
Estudio de las Lenguas en Internet medición Mayo 2005 · Web viewDaniel Pimienta, Daniel Prado y...
55
Doce años midiendo la diversidad lingüística en Internet: balance y perspectivas. Daniel Pimienta 1 , Daniel Prado 2 y Álvaro Blanco 3 RESUMEN Funredes y la Unión Latina han creado un método original utilizando buscadores y una muestra de palabras-concepto con los mejores equivalentes en diferentes lenguas latinas, así como en inglés y en alemán con el fin de medir la proporción de la presencia de estas lenguas en ciertos espacios de Internet, especialmente en la Web. Este método, aplicado desde 1996 hasta 2008, ha permitido crear indicadores interesantes para medir la diversidad lingüística. Asimismo, se ha llevado a cabo un estudio simple con el objetivo de evaluar la proyección de la cultura asociada a las lenguas latinas y al inglés. Este documento describe el método, sus resultados, ventajas y límites, además muestra una serie de métodos alternativos y sus resultados buscando establecer comparaciones y para concluir, presenta una evaluación de las perspectivas de un campo desprovisto de rigor científico en el periodo considerado ocasionando una cierta desinformación sobre la presencia del inglés, el cual que en la actualidad llama progresivamente la atención de organizaciones internacionales y del mundo universitario. Todos los datos detallados y pertinentes sobre el método y sus resultados se encuentran en libre acceso en la Web. Palabras clave: lenguas, Internet, Web, diversidad lingüística, políticas lingüísticas, indicadores. 1 Responsable de FUNREDES (http://funredes.org ), miembro del Comité Ejecutivo de la Red MAAYA (http://maaya.org ), investigador de la Universidad de Antillas-Guyana en Martinica. 2 Director de la Dirección Terminología e Industrias de la Lengua de la Unión Latina, Secretario Ejecutivo de la Red MAAYA. 3 Responsable de FUNREDES en España.
Transcript of Estudio de las Lenguas en Internet medición Mayo 2005 · Web viewDaniel Pimienta, Daniel Prado y...

Doce años midiendo la diversidad lingüística en Internet: balance y perspectivas.
Daniel Pimienta1, Daniel Prado2 y Álvaro Blanco3
RESUMEN
Funredes y la Unión Latina han creado un método original utilizando buscadores y una muestra de palabras-concepto con los mejores equivalentes en diferentes lenguas latinas, así como en inglés y en alemán con el fin de medir la proporción de la presencia de estas lenguas en ciertos espacios de Internet, especialmente en la Web. Este método, aplicado desde 1996 hasta 2008, ha permitido crear indicadores interesantes para medir la diversidad lingüística. Asimismo, se ha llevado a cabo un estudio simple con el objetivo de evaluar la proyección de la cultura asociada a las lenguas latinas y al inglés. Este documento describe el método, sus resultados, ventajas y límites, además muestra una serie de métodos alternativos y sus resultados buscando establecer comparaciones y para concluir, presenta una evaluación de las perspectivas de un campo desprovisto de rigor científico en el periodo considerado ocasionando una cierta desinformación sobre la presencia del inglés, el cual que en la actualidad llama progresivamente la atención de organizaciones internacionales y del mundo universitario. Todos los datos detallados y pertinentes sobre el método y sus resultados se encuentran en libre acceso en la Web.
Palabras clave: lenguas, Internet, Web, diversidad lingüística, políticas lingüísticas, indicadores.
1 Responsable de FUNREDES (http://funredes.org), miembro del Comité Ejecutivo de la Red MAAYA (http://maaya.org), investigador de la Universidad de Antillas-Guyana en Martinica.2 Director de la Dirección Terminología e Industrias de la Lengua de la Unión Latina, Secretario Ejecutivo de la Red MAAYA.3 Responsable de FUNREDES en España.

ÍNDICERESUMEN........................................................................................................................1I- INTRODUCCIÓN – NACIMIENTO DE UN PROYECTO........................................2II- CONTEXTO DEL PROYECTO..................................................................................4III- ANTECEDENTES DEL PROYECTO.......................................................................7IV- METODOLOGÍA.......................................................................................................8
4.1 – METODOLOGÍA LINGÜÍSTICA....................................................................104.2 – METODOLOGÍAS DE LOS BUSCADORES..................................................134.3 – METODOLOGÍA ESTADÍSTICA....................................................................154.4 – CREACIÓN DE INDICADORES.....................................................................16
V- RESULTADOS..........................................................................................................195.1- PRINCIPALES RESULTADOS.........................................................................195.2- ANÁLISIS POR PAÍS.........................................................................................225.5-OTROS ESPACIOS DE DIVERSIDAD LINGÜÍSTICA....................................245.6-DIVERSIDAD CULTURAL................................................................................24
VI-EVALUACIÓN DEL MÉTODO..............................................................................276.1-SU CARÁCTER ÚNICO Y SUS VENTAJAS....................................................276.2- LÍMITES E INCONVENIENTES.......................................................................28
VII- EVALUACIÓN DE OTROS MÉTODOS..............................................................28VIII- PERSPECTIVAS...................................................................................................34BIBLIOGRAFÍA.............................................................................................................35TABLA DE ILUSTRACIONES.....................................................................................37
AGRADECIMIENTOSAdemás de los autores muchas personas de la Unión Latina o de Funredes han participado en este proyecto, algunas de ellas han jugado un rol clave y merecen una especial atención: Marcelo Sztrum, quien ha tenido a su cargo al equipo de lingüistas para la selección de la muestra de palabras; Benoît Lamey, quien ha diseñado el programa limitando la intervención humana en las campañas de medición y Roger Price, quien ha aportado elementos esenciales para la estadística.
I- INTRODUCCIÓN – NACIMIENTO DE UN PROYECTO
En diciembre de 1995 durante la Cumbre de la Francofonía en Cotonú, se afirmó públicamente que el inglés estaba presente en 90% del Internet lo que hizo que esta cifra fuera utilizada para hacer declaraciones un poco hostiles contra Internet, esto desencadenó a su vez una reacción por parte de Funredes en defensa de Internet. Primero, intentamos localizar, en vano, la fuente de esta cifra; luego, buscamos una forma de reproducir algunas cifras aproximativas. La idea de utilizar la potencia de los buscadores (en un mundo dominado en aquella época por Altavista) y de establecer una primera estimación bastante aproximativa de la repartición del inglés, del francés y del español en la Web4 surgió naturalmente. Del mismo modo, llevamos a cabo otra estimación simple de la representación de las culturas asociadas a estas lenguas
4 Ver: http://funredes.org/lc2005/english/L1.html

midiendo y comparando5 la presencia de nombres de personajes célebres de diferentes categorías.
Estos dos procesos, y en particular el de la medición lingüística, obviamente carecían de valor científico pero nos permitieron:
1) Hacer una estimación bastante aproximativa (cerca del 80%) de la presencia del inglés en la Red,
2) Hacer un inventario de los obstáculos lingüísticos que hubo que superar para obtener un método fiable de medición de la diversidad lingüística en la Red basado en la cantidad de ocurrencias de una palabra dada en las páginas Web registradas por los buscadores.
3) Mostrar que la naturaleza mundial de la Red permitía una representación justa de la cultura francesa (al menos cuando ésta estaba claramente disociada de temas comerciales) mas no de la cultura española (su situación desde ese entonces ha cambiado).
Además, esto lanzó probablemente un proceso de colecta de informaciones relevantes para la arqueología de la Internet, así como datos valiosos para el análisis de los comportamientos históricos de los buscadores…
En cualquier caso, esta reacción preparó el terreno para lo se convertiría, en el periodo 1996-2006, la única campaña de mediciones reiteradas y coherentes de la presencia de un subconjunto de lenguas en la Web con una metodología y resultados establecidos transparentemente6.
A lo largo de estos 10 años, tuvimos que luchar constantemente contra una aguda desinformación sobre la presencia del inglés en la Red que contra todo análisis serio y hechos irrefutables siguió siendo estimada año tras año a 80% a pesar de la tremenda velocidad del avance de la demografía de Internet que muestra cifras que pasan de 80% a 40% de internautas anglófonos.
No se trató de una lucha en defensa del francés, sino más bien de la coherencia del rol de Funredes como Organización no gubernamental implicada en el campo de las TIC por el desarrollo7 y de defender la creación de contenidos locales. Era evidente que la amplia difusión de la presencia masiva, invasora y estable del inglés en la Red conspiraba contra la innegable necesidad de una política coherente de creación de contenidos en un mundo virtual que refleje la diversidad lingüística y cultural del mundo.
La publicación de un informe [UN] de la UNESCO que intenta presentar equitativamente las posiciones en este campo (Paolillo sostiene en su artículo que el porcentaje es de 80% teniendo como principal referencia los trabajos del equipo de OCLC; mientras que Pimienta, apoyado en una serie de estudios realizados por
5 Ver: http://funredes.org/lc2005/english/C1.html 6 Los otros métodos propuestos en esta época fueron aplicados una sola vez y el proceso metodológico de la mayoría de ellos no ha sido descrito claramente.7 Las ONG que trabajan en este campo intentan utilizar las TIC con el fin de permitir a las personas, comunidades y países cambiar de manera positiva su condición socio-económica. La diversidad lingüística en Internet es un tema importante en la lucha contra la brecha digital.

investigadores alrededor del mundo8, sostiene que el porcentaje de la presencia del inglés es de alrededor de 50%) ha marcado probablemente un giro histórico en este periodo conduciendo a una mayor apertura al tema, apoyando o despertando a su vez el interés de varios investigadores en este vasto, sin embargo olvidado, campo de estudios.
En estos últimos 12 años, Funredes y la Unión Latina siempre publicaron su método y sus resultados con una total transparencia pero no han llegado a dar una explicación clara y pedagógica de su trabajo, contentándose con presentar una serie de eventos y forzando al lector a seguir el orden cronológico para entender la situación. Este informe intentará resolver este problema y ofrecer un material completo que incluya un análisis y un planteamiento sintético de la evolución de los resultados obtenidos a partir de los diferentes estudios llevados a cabo por los investigadores o los responsables interesados en el campo de la diversidad lingüística en Internet en un momento en el que los cuestiones que están en juego reciben la atención que se merecen9.
Así pues, explicaremos los valores y límites de nuestro método y sus resultados, también analizaremos otros trabajos y presentaremos lo que nos parece ser sus límites.
Explicaremos por qué y cómo esta metodología, debido a la reciente evolución de los buscadores, se encuentra ante un impase y por qué esto nos ha llevado a crear herramientas más ambiciosas que reflejen la realidad de la totalidad de la Web.
Para concluir, trazaremos perspectivas generales para los estudios en este campo y presentaremos nuestras propuestas para continuar con la búsqueda de la medición de la diversidad lingüística y cultural en la Internet.
II- CONTEXTO DEL PROYECTO
Generalmente los especialistas discrepan cuando se trata de dar cifras demográficas sobre las lenguas, ya que las definiciones y las fronteras son complejas y no es fácil llegar a un consenso. Las informaciones que aparecen más abajo han sido tomadas principalmente de las cifras de David Crystal [CRY] y en lo que concierne a las lenguas latinas nuestras fuentes provienen de la Unión Latina.
El número de lenguas creadas por los seres humanos se estima a alrededor de 40 000, de las cuales 6 000 y 9 000 (las cifras varían según las estadísticas) aún se utilizan. Se estima que una lengua desaparece cada 2 meses en promedio.
En este contexto, las TIC pueden jugar un rol en la preservación de la memoria y la cuestión sobre si Internet es una oportunidad o una amenaza para la diversidad lingüística aparece espontáneamente.
La respuesta no es simple y depende de muchos parámetros sobre la lengua: ¿Es una lengua local, nacional, internacional o una lingua franca? ¿Proviene de un país 8 Algunos buenos artículos que no hayan sido seleccionadas en el informe final a falta de espacio pueden ser leídos aquí: http://funredes.org/lc/english/unesco/.9 Como lo afirma el último Foro para la Gobernanza de Internet que tuvo lugar en Río de Janeiro, en una mesa redonda consagrada a este tema, coordinada por el Ministro brasileño de la Cultura, Gilberto Gil y en la que el Presidente de la Red Maaya, Adama Samassekou, participó. Ver: http://www.intgovforum.org y en particular: http://www.intgovforum.org/Rio_Meeting/IGF2-Diversity-13NOV07.txt

desarrollado? ¿Existe una política lingüística? ¿Existe una política lingüística para el mundo virtual?
La clasificación simple que presentamos aquí abajo intenta resumir la situación. Esta clasificación no pretende proponer respuestas definitivas sino al contrario, tiene el deseo de incitar la reflexión sobre un tema al cual la sociedad civil no ha sido muy sensibilizada como para la diversidad biológica a pesar de la evidente correlación que existe entre ambas10. En la situación actual de nuestro planeta la ausencia de políticas que hagan frente a la reducción de la diversidad biológica podría ser perjudicial para el futuro, ¿Por qué no ocurriría lo mismo con la diversidad cultural?
Tipo de lengua ¿Internet es una oportunidad?Lenguas principales11 Internet podría amplificar la presencia de las lenguas sobretodo en
un periodo de transición en el que la repartición de internautas por lengua no se debe a la brecha digital.Nota: Nuestra tesis es que este periodo transitorio ya terminó para el inglés hace unos años atrás.
Lenguas oficiales de más de un país desarrollado (como el italiano o el neerlandés).
Existe una oportunidad en el mundo virtual que tiene que ser aprovechada, el estatus “internacional” de estas lenguas puede inspirar confianza a sus hablantes a interactuar cómodamente más allá de las fronteras de sus países.
Lenguas oficiales habladas en un solo país desarrollado (como el noruego, griego, danés, japonés)
Hace falta una política lingüística virtual enérgica para obtener una presencia en el mundo virtual similar o superior a la del mundo real, sin embargo los hablantes pueden sentir una barrera al interactuar con personas de otros países si utilizan sus lenguas.
Lenguas locales de países desarrollados (sardo, gallego, galés, frisón, etc.)
Estas lenguas se encuentran bajo amenaza debido a una fuerte presión proveniente del inglés y de la lengua nacional del país donde son habladas. A falta de una política lingüística virtual, el diagnóstico es incierto y además depende de diversos criterios; aunque el caso del catalán es un ejemplo de éxito tanto en el mundo virtual como en el mundo real.
Lingua franca de los hablantes de ciertos países en desarrollo (hausa, quechua, fula, suajili, etc.)
Puede haber un futuro positivo si la brecha digital es superada y si las políticas lingüísticas virtuales son definidas.
Lenguas de más de un país en desarrollo (aymara, guaraní, criollo, etc.) y que sólo son utilizadas por sus hablantes nativos.
En teoría puede haber un futuro positivo si la brecha digital es realmente superada; sin embargo, existe una clara correlación entre la pertenencia a las comunidades autóctonas y la falta de acceso que no parece dar señales de cambio. El caso del Paraguay en el que el guaraní se está armando de instrumentos consecuentemente con su estatus de lengua oficial debe ser seguido con interés.
Lenguas oficiales de un solo país en desarrollo (esloveno, albanés, etc.)
Estas lenguas se encuentran bajo una fuerte presión por parte del inglés y de las lenguas vecinas influyentes pudiendo provocar perspectivas negativas a falta de políticas virtuales.
Lenguas locales de países en desarrollo (chabacano, maya, mapuche, etc.)
Si la lengua dispone de las herramientas lingüísticas necesarias (especialmente, en primer lugar, de una escritura y una gramática establecidas y normalizadas), una política lingüística que vele por la creación de contenidos locales podría ser útil. Hoy en día existen pocos ejemplos positivos de este tipo.
Lenguas en peligro de extinción (como el ainu12)
Internet podría, en el peor de los casos, convertirse en una herramienta excepcional de conservación del patrimonio escrito y
10 La correlación entre las regiones del mundo que tienen una diversidad biológica baja / elevada y el número de lenguas habladas es importante.11Estimación del número de hablantes (primera o segunda lengua) para las principales lenguas habladas en el mundo:X = NÚMERO DE HABLANTES (MILLONES)LENGUASX > 500CHINO, INGLÉS, HINDI200 < X < 500ESPAÑOL, RUSO, ÁRABE(S)100 < X < 200BENGALÍ, PORTUGUÉS, JAPONÉS, INDONESIO, ALEMÁN, FRANCÉS12 http://fr.wikipedia.org/wiki/A%C3%AFnou_(langue_de_l%27ethnie_du_Japon)

