
Agrupamiento de Datos de Sección Cruzada · 16 Unión de corte transversal y series de tiempo Este...
83
Cochabamba, enero de 2013 Julio Humérez Quiroz Universidad Mayor de San Simón Facultad de Ciencias Económicas y Financieras Carrera de Economía Econometría de Datos de Panel Agrupamiento de Datos de Sección Cruzada
Transcript of Agrupamiento de Datos de Sección Cruzada · 16 Unión de corte transversal y series de tiempo Este...

Cochabamba, enero de 2013
Julio Humérez Quiroz
Universidad Mayor de San SimónFacultad de Ciencias Económicas y Financieras
Carrera de EconomíaEconometría de Datos de Panel
Agrupamiento de Datos de SecciónCruzada
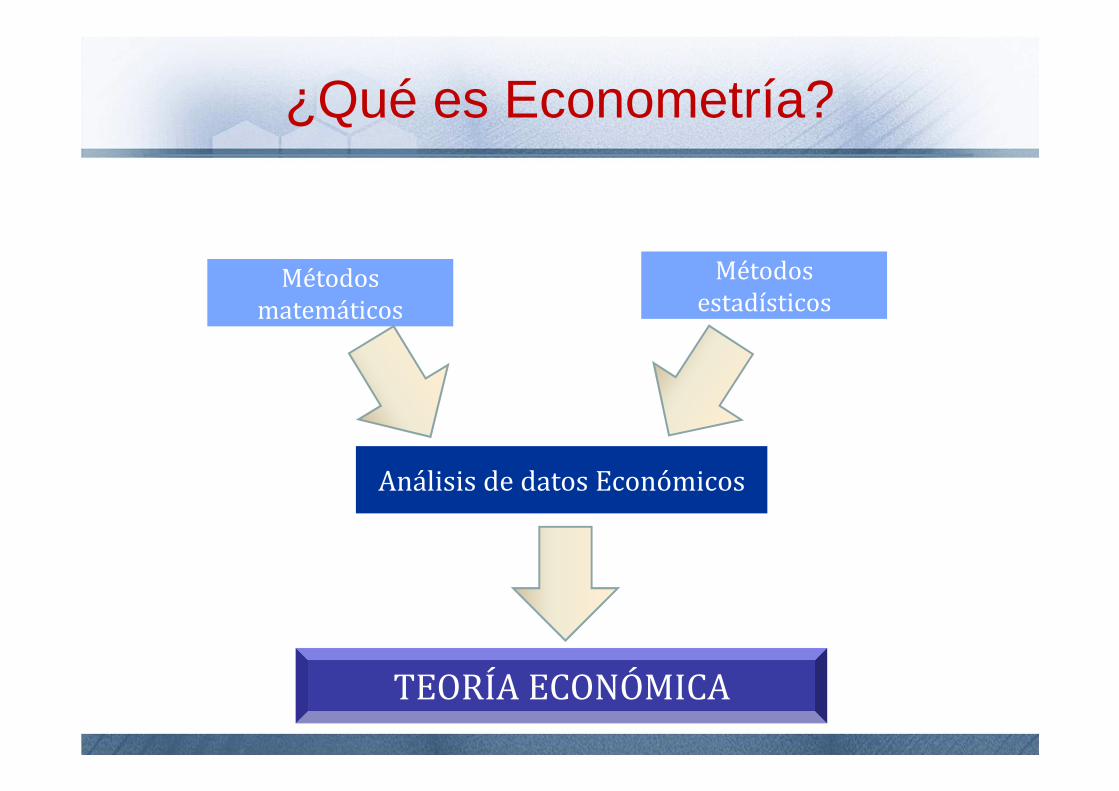
¿Qué es Econometría?
Análisis de datos Económicos
Métodos matemáticos
Métodos estadísticos
TEORÍA ECONÓMICA

TEORÍA ECONÓMICA
E.T. (libro de texto)
EstáticaAC como «patología»«particular-a-gral»
70`s Datos
E.D. A.S.T.(Box y Jenkins)
VAR(Sims et al.)
80`s
PGD: modeloEstadísticoEconómico
ExogeneidadWESESuE
TestsEC
«Gral-a-Part.»(Hendry et al.)
Co-I «Part-a-Gral.»(Engle y Granger)
Evolución de los dos principales enfoques de la Econometría
Panel Data
Calibración (Kydland y
Prescott, 1982)

Escuelas metodológicas actuales en Econometría
Evolución de los dos principales enfoques de la Econometría
MetodologíaUtiliza la teoría
económicaUtiliza el análisis
estadístico clásico
1. MCO Si Si
2. VAR No Si
3. Bayesiana Si No
Modelística General –a-ParticularM1 Modelo general (dinámico) SPGM ¿OK? ⇒ OK.M2 Restricciones impuestas sobre M1 SPGM ¿OK? ⇒ OKM3 Restricciones sobre M2 SPGM ¿OK? ⇒ OKM4 Restricciones sobre M3 SPGM ¿OK? ⇒ NO!!!SPGM = Supuestos sobre la prueba de Gauss-Markov

Tipos de datos
Una base de datos en panel contiene información para variosindividuos (hogares, personas, empresas, actividades económicas,sectores económicos, regiones, municipios, países, etc.) en eltiempo. (Muestra de individuos a lo largo del tiempo).
Datos de Corte Transversal: j = 1, 2, …, N
Datos de Series de Tiempo: t = 1, 2, …, T
Datos de Panel: j = 1, 2, …, N t = 1, 2, …, T
o Micropaneles (N > T)
o Macropaneles (T > N)
o El aspecto fundamental es esta bi-dimensionalidad de losdatos.
5

Ventajas y desventajas
Ventajas de usar datos de panel
Con N individuos y T periodos podríamos estimar N modelos deseries de tiempo y T modelos de corte transversal.
Ejemplo: yit = xit β + uit
Supone que el modelo lineal subyacente es el mismo para todos los individuos yperiodos.
Las ventajas de disponer de un panel tiene que ver con laposibilidad de agregar esta información de alguna manera, lo queresulta en las siguientes ventajas:
6

Ventajas y desventajas
a) El incremento en el tamaño de la muestra permite obtener estimadores consistentes y estadísticos de prueba más confiables.
b) Una mayor cantidad de datos implica más variabilidad entre ellos, menor colinealidad entre las variables, más grados de libertad y mayor eficiencia en las estimaciones (Hsiao, 2002).
c) Permite responder a preguntas que no pueden ser respondidascon otros datos.
d) Permite investigar si las relaciones entre las variables hancambiado con el tiempo, por medio de la prueba de Chow.
e) Permite realizar evaluaciones de impacto de políticaseconómicas realizadas en un momento determinado.
7

f) Alivia el problema de variables omitidas (Control de«heterogeneidad no-observable»). Por ejemplo, si no varían enel tiempo se pueden eliminar tomando diferencias.
Ejemplo:
wit = β1×educit + β2 × experit + β3× exper2it + ui + εit
g) Permite eliminar sesgos por agregación.
h) Varias más (Baltagi, 2002)
8
Ventajas y desventajas

Desventajas
No siempre es posible agregar información temporal y de cortetransversal (pueden ser más observaciones pero de poblacionesheterogéneas).
Los paneles son costosos de implementar y administrar.
Problemas de selectividad: auto-selección, no respuesta,«attrition».
Dimensión temporal corta.
Métodos econométricos algo más específicos y complejos; menosfamiliares e intuitivos.
Heterogeneidad no tratada.
Paneles incompletos.9
Ventajas y desventajas

MetodologíaTeoría Económica
Yt=ΑΚtαLt
β
Modelo Econométrico
Yt=ΑΚtαLt
βeε
Estimación
Pruebas de Especificación y Examen de Diágnóstico
¿El modelo es adecuado?
Sí
No
Prueba de algunas hipótesis
Uso del modelo para pronóstico y diseño de políticas
Datos

Agenda del Curso
El curso se enfocará en las propiedades asintóticas de losestimadores más que en las propiedades de muestrafinita.
El análisis asintótico nos permitirá dar un tratamientounificado a los distintos procedimientos de estimación ynos permitirá establecer todos los supuestos en términosde la población subyacente.
La primera parte del curso comprenderá modelos condatos de sección cruzada combinadas en el tiempo, queson útiles cuando se desea evaluar el impacto de cambiosde política.
11

