
clase0 la materia - Argentina.gob.ar la... · Algebra Lineal en GPUs. 8. Jerarquía de memorias....
29
ICNPG 2016 Aspectos Prácticos
Transcript of clase0 la materia - Argentina.gob.ar la... · Algebra Lineal en GPUs. 8. Jerarquía de memorias....

ICNPG 2016
Aspectos Prácticos

• Aprendizaje de nuevas técnicas de programación para explotar el potencial de las GPUs (tarjetas gráficas) como dispositivos aceleradores de cálculo.
• CUDA C: que contiene extensiones específicas del lenguaje C para tarjetas gráficas compatibles con la arquitectura CUDA (Compute Unified Device Architecture) para propósitos de cálculo general.
• Bibliotecas y herramientas de alto nivel para poder explotar el poder de calculo de las GPUs.
• El curso es práctico, con problemas sencillos de cálculo numérico.
• Estudiantes de postgrado de física, ingeniería y áreas relacionadas.

1. CUDA C Básico. Debugging y profiling.
2. Algoritmos básicos de paralelismo.
3. Thrust.
4. Introducción al uso de directivas: OpenACC, OpenMP.
5. Python y CUDA.
6. FFT.
7. Algebra Lineal en GPUs.
8. Jerarquía de memorias. Streams.
9. Optimización.

Tesla C2075,Tesla C2070
K20, GTX 780 (x5),
GTX Titan
GTX 480
gpgpu-fisica.cabib.local (10.73.25.207)
CCAD - Bariloche , Gerencia de Física
sysadmin: Gustavo Berman

• Las clases están on line
• Los problemas están on line
• Curso Hands-on:
• Trabajo de programación en clase.
• Guias de problemas ampliando el trabajo de clase.
http://fisica.cab.cnea.gov.ar/gpgpu/

Alejandro Kolton (Sólidos)
Mónica Denham (UnRN)
Karina Laneri (FiEstIn)
Pablo Cappagli (Radioterapia)
Flavio Colavecchia (Colisiones/Radioterapia)

problemas, dudas, consultas sobre el curso en general
Usar el subject!
todos los alumnos + profesores

problemas, dudas, consultas particulares
Usar el subject!
email dirigido sólo a los docentes

• Parcial: Envío de la solución de un problema seleccionado de las guías de trabajos prácticos:
• Códigos fuente (correctness, performance, códigos co-men-ta-dos!)
• Una informe con los resultados del problema propuesto
• Fecha de entrega a determinar, a lo sumo 10 días antes del final, estricto!
• Asistencia a todos los encuentros (se toma lista!!!)
• Final: multiple choice + un ejercicio en computadora
Evaluación

David B. Kirk, Wen-mei W. Hwu. Programming Massively Parallel Processors: A Hands-on Approach, Morgan Kaufmann, 2010.
Jason Sanders, Edward Kandrot, CUDA by Example, Addison-Wesley, 2010.
Robert Farber, CUDA Application Design and Development, Morgan Kaufman, 2011.
Shane Cook, CUDA Programming, Morgan Kaufman, 2012.
NVIDIA Inc., CUDA C Programming Guide, version 7.5, 2015.
biblio

