DESPLIEGUE Y PRUEBAS EN EL SERVIDOR BIG … · y tras la instalación y configuración de la...
6
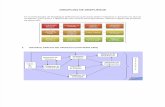
1. DESPLIEGUE DE LA DISTRIBUCIÓN CLOUDERA Como se explicaba en el artículo anterior (Conclusiones del Proyecto BIG DATA) una vez configurado el clúster con la versión 12.04 de Ubuntu y tras la instalación y configuración de la distribución de BIG DATA proporcionada por Cloudera, el siguiente paso es el despliegue de dicha distribución en el clúster, para lo que Cloudera proporciona un interface gráfico por medio de un navegador web, lo que facilitará en gran medi- da el trabajo a partir de este punto. Nada más acceder a la interface, se muestra un menú en el que se debe indicar qué despliegue se desea realizar, en nuestro caso “Cloudera Standard”, qué configuración del clúster se desea utilizar, seleccionando en nuestro caso de un namenode y de cinco datanodes (todos los nodos disponibles del clúster). Tras esto, se pregunta el tipo de servicio que se desea instalar inicialmente, seleccionando “Hadoop Core” (que incluye HDFS, MapReduce, Zookeeper, Oozie, Hive y Hue). Con estos datos se finalizará la configuración del clúster y se realizará la instalación de los servicios seleccionados: Hadoop Distributed File System, está dise- ñado para almacenar de forma fiable archi- vos muy grandes a través de las máquinas en un clúster grande. HDFS MAPREDUCE ZOOKEEPER HIVE HUE OOZIE Es el modelo de programación para Hadoop, hay procesos map y procesos reduce. Estos procesos generalmente están desarrollados en Java, aunque se pueden utilizar otros lenguajes mediante una utilidad llamada Hadoop Streaming. Administra la sincronización del clúster, aunque es una herramienta que está corriendo en back- ground y sobre la que no se accede de forma directa. Proporciona un lenguaje similar a SQL llamado HiveQL que puede transformarse en trabajos MapRedu- ce. No permite benefi- ciarse de un completo entorno ANSI-SQL, pero sí ofrece una escalabilidad multi- petabyte. Ofrece una interfaz gráfica basada en navegador web para hacer su trabajo en Hive. Administra el flujo de trabajo Hadoop. Esto no reemplaza el plani- ficador o herramientas BPM, pero propor- ciona ramificación if-then-else y control dentro de los trabajos Hadoop. www.alten.es Autor: Oliver O. BIG DATA DESPLIEGUE Y PRUEBAS EN EL SERVIDOR I+D+i
Transcript of DESPLIEGUE Y PRUEBAS EN EL SERVIDOR BIG … · y tras la instalación y configuración de la...

1. DESPLIEGUE DE LA DISTRIBUCIÓN CLOUDERA
Como se explicaba en el artículo anterior (Conclusiones del Proyecto BIG DATA) una vez configurado el clúster con la versión 12.04 de Ubuntu y tras la instalación y configuración de la distribución de BIG DATA proporcionada por Cloudera, el siguiente paso es el despliegue de dicha distribución en el clúster, para lo que Cloudera proporciona un interface gráfico por medio de un navegador web, lo que facilitará en gran medi-da el trabajo a partir de este punto.
Nada más acceder a la interface, se muestra un menú en el que se debe
indicar qué despliegue se desea realizar, en nuestro caso “Cloudera Standard”, qué configuración del clúster se desea utilizar, seleccionando en nuestro caso de un namenode y de cinco datanodes (todos los nodos disponibles del clúster). Tras esto, se pregunta el tipo de servicio que se desea instalar inicialmente, seleccionando “Hadoop Core” (que incluye HDFS, MapReduce, Zookeeper, Oozie, Hive y Hue). Con estos datos se finalizará la configuración del clúster y se realizará la instalación de los servicios seleccionados:
Hadoop Distributed File System, está dise-ñado para almacenar de forma fiable archi-vos muy grandes a través de las máquinas en un clúster grande.