Agenda del Curso
La segunda parte del curso trata los modelos estáticos dedatos de panel lineales en los que la teoría asintóticarelevante se da cuando la dimensión de corte transversal sehace grande mientras que los datos de series de tiempo semantienen fijos (N > T).
La tercera parte abarca los modelos dinámicos de datos depanel.
La cuarta parte del curso comprende modelos de datos depanel lineales en los que la teoría asintótica relevantesupone la dimensión temporal haciéndose grande y ladimensión de corte transversal manteniéndose fija (T > N).
12

Agenda del Curso
La evaluación del curso se realizará sobre la base detrabajos prácticos y un examen final.
Ponderaciones:
o Trabajos prácticos 40%
o Examen final 50%
o Asistencia 10%
13

El modelo básico de componentes de error
El modelo básico es:
xit vector de K variables explicativas (incluye una constante)
ββββ es un vector de coeficiente
El término de error incluye dos componentes, uno específicodel individuo y otro de la observación.
14
El modelo básico
1,..., ; 1,...,
it it it
it i it
y x u
u e
i N t T
= +
= +
= =
βµ

Evaluación de impacto de políticas
15
Modelos con datos de sección cruzada, sirven para muestras recolectadas en un mismo momento del tiempo, es decir, una “foto” a la realidad, por lo que las variables son estáticas.
Modelos con series de tiempo, muestran el comportamiento de una variable en un periodo de tiempo, dejando a un lado las relaciones con otras variables.
Este capítulo se enfocará en metodologías que combinan los dos tipos de muestras anteriores, pasando de una “foto” a un “video”, que muestra la dinámica de las variables en el tiempo, por medio de la agrupación de datos de corte transversal a través del tiempo.

16
Unión de corte transversal y series de tiempo
Este capítulo estudia la metodología econométrica que combina los procedimientos con datos de corte transversal y series de tiempo, para estudiar las características del tiempo sobre las relaciones entre las variables explicativas y explicadas.
Entonces los datos tienen dos dimensiones, una que identifica a la unidad de corte transversal (i) y otra para el tiempo (t). Por tanto, se requerirán nuevos procedimientos para explotar las características particulares que ofrece este tipo de datos.
Evaluación de impacto de políticas

17
Naturaleza de los datos de corte transversal agrupados en el tiempo. Existen dos tipos de agrupación:
1. Las muestras que agrupan datos en el tiempo, i.e., muestras aleatorias de corte transversal para la misma población en diferentes periodos del tiempo, pero no necesariamente consideran la misma muestra en cada uno de ellos.
2. Los paneles que agrupan las mismas unidades de corte transversal en diferentes periodos del tiempo, o sea, se agrupan datos de la misma muestra de corte transversal en distintos momentos del tiempo.
Evaluación de impacto de políticas

18
Para entender este tipo de conformación de los datos, se debe contar con un nuevo modelo teórico, mediante el cual se explicarán las características particulares de este tipo de agrupación:
donde Yit es la variable dependiente, Xit y Kit son las variables independientes y uit es el término del error; i denota las unidades de corte transversal de la muestra; t el periodo en el que se encuentra expresado el conjunto de variables para cada unidad de corte transversal i y dentro de un rango finito (1 a T).
0 1 2it it it itY X K uβ β β= + + + (1)
Evaluación de impacto de políticas

19
Corte transversal a lo largo del tiempo
Las muestras de corte transversal a lo largo del tiempo es la primera aproximación a las metodologías con paneles de datos. Esta permite estudiar relaciones entre las variables en distintos periodos del tiempo, facilitando la estimación de los efectos originados por choques exógenos sobre una o varias variables del modelo econométrico.
Estos beneficios no están presentes en los modelos de corte transversal, ya que las muestras son tomadas en un determinado periodo de tiempo y las relaciones entre variables son estudiadas bajo ese contexto, sin permitir comparaciones temporales.
Evaluación de impacto de políticas

Mínimos cuadrados agrupados (MCA)
20
La agrupación de datos permite establecer con mayor claridad los tipos de relación que se pueden generar entre las variables independientes y la explicada (Wooldridge, 2009).
La estimación se realiza a través de mínimos cuadrados agrupados (MCA), que consiste en aplicar el método de MCO a un conjunto de variables evaluadas en distintos periodos del tiempo.
Mínimos cuadrados agrupados (MCA)
Mínimos cuadrados agrupados (pooled OLS, en inglés) sirve para investigar si las relaciones entre las variables (explicativas y explicadas) han cambiado con el paso del tiempo.

Mínimos cuadrados agrupados (MCA)
21
Consiste en realizar estimaciones usando el conjunto de datos, sin hacer ninguna distinción entre grupos. Partiendo de (1) y utilizando el enfoque matricial se tiene:
Donde Yi es el vector de la variable dependiente; Zi es una matriz devariables explicativas y εεεεi es el vector de errores del modelo.
Para obtener los estimadores, se debe estimar (2) través de MCO. Estos resultan consistentes y eficientes como consecuencia del incremento del tamaño de la muestra, respecto a muestras de corte transversal.
Los estimadores están representados por la siguiente expresión:
i i iY Z β ε= + donde [ ]i it itZ X K= (2)

Prueba de Cambio Estructural de Chow
22
De acuerdo a (3) se puede establecer con mayor precisión si las relaciones evaluadas en un modelo de interés varían como consecuencia del paso del tiempo. Para conseguir conclusiones al respecto, se deben llevar a cabo pruebas de cambio estructural de Chow.
Prueba de Cambio Estructural de Chow
Teniendo en cuenta (2) y asumiendo t = 1, 2, el modelo estructural puede desglosarse en dos grupos, correspondientes a dos momentos del tiempo.
( ) ( )1
ˆMCA i i i iZ Z Z Yβ
−
′ ′= (3)

Prueba de Cambio Estructural de Chow
23
De esta forma se puede evaluar qué pasa en cada año con las variables de interés (ecuaciones 4 y 5).
1 0 1 1 2 1 1i i i iY X K uβ β β= + + + (4)Grupo 1:
2 0 1 2 2 2 2i i i iY X K uβ β β= + + + (5)Grupo 2:
Al estimar (4) y (5) mediante en forma agrupada, y por separado, lo que se quiere ver es si existe algún efecto del tiempo sobre las variables. Esto se consigue comparando los estimadores de los grupos 1 y 2. Si se encuentra una diferencia estadística entre ellos, es porque existe cambio estructural. Si los estimadores son los mismos, se dice que las relaciones de las variables no han cambiado en el tiempo.

Prueba de Cambio Estructural de Chow
24
En caso que se detecte cambio estructural, es importante evaluar la fuente de variación de las relaciones en el tiempo (cambio en el intercepto, en pendiente, o una combinación de las dos anteriores) mediante la prueba de Chow.
Cambio en intercepto
La primera causa de cambio estructural se debe a un cambio en el intercepto, i.e., que el paso del tiempo permitió que las variables se desplazaran de manera proporcional en los periodos. Para reconocer este efecto, se transforma el modelo (1) y se añade una variable dummy que separe la muestra en dos periodos. Esta variable se denomina D2 y toma el valor de 1 si t=2, y 0 si t=1. El modelo queda expresado como:

Prueba de Cambio Estructural de Chow
25
Manteniendo las mismas variables iniciales, los valores esperados para Yit están determinados por los periodos en los que están agrupados los datos (ec. (6.1) y (6.2)). Estos definen el pronóstico de la variable dependiente dado el cambio en el tiempo y manteniendo constante las variables explicativas.
1 2 10 2 2it it it iY X K D uβ β β δ= + + + + (6)
[ ]1 1 1 0 1 1 2 12 0| , ,i i i i iE Y KDX K Xβ β β= + += (6.1)
[ ] ( )2 2 2 0 1 2 2 22 1| 1, ,i i i i iE Y X X KDK δβ β β= + + += (6.2)
(t=1)
(t=2)

Prueba de Cambio Estructural de Chow
26
A través de (6.1) y (6.2) se puede identificar la diferencia en los estimadores de cada ecuación. Por ej., la ecuación (6.1) muestra teóricamente tres estimadores (β0, β1, β2), mientras que la ecuación (6.2) solo dos (β1, β2) iguales a (6.1) y uno distinto (β0, δ1).
La diferencia radica en el coeficiente que acompaña a la variable D2
y que se refiere al cambio de periodo en la muestra. Si δ1 resulta significativo estadísticamente, se dice que hay un cambio estructural debido al cambio en intercepto, i.e., un desplazamiento positivo (o negativo) de la curva referente al valor esperado de la variable dependiente Yit (ver gráfico).

