
Capítulo 2 Estadística descriptiva 23 Estadística descriptiva.

Objetivos
Al finalizar la unidad, el alumno:
• explicará el concepto de estadística y otros relacio- nados (muestra, población, estadístico, parámetro, etcétera)• describirá las diferentes técnicas para seleccionar una muestra• calculará las principales medidas centrales y de dis- persión de un conjunto de datos no agrupados, ya sea muestrales o poblacionales• dado un gran conjunto de datos, utilizará y construirá las clases de frecuencia y sus gráficos para analizar la distribución de dichos datos
Estadística descriptiva
UNIDAD
1


Introducción
A lo largo de su existencia el ser humano ha llevado a cabo análisis de una gran cantidad de datos o información, referentes a los problemas o actividades de sus comunidades. Por ejemplo, desde comienzos de la civilización se hacían representaciones gráficas y otros símbolos en pieles, rocas, palos de madera y paredes de cuevas para contar el número de personas, animales o cosas. Hacia el año 3000 a. C., los babilonios usaban pequeñas tablillas de arcilla para recopilar datos sobre la producción agrícola y los géneros vendidos o cambiados mediante el trueque. Mucho antes de construir las pirámides, los egipcios analizaban los datos de la población y la renta del país.
Otro ejemplo de recopilación y análisis de datos es el del imperio romano, cuyo primer gobierno, al verse en la necesidad de mantener control sobre sus esclavos y riquezas, recopiló datos sobre la población, superficie y renta de todos los territorios bajo su control.
Siguiendo con la historia de la recopilación de datos, a mediados del primer milenio, por el gran crecimiento de las poblaciones y para poder tener control sobre éstas, se comenzaron a efectuar censos poblacionales, como los de la Edad Media en Europa. Por ejemplo, los reyes caloringios1 Pipino el Breve y Carlomagno ordenaron hacer estudios minuciosos de las propiedades de la Iglesia en los años 758 y 762, respectivamente.
Conforme pasaba el tiempo, la recopilación y análisis de datos comenzaban a tener otro fin además de los censos y conocimiento de diferentes propiedades. Por ejemplo, en Inglaterra a principios del siglo XVI se realizó el registro de nacimientos y defunciones, con el cual en 1662 apareció el primer estudio de datos poblacionales, titulado Observations on the London Bills of Mortality (“Comentarios sobre las partidas de defunción en Londres”). Un estudio similar sobre la tasa de mortalidad en la ciudad de Breslau, en Alemania, realizado en 1691, fue utilizado por el astrónomo inglés Edmund Halley como base para la primera tabla de mortalidad. En el siglo XIX, con la generalización del método científicopara estudiar todos los fenómenos de las ciencias naturales y sociales, los investigadores aceptaron la necesidad de reducir la información a valores numéricos para evitar la ambigüedad de las descripciones verbales.
1.1 Estadística
Como se explicó, el ser humano tuvo la necesidad de crear una ciencia que redujera la información a valores numéricos para la mejor interpretación de los fenómenos; se le llamó estadística.
La estadística es una rama de las matemáticas aplicadas que proporciona métodos para reunir, organizar, analizar e interpretar información, y usarla para obtener diversas conclusiones que ayuden a tomar decisiones en la solución de problemas y en el diseño de experimentos.
Definición 1.1
1 Carolingia también llamada Carlovingia, fue una dinastía de reyes francos que gobernaron un vasto terri- torio de Europa Occidental desde el siglo VII hasta el siglo X d. C.; su nombre fue tomado de su más renombrado miembro, Carlomagno.

20
Actualmente la estadística es un método efectivo para describir con precisión los valores de datos económicos, políticos, sociales, psicológicos, biológicos o físicos, y una herramienta para relacionar y analizar dichos datos. Por esta razón, la estadística se divide en diferentes ramas, entre las más aplicadas y que analizaremos están la estadística descriptiva y la inferencial.
La primera de ellas se aborda en la presente unidad y será descrita más adelante, mientras que la segunda será estudiada en las unidades 9 y 10. Por ahora se verán dos conceptos fundamentales en el estudio de la estadística.
1.2 Población y muestra
La materia prima de la estadística son los conjuntos de números obtenidos al contar o medir elementos. Por tanto, al recopilar datos estadísticos se debe tener especial cuidado para garantizar que la información sea completay correcta; de este modo, el primer paso es determinar qué información y en qué cantidad se ha de reunir. Por ejemplo, en un censo es importante obtener el número de habitantes de forma completa y exacta; de la misma manera, cuando un físico quiere contar el número de colisiones por segundo entre las moléculas de un gas, debe empezar por determinar con precisión la naturaleza de los objetos a contar. Dado que la naturaleza de los fenómenos en estudio es muy variada, es necesario proporcionar una serie de definiciones referentes a los conjuntos de datos que se han de estudiar.
La población es el conjunto que incluye el total de elementos o datos cuyo conocimiento es de interés particular.
Cada uno de los elementos que intervienen en la definición de población es un individuo u objeto; se denominaron de esta manera, ya que originalmente el campo de actuación de la estadística fue el demográfico.
Dado que la información disponible consta frecuentemente de una porción o subconjunto de la población, introducimos un segundo concepto, el de muestra de una población.
La muestra es cualquier subconjunto de la población.
1. Si el conjunto de datos de interés está constituido por todos los promedios de un grupo de estudiantes de licenciatura de una universidad, cada uno de los estudiantes será un individuo estadístico, mientras que el conjunto de todos estos estudiantes será la población y una muestra podría ser el conjunto de todos los estudiantes del tercer cuatrimestre de ingeniería.
2. Si el conjunto de datos de interés está constituido por todos los promedios de los grupos de licenciatura, cada uno de los grupos será un individuo estadístico, mientras que el conjunto de todos estos grupos será la población y una muestra podría ser el conjunto de todos los grupos del tercer cuatrimestre de ingeniería.
Definición 1.2
Definición 1.3
Ejemplo 1

21
3. Si se está estudiando el resultado de ciertos experimentos químicos, cada uno de esos experimentos será un individuo estadístico y el conjunto de todos los posibles experimentos en esas condiciones será la población, mientras que una muestra podríaser un conjunto de resultados experimentales posibles en ciertas condiciones.
Más adelante se verá que el problema de muestreo no es tan simple, porque este concepto tiene mayor importancia dentro de la estadística inferencial; se profundizará en él en su momento.
1.2.1 Caracteres y variables estadísticas
Cuando se definió el concepto población, se mencionaron sus elementos, también llamados individuos; además, en el ejemplo 1 se observó que éstos pueden ser descritos por una o varias de sus propiedades o características.
El caracter de un elemento, individuo u objeto es cualquier característica por medio de la cual se
1. Si los individuos son personas, el sexo, el estado civil, el número de hermanos o su estatura son caracteres. 2. Si el individuo es una reacción química, el tiempo de reacción, la cantidad de producto obtenido o si éste es ácido o básico, son caracteres que pueden analizarse.
Un caracter es cuantitativo si es posible medirlo numéricamente o cualitativo si no admite medición. Por ejemplo, el número de hermanos y la estatura son caracteres cuantitativos, mientras que el sexo y el estado civil son caracteres cualitativos.
Los distintos valores que puede tomar un caracter cuantitativo configuran una variable estadística. Las variables estadísticas se clasifican en discretas y continuas.
Una variable estadística es discreta sólo cuando permite valores aislados, como números enteros.
Por ejemplo, la variable número de hermanos toma los valores 0, 1, 2, 3, 4 y 5. Este tipo de variables se caracterizan por obtenerse mediante un proceso de conteo (ver semejanza con las variables aleatorias discretas en la unidad 5).
Una variable estadística es continua cuando admite todos los valores de un intervalo.
Por ejemplo, la variable estatura, en cierta población estadística, toma cualquier valor en el intervalo 158-205 cm. Otro más es la temperatura de una persona. Este tipo
Definición 1.4
Ejemplo 2
Definición 1.5
Definición 1.6

22
de variables se caracteriza por obtenerse mediante mediciones (ver semejanzas con las variables aleatorias continuas en la unidad 7).
Las variable cualitativas pueden ser nominales si se trata de categorias (sexo, raza, etc.) y ordinales si implican orden (clase social, grado de preferencia).
1.2.2 Estadística descriptiva
Como ya se dijo, la estadística se divide en varias ramas, una de ellas es la estadística descriptiva. Después de haber estudiado los conceptos de población y muestra es posible definirla.
La estadística descriptiva es la parte de la estadística que organiza, resume y analiza la totalidad de elementos de una población o muestra.
Su finalidad es obtener información, organizarla, resumirla y analizarla, lo necesario para que pueda ser interpretada fácil y rápidamente y, por tanto, pueda utilizarse eficazmente.
El proceso que sigue la estadística descriptiva para el estudio de una cierta población o muestra consta de los siguientes pasos:
1. Selección de caracteres factibles de ser estudiados.2. Mediante encuesta o medición, obtención del valor de cada elemento en los
caracteres seleccionados.3. Obtención de números que sintetizan los aspectos más relevantes de una
distribución estadística (más adelante a dichos números los llamaremos parámetros para el caso de la población y estadísticos en las muestras).
4. Elaboración de tablas de frecuencias, mediante la adecuada clasificación de los individuos dentro de cada carácter (esto lo estudiaremos más adelante en eltema “Clases de frecuencias”).
5. Representación gráfica de los resultados (elaboración de gráficas estadísticas, a las que llamaremos histogramas).
1.3 Tipos de muestreo
Los especialistas en estadística se enfrentan a un complejo problemacuando, por ejemplo, toman una muestra para un sondeo de opinión o una encuesta electoral; seleccionar una muestra capaz de representar con exactitud las preferencias del total de la población noes tarea fácil, para tal efecto existen diferentes tipos de muestreo, los más conocidos se mencionan enseguida.
Muestreo aleatorio simple
Este tipo de muestreo se caracteriza porque cualquier elemento de la población en estudio tiene la misma posibilidad de ser seleccionado.
Definición 1.7

