
ELABORACIÓN DEL PLAN DE PRODUCCIÓN EN UNA EMPRESA …
325
ELABORACIÓN DEL PLAN DE PRODUCCIÓN EN UNA EMPRESA DEL SECTOR JABONES, INTEGRANDO MODELOS DE PROGRAMACIÓN LINEAL Y EL ANÁLISIS DE SERIES DE TIEMPO BOX-JENKINS. TRABAJO DE GRADO JUAN CAMILO DÍAZ HERRERA DIRECTOR Ing. JUAN CARLOS GARCÍA DÍAZ Ph. D PONTIFICIA UNIVERSIDAD JAVERIANA INGENIERÍA INDUSTRIAL ECONOMÍA BOGOTÁ D.C, ABRIL 2014
Transcript of ELABORACIÓN DEL PLAN DE PRODUCCIÓN EN UNA EMPRESA …

ELABORACIÓN DEL PLAN DE PRODUCCIÓN EN UNA EMPRESA DEL SECTOR
JABONES, INTEGRANDO MODELOS DE PROGRAMACIÓN LINEAL Y EL ANÁLISIS DE
SERIES DE TIEMPO BOX-JENKINS.
TRABAJO DE GRADO
JUAN CAMILO DÍAZ HERRERA
DIRECTOR
Ing. JUAN CARLOS GARCÍA DÍAZ Ph. D
PONTIFICIA UNIVERSIDAD JAVERIANA
INGENIERÍA INDUSTRIAL
ECONOMÍA
BOGOTÁ D.C, ABRIL 2014

ELABORACIÓN DEL PLAN DE PRODUCCIÓN EN UNA EMPRESA DEL SECTOR
JABONES, INTEGRANDO MODELOS DE PROGRAMACIÓN LINEAL Y EL ANÁLISIS DE
SERIES DE TIEMPO BOX-JENKINS.
TRABAJO DE GRADO PARA OPTAR POR LOS TÍTULOS DE
INGENIERO INDUSTRIAL Y
ECONOMISTA
JUAN CAMILO DÍAZ HERRERA
DIRECTOR
Ing. JUAN CARLOS GARCÍA DÍAZ Ph. D
PONTIFICIA UNIVERSIDAD JAVERIANA
INGENIERÍA INDUSTRIAL
ECONOMÍA
BOGOTÁ D.C, ABRIL 2014

A Dios y mis padres
Orlando y Ana Lucia

AGRADECIMIENTOS
El autor expresa sus más sinceros agradecimientos a
Profesor Juan Carlos García Díaz, docente de la Pontificia Universidad Javeriana y
director de este trabajo de grado por su guía y apoyo a través de sus conocimientos,
experiencias y visión.
A la profesora Martha Misas, docente de la Pontificia Universidad Javeriana por sus
pertinentes consejos y apoyo para la realización de este trabajo.
Y por último, a Alianzas y/o Industrias Alta Pureza S.A a través de la alta gerencia y todas
aquellas personas que de una forma u otra dedicaron su tiempo a colaborar en la
realización de este trabajo de grado.

TABLA DE CONTENIDO
1 INTRODUCCIÓN ......................................................................................................... 1 1.1 Presentación General del Trabajo ......................................................................... 1 1.2 Mercado de Marcas Propias a Nivel Global y Regional ......................................... 2 1.3 Mercado de Marcas Propias a Nivel Nacional ....................................................... 3 1.4 La Necesidad de un Buen Pronóstico en la Planeación ......................................... 3 1.5 Estructura General del Trabajo de Grado .............................................................. 5
2 PLAN AGREGADO DE PRODUCCIÓN ...................................................................... 8 2.1 Capacidad Operativa ............................................................................................. 8 2.2 Planificación de la Producción Utilizando Programación Lineal ............................. 9
3 CARACTERIZACIÓN DEL SISTEMA DE PRODUCCIÓN ........................................ 10 3.1 Descripción General de la Empresa .................................................................... 10
3.1.1 Reseña Histórica ........................................................................................... 10 3.1.2 Misión ........................................................................................................... 11 3.1.3 Visión ............................................................................................................ 11 3.1.4 Productos, Clientes y Participación ............................................................... 11 3.1.5 Organigrama ................................................................................................. 12
3.2 Proceso Productivo y Caracterización ................................................................. 12 3.3 Estaciones de Trabajo ......................................................................................... 14 3.4 Recursos ............................................................................................................. 15
3.4.1 Recurso Mano de Obra ................................................................................. 15 3.4.2 Recurso Máquina .......................................................................................... 16
3.5 Representantes Tipo ........................................................................................... 16 3.6 Estudio de Tiempos Estándar de Producción ...................................................... 17
3.6.1 Etapas del Estudio de Tiempos ..................................................................... 17 3.6.2 Seleccionar el Trabajador Tipo Para el Estudio de Tiempos ......................... 18 3.6.3 Registrar toda la información significativa. .................................................... 18 3.6.4 Desglosamiento de la operación por elementos ............................................ 18 3.6.5 Registro de los tiempos transcurridos por elemento ...................................... 19 3.6.6 Valoración del Desempeño del Operario ....................................................... 21 3.6.7 Determinación del tiempo estándar ............................................................... 22 3.6.8 Cálculo del tiempo estándar por elemento .................................................... 22
3.7 Capacidad Disponible .......................................................................................... 27 3.7.1 Cálculo capacidad disponible recurso Hombre ............................................. 28 3.7.2 Cálculo capacidad disponible recurso Máquina ............................................ 30
3.8 Costo Unitario de Producción .............................................................................. 31 3.8.1 Costos de mano de obra directa ................................................................... 32 3.8.2 Costos de materia prima e insumos .............................................................. 33 3.8.3 Costos de almacenamiento ........................................................................... 34 3.8.4 Costos fijos ................................................................................................... 36 3.8.5 Costos de ruptura ......................................................................................... 36 3.8.6 Costos de Contratar y Despedir .................................................................... 37
4 PRONÓSTICO DE LA DEMANDA EN EL HORIZONTE DE PLANEACIÓN ............. 39 4.1 Teoría General Sobre Decisión y Pronóstico con Series de Tiempo .................... 39
4.1.1 Descripción de los Pronósticos en la Planeación .......................................... 39 4.1.2 Funciones de pérdida de error de pronóstico simétricas. .............................. 40
4.2 Descripción de los Datos ..................................................................................... 40 4.3 Add In en Excel Para el Manejo de Series de Tiempo Para Uso Empresarial. ..... 42
4.3.1 Instalación de ASTEX en Microsoft Excel ..................................................... 43

4.3.2 Funcionamiento de ASTEX ........................................................................... 43 4.3.3 Estructura de ASTEX .................................................................................... 44
4.4 Metodología Lineal: Box-Jenkins Modelo ARIMA ................................................ 45 4.4.1 Modelo General ............................................................................................ 47 4.4.2 Etapa de Identificación .................................................................................. 49 4.4.3 Etapa de Estimación ..................................................................................... 60 4.4.4 Etapa de Diagnóstico .................................................................................... 61 4.4.5 Etapa de Pronóstico ...................................................................................... 64
4.5 Metodología comparativas ................................................................................... 69 4.6 Pronóstico del Mejor Modelo ............................................................................... 72 4.7 Capacidad Requerida del Horizonte de Planeación ............................................. 74
4.7.1 Capacidad Requerida Frente a Capacidad Disponible .................................. 74
5 PLANEACIÓN DE LA PRODUCCIÓN ...................................................................... 76 5.1 Construcción del Modelo de Programación Lineal ............................................... 76 5.2 Incorporación de atributos al conjunto de información ...................................... 83 5.3 Integración GAMS en ASTEX .............................................................................. 88 5.4 Resultados del Modelo ........................................................................................ 88
6 ANÁLISIS DE BENEFICIOS ECONÓMICOS DEL PLAN DE PRODUCCIÓN EN LA ORGANIZACIÓN ............................................................................................................. 93
6.1 Costo de Implementar la Propuesta .................................................................... 93 6.1.1 Costos de mano de obra ............................................................................... 93 6.1.2 Costos de licencias ....................................................................................... 94
6.2 Beneficios y Contribuciones del Proyecto ............................................................ 94 6.3 Comportamiento de las Variables Ante Cambios en la Demanda. ....................... 97 6.4 Análisis de Sensibilidad o Análisis Posóptimo ................................................... 100
7 CONCLUSIONES .................................................................................................... 102
8 RECOMENDACIONES............................................................................................ 103
9 BIBLIOGRAFÍA ....................................................................................................... 104
10 ANEXOS ............................................................................................................... 109 10.1 Caracterización de la Organización ................................................................... 109
10.1.1 Tabla de Referencias ................................................................................ 109 10.1.2 Productos, Clientes y Participación ........................................................... 110 10.1.3 Organigrama Alianzas y/o Industrias Alta Pureza S.A ............................... 112 10.1.4 Diagrama de Caja Negra .......................................................................... 112 10.1.5 Fichas Técnicas de Máquinas ................................................................... 113 10.1.6 Representantes Tipo ................................................................................. 118 10.1.7 Diagrama de Operaciones ........................................................................ 119 10.1.8 División de Operaciones por Elemento ..................................................... 124
10.2 Formas de Estudio de Tiempos ......................................................................... 126 10.2.1 Formato estándar para la realización del estudio de Tiempos ................... 126
10.3 Suplementos Personales .................................................................................. 127 10.4 Muestreo Del Trabajo ........................................................................................ 128 10.5 Procedimientos Matemáticos ............................................................................ 130
10.5.1 Desarrollo de Ecuación de Capacidad Disponible Recurso Hombre. ........ 130 10.6 Análisis de las Series de Tiempo ...................................................................... 131
10.6.1 Funciones de Pérdida de Pérdida de Error de Pronóstico Simétricas ....... 131 10.6.2 Funciones De Pérdida de Error de Pronóstico Asimétricas. ...................... 133 10.6.3 Descripción de los Datos .......................................................................... 136

10.6.4 Esquema Metodología ARIMA .................................................................. 140 10.6.5 Estabilización Varianza ............................................................................. 141 10.6.6 Prueba Dickey Fuller Aumentada ADF ...................................................... 142 10.6.7 Prueba de Raíz Unitaria para la serie LR1000 .......................................... 144 10.6.8 Función de Autocorrelación ACF y Función de Autocorrelación Parcial PACF 151 10.6.9 Metodologías SCAN, ESACF y MINIC ...................................................... 153 10.6.10 Identificación Serie LR1000 .................................................................... 159 10.6.11 Método de Máxima Verosimilitud (ML) .................................................... 171 10.6.12 Teoría Sobre Diagnósticos del Modelamiento ARIMA ............................. 174 10.6.13 Estimación-Diagnóstico Serie LR1000 .................................................... 182 10.6.14 Valor Real Vs Ajuste del Modelo ............................................................. 187 10.6.15 Esquema Rolling y Algoritmo en MATLAB .............................................. 189
10.7 Complemento ASTEX ....................................................................................... 193 10.7.1 Ventana Para la Instalación del Add/In ..................................................... 193 10.7.2 Estabilización de la Varianza con ASTEX ................................................. 193 10.7.3 Estabilización del Nivel Anderson con ASTEX .......................................... 200 10.7.4 Prueba de Raíz Unitaria ADF con ASTEX ................................................. 202 10.7.5 Diagnostico Normalidad y Media Cero con ASTEX ................................... 203 10.7.6 Integración GAMS –ASTEX para la planeación de la producción ............. 206
10.8 Códigos De Programación ................................................................................ 209 10.8.1 Código VBA para la Extracción de las Series de Interés en Consolidado de Ventas. 209 10.8.2 Código VBA para la Automatización de la Transformación Estabilizadora de Varianza ................................................................................................................. 209 10.8.3 Código GAMS para Plan de Producción ................................................... 213
10.9 Resultados ........................................................................................................ 217 10.9.1 Resultados de las transformaciones estabilizadoras de varianza. ............. 217 10.9.2 Resultados Estabilización Varianza Método Anderson .............................. 220 10.9.3 Resultados identificación series restantes ................................................. 221 10.9.4 Resultados Estimación-Diagnóstico Series Restantes .............................. 242 10.9.5 Resultados Diagnóstico Rolling con Rolling2.m. ....................................... 252 10.9.6 Pronósticos de los Mejores Modelos ......................................................... 282 10.9.7 Resultados Programación Lineal GAMS-ASTEX ...................................... 286 10.9.8 Resultados Análisis del Comportamiento de las Variables en la LP .......... 289 10.9.9 Resultados Análisis Posoptimal. ............................................................... 292
10.10 Plano de la Organización .................................................................................. 306 10.11 Tablas ............................................................................................................... 308
10.11.1 Tablas Para Pruebas de Raíz Unitaria. ................................................... 308 10.12 Modelos Comparativos ..................................................................................... 310
10.12.1 Ajuste modelos comparativos ................................................................. 310 10.12.2 Explicación Modelos Comparativos. ........................................................ 313

Índice de Tablas
Tabla 1 Disposición Recurso Mano de Obra .................................................................... 15
Tabla 2 Disposición Recurso Máquina ............................................................................. 16
Tabla 3 Tiempos estándar de producción unitarios .......................................................... 26
Tabla 4 Unidades teóricas de referencias por lote de 300kg ............................................ 26
Tabla 5 Tiempo necesario para la fabricación de 1 lote=300kg........................................ 27
Tabla 6 Capacidad máquina por estación de trabajo ....................................................... 31
Tabla 7 Capacidad máquina en tiempo normal ................................................................ 31
Tabla 8 Capacidad máquina en tiempo extra ................................................................... 31
Tabla 9 Costo de mano de obra directa en tiempo normal ............................................... 33
Tabla 10 Costos de materias primas ................................................................................ 33
Tabla 11 Costos desagregados de almacenamiento........................................................ 35
Tabla 12 Volumen Bodega almacenamiento .................................................................... 35
Tabla 13 Costos unitarios de almacenamiento por referencia .......................................... 36
Tabla 14 Costos fijos ....................................................................................................... 36
Tabla 15 Costo total de despedir un operario .................................................................. 38
Tabla 16 Valores típicos de y su transformación ........................................................... 50
Tabla 17 Resumen de potencias estabilizadoras de la varianza ...................................... 51
Tabla 18 Ordenes de integración basado en Anderson (1976) ........................................ 54
Tabla 19 Resumen Pruebas Raíz Unitaria ....................................................................... 55
Tabla 20 Grado del polinomio de tendencia TR500 ......................................................... 58
Tabla 21 Resumen Modelos Tentativos (1:50) ................................................................. 60
Tabla 22 Modelos Escogidos ........................................................................................... 63
Tabla 23 Evaluación dentro de muestra ARIMA ............................................................... 64
Tabla 24 Coeficientes de LINLIN ..................................................................................... 65
Tabla 25 Esquema Rolling LR1000 .................................................................................. 66
Tabla 26 Esquema Rolling R250 ..................................................................................... 67
Tabla 27 Esquema Rolling R500 ..................................................................................... 68
Tabla 28 Esquema Rolling R1500.................................................................................... 68
Tabla 29 Esquema Rolling R3000.................................................................................... 68
Tabla 30 Resultados evaluación dentro de muestra - Método Comparativo ..................... 69
Tabla 31 Resultados evaluación fuera de muestra R250 - Método Comparativo ............. 70
Tabla 32 Resultados evaluación fuera de muestra R500 - Método Comparativo ............. 70
Tabla 33 Resultados evaluación fuera de muestra R1000 - Método Comparativo ........... 71
Tabla 34 Resultados evaluación fuera de muestra R1500 - Método Comparativo ........... 71
Tabla 35 Resultados evaluación fuera de muestra R3000 - Método Comparativo ........... 71
Tabla 36 Efectividad ARIMA frente Automático ................................................................ 72
Tabla 37 Pronósticos ARIMA todas las series.................................................................. 73
Tabla 38 Pronóstico ARIMA Limite Superior .................................................................... 73
Tabla 39 Pronóstico ARIMA Límite Inferior ...................................................................... 73
Tabla 40 Capacidad requerida marzo 2014 - agosto 2014 ............................................... 74
Tabla 41 Grado utilización máquina marzo 2014 - agosto 2014 ....................................... 75
Tabla 42 Inventario de seguridad ..................................................................................... 87
Tabla 43 Costo de reserva de inventario de seguridad .................................................... 87
Tabla 44 Resultados LP Unidades a producir en Tiempo Normal .................................... 88
Tabla 45 Resultados LP Unidades a producir en Tiempo Extra ....................................... 89
Tabla 46 Resultados LP Inventario Final Producto Terminado ......................................... 89
Tabla 47 Resultados LP Número de Horas Extra Necesarias .......................................... 89
Tabla 48 Resultados LP Número de Trabajadores Necesarios ........................................ 89
Tabla 49 Resultados LP Número de Contrataciones por Estación ................................... 89

Tabla 50 Resultados LP Número de despidos por Estación............................................. 89
Tabla 51 Rangos de oscilación ........................................................................................ 92
Tabla 52 Costo variable Mano de Obra ........................................................................... 93
Tabla 53 Costos fijos de Mano de Obra Precios obtenidos de la página web www.dane.gov.co/candane/ ..................................................................................... 94
Tabla 54 Costos de licencias ........................................................................................... 94
Tabla 55 Método Propuesto Frente a Método Actual ....................................................... 96
Tabla 56 Tabla Transformaciones de potencia .............................................................. 141
Tabla 57 Resumen de test Dickey Fuller. ....................................................................... 144
Tabla 58 Tabla de prueba de Dickey Fuller Aumentada para LR1000 ........................... 145
Tabla 59 Pruebas F para escoger el número de rezagos en ADF .............................. 146
Tabla 60 Resultados propagación hacia atrás Lag Length Choice ................................. 147
Tabla 61 Regresión de prueba ADF LR1000 con constante y tendencia ASTEX ........... 149
Tabla 62 Regresión de prueba ADF LR1000 con constante sin tendencia ASTEX ........ 151
Tabla 63 Comportamientos típicos de ACF y PACF Tomado y modificado de Guerrero(2003) ...................................................................................................... 153
Tabla 64 Tabla SCAN .................................................................................................... 155
Tabla 65 Tabla Teórica SCAN para un proceso ARMA(2,2) .......................................... 155
Tabla 66 Tabla ESACF .................................................................................................. 157
Tabla 67 Tabla Teórica ESACF para un proceso ARMA(1,2) ........................................ 157
Tabla 68 Tabla MINIC .................................................................................................... 159
Tabla 69 Función de autocorrelación y Ljung Box Q - Stat LR1000 ............................... 160
Tabla 70 Función de Autocorrelación Parcial LR1000.................................................... 161
Tabla 71 Tabla SCAN serie LR1000 (1:50) .................................................................... 163
Tabla 72 Tabla ESCAF serie LR1000 (1:50) .................................................................. 164
Tabla 73 Tabla MINIC Serie LR1000 (1:50) ................................................................... 164
Tabla 74 Tabla BIC modelos SCAN y ESACF ............................................................... 165
Tabla 75 Tabla MAPE para la serie LR1000 (1:50) obtenida por ARIMAIN.m ................ 169
Tabla 76 Tabla RMSE para la serie LR1000 (1:50) obtenida por ARIMAIN.m ............... 169
Tabla 77 Tabla MAE para la serie LR1000 (1:50) obtenida por ARIMAIN.m .................. 169
Tabla 78 Modelos tentativos para la serie LR1000 (1:50) .............................................. 170
Tabla 79 Estimaciones preliminares LR1000(1:50) ........................................................ 183
Tabla 80 Estimación fase 2 LR1000(1:50) ..................................................................... 185
Tabla 81 Ejemplo Esquema Rolling ............................................................................... 190
Tabla 82 Serie R1000 Ordenada para Estabilización de Varianza ................................. 196
Tabla 83 Determinación λ de para la variable R1000 ..................................................... 197
Tabla 84 Transformación estabilizadora de varianza R1000 .......................................... 198
Tabla 85 Desviaciones Estándar de LR1000. Estabilización Nivel ................................. 200
Tabla 86 Resultados Anderson(1976) ASTEX ............................................................... 201
Tabla 87 Modelos tentativos para la serie DLR250 (1:45) .............................................. 224
Tabla 88 Identificación modelos tentativos serie TR500 (1:50) ...................................... 230
Tabla 89 Modelos tentativos para la serie DLR1500 (1:50) ............................................ 236
Tabla 90 Identificación modelos tentativos serie LR3000(1:50) ..................................... 241

Índice de Gráficas
Gráfica 1 Detrending TR500 ............................................................................................ 58
Gráfica 2 Detrending LR3000 .......................................................................................... 59
Gráfica 3 Evolución del costo total frente a la demanda ................................................... 97
Gráfica 4 Evolución de la fuerza de trabajo frente a la demanda ..................................... 98
Gráfica 5 Evolución del número de contrataciones frente a la demanda .......................... 99
Gráfica 6 Función de pérdida MSE Fuente: Realizado por el autor ................................ 132
Gráfica 7 Función de pérdida MAE Fuente: Realizado por el autor ................................ 132
Gráfica 8 Función de pérdida LINEX Fuente: Realizado por el autor ............................. 134
Gráfica 9 Función de pérdida LINLIN Fuente: Realizado por el autor ............................ 135
Gráfica 10 Ajuste Vs. Real serie R250(1:45) .................................................................. 187
Gráfica 11 Ajuste Vs. Real serie R500(1:50) .................................................................. 187
Gráfica 12 Ajuste Vs. Real serie R1000(1:50) ................................................................ 188
Gráfica 13 Ajuste Vs. Real serie R1500(1:50) ................................................................ 188
Gráfica 14 Ajuste Vs. Real serie R3000(1:50) ................................................................ 188
Gráfica 15 Transformación Estabilizadora de Varianza LR1000 .................................... 198
Gráfica 16 QQ plot modelo M8 serie LR1000(1:50) ....................................................... 204
Gráfica 17 QQ plot modelo M9 serie LR1000(1:50) ....................................................... 205
Gráfica 18 Pronóstico serie R500(1:45) ......................................................................... 283
Gráfica 19 Pronóstico serie R500(1:50) ......................................................................... 283
Gráfica 20 Pronóstico serie R1000(1:50) ....................................................................... 284
Gráfica 21 Pronóstico serie R1500(1:50) ....................................................................... 284
Gráfica 22 Pronóstico serie R3000(1:50) ....................................................................... 285
Gráfica 23 Evolución inventario R250 ante cambios en la demanda .............................. 289
Gráfica 24 Evolución inventario R500 ante cambios en la demanda .............................. 290
Gráfica 25 Evolución inventario R1000 ante cambios en la demanda ............................ 290
Gráfica 26 Evolución inventario R1500 ante cambios en la demanda ............................ 291
Gráfica 27 Evolución inventario R3000 ante cambios en la demanda ............................ 291

Índice de Ilustraciones
Ilustración 1 Cuotas de mercado de marca de distribuidor por país (volumen) .................. 3 Ilustración 2 Pestaña ASTEX ........................................................................................... 43 Ilustración 3 Ventana condiciones del modelo GAMS ASTEX ......................................... 88 Ilustración 4 Moldeadora por inyección .......................................................................... 113 Ilustración 5 Termoencogedora 1................................................................................... 114 Ilustración 6 Termoencogedora 2................................................................................... 115 Ilustración 7 Marmita...................................................................................................... 116 Ilustración 8 Estación Envase-Pesa-Tapa ...................................................................... 117 Ilustración 9 ACF Serie LR1000 ..................................................................................... 160 Ilustración 10 PACF Serie LR1000 ................................................................................ 161 Ilustración 15 Ventana Instalación ASTEX ..................................................................... 193 Ilustración 16 Formulario para la estabilización automática de la varianza ................... 195 Ilustración 17 Formulario Ordenar Serie ........................................................................ 196 Ilustración 18 Formulario Estabilización Nivel Anderson (1976) ..................................... 201 Ilustración 19 Mensaje no imprimir, Estb. Nivel Anderson .............................................. 202 Ilustración 20 Formulario Prueba de Raíz Unitaria ADF ASTEX .................................... 202 Ilustración 21 Formulario Supuesto Normalidad ............................................................. 204 Ilustración 22 Ventana Media Cero 1 ............................................................................. 205 Ilustración 23 Ventana Media Cero 2 ............................................................................. 206 Ilustración 24 Ventana modelo copiado con éxito ASTEX .............................................. 207 Ilustración 25 Ventana archivo .txt no encontrado ASTEX ............................................. 207

1
1 INTRODUCCIÓN
1.1 Presentación General del Trabajo
Los problemas relacionados con la escasez o abundancia de producción aparecen
cuando dos objetivos contrarios entre dos agentes económicos están presentes en un
mismo sistema. Las firmas desean maximizar sus beneficios sujetos a restricciones de
capacidad, demanda y presupuestos llevando a cabo una planificación adecuada de la
producción, considerando costos de producir como lo son los insumos necesarios como el
capital (máquina y equipo) y el trabajo (operarios); mientras que los consumidores desean
maximizar su función de utilidad sujetos a una restricción presupuestal además de sus
preferencias sobre consumo las cuales eventualmente pueden cambiar en el tiempo, lo
que cambiaría el comportamiento de la demanda y por tanto la firma debe ajustar su
producción ante cambios en la misma.
Dentro de las requerimientos establecidos por muchas organizaciones para poder llegar a
contar con un óptimo en su producción, minimizando sus costos de mantener y producir
sujeto a sus posibles restricciones anteriormente mencionadas, es vital contar con un
pronóstico de demanda eficiente para la toma de decisiones en el corto plazo. La forma
como muchas organizaciones realizan los pronósticos de demanda para la planificación y
toma de decisiones no es siempre la más adecuada debido a la poca información con la
que pueden contar y el escaso personal capacitado para dicha tarea.
Este concepto ha llevado al planteamiento de modelos exactos y heurísticos que
representen los distintos escenarios en los que se puede ver enfrentada la organización,
con aras de efectuar el proceso de toma de decisiones de la producción con la menor
incertidumbre posible, para buscar estrategias que impacten positivamente en las
utilidades.
En el presente trabajo de grado se proyecta la demanda de una organización de tamaño
mediano del sector de jabones en Bogotá utilizando la metodología de series de tiempo
lineal ARIMA propuesta por Box y Jenkins en la década de los 70, se comparan los
resultado del modelo con metodologías de pronósticos automáticos utilizados en muchas
organizaciones con el objeto de probar la eficiencia del pronóstico ARIMA bajo muestras
pequeñas en condiciones de demanda variante. Se procede entonces incluyendo el
modelo de pronóstico más adecuado en la optimización de la programación lineal, con el
objeto de mejorar la exactitud de los resultados en la implementación de un modelo de
programación para la planeación de la producción de una empresa e integrar ambas
herramientas para buscar hacer más robustos los resultados y minimizar la función de
costos de la organización.

2
1.2 Mercado de Marcas Propias a Nivel Global y Regional
El mercado oculto de marcas propias, conocidas también como marcas blancas, se define
como la marca que es proporcionada por una tienda, grande superficie, almacén o
superete y cuyo nombre es propio de dicho establecimiento. Este mercado tuvo su boom
en Europa en la década de los años noventa y se presentó en el momento en que las
aerolíneas crean sus propias cadenas low-cost de las cuales se comenzaron a formar
otras empresas de servicios que permitían brindarle al consumidor un servicio de bajo
costo. Sin embargo, fue en el siglo XXI cuando estas marcas propias comenzaron a entrar
con más fuerza en el mercado, esto es debido principalmente a que las estrategias
financiaras de las familias de clase media cambiaron, se endeudaban más, consumían
más, incrementaron su nivel de vida y gastaban mucho más de lo que su bolsillo podía
darles; ante esta necesidad de suplir la demanda de consumidores que cada vez buscan
un precio más accesible a sus necesidades y cuya masa fue creciendo, se crean
empresas que incursionaron en el mercado de marcas propias y estas impulsaron a otras
empresas en lo que se conoce hoy en día como el efecto imán (Véase Mejías y Valentín
2009).
Se cree que esta “oleada blanca” comenzó a formarse principalmente debido al contexto
económico que se presentaba en la Europa del siglo XXI. En el caso de España, por
ejemplo, el consumidor se vio en la obligación de reducir su gasto, por la necesidad de
incrementar su ahorro y controlar su margen presupuestal debido a la crisis crediticia y los
problemas de inflación causados por el encarecimiento del petróleo lo que ocasionó el
hundimiento del consumo y el desplome de la economía española, favoreciendo de esta
manera a las marcas cuya distribución se daba a través de las marcas blancas.
Las marcas propias han evolucionado desde sus inicios, han pasado de una competencia
de imitación de marcas de fabricante a un mercado con una identidad propia con una muy
buena relación calidad-precio. Con el paso del tiempo, la percepción que tiene el
consumidor a nivel global sobre las marcas propias ha cambiado mucho en cuanto a
calidad se refiere y ahora se piensa que las marcas propias son productos que pueden
competir muy fuertemente con marcas de fabricantes y son una muy buena alternativa
para mejorar las finanzas de la familia.
La cuota de participación de las marcas blancas en el mercado europeo es bastante alta y
este fenómeno ha venido creciendo todos los años. Según el Anuario internacional de la
Marca de Distribuidor de la PLMA (Private Label Manufacturers Association), para el 2013
las cuotas más elevadas de participación de marcas propias se situaban en Suiza con un
53% seguidos por España con 51% y Reino Unido con 45%. Mientras que el país con la
menor cuota de participación se presenta en Italia con un 20%.

3
Ilustración 1 Cuotas de mercado de marca de distribuidor por país (volumen)
Fuente: Anuario Internacional de la Marca de Distribuidor - PLMA
1.3 Mercado de Marcas Propias a Nivel Nacional
Tanto en el caso regional como a nivel nacional, los hábitos del consumidor no parecen
estar a favor del mercado de marcas propias; sin embargo, la cultura del consumo blanco
ha presentado crecimientos en los últimos años. Según la Federación Nacional de
Comerciantes - Fenalco, para el 2012 Colombia fue el país con mayor participación en
valor para marcas propias en la región con un 14% comparado con los demás países de
América Latina cuyos porcentajes se sitúan en una franja entre el 5 y el 10 por ciento.
Además, según un estudio de Raddar, en el 2011 ocho de cada diez colombianos
incluyeron al menos un producto de marca propia dentro de sus compras regulares.
Se observa que las cuotas de mercado de las marcas propias en la región están muy por
debajo de las participación que se le da a este nicho en el viejo continente. Inclusive,
Colombia que es el país con mayor participación en América Latina con un 14% no
alcanza a igualar al país con la menor cuota de participación de Europa con un 20%. Esto
parece no ser muy relevante, sin embargo si se observa el trasfondo de este mercado y
como lo señala la Dirección de Estudios Económicos de Fenalco, las micro, pequeñas y
medianas empresas Pyme, son las grandes beneficiadas con la comercialización de
marcas propias en las grandes superficies puesto que son las que producen de forma
masiva estos productos. Por lo tanto, al fomentar el consumo de marcas blancas en el
país se estaría incentivando de manera directa a las Pyme, la productividad nacional, el
producto interno, el empleo y se beneficiaría a la economía nacional en general. Un
ejemplo de este tipo de empresas a nivel nacional es Alianzas y/o Industrias Alta Pureza
S.A. la cual será la empresa de estudio para el presente trabajo de grado y de la cual se
hablará en detalle más adelante.
1.4 La Necesidad de un Buen Pronóstico en la Planeación
Como lo expone Schroeder (1996) y Chase et al. (2009), dentro de la clasificación de
tipos de pronósticos, el ordenamiento por grado de exactitud en el corto plazo muestra

4
que el mejor pronóstico dentro del tipo lineal es el método de series temporales Box-
Jenkins aplicando modelos autoregresivos de media móvil integrados (ARIMA por sus
siglas en ingles) para buscar el mejor ajuste de los valores del pasado con el fin de
realizar predicciones futuras.
La combinación de dos herramientas poderosas como lo son la optimización de
operaciones en ingeniería industrial utilizada para la planeación de la producción y la
metodología de series temporales de Box y Jenkins, puede llegar a mejorar
ostensiblemente la planificación de la producción en las empresas, minimizando el riesgo
de sobrecostos por excesos o faltantes en la producción. La metodología de Box y
Jenkins es una técnica econométrica utilizada en la economía para determinar el
comportamiento de series económicas univariadas como la inflación, desempleo o
Producto Interno Bruto (PIB); base para la emisión de juicios tanto a nivel
macroeconómico en las decisiones de política monetaria del Banco Central como a nivel
microeconómico en el caso de inversionistas y empresas para la toma decisiones
basando sus expectativas en pronósticos inflacionarios o del crecimiento de la economía
Como se verá en detalle más adelante, en muchas ocasiones se evalúan series de tiempo
como la demanda de un bien cuyas pérdidas asociadas a los errores de pronóstico son
distintas dependiendo del signo (excesos o faltantes) como una serie con función de
pérdida simétrica. Esto trae consigo una mala especificación y una minimización de
costos que pueden llegar a ser muy alejada de la realidad. El presente trabajo pronostica
la demanda de 5 referencias de jabón lavaloza a través de la comparación de resultados
obtenidos por un modelo y el modelo seleccionado automáticamente1 a
través del software comercial SPSS, con el uso de funciones de pérdida de error de
pronóstico simétricas y asimétricas. Los resultados son confrontados y se elige el mejor
modelo de pronóstico para la optimización del plan agregado de producción.
El objeto de estudio puede llegar a ser un problema si tenemos en cuenta que muchos
pronósticos en las PYMES hoy en día se realizan de forma sencilla y las empresas toman
decisiones de producción en el corto plazo que pueden llegar a ser erróneas lo cual
traería sobrecostos asimétricos atribuidos al exceso de inventarios o faltantes en los
pedidos por la baja producción para cumplir la demanda independiente y variable, esto
debido a la pobre planeación de la producción, la poca exactitud de los pronósticos y la
falta de un análisis más profundo a la hora de realizar pronósticos. Como lo expone
Chase, Jacobs y Aquilano (2009):
“Los pronósticos son vitales para toda organización de negocios, así como
para cualquier decisión importante de la gerencia. El pronóstico es la base de
la planeación corporativa a largo plazo. En las áreas funcionales de finanzas y
1 El término “automático” en el contexto de este trabajo hace referencia a el evento cuando el
método de pronóstico se realiza únicamente incluyendo la serie original en un paquete estadístico y este busca el modelo que más se ajuste a los datos mostrando las medidas de error de pronóstico, sin ningún análisis previo de la serie estudiada.

5
contabilidad, los pronósticos proporcionan el fundamento para la planeación
de presupuestos y el control de costos. El marketing depende del pronóstico
de ventas para planear productos nuevos, compensar al personal de ventas y
tomar otras decisiones clave. El personal de producción y operaciones utiliza
los pronósticos para tomar decisiones periódicas que comprenden la
selección de procesos, la planeación de las capacidades y la distribución de
las instalaciones, así como para tomar decisiones continuas acerca de la
planeación de la producción, la programación y el inventario.”
(Chase, Jacobs, & Aquilano, 2009, p. 468)
El problema surge entonces de dos diferentes fuentes. La primera, por falta de tiempo y
recursos en las organizaciones para tomar decisiones más precisas que les permitan
reducir sobrecostos de producción, pues como arguye Schroeder (1996) los modelos de
series de tiempo econométricos requieren un poco más de tiempo y son más costosos,
sin embargo estos se compensan por la exactitud de los resultados. La segunda fuente
surge de la comodidad a la hora de realizar pronósticos sencillos utilizando herramientas y
software convencionales los cuales realizan pronósticos de manera rápida, casi
automática y usando técnicas estructuradas por formulas previas donde la única fuente de
conocimiento que debe tener la persona son los pocos parámetros necesarios que pedirá
el programa para realizar el pronóstico, incluso en algunos programas se puede realizar
esta tarea automáticamente por medio de la optimización de dichos parámetros. Mientras
que el modelaje econométrico de series de tiempo es más complejo pues requiere
experticia y fundamentos teórico-prácticos por parte de la persona para realizar el modelo
de pronóstico que mejor se ajuste a la serie deseada.
Según una encuesta realizada por el Aberdeen Group en julio de 2011 por Peter Ostrow
sobre el manejo y las ventajas de los pronósticos de demanda en 304 organizaciones
entre abril y mayo de 2011, donde el 65% de las compañías fueron de América, 27% de
la región EMEA (Europa, Middle East and Africa por sus siglas en ingles) y 8% del pacifico
de Asia, se determinó que los ingresos totales de las compañías cuyo pronóstico de
ventas era mucho más confiable era 10 puntos porcentuales mayor que las demás
compañías, además esta confianza y efectividad en sus pronósticos mejora en 7.3 puntos
porcentuales el promedio de los logros por equipo en la cuota de ventas. Por lo que la
eficiencia y confianza de los pronósticos de venta en las organizaciones está encadenada
a una mejora en el rendimiento del día a día de la organización, esto se debe a que un
pronóstico más acertado ayuda a mejorar la toma de decisiones y mejora la planeación de
la producción e inventarios reduciendo así los costos ocultos derivados de un mal
pronóstico, Ostrow (2011).
1.5 Estructura General del Trabajo de Grado
El presente trabajo de grado estará conformado por 10 capítulos, los cuales se
especifican a continuación:

6
Capítulo 1. Introducción: Se hace una breve explicación del proyecto, se
caracteriza el sector en el cual el objeto de estudio se desenvuelve y la
problemática estudiada.
Capítulo 2. Plan Agregado de Producción: Para este capítulo se hace una
explicación breve de los conceptos de producción, planeación de la producción,
MPS, cálculo de capacidades productivas y otros conceptos fundamentales para el
entendimiento y desarrollo de este trabajo.
Capítulo 3. Caracterización del sistema de producción: Se describe de
manera general la organización del estudio, elementos que la componen, además
de la descripción detallada del proceso productivo. Dentro de este proceso se
escogen los representantes tipo y recursos humanos y máquina para concluir con
la elaboración del estudio de tiempos y el cálculo de la capacidad disponible, así
como de los costos de producción unitarios.
Capítulo 4. Pronóstico de la demanda en el horizonte de planeación: Para
este capítulo se realizará una breve introducción a la teoría de pronósticos y
decisión, en seguida se realiza la descripción de los datos que se utilizarán, se
continúa con la explicación y aplicación del modelo lineal univariado ARIMA a las
series de estudio la cual es comparada con los resultados de modelos
automáticos, para concluir con la selección del mejor modelo de pronóstico que
entrará a formar parte del cálculo de la capacidad requerida del horizonte de
planeación.
Capítulo 5. Planeación de la producción: Este capítulo describe la
construcción del modelo de Programación Lineal (LP) utilizado para la elaboración
matemática del plan de producción, así como las diferentes ramificaciones que
puede tomar para elaborar las estrategias de programación lineal que se pueden
acoplar a las necesidades de la organización. Concluye con los resultados que
arroja el modelo de LP y su interpretación.
Capítulo 6. Análisis de beneficios económicos del plan de producción: Para
este capítulo se intentará evaluar el proyecto en términos de costos de
implementación y beneficios y contribuciones del proyecto; se hará un análisis
financiero costo-beneficio, se analizarán e interpretaran los resultados y por último
se entrará a hablar sobre las contribuciones que brinda el proyecto.
Capítulo 7. Conclusiones: Se muestran todas las conclusiones del
desarrollo del trabajo, indicando los impactos de los métodos cuantitativos
utilizados sobre la identificación del problema.
Capítulo 8. Recomendaciones: Para este capítulo se hace una
retrospectiva de las problemáticas asociadas a las condiciones de la planta que
pueden llegar a influir en el desempeño normal de las operaciones, se dan una
serie de sugerencias, para que en el caso de que la empresa esté en disposición
de tomarlas las pueda acoger para su propio beneficio. Adicionalmente se harán
recomendaciones sobre los procedimientos lineales y no lineales del pronóstico
realizado en el trabajo.
Capítulos 9 y 10, presentan la bibliografía consultada y los anexos al
documento respectivamente.

7
Complementario al trabajo, se realizó un aplicativo (add-in) en Excel a través de códigos
de programación en el lenguaje Visual Basic para Aplicaciones (VBA), el cual tiene el
objetivo de automatizar algunos procedimientos teóricos de series de tiempo que serán
utilizados en este trabajo de grado así como otros procedimientos útiles para el manejo de
los pronósticos de la organización y que pueden llegar a ser utilizados en cualquier
momento que lo desee y bajo diferentes condiciones de entrada. Este aplicativo será
explicado en detalle desde el Capítulo 4, más específicamente en la Sección 4.3. y puede
ser consultado en el CD anexo a este documento.
Adicionalmente, se trabajó con el lenguaje de programación MATLAB para el desarrollo
del esquema rolling de evaluación fuera de muestra en el Capítulo 4 y el lenguaje GAMS
para la programación lineal del plan de producción en el Capítulo 5.
Se recomienda tener en los siguientes aspectos para el adecuado entendimiento del
presente trabajo
Todas las herramientas presentadas aquí son basadas en teorías estadísticas y
por tanto deben ser tratadas como tal. Estos modelos no están hechos para llegar
a ellos, sino para basarse en ellos. Son una guía de apoyo, más nunca una
evidencia tacita de la realidad, puesto que el carácter intrínseco de un modelo es
la representación abstracta, matemática y conceptual de un fenómeno o sistema
con el objetivo de describirlo, analizarlo y simularlo.
Debido a que el trabajo de grado está orientado a las carreras de Ingeniería
Industrial y Economía. Se recomienda el conocimiento previo de técnicas
estadísticas, matemáticas y econométricas para el adecuado entendimiento del
trabajo, particularmente en el Capítulo 4. Pronóstico de la demanda en el horizonte
de planeación .

8
2 PLAN AGREGADO DE PRODUCCIÓN
Dentro del entorno de la planeación de la producción se encuentran diferentes
requerimientos que intervienen en el sistema; éstos se pueden dividir en factores externos
fuera de nuestro alcance y control como comportamientos de los consumidores,
disponibilidad de materias primas, demanda del mercado, ciclos económicos o capacidad
externa y factores internos que podemos controlar como capacidad física actual, fuerza de
trabajo actual, niveles de inventario y actividades requeridas para producir. En general
existen 3 estrategias para planear la producción actualmente estas se dividen en
estrategias de ajuste, fuerza de trabajo estable (horas de trabajo variables) y estrategia de
nivel. Estas tres comprenden cambios en las horas de trabajo el inventario, la
acumulación de pedidos y el tamaño de la fuerza de trabajo. Véase Chase et al (2009).
Sistemas actuales de manufactura necesitan cada día más una planeación estructurada
de su producción teniendo en cuenta elementos que afectan los nivel de producción e
inventarios como las proyecciones en los niveles de ventas, los ciclos económicos de la
demanda, los cambios estructurales de la economía y los tendencias del comportamiento
de consumo. Los factores internos siempre son más fáciles de controlar y varían en cada
organización y por tanto cada empresa debe escoger el plan de producción que mejor se
adapte a sus características intrínsecas y considerando los resultados que se necesiten
como finalidad.
Everett et al. (1991) definen la planeación estratégica como “el proceso de reflexión
aplicado a la actual misión de la organización y a las condiciones actuales del medio en
que ésta ópera, el cual permite fijar lineamientos de acción que orienten las decisiones y
resultados futuros” por lo que la planeación de la producción dentro del marco de la
planeación estratégica debe estar guiado por la misión de la empresa y los factores
externos e internos que intervienen en la producción para mejorar la toma de decisiones y
la relación entre la producción y los insumos como capital, trabajo o mano de obra,
materiales y energía entre otros.
2.1 Capacidad Operativa
La capacidad se puede considerar en los negocios como la cantidad de producción
máxima que un sistema productivo es capaz de generar durante un periodo de tiempo
específico. Esta unidad de tiempo suele medirse como turnos o días hábiles al mes. En
términos efectivos la capacidad real es designada para efectos de planeación y depende
de lo que se piense producir.
Esta capacidad productiva se ve limitada en la mayoría de los casos por dos tipos de
recursos, las máquinas y el hombre, las cuales determinan la programación de las
actividades productivas en el horizonte de tiempo dado. Según la APICS2, la capacidad
se relaciona con la potencialidad técnica y económica que posee un sistema u
2 Sociedad Estadounidense de Control de Producción e Inventarios

9
organización productiva y la principal razón de una empresa es satisfacer la demanda de
los bienes y/o servicios sin exceder su capacidad, de ahí la importancia de cualquier
empresa de conocer sus límites, sus capacidades y su potencial.
Normalmente se hace referencia a capacidad disponible como el tiempo con el que
cuenta un recurso también llamado estación de trabajo para hacer uso de su potencial
productivo. Se conoce como capacidad requerida al tiempo que le consume a un recurso
el fabricar la demanda pronosticada de todos los productos en un periodo de tiempo. Por
último, se conoce como capacidad utilizada a el tiempo utilizado de la capacidad
disponible para llegar a cubrir la capacidad requerida.
2.2 Planificación de la Producción Utilizando Programación Lineal
La programación lineal PL es una herramienta de la investigación de operaciones que
ayuda a asignar los recursos escasos de un agente económico entre las distintas
demandas que compiten por estos recursos. Los recursos como se dijo anteriormente
pueden llegar a ser recursos de tiempo, dinero, materiales, máquinas, o recursos
derivados del talento humano y estos recursos poseen limitaciones que se conocen como
restricciones las cuales deben ser incluidas en la programación lineal. Esta herramienta
es aplicada por los gerentes para encontrar la mejor asignación de recursos, adoptando
todas sus posibles restricciones con el objeto de maximizar la función de beneficios de la
organización o minimizar los costos, al igual que proporcionar la información necesaria
sobre otros recursos y su utilización. En el Capítulo 5 de este trabajo se analiza y
desarrolla paso a paso la planeación de la producción por medio de este tipo de
optimización.
Desde la década de los años 50 la programación lineal (PL) ha sido una herramienta
fundamental para muchas empresas y ha ayudado a ahorrar miles de millones de dólares.
Como lo define Hillier y Lieberman (2010), el uso más común de programación lineal
abarca el problema general de asignar de la mejor manera posible, es decir, de forma
óptima, recursos que son limitados para la sociedad a actividades que compiten entre sí
por ellos. La programación lineal utiliza modelos matemáticos para representar estos y
otros tipos de problemas que se enfrentan en el cotidiano.
El adjetivo lineal se utiliza cuando todas las funciones dentro de la programación son
polinómicas de primer grado. Mientras que el adjetivo no lineal se utiliza cuando estas
funciones son representaciones no lineales, es decir funciones polinómicas de orden
superior. Mientras que el término programación se refiere a la planeación de las
actividades para obtener un óptimo.
El procedimiento general para resolver problemas de programación lineal se llama método
simplex el cual fue desarrollado por George Dantzig en 1947. Este procedimiento
algebraico con fundamentos geométricos es utilizado en varios paquetes de computadora
hoy en día y además brinda la posibilidad de realizar un análisis posóptimo del modelo
con el uso de herramientas como el análisis de sensibilidad.

10
3 CARACTERIZACIÓN DEL SISTEMA DE PRODUCCIÓN
Con el objetivo de llegar a entender el desarrollo de la planeación estratégica y los
pronósticos, en este capítulo se procederá a realizar la respectiva caracterización del
sistema productivo de la empresa de estudio ALIANZAS Y/O INDUSTRIAS ALTA
PUREZA S.A. pasando por su descripción general, su proceso productivo, sus recursos o
estaciones de trabajo, el cálculo del tiempo total por estación de trabajo y por producto, el
cálculo de las capacidades y el cálculo de los costos unitarios de producción.
3.1 Descripción General de la Empresa
Alianzas y/o Industrias Alta Pureza S.A. es una empresa colombiana constituida en el año
2000. Está orientada a la producción y comercialización de productos masivos en las
líneas de aseo del hogar, se ha consolidado en el país desarrollando portafolios de
productos innovadores con valores agregados y un alto estándar de calidad para los
clientes, las grandes superficies, los distribuidores y los pequeños comercios.
La idea de crear esta compañía surge de la necesidad de ALKOSTO S.A., de desarrollar
productos marca propia con pequeñas industrias; centros de negocios pequeños que por
su volumen de ventas y rotación, no ameritaban ser codificadas de manera directa.
La empresa se ha especializado en el desarrollo de marcas propias de sus clientes
principales, acompañándolos permanentemente en el seguimiento de las tendencias del
mercado y en el posicionamiento de sus marcas.
En vista de la gran aceptación y calidad de los productos bajo la sombrilla de la marca
ALKOSTO, los socios de la compañía deciden posesionar sus propias marcas,
registrando para ello la marca DESSIN, para todos los productos de la línea aseo hogar, y
la marca BODY BEAUTIES, para los productos de la línea aseo personal.
La organización tiene participación accionaria en cada una de las empresas productoras
de las líneas que comercializa, dando así la oportunidad a pequeños y medianos
empresarios de tener presencia con sus productos en el gran comercio colombiano.
3.1.1 Reseña Histórica
ALIANZAS S.A, es una empresa de tipo anónima legalmente constituida el 14 de julio de
2000 y cuya razón social es netamente la comercialización de productos de aseo y el
hogar, donde todos los productos se obtienen por Outsourcing a través de 9 proveedores;
no hay producción, solo comercialización. Por otro lado Industrias Alta Pureza S.A creada
en el 2007 y Plastiaromas S.A creada en el año 1998 son empresas productoras
independientes que fabricaban lava lozas y bolsas plásticas para la basura
respectivamente. Empresas que también hacen parte de la junta directiva del grupo.
Para el año 2008 se presenta la fusión estratégica entre Alianzas S.A e Industrias Alta
Pureza S.A como respuesta a presiones en cargas tributarias e impuestos en Industrias

11
Alta Pureza S.A. Creando así la nueva organización bajo el nombre Alianza y/o Industrias
alta Pureza S.A., la cual sigue teniendo el componente de comercialización bajo
externalización en Alianzas y el componente de producción de lava loza en Alta Pureza
S.A.
Es entonces importante aclarar que la realización del trabajo de grado está enfocada
hacia la planeación de la producción por parte del componente de Alta Pureza S.A, pues
es la que tiene procesos productivos en el grupo y como lo explica la Gerencia
Administrativa es la que más necesita de una planeación estratégica y un buen sistema
de pronósticos.
3.1.2 Misión
Es compromiso de la organización Alianzas y/o Industrias Alta Pureza S.A liderar el
mercado nacional colombiano, suministrando productos de aseo y limpieza a cada uno de
los hogares colombianos garantizando una excelente calidad y cumplimiento de las
normas de higiene y limpieza logrando el bien funcionamiento de los productos
manufacturados.
3.1.3 Visión
Convertirnos en empresa líder de los productos de aseo y limpieza en el ámbito nacional
e internacional, logrando una mejor calidad de vida, higiene y practicidad.
3.1.4 Productos, Clientes y Participación
Enfocados ya en Alta Pureza S.A, actualmente se producen lavalozas para dos grandes
mercados. Por un lado se tiene una participación en el marcado de marcas propias, y por
otro lado se cuenta con una marca privada llamada Dessin. Dentro de ambos mercados
se cuenta con una amplia gama de 58 referencias de la crema lava loza las cuales se
presentan en el Anexo 10.1.1. Tablas de Referencias.
Industrias Alta Pureza S.A cuenta con 4 clientes principales lo cuales son: Yep, Alkosto,
Makro (Aro) y Surtimax. La participación porcentual de los volúmenes de compra de cada
uno de estos clientes según los datos de ventas del mes de julio de 2013 se presenta en
el Anexo 10.1.2. Productos, Clientes y Participación.
Actualmente la empresa produce para 14 ciudades alrededor de Colombia, estas
ciudades son: Barranquilla, Bogotá, Cali, Cartagena, Cúcuta, Ibagué, Medellín, Montería,
Neiva, Pasto, Pereira, Santa Marta, Tunja y Villavicencio. La participación porcentual de
ventas en estas ciudades según datos del mes de julio de 2013 se presentan en el mismo
Anexo 10.1.2. Productos, Clientes y Participación. Como se puede observar, Bogotá
cuenta con más de la mitad de la participación en volúmenes de ventas, seguido por
Villavicencio, Medellín y Pereira. Sin embargo, el ordenamiento de ciudades a parte de la
capital puede variar un poco debido a las condiciones propias de cada mes.

12
3.1.5 Organigrama
Para consultar el organigrama diríjase a el Anexo 10.1.3. Organigrama Alianzas y/o
Industrias Alta Pureza S.A.
3.2 Proceso Productivo y Caracterización
El proceso de producción para la fabricación de jabón lavaloza comienza con la
elaboración del envase plástico el cual contendrá el producto terminado y que se realiza
dependiendo del volumen final para cada uno de los 5 posibles tamaños: 250, 500, 1000,
1500 y 3000 gramos. Por el momento la empresa únicamente produce envases para los
tamaños 1000g y 500g y los otros los externaliza en otra empresa. Este proceso de
fabricación del envase es un proceso completamente automatizado que genera dos
piezas por separado: la tapa y el envase mismo. Esta fabricación del envase comienza
cuando un operario mezcla una resina con un pigmento blanco en una caneca a una
proporción del 3 al 5%, la mezcla granular es succionada por la máquina de moldeo por
inyección HWA CHIN 210 – HC Series que lleva la mezcla a una tolva para ser
transportada por un embolo neumático el cual por medio de la transferencia de calor que
va creciendo desde 190, 200, 205 hasta los 210ºC progresivamente va generando la
pasta que por medio de inyección neumática va siendo empujada hasta pasar por una
boquilla que introduce la pasta en las cavidades del molde que genera la parte del envase
deseado y que luego son enfriados por la misma máquina para así poder llegar a producir
el envase deseado. La HWA CHIN 210 produce a un ciclo de 8 segundos en promedio por
cada 2 moldes (tapas o envase) dado que se tiene capacidad para dos cavidades a la
vez, su peso es de 6.8 toneladas y tiene una dimensión de 4.9x1.4x1.9 metros. Esta
máquina funciona las 24 horas del día de lunes a sábado debido a los costos tan altos en
el consumo de energía en la fase de preparación y alistamiento. Una vez terminado el
proceso de fabricación del envase se almacena en cajas como producto en proceso y se
ubica para su posterior uso.
La siguiente actividad dentro del proceso de fabricación del jabón lavaloza es el fajillado.
Esta actividad consiste en pegar por medio de un proceso de termosellado una película
plástica al envase, la cual se adhiere a partir del choque térmico que encoje la película y
hace que esta se auto selle en el envase. En este proceso el operario ubica la película
plástica en el envase el cual pasa a través de una banda que llega a una máquina la cual
le transfiere calor a una temperatura de 210ºC en promedio lo que hace que se encoja y
se auto adhiera la película al envase para salir por el otro lado de la máquina hacia un
contenedor y esperar por su posterior uso. El proceso de termo-sellado dentro de la
máquina toma entre 4 y 5 segundos mientras que el proceso de fajillado como tal toma
alrededor de 7 segundos según el concepto de expertos.
Paralelamente, se va realizando el proceso de mezclado del jabón lavaloza para poder
ser envaso en el molde previamente descrito. Este proceso de mezclado se realiza en
cuatro mezcladoras a temperatura ambiente de las cuales dos tienen una capacidad de
300kg cada una y las otras dos tienen una capacidad de 400 kg . Dado que la empresa
cuenta con 2 aromas para el jabón (limón y chicle) fueron destinadas dos mezcladoras

13
para un aroma y dos mezcladoras para el otro. Esta crema lavaloza es el resultado de la
mezcla de varios químicos los cuales deben ser pesados, dosificados y verificados
previamente antes de comenzar el proceso de mezclado. Estos insumos son
transportados al área de producción en el segundo piso por medio de un ascensor de
carga. Los componentes a mezclar dentro de la preparación son: ácido sulfónico,
carbonato de calcio, glicerina, silicato de sodio, carbonato de sodio, benzoato de sodio,
cuarzo, agua, fragancias (chicle, limón) y color (verde, rosa). Para realizar este proceso se
preserva el agua con benzoato de sodio agitándola constantemente, a continuación se
adiciona el ácido sulfónico y el carbonato de sodio manteniendo la agitación y se espera
que se genere su reacción química, en seguida se adiciona el carbonato de calcio a la
mezcla y posteriormente el cuarzo una vez más manteniendo la agitación. En seguida se
adiciona la glicerina y el silicato de sodio. Finalmente se adiciona la fragancia y el color a
la mezcla para terminar así el proceso de mezclado. Este proceso puede llegar a tardar
entre 80 y 120 minutos dependiendo de las condiciones ambientales y el tipo de mezcla.
Una vez terminada la mezcla, ésta entra a proceso de inspección por parte del ingeniero
de calidad para poder así determinar su adecuada consistencia, densidad, color, aroma,
viscosidad y otros.
Para poder llegar a envasar el producto mezclado, la crema lavaloza pasa directamente
de la mezcladora a la etapa de envasado por medio de una válvula que se abre y da paso
al material el cual cae por gravedad desde el segundo piso al primero hasta un embudo
que por medio de dos pistones neumáticos en combinación con un sistema eléctrico
empujan la cantidad deseada para cada uno de los tamaños de producto terminado. Esta
cantidad es graduada y programada por medio de sensores eléctricos los cuales terminan
diciéndole al pistón cuanta cantidad recoger del embudo y cuanta inyectar en el envase
final. Es en esta etapa que los tiempos de fabricación de las diferentes referencias según
su tamaño muestra su mayor variación, esto debido a que, por ejemplo, se envasará una
mayor cantidad de lavalozas de 250g que de 3000g en el mismo tiempo.
Una vez culminado el proceso de envasado, dentro del mismo puesto de trabajo del
operario, se procede a realizar la segunda inspección la cual tiene el objetivo de pesar el
producto terminado para garantizar que se le está entregando al cliente la cantidad que se
especifica en el envase. Esta inspección se le realiza a todos los productos terminados sin
excepción para llegar a garantizar una mejor calidad. Dentro de esta misma inspección de
pesaje, el operario tiene la oportunidad de verificar una vez más de manera visual y por
tacto la calidad del producto a entregar y está en la facultad de informar cualquier
inconformidad a sus supervisores. Una vez terminado el pesaje del producto se le
adiciona el código y pasa a ser almacenado en estantes para realizar el proceso de
secado el cual tiene una duración promedio de 24 horas a temperatura ambiente, esto con
el fin de obtener una consistencia ideal entre sólido y viscoso la cual es vital para lograr la
percepción de calidad en el producto final a los ojos del cliente.
En la etapa de embalaje del producto terminado se pueden tomar tres caminos diferentes.
El primero, si el amarre se realiza por medio de termo-sellado de a 6 o 7 lavalozas

14
apiladas una encima de la otra, el segundo si se empacan en cajas de una en una y el
último si el producto es una oferta “dos por uno” se termo-sellan de a dos productos
terminados apilados uno encima del otro y se ubican en cajas. Estos procesos de termo-
sellado se realizan de la misma manera que se realiza el proceso de fajillado, con los
mismos tiempos pero a temperaturas más elevadas de 300ºC. En seguida de esto el
producto es almacenado para su posterior despacho.
Cabe notar que el ordenamiento del proceso de producción cambia un poco si se trata de
una referencia tamaño 3000g, esto debido a que el proceso de fajillado se realiza después
de envasar, pesar, tapar y secar el material debido a que las dimensiones del envase no
permiten realizar un termosellado sin que se deforme el plástico por el calor. Por ello, al
envasar primero el jabón contenido en el envase sirve como soporte para que el envase
pase por la termoselladora y no se deforme el plástico. Una vez pase por la máquina, el
producto es empacado directamente en las cajas para esperar su despacho.
Los diagramas de operaciones para la producción del jabón lavaloza tanto para la
referencia tamaño 3000g como para las demás referencias pueden ser consultados como
Anexo 10.1.7. Diagrama de Operaciones al final del presente trabajo.
A manera ilustrativa se muestra en el Anexo 10.1.4. Diagrama de Caja Negra a
transformación del Estado A inicial el cual representa todas la materias primas a un
Estado B final que representa el producto terminado. Este proceso de transformación se
da a través de una “caja negra” que contiene una serie de recursos, herramientas,
insumos, conocimientos, formulas y acciones que alteran la materia prima para lograr el
producto terminado que satisface una necesidad.
3.3 Estaciones de Trabajo
En Alianzas y/o Industrias Alta Pureza S.A existen 5 estaciones de trabajo destinadas a
diferentes etapas del proceso productivo. Cada estación cuenta con diferentes recursos
los cuales serán descritos en la siguiente subsección. Una estación de trabajo está
definida como aquel espacio en la planta productiva donde los recursos hombre y/o
máquina se encargan de ciertos procesos de manera conjunta y que cumplen un fin
establecido para la organización.
1. La primera estación de trabajo es la de fabricación de cuerpos y tapas del envase
y comprende los procesos de fabricación y almacenamiento de envases.
2. La segunda estación es la de fajillado, la cual comprende los procesos de fajillar y
codificar.
3. La tercera estación es la de mezclado, la cual comprende los procesos de pesar,
dosificar y mezclar.
4. La cuarta estación es la de envasado, la cual comprende los procesos de envasar,
pesar y tapar.
5. La última estación es empacar y comprende únicamente la operación de empacar.

15
3.4 Recursos
Los recursos pueden ser clasificados den: mano de obra o humano, maquinaria,
materiales, recursos técnicos o tecnológicos y recursos financieros.
Como se mencionó anteriormente, se tendrá en cuenta para el desarrollo de este trabajo
los recursos mano de obra y recursos máquina. Cada estación puede contar con uno o
ambos recursos dependiendo de la estructura de cada una de ellas. A continuación se
dará paso a presentar los recursos con que se cuentan por cada una de las estaciones de
trabajo.
3.4.1 Recurso Mano de Obra
El recurso mano de obra es todo el trabajo que aportan los empleados de las diferentes
jerarquías organizacionales a la realización de las metas de la organización. El recurso de
mano de obra más específicamente se refiere a todo operario capacitado para una o
varias tareas específicas que permita a la organización cumplir con su meta productiva en
un horizonte determinado de tiempo.
Alianzas y/o Industrias Alta Pureza cuenta principalmente con un equipo de trabajo de 11
operarios capacitados3 para realizar tareas específicas de cada una de las etapas del
proceso.
Aunque cada operario tiene una fortaleza en una actividad de trabajo, puede existir el
caso que un operario tenga que cumplir funciones en otra actividad. En la práctica, las
actividades de envasar, pesar, tapar, fajillar y empacar se realizan por los mismos
operarios en todas las etapas y por tanto todos están capacitados para cualquiera de las 5
tareas. Sin embargo, la polivalencia disminuye en las etapas de fabricación de envases y
mezclado, esto debido a que son tareas que requieren un manejo mucho más
especializado de la máquina y por tanto no todos los operarios están en la capacidad de
hacerlo.
A continuación se presenta el número de operarios capacitados por estación de trabajo
para la disposición del recurso mano de obra.
Estación de trabajo Número de operarios
disponibles
Fabricación de envase (cuerpo y tapa) 1 operario
Mezclado 4 operarios
Fajillado, Envasado y Empacado 6 operarios
Tabla 1 Disposición Recurso Mano de Obra.
Fuente: Realizado por el Autor.
3 De acuerdo a información suministrada por la empresa correspondiente a la nómina del mes de
enero de 2014.

16
3.4.2 Recurso Máquina
Estos recursos máquina cuentan con una capacidad productiva al igual que el recurso
humano que limita la producción y la cual será descrita en una siguiente subsección.
La organización de estudio cuenta con un total de 9 máquinas especializadas para cada
estación productiva. Estas máquinas determinan la capacidad productiva más no quiere
decir que todas siempre están en uso constantemente. A continuación se presenta la
tabla con el número de máquinas por estación de trabajo.
Estación de trabajo Número de Máquinas
Fabricación de envase (cuerpo y tapa) 1 Máquina - Tipo A
Fajillado 2 Máquinas - Tipo B
Mezclado 4 Máquinas – Tipo C
Envasado 2 Máquinas – Tipo D
Empacado 1 Máquina – Tipo B
Tabla 2 Disposición Recurso Máquina.
Fuente: Realizado por el Autor.
En el Anexo 10.1.5 Fichas Técnicas de Máquinas se presenta las especificaciones
técnicas de cada uno de los tipos de máquina que la organización tiene como capital
productivo.
3.5 Representantes Tipo
Como se mencionó anteriormente la organización cuenta con un número considerable de
referencias organizadas según el tipo de cliente. Por lo que la determinación de las gamas
representativas de productos se dio a partir de dos principios que expone Sule (2001). El
primer principio establece que el representante tipo debe contener los procesos
tecnológicos de todos los demás componentes del grupo y el segundo que éste debe
contener, en la medida de lo posible, la mayor parte del gasto del tiempo de trabajo de
grupo, de este modo las desviaciones serán las mínimas.
La escogencia de estos representantes tipo es esencial para la adecuada planeación
productiva sin dejar de lado ninguna referencia relevante, además es vital para hacer
valer la capacidad de la planta esto debido a que de llegar a escoger inadecuadamente
estos representantes, se tendería el caso que se sub estima o sobre estima la capacidad
productiva de la organización trayendo consigo aproximaciones erradas de los modelos
planteados en los siguientes capítulos.
El análisis de escogencia del represéntate tipo se dio con el propósito que éste sea
exponente del proceso tecnológico del total de referencias en la organización. Estos
fueron divididos por los 5 posibles tamaños de envase. Esto se dio debido a que cumplen
las dos condiciones relevantes de Sule (2001) donde cada uno representa en su totalidad
el proceso tecnológico de todas las referencias que encierran el grupo productivo y
además demandan la totalidad del gasto en tiempo de trabajo.

17
En la práctica, la organización cuenta con 5 diferentes tamaños: 250g, 500g, 1000g,
1500g y 3000g, estos agrupan todas las posibles referencias de la organización puesto
que la única diferencia radica en el diseño de la etiqueta la cual está fuera del proceso
productivo ya que todas se externalizan a una empresa especializada en ello.
El Anexo 10.1.6. Representantes Tipo muestra la tabla con los 5 representantes tipo
escogidos para el desarrollo del trabajo de grado. Donde se hace la salvedad que debido
a que la venta real se hace por medio de una gran superficie, los ingresos de la
organización están determinados por el precio de venta a éste eslabón de la cadena y no
al consumidor final que adquiere el producto en la gran superficie.
3.6 Estudio de Tiempos Estándar de Producción
Un paso esencial dentro de los elementos para el desarrollo de la planeación de la
producción es el cálculo de los estándares de tiempos de producción para poder así
identificar ciertos aspectos importantes como los cuellos de botella o el cálculo de las
capacidades de proceso. Estos tiempos se pueden determinar con el uso de
estimaciones, registros históricos, conjeturas, consensos entre operarios o como en este
caso por medio de procedimientos de medición de trabajo con el estudio de tiempos en el
campo de Ingeniería de Métodos.
El estudio de tiempos se usa como una técnica que permite la medición del trabajo a partir
del registro de estándares de tiempos y ritmos de trabajo permitido para realizar una tarea
dada, con sus respectivos suplementos u holguras por fatiga y por retrasos personales e
inevitables, Niebel (2009). Este estudio de tiempos se efectúa en condiciones
determinadas y es de vital importancia para incrementar la eficiencia del personar
operativo y con ello reducir al mínimo la improductividad.
3.6.1 Etapas del Estudio de Tiempos
El estudio de tiempos requiere el seguimiento sistemático de las siguientes etapas las
cuales deberán seguirse en su totalidad con el objeto de identificar los estándares de
tiempos que puedan ser seguidos por la empresa y eviten así inconformidades con el
personal y posibles fallas.
1. Seleccionar el trabajador tipo para el estudio de tiempos
2. Registrar toda la información significativa
3. Desglosamiento de la operación por elementos
4. Registro de los tiempos transcurridos por elemento
5. Valoración del desempeño del operario
6. Determinación del tiempo estándar
A continuación se procede a explicar en detalle cada uno de las etapas del estudio y su
respectiva puesta en marcha.

18
3.6.2 Seleccionar el Trabajador Tipo Para el Estudio de Tiempos
La determinación del trabajador tipo para realizar el estudio de tiempos debe realizarse
con ayuda del supervisor de área o el jefe de planta dado que ellos tienen el contacto más
directo con los empleados y tienen un juicio más concreto para determinar la persona que
tenga un desempeño promedio, no muy calificado ni muy inexperto, lo que proporcionará
un estudio de tiempos mucho más satisfactorio. Este trabajador con ritmo promedio debe
desempeñar sus actividades de forma consistente y sistemática. Dado que en este caso
particular se puede decir que prácticamente cada actividad tiene asignado un operario
diferente y que por medio de charlas con el Ingeniero de producción ningún operario está
en período de prueba, sumado al hecho que se trata de una empresa pequeña, se
procedió entonces a realizar el muestreo de los operarios que intervenían en el proceso
en cada operación identificada en el momento del estudio.
A continuación de haber identificado los representantes tipo del estudio de tiempos, se
explicó brevemente a cada uno, en el momento que el estudio lo demandara, el objeto del
trabajo, se le dio espacio a alguna pregunta que este tuviese y se solicitó que trabajasen a
un ritmo normal con sus pausas acostumbradas con el objetivo de no distorsionar los
resultados del estudio. En seguida de esto se procedió a establecer la ubicación más
adecuada para observar todas las acciones del operario sin llegar a entorpecer sus
movimientos ni distraer su atención. Normalmente esto se realiza por medio de la
caminata suave y continua a unos dos metros de distancia para crear un ambiente de
cotidianidad y garantizar la confiabilidad de los tiempos. Lo más importante a la hora de
determinar la posición era siempre estar de pie, dado que puede llegar a generar
inconformidades entre el operario y el analista puesto que se da la idea que el analista es
un cómodo espectador mientras que el operario le toca todo el trabajo duro.
3.6.3 Registrar toda la información significativa.
En esta etapa el analista debe obtener toda la información posible acerca de la tarea que
está desempeñando el operario y las condiciones que pueden influir en la ejecución
adecuada. Esta información puede ser: máquinas, posición (de pie, sentado, etc),
herramientas manuales, soportes, condiciones de trabajo, materiales, nombre número del
operario, departamento, fecha de estudio, clima, ruido, estrés, etc. Todo esto con el objeto
de ser incluidos como holguras al tiempo normal del operario para así evitar establecer un
tiempo que esté por encima o por debajo del normal.
Para este trabajo se procedió a dejar un espacio en blanco en las Formas para la
observación de estudio de tiempos con el fin de incluir todos estos aspectos relevantes.
La forma tipo se puede consultar en el Anexo 10.2. Formas de Estudio de Tiempos al final
del documento. Mientas que todas los estudios de tiempo diligenciados se pueden
encontrar en el CD anexo a este documento en formato Excel.
3.6.4 Desglosamiento de la operación por elementos
Para facilidad del registro de tiempos por parte del analista es necesario subdividir las
operaciones por elementos o grupos de movimientos. Estos elementos individuales se

19
observan durante varios ciclos, por lo que deben ser elementos que se repitan
constantemente. Entre más subdividido este un proceso por elementos más exactas
serán las lecturas; sin embargo, estos elementos deben ser fácilmente medibles y por
tanto no pueden ser elementos que tomen muy poco tiempo, dado que dificultaría al
analista el registro adecuado de estos elementos en la forma. Por tanto, se recomienda
que estos elementos sean mayores a 0.02 minutos (1.2 segundos), de llegar a ser el caso
que existan elementos esenciales por debajo de estos tiempos mínimos se recomienda
que el procedimiento de toma de observaciones sea a través de la grabación de un video
y no con cronometro. Como se verá más adelante fue necesario acatar esta
recomendación debido a que algunos elementos esenciales para las referencias de
tamaño más pequeño tenían tiempos por debajo de lo recomendado. Algunas otras
recomendaciones que presenta Niebel (2009) a la hora de realizar el desglosamiento son:
1. Separar los elementos manuales de los de máquina debido a que no se le pueden
imponer desempeños u holguras iguales tanto a máquinas como a personas.
2. Separar los elementos constantes de los variables.
3. Cuando un elemento se repite, no se incluye una segunda descripción, solo se da
el mismo número de identificación que se usó cuando el elemento ocurrió por
primera vez.
Considerando estas recomendaciones presentadas con anterioridad y con ayuda del
diagrama de operaciones para la elaboración del Jabón Lavaloza, el cual puede ser
consultado en el Anexo 10.1.7. Diagrama de Operaciones, se procedió a identificar los
elementos tipo de cada operación. Cabe anotar que al diagrama de operaciones se le
deben adicionar los transportes, demoras y otros.
Al dirigirse al Anexo 10.1.8. División de Operaciones por Elemento se observa cómo
existen 12 actividades relacionadas con el proceso de producción de Lavalozas, éstas a
su vez se dividen en elementos principales que la componen. El proceso de las cinco
referencias (250g, 500g, 1000g, 1500g y 3000g) es en si el mismo, sin embargo los
tiempos estándar de producción cambian considerablemente debido a la diferencia en los
tamaños como se verá a continuación. Como se mencionó anteriormente para el caso de
la referencia de 3000g el orden del producción cambia un poco debido a que en la
práctica este producto no se puede fajillar antes de envasar puesto que por la altura del
envase, éste perdería su forma si no contiene nada por dentro que evite esta deformación
por el calor del proceso de termosellado.
3.6.5 Registro de los tiempos transcurridos por elemento
3.6.5.1 Cálculo del número de observaciones
Antes de comenzar el registro de tiempos por elemento es necesario la determinación del
número de ciclos o el número de observaciones a tomar para que la muestra sea
confiable. Para ello es necesario realizar un estudio piloto con un número de

20
observaciones no muy grande que permita identificar si es o no necesario realizar más
registros para obtener una muestra confiable.
El método que se utilizó para determinar el número de observaciones fue el método
estadístico donde a partir de un número de observaciones preliminares ( realizados en
la prueba piloto se obtiene el número de observaciones requeridas . Este método se
basa en que la mayoría de los estudios de tiempo sólo involucran muestras pequeñas
(n<30) por lo que debería utilizarse una distribución de probabilidad t y no una normal. Por
lo que según la ecuación de intervalo de confianza
√
donde el término puede considerarse un término de error expresado como una fracción
del promedio de las observaciones de la prueba piloto , entonces se tiene que
√
donde k equivale a una fracción aceptable del promedio piloto . A continuación se
procede a despejar el número de observaciones n y se obtiene
(
)
donde
t: Estadístico t obtenido a partir del nivel de confianza. Para un se tiene un
t=2.064.
s: Desviación estándar de las observaciones de la prueba piloto
√∑
: Promedio de las observaciones de la prueba piloto
k: Fracción aceptable del promedio . Normalmente igual a 0.05
n: Número de observaciones requeridas
Si el número de observaciones resultantes n es inferior o igual al número de
observaciones de la prueba piloto se tiene que el tamaño de la muestra determinado por
es lo suficientemente grande y por tanto tiene la confianza requerida. Sin embargo, si
n> entonces es necesario realizar dicho número de observaciones más para garantizar
la confianza requerida.
Para este caso se tomó un número preliminar de observaciones en la prueba piloto igual
a 5 para cada elemento de la actividad descrita y se tomo un de 0.05. Se encontró que
un 90% de las observaciones resultaron consistentes, es decir menor o igual a n, por

21
tanto para efectos de practicidad se tomaron 10 o más observaciones por elemento para
garantizar así la confiabilidad de los tiempos estándar.
3.6.5.2 Estructura del registro de tiempos para el estudio
El desarrollo de los registros de tiempos se realizó en la Forma para Observaciones del
Estudio de Tiempos basada en Niebel (2009) y modificada para las necesidades del
trabajo. Se presenta una forma para cada operación con su respectiva división en
subelementos. Una vez más, esta forma se puede encontrar como Anexo 10.2 al final de
este documento.
3.6.6 Valoración del Desempeño del Operario
Debido a que el estudio requiere la estandarización del tiempo que le toma a un operario
promedio realizar una tarea. Es necesario determinar un ajuste calificador el operario que
desarrolla las actividades. Por ello, previamente a la culminación del estudio de tiempos
por operación, el analista debe calificar justa e imparcialmente el desempeño del operario
que intervino en el proceso.
Según Niebel (2009) el desempeño estándar de una operación se define como el
rendimiento que obtienen naturalmente y sin esforzarse los trabajadores calificados
promedio, siempre que conozcan y ejecuten el método especificado para cada actividad.
A partir de este desempeño se podrán ajustar los tiempos hacia lo que el analista pudo
observar. Por ejemplo, si se presenta el caso que un operario realiza el elemento a un
ritmo que el analista piensa que es normal y el operario decide cambiar su ritmo de
trabajo en medio del estudio sea disminuyéndolo o aumentándolo es obligación del
analista ajustar y corregir dicho cambio para no perjudicar a los demás trabajadores al
estimar un tiempo estándar por encima o por debajo del normal.
Se procedió entonces a calificar el desempeño de los operarios por medio de tres
puntuaciones diferentes que por efectos de practicidad se tomaron los valores de 90, 100
y 110. Siendo 100 el desempeño estándar, 90 el desempeño bajo y 110 el desempeño
superior. Estas calificaciones fueron asignadas a cada operación dividida por elementos
tomando en cuenta los factores de habilidad, esfuerzo, condiciones de trabajo y
consistencia.
Desempeño Puntuación
Bajo 90
Estándar 100
Superior 110
De llegarse a dar el caso que todas las valoraciones del ritmo de trabajo fuesen siempre
determinadas a un desempeño estándar, se tendría que el Tiempo Observado (TO) por el
analista es exactamente igual al Tiempo Normal (TN) que resulta del ajuste por el
desempeño, esto debido a que la razón entre la calificación del desempeño y el
desempeño estándar sería igual a 1. El Tiempo Normal sería entonces el tiempo que
invierte un operario en ejecutar cada elemento a juicio del analista y tiende a ser

22
constante a lo largo de las observaciones dado que en la mayoría de casos se presenta
una tendencia a que el trabajador ejecute el elemento a la misma calificación de
desempeño durante el estudio.
Según Niebel (2009) es necesario que el analista decida si fija una calificación del ritmo
de trabajo para todo el estudio o si califica el elemento individualmente. De llegarse a
presentar el caso que los elementos individuales sean largos e incluyen movimientos
manuales diversificados, resulta mucho más práctico evaluar el desempeño de cada
elemento cuando este ocurre. Si por el contrario, los ciclos de trabajo pequeños se
recomienda evaluar el desempeño al estudio completo o una calificación promedio para
cada elemento.
La identificación de este desempeño se presenta en cada una de las Formas para la
Observación de Estudio de Tiempos de cada una de las observaciones y como se
mencionó anteriormente, estas dependen de la frecuencia del ciclo de trabajo de cada
operación.
3.6.7 Determinación del tiempo estándar
Una vez registrados los tiempos observados por el analista se procedió a realizar el
cálculo de los tiempos estándar de producción por elemento. Para ello se deben tener en
cuenta posibles valores atípicos que se presentan a la hora de realizar el estudio. Niebel
(2009) sugiere tener en cuenta los siguientes aspectos para el análisis de la consistencia
de los elementos observados:
Determinar si las variaciones se deben a la naturaleza del elemento en todas las
lecturas.
Verificar si existen variaciones debida a falta de habilidad o desconocimiento de la
tarea por parte del trabajador.
Determinar si existen variaciones que no se deben a la naturaleza del elemento,
sino que estén atribuidas al mal registro de los datos o a fallas de los equipos de
cronometro.
Si se determina que las variaciones no tienen causa aparente, es necesario
efectuar un análisis cuidadoso antes de ser eliminada la observación, si se
detectan causas no asignables se recomienda volver a la fase de observación.
Se recomienda que el formato en donde se registran los tiempos tenga una
columna de observación con el fin de identificar las posibles afectaciones a las
observaciones atípicas que se presentaron.
3.6.8 Cálculo del tiempo estándar por elemento
A manera ilustrativa se procede a realizar el cálculo del tiempo estándar promedio para la
agregación de las operaciones Envasar-Pesar-Tapar en el caso del producto tipo 250g.
Cabe anotar el hecho que dado los tiempos observados tan pequeños de producción por
operación, fue necesario en muchos casos combinar los elementos para poder así

23
obtener una medida más adecuada de los tiempos, de lo contrario se correría el riesgo de
obtener valores muy disparejos y poco realistas como lo arguye Niebel (2009).
1. Suma de las lecturas de los tiempos observados que han sido consideradas como
consistentes (TO: Tiempo observado)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
SUMA
TO
TO
Envasar 0.9 0.9 1 1 0.8 0.9 0.7 0.9 0.9 0.9 1.1 1 0.9 0.9 0.9 0.8 0.9 0.8 0.8 0.8 0.9 0.9 0.9 0.8 0.8 22.1
TO
Pesar 1.4 0.9 1.1 1.2 1.5 3 0.9 0.8 0.8 0.9 1.1 0.9 0.9 1.1 1.4 0.7 0.8 0.9 0.8 0.8 0.9 1.3 1.1 2.4 1.4 29.0
TO
Tapar 0.5 0.8 0.7 0.9 0.7 0.8 0.8 0.9 0.7 0.6 0.7 0.9 0.7 0.6 0.9 0.6 0.7 0.7 0.8 0.6 0.7 0.7 0.8 0.8 0.8 18.4
Nota: Todos los tiempos se encuentran en segundos
2. Como en este caso específico se está contando con un ritmo de trabajo para toda
la operación debido a los tiempos tan pequeños de producción, se procede a
calcular el tiempo normal de la siguiente forma.
Donde C corresponde a la calificación que se le da al desempeño (90, 100 o 110).
Para este caso tenemos que
Como se observa, dado que la operación pesar contó con un ritmo de trabajo más
alto que el estándar, su tiempo normal estará por encima del tiempo observado
puesto que de ser el caso de un trabajo normal el operario habría demorado en
promedio más de 29 segundos. Por ello se debe ajustar su desempeño.
3. A continuación se procedió a obtener el Tiempo Normal Promedio de todas las
observaciones realizadas, para ello se dividió el TN por operación sobre el número
de observaciones registradas n, así:
Se tiene entonces para el ejemplo que:

24
4. Asignar suplementos u holguras: Bajo la hipótesis que ningún operario puede
trabajar todos los días a un mismo ritmo, con un mismo tiempo estándar debido a
que las condiciones de trabajo están cambiando constantemente. Se sabe que
existen tres posibles interrupciones al trabajo. Estas son las interrupciones
personales (e.g. idas al baño), interrupciones que afectan incluso a los individuos
más fuertes en trabajos más ligeros y las interrupciones inevitables (e.g.
interrupción del supervisor). Sea cual sea el tipo de interrupción es necesario
determinar una holgura para el ajuste de tiempos.
Esta tabla de holguras relacionada con los posibles factores que afectan la
determinación de tiempos estándar de trabajo se puede consultar en el Anexo
10.3. Suplementos Personales al final de este documento. Además cada una de
las operaciones en las Formas para la Observación de Estudio de Tiempos cuenta
con su debido cálculo del porcentaje de holguras.
En este paso, al tiempo normal promedio se le suman las tolerancias por
suplementos concedidos, obteniendo así el Tiempo Estándar Elemental TEE bajo
la siguiente formula
Una vez más, para el ejemplo tenemos que:
Como se puede observar el porcentaje de holgura corresponde al 11%, esto
debido a que se suman 5% de necesidades personales, 4% de fatiga básica y 2%
de fatiga variable por trabajo de pie. (Véase Anexo 10.3. Suplementos Personales)
5. El último paso antes de hallar el tiempo estándar por operación, es el la
multiplicación del TEE por un factor de frecuencia f. Esta frecuencia responde a la
pregunta cu ntas eces se e ecuta el elemento para producir una unidad Si
e isten elementos repetiti os se dan por lo menos una ez en cada ciclo de la

25
operación de tal manera que se pondr si se dan una ez por operación o
si se dan 2 veces por operación. Tenemos que:
como en este caso particular se tiene que toda la operación es el mismo elemento
y que la frecuencia para producir una pieza en todos los casos es 1 tenemos que
los TE son iguales a los TEE.
6. Por último se procede a sumar todos los tiempos estándar por elemento para
obtener un solo tiempo estándar por operación.
∑
Para este caso particular se cuenta con que la sumatoria de los tiempos por
elementos es la misma que por operación. Sin embargo, para ejemplificar este
paso, se sumaran los tiempos estándar de las 3 operaciones para obtener un
tiempo estándar de Envasar-Pesar-Tapar.
Como se pudo observar, el tiempo estándar de estas 3 operaciones inclusive
conjuntamente es muy bajo, esto debido a el hecho que se trata de la presentación más
pequeña de 250g. En este punto y como se mencionó anteriormente, se puede observar
que las tres presentaciones aunque tienen el mismo proceso de producción, cuentan con
tiempos estándar completamente diferentes dado que el tiempo estándar del mismo
proceso Envasar-Pesar-Tapar para la referencia de 3000g es de 19.7 segundos lo que
representa que este tipo de producto se realiza en un tiempo 6 veces mayor que el de la
presentación de 250g.
Así las cosas, este proceso de seis pasos aquí descrito se realizó para cada una de las 5
estaciones de trabajo y para cada uno de los 5 tipos de productos. Al final se obtuvo una
matriz de 5 Estaciones por 5 tipos de productos (250g, 500g, 1000g, 1500g, 3000g). La
cual sumando cada una de las filas se obtiene el tiempo estándar total para producir una
sola unidad de cada tipo de producto.

