
CAPÍTULO 16 estadística descriptiva...
27
386 | Capítulo 16 Estadística Descriptiva Bernardo Frontana de la Cruz CAPÍTULO 16 ESTADÍSTICA DESCRIPTIVA 16.1 Introducción En general, el investigador que utiliza la estadística está interesado en estimar los valores que caracterizan a la población ‐ los parámetros‐ a partir de la información que obtiene de una muestra, usa la estadística como apoyo y guía en el avance de su investigación y en el conocimiento en las ciencias y en la ingeniería. Pero esto no es de provecho a menos que pueden primero obtener ciertas medidas descriptivas y algunas distribuciones empíricas con las cuáles puede hacer inferencias. Como veremos en los capítulos de inferencia estadística, siempre debemos hacer suposiciones acerca de la distribución de la población de la que se sacó la muestra, para lo cual la distribución empírica que se obtiene de una muestra sacada cuidadosamente y, además, esta distribución empírica es de suma importancia para validar la aceptación de una distribución teórica particular –vistas en los capítulos 12 y 113‐ y para analizar su aproximación. Por lo anterior, el estudio de las distribuciones empíricas y sus medidas descriptivas constituyen el objetivo de presente capítulo y es una etapa preliminar al estudio de la inferencia estadística; y no debe perderse de vista el propósito de la información ni olvidar que las inferencias son inciertas y que una parte considerable de la teoría estadística está dedicada en minimizar y medir dicha incertidumbre. Si bien es cierto que cuando se introducen a la computadora los datos crudos nos regresa las distribuciones empíricas y sus medidas descriptivas, para poder interpretarlos correctamente es indispensable conocer sobre la tabulación, el tamaño de los intervalos, algunas reglas, los métodos para graficar los datos empíricos y las definiciones sobre las medidas descriptivas De las tres clases de distribuciones con las que se trabaja en estadística, hasta ahora hemos estudiado las distribuciones de probabilidad de las variables aleatorias discretas y continuas –capítulos 12 y 13‐ que llamadas distribuciones del espacio muestral en la teoría de la probabilidad; en la estadística se conocen como las distribuciones de la(s) población(es); la segunda clase corresponde a las distribuciones de los estadísticos o distribuciones muestrales que vimos en el capítulo anterior. Este capítulo se dedicará al estudio de la tercera clase de distribuciones que se utilizan en las investigaciones estadísticas conocidas como las distribuciones de frecuencias. Al igual que las dos clases de distribuciones anteriores, las distribuciones de frecuencia también se estudiarán en su forma gráfica y se determinarán, por analogías, sus valores de tendencia central, de dispersión, de sesgo y aplanamiento; por la importancia que revisten para verificar si una distribución de frecuencia puede representarse con una distribución normal, como se verá más adelante. Como el nombre del capítulo lo indica, la estadística descriptiva es la rama de la estadística que estudia las técnicas para la correcta descripción de los datos de una muestra que se saca de la población, o bien de la propia población; a través de gráficas y tabulaciones y de sus medidas descriptivas de tendencia central, de dispersión de sesgo y curtosis; con objeto de sintetizar la información que contiene la muestra. Este capítulo lo estudiaremos a partir de un ejemplo y con analogías de los parámetros de las distribuciones teóricas que se estudiaron en el capítulo 11.
Transcript of CAPÍTULO 16 estadística descriptiva...

386 | C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a
Bernardo Frontana de la Cruz
CAPÍTULO 16 ESTADÍSTICA DESCRIPTIVA
16.1 Introducción En general, el investigador que utiliza la estadística está interesado en estimar los
valores que caracterizan a la población ‐ los parámetros‐ a partir de la información que obtiene de una muestra, usa la estadística como apoyo y guía en el avance de su investigación y en el conocimiento en las ciencias y en la ingeniería. Pero esto no es de provecho a menos que pueden primero obtener ciertas medidas descriptivas y algunas distribuciones empíricas con las cuáles puede hacer inferencias. Como veremos en los capítulos de inferencia estadística, siempre debemos hacer suposiciones acerca de la distribución de la población de la que se sacó la muestra, para lo cual la distribución empírica que se obtiene de una muestra sacada cuidadosamente y, además, esta distribución empírica es de suma importancia para validar la aceptación de una distribución teórica particular –vistas en los capítulos 12 y 113‐ y para analizar su aproximación.
Por lo anterior, el estudio de las distribuciones empíricas y sus medidas descriptivas constituyen el objetivo de presente capítulo y es una etapa preliminar al estudio de la inferencia estadística; y no debe perderse de vista el propósito de la información ni olvidar que las inferencias son inciertas y que una parte considerable de la teoría estadística está dedicada en minimizar y medir dicha incertidumbre. Si bien es cierto que cuando se introducen a la computadora los datos crudos nos regresa las distribuciones empíricas y sus medidas descriptivas, para poder interpretarlos correctamente es indispensable conocer sobre la tabulación, el tamaño de los intervalos, algunas reglas, los métodos para graficar los datos empíricos y las definiciones sobre las medidas descriptivas
De las tres clases de distribuciones con las que se trabaja en estadística, hasta ahora hemos estudiado las distribuciones de probabilidad de las variables aleatorias discretas y continuas –capítulos 12 y 13‐ que llamadas distribuciones del espacio muestral en la teoría de la probabilidad; en la estadística se conocen como las distribuciones de la(s) población(es); la segunda clase corresponde a las distribuciones de los estadísticos o distribuciones muestrales que vimos en el capítulo anterior. Este capítulo se dedicará al estudio de la tercera clase de distribuciones que se utilizan en las investigaciones estadísticas conocidas como las distribuciones de frecuencias.
Al igual que las dos clases de distribuciones anteriores, las distribuciones de frecuencia también se estudiarán en su forma gráfica y se determinarán, por analogías, sus valores de tendencia central, de dispersión, de sesgo y aplanamiento; por la importancia que revisten para verificar si una distribución de frecuencia puede representarse con una distribución normal, como se verá más adelante.
Como el nombre del capítulo lo indica, la estadística descriptiva es la rama de la estadística que estudia las técnicas para la correcta descripción de los datos de una muestra que se saca de la población, o bien de la propia población; a través de gráficas y tabulaciones y de sus medidas descriptivas de tendencia central, de dispersión de sesgo y curtosis; con objeto de sintetizar la información que contiene la muestra.
Este capítulo lo estudiaremos a partir de un ejemplo y con analogías de los parámetros de las distribuciones teóricas que se estudiaron en el capítulo 11.

C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a | 387
Bernardo Frontana de la Cruz
16.2 Tabulaciones de la muestra Supongamos una investigación que tiene por objeto conocer la resistencia generada
por una aleación de titanio, para lo cual se prueban 100 especímenes cuyos resultados en libras/pulgada cuadrada ‐psi‐ aparecen en la tabla 16.1
Tabla 16.1 resultados de la prueba a la resistencia de la aleación de titanio (psi)
139 153 154 136 166 169 147 152 156 154142 144 150 145 145 146 157 125 144 132150 154 148 149 160 147 158 164 153 135152 150 166 158 138 151 147 136 160 160154 150 151 154 138 154 158 134 146 154156 148 153 151 150 158 168 139 139 164160 148 138 141 158 156 167 155 144 147161 159 149 146 156 152 130 137 142 152163 141 148 139 153 171 141 143 156 164166 135 158 155 138 136 136 150 159 173
Estos datos prácticamente no proporcionan al investigador información alguna
sobre la resistencia de la aleación de titanio para tomar decisiones; por lo cual es necesario representarlos de alguna forma, obteniendo la información disponible lo más completa posible sacrificando el detalle de las observaciones originales.
Si se elige la forma tabular, son necesarias las siguientes definiciones. El rango es análogo a la definición dada en la sección 11.4.3 y se define como la
diferencia entre los valores máximo y mínimo de la muestra y corresponde a la longitud del intervalo donde se localizan todos los valores de la muestra:
á í (16.1)
Donde á es el valor máximo y í es el valor mínimo de la muestra,
respectivamente. De la muestra, para nuestro caso se tiene á 173 y í 125 con los cuáles 173 125 48 Conocido el rango, el siguiente paso consiste en agrupar los datos de manera
conveniente manteniendo una buena aproximación general de los valores registrados que se pierden en este paso. El número de grupos a seleccionar depende del rango, del tamaño de la muestra y del tamaño conveniente de cada grupo. Como se verá más adelante, si se seleccionan pocos grupos las pequeñas variaciones de los datos pueden confundir la visión general y, en contraparte, si se eligen muchos grupos no se obtiene una visión adecuadamente detallada. Los grupos se obtienen dividiendo el rango en intervalos que se conocen como intervalos de clase, dentro de los cuáles se colocan las observaciones correspondientes
Existen varias reglas empíricas para determinar el número de grupos o intervalos de clase, una de ellas consiste en dividir al rango entre 10 y 20 intervalos de clase, otra es