Prueba de Cambio Estructural de Chow
27
β0
β0 +δ1
(6.1)
(6.2)( )itE Y
Variables explicativas
δ1

Prueba de Cambio Estructural de Chow
28
Por lo tanto, se debe probar la significancia individual del estimador δ1 en la ecuación (6), por medio de la siguiente prueba de hipótesis:
H0: δ1 = 0 (No existe cambio en intercepto) (7)
H1: δ1 ≠ 0 (Existe cambio en intercepto) (8)
Para encontrar respuesta a la hipótesis de la expresión (7), se utiliza un estadístico t que permite verificar la significancia individual del coeficiente que acompaña a la dummy de tiempo.
Si se rechaza Ho, se concluye que hubo un cambio estructural en el modelo y que el paso del tiempo modificó los efectos de las variables del modelo pero no las relaciones entre ellas.

Prueba de Cambio Estructural de Chow
29
Cambio en pendiente
También pueden existir cambios de pendiente como consecuencia de la introducción de la interacción de D2 con una de las variables explicativas, p.e. Xit, como variable explicativa para el modelo de la ecuación (1). A través de la nueva variable se quiere verificar si la relación entre alguna variable explicativa y la dependiente cambia en el tiempo.
( )0 1 2 22it it it it itY X K D X u×β β δβ= + + + + (9)

Prueba de Cambio Estructural de Chow
30
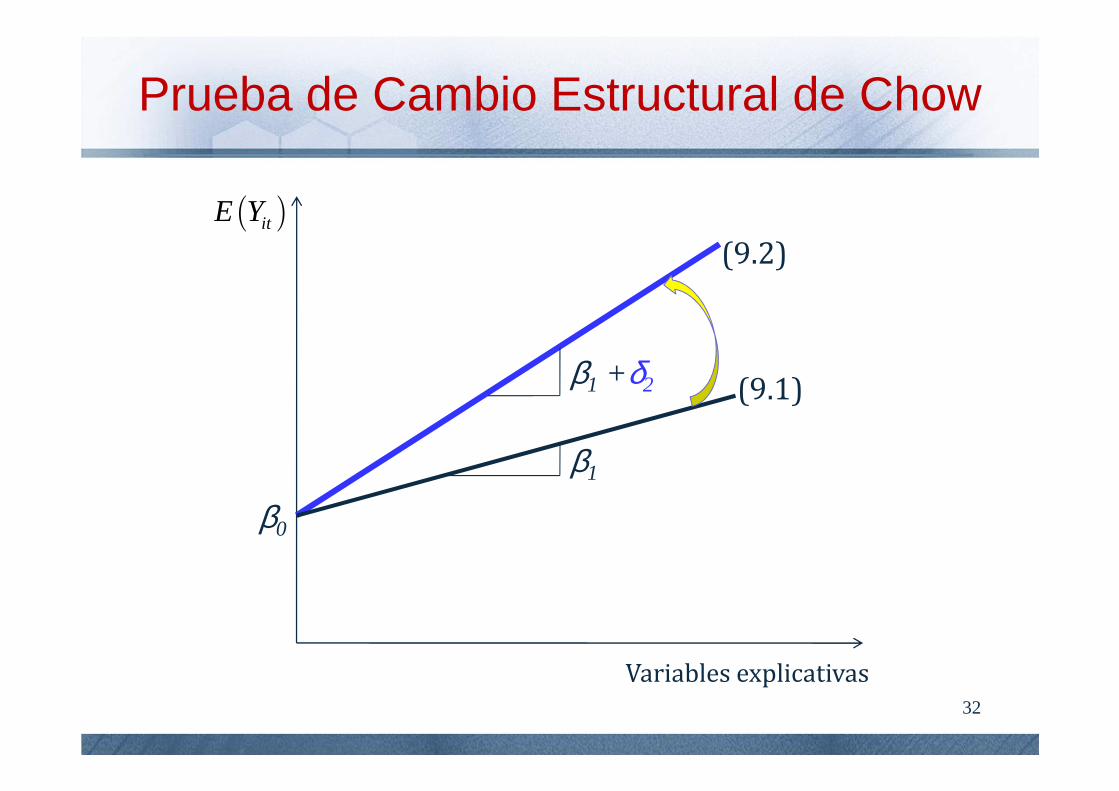
De acuerdo al modelo (9), los valores esperados para Yit dado t=1,2 muestra cómo cambian las relaciones entre la variable explicativa (Xit) y la dependiente (Yit) a través de dos periodos.
Estas expresiones identifican si las relaciones entre las variables del sistema varían como consecuencia del tiempo.
[ ]1 1 1 0 1 1 2 12 0| , ,i i i i iE Y KDX K Xβ β β= + += (9.1)
[ ] ( )2 2 2 0 1 2 2 22 21| , ,i i i i iE Y X K X KD β δβ β= + + += (9.2)
(t=1)
(t=2)

Prueba de Cambio Estructural de Chow
31
Esto se consigue comparando los estimadores correspondientes a cada año de la muestra. La ecuación (9.1) muestra teóricamente tres estimadores (β0, β1, β2), mientras que la ecuación (9.2) muestra dos estimadores (β0, β2) iguales y uno distinto ( β1+ δ2) respecto a (9.1).
La diferencia está en la existencia del coeficiente que acompaña a la variable Xit·D2. Si δ2 resulta significativo, se dice que hay un cambio estructural debido al cambio en pendiente, i.e., genera un movimiento positivo (negativo) de la curva que hace referencia al valor esperado de la variable dependiente.
Prueba de Cambio Estructural de Chow
32
β0
(9.1)
(9.2)( )itE Y
Variables explicativas
β1
β1 +δ2

Prueba de Cambio Estructural de Chow
33
Como en la prueba de cambio en intercepto, se requiere de una prueba de significancia individual que lleve a concluir la existencia de cambio estructural.
H0: δ2 = 0 (No hay cambio en pendiente) (10)
H1: δ2 ≠ 0 (Existe cambio en pendiente) (11)
Si |tc| > |tα/2, n-k |, se rechaza H0, entonces existe un cambio estructural (la relación entre Yit y Xit cambia con el paso del tiempo).

Prueba de Cambio Estructural de Chow
34
Cambio en intercepto y pendiente
Esta prueba mezcla las dos pruebas descritas anteriormente. El nuevo modelo contiene la dummy de tiempo (D2) y la interacciónde ésta con una variable explicativa (Xit·D2). Con esta especificación se quiere probar si la relación entre la variable explicada y una independiente cambia en el tiempo; asimismo si el cambio de periodo tiene algún efecto sobre el modelo a estimar. Por lo tanto, el nuevo modelo está dado por la siguiente ecuación:
0 1 2 2 2 21it it it it itY X K D D X u×β β β δ δ= + + + + + (12)

Prueba de Cambio Estructural de Chow
35
De la ecuación (12), los valores esperados para Yit dado t=1,2 son:
Si conjuntamente δ1 y δ2 resultan conjuntamente significativos, se dice que existió un cambio estructural debido al cambio en intercepto y pendiente, i.e., genera un desplazamiento y movimiento positivo (negativo) de la curva de valor esperado de la variable dependiente Yit.
[ ]1 1 1 0 1 1 2 12 0| , ,i i i i iE Y KDX K Xβ β β= + += (12.1)
[ ] ( ) ( )2 2 2 0 1 2 2 22 1 2| 1, ,i i i i iE KDY X K Xδβ β βδ= + + + += (12.2)
(t=1)
(t=2)

Prueba de Cambio Estructural de Chow
36
β0
(12.1)
(12.2)( )itE Y
Variables explicativas
β1
β1 +δ2
β0 +δ1

Prueba de Cambio Estructural de Chow
37
De acuerdo al gráfico anterior los coeficientes de interés son δ1 y δ2, siendo necesario verificar si los dos, al mismo tiempo, son iguales a cero o no. Para ello se utiliza una estadístico de prueba F. Formalmente,
H0: δ1 = δ2 = 0 (No hay cambio estructural) (13)
H1: δ1 ≠ 0, δ2 ≠ 0 (Existe cambio en intercepto y/o pend.) (14)
Si el estadístico de contraste:
( ) /~ ( , )
/R NR
cNR
SCR SCR JF F J n k
SCR n k
−= −
−

Estimador diferencia en diferencia
38
Si Fc > FJ,n-k, se dice que se rechaza H0, con lo que δ1 y δ2 son conjuntamente significativos. Entonces existe un cambio estructural en el modelo.
Estimador diferencia en diferencia
El estimador diferencia en diferencia (DD) es una alternativa para evaluar de forma directa los efectos de choques exógenos sobre las variables explicativas.
Este procedimiento es útil para explicar el impacto de alguna política económica. A la vez, es utilizada comúnmente en áreas de estudio económico como la evaluación de proyectos.