26
Tabla de Tiempos Estándar de producción ( 1 Unidad )
3000g 1500g 1000g 500g 250g
Fabricar Envase (Tapa y Cuerpo) 0.00 0.00 10.56 10.45 0.00
Fajillado 17.17 13.17 12.07 10.14 7.90
Mezclado 56.43 28.21 18.81 9.40 4.70
Envasado 24.53 11.72 8.07 5.06 3.62
Empacado 7.17 8.96 8.91 6.42 4.31
TOTAL Continuo
TOTAL producción4
105.30
105.30
62.07
48.89
58.42
35.79
41.48
21.02
20.53
12.63
1. Tiempo en segundos
Tabla 3 Tiempos estándar de producción unitarios
Fuente: Cálculos del Autor.
La tabla anterior muestra que el tiempo estándar de producción depende directamente del
tamaño del producto final a producir, por lo que la producción dentro de la capacidad del
proceso será diferente en cada uno, como se verá más adelante. Bajo el estudio de
tiempos previamente realizado, se observó que en promedio el tiempo estándar para
producir una unidad del lavaloza de tamaño 250g es cinco veces menor que la de producir
una unidad de 3000g, dos veces menor que la de producir una unidad de 500g y tres
veces menor que la de producir una unidad de 1000g y 1500g.
Debido a que el comportamiento de las operaciones de todas las referencias, excepto la
de 3000g, no es continuo sino que es un proceso que se puede desarrollar en dos etapas
paralelas como lo muestra el Anexo 10.1.7, fue necesario determinar el tiempo estándar
de producción consecuente con esta estructura de proceso, de lo contrario se entraría en
el sobre dimensionamiento de la cantidad de horas que tarda el proceso en la práctica,
este Tiempo de producción se presenta en la tabla de tiempos estándar de producción
(Tabla 3. Tiempos estándar de producción unitarios) en su última fila.
Adicionalmente, se sabe que cada lote de producción independiente del tamaño, está
determinado por la cantidad que se produce en la estación de mezcla la cual es siempre
de 300kg. Las unidades teóricas de producción por mezcla de 300kg son
Tipo de producto Unidades Teóricas
250g 1200 unidades
500g 600 unidades
1000g 300 unidades
1500g 200 unidades
3000g 100 unidades
Tabla 4 Unidades teóricas de referencias por lote de 300kg
Fuente: Realizado por el Autor.
4 Véase el Anexo 10.1.7 Diagrama de operaciones.

27
Esto determinaría que aunque el proceso de producción por unidad presenta que es
mucho más rápido la producción de una unidad de 250g que de 3000g, sucede lo
contrario cuando se habla por lotes. Debido a que la producción de un lote de 300kg
conlleva a la elaboración de 1100 unidades más de 250g que de 3000g, se generará que
la producción de un lote de 250g sea más lenta que la de 3000g, y que cualquier otra. En
principio esto sucede puesto que además de la mezcla, es necesario considerar los
tiempos de fajillado, envasado y empacado de cada una de esas 1100 unidades más por
lote, lo que demora más la producción por lote entre más pequeña sea la presentación.
Se tendría entonces que los tiempos estándar de producción de un lote de 300kg para
cada una de las referencias, considerando la estructura misma del proceso y las
necesidades personales es
Referencia 250g 500g 1000g 1500g 3000g
Horas 4h 13m 3h 30m 2h 59 2h 43m 2h 55m
Tabla 5 Tiempo necesario para la fabricación de 1 lote=300kg
Fuente: Cálculos del Autor.
Esto último, acorde a los estudios realizados en la planta, experiencia del supervisor y del
autor, está mucho más acorde con los tiempos de producción reales de la planta para un
lote. Si se hubiese tomado de manera continua, tiempos como el de la referencia de 250g
hubiesen estado cercanos a las 6 horas, cuando el proceso en realidad está representado
por un tiempo mucho más cercano a las 3 o 4 horas debido a su estructura paralela, esto
puede acarrear problemas de subestimación del tiempo productivo y complicaría el
requerimiento de satisfacción de la demanda, por lo que se tomarán como tiempos
estándar definitivos aquellos tiempos cuyo comportamiento reflejen la estructura real del
proceso, los cuales se encuentran en la Tabla 3. Tiempos estándar de producción
unitarios como Tiempo de producción.
3.7 Capacidad Disponible
La capacidad disponible está determinada por algunos autores como Kalenatic et al
(2007) como el potencial de un trabajador, una máquina, un centro de trabajo, un proceso,
una planta o una organización para fabricar productos por una unidad de tiempo. Esta
capacidad de tiempo delimitada por hasta cuánto está dispuesto a dar el proceso antes de
no poder llegar a producir más. Es decir, es el límite de unidades que se pueden producir
por unidad de tiempo. La capacidad del proceso suele expresarse para la disponibilidad
de un recurso requerido en la producción de una mezcla de productos en un periodo de
tiempo determinado. En la mayoría de los casos son la capacidad del recurso máquina:
Horas-Máquina por unidad de tiempo y la capacidad del recurso de mano de obra: Horas-
Hombre por unidad de tiempo.
Esta capacidad de producción de los recursos Hombre y/o Máquina que determina el
potencial del proceso se calcula en función de la cantidad de recursos en la estación de
trabajo y se multiplica por el número de días hábiles en el mes del horizonte de tiempo por
el número de turnos trabajados y por las horas que se trabaja en cada turno, al número

28
resultante se le restan las pérdidas originadas por el alistamiento, mantenimiento,
ausentismos, descansos y cualquier otro factor externo que de una u otra forma
disminuyan la capacidad del proceso.
A continuación se procede a realizar el cálculo de la capacidad disponible para cada uno
de los recursos en la organización.
3.7.1 Cálculo capacidad disponible recurso Hombre
Según lo mencionado anteriormente, tenemos que la capacidad del proceso para el
recurso Hombre se calcula como
donde
: Capacidad Total en la estación j en el periodo de tiempo t
Días hábiles en el periodo de tiempo t
: Número de turnos en la estación j
: Número de horas por turno en la estación j
A continuación es necesario restar a la Ecuación (A1) el número de horas dedicadas a
descanso oficial otorgado por la organización, ésta se calcula como
donde
: Número de horas dedicadas a descanso en el tiempo t
: Número horas de descansos por turno en el tiempo t
El segundo componente a sustraer de la capacidad total es el correspondiente a el tiempo
ocioso de los recursos. Este tiempo se calculó a partir de un muestreo del trabajo el cual
se puede consultar como Anexo 10.4 Muestreo del Trabajo al final de este documento y
en formato Excel en el CD anexo. Tenemos que la fórmula para su cálculo está dada por
donde
: Tiempo ocioso en la estación j en el periodo de tiempo t
Porcentaje del tiempo ocioso
La Ecuación (A3) nos dice que el tiempo ocioso de cada estación está determinado como
un porcentaje de todo el tiempo disponible para el trabajo sin contar los descansos.

29
La última ecuación a sustraer de Ec. (A1) hace referencia al tiempo dedicado por el
recurso Hombre al mantenimiento del recuso Máquina, este tiempo representa una
intersección entre ambos recursos, por lo que será utilizado por ambos para el desarrollo
de la planeación. La fórmula que determina este tiempo de alistamiento está dada por
donde
: Tiempo dedicado a mantenimiento en la estación j en el periodo de tiempo t
Porcentaje del tiempo dedicado a mantenimiento en la estación j
Tenemos entonces que al juntar las ecuaciones (A1), (A2), (A3) y (A4) se obtiene la
Capacidad Disponible del recurso Hombre, la cual determina cuantas
horas se pueden dedicar a producción en cada uno de los meses de horizonte de
planeación considerando el número total de trabajadores por estación
( )]
donde
: Número de trabajadores en la estación j
Realizando un poco de algebra se obtiene que5
donde
. Representa el porcentaje de tiempo productivo.
( ) Representa el número de horas totales dedicadas a
la producción por el recurso Hombre.
Para el desarrollo de este ejercicio se sabe que:
6
Debido al hecho que el modelo de programación presentado más adelante considera el
número de trabajadores como una variable, es necesario tener en cuenta esta capacidad
5 Para ver el desarrollo del algebra véase el Anexo 10.5. Procedimientos Matemáticos. 6 Se dan 15 minutos de descanso dos veces por turno y 60 minutos de almuerzo o descanso
dependiendo del turno.

30
como dinámica puesto que está variando dependiendo del valor intertemporal que tome
. Esto se considerará en el Capítulo 5 dentro de la programación lineal planteada. Sin
embargo, esta capacidad hombre está limitada por la capacidad del recurso máquina, la
cual es fija bajo el supuesto de que no se ampliará la capacidad máquina en el horizonte
de tiempo. Su cálculo se presenta a continuación.
3.7.2 Cálculo capacidad disponible recurso Máquina
El cálculo de la capacidad que dispone el recuso máquina está determinado de manera
muy similar a la forma como se realizó el desarrollo de la capacidad del recurso Hombre.
En general se tienen que
( )]
donde
: Capacidad disponible de máquina en la estación j en el periodo de
tiempo t
Número de máquinas en la estación j
Capacidad total disponible de máquina en la estación j en el periodo de
tiempo t
Tiempo ocioso de la máquina en la estación j
Tiempo dedicado a mantenimiento en la estación j
Se observa como la ecuación del recurso máquina no considera el número de horas
dedicas a descanso debido a que este tiempo es considerado dentro del tiempo ocioso de
la máquina. Organizando los términos y realizando algo de algebra como se realizó en Ec.
(B1) se tiene que
donde
. Representa el porcentaje de tiempo productivo de máquina.
Representa el número de horas totales dedicadas a la
producción por el recurso máquina.
Se tendrá entonces que la capacidad disponible del recurso máquina considerando los
valores de la Tabla 2. Disposición Recurso Máquina. para un tiempo de trabajo normal de
8 horas diarias por estación y por periodo será de

31
Tabla Capacidad Disponible Máquina Unidades: Horas
Estación de trabajo Marzo Abril Mayo Junio Julio Agosto
Fab. Envase 159.00 152.64 165.36 139.92 171.72 152.64
Fajillar 348.00 334.08 361.92 306.24 375.84 334.08
Mezclar 764.00 733.44 794.56 672.32 825.12 733.44
Envasar 280.00 268.80 291.20 246.40 302.40 268.80
Empacar 171.00 164.16 177.84 150.48 184.68 164.16
Tabla 6 Capacidad máquina por estación de trabajo
Fuente: Cálculos del Autor.
donde ∑ para cada valor de , será igual a
Capacidad máquina Tiempo Normal
Marzo 1722.00 Abril 1653.12 Mayo 1790.88 Junio 1515.36 Julio 1859.76
Agosto 1653.12
Tabla 7 Capacidad máquina en tiempo normal
Fuente: Cálculos del Autor.
el cual corresponde a la capacidad de la planta en cada uno de los meses considerados.
Ahora bien, la siguiente tabla considera la capacidad de la planta en tiempo extra, para un
turno “extra” de 4 horas adicionales a las ordinarias.
Capacidad máquina Tiempo Extra
Marzo 861.00 Abril 826.56 Mayo 895.44 Junio 757.68 Julio 929.88
Agosto 826.56
Tabla 8 Capacidad máquina en tiempo extra
Fuente: Cálculos del Autor.
3.8 Costo Unitario de Producción
El costo unitario se encuentra catalogado como el gasto económico que representa la
fabricación de una unidad de un producto determinado. El análisis y la determinación del
costo unitario de producción permiten llegar a conocer medidas de desempeño
organizacional que posibilitan una mejor administración de las operaciones. Este costo
mide el esfuerzo que se debe llevar a cabo para realizar adecuadamente una unidad de
un producto.
Así las cosas, la determinación del costo unitario de producción para cada una de las
referencias seleccionadas es fundamental para conocer cuan eficaz resultará la

32
construcción del plan agregado de producción en la organización. Dentro de la
desagregación del costo, Chase et al (2009) clasifica estos en (i) costos variables que
están en función directa del proceso de producción y que intervienen en la transformación
de la materia prima al producto final, (ii) costos fijos o todo egreso que permanece
invariante ante cambios en el proceso productivo y (iii) costos de oportunidad que son
aquellos costos de la inversión de los recursos con los que se dispone en oportunidades
económicas que generarán inevitablemente costos de la opción no realizada por ejemplo
los costos en los que se incurre por dejar de vender un producto.
Dentro de los costos variables y fijos se encuentran involucrados varios componentes
principales para su determinación los cuales serán explicados a continuación.
3.8.1 Costos de mano de obra directa
Los costos directos de mano de obra involucran aquellos costos asociados a la fuerza de
trabajo necesaria para su producción. Su representación está determinada por los
sueldos, salarios, bonos o comisiones de aquellos empleados cuyo ejercicio profesional
se involucre directamente con la fabricación del producto.
Cabe anotar que debido a la estructura de la programación lineal que se presentará más
adelante en el Capítulo 5. Planeación de la producción. resulta indispensable la
separación de este costo del costo unitario de producción para evitar problemas de
duplicación en la construcción de la estructura de los costos. Sin embargo, se presenta en
este apartado debido a que es parte esencial de la construcción de un costo unitario
variable.
A partir de la construcción de todos los costos posibles que acarrea el mantenimiento de
un empleado regular se construyó el costo de mantener un trabajador de mano de obra
directa. Los costos que debieron ser tenidos en cuenta para el caso particular de la
organización fueron costos de nómina como sueldos, salarios y prestaciones sociales,
costos de exámenes médicos que se realizan una vez cada año y por último y costos de
una dotación de un litro de leche diaria que se les debe dar a cada uno de los operarios
para evitar problemas de salud derivados del proceso productivo.
La Tabla 9. Costos de mano de obra directa en tiempo normal. presenta la forma como se
obtuvo dicho valor para cada operario. Debido a que todos los operarios ganan lo mismo
sin importar la estación de trabajo donde se encuentre, se tendrá un solo costo para todos
los tipos de operarios o auxiliares.

33
Nombre del costo Valor
Sueldo Mano de Obra Directa $616,000 Aportes A Fondos De Pensiones Y/O Cesantías $73,920 Aportes A Entidades Promotoras De Salud $52,360 Auxilio De Transporte $72,000 Aportes A.R.P (2.436%) $15,006 Parafiscales $55,440 Costo en leche $48,000 Costo en exámenes médicos (Mes) $6,233 Provisión Prima (8.3%*$ 688,000) $ 57,104 Provisión Cesantía (8.3%*$ 688,000) $ 57,104 Provisión Interés Cesantía (1%*$ 688,000) $ 6,880 Provisión Vacaciones (4.1%*$ 688,000) $ 25,681
Suma costos de mano de obra directa $ 1’031,500
Tabla 9 Costo de mano de obra directa en tiempo normal
Fuente: Cálculos del Autor. Datos suministrados por la organización.
Se tendría entonces que el costo de la hora ordinaria7 considerando todos los costos
adicionales al sueldo corresponde a $ 4,297.91 (donde $ 2,566.67 hace referencia al
sueldo y $ 1,731.24 a parafiscales y obligaciones legales del empleador). Además la hora
extra ordinaria8 al ser un 25% adicional a la hora ordinaria correspondería a $ 4,939.57
(donde $ 3,208.33 corresponden a la hora extra ordinaria y $ 1,731.24 a parafiscales y
obligaciones del patrón).
3.8.2 Costos de materia prima e insumos
Los costos de materia prima e insumos son aquellos costos de todos los elementos que
se incluyen en la elaboración del producto y que sufren algún tipo de transformación física
o química y que es incorporado al producto final. Los costos de materia prima varían muy
poco entre referencias puesto que en sí lo único que cambia es el costo de la fabricación
del envase tanto del cuerpo como de la tapa, el cual será mayor entre más grande sea el
tamaño de la referencia. Estos costos se definen a continuación para cada una de las
referencias, acorde a precios del 2014 por información entregada por la organización.
Cabe anotar que la forma de su cálculo se determinó por medio de un promedio simple
del costo de materias primas por gramos de 7 tipos de productos que varían según la
fragancia y el tipo de cliente, este costo promedio dio como resultado 0.84929 pesos por
gramo.
Costo Materia Prima
R250 $212.32
R500 $424.64
R1000 $849.29
R1500 $1,273.93
R3000 $2,547.86
Tabla 10 Costos de materias primas
Fuente: Alianzas y/o Industrias Alta Pureza S.A.
7 Entendiéndose como hora ordinaria una jornada de trabajo entre las 6:00am y las 10:00pm. 8 Ley 50/1990 Art 24.

34
3.8.3 Costos de almacenamiento
Los costos de almacenamientos son aquellos costos que se incrementan en relación
directa con el volumen y el tiempo de almacenamiento de la mercancía. Dentro de estos
costos se encuentran los costos financieros de inventario, costos de mantenimiento,
costos de explotación y costos de depreciación. Para este caso particular se tendrán en
consideración únicamente los costos de mantenimiento los cuales se determinan
directamente por el arriendo, pólizas de seguros, compañías de seguridad, limpieza,
agua, luz, gasolina, teléfono, internet, etc. y los costos de explotación
Para llegar a obtener adecuadamente los costos de almacenamiento fue necesario llevar
todos estos costos a un valor que corresponda al área comprendida dentro de la
organización para uso de bodega de almacenamiento de producto terminado únicamente,
no de materia prima ni otra área productiva o improductiva. Esto se logró haciendo uso del
plano de la organización y usando una escala de conversión para encontrar el área
dedicada al almacenamiento de producto terminado. Este plano se puede encontrar en el
Anexo 10.10. Plano de la organización. al final de este documento, así como su respectiva
tabla de conversiones para cada área dentro de la organización.
Se encontró entonces que el área dedicada a almacenamiento de producto terminado
dentro del total del área de la organización corresponde a la razón la cual
determina un porcentaje del 9.9% aproximadamente dedicado a almacenar el producto
terminado. Este porcentaje será utilizado entonces más adelante para el cálculo del costo
total.
Asimismo, fue necesario la obtención del porcentaje de participación de los costos de
explotación el cual se debe determinar por medio de la razón: horas hombre dedicadas al
almacenamiento en un tiempo determinado sobre el total de horas hombre en el tiempo
determinado. Esta razón se obtuvo a partir de la división promedio de para cada
referencia entre el tiempo que se dedica al almacenamiento dentro del tiempo total para la
producción de un lote de 300kg. Arrojando un porcentaje promedio de 14.59% de tiempo
dedicado a empacar dentro de la producción de un lote.
La desagregación de estos costos se presentan en la Tabla 11. Costos desagregados de
almacenamiento y están dados para un tiempo estándar de producción en un mes de
trabajo, tomando como referencia el mes de enero 2014 y considerando los porcentajes
de participación de cada costo en el total. La tabla muestra el costo total de
almacenamiento para un estándar de dos operarios promedio trabajando en
almacenamiento.

35
Tipo de costo Desagregado General Peso % Costo Real
Costos de Mantenimiento
Arriendo Almacenamiento $ 8,000,000 Teléfono $ 143,950 Celular $ 70,000 Asesoría técnica $550,000 Agua y Alcantarillado $149,110 Aseo Publico $149,620 Energía $5,716,000 Alarma / Seguridad $145,644
Suma 14,924,324 9.9% $1,478,028.26
Costos de Explotación
(Por operario)
Sueldo Mano de Obra Directa $616,000 Aportes A Fondos De Pensiones Y/O Cesantías $73,920 Aportes A Entidades Promotoras De Salud $52,360 Auxilio De Transporte $72,000 Aportes A.R.P (2.436%) $15,006 Parafiscales $55,440 Gasto en leche $48,000 Gasto en exámenes médicos $6,233
Suma $938,959 14.6% $137,021.62
TOTAL COSTO DE ALMACENAMIENTO NETO (2 operarios) $1,752,071.49
Tabla 11 Costos desagregados de almacenamiento
Fuente: Cálculos del Autor. Datos suministrados por la organización.
Sin embargo, este costo total así presentado es infructuoso para el desarrollo del plan de
producción que se presentará más adelante; esto debido al hecho que es necesario la
obtención de un costo unitario de almacenamiento para cada una de las referencias
presentadas. Este costo se obtuvo de la siguiente manera: primero se calculó el volumen
aproximado de la bodega de almacenamiento teniendo en cuenta una altura de 2.5
metros de alto puesto que por encima de ese nivel es altamente probable que las cajas
que se encuentran en la base sufran deformaciones y posiblemente perjudiquen la calidad
del producto final. Este valor se presenta en la siguiente tabla
Ancho <m> Largo <m> Alto <m> Volumen <m³>
Bodega 4.57 27.86 2.5 318.367
Tabla 12 Volumen Bodega almacenamiento
Fuente: Cálculos del Autor.
A continuación, se procedió a encontrar el volumen que ocupa cada producto dentro de la
bodega, dependiendo el tipo de referencia. Este volumen se calculó tomando las medidas
del diámetro y la altura de cada recipiente y calculando su el volumen como donde
corresponde el radio de cada uno y a su altura. Con este valor se calculó la capacidad
teórica de cada referencia en el total del volumen de la bodega, y se procedió a obtener el
costo unitario de almacenamiento como la razón entre esta capacidad teórica y el costo
total presentado al final de la Tabla 11. Costos desagregados de almacenamiento. Los
resultados de este procedimiento se documentaron en la siguiente tabla

36
Diámetro <m>
Alto <m>
Volumen <m³>
Capacidad (Unidades)
Costo Unitario de Almacenamiento
Pro
du
cto
R250 0.085 0.055 0.000312098 1020089 $1.72
R500 0.113 0.065 0.000651869 488392 $3.59
R1000 0.137 0.081 0.001194032 266632 $6.57
R1500 0.153 0.085 0.001562758 203721 $8.60
R3000 0.165 0.15 0.00320737 99261 $17.65
Tabla 13 Costos unitarios de almacenamiento por referencia
Fuente: Cálculos del Autor.
3.8.4 Costos fijos
Como se mencionó anteriormente los costos fijos son todos aquellos costos que no están
en función de la cantidad producida es decir que no son sensibles antes cambios en la
actividad económica sino que siempre deben ser pagados con una periodicidad frecuente
(diario, semanal, quincenal, mensual o anual).
Etapa Valor
Arriendo $ 8’000 000 Energía $ 5’7 6 000 Teléfono $ 143,950 Celular $ 70,000
Aseo Publico $ 149,110
Total $ 14’079,060
Tabla 14 Costos fijos
Fuente: Datos suministrados por la organización.
Ahora bien, existen otros costos que deben ser tenidos en cuenta a la hora del desarrollo
de un plan de producción, estos costos aunque no son muy frecuentes y su derivación
suele ser más compleja, son vitales para comprender como será el desempeño del plan
de producción. Entre estos costos se encuentran: costos de contratar y despedir personal
de producción y costos de ruptura nato, los cuales serán descritos y derivados a
continuación.
3.8.5 Costos de ruptura
Un costo de ruptura, también llamado costo de faltantes, se define cuando no hay
existencias suficientes para llegar a satisfacer la demanda en un periodo de terminado.
Este costo tiene varias manifestaciones dependiendo del tipo de inventario. Cuando las
máquinas u operarios se detiene por falta de inventarios este costo es llamado lucro
cesante mientras que cuando el costo se deriva por la falta de inventario final para suplir
la demanda es llamado costo de ruptura nato. Este último será tenido en cuenta más
adelante para la construcción de la función de costos asimétrica con la subproducción.
Debido a que el cálculo del costo de ruptura nato es difícil de obtener y poco frecuente en
su uso, además de sugerir la necesidad de un sistema muy eficiente de gestión de calidad
y de inventarios, aspecto muy pocas veces logrado en pequeñas y medianas empresas
del país, fue necesario conformarse con una derivación estimada y subjetiva de este costo

37
a partir de un estándar teórico. Autores como Arbones (1989) o Laumaille (2000)
consideran que estos costos se encuentran entre un 1% y un 4% de los ingresos por
venta, lo que querría decir que entre mayor cantidad de unidades no vendida mayor será
el costo de ruptura. Sin embargo, esta función de costos parecería comportarse de una
forma más exponencial que lineal, esto debido al hecho que entre mayor sea el número
de unidades que no satisficieron la demanda, más y peores complicaciones tendrá el ente
productor con el cliente. Además, este costo tendría cierto de grado de relación con la
persistencia a la reiterada subproducción y la tolerancia que se tenga por parte del cliente,
puesto que no es lo mismo dejar de satisfacer la demanda de medicamentos para un
hospital que para jabones lavaloza en una gran superficie, siendo la primera mucho más
costosa. Todo esto hace que su derivación sea bastante compleja.
Por ello se decidió, por medio de la gerencia administrativa y por las cualidades que se
tienen del producto en discusión, a considerar un costo de ruptura del 2% del precio
unitario de venta el cual determina el ingreso que se generará para cada referencia. Los
resultados se presentan a continuación.
Etapa Precio Costo de ruptura
R250 $ 790 $ 15.8
R500 $ 1,700 $ 34
R1000 $ 2,900 $ 58
R1500 $ 4,600 $ 92
R3000 $ 8,976 $ 179.52
Tabla 19 Costos de ruptura
Fuente: Cálculos del Autor.
3.8.6 Costos de Contratar y Despedir
Dentro de las organizaciones con procesos productivos de transformación de materias
primas en productos terminados es muy frecuente encontrar temporadas de crecimiento o
recesión de la producción. Aquellos períodos donde es necesario incrementar la
capacidad productiva resulta indispensable contratar más personal para poder cumplir con
la demanda, caso contrario con periodos de recesión donde resulta costoso mantener un
recurso humano improductivo. Es por ello que el modelo de planeación de producción
planteado más adelante sugiere considerar costos de contratar y despedir personal.
Más allá de los salarios que gana un trabajador, existen otros costos asociados al proceso
de contratación en cualquier organización. Estos costos están ligados muy
frecuentemente a procesos recursos humanos como entrenamiento, preparación y
aprendizaje del operario para cumplir su labor. Sin embargo, resulta necesario además
considerar costos de procesos de selección de candidatos como el Assestment Centers, o
incluso costos de papelería.
Para este caso particular se cuenta con costos de 4 exámenes médicos de ingreso
únicamente, debido a que los costos de papelería son insignificantes y no existen costos

38
adicionales derivados del proceso de selección. Por consiguiente el costo de contratación
será igual a
Tipo de costo Valor
Examen médico Ocupacional de Ingreso $ 25,300 Audiometría $ 15,700 Optometría $ 15,700
Espirometría $ 18,100
Total $ 74,800
Tabla 20 Costo total de contratar un operario
Fuente: Datos suministrados por la organización.
Asimismo, los costos de despedir tienen asociados costos por exámenes médicos que
aunque son menores que los de contratar, son significativos. Adicionalmente, los costos
de despedir están ligados a razones legales por medio de la liquidación de cada uno de
los empleados para un contrato a término fijo de un mes. Estos costos asociados al
proceso de despido se presentan a continuación.
Tipo de costo Valor
Examen Médico Ocupacional de Ingreso $ 25,300 Audiometría $ 15,700 Espirometría $ 18,100
Total $ 59,100
Tabla 15 Costo total de despedir un operario
Fuente: Datos suministrados por la organización.
Cabe mencionar que estos tipos de costos de despedir y contratar tienen un supuesto
fundamental detrás, y es el hecho que se está pensando que en el mercado laboral existe
un gran número de oferentes y que la búsqueda de un candidato es lo bastante rápida
como para suplir la demanda requerida en el mes sin entrar en conflictos derivados del
proceso de búsqueda.

39
4 PRONÓSTICO DE LA DEMANDA EN EL HORIZONTE DE PLANEACIÓN
El presente capítulo encierra uno de los aspectos más esenciales dentro de una buena
planeación de la producción, esto es, la proyección de la demanda requerida en el
horizonte de planeación. Este capítulo estará compuesto por siete secciones principales.
La primera una explicación general de la teoría de decisión y pronósticos con series de
tiempo; la segunda, una descripción de los datos que se van a emplear para este trabajo;
la tercera, una introducción de la funcionalidad, estructura y propósito del complemento
ASTEX en E cel “add-in” desarrollado como herramienta de an lisis a las series de
tiempo para la organización; la cuarta, la explicación y realización del pronóstico de la
demanda por medio del modelo ARIMA propuesto por Box-Jenkins 1970, en esta sección
se introducirá el código programado en lenguaje MATLAB para la búsqueda, selección y
evaluación del mejor modelo ARIMA; la quinta, un contraste del modelo lineal ARIMA con
modelos automáticos de series desarrollados por las industrias en su día a día y el
modelo de pronóstico actual manejado por la organización; la sexta parte presenta la
comparación y selección de la mejor metodología de pronóstico de la demanda y por
último la séptima sección presenta el cálculo de la capacidad requerida del horizonte de
planeación para poder así entrar a hacer uso de este pronóstico con fines de la
planeación de la producción en capítulos posteriores.
4.1 Teoría General Sobre Decisión y Pronóstico con Series de Tiempo
4.1.1 Descripción de los Pronósticos en la Planeación
Muchos autores defienden la posición sobre la importancia de un buen pronóstico en las
empresas hoy en día. Chase et al (2009) arguye que pronosticar es vital para todas las
decisiones de la gerencia y como base de la planeación corporativa de largo plazo.
Chatfield (1996), por ejemplo, expresa que el pronóstico de variables de una observada
serie de tiempo es un problema importante en muchas áreas incluyendo la economía,
la planeación de la producción, las ventas y los controles de inventarios. Evertt y Ronald
( 998 Sección 3) dicen te tualmente “Si bien todos los elementos de la administración
de operaciones son importantes, considero que los pronósticos son uno de los elementos
decisivos en la estructura de operaciones” y expone el ejemplo de los beneficios que trae
un buen pronóstico en la empresa Donaldson Company, Inc. Con ellos muchos otros
autores como Norman Geither y Greg Fraizer, Lee Krajewsky, Buffa Sarin, Adam y Ebert y
Riggs definen los pronóstico como un elemento vital a la hora de tener en cuenta la
planeación.
Los métodos de pronóstico en series de tiempo pueden estar divididos en tres
grupos según Chatfield (1996): los subjetivos, los univariados y los multivariados.
Los métodos subjetivos están basados en la intuición, el juicio personal y el conocimiento
de cada agente económico. Van desde la extrapolación hasta la técnica Delphi la cual son
preguntas hechas a un grupo de expertos para llegar a recabar información y

40
opiniones9. Los métodos univariados están basados en el ajuste de un modelo solo usado
el pasado de la serie. Los métodos multivariados dependen de una o más series llamadas
series explicativas o variables de predicción donde por ejemplo las ventas pueden
depender de cambios en los niveles de inventarios, o cambios es ciertos
indicadores económicos.
Siempre es recomendable hacer uso de dos o más métodos de pronóstico sin embargo la
escogencia del método dependerá de ciertas consideraciones como el objetivo
del pronóstico, la cantidad de datos con que se cuenta, el horizonte de planeación,
la descomposición de la serie e inclusive el departamento norte en la brújula de los
macro-procesos, el área de mercadeo quien otorga la información necesaria para definir
qué condiciones podrían llegar a afectar la demanda dentro del horizonte de tiempo
planeado para poder llegar a incorporar esos choques exógenos al modelo de pronóstico.
Harrison y Pearce (1972) recomiendan que no se debería hacer un pronóstico muy lejano
de la serie y además que este pronóstico no debe exceder la mitad de la longitud de
tiempo que se está usando en la serie univariado.
No importa cual método de pronóstico se utilice, siempre es indispensable un esquema de
monitoreo como por ejemplo el uso de señales de rastreo o TS (Tracking Signals) para
detectar posibles cambios o inconvenientes en nuestros pronósticos en el tiempo. Garden
(1983) explica este concepto más detalladamente.
4.1.2 Funciones de pérdida de error de pronóstico simétricas.
Las funciones de pérdida de error de pronóstico o funciones de costo de pronóstico
pueden ser divididas en dos grupos: las funciones de costos simétricas como el MAPE,
MAE, MSE o el RMSE y las funciones de costos asimétricas como LINLIN o LINEX que
como expresa Granger (1969) implican un pronóstico más complejo que depende tanto de
la distribución del error pronóstico como de la función de costo por sí misma. Estas
funciones presentan restricciones en su definición puesto que se deben presentar ciertas
condiciones para que una función sea catalogada como de costos. El Anexo 10.6.1.
Funciones de Pérdida muestra algunas de estas funciones las cuales se utilizarán a lo
largo de este capítulo.
4.2 Descripción de los Datos
Debido a que el propósito fundamental de este trabajo es la realización de un plan de
producción para la empresa de estudio, fue necesario obtener la demanda de Lavalozas
por medio de una variable que emule dicho fenómeno o por lo menos se aproxime lo
mejor posible al proceso estocástico que sigue la demanda, esta variable está
determinada por las ventas de la empresa dadas por el registro organizado de inventarios
o Kardex. Este registro permitió obtener el número total de unidades vendidas diariamente
de cada una de las 58 referencias de la empresa.
9 Para más detalle ver Everett y Ronald (1991) sobre técnicas cualitativas de pronóstico.

41
Teniendo en cuenta que una de las variables primordiales en un plan de producción es la
capacidad del proceso, se debe considerar el abarcar todas las referencias para poder
obtener una respuesta adecuada acerca de la utilización de capacidad máxima disponible.
Para ello y como se mencionó en la sección 3.5. Representantes Tipo, se procedió a
dividir las 58 referencias en 5 grandes categorías, estas categorías fueron determinadas
por los cinco diferentes pesos que se venden al mercado: 250g con 7 referencias, 500g
con 25 referencias, 1000g con 22 referencias, 1500g con 2 referencias y 3000g con 2
referencias. Esta categorización tiene un sustento práctico, debido a que dentro del
proceso productivo, la única diferencia que existe en tiempos de producción y capacidad
de proceso radica en el tamaño de la presentación del producto final, esto se demostró
anteriormente en la sección 3.6. Estudio de Tiempos Estándar de Producción.
Debido a que el programa contable Helisa10 que utiliza la empresa para el manejo de
inventarios y estados de resultados arroja los consolidados totales en Excel de todos los
productos de la organización y teniendo en cuenta que la organización cuenta con 255
referencias aparte de los lavalozas, los cuales únicamente se realizan bajo externalización
y no cuentan con un proceso productivo dentro de la planta, fue necesario extraer las
ventas de las 58 referencias de interés por medio de la programación de un código en
Visual Basic de Excel11. Este código permite obtener del archivo consolidado, el cual se
presenta con frecuencia diaria desde el primero de enero de 2010 hasta diciembre de
2013, para todas las 313 referencias (un total de 80106 observaciones), las ventas
mensuales de cada una de las referencias que se seleccionen previamente.
Una vez obtenido las ventas de las 58 referencias por separado, se procedió a construir
cada una de las cinco categorías previamente descritas. Sin embargo, dado que la
demanda que se obtiene de Helisa está dada en embalajes (cajas) vendidos, fue
necesario multiplicar cada uno de los embalajes por el número de unidades de lavaloza
que contiene cada embalaje. Esto es necesario de realizar previo a la construcción de las
categorías debido a que de lo contrario se estarían sumando embalajes de diferentes
cantidades y el final sólo tendríamos como resultado el número de embalajes vendidos
mezclados por referencias y no el número de unidades de lavaloza vendidos. Ya con las
unidades de lavaloza vendidas, se procede a sumar las ventas de cada una de las
referencias en cada categoría. Esto se pudo realizar, únicamente sabiendo que las
referencias que componen a cada una de esas cinco categorías cuentan con el mismo
proceso productivo y por tanto son en si el mismo producto.
De llegar a ser el caso de obtener que alguna de las referencias dejó de venderse, como
lo fue el caso de 7 referencias en la categoría de 1000g, fue necesario obviar dichas
10 Helisa es un software contable con fines administrativos y de gestión de inventarios, el cual
posee varias herramientas como la gestión de ventas y de compras, la administración de propiedad horizontal, la administración de inventario, el manejo de nómina y administración del recurso humano, entre otras. Para mayor información véase: www.helisa.com 11 El código se presenta como Anexo 10.8.1. Sección 1. Código VBA para la extracción de las
series de interés en consolidado de ventas al final de este documento.

42
referencias para la construcción de la categoría. Esto debido a que si dicha referencia
dejo de producirse, no debería ser tenida en cuenta para el pronóstico de la demanda
puesto que sesgaría hacia arriba los resultados.
En conclusión, se recopilaron cinco referencias de lavalozas en unidades de producto
terminado, cada una con tiempos de producción diferentes. Estas referencias fueron
250g, 500g, 1000g, 1500g y 3000g. La dimensión de tiempo de cada una de ellas está
dada desde enero de 2010 hasta febrero de 2014 con 50 observaciones en total a
diferencia de la presentación de 250g la cual va desde junio de 2010 hasta febrero de
2014 contando con 45 observaciones en total.
El Anexo 10.6.3. Descripción de los Datos muestra la compilación en niveles de las cinco
series en su forma final. Para propósitos de programación de códigos en los diferentes
paquetes estadísticos, estas series fueron llamadas R250, R500, R1000, R1500 y R3000
haciendo referencia a cada uno de los cinco tamaños.
Como se verá más adelante, estas series estarán divididas en dos períodos, cada uno
con un propósito diferente. El primer periodo, o periodo de estimación, corresponde a la
muestra desde el inicio (enero 2010 o junio 2010 para R250) hasta marzo de 2013, con un
total de 34 observaciones. Mientras que la evaluación rolling para observaciones fuera de
la muestra va desde abril 2013 hasta febrero de 2014 por un proceso de evaluación que
se explicará en detalle más adelante.
4.3 Add In en Excel Para el Manejo de Series de Tiempo Para Uso Empresarial.
Con el propósito de elaborar una herramienta sólida para el manejo adecuado de la
planeación de la demanda en la organización de estudio, se desarrolló paralelamente a
este trabajo de grado un aplicativo en forma de complemento de Microsoft Excel para
sistemas operativos Windows llamado también Excel Add In. Este complemento puede
ser consultado en el CD anexo a este documento y se presenta como una cinta de
opciones desplegada por una pestaña que permite realizar ciertos procesos que se
desarrollarán en este trabajo, así como el manejo adecuado, organizado y eficiente de los
datos de demanda en la organización.
Al complemento desarrollado se le dio el nombre de ASTEX por sus siglas: Análisis de
Series de Tiempo en Excel. Este complemento presenta diferentes opciones las cuales
serán explicadas en detalle a lo largo del trabajo cuando sea necesario. Cabe resaltar que
debido al lenguaje de programación que lo fundamenta, ASTEX funciona únicamente en
programas Microsoft Excel 2007 en adelante y en plataformas Windows.
A continuación se procederá a explicar cómo se logra montar el Add in de ASTEX en
cualquier Excel de cualquier computador, cómo funciona este complemento y cuál es su
estructura base.

43
4.3.1 Instalación de ASTEX en Microsoft Excel
Como se mencionó anteriormente, ASTEX es un complemento a Excel y por tanto debe
ser montado como tal. Para llegar a instalarlo es necesario tener tanto el complemento
ASTEX.xlam como un programa Excel activado y funcionando correctamente. Debido a
que ASTEX trabaja con un lenguaje de programación basado en Visual Basic para
Aplicaciones (VBA de aquí en adelante) el cual se lee a través de Macros y funciones, es
necesario que se tengan previamente habilitadas las mismas.
Se puede activar el complemento ASTEX siguiendo estos sencillos pasos:
1. Se guarda el archivo ASTEX.xlam en la carpeta que contiene los complementos
de Excel, la cual se puede encontrar en la mayoría de los casos en la ruta
“C:\Users\user\AppData\Roaming\Microsoft\AddIns” o puede ser consultada más
adelante al dar el botón de Examinar (Browse) en la ventada de Add-Ins.
2. Una vez incluido el archivo en la carpeta, se activa la ventana Add-Ins la cual
puede ser iniciada en la pestaña Programador o abriendo la ventana de opciones
de Excel, presionado el botón de complementos y luego el botón Ir. Cualquier
forma abrirá la ventana que se presenta en el Anexo10.7.1 Ventana Para la
Instalación del add-in donde el valor resaltado muestra que el complemento
ASTEX existe y solo es necesario activar la casilla y dar OK para comenzar a
hacer uso de él.
Una vez instalado ASTEX correctamente, aparecerá una pestaña (ver ilustración 2.
Pestaña ASTEX) con todas las opciones que este cuenta. Esta pestaña cuenta con
diferentes bloques de opciones, cada una con un código de programación asociado y con
una utilidad diferente.
Ilustración 2 Pestaña ASTEX
Fuente: Desarrollado por el Autor
Cabe anotar que esta pestaña estará disponible siempre que se abra un nuevo o viejo
archivo de Excel sin necesidad de repetir estos pasos de instalación cada vez.
4.3.2 Funcionamiento de ASTEX
El complemento ASTEX funciona a través de una serie de códigos de programación en el
lenguaje VBA realizados por el autor12, donde cada botón tiene asociado uno o más
bloques de códigos.
12 Con excepción del código para la realización del correlograma el cual fue tomado del blog web
de Slava Dedyunkhin, el cual puede visitarse en el siguiente enlace web: http://dedyukh.in/index.php/autocorrelation-in-excel

44
El lenguaje de programación VBA permite asociar códigos con objetos, lo que facilita la
interpretación, uso y desarrollo del código a través de un útil formulario que puede ser
abordado fácilmente por cualquier persona sin siquiera ver una sola línea de código. Esto
se desarrolló con el propósito que sea una herramienta fácilmente aplicable por cualquier
persona en la organización, eso sí, con cierto conocimiento en series temporales y
manejo de datos.
ASTEX funciona integrando la utilidad de una hoja de cálculo en Excel con códigos de
programación fundamentados en teoría de series de tiempo que permiten realizar tareas
de manera iterada, cuando se desee y cambiando a conveniencia las variables de
entrada. Estos códigos siguen la estructura de cualquier algoritmo, por lo que son pasos
ordenados que cumplen un objetivo específico.
Cabe anotar que ASTEX es un aplicativo en fase de prueba donde se intentará a largo
plazo incluirle muchas más funciones y corregir posibles errores (bugs) en el programa.
4.3.3 Estructura de ASTEX
La estructura de ASTEX es sencilla e intuitiva. En general, su disposición se realiza de
izquierda a derecha, esto es, desde el bloque Base de Datos hasta el bloque Pronóstico
(ver ilustración 2. Pestaña ASTEX).
Sin entrar en detalles puntuales sobre la finalidad de cada uno de sus botones, puesto
que muchos de ellos son fácilmente interpretables y otros se explicarán detalladamente
en secciones posteriores, se procede a exponer cual es el propósito de cada uno de los
bloques con los que cuenta ASTEX.
1. Base de Datos: en este bloque se permite al usuario importar referencias
puntuales del consolidado de ventas u otros archivos Excel y generar reportes de
ventas con ellas, también se permite exportar hojas puntuales tanto a otros
archivos Excel como archivos PDF o XML y enviar por correo electrónico el libro
actual.
2. Descriptivas: este bloque permite al usuario interactuar con la serie para
determinar sus propiedades estadísticas, histograma de frecuencias, prueba de
normalidad Jarque Bera, graficar series y realizar un análisis de Pareto para
determinar los pocos vetos vitales de los muchos triviales.
3. Identificación: este bloque permite analizar más profundamente la serie de interés
por medio de correlogramas, pruebas de raíz unitaria como la ADF, y análisis de
estabilización de varianza y nivel por medio de las metodologías de Guerrero
(2003) y Anderson (1976) respectivamente.
4. Formulación: en este bloque se permite la estimación de modelos autoregresivos
por medio del estimador de Mínimos Cuadrados Ordinarios OLS así como la
posibilidad de realizar regresiones lineales con dos o más variables, de verificar

45
diagnósticos de los supuestos del modelo ARIMA y la por último de realizar un
remuetreo de los coeficientes de la regresión por OLS (BootStrapping OLS).
5. Utilidades: este bloque permite al usuario realizar una variedad de interacciones
con la serie. Entre las opciones con que se cuenta está la desestacionalización de
la serie por medio del método aditivo o multiplicativo, los suavizados
exponenciales y aritméticos, filtro de Hodrick-Prescott, calcular la matriz de
covarianzas o correlación de varias variables, herramientas útiles para las series
de tiempo como el adelantar, rezagar, diferenciar, restar la media o el cambio
porcentual de una serie y por último la posibilidad de generar números aleatorios
por medio de diferentes distribuciones de probabilidad.
6. Diagnóstico: este bloque permite al usuario realizar un análisis de los pronósticos y
su efectividad. Esto por medio del cálculo de medidas de error de pronóstico como
MAD, MSE, RMSE, MAPE, Theil U1 y U2, descomposición del MSE, la realización
de la señal de rastreo o Tracking Signal, y gráficas de valores ajustados y
residuos.
7. Plan Producción: este bloque es exclusivamente dedicado a la realización del plan
de producción para la organización de estudio Alianzas y/o Industrias Alta Pureza
S.A integrando el software GAMS para ejecutar el modelaje matemático del plan a
través de ASTEX. Para más detalle diríjase al Capítulo 5. Plan de Producción en la
Sección 5.3. Integración GAMS en ASTEX. Aunque está enfocado en la
organización de estudio, es posible modificar esta opción para cualquier tipo de
organización de producción.
8. Ayuda: este último bloque permite al usuario consultar como es el funcionamiento
en detalle de cada uno de los botones y ver ejemplos aplicados para su mejor
entendimiento. De igual manera, la ayuda es accesible desde cualquier formulario.
4.4 Metodología Lineal: Box-Jenkins Modelo ARIMA
Esta metodología fue propuesta por George Box y Gwilym Jenkins en su libro llamado
Time Series Analysis, Forecasting and Control en 1970 y sigue un procedimiento basado
en modelos Autoregresivos Integrados de Medias Móviles (ARIMA), la cual será explicada
en detalle el siguiente apartado. Chatfield (1996) expone brevemente esta metodología
Box-Jenkins con la siguiente estructura lógica:
a. Identificación del modelo: En esta etapa se examinan los datos para determinar
cuál clase del proceso ARIMA parece ser apropiada para el conjunto de
información disponible.
b. Estimación: Se estiman los parámetros del modelo previamente escogido
usando las técnicas apropiadas para el ajuste de procesos ARIMA y estimación
del dominio del tiempo.
c. Diagnóstico y comprobación: Se examinan los residuales del modelo ajustado
para ver si el modelo es adecuado.
d. Considerar modelos alternativos si es necesario: Si por algún motivo el modelo
escogido parece ser inadecuado para el pronóstico, entonces es necesario probar

46
otro tipo de modelo autoregresivo integrado de media móvil hasta que se
encuentre el modelo más adecuado para los datos.
Box y Jenkins fueron desarrollando técnicas para tratar procesos no estacionarios con
series integradas basados en pruebas de raíz unitaria y usando diferencias en las series.
De esta forma el primer paso en la metodología es diferenciar la serie hasta que esta se
vuelva estacionaria, por lo que es necesario saber el grado de integración de la misma
para saber cuántas veces debe ser diferenciada, esto se logra examinando el
correlograma de varias diferencias hasta que se encuentre que una decae muy
rápidamente a cero y cuando cualquier ciclo estacional será completamente removido.
Además, Box y Jenkins desarrollaron modelos que fueron más robustos antes procesos
estacionales lo que llamaron a este el modelo SARIMA.
Los valores de p y q de los modelos SARIMA son seleccionados utilizando el
correlograma y la Función de Autocorrelación Parcial (ACF) donde se observa el periodo
estacional y se debería incluir en el modelo 13 . Una vez se tenga el modelo más
prometedor se estima por Mínimos Cuadrados Ordinarios MCO obteniendo la
minimización de la suma de residuales al cuadrado de manera similar que el modelo sin
efecto estacional ARMA. Sin embargo, existen varios otros modelos que pueden llegar a
estimar el modelo como por ejemplo las funciones de máxima verosimilitud o mínimos
cuadrados condicionales y no condicionales o la aproximación del filtro de Kalman.
A continuación se realiza según la metodología propuesta por Box y Jenkins el
diagnóstico comprobatorio del modelo que mejor se ajuste sea estacional o no. Esto se
logra mirando los residuos de la regresión para ver si son o no ruido blanco, es decir si
tienen comportamientos netamente estocásticos o hay algo más que puede estar
determinando a este modelo y que no lo estemos teniendo en cuenta. Para esto se hace
uso del correlograma de los residuos o de la prueba Q.
Cuando el mejor modelo es encontrado y se ajusta a los datos entonces se debe proceder
con el pronóstico de la variable para el horizonte de planeación, teniendo en cuenta el
razonamiento propuesto por Harrison y Pearce (1972) sobre el tamaño del pronóstico.
Continuando con la línea guía usada por Chatfield (1996) vemos que dado el conjunto de
datos en tiempo N, el pronóstico estaría determinado por las observaciones y los
residuales ajustados. Donde el mínimo error cuadrado promedio MMSE de la variable
en el tiempo N es valor esperado condicional de en el tiempo N, nombrada
como | , usando el hecho que el mejor pronóstico para
cualquier valor futuro del término de perturbación es cero.
Algunos paquetes estadísticos comúnmente usados otorgan la posibilidad de hacer la
modelación automática de modelos ARIMA pero con dudosos resultados como lo expone
Chatfield (1996, p. 75). Por lo que esta metodología Box-Jenkins al no ser automática se
basa en juicios más estructurados para la selección del modelo ARIMA apropiado acorde
a el análisis de series de tiempo univariado. Puede ser combinada con ajustes
estacionales como el método X-11 ARIMA y modelos multivariados generalizados.
13 Box y Jenkins (1970) hacen un conglomerado de las funciones de autocorrelación parcial de
varios modelos SARIMA como ejemplo.

47
Este método es bastante útil para series con una buena correlación de corto plazo, en la
cual los valores más inmediatos a la observación tienen una correlación más alta que
valores más lejanos a la misma. Relacionando esto con el trabajo de grado, a priori se
creería que el número de ventas puede llegar a estar relacionado más directamente con
su pasado inmediato, pues en realidad bajo las mismas condiciones que la subyacen
(Ceteris Paribus) la demanda de un producto un mes depende mucho de la demanda del
mismo los meses inmediatamente anteriores y no con los más lejanos, acorde con la
teoría del ciclo de vida de los productos (Introducción, crecimiento, madurez y descenso).
Pues como lo expone Lamb, Hair y McDaniel (2011, p. 379) el ciclo de vida de un bien es
bastante útil como herramienta o mecanismo de pronóstico dentro de las implicaciones
del Marketing Management, esto debido a que todos los productos pasan por unas etapas
que permiten calcular la ubicación de dicho producto en el ciclo haciendo uso de datos
históricos pues estos tienen a seguir una ruta predecible durante el ciclo de vida y por lo
tanto su pasado inmediatamente anterior tendrá una correlación más alta que el pasado
más alejado de la observación en un tiempo determinado dentro de su ciclo de vida.
El Anexo 10.6.4. Esquema Metodología ARIMA presenta una tabla que resume algunos
de los elementos a tener en cuenta en cada una de las preguntas que surgen en cada
etapa propuesta por el método Box-Jenkins. Este cuadro puede llegar a ser tomado como
una guía a la hora de entender el planteamiento del modelo ARIMA y será base de la
aplicación del modelo como se verá más adelante en esta sección.
4.4.1 Modelo General
Un modelo ARMA es un modelo del tipo estadístico que permite el modelaje de una serie
de tiempo y la predicción de su comportamiento. Este tipo de procedimiento es una
generalización de la combinación de dos modelos, uno autoregresivo (AR) y otro de
promedio móvil (MA), formando así el modelo ARMA, los cuales fueron estudiados a
profundidad por Wold (1954) y Bartlett (1946). El modelo tiene la siguiente forma.
donde y son polinomios de rezago en B de orden p y q respectivamente los
cuales forman el modelo ARMA(p,q), la serie representa un proceso estocástico
absoluto de ruido blanco que determina la fuerza con la que se mueve todo el sistema ya
que de lo contrario éste se quedaría quieto en todo momento; por último, la serie de
interés con media cero está representada por .
Según el teorema de representación de Wold (1954) , toda serie de tiempo estacionaria
débilmente puede ser descompuesta en dos partes, una determinística y otra estocástica,
no importa si ésta es lineal o no. En este caso el modelo ARMA representa este hecho,
puesto que está compuesto por una parte autoregresiva del tipo determinística y otra
parte promedio móvil del tipo estocástica.

48
La representación del modelo ARMA(p,q) puede darse de la siguiente forma, una vez
expandido el polinomio de rezagos para cada uno de los componentes
( ) (
)
donde al realizar la operación de rezago en B y despejar se tiene que
∑
∑
donde ∑ representa la parte autoregresiva hasta el orden p, ∑
la de promedios móvil hasta de orden q y .
Yaglom (1955) examinó que cierto tipo de no estacionariedad que representaba el
proceso de algunas series de tiempo, podía ser constituido mediante la toma sucesiva de
diferencias de la serie original hasta que ésta se represente como estacionaria. Esta toma
del operador de diferencias a la serie permitió la inclusión de procesos no
estacionarios a los modelos de Box y Jenkins, creando así los modelos ARIMA o
Autoregresivos integrados de promedios móviles, los cuales son una generalización de los
modelos ARMA.
Si el proceso original de obedece a uno del tipo no estacionario causado por una
tendencia en polinomio de orden d del tipo estocástica, denominada no estacionariedad
homogénea, es posible la construcción de un proceso estacionario a partir de la serie
original, donde por tanto el modelaje de un proceso ARIMA(p,d,q) estaría
determinado por la siguiente ecuación en diferencias
el término integrado trae consigo la siguiente definición: se dice que una serie es
integrada de orden d si es necesario diferenciarla d veces antes que ésta se represente
por un proceso estacionario hasta de orden dos, es decir débilmente estacionario.
Para determinar la estabilidad del modelo, es necesario que todas las raíces de su
ecuación auxiliar igualada a cero sean mayores que uno en magnitud. De lo contrario el
modelo no sería una representación estable puesto que no logra convergencia a nada.
Para aclarar esto, supóngase que se cuenta con un modelo ARMA(1,0) o lo que es lo
mismo AR(1), representado de la siguiente manera donde es una
constante y es ruido blanco.
Al tomar operador de rezago B a toda la ecuación se obtiene que
donde representa la ecuación auxiliar del modelo AR(1). Al igualar esta
ecuación auxiliar y despejar el operador de rezago B se encuentra que
, la
magnitud de esta última ecuación | | representa la raíz de dicha ecuación auxiliar, la
cual como se observa debe ser mayor que 1 en magnitud para que el modelo sea estable

49
o lo que es lo mismo | | , pues de lo contrario no sería posible obtener convergencia
y el modelo sería e plosi o. La rapidez de la “explosión” del modelo estaría determinada
por qué tan alejado de la unidad por su dominio positivo es .
Al tomar el valor esperado a toda la ecuación diferencial y bajo el
supuesto que la mejor predicción del valor esperado del error es cero debido al hecho
que se está minimizando la suma cuadrada de errores se tiene que
, debido al supuesto fundamental de los modelos ARMA sobre la
estacionariedad de la serie, se tiene que el valor esperado de la serie en el momento t es
el mismo para cada uno de los períodos de tiempo, por lo que . Este
supuesto permite obtener la siguiente igualdad
de igual manera como se realizó con el modelo ARMA(1,0) es posible encontrar la
estabilidad del modelo, la media y otras propiedades estadísticas para cualquier otra
combinación de parámetros {p,q}.
Es necesario mencionar que todo proceso MA(q) es estacionario puesto que es
representación de una suma de ruidos blancos, los cuales por definición son
independientes e idénticamente distribuidos y estacionarios.
Para una revisión profunda sobre la teoría, modelaje y representación de los modelos
ARMA(p,q) y ARIMA(p,d,q) véase: Chatfiled (1996), Guerrero (2003), Pankratz (1983),
Enders (1948), Fuller (1996), Hamilton (1994), Montenegro (2010) o Brockwell y Davis
(2002).
A continuación, se procederá a desarrollar a detalle cada una de las etapas del modelo
lineal propuesto ARIMA. Para la primera etapa se explicará la teoría a utilizar y se aplicará
ésta en el objeto de estudio planteado en este trabajo en cada uno de los pasos. Sin
embargo, paras las demás etapas se presentará la teoría primero y al final se mostrarán
los resultados de la estimación-diagnóstico-pronóstico. Todo esto para facilitar el
entendimiento del documento y vincular la teoría con la práctica para cada etapa.
Adicionalmente, donde sea necesario se acoplará la teoría con el desarrollo practico
utilizando el complemento ASTEX.
4.4.2 Etapa de Identificación
La etapa de identificación es la primera dentro del planteamiento del modelo ARIMA. Esta
etapa puede llegar a ser la más importante dentro del ciclo del método debido al hecho
que en esta etapa se está obteniendo e identificando por medio del análisis de la serie el
orden plausible que debería seguir cada parámetro. Se podría comparar con el momento
en que por medio de una radiografía un doctor evidencia la raíz del problema y se dispone
a atacarlo.

50
Debido a que por la teoría, el modelo únicamente puede desarrollarse con series
estacionarias, es necesario obtener una serie del tipo estacionaria de la original, esto para
que pueda ser representada como un ARMA (p, q) y poder encontrar el orden de los
polinomios autoregresivos, es decir p y de promedios móviles q, así como el orden de
integración de la serie para poder así cancelar la no estacionariedad homogénea de la
misma, esto se realiza por medio del operador de diferencias.
El desarrollo de esta etapa estará basado en la metodología propuesta por Guerrero
(2003) para la estabilización de la varianza, las técnicas de estabilización de nivel de
Anderson (1976) y las pruebas de raíz unitaria de Dickey y Fuller (1979) bajo los
lineamientos propuestos para su identificación en Enders (1948).
4.4.2.1 Estabilización de la Varianza
Debido a que la definición de estacionariedad nos dice que una serie es estacionaria
cuando sus momentos hasta de segundo orden no varían en función del tiempo, es decir
su media y su varianza no fluctúan con el paso del tiempo, es preciso buscar un método
que encuentre una transformación estabilizadora de la varianza en la serie original, esto
con la finalidad que no cambie en el tiempo y que sea posible su representación en el
modelo ARIMA.
La estabilización de la varianza bajo el método de transformación propuesto en Guerrero
(2003) y presentado en el Anexo 10.6.5 Estabilización Varianza requiere que no existan
observaciones negativas y la diferenciación para la estabilización del nivel puede llegar a
crear valores negativos, es necesario entonces por ello realizar primero la estabilización
de la varianza y luego a continuación la del nivel, el cual se verá en la siguiente sección.
La siguiente tabla muestra algunas potencias comúnmente utilizadas en la literatura y
sus transformaciones asociadas.
Valores de Transformación
-1.0
-0.5 √
0.0
0.5 √
1.0 (No sufre transformación)
Tabla 16 Valores típicos de y su transformación
Fuente: Tomado de Guerrero(2003,p.159)
Aplicación a la práctica
Con el objetivo de ahorrar tiempo y realizar de manera automática y cuando se desee los
resultados de la estabilización de la varianza propuesta por Guerrero (2003), se procedió
a hacer uso de ASTEX el cual tiene el propósito de realizar de manera automatizada
todos los pasos descritos anteriormente en la teoría de estabilización de la varianza según

51
Guerrero (2003)14. La forma detallada de uso del aplicativo ASTEX para la estabilización
de la varianza se puede consultar en el Anexo 10.7.2. Estabilización de la Varianza con
ASTEX. Con el objetivo de hacer más clara la explicación del aplicativo en la
estabilización de la varianza se presenta en dicho anexo la realización de un ejemplo de
este proceso paso a paso para la serie LR1000.
Teniendo claro este procedimiento se presenta a continuación la tabla que resume las
potencias que estabilizan las varianzas para cada uno de las variables de estudio,
siguiendo la misma metodología del ejemplo para R1000.15
Variable
R250 R500 R1000 R1500 R3000
Potencia 0.04434 -0.34133 0.22326 -0.26291 -0.13835
√
Notación usada
LR250
TR500
LR1000 LR1500 LR3000
Tabla 17 Resumen de potencias estabilizadoras de la varianza
Fuente: Cálculos del Autor.
4.4.2.2 Estabilización del Nivel
Una vez encontrada la transformación que logra estabilizar las variaciones de la
serie, se procede a estabilizar el nivel. Esto se logra por medio de la aplicación del
operador de diferencia el número de veces que sea necesario. Este operador , es la
herramienta para encontrar el orden de integración de la serie, es decir, el número de
veces que es necesario diferenciar la serie hasta que ésta se vuelva estacionaria. Como
se mencionó anteriormente, la letra I en el acrónimo ARIMA hace referencia a dicho orden
de integración y se escribe como .
En la práctica este orden de integración para la mayoría de variables económicas no
supera el segundo o tercer orden, ya que entre mayor sea éste cualquier choque exógeno
a la variable tendrá efectos más rápidos y permanentes lo que ocasionas que la serie
tienda a desviarse con mayor facilidad de su media, y esto es muy complejo de obtener
para una serie con comportamientos como la mayoría de series económicas. Es
recomendable no sobre diferenciar la serie, debido a que se pueden encontrar problemas
al intentar identificar un posible proceso generador de la serie observada (Véase Guerrero
(2003), p.159).
14 Este código se puede encontrar en el Anexo 10.8.2. Código VBA para la automatización de la
transformación estabilizadora de varianza. 15 Los resultados de las otras cuatro referencias se presentan en el Anexo 10.9.1. Resultados de
las transformaciones estabilizadoras de varianza.

52
Un operador de diferencias de primer orden o primera diferencia de la serie se define
como la resta entre la serie en el periodo t menos la serie un periodo de tiempo rezagada,
es decir en t-1, así
sin embargo, el orden de integración no se puede determinar arbitrariamente. En la
práctica existen varias herramientas posibles para identificar el orden de integración de la
serie, algunas más empíricas que otras. Anderson (1976, p. 116) propone un método
donde el grado de diferenciación requerido para que una serie sea estacionaria se puede
determinar mediante el cálculo de la desviación estándar muestral de las series
transformadas por la varianza y diferenciadas hasta el orden 3. Es decir
y las cuales se denotan como y , donde
∑ [ ∑
]
En este caso si d es el orden de integración de la serie requerido, se debe cumplir que
es decir, para un N suficientemente grande, se debe cumplir que el grado de
diferenciación necesario d está dado por la mínima desviación. Sin embargo, el mismo
Anderson explica que este método no siempre tiene porque funcionar y que debería verse
como una herramienta complementaria y jamás como un método definitivo.
Otro método más avanzado y comúnmente utilizado es el del problema de las raíces
unitarias del polinomio característico de la ecuación auxiliar. Según Guerrero, estas
pruebas se catalogan como un complemento formal a: (i) la gráfica de serie versus
tiempo, (ii) la ACF y PACF muestral16 y (iii) la varianza muestral de la serie con el objetivo
de identificar el orden de integración.
Dentro de las pruebas de raíz unitaria existen un abanico amplio de posibilidades, las más
comúnmente utilizadas son las pruebas paramétricas de Dickey Fuller Aumentada ADF y
las no paramétricas de Phillps Perron PP. Sin embargo, actualmente ha tomado bastante
popularidad la prueba Dickey Fuller con Mínimos Cuadrados Generalizados GLS-DF.
Todas estas pruebas trabajan bajo la misma hipótesis nula donde se dice que la serie
presenta raíz unitaria por lo que es una serie no estacionaria en media. El hecho que
presente raíz unitaria indica que las raíces de la ecuación auxiliar del polinomio
característico son menores o iguales que la unidad en magnitud, por lo que la serie sería
no estacionaria y los choques transitorios a la variable tendrían efectos permanentes. Por
lo que en la práctica todos los inversos de las raíces deben estar dentro del circulo
16 Una definición formal sobre la Función de Autocorrelación ACF y Función de Autocorrelación
Parcial PACF se presentará en la Sección 4.3.1.3. Identificación de los parámetros ARMA(p,q) más adelante en este capítulo.

53
unitario para que el modelo sea estable y converja a un estado estacionario (Steady
State) en el largo plazo. Es por ello que es requerimiento del modelo ARIMA que la serie
sea estacionaria y por ese motivo, ésta y la anterior sección han buscado estabilizar la
serie, de lo contrario el modelo no converge y se considera como un modelo explosivo.
En el Anexo 10.6.6. Prueba Dickey Fuller Aumentada ADF se da una breve explicación de
la prueba de raíz unitaria que se tendrá en cuenta para la estabilización del nivel de la
serie, en busca del orden de integración de cada una.
Aplicación a la práctica Anderson (1976, p.116)
El desarrollo de este ejercicio práctico se realizará complementando las pruebas de raíz
unitaria con la metodología propuesta por Anderson (1976). De manera similar a cómo se
desarrolló en la estabilización de la varianza, se tomará como ejemplo una de las series a
trabajar y se presentarán los resultados para las otras cuatro. Esto con el fin de no
extender innecesariamente este documento. Una vez más se tomará la serie para
ejemplificar la teoría presentada anteriormente y se hará uso del aplicativo creado en VBA
de Excel ASTEX. Este procedimiento se puede consultar en el Anexo 10.7.3.
Estabilización del Nivel con ASTEX.
De manera similar se realizó la misma operación para las otras cuatro variables donde se
registraron los resultados en el Anexo 10.9.2 Resultados Estabilización Varianza Método
Anderson. Como se puede observar en dicho anexo todas las desviaciones tienen su
mínimo en la primera diferencia para cada una de las series a excepción de la serie
LR1500 la cual tiene su mínimo en el evento cuando no es necesario tomar ninguna
diferencia a la serie. Sin embargo, es necesario notar que las series TR500, LR1000 y
LR3000 tienen valores muy cercanos entre las diferencia mínima y el siguiente valor más
alto, por lo que no es fuertemente evidente que sea necesario diferenciar la serie dicho
número de veces, cuestión que no sucede con las series LR250 y LR1500 donde el
siguiente valor mínimo está a más del doble del primero y por tanto la selección del orden
de integración es mucho más inclinada a ser .
Por ello es necesario argumentar mejor la respuesta con las prueba de raíz unitaria, para
evitar problemas de sobre o sub diferenciación, siendo ésta ultima la más grave debido a
que los resultados teóricos que se usan en las series de tiempo, únicamente son válidos
para series estacionarias, de lo contrario la interpretación sería errada y los pronósticos
traerían errores crecientes en el horizonte de tiempo además de subestimar la varianza
del pronóstico y perder capacidad adaptativa a efectos estacionarios en nivel. (Véase
Guerrero (2003), p. 160).
Considerando todo esto, se presenta en seguida la tabla que resume los resultados para
todas las variables acorde a la metodología propuesta por Anderson (1976).

54
Variable Orden de Integración
Tabla 18 Ordenes de integración basado en Anderson (1976)
Fuente: Realizado por el Autor.
Aplicación a la práctica pruebas de Raíz Unitaria
De la misma manera como se desarrolló en la estabilización de varianza y el nivel bajo el
método de Anderson (1976), se explicará en detalle los resultados de las salidas para la
variable LR1000, con el propósito de hacer más clara la asociación de la teoría
presentada anteriormente con el desarrollo práctico de este trabajo y se mostrarán aquí el
resumen de los resultados de las demás series temporales. Este procedimiento para la
variable LR1000 se presenta en el Anexo 10.6.7 Prueba de Raíz Unitaria para la Serie
LR1000
Resultados Prueba Raíz Unitaria
Serie ADF Observaciones Estadísticos17
para el modelo menos restringido presentó un estadístico t de -2.61 el cual para un total de 50
observaciones en es mayor que el valor critico a cualquier nivel de significancia por lo que se procedió a probar la significancia de la tendencia lineal. Esta dio que no era significativa puesto que es menor que un valor critico de 5.61 al 10%. Al estimar sin tendencia lineal habiendo realizado el método de propagación hacia atrás y logrando mantener se obtuvo que el
estadístico t que acompaña a era de -0.634 por lo
que para un al 10% no es posible
rechazar la hipótesis nula de raíz unitaria. Se probó que el componente determinístico del corrimiento no era significativo por medio de , por lo que se eliminó de la regresión y se probó el t estadístico de en el modelo (D5), una vez más realizando el método de propagación hacia atrás, arrojando un valor de 0.79 el cual es mayor que cualquier valor crítico y por tanto se concluye que no se puede rechazar que la serie tenga raíz unitaria. No tiene corrimiento ni tendencia determinística.
para el modelo menos restringido presentó un estadístico t de -4.99 el cual para un total de 50
observaciones en es menor que el valor critico a cualquier nivel de significancia por lo que la serie no
17 * simboliza significancia al 1%, ** al 5% y *** al 10% en las tablas Fuller (1976) y/o Dickey et al (1981). La
ausencia de estos simboliza no significancia.

55
presenta raíz unitaria. La serie además tiene tendencia determinística, la cual deberá ser eliminada por medio de algún método (detrend).
Solo constante significativa. Ver explicación arriba.
para el modelo menos restringido presentó un estadístico t de -1.53 el cual para un total de 50
observaciones en es mayor que el valor critico a cualquier nivel de significancia por lo que se procedió a probar la significancia de la tendencia lineal. Esta dio un el cual es menor que el nivel critico 5.61 al 10% por lo que reestimó el modelo ahora sin tendencia lineal, realizando la propagación hacia atrás cuyo resultado determinó el mismo . Este modelo arrojó un t estadístico
asociado a de , por lo que al
contrastarlo con el valor critico de -2.60 para una significancia del 10% no es posible rechazar la hipótesis nula de raíz unitaria. Se procedió a probar entonces el la significancia del corrimiento por medio de donde se obtuvo que el cual es menor que el valor critico de 3.94 a una significancia del 10%, es decir que el corrimiento debe ser sustraído del modelo. Se corrió entonces el modelo (D5) sin constante ni corrimiento realizado de nuevo la propagación hacia atrás, se observó que el valor t asociado a toma un valor de el cual es mucho más pequeño que cualquier valor crítico, por lo que no se puede rechazar la hipótesis nula de raíz unitaria. En tanto se tiene que el ultimo rezago sigue siendo el primer rezago significativo al 5% con un valor t de -2.57 y sigue existiendo ruido blanco en el término de perturbación .
para el modelo menos restringido presentó un estadístico t de -6.73 el cual para un total de 50
observaciones en es menor que el valor critico a cualquier nivel de significancia por lo que la serie no presenta raíz unitaria. La serie además tiene tendencia determinística, la cual deberá ser eliminada por medio de algún método puesto que el comportamiento es estacionario.
Tabla 19 Resumen Pruebas Raíz Unitaria
Fuente: Realizado por el Autor.
Por consiguiente para el análisis del modelaje ARIMA se trabajarán las series como la
transformación de la varianza para TR500 (detrend), LR1000 y LR3000 (detrend).
Mientras que se tomará la primera diferencia del logaritmo natural para las demás series.
Cabe resaltar por último que, conociendo el máximo número de rezagos acorde a lo visto
anteriormente, es posible realizar la prueba ADF en el complemento ASTEX de Excel.

56
Este procedimiento en ASTEX se presenta en el Anexo 10.7.4 Prueba de Raíz Unitaria
ADF con ASTEX
4.4.2.3 Identificación de los parámetros ARMA(p,q)
Una vez estabilizada la varianza y el nivel de las cinco series, es necesario proceder con
el ajuste del mejor modelo; para ello se debe observar, analizar e interpretar lo que la ACF
y la PACF nos quieren decir.
Previamente a entrar a discutir el orden de los modelos en la práctica para cada una de
las cinco series, resultará conveniente realizar un repaso rápido sobre lo que es una ACF
y PACF y cuál es su utilidad para esta etapa de identificación. Este repaso se puede
encontrar en el Anexo 10.6.8. Función de Autocorrelación ACF y Función de
Autocorrelación Parcial PACF
En general, la ACF y PACF pueden llegar a comportarse de muchas maneras debido a
los componentes estocásticos o de ruido que pueden entrar al sistema y dificultar la
concordancia entre las funcione teóricas y prácticas; sin embargo, autores como Chatfield
(1996), Enders (1948), Guerrero (2003) y muchos otros, han ejemplificado los
comportamientos típicos de las funciones para ciertos procesos autoregresivos, de media
y móvil y combinaciones de los dos. En general los procesos mixtos son bastante
complejos de determinar por medio de la ACF y PACF únicamente.
Por lo tanto, adicionalmente a este proceso se podrían realizar metodologías de búsqueda
de parámetros como el método SCAN (Smallest CANonical correlation method), ESACF
(Extended Sample Autocorrelation Function) o MINIC (MINimum Information Criterion) el
cual es un método que identifica de forma tentativa, con la búsqueda del mínimo criterio
de información, el orden de un proceso ARMA estacionario e invertible. Debido a que
estas herramientas serán utilizadas en esta fase de la etapa de identificación, es
conveniente abordar un poco de su teoría para entender cómo aplicarlo a la práctica. Por
ello el Anexo 10.6.9. Metodologías SCAN, ESACF y MINIC presenta la teoría detrás de
estos tres métodos.
Aplicación a la práctica
Con el propósito de hacer lo suficientemente claro el proceso de identificación por medio
de la ejemplificación de una serie, el documento base el Anexo 10.6.10. Identificación
Serie LR1000 presenta el ejemplo de la aplicación práctica, paso a paso y detallado de
cómo se identificó la serie de ejemplo con la cual se ha venido trabajando. En este anexo
se presenta además la creación de una función en MATLAB (ARIMAIN.m) con el
propósito de servir como ayuda adicional en el proceso de identificación de las series de
tiempo. Por consiguiente es importante que se revise este agregado.
Ahora bien, en el Anexo 10.9.3 Resultados Identificación Series Restantes es posible
consultar el análisis de los resultado del proceso de identificación de las series restantes

57
de una manera más compacta a la realizada para la serie de ejemplo LR1000. Este anexo
presenta las salidas de cada proceso y su respectiva interpretación.
Sustracción de la tendencia de las series LR3000 y TR500 (Detrending)
Como se señaló anteriormente, las pruebas de raíz unitaria para las series TR500 y
LR3000 mostraron que, además de ser series integradas de orden cero son series cuya
tendencia determinística debe ser sustraída por medio de algún proceso de eliminación de
tendencia (detrending) como filtros o regresiones, más no por medio de la diferenciación
puesto que la primera diferencia de un proceso que es estacionario en tendencia (TS)
conllevaría a que no sea invertible. En general, se sabe que estas dos series son
estacionarias pero poseen una tendencia determinística que debe ser sustraída por
alguno de estos métodos de detrending. A continuación se mostrará el proceso de
sustracción de tendencia para la serie TR500, se mostrarán los resultados del mismo
proceso para la serie LR3000 y se desarrollará el análisis de identificación de cada una de
las series.
El proceso de detrending para ambas series se llevó a cabo regresando la variable { }
contra una constante y un polinomio determinístico con tendencias de hasta grado n, es
decir18
Donde sigue un proceso estacionario. El orden aproximado del polinomio se obtuvo por
medio del método de propagación hacia atrás iterada, parecido a la forma como se obtuvo
el número de rezagos que debería ser incluido en la prueba ADF. Es decir, se debe
elegir un número lo suficientemente alto de n e ir probando la significancia estadística por
medio del estadístico t para el último grado n, significancia conjunta para los grupos de
rezagos por medio del estadístico F o bien por criterios de información como AIC o SIC.
Se prueba entonces la significancia del coeficiente por medio del estadístico t, si este
no permite rechazar la hipótesis nula de insignificancia, se reestima el modelo ahora hasta
n-1 donde se probará de nuevo la significancia de , así continua el proceso hasta
encontrar el grado del polinomio de tendencia determinística. En ese momento se
guardan los residuos quienes representan la serie original menos el valor ajustado
(tendencia), es decir la serie una vez sustraída la tendencia.
Para el caso de TR500 se tomó un valor de n igual a 7 donde se realizó el proceso de
propagación hacia atrás y del cual se obtuvieron los siguientes resultados
18 Siguiendo la notación de Enders (1948, p.166).

58
Prueba
(Ho)
Coeficiente
(t-stat) (AIC;SIC)
-5.51E-12
(-1.6649) (-10.251;-9.9461)
2.45E-13
(0.0058) (-10.2281;-9.9605)
-8.04E-10
(-1.5607) (-10.2682;-10.1808)
1.68E-08
(2.5721) (-10.254;-10.0631)
Tabla 20 Grado del polinomio de tendencia TR500
Fuente: Cálculos del Autor.
Se puede observar como es el cuarto grado del polinomio el que parece ser mayormente
apropiado para la tendencia de la serie TR500 puesto que su su coeficiente es
significativo determinado por el valor de estadístico t. Por lo que se estima la regresión
(D8) para un n igual a 4 y se guardan los residuos de dicha regresión. Estos
representan ahora la serie sin tendencia determinística y a la cual se le deberá ajustar un
modelo, la nueva serie fue renombrada como TR500dt. Estos resultados se pueden
evidenciar claramente en la siguiente gráfica.
Gráfica 1 Detrending TR500
Fuente: Realizado por el Autor.
Este mismo proceso de regresión iterativa hacia atrás con un n inicialmente grande de
grado siete se realizó para la serie LR3000, a la cual se llegó a obtener un polinomio de
grado 3 con significativo al 10% y con los menores criterios de
información. Se guardaron los residuos de dicha regresión y se procedió a usar estos
como la nueva serie de LR3000 sin tendencia determinística. A esta nueva serie se le dio
el nombre de LR3000dt.
-0,005
0
0,005
0,01
0,015
1 4 7 10 13 16 19 22 25 28 31 34 37 40 43 46 49
TR500
TR500_Aj
Residuos

59
Gráfica 2 Detrending LR3000
Fuente: Realizado por el Autor.
Observe como, tanto en la Gráfica 1 como en la Gráfica 2 una vez sustraído el
componente de tendencia determinística de las series se obtiene una serie rescaldada
con media cero y sin tendencia. Esto es importante, puesto que como lo expone Enders
(1948) hay una gran diferencia entre una serie con tendencia a una serie estacionaria. En
general, choques a series que son débilmente estacionarias producen efectos temporales
ya que se regresará al valor medio de largo plazo eventualmente. Sin embargo, choques
a series que contienen tendencia no implica convergencia de nuevo a una media de largo
plazo. Por ello fue necesario realizar el proceso de sustracción de la tendencia por medio
de la regresión (D10) y no diferenciándola debido a que la serie no presentó raíz unitaria y
por tanto el componente de tendencia estocástico no existe.
Al dirigirse a el Anexo 10.9.3. Resultados identificación series restantes observe que
sucede un hecho con estas dos series que las hace interesantes en su interpretación.
Ambas series, TR500 y LR3000, mostraron un comportamiento de la ACF que parece ser
no estacionario debido a la forma lenta de su caída (relativo al tamaño de la muestra),
siendo ésta más evidente en la primera que en la segunda. Sin embargo, las pruebas de
la presencia de raíz unitaria de Dickey y Fuller (1979) arrojaron que no lo son; es decir,
son series estacionarias. Las pruebas de ruido para ambas series mostraron un rechazo
enfático (al 1% de significancia) de dicha condición, por lo que es posible ajustar un
modelo lineal ARMA para ambas series.
Sin embargo, dado el procedimiento y la explicación anterior, fue necesario la sustracción
de la tendencia determinística, significativa en la prueba ADF para el modelo esto
indicaría que en la práctica se debe ajustar un modelo a las series TR500dt y LR3000dt y
no a las mencionadas anteriormente. La complejidad de este tema radica en que cuando
observamos los correlogramas de ambas series sin tendencia, estas series presentan la
característica típica de una serie de ruido la cual no puede ser pronosticada de su propio
pasado, al menos de manera lineal.
7
7,5
8
8,5
9
LR3000
LR3000_Aj
-1
0
1
Residuos

60
Para mitigar este inconveniente se procedió de la siguiente manera: (i) se identificaron
varios modelos tentativos ARMA para cada una de las series con tendencia; es decir,
TR500 y LR3000. (ii) Para la etapa de estimación y diagnóstico que se verá más adelante,
se les incluyó la tendencia determinística determinada por la regresión (D10) y se
encontró el mejor modelo que se ajuste a los datos con dichas condiciones. (iii) Este
mejor modelo, para cada una de las dos series, se pronosticó teniendo en cuenta dicha
tendencia, y (iv) se procedió a realizar el esquema rolling para evaluar su capacidad
predicativa en un horizonte de planeación. Esto se explicará con más detalle en la sección
dedicada a la etapa de pronóstico en este mismo capítulo.
Se realizó entonces el mismo procedimiento de identificación que se desarrolló para las
demás series de tiempo, este proceso se puede encontrar en el mismo Anexo 10.9.3
Resultados Identificación Series Restantes donde se identificaron las series R250 y
R1500.
A continuación se resume todos los modelos identificados para cada una de las series
acorde a los presentado en los Anexos 10.6.10 y 10.9.3.
Modelos Tentativo
R250 R500 R1000 R1500 R3000
M1 ARMA(1,0) ARMA(1,0) ARMA(1,0) ARMA(0,1) ARMA([1 4],1)
M2 ARMA(0,1) ARMA([1 3],0) ARMA(2,0) ARMA(0,[1 8]) ARMA(5,1)
M3 ARMA(6,0) ARMA(2,1) ARMA(2,1) ARMA(1,2) ARMA(6,1)
M4 ARMA(1,7) ARMA(1,2) ARMA(1,5) ARMA(7,1) ARMA(4,0)
M5 ARMA(1,2) ARMA(3,0) ARMA(6,1) ARMA(8,0) ARMA(5,0)
M6 ARMA(0,6) ARMA(3,1) ARMA(0,8) ARMA(3,3)
M7 ARMA(2,2) ARMA(1,4) ARMA(1,1) ARMA(4,4)
M8 ARMA(6,0) ARMA(1,5) ARMA(3,1) ARMA(1,3)
M9 ARMA(7,0) ARMA(6,3) ARMA(1,1)
M10 ARMA(1,2) ARMA(1,2)
M11 ARMA(1,1)
Tabla 21 Resumen Modelos Tentativos (1:50) Fuente: Realizado por el Autor.
Debido a que las tres etapas siguientes se realizaron por medio de la estimación de varios
modelos tentativos descritos en la etapa previa de identificación, además de la búsqueda
del modelo que cumpliera con los supuestos descritos en la etapa de diagnóstico, será
necesario entonces explicar primero la teoría detrás de las primeras dos etapas
(Estimación y Diagnóstico) y luego realizar la explicación y descripción de la etapa de
pronóstico para la evaluación fuera muestra bajo el esquema rolling.
4.4.3 Etapa de Estimación
Una vez identificados los modelos plausibles que se ajusten a las cinco series, o lo que es
lo mismo habiendo encontrado los órdenes p, q y el orden de integración de las series se
procede con la estimación de los parámetros y del modelo (D0), a recordar

61
el cual se espera sea una buena representación de cada una de las series de interés
.
La estimación del modelo ARIMA tentativo se puede realizar por varios métodos. Algunos
de estos son: Mínimos Cuadrados Incondicionales (ULS), Mínimos Cuadrados
Condicionales (CLS) o Máxima verosimilitud (ML). Este último será el método utilizado en
este trabajo y su explicación se puede encontrar en Anexo.10.6.11. Método de Máxima
Verosimilitud (ML).
4.4.4 Etapa de Diagnóstico
Debido al hecho que el modelo presentado aquí es simplemente una representación
aproximada y simplificada del verdadero mecanismo generador de datos que suscribe a la
serie en cuestión, es necesario la verificación de ciertos supuestos de la metodología para
que al final se filtre el modelo que presente la menor cantidad de fallas. Como lo dijeron
alguna vez George Box y Norman Draper en su libro Empirical Model-Building and
Response Surfaces “Esencialmente todos los modelos están mal, pero algunos son
útiles”19.
Los mecanismos esenciales de verificación de supuestos radican en el tratamiento
adecuado de los residuos que acompañan al modelo. El análisis de residuos es la forma
más simple de detectar la violación de supuestos. Esto en parte, debido al hecho que el
residuo, aquí denotado como , es la parte del sistema que no puede ser explicada por el
modelo, es el motor del sistema y mediante la cual el sistema pasa de ser estático a
dinámico.
El papel que desempeñan los residuos es vital para el adecuado pronóstico de una serie
de tiempo. Los residuos son el puente que comunica la realidad con el modelo puesto que
son la diferencia entre los valores observados y su estimado por el modelo, así
donde simboliza el valor ajustado del modelo y el cual a sufrido un proceso de análisis
de transformación de varianza y nivel como se vio anteriormente. El proceso generador
que rige a la serie de ruidos debe cumplir algunos supuestos para que el modelo sea el
adecuado. Por tanto, la verificación de estos supuestos es esencial para poder corregirse
o cambiar el modelo. Los cinco supuestos sobre el los residuos son:
Supuesto 1. tiene media cero.
Supuesto 2. tiene varianza constante.
Supuesto 3. es un proceso de ruido blanco.
19 Véase: Box, George E. P. y Norman R. Draper (1987). Empirical Model-Building and Response
Surfaces, p. 424, Wiley. ISBN 0-471-81033-9.

