
Cálculo Científico con Computadoras Paralelas
116
Cálculo Científico con Computadoras Paralelas Victorio E. Sonzogni CIMEC Centro Internacional de M ´ etodos Computacionales en Ingenier´ ıa INTEC, CONICET-UNL FICH, UNL Santa Fe, Argentina C ´ alculo Cient´ ıfico con Computadoras Paralelas – p. 1/11
Transcript of Cálculo Científico con Computadoras Paralelas

Cálculo Científico conComputadoras Paralelas
Victorio E. Sonzogni
CIMEC Centro Internacional de Metodos Computacionales en Ingenierıa
INTEC, CONICET-UNL
FICH, UNL
Santa Fe, Argentina
Calculo Cientıfico con Computadoras Paralelas – p. 1/110

Objetivos
Presentar una introducción al cálculo científico encomputadoras paralelas
Desde el punto de vista del ingeniero analista numérico
Programación de algoritmos de resolución numérica
Problema típico: solución de sistemas de ecuacionesalgebráicas simultáneas lineales (SEAL)
Estrategias de paralelización
Eficiencia y escalabilidad de programas paralelos
Calculo Cientıfico con Computadoras Paralelas – p. 2/110

Temario
Introducción - Arquitecturas de computadoras paralelas
Medidas de velocidad y eficiencia
Vectorización
Modelos y estrategias de paralelización
Programación en el modelo de memoria compartida
Programación en el modelo de memoria local
Algoritmos paralelos para álgebra lineal
Métodos directos e iterativos de resolución de SEAL
Paralelización en programas de elementos finitos
Métodos de descomposición del dominio
Calculo Cientıfico con Computadoras Paralelas – p. 3/110

Clase introductoria
Necesidades de cálculo intensivo en ingenierías
Evolución de las computadoras
Computadoras con varios procesadores
Arquitecturas paralelas
Aspectos de la programación paralela
Ejemplos de aplicación en mecánica computacional
Calculo Cientıfico con Computadoras Paralelas – p. 4/110

El cálculo en ingeniería
La evaluación de magnitudes que cuantifiquen el estadomecánico de estructuras, piezas industriales, recursosnaturales, tejidos orgánicos, etc. puede efectuarse poralgunas de las siguientes maneras:
Experimental
Analítica (Teórica)
Numérica
Calculo Cientıfico con Computadoras Paralelas – p. 5/110

El cálculo numérico
La metodología para realizar una simulación numéricaimplica:
Desarrollo de un modelo matemático → problemamatemático
Solución numérica del problema matemático
Desarrollo de software para la solución numérica
Verificación de los métodos numéricos con casossimples
Validación del modelo matemático con resultadosexperimentales
Utilización práctica para predecir comportamiento.
Calculo Cientıfico con Computadoras Paralelas – p. 6/110
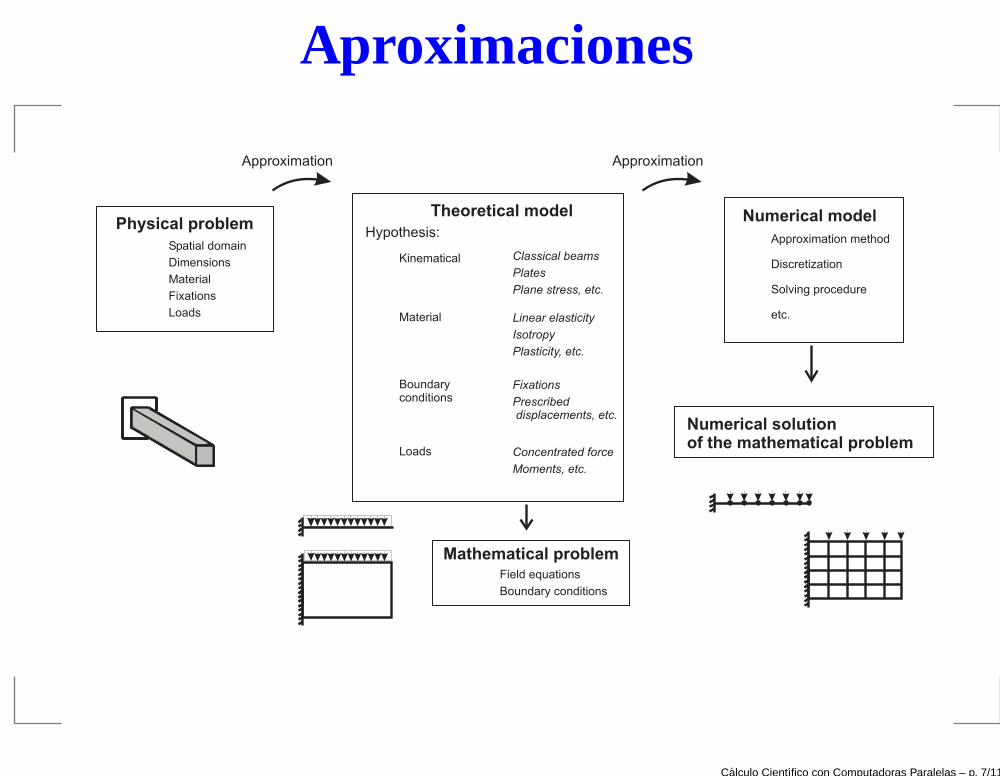
Aproximaciones
Physical problem
Dimensions
Spatial domain
Material
Fixations
Loads
Theoretical model
Material
Kinematical
Boundaryconditions
Loads
Hypothesis:
Classical beams
Plates
Plane stress, etc.
Linear elasticity
Isotropy
Plasticity, etc.
Fixations
Prescribeddisplacements, etc.
Concentrated force
Moments, etc.
Mathematical problemField equations
Boundary conditions
Numerical model
Approximation method
Discretization
etc.
Solving procedure
Numerical solutionof the mathematical problem
Approximation Approximation
Calculo Cientıfico con Computadoras Paralelas – p. 7/110

Problema físico
Physical problem
Dimensions
Spatial domain
Material
Fixations
Loads
Calculo Cientıfico con Computadoras Paralelas – p. 8/110

Modelo teórico
Theoretical model
Material
Kinematical
Boundaryconditions
Loads
Hypothesis:
Classical beams
Plates
Plane stress, etc.
Linear elasticity
Isotropy
Plasticity, etc.
Fixations
Prescribeddisplacements, etc.
Concentrated force
Moments, etc.
Mathematical problemField equations
Boundary conditions
Calculo Cientıfico con Computadoras Paralelas – p. 9/110
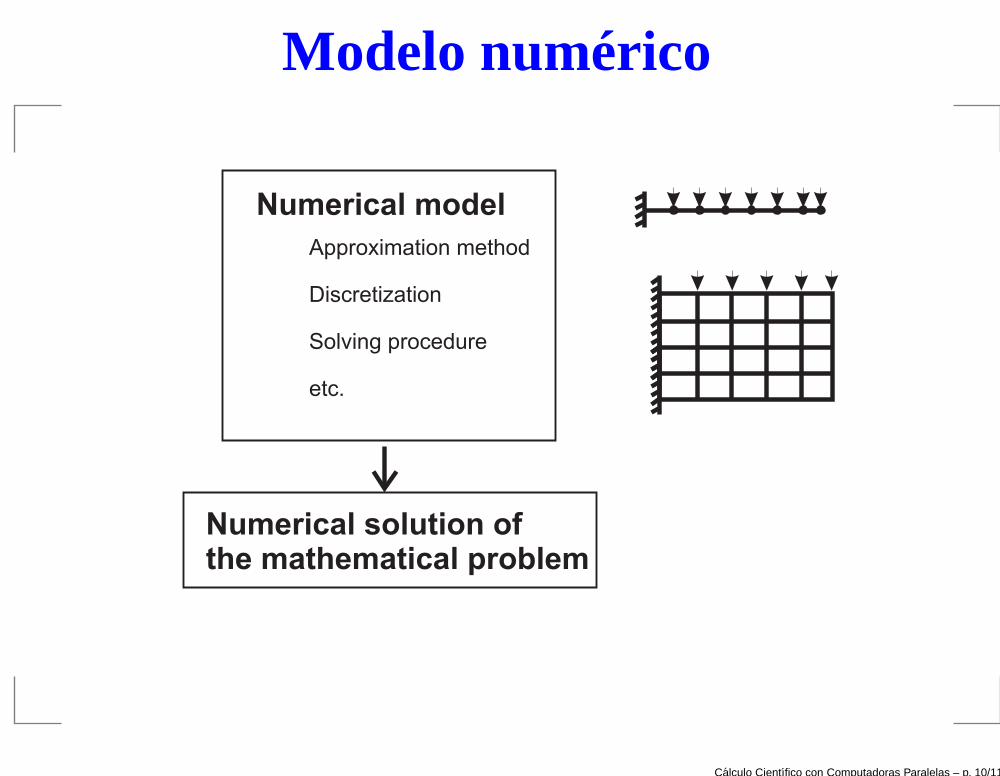
Modelo numérico
Numerical model
Approximation method
Discretization
etc.
Solving procedure
Numerical solutionthe mathematical problem
of
Calculo Cientıfico con Computadoras Paralelas – p. 10/110