Estimador diferencia en diferencia
39
El estimador DD se basa en experimentos naturales (o cuasi-experimentos), que ocurren cuando un evento exógeno al modelo, cambia el contexto en que las unidades de corte transversal se comportan. Lo anterior puede determinar que las relaciones económicas entre las variables involucradas en un determinado estudio sean distintas con el paso del tiempo.
Para evaluar dichas variaciones, se debe tener en cuenta (siempre) un grupo de control, que no es afectado por el choque exógeno, y un grupo de tratamiento, que si lo está. Los dos deben ser escogidos de forma aleatoria para evitar sesgos de selección.

Estimador diferencia en diferencia
40
Para revisar las diferencias relativas entre grupos, es pertinente dividir la muestra que caracteriza los datos de corte transversal en distintos periodos de tiempo, teniendo en cuenta escenarios antes y después de ocurrido el evento exógeno. Por lo cual, se tienen en cuenta los grupos de control y tratamiento en cada periodo de tiempo.
donde DT toma el valor de 1 si la unidad de corte transversal está en el grupo de tratamiento y 0 si es del grupo de control. La variables D2
toma el valor de 1 si t=2 y 0 si t=1. De esta manera, si se estima (13) por MCA se obtienen los estimadores de diferencia en diferencia de la forma:
0 1 2 2 3 2·it T T itY D D D D uα α α α= + + + + (13)

Estimador diferencia en diferencia
41
( ) ( )
( ) ( ) ( ) ( )
[ ] [ ]
2 2 1 1
0 1 2 3 0 1 0 2 0
2 3 2
3
ˆ
ˆ ˆ
ˆ ˆ
ˆ ˆ ˆ ˆ ˆ ˆ ˆ ˆ
ˆ ˆ ˆ ˆ
DD
DD T C T C
DD
DD
Y Y Y Yα
α α α α α α α α α α
α
α
α α α
α
= − − −
= + + + − + − + −
=
= + −
(14)
(15)
El estimador α3 de (13) captura la diferencia, primero, entre el grupo de control y el de tratamiento en cada uno de los periodos del experimento, segundo, se establece la diferencia entre los dos periodos de tiempo.
A partir de estas dos diferencias, se concluye que el efecto de un choque exógeno en el modelo está determinado por el coeficientede D2DT; ésta se refiere al grupo de tratamiento en el periodo después de ser afectadas las unidades de corte transversal; al mismo tiempo es el efecto de un cambio estructural.

Estimador diferencia en diferencia
42
Si se quiere evaluar el efecto de un choque exógeno (cambio estructural o impacto) sobre una variable explicativa, simplemente se plantea un modelo igual al de la ecuación (12) teniendo en cuenta la interacción entre la variable explicativa y la dummy de tiempo.
Los efectos de un cambio en la variable de interés Xit como consecuencia de una política se puede evidenciar mediante el estimador de δ2 . Este estimador mantiene las propiedades de MCO
siempre y cuando se cumplan los supuestos MRC, en especial, que no exista sesgo de endogeneidad.
( )0 1 1 22 2·it it it itY X D X D uδβ β δ= + + + + (16)

Estimador diferencia en diferencia
43
El estimador diferencia en diferencia funciona bien cuando se cuenta con información de corte transversal agrupada en el tiempo, o lo que es lo mismo, cuando no se cuenta con información para la misma unidad de corte transversal para los periodos en los que están recogidos los datos.
En caso que se tenga la misma muestra a lo largo del tiempo, se tendría un panel de datos y se utilizarían diferentes técnicas para llegar a las conclusiones esperadas. Estas metodologías se tratarán en el siguiente capítulo.

Caso práctico
44
Objetivo: evaluar el impacto que tuvo el Programa de Educación Rural (PER) en las tasas de eficiencia y calidad de la educación en las escuelas rurales que accedieron a dicho programa en Colombia.
El PER, originalmente, buscaba diseñar y ejecutar proyectos educativos en instituciones rurales para alcanzar 4 objetivos :
1. Aumentar la cobertura y calidad educativa.
2. Fortalecer la capacidad de gestión de los municipios e instituciones educativas en la identificación de necesidades, manejo de información, planeación y evaluación.
3. Mejorar las condiciones de convivencia en la institución educativa
4. Diseñar mecanismos que permitan una mejor comprensión de la situación de la educación media técnica rural.

Caso práctico
45
Con esta finalidad, el proyecto tendría una duración de diez años y se implementaría en tres etapas, cada una de tres años y medio.
Las primeras experiencias del PER comenzaron en el año 2002, y un año después se había implementado en más de 1,800 sedes en 12 departamentos del país.
El ejercicio pretende comparar los resultados académicos que obtuvieron los estudiantes que fueron intervenidos por el PER respecto a los mismos que hubiesen alcanzado las personas si no participaban en el programa.

Caso práctico
46
Partiendo de la metodología descrita en este capítulo, la mejor forma de estimar los efectos de una política de este tipo, es utilizando datos de corte transversal a lo largo del tiempo, ya que permiten analizar los efectos del PER sobre la eficiencia y la calidad de la educación en población rural.
Bajo la metodología de diferencias en diferencias, los resultados de un grupo de escuelas no participantes en el PER se utilizan como control para los valores del grupo de tratamiento. El modelo es el siguiente:
Yit : variable de interés para la evaluación (crecimiento en matrícula escolar, cambio en la tasa de aprobación, cambio en la tasa de reprobación y cambio en la tasa de deserción, en diferentes regiones)
0 1 2 3. .2004 . .2004it it it itY esc PER A esc PER A X uδ δ δ δ β= + + + × + + (17)

Caso práctico
47
esc.PERit : escuelas intervenidas por el programa PER
esc.PERit××××A.2004 : escuelas intervenidas en el año 2004
X : matriz de controles de la regresión
ββββ : vector de coeficientes
Hipótesis: el programa de educación rural (PER) tuvo un impacto
positivo sobre el crecimiento en matricula escolar y la tasa de aprobación, y negativo sobre la tasa de reprobación y la tasa de deserción.

Caso práctico
48
Variables a usar en el modeloVariables del
Modelo
Variables en la
Base
Descripción
Yit C_total, C_taprobaC_treproba, C_tdeser
Crecimiento en la matrícula, cambio en la tasas de aprobación, reprobación y deserción
Esc.PERit trata Variable dicótoma que toma un valor 1 si la escuela hace parte del programa PER y 0 e.o.c.
A.2004 d_04 Dicótoma que hace referencia al año 2004.
Xit log_gasto, familias, ataques, gini_av, nbi, tasa_urbanos, d_1
Gasto municipal en educación (por alumno, en log), porcentaje de familias en acción, actividad armada ilegal (por 100.000 habitantes, en log), GINI (avalúos de tierra), NBI, población urbana (en porcentaje)

Caso práctico
49
Estimación del modelo diferencias en diferencias

Caso práctico
50
Una vez se tiene las regresiones estimadas, se procede a establecer si las hipótesis planteadas son ciertas o no. Para la ecuación (17), el coeficiente de interés es δ3, dado que es el estimador del efecto que tuvo el programa PER sobre las escuelas rurales en el año 2004.
Para ello se utiliza la prueba de Chow. La prueba de hipótesis a seguir es la siguiente:
H0: δ3 = 0 (PER no tiene efectos sobre la tasa de deserción escolar)
H1: δ3 ≠ 0 (PER tiene efectos sobre la tasa de deserción escolar )(18)

Caso práctico
51
La prueba arroja un Fc = 70.94,con un p-valor de 0.000, esto quiere decir que Fc > FJ,n-k. De esta manera, se valida la existencia de un efecto del PER sobre la tasa de deserción escolar y dado que el coeficiente de la iteración esc.PER××××A.2004 es negativo, corrobora la hipótesis inicial de un impacto negativo del PER en 2004 sobre la tasa de deserción para el 2004.

Evaluación de Impacto
52
Calcular el efecto CAUSAL (impacto) de
la intervención P (programa o tratamiento) en
el resultado Y (indicador, medida del éxito)
Ejemplo: ¿cuál es el efecto de un
programa de transferencia monetaria (P) en
el consumo del hogar (Y)?