62
Supuesto 4. se distribuye normal, para todo t.
Supuesto 5. No existen observaciones aberrantes, atípicas o Outliers (observaciones ajenas a la serie de estudio).
Cada una de estos supuestos sobre los residuos tienen una verificación y posible
corrección. Más adelante se hará énfasis sobre este punto.
Existen otros tres supuestos fundamentales que se deben cumplir para que el modelo sea
el adecuado, y estos no tienen que ver con la verificación sobre sus residuos. A
continuación se enumeran:
Supuesto 6. El modelo debe ser parsimonioso.
Supuesto 7. El modelo debe ser admisible
Supuesto 8. El modelo debe ser estable en los parámetros.
Teniendo claro la estructura general para el diagnóstico del modelo estimado, se
pretenderá ahora profundizar en cada uno de estos supuestos, con el objetivo de
entender que nos quiere decir cada uno, como se puede verificar, que pruebas
estadísticas utilizar, y como corregirlo si es el caso (véase Guerrero (2003)). Una vez
más, debido a que el propósito del documento base es mostrar los resultados de cada
uno de los procesos aquí desarrollados, y no extenderse en teoría o procedimientos, el
Anexo 10.6.12. Teoría Sobre Diagnósticos del Modelamiento ARIMA presenta
detalladamente esta profundización sobre la teoría detrás de cada uno de los supuestos.
Aplicación práctica – Mejores modelos ARIMA encontrados
Teniendo en cuenta la etapa de identificación y diagnóstico, se procedió a buscar y
estimar aquellos modelos para cada una de las series se ajusten de manera adecuada.
Estos se obtuvieron estimando y reestimando varios modelos varias veces hasta que se
encontró el modelo que mejor desempeño tenia, teniendo en cuenta la teoría presentada
anteriormente en la etapa de la identificación bajo las técnicas ACF, PACF, SCAN,
ESACF, MINIC y la función programada en MATLAB ARI MAI N.
Cabe anotar aquí que los modelos presentados en esta sección corresponden a aquellos
modelos que, dentro de toda las observaciones, fueron meritorios de ser escogidos como
mejores modelos. Es decir, a diferencia de la evaluación fuera de muestra que se
presentará más adelante bajo el esquema rolling el cual se estima iteradamente para
diferentes tamaños de la muestra, en este paso si se está contemplando la muestra en su
totalidad.
Como se ha venido desarrollando a lo largo de este documento, se procederá a
ejemplificar detalladamente la serie LR1000 como se ha venido trabajando hasta ahora.
Esta ejemplificación se puede encontrar en el Anexo 10.6.13. Estimación-Diagnóstico
Serie LR1000.

63
Cabe anotar que se hizo uso del test estadístico de contraste de normalidad propuesto
por Shapiro y Wilk (1965) puesto que se considera un test con mayor potencia para
muestras pequeñas ( ). Este test usa el estadístico
∑
∑
donde son valores dados por los autores y para valores pares de o
para valores impares de . El cual será contrastado con valores críticos
proporcionados por tablas elaboradas por los autores para el tamaño muestral y el valor
de significancia dado. Además se dice que se rechaza la hipótesis nula de normalidad si
el estadístico es menor que el correspondiente valor crítico.
El Anexo 10.7.5 Diagnostico Normalidad y Media Cero con ASTEX muestra cómo fue
posible obtener los diagnósticos de normalidad con el test Shapiro Wilk y de media cero
acorde a la metodología propuesta en Guerrero (2003) por medio del complemento
ASTEX en Excel. Además se presenta cómo es posible obtener la gráfica Quantile-
Quantile o QQ plot para tener un veredicto adicional a la hora de decidir que la serie de
residuos se distribuye normalmente. Todo esto por medio de un ejemplo aplicado a la
serie LR1000.
En el Anexo 10.9.4 Resultados Estimación-Diagnóstico Series Restantes se presentan los
modelos escogidos para las series restantes. Su escogencia se basó en la misma lógica
de razonamiento presentado para la serie LR1000 anteriormente, la cual busca el ajuste
del mejor modelo lineal ARIMA para cada una de ellas en el trasfondo del supuesto
fundamental de parsimonia. Este anexo muestra las estimaciones de los diferentes
modelos preliminares y reestimaciones de cada una de las series con el objetivo de hacer
clara la idea de la escogencia del mejor modelo acorde a todas las características
presentadas hasta ahora y mostrar objetivamente el porqué de la escogencia de las series
que se utilizaron para el pronóstico.
A continuación se resume cada uno de los modelos escogidos para cada una de las
series de tiempo acorde a lo presentado en los anexos 10.6.13 y 10.9.4.
Serie Modelo
R250 ARIMA([1],1,[2 3 7])
R500
R1000 ARMA([1],[5])
R1500 ARI([1 2 3 4 8],1)
R3000 ARMA([1 4],[1]) + [
Tabla 22 Modelos Escogidos Fuente: Realizado por el Autor.

64
4.4.5 Etapa de Pronóstico
4.4.5.1 Evaluación dentro de la muestra
Una vez estimados y diagnosticados los modelos que mejor se ajustan a cada una de las
series, se procedió a realizar su evaluación dentro de muestra. Cabe anotar que, para
realizar la evaluación tanto dentro de muestra como por fuera de ella, cada una de las
variables tuvieron que ser transformada por medio de la función inversa a la función de
transformación de varianza que las acompaño a lo largo de las etapas, esto, para llegar a
obtener las unidades originales del pronóstico. Es decir que para todas las series excepto
para TR500, al valor pronosticado se le tomó la función exponencial para regresar a la
forma original, mientras que para la serie TR500 se tomó la función .
Además resulta necesario regresar a la serie original después de la diferenciación
realizada a las series DLR250 y DLR1500, por lo que se deben seguir los pasos
presentados a continuación para obtener la serie
1. Como la serie se encuentra en la primera diferencia del logaritmo natural, y se
sabe que la serie diferenciada corresponde a la serie en el momento t menos la
serie en el momento t-1, es decir , entonces se obtiene
el logaritmo natural de como .
2. Se procede tomando la función inversa del logaritmo, la cual corresponde al
función exponencial, para llegar a obtener la serie original . Es decir que
Ahora bien, se consideraron tres funciones de pérdida del error de pronóstico para validar
su precisión. Estas medidas fueron el error medio absoluto MAE, el error medio absoluto
en porcentaje MAPE y la raíz cuadrada del error cuadrático medio RMSE. La explicación
formal de cada una de estas funciones de pérdida se desarrolló en al inicio del presente
capítulo.
A continuación se presentan los resultados de la evaluación dentro de muestra para cada
una de las series de tiempo, en concordancia a los modelos encontrados a lo largo de
toda esta sección.
Resultados de la evaluación dentro de la muestra
Bajo el modelaje ARIMA(p,d,q)
Serie Modelo MAE MAPE RMSE
R250 ARIMA([1],1,[2 3 7]) 6328.35 40.130 10393.85
R500
8355.03 29.916 14375.12
R1000 ARMA([1],[5]) 3723.34 30.401 5222.07
R1500 ARI([1 2 3 4 8],1) 420.021 17.611 584.683
R3000 ARMA([1 4],[1]) + [ 420.88 15.549 600.321
Tabla 23 Evaluación dentro de muestra ARIMA

65
El Anexo 10.6.14 Valor Real Vs Ajuste del Modelo presenta visualmente el
comportamiento de ajuste de cada uno de los modelos frente a la serie real.
4.4.5.2 Evaluación fuera de la muestra
La evaluación fuera de muestra es un aspecto vital en el desarrollo de un buen modelo de
pronóstico ya que en la práctica, la mayoría de veces, los modelos que mejor se ajustan
dentro de muestra no necesariamente lo hacen fuera de ella. Es necesario acudir a la
búsqueda de un modelo que permita pronosticar de manera eficiente fuera de la muestra
para que sus resultados sean mucho más confiables para el plan de producción.
Es aquí donde entra a jugar un papel primordial la metodología rolling para la evaluación
de pronóstico de series de tiempo. Para ello, se desarrolló una función en MATLAB que
permite realizar el esquema rolling por medio de la incorporación de los diferentes
vectores autoregresivos y de media móvil en cada una de las etapas de estimación,
además de arrojar varias condiciones importantes vistas previamente en la teoría sobre el
diagnóstico del modelo.
Para la realización del esquema se hizo uso de la función de pérdida asimétrica tipo
LINLIN cuyos parámetros fueron calculados como la ponderación del costo de ruptura y el
costo de almacenamiento en la suma de los costos, considerando el dominio donde se
debe encontrar cada uno. Es decir
Donde está asociado a puesto que el costo de ruptura se da cuando hay un faltante
en la demanda que la producción no pudo satisfacer y por tanto el error tomaría valores
positivos, es decir en bajo la función LINLIN. Mientras que está asociado a
puesto que el costo de almacenamiento se da cuando hay un exceso en la producción y
es necesario el almacenamiento del producto terminado, es decir, cuando el error de
pronóstico se encuentra en su dominio negativo. Esto dio como resultados los siguientes
valores
Serie
R250 0.902 0.098 R500 0.905 0.096 R1000 0.898 0.102 R1500 0.915 0.085 R3000 0.910 0.090
Tabla 24 Coeficientes de LINLIN
Fuente: Realizado por el Autor.
Nótese que debido a la caracterización de los costos unitarios, el valor de la función de
pérdida dado por la ecuación (C4) tendrá una pendiente mucho más inclinada en la
derecha que en la izquierda puesto que un error positivo trae un costo mayor para la
organización que un error negativo cuyo peso no es tan significativo. En resumen, dejar

66
de vender un producto es más costoso para la empresa que almacenar el producto
faltante.
El Anexo 10.6.15. Esquema Rolling y Algoritmo en MATLAB presenta qué es y cómo se
realizó el esquema con el propósito de la evaluación fuera de muestra para la próxima
comparación con otros modelos de series de tiempo completamente automáticos.
Adicionalmente se presenta la descripción y explicación del algoritmo creado a través de
una función en MATLAB por medio de la ejemplificación de la serie LR1000.
Al correr al algoritmo se obtuvieron los siguientes resultados para el esquema Rolling de
la serie LR1000
Observe como la primera fila hace referencia a los resultados del pronóstico fuera de
muestra desde el período 40 (abril 2013) hasta el período 45 (septiembre 2013) bajo el
mejor modelo de ajuste hasta el conjunto de información disponible en el período 39
(marzo 2013). Una vez incluida la observación 40 (abril 2013) se reestima de nuevo el
modelo y se pronostica 6 periodos adelante, los cuales están registrados en la segunda
fila de la tabla, así continua el proceso hasta la inclusión de la observación 44 (agosto
2013) en la cual se pronosticó el modelo ARMA([1],[5]) 6 periodos adelante y se registró
en la fila 6 de la tabla.
Las mediadas de error de pronóstico se obtienen entonces desde la 4ª hasta la 9ª
columna20 las cuales representan cada uno de los horizontes del esquema. Note que
tanto las medidas simétricas de error de pronóstico, como la asimétrica LINLIN son
crecientes en los horizontes, lo que es completamente sensato si se piensa que entre más
lejano sea el horizonte de planeación mayor será la acumulación de errores en cada uno
de los horizontes. Es decir, es mucho más incierto pronosticar a períodos más lejanos que
a períodos más cercanos. Sin embargo, aunque estas medidas son crecientes no
20 No se deben obtener de cada fila puesto que no tendría sentido alguno para identificar como
está estimando el modelo en cada horizonte.
ROLLING R1000 Períodos ( )
Modelo 1 2 3 4 5 6
1 39 40 45 13989.17 11995.14 14020.30 17058.73 15052.77 13418.34 2 40 41 46 13253.81 14982.65 18229.38 15713.29 14791.21 13451.29 3 41 42 47 15473.16 18496.82 15851.93 14878.64 13830.81 13030.51 4 42 43 48 26045.60 19458.91 16848.84 15102.16 16625.72 14674.88 5 43 44 49 17128.56 15628.82 14318.61 15825.07 13530.75 13036.41 6 44 45 50 17166.10 15113.59 16363.00 13795.72 14147.87 13423.86 Medidas Simétricas
MAE: 7766.05 8243.10 8852.68 11898.35 11927.03 12288.46
RMSE: 5971.30 5971.51 7674.82 9878.40 9536.77 9505.12 MAPE: 24.07 23.74 30.62 35.38 34.05 33.67
Medidas Asimétricas
Granger(1969)-LINLIN: 5363.72 5363.91 6893.91 8873.27 8566.40 8537.97 Tabla 25 Esquema Rolling LR1000
Fuente: Cálculos del Autor.

67
parecen crecer desmesuradamente, lo cual da indicios que es posible realizar un
pronóstico hasta dicho horizonte de tiempo.
Ante la necesidad de validar algunos supuestos de los modelos para cada una de las 6
estimaciones en el esquema entra a jugar un papel importante la opción
opt i ons . Di agnos =' on' la cual presenta las propiedades del término de perturbación
para cada una de las estimaciones tanto gráficamente como con la ayuda de test
estadísticos al final de la salida. Estas se presentan en el Anexo 10.9.5. Resultados
Diagnóstico Rolling con Rolling2.m. Cabe anotar que las condiciones de parsimonia y
significancia de los parámetros fueron revisadas también para cada estimación.
A manera de ejemplo en el anexo se encuentra como seria la interpretación a la salida del
diagnóstico arrojado por el algoritmo para la primera estimación del método rolling de la
serie LR1000
Este mismo análisis se realizó para los demás modelos dentro de la estimación del
método rolling. Considerando además que se presentaron los mismos resultados de
decisión sobre el diagnóstico del término de perturbación para las restantes estimaciones.
Teniendo claro la estructura del esquema, se procede entonces a mostrar los resultados
de las demás series de tiempo, las cuales siguen exactamente la misma lógica que se
siguió en el modelo presentado anteriormente para la serie R1000. Si se presentaba el
caso de alguna violación relevante en alguno de los supuestos, se procedió entonces a su
reestimación o replanteamiento de la transformación para reestimar de nuevo el algoritmo
de manera que se satisfagan las condiciones dadas para realizar el rolling. Todas las
salidas del diagnóstico arrojadas por el algoritmo Rolling2 para las demás series de
tiempo se presentan en mismo el Anexo en 10.9.5 al final de este documento. A
continuación se muestran los resultados del esquema rolling para las cuatro series
restantes.
Tabla 26 Esquema Rolling R250
Fuente: Cálculos del Autor.
ROLLING R250 Períodos ( )
Modelo 1 2 3 4 5 6
1 34 35 40 31110.42 21255.79 28176 26035.18 28985.29 29155.87 2 35 36 41 31450.62 43658.36 42075.56 47198.02 48537.92 51753.32 3 36 37 42 39390.55 24391.22 48674.78 31494.59 61707.53 41624.04 4 37 38 43 39332.46 52526.08 52222.2 58536.51 60652.96 65244.59 5 38 39 44 67345.59 43036.55 63322.75 43853.84 71276.63 55723.11 6 39 40 45 43284.66 63727.54 44050.06 71661.06 55997.8 84992.83 Medidas Simétricas
MAE: 12895.98 14926.44 13991.52 18767.15 20895.21 18848.38
RMSE: 9632.16 12498.85 12184.88 14574.66 17764.95 13427.13 MAPE: 24.12 23.64 21.82 24.81 32.65 24.29
Medidas Asimétricas
Granger(1969)-LINLIN: 8686.53 11271.80 10988.65 13143.81 16020.90 12108.94

68
Tabla 27 Esquema Rolling R500
Fuente: Cálculos del Autor.
A continuación se procederá a realizar la metodología comparativa de pronósticos
automáticos para escoger así el mejor modelo que se ajuste a los datos de estudio,
ROLLING R500 Períodos ( )
Modelo 1 2 3 4 5 6
1 39 40 45 41889.18 43366.87 40239.40 41436.18 38891.69 39870.57 2 40 41 46 43798.38 47586.78 42565.14 45681.21 41538.12 44121.02 3 41 42 47 47217.06 40679.68 44996.54 39631.23 43193.90 38753.80 4 42 43 48 49245.89 39942.77 46317.38 46522.88 39078.94 44221.31 5 43 44 49 32148.29 41364.33 56403.60 28470.98 33659.25 40076.48 6 44 45 50 42209.15 57912.29 42197.98 34288.77 40849.26 34283.58 Medidas Simétricas
MAE: 32597.28 32296.44 32920.73 32054.31 16341.08 12869.92
RMSE: 25980.13 21177.60 23893.66 22903.78 15535.12 10255.67 MAPE: 34.07 26.37 47.40 37.48 42.55 32.83
Medidas Asimétricas
Granger(1969)-LINLIN: 23498.92 19155.05 21611.71 20716.38 14051.45 9276.21
ROLLING R1500 Períodos ( )
Modelo 1 2 3 4 5 6
1 39 40 45 2208.41 2183.13 2430.08 2430.15 2598.71 2615.79 2 40 41 46 2513.65 2652.67 2718.86 2793.09 2868.84 2946.67 3 41 42 47 2098.46 2121.63 2549.12 2252.06 2279.59 2314.86 4 42 43 48 2513.10 2542.57 2593.41 2626.93 2676.75 2713.70 5 43 44 49 2521.84 2572.95 2604.85 2654.63 2690.14 2739.28 6 44 45 50 2429.62 2406.99 2336.48 2317.62 2274.89 2268.43 Medidas Simétricas
MAE: 568.10 407.61 319.31 1134.08 979.77 979.77
RMSE: 400.50 281.80 224.00 662.80 599.61 599.61 MAPE: 15.17 13.98 11.20 17.99 16.80 16.80
Medidas Asimétricas
Granger(1969)-LINLIN: 366.27 257.71 204.85 606.14 548.35 548.35
Tabla 28 Esquema Rolling R1500
Fuente: Cálculos del Autor.
ROLLING R3000 Períodos ( )
Modelo 1 2 3 4 5 6
1 39 40 45 3540.17 2792.44 3293.22 3433.04 3652.50 2927.83 2 40 41 46 2808.25 3022.50 3198.15 4127.34 2729.31 2862.27 3 41 42 47 3047.08 3197.63 4121.83 2845.85 2878.24 2969.03 4 42 43 48 3275.31 4306.96 2888.44 2688.36 3074.33 3718.27 5 43 44 49 4148.55 2840.58 2658.45 3069.06 3501.19 2746.38 6 44 45 50 2622.23 2492.86 2651.17 2726.87 2474.45 2474.45 Medidas Simétricas
MAE: 760.47 194.14 290.13 1325.36 1094.25 1030.67
RMSE: 464.28 174.33 220.68 619.07 749.34 642.34 MAPE: 11.31 5.68 7.75 11.83 21.56 20.71
Medidas Asimétricas
Granger(1969)-LINLIN: 422.72 158.72 200.93 563.65 682.26 584.84
Tabla 29 Esquema Rolling R3000
Fuente: Cálculos del Autor.

69
realizar su análisis y pronóstico correspondiente y poder utilizarlos como insumo en la
planeación de la producción para el capítulo siguiente.
4.5 Metodología comparativas
El desarrollo de la metodología comparativa se realizó por medio de la obtención de
pronósticos automáticos que a través del software SPSS permiten simplemente con la
serie original (o transformada), obtener el modelo de ajuste entre varios métodos posibles,
intentando minimizar las funciones de pérdida de error de pronóstico. Para este caso
específico, la comparación de los resultados ARIMA con otras metodologías de pronóstico
se desarrolló a través de la serie original la cual se realizó simplemente solicitándole a
SPSS que buscara de forma automática el mejor modelo que se ajustara a dichos datos.
La metodología fue desarrollada tanto por dentro de muestra como por fuera de ella,
donde se utilizaron los mismos horizontes previamente establecidos bajo el modelo
ARIMA. Esto con el propósito de adoptar una estructura comparativa que permita analizar
la eficiencia del pronóstico ARIMA en las condiciones predichas, frente a metodologías
semiautomáticas que fácilmente pueden ser aplicadas sin conocimiento profundo en
series de tiempo. Cabe anotar que las medidas de error de pronóstico tanto simétricas
como asimétricas aquí estudiadas deben ser las mismas que las trabajadas en la
evaluación del modelo ARIMA, de lo contrario no tendría sentido alguno su comparación.
Estas medidas del error de pronóstico fueron obtenidas, una vez más, a través de la
opción “Diagnóstico de pronóstico” en el aplicati o ASTEX por lo que la metodología de
obtención teórica es la misma que la realizada para el modelo ARIMA.
Los resultados de los pronósticos dentro de muestra para cada una de las cinco series de
tiempo fueron los siguientes.
Resultados de la evaluación dentro de la muestra
Generación automática de pronóstico
Serie Modelo MAE MAPE RMSE
R250 Aditivo Winters 7552.39 106.57 9258.06
R500 Estacional Simple 9146.29 31.38 16845
R1000 Estacional Simple 3827.34 32.33 5972.41
R1500 Aditivo Winters 426.10 20.10 562.62
R3000 Aditivo Winters 509.64 20.78 667.10
Tabla 30 Resultados evaluación dentro de muestra - Método Comparativo
Fuente: Cálculos del Autor.
Como se observa, fueron dos los tipos de metodologías de series de tiempo que permiten
modelar las cinco variables. El método Aditivo de Winters y el método Estacional Simple.
Donde el ajuste y el comportamiento de los residuales de cada modelo en representación
gráfica se presentan en el Anexo 10.12.1. Ajuste modelos comparativos.
Note comparando con la Tabla 23. Evaluación dentro de muestra ARIMA, que por medio
del modelamiento ARIMA fue posible obtener los resultados esperados sobre la eficiencia

70
de estos para ajustarse mejor a una serie de tiempo. En total, entre todos los modelos y
todas las medidas de error, fue posible conseguir una eficiencia del 86.7% del modelo
ARIMA frente a los modelos comparativos. Es decir que el 86.7% de las veces (contadas
como 15 medidas de error (5 modelos x 3 medidas cada uno)) fue mejor el modelo
propuesto ARIMA frente al modelo comparativo. Con excepción de las series R250 y
R1500 cuyo porcentaje de efectividad del modelo ARIMA fue cercano al 70%, las demás
series obtuvieron una eficiencia del 100% frente al modelo comparativo. Lo que quiere
decir que todas las tres medidas de error fueron más pequeñas bajo la metodología de
análisis Box-Jenkins.
Teniendo en cuenta además que la teoría sobre pronósticos evidencia la necesidad de
pronosticar con el mejor modelo que se ajuste hasta el período de tiempo t (marzo 2013
en este caso) se deberá por tanto escoger el modelaje ARIMA para la realización del
pronóstico hasta h periodos adelante, puesto que éste tuvo un mejor desempeño
comparado con las metodologías automáticas.
De nuevo, debido a que la idea principal de este capítulo es el desarrollo de un pronóstico
adecuado y en muchas ocasiones un modelo que se ajusta bien a los datos dentro de
muestra no siempre lo hace fuera de ella, se procede a mostrar los resultados de la
evaluación fuera de muestra por medio del esquema rolling que permite comparar
horizonte a horizonte el comportamiento de la metodología automática de SPSS con el
modelo propuesto ARIMA.
Resultados evaluación por fuera de muestra (Rolling)
Comparación pronósticos automáticos y ARIMA
Serie: R250 Automático ARIMA
Horizonte Periodo RMSE MAE MAPE LINLIN RMSE MAE MAPE LINLIN
1 ABR2013-SEP2013 17225.9 14788.3 32.9 13336.5 12896.0 9632.2 24.1 8686.5 2 MAY2013-OCT2013 19002.5 15548.7 31.7 14022.2 14926.4 12498.9 23.6 11271.8 3 JUN2013-NOV2013 20081.5 14572.8 23.6 13142.2 13991.5 12184.9 21.8 10988.7 4 JUL2013-DIC2013 19893.8 14446.5 22.2 13028.3 18767.2 14574.7 24.8 13143.8 5 AGO2013-ENE2014 22065.7 20378.6 36.2 18377.9 20895.2 17765.0 32.7 16020.9 6 SEP2013-FEB2014 18043.7 13760.1 22.7 12409.2 18848.4 13427.1 24.3 12108.9
Tabla 31 Resultados evaluación fuera de muestra R250 - Método Comparativo
Fuente: Cálculos del Autor.
Resultados evaluación por fuera de muestra (Rolling)
Comparación pronósticos automáticos y ARIMA
Serie: R500 Automático ARIMA
Horizonte Periodo RMSE MAE MAPE LINLIN RMSE MAE MAPE LINLIN
1 ABR2013-SEP2013 26692.1 20820.2 29.2 18831.8 32597.3 25980.1 34.1 23498.9 2 MAY2013-OCT2013 24286.1 17689.5 24.4 16000.1 32296.4 21177.6 26.4 19155.1 3 JUN2013-NOV2013 29237.2 23088.2 62.7 20883.2 32920.7 23893.7 47.4 21611.7 4 JUL2013-DIC2013 35832.7 26929.7 83.8 24357.8 32054.3 22903.8 37.5 20716.4 5 AGO2013-ENE2014 26348.9 21081.8 68.1 19068.4 16341.1 15535.1 42.6 14051.5 6 SEP2013-FEB2014 30717.0 25105.5 81.5 22707.9 12869.9 10255.7 32.8 9276.2
Tabla 32 Resultados evaluación fuera de muestra R500 - Método Comparativo
Fuente: Cálculos del Autor.

71
Resultados evaluación por fuera de muestra (Rolling)
Comparación pronósticos automáticos y ARIMA
Serie: R1000 Automático ARIMA
Horizonte Periodo RMSE MAE MAPE LINLIN RMSE MAE MAPE LINLIN
1 ABR2013-SEP2013 9485.2 7012.6 28.9 6299.1 7766.0 5971.3 24.1 5363.7 2 MAY2013-OCT2013 8856.7 7462.9 31.9 6703.6 8243.1 5971.5 23.7 5363.9 3 JUN2013-NOV2013 9748.5 7844.4 30.7 7046.3 8852.7 7674.8 30.6 6893.9 4 JUL2013-DIC2013 12667.7 9709.8 33.4 8721.8 11898.3 9878.4 35.4 8873.3 5 AGO2013-ENE2014 11833.1 9316.4 33.4 8368.4 11927.0 9536.8 34.0 8566.4 6 SEP2013-FEB2014 13062.6 10815.2 41.8 9714.7 12288.5 9505.1 33.7 8538.0
Tabla 33 Resultados evaluación fuera de muestra R1000 - Método Comparativo
Fuente: Cálculos del Autor.
Resultados evaluación por fuera de muestra (Rolling)
Comparación pronósticos automáticos y ARIMA
Serie: R1500 Automático ARIMA
Horizonte Periodo RMSE MAE MAPE LINLIN RMSE MAE MAPE LINLIN
1 ABR2013-SEP2013 828.6 677.3 27.2 619.4 568.1 400.5 15.2 366.3 2 MAY2013-OCT2013 745.0 606.2 27.7 554.4 407.6 281.8 14.0 257.7 3 JUN2013-NOV2013 631.0 524.5 22.4 479.7 319.3 224.0 11.2 204.8 4 JUL2013-DIC2013 998.3 698.3 20.3 638.6 1134.1 662.8 18.0 606.1 5 AGO2013-ENE2014 956.1 641.8 18.3 587.0 979.8 599.6 16.8 548.4 6 SEP2013-FEB2014 985.7 699.1 20.9 639.4 979.8 599.6 16.8 548.4
Tabla 34 Resultados evaluación fuera de muestra R1500 - Método Comparativo
Fuente: Cálculos del Autor.
Resultados evaluación por fuera de muestra (Rolling)
Comparación pronósticos automáticos y ARIMA
Serie: R3000 Automático ARIMA
Horizonte Periodo RMSE MAE MAPE LINLIN RMSE MAE MAPE LINLIN
1 ABR2013-SEP2013 1011.5 878.4 24.7 799.7 760.5 464.3 11.3 422.7 2 MAY2013-OCT2013 868.7 753.3 26.0 685.9 194.1 174.3 5.7 158.7 3 JUN2013-NOV2013 888.1 802.6 27.6 730.7 290.1 220.7 7.7 200.9 4 JUL2013-DIC2013 981.0 861.5 24.8 784.4 1325.4 619.1 11.8 563.6 5 AGO2013-ENE2014 1229.3 1091.2 41.6 993.5 1094.2 749.3 21.6 682.3 6 SEP2013-FEB2014 1418.4 1325.6 52.7 1207.0 1030.7 642.3 20.7 584.8
Tabla 35 Resultados evaluación fuera de muestra R3000 - Método Comparativo
Fuente: Cálculos del Autor.
Los resultados entonces permiten concluir que por medio de las funciones de pérdida
simétricas y asimétricas, el análisis adecuado de la serie de tiempo por medio de un
modelo lineal ARIMA tiene una mejorar considerablemente la capacidad del pronóstico
respecto a los modelos automáticos cuyo análisis es prácticamente cero y por tanto
presenta resultados desconfiables. Este conclusión puede verse más claramente por
medio del porcentaje de efectividad total del modelaje ARIMA de cada una de las series
frente a la metodología automática, estos resultados se presentan a continuación

72
Resultados de la evaluación dentro de la muestra
% Efectividad Por Medida de Error
Serie % Efectividad Total MAE MAPE RMSE LINLIN
R250 79.2% 83.3% 83.3% 66.7% 83.3%
R500 54.2% 50.0% 50.0% 66.7% 50.0%
R1000 70.8% 83.3% 66.7% 66.7% 66.7%
R1500 91.7% 66.7% 100.0% 100.0% 100.0%
R3000 95.8% 83.3% 100.0% 100.0% 100.0%
Tabla 36 Efectividad ARIMA frente Automático
Fuente: Cálculos del Autor.
Es necesario evidenciar un aspecto relevante que se presentó en los resultados
anteriores. Debido al hecho que la serie R500 mostró claros indicios de ser una serie de
ruido blanco una vez se sustrajera la tendencia determinística y además se concluyó que
es necesario realizar el pronóstico de la tendencia para dicha serie, puesto que se hace
poco factible incorporar componentes autoregresivos o de media móvil que sean
significativos. Observe que la efectividad del método de detrending se encuentra muy
cercana al 50% frente al método comparativo. Esto se debe al hecho que el método
comparativo está realizando en sí mismo una metodología de sustracción de tendencia
para el pronóstico.
Esto llevaría a la conclusión de pensar que, cuando una serie es ruido blanco sobre una
tendencia determinística (no estocástica) ambos métodos (o cualquier método de filtrado
de componentes de tendencia y nivel) de sustracción de tendencia permiten llegar a
conseguir la misma efectividad en el pronóstico, esto a luz de las medias de error tanto
simétricos como asimétricos.
4.6 Pronóstico del Mejor Modelo
Una vez desarrollada la evaluación dentro y fuera de muestra lo único que resta es la
realización del pronóstico fuera del período de estimación del mejor modelo en cada uno
de los casos y para cada una de las series acorde al horizonte de planeación que se
utilizará en la planeación productiva de la firma.
Como se mencionó anteriormente debido a que la teoría del modelamiento ARIMA
determina que para realizar el pronóstico desde el período N+1 hasta el período N+h se
debe hacer uso del mejor modelo que ajuste a los datos basado en el conjunto de
información disponible hasta el periodo N. Es decir, los modelos que servirán para el
pronóstico definitivo serán los aquellos escogidos como mejores modelos en la etapa
previa de estimación y cuyo registro se encuentra en la Tabla 23. Evaluación dentro de
muestra ARIMA.
Acorde a todo lo estudiado en este capítulo se tiene que la matriz del nivel del pronóstico
está dada como

73
NIVEL Marzo Abril Mayo Junio Julio Agosto
R250 36837.618 61092.927 65992.114 82914.606 77794.333 92321.761
R500 30829.208 26971.608 23355.718 20049.490 17088.541 14482.041
R1000 13196.851 14428.579 17070.439 12797.259 12315.413 12749.441
R1500 3162.925 2808.459 3611.144 3097.795 2409.278 4030.850
R3000 2374.259 2814.331 1970.658 1881.219 1778.168 1752.499
Tabla 37 Pronósticos ARIMA todas las series
Fuente: Cálculos del Autor.
En el Anexo 10.9.6. Pronósticos de los Mejores Modelos se presenta gráficamente el
pronóstico desde el mes de marzo de 2014 hasta el mes de agosto de 2014 para cada
serie de tiempo, este pronóstico servirá de insumo para el capítulo siguiente en el
desarrollo de la programación lineal.
Es necesario entender además un aspecto relevante de todo este proceso y que no debe
ser perdido de vista. Debido a que cada una de las series que se pronosticaron
representan variables aleatorias cuyo valor ex ante es desconocido y por ello se intentó a
lo largo de todo este capítulo ajustar un modelo lineal que permitiera encontrar el
mecanismo generador de datos que subyace al proceso estocástico de cada variable, el
pronóstico de dicho modelo debe ser por tanto especificado dentro de un intervalo de
confianza que mitigar el riesgo ante la toma de decisiones organizacionales. Estos
intervalos se construyeron a partir de la dos limites a desviaciones estándar del error
del modelo, es decir [ √ ].
SUPERIOR Marzo Abril Mayo Junio Julio Agosto
R250 72881.14 122016.52 134068.78 179330.87 171464.32 212807.83
R500 759579.32 685684.51 608218.93 530853.10 456853.58 388652.04
R1000 23423.04 27166.20 32894.82 24806.18 23721.42 25039.25
R1500 4924.47 4510.99 5742.22 4858.61 3793.05 6714.99
R3000 3370.46 4320.18 3054.73 2870.16 2731.60 2701.28
Tabla 38 Pronóstico ARIMA Limite Superior
Fuente: Cálculos del Autor.
INFERIOR Marzo Abril Mayo Junio Julio Agosto
R250 794.09 169.34 0 0 0 0
R500 0 0 0 0 0 0
R1000 2970.66 1690.96 1246.06 788.34 909.41 459.63
R1500 1401.38 1105.93 1480.07 1336.98 1025.50 1346.71
R3000 1378.06 1308.49 886.59 892.28 824.74 803.72
Tabla 39 Pronóstico ARIMA Límite Inferior
Fuente: Cálculos del Autor.
Note que algunos valores debieron ser truncados a cero puesto que el presente estudio
se basa en el supuesto que la producción jamás puede tomar valores negativos.

74
4.7 Capacidad Requerida del Horizonte de Planeación
Dentro del desarrollo del plan de producción de la empresa es necesario el cálculo de la
capacidad requerida debido a que ésta es utilizada para determinar el tiempo que es
necesario en cada una de las estaciones de trabajo para la fabricación de las cantidades
pronosticadas anteriormente. Adicionalmente, se establecerá si la capacidad disponible
en un tiempo normal de trabajo para cada periodo de tiempo, como se vio en el capítulo 3,
es suficiente para lograr cubrir la capacidad requerida por la proyección de la demanda.
De ser insuficiente, es necesario el desarrollo de una estrategia que tenga como fin la
ampliación de la capacidad disponible en la planta.
En la sección 3.6 Estudio de tiempos fueron calcularon los tiempos estándar de
fabricación los cuales fueron denotados como donde el subíndice obedece a cada
una de las cinco etapas del proceso (Ver Tabla 3. Tiempos estándar de producción
unitarios). Para llegar a obtener esta capacidad requerida ( por la planta en cada una
de las etapas y para cada periodo de tiempo fue necesario multiplicar los tiempos
estándar de fabricación ( en cada etapa del proceso por la demanda pronosticada (
de cada uno de los periodos. Por lo que se tiene
Los resultados del cálculo de la capacidad requerida, en horas de producción necesarias
para satisfacer la demanda pronosticada se presentan en la siguiente tabla
2014
Estación Marzo Abril Mayo Junio Julio Agosto
Fabricación de envase 50.78 35.97 17.72 20.66 13.48 4.64 Fajillado 146.32 185.36 175.98 215.82 194.85 223.74
Mezclado 121.64 140.92 117.14 147.50 128.59 150.79 Envasado 77.27 95.32 86.10 105.77 94.60 109.67 Empacado 79.02 98.13 91.32 114.81 102.67 118.32
Tabla 40 Capacidad requerida marzo 2014 - agosto 2014 Fuente: Cálculos del Autor.
4.7.1 Capacidad Requerida Frente a Capacidad Disponible
Una vez calculada la capacidad requerida y la capacidad disponible como se realizó
previamente en la Sección 3.7. Capacidad Disponible se procede entonces a realizar el
cálculo del grado de utilización de la capacidad, esto es, el porcentaje en que la estación
de trabajo estará ocupada para satisfacer la demanda pronosticada dentro del horizonte
de planeación.
Debido a que la capacidad disponible de hombre está limitada por la capacidad máquina
se tienen entonces que el grado de utilización debe estar calculado con dicho parámetro.
La forma como se calcula dicho grado de utilización para cada una de las etapas en
cada periodo de tiempo para el recurso máquina está determinado por la siguiente
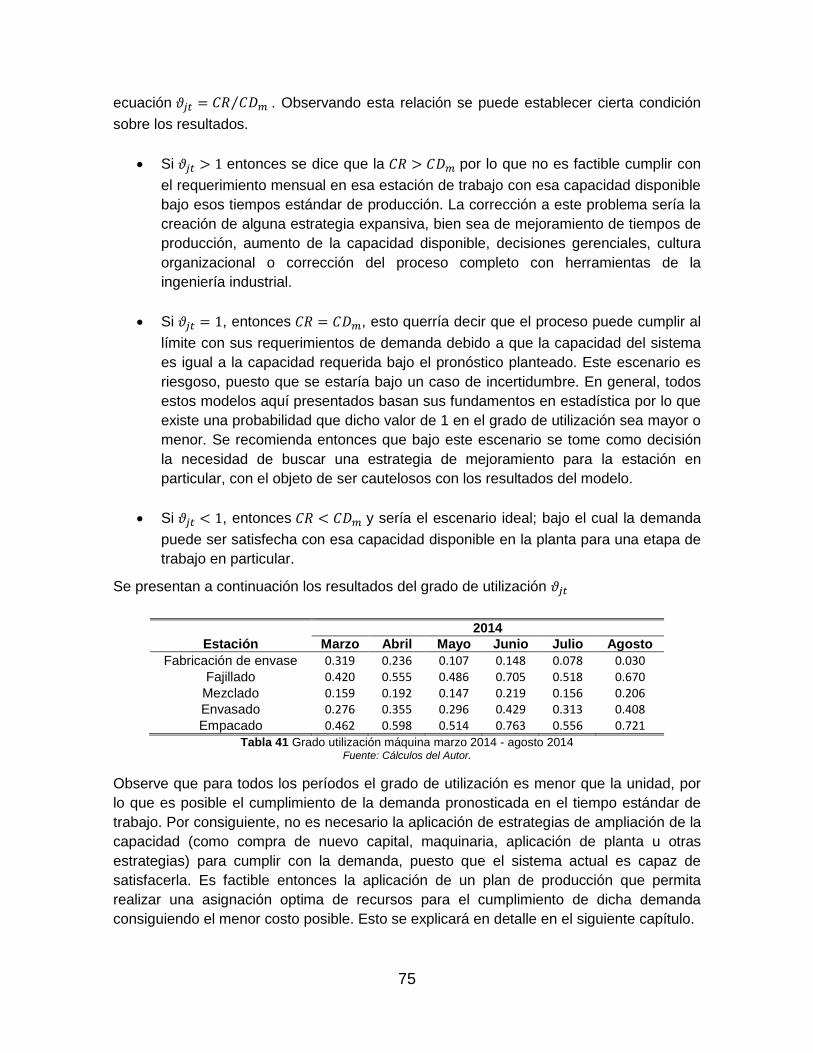
75
ecuación ⁄ . Observando esta relación se puede establecer cierta condición
sobre los resultados.
Si entonces se dice que la por lo que no es factible cumplir con
el requerimiento mensual en esa estación de trabajo con esa capacidad disponible
bajo esos tiempos estándar de producción. La corrección a este problema sería la
creación de alguna estrategia expansiva, bien sea de mejoramiento de tiempos de
producción, aumento de la capacidad disponible, decisiones gerenciales, cultura
organizacional o corrección del proceso completo con herramientas de la
ingeniería industrial.
Si , entonces , esto querría decir que el proceso puede cumplir al
límite con sus requerimientos de demanda debido a que la capacidad del sistema
es igual a la capacidad requerida bajo el pronóstico planteado. Este escenario es
riesgoso, puesto que se estaría bajo un caso de incertidumbre. En general, todos
estos modelos aquí presentados basan sus fundamentos en estadística por lo que
existe una probabilidad que dicho valor de 1 en el grado de utilización sea mayor o
menor. Se recomienda entonces que bajo este escenario se tome como decisión
la necesidad de buscar una estrategia de mejoramiento para la estación en
particular, con el objeto de ser cautelosos con los resultados del modelo.
Si , entonces y sería el escenario ideal; bajo el cual la demanda
puede ser satisfecha con esa capacidad disponible en la planta para una etapa de
trabajo en particular.
Se presentan a continuación los resultados del grado de utilización
2014
Estación Marzo Abril Mayo Junio Julio Agosto
Fabricación de envase 0.319 0.236 0.107 0.148 0.078 0.030
Fajillado 0.420 0.555 0.486 0.705 0.518 0.670
Mezclado 0.159 0.192 0.147 0.219 0.156 0.206
Envasado 0.276 0.355 0.296 0.429 0.313 0.408
Empacado 0.462 0.598 0.514 0.763 0.556 0.721
Tabla 41 Grado utilización máquina marzo 2014 - agosto 2014 Fuente: Cálculos del Autor.
Observe que para todos los períodos el grado de utilización es menor que la unidad, por
lo que es posible el cumplimiento de la demanda pronosticada en el tiempo estándar de
trabajo. Por consiguiente, no es necesario la aplicación de estrategias de ampliación de la
capacidad (como compra de nuevo capital, maquinaria, aplicación de planta u otras
estrategias) para cumplir con la demanda, puesto que el sistema actual es capaz de
satisfacerla. Es factible entonces la aplicación de un plan de producción que permita
realizar una asignación optima de recursos para el cumplimiento de dicha demanda
consiguiendo el menor costo posible. Esto se explicará en detalle en el siguiente capítulo.

76
5 PLANEACIÓN DE LA PRODUCCIÓN
Hoy en día existen varios software de diseño especial para la formulación eficiente de
modelos con un alto número de variables, parámetros, restricciones y funciones. Los
lenguajes de modelado más comúnmente utilizados debido a sus excelentes resultados
las últimas dos décadas son AMPL, MPL, GAMS y LINGO.
Para efectos de este ejercicio se hará uso del lenguaje GAMS (General Algebraic
Modeling System), el cual es un sistema de modelado de alto nivel para la programación
matemática y optimización. GAMS está adaptado para el modelaje de aplicaciones
complejas y de larga escala además de permitir la construcción de modelos que pueden
ser adaptados rápidamente a diferentes situaciones. Asimismo este lenguaje permite el
modelado de problemas de optimización lineal, entera, no lineal y mixto entre muchos
otros.
El presente capítulo tiene entonces el propósito de desarrollar un modelo cuantitativo para
la planeación de la producción con el uso de la programación lineal. Ciertamente este
capítulo recopila toda la información hasta aquí presentada, tanto del estudio de tiempos,
capacidades, recursos y costos como del mejor modelo de pronóstico el cual fue escogido
en el capítulo anterior. Se intentará abordar la evaluación de factibilidad del
abastecimiento de la demanda pronosticada bajo los lineamientos de la capacidad
disponible de la planta en un tiempo estándar de producción, así como el uso de
funciones de pérdida asimétricas en la función minimizadora que castiguen la sobre o sub
producción acorde a la demanda.
5.1 Construcción del Modelo de Programación Lineal
La construcción de la estructura que compone a la programación lineal se divide
generalmente en cinco partes: conjuntos, variables de decisión, parámetros, restricciones
y función objetivo.
Hillier y Lieberman (2010) presentan una forma estándar del modelo que agrupa estos
cinco componentes. Cualquier situación tentativa de ser modelada bajo los lineamientos
de dicha formulación matemática es vista como un problema de programación lineal. Esta
forma estándar consiste en la elección óptima de las variables de decisión
con el objetivo de maximizar o minimizar la siguiente función objetivo
sujeto a las siguientes las restricciones estructurales

77
donde para los conjuntos y representan las
constantes de entrada o parámetros. Se cuenta además con las siguientes restricciones
de no negatividad
las cuales en algunos casos pueden no ser incluidas si el modelo dice que cierta variable
no está restringida en su signo.
La construcción del modelo de programación lineal para la planeación agregada de
producción requiere tener las siguientes constantes de entrada:
i. Tiempo de producción por unidad por tipo de producto ii. Días hábiles por periodo del horizonte de planeación iii. Horas por turno en la jornada laboral iv. Número de turnos v. Número de etapas del proceso vi. Número de cada recurso (hombre y máquina) vii. Costos de fijos y variables viii. Demanda pronosticada para el horizonte de planeación
Todos estos parámetros de entrada fueron obtenidos y/o calculados a lo largo de este
trabajo y pueden ser consultados en los capítulos 3 y 4.
En general, si la función objetivo y las funciones que componen la restricción son
lineales, se tendrá entonces un problema de optimización lineal, con la siguiente forma
compacta del problema de programación
sujeto a
donde
.
: Vector de coeficientes de la función objetivo
: Matriz de restricciones de desigualdad
: Lado derecho de la desigualdad

78
: Matriz de restricciones de igualdad
: Lado derecho de la igualdad
: Limite inferior (Lower Bounds)
: Limite superior (Upper Bounds)
Se procederá entonces con el desarrollo de la estructura de programación lineal base,
ésta tiene como propósito la generalización del modelo que servirá como punto de partida
para la construcción del modelo que genere diferentes estrategias de producción, con una
característica mucho más realística y aplicada a la organización. El modelo base busca la
minimización del costo total de producción y la gestión de inventarios, cumpliendo con las
restricciones de capacidad de producción vistas en la sección 3.7 y la satisfacción de la
demanda proyectada en el capítulo 7.
5.1.1.1 Programación Lineal
Conjuntos:
: Periodo de tiempo
donde para : Horizonte de planeación
Tipo de producto
donde
Etapa del proceso productivo
donde
Para el caso particular se tiene que: meses, referencias, 3 etapas de
proceso.
Variables de decisión:
: Cantidad producida del producto tipo en el periodo : Cantidad en inventario (stock) del producto al final del periodo
Parámetros:
: Tiempo estándar de producción del producto tipo en la etapa de proceso
: Costo unitario de producción asociado al producto tipo
: Costo de ruptura nato del producto tipo
: Costo de almacenamiento del producto tipo
Precio del producto tipo : Capacidad de la etapa del proceso <Horas Hombre>
: Cantidad pronosticada del producto tipo en el período Capacidad máxima de almacenamiento en inventario de producto terminado.

79
donde representa la producción faltante o producción sobrante
.
Restricciones:
Restricción de demanda:
La interpretación práctica de esta ecuación determina que la cantidad de producto con la
que se cuenta al final del inventario en el periodo más la cantidad producida en el
periodo del mismo producto tipo menos lo que se demandó según el pronóstico del
producto tipo en el periodo debe ser igual a la cantidad que se tiene en inventario en el
periodo del producto tipo .
La segunda interpretación podría darse pensando que la cantidad de inventario con la que
se cuenta al final del periodo menos la cantidad de inventario con la que se cuenta al
final del periodo , esto es , debe ser igual a la diferencia entre lo que se
producirá y lo que se pronosticó en el periodo del producto tipo , es decir ; La cual se
podría llegar a escribir como
Es necesario mencionar que existen ciertos supuestos y lineamientos sobre esta
restricción:
i. A la luz de la programación lineal, el tratamiento que se le está dando al pronóstico
de la demanda es el de demanda real en sí, es decir que la variable aleatoria
de la serie de ventas está siendo tomada como la realización del mecanismo
generador de datos. Esto debido al hecho que la producción bajo la
programación lineal se está ajustando a dicha demanda como si esta fuera cierta y
busca una solución factible que logre satisfacer la demanda.
ii. Existe una asimetría de costos determinada por la estructura típica de un sistema
de inventarios. Por un lado, si entonces se estaría diciendo que la
diferencia en inventario entre el período de tiempo y debe ser positiva y por
tanto se asignaría un castigo (costo por la sobre-producción) por mantener ese
inventario de producto terminado en el almacén determinado por el costo de
almacenamiento ; mientras que si se obtendría que la diferencia
intertemporal entre los inventarios finales es negativa, lo cual se interpretaría como
la demanda faltante de producto terminado y se asignaría un castigo (costo por la
sub-producción) que está determinado por el costo de ruptura nato en el que
incurre la empresa por dejar de vender esa cantidad de producto.
Restricción de capacidad en inventario terminado:
∑

80
Para esta restricción se está diciendo que la suma del inventario de todos los productos
terminados en un tiempo no debe exceder nunca el inventario máximo de
almacenamiento determinado por el espacio físico de la bodega.
Restricción de capacidad de tiempo:
∑
Esta restricción dice que la suma de todos los tiempos estándares de producción de todos
los tipos de producto por la cantidad de producción de cada tipo nunca debe exceder la
capacidad del proceso para todos las etapas del mismo.
Restricciones de No-Negatividad
Tanto la cantidad en inventario como la cantidad producida jamás podrá ser negativa a lo
largo de toda la optimización.
Función Objetivo Minimizadora de Costos:
Para poder llegar a determinar la función objetivo que minimice todos los costos en los
que incurre la organización es necesario dividir esta función en dos grandes funciones. La
primera está determinada por los costos asociados al proceso productivo en sí, esta
función se denotará como , donde el parámetro puede incluir cualquier otra
variable de decisión que pueda determinar los costos para dicha función; como se verá
más adelante este parámetro puede llegar a incluir costos asimétricos de mano de obra,
determinados por costos de despedir o contratar personal o costos simétricos de
subcontratación o de trabajo en horas extra o como para este primer ejemplo en
particular, la minimización del nivel de inventario por período y por tipo de producto. Cabe
notar que esta función de costos debe ser diferenciable en todo su rango, convexa y
además debe cumplir que .
Por otro lado se cuenta con los costos asociados a la función de pérdida asimétrica de
error de producción la cual estará denotada usando la terminología de Cristoffersen &
Diebold (1997) como ( ) y que según Granger(1969) debe regirse bajo
unas restricciones y condiciones que puede o no incluirse en la realización, estas son:
( ) , lo que representa que cuando el error de pronóstico es cero, es
decir el pronóstico y el valor real son iguales, el costo asociado a dicho evento es
nulo.

81
para cualquier , lo que nos dice que siempre que exista un error
de pronóstico debe existir una función de costos asociada.
debe ser monotonicamente no decreciente en | |
Homogeneidad
Convexidad, continuidad y diferenciabilidad.
Como se mencionó anteriormente esta función de pérdida para el caso particular de las
ventas de un producto determinado presenta una estructura asimétrica debido a la
diferenciación en el momento de la asignación de los costos cuando el error es positivo
o negativo. Tenemos entonces que
{
Si la función de pérdida fuese simétrica alrededor del origen y la función de
distribución de los errores fuese simétrica alrededor de su media, entonces se tendría el
caso de una pérdida cuadrática con distribución normal en los errores. Mientras que bajo
el argumento que la función de costos asociada el error es asimétrica, se tendría una
situación más compleja, y dado que no se conoce la distribución de probabilidad de la
realización del proceso estocástico, se podría hallar una solución solo bajo casos
especiales y por tanto realizando supuesto específicos sobre la distribución. (Véase
McCullough (2000)).
Para el caso particular de la programación lineal base planteada anteriormente, la función
objetivo estaría determinada en su primer componente por una función que depende del
nivel de producción y el nivel de inventario en cuyo caso el parámetro que determina el
conjunto de información asociado a la producción sería igual a ; su interacción se
definiría entonces como el costo unitario de producción por el número de unidades a
producir sumado al costo unitario de almacenamiento multiplicado por el número de
unidades en inventario, esto, para cada uno de los tipo de productos en el tiempo.
∑∑
Para la construcción de la función de pérdida se debe notar antes que no tiene ninguna
restricción en su signo para ningún elemento del conjunto , por tanto es necesario hacer
una diferenciación en su signo para así poder asignarle el costo que corresponde. Este
problema debido a la asimetría de función de pérdida se abordará a partir de la
descomposición del dominio del error con el uso de estructuras dicotómicas que permitan
la diferenciación a la hora de la asignación del costo, esta metodología propuesta se
explica a continuación.

82
Metodología de descomposición del error21
Sea
igual al error en todo su domino negativo, lo que representaría una demanda
faltante debido a la sub-producción y igual el error en todo su dominio positivo, lo
que representaría un sobrante en la demanda debido a la sobre-producción. Se tiene que
donde por razones lógicas las dos variables y
no pueden ser diferentes de cero al
mismo tiempo, por lo que cuando una es diferente de cero la otra inmediatamente toma el
valor de cero y viceversa. Si por ejemplo decimos que tendríamos entonces que
, lo que representaría un faltante en la producción con un costo asignado
igual el costo de ruptura nato por dejar de vender dichos productos; mientras que si
entonces , lo que representaría un exceso de producción con un
costo asignado igual al costo de almacenamiento de ese producto sobrante.
Por consiguiente, el costo de pérdida de error estaría determinado de la siguiente
manera
( ) ∑∑
∑∑
Consolidando ambas funciones de costos y acorde a la forma estándar
presentada al comienzo de esta sección tendríamos el siguiente problema de
minimización
∑∑(
) ∑∑
∑∑
sujeto a
∑
∑
21 Adaptada para fines de este trabajo de Taha (2012)

83
5.2 Incorporación de atributos al conjunto de información
En la sección inmediatamente anterior se planteó un modelo tentativo base que se puede
acoplar al sistema de planeación de producción de muchas compañías cuyo fin sea
productivo. Sin embargo, es necesario la incorporación de ciertas otras variables
asociadas a las características de la organización estudiada que permitan mejorar y hacer
más robusto el modelo en términos de un acople más aproximado a la realidad.
La función de costos debe verse como una forma funcional que depende de
variables cuyas características afecten el nivel de producción y permitan la formación de
una estructura de producción variante en sus recursos disponibles. Estos recursos deben
ser fácilmente medibles, cuantificables y deben afectar directamente la productividad y la
producción.
La organización de estudio cuenta con un recurso humano y de capital que a través de su
capacidad, previamente hallada en capítulos anteriores, permiten evidenciar la dinámica
productiva de la organización. Esta capacidad cuya variabilidad depende del tiempo,
dimensiona la posibilidad de ajustar estos recursos disponibles de tal manera que hagan
mínima la función de costos. El conjunto de información se presenta como una relación
de interacción entre diferentes variables como: el número de trabajadores, la dinámica de
la fuerza laborar en los periodos de estudio y la posibilidad de usar las horas extra
ordinarias para incrementar la capacidad productiva y así cumplir con la demanda
especificada, además del nivel de inventarios y de producción presentados en la
programación lineal base previamente. Esta forma funcional estaría dada entonces como
( )
Donde mide el nivel de producción como el número de unidades producidas de la
referencia en el periodo de tiempo . Esta variable estará dividida como la producción en
el tiempo normal denotado como y producción en tiempo extra denotado como ;
denota la fuerza de trabajo como el número de trabajadores en la estación en el
tiempo ; determina el número de horas extra necesarias en la estación en el
período y por último y miden las dinámicas de los cambios en la fuerza de trabajo
a través del tiempo como el número de operarios a contratar y a despedir en la estación
en el período respectivamente.
Se tendrá entonces que la combinación del modelo base con esta complementación del
conjunto de información disponible se describe como la minimización de
la cual toma la siguiente forma

84
{∑∑
∑∑[ ]
}
{∑∑
∑∑
}
sujeto a
∑
∑
∑
∑[
]
∑[
]
∑[
]
∑

85
donde la ecuación (E0) describe el costo total a minimizar como la suma de las funciones
y estudiadas anteriormente la cual esta descrita como la suma de todas
las variables de decisión ponderadas por cada uno de sus costos respectivos. Las
ecuaciones (E1) a (E5) hacen referencia a las mismas ecuaciones descritas en la
programación lineal base, con la salvedad que se encuentran discriminadas por el tiempo
en hora extra y que se está considerando el volumen ( ) de cada uno de los tipos de
referencias para el cálculo de la utilización de la capacidad máxima de almacenamiento,
esto con el propósito de hacer más precisa la restricción planteada.
Las ecuaciones (E6) y (E7) describen el número de trabajadores necesarios en cada
una de las estaciones para cada periodo de tiempo como la multiplicación de cada tiempo
estándar de producción por el número de unidades a producir ponderado por el número
de número de hombres por hora hombre en un cada turno para cada periodo, esto para
todas las referencias estudiadas. Este ponderador se calcula de la siguiente forma
para tiempo normal
donde denota el número de horas por turno en tiempo normal y el número de
días hábiles en un mes dado. La forma de calcular es exactamente la misma,
solo que reemplazando por el número de horas por turno en tiempo extra .
Nótese que tanto en tiempo normal como en tiempo extra tienen como unidades el
número de hombres por hora hombre (i.e. ) por lo que la variable tomará las
unidades de hombres. Contrario a lo que dice la lógica sobre la discretitud de la variable
, esta variable tendrá una estimación en forma continua, debido a que la ponderación
del lado izquierdo de (E6) y (E7) arrojan valores continuos. Este problema de discretitud
no sugiere ser un problema grave, debido a la información intrínseca que esta variable
nos está queriendo decir; los decimales deben ser tomados como el trabajo necesario de
un hombre para cumplir con la producción lo que el modelo arroje como resultado.
La decisión sobre la variable puede verse a través de un umbral en 0.5, donde por
debajo de este umbral se dice que es necesario la contratación de un trabajador en medio
tiempo para ese periodo con el objetivo de cumplir con la demanda, de llegar a encontrar
que el valor decimal está por encima de ese umbral se dice que es necesaria la
contratación de un hombre adicional a lo que el valor entero de la variable me esté
diciendo. Por ejemplo, si el valor de , se decide por contratar 5 trabajadores en
tiempo completo y 1 en medio tiempo y si por el contrario se decide a contratar
8 trabajadores en tiempo completo.
La ecuación (E8) describe el número de horas extra necesarias para cumplir con la
demanda solicitada. Este valor, aunque es relativamente igual a solo que sin el
ponderador , es necesario de calcular debido a que en la práctica, el costo que se
asocia a la fuerza laboral en hora extra está considerado como el valor que se le paga a

86
cada trabajador por cada hora extra y no como un salario completo adicional. Además que
este costo es adicional al salario que se le paga a cada trabajador en tiempo normal
(considerado en ) y se supone que no es necesario la contratación adicional de
personal productivo para esta franja extra.
La ecuación (E9) describe la dinámica de la fuerza de trabajo de un periodo a un
período donde el número de trabajadores en se describe como la relación lineal entre
el número de trabajadores en tiempo normal en el periodo sumado al número de
personas contratadas en menos el número de trabajadores despedidos en ese mismo
período.
La ecuación (E10) más que una forma restrictiva del modelo es un indicador de
proporción entre lo que se produce y lo que se demanda en un periodo dado. Esta
proporción debe ser entendida como
{
La ecuación (E11) es simplemente el cálculo del número total de trabajadores necesarios
en el periodo de tiempo como la suma de todos los trabajadores en cada estación de
trabajo.
Las ecuaciones (E12) y (E13) corresponden exactamente la misma ecuación (B1) descrita
en la sección 3.7.1. Cálculo capacidad disponible recurso Hombre con la diferencia que se
está discriminando por tiempo normal y tiempo extra teniendo en cuenta , y el
número de descansos para cada uno de los tipos de tiempos. Debido a que la forma como
se calculan (E12) y (E13) presenta problemas de acotamiento puesto que se pueden
exceder las capacidades reales de la planta y subestimar su disponibilidad de recursos,
es necesario acotar la capacidad disponible del recurso hombre con la
capacidad fija del recurso máquina la cual fue calculada en la sección 3.7.2. Cálculo
capacidad disponible recurso Máquina en la ecuación (B2). Claro está que se supone de
antemano que la organización no tiene pensado aumentar la capacidad de este recurso
en el horizonte de tiempo, supuesto que fue comprobado en la organización por medio del
ingeniero de producción. Este acotamiento se describe en las ecuaciones (E14) y (E15).
La restricción (E16) determina que el nivel de inventario jamás puede bajar del
inventario de seguridad para cada tipo de producto Es necesario hacer énfasis en
esta ecuación debido a la importancia que tiene el inventario de seguridad en empresas
cuya demanda es tan volátil como la empresa de estudio. A continuación se presentará la
forma como se calculó dicho inventario de seguridad

87
Forma de obtención del inventario de seguridad para cada referencia.
Siguiendo la teoría de inventarios propuesta por George Plossl (1996) el inventario de
seguridad se calcula como una función de la desviación estándar del pronóstico
multiplicado por un nivel de confianza que depende del nivel promedio de ventas y se
determina a partir del valor del estadístico en una distribución normal estándar. Se tiene
entonces que
A continuación se presentará la forma del cálculo para una serie y se deja a
comprobación del lector el cálculo de las demás, esto con el propósito de no hacer
extenso el documento innecesariamente.
Se sabe por el Capítulo 4 que el pronóstico de la serie R1000, para cada uno de los 6
períodos en el horizonte de planeación es igual a
[13196.851 14428.579 17070.439 12797.259 12315.413 12749.441]
se tendría entonces que la y , acorde a Plossl (1996)
se recomienda el uso de un valor de igual a 95% es decir = 1.65. Por lo que el
inventario de seguridad para R1000 seria de unidades de
lavaloza.
A continuación se presentan los resultados del inventario de seguridad por periodo para
las demás variables
Referencia Inv. Seguridad
R250 32328.17 R500 10140.61
R1000 2929.21 R1500 947.47 R3000 689.95
Tabla 42 Inventario de seguridad
Fuente: Cálculos del Autor.
Cada uno de estas unidades de inventario de seguridad para cada referencia tiene
asociado consigo un costo de almacenamiento. Esta multiplicación entre y el inventario
de seguridad es llamado en la literatura costo de reserva de inventario. A continuación se
presenta dicho costo para cada una de las cinco referencias.
Referencia Costo de reserva de inventario de Seg.
R250 $ 51,078.51 R500 $ 33,565.43
R1000 $ 17,751.01 R1500 $ 7,513.43 R3000 $ 11,225.63
TOTAL $ 121,134
Tabla 43 Costo de reserva de inventario de seguridad
Fuente: Cálculos del Autor.

88
5.3 Integración GAMS en ASTEX
Con el propósito de dejar una herramienta sólida, fácil de usar y que permita a la
organización actualizar su plan de producción mes a mes sin necesidad de ver una sola
línea de código, lo cual muchas veces puede ser tedioso, se incorporó la opción del
modelamiento matemático de la programación lineal por medio de GAMS a través de
códigos de programación en VBA en ASTEX de forma mucho más intuitiva. Para ello se
modificó el código presentado por el ejemplo sudoku.xls en la página oficial de GAMS22
donde se da paso a la ejecución del código de GAMS desde el programa Microsoft Excel.
La explicación a detalle de esta integración GAMS-EXCEL se presenta en el Anexo 10.7.6
Integración GAMS-ASTEX para la planeación de la producción donde se explicará la
funcionalidad de cada una de las partes de dicho complemento y como puede ser
utilizado para el planeamiento adecuado de la producción.
5.4 Resultados del Modelo
Se procedió entonces a correr el modelo propuesto por la ecuaciones (E0) a (E17) desde
el aplicativo ASTEX-GAMS donde se obtuvieron los siguientes resultados para el tipo de
pronóstico en el nivel, es decir el valor puntual pronosticado y registrado en la Tabla 37.
Pronóstico ARIMA todas las series.
Ilustración 3 Ventana condiciones del modelo GAMS ASTEX
Fuente: Desarrollado por el Autor.
COSTO TOTAL DE LA PROPUESTA: $ 311’936,701.53
NÚMERO DE UNIDADES A PRODUCIR EN TIEMPO NORMAL
Marzo Abril Mayo Junio Julio Agosto
R250 65365.79 61092.93 65992.11 75449.79 77794.33 83101.99
R500 31157.82 23175.63 23355.72 0.00 17088.54 0.00
R1000 7526.06 14428.58 17070.44 12797.26 12315.41 12749.44
R1500 3260.39 2344.08 2512.30 3097.80 2409.28 4030.85
R3000 779.43 0.00 0.00 595.19 942.67 661.35 Tabla 44 Resultados LP Unidades a producir en Tiempo Normal
Fuente: Cálculos del Autor.
22
Véase: http://interfaces.gams-software.com/doku.php?id=env:spawning_gams_from_excel

89
NÚMERO DE UNIDADES A PRODUCIR EN TIEMPO EXTRA
Marzo Abril Mayo Junio Julio Agosto
R250 0.00 0.00 0.00 7464.82 0.00 9219.77
R500 0.00 3795.98 0.00 20049.49 0.00 14482.04
R1000 0.00 0.00 0.00 0.00 0.00 0.00
R1500 0.00 464.38 1098.84 0.00 0.00 0.00
R3000 1550.79 2814.33 1970.66 1286.03 835.50 1091.15 Tabla 45 Resultados LP Unidades a producir en Tiempo Extra
Fuente: Cálculos del Autor.
INVENTARIO FINAL DE PRODUCTO TERMINADO
Marzo Abril Mayo Junio Julio Agosto
R250 32328.17 32328.17 32328.17 32328.17 32328.17 32328.17
R500 10140.61 10140.61 10140.61 10140.61 10140.61 10140.61
R1000 2929.21 2929.21 2929.21 2929.21 2929.21 2929.21
R1500 947.47 947.47 947.47 947.47 947.47 947.47
R3000 689.96 689.96 689.96 689.96 689.96 689.96
Tabla 46 Resultados LP Inventario Final Producto Terminado Fuente: Cálculos del Autor.
NÚMERO DE HORAS EXTRA NECESARIAS
Marzo Abril Mayo Junio Julio Agosto
FebEnvase 0.00 0.00 0.00 0.00 0.00 0.00
Mezclado 26.19 62.12 42.55 88.61 14.11 72.12
Resto 22.68 70.43 39.95 183.90 12.22 153.34
Tabla 47 Resultados LP Número de Horas Extra Necesarias Fuente: Cálculos del Autor.
NÚMERO TRABAJADORES NECESARIOS
Marzo Abril Mayo Junio Julio Agosto
N° Total 6.10 6.06 6.08 5.81 5.81 5.81
Tabla 48 Resultados LP Número de Trabajadores Necesarios Fuente: Cálculos del Autor.
NÚMERO DE PERSONAS CONTRATADAS
Marzo Abril Mayo Junio Julio Agosto
FebEnvase 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
Mezclado 0.0000 0.0000 0.0120 0.0000 0.0000 0.0000
Resto 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
Tabla 49 Resultados LP Número de Contrataciones por Estación Fuente: Cálculos del Autor.
NÚMERO DE PERSONAS DESPEDIDAS
Marzo Abril Mayo Junio Julio Agosto
FebEnvase 0.00 0.00 0.00 0.00 0.00 0.00
Mezclado 0.78 0.00 0.00 0.10 0.00 0.00
Resto 4.12 0.04 0.00 0.16 0.00 0.00
Tabla 50 Resultados LP Número de despidos por Estación Fuente: Cálculos del Autor.

90
Lo primero y más relevante de todo a lo que es necesario prestarle atención es que en la
ventana de condiciones salientes del modelo GAMS (Ilustración 3. Ventana condiciones
del modelo GAMS ASTEX) aparezca que el estado del modelo es óptimo. Esta condición
nos está indicando que fue posible encontrar una solución factible al modelo de
programación lineal y por tanto los resultados arrojados son interpretables. En caso que el
modelo arroje una condición de no factibilidad (infeasible) será necesario revisar el
cumplimiento de las restricciones del modelo. Esta condición se da puesto que alguna de
ellas no se cumple y por tanto el lado derecho (RHS - Right Hand Side) de la ecuación no
satisface la condición del lado izquierdo (LHS – Left Hand Side) por lo que será necesario
el replanteamiento de la decisión a tomar.
En este caso el modelo satisface todas las restricciones y encontró un mínimo costo total
de la propuesta cercano a los 312 millones de pesos para todos los seis meses (Marzo-
Agosto) del horizonte de planeación. Además, observe que el modelo logró una
asignación de recurso optima que permite minimizar el costo total hasta dicho valor.
Note que el modelo permite evidenciar la necesidad de un replanteamiento de las
actividades que la organización actualmente venía realizando. A continuación se
describen ciertos puntos a tener en cuenta después de la corrida del modelo sobre este
tema:
1. Debido a que la organización viene utilizando todas sus horas extra de producción
durante todos los días, esto genera ineficiencias a la hora de la asignación óptima
de recursos. Gracias al plan de producción propuesto es posible evidenciar que
dicho recurso no debe ser utilizado todo el tiempo sino en ciertos periodos
dependiendo de la demanda. Esto reducirá costos de producción debido a que no
se está pagando horas extra todo el tiempo como se venía realizando; sobre este
tema de costos se hablará en el capítulo siguiente. La asignación del número de
horas extra se presenta en la Tabla 45.
2. El número óptimo de horas extra necesarias por cada una de las estaciones de
trabajo se presenta en la Tabla 47. Observe que la estación Fabricación de
Envase no demanda este recurso debido básicamente a que esta estación
únicamente fabrica envases para las referencias R500 y R1000 por lo tanto la
capacidad disponible sobrepasa la capacidad requerida en un nivel mucho mayor
que las demás y no hace falta el trabajo en horas extra. Las demás etapas
necesitan hacer uso de este recurso para poder fabricar el valor igual a la suma
de las unidades de cada una de las columnas de la Tabla 45. Por ejemplo, para el
mes de abril es necesario disponer de 132.55 horas hombre (62.12+70.43) extras
para llegar a fabricar 7074.69 unidades de lavaloza repartidas en 3795.98
unidades de la referencia R500, 464.38 de la referencia R1500 y 2814.33 de la
referencia R3000.

91
3. Observe en la Tabla 48 que el número de trabajadores necesarios pasa de un
valor inicial en febrero igual a 11 a marzo de 6.1 7 trabajadores. Esto quiere decir
que la organización puede disponer de solo 7 trabajadores y cumplir con la
demanda sin necesidad de sobrecostearse con 4 trabajadores más. Este número
de siete trabajadores se mantiene aproximado para todos los meses.
4. Note por la Tabla 50 que la mayoría de trabajadores que deben ser despedidos
vienen de la estación Resto, es decir de los procesos de Fajillado, Envasado,
Pesado, Tapado y Empacado, donde previamente estaban trabajando 7
trabajadores. Esto quiere decir que cerca de 3 trabajadores están siendo
improductivos en esta estación y por tanto podría validarse la posibilidad de
reorganizar la estructura de la fuerza laboral en la organización. Una vez se
trabaja con un número cercano a 7 trabajadores, el sistema se estabiliza y puede
cumplir con la demanda propuesta sin entrar en sobre costos.
Las estación de Fabricación de Envase no parece necesidad de contratar o
despedir personal. Eso quiere decir que con un número de trabajadores igual a 2
como se venía trabajando previamente, el sistema produce óptimamente.
La estación Mezclado necesita de un adecuado análisis. Aunque se dice que se
debe dejar de disponer de 0.78 trabajadores no se debe caer en el error de
pensar en despedir un trabajador (0.78 ). Esto debido a que la organización
necesita de esa fracción de 0.22 trabajadores para operar óptimamente.
Adicionalmente, se dice que es necesario disponer de este trabajador adicional
todo el tiempo normal, a diferencia de cómo se viene trabajando hasta el
momento donde trabaja solo medio tiempo.
5. Por último observe que es necesario disponer de un inventario de seguridad en
cada uno de los periodos de tiempo, esto con el propósito de minimizar el riesgo
de la organización a faltar a la demanda.
Al final de este documento, en el Anexo 10.9.5. Resultados programación lineal GAMS-
ASTEX es posible visualizar la forma como se presentan los resultados obtenidos en este
apartado por medio de ASTEX.
En este mismo Anexo 10.9.5 es posible encontrar las corridas simuladas de los modelos
bajo el escenario con un intervalo de confianza superior de a dos desviaciones estándar
del error del modelo y con un intervalo de confianza inferior a una desviación estándar. Se
obtu o un costo total m imo de $ 545’5 964 en el escenario m s alto y de $
95’909 70 . 8 en el escenario más bajo. Eso quiere decir que en el costo total para los
seis meses oscilará entre estas dos fronteras donde se espera que el valor más
aproximado este cercano a los 312 millones de pesos, como se obtuvo en el valor del
nivel.

92
El número de trabajadores entre estos dos escenarios oscila entre 5 y 10 trabajadores
totales por mes, con un valor para el nivel de 7 trabajadores, como se vio anteriormente.
En cuanto al número de horas extra necesarias, el valor total para todos los seis meses
oscila entre 664.7 horas hombre para el escenario más bajo y 1282.9 horas para el
escenario más bajo, con un nivel de 788.22 horas hombre para el escenario promedio.
A continuación se presenta el resumen de los rangos de fluctuación entre los cuales
oscilara el valor real de cada variable
Variable Inferior Promedio Superior
Costo Total $ 95’909 70 . 8 $ 3 ’936 70 .5 $ 545’5 964 Número de Trabajadores 5 trab/mes 7 trab/mes 10 trab/mes
Horas Hombre Extra 664.7 hh 788.22 hh 1282.9 hh
Tabla 51 Rangos de oscilación
Fuente: Cálculos del Autor.

93
6 ANÁLISIS DE BENEFICIOS ECONÓMICOS DEL PLAN DE PRODUCCIÓN EN LA
ORGANIZACIÓN
6.1 Costo de Implementar la Propuesta
Existen ciertos costos relevantes que deben ser tenidos en cuenta a la hora de
implementar la propuesta del plan de producción desarrollado en este trabajo. Con el
objetivo de planear una producción eficientemente es necesario dividir estos costos en
dos. El primer grupo corresponde a los costos de mano de obra y el segundo grupo a los
costos de licencias de los software que se utilizaron para el pronóstico y la programación
cuantitativa de la producción.
6.1.1 Costos de mano de obra
Este trabajo resaltó la necesidad de contar con un buen plan de producción, desarrollado
de manera más cuantitativa y menos empírica. Para ello se debe disponer de un personal
capacitado que asuma esta labor y realice la planeación anual, efectuando ajustes mes a
mes acorde a las necesidades que la planta así lo requiera y que presente conocimientos
en técnicas de análisis de datos y metodologías de series de tiempo.
En la actualidad la organización cuenta con un Ingeniero Industrial, capaz de ejercer las
labores de jefe de operaciones y de entender los conceptos presentados en este trabajo
sobre la programación lineal y sus componentes. Sin embargo, debido a que la propuesta
presenta la necesidad de un buen pronóstico en la planeación bajo modelos complejos de
series temporales con un conocimiento econométrico previo. Es necesario que este
ingeniero cuente con una capacitación sobre este tema puesto que los conocimientos que
se tienen sobre series de tiempo econométricas en la disciplina ingenieril son mucho más
básicos de lo que la propuesta presenta. Se tiene entonces que los costos relacionados a
la mano de obra para el Ingeniero a cargo son de
Criterio Peso Valor
Salario base - $ 3’300 000 Salud 8.5% $ 110,500
Pensión 12% $ 156,000 Riesgos Profesionales Tipo I: 0.522% $ 6,786
Parafiscales ICFB 3% SENA 2%
Cajas de compensación 4%
$ 39,000 $26,000 $ 52,000
Total mensual 30% $ 3’690,286 Subtotal anual - $ 0’ 83 43
Cesantías 1 Salario Base al año $ ’300 000 Intereses Cesantías 12% de cesantías $ 156,000
Prima 1 Salario Base al año $ ’300 000 Total Anual - $ 23’039,432
Tabla 52 Costo variable Mano de Obra
Fuente: Cálculos del Autor.

94
Acompañado de los siguientes costos fijos derivados de dos capacitaciones en cursos del
CANDANE (Centro de Formación en Estadística del DANE) que se dictarán por
funcionarios y contratistas del DANE en el 201423.
Criterio Duración Valor
Curso Series de Tiempo Abril 1 a mayo 9 de 2014 $ 440,000 Curso Programación SAS Abril 1 a mayo 9 de 2014 $ 300,000
Total - $ 740,000
Tabla 53 Costos fijos de Mano de Obra
Fuente: Precios obtenidos de la página web www.dane.gov.co/candane/
6.1.2 Costos de licencias
Para el desarrollo adecuado de esta propuesta es necesario la compra de las dos
licencias de software: el primero para el desarrollo adecuado del pronóstico a través del
SAS 9.4 con el módulo SAS/ETS y el segundo para la planeación eficiente de la
producción a través de GAMS. La siguiente tabla resume los costos
Software Costo de licencia Costo en pesos*
SAS® 9.4/ETS24
USD $ 2,510 $ 4’899 43 GAMS
25 USD $ 1,600 $ 3’ 960
Total - $ 8’0 03.5 * Basado en una tasa de cambio de $ 1951.85 pesos colombianos por dólar estadounidense del 6/04/2014 tomada del BANREP. La cifra está sujeta a TRM del día.
Tabla 54 Costos de licencias
Se tiene entonces que los costos totales de implementar la propuesta bajo los
lineamientos del trabajo y teniendo en cuenta la mano de obra, capacitaciones y licencias
llega a un aproximado de $ 12’45 89.5 ($ 8’76 03.5 fi os + $ 3’690 86 de sueldo
variable) el cual varía un poco dependiendo de la Tasa Representativa del Mercado
(TRM) que rija el día de la compra.
6.2 Beneficios y Contribuciones del Proyecto
Las herramientas presentadas por este trabajo de grado permiten abordar la perspectiva
de la planeación de la producción desde una óptica de pronósticos mucho más elaborada,
debido a la importancia que tienen estos en la finalidad de una planeación productiva.
Este proyecto brinda varias contribuciones y beneficios, por un lado en la parte
investigativa sobre la temática de pronósticos y por otro lado en la parte empírica aplicada
a una empresa real en el sector productivo de jabones a nivel nacional. A continuación se
desglosarán dichos beneficios para cada uno de estos dos temas.
El carácter investigativo de este trabajo proyectó la necesidad de una buena disciplina
hacia un tratamiento adecuado de los pronósticos en la planeación. Se observó que es
23 Véase la página web del DANE http://www.dane.gov.co/candane/ para mayor información sobre
los cursos. 24 Consultado en http://www.execinfosys.com/ProductsOld/PCBUNDLE_2.pdf 25 Tomado de: http://www.gams.com/sales/commercialp.htm para el Software GAMS/ALPHAECP
capaz de resolver problemas de programación lineal MINLP.

95
necesario reconocer el hecho que existen asimetrías en la función de pérdida del error de
pronóstico de las ventas y que esto puede llegar a afectar la planeación estratégica de la
producción, en la optimización de los recursos. Así como puede llegar a sesgar y
distorsionar los resultados del modelo de minimización de costos, trayendo consigo un
problema subyacente en la toma de decisiones en las organizaciones.
Se enfatizó también en la necesidad de contar con una metodología acorde al proceso
que describe la serie de tiempo a tratar. Debe dedicarse un mayor esfuerzo a la
realización eficiente de pronósticos que permitan la obtención de mejores resultados y
reduzcan costos en la organización. La contribución de este trabajo hacia este campo se
motivó al comparar dos tipos de modelos, uno lineal a través de la metodóloga ARIMA y
otro cuyo comportamiento era completamente automático y poco confiable.
Las contribuciones prácticas realizadas en este trabajo toman lugar en los beneficios
netos que acarrea la implementación del plan de producción propuesto en la empresa de
estudio. Los beneficios netos de la propuesta se dan como el ingreso total menos costo
total. Al multiplicar el valor demandado por cada uno de los precios de las referencias se
obtiene un ingreso total de $ 995’3 4 55.7 el cual al ser restado por los costos totales de
la propuesta $ 3 ’936 70 .5 se logra obtener un beneficio neto de $ 638’387,454.1.
Para obtener la cantidad que la propuesta logrará ahorrar, se deben obtener los costos en
los que incurre la organización actualmente. Los cálculos de estos costos se registran en
la Tabla 55. Método Propuesto Frente a Método Actual, observe que es necesario
contrastar los mismos costos que se calcularon en la propuesta, de lo contrario no tendría
sentido su comparación. Es decir que se tuvieron en cuenta costos de producción, costos
de almacenamiento de producto terminado, costos de mano de obra y costos de horas
extra. Los costos asociados a despedir y contratar personal se supone que son cero
puesto que la fuerza de trabajo se mantiene constante en el tiempo bajo la metodología
actual de producción en la organización.
Los resultados mostraron que el plan de producción propuesto logrará reducir los costos
en un 16.44% en 6 meses del horizonte de planeación, es decir un ahorro promedio
cercano a $ 0’35 08.04 por cada mes del horizonte.
Por último, el desarrollo de la programación lineal mostró la necesidad de contar con una
formulación cuantitativa del plan de producción para evitar la sobre o subproducción
derivada del tratamiento especulativo de la demanda.

