
Definición de variables aleatorias - UCEMA...2. Inferencia Estadística •Las magnitudes y σ2 son...
32
Estadística 2011 Clase 4 Maestría en Finanzas Universidad del CEMA Profesor: Alberto Landro Asistente: Julián R. Siri
Transcript of Definición de variables aleatorias - UCEMA...2. Inferencia Estadística •Las magnitudes y σ2 son...

Estadística2011
Clase 4
Maestría en FinanzasUniversidad del CEMA
Profesor: Alberto Landro
Asistente: Julián R. Siri

Clase 4
4. Estimación por Intervalos
5. Intervalos de Confianza
1. Pasos en un proceso estadístico
2. Inferencia Estadística
3. Estimación Puntual
6. Síntesis
7. Ejercicios

1. Plantear una hipótesis sobre una población.
2. Diseñar el experimento (Decidir qué datos recopilar).
1. Determinar la muestra
2. Definir las variables
3. Describir los datos obtenidos (luego de haber realizado el muestreo).
4. Realizar una inferencia sobre la población.
5. Cuantificar la confianza en la inferencia.
1. Pasos en un proceso estadístico

• Problema: Conocemos o suponemos la distribución de probabilidades de
una variable aleatoria en particular, pero… desconocemos el valor de
parámetro (o los parámetros) de dicha distribución.
• Solución: Tomamos una muestra aleatoria n de la distribución de
probabilidades conocida y, a partir de los estimadores muestrales
conocidos, inferimos los parámetros poblacionales desconocidos.
PROBLEMA DE ESTIMACIÓN
Puntual Intervalos
MP
2. Inferencia Estadística

2. Inferencia Estadística
• Las magnitudes y σ2 son parámetros fijos y desconocidos de la
población, mientras que las magnitudes y S2 son variables aleatorias
conocidas de la muestra (su valor depende de la muestra seleccionada). En
base a las mismas, podemos determina las respectivas funciones de
distribución.
–Teorema central del límite: A pesar que las distribuciones de la
población y de muestreo son diferentes, existe una relación entre ellas.
La distribución de las medias muestrales tiende a una normal,
aunque la distribución poblacional de la que provienen no lo sea.
Como el TLC nos dice que la media muestral tiene distribución
normal, basta con conocer la media y la varianza para poder
calcular las probabilidades.
x
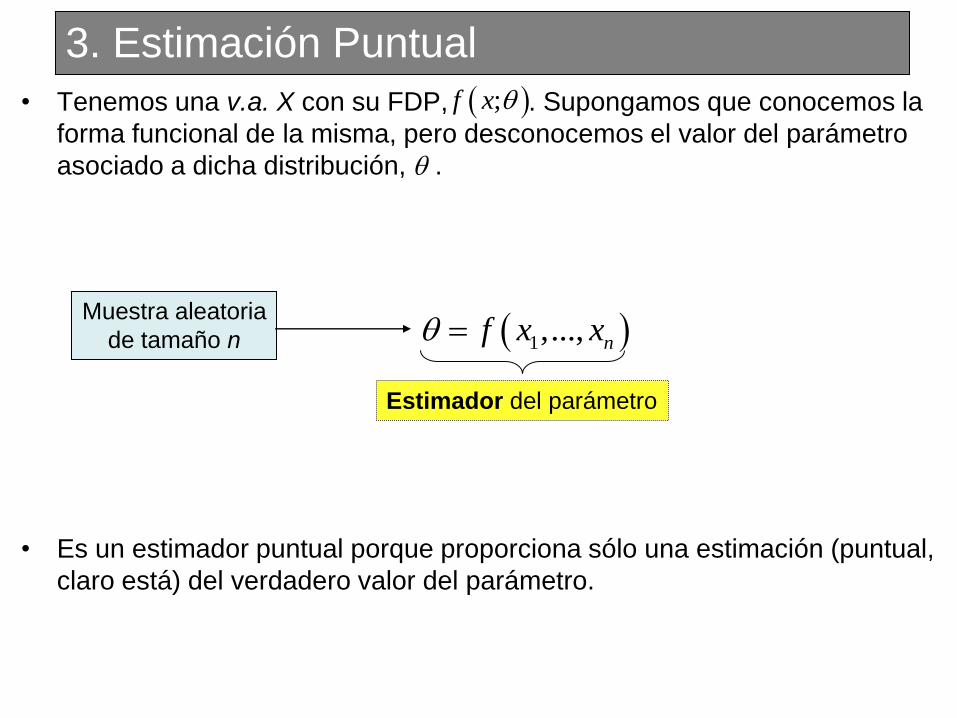
• Tenemos una v.a. X con su FDP, . Supongamos que conocemos la
forma funcional de la misma, pero desconocemos el valor del parámetro
asociado a dicha distribución, .
• Es un estimador puntual porque proporciona sólo una estimación (puntual,
claro está) del verdadero valor del parámetro.
Muestra aleatoria
de tamaño n
;f x
1,..., nf x x
Estimador del parámetro
3. Estimación Puntual