23
Por ejemplo, de la población estudiantil de una universidad se puede seleccionar una muestra aleatoria de 50 estudiantes para aplicar una encuesta y obtener cierto tipo de información. En estos casos, existen distintos métodos para respetar la aleatoriedad, el más común es asignarle un número diferente a cada estudiante y luego, con la ayuda de una tabla de números aleatorios, elegir un bloque de tamaño 50 de ésta y realizar las entrevistas a los alumnos seleccionados.
Muestreo estratificado
En este tipo de muestreo se divide la población en grupos que no se traslapen –es decir, que no tengan elementos en común– y se procede a realizar un muestreo aleatorio simple en cada uno de los grupos.
Por ejemplo, la población estudiantil de una universidad se puede dividir en grupos formados por diferentes especialidades (ingeniería industrial, ingeniería en sistemas,administración, etc.) y después de cada una de ellas se procede a seleccionar una muestra aleatoria para llevar a cabo una entrevista y obtener la información deseada.
Además de los dos tipos de muestreo mencionados, existe el muestreo sistemáticoy el muestreo por conglomerados. El problema de muestreo es más complejo de lo que parece; para un estudio más detallado del tema, el estudiante puede consultar el libro Elementos de muestreo, de Richard L. Scheaffer y William Mendenhall, de Grupo Editorial Iberoamérica.
1.3.1 Uso de tablas de números aleatorios
Como se mencionó, las muestras aleatorias se pueden obtener a partir de una tabla de números aleatorios. Se supone que se tiene una población de mil individuos y se quiere hacer un muestreo de diez de ellos. En este caso, primero se asigna un número del 000al 999 a cada miembro de la población y luego se elige de la tabla de números aleatorios un punto de arranque y se hace el recorrido hasta obtener el tamaño de la muestra de diez. Debido a que el tamaño de la población es mil, de los números que aparecen en la tabla se consideran sólo sus tres últimas cifras. Por ejemplo, sean los siguientes númerosaleatorios elegidos de una tabla.
Al elegir sus tres últimas cifras se obtienen los números que formarán la muestra: 061, 897, 108, 542, 975, 093, 135, 818, 499 y 605. Después se procede a seleccionar de la población a los individuos que les corresponden estos números.
De forma similar que en el caso de las mil personas, primero se asigna un número a cada elemento de la población desde 000 hasta 649 y posteriormente se elige un bloque de números aleatorios donde las tres primeras cifras sean menores a 649.
9173061
0746897
7392108
0015542
4757975
0195093
8122135
7996818
1321499
0559605

24
1.4 Parámetros y estadísticos
Los números que sintetizan los aspectos más relevantes de una distribución estadística pueden obtenerse tanto de una población como de una muestra y por consiguiente deben clasificarse: los primeros, obtenidos de la población, reciben el nombre de parámetros y los obtenidos de una muestra se llaman estadísticos o estimadores.
Los parámetros y estadísticos más comunes de la estadística descriptiva que seestudiarán en esta unidad se dividen, a su vez, en dos tipos:
1. Medidas centrales: media, mediana, moda, media geométrica, media armónica, media ponderada.
2. Medidas de dispersión: rango, varianza, desviación estándar, error estándar, coeficiente de variación, percentiles, rango intercuartil.
1.5 Medidas centrales
Si el conjunto de datos numéricos de una muestra de tamaño n (o población de tamaño N) es de la forma x1, x2,. . ., xn (o para la población x1, x2,. . ., xN), nos podemos preguntar por las características del conjunto de números que son de interés. En está sección se estudiarán los métodos para describir su localización y, en particular, el centro de los datos.
1.5.1 La media
Cuando una persona tiene en sus manos un conjunto de datos para analizarlos, generalmente calcula, en primera instancia, un promedio de éstos. Por ejemplo, dicha persona tiene las cantidades mensuales que ha ganado en los últimos seis meses (10 800, 9 700, 11 100, 8 950, 9 750 y 10 500) y desea conocer el valor que representa su salario promedio. En este caso, obtendrá su ingreso promedio al sumar las cantidades y dividir entre el número de meses que trabajó
10 800 + 9 700 + 11 100 + 8 950 + 9 750 + 10 500
———————————————————————————————————— = 10 133.33 6
El sueldo promedio es $10 133.33.
Como el caso anterior, existe una infinidad de problemas o casos prácticos en los que de un conjunto de datos se quiere conocer un valor central que refleje la influencia que tiene cada uno de los datos en él. La medida central más propicia para tales fines se define a continuación.
x1, x2,..., xn, la media muestral (promedio aritmético ) o estadístico media del conjunto es el estadístico que representa el promedio de los datos simbolizado por x(x barra), y se calcula
xx x x
n nxni
i
n1 2
1
1
Definición 1.8

25
De forma similar se define el parámetro media para las poblaciones finitas.
Dado el conjunto de datos poblacionales x1, x2,. . ., xN, se llama media poblacional o parámetro media del conjunto al parámetro representado por (miu o mu), y se calcula
x x xN N
xNi
i
N1 2
1
1
Un fabricante de pistones toma una muestra aleatoria de 20 de éstos, para medir su diámetro interno promedio. Con la información que el fabricante obtuvo dada en centímetros, se calcula su diámetro medio
Como se trata de una muestra, se calcula su estadístico
x=1
20[10.1 + 10.1 + 9.8 + 9.7 + 10.3 + 9.9 + 10 + 9.9 + 10.2 + 10.1 + 9.9 +
9.9 + 10.1 + 10.3 + 9.8 + 9.7 + 9.9 + 10 + 10 + 9.8] = 9.975
La media representa el valor promedio de todas las observaciones y por consiguiente cada uno de los datos influye de igual manera en el resultado; en ocasiones, cuando se tienen pocos datos que se alejan considerablemente del resto, el valor promedio encon-trado no refleja la realidad del caso.
Se quiere calcular el sueldo promedio de los trabajadores de una fábrica, eligiendo aleatoriamente a diez de ellos, con las siguientes cantidades:
Se calcula el sueldo promedio, y se tiene
x= 1
10 [2 000 + 2 200 + 2 500 + 2 200 + 1 800 + 25 000 + 2 400 + 2 300 + 2 800 + 2 400] = 4 560
donde el estadístico no refleja la realidad de los datos, puesto que el sueldo de 25 000 es mucho mayor a los demás e influye considerablemente en el valor promedio.
1.5.2 La mediana
Por lo expuesto al final de la subsección es necesario presentar otro tipo de medida central en la que valores muy extremosos, con respecto al resto, no tengan una influencia tan marcada como en la media. A dicha medida se le conoce, debido a su naturaleza, como mediana.
La mediana de un conjunto de datos es el valor medio de los datos cuando éstos se han ordenado en forma no decreciente en cuanto a su magnitud.
Definición 1.9
Ejemplo 3
10.1
9.9
10.1
9.8
10.0
9.9
9.9
10.0
10.2
10.0
9.8
10.1
10.1
9.9
9.7
10.3
10.3
9.8
9.9
9.7
Ejemplo 4
Dato
Sueldo 2 000 2 200 2 500 2 200 1 800 25 000 2 400 2 300 2 800 2 400
x10x1 x2 x3 x4 x5 x6 x7 x8 x9
Definición 1.10