Grandes desafíos de cálculo científico
Office and Technology (USA)High Performance Computing and Communication(HPCC)
Grandes desafíosModelado climáticoTurbulencia en mecánica de fluidosDispersión de contaminantesGenoma Humanoetc.
Calculo Cientıfico con Computadoras Paralelas – p. 11/110

Grandes desafíos de cálculo científico
Calculo Cientıfico con Computadoras Paralelas – p. 12/110

Necesidad de cálculo intensivo
interacción aerodinámica 3D entre el flujo de aire y unaestructura;
flujo 3D en una cámara de combustión ;
simulación numérica de reservorios de petróleo
etc.
Calculo Cientıfico con Computadoras Paralelas – p. 13/110

¿ Porqué se necesitan computadoras más veloces?
Alcanzar el grado de realismo indispensableMatemático
estabilidad de las solucionescomportamiento no linealsingularidades
Numérico: convergencia de las solucionesFísico: realismo en la representación del sistemaestudiado
Integración Métodos de solución - Herramientas dediseño (CAD)
Cálculo en tiempo real → procedimientos de control
Calculo Cientıfico con Computadoras Paralelas – p. 14/110

Evolución de la potencia de cálculo
Calculo Cientıfico con Computadoras Paralelas – p. 15/110

Por qué computación paralela ?
Computadoras clásicas → arquitectura de Von Neumann:único flujo de instrucciones y único flujo de datos.
Memory
ControlUnit
ProcessUnit
Un procesador toma datos de memoria; hace los cálculos yescribe el resultado en memoria. Proceso secuencial.
Calculo Cientıfico con Computadoras Paralelas – p. 16/110

Por qué computación paralela ?
Mejoras tecnológicas → mayor velocidad de cálculo.Límite físico → velocidad de la luz!.El ciclo de reloj interno de computadoras: nanosegundos
(1ns = 10−9s)En 1ns la electricidad viaja unos 30cm. La distancia entre
procesador y memoria puede ser una fracción importante deesa distancia.
Salida → procesamiento paralelo
en computadoras secuenciales
en computadoras paralelas
Calculo Cientıfico con Computadoras Paralelas – p. 17/110

Diseño de computadoras frente a los desafıos
Calculo Cientıfico con Computadoras Paralelas – p. 18/110

Paralelismo en computadoras sequenciales
La ejecución concurrente de diferentes tareas puedehacerse con varios procesadores, pero también encomputadoras con un solo procesador.
Calculo Cientıfico con Computadoras Paralelas – p. 19/110

Paralelismo en computadoras sequenciales
Una computadora tradicional (Von Neumann) tiene unaunidad funcional, una unidad de control, y una memoria.Un cálculo básico se hace en las siguientes etapas:
1. se trae una instrucción de memoria y se decodifica;
2. se calcula la dirección en memoria de los datosrequeridos;
3. se traen los datos;
4. se hace la cuenta en la unidad funcional;
5. se escribe el resultado nuevamente en memoria.
Calculo Cientıfico con Computadoras Paralelas – p. 20/110

Paralelismo en computadoras sequenciales
Hay varias maneras de introducir paralelismo encomputadoras secuenciales:
Multiples unidades funcionales
Pipelining
Instrucciones vectoriales
Encadenamiento
Organización de memoria
Calculo Cientıfico con Computadoras Paralelas – p. 21/110

Multiples unidades funcionales
La unidad funcional está dividida en varias unidadesque pueden trabajar concurrentemente.
Por ejemplo: una unidad de adición de punto flotante;una unidad de multiplicación de punto flotante; y unaunidad lógica.
El compilador distribuye la tarea de modo de evitartiempos muertos.
Calculo Cientıfico con Computadoras Paralelas – p. 22/110

Paralelismo en computadoras sequenciales
Hay varias maneras de introducir paralelismo encomputadoras secuenciales:
Multiples unidades funcionales
Pipelining
Instrucciones vectoriales
Encadenamiento
Organización de memoria
Calculo Cientıfico con Computadoras Paralelas – p. 23/110

Pipelining
Si una tarea se puede dividir en sub-tareas o pasos, launidad funcional también se puede dividir ensegmentos, cada uno responsable de cada sub-tarea.Línea de montaje.
Cada sub-tarea: un ciclo de reloj.
Diferentes sub-tareas se realizan concurrentemente.
Una vez que la linea de montaje está llena, se completauna tarea en cada unidad de tiempo.
El costo de llenar la línea de montaje depende de lacantidad de segmentos.
Calculo Cientıfico con Computadoras Paralelas – p. 24/110
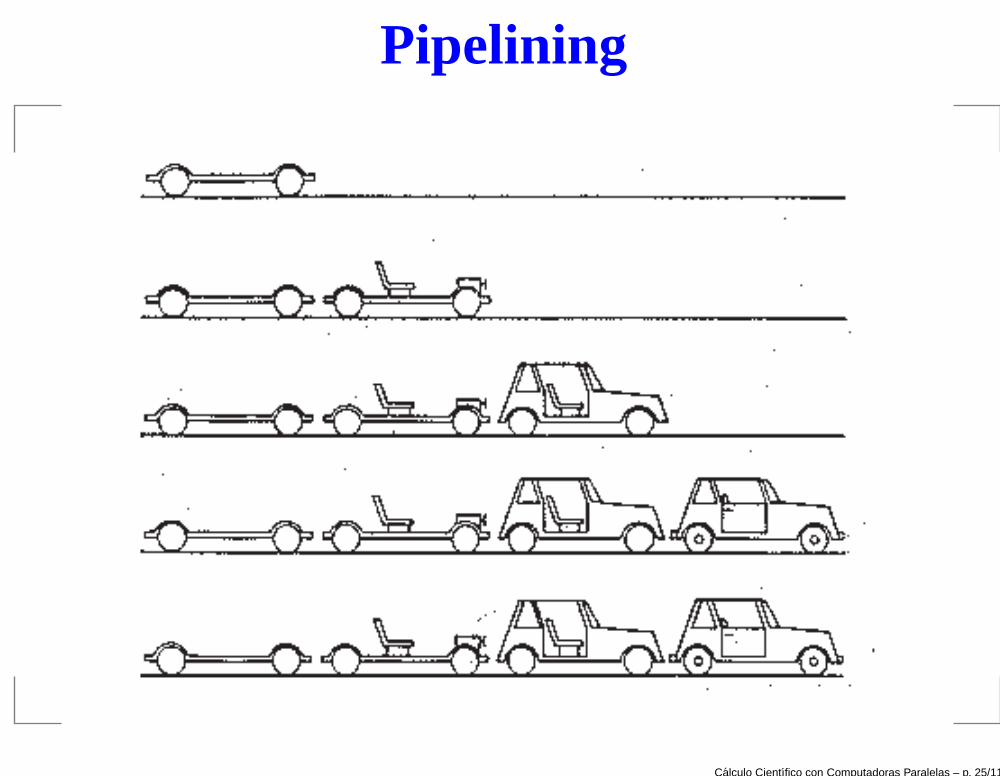
Pipelining
Calculo Cientıfico con Computadoras Paralelas – p. 25/110

Pipelining: adición en punto flotante
Calculo Cientıfico con Computadoras Paralelas – p. 26/110

Pipelining: adición en punto flotante
Calculo Cientıfico con Computadoras Paralelas – p. 27/110

