
Construcci on de una base de conocimiento lexico multil ng ...
16
Construcci´ on de una base de conocimiento l´ exico multil´ ıng¨ ue de amplia cobertura: Multilingual Central Repository Building a wide coverage multilingual lexical knowledge base: Multilingual Central Repository Aitor Gonzalez-Agirre Universidad del Pa´ ıs Vasco [email protected] German Rigau Universidad del Pa´ ıs Vasco [email protected] Resumen El uso de recursos sem´ anticos de amplia cobertura y dominio general se ha convertido en una pr´ actica com´ un y a menudo necesaria para los sistemas ac- tuales de Procesamiento del Lenguaje Natural (PLN). WordNet es, con mucho, el recurso sem´ antico m´ as uti- lizado en PLN. Siguiendo el ´ exito de WordNet, el pro- yecto EuroWordNet ha dise˜ nado una infraestructura sem´ antica multiling¨ ue para desarrollar wordnets para un conjunto de lenguas europeas. En EuroWordNet, estos wordnets est´ an interconectados con enlaces in- terling¨ u´ ısticos almacenados en el ´ ındice interlingual (en ingl´ es, interlingual-index o ILI). Siguiendo la ar- quitectura de EuroWordNet, el proyecto MEANING ha desarrollado las primeras versiones del Multilingual Central Repository (MCR) usando un ILI basado en WordNet 1.6. Con ello, se mantiene la compatibilidad entre los wordnets de diferentes idiomas y versiones. Esta versi´ on del MCR integra seis versiones diferen- tes de la WordNet ingl´ es (de 1.6 a 3.0) y tambi´ en wordnets en castellano, catal´ an, euskera e italiano, junto a m´ as de un mill´ on de relaciones sem´ anticas entre conceptos as´ ı como propiedades sem´ anticas de diferentes ontolog´ ıas. Recientemente hemos desarro- llado una nueva versi´ on del MCR usando un ILI ba- sado en WordNet 3.0. Esta nueva versi´ on del MCR integra wordnets de cinco idiomas diferentes: ingl´ es, castellano, catal´ an, euskera y gallego. La versi´ on ac- tual del MCR, al igual que la anterior, integra sis- tem´ aticamente miles de relaciones sem´ anticas entre conceptos. Adem´ as, el MCR se ha enriquecido con cerca de 460.000 propiedades sem´ anticas y ontol´ ogi- cas que incluyen Base Level Concepts, Top Ontology, WordNet Domains y AdimenSUMO, proporcionando coherencia ontol´ ogica a todos los wordnets y recursos sem´ anticos integrados en ella. Palabras clave Sem´ antica L´ exica, Bases de Conocimiento L´ exico, WordNet, EuroWordNet Abstract The use of wide coverage and general domain se- mantic resources has become a common practice and often necesary by existing systems Natural Language Processing (NLP). WordNet is by far the most wi- dely used semantic resource in NLP. Following the success of WordNet, the EuroWordNet project has de- signed a multilingual semantic infrastructure to deve- lop wordnets for a set of European languages. In Eu- roWordNet, these wordnets are interconnected with links stored in the Inter-Lingual Index (ILI). Follo- wing the EuroWordNet architecture, the MEANING project has developed the first versions of Multilingual Central Repository (MCR) using WordNet 1.6 as ILI. Thus, maintaining the compatibility between word- nets of different languages and versions. This version of the MCR integrates six different versions of the En- glish WordNet (1.6 to 3.0) and wordnets in Spanish, Catalan, Basque and Italian, along with more than a million semantic relationships between concepts and semantic properties different ontologies. We recently developed a new version of MCR using WordNet 3.0 as ILI. This new version of the MCR integrates word- nets of five different languages: English, Spanish, Ca- talan, Basque and Galician. The current version of MCR, like the previous one, systematically integrates thousands of semantic relations between concepts. In addition, the MCR is enriched with about 460,000 se- mantic and ontological properties including Base Le- vel Concepts, Top Ontology, WordNet Domains and AdimenSUMO, providing all ontological consistency the integrated semantic wordnets and resources on it. Keywords Lexical Semantics, Lexical Knowledge Bases, Word- Net, EuroWordNet This work is licensed under a Creative Commons Attribution 3.0 License Linguam´ atica — ISSN: 1647–0818 Vol. 5 N´ um. 1 - Julho 2013 - P´ ag. 13–28
Transcript of Construcci on de una base de conocimiento lexico multil ng ...

Construccion de una base de conocimiento
lexico multilıngue de amplia cobertura:Multilingual Central Repository
Building a wide coverage multilingual lexical knowledge base:
Multilingual Central Repository
Aitor Gonzalez-AgirreUniversidad del Paıs Vasco
German RigauUniversidad del Paıs Vasco
Resumen
El uso de recursos semanticos de amplia coberturay dominio general se ha convertido en una practicacomun y a menudo necesaria para los sistemas ac-tuales de Procesamiento del Lenguaje Natural (PLN).WordNet es, con mucho, el recurso semantico mas uti-lizado en PLN. Siguiendo el exito de WordNet, el pro-yecto EuroWordNet ha disenado una infraestructurasemantica multilingue para desarrollar wordnets paraun conjunto de lenguas europeas. En EuroWordNet,estos wordnets estan interconectados con enlaces in-terlinguısticos almacenados en el ındice interlingual(en ingles, interlingual-index o ILI). Siguiendo la ar-quitectura de EuroWordNet, el proyecto MEANINGha desarrollado las primeras versiones del MultilingualCentral Repository (MCR) usando un ILI basado enWordNet 1.6. Con ello, se mantiene la compatibilidadentre los wordnets de diferentes idiomas y versiones.Esta version del MCR integra seis versiones diferen-tes de la WordNet ingles (de 1.6 a 3.0) y tambienwordnets en castellano, catalan, euskera e italiano,junto a mas de un millon de relaciones semanticasentre conceptos ası como propiedades semanticas dediferentes ontologıas. Recientemente hemos desarro-llado una nueva version del MCR usando un ILI ba-sado en WordNet 3.0. Esta nueva version del MCRintegra wordnets de cinco idiomas diferentes: ingles,castellano, catalan, euskera y gallego. La version ac-tual del MCR, al igual que la anterior, integra sis-tematicamente miles de relaciones semanticas entreconceptos. Ademas, el MCR se ha enriquecido concerca de 460.000 propiedades semanticas y ontologi-cas que incluyen Base Level Concepts, Top Ontology,WordNet Domains y AdimenSUMO, proporcionandocoherencia ontologica a todos los wordnets y recursossemanticos integrados en ella.
Palabras clave
Semantica Lexica, Bases de Conocimiento Lexico,
WordNet, EuroWordNet
Abstract
The use of wide coverage and general domain se-mantic resources has become a common practice andoften necesary by existing systems Natural LanguageProcessing (NLP). WordNet is by far the most wi-dely used semantic resource in NLP. Following thesuccess of WordNet, the EuroWordNet project has de-signed a multilingual semantic infrastructure to deve-lop wordnets for a set of European languages. In Eu-roWordNet, these wordnets are interconnected withlinks stored in the Inter-Lingual Index (ILI). Follo-wing the EuroWordNet architecture, the MEANINGproject has developed the first versions of MultilingualCentral Repository (MCR) using WordNet 1.6 as ILI.Thus, maintaining the compatibility between word-nets of different languages and versions. This versionof the MCR integrates six different versions of the En-glish WordNet (1.6 to 3.0) and wordnets in Spanish,Catalan, Basque and Italian, along with more than amillion semantic relationships between concepts andsemantic properties different ontologies. We recentlydeveloped a new version of MCR using WordNet 3.0as ILI. This new version of the MCR integrates word-nets of five different languages: English, Spanish, Ca-talan, Basque and Galician. The current version ofMCR, like the previous one, systematically integratesthousands of semantic relations between concepts. Inaddition, the MCR is enriched with about 460,000 se-mantic and ontological properties including Base Le-vel Concepts, Top Ontology, WordNet Domains andAdimenSUMO, providing all ontological consistencythe integrated semantic wordnets and resources on it.
Keywords
Lexical Semantics, Lexical Knowledge Bases, Word-
Net, EuroWordNet
This work is licensed under aCreative Commons Attribution 3.0 License
Linguamatica — ISSN: 1647–0818Vol. 5 Num. 1 - Julho 2013 - Pag. 13–28

