agrupamiento (en particular, los jerarquicos) va-mos a necesitar calcular disimilaridades entre conjuntos disjuntos de las observa-ciones originales. Estas disimilaridades las podemos calcular a partir de las disi-milaridades originales punto a punto que hemos comentado en la seccion 4.2.1.
58

Supongamos que tenemos un banco de datos con n individuos cuyos ındices son1, . . . , n. Sean A y B dos subconjuntos disjuntos del conjunto de ındices de lamuestra 1, . . . , n, esto es, dos subconjuntos de observaciones disjuntos. ¿Comopodemos definir una disimilaridad entre A y B partiendo de las disimilaridadesentre los datos individuales? Se han propuesto muchos procedimientos. Si denota-mos la disimilaridad entre A y B como d(A,B) entonces las disimilaridades mashabitualmente utilizadas son las siguientes:
Enlace simple La disimilaridad entre los dos grupos es el mınimo de las disimi-laridades entre las observaciones de uno y de otro. Tomamos la disimilaridadde los objetos que mas se parecen en uno y otro grupo.
d(A,B) = mına∈A,b∈B
d(a, b)
Enlace completo Ahora tomamos como disimilaridad entre los grupos como elmaximo de las disimilaridades, en definitiva, la disimilaridad entre los objetosmas alejados o mas distintos.
d(A,B) = maxa∈A,b∈B
d(a, b)
Promedio La disimilaridad es el promedio de las disimilaridades entre todos losposibles pares.
d(A,B) =1
|A| × |B|∑
a∈A,b∈B
d(a, b)
donde |A| es el cardinal del conjunto A.
Es importante notar que solamente necesitamos conocer las disimilaridades entrelos individuos para poder calcular las disimilaridades entre grupos de individuos.
En la siguiente seccion nos vamos a ocupar de los metodos jerarquicos en loscuales es fundamental el procedimiento que elijamos para calcular distintas entregrupos.
4.3. Cluster jerarquico
La idea de estos procedimientos es construir una jerarquıa de particiones delconjunto de ındices.
Sea 1, . . . , n el conjunto de ındices que indexan las distintas observaciones.Supongamos que C1, . . . , Cr es una particion de este conjunto de ındices:
Ci ⊂ 1, . . . , n; son disjuntos dos a dos, Ci∩Cj = ∅ si i 6= j con i, j = 1, . . . , ny
∪ri=Ci = 1, . . . , n.
Dada una particion del conjunto de ındices podemos calcular la matriz r × r queen la posicion (i, j) tiene la disimilaridad entre el conjunto Ci y Cj , d(Ci, Cj) segunalguno de los procedimientos antes indicados.
Veamos los procedimientos jerarquicos aglomerativos. En estos procedimientosvamos a iniciar el agrupamiento con la particion: Ci = i con i = 1, . . . , n, esdecir, cada grupo es un individuo. En cada iteracion vamos agrupando el par deconjuntos (elementos de la particion que tengamos en esa iteracion) que esten masproximos segun la disimilaridad entre grupos que estemos utilizando. El procesocontinua hasta que tengamos un unico grupo.
Un esquema algorıtmico del procedimiento indicado puede ser el siguiente:
59

Paso 0 Tenemos grupos unitarios formados por cada una de las observaciones.Tenemos pues una particion inicial Ci = i con i = 1, . . . , n. En un principio,cada dato es un grupo.
Paso 1 Calculamos las disimilaridades entre los elementos de la particion. Paraello utilizamos cualquiera de los procedimientos antes indicados.
Paso 2 Agrupamos los dos conjuntos de la particion mas proximos y dejamos losdemas conjuntos igual. Tenemos ahora Ci con i = 1, . . . , k.
Paso 3 Si tenemos un solo conjunto en la particion paramos el procedimiento.
Paso 4 Volvemos al paso 1.
Hay una representacion grafica muy utilizada para describir los resultados deun cluster jerarquico aglomerativo como el que acabamos de describir. Esta repre-sentacion tiene el nombre de dendograma. En el dendograma se va mostrandoa que valor de la medida de disimilaridad se produce la union de los grupos y si-multaneamente que grupos se estan uniendo para esa disimilaridad. Tambien nospermite una valoracion rapida de cuantos grupos puede haber en el banco de datos.Simplemente trazando una linea horizontal a la altura en que tengamos el numerode grupos que pensamos que puede haber.
Nota de R 12 Veamos un ejemplo de analisis cluster. Los datos han sido obteni-dos de esta pagina. Tenemos cuatro variables que nos dan las puntuaciones obte-nidas en 25 escuelas de New Haven en aritmetica y lectura al principio del cuartocurso y al principio del sexto curso. Empezamos cargando el paquete cluster ? yleyendo los datos.
library(cluster)
x <- read.table("../data/achieve.txt")
names(x) <- c("centro", "lec4", "aritme4", "lec6", "aritme6")
attach(x)
Eliminamos la primera columna en que aparece el nombre de la escuela.
y <- x[, -1]
Hacemos un analisis cluster jerarquico utilizando la funcion agnes del paquetecluster.
y.ag <- agnes(y)
Veamos el dendograma.
plot(y.ag, which = 2)
60
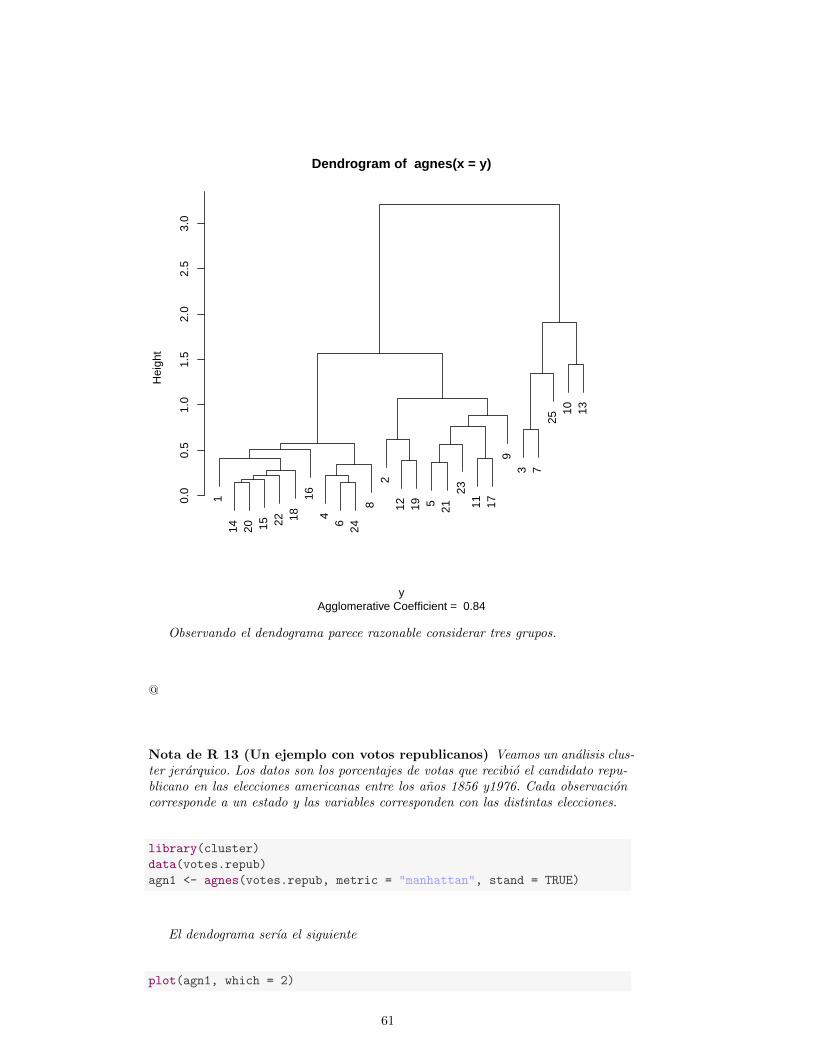
114 20 15 22 18
164
6 248
212 19 5 21
2311 17
93 7
2510 13
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Dendrogram of agnes(x = y)
Agglomerative Coefficient = 0.84y
Hei
ght
Observando el dendograma parece razonable considerar tres grupos.
@
Nota de R 13 (Un ejemplo con votos republicanos) Veamos un analisis clus-ter jerarquico. Los datos son los porcentajes de votas que recibio el candidato repu-blicano en las elecciones americanas entre los anos 1856 y1976. Cada observacioncorresponde a un estado y las variables corresponden con las distintas elecciones.
library(cluster)
data(votes.repub)
agn1 <- agnes(votes.repub, metric = "manhattan", stand = TRUE)
El dendograma serıa el siguiente
plot(agn1, which = 2)
61

Ala
bam
aG
eorg
iaA
rkan
sas
Loui
sian
aM
issi
ssip
piS
outh
Car
olin
aA
lask
aV
erm
ont
Ariz
ona
Mon
tana
Nev
ada
Col
orad
oId
aho
Wyo
min
gU
tah
Cal
iforn
iaO
rego
nW
ashi
ngto
nM
inne
sota
Con
nect
icut
New
Yor
kN
ew J
erse
yIll
inoi
sO
hio
Indi
ana
Mic
higa
nP
enns
ylva
nia
New
Ham
pshi
reW
isco
nsin
Del
awar
eK
entu
cky
Mar
ylan
dM
isso
uri
New
Mex
ico
Wes
t Virg
inia
Iow
aS
outh
Dak
ota
Nor
th D
akot
aK
ansa
sN
ebra
ska
Mai
neM
assa
chus
etts
Rho
de Is
land
Flo
rida
Nor
th C
arol
ina
Tenn
esse
eV
irgin
iaO
klah
oma
Haw
aii
Texa
s
020
4060
80
Dendrogram of agnes(x = votes.repub, metric = "manhattan", stand = TRUE)
Agglomerative Coefficient = 0.8votes.repub
Hei
ght
Pasamos ahora la matriz de distancias cambiamos el procedimiento para el calcu-lo de las disimilaridades entre grupos.
agn2 <- agnes(daisy(votes.repub), diss = TRUE, method = "complete")
plot(agn2, which = 2)
62

Ala
bam
aG
eorg
iaLo
uisi
ana
Ark
ansa
sF
lorid
aTe
xas
Mis
siss
ippi
Sou
th C
arol
ina
Ala
ska
Mic
higa
nC
onne
ctic
utN
ew Y
ork
New
Ham
pshi
reIn
dian
aO
hio
Illin
ois
New
Jer
sey
Pen
nsyl
vani
aM
inne
sota
Nor
th D
akot
aW
isco
nsin
Iow
aS
outh
Dak
ota
Kan
sas
Neb
rask
aA
rizon
aN
evad
aM
onta
naO
klah
oma
Col
orad
oId
aho
Wyo
min
g Uta
hC
alifo
rnia
Ore
gon
Was
hing
ton
Mis
sour
iN
ew M
exic
oW
est V
irgin
iaD
elaw
are
Ken
tuck
yM
aryl
and
Nor
th C
arol
ina
Tenn
esse
eV
irgin
iaH
awai
iM
aine
Mas
sach
uset
tsR
hode
Isla
ndV
erm
ont
050
100
150
200
250
Dendrogram of agnes(x = daisy(votes.repub), diss = TRUE, method = "complete")
Agglomerative Coefficient = 0.88daisy(votes.repub)
Hei
ght
Nota de R 14 Consideremos los datos ruspini. Apliquemos un cluster jerarquicoaglomerativo utilizando como disimilaridad entre grupos el promedio de las disimi-laridades y como medida de disimilaridad la distancia euclıdea.
ruspini.ag <- agnes(ruspini, metric = "euclidean", method = "average")
Representamos el dendograma.
plot(ruspini.ag, which = 2)
63

12 3
54 6 8
79 10 14 15 17 16 18 1911 12 13
2061
62 6663
64 6865
67 69 70 71 72 75 73 74 21 22 23 24 27 28 29 30 25 26 32 3531
36 3940
33 34 37 3841
42 4344 45
49 5153 50 54 52 55 5657
59 6058
4647 48
020
4060
8010
0
Dendrogram of agnes(x = ruspini, metric = "euclidean", method = "average")
Agglomerative Coefficient = 0.95ruspini
Hei
ght
Supongamos que decidimos quedarnos con cuatro grupos. Las clasificaciones delos datos son las siguientes.
cutree(ruspini.ag, 4)
## [1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
## [44] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4
Y ahora podemos representar los datos de modo que ponemos en un mismo colorlos datos que hemos clasificado en un grupo.
plot(ruspini, col = cutree(ruspini.ag, 4))
64
0 20 40 60 80 100 120
050
100
150
x
y
Un procedimiento jerarquico aglomerativo tiene interes cuando el banco de datosno tiene muchos individuos. En otro caso es muy difıcil de interpretar un dendo-grama o de seleccionar el numero de grupos que hay. En todo caso lo hemos de vercomo un analisis exploratorio para decidir el numero de grupos y posteriormenteutilizar algun metodo de particionamiento como los que vamos a ver.
4.4. Metodos de particionamiento
Suponemos ahora que tenemos una idea de cuantos grupos hay. Posiblementehemos realizado un analisis jerarquico previo con todos los datos o, si eran muchos,con una seleccion aleatoria de los datos. Tenemos pues una idea de cuantos grupostendremos que considerar. Obviamente podemos luego evaluar los resultados modi-ficando el numero de grupos. En principio, vamos a suponer que fijamos el numerode grupos a considerar. Suponemos pues que sabemos el numero de grupos y lodenotamos por k.
4.4.1. Metodo de las k-medias
El primer procedimiento que vamos a ver es el metodo de las k-medias (que poralguna extrana razon en la literatura de Inteligencia Artificial se le llama de lasc-medias lo que demuestra que cada persona copia a sus amigos o, simplemente,conocidos). Supongamos que tenemos C1, . . . , Ck una particion de 1, . . . , n. Un
65

modo bastante natural de valorar la calidad de del agrupamiento que la particionnos indica serıa simplemente considerar la siguiente funcion.
k∑i=1
∑j∈Ci
dE(xj , xCi)2, (4.4)
donde dE denota aquı la distancia euclıdea y
xCi =1
|Ci|∑j∈Ci
xj , (4.5)
es el vector de medias del grupo cuyos ındices estan en Ci. Una particion sera tantomejor cuanto menor sea el valor de la funcion dada en 4.4. El procedimiento deagrupamiento de las k-medias simplemente se basa en elegir como particion de losdatos aquella que nos da el mınimo de la funcion objetivo considerada en ecuacion4.4. Notemos que en muchos textos se hablan del algoritmo de las k-medias y seidentifica con un procedimiento concreto para encontrar el mınimo de la funcion.Aquı entendemos el procedimiento como la minimizacion de la funcion objetivo.De hecho, R ofrece hasta cuatro posibles procedimientos de los muchos que cabeproponer. Hay que diferenciar claramente el procedimiento del metodo de aplicaciondel mismo, del metodo de obtencion de dicho mınimo.
Es importante darnos cuenta de que el procedimiento que acabamos de veresta basado en la utilizacion de la distancia euclıdea y en que, dado un grupo,podemos calcular el vector de medias y esto solo lo podemos hacer si todas lasvariables son cuantitativas.
Nota de R 15 Aplicamos el k-medias.
ruspini.km <- kmeans(ruspini, 4)
Las clasificaciones son
ruspini.km$cluster
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
## 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 3 3 3 3 3 3 3 3 3 3
## 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
## 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
## 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75
## 2 2 2 1 2 2 1 1 1 1 1 1 1 1 1
Y representamos los resultados.
66
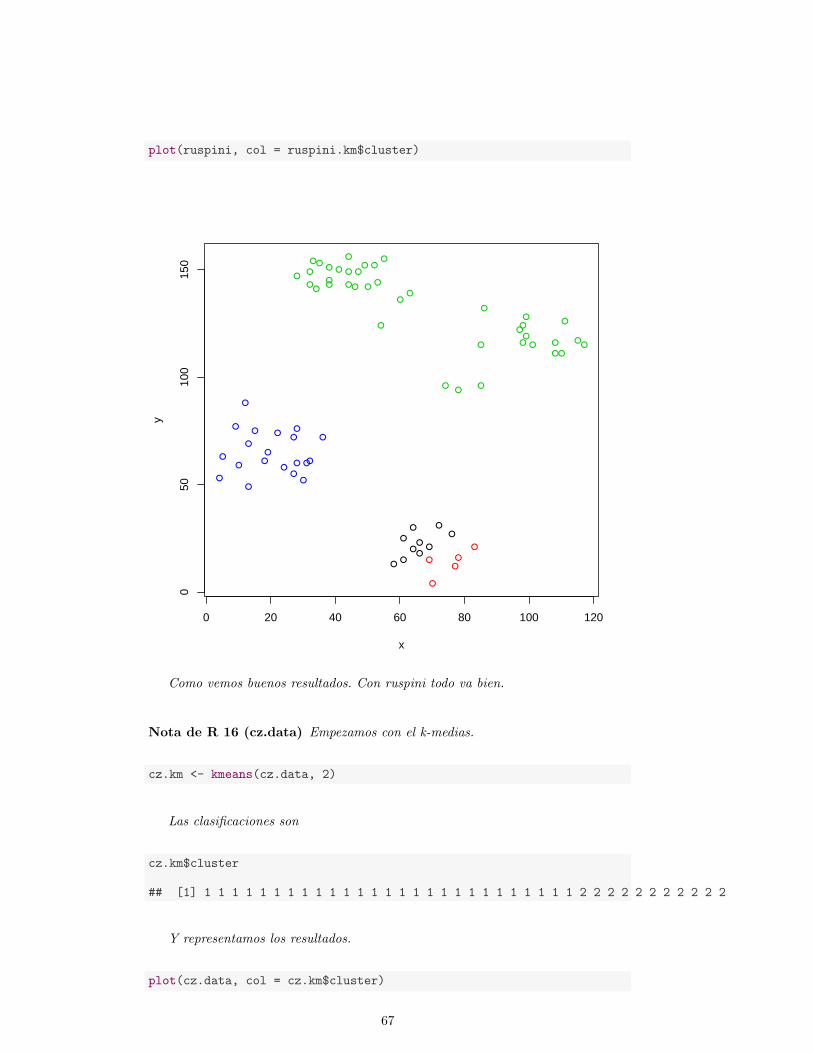
plot(ruspini, col = ruspini.km$cluster)
0 20 40 60 80 100 120
050
100
150
x
y
Como vemos buenos resultados. Con ruspini todo va bien.
Nota de R 16 (cz.data) Empezamos con el k-medias.
cz.km <- kmeans(cz.data, 2)
Las clasificaciones son
cz.km$cluster
## [1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
Y representamos los resultados.
plot(cz.data, col = cz.km$cluster)
67
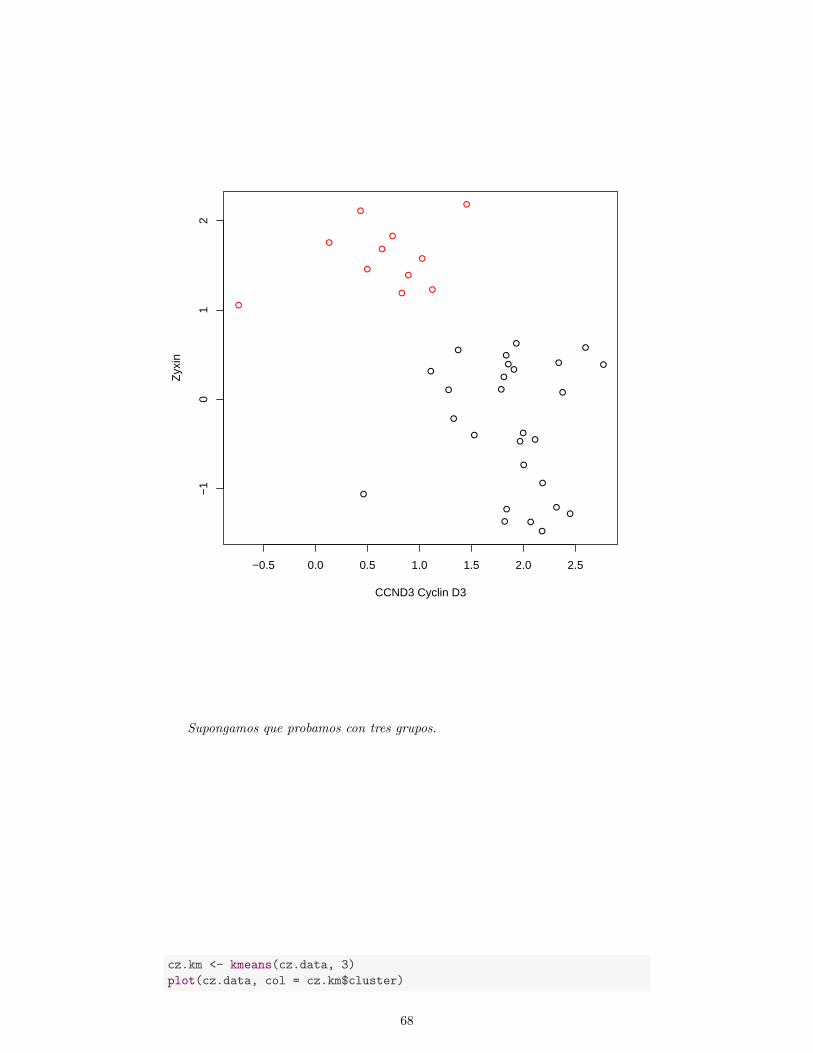
−0.5 0.0 0.5 1.0 1.5 2.0 2.5
−1
01
2
CCND3 Cyclin D3
Zyx
in
Supongamos que probamos con tres grupos.
cz.km <- kmeans(cz.data, 3)
plot(cz.data, col = cz.km$cluster)
68

−0.5 0.0 0.5 1.0 1.5 2.0 2.5
−1
01
2
CCND3 Cyclin D3
Zyx
in
Y finalmente con cuatro.
cz.km <- kmeans(cz.data, 4)
plot(cz.data, col = cz.km$cluster)
69

−0.5 0.0 0.5 1.0 1.5 2.0 2.5
−1
01
2
CCND3 Cyclin D3
Zyx
in
4.4.2. Particionamiento alrededor de los mediodes
¿Y si no podemos calcular el vector de medias? ¿Y si no tiene sentido calcular elvector de medias? ¿Como promediar dos configuraciones de puntos distintas? ¿Comopromediamos dos formas distintas descritas numericamente? Cuando el concepto depromedio aritmetico no tiene sentido podemos generalizar el procedimiento anteriory hablar de (perdon por el neologismo) de k-mediodes.
La idea ahora es sustituir esos centros calculados como vectores de medias delos individuos de un mismo grupo por individuos bien centrados, por individuostıpicos, que sustituyan a las medias.
Supongamos que tomamos k individuos de la muestra que denotamos por mi
con i = 1, . . . , k. Particionamos la muestra en k grupos de modo que el grupo Ciesta formado por los individuos mas proximos a mi que a cualquier otro mj conj 6= i,
Ci = l : d(l, i) = mınj 6=i
d(l, j).
Consideremos la siguiente cantidad:
k∑i=1
∑j∈Ci
d(j,mi). (4.6)
En el metodo de particionamiento alrededor de los mediodes nos planteamos encon-trar las observaciones m1, . . . ,mk que minimizan el valor dado en 4.6.
70
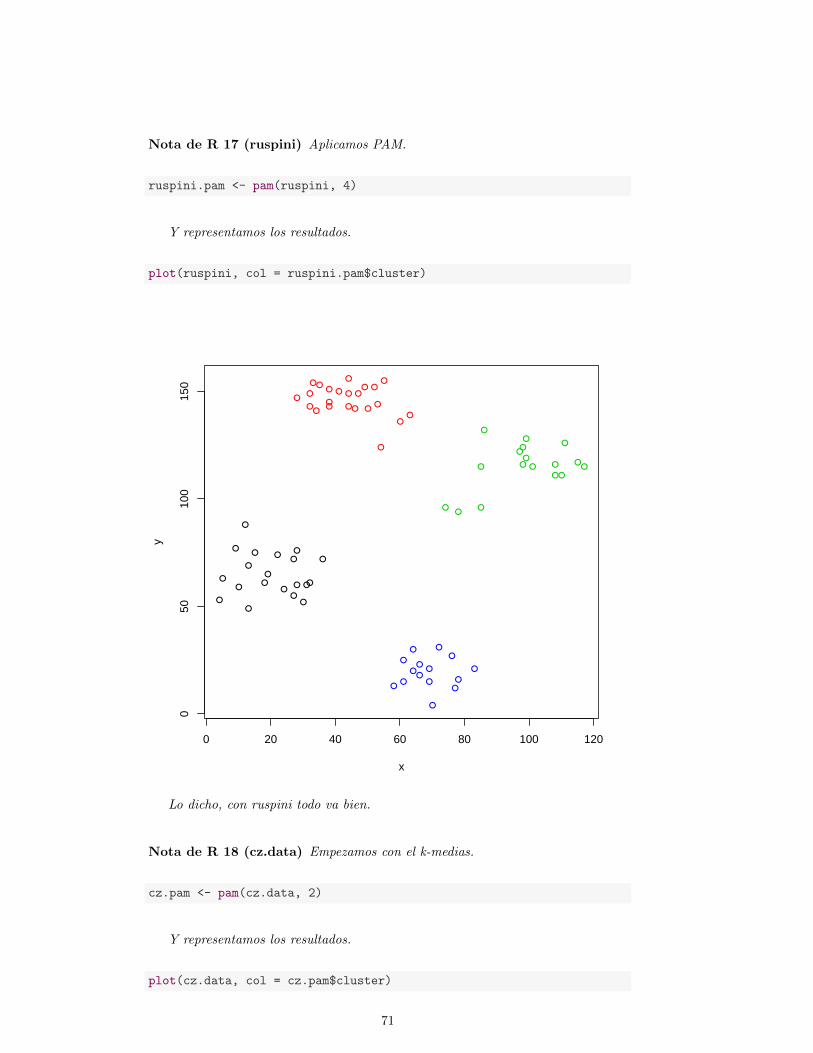
Nota de R 17 (ruspini) Aplicamos PAM.
ruspini.pam <- pam(ruspini, 4)
Y representamos los resultados.
plot(ruspini, col = ruspini.pam$cluster)
0 20 40 60 80 100 120
050
100
150
x
y
Lo dicho, con ruspini todo va bien.
Nota de R 18 (cz.data) Empezamos con el k-medias.
cz.pam <- pam(cz.data, 2)
Y representamos los resultados.
plot(cz.data, col = cz.pam$cluster)
71

−0.5 0.0 0.5 1.0 1.5 2.0 2.5
−1
01
2
CCND3 Cyclin D3
Zyx
in
Supongamos que probamos con tres grupos.
cz.pam <- pam(cz.data, 3)
plot(cz.data, col = cz.pam$cluster)
72
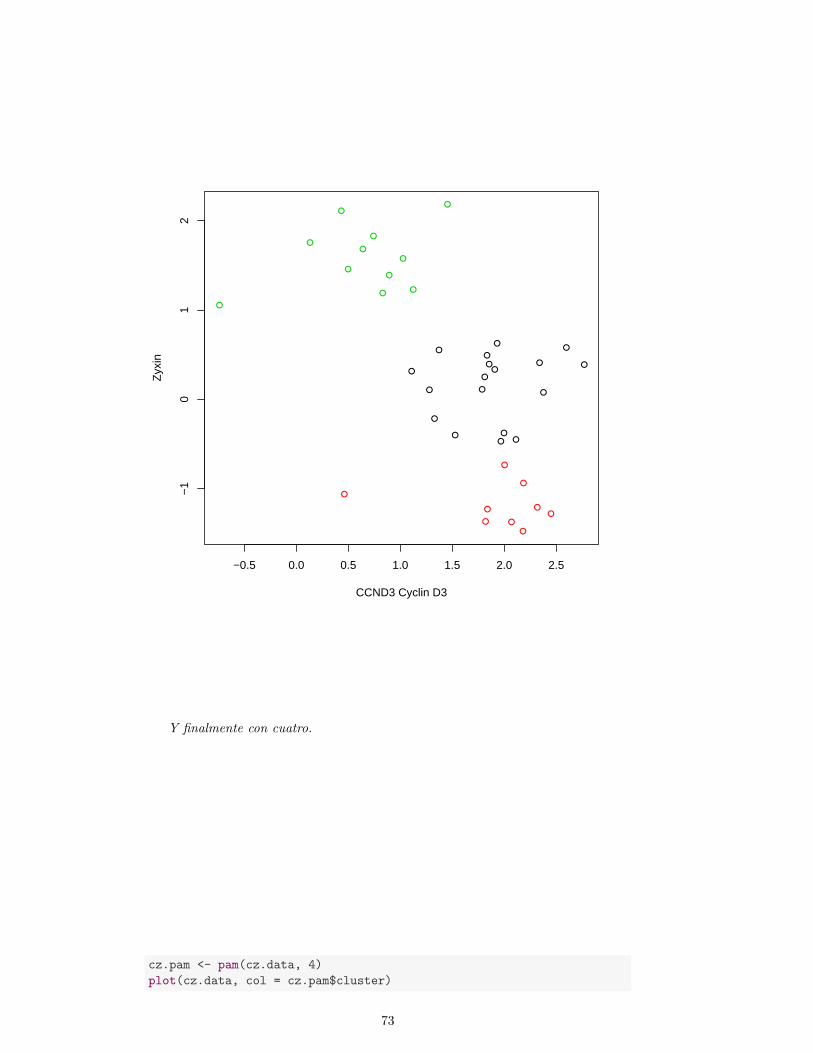
−0.5 0.0 0.5 1.0 1.5 2.0 2.5
−1
01
2
CCND3 Cyclin D3
Zyx
in
Y finalmente con cuatro.
cz.pam <- pam(cz.data, 4)
plot(cz.data, col = cz.pam$cluster)
73
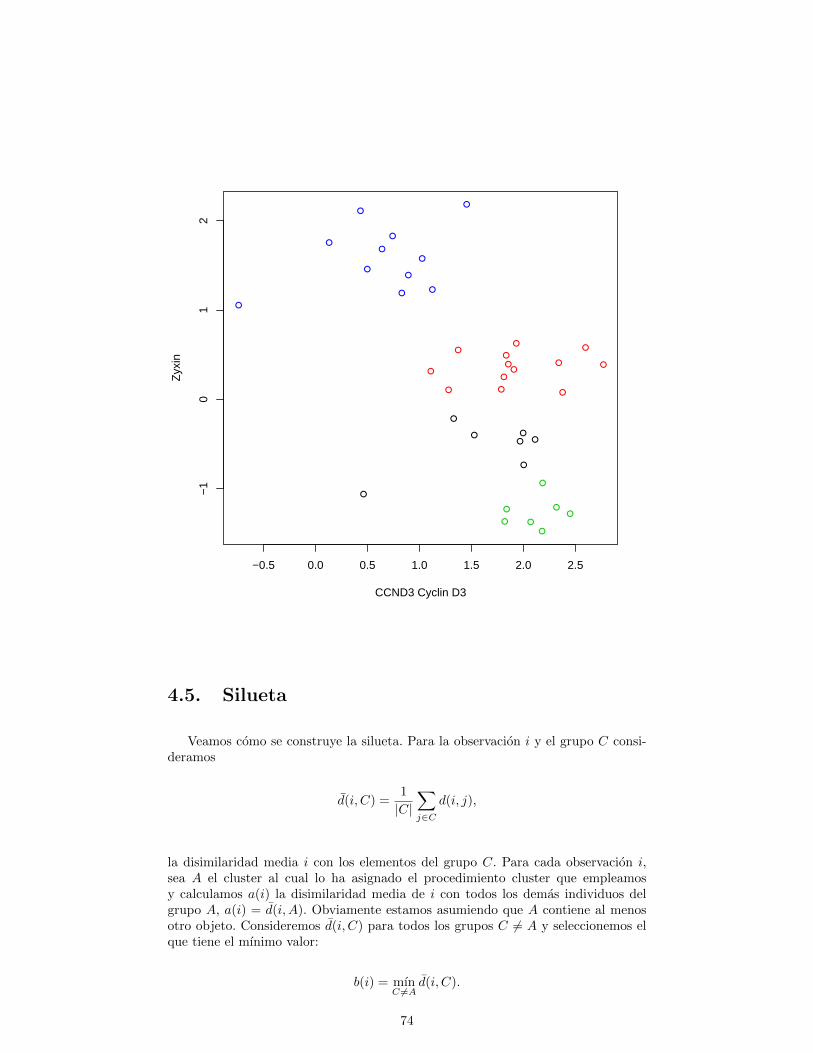
−0.5 0.0 0.5 1.0 1.5 2.0 2.5
−1
01
2
CCND3 Cyclin D3
Zyx
in
4.5. Silueta
Veamos como se construye la silueta. Para la observacion i y el grupo C consi-deramos
d(i, C) =1
|C|∑j∈C
d(i, j),
la disimilaridad media i con los elementos del grupo C. Para cada observacion i,sea A el cluster al cual lo ha asignado el procedimiento cluster que empleamosy calculamos a(i) la disimilaridad media de i con todos los demas individuos delgrupo A, a(i) = d(i, A). Obviamente estamos asumiendo que A contiene al menosotro objeto. Consideremos d(i, C) para todos los grupos C 6= A y seleccionemos elque tiene el mınimo valor:
b(i) = mınC 6=A
d(i, C).
74