Paralelismo en computadoras sequenciales
Hay varias maneras de introducir paralelismo encomputadoras secuenciales:
Multiples unidades funcionales
Pipelining
Instrucciones vectoriales
Encadenamiento
Organización de memoria
Calculo Cientıfico con Computadoras Paralelas – p. 28/110

Instrucciones vectoriales
Las instrucciones vectoriales especifican una operacióna llevar a cabo en un conjunto de datos ordenados enun arreglo unidimensional (vectores).
La unidad funcional está dividida en varios segmentos
También hay registros vectoriales donde puedeaccederse a los elementos de un vector en un ciclo detiempo.
Calculo Cientıfico con Computadoras Paralelas – p. 29/110

Paralelismo en computadoras sequenciales
Hay varias maneras de introducir paralelismo encomputadoras secuenciales:
Multiples unidades funcionales
Pipelining
Instrucciones vectoriales
Encadenamiento
Organización de memoria
Calculo Cientıfico con Computadoras Paralelas – p. 30/110

Encadenamiento
El encadenamiento se combina con el pipelining.
El resultado de una operación en pipelining se dirige aotra, sin esperar que la primera se complete.
Calculo Cientıfico con Computadoras Paralelas – p. 31/110

Encadenamiento
Aplicación típica: encadenar multiplicación y adición.
Calculo Cientıfico con Computadoras Paralelas – p. 32/110

Encadenamiento
do 1=1,nv5(i)=(v1(i)*v2(i))+v4(i)
end do
Calculo Cientıfico con Computadoras Paralelas – p. 33/110

Paralelismo en computadoras sequenciales
Hay varias maneras de introducir paralelismo encomputadoras secuenciales:
Multiples unidades funcionales
Pipelining
Instrucciones vectoriales
Encadenamiento
Organización de memoria
Calculo Cientıfico con Computadoras Paralelas – p. 34/110

Organización de memoria
El flujo de datos desde y hacia la memoria: parte críticadel diseño de computadoras.
Evitar pérdidas de tiempo moviendo datos.
Organización jerárquica de memoria.
Memoria → Cache → Registros
Re-uso
Memoria dividida en bancos, que pueden accederse enparalelo
Si los datos están en el mismo banco: conflicto debancos.
Calculo Cientıfico con Computadoras Paralelas – p. 35/110

Memoria jerárquica
Calculo Cientıfico con Computadoras Paralelas – p. 36/110

Supercomputadoras
El termino supercomputadora refiere al equipo máspoderoso disponible en ese momento.
Este término se usó por primera vez en 1964 cuando laCDC 6600 alcanzó 1 MFLOPS (un millon deoperaciones punto flotante por segundo).
Calculo Cientıfico con Computadoras Paralelas – p. 37/110

Supercomputadoras
Los equipos más poderosos pueden clasificarse en:
High Performance Workstations
Superservers
Near Supers
Large Supercomputers
High Performance Workstations → 10 ∼ 100MFLOPS;Superservers, → arriba de 500MFLOPS;Near Supers → en el orden de GFLOPS (gigaflops)Large Supercomputers → en el orden de TFLOPS
(teraflops).Como la velocidad de procesamiento cambia tan rápido, unmejor índice para clasificarlos parece ser el precio . . . .
Calculo Cientıfico con Computadoras Paralelas – p. 38/110

Supercomputadoras
Primera generación, 60’-70’:
pipelined CDC6600, CDC7600,STAR-100, etc,y el array processor ILLIAC IV.
Segunda generación:
CRAY-1 con instrucciones vectoriales,CDC CYBER 203.
Calculo Cientıfico con Computadoras Paralelas – p. 39/110

Supercomputadoras
Tercera generación :Combina procesadores vectoriales y array processors,
CDC CYBER 205, CRAY-2, CRAY-XMP, ETA-10, FujitsuVP-400, Hitachi s810/20, NEC SX2-400, etc.
Cuarta:Multiprocesadores: multiprocesadores vectoriales yMPP (massively parallel processors).
CRAY-3, CRAY-T90, CRAY T3E, CM5, Intel ParagonXP/5, Fujitsu VPP 500, NEC SX-4/32, etc.
En MPP pueden ponerse las máquinas actuales másveloces, como ASCI White, ASCI Red o ASCI Blue.
Calculo Cientıfico con Computadoras Paralelas – p. 40/110

Breve historia de las computadoras paralelas
La idea de cálculo paralelo es aún anterior a las modernascomputadoras.Menabrea, en 1842, refiriéndose a la máquina analítica deBabbage, de 1822, dijo:
When a long series of identical computations isto be performed, such as those required for theformation of numerical tables, the BabbageAnalytical Engine can be brought into play so as togive several results at the same time, which willgreatly abridge the whole amount of the processes.
Calculo Cientıfico con Computadoras Paralelas – p. 41/110

Breve historia de las computadoras paralelas
Primera calculadora electrónica digital de propósito múltiple: ENIAC(1943-1946).
25 unidades de cómputo independientes (adicionadores, multiplicadores), cada unasiguiendo su propia secuencia de operaciones y cooperando para resolver unproblema común.
Versión electrónica, discreta, de los analizadores diferenciales analógicos.
Método numérico: diferencias finitas
Variables asignadas a diferentes unidades.
I/O físicamente conectadas a un panel de enchufes, según las ecuaciones a resolver.
No había programa almacenado en la computadora. Cada nuevo problema requeríaredefinir la arquitectura.
Después vinieron computadora con programa almacenado, y casi 35 años de
computadoras mono-procesador
Calculo Cientıfico con Computadoras Paralelas – p. 42/110

Breve historia de las computadoras paralelas
UNIVAC 1 (1950), primera computadora comercial deprograma almacenado. Aritmética serial por bit: lasuma de números de 32 bits se efectuaba en 32 ciclosde máquina sumando un bit a otro.
IBMIBM 701 (1953). Primera computadora comercialcon aritmética paralela.IBM 704 (1955). Primera computadora comercialcon unidad de punto flotante. Se produjo durante 20años. Operaciones I/O usaban registros de launidad aritmética.IBM 709 (1958). Tenía canales de I/O: procesadoresseparados para I/O trabajando en paralelo con launidad aritmética.
Calculo Cientıfico con Computadoras Paralelas – p. 43/110

Breve historia de las computadoras paralelas
Entre 1950 y 1980:
Tecnología de transistores
Sólo sistemas basados en un único flujo de instrucciones y datostuvieron éxito comercial.
Diseños estructurales innovativosVon Neumann (1952): diseño un arreglo 2D de procesadores
Holland (1959): conjunto de procesadores que obedecían supropio flujo de instrucciones.
Pease (1977): Hipercubos de dimensiones 1, 2, ..n conectando2
n procesadores.
Millard (1975): Hipercubo con dos procesadores en cada nodo(comunicación y cálculo).
pero sin productos comercialmente viables
Calculo Cientıfico con Computadoras Paralelas – p. 44/110

Breve historia de las computadoras paralelas
En los 60’ y 70’ se introdujo más paralelismo en los monoprocesadores.
Ferranti ATLAS (1962)
Multiprogramas (tiempo compartido)
Memoria virtual
Acceso en paralelo a la memoria a través de bancos
Múltiples unidades funcionales.
Cache: buffer de alta velocidad entre la memoria y los registrosaritméticos.
Ejecución de instrucciones en pipelining: trae la instrucción;calcula la dirección de los operandos; trae los operandos; realizala operación.
CDC 6600 (1964, S, Cray):
Primera en usar el paralelismo funcional como característicadestacada.
Calculo Cientıfico con Computadoras Paralelas – p. 45/110

Breve historia de las computadoras paralelas
Seymour Cray funda Cray Research Inc. en 1972.
CRAY-1 (1976):Primera computadora vectorial12 unidades vectoriales funcionales (3 paravectores)Memoria accesible por 16 bancos8 registros vectoriales32 instrucciones vectoriales
CRAY X-MP (1982):2 CRAY-1 con memoria común, compartida.procesadores capaces de ejecutar sus propiasinstrucciones simultáneamente.
Calculo Cientıfico con Computadoras Paralelas – p. 46/110