¿ Dudas ?
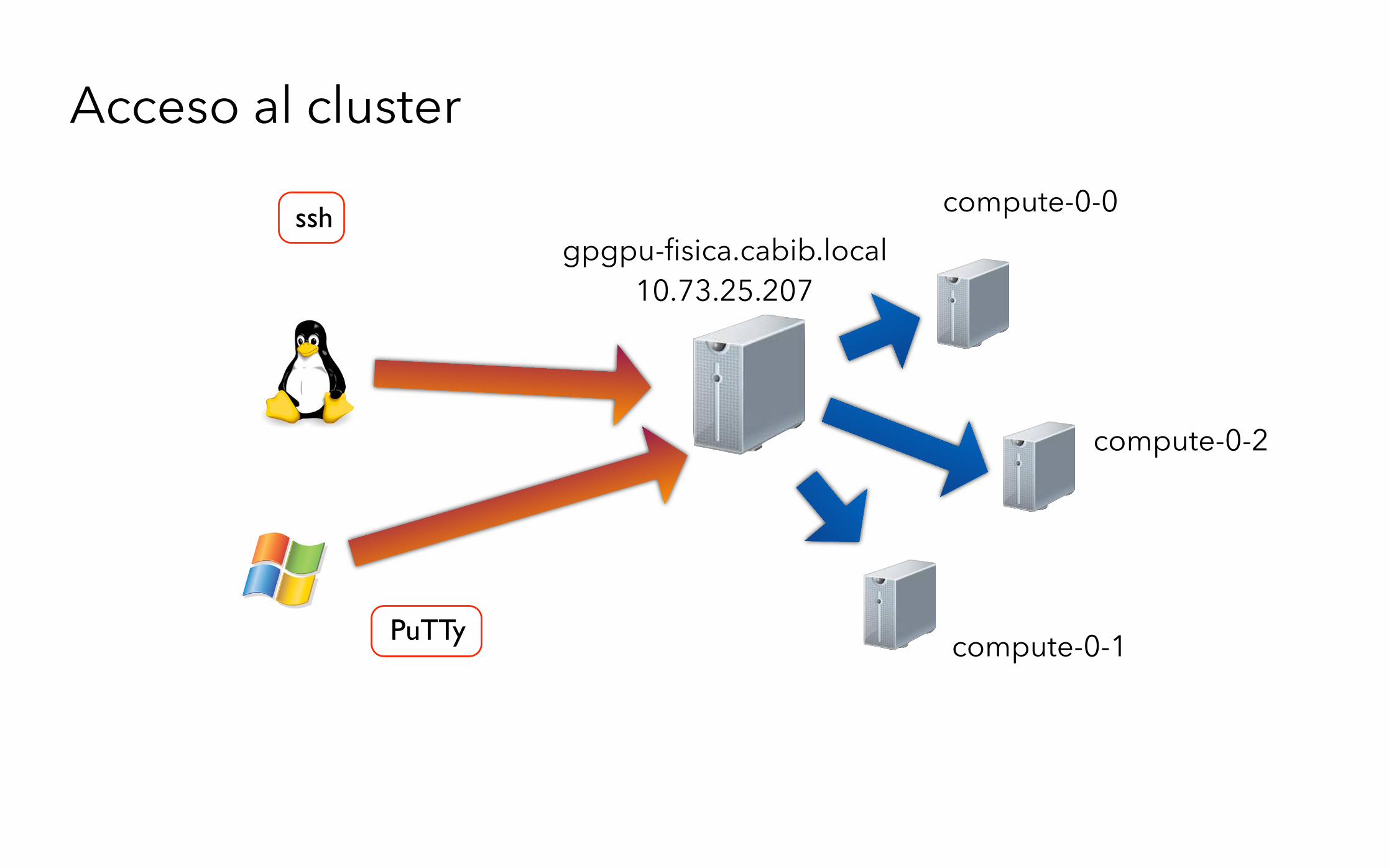
Acceso al cluster
gpgpu-fisica.cabib.local 10.73.25.207
compute-0-0
compute-0-2
compute-0-1PuTTy
ssh
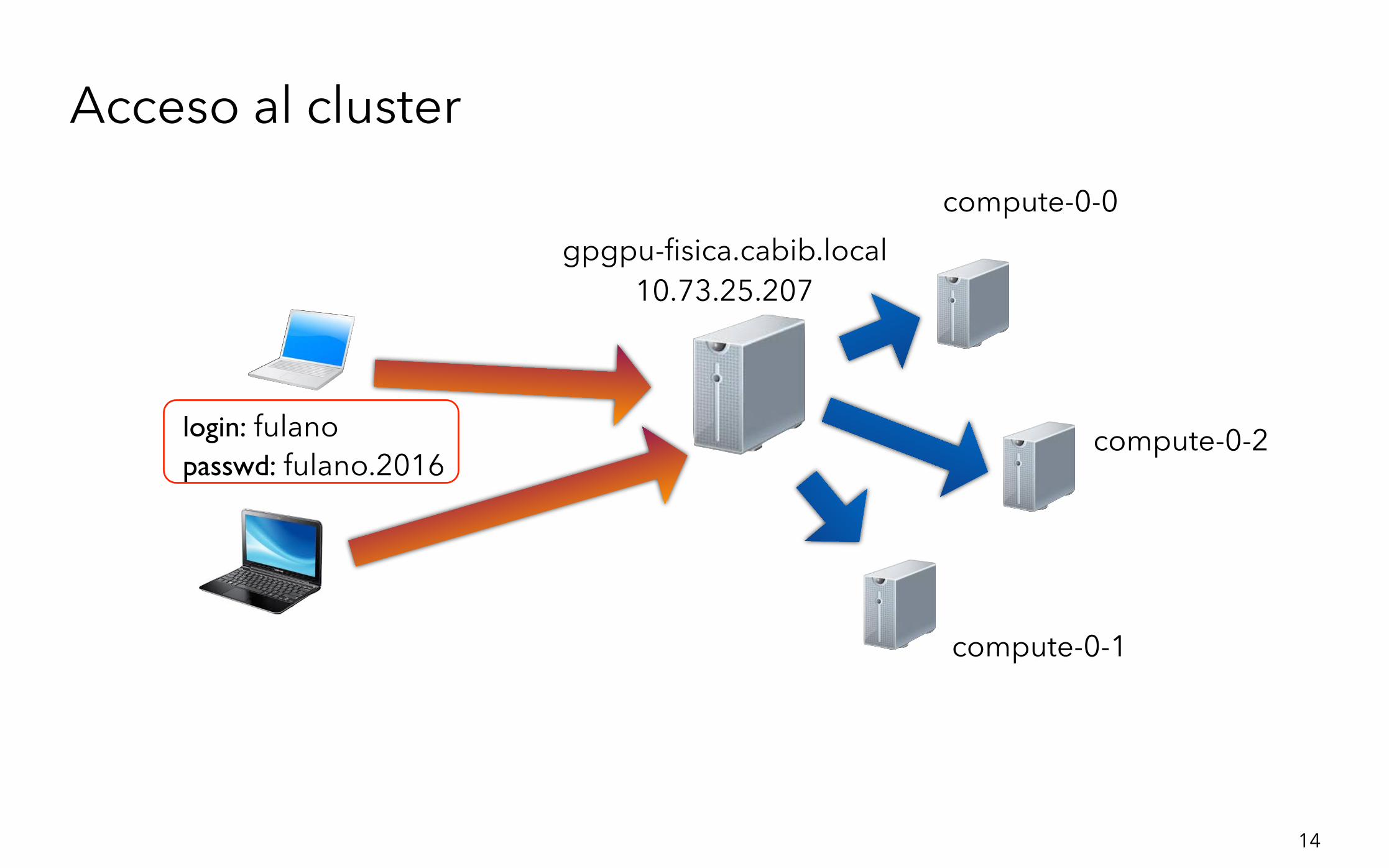
Acceso al cluster
14
gpgpu-fisica.cabib.local 10.73.25.207
compute-0-0
compute-0-2
compute-0-1
login: fulano passwd: fulano.2016