388 | C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a
Bernardo Frontana de la Cruz
la regla de Stirling dada por 3.3 1; otra más estipula que el número de intervalos es igual a la raíz cuadrada del tamaño de la muestra
√ . Estas u otras reglas para determinar el número de intervalos dependen a fin de cuentas de la experiencia y el buen juicio del investigador.
Aplicando estas reglas a nuestro ejemplo de la aleación de titanio se tiene
a) Elegir entre 10 y 20: se seleccionaría 10 b) Si Stirling, 3.3 100 1; se elegirían 14 o 15 c) Si √100 10
Debido a la experiencia, el investigador de nuestro ejemplo decide elegir 10
intervalos de clase y requiere conocer el intervalo de cada una dividiendo el rango entre el número de intervalos
ñ 4810 4,8~5
Conociendo el tamaño de los intervalos, se construye la tabla de todos los intervalos
comenzando con el valor más pequeño de la muestra y añadiendo 4 unidades puesto que el más pequeño ya está incluido, así, el primer intervalo será 125 ≤ x < 130 cuyas 5 unidades son 125, 126,127,128 y 129; razón por la cual se excluye el valor 130. Continuando de esta forma se tiene la columna de los intervalos de clase que corresponde a la primera de la tabla 16.1.
A los valores extremos de los intervalos de clase se llaman límites o fronteras de clase, y a los valores medios de las clases que representan las clases se les llama marcas de clase y las representaremos con ; las cuáles aparecen en la segunda columna de la tabla.
Determinados los intervalos y las marcas de clase, el siguiente paso consiste en observar cada elemento para ver a que intervalo corresponde y contar al final el número de elementos de la muestra que están contenidos en cada intervalo. El número final de cada intervalo se llama la frecuencia del intervalo ‐que la denotaremos con fr‐ y, para nuestra muestra, estos valores aparecen en la columna 3 de la tabla.
Las frecuencias relativas de los intervalos ‐que las simbolizaremos con frr‐ se obtienen dividiendo a cada una entre el tamaño de la muestra, y aparecen en la cuarta columna; y las frecuencias relativas acumuladas ‐denotadas con frra‐ que están en la última columna de la tabla se calculan de manera similar a como se hizo con las probabilidades acumuladas ‐ver capítulo 9‐ por ejemplo, hasta al límite superior de la primera clase se tiene 0.01 frecuencia relativa acumulada, hasta el límite superior de la segunda se tiene acumulada 0.01 0.03 0.04 y así sucesivamente.
La forma de garantizar que la tabla está construida correctamente consiste en lo siguiente:
1. La suma de las frecuencias debe ser igual al tamaño de la muestra, para nuestro ejemplo debe ser igual a100 como se muestra abajo de la tercera columna.
2. La suma de las frecuencias relativas debe ser igual a 1, como se indica en la cuarta columna, lo que permite decir que la distribución de frecuencias es

C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a | 389
Bernardo Frontana de la Cruz
análoga a una distribución de probabilidades y se llama la distribución empírica.
3. Puesto que hasta el límite superior del último intervalo hemos acumulado todas las frecuencias relativas, se debe tener el valor de uno, como en efecto aparece al final de la última columna. Esta distribución de frecuencias relativas acumuladas ‐frra‐ es análoga a la distribución de probabilidades acumulativa estudiada en el capítulo 9 y se conoce en estadística con el nombre de ojiva.
Tabla 16.2 Tabulación de frecuencias de la aleación de titanio
Intervalos Marcas de clase: x'
fr: frecuencias frr: frecuencias relativas
frra: frecuencias relativas
acumuladas
125 ≤ x < 130 127.5 1 0.01 0.01 130 ≤ x < 135 132.5 3 0.03 0.04 135 ≤ x < 140 137.5 15 0.15 0.19 140 ≤ x < 145 142.5 9 0.09 0.28 145 ≤ x < 150 147.5 15 0.15 0.43 150 ≤ x < 155 152.5 24 0.24 0.67 155 ≤ x < 160 157.5 16 0.16 0.83 160 ≤ x < 165 162.5 9 0.09 0.92 165 ≤ x < 170 167.5 6 0.06 0.98 170 ≤ x < 175 172.5 2 0.02 1
Suma 100 1
En esta tabla se han perdido los datos crudos de la muestra pero, a cambio, se ha ganado un conocimiento general de la misma; por ejemplo, al ver la tabla puede observarse que el intervalo 150 ≤ x < 155 contiene la mayor cantidad de los datos de la muestra ‐24‐ y es probable que en dicho intervalo está contenida el promedio o la media de la distribución de los datos; también se observa que en los dos primeros intervalos tan solo se encuentra el 4% de ellos en tanto que los dos últimos contienen el 8%.
A continuación se darán algunas reglas empíricas generales para la construcción de las tabulaciones de los datos de la muestra que ayudan a prevenir confusiones, a construir tabulaciones eficientes y a facilitar el ajuste de las distribuciones de frecuencia a las distribuciones teóricas que se requieren en la inferencia estadística, tomando en cuenta que siempre hay excepciones.
a) Se sugiere que el número de intervalos sea entre 10 y 20 ya que si es menor puede suceder que el ajuste de una distribución teórica a los datos sea inefectivo y, por el contrario, si es mayor que 20 se genera confusión en la interpretación de la tabulación y aumenta la sensibilidad con pequeñas fluctuaciones en los datos.
b) Si se eligen intervalos abiertos, como en nuestro caso, se debe tener mucho cuidado en la asignación de los elementos que pertenecen a ellos. Para determinar los intervalos cerrados se parte a la mitad la unidad del dígito menos significativo y comenzar el primer valor de los intervalos restándole

390 | C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a
Bernardo Frontana de la Cruz
dicha mitad; bajo esta forma, para nuestro ejemplo, los límites de los intervalos serían
Intervalos 124.5 ≤ x ≤ 129.5 129.5 ≤ x ≤ 134.5 134.5 ≤ x ≤ 139.5 139.5 ≤ x ≤ 144.5 144.5 ≤ x ≤ 149.5 149.5 ≤ x ≤ 154.5 154.5 ≤ x ≤ 159.5 159.5 ≤ x ≤ 164.5 164.5 ≤ x ≤ 169.5 169.5 ≤ x ≤ 174.5
c) Aunque es posible tener intervalos de clase de diferentes tamaños, siempre
es preferible que sean del mismo tamaño, de no ser así las proporciones relativas deben representarse por áreas.
d) Se debe cubrir el rango completo de los datos de la muestra, de lo contrario no se pueden calcular algunos de los estadísticos.
e) Los intervalos nunca deben traslaparse puesto que no puede determinarse dentro de cual intervalo cae algún valor particular.
16.3 Representaciones graficas de las distribuciones empíricas Las representaciones comúnmente utilizadas para graficar los datos de una muestra
son las distribuciones de frecuencia conocidos como histogramas, las distribuciones de frecuencia relativa y las distribuciones de frecuencias relativa acumulada.
16.3.1 Histogramas o diagramas de barras Los histogramas representan pictóricamente a las distribuciones de frecuencia y se
construyen con rectángulos adyacentes como se ilustra en la figura16.1 para el ejemplo de la aleación de titanio, cuyas bases son iguales al tamaño de los intervalos y alturas son iguales a las frecuencias correspondientes a cada intervalo. Si los rectángulos se duplican las alturas serán la mitad de las frecuencias. Para dibujar este histograma se utilizó el paquete Statgraphics, introduciendo los valores de la muestra y, como se observa, dio como resultado un histograma con 8 intervalos de manera automática.
Para que la presentación sea clara y a la vez sencilla como sucede en la literatura científica, la gráfica debe contener el título resumido, la ecuación utilizada si es que existe y las unidades de los valores de la muestra. Los ingenieros y científicos que trabajan con la estadística prefieren la claridad de las expresiones en lugar de la complejidad innecesaria.
Otra forma de dibujar las distribuciones de frecuencia es por medio de los
diagramas de barras como se muestran en las figuras 16.2 a 16.4