Breve historia de las computadoras paralelas
Computadoras multiprocesadores. SIMD
SOLOMON (Simultaneous Operation Linked OrdinalMOdular Network) (Slotnik, 1962)
Arreglo 2D de 32 × 32 elementos procesadores conmemoria local de 128 palabras y aritmética serialpor bit.
Único flujo de instrucciones, enviado por la unidadde control central.Memoria accesible por 16 bancosEsta máquina no se llegó a construir, pero dió lugara la ILLIAC IV, ICL DAP, ...
Calculo Cientıfico con Computadoras Paralelas – p. 47/110

Breve historia de las computadoras paralelas
Computadoras multiprocesadores. SIMD
ILLIAC IV (1967-1975):4 cuadrantes, cada uno con una unidad de control yun arreglo de 8 × 8 procesadores con 2K dememoria local.Cuadrantes conectados por un bus I/O.Muy ambicioso para su tiempo4 lenguajes desarrollados para ILLIAC (Tranquil,Glypnir, Actus, CFD Fortran)
ICL Distributed Array Processor (1972-1980):Arreglo de 64 × 64 procesadores con coneccionesnear-neighbour.
Calculo Cientıfico con Computadoras Paralelas – p. 48/110

Breve historia de las computadoras paralelas
Computadoras multiprocesadores.SIMD (Single Instruction stream - Single Data steam)
Una única instrucción es procesada simultáneamentesobre diferentes datos.
Connection Machine CM-1 y CM-2 (65536 proc.)
DAP 610 (4096 proc.)
MasPar MP-1 (1024 a 16384 proc.)
fueron desarrolladas durante la década de 1980
Calculo Cientıfico con Computadoras Paralelas – p. 49/110

Breve historia de las computadoras paralelas
Computadoras multiprocesadores.MIMD (Multiple Instruction stream - Multiple Data steam)
Varios flujos de instrucciones aplicados a diferentes flujosde datos.
CRAY X-MP y CRAY 2 (4 procesadores), ETA-10 (8procesadores).
Carnegie-Mellon C.mmp y Cm* (1972-1977):
16 minicomputadoras DEC PDP-11 completamenteconectadas a 16 módulos de memoria; espacio dedireccionamiento compartido
Cm*: memoria local, espacio de direccionamientovirtual compartido..
Calculo Cientıfico con Computadoras Paralelas – p. 50/110

Architectura de computadoras paralelas
Computadoras multiprocesadores.MIMD (Multiple Instruction stream - Multiple Data steam)
Cosmic Cube (Fox-Seitz, 1984):Hipercubo de 26 microprocesadores con un host (porej. VAX 11/780).Memoria localComunicación por intercambio de mensajes.Versión comercial: Intel iPSC
Calculo Cientıfico con Computadoras Paralelas – p. 51/110

Architectura de computadoras paralelas
Computadoras multiprocesadores.MIMD (Multiple Instruction stream - Multiple Data steam)
En la última década se construyeron los equipos másveloces compuestos por miles de procesadores. MIMD.
Clusters: en 1994 T. Sterling y D. Becker, en la NASA,construyeron un sistema de microprocesadoresconectados por redes de alta velocidad. ProyectoClusters Beowulf.
Redes de computadoras. A escala mundial. Redesheterogéneas. Proyectos: Genoma Humano; SETI(búsqueda de vida extraterrestre, etc.)
Calculo Cientıfico con Computadoras Paralelas – p. 52/110

Architectura de computadoras paralelas
Las computadoras paralelas pueden clasificarse segúndiferentes criterios:
Granularidad de hardware
Interconexión
Acceso a memoria
Control de flujo
etc.
Calculo Cientıfico con Computadoras Paralelas – p. 53/110

Granularidad de hardware
Granularidad Gruesa:Pocos procesadores poderosos ( 2, 4, 8 hasta 16 proc.)CRAY-2, CRYA-XMP, CRAY-YMP, IBM 3090, NEXC SX3, DEC VAX 9000, Silicon
Graphics 4d/340, ETA 10E, Fujitsu VPP 300, etc.
Granularidad fina:Cientos o miles de pequeños procesadores.Connection Machine CM2 (65536 proc.), DAP 610 (4096 proc.), MasPar MP 1 (1024 -
16384 proc.), MPP (ASCI RED, etc.)
Granularidad intermedia:Decenas o centenares de procesadores.Las hipercubos como Intel IPSC/860 (hasta 128 proc.), NCUBE (64 - 2048 proc.),
Meiko (4 - 512 proc.).
Calculo Cientıfico con Computadoras Paralelas – p. 54/110

Interconexión
Describe la topologıa de hardware.
Varias maneras de conectar los procesadores entre sí ycon la memoria.
Configuraciones estática o dinámica.
Calculo Cientıfico con Computadoras Paralelas – p. 55/110

Interconexión
En una configuración estática las conexiones son fijas, nopueden reconfigurarse.La topología estática, puede a su vez ser:
uni-dimensional (arreglos lineales o anilllos)
bi-dimensional (grillas)
tri-dimensional (cubos)
n−dimensional (hipercubo).
Calculo Cientıfico con Computadoras Paralelas – p. 56/110

Interconexiónes estáticas
(P: procesadores; M: memoria)Calculo Cientıfico con Computadoras Paralelas – p. 57/110

Hipercubos
Topología n−dimensional
Vértices del hipercubo son procesadores y los ladosson conexiones directas.
Cantidad de procesadores: p = 2n.
Cantidad de cables que llegan a un procesador:dimensión del espacio n = log2p.
También n es la cantidad de pasos necesarios paracomunicar un procesador con cualquier otro.
Topología de tamaño fijo: no puede crecer. (En un anilloo un arreglo lineal es fácil agregar un nodo y cada unorecibe dos cables, pero la cantidad de pasos paraalcanzar cualquier nodo crece con la cantidad deprocesadores p)
Calculo Cientıfico con Computadoras Paralelas – p. 58/110
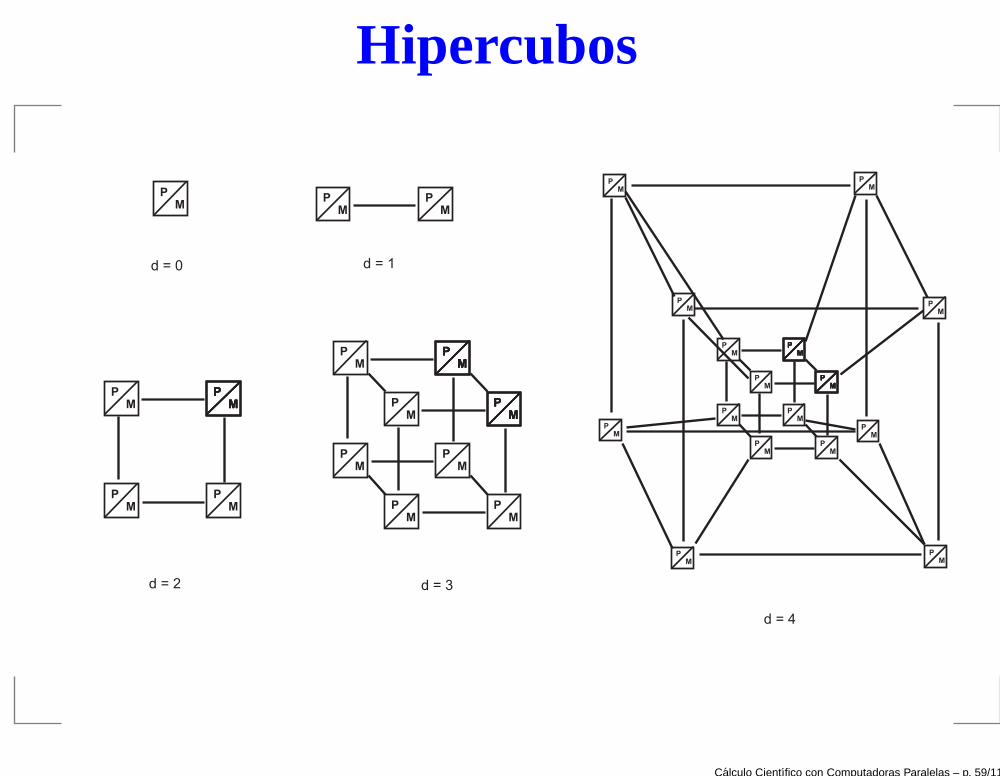
Hipercubos
MP
MP
MP
d = 1
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
MP
d = 0
d = 2 d = 3
d = 4
Calculo Cientıfico con Computadoras Paralelas – p. 59/110