26
Cálculo de la mediana
Dado el conjunto de datos muestrales x1, x2,. . ., xn, la mediana muestral o estadístico medianadel conjunto se representa por x(x tilde) y se obtiene ordenando primero en forma no decreciente estos n datos, los que se renombrarán según su posición por medio de tildes de la siguiente forma
x x xn1 2
Posteriormente se localiza el punto medio de los datos ordenados, con dos casos:
1. Cuando la cantidad de observaciones es impar, el valor medio del ordenamiento es el dato que se encuentre en la posición (n + 1)/ 2.
2. Cuando la cantidad de datos es par, de tal manera que resultan dos datos medios localizados en las posiciones n/ 2 y n/ 2 + 1, la mediana se considera el promedio de éstos.
Finalmente, se puede resumir el cálculo de la mediana con las siguientes fórmulas
x
x
x x
n
n n
, cuando la cantidad de datos es impar1
2
2 2
, cuando la cantidad de datos es par1
2
De forma similar se define el parámetro mediana.Dado el conjunto de datos poblacionales x1, x2,. . ., xN, la mediana poblacional o
parámetro mediana del conjunto es el parámetro representando por , y se calcula
x
x x
N
N N
,cuando la cantidad de datos es impar1
2
2 2
cuando la cantidad de datos es par1
2,
Dado el conjunto muestral de datos del ejemplo anterior, referente al sueldo promedio, se calcula su mediana.
La siguiente tabla muestra el conjunto de los diez datos
Ordenando los sueldos de menor a mayor y renombrándolos se obtiene
Dato
Sueldo 2 000 2 200 2 500 2 200 1 800 25 000 2 400 2 300 2 800 2 400
x10x1 x2 x3 x4 x5 x6 x7 x8 x9
2 300
Dato original
Datoordenado
Sueldo 1 800 2 000 2 200 2 200 2 400 2 400 2 500 2 800 25 000
x10x1 x2 x3x4x5 x6x7x8
x10x1~ ~~~~x2 x3 x4 x5 x6 x7 x8 x9
x9
~ ~ ~~ ~
Ejemplo 5

27
La cantidad de datos es diez y éste es un número par, por consiguiente la mediana muestral se encuentra con el promedio de los datos ordenados en las posiciones n/ 2 y n/ 2 + 1. Es decir, en las posiciones 10/ 2 = 5 y 10/ 2 + 1 = 6
xx x5 6
2
2 300 2 400
22 350
En la mediana se puede observar que el valor $25 000, el cual sobresalía con respecto a todos los demás, a diferencia de la media, no influye en el resultado de la mediana. Puesto que si en lugar de $25 000 se elige $5 000 o $100 000, el sueldo medio de los diez trabajadores seguirá siendo $2 350. Por lo cual se dice que la mediana es una medida central insensible de los datos.
1.5.3 La moda
Para algunos estudios es necesario encontrar el valor central de un conjunto de datos, en donde la medida de interés está basada en la repetición de éstos; por tanto, ninguna de las dos medidas analizadas es conveniente en este caso. Debido a su naturaleza, a esta medida se le da el nombre de moda y se define a continuación.
La moda de un conjunto de datos es el valor que se presenta en su distribución con mayor frecuencia.
La moda se simboliza por Mo para las muestras y para las poblaciones.
En la siguiente lista se muestran las calificaciones de 20 exámenes delingüística. Secalculade lingüística. Secalculaingüística. Se calcula la calificación que más se repite, es decir, la moda de la distribución de las calificaciones.
Después del conteo de los datos, se tiene
cinco datos con valor 5un dato con valor 6 y otro con valor 7
tres datos con valor 8 seis datos con valor 9 cuatro datos con valor 10
Por tanto, la moda es igual a 9; ya que es la calificación de mayor frecuencia.
Al calcular la moda es posible observar que es una medida completamente opuesta a la mediana en cuanto a su sensibilidad. Por ejemplo, si en el caso de las calificaciones un alumno con calificación 9 hubiese obtenido 5, la moda cambiaría a 5 (serían seis 5 y cinco 9). Así que con la sola alteración de un dato cambia completamente la moda, por tanto, se dice que ésta es sumamente sensible.
Definición 1.11
Ejemplo 6
5 8 9 9 8 10 9 5 10 5
6 5 10 10 8 9 7 9 5 9

28
La moda también presenta los siguientes dos problemas:
1. La moda puede no existir . Por ejemplo, se tienen las siguientes series de datos:
6, 7, 34, 4, 8 6, 3, 8, 9, 3, 8, 6 y 9
En ambas series de datos la frecuencia es la misma, es decir, no tienen moda. A los conjuntos de datos como los anteriores se les llama amodales o sin moda.
2. La moda puede no ser única . Por ejemplo, se tiene la siguiente serie de datos
6, 7, 9, 4, 8, 6, 6, 8, 9, 6, 8, 6, 9, 3, 9 y 9
En esta serie están los valores 6 y 9 como los de mayor frecuencia, ambos se repiten cinco veces. Al conjunto de datos que tiene más de una moda se le l lama multimodal; bimodal si son dos modas, y trimodal si son tres, etcétera.
1.5.4 Otros valores medios
Ya se han analizado los tres valores centrales más conocidos y utilizados en la estadística descriptiva. El primero de ellos fue el definido en la sección 1.5.1 como una media aritmética, sin embargo, existen distribuciones de datos para las cuales esta medida no es muy propicia, por lo que se definen y utilizan otro tipo de medidas centrales, la mediana y la moda. A continuación se verán otros tipos de promedios que son de utilidad en la estadística descriptiva.
Valor geométrico o media geométrica
La media geométrica de los datos x1, x2,. . ., xn se simboliza por MG y está definida como la raíz n-ésima del producto de las n mediciones.
MG x x xnn
1 2
Se calcula la media geométrica de 20 calificaciones de exámenes psicológicos
MG 5 8 9 9 8 10 9 5 10 5 6 5 10 10 8 9 7 9 5 9 7 544686820 .
De la definición de media geométrica se deduce que ésta no se puede aplicar cuando algún dato vale cero o la cantidad de datos es par y existe una cantidad impar negativa.
5 8 9 9 8 10 9 5 10 5
6 5 10 10 8 9 7 9 5 9
Ejemplo 7
Observación

29
Valor medio armónico o media armónica
La media armónica de los datos x1, x2,. . ., xn se simboliza por MA y está definida como el recíproco de la media aritmética de los recíprocos.
MA
n x n x x x
n
x x xii
n
n n
1
1 1
1
1 1 1 1 1 1 1
1 1 2 1 2
La principal aplicación de ésta es promediar las variaciones respecto del tiempo, es decir, cuando la misma distancia se recorre a diferentes tiempos.
Si se viaja de una ciudad a otra recorriendo los primeros 100 km a 80 kmph, los siguientes 100 km a 100 kmph y finalmente otros 100 km a 120 kmph, se calcula la velocidad media utilizando la mediaarmónica y se compara con las medias aritmética y geométrica.
MA1
1
3
1
80
1
100
1
120
97 2973.
x1
380 100 120
300
3100
MG 80 100 120 98 64853 .
Para tomar la decisión de qué media parece la más correcta, se calcula la velocidad promedio
Velocidad promediodistancia total recorrida
tiempo total
La distancia total recorrida es igual a 100 + 100 + 100 = 300 km.
El tiempo total de recorrido es 10080
100100
100120
3 0833. h.
Ahora se compara con la distancia total real recorrida las distancias que recorrería el automóvil con cada una de las velocidades promedio calculadas
Media aritmética: 3.0833 100 = 308.33 kmMedia geométrica: 3.0833 98.6485 = 304.166 km
Media armónica: 3.0833 97.2973 =300 km
(Nótese que el mejor resultado se obtiene con la media armónica).
Ejemplo 8
Observación

30
Valor medio ponderado o media ponderada
Para los casos en que cada dato tiene una importancia relativa en su distribución –la cual se denomina peso–, la media correspondiente más apropiada se obtiene sumando los productos de cada dato por su peso, llamando a dicha medida media ponderada.
En un conjunto de datos x1, x2,. . ., xn se llama pesos o ponderaciones respectivas de estos
datos a las cantidades w1, w2,. . ., wn que cumplen
a) wi [ ]0,1 , para todo valor de ib) w1 + w2 + . . . + wn = 1
La media ponderada del conjunto de datos x1, x2,. . ., xn, con pesos respectivos w1, w2,. . ., wn, se simboliza por MP y se calcula con la siguiente fórmula:
MP w xi ii
n
1
Se calcula la calificación promedio de un estudiante. La calificación está ponderada de lasiguiente forma: 10% tareas, 40% del primer examen bimestral y 50% del examen final. Las calificaciones del estudiante son 8, 9 y 4, respectivamente.
La calificación está ponderada, por tanto
MP = 0.1 8 + 0.4 9 + 0.5 4 = 6.4
En el caso de poblaciones, los parámetros correspondientes se calculan con las mismas formulas cambiando n por N.
Al analizar un conjunto de datos surge una duda: ¿tener las medidas centrales es suficiente para conocer su distribución? Después de estudiar la siguiente sección estoquedará claro.
Ejercicio 1
1. Calcula la media, mediana y moda del siguiente conjunto de datos
2. Calcula la media y mediana de los tiempos de llegada de seis aviones que aterrizan en un aeropuerto. Los tiempos (en minutos) son
3.5 4.2 2.9 3.8 4.0 2.8
Definición 1.12
Ejemplo 9
Nota
145 150 165 155 155 145 150
140 145 150 160 175 150 160