96
Costo Observaciones
Costos de Producción $ 88’035 786.7
Estos costos fueron calculados como la sumatoria del número de unidades producidas considerando el inventario de seguridad, multiplicado por el costo de producción unitario de cada una (Ver Tabla 10).
Costos de Almacenamiento
$ ’8 9 9.73
Este costo fue calculado como en número de unidades en almacenamiento de producto terminado (el cual corresponde al inventario de seguridad, como se vio anteriormente) multiplicado por el costo de mantener en inventario de cada una de las referencias (Ver Tabla 11).
Costos de Mano de Obra
$ 68’079 000
Estos costos fueron calculados teniendo una fuerza de trabajo constante de 9 operarios por mes, este valor fue obtenido por medio de la organización para el mes de febrero de 2014. Su cálculo se da multiplicando el número de empleados por el costo de cada uno de ellos ($ ’03 500.00, ver Tabla 9) y multiplicando este valor por seis meses del horizonte.
Costos de Horas Extra $ 0’89 644.96
Este costo fue calculado como la multiplicación entre la sumatoria del número de días hábiles al mes multiplicado por 4 horas extra trabajadas por cada empleado (según información dada de la organización) por el número total de empleados al mes (11) multiplicado por el costo de cada hora extra ordinaria ($ 3,208.33 ver Sección 3.8.1)
Costo Total Actual $ 377’734,235.71
Costo Propuesta $ 3 ’936 70 .5 Costo del Ingeniero $ 3’690 86
Total Costo Propuesto $ 315’626,987.5
AHORRO $ 62’107,248.21 17.42%
Tabla 55 Método Propuesto Frente a Método Actual
Fuente: Cálculos del Autor.
Según consultas con la gerencia administrativa, previo a la realización del estudio, se
evidenció la clara necesidad de contar con una planeación estratégica de la producción
más rigurosa y menos empírica. Indicadores como el porcentaje de pedidos no
entregados a tiempo pueden estar llegando al 15 o 20%, lo que genera (i) sobrecostos, (ii)
puede afectar la reputación de la empresa con los principales clientes, (iii) desmejora la
calidad y (iv) trae consigo una pérdida clara en los ingresos. La implementación de esta
propuesta conduciría a la notable reducción de este indicador debido a la función que
ejecutará el ingeniero de operaciones en el procedimiento programático en un ritmo
normal de trabajo para el abastecimiento de la demanda optimizando los recursos con los
que cuenta la organización. Esta reducción está basada además en los resultados de la
programación lineal y el sustento teórico que otorga la eficiencia de los pronósticos aquí
presentados, frente a los usados actualmente por la organización cuyo método se basa
completamente en técnicas cualitativas y no hay registros ni datos históricos de posibles

97
errores en la proyección de las ventas desde el comienzo de la alianza estratégica entre
las empresas Alianzas y Alta pureza en el año 2010.
6.3 Comportamiento de las Variables Ante Cambios en la Demanda.
Con el objetivo de realizar un análisis sobre cuán sensible son las variables de respuesta
ante cambios en la cantidad demandada, se procedió a observar el comportamiento de
diferentes variables ante cambios en dicha cantidad. Para ello se dispuso a incrementar
gradualmente la cantidad demandada y correr el modelo para cada simulación. Se
obtuvieron y guardaron los resultados de cada modelo y se procedió a graficar estos
comportamientos.
Esta simulación mostró que después de 35,039 unidades de cada referencia en cada
periodo de tiempo el modelo no es factible debido a que se sobrepasa la capacidad
requerida frente a la capacidad disponible der recurso máquina. Esto quiere decir que si
se demandara más de esta cantidad por cada uno de las referencias el sistema no sería
capaz de satisfacer la demanda y por tanto sería necesaria una estrategia de ampliación
de la capacidad.
A continuación se presenta la evolución del costo total de producción frente a cambios en
la cantidad demandada
Gráfica 3 Evolución del costo total frente a la demanda
Fuente: Realizado por el Autor
observe que debido al carácter lineal de la función objetivo, el costo total crece de manera
lineal ante cambios en la cantidad demandada. Sin embargo sucede un hecho relevante y
es el salto de pendiente que se da entre una demanda de 100 a 150 unidades de cada
producto. Entre estos dos puntos la función de costos crece mucho más rápido (con
pendiente más inclinada) que en los puntos siguientes. De ahí en adelante la pendiente
sigue siendo la misma para incrementos en la demanda. Note que está pendiente,
después de 150 unidades, puede ser calculada como
$ ,
$ 5.000.000,
$ 10.000.000,
$ 15.000.000,
$ 20.000.000,
$ 25.000.000,
$ 30.000.000,
$ 35.000.000,
0 200 400 600 800 1000 1200
Demanda
Costo Total

98
⁄
esto quiere decir que por cada unidad adicional de unidad demandada de cada una de las
referencias, el costo total se incrementará en $ 34,380.9 aproximadamente. Este concepto
es relacionado a la costó marginal de demanda el cual determina cuanto cambia el costo
total por cada unidad demandada adicional.
Este mismo concepto puede ser aplicado a la variable de fuerza de trabajado, puesto que
presenta la misma evolución frente a las unidades demandadas (ver Gráfica 4) el valor del
cambio marginal de una unidad adicional de demanda frente al número de trabajadores
será igual a . Esto quiere decir que por cada unidad adicional
de demanda es necesario disponer de una fracción de 0.00172 de trabajador adicional.
Por consiguiente es necesario que la demanda de cada uno de los productos incremente
en unidades para que sea necesario contratar un operario
adicional y poder satisfacer la demanda.
Gráfica 4 Evolución de la fuerza de trabajo frente a la demanda
Fuente: Realizado por el Autor
Adicionalmente se presentará como cambia la variable contratar ante cambios en la
cantidad demandada. Observe por la Gráfica 5 que la evolución del número de personar
contratadas es creciente en el número de unidades demandas pero marginalmente
decreciente cuando se está por llegar a las 35,089 unidades (después de las cuales el
sistema no es factible).
Este fenómeno sucede puesto que como se verá más adelante, cuando el sistema está
por llegar a dicho valor de demanda, la razón entre la capacidad disponible y la capacidad
requerida se hace cada vez más cercana a la unidad, esto hace que el sistema necesite
en mayor medida de los inventarios de producto terminado que de la producción misma
puesto que cercano a dicho valor no será posible producir más debido a la poca
capacidad disponible con la que se dispone. Al tener que “echar mano” de los in entarios
la cantidad de personal a contratar decrece gradualmente casi en una unidad puesto que
0
0,2
0,4
0,6
0,8
1
1,2
0 200 400 600 800 1000 1200
Nº
Tra
baj
ado
res
Demanda
Fuerza de trabajo

99
la gestión de inventarios suplirá la necesidad de satisfacción de la demanda dada la
eventual limitación de la capacidad.
Gráfica 5 Evolución del número de contrataciones frente a la demanda
Fuente: Realizado por el Autor
Este mismo fenómeno se puede validar observando las funciones de relación entre
inventario y cantidad demandada de cada una de las referencias estudiadas. Note en el
Anexo 10.9.8. Resultados Análisis del Comportamiento de las Variables en LP que al
principio del sistema (entre 5 y 5,000 unidades de lavaloza para cada referencia) la
evolución de cada nivel de inventario es marginalmente decreciente, esto se da puesto
que entre este rango de demanda el sistema tiene una relación de capacidad requerida
frente a capacidad disponible muy cercana a cero, por lo que el sistema no necesita de la
gestión de inventarios para poder suplir la demanda. Es decir que es capaz de producir lo
que la demanda requiere. Una vez se pase de dicho punto (entre 5,000 y 30,000
unidades) el sistema se estabiliza en un nivel de inventario fijo, diferente para cada una de
las referencias.
Sin embargo, observe que después de un valor de demanda entre 30,000 hasta 35,089
unidades de lavaloza el sistema comienza a guardar más inventario que el nivel fijo en el
cual venia. Esto se debe, como se mencionó anteriormente, a que el sistema necesita
“echar mano” de los in entarios para lograr satisfacer la demanda debido a la limitación
en términos de capacidad disponible del recurso máquina para unidades cercanas a las
35,089 unidades de lavaloza para cada una de las referencias. Por ello se dice que
después de dicho valor de demanda el sistema necesitará de una estrategia de
ampliación de la capacidad (compra de más capital), puesto que el LHS de la ecuación
es mayor que el RHS de dicha restricción, y el sistema será no factible.
-0,5
0
0,5
1
1,5
2
2,5
3
3,5
4
0 5000 10000 15000 20000 25000 30000 35000 40000
Nº
Co
ntr
atac
ion
es
Demanda
Contrataciones

100
6.4 Análisis de Sensibilidad o Análisis Posóptimo
El desarrollo del análisis de sensibilidad del modelo de Programación Lineal Mixta (MIP
por sus siglas en ingles Mixed Integer Programming) presentado en este capítulo se
obtuvo por medio del solver CPLEX en GAMS, el cual permite obtener la cuantificación de
los efectos en la solución óptima de diferentes cambios en los parámetros del modelo
matemático. Esto se realizó puesto que al correr el modelo, se da por sentado que los
valores de los parámetros se conocen con total certidumbre; sin embargo, en la realidad
no siempre se cumple esta situación puesto que variaciones en ciertas condiciones del
modelo (por ejemplo costos, capacidades o demanda) ocasionan cambios en los
coeficientes de la función objetivo.
Estos cambios en el modelamiento matemático pueden ser obtenidos sin necesidad de
reestimar el modelo, esto a través del análisis postótimo, el cual se relaciona con dos
aspectos importantes: (i) cambios en los coeficientes de las variables de decisión en la
función objetivo o (ii) cambios en los lados derechos RHS de las restricciones que definen
el modelo.
Para llevar a cabo en GAMS/CPLEX la sensibilidad del modelo fue necesario:
1. Activar en la ventana opciones-solvers la opción CPLEX en MIP y LP. Esto
permite que el programa reconozca el tipo de estructura que se incluirá al final del
código (Véase Anexo 10.8.3. Código GAMS para Plan de Producción).
2. Crear un archi o llamado “cplex.opt” el cual debe contener las siguientes dos
líneas de código en el:
objrng all
rhsrng all
Esto se realiza con el propósito de crear un fichero de opciones, en el cual se
identifica el requerimiento del análisis del rango de los coeficientes de la función
objetivo y de los términos independientes.
3. Por último se adicionan las siguientes líneas inmediatamente después de ejecutar
el modelo (MODEL PlanProduccion /ALL/) en GAMS:
option LP=CPLEX;
PlanProduccion.optfile=1;
Estas dos linear permitirán primero llamar a la opción previamente activada
CPLEX y segundo al fichero de opciones creado en el paso dos.
Una vez realizado este procedimiento se logró obtener el análisis de sensibilidad para el
RHS de cada una de las ecuaciones y para cada una de las variables. Este se registra en

101
el archivo (.lst - listing) anexo a GAMS. Para efectos prácticos se presentará como
ejemplo el análisis para cambios en el RHS de la ecuación (E2) es decir para el caso
especifico de la referencia R250 en cada periodo de tiempo t, es decir para
. La misma lógica que se presenta a continuación es aplicable a todos los análisis
para las demás variables y ecuaciones presentadas en el listing de CPLEX el cual puede
ser consultado en el Anexo 10.9.9. Resultados Análisis Posoptimal.
Bajo Nivel Alto Marginal
R250 .Marzo 35,310.00 36,837.61 37,810.00 $ 241.979
R250 .Abril 61,092.92 61,092.92 61,092.92 $ 242.655
R250 .Mayo 65,992.11 65,992.11 67,280.00 $ 243.092
R250 .Junio 82,914.60 82,914.60 82,914.60 $ 238.822
R250 .Julio 77,794.33 77,794.33 77,794.33 $ 240.402
R250 .Agosto 83,100.00 92,321.76 92,321.76 $ 226.858
Tabla 56 Análisis de sensibilidad (E2) R250; t=2,...6
Nota: Unidades de lavaloza
El cuadro anterior recoge el análisis de sensibilidad del término RHS de (E2), el cual nos
muestra directamente los limites inferior y superior de los valores de inventario para los
cuales la solución actual, entendida como las variables básicas y no como su
correspondiente valor, se mantiene como optima. Por consiguiente se puede decir que,
por ejemplo, para el mes de marzo el inventario de la referencia R250 puede variar entre
35,310 unidades y 37,810 unidades sin que esto afecte la optimalidad del modelo.
Observe además que el valor Marginal (conocido como Precio Sombra) dictamina en
cuanto se incrementará (o reducirá, ya que no necesariamente la relación tiene que ser
positiva para todas las variables) el costo total del modelo ante un cambio en una unidad
adicional de mantener en inventario una unidad de R250 en el mes. Por ejemplo
para el mes de julio, se dice que incrementar en una unidad adicional el inventario de la
referencia R250 incrementará en un total de $ 240.402 aproximadamente el costo total de
la organización para dicho mes. Este cambio se denomina cambio marginal el cual se
determina como la derivada parcial de la función objetivo ante un cambio infinitesimal en
una de las variables del modelo.
Esta información es de pertinencia para la organización ya que puede llevar a un proceso
de toma de decisiones mucho más eficiente que con valores puntuales arrojados por el
modelo. En general se dice que este análisis tiene como principal objetivo la identificación
del impacto que tiene el cambio de ciertos parámetros, variables o restricciones
relevantes como capacidades, materia prima o número de trabajadores, en el problema
original, sin que éste pierda su condición de optimalidad.

102
7 CONCLUSIONES
Una vez desarrollado el estudio del plan de producción para la empresa Alianzas y/o
Industrias Alta Pureza se llegaron a obtener las siguientes conclusiones:
1. Herramientas de la investigación de operaciones como el método de
programación lineal entera permiten establecer el plan de producción de la
organización aplicando diferentes estrategias que permitan la satisfacción de la
demanda pronosticada en el horizonte de planeación.
2. La caracterización del sistema de producción de la organización por medio de la
identificación de elementos claves como tiempos estándar de producción, costos
asociados al proceso productivo, diagrama de operaciones, representantes tipo,
capacidades disponibles, es relevante para el correcto modelamiento matemático
del plan de producción.
3. Los resultados del esquema rolling de evaluación de pronóstico fuera de muestra
con medidas de error tanto simétricas como asimétricas permitieron mostrar la
eficiencia de los modelos ARIMA frente al método comparativo. Además, se
concluye que para series estacionarias de ruido sobre un tendencia
determinística, el ajuste de algún método de sustracción de la tendencia traerá
resultados muy similares a la luz del esquema rolling.
4. Los resultados permitieron llegar a concluir por medio de las medidas de error
simétricas y asimétricas que la realización de un modelo de series de tiempo
lineal ARIMA realizado adecuadamente presenta un mejor rendimiento tanto
dentro como fuera de la muestra que las metodologías de estimación automáticas
de algunos paquetes estadísticos, las cuales son de suma desconfianza debido a
que no hay un análisis de series de tiempo detrás.
5. La herramienta desarrollada en Excel (ASTEX) permite que el uso de los modelos
de pronóstico y programación lineal sea más amigable para el manejo en un
ambiente empresarial.

103
8 RECOMENDACIONES
Se recomienda un estudio de la redistribución de la planta con el objetivo de contar
con una producción de trabajo continua que permita el flujo eficiente de materiales
acorde a las condiciones de trabajo de la organización. Esto se puede lograr con
ayuda de los tiempos estándar de trabajo presentados en este trabajo, además de
las capacidades de producción. Todo esto con el objetivo de lograr una
distribución de planta orientada a los procesos.
Se recomienda la complementación del trabajo incluyendo una política de
inventarios a través de la construcción de un manual que permita la adecuada
administración de los inventarios para reducir costos de mantener y abastecer.
Esto se puede lograr a través de las técnicas propuestas en este trabajo y por
medio de herramientas del análisis y la gestión de inventarios. En este punto, y
conectando con el punto anterior, se hace énfasis en la mejora de la distribución
de los inventarios de producto en proceso y producto terminado para el adecuado
aprovechamiento de la capacidad de la planta.
El modelo de programación productiva presentado en este trabajo es solo un tipo
de metodología de planeación estratégica de producción. Existe una extensa
diversidad de modelos que permiten llegar a el mismo objetivo, de diferentes
maneras y cada uno con sus debilidades y falencias. Por tanto, se recomienda
comparar los resultados del modelo de LP con modelos heurísticos como Teoría
de Restricciones (TOC) propuesto por Goldratt (1994) a partir de la determinación
de cuellos de botella buscando identificar las limitaciones del sistema y la
aplicación de sistemas que mejoren los problemas críticos de la empresa, o
modelos metaheurística de asignación de recursos como los algoritmos genéticos.
Se recomienda la confrontación de los modelos de pronóstico presentados aquí
con modelos multivariados tipo vector autoregresivo VAR para las series en
conjunto, con la incorporación de relaciones de cointegración de largo plazo entre
las referencias que conforman el sistema de producción. Además de la
confrontación con modelos que reconozcan la presencia de no linealidades en la
serie como modelos de redes neuronales artificiales (ANN) cuyo desarrollo
empírico en el campo del pronóstico de series de tiempo ha arrojado resultados
bastante eficientes en los últimos años debido a su representación no lineal del
proceso.

104
9 BIBLIOGRAFÍA
Chase, R. B., Jacobs, F. R., & Aquilano, N. J. (2009). Administración de operaciones,
producción y cadena de suministro (12ª edición ed.). Mc Graw Hill.
Wooldridge, J. M. (2009). Introduccion a la econometría. Un enfoque moderno (4ª edición
ed.). Cengage Learning Editores.
Schroeder, R. G. (1996). Administración de operaciones, toma de decisiones en la función
de operaciones. Mexico: McGraw Hill.
Montenegro, A. (1989). La funcion de autocorrelación y su empleo en el análisis de series
de tiempo. Revista Desarrollo y Sociedad (23), 16.
Box, G. E., & Jenkins, G. M. (1970). Time Series Analysis, Forecasting and Control. San
Francisco: Holden-Day.
Everett, A. E., & Jr. Ronald, E. J. (1991). Administración de la producción y de las
operaciones: conceptos, modelos y funcionamiento (4ª edición ed.). Pearson
Education.
Krajewski, L. J., Ritzman, L. P., & Malhotra, M. K. (2008). Administración de Operaciones.
Procesos y cadenas de valor (8ª edición ed.). Pearson Education.
Ostrow, P. (Junio de 2011). Sales Forecasting, How Top Performers Leverage the Past,
Visualize the Present, and Improve Their Future Revenue. Recuperado el 2013, de
Sales Logix: http://www.saleslogix.com/media/en-
us/docs/collateral/aberdeen_white_paper_sales_forecasting.pdf
Harrison, P. J., & Pearce, S. F. (1972). The use of trend curves as an aid to market
forecasting. Industrial Marketing Managment.
Harvey, A. C. (1989). Forecasting, Structural Time Series Models and the Kalman Filter.
Cambridge: Cambridge University Press.
Gardner, E. S. (1983). Automatic monitoring of forecast errors (Vol. 2). Journal of
Forecasting.
Zellner, A. (1986). Bayesian Estimation and Prediction Using Asymmetric Loss Functions.
Journal of Forecasting , 8, 446-451.
Varian, H. (1974). A Bayesian Approach to Real Estate Assessment. 195-208.
McCullough, B. (2000). Optimal Prediction with a General Loss Function. Journal of
Combinatorics Information & System Sciences , 25, 207-221.
Granger, W. C. (2001). Prediction with a Generalized Cost Function. (C. U. Press, Ed.)
Operational Research , 199-207.
Christoffersen, P. F., & Diebold, F. X. (1997). Optimal Prediction Under Asymmetric Loss.
Econometric Theory , 806-817.

105
Jalil, M. A., & Misas, M. (2007). Evaluación de pronósticos del tipo de cambio utilizando
redes neuronales y funciones de pérdida asimétricas. Revista Colombiana de
Estadística , 143-161.
GRECO, G. d. (1999). El desempeño macroeconómico colombiano Series estadísticas
(1905 - 1997) Segunda versión . Bogotá: BanRep.
Chang, J. F. (2006). Business Process Management Systems. Auerbach Publications.
Kendall, K. E., & Kendall, J. E. (2005). Análisis y Diseño de Sistemas (6ª Edición ed.).
Pearson Education Inc.
Laudon, K. C., & Laudon, J. P. (2012). Managment Information Systems (12ª ed.).
Pearson Education Inc.
Okoli , N. C., Obuka , N. S., Onyechi , P. C., & Ikwu , G. O. (2012). Modeling of Production
Plan and Scheduling of Manufacturing Process for a Plastic Industry in Nigeria .
Industrial Engineering Letters , 2.
Kaminsky , P., & Swaminathan , J. M. (2003). Effective Heuristics for Capacitated
Production Planning with Multiperiod Production and Demand with Forecast Band
Refinement. MANUFACTURING & SERVICE OPERATIONS MANAGEMENT , 6,
84–194 .
Goodwin , P., Önkal , D., & Thomson , M. (2009). Do forecasts expressed as prediction
intervals improve production planning decisions? European Journal of Operational
Research , 205, 195–201 .
Wang , R.-C., & Liang , T.-F. (2004). Applying possibilistic linear programming to
aggregate production planning. Int. J. Production Economics , 98, 328–341.
Byrne , P. J., & Heavey , C. (2006). The impact of information sharing and forecasting in
capacitated industrial supply chains: A case study . Int. J. Production Economics ,
420–437 .
Sujjaviriyasup, T., & Pitiruek, K. (2013). Hybrid ARIMA-support vector machine model for
agricultural production planning. Applied Mathematical Sciences , 2833-2840.
Tiacci, L., & Saetta, S. (2009). An approach to evaluate the impact of interaction between
demand forecasting method and stock control policy on the inventory system
performances. International Journal of Production Economics , 118, 63-71.
Yanradee, P., Pinnoi, A., & Charoenthavornying, A. (2001). Demand Forecasting and
Production Planning for Highly Seasonal Demand Situations: Case Study of a
Pressure Container Factory. ScienceAsia , 8.
Montenegro, A. (2011). Análisis de Series de Tiempo. Bogotá, Colombia: Editorial
Pontificia Universidad Javeriana.
Lamb, C. W., Hair, J. F., & McDaniel, C. (2011). Marketing. South-Western CENGAGE
Learning.

106
Chatfield, C. (1996). The Analysis Of Time Series: An Introduction. United Kingdom:
Chapman & Hall/CRC.
Chatfield, C., & Yar, M. (1988). Holt-Winters Forecasting: some practical isues (Vol. 37).
The Statistician.
Brown, R. G. (1963). Smoothing, Forecasting and Prediction. Englewood Cliffs, NJ:
Prentice-Hall.
West, M., & Harrison, P. J. (1989). Bayesian Forecasting and Dynamic Models. New York:
Springer-Verlag.
Montgomery, D. C., Johnson, L. A., & Gardiner, J. S. (1990). Forecasting and Time Series
Analysis (2ª edición ed.). New York: McGraw-Hill.
Gilchrist, W. (1976). Statistical Forecasting. London: Wiley.
Granger, C. J., & Newbold, P. (1986). Forecasting Economic Time Series (2ª edición ed.).
New York: Academic Press.
Gardner, E. S. (1985). Exponential Smoothing: the state of arte (Vol. 4). Journal of
Forecasting .
Pérez, F. O. (2007). Introducción a las series de tiempo. Métodos paramétricos (Vol. 1).
Medellin, Colombia: Universidad de Medellin.
Sule, D. R. (2001). Instalaciones de manufactura. é ico Thomson learning.
Niebel, F. (2009). Ingeniería Industrial. Métodos, estándares y diseño del trabajo. México:
McGraw-Hill Companies, Inc.
Kalenatic, D., López, C., & Gonzales, J. (2007). Modelo de ampliación de la capacidad
productiva . Revista Ingeniería .
Arbones, E. (1989). Logística Empresarial. Boixareu Editores.
Laumaille, R. (2000). Gestión de Stocks. GESTION 2000.
Guerrero, V. M. (2003). Anális estadístico de series de tiempo económicas (2ª edición
ed.). México: Thomson.
Anderson, O. D. (1976). Time Series Analysis and Forecasting (the Box-Jenkins
Approach). Londres: Butterworth.
Bartlett, M. S. (1946). On the theoretical specification of sampling properties of
autocorrelation time series. Journal of the Royal Statistical Society , B-8, 27.
Wold, H. (1954). A Study in the Analysis of Stationary Time Series. Almqvist & Wiksell.
Yaglom, A. M. (1955). Extrapolation, interpolation and filtering of stationary random
processes with rational spectral density. Tr. Mosk. Mat. Obs.
Pankratz, A. (1983). Forecasting with univariate Box–Jenkins models: concepts and
cases. New York: John Wiley & Sons.

107
Enders, W. (1948). Applied econometric time series (Second edition ed.). United States:
Wiley.
Fuller, W. A. (1996). Introduction to Statistical Time Series. John Wiley & Sons.
Hamilton, J. D. (1994). Time Series Analysis. Princeton University Press.
Brockwell, P. J., & Davis, R. J. (2002). Introduction to Time Series and Forecasting. Taylor
& Francis.
Dickey, D. A., & Fuller, W. A. (1979). Distribution of the Estimators for Autoregressive
Time Series with a Unit Root . Journal of the American Statistical Association 74
(366): 427–431. JSTOR .
Box, G. E., & Cox, D. R. (1964). An analysis of transformations. Journal of the Royal
Statistical Society , 211.
Fuller, W. A. (1976). Introduction to Statistical Time Series. New York: John Wiley.
Box, G., Jenkins, G., & Reinsel, G. (1994). Time Series Analysis: Forecasting and Control.
Wiley.
Tsay, R. S., & Tiao, G. C. (1985). Use of canonical analysis in time series model
identification. Biometrika 72 (2): 299-315.
Hannan, E. J., & Rissanen, J. (1982). Recursive estimation of mixed autoregression-
moving average order. 81-94.
Ljung, G. M., & Box, G. E. (1978). On a measure of lack of fit in time series model.
Biometrika 65 , 297.
Levenberg , K. (1944). A Method for the Solution of Certain Non-Linear Problems in Least
Squares. Quarterly of Applied Mathematics 2 , 164–168.
Marquardt, D. (1963). An Algorithm for Least-Squares Estimation of Nonlinear Parameters.
SIAM Journal on Applied Mathematics 11 (2) , 431–441.
Ansley, C. F., & Newbold, P. (1980). Finite Sample Properties of Estimators for
Autoregressive-Moving Average Models. Journal of Econometrics, 13 , 159–183.
Breusch, T. S. (1979). Testing for Autocorrelation in Dynamic Linear Models" . Australian
Economic Papers, 17 , 334–355.
Godfrey, L. G. (1978). Testing Against General Autoregressive and Moving Average Error
Models when the Regressors Include Lagged Dependent Variables . Econometrica,
46 , 1293–1302.
Jarque, C. M., & Bera, A. K. (1987). A test for normality of observations and regression
residuals. International Statistical Review 55 (2) , 163–172.
Fox, A. (1972). Outliers in Time Series. Journal of the Royal Statistical Society, B-34 , 350-
363.
Chang, I., & Tiao, G. (1983). Estimation of Time Series Parameters in the Presence of
Outliers. Technical Report 8, Statistics Research Center .

108
Chang, I., Tiao, G., & Chen, C. (1988). Estimation of Time Series Parameters in the
Presence of Outliers . Technometrics, 30, 2 , 193-204.
Tsay, R. (1988). Outliers, Level Shifts, and Variance Changes in Time Series. . Journal of
Forecasting, 7 , 1-20.
Chen, C., & Liu, L. (1993). Joint Estimation of Model Parameters and Outlier Effects in
Time Series. . Journal of the American Statistical Association, 88 , 284-297.
Shapiro, S. S., & Wilk, M. B. (1965). An Analysis of Variance Test for Normality (Complete
Samples). Biometrika , 52, 591-611.
Hillier, F. S., & Lieberman, G. J. (2010). Introducción a la Investigación de Operaciones
(Novena Edición ed.). McGraw Hill.
Taha, H. A. (2012). Investigación de Operaciones. Pearson.
Plossl, G. W. (1996). Control de la Produ i n de n entario ( era Edición ed.). é ico
Editorial Prentice Hall.
Mariño, H. (2001). Gerencia de Procesos. Alfaomega.
Goldratt, E. M. (1994). La Meta (Tercera edición ed.). Ediciones Castillo S.A .

109
10 ANEXOS
10.1 Caracterización de la Organización
10.1.1 Tabla de Referencias
REFERENCIA NOMBRE
TAMAÑO 250g
1280 LAVALOZA DESS IN LIMA LIMON 250 GR
1297 LAVALOZA DESS IN CHICLE 250 GR
7396 LAVALOZA CLEAN LINE CHICLE 12X4 UN 250 GR
7402 LAVALOZA CLEAN LINE LIMON 12X4 UN 250 GR
8216 LAVALOZA LIMON SURTIMAX 250 GRS X 32 UND
8224 LAVALOZA LIMON YEP X 250 GR X 48 UNDS
8231 LAVALOZA CHICLE YEP X 250 GR X 48 UNDS
TAMAÑO 500g
0702 LAVALOZA DESS IN CHICLE X 500 GR
0733 LAVALOZA DESS IN LIMON X 500 GR
1105 LAVALOZA DESS IN LIMA LIMON 500 GR
2287 LAVALOZA LIMON 500GR X 24 UNDS
2294 LAVALOZA CHICLE 500 GR X 24 UND
2300 LAVALOZA LIMON 500 GRS 12X2 UNDS
2317 LAVALOZA CHICLE 500 GR 12X2 UN
2830 LAVALOZA CONSUMO CHICLE CON GLIC 500 X24
2854
LAVALOZA CONSUMO CHICLE CON GLIC 500 2X12
2861
LAVALOZA CONSUMO LIMON CON GLICE 500 X24
2885
LAVALOZA CONSUMO LIMON CON GLIC 500 2X12
3329 LAVALOZA LIMON ALKOSTO X 500 GRS 1/24
3336 LAVALOZA CHICLE ALKOSTO X 500 GRS 1/24
3818 LAVALOZA LIMON ALKOSTO X 500 GRS 2/12
3825 LAVALOZA CHICLE ALKOSTO X 500 GRS 2/12
7198
LAVALOZA LIMON FOURPACKALK 500 6 X4 UNDS
7204 LAVALOZA CHICLE FOURPACK ALK 500 6X4
7372 LAVALOZA ARO CHICLE 500 PQT X 2 X12 UNDS
7389 LAVALOZA ARO LIMON 500 PQT X 2 X12 UNDS
7477 LAVALOZA LIMÒN SURTIMAX 500 2X9 UNDS
8223 LAVALOZA LIMON SURTIMAX 500 GR X 18 UNDS
8248 LAVALOZA LIMON YEP X 500 GR X 24 UNDS
8255 LAVALOZA CHICLE YEP X 500 GR X 24 UNDS
8262 LAVALOZA LIMON YEP 500 GR 12X2 UNDS
8279 LAVALOZA CHICLE YEP 500 GR 12X2 UNDS
TAMAÑO 1000g
0749 CREMA LAVALOZA ASTRAL LIMON 1000 GR X 6 2263 LAVALOZA DESS IN LIMON X 1000 GR 2270 LAVALOZA DESS IN CHICLE X 1000 GR 2324 LAVALOZA LIMON MAS X MENOS 1000 1X12 UN 2331 LAVALOZA ALOE VERA MAS XMENOS 1000 1X12 2348 LAVALOZA LIMON MAS X MENOS 1000 2X6
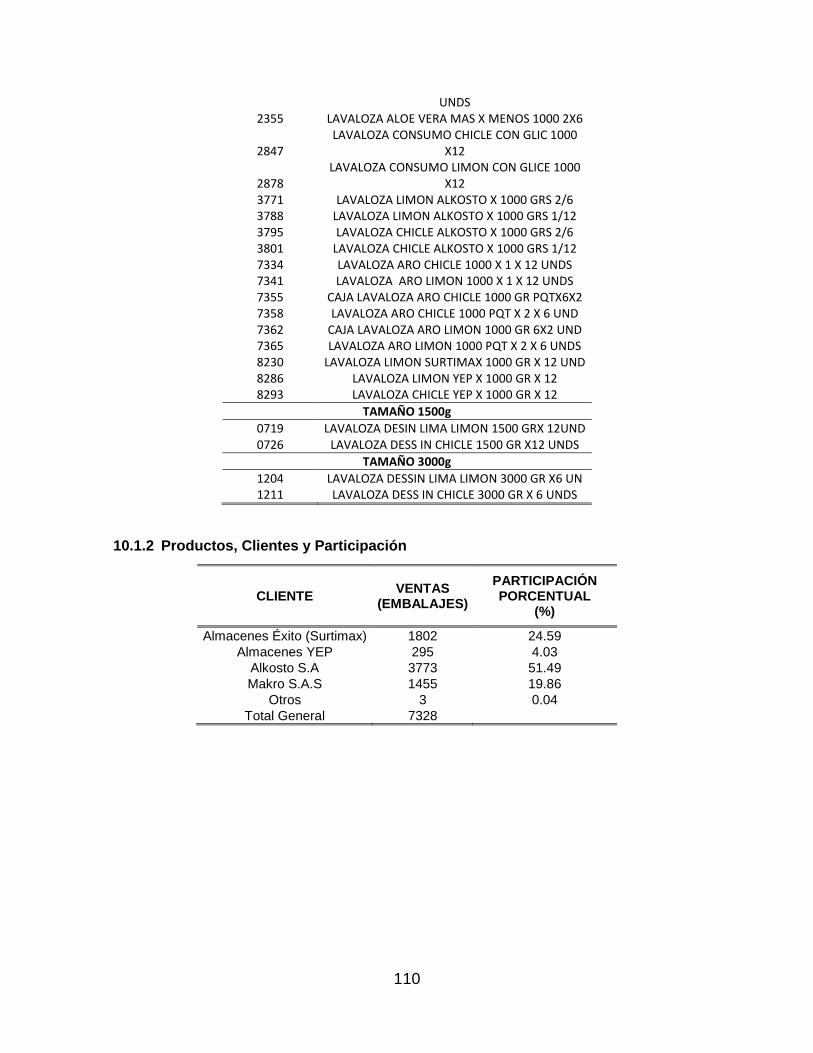
110
UNDS 2355 LAVALOZA ALOE VERA MAS X MENOS 1000 2X6
2847 LAVALOZA CONSUMO CHICLE CON GLIC 1000
X12
2878 LAVALOZA CONSUMO LIMON CON GLICE 1000
X12 3771 LAVALOZA LIMON ALKOSTO X 1000 GRS 2/6 3788 LAVALOZA LIMON ALKOSTO X 1000 GRS 1/12 3795 LAVALOZA CHICLE ALKOSTO X 1000 GRS 2/6 3801 LAVALOZA CHICLE ALKOSTO X 1000 GRS 1/12 7334 LAVALOZA ARO CHICLE 1000 X 1 X 12 UNDS 7341 LAVALOZA ARO LIMON 1000 X 1 X 12 UNDS 7355 CAJA LAVALOZA ARO CHICLE 1000 GR PQTX6X2 7358 LAVALOZA ARO CHICLE 1000 PQT X 2 X 6 UND 7362 CAJA LAVALOZA ARO LIMON 1000 GR 6X2 UND 7365 LAVALOZA ARO LIMON 1000 PQT X 2 X 6 UNDS 8230 LAVALOZA LIMON SURTIMAX 1000 GR X 12 UND 8286 LAVALOZA LIMON YEP X 1000 GR X 12 8293 LAVALOZA CHICLE YEP X 1000 GR X 12
TAMAÑO 1500g
0719 LAVALOZA DESIN LIMA LIMON 1500 GRX 12UND 0726 LAVALOZA DESS IN CHICLE 1500 GR X12 UNDS
TAMAÑO 3000g
1204 LAVALOZA DESSIN LIMA LIMON 3000 GR X6 UN 1211 LAVALOZA DESS IN CHICLE 3000 GR X 6 UNDS
10.1.2 Productos, Clientes y Participación
CLIENTE VENTAS
(EMBALAJES)
PARTICIPACIÓN PORCENTUAL
(%)
Almacenes Éxito (Surtimax) 1802 24.59
Almacenes YEP 295 4.03
Alkosto S.A 3773 51.49
Makro S.A.S 1455 19.86
Otros 3 0.04
Total General 7328
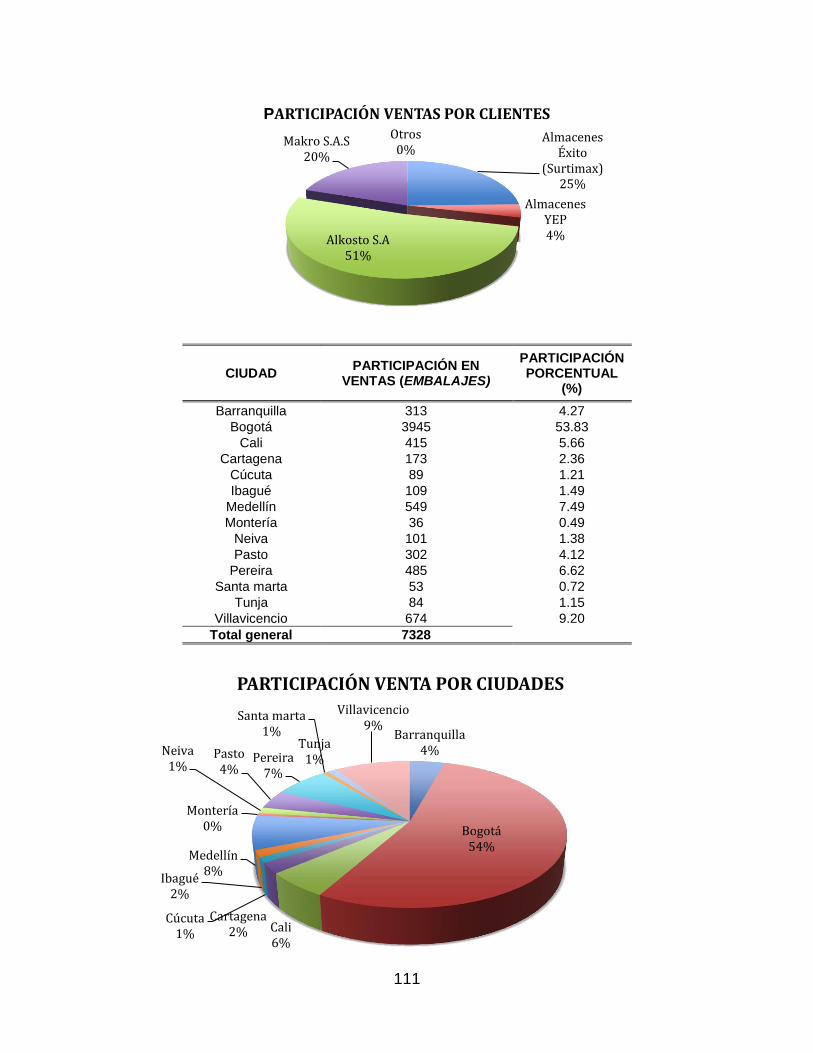
111
CIUDAD PARTICIPACIÓN EN
VENTAS (EMBALAJES)
PARTICIPACIÓN PORCENTUAL
(%)
Barranquilla 313 4.27
Bogotá 3945 53.83
Cali 415 5.66
Cartagena 173 2.36
Cúcuta 89 1.21
Ibagué 109 1.49
Medellín 549 7.49
Montería 36 0.49
Neiva 101 1.38
Pasto 302 4.12
Pereira 485 6.62
Santa marta 53 0.72
Tunja 84 1.15
Villavicencio 674 9.20
Total general 7328
Almacenes Éxito
(Surtimax) 25%
Almacenes YEP 4% Alkosto S.A
51%
Makro S.A.S 20%
Otros 0%
PARTICIPACIÓN VENTAS POR CLIENTES
Barranquilla 4%
Bogotá 54%
Cali 6%
Cartagena 2%
Cúcuta 1%
Ibagué 2%
Medellín 8%
Montería 0%
Neiva 1%
Pasto 4%
Pereira 7%
Santa marta 1%
Tunja 1%
Villavicencio 9%
PARTICIPACIÓN VENTA POR CIUDADES

112
10.1.3 Organigrama Alianzas y/o Industrias Alta Pureza S.A
10.1.4 Diagrama de Caja Negra

113
10.1.5 Fichas Técnicas de Máquinas
Máquina Tipo A
La maquinaria tipo A hace referencia a una la máquina de moldeo por inyección HWA
CHIN 210 – HC Series la cual se detalla a continuación.
Ilustración 4 Moldeadora por inyección
Marca HWA CHIN
Origen Taiwan
Funcionamiento Microcomputer Toggle
Type Injection Molding
Machine
Tipo HC Series
Modelo 210
Capacidad Max. de
presión
140 kg/cm^2
Peso 6.8 ton
Potencia Motor 22 kw
Tasa de Inyección Small: 203 cm^3/s
Medium: 265 cm^3/s
Large: 348 cm^3/s
Velocidad de giro del
tornillo
0-259 rpm
Voltaje 220 v
Largo 4.9 m
Ancho 1.4 m
Alto 1.0 m

114
Máquina Tipo B
La máquina tipo B hace referencia a una Termoencogedora industrial de Cemapack ltda.
con las siguientes especificaciones
Ilustración 5 Termoencogedora 1
Marca Cemapack ltda.
Origen Bogotá Colombia
Funcionamiento Termoencogido
Modelo 4030
Potencia Motor 1/8 HP
Temperatura de función Aprox 200ºC
Velocidad de banda 80
Voltaje 220v
Largo 100 cm
Alto 70 cm
Entrada 30x40 cm
Salida 30x40 cm
Nº Resistencias internas 4
Ancho Banda Trans. 40 cm
Largo Banda Trans. 150 cm
Temperatura 0 a 300ºC
Velocidad 0 a 100 rpm

115
Ilustración 6 Termoencogedora 2
Marca Termo Express
Origen Bogotá Colombia
Funcionamiento Termoencogido
Tipo motor Inducción monofásica
Modelo 4040
Resistencias 8 laterales
Ventiladores 2
Velocidad Motor 3450 rpm
Temperatura de función 320ºC
Velocidad de banda 65-70
Voltaje 220 v
Altura 175 cm
Largo cabina 120 cm
Ancho cabina 70 cm
Entrada 40 x 40 cm
Salida 40 x 40 cm
Ancho Banda Trans. 43 cm
Largo Banda Trans. 270 cm

116
Máquina Tipo C
La máquina C hace referencia a una marmita o mezcladora con las siguientes
especificaciones técnicas
Ilustración 7 Marmita
Marca Desconocido
Origen Desconocido
Funcionamiento Mezcladora
Alto 69 cm
Diámetro 79 cm
Capacidad Max. Almacen. 300kg
Boquilla 3’’
Velocidad Motor 1100 rpm
Potencia Motor 2 HP
Marca Motor Siemens
Hz 60
Material Acero Inoxidable calibre
18 doble pared
Voltaje 220 v

117
Máquina Tipo D
La máquina Tipo D representa toda una estación de trabajo con dos máquinas por cada
una. La primera es la envasadora la cual está compuesta por 2 pistones neumáticos y un
embudo y la segunda es una báscula para pesar el contenido neto del envase.
Ilustración 8 Estación Envase-Pesa-Tapa
Marca TecnoEmbalajes SAS
Origen Bogotá, Colombia
Funcionamiento Dosificado y pesado
Material Acero inoxidable 18
Manguera 6 mm
Marca bascula BBG
Modelo Bascula DY-24
Válvula 1/8 dosificador
Número de pistones 2
Sensores 2 eléctricos
Voltaje 110 v
Largo 85 cm
Ancho 46 cm
Alto mesa 1 m

118
10.1.6 Representantes Tipo
Representante Tipo Precio de Venta Imagen
Jabón Lavaloza por
250g $ 790 x unidad
Jabón Lavaloza por
500g $ 1,700 x unidad
Jabón Lavaloza por
1000g $ 2,900 x unidad
Jabón Lavaloza por
1500g $ 4,600 x unidad
Jabón Lavaloza por
3000g $ 8,976x unidad

119
10.1.7 Diagrama de Operaciones
DIAGRAMA DE OPERACIONES PARA LA PRODUCCIÓN DE UNA UNIDAD DE JABÓN LAVALOZA 250g.
ALIANZAS Y/O INDUSTRIAS ALTA PUREZA S.A
1
ENVASE
Fajillar
Código de Colores
Fabricación Envase
Fabricación Jabón
Lavaloza 250g
Ácidos, BenzoatosCarbonatos, Silicatos,Fragancias y Colores
JABÓN LAVALOZA
4.70 s Mezclar
21.69 s Códificar
4 Envasar0.98 s
3
7 Empacar4.31 s
Caja
Etiqueta
6.21 s
Pesar1.42 s
5 Tapar0.82 s
1
N° de operaciones: 7
N° de inspecciones : 1
N° de operaciones inspecciones: 1
Situación: Actual
Elaborado por: Juan Camilo Díaz
AlistamientoEnvasado0.41 s 1
6 Secar72 s

120
DIAGRAMA DE OPERACIONES PARA LA PRODUCCIÓN DE UNA UNIDAD DE JABÓN LAVALOZA 500g.
ALIANZAS Y/O INDUSTRIAS ALTA PUREZA S.A
2
3
ResinaPigmento
ENVASE
Fajillar
5.64 s
Código de Colores
Fabricación Envase
Fabricación Jabón
Lavaloza 500g
Fabricar Envase(Cuerpo)
Ácidos, BenzoatosCarbonatos, Silicatos,Fragancias y Colores
JABÓN LAVALOZA
9.40 s Mezclar
42.23 s Códificar
6 Envasar1.57 s
5
9 Empacar6.42 s
Caja
Etiqueta
4.81 s Fabricar Envase (Tapa)
1
7.91 s
Pesar1.58 s
7 Tapar1.09 s
1
N° de operaciones: 9
N° de inspecciones : 1
N° de operaciones inspecciones: 1
Situación: Actual
Elaborado por: Juan Camilo Díaz
AlistamientoEnvasado0.81 s 1
8 Secar144 s
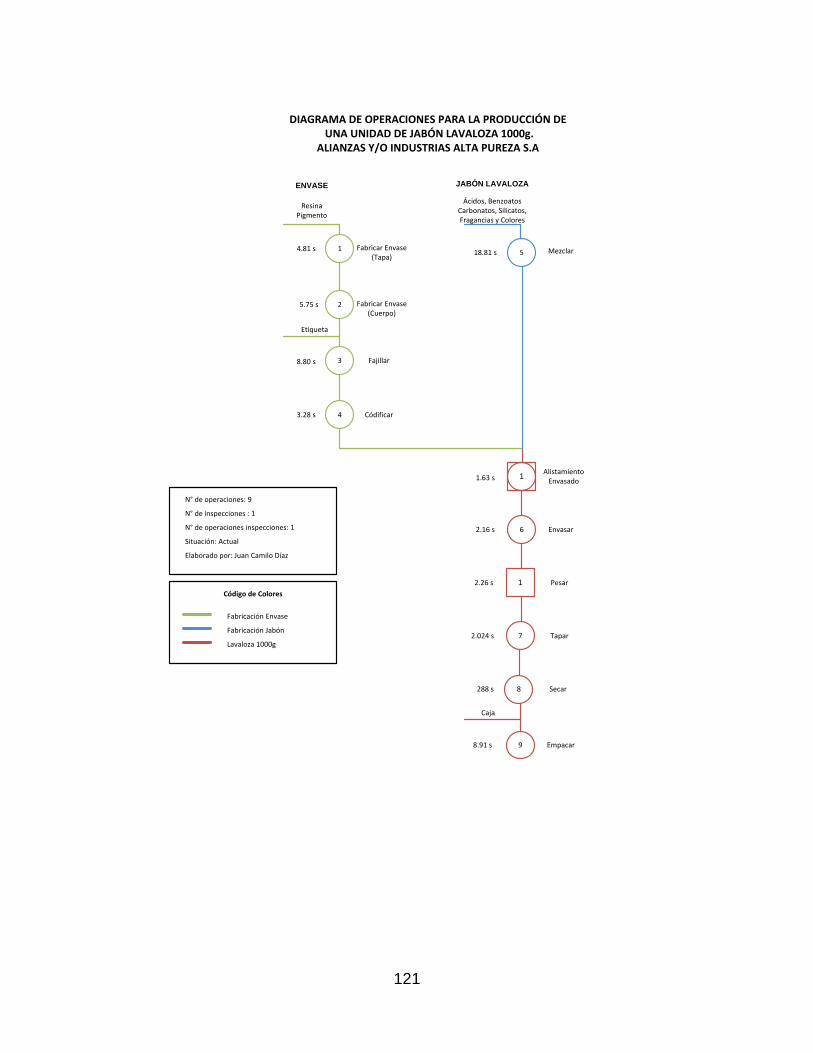
121
DIAGRAMA DE OPERACIONES PARA LA PRODUCCIÓN DE UNA UNIDAD DE JABÓN LAVALOZA 1000g.
ALIANZAS Y/O INDUSTRIAS ALTA PUREZA S.A
2
3
ResinaPigmento
ENVASE
Fajillar
5.75 s
Código de Colores
Fabricación Envase
Fabricación Jabón
Lavaloza 1000g
Fabricar Envase(Cuerpo)
Ácidos, BenzoatosCarbonatos, Silicatos,Fragancias y Colores
JABÓN LAVALOZA
18.81 s Mezclar
43.28 s Códificar
6 Envasar2.16 s
5
9 Empacar8.91 s
Caja
Etiqueta
4.81 s Fabricar Envase (Tapa)
1
8.80 s
Pesar2.26 s
7 Tapar2.024 s
1
N° de operaciones: 9
N° de inspecciones : 1
N° de operaciones inspecciones: 1
Situación: Actual
Elaborado por: Juan Camilo Díaz
AlistamientoEnvasado1.63 s 1
8 Secar288 s

122
DIAGRAMA DE OPERACIONES PARA LA PRODUCCIÓN DE UNA UNIDAD DE JABÓN LAVALOZA 1500g.
ALIANZAS Y/O INDUSTRIAS ALTA PUREZA S.A
1
ENVASE
Fajillar
Código de Colores
Fabricación Envase
Fabricación Jabón
Lavaloza 1500g
Ácidos, BenzoatosCarbonatos, Silicatos,Fragancias y Colores
JABÓN LAVALOZA
28.21 s Mezclar
23.35 s Códificar
4 Envasar3.05 s
3
7 Empacar8.96 s
Caja
Etiqueta
9.82 s
Pesar3.07 s
5 Tapar3.16 s
1
N° de operaciones: 7
N° de inspecciones : 1
N° de operaciones inspecciones: 1
Situación: Actual
Elaborado por: Juan Camilo Díaz
AlistamientoEnvasado2.44 s 1
6 Secar432 s

123
DIAGRAMA DE OPERACIONES PARA LA PRODUCCIÓN DE UNA UNIDAD DE JABÓN LAVALOZA 3000g.
ALIANZAS Y/O INDUSTRIAS ALTA PUREZA S.A
4 Fajillar
Código de Colores
Fajillado
Mezcado
Envasado
Ácidos, BenzoatosCarbonatos, Silicatos,Fragancias y Colores
JABÓN LAVALOZA
56.43 s Mezclar
53.84 s Códificar
2 Envasar5.87 s
1
7 Empacar7.17 s
Caja
Etiqueta
13.33 s
Pesar9.82 s
3 Tapar3.97 s
1
N° de operaciones: 7
N° de inspecciones : 1
N° de operaciones inspecciones: 1
Situación: Actual
Elaborado por: Juan Camilo Díaz
AlistamientoEnvasado4.88 s 1
6 Secar864 s
Lavaloza 3000g

124
10.1.8 División de Operaciones por Elemento
OPERACIÓN ELEMENTO
Moldear Automatizado -M- (500g y 1000g)
Almacenar base (envase)
Tomar base Apilar base
Ubicar en caja Transportar caja
Almacenar tapa (envase)
Tomar tapa Apilar tapa
Ubicar en caja Transportar caja
Fajillar
Tomar envase
Colocar etiqueta
Ubicar en máquina
Termo Sellar -M- Automatizado: 4 s/unidad
Recoger envase con etiqueta
Codificar
Tomar envase
Codificar
Apilar envase
Mezclar Jabón *
Alistar Marmita
Adicionar Agua
Adicionar sulfato 1
Adicionar sulfato 2
Adicionar sulfato 3
Mezclar
Adicionar Primer Carbonato de Calcio
Alistar segundo carbonato de calcio
Adicionar segundo Carbonato de Calcio
Alistar Carbonato de Sodio
Adicionar Carbonato de Sodio
Mezclar
Agregar Color
Alistar Tercer Carbonato de calcio
Adicionar Tercer Carbonato de Calcio
Alistar Cuarto Carbonato de Calcio
Adicionar Cuarto Carbonato de Calcio con agua
Mezclar
Adicionar primer Acido Sulfónico
Alistar Segundo Acido Sulfónico
Adicionar Segundo Acido Sulfónico
Alistar Quinto Carbonato de calcio
Adicionar quinto Carbonato de Calcio
Alistar Silicato y Cocoamida
Adicionar Silicato y Cocoamida
Alistar Glicerina y Aroma
Adicionar Glicerina y Aroma
Mezclar
Envasar
Alistar puesto de trabajo
Abrir válvula
Dejar llenar embudo
Tomar envase
Ubicar envase
Esperar llenado

125
Pasar producto a pesaje
Verificar Peso
Tomar producto
Pesar producto
Pasar producto a tapado
Tapar
Tomar producto
Tapar producto
Ubicar producto
Transportar producto a pasaje
Secar Esperar secado
Empacar
Alistar caja
Empacar
Sellar caja
Ubicar caja

126
10.2 Formas de Estudio de Tiempos
10.2.1 Formato estándar para la realización del estudio de Tiempos
Observaciones para la realización del estudio de tiempos Estudio Nº: 0 de Fecha: Página: 1 de
Operación: Operario: Analista: J.C Díaz
Nº de elemento -> 1 2 3 4 5 …
Descripción del elemento
Nota Ciclo RT TC TO TN RT TC TO TN RT TC TO TN RT TC TO TN RT TC TO TN RT TC TO TN
1
2
3
4
5
…
Resumen
TO Total
RT Global
TN Total
Nº de Observaciones
TN Promedio
% de Holgura
Tiempo Estándar Elemental
Número de Ocurrencias
TIEMPO ESTÁNDAR
Tiempo Estándar Total
Elementos Extraños Verificación de tiempos Resumen de holguras
Sim TC1 TC2 TO Descripción Tiempo de Terminación Necesidades Personales 5
A Tiempo de Inicio Fatiga básica 4
B Tiempo Transcurrido min Fatiga variable (de pie)
C TTAE
Especial
D TTDE % Holguras Total 9
E Tiempo Verificado Total
Observaciones:
F Tiempo Efectivo
G Tiempo Inefectivo
Verificación de Calificación Tiempo Registrado Total
Tiempo Sintético %
Tiempo No Contabilizado
Tiempo Observado % de Error de Registro

127
10.3 Suplementos Personales26
26 Véase: Introducción Al Estudio Del Trabajo O.I.T.; 4a. Edición Revisada 2004; Edit. Limusa,
Grupo Noriega Editores.
I P N - U P I I C S A
LABORATORIO DE INGENIERIA DE METODOS
SISTEMA DE SUPLEMENTOS POR DESCANSO EN PORCENTAJE DE LOS TIEMPOS BASICOS
H M1.- SUPLEMENTOS CONSTANTES
SUPLEMENTOS POR NECESIDADES PERSONALESSUPLEMENTO BASICO POR FATIGA
SUMA
549
74
11
2.- CANTIDADES VARIABLES AÑADIDAS AL SUPLEMENTO BASICO POR FATIGAA. SUPLEMENTO POR TRABAJAR DE PIEB. SUPLEMENTO POR POSTURA ANORMAL
I. LIGERAMENTE INCOMODAII. INCOMODA (INCLINADO)
III. MUY INCOMODA (ECHADO, Estirado)
C. LEVANTAMIENTO DE PESO Y USO DE FUERZA (TIRAR, EMPUJAR)2.5 ………………………………………………………….5.0 ………………………………………………………….7.5 ………………………………………………………….10 ………………………………………………………….12.5………………………………………………………….15 ………………………………………………………….17.5………………………………………………………….20 ………………………………………………………….22.5………………………………………………………….25 ………………………………………………………….30 ………………………………………………………….40 ………………………………………………………….50 ………………………………………………………….
D. DENSIDAD DE LA LUZ
I. LIGERAMENTE POR DEBAJO DE LO RECOMENDADO
II. BASTANTE POR DEBAJOIII. ABSOLUTAMENTE INSUFICIENTE
E. CALIDAD DEL AIREI. BUENA VENTILACION O AIRE LIBRE
II. MALA VENTILACION SIN EMANACIONESTOXICAS Y NOCIVAS
III. PROXIMIDAD DE HORNOS, ESCALERAS, ETC.F. TENSION VISUAL
I. TRABAJOS DE CIERTA PRECISIONII. TRABAJOS DE PRECISION FATIGOSOS
III. TRABAJOS DE GRAN PRECISION O MUY FATIGOSOS
2
027
0123468101214193358
025
05
5-15
025
4
137
123469
121518----
025
05
5-15
025
G. TENSION AUDITIVAI. SONIDO CONTINUOII. INTERMITENTE Y FUERTEIII. INTERMITENTE Y MUY FUERTEIV. ESTRIDENTE Y FUERTE
H. TENSION MENTALI. PROCESO BASTANTE COMPLEJOII. PROCESO COMPLEJO O
ATENCION MUY DIVIDIDAIII. MUY COMPLEJO
I. MONOTONIA MENTALTRABAJO ALGO MONOTONOTRABAJO BASTANTE MONOTONOTRABAJO MUY MONOTONO
J. MONOTONIA FISICAI. TRABAJO ALGO ABURRIDOII. TRABAJO ABURRIDOIII. TRABAJO MUY ABURRIDO
0255
14
8
014
025
0255
14
8
014
022

128
10.4 Muestreo Del Trabajo
La técnica de muestreo del trabajo es ampliamente utilizada como un método de análisis
del trabajo para la investigación de las proporciones del tiempo total al cual es dedicada
una actividad de una tarea o una situación de trabajo, así como la determinación del
grado de utilización de una máquina o un operario. La teoría detrás del muestreo del
trabajo se fundamenta en leyes de probabilidad que determinarán si un evento
determinado puede o no estar presente en un determinado instante de tiempo. (ver Niebel
(2012))
Sin entrar en teorías de muestro del trabajo27, se sabe que una variable aleatoria cuya
probabilidad de ocurrencia se determina por el número de éxitos en una secuencia de
ensayos de Bernoulli independientes entre sí, puede ser descrita por una distribución
Binomial con aproximación por muestras grandes a una distribución normal.
Dentro del uso del muestreo del trabajo con fines de determinación del grado de
utilización se ha diseñado un formulario en el que se registraron 16 estados posibles en
los que se podrían encontrar por un lado las 5 máquinas y por otro los 15 operarios por
etapa de proceso.
A continuación se presentan las fases en las que se llevó a cabo el muestreo del trabajo:
1. Fueron seleccionadas los posibles estado a observar dentro del estudio, para cada
recurso.
2. Se tomó una muestra preliminar de 40 observaciones, lo correspondiente a una
sección de trabajo de 5 horas, con el objetivo de determinar un valor estimado del
parámetro . Donde
3. Se calculó el número de observaciones requeridas para el muestreo, el cual es
una función de , del nivel de confianza determinado por la desviación normal
estándar y de los niveles de exactitud aceptada o también máximo error (en
porcentaje) tolerado , así
4. A continuación se preparó una programación de las observaciones tanto para el
recurso máquina como el recurso humano, de tal forma que sean aleatorias,
27 Para esto, véase Niebel(2012) y Chase et al (1997)

129
usando para ello la generación de números aleatorios que permitan construir el
programa de tiempos.
5. Se procedió con la observación, calificación y registro de la actividad en que el
trabajador o la máquina se encontraba en ese preciso instante de tiempo.
6. Se procedió a la construcción de la tabla que resume todos los eventos por
recurso para la determinación del grado de uso de cada uno de ellos.

130
10.5 Procedimientos Matemáticos
10.5.1 Desarrollo de Ecuación de Capacidad Disponible Recurso Hombre.
[
(
)]
Nomenclatura
Número de turnos en la etapa j
Días hábiles en el periodo de tiempo j
: Número de trabajadores en la etapa j
Número de máquinas en la etapa j
Horas por turno en la etapa j
Horas de descanso en la etapa j
Porcentaje de tiempo ocioso
Porcentaje de tiempo en mantenimiento
Sea
( ) ( )
considerando la capacidad real como: se tiene que
[ ]
factorizando y reordenando
sea se tiene que

131
10.6 Análisis de las Series de Tiempo
10.6.1 Funciones de Pérdida de Pérdida de Error de Pronóstico Simétricas
10.6.1.1 Mean Square Error (MSE) – Error Cuadrático Medio (ECM)
Fue introducido por Carl Friederich Gauss y es bastante utilizado en la literatura debido a
su conveniencia matemática. Presenta características importantes como lo es la
monotonicidad creciente, la simetría, la homogeneidad de grado dos y la diferenciabilidad
en todo su rango. Se presenta de la siguiente forma
( )
además puede llegar a ser subdividido en 3 diferentes partes a lo que se le llama
descomposición del MSE, donde se tiene
( )
( ) ( )
por estadística básica de definiciones de varianza y covarianza sabemos que
(
)
( ) ( )
( ) donde es el coeficiente de correlación de la
variable predicha y la real.
Tenemos entonces que al despejar los valores de interés, reemplazar y dividir todo
( ) nos queda que
(
)
( )
(
)
( )
( )
donde el primer término de la suma corresponde a la proporción del sesgo y mide que tan
lejos está la media de la serie original con la media del pronóstico, el segundo término
corresponde a la proporción de la varianza y mide si la volatilidad de mi predicción es
parecida a la volatilidad de los datos reales y por último el tercer término corresponde a la
proporción de covarianza y mide el residuo o los errores no explicados por las dos
anteriores, por tanto entre más pequeñas sean las proporciones de sesgo y varianza más
acertado estará el pronóstico.

132
Gráfica 6 Función de pérdida MSE
Fuente: Realizado por el autor
10.6.1.2 Mean Absolute Error (MAE) – Error Absoluto Medio (EAM)
Esta función de costos es monotonicamente creciente, simétrica, homogénea y
diferenciable en todo su rango a excepción de cuando .
( ) | |
Gráfica 7 Función de pérdida MAE
Fuente: Realizado por el autor
0
1
2
3
4
5
-2
-1,7
8
-1,5
6
-1,3
4
-1,1
2
-0,9
-0,6
8
-0,4
6
-0,2
4
-0,0
2
0,2
0,4
2
0,6
4
0,8
6
1,0
8
1,3
1,5
2
1,7
4
1,9
6
Co
sto
MSE
0
0,5
1
1,5
2
2,5
-2
-1,7
8
-1,5
6
-1,3
4
-1,1
2
-0,9
-0,6
8
-0,4
6
-0,2
4
-0,0
2
0,2
0,4
2
0,6
4
0,8
6
1,0
8
1,3
1,5
2
1,7
4
1,9
6
Co
sto
MAE

133
10.6.2 Funciones De Pérdida de Error de Pronóstico Asimétricas.28
10.6.2.1 Linex
La función de pérdida linex fue introducida por Varian (1974) y después analizada por
Zellner (1986), está dada por
{ ( )} [ ( ( )) ( ) ]
Esta función linex es llamada así puesto que presenta una forma casi lineal a un lado del
origen y una forma casi exponencial el otro lado del origen. Lo que le da un ponderación
del costo con mayor peso a los errores que están por el lado de exponencial que por el
lado lineal. El parámetro que juega el papel más importante en la función linex es el
parámetro , puesto que si entonces la función de pérdida de error de pronóstico
es aproximadamente lineal en la izquierda del origen y aproximadamente exponencial a la
derecha, de manera contraria, cuando entonces la función es aproximadamente
exponencial a la izquierda y aproximadamente lineal a la derecha. Si
entonces
( ) (( )
)
por lo tanto para un pequeño, el costo cuadrático está aproximadamente anidado
dentro del costo linex.
Zellner (1986) mostró que cuando la variable está distribuida normalmente, el valor
de predicción puede está dado por
donde representa la media muestral de la serie y la varianza poblacional, la cual
es reemplazada por la muestral en la práctica. Esto traería una función esperada de
costos igual a
( ( )) (
) ( )
28 Véase Christoffersen & Diebold (1997).

134
Gráfica 8 Función de pérdida LINEX
Fuente: Realizado por el autor
10.6.2.2 Linlin
Fue desarrollada por Granger (1969), donde consideró la función asimétrica de costos de
la siguiente manera
( ) [ | |
| |
Esta función de costos es llamada linlin debido a que es linealmente creciente en ambos
lados del origen con las pendientes y respectivamente. Por consiguiente el grado de
asimetría dependerá de la razón de las pendientes (i.e. / ( .
Tanto en la función de pérdida linlin como en la pérdida Linex es fácil permitir varianza
condicional dinámica cuando se construye la predicción óptima.
El valor esperado condicional el valor pronosticado en linlin está dado por
|
∫ |
∫ |
Se observa como la solución óptima del valor predicho está determinada por la
minimización del valor esperado de la función de costos
0
5
10
15
20
25
-2
-1,7
8
-1,5
6
-1,3
4
-1,1
2
-0,9
-0,6
8
-0,4
6
-0,2
4
-0,0
2
0,2
0,4
2
0,6
4
0,8
6
1,0
8
1,3
1,5
2
1,7
4
1,9
6
Co
sto
LINEX [δ1=0.8, δ2=9]

135
El parámetro determina la pendiente de la función de costos trucada para valores
cuando el pronóstico está por dejado del valor real, y el parámetro determina la
pendiente de la función de costos truncada cuando el pronóstico está por encima del valor
real. Tenemos entonces que las fórmulas para las expresiones truncadas del valor
esperado condicional estarían dadas por
{ | } ∫ |
{ | } ∫ |
Para esta función específica, Granger (1969) demostró que el pronóstico que minimiza la
pérdida esperada del valor pronosticado en el caso cuando la variable está distribuida
normalmente está dado por
(
)
donde es la media muestral de la serie de tiempo, es la desviación estándar
poblacional la cual es reemplazada por la muestral en la practica y es la función de
distribución acumulada de función de densidad normal estándar.
Gráfica 9 Función de pérdida LINLIN
Fuente: Realizado por el autor
012345678
-2-1
,79
-1,5
8-1
,37
-1,1
6-0
,95
-0,7
4-0
,53
-0,3
2-0
,11
0,1
0,3
10
,52
0,7
30
,94
1,1
51
,36
1,5
71
,78
1,9
9
Co
sto
LINLIN [δ1=3.5, δ2=2]

136
10.6.3 Descripción de los Datos
REFERENCIAS
AÑO MES R250 R500 R1000 R1500 R3000
2010
Enero 7056 7260 756 1080
Febrero 19056 10596 1740 1620
Marzo 21528 20532 1128 1716
Abril 15096 8964 1608 2298
Mayo
13800 15468 1584 2076
Junio 7776 22032 16380 2340 2442
Julio 5424 23592 17700 1068 2262
Agosto 4464 17400 24732 1500 1338
Septiembre 6048 13536 18924 1248 1644
Octubre 4992 12576 18096 1524 2262
Noviembre 4848 13824 11208 1596 1782
Diciembre 3792 10392 9528 1812 1458
2011
Enero 5856 14376 14196 2400 2844
Febrero 5616 15168 16080 2280 2178
Marzo 6240 28608 21492 1920 2256
Abril 2448 22008 7464 2208 2046
Mayo 4464 15240 7560 1680 1536
Junio 768 19992 7824 2400 1914
Julio 1200 23064 17064 3132 2970
Agosto 4752 21456 17520 2352 2880
Septiembre 1440 16008 9000 1620 1890
Octubre 3120 12984 10632 1356 1626
Noviembre 2640 6408 10236 2304 2490
Diciembre 3456 20352 9948 4260 4326
2012
Enero 7632 28794 11928 2400 1620
Febrero 21920 21030 12276 2652 3636
Marzo 4864 28662 11736 2424 2850
Abril 13360 29382 13320 2004 2652
Mayo 4992 16806 6660 2448 2694
Junio 15520 18654 7056 2424 3396
Julio 17184 37536 9456 3288 4146
Agosto 15680 91272 11460 2940 3570
Septiembre 13344 33708 3252 2340 2898
Octubre 47312 52776 4260 2136 3402
Noviembre 26288 49818 7104 2304 3426
Diciembre 24432 45600 7500 2148 3756
2013
Enero 18592 53910 14976 1932 2682
Febrero 54036 53682 17100 1908 3288
Marzo 12618 63186 15336 1848 3588
Abril 42862 72168 16788 3456 5322
Mayo 19360 39168 14076 2100 2994
Junio 46702 59850 23697 1740 2700
Julio 39866 114180 21060 2436 3378
Agosto 67768 61572 20286 2486 4140
Septiembre 68968 56190 33006 2700 2982
Octubre 50322 57264 19380 2604 2526
Noviembre 47584 17370 24252 2136 2958
Diciembre 68032 44676 33660 4992 5964
2014 Enero 36320 49932 13680 2424 1650
Febrero 73824 33906 14088 2076 2364

137
0
10000
20000
30000
40000
50000
60000
70000
80000
1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1
2010 2011 2012 2013 2014
R250
0
20000
40000
60000
80000
100000
120000
1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1
2010 2011 2012 2013 2014
R500

138
0
5000
10000
15000
20000
25000
30000
35000
40000
1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1
2010 2011 2012 2013 2014
R1000
0
1000
2000
3000
4000
5000
6000
1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1
2010 2011 2012 2013 2014
R1500

139
0
1000
2000
3000
4000
5000
6000
7000
1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1
2010 2011 2012 2013 2014
R3000
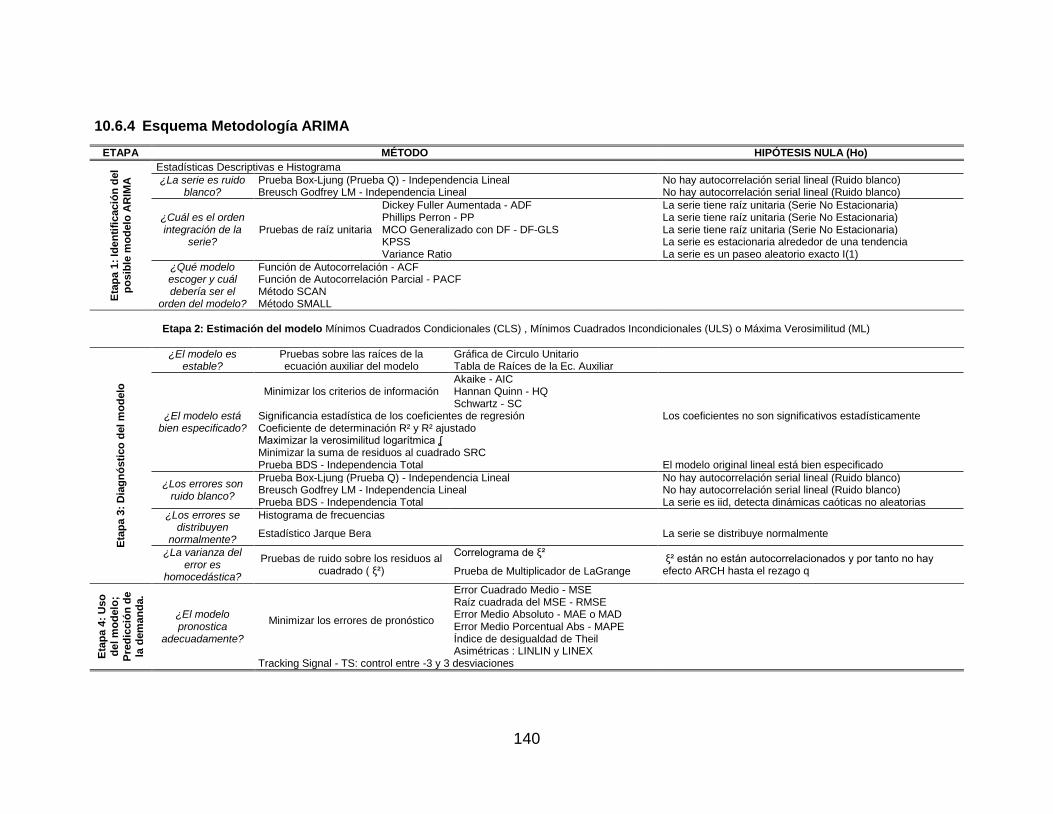
140
10.6.4 Esquema Metodología ARIMA
ETAPA MÉTODO HIPÓTESIS NULA (Ho)
Eta
pa
1:
Ide
nti
ficació
n d
el
po
sib
le m
od
elo
AR
IMA
Estadísticas Descriptivas e Histograma
¿La serie es ruido blanco?
Prueba Box-Ljung (Prueba Q) - Independencia Lineal No hay autocorrelación serial lineal (Ruido blanco) Breusch Godfrey LM - Independencia Lineal No hay autocorrelación serial lineal (Ruido blanco)
¿Cuál es el orden integración de la
serie? Pruebas de raíz unitaria
Dickey Fuller Aumentada - ADF La serie tiene raíz unitaria (Serie No Estacionaria) Phillips Perron - PP La serie tiene raíz unitaria (Serie No Estacionaria) MCO Generalizado con DF - DF-GLS La serie tiene raíz unitaria (Serie No Estacionaria) KPSS La serie es estacionaria alrededor de una tendencia Variance Ratio La serie es un paseo aleatorio exacto I(1)
¿Qué modelo escoger y cuál debería ser el
orden del modelo?
Función de Autocorrelación - ACF Función de Autocorrelación Parcial - PACF Método SCAN Método SMALL
Etapa 2: Estimación del modelo Mínimos Cuadrados Condicionales (CLS) , Mínimos Cuadrados Incondicionales (ULS) o Máxima Verosimilitud (ML)
Eta
pa
3:
Dia
gn
ós
tico
del m
od
elo
¿El modelo es estable?
Pruebas sobre las raíces de la ecuación auxiliar del modelo
Gráfica de Circulo Unitario Tabla de Raíces de la Ec. Auxiliar
¿El modelo está bien especificado?
Minimizar los criterios de información Akaike - AIC Hannan Quinn - HQ Schwartz - SC
Significancia estadística de los coeficientes de regresión Los coeficientes no son significativos estadísticamente Coeficiente de determinación R² y R² ajustado a imizar la erosimilitud logarítmica ʆ Minimizar la suma de residuos al cuadrado SRC Prueba BDS - Independencia Total El modelo original lineal está bien especificado
¿Los errores son ruido blanco?
Prueba Box-Ljung (Prueba Q) - Independencia Lineal No hay autocorrelación serial lineal (Ruido blanco) Breusch Godfrey LM - Independencia Lineal No hay autocorrelación serial lineal (Ruido blanco) Prueba BDS - Independencia Total La serie es iid, detecta dinámicas caóticas no aleatorias
¿Los errores se distribuyen
normalmente?
Histograma de frecuencias
Estadístico Jarque Bera La serie se distribuye normalmente
¿La varianza del error es
homocedástica?
Pruebas de ruido sobre los residuos al cuadrado ( ξ²)
Correlograma de ξ² ξ² est n no est n autocorrelacionados y por tanto no hay efecto ARCH hasta el rezago q Prueba de Multiplicador de LaGrange
Eta
pa
4:
Uso
de
l m
od
elo
;
Pre
dic
ció
n d
e
la d
em
an
da.
¿El modelo pronostica
adecuadamente?
Minimizar los errores de pronóstico
Error Cuadrado Medio - MSE Raíz cuadrada del MSE - RMSE Error Medio Absoluto - MAE o MAD Error Medio Porcentual Abs - MAPE Índice de desigualdad de Theil Asimétricas : LINLIN y LINEX
Tracking Signal - TS: control entre -3 y 3 desviaciones

141
10.6.5 Estabilización Varianza
Guerrero (2003) sugiere que el método para estabilizar la varianza de la serie debe llevar
a la elección de una potencia de tal manera que se satisfaga la relación
donde y representan la desviación estándar y la media de la variable
respectivamente y N el número total de observaciones con las que se cuenta, es decir la
dimensión del tiempo.
Para lograr encontrar la potencia que estabilice la varianza de la serie se deberá primero
dividir las N observaciones en H grupos donde cada uno deberá contener un total de
observaciones. En R se está dejando a un total de observaciones (para
) por fuera de los cálculos, bien sea al inicio o al final de la serie. Esto se realiza
con el propósito que exista homogeneidad entre el número de observaciones de los
grupos. A continuación se procede a estimar y de cada uno de los H grupos.
Una vez obtenidos estos dos parámetros se procede a reunirlos en una tabla que permita
observar el coeficiente de variabilidad CV de la relación a partir de la iteración de
potencias para cada uno de los H grupos. Como se mencionó, dicha relación debe
cumplir que sea igual a una constante, por lo que se busca la potencia que haga el menor
coeficiente de variabilidad y esa es catalogada como el para la transformación
estabilizadora de la varianza.
Potencia (
Grupo -1 -0.5 0 0.5 1
1
⁄
⁄
⁄
⁄
2
⁄
⁄
⁄
⁄
… …
⁄
⁄
⁄
⁄
… …
H
⁄
⁄
⁄
⁄
Coef. Variación
CV(-1) CV(-0.5) CV(0) CV(0.5) CV(1)
Tabla 57 Tabla Transformaciones de potencia

142
En la Tabla 56. Tabla de transformaciones de Potencia representa el promedio
ponderado de las observaciones del grupo H es decir
∑
√∑
se sabe además que el coeficiente de variación CV se calcula como la relación entre la
desviación estándar de todas las H observaciones para cada potencia y la media
, asi
se debe entonces encontrar el mínimo coeficiente de variación CV para satisfacer la
relación a partir de la aproximación de la relación
por lo tanto se tiene que la serie una vez transformada para estabilizar su varianza estará
dada por
{
la transformación logarítmica de para la potencia , se da cuando se observa el
limite cuando la tiende a cero de la transformación de potencia introducida por Box y
Cox (1964)
donde
10.6.6 Prueba Dickey Fuller Aumentada ADF
La prueba paramétrica ADF ha sido una de las más utilizadas en la práctica por su
eficiencia y simplicidad. Fue desarrollada por Dickey, D. A y Fuller, W. A. en 1979 y
presenta la siguiente estructura

143
∑
se tiene que las pruebas de hipótesis son
donde el termino de rezagos de la diferencia ∑ se agrega para que los residuos
resultantes sean ruido blanco, es decir que no tengan correlación serial entre ellos, de allí
el hecho que esta prueba sea del tipo paramétrica. Es importante recalcar que agregar
este término no cambia la dependencia de . El número de rezagos de se escoge o
bien corriendo la misma ecuación con un número lejano de rezagos y realizando una
iteración hacia atrás (Back Iteration Process) hasta que el último sea significativo y
encontrando ruido blanco por primera vez en el término de perturbación como se verá
en detalle más adelante, o por medio de criterios de información para la selección
automática como Akaike AIC, Schwarz SC, Hannan Quinn HQ el cual no siempre
garantiza ruido en .
Si entonces no depende del nivel anterior de la serie por lo que nada tiende a
devolver la serie cuando se aleja de su media y será por tanto una serie no estacionaria.
Para que la serie sea estacionaria se espera que , pues existirá un mecanismo que
devuelva la serie a su media si ésta se aleja.
Dickey y Fuller (1979) consideraron tres diferentes ecuaciones de regresión que pueden
ser utilizadas para llegar a probar la presencia de raíz unitaria. La principal diferencia
radica en la existencia de regresores determinísticos en (D5), la primera ecuación se
estima sin tendencia lineal ni corrimiento o constante, es decir (D5), la segunda se estima
únicamente con corrimiento , y la tercera con corrimiento y tendencia lineal , es
decir que se tendrían estas tres ecuaciones
∑
∑
∑
La hipótesis nula de se prueba con los mismos estadísticos de las tablas Fuller
(1976) mientras que las pruebas conjuntas de los coeficientes , y se prueban por
medio de estadísticos F llamados , y proporcionados por Dickey et al (1981)29.
Este estadístico toma el valor de
29 Las tablas Fuller (1976) y Dickey et al (1981) se pueden consultar al final de este documento en
el Anexo 10.11.1 Tablas Para Pruebas de Raíz Unitaria.

144
donde y corresponden a las sumas de residuos cuadrados de el modelo
restringido bajo Ho y no restringido respectivamente, corresponde al número de
restricciones, al número de observaciones usadas30 y a el número de parámetros
estimados en el modelo no restringido.
Se tiene entonces que
Modelo31
Hipótesis Estadístico
∑
∑
∑
Tabla 58 Resumen de test Dickey Fuller.
10.6.7 Prueba de Raíz Unitaria para la serie LR1000
Selección del número de rezagos en ADF
La selección del número de rezagos caracteriza un problema vital en las pruebas de raíz
unitaria ADF. En general, muy pocos rezagos pueden conllevar a que los residuos de la
regresión no se comporten como ruido blanco y por tanto el modelo no este capturando el
proceso real, mientras que una sobre dimensión de los rezagos hace que se reduzca la
potencia estadística del test a rechazar la hipótesis nula por la pérdida de grados de
libertad.
En pro de obtener una ecuación ADF con un número adecuado de rezagos se procedió32
a comenzar con un número relativamente alto de rezagos (en este caso 10) y se probó
la significancia estadística del último rezago por medio de el estadístico t. Si éste no es
significativo a un nivel de significancia dado, se reestima la regresión utilizando
rezagos, y se prueba de nuevo la significancia. Este proceso se detiene hasta que el
último rezago sea significativo estadísticamente y además que (y muy importante) se
obtenga por primera vez ruido blanco en el término de perturbación aleatorio Este
30 Se dice que es T y no N puesto que no representa el total de la muestra sino el número de datos
utilizados, el cual varía dependiendo del número de rezagos incluidos, y el orden de integración de la serie original. Es decir es el número de observaciones realmente utilizadas. 31 Tomado de Enders (1948, p.183). Tabla 4.2. 32 Siguiendo las indicaciones propuestas por Enders (1948)

145
último diagnóstico se probó por medio del estadístico Q de Ljung-Box y observando la
ACF de los residuos.
Para el ejemplo con la serie R1000, se tiene que el proceso generador de datos es
completamente desconocido, por lo que existen dos posibles caminos acorde a la serie de
tiempo, el primero que la serie pueda ser estacionaria en tendencia (TS), y el segundo
que el proceso de raíz unitaria contenga un término de corrimiento. Por consiguiente, el
planteamiento de la hipótesis nula determina que el proceso tiene raíz unitaria con
corrimiento, mientras que la hipótesis alterna establece que el proceso es TS, es decir
(D7).
Si no se tiene raíz unitaria se rechazará la hipótesis nula que y por tanto el proceso
es estacionario en tendencia, como lo plantea (D7).
Se estimó entonces la ecuación
∑
para un desde 1 hasta 10, en cada estimación se muestra el criterio de información
Akaike AIC, el criterio de Schwarz SIC, el valor del coeficiente de interés , su respectivo
estadístico t, y los valores de los estadísticos y , en concordancia a lo presentado en
la Tabla 57. Resumen de test Dickey Fuller.
AIC SIC t-stat 33
1 1.116478 1.272412 -0.406398 -2.946307 2.909644 4.352486
2 1.105032 1.301856 -0.331069 -2.211261 1.678211 2.516147
3 1.134791 1.373309 -0.333057 -2.076782 1.465419 2.158355
4 1.126266 1.407302 -0.244145 -1.450858 0.817609 1.19328
5 1.159157 1.483555 -0.308021 -1.722956 1.100391 1.644226
6 1.208023 1.576646 -0.344138 -1.772924 1.259111 1.888333
7 1.218849 1.632580 -0.440252 -2.113086 1.8221 2.728326
8 1.268110 1.727849 -0.537423 -2.272416 2.124501 3.181019
9 1.354340 1.861004 -0.536935 -1.965401 1.693466 2.54007
10 1.425883 1.980403 -0.585109 -1.876413 1.376393 2.053814
Tabla 59 Tabla de prueba de Dickey Fuller Aumentada para LR1000
Como se puede observar en la anterior tabla, el criterio de información de Akaike (AIC)
selecciona un número de rezagos igual a 2, mientras que el criterio de información de
Schwarz (SIC) selecciona un número de rezagos de 1, demostrando así que el criterio
33 Valores calcularos como
y
donde la hipótesis nula que
determina a está dada como y al menos un término diferentes de
cero. Mientras que la hipótesis nula que determina a está dada como y la el proceso es estacionario en tendencia TS es decir sigue un proceso tipo (D7). Las tablas de contraste de estos valores se encuentran en Dickey, David y Fuller (1981).

146
SIC tiende a escoger un modelo más parsimonioso que el AIC. Se tiene que al 5% de
significancia el valor critico en las tablas Fuller (1976) para la hipótesis nula de en
una muestra de 50 observaciones es de -3.50. Por lo tanto, los valores de escogidos por
ambos criterios de información son mayores que el valor critico, por lo que no se puede
rechazar la hipótesis nula de raíz unitaria.
Ahora bien, es más factible y confiable utilizar el algoritmo de propagación hacia atrás,
que permite encontrar el número de rezagos a través de la significancia del último y la
condición esencial de ruido blanco sobre el término de perturbación. En este tipo de
prueba se utilizan los estadísticos t y/o F para determinar el valor de , por lo tanto se
estimó la regresión (D7) para un igual a 10 donde se obtuvo que34
Al realizar la prueba t sobre el último coeficiente de se puede observar que
el valor de es menor que 10 rezagos, pues es insignificantico estadísticamente. Al
realizar la prueba conjunta para probar se obtuvo un estadístico F de 0.060
con un valor de probabilidad de 0.9417 con lo que se dice que se pueden eliminar los
rezagos 10 y 9, de manera similar se realizó con los demás rezagos, donde se llegó a
obtener los siguientes resultados
Ho F-Stat P-Value
0.060190 0.9417
0.322641 0.8089
0.417666 0.7944
0.383883 0.8552
0.373566 0.8891
0.539601 0.7965
0.482847 0.8571
0.520186 0.8465
0.468940 0.8849
Tabla 60 Pruebas F para escoger el número de rezagos en ADF
Como se puede observar, el estadístico F, no es permite rechazar la hipótesis nula ante la
incorporación iterada de ninguno de los rezagos. Lo que nos quiere decir esto es que la
prueba de ADF, la cual formalmente debería ser renombrada simplemente como DF pues
no e iste la parte “aumentada” a tra és de rezagos de las diferencias debería ser
estimada sin ningún componente rezagado de la primera diferencia del logaritmo natural.
Es decir el modelo
34 Estadísticos t en paréntesis (*)

147
Donde los estadísticos t se presentan en paréntesis redondo. La misma metodología de
análisis para la escogencia de los rezagos a partir de la propagación hacia atrás se llevó a
cabo para las demás series, donde se obtuvieron los siguientes resultados35.
Ljung-Box Q Stat para
Serie 3 6 9 12
LR250
1
2.759**
(2.492)
0.036**
(2.644)
-0.398**
(-2.612)
-0.446*
(-3.287) 0.914 0.955 0.615 0.830
TR500
0
0.005*
(4.421)
-5.9E-05*
(-2.986)
-0.666*
(-4.99) - 0.693 0.880 0.953 0.985
LR1000
0
4.053*
(3.62)
0.001
(0.273)
-0.430*
(-3.6) - 0.924 0.628 0.693 0.825
LR1500
7
4.071
(1.591)
0.002
(0.478)
-0.530
(-1.526)
-0.353**
(-2.40) 0.802 0.960 0.534 0.704
LR3000
0
7.419*
(6.78)
0.014*
(3.732)
-0.988*
(-6.73) - 0.407 0.271 0.387 0.543
Tabla 61 Resultados propagación hacia atrás Lag Length Choice
La tabla 60 debe ser entendida de la siguiente manera. La primera columna contiene el
nombre de la serie y el tipo de estadístico contrastado en las tablas Fuller (1976) en
donde simboliza que se probó todas las series con constante y tendencia, la segunda
columna presenta el número de rezagos escogidos después de realizar la metodología de
propagación hacia atrás, la tercera columna muestra el valor estimado del corrimiento, la
cuarta columna muestra el coeficiente estimado asociado al término de tendencia, la
quinta columna presenta el coeficiente asociado al término del primer rezago de la
variable dependiente es decir el coeficiente de interés para la prueba de raíz unitaria, la
sexta columna presenta el valor del coeficiente asociado al último rezago que dio
significativamente diferente de cero una vez realizado el método de propagación hacia
atrás es decir al rezago indicado en la segunda columna y por último, de las columnas
siete a la diez se presentan los valores de probabilidad de la prueba portmanteau de
Ljung-Box para los rezagos 3, 6, 9 y 12, la cual muestra como el término de perturbación
no guarda autocorrelación serial entre sus rezagos y por tanto son un proceso de ruido
blanco.
Como se mencionó anteriormente, las pruebas ADF pueden ser desarrolladas incluyendo
diferentes especificaciones en la ecuación que las representa. Esas especificaciones
pueden ser solo un intercepto , una tendencia e intercepto , o ninguna de las dos.
Esta parte es fundamental puesto que si la prueba llegase a estar mal especificada, el
35 Estadístico t en paréntesis (*), * simboliza significancia al 1%, ** al 5% y *** al 10% y corresponde a el coeficiente asociado al último rezago significativo y que cumple con ruido blanco en el error.