HDFS MAPREDUCE ZOOKEEPER HIVE HUE OOZIE
Es el modelo de programación para Hadoop, hay procesos map y procesos reduce. Estos procesos generalmente están desarrollados en Java, aunque se pueden utilizar otros lenguajes mediante una utilidad llamada Hadoop Streaming.
Administra la sincronización del clúster, aunque es una herramienta que está corriendo en back-ground y sobre la que no se accede de forma directa.
Proporciona un lenguaje similar a SQL llamado HiveQL que puede transformarse en trabajos MapRedu-ce. No permite benefi-ciarse de un completo entorno ANSI-SQL, pero sí ofrece una escalabilidad multi-petabyte.
Ofrece una interfaz gráfica basada en navegador web para hacer su trabajo en Hive.
Administra el flujo de trabajo Hadoop. Esto no reemplaza el plani-ficador o herramientas BPM, pero propor-ciona ramificación if-then-else y control dentro de los trabajos Hadoop.
www.alten.es
Autor: Oliver O.
BIG DATADESPLIEGUE Y PRUEBAS EN EL
SERVIDOR
I+D+i

BIG DATAUna vez finalizado el despliegue en el clúster, se muestra una pantalla principal donde aparecerán todos los servicios desplegados y el estado de los mismos, debiendo asegurarnos que no se hayan producido errores o warnings durante dicho despliegue, solventándolos en caso de haberse producido.
En este punto, se irán añadiendo otros servicios al clúster que facilita-rán las pruebas que se realizarán posteriormente:
HBase: Es un almacén de claves-valores escalable. Funciona muy pare-cido a un hash-map persistente. No es una base de datos relacional a pesar de su nombre HBase.
Sqoop: Proporciona una transferencia de datos bidireccional entre Hadoop (HDFS) y una base de datos relacional.
Solr: Es un servicio distribuido para los datos de indexación y búsque-da almacenados en HDFS.
FlumeNG: Es un cargador en tiempo real para el streaming de datos en Hadoop. Almacena datos en HDFS y HBase. Ofrece una mejora sobre la herramienta Flume inicial.
Al igual que antes, una vez instalado cada servicio la herramienta indi-ca que servicios hay que reiniciar, siendo necesario finalmente realizar un nuevo despliegue del clúster para que se apliquen correctamente todos los cambios de configuración realizados.
En nuestro caso, tuvimos que realizar tres ajustes en la configura-ción:
El tamaño del heap del proceso de Java: hubo que modificarlo a los valores por defecto (1Gb).
La velocidad del interface de red: aunque por defecto viene a “Gi-gabit” hubo que ajustarlo a “fast”.
Impala no presente en Hue: hubo que acceder a la configuración de Hue y marcar la opción de Impala Service a “none”.
Para cada una de estas modificaciones, la herramienta indica qué ser-vicios se necesitan reiniciar o si es preciso realizar un nuevo despliegue para que se apliquen los cambios. Finalmente, se obtendrá una panta-lla principal sin alertas ni errores y con todos los servicios activos.
La herramienta Hue, centraliza los portales y editores de todas las herramientas instaladas en el clúster. Para acceder a ella se nece-sita establecer un túnel ssh, que haga corresponder el puerto local 127.0.0.1:8888 con la ip/puerto en el cual corre Hue; en nuestro caso 10.1.1.10:8888. Es entonces, cuando se puede acceder desde un navegador web a la herramienta a través de una url del tipo: http://localhost:8888/
Después de una pequeña configuración de la herramienta, donde se pueden cargar ejemplos y modificar la base de usuarios, la herramien-ta estaría lista.