Evaluación de Impacto
53
Inferencia causal
¿Cuál es el efecto de P en Y?
Respuesta:
a= (Y | P=1)-(Y | P=0)
Problema de FALTA DE DATOS
Para un beneficiario del programa:
observamos (Y | P=1):
El nivel de consumo (Y) con un programa de transferencia monetaria (P)

Evaluación de Impacto
54
Pero no observamos (Y | P=0):
El nivel de consumo (Y) sin un programa de transferencia monetaria (P)
Solución
Estimar lo que hubiera sucedido a Y en ausencia de P
Esto se denomina… CONTRAFACTUAL
La clave de una evaluación de impacto es tener un contrafactual
válido.

Evaluación de Impacto
55
Cálculo del impacto de P en Y
a= (Y | P=1) - (Y | P=0)
OBSERVAR (Y | P=1) Intención de Tratar (ITT)
‒ A quienes se ofreció tratamiento
Tratamiento en Tratados (TOT)‒ Quienes están recibiendo
tratamiento
CALCULAR contrafactual
para (Y | P=0)‒ Utilizar grupo de
comparación o de control
IMPACTO = resultado con tratamiento - contrafactual
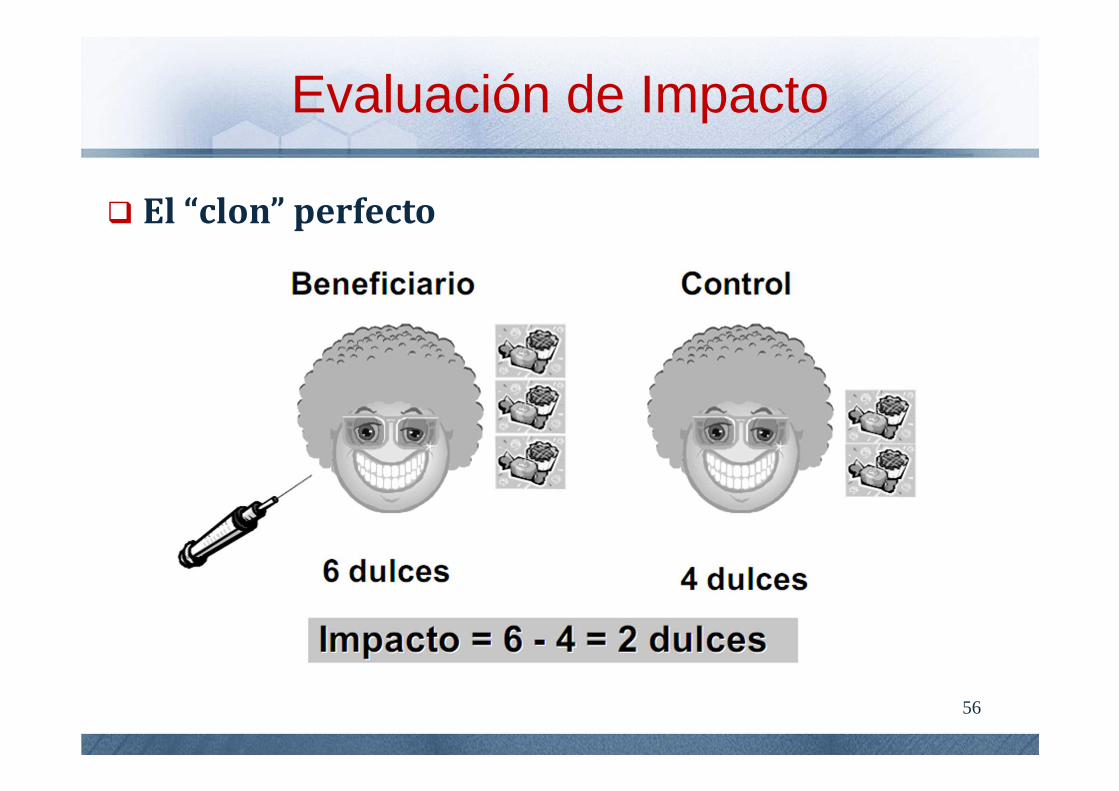
Evaluación de Impacto
56
El “clon” perfecto
Evaluación de Impacto
57
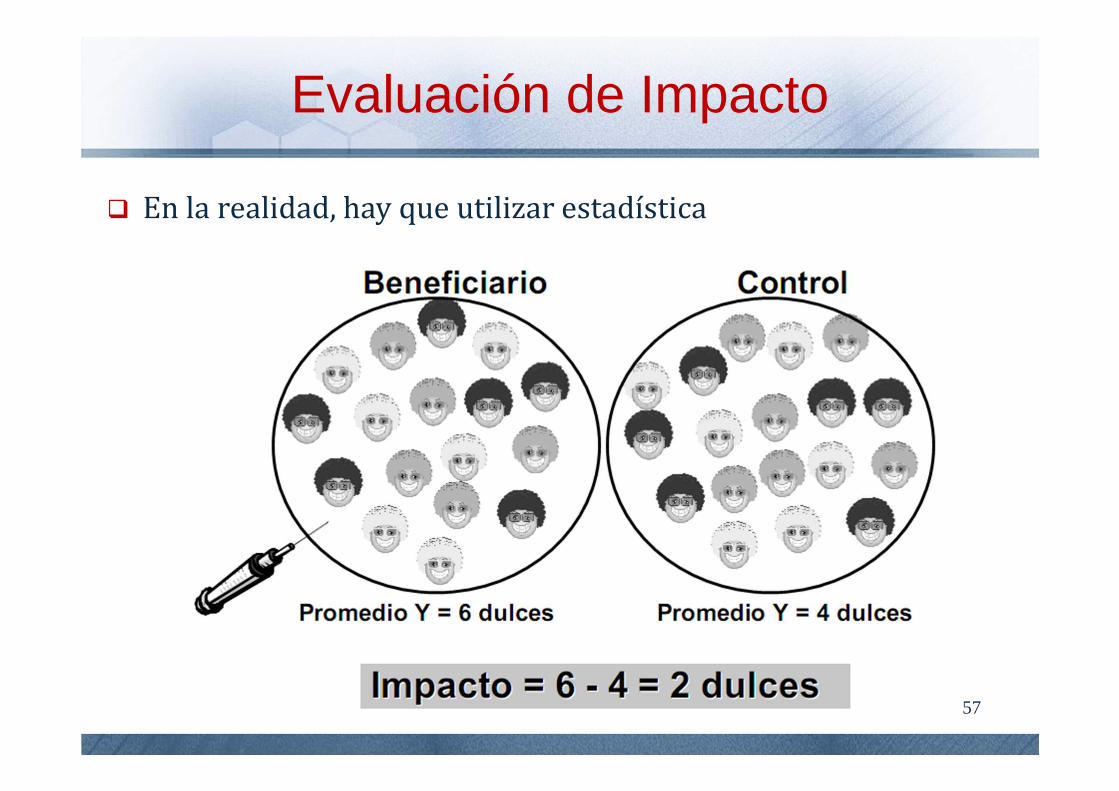
En la realidad, hay que utilizar estadística

Evaluación de Impacto
58
Obtención de un buen contrafactual
Entender el proceso de GENERACIÓN DE DATOS
Proceso conductual por el que se determina la participación en el programa (tratamiento)
¿Cómo se asignan los beneficios?
¿Cuáles son las reglas de elegibilidad?
La observación tratada y el contrafactual:
tienen características idénticas, con excepción de los beneficios de la intervención

Evaluación de Impacto
59

Evaluación de Impacto
60
Estudio de caso
¿Cuál es el efecto de un programa de transferencia monetaria (P) en el consumo del hogar (Y)? Programa PROGRESA/OPORTUNIDADES
Programa nacional contra la pobreza en México
Comenzó en 1997 5 millones de beneficiarios hacia 2004 Elegibilidad: basada en índice de pobreza
Transferencias monetarias Condicionadas a la asistencia escolar y visitas a centros de salud
Evaluación de impacto rigurosa con gran cantidad de datos 506 comunidades, 24 mil hogares Datos iniciales, 1997; seguimiento, 2008
Muchos resultados de interés. Aquí consideramos: Estándar de vida: consumo per cápita

Evaluación de Impacto
61
Elegibilidad e Inscripción

Evaluación de Impacto
62
Medición de impacto
1) Inferencia causal
Contrafactuales
Contrafactuales falsos:
Antes y después (previo-posterior)
Inscrito - no inscrito (manzanas y naranjas)
2) Métodos de evaluación de impacto:
Controles aleatorios
Promoción aleatoria (IV)
Diseño de discontinuidad (RDD)
Diferencia en diferencias
Pareamiento/matching