148
poder estadístico36 puede llegar a caer casi a cero. El graficar la serie y observar sus
Funciones de Autocorrelación (ACF), en muchas ocasiones es útil a la hora de indicar si
existe o no la presencia de componentes determinísticos que deberían ser incluidos en la
prueba. Sin embargo, Enders (1948, p. 210) recomienda realizar el siguiente
procedimiento para las pruebas de raíz unitaria:
1. Estimar el modelo menos restringido, es decir con intercepto y tendencia en forma
transformada de varianza y luego comprobar la significancia estadística de
probando la hipótesis nula por medio del valor de probabilidad de los
valores críticos de Fuller (1976). Si los resultados muestran que no se rechaza la
hipótesis nula, es decir los datos siguen un proceso no estacionario (i.e. el valor
absoluto del estadístico t computado en la regresión es menor que el valor
absoluto del valor crítico de la tabla Fuller (1976), o lo que es lo mismo, si la
probabilidad es mayor que algún nivel se significancia predicho), entonces es
necesario saltar al paso dos y comprobar la significancia del componente de
tendencia en la regresión de prueba. Si la hipótesis nula es rechazada se termina
el proceso y no se concluye que la secuencia { } no contiene raíz unitaria.
2. Si la hipótesis nula no es rechazada, es necesario entonces determinar si se
incluyeron más componentes determinísticos de los que deberían haberse
incluido. Esto debido a que la presencia de estos regresores puede reducir la
potencia estadística de la prueba. Por lo tanto, se procede a probar la significancia
del término de tendencia al contrastar la hipótesis usando el
estadístico de las tablas Dickey, et al (1981). Si el coeficiente que acompaña a
la tendencia no es significativo se salta al paso 3. Por el contrario, si es
significativo entonces se prueba de nuevo por la presencia de raíz unitaria usando
una distribución normal estándar. Si la hipótesis nula de raíz unitaria es rechazada,
entonces se termina el proceso y se concluye que la serie no tiene raíz unitaria. De
lo contrario, se concluye que la serie tiene raíz unitaria.
3. Se estima entonces el modelo sin tendencia . Se prueba por la presencia de raíz
unitaria contrastando el estadístico t que acompaña a con los valores críticos de
Fuller (1976). Si la hipótesis nula es rechazada se concluye que la serie no tiene
raíz unitaria. Caso contrario, se prueba la significancia del término de la constante
probando la hipótesis nula usando el estadístico de las tablas
Dickey, et al (1981). Si este corrimiento no es significativo, es decir que no se
rechaza la hipótesis nula, se procede a el paso 4. Si por el contrario, la hipótesis
nula es rechazada, es decir que el corrimiento es significativo, se prueba por la
presencia de raíz unitaria usando la distribución normal estándar. Si la hipótesis
nula de raíz unitaria es rechazada entonces se concluye que la serie no tiene raíz
unitaria y por tanto es estacionaria. Caso contrario, se dice que la serie tiene raíz
unitaria.
36 Probabilidad de cometer el error tipo II o probabilidad de no rechazar Ho cuando esta es falsa.

149
4. Se estima el modelo sin constante ni tendencia. Se contrasta el estadístico t que
acompaña a con los valores críticos de Fuller (1976) para determinar la
presencia de raíz unitaria. Si la hipótesis nula de raíz unitaria es rechazada, se
concluye entonces que la serie no tiene raíz unitaria, caso contrario se concluye
que la serie si tiene raíz unitaria.
Aplicando estos pasos a la serie de interés LR1000 se tendrá que estimar primero el
modelo menos restringido, es decir la ecuación (D8) la cual contiene corrimiento y
tendencia lineal. Es esta ecuación, el estadístico t toma el valor de -3.599 para la hipótesis
nula , es decir la presencia de raíz unitaria. Se debe entonces contrastar este
estadístico de prueba con los valores críticos de Fuller (1976) los cuales reportan para un
total de 50 observaciones con tendencia e intercepto un valor de -3.18, -3.50 y -3.80 para
significancias del 10%, 5% y 2.5% respectivamente. Esto quiere decir que la probabilidad
toma un valor entre 0.025 y 0.05. A continuación, se presenta la tabla de resultados para
este primer paso, la cual fue obtenida por medio del complemento ASTEX, este
componente se explicará más adelante en esta sección.
Prueba: Dickey-Fuller Aumentada {Con Constante, Con Tendencia}
Hipótesis Nula: LR1000 Tiene raíz unitaria (No estacionaria)
Variable: LR1000
Rezagos: 0
23/03/2014 22:10
Estadístico Prob.*
Estadístico de prueba Dickey-Fuller Aumentado -3.59978 (0.025, 0.05]
Valores Críticos 1% -4.15
2% -3.80
5% -3.50
10% -3.18
*Basado en valores críticos MacKinnon (1996). Para una
distribución del estadístico t
Tabla 62 Regresión de prueba ADF LR1000 con constante y tendencia ASTEX
Bien se puede concluir que al 5% se rechaza que la serie tenga raíz unitaria y por tanto el
proceso culminaría, o ser más estricto y continuar a un nivel del 1% (o incluso 2.5%)
donde no es posible rechazar la hipótesis nula que la serie tiene raíz unitaria. Sin
embargo, debido al tamaño tan pequeño de la muestra y que la potencia estadística se
pudo haber reducido aún más debido a la potencial presencia de uno o ambos
componentes determinísticos innecesarios en (D8) es recomendable continuar al
siguiente paso de la prueba.
En el paso dos del procedimiento es necesario predeterminar si se sobreparametrizó
innecesariamente la estimación por medio de algún componente determinístico adicional.

150
Se procede entonces a probar la significancia de la presencia del componente de
tendencia lineal bajo el contraste de la prueba usando el estadístico de las
tablas Dickey, et al (1981). Para ello se estima el modelo no restringido, es decir (D8) se
guarda la suma de residual cuadrada y se estima el modelo bajo la restricción de la
hipótesis nula, es decir el modelo únicamente con constante y se
guarda el . Con estos dos valores se construye el estadístico F como sigue
donde es igual a 2 restricciones impuestas en la hipótesis nula, es igual a 49
observaciones utilizadas y es igual a 3 parámetros estimados en el modelo no
restringido (D8). Se tendrá entonces que
Este valor de se contrasta con los valores críticos de Dickey, et al (1981) los cuales
toman el valor de 5.61 y 6.73 para niveles de significancia del 10% y del 5%
respectivamente, con un tamaño de muestra igual a 50 observaciones. Se dice entonces
que al 5% de significancia el valor de es más pequeño que el valor critico reportado al
0.1 de significancia y por tanto no es posible rechazar la hipótesis nula ,
procediendo así a quitar la tendencia de (D8) y saltando al paso 3. El modelo reestimado,
ahora sin tendencia lineal se presenta a continuación
al cual se le realizó el mismo procedimiento de propagación hacia atrás para determinar el
número de rezagos que deberían ser incluidos, el cual arrojó de nuevo cero. Se puede
observar como los coeficientes entre (D9) y (D8) no presentan una variación tan
significativa entre modelos, lo que determina que el término de tendencia lineal no
aportaba relevancia en el cambio de la serie. Se tiene entonces que el estadístico t
asociado a la prueba toma ahora el valor de -3.63, dado que el valor critico
reportado para 50 observaciones solo con constante corresponde a -3.58 para el 1% se
dice que se rechaza la hipótesis nula a cualquier nivel de significancia puesto que el valor
del estadístico de prueba es menor que cualquier valor crítico y por tanto se concluye que
la serie no tiene raíz unitaria, es decir que y además tiene corrimiento
significativo, determinado por mayor que el valor critico 4.86 a una
significancia del 5% lo que permite rechazar que

151
Prueba: Dickey-Fuller Aumentada {Con Constante, Sin Tendencia} Hipótesis Nula: LR1000 Tiene raíz unitaria (No estacionaria) Variable: LR1000 Rezagos: 0 23/03/2014 22:16
Estadístico Prob.* Estadístico de prueba Dickey-Fuller Aumentado -3.638379 Menor a 0.01
Valores Críticos 1% -3.58 2.5% -3.22 5% -2.93 10% -2.60 *Basado en valores críticos MacKinnon (1996). Para una
distribución del estadístico t Tabla 63 Regresión de prueba ADF LR1000 con constante sin tendencia ASTEX
10.6.8 Función de Autocorrelación ACF y Función de Autocorrelación Parcial PACF
Para poder medir la covarianza se debe tener en cuenta que en la teoría su valor
estadístico mide el grado de variabilidad conjunta entre dos variables aleatorias diferentes
respecto a su media , sin embargo en el caso de
la serie de tiempo contamos con una única variable por lo que su covarianza estará
determinada entre un dato y otro rezagado o adelantado periodos de tiempo dentro de la
misma serie, tenemos entonces que
La anterior ecuación representa la función de autocovarianza de la serie , si
suponemos que la serie de tiempo es estacionaria tendríamos entonces que su media no
cambia en el tiempo ( ) por lo que quedaría:
( )( )
Existen algunas consideración a tener en cuenta en la función de autocovarianza:
Una serie que presente ruido blanco tiene la característica que sus
autocovarianzas son cero para todos los rezagos o adelantos pues no hay
relación entre los datos de la serie en promedio
La autocovarianza del rezago es la misma que la del adelanto del mismo . i.e.
.
La autocovarianza de un rezago es igual a la varianza de la variable
estocástica. i.e. .
En la práctica ya que no contamos con el verdadero valor de la media poblacional de la
variable, , es necesario estimarlo con la media muestral conocida como . Con lo que
obtendríamos una ecuación de la siguiente forma:

152
∑ | |
| |
En las series de tiempo es bastante común perder datos puesto que en un modelo que
utilice rezagos se estará perdiendo una cantidad de datos. Por consiguiente al igual que
en cortes transversales entre mayor sea la cantidad de periodos en consideración más
consistente será el modelo.
Una vez tenemos la función de autocovarianza estimada es fácil y mucho más útil el
construir la Función de Autocorrelación ACF la cual está dada como la covarianza sobre
la raíz cuadrada de la multiplicación entre las varianzas y está normalizada entre 0 y 1 lo
cual hace mucho más fácil su interpretación (Wooldridge, 2009):
√
Si se supone que la serie es estacionaria se tiene que , que como se
dijo anteriormente es igual a la función de autocovarianza con un , por lo que la
función de autocorrelación quedaría determinada por:
Teniendo en cuenta esto podemos notar varias cosas: la función de autocorrelación
únicamente se debería analizar profundamente antes de determinar si la serie es
estacionaria, cuando el rezago es tendríamos que la autocorrelación es igual a 1 por
lo que en la mayoría de casos no se tiene en cuenta este rezago en la función y por ultimo
notamos que la autocorrelación bajo estacionalidad está midiendo cuan correlacionada
esta la variable en el rezago de la variable sin rezagos .
La ACF se dibuja en una gráfica de en el eje de las ordenadas y los rezados en el
eje de las abscisas, este tipo de gráficas lleva el nombre de correlograma y es la principal
guía objetiva para determinar un modelo posible para la serie de tiempo. En el
correlograma se evidencian dos líneas de significancia usualmente punteadas las cuales
determinan el intervalo de confianza y están determinadas por √ ⁄ , donde es el
número de observaciones. Este correlograma entonces nos ayudara a determinar si la
serie es o no ruido blanco, de serlo no habrá ninguna línea que sea significativa (es decir
que sobresalga por encima de las líneas punteadas del intervalo de confianza) y no será
posible realizar un modelo ya que el pronóstico del siguiente evento no está determinado
por ningún evento anterior, esto se mira en el valor de probabilidad asociado a la prueba
de hipótesis de las autocorrelaciones, donde la hipótesis nula dice que la serie es ruido
blanco , por lo que si el valor de probabilidad es muy alto no se podrá
rechazar que la serie es ruido.

153
La Función de Autocorrelación Parcial PACF es una herramienta que ayuda en el proceso
de identificación ya que no es posible hacerlo únicamente con la ACF. Como lo expone
Guerrero, la PACF es útil puesto que adquiere varias características las cuales dependen
del orden del proceso generador de datos y el tipo de parámetros involucrados. La PACF
se define como la autocorrelación serial que existe entre un periodo y uno
eliminando o extrayendo todos los posibles efectos de otros rezagos entre dichos
periodos de tiempo.
Las diferentes interpretaciones de los comportamientos de la ACF y PACF conllevan a
identificar correctamente el orden de los parámetros p y q del componente Autoregresivo
y de Media móvil respectivamente. Por ejemplo, para una serie estacionaria, la ACF suele
converger a cero muy rápidamente. Otros comportamientos típicos de la ACF y PACF
para procesos AR, MA y ARMA se presentan en la siguiente tabla
Proceso ACF PACF
AR(p) Convergencia asintótica a cero. Tiene p autocorrelaciones significativas (distintas de
cero) únicamente.
MA(q) Tiene q autocorrelaciones
significativas (distintas de cero) únicamente.
Convergencia asintótica a cero.
ARMA(p,q)
Comportamiento irregular de las primeras q autocorrelaciones y
después converge a cero asintóticamente.
Sucesión infinita convergente
asintóticamente a cero.
Tabla 64 Comportamientos típicos de ACF y PACF
Tomado y modificado de Guerrero(2003)
10.6.9 Metodologías SCAN, ESACF y MINIC37
Método SCAN Smallest CANonical correlation
El método SCAN o de correlación canónica más pequeña por sus siglas en inglés, tiene el
objetivo de identificar tentativamente el orden de un proceso ARMA estacionario o no
estacionario. Esta técnica fue propuesta por Tsay y Tiao (1985) y después Box et al
(1994) y Choi (1990) brindaron descripciones útiles de su algoritmo.
Dado un proceso estacionario o no estacionario de serie de tiempo con la
sustracción de su media (mean corrected) con un verdadero orden
autoregresivo igual a , y con un verdadero orden de promedio móvil igual a , es
posible utilizar el método SCAN para encontrar los eigenvalores ( o valores propios) de la
matriz de correlación del proceso ARMA.
37 Las metodologías SCAN, ESACF y MINIC fueron tomadas de SAS 9.1. User Guide con
traducción no oficial realizada por el autor.

154
Para la prueba de un proceso autoregresivo de orden y un proceso de
media móvil , se deben seguir los siguientes pasos.
1. Sea se calcula la siguiente matriz cuadrada de
dimensiones .
(∑
)
(∑
)
(∑
)
(∑
)
donde va desde hasta .
2. Se procede a buscar el eigenvalor más pequeño, de y su
correspondiente eigenvalor normalizado,
. La
correlación canónica estimada seria igual a dicho valor propio mas pequeño
.
3. Usando como coeficiente de AR( ), se obtienen lo residuos de
a , dados por la siguiente formula:
.
4. De la autocorrelación muestral de los residuos, , se aproxima el error
estándar de la correlación canónica cuadrada estimada por
donde ∑
Se tiene entonces que el estadístico de prueba a ser usado como criterio de información
es
(
)
el cual se distribuye asintóticamente como una Chi-cuadrada con un grado de libertad
solo si y o si y . Para y se dice que hay más

155
de una correlación canónica teórica igual a cero entre y . Dado que
son las correlaciones canónicas más pequeñas para todo los percentiles de
son menores que los de la ; por ello, Tsay y Tiao (1985) establecieron que es seguro y
prudente asumir una . Para y no se pueden hacer conclusiones acerca de
la distribución de
La tabla SCAN (ver Tabla 64) es construida usando para determinar cual de los
eigenvalores es significativamente diferente de cero. Los órdenes del ARMA son
identificados tentativamente al buscar un patrón rectangular máximo el cual las
son insignificanticas para todos los ordenes de prueba y . Puede que
exista más de un par de valores que permitan la obtención de dicho rectángulo.
En este caso se debería aplicar el principio de parsimonia y el número de ítems
insignificanticos en el patrón del rectángulo debería ayudar a determinar el orden. La
Tabla 65 representa un ejemplo de un patrón rectangular teórico asociado a una modelo
ARMA(2,2).
MA
AR 0 1 2 3 . .
0 C(0,0) C(0,1) C(0,2) C(0,3) . .
1 C(1,0) C(1,1) C(1,2) C(1,3) . .
2 C(2,0) C(2,1) C(2,2) C(2,3) . .
3 C(3,0) C(3,1) C(3,2) C(3,3) . .
. . . . . . .
. . . . . . .
Tabla 65 Tabla SCAN
MA
AR 0 1 2 3 4 5 6
0 * X X X X X X
1 * X X X X X X
2 * X 0 0 0 0 0
3 * X 0 0 0 0 0
4 * X 0 0 0 0 0
X = Termino significativo
0=Termino no significativo
* = No patrón
Tabla 66 Tabla Teórica SCAN para un proceso ARMA(2,2)
Como se puede observar, para un proceso ARMA (2,2) el patrón de términos
insignificanticos comenzaría en la columna 2, fila 2 según el método SCAN.
Método ESACF Extended Sample Autocorrelation Function
El método ESACF o método de función de autocorrelación muestral extendida por sus
siglas en inglés, es también un método para identificar tentativamente el orden de un

156
proceso ARMA y está basado en la estimación de los parámetros autoregresivos por
medio de mínimos cuadrados iterados. La técnica fue propuesta por Tsay y Tiao (1985) y
más adelante Choi (1990) propuso una descripción útil para su algoritmo.
Dado un proceso estacionario o no estacionario de serie de tiempo con la
sustracción de su media (mean corrected) con un verdadero orden
autoregresivo igual a , y con un verdadero orden de promedio móvil igual a , es
posible utilizar el método ESACF para estimar los órdenes desconocidos y por
medio del análisis de las funciones de autocorrelación asociados con los filtros de las
diferentes series de la forma
∑
donde representa el operador de rezago, también llamado L. Además
representa la prueba para el orden autoregresivo y para el promedio
móvil.
son los parámetros a estimar del proceso autoregresivo bajo el supuesto que
la serie sigue un proceso .
Para modelos puramente autoregresivos es decir donde el orden , se usa Mínimos
Cuadrados Ordinarios (MCO) para estimar consistentemente . Para modelos con
ambos componentes , los estimadores consistentes son obtenidos por medio
de la formula iterada de recursión de mínimos cuadrados, la cual es inicializada por los
estimadores de un autoregresivo puro:
(
)
el j-esimo rezago de la función de autocorrelación muestral de la serie filtrada,
, es la
función de autocorrelación muestral extendida, y es denotada como (
)
El error estándar de es calculado de la manera usual por medio de la aproximación
de Bartlett de la varianza de la ACF muestral.
∑
Si el modelo es un proceso , entonces el la serie filtrada
sigue un
modelo para tal que
Adicionalmente, Tsay y Tiao (1985) mostraron que el método ESACF satisface

157
donde es una constante diferente de cero o una variable aleatoria
continua que fluctúa entre -1 y 1.
La tabla ESACF (ver Tabla 66) es construida usando las autocorrelaciones muéstrales
extendidas para y y para identificar el
orden del proceso ARMA. Estos ordenes son identificados tentativamente buscando un
patrón triangular derecho con vértices localizados en y y en el cual
todos los elementos no son significativos (basado en una función de autocorrelación
asintóticamente normal). Por lo tanto el vértice de el triangulo identifica el orden del
. La Tabla 67 muestra el patrón teórico asociado a un modelo .
MA
AR 0 1 2 3 . .
0 . .
1 . .
2 . .
3 . .
. . . . . . .
. . . . . . .
Tabla 67 Tabla ESACF
MA
AR 0 1 2 3 4 5 6
0 * X X X X X X
1 * X 0 0 0 0 0
2 * X X 0 0 0 0
3 * X X X 0 0 0
4 * X X X X 0 0
X = Termino significativo
0=Termino no significativo
* = No patrón
Tabla 68 Tabla Teórica ESACF para un proceso ARMA(1,2)
Método MINIC MINimum Information Criterion
El método MINIC o de mínimo criterio de información por sus siglas en inglés, es también
un método para identificar tentativamente el orden de un proceso ARMA estacionario y no
estacionario. Hannan and Rissanen (1982) propusieron este método, y Box et al (1994) y
Choi (1990) dieron una descripción útil de su algoritmo.
Dado un proceso estacionario o no estacionario de serie de tiempo con la
sustracción de su media (mean corrected) con un verdadero orden

158
autoregresivo igual a , y con un verdadero orden de promedio móvil igual a , es
posible utilizar el método MINIC para calcular los criterios de información (o funciones de
penalidad) para varios ordenes de modelos autoregresivos y de medias móvil.
Si una serie estacionaria e invertible sigue un proceso de la forma
entonces su error puede ser aproximado por un proceso AR de orden alto (o superior),
asi
donde los parámetros estimados son obtenidos por medio de estimadores de Yule-
Walker. La escogencia del orden autoregresivo, , es determinado por el orden que
minimiza el criterio de información Akaike AIC, en el rango
( ) (
)
donde
∑
Note que Hannan y Risannen (1982) utilizaron criterios de información Bayesianos (BIC)
para determinar el orden autoregresivo usado para estimar la serie de los errores. Sin
embargo, Box et al (1994) y Choi (1990) recomiendan el eso del criterio AIC.
Una vez la serie de errores ha sido estimada para la prueba del orden autoregresivo
y del promedio móvil , se procede a estimar por MCO
y del siguiente modelo de regresión
∑
∑
de los parámetros anteriormente estimado, el BIC es entonces calculado de la siguiente
forma
( ) (
)
donde

159
∑ ∑
∑
donde .
La tabla MINIC (ver Tabla 68) es construida utilizando el . Si ,
entonces la anterior regresión mostrada puede llegar a fallar debido a la dependencia
lineal en la serie de errores estimada y en la corrección promedio de la serie. Los valores
que no pueden ser calculados son establecidos en la tabla como faltantes. Para
largos ordenes autoregresivos y de media móvil con relativamente pocas observaciones
puede resultar en un ajuste cercanamente perfecto. Esta condición puede ser identificada
encontrando el más alto valor negativo del , en la tabla. La idea entonces es
encontrar el valor mínimo en dicha tabla.
MA
AR 0 1 2 3 . .
0 BIC(0,0) BIC(0,1) BIC(0,2) BIC(0,3) . .
1 BIC(1,0) BIC(1,1) BIC(1,2) BIC(1,3) . .
2 BIC(2,0) BIC(2,1) BIC(2,2) BIC(2,3) . .
3 BIC(3,0) BIC(3,1) BIC(3,2) BIC(3,3) . .
. . . . . . .
. . . . . . .
Tabla 69 Tabla MINIC
10.6.10 Identificación Serie LR1000
La aplicación práctica tomará como ejemplo la serie y se desarrollará de la
siguiente manera. Primero se observará el comportamiento de las funciones de
autocorrelación ACF y autocorrelación parcial PACF para determinar uno o más
ordenamientos tentativos para el modelo En seguida se desarrollarán las
metodologías SCAN, ESACF y MINIC presentadas anteriormente para corroborar y/o
complementar los modelos tentativos para la serie. Recuerde que el algoritmo Box-
Jenkins determina que es necesario probar varios modelos antes de tomar uno como
definitivo para el pronóstico, por lo que mostrar todas las salidas e intentos de encontrar el
mejor modelo bajo el algoritmo de Box-Jenkins resulta además de improductivo,
inoficioso. En este paso se obtendrán los modelos más plausibles para ser estimados y se
encontrará más adelante un modelo definitivo para cada una de las cinco series.
Para observar el comportamiento de las funciones de autocorrelación y autocorrelación
parcial se procede entonces a oprimir el botón “Correlograma” dentro del aplicati o
ASTEX
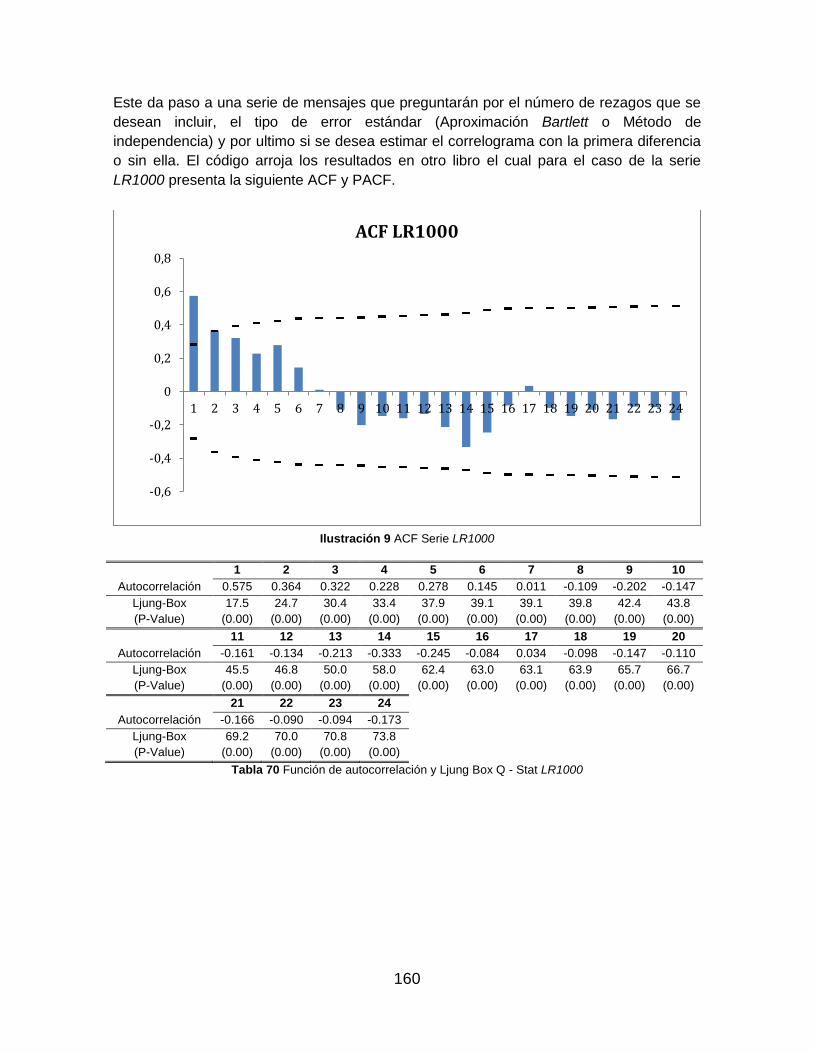
160
Este da paso a una serie de mensajes que preguntarán por el número de rezagos que se
desean incluir, el tipo de error estándar (Aproximación Bartlett o Método de
independencia) y por ultimo si se desea estimar el correlograma con la primera diferencia
o sin ella. El código arroja los resultados en otro libro el cual para el caso de la serie
LR1000 presenta la siguiente ACF y PACF.
Ilustración 9 ACF Serie LR1000
1 2 3 4 5 6 7 8 9 10
Autocorrelación 0.575 0.364 0.322 0.228 0.278 0.145 0.011 -0.109 -0.202 -0.147
Ljung-Box
(P-Value)
17.5
(0.00)
24.7
(0.00)
30.4
(0.00)
33.4
(0.00)
37.9
(0.00)
39.1
(0.00)
39.1
(0.00)
39.8
(0.00)
42.4
(0.00)
43.8
(0.00)
11 12 13 14 15 16 17 18 19 20
Autocorrelación -0.161 -0.134 -0.213 -0.333 -0.245 -0.084 0.034 -0.098 -0.147 -0.110
Ljung-Box
(P-Value)
45.5
(0.00)
46.8
(0.00)
50.0
(0.00)
58.0
(0.00)
62.4
(0.00)
63.0
(0.00)
63.1
(0.00)
63.9
(0.00)
65.7
(0.00)
66.7
(0.00)
21 22 23 24
Autocorrelación -0.166 -0.090 -0.094 -0.173
Ljung-Box
(P-Value)
69.2
(0.00)
70.0
(0.00)
70.8
(0.00)
73.8
(0.00)
Tabla 70 Función de autocorrelación y Ljung Box Q - Stat LR1000
-0,6
-0,4
-0,2
0
0,2
0,4
0,6
0,8
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
ACF LR1000

161
Ilustración 10 PACF Serie LR1000
1 2 3 4 5 6 7 8 9 10
Autocor Parcial 0.575 0.051 0.141 -0.026 0.186 -0.170 -0.087 -0.202 -0.098 0.022
11 12 13 14 15 16 17 18 19 20
Autocor Parcial -0.024 0.083 -0.136 -0.145 0.015 0.185 0.116 -0.247 -0.021 -0.058
21 22 23 24
Autocor Parcial -0.179 -0.078 -0.037 -0.069
Tabla 71 Función de Autocorrelación Parcial LR1000
Observe como la función de autocorrelación parece decrecer asintóticamente de manera
un tanto rápida, lo que llevaría a pensar una vez más que la serie es estacionaria puesto
que comportamientos típicos de la ACF en series no estacionarias estarían ligados a un
decrecimiento muy lento de las autocorrelaciones entre sus rezagos. Note además como
el estadístico propuesto por Ljung-Box (1978) 38 para probar si un grupo de hasta
autocorrelaciones son significativamente diferentes de cero permite rechazar la hipótesis
nula para cualquiera de estos grupos a lo largo de los 24 rezagos probados. Es
decir, la serie no es ruido blanco y puede ser pronosticada de su pasado. Este aspecto es
fundamentalmente importante puesto que como se verá más adelante el estadístico
Ljung-Box servirá para (i) determinar que los residuos de un modelo tienen
autocorrelación cero y (ii) determinar que algunas de las series después de sustraer
componentes determinísticos no se pueden pronosticar de su propio pasado por lo menos
de manera lineal.
Ahora bien, dado que la serie es estacionaria, la convergencia asintótica de la ACF
sugiere entonces la posibilidad de estar bajo la presencia de un autoregresivo del orden
dictado por la caída abrupta del rezago en la PACF. Es decir, un modelo plausible que
38 El estadístico Q de Ljung-Box (1978) está dado por ∑
y tiene un
desempeño mejor para muestras pequeñas que el estadístico Q de Box-Pierce.
-0,4
-0,3
-0,2
-0,1
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
PACF LR1000

162
puede llegar a ajustar bien en este tipo de serie sería indiscutiblemente un autoregresivo
de orden uno AR(1).
Sin embargo, debido a que se está ante la presencia de una ACF muestral y no
poblacional, las autocorrelaciones entre rezagos pueden distar del verdadero mecanismo
generador de datos que rige al proceso estocástico. Es decir, existe la posibilidad que el
modelo no solo sea significativo en el rezago 1, sino también en otro rezago o que se
esté parado bajo un modelo mixto cuando y que éste permita ayudar a mejorar la
explicación del modelo, por lo menos de dentro de muestra.
Ahora bien, un modelo solo con estas características, es el perfecto ejemplo para un tipo
de representación polinómicas que se a usta “bien” a los datos dentro de muestra pero
que no necesariamente lo haga fuera de ella para períodos más lejanos a uno; esto se
tiene puesto que al realizar un pronóstico fuera de muestra períodos adelante con este
tipo de modelos se está diciendo que el dato inmediatamente anterior es ajustado por un
ponderador período a período, esto debido a que el valor esperado del término de
perturbación debería ser cero si se cumple con el supuesto 1 que se verá más adelante
(i.e. para ). Además no hay componentes ayuden a capturar las dinámicas
relacionales entre los periodos más lejanos limitando así el modelo a cumplir
adecuadamente con pronósticos de corto plazo (1 o dos periodos máximo) pero quedar
estancado para periodos más lejanos.
Por ello se pueden llagar a utilizar herramientas que hagan más robusta la etapa de
identificación, como las metodologías SCAN, ESACF y MINIC vistas anteriormente con el
objetivo de encontrar un modelo que además de la identificación por los correlogramas
permita identificar adecuadamente el orden del proceso estacionario ARIMA, por medio
de la búsqueda de la correlación canónica más pequeña, la ACF extendida y del orden
que haga mínimo el criterio de información Bayesiano BIC. Se espera eso sí, que el
mínimo criterio de información en la tabla MINIC se encuentre en o muy cercano al
modelo AR(1) hallado en los correlogramas puesto que se logra con él, maximizar la
función de verosimilitud logarítmica y además con un número muy pequeño de rezagos
(k), condiciones para que un criterio de información se haga mínimo.
La forma como se obtuvieron estas tres metodologías fue a través del software comercial
SAS 9.1 en su módulo SAS/ETS, el cual permite realizar por medio del procedimiento
ARIMA (PROC ARIMA), todo el algoritmo de Box-Jenkins para la identificación,
estimación, diagnóstico y pronóstico de series de tiempo estacionarias. Se le pidió
entonces que mostrara los resultados de estas metodologías para un máximo entre 1 y 7
rezagos en la parte autoregresiva y entre 0 y 7 en de la de media móvil, es decir
y , esto debido a que se sabe que debe existir una parte explicada
por medio de un componente autoregresivo dado lo encontrado en el correlograma
anteriormente, pero no se limita el orden de media móvil .

163
Para el método SCAN, los resultados de los valores de probabilidad de contraste de
con una acorde a lo establecido por Tsay y Tiao (1985) se muestran en la
siguiente matriz dada por la representación en la Tabla 64. Tabla SCAN. Recuerde que en
este método se busca aquel o aquellos puntos donde las probabilidades de ahí
en adelante se hacen muy altas, lo que determinaría que seguirían un patrón rectangular
en el cual las son insignificanticas para todos los ordenes de prueba y
SCAN - Valores de Probabilidad - ARMA(p+d,q)
MA
0 1 2 3 4 5 6 7
AR
1 0.7433 0.3954 0.7914 0.3021 0.0839 0.4594 0.5665 0.4243
2 0.3794 0.6528 0.5533 0.6280 0.1067 0.5726 0.8512 0.7759
3 0.9573 0.5307 0.8679 0.2815 0.1437 0.7925 0.6096 0.6607
4 0.1709 0.4114 0.2753 0.5992 0.2445 0.5586 0.9428 0.6523
5 0.1914 0.2762 0.1865 0.2341 0.4440 0.4981 0.5232 0.6674
6 0.4573 0.5648 0.6067 0.5153 0.6858 0.9346 0.8136 0.8924
7 0.1292 0.5537 0.4470 0.5194 0.7844 0.8664 0.8195 0.7899
Tabla 72 Tabla SCAN serie LR1000 (1:50)
Observe como para una significancia del los valores resaltados muestran el inicio
de un patrón rectangular de términos no significativos. Haciendo un análisis un tanto más
detallado sobre la tabla SCAN se observa como el orden (1,0) podría haber sido un
modelo tentativo si no fuese porque no se desdibuja un patrón rectangular en él,
determinado por la significancia del orden (1,4). Sin embargo, la previa conjetura sobre el
modelo se ve validada si tomamos una significancia del
donde de hecho, el único modelo que se obtendría sería el encontrado en los
correlogramas. Sin embargo, se da una significancia un poco más alta para no restringir
tanto la posible conformación de otros modelos que pueden ser probados y
diagnosticados y que podrían llegar a tener un mejor desempeño que el AR(1).
La tabla SCAN nos permite entonces evidenciar 2 modelos tentativos
adicionales: (i) ARIMA(2,0) y (ii) ARIMA(1,5). Empero, se debe probar la significancia
estadística de cada uno de los parámetros de cada modelo, puesto que se debe
garantizar que el modelo sea parsimonioso, permitiendo estimar un orden tentativo con la
menor cantidad de parámetros posibles. Por ejemplo para el caso (ii) del ARIMA(1,5),
observando la PACF el rezago y deban ser excluidos del modelo
pues su presencia, muy posiblemente, no sea representativa y por tanto su inclusión
violaría el principio de parsimonia; sin embargo, esto debe ser constatado en la etapa de
estimación.

164
Ahora bien, los valores de probabilidad de la metodología ESCAF propuesta por Tsay y
Tiao (1985) la cual se construye utilizando las autocorrelaciones muéstrales extendidas
, presentó los siguientes resultados
ESACF - Valores de Probabilidad - ARMA(p+d,q)
MA
0 1 2 3 4 5 6 7
AR
1 0.5785 0.2653 0.7698 0.4319 0.0736 0.4563 0.9643 0.5775
2 0.0385 0.237 0.7892 0.7357 0.1215 0.6268 0.8808 0.8919
3 0.6971 0.0137 0.8149 0.7958 0.1657 0.7115 0.7635 0.7871
4 0.7963 0.0689 0.7702 0.7565 0.1069 0.6591 0.9886 0.6032
5 0.001 0.022 0.0071 0.0688 0.2406 0.5879 0.844 0.7686
6 0.0041 0.2475 0.3231 0.1211 0.3139 0.998 0.8639 0.9848
7 0.0077 0.0018 0.4182 0.1486 0.4648 0.5668 0.8398 0.9609
Tabla 73 Tabla ESCAF serie LR1000 (1:50)
La identificación de los órdenes tentativos de dio por medio de la caracterización de un
patrón triangular derecho con vértices localizados en y . Se
encontró que existen 2 modelos adicionales que deberían ser tenidos en cuenta para la
etapa de estimación, estos modelos son (i) ARIMA(2,1) y (ii) ARIMA(6,1). Una vez más,
dado que estas herramientas aquí presentadas son una ayuda estadística para identificar
el orden del modelo ARIMA y nunca deben ser tomados como un resultado definitivo al
método, se deberá evaluar la significancia estadística y el diagnóstico de varios modelos
para garantizar que sea parsimonioso y además que cumpla con los supuestos en la
etapa de diagnóstico. El propósito de esta etapa es simplemente la identificación tentativa
de varios modelos plausibles de ser estimados.
La tabla MINIC presentada por Hannan y Rissannen (1982) no sugiere la necesidad de
encontrar patrones de comportamientos triangulares o rectangulares, simplemente se
busca el mínimo BIC (es decir el valor más negativo) dentro de la tabla y el modelo
asociado a dicho valor será el que minimice el criterio de información. Esta tabla resulta
más conveniente para realizar una comparación entre modelos tentativos arrojados por
dos anteriores métodos SCAN y ESACF. A continuación se presentan los resultados
obtenidos
MINIC – Criterio de información BIC
MA
0 1 2 3 4 5 6 7
AR
1 -2.0207 -1.9471 -1.9156 -1.8717 -1.8130 -1.7762 -1.7000 -1.7136
2 -1.9443 -1.8793 -1.8377 -1.7939 -1.7348 -1.7109 -1.6376 -1.6640
3 -1.9129 -1.8509 -1.7927 -1.7199 -1.6599 -1.6344 -1.5593 -1.5939
4 -1.8487 -1.7857 -1.7345 -1.6628 -1.5855 -1.5670 -1.4949 -1.5171
5 -1.8117 -1.7482 -1.6783 -1.6106 -1.5609 -1.4947 -1.4278 -1.4398
6 -1.7651 -1.7620 -1.6907 -1.6133 -1.5377 -1.4684 -1.3911 -1.3771
7 -1.7530 -1.7420 -1.6720 -1.5975 -1.5232 -1.4615 -1.3911 -1.3147
Tabla 74 Tabla MINIC Serie LR1000 (1:50)

165
Como se puede observar, la combinación de que hace mínimo el criterio de
información Bayesiano se da en la intersección entre AR 1 y MA 0, lo cual correspondería
a un modelo ARMA(1,0) o lo que es lo mismo ARIMA(1,0,0). Como se mencionó
anteriormente, este resultado es complementarte sensato si se observa que este modelo
es el que mayor acople tuvo dada la interpretación de la ACF y PACF que se mencionó
anteriormente. Sin embargo, estos criterios de información deberán ser tenidos en cuenta
a la hora de realizar comparaciones entre modelos, es decir, cada uno de los 5 modelos
previamente identificados, tienen asociado consigo un valor de BIC que se muestra en la
tabla anterior, como se observa en la siguiente tabla
Modelo Tentativo
BIC
ARMA(1,0) -2.0271
ARMA(2,0) -1.9443
ARMA(2,1) -1.8793
ARMA(1,5) -1.7762
ARMA(6,1) -1.7620
Tabla 75 Tabla BIC modelos SCAN y ESACF
Adicional a estos métodos, se programó una función en el lenguaje MATLAB que tiene el
propósito de servir como ayuda adicional para la identificación del mejor modelo por
medio de la búsqueda iterativa de combinaciones de parámetros p, q que hagan mínima
una función de pérdida de pronóstico predicha dentro de muestra, esta función lleva el
nombre de ARI MAI N la cual esta autocontenida en un archivo. m y será explicada a
continuación.
ARI MAI N permite evaluar muchas posibles estimaciones de 39 y encontrar aquella
combinación que haga mínimo el error de pronóstico ingresado como input en la función.
Esto permite encontrar modelos que se ajusten bien a los datos dentro de la muestra bajo
las condiciones del algoritmo y bajo dicha función de perdida solicitada; todo esto para un
rango máximo de componentes autoregresivos y de media móvil requeridos (MaxP y
MaxQ).
Cabe resaltar de manera enfática que tanto para este tipo de método de identificación
como para los tres anteriores, el código ARI MAI N fue tomado como un complemento
adicional para determinar los polinomios y de la ecuación diferencial (D0), más
nunca fueron tomados como resultados determinantes del tipo de modelo. Esto quiere
39 Es preciso mencionar que, a diferencia los métodos SCAN, ESCAF y MINIC, las estimaciones
no se realizan para los rezagos …p o …q, sino para los absolutos de p y q. Por ejemplo: si el valor mínimo de la función de pérdida de error de pronóstico se encuentra en la intersección p=3 y
q=2, entonces el polinomio que los representa estará dado por
y
no por
. Esto se realizó de esta manera para
permitir identificar de manera preliminar a la estimación modelos con diferentes ordenes y que, utilizando menor cantidad de parámetros, pueden llegar a ajustarse adecuadamente a los datos estudiados.

166
decir que, con ayuda de las funciones de autocorrelación, autocorrelación parcial, los
métodos SCAN, ESACF y MINIC, la condición trascendental de cumplimiento de
parsimonia en los polinomios de la ecuación representativa, la estabilidad de los
parámetros del modelo, los demás supuestos de validación del mismo y el código
ARI MAI N para ver el mejor modelo dentro de muestra en un rango de posibilidades, se
logrará identificar un modelo que ratifique se considerado como un buen modelo de ajuste
de la serie estudiada y que puede llegar a ser usado para el pronóstico.
A continuación se describen los elementos que componen a la función y se presentan los
resultados obtenidos acorde a la identificación del modelo.
La función [ s t dEr r or , MAPE, MAE, RMSE] =ARI MAI N( ser i e, opt i ons) expresa la
necesidad de dos condiciones de entrada, la primera hace referencia a la serie que se
desea evaluar, original y sin transformaciones ni de varianza ni de nivel, y la segunda a
una estructura de opciones que tienen valores por defecto si estas no son ingresadas por
el usuario y que se describirán más adelante. La función cuenta además con tres posibles
salidas o outputs, el primero hace referencia al error estándar del modelo cuyo valor haga
mínimo la función de pérdida predicha, y los tres siguientes corresponden a las matrices
de filas por columnas con todos los valores posibles de cada una de
las funciones de pérdida MAPE, MAE y RMSE en cada combinación, este tema se verá
más adelante para el ejemplo de la serie LR1000 como se ha venido trabajando en esta
sección. La lectura de estas tres matrices se da de la misma manera que como se realizó
con la tabla MINIC.
La estructura opt i ons tiene entonces los siguientes componentes:
MaxP: corresponde el máximo número de componentes autoregresivos a
considerar. Por defecto se tiene 1.
MaxQ: corresponde al máximo número de componentes de media móvil a
considerar. Por defecto se tiene 1.
D: corresponde al orden de integración de la serie. Por defecto se tiene 0.
Ti pEr r or : corresponde al tipo de error que se tendrá en cuenta para mostrar un
resultado de diagnóstico preliminar, para crear el vector de errores st dEr r or
dentro de la muestra y para realizar el pronóstico fuera de muestra solo si se
ingresa un valor mayor a cero para Per Pr onos . Este toma la forma de
“string” es decir que debe ingresarse como carácter de alguno de estos tipos de
error:
' MAE' - Error Medio Absoluto
' RMSE' - Raíz cuadrada del Error Cuadrático Medio
' MAPE' - Error Medio Absoluto en Porcentaje

167
Por defecto se tiene ' RMSE' .
Tr ans: hace referencia al tipo de transformación de varianza que sufre la serie,
ésta puede tomar las siguientes formas:
' Log' - transformación tipo Logarítmica
' Rai z ' - transformación tipo raíz cuadrada √
‘ I n Rai z ' - transformación tipo inversa de raíz cuadrada √
' I nv ' - transformación tipo inversa
' BoxCox' - transformación tipo Box-Cox (1965) véase Sección. 4.4.2.2
' Or i g' - no sufre ningún tipo de transformación
Por defecto se tiene ' Or i g' .
d1_LI NEX y d2_LI NEX: corresponden a los valores de y de la función
LINEX presentada al inicio de este capítulo estos valores únicamente serán
tenidos en cuenta para el pronóstico fuera de muestra, es decir si Per Pr onos>0.
Por defecto ambos valores son cero
d1_LI NLI N y d2_LI NLI N: corresponden a los valores de y de la función
LINLIN presentada al inicio de este capítulo. estos valores únicamente serán
tenidos en cuenta para el pronóstico fuera de muestra, es decir si Per Pr onos>0.
Por defecto ambos valores son cero.
Per Pr onos : corresponde al número de períodos a pronosticar. Si este es mayor
que cero, se generará la evaluación del pronóstico por fuera de muestra
contrastando con los valores de la serie original dada por Ser Or g. Por defecto
toma el valor de cero.
Ser Or g: corresponde a la serie original, la cual servirá para evaluar el pronóstico
fuera de muestra acorde al mejor modelo escogido según el criterio de función de
pérdida dado por Ti pEr r or . Por defecto se tiene que el valor será el mismo de
ser i e.
Di agnos : toma el valor de ‘ on’ si se desea observar al final el proceso el
diagnóstico del término de perturbación mostrado tanto por medio de tests
estadísticos (media cero bajo Guerrero (2003, p.144), prueba de normalidad
Jarque Bera (utilizado si la muestra es grande), prueba de normalidad Lillierfors y
el valor de probabilidad del estadístico Q de Ljung-Box en T/4 para determinar que
no exista autocorrelación en los errores) como por medio de una representación
visual dada por el ajuste y pronóstico de la serie, la función de autocorrelación
ACF para determinar si existe autocorrelación cero, la gráfica de ajuste de la
función de densidad de una normal estándar con la función de densidad de

168
probabilidad del término de perturbación y por último la gráfica de la serie de
residuos con limites para determinar la potencial existencia de
Outliers, así como la línea donde se encuentra la media. Todo esto se obtiene con
la finalidad de ir descartando modelos cuyo diagnóstico no sea el adecuado.
Caso contrario tomará el valor ‘ of f ’ si no se desea imprimir los diagnósticos.
El valor por defecto es ‘ of f ’ .
ARLags y MALags : corresponden a una opción adicional para la estimación del
modelo ARIMA en el cual se ingresan los vectores de posibles rezagos en AR o
MA los cuales no podrán ser tenidos en cuenta únicamente por el algoritmo. Es
decir, si se desea evaluar el modelo
este deberá ser ingresado como ARLags=[ 1, 3] y MALags=[ 2, 4] . Por defecto
se tiene ARLags=[ ] y MALags=[ ] , caso contrario se estimará el modelo con
estos vectores de parámetros y no se obtendrá ningún valor para los últimos tres
outputs de la función.
Teniendo clara la disposición de la función ARI MAI N se procedió a ejecutar el código en
MATLAB con las siguiente estructura de opciones considerada para el ejemplo que se
venía trabajando con LR1000.
opt i ons. MaxP = 7; opt i ons. MaxQ = 7; opt i ons. Tr ans = Log; opt i ons. Ti pEr r or = ' MAPE' ; opt i ons. Di agnos = ' of f ' ; ser i e = R1000( 1: 50) ; [ s t dEr r or , MAPE, MAE, RMSE] =ARI MAI N( ser i e, opt i ons) ;
Observe como al no ingresar las demás opciones, estas tomarán el valor por defecto que
se mencionó anteriormente. Se tiene entonces que se obtendrán tres matrices40 MAPE,
MAE y RMSE de 8 filas por 8 columnas cada una, cada una con las funciones de pérdida
evaluadas dentro del abanico de posibles combinaciones dado por MaxP y MaxQ.
Además, se está especificando que el grado de diferenciación será el valor por defecto,
que corresponde a cero, acorde a la teoría presentada anteriormente. Por último se le
está pidiendo al código que transforme la varianza acorde a una función logarítmica de la
serie TR1000.
Se tiene entonces que las matrices obtenidas a través de la función ARI MAI N fueron las
40 Únicamente con el objetivo de ejemplificar las posibles salidas del código en ARIMAIN.m se
obtuvieron las tres matrices. Sin embargo, si es de interés del investigador únicamente minimizar, por ejemplo, la suma de errores al cuadrado se pedirá únicamente que se muestran los resultados de la matriz RMSE y no de las otras dos marices. Es decir que el output deberá ser especificado como [ st dEr r or , ~, ~, RMSE] =ARI MAI N( ser i e, opt i ons) ;
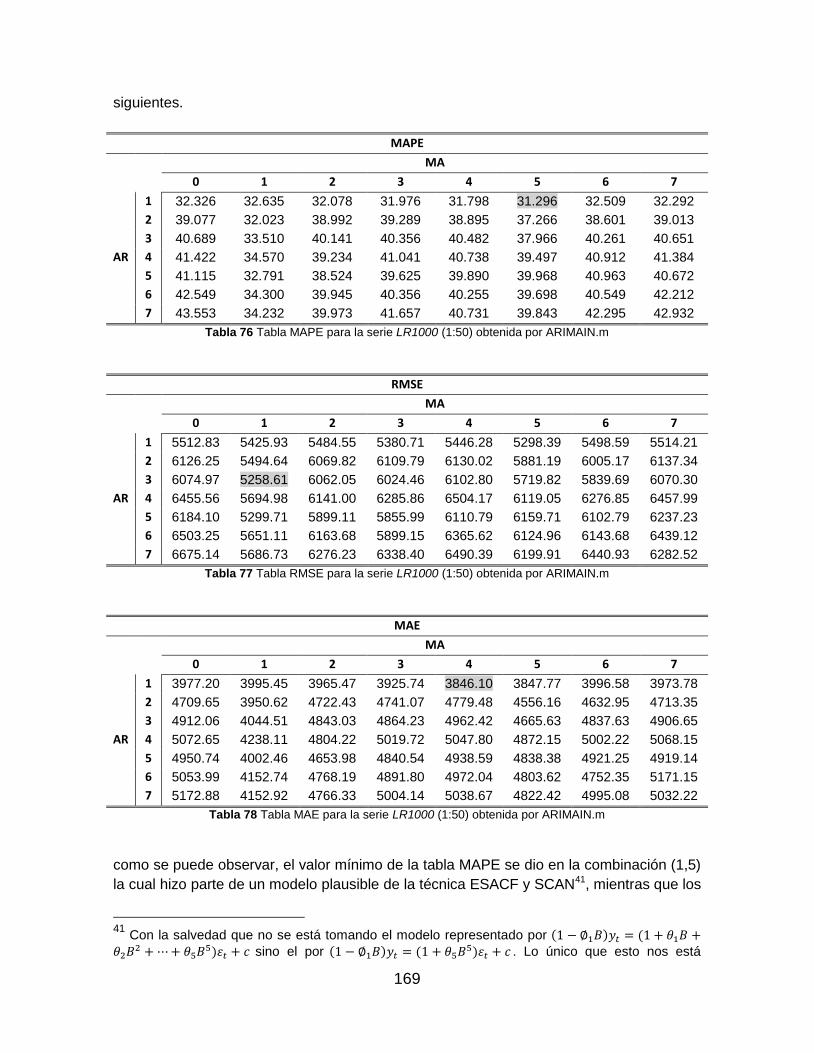
169
siguientes.
MAPE
MA
0 1 2 3 4 5 6 7
AR
1 32.326 32.635 32.078 31.976 31.798 31.296 32.509 32.292
2 39.077 32.023 38.992 39.289 38.895 37.266 38.601 39.013
3 40.689 33.510 40.141 40.356 40.482 37.966 40.261 40.651
4 41.422 34.570 39.234 41.041 40.738 39.497 40.912 41.384
5 41.115 32.791 38.524 39.625 39.890 39.968 40.963 40.672
6 42.549 34.300 39.945 40.356 40.255 39.698 40.549 42.212
7 43.553 34.232 39.973 41.657 40.731 39.843 42.295 42.932
Tabla 76 Tabla MAPE para la serie LR1000 (1:50) obtenida por ARIMAIN.m
RMSE
MA
0 1 2 3 4 5 6 7
AR
1 5512.83 5425.93 5484.55 5380.71 5446.28 5298.39 5498.59 5514.21
2 6126.25 5494.64 6069.82 6109.79 6130.02 5881.19 6005.17 6137.34
3 6074.97 5258.61 6062.05 6024.46 6102.80 5719.82 5839.69 6070.30
4 6455.56 5694.98 6141.00 6285.86 6504.17 6119.05 6276.85 6457.99
5 6184.10 5299.71 5899.11 5855.99 6110.79 6159.71 6102.79 6237.23
6 6503.25 5651.11 6163.68 5899.15 6365.62 6124.96 6143.68 6439.12
7 6675.14 5686.73 6276.23 6338.40 6490.39 6199.91 6440.93 6282.52
Tabla 77 Tabla RMSE para la serie LR1000 (1:50) obtenida por ARIMAIN.m
MAE
MA
0 1 2 3 4 5 6 7
AR
1 3977.20 3995.45 3965.47 3925.74 3846.10 3847.77 3996.58 3973.78
2 4709.65 3950.62 4722.43 4741.07 4779.48 4556.16 4632.95 4713.35
3 4912.06 4044.51 4843.03 4864.23 4962.42 4665.63 4837.63 4906.65
4 5072.65 4238.11 4804.22 5019.72 5047.80 4872.15 5002.22 5068.15
5 4950.74 4002.46 4653.98 4840.54 4938.59 4838.38 4921.25 4919.14
6 5053.99 4152.74 4768.19 4891.80 4972.04 4803.62 4752.35 5171.15
7 5172.88 4152.92 4766.33 5004.14 5038.67 4822.42 4995.08 5032.22
Tabla 78 Tabla MAE para la serie LR1000 (1:50) obtenida por ARIMAIN.m
como se puede observar, el valor mínimo de la tabla MAPE se dio en la combinación (1,5)
la cual hizo parte de un modelo plausible de la técnica ESACF y SCAN41, mientras que los
41 Con la salvedad que no se está tomando el modelo representado por
sino el por
. Lo único que esto nos está

170
dos valores mínimos de las tablas MAE y RMSE se dieron en la combinación (3,1) y (4,1)
lo que incluiría en la etapa de identificación otros tres modelos plausibles que deberían
ser estimados y probados.
Estas tablas de funciones de pérdida aquí presentadas tiene un sustento teórico si sé
sabe que la combinación que haga mínimo alguna de estas funciones, es aquel que se
ajusta mejor a los datos reales y por tanto deberá ser considerado como un orden posible
en las siguientes dos etapas de Box-Jenkins. Ahora bien, estas tablas son al igual que las
demás, una ayuda complementaria para identificar el orden tentativo del modelo y no
como aplicación definitiva al método.
Note además que algunos los órdenes posibles son compartidos entre metodologías, en
este caso el modelo ARIMA(1,5) presentó la mayor cantidad de repeticiones entre
métodos (SCAN, ESACF y MAE). Además, una observación más minuciosa sobre la
matriz RMSE (ver Tabla 76) y MAE (ver Tabla 77) permite evidenciar que el segundo valor
mínimo de la función de pérdida en ambas tablas viene dado por la intersección
ARIMA(1,5) con 5298.39 y 3847.77 respectivamente, a lo cual será necesario darle una
mayor inspección a dicho modelo, puesto que puede estar ajustándose bien a los datos
pero ser un modelo “mal omportado” estadísticamente hablando.
Los resultados que nos muestran las tablas generadas por ARI MAI N manifiestan un símil
con los resultados determinados en la tabla MINIC propuesta por Hannan y Rissannen
(1982), donde se obtienen resultados que permiten comparar entre modelos y que pueden
ayudar a inclinar la balanza ante una situación de indecisión entre dos modelos tentativos.
Así las cosas, se tendrá que existen 8 modelos tentativos a considerar en las siguientes
dos etapas, los cuales están dados por loa distintos métodos de identificación
presentados en esta sección. Estos modelos son:
Modelo Tentativo
Representaciones polinómicas
M1 ARMA(1,0)
M2 ARMA(2,0)
M3 ARMA(2,1)
M4 ARMA(1,5)
M5 ARMA(6,1)
M6 ARMA(3,1)
M7 ARMA(1,4)
M8 ARMA(1,5)
Tabla 79 Modelos tentativos para la serie LR1000 (1:50)
Sin embargo y como se mencionó anteriormente, estos modelos están sujetos a cambios
una vez se entre en la etapa de estimación. Estos cambios están dados en pro de
dejando ver, es que el modelo ARIMA(1,5) se ajusta bien a los datos sin necesidad de hacer uso de los rezagos anteriores al de media móvil 5. Sin embargo y de manera importante, no dice nada sobre la significancia de cada coeficiente.

171
encontrar el o los polinomios de rezagos que caracterizan el proceso autoregresivo y el de
media móvil, es decir y .
En particular, puede darse el caso que ninguno de estos modelos sea meritorio de ser
escogido puesto que (i) puede existir un polinomio o una combinación de ellos que se
ajuste mejor a los datos y/o que pronostique mejor fuera de muestra y (ii) en este tipo de
métodos se est considerando únicamente alores “tentativos” de los componentes
autoregresivos y de media móvil, es decir ARMA(3,0) corresponde a la representación
polinómica
en los métodos SCAN, ESACF y MINIC o
en la función propuesta en MATLAB y no se está discutiendo la
posibilidad, por ejemplo si la representación real del modelo está dada por
, de incluir el primer rezago en el modelo tentativo arrojado por
ARIMAIN si este es en verdad significativo para el modelo o lo que es lo mismo eliminar el
segundo rezago del modelo tentativo arrojado por SCAN, ESACF o MINIC si este en
verdad no lo es. Por lo que la representación , muy
posiblemente tenga un mejor desempeño mucho mejor por ser una representación más
parsimoniosa del modelo arrojado por SCAN, ESACF o MINIC y por ser un modelo que
aproveche mejor la información disponible que el modelo arrojado por ARIMAIN.
De la misma manera se puede presentar para cualquier otro tipo de polinomio que no se
considera bajo estos métodos, por ejemplo
o inclusive polinomios del tipo multiplicativo los cuales pueden capturar una mayor
cantidad de información siendo más parsimoniosos, como
o cualquier infinidad de posibles combinaciones entre polinomios AR y MA y dentro de
cada uno de ellos. Es por esto que se hace necesario para el investigador probar varios
modelos y encontrar aquel con el que se sienta más a gusto y que cumpla los supuestos
sobre el término del error y el principio de parsimonia.
10.6.11 Método de Máxima Verosimilitud (ML)42
La función de verosimilitud es maximizada por medio de mínimos cuadrados no lineales
usando el algoritmo de Marquardt (véase Levenberg (1944) y Marquardt (1963)) sugerido
por Box y Jenkins (1970) en su libro. Este método está fundamentado en un desarrollo en
series de Taylor que linealiza los errores condicionado al hecho que se conocen los
errores muéstrales y los valores iniciales de los parámetros y . Según Guerrero (2003)
42 Tomado de SAS 9.1. User Guide con traducción no oficial realizada por el autor.

172
es necesario tener en cuenta que el proceso de estimación puede llegar a ser sensible a
los valores iniciales de los parámetros, por lo que si estos valores no son cercanos a los
valores definitivos, es posible que el modelo iterado jamás converja o posiblemente
encontrar paramentos estimados por fuera de la región factible debido al problema de
falta de restricciones sobre los parámetros. Sin embargo, este algoritmo de Marquardt
(1963) no solo permite obtener estimaciones puntuales, sino también intervalos de
confianza.
Los estimadores de Máxima Verosimilitud pueden ser más complejos de calcular que los
estimadores por el método de mínimos cuadrados condicionales, sin embargo, estos
pueden ser preferidos en ciertos casos, como lo explica Ansley y Newbold (1980).
Si se considera el modelo univariado ARMA como el presentado en la ecuación (D0)
donde es una secuencia independiente de innovaciones normalmente distribuidas
y es la media de las serie observada. Entonces la función de verosimilitud
logarítmica puede ser escrita como:
| |
donde es el número de observaciones, es la varianza de como una función de los
parámetros y , es la matriz de varianza covarianza y | | representa el determinante.
El vector denota la serie de tiempo menos la parte estructural del modelo , escrita
como el vector de dimensiones ( X 1), así
[
] [
]
Por tanto, el estimador de máxima verosimilitud de la varianza es
nótese que el estimador de la varianza está dividido por , donde es el número de
parámetros en el modelo, en logar de solo por .
La verosimilitud logarítmica concentrada con respecto a la varianza puede ser tomada
como una constante aditiva, así
| |

173
sea la parte inferior de la matriz triangular con elementos positivos en la diagonal tal
que y el vector . La verosimilitud logarítmica concentrada con respecto a
puede ser escrita como
| |
o
(| |
| |
)
Entonces, el estimador de máxima verosimilitud es calculado utilizando el algoritmo
Marquardt (1963) para lograr minimizar la siguiente suma de cuadrados
| | | |
la principal ventaja del método de Máxima verosimilitud radica en el hecho que no solo
proporciona una estimación de los parámetros de (D0) sino también una estimación de la
matriz de varianza covarianza para los parámetros estimados. Esta estimación, es válida
para muestras grandes si la aproximación lineal por series de Taylor del error es válida
dentro de una vecindad de los valores de los parámetros estimados.
Guerrero (2003) expone ciertos problemas que se pueden presentar en esta etapa de
estimación de parámetros por medio de la máxima verosimilitud.
1. Redundancia de parámetros: este se presenta cuando existen factores
aproximadamente comunes en los polinomios AR y MA. Por ejemplo, considérese
el modelo
el cual podría ser escrito de manera equivalente como
teniendo en cuenta el principio de parsimonia que establece que resulta preferible
trabajar con un número finito de parámetros que con un número infinito de ellos,
sobre todo si la explicación que se tiene del fenómeno es la misma. Es decir, entre
más parámetros se ahorren en el modelo mejor. tenemos que el segundo modelo
es una representación más parsimoniosa del proceso y permite estimar con mayor
precisión el proceso AR.
2. Supuesto de Normalidad: este problema obedece al hecho que se está
suponiendo que los errores se distribuyen como ruido blanco gaussiano (i.e. se

174
distribuye normalmente). Sin embargo, esta suposición es válida bajo el uso de la
transformación “normalizante” de potencia modificada por Box y Cox (1964) para
evitar la discontinuidad en la potencia vista en la sección 4.3.2.1 Estabilización
de varianza. Empero, utilizar esta transformación con el objeto de validar la
suposición del modelo, no garantiza que se satisfaga la suposición ni que sea un
modelo adecuado. Por lo que este supuesto debe ser validado, así como ciertos
otros, en la etapa de diagnóstico como se presentará a continuación.
10.6.12 Teoría Sobre Diagnósticos del Modelamiento ARIMA
10.6.12.1 Supuesto 1. tiene media cero.
La importancia del supuesto de media cero, radica del hecho que el valor esperado del
error debe ser cero para poder descartar que exista una parte determinística en la serie
estimada de residuos que no ha sido incluida por el modelo y que debería incluirse.
Además esto traería problemas a la hora de encontrar la media y varianza del modelo ya
que como se vio en el apartado 4.3.1 Modelo General, al comienzo de esta sección, no se
podría hacer cero y este debería ser incluido en la media y varianza de la serie.
Verificación
Para verificar este supuesto basta con calcular la media aritmética y la desviación
estándar de , así
∑
√∑
donde . Esto con el objetivo de llegar a construir el cociente
√
donde si el valor absoluto de este cociente | | es menor que dos, se podría llegar a
concluir que no hay evidencia significativa de que el valor promedio del proceso de ruido
blanco sea distinta de cero, y viceversa. Entonces
{| | | |

175
Corrección
Las correcciones a la violación de este supuesto deberán realizarse progresivamente en
el siguiente orden,
Verificar si es necesario incluir un término autoregresivo al modelo.
Verificar si requiere diferenciarse una vez más la serie para conseguir que esta
sea estacionaria.
Inclusión de una tendencia determinística en el modelo (D0), la cual debe ser
estimada.
10.6.12.2 Supuesto 2. tiene varianza constante.
Verificación
Realizar una gráfica de los residuos contra el tiempo, con el objetivo de identificar
visualmente, si la varianza muestra o no estar en función del tiempo. Esta verificación se
realiza visualmente debido a que únicamente las variaciones muy notorias pueden
provocar problemas. Para ver ejemplos sobre comportamientos típicos de la varianza del
residuo véase Guerrero (2003, p. 145.).
Corrección
Verificar o aplicar la transformación potencia para estabilizar la varianza de la
serie. Véase el apartado 4.3.2.1. Estabilización de la varianza.
10.6.12.3 Supuesto 3. es Ruido Blanco.
Es necesario que las variables aleatorias sean mutuamente independientes, esto
implica que los residuos del modelo no tengan autocorrelación serial por lo que deben ser
un proceso estocástico de ruido blanco, es decir que no se pueden predecir de su propio
pasado. Este supuesto es fundamental, puesto que la violación del mismo conlleva a
pensar que hay dinámicas de corto o largo plazo, que el modelo puede no estar
capturando y que otro si lo haga. Este supuesto puede verificarse de varias maneras.
Verificación
Calcular la ACF muestral de la serie de residuos, donde debe cumplirse que
para todo .
Prueba de significancia conjunta a través del cálculo del Estadístico de Box-
Ljung (1978). Donde

176
esta prueba tiene el siguiente estadístico
∑(
)
donde bajo , → , lo que representa para muestras grandes
que
∑(
√
)
→
Por lo que si la hipótesis nula es cierta, entonces la autocorrelación para todo
debe estar cerca de cero y no debería ser muy grande. De lo contrario, si es
grande, se rechazaría .
Para más detalle sobre esta prueba véase Ljung y Box (1978).
Prueba de independencia lineal Breusch-Godfrey, bajo la hipótesis nula
En la que se corren los residuos estimados contra las variables originales del
modelo y rezagos de . Así,
Si la hipótesis nula es cierta, entonces la serie de ruidos estimados no tendría
nada que ver con su pasado ni con las variables originales del modelo y por tanto
todos los parámetros de y deberían no ser significativos. Además que el
coeficiente de determinación debería ser cercano a cero. .
Para más detalle sobre esta prueba véase Breusch (1979) y Godfrey (1978).
Corrección
Si la serie de residuos no sigue un proceso de ruido blanco, esto se debe a que las
autocorrelaciones corresponden a cierto otro proceso ARMA por lo que se recomienda
Graficar el correlograma de los residuos estimados.
Tratar de identificar algún proceso ARMA para los residuos viendo los valores de
.

177
Este posible proceso podría sugerir modificaciones al modelo original.
10.6.12.4 Supuesto 4. se distribuye normal.
Al principio de la etapa de estimación se dio a conocer la metodología de máxima
verosimilitud utilizada para estimar los parámetros. Dentro de ésta se realizó el supuesto
que los errores aleatorios son una secuencia independiente de innovaciones
normalmente distribuidas , todo esto bajo la estructura de la ecuación (D0).
Este supuesto permitió la construcción y estimación de la función de verosimilitud
logarítmica, por lo que en esta etapa se deberá verificar dicho supuesto de normalidad.
Verificación
Dentro verificación de este supuesto se esperaría que observaciones
estarían por fuera del intervalo , esta verificación se puede realizar
Con la gráfica de residuos contra el tiempo, como se usó con el Supuesto 2.
Histograma de los residuos, visualmente observando la asimetría y la curtosis.
Con una gráfica de sobre posición de funciones de densidad de la normal estándar
y la función de densidad del término de perturbación.
Prueba de bondad de ajuste de la distribución normal, Jarque Bera para muestras
grandes. (Véase Jarque y Bera (1987)), el test Lilliefors el cual muestra tener un
desempeño mejor en muestras pequeñas y está basado en la prueba de
Kolmogorov-Smirnov o el test Shapiro Wilk el cual también tiene un desempeño
mejor para muestras pequeñas.
Corrección
Las violaciones a este supuesto tienen que ser bastante notorias para llegar a pensar que
puede traer problemas. Esto debido al hecho que este supuesto deberá cumplirse para
los errores aleatorios y no necesariamente para los residuos . En caso de violación
del supuesto se puede recurrir a
Realizar una transformación normalizante como la de Box y Cox (1964), donde
{
( )
Realizar o revisar la transformación para la estabilización de la varianza vista en la
sección 4.3.2.1. Estabilización de la varianza, al comienzo de este capítulo.
10.6.12.5 Supuesto 5. No existen observaciones Outliers.

178
Las observaciones aberrantes o Outliers son frecuentemente encontradas en series
tomadas empíricamente y cuya presencia pueden llegar a alterar los resultados debido a
la distorsión que estos traen en las funciones de autocorrelación. El estudio de la
presencia de Outliers en los modelo ARIMA han sido un campo de estudio bastante activo
los últimos años. (i) Fox (1972) propone el uso de un test basado en la razón de máxima
verosimilitud para detectarlos, luego (ii) Chang y Tiao (1983) y Chang, Tiao y Chen (1988)
profundizan en los resultados de Fox (1972) en los modelos ARIMA mostrando un
procedimiento iterativo para la detección de Outliers y la estimación de parámetros. Más
adelante (iii) Tsay (1988) generaliza este procedimiento por medio de la detección de
cambios de nivel y cambios temporales. Debido a la confusión que existe entre los
cambios de nivel en la serie debido a cambios estructurales y la presencia de Outliers en
las innovaciones (iv) Balke (1993) propone un método para resolver esta confusión. Por
último (v) Chen y Liu (1993) proponen una metodología para su detección que presenta
mejoras significativas a todas las anteriores y parece ser ampliamente utilizada hoy en
día.
Verificación
La principal herramienta para detectar un Outlier es el conocimiento del investigador sobre
la serie que trabaja. Si llegase a detectar una observación posiblemente sospechosa, es
obligación de él buscar una explicación del por qué dicha observación se encuentra tan
desviada del resto, debe indagar en la fuente principal, si fue un error de digitación, error
humano, cambio estructural, error de copiado de los datos o simplemente que dicha
observación se debió a causas naturales del proceso.
Además de las técnicas presentadas por los autores mencionados anteriormente,
Guerrero (2003) propone
Realizar una inspección visual por medio de la gráfica de residuos contra el
tiempo.
Un residuo que se encuentre fuera del intervalo debería ser causa de
sospecha debido al hecho que pudo ocurrir por dos causas: (i) la probabilidad de
ocurrencia fue del 0.2% (muy improbable) y (ii) el residuo no fue generado por el
mismo proceso generador del resto de la serie.
Corrección
Antes de entrar a corregir el problema y perjudicar el análisis se debe tener evidencias
solidas tanto cuantitativas como cualitativas que dicha observación es en efecto atípica
para el proceso que generó los datos. Si se encuentra que esta observación corresponde
a un cambio estructural deberán tomarse diferentes medidas. Si por el contrario se
encuentra que dicha observación es en particular un Outlier deberá corregirse este error
mediante la entrevista con expertos en el tema, directores de operaciones, gerentes o por

179
medio de la interpolación de la serie. Sin embargo este problema es meritorio de un
profundo análisis.
10.6.12.6 Supuesto 6. Parsimonia.
Verificación
Para determinar que el modelo es parsimonioso se recurre la construcción de intervalos
de aproximadamente 95% de confianza para cada uno de los parámetros del modelo, así
( √ ( ) √ ( ))
Se debe observar si el valor cero (0) se encuentra por dentro del intervalo, esto para
determinar estadísticamente que dicho parámetro debería o no estar incluido dentro del
modelo.
Corrección
Si el valor cero (0) es un valor que se encuentra dentro del intervalo para el
correspondiente parámetro, será necesario reestimar el modelo sin él y verificar su
parsimonia nuevamente. Sin embargo, estas pruebas están para ayudar a la toma de
decisiones y nunca deben ser vistas como determinación tacita de una decisión. Por ello
si el proceso determina que este parámetro debe ser obligatoriamente incluido en el
modelo, deberá hacerse caso omiso de dicha prueba.
10.6.12.7 Supuesto 7. Admisibilidad.
Como lo explica Guerrero (2003, p. 120) la región admisible para los parámetros del
modelo se logra obtener como consecuencia de las condiciones de estacionariedad e
invertivilidad para los modelos. Como se explicó anteriormente, un modelo AR(1) es
estacionario si y solo si , por lo que su región admisible se representaría como
De la misma manera, un proceso AR(2) sería estacionario si satisface: (i) , (ii)
y (iii) . Por lo que estas tres condiciones forman un triangulo el
cual corresponde a su región admisible, y se representa como
-1 0 1
ø
Ilustración 11 Región admisible AR(1)

180
De la misma manera el modelo ARMA(1,1) será estacionario e invertible si el valor
absoluto del coeficiente componente autoregresivo y del promedio móvil es menor que la
unidad. | | y | | . Situación que se representa dentro de un cuadrado con una
diagonal transversa a él. Esta diagonal donde representa el caso general en el que
el modelo ARMA(1,1) es indistinguible de un proceso de ruido blanco, como lo expone
Guerrero. Tenemos entonces que su región admisible estaría dada por
Verificación
Para estos tres casos aquí presentados más los de los modelos MA(1) y MA(2) resulta
sencillo determinar si el modelo es admisible o no, únicamente determinando si los
parámetros se encuentra en los rangos de admisibilidad. Sin embargo, para modelos con
mayor número de parámetros resulta más complejo. Esto verificación podría verificarse de
acuerdo a las condiciones de estacionariedad o invertivilidad que corresponden a los
polinomios de rezado que intervienen.
Corrección
Se debe tener en consideración los siguientes puntos
𝜙 𝜙
𝜙
𝜙
𝜙 𝜙 𝜙 𝜙
1
-1
-2 2
𝜃
𝜙 -1 1
1
-1
Ilustración 12 Región admisible AR(2)
Ilustración 13 Región admisible ARMA (1,1)

181
Siempre ver el intervalo de confianza de las estimaciones, dado que los
parámetros suelen darse como estimaciones puntuales y puede sesgar el modelo
a la no admisibilidad.
Deben fijarse los parámetros en los valores que vuelven admisible al modelo.
De no ser admisible el modelo se debe revisar de nuevo la estimación de los
parámetros.
10.6.12.8 Supuesto 8. Estabilidad en los parámetros.
Verificación
Este último supuesto es de carácter vital para el buen desempeño del modelo. Su
derivación, como se mencionó anteriormente, viene de las raíces de la ecuación auxiliar
del modelo. En general, todo modelo, sin excepción, debe asegurar que los inversos de
las raíces de la ecuación auxiliar, también llamado polinomio característico, sean menores
que la unidad en magnitud. Es decir bajo la representación de un circulo unitario como el
de la Ilustración 14, se espera que estos inversos de las raíces se encuentren dentro del
circulo unitario.
Esta estabilidad del modelo determina que existe convergencia hacia el estado
estacionario (Steady State), de lo contrario el modelo diverge y se considera explosivo.
La principal causa de la inestabilidad es la redundancia de parámetros. Por lo que
conviene revisar la posible existencia de correlaciones altas (positivas o negativas) entre
los distintos parámetros para evitar así la inestabilidad. Para conseguir este propósito es
necesario realizar esta correlación entre parejas de parámetros estimados.
( ) ( ) ( )
√ ( ) ( )
𝜃
𝜙 -1 1
1
-1
Ilustración 14 Circulo unitario

182
Corrección
Cancelar parámetros redundantes (con coeficiente de correlación alta).
Eliminación de factores aproximadamente comunes en los polinomios AR y MA.
10.6.13 Estimación-Diagnóstico Serie LR1000
En esta etapa de estimación-diagnóstico, se pretende filtrar todos los modelos posibles
con el objetivo de encontrar aquel que cumpla todos los supuestos y además se ajuste
adecuadamente a las serie trabajada.
A continuación, la Tabla 79. Estimaciones preliminares serie LR1000(1:50) reporta los
resultados para las estimaciones preliminares encontradas en la etapa de identificación
(Véase Tabla 78. Modelos tentativos para la serie LR1000(1:50)). Cada uno de los
coeficientes estimados tiene consigo su respectivo estadístico t asociado en paréntesis,
así como los criterios de información AIC y SIC y algunas medidas de diagnóstico. Esta
misma notación se utilizará para todas las demás estimaciones de las series restantes.
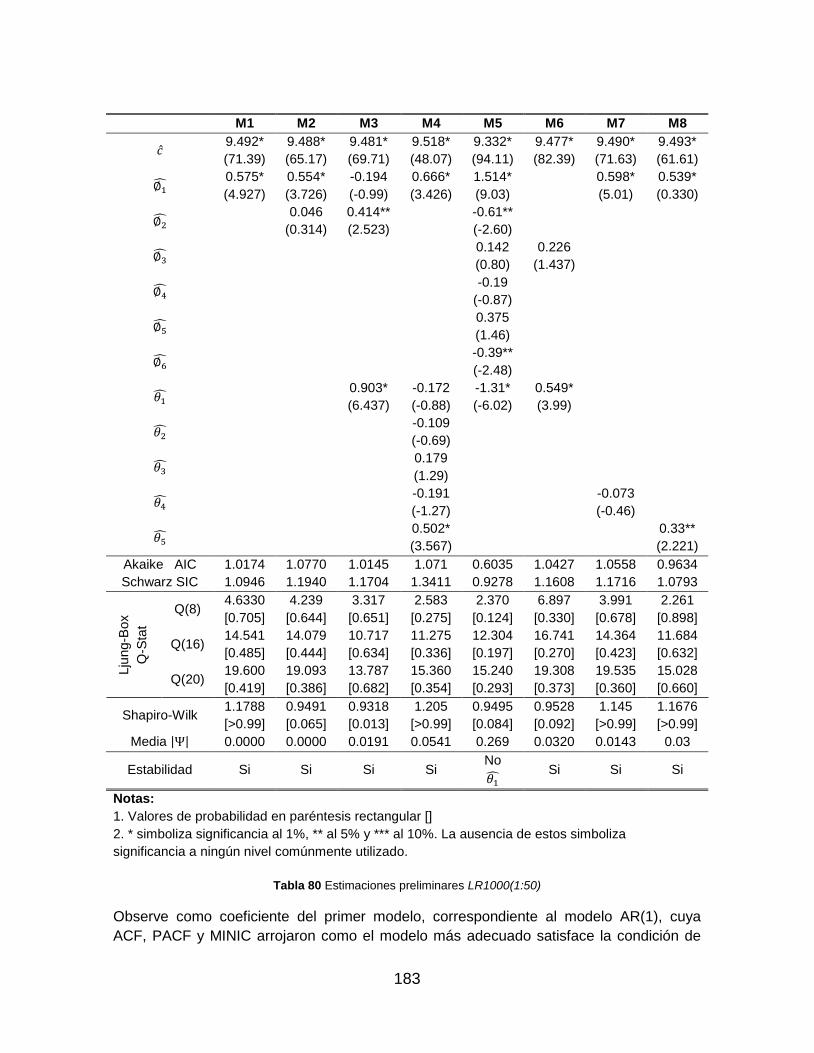
183
M1 M2 M3 M4 M5 M6 M7 M8
9.492*
(71.39)
9.488*
(65.17)
9.481*
(69.71)
9.518*
(48.07)
9.332*
(94.11)
9.477*
(82.39)
9.490*
(71.63)
9.493*
(61.61)
0.575*
(4.927)
0.554*
(3.726)
-0.194
(-0.99)
0.666*
(3.426)
1.514*
(9.03)
0.598*
(5.01)
0.539*
(0.330)
0.046
(0.314)
0.414**
(2.523)
-0.61**
(-2.60)
0.142
(0.80)
0.226
(1.437)
-0.19
(-0.87)
0.375
(1.46)
-0.39**
(-2.48)
0.903*
(6.437)
-0.172
(-0.88)
-1.31*
(-6.02)
0.549*
(3.99)
-0.109
(-0.69)
0.179
(1.29)
-0.191
(-1.27)
-0.073
(-0.46)
0.502*
(3.567)
0.33**
(2.221)
Akaike AIC
Schwarz SIC
1.0174
1.0946
1.0770
1.1940
1.0145
1.1704
1.071
1.3411
0.6035
0.9278
1.0427
1.1608
1.0558
1.1716
0.9634
1.0793
Lju
ng-B
ox
Q-S
tat
Q(8) 4.6330
[0.705]
4.239
[0.644]
3.317
[0.651]
2.583
[0.275]
2.370
[0.124]
6.897
[0.330]
3.991
[0.678]
2.261
[0.898]
Q(16) 14.541
[0.485]
14.079
[0.444]
10.717
[0.634]
11.275
[0.336]
12.304
[0.197]
16.741
[0.270]
14.364
[0.423]
11.684
[0.632]
Q(20) 19.600
[0.419]
19.093
[0.386]
13.787
[0.682]
15.360
[0.354]
15.240
[0.293]
19.308
[0.373]
19.535
[0.360]
15.028
[0.660]
Shapiro-Wilk 1.1788
[>0.99]
0.9491
[0.065]
0.9318
[0.013]
1.205
[>0.99]
0.9495
[0.084]
0.9528
[0.092]
1.145
[>0.99]
1.1676
[>0.99]
Media | | 0.0000 0.0000 0.0191 0.0541 0.269 0.0320 0.0143 0.03
Estabilidad Si Si Si Si No
Si Si Si
Notas:
1. Valores de probabilidad en paréntesis rectangular []
2. * simboliza significancia al 1%, ** al 5% y *** al 10%. La ausencia de estos simboliza
significancia a ningún nivel comúnmente utilizado.
Tabla 80 Estimaciones preliminares LR1000(1:50)
Observe como coeficiente del primer modelo, correspondiente al modelo AR(1), cuya
ACF, PACF y MINIC arrojaron como el modelo más adecuado satisface la condición de

184
estabilidad puesto que el absoluto del inverso de la raíz de la ecuación auxiliar es menor
que la unidad, es decir | | y además es significativo al 1%. Asimismo, el estadístico
Ljung-Box Q indica que tanto hasta el rezago 8 como el 16 y el 20 los residuos no son
significativamente diferentes de cero. Esto indica que el modelo AR(1) se ajusta bien a los
datos puesto el modelo está utilizando la información disponible determinado por la poca
significancia de los residuos.
Observando el segundo modelo M2 se observa como el único coeficiente que no es
significativamente diferente de cero es el coeficiente , indicando que al incluir el
segundo rezago de el modelo no necesita de éste para explicar la serie. Por lo que al
ser sustraído del modelo para cumplir la condición de parsimonia conllevaría a pararse de
nuevo en M1.
El modelo M3 nos está dejando ver que al incluir el componente estocástico de media
móvil de orden 1 en M2, este hace que el segundo rezago de sea significativo y no
necesite del primer rezago para estimar . Por lo que se deberá probar el M3 ahora
sustrayendo el primer rezago autoregresivo y probando de nuevo su significancia y
condiciones de diagnóstico. Esto se verá más adelante en la reestimación de los modelos
preliminares en la Tabla 80 por lo que su explicación dependerá de la sustracción de
del modelo.
El modelo M4 presentó poca significancia estadística de los coeficientes de media móvil
de 1 a 4 rezagos. Por lo que se deberán ir sustrayendo del modelo dependiendo de cuál
sea el más insignificativo y reestimado (i.e. el que presente el valor de probabilidad más
alto), este proceso iterativo llevará a un modelo del tipo M8, es decir
el cual presenta significancia estadística en cada uno de sus rezagos. Este modelo se
registró en la Tabla 79. Estimaciones preliminares LR1000(1:50) puesto que fue el modelo
tentativo que arrojó el método ARI MAI N en la matriz MAPE. En general, M8 presenta un
mejor desempeño que M1 puesto que la inclusión del rezago 5 de media móvil permite
reducir los criterios de información AIC y SIC por lo que dicho rezago ayuda
significativamente a la reducción de la suma de cuadrados del error. Adicionalmente, la
prueba Ljung-Box de los residuos tanto hasta 8 como 16 y 20 rezagos presentaron una
mayor insignificancia que M1 determinada por un valor de probabilidad más alto. Por lo
que se podría pensar que el modelo M8 captura de manera más adecuada el conjunto de
información disponible que el modelo M1 para estimar la serie de tiempo, mejorando las
dinámicas de corto y largo plazo del modelo M1. Sin embargo, se deberá contrastar su
desempeño con la reestimación de los modelos preliminares presentados en la Tabla 79.
EL modelo M5 presentó el menor criterio de información de todos. Sin embargo, presenta
ciertas otras condiciones que permiten descartarlo como un modelo adecuado. El inverso
de dos de las raíces de la ecuación auxiliar del modelo están por fuera del circulo unitario;