31
3. Calcula la media geométrica del conjunto de datos del ejercicio anterior. 4. Calcula la media armónica del viaje redondo que realiza un chofer de una línea de
camiones cuya ruta es de 520 km, si de ida lo recorrió por una autopista a 101 kmph y de regreso por otra a velocidad promedio de 75 kmph.
5. En una muestra de 100 pistones se encontró que 55 tenían un diámetro interno de 10.5 cm, 25 de 10.0 y el restante de 10.75. Utiliza las frecuencias relativas de los pistones para calcular la media ponderada de su diámetro interno.
1.6 Medidas de dispersión
Para un análisis más completo de la distribución de los datos, el estudio de sus medidas centrales no es suficiente, puesto que en diferentes conjuntos de datos puede haber medidas centrales iguales, por tanto, no se tendría conocimiento de la forma de su distribución.
Por ejemplo, se tienen dos conjunto de datos, uno contiene los valores 20, 12, 15, 16, 13 y 14, y el segundo 5, 0, 50, 17, 8 y 10; se calcula su media.
Como se puede verificar en ambos casos se obtiene 15. Pero si se representan los valores en una recta, es notable que las observaciones del segundo conjunto tienen una distribución (variación) mucho mayor.
Por tanto, es necesario realizar un estudio de la distribución de los datos con respecto a su valor central, es decir, se necesita un valor que indique una medida para comparar las dispersiones de datos entre diferentes conjuntos; estas medidas son valores de dispersión o variabilidad del conjunto de datos.
1.6.1 Rango
Es el primer valor que nos muestra cómo están distribuidos (dispersos) los datos. El rangode las observaciones está simbolizado por r para la muestra y R para la población. El rango es una medida de variación de los datos que lo único que muestra es el tamaño o longitud del intervalo en el que los datos se encuentran distribuidos y es:
El rango es igual a el valor mayor menos el valor menor de los datos.Definición 1.13

32
Por ejemplo, para los datos muestrales de los dos conjuntosde datos anteriores
• en el primer conjunto su rango vale r1 = 20 – 12 = 8, es decir, los datos de este conjunto están distribuidos a lo largo de un intervalo de longitud 8
• en el segundo conjunto su rango vale, r2 = 50 – 0 = 50, es decir, los datos de este conjunto están distribuidos a lo largo de un intervalo de longitud 50
Los elementos del segundo conjunto tienen una separación mayor entre ellos, pero el resultado no muestra el comportamiento de los datos con respecto a su media.
1.6.2 Varianza y desviación estándar
Otra medida de dispersión de los datos que está relacionada directamente con la media del conjunto es la varianza.
Se llama varianza de un conjunto de datos al promedio de los cuadrados de las desviaciones de cada uno de los datos con respecto a su valor medio.
Si se tienen n datos muestrales, x1, x2,. . ., xn con valor medio igual a x , los cuadrados de las desviaciones de cada uno de los datos con respecto a su valor medio serán ( )x x1
2, ( )x x2
2, etcétera. Al igual que en los valores medios, la varianza puede definirse con respecto a la
muestra o a la población.
Respecto a la muestra
La varianza muestral o estadístico varianza del conjunto de datos x1, x2,. . ., xn, se representa por s2datos con respecto a x, y se calcula
s2 21
1nx xi
i
n( )
Sobre la definición anterior podemos decir que denota la intención de una medida variacional de un conjunto de datos, sólo que más adelante (unidades 9 y 10) se verá que es conveniente definir el estadístico varianza dividiendo entre n – 1 en lugar de n. Para distinguirlas, se les asignan nombres diferentes, los cuales se justificarán hasta la unidad 9, cuando se analice el tema “Estimadores puntuales”. Mientras tanto se define
La varianza sesgada como sn
x xn ii
n2 21
1
( )
Definición 1.14
Definición 1.15

33
La varianza insesgada como sn
x xn ii
n
11
2 211
( )
Pero, ¿por qué dos definiciones diferentes en lugar de una? Porque la varianza sesgada refleja perfectamente el significado de una medida de dispersión y por consiguiente tiene una gran aplicación en el estudio de las probabilidades. Mientras que la varianza insesgada, es más propicia para los cálculos estadísticos y se emplea generalmente para las muestras.
Respecto a la población
De forma similar para poblaciones finitas se define el parámetro varianza poblacional, el cual está representado por 2.
Dado el conjunto de datos poblacionales x1, x2,. . ., xn, con valor medio , se define la varianza poblacional
Varianza poblacional * 2 21
1Nxi
i
N( )
La varianza se calcula con los cuadrados de las desviaciones y, por tanto, no está en las mismas unidades que los datos. Por consiguiente, se introduce una nueva medida de dispersión de la siguiente forma:
Se llama desviación estándar de un conjunto de datos a la raíz cuadrada positiva de la varianza, es decir
2o s s2
Se calcula la varianza insesgada y la desviación estándar de cada uno de los dos conjuntosde la sección 1.6:
Primer conjunto: 20, 12, 15, 16, 13 y 14. Anteriormente se encontró que x = 15.
sn
x xn ii
n
11
2 2
2 2 2
1
1
1
6 120 15 12 15 15 15
( )
( ) ( ) ( ) ( ) ( ) ( )16 15 13 15 14 15
1
525 9 0 1 4 1 8
2 2 2
La desviación estándar es sn – 1 = 8 2 8284. .
Definición 1.16
Ejemplo 10
* En las unidades 5 y 7 se presenta una definición más general, la cual se puede aplicar tanto a poblaciones finitas como infinitas.

34
Segundo conjunto: 5, 0, 50, 17, 8 y 10. Anteriormente se encontró que x = 15.
sn
x xn ii
n
11
2 2
2 2 2
11
16 1
5 15 0 15 50 15
( )
( ) ( ) ( ) (117 15 8 15 10 15
1
5100 225 1225 4 49 25 325
2 2 2) ( ) ( )
..6
La desviación estándar es sn – 1 = 325 6 18 0444. . .
Cálculo de las varianzas
Para los cálculos se acostumbra emplear otra representación equivalente a la de varianza, determinada por las siguientes fórmulas:
Varianza sesgada sn
x xn ii
n2 2 21
1
Varianza insesgada sn
xn
nxn i
i
n
11
2 2 211 1
Se calcula la varianza insesgada para los conjuntos de datos del ejemplo 10, empleando las últimas fórmulas para la varianza, y se verifica que coincidan los resultados.
Primer conjunto: 20, 12, 15, 16, 13 y 14.
sn
xn
nxn i
i
n
11
2 2 2 2 2 2 2 2 21
1 1
1
6 120 12 15 16 13 14
6
6 115
1
5400 144 225 256 169 196
6
5225 278 270
2( )
88
Segundo conjunto: 5, 0, 50, 17, 8 y 10.
sn
xn
nxn i
i
n
11
2 2 2 2 2 2 2 2 21
1 1
1
6 15 0 50 17 8 10
6
6 115
1
525 0 2500 289 64 100
6
5225 595 6 270 325
2( )
. .66
En los cálculos anteriores se observa que en ambos casos coinciden los resultadoscon los del ejemplo 10.
Ejemplo 11

35
Ejercicio 2
1. Calcula el rango y la varianza insesgada del siguiente conjunto de datos:
2. Calcula la desviación estándar de los tiempos de llegada de ocho aviones que aterrizan en un aeropuerto. Los tiempos en minutos son 3.5, 4.2, 2.9, 3.8, 4.0 y 2.8.
3. En los envases de leche, la cantidad de líquido no es siempre un litro, por lo que se toma una muestra de diez envases, y se obtienen los siguientes valores:
0.95 1.01 0.97 0.95 1.0 0.97 0.95 1.01 0.95 0.98
Calcula la varianza.
1.7 Clases de frecuencia
Hasta ahora se ha trabajado sólo con muestras o poblaciones menores de 30 elementos, cuyos cálculos no han sido tan laboriosos; pero qué pasa cuando la cantidad de datos es considerable o éstos provienen de mediciones que hagan más laborioso el cálculo de sus medidas centrales o de variación. Además de lo anterior, puede ser que sólo necesitemos un resumen más compacto del conjunto de datos o incluso tener una representación gráfica del comportamiento de su distribución, por lo que siendo un conjunto con gran cantidad de datos (por ejemplo, 200) visualizarlos todos, para poder estudiar su distribución, no es factible, por consiguiente, es necesario emplear alguna otra estrategia de análisis.
El problema mencionado se puede resolver fácilmente distribuyendo los datos por medio de intervalos, lo que da origen a la siguiente definición:
Dado un conjunto de datos, se llama intervalos de clase o clases de frecuencia o simplemente clases a los intervalos que por parejas son ajenos o disjuntos y contienen todos los datos del conjunto.
Una pareja de intervalos son disjuntos si no tienen elementos en común. Con respecto a la cantidad de intervalos de clase, se pide que no sea una cantidad excesiva o insuficiente. No existe una regla determinante para obtener la cantidad de intervalos cuando se tienen n datos. Algunos especialistas en estadística emplean el entero más cercano a la raíz de n, otros el entero más cercano a log(n), o bien la llamada regla de Sturges, en la cual se toma como el tamaño de la muestra el entero más cercano a 3.3logn + 1 con n cantidad de datos correspondientes a las observaciones. Para efectos de este libro, se empleará una cantidad de intervalos que, dependiendo del valor de n, se encuentre entre cinco y veinte.
Con respecto a los intervalos de clase, no es un requisito que sean de igual longitud, sin embargo, aquí habrá restricción a clases de igual longitud.
145 150 165 155 155 145 150
140 145 150 160 175 150 160
Definición 1.17
Nota