C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a | 391
Bernardo Frontana de la Cruz
Otra forma de dibujar las distribuciones de frecuencia es por medio de los
diagramas de barras como se muestran en las figuras 16.2 a 16.4. Como se observa, el primero de ellos se construyó con tres intervalos de clase y el segundo con 25; si se observa, en ellos pueden verse con claridad las limitaciones señaladas en la sección anterior; por otra parte, el diagrama de barras de la figura 16.4 se construyó con los 10 intervalos utilizados para la tabulación del ejemplo que venimos trabajando. Si se observa, este diagrama proporciona una representación más clara de la distribución de frecuencias y en él los rectángulos están centrados en las marcas de clase que aparecen en la segunda columna de la tabla 16.2.
Figura 16.1 Histograma de la aleación de titanio
psi
frecu
enci
a
120 130 140 150 160 170 1800
5
10
15
20
25
30
0
10
20
30
40
50
60
70
124.5 ‐ 141.5 141.5 ‐ 158.5 158.5 ‐ 175.5
frecue
ncias
psi
Figura 16.2 Diagrama de barras con 3 intervalos

392 | C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a
Bernardo Frontana de la Cruz
Figura 16.4 Diagrama de barras de la aleación del titanio
psi
122.5 127.5 132.5 137.5 142.5 147.5 152.5 157.5 162.5 167.5 172.5 177.5
fr: fr
ecue
ncia
0
5
10
15
20
25
30
0
2
4
6
8
10
12frecue
ncias
psi
Figura 16.3 Diagrama de barras con 25 intervalos

C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a | 393
Bernardo Frontana de la Cruz
16.3.2 Polígonos de frecuencia relativa y de frecuencia relativa acumulada Los polígonos de frecuencia son representaciones diferentes de los histogramas. El
de frecuencias relativas se construye uniendo con líneas rectas los puntos (marca de clase, frecuencia relativa de la clase); para el ejemplo del titanio dicho polígono aparece en la figura 16.5 en la cual el segundo punto del polígono correspondiente al ejemplo del titanio es (127.5, 0.01), el tercero (132.5, 0.03) y así sucesivamente. Cabe observar que para cerrar el polígono se añaden intervalos del mismo tamaño en los extremos cuyos puntos de cierre son (las marcas de clase, frecuencia = 0). Esta es la distribución empírica análoga a las distribuciones teóricas.
Figura 16.5 Polígono de frecuencias relativas
de la aleación del titanio
psi
115 120 125 130 135 140 145 150 155 160 165 170 175 180 185
frr :
frecu
enci
a re
lativ
a
0.00
0.05
0.10
0.15
0.20
0.25
0.30
Por otro lado, el polígono de frecuencias relativas acumuladas se construye uniendo
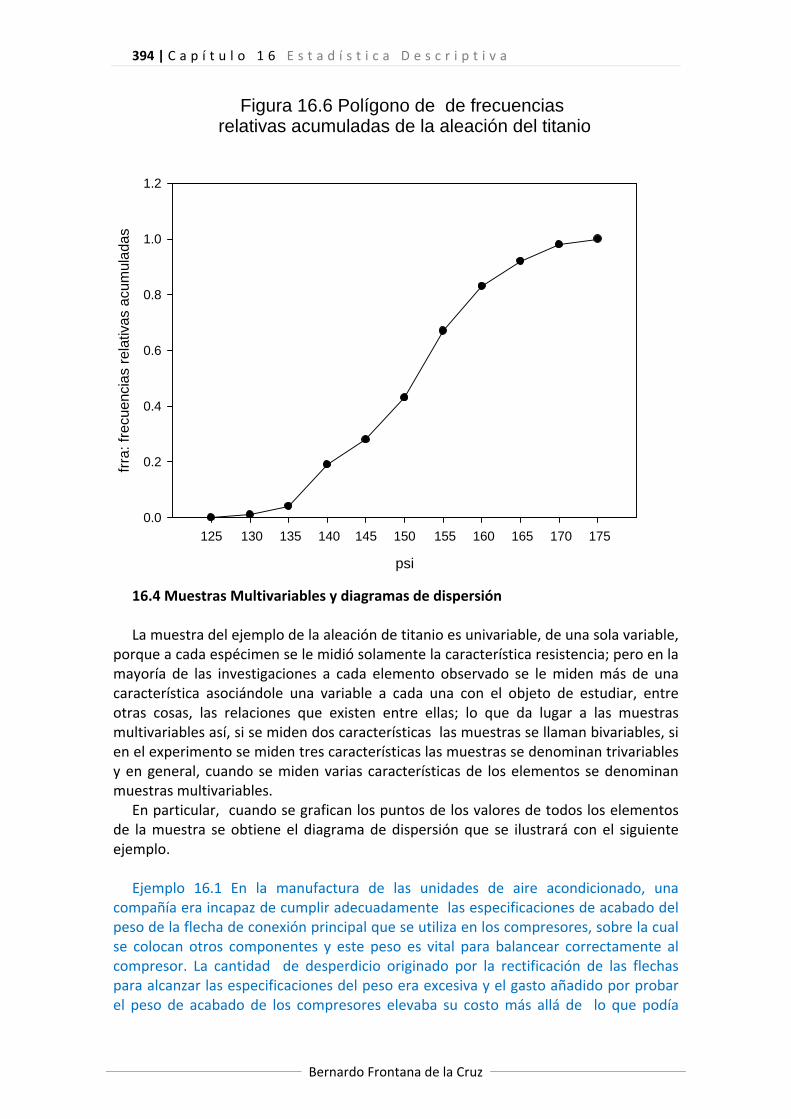
con líneas rectas los puntos (límite superior de la clase, frecuencia relativa acumulada de la clase) comenzando con el punto (límite inferior de la clase 1, 0) y terminando con el punto (límite superior de la clase 1, 1) puesto que en el primero la frecuencia relativa acumulada es 0 y en el ultimo es 1. Para el ejemplo de la aleación de titanio este polígono aparece en la figura 16.6. Cabe observar la similitud que existe entre este polígono de frecuencias relativas acumuladas y la distribución de probabilidades acumuladas estudiada en el capítulo 9.
394 | C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a
Bernardo Frontana de la Cruz
Figura 16.6 Polígono de de frecuencias relativas acumuladas de la aleación del titanio
psi
125 130 135 140 145 150 155 160 165 170 175
frra:
frec
uenc
ias
rela
tivas
acu
mul
adas
0.0
0.2
0.4
0.6
0.8
1.0
1.2
16.4 Muestras Multivariables y diagramas de dispersión La muestra del ejemplo de la aleación de titanio es univariable, de una sola variable,
porque a cada espécimen se le midió solamente la característica resistencia; pero en la mayoría de las investigaciones a cada elemento observado se le miden más de una característica asociándole una variable a cada una con el objeto de estudiar, entre otras cosas, las relaciones que existen entre ellas; lo que da lugar a las muestras multivariables así, si se miden dos características las muestras se llaman bivariables, si en el experimento se miden tres características las muestras se denominan trivariables y en general, cuando se miden varias características de los elementos se denominan muestras multivariables.
En particular, cuando se grafican los puntos de los valores de todos los elementos de la muestra se obtiene el diagrama de dispersión que se ilustrará con el siguiente ejemplo.
Ejemplo 16.1 En la manufactura de las unidades de aire acondicionado, una
compañía era incapaz de cumplir adecuadamente las especificaciones de acabado del peso de la flecha de conexión principal que se utiliza en los compresores, sobre la cual se colocan otros componentes y este peso es vital para balancear correctamente al compresor. La cantidad de desperdicio originado por la rectificación de las flechas para alcanzar las especificaciones del peso era excesiva y el gasto añadido por probar el peso de acabado de los compresores elevaba su costo más allá de lo que podía

