Caracterización de anomalías en trá co P2P mediante ...
144
Transcript of Caracterización de anomalías en trá co P2P mediante ...

Caracterización de anomalías en
trá�co P2P mediante autómatas de
estados �nitos
Departamento de Teoría de la Señal, Telemática yComunicaciones
Proyecto Fin de Carrera
Jesús Javier Nuño García
Directores:Jesús Esteban Díaz VerdejoGabriel Maciá Fernández


D. Jesús Esteban Díaz Verdejo y D. Gabriel Maciá Fernández, profesores de la EscuelaTécnica Superior de Ingenierías Informática y Telecomunicación del Departamento deTeoría de la Señal, Telemática y Comunicaciones, como Directores del Proyecto Fin deCarrera de D. Jesús Javier Nuño García
DECLARAN
que este trabajo, con título �Caracterización de anomalías en trá�co P2P con autó-matas de estados �nitos�, ha sido elaborado por el alumno mencionado bajo nuestrasupervisión y autorizamos su defensa ante el tribunal que corresponda.
Y para que conste, �rmamos el presente documento, en Granada, a 1 de septiembrede 2009.
D. Jesús Esteban Díaz Verdejo D. Gabriel Maciá Fernández
i

ii

Jesús Javier Nuño García, con DNI nº 75.144.433-Y, alumno de Ingeniería Informá-tica de la Escuela Técnica Superior de Ingenierías Informática y Telecomunicación dela Universidad de Granada, autoriza que se expida una copia del presente documentode Proyecto Fin de Carrera a la biblioteca del Centro, a �n de poder ser consultada oreferenciada por aquellas personas que lo deseen.
Granada, a 1 de septiembre de 2009
Jesús Javier Nuño García
iii

iv

Caracterización de anomalías en trá�co P2Pmediante autómatas de estados �nitos
Jesús Javier Nuño García
Palabras clave: Protocolo eDonkey, anomalía, autómata de estados �nitos, IDS, P2P.
Resumen:
El popular protocolo para redes peer-to-peer `eDonkey', de�ne un modo de intercambiode mensajes entre ciertas entidades involucradas en una comunicación. En particular,establece la secuencia y tipo de tramas intercambiadas entre dos nodos (peers) de lared P2P. Para cada situación, este protocolo tiene de�nido una serie de intercambios demensajes consecutivos. Para cada uno de estos escenarios se puede de�nir un autómatade estados �nitos que modele el comportamiento del protocolo.Mediante el desarrollo de una aplicación con conocimiento acerca de estos autómatas,
se puede analizar el comportamiento de las entidades en el uso del protocolo. A partir delos resultados obtenidos, estos comportamientos se podrán clasi�car como permitidos ono, dependiendo de si han seguido la especi�cación del protocolo instanciada en los autó-matas. Los comportamientos no acordes a dichos autómatas podrán, consecuentemente,clasi�carse como anómalos desde el punto de vista de la seguridad de los sistemas.En este proyecto se modela e implementa un entorno de análisis que permite evaluar las
posibles anomalías existentes en el protocolo `eDonkey' mediante autómatas de estados�nitos. Adicionalmente, se diseñan y realizan una serie de pruebas de evaluación paracomprobar el correcto funcionamiento de la aplicación, así como su rendimiento.
v

vi

Anomaly characterization in P2P tra�c with�nite-state machines
Jesús Javier Nuño García
Keywords: eDonkey protocol, anomaly, �nite-state machine, IDS, P2P.
Abstract:
The popular peer-to-peer protocol `eDonkey', de�nes message exchange between cer-tain entities involved in a communication. In particular, it establishes the sequence andtype of frames exchanged between two P2P network nodes (peers). For every possiblesituation, this protocol de�nes a series of consecutive message exchange. For each of thesescenarios, a �nite-state machine can be de�ned to model the protocol's behavior.By developing an application with information about these �nite-state machines, the
behavior of the communication entities, related to the use of the protocol, can be analy-zed. From the results obtained, these behaviors may be classi�ed as allowed or not,depending on whether they have followed the protocol speci�cation as instantiated in�nite-state machines. Those behaviors not coherent with these �nite-state machines canbe consequently classi�ed as abnormal from a system security point of view.In this project, an environment is modeled and implemented. It makes it possible to
evaluate possible anomalies in `eDonkey' protocol by �nite-state machines. In order tocheck the correct implementation of the application, as well as its performance, a seriesof tests are designed, being their result clearly discussed.
vii

viii

Agradecimientos
Estoy especialmente agradecido a mis padres y mi hermana, por el apoyo incondicionalque me han dado durante toda mi carrera.Especial agradecimiento a mis compañeros, por su ayuda, dedicación, buen hacer y
compañerismo, dado que gracias a ellos he conseguido aprender mucho más de lo imagi-nable.Y por último, dar in�nitas gracias a mis directores D. Jesús Esteban Díaz Verdejo y
D. Gabriel Maciá Fernández por el interés, la motivación y el apoyo que me han prestadodurante tanto tiempo.Gracias a todos.
ix

x

Licencia
<Caracterización de anomalías en trá�co P2P mediante autómatas de estados �nitos>Copyright © <2009> <Jesús Javier Nuño García>Este Programa es Software Libre: usted puede redistribuirlo y/o modi�carlo bajo los
términos de la Licencia Publica General GNU como es publicada por la Fundacion deSoftware Libre; en la 3ª versión de la licencia, o (a su opción) cualquier versión posterior.Este programa es distribuido con la esperanza de que sea útil, pero SIN GARANTÍA
ALGUNA; sin siquiera la garantía implícita de VALOR COMERCIAL o FORMADOPARA UN PROPÓSITO EN PARTICULAR. Vea la Licencia Publica General GNUpara más detalles.Usted debe haber recibido una copia de la Licencia Publica General GNU junto con
este programa. Si no, vaya a <http://www.gnu.org/licenses/>.
xi

xii



Índice general
0. Descripción del problema y especi�caciones 1
1. Introducción 31.1. Las redes en la actualidad . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2. ¾Qué son las redes P2P y por qué son importantes? . . . . . . . . . . . . . 51.3. El protocolo `eDonkey' . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.4. Justi�cación del proyecto . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2. Fundamentos tecnológicos 192.1. Teoría de autómatas de estados �nitos . . . . . . . . . . . . . . . . . . . . 192.2. Paradigma cliente-servidor . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.3. Modelado de protocolos con autómatas de estados �nitos . . . . . . . . . . 252.4. Herramientas y utilidades . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3. Análisis 373.1. Procedimientos en el protocolo `eDonkey' . . . . . . . . . . . . . . . . . . 373.2. Análisis de requisitos y funcionalidades de la aplicación . . . . . . . . . . . 593.3. Discusión del análisis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4. Diseño e implementación 654.1. Estructura modular de la aplicación . . . . . . . . . . . . . . . . . . . . . 654.2. Descripción de las estructuras de datos utilizadas . . . . . . . . . . . . . . 74
5. Evaluación 815.1. Diseño de las pruebas de evaluación . . . . . . . . . . . . . . . . . . . . . . 815.2. Evaluación de la funcionalidad de la aplicación . . . . . . . . . . . . . . . 885.3. Evaluación del rendimiento de la aplicación . . . . . . . . . . . . . . . . . 94
6. Plani�cación y estimación de recursos 976.1. Plani�cación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 976.2. Recursos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
xv

Índice general
6.3. Estudio económico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
7. Logros y conclusiones 1037.1. Logros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1037.2. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
Bibliografía 105
Apéndice 107
A. Descripción de los métodos utilizados 107
xvi

Índice de �guras
1.1. Millones de usuarios conectados a Internet (enero de 2009). . . . . . . . . 31.2. Porcentaje de población que se conecta a Internet en los quince países más
poblados (enero 2009). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.3. Distribución porcentual del trá�co de Internet en Alemania en 2007. . . . 41.4. Interfaz del cliente `eMule'. . . . . . . . . . . . . . . . . . . . . . . . . . . 81.5. Porcentaje de uso de protocolos P2P en Alemania en 2007 (véase [2]). . . 91.6. Estructura de la red `eMule' (protocolo `eDonkey'). . . . . . . . . . . . . . 111.7. Estructura de una trama del protocolo `eDonkey'. . . . . . . . . . . . . . . 16
2.1. Autómata de ejemplo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.2. Autómata de ejemplo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.3. Ejemplo de AFD. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.4. Ejemplo de AFND. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.5. Ejemplo de conexión entre dos computadores cualesquiera. . . . . . . . . . 242.6. Ejemplo de intercambio de paquetes entre dos nodos de una red P2P. . . . 262.7. Ejemplo de información extraída en el intercambio de tramas entre dos
nodos en la red. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262.8. Información extraída de tres tramas. . . . . . . . . . . . . . . . . . . . . . 272.9. Ejemplo de modelado de protocolo con un autómata. . . . . . . . . . . . . 272.10. Conexión entre los tres elementos principales de la STL. . . . . . . . . . . 282.11. Costes en tiempo (aproximados) para fork() y pthread_create(). . . . . . . 332.12. Grupos funcionales de rutinas Pthread. . . . . . . . . . . . . . . . . . . . . 34
3.1. Conexión con ID alto. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393.2. Conexión con ID bajo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403.3. Conexión rechazada. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403.4. Establecimiento de conexión modelado con autómata de estados �nitos. . 413.5. Secuencia de mensajes al inicio de la conexión. . . . . . . . . . . . . . . . 423.6. Secuencia de mensajes al inicio de la conexión modelada con autómata de
estados �nitos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 423.7. Secuencia de mensajes de búsqueda de archivos. . . . . . . . . . . . . . . . 43
xvii

Índice de �guras
3.8. Autómata de estados �nitos para la búsqueda de archivos. . . . . . . . . . 443.9. Secuencia de mensajes para el mecanismo de callback. . . . . . . . . . . . 443.10. Secuencia de mensajes para el mecanismo de callback modelada con auto-
mata de estados �nitos (Cliente A). . . . . . . . . . . . . . . . . . . . . . . 453.11. Secuencia de mensajes para el mecanismo de callback modelada con auto-
mata de estados �nitos (Servidor). . . . . . . . . . . . . . . . . . . . . . . 453.12. Secuencia de mensajes para el mecanismo de callback modelada con auto-
mata de estados �nitos (Cliente B). . . . . . . . . . . . . . . . . . . . . . . 453.13. Ciclo de keep-alive UDP. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 463.14. Secuencia keep-alive UDP. . . . . . . . . . . . . . . . . . . . . . . . . . . . 463.15. Secuencia keep-alive UDP modelada con autómata de estados �nitos. . . . 473.16. Handshake inicial de los clientes `eMule'. . . . . . . . . . . . . . . . . . . . 483.17. Handshake inicial de los clientes `eMule' modelado con autómata de esta-
dos �nitos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 483.18. Identi�cación segura. `A' no tiene la clave pública de `B'. . . . . . . . . . . 493.19. Identi�cación segura. `A' tiene la clave pública de `B'. . . . . . . . . . . . 493.20. Identi�cación segura modelada con autómata de estados �nitos. . . . . . . 503.21. Solicitud de �chero. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 503.22. Solicitud de archivo fallida. Archivo no encontrado. . . . . . . . . . . . . . 513.23. Solicitud de �chero modelada con autómata de estados �nitos. . . . . . . . 513.24. Cola de espera para una solicitud de un archivo. . . . . . . . . . . . . . . . 523.25. Cola de espera para una solicitud de un archivo modelada con autómata
de estados �nitos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 533.26. Descarga de un archivo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 533.27. Descarga de un archivo modelada con autómata de estados �nitos. . . . . 543.28. Detalles del mensaje de la parte de un archivo. . . . . . . . . . . . . . . . 543.29. Detalles del mensaje de la parte de un archivo modelado con autómata de
estados �nitos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 553.30. Intercambio de fragmentos de archivo. . . . . . . . . . . . . . . . . . . . . 553.31. Intercambio de fragmentos de archivo modelado con autómata de estados
�nitos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 563.32. Solicitud de vista de archivos compartidos. . . . . . . . . . . . . . . . . . . 563.33. Consulta de archivos y carpetas compartidos. . . . . . . . . . . . . . . . . 573.34. Solicitudes de vista de archivos y carpetas denegadas. . . . . . . . . . . . 573.35. Vista de archivos y carpetas compartidos modelada con autómata de es-
tados �nitos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 583.36. Solicitud de hash de fragmento de archivo. . . . . . . . . . . . . . . . . . . 583.37. Solicitud de hash de fragmento de archivo modelada con autómata de
estados �nitos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 583.38. Obtención de la previsualización de un archivo. . . . . . . . . . . . . . . . 593.39. Obtención de la previsualización de un archivo modelada con autómata
de estados �nitos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 593.40. Mensaje de re-solicitud de archivo. . . . . . . . . . . . . . . . . . . . . . . 603.41. Mensaje de re-solicitud de archivo modelado con autómata de estados �nitos. 60
xviii

Índice de �guras
3.42. Estructura principal del programa. . . . . . . . . . . . . . . . . . . . . . . 61
4.1. Estructura en módulos del programa principal. . . . . . . . . . . . . . . . 664.2. Autómata de ejemplo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 724.3. Autómata de ejemplo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 734.4. Esquema de un objeto de la clase `estado'. . . . . . . . . . . . . . . . . . . 754.5. Autómata con un estado. . . . . . . . . . . . . . . . . . . . . . . . . . . . 754.6. Objeto `estado' para el estado de la Figura 4.5.. . . . . . . . . . . . . . . . 764.7. Autómata con un estado. . . . . . . . . . . . . . . . . . . . . . . . . . . . 764.8. Objeto `estado' para el estado de la Figura 4.7. . . . . . . . . . . . . . . . 764.9. Autómata con tres estados. . . . . . . . . . . . . . . . . . . . . . . . . . . 764.10. Objeto `estado' para el estado de la Figura 4.9. . . . . . . . . . . . . . . . 774.11. Estructura de un objeto de la clase `datosFlujo'. . . . . . . . . . . . . . . 794.12. Relaciones entre las clases diseñadas. . . . . . . . . . . . . . . . . . . . . . 794.13. Diagrama de clases de diseño para la aplicación desarrollada. . . . . . . . 80
5.1. Estadísticas generales de los �cheros de prueba. . . . . . . . . . . . . . . . 825.2. Estadísticas del uso de protocolos para el �chero de pruebas nº1. . . . . . 825.3. Estadísticas del uso de protocolos para el �chero de pruebas nº2. . . . . . 835.4. Estadísticas del uso de protocolos para el �chero de pruebas nº3. . . . . . 835.5. Estadísticas del uso de protocolos para el �chero de pruebas nº4. . . . . . 845.6. Autómata correspondiente a �Búsqueda de archivos�. . . . . . . . . . . . . 845.7. Autómata correspondiente a �Establecimiento de conexión�. . . . . . . . . 845.8. Autómata correspondiente a �Secuencia de inicio de conexión�. . . . . . . . 855.9. Autómata correspondiente a �Búsqueda de archivos�. . . . . . . . . . . . . 855.10. Autómata correspondiente a �Establecimiento de conexión�. . . . . . . . . 865.11. Autómata correspondiente a �Secuencia de inicio de conexión�. . . . . . . . 865.12. Autómata correspondiente a �Búsqueda de archivos�. . . . . . . . . . . . . 865.13. Autómata correspondiente a �Handshake inicial�. . . . . . . . . . . . . . . 865.14. Autómata correspondiente a �Nueva secuencia de inicio de conexión�. . . . 875.15. Autómata correspondiente a �Ofrecer �cheros�. . . . . . . . . . . . . . . . 875.16. Muestra de una trama `eDonkey' con Wireshark. . . . . . . . . . . . . . . 905.17. Salida observada para la Prueba 5. . . . . . . . . . . . . . . . . . . . . . . 925.18. Salida observada para la Prueba 6. . . . . . . . . . . . . . . . . . . . . . . 935.19. Salida observada para la Prueba 7. . . . . . . . . . . . . . . . . . . . . . . 935.20. Tiempos de ejecución de las pruebas realizadas. . . . . . . . . . . . . . . . 955.21. Actividad del grafo de llamadas. . . . . . . . . . . . . . . . . . . . . . . . 955.22. Mediciones de tiempos para algunos métodos de la aplicación. . . . . . . . 95
6.1. Esquema de las tareas inicialmente plani�cadas. . . . . . . . . . . . . . . . 986.2. Diagrama de Gantt. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
A.1. Ejemplo de estado. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109A.2. Ejemplo de estado tras la llamada a `setMensaje'. . . . . . . . . . . . . . . 109A.3. Ejemplo de estado con un mensaje. . . . . . . . . . . . . . . . . . . . . . . 109
xix

Índice de �guras
A.4. Ejemplo de estado con un mensaje tras la llamada a `setMensaje'. . . . . . 109
xx



Capıtulo 0Descripción del problema yespeci�caciones
Descripción del problema
En la actual sociedad de la información, existe un gran número de usuarios con accesoa Internet. Gran parte del uso que se hace de Internet, está asociado debido a las redespeer-to-peer, las que, de manera super�cial, se pueden de�nir como redes formadas poruna serie de nodos interconectados entre sí, en los que cada uno de ellos puede actuarcomo cliente y como servidor al mismo tiempo.Actualmente existen un gran número de aplicaciones compatibles con este tipo de
redes. Dichas aplicaciones funcionan gracias a un protocolo subyacente, el cual controlael funcionamiento de estas redes. Existen múltiples protocolos P2P a día de hoy; uno delos más conocidos y extendidos es el protocolo `eDonkey'.Dentro del comportamiento habitual de este protocolo, existen una serie de acciones
básicas que se pueden clasi�car según la naturaleza de la conexión: cliente-cliente ocliente-servidor. Se pretende detectar el mal uso del protocolo con la �nalidad de intentardetectar potenciales problemas de seguridad (ataques, vulnerabilidades, etc.).Por ello, se propone el desarrollo de una aplicación capaz de analizar los �ujos pro-
ducidos por este protocolo y clasi�carlos en acordes a la especi�cación o no. En esteúltimo caso se dirá que son �ujos anómalos y, en consecuencia, requieren un análisis deseguridad.
Especi�caciones de la aplicación
� Debe detectar �ujos anómalos en el protocolo P2P `eDonkey'.
� Debe ser �exible, es decir, debe tener la capacidad de ser modi�cada por tercerossin excesiva di�cultad.
� Debe ser extensible respecto a otros protocolos.
1

0. Descripción del problema y especi�caciones
� Debe estar desarrollada en el lenguaje ANSI C++.
� Debe aceptar, para su análisis, �cheros con tramas o bien analizar un protocolo envivo a través de una interfaz de red.
� La especi�cación/de�nición de los autómatas debe ser sencilla e independiente delprograma principal.
2

Capıtulo 1Introducción
1.1. Las redes en la actualidad
Las redes de comunicaciones constituyen una parte importante de la comunicaciónen la actual sociedad de la información. Años atrás, estas sólo estaban al alcance dealgunos pocos, como organismos o�ciales y al ámbito militar. Pero la �losofía de compartirinformación, tan de moda en la actualidad, ha hecho que las redes de comunicaciones seexpandan (y sigan haciéndolo) a gran velocidad, de modo que permiten estar comunicadocon el resto del mundo.Una prueba de ello es la gran cantidad de usuarios con acceso a Internet. En la Figura
1.1 se muestra la cantidad de usuarios con acceso a Internet de los quince países máspoblados, como se puede consultar en [2].La imagen no ofrece demasiada precisión, ya que muestra las cantidades en millones
de usuarios pero no indica cuántos habitantes tiene cada uno de los países mostrados yaque, por ejemplo, China está más poblada que Italia. Por ello se muestra en la Figura1.2 la relación habitantes/usuarios con acceso a Internet.
Figura 1.1: Millones de usuarios conectados a Internet (enero de 2009).
3

1. Introducción
Figura 1.2: Porcentaje de población que se conecta a Internet en los quince países máspoblados (enero 2009).
En la Figura 1.2 se puede apreciar mejor la proporción de usuarios con acceso a In-ternet, en especial en los países más desarrollados, como Reino Unido o Corea del Sur,en los que la mayor parte de la población dispone de dicho acceso. Sin embargo, India esjustamente el punto opuesto, incluso siendo el segundo país más poblado del planeta.Internet ofrece a día de hoy una ingente cantidad de usos y servicios, como por ejemplo:
FTP, mensajería instantánea, streaming, redes P2P, correo electrónico, trá�co HTTP, etc.Esto hace que existan millones de usuarios con acceso a la Red y que los servicios sean
cada vez más demandados. El trá�co existente en Internet corresponde mayoritariamentea redes P2P, como se explica en [2], como evidencia el estudio realizado por la compañía`iPoque' en 2007 en Alemania (véase la Figura 1.3).Como se puede apreciar, las redes P2P tienen una gran aceptación entre la comunidad
de usuarios que conforma Internet, ya que el trá�co producido por este tipo de redes esmuy superior al resto de trá�co en Internet. Ni siquiera el trá�co HTTP o de Streamingpuede compararse en la actualidad con el generado por las redes P2P.
Figura 1.3: Distribución porcentual del trá�co de Internet en Alemania en 2007.
4

1. Introducción
1.2. ¾Qué son las redes P2P y por qué son importantes?
Existen múltiples de�niciones que de las redes P2P. Una de ellas, de acuerdo a [3], es:
�Las redes peer-to-peer (P2P) son unas redes en las que existe como prin-cipio básico la compartición de recursos entre computadoras. Tales recursosincluyen procesamiento, conocimiento, almacenamiento de datos e informa-ción de bases de datos distribuidas.�
En los últimos años, se ha invertido aproximadamente medio billón de dólares encompañías dedicadas al desarrollo de sistemas P2P.Este interés es debido al éxito de muchas aplicaciones, como, por ejemplo, `Napster'
(hoy en día ya desaparecida) o `eMule'. El concepto de compartición de recursos no estotalmente nuevo, ya que los sistemas P2P son una evolución natural en la arquitecturade sistemas.Lo que caracteriza a una red P2P es que la relación es directa entre los equipos que
actúan como iguales, ya que los computadores pueden actuar como clientes y servidores almismo tiempo. El comportamiento de dichas computadoras se determinará dependiendode los requerimientos del sistema en cada momento. Por ejemplo, un computador `A'envía una solicitud de un �chero a un computador `B'. En este momento, el computador`B' estaría actuando de servidor y el `A' sería el cliente. Poco después, es el computador`B' el que envía una solicitud de archivo al computador `A', por lo que, en este caso elcomportamiento es justo el contrario, ya que `A' sería el servidor y `B' el cliente.Las redes peer-to-peer permiten a los usuarios hacer uso de toda la información dispo-
nible en la red, ayudan a realizar grandes trabajos computacionales que antes no eranposibles y, además, su implementación no tiene un gran coste para pequeñas compañíase incluso, para uso particular. Estas redes cuentan con la ventaja de tener acceso distri-buido a determinados recursos. En de�nitiva, una red P2P tiene grandes bene�cios encostes y un procesamiento veloz.Existen una serie de características comunes ampliamente aceptadas en relación a los
sistemas P2P:
� Un peer es cada uno de los nodos que forma parte de una red P2P, siendo habi-tualmente un computador que puede actuar tanto de cliente como de servidor. Estecomportamiento se determinará por los requerimientos del sistema en un momen-to concreto. En algunos sistemas P2P, un peer puede actuar como cliente y comoservidor al mismo tiempo.
� Una red P2P consiste en, al menos, dos o más peers.
� Los peers son capaces de intercambiar recursos directamente entre ellos, como ar-chivos, información, procesamiento, etc.
� Los servidores dedicados puede que estén o no presentes en un sistema P2P, de-pendiendo de la naturaleza de las aplicaciones. Sin embargo, el comportamiento dela mayoría de estos servidores se limita a permitir a los peers descubrirse los unosa los otros. Dicho de otra manera, asumen el papel de agentes.
5

1. Introducción
� Los peers pueden entrar o abandonar un sistema con total libertad.
� Los peers pueden pertenecer a diferentes usuarios. Lo normal en un sistema P2Pes tener millones de usuarios.
1.2.1. Ventajas de un sistema P2P
La mayoría de los sistemas P2P tienen las siguientes ventajas:
� La carga de trabajo se reparte entre todos los peers. Es posible que existan millonesde computadores en una red P2P que proporcionen grandes cantidades de datos yprocesamiento.
� Muchos computadores tienen recursos que no se usan. Por ejemplo, en una o�cina,los computadores no se usan durante un determinado horario (normalmente porla noche). Un sistema P2P puede utilizar estos computadores con sus recursoscorrespondientes, para así maximizar el uso.
� Ciertas empresas podrían ahorrar mucho dinero mediante una buena utilización delas instalaciones que existen, en lo que a sistemas P2P se re�ere.
� No se necesita un control centralizado ni un riguroso manejo de una red P2P.
� La escalabilidad en una red P2P se hace evidente debido a que, si existen nuevospeers, pueden unirse al sistema P2P de una manera muy sencilla.
� Una red P2P funcionará incluso si algunos de sus peers no funcionan correctamente.De esta manera, se hace más tolerante a fallos que otros sistemas.
� Los usuarios de una red P2P pueden entrar y salir cuando quieran. Así, dichosusuarios pueden mantener el control de sus recursos.
1.2.2. Inconvenientes de un sistema P2P
Aunque los sistemas P2P proporcionan grandes bene�cios, no son sistemas infalibles.Una red P2P puede no ser la herramienta apropiada para determinadas tareas. A conti-nuación se muestra una serie de desventajas de estos sistemas:
� Las redes P2P pueden ser utilizadas con �nes maliciosos, como pueden ser ataquesde denegación de servicio contra un sitio web concreto.
� Establecer estándares en un sistema P2P es una tarea compleja.
� Para algunas tareas especí�cas, la carga de trabajo no se puede compartir entre lospeers.
� Resulta una tarea complicada que los usuarios de un sistema lleguen a obtenerbene�cios económicos de una red P2P.
6