1 Introduccion
A pesar del progreso realizado en los ultimosanos en el area del Procesamiento del LenguajeNatural (PLN), aun estamos lejos de comprenderautomaticamente textos en lenguaje natural. Eluso de bases de conocimiento de amplia cobertu-ra es una practica comun en los sistemas de PLNavanzados. Sin duda, la base de conociminto masutilizada es WordNet1 (Fellbaum, 1998). No obs-tante, la construccion de bases de conocimientocon cobertura suficiente pare procesar textos dedominio general requiere de un esfuerzo enorme.Este esfuerzo solo pueden realizarlo grandes gru-pos de investigacion durante largos periodos dedesarrollo. Por ejemplo, en el caso del WordNetdesarrollado en Princeton para el ingles, en masde diez anos de construccion manual (desde 1995hasta 2006, es decir, de la version 1.5 a la 3.0)crecio de 103.445 a 235.402 relaciones semanti-cas2, lo que representa un crecimiento de apro-ximadamente mil nuevas relaciones por mes. Sinembargo, en 2008, el grupo de Princeton distri-buyo un nuevo recurso con 458.825 palabras delas definiciones de WordNet, manualmente anota-das con el correspondiente sentido de WordNet3.Afortunadamente, en los ultimos anos, la comuni-dad investigadora ha desarrollado un amplio con-junto de recursos semanticos de amplia cobertu-ra vinculados a distantas versiones de WordNet.A lo largo de los ultimos anos, muchos de es-tos recursos han sido integrados en el Multilin-gual Central Repository (MCR) (Atserias et al.,2004; Gonzalez-Agirre, Laparra e Rigau, 2012a;Gonzalez-Agirre, Laparra e Rigau, 2012b). ElMCR sigue el modelo propuesto por el proyec-to europeo EuroWordNet4 (LE-2 4003) (Vossen,1998). EuroWorNet diseno una base de la datoslexical multilingue con wordnets de varios idio-mas europeos, estructuras de forma analoga alWordNet ingles. La version actual del MCR esel resultado del Proyecto Europeo MEANING5
(IST-2001-34460) (Rigau et al., 2002), ası co-mo de los proyectos KNOW6 (TIN2006-15049-C03), KNOW27 (TIN2009-14715-C04) y de va-rias acciones complementarias asociadas al pro-yecto KNOW2.
El artıculo esta estructurado como sigue: Enla seccion 2 realizamos un repaso de las basesde conocimiento lexico existentes, introduciendo
1http://wordnet.princeton.edu2Las relaciones simetricas solo se contabilizan una vez.3http://wordnet.princeton.edu/glosstag.shtml4http://www.illc.uva.nl/EuroWordNet5http://nlp.lsi.upc.edu/projectes/meaning6http://ixa.si.ehu.es/know7http://ixa.si.ehu.es/know2
tambien la primera version del Multilingual Cen-tral Repository (MCR). A continuacion la seccion3 presenta la ultima version del MCR y el WebEuroWordNet Interface (WEI), incluyendo unadetallada descripcion de la estructura de la ba-se de satos empleada para implementar el MCR.Por ultimo, en la seccion 4 redactamos algunasconclusiones, y marcamos el camino para traba-jos futuros.
2 Bases de Conocimiento Lexicas
Este seccion proporciona una revision de lasbases de conocimiento lexico para el Procesa-miento de Lenguaje Natural (PLN). La seccionesta dividida en tres partes. Primero, el aparta-do 2.1 revisa los conceptos mas importantes re-lacionados con las tareas de PLN, y el uso delos recursos semanticos de amplia cobertura. Elsiguiente apartado presenta las principales me-todologıas, estrategias y tecnicas empleadas parala construccion manual de recursos semanticos degran tamano (apartado 2.2). Finalmente, el apar-tado 2.3 presenta la primera version del Multilin-gual Central Repository (MCR).
2.1 Conocimiento Lexico y PLN
En el contexto del Procesamiento del Lengua-je Natural (PLN), la semantica estudia el signifi-cado, y en concreto se centra en la relacion entresignificantes, tales como las palabras, las frases,los signos y sımbolos. En particular, la SemanticaLexica estudia el significado individual de las pa-labras y sus relaciones. La semantica lexica tam-bien estudia como esta organizado el lexico y co-mo el significado lexico esta interrelacionado. Sumayor objetivo es estructurar un modelo de lexi-co a traves de la categorizacion de tipos de rela-cion entre palabras. La semantica lexica se centraen el estudio de las unidades lexicas. Las unida-des lexicas son los elementos basicos de un lexico(el vocabulario) y pueden ser consideradas comola unidad mınima de significado.
2.2 Construccion manual de Bases de Co-nocimiento
La tarea de Procesamiento de Lenguaje Na-tural (PLN) requiere de enormes bases de co-nocimiento semantico como respaldo de procesossemanticos intensos. Por ello, en los ultimos anosel desarrollo de recursos lexicos y semanticos deamplia cobertura ha sido un objetivo prioritariode investigacion.
14– Linguamatica Aitor Gonzalez-Agirre e German Rigau

La construccion de estas bases de conocimien-to requiere del esfuerzo de grandes grupos de in-vestigacion a lo largo de periodos de desarrolloprolongados. Sin embargo, estas bases de conoci-miento, aun hoy en dıa, no parecen ser lo suficien-temente ricos como para se empleados directa-mente en aplicaciones semanticas avanzadas. Pa-rece que las aplicaciones de PLN no podran me-jorar sin la incorporacion de conocimiento masdetallado, rico y de proposito general.
Es mas, todos los idiomas encapsulan el cono-cimiento de modos distintos. Esta variacion en-tre idiomas es uno de los problemas principalesque impide el uso extendido de las tecnologıasde PLN. Una de las soluciones propuestas es lade adoptar una representacion conceptual comunque factorice la variacion dentro de un idioma ytambien con el resto de los idiomas.
La necesidad de grandes bases de conocimien-to semantico se puede vislumbrar observando lacantidad de proyectos que actualmente constru-yen recursos de este tipo. Proyectos como Word-Net8 (Fellbaum, 1998), FrameNet9 (Baker, Fill-more e Lowe, 1998), VerbNet10 (Kipper et al.,2006), SUMO11 (Niles e Pease, 2001) o Cyc12
(Lenat, 1995) han dedicado decadas y miles dehoras de trabajo a la construccion manual de es-tos recursos de conocimiento semantico. Por des-gracia, la construccion manual de estos recursoslimita de forma severa su cobertura y escala.
Por ejemplo, la gran mayorıa de ontologıas for-males se han desarrollado para dominios particu-lares13. Las ontologıas son representaciones for-males de un conjunto de conceptos dentro de undominio, y de la relaciones entre dichos concep-tos, normalmente incluyendo una taxonomıa y unconjunto de relaciones semanticas. Las ontologıassuelen ser empleadas para razonar sobre las pro-piedades de dichos dominios, y tambien puedenser usadas para definir el dominio en sı (Alvez,Lucio e Rigau, 2012).
2.2.1 WordNet
WordNet14 (Miller et al., 1991; Fellbaum,1998) es una base de conocimiento lexica para elidioma ingles. Esta inspirada por teorıas psico-linguisticas y computacionales sobre la memoria
8http://wordnet.princeton.edu9http://framenet.icsi.berkeley.edu
10http://verbs.colorado.edu/~mpalmer/projects/verbnet.html
11http://www.ontologyportal.org/12http://www.cyc.com13http://protegewiki.stanford.edu/wiki/Protege_
Ontology_Library14http://wordnet.princeton.edu/
lexica humana. Contiene informacion codificadamanualmente sobre nombres, verbos, adjetivos yadverbios del ingles, y esta organizada entornoa la nocion de synset. Un synset es un conjuntode palabras de la misma categorıa morfosintacti-ca que pueden ser intercambiados en un contex-to dado. Por ejemplo, 〈student, pupil, educatee〉forman un synset porque pueden ser utilizadospara referirse al mismo concepto. Un synset escomunmente descrito por una gloss o definicion,que en el caso del synset anterior es “a lear-ner who is enrolled in an educational institu-tion”, y ademas, por un conjunto explıcito de re-laciones semanticas con otros synsets. Cada syn-set representa un concepto que esta relaciona-do con otros conceptos mediante una gran va-riedad de relaciones semanticas, incluyendo hi-peronimia/hiponimia, meronimia/holonimia, an-tonimia, etc. Los synsets estan enlazados entreellos mediante relaciones lexicas y semantico-conceptuales. WordNet tambien codifica 26 ti-pos diferentes de relaciones semanticas. WordNetesta disponible de modo publico y gratuito parasu descarga. La version actual de WordNet es la3.1. Su estructura lo convierte en una herramien-ta util para la linguıstica computacional y el pro-cesamiento de lenguaje natural. Resulta evidenteque WordNet se ha convertido en un estandar enel PLN. De hecho, WordNet es usado en todoel mundo como base para anclar distintos tiposde conocimiento semantico, incluyendo wordnetsde otros idiomas (Vossen, 1998), conocimiento dedominios (Magnini e Cavaglia, 2000) u ontologıas
como la Top Ontology (Alvez et al., 2008) o Adi-
menSUMO (Alvez, Lucio e Rigau, 2012).
WordNet ha sido creado y esta siendo man-tenido por el Cognitive Science Laboratory de laUniversidad de Princeton inicialmente bajo la di-reccion del profesor George A. Miller y actual-mente por la profesora Christiane D. Fellbaum.Su desarrollo comenzo en 1985. A lo largo de losanos el proyecto ha recibido financiacion de dife-rentes agencias del gobierno americano. WordNetha sido empleado en una amplia variedad de ta-reas de PLN, tales como Information Extraction(Stevenson e Greenwood, 2006), Automatic Sum-maritzation (Chaves, 2001), Question Answering(Moldovan e Rus, 2001), Lexical Expansion (Pa-rapar, Barreiro e Losada, 2005), etc.
La difusion y el exito de WordNet ha provo-cado la aparicion de multitud de proyectos conel objetivo de construir wordnets para otros idio-mas, tomando como referencia la version inglesa.Por ejemplo, catalan (Benıtez et al., 1998), cas-tellano (Atserias et al., 1997), euskera (Agirre et
Multilingual Central Repository Linguamatica – 15