C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a | 395
Bernardo Frontana de la Cruz
ofrecerse. El ingeniero de producción consideró que si se pesaban los moldes rugosos o sin maquinar antes y después de maquinarlos podía tener información sobre el peso de la flecha acabada, tomó una muestra de 25 moldes y midió cada uno antes y después de maquinarlo. Los resultados se presentan en la tabla 16.3.
Tabla 16.3 Peso de los moldes rugosos y acabados
Número de molde peso rugoso (kg) peso maquinado (kg)
1 6.053 4.586
2 5.954 4.509
3 5.931 4.520
4 5.909 4.421
5 5.898 4.487
6 5.887 4.487
7 5.876 4.454
8 5.865 4.421
9 5.854 4.432
10 5.854 4.410
11 5.843 4.410
12 5.843 4.421
13 5.832 4.443
14 5.810 4.388
15 5.799 4.388
16 5.788 4.399
17 5.788 4.377
18 5.777 4.344
19 5.766 4.377
20 5.766 4.388
21 5.766 4.399
22 5.755 4.388
23 5.711 4.355
24 5.711 4.399
25 5.656 4.311
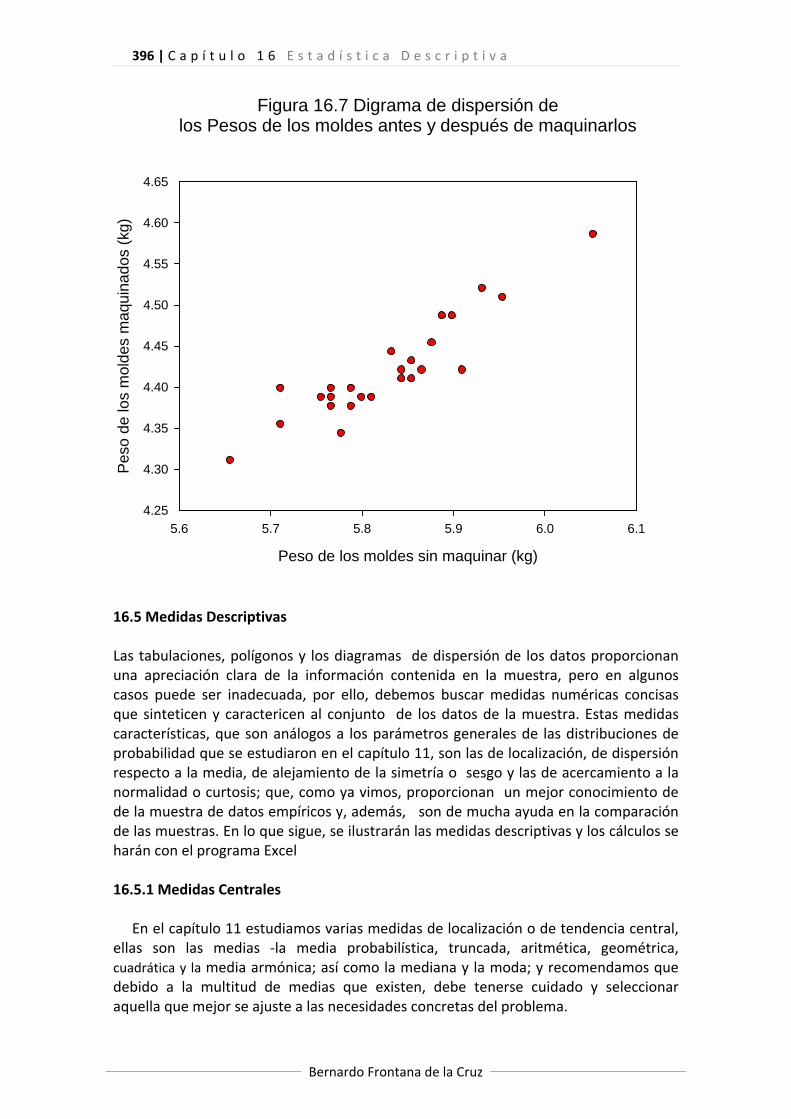
El diagrama de dispersión correspondiente aparece en la figura 16.7 en la que se
observa una tendencia lineal positiva, es decir, al aumentar el peso de los moldes sin maquinar, aumentan los pesos de los maquinados.
Estos diagramas de mucha utilidad para analizar la correlación de las variables y
determinar las líneas de regresión que se estudiarán en un capítulo posterior.
396 | C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a
Bernardo Frontana de la Cruz
Figura 16.7 Digrama de dispersión delos Pesos de los moldes antes y después de maquinarlos
Peso de los moldes sin maquinar (kg)
5.6 5.7 5.8 5.9 6.0 6.1
Pes
o de
los
mol
des
maq
uina
dos
(kg)
4.25
4.30
4.35
4.40
4.45
4.50
4.55
4.60
4.65
16.5 Medidas Descriptivas Las tabulaciones, polígonos y los diagramas de dispersión de los datos proporcionan una apreciación clara de la información contenida en la muestra, pero en algunos casos puede ser inadecuada, por ello, debemos buscar medidas numéricas concisas que sinteticen y caractericen al conjunto de los datos de la muestra. Estas medidas características, que son análogos a los parámetros generales de las distribuciones de probabilidad que se estudiaron en el capítulo 11, son las de localización, de dispersión respecto a la media, de alejamiento de la simetría o sesgo y las de acercamiento a la normalidad o curtosis; que, como ya vimos, proporcionan un mejor conocimiento de de la muestra de datos empíricos y, además, son de mucha ayuda en la comparación de las muestras. En lo que sigue, se ilustrarán las medidas descriptivas y los cálculos se harán con el programa Excel 16.5.1 Medidas Centrales
En el capítulo 11 estudiamos varias medidas de localización o de tendencia central, ellas son las medias ‐la media probabilística, truncada, aritmética, geométrica, cuadrática y la media armónica; así como la mediana y la moda; y recomendamos que debido a la multitud de medias que existen, debe tenerse cuidado y seleccionar aquella que mejor se ajuste a las necesidades concretas del problema.

C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a | 397
Bernardo Frontana de la Cruz
En los siguientes apartados de esta sección estudiaremos estas medidas de localización analizando las analogías con relación a los parámetros definidos en el capítulo mencionado.
16.5.1.1 La media, media aritmética o Promedio ‐ ‐
Si la media probabilística de una distribución de probabilidades de una variable
aleatoria discreta se definió como la suma ponderada de los valores de la variable aleatoria pesados por sus probabilidades correspondientes,
Como la muestra se saca de la población aleatoriamente, cada elemento tiene la
misma probabilidad de ser elegida y si es de tamaño es , la probabilidad es ; que al
sustituirla en la expresión anterior se tiene la definición de la media de la muestra
∑ ∑ (16.2)
Cabe observar que esta expresión corresponde a la media aritmética o promedio
definida en el capítulo 11 y, no menos importante, que también corresponde a los valores del estadístico media que estudiamos en el capítulo anterior.
Con referencia al ejemplo de la aleación de titanio la media es
139 142 150 152 164 173150.34
Cuando los datos están agrupados la media se calcula sumando el producto de
las marcas de clase por las frecuencias de las clase y dividiendo entre el tamaño de la muestra, la ecuación es
∑
(16.3)
Que aplicándola al ejemplo de la aleación de titanio nos da 127.5 1 132.5 3 167.5 6 172.5 2
10015075100 150.75
16.5.1.2 La media Geométrica ‐ ‐ Esta media guarda correspondencia con la ecuación (11.6) y se define como
… ∏ (16.4)