36
1.7.1 Construcción de clases de frecuencia
Para la construcción de los intervalos de clase o clases de frecuencia existen diferentes técnicas, al igual que en la elección de la cantidad de clases no existe un método determinante o una fórmula general. Lo único que debe respetarse es:
• un mismo dato no debe de pertenecer a dos intervalos diferentes• todos los datos deben de estar distribuidos en los intervalos formados
Aquí se construirán los intervalos de clase de un conjunto de datos {x1, x2,. . ., xn}, de acuerdo con los siguientes puntos:
1. Se calcula el rango del conjunto de datos.2. Se divide el rango entre la cantidad de clases o intervalos que queremos tener y
el valor calculado será la longitud decada una de éstas en las que se distribuirán los datos.
3. Para formar las clases o intervalos se consideran cerrados los extremos izquierdos de los intervalos y los derechos se consideran abiertos, tomando a la última claseen ambos extremos cerrada.
Dado un conjunto de datos donde el valor más pequeño es 5 y el más grande 75. Construye diez intervalos de clase para dicho conjunto de datos.
El rango del conjunto es: r = 75 – 5 = 70. Como queremos tener diez intervalos de clase dividimos el rango 70 entre diez y obtenemos siete. Este valor será la longitud de cada una de las clases de frecuencia. Por tanto, las diez clases son
[5,12), [12,19), [19,26), [26,33), [33,40), [40,47), [47,54), [54,61), [61,68), [68,75]
Recuérdese que un intervalo de la forma [26,33) indica que se consideran todos los valores que están entre 26 y 33, incluyendo el 26 y excluyendo el 33.
1.7.2 Frecuencias relativas
Empleamos la construcción de los intervalos de clase para estudiar de forma simplificada la distribución de los datos, por tanto, después de construir los intervalos de clase, contamos la cantidad de datos que caen en cada uno. A dicha cantidad se le llama frecuencia de la clase o frecuencia de clase o frecuencia absoluta y se simboliza por fi, donde irepresenta el número de la clase y
f ii
nn
1
Se llama frecuencia relativa de una clase i al cociente de la cantidad de datos que se encuentran en ésta con respecto del total de datos en el conjunto y se simboliza por
ff
nri
donde n representa la cantidad total de datos.
Ejemplo 12
Definición 1.18

37
Se consideran lascalificaciones (con escala de cero a 100) de 80 estudiantes en la materia física experimental, se distribuyen en siete clases de frecuencias y se calculan las frecuencias relativas de las clases:
Lo primero es construir las siete clases de frecuencia, encontrando el valor más grande 100 y el más pequeño 30, por tanto, el rango vale r = 100 – 30 = 70.
Como se piden siete clases de frecuencias, se divide 70 entre siete y el resultado es diez. Es decir, la longitud de las clases de frecuencia será de diez unidades.
El primer intervalo es [30, 40), es decir, todos los datos que sean mayores o iguales a 30 pero menores a 40; los datos son 30, 38, 30, 30, 30, 35, 36 y 30, ocho en total.
Este proceso de conteo se continúa hasta llegar a la última clase.Al realizar el conteo de elementos por clase se recomienda que los datos contados
se marquen para evitar una equivocación. Por ejemplo, después del primer conteo la tabla queda de la siguiente forma
Finalmente, se calculan las frecuencias relativas por clase, dividiendo las frecuencias entre la cantidad total de datos, en este caso 80, y se obtiene
Ejemplo 13
30 88 96 100 45 38 78 89 68 88
68 100 100 68 69 79 98 94 30 46
30 86 85 89 94 99 100 45 30 35
36 76 78 81 80 40 67 58 89 58
98 90 100 100 68 70 83 85 68 56
30 67 78 98 100 86 69 79 52 45
89 78 65 60 69 76 78 77 89 98
99 91 100 48 68 84 67 69 46 79
30 88 96 100 45 38 78 89 68 88
68 100 100 68 69 79 98 94 30 46
30 86 85 89 94 99 100 45 30 35
36 76 78 81 80 40 67 58 89 58
98 90 100 100 68 70 83 85 68 56
30 67 78 98 100 86 69 79 52 45
89 78 65 60 69 76 78 77 89 98
99 91 100 48 68 84 67 69 46 79

38
Tanto en estadística como en probabilidad tiene un interés particular la acumulación de frecuencias, por lo que se definen dos nuevas medidas en las clases de frecuencia: frecuencia acumulada y la frecuencia relativa acumulada.
Se llama frecuencia acumulada a la función que representa la suma de las frecuencias por clase, y se simboliza por Fi .
Se llama frecuencia relativa acumulada a la función que representa la suma de las frecuencias relativas por clase y se simboliza por Fr .
Cálculo de las frecuencias acumuladas
Dado un conjunto con n datos, se divide en m intervalos de clase con frecuencias f1, f2, . . ., fm, tales que f1 + f2 + . . . + fm = n (cantidad total de datos).
Bajo estas condiciones la frecuencia acumulada está dada por
F x fii
x xi
( ) 1
Mientras que para el caso de la frecuencia relativa acumulada, las frecuencias relativas por clase son
fn
fn
fnm1 2, ,..., ;
se cumplefn
fn
fnm1 2 1 y, por tanto, se tiene
Frecuencia relativa acumulada de una clase i es el cociente de la frecuencia acumulada de clase i entre la cantidad total de datos n, es decir
FFnri
Debido a que en las frecuencias por clase no es de interés el valor de cada elemento sino sólo la cantidad de estos en la clase, se acostumbra realizar el conteo por medio de las barras como antiguamente se llevaba a cabo; es decir, se pone una barra vertical por elemento contado y cada vez que se llega a cuatro barras la quinta se coloca en diagonal. Por ejemplo, para contar ocho elementos:
Definición 1.19
Definición 1.20

39
Con esta forma de conteo se puede construir, a partir de la tabla 1.1, una tabla similar que contenga las frecuencias acumuladas
1.7.3 Media, mediana y moda en clases de frecuencia
Al igual que se realizó con un conjunto de datos del cual se obtuvieron sus medidas centrales y de desviación, éstas se pueden obtener para las clases de frecuencia empleando los puntos medios de las clases y sus frecuencias de clase.
Sea k el número de clases, xi el punto medio de la i-ésima clase y fi la frecuencia de la i-ésima clase, entonces el valor de la media aritmética se calcula con la fórmula
xf xni i
i
k
1
Otro valor promedio importante es la mediana (Md ), que divide la distribución en dos áreas iguales; numéricamente se compara con la media aritmética x.
Se puede obtener el cálculo de la mediana con la siguiente fórmula:
donde
L = límite inferior de clase mediana l = longitud del intervalo de clase mediana
M L l
nC
fd2
n2
= mitad de las observaciones
C = frecuencia acumulada anterior a la clase mediana f = frecuencia del intervalo de clase mediana
Definición 1.21

40
La clase mediana es el intervalo que incluye la mitad de las observaciones; es posible definirla al calcular la frecuencia acumulada F.
Con los datos del ejemplo 13, se calcula la mediana Md.
El intervalo de clase mediana es [70, 80), ya que F5 = 46 incluye a la mitad de las obser-vaciones n/ 2 = 80/ 2 = 40; l = 80 – 70 = 10.
M L l
nC
fd2 70 10
40 34
1270 10
6
12770 5 75
El valor promedio moda (Mo ), que se comparará con los valores numéricos de la media aritmética x y la mediana Md, se calcula con la fórmula:
donde
L = límite inferior de la clase modal l = longitud del intervalo de clase modal
M L ld
d do
1
1 2
d1 = diferencia en frecuencia del intervalo de clase modal con el anterior d2 = diferencia en frecuencia del intervalo de clase modal con el posterior
La clase modal es el intervalo que tiene en su frecuencia el número mayor.
Con los datos del ejemplo 13, se calcula el valor promedio moda (Mo ).
El intervalo de clase modal es [90, 100] ya que la mayor frecuencia está en F7 = 19 con L = 90, l = 10, d1 = 19 – 15 = 4 y d2 = 19 – 0 = 19.
M L ld
d do1
1 290 10
4
19 490 10
4
2390 10(.. ) .
.
1739 90 1 739
91 74 92
1.7.4 Varianza en clases de frecuencia
De forma similar a la media de clases de frecuencia se pueden definir las varianzas sesgada e insesgada de las clases de frecuencia.
Si fi y xi son la frecuencia y el punto medio de la i-ésima clase, respectivamente, y n es la suma de las frecuencias, entonces la varianza sesgada s2 se calcula con la fórmula
sn
f x xi ii
k2 21
1
( )
Ejemplo 14
Ejemplo 15
Definición 1.22

41
La varianza insesgada s2 se calcula con la fórmula
sn
f x xi ii
k2 2
1
1
1( )
La desviación estándar por clases de frecuencia seguirá siendo la raíz cuadrada positiva de la varianza correspondiente.
La media y varianza por clases de frecuencia generalmente se emplean para observar la distribución de datos muestrales, pero en caso de querer definir estas medidas para datos poblacionales se realiza de forma similar, sustituyendo la n por N, xpor y s por , como se hizo en las secciones 1.5 y 1.6.
Se calcula la varianza sesgada de las clases de frecuencia con los datos del ejemplo 13.Para realizar los cálculos más fácilmente se utilizará la tabla 1.2, tan sólo intro-a tabla 1.2, tan sólo intro-tan sólo intro-
duciendo algunas columnas:
La suma de la quinta columna dividida entre 80 corresponde al valor promedio de la media aritmética.
x5 770
8072 125 72
.
Por la definición de varianza sesgada se tiene
s2 1
8030 640 382 984 383( ) .
Mientras que la desviación estándar correspondiente es
s s2 383 19 57.
Definición 1.23
Nota
Ejemplo 16