oral y en el mejor de los casos, en un acelerador de políticas de rehabilitación de la lengua.
Lenguas en serio peligro de extinción (como el yagán13)
Internet podría al menos dar a conocer el patrimonio que esta lengua deja si se llevan a cabo campañas de digitalización de urgencia.
El rol de Internet con respecto a las lenguas
El mensaje principal que emana de este cuadro es la necesidad de crear políticas lingüísticas tanto el mundo real (el catalán es una buena referencia de estudio) como en el mundo virtual (sin duda alguna es interesante analizar las acciones francófonas, nuestros resultados parecen dar crédito a su política voluntarista de creación de contenidos).
Con la finalidad de construir una verdadera política sería conveniente obtener en primer lugar cifras útiles de la situación en un momento dado para evaluar los efectos de las políticas a partir de indicadores fiables. Hoy en día, una política lingüística completa debe incluir un elemento específico para el mundo virtual ya que aquí la lógica y la dinámica obedecen a reglas diferentes; partiendo de este punto, la necesidad de disponer de datos fiables sobre la presencia de las lenguas en Internet aparece naturalmente.
En este campo la situación ha sido paradójica y frustrante. La historia de las redes está en estrecha relación con la historia del mundo de la investigación y la universidad; sin embargo, con la llegada de la Red y el crecimiento de la actividad comercial en línea, el estudio de la evolución demográfica de Internet y de sus comportamientos ha sido dejado exclusivamente en manos del sector privado y, de manera aún más peligrosa, del sector marketing exponiendo estos datos esenciales al servicio de los intereses financieros de sociedades comerciales. La ausencia de transparencia de los métodos y la falta de rigor científico de las cifras publicadas sobre la demografía de Internet y en especial sobre la demografía lingüística nos hace creer que estos datos han podido ser inspirados por otros intereses que la simple observación. En un campo en el que la demografía avanza a una velocidad sin precedente en la historia del hombre esto ha permitido que el mito según el cual la presencia del inglés en la Web supera el 80% perdure. ¡Esta creencia masivamente mediatizada que no ha recibido ninguna crítica entre 1996 y 2006 ha sido apoyada principalmente por operaciones comerciales y algunos estudios carentes de la solidez elemental que el mundo académico reclama normalmente!
Esta época parece haber quedado atrás, hoy las instituciones como Maaya14, que surgió en la Cumbre Mundial de la Sociedad de la Información, iniciativas de la UNESCO15
que ofrecen un real seguimiento y los proyectos universitarios como el Language Observatory Project16 (http://www.language-observatory.org/) son prueba del creciente interés de responsables de políticas publicas y universitarios de retomar el control en este campo y contribuir de forma significativa al surgimiento de políticas lingüísticas virtuales basadas en indicadores fiables.
En este contexto, nuestro proyecto puede ser considerado como un intento pionero y comprometido de investigación-acción de parte de la sociedad civil de resistir al mar de
13 http://en.wikipedia.org/wiki/Yagan14 Red Mundial para la Diversidad Lingüística - http://maaya.org15Ver: http://www.unesco.org/cgi-bin/Webworld/portal_observatory/cgi/page.cgi?d=1&g=Cultural_Diversity_and_Multilingualism/index.shtml16 Dirigifo por el profesor Mikami, de la Nagaoka University of Technology, el Language Observatory (http://www.language-observatory.org/) está constituido de un consorcio internacional de colaboradores.

desinformación en un campo estratégico de la Internet. Nuestros trabajos hacen referencia de manera particular a cuestiones fundamentales como la brecha digital y la diversidad en el mundo virtual e indirectamente a la cuestión general de la gobernanza de la Internet (que en la actualidad se focaliza con intensidad en la cuestión de los nombres de dominio internacionales aunque sólo se trate de la parte visible del iceberg de la diversidad lingüística en la Red [KID]).
III- ANTECEDENTES DEL PROYECTO
Las personas interesadas encontrarán todos los antecedentes del proyecto en las páginas Web anteriores del sitio de Funredes17, todas las campañas de medición están clasificadas (de L1 a L5 y 2005 para el estudio lingüístico y de C1 a C3 para el estudio sobre la cultura, así como la última campaña). El nuevo sitio18 presenta los resultados después del 2005.
El siguiente cuadro resume las etapas del proyecto:
Fecha Estudio de las lenguas en Internet Presencia del inglés en la Red / Buscador utilizado
Estudio de la presencia cultural en Internet
06/96 L1: resultados bastante aproximativos— inglés, francés y español— la Web
~80 %
Altavista
C1: primer resultado sobre la cultura
03/97 L2: repetición de L1 ~80 %Altavista
03/98 L3: repetición con una muestra más grande— Método del “complemento del espacio vacío”— Análisis del método Alis — Decisión de consolidar el método en colaboración con la Unión Latina
~80 %
Altavista
09/98 L4: primer estudio realizado con una metodología fiable, en cooperación con la Unión Latina y con el apoyo financiero de la Agencia de la Francofonía —Incorporación del italiano, portugués y rumano— Incorporación de Usenet— Inicio de la creación de indicadores lingüísticos
75 %
Hotbot
Dejanews
C2: segundo resultado sobre la cultura con varias mejoras de la muestra y del modelo de clasificación.Notable mejora de la presencia de personajes franceses y españoles.
17 http://funredes.org/lc2005/18 http://funredes.org/lc/
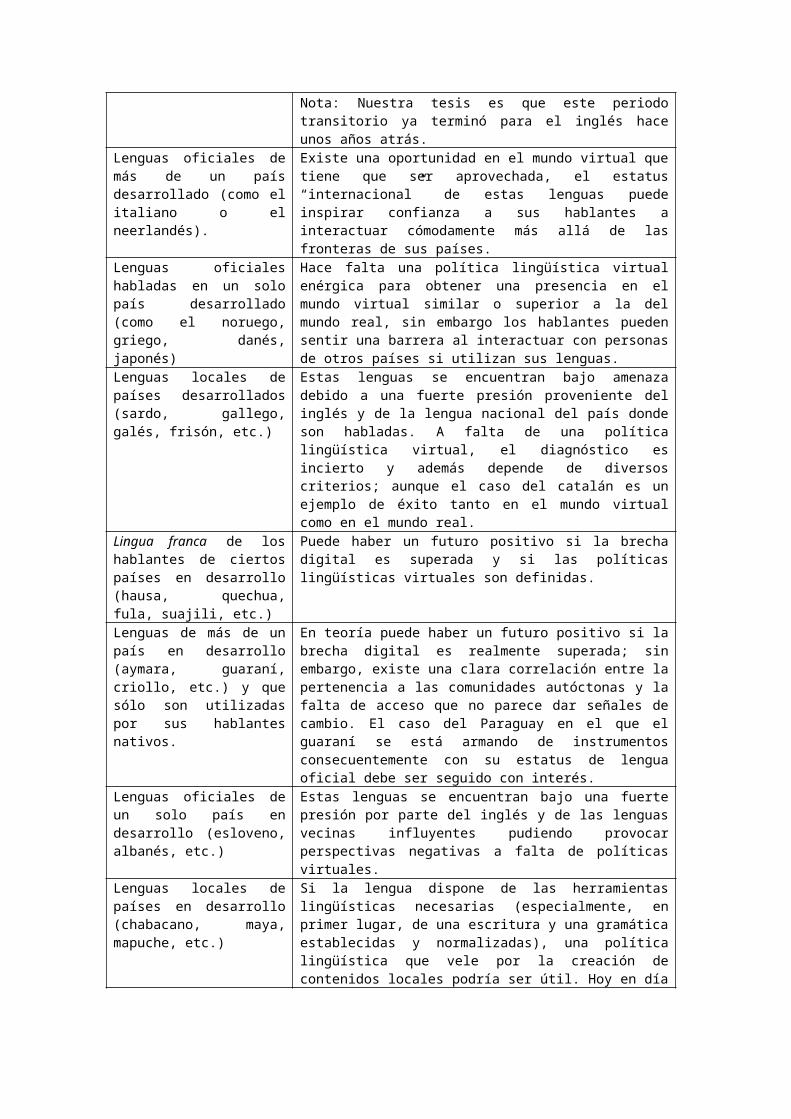
08/00 L5: segundo estudio realizado con una metodología fiable, en colaboración con la Unión Latina — Creación de un programa con el objetivo de generar automáticamente todo el proceso desde de consulta a los buscadores hasta los resultados estadísticos — Incorporación del alemán
60 %
Google + Fast
01/0106/0108/0110/0102/0202/0302/0405/0403/05
Ningún cambio19 de 55 %à47 %
FastYahooGoogle
C3, sept. 2001
10/05 Nuevos indicadores por país y por lengua
45 %Google
Nueva campaña sobre la cultura
03/06 Ningún cambio 45 %Google
12/07 Incorporación del catalán 45 %Yahoo
05/08 Yahoo Nueva campaña sobre la cultura
Cronología del proyecto
Setiembre de 1998 marca el principio de la fiabilidad de los métodos y resultados de nuestro estudio. Setiembre de 2000 marca el inicio de una gestión profesional y sistemática del proyecto con la puesta en marcha de un programa en PHP20 para la automatización de la totalidad del proceso y el mantenimiento de la base de datos de los resultados. Después del 2005 comenzamos a experimentar dificultades para validar los resultados debido al nuevo comportamiento de los buscadores.
IV- METODOLOGÍA
La metodología establecida reposa en la combinación de los siguientes elementos:
El uso de la función para contar las ocurrencias de los buscadores21; Una muestra de palabras-concepto en una selección de lenguas dadas; Un conjunto de herramientas estadísticas.
El buscador permite contar el número de páginas que contienen una palabra dada (o una expresión). Para ser utilizado en el marco de nuestro estudio el buscador seleccionado debe responder a criterios específicos:
19 http://funredes.org/lc2005/L6/english/evol.html20 PHP es un lenguaje de programación utilizado para crear páginas Web dinámicas. 21 La cifra dada por los buscadores en cuanto al número de páginas.

Ofrecer cifras fiables para realizar el conteo; Permitir un trato justo de los signos diacríticos22; Cubrir la mayor parte del espacio analizado que sea posible
La muestra de palabras que serán aplicadas al buscador seleccionado para contar las ocurrencias de las páginas debe ser construida con el fin de obtener (para un mismo concepto entre las lenguas de estudio):
Una equivalencia sintáctica perfecta; La mejor equivalencia semántica; Una neutralidad cultural.
Los valores de aparición de cada palabra medidos por los buscadores son compilados para cada concepto23, estos valores son tratados como una variable aleatoria cuya distribución es tratada a su vez de forma estadística (promedio, varianza, intervalo de confianza con la Ley de Fisher).
El resultado es una estimación del peso de las lenguas de estudio con respecto al inglés tal y como es medido en el índice del buscador24. En ciertas circunstancias (el factor clave es el tamaño del índice) se procede con prudencia a extrapolar el resultado como una representación justa de la repartición de las lenguas en la Web (visible)25.
Para obtener el porcentaje absoluto de las lenguas de estudio en el espacio medido es necesario determinar el peso absoluto del inglés, lo que desafortunadamente no es posible a través del método y debe ser establecido haciendo una comparación manual de diferentes fuentes y una estimación del peso del resto de las lenguas.
Las múltiples repeticiones del método permiten obtener una visión de la evolución de la presencia de las lenguas en el espacio y apreciar al mismo tiempo el valor de un método que ha proporcionado resultados coherentes a los largo de las mediciones.
El espacio Web ha constituido el principal objeto de estudio pero también hemos estudiado en repetidas ocasiones otros espacios (por ejemplo, los “newsgroups” o, más recientemente, la blogósfera o Wikipedia).
La descripción de más detalles sobre la metodología pasa por:- Los criterios precisos para la validación y utilización de buscadores;- Los criterios lingüísticos que han sido utilizados para construir la muestra de términos (y las correcciones necesarias en ciertos casos);
22Los signos diacríticos presentes en la mayor parte de lenguas que utilizan el alfabeto latín, pero ausente en el inglés, permiten con frecuencia, como se sabe, identificar diferentes significados (caña en español tiene un significado distinto a cana, côte en francés es distinto a cote o côté). Regido desde el principio bajos las reglas de la lengua inglesa tendía a impedir la codificación de los signos diacríticos.23 Con las correcciones apropiadas en algunos casos24 Se entiende por “índice del motor” el total de páginas Web indexadas por el buscador. El porcentaje de la Web visible pasó a partir del inicio del estudio de más del 80% a menos del 30%. Es razonable considerar que los resultados representaban la totalidad del espacio cuando la proporción era de más del 80%. A partir de 2005, la realidad es que los buscadores indexan menos del 30% del universo de la Web y sesgos lingüísticos indirectas en la selección del índice han que la extrapolación sea imposible. Esta tendencia parece acentuarse y volverse irreversible (ver el esquema en la parte “buscadores”).25 La Web invisible o Web profundo es la suma de páginas dinámicas creadas por bases de datos u otros mecanismos de programación de páginas dinámicas. Algunos autores consideran que la Web invisible podría ser de 100 a 500 veces más extenso que la Web visible [WP].