al., 2002), arabe (Rodrıguez et al., 2008), etc. 15
Algunos esfuerzos se han centrado en el desa-rrollo de wordnets multilingues, como EuroWord-Net16 (Vossen, 1998), MultiWordNet17 (Pianta,Bentivogli e Girardi, 2002), Balkanet (Stamouet al., 2002b) o mas recientemente, el Word-Net Asiatico18 (Sornlertlamvanich, Charoenporne Isahara, 2010), o wordnets de dominios parti-culares, como EuroTerm (Stamou et al., 2002a)o JurWordNet19 (Sagri, Tiscornia e Bertagna,2004).
La Global WordNet Association20 es una or-ganizacion sin fines lucrativos que proporcionaun marco para establecer contactos, compartir ydiscutir sobre los wordnets que se desarrollan entodos los idiomas del mundo.
2.2.2 EuroWordNet
El proyecto EuroWordNet21 (Vossen, 1998) di-seno una arquitectura completa para el desarrollode una base de conocimiento multilingue que in-cluyera varios wordnets de idiomas europeos (en-tre ellos, holandes, italiano, castellano, aleman,frances, checo y estonio). En EuroWordNet, cadaWordNet representa un unico sistema interno delexicalizaciones siguiendo la estructura del word-net ingles. Los wordnets de los distintos idio-mas estan ligados mediante el Inter-Lingual In-dex (abreviado como ILI). Estas conexiones per-miten acceder a palabras similares en cualquie-ra de los idiomas integrados en el arquitecturaEuroWordNet. Ademas, el ILI da acceso a unaontologıa linguıstica compuesta por 63 relacionessemanticas distintas. Esta ontologıa proporcionauna categorizacion comun para todos los idiomas,mientras que las distinciones especıficas de cadaidioma estan en cada uno de los wordnets locales.
Aunque el proyecto EuroWordNet se con-cluyo en el verano de 1999, muchos de sus princi-pios siguen aun vigentes. Por ejemplo, el disenode la arquitectura multilingue, los Base Concepts,las relaciones, la ontologıa, etc. se han seguidousando por grupos de investigacion que estandesarrollando wordnets en otros idiomas (comopor ejemplo, el castellano, el euskera, el catalany el gallego) usando buena parte de la especifica-
15Una lista de wordnets actualmente en desarrollo pue-de encontrarse en http://www.globalwordnet.org/gwa/wordnet_table.html
16http://www.illc.uva.nl/EuroWordNet/17http://multiwordnet.fbk.eu/18http://www.asianwordnet.org19http://www.ittig.cnr.it/Ricerca/materiali/
JurWordNet/JurWordNetEng.htm20http://www.globalwordnet.org21http://www.illc.uva.nl/EuroWordNet/
cion de EuroWordNet. Si los wordnets son com-patibles con la especificacion, pueden ser anadi-dos a una base de datos comun, y mediante el ILI,ser conectados con otros wordnets, permitiendo eluso aplicaciones multilingues de lenguaje natural.
2.2.3 Base Concepts
The nocion de los Base Concepts (a partir deahora BC) fue introducida en EuroWordNet. Sesupone que los BC son conceptos que juegan unpapel importante en los diversos wordnets de di-ferentes idiomas. Este rol puede ser definido me-diante dos criterios principales:
Una posicion elevada en la jerarquıasemantica.
Tener muchas relaciones con otros concep-tos.
Por lo tanto, los BC son los bloques fundamen-tales para el establecimiento de relaciones en unwordnet y dar informacion acerca de los patro-nes dominantes de lexicalizacion en los idiomas.De este modo, los Lexicografic Files (o Super-sentidos) de WordNet pueden ser consideradoscomo el conjunto mas basico de BC. Siguiendoestos criterios, en EuroWordNet se selecciono unconjunto de BC para que se alcanzara un maximode cobertura y compatibilidad durante el desa-rrollo de los wordnets de los distintos idiomas.Inicialmente, se selecciono un conjunto de 1.024Common Base Concepts extraıdos de WordNet1.5 (conceptos que actuan como BC en al menosdos idiomas), considerando solamente los word-nets en ingles, holandes, espanol e italiano.
Los Basic Level Concepts (Rosch e Lloyd,1978) (a partir de ahora BLC) son el resultadode un compromiso entre dos principios de carac-terizacion opuestos:
Representar tantos conceptos como sea po-sible.
Representar tantas caracterısticas como seaposible.
Ası, los BLC tıpicamente deberıan ocurrir enniveles de abstraccion medios, es decir, en po-siciones intermedias de las jerarquıas. Con es-ta idea en mente, disenamos un algoritmo queutiliza propiedades estructurales basicas de cual-quier version de WordNet para obtener un con-junto completo de BLC que represente a todossus sustantivos y verbos (Izquierdo, Suarez e Ri-gau, 2007)22. Para seleccionar los BLCs de forma
22http://adimen.si.ehu.es/web/BLC
16– Linguamatica Aitor Gonzalez-Agirre e German Rigau

automatica, el programa calcula el numero totalde relaciones del synset o el numero de relacionesde hiponımia y descarta los BLCs que no repre-sentan al menos un numero determinado de syn-sets descendientes. Estos BLCs automaticos sehan utilizado para Word Sense Disambiguationbasada en clases semanticas (Izquierdo, Suarez eRigau, 2009; Izquierdo, Suarez e Rigau, 2010) ypara facilitar la conexion de WordNet con la on-tologıa del proyecto KYOTO (Laparra, Rigau eVossen, 2012).
2.2.4 Top Ontology
Para maximizar un desarrollo uniforme yconsistente de los wordnets, el proyecto Euro-WordNet categorizo los Base Concepts usandola Top Ontology, que fue disenado especıfica-mente para este proposito. La Top Ontology23
(Rodrıguez et al., 1998) esta basada en clasi-ficaciones linguısticas ya existentes y adapta-da para representar la diversidad de los Ba-se Concepts. Es importante tener en cuentaque los Top Concepts representan caracterısti-cas semanticas que puede ser aplicadas de formaconjuntiva. Por ejemplo, es posible obtener gru-pos complejos de caracteristicas, como Contai-ner+Living+Part+Solid, que puede ser aplicado,por ejemplo, a un “vaso sanguıneo”.
El primer nivel de la Top Ontology esta divi-dido en tres tipos:
1stOrderEntity (corresponde a objetos y sus-tancias concretas y perceptibles)
2ndOrderEntity (estados, situaciones yeventos)
3rdOrderEntitiy (entidades mentales comolas ideas, conceptos y conocimientos)
Ası, la Top Ontology de EuroWordNet esta or-ganizada mediante 63 caracterısticas que puedenser combinadas. La ontologıa esta especialmen-te disenada para ayudar en la codificacion de lasrelaciones lexico-semanticas en WordNet. Sin em-bargo, durante el proyecto EuroWordNet solo sepudieron caracterizar con etiquetas de la TO losBase Concepts (BC) seleccionados en el proyecto.
Muchas de las subdivisiones de la TO son dis-juntas. Por ejemplo, un concepto no puede ser ala vez Natural y Artifact. Explotando estas in-compatibilidades entre las caracterısticas de laTO podemos localizar inconsistencias ontologicasen la jerarquıa de WordNet. Para ello, simple-mente debemos heredar las caracterısticas de la
23http://www.illc.uva.nl/EuroWordNet/corebcs/ewnTopOntology.html
TO asignadas a los BC a traves de la jerarquıa dehiponimia de WordNet. Para evitar la herencia decategorıas incompatibles podemos incluir algunospuntos de bloqueo en la jerarquıa de hiponimia.De esta forma, hemos desarrollado un conjuntode herramientas para el control de la consisten-cia de la anotacion y obtener su expansion. Parademostrar la consistencia de la anotacion, hemoscomprobado que no hay incompatibilidad en laanotacion de la parte nominal de WordNet 1.6cuando se utilizan los puntos de bloqueo. La ex-pansion de la anotacion se puede obtener cuandola anotacion es consistente. Siguiendo este pro-ceso hemos obtenido una anotacion consistentede la parte nominal de WorNet24 (Alvez et al.,2008).
2.2.5 WordNet Domains
Uno de los problemas de WordNet es su ni-vel de granularidad. Hay conceptos cuyas dife-rencias a nivel semantico son virtualmente inde-tectables. WordNet Domains25 (WND) (Mag-nini et al., 2002) es un recurso lexico desarrolladoen el ITC-IRST por (Magnini e Cavaglia, 2000)donde los synsets han sido anotados de un modosemi-automatico con una o mas etiquetas de do-minio, escogidas de un conjunto de 165 etiquetasorganizadas jerarquicamente. Los usos de WNDincluyen el poder de reducir el nivel de polisemiade las palabras y agrupar aquellos sentidos quepertenecen al mismo dominio. Por ejemplo, pa-ra la palabra bank (banco, en ingles), siete de susdiez sentidos en WordNet no comparten dominio,reduciendo de este modo la polisemia. Ademas,un dominio puede incluir synsets de diferentescategorıas morfosintacticas. Por ejemplo, MEDI-CINE puede contener sentidos de nombres y deverbos. Un dominio tambien puede incluir senti-dos de diferentes sub-jerarquias de WordNet. Porejemplo SPORTS tiene conceptos subclase de li-feform, physical-object, act, location, etc. Sin em-bargo, la construccion de WND ha seguido unproceso semi-automatico y aunque su anotacionha sido revisada (Bentivogli et al., 2004), aunpodemos encontrar facilmente muchas inconsis-tencias en su anotacion (Castillo, Real e Rigau,2004). Es por ello que se han propuesto y desa-rrollado metodos mas robustos para la asigna-cion de etiquetas de dominio a traves de Word-Net (Gonzalez, Rigau e Castillo, 2012; Gonzalez-Agirre, Castillo e Rigau, 2012).
24http://adimen.si.ehu.es/web/WordNet2TO25http://wndomains.fbk.eu/
Multilingual Central Repository Linguamatica – 17