Cuadro 4.2: Silueta media y estructura en un conjunto de datos
SC Interpretacion0,71− 1,00 Fuerte estructura0,51− 0,70 Estructura razonable0,26− 0,50 Estructura debil. Probar otros metodos≤ 0,25 No se encuentra estructura
El grupo B donde se alcanza este mınimo, es decir, d(i, B) = b(i) se le llama vecinodel objeto i. 3 Definimos s(i) como
s(i) = 1− a(i)
b(i)si a(i) < b(i), (4.7)
= 0 si a(i) = b(i), (4.8)
=b(i)
a(i)− 1 si a(i) > b(i). (4.9)
Esto se puede expresar en una unica ecuacion como
s(i) =b(i)− a(i)
maxa(i), b(i).
En el caso en que el grupo A contenga un unico objeto no esta muy claro comodefinir a(i). Tomaremos s(i) = 0 que es una eleccion arbitraria. Se comprueba confacilidad que −1 ≤ s(i) ≤ 1 para cualquier objeto i.
Para interpretar el significado de s(i) es bueno ver los valores extremos. Si s(i)es proximo a uno significa que a(i) es mucho menor que b(i) o lo que es lo mismo,que el objeto i esta bien clasificado pues la disimilaridad con los de su propio grupoes mucho menor que la disimilaridad con los del grupo mas proximo que no es elsuyo. Un valor proximo a cero significa que a(i) y b(i) son similares y no tenemosmuy claro si clasificarlo en A o en B. Finalmente un valor de s(i) proximo a −1significa que a(i) es claramente mayor que b(i). Su disimilaridad media con B esmenor que la que tiene con A. Estarıa mejor clasificado en B que en A. No esta bienclasificado.
Los valores de s(i) apareceran representados para cada cluster en orden decre-ciente. Para cada objeto se representa una barra horizontal con longitud propor-cional al valor s(i). Una buena separacion entre grupos o cluster viene indicadapor unos valores positivos grandes de s(i). Ademas de la representacion grafica seproporciona un analisis descriptivo. En concreto la media de los valores de la siluetadentro de cada cluster y la media de la silueta para todo el conjunto de datos. Laclasificacion sera tanto mejor cuanto mayor sean estos valores medios. De hecho, sepuede decidir el numero de grupos en funcion del valor medio de las silueta sobretoda la muestra. Vamos probando distintos numeros de grupos y nos quedamos conel numero que nos da la silueta media maxima.
¿Cuando podemos decir que hay estructura de grupos en los datos que estamosanalizando? Experiencias con datos sugieren la tabla 4.2.
Nota de R 19 (ruspini) Veamos el resumen de la silueta.
3No parece un nombre inadecuado.
75
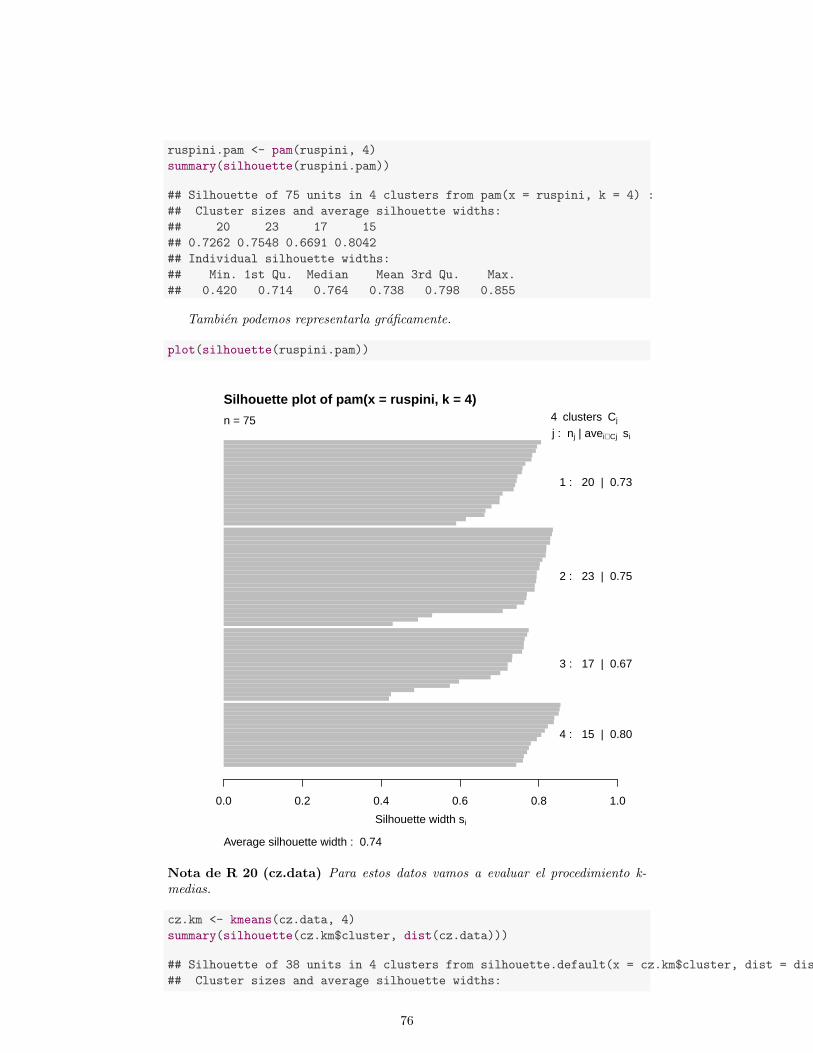
ruspini.pam <- pam(ruspini, 4)
summary(silhouette(ruspini.pam))
## Silhouette of 75 units in 4 clusters from pam(x = ruspini, k = 4) :
## Cluster sizes and average silhouette widths:
## 20 23 17 15
## 0.7262 0.7548 0.6691 0.8042
## Individual silhouette widths:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.420 0.714 0.764 0.738 0.798 0.855
Tambien podemos representarla graficamente.
plot(silhouette(ruspini.pam))
Silhouette width si
0.0 0.2 0.4 0.6 0.8 1.0
Silhouette plot of pam(x = ruspini, k = 4)
Average silhouette width : 0.74
n = 75 4 clusters Cj
j : nj | avei∈Cj si
1 : 20 | 0.73
2 : 23 | 0.75
3 : 17 | 0.67
4 : 15 | 0.80
Nota de R 20 (cz.data) Para estos datos vamos a evaluar el procedimiento k-medias.
cz.km <- kmeans(cz.data, 4)
summary(silhouette(cz.km$cluster, dist(cz.data)))
## Silhouette of 38 units in 4 clusters from silhouette.default(x = cz.km$cluster, dist = dist(cz.data)) :
## Cluster sizes and average silhouette widths:
76
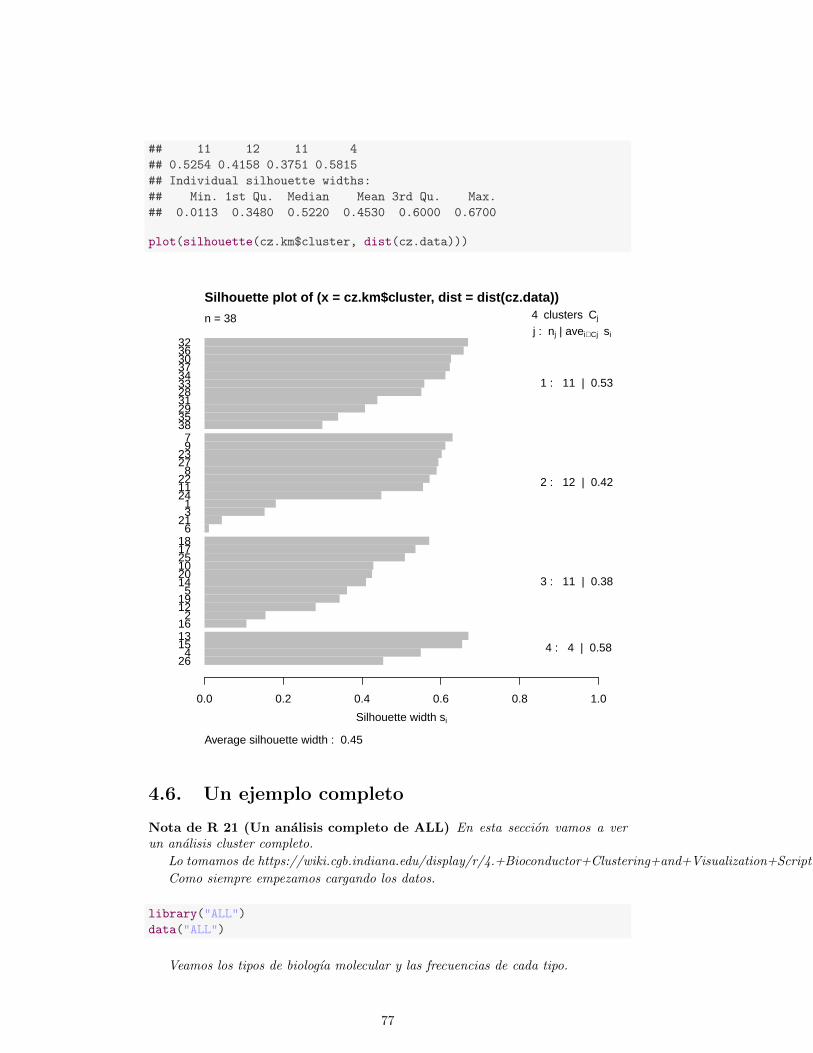
## 11 12 11 4
## 0.5254 0.4158 0.3751 0.5815
## Individual silhouette widths:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.0113 0.3480 0.5220 0.4530 0.6000 0.6700
plot(silhouette(cz.km$cluster, dist(cz.data)))
264
151316
21219
5142010251718
621
31
241122
82723
97
3835293128333437303632
Silhouette width si
0.0 0.2 0.4 0.6 0.8 1.0
Silhouette plot of (x = cz.km$cluster, dist = dist(cz.data))
Average silhouette width : 0.45
n = 38 4 clusters Cj
j : nj | avei∈Cj si
1 : 11 | 0.53
2 : 12 | 0.42
3 : 11 | 0.38
4 : 4 | 0.58
4.6. Un ejemplo completo
Nota de R 21 (Un analisis completo de ALL) En esta seccion vamos a verun analisis cluster completo.
Lo tomamos de https://wiki.cgb.indiana.edu/display/r/4.+Bioconductor+Clustering+and+Visualization+Script.
Como siempre empezamos cargando los datos.
library("ALL")
data("ALL")
Veamos los tipos de biologıa molecular y las frecuencias de cada tipo.
77
table(ALL$mol.biol)
##
## ALL1/AF4 BCR/ABL E2A/PBX1 NEG NUP-98 p15/p16
## 10 37 5 74 1 1
En concreto vamos a quedarnos con dos tipos.
selSamples <- is.element(ALL$mol.biol, c("ALL1/AF4", "E2A/PBX1"))
Nos quedamos con las muestras (columnas) que corresponden a esa biologıa mo-lecular.
ALLs <- ALL[, selSamples]
No vamos a trabajar con todos los genes. En lugar de ello vamos a filtrar aten-diendo a criterios basados en sus niveles de expresion. Quizas podrıamos decir quefiltramos de acuerdo con criterios estadısticos. Obviamente otro filtraje de genespodrıa basarse en criterios biologicos atendiendo a algun conocimiento previo sobrelos mismos.
En concreto los criterios estadısticos seran que el nivel medio de expresion seamayor que un cierto valor mınimo tanto en un tipo de biologıa molecular como enel otro. Podemos utilizar la funcion apply para calcular las medias. Notemos quela matriz que usamos son las expresiones de ALLs exprs(ALLs) y consideramoslas columnas donde se verifica ALLs$mol.bio == "ALL1/AF4", es decir, donde labiologıa molecular es la primera de las consideradas.
m1 <- apply(exprs(ALLs)[, ALLs$mol.bio == "ALL1/AF4"], 1, mean)
Ahora podemos considerar que filas son tales que esta media (calculada para cadagen) es mayor que el valor log2(100).
s1 <- (m1 > log2(100))
¿Cuantos genes verifican este criterio?
table(s1)
## s1
## FALSE TRUE
## 9186 3439
Vemos que hay 3439.Hacemos lo mismo con el segundo tipo de biologıa molecular.
m2 <- apply(exprs(ALLs)[, ALLs$mol.bio == "E2A/PBX1"], 1, mean)
s2 <- (m2 > log2(100))
Podemos ver la tabla de los genes que verifican y no la condicion.
table(s2)
## s2
## FALSE TRUE
## 9118 3507
78

Podemos ver la tabla de contingencia en donde mostramos el numero de genesque verifican las dos condiciones, solamente una o bien ninguna.
table(s1, s2)
## s2
## s1 FALSE TRUE
## FALSE 8863 323
## TRUE 255 3184
A partir de ahora nos quedamos con los genes que verifican los dos criterios.Notemos que s1 es TRUE cuando se verifica la primera condicion y s2 es TRUEcuando se verifica la segunda. Mediante el signo | indicamos la interseccion, estoes, ha de darse la primera y la segunda.
ALLs <- ALLs[s1 | s2, ]
Podemos ver el numero de filas y columnas de ALLs para comprobar que vamosbien.
dim(ALLs)
## Features Samples
## 3762 15
Y vamos bien.
Vamos a considerar tambien que los niveles de expresion sean suficientementevariables. En concreto la condicion sera que la desviacion absoluta respecto de lamediana (o simplemente mad) supere un cierto valor. Primero hemos de calcular ladesviacion absoluta respecto de la mediana de cada fila.
gen.mad <- apply(exprs(ALLs), 1, mad)
En concreto nos quedamos con los genes que tienen un valor de la desviacionabsoluta respecto de la mediana superior a 1.4.
ALLs <- ALLs[gen.mad > 1.4, ]
Otra vez, veamos que datos tenemos.
dim(ALLs)
## Features Samples
## 58 15
Pocos. No tenemos muchos ahora. Mejor. Menos problemas para clasificar.
Vemos un cluster jerarquico aglomerativo de los genes.
genes.ag <- agnes(exprs(ALLs))
plot(genes.ag, which = 2)
79
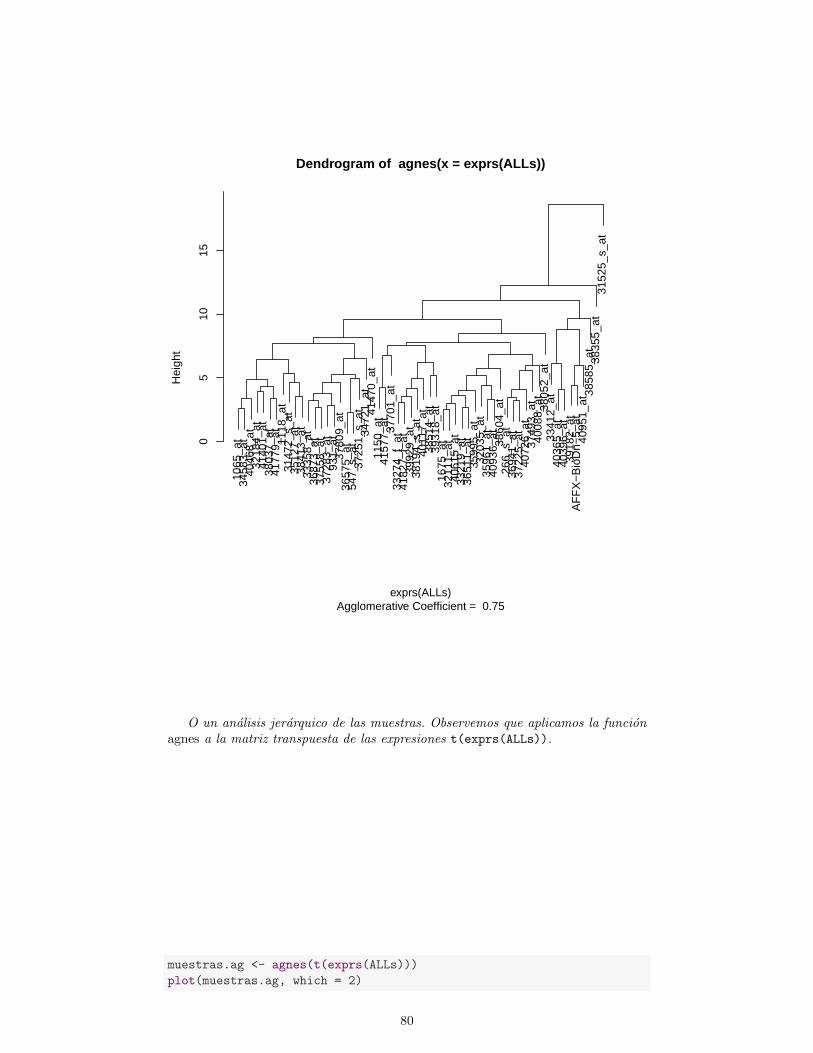
1065
_at
3458
3_at
4046
8_at
3218
4_at
4140
1_at
3803
7_at
4177
9_at
1118
_at
3147
2_s_
at35
127_
at38
413_
at33
358_
at36
873_
at37
558_
at37
283_
at93
1_at
3780
9_at
3657
5_at
547_
s_at
3725
1_s_
at34
721_
at41
470_
at11
50_a
t41
577_
at 3770
1_at
3327
4_f_
at41
827_
f_at
3992
9_at
3819
4_s_
at40
117_
at38
514_
at39
318_
at16
75_a
t32
111_
at40
615_
at33
219_
at36
511_
at35
995_
at32
035_
at35
961_
at40
936_
at38
604_
at26
6_s_
at36
941_
at37
225_
at40
726_
at37
493_
at40
088_
at 3805
2_at
3341
2_at
4036
5_at
4039
6_at
3918
2_at
AF
FX
−B
ioD
n−5_
at40
951_
at38
585_
at 3835
5_at
3152
5_s_
at
05
1015
Dendrogram of agnes(x = exprs(ALLs))
Agglomerative Coefficient = 0.75exprs(ALLs)
Hei
ght
O un analisis jerarquico de las muestras. Observemos que aplicamos la funcionagnes a la matriz transpuesta de las expresiones t(exprs(ALLs)).
muestras.ag <- agnes(t(exprs(ALLs)))
plot(muestras.ag, which = 2)
80
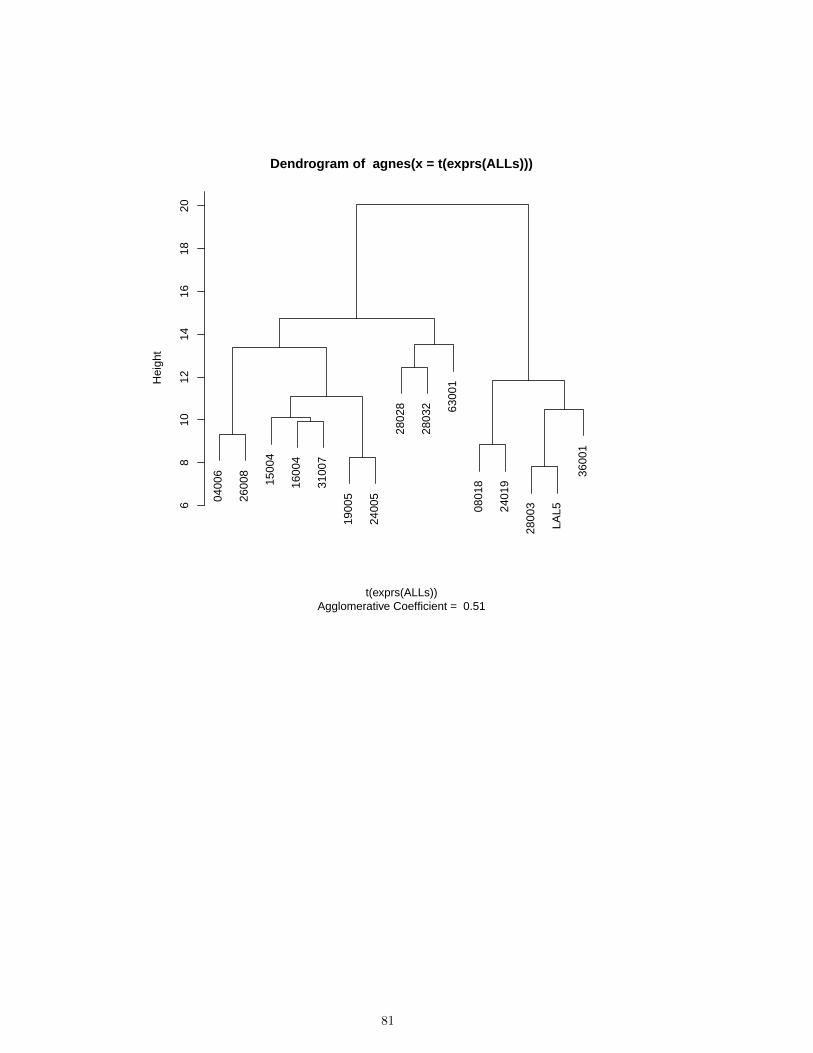
0400
6
2600
8
1500
4
1600
4
3100
7
1900
5
2400
5
2802
8
2803
2 6300
1
0801
8
2401
9
2800
3
LAL5
3600
1
68
1012
1416
1820
Dendrogram of agnes(x = t(exprs(ALLs)))
Agglomerative Coefficient = 0.51t(exprs(ALLs))
Hei
ght
81

82

Capıtulo 5
Analisis discriminante o decomo clasificar con muestrade entrenamiento
Discriminar es clasificar. Es una palabra mal vista. Cuando una persona le dice aotra: “Usted me discrimina” esta indicando algo negativo en la medida en que piensaque lo esta separando para perjudicarle. Se asume la discriminacion como algo quese realiza en un sentido negativo. Pues no. El analisis discriminante simplemente serefiere al problema de clasificar en distintos grupos un conjunto de observacionesvectoriales. Clasificar y discriminar se usan como sinonimos.
Tenemos distintos conjuntos de datos multivariantes. ¿Que quiere que tenemosgrupos y que pretendemos hacer con ellos? Una biologa ha recogido una serie deanimales y ha observado en cada uno unas caracterısticas numericas. Esta biologaha podido clasificar a los animales en distintas especies utilizando las variables xde las que dispone y, posiblemente, algunas otras cuya consecucion ya no es tansimple y, en ocasiones, ni posible. Esta interesada en disenar un procedimiento que,partiendo de las variables de las que siempre dispone x, le permita decidir la especiea la que pertenece un animal futuro del cual solamente tiene las caracterısticas x.Tiene esta persona un problema de clasificacion que pretende hacer bien y clasificara cada animal en su especie con un esfuerzo pequeno.
Otro ejemplo puede ser el siguiente. Una persona ha pasado una enfermedad(como la hidatidosis) y por lo tanto guarda en su organismo anticuerpos frente alvirus que lo infecto y le causo la enfermedad. A este individuo se le controla a lolargo de los anos. Cuando se le aplica un procedimiento diagnostico el resultadopuede ser positivo debido a dos razones: el individuo ha recaıdo en la enfermedad ypor lo tanto ha de ser tratado. Sin embargo, si el procedimiento es muy sensible elresultado positivo del test puede ser simplemente producidos por los anticuerpos quela persona conserva. Diferenciar una situacion de la otra supone otra exploracion(placas del torax) y, por ello, una complicacion adicional. En la realizacion del testse han recogido la presencia o ausencia de una serie de aminoacidos. Tenemos quenuestro vector de caracterısticas son variables binarias o dicotomicas y pretendemospoder decidir a partir de ellas si la persona esta sana sin anticuerpos, sana conanticuerpos o finalmente enferma utilizando la presencia o ausencia de los distintosanticuerpos. Este es un segundo problema de interes a tratar aquı.
Pretendemos clasificar a un individuo dado utilizando algunas caracterısticasdel mismo. Pero para poder hacerlo tenemos que conocer para una muestra, quepodemos llamar muestra de entrenamiento (training sample), en que grupo esta ca-da individuo con los que trabajamos. Esto hace bastante natural el nombre mas
83

utilizado en el contexto de la Informatica de clasificacion supervisada.
Nota de R 22 (Cristales en la orina) Tenemos pacientes de los cuales se co-nocen algunas variables obtenidas de un analisis de orina. En concreto las variablesnos dan la gravidez especıfica (grav), la osmolaridad (osmo), la conductibilidad (con-duc), la concentracion de urea (urea) y la concentracion de calcio (calcio). Tambientenemos una variable que nos indica la presencia o ausencia de cristales en la orinadel individuo (grupo donde 1 indica ausencia y 2 indica presencia). El problemaque nos planteamos es disenar un procedimiento de clasificacion de modo que, dadoel vector de caracterısticas de la orina, nos permita clasificar a un individuo en unode los dos posibles grupos, esto es, que va a desarrollar cristales en la orina o no.En el diseno del procedimiento pretendemos utilizar la informacion que ya tenemos,esto es, conocemos para una serie de individuos si tiene o no cristales y los vectoresde caracterısticas asociados. En una observacion futura tendremos el vector de ca-racterısticas pero no conoceremos la clasificacion. Leemos los datos de un fichero deSPSS utilizando el paquete foreign ? y mostramos las seis primeras observaciones.
library(foreign)
x <- read.spss(file = "../data/cristal.sav", to.data.frame = T)
x[x == -1] <- NA
cc <- complete.cases(x)
x <- x[cc, ]
Veamos algunos datos.
head(x)
## IND GRUPO GRAV PH OSMO CONDUC UREA CALCIO
## 2 2 ausencia de cristales 1.017 5.74 577 20.0 296 4.49
## 3 3 ausencia de cristales 1.008 7.20 321 14.9 101 2.36
## 4 4 ausencia de cristales 1.011 5.51 408 12.6 224 2.15
## 5 5 ausencia de cristales 1.005 6.52 187 7.5 91 1.16
## 6 6 ausencia de cristales 1.020 5.27 668 25.3 252 3.34
## 7 7 ausencia de cristales 1.012 5.62 461 17.4 195 1.40
Incluimos un analisis descriptivo de los datos.
summary(x)
## IND GRUPO GRAV PH OSMO
## Min. : 2.0 ausencia de cristales :44 Min. :1.00 Min. :4.76 Min. : 187
## 1st Qu.:21.0 presencia de cristales:33 1st Qu.:1.01 1st Qu.:5.53 1st Qu.: 410
## Median :40.0 Median :1.02 Median :5.94 Median : 594
## Mean :40.3 Mean :1.02 Mean :6.04 Mean : 614
## 3rd Qu.:60.0 3rd Qu.:1.02 3rd Qu.:6.40 3rd Qu.: 803
## Max. :79.0 Max. :1.04 Max. :7.94 Max. :1236
## CONDUC UREA CALCIO
## Min. : 5.1 Min. : 10 Min. : 0.17
## 1st Qu.:14.3 1st Qu.:159 1st Qu.: 1.45
## Median :21.4 Median :255 Median : 3.16
## Mean :20.9 Mean :262 Mean : 4.16
## 3rd Qu.:27.0 3rd Qu.:362 3rd Qu.: 6.19
## Max. :38.0 Max. :620 Max. :14.34
84
Nota de R 23 (Diabetes) Los datos corresponden a una serie de personas delas cuales conocemos informacion que previsiblemente nos permitira predecir si sondiabeticos o no. Incluso dentro de los diabeticos pretendemos discriminar (distin-guir) entre diabetes clınica y diabetes manifiesta. La variable tipo nos indica enque grupo esta la persona observada de los tres grupos indicados. El resto de varia-bles nos describen al paciente: peso es el peso relativo, gpb es la glucosa plasmaticaen ayunas, garea el area bajo la curva de la glucosa, iarea el area bajo la curva deinsulina y sspg la glucosa plasmatica en estado estacionario. Pretendemos clasificara un individuo en uno de los tres grupos posibles teniendo en cuenta las variablesconsideradas.
library(foreign)
x <- read.spss(file = "../data/diabetes.sav", to.data.frame = T)
head(x)
## IND PESO GPB GAREA IAREA SSPG TIPO LIAREA
## 1 1 0.81 80 356 124 55 control 4.820
## 2 2 0.95 97 289 117 76 control 4.762
## 3 3 0.94 105 319 143 105 control 4.963
## 4 4 1.04 90 356 199 108 control 5.293
## 5 5 1.00 90 323 240 143 control 5.481
## 6 6 0.76 86 381 157 165 control 5.056
Veamos un breve analisis descriptivo de los datos.
summary(x)
## IND PESO GPB GAREA IAREA SSPG
## Min. : 1 Min. :0.710 Min. : 70 Min. : 269 Min. : 10 Min. : 29
## 1st Qu.: 37 1st Qu.:0.880 1st Qu.: 90 1st Qu.: 352 1st Qu.:118 1st Qu.:100
## Median : 73 Median :0.980 Median : 97 Median : 413 Median :156 Median :159
## Mean : 73 Mean :0.977 Mean :122 Mean : 544 Mean :186 Mean :184
## 3rd Qu.:109 3rd Qu.:1.080 3rd Qu.:112 3rd Qu.: 558 3rd Qu.:221 3rd Qu.:257
## Max. :145 Max. :1.200 Max. :353 Max. :1568 Max. :748 Max. :480
## TIPO LIAREA
## diabetes manifiesta:33 Min. :2.30
## diabetes quimica :36 1st Qu.:4.77
## control :76 Median :5.05
## Mean :5.02
## 3rd Qu.:5.40
## Max. :6.62
El capıtulo esta organizado del siguiente modo. Empezamos (seccion 5.1) recor-dando el teorema de Bayes con un ejemplo muy simple de urnas (no funerarias).De este modo vemos la idea basica del metodo de clasificacion basado en probabi-lidades a posteriori. Consideramos, en la seccion 5.2, el caso (de interes puramenteacademico) de dos poblaciones normales univariantes con la misma varianza y conlos parametros conocidos 1. En la seccion 5.3 abordamos la situacion con dos pobla-ciones normales multivariantes. Allı consideramos tanto el caso en que las matricesde covarianzas son la misma como cuando son distintas. En la seccion 5.4 nos plan-teamos la estimacion de los vectores de medias y las matrices de covarianzas yvemos la implementacion practica del metodo. El problema de la reduccion de ladimension dentro del problema de la clasificacion es considerado en la seccion 5.7
1En datos reales los parametros no son conocidos.
85