- Las herramientas estadísticas utilizadas para alcanzar los resultados finales;- La creación de indicadores a partir de resultados o a partir una forma de uso diferente de los buscadores;- La naturaleza, el significado y límites de los resultados obtenidos.
4.1 – METODOLOGÍA LINGÜÍSTICALa lista de 57 conceptos utilizados en español para la comparación lingüística es la siguiente:
ambigüedad, casualidad, queso, contabilidad, contigüidad, peligroso, diciembre, densidad, disparidad, divisibilidad, elasticidad, electricidad, febrero, feminidad, fertilidad, fidelidad, fraternidad, viernes, heterosexualidad, homosexualidad, caballo, humedad, enfermedad, inmortalidad, inmunidad, incompatibilidad, infalibilidad, inferioridad, infidelidad, inestabilidad, inviolabilidad, irregularidad, irresponsabilidad, junio, rodilla, cuchillo, pulmón, masculinidad, lunes, octubre, paridad, probabilidad, productividad, pubertad, responsabilidad, sexualidad, singularidad, superioridad, jueves, hoy, verdad, martes, uniformidad, universalidad, universidad, miércoles, amarillo
A continuación presentamos dos ejemplos del conjunto de palabras asociadas a un concepto en las diferentes lenguas estudiadas. Las palabras que aparecen en cursiva son aquellas que no están correctamente escritas pero que serán igualmente medidas (como en el caso de las palabras en francés después de eliminar los signos diacríticos). Las palabras que aparecen en MAYÚSCULA son aquellas que tienen problemas de homografía interlingüística u otros (y que necesitan un trato particular).
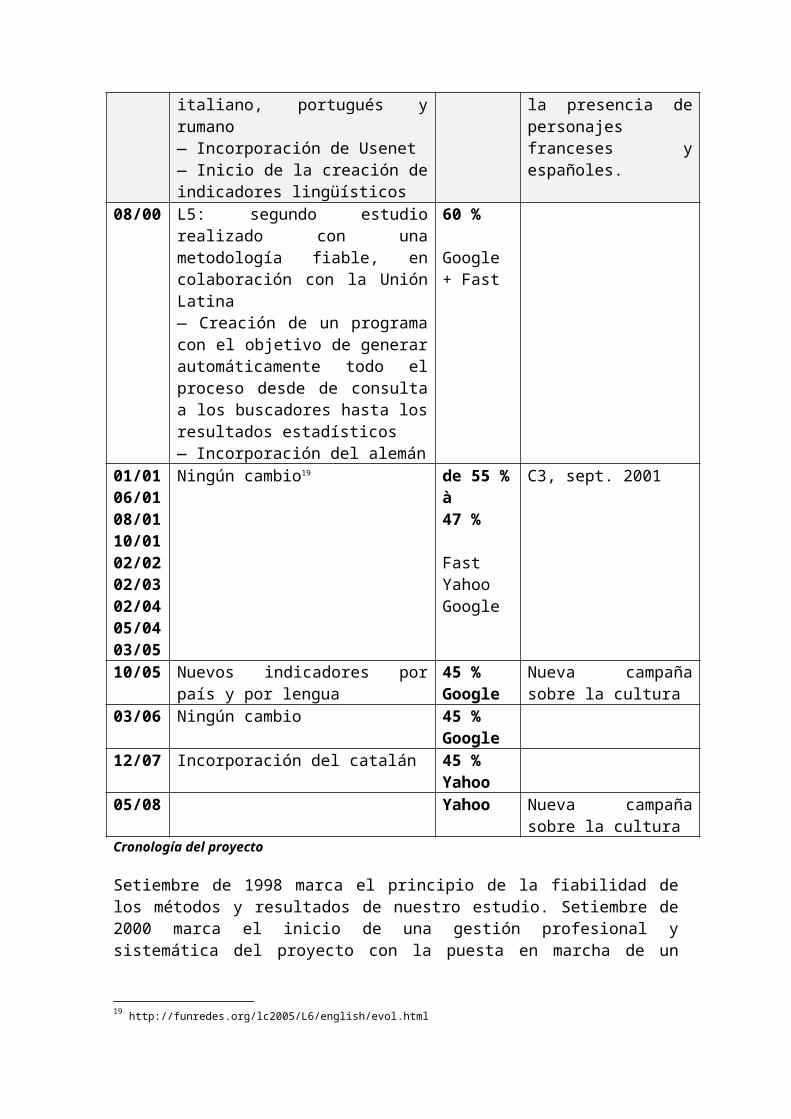
El cuadro completo, que contiene un poco más de 1 700 palabras, puede ser consultado aquí: http://funredes.org/lc/english/historia/listapa.htm.
Anglais Espagnol français italien portugais roumain allemand catalanFidelityfidelitiesfaithfulnessfaithfulnesses
FidelidadFIDELIDADES
fidélitéfidelitefidélitésfidelites
Fedeltàfedelta
FidelidadeFIDELIDADES
fidelitatefidelitateafidelităţiifidelitatiifidelităţifidelitatifidelităţilefidelitatilefidelităţilorfidelitatilor
TREUE TREUEN
fidelitat FIDELITATS
MondayMondays
Lunes lundilundis
lunedìlunedi
segunda-feirasegundas-feiras
lunilunea
montag MONTAGESmontags MONTAGE MONTAGEN
Dilluns
Ejemplo de palabras utilizadas en la muestra
Decidimos establecer criterios para obtener las mejores equivalencias, con esto en mente sometimos a pruebas y filtramos una gran cantidad de conceptos26, no pudimos alcanzar la perfección y fue necesario llevar a cabo tratamientos posteriores para evitar el sesgo estadístico (como lo muestra el cuadro anterior; por ejemplo, fue necesario compartir el resultado del término fidelidades entre el español y el portugués o deducir
26 Evaluamos varios cientos de palabras antes de formar el cuadro final y el proceso es el resultado de un trabajo de equipo intenso que duró varios meses caracterizado por una estrecha colaboración entre la Unión Latina y Funredes.
las ocurrencias francesas de montage et montages para calcular las del alemán). En ciertos casos, toleramos problemas bien diferenciados como parte de la alteración aceptable del estudio (por ejemplo, el hecho que Treue y TREUEN también son formas del adjetivo fidel, aumentando la semántica de las palabras en alemán).
La lista a continuación describe los criterios aplicados para crear la muestra.
Criterio nº 1: Neutralidad cultural Definición: propiedad de una palabra con respecto a la frecuencia de su aparición en el lenguaje en función de la cultura.Ejemplos: vino, perfume, gastronomía no son palabras culturalmente neutras en francés.Regla: Descartar los términos que están claramente influenciados por la cultura.
Criterio nº 2: Homografía interlingüísticaDefinición: La ortografía de un término en una lengua es idéntica a la de un término en otra lengua, el significado puede ser el mismo o no. Es prudente tomar en cuenta las homografías reales cuando la escritura es exactamente la misma (diacríticos incluidos) y las homografías sutiles cuando la única diferencia se encuentra en los signos diacríticos.Ejemplo: casa tiene el mismo significado en español y en portugués, red significa sistema o malla en español y rojo en inglés, gestión en español y gestion en francés tienen significados similares. La homografía interlingüística también puede limitarse a una parte de una palabra compuesta como en el uso inglés de Mardi gras.Reglas:- Evitar las palabras de menos de cuatros letras para limitar las homografías con las lenguas que no están en el marco del estudio;- Cuando una palabra con una homografía se encuentra en la muestra (lo que suele ser común entre el español y el portugués), dividir el número de páginas en proporción de la presencia de las lenguas (las palabras en mayúscula en el cuadro que presentamos respetan esta regla);- Siempre y cuando sea posible, corregir el conteo eliminando la palabra o la expresión homográfica (por ejemplo, el resultado de mardi en francés se obtiene después de haber sustraído el resultado de Mardi Gras en inglés).
Criterio nº 3: Homografía por préstamo Definición: una palabra de una lengua es aceptada tal cual en otra lengua.Ejemplo: las palabras en inglés business, sandwich o software son aceptadas en muchas otras lenguas. La palabra en francés déjà vu se dice tal cual en inglés.Regla: Descartar todos los términos que tengan esta propiedad.
Criterio nº 4: Homografía con abreviaciones o acrónimosDefinición: una palabra de una lengua dada tiene la misma escritura que una abreviación o un acrónimo en otra lengua.Ejemplos: el número sept se confunde con la abreviación de September en inglés.Regla: Descartar de la muestra tales términos. Dado que se deben evitar las palabras de menos de cuatro letras estamos relativamente protegidos contra esta situación.
Criterio nº 5: Homografía con nombres propios frecuentesDefinición: una palabra de una lengua dada tiene la misma escritura que un nombre propio usual en otra lengua.
Ejemplos: Julio significa julio (mes de julio) en español, pero también es un nombre bastante común. Windows también es el nombre de una marca de programas frecuentemente citado en Internet.Regla: Descartar esos términos.
Criterio nº 6: Homografía con posibles errores de tecleo o de ortografíaDefinición: la escritura de un término con un error común de ortografía corresponde a un término en otra lengua.Ejemplos: si es escribe embassador, en inglés, con una sola “s” corresponde al mismo concepto en rumano.Regla: Descartar el término sólo si la lengua meta es el inglés (es el único caso en el que podría causar un importante efecto estadístico).
Criterio nº 7: Polisemia o campos semánticos diferentesDefinición: cuando una misma palabra tiene diferentes significados expresados en varias palabras en otras lenguas.Ejemplo: prix en francés se traduce a la vez por price y prime en inglés, y por premio y precio en español.Regla: Descartar esos términos o asegurarse de hacer una comparación incluyendo todos los significantes que completarían una significado equivalente en las lenguas que lo necesiten.
Criterio nº 8: Falta de correspondencia Morfosintáctica Definición: cuando la misma palabra posee diferentes funciones en una lengua y necesita varios equivalentes en otra.Ejemplos: Love en inglés corresponde a la vez al sustantivo amour y al verbo aimer en diferentes conjugaciones en francés (aime, aimes, aimons, aimez, aiment…).Regla: Evitar estos términos. Es por esta razón que no hay verbos en la muestra.
Criterio 9: Características gramaticales discordantes Definición: la misma palabra en una lengua necesita ser declinada en otras lenguas.Ejemplos: yellow corresponde en español a amarillo, amarilla, amarillos, amarillas. El par instability / instabilities en inglés corresponde a las siguientes variantes rumanas: instabilitate, instabilitatea, instabilităţii, instabilităţi, instabilităţile, instabilităţilor.Regla: estas palabras son aceptadas si se multiplican en las otras lenguas las variantes en género, número y caso cuando el equivalente lo requiere. Esto explica porqué el número de palabras en la muestra puede ser tan distinto en función de la lengua.
Criterio nº 10: SinonimiaDefinición: cuando un mismo concepto en una lengua es expresado en varias palabras según el país en el que se utiliza.Ejemplos: según el país hispanohablante en el que sea utilizado, essence se dice nafta, gasolina, carburante, etc. Regla: estas palabras se aceptan siempre y cuando se multipliquen las variantes sinonímicas nacionales o regionales.
Criterio nº 11: Variación ortográfica Definición: cuando una misma palabra tiene diferentes ortografías según el país en el que se utilice.

Ejemplo: Theater en inglés americano y theatre en inglés británico. Electricidade en Portugal y eletricidade en Brazil.Regla: estas palabras se aceptan siempre y cuando se multipliquen las variantes ortográficas.
La aplicación de estos once criterios permitió establecer la lista actual que permanece invariable desde el comienzo del proceso, cada nueva lengua ha sido agregada a partir de la misma muestra.
Tratamiento posteriorComo lo muestran los dos ejemplos mencionados anteriormente, en esta muestra no ha sido posible realizar la filtración completa para eliminar todos los problemas lingüísticos (la probabilidad de encontrar homografías interlingüísticas es bastante elevada) y a veces es necesario llevar a cabo algunos tratamientos posteriores para reducir sesgos estadísticos indeseables. La decisión de corregir o no las cifras de conteo se basó en elementos estadísticos pragmáticos; la corrección generalmente se lleva a cabo utilizando una regla simple de proporcionalidad. La situación que se presenta con más frecuencia es la del sufijo plural –idades muy común en español y en portugués; se tomó la decisión de dividir la cantidad de ocurrencias entre las lenguas concernidas de manera proporcional. Todas las otras situaciones que tuvieron que ser tratadas de forma particular están descritas en informes anteriores27.
Todas estas labores de tratamiento posterior han sido integradas en el programa del proyecto y se efectúan sin intervención humana. Sin embargo, en cada campaña se lleva a cabo sistemáticamente un examen manual completo de los resultados (con la ayuda de un programa que detecta las anomalías estadísticas) con el fin detectar posibles situaciones desagradables.
Intento de modificación de la muestra En un momento dado, se pensó utilizar términos complejos28 (o expresiones compuestas de más de una palabra) en vez de palabras sueltas para evitar las homografías. El resultado fue extremamente decepcionante, perdimos una gran parte de nuestro tiempo. El conteo obtenido fue muy extraño, en muchos casos éste registró a la expresión inglesa utilizada muy por debajo de las otras. El análisis del fenómeno nos condujo al diagnóstico de comportamientos caóticos que atribuimos a la pérdida de un carácter linear de la función matemática correspondiente.
Los siguientes ejemplos ilustran la situación:
En inglés Cantidad de ocurrencias En francés Cantidad de ocurrencias« networks » 3 834 260 « reseaux » 326 250« development » 21 258 510 « developpement » 909 790« networks and development » 201 « reseaux et developpement » 61
« note bank » = 150 000 « billet de banque » = 123 000 «billete de banco » = 18 700
4.2 – METODOLOGÍAS DE LOS BUSCADORES
27 Ver el ejemplo: http://funredes.org/lc2005/english/L4index.html28 Se creó una nueva muestra de más de 200 expresiones.