2.2.6 SUMO y AdimenSUMO
SUMO26 (Niles e Pease, 2001) fue creadopor el IEEE Standard Upper Ontology WorkingGroup. Su objetivo era desarrollar una ontologıaestandard de alto nivel para promover el inter-cambio de datos, la busqueda y extraccion deinformacion, la inferencia automatica y el pro-cesamiento del lenguaje natural. SUMO proveedefiniciones para terminos de proposito generalresultantes de fusionar diferentes ontologıas li-bres de alto nivel (ej. la ontologıa de alto nivelde Sowa, axiomas temporales de Allen, mereoto-pologıa formal de Guarino, etc.).
SUMO consiste en un conjunto de conceptos,relaciones y axiomas que formalizan una onto-logıa de alto nivel. Una ontologıa de alto nivelesta limitada a conceptos que son meta, generi-cos o abstractos. Por tanto, estos conceptos sonsuficientemente genericos como para caracterizarun amplio rango de dominios. Aquellos conceptosque son de dominios especificos o particulares noestan incluidos en una ontologıa de alto nivel.
SUMO esta organizada en tres niveles. La par-te superior y la parte central consisten en aproxi-madamente 1.000 terminos y 4.000 axiomas, de-pendiendo de la version. El tercer nivel contieneontologıas de dominio. En total, cuando todas lasontologıas de dominio son combinadas, SUMOconsiste en aproximadamente 20.000 terminos ycerca de 70.000 axiomas.
Ademas, los desarrolladores de SUMO hancreado un enlace completo a WordNet (Niles ePease, 2003).
AdimenSUMO27 (Alvez, Lucio e Rigau, 2012)es una reconversion de SUMO a una ontologıade primera orden operativa. Ası, AdimenSUMOpuede ser utilizada para el razonamiento formalpor demostradores de teoremas de logicas de pri-mer orden (como E-prover o Vampire). Al estartambien enlazado a WordNet, AdimenSUMO seconvierte en una herramienta muy potente pa-ra realizar razonamiento avanzado. Por ejemplo,utilizando demostradores de teoremas avanzados,es facil inferir de AdimenSUMO que ningunaplanta tiene cerebro (ni otras partes de animal).
2.3 Multilingual Central Repository
Uno de los principales resultados del proyec-to MEANING28 fue el desarrollo de la prime-ra version del Multilingual Central Repository
26http://www.ontologyportal.org27http://adimen.si.ehu.es/web/AdimenSUMO28http://nlp.lsi.upc.edu/projectes/meaning
(MCR)29 (Atserias et al., 2004) para mantener lacompatibilidad entre wordnets de distintos idio-mas y versiones, tanto nuevos como anteriores,ası como el nuevo conocimiento que se fuera ad-quiriendo.
Todo el diseno del MCR sigue la arquitecturapropuesta por EuroWordNet. Esta arquitecturahace posible desarrollar wordnets locales de for-ma relativamente independiente, garantizando almismo tiempo un alto nivel de compatibilidad.Esta estructura multilingue permite transportarel conocimiento de un wordnet al resto de word-nets a traves del ILI (Inter-Lingual Index), man-teniendo la compatibilidad entre todos ellos. Deesta forma, la estructura del ILI (incluyendo laTop Ontology (Vossen et al., 1997), Wordnet Do-mains (Magnini e Cavaglia, 2000) y la ontologıaSUMO (Niles e Pease, 2001)) actua como la co-lumna vertebral que permite transferir el cono-cimiento adquirido de cada uno de los wordnetslocales al resto. Del mismo modo, los diferentesrecursos (ej. las diferentes ontologıas) estan rela-cionadas mediante el ILI, y en consecuencia tam-bien pueden ser validados entre ellos (Alvez et
al., 2008; Alvez, Lucio e Rigau, 2012).
El MCR solo incluye conocimiento concep-tual. Esto significa que tan solo las relacionessemanticas entre synsets pueden ser integradas ytransportadas entre los diferentes wordnets. Aunası, cuando sea necesario, las relaciones adqui-ridas pueden mantenerse sub-especificadas. Enese sentido, pueden integrarse y transportarse aotros idiomas o procesos. Por ejemplo, la relacion<gain> involved <money> capturada como unobjeto-directo tıpico, mas tarde puede detallar-se como <gain> involved-patient <money> y serportada al wordnet en castellano como <ganar>involved-patient <dinero>.
La version del MCR desarrollada en el marcodel proyecto MEANING contiene seis versionesdistintas del WordNet ingles (Fellbaum, 1998)(de la 1.5 a la 3.0) junto con mas de un millon derelaciones semanticas entre synsets adquiridas deWordNet, eXtended WordNet (Mihalcea e Mol-dovan, 2001), y preferencias de seleccion adquiri-das de SemCor (Agirre e Martınez, 2001; Agirree Martınez, 2002) y del British National Corpus(BNC) (McCarthy, 2001). Esta version del MCRtambien incluye wordnets del castellano (Atseriaset al., 1997), italiano (Bentivogli, Pianta e Girar-di, 2002), euskera (Agirre et al., 2002) y catalan(Benıtez et al., 1998). Esta version usa un ILIbasado en WordNet 1.6.
Como estos recursos han sido desarrolladosusando diferentes versiones de WordNet (de la
29http://adimen.si.ehu.es/web/MCR
18– Linguamatica Aitor Gonzalez-Agirre e German Rigau

1.5 a la 3.0), hemos tenido que aplicar una tecno-logıa que alineara los wordnets automaticamen-te WordNet Mappings30 (Daude, 2005). Estatecnologıa proporciona enlaces entre synsets dediferentes versiones de WordNets, manteniendola compatibilidad de todos los recursos que usanuna determinada version de WordNet. Ademas,esta tecnologıa permite realizar el transporte detodo el conocimiento asociado a una version deWordNet al resto de versiones.
Al termino del proyecto MEANING, el MCRha continuado su desarrollo y mejora en los pro-yectos nacionales KNOW31 y KNOW232, ası co-mo varias acciones complementarias, con especialenfasis en los idiomas ingles, castellano, catalan,euskera y gallego.
La version actual del MCR integra, siguiendola arquitectura EuroWordNet, wordnets de cin-co idiomas diferentes: ingles, castellano, catalan,euskera y gallego. El Inter-Lingual-Index (ILI)permite la conectividad entre las palabras en unidiomas con las traducciones equivalentes en cual-quiera de las otras lenguas gracias a los enlacesgenerados automaticamente. El ILI actual corres-ponde a la version 3.0 de WordNet.
Por ello, el MCR constituye un recurso mul-tilingue de amplia cobertura que puede ser degran utilidad para un gran numero de pro-cesos semanticos que requieren de conocimien-tos linguıstico-semanticos ricos y complejos (porejemplo, ontologıas para la web semantica). Ası,el MCR esta siendo utilizado en multiples proyec-tos y desarrollos. Por ejemplo, los proyectos euro-peos KYOTO33, PATHS34, OpeNER35 y News-Reader36, y el proyecto nacional SKaTer37.
2.3.1 MCR usando ILI 1.6
La version del MCR que usa un ILI basado enWordNet 1.6 tiene los siguientes componentes:
ILI (version WordNet 1.6):
• WordNet 1.6 (Fellbaum, 1998)
• Base Concepts (Izquierdo, Suarez e Ri-gau, 2007)
• Top Ontology (Alvez et al., 2008)
30http://www.talp.upc.edu/index.php/technology/resources/multilingual-lexicons-and-machine-translation-resources/multilingual-lexicons/98-wordnet-mappings
31http://ixa2.si.ehu.es/know32http://ixa2.si.ehu.es/know233http://www.kyoto-project.eu34http://www.paths-project.eu35http://www.opener-project.org/36http://www.newsreader-project.eu/37http://nlp.lsi.upc.edu/skater
• WordNet Domains (Bentivogli et al.,2004)
• AdimenSUMO (Alvez, Lucio e Rigau,2012)
Wordnets locales:
• WordNet ingles: versiones 1.5, 1.6, 1.7.1,2.0, 2.1, 3.0 (Fellbaum, 1998)
• wordnets castellano y catalan (Benıtezet al., 1998), italiano (Bentivogli, Piantae Girardi, 2002) y euskera (Agirre et al.,2002).
• eXtended WordNet (Mihalcea e Moldo-van, 2001)
Preferencias semanticas:
• Adquiridas de SemCor (Agirre eMartınez, 2002)
• Adquiridas del BNC (McCarthy, 2001)
Instancias
• Entidades nombradas (Alfonseca e Ma-nandhar, 2002)
Inicialmente, la mayor parte del conocimien-to que pretendıamos integrar en el MCR estabaalineado a WordNet 1.6, el WordNet italiano ode MultiWordNet Domains, estos ultimos desa-rrollados usando un ILI basado en WordNet 1.6(Bentivogli, Pianta e Girardi, 2002; Magnini eCavaglia, 2000). Por tanto, el MCR usando unILI basado en WordNet 1.6 minimizaba efectossecundarios con otras iniciativas europeas (pro-yectos Balkanet, EuroTerm, etc.) y otros word-nets desarrollados alrededor de la Global Word-Net Association. Sin embargo, el ILI para loswordnets del castellano, catalan y euskera era elWordNet 1.5 (Atserias et al., 1997; Benıtez et al.,1998), ası como la Top Ontology de EuroWord-Net y los Base Concepts asociados. Por tanto,estos ultimos recursos debieron transportarse ala version WordNet 1.6 (Atserias, Villarejo e Ri-gau, 2003). Ademas, la version final del MCR conILI basado en WordNet 1.6 terminada al finaldel proyecto KNOW2 contiene versiones mejora-das de Base Concepts (Izquierdo, Suarez e Rigau,
2007), Top Ontology (Alvez et al., 2008), Word-Net Domains (Bentivogli et al., 2004) y Adimen-
SUMO (Alvez, Lucio e Rigau, 2012). Sin embar-go, muchos de sus componentes tenıan licenciasrestrictivas y no podıan distribuirse de forma li-bre e integrada con el resto del MCR38. Por ello, ypara actualizar los recursos existentes decidimosactualizar el ILI a WordNet 3.0.
38Esta version puede consultarse en http://adimen.si.ehu.es/cgi-bin/wei1.6/public/wei.consult.perl
Multilingual Central Repository Linguamatica – 19