Copiando los códigos[flavioc@gpgpu-fisica~]$ls/share/apps/codigos
common ejemplos_thrustSUMA-VectoresHola_mundo
[flavioc@gpgpu-fisica~]$mkdiricnpg2015
[flavioc@gpgpu-fisica~]$cdicnpg2015/
[flavioc@gpgpu-fisicaicnpg2015]$cp-R/share/apps/codigos/Hola_mundo/.
[flavioc@gpgpu-fisicaicnpg2015]$ls
Hola_mundo
[flavioc@gpgpu-fisicaicnpg2015]$cdHola_mundo
[flavioc@gpgpu-fisicaHola_mundo]$ls
hola_mundo_io.chola_mundo_io.hmain_hola_mundo.cMakefilesubmit_cpu.sh

Hola Mundo#include<stdio.h>#include<stdlib.h>#include<sys/time.h>#include"hola_mundo_io.h"
#ifndefVECES#defineVECES10#endif
intmain(){inti;for(i=0;i<VECES;i++){printf("%d:",i);imprime_hola_mundo();}
return0;}
main_hola_mundo.c

Hola Mundo#include<stdio.h>#include<stdlib.h>#include<sys/time.h>#include"hola_mundo_io.h"
#ifndefVECES#defineVECES10#endif
intmain(){inti;for(i=0;i<VECES;i++){printf("%d:",i);imprime_hola_mundo();}
return0;}
intimprime_hola_mundo();
hola_mundo_io.h
#include<stdio.h>
#include"hola_mundo_io.h"
intimprime_hola_mundo()
hola_mundo_io.c
main_hola_mundo.c

Compilando y corriendo[flavioc@gpgpu-fisicaHola_mundo]$gcchola_mundo_io.cmain_hola_mundo.c-omain[flavioc@gpgpu-fisicaHola_mundo]$./main0:HolaMundo!1:HolaMundo!2:HolaMundo!3:HolaMundo!4:HolaMundo!5:HolaMundo!6:HolaMundo!7:HolaMundo!8:HolaMundo!9:HolaMundo![flavioc@gpgpu-fisicaHola_mundo]$

Compilando con Makefile# CompiladoryflagsdelcompiladorydellinkerCC=gccCFLAGS=CPPFLAGS=LDFLAGS=## Nombredelejecutable#BIN=main## Archivosfuentes#SOURCES=$(shellecho*.c)## Objetosapartirdelosfuentes#OBJECTS=$(patsubst%.c,%.o,$(SOURCES))## Rules#all:$(BIN)
$(BIN):$(OBJECTS) $(CC)$(CFLAGS)$(LDFLAGS)-o$@$^
%.o:%.c $(CC)$(CPPFLAGS)$(CFLAGS)-o$@-c$<
.PHONY:allclean
clean: rm-f.depend*.o$(BIN)
Makefile