La totalidad del proceso de este estudio se caracterizó por una adaptación permanente a los nuevos comportamientos de los buscadores. La actividad principal de cada campaña de mediciones consistió en verificar si los buscadores podían responder a los objetivos de la metodología, y en numerosos casos, a comprender la razón por la cual se obtuvieron resultados nulos. A pesar de que la parte lingüística de la metodología demandó de una importante concentración en este proyecto, nada como la naturaleza de los buscadores, la cual resultó ¡una larga e imprevisible carga de trabajo a lo largo de las campañas de medición!
Nuestra observación de la diversidad lingüística en la Red nos llevó a verificar con atención el comportamiento de cada buscador disponible (e independiente) con los signos diacríticos y el conteo de páginas. En un contexto no muy transparente (y de frecuentes cambios) de la parte de los proveedores de buscadores, nos vimos obligados continuamente a multiplicar las evaluaciones para comprender ciertos cambios en los resultados. En varias oportunidades los resultados obtenidos estuvieron a punto de hacernos perder la confianza en nuestro método pero luego de varias semanas de esfuerzo descubrimos finalmente las razones que se escondían detrás de estos extraños datos que nos proporcionaban resultados nada fiables29.
Al principio, después de algunos ajustes de la metodología, frecuentemente descubríamos con satisfacción que los buscadores ofrecían resultados estadísticamente bastante cercanos y eso reafirmó nuestra confianza en el método. Sin embargo, la situación divergió progresivamente con el tiempo y hoy parece estar condenada al fracaso. El siguiente esquema explica la causa:
Tres fenómenos nos impiden continuar con nuestra metodología basada en los buscadores:
1) Los índices representan ahora menos del 30% del ciberespacio (contra más del 80% en el pasado) y responden cada vez más a criterios comerciales (desconocidos) aumentando considerablemente el sesgo lingüístico30.
29 Precisamente desde 2005, nos encontramos en esta situación con Google. Luego de varios meses de intento nos vimos obligados a abandonar este buscador y utilizar Yahoo! (Altavista). El número de ocurrencias proporcionado por Google para una palabra dada con cualquier parámetro de lengua y de dominio era, contra toda lógica, mucho menor que la suma del número de ocurrencias por lenguas o por dominio…30 Eso podría conducir a la pérdida irreparable de nichos para Google como en el caso de usar Exalead para hacer búsquedas en la Red francófona.ENSEMBLE DU WEB
GOOGLEALTAVISTAAUTRES
ENSEMBLE DU WEB GOOGLE YAHOO / ALTAVISTA AUTRES
EVOLUCIÓN DE LA WEB Y LOS BUSCADORES ENTRE 1998 Y 2008
OTROS OTROS OTROS

2) Los buscadores son cada vez más “inteligentes” (por ejemplo, buscan conceptos en diferentes lenguas), lo que hace que el conteo se vuelva absurdo.
3) El aumento de la publicidad en las páginas Web sesga nuestros resultados31.
Si logramos vencer estos obstáculos, aún podríamos sostener que nuestro método permite comparar el sesgo lingüístico de diferentes buscadores pero ya no nos encontramos en condición de pretender que los resultados de un buscador dado representen las lenguas en la totalidad de la Web.
En realidad, la observación de la curva de la evolución de la posición de las lenguas a los largo de nuestras campañas (cf. capítulo V - Resultados) ya ha sido alterada por importantes cambios en el comportamiento de los buscadores. En 2001, todas las lenguas medidas han retrocedido en la misma proporción que el inglés contradiciendo la tendencia observada. ¿Es que acaso el inglés resurgió de pronto en la Web? ¿La creciente presencia de países asiáticos ha reforzado el inglés? Un análisis cuidadoso y paciente32 nos llevó a la conclusión que esta situación solo era el reflejo de la modificación del índice de Google que, en una fase transitoria, aumentaba fuertemente la presencia del inglés (fenómenos que como bien lo habíamos observado o deducido siempre ha existido).
Entre 2003 y 2004, Google y Yahoo eran los candidatos que mejor respondían a nuestras exigencias. La importancia del índice de Google (3 mil millones de páginas) y la claridad de su gestión de los signos diacríticos nos llevó de ese entonces a utilizar ese buscador. MSN fue descartado por tener una clara tendencia a favorecer el inglés y Exalead por favorecer el francés. La mayor parte de los otros buscadores estaban relacionados con otros buscadores ya existentes o no contaban con un buen índice.
En 2006, el estudio debió hacer frente a un gran periodo (4 campañas) de resultados divergentes y a la imposibilidad de encontrar una explicación coherente ante el comportamiento de los buscadores y estuvimos a punto de poner un punto final al proyecto. Finalmente, encontramos la explicación en lo que hemos bautizado como la operación Big Daddy33 de Google que consistió en una modificación total de su índice y de los servidores que albergaban la base de datos de exploración. La redefinición total del índice creó un largo periodo de transición para reconstruirlo y percibimos la que reconstrucción tenía una clara tendencia a comenzar por la Web inglés falseando completamente los resultados que obtuvimos en esta fase. Progresivamente, los resultados volvieron a ser coherentes34 y volvió la confianza… pero esto no duró mucho tiempo, algunos meses después que Google utilizara estos nuevos “trucos”, el buscador se volvió completamente inútil para nuestro proyecto. Esto nos costó varios meses de trabajo en 2007 y nos obligó a volver a trabajar con Yahoo! (que utiliza el buscador de Altavista) hasta que finalmente decidimos buscar otra manera de continuar con nuestro estudio (lo describiremos más adelante).
31 Cada vez es más frecuente que las páginas que no son en inglés contengan avisos publicitarios en inglés.32 Pasamos varios meses a verificando y descartando diferentes hipótesis para explicar semejante situación (por ejemplo, saber si la progresión exponencial de países asiáticos desencadenó una alza del inglés).33 Ver: http://vision2form.nl/Websitedesign/search-engine-optimization/bigdaddy-structure.html 34 Siempre hemos considerado el hecho que las nuevas campañas siempre muestran una especie de continuidad con los datos históricos como la mejor garantía de nuestro método y siempre hemos seguido de cerca los cambios de tendencias de argumentos válidos sobre lo que sucede en el campo.
4.3 – METODOLOGÍA ESTADÍSTICA
El total de los 57 valores del número total de páginas que contienen una de las palabras de cada concepto en cada lengua dividido por el valor equivalente en inglés (lo que representa el porcentaje de una lengua dada con respecto al inglés) es tratado como una variable aleatoria a la que se le aplican las herramientas tradicionales para una distribución normal (o función de Gauss).
El coeficiente de varianza35 es calculado de la siguiente manera; un valor de 0 indica un valor constante (absolutamente imposible que esto ocurra); un valor de 1 indica una función exponencial lo que representa una situación aleatoria normal. Entre 0 y 1, el coeficiente de varianza indica un buen resultado (con un poco de intervalo) y un valor claramente superior a 1 indica una función hiperexponencial tratándose por lo tanto de un método poco fiable. Este valor es utilizado para controlar las medidas y detectar las anomalías. De manera general, la campaña de medidas siempre ha dado resultados estadísticos admisibles basados en este indicador. Posteriormente, los intervalos de confianza de 90% y 99% de los resultados son calculados con la ayuda de la ley matemática de Student-Fisher que permite situar la validez de los resultados en un recuadro.
4.4 – CREACIÓN DE INDICADORES
El primer indicador que fue creado representa la presencia de una lengua en Internet con respecto a su presencia en el mundo real (lo que llamamos presencia ponderada). Un coeficiente igual a 1 traduce un resultado normal, si es inferior a 1 esto significa una presencia virtual débil (como lo constatamos en el caso del español y del portugués en las primeras publicaciones); si es superior a 1, hablamos de una fuerte presencia virtual (como lo constatamos en el caso del inglés y en menor escala en el francés, el italiano y el alemán). El perfeccionamiento de este indicador para una lengua dada demuestra la manera en la se podría mejorar la presencia virtual de la lengua y llegar a tener una presencia normal o superior. En el caso del inglés, cuyo coeficiente aún es ampliamente superior a 1, los doce años de medición han mostrado una baja (de 7 a 4), luego una posición más estable (con el límite anteriormente explicado: los resultados obtenidos después del 2005 no representan la totalidad de la Web). Este indicador podría ser útil para medir la eficacidad de una política lingüística virtual.
Utilizando la estimación del número de internautas por lengua dada (proporcionada durante varios años por GlobalStat36 y a partir de 2005 por Internet Worldstats37), es posible establecer un indicador de la productividad lingüística (la cantidad de páginas producidas por los internautas, la cual normalizamos de modo que obtuviéramos un promedio de 1). No obstante, conviene señalar que la escaza fiabilidad de las cifras de estas organizaciones (estimamos que la realidad se encuentra en un margen de más o menos 20%) tiene un impacto de la misma proporción en estos indicadores.
35 El coeficiente de varianza es la raíz cuadrada de la diferencia tipo al cuadrado dividido por el promedio al cuadrado.36 http://global-reach.biz/globstats/index.php3 37 http://www.internetworldstats.com/

Uno de los primeros resultados interesantes de nuestras mediciones fue descubrir que la diferencia entre los grandes productores y los pequeños productores no es muy significativa y que el resultado de la mayor parte de lenguas medidas es cerca de 1, lo implica una especie de regla natural entre la proporción de productores de contenidos y el número total de internautas. En materia de política lingüística, esto significa que la primera cosa por hacer para que una política refuerce la producción de contenidos de una lengua dada es ¡aumentar el número de usuarios! Otra lección que podemos retener de este indicador es que la aparente ley natural de proporcionalidad tiende a desaparecer estos últimos años, esto se puede interpretar por el hecho de que los internautas recientes tienden a ser más consumidores que productores (a pesar del auge de los blogs) haciendo valer nuevas políticas más orientadas a la alfabetización digital que a la accesibilidad.
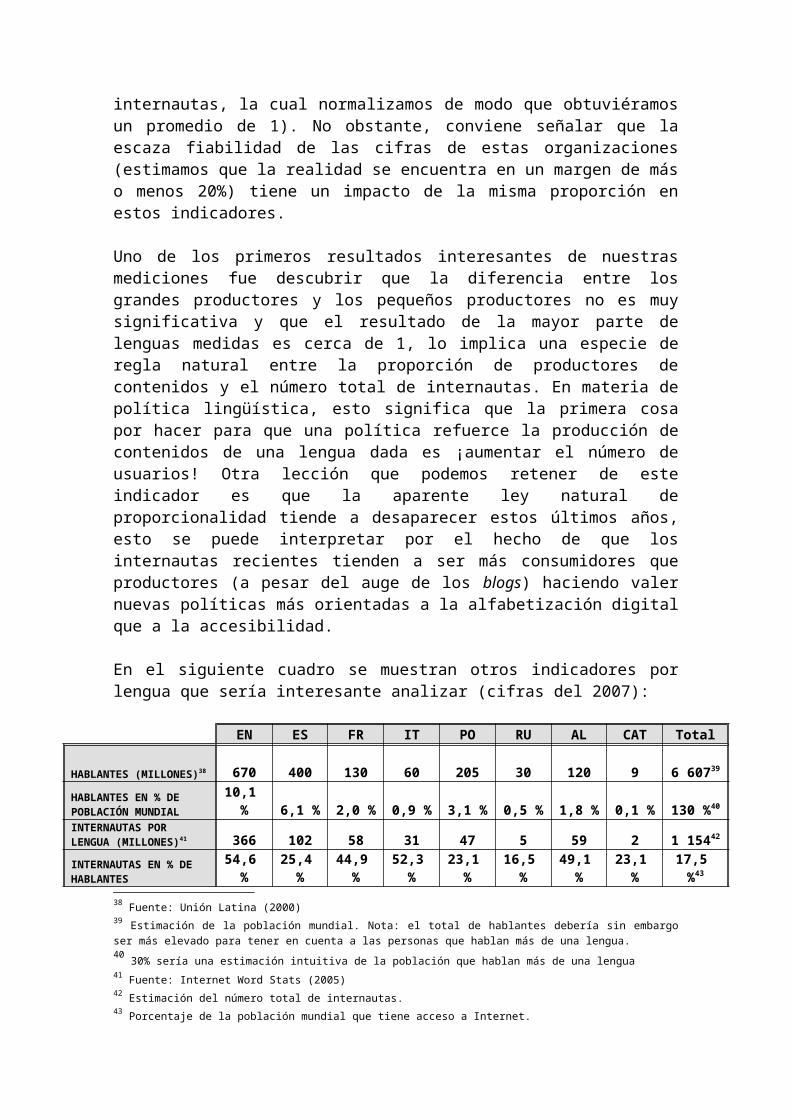
En el siguiente cuadro se muestran otros indicadores por lengua que sería interesante analizar (cifras del 2007):
EN ES FR IT PO RU AL CAT Total
HABLANTES (MILLONES)38 670 400 130 60 205 30 120 9 6 60739
HABLANTES EN % DE POBLACIÓN MUNDIAL 10,1 % 6,1 % 2,0 % 0,9 % 3,1 % 0,5 % 1,8 % 0,1 % 130 %40
INTERNAUTAS POR LENGUA (MILLONES)41 366 102 58 31 47 5 59 2 1 15442
INTERNAUTAS EN % DE HABLANTES 54,6 % 25,4 % 44,9 % 52,3 % 23,1 % 16,5 % 49,1 % 23,1 % 17,5 %43
INTERNAUTAS EN % DE POBLACIÓN MUNDIAL 5,5 % 1,5 % 0,9 % 0,5 % 0,7 % 0,1 % 0,9 % 0,0 % 17,5 %% DE INTERNAUTAS POR LENGUA 32 % 9 % 5 % 3 % 4 % 0 % 5 % 0,2 % 130 %
% DE PAGINAS WEB POR LENGUA44 45,0 % 3,8 % 4,4 % 2,7 % 1,4 % 0,3 % 5,9 % 0,1 % 100 %PRODUCTIVIDAD LINGÜÍSTICA POR LENGUA45 1,42 0,43 0,87 0,98 0,34 0,66 1,16 0,74 1PAGINAS WEB POR INTERNAUTA EN UNA LENGUA DAD 4,44 0,63 2,24 2,93 0,45 0,62 3,25 0,96
Indicadores lingüísticos
La relación entre el número de hablantes y de internautas de una lengua dada (internautas en % de hablantes, una especie de indicador de la penetración de la lengua en la Internet) advierte la futura evolución del crecimiento. Cuando una lengua alcanza el 50% de penetración es necesario esperar que la inflexión en la curva de crecimiento haya sido realizada y que vaya a comenzar a ser asintótica. La principal causa de la disminución relativa de la lengua inglesa en la Red se debe simplemente a que se 38 Fuente: Unión Latina (2000)39 Estimación de la población mundial. Nota: el total de hablantes debería sin embargo ser más elevado para tener en cuenta a las personas que hablan más de una lengua.40 30% sería una estimación intuitiva de la población que hablan más de una lengua 41 Fuente: Internet Word Stats (2005)42 Estimación del número total de internautas.43 Porcentaje de la población mundial que tiene acceso a Internet.44 Fuente: Funredes / Unión Latina (2005)45 Ratio entre le % de páginas Web por lengua y el % de usuarios de Internet por lengua

encuentra en esta situación como consecuencia de su precoz y transitoria presencia inicial46.
El porcentaje de internautas por lengua proporcionalmente al número de usuarios es un indicador de la brecha numérica y lingüística y se debe interpretar de esta manera: “17,5% de la población mundial estaba conectada a Internet en 2007, de los cuales 5,5% eran internautas que hablaban inglés”.
El porcentaje de internautas por lengua es un dato importante que permite comprender la diversidad lingüística en Internet y muestra una evolución fuerte y constante desde el inicio.
Desde 2001 se produce la segunda serie de indicadores, más centrada en las medidas por país (exigiendo nuevas astucias metodológicas). Estos indicadores aportan una valiosas informaciones sobre la dinámica de la producción de contenidos por lengua y por país y han sido progresivamente extendidas en nuestro estudio al francés, español, inglés y portugués (cuatro lenguas utilizadas en varios países, lo interesante es observar la contribución por país).
Estos indicadores pudieron ser creados gracias a que los buscadores ofrecían la posibilidad de medir las ocurrencias de las páginas por país para una búsqueda dada. Nosotros ejecutamos nuestro programa varias veces para diferentes países con el fin de obtener estos resultados.
La dificultad metodológica reside en el hecho de que no basta medir la muestra por nombres de dominio nacionales, sino que también hay que tener en cuenta los dominios genéricos de primer nivel (TLD)47 ampliamente utilizados en los países estudiados y repartirlos entre estos países. Para esto es necesario realizar una estimación del uso de dominios de primer nivel de un país (cifra que obtuvimos gracias a colegas que trabajan en los Centros de Información de Redes (NIC) o en documentación sobre el dominio).
Los resultados que obtuvimos son extremadamente ricos en enseñanzas y constituyen excelente aportes para los responsables políticos ya que pueden ser compilados por región y dar indicaciones de la medida de la brecha digital entre el Norte y el Sur; además, pueden dar una idea de la producción de contenido en una lengua extranjera dada por país. El método no permite obtener resultados muy precisos por lo tanto es conveniente tomarlos con prudencia48. Para mayor información ver el capítulo 5.3.
46 El caso Minitel en Francia muestra que cuando se alcanza el 60 % de penetración del crecimiento se vuelve lento a pesar de la ausencia de costos directos.47 Principalmente los dominios “com” y “org”.48 Especialmente en lo que concierne a los porcentajes de sitios Web estadounidenses que se encuentran bajo el nombre de dominio .us, una cifra difícil de obtener y que calculamos con pruebas y errores para alcanzar un total de 100%.