5.1. Un problema de probabilidad sencillo
Veamos un problema de probabilidad basico que nos servira para introducir elprocedimiento de clasificacion que vamos a utilizar. No le falta ningun detalle ymuchos lo hemos resuelto. Tenemos dos urnas. En la primera de ellas hay una bolablanca y dos negras mientras que en la segunda urna hay dos bolas blancas y unanegra. Elegimos al azar una urna (no sabemos cual es la elegida). Posteriormente dela urna elegida, elegimos a su vez una bola. Resulta que la bola elegida es blanca.La pregunta que nos hacemos es: ¿De que urna la hemos elegido? La solucion es unaaplicacion del teorema de Bayes (ver 1.2.3). Denotamos Bi el suceso consistente enque la bola ha sido extraıda de la i-esima urna y por el A el suceso de que la bolaes blanca. A priori, antes de realizar el experimento, las dos urnas tenıan la mismaprobabilidad (elegimos al azar una de las urnas) y por tanto la probabilidad (previao a priori) de los sucesos Bi serıan P (Bi) = 1/2. No sabemos si la urna elegida hasido la primera o la segunda pero nos podemos plantear que probabilidad tenemosde que sea blanca si efectivamente es la urna 1 la elegida y lo mismo para la dos.Es obvio que P (A | B1) = 1/3 y P (A | B2) = 2/3. Esta informacion se puedecombinar aplicando el teorema de Bayes para determinar la probabilidad de que seala primera o la segunda urna la elegida sabiendo (teniendo pues una informacionadicional sobre el experimento) que ha salido blanca. En concreto tenemos que
P (Bi | A) = P (A|Bi)P (Bi)∑kj=1 P (A|Bj)P (Bj)
. Finalmente podemos comprobar que P (B1 | A) =
1/3 y P (B2 | A) = 2/3.
Las probabilidades P (B1) y P (B2) reciben el nombre de probabilidades apriori. Vamos a denotarlas en lo que sigue por πi, esto es, la probabilidad de la urnai. Nuestra informacion consiste en la ocurrencia del suceso A (la bola ha sido blanca)de modo que las probabilidades P (A | B1) y P (A | B2) serıan las verosimilitudesde que ocurra lo que ha ocurrido si la urna es la primera o la segunda. Finalmentetenemos P (B1 | A) y P (B2 | A) que nos darıan las probabilidades a posteriori.
Hemos de tomar una decision: ¿cual fue la urna elegida? Parece natural elegiraquella que tiene a posteriori una maxima probabilidad y quedarnos con la segundaurna.
Vamos a reescribir lo que acabamos de hacer que nos acerque al planteamientomas generico del problema. Supongamos que describimos el color de la bola elegidamediante una variable dicotomica o binaria. Consideramos la variable aleatoria Xque vale uno si es blanca la bola y cero en otro caso. Es lo que se llama unavariable indicatriz pues nos indica si se ha producido el suceso que nos interesa. 2
El comportamiento aleatorio de X, su distribucion de probabilidad, depende queestemos extrayendo una bola de la primera o de la segunda urna. En concreto en laprimera urna X sigue una distribucion Bernoulli con probabilidad de exito p1 = 1/3mientras que en la segunda urna tenemos una Bernoulli con probabilidad de exitop2 = 2/3. Cada urna es una poblacion distinta donde el comportamiento aleatoriode la misma cantidad es distinto. X en la i-esima poblacion tiene una funcion deprobabilidad
fi(x) = pxi (1− pi)1−x con x = 0, 1.
Tenıamos unas probabilidades a priori de que X estuviera siendo observada en lapoblacion i-esima que denotamos por π(i) donde π(1) + π(2) = 1 y π(1), π(2) ≥ 0.Las probabilidades a posteriori obtenidas por la aplicacion del teorema de Bayesvienen dadas por
π(i | x) =fi(x)π(i)
f1(x)π(1) + f2(x)π(2).
2Si A es el suceso de interes entonces X(ω) = 1 si ω ∈ A y cero en otro caso. A veces se denotacomo X(ω) = 1A(ω).
86

Finalmente nos hemos quedado con la poblacion i tal que tenıa un valor de π(i | x)mayor, aquella que, una vez observado el valor de X = x, hacıa mas probable lapoblacion.
5.2. Dos poblaciones normales
Supongamos ahora que tenemos que decidir entre dos poblaciones basandonosen un valor aleatorio continuo con distribucion normal. En concreto supondremosque en la primera poblacion X es normal con media µ1 y varianza σ2. En la segundapoblacion X tiene distribucion normal con media µ2 y varianza σ2. Graficamente enla figura ?? aparece la situacion con la que nos encontramos. Supongamos conocidoslos valores de las media y la varianza comun. Observamos un valor de la variableX =x: ¿cual de las dos distribuciones lo ha generado? De otro modo: ¿a que poblacionpertenece este valor generado?
La idea para clasificar este valor generado es la misma de antes. Ahora tendremos
fi(x) = f(x | µi, σ2) =1√2πσ
exp
(− 1
2σ2(x− µi)2
),
aunque fi(x) no es la probabilidad del valor x asumiendo que estamos en la po-blacion i. No obstante, fi(x)dx sı que tiene este sentido. Hablando en un sentidoamplio tenemos una interpretacion similar. La observacion x la clasificarıamos enla poblacion 1 si
π(1)f(x | µ1, σ2)
π(2)f(x | µ2, σ2)> 1,
Facilmente comprobamos que esto equivale con que
1
σ2(µ1 − µ2)
(x− 1
2(µ1 + µ2)
)> log
π(2)
π(1).
5.3. Dos normales multivariantes
En la seccion 5.2 nos planteabamos la situacion de dos normales univariantes. Enlas aplicaciones es mas habitual el caso en que trabajamos con varias caracterısticassimultaneamente. En particular, vamos a asumir ahora que X puede pertenecer auna de dos poblaciones normales multivariantes. La primera con vector de mediasµ1 y matriz de covarianzas Σ y la segunda con vector de medias µ2 y matriz de cova-rianzas Σ. Dada una observacion multivariante x, la clasificaremos en la poblacion1 si
π(1)f(x | µ1,Σ)
π(2)f(x | µ2,Σ)> 1,
pero,
f(x | µ1,Σ)
f(x | µ2,Σ)=
exp
[− 1
2(x− µ1)′Σ−1(x− µ1) +
1
2(x− µ2)′Σ−1(x− µ2)
]=
exp
[(µ1 − µ2)′Σ−1x− 1
2(µ1 − µ2)′Σ−1(µ1 + µ2)
]. (5.1)
Sea λ = Σ−1(µ1 − µ2), entonces la observacion es asignada a la primera poblacionsi
D(x) = λ′[x− 1
2(µ1 + µ2)
]> log
π(2)
π(1). (5.2)
87

Notemos que la ecuacion D(x) = log π(2)π(1) nos define un hiperplano que separa las
dos poblaciones.¿Que ocurre si no asumimos que tenemos una misma matriz de covarianzas? En
este caso se tiene que:
Q(x) = logf(x | µ1,Σ1)
f(x | µ2,Σ2)=
1
2log|Σ2||Σ1|
− 1
2(x− µ1)′Σ−1
1 (x− µ1) +1
2(x− µ2)′Σ−1
2 (x− µ2) =
1
2log|Σ2||Σ1|
− 1
2
[x′(Σ−1
1 − Σ−12 )x− 2x′(Σ−1
1 µ1 − Σ−12 µ2)
]. (5.3)
Como en el caso anterior asignamos la observacion x a la primera poblacion si
Q(x) > logπ(2)
π(1).
Notemos que ahora Q(x) = log π(2)π(1) no es un hiperplano sino que tenemos una
superficie no plana.
5.4. Dos poblaciones normales multivariantes conparametros desconocidos
Lo visto en las secciones anteriores tenıa como objeto mostrar de un modosuave la transicion desde el resultado probabilıstico basico, el teorema de Bayes, ysu aplicacion en el problema de la clasificacion. Sin embargo, no es real asumir queconocemos completamente la distribucion de las observaciones en cada poblacion oclase. En las aplicaciones los vectores de medias y la matriz o matrices de covarianzasno son conocidas. Hemos de estimarlas a partir de los datos. Veamos primero comohacerlo y luego como usar estos parametros en el procedimiento de clasificacion.
Empezamos por el caso en que tenemos dos poblaciones normales con vectoresde medias µ1 y µ2 y matrices de covarianzas Σ1 y Σ2. Lo que tenemos son dosmuestras aleatorias correspondientes a cada una de las poblaciones.
Supongamos que tenemos ni individuos de la poblacion i y los vectores de ca-racterısticas son los vectores columna xij ∈ Rd (con i = 1, 2 y j = 1, . . . , ni).Denotamos
xi· =
∑nij=1 xij
ni, x·· =
∑2i=1
∑nij=1 xij
n(5.4)
donde n = n1 + n2. Sea Si la matriz de varianzas o de dispersion de la poblacion i,es decir,
Si =
∑nij=1(xij − xi·)(xij − xi·)′
ni − 1. (5.5)
El vector µi es estimado mediante µi = xi·. La matriz Σi la estimamos medianteSi. En el caso particular en que asumamos que Σ = Σ1 = Σ2 entonces la matriz decovarianzas comun la estimamos con
Sp =
∑2i=1(ni − 1)Sin− 2
.
¿Como clasificamos? Las distribuciones teoricas que suponıamos conocidas sonreemplazadas por las distribuciones normales con los parametros estimados.
88

Si asumimos una matriz de covarianza comun a ambas poblaciones entoncesasignamos x a la primera poblacion si
Ds(x) > logπ(2)
π(1), (5.6)
donde
Ds(x) = λ′(x− 1
2(x1· + x2·) (5.7)
yλ = S−1
p (x1· − x2·). (5.8)
La funcion Ds recibe el nombre de funcion discriminante lineal. La razon es obvia:clasificamos en uno o en otro grupo utilizando una funcion lineal de las distintasvariables.
En el caso particular en que π(1) = π(2), esto es, consideramos a priori igual-mente probables ambos grupos entonces la regla de clasificacion propuesta serıa:clasificamos en la poblacion o clase 1 si,
λ′x >1
2(λ′x1· + λ′x2·).
Es es el procedimiento que propuso R.A. Fisher en 1936.Notemos que las probabilidades de pertenencia a posteriori a cada una de las
poblaciones pueden ser estimadas mediante
π(i|x) =π(i)f(x|xi·,Sp)
π(1)f(x|x1·,Sp) + π(2)f(x|x2·,Sp). (5.9)
Una vez tenemos las probabilidades a posteriori estimadas el individuo es clasificadoen el grupo que tiene una mayor probabilidad a posteriori.
En la situacion mas general no asumiremos una misma matriz de covarianzasen las dos poblaciones. En este caso estimamos la matriz Σi mediante la matriz Sidada en la ecuacion 5.5. Las probabilidades a posteriori las estimamos como
π(i|x) =π(i)f(x|xi·, Si)
π(1)f(x|x1·, S1) + π(2)f(x|x2·, S2). (5.10)
Nota de R 24 Vamos a trabajar con los datos de cristales en la orina. Esta notaes un ejemplo de analisis discriminante lineal con dos grupos. Consideramos doscasos. En el primero las probabilidades a priori de cada grupo se asumen igualesentre sı y, por lo tanto, iguales a 0,5. En el segundo caso, las probabilidades a prioricoinciden con las proporciones observadas dentro de la muestra de cada una de laspoblaciones o clases. Leemos los datos.
library(foreign)
x <- read.spss(file = "../data/cristal.sav", to.data.frame = T)
Definimos el valor -1 como dato faltante.
x[x == -1] <- NA
Eliminamos del estudio todos los casos en los que hay algun dato faltante.
cc <- complete.cases(x)
attach(x[cc, ])
Suponemos matrices de covarianzas iguales y probabilidades a priori iguales.
89

library(MASS)
z <- lda(GRUPO ~ CALCIO + CONDUC + GRAV + OSMO + PH + UREA, prior = c(1, 1)/2)
Veamos como recuperar los distintos elementos del analisis.
attributes(z)
## $names
## [1] "prior" "counts" "means" "scaling" "lev" "svd" "N" "call"
## [9] "terms" "xlevels"
##
## $class
## [1] "lda"
Las probabilidades a priori vienen dadas por
z$prior
## ausencia de cristales presencia de cristales
## 0.5 0.5
El numero de datos por grupo es
z$counts
## ausencia de cristales presencia de cristales
## 44 33
El vector de medias estimado en cada grupo lo obtenemos con
z$means
## CALCIO CONDUC GRAV OSMO PH UREA
## ausencia de cristales 2.629 20.55 1.015 561.7 6.126 232.4
## presencia de cristales 6.202 21.38 1.022 682.9 5.927 302.4
Vamos a obtener las probabilidades a posteriori. Observar la opcion CV=TRUE.
z <- lda(GRUPO ~ CALCIO + CONDUC + GRAV + OSMO + PH + UREA, prior = c(1, 1)/2, CV = TRUE)
attributes(z)
## $names
## [1] "class" "posterior" "terms" "call" "xlevels"
Obtengamos las probabilidades a posteriori.
head(z$posterior)
## ausencia de cristales presencia de cristales
## 1 0.6411 0.35893
## 2 0.8700 0.12997
## 3 0.8484 0.15162
## 4 0.9053 0.09466
## 5 0.5762 0.42381
## 6 0.8968 0.10321
90

y las clasificaciones para cada los distintos casos.
head(z$class)
## [1] ausencia de cristales ausencia de cristales ausencia de cristales
## [4] ausencia de cristales ausencia de cristales ausencia de cristales
## Levels: ausencia de cristales presencia de cristales
Las probabilidades a priori corresponden con proporciones observadas.
z1 <- lda(GRUPO ~ CALCIO + CONDUC + GRAV + OSMO + PH + UREA, CV = TRUE)
Las probabilidades a posteriori son ahora
head(z1$posterior)
## ausencia de cristales presencia de cristales
## 1 0.7043 0.29573
## 2 0.8992 0.10075
## 3 0.8818 0.11820
## 4 0.9273 0.07272
## 5 0.6445 0.35553
## 6 0.9205 0.07946
5.5. Analisis discriminante con mas de dos pobla-ciones normales
Supongamos que tenemos unas probabilidades a priori π(i) de que el caso per-tenezca al grupo i con i = 1, . . . , g (obviamente
∑gi=1 π(i) = 1). Si x son las carac-
terısticas de un caso entonces vamos a asumir que x tiene una distribucion normalmultivariante con media µi y matriz de varianzas Σi en la clase i. Su densidad deprobabilidad viene dada por
f(x | µi,Σi) = (2π)−d/2 | Σi |−1/2 exp−1
2(x− µi)′Σ−1
i (x− µi). (5.11)
Utilizando el teorema de Bayes tenemos que las probabilidades a posteriori vienendadas por
π(i | x) =π(i)f(x | µi,Σi)∑gj=1 π(j)f(x | µj ,Σj)
. (5.12)
Un metodo de clasificacion consiste en clasificar al individuo con caracterısticas xen la clase o grupo tal que la probabilidad a posteriori π(i | x) es maxima o lo quees lo mismo: clasificamos en el grupo tal que
π(i)f(x|µi,Σi) = maxjπjf(x|µj ,Σj).
Obviamente, habitualmente no conocemos los parametros (µi,Σi) de las distintasclases por lo que hemos de estimarlos.
Supongamos que tenemos ni individuos en la clase i y los vectores de carac-terısticas son los vectores columna xij ∈ Rd (con i = 1, . . . , g y j = 1, . . . , ni).Denotamos
xi· =
∑nij=1 xij
ni, x·· =
∑gi=1
∑nij=1 xij
n(5.13)
91

donde n =∑gi=1 ni. Sea Si la matriz de varianzas o de dispersion de la clase i, es
decir,
Si =
∑nij=1(xij − xi·)(xij − xi·)′
ni − 1. (5.14)
El vector µi es estimado mediante µi = xi·. En cuanto a la estimacion de las matricesΣi se utilizan dos estimadores. En el caso en que asumamos que todas son igualesentonces el estimador de Σ = Σ1 = . . . = Σg es Σ = Sp donde
Sp =
∑gi=1(ni − 1)Sin− g
.
Si no asumimos que las distintas matrices de varianzas son iguales entonces cadaΣi es estimada mediante Si.
Es claro que el procedimiento indicado en la ecuacion 5.5 no es aplicable puesno conocemos los parametros. Veamos como queda el procedimiento en las dossituaciones posibles: asumiendo igualdad de las matrices de covarianzas y asumiendoque son distintas.
Bajo la hipotesis de matriz de covarianza comun tendremos que
log[π(i)f(x|xi·,Sp)] = log π(i) + c− 1
2(x− xi·)′S−1
p (x− xi·).
Le quitamos a log[π(i)f(x|xi·,Sp)] la parte que no depende de i dada por c− 12x′S−1p x
y obtenemos la funcion
Li(x) = log π(i) + x′i·S−1p (x− 1
2xi·).
Asignamos x al grupo que tiene un valor mayor de la funcion Li(x). Estas funcionesreciben el nombre de funciones discriminantes. Observemos que las diferencias entredistintas funciones Li son hiperplanos y por ello se habla de analisis discriminantelineal.
En el caso en que no se asume una matriz de varianzas comun entoncesla regla de clasificacion consiste en clasificar donde es maxima la siguiente funcion
Qi(x) = 2 log π(i)− log |Si| − (x− xi·)′S−1i (x− xi·). (5.15)
Notemos que el ultimo termino no es mas que la distancia de Mahalanobis de x alcentro estimado de la clase, xi·. La diferencia entre las funciones Qi para dos clasesdistintas es una funcion cuadratica y por ello el metodo recibe el nombre de analisisdiscriminante cuadratico.
5.6. Valoracion del procedimiento de clasificacion
Nuestros datos son (xi, yi) con i = 1, . . . , n siendo xi el vector de caracterısticadel individuo y denotando yi la clase poblacion o grupo al que pertenece realmenteel individuo. Tenemos unas probabilidades a posteriori π(j|x) para cada x que nosqueramos plantearla. Clasificamos x en la clase j tal que tiene maxima probabilidadde las posibles. Pero el metodo ası construido, ¿va bien o es un desastre? Pareceque todos coincidimos en que ir bien quiere decir clasificar a los individuos en losgrupos a los que realmente pertenecen.
Una primera practica que pretende valorar la probabilidad (y por lo tanto lafrecuencia de veces que ocurre) de una clasificacion correcta es, una vez estimadaslas probabilidades a posteriori para los propios elementos de la muestra. Esto es,nos planteamos clasificar a los individuos utilizados para construir el procedimiento
92

de clasificacion. Tendremos para cada data, yi, el grupo al que pertenece e y∗i elgrupo en el que lo clasificamos. Podemos considerar una valoracion del resultado dela clasificacion la siguiente cantidad,
I =
n∑i=1
δyi,y∗in
, (5.16)
donde δy,y∗ = 1 si y = y∗ y cero en otro caso. La cantidad definida en 5.16 es deuso habitual en la literatura de reconocimiento de patrones. Es, sin duda, un modorazonable de valorar la calidad del procedimiento de clasificacion. Se queda pobre.Al menos parece insuficiente. ¿Como nos equivocamos cuando clasificamos? La si-guiente opcion habitual es utilizar la tabla de clasificacion en donde cruzamos losvalores (yi, y
∗i ). En esta tabla tendremos en la fila (r, c) el numero de casos que ori-
ginalmente son de la clase r y los hemos clasificado en el grupo c. Valorando la tablade clasificacion podemos valorar el metodo de clasificacion. Es importante tener encuenta aquı que no todos los errores de clasificacion tienen la misma importancia.
Independientemente de la valoracion numerica que hagamos del procedimientode clasificacion hemos de tener en cuenta sobre que casos estamos realizando estavaloracion. Si un mismo caso lo utilizamos para construir el procedimiento de valo-racion y lo volvemos a utilizar para clasificarlo estamos sesgando la valoracion delprocedimiento a favor del mismo. Un procedimiento de clasificacion siempre ira me-jor con los casos que utilizamos para construirlo y peor sobre otros casos. Hemosde intentar corregirlo.
Una primera idea es dejar uno fuera cada vez. Para cada j consideramos todala muestra menos xj . Utilizando el resto de la muestra estimamos los vectores demedias y las matrices de covarianzas y, finalmente, las probabilidades a posterioridel individuo j en cada clase. Lo clasificamos del modo habitual. Repetimos elprocedimiento para cada j y construimos la tabla correspondiente. En ingles es latecnica conocida como leaving one out. Realmente el metodo de clasificacion quevaloramos en cada ocasion no es exactamente el mismo pero no es muy diferente. Encada ocasion solamente estamos prescindiendo de un caso y los vectores de mediasy matrices de covarianzas no se modifican mucho. Estamos valorando esencialmenteel mismo metodo.
Una segunda opcion; mejor en su validez peor en sus necesidades. Si tenemos unamuestra de tamano n elegimos una muestra sin reemplazamiento de tamano m. Losm datos seleccionados son utilizadas para estimar las probabilidades a posteriori ylos n−m restantes son clasificados y podemos valorar las distintas proporciones deerror. Es una estimacion del error basada en un metodo de aleatorizacion. Si elegimoslas sucesivas muestras con reemplazamiento tendrıamos un metodo bootstrap.
Nota de R 25 (Los datos iris de Fisher) Consideremos los datos iris tratadosoriginalmente por Fisher. Vemos como se utiliza una muestra para estimar las ma-trices de covarianzas y los vectores de medias mientras que clasificamos a los indi-viduos no utilizados en la estimacion de los parametros. Se utilizan los datos irisde Fisher.
library(MASS)
data(iris3)
Iris <- data.frame(rbind(iris3[, , 1], iris3[, , 2], iris3[, , 3]), Sp = rep(c("s", "c", "v"),
rep(50, 3)))
Tomamos una muestra y con esta muestra estimamos los vectores de medias yla matriz de covarianzas.
93

train <- sample(1:150, 75)
table(Iris$Sp[train])
z <- lda(Sp ~ ., Iris, prior = c(1, 1, 1)/3, subset = train)
Con los estimadores podemos ahora clasificar los demas datos de la muestra.
predict(z, Iris[-train, ])$class
## [1] s s s s s s s s s s s s s s s s s s s s s s s s s s c c c c c c c c c c c c c c c v c
## [44] c c c c c c v v v v v v v v v v v v v v v v v v c v v v v v v v
## Levels: c s v
Nota de R 26 Seguimos con los datos de la orina. Notemos que consideramosprobabilidades a priori correspondientes a las proporciones en la muestra. Nos li-mitamos a construir la tabla de clasificacion. Suponemos matrices de covarianzasiguales y probabilidades a priori dadas por las proporciones de cada clase en lamuestra.
library(foreign)
x <- read.spss(file = "../data/cristal.sav", to.data.frame = T)
x[x == -1] <- NA
cc <- complete.cases(x)
x <- x[cc, ]
attach(x)
Realizamos un analisis discriminante lineal.
z1 <- lda(GRUPO ~ CALCIO + CONDUC + GRAV + OSMO + PH + UREA, CV = TRUE)
Construimos la tabla de clasificaciones.
table(GRUPO, z1$class)
##
## GRUPO ausencia de cristales presencia de cristales
## ausencia de cristales 42 2
## presencia de cristales 14 19
Nota de R 27 (Correo basura) Consideramos unos datos de correo electroni-co. El objetivo del analisis es decidir si el correo es basura o no basandonos eninformacion de dicho correo. Estos datos se pueden encontrar en D.J. Newman andMerz [1998]. Los datos los podemos encontrar en http: // mlearn. ics. uci. edu/
databases/ spambase/ y en particular la descripcion de estos datos la tenemos enhttp: // mlearn. ics. uci. edu/ databases/ spambase/ spambase. DOCUMENTATION .
Realizamos un analisis discriminante linear y un analisis cuadratico. Vemos queel lineal nos proporciona mejores resultados.
library(MASS)
x <- read.table(file = "../data/spambase_data", sep = ",")
attach(x)
xnam <- paste("V", 1:57, sep = "")
(fmla <- as.formula(paste("y ~ ", paste(xnam, collapse = "+"))))
y <- x[, 58]
94

Realizamos el analisis discriminante lineal.
z <- lda(fmla, data = x, prior = c(1, 1)/2, CV = T)
La tabla de clasificacion es la siguiente.
table(V58, z$class)
##
## V58 0 1
## 0 2625 163
## 1 265 1548
Realizamos el analisis discriminante cuadratico y obtenemos la nueva tabla declasificacion.
z <- qda(fmla, data = x, prior = c(1, 1)/2, CV = T)
table(V58, z$class)
##
## V58 0 1
## 0 2086 695
## 1 86 1723
Vamos a realizar una valoracion de los resultados de clasificacion con el analisisdiscriminante lineal utilizando remuestreo. Elegimos la muestra de entrenamientocomo una seleccion aleatoria de los datos.
entrenamiento <- sample(nrow(x), 2000)
Vemos la distribucion del correo en la muestra de entrenamiento.
table(y[entrenamiento])
##
## 0 1
## 1207 793
Realizamos el analisis discriminante lineal.
z <- lda(fmla, data = x, prior = c(1, 1)/2, subset = entrenamiento)
Vemos la tabla de clasificacion sobre los datos de entrenamiento.
table(predict(z, x[entrenamiento, ])$class, y[entrenamiento])
##
## 0 1
## 0 1149 108
## 1 58 685
Vemos la tabla de clasificacion sobre el resto de los datos.
95

table(predict(z, x[-entrenamiento, ])$class, y[-entrenamiento])
##
## 0 1
## 0 1486 162
## 1 95 858
Repetimos en muestras con reemplazamiento.
entrenamiento <- sample(nrow(x), 2000, replace = T)
table(y[entrenamiento])
##
## 0 1
## 1220 780
z <- lda(fmla, data = x, prior = c(1, 1)/2, subset = entrenamiento)
Vemos la tabla de clasificacion sobre los datos de entrenamiento.
table(predict(z, x[entrenamiento, ])$class, y[entrenamiento])
##
## 0 1
## 0 1155 112
## 1 65 668
Vemos la tabla de clasificacion sobre el resto de los datos.
table(predict(z, x[-entrenamiento, ])$class, y[-entrenamiento])
##
## 0 1
## 0 1687 190
## 1 101 978
5.7. Variables discriminantes canonicas o discrimi-nantes lineales
Vamos a estudiar una tecnica de reduccion de la dimension relacionada con elplanteamiento que del analisis discriminante lineal hizo Fisher. Consideramos lasmatrices W y B definidas como
W =
g∑i=1
ni∑j=1
(xij − xi·)(xij − xi·)′ =
g∑i=1
(ni − 1)Si, (5.17)
y
B =
g∑i=1
ni∑j=1
(xi· − x··)(xi· − x··)′ =
g∑i=1
ni(xi· − x··)(xi· − x··)′ (5.18)
Notemos que
Sp =W
n− g(5.19)
96