1. Introducción
� Un peer abandona el sistema de acuerdo a lo que haga su propietario con él. Poreso, no se puede garantizar que un recurso en particular esté disponible siempre,exceptuando algunas redes P2P diseñadas a tal �n. Por ejemplo, el propietariopuede apagar su computador o borrar un archivo. Por tanto, es difícil predecir elrendimiento total del sistema.
� También es una tarea complicada prevenir el intercambio ilegal de material concopyright.
� Los sistemas P2P más populares pueden generar una gran cantidad de trá�co enla red. Por eso, por ejemplo, no se suele permitir el uso de este tipo de programasen algunas facultades, ya que el rendimiento de la red descendería en gran medida.
1.2.3. Clientes de redes P2P
De acuerdo a [4, 5], uno de los clientes P2P más populares en la actualidad es `eMule'.Ya que las diversas redes P2P de compartición de archivos existentes no son capaces decomunicarse entre sí, es necesario ser cuidadoso con el cliente que se elige. Se puede optarpor escoger un cliente el cual disponga de acceso a una red muy grande, o algún clienteque sea capaz de conectarse a varias redes al mismo tiempo.Algunos de los clientes P2P más populares en la actualidad son `Gnutella', `Bittorrent',
o `eMule', aunque existen otros muchos clientes más. Es necesario destacar que es el clienteel que se conecta a la red P2P, pero esto no signi�ca que sea el único que pueda hacerlo.En otras palabras y, poniendo de base un ejemplo, existen varios programas cliente queson capaces de conectarse a la red `Gnutella'; estos pueden ser, por ejemplo, `Morpheus',`BearShare', `LimeWire', etc.Aquí es donde juega un papel fundamental el cliente `eMule'. Dicho cliente no es más
que una interfaz que hace uso de la red P2P `eDonkey'. Al igual que otros clientes, escapaz de buscar archivos, descargárselos y poder compartirlos con los demás miembrosde dicha red. Asimismo, permite al usuario ser un miembro más de la extensa red P2Pde la cual `eMule' hace uso.Como se puede ver en la Figura 1.4, `eMule' proporciona una interfaz en la que sus
funciones principales se aprecian con facilidad. Es por ello que, en la actualidad, sea unode los clientes más aceptados y utilizados por los usuarios de la red `eDonkey'.Aunque otros protocolos han ido ganando terreno con el paso de los años, es innegable
que el protocolo `eDonkey' sigue siendo ampliamente utilizado.Por tanto, dada su gran extensión, sería interesante disponer de un detector de anoma-
lías que fuera capaz de mostrar cualquier comportamiento extraño que pudiera producirseen el uso de protocolos P2P. De esta manera, se podrían evaluar dichos comportamien-tos y tomar decisiones acerca de la vulnerabilidad de un determinado computador antedichos comportamientos.
7

1. Introducción
Figura 1.4: Interfaz del cliente `eMule'.
Aquí es donde juega un importante papel la aplicación a desarrollar. Esta aplicaciónse centra en el protocolo `eDonkey' que, como se ha detallado, es uno de los más utili-zados en la actualidad. Dicho programa debe ser capaz de tomar como entrada �ujos deinformación en Internet, evaluar si pertenecen al protocolo `eDonkey' o no, y juzgar subuen funcionamiento, tomando decisiones de si está funcionando con normalidad o no.El objetivo es prevenir a las redes peer-to-peer de usos no autorizados.
1.3. El protocolo `eDonkey'
De acuerdo a [6, 7], el protocolo de compartición de �cheros `eDonkey' es uno de losprotocolos para redes P2P más conocidos. En un principio se usó para el cliente llamado`eDonkey2000' y, además, por algunos otros clientes de código abierto (open source) como,por ejemplo, `mldonkey'. En algunos países, el protocolo `eDonkey' es el protocolo P2Pde compartición de archivos más popular entre todos los usuarios.Muestra de ello son los resultados del estudio realizado en Alemania en 2007 por la
compañía `iPoque', que se puede consultar en [2], la cual obtuvo los resultados mostradosen la Figura 1.5 acerca del porcentaje de uso de protocolos peer-to-peer.Básicamente, la red `eDonkey' es una red de compartición de archivos peer-to-peer que
usa aplicaciones cliente ejecutándose en los sistemas �nales que están conectados a unared distribuida o a servidores dedicados.El protocolo `eDonkey' no está completamente descentralizado, ya que usa servidores
que ofrecen mecanismos para la comunicación.
8

1. Introducción
Figura 1.5: Porcentaje de uso de protocolos P2P en Alemania en 2007 (véase [2]).
A diferencia de otros protocolos P2P, la red `eDonkey' tiene una estructura basada enel paradigma cliente/servidor (véase Capítulo 2). Los servidores no comparten ningúnarchivo. El papel que juegan es manejar la distribución de la ubicación de la informacióny operar con unos diccionarios centrales, que almacenan la información acerca de los�cheros que se comparten y sus respectivas localizaciones en los clientes.En la red `eDonkey' los clientes son los únicos nodos que comparten recursos. Sus
archivos se indexan mediante los servidores. Si un cliente quiere descargarse un archivoo parte de él, primero se debe conectar vía TCP a un servidor o enviar una petición debúsqueda vía UDP a uno o más servidores para obtener la información necesaria acercade qué clientes ofrecen el archivo que se solicita.La red `eDonkey' usa un hash MD4 de 16 bytes para identi�car unívocamente a los ar-
chivos, independientemente de su nombre. El algoritmo de hashing no es infalible (puedehaber colisiones), pero ofrece una alta �abilidad. Este hash implica que, en una búsque-da, son necesarios un par de pasos previos. Primero, se le envía al servidor una ordende búsqueda completa de texto con el nombre del archivo. La correspondiente respuestaincluye aquellos archivos que tienen un nombre asociado el cual coincide completamentecon el texto que se mandó buscar. En segundo lugar, el cliente solicita las fuentes alservidor para un determinado hash de un archivo. Finalmente, el cliente se conecta alas fuentes indicadas para solicitar la transferencia del archivo. La transferencia de dichoarchivo tiene lugar directamente entre los dos clientes participantes, sin involucrar a losservidores, para así minimizar el coste de la operación.Un cliente que use el protocolo `eDonkey' es capaz de transferirse un único archivo de
múltiples fuentes, lo cual provoca que se mejore la velocidad de transferencia y se reduzcael riesgo de quedarse con archivos sin transferirse del todo. Los archivos se trans�eren entrozos de 9,28 MB. Los archivos que se trans�eren parcialmente también son compartidospor el cliente y pueden transferirse a otros usuarios. El hash MD4 permite identi�car siun determinado �chero es el que se está solicitando o no. Como en el protocolo `eDonkey'se comparten los trozos de un archivo por separado, se pueden llegar a identi�car aquellosque están corruptos. Todas estas características hacen que el uso de este protocolo seaideal para transferir archivos grandes, como por ejemplo, archivos de vídeo.
9

1. Introducción
A continuación, se muestra una descripción general del funcionamiento del protocolo`eDonkey'.
1.3.1. Descripción general del protocolo `eDonkey'
Tal y como se de�ne en [9], la red `eDonkey' está formada por varios cientos de servi-dores y millones de clientes. Cada cliente está precon�gurado con una lista de servidoresy una lista de archivos compartidos en su sistema de archivos local y usa una única co-nexión a uno de los servidores mencionados para obtener información acerca del archivodeseado y otros clientes disponibles. Dicho cliente `eMule' también puede utilizar varioscientos de conexiones TCP a otros clientes los cuales suelen subir y bajar determinadosarchivos. Cada uno de ellos mantiene una cola de subida para cada uno de los archivosque comparte. Así, los clientes que deseen descargar algún tipo de archivo se unen a lacola y se colocan al �nal de esta, y van avanzando gradualmente hasta que alcanzanla primera posición, que es cuando comienzan a descargar el archivo. Un cliente puededescargar el mismo archivo de varios clientes `eMule', obteniendo así diferentes fragmen-tos de cada uno de ellos, y también puede subir un trozo de un archivo que aún no seha terminado de descargar. Finalmente, `eMule' amplía las capacidades de `eDonkey' ypermite a los clientes intercambiar información acerca de los servidores, de otros clientesy de archivos. Nótese que ambos, cliente y servidor, se comunican mediante TCP.El servidor emplea una base de datos interna en la cual almacena información acerca de
clientes y archivos. Un servidor `eMule' no almacena ningún archivo, sino que actúa comouna o�cina de interconexión de clientes `eMule'. Una función adicional del servidor, la cualse está volviendo obsoleta, es hacer un puente entre dos clientes que se conectan a travésde un cortafuegos y no son capaces de aceptar conexiones entrantes. La funcionalidadde este puente incrementa considerablemente la carga en el servidor. `eMule' usa UDPpara mejorar las capacidades del cliente frente al servidor y otros clientes. La habilidadde los clientes para enviar y recibir mensajes UDP no siempre está disponible, ya que noes obligatoria para que dichos clientes funcionen correctamente. Por ello, uno de estosclientes funcionaría perfectamente aunque un cortafuegos le impida enviar y recibir estosmensajes UDP.A continuación se mostrará una descripción detallada del proceso seguido en las cone-
xiones realizadas por el protocolo `eDonkey' entre cliente-servidor y entre cliente-cliente.
Conexión cliente-servidor
Al inicio, el cliente se conecta a un servidor `eMule' usando una conexión TCP. Elservidor proporciona al cliente un ID de cliente que es válido sólo durante el tiempode vida de la conexión cliente-servidor. Siguiendo el establecimiento de la conexión, elcliente envía al servidor su lista de archivos compartidos. El servidor almacena la listaen su base de datos interna, la cual normalmente contiene cientos de miles de archivosdisponibles en sus clientes activos. El cliente `eMule' también envía su lista de descargaque contiene los archivos que desea descargar en ese momento.La red mostrada en la Figura 1.6 esquematiza la estructura de red que sigue `eMule',
10

1. Introducción
la cual no sigue la topología de una red convencional, sino que se trata de una red lógicasituada por encima de la red física (overlay network). Los nodos están conectados entresí por enlaces lógicos, cada uno de los cuales está implementado por un camino a travésde enlaces físicos en la red subyacente.Cada cierto tiempo, el cliente envía solicitudes de búsqueda de archivos que son respon-
didas mediante una búsqueda de resultados. Una transacción de búsqueda normalmenteva seguida de una petición de fuentes para un archivo especí�co. Esta petición es contes-tada mediante una lista de fuentes (IP y puerto) de las que el solicitante puede descargarel archivo.Después de establecer la conexión, el servidor `eMule' envía al cliente una lista de
otros clientes que tienen los archivos que desea descargar el cliente que se conecta (dichosclientes son llamados `fuentes'). Desde este punto, el cliente `eMule' comienza a establecerconexiones con otros clientes. Nótese que la conexión TCP cliente-servidor se mantieneabierta durante toda la sesión del cliente. Después del intercambio inicial (handshake),las transacciones son provocadas principalmente por la actividad de los usuarios.El protocolo UDP se usa para comunicaciones con otros servidores que no son el
servidor al cual está conectado el cliente en ese momento. El propósito de los mensajesUDP es la mejora de la búsqueda de archivos, la mejora de la búsqueda de fuentes y,�nalmente, el envío de mensajes keep-alive (asegurarse de que todos los servidores `eMule'de la lista de servidores del cliente son válidos).
Figura 1.6: Estructura de la red `eMule' (protocolo `eDonkey').
11

1. Introducción
Conexión cliente-cliente
Un cliente `eMule' se conecta a otro (una fuente) con la �nalidad de descargar unarchivo, el cual está dividido en partes fragmentadas. Dicho cliente puede descargarse elmismo archivo de varios clientes, obteniendo así distintos fragmentos de cada uno.Cuando dos clientes se conectan, intercambian información de capacidad y negocian
el comienzo de una descarga (o subida, depende de la perspectiva). Cada cliente tieneuna cola de subida en la cual mantiene una lista de clientes que están esperando paradescargar determinados archivos. Cuando esta cola está vacía, una petición de descargadará como resultado más probable un comienzo de descarga inmediato (a menos que,por ejemplo, el solicitante esté prohibido). Pero cuando la cola de descarga no está vacía,la solicitud de descarga dará como resultado la adición del cliente solicitante a la cola.Sólo se da servicio a unos pocos clientes en un momento dado, proporcionando para cadauno de ellos un ancho de banda mínimo de 2.4 KB/seg. Uno de los clientes que estédescargando un archivo puede ser reemplazado por otro cliente que estaba esperando yque tenga un mayor ranking en la cola que él.Cuando un cliente que desea descargar algún �chero alcanza la primera posición de la
cola, el cliente que posee dicho �chero inicia una conexión con él, con el �n de enviarle laspartes del archivo que necesita. Un cliente `eMule' puede estar al mismo tiempo esperandoen las colas de otros clientes para descargar las mismas partes del archivo de cada uno deellos. Cuando el cliente solicitante termina de descargarse las partes correspondientes (deuno de los otros clientes), no le noti�ca al resto que le eliminen de sus colas; lo que hacees, simplemente, rechazar que le envíen el archivo cuando alcance la primera posición enlas otras colas.`eMule' emplea un sistema de crédito con el �n de promover las subidas de archivos.
Para evitar la suplantación de identidad, `eMule' asegura el sistema de crédito usandocriptografía de clave pública RSA.Las conexiones de los clientes pueden usar un conjunto de mensajes no de�nidos por
el protocolo `eDonkey'. Dichos mensajes son una ampliación del protocolo. El protocoloextendido se usa para la implementación del sistema de crédito, para intercambio generalde información (tales como actualización de la lista de servidores y fuentes) y para mejorarel rendimiento mediante el envío y la recepción de fragmentos de archivo comprimidos.La conexión del cliente `eMule' utiliza UDP de una manera limitada para, periódica-
mente, comprobar el estado del cliente en la cola de subida de sus clientes peer mientrasestá esperando para descargarse un archivo.
1.3.2. ID del cliente
El ID del cliente es un identi�cador de 4 bytes que es proporcionado por el servidorcuando realizan un intercambio de tramas con el objetivo de �ponerse de acuerdo� (cono-cido como handshake). Este ID es válido sólo durante el tiempo de vida de una conexiónTCP cliente-servidor aunque, en el caso de que el cliente tenga un ID alto, todos losservidores le asignarán el mismo ID, a no ser que cambie su IP. Los ID de los clientesestán divididos en ID bajos e ID altos. El servidor `eMule' típicamente asignará a un
12

1. Introducción
cliente un ID bajo cuando este no pueda aceptar conexiones entrantes. Tener un ID bajorestringe el uso que hace el cliente de la red `eMule' y podría resultar en que el servidorrechazara la conexión del cliente. Un ID alto se calcula en base a la dirección IP de uncliente, tal y como se describe a continuación.Un ID alto se le da a los clientes que permiten a otros clientes conectarse libremente
al puerto TCP de `eMule' de su host. Un cliente con un ID alto no tiene restriccionesen el uso de la red `eMule'. Cuando el servidor no puede establecer una conexión TCPcon el puerto del cliente de `eMule', entonces a este cliente se le asigna un ID bajo, loque suele ocurrir principalmente con los clientes que tienen un cortafuegos que restringelas conexiones entrantes. Un cliente también puede recibir un ID bajo en los siguientescasos:
� Cuando el cliente está conectado a través de NAT o un servidor proxy.
� Cuando el servidor al que se conecta el cliente está muy ocupado (provocando asíque el contador de reconexión con el servidor expire).
Los ID altos se calculan de la siguiente manera: si se asume que la dirección IP del hostes X.Y.Z.W, entonces su ID será X + 2^8 * Y + 2^16 * Z + 2^24 * W (representaciónbig endian). Un ID bajo es siempre menor que la cifra 16777216 (0x1000000).Un cliente con un ID bajo no tiene IP pública a la cual se puedan conectar otros
clientes, por lo que todas las conexiones se deben realizar a través del servidor `eMule',es decir, el servidor indica al cliente con ID bajo que realice una conexión saliente con elotro cliente que desea conectar con él. Esto aumenta la carga computacional del servidory provoca que no suelan aceptar clientes con un ID bajo. Además, esto signi�ca que uncliente con un ID bajo no puede conectarse con otro cliente que también tenga ID bajoy que esté en otro servidor.Para que en `eMule' se soportaran los clientes con ID bajo, se introdujo un mecanismo
de callback. Mediante este mecanismo, un cliente con ID alto solicita, a través del servidor`eMule', que un cliente con ID bajo se conecte a él, con el �n de intercambiar determinadosarchivos, ya un cliente con ID bajo no admite conexiones entrantes (véase Apartado 3.1.1).
1.3.3. ID del usuario
`eMule' soporta un sistema de crédito con el �n de animar a los usuarios a compar-tir archivos. Cuantos más archivos trans�era un usuario a otros usuarios, más créditosrecibirá y más rápido ascenderá en las colas de espera de otros clientes.El ID de usuario es un GUID de 16 bytes (128 bits) que se crea concatenando números
aleatorios. El 6º y el 15º no son aleatorios; sus valores son 14 y 111 respectivamente.Mientras que un ID de cliente es válido sólo durante una sesión de un cliente con unservidor especí�co, un ID de usuario (también llamado hash de usuario) es único y seusa para identi�car a un cliente a través de diferentes sesiones (el ID de usuario identi-�ca la estación de trabajo). Este ID juega un papel importante en el sistema de crédito;esta característica proporciona a los hackers una motivación para suplantar la identidadde otros usuarios con el �n de adquirir sus privilegios, obtenidos gracias a sus créditos.
13

1. Introducción
`eMule' soporta un esquema de cifrado que se diseñó para prevenir fraudes y suplanta-ciones de identidad de otros usuarios. La implementación es un simple intercambio dereto-respuesta que tiene un cifrado RSA de clave pública/privada.Cuando un cliente envía un �chero a su peer, el cliente que descarga el archivo actualiza
su sistema de crédito de acuerdo a la cantidad de datos transmitidos. Nótese que elsistema de crédito no es global; el crédito de una transferencia lo mantiene localmenteel cliente que descarga, y se tendrá en cuenta únicamente cuando el cliente que envía elarchivo (el que gana el crédito) realiza una petición de descarga a ese cliente especí�co.El crédito se calcula como el mínimo entre:
1. totalsubido∗2totalbajado . Cuando la descarga es cero, a la expresión se le asigna el valor 10.
2.√totalsubido+ 2. Cuando el total de subida sea menor que 1 MB, la expresión
toma el valor 1.
La cantidad de subida o bajada se calcula en megabytes. En cualquier caso, el créditono puede exceder de 10 ni ser menor que 1.
1.3.4. ID del archivo
Los ID de los archivos se usan tanto para identi�car unívocamente archivos en la red,como para detectar y recuperar archivos corruptos. Nótese que `eDonkey' no utiliza elnombre del archivo para identi�carlo unívocamente y catalogarlo; un archivo se iden-ti�ca con un ID único creado mediante el hashing de su contenido. Los ID se utilizanprincipalmente por dos motivos:
� Generar un ID único para el archivo.
� Detección y recuperación de partes corruptas.
Los archivos están identi�cados unívocamente por un hash GUID de 128 bits, calculadopor el cliente y basado en el contenido del �chero. Este GUID se calcula aplicando elalgoritmo MD4 a los datos de los archivos. Cuando se calcula el ID del archivo, dichoarchivo se divide en partes, cada una de 9.28 MB. Se calcula un GUID por separadode cada parte y luego todos los hash se combinan para obtener un ID de archivo único.Cuando un cliente que está descargando algo completa la descarga de una parte delarchivo, calcula el hash de esta parte y lo compara con el hash de esa parte que leha enviado su peer. Si la parte está corrupta, entonces el cliente intentará recuperarlasustituyendo bits gradualmente (180 KB) hasta que los hash sean los mismos.El hash principal (raíz) se calcula con cada parte del �chero, usando el algoritmo SHA-
1, basado en bloques de 180 KB de tamaño. Proporciona un nivel mayor de �abilidad yrecuperación de fallos.
1.3.5. Límites �blandos� y �duros�
La con�guración del servidor incluye dos tipos de límites en el número de usuariosactivos, los llamados límites �blandos� y límites �duros�. El límite duro es mayor o igual al
14

1. Introducción
límite blando. Cuando el número de usuarios activos alcanza el límite blando, el servidordeja de aceptar clientes nuevos si tienen un ID bajo. Cuando la cuenta de usuarios alcanzael límite duro, entonces el servidor está completo y no acepta la conexión de ningún clientemás.
1.3.6. ¾Cómo selecciona `eMule' qué parte de archivo descargar?
`eMule' selecciona selectivamente el orden en el que se descargan las partes con elobjetivo de maximizar la tasa de transferencia global y los archivos compartidos. Cadaarchivo está dividido en partes de 9.28 MB y cada parte está dividida en bloques de 180KB. El orden en el que se descargan las partes lo determina el cliente que descarga, elcual envía mensajes de solicitudes de partes concretas del archivo. Dicho cliente puededescargar una única parte de cada fuente en un momento determinado, y todos los bloquesque son solicitados de la misma fuente residen en la misma parte. La prioridad (o rating)de descarga de las partes sigue los siguientes principios (en el orden en que aparecen):
1. La frecuencia de los trozos (disponibilidad), ya que los trozos más �raros� se des-cargan lo más rápidamente posible para ser una nueva fuente disponible.
2. Las partes que se usan para la previsualización (primer y último trozo), compro-bación de un �chero (p. ej., mp3, película).
3. Solicitud de estado (con una descarga en proceso), se intenta solicitar a cada fuenteun trozo diferente. Así se extienden las solicitudes entre todas las fuentes.
4. Completitud (el más inminente en completarse), los trozos recuperados parcialmen-te deberían completarse antes de comenzar a descargar uno nuevo.
El criterio de frecuencia de�ne tres zonas: común, raro y muy raro. Dentro de cadazona, el criterio tiene un peso especí�co, usado para calcular los ratings de las partes.Las partes con menos rating se descargan primero. La siguiente lista especi�ca los rangosde rating de los archivos, de acuerdo a los principios de�nidos más arriba:
0-9999 partes muy raras no solicitadas o solicitadas.
10000-19999 previsualizaciones de partes y partes raras no solicitadas.
20000-29999 la mayoría de las partes comunes no solicitadas y completas.
30000-39999 previsualizaciones de partes y partes raras solicitadas.
40000-49999 partes comunes no completadas y solicitadas.
Este algoritmo normalmente selecciona primero las partes más raras. Sin embargo, laspartes parcialmente completadas que están cerca de completarse pueden ser selecciona-das preferentemente también. Para las partes comunes, las descargas se extienden entrefuentes diferentes.
15

1. Introducción
1.3.7. Características generales de la codi�cación de mensajes delprotocolo `eDonkey'
Todos los mensajes se codi�can como little-endian y no en big-endian, aunque esteúltimo sea el orden convencional de bytes en redes. Esto se puede explicar sencillamentepor el hecho de que los clientes y/o servidores son aplicaciones basadas en MicrosoftWindows y corriendo en procesadores Intel.Todos los mensajes tienen, al menos, 6 bytes de cabecera. Algunos tendrán bytes adi-
cionales conteniendo cierta información, dependiendo del tipo de mensaje que contienen.La cabecera sigue la siguiente estructura (véase Figura 1.7):
Protocolo: Un único byte indicando el ID del protocolo, que es 0xE3 para `eDonkey' y0xC5 para `eMule'.
Tamaño: cuatro bytes indicando el tamaño del mensaje, sin incluir la cabecera. Porejemplo, en caso de que el mensaje no incluya carga útil (payload) entoncesel tamaño será cero.
Tipo: Un byte indicando el tipo. Un único mensaje con un ID.
1.4. Justi�cación del proyecto
En los apartados anteriores se ha puesto de mani�esto que las redes P2P son am-pliamente utilizadas en la actualidad, ya que poseen ciertas propiedades que una redconvencional no tiene. También se ha hecho mención al protocolo para redes peer-to-peer`eDonkey', uno de los más ampliamente utilizados en este tipo de redes, así como suscaracterísticas principales y su funcionamiento general.Resulta evidente que garantizar la seguridad en las redes de comunicación es uno de los
puntos más importantes que las conciernen. Por ello, es necesario aportar mecanismosde seguridad tales como contraseñas, cortafuegos o control de los registros de accesoa las mismas ya que, sin estas medidas, gran cantidad de información se podría vercomprometida.
Figura 1.7: Estructura de una trama del protocolo `eDonkey'.
Una de las herramientas existentes en la actualidad que forman parte de la seguridaden redes de comunicación son los llamados Sistemas de Detección de Intrusiones (IDS,Intrusion Detection Systems), como se puede consultar en [8]. Dichos sistemas se utilizanpara detectar accesos no autorizados a una red o a un computador en particular. LosIDS de red incorporan mecanismos para analizar el trá�co de la red o de un sistema enconcreto y alertar cuando se produce algún tipo de comportamiento extraño.Una de las categorías en las que se pueden dividir los IDS de acuerdo a su modelo
de detección es aquella en la que se detecta un comportamiento anómalo dentro del
16