V- RESULTADOS
5.1- PRINCIPALES RESULTADOS
Los principales resultados de las diferentes campañas de medida están presentados a continuación en forma de gráficos y cuadros.
Presencia de las lenguas en la Web con respecto al inglés
El cuadro se lee de la siguiente manera: por 100 páginas en inglés en la Web tenemos en setiembre de 1998, 3 páginas en español, 4 en francés, 2 en italiano, 1 en portugués y se necesitan 500 páginas en inglés para tener 1 en rumano.
ES FR IT PT RO AL CAT09/98 3.37 % 3,75 % 2,00 % 1,09 % 0,20 %08/00 8,41 % 7,33 % 4,60 % 3,95 % 0,37 % 11,00 %01/01 9,46 % 7,89 % 4,93 % 4,44 % 0,33 % 11,43 %10/01 11,36 % 9,14 % 6,15 % 5,61 % 0,36 % 14,08 %02/02 11,60 % 9,60 % 6,51 % 5,62 % 0,33 % 14,41 %
02/03 10,83 % 8,82 % 5,28 % 4,55 % 0,23 % 13,87 %05/04 10,19 % 10,64 % 6,15 % 4,02 % 0,31 % 17,02 %
03/05 10,23 % 11,00 % 6,77 % 4,15 % 0,37 % 15,42 %
08/07 8,33 % 10,21 % 6,01 % 2,97 % 0,50 % 13,17 % 0,27 %
11/07 8,45 % 9,80 % 5,92 % 3,09 % 0,63 % 13,12 % 0,30 %Presencia de las lenguas latinas (y del alemán) en la Web con respecto al inglés
Intervalos de confianza para los resultados del 2008
99 % 90 % 90 % 99 %Español 6,56 7,48 10,74 11,66Francés 8,19 8,98 11,77 12,56Portugués 4,01 4,65 6,9 7,53Italiano 1,82 2,24 3,73 4,15Rumano 0,52 0,63 0,99 1,09Alemán 7,78 8,53 11,18 11,93Catalán 0,25 0,29 0,44 0,49
Intervalos de confianza de la presencia de lenguas en la Web
Este cuadro se interpreta de la siguiente manera: Existe 99% de probabilidades que el porcentaje de páginas Web en francés con respecto al inglés se encuentre entre 8,19% y 12,56%; existe 90% de probabilidades que el porcentaje de páginas Web en italiano con respecto al inglés se encuentre entre 2,24% y 3,73%.

Evolución de las lenguas latinas (y el alemán) con respecto al inglés
0,00%
2,00%
4,00%
6,00%
8,00%
10,00%
12,00%
14,00%
16,00%
18,00%
Español
Francés
Italiano
PortuguésRumano
Alemán
Catalán
Evolución de las lenguas latinas (y el alemán) con respecto al inglés
El análisis gráfico muestra dos fenómenos que han sido explicados en la parte metodología de este informe:
En 2003, la presencia de todas las lenguas medidas disminuyó en la misma proporción con respecto al inglés, pero finalmente esto fue interpretado como el resultado de una situación transitoria sujeta al cambio de indexación de Google y no como una verdadera disminución de la presencia de estas lenguas en la Web. Una extrapolación entre 2002 y 2004 reflejaría con mayor fidelidad la realidad, como la curva tiende a indicarlo.
Según las curvas, a partir de 2005 se constata una caída de la presencia de todas las lenguas medidas desafortunadamente, más allá de esta fecha, es imposible extrapolar los resultados de la indexación de los buscadores como una representación fiel de la realidad en la Web. Lo que se mide solo puede ser considerado como una realidad de lo que está indexado por un buscador específico y demuestra un sesgo creciente en favor del inglés en los buscadores más comunes.
En cuanto a las lenguas estudiadas, distinguimos un primer impulso del español y del portugués entre 1998 y 2002 originado por los esfuerzos de América Latina por tener acceso a Internet, seguida distinguimos una disminución relativa con respecto al francés, alemán e italiano. En 2007 comenzó un refuerzo tardío de la presencia del rumano en la Red que merece ser seguido con el fin de confirmar si se trata del comienzo de un movimiento más amplio.
El siguiente cuadro constituye una estimación de la presencia absoluta de las lenguas en la Red, se obtuvo a partir de una estimación de la cantidad de páginas en inglés. La estimación del inglés se establece por iteración jugando con los valores de otras lenguas. Cada vez es más difícil establecer esta estimación con precisión debido a la explosión del número de usuario en Asia y al sesgo inherente a los buscadores.
EN ES FR IT PT RO AL CAT Suma49Resto del mundo50

09/98 75,0 % 2,53 % 2,81 % 1,50 % 0,82 % 0,15 % 3,75 % 11,56 % 13,44 %08/00 60,0 % 5,05 % 4,40 % 2,76 % 2,37 % 0,22 % 3,00 % 17,80 % 22,20 %01/01 55,0 % 5,20 % 4,34 % 2,71 % 2,44 % 0,18 % 6,29 % 21,16 % 23,84 %06/01 52,0 % 5,69 % 4,61 % 3,06 % 2,81 % 0,17 % 6,98 % 23,31 % 24,69 %08/01 51,0 % 5,73 % 4,66 % 3,14 % 2,84 % 0,18 % 7,01 % 23,55 % 25,45 %10/01 50,7 % 5,76 % 4,63 % 3,12 % 2,84 % 0,18 % 7,14 % 23,68 % 25,62 %02/02 50,0 % 5,80 % 4,80 % 3,26 % 2,81 % 0,17 % 7,21 % 24,04 % 25,97 %02/03 49,0 % 5,31 % 4,32 % 2,59 % 2,23 % 0,11 % 6,80 % 21,35 % 29,65 %02/04 47,0 % 4,84 % 4,78 % 2,86 % 2,05 % 0,19 % 7,21 % 21,94 % 31,06 %05/04 46,3 % 4,72 % 4,93 % 2,85 % 1,86 % 0,14 % 7,88 % 22,38 % 31,32 %
03/05 45,0 % 4,60 % 4,95 % 3,05 % 1,87 % 0,17 % 6,94 % 21,57 % 33,43 %
08/07 45,0 % 3,75 % 4,59 % 2,70 % 1,34 % 0,23 % 5,93 % 0,12 % 18,53 % 36,47 %
11/07 45,0 % 3,80 % 4,41 % 2,66 % 1,39 % 0,28 % 5,90 % 0,14 % 18,46 % 36,54 %Estimación de la presencia absoluta de las lenguas en la Red
La asíntota aparente del inglés a 45% se debe probablemente a un nuevo sesgo de los buscadores más que a un verdadero fenómeno sobre la topología lingüística de la Red. Si la curva de usuarios anglófonos es un indicador fiable de las tendencias como se podría pensar (ver a continuación), la presencia del inglés en la Red (en oposición a la indexación de los buscadores) se encuentra probablemente por debajo del 40% y el resto por encima del 40% (principalmente debido a la presencia masiva del chino).
96 97 98 99 00 01 02 03 04 05 07INTERNAUTAS51 40 72 91 148 192 231 234 288 280 300 366
% INTERNAUTAS 80 % 62 % 60 % 60 % 49 % 44 % 37 % 40 % 30 % 27 % 32 %% PAGINAS 75,0 % 60,0 % 51,0 % 50,0 % 49,0 % 47,0 % 45,0 % 45,0 %
Evolución, en porcentaje, de los internautas anglófonos y la producción de páginas Web en inglés
El comportamiento particular de la curva entre 2005 y 2007 es la consecuencia del cambio de fuente de datos entre GlobalStat (que dejó de proveer estos datos) e InternetWorldStats, también es una advertencia con respecto a los límites de estos resultados debiendo ser considerárseles bastante aproximativos (+-20%) ya que la metodología está fundada en fuentes nacionales diversas que no pueden tener enfoques normalizados.
49 Suma de las lenguas estudiadas excepto el inglés.50 Suma del total de las otras lenguas del mundo.51 En millones. Fuente: Global Reach hasta 2005, luego Internetworldstats.
AnnéeAnnée

5.2- ANÁLISIS POR PAÍS
Los resultados más interesantes e innovadores de nuestro estudio han sido obtenidos gracias a la automatización de las medidas al momento de la aplicación del método nombre de dominio por nombre de dominio con el fin de establecer resultados país por país para el inglés, francés, español y portugués. Esto permite obtener datos que despierten la curiosidad.
La totalidad de resultados por cada lengua puede ser consultada en el sitio: http://funredes.org/lc/francais/medidas/sintesis.htm (año 2005), así como en: http://dtil.unilat.org/LI/2007/index_es.htm (año 2007).
El interesante número de resultados es demasiado extenso como para describirlo en detalle en este artículo. Seguidamente explicaremos solo algunos hechos notables.
11/2007 5/2005 3/2003FRANCIA 60 % -1,09 60 % - 0,82 54 % - 0,96CANADÁ 20 % - 1,06 19 % - 1,27 24 % - 1,83BÉLGICA 7 % - 0,60 8 % - 1,55 7 % - 2,21SUIZA 5 % - 0,87 5 % - 2,78 6 % - 2,17OTROS 8 % - 0,84 8 % - 1,38 9 % - 3,10
Principales países editores de páginas Web en francés: porcentaje total de páginas en francés seguido de la productividad52.
Canadá (Quebec en especial) fue un pionero en la producción de contenidos en la Red y es por esta razón que hoy en día parece en relativo descenso; por el contrario, Francia tuvo una producción tardía pero conoció una fuerte expansión en 2005. Se pueden observar dos tendencias, la primera, una disminución general de la productividad (excepto por Francia) y la segunda, una fuerte disminución en Bélgica y Suiza señalando la llegada de una enorme cantidad de nuevos usuarios de Internet, pero poca producción.
11/2007 5/2005 3/2003EUROPA 75 % 79 % 71 %AMÉRICA 22 % 21 % 25 %ÁFRICA/MEDIO ORIENTE 0,3 % 0,4 % 0,4 %ASIA/OCEANÍA 0,2 % 0,4 % 0,4 %SIN CLASIFICAR 2,11 % 2,11 % 0,19 %
Producción de páginas Web en francés por región
La triste realidad de la brecha digital se manifiesta en los resultados correspondientes a África y aún no se ha podido constatar ningún cambio. Los países francófonos en desarrollo que aparecen como los más productivos en 2007 son Marruecos y Senegal, pero cabe destacar que Alemania y Gran Bretaña producen por si solos más páginas Web en francés que todo el continente africano.
En lo que respecta al español, el siguiente cuadro presenta los principales productores de contenido y su productividad
52 Calculado como la relación entre % de la producción y el % de internautas por página

2007 2005 2001ESPAÑA 56 % - 3,4 48 % - 2,4 54 % - 2,7ESTADOS UNIDOS 10 % - 0,4 14 % - 0,4
5 % - 0,12
ARGENTINA 9.4 % - 0,953 10,6 % - 1,9 9,6 % - 1,3MÉXICO 8.4 % - 0,45 7,4 % - 0,5 8,6 % - 0,45
Principales países productores de páginas Web en español
En 2001, los Estados Unidos contaban con más internautas hispanohablantes que España pero este último produjo 54% de la producción de contenidos en español contra 5% de los Estados Unidos. Desde entonces, la producción estadounidense mejora pero no llega a alcanzar el valor promedio de 1. También podemos observar que la productividad de México, cuya población de inmigrantes a los Estados Unidos es la más grande, no es mayor que la de este último: en materia de política pública de creación de contenido en español existe un mensaje claro que consiste en concentrar la producción mexicana entre la frontera virtual…
La mayor productividad se encuentra en Cuba de 3,4 en 2001 a 4,3 en 2007, seguido de cerca por Nicaragua. Esto se traduce a la vez en un número reducido de internautas y una política eficaz de sistematización de publicación en la Red en el mundo universitario.
11/2007 5/2005ESTADOS UNIDOS 66 % - 1 51 % - 0,8REINO UNIDO 6,5 % - 0,6 7,2 % - 0,6CANADÁ 3,5 % - 0,7 5 % - 0,7AUSTRALIA 1,5 % - 0,3 1,8 % - 0,4ALEMANIA 1,2 % - 39 1,9 % - 57
Principales países productores de páginas Web en inglés
La presencia de Alemania como gran productor ilustra un fenómeno previsible: numerosos países no anglófonos contribuyen de forma consecuente con la producción de contenidos en inglés.
Ciertos dominios Internet de pequeños estados insulares muestran resultados anormalmente elevados de producción de contenidos en inglés ya que sus nombres de dominio nacionales han sido vendidos al extranjero con fines comerciales, como Vanuatu (.tv), Niue (.nu), Micronesia (.fm) y Samoa (.ws).
La brecha digital es extremamente palpable en los resultados: por ejemplo, la producción total de África llega a penas al 0,33% (de la cual 99% proviene de Sudáfrica) y cualquier país no anglófono del OCDE produce más de 0,1% de este total y muchos países como Alemania, Francia, Italia o Japón producen más contenidos en inglés que toda África incluyendo a Sudáfrica…
11/2007 5/2005
53 Una baja de la productividad con un tal porcentaje de producción de contenidos indica un aumento del número de internautas sin que preceda a un aumento de la producción de contenidos.