Evaluación de Impacto
63
Contrafactuales falsos
Dos contrafactuales comunes que deben evitarse:
Antes y después (previo-posterior)
Datos sobre los mismos individuos antes y después de la intervención
Inscritos-no inscritos (manzanas y naranjas)
Datos sobre un grupo de individuos inscrito en el programa, y otro grupo no inscrito
• No conocemos la causa
Ambos contrafactuales pueden llevar a resultados
sesgados.
Evaluación de Impacto
64
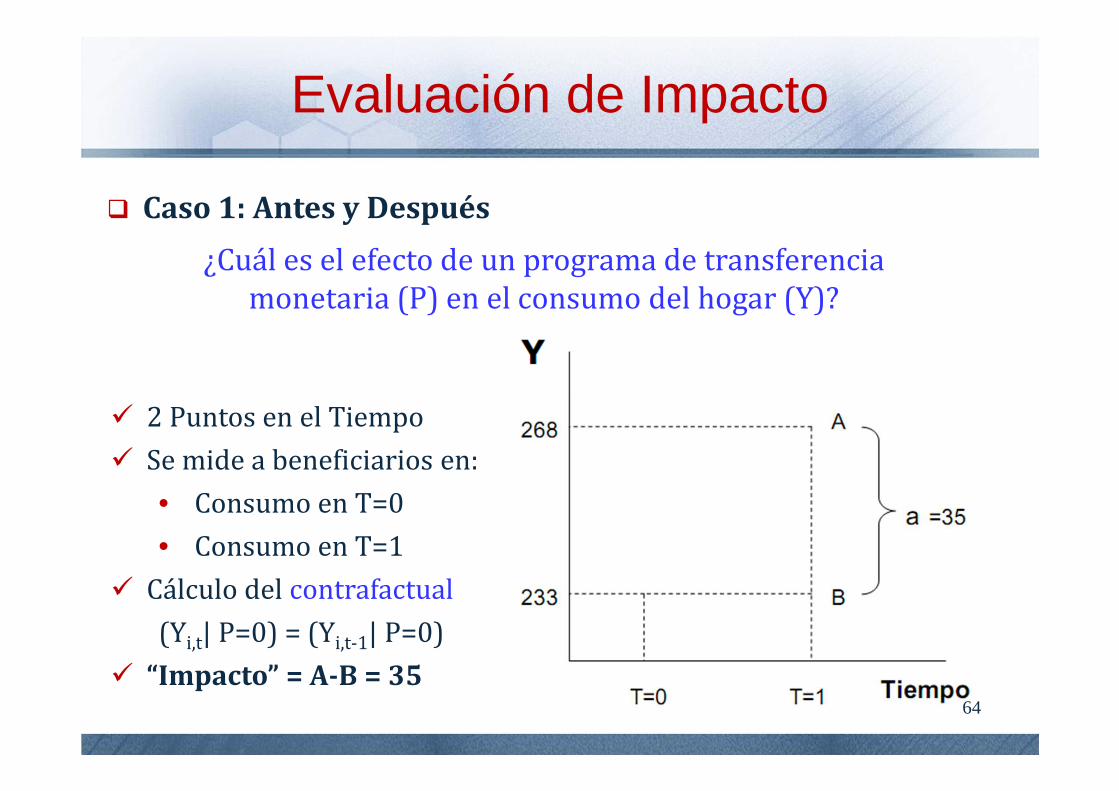
Caso 1: Antes y Después
¿Cuál es el efecto de un programa de transferencia monetaria (P) en el consumo del hogar (Y)?
2 Puntos en el Tiempo
Se mide a beneficiarios en:
• Consumo en T=0
• Consumo en T=1
Cálculo del contrafactual
(Yi,t| P=0) = (Yi,t-1| P=0)
“Impacto” = A-B = 35
Evaluación de Impacto
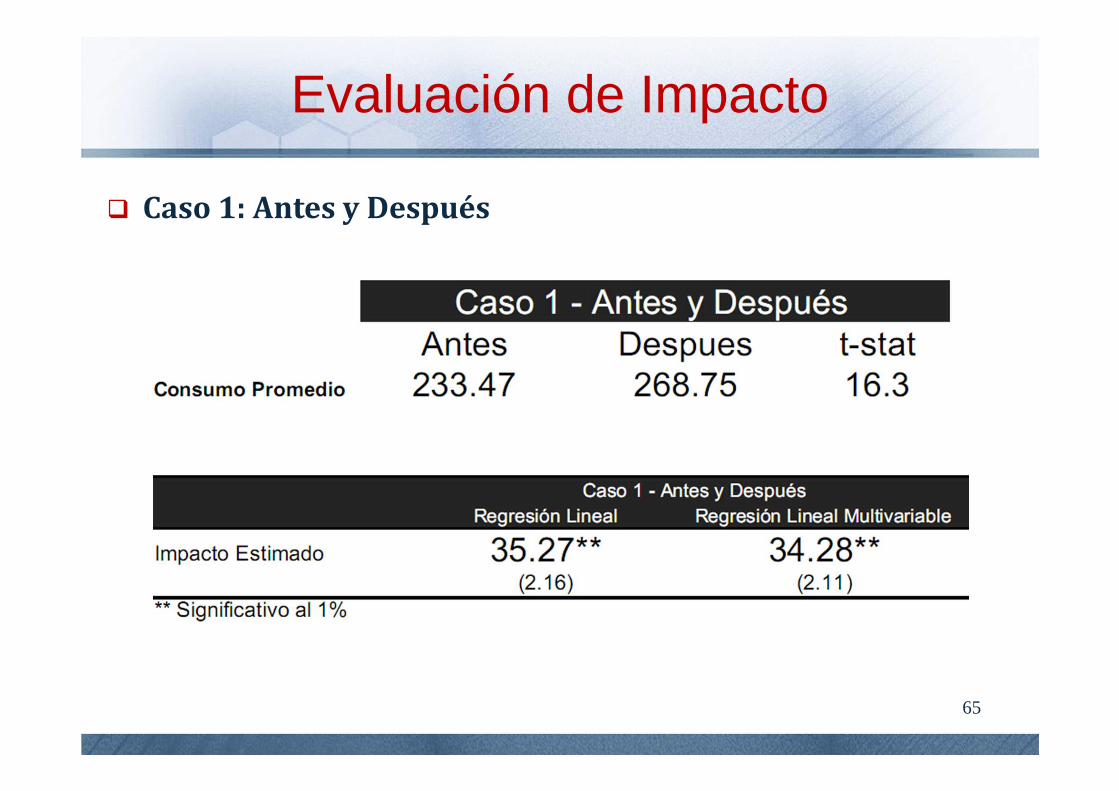
65
Caso 1: Antes y Después
Evaluación de Impacto
66
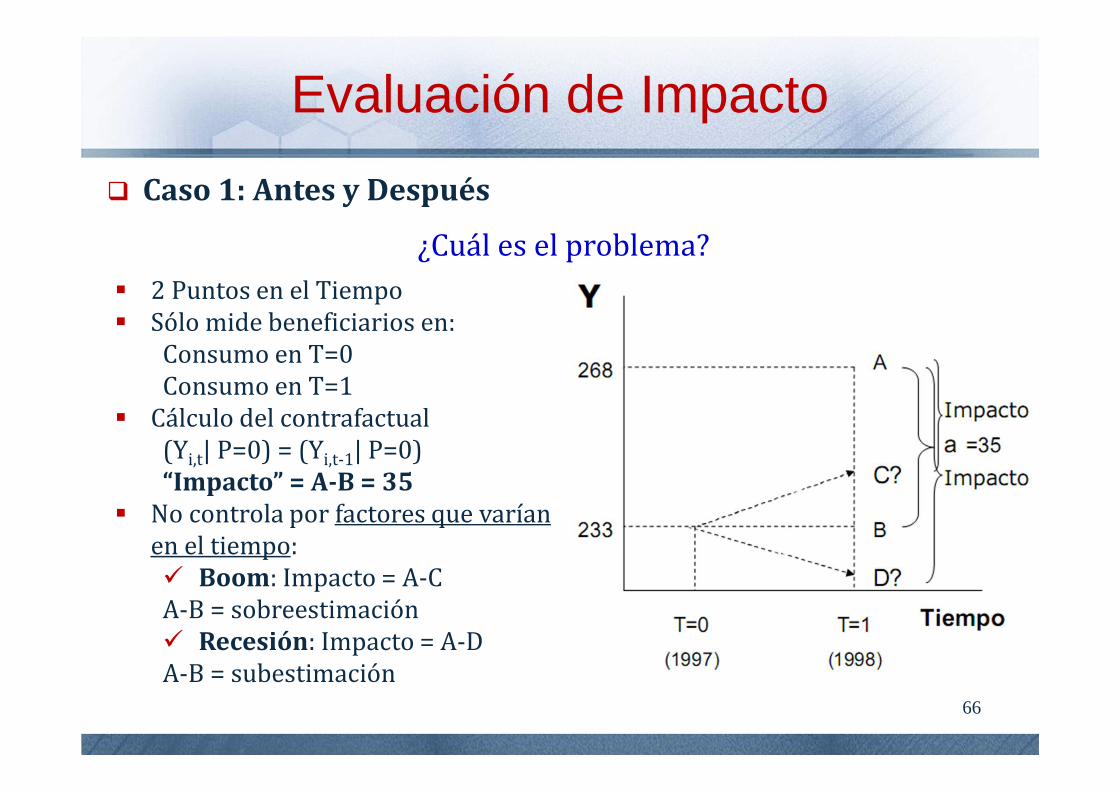
Caso 1: Antes y Después
¿Cuál es el problema? 2 Puntos en el Tiempo Sólo mide beneficiarios en:
Consumo en T=0Consumo en T=1
Cálculo del contrafactual(Yi,t| P=0) = (Yi,t-1| P=0)“Impacto” = A-B = 35
No controla por factores que varían en el tiempo: Boom: Impacto = A-CA-B = sobreestimación Recesión: Impacto = A-DA-B = subestimación