185
el inverso de raíz asociada al coeficiente presentó el valor de 1.02 y el de de 1.314
por lo que se considera un modelo inestable en parámetros y por tanto explosivo y poco
confiable. Adicionalmente, la sustracción iterada de parámetros no significativos termina
llevando a un modelo del tipo M3 sin el coeficiente .
Los modelos M6 y M7 presentaron poca significancia en los parámetros y
respectivamente. Por lo que al sustraerlos, se llegará a un modelo y
M1 respectivamente. Es decir que se deberá probar en la siguiente fase de reestimación
el modelo MA(1) y comparar su desempeño con los demás modelos.
Resumiendo, se tiene que para el siguiente filtro pasarán a probarse únicamente 4
modelos, estos deberán ser comparados entre sí y se deberá escoger aquel modelo que
cumpla con todas las condiciones de diagnóstico. Los resultados se registran a
continuación
M1 M8 M9 M10
9.492*
(71.39)
9.493*
(61.61)
9.485*
(60.58)
9.465*
(104.4)
0.575*
(4.927)
0.539*
(0.330)
0.369**
(2.125)
0.774*
(6.551)
0.561*
(4.641)
0.33**
(2.221)
Akaike AIC
Schwarz SIC
1.0174
1.0946
0.9634
1.0793
0.9990
1.1160
1.1035
1.1799
Lju
ng-B
ox
Q-S
tat
Q(8) 4.6330
[0.705]
2.261
[0.898]
3.989
[0.678]
11.167
[0.132]
Q(16) 14.541
[0.485]
11.684
[0.632]
10.738
[0.706]
21.946
[0.109]
Q(20) 19.600
[0.419]
15.028
[0.660]
14.693
[0.683]
30.555
[0.134]
Shapiro-Wilk 1.1788
[>0.99]
1.1676
[>0.99]
0.9257
[<0.01]
0.9667
[0.352]
Media | | 0.0000 0.03 0.0486 0.0211
Estabilidad Si Si Si Si
Notas:
1. Valores de probabilidad en paréntesis rectangular []
2. * simboliza significancia al 1%, ** al 5% y *** al 10%. La ausencia de estos
simboliza significancia a ningún nivel comúnmente utilizado.
Tabla 81 Estimación fase 2 LR1000(1:50)

186
Se puede observar ahora que todos los modelos son significativos en parámetros, por lo
que la escogencia de uno de ellos para ser catalogado como la mejor aproximación del
mecanismo generador de datos que rige al proceso estocástico de la serie LR1000.
Depende ahora de criterios del investigador sobre la interpretación de los diagnósticos y
criterios de información.
El modelo M10 aunque cumple con todas las condiciones, es un modelo que utiliza muy
poca información disponible puesto que los residuos parecen guardar cierto grado de
correlación serial entre ellos. Esto también se puede ver puesto que es el modelo cuyos
criterios de información son los más altos de todos.
Se tiene entonces que la competencia está ahora entre tres candidatos, correspondientes
a los tres primeros modelos de la Tabla 80. Sin embargo, es el modelo M8 quien muestra
un mejor desempeño debido básicamente a 2 razonamientos. El primero, fue el que
presentó un menor criterio de información tanto AIC como SIC y segundo y más
importante, este modelo captura adecuadamente las relaciones de corto y largo plazo
evidenciadas en la poca correlación serial que sufren los residuales tanto para los rezagos
8 como el 16 y 20. Si se observa esto en el modelo M1, se tiene que es un modelo
evidentemente bueno capturando las relaciones dinámicas del proceso en el corto plazo
pero sufre de más correlación serial entre los grupos de rezagos más lejanos, conjetura
que valida los supuestos preliminares en la etapa de identificación.
En cuanto al modelo M9 parece ser un fuerte competidor del modelo M8 debido a que
captura, con una cantidad menor de información puesto que solo utiliza dos rezagos en el
autoregresivo y 1 en el de media móvil, ciertas condiciones son parecidas a las del
modelo M8. Sin embargo, un supuesto comúnmente utilizado en el análisis de series de
tiempo es la distribución gaussiana de las innovaciones, es decir el cumplimiento de
normalidad en los residuos. Si se observa la prueba de contraste de normalidad de
Shapiro Wilk realizada por medio de ASTEX, ésta permite rechazar la hipótesis nula que
la serie proviene de población normalmente distribuida a diferencia del modelo M8. Por
lo que se escogería entonces este último modelo como el más adecuado.
Se tiene entonces que el modelo escogido para la serie LR1000 a partir de toda la
información suministrada en este capítulo y lo visto en las 3 primeras etapas de Box-
Jenkins corresponde al modelo M8, es decir el polinomio

187
10.6.14 Valor Real Vs Ajuste del Modelo
Gráfica 10 Ajuste Vs. Real serie R250(1:45)
Gráfica 11 Ajuste Vs. Real serie R500(1:50)
0
10000
20000
30000
40000
50000
60000
70000
80000
90000
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43
Un
ida
de
s
Real Vs. Ajuste R250
Real
Ajustado
0
20000
40000
60000
80000
100000
120000
1 3 5 7 9 1113151719212325272931333537394143454749
Un
ida
de
s
Real Vs. Ajuste R500
Real
Ajustado

188
Gráfica 12 Ajuste Vs. Real serie R1000(1:50)
Gráfica 13 Ajuste Vs. Real serie R1500(1:50)
Gráfica 14 Ajuste Vs. Real serie R3000(1:50)
0
5000
10000
15000
20000
25000
30000
35000
40000
1 3 5 7 9 1113151719212325272931333537394143454749
Un
ida
de
s
Real Vs. Ajuste R1000
Real
Ajustado
0
1000
2000
3000
4000
5000
6000
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41
Un
ida
de
s
Real Vs. Ajuste LR1500
Real
Ajustado
0
1000
2000
3000
4000
5000
6000
7000
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45
Un
ida
de
s
Real Vs. Ajuste R3000
Real
Ajustado

189
10.6.15 Esquema Rolling y Algoritmo en MATLAB
Esquema Rolling
El esquema rolling de evaluación de pronóstico fuera de muestra involucra la posibilidad
del reconocimiento de la entrada sucesiva de observaciones que se van generando desde
el proceso estocástico período a período y que de por sí modifican el conjunto de
información disponible en el período t, sobre el cual se estima inicialmente un modelo
tentativo. Esta metodología permite la reestimación del modelo ARIMA(p,d,q) a lo largo
del tiempo para cada nueva observación que se incluye período a período en la muestra
inicial. En general el esquema Rolling permitirá registrar dos aspectos importantes,
primero servirá como punto de comparación entre las diferentes metodologías planteadas
y segundo mostrará hasta que horizonte es capaz de pronosticar el modelo, aspecto
esencial a tener en cuenta en un plan de producción.
Este esquema Rolling supone la necesidad de dividir la muestra en dos submuestras, la
primera una muestra de estimación y otra de evaluación. La forma como se realizó el
esquema se da de la siguiente manera:
Considere el número de observaciones que se utilizarán como la submuestra de
estimación inicial donde se buscará el mejor modelo el cual será
empleado para realizar únicamente el pronóstico de h periodos hacia delante. Esto, desde
la última observación en hasta . Una vez se adiciona el siguiente
dato a la muestra, es reestimado un nuevo modelo ARIMA y pronosticado h
periodos adelante. El proceso continúa estimando y pronosticado hasta que la muestra
estimada tenga un valor de observaciones y se encuentre un modelo
, esto debido a que no tendría sentido alguno la estimación de valores
adicionales si no es posible confrontarlos con valores reales para su evaluación fuera de
muestra.
Por ejemplo, para el caso de TR500 se cuenta con un total de observaciones N=50, si se
toma un total de T= 11 se tendría un valor de =39, que correspondería a el número
inicial de observaciones al que se buscará el mejor modelo y se
pronosticará desde la observación 40 hasta la 45 para un h=6 periodos. Una vez es
incluida la observación 40 en la muestra de estimación, es reestimado y encontrado un
nuevo modelo el cual servirá para el pronóstico de las observaciones 41
a la observación 46. Así, hasta llegar a la estimación del modelo con 44
observaciones dentro de muestra y el pronóstico desde la observación 45 hasta la 50.
Estimaciones posteriores no tendrían sentido debido a que no habría como evaluarlas.
Este esquema se resume en la siguiente tabla para un h=6 y un T=11 en la serie TR500
con N=50

190
Pronóstico
Modelo Nº Obs Desde Hasta
39 40 45
40 41 46
41 42 47
42 43 48
43 44 49
44 45 50
Tabla 82 Ejemplo Esquema Rolling
Al terminar el esquema se concluye con una matriz de (T-h)+1 x h donde cada una de las
filas es el pronóstico de h periodos adelante de cada una de las (T-h)+1 estimaciones
ARIMA y cada una de las columnas de dicha matriz debe ser evaluada bajo algún tipo de
función de pérdida de error de pronóstico, bien sea simétrico o asimétrico como las vistas
al comienzo de este capítulo, con el objetivo de llegar a determinar cómo está
pronosticando el modelo ARIMA en cada uno de los horizonte de tiempo. Es decir, en el
horizonte 1 se contrastarán todos los pronósticos realizados para la siguiente observación
después del período de estimación en cada modelo, para el horizonte 2 todos los
segundos pronósticos después del periodo de estimación de cada modelo y así
sucesivamente hasta completar el horizonte 6, el cual corresponde a todos los pronósticos
del período 6 después de la última observación en cada uno de los modelos estimados.
El presente trabajo consideró un T igual a 11 en todas las series puesto que se terminará
con una matriz de 6x6, la cual tiene como propósito realizar la evaluación para 6 períodos
(número de filas) adelante debido simplemente a que se está trabajando con una muestra
pequeña. Sin embargo, si el tamaño de la muestra es el adecuado, es posible realizar un
número de estimaciones tal que permita encontrar un valor de medida fuera de muestra
con más observaciones de las estudiadas en este trabajo.
Aplicación Práctica – Algoritmo en MATLAB para la evaluación fuera de muestra
Rolling.
El desarrollo práctico de la estimación, diagnóstico, pronóstico y evaluación fuera de
muestra del análisis de las cinco series temporales estudiadas se desarrolló en MATLAB
a partir de la elaboración de un código de programación cuyo objetivo es la evaluación
fuera de muestra bajo el esquema rolling con medias de error simétrico y/o asimétrico
para cada modelo de estimación. Esta estimación viene acompañada de un diagnóstico
del término de perturbación como se describe en la teoría. A continuación se describe la
lógica detrás del algoritmo en MATLAB y como se ha venido trabajando hasta el
momento, se mostrarán los resultados para todas las series.
Descripción del algoritmo
La programación del algoritmo se llevó a cabo a partir de la creación de dos funciones,
una principal llamada Rolling2 y una auxiliar llamada ARIMAFUERA2 ambas

191
autocontenidas en archivos .m en MATLAB y con la condición que la primera hace uso de
la segunda dentro de su función.
La función Rol l i ng2( ser i e, opt i ons) declara la necesidad del ingreso de dos
condiciones de entrada. La primera, <ser i e>, hace referencia a la serie original (sin
transformaciones) que se desea evaluar, en este caso específico TR500. Se dice que no
se deben ingresar transformaciones puesto que el algoritmo brinda la posibilidad de
ingresar el grado de diferenciación de la serie y la función estabilizadora de la varianza
acorde a lo presentado en secciones anteriores. La entrada <opt i ons> es una
declaración del tipo estructura que permite el ingreso de todas las opciones que se
necesitan para el esquema rolling. Esta estructura presenta las siguientes opciones:
ARLags : hace referencia a la matriz de vectores autoregresivos para cada
periodo de estimación, donde cada una de las filas corresponde a cada una de las
estimaciones a realizar en el rolling. Este número de filas debe coincidir con el
número de filas de MALags , mientras que el número de columnas no trae consigo
ninguna restricción, además que debe ser llenada con NaN cuando sea necesario.
Más adelante se mostrará un ejemplo sobre esta entrada.
MALags : hace referencia a la matriz de vectores de media móvil para cada periodo
de estimación, donde cada una de las filas corresponde a cada una de las
estimaciones a realizar en el rolling. Este número de filas debe coincidir con el
número de filas de ARLags , mientras que el número de columnas no trae consigo
ninguna restricción, además que debe ser llenada con NaN cuando sea necesario.
Más adelante se mostrará un ejemplo sobre esta entrada.
D: hace referencia a el grado de diferenciación de la serie u orden de integración.
El valor por defecto es 0.
h: hace referencia al horizonte de pronosticación dentro del esquema rolling. Para
este caso específico h toma el valor de 6 periodos adelante.
Di agnos : toma el valor de ‘ on’ si se desea observar al final de cada estimación
el diagnóstico del término de perturbación mostrando una ayuda tanto por medio
de tests estadísticos (media cero bajo Guerrero (2003, p.144) y prueba de
normalidad Jarque Bera y Lilliefors al 95% de confianza) como por medio de una
representación visual. Esta última dada por el ajuste y pronóstico de la serie, la
función de autocorrelación ACF para determinar si existe autocorrelación cero, la
gráfica de ajuste de la función de densidad de una normal estándar con la función
de densidad de probabilidad del término de perturbación y por último la gráfica de
la serie de residuos con limites para determinar la potencial existencia
de Outliers, así como la línea donde se encuentra la media.
Caso contrario tomará el valor ‘ of f ’ si no se desea imprimir los diagnósticos.

192
El valor por defecto es ‘ of f ’ .
Tr ans: hace referencia al tipo de transformación de varianza que sufre la serie,
ésta puede tomar las siguientes forma:
' Log' - transformación tipo logarítmica
' Rai z ' - transformación tipo raíz cuadrada √
‘ I n Rai z ’ - transformación tipo inversa de raíz cuadrada √
' I nv ' - transformación tipo inversa
' BoxCox' - transformación tipo Box-Cox (1965) véase Sección. 4.4.2.2
' Or i g' - no sufre ningún tipo de transformación
Por defecto se tiene ' Or i g' .
d1_LI NEX y d2_LI NEX: corresponden a los valores de y de la función
LINEX presentada al inicio de este capítulo.
d1_LI NLI N y d2_LI NLI N: corresponden a los valores de y de la función
LINLIN presentada al inicio de este capítulo.
Nótese como por medio del número de filas de ARLags o MALags y el input h se puede
llegar a obtener el valor de T es decir el valor desde el cual se comienza a estimar el
primer modelo, simplemente como ( ) . Es decir que en este caso
particular .
Se procedió entonces a estimar el esquema rolling con el algoritmo propuesto para la
serie LR1000, éste se realizó ingresando el mejor modelo en cada una de las
estimaciones del esquema tanto en el componente autoregresivo como el de media móvil
si era el caso. Además se incluyó del orden de diferenciación D=0 y la transformación tipo
inversa de raíz, acorde a lo visto en la etapa de identificación.
Se tiene entonces que las condiciones de entrada del algoritmo en MATLAB para la serie
LR1000 son :
% Ar gument os de ent r ada opt i ons. ARLags =[ 1] ; opt i ons. MALags =[ 5] ; opt i ons. h =6; opt i ons. Di agnos =' on' ; opt i ons. d1_LI NLI N =Cal _d1_LI NLI N( 3) ; opt i ons. d2_LI NLI N =Cal _d2_LI NLI N( 3) ; opt i ons. Tr ans =' Log' ; ser i e =R1000;

193
Rol l i ng2( ser i e, opt i ons) ;
La estructura <opt i ons> del algoritmo permite identificar cuales opciones son incluidas y
cuáles no, es decir, existen unas condiciones default o por defecto que permiten realizar
el procedimiento si el usuario no ingresa una opción. Por ejemplo, en este caso no se
incluyeron las opciones d1_LI NLEX ni d2_LI NLEX debido a que no serán utilizadas y
por tanto el algoritmo no las tiene en cuenta y no imprimirá resultados de estas, además
se tomó el valor del orden de integración por defecto es decir D=0. Las opciones
d1_LI NLI N y d2_LI NLI N representan posiciones en los vectores de la Tabla 24
representados por las columnas 2 y 3 respectivamente, en este caso la posición 2 hace
referencia a la serie LR1000.
Para este caso particular el modelo de estimación previamente identificado ARMA([1],[5])
para la serie LR1000 entre las observaciones (1:50) se presentó como el mejor modelo a
lo largo de todas las corridas del esquema rolling. Es decir, el modelo se mantuvo al ir
incluyendo una observación en cada período. Observe además que la función Rolling2
permite identificar esta condición de entrada puesto que no es necesario ingresar una
matriz de rezagos AR ni MA, sino que la función identifica ese modelo como el único
modelo a estimar a lo largo de todas las seis corridas el esquema.
10.7 Complemento ASTEX
10.7.1 Ventana Para la Instalación del Add/In
Ilustración 15 Ventana Instalación ASTEX
10.7.2 Estabilización de la Varianza con ASTEX

194
El código de programación a través de ASTEX básicamente pide al usuario que
seleccione la serie de interés en el programa Microsoft Excel, se solicita de manera
opcional que se le dé un nombre a la serie y que seleccione si desea obtener la potencia
que minimice el coeficiente de variación automáticamente o si desea ver los resultados
para una potencia especificada por el mismo.
Es importante aclarar en este punto que la idea de Búsqueda automática de la potencia
dista por completo de su estimación exacta. Para ello Box y Cox (1964) mostraron que el
estimador de máxima verosimilitud de es aquel que minimiza el error cuadrático medio
del modelo ajustado de la serie de datos normalizada. Dentro de esto se estaría tratando
la potencia como un parámetro de transformación que puede ser estimado de los datos.
Incluyendo así el parámetro en el modelo
y por tanto escogiendo dicho valor de lambda que haga mínima la función de
pérdida del error (para una discusión más amplia sobre este tema diríjase a Box y Cox
( 964) o Weil ( 006)). Por ello “el método est basado en apro imaciones y que por
consiguiente, conviene utilizarlo esencialmente para discriminar entre transformaciones
que a priori se consideren apropiadas, como la transformación logarítmica o la lineal, más
no para obtener estimaciones exactas del parámetro con mucha e actitud” (Guerrero
(2003), p. 110)
Debido a que la serie debe estar ordenada de una manera específica como se mencionó
en la teoría, dividiéndolo en H grupos de R observaciones cada uno, se incluyó también la
posibilidad al usuario de agruparlos de manera automática a través de un botón en el
formulario del usuario (ver ilustración 16). Por último se le pide al usuario que seleccione
la celda donde desea imprimir los resultados en Excel.
Sin entrar en detalles sobre la programación se intentará mostrar a partir de la realización
de un ejemplo paso a paso la funcionalidad del código en ASTEX. Por lo que se
procederá a utilizar la serie R1000 como referencia.

195
Ilustración 16 Formulario para la estabilización
automática de la varianza
Primero que nada se abre el formulario Transformación Estabilizadora de Varianza el cual
contiene de manera interactiva para el usuario el código de programación desarrollado.
Este formulario puede ser accedido desde el botón “Estab Varianza” en la cinta de
opciones, el cual se representa como
Debido a que la variable R1000 se encuentra en una sola columna, fue necesario hacer
uso del botón Ordenar Serie dentro del formulario. Al hacer click en éste se abre otro
formulario que guiará al usuario en el ordenamiento de la serie como se muestra en el
ilustración 17. Dicho formulario se encuentra dividido en cuatro partes: en la primera se le
pide al usuario que seleccione la serie original la cual debe ser de dimensiones Nx1, ésta
se preselecciona automáticamente acorde a lo que el usuario tenga seleccionado en la
hoja de cálculo, en la segunda parte se pide que se seleccione si la serie está dada en
periodicidad mensual o trimestral, la tercera se pide que se establezcan las condiciones
iniciales de la serie, esto es, primer mes (o trimestre) y el año de inicio, por último se le
pide al usuario que diga en que celda desea imprimir los resultados.

196
Ilustración 17 Formulario Ordenar Serie
Una vez llenado el formulario Ordenar Serie se procede a dar click en el botón “Aceptar”
esto hará que se imprima la serie ordenada en la salida seleccionada, de esta manera
R1
00
0
Año-> 2010 2011 2012 2013
Enero 7260 14196 11928 14976
Febrero 10596 16080 12276 17100
Marzo 20532 21492 11736 15336
Abril 8964 7464 13320 16788
Mayo 15468 7560 6660 14076
Junio 16380 7824 7056 23697
Julio 17700 17064 9456 21060
Agosto 24732 17520 11460 20286
Septiembre 18924 9000 3252 33006
Octubre 18096 10632 4260 19380
Noviembre 11208 10236 7104 24252
Diciembre 9528 9948 7500 33660
Tabla 83 Serie R1000 Ordenada para Estabilización de Varianza
como se puede observar la serie que estaba en columnas quedó ordenada según los
requerimientos propuestos por Guerrero (2003), donde todos los H grupos presentan
homogeneidad en el número de observaciones. Para este caso específico se cuenta con
que H = 4 y R = 12. Donde fueron descartados los dos primeros datos del 2014.
Una vez ordenada la serie se da paso a la estabilización de la varianza. Para ello se
llenan los requerimientos pedidos en el formulario Transformación Estabilizadora de
Varianza (ilustración 16). Como primera instancia se han ingresado manualmente las
potencias a evaluar acorde a los valores de la Tabla 16. Valores típicos de y su
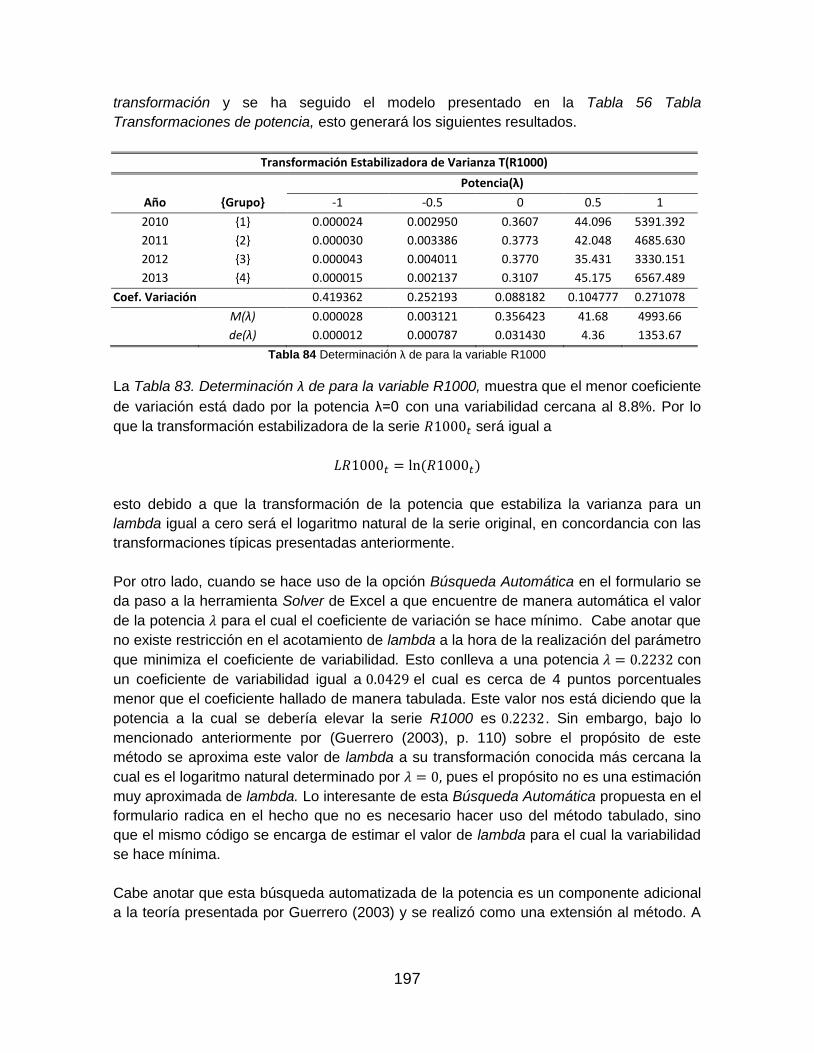
197
transformación y se ha seguido el modelo presentado en la Tabla 56 Tabla
Transformaciones de potencia, esto generará los siguientes resultados.
Transformación Estabilizadora de Varianza T(R1000)
Potencia(λ)
Año {Grupo} -1 -0.5 0 0.5 1
2010 {1} 0.000024 0.002950 0.3607 44.096 5391.392
2011 {2} 0.000030 0.003386 0.3773 42.048 4685.630
2012 {3} 0.000043 0.004011 0.3770 35.431 3330.151
2013 {4} 0.000015 0.002137 0.3107 45.175 6567.489
Coef. Variación 0.419362 0.252193 0.088182 0.104777 0.271078
M(λ) 0.000028 0.003121 0.356423 41.68 4993.66
de(λ) 0.000012 0.000787 0.031430 4.36 1353.67
Tabla 84 Determinación λ de para la variable R1000
La Tabla 83. Determinación λ de para la variable R1000, muestra que el menor coeficiente
de variación está dado por la potencia λ=0 con una variabilidad cercana al 8.8%. Por lo
que la transformación estabilizadora de la serie será igual a
esto debido a que la transformación de la potencia que estabiliza la varianza para un
lambda igual a cero será el logaritmo natural de la serie original, en concordancia con las
transformaciones típicas presentadas anteriormente.
Por otro lado, cuando se hace uso de la opción Búsqueda Automática en el formulario se
da paso a la herramienta Solver de Excel a que encuentre de manera automática el valor
de la potencia para el cual el coeficiente de variación se hace mínimo. Cabe anotar que
no existe restricción en el acotamiento de lambda a la hora de la realización del parámetro
que minimiza el coeficiente de variabilidad. Esto conlleva a una potencia con
un coeficiente de variabilidad igual a el cual es cerca de 4 puntos porcentuales
menor que el coeficiente hallado de manera tabulada. Este valor nos está diciendo que la
potencia a la cual se debería elevar la serie R1000 es . Sin embargo, bajo lo
mencionado anteriormente por (Guerrero (2003), p. 110) sobre el propósito de este
método se aproxima este valor de lambda a su transformación conocida más cercana la
cual es el logaritmo natural determinado por pues el propósito no es una estimación
muy aproximada de lambda. Lo interesante de esta Búsqueda Automática propuesta en el
formulario radica en el hecho que no es necesario hacer uso del método tabulado, sino
que el mismo código se encarga de estimar el valor de lambda para el cual la variabilidad
se hace mínima.
Cabe anotar que esta búsqueda automatizada de la potencia es un componente adicional
a la teoría presentada por Guerrero (2003) y se realizó como una extensión al método. A

198
continuación en la Tabla 84. Transformación estabilizadora de varianza R1000 se
presentan los resultados obtenidos por el código
Transformación Estabilizadora de Varianza T(R1000)
Potencia(λ)
Año {Grupo} 0.223257367 Sh Zh
2010 {1} 3.083910 5391.39 14949.00
2011 {2} 3.095590 4685.63 12418.00
2012 {3} 2.866258 3330.15 8834.00
2013 {4} 2.870713 6567.49 21134.75
Coef. Variación 0.042915
M(λ) 2.979118
de(λ) 0.127849
N= 50
n= 48
H= 4
R= 12
Tabla 85 Transformación estabilizadora de varianza R1000
La Gráfica 15. Transformación Estabilizadora de Varianza LR1000 muestra la diferencia
visualmente sobre la serie original R1000 y la transformada LR1000, se observa como los
picos altos de variabilidad disminuyeron considerablemente debido al uso de la potencia
λ Visualmente parece no existir la necesidad de estabilizar la media a la serie debido a
que el nivel de ésta está no cambiando en el tiempo, pero esto se concluirá únicamente
con un análisis profundo, el cual se desarrollará en la siguiente sección.
Gráfica 15 Transformación Estabilizadora de Varianza LR1000
0
2
4
6
8
10
12
0
5000
10000
15000
20000
25000
30000
35000
40000
1 3 5 7 9 11131517192123252729313335373941434547
R1000
LR1000

199
Con el propósito de llegar a detallar aún más el proceso utilizado, se procede a mostrar
los cálculos para el año 2010 o Grupo {1} en la Tabla 83. Determinación λ de para la
variable R1000 con el método manual. Primero se calcula el promedio simple del grupo
con las R=12 observaciones
( )
en seguida se procede a calcular la desviación estándar del grupo, así
√
( )
( )
( )
de estos dos parámetros se obtiene que
los cuales corresponden a los resultados del primero renglón de la Tabla 83. Lo siguiente
es calcular la media y la varianza de la columna correspondiente a la potencia -1 y de esta
manera calcular el coeficiente de variabilidad a partir de la división de la media con la
desviación de cada potencia. De este modo se tiene que
∑ (
)
√
∑ [(
) ]
donde se obtiene que el coeficiente de variabilidad está dado por
el cual corresponde a el resultado para la primera columna de la Tabla 83, de la misma
manera se realiza el cálculo del CV para cada una de las 5 potencias. Las cuales se
realizan de manera automática por medio del código presentado.

200
10.7.3 Estabilización del Nivel Anderson con ASTEX
El método de Anderson (1976) es bastante mecánico, sencillo e intuitivo. Como se
mencionó anteriormente, en el primer paso es necesario obtener las 3 diferenciaciones de
la serie transformada es decir y . Una vez realizada la
diferenciación hasta de orden 3, sencillamente queda aplicar la ecuación de desviación
estándar (D4) a cada una de las cuatro diferencias teniendo en cuenta el número de
grados de libertad que se pierden por el orden de la diferenciación. De estas cuatro
desviaciones se escoge el mínimo y el orden de la diferencia asociado debería coincidir
con el orden de integración requerido o por lo menos sugerirlo. De modo tal que se
obtiene para la serie
Orden de integración 0 1 2 3
Desviación Estándar 0.233165 0.195276 0.491233 1.518315
Tabla 86 Desviaciones Estándar de LR1000. Estabilización Nivel
Se puede observar que para el caso específico de la variable , es en la diferencia
de primer orden donde se presenta el mínimo valor. Esto estaría dando
evidencia que el orden de integración de dicha variable sería y por tanto se
necesitaría diferenciarla una vez para que ésta se vuelva estacionaria en media. Sin
embargo, esta conclusión deberá ser complementada con las pruebas de raíz unitaria
más adelante puesto que si se observa bien, la diferencia entre el orden de integración 1 y
el 0 no es tan significativamente diferente, y como lo siguiere Guerrero (2003) se debe
tener mucho cuidado en tomar este valor como definitivo si la diferencia no es
significativamente alta.
Haciendo uso de ASTEX se da la opción al usuario de realizar este procedimiento
automáticamente para cualquier serie mediante de la ejecución del código de
programación en VBA E cel el cual est contenido en el botón “Estab. Nivel Anderson”
en la cinta de opciones de ASTEX y presenta la siguiente forma
Al presionar esta opción se abre un formulario (ver ilustración 18. Formulario
Estabilización Nivel Anderson (1976)), el cual pide al usuario seleccionar el vector de la
serie de entrada, que en este caso correspondía a cada una de las cinco series
transformadas de varianza, además de preguntarle al usuario si desea ver los resultados
de las desviaciones estándar acorde a la ecuación (D4) presentada anteriormente para
cada una de las 3 diferencias posibles.
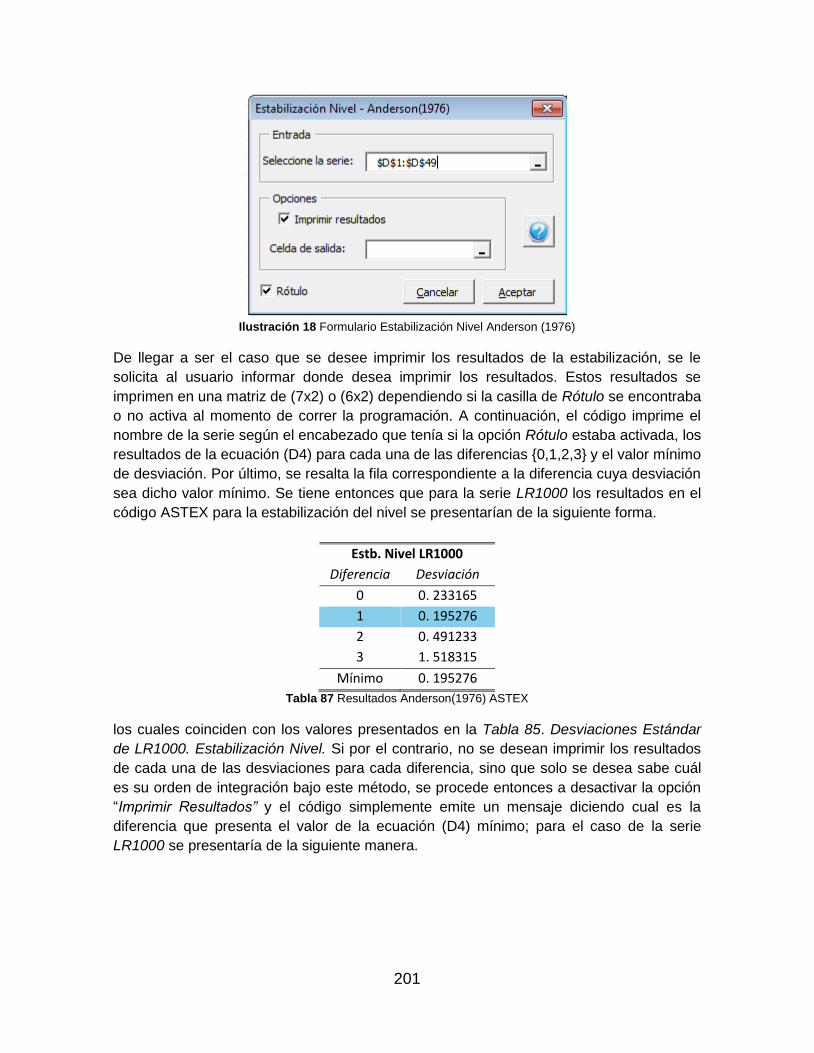
201
Ilustración 18 Formulario Estabilización Nivel Anderson (1976)
De llegar a ser el caso que se desee imprimir los resultados de la estabilización, se le
solicita al usuario informar donde desea imprimir los resultados. Estos resultados se
imprimen en una matriz de (7x2) o (6x2) dependiendo si la casilla de Rótulo se encontraba
o no activa al momento de correr la programación. A continuación, el código imprime el
nombre de la serie según el encabezado que tenía si la opción Rótulo estaba activada, los
resultados de la ecuación (D4) para cada una de las diferencias {0,1,2,3} y el valor mínimo
de desviación. Por último, se resalta la fila correspondiente a la diferencia cuya desviación
sea dicho valor mínimo. Se tiene entonces que para la serie LR1000 los resultados en el
código ASTEX para la estabilización del nivel se presentarían de la siguiente forma.
Estb. Nivel LR1000
Diferencia Desviación
0 0. 233165
1 0. 195276
2 0. 491233
3 1. 518315
Mínimo 0. 195276
Tabla 87 Resultados Anderson(1976) ASTEX
los cuales coinciden con los valores presentados en la Tabla 85. Desviaciones Estándar
de LR1000. Estabilización Nivel. Si por el contrario, no se desean imprimir los resultados
de cada una de las desviaciones para cada diferencia, sino que solo se desea sabe cuál
es su orden de integración bajo este método, se procede entonces a desactivar la opción
“ mprimir Resultados” y el código simplemente emite un mensaje diciendo cual es la
diferencia que presenta el valor de la ecuación (D4) mínimo; para el caso de la serie
LR1000 se presentaría de la siguiente manera.

202
Ilustración 19 Mensaje no imprimir, Estb. Nivel Anderson
10.7.4 Prueba de Raíz Unitaria ADF con ASTEX
Simplemente seleccionando previamente la serie y presionando el botón
se da paso entonces al formulario de raíz unitaria (ver ilustración 20), el cual pregunta al
usuario por la posibilidad de incorporar la constante y tendencia (D7), solo la constante
(D6) o ninguna de ellas (D5) dentro del modelo de regresión auxiliar estimado por el
método de mínimos cuadrados ordinarios y cuyo estadístico de prueba corresponde al
valor o del coeficiente de interés .
Al seleccionar las opciones de entrada y dar “Aceptar” aparecer un mensa e preguntando
como desea llamar la nueva hoja que se generará con resultados de la prueba de raíz
unitaria ADF exactamente iguales a los mostrados en las tablas 61 y 62. Por defecto el
programa recomendará un nombre de hoja dependiendo si la serie incluye o no rótulos, es
decir, si esta opción fue o no seleccionada en el formulario.
Ilustración 20 Formulario Prueba de Raíz Unitaria ADF ASTEX

203
10.7.5 Diagnostico Normalidad y Media Cero con ASTEX
Simplemente teniendo la serie de residuos del modelo estimado, la cual se puede obtener
desde cualquier paquete estadístico, es posible realizar un diagnóstico de normalidad,
autocorrelación y media cero desde ASTEX. Como se mencionó anteriormente, debido a
que la muestra es menor a 50 observaciones, se hizo uso del estadístico Shapiro Wilk
para probar normalidad. Esto puesto que el estadístico Jarque Bera, el cual puede ser
obtenido desde el botón
presenta complicaciones para muestras pequeñas como la estudiada en este caso. Es por
ello que para llegar a obtener el test de normalidad Shapiro Wilk, es necesario
preseleccionar la serie de residuos y dar click en
el cual desplegará una lista con dos opciones “Distribución normal” y “Media Cero” a lo
que se da click en “Distribución Normal”. Se abrir entonces un formulario igual al
presentado en la Ilustración 21 el cual viene con el rango de entrada preseleccionado y
simplemente es necesario ingresar la celda donde se desean imprimir los resultados del
test, seleccionar la prueba Shapiro Wilk de la lista de opciones y dar click en “Aceptar”. Se
mostrarán entonces los resultados del test tanto por medio del estadístico como por
medio de su valor de probabilidad, todo esto determinado por las tablas Shapiro y Wilk
(1965).

204
Ilustración 21 Formulario Supuesto Normalidad
Ahora bien, si se desea ver el grafico QQ-Plot para probar normalidad de manera visual.
Se procede a seleccionar el botón “QQ Normal” dentro del formulario de la ilustración 21
teniendo diligenciado el rango de entrada y la celda de salida. Este arrojó las siguientes
gráficas para los modelos M8 y M9
Gráfica 16 QQ plot modelo M8 serie LR1000(1:50)

205
Gráfica 17 QQ plot modelo M9 serie LR1000(1:50)
donde es posible ver como se soportan los resultados del test Shapiro Wilk puesto que los
puntos dentro de la gráfica de M9 parecen no ajustarse tan bien a la línea de tendencia
lineal como lo hace el modelo M8 donde están más pegados a la línea. Esto permite
evidenciar una vez más que los residuos del modelo M9 no provienen de una población
normal, mientras que los del modelo M8 sí.
Por último, los resultados de la verificación del supuesto 1 del modelo, el cual fue tomado
de la teoría de Guerrero (2003) se obtienen por medio del mismo botón diagnóstico visto
anteriormente pero ahora presionando la opción “ edia Cero” la cual desplegar dos
ventanas consecutivas. La primera ventana (Ilustración 22) tendrá preseleccionada la
serie de residuos a la cual se le realizara la prueba, y la segunda ventana (Ilustración 23)
preguntará por donde desea imprimir los resultados del test. Este debe ser una sola celda.
Ilustración 22 Ventana Media Cero 1

206
Ilustración 23 Ventana Media Cero 2
una vez ingresado las entradas en las dos ventanas, se imprimirán los resultados de la
prueba de media cero, mostrando el valor absoluto de y la decisión de rechazo o no del
supuesto dependiendo si | | es menor o mayor que dos. Estos resultados fueron
registrados anteriormente en las tablas 78 y 79 para cada uno de los modelos estimados.
10.7.6 Integración GAMS –ASTEX para la planeación de la producción
Para llegar a utilizar el complemento simplemente se presiona el botón GAMS-ASTEX en
el grupo Plan Producción
el cual da paso a una hoja de cálculo con las matrices de respuesta de las variables de
interés para la toma de decisiones de la organización. En esta página se pueden
encontrar siete botones. A continuación se procederá a explicar la funcionalidad de cada
uno de ellos.
1. Buscar Archivo (.txt): éste botón abre una ventana de búsqueda de archivos
internos del tipo (.txt) en el computados donde se esté trabajando. Se procede a
buscar entonces el archivo de texto que contiene el código en GAMS desde el cual
se trabajará en ASTEX. Es posible identificar que el archivo fue preseleccionado
satisfactoriamente puesto que se copiará la ruta del mismo en la celda contigua
derecha a RUTA GAMS (.txt).
2. Copiar Modelo (.txt): una vez preseleccionada la ruta del archivo de texto en el
paso anterior, se procede a copiar este archivo en el Input Box que leerá GAMS
externamente desde Excel. De llegarse a copiar con éxito el modelo entonces se
desplegará una ventana informativa del siguiente tipo

207
Ilustración 24 Ventana modelo copiado con éxito ASTEX
caso contrario, si la ruta no es correcta o no existe entonces se desplegará una
ventana del siguiente tipo
Ilustración 25 Ventana archivo .txt no encontrado ASTEX
cabe anotar que este botón no estará disponible sino hasta el momento en el que
se haya buscado un archivo en el paso anterior.
3. Editar Modelo (opcional): una vez se halla copiado el modelo correctamente es
posible editarlo directamente desde ASTEX por medio del botón Editar Modelo.
Este da paso a una nueva hoja la cual mostrará el cogido GAMS con el que se
trabajará y desde el cual será posible su edición directa antes de correr el modelo.
Cabe anotar que si se desea editar directamente en el archivo .txt desde el cual
fue leído el código, deben seguirse los pasos 1 y 2 para que tenga efectos sobre la
corrida del modelo. Este botón permite por tanto la edición directa sin necesidad
de realizar los pasos previos de búsqueda y copiado del modelo.
4. Editar Datos (opcional): este botón permite la edición de datos de entrada del
modelo como parámetros y constantes desde Excel. Se abrirá una hoja de cálculo
la cual contiene diferentes tablas, una para cada parámetro, y desde la cual la
organización tiene la posibilidad de editar condiciones de entrada si estas
cambian. Es decir, si por ejemplo los costos de almacenamiento de producto
terminado cambian por alguna circunstancia, es posible editar estos valores
fácilmente gracias a este botón.

208
5. Resolver Plan de Producción: una vez se tenga consignado el modelo deseado
a correr desde GAMS y se esté satisfecho con las condiciones de entrada del
modelo, se procederá entonces a ejecutar el plan de producción por medio de este
botón. Al oprimirlo, se da paso a ejecutar GAMS desde ASTEX de manera externa,
sin necesidad siquiera de tener GAMS abierto. Una vez ejecutado el modelo desde
GAMS aparecerá dentro de cada una de las matrices de la página principal los
resultados de cada variable de decisión del plan de producción. Estas variables
son:
Costo total de la propuesta
Número de unidades a producir en tiempo normal
Número de unidades a producir en tiempo extra
Inventario final de producto terminado
Número de horas extra necesarias
Número de trabajadores totales necesarios
Número de personas contratas
Número de personas despedidas
Además de cada una de las variables de respuesta, aparecerá una ventana la cual
tiene el propósito de otorgar información sobre las condiciones de corrida del
modelo como el método utilizado, el número de ecuaciones, número de variables,
el estado de la solución del mismo (optimo o no factible) , número de iteraciones y
el tiempo computacional invertido. Para el ejemplo propuesto véase Ilustración 3.
Ventana condiciones del modelo GAMS ASTEX.
Cabe anotar que si el cogido de programación está mal estructurado, aparecerá
una ventana en ASTEX indicando dicha condición y por tanto no se presentará
ningún resultado.
6. Ver Listing (opcional): un Listing es un archivo de GAMS que permite visualizar
todas las salidas, condiciones y resultados entregados por el modelo en un archivo
tipo texto. Esta opción permite por tanto visualizar este resultado en el lenguaje
GAMS desde ASTEX. Se abrirá una hoja la cual permite visualizar este Listing
desde un Input Box.
7. Limpiar Todo: este botón permite limpiar todas las matrices dentro de respuesta y
las condiciones de salida del modelo para una nueva reestimación. Cabe anotar
que no se borrará nada dentro de los datos de entrada o el modelo, únicamente
las condiciones de salida del mismo.

209
10.8 Códigos De Programación
10.8.1 Código VBA para la
Extracción de las Series de
Interés en Consolidado de
Ventas.
Sub ExtracciónInfo()
‘**************************************************
‘* Realizado por Juan Camilo Díaz H *
‘* Fecha 6 diciembre 2013 *
‘* Pontificia Uni ersidad Ja eriana *
‘**************************************************
Dim LastRow As Long
Application.ScreenUpdating = False
Application.Calculation = xlCalculationManual
LastRow =
ThisWorkbook.Sheets("Consolidado").Range("A" &
Rows.Count).End(xlUp).Row
Ref = ActiveSheet.Range(Selection.Address)
Sum = 0
For i = 2 To 49
For j = 2 To LastRow
If
ThisWorkbook.Sheets("Consolidado").Range("D" & j)
= Ref Then
If
Year(ThisWorkbook.Sheets("Consolidado").Range("B"
& j)) = ActiveSheet.Range("A" & i) Then
If
Month(ThisWorkbook.Sheets("Consolidado").Range("
B" & j)) = ActiveSheet.Range("B" & i) Then
Sum = Sum +
ThisWorkbook.Sheets("Consolidado").Range("H" & j)
End If
End If
End If
Next j
ActiveSheet.Range("C" & i) = Sum
Sum = 0
Next i
MsgBox "Proceso terminado", vbInformation
Application.ScreenUpdating = True
Application.Calculation = xlCalculationAutomatic
End Sub
10.8.2 Código VBA para la
Automatización de la
Transformación
Estabilizadora de Varianza
Ordenamiento de la Serie
Sub OrdenaSerie(R As Range, mensual As Integer,
trimestral As Integer, InputMes As Integer,
InputTrimes As Integer, InputYear As Integer, rot As
Integer, OutPut As Range)
Dim Fecha As Date
Dim ChangeYears As Integer
On Error Resume Next
Application.ScreenUpdating = False
Application.Calculation = xlCalculationManual
If mensual = 1 Then
Fecha = "" & InputMes & "/" & InputYear & "" 'Fecha
de inicio de la serie Opciones: Mensual
End If
If trimestral = 1 Then
If InputTrimes = 1 Then InputTrimes1 = 1
If InputTrimes = 2 Then InputTrimes1 = 4
If InputTrimes = 3 Then InputTrimes1 = 7
If InputTrimes = 4 Then InputTrimes1 = 10
Fecha = "" & InputTrimes1 & "/" & InputYear & ""
'Fecha de inicio de la serie Opciones: TriMensual
End If
n = R.Rows.Count
m = R.Columns.Count
ReDim iYear(n - rot)
ReDim iMonth(n - rot)
' Creacion ID Mensual
If mensual = 1 Then
ReDim mes(n - rot)
For i = 1 To n - rot
mes(i) = DateAdd("m", i - 1, Fecha)
iYear(i) = Year(mes(i))
iMonth(i) = Month(mes(i))
Next i
End If
'Creacion ID Trimestral
If trimestral = 1 Then
ReDim trimes(n - rot)
For i = 1 To n - rot
trimes(i) = DateAdd("q", i - 1, Fecha)
iYear(i) = Year(trimes(i))
iMonth(i) = Month(trimes(i))
Next i
End If
ChangeYears = 0
For i = 1 To n - rot - 1
If iYear(i) <> iYear(i + 1) Then
ChangeYears = ChangeYears + 1
End If

210
Next i
If mensual = 1 Then
If rot = 1 Then OutPut(1, 1) = R(1, 1)
If rot = 0 Then OutPut(1, 1) = "Serie"
Range(OutPut(1, 1), OutPut(13, 1)).Merge
OutPut(1, 1).Font.Bold = True
OutPut(1, 2) = "Año->"
OutPut(1, 2).Font.Bold = True
OutPut(2, 2) = 1
OutPut(3, 2) = 2
OutPut(4, 2) = 3
OutPut(5, 2) = 4
OutPut(6, 2) = 5
OutPut(7, 2) = 6
OutPut(8, 2) = 7
OutPut(9, 2) = 8
OutPut(10, 2) = 9
OutPut(11, 2) = 10
OutPut(12, 2) = 11
OutPut(13, 2) = 12
For i = 0 To ChangeYears
OutPut(1, 3 + i) = InputYear + i
OutPut(1, 3 + i).Font.Bold = True
Next i
K = 1
For i = 1 To 12
If iMonth(K) = OutPut(i + 1, 2) Then
OutPut(i + 1, 3) = R(K + rot)
K = K + 1
End If
Next i
conta = 1
For i = 1 To ChangeYears
For j = 1 + rot To n
If iYear(j - rot) = OutPut(1, 3 + i) Then
conta = conta + 1
OutPut(conta, 3 + i) = R(j)
End If
Next j
conta = 1
Next i
OutPut(2, 2) = "Enero"
OutPut(3, 2) = "Febrero"
OutPut(4, 2) = "Marzo"
OutPut(5, 2) = "Abril"
OutPut(6, 2) = "Mayo"
OutPut(7, 2) = "Junio"
OutPut(8, 2) = "Julio"
OutPut(9, 2) = "Agosto"
OutPut(10, 2) = "Septiembre"
OutPut(11, 2) = "Octubre"
OutPut(12, 2) = "Noviembre"
OutPut(13, 2) = "Diciembre"
With OutPut(1, 1)
.Orientation = xlUpward
.HorizontalAlignment = xlCenter
.VerticalAlignment = xlCenter
.BorderAround
End With
With Range(OutPut(1, 2), OutPut(13, 3 +
ChangeYears))
.HorizontalAlignment = xlCenter
.Font.Size = 10
End With
End If
If trimestral = 1 Then
If rot = 1 Then OutPut(1, 1) = R(1, 1)
If rot = 0 Then OutPut(1, 1) = "Serie"
Range(OutPut(1, 1), OutPut(5, 1)).Merge
OutPut(1, 1).Font.Bold = True
OutPut(1, 2) = "Año->"
OutPut(1, 2).Font.Bold = True
OutPut(2, 2) = 1
OutPut(3, 2) = 4
OutPut(4, 2) = 7
OutPut(5, 2) = 10
For i = 0 To ChangeYears
OutPut(1, 3 + i) = InputYear + i
OutPut(1, 3 + i).Font.Bold = True
Next i
K = 1
For i = 1 To 4
If iMonth(K) = OutPut(i + 1, 2) Then
OutPut(i + 1, 3) = R(K + rot)
K = K + 1
End If
Next i
conta = 1
For i = 1 To ChangeYears
For j = 1 + rot To n
If iYear(j - rot) = OutPut(1, 3 + i) Then
conta = conta + 1
OutPut(conta, 3 + i) = R(j)
End If
Next j
conta = 1
Next i
OutPut(2, 2) = "I Trim"
OutPut(3, 2) = "II Trim"
OutPut(4, 2) = "III Trim"
OutPut(5, 2) = "IV Irim"
With OutPut(1, 1)
.Orientation = xlUpward
.HorizontalAlignment = xlCenter
.VerticalAlignment = xlCenter
.BorderAround
End With

211
With Range(OutPut(1, 2), OutPut(5, 3 +
ChangeYears))
.HorizontalAlignment = xlCenter
.Font.Size = 10
End With
End If
Range(OutPut(1, 2), OutPut(1, 3 +
ChangeYears)).Select
With Selection.Borders(xlEdgeBottom)
.LineStyle = xlDouble
.Weight = xlThick
.ColorIndex = xlAutomatic
End With
OutPut(1, 1).Select
Application.ScreenUpdating = True
Application.Calculation = xlCalculationAutomatic
End Sub
Estabilización de la Varianza
Sub EstabVarianza(R As Range, OutPut As Range,
TituloSerie As String, Lambda As Double, automatic
As Boolean)
'CÓDIGO: +++TRANSFORMACIÓN
ESTABILIZADORA DE VARIANZA+++ *
'* Basado en teoría:
*
'* Líbro: Análisis Estadístico de Series de
tiempo económicas *
'* Autor: Víctor Manuel Guerrero
*
'* 2ª Edición Editorial: Thompson Página:
108 *
'* Realizado Por: Juan Camilo Díaz H
*
'* Fecha: Octubre 2013
*
'* PONTIFICIA UNIVERSIDAD JAVERIANA
*
'*
*
'* No tocar ni cambiar nada del código que se
presenta a continuación *
'*************************************************************
*************************************
'Para seleccionar la serie sin rotulo y seleccionar el
rotulo por aparte
On Error Resume Next
Application.ScreenUpdating = False
n = R.Rows.Count
m = R.Columns.Count
Ntot = 0
Nb = 0
nReal = 0
ReDim Nblanco(m)
For i = 1 To m
For j = 1 To n
If R(j, i) <> "" Then
Ntot = Ntot + 1
End If
If R(j, i) = "" Then
Nb = Nb + 1
End If
Next j
Nblanco(i) = Nb
Nb = 0
Next i
For i = 1 To m
NTblanco = NTblanco + Nblanco(i)
Next i
'Número de columnas que están completas
H = 0
For i = 1 To m
If Nblanco(i) = 0 Then
H = H + 1
End If
Next i
nReal = n * H
ReDim Zyear(H)
ReDim Syear(H)
'Cálculo de Zbarra h
cont1 = 0
For i = 1 To m
If Nblanco(i) = 0 Then
For j = 1 To n
SumZ = SumZ + R(j, i)
Next j
Zyear(i - cont1) = SumZ / n
SumZ = 0
Else
cont1 = cont1 + 1
End If
Next i
'Cálculo de Sh
cont2 = 0
For i = 1 To m
If Nblanco(i) = 0 Then
For j = 1 To n
SumS = SumS + (R(j, i) - Zyear(i - cont2)) ^ 2
Next j
Syear(i - cont2) = Sqr(SumS / (n - 1))
SumS = 0
Else
cont2 = cont2 + 1
End If
Next i

212
OutPut(1, 1) = "Transformación Estabilizadora de
Varianza T(" & TituloSerie & ")"
OutPut(1, 1).Font.Bold = True
OutPut(3, 1) = "Año"
OutPut(3, 1).Font.Bold = True
OutPut(4 + H, 1) = "Coef. Variación"
OutPut(4 + H, 1).Font.Bold = True
Range(OutPut(4 + H, 1), OutPut(4 + H, 2)).Merge
OutPut(4 + H + 3, 2) = "N="
OutPut(4 + H + 3, 3) = Ntot
OutPut(4 + H + 4, 2) = "n="
OutPut(4 + H + 4, 3) = nReal
OutPut(4 + H + 5, 2) = "H="
OutPut(4 + H + 5, 3) = H
OutPut(4 + H + 6, 2) = "R="
OutPut(4 + H + 6, 3) = n
OutPut(3, 2) = "{Grupo}"
OutPut(3, 2).Font.Bold = True
OutPut(2, 3) = "Potencia(" & ChrW(955) & ")"
OutPut(2, 3).Font.Bold = True
OutPut(3, 3) = Lambda
For i = 1 To H
OutPut(3 + i, 2) = "{" & i & "}"
Next i
For i = 1 To m
If Nblanco(i) = 0 Then
Fecha = R(1, i).Offset(-1, 0)
GoTo sigue
End If
Next i
sigue:
For i = 0 To (H - 1)
OutPut(4 + i, 1) = Fecha + i
Next i
OutPut(4 + H + 1, 2) = "M(" & ChrW(955) & ")"
OutPut(4 + H + 1, 2).Font.Italic = True
OutPut(4 + H + 2, 2) = "det(" & ChrW(955) & ")"
OutPut(4 + H + 2, 2).Font.Italic = True
OutPut(3, 4) = "Sh"
OutPut(3, 4).Font.Bold = True
OutPut(3, 5) = "Zh"
OutPut(3, 5).Font.Bold = True
For i = 1 To H
OutPut(3 + i, 4) = Syear(i)
OutPut(3 + i, 5) = Zyear(i)
Next i
For i = 1 To H
OutPut(3 + i, 3).Formula = "=" & OutPut(3 + i,
4).Address & "/" & OutPut(3 + i, 5).Address & "^(1-" &
OutPut(3, 3).Address & ")" & ""
Next i
'Cálculo Promedio M(Lambda)
OutPut(4 + H + 1, 3).Formula = "=AVERAGE(" &
Range(OutPut(4, 3), OutPut(3 + H, 3)).Address & ")"
'Cálculo de det(Lambda)
OutPut(4 + H + 2, 3).Formula = "=STDEV(" &
Range(OutPut(4, 3), OutPut(3 + H, 3)).Address & ")"
'Coeficiente de Variación
OutPut(4 + H, 3).Formula = "=" & OutPut(4 + H + 2,
3).Address & "/" & OutPut(4 + H + 1, 3).Address & ""
For i = 1 To (H + 3)
OutPut(3 + i, 3).NumberFormat = "0.0000000"
Next i
For i = 1 To H
OutPut(3 + i, 4).NumberFormat = "0.00"
Next i
For i = 1 To H
OutPut(3 + i, 5).NumberFormat = "0.00"
Next i
For j = 1 To 5
For i = 1 To 4 + H + 6
OutPut(i, j).HorizontalAlignment = xlCenter
OutPut(i, j).Font.Size = 11
Next i
Next j
Range(OutPut(1, 1), OutPut(1, 5)).Merge
'Bordes Dobles
Range(OutPut(1, 1), OutPut(1, 5)).Select
With Selection.Borders(xlEdgeBottom)
.LineStyle = xlDouble
.Weight = xlThick
.ColorIndex = xlAutomatic
End With
With Selection.Borders(xlEdgeTop)
.LineStyle = xlDouble
.Weight = xlThick
.ColorIndex = xlAutomatic
End With
Range(OutPut(2, 3), OutPut(2, 3)).Select
With Selection.Borders(xlEdgeBottom)
.LineStyle = xlContinuous
.Weight = xlThin
.ColorIndex = xlAutomatic
End With
Range(OutPut(3, 1), OutPut(3, 5)).Select
With Selection.Borders(xlEdgeBottom)
.LineStyle = xlContinuous
.Weight = xlThin
.ColorIndex = xlAutomatic
End With
Range(OutPut(3 + H, 1), OutPut(3 + H, 5)).Select
With Selection.Borders(xlEdgeBottom)
.LineStyle = xlContinuous
.Weight = xlThin
.ColorIndex = xlAutomatic
End With
Range(OutPut(4 + H, 1), OutPut(4 + H, 5)).Select
With Selection.Borders(xlEdgeBottom)

213
.LineStyle = xlDouble
.Weight = xlThick
.ColorIndex = xlAutomatic
End With
Range(OutPut(4 + H + 6, 1), OutPut(4 + H + 6,
5)).Select
With Selection.Borders(xlEdgeBottom)
.LineStyle = xlDouble
.Weight = xlThick
.ColorIndex = xlAutomatic
End With
OutPut(4 + H, 3).Select
'Goalseek
If automatic = True Then
Application.DisplayAlerts = False
OutPut(4 + H, 3).goalseek Goal:=0,
ChangingCell:=OutPut(3, 3)
Application.DisplayAlerts = True
End If
For i = 1 To (H + 3)
OutPut(3 + i, 3).NumberFormat = "0.000000"
Next i
Application.ScreenUpdating = True
End
10.8.3 Código GAMS para Plan de Producción
$ONTEXT PROBLEMA DE OPTIMIZACIÓN ENTERA PARA LA PLANEACIÓN DE LA PRODUCCIÓN Realizado Por: Juan Camilo Díaz H Fecha: 02/2014 $OFFTEXT $Title Plan de producción para ALIANZAS Y/O INDUSTRIAS ALTA PUREZA S.A **______________________Declaración de escalares SCALAR CMA capacidad maxima de almacenamiento en inventario /318.387/ *CMA en metros cubicos CW costo de tener un trabajador /1031500/ *CW en $/Trabajador CHE costo de una hora extra ordinaria /4939.57/ *CHE en $/horaextra Ley 50/1990 Art.24 CH costo de contratar un trabajador /74800/ *CH en $/trabajador CF costo de despedir un trabajador /59100/ *CF en $/trabajador PorOcio porcentaje de tiempo ocioso /0.09/ PorMant porcentaje de tiempo en mantenimiento /0.08/ Turnos numero de turnos en un dia /1/ HorTurnNorm numero de horas por turno en tiempo normal /8/ HorTurnExtra numero de horas por turno en tiempo extra /4/ HorDescTN numero de horas de descanso en tiempo normal /1.5/
HorDescTE numero de horas de descanso en tiempo extra /0/ ; **____________________Declaración de conjuntos SETS t periodo de tiempo /Febrero,Marzo,Abril,Mayo,Junio,Julio,Agosto/ i tipo de producto /R250,R500,R1000,R1500,R3000/ j etapa del proceso /FabEnvase,Mezclado,Resto/; **____________________Declaración de variables VARIABLES yn(i,t) cantidad producida de producto i en el periodo t en tiempo normal ye(i,t) cantidad producida de producto i en el periodo t en tiempo extra s(i,t) cantidad en inventario del producto i al final del periodo t ct costo total ep(i,t) error positivo en(i,t) error negativo nhe(j,t) numero de horas extra necesarias en la estacion j en el periodo t wn(j,t) nivel de fuerza de trabajo en el periodo t en la etapa j en T normal we(j,t) nivel de fuerza de trabajo en el periodo t en la etapa j en T extra h(j,t) cambio en la fuerza de trabajo por contratacion en el periodo t f(j,t) cambio en la fuerza de trabajo por despido en el periodo t wtot(t) numero de trabajadores totales en la empresa en el tiempo t prop(i,t) proporcion producido sobre demanda del producto i en el tiempo t CapDispN(t) capacidad disponible en tiempo normal en el periodo t CapDispE(t) capacidad disponible en tiempo extra en el periodo t ; POSITIVE VARIABLES yn,ye,s,ep,en,nhe,wn,we,h,f; POSITIVE VARIABLES prop,wtot,CapDispN,CapDispE; FREE VARIABLE ct;

214
PARAMETER numhN(t) numero de hombres por hora hombre en el periodo t en tiempo normal *en trabajador/HoraHombre para 8 horas de trabajo numhE(t) numero de hombres por hora hombre en el periodo t en tiempo extra *en trabajador/HoraHombre para 4 horas de trabajo en TE Total 12 horas ; **____________________Declaración de parámetros (Vectores) CAMIAR EL DIRECTORIO!!!!! C:/ Parameter Cu(i); $gdxin C:\Users\user\Documents\GDXGAMSTESIS\CostoUnitarioNormal.gdx $load Cu display Cu; Parameter Cr(i); $gdxin C:\Users\user\Documents\GDXGAMSTESIS\CostoRuptura.gdx $load Cr display Cr; Parameter Ca(i); $gdxin C:\Users\user\Documents\GDXGAMSTESIS\CostoAlmacenamiento.gdx $load Ca display Ca; Parameter Pr(i); $gdxin C:\Users\user\Documents\GDXGAMSTESIS\Precio.gdx $load Pr display Pr; Parameter Ii(i); $gdxin C:\Users\user\Documents\GDXGAMSTESIS\InventarioInicial.gdx $load Ii
display Ii; Parameter Wi(j); $gdxin C:\Users\user\Documents\GDXGAMSTESIS\TrabajadoresInicial.gdx $load Wi display Wi; Parameter CapMaqN(t); $gdxin C:\Users\user\Documents\GDXGAMSTESIS\CapacidadMaqN.gdx $load CapMaqN display CapMaqN; Parameter CapMaqE(t); $gdxin C:\Users\user\Documents\GDXGAMSTESIS\CapacidadMaqE.gdx $load CapMaqE display CapMaqE; Parameter aN(i); $gdxin C:\Users\user\Documents\GDXGAMSTESIS\HoraNormal.gdx $load aN display aN; Parameter aE(i); $gdxin C:\Users\user\Documents\GDXGAMSTESIS\HoraExtra.gdx $load aE display aE; Parameter vol(i); $gdxin C:\Users\user\Documents\GDXGAMSTESIS\Volumen.gdx $load vol display vol; Parameter SS(i); $gdxin C:\Users\user\Documents\GDXGAMSTESIS\ss.gdx $load SS
display SS; Parameter DiasHabiles(t); $gdxin C:\Users\user\Documents\GDXGAMSTESIS\DiasHabiles.gdx $load DiasHabiles display DiasHabiles; loop (t$(ord(t)>1), numhN(t)=(1/(HorTurnNorm*DiasHabiles(t)))); loop (t$(ord(t)>1), numhE(t)=(1/(HorTurnExtra*DiasHabiles(t)))); Parameter TeN(j,i); $gdxin C:\Users\user\Documents\GDXGAMSTESIS\TENormal.gdx $load TeN display TeN; Parameter TeE(j,i) $gdxin C:\Users\user\Documents\GDXGAMSTESIS\TEExtra.gdx $load TeE display TeE; Parameter dem(i,t) $gdxin C:\Users\user\Documents\GDXGAMSTESIS\Demanda.gdx $load dem display dem; **______________________Declaración de ecuaciones EQUATIONS Target funcion objetivo ResError(i,t) error de produccion (1) SatDem(i,t) satisfaccion de la demanda (2) CapDisN(t) capacidad disponible T normal (3) CapDisE(t) capacidad disponible T extra (4)

215
CapAlm(t) capacidad de almacenamiento (5) FuerzaTrabajoN(j,t) fuerza de trabajo T normal (6) FuerzaTrabajoE(j,t) fuerza de trabajo T extra (7) HorasExtra(j,t) horas extra (8) CambioFuerza(j,t) cambio en la fuerza de trabajo (9) DetProporcion(i,t) proporcion producido sobre demanda (10) DetTrabTot(t) trabajadores totales en la empresa (11) DetCapDisN(t) calculo capacidad disponible en T normal (12) DetCapDisE(t) calculo capacidad disponible en T extra (13) ResCapMaqN(t) limitar capacidad disponible T normal (14) ResCapMaqE(t) limitar capacidad disponible T extra (15) Safty(i,t) inventario de seguridad (16) ; * Funcion Objetivo con fuerza de trabajo PONER QUE t VAYA DESDE 2 HASTA 7 // $ord(t)>1 Target.. ct=E=(sum((i,t),(Cu(i)*(yn(i,t)+ye(i,t))+(Ca(i)*s(i,t)))))+(sum((i,t),(Ca(i)*ep(i,t))+(Cr(i)*en(i,t))))+sum((j,t),(CHE*nhe(j,t)+CW*wn(j,t)+CH*h(j,t)+CF*f(j,t))); *(1) Restricción de error de producción ResError(i,t)$(ord(t)>1).. ep(i,t)-en(i,t)=E=yn(i,t)+ye(i,t)-dem(i,t); *(2) Restricción de satisfacción de la demanda SatDem(i,t)$(ord(t)>1).. s(i,t-1)+yn(i,t)+ye(i,t)-dem(i,t)=E=s(i,t); *(3) Restricción de capacidad disponible de producción en tiempo normal CapDisN(t)$(ord(t)>1).. sum(i,(aN(i)*yn(i,t)))=L=CapDispN(t);
*(4) Restricción de capacidad disponible de producción en tiempo extra CapDisE(t)$(ord(t)>1).. sum(i,(aE(i)*ye(i,t)))=L=CapDispE(t); *(5) Restricción de almacenamiento disponible CapAlm(t)$(ord(t)>1).. sum(i,s(i,t)*vol(i))=L=CMA; *(6) Fuerza de trabajo T normal FuerzaTrabajoN(j,t)$(ord(t)>1).. sum(i,(numhN(t)*TeN(j,i)*yn(i,t)))=L=wn(j,t); *(7) Fuerza de trabajo T extra FuerzaTrabajoE(j,t)$(ord(t)>1).. sum(i,(numhE(t)*TeE(j,i)*ye(i,t)))=L=we(j,t); *(8) Restricción de horas extra HorasExtra(j,t)$(ord(t)>1).. sum(i,(TeE(j,i)*ye(i,t)))=E=nhe(j,t); *(9) Restricción de cambio en la fuerza de trabajo CambioFuerza(j,t)$(ord(t)>1).. wn(j,t-1)+h(j,t)-f(j,t)=E=wn(j,t); *(10) PROPORCION PRODUCIDO =1 PRODUCE LO MISMO QUE DEMANDA (SOLUCION TRIVIAL), >1 PRODUCE MAS DE LO QUE DEMANDA, <1 PRODUCE MENOS DE LO QUE DEMANDA DetProporcion(i,t)$(ord(t)>1).. (yn(i,t)+ye(i,t))/dem(i,t)=E=prop(i,t); *(11) TRABAJADORES TOTALES EN LA EMPRESA DetTrabTot(t)$(ord(t)>1).. sum(j,wn(j,t))=E=wtot(t); *(12) Determinacion de capacidad en tiempo normal DetCapDisN(t)$(ord(t)>1).. (1-PorOcio-PorMant)*wtot(t)*(Turnos*DiasHabiles(t)*(HorTurnNorm-HorDescTN))=E=CapDispN(t); *(13) Determinacion de capacidad en tiempo normal DetCapDisE(t)$(ord(t)>1).. (1-PorOcio-PorMant)*wtot(t)*(Turnos*DiasHabiles(t)*(HorTurnExtra-HorDescTE))=E=CapDispE(t); *LIMITAR LAS CAPACIDADES SEGUN EL MAXIMO QUE ME DEJA LAS MAQUINAS *(14) Restriccion Capacidad Maquina Normal
ResCapMaqN(t)$(ord(t)>1).. CapDispN(t)=L=CapMaqN(t); *(15) Restriccion Capacidad Maquina Extra ResCapMaqE(t)$(ord(t)>1).. CapDispE(t)=L=CapMaqE(t); *(16) Restricción Inventario de seguridad Safty(i,t)$(ord(t)>1).. s(i,t)=G=SS(i); *Condiciones iniciales *Inventario inicial en Febrero s.fx(i,'Febrero') = Ii(i); *Fuerza de trabajo en Febrero wn.fx(j,'Febrero') = Wi(j); *wn.fx(j,t) = Wi(j); **_____________________OPCIONES FINALES DEL MODELO MODEL PlanProduccion /ALL/; *---------------------------------------------------------------- * Pasos Para el análisis de sensibilidad * * (1) Crear un archivo llamado "cplex.opt" con estas dos lineas: * * objrng * rhsrng * * (2) Adicionar las siguientes dos linead en el programa GAMS: option lp=cplex; PlanProduccion.optfile=1; option limrow = 3000; option limcol = 5000; option iterlim = 500000; PlanProduccion.reslim = 150; option sysout = on; option mip=cplex; *y.fx(i,t) = dem(i,t); NLP MIP MAXIMIZING SOLVE PlanProduccion USING MIP MINIMIZING ct;

216
******************************************************************************** $if exist C:\Users\user\Documents\GDXGAMSTESIS\solution.txt $call del C:\Users\user\Documents\GDXGAMSTESIS\solution.txt file fle /C:\Users\user\Documents\GDXGAMSTESIS\solution.txt/; putclose fle, " PLAN DE PRODUCCIÓN"/ " ALIANZAS Y/O INDUSTRIAS ALTA PUREZA S.A"/ " Realizado por: Juan Camilo Díaz H"/ " -----------"/ " Método: MIP"/ " Ecuaciones: ",PlanProduccion.numequ:0:0/ " Variables: ",PlanProduccion.numvar:0:0/ " Estado del Modelo: ",PlanProduccion.tmodstat/ " Estado del Solver: ",PlanProduccion.tsolstat/ " # Iteraciones: ",PlanProduccion.iterusd:0:0/ " Tiempo CPU: ",PlanProduccion.resusd:0/; $if exist C:\Users\user\Documents\GDXGAMSTESIS\solution.gdx $call del C:\Users\user\Documents\GDXGAMSTESIS\solution.gdx execute_unload "C:\Users\user\Documents\GDXGAMSTESIS\solution.gdx",ct,yn.l,ye.l,s.l,nhe.l,wtot.l,h.l,f.l; *$ONTEXT DISPLAY ct.l,yn.l,ye.l,s.l; DISPLAY ep.l,en.l; DISPLAY wn.l,we.l,h.l,f.l,nhe.l; *Ver Variables Creadas DISPLAY prop.l,wtot.l,CapDispN.l,CapDispE.l; OPTIONS decimals=8; DISPLAY numhN,numhE; *$OFFTEXT

217
10.9 Resultados
10.9.1 Resultados de las transformaciones estabilizadoras de varianza.
SERIE R250
Transformación Estabilizadora de Varianza T(R250)
Potencia(λ)
Año {Grupo} -1 -0.5 0 0.5 1
2011 {1} 0.000154 0.009096 0.5381 31.837 1883.485
2012 {2} 0.000037 0.004935 0.6568 87.403 11631.780
2013 {3} 0.000010 0.002060 0.4357 92.134 19484.912
Coef. Variación 1.143968 0.659548 0.2036 0.476 0.802
M(λ) 0.000067 0.005364 0.543519 70.458010 11000.058759
det(λ) 0.000076 0.003538 0.110655 33.530558 8817.701750
Transformación Estabilizadora de Varianza T(R250) - Búsqueda Automática
Potencia(λ)
Año {Grupo} 0.044344042 Sh Zh
2011 {1} 0.772774 1883.48 3500.00
2012 {2} 1.013433 11631.78 17710.67
2013 {3} 0.700430 19484.91 44725.83
Coef. Variación 0.197702
M(λ) 0.828879
det(λ) 0.163871

218
SERIE R500
Transformación Estabilizadora de Varianza T(R500)
Potencia(λ)
Año {Grupo} -1 -0.5 0 0.5 1
2010 {1} 0.000020 0.002513 0.3161 39.758 5001.289
2011 {2} 0.000018 0.002400 0.3218 43.142 5783.568
2012 {3} 0.000014 0.002787 0.5422 105.468 20515.249
2013 {4} 0.000007 0.001628 0.3913 94.056 22606.347
Coef. Variación 0.393550 0.212975 0.267999 0.481765 0.695962
M(λ) 0.000015 0.002332 0.392851 70.605967 13476.613266
det(λ) 0.000006 0.000497 0.105284 34.015501 9379.205704
Transformación Estabilizadora de Varianza T(R500) - Búsqueda Automática
Potencia(λ)
Año {Grupo} -0.341328168 Sh Zh
2010 {1} 0.011653 5001.29 15824.00
2011 {2} 0.011360 5783.57 17972.00
2012 {3} 0.014846 20515.25 37836.50
2013 {4} 0.009274 22606.35 57768.00
Coef. Variación 0.195212
M(λ) 0.011783
det(λ) 0.002300

219
SERIE R1500
Transformación Estabilizadora de Varianza T(R1500)
Potencia(λ)
Año {Grupo} -1 -0.5 0 0.5 1
2010 {1} 0.000183 0.007078 0.2734 10.561 407.914
2011 {2} 0.000141 0.006821 0.3289 15.865 765.128
2012 {3} 0.000059 0.002934 0.1455 7.215 357.792
2013 {4} 0.000143 0.007170 0.3605 18.127 911.436
Coef. Variación 0.395559 0.341571 0.342228 0.383480 0.442893
M(λ) 0.000132 0.006001 0.277091 12.941813 610.567627
det(λ) 0.000052 0.002050 0.094828 4.962930 270.416249
Transformación Estabilizadora de Varianza T(R1500) - Búsqueda Automática
Potencia(λ)
Año {Grupo} -0.262914207 Sh Zh
2010 {1} 0.040029 407.91 1492.00
2011 {2} 0.042854 765.13 2326.00
2012 {3} 0.018681 357.79 2459.00
2013 {4} 0.045949 911.44 2528.17
Coef. Variación 0.335434
M(λ) 0.036878
det(λ) 0.012370

220
SERIE R3000
Transformación Estabilizadora de Varianza T(R3000)
Potencia(λ)
Año {Grupo} -1 -0.5 0 0.5 1
2010 {1} 0.000129 0.005527 0.2365 10.122 433.196
2011 {2} 0.000132 0.006488 0.3187 15.655 769.013
2012 {3} 0.000067 0.003745 0.2109 11.874 668.604
2013 {4} 0.000086 0.005138 0.3059 18.207 1083.822
Coef. Variación 0.312411 0.217761 0.195758 0.261445 0.365171
M(λ) 0.000104 0.005225 0.267991 13.964693 738.658757
det(λ) 0.000032 0.001138 0.052461 3.651000 269.736887
Transformación Estabilizadora de Varianza T(R3000) - Búsqueda Automática
Potencia(λ)
Año {Grupo} -0.138346093 Sh Zh
2010 {1} 0.083653 433.20 1831.50
2011 {2} 0.108496 769.01 2413.00
2012 {3} 0.069131 668.60 3170.50
2013 {4} 0.098736 1083.82 3543.50
Coef. Variación 0.191821
M(λ) 0.090004
det(λ) 0.017265
10.9.2 Resultados Estabilización Varianza Método Anderson
Estb. Nivel LR250 Estb. Nivel TR500 Estb. Nivel LR500
Diferencia Desviación Diferencia Desviación Diferencia Desviación
0 1.41126998 0 3.45478E-06 0 0.43618976
1 0.61093703 1 2.88923E-06 1 0.24317616
2 2.01351531 2 6.46151E-06 2 0.57910125
3 7.33771465 3 1.72104E-05 3 1.55907115
Mínimo 0.61093703 Mínimo 2.88923E-06 Mínimo 0.24317616
Estb. Nivel LR1500 Estb. Nivel LR3000
Diferencia Desviación Diferencia Desviación
0 0.115090968 0 0.13264587
1 0.117223558 1 0.121085
2 0.29075827 2 0.31107009
3 0.843288884 3 0.95741876
Mínimo 0.115090968 Mínimo 0.121085

221
10.9.3 Resultados identificación series restantes
10.9.3.1 Serie DLR250
1 2 3 4 5 6 7 8 9 10
Autocorrelación -0.535 0.153 -0.047 0.095 -0.162 0.283 -0.336 0.192 -0.089 -0.008
PACF -0.535 -0.186 -0.072 0.090 -0.089 0.216 -0.130 -0.069 -0.053 -0.119
Ljung-Box 10.313 11.184 11.269 11.630 12.714 16.130 21.143 22.849 23.232 23.235
(P-Value) 0.001 0.004 0.010 0.020 0.026 0.013 0.004 0.004 0.006 0.010
11 12 13 14 15 16 17 18 19 20
Autocorrelación 0.091 -0.007 -0.054 -0.012 -0.009 -0.084 0.008 0.015 -0.004 0.091
PACF 0.137 0.068 0.098 -0.123 -0.132 -0.220 -0.288 -0.037 0.047 0.137
Ljung-Box 23.670 23.673 23.841 23.850 23.855 24.339 24.344 24.361 24.362 23.670
(P-Value) 0.014 0.023 0.033 0.048 0.068 0.082 0.110 0.144 0.183 0.014
21 22 23 24
Autocorrelación -0.135 0.195 -0.104 0.053
PACF -0.086 0.094 0.016 -0.043
Ljung-Box 25.970 29.642 30.785 31.104
(P-Value) 0.167 0.099 0.101 0.120
-0,8
-0,6
-0,4
-0,2
0
0,2
0,4
0,6
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
ACF DLR250
-0,8
-0,6
-0,4
-0,2
0
0,2
0,4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
PACF DLR250

222
SCAN - Valores de Probabilidad - ARMA(p+d,q)
MA
0 1 2 3 4 5 6 7
0 <.0001 0.1635 0.4580 0.4910 0.3442 0.1343 0.1056 0.3832
AR
1 0.3366 0.8085 0.5513 0.5891 0.8843 0.3973 0.1663 0.8566
2 0.6035 0.5642 0.9751 0.9115 0.5354 0.5285 0.3089 0.9349
3 0.6583 0.7977 0.9119 0.9684 0.7108 0.9613 0.4233 0.7709
4 0.3664 0.8589 0.7396 0.6779 0.8245 0.5418 0.5875 0.4733
5 0.1600 0.5514 0.7953 0.9691 0.8117 0.7936 0.7940 0.6631
6 0.5541 0.5033 0.5737 0.4804 0.7996 0.7703 0.9175 0.8700
7 0.5683 0.8961 0.9773 0.6921 0.8945 0.7000 0.9002 0.9042
ESACF - Valores de Probabilidad - ARMA(p+d,q)
MA
0 1 2 3 4 5 6 7
0 0.0001 0.1647 0.4500 0.4836 0.3386 0.1394 0.1314 0.4158
AR
1 0.1379 0.5841 0.3691 0.7068 0.9785 0.4311 0.1178 0.9755
2 0.0106 0.4964 0.9698 0.8715 0.8885 0.7009 0.1229 0.8065
3 0.0032 0.4621 0.7964 0.9674 0.7254 0.9566 0.1234 0.9439
4 0.0220 0.0340 0.8219 0.9705 0.7244 0.8848 0.1733 0.8372
5 0.0107 0.6079 0.5714 0.9309 0.9302 0.7496 0.5919 0.4297
6 0.0377 0.1789 0.5440 0.8753 0.1349 0.1837 0.9812 0.6976
7 0.0050 0.5932 0.9613 0.2731 0.9867 0.0965 0.3283 0.6860
MINIC – Criterio de información BIC
MA
0 1 2 3 4 5 6 7
0 -0.7888 -1.0981 -1.0947 -1.0799 -1.0790 -1.1854 -1.3140 -1.3099
AR
1 -1.4581 -1.3676 -1.3093 -1.2226 -1.1650 -1.2125 -1.5645 -1.5433
2 -1.3766 -1.2835 -1.2174 -1.1289 -1.0834 -1.1544 -1.5231 -1.4634
3 -1.3377 -1.2534 -1.1595 -1.0673 -0.9924 -1.0671 -1.5039 -1.4398
4 -1.2496 -1.1642 -1.0715 -0.9777 -0.8995 -1.0078 -1.4140 -1.3674
5 -1.4008 -1.3148 -1.2232 -1.1330 -1.1893 -1.1247 -1.5039 -1.5735
6 -1.7612 -1.6825 -1.5895 -1.4988 -1.4416 -1.6047 -1.5370 -1.5267
7 -1.7204 -1.6279 -1.5441 -1.4509 -1.3859 -1.6060 -1.5262 -1.7376

223
MAPE
MA
0 1 2 3 4 5 6 7
0 55.089 69.264 74.810 74.745 73.739 68.548 71.296
AR
1 48.107 48.901 48.882 48.001 48.470 48.108 48.928 46.942
2 69.597 49.417 67.459 68.531 69.314 69.635 64.958 66.099
3 73.711 55.128 69.200 71.784 73.793 73.679 68.144 71.644
4 74.405 54.950 69.075 74.405 72.402 73.703 68.589 70.519
5 72.961 54.820 68.722 73.111 72.837 69.711 68.449 71.046
6 70.119 54.542 65.756 70.358 70.122 70.120 70.364 69.658
7 67.780 53.863 63.379 68.084 67.214 67.832 67.327 66.936
RMSE
MA
0 1 2 3 4 5 6 7
0 12189.76 15576.03 16114.63 15937.64 15420.26 16790.20 17949.78
AR
1 11551.11 11318.72 11124.58 11568.19 11524.52 11591.94 11930.67 12959.36
2 15418.68 11160.06 15903.76 15308.32 15480.62 15057.28 16474.39 18171.19
3 15908.78 12194.19 15567.08 14603.67 15953.11 15338.07 16898.32 17985.29
4 15715.52 11942.68 15412.52 15745.91 15706.45 15419.08 16837.72 18466.60
5 14920.22 11906.43 14728.67 14930.45 14829.37 13726.77 16730.56 17718.34
6 16796.47 11930.79 16349.60 16899.35 16786.30 16796.85 16937.91 18771.65
7 18319.66 12811.80 18472.27 18355.52 18578.90 18063.01 18835.71 17584.75
MAE
MA
0 1 2 3 4 5 6 7
0 8045.66 10102.57 10368.94 10408.53 10140.51 10362.32 10960.14
AR
1 7772.06 7676.78 7468.78 7868.39 7763.50 7777.19 7897.56 8010.64
2 10011.64 7520.22 9532.99 9974.38 9988.28 9940.99 10127.96 10720.39
3 10148.29 8051.18 10149.01 9493.47 10140.42 10123.64 10117.45 10943.07
4 10251.12 7900.43 9983.58 10246.67 9814.51 10114.77 10344.97 10815.90
5 9953.33 7994.43 9758.47 9976.74 9903.44 9197.06 10278.74 10602.26
6 10391.61 7850.11 10060.37 10366.71 10394.74 10392.30 10414.69 10805.58
7 10447.28 8098.46 10427.05 10431.49 10361.29 10229.52 10610.75 10135.57
El correlograma de la primera diferencia del logaritmo natural de R250 muestra el típico
comportamiento de un modelo autoregresivo de orden con un coeficiente negativo. Al
observar en la gráfica de contra (es decir, la ACF) las barras convergen a cero
geométricamente, esto permite pensar que el haber tomado la primera diferencia de
LR250 hizo que la serie fuese estacionaria. Se sabe además que es negativo puesto
que la convergencia se da en forma oscilatoria alrededor de cero. Por lo que se esperará
que al estimar el modelo en la siguiente etapa el coeficiente asociado sea negativo.
El valor de probabilidad del estadístico Q de Ljung-Box (1978) da evidencia que la serie
no es ruido blanco por lo menos hasta el rezago al 5% de significancia. Esto