BRASIL 71 % - 0,90 71 % - 0,95PORTUGAL 15 % - 0,98 17 % - 1,0ESTADOS UNIDOS 4 % - 5,0 8 % - 5,4ESPAÑA 3,8 % - 3,7 2,3 % - 1,2
Principales países productores de páginas Web en portugués
Lo más notable es la estabilidad de estos resultados… y la productividad en Estados Unidos que contrasta con las mismas cifras en el caso del español.
5.5-OTROS ESPACIOS DE DIVERSIDAD LINGÜÍSTICA
En los primeros años las medidas se efectuaron en el espacio Usenet y dieron lugar a resultados interesantes54. Recientemente, intentamos evaluar la situación en la blogósfera, los resultados obtenidos con diferentes buscadores de blogs son tan heterogéneos que no vale la pena publicarlos. El hecho es que hoy cada buscador de blogs está asociado a un servidor particular de espacios blogs y sólo efectúa búsquedas en este índice. Sería útil contar con un metabuscador que pueda concatenar los resultados de diferentes buscadores de blogs.
Los resultados obtenidos a partir de Wikipedia, cuyas estadísticas multilingües son impresionantes55, merecen ser mencionados ya que ellos confirman que en verdad se trata de uno de los espacios más abiertos a la diversidad lingüística en la Red.
Inglés 2,259,431 23.078 %Alemán 715,830 7.312 %Francés 629,004 6.425 %Polonés 475,566 4.857 %Japonés 472,691 4.828 %Italiano 418,969 4.279 %Neerlandés 413,325 4.222 %Portugués 363,323 3.711 %Español 337,860 3.451 %
Proporción de artículos por lengua en Wikipedia (Fuente: Wikipedia, 07/2008)
5.6-DIVERSIDAD CULTURAL
La metodología que utilizamos para registrar la presencia de la cultura en la Red es bastante simple, incluso simplista, y solo puede ser tomada en consideración de forma aproximativa ya que no puede abordar el tema en toda su complejidad. Primero seleccionamos algunos temas y propusimos para cada uno de ellos una larga, pero inexhausta, lista de personalidades que están relacionadas con un tema (por ejemplo, Albert Einstein para la ciencia o Pablo Picasso para las artes gráficas). Luego, medimos “el índice de citación” y compilamos los resultados; a partir de estos resultados establecimos un indicador simple y observamos su evolución a lo largo de cinco campañas de medición (1996, 1998, 2001, 2005 et 2008) lo que nos ofreció una perspectiva de estos últimos 12 años.54 Ver: http://www.funredes.org/lc2005/english/L4index.html55 Ver: http://fr.wikipedia.org/wiki/Wikip%C3 %A9dia:Statistiques_internationales

Los temas escogidos fueron: Literatura Ciencias Música (todos los géneros) Cine Artes gráficas Política Personalidades (persona célebre o presente en los medios de comunicación por
alguna razón) Historia Ficción (Drácula o Cenicienta, por ejemplo) Una palabra (personalidades extraídas de diferentes temas en una sola palabra
como Einstein o Picasso)
Efectuamos cálculos en un total de cerca de 1 200 personalidades56. A continuación presentamos algunos ejemplos de los resultados obtenidos (el total de resultados puede ser consultado en el sitio Web de Funredes57).
PRIMERAS POSICIONES EN LITERATURA2008 2005 2001
1William Shakespeare 0 1 William Shakespeare 0 1 William Shakespeare 0
2 Oscar Wilde 2 2 René Descartes 26 2 Victor Hugo 1
3 Victor Hugo 3 3Gabriel García Márquez 34 3 Oscar Wilde -1
4 Charles Dickens 4 4 Oscar Wilde -1 4 Charles Dickens 2
5 Agatha Christie 21 5 J.R.R. Tolkien 7 5 William James 0
6 Paulo Coelho 3 6 Victor Hugo -4 6 James Joyce 2
7 J.R.R. Tolkien -2 7 Lord Byron 14 7 Ernest Hemingway 7
8Ernest Hemingway 15 8 Charles Dickens -4 8 Walt Whitman -1
9 Edgar Poe 9 9 Paulo Coelho 53 9 Edgar Poe -5
10 Jules Verne 1 10 Emmanuel Kant 2010 Henry James 1
Posición de la literatura en la Red
PRIMERAS POSICIONES EN CIENCIA2008 2005 2001
1 Albert Einstein 0 1 Albert Einstein 0 1 Albert Einstein 0
2 Noam Chomsky 1 2 Marie Curie 0 2 Marie Curie 9
3 Charles Darwin 1 3 Noam Chomsky 4 3 Charles Darwin 0
4 Marie Curie -2 4 Charles Darwin -1 4 Sigmund Freud 0
5 Sigmund Freud 4 5 Isaac Newton 0 5 Isaac Newton -3
6 Isaac Newton -1 6 Blaise Pascal 4 6 Thomas Edison 0
7 Thomas Edison 5 7 Galileo Galilei 4 7 Noam Chomsky 0
8 Carl Sagan 2 8Alexander Von Humboldt 4 8 Louis Pasteur 0
9 Milton Friedman 4 9 Sigmund Freud -5 9 Carl Sagan -4
10 Galileo Galilei -3 10 Carl Sagan -1 10 Blaise Pascal -1
56 La única modificación fue efectuada en la segunda campaña con el fin de obtener una muestra de personalidades más completa, posteriormente conservamos la misma muestra.57 Ver: http ://funredes.org/lc/espanol/cultura08/cultura08.htm
11 Blaise Pascal -5 11 Louis Pasteur -3 11 Galileo Galilei -1
12 Louis Pasteur -1 12 Thomas Edison -6 12 Alexander Von Humboldt 2Posición de la ciencia en la Red
PRIMERAS POSICIONES EN ARTES GRÁFICAS2008 2005 2001
1Leonardo Da Vinci 0 1
Leonardo Da Vinci 0
Leonardo Da Vinci 0
2 Andy Warhol 1 2 Salvador Dalí 1 2 Andy Warhol 0
3 Salvador Dali -1 3 Andy Warhol -1 3 Salvador Dalí 0
4 Pablo Picasso 6 4 Frida Kahlo 7 4 Pablo Picasso 0
5Vincent Van Gogh 6 5 Paul Cézanne 9 5 Vincent Van Gogh 0
6 Claude Monet 1 6 Henri Matisse 6 6 Claude Monet 0
7 Frida Kahlo -3 7 Claude Monet -1 7 El Greco 1
8 Gustav Klimt 1 8 El Greco -1 8 Marc Chagall 4
9 El Greco -1 9 Gustav Klimt 6 9 Diego Rivera -2
10 Joan Miro 4 10 Pablo Picasso -6 10 Paul Klee 1
11 Paul Gauguin 4 11 Vincent Van Gogh -6 11 Frida Kahlo -2
1Leonardo Da Vinci 0 1
Leonardo Da Vinci 0
Leonardo Da Vinci 0
Posición de las artes graficas en la Red
PRIMERAS POSICIONES EN UN PALABRA58
2008 2005 2001
1 Washington 0 1 Washington 0 1 Washington 0
2 Clinton 2 2 Kennedy 5 2 Christ 1
3 Dalí 34 3 Lincoln 1 3 Clinton 1
4 Disney 1 4 Clinton -1 4 Lincoln -2
5 Lincoln -2 5 Disney 0 5 Disney 0
6 Christ 3 6 Jefferson 2 6 Newton 0
7 Kennedy -5 7 Newton -1 7 Kennedy 2
8 Madonna 27 8 Einstein 5 8 Jefferson -1
9 Jefferson -3 9 Christ -7 9 Gore 7
10 Bach 18 10 Darwin 18 10 Dalí 39
11 Hugo 5 11 Show 1 11 Joyce 0
12 Gore 6 12 Shakespeare 4 12 Shaw 1Posición de la cultura en la Red (en una palabra)
¿Qué nos revelan estas mediciones?
En primer lugar, cuando la cultura y el comercio están estrechamente relacionados (como es el caso de la música y el cine), el sesgo hacia la cultura americana es evidente. Sin embargo, cuando los temas son autoportadores en cuanto se refiere a la cultura (como en literatura, ciencia o artes gráficas), la representación cultural en la Red medida a partir de las personalidades, no está sesgada. La presencia de autores en literatura francesa o de investigadores franceses es tan evidente como la presencia de pintores españoles. Las dos primeras campañas revelaron una desventaja para la representación cultural francesa y más aún para la cultura española pero que fue superada en 2005. Desde entonces, no ha habido un cambio significativo y es por esta razón que la campaña 2008 será probablemente la última que se lleve a cabo con esta metodología.58 Cabe señalar que “Bush” no forma parte de la muestra, por el contrario en 2008, él llego segundo delante de “Clinton”.

Internet es un medio de comunicación y los eventos de la vida real se reflejan rápidamente pudiendo desaparecer con la misma rapidez… Esto explica la aparición y la caída de ciertas personalidades que son propulsadas por un evento histórico (como una película sobre el Che Guevara en 2008) o, de forma más sutil, por una tendencia sociológica que los ponga de moda (las respectivas evoluciones de la cibercelebridad de Albert Camus y Jean-Paul Sartre son ejemplos interesantes).
Una cierta “cultura mundial” puede ser percibida en la Red y aunque no se haya realizado ninguna medida es muy probable que esta cultura tenga tendencia a excluir elementos o personalidades muy importantes y extremadamente pertinentes frente a las culturas locales pero que no hayan sabido encontrar un lugar a escala mundial. Sin embargo, como para la lengua, saber cómo la cultura de las minoridades (o la cultura de las víctimas de la brecha digital, como las poblaciones autóctonas) está representada en la red es una cuestión que aún queda por resolver.
VI-EVALUACIÓN DEL MÉTODO
6.1-SU CARÁCTER ÚNICO Y SUS VENTAJAS
El método posee las siguientes ventajas:
— Utiliza de manera lógica y productiva las herramientas más polivalentes de Internet: los buscadores, aunque estos se limiten al espacio de búsqueda indexado. Sin embargo, durante varios años existió un argumento de peso frente a este límite: ¿Cuál es el interés práctico de una página que no está referenciada fuera de un pequeño círculo de amigos?
— Durante varios años, fue uno de los pocos métodos que mostraba con transparencia su manera de proceder (incluyendo todos los datos utilizados o producidos).
— Incluso si efectivamente es imposible proponer una selección de términos perfecta y culturalmente neutra se tomaron todas las precauciones necesarias, tanto desde un punto de vista lingüístico como cultural, para minimizar el sesgo y ofrecer un conjunto de datos prácticamente equivalente a resultados fiables.
— El método estadístico es riguroso y utiliza medio estandarizados. La coherencia de las 13 campañas de medición que se han realizado permitió aumentar la confianza en los resultados obtenidos.
— Contrariamente a otros métodos existentes, éste nos permitió evaluar el contenido de otros espacios a parte de la Web y obtener resultados precisos por lengua y por país (única aproximación de este modo que condujo a la creación de potentes indicadores).
— Hasta el día de hoy, es el único método que ofrece un conjunto de medidas coherentes para poner este tema en perspectiva (todas las otras proposiciones se han limitado por lo general a una evaluación repetida al menos una vez en el mejor de los casos).