Estas matrices reciben el nombre de matrices intra grupos y entre grupos respec-tivamente. Son las versiones matriciales de las sumas de cuadrados intra y entregrupos habituales en analisis de la varianza.
Es claro que cuando mas agrupados esten los datos dentro de los grupos y masseparados esten para grupos distintos tendremos que la magnitud de W ha de sermenor que la de B. Supongamos que reducimos las observaciones multivariantes xija datos univariantes mediante tomando zij = c′xij . Las sumas de cuadrados intray entre vendrıan dadas por c′Wc y c′Bc. El cociente Fc = c′Bc/c′Wc nos comparala variabilidad intra con la variabilidad entre. Fisher (1936) introdujo el analisisdiscriminante lineal buscando el vector c tal que el cociente Fc sea el mayor posible.Ese fue su objetivo inicial.
La matriz W es suma de matrices semidefinidas positivas por lo que es defi-nida positiva y consideramos su descomposicion de Cholesky dada por W = T ′T .Tomamos b = Tc. Se tiene
Fc =c′Bc
c′Wc=b′(T ′)−1BT−1b
b′b=b′Ab
b′b= a′Aa, (5.20)
donde a = b/ ‖ b ‖, esto es, a tiene modulo unitario y A = (T ′)−1BT−1. Se nosplantea el problema de maximizar a′Aa con la restriccion de ‖ a′a ‖= 1. Por re-sultados estandar del algebra lineal se tiene que a1 es el vector propio de A con elmayor propio λ1 verificando que λ1 = a′1Aai. Hemos encontrado una combinacionlineal que, en el sentido que hemos indicado, es optima a la hora de separar losgrupos. Parece logico buscar la siguiente combinacion lineal que verifique el mis-mo criterio de optimalidad pero que el vector correspondiente sea ortogonal al yacalculado. Nos planteamos pues maximizar a′Aa con la restriccion de ‖ a ‖= 1 yque sea ortogonal con el anterior. La solucion viene dada por el vector propio deA asociado a su segundo valor propio por orden de magnitud, λ2 (Aa2 = λ2a2 porlo que λ2 = a′2Aa2). Procedemos del mismo modo obteniendo k direcciones ortogo-nales que nos dan las combinaciones optimas que separan a los grupos. El valor dek es el mınimo entre el numero de grupos menos uno, g − 1 y el numero de datosn, k = mın g − 1, n. Notemos que los sucesivos ar constituyen una base ortonormaltales que
(T ′)−1BT−1ar = Aar = λrar,
con λ1 ≥ λ2 ≥ . . . ≥ λk. Si multiplicamos por la izquierda por la matriz T−1(n −g)1/2 se deduce que
W−1Bcr = λrcr,
donde cr = (n − g)1/2T−1ar. En consecuencia W−1B tiene valores propios λr yvectores propios cr con r = 1, . . . , k. Ademas los vectores ar = Tcr(n − g)−1/2
constituyen una base ortonormal. Consideremos la matriz C que tiene por fila r-esima el vector cr. Sea zij = Cxij . Estos valores reciben el nombre de coordenadasdiscriminantes. Vemos que estas coordenadas pretenden destacar las diferenciasentre los grupos con un orden decreciente de relevancia. Tenemos que decidir concuantas de ellas nos quedamos. Es habitual estudiar los cocientes∑j
i=1 λi∑ki=1 λi
(5.21)
como funcion de j y quedarse con las coordenadas discriminantes hasta un j proximoa uno.
Es muy importante darse cuenta que las coordenadas discriminantes estan tipi-ficadas y son independientes entre ellas. Recordemos que W = T ′T y que la matrizde covarianzas agrupada viene dada por Sp = W/(g − 1). Por tanto tendremos que
c′rSpcs = (n− g)−1c′rT′Tcs = a′ras = δrs, (5.22)
97
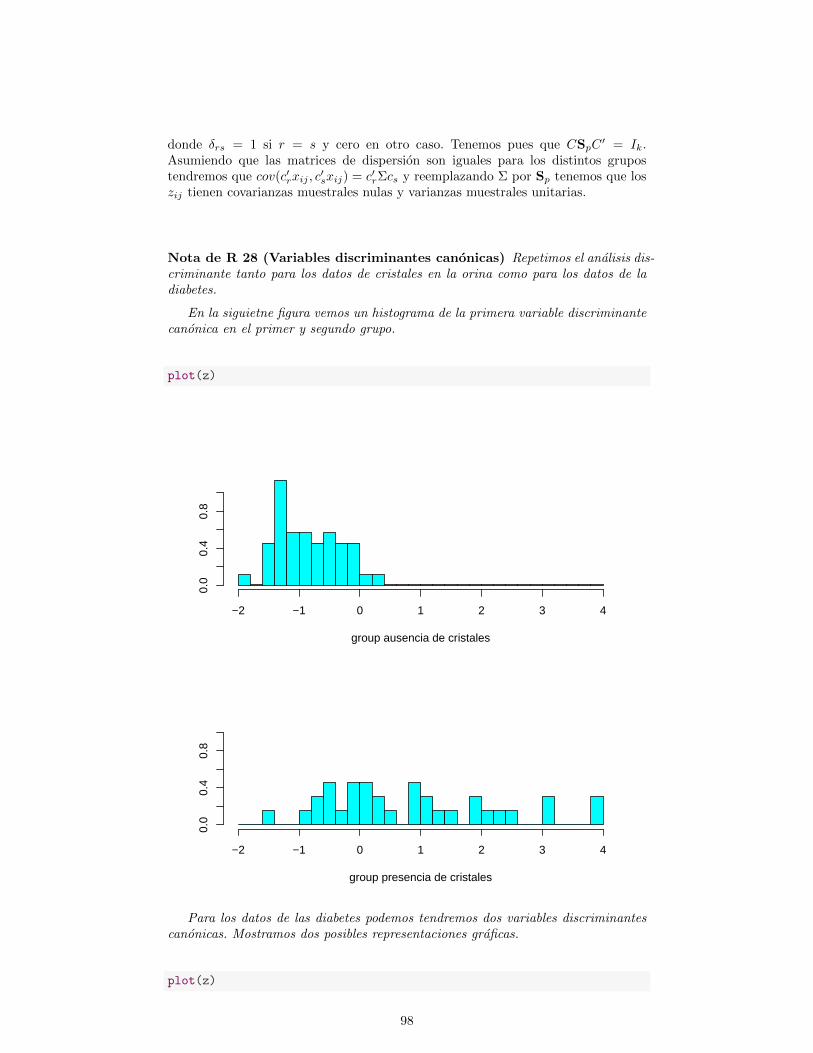
donde δrs = 1 si r = s y cero en otro caso. Tenemos pues que CSpC′ = Ik.
Asumiendo que las matrices de dispersion son iguales para los distintos grupostendremos que cov(c′rxij , c
′sxij) = c′rΣcs y reemplazando Σ por Sp tenemos que los
zij tienen covarianzas muestrales nulas y varianzas muestrales unitarias.
Nota de R 28 (Variables discriminantes canonicas) Repetimos el analisis dis-criminante tanto para los datos de cristales en la orina como para los datos de ladiabetes.
En la siguietne figura vemos un histograma de la primera variable discriminantecanonica en el primer y segundo grupo.
plot(z)
−2 −1 0 1 2 3 4
0.0
0.4
0.8
group ausencia de cristales
−2 −1 0 1 2 3 4
0.0
0.4
0.8
group presencia de cristales
Para los datos de las diabetes podemos tendremos dos variables discriminantescanonicas. Mostramos dos posibles representaciones graficas.
plot(z)
98
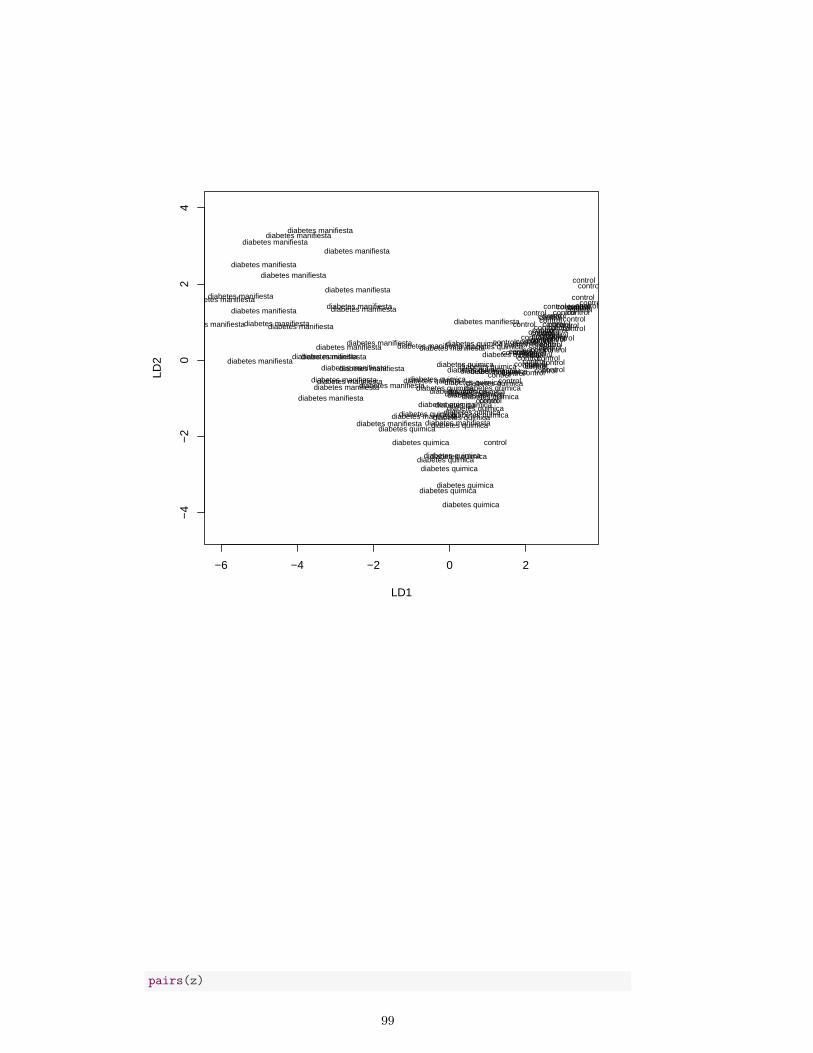
−6 −4 −2 0 2
−4
−2
02
4
LD1
LD2
control
controlcontrol
controlcontrol
controlcontrol
control
control
control
control
control
controlcontrol
control
control
control
control
control
control
control
control
controlcontrolcontrol
control
controlcontrolcontrol
control
control
controlcontrolcontrol
control
control
control
control
control control
control
control
controlcontrol
control
controlcontrol
control
control
control
control
control
controlcontrolcontrol
control
controlcontrol
diabetes quimica
controlcontrol
diabetes quimicadiabetes quimica
control
diabetes quimica
diabetes quimicacontrol
control
control
control
diabetes quimica
controlcontrolcontrol
control controldiabetes quimica
controlcontrol
control
control
control
diabetes quimica
control
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimicadiabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimicadiabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimicadiabetes quimicadiabetes quimica
diabetes quimicadiabetes quimica
diabetes quimica
diabetes manifiestadiabetes manifiesta
diabetes manifiesta
diabetes manifiesta diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiestadiabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiestadiabetes manifiesta
pairs(z)
99

LD1
−4 −2 0 2
−6
−4
−2
02
4
control
controlcontrol
controlcontrol
control
controlcontrolcontrol
control
control
control
controlcontrol
control
control
control
controlcontrol
controlcontrol
control
controlcontrolcontrol
control
controlcontrolcontrol
control
control
controlcontrolcontrol
controlcontrolcontrol
controlcontrol
control
controlcontrol
controlcontrolcontrol
controlcontrol
controlcontrol
controlcontrolcontrol controlcontrolcontrol
controlcontrolcontrol
diabetes quimica
controlcontrol
diabetes quimicadiabetes quimica
control
diabetes quimica
diabetes quimicacontrolcontrol
control
control
diabetes quimica
controlcontrolcontrol
control
control
diabetes quimica
controlcontrolcontrol
control
controldiabetes quimica
control
diabetes quimicadiabetes quimica diabetes quimicadiabetes quimicadiabetes quimicadiabetes quimica
diabetes quimica
diabetes quimicadiabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimicadiabetes quimica
diabetes quimicadiabetes quimicadiabetes quimicadiabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimicadiabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes manifiestadiabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiestadiabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiestadiabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiestadiabetes manifiesta
diabetes manifiesta
diabetes manifiestadiabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiestadiabetes manifiestadiabetes manifiesta
diabetes manifiesta
−6 −4 −2 0 2 4
−4
−2
02
control
controlcontrol
controlcontrol
controlcontrol
control
control
control
control
control
controlcontrol
control
controlcontrol
control
control
controlcontrol
control
controlcontrolcontrol
control
controlcontrolcontrol
control
control
controlcontrolcontrolcontrol
control
controlcontrol
controlcontrolcontrol
control
controlcontrol
control
controlcontrol
controlcontrol
control
control
control
controlcontrolcontrol
control
controlcontrol
diabetes quimicacontrol
control
diabetes quimicadiabetes quimica
control
diabetes quimica
diabetes quimicacontrol
control
control
control
diabetes quimica
controlcontrolcontrol
controlcontroldiabetes quimica
controlcontrolcontrol
control
control
diabetes quimica
control
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimicadiabetes quimica
diabetes quimicadiabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimicadiabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimica
diabetes quimicadiabetes quimicadiabetes quimica
diabetes quimicadiabetes quimica
diabetes quimica
diabetes manifiestadiabetes manifiesta
diabetes manifiesta
diabetes manifiestadiabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiestadiabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiesta
diabetes manifiestadiabetes manifiesta
LD2
5.8. Algunos ejemplos
Nota de R 29 En la seccion ?? tenemos una descripcion de los mismos. Realiza-mos un analisis discriminante en donde a partir de las caracterısticas morfologicaspretendemos saber si es una abeja reina o bien es una obrera.
library(MASS)
x <- read.table(file = "../data/wasp.dat", header = T)
attach(x)
Aplicamos un analisis discriminante lineal y mostramos los histogramas de lavariable discriminante canonica.
z <- lda(caste ~ TL + WL + HH + HW + TH + TW + G1L + G2Wa, prior = c(1, 1)/2)
plot(z)
100
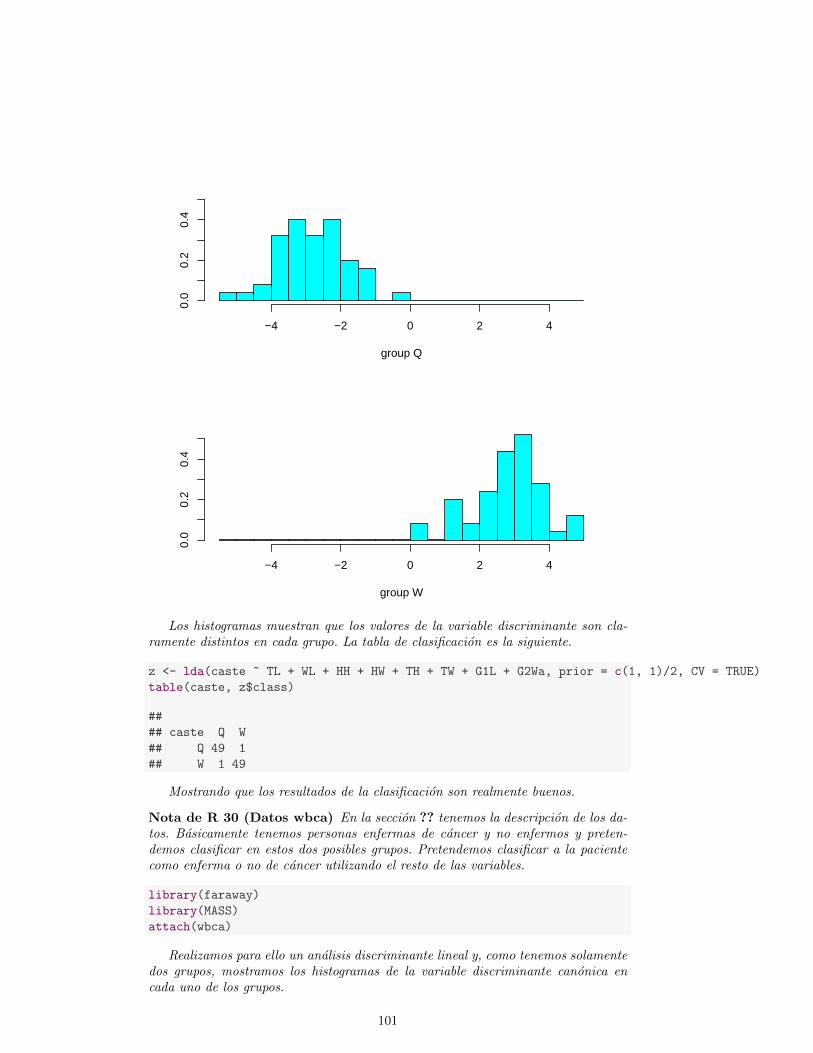
−4 −2 0 2 4
0.0
0.2
0.4
group Q
−4 −2 0 2 4
0.0
0.2
0.4
group W
Los histogramas muestran que los valores de la variable discriminante son cla-ramente distintos en cada grupo. La tabla de clasificacion es la siguiente.
z <- lda(caste ~ TL + WL + HH + HW + TH + TW + G1L + G2Wa, prior = c(1, 1)/2, CV = TRUE)
table(caste, z$class)
##
## caste Q W
## Q 49 1
## W 1 49
Mostrando que los resultados de la clasificacion son realmente buenos.
Nota de R 30 (Datos wbca) En la seccion ?? tenemos la descripcion de los da-tos. Basicamente tenemos personas enfermas de cancer y no enfermos y preten-demos clasificar en estos dos posibles grupos. Pretendemos clasificar a la pacientecomo enferma o no de cancer utilizando el resto de las variables.
library(faraway)
library(MASS)
attach(wbca)
Realizamos para ello un analisis discriminante lineal y, como tenemos solamentedos grupos, mostramos los histogramas de la variable discriminante canonica encada uno de los grupos.
101
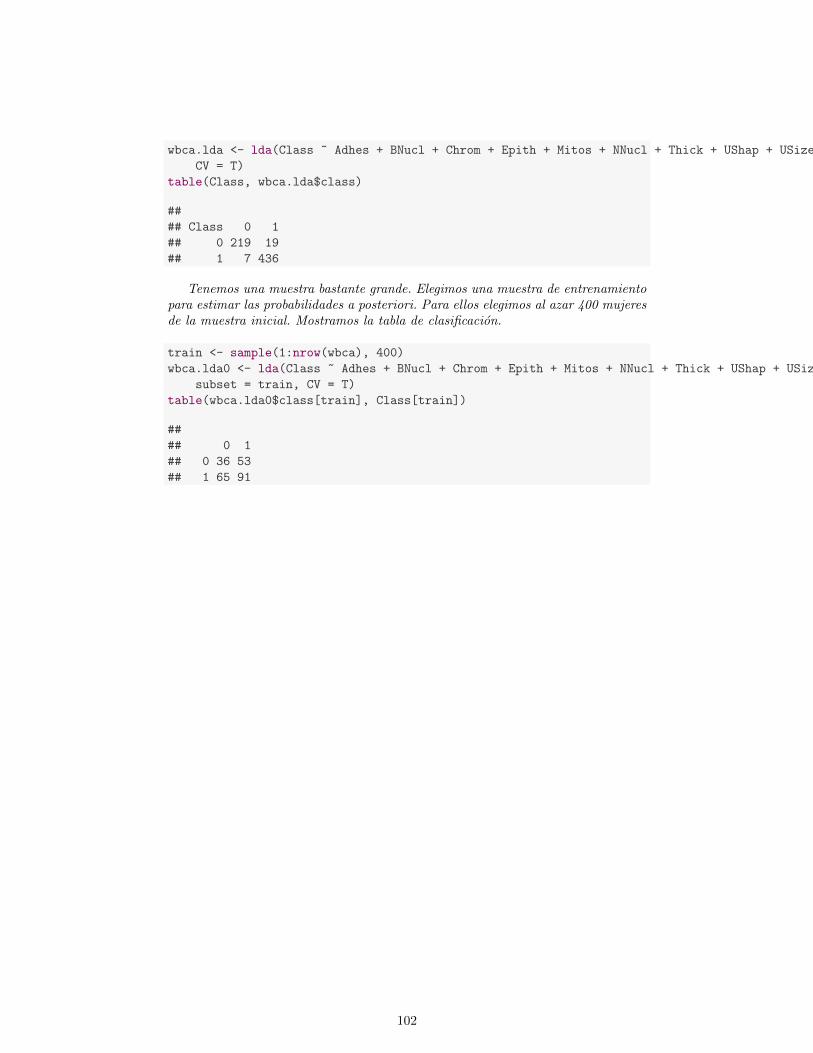
wbca.lda <- lda(Class ~ Adhes + BNucl + Chrom + Epith + Mitos + NNucl + Thick + UShap + USize,
CV = T)
table(Class, wbca.lda$class)
##
## Class 0 1
## 0 219 19
## 1 7 436
Tenemos una muestra bastante grande. Elegimos una muestra de entrenamientopara estimar las probabilidades a posteriori. Para ellos elegimos al azar 400 mujeresde la muestra inicial. Mostramos la tabla de clasificacion.
train <- sample(1:nrow(wbca), 400)
wbca.lda0 <- lda(Class ~ Adhes + BNucl + Chrom + Epith + Mitos + NNucl + Thick + UShap + USize,
subset = train, CV = T)
table(wbca.lda0$class[train], Class[train])
##
## 0 1
## 0 36 53
## 1 65 91
102

Capıtulo 6
Regresion
El problema que se trata en este tema es basico. Estudiar relaciones entre unavariable que llamaremos variable respuesta y una (o mas de una) variable que lla-maremos variables predictoras. Tambien se utilizan las denominaciones de variabledependiente para la variable respuesta y variables independientes en lugar en pre-dictoras.
Si denotamos a la variable respuesta por Y (al valor observado lo denotaremospor y) y a la variable predictora por X nuestro problema es intentar conocer el valorde Y cuando conocemos el valor de la variable X.
Nota de R 31 (notaR100) El primer conjunto de datos fueron publicados porFisher[Fisher, 1947]. El fichero contiene tres variables correspondientes al peso delcorazon, el peso del cuerpo y el sexo de una muestra de gatos. Tenemos 47 hembrasy de 97 machos.
library(MASS)
attach(cats)
names(cats)
Empezamos representando el peso del corazon frente al peso del cuerpo para lashembras.
plot(Bwt[Sex == "F"], Hwt[Sex == "F"])
103
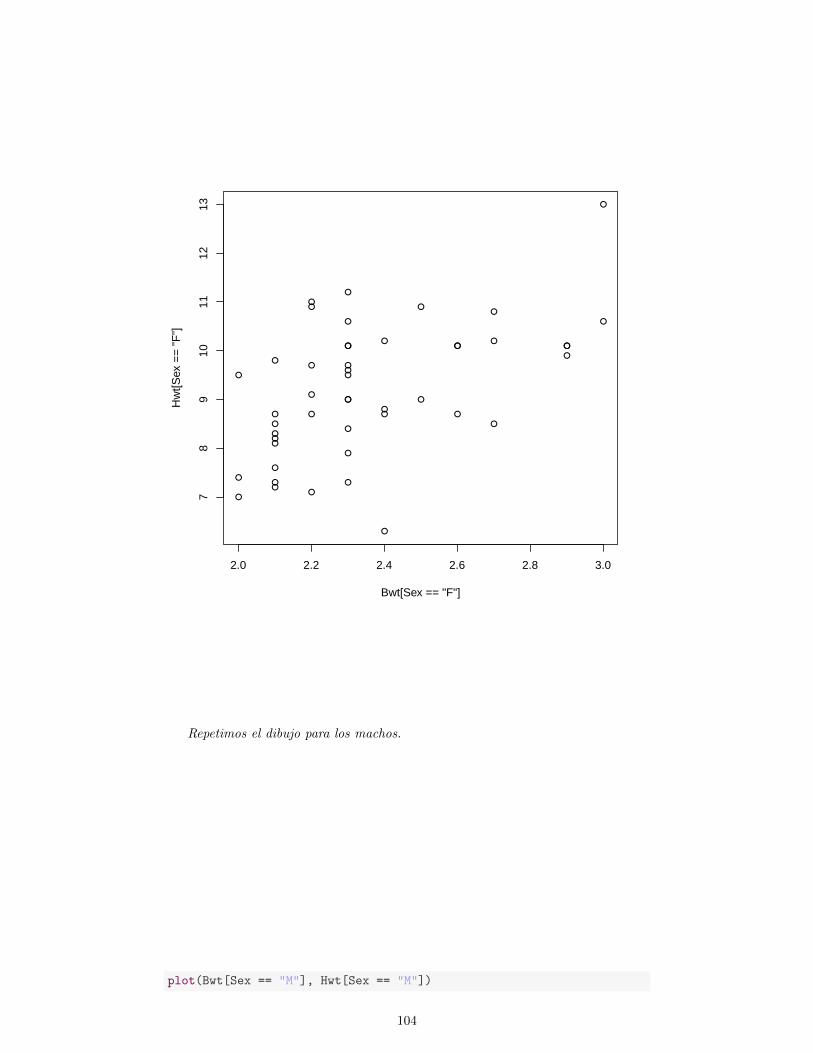
2.0 2.2 2.4 2.6 2.8 3.0
78
910
1112
13
Bwt[Sex == "F"]
Hw
t[Sex
==
"F
"]
Repetimos el dibujo para los machos.
plot(Bwt[Sex == "M"], Hwt[Sex == "M"])
104
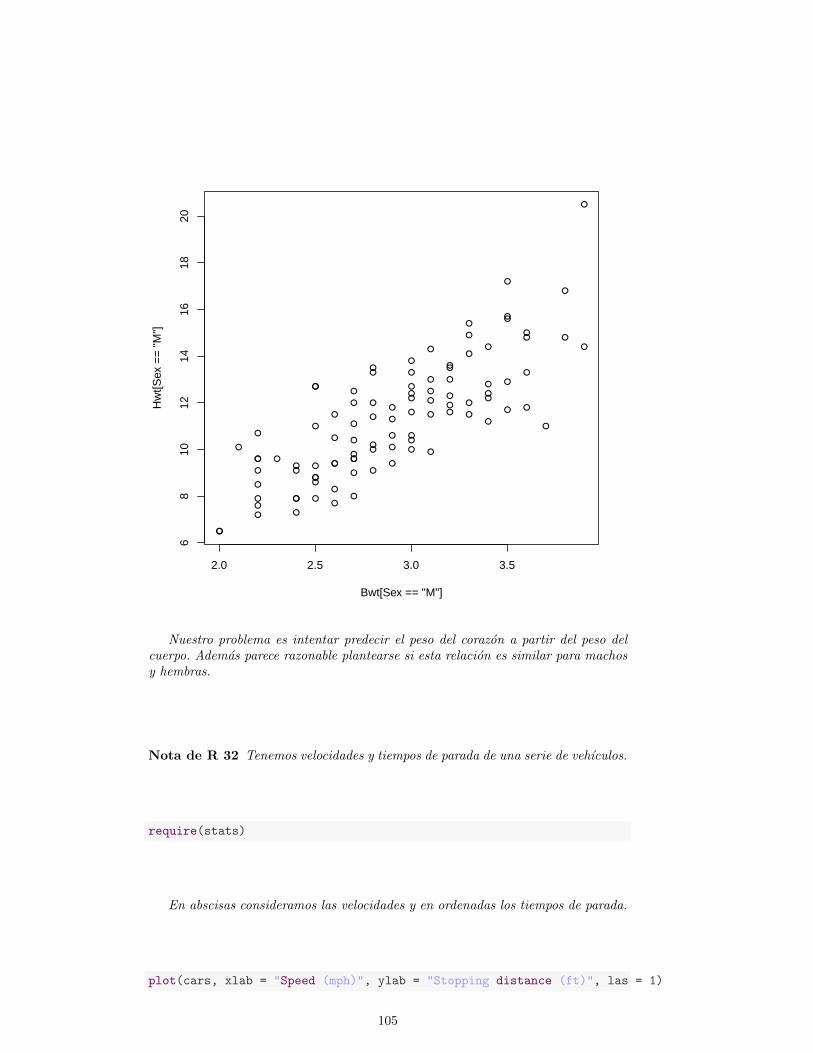
2.0 2.5 3.0 3.5
68
1012
1416
1820
Bwt[Sex == "M"]
Hw
t[Sex
==
"M
"]
Nuestro problema es intentar predecir el peso del corazon a partir del peso delcuerpo. Ademas parece razonable plantearse si esta relacion es similar para machosy hembras.
Nota de R 32 Tenemos velocidades y tiempos de parada de una serie de vehıculos.
require(stats)
En abscisas consideramos las velocidades y en ordenadas los tiempos de parada.
plot(cars, xlab = "Speed (mph)", ylab = "Stopping distance (ft)", las = 1)
105
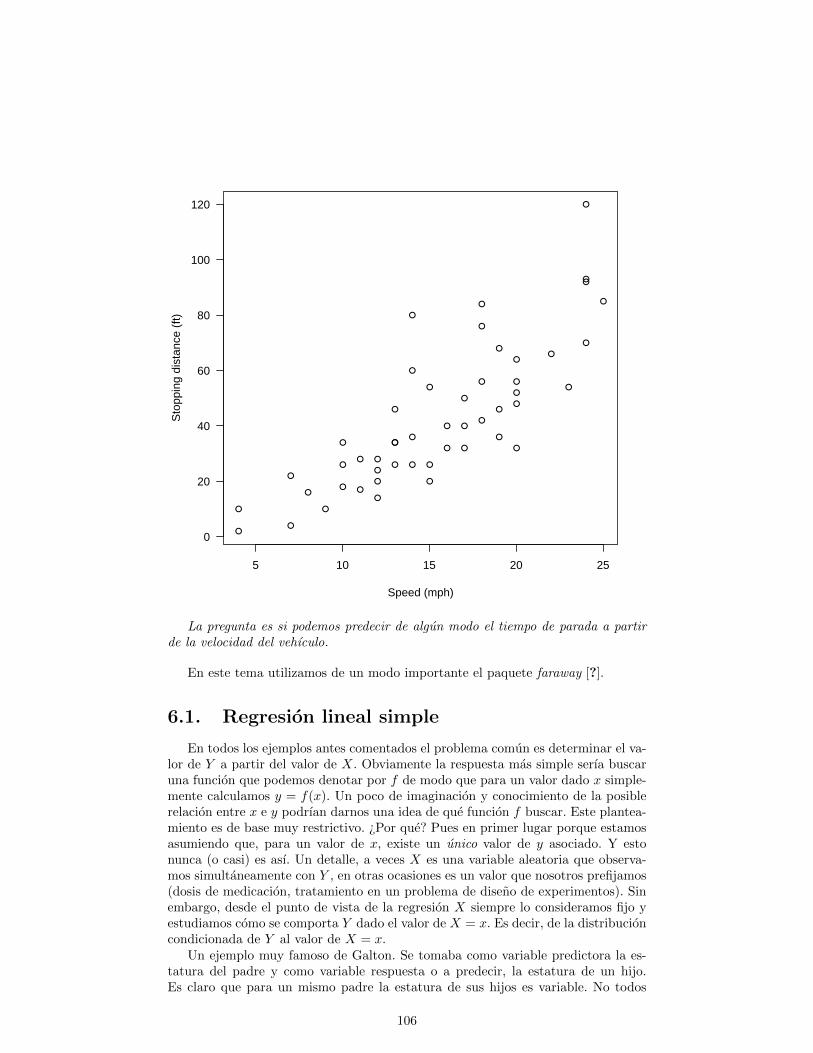
5 10 15 20 25
0
20
40
60
80
100
120
Speed (mph)
Sto
ppin
g di
stan
ce (
ft)
La pregunta es si podemos predecir de algun modo el tiempo de parada a partirde la velocidad del vehıculo.
En este tema utilizamos de un modo importante el paquete faraway [?].
6.1. Regresion lineal simple
En todos los ejemplos antes comentados el problema comun es determinar el va-lor de Y a partir del valor de X. Obviamente la respuesta mas simple serıa buscaruna funcion que podemos denotar por f de modo que para un valor dado x simple-mente calculamos y = f(x). Un poco de imaginacion y conocimiento de la posiblerelacion entre x e y podrıan darnos una idea de que funcion f buscar. Este plantea-miento es de base muy restrictivo. ¿Por que? Pues en primer lugar porque estamosasumiendo que, para un valor de x, existe un unico valor de y asociado. Y estonunca (o casi) es ası. Un detalle, a veces X es una variable aleatoria que observa-mos simultaneamente con Y , en otras ocasiones es un valor que nosotros prefijamos(dosis de medicacion, tratamiento en un problema de diseno de experimentos). Sinembargo, desde el punto de vista de la regresion X siempre lo consideramos fijo yestudiamos como se comporta Y dado el valor de X = x. Es decir, de la distribucioncondicionada de Y al valor de X = x.
Un ejemplo muy famoso de Galton. Se tomaba como variable predictora la es-tatura del padre y como variable respuesta o a predecir, la estatura de un hijo.Es claro que para un mismo padre la estatura de sus hijos es variable. No todos
106