• Sobre la misma X supongamos que obtenemos dos estimaciones de ,
generando así los siguientes estimadores:
• Diremos entonces que, con cierta confianza (entiéndase probabilidad), el
verdadero valor del parámetro estará contenido en el intervalo entre
dichos estimadores.
• Introducimos así la noción de distribución de probabilidades de un
estimador.
2 1,..., nx x
1 1,..., nx x
4. Estimación por Intervalos

• Ampliando sobre el concepto, tenemos que:
• Este intervalo se conoce como un intervalo de confianza de tamaño
para .
= coeficiente de confianza
1
1 2Pr 1 0 1
1
nivel de significancia
4. Estimación por Intervalos

5. Intervalos de Confianza
•Dado que y
•Como x tiene una distribución normal, tenemos una certeza (1-α)% que x se
encuentra en el intervalo
•Como no conocemos no podemos evaluar el intervalo, por lo que nos
centramos en x en lugar de basarnos en . Al cambiar el marco de referencia,
suponemos que x es fijo y que varia normalmente alrededor de x.
E x nn
xVar x
2
%x Zn
%x Zn
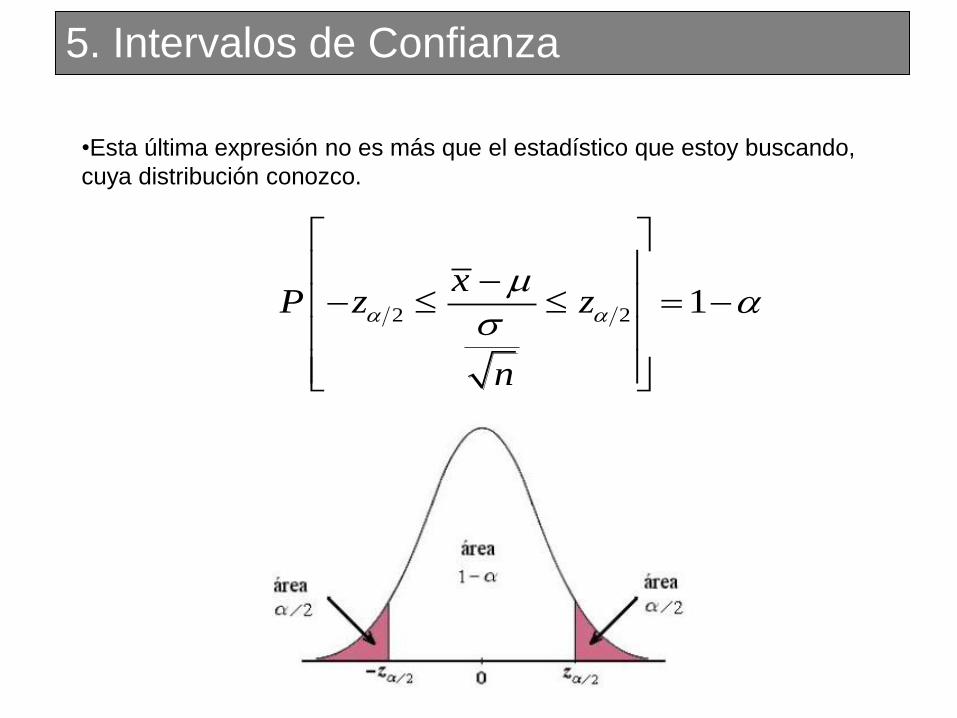
5. Intervalos de Confianza
•Esta última expresión no es más que el estadístico que estoy buscando,
cuya distribución conozco.
2 2 1x
P z z
n