3 Multilingual Central Repository 3.0
La version actual del MCR usa un ILI basa-do en WordNet 3.0 e integra, siguiendo el mo-delo propuesto por EuroWordNet y MEANING,wordnets de cinco idiomas distintos, incluyendoel ingles, castellano, catalan, euskera y gallego.Como en la version anterior, los wordnets estanconectados a traves del Inter-Lingual-Index (ILI)permitiendo conectar palabras de un idioma conlas palabras equivalentes en los otros idiomastambien integrados en el MCR. Como la versionactual del ILI del MCR es la correspondiente ala version 3.0 del WordNet en ingles, la mayorıadel conocimiento ontologico ha sido transportadodesde las versiones anteriores al nuevo MCR 3.0.Ası, la mayorıa de los recursos transportados hantenido que ser alineados a la nueva version. Ladescripcion completa del proceso empleado parallevar a cabo el transporte y actualizacion de to-dos los recursos se puede consultar en (Gonzalez-Agirre, Laparra e Rigau, 2012b; Gonzalez-Agirre,Laparra e Rigau, 2012a).
Ademas, para poder interactuar con el MCRy actualizar su contenido, hemos actualizado elWeb EuroWordNet Interface (WEI), una nuevainterfaz web para navegar y editar el MCR 3.0.
3.1 Web EuroWordNet Interface
El Web EuroWordNet Interface (WEI)(Benıtez et al., 1998) permite consultar y editarla informacion contenida en el MCR. WEI usatechnologıa CGI, lo que significa que todos losdatos se procesan solo en el servidor y los usua-rios trabajan con clientes ligeros con capacidadde navegacion web HTML. Todos los datosse almacenan en una base de datos MySQL.La interfaz se ha ido actualizando desde sudesarrollo inicial en el proyecto EuroWordNet.
WEI permite navegar, consultar y editar la in-formacion asociada a un item (que puede ser unsynset, una palabra, un variant o un ILI) de unode los wordnets integrados en el MCR. La apli-cacion WEI consulta la informacion correspon-diente a ese item y la informacion ontologica aso-ciada a los ILIs correspondientes. La aplicaciontambien permite consultar por los synsets rela-cionados del propio wordnet origen de la consul-ta (usando las relaciones codificadas en el MCRde hiperonimia, hiponimia, meronimia, etc.), ode algun otro wordnet integrado en el MCR (atraves del ILI).
La aplicacion consta de dos marcos. En el mar-co superior introducimos los parametros para labusqueda, y en inferior nos muestra los resulta-
dos de la consulta. Los diferentes parametros debusqueda son los siguientes:
Item: el item que pretendemos buscar, quepuede ser una palabra, un synset, un varianto un ILI.
Tipo de item: el tipo del item que pre-tendemos buscar (palabra, variant, synset oILI).
PoS: la categorıa gramatical del item (nom-bres, verbos, adjetivos o adverbios).
Relacion: que se carga dinamicamente des-de la base de datos (sinonimos, hiponimos,hiperonimos, etc.)
WordNet origen: el wordnet desde donderealizamos la consulta.
WordNet navegacion: el wordnet al cualseguimos las relaciones.
Glossa: si esta seleccionado se muestran lasglosas de los synsets.
Score: si esta seleccionado se muestran losvalores de confianza.
Rels: si esta seleccionado muestra informa-cion acerca de las relaciones que el synsettiene en todos los wordnets seleccionados.
Full: si esta seleccionado realiza una busque-da transitiva por todas las relaciones.
WordNets mostrados: wordnets seleccio-nados.
WEI tambien permite editar el contenido delMCR. Su funcionamiento es exactamente igual ala consulta, pero en modo edicion, tanto los syn-sets como los ILIs pueden seleccionarse y editar-se. Al editar un synset nos aparece una pantallade donde podemos anadir, eliminar o modificarlos variants del synset, modificar su glosa y ejem-plos, ası como las relaciones que tiene con otrossynsets (en la Figura 1 se puede ver un ejemplopara el sentido 1 de “party”). Al editar un ILI nosaparece una pantalla donde podremos anadir, eli-minar o modificar la informacion ontologica aso-ciada al ILI.
3.1.1 Marcas para synsets y variants
En la nueva version del WEI es posible asig-nar propiedades especiales o marcas a variantsy a synsets. Tambien podemos anadir una pe-quena nota o comentario que especifica mejorpor que hemos asignado una marca determina-da. Uno de los objetivos de las marcas es permi-tir una edicion mas rapida mediante WEI, siendo
20– Linguamatica Aitor Gonzalez-Agirre e German Rigau

Figura 1: Captura de pantalla de la interfaz de edicion, mostrando el sentido 1 de “party”.
capaces de marcar y anotar un synset, facilitandouna posterior revision y correccion. Otra ventajaes aumentar la cantidad de informacion almace-nada en cada variant y synset.
Las marcas disponibles son las siguientes:
Marcas de variant:
• DUBLEX: Para aquellos variants conuna lexicalizacion dudosa.
• INFL: Indica que un variant es flexivo.Necesario para el wordnet en euskera.
• RARE: Variant muy poco usado u endesuso.
• SUBCAT: Subcategorizacion. Se usapara aquellos variant que deben tenersubcategorizacion.
• VULG: Para aquellos variant que sonvulgares, rudos u ofensivos.
Marcas de synset:
• GENLEX: Conceptos generales no lexi-calizados que son introducidos para or-ganizar mejor la jerarquıa.
• HYPLEX: Indica que el hiperonimo tie-ne identica lexicalizacion.
• SPECLEX: Termimos especificos deciertos dominios, y que deben ser com-probados.
Anotar marcas usando el WEI es muy simple.Tan solo hay que buscar un synset o variant yanotarlo usando la interfaz de edicion, seleccio-nando las marcas deseadas. En una sola venta-na se pueden editar las marcas y comentarios de
todos los variant contenidos en un synset (inclu-yendo mas de uno, o incluso todos, a la vez), y lamarca y el comentario del propio synset.
3.2 Diseno de la Base de Datos para elMCR
Actualmente, el MCR esta almacenado en unabase de datos relacional consistente de 40 ta-blas39. Este apartado describe cada una de lastablas necesarias para que el MCR funcione co-rrectamente.
La tabla principal del MCR es la tabla quecontiene el Inter-Lingual Index (ILI):
wei ili record: Contiene los identificadoresde los ILI, en formato ili-30-xxxxxxx-y (las xindican el offset del synset, y las y represen-tan la categoria gramatical o Part-Of-Speech(PoS)). Cada registro tambien almacena elorigen del ILI (el WordNet del que provie-ne), si es un Base Concept o no, el ficherolexicografico, y si es una instancia o no.
Cada uno de los idiomas incluidos en el MCR(incluyendo el ingles) esta ligado al ILI, y com-puesto por cinco tablas. Cada idioma tiene supropio codigo de 3 letras, que esta indicado porxxx en la lista siguiente:
39La distribucion actual ha sido probada sobre MySQLy PostgreSQL.
Multilingual Central Repository Linguamatica – 21