224
permite entonces el poder buscar un modelo ARMA que se acople a los datos de la serie
de estudio.
Al observar los resultados de la metodología SCAN y ESCAF se encuentra un consenso
en el número de modelos que deberían ser estimados en la siguiente etapa. Dos patrones
rectangulares y triangulares inferiores derechos se forman en los mismos puntos para la
metodología SCAN y ESACF respectivamente. Estas conexiones se dan en lo modelos
AR(1) y MA(1) de la serie transformada de varianza LR500, es decir que se tendrá un
modelo más a tener en consideración para la siguiente etapa adicional al modelo tentativo
encontrado por los correlogramas.
En cuanto al mínimo criterio de información, el cual corresponde a -1.7612, tiene su
intersección en un modelo autoregresivo de orden seis AR(6). Esto parece estar arrojaron
un modelo con un orden diferente a las pruebas anteriores, pero que deberá ser ensayado
en la siguiente etapa puesto que la minimización del criterio de información Bayesiano
indica que la inclusión de ese número de parámetros en el modelo permite minimizar
dicho criterio de información dado por la poca penalidad que dan estos parámetros ( y )
a la suma de residuos cuadrados. Por lo que se tendría con este un tercer modelo
tentativo.
En cuanto a los resultados arrojados por el método propuesto ARIMAIN, se logró un
consenso de un modelo del tipo ARMA(1,2) por parte de las funciones de pérdida RMSE y
MAE. Mientras que el resultado de la matriz MAPE determinó un modelo del tipo
ARMA(1,7). En cualquiera de los dos casos se está encontrando un modelo cuyo
componente autoregresivo es de primer orden, acorde a lo presentado en la ACF, PACF,
SCAN y ESACF pero que utiliza información de los errores del rezago 2 y 7
respectivamente para mejorar las relaciones dinámicas de corto y largo plazo. Sin
embargo, como se realizó anteriormente para la serie LR1000, es necesario probar la
significancia de cada coeficiente en cada modelo y validar su diagnóstico.
Se tendrá entonces cinco modelos preliminares a ser estimados para la serie DLR250
(ver Tabla 87). Note que estos modelos pueden ser nombrados de manera diferente
dependiendo de qué serie se esté hablando. Por ejemplo, el modelo M2 puede ser
representado como ARMA(0,1) o MA(1) para la serie DLR250, o como un ARIMA(0,1,1) o
IMA(1,1) para la serie LR250. Lo mismo sucede con las pseudorepresentaciones de los
demás modelos.
Modelo Tentativo
Representaciones polinómicas
M1 ARMA(1,0)
M2 ARMA(0,1)
M3 ARMA(6,0)
M4 ARMA(1,7)
M5 ARMA(1,2)
Tabla 88 Modelos tentativos para la serie DLR250 (1:45)

225
10.9.3.2 Serie TR500
1 2 3 4 5 6 7 8 9 10
Autocorrelación 0.528 0.315 0.309 0.280 0.184 0.201 0.207 0.081 0.046 0.064
PACF 0.528 0.050 0.174 0.067 -0.029 0.097 0.041 -0.116 -0.003 0.000
Ljung-Box 11.744 16.028 20.279 23.853 25.440 27.390 29.533 29.869 29.980 30.204
(P-Value) 0.001 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.001
11 12 13 14 15 16 17 18 19 20
Autocorrelación 0.120 0.069 0.020 -0.142 -0.198 -0.155 -0.045 -0.012 -0.029 -0.086
PACF 0.104 -0.032 -0.050 -0.244 -0.091 0.004 0.137 0.069 0.014 -0.088
Ljung-Box 31.026 31.308 31.333 32.615 35.231 36.891 37.037 37.048 37.116 37.734
(P-Value) 0.001 0.002 0.003 0.003 0.002 0.002 0.003 0.005 0.008 0.010
21 22 23 24
Autocorrelación -0.062 0.000 -0.179 -0.186
PACF 0.052 0.052 -0.313 -0.075
Ljung-Box 38.076 38.076 41.289 44.985
(P-Value) 0.013 0.018 0.011 0.006
-0,8
-0,6
-0,4
-0,2
0
0,2
0,4
0,6
0,8
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
ACF TR500
-0,4
-0,2
0
0,2
0,4
0,6
0,8
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
PACF TR500

226
1 2 3 5 6 7 8 9 10
Autocorrelación 0.200 -0.190 -0.144 -0.194 -0.073 -0.025 -0.132 -0.084 0.000
PACF 0.200 -0.239 -0.055 -0.207 -0.057 -0.131 -0.230 -0.155 -0.185
Ljung-Box 1.679 3.236 4.159 6.543 6.798 6.830 7.725 8.104 8.104
(P-Value) 0.195 0.198 0.245 0.257 0.340 0.447 0.461 0.524 0.619
11 12 13 15 16 17 18 19 20
Autocorrelación 0.141 0.185 0.199 -0.139 -0.026 0.029 0.043 -0.035 -0.146
PACF -0.022 -0.004 0.080 -0.083 -0.015 0.001 0.072 -0.052 -0.128
Ljung-Box 9.241 11.279 13.725 15.319 15.366 15.428 15.567 15.665 17.466
(P-Value) 0.600 0.505 0.394 0.429 0.498 0.565 0.623 0.679 0.623
21 22 23
Autocorrelación -0.045 0.150 -0.078
PACF 0.054 0.137 -0.213
Ljung-Box 17.645 19.754 20.359
(P-Value) 0.671 0.598 0.620
-0,5
-0,4
-0,3
-0,2
-0,1
0
0,1
0,2
0,3
0,4
0,5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
ACF TR500dt
-0,4
-0,3
-0,2
-0,1
0
0,1
0,2
0,3
0,4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
PACF TR500dt

227
SCAN - Valores de Probabilidad - ARMA(p+d,q)
MA
0 1 2 3 4 5 6 7
0 <.0001 0.0088 0.0155 0.038 0.0855 0.0781 0.1215 0.1997
AR
1 0.5173 0.0642 0.7376 0.9807 0.6479 0.4218 0.9507 0.6067
2 0.0222 0.2976 0.9279 0.8681 0.4949 0.4424 0.5735 0.6172
3 0.5021 0.7073 0.6658 0.4262 0.7319 0.6127 0.9107 0.779
4 0.5055 0.8799 0.5541 0.7498 0.599 0.6548 0.5463 0.8206
5 0.2397 0.4749 0.4669 0.6362 0.6455 0.6644 0.7786 0.8489
6 0.9666 0.859 0.9436 0.8698 0.6325 0.9455 0.9729 0.9207
7 0.8506 0.9207 0.9404 0.7301 0.8977 0.95 0.9041 0.9469
ESACF - Valores de Probabilidad - ARMA(p+d,q)
MA
0 1 2 3 4 5 6 7
0 <.0001 0.0136 0.02 0.0463 0.103 0.095 0.1454 0.2454
AR
1 0.3765 0.0842 0.765 0.9894 0.7054 0.4701 0.9899 0.5866
2 0.0706 0.0374 0.6092 0.993 0.7101 0.2445 0.9673 0.6709
3 0.0406 0.0502 0.6304 0.6003 0.755 0.4896 0.9116 0.662
4 0.0007 0.4198 0.0631 0.4113 0.5605 0.3778 0.9685 0.5459
5 0.0036 0.4143 0.0021 0.239 0.0692 0.4789 0.8708 0.9396
6 0.8826 0.337 0.68 0.4809 0.4107 0.4992 0.9772 0.9135
7 0.2191 0.231 0.6646 0.8033 0.5774 0.7485 0.9713 0.7941
MINIC – Criterio de información BIC
MA
0 1 2 3 4 5 6 7
0 -12.550 -12.667 -12.652 -12.646 -12.615 -12.638 -12.722 -12.730
AR
1 -13.143 -13.105 -13.083 -13.031 -12.959 -12.926 -12.916 -12.844
2 -13.102 -13.054 -13.025 -12.961 -12.887 -12.860 -12.838 -12.767
3 -13.097 -13.027 -12.960 -12.885 -12.817 -12.791 -12.767 -12.692
4 -13.022 -12.960 -12.887 -12.817 -12.739 -12.715 -12.689 -12.643
5 -13.015 -12.937 -12.860 -12.806 -12.734 -12.682 -12.614 -12.570
6 -12.988 -12.917 -12.844 -12.766 -12.688 -12.611 -12.538 -12.492
7 -12.917 -12.844 -12.767 -12.689 -12.613 -12.613 -12.540 -12.492
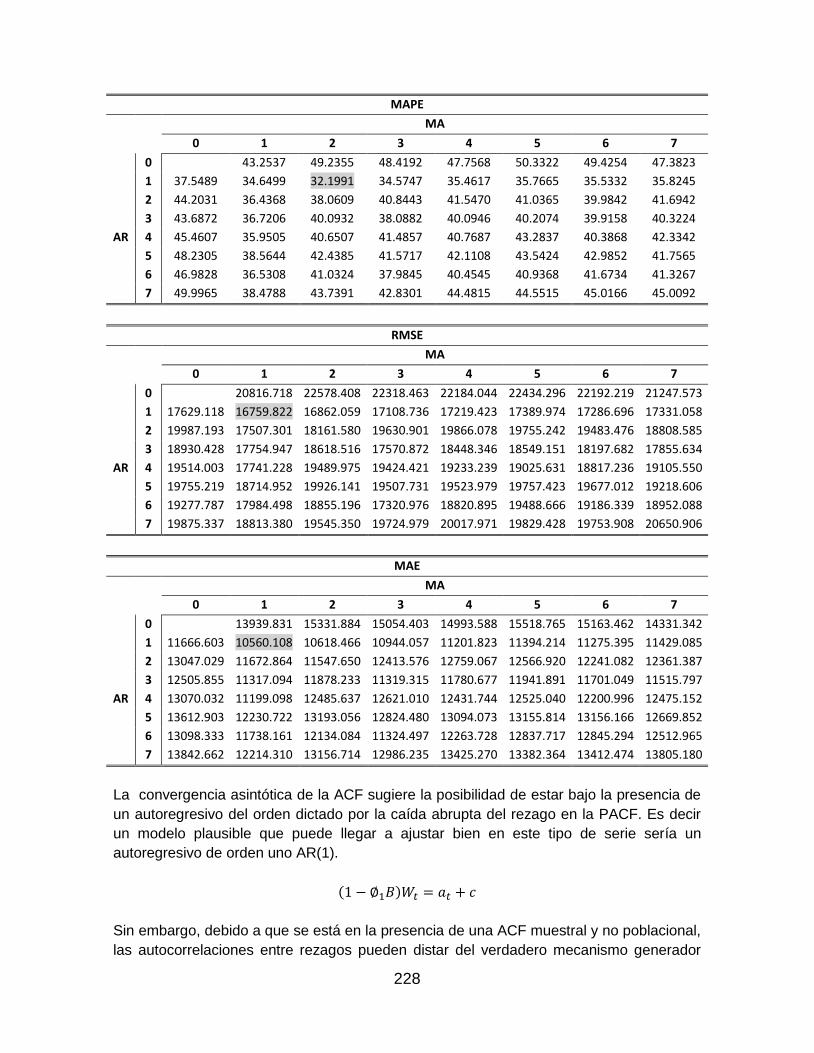
228
MAPE
MA
0 1 2 3 4 5 6 7
0 43.2537 49.2355 48.4192 47.7568 50.3322 49.4254 47.3823
AR
1 37.5489 34.6499 32.1991 34.5747 35.4617 35.7665 35.5332 35.8245
2 44.2031 36.4368 38.0609 40.8443 41.5470 41.0365 39.9842 41.6942
3 43.6872 36.7206 40.0932 38.0882 40.0946 40.2074 39.9158 40.3224
4 45.4607 35.9505 40.6507 41.4857 40.7687 43.2837 40.3868 42.3342
5 48.2305 38.5644 42.4385 41.5717 42.1108 43.5424 42.9852 41.7565
6 46.9828 36.5308 41.0324 37.9845 40.4545 40.9368 41.6734 41.3267
7 49.9965 38.4788 43.7391 42.8301 44.4815 44.5515 45.0166 45.0092
RMSE
MA
0 1 2 3 4 5 6 7
0 20816.718 22578.408 22318.463 22184.044 22434.296 22192.219 21247.573
AR
1 17629.118 16759.822 16862.059 17108.736 17219.423 17389.974 17286.696 17331.058
2 19987.193 17507.301 18161.580 19630.901 19866.078 19755.242 19483.476 18808.585
3 18930.428 17754.947 18618.516 17570.872 18448.346 18549.151 18197.682 17855.634
4 19514.003 17741.228 19489.975 19424.421 19233.239 19025.631 18817.236 19105.550
5 19755.219 18714.952 19926.141 19507.731 19523.979 19757.423 19677.012 19218.606
6 19277.787 17984.498 18855.196 17320.976 18820.895 19488.666 19186.339 18952.088
7 19875.337 18813.380 19545.350 19724.979 20017.971 19829.428 19753.908 20650.906
MAE
MA
0 1 2 3 4 5 6 7
0 13939.831 15331.884 15054.403 14993.588 15518.765 15163.462 14331.342
AR
1 11666.603 10560.108 10618.466 10944.057 11201.823 11394.214 11275.395 11429.085
2 13047.029 11672.864 11547.650 12413.576 12759.067 12566.920 12241.082 12361.387
3 12505.855 11317.094 11878.233 11319.315 11780.677 11941.891 11701.049 11515.797
4 13070.032 11199.098 12485.637 12621.010 12431.744 12525.040 12200.996 12475.152
5 13612.903 12230.722 13193.056 12824.480 13094.073 13155.814 13156.166 12669.852
6 13098.333 11738.161 12134.084 11324.497 12263.728 12837.717 12845.294 12512.965
7 13842.662 12214.310 13156.714 12986.235 13425.270 13382.364 13412.474 13805.180
La convergencia asintótica de la ACF sugiere la posibilidad de estar bajo la presencia de
un autoregresivo del orden dictado por la caída abrupta del rezago en la PACF. Es decir
un modelo plausible que puede llegar a ajustar bien en este tipo de serie sería un
autoregresivo de orden uno AR(1).
Sin embargo, debido a que se está en la presencia de una ACF muestral y no poblacional,
las autocorrelaciones entre rezagos pueden distar del verdadero mecanismo generador

229
de datos que rige al proceso estocástico. Es decir, existe la posibilidad que el modelo no
solo sea significativo en el rezago 1, sino también en el tercer rezago y que este ayuda a
mejorar la explicación del modelo, por lo menos de dentro de muestra. Por lo que se
tendría un modelo
Para el método SCAN observe como para una significancia del 0.1 los valores resaltados
muestran el inicio de un patrón rectangular de términos no significativos. Haciendo un
análisis un tanto más detallado sobre la tabla SCAN se observa como el orden (1,0)
podría haber sido un modelo tentativo si no fuese porque no se desdibuja un patrón
rectangular en él. Sin embargo, la previa conjetura sobre el modelo
se ve validada si miramos la primera columna de la tabla, donde el primer modelo
AR(1) trae consigo un valor de probabilidad alto, y luego vuelve a serlo el modelo AR(3),
pasando por encima del modelo AR(2).
La tabla SCAN nos permite evidenciar 4 modelos tentativos adicionales:
(i) ARIMA(2,1), (ii) ARIMA(1,2), (iii) ARIMA(3,0) y (iv) ARIMA(0,6). Empero, se debe
probar la significancia estadística de cada uno de los parámetros de cada modelo, puesto
que se debe garantizar que el modelo sea parsimonioso, permitiendo estimar un orden
tentativo con la menor cantidad de parámetros posibles. Por ejemplo para el caso (iv) del
ARIMA(3,0), observando la PACF el rezago deba ser excluido del modelo pues
su presencia, muy posiblemente, no sea representativa y por tanto su inclusión violaría el
principio de parsimonia.
Ahora bien, los valores de probabilidad de la metodología ESCAF propuesta por Tsay y
Tiao (1985) la cual se construye utilizando las autocorrelaciones muéstrales extendidas
mostró que existen 3 modelos adicionales que deberían ser tenidos en cuenta para
la etapa de estimación, estos modelos son (i) ARIMA(2,2), (ii) ARIMA(6,0), (iii)
ARIMA(7,0).
Los resultados de la tabla MINIC mostraron que la combinación de que hace
mínimo el criterio de información Bayesiano se da en la intersección entre AR 1 y MA 0, lo
cual correspondería a un modelo ARMA(1,0). Este resultado es complementarte sensato
si se observa que este modelo es el que mayor acople tuvo dada la interpretación de la
ACF y PACF que se mencionó anteriormente.
El valor mínimo de la tabla MAPE se dio en la combinación (1,2) la cual hizo parte de un
modelo tentativo de la técnica ESACF y SCAN, mientras que los dos valores mínimos de
las tablas MAE y RMSE se dieron en la combinación (1,1) lo que incluiría en la etapa de
identificación otro modelo que debería ser estimado y diagnosticado.

230
Modelo Tentativo
Representaciones polinómicas
M1 ARMA(1,0)
M2 ARMA([1 3],0)
M3 ARMA(2,1)
M4 ARMA(1,2)
M5 ARMA(3,0)
M6 ARMA(0,6)
M7 ARMA(2,2)
M8 ARMA(6,0)
M9 ARMA(7,0)
M10 ARMA(1,2)
M11 ARMA(1,1)
Tabla 89 Identificación modelos tentativos serie TR500 (1:50)

231
10.9.3.3 Serie DLR1500
1 2 3 4 5 6 7 8 9 10
Autocorrelación 0.406 0.335 0.138 0.268 0.257 0.384 0.237 0.223 -0.001 0.026
PACF 0.406 0.203 -0.066 0.217 0.128 0.217 -0.012 0.017 -0.191 -0.091
Ljung-Box 6.947 11.790 12.641 15.922 19.032 26.178 28.978 31.535 31.535 31.573
(P-Value) 0.008 0.003 0.005 0.003 0.002 0.000 0.000 0.000 0.000 0.000
11 12 13 14 15 16 17 18 19 20
Autocorrelación 0.031 -0.001 0.014 -0.020 -0.149 -0.127 -0.178 -0.097 -0.102 -0.100
PACF -0.008 -0.177 0.014 -0.023 -0.130 0.022 -0.058 0.048 0.009 0.021
Ljung-Box 31.628 31.628 31.640 31.665 33.142 34.269 36.570 37.281 38.116 38.960
(P-Value) 0.001 0.002 0.003 0.004 0.004 0.005 0.004 0.005 0.006 0.007
21 22 23 24
Autocorrelación -0.129 -0.240 -0.356 -0.226
PACF 0.019 -0.176 -0.204 -0.031
Ljung-Box 40.448 45.847 58.544 64.006
(P-Value) 0.007 0.002 0.000 0.000
-0,5
-0,4
-0,3
-0,2
-0,1
0
0,1
0,2
0,3
0,4
0,5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
ACF LR1500
-0,4
-0,3
-0,2
-0,1
0
0,1
0,2
0,3
0,4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
PACF LR1500

232
1 2 3 4 5 6 7 8 9 10
Autocorrelación -0.341 0.020 -0.254 0.142 -0.049 0.090 -0.057 0.170 -0.224 0.032
PACF -0.341 -0.109 -0.325 -0.089 -0.095 -0.026 -0.021 0.177 -0.090 -0.072
Ljung-Box 4.784 4.802 7.609 8.508 8.620 9.001 9.159 10.616 13.242 13.297
(P-Value) 0.029 0.091 0.055 0.075 0.125 0.174 0.241 0.224 0.152 0.208
11 12 13 14 15 16 17 18 19 20
Autocorrelación 0.064 0.022 0.036 0.053 -0.120 -0.007 -0.058 0.161 -0.075 -0.061
PACF 0.115 -0.019 0.082 0.186 -0.024 -0.034 -0.020 0.059 -0.080 -0.107
Ljung-Box 13.529 13.557 13.638 13.815 14.761 14.764 15.009 16.985 17.433 17.750
(P-Value) 0.260 0.330 0.400 0.464 0.469 0.542 0.595 0.524 0.561 0.604
21 22 23 24
Autocorrelación 0.030 0.131 -0.101 -0.062
PACF -0.002 0.105 0.015 -0.115
Ljung-Box 17.830 19.450 20.494 20.916
(P-Value) 0.660 0.617 0.612 0.644
-0,5
-0,4
-0,3
-0,2
-0,1
0
0,1
0,2
0,3
0,4
0,5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
ACF DLR1500
-0,5
-0,4
-0,3
-0,2
-0,1
0
0,1
0,2
0,3
0,4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
PACF DLR1500
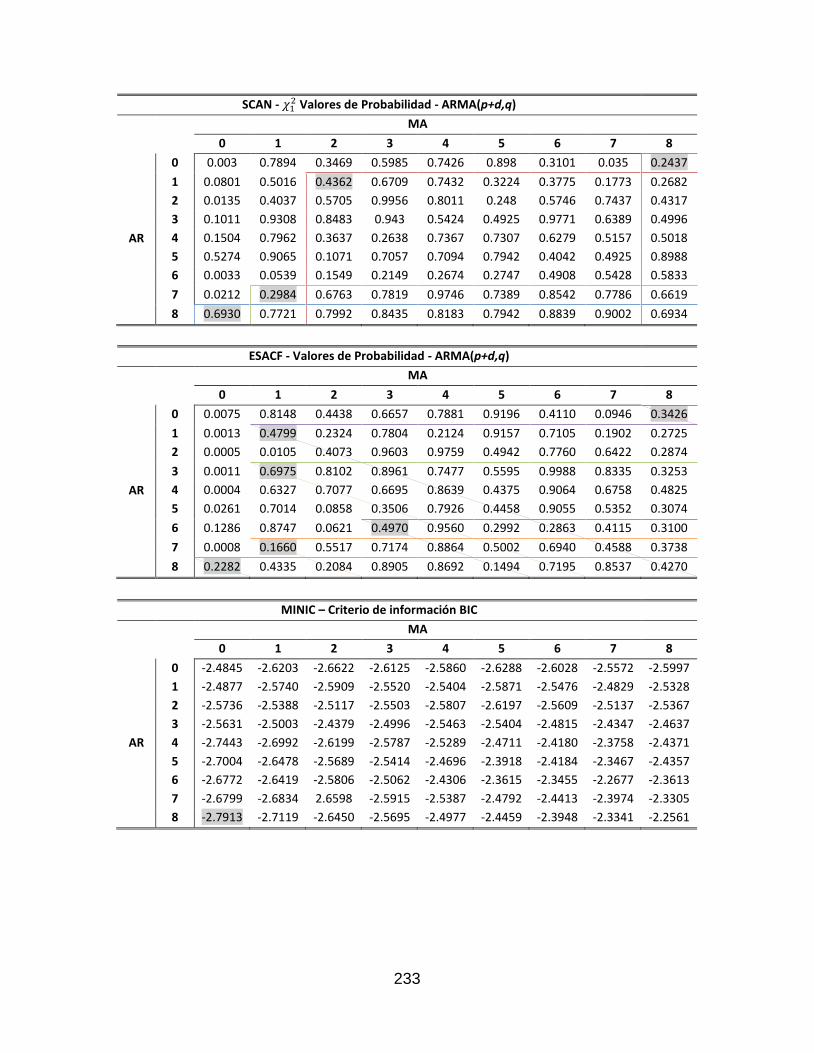
233
SCAN - Valores de Probabilidad - ARMA(p+d,q)
MA
0 1 2 3 4 5 6 7 8
0 0.003 0.7894 0.3469 0.5985 0.7426 0.898 0.3101 0.035 0.2437
AR
1 0.0801 0.5016 0.4362 0.6709 0.7432 0.3224 0.3775 0.1773 0.2682
2 0.0135 0.4037 0.5705 0.9956 0.8011 0.248 0.5746 0.7437 0.4317
3 0.1011 0.9308 0.8483 0.943 0.5424 0.4925 0.9771 0.6389 0.4996
4 0.1504 0.7962 0.3637 0.2638 0.7367 0.7307 0.6279 0.5157 0.5018
5 0.5274 0.9065 0.1071 0.7057 0.7094 0.7942 0.4042 0.4925 0.8988
6 0.0033 0.0539 0.1549 0.2149 0.2674 0.2747 0.4908 0.5428 0.5833
7 0.0212 0.2984 0.6763 0.7819 0.9746 0.7389 0.8542 0.7786 0.6619
8 0.6930 0.7721 0.7992 0.8435 0.8183 0.7942 0.8839 0.9002 0.6934
ESACF - Valores de Probabilidad - ARMA(p+d,q)
MA
0 1 2 3 4 5 6 7 8
0 0.0075 0.8148 0.4438 0.6657 0.7881 0.9196 0.4110 0.0946 0.3426
AR
1 0.0013 0.4799 0.2324 0.7804 0.2124 0.9157 0.7105 0.1902 0.2725
2 0.0005 0.0105 0.4073 0.9603 0.9759 0.4942 0.7760 0.6422 0.2874
3 0.0011 0.6975 0.8102 0.8961 0.7477 0.5595 0.9988 0.8335 0.3253
4 0.0004 0.6327 0.7077 0.6695 0.8639 0.4375 0.9064 0.6758 0.4825
5 0.0261 0.7014 0.0858 0.3506 0.7926 0.4458 0.9055 0.5352 0.3074
6 0.1286 0.8747 0.0621 0.4970 0.9560 0.2992 0.2863 0.4115 0.3100
7 0.0008 0.1660 0.5517 0.7174 0.8864 0.5002 0.6940 0.4588 0.3738
8 0.2282 0.4335 0.2084 0.8905 0.8692 0.1494 0.7195 0.8537 0.4270
MINIC – Criterio de información BIC
MA
0 1 2 3 4 5 6 7 8
0 -2.4845 -2.6203 -2.6622 -2.6125 -2.5860 -2.6288 -2.6028 -2.5572 -2.5997
AR
1 -2.4877 -2.5740 -2.5909 -2.5520 -2.5404 -2.5871 -2.5476 -2.4829 -2.5328
2 -2.5736 -2.5388 -2.5117 -2.5503 -2.5807 -2.6197 -2.5609 -2.5137 -2.5367
3 -2.5631 -2.5003 -2.4379 -2.4996 -2.5463 -2.5404 -2.4815 -2.4347 -2.4637
4 -2.7443 -2.6992 -2.6199 -2.5787 -2.5289 -2.4711 -2.4180 -2.3758 -2.4371
5 -2.7004 -2.6478 -2.5689 -2.5414 -2.4696 -2.3918 -2.4184 -2.3467 -2.4357
6 -2.6772 -2.6419 -2.5806 -2.5062 -2.4306 -2.3615 -2.3455 -2.2677 -2.3613
7 -2.6799 -2.6834 2.6598 -2.5915 -2.5387 -2.4792 -2.4413 -2.3974 -2.3305
8 -2.7913 -2.7119 -2.6450 -2.5695 -2.4977 -2.4459 -2.3948 -2.3341 -2.2561

234
MAPE
MA
0 1 2 3 4 5 6 7 8
0 22.3510 27.3108 27.1637 27.4174 27.1518 27.2665 27.3366 25.9047
AR
1 24.5125 22.4911 20.1476 24.7904 24.5260 24.0422 24.5855 24.4142 24.1443
2 27.4390 22.4504 22.4791 27.4220 27.5872 27.3147 27.4499 27.4425 25.9624
3 27.3751 22.8880 28.0561 23.1516 27.4635 28.1628 28.3497 27.3973 26.4120
4 27.4088 22.3517 27.4791 28.2057 23.2468 27.3618 27.4141 27.4806 26.0187
5 27.0744 22.7733 27.0748 27.8212 27.5909 22.4298 27.0623 27.2723 26.0791
6 27.4807 22.1513 27.4228 27.9105 27.5420 27.3244 23.2807 28.1229 26.0142
7 27.6859 22.4665 27.7932 28.5355 27.6679 27.6264 27.5347 24.2554 27.0067
8 24.6528 21.8742 24.6260 22.8612 24.6390 23.9983 24.6672 24.5211 23.0697
RMSE
MA
0 1 2 3 4 5 6 7 8
0 693.715 871.652 872.867 875.030 868.332 872.388 868.474 799.576
AR
1 774.605 695.543 651.930 762.826 773.966 761.907 772.587 772.379 733.077
2 870.644 687.969 775.787 867.675 872.310 867.123 872.432 862.780 796.156
3 883.073 691.280 912.445 829.170 885.208 853.642 837.025 873.511 769.218
4 874.478 693.715 872.879 851.935 811.478 839.342 873.530 868.409 796.983
5 864.348 704.974 863.878 835.109 856.034 781.483 865.114 861.957 776.641
6 865.869 696.492 866.124 849.474 868.135 863.722 804.985 851.213 797.533
7 881.274 698.841 865.521 866.137 881.744 874.722 867.798 799.905 824.477
8 744.707 657.517 733.804 661.900 744.419 708.602 744.767 734.661 723.293
MAE
MA
0 1 2 3 4 5 6 7 8
0 501.981 608.811 609.674 614.360 601.733 608.385 612.767 574.015
AR
1 553.376 499.930 462.351 557.078 553.389 536.168 554.138 551.272 544.740
2 610.445 503.370 524.520 614.662 615.869 604.842 611.067 611.524 572.274
3 615.722 517.403 638.911 550.642 617.387 620.281 628.874 614.905 576.730
4 619.371 502.007 619.827 623.057 549.856 614.858 619.120 620.726 580.107
5 597.985 515.261 598.045 610.155 605.340 530.201 597.748 606.697 563.320
6 609.779 509.315 608.935 617.269 614.030 604.704 554.727 622.601 575.558
7 627.985 508.443 626.287 640.087 627.549 621.930 624.263 579.140 604.765
8 564.173 495.222 558.353 518.949 563.725 541.019 564.611 564.844 538.749
La serie de la primera diferencia del logaritmo natural de la referencia 1500 mostró un
correlograma a primera vista poco significativo. Sin embargo, el estadístico Q de Ljung-
Box (1978) da indicios de estar parado en un proceso donde existe autocorrelación serial
lineal para los 4 primeros rezagos y muy poca para los rezagos más lejanos, por lo menos
a un nivel de significancia del 10%. Es decir, hay muy poca autocorrelación lineal para
grupos de rezagos muy distantes.

235
Sin embargo, sí hay que dar un indicio de cuál podría ser el modelo ARMA que podría
llegar a derivarse de la interpretación de las funciones ACF y PACF, habría entonces que
inclinarse por un modelo de media móvil de orden uno es decir un MA(1) para la serie
DLR1500, Esto debido al hecho que la autocorrelación tiende a caer rápidamente, pero no
de manera abrupta, en la función de autocorrelación parcial mientras que si lo hace
después del primer rezago en la función PACF. Se podría además pensar en incluir el
octavo rezago de media móvil en la ecuación intentando modelar lo más posible las
dinámicas de relaciones más lejanas entre rezagos, sin embargo es necesario la
verificación de la significancia de este en la etapa de estimación. Es decir, se tendría un
segundo modelo ARMA(0,[1 8]).
Ahora bien, el método SCAN a una significancia del 10% permite encontrar un patrón
rectangular en cuatro nuevos modelos que deben ser probados en la etapa de estimación.
Estos modelos fueron ARMA(1,2), ARMA(7,1), ARMA(8,0) y ARMA(0,8). Observe que el
modelo preliminar ARMA(0,[1 8]) podría ser validado si observamos más detalladamente
los resultados de la metodología SCAN (y el método SCAN), la primera fila presentaría el
inicio de un patrón rectangular derecho al 5% de significancia en el rezago MA 1
determinado por el comienzo del elemento no significativo, de no ser por la probabilidad
menor a 5% que hay en el rezago MA 7 de esa mima fila y que permite dibujar un patrón
para el rezago 8. Esto da evidencias que un modelo como ARMA(0,[1 8]) podría llegar a
acoplarse bien a este tipo de estructuras ya que muy posiblemente no todos los rezagos
de un modelo ARMA(0,8) lleguen a acoplarse bien al mecanismo generador de datos que
rige a este proceso estocástico en particular.
La metodología ESACF siguiere 3 modelos adicionales a los presentados hasta el
momento, estos son ARMA(1,1), ARMA(3,1) y ARMA(6,3). Sin embargo, se cree que no
todos logren ser modelos bien comportados estadísticamente puesto que la ACF y PACF
mostraron rezagos poco significativos para componentes autoregresivos lejanos.
Para este caso específico se consiguió un consenso entre las tres matrices MAPE, MAE y
RMSE del método ARIMAIN. Fue el modelo ARMA(1,2) el cual presentó la menor función
de pérdida asociada a los errores de pronóstico. Por lo que se incluiría como un modelo a
considerar dentro de los vistos anteriormente puesto que su representación polinómica
difiere del modelo arrojado por SCAN. Para este caso particular es necesario probar la
significancia del coeficiente el cual determinará si estamos parados en un modelo del
tipo o uno del tipo
. Todo esto bajo la
suposición que el coeficiente es significativamente diferente de cero.
En general se tiene que, dado el comportamiento de las funciones ACF y PACF, los
métodos SCAN, ESACF y MINIC y la metodología propuesta ARIMAIN existen diez
modelos preliminares a ser estimados de manera tentativa. Estos modelos se presentan a
continuación.

236
Modelo Tentativo
Representaciones polinómicas
M1 ARMA(0,1)
M2 ARMA(0,[1 8])
M3 ARMA(1,2)
M4 ARMA(7,1)
M5 ARMA(8,0)
M6 ARMA(0,8)
M7 ARMA(1,1)
M8 ARMA(3,1)
M9 ARMA(6,3)
M10 ARMA(1,2)
Tabla 90 Modelos tentativos para la serie DLR1500 (1:50)

237
10.9.3.4 Serie LR3000
1 2 3 4 5 6 7 8 9 10
Autocorrelación 0.414 0.283 0.359 0.405 0.314 0.295 0.347 0.269 0.141 0.154
PACF 0.414 0.135 0.248 0.226 0.068 0.080 0.122 -0.017 -0.128 -0.053
Ljung-Box 7.201 10.660 16.378 23.854 28.486 32.712 38.729 42.469 43.524 44.837
(P-Value) 0.007 0.005 0.001 0.000 0.000 0.000 0.000 0.000 0.000 0.000
11 12 13 14 15 16 17 18 19 20
Autocorrelación 0.117 -0.032 0.062 -0.036 -0.035 -0.042 -0.081 -0.209 -0.152 -0.058
PACF -0.118 -0.233 0.040 -0.170 0.006 0.053 -0.017 -0.132 0.070 0.113
Ljung-Box 45.620 45.681 45.921 46.002 46.085 46.205 46.685 50.018 51.872 52.151
(P-Value) 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000
21 22 23 24
Autocorrelación -0.146 -0.239 -0.288 -0.145
PACF -0.041 -0.045 -0.208 0.030
Ljung-Box 54.032 59.418 67.700 69.952
(P-Value) 0.000 0.000 0.000 0.000
-0,8
-0,6
-0,4
-0,2
0
0,2
0,4
0,6
0,8
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
ACF LR3000
-0,4
-0,3
-0,2
-0,1
0
0,1
0,2
0,3
0,4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
PACF LR3000

238
1 2 3 4 5 6 7 8 9 10
Autocorrelación -0.060 -0.262 -0.079 0.061 -0.070 -0.072 0.062 0.050 -0.065 0.033
PACF -0.060 -0.266 -0.123 -0.029 -0.132 -0.105 -0.009 -0.013 -0.070 0.034
Ljung-Box 0.150 3.107 3.381 3.551 3.781 4.032 4.221 4.353 4.581 4.641
(P-Value) 0.699 0.212 0.337 0.470 0.581 0.672 0.754 0.824 0.869 0.914
11 12 13 14 15 16 17 18 19 20
Autocorrelación 0.031 -0.168 0.046 -0.047 -0.073 0.066 0.092 -0.162 -0.078 0.161
PACF -0.004 -0.181 0.037 -0.160 -0.150 0.004 -0.022 -0.237 -0.117 0.019
Ljung-Box 4.695 6.370 6.503 6.646 7.004 7.305 7.917 9.924 10.407 12.587
(P-Value) 0.945 0.896 0.926 0.948 0.958 0.967 0.968 0.934 0.942 0.894
21 22 23 24
Autocorrelación 0.098 -0.027 -0.157 0.068
PACF -0.041 0.046 -0.171 -0.074
Ljung-Box 13.434 13.500 15.977 16.467
(P-Value) 0.893 0.918 0.856 0.870
-0,5
-0,4
-0,3
-0,2
-0,1
0
0,1
0,2
0,3
0,4
0,5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
ACF LR3000dt
-0,4
-0,3
-0,2
-0,1
0
0,1
0,2
0,3
0,4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
PACF LR3000dt

239
SCAN - Valores de Probabilidad - ARMA(p+d,q)
MA
0 1 2 3 4 5 6 7
0 0.0041 0.0691 0.0082 0.001 0.0524 0.1166 0.0557 0.0245
AR
1 0.2189 0.2683 0.7658 0.1260 0.7988 0.4909 0.7580 0.1881
2 0.0337 0.5619 0.1622 0.2472 0.3887 0.8136 0.4004 0.2322
3 0.0025 0.1646 0.3835 0.7136 0.6426 0.4909 0.4373 0.5026
4 0.4106 0.8615 0.6652 0.5988 0.7483 0.5300 0.5455 0.6637
5 0.5729 0.7776 0.8224 0.7491 0.5803 0.9624 0.9985 0.7422
6 0.3931 0.5710 0.7495 0.9000 0.8085 0.9989 0.9656 0.7596
7 0.2243 0.5003 0.6731 0.8286 0.8732 0.9025 0.9285 0.8025
ESACF - Valores de Probabilidad - ARMA(p+d,q)
MA
0 1 2 3 4 5 6 7
0 0.0096 0.1049 0.0341 0.0082 0.0984 0.1854 0.1226 0.0971
AR
1 0.008 0.592 0.857 0.1047 0.7642 0.7251 0.8442 0.1475
2 0.0054 0.039 0.8316 0.089 0.7906 0.7317 0.7961 0.2614
3 0.0004 0.3219 0.2107 0.6028 0.649 0.8759 0.4143 0.1936
4 0.0597 0.6421 0.4019 0.0917 0.6222 0.6626 0.5556 0.1883
5 0.0012 0.6665 0.8648 0.537 0.35 0.8839 0.972 0.2512
6 0.0015 0.5138 0.7807 0.4659 0.4044 0.8752 0.9793 0.3221
7 0.0023 0.0872 0.307 0.4472 0.5707 0.6719 0.6878 0.7208
MINIC – Criterio de información BIC
MA
0 1 2 3 4 5 6 7
0 -2.4715 -2.4016 -2.3458 -2.2699 -2.3508 -2.5097 -2.4950 -2.4660
AR
1 -2.4719 -2.6621 -2.6631 -2.5855 -2.6138 -2.5691 -2.5136 -2.4796
2 -2.4165 -2.6486 -2.5851 -2.5074 -2.5365 -2.5039 -2.4424 -2.4026
3 -2.4335 -2.6042 -2.5275 -2.5343 -2.5339 -2.5665 -2.5258 -2.5357
4 -2.6410 -2.6572 -2.5823 -2.5229 -2.4564 -2.5126 -2.4996 -2.4966
5 -2.7146 -2.6376 -2.5604 -2.5043 -2.4457 -2.4585 -2.4267 -2.4433
6 -2.6684 -2.5904 -2.5198 -2.4590 -2.3979 -2.4442 -2.3662 -2.3698
7 -2.6177 -2.5396 -2.4669 -2.4703 -2.4054 -2.4721 -2.4044 -2.3591

240
MAPE
MA
0 1 2 3 4 5 6 7
0 27.7313 29.1117 27.3003 27.1389 28.5687 28.3797 26.1179
AR
1 26.3233 22.0758 26.3139 26.1440 24.3367 26.2843 25.9874 25.5106
2 27.9523 26.6990 22.0689 26.2093 26.1674 28.0552 27.8442 25.6709
3 25.4770 25.1911 25.4517 24.3743 24.3550 25.3552 25.2568 25.0740
4 22.6936 22.6624 22.6674 22.7103 21.6537 22.5658 22.6601 22.1445
5 26.8562 26.6604 26.5552 26.3046 24.8786 24.1806 26.8468 24.8037
6 27.0439 26.2509 26.5677 25.2686 25.0419 26.8261 26.9930 25.4744
7 24.3419 24.3227 24.2572 23.8757 22.2074 23.6919 24.4309 24.3844
RMSE
MA
0 1 2 3 4 5 6 7
0 954.7110 989.7878 960.9156 919.3683 954.6413 974.6567 947.3513
AR
1 934.4225 774.9854 934.3813 928.5690 883.1452 925.4138 933.9440 929.7670
2 968.3920 936.5924 755.4113 952.8434 907.7004 946.3705 968.6960 941.0537
3 915.3780 914.6914 909.6730 815.3166 880.2095 910.8437 914.2129 914.3087
4 768.5590 768.7459 748.0707 768.4628 726.4190 760.9641 768.0976 762.1096
5 894.2851 894.2729 889.0147 898.9939 847.5419 842.8445 896.0739 884.6215
6 945.5332 933.0592 925.2396 919.3337 885.2176 923.2844 860.5669 929.7928
7 913.7641 913.1080 911.9017 913.1519 859.3776 892.3402 914.5283 847.5534
MAE
MA
0 1 2 3 4 5 6 7
0 698.3975 736.6609 695.9397 682.5526 719.9707 724.7853 677.1479
AR
1 671.8743 570.2194 671.5430 674.0071 619.8978 669.3740 663.9741 659.5757
2 718.6782 684.8443 550.4712 676.8909 670.9456 715.4732 715.7172 669.1389
3 674.1866 666.8036 675.5881 618.6949 634.9549 668.1533 667.3293 665.2371
4 574.4397 573.6878 572.3920 574.7976 545.3364 570.3821 578.3856 559.8047
5 692.6350 687.3749 685.6811 682.5329 638.0057 614.4232 693.7877 653.9686
6 702.4733 676.5760 691.5056 665.9882 647.9229 694.2569 673.4394 670.6232
7 658.7846 656.5033 657.8981 646.4526 597.5844 644.9735 662.0828 636.9221
El correlograma de la serie de evidencia para pensar en un modelo del tipo AR(4) con la
inclusión de rezagos 1 y 4 únicamente debido a su grado de significancia estadística. Este
modelo podría estar acompañado de un componente de media móvil en el rezago uno
que permita recoger las dinámicas de ajuste en el corto plazo determinadas por el término
aleatorio del error en el primer rezago. Es decir que se puede estar pensando en un
modelo del tipo ARMA([1 4],1).

241
Note que aunque el rezago 23 parece significativo estadísticamente, no necesariamente
indica que deba ser incluido, esto debido a que se está tratando con un correlograma
muestral, y por tanto es posible conseguir un rezago significativo de 20 posibles cuando
en verdad no lo es, con un intervalo de confianza del 95%.
Combinando entonces este análisis con los resultados obtenidos por las metodologías
SCAN, ESACF, MINIC y ARIMAIN se obtienen entonces los siguientes modelos tentativos
Modelo
Tentativo
Representaciones polinómicas
M1 ARMA([1 4],1)
M2 ARMA(5,1)
M3 ARMA(6,1)
M4 ARMA(4,0)
M5 ARMA(5,0)
M6 ARMA(3,3)
M7 ARMA(4,4)
M8 ARMA(1,3)
M9 ARMA(1,1)
Tabla 91 Identificación modelos tentativos serie LR3000(1:50)

242
10.9.4 Resultados Estimación-Diagnóstico Series Restantes
10.9.4.1 Serie DLR250
M1 M2 M3 M4 M5 M6
0.051 (0.88)
0.057 (1.53)
0.128 (0.78)
0.059 (1.39)
0.053 (1.26)
0.079* (4.68)
-0.6277*
(-5.1)
-0.709* (-3.2)
-0.590* (-4.59)
-0.725* (-5.54)
-0.838* (-23.4)
-0.226* (-0.9)
-0.078 (-0.26)
-0.043 (0.01)
-0.035 (-0.04)
0.213 (1.21)
-0.623* (-5.30)
-0.237
(-1.286) -0.575* (-16.4)
0.359
(10.32)
-0.336** (-2.13)
-0.784* (-16.8)
Akaike AIC Schwarz SIC
1.9246 2.065
1.9484 2.0295
2.1685 2.4701
1.888 2.01
1.938 2.060
1.512 1.717
Lju
ng-B
ox
Q-S
tat
Q(8) 6.9887 [0.430]
12.984 [0.073]
2.614 [0.956]
3.658 [0.723]
4.843 [0.564]
3.198 [0.525]
Q(16) 12.091 [0.672]
20.165 [0.166]
7.1831 [0.970]
11.210 [0.669]
10.617 [0.716]
15.256 [0.228]
Q(20) 12.861 [0.846]
20.999 [0.337]
13.354 [0.770]
11.070 [0.891]
17.755 [0.338]
Shapiro-Wilk 0.9673 [0.490]
0.9844 [0.924]
0.9822 [0.903]
0.9548 [0.305]
0.9800 [0.735]
0.965 [0.355]
Media | | 6.12E-14 0.1308 2.77E-12 0.6109 0.0422 0.0513
0.687 0.678 0.680 0.557 0.601 0.464
Estabilidad Si Si Si Si Si Si
Notas:
1. Valores de probabilidad en paréntesis rectangular []
2. * simboliza significancia al 1%, ** al 5% y *** al 10%. La ausencia de estos simboliza no
significancia a algún nivel comúnmente utilizado.
Dentro de todas las posibles identificaciones tentativas únicamente M1, M2 y M4
presentaron significancia en todos sus coeficientes. Adicionalmente los modelo M3 y M5

243
terminan llevando al modelo M1 una vez sustraído sus componentes poco significativos.
Al observar detalladamente cada modelo es posible evidenciar que el modelo cuya
representación se da por medio del primer rezago de media móvil es decir, M2 no parece
aprovechar muy bien las dinámicas de corto plazo debido a la que se rechaza la
presencia de ruido hasta el rezago 8 en el término de perturbación. Esto hace que se
descarte el modelo.
Aunque el modelo M1 es un modelo bien comportado estadísticamente, la inclusión del
rezago 7 de media móvil permite mejorar su comportamiento debido a la reducción en la
sumatoria de cuadrados sin penalidad por la inclusión, indicada en la reducción de los
criterios de información. Todo esto sin sacrificar la parsimonia del modelo.
Ahora bien, aunque el modelo M4 parece ser el modelo definitivo, es necesario revisar si
por medio de la inclusión de otros rezagos significativos antes del séptimo de media móvil
el modelo mejoraría sus propiedades. Esto se logró incluyendo el rezago 2 y el 3 de
media móvil al modelo M4. Estos rezagos permiten mejorar los criterios de información,
consiguiendo los más bajos entre los seis modelos y permite además, y muy importante,
obtener una desviación estándar del error más pequeña que la de los modelos M1 y M4.
Este aspecto es esencial para alcanzar un buen modelo de pronóstico. Este modelo se
registró en M6.
10.9.4.2 Serie TR500
Acorde a lo mencionado anteriormente sobre la necesidad de la inclusión de la tendencia
determinística en la estimación del modelo y la condición de ruido blanco una vez
sustraída la misma. No fue posible el ajuste de ninguno de los once modelos preliminares
una vez se incluye la tendencia en la estimación. Esto sucede puesto que el entrar en la
estimación los componentes de tendencia hace que cuando se intente incluir un
autoregresivo o media móvil de cualquier tipo este se vuelva muy poco significativo (con
valores del estadístico t muy cercanos a cero), debido a que se está intentando estimar un
ruido blanco.
Es por esto que se decidió a escoger el modelo únicamente con tendencia el cual tiene
ciertas peculiaridades de las cuales se justifica un análisis más profundo. El modelo
estimado únicamente con componentes determinísticos de tendencia induce a estar
parados en una regresión de detrending del tipo (D10) donde el término de perturbación
necesariamente representará a la serie una vez sustraída la tendencia determinística. De
la regresión escogida, una vez sustraídos los componentes no significativos se tiene que

244
donde el error será igual a la variable original menor los componentes de tendencia
significativos para la serie
es decir que el error será simplemente la serie original rescalda en media cero debido a la
sustracción de la tendencia (i.e. ) por lo que la condición de media cero se
cumple muy bien con un | | | | . Acorde a lo mencionado en la sección de
identificación de las series restantes, se encontró que la serie TR500dt mostraba
evidencias claras de ser un ruido blanco, por lo que la condición de no autocorrelación
serial en los residuos del modelo se cumple de igual manera. Sin embargo, no se puede
estar hablar de ruido blanco gaussiano a menos que la serie original siga una distribución
normal y dicha condición no se cumple por lo que el estadístico de Shapiro Wilk es igual a
0.862 con un valor de probabilidad por debajo de 0.01. Dicha situación sucede de igual
manera si la serie hubiese sido estabilizada de varianza por medio de una función
logarítmica, Box-Cox o una normalización del tipo . Por lo que el
replanteamiento de la transformación no permite su corrección.
Por consiguiente el modelo será pronosticado utilizando el componente de tendencia
únicamente debido a la característica de ruido en el error y la imposibilidad de ajustar un
modelo con dicha tendencia. Sin embargo, cabe anotar que no siempre sucederá esta
misma situación, como se verá más adelante en la serie LR3000, aunque también era
ruido blanco en tendencia, si fue posible ajustar un modelo ARMA significativo incluyendo
la tendencia y mejorando así las propiedades del modelo. Se dice entonces, siendo más
formales, que en este caso específico no se está estimando en si un modelo ARMA dado
que no existen componentes de error o autoregresivos que estimar, únicamente la
tendencia.

245
10.9.4.3 Serie DLR1500
TABLA 1 DE 2
M1 M2 M3 M4 M5 M6 M7 M8
0.011** (2,45)
0.021 (1.3)
0.01* (2.5)
0.014 (1.68)
0.014 (1.3)
0.022 (1.3)
0.01* (2.89)
0.01*** (1.75)
-0.827* (-11.8)
-1.052* (-3.99)
-0.533* (-3.2)
0.1504 (0.972)
0.017 (0.09)
-1.055* (-3.96)
-0.706* (-3.7)
-0.204 (-1.2)
-1.013* (-3.51)
-0.553** (-2.4)
-0.217 (-1.2)
-1.015* (-3.52)
-0.546** (-2.24)
-0.580** (-2.14)
-0.070 (-0.3)
-0.498** (-2.17)
-0.206 (-0.9)
-0.444* (-3.03)
-0.087 (-0.4)
0.311*** (1.97)
-0.947* (-16.6)
-0.840* (-13.1)
0.0237 (0.383)
0.49*** (1.73)
-0.384* (-2.9)
-0.962* (-32.6)
-0.77* (-5.66)
-0.934* (-15.2)
-0.539* (-4.9)
-0.235***
(-1.7)
0.276**
(2.1)
0.4189*
(3.4)
-0.007 (-0.05)
-0.605* (-6.31)
0.239* (5.28)
0.580* (4.66)
Akaike AIC Schwarz SIC
0.2407 0.3180
0.3195 0.4353
0.1771 0.333
0.2096 0.5820
0.2120 0.5882
0.1234 0.4709
0.2544 0.3713
0.325 0.5237
Lju
ng
-Box
Q-S
tat
Q(8) 6.8243 [0.447]
5.9271 [0.431]
6.283 [0.280]
4.229 [0.04]
3.3792 [0.066]
8.639 [0.003]
6.246 [0.396]
5.825 [0.213]
Q(16) 11.695 [0.634]
13.319 [0.332]
11.903 [0.536]
5.381 [0.716]
4.819 [0.777]
12.160 [0.144]
11.246 [0.667]
11.510 [0.486]
Q(20) 13.369 [0.819]
14.120 [0.721]
14.294 [0.646]
8.412 [0.752]
7.77 [0.802]
14.788 [0.253]
12.311 [0.831]
13.089 [0.666]
Shapiro-Wilk 1.293
[>0.99] 1.285
[>0.99] 0.949 [0.06]
0.979 [0.740]
0.976 [0.624]
1.34 [>0.99]
0.9653 [0.326]
0.963 [0.297]
Media | | 0.888 0.065 0.7144 0.0062 3.59E-11 0.0246 0.3108 0.052
0.2625 0.2697 0.244 0.2195 0.2186 0.2164 0.2606 0.2581
Estabilidad Si Si Si Si Si Si Si Si
Notas: 1. Valores de probabilidad en paréntesis rectangular [] 2. * simboliza significancia al 1%, ** al 5% y *** al 10%. La ausencia de estos simboliza no significancia a algún nivel comúnmente utilizado.

246
TABLA 2 DE 2
M9 M10 M11 M12
0.02
(1.34) 0.01* (2.93)
0.0148 (1.10)
0.0073 (0.797)
-0.022 (-0.09)
-0.799 (-10.97)
-0.535* (-3.9)
-0.011 (-0.05)
-0.673* (-4.4)
-0.408***
(-1.9)
-0.469* (-3.1)
-0.188 (-1.12)
-0.454* (-3.2)
-0.129 (-0.8)
-0.084 (-0.5)
0.353* (3.2)
-0.739* (-3.6)
-0.499* (-11.38)
-0.359 (-1.1)
-0.920* (-14.51)
0.759* (4.09)
-0.746* (-20.12)
0.4816* (14.18)
Akaike AIC Schwarz SIC
0.3505 0.7601
0.1383 0.2553
0.1065 0.3572
0.1831 0.3376
Lju
ng-B
ox
Q-S
tat
Q(8) 7.633 [0.006]
5.9703 [0.427]
1.9708 [0.578]
6.055 [0.301]
Q(16) 11.794 [0.108]
11.697 [0.631]
3.995 [0.970]
10.753 [0.631]
Q(20) 13.993 [0.233]
14.024 [0.728]
7.109 [0.955]
12.475 [0.771]
Shapiro-Wilk 0.9835 [0.851]
0.9429 [0.037]
0.972 [0.513]
1.396 [>0.99]
Media | | 0.0122 0.7955 5.6E-12 0.1899
0.2312 0.2445 0.2232 0.2468
Estabilidad Si Si Si Si
Notas:
1. Valores de probabilidad en paréntesis rectangular []
2. * simboliza significancia al 1%, ** al 5% y *** al 10%. La ausencia de estos simboliza no
significancia a algún nivel comúnmente utilizado.

247
Observe en el modelo M2 como la intuición previa sobre la inclusión del coeficiente de
media móvil en el octavo rezago se ve validada por su alta significancia estadística, sin
embargo incluir éste no trae beneficios en la reducción de la suma de residuos al
cuadrado debido que es mitigado por los efectos de estimar un parámetro adicional.
Lo que compete al modelo M4, éste parece estar estimando adecuadamente. Sin
embargo existen ciertos aspectos que lo hacen poco deseable. Primero, la forma como se
presentan los coeficientes, los cuales son todos significativos, parece dar indicios claros
de la presencia de coeficientes redundantes que violarían el principio de parsimonia por
completo. Este es el ejemplo claro que no siempre el hecho que todos los coeficientes
sean significativos, significa que se cumple con dicho principio. Un cambio en un
parámetro puede compararse con un cambio en otro parámetro, sin que la suma de
cuadrados se altere (Guerrero (2003)) por lo que parámetros estimados con correlaciones
altas tanto positivas como negativas son indicadores de casusas de inestabilidad en el
modelo. La forma como se observa la correlación entre dos coeficientes estimados para la
detección de posibles coeficientes redundantes se da bajo la siguiente formula estadística
comúnmente utilizada
( ) ( )
√ ( )
√( )( )
Si tomamos por ejemplo los coeficientes y estimados para el
modelo M4, se tendrá que
( ) √
por lo que la correlación entre estos dos coeficientes es sumamente alta y se sabe que se
está bajo la presencia de dos coeficientes redundantes. Este mismo fenómeno ocurre
entre los coeficientes y , y ,
y y por ultimo y . Es decir que existe dentro
de todos estos parámetros muchos que podrían catalogarse como factores
aproximadamente comunes en el polinomio autoregresivo. Este problema se corrige
entonces cancelando dichos parámetros y reestimando el modelo. Al realizar esto, los
resultados determinaron que ninguno de los parámetros era significativo, por lo que el
modelo no es un modelo adecuado. En parte esto se podía comprobar si se observaba
que M4, por más que tenía muchos rezagos significativos, era incapaz de capturar las
dinámicas de la información disponible para corto plazo, esto si se observa el estadístico
Ljung-Box para el rezago 8.

248
En cuanto al modelo M5, una vez se realiza el proceso de sustracción iterada de
coeficientes, comenzando por el menos significativo se llega a encontrar un modelo del
tipo M11 el cual permite obtener un criterio de información AIC y SIC más pequeño así
como una evidencia tacita de ruido blanco en el término de perturbación determinado por
valores de probabilidad más elevados. Esto lo que está queriendo decir es que el modelo
M11 permite capturar bastante mejor las dinámicas que subyacen al proceso estocástico
que rige la serie, puesto que utiliza de una manera mucho más adecuada la información
con la que dispone. Por consiguiente este nuevo modelo reestimado se postula como un
buen candidato.
De la misma manera que con el modelo M5, el modelo M6 presentó coeficientes poco
significativos, por lo que la sustracción iterada de los mismos permitió alcanzar un modelo
mucho más parsimonioso con menores valores de los criterios de información y ahora con
ruido en el término del error. Este modelo se registró en M12 para su póstuma
comparación.
En cuanto al modelo M7 y M8, la eliminación iterada de rezagos no significativos conduce
en ambos casos a un modelo del tipo M1. Por lo que ambos modelos son descartados
directamente. De manera similar sucedió con los modelos M3 y M9 los cuales por medio
de la misma estrategia de eliminación-reestimación-validación se logró llegar a un modelo
del tipo M10.
Es decir, se tienen al final 3 candidatos posibles, los cuales corresponden a las últimas
tres columnas de la segunda tabla (Tabla 2 de 2). estos modelos son M10, M11 y M12. Se
decidió por escoger el modelo M11 puesto que fue el modelo que presento un mejor
diagnóstico de los tres, determinado por una muy buena captura de las dinámicas tanto
de corto como de largo plazo, determinado por la poca significancia de las
autocorrelaciones en el termino del error, una media mucho más cercana a cero y fue el
modelo con menor desviación estándar de los tres en el término de perturbación.

249
10.9.4.4 Serie LR3000
TABLA 1 DE 2
M1 M2 M3 M4 M5 M6 M7
7.286* (87.34)
7.31* (116.8)
7.30* (89.5)
7.47* (169.4)
7.45* (171.3)
7.47* (188.1)
7.40* (80.09)
0.309** (2.138)
0.306*** (1.99)
0.325*** (1.77)
-0.288*** (-1.80)
-0.293*** (-1.75)
-0.380 (-1.26)
-0.265 (-1.60)
-0.255 (-1.56)
-0.432** (-2.49)
-0.436** (-2.41)
-0.784* (-3.99)
0.114 (0.64)
0.086 (0.45)
-0.186 (-1.03)
-0.223 (-1.16)
0.0578 (0.20)
0.289** (2.28)
0.254 (1.32)
0.264 (1.31)
0.0563 (0.32)
0.091 (0.489)
-0.708* (-5.8)
0.012 (0.07)
-0.063 (-0.312)
-0.134
(-0.768)
0.1036 (0.6)
-0.99*
(-7.359) -0.99*
(-11.26) -0.99* (-6.19)
0.137 (0.54)
0.476**
(2.4)
-0.56** (-2.4)
0.874* (25.6)
0.0018* (8.72)
0.0017* (10.37)
0.0017* (9.07)
0.0013* (7.37)
0.0013* (7.72)
0.0013* (7.83)
0.0015* (4.52)
-3.3E-0.5*
(-8.30) -3.1E.05*
(-9.60) -3.1E-05*
(-8.74) -2.2E-05*
(-5.96) -2.3E-05*
(-6.26) -2.3E-05*
(-6.25) -2.3E-05*
(-3.88)
Akaike AIC Schwarz SIC
-0.1914 0.0470
-0.1652 0.1960
-0.1025 0.3029
0.2042 0.4824
0.2358 0.5570
0.1543 0.5086
0.2161 0.4149
Lju
ng-B
ox
Q-S
tat
Q(8) 3.815 [0.576]
1.568 [0.456]
1.7247 [0.189]
2.616 [0.855]
2.095 [0.553]
3.680 [0.159]
16.00 [0.014]
Q(16) 10.709 [0.635]
8.170 [0.612]
7.462 [0.589]
8.010 [0.784]
8.329 [0.684]
9.333 [0.501]
21.709 [0.085]
Q(20) 14.851 [0.606]
10.662 [0.712]
10.106 [0.685]
10.772 [0.823]
11.052 [0.749]
16.566 [0.280]
33.325 [0.015]
Shapiro-Wilk 0.9806 [0.741]
0.9821 [0.804]
0.9840 [0.867]
0.9744 [0.5177]
0.9703 [0.4464]
0.9734 [0.489]
0.978 [0.665]
Media | | 0.2533 0.10056 0.00399 7.98E-11 5.29E-11 0.1134 0.0414
Estabilidad Si Si Si Si Si Si Si
Notas: 1. Valores de probabilidad en paréntesis rectangular [] 2. * simboliza significancia al 1%, ** al 5% y *** al 10%. La ausencia de estos simboliza no significativo a algún nivel comúnmente utilizado.
3. Y Corresponden a los coeficientes de los grados de tendencia y respectivamente.

250
TABLA 2 DE 2 M8 M9
7.47*
(174.7) 7.41*
(194.0)
0.116
(0.199) 0.574* (4.25)
-0.455 (-0.77)
-0.96* (-17.7)
-0.254 (-1.03)
0.188
(1.023)
0.0013* (7.44)
0.0015* (9.6)
-2.24E-05*
(-6.00) -2.58E-05*
(-7.83)
Akaike AIC Schwarz SIC
0.1927 0.4630
0.0822 0.2752
Lju
ng-B
ox
Q-S
tat
Q(8) 3.711 [0.446]
7.357 [0.289]
Q(16) 9.042 [0.699]
13.707 [0.472]
Q(20) 14.983 [0.526]
20.102 [0.327]
Shapiro-Wilk 1.313
[>0.99] 1.367
[>0.99] Media | | 0.0124 0.9915
Estabilidad Si Si
Notas:
1. Valores de probabilidad en paréntesis rectangular []
2. * simboliza significancia al 1%, ** al 5% y *** al 10%. La ausencia de estos simboliza no
significativo a algún nivel comúnmente utilizado.
3. Y Corresponden a los coeficientes de los grados
de tendencia y respectivamente.

251
Observe que se estimaron para todos los tipos de modelos plausibles revisados en la
etapa de identificación los grados de tendencia determinística que fueron identificados
previamente. Estos compontes de tendencia presentaron significancia estadística fuerte
(menor al 1%) para cualquier modelo que se halla estimado dentro de los 8 modelos
tentativos. Esto deja ver una vez más que dicho componente debe hacer parte tanto de la
estimación del modelo como del pronóstico del mismo.
Ahora bien, no todos los modelos identificados presentan comportamientos ideales para el
ajuste de la serie con tendencia determinística. Es decir, estimar modelos con y sin la
tendencia, aunque no cambian la significancia del componente determinístico de la
tendencia como se mencionó, si cambian la forma como el modelo es identificado, puesto
que se está estimando el mejor modelo con su parte de tendencia. Por ejemplo, el modelo
AR(1) que se ajusta a los datos adecuadamente sin incluir tendencia presenta un
coeficiente poco significativo al incluir este componente determinístico dentro del
modelo. Esto en parte tiene que ver con lo mencionado anteriormente sobre el hecho que
las serie sea ruido blanco una vez realizado el proceso de detrending. Sin embargo, como
se observa, es posible la identificación de un modelo de ajuste ARMA para una serie de
este tipo, solo si se estima la tendencia y se ajusta un modelo adecuado con ella.
Fuer por esto que se decidió por la elección del modelo M1 como el mejor modelo de
ajuste. Esto se debe al hecho que además de ser un modelo parsimonioso, es el modelo
con menor desviación estándar en el término de perturbación, condición esencial para el
adecuado funcionamiento del pronóstico. Este modelo cuenta además con
autocorrelación serial cero en los residuales, se distribuyen normalmente bajo la prueba
de contraste de Shapiro Wilk y tienen media cero determinada por el coeficiente | |
en la prueba de media presentada por Guerrero (2003). Todas estas condiciones de
diagnóstico permitirán realizar un pronóstico mucho más adecuado puesto que el modelo
estará bien comportando. Un aspecto además importante que presentó esta serie fue el
menor criterio de información tanto AIC como SIC de todos los tipos de modelos sumado
al hecho que los modelo M2 y M3 una vez realizado el proceso de sustracción iterativa de
los coeficientes poco significativos, de manera similar a como se realizó para la serie
LR1000, terminen llevando a un modelo del tipo M1. Esto lleva a pensar que dicho modelo
puede ser meritorio de ser elegido como el mejor.

252
10.9.5 Resultados Diagnóstico Rolling con Rolling2.m.
10.9.5.1 Serie R250
Modelo 1
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 1: 0. 11861 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 1: 0. 21868 Val i daci ón del supuest o

253
Modelo 2
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 2: 0. 013207 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 2: 0. 3915 Val i daci ón del supuest o

254
Modelo 3
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 3: 0. 086971 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 3: 0. 30986 Val i daci ón del supuest o
Modelo 4

255
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 4: 0. 023087 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 4: 0. 38621 Val i daci ón del supuest o
Modelo 5

256
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 5: 0. 061544 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 5: 0. 5 Val i daci ón del supuest o
Modelo 6

257
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 6: 0. 061664 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 6: 0. 5 Val i daci ón del supuest o
10.9.5.2 Serie R500
Modelo 1

258
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 1: 0. 023473 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 1: 0. 5 Val i daci ón del supuest o
Modelo 2

259
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 2: 0. 22471 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 2: 0. 5 Val i daci ón del supuest o
Modelo 3

260
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 3: 0. 024607 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 3: 0. 5 Val i daci ón del supuest o
Modelo 4

261
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 4: 0. 0021542 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 4: 0. 2451 Val i daci ón del supuest o
Modelo 5

262
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 5: 0. 25206 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 5: 0. 5 Val i daci ón del supuest o
Modelo 6

263
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 6: 0. 23342 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 6: 0. 5 Val i daci ón del supuest o
10.9.5.3 Serie R1000
Modelo 1

264
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 1: 0. 069637 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 1: 0. 25098 Val i daci ón del supuest o
Se tiene que el término de perturbación muestra que no existe autocorrelación
significativa estadísticamente, lo que conduciría a una serie de errores de ruido blanco
validando así el supuesto de variables aleatorias mutuamente independientes.
El supuesto de normalidad se ve satisfecho tanto en las pruebas del estadístico Lilliefors,
pues no se logra rechazar la hipótesis nula de normalidad, como en la gráfica de acople
de la función de densidad de la normal estándar con la función de densidad del termino de
perturbación, como lo muestra los resultados del algoritmo.
La ultima gráfica en la coordenada (2,2) nombrada como Error vs Tiempo presenta
condiciones importantes para validar otros supuestos. Se muestran 2 limites en color rojo,
estos representan los intervalos los cuales determinarán si existen o no
observaciones aberrantes o Outliers en los datos. De llegar a mostrar observaciones
aberrantes, es decir cuando algún dato sobrepase la frontera de dichos limites, se
considerará la posibilidad de que la ocurrencia de dicho valor haya sido poco probable

265
que ocurriese bajo el proceso estocástico que describe la serie. En ese caso se mostrará
una barra color amarillo claro donde se halla sobrepasado el límite, advirtiendo que dicho
evento ocurrió. Sin embargo, la declaración de una observación como Outlier debe
estudiarse bien por la persona que realiza el estudio, y no es condición vital para
determinar que el modelo está mal especificado, si se llegase a explicar su procedencia.
Para este ejemplo particular observe que la gráfica muestra una observación aberrante en
el número 32; sin embargo se cree que esto no afecta el diagnóstico puesto que
consultando con la organización no fue posible hallar algún tipo de error en la toma de
datos en ese período de tiempo particular. Se contrasto además la forma de obtención de
la serie acorde al método del autor y al método de la organización y se evidencio que fue
la misma. Por lo tanto no hay indicios para mostrar que se deba tratar esta observación
como un outliers.
Dentro de la misma gráfica se puede observar que la varianza del error parece no variar a
lo largo del tiempo mostrando que se valida el supuesto 2 visto en la anterior sección. Por
último, se observa como dentro de la gráfica la media de la serie, representada como la
línea puntada roja de color más oscuro, se encuentra muy cercana a cero. Condición que
determina la verificación del supuesto 1 justificada además por el valor de | |
mostrado como salida del algoritmo donde | | toma el valor de 0.069 según la
terminología vista en la teoría de la sección anterior por Guerrero (2003, p.144).
Modelo 2
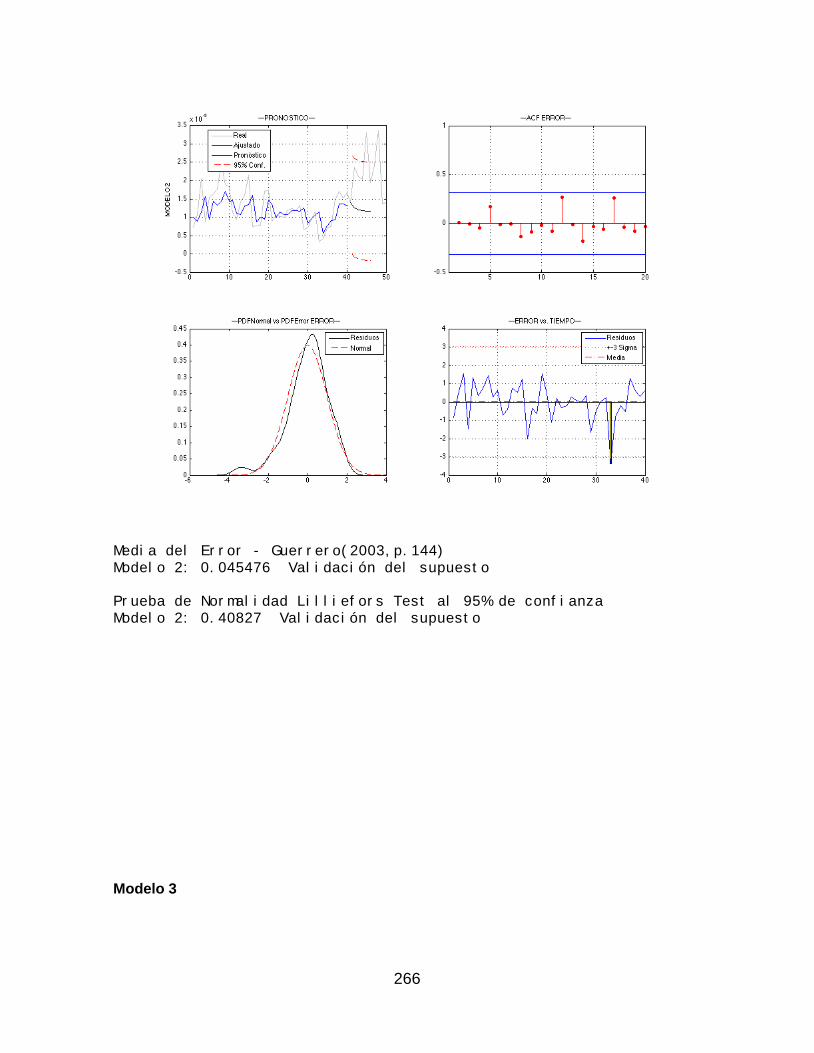
266
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 2: 0. 045476 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 2: 0. 40827 Val i daci ón del supuest o
Modelo 3

267
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 3: 0. 050012 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 3: 0. 3497 Val i daci ón del supuest o
Modelo 4

268
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 4: 0. 053278 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 4: 0. 5 Val i daci ón del supuest o
Modelo 5

269
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 5: 0. 076825 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 5: 0. 078421 Val i daci ón del supuest o
Modelo 6
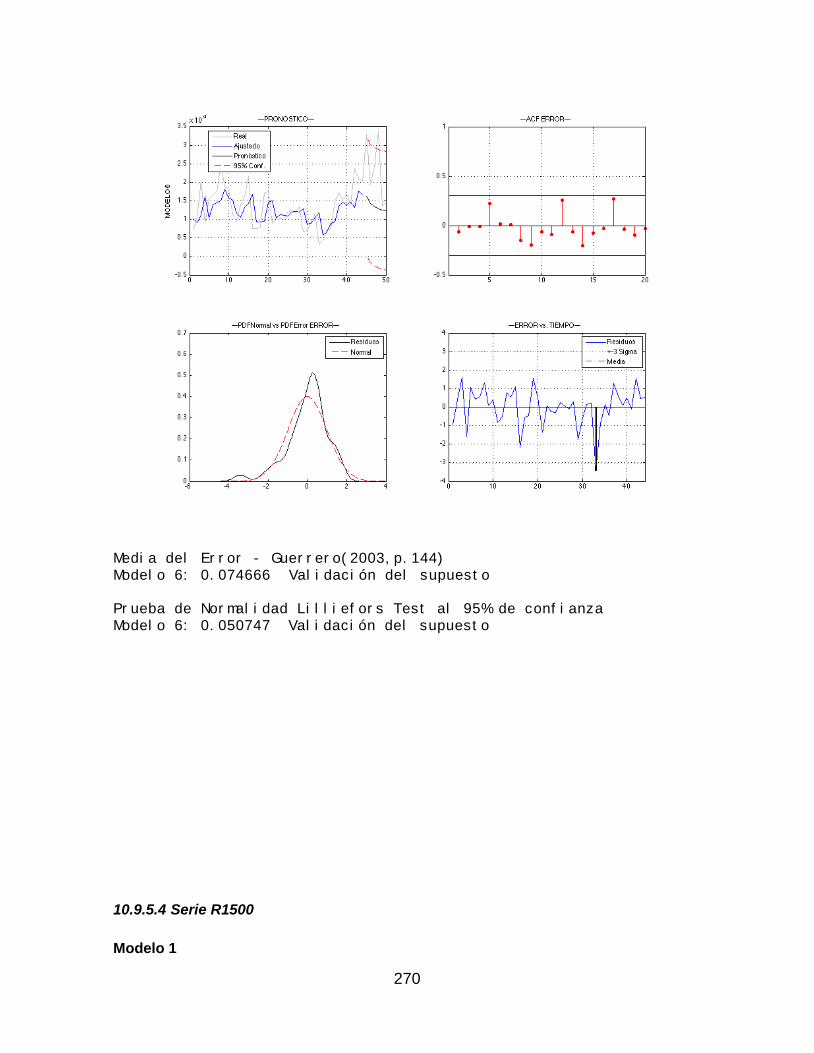
270
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 6: 0. 074666 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 6: 0. 050747 Val i daci ón del supuest o
10.9.5.4 Serie R1500
Modelo 1

271
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 1: 0. 5623 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 1: 0. 5 Val i daci ón del supuest o
Modelo 2

272
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 2: 0. 049686 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 2: 0. 37314 Val i daci ón del supuest o
Modelo 3

273
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 3: 0. 097185 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 3: 0. 41884 Val i daci ón del supuest o
Modelo 4
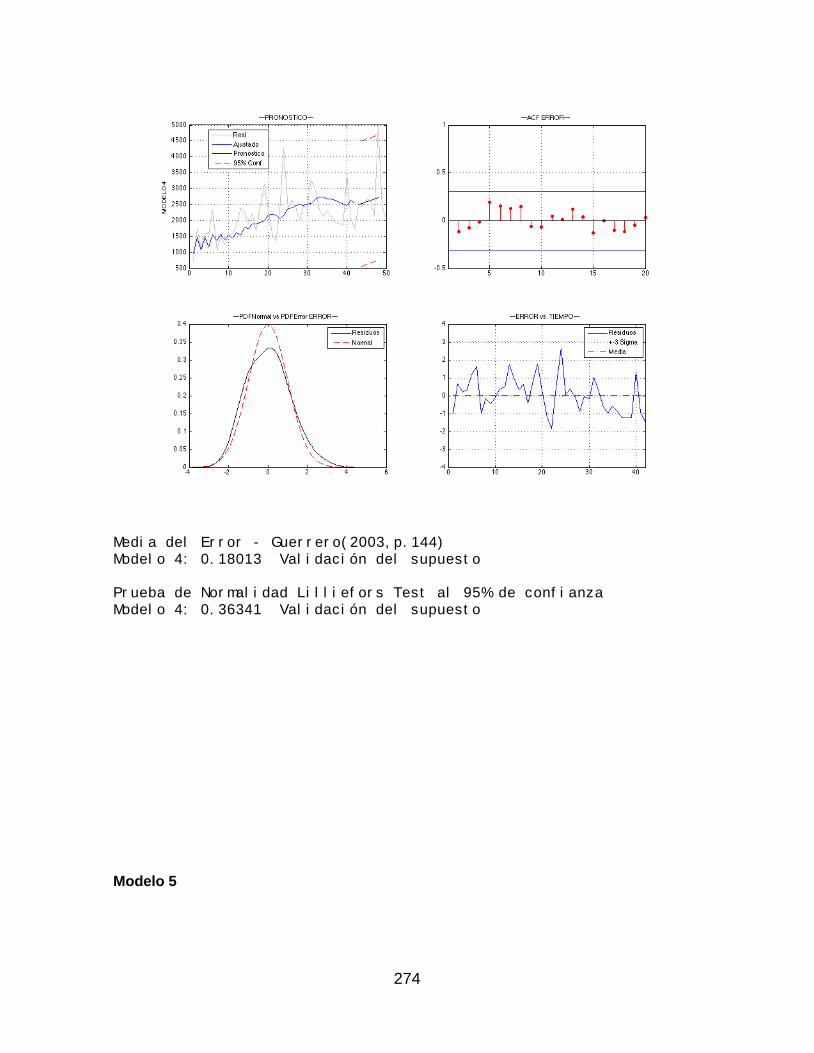
274
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 4: 0. 18013 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 4: 0. 36341 Val i daci ón del supuest o
Modelo 5

275
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 5: 0. 1741 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 5: 0. 38979 Val i daci ón del supuest o
Modelo 6
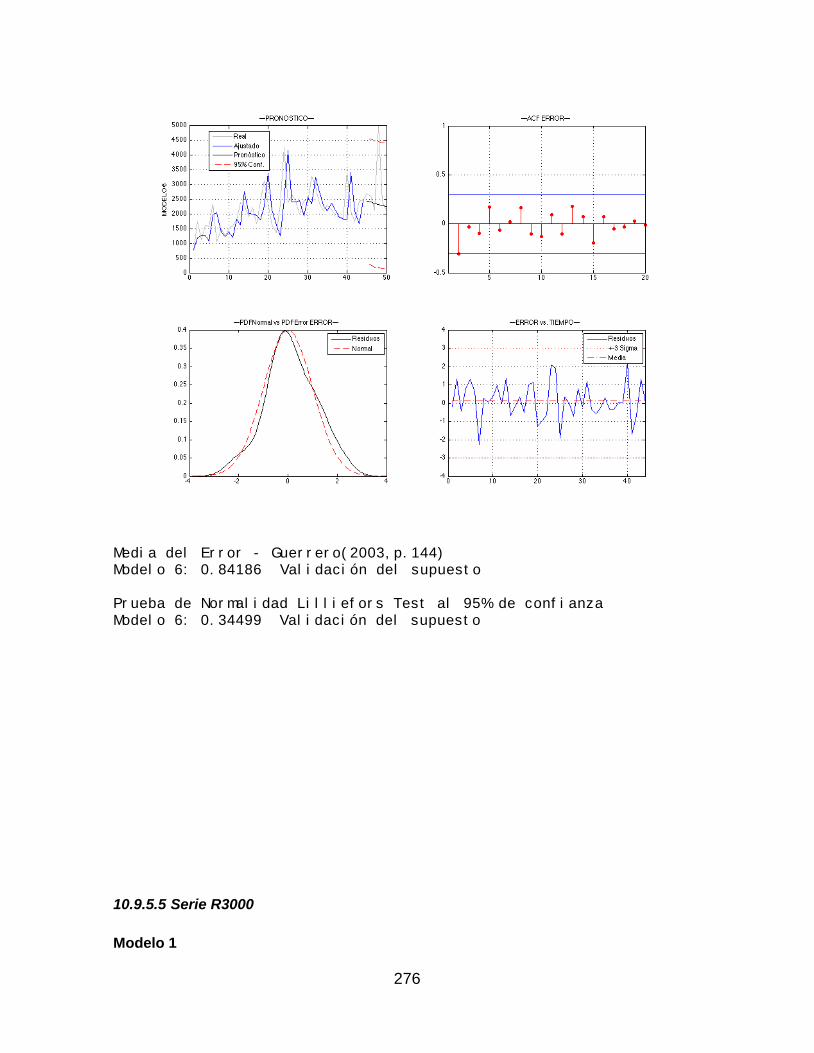
276
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 6: 0. 84186 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 6: 0. 34499 Val i daci ón del supuest o
10.9.5.5 Serie R3000
Modelo 1

277
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 1: 0. 58243 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 1: 0. 24977 Val i daci ón del supuest o
Modelo 2

278
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 2: 0. 41029 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 2: 0. 5 Val i daci ón del supuest o
Modelo 3

279
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 3: 0. 41527 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 3: 0. 5 Val i daci ón del supuest o
Modelo 4

280
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 4: 0. 38316 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 4: 0. 5 Val i daci ón del supuest o
Modelo 5

281
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 5: 0. 41156 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 5: 0. 5 Val i daci ón del supuest o
Modelo 6

282
Medi a del Er r or - Guer r er o( 2003, p. 144) Model o 6: 0. 26936 Val i daci ón del supuest o Pr ueba de Nor mal i dad Li l l i ef or s Test al 95% de conf i anza Model o 6: 0. 30422 Val i daci ón del supuest o
10.9.6 Pronósticos de los Mejores Modelos

283
Gráfica 18 Pronóstico serie R500(1:45)
Gráfica 19 Pronóstico serie R500(1:50)
0
10000
20000
30000
40000
50000
60000
70000
80000
90000
100000
1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7
2010 2011 2012 2013 2014
Lav
alo
zas
Pronóstico R250
Pronóstico
R250
0
20000
40000
60000
80000
100000
120000
1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7
2010 2011 2012 2013 2014
Lav
alo
zas
Pronóstico R500
Pronóstico
R500

284
Gráfica 20 Pronóstico serie R1000(1:50)
Gráfica 21 Pronóstico serie R1500(1:50)
0
5000
10000
15000
20000
25000
30000
35000
40000
1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7
2010 2011 2012 2013 2014
Lav
alo
zas
Pronóstico R1000
Pronóstico
R1000
0
1000
2000
3000
4000
5000
6000
1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7
2010 2011 2012 2013 2014
Lav
alo
zas
Pronóstico R1500
Pronóstico
R1500

285
Gráfica 22 Pronóstico serie R3000(1:50)
0
1000
2000
3000
4000
5000
6000
7000
1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7 9 11 1 3 5 7
2010 2011 2012 2013 2014
Lav
alo
zas
Pronóstico R3000
Pronóstico
R3000

286
10.9.7 Resultados Programación Lineal GAMS-ASTEX
10.9.7.1 Forma de Presentación de Resultados ASTEX
10.9.7.2 Resultados Intervalo de Confianza Superior
COSTO TOTAL DE LA PROPUESTA: $ 545’522,964.09
NÚMERO DE UNIDADES A PRODUCIR EN TIEMPO NORMAL
Marzo Abril Mayo Junio Julio Agosto
R250 150721.42 122016.52 134068.78 124437.09 171464.32 162864.10
R500 31157.82 26971.61 23355.72 13746.16 17088.54 0.00
R1000 20675.09 27166.20 32894.82 24806.18 23721.42 25039.25
R1500 5751.35 4510.99 5597.39 4858.61 3793.05 6714.99
R3000 84.00 523.90 0.00 817.34 2731.60 1098.94