398 | C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a
Bernardo Frontana de la Cruz
La principal utilidad de esta media es la trasformación en el manejo estadístico
de variables con distribución no normal y cuando se necesita multiplicar los datos de la muestra para producir un total; y conviene tener presente que esta media es menos sensible que la media a los valores extremos, y sus principales desventajas son que su cálculo es más difícil, no está determinada para 0, y sólo se aplica si todos los valores de la muestra son positivos.
Para el ejemplo que nos ocupa su valor es
√139 142 150 … 152 164 173 150.01 Con base en los resultados de las medias anteriores se verifica ‐y en lo general
puede demostrarse‐ que la media aritmética siempre es igual o superior a media geométrica:
(16.5)
En efecto 150.34 150.01 16.5.1.3 La media armónica ‐x ‐ Al igual que la anterior, esta media se utiliza para muestras que no contengan el
0 y, en analogía con la ecuación (11.7) se define como
x∑
(16.6)
Las principales ventajas que tiene esta media son que resulta la baja influencia
por los valores grandes en la muestra, en ciertos casos es más representativa que la media; a cambio, sus principales desventajas consisten en que si se influencía por los valores pequeños, no está determinada para valores iguales a cero; por eso no es aconsejable su empleo en muestras donde existan valores muy pequeños.
Para nuestro ejemplo se tiene
x100
1139
1142
1150
1152
1164
1173
149.69
16.5.1.4 Media Cuadrática, valor medio cuadrático o RMS ‐x ‐ Es una medida de localización de la magnitud de una cantidad variable que
puede calcularse para variables aleatorias discretas ‐que incluyen el cero o valores negativos‐, o continuas; y se define como la raíz cuadrada de la media aritmética de los cuadrados de los valores:

C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a | 399
Bernardo Frontana de la Cruz
x (16.7)
Para nuestro ejemplo tenemos
x 150.663
Independientemente de los signos de los valores de la muestra ‐como ocurre en los errores de las mediciones‐esta media no se influye los efectos del signo y proporciona la unidad de medida original.
16.5.1.5 Media Truncada o acotada ‐ ‐ Para evitar la influencia de los valores extremos menores y mayores de los datos
de la muestra, como sucede en la media aritmética o promedio , esta de medida de localización solamente toma en cuenta los valores comprendidos entre el segundo y el tercer fractil – o cuantil‐ conocido como el rango intercuartilítico. Para estudiarla nos apoyaremos en los cuantiles o fractiles definidos en el capítulo 11.
16.5.1.5.1 Cuantiles o fractiles ‐ ‐ El fractil o cuantil de los datos de una muestra, denotado con , se define
como el valor de la muestra que hasta ese valor acumula % o fracción de ella, cuando se arreglan en orden ascendente. Cabe observar que el fractil debe corresponder a un valor de la muestra y suele darse en porcentaje o en fracción de la unidad. Así, . = significa el valor de la muestra que hasta ese punto acumula el 0.25 o el 25% de sus valores, cuando los datos están arreglado en orden ascendente; o bien, . es el valor de la muestra que hasta ese punto acumula 0.75 o el 75 % de los valores de la muestra. En estos dos casos se dice que
. y . son los fractiles 0.25 y 0.75, los cuantiles 25% y 75% o también que son los cuartiles , respectivamente. Los subíndices de significan el número de cuartil, recuérdese que es la mediana que se estudiará más adelante. El rango intercuartilítico es el la longitud del intervalo en el que está incluida la mitad de los valores centrales de la muestra; o sea entre los cuartiles 75% y 25%
Rango intercuartilítico . . (16.8) Con estos antecedentes acerca de los fractiles, definimos la media truncada o
media acotada como el promedio de los valores de la muestra comprendidos en el rango intercuartilítico de la muestra; es decir, el promedio de los valores que no toman en cuenta a los que están antes del primer cuartil y después del tercero.
Al ordenar la muestra de los datos del ejemplo de la aleación de titanio, abajo se presenta una parte de la tabla de los datos ordenados en el rango intercuartilítico.

400 | C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a
Bernardo Frontana de la Cruz
Datos No. espécimen No. intercuartil
144 26 1144 27 2144 28 3… … …
156 73 48156 74 49157 75 50
Con estos datos se tiene
x144 144 144 156 156 157
50 150.72 16.5.1.6 La moda ‐ ‐ Es la medida de tendencia central que se define como el valor de la muestra que
tiene mayor frecuencia o bien la marca de clase del intervalo con mayor frecuencia relativa. Para nuestro ejemplo
x m 154, ya que se repite 7 veces en la muestra. O bien, con referencia a la figura 16.4 x m 152,5 que corresponde a la marca de clase que tiene mayor
frecuncia relativa. Cuando los daros de la muestra están agrupados, la moda se calcula con la
siguiente ecuación x m l ∆ (16.9)
Donde l es el límite inderior de la clase de mayor frecuencia, a es el valor
absoluto de la diferencia entre la frecuencia de esta clase y la de la clase presedente, b es el valor absoluto de la diferencia entre la frecuencia de la clase modal y la de la clase siguiente y ∆ es el ancho de la clase modal; así, para nuestro ejemplo y, con referencia al segmento de la tabla 16.2 mostrada abajo se tiene
145 ≤ x < 150 147.5 15 0.15 0.43 150 ≤ x < 155 152.5 24 0.24 0.67 155 ≤ x < 160 157.5 16 0.16 0.83
x m l ∆ 150 24 1524 15 24 16
5 152.65

C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a | 401
Bernardo Frontana de la Cruz
16.5.1.7 La mediana – , ‐ Otra de las medidas centrales de los datos de una muestra es la mediana que no
se ve influenciada por los valores extremos de la muestra y se define como aquel valor que divide en dos partes iguales a la muestra cuando los datos se encuentran ordenados; como la mediana es el segundo cuartil ‐ ‐ a cada lado de la mediana se tiene 0.5 de frecuencia relativa o el 50% de los datos; es decir:
Si el tamaño de la muestra es y la cantidad de datos de la muestra es impar el valor de la mediana es
/ (16.10)
Y si es par
⁄ (16.11)
Al igual que con la media, la mediana no siempre coincide uno a uno con un valor
de la muestra. Para nuestro ejemplo, 100, con los datos ordenados de menor a mayor, el
valorde la mediana es
2151 151
2 151 Cuando los datos dela muestra están agrupados, el valor aproximado de la
mediana se determina con la siguiente ecuación
l ) ∆ (16.12)
En donde ∆ es el ancho de la clase modal, l es el límite inferior de la clase
mediana, n es el tamaño de la muestra, f es la frecuencia de la clase mediana y t es la frecuencia acumulada hasta el intervalos precedente a la clase mediana;así, para el ejemplo de la aleación detitanio y con la sección de la tabla mostrada arriba se tiene
150 ) 5 152.65
En resumen, las diferentes medidas centrales están contenidas en el intervalo
149.5≤ x ≤ 154.5 donde se considera que está concentrada la distribución de frecuencias son:
La media, media aritmética o promedio es 150.34 La media truncada es: x 150.720 La media geométrica es 150.014 La media cuadrática es: x 150.663 La media armónica es: x 149.686

402 | C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a
Bernardo Frontana de la Cruz
La moda es x m 154 ‐7 especímenes con esta medida‐ o x m 152,5 ‐la marca de clase de mayor frecuencia‐ x 152.65, cuando los datos están agrupados La mediana es 151
152.65, cuando los datos están agrupados 16.5.2 Medidas de dispersión de la muestra
Además de las medidas de localización, las de dispersión de la muestra son de igual importancia, y son cantidades que indican la cercanía o el alejamiento de los valores de dicha muestra con respecto a su media ‐ ‐. Las principales medidas de dispersión son la varianza, la desviación estándar, el rango, el rango intercuartilíco y el coeficiente de variación; y son correlativos a los parámetros generales de las distribuciones de probabilidad estudiados en el capítulo 11. A continuación se estudiarán dichas medidas.
16.5.2.1 La Varianza ‐ ‐
Al igual que sucede con las medidas centrales, con los datos de la muestra obtenida se obtienen los valores de los estadísticos ‐estimadores‐ que se llaman estimados del estadístico que se desee calcular; así si se sustituyen los valores de la muestra en el estadístico varianza definido por las ecuaciones (15.15’) y (15.16) del capítulo anterior se obtienen las definiciones de la varianza de una muestra
s ∑ ∑ (16.13)
O
∑ (16.14)
Conviene recordar que esta última expresión corresponde a la varianza insesgada
como lo demostraremos en el próximo capítulo. Los valores de las varianzas de la muestra del ejemplo de la aleación de titanio son
s 150.34 97.184 O
150.34 98.166 Cuando los datos ya están agrupados, la varianza aproximada se calcula
mediante las expresiones
s∑ ∑
(16.15)