Figura 2: Estructura de la Base de Datos para el MCR y el WEI.
wei xxx-30 to ili: Esta tabla conecta elILI (por ejemplo, ili-30-00001740-a) con elnumero de synset (por ejemplo, eng-30-00001740-a).
wei xxx-30 relation: Esta tabla contienetodas las relaciones del wordnet. Cada regis-tro (que es la instancia de una relacion) guar-da un codigo que indica el tipo de relacion(que se almacena de la tabla wei relations),la direccion de la relacion (synset origen ysynset destino), el valor de confianza y elwordnet del que proviene.
wei xxx-30 synset: Aquı se almacena lainformacion acerca del synset: el identifica-dor, el numero de descendientes, la glosa, elnivel en el que se encuentra (contando desdearriba), y finalmente una marca (opcional)y un comentario del synset (opcional).
wei xxx-30 variant: Aquı se almacenantodos los variant del wordnet. Cada regis-
tro representa un unico variant y contiene lasiguiente informacion: el variant, el sentidode la palabra, el identificador de synset, unvalor de confianza, el experimento del queproviene (opcional), y finalmente la marca(opcional) y el comentario del variant (op-cional).
wei xxx-30 examples: En esta tabla se lis-tan todos los ejemplos del wordnet. Cadaejemplo esta identificado por el numero desynset, la palabra y el sentido.
Anadir un nuevo idioma es tan facil como crearlas cinco nuevas tablas con el patron anterior yun codigo de 3 letras que lo representa.
Ademas de los wordnets, el MCR integra otrosrecursos (dominios, ontologıas, marcas, etc.). Lastablas que contienen esta informacion son las si-guientes:
Dominios:
22– Linguamatica Aitor Gonzalez-Agirre e German Rigau

wei domains: Esta tabla representa la je-rarquıa de WordNet Domains usando tuplasorigen-destino.
wei ili to domains: Cada registro enlazaun dominio a un ILI. Tambien se indica elwordnet del que proviene. Esta tabla es uni-ca, haciendo que la informacion de dominioseste compartida entre todos los wordnets.
AdimenSUMO:
wei sumo relations: Esta tabla representala jerarquıa de AdimenSUMO usando tuplasorigen-destino. Tambien incluye un campoque indica si se trata de una sub-clase o no.
wei ili to sumo: Cada registro enlaza unaetiqueta de AdimenSUMO a un ILI. Tam-bien se indica el wordnet del que proviene.Al igual que la tabla de dominios, esta tablaes unica, haciendo que la informacion de do-minios este compartida entre todos los word-nets.
Top Ontology:
wei to relations: Esta tabla representa lajerarquıa de Top Ontology usando tuplasorigen-destino. Tambien incluye un campoque indica el tipo de la relacion.
wei ili to to: Cada registro enlaza una eti-queta de Top Ontology a un ILI. Tambien seindica el wordnet del que proviene. Al igualque la tabla de dominios y la de Adimen-SUMO, esta tabla es unica, haciendo que lainformacion de dominios este compartida en-tre todos los idiomas.
wei to record: Esta tabla almacena, paracada etiqueta de Top Ontology, la glosa aso-ciada a ella.
Marcas:
mark values synset: Valores permitidospara las marcas de synset, asi como su des-cripcion.
mark values variant: Valores permitidospara las marcas de variant, asi como su des-cripcion.
El resto de tablas incluidas en el MCR son lassiguientes:
wei relations: Esta tabla contiene todas lasrelaciones posibles en el MCR. Cada relaciontiene un identificador, un nombre, sus pro-piedades y una nota (opcional). Tambien se
indica si es inversa (en caso de que sea po-sible) y a que grupo de relaciones pertenece(ver mas abajo). El codigo ID que aparece enesta tabla es el que esta reflejado en las tablawei xxx-30 relation. Esta tabla es la que per-mite realizar busquedas mediante el WEI.
wei relations group: Aquı se almacenanlos super-grupos de relaciones (sinonimos,hiperonimos, meronimos, causa, etc.). Elcodigo ID que aparece en esta tabla es elque esta reflejado en la tabla wei relations.
wei languages: Los wordnets disponiblesen el MCR. Para cada wordnet se indica elcodigo, el nombre y el color con el que debede aparecer en el WEI.
wei lexnames: Aquı se almacenan los fiche-ros lexicograficos de WordNet. Cada entra-da tiene un codigo (el indicado en la tablawei ili record) y un nombre descriptivo.
wei wn counters: La interfaz del WEI per-mite la creacion de nuevos synset. Para evi-tar solapamientos y problemas futuros, cadaPoS tiene su propio numero de offset, em-pezando desde el 800.000. Esta tabla guardalos numeros que deben adoptar los nuevossynsets que se creen en cada categorıa gra-matical.
La figura 2 muestra la estructura completa delMCR.
3.3 Estado actual del MCR
En este apartado se presenta el estado ac-tual del MCR, incluyendo el progreso respectoal WordNet ingles. La tabla 1 muestra la canti-dad actual de synsets y variants, el numero deglosas y el numero de ejemplos de cada wordnet,distinguiendo entre las distintas categorıas gra-maticales o PoS.
Como ejemplo de la informacion contenida enel MCR podemos analizar el sentido 4 de “party”,que se muestra en la figura 3. En la columna de laizquierda podemos ver el ILI (ili-30-07447641-n),y debajo de el, la informacion asociada al ILI:
WordNet Domains: free time, sociology.
Fichero semantico de WordNet: event.
AdimenSUMO: Meeting.
Top Ontology: Agentive, BoundedEvent,Communication, Purpose, Social.
En la siguiente columna se muestra los synsetsasociados de cada wordnet y los variants que hay
Multilingual Central Repository Linguamatica – 23