Toro 3D
Toro 3D usado en CRAY T3D (MPP) Cada nodo formaparte de tres anillos.
Calculo Cientıfico con Computadoras Paralelas – p. 60/110

Topologías dinámicas
Las topologías dinámicas tienen llaves (switchs) quepermiten cambiar la configuración.
Pueden ser: single-stage, multi-stage o crossbar.
La forma más simple de conectar varios procesadoreses a través de un bus
Un nodo puede conectarse con cualquier otro, ypuede expandirse la red facilmente.Pero puede tener problemas de congestión
Calculo Cientıfico con Computadoras Paralelas – p. 61/110

Topologías dinámicas
P
P
P
P
M M M M
P
M
P P P P
(a) Crossbar (b) Bus.
(P: processor; M: memory)
Calculo Cientıfico con Computadoras Paralelas – p. 62/110

Interconexiones
Puede interpretarse que las interconexiones entran en unade los siguientes grupos:
Cada procesador está directamente conectado a todoslos otros.
Cada procesador está conectado a todos los otros pormedio de switches.
Cada procesador está conectado solamente aalguno(s) procesadores. Se precisan varios pasos paraalcanzar a cualquier otro en la red.
Calculo Cientıfico con Computadoras Paralelas – p. 63/110

Acceso a la memoria
La forma en que los procesadores pueden acceder a lamemoria permite clasificarlos en memoria compartida ymemoria local.
Memoria compartida: todos los procesadores puedenacceder a cualquier posición en la memoria. ( CRAY 2, Cray
YMP, SGI Origin 2000, DEC Alpha Server 8000, etc.)
Memoria local: cada procesador accede solamente asu propia memoria. (Hipercubos, MPP o clusters de microprocesadores.)
La manera de programar en computadoras paralelasdepende en gran parte de como es el acceso a la memoria.En arquitecturas de memoria local se precisa manejarenvío de mensajes.
Calculo Cientıfico con Computadoras Paralelas – p. 64/110
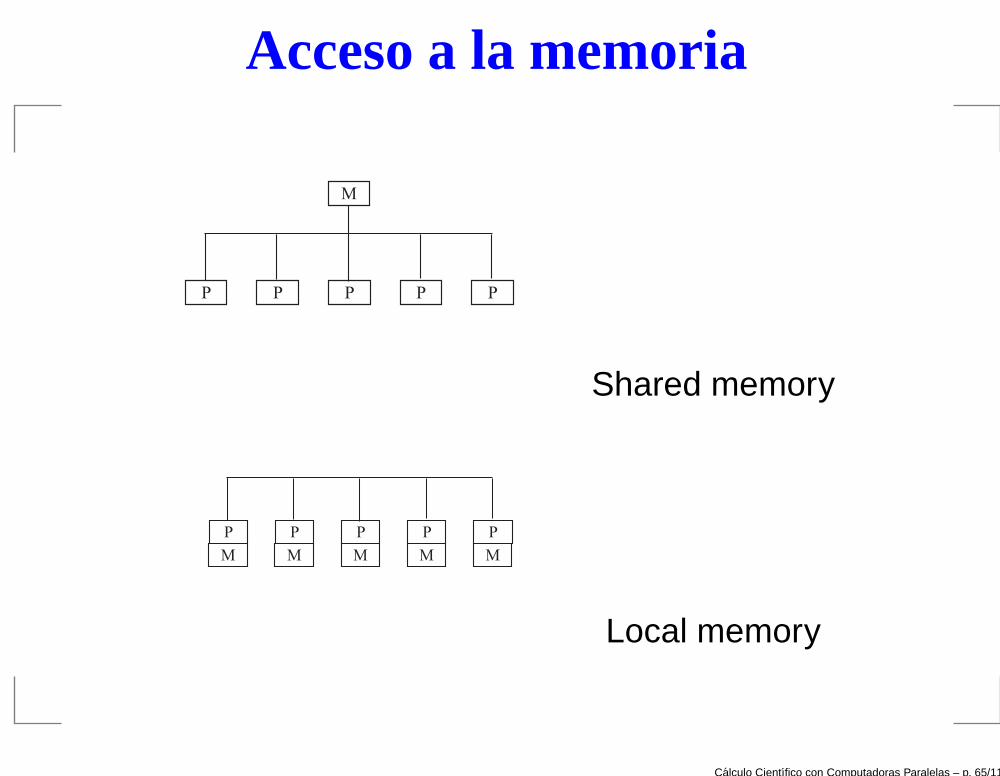
Acceso a la memoria
P
M
P P P P
Shared memory
P P P P P
M M MMM
Local memory
Calculo Cientıfico con Computadoras Paralelas – p. 65/110

Ubicación de la memoria
Un tópico diferente es la localización de la memoria. Éstapuede ser centralizada o distribuida.
Memoria centralizada : físicamente en un lugar.
Memoria distribuida: está particionada y cada parteasociada a un procesador.
Generalmente la memoria centralizada es de accesocompartido, y la memoria distribuida de acceso local, perohay casos la memoria físicamente distribuida pero deacceso compartido (SGI Power Challenge Array, ConvexExemplar, CM 2, BBN, Myrias, etc.).
Calculo Cientıfico con Computadoras Paralelas – p. 66/110

Control de flujo
Una clasificación popular, introducida por Flynn (1966),está basada en la concurrencia de flujos de instrucciones ydatos.Clasifica las computadoras en cuatro grupos:
SISD
SIMD
MISD
MIMD
Calculo Cientıfico con Computadoras Paralelas – p. 67/110
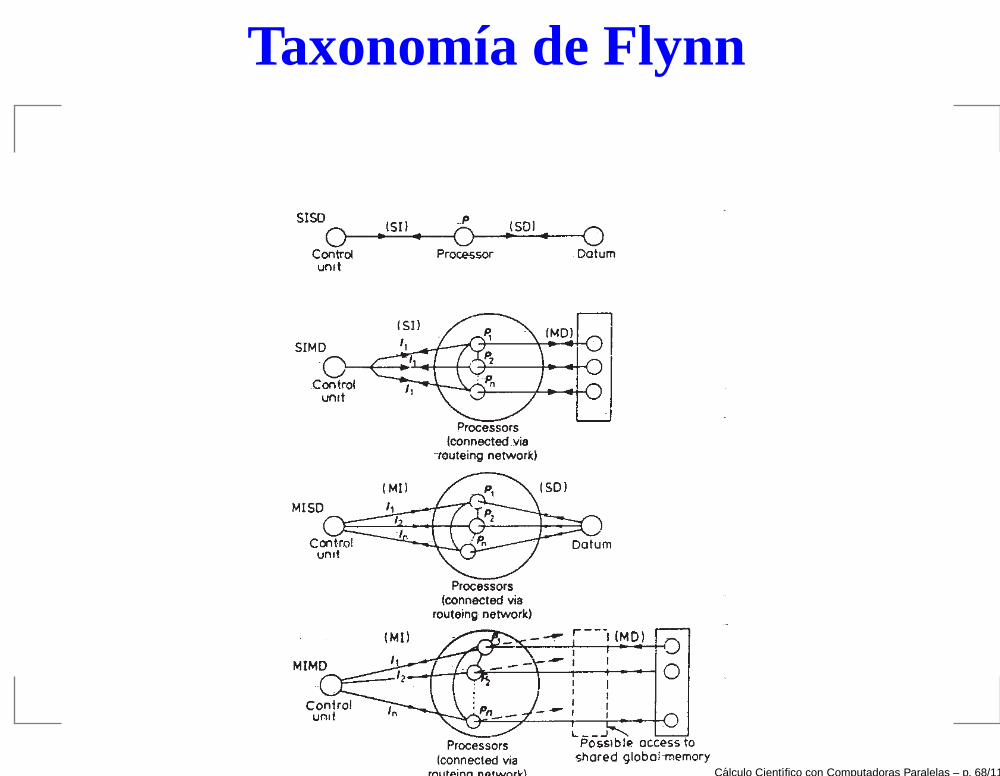
Taxonomía de Flynn
Calculo Cientıfico con Computadoras Paralelas – p. 68/110