1. Introducción
trá�co analizado (detección de anomalías). Para ello, este tipo de IDS obtiene estadísticassobre el trá�co típico en la red, se detectan cambios en los patrones de utilización ocomportamiento del sistema y se utilizan modelos estadísticos y se buscan desviacionesestadísticas signi�cantes.Sería, por tanto, una herramienta útil un IDS que sea capaz de analizar trá�co P2P y
que fuera del tipo de IDS que alerten de alguna clase de anomalía cuando sea detecta-da. De esta manera, se está alertando al usuario cuando se detecta en dicho trá�co uncomportamiento no habitual.El objetivo de este proyecto es el desarrollo de una aplicación que haga las funciones de
un IDS capaz de detectar anomalías en trá�co peer-to-peer y mostrar resultados acercadel trá�co no reconocido. Dado el amplio uso del protocolo `eDonkey' en la actualidad,se ha decidido centrar el IDS en dicho protocolo. Para implementar los mecanismos dedetección de anomalías, se ha optado por el uso de técnicas basadas en autómatas deestados �nitos, que se describen en el Capítulo 2.La memoria seguirá la siguiente estructura:
� Capítulo 2: Se describirán los fundamentos tecnológicos necesarios para conocer có-mo funcionan los autómatas de estados �nitos, ya que son utilizados en el modeladodel protocolo `eDonkey'. También se explicará en qué consiste el paradigma cliente-servidor, puesto que es este paradigma el utilizado en el protocolo mencionado. Porúltimo, se detallará cómo realizar el modelado de protocolos con autómatas de esta-dos �nitos y una serie de herramientas y utilidades adicionales que serán prácticasde cara a la elaboración de la aplicación.
� Capítulo 3: En este capítulo se describirá la estructura general y las funcionalidadesque ha de tener la aplicación a desarrollar para poder detectar anomalías en unprotocolo P2P. Asimismo, se mostrará el análisis del funcionamiento del protocolo`eDonkey' y se realizará su modelado con autómatas de estados �nitos, puesto quela aplicación necesitará esta información para poder funcionar correctamente.
� Capítulo 4: Se describirá la estructura de la aplicación con un nivel de detalle ma-yor, para poder comprender su funcionamiento. Se desglosará dicha estructura enmódulos y se explicará la misión de cada uno de ellos, así como el funcionamientoglobal de la aplicación mediante dichos módulos. Se detallará también la jerar-quía de clases utilizadas, que han hecho posible la elaboración de los módulos yamencionados.
� Capítulo 5: Aquí se realizará la evaluación de la aplicación en dos bloques. El prime-ro de ellos será la comprobación del buen funcionamiento de la aplicación mediante�cheros con trazas de trá�co, los cuales han sido adquiridos en diferentes escenariospertenecientes al protocolo `eDonkey'. El segundo bloque veri�ca la e�ciencia de laaplicación, mediante diferentes mediciones de tiempos y análisis de los cuellos debotella de la aplicación.
� Capítulo 6: Se mostrará la plani�cación inicial que se realizó al inicio del proyectoy el desglose de tareas a llevar a cabo. También se mostrará la evaluación de costes
17

1. Introducción
asociados al desarrollo de la aplicación.
� Capítulo 7: Por último, se mostrarán una serie de conclusiones y logros �nales, alos cuales se ha llegado durante el desarrollo y estudio de la aplicación.
18

Capıtulo 2Fundamentos tecnológicos
Tal y como se ha comentado en el Capítulo 1, en este proyecto se aborda la imple-mentación de un sistema de detección de intrusiones (IDS) diseñado para la detección deanomalías en protocolos P2P y, más concretamente, para el protocolo `eDonkey'. Aun-que existen numerosas técnicas disponibles para este tipo de análisis, se ha optado porla utilización de autómatas de estados �nitos con el �n de explorar sus posibilidades eneste campo.Para realizar esta tarea, es necesario conocer ciertos fundamentos de teoría de autóma-
tas de estados �nitos y también del paradigma cliente-servidor, ya que éste es intrínseco alprotocolo que se va a estudiar y a todos los protocolos P2P en general. También se incluyeuna sección que ayuda a entender cómo se puede realizar un modelado del comporta-miento del protocolo mediante autómatas de estados �nitos. Por último, se muestra unasección de herramientas y utilidades, en la cual se exponen las bibliotecas más relevantes,de las cuales hará uso la aplicación, y otros programas útiles.
2.1. Teoría de autómatas de estados �nitos
El diagrama de transición de un autómata de estados �nitos es un grafo en el que losnodos representan los distintos estados y los arcos las transiciones entre los estados. Unautómata está formado por uno o más estados. Cada arco va etiquetado con un símboloasociado a dicha transición. Para facilitar la visualización del diagrama de transición,el estado inicial y los �nales vienen señalados de forma especial (por ejemplo, con unángulo el estado inicial y con un doble círculo los �nales). En cada paso, el autómatalee un símbolo de entrada y, según el estado en que se encuentre, cambia de estado ypasa a leer el siguiente símbolo. Así sucesivamente hasta que termine de leer todos lossímbolos de entrada. Si en ese momento la máquina alcanza un estado �nal, se dice queel autómata acepta la secuencia de símbolos de entrada. Si no está en un estado �nal, larechaza.Para clari�carlo, en la Figura 2.1 se muestra un ejemplo de autómata para crear frases
sencillas. Los estados son los círculos y las transiciones son las �echas que los unen. Las
19

2. Fundamentos tecnológicos
transiciones están nombradas con el valor que debe recibir el autómata para transitar deun estado a otro. Es decir:
� Artículo: El, la, los, las, un, una, unos, unas.
� Nombre: Cualquier nombre común.
� Verbo: Cualquier verbo.
� Adjetivo: Cualquier adjetivo.
Si, por ejemplo, se recibe la frase �el coche es azul�, este autómata la aceptaría, yaque, �el� es un artículo, por lo que transitaría de q0 a q1 (q0 está marcado como estadoinicial); �coche� es un nombre común, por lo que transitaría de q1 a q2; �es� es un verbo,así que se transitaría de q2 a q3; y, por último, �azul� es un adjetivo, por lo que transitaríade q3 a q4, que es un estado �nal (marcado con un círculo doble), concluyéndose que elautómata acepta la frase. Una palabra es cada uno de los términos de la frase que puedehacer transitar a un autómata de un estado a otro.Se pueden elaborar autómatas más complejos. Se muestra uno en la Figura 2.2, con
un bucle. Este aceptaría, por ejemplo, la frase: �el coche es azul y está rayado�, ya que,en q4 aceptaría la conjunción �y� y transitaría de q4 a q2; y �está rayado� son un verboy un adjetivo, que le harían llegar al estado �nal (puede haber más de uno).Como se puede apreciar, los autómatas son útiles para modelar un determinado com-
portamiento. Por ello, se pueden utilizar como herramienta para modelar protocolos, yaque se puede representar este comportamiento.
Figura 2.1: Autómata de ejemplo.
Figura 2.2: Autómata de ejemplo.
20

2. Fundamentos tecnológicos
2.1.1. Autómatas de estados �nitos determinísticos
Como se explica en [10], un autómata de estados �nitos determinístico (AFD) es aquelcuyo estado �nal está determinado unívocamente por el estado inicial y los símbolosobservados por el autómata. Está formado por una quíntupla M = (Q,A, δ, q0, F ) en laque:
� Q es un conjunto �nito llamado conjunto de estados.
� A es un alfabeto (conjunto de símbolos observables) llamado alfabeto de entrada.
� δ es una aplicación llamada función de transición:δ(Q) : Q×A→ Q
� q0 es un elemento de Q, llamado estado inicial.
� F es un subconjunto de Q, llamado conjunto de estados �nales.
Un ejemplo de autómata �nito determinista es el mostrado en la Figura 2.3, en el quelos elementos de la quíntupla serían los siguientes:
� Q = {q0, q1, q2}
� A = {a, b}
� Función de transición:δ(q0, a) = q0δ(q0, b) = q1δ(q1, a) = q2δ(q1, b) = q1δ(q2, a) = q2δ(q2, b) = q2
� Estado inicial = q0
� F = {q0, q1}
2.1.2. Autómatas de estados �nitos no determinísticos
Un autómata �nito no determinístico (AFND) es aquel en el que existe al menos unestado en el que es posible más de una transición para el mísmo símbolo. Dicho de otraforma, un AFND es aquel en el que, dada una secuencia de símbolos observables, el estado�nal y/o la secuencia de estados seguidos por el autómata no es predecible (unívoca).Queda de�nido por una quíntupla M = (Q,A, δ, q0, F ) en que:
� Q es un conjunto �nito llamado conjunto de estados.
� A es un alfabeto (conjunto de símbolos observables) llamado alfabeto de entrada.
21

2. Fundamentos tecnológicos
Figura 2.3: Ejemplo de AFD.
� δ es una aplicación llamada función de transición:δ(Q) : Q×A→ ℘(Q×A)
� q0 es un elemento de Q, llamado estado inicial. Puede haber varios estados iniciales.
� F es un subconjunto de Q, llamado conjunto de estados �nales.
Una secuencia de observaciones se dice aceptada por un AFND si, siguiendo en cadamomento alguna de las opciones posibles, se llega a un estado �nal.En la Figura 2.4 se muestra un ejemplo de AFND. Por ejemplo, en q0 se puede recibir
el símbolo `a' y llevar a varios estados diferentes según la función de transición δ. Loselementos de la quíntupla serían los siguientes:
� Q = {q0, q1, q2}
� A = {a, b, c}
� Función de transición:δ(q0, a) = {q0, q1, q2}δ(q0, b) = {q1, q2}δ(q0, c) = {q2}δ(q1, a) = Øδ(q1, b) = {q1, q2}δ(q1, c) = {q2}δ(q2, a) = Øδ(q2, b) = Øδ(q2, c) = {q2}
� Estado inicial = q0
� F = {q0, q1, q2}
22

2. Fundamentos tecnológicos
Figura 2.4: Ejemplo de AFND.
2.2. Paradigma cliente-servidor
La comunicación entre cliente y servidor se puede realizar con el protocolo TCP o conUDP, mediante el establecimiento de una conexión. Mediante una conexión, dos entidadesse ponen de acuerdo para realizar un determinado intercambio de datos, como se verámás adelante. Es necesario destacar que este concepto sólo es aplicable al protocolo TCP,ya que UDP es no orientado a conexión y, por tanto, no se necesita una conexión previa.Sin embargo, de aquí en adelante, en el contexto UDP se entenderá que dos entidadesintercambiarán información dentro de una conexión.Para poder analizar los mensajes intercambiados en el protocolo, es necesario extraerlos
primero, de modo que, la forma de observar estos mensajes P2P entre dos peers, consisteen extraer los datos de la conexión mediante la identi�cación de las duplas IP/puerto. Elpeer que inicie la conexión será el cliente y el que recibe esta conexión entrante será elservidor. Este es el procedimiento utilizado en este proyecto para extraer los mensajes.Una comunicación TCP o UDP está determinada por los siguientes elementos:
� IP origen.
� IP destino.
� Puerto origen.
� Puerto destino.
Dentro de una comunicación TCP o UDP existen �ujos de información, productodel diálogo entre dos peers. Un �ujo es el intercambio de información que realizan dosentidades, dentro de una conexión. Nótese que dentro de una misma conexión puedenaparecer varios �ujos diferentes, debido a los mensajes intercambiados entre los dos peers.Para clari�car estos conceptos, supóngase la situación de la Figura 2.5. En ella se muestrauna supuesta conexión entre dos computadores. Para cada uno de ellos, se muestra la IPy el puerto.
23

2. Fundamentos tecnológicos
Figura 2.5: Ejemplo de conexión entre dos computadores cualesquiera.
Supóngase ahora que los computadores mostrados en la Figura 2.5 son un cliente yun servidor en una red P2P, que intercambian cierta información. Considérese que laconexión entre los dos computadores permanece abierta durante un tiempo prolongado.Durante este tiempo, el cliente y el servidor pueden intercambiar, por ejemplo, la in-formación correspondiente a un establecimiento de conexión. Dicho establecimiento deconexión se correspondería con un �ujo de información. De la misma manera, durante es-ta conexión, posteriormente puede haber un intercambio de información correspondientea una búsqueda de archivos, que se correspondería con otro �ujo. Por tanto, durante laconexión, ha habido dos �ujos de información.Dada la naturaleza P2P del protocolo `eDonkey', es obvio que hace uso del modelo
cliente-servidor. Un servidor es una aplicación que permite el acceso remoto a ciertosrecursos software o hardware que existen en un host determinado, como se explica en[11]. Una aplicación servidora se caracteriza por encontrarse inicialmente en un estadolatente de escucha sin realizar ninguna función, hasta que recibe una solicitud remotapara desarrollar un servicio ofertado por parte de un cliente. Un cliente es una aplicacióna través de la cual un usuario contacta con un servidor con el �n de llevar a cabo eldesarrollo de un servicio concreto que se oferta.Es a través de la consideración del estado de escucha de la parte servidora cómo
el paradigma cliente-servidor permite resolver de forma sencilla el problema conocidocomo rendez-vous, el cual hace referencia a la sincronización a priori necesaria en lainicialización de dos aplicaciones de usuario para hacer posible la comunicación entreellas.Un servicio que sigue el modelo cliente-servidor se desarrolla en los siguientes pasos:
� Inicialmente debe ejecutarse la aplicación servidora, pasando esta a modo de escu-cha y quedando a la espera de recibir solicitudes de servicio. Es lo que se conocecomo puesta en marcha pasiva del servicio.
� La ejecución de la aplicación cliente dará lugar al envío de una solicitud de serviciohacia el servidor. Esto supone una puesta en marcha activa del servicio.
� El servidor responderá a dicha solicitud de acuerdo con la aplicación desarrollada,llevándose a cabo el intercambio de información necesario para hacer efectivo elservicio.
� Tras el desarrollo de dicho servicio, el servidor volverá al estado de escucha a laespera de nuevas solicitudes. Por otro lado, el cliente �nalizará su ejecución.
24

2. Fundamentos tecnológicos
Características del cliente: Los clientes comparten una serie de características, lascuales son:
� Son invocados por el usuario.
� Inician el contacto con el servidor.
� Pueden comunicarse con:
� Varios servidores alternativamente.
� Varios servidores simultáneamente.
� El mismo servidor concurrentemente.
Características del servidor: Los servidores también tienen una serie de propiedadescomunes:
� Esperan pasivamente la llegada de peticiones de clientes.
� Pueden gestionar peticiones simultáneas de varios clientes, aunque no siempre esasí.
� En la misma máquina pueden estar funcionando varios servidores de diferentesservicios.
2.3. Modelado de protocolos con autómatas de estados
�nitos
El comportamiento de protocolos puede ser modelado sin ambigüedad mediante lasindicaciones realizadas a continuación en esta sección y haciendo uso de las herramientasanteriormente expuestas.A modo de ejemplo, se supondrá el intercambio de tramas del protocolo `eDonkey' de
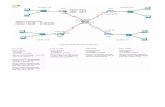
la Figura 2.6. En ella se puede apreciar que existen dos nodos en la red, con direccionesIP1 e IP2, que intercambian tres tramas durante una conexión.Para poder modelar este comportamiento mediante autómatas de estados �nitos, se
ha de conocer el alfabeto a utilizar. Este alfabeto estará determinado por un campodenominado �tipo�, existente en las tramas pertenecientes al protocolo `eDonkey'. Dichocampo está formado por dos dígitos en hexadecimal, los cuales identi�can unívocamenteel tipo o naturaleza del mensaje. Por tanto, el intercambio de mensajes quedaría reducido,por ejemplo, a lo mostrado en la Figura 2.7 y, en este caso, la información extraída delas tramas intercambiadas (secuencia observable) es la mostrada en la Figura 2.8.
25

2. Fundamentos tecnológicos
Figura 2.6: Ejemplo de intercambio de paquetes entre dos nodos de una red P2P.
Figura 2.7: Ejemplo de información extraída en el intercambio de tramas entre dos nodosen la red.
Entonces es posible que el intercambio de mensajes mostrado tenga algún signi�cadoconcreto dentro del protocolo analizado. Por ejemplo, que impliquen un establecimientode conexión o una determinada solicitud propia del protocolo examinado. Con el objetivode comprobarlo, se puede elaborar un autómata asociado a ese �ujo de información,como se muestra en la Figura 2.9. En dicha Figura se puede observar cómo los mensajesintercambiados entre los dos peers provocan que el autómata transite de un estado aotro, hasta alcanzar un estado �nal.Siguiendo el procedimiento mostrado en este ejemplo, se podría modelar el comporta-
miento de cualquier protocolo y, en particular, los protocolos P2P, mediante autómatasde estados �nitos. En este proyecto se ha utilizado esta técnica para modelar el compor-tamiento del protocolo `eDonkey'. El análisis pertinente para derivar los correspondientesautómatas se detalla en el Capítulo 3.
26

2. Fundamentos tecnológicos
2.4. Herramientas y utilidades
A continuación se muestran una serie de herramientas necesarias en el desarrollo de laaplicación. Se han utilizado recursos disponibles para algunas de las funcionalidades ne-cesarias. Del conjunto de bibliotecas de funciones utilizadas en la aplicación, se muestrana continuación las más destacadas, así como una serie de programas prácticos.
Figura 2.8: Información extraída de tres tramas.
Figura 2.9: Ejemplo de modelado de protocolo con un autómata.
2.4.1. Biblioteca `Standard Template Library '
Esta biblioteca ha sido utilizada debido a las múltiples estructuras de datos que pro-porciona. Dichas estructuras de datos han resultado de utilidad en el desarrollo de losautómatas de estados �nitos, así como del almacén/clasi�cador de �ujos utilizado (véaseCapítulo 4).Como se indica en [13, 14], la Standard Template Library, también conocida como
STL, es una colección de estructuras de datos genéricas y algoritmos escritos en C++.La STL no es la primera de tales bibliotecas, ya que la mayoría de los compiladores deC++ proporcionan bibliotecas de funciones con una intención similar, y también estándisponibles muchas de ellas de tipo comercial. Uno de los problemas de las bibliotecas dediferentes vendedores es que son incompatibles entre ellas, por lo que los programadoresestán estudiando continuamente nuevas, y migrando de un proyecto a otro, y de un com-pilador a otro. La STL ha sido adoptada como un estándar por la International StandardsOrganization, International Electrotechnical Commission (ISO/IEC) y por la AmericanNational Standards Institute (ANSI), lo que signi�ca que la STL es una extensión dellenguaje que todos los compiladores soportan y está fácilmente disponible.El concepto de STL está basado en la separación de datos y operaciones. Los datos
están manejados por clases de contenedores, mientras que las operaciones están de�nidaspor algoritmos con�gurables. Los iteradores son la unión entre estos dos componentes, yaque permiten a los algoritmos interactuar con cualquier contenedor, tal y como se ilustraen la Figura 2.10.
27

2. Fundamentos tecnológicos
Figura 2.10: Conexión entre los tres elementos principales de la STL.
En cierto modo, el concepto de STL contradice la idea original de la programaciónorientada a objetos: la STL separa los datos y los algoritmos en vez de combinarlos. Enprincipio, se puede combinar todo tipo de contenedores con todo tipo de algoritmos, porlo que el resultado es una extensión �exible pero aún pequeña.
2.4.2. Biblioteca `Libpcap'
Mediante esta biblioteca ha sido posible la captura de trá�co de un �chero con trazasde trá�co o de una interfaz de red, así como el procesamiento de cada trama (véaseCapítulo 4).La biblioteca de funciones `libpcap' (o `pcap'), como se detalla en [15], es un conjunto
de funciones de código abierto escritas en C con el objetivo de ofrecer al programadoruna interfaz desde donde es posible capturar paquetes de la interfaz de red. `Libpcap'tiene la ventaja de ser portable entre diferentes sistemas operativos y, además, ofrece unaserie de funciones sencillas de utilizar que cubren todos los requisitos deseables respectode la captura y gestión de tramas.A continuación se muestran una serie de estructuras y métodos relevantes para el
manejo de esta biblioteca, que se utilizarán en la aplicación.
Principales estructuras utilizadas y funcionalidades
Información de interfaces. La llamada a pcap_findalldevs, construye una lista en-lazada de estructuras pcap_if (pcap_if = pcap_if_t), en la cual se recoge toda lainformación de cada una de las interfaces de red instaladas.
struct pcap_if
{
struct pcap_if * next; //enlace a la siguiente definición de
interfaz
char * name; //nombre de la interfaz (eth0, wlan0...)
char * description; //descripción de la interfaz o NULL
struct pcap_addr * addresses;//lista enlazada de direcciones
28

2. Fundamentos tecnológicos
asociadas a esta interfaz
u_int flags; //PCAP_IF_ interface flags
};
Una interfaz puede tener varias direcciones. Para contenerlas todas se crear una listacon una estructura pcap_addr por cada una.
struct pcap_addr
{
struct pcap_addr * next; //enlace a la siguiente dirección
struct sockaddr * addr; //dirección
struct sockaddr * netmask; //máscara de red
struct sockaddr * broadaddr; //dirección de broadcast para
esa dirección
struct sockaddr * dstaddr; // dirección de destino
};
Estadísticas. Mediantes la llamada a pcap_stats se obtiene la siguiente estructura coninformación estadística.
struct pcap_stat
{
u_int ps_recv; //número de paquetes recibidos
u_int ps_drop; //número de paquetes no procesados
u_int ps_ifdrop; //paquetes no procesados por cada interfaz
(aún no soportado)
};
Paquetes. Cada paquete del dump_file (archivo donde se encuentran tramas almace-nadas) va precedido por esta cabecera genérica, de modo que un mismo �chero puedecontener paquetes heterogéneos.
struct pcap_pkthdr
{
struct timeval ts; //timestamp (marca de tiempo)
bpf_u_int32 caplen; //tamaño del paquete al ser capturado
bpf_u_int32 len; //tamaño real del paquete en el fichero;
};
struct pcap_file_header
{
bpf_u_int32 magic;
u_short version_major;
u_short version_minor;
bpf_int32 thiszone; //correción de GMT a local
29

2. Fundamentos tecnológicos
bpf_u_int32 sigfigs; //precisión de los timestamps
bpf_u_int32 snaplen; //tamaño máximo salvado de cada paquete
bpf_u_int32 linktype; //tipo de dataLink
};
La estructura `pcap_t'. La estructura pcap_t, que aparece en numerosas funciones, esuna estructura opaca para el usuario. Por lo tanto no es necesario detallar el contenido;sólo es necesario conocer que `libpcap' almacena en este tipo de estructura el valor deciertas variables internas.
Métodos para obtener información del sistema
int pcap_lookupnet(char * device, bpf_u_int32 * netp,
bpf_u_int32 * maskp, char * errbuf)
Una vez obtenido el nombre de una interfaz válida, es posible consultar su direcciónde red (diferente a su dirección IP) y su máscara de subred. El parámetro device es unpuntero a un vector de caracteres que contiene el nombre de una interfaz de red válida,netp y maskp son dos punteros a bpf_u_int32 en los que la función escribirá la direcciónde red y la máscara respectivamente. En caso de error la función devuelve -1 y unadescripción del error en errbuf.
Métodos para capturar paquetes
Existen varias funciones para capturar paquetes. Las principales diferencias entre ellasson: el número de paquetes que se desea capturar, el modo de captura (normal o pro-miscuo) y la manera en que se de�nen sus funciones de llamada o callbacks (la funcióninvocada cada vez que se captura un paquete).
pcap_t * pcap_open_live(char * device, int snaplen, int promisc,
int to_ms, char * errbuf)
Antes de entrar en el bucle de captura hay que obtener un descriptor de tipo pcap_t,para lo cual se emplea esta función. El primer parámetro (char * device) es el nombredel dispositivo de red en el que se desea iniciar la captura (los valores ANY o NULL fuerzanla captura en todos los dispositivos disponibles).El segundo argumento (int snaplen) especi�ca el número máximo de bytes a capturar.
El argumento promisc indica el modo de apertura: un valor distinto de 0 iniciara lacaptura en modo promiscuo, 0 para modo normal.Los programas basados en `libpcap' se ejecutan en la zona de usuario pero la captura
en sí se realiza en la zona del núcleo. Se hace por lo tanto necesario un cambio deárea. Estos cambios son muy costosos y es necesario evitarlos si se quiere optimizarel rendimiento, por eso esta función permite especi�car mediante el parámetro to_ms
30

2. Fundamentos tecnológicos
cuántos milisegundos se desea que el núcleo agrupe paquetes antes de pasarlos todossimultáneamente a la zona de usuario. Si la función devuelve NULL, se habrá producidoun error y puede encontrarse una descripción del mismo en errbuf.
int pcap_loop(pcap_t * p, int cnt, pcap_handler callback,
u_char * user)
Esta función se utiliza para capturar y procesar los paquetes. El parámetro cnt in-dica el número máximo de paquetes a procesar antes de salir; cnt = -1 se usa paracapturar inde�nidamente. El siguiente parámetro, callback, es un puntero a la funciónque será invocada para procesar el paquete. Para que un puntero a función sea de tipopcap_handler, debe recibir unos parámetros:
� Puntero u_char: Es un puntero al propio paquete.
� Estructura pcap_pkthdr.
La función devuelve el número de paquetes capturados o -1 en caso de error, en cuyocaso se puede emplear las funciones pcap_perror() y pcap_geterr() para mostrar unmensaje más descriptivo de dicho error. En caso de error se devolverá un número negativoo 0 si el número de paquetes especi�cados por cnt se ha completado con éxito.
Métodos para manejar �ltros
Un �ltro es una cadena que de�ne los paquetes que va a capturar y procesar la interfazde red. Su principal uso es para librar al núcleo (kernel) de carga de trabajo.
int pcap_compile(pcap_t * p, struct bpf_program * fp, char * str,
int optimize, bpf_u_int32 netmask)
Esta función se emplea para compilar un programa de �ltrado (char * str) en suBPF equivalente (bpf_u_int32 netmask).Es posible que durante la compilación, el programa original se modi�que para op-
timizarlo. El parámetro netmask es la máscara de la red local, que puede obtenersellamando a pcap_lookupnet. En caso de que la función devuelva -1, se habrá producidoun error. Para una descripción más detallada de lo sucedido se puede emplear la funciónpcap_geterr().
int pcap_setfilter(pcap_t * p, struct bpf_program * fp)
Una vez compilado el �ltro sólo es necesario aplicarlo; para ello es su�ciente pasarcomo parámetro a esta función el resultado de compilar el �ltro con pcap_compile.En caso de error la función devolverá -1 y puede obtenerse una descripción más deta-
llada del error con pcap_geterr().
31