C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a | 403
Bernardo Frontana de la Cruz
∑ ∑
(16.16)
Con apoyo en la tabla 16.2 para nuestro ejemplo se tiene
Intervalos Marcas de clase: x'
fr: frecuencias frr: frecuencias relativas
frra: frecuencias relativas
acumuladas
125 ≤ x < 130 127.5 1 0.01 0.01 130 ≤ x < 135 132.5 3 0.03 0.04 135 ≤ x < 140 137.5 15 0.15 0.19 140 ≤ x < 145 142.5 9 0.09 0.28 145 ≤ x < 150 147.5 15 0.15 0.43 150 ≤ x < 155 152.5 24 0.24 0.67 155 ≤ x < 160 157.5 16 0.16 0.83 160 ≤ x < 165 162.5 9 0.09 0.92 165 ≤ x < 170 167.5 6 0.06 0.98 170 ≤ x < 175 172.5 2 0.02 1
Suma 100 1
s 127.52 172.52 1 127.5 2 172.5 296.188
Y para la varianza insesgada
127.52 172.52 1 127.5 2 172.5 297.159
16.5.2.2 La desviación estándar ‐ ‐ En virtud de que la varianza tiene las unidades de al cuadrado, entonces se
utiliza la desviación estándar que se define como la raíz cuadrada de la varianza para obtener las unidades originales.
√s (16.17)
O √s (16.18) Para nuestro ejemplo se tiene
√97.184 9.858 √98.166 9.908

404 | C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a
Bernardo Frontana de la Cruz
Si calculamos un intervalo que en valor absoluto este alejado de la media una
desviación estandar se tiene s x s 150.34 9.858 x 150.34 9.858 140.4321213 x
160.2478787 Si contamos el número de elementos de la muestra contenidos en este intervalo
observamos que son 68, por lo que una regla práctica consiste en que aproximadamente el 68% de los datos de la muestra están contenidos en un intervalos de .
16.5.2.3 El rango ‐ r ‐ Esta medida ya la estudiamos al hacer la tabulación y aparece en la ecuación
(16.1), y corresponde a la longitud de intervalo donde se encuentran todos los valores de la muestra; para nuestro ejemplo tenemos
173 125 48
16.5.2.4 El rango intercuartilítico El rango intercuartilítico ya se definió y está dado por la ecuación (16.8) como la
longitud de intervalo donde se encuentran la mitad de los valores centrales de la muestra comprendidos ‐entre el primero y el tercer cuartil‐; es decir, que excluye a los valores que están antes del primer cuartil y después del tercero. Para el ejemplo que venimos trabajando tenemos
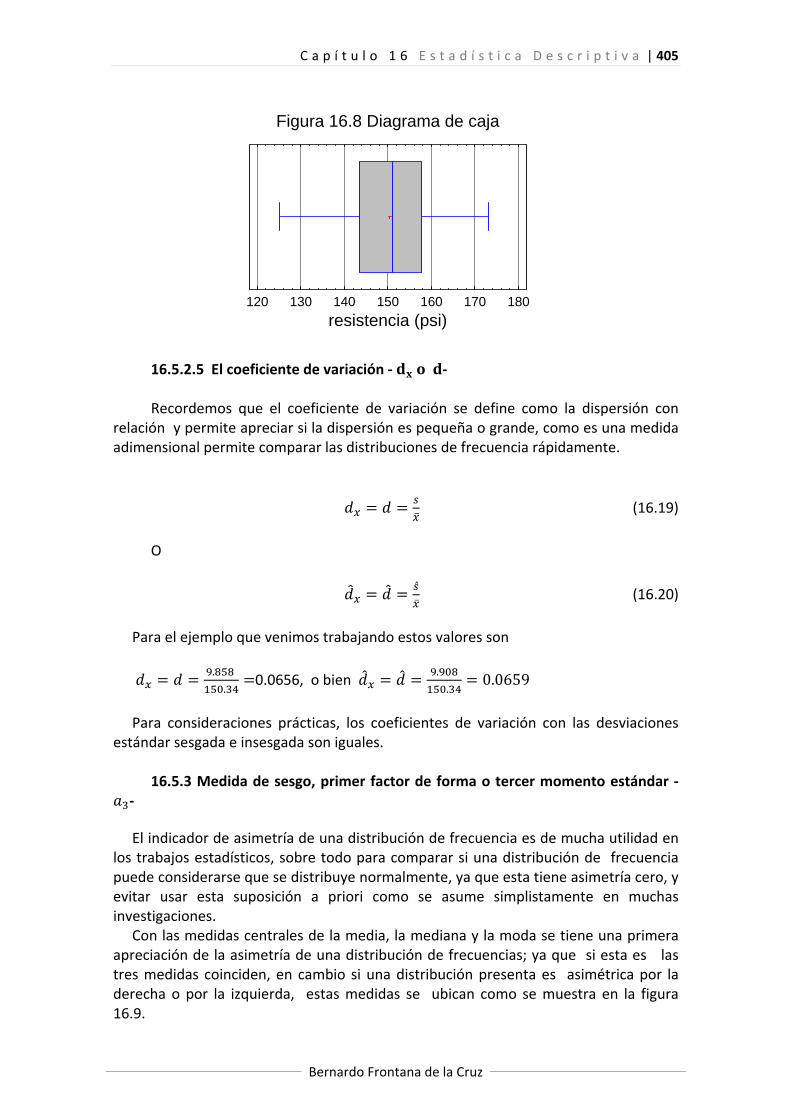
Rango intercuartilítico 157 144 13 El diagrama de la figura 16.8, conocido como Diagrama de Caja o de Caja y
Bigotes refleja algunos de los resultados determinados en nuestro ejemplo de la aleación de titanio; ellos son, los valores mínimo y máximo de la muestra con las rayas verticales extremas, la media con el punto dentro de la caja, el rango intercuartilítico que es el intervalo de la base de la caja, y la caja simboliza la mitad de los valores centrales de la muestra contenidos en el rango intercuartilítico.
C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a | 405
Bernardo Frontana de la Cruz
16.5.2.5 El coeficiente de variación ‐ ‐ Recordemos que el coeficiente de variación se define como la dispersión con
relación y permite apreciar si la dispersión es pequeña o grande, como es una medida adimensional permite comparar las distribuciones de frecuencia rápidamente.
(16.19)
O
(16.20)
Para el ejemplo que venimos trabajando estos valores son
. .
0.0656, o bien ..
0.0659 Para consideraciones prácticas, los coeficientes de variación con las desviaciones
estándar sesgada e insesgada son iguales. 16.5.3 Medida de sesgo, primer factor de forma o tercer momento estándar ‐
‐
El indicador de asimetría de una distribución de frecuencia es de mucha utilidad en los trabajos estadísticos, sobre todo para comparar si una distribución de frecuencia puede considerarse que se distribuye normalmente, ya que esta tiene asimetría cero, y evitar usar esta suposición a priori como se asume simplistamente en muchas investigaciones.
Con las medidas centrales de la media, la mediana y la moda se tiene una primera apreciación de la asimetría de una distribución de frecuencias; ya que si esta es las tres medidas coinciden, en cambio si una distribución presenta es asimétrica por la derecha o por la izquierda, estas medidas se ubican como se muestra en la figura 16.9.
Figura 16.8 Diagrama de caja
resistencia (psi)120 130 140 150 160 170 180
40
Envalormedalta‐una p
Eldesvhay Fishepara normde asde ha
Fi El
distrnúmnúmtieneque y a laes mmed
Adotrasde as
Patercegenelos m
Cocentr
06 | C a p í t
n efecto, si res extremiana ‐ en el; entonces, primera me coeficientiaciones demás valoreer, junto coasumir que
mal. Estas msimetría quacer su gráf
igura 16.9 P
eje de simibución y, sero de valoero de desve asimetría la de la izqua inversa, h
más larga quia a la izquidemás del s medidas msimetría de ara estudiaer y cuarto erales corremomentos conocida unral o mome
u l o 1 6
se toma enos, que ya centro de la posición
edida de la se de asimee la media ses distintos n las medide puede acmedidas de ue presentafica.
Posiciones d
metría es unsi la distribuores a la derviaciones copositiva ‐o uierda, es dhay asimetríe la de la derda. coeficientemás precisaPearson qur los coeficmomentos espondientecentrales dea muestra nto centrad
E s t a d í s t
Bernardo
n cuenta laa se ha cola distribucn relativa desimetría de etría de la son positivaa la derec
das de apunceptarse quasimetría s una distrib
de la media,
na recta parución bajo erecha y a laon signo poa la derechdecir, si hayía negativa erecha, lo q
e de asimetas son el coue no se estcientes de estándar; r
es que se ee manera gede datos ddo de orden
t i c a D e s
o Frontana d
atracción qomentado ción‐ y la moe las mediaduna distribdistribució
as o negativcha de la mntamiento ue la distribon indicadobución esta
, mediana y
ralela al ejeestudio es izquierda dsitivo que ca‐ si la cola valores má‐o a la izquque significa
tría de Fishoeficiente detudiarán en asimetría yrespectivamstudiaron eeneral. de tamañon como
s c r i p t i v
de la Cruz
que la medanteriormeoda ‐ que pdas centraliución. ón proporcivas. Una asimedia. El co curtosis sbución estaores que pedística de
y moda para
e vertical qsimétrica, ede la mediacon signo nea a la derechás separadouierda‐ si laa que hay v
er que se de asimetríaeste libro.
y curtosis tamente ‐que en el capítu
: x1, x2,...,
a
dia aritméticente y las presenta unización pue
iona una idmetría posoeficiente son comúndística siguermiten estuna muest
a distribucio
ue pasa poentonces sea; lo que eqegativo. Poha de la meos de la med cola izquievalores más
definirá má de Bowley
ambién conson análogulo 11‐; nec
, xn; se def
ca siente podefinicione
na ordenadaeden servir c
dea sobre itiva implicade asimetrmente utilize la distribablecer el gra sin nece
ones asimét
or la media e tiene el muivale al mr el contraredia es más dia a la dererda de la ms separados
ás abajo, exy y el coefic
nocidos comos a parámcesitamos d
fine el mom
(1
or los es de a más como
si las a que ría de zadas ución grado esidad
tricas
de la mismo mismo rio, se larga echa; media de la
xisten ciente
mo el metros efinir
mento
16.21)