6.2- LÍMITES E INCONVENIENTES
El método propuesto presenta sin embarga algunos límites de diferentes tipos:
- Está limitado a un pequeño número de lenguas y el costo marginal para agregar una nueva lengua es relativamente elevado. Definitivamente, no es el método más adecuado para hacer generalizaciones con respecto a la presencia de las lenguas en la Web; no obstante, se pueden aplicar algoritmos de reconocimiento de lengua en las bases de datos de páginas Web (como para el estudio del LOP) y esto constituirá muy probablemente el método estándar del futuro.
- No provee un valor absoluto por lengua y la estimación de la presencia absoluta del inglés está establecida por un proceso que se vuelve cada vez más problemático ya que no disponemos de un proceso sistemático.
- Cuantifica la presencia de las lenguas en la parte indexada de los buscadores. Este inconveniente, desde nuestro punto de vista, no tuvo importancia durante la primera parte del estudio, la extrapolación era pertinente ya que los buscadores cubrían más del 60% de la Web visible y los espacios cubiertos eran muy similares. A partir de 2005 este inconveniente se volvió preponderante y en la actualidad la evolución de los buscadores constituye un argumento de peso contra este método, al menos mientras que no se pueda aplicar independientemente de estos buscadores.
- Algunos indicadores se basan en cifras que pueden ser controversiales (como el número de personas que hablan una lengua en el mundo) o poco fiables (como el número de personas que hablan una lengua dada y utilizan Internet). Naturalmente, esto tiene consecuencias en el intervalo de confianza de algunos de nuestros indicadores.
VII- EVALUACIÓN DE OTROS MÉTODOS
Un cierto número de métodos alternativos para medir el espacio ocupado por las diferentes lenguas en la Red han sido creados al paso del tiempo y varios otros resultados han sido publicados sin que los métodos hayan sido descritos.
Babel Team: una iniciativa común de Alis Technologies y de Internet Society
La primera iniciativa presentada como la pionera en la materia, aunque se efectuó varios meses después de nuestros primeros estudios, fue llevada a cabo por la sociedad canadiense Alis Technologies y se publicó con la ayuda de Internet Society en junio 1997. Aún cuando el informe59 prometía efectuar dos mediciones por año, este se limitó a un único experimento. Cabe señalar que este estudio propuso el primer intento de lo que se convertiría en el método utilizado posteriormente en 1992 y 2002 por el OCLC (ver a continuación), con el fin de apoyar la proyección mediática de la cifra constante de 80% para la presencia del inglés en la Web durante este periodo.
El método Alis se basa en una muestra aleatoria de 8 000 páginas incial de sitios Internet60en los cuales se aplicó un algoritmo de reconocimiento de lengua (capaz de
59 http://alis.isoc.org/palmares.en.html60 El número efectivo de sitios analizado sobrepasa ligeramente los 3 000.
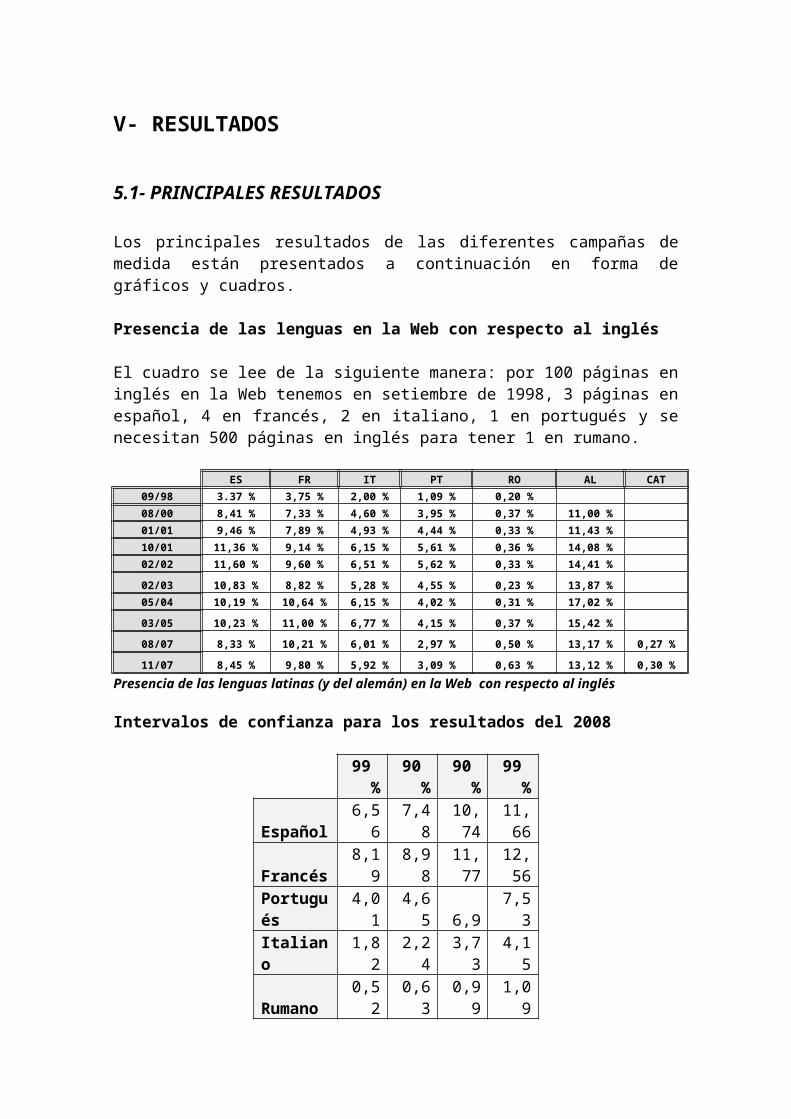
identificar 17 lenguas diferentes) con el objetivo de obtener la repartición de lenguas luego de extrapolar los resultados a la totalidad de la Web (antes de la extrapolación, se lleva a cabo una verificación manual del subconjunto de sitios para detectar errores de reconocimiento y corregir los resultados de una forma que no se describe en la documentación).
El método e incluso algunos datos (lista de direcciones IP analizadas) se exponen de manera transparente, su principal inconveniente reside en el hecho que este método no ha sido probado varias veces a pesar de la promesa inicial.
El método OCLC presenta claros límites que desde nuestro punto de vista quitan todo crédito a los resultados61 y es importante comprenderlos para evaluar este método, que sigue siendo la principal referencia en la materia.
1) Este método supone que la página incial representa la repartición de las lenguas en todo el sitio mientras que existen numerosos sitios en otras lenguas que poseen una página inicial en inglés o bilingües.
2) Los algoritmos de reconocimiento de lengua no son completamente fiables (incluso si han sido mejorados a partir de 1997) y tienden a proveer resultados que favorecen el inglés (hoy en día el LOP estima el margen de error a 10%), pero este es solo un problema menor comparado con los dos siguientes.
3) Desde un punto de vista estadístico, se puede poner en duda que 3 000 servidores seleccionados al azar puedan representar un universo que contaba en ese entonces con cerca de 1 millón (0,3%)... Desde luego, es cierto que, por ejemplo, los sondeos políticos permiten prever con precisión los resultados de una elección, pero la muestra no se toma al azar; al contrario, se la construye con cuidado para obtener un justa representación de la estructura del corpus electoral (edad, sexo, ubicación…), lo que no parece ser el caso de Alis. Además, la única forma de evaluar esta hipótesis de trabajo no se ha llevado a cabo, lo que nos conduce al último y principal límite
4) Por lo general, para una semejante metodología, uno no se limita a realizar un único sorteo de medidas al azar, al contrario, es conveniente repetirlo un buen número de veces (por ejemplo 100) y analizar la distribución de la variable aleatoria para comprender su comportamiento estadístico (como lo hicimos con nuestro método). Realizar este experimento una sola vez carece totalmente de sentido en términos estadísticos (incluso si comprendemos que la verificación manual que este método requiere hace que esto sea difícil).
Si las medidas hubieran sido tomadas varias veces, los resultados hubieran podido ser analizados estadísticamente y hubiera sido posible obtener un intervalo de confianza en torno a un promedio para cada resultado de cada lengua. Hubiera sido juicioso luego verificar el primer punto referente a los sesgos asociados a los algoritmos de reconocimiento lingüístico.
Proyecto OCLC de caracterización de la Red
OCLC es un proyecto célebre que ha presentado por muchos años datos fiables sobre el perfil demográfico de Internet. Sin embargo, los datos sobre la presencia de las lenguas en la Web se obtuvieron retomando y continuando con la metodología de Alis y sufren
61 Los resultados señalan un porcentaje de inglés en la Web superior a 80%
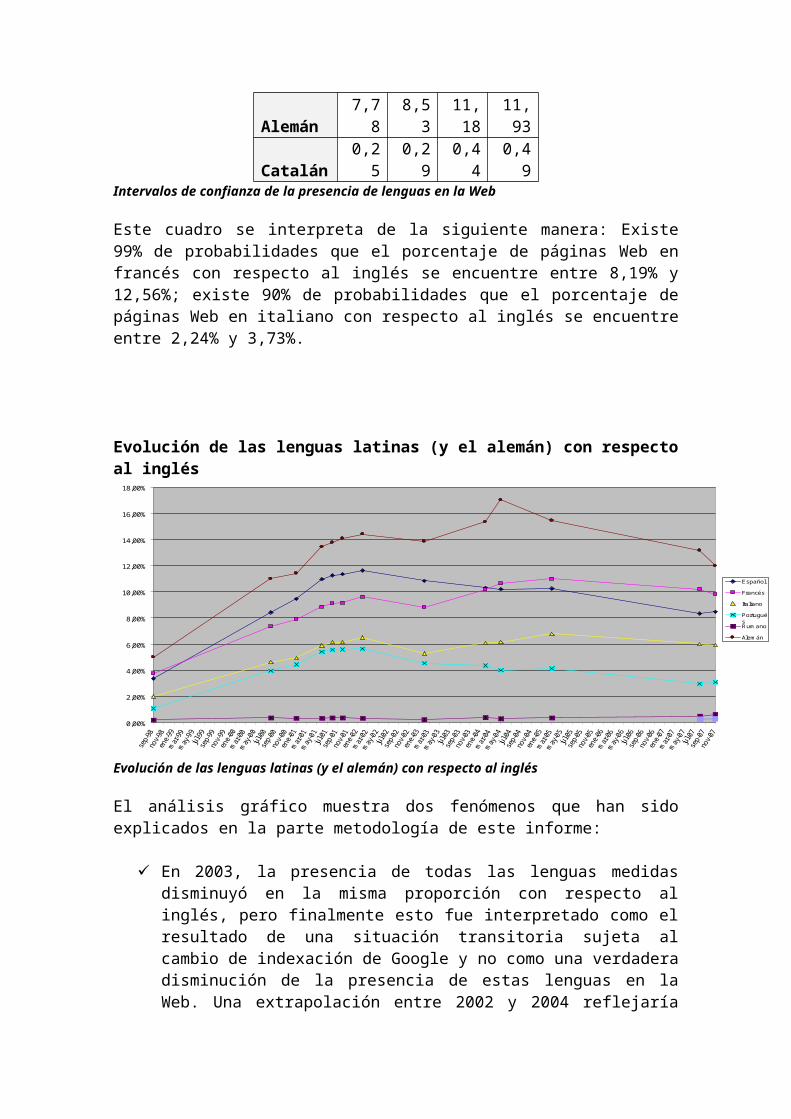
de los mismos límites descritos anteriormente. OCLC enunciaba el mismo valor (72%) para la presencia del inglés en la Web en 1999 y 2002 en las dos únicas campañas de medida realizadas con la misma metodología62.
La última publicación [OCLC2] realizada en 2002 concluye por un lado que “el crecimiento de la Web pública medida gracias al número de sitios Web ha alcanzado una tope” y por otro lado que “no hay ningún signo que indique que la repartición del contenido concentrado en los Estados Unidos y dominado por el inglés tienda a globalizarse”. Al mismo momento, nuestro estudio mostró una presencia del inglés en 50% y ¡una pronunciada tendencia a la globalización de la Web! Siendo la única fuente de información norte-americana sobre el tema y beneficiando del prestigioso apoyo del OCLC, este estudio sostuvo, teniendo como base un método defectuoso, que la presencia del inglés era constante en el universo de la Web a pesar de las evidentes y visibles tendencias que indicaban lo contrario. Involuntariamente, este proyecto sirvió de referencia a los medios de comunicación que divulgaron la idea de que la Web estaba dominada por el inglés en una proporción constante de alrededor del 80%; incluso después de un tiempo cuando se volvía evidente que la demografía de la Web se desarrollaba a una velocidad increíble. Este proyecto siguió siendo la referencia de artículos sobre el tema hasta 2005, como el de Paolillo [UN], mientras que se registraba una caída de la proporción de usuarios anglófonos en Internet ¡de 60% a 30% entre 1999 y 2005!
Estudio Inktomi
En el mes de febrero 2000, Inktomi, un antiguo buscador63, promovía gracias a una muy buena campaña publicitaria los resultados de su “estudio”64 sobre la presencia del inglés en la Web, obteniendo los siguientes resultados:
LENGUA PROPORCION (%)
inglés 86,54alemán 5,83francés 2,36italiano 1,55español 1,23
portugués 0,75neerlandés 0,54finlandés 0,50
sueco 0,36japonés 0,34
Resultados del estudio Inktomi
A pesar de la asombrosa afirmación que señalaba un total de 100% del universo Web por las lenguas anteriormente mencionadas (omitiendo varias otras lenguas presentes en la Red) indicando que el valor absoluto real del inglés obviamente debía ser calculado teniendo el cuenta el resto de lenguas, esta operación comercial fue considerada como 62 Ver: http://www.oclc.org/research/projects/archive/wcp/stats/intnl.htm 63 Comprado en 2002 por Yahoo!, hoy en día ha desaparecido.64 Jamás se citó una sola referencia sobre el método puesto en marcha.
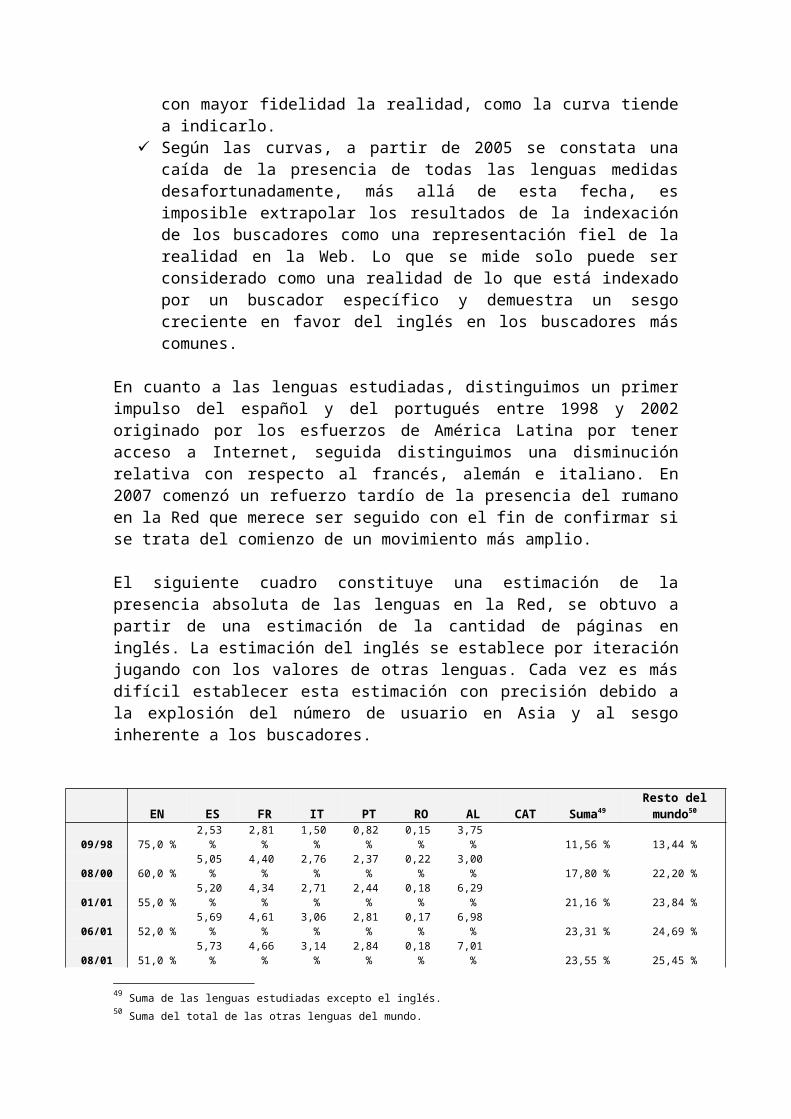
una fuente fiable y contribuyó gravemente a la desinformación sobre la posición del inglés en la Red en 2000 y durante los siguientes años la estimaron a 80%. Este hecho revela igualmente una falta de interés científico en este tema; si podemos estimar que el resto de lenguas alcanzar un 20% entonces el valor absoluto de la presencia del inglés en la Web, según el estudio Inktomi, sería de 70% aproximadamente.
El método del complemento del conjunto vacío
A partir de marzo 1998 con Altavista (y luego con Google) descubrimos que algunos buscadores tenían la cortesía de dar informaciones sobre la composición de las páginas indexadas en función de las lenguas tal y como ellos las percibían. Haciendo una búsqueda sobre una expresión como “-bhjvfvvj” (indicando una búsqueda por todo excepto nada) la respuesta sería la totalidad del índice con la cantidad total de páginas indexadas por el buscador. La misma búsqueda en una lengua dada produciría una estimación del número de páginas indexadas en esta lengua. El formato de la expresión de búsqueda nos llevó a llamar a este método simple para obtener una primera estimación aproximativa de las lenguas en la Web “el método del complemento del conjunto vacío”. Indudablemente este método refleja el importante del sesgo de los algoritmos de reconocimiento de lengua a favor del inglés65 y debe ser considerado únicamente como una aproximación básica de las lenguas en la Web. En todo caso, nosotros utilizamos frecuentemente66 este método para verificar la evolución del inglés y la aparición de nuevas lenguas.
El 3 de julio del 2008, Google indicaba esta repartición en su base de datos67:LENGUA PAGINAS PORCENTAJEárabe 340.000.000 0,68 %búlgaro 169.000.000 0,34 %catalán 46.400.000 0,09 %chino (simplificado) 3.770.000.000 7,49 %chino (tradicional) 796.000.000 1,58 %croata 113.000.000 0,22 %checo 269.000.000 0,53 %danés 249.000.000 0,49 %neerlandés 583.000.000 1,16 %inglés 25.580.000.000 50,82 %estonio 129.000.000 0,26 %finlandés 225.000.000 0,45 %francés 1.750.000.000 3,48 %alemán 2.470.000.000 4,91 %griego 148.000.000 0,29 %hebreo 290.000.000 0,58 %húngaro 278.000.000 0,55 %islandés 27.100.000 0,05 %indonesio 132.000.000 0,26 %italiano 951.000.000 1,89 %japonés 3.040.000.000 6,04 %coreano 968.000.000 1,92 %letón 43.200.000 0,09 %
65 Para sentir ese sesgo, basta con hacer algunas búsquedas de palabras en inglés y de constatar la elevada tasa de páginas de otras lenguas que son consideradas como páginas en inglés.66 A pesar de que de vez en cuando los buscadores dejar de ofrecer esta función.67 Estos datos deben ser tomados con precaución ya que los resultados cambian notablemente de una medida a la otra…
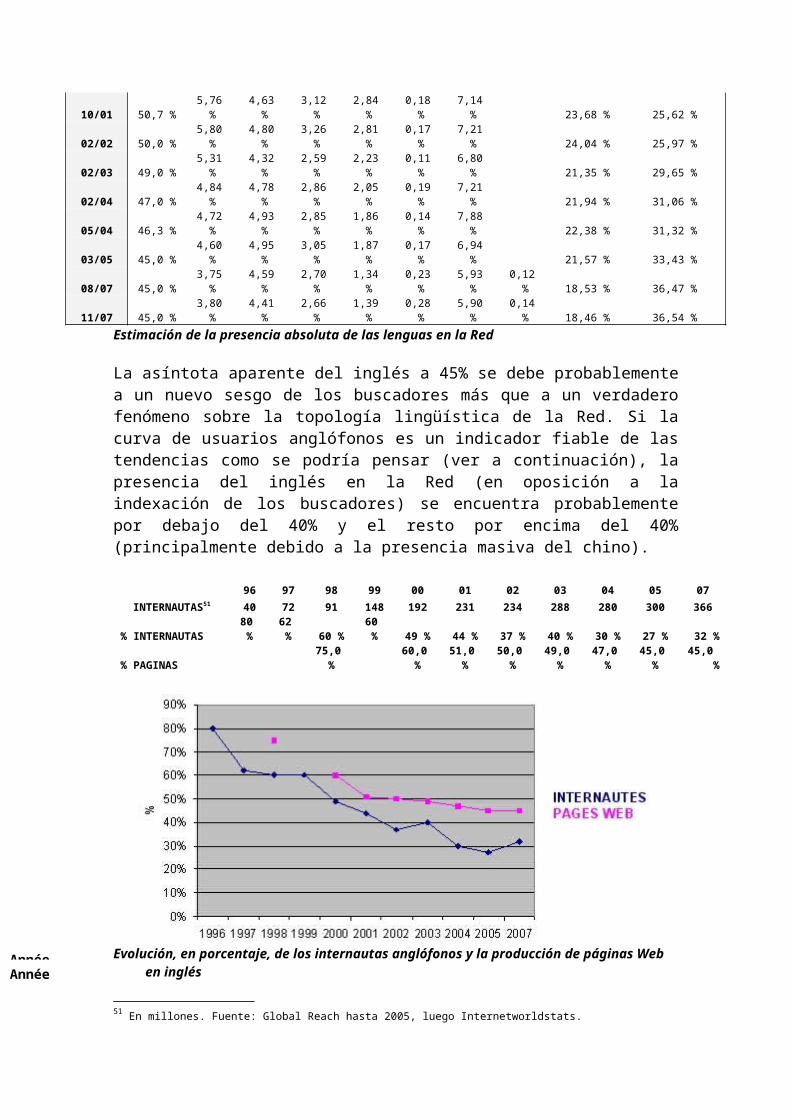
lituano 95.600.000 0,19 %noruego 255.000.000 0,51 %polonés 675.000.000 1,34 %portugués 828.000.000 1,65 %rumano 254.000.000 0,50 %ruso 1.470.000.000 2,92 %serbio 61.800.000 0,12 %eslovaco 181.000.000 0,36 %esloveno 97.500.000 0,19 %español 2.180.000.000 4,33 %sueco 116.000.000 0,23 %turco 835.000.000 1,66 %armenio 2 0,00 %bielorruso 959.000 0,00 %esperanto 3.740.000 0,01 %persa 116.000.000 0,23 %tagalog 8.300.000 0,02 %tailandés 418.000.000 0,83 %ucraniano 69.100.000 0,14 %vietnamita 301.000.000 0,60 %TOTAL 50.332.699.002 100,00 %
Repartición lingüística de las páginas indexadas por Google
El seguimiento de estas informaciones nos permitió constatar que un gran número de fuentes había utilizado este método a partir d 2000 con el fin de establecer su propia estimación de las lenguas en la Red68. En todo caso, a partir de 2005, los resultados que Google presenta con este método no son para nada fiables ya que estos varían de forma considerable de un día al otro.
Estudio Xerox
En 2001, un estudio fue publicado [XER] utilizando una técnica lingüística inédita basada en la frecuencia de aparición de palabras usuales en textos como índice de previsión. Este estudio presenta los resultados de 1996, 1999 y 2000 y merece ser considerado como el primer estudio de la presencia de las lenguas en la Web. Este método ha presentado resultados más bajos que los nuestros.
Con respecto al inglés
XEROX10/96
XEROX8/99
XEROX2/2000
FUNREDES8/2000
alemán 3,8 % 7,1 % 6,9 % 11 %francés 3,7 % 5,4 % 5,7 % 7,33 %español 1,7 % 4,0 % 3,9 % 8,41 %italiano 2,0 % 2,9 % 2,8 % 4,60 %portugués 1,7 % 2,1 % 2,4 % 3,95 %Resultados del estudio Xerox
Language Observatory Project (LOP)69
68 Es el caso, por ejemplo, de VilaWeb que ha realizado una buena campaña publicitaria difundiendo tales resultados en 2001.69 http://www.language-observatory.org/