2. Fundamentos tecnológicos
Métodos para manejar �cheros relacionados con la captura de trá�co
pcap_open_offline(filename, errbuf)
Este método sirve para abrir un �chero con paquetes ya guardados en formato tcpdumpen modo lectura.Los parámetros son: filename para indicar la ruta del �chero, devuelve NULL en caso
de que la función falle. Para consultar la descripción del error, se utiliza errbuf.
2.4.3. Biblioteca `Pthread '
Mediante esta biblioteca de funciones, ha sido posible la programación multihebradade la aplicación, permitiendo concurrentemente analizar �ujos de varios �cheros de red,así como de interfaces de red. También ha sido fundamental para la extracción de �ujosdel almacén/clasi�cador de �ujos implementado, realizando esta tarea entre varias hebraspara liberar de carga a la hebra principal (véase Capítulo 4).En arquitecturas de multiprocesadores con memoria compartida, tales como los SMP,
las hebras se pueden utilizar para implementar paralelismo, como se puede consultaren [19]. Históricamente, los fabricantes de hardware tenían implementadas sus propiasversiones de hebras, convirtiendo así la portabilidad en un problema que concernía alos desarrolladores de software. En los sistemas UNIX, se ha especi�cado una interfaz deprogramación de hebras estandarizada en lenguaje C, mediante el estándar IEEE POSIX1003.1c. Las implementaciones adheridas a este estándar se conocen como hebras POSIXo Pthreads.
¾Por qué usar `Pthreads'?
� La principal motivación para usar Pthreads es para realizar programas con unagran ganancia en rendimiento.
� Cuando se compara con el coste de crear y mantener un proceso, una hebra puedegenerarse con mucha menos sobrecarga por parte del sistema operativo.
Por ejemplo, la tabla mostrada en la Figura 2.11 compara los resultados en tiempode cómputo para la subrutina fork() (crear un proceso hijo) y para la subrutinapthread_create() (crear una hebra). Los tiempos re�ejan las creaciones de 50000procesos/hebras, que se midieron mediante la utilidad time, en segundos, sin ningúntipo de optimización.
� Todas las hebras de un proceso comparten el mismo espacio de direcciones. Laintercomunicación entre hebras es más e�ciente en muchos casos y más fácil deusar que la intercomunicación entre procesos.
� Las aplicaciones programadas mediante hebras ofrecen una potencial ganancia enrendimiento y ventajas frente a las aplicaciones sin hebras de otras maneras:
32

2. Fundamentos tecnológicos
fork() pthread_create()
Plataforma real user sys real user sys
AMD 2.4 GHz Opteron (8 cpu/nodo) 41.07 60.08 9.01 0.66 0.19 0.43IBM 1.9 GHz POWER5 p5-575 (8 cpu/nodo) 64.24 30.78 27.68 1.75 0.69 1.10
IBM 1.5 GHz POWER4 (8 cpu/nodo) 104.05 48.64 47.21 2.01 1.00 1.52INTEL 2.4 GHz Xeon (2 cpu/nodo) 54.95 1.54 20.78 1.64 0.67 0.90
INTEL 1.4 GHz Itanium2 (4 cpu/nodo) 54.54 1.07 22.22 2.03 1.26 0.67
Figura 2.11: Costes en tiempo (aproximados) para fork() y pthread_create().
� Solapamiento de trabajo de la CPU con entrada/salida: Por ejemplo, un programapuede tener secciones donde se lleve a cabo una larga operación de entrada/salida.Mientras una hebra está esperando una llamada al sistema de entrada/salida paracompletarse, el trabajo intensivo de la CPU lo pueden realizar otras hebras.
� Programación con prioridades y/o en tiempo real: Las tareas que son más im-portantes pueden ser programadas para reemplazar o interrumpir otras tareascon menor prioridad.
� Manejo de eventos asíncronos: Las tareas cuyos eventos (de frecuencia y du-ración indeterminada) pueden estar entremezclados. Por ejemplo, un servidorweb puede transferir datos de una solicitud previa y manejar solicitudes nuevasal mismo tiempo.
� El motivo principal para considerar el uso de Pthreads en una arquitectura SMPes para conseguir un rendimiento óptimo.
La API Pthread
� La API Pthread se de�ne en el estándar ANSI/IEEE POSIX 1003.1 - 1995.
� Las subrutinas que comprenden la API Pthread pueden agruparse informalmenteen tres clases principales:
� Manejo de hebras: La primera clase de estas funciones trabaja directamentecon las hebras (creándolas, uniéndolas, etc.). También incluyen funciones paraestablecer o consultar algún atributo de la hebra.
� Mutexes: La segunda clase de estas funciones están relacionadas con la sin-cronización. El nombre es mutex debido a la abreviatura de mutual exclusion.Las funciones mutex proporcionan funcionalidades para crear, destruir, blo-quear y desbloquear mutexes. También existen funciones relacionadas con losatributos de dichos mutexes, las cuales pueden establecer un atributo nuevo omodi�carlo.
� Variables de condición: La tercera clase de funciones manejan comunicacionesentre hebras que comparten un mutex. Están basadas en condiciones especi-�cadas por el programador. Esta clase incluye funciones para crear, destruir,
33

2. Fundamentos tecnológicos
bloquear y desbloquear hebras en base a valores de variables especi�cados.También se incluyen funciones para consultar o establecer atributos en lasvariables de condición.
� Convenciones de nombrado: Como se muestra en la tabla de la Figura 2.12, todoslos identi�cadores de la biblioteca de hebras comienzan por pthread_.
� La API Pthread contiene más de 60 subrutinas.
� Debido a la portabilidad, la cabecera pthread.h se debe incluir en cada �cherofuente que utilice la biblioteca Pthread.
� El estándar POSIX actual está de�nido en lenguaje C.
2.4.4. Wireshark
Como se puede consultar en [17], wireshark es un analizador de paquetes de la red. Unanalizador de este tipo intentará capturar los paquetes de la red y mostrar los datos dedichos paquetes lo más detalladamente posible.Se podría decir que un analizador de paquetes de la red es un dispositivo medidor que
se usa para examinar qué está pasando dentro de un cable de red.Algunos usos de Wireshark son:
� Buscar problemas en la red por los administradores de redes.
� Examinar problemas de seguridad por ingenieros en este campo.
� Depurar implementaciones de protocolos por desarrolladores de software.
� Estudiar el funcionamiento de un protocolo de red.
En este proyecto, esta herramienta será útil para analizar el funcionamiento del proto-colo `eDonkey'.
Pre�jo de las rutinas Grupo funcional
pthread_ Las propias hebras y subrutinas generalespthread_attr_ Atributos de las hebraspthread_mutex_ Mutexes
pthread_mutexattr_ Atributos de los mutexespthread_cond_ Variables de condición
pthread_condattr_ Atributos de las condicionespthread_key_ Claves de datos especí�cos de las hebras
Figura 2.12: Grupos funcionales de rutinas Pthread.
34

2. Fundamentos tecnológicos
2.4.5. Doxygen
Doxygen, como se puede consultar en [20], es un generador de documentación quese utiliza para documentar múltiples lenguajes de programación, como pueden ser C++,Java o Python, entre otros. Como es fácilmente adaptable, funciona en varias plataformas.Doxygen es una herramienta para escribir documentación de referencia en el software.
Esta documentación se escribe aparte del código, y es relativamente fácil mantenerla ac-tualizada. Doxygen puede crear referencias cruzadas entre el código y la documentación,por lo que un lector de documentos puede desplazarse fácilmente hacia el código.
35

2. Fundamentos tecnológicos
36

Capıtulo 3Análisis
En este capítulo se aborda el análisis del proyecto. En él se detalla el modelado del pro-tocolo `eDonkey' mediante autómatas de estados �nitos, ya que es una parte fundamentalen el funcionamiento de la aplicación. También se detallan los requisitos y funcionalidadesde dicha aplicación, así como su estructura principal.
3.1. Procedimientos en el protocolo `eDonkey'
A continuación se detallan los procedimientos más relevantes del protocolo `eDonkey'en base al intercambio de mensajes, con todos los diálogos mostrados, como se detalla en[9]. El objetivo es derivar los autómatas de estados �nitos correspondientes a cada unode los procedimientos del protocolo. Dichos procedimientos o diálogos se dividen en:
� Comunicación TCP entre el cliente y el servidor:
� Establecimiento de conexión.
� Intercambio de mensajes al inicio de la conexión.
� Búsqueda de archivos.
� Mecanismo de callback.
� Comunicación UDP entre el cliente y el servidor:
� Keep-alive del servidor.
� Información de estado.
� Comunicación TCP entre dos clientes:
� Handshake inicial.
� Identi�cación segura del usuario.
� Solicitud de �cheros.
� Transferencia de datos.
37

3. Análisis
� Consulta de los archivos y carpetas compartidos.
� Intercambio de los hash de fragmentos de archivos.
� Obtención de la previsualización de un archivo.
� Comunicación UDP entre dos clientes.
� Uso del protocolo UDP en escenarios relacionados con la descarga de archivos.
En todos los diálogos posibles existen �escenarios� (situaciones donde se producenintercambios de mensajes) entre el cliente y el servidor o entre dos clientes. Dichos es-cenarios, que no son más que un intercambio de mensajes a lo largo del tiempo, puedenmodelarse mediante autómatas de estados �nitos, siguiendo el procedimiento mostradoen el Capítulo 2.A continuación se recorren los posibles diálogos más destacados, con los escenarios más
importantes conocidos para dichos diálogos y con el intercambio de mensajes correspon-diente y su modelado mediante un autómata de estados �nitos.
3.1.1. Comunicación TCP cliente-servidor
Cada cliente se conecta exactamente a un servidor usando una conexión TCP. Elservidor asigna al cliente un ID, que será usado para identi�carle durante toda la sesióncon ese servidor (un cliente con ID alto lo ha obtenido siempre a partir de su direcciónIP, como se explica en la sección 1.3.2). Para poder operar, el cliente `eMule' requieresiempre que se establezca una conexión con un servidor. Dicho cliente no puede estarconectado a varios servidores al mismo tiempo ni tampoco cambiar de uno a otro demanera dinámica sin la intervención directa del usuario.
Establecimiento de conexión
Cuando se establece la conexión con un servidor, el cliente intenta conectar con va-rios servidores en paralelo, pero abandona todos los intentos una vez se haya conectadoexitosamente a uno.Existen tres posibles casos de establecimiento de conexión:
� Conexión con ID alto: El servidor asigna un ID alto al cliente que se conecta.
� Conexión con ID bajo: El servidor asigna un ID bajo al cliente que se conecta.
� Sesión rechazada: El servidor rechaza al cliente.
Existe, por supuesto, el caso trivial en el que el servidor está caído o es inalcanzable.La Figura 3.1 describe la secuencia de mensajes que da lugar a una conexión con ID
alto. En este caso, el cliente establece una conexión TCP con el servidor y le envía unmensaje de login. El servidor se conecta al cliente usando otra conexión TCP y realizaun handshake cliente-cliente para asegurarse de que el cliente al que se conecta tiene lacapacidad de aceptar conexiones de otros clientes `eMule'. Tras completar el handshake elservidor termina la segunda conexión y completa el handshake cliente-servidor enviando
38

3. Análisis
un mensaje de cambio de ID (`ID change'). El mensaje de `eMule' info está representadoen la Figura con color gris por el hecho de pertenecer a una extensión del protocolo, quees parte de `eDonkey'.La Figura 3.2 describe la secuencia de mensajes que dan lugar a una conexión con ID
bajo. En este caso, el servidor falla al intentar conectarse al cliente que se conecta a él,por lo que se le asigna un ID bajo. El servidor suele enviar un mensaje de precaución,de la forma: �Warning [detalles del servidor] � You have a low ID. Please review yournetwork con�g and/or your settings�.Los handshake correspondientes a conexiones tanto de ID alto como de ID bajo, �nal-
mente se completan con el mensaje de cambio de ID, el cual asigna al cliente un ID parasu conexión con el servidor.La Figura 3.3 describe la secuencia de mensajes que se suceden para una conexión
rechazada por el servidor. Dicho servidor podría actuar así debido a que el cliente tieneun ID bajo o cuando alcanzan su capacidad máxima. El mensaje del servidor contendráuna breve cadena que describe el motivo del rechazo.
Figura 3.1: Conexión con ID alto.
39

3. Análisis
Figura 3.2: Conexión con ID bajo.
El modelado de los tres tipos de conexiones con un autómata daría lugar a lo mostradoen la Figura 3.4, en la que se representa el intercambio de mensajes que se producenentre cliente y servidor. La sintaxis seguida por el mensaje que acompaña a la �echaes �mensaje del cliente/mensaje del servidor�, ya que los autómatas están diseñados decara a considerarlos como si se vieran desde el propio cliente. Por ejemplo, para llegar alescenario �nal en el que al cliente se le asigna un ID bajo, primero el cliente se conectamediante TCP al servidor (q0 � q1); tras esto, el cliente envía un mensaje de login alservidor (q1 � q2); entonces el servidor se conecta con este cliente para veri�car queacepta conexiones entrantes (q2 � q3); al comprobar que no puede, el cliente recibe unmensaje del servidor (q3 � q9); por último, el cliente recibe un mensaje de cambio deID (q9 � q10). Es en este punto donde se llega a la conclusión de que al cliente se le haasignado un ID bajo.
Figura 3.3: Conexión rechazada.
40

3. Análisis
Figura 3.4: Establecimiento de conexión modelado con autómata de estados �nitos.
Es viable unir los tres posibles escenarios en un solo autómata, ya que comparten partede los mensajes intercambiados y la utilización y gestión de este autómata no es compleja.En realidad, sería posible de�nir un único autómata capaz de modelar todo el protocoloconsiderando todos los escenarios posibles. Sin embargo, por razones operativas y de es-calabilidad, se usarán autómatas parciales, correspondientes a escenarios concretos. Enel caso de considerar un único autómata, resultaría muy complejo analizar el protocoloy modelar nuevos escenarios y añadirlos a la especi�cación. Análogamente en este caso,los tres escenarios se podían haber modelado con tres autómatas más pequeños, que son,en realidad, tres sub-autómatas del mostrado en la Figura 3.4. Sin embargo, como se hacomentado, el autómata �nal resultante no es tan complejo como para dividirlo. Ade-más, los tres sub-autómatas forman parte del establecimiento de conexión entre clientey servidor (mismo escenario).
Intercambio de mensajes al inicio de la conexión
Tras un establecimiento de conexión exitoso, el cliente y el servidor intercambian algu-nos mensajes. El propósito de estos mensajes es actualizar ambas partes, contemplandoel estado de los peers. El cliente comienza ofreciendo al servidor una lista con sus archivoscompartidos y luego realiza una petición de actualización de su lista de servidores. Elservidor le envía su estado y su versión y luego la lista de todos los servidores `eMule' queconoce, junto con algunos detalles más del propio servidor. Finalmente, el cliente realizauna petición de fuentes (es decir, otros clientes a los que pueda acceder que contenganpartes de archivos en su lista de descarga) y el servidor le contesta con una serie demensajes, uno por cada archivo de la lista de descarga del cliente. La Figura 3.5 ilustraesta secuencia.
41

3. Análisis
Figura 3.5: Secuencia de mensajes al inicio de la conexión.
El modelado de la serie de mensajes expuestos en la Figura 3.5 se correspondería conel autómata de la Figura 3.6.
Búsqueda de archivos
La búsqueda de archivos la inicia el usuario. La operación es simple: se envía una soli-citud de búsqueda al servidor y este contesta con un resultado. Cuando existen múltiplesresultados, el mensaje con el resultado de la búsqueda se comprime. Tras esto, el usuariodecide descargar uno o más archivos, por lo que envía peticiones de búsqueda de fuentespara cada uno de estos archivos y el servidor contesta con una lista de fuentes para cadauno de dichos archivos. El servidor puede enviar un mensaje de estado opcional, antesde la respuesta con las fuentes encontradas.
Figura 3.6: Secuencia de mensajes al inicio de la conexión modelada con autómata deestados �nitos.
42

3. Análisis
El mensaje de estado contiene información acerca del número de usuarios y archivossoportados por el servidor. Es importante señalar que también existe una secuencia demensajes UDP para mejorar la habilidad de un cliente para localizar fuentes en lasbúsquedas de archivos. Tras veri�car que las fuentes obtenidas son nuevas, el cliente`eMule' inicia un intento de conexión y las añade a su lista de fuentes. El orden en el quese contacta con las fuentes es el orden con el que el cliente las recibió.El cliente `eMule' se va conectando a las fuentes en el orden en el que están en su lista
de fuentes. No hay ningún mecanismo de prioridad para decidir a qué fuente conectar,pero sí existe un complicado arti�cio para resolver situaciones donde se le pueden enviarmúltiples solicitudes a una misma fuente porque esta posea varios de los archivos de lalista de descarga del cliente (nótese que `eMule' sólo permite una única conexión entreclientes). El algoritmo de selección está basado en las especi�caciones de prioridad delusuario pero, si no existen, por defecto se atiende al orden alfabético. La Figura 3.7muestra este mecanismo, mientras que la Figura 3.8 muestra el autómata resultante.
Mecanismo de callback
El mecanismo de callback se diseñó para superar la incapacidad de los clientes conID bajo de aceptar conexiones entrantes y, así, poder compartir sus archivos con otrosclientes. El mecanismo es simple: en el caso de que `A' y `B' estén conectados al mismoservidor `eMule' y `A' necesite un archivo que posee `B', pero `B' tenga un ID bajo,entonces `A' puede enviar al servidor una solicitud de callback al servidor, para que estele solicite a `B' que se conecte con `A'. El servidor, que ya tiene una conexión TCPestablecida con `B', le envía a `B' un mensaje de callback con la dirección IP y puertode `A'. Entonces `B' ya puede conectarse con `A' y enviarle el archivo que le falta, sinmás sobrecarga en el servidor. Obviamente, sólo un cliente con ID alto puede realizarsolicitudes de callback hacia clientes con ID bajo (un cliente con ID bajo no puede aceptarconexiones entrantes). La Figura 3.9 describe esta secuencia.
Figura 3.7: Secuencia de mensajes de búsqueda de archivos.
43

3. Análisis
Figura 3.8: Autómata de estados �nitos para la búsqueda de archivos.
Existe también una característica que permite a dos clientes con ID bajo intercambiararchivos a través de la conexión que tienen con el servidor, utilizándola como una pasarela.Pero la mayoría de servidores no soportan esta opción ya que produce una gran sobrecargaen ellos.Los autómatas que modelan este intercambio de mensajes se muestran en las Figuras
3.10, 3.11 y 3.12. El motivo de de�nir, en este caso, tres autómatas es porque existentres entidades que participan en el proceso. Si se considerara solamente una de ellas, nose podrían apreciar todos los intercambios de mensajes, porque siempre hay alguno queinvolucra a una tercera entidad no representada.
Figura 3.9: Secuencia de mensajes para el mecanismo de callback.
44

3. Análisis
Figura 3.10: Secuencia de mensajes para el mecanismo de callback modelada con auto-mata de estados �nitos (Cliente A).
Figura 3.11: Secuencia de mensajes para el mecanismo de callback modelada con auto-mata de estados �nitos (Servidor).
Figura 3.12: Secuencia de mensajes para el mecanismo de callback modelada con auto-mata de estados �nitos (Cliente B).
3.1.2. Comunicación UDP cliente-servidor
El cliente `eMule' y el servidor usan el protocolo no �able UDP para keep-alive y paramejoras en las búsquedas. La cantidad de paquetes UDP que genera un cliente `eMule'puede alcanzar el 5% del total de paquetes, pero depende del número de servidores enla lista del cliente, del número de fuentes para cada archivo de su lista de descarga y delnúmero de búsquedas realizadas por el usuario. Estos paquetes se van enviando de acuerdocon un contador que expira cada 100 ms. Si se tiene en cuenta que sólo existe una hebraresponsable del trá�co UDP saliente, se obtiene una tasa máxima de 10 paquetes/seg.
Keep-alive del servidor e información de estado
El cliente comprueba, periódicamente, el estado de los servidores de su lista de servido-res. Esta comprobación se realiza usando los mensajes de solicitud de estado del servidorUDP y de solicitud de descripción del servidor UDP. El esquema keep-alive que se des-cribe a continuación no genera más de una docena de paquetes por hora. En cualquiercaso, la tasa máxima es de 0.2 paquetes/seg (o un paquete cada 5 segundos). Cuando secomprueba el estado de un servidor, el cliente primero envía un mensaje de solicitud deestado y posteriormente, sólo una vez cada dos intentos, una solicitud de descripción delservidor, tal y como se muestra en la Figura 3.13.
45

3. Análisis
Figura 3.13: Ciclo de keep-alive UDP.
El mensaje de solicitud de estado incluye un número aleatorio que el servidor incluyeen su mensaje de respuesta. En caso de que el número que envíe el servidor sea diferenteal reto del cliente, el mensaje se descartará. Cada vez que el cliente envía un mensajede este tipo, incrementa en una unidad un contador de intentos. Cualquier mensajerecibido por parte del servidor (incluyendo resultados de búsquedas, etc), pone a cerodicho contador. Cuando este contador alcanza un número límite, el cual es con�gurable,el servidor se considera �muerto� y se quita de la lista de servidores del cliente. Lasrespuestas proporcionadas por un servidor incluyen varios tipos de datos. La respuestaa una solicitud de estado incluye el número actual de usuarios y archivos en el servidory también los límites blandos y duros (descritos anteriormente). La respuesta a unasolicitud de descripción del servidor incluye el nombre de este y una cadena de texto conuna breve descripción. La Figura 3.14 ilustra el intercambio de mensajes en una secuenciakeep-alive completa entre un cliente y un servidor y el modelado resultante se encuentraen la Figura 3.15.
Figura 3.14: Secuencia keep-alive UDP.
46

3. Análisis
Figura 3.15: Secuencia keep-alive UDP modelada con autómata de estados �nitos.
En esta situación, se han podido unir los dos escenarios en un mismo autómata. Estoes porque en el primer escenario sólo se indicaban las solicitudes que realizaba el clienteal servidor y la frecuencia con las que las realizaba. Sin embargo, en el segundo escenario,se muestran las solicitudes junto con sus respuestas, por lo que existe una parte comúnentre los dos escenarios que se pueden resumir en un solo autómata sencillo.
3.1.3. Comunicación TCP cliente-cliente
Tras registrarse en el servidor y enviarle solicitudes de archivos y fuentes, el cliente`eMule' necesita contactar con otros clientes con el objetivo de descargarse los �cherosque desee. Así, se crea una conexión TCP dedicada para cada par {archivo, cliente}.Las conexiones se cierran cuando no hay actividad en un socket durante un tiempodeterminado (40 segundos por defecto) o cuando el peer cierra la conexión.Con el objetivo de proporcionar tasas de descarga razonables, `eMule' no permite a un
cliente comenzar la descarga de un archivo hasta que no pueda ofrecerle una tasa mínima(la cual es 2.4 KB/seg).
Handshake inicial
El handshake inicial es simétrico, ya que ambas partes se envían la misma informa-ción. Los clientes intercambian información acerca del otro, la cual incluye identi�cación,versión e información acerca de determinadas capacidades. Participan dos tipos de men-sajes: el mensaje de `Hello' y el mensaje de información acerca del `eMule'. El primerode ellos es parte del protocolo `eDonkey' y es compatible con los clientes. El segundo esparte del protocolo extendido del cliente, el cual es único en `eMule'. En la Figura 3.16se muestra este funcionamiento, y su autómata correspondiente es el de la Figura 3.17.
47

3. Análisis
Figura 3.16: Handshake inicial de los clientes `eMule'.
Figura 3.17: Handshake inicial de los clientes `eMule' modelado con autómata de estados�nitos.
En este autómata se incluyen tanto los mensajes intercambiados del protocolo `eDon-key', como la extensión del protocolo proporcionada por `eMule'. Como se puede apreciar,no es necesario disponer de la extensión de `eMule' para poder satisfacer este escenario.
Identi�cación segura del usuario
En el Apartado 1.3.3 se describió brevemente los ID del usuario y la motivación quepueden tener otros para suplantar la identidad de un determinado usuario. La identi�-cación segura es parte de la extensión de `eMule'. En el caso de que los clientes soporteneste tipo de identi�cación, esta tiene lugar justo después del handshake inicial. El propó-sito de la identi�cación segura es prevenir la suplantación de identidad. Es un esquemasimple basado en RSA. Cuando se aplica dicha identi�cación, suponiendo dos clientes `A'y `B', tienen lugar los siguientes pasos:
1. En el handshake inicial, `B' indica que soporta la identi�cación segura y que deseautilizarla.
2. El cliente `A' reacciona enviando un mensaje de identi�cación segura, el cual indicasi `A' necesita la clave pública de `B' o no, y que también contiene un reto de 4bytes que `B' tiene que �rmar.
48

3. Análisis
3. En el caso de que `A' haya indicado que necesita la clave pública de `B', entonces`B' se la envía.
4. `B' envía un mensaje �rmado que se crea usando el reto recibido y una palabradoble adicional que es la dirección IP de `A', en el caso de que `B' tenga un IDbajo, o el ID de `B' en el caso de que tenga ID alto.
Las Figuras 3.18 y 3.19 ilustran dicha secuencia de mensajes. El autómata se muestraen la Figura 3.20.En este caso se muestra un autómata único en el que ha sido posible unir varios
escenarios debido a su sencillez y al hecho de compartir mensajes entre ellos.
Solicitud de �cheros
Como ya se describió, se crea una conexión para cada par {cliente, �chero}. Inmediata-mente después del establecimiento de conexión, el cliente envía varios mensajes indicandoel archivo que desea descargar (Figura 3.21). Existen varios casos en la solicitud de �-cheros y se describen a continuación.
Figura 3.18: Identi�cación segura. `A' no tiene la clave pública de `B'.
Figura 3.19: Identi�cación segura. `A' tiene la clave pública de `B'.
49

3. Análisis
Figura 3.20: Identi�cación segura modelada con autómata de estados �nitos.
Figura 3.21: Solicitud de �chero.
Intercambio básico de mensajes. Está compuesto por cuatro mensajes. En primerlugar, `A' envía un mensaje de solicitud de archivo e inmediatamente después, otro conel ID del archivo que se solicita. `B' responde a la solicitud de archivo con una solicitudde respuesta de archivo. Al mensaje con el ID del archivo solicitado contesta con unmensaje de estado del �chero.El protocolo extendido añade dos mensajes a esta secuencia: una solicitud de fuentes y
una respuesta a esta solicitud. Esta extensión se utiliza para transmitir las fuentes de `B'(en el caso de que `B' sea el cliente que descarga) a `A'. No existe ningún requerimientoque establezca que `B' necesite descargar el archivo completo para poder compartir partescon otros clientes, por lo que `B' puede enviar a `A' otros fragmentos del �chero que tengacompletos.
Escenario de archivo no encontrado. Se produce cuando `A' solicita un archivo a `B'pero `B' no disponga de dicho archivo en su lista de archivos compartidos. `B' no envíala respuesta de solicitud de archivo, sino que envía un mensaje de archivo no encontrado,inmediatamente después de recibir el mensaje con el ID del archivo que se solicita (Figura3.22). Asimismo, el autómata que modela tanto la solicitud de un �chero como el escenariode un �chero no encontrado es el de la Figura 3.23.
50