Control de flujo
SISD: Single Instruction flow - Single Data flowArquitecturas secuenciales (von Neumann): un únicoflujo de instrucciones y un único flujo de datos. (CDC6600, o la mayoría de las computadoras personales)
SIMD: Single Instruction flow - Multiple Data flowUn único flujo de instrucciones se ejecutasimultaneamente, por varios procesadores, sobrediferentes datos. ( Computadoras vectoriales;computadoras paralelas como ILLIAC IV, y algunas degrano fino: Connection Machine CM 1, CM 2, DAP 610,MasPasr MP 1, etc.).
Calculo Cientıfico con Computadoras Paralelas – p. 69/110

Control de flujo
MISD: Multiple Instruction flow - Single Data flowNo es fácil hallar ejemplos de esta categoría. Losllamados systolic arrays pueden ser vistos comocomputadoras MISD: diferentes procesadores ejecutandiferentes instrucciones sobre el mismo flujo de datos.
MIMD: Multiple Instruction flow - Multiple Data flowLas modernas supercomputadoras caen en esta clase.Cada procesador ejecuta sus propias instruccionessobre diferentes datos.(Hipercubos, CRAY, MPP, clusters, etc.)
Calculo Cientıfico con Computadoras Paralelas – p. 70/110

Arquitecturas de computadoras paralelas
Calculo Cientıfico con Computadoras Paralelas – p. 71/110

Arquitecturas de computadoras paralelas
Classificaci on modernaLas computadoras paralelas actuales caen en laclasificación de MIMD. Se usan otros criterios declasificación. Por ejemplo:
Symmetric Multiprocessors (SMP)
Massively Parallel Processors (MPP)
Cache-Coherent Non Uniform Memory Access(cc-NUMA )
Clusters
Distributed Systems
Calculo Cientıfico con Computadoras Paralelas – p. 72/110

Arquitecturas de computadoras paralelas
Symmetric Multiprocessors (SMP)
Computadoras con varios procesadores altamenteacoplados (o que comparten todo). Grano grueso.Comparten: memoria, bus, sistemas de I/O, etc. Unaúnica copia del SO corre en todos los procesadores.(Computadoras de grano grueso o de memoriacompartida, suelen caer en este tipo. También una PCcon Pentium dual.)
Calculo Cientıfico con Computadoras Paralelas – p. 73/110

Arquitecturas de computadoras paralelas
Massively Parallel Processors (MPP)
Sistemas de grano fino. Muchos procesadores que nocomparten nada. Cada uno tiene su memoria. En cadanodo corre una copia del SO. Están conectados por redde alta velocidad. ( CRAY T3D, CRAY 90, CM 5, CM200, Intel Paragon, ASCI Red, ASCI White, etc.
Calculo Cientıfico con Computadoras Paralelas – p. 74/110

Arquitecturas de computadoras paralelas
Cache-Coherent Non Uniform Memory Access(cc-NUMA )
Cada procesador tiene su memoria, pero el acceso aésta es compartido. Lógicamente cualquier procesadorpuede ver cualquier lugar en la memoria. Pero eltiempo de acceso es diferente, según donde seencuentre. Los valores de variables en el cache decada procesador deben ser coherentes con los valoresen la memoria principal. El SO actualiza los valores decache. Ej: Convex Exemplar SPP 1600/XA, SGI PowerChallenge
Calculo Cientıfico con Computadoras Paralelas – p. 75/110

Arquitecturas de computadoras paralelas
Clusters
Conjunto de microprocesadores, PC, o estaciones detrabajo interconectados con red de alta velocidad.
Distributed Systems
Red convencional de computadoras independientes.Puede ser muy heterogénea en arquitectura, velocidadde procesamiento, etc.
Calculo Cientıfico con Computadoras Paralelas – p. 76/110
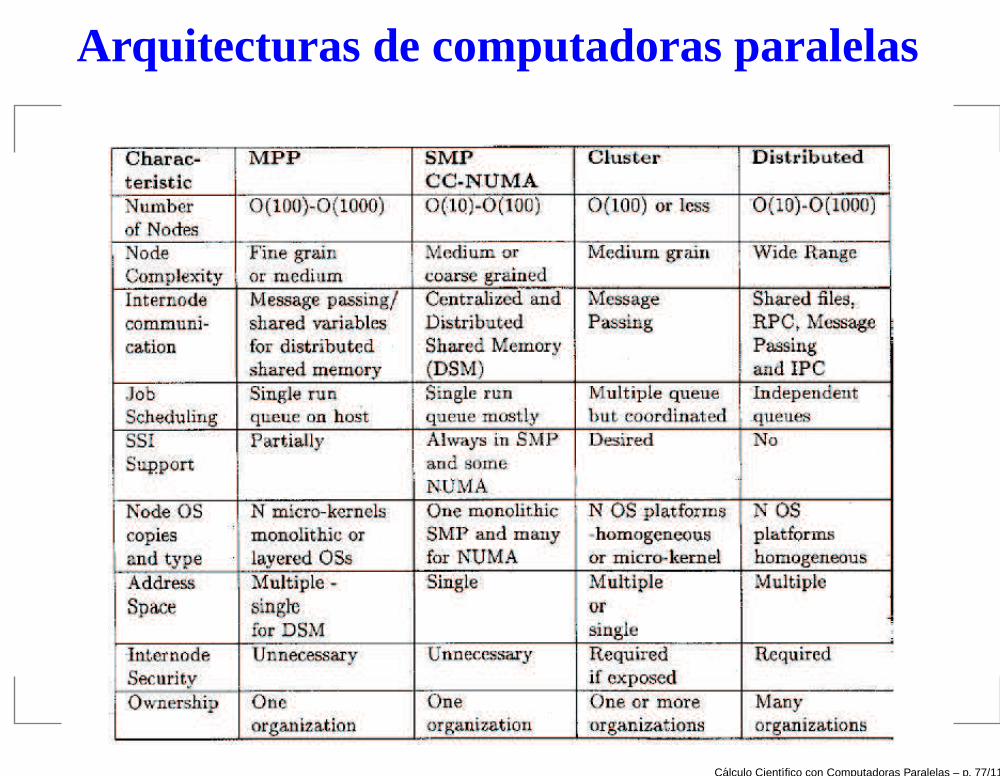
Arquitecturas de computadoras paralelas
Calculo Cientıfico con Computadoras Paralelas – p. 77/110

Top 500
Calculo Cientıfico con Computadoras Paralelas – p. 78/110
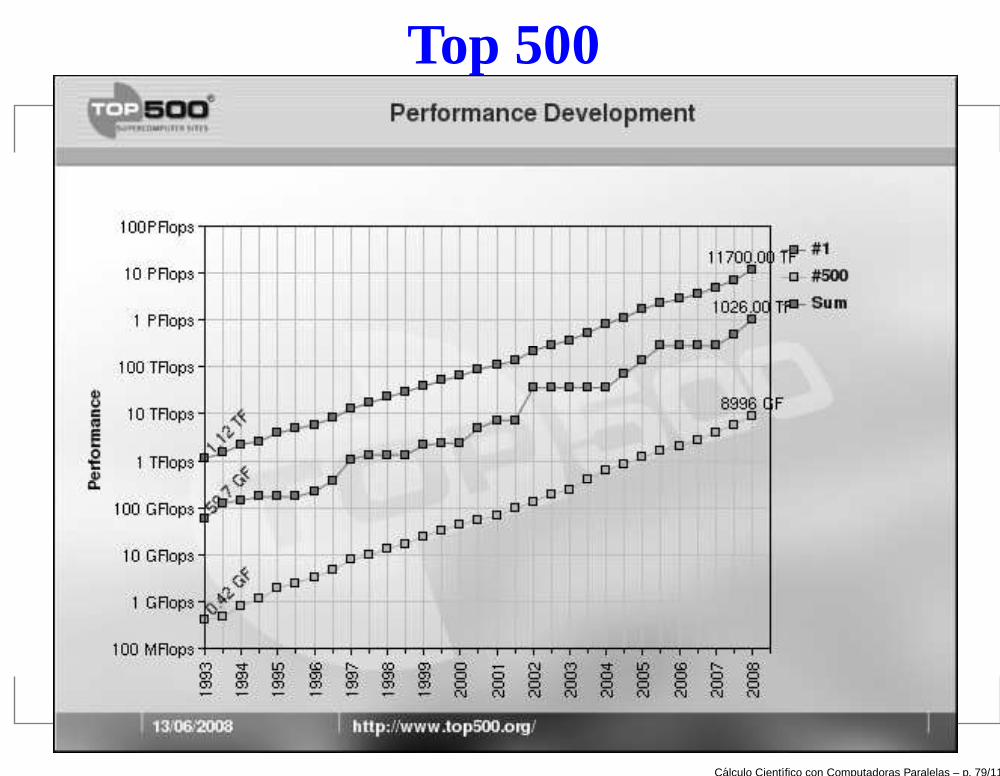
Top 500
Calculo Cientıfico con Computadoras Paralelas – p. 79/110