los hijos de un mismo padre miden lo mismo. No tiene ningun sentido asumir unarelacion funcional entre la estatura de un padre y la de un hijo.
Tan tontos no son los estadısticos (que no estadistas). De hecho, lo que se mode-liza es la relacion entre el valor x y el valor medio de la variable Y dado ese valor x.Siguiendo con el ejemplo de Galton. Si consideramos un padre de estatura X = 178centımetros. Supondremos que la media de la variable Y que nos da la estaturaaleatoria de un hijo es la que se relaciona con x. Denotemos por E[Y | x] esta media(estatura media de todos los hijos de un padre con estatura 178 centımetros). He-mos de admitir que ademas de lo que mide el padre, algo tendra que decir la madre,y tambien otros muchos factores que todos podemos imaginar. De modo que Y ,conocida la estatura del padre, sigue siendo una cantidad aleatoria. De hecho, seasume que la distribucion de Y es normal cuya media depende de Y , E[Y | x], perocuya varianza no depende de x, es decir, es una cantidad constante que denotaremospor σ2. En resumen, estamos asumiendo que
Y ∼ N(E[Y | x], σ2). (6.1)
En el modelo de regresion mas simple con el que se trabaja se asume que la mediacondicionada E[Y | x] es una funcion lineal de x, en otras palabras, se asume que
E[Y | x] = β0 + β1x. (6.2)
Las hipotesis asumidas en 6.1 y 6.2, podemos expresarlas conjuntamente diciendoque la variable respuesta Y se puede expresar como
Y = β0 + β1x+ ε, (6.3)
dondeε ∼ N(0, σ2). (6.4)
En la formulacion de 6.3 expresamos el valor aleatorio de Y como suma de unaparte que sistematicamente depende de x (la componente sistematica del modelo)y un termino aleatorio con distribucion normal, un termino de error o desajuste delmodelo. En esta variable normal con media cero y varianza constante σ2 estamosincluyendo todas las posibles causas que influyen el valor de Y y que no vienendadas por la variable predictora.
No consideramos un solo valor aleatorio de Y dado un valor fijo de x. Realmente,tenemos n valores observados cuyos valores son independientes entre sı pero notienen la misma distribucion. Hemos de pensar que cad a Yi tiene una variablepredictora distinta que influye en la distribucion de Yi. Tenemos pares (xi, Yi) dondela xi viene dada y consideramos la distribucion de Yi condicionada a xi, es decir,Yi | xi.
Resumiendo, estamos asumiendo que Yi ∼ N(β0+β1xi, σ2) y que los distintos Yi
son independientes entre si. Utilizando propiedades de la distribucion normal multi-variante tenemos que estas hipotesis las podemos expresar conjuntamente diciendoque
Y ∼ Nn(Xβ, σ2In×n), (6.5)
donde
Y =
Y1
...Yn
X =
1 x1
......
1 xn
β =
[β0
β1
]Si consideramos que
ε =
ε1...εn
107

donde los εi ∼ N(0, σ2) e independientes entre si. Entonces el modelo dado en 6.5lo podemos reescribir como
Y = Xβ + ε, (6.6)
con ε ∼ Nn(0, σ2In×n).Este modelo probabilıstico es conocido como el modelo de regresion lineal
simple. No lo estudiaremos en mas detalle porque nos vamos a ocupar de la situa-cion mas general en que tenemos mas de una variable predictora. No es mas queun caso particular y sin mucha dificultad adicional se puede estudiar el situaciongeneral de regresion lineal multiple.
6.2. Regresion lineal multiple
Pretendemos determinar la relacion que liga a una variable respuesta Y comofuncion de p− 1 variables predictoras, x1, . . . , xp−1. Siguiendo el razonamiento an-terior podemos plantearnos un modelo muy general como el que sigue.
Y = f(x1, . . . , xn) + ε, (6.7)
donde f es una funcion desconocida y ε es el termino del error. Vamos a asumiruna situacion mas simple. En concreto que la funcion f es lineal de modo que larelacion serıa Y = β0 + β1x1 + . . . + βp−1xp−1. Realmente observamos n vectores(yi, xi1, . . . , xi,p−1) en consecuencia nuestro modelo estocastico ha de considerar elmodelo para los n valores aleatorios Yi, donde cada Yi tiene asociado un vector xi.Vamos a suponer que para una combinacion de valores (xi1, . . . , xi,p−1) vamos aobservar un valor aleatorio Yi con distribucion normal cuya media es β0 + β1xi1 +. . .+βp−1xi,p−1 y cuya varianza va a ser constante e igual a σ2. Ademas los distintosYi son independientes entre si.
Vamos a formular conjuntamente estas hipotesis. Denotaremos
Y =
Y1
...Yn
X =
1 x11 . . . x1,p−1
......
...1 xn1 . . . xn,p−1
β =
β0
β1
...βp−1
ε =
ε1...εn
El modelo estocastico basico es el que sigue
Y = Xβ + ε. (6.8)
En este modelo a Xβ le llamaremos la parte sistematica mientras que ε es la com-ponente aleatoria del modelo. Estamos expresando los datos como la suma de unaparte sistematica mas una parte aleatoria. La parte sistematica es la media del vec-tor Y . Notemos que la dimension del espacio en que estamos trabajando es n, elnumero de observaciones. El vector de medias o parte sistematica del modelo tienedimension p por lo que la parte no explicada, el residuo, tiene dimension n− p.
6.3. Estimacion de β
¿Como estimamos los parametros β? Nuestros datos son (yi, xi1, . . . , xi,p−1)con i = 1, . . . , n. Nuestro objetivo es estimar los coeficientes β de modo que Xβeste proximo a y. En concreto vamos a minimizar
n∑i=1
ε2i = ε′ε = (y −Xβ)′(y −Xβ). (6.9)
108

Espacio
engendrado
por X
yResiduo
Valor ajustado
Figura 6.1: Expresamos la observacion y como suma ortogonal de una parte sis-tematica mas un residuo.
Si desarrollamos la expresion anterior tendremos que
(y −Xβ)′(y −Xβ) = y′y − 2β′X ′y + +β′X ′Xβ.
Diferenciando respecto de los distintos βj e igualando a cero nos da el siguientesistema de ecuaciones normales:
X ′Xβ = X ′y. (6.10)
Si asumimos que la matriz X ′X es una matriz no singular entonces tendremos que
β = (X ′X)−1X ′y, (6.11)
y en consecuencia se sigue que
Xβ = X(X ′X)−1X ′y = Hy. (6.12)
La matriz H = X(X ′X)−1X ′y = Hy es la matriz de proyeccion de y sobre elespacio engendrado por los p vectores columna de la matriz X. Es una matriz n×n.
Utilizando la matriz H podemos calcular las predicciones para cada una de losxi originales. Vienen dadas por
y = Hy = Xβ. (6.13)
Tambien tenemos los residuos, esto es, las diferencias entre los valores observadosoriginalmente y las predicciones que de ellos hacemos. Los residuos en terminos dela matriz H vienen dados por
ε = y −Hy = (I −H)y. (6.14)
Finalmente, hemos determinado los coeficientes que nos minimizaban la suma decuadrados. El valor mınimo que hemos obtenido que recibe el nombre de suma decuadrados residual o suma de cuadrados del error que viene dada por
SS(Error) =
n∑i=1
(yi − yi)2, (6.15)
y serıa, como funcion de la matriz H,
ε′ε = y′(I −H)(I −H)y = y′(I −H)y. (6.16)
109

Veamos una interpretacion geometrica que nos ayude a entender que son los estima-dores mınimo cuadraticos que utilizamos. Estamos minimizando (y−Xβ)′(y−Xβ).Si vemos la figura 6.1 el valor de β que nos da el mınimo coincide con el punto quenos da la proyeccion ortogonal de y sobre el plano que viene engendrado por lascolumnas de la matriz X. De este modo es claro que
(y − y1n)′(y − y1n) = (y −Xβ)′(y −Xβ) + (y − y1n)′(y − y1n). (6.17)
o de otro modo la ecuacion anterior la podemos expresar comon∑i=1
(yi − y)2 =
n∑i=1
(yi − yi)2 +
n∑i=1
(yi − y)2. (6.18)
Las sumas de cuadrados que acabamos de considerar reciben la siguiente denomi-nacion:
Suma de cuadrados total
SS(Total) = (y − y1n)′(y − y1n) =
n∑i=1
(yi − y)2. (6.19)
Suma de cuadrados del error
SS(Error) = (y −Xβ)′(y −Xβ) =
n∑i=1
(yi − yi)2. (6.20)
Suma de cuadrados de la regresion
SS(Regresion) = (y − y1n)′(y − y1n) =
n∑i=1
(yi − y)2. (6.21)
6.4. Algunos casos particulares
Supongamos en primer lugar la situacion en que no tenemos ningun predictor.Esto es, nuestro modelo es Y = µ+ ε. En este caso se tiene que la matriz de disenoX = 1n = (1, . . . , 1)′, X ′X = n y, finalmente, β = (X ′X)−1X ′y = 1
n1′ny = y.El segundo ejemplo que podemos considerar serıa con una sola variable pre-
dictora o lo que es lo mismo, el modelo de regresion lineal simple. En este caso,tendremos Y1
...Yn
=
1 x1
......
1 xn
[β0
β1
]+
ε1...εn
Notemos que podemos hacer Yi = β0 + β1x + β1(xi − x) + εi. Nuestra matriz dediseno serıa
X =
1 x1 − x...
...1 xn − x
con
X ′X =
[n 00∑ni=1(xi − x)2
]Finalmente se comprueba sin dificultad que
β =
∑ni=1(xi − x)yi∑ni=1(xi − x)2
(6.22)
110

6.5. Verosimilitud
Dados los datos (xi, yi) con i = 1, . . . , n la verosimilitud de y = (y1, . . . , yn)′
vendrıa dada por
L(β, σ) =1
(2π)n2 σn
exp− 1
2σ2(y −Xβ)′(y −Xβ) (6.23)
y la logverosimilitud serıa
l(β, σ) =n
2log(2π)− n log σ − 1
2σ2(y −Xβ)′(y −Xβ). (6.24)
El estimador maximo verosımil de β se obtiene maximizando cualquiera de las dosfunciones anteriores. Es obvio que el maximo respecto de β se obtiene como elvalor que minimiza (y −Xβ)′(y −Xβ), en definitiva, que los estimadores maximoverosımiles no son mas que los estimadores mınimo cuadraticos.
6.6. Algunos ejemplos
Nota de R 33 (Un ejemplo de regresion lineal simple) En este banco de da-tos (Orange) tenemos la variable predictora que nos da la edad del arbol y comovariable respuesta la circunferencia del arbol.
Obtenemos el ajuste de regresion lineal simple con la funcion lm. La salida basicaque produce nos muestra los estimadores mınimo cuadraticos de los coeficientes β.Vemos tambien como obtener las predicciones y los residuos observados. Finalmentemostramos los residuos frente a las predicciones de los valores. En principio, bajola hipotesis de que el error tiene varianza constante no debieramos de observarresiduos mayores cuando las predicciones son mayores. En este caso parece que esesto lo que observamos. Leemos los datos.
data(Orange)
attach(Orange)
Representamos en abscisas la edad y en ordenadas el numero de anillos. Ajus-tamos el modelo de regresion lineal simple y anadimos la recta de regresion a losdatos.
plot(age, circumference)
lm(circumference ~ age, data = Orange)
##
## Call:
## lm(formula = circumference ~ age, data = Orange)
##
## Coefficients:
## (Intercept) age
## 17.400 0.107
abline(lm(circumference ~ age, data = Orange))
111

500 1000 1500
5010
015
020
0
age
circ
umfe
renc
e
Vamos a explorar la informacion que podemos obtener del ajuste.
orange.lm <- lm(circumference ~ age, data = Orange)
attributes(orange.lm)
## $names
## [1] "coefficients" "residuals" "effects" "rank" "fitted.values"
## [6] "assign" "qr" "df.residual" "xlevels" "call"
## [11] "terms" "model"
##
## $class
## [1] "lm"
Los valores ajustados o predicciones los obtenemos con
orange.lm$fitted.values
## 1 2 3 4 5 6 7 8 9 10 11 12
## 30.00 69.08 88.30 124.60 148.83 163.89 186.31 30.00 69.08 88.30 124.60 148.83
## 13 14 15 16 17 18 19 20 21 22 23 24
## 163.89 186.31 30.00 69.08 88.30 124.60 148.83 163.89 186.31 30.00 69.08 88.30
## 25 26 27 28 29 30 31 32 33 34 35
## 124.60 148.83 163.89 186.31 30.00 69.08 88.30 124.60 148.83 163.89 186.31
Y los residuos observados se obtiene con
112

orange.lm$residuals
## 1 2 3 4 5 6 7 8
## 0.001451 -11.076488 -1.295146 -9.597057 -28.833920 -21.888536 -41.310304 3.001451
## 9 10 11 12 13 14 15 16
## -0.076488 22.704854 31.402943 23.166080 39.111464 16.689696 0.001451 -18.076488
## 17 18 19 20 21 22 23 24
## -13.295146 -16.597057 -33.833920 -24.888536 -46.310304 2.001451 -7.076488 23.704854
## 25 26 27 28 29 30 31 32
## 42.402943 30.166080 45.111464 27.689696 0.001451 -20.076488 -7.295146 0.402943
## 33 34 35
## -6.833920 10.111464 -9.310304
Nota de R 34 (Precio de la vivienda) Vamos a trabajar con un banco de datosrelativo a precios de la vivienda. Es un fichero que viene con el paquete SPSS.Tenemos las siguientes variables:
VALTERR Valor de tasacion del terreno.
VALMEJOR Valor de tasacion de las mejoras.
VALTOT Valor de tasacion total.
PRECIO Precio de venta.
TASA Razon del precio de venta sobre el valor de tasacion total.
BARRIO Barrio en el que se encuentra la vivienda.
Nos planteamos predecir el precio de venta de la vivienda utilizando como variablespredictoras el valor de tasacion del terreno y de las mejoras. Notemos que el valortotal no es mas que la suma de la tasacion del terreno mas el valor de las mejo-ras. Comenzamos leyendo los datos. Notemos que por estar en formato de SPSSutilizamos el paquete foreign ?.
library(foreign)
x <- read.spss(file = "../data/venta_casas.sav", to.data.frame = T)
attach(x)
Nos planteamos predecir el precio de la vivienda utilizando como variables pre-dictoras el precio de terreno y el valor de las mejoras.
(casas.lm <- lm(precio ~ valterr + valmejor))
##
## Call:
## lm(formula = precio ~ valterr + valmejor)
##
## Coefficients:
## (Intercept) valterr valmejor
## 767.408 3.192 0.478
113

6.7. Distribucion muestral de β
Hemos visto que β = (X ′X)−1X ′Y . Aplicando propiedades simples de la mediatenemos que
Eβ = (X ′X)−1X ′(EY ) = β, (6.25)
o, lo que es lo mismo, que β es un estimador insesgado de β, el estimador tienepor vector de medias el vector de parametros que estima. Es una buena propiedad.La matriz de covarianzas del error se obtiene facilmente como
var(β) = (X ′X)−1X ′(σ2I)X(X ′X)−1 = (X ′X)−1σ2. (6.26)
Esta matriz de covarianzas depende de la varianza desconocida del error σ2. Siestimamos esta varianza tendremos un estimador de dicha matriz de covarianzas.Se puede probar que
E[SS(Error)] = (n− p)σ2 (6.27)
de donde, un estimador insesgado para la varianza σ2 viene dado por
σ2 =ε′ε
n− p. (6.28)
Ya podemos estimar var(β). Este estimador serıa
var(β) = (X ′X)−1σ2. (6.29)
Si (X ′X)−1 = [aij ]i,j=1,...,p entonces el estimador de la varianza de βi, var(βi), serıa
aiiσ2. Recordemos que βi es un estimador insesgado de βi y por lo tanto su varianza
coincide con su error cuadratico medio. Finalmente el error estandar de βi, es decir,su desviacion tıpica (raız cuadrada de su varianza) serıa
SE(βi) =√aiiσ. (6.30)
Realmente de β sabemos mas cosas: β = (X ′X)−1X ′Y y puesto que Y ∼Nn(Xβ, σ2In×n) entonces, por propiedades basicas de la distribucion normal mul-tivariante (ver apartado 1.4) se tiene que
β ∼ Np(β, (X ′X)−1σ2). (6.31)
Nota de R 35 Una vez realizado el ajuste con la funcion summary podemos ob-servar los valores estimados de σ (etiquetado como Residual standard error y los
errores estandar de βi.Veamos el resumen basico del ajuste de regresion donde la respuesta es el precio
de la vivienda y los predictores son el valor del terreno y el valor de las mejoras.
summary(casas.lm)
##
## Call:
## lm(formula = precio ~ valterr + valmejor)
##
## Residuals:
## Min 1Q Median 3Q Max
## -153634 -10451 -576 8690 356418
##
## Coefficients:
114

## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 7.67e+02 1.29e+03 0.59 0.55
## valterr 3.19e+00 5.34e-02 59.78 <2e-16 ***
## valmejor 4.78e-01 2.55e-02 18.73 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 28100 on 2437 degrees of freedom
## Multiple R-squared: 0.676,Adjusted R-squared: 0.675
## F-statistic: 2.54e+03 on 2 and 2437 DF, p-value: <2e-16
6.8. Bondad de ajuste
Hemos supuesto una relacion lineal entre la media de la variable respuesta y lasvariables predictoras. Asumiendo la relacion hemos considerado una funcion objeti-vo y minimizando dicha funcion hemos obtenido los estimadores mınimo cuadrati-cos. Sin embargo, la primera pregunta que hay que responder es: ¿tenemos un ajusterazonable? La respuesta se da utilizando medidas que comparan los valores observa-dos con las predicciones asumiendo el modelo, es decir, comparando yi con yi paralos distintos datos. En concreto, con diferencia la mas utilizada es el coeficientede determinacion que se denota por R2 y se define como
R2 = 1−∑ni=1(yi − yi)2∑ni=1(yi − yi)2
= 1− SS(Error)
SS(Total). (6.32)
Es habitual denominar a∑ni=1(yi− yi)2, suma de cuadrados del error mientras
que a SS(Regresion) =∑ni=1(yi − y)2 se le llama suma de cuadrados de la
regresion. Tenemos pues que
R2 =
∑ni=1(yi − y)2∑ni=1(yi − yi)2
=SS(Regresion)
SS(Total). (6.33)
El ajuste que estamos realizando se supone que sera tanto mejor cuanto mas pe-quena sea SS(Error). Tampoco serıa natural que SS(Error) fuera nula pues serıatanto como asumir que los distintos valores aleatorios son iguales a su media. No-temos que SS(Total) es una cuantificacion de la variabilidad de los distintos yi sintener en cuenta las variables predictoras mientras que SS(Error) nos cuantifica lavariacion residual despues de utilizar las variables predictoras. Es de esperar queun mejor ajuste vaya acompanado de un valor de SS(Error) pequeno en relacioncon SS(Total). Esa es la idea del coeficiente de determinacion. Toma valores entre0 y 1 y cuanto mas cerca de 1 mejor es el ajuste.
Tiene un pequeno inconveniente y es que no tiene en cuenta el numero de va-riables predictoras que estamos utilizando para predecir la variable respuesta. Unapequena modificacion de R2 para incorporar esta informacion es el coeficiente dedeterminacion ajustado que podemos denotar R2-ajustado y se define como
R2 − ajustado = 1−∑ni=1(yi − yi)2/(n− p)∑ni=1(yi − y)2/(n− 1)
, (6.34)
donde suponemos que tenemos p− 1 variables predictoras.
115

6.9. Valoracion de las hipotesis del modelo
Un modelo de regresion lineal multiple supone, como hemos visto, varias hipote-sis. Es necesario valorar lo razonables, lo asumibles que son estas hipotesis. Lashipotesis del modelo que vamos a valorar son las siguientes:
1. ¿Tenemos errores independientes, con la misma varianza y con distribucionnormal? Esto es, nos preguntamos si es asumible la hipotesis ε ∼ Nn(0, σ2In×n).
2. Asumimos que E[Yi | xi] = β0 + β1xi1 + . . .+ βp−1xi,p−1.
Los errores ε no son directamente observables. Observamos los residuos ε = y − yque no es lo mismo. Las propiedades de ambos vectores son distintas. En particular,estamos asumiendo que var(ε) = σ2In×n. Sin embargo, esta afirmacion no es ciertapara los residuos observados ε. Notemos que
y = X(X ′X)−1X ′y = Hy.
De modo que
ε = y − y = (I −H)y = (I −H)Xβ + (I −H)ε = (I −H)ε.
La tercera igualdad anterior es consecuencia de que HXβ = Xβ porque H es lamatriz de proyeccion sobre el espacio engendrado por las columnas de X y Xβesta en este espacio por lo que la proyeccion es el propio punto. Notemos que I−Htambien es una matriz de proyeccion (sobre el espacio ortogonal al engendrado porlas columnas de X) de modo que (I −H)2 = I −H. Aplicando esta propiedad setiene que
var(ε) = var(I −H)ε = (I −H)σ2, (6.35)
ya que var(ε) = σ2In×n. Vemos pues que, aunque asumimos que los errores ε sonincorrelados y con la misma varianza, esto no es cierto para los residuos ε.
Homogeneidad de la varianza
La mera observacion de los residuos sin considerar su posible asociacion conotra variable no nos proporciona informacion sobre si la varianza de los mismoses constante. Hemos de considerarlos en relacion con otras variables. Es habitualconsiderar un diagrama de puntos de los residuos ε como funcion de las prediccionesy. Cuando la varianza es constante debemos de observar los residuos dispersos deun modo aleatorio respecto del eje de abscisas. Tambien podemos ver un compor-tamiento no aleatorio alrededor del eje de abscisas cuando la parte estructural delmodelo no es lineal, es decir, cuando no se verifica que EY = Xβ.
Nota de R 36 Los datos que vamos a utilizar para valorar las hipotesis del modeloson los datos savings contenido en la librerıa faraway (?). Se pretende estudiar larelacion que liga la fraccion de ahorro con la proporcion de poblacion menor de15 anos, mayor de 75 y las variables dpi y ddpi. El siguiente diagrama de puntosmuestra en abscisas las predicciones y en ordenadas los residuos. No parece enprincipio que no podamos asumir una varianza constante. Vemos tambien que nosindica los tres paıses con los residuos mas extremos: Chile, Filipinas y Zambia.
library(faraway)
data(savings)
attach(savings)
Hacemos el ajuste lineal.
116

savings.lm <- lm(sr ~ pop15 + pop75 + dpi + ddpi, savings)
Notemos que elegimos el primer dibujo.
plot(savings.lm, which = 1)
6 8 10 12 14 16
−10
−5
05
10
Fitted values
Res
idua
ls
lm(sr ~ pop15 + pop75 + dpi + ddpi)
Residuals vs Fitted
Zambia
Chile
Philippines
Cuando no tenemos una varianza constante una opcion es transformar las varia-bles. Si y es la variable original y h(y) la transformada queremos determinar h demodo que la transformada tenga varianza constante. Transformaciones habitualesque podemos valorar son la raız cuadrada o el logaritmo de la variable respuesta.
¿Que tipo de representacion cabe esperar cuando la varianza no es constante?Veamos distintas representaciones de los residuos frente a los valores ajustadoscorrespondiendo a varianza constante, varianzas no constantes y situaciones en queno hay linealidad.
Nota de R 37 (Hipotesis del modelo de regresion) Ilustramos como obser-varıamos residuos cuya varianza es constante. En la siguiente figura tenemos 50posibles residuos en donde la varianza es constante.
par(mfrow = c(2, 2))
for (i in 1:4) plot(1:50, rnorm(50))
117

0 10 20 30 40 50
−2
−1
01
1:50
rnor
m(5
0)
0 10 20 30 40 50
−2
−1
01
1:50
rnor
m(5
0)
0 10 20 30 40 50
−2
−1
01
2
1:50
rnor
m(5
0)
0 10 20 30 40 50
−1
01
2
1:50
rnor
m(5
0)
En la siguiente figura tenemos como abscisas valores que van de 1 a 50 enincrementos unitarios. El valor de residuo que generamos tienen varianza creciente.En concreto vamos multiplicando el valor con distribucion N(0, 1) por una constantec. La varianza es del orden del cuadrado del valor por el que multiplicamos.
par(mfrow = c(2, 2))
for (i in 1:4) plot(1:50, (1:50) * rnorm(50))
118
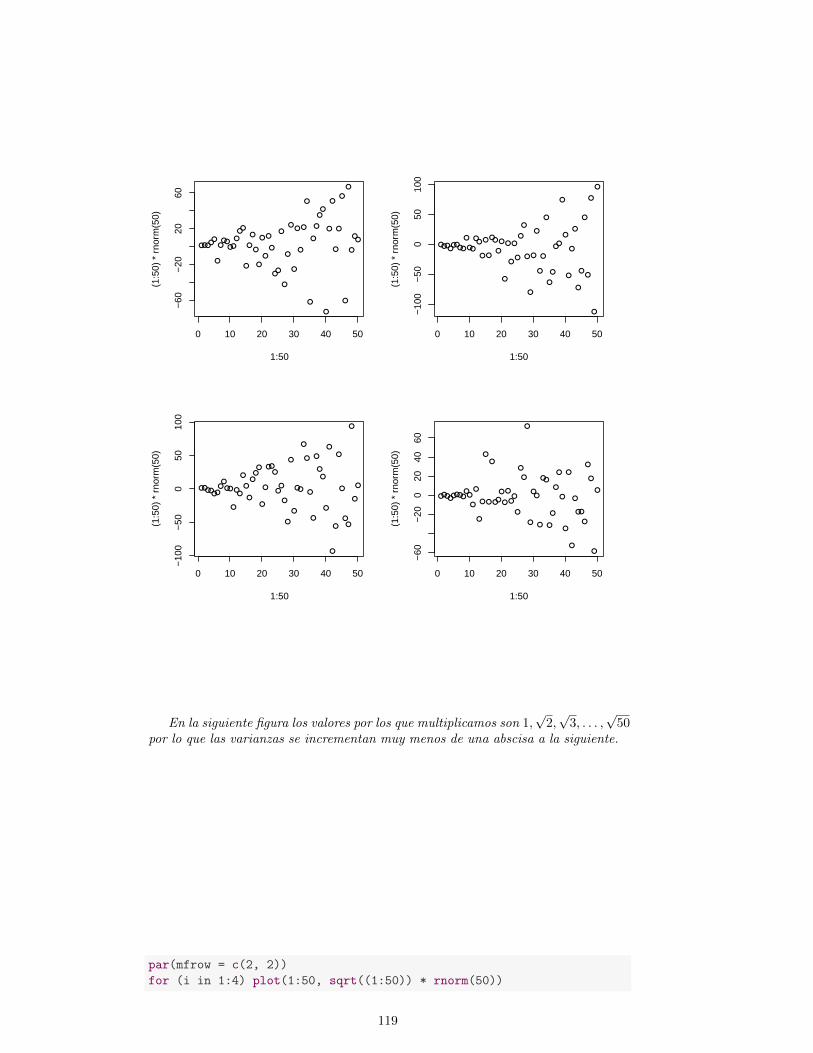
0 10 20 30 40 50
−60
−20
2060
1:50
(1:5
0) *
rno
rm(5
0)
0 10 20 30 40 50
−10
0−
500
5010
0
1:50
(1:5
0) *
rno
rm(5
0)
0 10 20 30 40 50
−10
0−
500
5010
0
1:50
(1:5
0) *
rno
rm(5
0)
0 10 20 30 40 50
−60
−20
020
4060
1:50
(1:5
0) *
rno
rm(5
0)
En la siguiente figura los valores por los que multiplicamos son 1,√
2,√
3, . . . ,√
50por lo que las varianzas se incrementan muy menos de una abscisa a la siguiente.
par(mfrow = c(2, 2))
for (i in 1:4) plot(1:50, sqrt((1:50)) * rnorm(50))
119

0 10 20 30 40 50
−10
−5
05
10
1:50
sqrt
((1:
50))
* r
norm
(50)
0 10 20 30 40 50
−15
−5
05
1015
20
1:50
sqrt
((1:
50))
* r
norm
(50)
0 10 20 30 40 50
−5
05
1015
20
1:50
sqrt
((1:
50))
* r
norm
(50)
0 10 20 30 40 50
−15
−5
05
10
1:50
sqrt
((1:
50))
* r
norm
(50)
Finalmente en la siguiente figura mostramos un ejemplo de un residuo no lineal.Es un caso en que no podemos suponer que la media es una funcion lineal de lospredictores.
par(mfrow = c(2, 2))
for (i in 1:4) plot(1:50, cos((1:50) * pi/25) + rnorm(50))
par(mfrow = c(1, 1))
120

0 10 20 30 40 50
−2
01
23
4
1:50
cos(
(1:5
0) *
pi/2
5) +
rno
rm(5
0)
0 10 20 30 40 50
−3
−2
−1
01
2
1:50
cos(
(1:5
0) *
pi/2
5) +
rno
rm(5
0)
0 10 20 30 40 50
−2
−1
01
2
1:50
cos(
(1:5
0) *
pi/2
5) +
rno
rm(5
0)
0 10 20 30 40 50
−2
−1
01
23
1:50
cos(
(1:5
0) *
pi/2
5) +
rno
rm(5
0)
Normalidad
La siguiente hipotesis a valorar es la normalidad de los errores. La herramientagrafica mas habitual es el dibujo q-q o la representacion cuantil-cuantil. Ordenamoslos residuos y representamos los residuos ordenados en funcion de Φ−1( i
n+1 ) parai = 1, . . . , n. Si los residuos tienen una distribucion normal entonces deben estaralineados. El histograma no es muy adecuado para ver la normalidad de los residuos.
Nota de R 38 (Dibujos cuantil-cuantil) Para los datos savings representamosun dibujo q-q. En la figura que sigue mostramos como hacerlo despues de ajustar elmodelo y utilizando la funcion plot (realmente estamos utilizando plot.lm).
plot(savings.lm, which = 2)
121