3. Análisis
Figura 3.22: Solicitud de archivo fallida. Archivo no encontrado.
Figura 3.23: Solicitud de �chero modelada con autómata de estados �nitos.
En este caso, se ha podido, una vez más, unir varios escenarios dentro de un mismoautómata. La parte inicial corresponde a la búsqueda de archivos en ambos casos, perose diferencia en la parte �nal en caso de que el archivo no se haya encontrado, o bien enel caso de que sí se haya encontrado.
Adición de archivos a la cola de subida. En el caso de que `B' disponga de un determi-nado archivo que se le ha solicitado y su cola de subida no esté vacía, signi�ca que existenclientes que se están descargando archivos de él y probablemente existirán también otrosclientes en cola. `A' y `B' realizan el handshake completo, pero cuando `A' solicita a `B'la descarga de un archivo, `B' le añade a la cola de subida y le envía un mensaje deranking, el cual contiene la posición de `A' en la cola.
Gestión de la cola de subida. Para cada archivo enviado, el cliente mantiene una colade subida con prioridad. La prioridad de cada cliente en dicha cola se calcula en base
51

3. Análisis
al tiempo que lleva el cliente en la cola y un modi�cador de prioridad, llamado rating(Figura 3.24).En la cabeza de la cola están los clientes que tienen la puntuación más alta. Dicha
puntuación se calcula usando la siguiente fórmula:
puntuacion = rating×segundosEnLaCola100
Puede ser in�nito en caso de que el cliente que descarga esté de�nido como amigo. Elvalor del rating inicial es 100, excepto para los usuarios prohibidos (expulsados), cuyorating es 0 (y así se evita que alcancen la cabeza de la cola). El rating es modi�cado obien por el crédito del cliente que descarga (cuyo rango es del 1 al 10) o por la prioridaddel archivo que se envía (0.2 � 1.8) el cual lo modi�ca el cliente que lo envía. Cuandola puntuación de un cliente es mayor que la del resto de los clientes de la cola, entoncescomienza la descarga del archivo. El cliente estará descargando dicho archivo a no serque se dé una de las siguientes situaciones:
1. El usuario desconecta al cliente que envía el archivo.
2. El cliente que descarga tiene todas las partes que necesita.
3. El cliente que descarga es adelantado por otro que tiene más prioridad que él.
Con el objetivo de permitir a un cliente que acaba de comenzar a descargar archivosobtener algunos megabytes antes de ser adelantado por otro, `eMule' impulsa el ratinginicial del cliente que descarga a 200 durante los primeros 15 minutos.El autómata que modela el escenario de la Figura 3.24 es el de la Figura 3.25.
Figura 3.24: Cola de espera para una solicitud de un archivo.
52

3. Análisis
Figura 3.25: Cola de espera para una solicitud de un archivo modelada con autómata deestados �nitos.
Alcanzando el inicio de la cola de subida. Cuando `A' alcanza el inicio de la cola desubida de `B', `B' se conecta a `A', realiza el handshake inicial y luego envía un mensajede aceptación para la cola de subida. `A' puede ahora elegir entre continuar y comenzara descargar el archivo enviando una solicitud, o bien cancelar la descarga (en caso de queya tenga el fragmento de otra fuente) enviando un mensaje de cancelación de transferen-cia. La Figura 3.26 ilustra estas opciones y el autómata correspondiente se muestra enla Figura 3.27. Debido a que los dos escenarios sólo se diferencian en el mensaje �nal, esposible aunarlos en un mismo autómata, clari�cando en el estado �nal las dos posiblestransiciones.
Figura 3.26: Descarga de un archivo.
53

3. Análisis
Figura 3.27: Descarga de un archivo modelada con autómata de estados �nitos.
Transferencia de datos
El paquete de datos. El envío y recepción de fragmentos de archivos es la mayor partede la actividad de la red `eMule'. El tamaño de un fragmento enviado puede variar entre5000 y 15000 bytes (dependiendo también de la compresión). Con el objetivo de evitarla fragmentación, los mensajes de partes de �cheros se envían en trozos y cada trozo enun paquete TCP por separado. En la versión 0.30e de `eMule', el tamaño máximo de unapieza es de 1300 bytes (nótese que este número se re�ere únicamente a la carga útil delpaquete TCP). En otras palabras, mientras cada mensaje de control se envía en un únicopaquete TCP, a veces, junto con otro mensaje, los mensajes de datos están divididos envarios paquetes TCP. El primer paquete contiene la cabecera del mensaje de la parte delarchivo que se envía. El resto de los paquetes contienen sólo datos. En caso de que elpaquete se divida, en el primero de ellos se envía un recordatorio (el que lleva el mensajede cabecera) que lo indica. Los detalles se muestran en la Figura 3.28, y el autómata quelo modela es el de la Figura 3.29.
Figura 3.28: Detalles del mensaje de la parte de un archivo.
54

3. Análisis
Figura 3.29: Detalles del mensaje de la parte de un archivo modelado con autómata deestados �nitos.
Secuencia de transferencia de datos. Una secuencia de transferencia de una parte con-creta puede comenzar inmediatamente después de la respuesta a la solicitud del archivo.El cliente que descarga, `A', envía una solicitud de comienzo de envío, la cual se respondemediante otro mensaje de aceptación. Inmediatamente después de esto, `A' comienza asolicitar fragmentos de archivo y `B' contesta enviando las partes solicitadas.Cuando ambos clientes soportan el protocolo extendido, los fragmentos del archivo se
pueden enviar comprimidos. Dicho protocolo también soporta un mensaje adicional deinformación que puede ser enviado justo antes del mensaje de aceptación de envío. Estasecuencia está ilustrada en la Figura 3.30 y el autómata que lo modela es el de la Figura3.31.
Figura 3.30: Intercambio de fragmentos de archivo.
55

3. Análisis
Figura 3.31: Intercambio de fragmentos de archivo modelado con autómata de estados�nitos.
Consulta de los archivos y carpetas compartidos
Hay dos tipos de mensajes que manejan la visualización de los archivos y carpetascompartidas por los clientes peer. El primero es el mensaje de visualización de archivoscompartidos, el cual se envía justo tras el handshake inicial. Este mensaje siempre escontestado por otro de respuesta. Cuando el cliente que contesta desea esconder su listade archivos compartidos, la respuesta no contendrá ningún archivo (en vez de enviarun mensaje que signi�que que el acceso ha sido denegado). La Figura 3.32 muestra lasecuencia de mensajes.El segundo mensaje comienza con una solicitud de vista de la lista de las carpetas
compartidas, el cual es respondido con la lista de las carpetas y, tras esto, para cada car-peta del mensaje de respuesta, un mensaje para mostrar el contenido de la misma. Cadauno de estos mensajes es contestado con una lista de contenidos. Se puede comprobar enla Figura 3.33. En caso de que el cliente esté con�gurado para bloquear las solicitudesde archivos y carpetas compartidos, contesta con un mensaje de denegación, como semuestra en la Figura 3.34.Los intercambios de mensajes pueden modelarse con el autómata de la Figura 3.35.
Dado que los escenarios se sitúan en el mismo contexto, se puede elaborar un autómatacon tan sólo ocho estados que sea capaz de recoger los cuatro escenarios.
Figura 3.32: Solicitud de vista de archivos compartidos.
56

3. Análisis
Figura 3.33: Consulta de archivos y carpetas compartidos.
Figura 3.34: Solicitudes de vista de archivos y carpetas denegadas.
Intercambio de los hash de fragmentos de archivo
Con el objetivo de obtener los hash de partes de archivo, se envía una solicitud, a lacual el cliente contestará con un mensaje de respuesta de hash, que contendrá dicho hashdel fragmento del archivo. La Figura 3.36 ilustra este hecho y el autómata que lo modelaes el de la Figura 3.37.
Obtención de la previsualización de un archivo
El cliente puede pedir a su peer obtener la previsualización de un archivo descarga-do. Las previsualizaciones dependen de las aplicaciones y de los tipos de archivos. Lasversiones más antiguas de `eMule' (0.30e) soportan la previsualización de imágenes. Elescenario se detalla en la Figura 3.38 y el autómata correspondiente en la Figura 3.39.
57

3. Análisis
Figura 3.35: Vista de archivos y carpetas compartidos modelada con autómata de estados�nitos.
Figura 3.36: Solicitud de hash de fragmento de archivo.
Figura 3.37: Solicitud de hash de fragmento de archivo modelada con autómata de esta-dos �nitos.
58

3. Análisis
Figura 3.38: Obtención de la previsualización de un archivo.
Figura 3.39: Obtención de la previsualización de un archivo modelada con autómata deestados �nitos.
3.1.4. Comunicación UDP cliente-cliente
El cliente `eMule' envía periódicamente mensajes usando el protocolo UDP. En la ver-sión de `eMule' 0.30e, los mensajes UDP se usan únicamente para que el cliente preguntea su peer la posición en la que está en la cola de descarga. El esquema simple solicitud-respuesta se inicia con un mensaje de re-solicitud de un �chero concreto. Existen tresposibles respuestas para este mensaje:
1. Posición en la cola: La posición del cliente en la cola del que envía.
2. Cola completa: La cola del cliente que envía está llena.
3. Archivo no encontrado: El cliente no tiene el archivo solicitado en su lista.
El mensaje de re-solicitud se envía en intervalos de aproximadamente 20 minutos paracada cliente que el peer que envía haya añadido a su cola de descarga (Figura 3.40). Elautómata que lo modela es el de la Figura 3.41.
3.2. Análisis de requisitos y funcionalidades de la aplicación
En base a lo detallado hasta este punto, resulta sencillo evidenciar que la aplicacióna desarrollar necesita una determinada información para poder funcionar correctamente,por lo que los elementos a considerar serían:
� Información de entrada a la aplicación acerca de los autómatas.
� Ficheros con trazas de trá�co a analizar también como bloque de entrada, o bienuna interfaz de red para realizar una captura en vivo. Es decir, un sensor queproporcione información acerca del trá�co a analizar.
59

3. Análisis
Figura 3.40: Mensaje de re-solicitud de archivo.
Figura 3.41: Mensaje de re-solicitud de archivo modelado con autómata de estados �nitos.
� Un programa principal que construya los autómatas y analice las trazas de trá�coproporcionado.
� Una salida que proporcione información acerca del trá�co analizado.
Por tanto, la estructura principal del programa, que cumpla estos requisitos, sigue laestructura mostrada en la Figura 3.42. En dicha �gura, pueden observarse los siguientesbloques, los cuales se detallan a continuación.
Sensor
El sensor de entrada es el bloque que proporciona datos acerca del trá�co que se quiereanalizar en busca de un determinado comportamiento. Este sensor puede ofrecer el trá�coa la aplicación de dos posibles tipos de fuentes de trá�co. La primera de ellas es un �cherocon trazas de trá�co. La segunda es indicar una interfaz de red para realizar una captura
60

3. Análisis
de trá�co en vivo e introducirla en la aplicación sin necesidad de almacenar los datos enun �chero.Los �cheros con trazas de trá�co deben estar en formato pcap, ya que la biblioteca
utilizada en la aplicación (véase Apartado 2.4.2) es capaz de trabajar con este tipo de�cheros de manera sencilla. Por tanto, la funcionalidad principal de este sensor es ofrecera la aplicación información acerca del trá�co.
Autómatas
Tal y como se ha detallado anteriormente, el modelado del protocolo con autómatasde estados �nitos es fundamental para comprobar su funcionamiento. Ya que se necesitaanalizar trá�co en busca de determinados patrones de comportamiento, es necesariointroducir a la aplicación un almacén de datos con información acerca de los autómatasque modelan el protocolo. Es decir, el objetivo es proporcionar al programa la descripciónde los autómatas de�nidos previamente.Dicha información estará almacenada en un �chero. El principal motivo de ser una
entrada externa a la aplicación es la �exibilidad, ya que las modi�caciones sobre estosautómatas pueden ser continuas y variar con el paso del tiempo. De esta manera, se evitala potencial necesidad de modi�car el código fuente. Si no se proporcionaran de estamanera, sería una tarea tediosa realizar dichas modi�caciones.Para ello es necesario conocer en detalle el protocolo a analizar y poder derivar de él los
autómatas de estados �nitos correspondientes. Una vez se introduzca esta informaciónen el mencionado �chero (véase Sección 4.1.7), la aplicación construirá en memoria laestructura de estos autómatas y ya dispondrá de información su�ciente como para evaluarel trá�co de entrada.
Programa principal
La funcionalidad básica del programa principal es tomar toda la información de la quedispone en los bloques de entrada, construir los autómatas que se le indican y analizarel trá�co para, �nalmente, mostrar una salida con determinados resultados.
Figura 3.42: Estructura principal del programa.
61

3. Análisis
En base al trá�co proporcionado, este bloque también debe clasi�car los �ujos deinformación reconocidos. Un �ujo es el intercambio de datos entre dos determinadasentidades (peers en este caso) durante un tiempo. A grandes rasgos, el programa principaltomará todo el trá�co y lo clasi�cará en �ujos de información en base a las característicaspropias de una conexión, estas son, IP y puerto origen y destino. Dado que durante unaconexión pueden haber varios �ujos, se utilizarán parámetros adicionales para distinguirentre ellos. Como en el protocolo UDP no existen conexiones, el programa principalutilizará otros criterios para poder detectar los �ujos de información, como se explicarámás adelante.En su labor de análisis del trá�co (parsing) el programa principal puede mostrar, para
cada �ujo analizado, uno de los siguientes resultados:
� El �ujo de información está siguiendo un comportamiento esperado, ya que se halogrado modelar mediante uno de los autómatas de�nidos. Por tanto, se mostraráun mensaje indicando que el �ujo responde a un autómata.
� No existe de�nido ningún autómata que sea capaz de modelar la información conte-nida en el �ujo que se está examinando. Por tanto, es posible que no estén todos losautómatas que modelan el protocolo, o bien que sí estén todos pero que no logrenexplicar adecuadamente el �ujo observado. Se mostrará un mensaje indicando queel �ujo analizado no se ha reconocido.
� Es posible que un �ujo de datos esté incompleto, y que le falte muy poca informaciónpara ser modelado mediante un autómata pero que, por alguna razón, este �ujoestá truncado. Esto se re�ejará en la aplicación mostrando un mensaje de autómataincompleto. Se considera que un autómata está incompleto cuando se reconocenmás del 80% de los estados, pero no en su totalidad. Este umbral es simplementeorientativo y puede ser con�gurable por el usuario.
Salida
El bloque de salida es el que toma los resultados que proporciona el programa principalacerca del trá�co analizado. Este bloque representa de forma esquematizada los �ujosdetectados en el trá�co analizado, su correspondencia con autómatas de�nidos y unasestadísticas globales acerca de las detecciones realizadas.Más concretamente, la información mostrada detallará todas las propiedades de todas
las conexiones detectadas con sus �ujos de información asociados: IP origen, IP destino,puerto origen y puerto destino; también mostrará la información que se ha intercambiadoentre los dos peers a lo largo de esa conexión y, por último, si el �ujo de informaciónha sido reconocido en base a los autómatas introducidos en el archivo de datos de en-trada. Asimismo, muestra unas estadísticas sobre el porcentaje de �ujos reconocidos, noreconocidos e incompletos.Por tanto, es el bloque que muestra las conclusiones acerca de toda la tarea realiza-
da por el programa principal y es el encargado de clasi�car los �ujos en acordes a laespeci�cación de autómatas o no.
62

3. Análisis
3.3. Discusión del análisis
Tras el estudio del protocolo `eDonkey', así de como el de la extensión proporcionadapor `eMule', se ha propuesto un modelado para los diferentes escenarios posibles en dichoprotocolo.Dichos escenarios corresponden a diálogos tanto TCP como UDP entre clientes y servi-
dores. Como se comentó anteriormente, los autómatas representan partes o interaccionesentre dos determinados peers que usan el protocolo. Por tanto, es necesario establecer unalineamiento entre los eventos que tienen lugar en un �ujo de información y los autómatasasociados.Un autómata sucede a otro. Es decir, todos los autómatas están unidos mediante algún
punto común. Por ejemplo, el realizado para el establecimiento de conexión entre cliente yservidor (que ya recogía tres posibles escenarios) le sucede el que representa los mensajesintercambiados al inicio de la conexión entre el mismo cliente y servidor. La razón desepararlos es por motivos de complejidad y escalabilidad.Es necesario tener en cuenta que el comportamiento del protocolo va variando con el
tiempo, y con él, van surgiendo nuevas versiones que proporcionan nuevos escenarios omodi�can los ya existentes. Si fuera necesario añadir nuevos autómatas, en esta situaciónsería sencillo. Sin embargo, si se uni�ca todo en un gran autómata general, la tarea seríamucho más compleja.Una buena propuesta para no tener que actualizar la aplicación sería un nuevo mó-
dulo que sea capaz de generar automáticamente modelados en base a la observacióndel comportamiento del protocolo. Pero sería necesario hacer distinción de lo que es uncomportamiento correcto y uno anómalo mediante el aprendizaje de la aplicación en unentorno controlado en el que solamente se produzcan diálogos libres de anomalías, yaque, si no fuera así, cualquier comportamiento sería susceptible de ser catalogado comonormal.
63

3. Análisis
64

Capıtulo 4Diseño e implementación
En este capítulo se detalla la arquitectura de la aplicación, así como de su estructura enmódulos y los elementos necesarios para construirlos. Está destinado a explicar detallesde la implementación y diseño del software.
4.1. Estructura modular de la aplicación
Una vez se ha propuesto el modelado mediante autómatas de estados �nitos en elCapítulo 3 para los diferentes escenarios, en esta sección se analiza la estructura detalladade la aplicación, así como las principales di�cultades en su diseño, para poder de�nirlas soluciones propuestas. Más concretamente, se detallan cada una de las partes delprograma principal, bloque fundamental de�nido en la Sección 3.2.Para conseguir implementar el modelado del protocolo `eDonkey' y comprobar su co-
rrecto funcionamiento, el programa principal debe tener una estructura muy de�nida ybasada en módulos, para proporcionar al núcleo información su�ciente para cumplir losrequisitos propuestos.Dichos módulos y estructuras se dividirán en las siguientes categorías:
� Módulo de preprocesamiento.
� Módulo de detección de �ujos.
� Almacén/clasi�cador de �ujos.
� Módulo de extracción y análisis de �ujos.
De esta manera, se utilizará la estructura mostrada en la Figura 4.1, en la cual sedetalla en profundidad la estructura interna del programa principal.Como se muestra en la Figura 4.1, la aplicación principal está dividida en una serie de
módulos. Los módulos de preprocesamiento y detección de �ujos se ejecutan para cadatrama analizada, mientras que el módulo de extracción y análisis lo hace paralelamenteal resto. Dichos módulos se detallan a continuación.
65

4. Diseño e implementación
Figura 4.1: Estructura en módulos del programa principal.
4.1.1. Preprocesamiento
Este módulo es el encargado de tomar como entrada el trá�co que le proporciona elsensor de manera externa. En esta primera fase se preparan las tramas antes de enviarlasal siguiente módulo.La misión principal del módulo de preprocesamiento es realizar un �ltrado en el que
solamente pasan tramas útiles de cara al análisis. Este tipo de tramas son aquellas quecontienen segmentos TCP y UDP. De esta manera, se ahorra carga computacional a otrosmódulos, ya que el trá�co entrante está siendo limitado a aquel que contiene informaciónrelevante para su análisis.Este módulo también realiza una distinción de las tramas que tienen carga útil (pay-
load) con las que no, ya que pueden ser interpretadas de manera errónea por el módulode detección de �ujos.Por tanto, el módulo de preprocesamiento examina tanto las cabeceras de las tramas
entrantes para poder �ltrarlas en base a una determinada regla establecida (en este caso,segmentos TCP y UDP), así como la carga útil de dichas tramas, para descartar aquellasque no tengan un tamaño acorde con el esperado.
4.1.2. Detección de �ujos
El módulo detector de �ujos es uno de los más importantes y es donde reside unade las partes más importantes de la aplicación. Es el encargado de clasi�car las tramasrecibidas por el módulo de preprocesamiento en �ujos de información en base a algunaconexión entre dos peers. Clasi�car estos �ujos no es una tarea sencilla ya que existendeterminados escenarios que es necesario contemplar.Por tanto, los escenarios contemplados son los siguientes:
� Que en una conexión entre dos peers se produzcan varios �ujos de información.Por ejemplo, un cliente y un servidor pueden intercambiar, durante una mismaconexión, varios �ujos pertenecientes a búsquedas de archivos.
66

4. Diseño e implementación
� Que se produzcan varias conexiones en paralelo, ya que el sensor puede proporcionarinformación de varias fuentes al mismo tiempo.
� Que un mensaje `eDonkey' esté separado en varias tramas.
� Que una trama contenga más de un mensaje del protocolo.
El módulo de preprocesamiento detallado anteriormente, ayuda a la detección de �ujosmediante una tarea adicional. Esta es la de noti�car la �nalización de un �ujo, por haber�nalizado la conexión entre dos peers. Esto lo realiza mediante la recepción de segmentosTCP cuyo bit de cabecera FIN esté activo. En ese caso, signi�cará la �nalización de unaconexión y, por tanto, de su �ujo (o �ujos) asociado (nótese que, como se detalló en 2.2,dentro de ese �ujo aparente pueden existir varios de ellos). En este momento envía almódulo de extracción y análisis dicho �ujo para su examen. Mediante esta tarea, se evitaenviar al módulo de extracción y análisis trá�co innecesario ya que, debido a que se hadetectado el �nal de un �ujo, evita realizar esta tarea al módulo siguiente. Esto es sóloaplicable al protocolo TCP. Para el UDP se utilizará el procedimiento de �ujos �antiguos�detallado en 4.1.4.El módulo de detección de �ujos resuelve la tarea de separar los mensajes intercam-
biados entre dos peers y clasi�carlos en �ujos. Sin embargo, no contempla que, dentrode la conexión analizada, pueden existir varios �ujos de información, como se explicóanteriormente. Por lo que dentro de lo que en este módulo se considera un �ujo, puedenexistir realmente varios de ellos. Pero este problema lo resuelve el módulo de extraccióny análisis, como se explicará más adelante.Como estas situaciones anteriores, pueden producirse muchos casos, producto de las
combinaciones de trá�co proporcionadas por el sensor y de la actividad que tenga elprotocolo en un momento determinado. Es decir, numerosos mensajes de numerosas co-nexiones pueden aparecer entremezclados. Por tanto, la detección de �ujos de informaciónno es una tarea sencilla. La detección de �ujos sigue los siguientes pasos:
1. En el caso del protocolo `eDonkey', los mensajes intercambiados entre los peerstienen un campo �protocolo�, el cual almacena una determinada información carac-terística del protocolo. En protocolo `eDonkey', dicho campo toma el valor 0xE3.Como se ha visto en el Capítulo 3, `eMule' proporciona una serie de funcionalidadesadicionales al protocolo `eDonkey'. Los mensajes pertenecientes a estas extensionestoman el valor 0xC5 en el campo �protocolo� mencionado.Por tanto, las tramas recibidas del módulo de preprocesamiento son examinadas enbusca de características propias del protocolo P2P que se está analizando. En estecaso, se busca que el campo �protocolo� tome los valores mencionados. En ciertomodo, este paso realiza un �ltrado de las tramas que únicamente pertenecen alprotocolo analizado.
2. Para cada una de las tramas seleccionadas, se buscan en ellas los rasgos caracterís-ticos de una determinada conexión, es decir, la IP origen y destino, y los puertosorigen y destino. Para ello, se accede a la cabecera de dichas tramas, en busca dela información mencionada.
67

4. Diseño e implementación
3. Una vez llegado a este punto, se puede crear una estructura de datos que almaceneun �ujo de información, ya que se dispone de datos su�cientes. A este �ujo se leañade una marca de tiempo, que se corresponde con el instante en el que se recibióel primer paquete de dicho �ujo entre los dos peers.Las tramas llegadas hasta este punto (las pertenecientes a `eDonkey' o su extensión`eMule') poseen un campo �tipo� que almacena una cifra en hexadecimal que indicaqué tipo de mensaje es (establecimiento de conexión, búsqueda de archivos, etc.).La información contenida en este campo se añadirá a la estructura de datos queconforma un �ujo de información.El campo �tipo� puede aparecer más de una vez dentro de la misma trama. En esecaso se añadirá, de la misma manera que se indicó anteriormente, a la estructurade datos que almacena información acerca del �ujo.
4. Por último, se busca en el almacén/clasi�cador global si existe algún �ujo de in-formación con las mismas características del obtenido en el paso 3 (mismas IP ymismos puertos). En caso a�rmativo, signi�ca que ya existía una conexión idéntica,por lo que los datos obtenidos en el paso 3 son datos nuevos pertenecientes a unaconexión que ya estaba contemplada. Por tanto, todos los campos �tipo� recopila-dos en el paso anterior, se añaden junto con los ya existentes en la estructura dedatos dentro del almacén/clasi�cador de �ujos.En caso contrario, signi�ca que se han obtenido datos de una conexión nueva, porlo que se añade un �ujo nuevo al almacén/clasi�cador de �ujos.
El problema de detectar varios sub�ujos dentro de un �ujo de información concreto se re-suelve como se explica a continuación. Cuando se extrae un �ujo del almacén/clasi�cador,se envía a analizar (parsing) como se verá más adelante. Si el módulo de extracción yanálisis, al comparar el �ujo con los autómatas, llega a un estado �nal sin haber termi-nado de examinar todos los mensajes del �ujo, entonces se entiende que dentro de ese�ujo había otro más pequeño, por lo que el resto de mensajes que no se han examinadose vuelven a incluir en el almacén/clasi�cador.
4.1.3. Almacén/clasi�cador de �ujos
El almacén/clasi�cador de �ujos es una estructura de datos global a toda la aplicación.Su funcionalidad básica es servir de almacén para los �ujos que le proporciona el módulode detección de �ujos.Es un contenedor en el que se almacenan estructuras de datos que se corresponderían
con contenido acerca de conexiones y �ujos de información. Aunque puedan analizarsevarios �ujos simultáneamente, hay que tener en cuenta que esta estructura es global atoda la aplicación, por lo que habrá que tomar precauciones para evitar problemas deinconsistencia, como se verá más adelante.Este almacén/clasi�cador es utilizado por dos módulos, ya que el de detección de �ujos
inserta nuevos elementos, mientras que el módulo de extracción y análisis, como su propionombre indica, extrae �ujos para posteriormente analizarlos.
68