Top 500 - June 2008
Site Computer Processors Rmax Rpeak, Power Kw
1. DOE/NNSA/LANL United States Roadrunner - BladeCenterQS22/LS21 Cluster, PowerXCell 8i 3.2 Ghz / Opteron DC 1.8 GHz ,Voltaire Infiniband IBM 122400 1026.00 1375.78 2345.50
2. DOE/NNSA/LLNL United States DOE/NNSA/LLNL United StatesBlueGene/L - eServer Blue Gene Solution IBM, Opteron 2.4 GHzdual core Cray Inc. 212992 478.20 596.38 2329.60
3. Argonne National Laboratory United States Blue Gene/P SolutionIBM 163840 450.30 557.06 1260.00
4. Texas Advanced Computing Center/Univ. of Texas United StatesRanger - SunBlade x6420, Opteron Quad 2Ghz, Infiniband SunMicrosystems 62976 326.00 503.81 2000.00
5. DOE/Oak Ridge National Laboratory United States Jaguar - CrayXT4 QuadCore 2.1 GHz Cray Inc. 30976 205.00 260.20 1580.71
Calculo Cientıfico con Computadoras Paralelas – p. 80/110

Niveles de paralelismo
El paralelismo puede ser ejecutado en diferentes niveles:
Nivel de trabajo (Job level)
Nivel de programa
Nivel inter-instrucciones
Nivel intra-instrucciones
Calculo Cientıfico con Computadoras Paralelas – p. 81/110

Niveles de paralelismo
Nivel de trabajo (Job level)
Llevado a cabo principalmente por el SO. Administralos diferentes trabajos/programas en el equipo demultiproceso.Puede tomar la forma de:
multiprogramamultiproceso
Calculo Cientıfico con Computadoras Paralelas – p. 82/110

Niveles de paralelismo
Nivel de programa
Realizado por el código. Dentro del programa deaplicación. Se puede introducir el concepto degranularidad de tareas.El paralelismo a nivel de programa puede ser divididoen:
tareas de granularidad finatareas de granularidad gruesa
Calculo Cientıfico con Computadoras Paralelas – p. 83/110

Niveles de paralelismo
Nivel inter-instrucciones
Realizado por el compilador.Requiere que el compilador analice la dependencia dedatos entre instrucciones y superpongasub-operaciones de diferentes instrucciones.
Nivel intra-instrucciones
Implícito en el hardware.Existencia de unidades funcionales separadas (adición,multiplicación, lógica); operaciones vectoriales,pipelining, encadenamiento, etc.
Calculo Cientıfico con Computadoras Paralelas – p. 84/110

Modelos de programación paralela
Memoria compartida
Intercambio de mensajes
Calculo Cientıfico con Computadoras Paralelas – p. 85/110

Modelos de programación paralela
Memoria compartida
Para computadoras de memoria compartidaUn procesador inicia la ejecución. Cuando una tarealo requiere, abre varios hilos (threads) de ejecuciónen diferentes procesadores.Requiere:
Zonas memoria compartidaSincronización
Calculo Cientıfico con Computadoras Paralelas – p. 86/110

Modelos de programación paralela
Intercambio de mensajes
Para computadoras de memoria localCada procesador corre su propio programa. Precisaintercambiarse información.Requiere:
comunicación
Calculo Cientıfico con Computadoras Paralelas – p. 87/110

Lenguajes para programación paralela
FORTRAN, C, C++
Memoria compartida:funciones de bajo niveldirectivas al compilador y extensiones (OMP)macro-lenguajes (Ej: Force, etc.)
Memoria local:funciones básicas de comunicaciónsoftware portable de comunicación (PVM, MPI)extensiones al lenguaje (HPF)librerías (PETSc)
Calculo Cientıfico con Computadoras Paralelas – p. 88/110

Uno debe elegir...
modelo matemático
Calculo Cientıfico con Computadoras Paralelas – p. 89/110

Uno debe elegir...
modelo matemático
modelo numérico
Calculo Cientıfico con Computadoras Paralelas – p. 89/110

Uno debe elegir...
modelo matemático
modelo numérico
algoritmos de solución
Calculo Cientıfico con Computadoras Paralelas – p. 89/110

Uno debe elegir...
modelo matemático
modelo numérico
algoritmos de solución
programación del código
Calculo Cientıfico con Computadoras Paralelas – p. 89/110

Uno debe elegir...
modelo matemático
modelo numérico
algoritmos de solución
programación del código
pero también
Calculo Cientıfico con Computadoras Paralelas – p. 89/110

Uno debe elegir...
modelo matemático
modelo numérico
algoritmos de solución
programación del código
pero también
arquitectura de hardware
Calculo Cientıfico con Computadoras Paralelas – p. 90/110

Uno debe elegir...
modelo matemático
modelo numérico
algoritmos de solución
programación del código
pero también
arquitectura de hardware
modelo de programación paralela
Calculo Cientıfico con Computadoras Paralelas – p. 90/110

Uno debe elegir...
modelo matemático
modelo numérico
algoritmos de solución
programación del código
pero también
arquitectura de hardware
modelo de programación paralela
lenguaje
Calculo Cientıfico con Computadoras Paralelas – p. 90/110

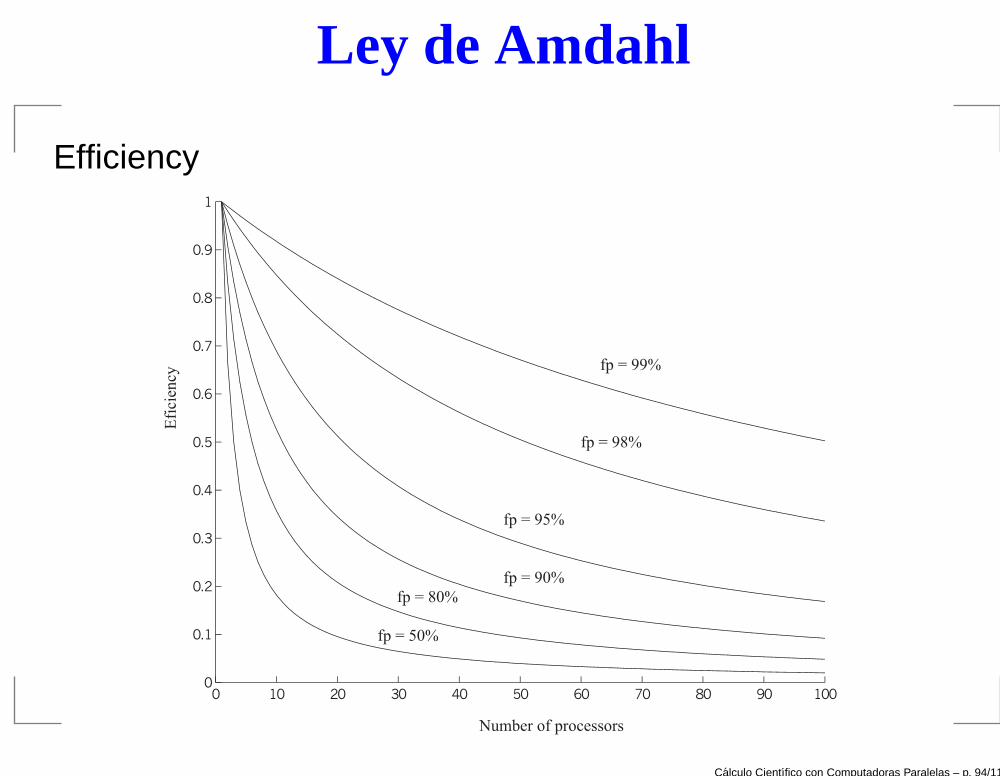
Eficiencia de programas paralelos
Speedup:
Sp =ts
tp
Eficiencia:
Ep =Sp
p=
ts
ptp
ts : tiempo de ejecución secuencial de un programa;tp : tiempo de ejecución paralela con p procesadores.
Idealmente : Sp → p and Ep → 1
En la práctica: Sp ≤ p and Ep ≤ 1
Calculo Cientıfico con Computadoras Paralelas – p. 91/110