Para la realización de las pruebas, se descarga la base de datos de muestra Sakila, y se carga tanto en la base de datos MySql (que utiliza el clúster para almacenar su propia configuración) como en la base de datos PostgreSQL (que instalaremos para dichas pruebas). Para la realización de las diferentes pruebas es conveniente revisar la docu-mentación relativa a la Shell de Hadoop para familiarizarse con los comandos propios de los que dispone. Para ello podemos acceder a la documentación oficial disponible en:
2. LA HERRAMIENTA HUE
1.1/ AÑADIR NUEVOS SERVICIOS
3. COLECCIÓN DE PRUEBAS
www.alten.es
http://hadoop.apache.org/docs/r0.19.0/index.html

BIG DATAEl primer paso para utilizar Hadoop es poner los datos en HDFS. Para la primera prueba, que se muestra a continuación, se recibe una copia de un libro de Mark Twain y una de un libro de James Fenimore Coo-per y se copian estos textos en HDFS.
Para ello descargamos dichos libros accediendo a la página http://www.gutenberg.org mediante el comando wget, llamando después a hadoop para que lleve ambos ficheros a HDFS mediante la sentencia: hadoop fs -put <localsrc>...<dst>
En este caso de uso, Hadoop puede proporcionar cierta crítica literaria haciendo una sencilla comparación entre los libros que habíamos descargado anteriormente de Twain y Cooper. La prueba Flesch-Kincaid calcula el nivel de lectura de un texto en particular. Uno de los factores en este análisis es la longitud media de la frase aunque el análisis sin-táctico de frases resulta ser más complicado que sólo buscar el carácter punto. El paquete OpenNLP y el paquete Python NLTK, tienen excelen-tes programas de análisis de frases. Para este ejemplo, se utilizará la longitud de la palabra como un sustituto para el número de sílabas en una palabra.
Como se ha comentado en alguna ocasión, no es necesario conocer Java para programar trabajos de MapReduce. En este ejemplo de Ma-pReduce se utiliza Hadoop Streaming para procesar un “map” escrito en Python y un “reduce” usando AWK para obtener la crítica literaria. Los comandos para ello serían:
hadoop jar /usr/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming-2.0.0-mr1-cdh4.6.0.jar -input Twain.txt -output Tstats -file ./mapper.py -file ./statsreducer.awk -mapper ./mapper.py -reducer ./statsreducer.awk
hadoop jar /usr/lib/hadoop-0.20-mapreduce/contrib/streaming/ha-doop-streaming-2.0.0-mr1-cdh4.6.0.jar -input Cooper.txt -output Cstats -file ./mapper.py -file ./statsreducer.awk -mapper ./mapper.py -reducer ./statsreducer.awk
Las longitudes de las palabras se clasifican en orden numérico y se pre-sentan al reductor de forma ordenada. En los ejemplos obtenidos vemos que la clasificación de los datos está integrada en la infraestructura de MapReduce, aunque no se requiere para obtener la salida correcta. Tras el análisis de ambos textos, los fans de Mark Twain, felizmente pueden relajarse sabiendo que Hadoop encuentra que Cooper usa palabras más largas, con una desviación estándar impactante. Eso, por supuesto, asumiendo que las palabras más cortas son mejores.
El Proyecto Sqoop es un proyecto Apache basado en JDBC de código abierto para el movimiento de datos entre base de datos y Hadoop. Sqoop fue creado originalmente en un hackathon en Cloudera y des-pués paso a código abierto.
Mover datos de HDFS a una base de datos relacional es un caso de uso común. HDFS y Map-Reduce son muy buenos para hacer el trabajo pesado. Para consultas sencillas o almacenamiento de back-end de un sitio web, almacenamiento en caché de la salida Map-Reduce en un almacén relacional es un buen patrón de diseño. Se puede evitar volver a ejecutar el Map-Reduce del contador de palabras con sólo Sqooping los resultados en MySQL.
En esta prueba se van a pasar los datos que se han generado anterior-mente sobre Twain y Cooper a una base de datos relacional previamen-te creada utilizando Sqoop, con una llamada parecida a esta:
La mayoría de los tutoriales de Hadoop utilizan el ejemplo del contador de palabras que se incluye en el archivo de ejemplo jar de Hadoop. Resulta que una gran parte del análisis consiste en contar y agregar. Es por eso que aprovecharemos los ficheros cargados en la prueba uno, para realizar esta prueba en nuestro clúster.