4. Diseño e implementación
4.1.4. Extracción y análisis
El último de los módulos es el de extracción y análisis, que lleva a cabo la tarea decomparar los �ujos del almacén/clasi�cador con la estructura de autómatas existente enla aplicación. Denominamos a esta tarea como parsing.Para cumplir esta funcionalidad, este módulo debe considerar cuándo un �ujo está
listo para ser analizado, por lo que se plantea el problema de saber si una conexiónse da por terminada o, por el contrario, va a seguir añadiendo información al �ujo delalmacén/clasi�cador.Para resolver este problema, este módulo extrae los �ujos considerados como �antiguos�
y los analiza. Un �ujo se considera �antiguo� cuando lleva un determinado tiempo sinactualizarse. Este tiempo es con�gurable y por defecto está establecido a 5 segundos. Poreste motivo, todos los �ujos del almacén/clasi�cador llevan una marca de tiempo.El criterio utilizado para la consideración de �ujos �antiguos� se detalla a continuación,
aunque se plantean dos problemas principales:
1. Como se explicó anteriormente, el sensor puede proporcionar trazas de trá�co tantode un �chero estático como de una captura en vivo, procedente de una interfaz dered.El análisis de un �chero almacenado en disco se lleva a cabo relativamente rápido sies comparada con una captura en vivo. En esta última, no se puede saber a prioricon qué velocidad se van a capturar las tramas, puesto que la actividad entre dosdeterminados peers en una conexión depende en parte del usuario, ya que puedeprovocar voluntariamente una determinada actividad.Por ejemplo, puede existir una conexión entre cliente y servidor abierta durantemucho tiempo y, sin embargo, no existir ningún tipo de actividad.
2. Es necesario considerar que una conexión entre dos peers puede haber �nalizado yla aplicación no ser consciente de ello, debido a que el tipo de conexión sea UDP,puesto que nunca se recibe una trama de �nalización de conexión, como se explicóen la Sección 2.2.
En ambos casos es importante considerar el criterio de �ujo �antiguo�: Se establece unavariable global que indica un umbral de tiempo máximo. Si un �ujo lleva sin actualizarseigual o más tiempo del indicado en este umbral, se considera una conexión terminada,por lo que se extrae del almacén/clasi�cador y se analiza. Para proporcionar �exibilidada la aplicación, este umbral puede ser modi�cado sin repercutir negativamente en otrosmódulos.Por tanto, la tarea principal del módulo de extracción y análisis es examinar el al-
macén/clasi�cador en busca de �ujos antiguos. Cuando encuentre un �ujo apto para serexaminado, lo extrae del almacén/clasi�cador y proceda a su análisis.
4.1.5. Justi�cación de los módulos
La estructura modular de la aplicación está diseñada de manera que aporte �exibilidad.Los módulos podrían modi�carse sin excesiva di�cultad con el objetivo de ser útiles en
69

4. Diseño e implementación
el análisis de otros protocolos.El módulo de preprocesamiento realiza un �ltrado de tramas y libera de carga al núcleo
de la aplicación, por lo que su funcionalidad se hace evidente.El módulo de detección de �ujos es fundamental a la hora de encontrar, parcialmente,
los �ujos de información dentro de varias conexiones.El almacén/clasi�cador es una estructura intermediaria entre dos módulos. Es esencial
disponer de una estructura de este tipo para poder almacenar información acerca de los�ujos y conexiones detectadas.Por último, el módulo de extracción y análisis realiza la tarea �nal, en la que extrae
�ujos según un determinado criterio y realiza el parsing de estos, proporcionando unosresultados ya visibles.
4.1.6. Diseño global de la implementación
El programa se ha diseñado de manera multihebrada. Es posible ejecutarlo para varios�cheros e interfaces de red al mismo tiempo, los cuales se analizarán concurrentementepara, �nalmente, mostrar un resultado global. Por cada �chero con trazas o interfaz aanalizar, se crea una hebra inicial que se encarga de procesar su información por separado.En la aplicación, la estructura del almacén/clasi�cador de �ujos es global a todas lashebras. Sin embargo, el módulo de preprocesamiento y parte del de detección de �ujoslos ejecutan cada hebra independientemente de las demás. El motivo de esto es que unaparte del módulo de detección de �ujos accede al almacén/clasi�cador como se puede veren la Figura 4.1. Como esta es una estructura global, es necesario controlar las hebraspara no crear problemas de inconsistencia.Debido al diseño multihebrado, es necesario considerar el problema de la exclusión
mutua, ya que existen secciones críticas que pueden ser ejecutadas por varias hebras ala vez, pudiendo producir un resultado inconsistente. La sección crítica sería, en estecaso, los accesos al almacén/clasi�cador de tramas, ya que está siendo actualizado pormúltiples hebras que analizan los módulos de entrada.Por tanto, es necesario garantizar que no se produce un acceso simultáneo al alma-
cén/clasi�cador de �ujos por varias hebras. Mediante el uso de mutexes de la biblioteca`Pthread' (véase Sección 2.4.3) se logra este objetivo.Al mismo tiempo que la ejecución del módulo de preprocesamiento y detección de
�ujos, existe inicialmente otra hebra independiente que ejecuta el módulo de extraccióny análisis de �ujos del almacén/clasi�cador. Esta hebra se encarga de revisar este al-macén/clasi�cador y comprobar periódicamente si existen �ujos �antiguos�. El problemade este modo de procesamiento es que podrían existir múltiples hebras añadiendo �ujosal almacén/clasi�cador mientras que sólo una se encargaría de la extracción y análisis;es decir, podría producir un desbordamiento del almacén/clasi�cador si aumenta de-masiado de tamaño. Esto se soluciona mediante otro diseño multihebrado: el hilo quecontrola el módulo de extracción y análisis comprueba periódicamente el tamaño delalmacén/clasi�cador; si el tamaño es mayor que un umbral establecido, genera otras he-bras que ayudan a liberar carga de la principal. Cuando estas hebras �nalizan su trabajo,mueren automáticamente y permanece la principal que controlaba este módulo.
70

4. Diseño e implementación
Esta solución multihebrada del módulo de extracción y análisis plantea nuevamenteun problema: el acceso en exclusión mutua al almacén/clasi�cador. Pero se soluciona dela misma manera que anteriormente, ya que se usan mutexes que garantizan la exclusiónmutua.
4.1.7. Formato del �chero de autómatas
Un usuario con algunas nociones acerca del funcionamiento de la aplicación podríaintroducir información acerca de nuevos autómatas, modi�car los ya existentes, o eliminaralguno de ellos. En de�nitiva, es capaz de manejar la información que tiene la aplicaciónacerca del protocolo.Para hacer posible esto, se ha de�nido un tipo de �lenguaje� en el que escribir los
autómatas. Estos residen en un �chero, el cual se puede editar para modi�car dichainformación.Las características principales de la sintaxis de este �chero son las siguientes:
� El carácter `%' indica un comentario. Se deben comentar líneas completas, siendoeste carácter el primero de la línea. No se admiten líneas en blanco en el �chero, yaque se entiende que no están comentadas y, por lo tanto, tienen algún signi�cado.
� Todos los estados que conforman todos los autómatas se consideran un solo conjuntoy siguen una numeración. Es decir, si se escribe un autómata con cinco estados, senumerarán 0, 1, 2, 3 y 4. Si luego se escribe otro autómata con tres estados, aunquesea independiente del anterior, la numeración de los estados será 5, 6 y 7. Y asísucesivamente.
� El �nal de línea se indica con el carácter `$' o bien con el carácter `*' si es el estado�nal, en el cual el autómata deberá llevar un nombre.
El formato de las líneas de descripción de un autómata es:
NUM_ESTADO S/N S/N [# CADENA NUM_ESTADO_DESTINO [# ... ]] $
[NOMBRE_AUTOMATA *]
1. NUM_ESTADO indica el número del estado. Por ejemplo, 0 o 1.
2. S/N indica si el estado es inicial o no, en el primer caso. En el segundo caso indicasi el estado es �nal o no.
3. # CADENA NUM_ESTADO_DESTINO indica la relación de transiciones. Es decir, hacereferencia a la cadena asociada a la transición y al número del estado al que setransita. Puede haber tantas cadenas como se desee. Se indica que no hay mástransiciones con $
4. NOMBRE_AUTOMATA indica el nombre del autómata. Es necesario indicarlo cuando elestado es �nal.
71

4. Diseño e implementación
Se muestra el proceso de creación del archivo de descripción del autómata representadoen la Figura 4.2.Si se quisiera escribir con la sintaxis indicada en este autómata, sería necesario seguir
los siguientes pasos:
� El estado q0 se nombrará como `0', suponiendo que sea el primer estado del �cherode autómatas. Si no es así, se continuará la numeración del último estado que hay.De la misma manera, el estado q1 se nombrará como `1' y el estado q2 se nombrarácomo `2'.
� Tras el número identi�cador del estado, se ha de indicar si los estados son inicialesy/o �nales. Por tanto, para el estado q0 se indicará `S' y `N' ya que es inicial y noes �nal. Para el estado q1 se indicará `N' y `N', ya que ni es inicial ni es �nal. Ypor último, para el estado q2 se indicará `N' y `S' ya que no es inicial y es �nal.
� Tras esto, se añaden unos separadores para indicar las posibles transiciones haciaotros estados. Para el estado q0, se añadirá el separador `#', ya que tiene unatransición hacia el estado q1. Para el estado q1 se añadirá el separador `#', ya quetiene una transición hacia el estado q2. Por último, para el estado q2 se añadirá elseparador `$', ya que no tiene transiciones hacia ningún otro estado.
� Tras indicar los separadores, es necesario mostrar las transiciones. Para el estadoq0, se debería indicar `AA 1' ya que, si recibe el mensaje `AA' transita al estadonumerado como `1'. Para el estado q2 se ha de indicar `BB 2', ya que, si recibeel mensaje `BB' transita al estado numerado como `2'. Para el estado q2 no seescribiría nada, ya que no tiene transiciones.
� El siguiente paso es indicar que los autómatas no tienen ninguna transición más.Para esto, en el estado q0 se escribirá el carácter `$' para indicar que no tiene mástransiciones. Para el estado q1 también se escribirá el carácter `$' por el mismomotivo.
� El último paso es indicar el nombre del autómata. Hasta este punto, las descrip-ciones de todos los estados terminan con el carácter `$'. Para el estado q2, que esel estado �nal, se ha de indicar el nombre. Para ello, tras el carácter `$' se escribeel nombre y se indica que el autómata llega a su �n con el carácter `*'.
El resultado �nal para el autómata de la Figura 4.2 sería un archivo con el siguientecontenido:
Figura 4.2: Autómata de ejemplo.
72

4. Diseño e implementación
% Sintaxis del autómata de la Figura 4.2
0 S N # AA 1 $
1 N N # BB 2 $
2 N S $ Ejemplo *
Se muestra ahora un ejemplo más complejo en la Figura 4.3.Se supondrá que el autómata de la Figura 4.3 se quiere añadir a continuación del
autómata de la Figura 4.2. Los pasos a seguir son:
� El estado q0 se nombrará como `3', ya que el último estado del autómata de laFigura 4.2 es el estado `2'. Siguiendo esta misma regla, los estados q1, q2 y q3 senumerarán como `4', `5' y `6' respectivamente.
� Los siguientes caracteres para los estados q0, q1, q2 y q3 serán `S N', `N N', `N N'y `N S' respectivamente, siguiendo la regla de estados iniciales y �nales.
� Los separadores para q0, q1, q2 y q3 son `#', `#', `# y `$' respectivamente, siguiendola norma del carácter añadido si tienen transiciones o no.
� Los siguientes caracteres para q0 serán: `AA 4', separador `#', `CC 6', separador`#', `DD 5', indicador de �n de transiciones `$'.
� Los siguientes caracteres para q1 serían: `BB 6', indicador de �n de transiciones `$'.
� Los siguientes caracteres para q2 serían: `EE 6', indicador de �n de transiciones `$'.
� El siguiente carácter para q3 sería: indicador de �n de transiciones `$'.
� Por último, en el estado �nal q3 se añadiría: `Ejemplo 2 *', para indicar el nombredel autómata y su �n.
El �chero resultante sería el siguiente:
Figura 4.3: Autómata de ejemplo.
73

4. Diseño e implementación
% Sintaxis del autómata de la Figura 4.2
0 S N # AA 1 $
1 N N # BB 2 $
2 N S $ Ejemplo *
%
%
%
% Sintaxis del autómata de la Figura 4.3
3 S N # AA 4 # CC 6 # DD 5 $
4 N N # BB 6 $
5 N N # EE 6 $
6 N S $ Ejemplo 2 *
Como se puede apreciar, es sencillo añadir autómatas nuevos en la especi�cación. Sóloes necesario continuar las numeraciones de los estados, y añadir, para cada uno de ellos,sus propiedades y transiciones en una sola línea.
4.2. Descripción de las estructuras de datos utilizadas
En base a la Figura 4.1, la aplicación está construida mediante diversos módulos deprocesamiento, cada uno de ellos destinado a realizar una tarea independiente. El diseñoespecí�co de la aplicación se corresponde con el detallado en los siguientes apartados.
4.2.1. Diseño de los estados de los autómatas
Los autómatas de estados �nitos están divididos en uno o más estados. Como se explicóen 2.1, se puede transitar de un estado a otro teniendo en cuenta una serie de palabrasaceptadas. Para realizar el diseño de los estados que componen un autómata, se ha de�ni-do una clase a tal efecto. La clase `estado' es la base del funcionamiento de la aplicación.Agrupa todas las funciones para el manejo de estados de un autómata. Un estado seconsidera un conjunto de elementos y está diseñado, en base a sus funcionalidades, de lasiguiente manera:
� Un identi�cador (un número entero) único globalmente. Es decir, dado un identi�-cador, se puede conocer con certeza a qué estado pertenece.
� Una variable booleana que indica si el estado es inicial.
� Una variable booleana que indica si el estado es �nal.
� Un nombre que proporciona una descripción de ese estado (una cadena de carac-teres).
� Un puntero a una estructura `mensaje' (se detalla a continuación).
74

4. Diseño e implementación
� Una estructura `mensaje', la cual indica las posibles transiciones que tiene un estadohacia otros estados y los motivos por los cuales transitaría. Dicha estructura estácompuesta por:
� Un motivo por el cual transitaría a otro estado (una cadena de caracteres). Eneste caso, un motivo es la recepción de determinados mensajes en el protocolo.
� Un puntero a otro mensaje siguiente (puede haberlo o no).
� Un puntero hacia el estado al cual transitaría en el caso de que se veri�quenciertas condiciones relacionadas con un determinado mensaje.
Lo que se implementa es una lista enlazada con los diferentes mensajes que puedenaparecer en cada estado. De forma esquemática, un estado se asemeja a la estructuramostrada en la Figura 4.4.A continuación se muestran una serie de ejemplos para ilustrar el funcionamiento de
la clase `estado'.
� Ejemplo 1: Se muestra un autómata con un solo estado. En la Figura 4.5 se muestrael autómata en cuestión y en la Figura 4.6 se muestra la correspondencia de dichoautómata con la estructura de datos utilizada.
� Ejemplo 2: Autómata con un solo estado. Acepta un número indeterminado demensajes identi�cados con el tipo `44' (Figuras 4.7 y 4.8).
� Ejemplo 3: Autómata con tres estados (Figura 4.9). Se muestra el objeto `estado'para el estado q0 en la Figura 4.10.
Figura 4.4: Esquema de un objeto de la clase `estado'.
Figura 4.5: Autómata con un estado.
75

4. Diseño e implementación
Figura 4.6: Objeto `estado' para el estado de la Figura 4.5..
Figura 4.7: Autómata con un estado.
Figura 4.8: Objeto `estado' para el estado de la Figura 4.7.
Figura 4.9: Autómata con tres estados.
76

4. Diseño e implementación
Figura 4.10: Objeto `estado' para el estado de la Figura 4.9.
Los métodos que se implementan en esta clase se detallan en el Apéndice A.
4.2.2. Diseño de los autómatas
Como se explicó en la Sección 2.1, un autómata está formado por uno o más estados.En base a la especi�cación de los autómatas indicada en el archivo de entrada del progra-ma principal, pueden existir cero o más autómatas en la aplicación. La clase `automatas'alberga todos los que se han de�nido. Es decir, esta clase contendrá un conjunto de es-tados entrelazados entre sí mediante punteros. Es por esto que la clase `estado' es unageneralización de `automatas' o, dicho de otra manera, se dice que la clase `automatas'hereda (o es una especi�cación) de la clase `estado'. El motivo de esto es, como se ha ex-plicado, que la clase `automatas' está compuesta por un número determinado de estados.Por tanto, esta clase debe tener conocimiento de cómo es un objeto `estado', así como detodas sus funciones, para poder manejarlo con otras funciones más especí�cas y poderproporcionar un nivel de encapsulado mayor.Una instanciación de la clase `automatas' está compuesta simplemente por un vector
dinámico, en el que cada casilla alberga un objeto `estado'. El desplazamiento de unestado a otro mediante los punteros que se encuentran dentro de sus mensajes equivaldríaa moverse a través de las casillas de este vector dinámico.Por tanto, con un objeto de la clase `automatas' se puede representar por completo un
conjunto de autómatas reales y comprobar su funcionamiento.Los métodos pertenecientes a esta clase se detallan en el Apéndice A.
4.2.3. Diseño de un �ujo de información
Como se explicó en la Sección 2.2, una conexión entre dos peers se identi�ca median-te cuatro elementos: Las IP origen y destino y los puertos origen y destino. La clase`datosFlujo' se basa en la existencia de �ujos de información dentro de una conexiónentre cliente y servidor, o bien entre dos clientes. En el protocolo UDP, también existenestas características, pero no se necesita un establecimiento de conexión previo ni una�nalización como ocurre en el contexto TCP. Por tanto, la estructura de datos es igual-mente válida para los dos protocolos. Mediante estos �ujos, los peers intercambian ciertacantidad de información relacionada con el protocolo.
77

4. Diseño e implementación
La clase `datosFlujo' incluirá la información de dichos �ujos, junto con otra añadida yaque, como se explicará más adelante, es necesario tener en cuenta el momento en el queocurren cambios en el �ujo de información y qué información se está intercambiando.Por lo tanto, esta clase tendrá los siguientes elementos:
� Una cadena de caracteres donde se almacenará la IP origen.
� Una cadena de caracteres donde se almacenará la IP destino.
� Un número entero indicando el puerto origen.
� Un número entero indicando el puerto destino.
� Una variable en coma �otante de doble precisión para indicar el momento (times-tamp) en el que suceden cambios en un determinado �ujo de información. Estoscambios se re�eren a la adición de información nueva a un objeto de esta clase; enel momento en el que se añada algún dato nuevo, se considerará que se ha produci-do un cambio y se actualizará el timestamp. Esta variable es útil para determinarcuándo un �ujo es �antiguo� y puede ser analizado.
� Un vector de cadenas de caracteres en el que se almacenará, con el paso del tiem-po, la información intercambiada entre dos peers dentro de la misma conexión, esdecir, contendrá determinados datos del protocolo. Estos datos son los tipos de losmensajes intercambiados.
Por tanto, la estructura de un objeto de la clase `datosFlujo' será la de la Figura 4.11.Los métodos pertenecientes a esta clase se detallan en el Apéndice A.
4.2.4. Diseño del almacén/clasi�cador de �ujos
Como en el trá�co proporcionado por el sensor es muy probable que existan nume-rosas conexiones (y por tanto, numerosos �ujos de información), es necesario un alma-cén/clasi�cador de �ujos global que almacene toda esta información. La clase `clasi�ca-dorFlujos' se ha diseñado con tal �n, ya que es capaz de almacenar un conjunto de objetosde la clase `datosFlujo'. Es decir, la clase `clasi�cadorFlujos' tiene una sola variable miem-bro, consistente en un vector dinámico (es decir, que varía su tamaño dinámicamente)en el que en cada casilla almacena un objeto de la clase `datosFlujo'.Esto explica la herencia entre estas dos clases: la clase `datosFlujo' es una generali-
zación de la clase `clasi�cadorFlujos', ya que esta última está formada por un númerodeterminado de objetos de la clase `datosFlujo'. Por ello, es necesario que sepa manejarlos,conozca todas sus funciones y sus variables miembro, ya que va a necesitar modi�carlospara darle una estructura de un almacén/clasi�cador aparente, y mostrar un mayor gradode encapsulado y simplicidad a la hora de utilizar un objeto de esta clase.También existe una relación de agregación de composición entre la clase `autómatas'
y la clase `clasi�cadorFlujos', ya que la primera está compuesta de elementos de la clase`clasi�cadorFlujos', aunque sólo está formado por uno.Es decir, la relación básica entre las clases sería la mostrada en la Figura 4.12.
78

4. Diseño e implementación
Figura 4.11: Estructura de un objeto de la clase `datosFlujo'.
Figura 4.12: Relaciones entre las clases diseñadas.
4.2.5. Diagrama de clases
Partiendo de las estructuras de datos detalladas anteriormente, se puede elaborar undiagrama completo que muestre los métodos y las relaciones entre las clases. En la Figura4.13 se muestra el diagrama detallado el cual representa la elaboración de clases dentro dela aplicación que se ha desarrollado. En él se pueden distinguir varios elementos: las clasesdiseñadas, las relaciones entre ellas, las variables miembro y los métodos implementadosen cada una de ellas.Existen dos relaciones de herencia principales, las cuales se ven re�ejadas en el diagrama
de clases de diseño:
� La primera de ellas es una generalización de la clase `automatas' a la clase `es-tado' y la segunda es una generalización de la clase `clasi�cadorFlujos' a la clase`datosFlujo'.
� La segunda de las relaciones es una agregación de composición, o solamente com-posición entre la clase `clasi�cadorFlujos' y `automatas'. El motivo de eso es quela clase `automatas' está compuesta por elementos del tipo `clasi�cadorFlujos'. Lamultiplicidad de los extremos indica que debe existir un objeto de la clase `au-tomatas' para que exista un objeto de la clase `clasi�cadorFlujos', y sólo existiráuno.
79

4. Diseño e implementación
Figura 4.13: Diagrama de clases de diseño para la aplicación desarrollada.
80

Capıtulo 5Evaluación
El objetivo de este capítulo es comprobar el buen funcionamiento de la aplicación. Paraello, primero se muestran una serie de pruebas a ejecutar, que veri�carán su buen fun-cionamiento. Por último, se realizarán pruebas para medir la velocidad y el rendimeintode la aplicación.
5.1. Diseño de las pruebas de evaluación
Con el objetivo de facilitar la evaluación de la aplicación, se han elaborado una seriede �chas de pruebas para la aplicación, las cuales se detallan a continuación.Las pruebas se han diseñado de manera que pueda probarse las funcionalidad de la
aplicación. Por ello, se comienza con pruebas simples para avanzar en pruebas de mayorcomplejidad, que requieran más carga computacional.Con las pruebas propuestas se pretende evaluar el buen funcionamiento de la aplicación,
es decir, comprobar que, para una serie de �cheros con trazas de trá�co, es capaz dereconocer �ujos de información acordes con la especi�cación de autómatas introducida.En las pruebas propuestas se muestra la con�guración del �chero de autómatas y se
introducirán �cheros con trazas de trá�co, adquiridos en situaciones controladas, por loque también se detallará el resultado esperado. Asimismo, se muestra el contenido de los�cheros con trazas de trá�co, para poder comprender mejor los resultados obtenidos.Es muy importante destacar que las versiones de los autómatas realizados son una
mera referencia, puesto que la versión indicada puede no coincidir con la actual. Laespeci�cación de autómatas está escrita para versiones del cliente `eMule' del año 2008,aunque también incluye algunas del año 2009.Los �cheros de prueba son los siguientes:
1. 1-establecimiento_conexion.pcap.
2. 2-buscar.pcap.
3. 3-cliente_cliente.pcap.
81

5. Evaluación
4. 4-de_todo.pcap.
En la Figura 5.1 se muestra una tabla con un resumen estadístico de los �cheros deprueba.
5.1.1. Ficheros de trazas
Son �cheros con trazas de trá�co que se han obtenido en determinadas situaciones.Para ello, se ha hecho uso de la aplicación `wireshark' y `eMule' (véase Capítulo 2).
Fichero 1
Este �chero contiene los mensajes intercambiados entre dos peers cliente y servidor,los cuales realizan un establecimiento de conexión.En la Figura 5.2 se muestran las estadísticas del uso de protocolos en el �chero. En
este �chero existen �ujos asociados con el establecimiento de conexión entre un cliente yun servidor.
Fichero 2
El segundo de los �cheros de prueba se corresponde con el trá�co producido entre uncliente y un servidor con motivo de una búsqueda de archivos, por lo que existirán �ujosasociados con las búsquedas de archivos. En la Figura 5.3 se muestran estadísticas en eluso de protocolos.
Fichero Paquetes capturados Tiempo entre el primery el último paquete
Bytes totalestransmitidos
1 18 0.368 s. 23062 4 2.161 s. 3453 180 2.560 s. 199844 4959 232.919 s. 1672320
Figura 5.1: Estadísticas generales de los �cheros de prueba.
Figura 5.2: Estadísticas del uso de protocolos para el �chero de pruebas nº1.
82