287
NÚMERO DE UNIDADES A PRODUCIR EN TIEMPO EXTRA
Marzo Abril Mayo Junio Julio Agosto
R250 0.00 0.00 0.00 54893.78 0.00 49943.73
R500 0.00 0.00 0.00 6303.33 0.00 14482.04
R1000 0.00 0.00 0.00 0.00 0.00 0.00
R1500 0.00 0.00 144.83 0.00 0.00 0.00
R3000 3563.69 3796.28 3054.73 2052.81 0.00 1602.34
INVENTARIO FINAL DE PRODUCTO TERMINADO
Marzo Abril Mayo Junio Julio Agosto
R250 81640.28 81640.28 81640.28 81640.28 81640.28 81640.28
R500 10140.61 10140.61 10140.61 10140.61 10140.61 10140.61
R1000 5852.05 5852.05 5852.05 5852.05 5852.05 5852.05
R1500 1676.88 1676.88 1676.88 1676.88 1676.88 1676.88
R3000 1011.23 1011.23 1011.23 1011.23 1011.23 1011.23
NÚMERO DE HORAS EXTRA NECESARIAS
Marzo Abril Mayo Junio Julio Agosto
FebEnvase 0.00 0.00 0.00 0.00 0.00 0.00
Mezclado 60.18 64.11 52.81 129.57 0.00 138.01
Resto 52.12 55.52 46.15 330.79 0.00 353.68
NÚMERO TRABAJADORES NECESARIOS
Marzo Abril Mayo Junio Julio Agosto
N° Total 9.52 9.20 9.21 9.19 9.34 9.34
NÚMERO DE PERSONAS CONTRATADAS
Marzo Abril Mayo Junio Julio Agosto
FebEnvase 0.00 0.00 0.00 0.00 0.00 0.00
Mezclado 0.16 0.00 0.01 0.00 0.00 0.00
Resto 0.00 0.00 0.00 0.00 0.15 0.00
NÚMERO DE PERSONAS DESPEDIDAS
Marzo Abril Mayo Junio Julio Agosto
FebEnvase 0.00 0.00 0.00 0.00 0.00 0.00
Mezclado 0.00 0.00 0.00 0.02 0.00 0.00
Resto 1.64 0.32 0.00 0.00 0.00 0.00

288
10.9.7.3 Resultados Intervalo de Confianza Inferior
COSTO TOTAL DE LA PROPUESTA: $ 195’909,702.18
NÚMERO DE UNIDADES A PRODUCIR EN TIEMPO NORMAL
Marzo Abril Mayo Junio Julio Agosto
R250 24249.11 30631.13 31953.78 34706.47 30959.34 32078.73
R500 31157.82 17951.34 20390.96 3756.95 17088.54 10220.43
R1000 1210.75 8059.77 9158.25 6792.80 6612.41 6604.54
R1500 2027.08 544.34 195.48 2217.39 1717.39 1964.90
R3000 227.41 0.00 0.00 39.14 14.88 0.00
NÚMERO DE UNIDADES A PRODUCIR EN TIEMPO EXTRA
Marzo Abril Mayo Junio Julio Agosto
R250 0.00 0.00 0.00 0.00 0.00 0.00
R500 0.00 9020.27 2964.76 16292.54 0.00 4261.61
R1000 0.00 0.00 0.00 0.00 0.00 0.00
R1500 0.00 1412.86 2350.12 0.00 0.00 723.89
R3000 1459.41 2061.41 1428.62 1347.61 1286.57 1278.11
INVENTARIO FINAL DE PRODUCTO TERMINADO
Marzo Abril Mayo Junio Julio Agosto
R250 9233.26 9233.26 9233.26 9233.26 9233.26 9233.26
R500 10140.61 10140.61 10140.61 10140.61 10140.61 10140.61
R1000 1727.00 1727.00 1727.00 1727.00 1727.00 1727.00
R1500 594.93 594.93 594.93 594.93 594.93 594.93
R3000 544.66 544.66 544.66 544.66 544.66 544.66
NÚMERO DE HORAS EXTRA NECESARIAS
Marzo Abril Mayo Junio Julio Agosto
FebEnvase 0.00 0.00 0.00 0.00 0.00 0.00
Mezclado 24.64 72.11 52.30 68.58 21.73 39.68
Resto 21.35 102.83 63.89 125.14 18.82 53.60
NÚMERO TRABAJADORES NECESARIOS
Marzo Abril Mayo Junio Julio Agosto
N° Total 4.32 4.32 4.32 4.05 4.05 4.05

289
NÚMERO DE PERSONAS CONTRATADAS
Marzo Abril Mayo Junio Julio Agosto
FebEnvase 0.00 0.00 0.00 0.00 0.00 0.00
Mezclado 0.00 0.00 0.00 0.00 0.00 0.00
Resto 0.00 0.00 0.00 0.00 0.00 0.00
NÚMERO DE PERSONAS DESPEDIDAS
Marzo Abril Mayo Junio Julio Agosto
FebEnvase 0.00 0.00 0.00 0.00 0.00 0.00
Mezclado 1.31 0.00 0.00 0.08 0.00 0.00
Resto 5.37 0.00 0.00 0.20 0.00 0.00
10.9.8 Resultados Análisis del Comportamiento de las Variables en la LP
Gráfica 23 Evolución inventario R250 ante cambios en la demanda
0
10000
20000
30000
40000
50000
60000
70000
0 5000 10000 15000 20000 25000 30000 35000 40000
Un
idad
es
Inventario R250

290
Gráfica 24 Evolución inventario R500 ante cambios en la demanda
Gráfica 25 Evolución inventario R1000 ante cambios en la demanda
0
10000
20000
30000
40000
50000
60000
70000
0 5000 10000 15000 20000 25000 30000 35000 40000
Un
idad
es
Inventario R500
0
10000
20000
30000
40000
50000
60000
0 5000 10000 15000 20000 25000 30000 35000 40000
Un
idad
es
Inventario R1000

291
Gráfica 26 Evolución inventario R1500 ante cambios en la demanda
Gráfica 27 Evolución inventario R3000 ante cambios en la demanda
-1000
0
1000
2000
3000
4000
5000
6000
0 5000 10000 15000 20000 25000 30000 35000 40000
Un
idad
es
Inventario R1500
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 5000 10000 15000 20000 25000 30000 35000 40000
Un
idad
es
Inventario R3000

292
10.9.9 Resultados Análisis Posóptimal.
S O L V E S U M M A R Y MODEL PlanProduccion OBJECTIVE ct TYPE MIP DIRECTION MINIMIZE SOLVER CPLEX FROM LINE 263 **** SOLVER STATUS 1 Normal Completion **** MODEL STATUS 1 Optimal **** OBJECTIVE VALUE 311936701.5278 RESOURCE USAGE, LIMIT 0.046 150.000 ITERATION COUNT, LIMIT 178 500000 IBM ILOG CPLEX Jul 4, 2012 23.9.1 WIN 33924.33953 VS8 x86/MS Windows --- GAMS/Cplex licensed for continuous and discrete problems. Cplex 12.4.0.1 Reading parameter(s) from "C:\Users\user\Documents\gamsdir\projdir\cplex.opt" >> objrng all >> rhsrng all Finished reading from "C:\Users\user\Documents\gamsdir\projdir\cplex.opt" LP status(1): optimal Optimal solution found. Objective : 311936701.527847 EQUATION NAME LOWER CURRENT UPPER ------------- ----- ------- ----- Target -INF 0 +INF ResError(R250, Marzo) -6.537e+004 -3.684e+004 +INF ResError(R250, Abril) -6.109e+004 -6.109e+004 -6.109e+004 ResError(R250, Mayo) -6.599e+004 -6.599e+004 +INF ResError(R250, Junio) -8.291e+004 -8.291e+004 -8.291e+004 ResError(R250, Julio) -7.779e+004 -7.779e+004 -7.779e+004 ResError(R250, Agosto) -INF -9.232e+004 -9.232e+004 ResError(R500, Marzo) -3.116e+004 -3.083e+004 +INF ResError(R500, Abril) -INF -2.697e+004 -2.697e+004 ResError(R500, Mayo) -INF -2.336e+004 -2.336e+004 ResError(R500, Junio) -2.005e+004 -2.005e+004 -2.005e+004 ResError(R500, Julio) -INF -1.709e+004 -1.709e+004 ResError(R500, Agosto) -INF -1.448e+004 -1.448e+004 ResError(R1000, Marzo) -INF -1.32e+004 -7526 ResError(R1000, Abril) -INF -1.443e+004 -1.443e+004 ResError(R1000, Mayo) -INF -1.707e+004 -1.707e+004
ResError(R1000, Junio) -1.28e+004 -1.28e+004 -1.28e+004 ResError(R1000, Julio) -INF -1.232e+004 -1.232e+004 ResError(R1000, Agosto) -1.275e+004 -1.275e+004 -1.275e+004 ResError(R1500, Marzo) -3260 -3163 +INF ResError(R1500, Abril) -2808 -2808 -2808 ResError(R1500, Mayo) -3611 -3611 -3611 ResError(R1500, Junio) -3098 -3098 +INF ResError(R1500, Julio) -2409 -2409 +INF ResError(R1500, Agosto) -INF -4031 -4031 ResError(R3000, Marzo) -INF -2374 -2330 ResError(R3000, Abril) -INF -2814 -2814 ResError(R3000, Mayo) -INF -1971 -1971 ResError(R3000, Junio) -1881 -1881 -1881 ResError(R3000, Julio) -1778 -1778 -1778 ResError(R3000, Agosto) -1752 -1752 -1752 SatDem(R250, Marzo) 3.531e+004 3.684e+004 3.781e+004 SatDem(R250, Abril) 6.109e+004 6.109e+004 6.109e+004 SatDem(R250, Mayo) 6.599e+004 6.599e+004 6.728e+004 SatDem(R250, Junio) 8.291e+004 8.291e+004 8.291e+004 SatDem(R250, Julio) 7.779e+004 7.779e+004 7.779e+004 SatDem(R250, Agosto) 8.31e+004 9.232e+004 9.232e+004 SatDem(R500, Marzo) 3.05e+004 3.083e+004 3.154e+004 SatDem(R500, Abril) 2.318e+004 2.697e+004 2.697e+004 SatDem(R500, Mayo) 2.262e+004 2.336e+004 2.336e+004 SatDem(R500, Junio) 2.005e+004 2.005e+004 2.005e+004 SatDem(R500, Julio) 6849 1.709e+004 1.709e+004 SatDem(R500, Agosto) 0 1.448e+004 1.448e+004 SatDem(R1000, Marzo) 1.208e+004 1.32e+004 1.37e+004 SatDem(R1000, Abril) 1.341e+004 1.443e+004 1.443e+004 SatDem(R1000, Mayo) 1.579e+004 1.707e+004 1.707e+004 SatDem(R1000, Junio) 1.28e+004 1.28e+004 1.28e+004 SatDem(R1000, Julio) 7118 1.232e+004 1.232e+004 SatDem(R1000, Agosto) 1.275e+004 1.275e+004 1.275e+004 SatDem(R1500, Marzo) 3065 3163 3556 SatDem(R1500, Abril) 2808 2808 2808 SatDem(R1500, Mayo) 3611 3611 3611 SatDem(R1500, Junio) 3098 3098 4472 SatDem(R1500, Julio) 2409 2409 3163 SatDem(R1500, Agosto) 3329 4031 4031 SatDem(R3000, Marzo) 823.5 2374 2418 SatDem(R3000, Abril) 0 2814 2814 SatDem(R3000, Mayo) 0 1971 1971 SatDem(R3000, Junio) 1881 1881 1881 SatDem(R3000, Julio) 1778 1778 1778 SatDem(R3000, Agosto) 1752 1752 1752 CapDisN(Marzo) -5.232 0 1.102 CapDisN(Abril) -1.263 0 +INF CapDisN(Mayo) -0.6202 0 1.613
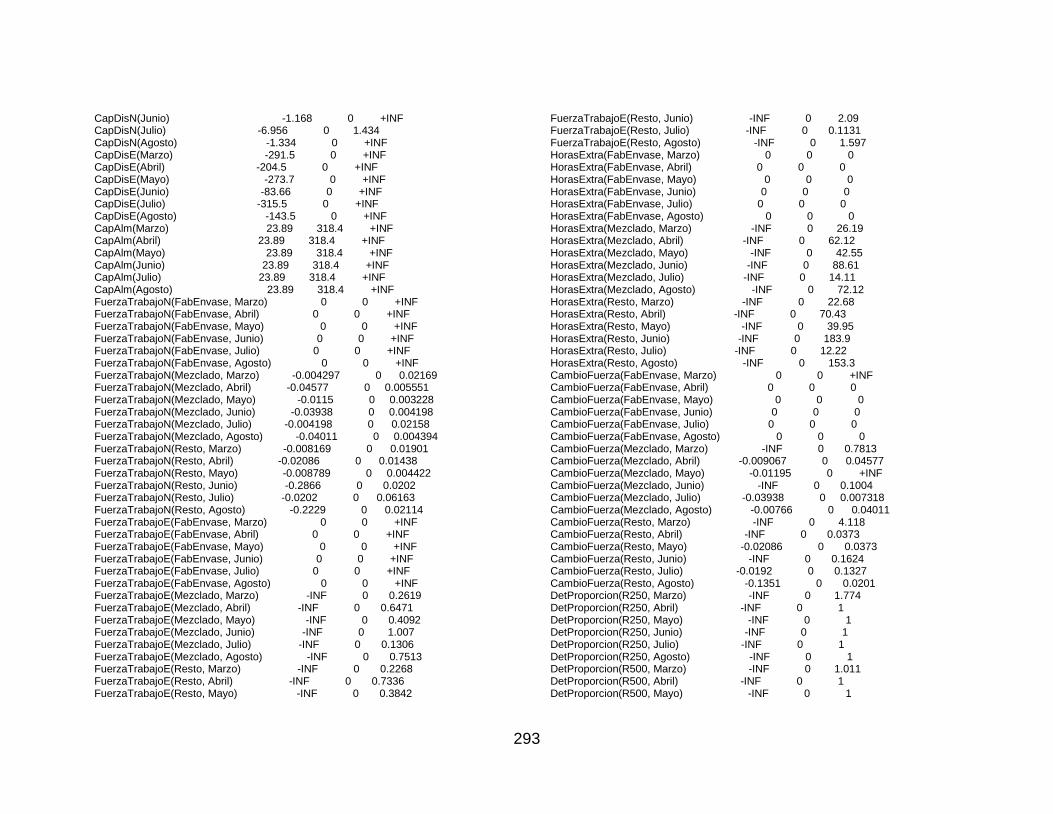
293
CapDisN(Junio) -1.168 0 +INF CapDisN(Julio) -6.956 0 1.434 CapDisN(Agosto) -1.334 0 +INF CapDisE(Marzo) -291.5 0 +INF CapDisE(Abril) -204.5 0 +INF CapDisE(Mayo) -273.7 0 +INF CapDisE(Junio) -83.66 0 +INF CapDisE(Julio) -315.5 0 +INF CapDisE(Agosto) -143.5 0 +INF CapAlm(Marzo) 23.89 318.4 +INF CapAlm(Abril) 23.89 318.4 +INF CapAlm(Mayo) 23.89 318.4 +INF CapAlm(Junio) 23.89 318.4 +INF CapAlm(Julio) 23.89 318.4 +INF CapAlm(Agosto) 23.89 318.4 +INF FuerzaTrabajoN(FabEnvase, Marzo) 0 0 +INF FuerzaTrabajoN(FabEnvase, Abril) 0 0 +INF FuerzaTrabajoN(FabEnvase, Mayo) 0 0 +INF FuerzaTrabajoN(FabEnvase, Junio) 0 0 +INF FuerzaTrabajoN(FabEnvase, Julio) 0 0 +INF FuerzaTrabajoN(FabEnvase, Agosto) 0 0 +INF FuerzaTrabajoN(Mezclado, Marzo) -0.004297 0 0.02169 FuerzaTrabajoN(Mezclado, Abril) -0.04577 0 0.005551 FuerzaTrabajoN(Mezclado, Mayo) -0.0115 0 0.003228 FuerzaTrabajoN(Mezclado, Junio) -0.03938 0 0.004198 FuerzaTrabajoN(Mezclado, Julio) -0.004198 0 0.02158 FuerzaTrabajoN(Mezclado, Agosto) -0.04011 0 0.004394 FuerzaTrabajoN(Resto, Marzo) -0.008169 0 0.01901 FuerzaTrabajoN(Resto, Abril) -0.02086 0 0.01438 FuerzaTrabajoN(Resto, Mayo) -0.008789 0 0.004422 FuerzaTrabajoN(Resto, Junio) -0.2866 0 0.0202 FuerzaTrabajoN(Resto, Julio) -0.0202 0 0.06163 FuerzaTrabajoN(Resto, Agosto) -0.2229 0 0.02114 FuerzaTrabajoE(FabEnvase, Marzo) 0 0 +INF FuerzaTrabajoE(FabEnvase, Abril) 0 0 +INF FuerzaTrabajoE(FabEnvase, Mayo) 0 0 +INF FuerzaTrabajoE(FabEnvase, Junio) 0 0 +INF FuerzaTrabajoE(FabEnvase, Julio) 0 0 +INF FuerzaTrabajoE(FabEnvase, Agosto) 0 0 +INF FuerzaTrabajoE(Mezclado, Marzo) -INF 0 0.2619 FuerzaTrabajoE(Mezclado, Abril) -INF 0 0.6471 FuerzaTrabajoE(Mezclado, Mayo) -INF 0 0.4092 FuerzaTrabajoE(Mezclado, Junio) -INF 0 1.007 FuerzaTrabajoE(Mezclado, Julio) -INF 0 0.1306 FuerzaTrabajoE(Mezclado, Agosto) -INF 0 0.7513 FuerzaTrabajoE(Resto, Marzo) -INF 0 0.2268 FuerzaTrabajoE(Resto, Abril) -INF 0 0.7336 FuerzaTrabajoE(Resto, Mayo) -INF 0 0.3842
FuerzaTrabajoE(Resto, Junio) -INF 0 2.09 FuerzaTrabajoE(Resto, Julio) -INF 0 0.1131 FuerzaTrabajoE(Resto, Agosto) -INF 0 1.597 HorasExtra(FabEnvase, Marzo) 0 0 0 HorasExtra(FabEnvase, Abril) 0 0 0 HorasExtra(FabEnvase, Mayo) 0 0 0 HorasExtra(FabEnvase, Junio) 0 0 0 HorasExtra(FabEnvase, Julio) 0 0 0 HorasExtra(FabEnvase, Agosto) 0 0 0 HorasExtra(Mezclado, Marzo) -INF 0 26.19 HorasExtra(Mezclado, Abril) -INF 0 62.12 HorasExtra(Mezclado, Mayo) -INF 0 42.55 HorasExtra(Mezclado, Junio) -INF 0 88.61 HorasExtra(Mezclado, Julio) -INF 0 14.11 HorasExtra(Mezclado, Agosto) -INF 0 72.12 HorasExtra(Resto, Marzo) -INF 0 22.68 HorasExtra(Resto, Abril) -INF 0 70.43 HorasExtra(Resto, Mayo) -INF 0 39.95 HorasExtra(Resto, Junio) -INF 0 183.9 HorasExtra(Resto, Julio) -INF 0 12.22 HorasExtra(Resto, Agosto) -INF 0 153.3 CambioFuerza(FabEnvase, Marzo) 0 0 +INF CambioFuerza(FabEnvase, Abril) 0 0 0 CambioFuerza(FabEnvase, Mayo) 0 0 0 CambioFuerza(FabEnvase, Junio) 0 0 0 CambioFuerza(FabEnvase, Julio) 0 0 0 CambioFuerza(FabEnvase, Agosto) 0 0 0 CambioFuerza(Mezclado, Marzo) -INF 0 0.7813 CambioFuerza(Mezclado, Abril) -0.009067 0 0.04577 CambioFuerza(Mezclado, Mayo) -0.01195 0 +INF CambioFuerza(Mezclado, Junio) -INF 0 0.1004 CambioFuerza(Mezclado, Julio) -0.03938 0 0.007318 CambioFuerza(Mezclado, Agosto) -0.00766 0 0.04011 CambioFuerza(Resto, Marzo) -INF 0 4.118 CambioFuerza(Resto, Abril) -INF 0 0.0373 CambioFuerza(Resto, Mayo) -0.02086 0 0.0373 CambioFuerza(Resto, Junio) -INF 0 0.1624 CambioFuerza(Resto, Julio) -0.0192 0 0.1327 CambioFuerza(Resto, Agosto) -0.1351 0 0.0201 DetProporcion(R250, Marzo) -INF 0 1.774 DetProporcion(R250, Abril) -INF 0 1 DetProporcion(R250, Mayo) -INF 0 1 DetProporcion(R250, Junio) -INF 0 1 DetProporcion(R250, Julio) -INF 0 1 DetProporcion(R250, Agosto) -INF 0 1 DetProporcion(R500, Marzo) -INF 0 1.011 DetProporcion(R500, Abril) -INF 0 1 DetProporcion(R500, Mayo) -INF 0 1

294
DetProporcion(R500, Junio) -INF 0 1 DetProporcion(R500, Julio) -INF 0 1 DetProporcion(R500, Agosto) -INF 0 1 DetProporcion(R1000, Marzo) -INF 0 0.5703 DetProporcion(R1000, Abril) -INF 0 1 DetProporcion(R1000, Mayo) -INF 0 1 DetProporcion(R1000, Junio) -INF 0 1 DetProporcion(R1000, Julio) -INF 0 1 DetProporcion(R1000, Agosto) -INF 0 1 DetProporcion(R1500, Marzo) -INF 0 1.031 DetProporcion(R1500, Abril) -INF 0 1 DetProporcion(R1500, Mayo) -INF 0 1 DetProporcion(R1500, Junio) -INF 0 1 DetProporcion(R1500, Julio) -INF 0 1 DetProporcion(R1500, Agosto) -INF 0 1 DetProporcion(R3000, Marzo) -INF 0 0.9815 DetProporcion(R3000, Abril) -INF 0 1 DetProporcion(R3000, Mayo) -INF 0 1 DetProporcion(R3000, Junio) -INF 0 1 DetProporcion(R3000, Julio) -INF 0 1 DetProporcion(R3000, Agosto) -INF 0 1 DetTrabTot(Marzo) -0.008169 0 0.03879 DetTrabTot(Abril) -6.31 0 0.009751 DetTrabTot(Mayo) -0.0115 0 0.004422 DetTrabTot(Junio) -6.56 0 0.009843 DetTrabTot(Julio) -0.009843 0 0.04776 DetTrabTot(Agosto) -6.56 0 0.0103 DetCapDisN(Marzo) -1.102 0 5.232 DetCapDisN(Abril) -1127 0 1.263 DetCapDisN(Mayo) -1.613 0 0.6202 DetCapDisN(Junio) -1063 0 1.168 DetCapDisN(Julio) -1.434 0 6.956 DetCapDisN(Agosto) -1159 0 1.334 DetCapDisE(Marzo) -520.6 0 291.5 DetCapDisE(Abril) -502.7 0 204.5 DetCapDisE(Mayo) -543.6 0 273.7 DetCapDisE(Junio) -479.2 0 83.66 DetCapDisE(Julio) -588.1 0 315.5 DetCapDisE(Agosto) -522.7 0 143.5 ResCapMaqN(Marzo) 553.1 1722 +INF ResCapMaqN(Abril) 526.2 1653 +INF ResCapMaqN(Mayo) 571.7 1791 +INF ResCapMaqN(Junio) 452.6 1515 +INF ResCapMaqN(Julio) 555.4 1860 +INF ResCapMaqN(Agosto) 493.7 1653 +INF ResCapMaqE(Marzo) 340.4 861 +INF ResCapMaqE(Abril) 323.8 826.6 +INF ResCapMaqE(Mayo) 351.8 895.4 +INF
ResCapMaqE(Junio) 278.5 757.7 +INF ResCapMaqE(Julio) 341.8 929.9 +INF ResCapMaqE(Agosto) 303.8 826.6 +INF Safty(R250, Marzo) 3.233e+004 3.233e+004 3.233e+004 Safty(R250, Abril) 3.233e+004 3.233e+004 3.233e+004 Safty(R250, Mayo) 3.233e+004 3.233e+004 3.233e+004 Safty(R250, Junio) -INF 3.233e+004 3.233e+004 Safty(R250, Julio) 3.233e+004 3.233e+004 3.233e+004 Safty(R250, Agosto) 2.311e+004 3.233e+004 3.233e+004 Safty(R500, Marzo) 1.014e+004 1.014e+004 1.085e+004 Safty(R500, Abril) 1.014e+004 1.014e+004 1.014e+004 Safty(R500, Mayo) -INF 1.014e+004 1.014e+004 Safty(R500, Junio) 1.014e+004 1.014e+004 1.014e+004 Safty(R500, Julio) 1.014e+004 1.014e+004 1.014e+004 Safty(R500, Agosto) 0 1.014e+004 1.014e+004 Safty(R1000, Marzo) 2929 2929 3265 Safty(R1000, Abril) 2929 2929 2929 Safty(R1000, Mayo) -INF 2929 2929 Safty(R1000, Junio) 2929 2929 2929 Safty(R1000, Julio) -INF 2929 2929 Safty(R1000, Agosto) 2929 2929 2929 Safty(R1500, Marzo) 947.5 947.5 947.5 Safty(R1500, Abril) 947.5 947.5 947.5 Safty(R1500, Mayo) 947.5 947.5 947.5 Safty(R1500, Junio) 947.5 947.5 947.5 Safty(R1500, Julio) 947.5 947.5 1319 Safty(R1500, Agosto) 245.8 947.5 947.5 Safty(R3000, Marzo) 690 690 734 Safty(R3000, Abril) 690 690 690 Safty(R3000, Mayo) -INF 690 690 Safty(R3000, Junio) -INF 690 690 Safty(R3000, Julio) -INF 690 690 Safty(R3000, Agosto) 690 690 690 VARIABLE NAME LOWER CURRENT UPPER ------------- ----- ------- ----- yn(R250, Febrero) 0 212.3 +INF yn(R250, Marzo) 211.4 212.3 214.6 yn(R250, Abril) 211.2 212.3 212.3 yn(R250, Mayo) 206.5 212.3 213.5 yn(R250, Junio) 212.3 212.3 212.3 yn(R250, Julio) 200.4 212.3 214.6 yn(R250, Agosto) 212.3 212.3 212.3 yn(R500, Febrero) 0 424.6 +INF yn(R500, Marzo) 387 424.6 427.6 yn(R500, Abril) 424.6 424.6 424.8 yn(R500, Mayo) 422.5 424.6 425.8

295
yn(R500, Junio) 424.6 424.6 +INF yn(R500, Julio) 424.2 424.6 427.5 yn(R500, Agosto) 424.6 424.6 +INF yn(R1000, Febrero) 0 849.3 +INF yn(R1000, Marzo) 847.2 849.3 853.2 yn(R1000, Abril) 842.5 849.3 849.3 yn(R1000, Mayo) 843.9 849.3 850 yn(R1000, Junio) 790.6 849.3 849.3 yn(R1000, Julio) 846.7 849.3 852.7 yn(R1000, Agosto) 787.8 849.3 849.3 yn(R1500, Febrero) 0 1274 +INF yn(R1500, Marzo) 1263 1274 1279 yn(R1500, Abril) 1274 1274 1274 yn(R1500, Mayo) 1273 1274 1275 yn(R1500, Junio) 1262 1274 1274 yn(R1500, Julio) 1170 1274 1278 yn(R1500, Agosto) -7.665 1274 1274 yn(R3000, Febrero) 0 2548 +INF yn(R3000, Marzo) 2525 2548 2562 yn(R3000, Abril) 2548 2548 +INF yn(R3000, Mayo) 2544 2548 +INF yn(R3000, Junio) 2548 2548 2548 yn(R3000, Julio) 2530 2548 2558 yn(R3000, Agosto) 2548 2548 2548 ye(R250, Febrero) 0 212.3 +INF ye(R250, Marzo) 210.1 212.3 +INF ye(R250, Abril) 212.3 212.3 +INF ye(R250, Mayo) 211.2 212.3 +INF ye(R250, Junio) 212.3 212.3 212.3 ye(R250, Julio) 210.1 212.3 +INF ye(R250, Agosto) 212.3 212.3 212.3 ye(R500, Febrero) 0 424.6 +INF ye(R500, Marzo) 421.6 424.6 +INF ye(R500, Abril) 424.5 424.6 424.6 ye(R500, Mayo) 423.5 424.6 +INF ye(R500, Junio) 389.5 424.6 424.6 ye(R500, Julio) 421.8 424.6 +INF ye(R500, Agosto) -15.17 424.6 424.6 ye(R1000, Febrero) 0 849.3 +INF ye(R1000, Marzo) 845.4 849.3 +INF ye(R1000, Abril) 849.3 849.3 +INF ye(R1000, Mayo) 848.6 849.3 +INF ye(R1000, Junio) 849.3 849.3 +INF ye(R1000, Julio) 845.8 849.3 +INF ye(R1000, Agosto) 849.3 849.3 +INF ye(R1500, Febrero) 0 1274 +INF ye(R1500, Marzo) 1269 1274 +INF ye(R1500, Abril) 1274 1274 1274
ye(R1500, Mayo) 1274 1274 1275 ye(R1500, Junio) 1274 1274 +INF ye(R1500, Julio) 1270 1274 +INF ye(R1500, Agosto) 1274 1274 +INF ye(R3000, Febrero) 0 2548 +INF ye(R3000, Marzo) 2533 2548 2571 ye(R3000, Abril) 2532 2548 2548 ye(R3000, Mayo) 2532 2548 2552 ye(R3000, Junio) 2548 2548 2548 ye(R3000, Julio) 2538 2548 2566 ye(R3000, Agosto) 2548 2548 2548 s(R250, Febrero) -INF 1.58 +INF s(R250, Marzo) 0.6764 1.58 +INF s(R250, Abril) 0.437 1.58 +INF s(R250, Mayo) -4.27 1.58 +INF s(R250, Junio) -3.836 1.58 13.54 s(R250, Julio) -13.54 1.58 +INF s(R250, Agosto) -226.9 1.58 +INF s(R500, Febrero) -INF 3.31 +INF s(R500, Marzo) -34.32 3.31 +INF s(R500, Abril) -1.142 3.31 +INF s(R500, Mayo) 1.142 3.31 38.45 s(R500, Junio) -5.024 3.31 +INF s(R500, Julio) 2.856 3.31 +INF s(R500, Agosto) -436.5 3.31 +INF s(R1000, Febrero) -INF 6.06 +INF s(R1000, Marzo) 3.937 6.06 +INF s(R1000, Abril) -0.6917 6.06 +INF s(R1000, Mayo) 0.6929 6.06 64.75 s(R1000, Junio) -8.816 6.06 +INF s(R1000, Julio) 3.449 6.06 67.51 s(R1000, Agosto) -864.7 6.06 +INF s(R1500, Febrero) -INF 7.93 +INF s(R1500, Marzo) -3.219 7.93 +INF s(R1500, Abril) -6.395e-014 7.93 +INF s(R1500, Mayo) 7.929 7.93 +INF s(R1500, Junio) -3.76 7.93 +INF s(R1500, Julio) -96.17 7.93 +INF s(R1500, Agosto) -1274 7.93 +INF s(R3000, Febrero) -INF 16.27 +INF s(R3000, Marzo) 1.776e-014 16.27 +INF s(R3000, Abril) 1.776e-014 16.27 +INF s(R3000, Mayo) -1.066e-014 16.27 163.3 s(R3000, Junio) -16.27 16.27 163.3 s(R3000, Julio) -32.54 16.27 163.3 s(R3000, Agosto) -2573 16.27 +INF ct -INF 1 +INF ep(R250, Febrero) 0 1.58 +INF

296
ep(R250, Marzo) 0.6764 1.58 +INF ep(R250, Abril) 0 1.58 +INF ep(R250, Mayo) -4.27 1.58 2.723 ep(R250, Junio) -3.836 1.58 +INF ep(R250, Julio) 0 1.58 +INF ep(R250, Agosto) -15.8 1.58 +INF ep(R500, Febrero) 0 3.31 +INF ep(R500, Marzo) -34 3.31 +INF ep(R500, Abril) -34 3.31 +INF ep(R500, Mayo) -34 3.31 +INF ep(R500, Junio) -31.83 3.31 +INF ep(R500, Julio) -34 3.31 +INF ep(R500, Agosto) -34 3.31 +INF ep(R1000, Febrero) 0 6.06 +INF ep(R1000, Marzo) -58 6.06 +INF ep(R1000, Abril) -58 6.06 +INF ep(R1000, Mayo) -58 6.06 +INF ep(R1000, Junio) -52.63 6.06 +INF ep(R1000, Julio) -58 6.06 +INF ep(R1000, Agosto) -55.39 6.06 +INF ep(R1500, Febrero) 0 7.93 +INF ep(R1500, Marzo) -3.219 7.93 +INF ep(R1500, Abril) 0 7.93 +INF ep(R1500, Mayo) 0 7.93 +INF ep(R1500, Junio) -3.76 7.93 7.931 ep(R1500, Julio) -92 7.93 19.62 ep(R1500, Agosto) -92 7.93 +INF ep(R3000, Febrero) 0 16.27 +INF ep(R3000, Marzo) -179.5 16.27 +INF ep(R3000, Abril) -179.5 16.27 +INF ep(R3000, Mayo) -179.5 16.27 +INF ep(R3000, Junio) -163.3 16.27 +INF ep(R3000, Julio) -147 16.27 +INF ep(R3000, Agosto) -130.7 16.27 +INF en(R250, Febrero) 0 15.8 +INF en(R250, Marzo) -1.58 15.8 +INF en(R250, Abril) 0 15.8 +INF en(R250, Mayo) -1.58 15.8 +INF en(R250, Junio) 3.836 15.8 +INF en(R250, Julio) 0 15.8 +INF en(R250, Agosto) 0.6758 15.8 244.2 en(R500, Febrero) 0 34 +INF en(R500, Marzo) -3.31 34 +INF en(R500, Abril) -3.31 34 38.45 en(R500, Mayo) 29.55 34 36.17 en(R500, Junio) 31.83 34 +INF en(R500, Julio) 25.67 34 34.45 en(R500, Agosto) 33.55 34 473.8
en(R1000, Febrero) 0 58 +INF en(R1000, Marzo) -6.06 58 60.12 en(R1000, Abril) 55.88 58 64.75 en(R1000, Mayo) 51.25 58 63.37 en(R1000, Junio) 52.63 58 +INF en(R1000, Julio) 43.12 58 60.61 en(R1000, Agosto) 55.39 58 +INF en(R1500, Febrero) 0 92 +INF en(R1500, Marzo) -7.93 92 +INF en(R1500, Abril) 0 92 +INF en(R1500, Mayo) 0 92 +INF en(R1500, Junio) -7.93 92 +INF en(R1500, Julio) -7.93 92 +INF en(R1500, Agosto) -7.93 92 1374 en(R3000, Febrero) 0 179.5 +INF en(R3000, Marzo) -16.27 179.5 195.8 en(R3000, Abril) 163.3 179.5 195.8 en(R3000, Mayo) 163.3 179.5 195.8 en(R3000, Junio) 163.3 179.5 +INF en(R3000, Julio) 147 179.5 +INF en(R3000, Agosto) 130.7 179.5 +INF nhe(FabEnvase, Febrero) 0 4940 +INF nhe(FabEnvase, Marzo) 0 4940 +INF nhe(FabEnvase, Abril) 0 4940 +INF nhe(FabEnvase, Mayo) 0 4940 +INF nhe(FabEnvase, Junio) 0 4940 +INF nhe(FabEnvase, Julio) 0 4940 +INF nhe(FabEnvase, Agosto) 0 4940 +INF nhe(Mezclado, Febrero) 0 4940 +INF nhe(Mezclado, Marzo) 4079 4940 6455 nhe(Mezclado, Abril) 4339 4940 4986 nhe(Mezclado, Mayo) 4939 4940 5879 nhe(Mezclado, Junio) 4735 4940 4940 nhe(Mezclado, Julio) 4360 4940 6867 nhe(Mezclado, Agosto) 4702 4940 5026 nhe(Resto, Febrero) 0 4940 +INF nhe(Resto, Marzo) 4509 4940 6689 nhe(Resto, Abril) 4859 4940 4988 nhe(Resto, Mayo) 4939 4940 5722 nhe(Resto, Junio) 4734 4940 4940 nhe(Resto, Julio) 4510 4940 7164 nhe(Resto, Agosto) 4701 4940 4977 wn(FabEnvase, Febrero) -INF 1.032e+006 +INF wn(FabEnvase, Marzo) 1.31e+005 1.032e+006 +INF wn(FabEnvase, Abril) 0 1.032e+006 +INF wn(FabEnvase, Mayo) 5.398e+004 1.032e+006 +INF wn(FabEnvase, Junio) 0 1.032e+006 +INF wn(FabEnvase, Julio) 1.496e+005 1.032e+006 +INF

297
wn(FabEnvase, Agosto) 0 1.032e+006 +INF wn(Mezclado, Febrero) -INF 1.032e+006 +INF wn(Mezclado, Marzo) 9.343e+005 1.032e+006 1.217e+006 wn(Mezclado, Abril) 1.022e+006 1.032e+006 1.156e+006 wn(Mezclado, Mayo) 8.513e+005 1.032e+006 1.051e+006 wn(Mezclado, Junio) 9.933e+005 1.032e+006 1.07e+006 wn(Mezclado, Julio) 9.933e+005 1.032e+006 1.166e+006 wn(Mezclado, Agosto) 9.933e+005 1.032e+006 1.081e+006 wn(Resto, Febrero) -INF 1.032e+006 +INF wn(Resto, Marzo) 9.944e+005 1.032e+006 1.124e+006 wn(Resto, Abril) 1.022e+006 1.032e+006 1.048e+006 wn(Resto, Mayo) 9.548e+005 1.032e+006 1.048e+006 wn(Resto, Junio) 1.015e+006 1.032e+006 1.071e+006 wn(Resto, Julio) 1.015e+006 1.032e+006 1.131e+006 wn(Resto, Agosto) 1.015e+006 1.032e+006 1.081e+006 we(FabEnvase, Marzo) 0 -0 +INF we(FabEnvase, Abril) 0 -0 +INF we(FabEnvase, Mayo) 0 -0 +INF we(FabEnvase, Junio) 0 -0 +INF we(FabEnvase, Julio) 0 -0 +INF we(FabEnvase, Agosto) 0 -0 +INF we(Mezclado, Marzo) -0 -0 1.515e+005 we(Mezclado, Abril) -0 -0 4471 we(Mezclado, Mayo) -0 -0 9.77e+004 we(Mezclado, Junio) -0 -0 11.02 we(Mezclado, Julio) -0 -0 2.081e+005 we(Mezclado, Agosto) -0 -0 8271 we(Resto, Marzo) -0 -0 1.75e+005 we(Resto, Abril) -0 -0 4605 we(Resto, Mayo) -0 -0 8.141e+004 we(Resto, Junio) -0 -0 9.186 we(Resto, Julio) -0 -0 2.403e+005 we(Resto, Agosto) -0 -0 3577 h(FabEnvase, Febrero) 0 7.48e+004 +INF h(FabEnvase, Marzo) -5.91e+004 7.48e+004 +INF h(FabEnvase, Abril) 0 7.48e+004 +INF h(FabEnvase, Mayo) 0 7.48e+004 +INF h(FabEnvase, Junio) 0 7.48e+004 +INF h(FabEnvase, Julio) 0 7.48e+004 +INF h(FabEnvase, Agosto) 0 7.48e+004 +INF h(Mezclado, Febrero) 0 7.48e+004 +INF h(Mezclado, Marzo) -5.91e+004 7.48e+004 +INF h(Mezclado, Abril) 6.517e+004 7.48e+004 +INF h(Mezclado, Mayo) -4.947e+004 7.48e+004 8.443e+004 h(Mezclado, Junio) -5.91e+004 7.48e+004 +INF h(Mezclado, Julio) 3.593e+004 7.48e+004 +INF h(Mezclado, Agosto) -9895 7.48e+004 +INF h(Resto, Febrero) 0 7.48e+004 +INF
h(Resto, Marzo) -5.91e+004 7.48e+004 +INF h(Resto, Abril) -5.91e+004 7.48e+004 +INF h(Resto, Mayo) -4.918e+004 7.48e+004 +INF h(Resto, Junio) -5.91e+004 7.48e+004 +INF h(Resto, Julio) 3.577e+004 7.48e+004 +INF h(Resto, Agosto) -9724 7.48e+004 +INF f(FabEnvase, Febrero) 0 5.91e+004 +INF f(FabEnvase, Marzo) -7.48e+004 5.91e+004 +INF f(FabEnvase, Abril) 0 5.91e+004 +INF f(FabEnvase, Mayo) 0 5.91e+004 +INF f(FabEnvase, Junio) 0 5.91e+004 +INF f(FabEnvase, Julio) 0 5.91e+004 +INF f(FabEnvase, Agosto) 0 5.91e+004 +INF f(Mezclado, Febrero) 0 5.91e+004 +INF f(Mezclado, Marzo) -7.48e+004 5.91e+004 1.563e+005 f(Mezclado, Abril) -6.517e+004 5.91e+004 +INF f(Mezclado, Mayo) -7.48e+004 5.91e+004 +INF f(Mezclado, Junio) 2.023e+004 5.91e+004 7.907e+004 f(Mezclado, Julio) -3.593e+004 5.91e+004 +INF f(Mezclado, Agosto) 9895 5.91e+004 +INF f(Resto, Febrero) 0 5.91e+004 +INF f(Resto, Marzo) -3.357e+004 5.91e+004 9.617e+004 f(Resto, Abril) 4.246e+004 5.91e+004 6.902e+004 f(Resto, Mayo) 4.918e+004 5.91e+004 +INF f(Resto, Junio) 2.007e+004 5.91e+004 7.553e+004 f(Resto, Julio) -3.577e+004 5.91e+004 +INF f(Resto, Agosto) 9724 5.91e+004 +INF wtot(Marzo) -2.684e+004 -0 6.71e+004 wtot(Abril) -9634 -0 1.664e+004 wtot(Mayo) -5.381e+004 -0 9077 wtot(Junio) -1.149e+004 -0 3.887e+004 wtot(Julio) -1.149e+004 -0 7.222e+004 wtot(Agosto) -1.149e+004 -0 4.92e+004 prop(R250, Marzo) -3.329e+004 -0 +INF prop(R250, Abril) -6.983e+004 -0 5.52e+004 prop(R250, Mayo) -3.861e+005 -0 7.543e+004 prop(R250, Junio) -4.49e+005 -0 9.92e+005 prop(R250, Julio) -9.307e+005 -0 4.213e+005 prop(R250, Agosto) -2.109e+007 -0 1.396e+006 prop(R500, Marzo) -1.16e+006 -0 +INF prop(R500, Abril) -1.201e+005 -0 1.015e+006 prop(R500, Mayo) -5.063e+004 -0 1.04e+005 prop(R500, Junio) -7.046e+005 -0 4.346e+004 prop(R500, Julio) -7759 -0 1.424e+005 prop(R500, Agosto) -6.369e+006 -0 6576 prop(R1000, Marzo) -2.802e+004 -0 +INF prop(R1000, Abril) -9.742e+004 -0 3.064e+004 prop(R1000, Mayo) -9.162e+004 -0 1.153e+005

298
prop(R1000, Junio) -7.511e+005 -0 6.868e+004 prop(R1000, Julio) -3.216e+004 -0 1.832e+005 prop(R1000, Agosto) -7.834e+005 -0 3.329e+004 prop(R1500, Marzo) -3.526e+004 -0 +INF prop(R1500, Abril) -2.227e+004 -0 3.131e+004 prop(R1500, Mayo) -3.818 -0 2.864e+004 prop(R1500, Junio) -3.621e+004 -0 3.276 prop(R1500, Julio) -2.508e+005 -0 2.816e+004 prop(R1500, Agosto) -5.166e+006 -0 4.196e+005 prop(R3000, Marzo) -3.863e+004 -0 +INF prop(R3000, Abril) -4.579e+004 -0 4.579e+004 prop(R3000, Mayo) -3.206e+004 -0 3.206e+004 prop(R3000, Junio) -3.377e+005 -0 3.061e+004 prop(R3000, Julio) -2.903e+005 -0 5.786e+004 prop(R3000, Agosto) -2.576e+005 -0 8.554e+004 CapDispN(Marzo) -199 -0 497.5 CapDispN(Abril) -74.41 -0 128.5 CapDispN(Mayo) -383.6 -0 64.71 CapDispN(Junio) -96.82 -0 327.5 CapDispN(Julio) -78.89 -0 495.8 CapDispN(Agosto) -88.75 -0 380 CapDispE(Marzo) -323.3 -0 808.4 CapDispE(Abril) -120.9 -0 208.9 CapDispE(Mayo) -623.4 -0 105.2 CapDispE(Junio) -157.3 -0 532.2 CapDispE(Julio) -128.2 -0 805.7 CapDispE(Agosto) -144.2 -0 617.5 LOWER LEVEL UPPER MARGINAL ---- EQU Target . . . 1.000 Target funcion objetivo ---- EQU ResError error de produccion (1) LOWER LEVEL UPPER MARGINAL R250 .Marzo -3.684E+4 -3.684E+4 -3.684E+4 1.580 R250 .Abril -6.109E+4 -6.109E+4 -6.109E+4 . R250 .Mayo -6.599E+4 -6.599E+4 -6.599E+4 1.580 R250 .Junio -8.291E+4 -8.291E+4 -8.291E+4 -3.836 R250 .Julio -7.779E+4 -7.779E+4 -7.779E+4 . R250 .Agosto -9.232E+4 -9.232E+4 -9.232E+4 -15.800 R500 .Marzo -3.083E+4 -3.083E+4 -3.083E+4 3.310 R500 .Abril -2.697E+4 -2.697E+4 -2.697E+4 -34.000
R500 .Mayo -2.336E+4 -2.336E+4 -2.336E+4 -34.000 R500 .Junio -2.005E+4 -2.005E+4 -2.005E+4 -31.832 R500 .Julio -1.709E+4 -1.709E+4 -1.709E+4 -34.000 R500 .Agosto -1.448E+4 -1.448E+4 -1.448E+4 -34.000 R1000.Marzo -1.320E+4 -1.320E+4 -1.320E+4 -58.000 R1000.Abril -1.443E+4 -1.443E+4 -1.443E+4 -58.000 R1000.Mayo -1.707E+4 -1.707E+4 -1.707E+4 -58.000 R1000.Junio -1.280E+4 -1.280E+4 -1.280E+4 -52.633 R1000.Julio -1.232E+4 -1.232E+4 -1.232E+4 -58.000 R1000.Agosto -1.275E+4 -1.275E+4 -1.275E+4 -55.389 R1500.Marzo -3162.925 -3162.925 -3162.925 7.930 R1500.Abril -2808.459 -2808.459 -2808.459 . R1500.Mayo -3611.145 -3611.145 -3611.145 . R1500.Junio -3097.796 -3097.796 -3097.796 7.930 R1500.Julio -2409.278 -2409.278 -2409.278 7.930 R1500.Agosto -4030.850 -4030.850 -4030.850 -92.000 R3000.Marzo -2374.260 -2374.260 -2374.260 -179.520 R3000.Abril -2814.332 -2814.332 -2814.332 -179.520 R3000.Mayo -1970.658 -1970.658 -1970.658 -179.520 R3000.Junio -1881.219 -1881.219 -1881.219 -163.250 R3000.Julio -1778.168 -1778.168 -1778.168 -146.980 R3000.Agosto -1752.499 -1752.499 -1752.499 -130.710 ---- EQU SatDem satisfaccion de la demanda (2) LOWER LEVEL UPPER MARGINAL R250 .Marzo 36837.618 36837.618 36837.618 241.979 R250 .Abril 61092.927 61092.927 61092.927 242.655 R250 .Mayo 65992.114 65992.114 65992.114 243.092 R250 .Junio 82914.606 82914.606 82914.606 238.822 R250 .Julio 77794.333 77794.333 77794.333 240.402 R250 .Agosto 92321.761 92321.761 92321.761 226.858 R500 .Marzo 30829.208 30829.208 30829.208 470.816 R500 .Abril 26971.609 26971.609 26971.609 436.498 R500 .Mayo 23355.718 23355.718 23355.718 435.356 R500 .Junio 20049.491 20049.491 20049.491 438.666 R500 .Julio 17088.542 17088.542 17088.542 433.642 R500 .Agosto 14482.042 14482.042 14482.042 436.498 R1000.Marzo 13196.852 13196.852 13196.852 858.106 R1000.Abril 14428.579 14428.579 14428.579 862.042 R1000.Mayo 17070.440 17070.440 17070.440 861.350 R1000.Junio 12797.259 12797.259 12797.259 867.410 R1000.Julio 12315.414 12315.414 12315.414 858.595 R1000.Agosto 12749.442 12749.442 12749.442 864.655 R1500.Marzo 3162.925 3162.925 3162.925 1368.884 R1500.Abril 2808.459 2808.459 2808.459 1365.666 R1500.Mayo 3611.145 3611.145 3611.145 1365.666

299
R1500.Junio 3097.796 3097.796 3097.796 1373.595 R1500.Julio 2409.278 2409.278 2409.278 1369.835 R1500.Agosto 4030.850 4030.850 4030.850 1273.665 R3000.Marzo 2374.260 2374.260 2374.260 2523.998 R3000.Abril 2814.332 2814.332 2814.332 2523.998 R3000.Mayo 1970.658 1970.658 1970.658 2523.998 R3000.Junio 1881.219 1881.219 1881.219 2540.268 R3000.Julio 1778.168 1778.168 1778.168 2556.538 R3000.Agosto 1752.499 1752.499 1752.499 2572.808 ---- EQU CapDisN capacidad disponible T normal (3) LOWER LEVEL UPPER MARGINAL Marzo -INF . . -1525.749 Abril -INF -1.263 . . Mayo -INF . . -384.804 Junio -INF -1.168 . . Julio -INF . . -1027.052 Agosto -INF -1.334 . . ---- EQU CapDisE capacidad disponible T extra (4) LOWER LEVEL UPPER MARGINAL Marzo -INF -291.533 . . Abril -INF -204.459 . . Mayo -INF -273.655 . . Junio -INF -83.660 . . Julio -INF -315.479 . . Agosto -INF -143.506 . . ---- EQU CapAlm capacidad de almacenamiento (5) LOWER LEVEL UPPER MARGINAL Marzo -INF 23.891 318.387 . Abril -INF 23.891 318.387 . Mayo -INF 23.891 318.387 . Junio -INF 23.891 318.387 . Julio -INF 23.891 318.387 . Agosto -INF 23.891 318.387 . ---- EQU FuerzaTrabajoN fuerza de trabajo T normal (6) LOWER LEVEL UPPER MARGINAL FabEnvase.Marzo -INF . . .
FabEnvase.Abril -INF . . . FabEnvase.Mayo -INF . . . FabEnvase.Junio -INF . . . FabEnvase.Julio -INF . . . FabEnvase.Agosto -INF . . . Mezclado .Marzo -INF . . -7.014E+5 Mezclado .Abril -INF . . -1.022E+6 Mezclado .Mayo -INF . . -1.111E+6 Mezclado .Junio -INF . . -9.365E+5 Mezclado .Julio -INF . . -9.277E+5 Mezclado .Agosto -INF . . -1.022E+6 Resto .Marzo -INF . . -8.257E+5 Resto .Abril -INF . . -1.022E+6 Resto .Mayo -INF . . -9.874E+5 Resto .Junio -INF . . -9.366E+5 Resto .Julio -INF . . -9.274E+5 Resto .Agosto -INF . . -1.022E+6 ---- EQU FuerzaTrabajoE fuerza de trabajo T extra (7) LOWER LEVEL UPPER MARGINAL FabEnvase.Marzo -INF . . . FabEnvase.Abril -INF . . . FabEnvase.Mayo -INF . . . FabEnvase.Junio -INF . . . FabEnvase.Julio -INF . . . FabEnvase.Agosto -INF . . . Mezclado .Marzo -INF . . EPS Mezclado .Abril -INF . . EPS Mezclado .Mayo -INF . . EPS Mezclado .Junio -INF . . EPS Mezclado .Julio -INF . . EPS Mezclado .Agosto -INF . . EPS Resto .Marzo -INF . . EPS Resto .Abril -INF . . EPS Resto .Mayo -INF . . EPS Resto .Junio -INF . . EPS Resto .Julio -INF . . EPS Resto .Agosto -INF . . EPS ---- EQU HorasExtra horas extra (8) LOWER LEVEL UPPER MARGINAL FabEnvase.Marzo . . . . FabEnvase.Abril . . . . FabEnvase.Mayo . . . .

300
FabEnvase.Junio . . . . FabEnvase.Julio . . . . FabEnvase.Agosto . . . . Mezclado .Marzo . . . -4939.570 Mezclado .Abril . . . -4939.570 Mezclado .Mayo . . . -4939.570 Mezclado .Junio . . . -4939.570 Mezclado .Julio . . . -4939.570 Mezclado .Agosto . . . -4939.570 Resto .Marzo . . . -4939.570 Resto .Abril . . . -4939.570 Resto .Mayo . . . -4939.570 Resto .Junio . . . -4939.570 Resto .Julio . . . -4939.570 Resto .Agosto . . . -4939.570 ---- EQU CambioFuerza cambio en la fuerza de trabajo (9) LOWER LEVEL UPPER MARGINAL FabEnvase.Marzo . . . 74800.000 FabEnvase.Abril . . . . FabEnvase.Mayo . . . . FabEnvase.Junio . . . . FabEnvase.Julio . . . . FabEnvase.Agosto . . . . Mezclado .Marzo . . . -5.910E+4 Mezclado .Abril . . . 65165.885 Mezclado .Mayo . . . 74800.000 Mezclado .Junio . . . -5.910E+4 Mezclado .Julio . . . 35928.882 Mezclado .Agosto . . . -9895.143 Resto .Marzo . . . -5.910E+4 Resto .Abril . . . -5.910E+4 Resto .Mayo . . . -4.918E+4 Resto .Junio . . . -5.910E+4 Resto .Julio . . . 35772.322 Resto .Agosto . . . -9724.352 ---- EQU DetProporcion proporcion producido sobre demanda (10) LOWER LEVEL UPPER MARGINAL R250 .Marzo . . . EPS R250 .Abril . . . EPS R250 .Mayo . . . EPS R250 .Junio . . . EPS R250 .Julio . . . EPS
R250 .Agosto . . . EPS R500 .Marzo . . . EPS R500 .Abril . . . EPS R500 .Mayo . . . EPS R500 .Junio . . . EPS R500 .Julio . . . EPS R500 .Agosto . . . EPS R1000.Marzo . . . EPS R1000.Abril . . . EPS R1000.Mayo . . . EPS R1000.Junio . . . EPS R1000.Julio . . . EPS R1000.Agosto . . . EPS R1500.Marzo . . . EPS R1500.Abril . . . EPS R1500.Mayo . . . EPS R1500.Junio . . . EPS R1500.Julio . . . EPS R1500.Agosto . . . EPS R3000.Marzo . . . EPS R3000.Abril . . . EPS R3000.Mayo . . . EPS R3000.Junio . . . EPS R3000.Julio . . . EPS R3000.Agosto . . . EPS ---- EQU DetTrabTot trabajadores totales en la empresa (11) LOWER LEVEL UPPER MARGINAL Marzo . . . 2.0579E+5 Abril . . . EPS Mayo . . . 53976.435 Junio . . . EPS Julio . . . 1.4961E+5 Agosto . . . EPS ---- EQU DetCapDisN calculo capacidad disponible en T normal (12) LOWER LEVEL UPPER MARGINAL Marzo . . . 1525.749 Abril . . . EPS Mayo . . . 384.804 Junio . . . EPS Julio . . . 1027.052 Agosto . . . EPS

301
---- EQU DetCapDisE calculo capacidad disponible en T extra (13) LOWER LEVEL UPPER MARGINAL Marzo . . . EPS Abril . . . EPS Mayo . . . EPS Junio . . . EPS Julio . . . EPS Agosto . . . EPS ---- EQU ResCapMaqN limitar capacidad disponible T normal (14) LOWER LEVEL UPPER MARGINAL Marzo -INF 553.150 1722.000 . Abril -INF 526.195 1653.120 . Mayo -INF 571.721 1790.880 . Junio -INF 452.576 1515.360 . Julio -INF 555.435 1859.760 . Agosto -INF 493.720 1653.120 . ---- EQU ResCapMaqE limitar capacidad disponible T extra (15) LOWER LEVEL UPPER MARGINAL Marzo -INF 340.400 861.000 . Abril -INF 323.812 826.560 . Mayo -INF 351.828 895.440 . Junio -INF 278.509 757.680 . Julio -INF 341.806 929.880 . Agosto -INF 303.828 826.560 . ---- EQU Safty inventario de seguridad (16) LOWER LEVEL UPPER MARGINAL R250 .Marzo 32328.173 32328.173 +INF 0.904 R250 .Abril 32328.173 32328.173 +INF 1.143 R250 .Mayo 32328.173 32328.173 +INF 5.850 R250 .Junio 32328.173 32328.173 +INF . R250 .Julio 32328.173 32328.173 +INF 15.124 R250 .Agosto 32328.173 32328.173 +INF 228.438 R500 .Marzo 10140.612 10140.612 +INF 37.629 R500 .Abril 10140.612 10140.612 +INF 4.452 R500 .Mayo 10140.612 10140.612 +INF . R500 .Junio 10140.612 10140.612 +INF 8.334 R500 .Julio 10140.612 10140.612 +INF 0.454
R500 .Agosto 10140.612 10140.612 +INF 439.808 R1000.Marzo 2929.210 2929.210 +INF 2.123 R1000.Abril 2929.210 2929.210 +INF 6.752 R1000.Mayo 2929.210 2929.210 +INF . R1000.Junio 2929.210 2929.210 +INF 14.876 R1000.Julio 2929.210 2929.210 +INF . R1000.Agosto 2929.210 2929.210 +INF 870.715 R1500.Marzo 947.469 947.469 +INF 11.149 R1500.Abril 947.469 947.469 +INF 7.930 R1500.Mayo 947.469 947.469 +INF 0.001 R1500.Junio 947.469 947.469 +INF 11.690 R1500.Julio 947.469 947.469 +INF 104.100 R1500.Agosto 947.469 947.469 +INF 1281.595 R3000.Marzo 689.959 689.959 +INF 16.270 R3000.Abril 689.959 689.959 +INF 16.270 R3000.Mayo 689.959 689.959 +INF . R3000.Junio 689.959 689.959 +INF . R3000.Julio 689.959 689.959 +INF . R3000.Agosto 689.959 689.959 +INF 2589.078 ---- VAR yn cantidad producida de producto i en el periodo t en tiempo normal LOWER LEVEL UPPER MARGINAL R250 .Febrero . . +INF 212.320 R250 .Marzo . 65365.791 +INF . R250 .Abril . 61092.927 +INF . R250 .Mayo . 65992.114 +INF . R250 .Junio . 75449.789 +INF . R250 .Julio . 77794.333 +INF . R250 .Agosto . 83101.991 +INF . R500 .Febrero . . +INF 424.640 R500 .Marzo . 31157.821 +INF . R500 .Abril . 23175.628 +INF . R500 .Mayo . 23355.718 +INF . R500 .Junio . . +INF 0.003 R500 .Julio . 17088.542 +INF . R500 .Agosto . . +INF 0.003 R1000.Febrero . . +INF 849.290 R1000.Marzo . 7526.062 +INF . R1000.Abril . 14428.579 +INF . R1000.Mayo . 17070.440 +INF . R1000.Junio . 12797.259 +INF . R1000.Julio . 12315.414 +INF . R1000.Agosto . 12749.442 +INF . R1500.Febrero . . +INF 1273.930 R1500.Marzo . 3260.394 +INF . R1500.Abril . 2344.078 +INF .

302
R1500.Mayo . 2512.303 +INF . R1500.Junio . 3097.796 +INF . R1500.Julio . 2409.278 +INF . R1500.Agosto . 4030.850 +INF . R3000.Febrero . . +INF 2547.860 R3000.Marzo . 779.433 +INF . R3000.Abril . . +INF 0.007 R3000.Mayo . . +INF 3.810 R3000.Junio . 595.190 +INF . R3000.Julio . 942.671 +INF . R3000.Agosto . 661.346 +INF . ---- VAR ye cantidad producida de producto i en el periodo t en tiempo extra LOWER LEVEL UPPER MARGINAL R250 .Febrero . . +INF 212.320 R250 .Marzo . . +INF 2.259 R250 .Abril . . +INF 0.003 R250 .Mayo . . +INF 1.146 R250 .Junio . 7464.817 +INF . R250 .Julio . . +INF 2.256 R250 .Agosto . 9219.771 +INF . R500 .Febrero . . +INF 424.640 R500 .Marzo . . +INF 2.991 R500 .Abril . 3795.981 +INF . R500 .Mayo . . +INF 1.142 R500 .Junio . 20049.491 +INF . R500 .Julio . . +INF 2.856 R500 .Agosto . 14482.042 +INF . R1000.Febrero . . +INF 849.290 R1000.Marzo . . +INF 3.938 R1000.Abril . . +INF 0.001 R1000.Mayo . . +INF 0.693 R1000.Junio . . +INF 1.3970E-4 R1000.Julio . . +INF 3.449 R1000.Agosto . . +INF 1.3970E-4 R1500.Febrero . . +INF 1273.930 R1500.Marzo . . +INF 4.711 R1500.Abril . 464.381 +INF . R1500.Mayo . 1098.841 +INF . R1500.Junio . . +INF 0.001 R1500.Julio . . +INF 3.761 R1500.Agosto . . +INF 0.001 R3000.Febrero . . +INF 2547.860 R3000.Marzo . 1550.785 +INF . R3000.Abril . 2814.332 +INF . R3000.Mayo . 1970.658 +INF .
R3000.Junio . 1286.030 +INF . R3000.Julio . 835.497 +INF . R3000.Agosto . 1091.154 +INF . ---- VAR s cantidad en inventario del producto i al final del periodo t LOWER LEVEL UPPER MARGINAL R250 .Febrero 3800.000 3800.000 3800.000 -240.399 R250 .Marzo . 32328.173 +INF . R250 .Abril . 32328.173 +INF . R250 .Mayo . 32328.173 +INF . R250 .Junio . 32328.173 +INF . R250 .Julio . 32328.173 +INF . R250 .Agosto . 32328.173 +INF . R500 .Febrero 9812.000 9812.000 9812.000 -467.506 R500 .Marzo . 10140.612 +INF . R500 .Abril . 10140.612 +INF . R500 .Mayo . 10140.612 +INF . R500 .Junio . 10140.612 +INF . R500 .Julio . 10140.612 +INF . R500 .Agosto . 10140.612 +INF . R1000.Febrero 8600.000 8600.000 8600.000 -852.046 R1000.Marzo . 2929.210 +INF . R1000.Abril . 2929.210 +INF . R1000.Mayo . 2929.210 +INF . R1000.Junio . 2929.210 +INF . R1000.Julio . 2929.210 +INF . R1000.Agosto . 2929.210 +INF . R1500.Febrero 850.000 850.000 850.000 -1360.954 R1500.Marzo . 947.469 +INF . R1500.Abril . 947.469 +INF . R1500.Mayo . 947.469 +INF . R1500.Junio . 947.469 +INF . R1500.Julio . 947.469 +INF . R1500.Agosto . 947.469 +INF . R3000.Febrero 734.000 734.000 734.000 -2507.728 R3000.Marzo . 689.959 +INF . R3000.Abril . 689.959 +INF . R3000.Mayo . 689.959 +INF . R3000.Junio . 689.959 +INF . R3000.Julio . 689.959 +INF . R3000.Agosto . 689.959 +INF . LOWER LEVEL UPPER MARGINAL ---- VAR ct -INF 3.1194E+8 +INF .

303
ct costo total ---- VAR ep error positivo LOWER LEVEL UPPER MARGINAL R250 .Febrero . . +INF 1.580 R250 .Marzo . 28528.173 +INF . R250 .Abril . . +INF 1.580 R250 .Mayo . . +INF . R250 .Junio . . +INF 5.416 R250 .Julio . . +INF 1.580 R250 .Agosto . . +INF 17.380 R500 .Febrero . . +INF 3.310 R500 .Marzo . 328.612 +INF . R500 .Abril . . +INF 37.310 R500 .Mayo . . +INF 37.310 R500 .Junio . . +INF 35.142 R500 .Julio . . +INF 37.310 R500 .Agosto . . +INF 37.310 R1000.Febrero . . +INF 6.060 R1000.Marzo . . +INF 64.060 R1000.Abril . . +INF 64.060 R1000.Mayo . . +INF 64.060 R1000.Junio . . +INF 58.693 R1000.Julio . . +INF 64.060 R1000.Agosto . . +INF 61.449 R1500.Febrero . . +INF 7.930 R1500.Marzo . 97.469 +INF . R1500.Abril . . +INF 7.930 R1500.Mayo . . +INF 7.930 R1500.Junio . . +INF . R1500.Julio . . +INF . R1500.Agosto . . +INF 99.930 R3000.Febrero . . +INF 16.270 R3000.Marzo . . +INF 195.790 R3000.Abril . . +INF 195.790 R3000.Mayo . . +INF 195.790 R3000.Junio . . +INF 179.520 R3000.Julio . . +INF 163.250 R3000.Agosto . . +INF 146.980 ---- VAR en error negativo LOWER LEVEL UPPER MARGINAL R250 .Febrero . . +INF 15.800 R250 .Marzo . . +INF 17.380
R250 .Abril . . +INF 15.800 R250 .Mayo . . +INF 17.380 R250 .Junio . . +INF 11.964 R250 .Julio . . +INF 15.800 R250 .Agosto . . +INF . R500 .Febrero . . +INF 34.000 R500 .Marzo . . +INF 37.310 R500 .Abril . . +INF . R500 .Mayo . . +INF . R500 .Junio . . +INF 2.168 R500 .Julio . . +INF . R500 .Agosto . . +INF . R1000.Febrero . . +INF 58.000 R1000.Marzo . 5670.790 +INF . R1000.Abril . . +INF . R1000.Mayo . . +INF . R1000.Junio . . +INF 5.367 R1000.Julio . . +INF . R1000.Agosto . . +INF 2.611 R1500.Febrero . . +INF 92.000 R1500.Marzo . . +INF 99.930 R1500.Abril . . +INF 92.000 R1500.Mayo . . +INF 92.000 R1500.Junio . . +INF 99.930 R1500.Julio . . +INF 99.930 R1500.Agosto . . +INF . R3000.Febrero . . +INF 179.520 R3000.Marzo . 44.041 +INF . R3000.Abril . . +INF . R3000.Mayo . . +INF . R3000.Junio . . +INF 16.270 R3000.Julio . . +INF 32.540 R3000.Agosto . . +INF 48.810 ---- VAR nhe numero de horas extra necesarias en la estacion j en el periodo t LOWER LEVEL UPPER MARGINAL FabEnvase.Febrero . . +INF 4939.570 FabEnvase.Marzo . . +INF 4939.570 FabEnvase.Abril . . +INF 4939.570 FabEnvase.Mayo . . +INF 4939.570 FabEnvase.Junio . . +INF 4939.570 FabEnvase.Julio . . +INF 4939.570 FabEnvase.Agosto . . +INF 4939.570 Mezclado .Febrero . . +INF 4939.570 Mezclado .Marzo . 26.187 +INF . Mezclado .Abril . 62.121 +INF .

304
Mezclado .Mayo . 42.553 +INF . Mezclado .Junio . 88.606 +INF . Mezclado .Julio . 14.109 +INF . Mezclado .Agosto . 72.122 +INF . Resto .Febrero . . +INF 4939.570 Resto .Marzo . 22.682 +INF . Resto .Abril . 70.430 +INF . Resto .Mayo . 39.954 +INF . Resto .Junio . 183.903 +INF . Resto .Julio . 12.220 +INF . Resto .Agosto . 153.337 +INF . ---- VAR wn nivel de fuerza de trabajo en el periodo t en la etapa j en T norma l LOWER LEVEL UPPER MARGINAL FabEnvase.Febrero . . . 9.5670E+5 FabEnvase.Marzo . . +INF 9.0051E+5 FabEnvase.Abril . . +INF 1.0315E+6 FabEnvase.Mayo . . +INF 9.7752E+5 FabEnvase.Junio . . +INF 1.0315E+6 FabEnvase.Julio . . +INF 8.8189E+5 FabEnvase.Agosto . . +INF 1.0315E+6 Mezclado .Febrero 2.000 2.000 2.000 1.0906E+6 Mezclado .Marzo . 1.219 +INF . Mezclado .Abril . 1.219 +INF . Mezclado .Mayo . 1.231 +INF . Mezclado .Junio . 1.130 +INF . Mezclado .Julio . 1.130 +INF . Mezclado .Agosto . 1.130 +INF . Resto .Febrero 7.000 7.000 7.000 1.0906E+6 Resto .Marzo . 2.882 +INF . Resto .Abril . 2.845 +INF . Resto .Mayo . 2.845 +INF . Resto .Junio . 2.683 +INF . Resto .Julio . 2.683 +INF . Resto .Agosto . 2.683 +INF . ---- VAR we nivel de fuerza de trabajo en el periodo t en la etapa j en T extra LOWER LEVEL UPPER MARGINAL FabEnvase.Marzo . . +INF EPS FabEnvase.Abril . . +INF EPS FabEnvase.Mayo . . +INF EPS FabEnvase.Junio . . +INF EPS FabEnvase.Julio . . +INF EPS
FabEnvase.Agosto . . +INF EPS Mezclado .Marzo . 0.262 +INF . Mezclado .Abril . 0.647 +INF . Mezclado .Mayo . 0.409 +INF . Mezclado .Junio . 1.007 +INF . Mezclado .Julio . 0.131 +INF . Mezclado .Agosto . 0.751 +INF . Resto .Marzo . 0.227 +INF . Resto .Abril . 0.734 +INF . Resto .Mayo . 0.384 +INF . Resto .Junio . 2.090 +INF . Resto .Julio . 0.113 +INF . Resto .Agosto . 1.597 +INF . ---- VAR h cambio en la fuerza de trabajo por contratacion en el periodo t LOWER LEVEL UPPER MARGINAL FabEnvase.Febrero . . +INF 74800.000 FabEnvase.Marzo . . +INF . FabEnvase.Abril . . +INF 74800.000 FabEnvase.Mayo . . +INF 74800.000 FabEnvase.Junio . . +INF 74800.000 FabEnvase.Julio . . +INF 74800.000 FabEnvase.Agosto . . +INF 74800.000 Mezclado .Febrero . . +INF 74800.000 Mezclado .Marzo . . +INF 1.3390E+5 Mezclado .Abril . . +INF 9634.115 Mezclado .Mayo . 0.012 +INF . Mezclado .Junio . . +INF 1.3390E+5 Mezclado .Julio . . +INF 38871.118 Mezclado .Agosto . . +INF 84695.143 Resto .Febrero . . +INF 74800.000 Resto .Marzo . . +INF 1.3390E+5 Resto .Abril . . +INF 1.3390E+5 Resto .Mayo . . +INF 1.2398E+5 Resto .Junio . . +INF 1.3390E+5 Resto .Julio . . +INF 39027.678 Resto .Agosto . . +INF 84524.352 ---- VAR f cambio en la fuerza de trabajo por despido en el periodo t LOWER LEVEL UPPER MARGINAL FabEnvase.Febrero . . +INF 59100.000 FabEnvase.Marzo . . +INF 1.3390E+5 FabEnvase.Abril . . +INF 59100.000 FabEnvase.Mayo . . +INF 59100.000

305
FabEnvase.Junio . . +INF 59100.000 FabEnvase.Julio . . +INF 59100.000 FabEnvase.Agosto . . +INF 59100.000 Mezclado .Febrero . . +INF 59100.000 Mezclado .Marzo . 0.781 +INF . Mezclado .Abril . . +INF 1.2427E+5 Mezclado .Mayo . . +INF 1.3390E+5 Mezclado .Junio . 0.100 +INF . Mezclado .Julio . . +INF 95028.882 Mezclado .Agosto . . +INF 49204.857 Resto .Febrero . . +INF 59100.000 Resto .Marzo . 4.118 +INF . Resto .Abril . 0.037 +INF . Resto .Mayo . . +INF 9920.289 Resto .Junio . 0.162 +INF . Resto .Julio . . +INF 94872.322 Resto .Agosto . . +INF 49375.648 ---- VAR wtot numero de trabajadores totales en la empresa en el tiempo t LOWER LEVEL UPPER MARGINAL Marzo . 4.101 +INF . Abril . 4.064 +INF . Mayo . 4.076 +INF . Junio . 3.813 +INF . Julio . 3.813 +INF . Agosto . 3.813 +INF . ---- VAR prop proporcion producido sobre demanda del producto i en el tiempo t LOWER LEVEL UPPER MARGINAL R250 .Marzo . 1.774 +INF . R250 .Abril . 1.000 +INF . R250 .Mayo . 1.000 +INF . R250 .Junio . 1.000 +INF . R250 .Julio . 1.000 +INF . R250 .Agosto . 1.000 +INF . R500 .Marzo . 1.011 +INF . R500 .Abril . 1.000 +INF . R500 .Mayo . 1.000 +INF . R500 .Junio . 1.000 +INF . R500 .Julio . 1.000 +INF . R500 .Agosto . 1.000 +INF . R1000.Marzo . 0.570 +INF . R1000.Abril . 1.000 +INF . R1000.Mayo . 1.000 +INF .
R1000.Junio . 1.000 +INF . R1000.Julio . 1.000 +INF . R1000.Agosto . 1.000 +INF . R1500.Marzo . 1.031 +INF . R1500.Abril . 1.000 +INF . R1500.Mayo . 1.000 +INF . R1500.Junio . 1.000 +INF . R1500.Julio . 1.000 +INF . R1500.Agosto . 1.000 +INF . R3000.Marzo . 0.981 +INF . R3000.Abril . 1.000 +INF . R3000.Mayo . 1.000 +INF . R3000.Junio . 1.000 +INF . R3000.Julio . 1.000 +INF . R3000.Agosto . 1.000 +INF . ---- VAR CapDispN capacidad disponible en tiempo normal en el periodo t LOWER LEVEL UPPER MARGINAL Marzo . 553.150 +INF . Abril . 526.195 +INF . Mayo . 571.721 +INF . Junio . 452.576 +INF . Julio . 555.435 +INF . Agosto . 493.720 +INF . ---- VAR CapDispE capacidad disponible en tiempo extra en el periodo t LOWER LEVEL UPPER MARGINAL Marzo . 340.400 +INF . Abril . 323.812 +INF . Mayo . 351.828 +INF . Junio . 278.509 +INF . Julio . 341.806 +INF . Agosto . 303.828 +INF .

306
10.10 Plano de la Organización43
43 Obtenido de Alianzas y/o Industrias Alta Pureza S.A por medio de la gerencia administrativa.
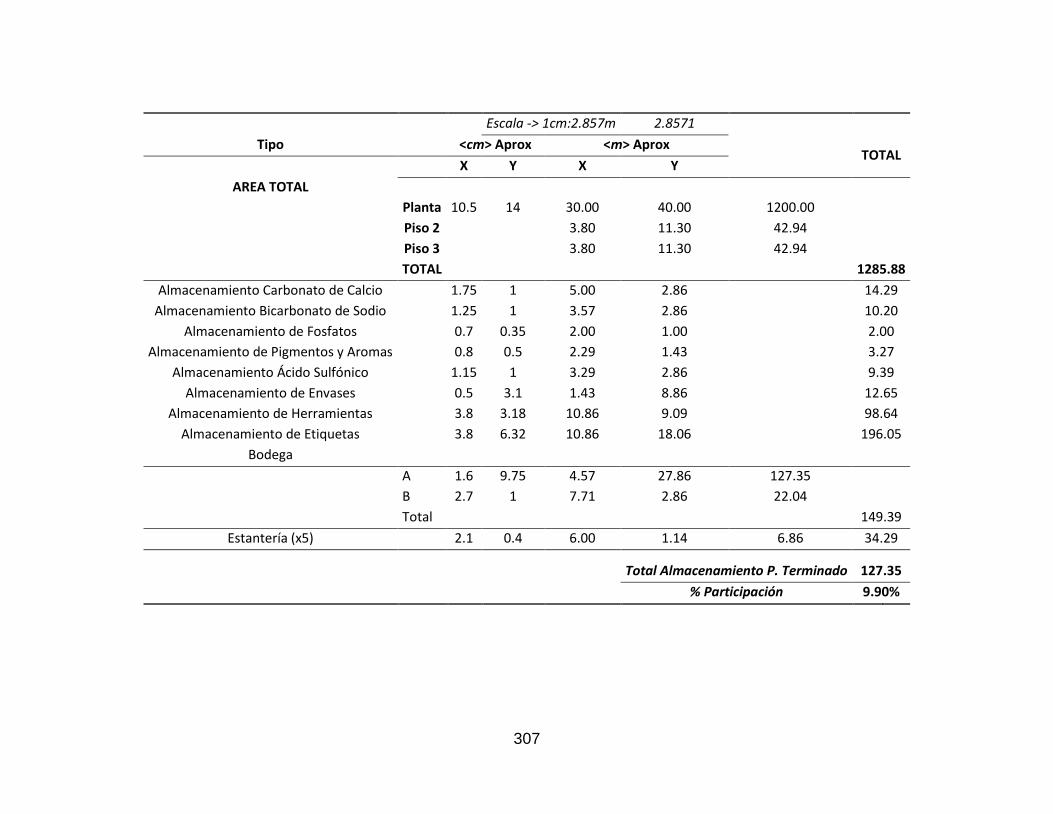
307
Escala -> 1cm:2.857m 2.8571
Tipo <cm> Aprox <m> Aprox
TOTAL
X Y X Y
AREA TOTAL
Planta 10.5 14 30.00 40.00 1200.00
Piso 2 3.80 11.30 42.94
Piso 3 3.80 11.30 42.94
TOTAL 1285.88
Almacenamiento Carbonato de Calcio 1.75 1 5.00 2.86 14.29
Almacenamiento Bicarbonato de Sodio 1.25 1 3.57 2.86 10.20
Almacenamiento de Fosfatos 0.7 0.35 2.00 1.00 2.00
Almacenamiento de Pigmentos y Aromas 0.8 0.5 2.29 1.43 3.27
Almacenamiento Ácido Sulfónico 1.15 1 3.29 2.86 9.39
Almacenamiento de Envases 0.5 3.1 1.43 8.86 12.65
Almacenamiento de Herramientas 3.8 3.18 10.86 9.09 98.64
Almacenamiento de Etiquetas 3.8 6.32 10.86 18.06 196.05
Bodega
A 1.6 9.75 4.57 27.86 127.35
B 2.7 1 7.71 2.86 22.04
Total 149.39
Estantería (x5) 2.1 0.4 6.00 1.14 6.86 34.29
Total Almacenamiento P. Terminado 127.35
% Participación 9.90%

308
10.11 Tablas
10.11.1 Tablas Para Pruebas de Raíz Unitaria.
Distribuciones Acumuladas Empíricas de
Nivel de Significancia
Muestra de tamaño 0.01 0.025 0.05 0.10
Estadístico : Sin constante ni Tendencia ( )
25 -2.66 -2.26 -1.95 -1.60
50 -2.62 -2.25 -1.95 -1.61
100 -2.60 -2.24 -1.95 -1.61
250 -2.58 -2.23 -1.95 -1.62
300 -2.58 -2.23 -1.95 -1.62
-2.58 -2.23 -1.95 -1.62
Estadístico : Constante pero sin Tendencia ( )
25 -3.75 -3.33 -3.00 -2.62
50 -3.58 -3.22 -2.93 -2.60
100 -3.51 -3.17 -2.89 -2.58
250 -3.46 -3.14 -2.88 -2.57
300 -3.44 -3.13 -2.87 -2.57
-3.43 -3.12 -2.86 -2.57
Estadístico : Con Constante y Tendencia ()
25 -4.38 -3.95 -3.60 -3.24
50 -4.15 -3.80 -3.50 -3.18
100 -4.04 -3.73 -3.45 -3.15
250 -3.99 -3.69 -3.43 -3.13
300 -3.98 -3.68 -3.42 -3.13
-3.96 -3.66 -3.41 -3.12
Tomada de: Enders (1948 p. 439, la cual fue reproducida por Fuller (1976). Usada con el
permiso de John Wiley & Sons, Inc.

309
Distribuciones Empíricas de
Nivel de Significancia
Muestra de tamaño 0.10 0.05 0.025 0.01
25 4.12 5.18 6.30 7.88
50 3.94 4.86 5.80 7.06
100 3.86 4.71 5.57 6.70
250 3.81 4.63 5.45 6.52
500 3.79 4.61 5.41 6.47
3.78 4.59 5.38 6.43
25 4.67 5.68 6.75 8.21
50 4.31 5.13 5.94 7.02
100 4.16 4.88 5.59 6.50
250 4.07 4.75 5.40 6.22
500 4.05 4.71 5.35 6.15
4.03 4.68 5.31 6.09
25 5.91 7.24 8.65 10.61
50 5.61 6.73 7.81 9.31
100 5.47 6.49 7.44 8.73
250 5.39 6.34 7.25 8.43
500 5.36 6.30 7.20 8.34
5.34 6.25 7.16 8.27
Tomado de Enders (1948, p.440) la cual fue obtenida de Dickey, David y Wayne A. Fuller
(1981) y fue usada con el permiso de la sociedad de econometría.

310
10.12 Modelos Comparativos
10.12.1 Ajuste modelos comparativos
-20000
-10000
0
10000
20000
30000
40000
50000
60000
70000
80000
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
Un
ida
de
s V
en
did
as
Pronóstico R250 Winters Aditivo
R250 Winters Aditivo
-30000
-20000
-10000
0
10000
20000
30000
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43
Re
sid
uo
s (U
nid
ad
es)

311
0
20000
40000
60000
80000
100000
120000
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
Un
ida
de
s V
en
did
as
Pronóstico R500 Estacional Simple
R500 Winters Aditivo
-40000
-20000
0
20000
40000
60000
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49Re
sid
uo
s (U
nid
ad
es)
0
5000
10000
15000
20000
25000
30000
35000
40000
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
Un
ida
de
s V
en
did
as
Pronóstico R1000 Estacional Simple
R1000 Estacional Simple
-20000
-10000
0
10000
20000
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
Re
sid
uo
s (U
nid
ad
es)

312
0
1000
2000
3000
4000
5000
6000
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
Un
ida
de
s V
en
did
as
Pronóstico R1500 Winters Aditivo
R1500 Winters Aditivo
-2000
-1000
0
1000
2000
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
Re
sid
uo
s (u
nid
ad
es)
0
1000
2000
3000
4000
5000
6000
7000
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
Un
ida
de
s V
en
did
as
Pronóstico R3000 Winters Aditivo
R3000 Winters Aditivo
-2000
0
2000
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
Re
sid
uo
s (U
nid
ad
es)

313
10.12.2 Explicación Modelos Comparativos.
10.12.2.1 Modelo Aditivo Winters
El método Aditivo Winters suele aplicarse cuando en la serie de tiempo existe la presencia
de componentes de tendencia y estacionalidad ya sea de forma aditiva o multiplicativa. Se
intenta entones suavizar los datos por medio del método exponencial de Holt-Winters
cuando el componente sistemático de la demanda tiene un nivel, una tendencia y un
factor estacional.
Características del Método de Holt-Winters
En este tipo de técnicas se hace uso de datos históricos para obtener una nueva
serie más suave q partir de la cual se hace la previsión.
Se toman en consideración todos los datos previos al periodo de previsión
disponibles, aunque se les otorgan pesos decrecientes exponencialmente a
medida que se distancian de dicho periodo.
El método aditivo es mejor cuando el patrón estacional no depende del valor de los datos,
ósea que el patrón estacional no cambia conforma la serie incrementa o disminuye su
valor. A diferencia del multiplicativo que se presenta cuando el patrón estacional en los
datos depende del tamaño de los mismos, es decir que la magnitud del patrón estacional
se incrementa conforma los valores aumentan y decrece cuando los valores de los datos
disminuyen.
Cuando la serie tiene una tendencia, al menos localmente, y un patrón estacional
constante se deberá ajustar un modelo del tipo
donde el valor del pronóstico está dado por
donde se observa que el modelo aditivo se le resta el factor estacional. Este método
entonces calcula los estimados de tres componentes: nivel, tendencia y estacionalidad.
Además calcula los estimados dinámicos con tres ecuaciones para los tres componentes.
Estas ecuaciones dan una mayor ponderación a observaciones recientes y menos
observaciones pasadas. Las ponderaciones decrecen geométricamente a una tasa
constante.

314
Observe que a cada parámetro de la suavización Winter se le da un calor de entre cero y
uno, cuanto mayor sea ese valor, mayor peso se le dara a la observación más reciente.
Para el procedimiento entonces se tiene que
1. Se calcula el promedio de cada una de las dos últimas estaciones de datos y se calcula
la tendencia de crecimiento promedio.
∑
2. Se calcula el promedio global para estimar la constante del nivel.
(
)
3. Se calculan los factores estacionales para cada estación y se normalizan.
4. Pronosticar para periodos en el futuro.


