Evaluación de Impacto
67
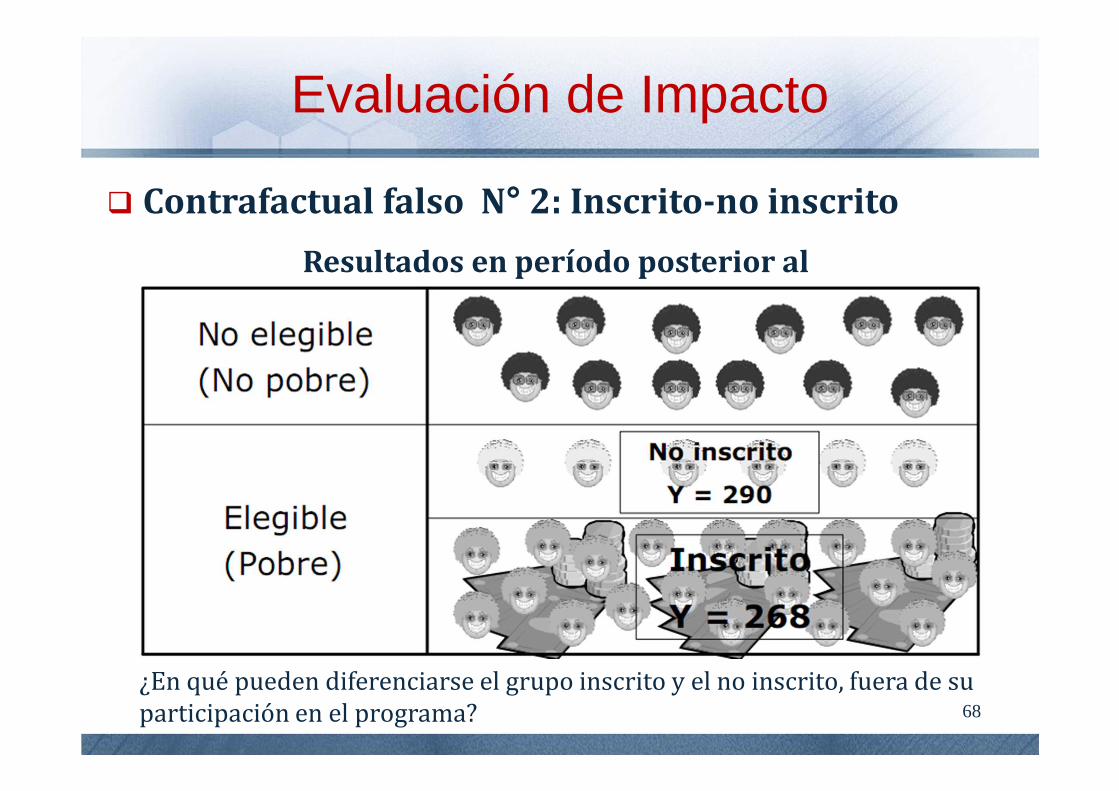
Contrafactual falso N° 2: Inscrito-no inscrito
Datos posteriores al tratamiento en 2 grupos
Inscrito: grupo de tratamiento
No inscrito: grupo de “control” (contrafactual)
Los no elegibles para participar
Los que optan por NO participar
Sesgo de selección
El motivo de la no inscripción puede estar correlacionadocon el resultado (Y)
Es posible controlar las características observables
¡Pero no es posible controlar las no observables!
El impacto estimado se confunde con otros factores
Evaluación de Impacto
68
Contrafactual falso N° 2: Inscrito-no inscrito
Resultados en período posterior al
tratamiento(1998)
¿En qué pueden diferenciarse el grupo inscrito y el no inscrito, fuera de su participación en el programa?
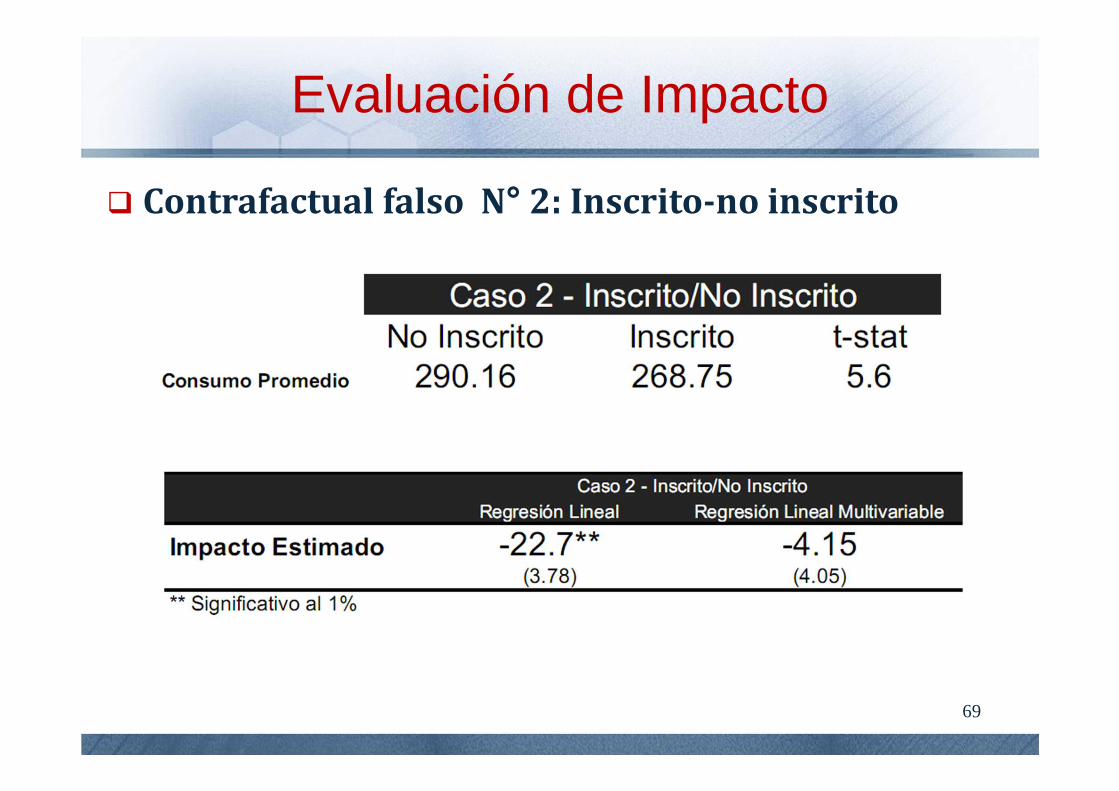
Evaluación de Impacto
69
Contrafactual falso N° 2: Inscrito-no inscrito