42
Ejercicio 3
1. En la siguiente tabla se dan los tiempos de llegada en minutos de 60 aviones a un aeropuerto.
a) distribuye los datos en cinco clases de frecuencia b) calcula su media y varianza sesgada por medio de las clases anteriores
2. Una máquina despachadora de refrescos de un centro comercial parece estar fallando, puesto que el encargado ha recibido varias quejas en la última semana; él decide registrar la cantidad de contenido en 40 vasos despachados por dicha máquina y dividirlos en tres clases de igual longitud, si 70% o más de los refrescos despachados se encuentra en la clase media, el encargado seguirá trabajando con la máquina, en caso contrario la mandará reparar. Los valores (en mililitros) medidos son:
a) divide los valores en tres clases de frecuencia de igual longitud, calcula sus frecuencias relativas e indica si el encargado tendrá que reparar la máquina o no b) calcula la cantidad de líquido promedio que despacha la máquina, empleando las clases de frecuencia del inciso anterior
3. Si en el ejercicio anterior, además de la consideración del porcentaje, se toma en cuenta la desviación estándar de las clases de frecuencia, por medio del criterio “ la máquina se reparará en caso de que la desviación estándar sea mayor a seis”, determina si el fabricante, según los datos observados, tendrá que reparar la máquina. 4. Se estudió el tiempo de vida de 90 personas con SIDA y se anotó su duración en meses, y se obtuvo
Ordena en diez clases de frecuencia y calcula la media y varianza de los datos.
2.6 3.9 4.5 4.0 3.7 3.2 5.7 4.3 3.8 3.6
4.7 6.1 6.0 5.0 4.5 6.2 3.4 2.9 3.6 4.1
2.5 2.8 3.2 3.1 4.6 5.2 6.1 4.5 4.1 3.8
7.2 3.4 7.9 3.6 3.6 4.8 5.2 6.3 8.2 5.3
3.9 4.6 4.5 5.7 4.8 6.9 6.3 2.6 2.5 6.8
8.0 5.6 3.9 4.6 4.8 5.9 6.2 3.2 4.5 5.0
34.0 28.5 18.0 34.9 25.8 16.9 15.8 19.0 11.5 25.9 38.9 34.0 16.8 27.8 26.5
24.6 22.8 16.8 39.0 42.0 48.0 34.8 33.0 23.9 27.5 35.8 36.9 26.7 26.8 34.7
35.9 25.8 24.8 45.8 18.9 35.8 35.8 46.9 36.8 35.9 52.0 33.6 24.8 25.9 26.8
26.8 29.4 37.8 35.9 10.8 25.8 35.8 26.8 25.7 26.9 27.9 38.5 35.8 30.2 28.6
33.1 34.7 45.9 56.8 45.8 25.8 50.2 42.9 46.8 48.9 47.5 48.2 42.5 40.8 27.9
24.8 46.8 40.7 18.9 22.0 29.5 31.9 48.2 34.8 47.2 27.0 39.8 45.8 40.4 38.2
245.6 236.9 240.7 235.9 247.8 246.5 230.8 250.6 248.0 247.4
238.6 240.0 246.9 258.9 245.6 248.5 246.8 245.6 247.8 256.0
243.0 243.3 240.6 250.2 249.6 243.8 246.9 247.8 243.0 246.4
230.5 228.9 235.7 248.9 248.9 245.7 240.8 246.8 246.2 250.0

43
1.8 Gráficas
Las gráficas a las que se hace referencia en estadística descriptiva deben mostrar la distribución de las frecuencias o frecuencias acumuladas del conjunto de datos, con lo cual se podrá entender e interpretar fácilmente su comportamiento.
Por tanto, es necesario introducir un nuevo método gráfico para la interpretación de datos, entre los gráficos más comunes están
• diagrama de barras• polígono de frecuencias• diagrama circular o de pastel
1.8.1 Diagrama de barras
Uno de los gráficos que más se emplean para representar un conjunto de datos es el diagrama de barras, donde se grafican una serie de rectángulos sobre un sistema de referencia. Cuando se construyen los rectángulos con sus bases sobre cada uno de los intervalos de clase y con sus alturas las frecuencias correspondientes de clase, el gráfico se llama histograma.
Un histograma
La construcción de histogramas comienza prácticamente igual que en las clases de frecuencia:
1. Se construyen los intervalos de clase.2. Se encuentra el punto medio de cada intervalo de clase.3. En el plano cartesiano, en el eje de las abscisas, se distribuirán los puntos
medios de las clases de frecuencia, mientras que en el eje de las ordenadas se distribuirán las frecuencias de los datos. Finalmente, se construye el histograma graficando una barra por cada clase, y cuyo centro será el punto medio de ésta, de tal manera que la altura de la barra es la frecuencia o fre-cuencia relativa y la base de los rectángulos está definida por los límites de cada clase.
Para facilitar la construcción de un histograma es recomendable emplear sólo intervalos de clase de igual longitud, ya que en dado caso las frecuencias de las clases se grafican de manera proporcional a las alturas de los rectángulos y además es mucho más fácil comparar las diferencias entre frecuencias cuando los rectángulos tienen la misma base.
Se construye un histograma para las clases de frecuencia y la frecuencia acumulada del ejemplo 13.
Definición 1.24
Ejemplo 17

44
Empleando la tabla 1.2:
Se grafican los puntos medios de los intervalos (tercera columna) y se trazan los rectángulos con sus bases iguales a la longitud de la clase y con las alturas correspon-dientes a su frecuencia, como se muestra en las siguientes figuras:
Para las frecuencias relativas el histograma es el mismo, sólo se divide cada frecuencia entre el total de datos.
Modelos de distribución de datos
Los histogramas no sólo nos ayudan a ubicar el centro y visualizar la variabilidad de los datos, sino también la forma en que se distribuyen; por tanto, los podemos clasificar en
• simétricos• sesgados hacia la izquierda o la derecha• multimodales
0
4
87
12
19
15
25 35 45 55 65 75 85 95 105
158
34
19
46
80
61
f
a)
025 35 45 55 65 75 85 95 105
F (x)
b)
Nota