C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a | 407
Bernardo Frontana de la Cruz
Cabe observar que 1; 0 El coeficiente de asimetría de Fisher es el que se utiliza normalmente porque lo que
interesa es mantener el signo de las desviaciones con respecto a la media, para averiguar si son mayores las que ocurren a la derecha o a la izquierda de la media. Puesto que las desviaciones centrales de orden 1 son iguales a cero y las de orden 2 son iguales a la varianza, entonces las que siguen en sencillez son las de orden 3. El coeficiente de asimetría de Fisher, representado por ‐que en los parámetros generales se denota con ‐ se define como
(16.22)
Donde es el tercer momento en torno a la media y es la desviación estándar. Cabe observar que es un valor sin dimensiones y siempre está conforme al signo de cuyo valor puede ser negativo, cero o positivo; entonces,
Si = 0, la distribución es simétrica. Si > 0, la distribución es asimétrica positiva y su cola está a la derecha Si < 0, la distribución es asimétrica negativa y su cola está a la izquierda Sustituyendo (16.21) en (16.22) para 3 se obtiene
∑
(16.23)
Calculemos el coeficiente de sesgo de Fisher a nuestro ejemplo.
139 150.34 142 150.34 150 150.34 173 150.34 1009.908
0.068
9.907878714 Lo que nos indica que la distribución de frecuencias correspondiente tiene un sesgo
muy pequeño hacia la izquierda. 16.5.4 Parámetro de aplanamiento o curtosis, segundo factor de forma o
cuarto momento estándar ‐ ‐
Con este parámetro se mide la repartición de las frecuencias relativas de los datos de la muestra entre el centro y los extremos, tomando como comparación de referencia la distribución Normal o de Gauss que, como ya vimos, su coeficiente de curtosis es 3; en otros términos, para determinar el aplanamiento de una distribución, se usa la distribución normal estándar como referencia puesto que para ella 3. El indicador usado con más frecuencia para esta medida es el coeficiente de curtosis de Fisher, definido por

408 | C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a
Bernardo Frontana de la Cruz
∑
3 (16.24)
Puesto que todos los valores del primer miembro del lado derecho son positivos
pero pueden ser mayores o menores que 3, entonces el coeficiente de curtosis puede tomar las siguientes magnitudes y significan lo siguiente
Si > 0, la distribución es más picuda de la normal estándar Si = 0, la distribución tiene la misma forma que la distribución normal estándar Si < 0, la distribución menos picuda que la normal estándar Existen otros coeficientes de curtosis como el de Kelley o el percentílico, que no se
estudiarán en este libro. La comparación con la distribución normal permite definir a las distribuciones de
frecuencia como platicúrticas o más aplastadas que la normal; distribuciones mesocúrticas, con igual apuntamiento que la normal; y distribuciones leptocúrticas, esto es, más apuntadas que la normal.
El valor del coeficiente de aplanamiento para nuestro ejemplo es
139 150.34 142 150.34 150 150.34 173 150.34 1009.908 3
0.435
Lo que significa que la distribución de frecuencias de la alación de aluminio es
platicúrticas o sea ligeramente chata en comparación con la forma de la distribución normal estándar.
En resumen, el conocimiento de los valores de localización, dispersión, sesgo y
curtosis, analizados en las secciones anteriores; constituyen el conjunto de valores útiles y necesarios que permiten caracterizar a la distribución de frecuencias de la muestra los cuáles, junto con las tabulaciones, los histogramas y los polígonos de frecuencia nos proporcionan un panorama mucho más amplio de la muestra; que el confuso e indescifrable que nos ofrecen los datos crudos.
16.6 Ajuste de una distribución teórica a los datos de la muestra Otro aspecto importante de las investigaciones estadísticas que nos ofrece la
muestra, con base en la teoría de la probabilidad, consiste en determinar la distribución de la población de donde se sacaron los datos. Salvo que se trabajara un censo en cuyo caso la muestra se convierte en la población misma, en realidad la distribución de la población no se conoce con exactitud; por lo que podemos asumir razonablemente y debemos probar si la distribución de la población propuesta es aquella de la cual se extrajo la muestra. Como vimos anteriormente, las distribuciones de la población son las distribuciones teóricas que estudiamos en los capítulos de las variables aleatorias discretas y continuas –caps. 12 y 13‐