Figura 3: Informacion almacenada en el MCR para el sentido 4 de “party”.
en cada uno de ellos, indicando el variant y elnumero de sentido de dicha palabra (el numerofinal despues del simbolo “ ”):
Ingles: party (4).
Euskera: jaialdi (2), festa (1), besta (3),jai (6).
Castellano: fiesta (2).
Gallego: festa (3).
Catalan: festa (3).
En la columna de la derecha estan las glosaso definiciones para cada uno de los wordnets (eneste caso, el gallego no tiene esta informacion),ası como ejemplos de uso de las palabras (que semuestran en cursiva).
Por ultimo, en la parte inferior se enumeranlas relaciones de estos synset (que en este casocoinciden):
has hyponym: Indica que el synset tiene11 hiponimos.
gloss: Indica que 2 de las palabras que apa-recen en la glossa estan desambiguadas, y li-gadas al synset correspondiente. En este casoson entertainment e interaction, que pode-mos ver en la glossa en ingles.
has hyperonym: Indica que el synset tieneun hiperonimo.
rgloss: Reverse gloss. Indica que este synsetaparece desambiguado en 36 glosas de otrossynets.
related to: Indica que otros synset esta re-lacionados con este. En este caso es el sen-tido 1 de “party” en ingles, definido comohave or participate in a party, o el sentido 4de “festejar” en castellano.
4 Conclusiones y Trabajo Futuro
Como hemos visto, la construccion de bases deconocimiento con cobertura suficiente pare pro-cesar textos de dominio general requiere de unesfuerzo enorme. Este esfuerzo solo pueden rea-lizarlo grandes grupos de investigacion durantelargos periodos de desarrollo. Afortunadamente,en los ultimos anos, la comunidad investigadoraha desarrollado un amplio conjunto de recursossemanticos de amplia cobertura vinculados a dis-tantas versiones de WordNet. A lo largo de losultimos anos, muchos de estos recursos han si-do integrados en el Multilingual Central Reposi-tory (MCR). Primero usando un ILI basado enWordNet 1.6. Esta version, aunque demostro elpotencial de la propuesta contenıa recursos con li-cencias restrictivas que impedıan su distribucionintegrada. La version que usa el ILI basado enWordNet 3.0 no contiene recursos que tengan li-cencias restrictivas y puede distribuirse de formaintegrada40.
Como vemos, integrar todos estos recursos enuna unica infraestructura tambien es una tareacompleja que requiere de un esfuerzo continua-do. Por un lado, continuamente aparecen nuevosrecursos potencialmente interesantes, y por otro,los antiguos recursos se siguen actualizando.
En el marco del proyecto SKaTer planeamosseguir enriqueciendo el MCR con nuevos recur-sos. Entre otros, los ya integrados en la versiondel MCR con el ILI basado en WordNet 1.6. Porejemplo, el resto de versiones de WordNet ingles(1.5, 1.6, 1.7, 1.7.1, 2.0 y 2.1, ya que resulta muypractico poder consultar todas las versiones deWordNet simultaneamente). Tambien pensamosrecuperar y integrar al nuevo ILI las preferenciasde seleccion adquiridas de SemCor, ası como in-
40La mayor parte de los recursos integrados en estaversion tiene licencia Creative Commons Attribution 3.0Unported (CC BY 3.0) http://creativecommons.org/licenses/by/3.0
24– Linguamatica Aitor Gonzalez-Agirre e German Rigau
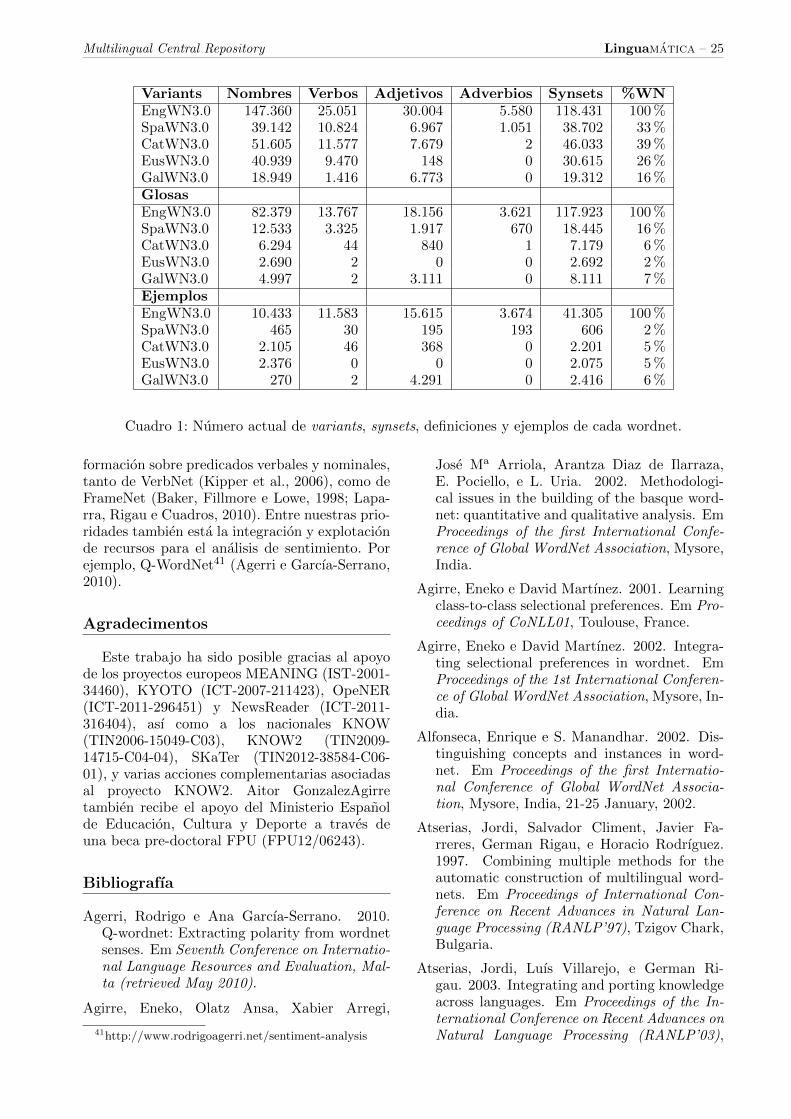
Variants Nombres Verbos Adjetivos Adverbios Synsets %WNEngWN3.0 147.360 25.051 30.004 5.580 118.431 100 %SpaWN3.0 39.142 10.824 6.967 1.051 38.702 33 %CatWN3.0 51.605 11.577 7.679 2 46.033 39 %EusWN3.0 40.939 9.470 148 0 30.615 26 %GalWN3.0 18.949 1.416 6.773 0 19.312 16 %GlosasEngWN3.0 82.379 13.767 18.156 3.621 117.923 100 %SpaWN3.0 12.533 3.325 1.917 670 18.445 16 %CatWN3.0 6.294 44 840 1 7.179 6 %EusWN3.0 2.690 2 0 0 2.692 2 %GalWN3.0 4.997 2 3.111 0 8.111 7 %EjemplosEngWN3.0 10.433 11.583 15.615 3.674 41.305 100 %SpaWN3.0 465 30 195 193 606 2 %CatWN3.0 2.105 46 368 0 2.201 5 %EusWN3.0 2.376 0 0 0 2.075 5 %GalWN3.0 270 2 4.291 0 2.416 6 %
Cuadro 1: Numero actual de variants, synsets, definiciones y ejemplos de cada wordnet.
formacion sobre predicados verbales y nominales,tanto de VerbNet (Kipper et al., 2006), como deFrameNet (Baker, Fillmore e Lowe, 1998; Lapa-rra, Rigau e Cuadros, 2010). Entre nuestras prio-ridades tambien esta la integracion y explotacionde recursos para el analisis de sentimiento. Porejemplo, Q-WordNet41 (Agerri e Garcıa-Serrano,2010).
Agradecimentos
Este trabajo ha sido posible gracias al apoyode los proyectos europeos MEANING (IST-2001-34460), KYOTO (ICT-2007-211423), OpeNER(ICT-2011-296451) y NewsReader (ICT-2011-316404), ası como a los nacionales KNOW(TIN2006-15049-C03), KNOW2 (TIN2009-14715-C04-04), SKaTer (TIN2012-38584-C06-01), y varias acciones complementarias asociadasal proyecto KNOW2. Aitor GonzalezAgirretambien recibe el apoyo del Ministerio Espanolde Educacion, Cultura y Deporte a traves deuna beca pre-doctoral FPU (FPU12/06243).
Bibliografıa
Agerri, Rodrigo e Ana Garcıa-Serrano. 2010.Q-wordnet: Extracting polarity from wordnetsenses. Em Seventh Conference on Internatio-nal Language Resources and Evaluation, Mal-ta (retrieved May 2010).
Agirre, Eneko, Olatz Ansa, Xabier Arregi,
41http://www.rodrigoagerri.net/sentiment-analysis
Jose Ma Arriola, Arantza Diaz de Ilarraza,E. Pociello, e L. Uria. 2002. Methodologi-cal issues in the building of the basque word-net: quantitative and qualitative analysis. EmProceedings of the first International Confe-rence of Global WordNet Association, Mysore,India.
Agirre, Eneko e David Martınez. 2001. Learningclass-to-class selectional preferences. Em Pro-ceedings of CoNLL01, Toulouse, France.
Agirre, Eneko e David Martınez. 2002. Integra-ting selectional preferences in wordnet. EmProceedings of the 1st International Conferen-ce of Global WordNet Association, Mysore, In-dia.
Alfonseca, Enrique e S. Manandhar. 2002. Dis-tinguishing concepts and instances in word-net. Em Proceedings of the first Internatio-nal Conference of Global WordNet Associa-tion, Mysore, India, 21-25 January, 2002.
Atserias, Jordi, Salvador Climent, Javier Fa-rreres, German Rigau, e Horacio Rodrıguez.1997. Combining multiple methods for theautomatic construction of multilingual word-nets. Em Proceedings of International Con-ference on Recent Advances in Natural Lan-guage Processing (RANLP’97), Tzigov Chark,Bulgaria.
Atserias, Jordi, Luıs Villarejo, e German Ri-gau. 2003. Integrating and porting knowledgeacross languages. Em Proceedings of the In-ternational Conference on Recent Advances onNatural Language Processing (RANLP’03),
Multilingual Central Repository Linguamatica – 25

pp. 31–37, Borovets, Bulgaria, September,2003.
Atserias, Jordi, Luıs Villarejo, German Rigau,Eneko Agirre, John Carroll, Piek Vossen, eBernardo Magnini. 2004. The meaning mul-tilingual central respository. Em Proceedingsof the Second International Global WordNetConference (GWC’04).
Baker, Collin F., Charles J. Fillmore, e John B.Lowe. 1998. The berkeley framenet project.Em Proceedings of the COLING-ACL, pp. 86–90.
Bentivogli, Luisa, Pamela Forner, Bernardo Mag-nini, e Emanuele Pianta. 2004. Revising thewordnet domains hierarchy: semantics, cove-rage and balancing. Em Proceedings of theWorkshop on Multilingual Linguistic Ressour-ces, pp. 101–108. Association for Computatio-nal Linguistics.
Bentivogli, Luisa, E. Pianta, e C. Girardi. 2002.Multiwordnet: developing an aligned multilin-gual database. Em Proceedings of the FirstInternational Conference on Global WordNet,Mysore, India.
Benıtez, Laura, Sergi Cervell, Gerard Escude-ro, Monica Lopez, German Rigau, e MarionaTaule. 1998. Methods and tools for buildingthe catalan wordnet. Em Proceedings of EL-RA Workshop on Language Resources for Eu-ropean Minority Languages, Granada, Spain.
Castillo, Mauro, Francis Real, e German Rigau.2004. Automatic assignment of domain labelsto wordnet. Em Proceeding of the 2nd Inter-national WordNet Conference, pp. 75–82.
Chaves, R. P. 2001. Wordnet and automa-ted text summarization. Em Proceedings of6th Natural Language Processing Pacific RimSymposium NLPRS 2001, pp. 109–116, Tok-yo, Japan, Jan, 2001.
Daude, Jordi. 2005. Enlace de Jerarquıas Usan-do el Etiquetado por Relajacion. Tese de dou-toramento, Universitat Politecnica de Cata-lunya, July, 2005.
Fellbaum, Christiane. 1998. WordNet. An Elec-tronic Lexical Database. Language, Speech,and Communication. The MIT Press.
Gonzalez, Aitor, German Rigau, e Mauro Cas-tillo. 2012. A graph-based method to im-prove wordnet domains. Em Proceedings ofthe Computational Linguistics and IntelligentText Processing (CICLING’12), pp. 17–28.Springer.
Gonzalez-Agirre, A., E. Laparra, e G. Rigau.2012a. Multilingual central repository version3.0. Em Proceedings of the 8th InternationalConference on Language Resources and Eva-luation (LREC 2012), pp. 2525–2529.
Gonzalez-Agirre, A., E. Laparra, e G. Rigau.2012b. Multilingual central repository version3.0: upgrading a very large lexical knowledgebase. Em Proceedings of the 6th Global Word-Net Conference (GWC’12).
Gonzalez-Agirre, Aitor, Mauro Castillo, e Ger-man Rigau. 2012. A proposal for impro-ving wordnet domains. Em Nicoletta Cal-zolari (Conference Chair), Khalid Choukri,Thierry Declerck, Mehmet Ugur Dogan, Ben-te Maegaard, Joseph Mariani, Jan Odijk, eStelios Piperidis, editores, Proceedings of theEight International Conference on LanguageResources and Evaluation (LREC’12), Istan-bul, Turkey, may, 2012. European LanguageResources Association (ELRA).
Izquierdo, R., A. Suarez, e G. Rigau. 2007. Ex-ploring the automatic selection of basic levelconcepts. Em Proceedings of RANLP.
Izquierdo, Ruben, Armando Suarez, e GermanRigau. 2009. An empirical study on class-based word sense disambiguation. Em Pro-ceedings of the 12th Conference of the Euro-pean Chapter of the Association for Compu-tational Linguistics, pp. 389–397. Associationfor Computational Linguistics.
Izquierdo, Ruben, Armando Suarez, e GermanRigau. 2010. Gplsi-ixa: Using semantic clas-ses to acquire monosemous training examplesfrom domain texts. Em Proceedings of the5th International Workshop on Semantic Eva-luation, pp. 402–406, Uppsala, Sweden, July,2010. Association for Computational Linguis-tics.
Kipper, Karin, Anna Korhonen, Neville Ryant,e Martha Palmer. 2006. Extending verbnetwith novel verb classes. Em Proceedings ofLREC, volume 2006, pp. 1.
Laparra, Egoitz, German Rigau, e Montse Cua-dros. 2010. Exploring the integration of word-net and framenet. Em Proceedings of the5th Global WordNet Conference (GWC’10),Mumbai (India), January, 2010.
Laparra, Egoitz, German Rigau, e Piek Vos-sen. 2012. Mapping wordnet to the kyo-to ontology. Em Nicoletta Calzolari (Con-ference Chair), Khalid Choukri, Thierry De-clerck, Mehmet Ugur Dogan, Bente Maegaard,
26– Linguamatica Aitor Gonzalez-Agirre e German Rigau