−2 −1 0 1 2
−2
−1
01
23
Theoretical Quantiles
Sta
ndar
dize
d re
sidu
als
lm(sr ~ pop15 + pop75 + dpi + ddpi)
Normal Q−Q
Zambia
Chile
Philippines
En la siguiente figura aparece un dibujo q-q utilizando las funciones qqnorm queconstruye el dibujo y qqline que anade una lınea uniendo el primer y tercer cuartil.Como vemos es el mismo dibujo.
qqnorm(residuals(savings.lm), ylab = "Residuos")
qqline(residuals(savings.lm))
122
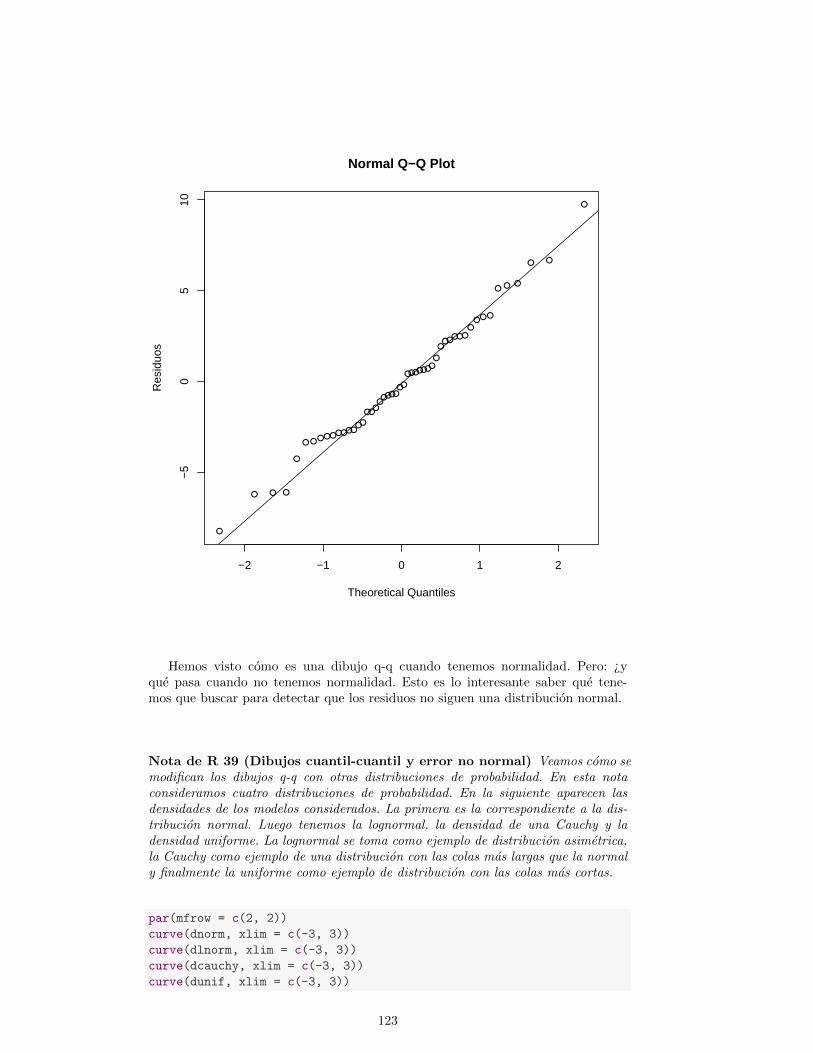
−2 −1 0 1 2
−5
05
10
Normal Q−Q Plot
Theoretical Quantiles
Res
iduo
s
Hemos visto como es una dibujo q-q cuando tenemos normalidad. Pero: ¿yque pasa cuando no tenemos normalidad. Esto es lo interesante saber que tene-mos que buscar para detectar que los residuos no siguen una distribucion normal.
Nota de R 39 (Dibujos cuantil-cuantil y error no normal) Veamos como semodifican los dibujos q-q con otras distribuciones de probabilidad. En esta notaconsideramos cuatro distribuciones de probabilidad. En la siguiente aparecen lasdensidades de los modelos considerados. La primera es la correspondiente a la dis-tribucion normal. Luego tenemos la lognormal, la densidad de una Cauchy y ladensidad uniforme. La lognormal se toma como ejemplo de distribucion asimetrica,la Cauchy como ejemplo de una distribucion con las colas mas largas que la normaly finalmente la uniforme como ejemplo de distribucion con las colas mas cortas.
par(mfrow = c(2, 2))
curve(dnorm, xlim = c(-3, 3))
curve(dlnorm, xlim = c(-3, 3))
curve(dcauchy, xlim = c(-3, 3))
curve(dunif, xlim = c(-3, 3))
123
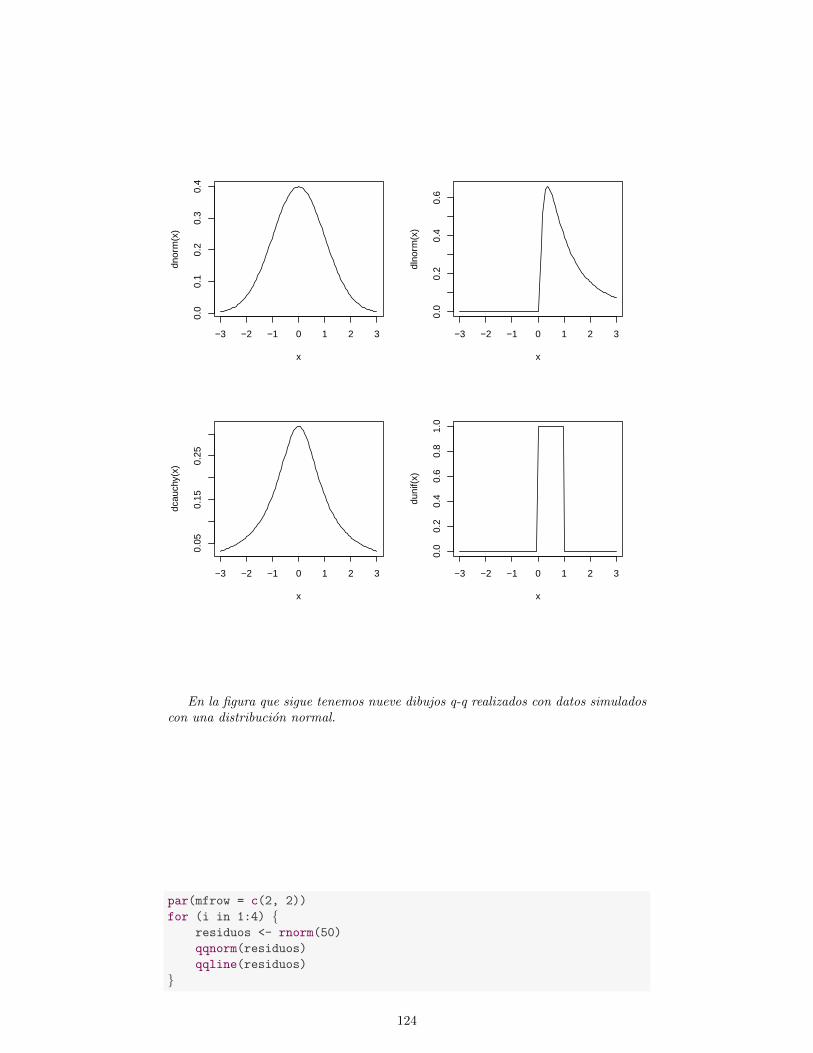
−3 −2 −1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
x
dnor
m(x
)
−3 −2 −1 0 1 2 3
0.0
0.2
0.4
0.6
x
dlno
rm(x
)
−3 −2 −1 0 1 2 3
0.05
0.15
0.25
x
dcau
chy(
x)
−3 −2 −1 0 1 2 3
0.0
0.2
0.4
0.6
0.8
1.0
x
duni
f(x)
En la figura que sigue tenemos nueve dibujos q-q realizados con datos simuladoscon una distribucion normal.
par(mfrow = c(2, 2))
for (i in 1:4) residuos <- rnorm(50)
qqnorm(residuos)
qqline(residuos)
124
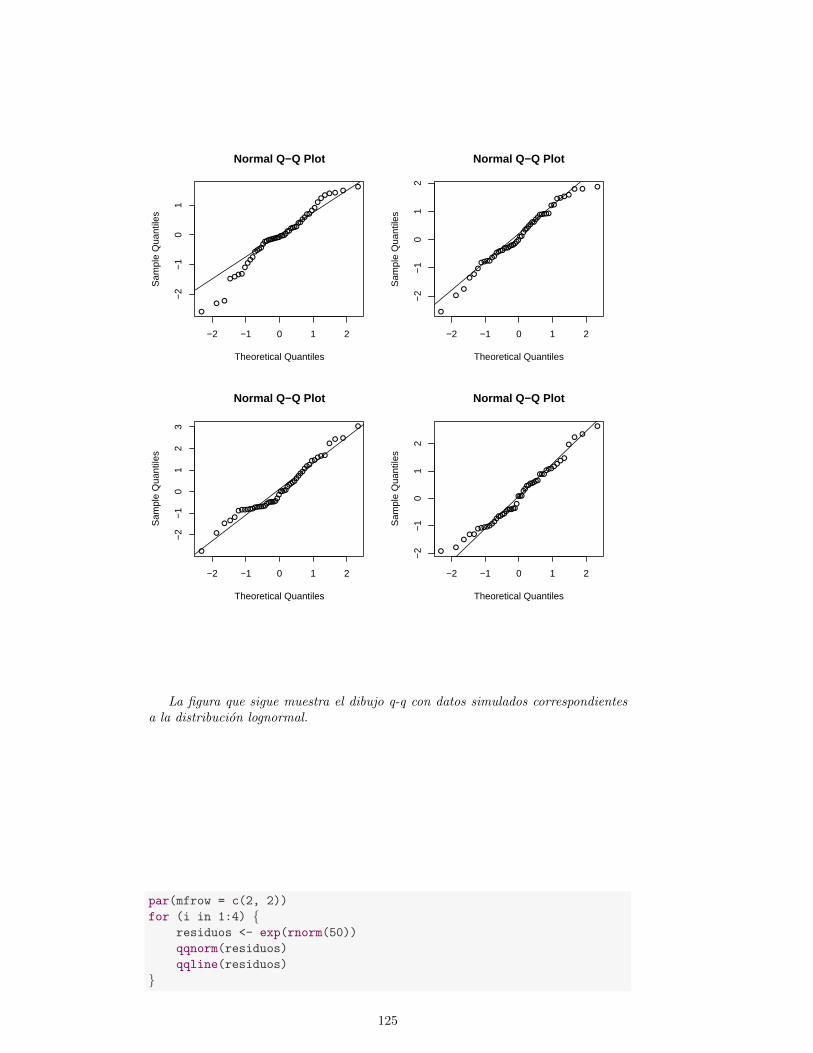
−2 −1 0 1 2
−2
−1
01
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
−2 −1 0 1 2
−2
−1
01
2
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
−2 −1 0 1 2
−2
−1
01
23
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
−2 −1 0 1 2
−2
−1
01
2
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
La figura que sigue muestra el dibujo q-q con datos simulados correspondientesa la distribucion lognormal.
par(mfrow = c(2, 2))
for (i in 1:4) residuos <- exp(rnorm(50))
qqnorm(residuos)
qqline(residuos)
125

−2 −1 0 1 2
01
23
45
6
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
−2 −1 0 1 2
02
46
810
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
−2 −1 0 1 2
05
1015
2025
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
−2 −1 0 1 2
02
46
8
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
La figura que sigue muestra el dibujo q-q con datos simulados correspondientesa la distribucion de Cauchy.
par(mfrow = c(2, 2))
for (i in 1:4) residuos <- rcauchy(50)
qqnorm(residuos)
qqline(residuos)
126
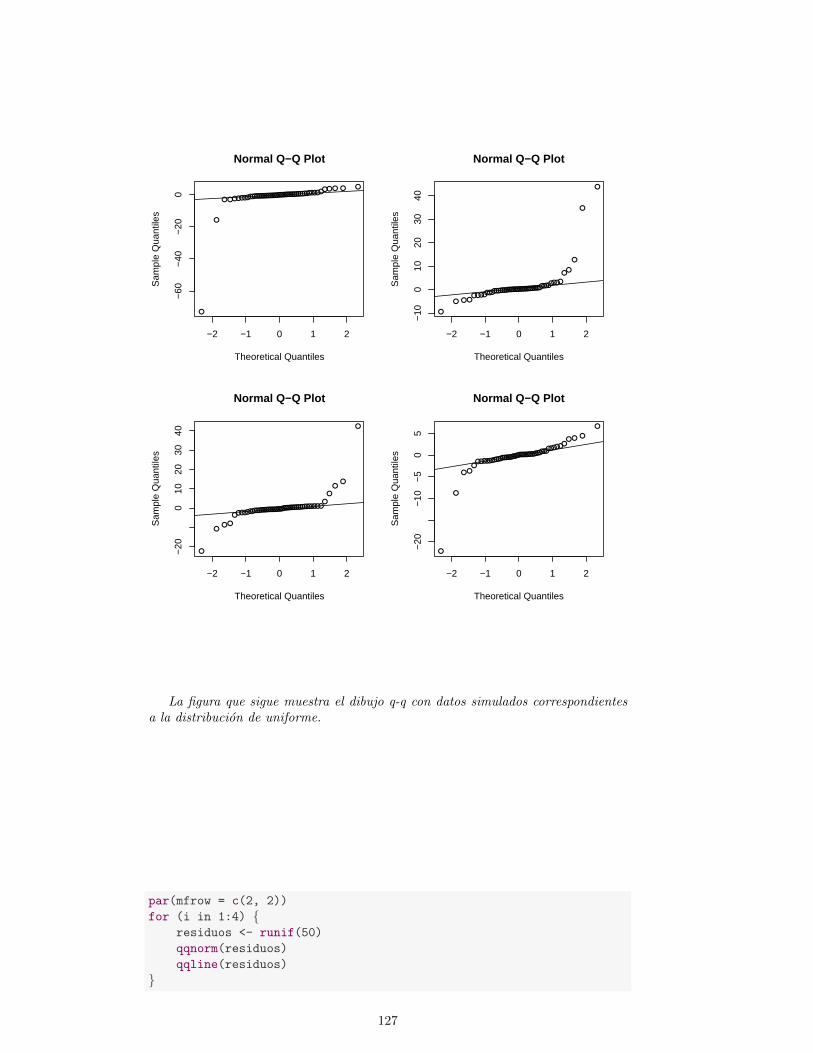
−2 −1 0 1 2
−60
−40
−20
0
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
−2 −1 0 1 2
−10
010
2030
40
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
−2 −1 0 1 2
−20
010
2030
40
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
−2 −1 0 1 2
−20
−10
−5
05
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
La figura que sigue muestra el dibujo q-q con datos simulados correspondientesa la distribucion de uniforme.
par(mfrow = c(2, 2))
for (i in 1:4) residuos <- runif(50)
qqnorm(residuos)
qqline(residuos)
127
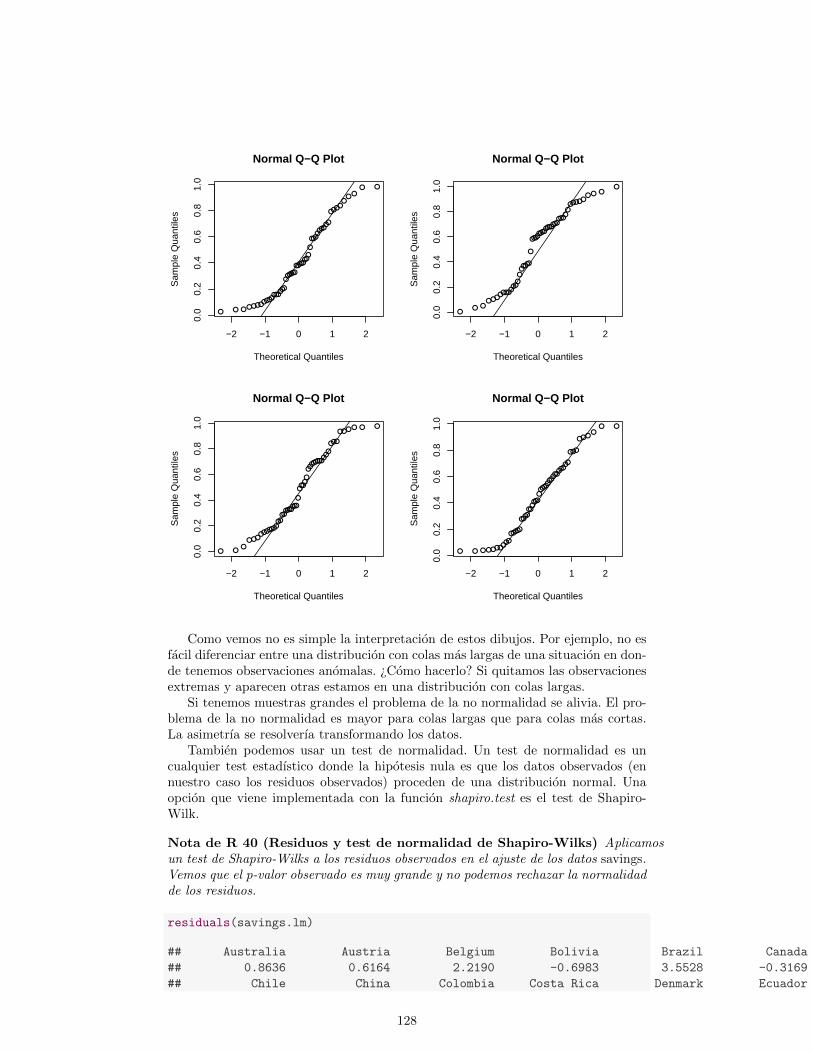
−2 −1 0 1 2
0.0
0.2
0.4
0.6
0.8
1.0
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
−2 −1 0 1 2
0.0
0.2
0.4
0.6
0.8
1.0
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
−2 −1 0 1 2
0.0
0.2
0.4
0.6
0.8
1.0
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
−2 −1 0 1 2
0.0
0.2
0.4
0.6
0.8
1.0
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Como vemos no es simple la interpretacion de estos dibujos. Por ejemplo, no esfacil diferenciar entre una distribucion con colas mas largas de una situacion en don-de tenemos observaciones anomalas. ¿Como hacerlo? Si quitamos las observacionesextremas y aparecen otras estamos en una distribucion con colas largas.
Si tenemos muestras grandes el problema de la no normalidad se alivia. El pro-blema de la no normalidad es mayor para colas largas que para colas mas cortas.La asimetrıa se resolverıa transformando los datos.
Tambien podemos usar un test de normalidad. Un test de normalidad es uncualquier test estadıstico donde la hipotesis nula es que los datos observados (ennuestro caso los residuos observados) proceden de una distribucion normal. Unaopcion que viene implementada con la funcion shapiro.test es el test de Shapiro-Wilk.
Nota de R 40 (Residuos y test de normalidad de Shapiro-Wilks) Aplicamosun test de Shapiro-Wilks a los residuos observados en el ajuste de los datos savings.Vemos que el p-valor observado es muy grande y no podemos rechazar la normalidadde los residuos.
residuals(savings.lm)
## Australia Austria Belgium Bolivia Brazil Canada
## 0.8636 0.6164 2.2190 -0.6983 3.5528 -0.3169
## Chile China Colombia Costa Rica Denmark Ecuador
128

## -8.2422 2.5360 -1.4517 5.1251 5.4002 -2.4056
## Finland France Germany Greece Guatamala Honduras
## -1.6811 2.4755 -0.1807 -3.1162 -3.3553 0.7100
## Iceland India Ireland Italy Japan Korea
## -6.2106 0.5087 3.3911 1.9268 5.2815 -6.1070
## Luxembourg Malta Norway Netherlands New Zealand Nicaragua
## -1.6708 2.9749 -0.8718 0.4255 2.2856 0.6464
## Panama Paraguay Peru Philippines Portugal South Africa
## -3.2942 -6.1258 6.5394 6.6750 -0.7684 0.4832
## South Rhodesia Spain Sweden Switzerland Turkey Tunisia
## 1.2914 -0.6712 -4.2603 2.4868 -2.6657 -2.8179
## United Kingdom United States Venezuela Zambia Jamaica Uruguay
## -2.6924 -1.1116 3.6325 9.7509 -3.0185 -2.2638
## Libya Malaysia
## -2.8295 -2.9709
shapiro.test(residuals(savings.lm))
##
## Shapiro-Wilk normality test
##
## data: residuals(savings.lm)
## W = 0.987, p-value = 0.8524
Incorrelacion de los errores
Estamos asumiendo que los errores son incorrelados. La correlacion entrelos datos pueden venir de que han sido observados proximos bien en el tiempo bienen el espacio. ¿Como contrastar si los residuos son incorrelados?
Un test de la hipotesis de incorrelacion es el test de Durbin-Watson que utilizael siguiente estadıstico
DW =
∑ni=2(εi − εi−1)2∑n
i=1 ε2i
, (6.36)
bajo la hipotesis nula de incorrelacion la distribucion es una combinacion lineal dedistintas distribuciones χ2.
Nota de R 41 Vamos a aplicar el test de Durbin-Watson de correlacion serial.
library(lmtest)
Aplicamos el test de Durbin-Watson.
dwtest(savings.lm)
##
## Durbin-Watson test
##
## data: savings.lm
## DW = 1.934, p-value = 0.3897
## alternative hypothesis: true autocorrelation is greater than 0
129

Observaciones anomalas y observaciones influyentes
Algunas observaciones no ajustan bien al modelo y son llamadas observacionesanomalas. Otras observaciones influyen mucho en el ajuste y lo modifican de unmodo substantivo. Estas ultimas reciben el nombre de observaciones influyentes.Una observacion dada puede ser o bien anomala o bien influyente o ambas cosas.
Empecemos estudiando que se entiende por influencia de una observacion. Lla-maremos a hi = Hii, esto es, el valor en la posicion (i, i) de la matriz H la influencia(leverage en ingles). Notemos que var(εi) = σ2(1 − hi). En consecuencia, una in-fluencia alta supone una varianza del correspondiente residuo baja. Forzamos alajuste a que este proximo a yi. Se tiene que
∑pi=1 hi = p. En consecuencia el valor
medio de los hi es p/n. Como una regla simple de aplicar si la influencia hi es mayorque 2p/n debemos de observar el dato con atencion. Buscamos valores grandes delas influencias.
Nota de R 42 Calculamos las influencias para los datos savings. En la siguientefigura aparece una representacion de las influencias respecto de los residuos estan-darizados. Calculamos las influencias.
savings.inf <- influence(savings.lm)
savings.inf$hat
## Australia Austria Belgium Bolivia Brazil Canada
## 0.06771 0.12038 0.08748 0.08947 0.06956 0.15840
## Chile China Colombia Costa Rica Denmark Ecuador
## 0.03730 0.07796 0.05730 0.07547 0.06272 0.06373
## Finland France Germany Greece Guatamala Honduras
## 0.09204 0.13620 0.08736 0.09662 0.06049 0.06008
## Iceland India Ireland Italy Japan Korea
## 0.07050 0.07145 0.21224 0.06651 0.22331 0.06080
## Luxembourg Malta Norway Netherlands New Zealand Nicaragua
## 0.08635 0.07940 0.04793 0.09061 0.05422 0.05035
## Panama Paraguay Peru Philippines Portugal South Africa
## 0.03897 0.06937 0.06505 0.06425 0.09715 0.06510
## South Rhodesia Spain Sweden Switzerland Turkey Tunisia
## 0.16081 0.07733 0.12399 0.07359 0.03964 0.07457
## United Kingdom United States Venezuela Zambia Jamaica Uruguay
## 0.11651 0.33369 0.08628 0.06433 0.14076 0.09795
## Libya Malaysia
## 0.53146 0.06523
Y las representamos.
plot(savings.lm, which = 5)
130

0.0 0.1 0.2 0.3 0.4 0.5
−2
−1
01
23
Leverage
Sta
ndar
dize
d re
sidu
als
lm(sr ~ pop15 + pop75 + dpi + ddpi)
Cook's distance
1
0.5
0.5
1
Residuals vs Leverage
Libya
Japan
Zambia
Notemos que Libia es el pais que tiene un mayor valor de la influencia.
Otra posibilidad es para encontrar observaciones anomalas consiste en trabajarcon los residuos estudentizados. Veamos su definicion. Notemos que var(εi) = σ2(1−hi) lo que sugiere tomar
ri =εi
σ√
1− hi(6.37)
Estos son los residuos estudentizados. Si el modelo que asumimos es correcto enton-ces la varianza de estos residuos es uno y son aproximadamente incorrelados. Note-mos que la estudentizacion corrige las varianzas desiguales de los residuos cuandolas varianzas de los errores son iguales entre si. En otro caso esto no es cierto. Silas varianzas de los errores no son iguales (tenemos heterocedasticidad) entonces laestudentizacion no hace homogeneas las varianzas de los residuos.
Algunos autores (y programas) tienden a usar en lugar de los residuos originales,los residuos estudentizados.
Una observacion anomala es una observacion que no se ajusta a nuestro mo-delo. Hemos de protegernos frente a este tipo de puntos. Un test para observacionesanomalas es util si nos permite distinguir entre observaciones que son realmenteanomala y aquellas que simplemente tienen un residuo grande aunque no excepcio-nalmente grande.
Para detectar este tipo de puntos, lo que hacemos es excluir el punto i-esimo yajustamos el modelo sin ese punto obteniendo los estimadores β(i) y σ2
(i). Tendremos
131

para el punto i-esimo la siguiente estimacion
y(i) = x′iβ(i). (6.38)
Si el valor yi − y(i) es grande entonces el caso i es una observacion anomala. Conobjeto de valorar si estos nuevos residuos son anormales hemos de estandarizarlos.Notemos que
var(yi − y(i)) = σ2(i)(1 + x′i(X
′(i)X(i))
−1xi)
de modo que podemos definir los residuos jackknife como
ti =yi − y(i)√
var(yi − y(i))=
yi − y(i)
σ(i)
√1 + x′i(X
′(i)X(i))−1xi
∼ tn−p−1,
asumiendo que el modelo es correcto. Se tiene la siguiente expresion
ti =εi
σ(i)
√1− hi
= ri
(n− p− 1
n− p− r2i
)1/2
.
Puesto que cada uno de los ti sigue una distribucion conocida podemos contrastar sitenemos una observacion anomala. En principio el procedimiento serıa simplementefijar un nivel de significacion α y determinar el percentil 1− α
2 de una distribuciont de Student con n − p − 1 grados de libertad. Si denotamos el percentil comotn−p−1,1−α2 entonces residuos que no esten en el intervalo [−tn−p−1,1−α2 , tn−p−1,1−α2 ]serıan sospechosos. Esto no es adecuado. Porque estamos analizando n residuosestudentizados. Con uno solo sı que serıa aplicable el razonamiento. Tenemos unproblema de muchos tests simultaneamente considerados. Si aplicamos la correccionde Bonferroni tendrıamos que corregir el nivel de significacion α y trabajar conα/n. Por tanto, consideramos como sospechosos aquellos residuos estandarizadosque esten fuera del intervalo [−tn−p−1,1− α
2n, tn−p−1,1− α
2n].
Nota de R 43 (Residuos estudentizados) Calculamos para los datos savingslos residuos estudentizados con la funcion rstudent. La pregunta que nos hacemoses si alguno de estos residuos es muy grande o muy pequeno. Comparamos el modulode los residuos estandarizados con tn−p−1,1− α
2n.
savings.rs <- rstudent(savings.lm)
Comparamos los residuos con el percentil correspondiente.
abs(savings.rs) > qt(1 - 0.05/(50 * 2), 44)
## Australia Austria Belgium Bolivia Brazil Canada
## FALSE FALSE FALSE FALSE FALSE FALSE
## Chile China Colombia Costa Rica Denmark Ecuador
## FALSE FALSE FALSE FALSE FALSE FALSE
## Finland France Germany Greece Guatamala Honduras
## FALSE FALSE FALSE FALSE FALSE FALSE
## Iceland India Ireland Italy Japan Korea
## FALSE FALSE FALSE FALSE FALSE FALSE
## Luxembourg Malta Norway Netherlands New Zealand Nicaragua
## FALSE FALSE FALSE FALSE FALSE FALSE
## Panama Paraguay Peru Philippines Portugal South Africa
## FALSE FALSE FALSE FALSE FALSE FALSE
## South Rhodesia Spain Sweden Switzerland Turkey Tunisia
132