45
Histogramas simétricos
Presentan la distribución en forma de campana, es decir, la mitad izquierda es una imagen reflejada de la mitad derecha. Como muestra la figura 1.2a, se cumple x = Md = Mo.
Histogramas sesgados
Presentan una distribución en la que alguna de las colas está más alargada en comparación con la otra. Se llaman sesgados a la derecha o positivamente sesgados si la cola derecha es la que está más alargada. Como lo muestra la figura 1.2b, se cumple Mo < Md < x. Se les llama sesgados a la izquierda o negativamente cuando la cola izquierda es la más alargada. Como lo muestra la figura 1.2c, se cumple x < Md < Mo.
Histogramas multimodales
Tienen en su distribución más de un pico (ver figura 1.2d). En caso de dos picos bimodal, en caso de tres, trimodal etcétera.
Retomando los datos del ejemplo 13 y comparando los valores promedio calculados x = 72, Md = 75, Mo = 92, el modelo asociado con las 80 calificaciones de física experimental es sesgado a la izquierda.
a) b)
c) d)
Ejemplo 18
46
1.8.2 Polígono de frecuencias
En ciertas áreas de estudio se requiere que las representaciones gráficas de la distribución de las frecuencias de datos sean hechas por líneas en lugar de barras. Por ejemplo, al realizar un estudio sobre los pronósticos de algún evento se visualiza mejor la distribución de sus frecuencias y sus tendencias si se unen sus puntos medios con segmentos rectilíneos en lugar de trazar barras.
Un polígono de frecuenciasuniendo por líneas los puntos medios de cada intervalo, donde xi es el punto medio de clase i y fisu frecuencia. Debido a su forma también se le suele llamar .
Construcción de un gráfico poligonal
1. Se crean los intervalos de clase.2. Se encuentra el punto medio de cada intervalo de clase.3. En el plano cartesiano, en el eje de las abscisas, se distribuirán los puntos
medios de las clases de frecuencia, mientras que en el eje de las ordenadas se distribuirán las frecuencias de los datos. Finalmente, se construye el gráfico poligonal uniendo los puntos obtenidos.
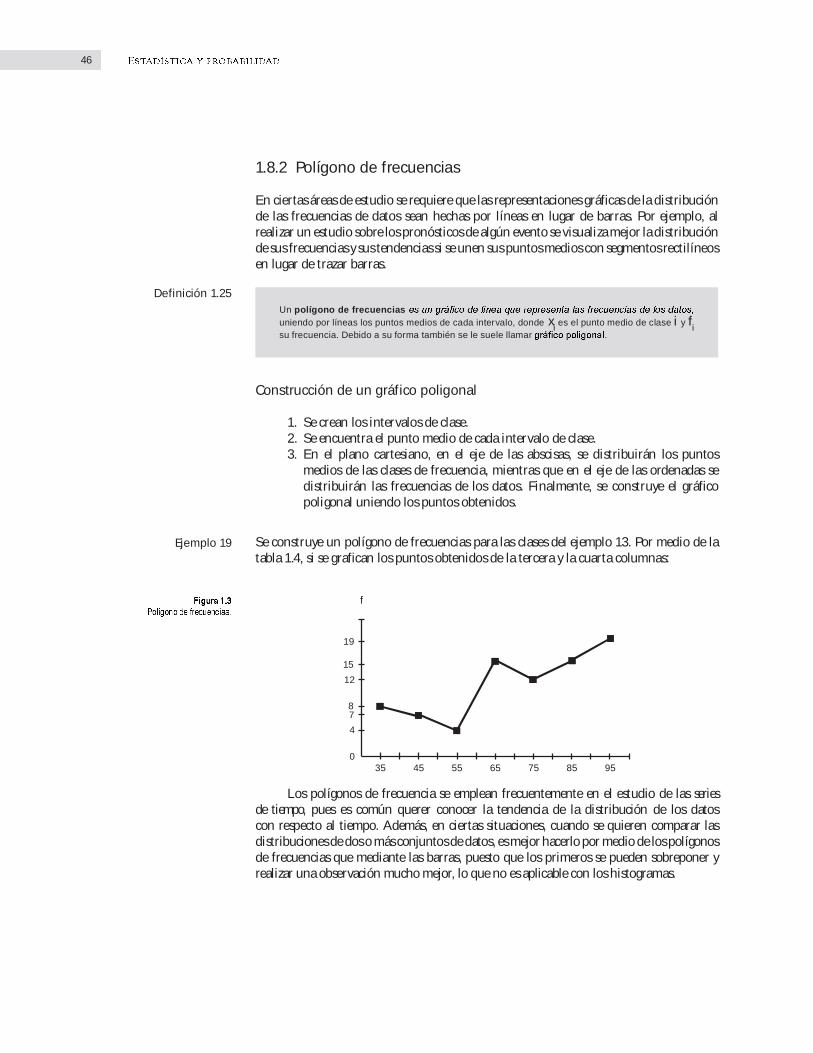
Se construye un polígono de frecuencias para las clases del ejemplo 13. Por medio de la tabla 1.4, si se grafican los puntos obtenidos de la tercera y la cuarta columnas:
Los polígonos de frecuencia se emplean frecuentemente en el estudio de las series de tiempo, pues es común querer conocer la tendencia de la distribución de los datos con respecto al tiempo. Además, en ciertas situaciones, cuando se quieren comparar las distribuciones de dos o más conjuntos de datos, es mejor hacerlo por medio de los polígonos de frecuencias que mediante las barras, puesto que los primeros se pueden sobreponer y realizar una observación mucho mejor, lo que no es aplicable con los histogramas.
Definición 1.25
Ejemplo 19
f
12
4
78
0
19
15
35 45 55 65 75 85 95

47
A los polígonos de frecuencia que se elaboran con las frecuencias acumuladas o las frecuencias relativas acumuladas se les llama ojivas .
Se construye la ojiva para las frecuencias relativas acumuladas del ejemplo 13.
1.8.3 Diagrama circular o de pastel
Otro tipo de representación gráfica de la distribución de datos muy empleado, cuando se quieren ilustrar las proporciones de los datos de tal forma que llamen la atención, sonlos diagramas circulares.
Un diagrama circular frecuencias relativas del conjunto de datos. Por su forma también se le suele llamar diagrama de pastel .
Construcción de un diagrama circular
1. Se crean los intervalos de clase.2. Se calculan las frecuencias relativas por clase.3. A partir del centro de un círculo se trazan sectores proporcionales al área que
representen la frecuencia relativa por clase.
Se construye un diagrama circular que represente la distribución por clases de frecuencias relativas para las estaturas (en centímetros) de la siguiente muestra de 50 personas.
Definición 1.26
0.4250
0.1875
1
0
0.2375
0.10
0.7625
0.5750
1 2 3 4 5 6 7
Definición 1.28
Ejemplo 21
Ejemplo 20

48
Como son 50 datos y se van a distribuir en siete clases, primero se calcula el rango del conjunto r = 186.4 – 158.4 = 28
Se quieren obtener siete clases, por tanto, se divide el rango 28 entre siete y el resultado es cuatro. Este valor será la longitud de cada una de las clases de frecuencia. Es decir
[158.4,162.4), [162.4,166.4), [166.4,170.4), [170.4,174.4), [174.4,178.4), [178.4,182.4), [182.4,186.4)
Para obtener el área que representa la frecuencia relativa en el digrama circular, se multiplica la frecuencia relativa por 360°.
Con el avance de la informática y la creación de software, han aumentado lasrepresentaciones gráficas para las distribuciones de los datos; en esta unidad sólo se han ilustrado algunas de ellas. A continuación se mencionan otros tipos de diagramas:
• anillos• superficies• cotizaciones• cilíndricas• cónicas• piramidales
Todaséstas se pueden encontrar en software estadístico para computadora.
1224%
918%
24%
24%
510%
816%
1224%
a)
24%
18%4%4%10%
16%
24%
b)
Intervalo
i
Clase
iConteo
Frecuenciarelativa
Frecuenciaf i
1 [158.4, 162.4)
[162.4, 166.4)
[166.4, 170.4)
[170.4, 174.4)
[174.4, 178.4)
[178.4, 182.4)
[182.4, 186.4]
2
2
3
4
5
6
7
0.04
0.10
0.16
0.24
0.24
0.18
0.042
9
12
12
8
5

49
Ejercicio 4
1. Con los datos del ejercicio 3, numeral 1, traza los gráficos de barras y poligonal paralas frecuencias señaladas.
2. Con los datos del ejercicio 3, numeral 2, construye un diagrama de pastel que represente las proporciones mencionadas.
Ejercicios propuestos
1. Calcula la media, mediana, moda y varianza insesgada del siguiente conjunto de datos
2. Calcula las frecuencias relativas de los datos del ejercicio anterior. 3. Calcula la media geométrica del conjunto de datos del ejercicio 1. 4. Calcula la media geométrica de las edades (en años) de ocho personas: 20, 23, 24,
22, 19, 22, 25 y 27. 5. Calcula la media armónica del viaje redondo que realizó una persona de México a
Querétaro (210 km), si de ida lo recorrió a una velocidad de 130 kmph y de regreso a 110 kmph.
6. Si una persona viajó 400 km en cuatro tramos de 100 km cada uno, con velocidades de 100, 130, 90 y 110 kmph, respectivamente, calcula con base en la media armónica la velocidad media con la que realizó el viaje.
7. Los siguientes datos muestran los diámetros internos en centímetros de 20 pistones, calcula su diámetro interno medio y su desviación estándar.
8. Ciertos fabricantes de llantas quieren saber la duración promedio de su producto según el uso de diferentes conductores, para lo cual se toma una muestra aleatoria de 100 de sus compradores, los cuales reportaron la duración de sus llantas en miles de kilómetros
Con estos datos, calcula la duración promedio de las llantas y su varianza insesgada, dividiendo el conjunto de datos en diez clases de frecuencias.
18 19 18 16 11 10 26 18
20 22 24 19 18 11 16 20
12.1 11.9 12.2 11.7 11.9 12.4 12.1 12.0 11.6 11.9
13.0 12.8 11.8 12.4 12.3 11.9 12.2 11.9 12.1 12.2
55.3 59.5 60.0 48.6 59.1 63.5 56.3 55.0 53.7 52.8
50.5 56.7 60.8 67.6 68.0 64.4 58.0 49.9 65.4 47.9
45.2 68.1 56.5 50.5 51.2 55.9 61.8 73.0 65.3 60.0
56.6 57.3 49.9 69.5 50.2 52.1 56.7 56.2 52.9 55.0
49.8 51.4 56.8 60.1 56.7 55.9 55.2 65.0 54.8 50.2
56.7 67.0 58.8 57.9 49.9 50.6 58.6 54.8 53.8 52.0
52.8 51.9 61.0 62.5 64.2 67.1 59.9 58.1 56.7 54.0
56.3 53.9 52.0 52.9 51.9 56.0 58.1 52.0 57.0 56.1
49.9 61.0 62.5 51.8 50.1 50.8 60.2 57.8 53.2 51.8
60.1 60.9 56.8 48.0 58.9 57.6 59.7 60.7 63.6 65.3