5. Intervalos de Confianza
Despejando
2 2
2 2
1
1
P z x zn n
P x z x zn n
(1)

5. Intervalos de Confianza
• EJEMPLO: Supongamos que se desea estimar el promedio de las estaturas de todos los habitantes masculinos, de mas de 25 años, de la Ciudad de Buenos Aires. Para ello, se toma una muestra de 100 personas. Asimismo, se sabe que la dispersión es igual a 8 cm. De la muestra de 100 personas, se sabe que la estatura promedio es de 172,3 cm. Supongamos que deseamos calcular un intervalo de confianza para la media poblacional con un nivel de confianza del 95%. Si se sabe que las estaturas se distribuyen normalmente, podremos utilizar el estadístico que recién hemos obtenido. Luego de despejar:
8 8172,3 1,96 172,3 1,96 0.95
10 10
170,732 173,868 0.95
P
P

5. Intervalos de Confianza
•Longitud del intervalo (L): para un intervalo de confianza determinado sería:
Y numéricamente sería L=173.868-170.732=3.136= 2 * 1.96 * 8/10
22L zn
2 2x z x zn n

5. Intervalos de Confianza
•Mayor seguridad se logrará a partir de una mayor longitud del intervalo. Por
ejemplo, si deseo que mi estimación sea del 99%:
172,3 2,58*8 /10 172,3 2,58*8 /10 0,99
170,236 174,364 0,99
1 :99% 2*2,58*8 /10 4,128
P m
P m
L

5. Intervalos de Confianza
• Supongamos que deseamos una longitud y una seguridad determinada. La
única variable de ajuste será la cantidad de observaciones:
• Por ejemplo, en nuestro último ejercicio numérico, obtuvimos con n=100 y
(1- α) = 99% una L = 4,128. Supongamos que deseamos mantener la
seguridad al tiempo que reducimos la longitud a solo 2 cm:
•Por lo tanto, deberé aumentar mi muestra en 326 observaciones.
2
2
2
2 2
42
zL z n
Ln
2
2 2 22
2 2
4 4 2,58 8426
2
zn
L

5. Intervalos de Confianza
•Supongamos ahora que deseamos construir un intervalo de confianza para la
media poblacional, cuando se muestrea una distribución normal con varianza
desconocida. Sean una sucesión de variables aleatorias
independientes e igualmente distribuidas, en donde .
•Mi primer objetivo será encontrar el estadístico . A priori, se que es un
estimador consistente (eficiente e insesgado) de , en donde:
y en donde aunque ahora desconozco σ.
x
1
n
i
i
X
xn
2
;x Nn
1,..., nx x 2;ix N

5. Intervalos de Confianza
• Sin embargo, puede demostrarse que S2 es un estimador insesgado de
σ2, siendo:
• Puede demostrarse entonces que
• Y por lo tanto:
2
2 1
( )
1
n
i
i
X X
Sn
1n GL
xt
S
n
1 1 1n n
S SP x t x t
n n
(2)

5. Intervalos de Confianza
• Volvamos a nuestro ejemplo numérico pero supongamos que desconocemos σ2
(aunque conocemos S = 8,7) y que se toma una muestra de 20 personas en lugar de 100 (es decir, ahora n = 20). Reemplazando, obtendremos:
Ahora bien, puede demostrarse asimismo que si n tiende a
Infinito, por TLC, entonces:
Y, por lo tanto:
(0;1)x
NS
n
2 2 1S S
P x z x zn n
8,7 8,7172,3 2,093 172,3 2,093 0.95
4,472 4,472
167,57 177,03 0.95
P
P
(3)
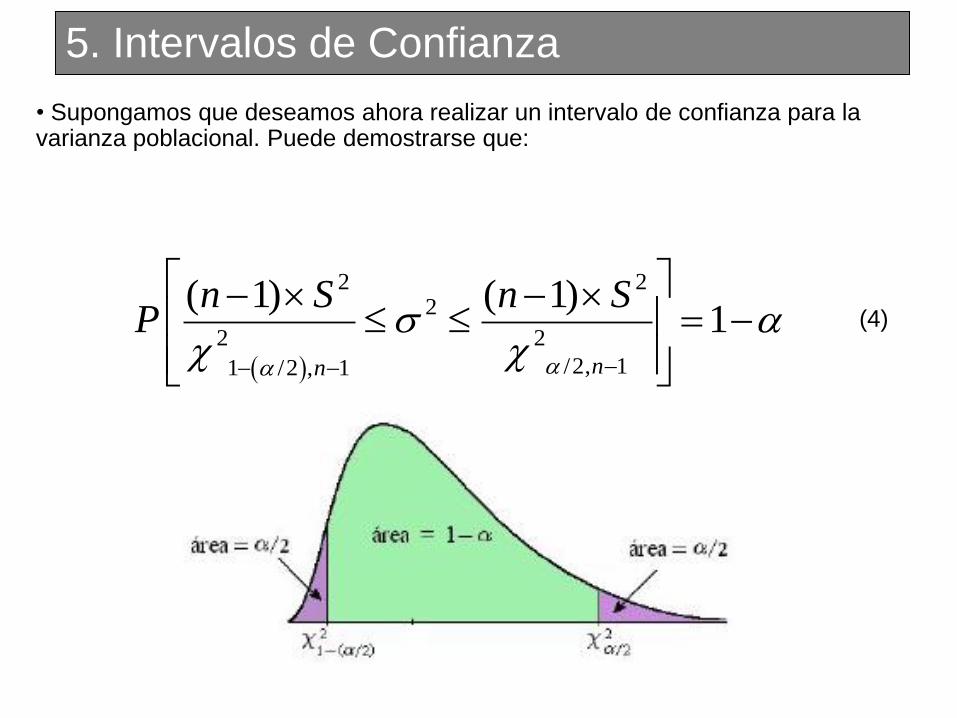
5. Intervalos de Confianza
• Supongamos que deseamos ahora realizar un intervalo de confianza para la varianza poblacional. Puede demostrarse que:
2 22
2 2
/2, 11 /2 , 1
( 1) ( 1)1
nn
n S n SP
(4)