## FALSE FALSE FALSE FALSE FALSE FALSE
## United Kingdom United States Venezuela Zambia Jamaica Uruguay
## FALSE FALSE FALSE FALSE FALSE FALSE
## Libya Malaysia
## FALSE FALSE
Un punto influyente es aquel que cuando lo quitamos causa una modificacionimportante del ajuste. Un punto influyente puede ser o no una observacion anomala,puede tener o no una alta influencia pero tendera a tener al menos una de las dospropiedades. El estadıstico de Cook es una de las maneras de medir la influencia.Se define como
Di =(yi − y(i))
′(yi − y(i))
pσ2=
1
pr2i
hi1− hi
. (6.39)
Nota de R 44 Con los datos savings representamos las distancias de Cook y lasobtenemos utilizando la funcion Cooks.distance. Vemos Lıbia, Zambia y Japon sonobservaciones que influyen mucho en el ajuste. Habrıa que valorar el ajuste con ysin estas observaciones.
plot(savings.lm, which = 4)
0 10 20 30 40 50
0.00
0.05
0.10
0.15
0.20
0.25
Obs. number
Coo
k's
dist
ance
lm(sr ~ pop15 + pop75 + dpi + ddpi)
Cook's distance
Libya
Japan
Zambia
Tambien podemos ver los valores de la distancia de Cook.
133

cooks.distance(savings.lm)
## Australia Austria Belgium Bolivia Brazil Canada
## 8.036e-04 8.176e-04 7.155e-03 7.279e-04 1.403e-02 3.106e-04
## Chile China Colombia Costa Rica Denmark Ecuador
## 3.781e-02 8.157e-03 1.879e-03 3.208e-02 2.880e-02 5.819e-03
## Finland France Germany Greece Guatamala Honduras
## 4.364e-03 1.547e-02 4.737e-05 1.590e-02 1.067e-02 4.742e-04
## Iceland India Ireland Italy Japan Korea
## 4.353e-02 2.966e-04 5.440e-02 3.919e-03 1.428e-01 3.555e-02
## Luxembourg Malta Norway Netherlands New Zealand Nicaragua
## 3.994e-03 1.147e-02 5.559e-04 2.744e-04 4.379e-03 3.226e-04
## Panama Paraguay Peru Philippines Portugal South Africa
## 6.334e-03 4.157e-02 4.401e-02 4.522e-02 9.734e-04 2.405e-04
## South Rhodesia Spain Sweden Switzerland Turkey Tunisia
## 5.267e-03 5.659e-04 4.056e-02 7.335e-03 4.224e-03 9.562e-03
## United Kingdom United States Venezuela Zambia Jamaica Uruguay
## 1.497e-02 1.284e-02 1.886e-02 9.663e-02 2.403e-02 8.532e-03
## Libya Malaysia
## 2.681e-01 9.113e-03
6.10. Inferencia sobre el modelo
Hemos formulado un modelo probabilıstico en donde relacionamos la variablerespuesta con una serie de variables predictoras. Es claro que el experimentadorintroduce en el modelo como variables predictoras variables que a priori sospechaque pueden ser relevantes a la hora de predecir. Esto no quiere decir que luegopodamos prescindir de alguna o algunas de ellas. Bien porque se demuestra quedicha variable no es relevante o bien porque la informacion que contiene esa variablepredictora esta contenida en las otras.
Supongamos que nos planteamos el siguiente contraste de hipotesis: H0 : βi1 =. . . = βir = 0 frente a la alternativa H1 : No H0. Si un coeficiente determinado βi esnulo entonces la variable respuesta Y no dependerıa de la variable asociada a dichocoeficiente. En definitiva, la hipotesis nula considerada se podrıa formular diciendoque la variable Y no depende de las variables xi1 , . . . , xir . ¿Como contrastar lashipotesis indicadas? Se puede hacer mediante el test del cociente de verosimilitudes,es decir, utilizando el estadıstico
Λ =max(β,σ)∈Ω0
L(β, σ)
max(β,σ)∈Ω L(β, σ)(6.40)
siendo L(β, σ) = 1
(2π)n2 σn
exp− 12σ2 (y − Xβ)′(y − Xβ), Ω0 = (β, σ) ∈ Rp ×
(0,+∞) : βi1 = . . . = βir = 0 y Ω = Rp × (0,+∞). Como es habitual en untest del cociente de verosimilitudes rechazarıamos la hipotesis nula si Λ es pequeno(menor que una cierta constante) que se prueba es equivalente a que
SS(Error)Ω0− SS(Error)Ω
SS(Error)Ω
sea grande (mayor que una cierta constante). Denotamos por SS(Error)Ω0 la sumade cuadrados del error bajo la hipotesis nula y SS(Error)Ω la suma de cuadradossobre todo el espacio parametrico. Bajo la hipotesis nula se verifica que
SS(Error)Ω0− SS(Error)Ω
σ2r∼ χ2
r
134

ySS(Error)Ω
σ2(n− p)∼ χ2
n−p
ademas ambas cantidades son independientes. Por ello se verifica que
F =(SS(Error)Ω0 − SS(Error)Ω)/r
(SS(Error)Ω)/(n− p)∼ Fr,n−p.
De modo que rechazaremos la hipotesis nula de que H0 : βi1 = . . . = βir = 0 si
F > Fr,n−p,1−α
donde Fr,n−p,1−α es el percentil 1− α de una F con r y n− p grados de libertad.¿Realmente depende la variable respuesta de alguna de las variables predictoras?
Realmente nos estamos planteando la hipotesis de que todos los coeficientes, salvo eltermino constante β0, valen cero, es decir, la hipotesis nula H0 : β1 = . . . = βp−1 =0. En este caso tendremos que
F =((y − 1ny)′(y − 1ny)− (y −Xβ)′(y −Xβ))/(p− 1)
(y −Xβ)′(y −Xβ)/(n− p)∼ Fp−1,n−p.
Como segundo caso tendrıamos la situacion en que contrastamos que un solo coe-ficiente vale cero, es decir, la hipotesis nula H0 : βi = 0 frente a la alternativaH1 : βi 6= 0. Tenemos que bajo la hipotesis nula indicada
ti =βi
SE(βi)∼ tn−p
donde SE(βi) es el error estandar de βi y viene dado en ecuacion 6.30. Se tiene, dehecho, que
F = t2i .
Rechazaremos la hipotesis nula si
|ti| > tn−p,1−α2
o bien siF = t2i > F1,n−p,1−α2 .
Ambos procedimientos son equivalentes como se puede ver facilmente.
Nota de R 45 (Contrastes sobre los coeficientes) Utilizando los datos savingspodemos ver en la ultima lınea el contraste de que todas las variables predictoras tie-nen su coeficiente asociado nulo. El p-valor es 0,0007904, es decir, es muy pequenopor lo que rechazamos la hipotesis nula. Al menos una de las variables predictorastiene su coeficiente asociado no nulo.
Cuando contrastamos la hipotesis de que cada coeficiente valga cero vemos queno podemos rechazarlo para las variables pop75 y dpi.
Realizamos un summary del modelo de regresion ajustado.
summary(savings.lm)
##
## Call:
## lm(formula = sr ~ pop15 + pop75 + dpi + ddpi, data = savings)
##
135

## Residuals:
## Min 1Q Median 3Q Max
## -8.242 -2.686 -0.249 2.428 9.751
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 28.566087 7.354516 3.88 0.00033 ***
## pop15 -0.461193 0.144642 -3.19 0.00260 **
## pop75 -1.691498 1.083599 -1.56 0.12553
## dpi -0.000337 0.000931 -0.36 0.71917
## ddpi 0.409695 0.196197 2.09 0.04247 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.8 on 45 degrees of freedom
## Multiple R-squared: 0.338,Adjusted R-squared: 0.28
## F-statistic: 5.76 on 4 and 45 DF, p-value: 0.00079
Podemos tener intervalos de confianza para cada uno de los coeficientes βi.
Teniendo en cuenta que βi−βiSE(βi)
∼ tn−p entonces el intervalo de confianza al nivel
1− α para el coeficiente βi serıa
βi ± tn−p,1−α2 SE(βi).
Nota de R 46 (Intervalos de confianza) Calculamos los intervalos de confian-za para los coeficientes de savings con la funcion confint.
confint(savings.lm)
## 2.5 % 97.5 %
## (Intercept) 13.753331 43.378842
## pop15 -0.752518 -0.169869
## pop75 -3.873978 0.490983
## dpi -0.002212 0.001538
## ddpi 0.014534 0.804856
Supongamos que consideramos un vector de predictores x0 y pretendemos pre-decir la correspondiente media de la variable respuesta. Esta media viene dada por
E[Y |x0] = x′0β.
La estimacion de esta media esx′0β,
que tiene varianzavar(x′0β) = x′0(X ′X)−1x0σ
2.
Esta varianza la estimamos mediante
var(x′0β) = x′0(X ′X)−1x0σ2.
Y el intervalo de confianza serıa
x′0β ± tn−p,1−α2 σ√x′0(X ′X)−1x0.
136

Supongamos que, en lugar de predecir la media de la variable respuesta para unconjunto de predictores dados, pretendemos predecir la propia variable respuesta.Recordemos que segun nuestro modelo tenemos
Y = x′0β + ε.
En consecuencia la prediccion de la propia observacion serıa
x′0β
pero hay que considerar la varianza anadida por el error ε de modo que la varianzaal predecir Y dado x0 serıa
var(x′0β) + σ2
que estimarıamos como
var(x′0β) + σ2 = x′0(X ′X)−1x0σ2 + σ2 = (x′0(X ′X)−1x0 + 1)σ2.
Finalmente tendremos que el intervalo de confianza para una observacion Y quetiene predictores x0 es el siguiente
x′0β ± tn−p,1−α2 σ√x′0(X ′X)−1x0 + 1
Nota de R 47 Con los datos savings consideramos como obtener las prediccio-nes, intervalos de confianza para las medias y para las predicciones. Utilizamos lospropios datos que se han utilizado para ajustar el modelo. Con la funcion predictobtenemos las predicciones ası como los intervalos de confianza para las mediasde las predicciones (predict con la opcion interval=confidence) y los intervalos deconfianza para las observaciones (predict con la opcion interval=”prediction”).
Primero obtengamos las predicciones para los propios datos.
savings.lm <- lm(sr ~ pop15 + pop75 + dpi + ddpi, savings)
predict(savings.lm)
## Australia Austria Belgium Bolivia Brazil Canada
## 10.566 11.454 10.951 6.448 9.327 9.107
## Chile China Colombia Costa Rica Denmark Ecuador
## 8.842 9.364 6.432 5.655 11.450 5.996
## Finland France Germany Greece Guatamala Honduras
## 12.921 10.165 12.731 13.786 6.365 6.990
## Iceland India Ireland Italy Japan Korea
## 7.481 8.491 7.949 12.353 15.819 10.087
## Luxembourg Malta Norway Netherlands New Zealand Nicaragua
## 12.021 12.505 11.122 14.224 8.384 6.654
## Panama Paraguay Peru Philippines Portugal South Africa
## 7.734 8.146 6.161 6.105 13.258 10.657
## South Rhodesia Spain Sweden Switzerland Turkey Tunisia
## 12.009 12.441 11.120 11.643 7.796 5.628
## United Kingdom United States Venezuela Zambia Jamaica Uruguay
## 10.502 8.672 5.587 8.809 10.739 11.504
## Libya Malaysia
## 11.720 7.681
En segundo lugar, obtenemos los intervalos de confianza para la prediccion de lamedia.
137

predict(savings.lm, interval = "confidence")
## fit lwr upr
## Australia 10.566 8.573 12.559
## Austria 11.454 8.796 14.111
## Belgium 10.951 8.686 13.216
## Bolivia 6.448 4.157 8.739
## Brazil 9.327 7.307 11.347
## Canada 9.107 6.059 12.155
## Chile 8.842 7.363 10.321
## China 9.364 7.225 11.502
## Colombia 6.432 4.598 8.265
## Costa Rica 5.655 3.551 7.759
## Denmark 11.450 9.532 13.368
## Ecuador 5.996 4.062 7.929
## Finland 12.921 10.597 15.245
## France 10.165 7.338 12.991
## Germany 12.731 10.467 14.994
## Greece 13.786 11.405 16.167
## Guatamala 6.365 4.482 8.249
## Honduras 6.990 5.113 8.867
## Iceland 7.481 5.447 9.514
## India 8.491 6.444 10.539
## Ireland 7.949 4.420 11.477
## Italy 12.353 10.378 14.328
## Japan 15.819 12.199 19.438
## Korea 10.087 8.198 11.975
## Luxembourg 12.021 9.770 14.271
## Malta 12.505 10.347 14.663
## Norway 11.122 9.445 12.799
## Netherlands 14.224 11.919 16.530
## New Zealand 8.384 6.601 10.168
## Nicaragua 6.654 4.935 8.372
## Panama 7.734 6.222 9.246
## Paraguay 8.146 6.128 10.163
## Peru 6.161 4.207 8.114
## Philippines 6.105 4.164 8.046
## Portugal 13.258 10.871 15.646
## South Africa 10.657 8.703 12.611
## South Rhodesia 12.009 8.937 15.080
## Spain 12.441 10.311 14.571
## Sweden 11.120 8.423 13.817
## Switzerland 11.643 9.565 13.721
## Turkey 7.796 6.271 9.321
## Tunisia 5.628 3.536 7.719
## United Kingdom 10.502 7.888 13.117
## United States 8.672 4.247 13.096
## Venezuela 5.587 3.338 7.837
## Zambia 8.809 6.866 10.752
## Jamaica 10.739 7.865 13.612
## Uruguay 11.504 9.107 13.901
## Libya 11.720 6.136 17.303
## Malaysia 7.681 5.725 9.637
138

Y finalmente obtenemos los intervalos de confianza para la prediccion de la ob-servacion.
predict(savings.lm, interval = "prediction")
## Warning: predictions on current data refer to future responses
## fit lwr upr
## Australia 10.566 2.65239 18.48
## Austria 11.454 3.34674 19.56
## Belgium 10.951 2.96408 18.94
## Bolivia 6.448 -1.54594 14.44
## Brazil 9.327 1.40632 17.25
## Canada 9.107 0.86361 17.35
## Chile 8.842 1.04174 16.64
## China 9.364 1.41206 17.32
## Colombia 6.432 -1.44364 14.31
## Costa Rica 5.655 -2.28779 13.60
## Denmark 11.450 3.55427 19.35
## Ecuador 5.996 -1.90361 13.89
## Finland 12.921 4.91740 20.92
## France 10.165 2.00061 18.33
## Germany 12.731 4.74420 20.72
## Greece 13.786 5.76572 21.81
## Guatamala 6.365 -1.52194 14.25
## Honduras 6.990 -0.89571 14.88
## Iceland 7.481 -0.44375 15.40
## India 8.491 0.56345 16.42
## Ireland 7.949 -0.48378 16.38
## Italy 12.353 4.44367 20.26
## Japan 15.819 7.34744 24.29
## Korea 10.087 2.19862 17.98
## Luxembourg 12.021 4.03802 20.00
## Malta 12.505 4.54786 20.46
## Norway 11.122 3.28141 18.96
## Netherlands 14.224 6.22601 22.22
## New Zealand 8.384 0.52059 16.25
## Nicaragua 6.654 -1.19581 14.50
## Panama 7.734 -0.07263 15.54
## Paraguay 8.146 0.22559 16.07
## Peru 6.161 -1.74359 14.06
## Philippines 6.105 -1.79621 14.01
## Portugal 13.258 5.23607 21.28
## South Africa 10.657 2.75248 18.56
## South Rhodesia 12.009 3.75673 20.26
## Spain 12.441 4.49157 20.39
## Sweden 11.120 3.00037 19.24
## Switzerland 11.643 3.70738 19.58
## Turkey 7.796 -0.01362 15.60
## Tunisia 5.628 -2.31147 13.57
## United Kingdom 10.502 2.40955 18.60
## United States 8.672 -0.17340 17.52
## Venezuela 5.587 -2.39507 13.57
## Zambia 8.809 0.90760 16.71
139

## Jamaica 10.739 2.55827 18.92
## Uruguay 11.504 3.47853 19.53
## Libya 11.720 2.24140 21.20
## Malaysia 7.681 -0.22396 15.59
6.11. Seleccion de variables
Habitualmente tenemos un gran conjunto de variables y pretendemos determinarun buen conjunto de variables. ¿En que sentido bueno? En primer lugar, bueno enel sentido de sencillo. Tener pocas variables supone un modelo mas simple, masfacil de entender. Es bueno tener pocas variables porque luego no tendremos querecoger esta informacion. Es bueno porque los estimadores de los parametros queintervienen en el modelo son mucho menos variables.
Dos son las aproximaciones al problema de la seleccion de variables. En la prime-ra vamos comparando modelos sucesivos y, basicamente, consideramos si los modelossucesivos que comparamos difieren significativamente como modelos. En la segun-da se adopta una medida de calidad global del ajuste y se plantea el problema dedeterminar el modelo que optimiza ese criterio global.
6.11.1. Procedimientos que comparan modelos
Tres procedimientos se pueden considerar: seleccion backward, seleccion for-ward y seleccion stepwise. En el primer procedimiento, seleccion backward(seleccion hacia atras), empezamos el proceso de seleccion con un modelo en quetenemos todas las variables consideradas a priori. Elegimos aquella que, cuando laquitamos, el p-valor resultante de comparar ambos modelos (completo y aquel quele falta la variable considerada) es mayor. Si este p-valor es mayor que un valor αpreviamente especificado entonces eliminamos la variable del modelo. Y ası conti-nuamos hasta que al eliminar una variable el p-valor correspondiente sea menor queel α elegido.
El procedimiento seleccion forward (o hacia adelante) empezamos con unmodelo en el cual solamente tenemos la constante. Elegimos para entrar la variabletal que cuando se incorpora el modelo cambia lo mas posible. Esto es, el p-valores el mas significativo. Si el p-valor de la comparacion de los modelos es menorque α (siempre elegido antes de iniciar el proceso de seleccion y no reajustado a lolargo del mismo) entonces la variable entra en el modelo. Continuamos hasta queel modelo no cambia significativamente.
El procedimiento mas usado es el seleccion stepwise (hacia adelante y haciaatras). Vistos los anteriores es de esperar como funciona este metodo. Despues de lainclusion de una variable consideramos la posible exclusion de las variables que estanen el modelo. Si es posible eliminar una lo hacemos y nos planteamos la inclusionde la variable que produzca un cambio mas significativo.
Nota de R 48 (Seleccion hacia atras) Utilizamos los datos state y aplicamosun procedimiento de seleccion backward.
data(state)
statedata <- data.frame(state.x77, row.names = state.abb, check.names = T)
g <- lm(Life.Exp ~ ., data = statedata)
summary(g)
##
140

## Call:
## lm(formula = Life.Exp ~ ., data = statedata)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.4890 -0.5123 -0.0275 0.5700 1.4945
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 7.09e+01 1.75e+00 40.59 < 2e-16 ***
## Population 5.18e-05 2.92e-05 1.77 0.083 .
## Income -2.18e-05 2.44e-04 -0.09 0.929
## Illiteracy 3.38e-02 3.66e-01 0.09 0.927
## Murder -3.01e-01 4.66e-02 -6.46 8.7e-08 ***
## HS.Grad 4.89e-02 2.33e-02 2.10 0.042 *
## Frost -5.74e-03 3.14e-03 -1.82 0.075 .
## Area -7.38e-08 1.67e-06 -0.04 0.965
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.745 on 42 degrees of freedom
## Multiple R-squared: 0.736,Adjusted R-squared: 0.692
## F-statistic: 16.7 on 7 and 42 DF, p-value: 2.53e-10
g <- update(g, . ~ . - Area)
summary(g)
##
## Call:
## lm(formula = Life.Exp ~ Population + Income + Illiteracy + Murder +
## HS.Grad + Frost, data = statedata)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.4905 -0.5253 -0.0255 0.5716 1.5037
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 7.10e+01 1.39e+00 51.17 < 2e-16 ***
## Population 5.19e-05 2.88e-05 1.80 0.079 .
## Income -2.44e-05 2.34e-04 -0.10 0.917
## Illiteracy 2.85e-02 3.42e-01 0.08 0.934
## Murder -3.02e-01 4.33e-02 -6.96 1.5e-08 ***
## HS.Grad 4.85e-02 2.07e-02 2.35 0.024 *
## Frost -5.78e-03 2.97e-03 -1.94 0.058 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.736 on 43 degrees of freedom
## Multiple R-squared: 0.736,Adjusted R-squared: 0.699
## F-statistic: 20 on 6 and 43 DF, p-value: 5.36e-11
141
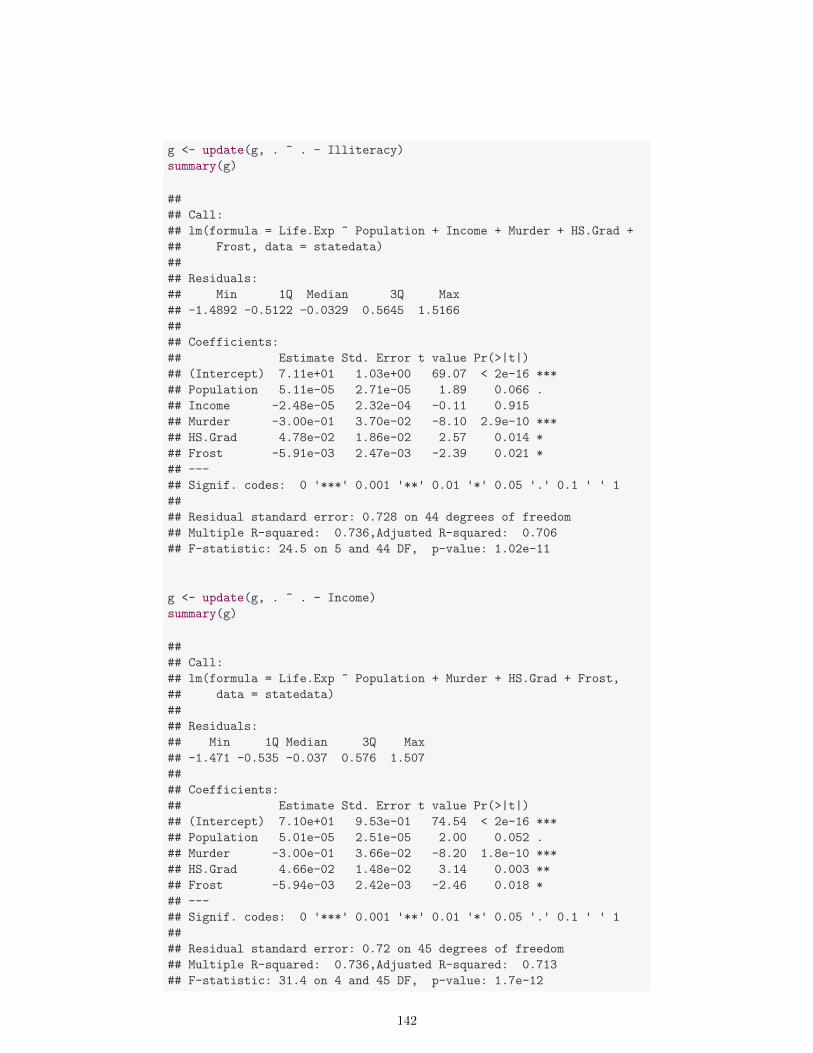
g <- update(g, . ~ . - Illiteracy)
summary(g)
##
## Call:
## lm(formula = Life.Exp ~ Population + Income + Murder + HS.Grad +
## Frost, data = statedata)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.4892 -0.5122 -0.0329 0.5645 1.5166
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 7.11e+01 1.03e+00 69.07 < 2e-16 ***
## Population 5.11e-05 2.71e-05 1.89 0.066 .
## Income -2.48e-05 2.32e-04 -0.11 0.915
## Murder -3.00e-01 3.70e-02 -8.10 2.9e-10 ***
## HS.Grad 4.78e-02 1.86e-02 2.57 0.014 *
## Frost -5.91e-03 2.47e-03 -2.39 0.021 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.728 on 44 degrees of freedom
## Multiple R-squared: 0.736,Adjusted R-squared: 0.706
## F-statistic: 24.5 on 5 and 44 DF, p-value: 1.02e-11
g <- update(g, . ~ . - Income)
summary(g)
##
## Call:
## lm(formula = Life.Exp ~ Population + Murder + HS.Grad + Frost,
## data = statedata)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.471 -0.535 -0.037 0.576 1.507
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 7.10e+01 9.53e-01 74.54 < 2e-16 ***
## Population 5.01e-05 2.51e-05 2.00 0.052 .
## Murder -3.00e-01 3.66e-02 -8.20 1.8e-10 ***
## HS.Grad 4.66e-02 1.48e-02 3.14 0.003 **
## Frost -5.94e-03 2.42e-03 -2.46 0.018 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.72 on 45 degrees of freedom
## Multiple R-squared: 0.736,Adjusted R-squared: 0.713
## F-statistic: 31.4 on 4 and 45 DF, p-value: 1.7e-12
142

g <- update(g, . ~ . - Population)
summary(g)
##
## Call:
## lm(formula = Life.Exp ~ Murder + HS.Grad + Frost, data = statedata)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.502 -0.539 0.101 0.592 1.227
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 71.03638 0.98326 72.25 <2e-16 ***
## Murder -0.28307 0.03673 -7.71 8e-10 ***
## HS.Grad 0.04995 0.01520 3.29 0.002 **
## Frost -0.00691 0.00245 -2.82 0.007 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.743 on 46 degrees of freedom
## Multiple R-squared: 0.713,Adjusted R-squared: 0.694
## F-statistic: 38 on 3 and 46 DF, p-value: 1.63e-12
6.11.2. Procedimientos basados en criterios
Estamos ajustando un modelo de regresion lineal multiple con algun proposito.Podemos fijarnos en una medida global de calidad del ajuste y buscar la seleccionde variables que nos da el optimo segun ese criterio.
Una medida global puede ser AIC (Akaike Information Criterion) definido como
AIC = −2 max logverosimilitud+ 2p.
A partir de la definicion de esta medida global es claro que un valor pequenoindica un mejor ajuste.
Nota de R 49 (Seleccion de variables) Notemos que con en la funcion steppodemos indicar con el argumento direction si queremos both (stepwise), o bienbackward o bien forward.
data(state)
statedata <- data.frame(state.x77, row.names = state.abb, check.names = T)
g <- lm(Life.Exp ~ ., data = statedata)
step(g)
## Start: AIC=-22.18
## Life.Exp ~ Population + Income + Illiteracy + Murder + HS.Grad +
## Frost + Area
##
## Df Sum of Sq RSS AIC
## - Area 1 0.00 23.3 -24.2
## - Income 1 0.00 23.3 -24.2
## - Illiteracy 1 0.00 23.3 -24.2
143

## <none> 23.3 -22.2
## - Population 1 1.75 25.0 -20.6
## - Frost 1 1.85 25.1 -20.4
## - HS.Grad 1 2.44 25.7 -19.2
## - Murder 1 23.14 46.4 10.3
##
## Step: AIC=-24.18
## Life.Exp ~ Population + Income + Illiteracy + Murder + HS.Grad +
## Frost
##
## Df Sum of Sq RSS AIC
## - Illiteracy 1 0.00 23.3 -26.2
## - Income 1 0.01 23.3 -26.2
## <none> 23.3 -24.2
## - Population 1 1.76 25.1 -22.5
## - Frost 1 2.05 25.3 -22.0
## - HS.Grad 1 2.98 26.3 -20.2
## - Murder 1 26.27 49.6 11.6
##
## Step: AIC=-26.17
## Life.Exp ~ Population + Income + Murder + HS.Grad + Frost
##
## Df Sum of Sq RSS AIC
## - Income 1 0.0 23.3 -28.2
## <none> 23.3 -26.2
## - Population 1 1.9 25.2 -24.3
## - Frost 1 3.0 26.3 -22.1
## - HS.Grad 1 3.5 26.8 -21.2
## - Murder 1 34.7 58.0 17.5
##
## Step: AIC=-28.16
## Life.Exp ~ Population + Murder + HS.Grad + Frost
##
## Df Sum of Sq RSS AIC
## <none> 23.3 -28.2
## - Population 1 2.1 25.4 -25.9
## - Frost 1 3.1 26.4 -23.9
## - HS.Grad 1 5.1 28.4 -20.2
## - Murder 1 34.8 58.1 15.5
##
## Call:
## lm(formula = Life.Exp ~ Population + Murder + HS.Grad + Frost,
## data = statedata)
##
## Coefficients:
## (Intercept) Population Murder HS.Grad Frost
## 7.10e+01 5.01e-05 -3.00e-01 4.66e-02 -5.94e-03
Utilizamos stepAIC de la librerıa MASS ?.
library(MASS)
data(state)
statedata <- data.frame(state.x77, row.names = state.abb, check.names = T)
g <- lm(Life.Exp ~ ., data = statedata)
144
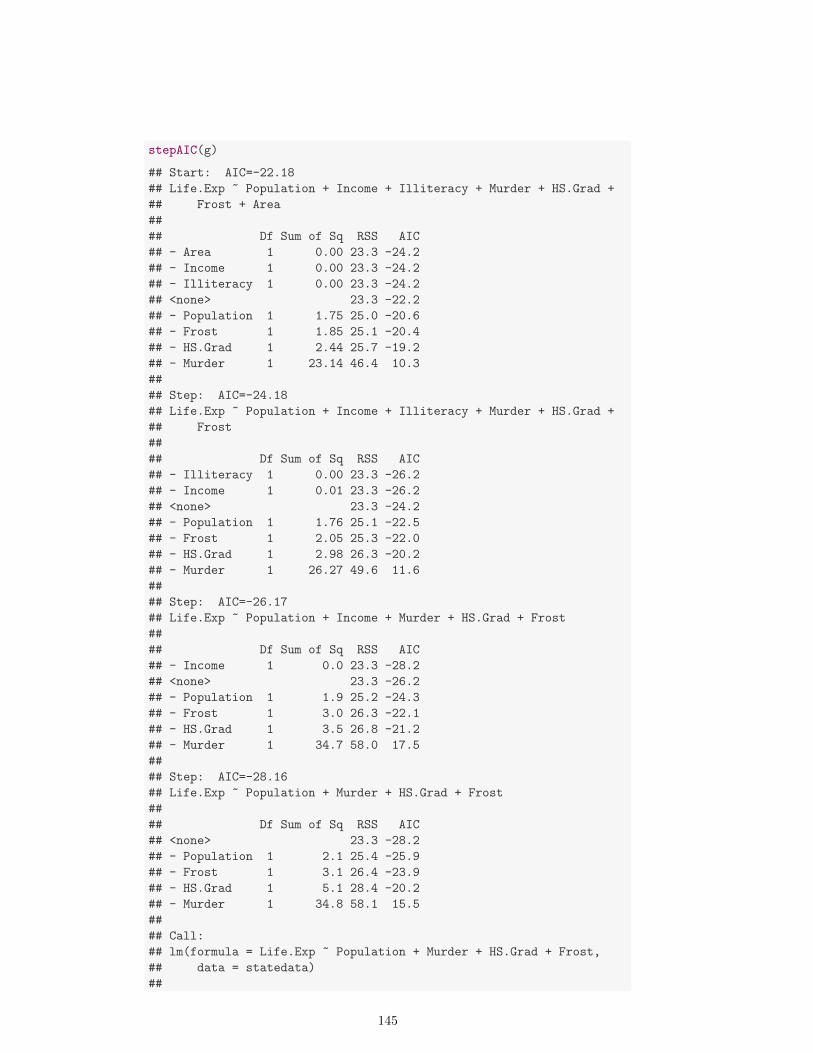
stepAIC(g)
## Start: AIC=-22.18
## Life.Exp ~ Population + Income + Illiteracy + Murder + HS.Grad +
## Frost + Area
##
## Df Sum of Sq RSS AIC
## - Area 1 0.00 23.3 -24.2
## - Income 1 0.00 23.3 -24.2
## - Illiteracy 1 0.00 23.3 -24.2
## <none> 23.3 -22.2
## - Population 1 1.75 25.0 -20.6
## - Frost 1 1.85 25.1 -20.4
## - HS.Grad 1 2.44 25.7 -19.2
## - Murder 1 23.14 46.4 10.3
##
## Step: AIC=-24.18
## Life.Exp ~ Population + Income + Illiteracy + Murder + HS.Grad +
## Frost
##
## Df Sum of Sq RSS AIC
## - Illiteracy 1 0.00 23.3 -26.2
## - Income 1 0.01 23.3 -26.2
## <none> 23.3 -24.2
## - Population 1 1.76 25.1 -22.5
## - Frost 1 2.05 25.3 -22.0
## - HS.Grad 1 2.98 26.3 -20.2
## - Murder 1 26.27 49.6 11.6
##
## Step: AIC=-26.17
## Life.Exp ~ Population + Income + Murder + HS.Grad + Frost
##
## Df Sum of Sq RSS AIC
## - Income 1 0.0 23.3 -28.2
## <none> 23.3 -26.2
## - Population 1 1.9 25.2 -24.3
## - Frost 1 3.0 26.3 -22.1
## - HS.Grad 1 3.5 26.8 -21.2
## - Murder 1 34.7 58.0 17.5
##
## Step: AIC=-28.16
## Life.Exp ~ Population + Murder + HS.Grad + Frost
##
## Df Sum of Sq RSS AIC
## <none> 23.3 -28.2
## - Population 1 2.1 25.4 -25.9
## - Frost 1 3.1 26.4 -23.9
## - HS.Grad 1 5.1 28.4 -20.2
## - Murder 1 34.8 58.1 15.5
##
## Call:
## lm(formula = Life.Exp ~ Population + Murder + HS.Grad + Frost,
## data = statedata)
##
145