Evaluación de Impacto
70
Considere los resultados……
¿Cuál resultado es el más cierto?
Problema con Antes-Después:
No se consideran otros factores que varían en el tiempo
Problema con Inscrito- No Inscrito:
No sabemos si otros factores, aparte de la intervención, inciden en el resultado
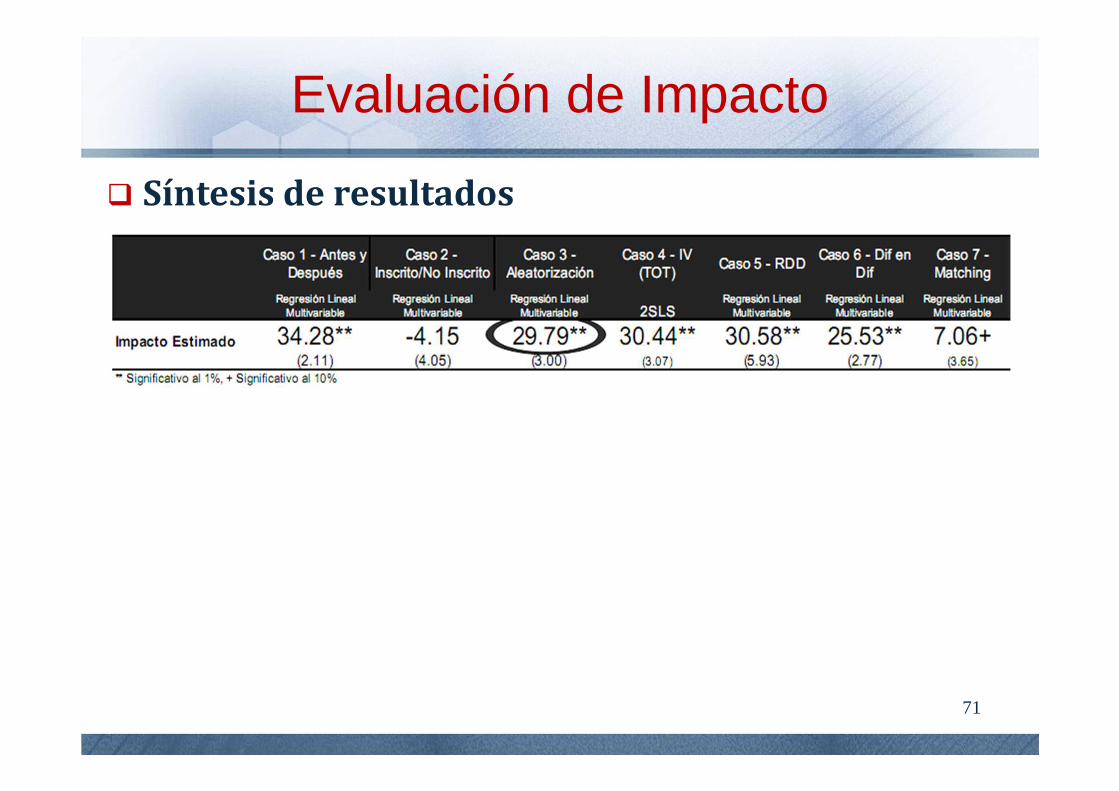
Evaluación de Impacto
71
Síntesis de resultados

Cochabamba, enero de 2013
Julio Humérez Quiroz
Universidad Mayor de San SimónFacultad de Ciencias Económicas y Financieras
Carrera de EconomíaEconometría de Datos de Panel
Agrupamiento de Datos de SecciónCruzada

Teoría Asintótica Básica: Convergenciaen Probabilidad
1) Una secuencia de v.a. xN: N = 1, 2, … converge en
probabilidad a la constante a si para todo ε > 0,
P[ |xN – a| > ε] → 0 cuando N → ∞
En general, escribimos y decimos que a es el
plim de xN.
2) En el caso especial en que a = 0, también decimos que xN
es op(1) (o minúscula p 1). En este caso escribimos xN =
op(1) ó
73
ax pN →
.0→pNx

Teoría Asintótica Básica
3) Una secuencia de v.a. xN está limitada en probabilidad(bounded in probability) ssí para cada ε > 0, existe un bε < ∞y un entero Nε, tal que
P[ |xN| ≥ bε] < ε para todo N ≥ Nε
En este caso escribimos xN = Op(1) (xN es o mayúscula p 1).
Lema 1: si , entonces xN = Op(1)
74
ax pN →

Teoría Asintótica Básica4) Una secuencia aleatoria xN: N = 1, 2, … es op(Nδ) para δ ∈ ℜ, si
N-δ xN = op(1).
Lema 2: si wN = op(1), xN = op(1), yN = Op(1), y zN = Op(1), entonces
(i) wN + xN = op(1)
(ii) yN + zN = Op(1)
(iii) yN · zN = Op(1)
(iv) xN ·zN = op(1)
Todas las definiciones anteriores se aplican elemento porelemento a secuencias de vectores y matrices.
75

Teoría Asintótica Básica
Lema 3: Sea ZN: N = 1, 2, ... una secuencia de matrices J×K tal que ZN = op(1), y sea xN una secuencia de vectores aleatorios J×1 tal que xN = Op(1). Entonces Z’N xN = op(1).
Lema 4 (Teorema de Slutsky): Sea g: ℜK → ℜJ una función continua en algún punto c ∈ ℜK. Sea xN: N = 1, 2, ... una secuencia de vectores aleatorios K×1 tal que . Entonces cuando N → ∞. En otras palabras: plim g(xN) = g(plim xN) si g(·) es continua en plimxN.
76
cx pN →
)()( cgxg pN →

Teoría Asintótica Básica
Definición 1: Sea (Ω,ℑ,P) un espacio de probabilidad.Una secuencia de eventos ΩN: N = 1, 2, ... ⊂ ℑ se diceque ocurre con probabilidad aproximándose a uno(w.p.a 1) ssí P(ΩN) → 1 cuando N → ∞.
Corolario 1: Sea ZN: N = 1, 2, ... una secuencia dematrices aleatorias K×K, y sea A una matriz invertibleno aleatoria K×K. Si , entonces:
77
AZ pN →
(1)
(2)
1; w.p.aexiste1−NZ
1 1 1 1o plimpN NZ A Z A− − − −→ =

Teoría Asintótica Básica: Convergenciaen Distribución
Definición 2: Una secuencia de v.a. xN: N = 1, 2, …converge en distribución a la v.a.c. x ssí
FN(ξ) → F(ξ) cuando N → ∞ para todo ξ∈ℜ
Donde FN es la función de distribución acumulada de xN y Fes la función de distribución acumulada de x. En este casoescribimos:
78
.xx dN →

Teoría Asintótica Básica
Definición 3: Una secuencia de vectores aleatorios xN: N = 1, 2, ... K×1 converge en distribución al vector aleatorio continuo x ssí para cualquier vector no aleatorio K×1, c tal que c’c = 1, y escribimos
Lema 5: Si , donde x es cualquier vector aleatorio K×1, entonces xN = Op(1)
79
,'' xcxc dN →
.xx dN →
xx dN →

Teoría Asintótica Básica
Lema 6 (Continuous mapping theorem): Sea xN una secuencia de vectores aleatorios de dimensión K×1, tal que
Si g: ℜK → ℜJ es una función continua, entonces
80
xx dN →
)()( xgxg dN →

Teoría Asintótica Básica
Corolario 2: Si zN es una secuencia de vectores
aleatorios de dimensión K×1, tal que
Entonces:
1) Para cualquier matriz no aleatoria K×M, A,
2)
81
)V,0(Normal→dNz
)VAA',0(NormalA' →dNz
21-V' Kd
NN zz χ→

Teoría Asintótica Básica
Lema 7: Sean xN y zN secuencias de vectores aleatorios de dimensión K×1. Si
Teorema 1: Sea wj: j = 1, 2, … una secuencia de vectores aleatorios G×1, iid tal que E(|wjg|) < ∞, g = 1, 2,
…, G. Entonces la secuencia satisface la ley débil de los grandes números (LDGN):
donde µw = E(wj).
82
zxzxzz dN
pNN
dN →→−→ entonces,0y,
wpN
jjwN µ→∑
=
−
1
1

Teoría Asintótica Básica
Teorema 2 (Lindeberg-Levy): Sea wj: j = 1, 2, … una secuencia de vectores aleatorios G×1, iid tal que E(w2
jg)
< ∞, g = 1, 2, …, G y E(wj)=0. Entonces la secuencia satisface el teorema central del límite (TCL):
donde B = Var(wj) = E(wj wj’).
83
B) Normal(0,1
2/1 →∑=
− dN
jjwN


