5. Intervalos de Confianza
•EJEMPLO: Supongamos que se toma una muestra de 27 focos de luz. Supongamos que S2 = 98 horas. Si la duración de esos focos sigue una distribución normal, busquemos un intervalo con el 90% de confianza para la desviación estándar poblacional de la duración de esos focos.
–Reemplazando en la ecuación anterior por los datos dados, obtenemos entonces que:
2
2
(27 1) 98 (27 1) 980.9
38,885 15,379
65.52655 165.6805 0.9
8.094847 12.87169 0.9
P
P
P

5. Intervalos de Confianza
•Supongamos ahora que deseo saber entre que valores se encuentra la diferencia entre dos medias poblacionales. Partimos entonces de los siguientes supuestos:
a) Sea una sucesión de variables aleatorias independientes e idénticamente distribuidas (i.i.d.), en donde
b) Sea una sucesión de variables aleatorias independientes e idénticamente distribuidas (i.i.d.), en donde
•Siendo ambas sucesiones de variables aleatorias independientes (covarianza nula), se verifica que:
22
;yx
x y
x y
x y Nn n
1,..., nx x 2;i x xx N
1,..., ny y
2;i y yy N

5. Intervalos de Confianza
• Si suponemos que las varianzas son idénticas y conocidas,
• Por lo que,
2 2
( )(0;1)
x y
x y
x yN
n n
2 2 2 2
2 2( ) ( ) 1x y
x y x y
P x y z x y zn n n n
(5)

5. Intervalos de Confianza
•Si en cambio desconocemos σ2x y σ2
y aunque sabemos que son iguales
en donde,
Y nuevamente puede demostrarse que si n tiende a infinito,
2 2
2 2
2 2 2 2
( ) ( ) 1n n n nx y x y
x y
x y x y
S S S SP x y t x y t
n n n n
2 2 2 2
2 2( ) ( ) 1x y
x y x y
S S S SP x y z x y z
n n n n
2 2
21 1
2
x x y y
x y
n S n SS
n n
(6)
(7)

5. Intervalos de Confianza
• Por último supongamos que
a) Sea una sucesión de variables aleatorias independientes e igualmente distribuidas (i.i.d.), en donde X posee cualquier distribución y nx tiende a ∞
b) Sea una sucesión de variables aleatorias independientes e igualmente distribuidas (i.i.d.), en donde Y posee cualquier distribución y ny tiende a ∞
Por lo tanto, al igual que antes:
• Si desconocemos las varianzas,
2 22 2
2 2( ) ( ) 1y yx x
x y
x y x y
P x y z x y zn n n n
2 2 2 2
2 2( ) ( ) 1y y y y
x y
x y x y
S S S SP x y z x y z
n n n n
1,..., nx x
1,..., ny y
(8)
(9)