La ejecución del trabajo de conteo de palabras genera una gran canti-dad de mensajes. Hadoop proporciona una gran cantidad de detalles sobre las tareas de Mapeo y Reducción de los programas que ejecuta en su nombre. El significado de cada uno de esos mensajes viene a reflejar todo el trabajo realizado por Hadoop, en resumen muestra información sobre:
o Chequeo para ver si existe el archivo de entrada.
o Chequeo para ver si el directorio de salida existe y en caso ne-gativo, cancelar el trabajo. Nada peor que sobrescribir horas de computación por un simple error de tecla.
o Distribuye el archivo jar de Java para todos los nodos responsa-bles de hacer el trabajo.
o Ejecuta la fase de asignación del trabajo. Normalmente, éste analiza el archivo de entrada y emite un par de clave-valor. Hay que tener en cuenta que la clave y el valor pueden ser objetos.
o Ejecuta la fase de clasificación, que ordena la salida del mapea-dor basada en la clave.
o Ejecuta la fase de reducción, por lo general esto se sintetiza en el flujo de clave-valor y escribir la salida a HDFS.
o Creando muchas métricas sobre la marcha.
Desde la herramienta Hue se vería así:
3.1/ PRUEBA UNO: PONER DATOS EN HDFS 3.3/ PRUEBA TRES: FLESCH KINCAID
3.4/ PRUEBA CUATRO: MOVER DATOS DE HDFS A MYSQL CON SQOOP
3.2/ PRUEBA DOS: CONTADOR DE PALABRAS
www.alten.es

sqoop export -D sqoop.export.records.per.statement=1 --connect “jdbc:mysql://localhost/mydemo” --table wordcount --fields-terminated-by ‘\t’ --username userDemo --password pass1 --export-dir /user/userDe-mo/HF.out
Finalmente, los datos estarán cargados en la base de datos y se podrán visualizar mediante una consulta del tipo:
select * from wordcount;
Sqoop también permite insertar datos en Hadoop HDFS, la funcionali-dad bidireccional se controla a través del parámetro de importación. La base de datos de ejemplo que viene con el producto tiene algunos conjuntos de datos simples que se pueden utilizar para este propósito.
Para importar datos desde una base de datos MySql mediante Sqoop se utilizará una llamada como ésta:
sqoop import --connect “jdbc:mysql://localhost/sakila” --table language --username userDemo --password ****
Y para realizar esa misma importación de datos mediante Sqoop, pero desde una base de datos PostgreSQL, se modificaría la llamada para ajustar los datos de conexión de la nueva base de datos:
sqoop import --connect jdbc:postgresql://localhost:5432/dvdrental --table language --username userDemo --password ****
Para ambos casos, se puede observar que se obtienen los siguientes ficheros resultantes:
¿Por qué hay cuatro archivos diferentes? ¿Cada uno de ellos contiene sólo una parte de los datos?
La explicación radica en que Sqoop es una utilidad altamente parale-lizada que tiene un límite por defecto de cuatro conexiones JDBC. Por eso existen cuatro ficheros de datos en HDFS, generados por cada una de las conexiones.
3.5/ PRUEBA CINCO: IMPORTAR DATOS EN HDFS DESDE MYSQL O PROSTGRESQL CON SQOOP
3.6/ PRUEBA SEIS: UNIR DATOS MYSQL A DATOS POST-GRESQL MEDIANTE HIVE
Esta prueba consiste en unificar datos de MySQL y datos de Postgre- SQL . No es un ejemplo especialmente relevante para las dos tablas triviales que se usarán en el ejemplo, pero sí será de gran importancia cuando existan múltiples terabytes o petabytes de datos a tratar.