C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a | 409
Bernardo Frontana de la Cruz
La construcción del histograma nos da buena luz para sugerir una distribución particular para la población y probar si esta idea es o no razonable. Estas pruebas de ajuste las estudiaremos en el capítulo siguiente.
En esencia, la técnica para ajustar una distribución teórica a los datos de una muestra consiste en determinar, para cada intervalo de clase, las frecuencias esperadas con base en la distribución teórica o de la población postulada y compararlas con las frecuencias observadas en la muestra, si las discrepancias son muy grandes entonces se rechaza que la muestra observada venga de la distribución de la población propuesta; por el contrario, si las discrepancias son razonablemente pequeñas podemos suponer que la distribución propuesta es una buena aproximación a la de la población.
La técnica para el ajuste consiste de los siguientes pasos: 1. Hacer la tabulación de los datos de la muestra en intervalos de clases y
determinar la frecuencia de cada clase que denotaremos con . Con ella se puede proponer una distribución de la población
2. Si se desconocen los parámetros media ‐ ‐ y desviación estándar ‐ ‐no se proponen, calcular los estimados media ‐ ‐ y desviación estándar ‐ ‐ de la muestra.
3. Estandarizar los límites de clase con la transformación
o (16.25)
4. Calcular las probabilidades de cada intervalo de clase bajo la distribución
teórica supuesta
(16.26)
5. Multiplicar las probabilidades anteriores por el tamaño de la muestra para
obtener las frecuencias esperadas representadas con . 6. Para cada intervalo de clase se encuentra el valor de
(16.27)
7. Para analizar las discrepancias se calculan las sumas de las frecuencias
observadas, las esperados y de ; en particular, como se verá más adelante, esta última suma es necesaria para probar la bondad del ajuste de la distribución de la población supuesta a partir de los datos de la muestra.
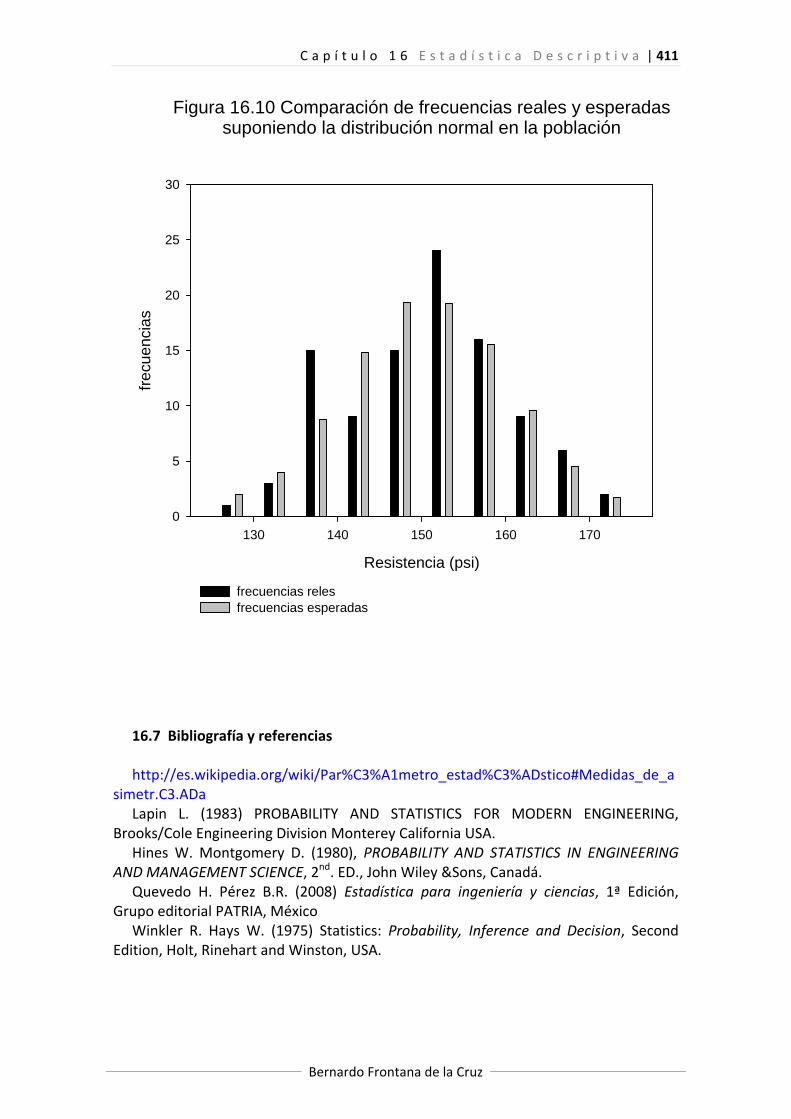
Aplicando este algoritmo al ejemplo de la aleación de titanio se tiene la tabla 16.4
cuya construcción se explica a continuación.
Límites superiores de clase
130 1 ‐2.06 0.0197 0.0197 1.97 0.48 127.5
135 3 ‐1.56 0.0594 0.0397 3.97 0.24 132.5

410 | C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a
Bernardo Frontana de la Cruz
140 15 ‐1.05 0.1469 0.0875 8.75 4.46 137.5
145 9 ‐0.54 0.2946 0.1477 14.77 2.25 142.5
150 15 ‐0.03 0.488 0.1934 19.34 0.97 147.5
155 24 0.47 0.6808 0.1928 19.28 1.16 152.5
160 16 0.98 0.8365 0.1557 15.57 0.01 157.5
165 9 1.49 0.9319 0.0954 9.54 0.03 162.5
170 6 1.99 0.9767 0.0448 4.48 0.52 167.5
175 2 2.50 0.9938 0.0171 1.71 0.05 172.5
Sumas= 100 0.9938 99.38 10.17
Las columnas primera límites superiores de clase‐, segunda valores de las
frecuencias observadas ‐ ‐ y última ya están contenidas en la tabla 16.2 y no requieren explicación. La columna de las marcas de clase ‐ ‐ puede evitarse pero se puso para facilitar la grafica.
Si se observa la Figura 16.4 se presume que los datos emergieron de una población que se distribuye normalmente, pero como no se sugieren los valores de sus parámetros media ‐ ‐ y desviación estándar ‐ ‐, entonces los valores de la columna corresponden a los estandarizados de los límites superiores de los intervalos, con
los estimados media ‐ 150.34‐ y desviación estándar – 9.86‐ de la muestra calculados previamente.
Entrando con los valores anteriores a la tabla de la distribución normal, se determinan los de la probabilidad acumulada , con ellos se determinan las probabilidades para cada intervalo de clase.
Los valores de las frecuencias esperadas ‐ ‐ se obtienen multiplicando las probabilidades anteriores por el tamaño de la muestra 100.
Finalmente, los valores de se determinan aplicando la ecuación (16.27). La gráfica comparativa de y aparece en la Figura 16.10,
C a p í t u l o 1 6 E s t a d í s t i c a D e s c r i p t i v a | 411
Bernardo Frontana de la Cruz
Figura 16.10 Comparación de frecuencias reales y esperadassuponiendo la distribución normal en la población
Resistencia (psi)
130 140 150 160 170
frecu
enci
as
0
5
10
15
20
25
30
frecuencias relesfrecuencias esperadas
16.7 Bibliografía y referencias http://es.wikipedia.org/wiki/Par%C3%A1metro_estad%C3%ADstico#Medidas_de_a
simetr.C3.ADa Lapin L. (1983) PROBABILITY AND STATISTICS FOR MODERN ENGINEERING,
Brooks/Cole Engineering Division Monterey California USA. Hines W. Montgomery D. (1980), PROBABILITY AND STATISTICS IN ENGINEERING
AND MANAGEMENT SCIENCE, 2nd. ED., John Wiley &Sons, Canadá. Quevedo H. Pérez B.R. (2008) Estadística para ingeniería y ciencias, 1ª Edición,
Grupo editorial PATRIA, México Winkler R. Hays W. (1975) Statistics: Probability, Inference and Decision, Second
Edition, Holt, Rinehart and Winston, USA.

Nombre de archivo: CAPÍTULO 16 estadística descriptiva (Reparado2).docx Directorio: C:\Documents and Settings\bfc\Mis documentos\g‐1)
Capítulos de mi libro de Probabilidad y estadística 2007‐2009 Plantilla: C:\Documents and Settings\bfc\Datos de
programa\Microsoft\Plantillas\Normal.dotm Título: Asunto: Autor: fACULTAD DE INGENIERÍA Palabras clave: Comentarios: Fecha de creación: 11/01/2010 15:32:00 Cambio número: 37 Guardado el: 16/06/2010 20:18:00 Guardado por: FACULTAD DE INGENIERÍA Tiempo de edición: 2,440 minutos Impreso el: 30/08/2010 13:10:00 Última impresión completa Número de páginas: 26 Número de palabras: 7,692 (aprox.) Número de caracteres: 42,308 (aprox.)