Joseph Mariani, Jan Odijk, e Stelios Piperi-dis, editores, Proceedings of the Eight Inter-national Conference on Language Resourcesand Evaluation (LREC’12), Istanbul, Turkey,may, 2012. European Language Resources As-sociation (ELRA).
Lenat, Douglas B. 1995. Cyc: A large-scale in-vestment in knowledge infrastructure. Com-munications of the ACM, 38(11):33–38.
Magnini, Bernardo e G. Cavaglia. 2000. Integra-ting subject field codes into wordnet. Em Pro-ceedings of the Second Internatgional Confe-rence on Language Resources and Evaluation(LREC), Athens. Greece.
Magnini, Bernardo, C. Satrapparava, G. Pezzulo,e A. Gliozzo. 2002. The role of domains infor-mations. Em In Word Sense Disambiguation,Treto, Cambridge, July, 2002.
McCarthy, Diana. 2001. Lexical Acquisitionat the Syntax-Semantics Interface: Diathe-sis Aternations, Subcategorization Frames andSelectional Preferences. Tese de doutoramen-to, University of Sussex.
Mihalcea, Rada e Dan Moldovan. 2001. extendedwordnet: Progress report. Em Proceedings ofNAACL Workshop WordNet and Other Lexi-cal Resources: Applications, Extensions andCustomizations, pp. 95–100, Pittsburg, PA,USA.
Miller, G. A., R. Beckwith, Christiane Fellbaum,D. Gross, K. Miller, e R. Tengi. 1991. Five pa-pers on wordnet. Special Issue of the Interna-tional Journal of Lexicography, 3(4):235–312.
Moldovan, Dan e Vasile Rus. 2001. Logic formtransformation of wordnet and its applicabi-lity to question answering. Em In Proceedingsof ACL 2001, pp. 394–401.
Niles, I. e Adam Pease. 2001. Towards a stan-dard upper ontology. Em Chris Welty e BarrySmith, editores, Proceedings of the 2nd Inter-national Conference on Formal Ontology inInformation Systems (FOIS-2001), Ogunquit,Maine.
Niles, I. e Adam Pease. 2003. Linking lexiconsand ontologies: Mapping wordnet to the sug-gested upper merged ontology. Em Procee-dings of the International Conference on In-formation and Knowledge Engineering (IKE),Las Vegas, Nevada.
Parapar, David, Alvaro Barreiro, e David E. Lo-sada. 2005. Query expansion using wordnetwith a logical model of information retrieval.Em Proceedings of IADIS AC, pp. 487–494.
Pianta, Emanuele, Luisa Bentivogli, e ChristianGirardi. 2002. Multiwordnet: developing analigned multilingual database. Em Procee-dings of the First International Conference onGlobal WordNet, January, 2002.
Rigau, German, Bernardo Magnini, Eneko Agi-rre, Piek Vossen, e John Carroll. 2002. Mea-ning: A roadmap to knowledge technologies.Em Proceedings of COLING Workshop ARoadmap for Computational Linguistics, Tai-pei, Taiwan.
Rodrıguez, Horacio, Salvador Climent, Piek Vos-sen, Laura Bloksma, Wim Peters, AntoniettaAlonge, Francesca Bertagna, e Adriana Ro-ventini. 1998. The top-down strategy for buil-ding eurowordnet: Vocabulary coverage, baseconcepts and top ontology. Computers andthe Humanities, 32(2-3):117–152.
Rodrıguez, Horacio, David Farwell, Javier Fa-rreres, Manuel Bertran, Musa Alkhalifa,Ma Antonia Martı, William J. Black, Sabri El-kateb, James Kirk, Adam Pease, Piek Vossen,e Christiane Fellbaum. 2008. Arabic word-net: Current state and future extensions. EmProceedings of the Fourth International Glo-bal WordNet Conference - GWC 2008, Szeged,Hungary, January, 2008.
Rosch, Eleanor e B. Lloyd. 1978. Cognition andCategorization. Lawrence Erlbaum Associa-tes, Hillsdale NJ, USA.
Sagri, Maria Teresa, Daniela Tiscornia, e Fran-cesca Bertagna. 2004. Jur-wordnet. EmProceedings of the Second International Glo-bal WordNet Conference (GWC’04). Panel onfigurative language, January, 2004.
Sornlertlamvanich, Virach, Thatsanee Charoen-porn, e Hitoshi Isahara. 2010. Language re-source management system for asian word-net collaboration and its web service appli-cation. Em Proceedings of the Seventh con-ference on International Language Resourcesand Evaluation (LREC’10), Valletta, Malta,may, 2010. European Language Resources As-sociation (ELRA).
Stamou, Sofia, Alexandros Ntoulas, Jeroen Hop-penbrouwers, Maximiliano Saiz-Noeda, e Di-mitris Christoudoulakis. 2002a. Euroterm:Extending the eurowordnet with domain-specific terminology using an expand modelapproach. Em Proceedings of the 1st GlobalWordNet Association conference, Mysore, In-dia.
Stamou, Sofia, Kemal Oflazer, Karel Pala, Dimi-tris Christoudoulakis, Dan Cristea, Dan Tufis,
Multilingual Central Repository Linguamatica – 27

Svetla Koeva, George Totkov, Dominique Du-toit, e Maria Grigoriadou. 2002b. Balkanet: Amultilingual semantic network for the balkanlanguages. Em Proceedings of the 1st GlobalWordNet Association conference.
Stevenson, Mark e Mark A. Greenwood. 2006.Learning Information Extraction PatternsUsing WordNet. Em Proceedings of the 5thIntl. Conf. on Language Resources and Eva-luations, LREC 2006 22 - 28 May 2006, volu-me 2006, pp. 95–102.
Vossen, Piek. 1998. EuroWordNet: A Multi-lingual Database with Lexical Semantic Net-works. Kluwer Academic Publishers.
Vossen, Piek, L. Bloksma, Horacio Rodrıguez,Salvador Climent, A. Roventini, F. Bertagna,e A. Alonge. 1997. The eurowordnet baseconcepts and top-ontology. Relatorio tecni-co, Deliverable D017D034D036 EuroWordNetLE2-4003.
Alvez, Javier, Jordi Atserias, Jordi Carrera, Sal-vador Climent, Egoitz Laparra, Antoni Oliver,e German Rigau. 2008. Complete and consis-tent annotation of wordnet using the top con-cept ontology. Em Proceedings of the the 6thConference on Language Resources and Eva-luation (LREC 2008), Marrakech (Morocco),May, 2008.
Alvez, Javier, Paqui Lucio, e G. Rigau. 2012.Adimen-sumo: Reengineering an ontology forfirst-order reasoning. International Journalon Semantic Web and Information Systems,8(4):80–116.
28– Linguamatica Aitor Gonzalez-Agirre e German Rigau


