Existen dos enfoques fundamentales para unir diferentes fuentes de datos. Dejando los datos en reposo y utilizar una tecnología frente a mover los datos a un único almacenamiento para realizar la unión. Por lo económico de Hadoop y por su rendimiento, la opción de mover los datos en HDFS y realizar el trabajo pesado con MapReduce resulta una elección sencilla ya que las limitaciones de ancho de banda de red crearían una barrera fundamental si se tratara de unir datos en reposo con otra tecnología.
Para usar el lenguaje de consulta de Hive, existe un subconjunto de SQL llamado Hiveql que requiere los metadatos de la tabla. Hive puede definir los metadatos con los archivos existentes en HDFS, para esto, Sqoop proporciona un atajo muy conveniente con la opción create-hive-table. Hive no proporciona las semánticas de transacción y no es un reemplazo para MySQL o PostgreSQL, pero si se tiene algún trabajo pesado en forma de uniones de tablas, incluso si se tienen algunas tablas más pequeñas, o si se tienen que hacer productos cartesianos desagradables, Hadoop es la herramienta de elección.
Para realizar esta prueba se puede utilizar la consola del clúster o bien la herramienta Hue y su interfaz gráfica en el navegador.
En ambos casos se importarán los datos desde MySql y desde Postgre- SQL (tal y como se realizó anteriormente), y se utilizará Hive para crear dos tablas, que interpretarán los datos contenidos en cada uno de esos dos ficheros. Una vez creadas dichas tablas, bastará realizar el join de ambas para obtener la unión de los datos.
Para importar la tabla staff de PostgreSQL de la BD dvdrental en hdfs:
sqoop import --connect jdbc:postgresql://localhost:5432/dvdrental --table staff --username userDemo --password pass1
Para importar la tabla customer de MySQL de la BD sakila en hdfs:
sqoop import --connect “jdbc:mysql://localhost/sakila” --table customer --username userDemo --password pass1
Ahora simplemente habría que crear las tablas y realizar el join corres-pondiente mediante el lenguaje sql clásico.
hadoop fs -ls languageFound 6 items
0 2014-04-14 15:06 language/_SUCCESS0 2014-04-14 15:05 language/_logs90 2014-04-14 15:06 language/part-m-0000045 2014-04-14 15:06 language/part-m-0000145 2014-04-14 15:06 language/part-m-0000290 2014-04-14 15:06 language/part-m-00003
BIG DATA
www.alten.es

3.7/ PRUEBA SIETE: UNIFICAR DATOS DE POSTGRESQL Y MYSQL MEDIANTE PIG
3.8/ PRUEBA OCHO: ACCEDER A LOS ARCHIVOS HDFS A TRAVÉS DE NFS MEDIANTE FUSE
El sistema de archivos de red (NFS) es un protocolo de sistema de archivos distribuido que permite el acceso a archivos en un equipo remoto en una manera similar a cómo se accede al sistema de archivos local. Con una puerta de enlace para NFS Hadoop, se permite así a las aplicaciones basadas en archivos realizar operaciones de lectura y escritura operaciones directamente sobre Hadoop, simplificando enor-memente la gestión de datos y ampliando la integración de Hadoop en conjuntos de herramientas existentes.
Pig es un lenguaje procedural que al igual que Hive, por detrás genera código MapReduce. Para esta prueba, se unirá la tabla de clientes y la tabla de gerentes de la prueba anterior, pero en esta ocasión con la ayuda de la herramienta Pig. De la misma manera que en la prueba anterior, aunque se puede trabajar sobre la línea de comandos, hay varias interfaces gráficas de usuario (como Hue) que funcionan muy bien con Hadoop.
Con el acceso NFS a HDFS, se puede montar el clúster HDFS como un volumen en los equipos cliente y tener una línea de comandos nativa, secuencias de comandos o la interfaz de usuario del explorador de archivos para ver los archivos HDFS y cargar datos en HDFS.