## Coefficients:
## (Intercept) Population Murder HS.Grad Frost
## 7.10e+01 5.01e-05 -3.00e-01 4.66e-02 -5.94e-03
Vemos que se obtiene el mismo resultado.
6.12. Algunos ejemplos
Terminamos el tema con algunos ejemplos.
Nota de R 50 Son unos datos sobre el abulon. Es un molusco. Se trata de predecirsu edad a partir de una serie de caracterısticas fısicas. Los datos se pueden encontraren http://www.liacc.up.pt/˜ltorgo/Regression/DataSets.html.
La edad del abalon se calcula habitualmente cortando la concha y contando elnumero de anillos utilizando un microscopio. Es una tarea bastante laboriosa. Sepretende predecir la edad del animal utilizando distintas medidas que son mas facilesde obtener.
Vemos como quitando un par de observaciones con un leverage alto el ajustemejora.
x <- read.table(file = "../data/abalone.dat", sep = ",")
attach(x)
xnam <- paste("V", 1:8, sep = "")
(fmla <- as.formula(paste("y ~ ", paste(xnam, collapse = "+"))))
## y ~ V1 + V2 + V3 + V4 + V5 + V6 + V7 + V8
y <- log(x[, 9])
y.fit <- lm(fmla, data = x)
summary(y.fit)
##
## Call:
## lm(formula = fmla, data = x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.3791 -0.1317 -0.0159 0.1112 0.8043
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.34118 0.02691 49.83 < 2e-16 ***
## V1I -0.09249 0.00945 -9.78 < 2e-16 ***
## V1M 0.00893 0.00769 1.16 0.2461
## V2 0.53305 0.16700 3.19 0.0014 **
## V3 1.42358 0.20560 6.92 5.1e-12 ***
## V4 1.20663 0.14181 8.51 < 2e-16 ***
## V5 0.60825 0.06696 9.08 < 2e-16 ***
## V6 -1.65705 0.07545 -21.96 < 2e-16 ***
## V7 -0.83550 0.11942 -7.00 3.1e-12 ***
## V8 0.60681 0.10382 5.84 5.5e-09 ***
## ---
146
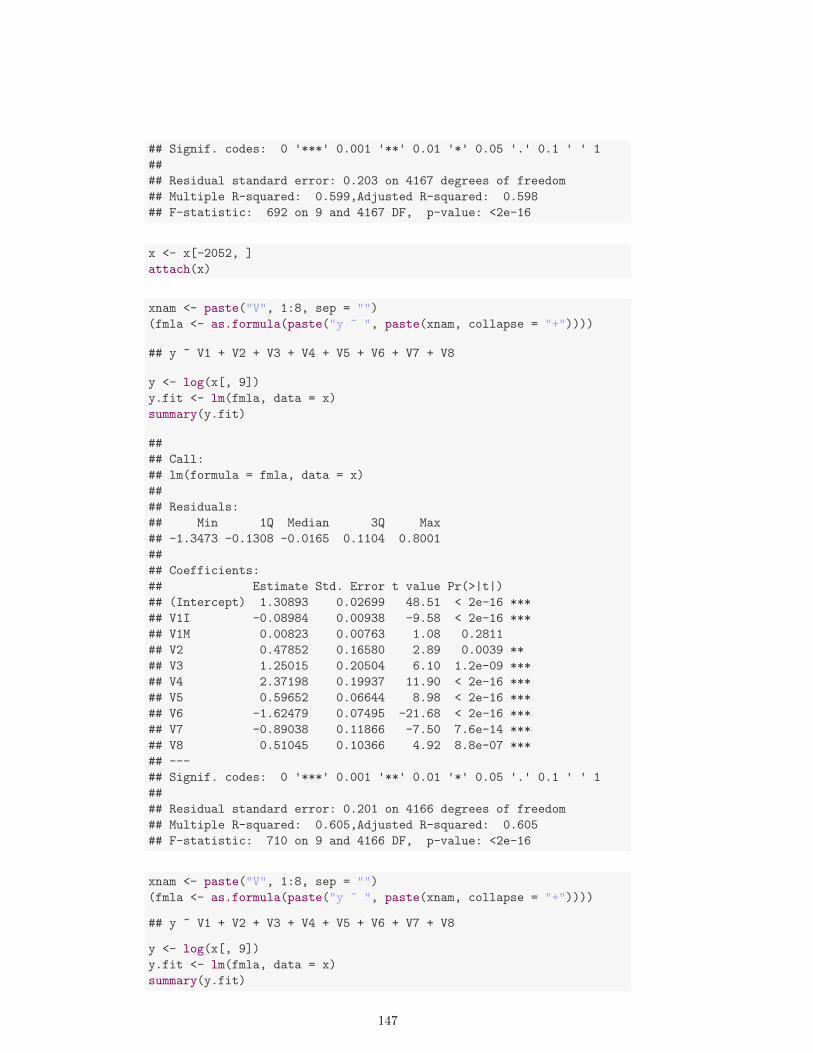
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.203 on 4167 degrees of freedom
## Multiple R-squared: 0.599,Adjusted R-squared: 0.598
## F-statistic: 692 on 9 and 4167 DF, p-value: <2e-16
x <- x[-2052, ]
attach(x)
xnam <- paste("V", 1:8, sep = "")
(fmla <- as.formula(paste("y ~ ", paste(xnam, collapse = "+"))))
## y ~ V1 + V2 + V3 + V4 + V5 + V6 + V7 + V8
y <- log(x[, 9])
y.fit <- lm(fmla, data = x)
summary(y.fit)
##
## Call:
## lm(formula = fmla, data = x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.3473 -0.1308 -0.0165 0.1104 0.8001
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.30893 0.02699 48.51 < 2e-16 ***
## V1I -0.08984 0.00938 -9.58 < 2e-16 ***
## V1M 0.00823 0.00763 1.08 0.2811
## V2 0.47852 0.16580 2.89 0.0039 **
## V3 1.25015 0.20504 6.10 1.2e-09 ***
## V4 2.37198 0.19937 11.90 < 2e-16 ***
## V5 0.59652 0.06644 8.98 < 2e-16 ***
## V6 -1.62479 0.07495 -21.68 < 2e-16 ***
## V7 -0.89038 0.11866 -7.50 7.6e-14 ***
## V8 0.51045 0.10366 4.92 8.8e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.201 on 4166 degrees of freedom
## Multiple R-squared: 0.605,Adjusted R-squared: 0.605
## F-statistic: 710 on 9 and 4166 DF, p-value: <2e-16
xnam <- paste("V", 1:8, sep = "")
(fmla <- as.formula(paste("y ~ ", paste(xnam, collapse = "+"))))
## y ~ V1 + V2 + V3 + V4 + V5 + V6 + V7 + V8
y <- log(x[, 9])
y.fit <- lm(fmla, data = x)
summary(y.fit)
147

##
## Call:
## lm(formula = fmla, data = x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.3473 -0.1308 -0.0165 0.1104 0.8001
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.30893 0.02699 48.51 < 2e-16 ***
## V1I -0.08984 0.00938 -9.58 < 2e-16 ***
## V1M 0.00823 0.00763 1.08 0.2811
## V2 0.47852 0.16580 2.89 0.0039 **
## V3 1.25015 0.20504 6.10 1.2e-09 ***
## V4 2.37198 0.19937 11.90 < 2e-16 ***
## V5 0.59652 0.06644 8.98 < 2e-16 ***
## V6 -1.62479 0.07495 -21.68 < 2e-16 ***
## V7 -0.89038 0.11866 -7.50 7.6e-14 ***
## V8 0.51045 0.10366 4.92 8.8e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.201 on 4166 degrees of freedom
## Multiple R-squared: 0.605,Adjusted R-squared: 0.605
## F-statistic: 710 on 9 and 4166 DF, p-value: <2e-16
Nota de R 51 (Un ejemplo de produccion) Se trata de unos datos utilizadospara reducir costes de produccion. En concreto se pretende valorar el consumo deagua en una fabrica. Se tiene el consumo de agua en distintos meses (en galones)como variable respuesta. Las variables predictoras serıan la temperatura media enel mes, la produccion (en libras), numero de dıas que ha funcionado la fabricadurante ese mes, numero de personas trabajando. Los datos han sido obtenidos dehttp://www.statsci.org/data/general/water.html.
x <- read.table(file = "../data/agua.txt", header = T)
attach(x)
Ajustamos el modelo.
a.lm <- lm(agua ~ temperatura + produccion + dias + personas)
summary(a.lm)
##
## Call:
## lm(formula = agua ~ temperatura + produccion + dias + personas)
##
## Residuals:
## Min 1Q Median 3Q Max
## -445.0 -131.5 2.6 109.0 368.5
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
148

## (Intercept) 6360.3373 1314.3916 4.84 0.00041 ***
## temperatura 13.8689 5.1598 2.69 0.01975 *
## produccion 0.2117 0.0455 4.65 0.00056 ***
## dias -126.6904 48.0223 -2.64 0.02165 *
## personas -21.8180 7.2845 -3.00 0.01117 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 249 on 12 degrees of freedom
## Multiple R-squared: 0.767,Adjusted R-squared: 0.689
## F-statistic: 9.88 on 4 and 12 DF, p-value: 0.000896
Introducimos un termino cuadratico y otro cubico en la produccion.
b.lm <- lm(agua ~ temperatura + poly(produccion, 3) + dias + personas)
summary(b.lm)
##
## Call:
## lm(formula = agua ~ temperatura + poly(produccion, 3) + dias +
## personas)
##
## Residuals:
## Min 1Q Median 3Q Max
## -435.9 -103.8 29.4 123.9 388.4
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 8734.09 2393.47 3.65 0.0045 **
## temperatura 14.52 6.52 2.23 0.0502 .
## poly(produccion, 3)1 2742.29 851.98 3.22 0.0092 **
## poly(produccion, 3)2 208.89 337.56 0.62 0.5499
## poly(produccion, 3)3 -108.68 357.64 -0.30 0.7675
## dias -138.47 66.88 -2.07 0.0652 .
## personas -18.69 9.87 -1.89 0.0875 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 266 on 10 degrees of freedom
## Multiple R-squared: 0.779,Adjusted R-squared: 0.647
## F-statistic: 5.88 on 6 and 10 DF, p-value: 0.00736
Veamos los distintos procedimientos graficos para el diagnostico del modelo.
plot(a.lm, which = 1)
149

3000 3500 4000
−40
0−
200
020
040
0
Fitted values
Res
idua
ls
lm(agua ~ temperatura + produccion + dias + personas)
Residuals vs Fitted
14
6
15
plot(a.lm, which = 2)
150

−2 −1 0 1 2
−2
−1
01
2
Theoretical Quantiles
Sta
ndar
dize
d re
sidu
als
lm(agua ~ temperatura + produccion + dias + personas)
Normal Q−Q
14
6
17
plot(a.lm, which = 3)
151

3000 3500 4000
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
Fitted values
Sta
ndar
dize
d re
sidu
als
lm(agua ~ temperatura + produccion + dias + personas)
Scale−Location
14
6
17
plot(a.lm, which = 4)
152
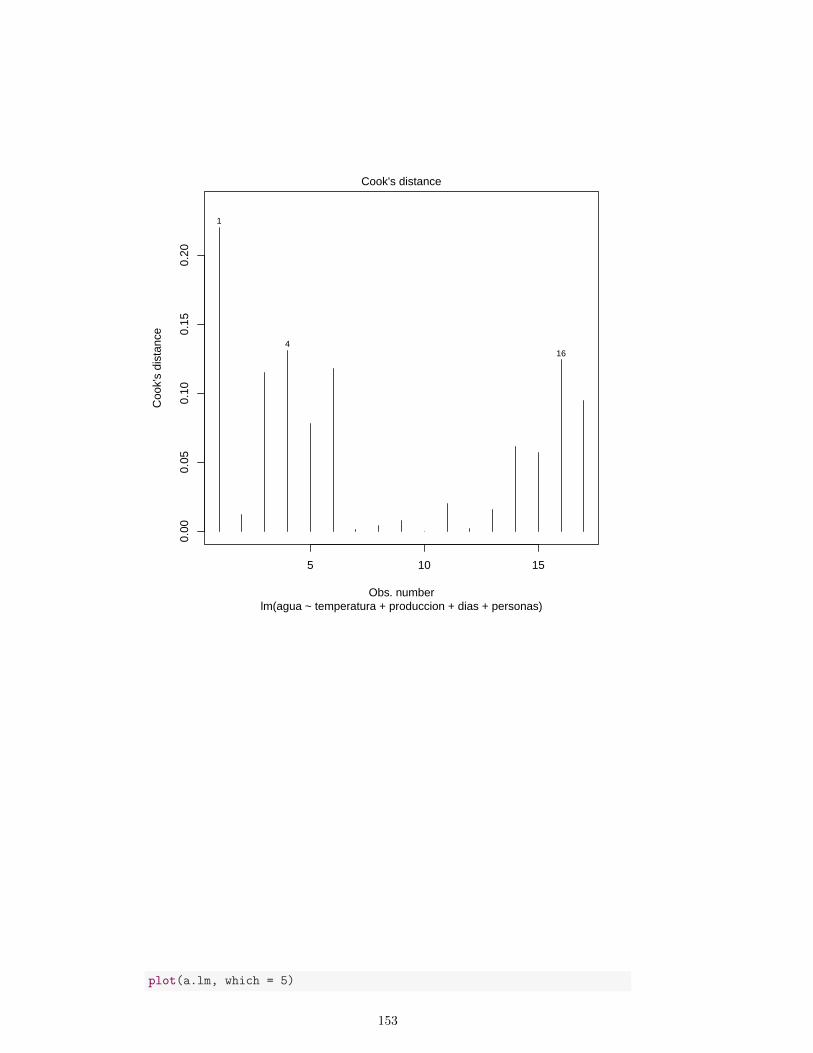
5 10 15
0.00
0.05
0.10
0.15
0.20
Obs. number
Coo
k's
dist
ance
lm(agua ~ temperatura + produccion + dias + personas)
Cook's distance
1
416
plot(a.lm, which = 5)
153

0.0 0.1 0.2 0.3 0.4 0.5 0.6
−2
−1
01
2
Leverage
Sta
ndar
dize
d re
sidu
als
lm(agua ~ temperatura + produccion + dias + personas)
Cook's distance
1
0.5
0.5
1
Residuals vs Leverage
1
4
16
plot(a.lm, which = 6)
154

0.00
0.05
0.10
0.15
0.20
Leverage hii
Coo
k's
dist
ance
0 0.1 0.2 0.3 0.4 0.5 0.6
lm(agua ~ temperatura + produccion + dias + personas)
0
0.511.52
Cook's dist vs Leverage hii (1 − hii)
1
416
Intervalo de confianza para observaciones.
predict(a.lm, interval = "prediction")
## Warning: predictions on current data refer to future responses
## fit lwr upr
## 1 3205 2521 3890
## 2 2750 2131 3370
## 3 2657 2036 3278
## 4 3228 2601 3854
## 5 3214 2563 3864
## 6 3529 2940 4119
## 7 3538 2945 4132
## 8 3138 2556 3720
## 9 3116 2526 3706
## 10 3283 2664 3903
## 11 3469 2825 4113
## 12 3148 2501 3795
## 13 2913 2309 3517
## 14 3367 2803 3931
## 15 3627 3050 4203
## 16 4362 3691 5034
## 17 3617 3026 4208
155
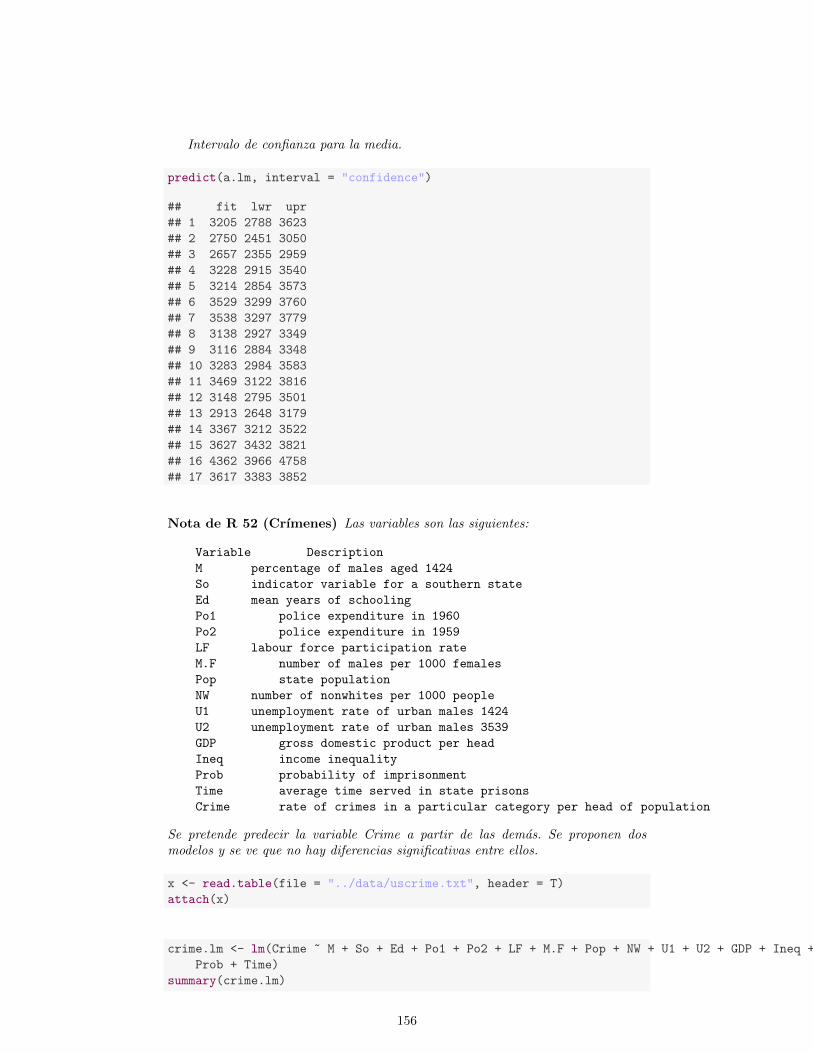
Intervalo de confianza para la media.
predict(a.lm, interval = "confidence")
## fit lwr upr
## 1 3205 2788 3623
## 2 2750 2451 3050
## 3 2657 2355 2959
## 4 3228 2915 3540
## 5 3214 2854 3573
## 6 3529 3299 3760
## 7 3538 3297 3779
## 8 3138 2927 3349
## 9 3116 2884 3348
## 10 3283 2984 3583
## 11 3469 3122 3816
## 12 3148 2795 3501
## 13 2913 2648 3179
## 14 3367 3212 3522
## 15 3627 3432 3821
## 16 4362 3966 4758
## 17 3617 3383 3852
Nota de R 52 (Crımenes) Las variables son las siguientes:
Variable Description
M percentage of males aged 1424
So indicator variable for a southern state
Ed mean years of schooling
Po1 police expenditure in 1960
Po2 police expenditure in 1959
LF labour force participation rate
M.F number of males per 1000 females
Pop state population
NW number of nonwhites per 1000 people
U1 unemployment rate of urban males 1424
U2 unemployment rate of urban males 3539
GDP gross domestic product per head
Ineq income inequality
Prob probability of imprisonment
Time average time served in state prisons
Crime rate of crimes in a particular category per head of population
Se pretende predecir la variable Crime a partir de las demas. Se proponen dosmodelos y se ve que no hay diferencias significativas entre ellos.
x <- read.table(file = "../data/uscrime.txt", header = T)
attach(x)
crime.lm <- lm(Crime ~ M + So + Ed + Po1 + Po2 + LF + M.F + Pop + NW + U1 + U2 + GDP + Ineq +
Prob + Time)
summary(crime.lm)
156

##
## Call:
## lm(formula = Crime ~ M + So + Ed + Po1 + Po2 + LF + M.F + Pop +
## NW + U1 + U2 + GDP + Ineq + Prob + Time)
##
## Residuals:
## Min 1Q Median 3Q Max
## -395.7 -98.1 -6.7 113.0 512.7
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -5984.288 1628.318 -3.68 0.00089 ***
## M 8.783 4.171 2.11 0.04344 *
## So -3.803 148.755 -0.03 0.97977
## Ed 18.832 6.209 3.03 0.00486 **
## Po1 19.280 10.611 1.82 0.07889 .
## Po2 -10.942 11.748 -0.93 0.35883
## LF -0.664 1.470 -0.45 0.65465
## M.F 1.741 2.035 0.86 0.39900
## Pop -0.733 1.290 -0.57 0.57385
## NW 0.420 0.648 0.65 0.52128
## U1 -5.827 4.210 -1.38 0.17624
## U2 16.780 8.234 2.04 0.05016 .
## GDP 0.962 1.037 0.93 0.36075
## Ineq 7.067 2.272 3.11 0.00398 **
## Prob -4855.266 2272.375 -2.14 0.04063 *
## Time -3.479 7.165 -0.49 0.63071
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 209 on 31 degrees of freedom
## Multiple R-squared: 0.803,Adjusted R-squared: 0.708
## F-statistic: 8.43 on 15 and 31 DF, p-value: 3.54e-07
crime.lm2 <- lm(Crime ~ M + Ed + Po1 + U2 + Ineq + Prob)
summary(crime.lm2)
##
## Call:
## lm(formula = Crime ~ M + Ed + Po1 + U2 + Ineq + Prob)
##
## Residuals:
## Min 1Q Median 3Q Max
## -470.7 -78.4 -19.7 133.1 556.2
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -5040.50 899.84 -5.60 1.7e-06 ***
## M 10.50 3.33 3.15 0.0031 **
## Ed 19.65 4.48 4.39 8.1e-05 ***
## Po1 11.50 1.38 8.36 2.6e-10 ***
## U2 8.94 4.09 2.18 0.0348 *
## Ineq 6.77 1.39 4.85 1.9e-05 ***
## Prob -3801.84 1528.10 -2.49 0.0171 *
157

## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 201 on 40 degrees of freedom
## Multiple R-squared: 0.766,Adjusted R-squared: 0.731
## F-statistic: 21.8 on 6 and 40 DF, p-value: 3.42e-11
Podemos ver que no hay diferencias significativas entre ambos modelos.
anova(crime.lm, crime.lm2)
## Analysis of Variance Table
##
## Model 1: Crime ~ M + So + Ed + Po1 + Po2 + LF + M.F + Pop + NW + U1 +
## U2 + GDP + Ineq + Prob + Time
## Model 2: Crime ~ M + Ed + Po1 + U2 + Ineq + Prob
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 31 1354946
## 2 40 1611057 -9 -256111 0.65 0.75
158

Capıtulo 7
De como usar R en untiempo razonable (no facil,no)
En este capıtulo se incluyen algunos consejos practicos para trabajar con R. Lasposibilidades son enormes. Sin embargo, de tantas que tiene lo mas probable es que elusuario ocasional no llegue a conocer ninguna de ellas. Antes lo habra abandonado.Y con razon. Si llevas anos utilizandolo con unas pocas lıneas de codigo haces loque con programas basados en menu te cuesta horas (y cuando lo vuelves a repetirte vuelve a costar horas porque tu aprendizaje no te ahorra tiempo futuro lo que enR no ası). Pero lo de anos usando algo es una utopıa que solo se pueden permitirunos cuantos profesores universitarios sin nada mejor que hacer y muchos horas quellenar de su importante tiempo.
Cuando usamos un programa informatico hay dos problemas fundamentales que,dependiendo de la persona, uno puede ser mucho mayor que el otro. Un problemaes el manejo del dichoso programa. ¿Como se ha disenado el interfaz? ¿Donde hanpuesto tal o cual opcion de la tecnica? En fin, no vale la pena seguir. Se asume que unbuen menu es la clave de un buen programa (sobre todo, para un usuario inexperto).En definitiva, se trata de eliminar cualquier tipo de aprendizaje (inicial o posterior)para que sea de uso inmediato. Algunas personas (entre las que me encuentro)piensan que eso no esta tan claro. Se acaba pagando el pato. Lo que no pierdes (nome atreve a hablar de ganar) al principio lo pierdes mas tarde. Programas como Rbasados en el uso de un lenguaje sencillo permiten un aprendizaje rapido y profundo.Aprendes Estadıstica al mismo tiempo que aprendes a manejar el programa. Y,desde un punto de vista docente, es una razon importante para utilizarlo.
En este capıtulo he ido incluyendo distintas cuestiones basicas para el uso delprograma. Desde el como conseguirlo o instalarlo hasta como trabajar con el. Muchode lo que sigue se basa en mi propia experiencia. De hecho, muchos estudiantes alos que sugieres formas de trabajo, utilizan otros trucos que les resultan mas utiles.Mi edad (y cerrazon mental) me impiden cada vez mas adaptarme a nuevas ideas.Es importante darse cuenta de que es un programa abierto y que, facilmente, lopuedes integrar con otras herramientas informaticas. La idea es: elige el editor quequieras. Genera las figuras en formatos distintos y utiliza el procesador de textosque se quiera. En fin, de esto vamos a tratar.
159

7.1. Instalacion y como trabajar con R
La direccion basica es http://cran.r-project.org. Allı se tienen tanto lasfuentes como versiones compiladas para Windows, Mac y Linux.
7.1.1. R y Windows
Los puntos a seguir para una instalacion son los siguientes:
1. a) Traer la distribucion base de cran.
b) El programa se instala simplemente ejecutandolo.
c) Una vez instalado en el menu principal teneis una herramienta que per-mite seleccionar el espejo desde traer los paquetes adicionales comoda-mente.
2. Una vez instalado el programa la opcion mas comoda es utilizar el programaTinn-R. Vamos escribiendo el codigo en su editor y tiene muchas herramientaspara interactuar con R. Es, sin duda, la mejor opcion para Windows.
3. Una segunda opcion es utilizar RWinEdt. Para poder usarlo hay que tenerinstalado Winedt. Es un programa shareware muy util para escribir en LATEX.Una vez instalado WinEdt cargamos el paquete RWinEdt ?.
7.1.2. R y Linux
Es mi opcion personal de trabajo. La recomiendo definitivamente. Por Linux yporque el trabajo con R es muy comodo. 1
Instalacion 1. Para Linux hay distintas versiones compiladas que puedes encon-trar en cran.
2. No es complicado compilar R a partir de las fuentes. Hay que tener laprecaucion de tener gfortran.
3. Cuando instalamos R en Linux hemos de instalar previamente la librerıaBLAS.
Edicion con Emacs y ESS En Linux sin duda la mejor opcion de trabajoes utilizar Emacs con el paquete Emacs Speaks Statistics (ESS) 2.
¿Como trabajamos con Emacs y ESS?
1. Abrimos el fichero R con emacs.
2. Abrimos una nueva ventana (mejor separada) con CTRL x 52.
3. En la nueva ventana marcamos el icono de R.
4. Utilizamos la ventana donde esta el codigo para editar y podemosusar los distintos controles que nos da el menu ESS de emacs pode-mos trabajar muy comodamente.
7.2. ¿Como instalar un paquete?
Supongamos que queremos instalar el paquete UsingR ?.
install.packages``UsingR''
1Imagino a un usuario de Windows tıpico sonreir ante la afirmacion anterior. Me alegro de quepueda sonreir despues de los lloros continuos usando esa cosa llamada Windows (que no sistemaoperativo).
2La mejor opcion es acudir a la pagina de los paquetes binarios y buscar en la distribucioncorrespondiente donde teneis el paquete
160

7.3. ¿Como fijar el directorio de trabajo?
Empezamos una sesion de R y todo nuestro trabajo (datos, codigo R) lo tenemosen un directorio. Hemos de tener un acceso comodo a estos ficheros. ¿Como hacerlo?
En Linux no hay problema. Simplemente con la consola nos vamos al directoriocorrespondiente y ejecutamos R. Automaticamente hemos fijado el directorio detrabajo como aquel en que iniciamos el programa.
En Windows lo recomendable es utilizar el menu y cambiar el directorio al detrabajo. Yo recomiendo una vez hecho esto ejecutar:
getwd()
Nos devuelve todo el camino hasta dicho directorio. Lo que nos devuelve esta funcion(por ejemplo C: Mis documentos ad prog) lo ponemos entre comillas dobles yejecutamos
setwd("C:\ Mis documentos\ ad\ prog")
De este modo hemos fijado el directorio de trabajo.
7.4. Etiquetas de valor y de variable
Para denotar una variable utilizamos siempre una expresion breve y simple. Sinembargo, es conveniente que la variable tenga una etiqueta explicativa del significadode la variable. Dicha etiqueta ha de ser clara y no muy larga.
7.4.1. ¿Como etiquetar una variable?
Supongamos que la variable a etiquetar es x en el data frame datos. Usamos lalibrerıa ?.
library(Hmisc
label(datos$x) = "Ejemplo de etiqueta"
7.5. Elaboracion de un informe a partir del codigoR
Una vez hemos analizado un banco de datos hemos de elaborar un informe.Normalmente nos va a llevar mas tiempo esta segunda parte que la primera.
7.5.1. Sweave
Es conveniente consultar esta pagina. Un documento de gran utilidad donde verla utilizacion de Sweave es este tutorial.
7.6. R y Octave/Matlab
Es frecuente que un usuario de Octave/Matlab utilice R. En este enlace y eneste teneis tablas de equivalencia entre los comandos en ambos programas.
Tambien se puede encontrar en http://mathesaurus.sourceforge.net/matlab-python-xref.pdf una tabla de equivalencias entre Matlab/Octave, Python y R.
161

162

Bibliografıa
H. Abdi and L. J. Williams. Principal component analysis. Wiley Interdiscipli-nary Reviews: Computational Statistics, 2(4):433–459, 2010. URL /home/gag/
BIBLIOGRAFIA/REPRINTS/AbdiWilliams10.pdf.
C.L. Blake D.J. Newman, S. Hettich and C.J. Merz. UCI repository of machi-ne learning databases, 1998. URL http://www.ics.uci.edu/$\sim$mlearn/
MLRepository.html.
E.R. Dougherty. Probability and Statistics for the Engineering, Computing andPhysical Sciences. Prentice Hall International Editions, 1990.
R.A. Fisher. The analysis of covariance method for the relation between a part andthe whole. Biometrics, 3:65–68, 1947.
L. Kaufman and P.J. Rousseeuw. Finding Groups in Data. An Introduction toCluster Analysis. Wiley, 1990.
C.R. Rao. Linear Statistical Inference and Its Applications. Wiley, 1967.
J. Verzani. Using R for Introductory Statistics. Chapman & Hall / CRC, 2005.
163


