Desde 2003, el Language Observatory Project (LOP) es llevado a cabo en la universidad japonesa Nagaoka University of Technology. En el marco de este proyecto se ha desarrollado un programa de reconocimiento lingüístico que permite identificar las lenguas, scripts y codificaciones de una página Web con la ayuda de una metodología estadística ampliamente utilizada en el tratamiento de texto que se supone identifica 350 lenguas y presenta un margen de error de 9%. Con la ayuda de un robot de indexación (crawler) desarrollado por la Universidad de Milano, el LOP colectó en 2006 y 2007 e identificó cerca de 100 millones de páginas africanas y asiáticas (excepto por China, Japón y Coreo con el fin de evitar procesar datos masivos).
El estudio muestra que en 2006 y 2007 respectivamente, 40% y 41% de las páginas Web teniendo un nombre de dominio nacional asiático y 73% y 82% de las páginas Web teniendo un nombre de dominio nacional africano estaban escritas en inglés (ver [LOP1] y [LOP2]). Este proyecto se extenderá a dominios nacionales de otras regiones y a dominios genéricos.
El LOP obtuvo los siguientes resultados para las lenguas de nuestro estudio (2007):
inglés español francés italiano Portugués rumano alemán catalánAsia 41,5 % 0,02 % 0,25 % 0,01 % 0,03 % 0,03 % 0,21 % 0,04 %
África 82,1 % 0,11 % 7,0 % 0,07 % 1,2 % 0,03 % 0,82 % 0,04 %Resultados del estudio de Language Observatory Project
El LOP congrega un extenso consorcio de científicos y especialistas de universidades y organizaciones en 20 países diferentes y tiene seguramente el potencial de convertirse en un proyecto de referencia para la medición de la diversidad lingüística en Internet, su orientación actual hace de él una herramienta única para el control de la presencia de lenguas minoritarias. Cuando, y si es que, el espacio explorado se extienda a la integralidad de la Web obtendremos el resultado esperado durante años (en el límite del algoritmo de reconocimiento lingüístico que tiene un margen de error cercano al 10%).
Proyecto de la Universitat Politècnica de Catalunya (UPC) / Institut d'Estadística de Catalunya (IDESCAT)
Este proyecto que comenzó en 2003 con IDESCAT y fue realizado por la UPC consistió en la colecta de una base de datos de algunos 30 millones de dominios a partir de los cuales se extrajo un subconjunto de 2 millones de dominios a los que se le aplicaron algoritmos de reconocimiento lingüístico como el LOP.
El proyecto muestra los siguientes resultados para la campaña 2005, los cuales son bastante cercanos al de nuestro estudio:
Lengua UPC FUNREDESinglés 42,9 % 45 %catalán 0,16 % 0,14 % (2007)español 3,4 % 4,60 %
alemán 6,2 % 6,94 %francés 6,2 % 4,95 %italiano 7,9 % 3,05 %
Resultados 2005 del estudio UPC / Idescat

Y los resultados siguientes para 2006, muy diferentes de la primera campaña:
Lengua UPCinglés 71,8 %catalán 0,47 %español 2,14 %alemán 14,5 %francés 3,8 %italiano 0,7 %
Résultados 2006 del estudio UPC / Idescat
Diversidad cultural en la Red
A nuestro conocimiento, el único otro intento de medir la diversidad cultural en la Red es la que se llevó a cabo por unos investigadores españoles en 2003 [CER]. El hecho es que el trabajo se contentó con retomar nuestro método intentando mejorarlo pero estas mejoras marginales70, que parecen necesitar una importante inversión71, no ofrecen nuevos resultados significativos.
VIII- PERSPECTIVAS
El campo de la investigación de la diversidad lingüística en Internet sale de un periodo de dificultades y de falta de interés de la parte de organismos internacionales y del mundo universitario revelando la necesidad de crear políticas lingüísticas para proteger y promover las lenguas en la Red y de disponer de indicadores fiables.Proyectos tales como el LOP proponen nuevos enfoques que pueden producir una vasta cantidad de informaciones sobre la presencia de las lenguas en la Web. Sin embargo, las exigencias son complejas y van más allá de la proporción de lenguas en la Web. El uso de las lenguas en los correos, en las conversaciones por la Internet y en los sitios visitados aún son datos desconocidos a pesar que son más importantes que la presencia estática de las lenguas72.
En este contexto, el estudio de Funredes y de la Unión Latina sería sintomático del periodo prehistórico de la diversidad lingüística en la Red y la evolución actual de los buscadores muestra que nuestro método ha llegado a sus límites. Sin embargo, todavía podría perdurar un nicho para un método alternativo que pueda validar los resultados de los métodos basados en el uso de algoritmos de reconocimiento de lenguas, no muy preciso por el momento. El esfuerzo por conseguir que este tipo de método continúe proporcionando resultados pertinentes pasa por una reestructuración que lo libera del uso de los buscadores.
70 Como siempre lo hemos mencionado, nuestro método es demasiado simple como para reflejar la complejidad de la cultura y las pocas mejoras aportadas por investigadores no han permitido cambiar esta realidad, ni ofrecer un cambio de paradigma para la interpretación de los resultados. 71 Debemos admitir nuestra sorpresa cuando leímos este trabajo y descubrimos que el grupo de investigadores prefirió contactar una empresa para rehacer el programa de medición que habíamos hecho en vez de ¡contactarnos para establecer una posible colaboración!72 Los enfoques utilizados por Alexa.com con el fin de medir el comportamiento lingüístico de los usuarios parece muy prometedor.

Para que nuestros métodos sigan desarrollándose se necesita de una exploración sistemática de la Web (crawling) con una aplicación simultánea del componente lingüístico que permita incrementar los contadores y verificar los resultados al final del ejercicio, esto abriría la puerta a tratamientos paralelos para las páginas digitales y permitiría considerar la posibilidad de evaluar la calidad de las páginas bajo ciertos criterios además del conteo de palabras de nuestro método.
En la actualidad, estudiamos la factibilidad y el costo de semejante avance y estamos en la búsqueda de colaboradores para llevar a cabo la ardua tarea de la exploración automática de la Web.
Además, estamos considerando la posibilidad de agregar la lengua creole en la lista de lenguas tratadas, con la colaboración de la Universidad de Antillas – Guyana.
BIBLIOGRAFÍA
[CRY] Language and the Internet, David Crystal, Cambridge University Press, 2001
[WP] WHITE PAPER: The Deep Web: Surfacing Hidden Value, Michael K. BergmanAnn Arbor, MI: Scholarly Publishing Office, University of Michigan, University Library vol. 7, no. 1, August, 2001http://quod.lib.umich.edu/cgi/t/text/text-idx?c=jep;view=text;rgn=main;idno=3336451.0007.104
[UN]Mesurer la diversité linguistique sur l’internet. Paolillo, J., Pimienta, D., Prado, D. et al. . – Revisado y acompañado de una introducción del Institut de statistique de l’UNESCO Montréal (Canada). – Montréal : UNESCO, 2005 (CI.2005/WS/06) in: http://portal.unesco.org/ci/fr/ev.php-URL_ID=20882&URL_DO=DO_TOPIC&URL_SECTION=201.html
[OCLC1] How "World Wide" is the Web? Lavoie, B. F. and E. T. O'Neill Annual Review of OCLC Research 1999.http://digitalarchive.oclc.org/da/ViewObject.jsp?objid=0000003496
[OCLC2] Trends in the Evolution of the Public Web: 1998 - 2002. O'Neill, Edward T, Brian F. Lavoie, and Rick Bennett. D-Lib Magazine, 9.4. 2003.http://www.dlib.org/dlib/april03/lavoie/04lavoie.html
[XER] Estimation of English and non-English Language Use on the WWW, Gregory Grefenstette & Julien Noche. http://arxiv.org/ftp/cs/papers/0006/0006032.pdf
[LOP1] “A Language and Character Set Determination Method Based on N-gram Statistics.” I. Suzuki, Y. Mikami and ale. In ACM Transactions on Asian Language Information Processing, Vol.1, No.3, September 2002, pp.270-279.

[LOP2] Analysis of the Asian Languages on the Web Based on N-gram Language Identification, S. T. Nandasara and ale. In ICTer Journal, Volume 1, Issue 1, 2008
[CAT] Estadística de la presència del català a la xarxa d'Internet i de les característiques dels Webs Catalans, Frederic Monràs and al, Llengua i ús: Revista tècnica de política lingüística, ISSN 1134-7724, Nº. 37, 2006 , pags. 62-66
[CER] Iconos culturales hispanos en Internet (lo que ven los buscadores), Luis Cueto Álvarez de Sotomayor, Chimo Soler Herreros y Javier Noya, 2004http://cvc.cervantes.es/obref/anuario/anuario_04/cueto_soler_noya/default.htm
[KID] Comment assurer la présence d’une langue dans le cyberespace ? Diki-Kidiri, Marcel, Unesco CI.2007/WS/1. 2007 http://unesdoc.unesco.org/images/0014/001497/149786F.pdf

TABLA DE ILUSTRACIONESEl rol de Internet con respecto a las lenguas 6Cronología del proyecto 8Ejemplo de palabras utilizadas en la muestra 10Indicadores lingüísticos 17Presencia de las lenguas latinas (y del alemán) en la Red con respecto al inglés 19Intervalos de confianza de la presencia de lenguas en la Red 19Estimación de la presencia absoluta de las lenguas en la Red 21Evolución, en porcentaje, de los internautas anglófonos y la producción de páginas Web en inglés 21Principales países editores de páginas Web en francés: porcentaje total de páginas en francés seguido de la
productividad. 22Producción de páginas Web en francés por región 22Principales países productores de páginas Web en español 23Principales países productores de páginas Web en inglés 23Principales países productores de páginas Web en portugués 24Proporción de artículos por lengua en Wikipedia (Fuente: Wikipedia, 07/2008) 24Posición de la literatura en la Red 25Posición de la ciencia en la Red 26Posición de las artes graficas en la Red 26Posición de la cultura en la Red (en una palabra) 26Resultados del estudio Inktomi 31Repartición lingüística de las páginas indexadas por Google 32Resultados del estudio Xerox 33Resultados del estudio de Language Observatory Project 33Resultados 2005 del estudio UPC / Idescat 34Résultados 2006 del estudio UPC / Idescat 34


