Eficiencia de programas paralelos
Ley de Amdahl:
Si el programa no puede paralelizarse completamente, y sifs es la fracción serial del programa, a medida queaumenta la cantidad de procesadores (p → ∞) el speedupestá acotado por
Sp ≤1
fs
Por ejemplo:para fs = 10% → Sp ≤ 10
Calculo Cientıfico con Computadoras Paralelas – p. 92/110

Ley de Amdahl
SpeedupS
pee
du
p
Number of processors
fp = 99%
fp = 98%
fp = 95%
fp = 90%
fp = 80%fp = 50%
ideal
Calculo Cientıfico con Computadoras Paralelas – p. 93/110
Ley de Amdahl
EfficiencyE
fici
ency
Number of processors
fp = 99%
fp = 98%
fp = 95%
fp = 50%
fp = 90%
fp = 80%
Calculo Cientıfico con Computadoras Paralelas – p. 94/110

Ley de Gustafson
Ley de Amdahl → fracción serial fs independiente de p.Pero la fracción serial depende de la cantidad deoperaciones realizadas.Gustafson (1988) lo plantea así: ¿ Cuál sería el tiempopara procesar secuencialemnte un dado programaparalelo?Sea f∗
sla fracción secuencial de las operaciones en el
programa paralelo con p procesadoers.
Sp =ts
tp= p + f∗
s(1 − p)
Calculo Cientıfico con Computadoras Paralelas – p. 95/110

Ley de Gustafson
SpeedupS
pee
du
p
Number of processors
fp = 50%
fp = 80%
fp = 90%
fp = 95%
fp = 98%
ideal
Calculo Cientıfico con Computadoras Paralelas – p. 96/110

Eficiencia de programas paralelos
Escalabilidad:
Capacidad de mantener la eficiencia aproximadamenteconstante a medida que la cantidad de procesadoresaumenta.
A aumentar p → el tiempo de cálculo disminuye
Pero al aumentar p → el tiempo de comunicación ycoordinación aumenta
Calculo Cientıfico con Computadoras Paralelas – p. 97/110

Programación paralela
Formas de usar el paralelismo
paralelismo de control: permite procesar variasinstrucciones al mismo tiempo. Cada una enprocesadores diferentes.
paralelismo de flujo: trabajo realizado en una línea demontaje (pipeline)
paralelismo de datos: una operación se realizasimultáneamente sobre diferentes datos. Cada datoasociado a un procesador.
Se puede asociar estas clases de paralelismo con lasarquitecturas de Flynn: MIMD, MISD y SIMD,respectivamente.
Calculo Cientıfico con Computadoras Paralelas – p. 98/110

Programación paralela
Grado de participación del programador
paralelismo implícito: la división de tareas en hiloparalelos es realizada principalmente por el compilador.La participación del programador es -por tanto- mínima.En computadoras de memoria compartida es típicaesta forma de trabajo, pero actualmente tambiéndisponible en arquitecturas de memoria local.
paralelismo explícito: la división de tareas en hiloparalelos es realizada explícitamente por elprogramador.
Calculo Cientıfico con Computadoras Paralelas – p. 99/110

Solución de sistemas de ecuaciones
La aplicación del método de los elementos finitos -u otrométodo numérico- conduce a la resolución del sistema deecuaciones:
Ku = p
Que puede hacerse por:
Métodos directos
Métodos iterativos
Métodos de decomposición de dominio
Calculo Cientıfico con Computadoras Paralelas – p. 100/110

Métodos directos
Solución cerrada ("exacta")
Factorización LU → buena para varios sistemas con lamisma matriz
Puede evitarse ensamble de la matriz → método frontal
Caro para grandes sistemas: O(n3) ops (matriz llena)
Calculo Cientıfico con Computadoras Paralelas – p. 101/110

Métodos iterativos
Solución con una dada tolerancia
Buena estimación inicial → solución rápida
No se requiere la matriz completa (sólo productomatriz-vector)
Para grandes sistemas, requiere memoria grande(espacio Krylov)
Calculo Cientıfico con Computadoras Paralelas – p. 102/110

Métodos de decomposición del dominio
Divide el dominio en subdominios
Incógnitas internas - interfaz
La solución del sistema completo puede serparticionada en:
g.d.l. internos (en paralelo) directog.d.l. interfaz (acoplado) iterativo
Intermedio entre solución directa e iterativa
Eficiente precondicionador del problema de interfaz
Calculo Cientıfico con Computadoras Paralelas – p. 103/110

Métodos de decomposición del dominio
Calculo Cientıfico con Computadoras Paralelas – p. 104/110

Problemas de campos acoplados
Problemas de interacción de dos campos o disciplinas
Interacción fluido-estructuraflutter en alas de avión
ver Tacomaflujo sanguíneo en arteria elásticaetc.
Interacción de dos campos diferentes: térmico,electromagnético, deformación de un sólido, ...
Calculo Cientıfico con Computadoras Paralelas – p. 105/110

Problemas de campos acoplados
Problemas de interacción de dos campos o disciplinas
W1
W2
G
Calculo Cientıfico con Computadoras Paralelas – p. 106/110

Cluster Beowulf en CIMEC
Clusters de microprocesadores que corren SO libres (ej.GNU/Linux) se denominan "clusters Beowulf".Según Sterling (“How to build a Beowulf” ) un “clusterBeowulf” es: “A cluster of mass-market commodityoff-the-shelf (M2COTS) PC’s interconnected by low costLAN technology running an open source code Unix-like OSand executing parallel applications programmed with andindustry standard message passing model and library.”
Calculo Cientıfico con Computadoras Paralelas – p. 107/110

Cluster Beowulf Gerónimo en CIMEC
Server :Intel Pentium IV PC, 1.8 Ghz, 256 Mb RAM RIMM. HD80 Gb, with carrries 2 3COM 3c509 (Vortex) Nic cards
Nodes (x 9)Intel Pentium IV, 2.4 Ghz, 1024 MB RAM DDR 333MHz,1 3COM 3c509 (Vortex) Nic card
Nodes (x 9)Intel Pentium IV, 1.7 Ghz, 512 MB RAM RIMM400/800Mhz. 1 3COM 3c509 (Vortex) Nic card
Network3COM Fast Ethernet SuperStack switch.
Calculo Cientıfico con Computadoras Paralelas – p. 108/110

Beowulf cluster at CIMEC
Calculo Cientıfico con Computadoras Paralelas – p. 109/110

Cluster Beowulf Aquiles en CIMECServer :Intel Pentium4 Prescott 3.0 GHz, motherboards Intel 3.0 GHz y 3 GBmemoria RAM (DDR a 400 MHz), con Gigabit Lan on board, 2TBytes de almacenamiento (disco SATA 150 and ATA-100 slots), 1unidad de diskette 3.5", 1 placa video Gforce XFX de 64 MB 8X, y 1fuente alimentación 300 W con 2 ventiladores. Discos rígidos (10),Western Digital WD 2000 JD 200 GB capacidad, con 8 MB buffer yveloc. 7200 RPM, interface SATA.
Nodes (x 82)Intel Pentium 4 Prescott de 3.0 GHz y 2 GB memoria RAM (DDR a400 MHz), motherboards Intel de 3.0GHz, con Gigabit Lan on board,1 unidad diskette 3.5", placa video AGP y fuente alimentación 300 Wcon 2 ventiladores.
Network
2 switch Gigabit ethernet ( 1 Gbit/s), marca 3Com Super Stack 3Switch 3870, con 48 puertos c/u.
Calculo Cientıfico con Computadoras Paralelas – p. 110/110


