50
9. Con base en los datos del ejercicio anterior traza un histograma para las clases de frecuencias encontradas.
10. Haciendo uso de las fórmulas respectivas, encuentra la mediana y la moda de la duración de las llantas del ejercicio 8 y compáralas con la media encontrada. Obtén también el tipo de modelo asociado.
11. En la siguiente tabla se muestran los errores tipográficos por página que comete una secretaria en 100 páginas.
a) divide a los datos en ocho clases de frecuencia y calcula la media por clases b) calcula la varianza de clase
12. Traza un histograma del ejercicio anterior. 13. La siguiente lista muestra las calificaciones de los alumnos de dos grupos de 30
alumnos, cada uno. Determina la calificación promedio por grupo, su varianza insesgada y qué grupo tiene calificaciones más homogéneas.
Autoevaluación
Indica la respuesta correcta.
1. La Bolsa Mexicana de Valores ha tenido diferentes alzas y bajas en puntosporcentuales durante la primer quincena de junio de 2000
0 2 3 2 1 5 2 1 6 3
1 5 6 2 3 2 2 2 4 5
5 3 2 6 7 1 3 7 2 3
4 4 5 8 1 3 4 7 3 8
0 5 3 2 4 4 6 7 8
9 2 4 6 2 3 4 7 6 4
5 4 6 7 7 2 1 3 8 2
4 5 6 2 7 2 5 5 1 8
3 4 7 8 2 8 1 3 4 4
3 5 6 2 4 2 6 8 1 7
10
8 8 3 5 10 9 4 7 1 3
8 9 7 7 7 2 3 8 8 9
7 8 4 5 6 6 10 6 3 8
Grupo 1
10 10 8 0 0 2 8 4 1 4
8 5 2 10 10 10 9 8 9 2
3 3 1 1 2 4 8 6 3 8
Grupo 2

51
Calcula el porcentaje medio obtenido en dicha quincena
a) 3.8 b) 15 c) 1.5 d) 0.38
2. Los precios del barril de petróleo crudo exportado por México durante 16 días del año 2000 fueron
Considerando estos precios, calcula la desviación estándar muestral de la variabilidad de los precios en esos 16 días
a) 1.3456 b) 0.6237 c) 0.3053 d) 0.4672
3. Calcula la moda de los precios del petróleo del ejercicio anterior
a) 31.5 b) 32.0 c) 32.5 d) 31.0
4. Calcula la media de los precios del petróleo del ejercicio 2. Asimismo, calcula mediana, moda y media geométrica de dichos precios y determina cuál de estas medidas es más próxima al valor medio
a) mediana b) moda c) media geométrica
5. Un chofer de una línea de camiones viajó 1 000 km en cuatro tramos de 250 km cada uno, con velocidades de 90, 80, 95 y 85 kmph, respectivamente. Calcula, conbase en la media armónica, la velocidad media con la que realizó el viaje
a) 87.14 kmph b) 89.4 kmph c) 85 kmph d) 87.5 kmph
31.5 31.0 32.0 32.5 32.5
32.0 31.5 31.0 30.9 31.8
31.2 30.5 31.5
30.6 32.0 32.0

52
6. Los siguientes datosmuestran los sueldos de 90 personaselegidas aleatoriamente.Los siguientes datos muestran los sueldos de 90 personas elegidas aleatoriamente. Ordena los datos en diez clases de frecuencia de igual longitud y calcula media aritmética x, mediana Md y moda Mo
La distribución es a) sesgada a la derecha b) simétrica c) sesgada a la izquierda d) bimodal
7. Calcula la desviación estándar del ejercicio anterior
a) 23.45 b) 18.93 c) 12.16 d) 15.34
8. En la siguiente lista se muestran las calificaciones de los alumnos, de cuatro muestras de diez alumnos, cada una. Por medio de su varianza insesgada, determina qué muestra resultó más homogénea en sus calificaciones.
a) muestra 1 b) muestra 2 c) muestra 3 d) muestra 4
9. Indica cuál de los siguientes incisos define mejor el concepto de estadística descriptiva
a) parte de la estadística que sirve para obtener inferencias de la población a partir de los datos muestrales
b) partede laestadísticaquesirvepara llevar acabo losdiseñosdeexperimentosyarte de la estadística que sirve para llevar a cabo los diseños de experimentos y poder tomar una decisión
c) partedelaestadísticaquesirveparadescribir la totalidad deelementosdeunaparte de la estadística que sirve para describir la totalidad de elementos de una población o muestra
d) partedelaestadísticaquesirveparaestimar losparámetrosdeunapoblación conparte de la estadística que sirve para estimar los parámetros de una población con base en un muestreo aleatorio
8 5 2 10 10 9 4 7 1 3
1 2 4 8 6 10 10 8 8 9
7 8 4 5 6 10 9 8 9 2
10 10 9 8 9 2 8 4 8 6
Muestra 1
Muestra 2
Muestra 3
Muestra 4

53
Respuestas de los ejercicios
Ejercicio 1
1. media = 153.214; mediana = 150; moda = 150
2. media= 3.533; mediana= 3.65media = 3.533; mediana = 3.65
3. 3.4923.492
4. 86.0886.08
5. 10.42510.425
Ejercicio 2
1. rango = 35; varianza = 86.95
2. 0.57850.5785
3. 0.000630.00063
Ejercicio 3
1. a) [2.50, 3.64), [3.64, 4.78), [4.78, 5.92), [5.92, 7.06), [7.06, 8.20] b) media 4.704; varianza 1.922
2. a) [228.9, 238.9), [238.9, 248.9), [248.9, 258.9]; frecuencias relativas: f1 = 0.175,
f2 = 0.625, f3 = 0.200; se tendrá que reparar la máquinab) 244.15
3. desviación estándar = 6.12; se tendrá que reparar la máquina
4. [10.8, 15.4), [15.4, 20.0), [20.0, 24.6), [24.6, 29.2), [29.2, 33.8), [33.8, 38.4), [38.4, 43.0),, [15.4, 20.0), [20.0, 24.6), [24.6, 29.2), [29.2, 33.8), [33.8, 38.4), [38.4, 43.0),[15.4, 20.0), [20.0, 24.6), [24.6, 29.2), [29.2, 33.8), [33.8, 38.4), [38.4, 43.0),, [20.0, 24.6), [24.6, 29.2), [29.2, 33.8), [33.8, 38.4), [38.4, 43.0),[20.0, 24.6), [24.6, 29.2), [29.2, 33.8), [33.8, 38.4), [38.4, 43.0),, [24.6, 29.2), [29.2, 33.8), [33.8, 38.4), [38.4, 43.0),[24.6, 29.2), [29.2, 33.8), [33.8, 38.4), [38.4, 43.0),, [29.2, 33.8), [33.8, 38.4), [38.4, 43.0),[29.2, 33.8), [33.8, 38.4), [38.4, 43.0),, [33.8, 38.4), [38.4, 43.0),[33.8, 38.4), [38.4, 43.0),, [38.4, 43.0),[38.4, 43.0),, [43.0, 47.6), [47.6, 52.2), [52.2, 56.8]; media= 33.14; varianzasesgada=91.84, [47.6, 52.2), [52.2, 56.8]; media=33.14; varianzasesgada=91.84[47.6, 52.2), [52.2, 56.8]; media= 33.14; varianzasesgada=91.84, [52.2, 56.8]; media=33.14; varianzasesgada=91.84[52.2, 56.8]; media=33.14; varianzasesgada=91.84; media = 33.14; varianza sesgada = 91.84

54
Ejercicio 4
1.
2.
Respuestas de los ejercicios propuestos
1. media = 17.875; mediana = 18; moda = 18; varianza insesgada = 19.7167
2.
3. media geométrica = 17.3014
4. media geométrica = 22.6196
5. media armónica = 119.1667
6. media armónica = 105.5567
7. media = 12.12; desviación estándar = 0.3443
8. rango = 28; longitud de clase = 2.8. Las clases y sus puntos medios se muestran en la tabla. Media= 56.212; varianzainsesgada= 61.263Media = 56.212; varianza insesgada = 61.263
0
4
8
12
16
20
3.07 4.21 5.35 6.49 7.630
4
8
12
16
20
3.07 4.21 5.35 6.49 7.63
10 11 16 18 19 20 22 24 26Frecuencia
Valor116
216
216
216
216
116
116
116
416

55
9.
10. mediana = 56.7; modelo asociado asimétrico positivo
11. rango = 10; longitud de clase = 1.25. Las clases y sus puntos medios se muestran en la tabla. Media= 4.225; varianzainsesgada= 5.564Media = 4.225; varianza insesgada = 5.564
1 146.4[45.0, 47.8)
2
3
4
5
6
7
8
9
10
6
4
1
7
14
23
14
17
13[47.8, 50.6)
[50.6, 53.4)
[53.4, 56.2)
[56.2, 59.0)
[59.0, 61.8)
[61.8, 64.6)
[64.6, 67.4)
[67.4, 70.2)
[70.2, 73.0]
66.0
68.8
71.6
63.2
60.4
57.6
54.8
52.0
49.2
0
5
10
15
20
25
46.4 49.2 52 54.8 57.6 60.4 63.2 66 68.8 71.6
56
12.
13. grupo 1: media = 6.3 y varianza insesgada = 6.1896 grupo 2: media = 5.3 y varianza insesgada = 12.355 el grupo más homogéneo fue el 1
Respuestas de la autoevaluación
1. d)
2. b)
3. b)
4. c)
5. a)
6. a)
7. d)
8. c)
9. c)
02
810
15
1921
1411
0.625 1.875 3.125 4.375 5.625 6.875 8.125 9.375