Compilando y corriendo[flavioc@gpgpu-fisicaHola_mundo]$makegcc-ohola_mundo_io.o-chola_mundo_io.cgcc-omain_hola_mundo.o-cmain_hola_mundo.cgcc-omainhola_mundo_io.omain_hola_mundo.o[flavioc@gpgpu-fisicaHola_mundo]$./main0:HolaMundo!1:HolaMundo!2:HolaMundo!3:HolaMundo!4:HolaMundo!5:HolaMundo!6:HolaMundo!7:HolaMundo!8:HolaMundo!9:HolaMundo![flavioc@gpgpu-fisicaHola_mundo]$

Corriendo en las colas del cluster
• Cada trabajo (job) tiene un nombre y un número, y necesitamos un script para enviar el código a correr
• submit.sh es el script para enviar el código a las colas de ejecución
• qsub submit.sh Envía el código a la cola de ejecución y genera un número de trabajo xx y nombre
• qstat -f Consulta la cola de ejecución
• qdel xx Borrar el trabajo xx enviado
21

Las colas del cluster[flavioc@gpgpu-fisicaHola_mundo]$qsubsubmit_cpu.shYourjob148("HolaMundo")hasbeensubmitted[flavioc@gpgpu-fisicaHola_mundo]$qstat-fqueuenameqtyperesv/used/tot.load_avgarchstates---------------------------------------------------------------------------------cpu.q@compute-0-0.localBIP0/0/20.16linux-x64---------------------------------------------------------------------------------cpu.q@compute-0-1.localBIP0/0/20.00linux-x64---------------------------------------------------------------------------------cpu.q@compute-0-2.localBIP0/0/20.00linux-x64...---------------------------------------------------------------------------------gpu.q@compute-0-0.localBIP0/0/20.16linux-x64---------------------------------------------------------------------------------gpu.q@compute-0-1.localBIP0/0/20.00linux-x64---------------------------------------------------------------------------------gpu.q@compute-0-2.localBIP0/0/20.00linux-x64---------------------------------------------------------------------------------gpu.q@compute-0-3.localBIP0/0/20.08linux-x64---------------------------------------------------------------------------------gpu.q@compute-0-4.localBIP0/0/20.00linux-x64---------------------------------------------------------------------------------gpu.q@compute-0-5.localBIP0/0/20.26linux-x64
############################################################################-PENDINGJOBS-PENDINGJOBS-PENDINGJOBS-PENDINGJOBS-PENDINGJOBS############################################################################1480.00000HolaMundoflaviocqw09/30/201320:57:131

Corriendo en el cluster#!/bin/bash#Elpathdeejecuciondeljobeseldirectorioactual#$-cwd#Reunestdoutystderren.oxx#$-jy#Bourneshellparaeljob#$-S/bin/bash#Nombredeljob#$-NHolaMundo#pidolacolacpu.q#$-qcpu.q##imprimeelnombredelnodohostname#ejecutoelbinario./main
submit_cpu.sh
elijo la cola de ejecución
• cpu.q: cola de ejecución en cpu
• gpu.q: cola de ejecución en gpu
comandos del sistema de colas

Sistema de colas
gpgpu-fisica.cabib.local 10.73.25.207
compute-0-0
compute-0-2
compute-0-1
qsub submit_job.sh

Sistema de colas
25
gpgpu-fisica.cabib.local 10.73.25.207
compute-0-0
compute-0-2
compute-0-1
qstat -f
job xx

Sistema de colas
gpgpu-fisica.cabib.local 10.73.25.207
compute-0-0
compute-0-2
compute-0-1
submit_job.oxx

Módulos
La forma de incluir datos (Variables del Entorno, environment variables)
para la compilación con distintos compiladores o bibliotecas.

Módulosflavioc@gpgpu-fisica~]$moduleavail------------------------------------------/usr/share/Modules/modulefiles---------------------------------------dotmodule-infonullrocks-openmpi_ibmodule-cvsmodulesrocks-openmpiuse.own-------------------------------------------------/etc/modulefiles----------------------------------------------openmpi-x86_64------------------------------------------/share/apps/modules/modulefiles--------------------------------------cudalammpi/gnumpich2/gnuopenmpi/gnuintel/intel-12lammpi/intel-12mpich2/intel-12openmpi/intel-12[flavioc@gpgpu-fisica~]$modulelistCurrentlyLoadedModulefiles:1)rocks-openmpi[flavioc@gpgpu-fisica~]$moduleloadcuda-7.0[flavioc@gpgpu-fisica~]$modulelistCurrentlyLoadedModulefiles:1)rocks-openmpi2)cuda-7.0[flavioc@gpgpu-fisica~]$

module load cuda-7.5


