5. Evaluación
Figura 5.3: Estadísticas del uso de protocolos para el �chero de pruebas nº2.
Fichero 3
El tercer �chero corresponde con el trá�co producido en una conexión entre dos clientes.Es algo más complejo, puesto que contiene más cantidad de trá�co que los ejemplosanteriores. En él existen �ujos asociados a la conexión entre dos clientes, como puede serhandshakes iniciales. En la Figura 5.4, al igual que en los ejemplos anteriores, se muestralas estadísticas del uso de protocolos.
Fichero 4
Para �nalizar, el último de los �cheros contiene una gran cantidad de trazas de trá�co,ya que contiene mensajes de todo tipo, tanto de cliente-cliente, como de cliente-servidor,por lo que existen �ujos de todo tipo, estos pueden ser, establecimiento de conexión,secuencia de inicio de conexión, etc. En la Figura 5.5 las estadísticas del uso de protocolos.
5.1.2. Prueba 1
La prueba se realizará con el �chero nº2. El archivo de descripción de autómatascontiene el autómata correspondiente a �Búsqueda de archivos� mostrado en la Figura5.6, por lo que el contenido del �chero es el siguiente:
Figura 5.4: Estadísticas del uso de protocolos para el �chero de pruebas nº3.
83

5. Evaluación
Figura 5.5: Estadísticas del uso de protocolos para el �chero de pruebas nº4.
Figura 5.6: Autómata correspondiente a �Búsqueda de archivos�.
% Búsqueda de archivos
0 S N # 16 1 $
1 N N # 33 2 $
2 N S $ Busqueda de archivos *
%
Como se puede ver, en la especi�cación de autómatas se ha incluido informaciónsu�ciente como para que el contenido del �chero de trazas sea reconocido, por lo que seespera que se reconozcan todos los �ujos.
5.1.3. Prueba 2
En esta prueba se incluirán en la especi�cación de autómatas algunos nuevos. Estosson, �Establecimiento de conexión�, �Secuencia de inicio de conexión� y �Búsqueda dearchivos�. Se ejecutará con el �chero nº1. Los autómatas introducidos son en el �cherode especi�cación son los mostrados en las Figuras 5.7, 5.8 y 5.9, por lo que el contenidodel �chero es el siguiente:
Figura 5.7: Autómata correspondiente a �Establecimiento de conexión�.
84

5. Evaluación
Figura 5.8: Autómata correspondiente a �Secuencia de inicio de conexión�.
Figura 5.9: Autómata correspondiente a �Búsqueda de archivos�.
% Establecimiento de conexión
0 S N # 01 1 $
1 N N # 40 2 $
2 N N # 34 3 $
3 N S $ Establecimiento de conexion *
%
%
% Secuencia de inicio de conexión
4 S N # 14 5 $
5 N N # 32 6 $
6 N N # 41 7 $
7 N S $ Secuencia de inicio de conexion *
%
%
% Handshake inicial
8 S N # 01 9 $
9 N N # 4C 10 $
10 N S $ Handshake inicial * %
%
Según la especi�cación indicada, el resultado esperado es que se reconozcan todoslos �ujos que existe en las trazas de trá�co, ya que la especi�cación de los autómatassupuestamente incluye información su�ciente.
5.1.4. Prueba 3
Se tomará el �chero de pruebas y la misma especi�cación de autómatas que en laPrueba 2, con una modi�cación, ya que en el �chero de trazas de trá�co se borrará unode los mensajes. Este mensaje será aquel que contiene los mensajes con campo �tipo� conlos valores `32' y `41' correspondientes a la Figura 5.8. El resultado esperado es que el�ujo correspondiente a este autómata no se reconozca. No se mostrará como incompletoporque no se cumple el requisito de reconocer el 80% de los mensajes.
85

5. Evaluación
5.1.5. Prueba 4
En esta prueba se utilizará también el mismo procedimiento que en la Prueba 3, peroen este caso se desea comprobar el reconocimiento de los �ujos incompletos.En el código fuente está indicado que un autómata se considera incompleto cuando
se reconocen más del 80% de los estados. Para poder probar esto, este dato sufrirá unamodi�cación y se disminuirá al 30%. De esta manera, el �ujo que en la Prueba 4 no sereconocía, ahora se espera que se muestre como incompleto, en lugar de no reconocido.
5.1.6. Prueba 5
Ahora la especi�cación de autómatas es algo más completa, ya que su contenido será elmostrado en las Figuras 5.10, 5.11, 5.12, 5.13, 5.14 y 5.15. Los autómatas añadidos hansido �Búsqueda de archivos�, �Nueva secuencia de inicio de conexión� y �Ofrecer �cheros�.Por tanto, el contenido del �chero es el siguiente:
Figura 5.10: Autómata correspondiente a �Establecimiento de conexión�.
Figura 5.11: Autómata correspondiente a �Secuencia de inicio de conexión�.
Figura 5.12: Autómata correspondiente a �Búsqueda de archivos�.
Figura 5.13: Autómata correspondiente a �Handshake inicial�.
86

5. Evaluación
Figura 5.14: Autómata correspondiente a �Nueva secuencia de inicio de conexión�.
Figura 5.15: Autómata correspondiente a �Ofrecer �cheros�.
% Establecimiento de conexión
0 S N # 01 1 $
1 N N # 40 2 $
2 N N # 34 3 $
3 N S $ Establecimiento de conexion *
%
%
% Secuencia de inicio de conexión
4 S N # 14 5 $
5 N N # 32 6 $
6 N N # 41 7 $
7 N S $ Secuencia de inicio de conexion *
%
%
% Búsqueda de archivos
8 S N # 16 9 $
9 N N # 33 10 $
10 N S $ Busqueda de archivos *
%
%
% Handshake inicial
11 S N # 01 12 $
12 N N # 4C 13 $
13 N S $ Handshake inicial *
%
%
% Nueva secuencia de inicio de conexión
14 S N # 38 15 $
15 N N # 14 16 $
16 N N # 32 17 $
87

5. Evaluación
17 N N # 41 18 $
18 N S $ Nueva secuencia de inicio de conexion *
%
%
% Ofrecer ficheros
19 S N # 15 20 $
20 N S $ Ofrecer ficheros *
%
El �chero utilizado en este caso es el nº3. Ya que el contenido del �chero es bastanteamplio y no se conoce a priori la cantidad de �ujos existentes, se espera que se reconozcanlos �ujos asociados con los autómatas especi�cados, ya que, en el escenario contempladoen el �chero de pruebas, se intercambia bastante información. De toda esta información,el �chero de autómatas sólo la contiene parcialmente.
5.1.7. Prueba 6
En esta prueba se utilizará la misma especi�cación de autómatas que en la Prueba 5.En este caso, el �chero utilizado es el nº4, el cual contiene trazas de trá�co de todo tipo.En este caso, tampoco se conoce a priori su contenido pero, dada la especi�cación de
los autómatas, se considera que se reconocerán los �ujos existentes que se correspondancon la especi�cación en el �chero de autómatas. De la misma manera que en la Prueba 5,en el �chero nº4 se intercambia gran cantidad de información, de la cual sólo se especi�cauna parte de ella en el �chero de especi�cación de autómatas.
5.1.8. Prueba 7
Con el �n de comprobar el buen funcionamiento de la concurrencia de la aplicación,se realizará la evaluación de la aplicación para los �cheros nº1, nº2, nº3 y nº4 al mismotiempo. El contenido del �chero de autómatas es el mismo que en la Prueba 5. El resultadodebe ser unas estadísticas generales de la unión de todos los �cheros por separado.
5.2. Evaluación de la funcionalidad de la aplicación
En esta sección se ha evaluado la funcionalidad de la aplicación para cada una de las�chas de prueba elaboradas anteriormente.
5.2.1. Resultados para la Prueba 1
En este caso, el resultado mostrado por la aplicación es el siguiente:
IP origen: 192.168.1.4
IP destino: 87.230.83.44
Puerto origen: 34763
88

5. Evaluación
Puerto destino: 4661
Flujo observado: 16 33
Flujo reconocido: Busqueda de archivos
---------------------------------------------------------------------
Numero de flujos totales: 1
Porcentaje de flujos reconocidos: 100 %
Porcentaje de flujos no reconocidos: 0 %
Porcentaje de flujos incompletos: 0 %
---------------------------------------------------------------------
5.2.2. Resultados para la Prueba 2
Ahora, el resultado mostrado por la aplicación para esta prueba es el siguiente:
IP origen: 87.230.83.44
IP destino: 192.168.1.4
Puerto origen: 34648
Puerto destino: 36121
Flujo observado: 01 4C
Flujo reconocido: Handshake inicial
----------------
IP origen: 192.168.1.4
IP destino: 87.230.83.44
Puerto origen: 43742
Puerto destino: 4661
Flujo observado: 01 40 34
Flujo reconocido: Establecimiento de conexion
----------------
IP origen: 192.168.1.4
IP destino: 87.230.83.44
Puerto origen: 43742
Puerto destino: 4661
Flujo observado: 14 32 41
Flujo reconocido: Secuencia de inicio de conexion
---------------------------------------------------------------------
Numero de flujos totales: 3
Porcentaje de flujos reconocidos: 100 %
Porcentaje de flujos no reconocidos: 0 %
Porcentaje de flujos incompletos: 0 %
---------------------------------------------------------------------
Como se puede observar, cuanto más grande es el �chero y más paquetes contiene,más �ujos son detectados en su interior. En esta prueba, se han reconocido todos los�ujos observados en el �chero de trazas. Se puede comprobar que un establecimiento de
89

5. Evaluación
conexión implica tres �ujos de información y, por tanto, tres autómatas ya modeladosanteriormente. A modo ilustrativo, en la Figura 5.16 se puede observar con wireshark,como se puede ver en [17] el contenido de una trama de este �chero, cuyo campo �tipo�es `01'.
5.2.3. Resultados para la Prueba 3
En este caso, la salida de la aplicación muestra lo siguiente:
IP origen: 87.230.83.44
IP destino: 192.168.1.4
Puerto origen: 34648
Puerto destino: 36121
Flujo observado: 01 4C
Flujo reconocido: Handshake inicial
----------------
IP origen: 192.168.1.4
IP destino: 87.230.83.44
Puerto origen: 43742
Puerto destino: 4661
Flujo observado: 01 40 34
Flujo reconocido: Establecimiento de conexion
----------------
IP origen: 192.168.1.4
Figura 5.16: Muestra de una trama `eDonkey' con Wireshark.
90

5. Evaluación
IP destino: 87.230.83.44
Puerto origen: 43742
Puerto destino: 4661
Flujo observado: 14
Flujo no reconocido
---------------------------------------------------------------------
Numero de flujos totales: 3
Porcentaje de flujos reconocidos: 66.6667 %
Porcentaje de flujos no reconocidos: 33.3333 %
Porcentaje de flujos incompletos: 0 %
---------------------------------------------------------------------
La ejecución de la aplicación ha mostrado los resultados esperados. La traza borrada,como se puede comprobar, contenía dos mensajes `eDonkey': uno con tipo `32' y otro contipo `41'. Por tanto, el �ujo no es reconocido, ya que no hay información su�ciente, y elresultado es el esperado.
5.2.4. Resultados para la Prueba 4
Para ejecutar esta prueba, se modi�cará el porcentaje que establece cuándo un autó-mata es incompleto al 30%. De manera que, utilizando el �chero de pruebas indicado, elresultado es el siguiente:
IP origen: 87.230.83.44
IP destino: 192.168.1.4
Puerto origen: 34648
Puerto destino: 36121
Flujo observado: 01 4C
Flujo reconocido: Handshake inicial
----------------
IP origen: 192.168.1.4
IP destino: 87.230.83.44
Puerto origen: 43742
Puerto destino: 4661
Flujo observado: 01 40 34
Flujo reconocido: Establecimiento de conexion
----------------
IP origen: 192.168.1.4
IP destino: 87.230.83.44
Puerto origen: 43742
Puerto destino: 4661
Flujo observado: 14
Flujo incompleto
---------------------------------------------------------------------
91

5. Evaluación
Numero de flujos totales: 3
Porcentaje de flujos reconocidos: 66.6667 %
Porcentaje de flujos no reconocidos: 0 %
Porcentaje de flujos incompletos: 33.3333 %
---------------------------------------------------------------------
Como se puede observar, la salida muestra un resultado esperado ya que, cambiando elcriterio de �ujos incompletos, se ha conseguido que se reconozca la modi�cación realizadaen el �chero de trazas.
5.2.5. Resultados para la Prueba 5
En este caso, se mostrará sólo el resultado de las estadísticas de la salida del programa,ya que el resto del contenido es bastante extenso, del cual se muestra un resumen en leFigura 5.17:
---------------------------------------------------------------------
Numero de flujos totales: 18
Porcentaje de flujos reconocidos: 44.4444 %
Porcentaje de flujos no reconocidos: 55.5556 %
Porcentaje de flujos incompletos: 0 %
---------------------------------------------------------------------
Como se puede observar, el resultado es aproximado al esperado. Con una especi�caciónde autómatas simple, se han logrado reconocer el 44.44% de los �ujos observados, todosellos relacionados con el �chero de especi�cación de autómatas.
5.2.6. Resultados para la Prueba 6
Una vez más, se muestran sólo los resultados estadísticos de la salida, puesto que los�ujos observados en el �chero de trazas es extenso. Los resultados son los siguientes, yun resumen de la salida es el mostrado en la Figura 5.18:
---------------------------------------------------------------------
Numero de flujos totales: 200
Porcentaje de flujos reconocidos: 50 %
Autómata Número de veces observado
Handshake inicial 8Flujos no reconocidos 10
Figura 5.17: Salida observada para la Prueba 5.
92

5. Evaluación
Autómata Número de veces observado
Handshake inicial 92Establecimiento de conexión 3
Secuencia de inicio de conexión 3Búsqueda de archivos 2Flujos no reconocidos 100
Figura 5.18: Salida observada para la Prueba 6.
Porcentaje de flujos no reconocidos: 50 %
Porcentaje de flujos incompletos: 0 %
---------------------------------------------------------------------
Como se puede observar, la cantidad de �ujos observados es considerable. El resultadomostrado en la salida era predecible, ya que, de un �chero extenso, se reconocen los �ujosque se corresponden con los autómatas especi�cados. Estos son el 50% de todos los �ujosobservados en el �chero de pruebas.
5.2.7. Resultados para la Prueba 7
En esta última prueba, los resultados han sido los siguientes, y un resumen de la salidaobservada se muestra en la Figura 5.19:
---------------------------------------------------------------------
Numero de flujos totales: 222
Porcentaje de flujos reconocidos: 50.4505 %
Porcentaje de flujos no reconocidos: 49.5495 %
Porcentaje de flujos incompletos: 0 %
---------------------------------------------------------------------
Prestando atención al número de �ujos totales, se puede veri�car que coincide con lasuma de los �ujos observados de los �cheros analizados por separado. Las estadísticasson globales a todos los �ujos, por lo que la concurrencia de la aplicación funciona tal ycomo se esperaba.
Autómata Número de veces observado
Handshake inicial 101Establecimiento de conexión 4
Secuencia de inicio de conexión 4Búsqueda de archivos 3Flujos no reconocidos 110
Figura 5.19: Salida observada para la Prueba 7.
93

5. Evaluación
5.2.8. Conclusiones de la evaluación de funcionalidades
Salvo la prueba 1 (y en parte la prueba 2) los resultados de la aplicación son bastantepositivos. En una situación real de trá�co P2P producido por el protocolo `eDonkey'se han reconocido el 50'4505% (analizando todos los �cheros de trazas de prueba conun número reducido de autómatas) de los autómatas, que es prácticamente la mitad.Teniendo en cuenta que el �chero de especi�cación de autómatas contenía solamentedetalles de seis de ellos, el porcentaje de reconocimiento es bastante alto. Completandoel �chero de especi�cación se lograría un comportamiento mucho más �able.El principal inconveniente de la especi�cación de autómatas es la continua actualización
del protocolo `eDonkey', que convierte dichas especi�caciones en obsoletas en relativa-mente poco tiempo. Por tanto, sería interesante un módulo en la aplicación que fueracapaz de deducir el comportamiento del protocolo `eDonkey' simplemente en base a sufuncionamiento, de manera que pudiera elaborar los patrones de reconocimiento por sísolo.
5.3. Evaluación del rendimiento de la aplicación
A continuación, se muestran medidas del rendimiento de la aplicación. Para podermedir tiempos de ejecución, se ha utilizado la herramienta time de Linux, la cual ofreceinformación precisa de los tiempos de ejecución de los programas. En la Figura 5.20se muestra una tabla en la que se miden los tiempos de ejecución de cada una de laspruebas. Como se puede observar, los tiempos mostrados son bastante bajos, incluso conlos cuatro �cheros de prueba ejecutándose simultáneamente. Esto prueba la e�ciencia delas hebras ya que, incluso con �cheros grandes, los resultados en tiempo son buenos.Otra de las medidas de rendimiento realizadas con la aplicación, es el análisis de los
cuellos de botella existentes. Conociendo este dato, se podría realizar una mejora quedisminuyera los tiempos de ejecución.En la Figura 5.21 se muestra un árbol de llamadas, realizado mediante VTune, como
se puede consultar en [16], con la actividad que producen dichas llamadas que se hacendurante la ejecución de la aplicación. Las pruebas se han realizado para la ejecución delprograma con los datos de la �cha de la Prueba 8, ya que contiene un gran número detrazas y las llamadas se realizan de manera multihebrada, por lo que proporciona unasmejores estimaciones en los resultados.En el grafo de la Figura 5.21 se muestra el árbol de llamadas resultado de la ejecución
de la aplicación. La función que más llamadas produce es pthread_join(), función quese utiliza para unir hebras. Dada la naturaleza multihebrada del programa y de la �chade prueba utilizada, es lógico veri�car este hecho. Asimismo, se muestran enmarcadas enrojo las funciones que más tiempo consumen del total de la ejecución del programa.En la Figura 5.22 se muestra el porcentaje de ticks de reloj que consumen determina-
das llamadas al programa. Como se puede apreciar en dicha �gura, la función que másticks consume está relacionada con el almacén/clasi�cador existente, debido a que estaestructura es utilizada por varios módulos y está siendo continuamente actualizada, comose vio anteriormente. También se proporciona un detalle preciso del porcentaje de ticks
94

5. Evaluación
de reloj que ha ejecutado cada procesador del computador en el que se ejecuta.
Prueba Tiempo de ejecución
1 0.004 s.2 0.004 s.3 0.004 s.4 0.004 s.5 0.004 s.6 0.012 s.7 0.472 s.8 0.536 s.
Figura 5.20: Tiempos de ejecución de las pruebas realizadas.
Figura 5.21: Actividad del grafo de llamadas.
Figura 5.22: Mediciones de tiempos para algunos métodos de la aplicación.
95

5. Evaluación
5.3.1. Conclusiones de la evaluación del rendimiento
Como se ha mostrado anteriormente, se han realizado una serie de pruebas de rendi-miento a la aplicación desarrollada. Analizando los cuellos de botella de la aplicación, sepuede concluir que una posible optimización residiría en tratar de reducir el número dehebras utilizadas en el almacén/clasi�cador general, ya que es la parte que más tiempoconsume.Por otro lado, resulta inevitable constatar que, si se reduce el número de hebras,
probablemente aumentaría la carga de trabajo de otros módulos. Por lo tanto, aunquelas hebras consuman una gran cantidad de tiempo de la ejecución del programa, laprogramación multihebrada es una buena solución. Los buenos tiempos mostrados sedeben, en parte, a optimizaciones del compilador realizadas.
96

Capıtulo 6Plani�cación y estimación de recursos
En este capítulo se mostrará la plani�cación inicial que se hizo para el proyecto, asícomo los recursos utilizados en él. Por último, se muestra un estudio económico realizado.
6.1. Plani�cación
Para poder calcular la duración del proyecto, inicialmente se dividió en una serie detareas con una duración aproximada. Las tareas se dividen en las siguientes:
� Plani�cación: En ella se realizaba una plani�cación inicial de la duración estimadadel proyecto. No es una tarea sencilla calcular a priori dicha duración, por lo quese incluye un punto de replani�cación, en el que se replanteaban objetivos y semodi�caban las asignaciones de tiempo.
� Estudio del arte: En este estudio, el objetivo es familiarizarse con el proyecto y lasmaterias relacionadas. Por ello, es necesario realizar un estudio de estos puntos y,al �nal, entregar una parte de documentación referente a lo estudiado.
� Desarrollo y análisis: En esta sección se realiza el análisis del protocolo `eDon-key', así como el diseño de la solución propuesta. Realización de una parte de ladocumentación con esta información detallada. Programación de la aplicación.
� Pruebas: Fase en la que se realiza la evaluación de la aplicación desarrollada, a �nde veri�car su funcionamiento e ilustrarlo mediante algunos ejemplos.
� Documentación: Capítulo �nal en el que se documenta debidamente los pasos se-guidos y la motivación para el desarrollo del proyecto. Entrega de la documentación�nal.
En la Figura 6.1 se muestran estas tareas, mientras que en la Figura 6.2 se muestran eldiagrama de Gantt correspondiente.
97

6. Plani�cación y estimación de recursos
Figura 6.1: Esquema de las tareas inicialmente plani�cadas.
98

6. Plani�cación y estimación de recursos
Figura 6.2: Diagrama de Gantt.
99

6. Plani�cación y estimación de recursos
6.2. Recursos
Los recursos utilizados se pueden clasi�car en tres bloques, atendiendo a su naturaleza.
6.2.1. Recursos software
� Sistema operativo Ubuntu 8.04 Hardy Heron.
� Editor de imágenes GIMP.
� Gestor de proyectos Planner.
� Editor para LATEX: LYX 1.6.3.
� Microsoft O�ce 2007.
� Wireshark (véase [17]).
� Cliente eMule (véase [18]).
� Herramienta para documentación de código Doxygen (véase [20]).
� Herramienta para dibujar diagramas estructurados Dia 0.96.1.
� Editor de textos KWrite.
� Compilador gcc.
� Herramienta de creación de autómatas JFlap.
6.2.2. Recursos hardware
� PC con procesador Intel Centrino Duo 2 GHz con 1GB de memoria principal y 200GB de disco duro.
� Tarjeta de red Intel ipw3945abg.
6.2.3. Recursos humanos
� Dos profesores del Departamento de Teoría de la Señal, Telemática y Comunicacio-nes de la Escuela Técnica Superior de Ingenierías Informática y Telecomunicaciónde la Universidad de Granada, como directores del proyecto.
� Un alumno de Ingeniería Informática de la Escuela Técnica Superior de IngenieríasInformática y Telecomunicación de la Universidad de Granada, como desarrolladordel proyecto.
6.3. Estudio económico
A continuación se muestra un análisis de costes asociado al desarrollo de la aplicación.
100

6. Plani�cación y estimación de recursos
6.3.1. Costes asociados a los materiales
Respecto a los costes de los materiales, será necesario incluir los costes asociado alequipo informático utilizado en la realización del proyecto. Este se calculará mediante elprorrateo del coste del propio equipo entre un tiempo, el cual se ha estimado que seancuatro años, ya que se trata de un equipo informático que se calcula se volverá obsoletotras ese período.Por tanto, sabiendo que el equipo informático tuvo un precio original de 200 ¿, y
teniendo en cuenta que la duración de la realización del proyecto es de, aproximadamente,300 días, esto sumaría un total de 410.51 ¿ a abonar en concepto de materiales.Adicionalmente, se incluyen los gastos correspondientes a licencias software, los cuales
sumarían un total de 1000 ¿.
6.3.2. Costes de mano de obra
La estimación de los costes se calculará en base al tiempo aproximado empleado en larealización del proyecto.En España, cada día tiene disponibles 8 horas laborables y esto es lo que considerare-
mos.A continuación se detallan todas las fases del proyecto, cada una con el tiempo estimado
de duración:
� Plani�cación:
� Plani�cación inicial: 72 horas.
� Corrección de la plani�cación: 40 horas.
� Elaboración de presupuesto: 56 horas.
� Estudio del arte:
� Estudio de los protocolos implicados: 136 horas.
� Elección de las aplicaciones a estudiar y justi�cación: 56 horas.
� Estudio del funcionamiento de las aplicaciones elegidas: 280 horas.
� Desarrollo y análisis:
� Captura de trá�co P2P: 56 horas.
� Estudio del trá�co generado por aplicaciones estudiadas en base al trá�cocapturado: 264 horas.
� Establecimiento de patrones en función del funcionamiento de las aplicacionesP2P: 240 horas.
� Pruebas:
� Veri�cación del funcionamiento de la aplicación desarrollada: 640 horas.
� Documentación:
101

6. Plani�cación y estimación de recursos
� Descripción del funcionamiento de los protocolos propios de la arquitecturaTCP/IP: 80 horas.
� Descripción del funcionamiento de las aplicaciones elegidas en base a sus pro-tocolos: 120 horas.
� Descripción del funcionamiento de las aplicaciones elegidas en base al trá�coque generan: 160 horas.
� Descripción de los patrones elaborados en base al trá�co de las aplicaciones:120 horas.
� Estudio económico: 80 horas.
� Total: 2400 horas.
Teniendo en cuenta la duración considerada del proyecto, el precio total correspondientea la mano de obra, sería de 120000 ¿.
6.3.3. Otros costes
Se incluirán los costes asociados a reuniones con el cliente, tanto para comprender lasespeci�caciones iniciales del proyecto, como para dialogar con el susodicho cliente acercadel transcurso del proyecto para la resolución de posibles dudas y/o potenciales mejoras.Se calcula que, a lo largo del tiempo estimado de realización del proyecto, se realizarán
15 reuniones, cada una de 1 hora de duración.Dado que se estima que el precio de trabajo de una hora es de 50 ¿, la suma total del
coste asociado a las reuniones sería de 750 ¿.
6.3.4. Total
La suma total correspondería a un total de 120750 ¿.
102

Capıtulo 7Logros y conclusiones
En esta sección se indican los logros obtenidos mediante la realización del proyecto,así como las conclusiones a las que se ha podido llegar.
7.1. Logros
� Comprender el funcionamiento del protocolo `eDonkey'.
� Entender el funcionamiento de las redes peer-to-peer.
� Entender el funcionamiento de los autómatas de estados �nitos.
� Aprender a modelar comportamientos de protocolos mediante autómatas de estados�nitos.
� Lograr diseñar una aplicación que sea capaz de realizar un proceso de determinadainformación mediante autómatas de estados �nitos.
� Conocer el funcionamiento de la aplicación Wireshark, y cómo trata cada tipo detrama.
� Comprender el funcionamiento de la herramienta VTune para la realización deanálisis de rendimiento de aplicaciones.
� Aprender cómo afrontar un proyecto de cierta envergadura y realizar una buenadocumentación.
7.2. Conclusiones
� Las herramientas de modelado de protocolos mediante autómatas de estados �nitosson e�caces para la detección de anomalías en dichos protocolos. Sin embargo, esuna tarea complicada de�nir completamente todo el comportamiento (diseñar losautómatas).
103