SINTESIS
• Si deseamos realizar un intervalo de confianza para la media poblacional, con σ conocido, deberemos usar la expresión (1).
• Si deseamos realizar un intervalo de confianza para la media poblacional, con σ desconocido, deberemos usar la expresión (2).
• Aunque, si n es suficientemente grande, puede utilizarse la expresión (3)
• Si deseamos realizar un intervalo de confianza para la varianza poblacional, deberemos usar la expresión (4)
• Si deseamos realizar un intervalo de confianza para la diferencia de medias poblacionales, con ambos s conocidos e iguales, deberemos usar la expresión (5)
6. Síntesis

• Si deseamos realizar un intervalo de confianza para la diferencia de medias poblacionales, con ambos s desconocidos e iguales, deberemos usar la expresión (6) donde S será igual a (7)
• Si deseamos realizar un intervalo de confianza para la diferencia de medias poblacionales, con ambos s conocidos y distintos, y en donde las xi y las yi poseen cualquier distribución de probabilidades, deberemos usar la expresión (8)
• Si deseamos realizar un intervalo de confianza para la diferencia de medias poblacionales, con ambos s desconocidos y distintos, y en donde las xi y las yi poseen cualquier distribución de probabilidades, deberemos usar la expresión (9)
6. Síntesis

7. Ejercicios
Ejercicio 1:
Un fabricante de fibras sintéticas desea estimar la tensión de ruptura media de una fibra. Diseña un experimento en el que se observan las tensiones de ruptura, en libras, de 16 hilos del proceso seleccionados aleatoriamente. Las tensiones son: 20,8 ; 20,6 ; 21,0 ; 20,9 ; 19,9 ; 20,2 ; 19,8 ; 19,6 ; 20,9 ; 21,1 ; 20,4 ; 20,6 ; 19,7 ; 19,6 ; 20,3 y 20,7.
Supóngase que la tensión de ruptura de una fibra se encuentra modelada por una distribución normal con desviación estándar de 0,45 libras.
Construir un intervalo de confianza estimado del 98% para el valor real de la tensión de ruptura promedio de la fibra.

7. Ejercicios
Ejercicio 2:
La Cámara de Comercio de Buenos Aires se encuentra interesada en estimar la cantidad promedio de dinero que gasta la gente que asiste a convenciones calculando comidas, alojamiento y entretenimiento por día. De las distintas convenciones que se llevan a cabo en la ciudad, se seleccionaron 16 personas y se les preguntó la cantidad que gastaban por día. Se obtuvo la siguiente información en ARS: 150, 175, 163, 148, 142, 189, 135, 174, 168, 152, 158, 184, 134, 146, 155, 163. Si se supone que la cantidad de dinero gastada en un día es una variable aleatoria distribuida normalmente, obtener los intervalos de confianza estimados del 90%, 95% y 98% para la cantidad promedio real.

7. Ejercicios
Ejercicio 3:
Dos universidades financiadas por el gobierno tienen métodos distintos para inscribir a sus alumnos a principios de cada semestre. Las dos desean comparar el tiempo promedio que les toma a los estudiantes completar el trámite de inscripción. En cada universidad se anotaron los tiempos de inscripción para 100 alumnos seleccionados al azar. Las medias y las desviaciones estándares muestrales son las siguientes:
Media Universidad x = 50,2
Desvío Universidad x (Sx): 4,8
Media Universidad y = 52,9
Desvío Universidad y (Sy): 5,4
Si se supone que el muestreo se llevo a cabo sobre dos poblaciones distribuidas normalmente e independientes, obtener los intervalos de confianza estimados del 90%, 95% y 99% para la diferencia de las medias del tiempo de inscripción para las dos Universidades.

7. Ejercicios
Ejercicio 4:
En dos ciudades se llevó a cabo una encuesta sobre el costo de vida para obtener el gasto promedio en alimentación en familias constituidas por cuatro personas. De cada ciudad se seleccionó aleatoriamente una muestra de 20 familias y se observaron sus gastos semanales de alimentación. Las medias y las desviaciones estándares muestrales fueron las siguientes:
Media muestral ciudad x: 135
Desvío muestral ciudad x (Sx): 15
Media muestral ciudad y: 122
Desvío muestral ciudad y (Sy): 10
Si se supone que se muestrearon dos poblaciones independientes con distribución normal cada una y varianzas iguales, obtener los intervalos de confianza estimados del 95% y 99% para la diferencia de medias poblacionales.

7. Ejercicios
Ejemplo 5:
Mediante el uso de los datos del ejercicio 2 obtener un intervalo de confianza estimado del 95% para la varianza poblacional.

Me pueden escribir a:
Las presentaciones estarán colgadas en:
www.cema.edu.ar/u/jrs06
FIN


