En esta prueba, se realiza la instalación y configuración de esta herra-mienta, para ello hay que descargarlo mediante el comando “apt-get install hadoop-hdfs-fuse”. A continuación se crea la carpeta fusemnt y se define un punto de montaje con el comando “hadoop-fuse-dfs dfs://namenode:8020 /fusemnt”. Una vez montado, ya se pueden ejecutar operaciones como si estuvieran en el punto de montaje.
Flume es un servicio distribuido para agregar y mover grandes canti-dades de datos a HDFS. Cuenta con una arquitectura simple y flexible basada en el streaming de flujos de datos.
En esta prueba se define un fichero para ser inyectado en la base de datos MySQL, para ello seleccionamos el fichero “part_m_00001” generado en una de las anteriores pruebas y modificamos el fichero de configuración de Flume “flumeconf/hdfs2dbloadfile.conf” para asignar el fichero seleccionado como primer agente. Una vez configurado, se lanza la inyección de datos mediante el comando “flume-ng agent -f ./flumeconf/hdfs2dbloadfile.conf -n agent1” y podremos observar cómo los datos contenidos en el fichero se cargaron en la base de datos.
BIG DATA
3.9/ PRUEBA NUEVE: CREAR UN ARCHIVO LISTO PARA CARGAR CON FLUME (INYECTOR DE DATOS)
www.alten.es

BIG DATAOozie es un sistema de planificación de flujos de trabajo para gestionar los trabajos de Hadoop. Es un motor basado en un servidor especializado en la gestión de flujos de trabajo con las acciones que se ejecutan en MapReduce y Pig.
En esta prueba, Oozie encadenará a voluntad varios trabajos de Hadoop. Para ello se utilizará un buen conjunto de ejemplos incluidos en el fichero oozie-examples.tar.gz, contenido en la propia distribución de Cloudera.
El primer paso será modificar el workflow de sqoop para que use nues-tra base de datos de ejemplo y modificar el fichero de configuración “examples/apps/sqoop/job.properties” para ajustarlo a las pruebas que vamos a realizar. Una vez configurado, se cargan los ejemplos en HDFS y se remiten los trabajos a Oozie:
HBase es un almacén de clave-valor de alto rendimiento. Si el caso de uso requiere escalabilidad y sólo requiere de la base de datos el equi-valente a las transacciones de confirmación automática, HBase hace realmente un excelente trabajo en el almacenamiento de clave-valor de alto rendimiento y fácilmente puede ser la tecnología a usar.
Esta última prueba usará la interfaz REST ofrecida con HBase para insertar clave-valores en una tabla HBase mediante llamadas curl. Esta prueba es el código para dar conocimientos básicos de Hbase. Es simple por su diseño y de ninguna manera representa el alcance de la funcionalidad de HBase. Para conocer todas sus funcionalidades es recomendable la lectura del libro “HBase, The Definitive Guide“, de Lars George.
Para la prueba, los pasos a realizar desde la interface Shell serían:o Acceder a la línea de comandos mediante “hbase shell”o Crear una tabla con una única columnao Insertar un registro en esa tablao Ver la descripción de la tabla con “describe ‘mytable’ ”o Escanear la tabla con “scan ‘mytable’ ”
Desde la interface REST:o Comprobar el estado del servidor mediante “curl http://name-
node:20550/status/cluster”o Escanear el contenido de la tabla que habíamos creado
mediante “curl http://namenode:20550/mytable/*”- Este escaneo proporciona el schema necesario para
poder insertar datos en la tabla de Hbaseo Añadir con curl una entrada mediante “RESTinsertedKey”o Comprobar desde la interface Shell que el dato fue insertado
correctamente mediante “scan ‘mytable’ ”
En la interface web se visualizaría así:
3.10/ PRUEBA DIEZ: AÑADIENDO FLUJO DE TRABAJO PARA MÚLTIPLES TAREAS CON OOZIE 3.11/ PRUEBA ONCE: HBASE
www.alten.es