7. Logros y conclusiones
� El protocolo `eDonkey' es un protocolo difícil de modelar, ya que surgen versionesnuevas con el paso de los meses. Por ello, una determinada especi�cación podríaquedar obsoleta en poco tiempo.
� Una posible mejora sería, como se comentó anteriormente, un módulo capaz deaprender por sí mismo el comportamiento de un determinado protocolo, para evitarel trabajo de la especi�cación de autómatas.
104

Bibliografía
[1] http://www.techcrunch.com/2009/01/23/comscore-internet-population-passes-one-billion-top-15-countries/
[2] http://www.ipoque.com/resources/internet-studies/internet-study-2007.
[3] Wai-Sing Loo, A. (2007): �Peer-to-peer Computing: Building Supercomputers withWeb Technologies�. Springer. ISBN: 1846283817, 9781846283819.
[4] Wang, W. (2004): �Steal this �le sharing book: what they won't tell you about �lesharing�. No Starch Press. ISBN: 159327050X, 9781593270506.
[5] Millán Tejedor, R. J. (2006): �Las redes P2P (peer to peer)�. Creaciones Copyright.ISBN: 849630020X, 9788496300200.
[6] Hemmje, M.; Neuhold, E. J.; Niederee, C; Risse, T. (2005): �From integrated publica-tion and information systems to virtual information and knowledge environments�.Springer. ISBN: 3540245510, 9783540245513.
[7] Asensio Asensio, G. (2006): �Seguridad en Internet�. Ediciones Nowtilus S.L. ISBN:8497632931, 9788497632935.
[8] Barnard, R. L. (1988): �Intrusion Detection Systems�. Gulf Professional Publishing.ISBN: 0750694270, 9780750694278.
[9] Kulbak, Y.; Bickson, D; Kirkpatrick, S. (2004): �The eMule protocol speci�cation�.School of Computer Science and Engineering.The Hebrew University of Jerusalem,Jerusalem.
[10] http://decsai.ugr.es/%7Esmc/docencia/mci/automata.pdf
[11] García Teodoro, P.; Díaz Verdejo, J. E.; López Soler, J. M. (2003): �Transmisión deDatos y Redes de Computadores�. Prentice Hall. ISBN: 9788420539195.
[12] Larman, C. (2006): �UML y Patrones�. Prentice Hall. ISBN: 8420534382.
105

Bibliografía
[13] Robson, R. (2000): �Using the STL: the C++ standard template library�. Springer.ISBN: 0387988572, 9780387988573.
[14] Josuttis, N. M. (2002): �The C++ Standard Library: A Tutorial and Reference�.Addison-Wesley. ISBN: 0201379260, 9780201379266.
[15] López Monge, A. (2005): �Aprendiendo a programar con Libpcap�. URL:http://www.e-ghost.deusto.es/docs/2005/conferencias/pcap.pdf.
[16] http://software.intel.com/en-us/intel-vtune/
[17] http://www.wireshark.org/
[18] http://www.emule-project.net/
[19] https://computing.llnl.gov/tutorials/pthreads/
[20] http://www.doxygen.org/
106

Apendice ADescripción de los métodos utilizados
En esta sección se incluyen la descripción del funcionamiento de los métodos de lasclases detalladas en el Capítulo 4. También se incluye al �nal unos detalles generalesacerca del uso de la aplicación.
Métodos de la clase `estado'
Los métodos principales de la clase estado son los siguientes:
estado()
Constructor por defecto de la clase. Inicializa:
� Identi�cador a 0.
� Estado inicial a false.
� Estado �nal a false.
� Puntero a mensaje a null.
estado(const estado & orig)
Constructor de copias de la clase. Copia el objeto de la clase estado pasado porparámetro en el objeto implícito el cual llama al constructor de copias.
eliminar(mensaje * p)
Libera la memoria asociada a una lista enlazada de elementos mensaje.
virtual ~estado()
Destructor de la clase.
107

A. Descripción de los métodos utilizados
void setID(const int & a)
Establece el valor del identi�cador propio de cada estado al valor entero que se pasapor parámetro a este procedimiento.
int getID()
Obtiene el valor del identi�cador del estado implícito que llama a la función, y lodevuelve.
void setInicial(const bool & a)
Modi�ca la variable booleana de un estado que indica si dicho estado es inicial o no, yla cambia al valor a pasado por parámetro.
bool getInicial()
Obtiene el valor booleano del objeto estado implícito que indica si dicho estado esinicial o no y lo devuelve.
void setFinal(const bool & a)
Modi�ca la variable miembro de un estado que indica si dicho estado es �nal o no y laestablece al valor pasado por parámetro.
bool getFinal()
Devuelve el valor de la variable miembro final que indica si el estado implícito es �nalo no.
void setMensaje(const string & mot, estado * nxt)
Este procedimiento añade un nuevo mensaje a la lista de mensajes del estado. En suinterior, pueden ocurrir dos situaciones:
� Que no exista ningún mensaje para ese estado: actualiza el valor del puntero delestado y añade un mensaje nuevo. Es decir, a modo de ejemplo:
Se parte del estado de la Figura A.1. Si se realiza la llamada a este procedimientocon el argumento primero con valor `B7' y el segundo es un puntero al estado 0,entonces resultaría el estado de la Figura A.2.
� Que ya existan mensajes: En este caso habría que recorrer la lista de todos losmensajes existentes y añadir uno nuevo al �nal. Es decir, siguiendo con el ejemplo:
Se parte del estado de la Figura A.3. Si ahora se realiza la llamada al procedimiento,con parámetros `47' y un puntero a un hipotético estado q2, entonces resultaría lomostrado en la Figura A.4.
108

A. Descripción de los métodos utilizados
Figura A.1: Ejemplo de estado.
Figura A.2: Ejemplo de estado tras la llamada a `setMensaje'.
Figura A.3: Ejemplo de estado con un mensaje.
Figura A.4: Ejemplo de estado con un mensaje tras la llamada a `setMensaje'.
109

A. Descripción de los métodos utilizados
mensaje * getMensaje()
Devuelve el valor del puntero al primer mensaje del objeto implícito estado que realizala llamada a esta función.
string getNombre()
Obtiene la descripción (en caso de haber alguna) del objeto implícito que hace lallamada, y lo devuelve.
void setNombre(const string & nombre)
Establece el valor de la descripción de un objeto de la clase estado al valor concretoque se pasa como parámetro del procedimiento.
void setNull()
Modi�ca, para un objeto estado implícito, el valor de su puntero a la lista de mensajes,y lo cambia a valor null.
int numeroMensajes()
Cuenta el número de mensajes que tiene un objeto estado y lo devuelve como pará-metro. En el ejemplo de la Figura A.4 devolvería 2.
friend ostream & operator�(ostream & fo, estado & e)
Sobrecarga del operador `<�<' para permitirle mostrar por pantalla todas las variablesmiembro de un estado, incluyendo la lista de mensajes que tiene con el detalle de cadauno de ellos.
estado & operator=(const estado & orig)
Sobrecarga del operador `=' para permitir a un estado poder igualarlo a otro. Tienela misma funcionalidad que el constructor de copias de la clase, pero este requiere mássimplicidad a la hora de utilizarlo.
Métodos de la clase `automatas'
Los principales métodos de esta clase se detallan a continuación:
automatas()
Constructor por defecto de la clase. Se inicializan las variables estadísticas a cero.También se inicializan los mutexes.
110

A. Descripción de los métodos utilizados
automatas(const automatas & orig)
Constructor de copias de la clase. Para copiar un vector a otro, sólo es necesarioutilizar el operador de asignación, ya que se encuentra sobrecargado y se puede utilizarcon sencillez gracias al encapsulado proporcionado por las clases.
virtual ~automatas()
Destructor de la clase. No es necesario liberar memoria, ya que esta función se encuentraintegrada en la clase vector. Se destruyen los mutexes.
void setTamanio(const int & n)
Aunque el vector utilizado como variable miembro de la clase es dinámico, sí es ne-cesario inicializar dicho vector a un tamaño inicial. Con este procedimiento se logra eseobjetivo, estableciendo el tamaño del vector al parámetro entero del módulo.
void muestraV()
Procedimiento de ayuda el cual solamente muestra el contenido de cada casilla delvector del objeto automatas. Gracias a que el operador `<�<' está sobrecargado en laclase estado, es posible realizar esta operación, ya que en cada casilla del vector seencuentra un elemento de este tipo.
vector<estado> devuelveV()
Devuelve el vector que forma parte de un objeto de la clase automatas, el cual llamaa esta función.
extraeFlujosAntiguos()
Procedimiento de la hebra encargada de la extracción y análisis. Comprueba perió-dicamente si existen �ujos �antiguos� que extraer del almacén/clasi�cador. Si el alma-cén/clasi�cador tiene un tamaño mayor que un umbral, se crean hebras que ayudan aliberar carga de la hebra principal.
void leerAutomatas(const char * nombre)
Lee una serie de autómatas contenidos en un �chero. La utilidad de este procedimientoreside en construir el vector de objetos estado a partir de información contenida en un�chero de texto. Esta información está relacionada con el funcionamiento del protocoloque se quiere examinar, en este caso `eDonkey'.Se establece un tamaño inicial para el vector de objetos estado. Cada casilla del
vector se rellena con los datos del �chero, estableciendo las variables miembro a un valoradecuado para su posterior veri�cación.
111

A. Descripción de los métodos utilizados
int leerTramas(const int & modo, const char * nombre)
Otra de las funciones destacadas la que lee un �chero de tramas almacenado en discoo abre una interfaz de red para un modo de captura en vivo. El formato del �chero detramas debe ser pcap, ya que la biblioteca utilizada trabaja con este tipo de �cheros(véase Sección 2.4.2).En esta función se observan dos funcionalidades principales:
� Si el argumento modo es igual a 0: Signi�ca que se ha llamado al programa con laintención de examinar si un determinado �chero de tramas almacenado cumple unaserie de patrones de funcionamiento.En este modo, el parámetro nombre es el nombre del �chero pcap que contiene lastramas a examinar.
� Si el argumento modo es igual a 1: En este caso se ha elegido la opción de abrir unainterfaz de red para hacer un análisis en vivo de un determinado protocolo P2P.En este modo se establece la captura de trá�co en modo promiscuo y se indica un�ltro, ya que realiza una captura de trá�co más e�ciente debido a que ahorra costecomputacional. El �ltro establecido por defecto es �tcp�.En este modo, el parámetro nombre es el nombre de la interfaz de red para lacaptura en vivo.
La función devuelve un código de error (EXIT_FAILURE) en caso de que se produzcaalgún error, o un valor de retorno indicando éxito (EXIT_SUCCESS) en caso de que seejecute con normalidad.
muestraEstadisticas()
Muestra las estadísticas correspondientes de los resultados del análisis de los �ujosdetectados.
bool comparaAutomata(datosFlujo datos)
Realiza el parsing de un autómata. Es decir, en base a todos los autómatas construidosa partir de un �chero dado de autómatas, los cuales proporcionan información acerca deun determinad protocolo (en este caso, el protocolo `eDonkey'), comprueba si un �ujo estásiguiendo el patrón de�nido en alguno de estos autómatas. Mediante este procedimientose llega a la conclusión de si el funcionamiento del protocolo se modela mediante losautómatas de�nidos o no.El parámetro datos se corresponde con el �ujo de información determinado que se va
a analizar para ver si cumple o no con ciertos patrones de funcionamiento.La función devuelve true en caso de poder modelar el �ujo observado mediante un
autómata, o estar este �ujo incompleto, y false en caso contrario.
void comparaTodo()
112

A. Descripción de los métodos utilizados
Extrae todos los �ujos de información existentes en el almacén/clasi�cador. Se realizael parsing de cada uno de los �ujos extraídos.
operator=(const automatas & orig)
Sobrecarga del operador `=' de la clase.
int getNumeroEstados(vector <estado> V, const int & i)
Devuelve, para un vector de objetos estado dado y una posición dentro de ese vector,el número de posiciones (o estados) que restan hasta encontrar un estado �nal.
Funciones auxiliares
Funciones que no forman parte de la clase, pero son necesarias por proporcionar algunasfuncionalidades imprescindibles para manejar un objeto de la clase automatas.
inline int hex2int(const char * cadena)
Convierte una cadena de caracteres pasada por parámetro que contiene un número enhexadecimal en el número entero correspondiente.
void parsingAutomata(datosFlujo datos)
Realiza el parsing de un autómata. Es decir, en base a todos los autómatas construidosa partir de un �chero dado de autómatas, los cuales proporcionan información acerca deun determinad protocolo (en este caso, el protocolo `eDonkey'), comprueba si un �ujo estásiguiendo el patrón de�nido en alguno de estos autómatas. Mediante este procedimientose llega a la conclusión de si el funcionamiento del protocolo se modela mediante losautómatas de�nidos o no.El parámetro datos se corresponde con el �ujo de información determinado que se va
a analizar para ver si cumple o no con ciertos patrones de funcionamiento.La función devuelve true en caso de poder modelar el �ujo observado mediante un
autómata, o estar este �ujo incompleto, y false en caso contrario.Esta función no pertenece a la clase.
liberarCarga(void * arg)
Función de las hebras encargadas de liberar la carga de la hebra principal del módulode extracción y análisis. El parámetro arg indica la cantidad de trabajo que tendrán lasnuevas hebras creadas.
void evaluaFinFlujo(const string & IPorigen,
const string & IPdestino, const int & puertoOrigen,
const int & puertoDestino, const bool & finTCP)
113

A. Descripción de los métodos utilizados
Uno de los procedimientos principales de la aplicación es aquel que determina cuándoes el inicio y cuándo el �n de un determinado �ujo de información. Esta función se llamapara cada trama TCP o UDP que no tenga carga útil.Dentro de ella, se comprueba que la trama sea TCP y tenga el bit FIN activado. En
este caso, signi�cará que se ha recibido una trama de �nalización de una conexión, por loque, desde que se inició la transmisión de datos hasta ese punto, se considera un �ujo. Enese caso, se ha de examinar a cuál de todos los �ujos existentes corresponde esa trama de�nalización de conexión TCP. Cuando se encuentre una coincidencia, se extraerá dicho�ujo del almacén/clasi�cador y se analizará para veri�car si coincide con alguno de losautómatas conocidos.
void rellenaClasificadorFlujos(const string & IPorigen,
const string & IPdestino, const int & puertoOrigen,
const int & puertoDestino, const char * payload)
Mediante este procedimiento, correspondiente al módulo de detección de �ujos deta-llado en el Apartado 4.1.2, se clasi�can las tramas leídas en �ujos de información. Dichoprocedimiento puede ser modi�cado para la compatibilidad con otros protocolos ya quees en él donde se realizan las funciones intrínsecas al protocolo `eDonkey'. Para ello, selee la carga útil de la trama antes de operar con ella, ya que los datos de la cabecerase incluyen en los parámetros de este procedimiento. Los pasos que se siguen son lossiguientes:
� Se comprueba que la trama tenga una carga útil lo su�cientemente grande como pa-ra ser examinada. Si los datos de la trama tienen un tamaño inferior a 11 caracteres,no se considerará.
� Se comprueba que la trama pertenezca al protocolo `eDonkey' o a la extensión delprotocolo proporcionada por `eMule'. Esto se conoce gracias a un parámetro tipo
el cual es `E3' en el caso de que la trama pertenezca a `eDonkey' o `C5' si pertenecea `eMule'.
� Se examina el tamaño de la carga útil mediante un parámetro existente a tal efecto.Si el tamaño es superior a 100000 bytes, se considera que la información es erróneay se descarta la trama, ya que no existen tramas tan grandes.
� Dependiendo del tamaño del almacén/clasi�cador de �ujos:
� Si el almacén/clasi�cador no contiene ningún �ujo de información, se crea-rá uno nuevo y se introducirán los datos referentes a la trama que se estáexaminando en él.
� Si el almacén/clasi�cador ya tiene otros �ujos anteriores, se comprobará cadauno de ellos para veri�car si la trama que se está examinando pertenece a un�ujo de información ya existente. En el caso de no haber ninguna coincidencia,se creará uno nuevo.
114

A. Descripción de los métodos utilizados
� El proceso se repite tantas veces como existan datos referentes al protocolo `eDon-key'. Esto sucede ya que, en una misma trama, pueden aparecer de manera enca-denada, varias �subtramas� pertenecientes al protocolo `eDonkey'.
void my_callback(u_char * args, const struct pcap_pkthdr * header,
const u_char * packet)
Este procedimiento corresponde con el módulo de preprocesamiento explicado en elApartado 4.1.1, y está ligado a la función de la biblioteca pcap, llamada pcap_loop.Dicho procedimiento se ejecuta para cada trama leída con pcap_loop, por lo que dentrose puede escribir el código que se desee.Una de las funciones básicas que se ha implementado dentro de este procedimiento,
es el �ltrado de tramas que no se necesitan evaluar. Conforme se van leyendo estastramas, se accede a los distintos niveles de información de la cabecera. De esta manera,se pueden desechar las tramas que no pertenezcan ni al protocolo TCP ni al UDP, puestoque son únicamente las que proporcionan información relevante para la evaluación conlos autómatas.La segunda y última de las funciones destacadas dentro de este módulo es el trata-
miento de la carga útil de la trama leída. Dado que no todos los caracteres leídos tienenpor qué ser ASCII, entonces no todos pueden ser representados por algún carácter quepueda ser leído e interpretado por un lector cualquiera. Para un mejor tratamiento de lainformación contenida en las cargas útiles, la opción tomada es realizar una conversiónde todos los caracteres a base hexadecimal. Con esta transformación es posible identi-�car los protocolos a los que pertenece cada trama, así como otro tipo de informaciónrelevante para la construcción de las diferentes estructuras que conforman la aplicación.Una vez realizada la conversión mencionada, la trama se envía para incluirla dentro
del almacén/clasi�cador de �ujos, en caso de que tenga carga útil, o bien es examinadapara comprobar si proporciona algún tipo de información referente al �nal de un �ujo deinformación, en caso de no tener carga útil.
Métodos de la clase `datosFlujo'
Esta clase tiene los siguientes métodos:
datosFlujo()
Constructor por defecto de la clase. No es necesario inicializar ninguna variable miem-bro del objeto, pues ni las cadenas, ni los números enteros, ni los vectores necesitaninicializarse.
datosFlujo(const datosFlujo & orig)
Constructor de copias de la clase. Realiza una copia simple de todos los elementos delobjeto orig pasado por parámetro al objeto implícito.
115

A. Descripción de los métodos utilizados
virtual ~datosFlujo()
Destructor de la clase. No realiza liberación de memoria de ningún tipo puesto queno es necesario reservar memoria para crear un objeto de la clase. Todas las variablesmiembro son objetos ya encapsulados que incorporan sus propios destructores.
string getIPorigen()
Devuelve el valor de la variable miembro que almacena la IP origen para el objeto quellama a esta función.
void setIPorigen(const string & IP)
Establece el valor de la variable que almacena la IP origen del objeto que llama a lafunción al valor pasado por parámetro, IP.
string getIPdestino()
Obtiene el valor de la variable miembro que almacena la IP destino del objeto implícitoy la devuelve.
void setIPdestino(const string & IP)
Establece el valor de la variable IP destino del objeto implícito al valor que se le pasapor parámetro a la función.
int getPuertoOrigen()
Esta función toma el valor del puerto origen del objeto implícito que la llama, y lodevuelve.
void setPuertoOrigen(const int & puerto)
Establece el valor de la variable miembro que almacena el puerto origen al valor indi-cado en el parámetro de la función.
int getPuertoDestino()
Devuelve el valor de la variable miembro que almacena el puerto destino para el objetoimplícito que llama a la función.
void setPuertoDestino(const int & puerto)
Establece el valor del puerto destino del objeto que realiza la llamada al valor delparámetro de la función.
int getTimestamp()
116

A. Descripción de los métodos utilizados
Obtiene el valor de la variable miembro que almacena la marca de tiempo (timestamp)y la devuelve.
void setTimestamp(const int & timestamp)
Establece el valor del timestamp de un objeto de la clase datosFlujo al valor que sele pasa por parámetro al procedimiento.
vector<string> getTypes()
Devuelve, para el objeto implícito que realiza la llamada a la función, un vector decadenas que contiene la información propia del protocolo transmitida entre dos peers.
void setTypes(const string & type)
Mediante este procedimiento se añade al �nal del vector de cadenas que forma partede las variables miembro, la información contenida en el parámetro de la función.
friend ostream & operator�(ostream & fo, datosFlujo & d)
Sobrecarga del operador `<�<' para un objeto de la clase datosFlujo. Mediante esteoperador se puede mostrar por pantalla toda la información de las variables miembro delobjeto implícito.
Métodos de la clase `clasi�cadorFlujos'
Las funciones y procedimientos de esta clase son los siguientes:
clasificadorFlujos()
Constructor de la clase. Dado que la única variable miembro de un objeto de esta clasees un vector de la STL, se inicializa dicho vector un una función diseñada a tal efecto.
clasificadorFlujos(const clasificadorFlujos & orig)
Constructor de copias de la clase. Ya que sólo está compuesta por un vector, sólo esnecesario copiar el contenido de este.
virtual ~clasificadorFlujos()
Destructor de la clase. Ya que está formada por un objeto de la STL, no es necesarioimplementar un destructor, puesto que la STL ya implementa funciones a tal efecto.
int tamClasificador()
Para un objeto de la clase clasificadorFlujos determinado, devuelve el tamaño delvector de ese objeto.
117

A. Descripción de los métodos utilizados
datosFlujo getPosicion(const int & i)
Para un objeto implícito que llama a esta función, devuelve el contenido (es decir, unobjeto datosFlujo) que se encuentra en la posición que indica el parámetro i.
void setPosicion(const datosFlujo & nueva)
Añade un nuevo �ujo de datos, es decir, un nuevo objeto de la clase datosFlujo, alclasi�cador de �ujos.
string getIPorigen(const int & i)
Devuelve el valor de la IP origen del objeto datosFlujo que se encuentra en la posicióni del objeto que llama a la función.
void setIPorigen(const int & i, const string & str)
Establece el valor de la IP origen de un objeto de la clase datosFlujo situado en laposición i al valor str pasado por parámetro.
string getIPdestino(const int & i)
Devuelve el valor de la IP destino del objeto datosFlujo que se encuentra en la posicióni del objeto que llama a la función.
void setIPdestino(const int & i, const string & str)
Establece el valor de la IP destino de un objeto de la clase datosFlujo situado en laposición i al valor str pasado por parámetro.
int getPuertoOrigen(const int & i)
Devuelve el valor del puerto origen del objeto datosFlujo que se encuentra en laposición i del objeto que llama a la función.
void setPuertoOrigen(const int & i, const int & puerto)
Establece el valor del puerto origen de un objeto de la clase datosFlujo situado en laposición i al valor puerto pasado por parámetro.
int getPuertoDestino(const int & i)
Devuelve el valor del puerto destino del objeto datosFlujo que se encuentra en laposición i del objeto que llama a la función.
void setPuertoDestino(const int & i, const int & puerto)
118

A. Descripción de los métodos utilizados
Establece el valor del puerto destino de un objeto de la clase datosFlujo situado enla posición i al valor puerto pasado por parámetro.
double getTimestamp(const int & i)
Devuelve el valor de la marca de tiempo del objeto datosFlujo que se encuentra enla posición i del objeto que llama a la función.
void setTimestamp(const int & i, const double & _timestamp)
Establece el valor de la marca de tiempo de un objeto de la clase datosFlujo situadoen la posición i al valor _timestamp pasado por parámetro.
vector<string> getTypes(const int & i)
Devuelve el vector de cadenas situado en la posición i del almacén/clasi�cador, quealmacena la información del protocolo para dos peers determinados.
void setTypes(const int & i, const string & str)
Añade en el vector de cadenas situado en la posición i del almacén/clasi�cador, coninformación del protocolo y las tramas intercambiadas entre dos peers la información delparámetro str.
datosFlujo BorrarElemento(const int & i)
Para un objeto de la clase clasificadorFlujos determinado, borra el objeto datosFlujo(es decir, borra toda la información referente a un �ujo de datos) situado en la posicióni del almacén/clasi�cador. Finalmente, devuelve este elemento.
Detalles generales del uso de la aplicación
A modo de ayuda, se muestran una serie de pautas en la utilización de la aplicación:
� La aplicación ya está compilada. En caso de que se desee compilar de nuevo, tansólo es necesario ejecutar la orden make. No requiere ningún tipo de instalación.
� El ejecutable del programa se encuentra en el directorio ./bin/.
� El �chero de autómatas se encuentra en ./dat/automatas.dat.
� Todo el código está documentado con la herramienta �Doxygen� (véase Sección2.4.5). Se puede acceder a esta documentación mediante el HTML ./doc/index.html.
� Los archivos de cabeceras se encuentran en ./include/.
� Existe un manual de referencia con la documentación del código, en formato pdf.Dicho manual se encuentra en ./latex/refman.pdf.
119

A. Descripción de los métodos utilizados
� Se ha creado una biblioteca con la estructura de la aplicación, con el �n de facilitarsu uso en el futuro. Dicha biblioteca se encuentra en ./lib/libpfc.a.
� Los �cheros objeto producto de la compilación de la aplicación se encuentran en./obj/. Para borrarlos, es necesario ejecutar la orden ./make clean.
� En el directorio ./pcap/ se incluyen algunos �cheros de ejemplo con trazas detrá�co. Los resultados de la ejecución de estos �cheros se muestran, a modo deejemplo, en el directorio ./resultados/.
� Los �cheros con el código fuente se encuentran en ./src/.
� A continuación se muestra un ejemplo de uso de la aplicación. Si se deseara ejecutardicha aplicación para dos �cheros del directorio ./pcap/ y para una interfaz de reddenominada eth0, la llamada sería la siguiente (es necesario otorgar permisos desuperusuario si se desea analizar una interfaz de red):
./bin/p2pdetector -f ./pcap/1-establecimiento_conexion.pcap
-f ./pcap/2-buscar.pcap -i eth0
120